JP7187635B2 - 疎要素を密行列に変換するためのシステムおよび方法 - Google Patents
疎要素を密行列に変換するためのシステムおよび方法 Download PDFInfo
- Publication number
- JP7187635B2 JP7187635B2 JP2021147894A JP2021147894A JP7187635B2 JP 7187635 B2 JP7187635 B2 JP 7187635B2 JP 2021147894 A JP2021147894 A JP 2021147894A JP 2021147894 A JP2021147894 A JP 2021147894A JP 7187635 B2 JP7187635 B2 JP 7187635B2
- Authority
- JP
- Japan
- Prior art keywords
- sparse
- unit
- dense
- elements
- element access
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Theoretical Computer Science (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- Computing Systems (AREA)
- Complex Calculations (AREA)
- Error Detection And Correction (AREA)
- Multi Processors (AREA)
- Magnetic Resonance Imaging Apparatus (AREA)
Description
背景
この明細書は、一般に、回路系を用いて行列を処理することに関する。
この明細書に記載される主題の1つの革新的な局面によれば、行列プロセッサを用いて、疎から密への、または密から疎への行列変換を実行することができる。一般に、高性能計算システムは、行列を処理するために線形代数ルーチンを用い得る。いくつかの例においては、行列のサイズは1つのデータストレージにはまるには大きすぎるかもしれず、行列の異なる部分は、分散型データストレージシステムの異なる位置に疎に格納され得る。行列をロードするために、計算システムの中央処理ユニットは、別の回路系に行列の異なる部分にアクセスするよう命令し得る。この回路系は、ネットワークトポロジーに従って構成された複数のメモリコントローラを含んでもよく、疎データは、予め定められるルールの組に基いて、区分され格納されてもよい。各メモリコントローラは、予め定められるルールの組に基いて疎データを集めて、疎データ上において同時計算を実行し、および、中央処理ユニットがその後の処理を実行するために、ともに連結することができる密行列を生成してもよい。
もよい。複数個の疎要素のうちの特定の疎要素のアイデンティティが、第1の密行列と関連付けられる疎要素の第1の部分集合のうちの1つのアイデンティティと一致する、と判断することに応じて、第1の疎要素アクセスユニットは、特定の疎要素を含む第1の密行列と関連付けられる疎要素の第1の部分集合をフェッチするよう構成されてもよい。
詳細な記載
一般に、データは行列の形式において表すことができ、計算システムは線形代数アルゴリズムを用いてデータを操作し得る。行列は一次元のベクトルまたは多次元行列であり得る。行列は、データベーステーブルまたは変数などのようなデータ構造によって表されてもよい。しかしながら、行列のサイズが大きすぎると、1つのデータストレージに行列全体を格納することは可能ではないかもしれない。密行列は複数の疎要素に変換され得、各疎要素は異なるデータストレージに格納され得る。密行列の疎要素は行列であってもよく、行列のうちの小さな部分行列(たとえば単一値要素、行、列、または部分行列)のみが非零値を有する。計算システムが密行列にアクセスすることを必要とするときに、中央処理ユニット(CPU)は、データストレージの各々に到達するスレッドを開始して、格納された疎要素をフェッチしてもよく、そして、疎密変換を適用して密行列を戻す。しかしながら、それが疎要素すべてをフェッチするのにかかる時間の量は長いかもしれず、CPUの計算帯域幅は結果として十分に利用されないかもしれない。いくつかの場合では、計算システムはいくつかの密行列の疎要素にアクセスして新たな密行列を形成する必要があるかもしれず、それらの密行列は等しい次元を有さないかもしれない。異なる密行列の疎要素をフェッチするようデータストレージの各々に到達するスレッドと関連付けられるCPUアイドル時間は、異なる待ち時間に遭遇し得、さらに、計算装置の性能に望ましくない態様で影響を与えるかもしれない。いくつかの場合では、計算システムはいくつかの密行列の疎要素にアクセスして新たな密行列を形成する必要があるかもしれず、それらの疎要素は等しい次元を有さないかもしれない。異なる密行列の疎要素をフェッチするようデータストレージの各々に到達するスレッドと関連付けられるCPUアイドル時間は、異なる待ち時間に遭遇し得、さらに、計算装置の性能に望ましくない態様で影響を与えるかもしれない。CPUから分離しているハードウェア疎密変換ユニットは、プロセッサの計算帯域幅をCPU動作から独立した疎要素の収集および疎要素の密行列への変換によって、増大させ得る。
4は、更新された密行列を対応する疎要素に変換し、したがって、データ片106a~106kに格納された1つ以上の疎要素を更新してもよい。
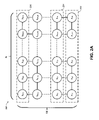
密行列から変換される疎要素を区分するよう構成されてもよい。疎要素アクセスユニットX1,1~XM,Nの各行は、特定の密行列から変換される疎要素にアクセスするよう区分されてもよい。たとえば、疎密変換ユニット200は、コンピュータモデルの1,000個の異なるデータベーステーブルに対応する密行列から変換される疎要素にアクセスするよう構成されてもよい。データベーステーブルの1つ以上は異なるサイズを有してもよい。疎要素アクセスユニットの第1番目の行202は、データベーステーブル1番~データベーステーブル100番から変換される疎要素にアクセスするよう構成されてもよく、疎要素アクセスユニットの第2番目の行204は、データベーステーブル101番~データベーステーブル300番から変換される疎要素にアクセスするよう構成されてもよく、疎要素アクセスユニットのM番目の行206は、データベーステーブル751番~データベーステーブル1,000番から変換される疎要素にアクセスするよう構成されてもよい。いくつかの実現例では、区分は、疎密変換ユニット200を用いて、プロセッサが疎要素にアクセスする前に、ハードウェア命令によって構成されてもよい。
するよう構成されてもよく、疎要素アクセスユニットX1,2は、データベーステーブル
1番の疎要素201番~500番にアクセスするよう構成されてもよい。別の例として、データベーステーブル2番に対応する密行列は500個の疎要素に変換されてもよく、500の疎要素は上に記載されるような第1番目の行202によってアクセス可能である。疎要素アクセスユニットX1,1は、データベーステーブル2番の疎要素1番~50番にアクセスするよう構成されてもよく、疎要素アクセスユニットX1,2は、データベーステーブル2番の疎要素51番~200番にアクセスするよう構成されてもよい。別の例として、データベーステーブル1,000番に対応する密行列は10,000個の疎要素に変換されてもよく、10,000個の疎要素は上に記載されるような第M番目の行206によってアクセス可能である。疎要素アクセスユニットXM,1は、データベーステーブル1,000番の疎要素1番~2,000番にアクセスするよう構成されてもよく、疎要素アクセスユニットXM,Nは、データベーステーブル1,000番の疎要素9,000番~10,000番にアクセスするよう構成されてもよい。
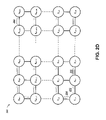
たは動的に生成されてもよい。たとえば、ルーティングスキームはルックアップテーブルであってもよい。いくつかの実現例では、疎要素アクセスユニットは、要求224を要求224に基いて別の疎要素アクセスユニットに同報通信するよう構成されてもよい。たとえば、要求224は要求された疎要素の識別を含んでもよく(たとえばデータベーステーブル1番、疎要素1番~50番)、疎要素アクセスユニットX1,2は、要求224を疎要素アクセスユニットX2,2および/または疎要素アクセスユニットX1,3に同報通信するべきであるかどうかを、識別に基づいて判断してもよい。同報通信プロセスは、メッシュネットワークを介して伝搬し、疎要素アクセスユニットXM,Nは疎要素アクセスユニットXM,N-1から要求230を受ける。
密行列を生成した後、その疎要素アクセスユニットは、同報通信された要求の送信側にその密行列を転送するよう構成されてもよい。ここでは、疎要素アクセスユニットXM,Nは密行列246を疎要素アクセスユニットXM,N-1に転送する。次のサイクルで、疎要素アクセスユニットXM,N-1は、密行列246を疎要素アクセスユニットXM,N-1に転送するよう構成される。このプロセスは、疎要素アクセスユニットX2,1が密行列246を疎要素アクセスユニットX1,1に転送するまで継続する。
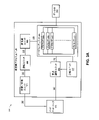
は、疎要素アクセスユニットX1,1~XM,Nの任意の1つであってもよい。一般に、疎要素アクセスユニット300は、ノードネットワーク320から、1つ以上のデータ片に格納された疎要素をフェッチし、フェッチされた疎要素を密行列に変換する要求342を受けるよう構成される。いくつかの実現例では、処理ユニット316が、ノードネットワーク320における疎要素アクセスユニットに対して、疎要素を用いて生成された密行列を求める要求を送信する。疎要素アクセスユニットは、疎要素アクセスユニット300に要求342を同報通信してもよい。同報通信された要求342のルーティングは図2Bにおける記載に類似してもよい。疎要素アクセスユニット300は、要求識別ユニット302、データフェッチユニット304、疎低減ユニット306、連結ユニット308、圧縮/伸長ユニット310、および分割ユニット312を含む。ノードネットワーク320は二次元のメッシュネットワークであってもよい。処理ユニット316は処理ユニット102と類似してもよい。
れた疎要素346を受け、フェッチされた疎要素346の次元を論理演算、算術演算または両方の組合せによって100×1に低減することによって疎低減要素348を生成してもよい。疎低減ユニット306は疎低減要素348を連結ユニット308に出力するように構成される。
密変換ユニット200は、M×N個の疎要素アクセスユニットX1,1~XM,Nを含み、それらは物理的にまたは論理的にM個の行およびN個の列に配列される。疎要素アクセスユニットX1,1~XM,Nの各行は、特定の密行列から変換される疎要素にアクセスするよう区分されてもよい。いくつかの実現例では、疎要素アクセスユニットの第1の群は第1の疎要素アクセスユニットおよび第2の疎要素アクセスユニットを含んでもよい。たとえば、疎密変換ユニット200の第1番目の行は疎要素アクセスユニットX1,1および、X1,2を含んでもよい。いくつかの実現例では、疎要素アクセスユニットの第1の群および疎要素アクセスユニットの第2の群は二次元のメッシュ構成で配列されてもよい。いくつかの実現例では、疎要素アクセスユニットの第1の群および疎要素アクセスユニットの第2の群は二次元の円環面構成で配列されてもよい。
これらの疎要素が格納されているデータ片からこれらの疎要素をフェッチしてもよい。
ータベーステーブル1番の1番)がルックアップテーブルに含まれている場合には、要求識別ユニット302は、特定の要求された疎要素をフェッチするよう、信号344をデータフェッチユニット304に送信してもよい。
要素350を圧縮して、ノードネットワーク320のための密行列352を生成するよう構成されてもよい。
上のモジュール、サブプログラムまたは部分を格納するファイル)において、他のプログラムまたはデータ(たとえばマークアップ言語ドキュメントに格納される1つ以上のスクリプト)を保持するファイルの一部に格納され得る。コンピュータプログラムは、1つの場所に位置するかもしくは複数の場所にわたって分散され通信ネットワークによって相互接続される1つのコンピュータまたは複数のコンピュータ上で実行されるように展開され
得る。
ィカルユーザーインターフェイスもしくはウェブブラウザを有するクライアントコンピュータといったフロントエンドコンポーネントを含む計算システムにおいて実現され得るか、または1つ以上のそのようなバックエンドコンポーネント、ミドルウェアコンポーネントもしくはフロントエンドコンポーネントの任意の組合せの計算システムにおいて実現され得る。システムのコンポーネントは、たとえば通信ネットワークといったデジタルデータ通信の任意の形態または媒体によって相互接続され得る。通信ネットワークの例は、ローカルエリアネットワーク(「LAN」)およびワイドエリアネットワーク(「WAN」)、たとえばインターネットを含む。
Claims (15)
- 疎要素を密行列に変換するためのシステムであって、
複数の疎要素アクセスユニットを備え、前記複数の疎要素アクセスユニットの各疎要素アクセスユニットは、
それぞれの制御信号を受信し、
前記それぞれの制御信号に基づいて、前記疎要素アクセスユニットに対応するデータ片に格納された疎要素にアクセスし、
前記データ片から得られる前記疎要素に適用される変換に基づいて出力密行列を生成し、
前記出力密行列を前記システムのノードネットワークに与えるよう構成されている、システム。 - 前記それぞれの制御信号に対応する命令を受けるよう構成される疎密変換ユニットをさらに備え、
前記複数の疎要素アクセスユニットは、前記疎密変換ユニットに位置する、請求項1に記載のシステム。 - 前記疎密変換ユニットは、行次元および列次元を含む多次元疎密変換ユニットである、請求項2に記載のシステム。
- 前記複数の疎要素アクセスユニットは、前記多次元疎密変換ユニットのそれぞれの次元に沿って配置されている、請求項3に記載のシステム。
- 前記複数の疎要素アクセスユニットの各々は、
前記疎要素に前記変換を適用して前記出力密行列を生成するように構成されたそれぞれの第1のユニットを含む、請求項2に記載のシステム。 - 前記第1のユニットは連結ユニットであり、
前記変換は連結演算に基づく、請求項5に記載のシステム。 - 前記第1のユニットは圧縮/伸長ユニットであり、
前記変換は、前記疎要素を圧縮する演算に基づく、請求項5に記載のシステム。 - 複数の疎要素アクセスユニットを含むシステムを用いて疎要素を密行列に変換するための方法であって、
疎要素アクセスユニットがそれぞれの制御信号を受信することと、
前記それぞれの制御信号に基づいて、前記疎要素アクセスユニットが、前記疎要素アクセスユニットに対応するデータ片に格納された疎要素にアクセスすることと、
前記データ片から得られる前記疎要素に前記疎要素アクセスユニットによって適用される変換に基づいて、出力密行列を生成することと、
前記出力密行列を前記システムのノードネットワークに与えることとを含む、方法。 - 前記システムは、命令を受けるように構成された疎密変換ユニットを含み、
前記複数の疎要素アクセスユニットは、前記疎密変換ユニットに位置しており、
前記方法は、前記疎密変換ユニットが、前記複数の疎要素アクセスユニットの各々についてそれぞれの制御信号に対応する命令を受けることを含む、請求項8に記載の方法。 - 前記疎密変換ユニットは、行次元および列次元を含む多次元疎密変換ユニットである、請求項9に記載の方法。
- 前記複数の疎要素アクセスユニットは、前記多次元疎密変換ユニットのそれぞれの次元に沿って配置される、請求項10に記載の方法。
- 前記複数の疎要素アクセスユニットの各々は、前記疎要素を変換するように構成されたそれぞれの第1のユニットを含み、
前記方法は、前記第1のユニットが前記疎要素に前記変換を適用して前記出力密行列を生成することを含む、請求項9に記載の方法。 - 前記第1のユニットは連結ユニットであり、
前記変換を適用することは、
前記疎要素に連結演算を適用することと、
前記連結演算に基づいて前記疎要素を連結して前記出力密行列を生成することとを含む、請求項12に記載の方法。 - 前記第1のユニットは圧縮/伸長ユニットであり、
前記変換を適用することは、
前記疎要素に圧縮演算を適用することと、
前記圧縮演算に基づいて前記疎要素を圧縮して前記出力密行列を生成することとを含む、請求項12に記載の方法。 - システムの疎要素アクセスユニットによって疎要素を密行列に変換するために用いられる命令を格納したコンピュータプログラムであって、前記命令は、請求項8~14のいずれか1項に記載の方法を引き起こすようプロセッサによって実行可能である、コンピュータプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022191957A JP7797365B2 (ja) | 2016-02-05 | 2022-11-30 | 疎要素を密行列に変換するためのシステムおよび方法 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/016,420 | 2016-02-05 | ||
| US15/016,420 US9805001B2 (en) | 2016-02-05 | 2016-02-05 | Matrix processing apparatus |
| JP2019085959A JP6978467B2 (ja) | 2016-02-05 | 2019-04-26 | 疎要素を密行列に変換するためのシステムおよび方法 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019085959A Division JP6978467B2 (ja) | 2016-02-05 | 2019-04-26 | 疎要素を密行列に変換するためのシステムおよび方法 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022191957A Division JP7797365B2 (ja) | 2016-02-05 | 2022-11-30 | 疎要素を密行列に変換するためのシステムおよび方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022000781A JP2022000781A (ja) | 2022-01-04 |
| JP7187635B2 true JP7187635B2 (ja) | 2022-12-12 |
Family
ID=57708453
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016251060A Active JP6524052B2 (ja) | 2016-02-05 | 2016-12-26 | 疎要素を密行列に変換するためのシステムおよび方法 |
| JP2019085959A Active JP6978467B2 (ja) | 2016-02-05 | 2019-04-26 | 疎要素を密行列に変換するためのシステムおよび方法 |
| JP2021147894A Active JP7187635B2 (ja) | 2016-02-05 | 2021-09-10 | 疎要素を密行列に変換するためのシステムおよび方法 |
| JP2022191957A Active JP7797365B2 (ja) | 2016-02-05 | 2022-11-30 | 疎要素を密行列に変換するためのシステムおよび方法 |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016251060A Active JP6524052B2 (ja) | 2016-02-05 | 2016-12-26 | 疎要素を密行列に変換するためのシステムおよび方法 |
| JP2019085959A Active JP6978467B2 (ja) | 2016-02-05 | 2019-04-26 | 疎要素を密行列に変換するためのシステムおよび方法 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022191957A Active JP7797365B2 (ja) | 2016-02-05 | 2022-11-30 | 疎要素を密行列に変換するためのシステムおよび方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (6) | US9805001B2 (ja) |
| EP (2) | EP4160448A1 (ja) |
| JP (4) | JP6524052B2 (ja) |
| KR (4) | KR101980365B1 (ja) |
| CN (2) | CN107045493B (ja) |
| BR (1) | BR102016030970A8 (ja) |
| SG (2) | SG10201808521PA (ja) |
| TW (4) | TWI718604B (ja) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11256508B2 (en) | 2013-07-15 | 2022-02-22 | Texas Instruments Incorporated | Inserting null vectors into a stream of vectors |
| US11249759B2 (en) * | 2013-07-15 | 2022-02-15 | Texas Instruments Incorporated | Two-dimensional zero padding in a stream of matrix elements |
| US9805001B2 (en) * | 2016-02-05 | 2017-10-31 | Google Inc. | Matrix processing apparatus |
| US10635739B1 (en) | 2016-08-25 | 2020-04-28 | Cyber Atomics, Inc. | Multidimensional connectivity graph-based tensor processing |
| US10621268B1 (en) | 2016-08-25 | 2020-04-14 | Cyber Atomics, Inc. | Multidimensional tensor processing |
| US10489481B1 (en) * | 2017-02-24 | 2019-11-26 | Cyber Atomics, Inc. | Efficient matrix property determination with pipelining and parallelism |
| JP6912703B2 (ja) * | 2017-02-24 | 2021-08-04 | 富士通株式会社 | 演算方法、演算装置、演算プログラム及び演算システム |
| US10936942B2 (en) * | 2017-11-21 | 2021-03-02 | Google Llc | Apparatus and mechanism for processing neural network tasks using a single chip package with multiple identical dies |
| CN108804684B (zh) * | 2018-06-13 | 2020-11-03 | 北京搜狗科技发展有限公司 | 一种数据处理方法和装置 |
| US10719323B2 (en) | 2018-09-27 | 2020-07-21 | Intel Corporation | Systems and methods for performing matrix compress and decompress instructions |
| CN113794709B (zh) * | 2021-09-07 | 2022-06-24 | 北京理工大学 | 一种用于二值稀疏矩阵的混合编码方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014199545A (ja) | 2013-03-29 | 2014-10-23 | 富士通株式会社 | プログラム、並列演算方法および情報処理装置 |
| US20150067009A1 (en) | 2013-08-30 | 2015-03-05 | Microsoft Corporation | Sparse matrix data structure |
Family Cites Families (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5625836A (en) | 1990-11-13 | 1997-04-29 | International Business Machines Corporation | SIMD/MIMD processing memory element (PME) |
| US5765011A (en) | 1990-11-13 | 1998-06-09 | International Business Machines Corporation | Parallel processing system having a synchronous SIMD processing with processing elements emulating SIMD operation using individual instruction streams |
| US5752067A (en) | 1990-11-13 | 1998-05-12 | International Business Machines Corporation | Fully scalable parallel processing system having asynchronous SIMD processing |
| GB2251320A (en) * | 1990-12-20 | 1992-07-01 | Motorola Ltd | Parallel processor |
| JP2557175B2 (ja) * | 1992-05-22 | 1996-11-27 | インターナショナル・ビジネス・マシーンズ・コーポレイション | コンピュータ・システム |
| US5446908A (en) | 1992-10-21 | 1995-08-29 | The United States Of America As Represented By The Secretary Of The Navy | Method and apparatus for pre-processing inputs to parallel architecture computers |
| US5644517A (en) | 1992-10-22 | 1997-07-01 | International Business Machines Corporation | Method for performing matrix transposition on a mesh multiprocessor architecture having multiple processor with concurrent execution of the multiple processors |
| JP3348367B2 (ja) * | 1995-12-06 | 2002-11-20 | 富士通株式会社 | 多重アクセス方法および多重アクセスキャッシュメモリ装置 |
| JP3639206B2 (ja) * | 2000-11-24 | 2005-04-20 | 富士通株式会社 | 共有メモリ型スカラ並列計算機における並列行列処理方法、及び記録媒体 |
| JP3980488B2 (ja) | 2001-02-24 | 2007-09-26 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 超並列コンピュータ・システム |
| IL157514A0 (en) | 2001-02-24 | 2004-03-28 | Ibm | Class network routing |
| US6898691B2 (en) * | 2001-06-06 | 2005-05-24 | Intrinsity, Inc. | Rearranging data between vector and matrix forms in a SIMD matrix processor |
| US6961888B2 (en) | 2002-08-20 | 2005-11-01 | Flarion Technologies, Inc. | Methods and apparatus for encoding LDPC codes |
| US8380778B1 (en) * | 2007-10-25 | 2013-02-19 | Nvidia Corporation | System, method, and computer program product for assigning elements of a matrix to processing threads with increased contiguousness |
| WO2011156247A2 (en) | 2010-06-11 | 2011-12-15 | Massachusetts Institute Of Technology | Processor for large graph algorithm computations and matrix operations |
| US8549259B2 (en) | 2010-09-15 | 2013-10-01 | International Business Machines Corporation | Performing a vector collective operation on a parallel computer having a plurality of compute nodes |
| US8996518B2 (en) * | 2010-12-20 | 2015-03-31 | Sas Institute Inc. | Systems and methods for generating a cross-product matrix in a single pass through data using single pass levelization |
| CN102141976B (zh) | 2011-01-10 | 2013-08-14 | 中国科学院软件研究所 | 稀疏矩阵的对角线数据存储方法及基于该方法的SpMV实现方法 |
| US9665531B2 (en) | 2012-06-13 | 2017-05-30 | International Business Machines Corporation | Performing synchronized collective operations over multiple process groups |
| US9170836B2 (en) * | 2013-01-09 | 2015-10-27 | Nvidia Corporation | System and method for re-factorizing a square matrix into lower and upper triangular matrices on a parallel processor |
| US9471377B2 (en) | 2013-11-13 | 2016-10-18 | Reservoir Labs, Inc. | Systems and methods for parallelizing and optimizing sparse tensor computations |
| CN103984527B (zh) * | 2014-04-01 | 2017-12-15 | 杭州电子科技大学 | 优化稀疏矩阵向量乘提升不可压缩管流模拟效率的方法 |
| US9715481B2 (en) | 2014-06-27 | 2017-07-25 | Oracle International Corporation | Approach for more efficient use of computing resources while calculating cross product or its approximation for logistic regression on big data sets |
| US9898441B2 (en) * | 2016-02-05 | 2018-02-20 | Google Llc | Matrix processing apparatus |
| US9805001B2 (en) * | 2016-02-05 | 2017-10-31 | Google Inc. | Matrix processing apparatus |
-
2016
- 2016-02-05 US US15/016,420 patent/US9805001B2/en active Active
- 2016-12-22 US US15/389,381 patent/US9798701B2/en active Active
- 2016-12-26 JP JP2016251060A patent/JP6524052B2/ja active Active
- 2016-12-29 EP EP22194202.2A patent/EP4160448A1/en active Pending
- 2016-12-29 TW TW108126777A patent/TWI718604B/zh active
- 2016-12-29 KR KR1020160183047A patent/KR101980365B1/ko active Active
- 2016-12-29 TW TW105143869A patent/TWI624763B/zh active
- 2016-12-29 EP EP16207251.6A patent/EP3203382A1/en not_active Ceased
- 2016-12-29 TW TW107112523A patent/TWI670613B/zh active
- 2016-12-29 BR BR102016030970A patent/BR102016030970A8/pt not_active Application Discontinuation
- 2016-12-29 TW TW110100489A patent/TWI781509B/zh active
- 2016-12-30 SG SG10201808521PA patent/SG10201808521PA/en unknown
- 2016-12-30 SG SG10201610977QA patent/SG10201610977QA/en unknown
-
2017
- 2017-01-13 CN CN201710025742.3A patent/CN107045493B/zh active Active
- 2017-01-13 CN CN202010713206.4A patent/CN112000919B/zh active Active
- 2017-09-05 US US15/695,144 patent/US10417303B2/en active Active
-
2019
- 2019-04-26 JP JP2019085959A patent/JP6978467B2/ja active Active
- 2019-05-14 KR KR1020190056428A patent/KR102112094B1/ko active Active
- 2019-09-16 US US16/571,749 patent/US10719575B2/en active Active
-
2020
- 2020-05-12 KR KR1020200056346A patent/KR102483303B1/ko active Active
- 2020-07-14 US US16/928,242 patent/US11366877B2/en active Active
-
2021
- 2021-09-10 JP JP2021147894A patent/JP7187635B2/ja active Active
-
2022
- 2022-06-16 US US17/842,420 patent/US20220391472A1/en active Pending
- 2022-11-30 JP JP2022191957A patent/JP7797365B2/ja active Active
- 2022-12-26 KR KR1020220184672A patent/KR102635985B1/ko active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014199545A (ja) | 2013-03-29 | 2014-10-23 | 富士通株式会社 | プログラム、並列演算方法および情報処理装置 |
| US20150067009A1 (en) | 2013-08-30 | 2015-03-05 | Microsoft Corporation | Sparse matrix data structure |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7187635B2 (ja) | 疎要素を密行列に変換するためのシステムおよび方法 | |
| JP7023917B2 (ja) | 疎要素を密行列に変換するためのシステムおよび方法 | |
| HK40055790A (en) | Matrix processing apparatus | |
| HK40042911A (en) | Matrix processing apparatus | |
| HK40042911B (en) | Matrix processing apparatus | |
| HK40055790B (zh) | 矩阵处理装置 | |
| HK1242808A1 (en) | Matrix processing apparatus | |
| HK1242810A (en) | Matrix processing apparatus | |
| HK1242810A1 (en) | Matrix processing apparatus | |
| HK1242808B (zh) | 矩阵处理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20211008 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20211008 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20211012 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20221027 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20221101 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20221130 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7187635 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |