JP4963018B2 - スケジューリング方法およびスケジューリング装置 - Google Patents
スケジューリング方法およびスケジューリング装置 Download PDFInfo
- Publication number
- JP4963018B2 JP4963018B2 JP2005235582A JP2005235582A JP4963018B2 JP 4963018 B2 JP4963018 B2 JP 4963018B2 JP 2005235582 A JP2005235582 A JP 2005235582A JP 2005235582 A JP2005235582 A JP 2005235582A JP 4963018 B2 JP4963018 B2 JP 4963018B2
- Authority
- JP
- Japan
- Prior art keywords
- execution unit
- identifier
- executed
- information
- thread
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/52—Program synchronisation; Mutual exclusion, e.g. by means of semaphores
- G06F9/526—Mutual exclusion algorithms
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/461—Saving or restoring of program or task context
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
Description
管理ユニットによってスケジューリングを行うこの方法では、管理ユニットとプロセッサ間の通信において、メッセージ遅延が起きることが多く、スレッドの実行を遅延させてしまうという問題がある。この問題を解決するために、各プロセッサによって自己支配的にスケジューリングする方法が考えられる。この方法では各プロセッサ上でおのおのスケジューラを実行し、共有メモリにあるタスクキューにアクセスして、実行するスレッドを選択する。
特に、ユーザレベルスケジューラを実行しているカーネルスレッドは各プロセッサ上のカーネルレベルスケジューラによってスケジューリングされ、他のカーネルスレッドによってプリエンプト(横取り)される可能性があるため、タスクキューのロックはより深刻な問題を引き起しかねない。この場合、横取りされた際にそのカーネルスレッドで動作するユーザレベルスケジューラがロックを取得していた場合には、他のプロセッサのスレッド上で動作するユーザレベルスケジューラがロックが解除されるまでスケジューリングすることができなくなる。
また、本発明のこの態様は、各プロセッサ上で直接動作するスケジューラだけではなく、各プロセッサ上のスケジューラが提供するスレッド上で動作するユーザレベルスケジューリングを用いるシステムに適用してもよい。
なお、上記説明は、プロセッサA、・・・を、プロセッサA、・・・上で動作するユーザレベルスケジューラを実行するスレッド(たとえばスレッドa、・・・)に置き換えれば、ユーザレベルスケジューラを実行するシステムにも適用することができる。具体的には、ユーザレベルスケジューラを実行するシステムにおいて、たとえばプロセッサA上で動作するユーザレベルスケジューラを実行するスレッドaも、割り込みによってプリエンプトされる可能性がある。スレッドaは、タスクキューがロックされた状態でプリエンプトされると、ほかのスレッドは、スレッドaが割り込み処理から復帰し、ロックが解除されるまでスケジューリングを行うことができない。すなわち、ユーザレベルスケジューラを用いるシステムにおいても同じように、タスクキューのロック起因して、システムは処理効率が低下し、不安定になりかねない問題がある。
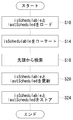
ここで、図1に示すマルチプロセッサシステム100は、カーネルスケジューラのみをを用いるマルチプロセッサシステムであるが、マルチプロセッサシステム100に用いられたスケジューリング方法は、各プロセッサ上で動作するスレッド上で実現されたユーザレベルスケジューラを用いたシステムにも適用することができる。その場合、スケジューリング中に割り込みを受け付けるか否かのジレンマを解消することができるとともに、前述した、ユーザレベルスケジューラを用いることに起因する問題も解消することができる。
Claims (10)
- マルチプロセッサシステムに含まれる複数のプロセッサのいずれにおいても実行可能な実行対象となる各実行単位に、当該実行単位とは分離して保存される識別子を付与し、
各実行単位のそれぞれが実行可能な状態にあるか、あるいはあるプロセッサで実行中であって別のプロセッサからは実行不可能な状態であるかを前記実行単位の識別子に対応づけて示す実行可否情報と、各実行単位のうちの、直近に実行された実行単位の識別子を示す直近実行情報とを含む実行単位情報を保持し、
実行単位情報に基づいて、直近に実行された実行単位の識別子以外の識別子を優先的に選出する制約の下でいずれかの実行可能な実行単位の識別子を、プロセッサによって実行される実行単位の識別子として選出するとともに、実行単位情報を更新することを特徴とするスケジューリング方法。 - 前記実行単位情報が、各プロセッサがアクセス可能なメモリに保持され、
前記選出および更新は、選出された識別子に対応する実行単位を実行するプロセッサ自身によって行われることを特徴とする請求項1記載のスケジューリング方法。 - 実行可否情報は、各実行単位について識別子として1ビットを割り当てたビット列として保持され、
前記選出および更新は、不可分操作によって行われることを特徴とする請求項1または2記載のスケジューリング方法。 - 直近に実行された実行単位に対応するビットが末尾になるようにビット列をローテートし、
ローテートされたビット列の先頭から順に実行可能な実行単位のビットを検索することによって前記選出を行うことを特徴とする請求項3記載のスケジューリング方法。 - マルチプロセッサシステムに含まれる複数のプロセッサのいずれにおいても実行可能な実行対象となる各実行単位のそれぞれが実行可能な状態にあるか、あるいはあるプロセッサで実行中であって別のプロセッサからは実行不可能な状態であるかを、それぞれの実行単位に対して付与された識別子に対応づけて示す実行可否情報と、各実行単位のうちの、直近に実行された実行単位の識別子を示す直近実行情報とを含む実行単位情報を、前記各実行単位とは分離して保持する実行単位情報保持部と、
実行単位情報に基づいて、直近に実行された実行単位の識別子以外の識別子を優先的に選出する制約の下でいずれかの実行可能な実行単位の識別子を、プロセッサによって実行される実行単位の識別子として選出する実行単位選出部と、
前記選出に伴い、実行単位情報を更新する実行単位情報更新部とを備えることを特徴とするスケジューリング装置。 - 実行単位情報保持部は、各プロセッサがアクセス可能なメモリに実行単位情報を保持し、
実行単位選出部および実行単位情報更新部は、選出された識別子に対応する実行単位を実行するプロセッサ自身により構成されることを特徴とする請求項5記載のスケジューリング装置。 - 実行単位情報保持部は、実行可否情報を、各実行単位について識別子として1ビットを割り当てたビット列として保持し、
実行単位選出部および実行単位情報更新部は、不可分操作によって前記選出および更新を行うことを特徴とする請求項5または6記載のスケジューリング装置。 - 実行単位選出部は、直近に実行された実行単位に対応するビットが末尾になるようにビット列をローテートし、
ローテートされたビット列の先頭から順に実行可能な実行単位のビットを検索することによって前記選出を行うことを特徴とする請求項7記載のスケジューリング装置。 - マルチプロセッサシステムに含まれる複数のプロセッサのいずれにおいても実行可能な実行対象となる各実行単位のそれぞれが実行可能な状態にあるか、あるいはあるプロセッサで実行中であって別のプロセッサからは実行不可能な状態であるかを、それぞれの実行単位に対して付与された識別子に対応づけて示す実行可否情報と、各実行単位のうちの、直近に実行された実行単位の識別子を示す直近実行情報とを含む実行単位情報を、前記各実行単位とは分離して保持する機能と、
実行単位情報に基づいて、直近に実行された実行単位の識別子以外の識別子を優先的に選出する制約の下でいずれかの実行可能な実行単位の識別子を、プロセッサによって実行される実行単位の識別子として選出するとともに、実行単位情報を更新する機能とをコンピュータに実行せしめることを特徴とするプログラム。 - プログラムを記憶した記憶媒体であって、
前記プログラムは、
マルチプロセッサシステムに含まれる複数のプロセッサのいずれにおいても実行可能な実行対象となる各実行単位のそれぞれが実行可能な状態にあるか、あるいはあるプロセッサで実行中であって別のプロセッサからは実行不可能な状態であるかを、それぞれの実行単位に対して付与された識別子に対応づけて示す実行可否情報と、各実行単位のうちの、直近に実行された実行単位の識別子を示す直近実行情報とを含む実行単位情報を、前記各実行単位とは分離して保持する機能と、
実行単位情報に基づいて、直近に実行された実行単位の識別子以外の識別子を優先的に選出する制約の下でいずれかの実行可能な実行単位の識別子を、プロセッサによって実行される実行単位の識別子として選出するとともに、実行単位情報を更新する機能とをコンピュータに実行せしめることを特徴とする記憶媒体。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005235582A JP4963018B2 (ja) | 2005-08-15 | 2005-08-15 | スケジューリング方法およびスケジューリング装置 |
| CN2006800179477A CN101180609B (zh) | 2005-08-15 | 2006-05-31 | 调度方法以及调度装置 |
| PCT/JP2006/310907 WO2007020739A1 (ja) | 2005-08-15 | 2006-05-31 | スケジューリング方法およびスケジューリング装置 |
| EP06756827A EP1923784A4 (en) | 2005-08-15 | 2006-05-31 | SCHEDULING PROCEDURE AND SCHEDULING EQUIPMENT |
| US11/996,361 US8375390B2 (en) | 2005-08-15 | 2006-05-31 | Scheduling method and scheduling apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005235582A JP4963018B2 (ja) | 2005-08-15 | 2005-08-15 | スケジューリング方法およびスケジューリング装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007052511A JP2007052511A (ja) | 2007-03-01 |
| JP4963018B2 true JP4963018B2 (ja) | 2012-06-27 |
Family
ID=37757408
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005235582A Active JP4963018B2 (ja) | 2005-08-15 | 2005-08-15 | スケジューリング方法およびスケジューリング装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US8375390B2 (ja) |
| EP (1) | EP1923784A4 (ja) |
| JP (1) | JP4963018B2 (ja) |
| CN (1) | CN101180609B (ja) |
| WO (1) | WO2007020739A1 (ja) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7647483B2 (en) | 2007-02-20 | 2010-01-12 | Sony Computer Entertainment Inc. | Multi-threaded parallel processor methods and apparatus |
| US8589943B2 (en) | 2007-08-15 | 2013-11-19 | Sony Computer Entertainment Inc. | Multi-threaded processing with reduced context switching |
| JP5324934B2 (ja) * | 2009-01-16 | 2013-10-23 | 株式会社ソニー・コンピュータエンタテインメント | 情報処理装置および情報処理方法 |
| US8352946B2 (en) * | 2009-08-11 | 2013-01-08 | International Business Machines Corporation | Managing migration ready queue associated with each processor based on the migration ready status of the tasks |
| CN101996082B (zh) * | 2009-08-28 | 2014-06-11 | 国际商业机器公司 | 协处理器系统和在本地存储器上加载应用程序的方法 |
| US8056080B2 (en) * | 2009-08-31 | 2011-11-08 | International Business Machines Corporation | Multi-core/thread work-group computation scheduler |
| US9354883B2 (en) | 2014-03-27 | 2016-05-31 | International Business Machines Corporation | Dynamic enablement of multithreading |
| US9594660B2 (en) | 2014-03-27 | 2017-03-14 | International Business Machines Corporation | Multithreading computer system and program product for executing a query instruction for idle time accumulation among cores |
| US9417876B2 (en) | 2014-03-27 | 2016-08-16 | International Business Machines Corporation | Thread context restoration in a multithreading computer system |
| US10102004B2 (en) | 2014-03-27 | 2018-10-16 | International Business Machines Corporation | Hardware counters to track utilization in a multithreading computer system |
| US9218185B2 (en) | 2014-03-27 | 2015-12-22 | International Business Machines Corporation | Multithreading capability information retrieval |
| US9804846B2 (en) | 2014-03-27 | 2017-10-31 | International Business Machines Corporation | Thread context preservation in a multithreading computer system |
| US9921848B2 (en) | 2014-03-27 | 2018-03-20 | International Business Machines Corporation | Address expansion and contraction in a multithreading computer system |
| US10101963B2 (en) * | 2016-08-16 | 2018-10-16 | Hewlett Packard Enterprise Development Lp | Sending and receiving data between processing units |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2253428A5 (ja) * | 1973-11-30 | 1975-06-27 | Honeywell Bull Soc Ind | |
| US4796178A (en) * | 1985-10-15 | 1989-01-03 | Unisys Corporation | Special purpose processor for off-loading many operating system functions in a large data processing system |
| JP2505526B2 (ja) * | 1988-04-11 | 1996-06-12 | 沖電気工業株式会社 | タスクのビットマップ管理方法 |
| JP2804478B2 (ja) * | 1988-05-26 | 1998-09-24 | 株式会社日立製作所 | タスク制御方式及びオンライン・トランザクション・システム |
| JPH02242434A (ja) * | 1989-03-16 | 1990-09-26 | Hitachi Ltd | タスクのスケジューリング方法 |
| JPH0424828A (ja) * | 1990-05-21 | 1992-01-28 | Fuji Xerox Co Ltd | マルチタスク管理方式 |
| JPH07146799A (ja) | 1993-11-22 | 1995-06-06 | Hitachi Ltd | マルチタスク・システムにおけるタスク切り換え方法 |
| US20030191794A1 (en) * | 2000-02-17 | 2003-10-09 | Brenner Larry Bert | Apparatus and method for dispatching fixed priority threads using a global run queue in a multiple run queue system |
| CN1152306C (zh) * | 2001-01-23 | 2004-06-02 | 英业达股份有限公司 | 防止多处理器计算机中各处理器间进程发生冲突的方法 |
| US8566828B2 (en) | 2003-12-19 | 2013-10-22 | Stmicroelectronics, Inc. | Accelerator for multi-processing system and method |
| US7802255B2 (en) * | 2003-12-19 | 2010-09-21 | Stmicroelectronics, Inc. | Thread execution scheduler for multi-processing system and method |
-
2005
- 2005-08-15 JP JP2005235582A patent/JP4963018B2/ja active Active
-
2006
- 2006-05-31 WO PCT/JP2006/310907 patent/WO2007020739A1/ja active Application Filing
- 2006-05-31 EP EP06756827A patent/EP1923784A4/en not_active Ceased
- 2006-05-31 US US11/996,361 patent/US8375390B2/en active Active
- 2006-05-31 CN CN2006800179477A patent/CN101180609B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20090031315A1 (en) | 2009-01-29 |
| EP1923784A1 (en) | 2008-05-21 |
| CN101180609A (zh) | 2008-05-14 |
| JP2007052511A (ja) | 2007-03-01 |
| US8375390B2 (en) | 2013-02-12 |
| EP1923784A4 (en) | 2010-02-17 |
| WO2007020739A1 (ja) | 2007-02-22 |
| CN101180609B (zh) | 2011-06-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4963018B2 (ja) | スケジューリング方法およびスケジューリング装置 | |
| JP4526412B2 (ja) | マルチプロセッサシステムにおけるタスク管理方法および装置 | |
| US9588810B2 (en) | Parallelism-aware memory request scheduling in shared memory controllers | |
| CN104572568B (zh) | 读锁操作方法、写锁操作方法及系统 | |
| US20070294702A1 (en) | Method and apparatus for implementing atomicity of memory operations in dynamic multi-streaming processors | |
| US9378069B2 (en) | Lock spin wait operation for multi-threaded applications in a multi-core computing environment | |
| WO2011103825A2 (zh) | 多处理器系统负载均衡的方法和装置 | |
| KR20060132852A (ko) | 멀티 프로세서 시스템에서 프로세서 태스크 이동 방법 및장치 | |
| CN103729480A (zh) | 一种多核实时操作系统多个就绪任务快速查找及调度方法 | |
| US20120030430A1 (en) | Cache control apparatus, and cache control method | |
| US20130152100A1 (en) | Method to guarantee real time processing of soft real-time operating system | |
| US10223269B2 (en) | Method and apparatus for preventing bank conflict in memory | |
| JPH11282815A (ja) | マルチスレッド計算機システム及びマルチスレッド実行制御方法 | |
| JP4926364B2 (ja) | ダイナミックマルチストリーミングプロセッサでメモリ操作の原子性を実現するための方法と装置 | |
| JP7042105B2 (ja) | プログラム実行制御方法および車両制御装置 | |
| JP7346649B2 (ja) | 同期制御システムおよび同期制御方法 | |
| WO2000033175A2 (en) | Method for increasing efficiency of multiprocessing systems | |
| KR20230121884A (ko) | 어드레스 매핑 인식 태스킹 메커니즘 | |
| JP7217341B2 (ja) | プロセッサおよびレジスタの継承方法 | |
| JPH08292932A (ja) | マルチプロセッサシステムおよびマルチプロセッサシステムにおいてタスクを実行する方法 | |
| KR102563648B1 (ko) | 멀티 프로세서 시스템 및 그 구동 방법 | |
| JP6445876B2 (ja) | リソース割当装置、リソース割当システム、および、リソース割当方法 | |
| JP6251417B2 (ja) | ストレージシステム、及び、記憶制御方法 | |
| US11860785B2 (en) | Method and system for efficient communication and command system for deferred operation | |
| JP2023179057A (ja) | 演算処理装置および演算処理方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080722 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20101125 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110127 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110712 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110823 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120321 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120321 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4963018 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150406 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |