JP6884149B2 - マルチスレッドアクセスのためのソフトウェア定義のfifoバッファ - Google Patents
マルチスレッドアクセスのためのソフトウェア定義のfifoバッファ Download PDFInfo
- Publication number
- JP6884149B2 JP6884149B2 JP2018529209A JP2018529209A JP6884149B2 JP 6884149 B2 JP6884149 B2 JP 6884149B2 JP 2018529209 A JP2018529209 A JP 2018529209A JP 2018529209 A JP2018529209 A JP 2018529209A JP 6884149 B2 JP6884149 B2 JP 6884149B2
- Authority
- JP
- Japan
- Prior art keywords
- request
- buffer controller
- buffer
- write
- processing device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000000872 buffer Substances 0.000 title claims description 221
- 238000000034 method Methods 0.000 claims description 64
- 230000004044 response Effects 0.000 claims description 14
- 230000008569 process Effects 0.000 claims description 9
- 230000000903 blocking effect Effects 0.000 claims description 6
- 230000004931 aggregating effect Effects 0.000 claims 4
- 238000010586 diagram Methods 0.000 description 13
- 230000006870 function Effects 0.000 description 11
- 238000004590 computer program Methods 0.000 description 8
- 230000009471 action Effects 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 230000001960 triggered effect Effects 0.000 description 3
- 230000000694 effects Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0655—Vertical data movement, i.e. input-output transfer; data movement between one or more hosts and one or more storage devices
- G06F3/0659—Command handling arrangements, e.g. command buffers, queues, command scheduling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F5/00—Methods or arrangements for data conversion without changing the order or content of the data handled
- G06F5/06—Methods or arrangements for data conversion without changing the order or content of the data handled for changing the speed of data flow, i.e. speed regularising or timing, e.g. delay lines, FIFO buffers; over- or underrun control therefor
- G06F5/10—Methods or arrangements for data conversion without changing the order or content of the data handled for changing the speed of data flow, i.e. speed regularising or timing, e.g. delay lines, FIFO buffers; over- or underrun control therefor having a sequence of storage locations each being individually accessible for both enqueue and dequeue operations, e.g. using random access memory
- G06F5/12—Means for monitoring the fill level; Means for resolving contention, i.e. conflicts between simultaneous enqueue and dequeue operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/0604—Improving or facilitating administration, e.g. storage management
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/0671—In-line storage system
- G06F3/0673—Single storage device
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Information Transfer Systems (AREA)
- Memory System (AREA)
Description
Claims (15)
- 実行可能なデータを格納するメモリデバイスを提供することと、
前記メモリデバイスに結合され、前記実行可能なデータを抽出及び実行するように動作可能な処理デバイスを提供することと、
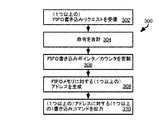
前記処理デバイスによって、バッファ初期化命令をアプリケーションから受信することと、
前記バッファ初期化命令に応じて、
前記処理デバイスによって、バッファとして前記メモリデバイスの一部分を割り当てること、
前記処理デバイスによって、前記メモリデバイスの前記一部分を参照するためにハードウェアバッファコントローラのある状態を引き起こすこと、及び
前記処理デバイスによって、前記ハードウェアバッファコントローラへの参照をアプリケーションへ返すことと、
前記処理デバイスによって、前記アプリケーションを実行することであって、前記アプリケーションから前記バッファにアクセスするためのリクエストを実行することを含み、前記リクエストが、前記ハードウェアバッファコントローラへの前記参照のみにアドレス指定され、前記メモリデバイスの前記一部分内の何れのアドレスも含まない、前記アプリケーションを実行することと、
前記リクエストに応じて、前記処理デバイスによって前記リクエストを前記ハードウェアバッファコントローラに入力することと、
前記ハードウェアバッファコントローラによって、前記リクエストを処理することであって、前記リクエストを処理することが前記リクエスト毎に、
前記ハードウェアバッファコントローラの前記状態に基づいて前記メモリデバイスの前記一部分内のアドレスを生成すること、
前記アドレスを含むメモリアクセス命令を前記メモリデバイスへ出力すること、及び
前記ハードウェアバッファコントローラの前記状態を更新すること
により行われる、前記リクエストを処理することと
を含む、方法。 - 前記ハードウェアバッファコントローラは先入れ先出し(FIFO)バッファを実施し、
前記ハードウェアバッファコントローラの前記状態は読み出しポインタ及び書き込みポインタを含み、
前記ハードウェアバッファコントローラの前記状態を更新することは、前記リクエストの内の書き込みリクエスト毎に前記書き込みポインタをインクリメントすることを含み、
前記ハードウェアバッファコントローラの前記状態を更新することは、前記リクエストの内の読み出しリクエスト毎に前記読み出しポインタをインクリメントすることを含む、
請求項1に記載の方法。 - 前記書き込みポインタをインクリメントすることは、1クロック周期中に受信された複数の書き込みリクエストの数を特定することと、前記複数の書き込みリクエストの前記数だけ前記書き込みポインタをインクリメントすることとを含み、
前記読み出しポインタをインクリメントすることは、前記クロック周期中に受信された複数の読み出しリクエストの数を特定することと、前記複数の読み出しリクエストの前記数だけ前記読み出しポインタをインクリメントすることとを含む、
請求項2に記載の方法。 - 前記ハードウェアバッファコントローラの前記状態に基づいて前記バッファ内の前記アドレスを生成することは、前記リクエストの内の書き込みリクエスト毎に前記書き込みポインタの現在値を出力することを含み、
前記ハードウェアバッファコントローラの前記状態に基づいて前記バッファ内の前記アドレスを生成することは、前記リクエストの内の読み出しリクエスト毎に前記読み出しポインタの現在値を出力することを含む、
請求項2に記載の方法。 - 前記処理デバイスによって、前記書き込みリクエストの量と前記読み出しリクエストの量との差を計算することと、
前記処理デバイスによって、前記差が第1の閾値よりも少なくゼロではないと判定することと、
前記差が第1の閾値よりも少なくゼロではないと判定することに応じて、前記処理デバイスによって、前記バッファがほぼ空であることを示すイベントを出力することと、
前記バッファがほぼ空であることを示す前記イベントに応じて、前記処理デバイスによって、前記処理デバイスによって実行される1つ以上の実行スレッドが読み出しリクエストを生成することをブロックすることと
を更に含む、請求項4に記載の方法。 - 前記ハードウェアバッファコントローラによって、前記書き込みリクエストの量と前記読み出しリクエストの量との差を計算することと、
前記ハードウェアバッファコントローラによって、前記差が第1の閾値よりも大きいと判定することと、
前記差が第1の閾値よりも大きいと判定することに応じて、前記ハードウェアバッファコントローラによって、前記バッファがほぼ満杯であることを示すイベントを出力することと、
前記バッファがほぼ満杯であることを示す前記イベントに応じて、前記処理デバイスによって、前記処理デバイスによって実行される1つ以上の実行スレッドが書き込みリクエストを生成することをブロックすることと
を更に含む、請求項4に記載の方法。 - 前記ハードウェアバッファコントローラによって前記リクエストを処理することは、
前記リクエストの内の複数の書き込みリクエストを集計することと、
前記複数の書き込みリクエストに対応する前記バッファ内の複数のアドレスを含む集計書き込み命令を前記メモリデバイスへ送信することと、
前記リクエストの内の複数の読み出しリクエストを集計することと、
前記複数の読み出しリクエストに対応する前記バッファ内の複数のアドレスを含む集計読み出し命令を前記メモリデバイスへ送信することと
を更に含み、
前記複数の書き込みリクエストは、前記リクエストの内のその他のリクエストが前記ハードウェアバッファコントローラに入力されるよりも前に、前記書き込みリクエストの内の少なくとも1つの書き込みリクエストが受信されるような重複方式で、複数の実行スレッドによって発行される、
請求項1に記載の方法。 - 前記処理デバイスによって、前記ハードウェアバッファコントローラの前記状態を評価することと、
前記処理デバイスによって、前記ハードウェアバッファコントローラの前記状態が閾条件を満たすと判定することと、
前記ハードウェアバッファコントローラの前記状態が前記閾条件を満たすと判定することに応じて、前記処理デバイスによって、前記ハードウェアバッファコントローラを参照する更なるリクエストを前記複数の実行スレッドが発行することをブロックすることと
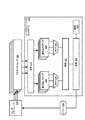
を更に含む、請求項7に記載の方法。 - 実行可能なデータを格納するためのメモリデバイスと、
処理デバイスと、
前記処理デバイスに動作可能に結合されたハードウェアバッファコントローラと
を含み、
前記処理デバイスは、前記メモリデバイスに結合され、前記実行可能なデータを抽出及び実行するように動作可能であり、前記処理デバイスは、バッファリクエストをアプリケーションから受信すること、並びに、前記バッファリクエストに応じて、
前記メモリデバイスの一部分を前記バッファリクエストのためのバッファとして割り当てること、
前記メモリデバイスの前記一部分を参照するために前記ハードウェアバッファコントローラのある状態を引き起こすこと、及び
前記ハードウェアバッファコントローラへの参照を前記アプリケーションへ返すこと
をするようにプログラムされ、
前記ハードウェアバッファコントローラは、前記処理デバイス及び前記メモリデバイスに結合され、前記ハードウェアバッファコントローラは、
前記メモリデバイス内の何れの格納位置に対する何れのアドレスも含まず、前記ハードウェアバッファコントローラのみにアドレス指定されたメモリアクセスリクエストを前記処理デバイスにより実行される前記アプリケーションから受信すること、
前記ハードウェアバッファコントローラの状態に基づいて、前記メモリデバイスの前記一部分内の生成アドレスを生成すること、
前記生成アドレスを含むメモリアクセス命令を前記メモリデバイスへ出力すること、
前記ハードウェアバッファコントローラの前記状態を更新すること
をするようにプログラムされる、
システム。 - 前記ハードウェアバッファコントローラの前記状態は先入れ先出し(FIFO)バッファを実施し、
前記ハードウェアバッファコントローラは、前記リクエストの内の書き込みリクエスト毎に書き込みポインタをインクリメントすることによって、前記ハードウェアバッファコントローラの前記状態を更新するように更にプログラムされ、
前記ハードウェアバッファコントローラの前記状態を更新することは、前記リクエストの内の読み出しリクエスト毎に読み出しポインタをインクリメントすることを含み、
前記ハードウェアバッファコントローラは、1クロック周期中に受信された複数の書き込みリクエストの数を特定することと、前記複数の書き込みリクエストの前記数だけ前記書き込みポインタをインクリメントすることとによって、前記書き込みポインタをインクリメントするように更にプログラムされ、
前記ハードウェアバッファコントローラは、前記クロック周期中に受信された複数の読み出しリクエストの数を特定することと、前記複数の読み出しリクエストの前記数だけ前記読み出しポインタをインクリメントすることとによって、前記読み出しポインタをインクリメントするように更にプログラムされる、
請求項9に記載のシステム。 - 前記ハードウェアバッファコントローラは、前記リクエストの内の書き込みリクエスト毎に前記書き込みポインタの現在値を出力することによって、前記ハードウェアバッファコントローラの前記状態に基づいて、前記バッファに割り当てられた前記メモリデバイスの前記一部分内の前記生成アドレスを生成するように更にプログラムされ、
前記ハードウェアバッファコントローラは、前記リクエストの内の読み出しリクエスト毎に前記読み出しポインタの現在値を出力することによって、前記ハードウェアバッファコントローラの前記状態に基づいて、前記バッファに割り当てられた前記メモリデバイスの前記一部分内の前記生成アドレスを生成するように更にプログラムされる、
請求項10に記載のシステム。 - 前記ハードウェアバッファコントローラは、
前記書き込みリクエストの量と前記読み出しリクエストの量との差を計算すること、及び
前記差が第1の閾値よりも少なくゼロではない場合に、前記バッファがほぼ空であることを示すイベントを出力すること
をするように更にプログラムされ、
前記処理デバイスは、前記バッファがほぼ空であることを示す前記イベントに応じて、前記処理デバイスによって実行される1つ以上の実行スレッドが読み出しリクエストを生成することをブロックするように更にプログラムされる、
請求項11に記載のシステム。 - 前記ハードウェアバッファコントローラは、
前記書き込みリクエストの量と前記読み出しリクエストの量との差を計算すること、及び
前記差が第2の閾値よりも大きい場合に、前記処理デバイスによって、前記バッファがほぼ満杯であることを示すイベントを出力すること
をするように更にプログラムされ、
前記処理デバイスは、前記バッファがほぼ満杯であることを示す前記イベントに応じて、前記処理デバイスによって実行される1つ以上の実行スレッドが書き込みリクエストを生成することをブロックするように更にプログラムされる、
請求項12に記載のシステム。 - 前記ハードウェアバッファコントローラは、
前記リクエストの内の複数の書き込みリクエストを集計することと、
前記複数の書き込みリクエストに対応する前記バッファ内の複数のアドレスを含む集計書き込み命令を前記メモリデバイスへ送信することと、
前記リクエストの内の複数の読み出しリクエストを集計することと、
前記複数の読み出しリクエストに対応する前記バッファ内の複数のアドレスを含む集計読み出し命令を前記メモリデバイスへ送信することと
によって前記リクエストを処理するように更にプログラムされる、請求項9に記載のシステム。 - 前記ハードウェアバッファコントローラは、前記リクエストの内のその他のリクエストが前記ハードウェアバッファコントローラに入力されるよりも前に、前記書き込みリクエストの内の少なくとも1つの書き込みリクエストが受信されるような重複方式で、前記処理デバイスによって実行される複数の実行スレッドから前記複数の書き込みリクエストを受信するようにプログラムされ、前記ハードウェアバッファコントローラは、
前記ハードウェアバッファコントローラの前記状態を評価すること、及び
前記ハードウェアバッファコントローラの前記状態が閾条件を満たす場合に、前記ハードウェアバッファコントローラを参照する更なるリクエストを前記複数の実行スレッドが発行することを、前記処理デバイスによってブロックすることを引き起こすこと
をするように更にプログラムされる、請求項14に記載のシステム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/966,631 | 2015-12-11 | ||
| US14/966,631 US10585623B2 (en) | 2015-12-11 | 2015-12-11 | Software defined FIFO buffer for multithreaded access |
| PCT/US2016/066106 WO2017100748A1 (en) | 2015-12-11 | 2016-12-12 | Software defined fifo buffer for multithreaded access |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2019502201A JP2019502201A (ja) | 2019-01-24 |
| JP2019502201A5 JP2019502201A5 (ja) | 2020-01-09 |
| JP6884149B2 true JP6884149B2 (ja) | 2021-06-09 |
Family
ID=59013408
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018529209A Active JP6884149B2 (ja) | 2015-12-11 | 2016-12-12 | マルチスレッドアクセスのためのソフトウェア定義のfifoバッファ |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US10585623B2 (ja) |
| EP (1) | EP3387513A4 (ja) |
| JP (1) | JP6884149B2 (ja) |
| KR (1) | KR20180107091A (ja) |
| CN (1) | CN108292162B (ja) |
| WO (1) | WO2017100748A1 (ja) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10095408B2 (en) * | 2017-03-10 | 2018-10-09 | Microsoft Technology Licensing, Llc | Reducing negative effects of insufficient data throughput for real-time processing |
| CN108038006B (zh) * | 2017-11-14 | 2022-02-08 | 北京小鸟看看科技有限公司 | 头戴显示设备的控制方法、设备及系统 |
| KR102421103B1 (ko) * | 2018-01-04 | 2022-07-14 | 에스케이하이닉스 주식회사 | 컨트롤러, 이를 포함하는 메모리 시스템 및 그것들의 동작 방법 |
| US10713746B2 (en) | 2018-01-29 | 2020-07-14 | Microsoft Technology Licensing, Llc | FIFO queue, memory resource, and task management for graphics processing |
| US11068308B2 (en) | 2018-03-14 | 2021-07-20 | Texas Instruments Incorporated | Thread scheduling for multithreaded data processing environments |
| US10719268B2 (en) | 2018-06-29 | 2020-07-21 | Microsoft Technology Licensing, Llc | Techniques for safely and efficiently enqueueing and dequeueing data on a graphics processor |
| US10963385B2 (en) * | 2019-01-18 | 2021-03-30 | Silicon Motion Technology (Hong Kong) Limited | Method and apparatus for performing pipeline-based accessing management in a storage server with aid of caching metadata with cache module which is hardware pipeline module during processing object write command |
Family Cites Families (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07118187B2 (ja) | 1985-05-27 | 1995-12-18 | 松下電器産業株式会社 | 先入れ先出し記憶装置 |
| US4894797A (en) | 1986-11-17 | 1990-01-16 | Amp Incorporated | FIFO data storage system using PLA controlled multiplexer for concurrent reading and writing of registers by different controllers |
| US5581705A (en) | 1993-12-13 | 1996-12-03 | Cray Research, Inc. | Messaging facility with hardware tail pointer and software implemented head pointer message queue for distributed memory massively parallel processing system |
| KR0139887B1 (ko) | 1994-02-17 | 1999-02-18 | 김광호 | 영상메모리의 데이타 혼선방지회로 |
| US6115761A (en) | 1997-05-30 | 2000-09-05 | Lsi Logic Corporation | First-In-First-Out (FIFO) memories having dual descriptors and credit passing for efficient access in a multi-processor system environment |
| US5978868A (en) * | 1997-08-28 | 1999-11-02 | Cypress Semiconductor Corp. | System for generating buffer status flags by comparing read and write pointers and determining direction of progression of read pointer with respect to write pointer |
| US6044030A (en) | 1998-12-21 | 2000-03-28 | Philips Electronics North America Corporation | FIFO unit with single pointer |
| US6756986B1 (en) | 1999-10-18 | 2004-06-29 | S3 Graphics Co., Ltd. | Non-flushing atomic operation in a burst mode transfer data storage access environment |
| US20040098519A1 (en) | 2001-03-16 | 2004-05-20 | Hugo Cheung | Method and device for providing high data rate for a serial peripheral interface |
| US7206904B2 (en) * | 2002-03-20 | 2007-04-17 | Hewlett-Packard Development Company, L.P. | Method and system for buffering multiple requests from multiple devices to a memory |
| CN1201234C (zh) * | 2003-03-28 | 2005-05-11 | 港湾网络有限公司 | 多通道先进先出数据缓冲存储装置 |
| KR20060003349A (ko) | 2003-04-17 | 2006-01-10 | 톰슨 라이센싱 에스.에이. | 데이터 요청 및 전송 장치, 및 프로세스 |
| US7181563B2 (en) | 2003-10-23 | 2007-02-20 | Lsi Logic Corporation | FIFO memory with single port memory modules for allowing simultaneous read and write operations |
| US8135915B2 (en) | 2004-03-22 | 2012-03-13 | International Business Machines Corporation | Method and apparatus for hardware assistance for prefetching a pointer to a data structure identified by a prefetch indicator |
| US6956776B1 (en) * | 2004-05-04 | 2005-10-18 | Xilinx, Inc. | Almost full, almost empty memory system |
| US9436432B2 (en) | 2005-12-30 | 2016-09-06 | Stmicroelectronics International N.V. | First-in first-out (FIFO) memory with multi-port functionality |
| US9015375B2 (en) | 2006-04-11 | 2015-04-21 | Sigmatel, Inc. | Buffer controller, codec and methods for use therewith |
| JP2008293484A (ja) * | 2007-04-27 | 2008-12-04 | Panasonic Corp | バッファメモリ共有装置 |
| WO2009067538A1 (en) | 2007-11-19 | 2009-05-28 | Mentor Graphics Corporation | Dynamic pointer dereferencing and conversion to static hardware |
| GB2469299B (en) * | 2009-04-07 | 2011-02-16 | Imagination Tech Ltd | Ensuring consistency between a data cache and a main memory |
| CN101661386B (zh) * | 2009-09-24 | 2013-03-20 | 成都市华为赛门铁克科技有限公司 | 多硬件线程处理器的业务处理装置及其业务处理方法 |
| US8908564B2 (en) * | 2010-06-28 | 2014-12-09 | Avaya Inc. | Method for Media Access Control address learning and learning rate suppression |
| US9098462B1 (en) * | 2010-09-14 | 2015-08-04 | The Boeing Company | Communications via shared memory |
| US8949547B2 (en) * | 2011-08-08 | 2015-02-03 | Arm Limited | Coherency controller and method for data hazard handling for copending data access requests |
| JP5842206B2 (ja) * | 2012-01-27 | 2016-01-13 | 株式会社トプスシステムズ | プロセッサ・コア、およびマルチコア・プロセッサ・システム |
| US9542227B2 (en) | 2012-01-30 | 2017-01-10 | Nvidia Corporation | Parallel dynamic memory allocation using a lock-free FIFO |
| US20130198419A1 (en) * | 2012-01-30 | 2013-08-01 | Stephen Jones | Lock-free fifo |
| US9639371B2 (en) | 2013-01-29 | 2017-05-02 | Advanced Micro Devices, Inc. | Solution to divergent branches in a SIMD core using hardware pointers |
| WO2014142836A1 (en) * | 2013-03-13 | 2014-09-18 | Empire Technology Development, Llc | Memory allocation accelerator |
| US9672008B2 (en) * | 2014-11-24 | 2017-06-06 | Nvidia Corporation | Pausible bisynchronous FIFO |
-
2015
- 2015-12-11 US US14/966,631 patent/US10585623B2/en active Active
-
2016
- 2016-12-12 KR KR1020187018862A patent/KR20180107091A/ko not_active Application Discontinuation
- 2016-12-12 CN CN201680070274.5A patent/CN108292162B/zh active Active
- 2016-12-12 JP JP2018529209A patent/JP6884149B2/ja active Active
- 2016-12-12 WO PCT/US2016/066106 patent/WO2017100748A1/en active Application Filing
- 2016-12-12 EP EP16874038.9A patent/EP3387513A4/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| WO2017100748A1 (en) | 2017-06-15 |
| KR20180107091A (ko) | 2018-10-01 |
| US10585623B2 (en) | 2020-03-10 |
| EP3387513A1 (en) | 2018-10-17 |
| CN108292162B (zh) | 2021-08-31 |
| JP2019502201A (ja) | 2019-01-24 |
| EP3387513A4 (en) | 2019-07-10 |
| CN108292162A (zh) | 2018-07-17 |
| US20170168755A1 (en) | 2017-06-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6884149B2 (ja) | マルチスレッドアクセスのためのソフトウェア定義のfifoバッファ | |
| JP6888019B2 (ja) | メモリアクセスコマンドの転送記述子 | |
| US10877757B2 (en) | Binding constants at runtime for improved resource utilization | |
| TWI489385B (zh) | 一種用於預先擷取快取線的電腦實作方法與子系統 | |
| US10620994B2 (en) | Continuation analysis tasks for GPU task scheduling | |
| US20210192046A1 (en) | Resource Management Unit for Capturing Operating System Configuration States and Managing Malware | |
| US20200117623A1 (en) | Adaptive Interrupt Coalescing | |
| JP2019502201A5 (ja) | ||
| US11782761B2 (en) | Resource management unit for capturing operating system configuration states and offloading tasks | |
| JP6966999B2 (ja) | マルチスレッド処理を調整するためのハードウェアアクセスカウンタとイベント生成 | |
| US11630698B2 (en) | Resource management unit for capturing operating system configuration states and swapping memory content | |
| US20190361805A1 (en) | Spin-less work-stealing for parallel copying garbage collection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191121 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20191121 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20201125 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20201201 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210226 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20210226 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210413 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210511 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6884149 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |