JP6251417B2 - ストレージシステム、及び、記憶制御方法 - Google Patents
ストレージシステム、及び、記憶制御方法 Download PDFInfo
- Publication number
- JP6251417B2 JP6251417B2 JP2016556061A JP2016556061A JP6251417B2 JP 6251417 B2 JP6251417 B2 JP 6251417B2 JP 2016556061 A JP2016556061 A JP 2016556061A JP 2016556061 A JP2016556061 A JP 2016556061A JP 6251417 B2 JP6251417 B2 JP 6251417B2
- Authority
- JP
- Japan
- Prior art keywords
- queue
- processor
- data
- shared
- assigned
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims description 211
- 230000007423 decrease Effects 0.000 claims description 17
- 230000007717 exclusion Effects 0.000 description 34
- 238000004590 computer program Methods 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0655—Vertical data movement, i.e. input-output transfer; data movement between one or more hosts and one or more storage devices
- G06F3/0659—Command handling arrangements, e.g. command buffers, queues, command scheduling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/10—Program control for peripheral devices
- G06F13/12—Program control for peripheral devices using hardware independent of the central processor, e.g. channel or peripheral processor
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/38—Information transfer, e.g. on bus
- G06F13/382—Information transfer, e.g. on bus using universal interface adapter
- G06F13/385—Information transfer, e.g. on bus using universal interface adapter for adaptation of a particular data processing system to different peripheral devices
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/061—Improving I/O performance
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/0671—In-line storage system
- G06F3/0673—Single storage device
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/0671—In-line storage system
- G06F3/0683—Plurality of storage devices
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/52—Program synchronisation; Mutual exclusion, e.g. by means of semaphores
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/061—Improving I/O performance
- G06F3/0613—Improving I/O performance in relation to throughput
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Software Systems (AREA)
- Multi Processors (AREA)
- Information Transfer Systems (AREA)
Description
<第1の実施形態>
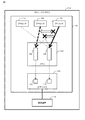
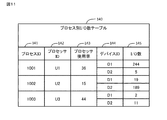
コントローラ2aは、複数のキューの内の利用負荷指標が最大のキューである第1のキューについて、そのキューのキュー種別を、共有から専有に変更するか否か判定してよい。ここで、利用負荷指標とは、キューにおける1のプロセッサあたりの利用負荷の大きさを示す指標であって、そのキューに割り当てられているプロセッサ数が多くなると小さくなり、各プロセッサからそのキューにデータが格納された頻度が大きくなると大きくなる値であってよい。
<第2の実施形態>
Claims (10)
- 複数プロセッサを含んだコントローラと、
記憶デバイスが接続されるインターフェイスデバイスと、
前記インターフェイスデバイスに関連付けられており専有キューと共有キューとを含んだ複数のキューと、
を有し、
前記複数のキューの各々には、そのキューに割り当てられているプロセッサから前記インターフェイスデバイスへ送られるデータが格納され、前記複数のキューの各々から前記インターフェイスデバイスにデータが送られるようになっており、
前記専有キューは、1つのプロセッサだけが割り当てられているキューであり、データの格納時に排他処理が不要なキューであり、
前記共有キューは、複数の前記プロセッサが割り当てられているキューであり、データの格納時に排他処理が必要なキューであり、
前記コントローラは、
前記専有キューに割り当てられたプロセッサと、前記共有キューに割り当てられたプロセッサと、の割当てを切替えた場合に、前記共有キューにデータが格納される共有頻度が所定の閾値以上小さくなる場合に、前記割当ての切替えを実行する
ストレージシステム。 - 前記コントローラは、
前記複数のプロセッサがそれぞれ前記インターフェイスデバイスへデータを発行したデータ発行頻度に基づいて、前記専有キューに割り当てるプロセッサを決定する
請求項1記載のストレージシステム。 - 複数プロセッサを含んだコントローラと、
記憶デバイスが接続されるインターフェイスデバイスと、
前記インターフェイスデバイスに関連付けられており専有キューと共有キューとを含んだ複数のキューと、
を有し、
前記複数のキューの各々には、そのキューに割り当てられているプロセッサから前記インターフェイスデバイスへ送られるデータが格納され、前記複数のキューの各々から前記インターフェイスデバイスにデータが送られるようになっており、
前記専有キューは、1つのプロセッサだけが割り当てられているキューであり、データの格納時に排他処理が不要なキューであり、
前記共有キューは、複数の前記プロセッサが割り当てられているキューであり、データの格納時に排他処理が必要なキューであり、
前記コントローラは、
前記複数のキューの内の利用負荷指標が最大のキューである第1のキューについて、そのキューのキュー種別を、共有から専有に変更するか否か判定するようになっており、
前記利用負荷指標は、キューにおける1のプロセッサあたりの利用負荷の大きさを示す指標であって、そのキューに割り当てられているプロセッサ数が多くなると小さくなり、各プロセッサからそのキューにデータが格納された頻度が大きくなると大きくなる値である
ストレージシステム。 - 前記コントローラは、
前記第1のキューに割り当てられている複数のプロセッサの内、前記第1のキューにデータを格納する頻度が最小のプロセッサを、前記複数のキューの内の前記利用負荷指標が最小のキューである第2のキューに割り当てる割当て切替えを実行したと仮定した場合の前記第1のキューの利用負荷指標及び前記第2のキューの利用負荷指標をそれぞれ推定し、
前記推定された第1のキューの利用負荷指標が、前記推定された第2のキューの利用負荷指標よりも大きい場合、前記第2のキューに前記最小のプロセッサを割り当てる割当て切替えを実行する
請求項3記載のストレージシステム。 - 前記利用負荷指標は、キューに割り当てられているプロセッサ数の逆数と、各プロセッサからそのキューにデータが格納された頻度の合計との積に基づく値である
請求項4記載のストレージシステム。 - 複数プロセッサを含んだコントローラと、
記憶デバイスが接続されるインターフェイスデバイスと、
前記インターフェイスデバイスに関連付けられており専有キューと共有キューとを含んだ複数のキューと、
を有し、
前記複数のキューの各々には、そのキューに割り当てられているプロセッサから前記インターフェイスデバイスへ送られるデータが格納され、前記複数のキューの各々から前記インターフェイスデバイスにデータが送られるようになっており、
前記専有キューは、1つのプロセッサだけが割り当てられているキューであり、データの格納時に排他処理が不要なキューであり、
前記共有キューは、複数の前記プロセッサが割り当てられているキューであり、データの格納時に排他処理が必要なキューであり、
前記複数のプロセッサのそれぞれでプロセスを実行することによりデータが発行されるようになっており、
前記コントローラは、
前記共有キューにデータが格納される頻度である共有頻度及び前記専有キューに割り当てられたプロセッサの負荷に関する所定の条件が満たされた場合、前記共有キューに割り当てられたいずれかのプロセッサで実行されているプロセスを、前記専有キューに割り当てられたプロセッサに移動させるプロセス移動を実行する
ストレージシステム。 - 前記所定の条件とは、前記プロセスを移動させた場合に前記共有キューにデータが格納される共有頻度が所定の閾値以上小さくなり、且つ、前記専有キューに割り当てられたプロセッサの負荷が所定の閾値未満である
請求項6記載のストレージシステム。 - ストレージシステムにおけるデータの記憶制御方法であって、
前記ストレージシステムは、複数のプロセッサを含んだコントローラと、記憶デバイスが接続されるインターフェイスデバイスと、前記インターフェイスデバイスに関連付けられており専有キューと共有キューを含んだ複数のキューと、を有し、
前記専有キューは、1つのプロセッサだけが割り当てられているキューであり、
前記共有キューは、複数の前記プロセッサが割り当てられているキューであり、
前記コントローラは、
前記インターフェイスデバイスへ送られるデータが前記専有キューに割り当てられたプロセッサから発行されたものである場合、排他処理を行わずに前記データを前記専有キューに格納し、
前記インターフェイスデバイスへ送られるデータが前記共有キューに割り当てられたプロセッサから発行されたものである場合、排他処理を行って前記データを前記共有キューに格納し、
前記専有キューに割り当てられたプロセッサと、前記共有キューに割り当てられたプロセッサと、の割当てを切替えた場合に、前記共有キューにデータが格納される共有頻度が所定の閾値以上小さくなる場合に、前記割当ての切替えを実行する
記憶制御方法。 - ストレージシステムにおけるデータの記憶制御方法であって、
前記ストレージシステムは、複数のプロセッサを含んだコントローラと、記憶デバイスが接続されるインターフェイスデバイスと、前記インターフェイスデバイスに関連付けられており専有キューと共有キューを含んだ複数のキューと、を有し、
前記専有キューは、1つのプロセッサだけが割り当てられているキューであり、
前記共有キューは、複数の前記プロセッサが割り当てられているキューであり、
前記コントローラは、
前記インターフェイスデバイスへ送られるデータが前記専有キューに割り当てられたプロセッサから発行されたものである場合、排他処理を行わずに前記データを前記専有キューに格納し、
前記インターフェイスデバイスへ送られるデータが前記共有キューに割り当てられたプロセッサから発行されたものである場合、排他処理を行って前記データを前記共有キューに格納し、
前記複数のキューの内の利用負荷指標が最大のキューである第1のキューについて、そのキューのキュー種別を、共有から専有に変更するか否か判定するようになっており、
前記利用負荷指標は、キューにおける1のプロセッサあたりの利用負荷の大きさを示す指標であって、そのキューに割り当てられているプロセッサ数が多くなると小さくなり、各プロセッサからそのキューにデータが格納された頻度が大きくなると大きくなる値である
記憶制御方法。 - ストレージシステムにおけるデータの記憶制御方法であって、
前記ストレージシステムは、複数のプロセッサを含んだコントローラと、記憶デバイスが接続されるインターフェイスデバイスと、前記インターフェイスデバイスに関連付けられており専有キューと共有キューを含んだ複数のキューと、を有し、
前記専有キューは、1つのプロセッサだけが割り当てられているキューであり、
前記共有キューは、複数の前記プロセッサが割り当てられているキューであり、
前記複数のプロセッサのそれぞれでプロセスを実行することによりデータが発行されるようになっており、
前記コントローラは、
前記インターフェイスデバイスへ送られるデータが前記専有キューに割り当てられたプロセッサから発行されたものである場合、排他処理を行わずに前記データを前記専有キューに格納し、
前記インターフェイスデバイスへ送られるデータが前記共有キューに割り当てられたプロセッサから発行されたものである場合、排他処理を行って前記データを前記共有キューに格納し、
前記共有キューにデータが格納される頻度である共有頻度及び前記専有キューに割り当てられたプロセッサの負荷に関する所定の条件が満たされた場合、前記共有キューに割り当てられたいずれかのプロセッサで実行されているプロセスを、前記専有キューに割り当てられたプロセッサに移動させるプロセス移動を実行する
記憶制御方法。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2014/078497 WO2016067339A1 (ja) | 2014-10-27 | 2014-10-27 | ストレージシステム、及び、記憶制御方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2016067339A1 JPWO2016067339A1 (ja) | 2017-06-29 |
| JP6251417B2 true JP6251417B2 (ja) | 2017-12-20 |
Family
ID=55856734
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016556061A Expired - Fee Related JP6251417B2 (ja) | 2014-10-27 | 2014-10-27 | ストレージシステム、及び、記憶制御方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US10162571B2 (ja) |
| JP (1) | JP6251417B2 (ja) |
| WO (1) | WO2016067339A1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220269540A1 (en) * | 2021-02-25 | 2022-08-25 | Seagate Technology Llc | NVMe POLICY-BASED I/O QUEUE ALLOCATION |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5239649A (en) * | 1989-10-30 | 1993-08-24 | International Business Machines Corporation | Channel path load balancing, through selection of storage volumes to be processed, for long running applications |
| US5506987A (en) * | 1991-02-01 | 1996-04-09 | Digital Equipment Corporation | Affinity scheduling of processes on symmetric multiprocessing systems |
| US5185861A (en) * | 1991-08-19 | 1993-02-09 | Sequent Computer Systems, Inc. | Cache affinity scheduler |
| US5217738A (en) * | 1992-04-17 | 1993-06-08 | Board Of Trustees Operating Michigan State University | Method for the treatment of harvested plant parts with L(+) adenosine or 1-triacontanol |
| US5872972A (en) * | 1996-07-05 | 1999-02-16 | Ncr Corporation | Method for load balancing a per processor affinity scheduler wherein processes are strictly affinitized to processors and the migration of a process from an affinitized processor to another available processor is limited |
| US5889989A (en) * | 1996-09-16 | 1999-03-30 | The Research Foundation Of State University Of New York | Load sharing controller for optimizing monetary cost |
| US6292822B1 (en) * | 1998-05-13 | 2001-09-18 | Microsoft Corporation | Dynamic load balancing among processors in a parallel computer |
| US6735769B1 (en) | 2000-07-13 | 2004-05-11 | International Business Machines Corporation | Apparatus and method for initial load balancing in a multiple run queue system |
| JP4186575B2 (ja) | 2002-09-30 | 2008-11-26 | 日本電気株式会社 | メモリアクセス装置 |
| JP4250989B2 (ja) * | 2003-03-26 | 2009-04-08 | 日本電気株式会社 | メモリアクセス制御装置 |
| JP2006318139A (ja) * | 2005-05-11 | 2006-11-24 | Matsushita Electric Ind Co Ltd | データ転送装置、データ転送方法およびプログラム |
| US8149708B2 (en) * | 2006-04-20 | 2012-04-03 | Cisco Technology, Inc. | Dynamically switching streams of packets among dedicated and shared queues |
| JP2008276326A (ja) | 2007-04-25 | 2008-11-13 | Hitachi Ltd | 記憶制御装置及び記憶制御装置の仮想メモリ制御方法 |
| JP5347451B2 (ja) | 2008-11-26 | 2013-11-20 | 富士通株式会社 | マルチプロセッサシステム、競合回避プログラム及び競合回避方法 |
| US8578106B1 (en) | 2012-11-09 | 2013-11-05 | DSSD, Inc. | Method and system for queue demultiplexor with size grouping |
| US8595385B1 (en) | 2013-05-28 | 2013-11-26 | DSSD, Inc. | Method and system for submission queue acceleration |
| KR20150017526A (ko) * | 2013-08-07 | 2015-02-17 | 삼성전자주식회사 | 메모리 명령 스케줄러 및 메모리 명령 스케줄링 방법 |
-
2014
- 2014-10-27 WO PCT/JP2014/078497 patent/WO2016067339A1/ja active Application Filing
- 2014-10-27 JP JP2016556061A patent/JP6251417B2/ja not_active Expired - Fee Related
- 2014-10-27 US US15/509,476 patent/US10162571B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| WO2016067339A1 (ja) | 2016-05-06 |
| JPWO2016067339A1 (ja) | 2017-06-29 |
| US10162571B2 (en) | 2018-12-25 |
| US20170286018A1 (en) | 2017-10-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7913257B2 (en) | Scheduling method, scheduling apparatus and multiprocessor system | |
| JP4963018B2 (ja) | スケジューリング方法およびスケジューリング装置 | |
| KR20150139408A (ko) | 이종의 저장 매체들을 이용하는 분산 파일 시스템을 구동하는 전자 시스템, 및 그것의 데이터 저장 방법 및 관리 방법 | |
| JP2008257572A (ja) | 論理区画に動的に資源割り当てを行うストレージシステム及びストレージシステムの論理分割方法 | |
| US9213560B2 (en) | Affinity of virtual processor dispatching | |
| US10164904B2 (en) | Network bandwidth sharing in a distributed computing system | |
| US9507633B2 (en) | Scheduling method and system | |
| WO2013035246A1 (ja) | 仮想計算機制御装置、仮想計算機制御方法、仮想計算機制御プログラム、及び集積回路 | |
| JPWO2017056310A1 (ja) | 計算機および計算機の制御方法 | |
| US7793051B1 (en) | Global shared memory subsystem | |
| JP5158576B2 (ja) | 入出力制御システム、入出力制御方法、及び、入出力制御プログラム | |
| JP6251417B2 (ja) | ストレージシステム、及び、記憶制御方法 | |
| JP2012221217A (ja) | メモリ管理装置、メモリ管理方法、および、制御プログラム | |
| JP2015191604A (ja) | 制御装置、制御プログラム、および制御方法 | |
| JP4789269B2 (ja) | ベクトル処理装置及びベクトル処理方法 | |
| CN105630593A (zh) | 用于处理中断的方法 | |
| US20130247065A1 (en) | Apparatus and method for executing multi-operating systems | |
| JP2014078214A (ja) | スケジュールシステム、スケジュール方法、スケジュールプログラム、及び、オペレーティングシステム | |
| JP6836536B2 (ja) | ストレージシステム及びio処理の制御方法 | |
| JP2013041361A (ja) | リソース調停システム及び調停方法 | |
| CN114637594A (zh) | 多核处理设备、任务分配方法、装置及存储介质 | |
| JP6445876B2 (ja) | リソース割当装置、リソース割当システム、および、リソース割当方法 | |
| JP4872942B2 (ja) | ストレージシステム、ストレージ装置、優先度制御装置および優先度制御方法 | |
| CN111274161A (zh) | 用于加速串行化算法的具有可变等待时间的位置感知型存储器 | |
| JP4727480B2 (ja) | 情報処理方法、情報処理システム、情報処理装置、マルチプロセッサ、情報処理プログラム及び情報処理プログラムを記憶したコンピュータ読み取り可能な記憶媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20170301 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170905 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20171031 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171124 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6251417 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |