JP6920277B2 - 広いデータ要素のためのレジスタのペアを用いた偶数要素演算および奇数要素演算を有する混合幅simd演算 - Google Patents
広いデータ要素のためのレジスタのペアを用いた偶数要素演算および奇数要素演算を有する混合幅simd演算 Download PDFInfo
- Publication number
- JP6920277B2 JP6920277B2 JP2018502231A JP2018502231A JP6920277B2 JP 6920277 B2 JP6920277 B2 JP 6920277B2 JP 2018502231 A JP2018502231 A JP 2018502231A JP 2018502231 A JP2018502231 A JP 2018502231A JP 6920277 B2 JP6920277 B2 JP 6920277B2
- Authority
- JP
- Japan
- Prior art keywords
- data elements
- destination
- source
- simd
- register
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000013598 vector Substances 0.000 claims description 145
- 238000000034 method Methods 0.000 claims description 43
- 230000006870 function Effects 0.000 claims description 21
- 238000013507 mapping Methods 0.000 claims description 9
- 230000009471 action Effects 0.000 description 7
- 238000004891 communication Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30032—Movement instructions, e.g. MOVE, SHIFT, ROTATE, SHUFFLE
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
- G06F9/30109—Register structure having multiple operands in a single register
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
- G06F9/30112—Register structure comprising data of variable length
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8007—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors single instruction multiple data [SIMD] multiprocessors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8053—Vector processors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
Description
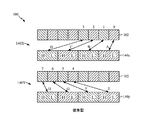
100X SIMD命令
100Y SIMD命令
102 ソースオペランド
104x 宛先オペランド
104y 宛先オペランド
120X SIMD命令
120Y SIMD命令
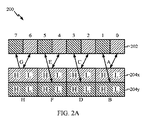
200 SIMD命令
202 ソースベクトルオペランド
202 単一のレジスタ
204x 第1のレジスタ
204y 第2のレジスタ
220 SIMD命令
220 混合幅SIMD命令
222 単一のレジスタ
222 ソースオペランド
222 第1のソースベクトルオペランド
223 単一のレジスタ
223 ソースオペランド
223 第2のソースベクトルオペランド
224x 第1のレジスタ
224x 第1の宛先ベクトルオペランド
224y 第2のレジスタ
224y 第2の宛先ベクトルオペランド
240 SIMD命令
240 混合幅SIMD命令
242x 第1のレジスタ
242y 第2のレジスタ
244 レジスタ
300 方法
350 方法
400 ワイヤレスデバイス
402 プロセッサ
422 システムオンチップデバイス
426 ディスプレイコントローラ
428 ディスプレイ
430 入力デバイス
432 メモリ
434 コーダ/デコーダ(コーデック)
436 スピーカー
438 マイクロフォン
440 ワイヤレスコントローラ
442 ワイヤレスアンテナ
444 電源
Claims (8)
- 混合幅単一命令複数データ(SIMD)演算を実行する方法であって、
プロセッサによって、
第1のソースレジスタを備える第1のソースベクトルオペランドであって、前記第1のソースレジスタが第1のビット幅の第1のセットのソースデータ要素を備える、第1のソースベクトルオペランドと、
第2のビット幅の宛先データ要素を備える宛先ベクトルオペランドと
を備えるSIMD命令を受信するステップであって、
前記第2のビット幅が前記第1のビット幅の2倍であり、
前記宛先ベクトルオペランドが、前記宛先データ要素の第1のサブセットを備える第1の宛先レジスタと、前記宛先データ要素の第2のサブセットを備える第2の宛先レジスタとを含む宛先レジスタのペアを備え、
前記第1のソースレジスタが、宛先レジスタの前記ペアに対応する単一のレジスタである、ステップと、
前記第1のセットのソースデータ要素の順序に基づいて、前記プロセッサにおいて前記SIMD命令を実行するステップであって、前記第1のセットのソースデータ要素の前記順序は、前記第1のセットのソースデータ要素と前記宛先データ要素との間のマッピングを提供するために割り当てられ、
前記第1のセットの偶数番号のソースデータ要素から、前記第1の宛先レジスタ内の前記宛先データ要素の前記第1のサブセットを生成するステップと、
前記第1のセットの奇数番号のソースデータ要素から、前記第2の宛先レジスタ内の前記宛先データ要素の前記第2のサブセットを生成するステップと
を備える、ステップと
を備え、
前記第1のセットのソースデータ要素がそれぞれのSIMDレーン内にあり、
前記マッピングに従って、前記ソースデータ要素の各々から、前記それぞれのSIMDレーン、または前記それぞれのSIMDレーンに隣接するSIMDレーン内のそれぞれの宛先データ要素を生成する、方法。 - 前記SIMD命令が、前記第1のセットの前記ソースデータ要素の二乗関数、左シフト関数、インクリメント、または一定値による加算のうちの1つである、請求項1に記載の方法。
- 混合幅単一命令複数データ(SIMD)演算を実行する方法であって、
プロセッサによって、
第1のビット幅のソースデータ要素を備えるソースベクトルオペランドと、
宛先レジスタを備える宛先ベクトルオペランドであって、前記宛先レジスタが第2のビット幅の宛先データ要素を備える、宛先ベクトルオペランドと
を備えるSIMD命令を受信するステップであって、
前記第2のビット幅が前記第1のビット幅の半分であり、
前記ソースベクトルオペランドが、前記ソースデータ要素の第1のサブセットを備える第1のソースレジスタと、前記ソースデータ要素の第2のサブセットを備える第2のソースレジスタとを含むソースレジスタのペアを備え、
前記宛先レジスタが、ソースレジスタの前記ペアに対応する単一のレジスタである、ステップと、
前記宛先データ要素の順序に基づいて、前記プロセッサにおいて前記SIMD命令を実行するステップであって、前記宛先データ要素の前記順序は、前記ソースデータ要素と前記宛先データ要素との間のマッピングを提供するために割り当てられ、
前記ソースデータ要素の前記第1のサブセットから偶数番号の宛先データ要素を生成するステップと、
前記ソースデータ要素の前記第2のサブセットから奇数番号の宛先データ要素を生成するステップと
を備える、ステップと
を備え、
前記宛先データ要素がそれぞれのSIMDレーン内にあり、
前記マッピングに従って、前記それぞれのSIMDレーン、または前記それぞれのSIMDレーンに隣接するSIMDレーン内のソースデータ要素から、前記宛先データ要素の各々を生成する、方法。 - 前記SIMD命令が、前記ソースデータ要素の右シフト関数である、請求項3に記載の方法。
- プロセッサによって実行されると、前記プロセッサに混合幅単一命令複数データ(SIMD)演算を実行させる、前記プロセッサによって実行可能な命令を備える非一時的コンピュータ可読記憶媒体であって、
第1のソースレジスタを備える第1のソースベクトルオペランドであって、前記第1のソースレジスタが第1のビット幅の第1のセットのソースデータ要素を備える、第1のソースベクトルオペランドと、
第2のビット幅の宛先データ要素を備える宛先ベクトルオペランドと
を備えるSIMD命令であって、
前記第2のビット幅が前記第1のビット幅の2倍であり、
前記宛先ベクトルオペランドが、前記宛先データ要素の第1のサブセットを備える第1の宛先レジスタと、前記宛先データ要素の第2のサブセットを備える第2の宛先レジスタとを含む宛先レジスタのペアを備え、
前記第1のソースレジスタが、宛先レジスタの前記ペアに対応する単一のレジスタである、SIMD命令と、
前記第1のセットのソースデータ要素の順序に基づいて、
前記第1のセットの偶数番号のソースデータ要素から、前記第1の宛先レジスタ内の前記宛先データ要素の前記第1のサブセットを生成するためのコードと、
前記第1のセットの奇数番号のソースデータ要素から、前記第2の宛先レジスタ内の前記宛先データ要素の前記第2のサブセットを生成するためのコードと
を備え、前記第1のセットのソースデータ要素の前記順序は、前記第1のセットのソースデータ要素と前記宛先データ要素との間のマッピングを提供するために割り当てられ、
前記第1のセットのソースデータ要素がそれぞれのSIMDレーン内にあり、
前記マッピングに従って、前記ソースデータ要素の各々から、前記それぞれのSIMDレーン、または前記それぞれのSIMDレーンに隣接するSIMDレーン内のそれぞれの宛先データ要素を生成するためのコードを備える、非一時的コンピュータ可読記憶媒体。 - 前記SIMD命令が、前記第1のセットの前記ソースデータ要素の二乗関数、左シフト関数、インクリメント、または一定値による加算のうちの1つである、請求項5に記載の非一時的コンピュータ可読記憶媒体。
- プロセッサによって実行されると、前記プロセッサに混合幅単一命令複数データ(SIMD)演算を実行させる、前記プロセッサによって実行可能な命令を備える非一時的コンピュータ可読記憶媒体であって、
第1のビット幅のソースデータ要素を備えるソースベクトルオペランドと、
宛先レジスタを備える宛先ベクトルオペランドであって、前記宛先レジスタが第2のビット幅の宛先データ要素を備える、宛先ベクトルオペランドと
を備えるSIMD命令であって、
前記第2のビット幅が前記第1のビット幅の半分であり、
前記ソースベクトルオペランドが、前記ソースデータ要素の第1のサブセットを備える第1のソースレジスタと、前記ソースデータ要素の第2のサブセットを備える第2のソースレジスタとを含むソースレジスタのペアを備え、
前記宛先レジスタが、ソースレジスタの前記ペアに対応する単一のレジスタである、SIMD命令と、
前記宛先データ要素の順序に基づいて、
前記ソースデータ要素の前記第1のサブセットから偶数番号の宛先データ要素を生成するためのコードと、
前記ソースデータ要素の前記第2のサブセットから奇数番号の宛先データ要素を生成するためのコードと
を備え、前記宛先データ要素の前記順序は、前記ソースデータ要素と前記宛先データ要素との間のマッピングを提供するために割り当てられ、
前記宛先データ要素がそれぞれのSIMDレーン内にあり、
前記マッピングに従って、前記それぞれのSIMDレーン、または前記それぞれのSIMDレーンに隣接するSIMDレーン内のソースデータ要素から、前記宛先データ要素の各々を生成するためのコードを備える、非一時的コンピュータ可読記憶媒体。 - 前記SIMD命令が、前記ソースデータ要素の右シフト関数である、請求項7に記載の非一時的コンピュータ可読記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/805,456 | 2015-07-21 | ||
| US14/805,456 US10489155B2 (en) | 2015-07-21 | 2015-07-21 | Mixed-width SIMD operations using even/odd register pairs for wide data elements |
| PCT/US2016/038487 WO2017014892A1 (en) | 2015-07-21 | 2016-06-21 | Mixed-width simd operations having even-element and odd-element operations using register pair for wide data elements |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2018525731A JP2018525731A (ja) | 2018-09-06 |
| JP2018525731A5 JP2018525731A5 (ja) | 2020-02-20 |
| JP6920277B2 true JP6920277B2 (ja) | 2021-08-18 |
Family
ID=56204087
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018502231A Active JP6920277B2 (ja) | 2015-07-21 | 2016-06-21 | 広いデータ要素のためのレジスタのペアを用いた偶数要素演算および奇数要素演算を有する混合幅simd演算 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US10489155B2 (ja) |
| EP (1) | EP3326060B1 (ja) |
| JP (1) | JP6920277B2 (ja) |
| KR (1) | KR102121866B1 (ja) |
| CN (1) | CN107851010B (ja) |
| BR (1) | BR112018001208B1 (ja) |
| ES (1) | ES2795832T3 (ja) |
| HU (1) | HUE049260T2 (ja) |
| WO (1) | WO2017014892A1 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2540943B (en) * | 2015-07-31 | 2018-04-11 | Advanced Risc Mach Ltd | Vector arithmetic instruction |
| US10698685B2 (en) * | 2017-05-03 | 2020-06-30 | Intel Corporation | Instructions for dual destination type conversion, mixed precision accumulation, and mixed precision atomic memory operations |
| CN109298886A (zh) * | 2017-07-25 | 2019-02-01 | 合肥君正科技有限公司 | Simd指令执行方法、装置及处理器 |
| US20190272175A1 (en) * | 2018-03-01 | 2019-09-05 | Qualcomm Incorporated | Single pack & unpack network and method for variable bit width data formats for computational machines |
| CN111324354B (zh) * | 2019-12-27 | 2023-04-18 | 湖南科技大学 | 一种融合寄存器对需求的寄存器选择方法 |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5673321A (en) | 1995-06-29 | 1997-09-30 | Hewlett-Packard Company | Efficient selection and mixing of multiple sub-word items packed into two or more computer words |
| US6202141B1 (en) | 1998-06-16 | 2001-03-13 | International Business Machines Corporation | Method and apparatus for performing vector operation using separate multiplication on odd and even data elements of source vectors |
| US7127593B2 (en) * | 2001-06-11 | 2006-10-24 | Broadcom Corporation | Conditional execution with multiple destination stores |
| US6922716B2 (en) | 2001-07-13 | 2005-07-26 | Motorola, Inc. | Method and apparatus for vector processing |
| US7107305B2 (en) | 2001-10-05 | 2006-09-12 | Intel Corporation | Multiply-accumulate (MAC) unit for single-instruction/multiple-data (SIMD) instructions |
| KR100553252B1 (ko) * | 2002-02-01 | 2006-02-20 | 아바고테크놀로지스코리아 주식회사 | 휴대용 단말기의 전력 증폭 장치 |
| US7376812B1 (en) | 2002-05-13 | 2008-05-20 | Tensilica, Inc. | Vector co-processor for configurable and extensible processor architecture |
| US7668897B2 (en) | 2003-06-16 | 2010-02-23 | Arm Limited | Result partitioning within SIMD data processing systems |
| US7275148B2 (en) * | 2003-09-08 | 2007-09-25 | Freescale Semiconductor, Inc. | Data processing system using multiple addressing modes for SIMD operations and method thereof |
| GB2411975B (en) * | 2003-12-09 | 2006-10-04 | Advanced Risc Mach Ltd | Data processing apparatus and method for performing arithmetic operations in SIMD data processing |
| GB2409068A (en) * | 2003-12-09 | 2005-06-15 | Advanced Risc Mach Ltd | Data element size control within parallel lanes of processing |
| US7353244B2 (en) * | 2004-04-16 | 2008-04-01 | Marvell International Ltd. | Dual-multiply-accumulator operation optimized for even and odd multisample calculations |
| US7400271B2 (en) * | 2005-06-21 | 2008-07-15 | International Characters, Inc. | Method and apparatus for processing character streams |
| CN1964490A (zh) * | 2005-11-09 | 2007-05-16 | 松下电器产业株式会社 | 一种滤波器及滤波方法 |
| CN104115115B (zh) | 2011-12-19 | 2017-06-13 | 英特尔公司 | 用于多精度算术的simd整数乘法累加指令 |
| US10866807B2 (en) * | 2011-12-22 | 2020-12-15 | Intel Corporation | Processors, methods, systems, and instructions to generate sequences of integers in numerical order that differ by a constant stride |
| US10628156B2 (en) | 2013-07-09 | 2020-04-21 | Texas Instruments Incorporated | Vector SIMD VLIW data path architecture |
-
2015
- 2015-07-21 US US14/805,456 patent/US10489155B2/en active Active
-
2016
- 2016-06-21 CN CN201680041468.2A patent/CN107851010B/zh active Active
- 2016-06-21 JP JP2018502231A patent/JP6920277B2/ja active Active
- 2016-06-21 WO PCT/US2016/038487 patent/WO2017014892A1/en active Application Filing
- 2016-06-21 KR KR1020187001696A patent/KR102121866B1/ko active IP Right Grant
- 2016-06-21 BR BR112018001208-4A patent/BR112018001208B1/pt active IP Right Grant
- 2016-06-21 EP EP16732213.0A patent/EP3326060B1/en active Active
- 2016-06-21 HU HUE16732213A patent/HUE049260T2/hu unknown
- 2016-06-21 ES ES16732213T patent/ES2795832T3/es active Active
Also Published As
| Publication number | Publication date |
|---|---|
| HUE049260T2 (hu) | 2020-09-28 |
| WO2017014892A1 (en) | 2017-01-26 |
| BR112018001208B1 (pt) | 2023-12-26 |
| BR112018001208A2 (pt) | 2018-09-11 |
| CN107851010A (zh) | 2018-03-27 |
| KR102121866B1 (ko) | 2020-06-11 |
| EP3326060B1 (en) | 2020-03-25 |
| US20170024209A1 (en) | 2017-01-26 |
| KR20180030986A (ko) | 2018-03-27 |
| US10489155B2 (en) | 2019-11-26 |
| CN107851010B (zh) | 2021-11-12 |
| EP3326060A1 (en) | 2018-05-30 |
| ES2795832T3 (es) | 2020-11-24 |
| JP2018525731A (ja) | 2018-09-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6920277B2 (ja) | 広いデータ要素のためのレジスタのペアを用いた偶数要素演算および奇数要素演算を有する混合幅simd演算 | |
| JP6373425B2 (ja) | 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 | |
| US20150212972A1 (en) | Data processing apparatus and method for performing scan operations | |
| JP5607832B2 (ja) | 汎用論理演算の方法および装置 | |
| CN107533460B (zh) | 紧缩有限冲激响应(fir)滤波处理器、方法、系统和指令 | |
| CN107851013B (zh) | 数据处理装置和方法 | |
| JP2009015556A (ja) | Simd型マイクロプロセッサ | |
| US20220206796A1 (en) | Multi-functional execution lane for image processor | |
| CN110574007B (zh) | 执行双输入值绝对值和求和操作的电路 | |
| CN107851016B (zh) | 向量算术指令 | |
| JP2013246816A (ja) | ミニコア基盤の再構成可能プロセッサ及びその再構成可能プロセッサを利用した柔軟な多重データ処理方法 | |
| JP2006260381A (ja) | 演算処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180123 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20190605 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200108 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20200108 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20200514 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20200611 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20200622 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200923 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20201221 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210413 |
|
| C60 | Trial request (containing other claim documents, opposition documents) |
Free format text: JAPANESE INTERMEDIATE CODE: C60 Effective date: 20210413 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20210423 |
|
| C21 | Notice of transfer of a case for reconsideration by examiners before appeal proceedings |
Free format text: JAPANESE INTERMEDIATE CODE: C21 Effective date: 20210426 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210705 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210726 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6920277 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |