JP6176111B2 - 分散処理管理装置及び分散処理管理方法 - Google Patents
分散処理管理装置及び分散処理管理方法 Download PDFInfo
- Publication number
- JP6176111B2 JP6176111B2 JP2013528921A JP2013528921A JP6176111B2 JP 6176111 B2 JP6176111 B2 JP 6176111B2 JP 2013528921 A JP2013528921 A JP 2013528921A JP 2013528921 A JP2013528921 A JP 2013528921A JP 6176111 B2 JP6176111 B2 JP 6176111B2
- Authority
- JP
- Japan
- Prior art keywords
- phase
- distributed
- processing time
- time
- processes
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/26—Visual data mining; Browsing structured data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5066—Algorithms for mapping a plurality of inter-dependent sub-tasks onto a plurality of physical CPUs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Debugging And Monitoring (AREA)
Description
前記複数の処理は、複数のフェーズで実行される。該複数のフェーズは、前記各処理のための入力データを読み込み、該入力データに第1の処理を施すことにより得られる出力データを後段のフェーズに送るMapフェーズと、当該出力データに対して第2の処理を行うReduceフェーズと、を少なくとも含む。前記選択部は、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する。
前記複数の処理は、複数のフェーズで実行される。該複数のフェーズは、前記各処理のための入力データを読み込み、該入力データに第1の処理を施すことにより得られる出力データを後段のフェーズに送るMapフェーズと、当該出力データに対して第2の処理を行うReduceフェーズと、を少なくとも含む。前記コンピュータが、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する。
〔システム構成〕
図1は、第1実施形態における分散処理システム1の構成例を概念的に示す図である。第1実施形態における分散処理システム1は、マスタ装置10、複数のスレーブ装置20(#1、#2、・・・、#n)を有する。上述の分散処理管理装置は、マスタ装置10上で実現される。これにより、マスタ装置10は、分散処理管理装置と呼ぶこともできる。各スレーブ装置20(#1、#2、・・・、#n)はそれぞれ同じ機能を持てばよいため、特に個々を区別する必要がある場合を除き、スレーブ装置20と総称する。
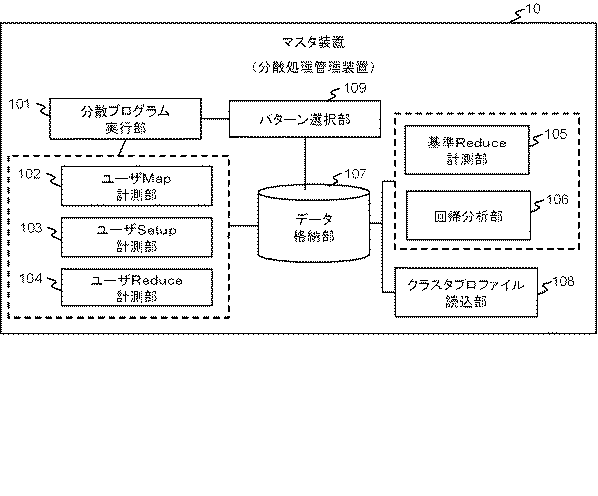
図2は、第1実施形態におけるマスタ装置10の構成例を概念的に示す図である。図2に示されるように、マスタ装置10は、分散プログラム実行部101、ユーザMap計測部102、ユーザSetup計測部103、ユーザReduce計測部104、基準Reduce計測部105、回帰分析部106、データ格納部107、クラスタプロファイル読込部108、パターン選択部109等を有する。マスタ装置10は、例えば、メモリに格納されるプログラムがCPU11により実行されることにより、図2に示される各処理部をそれぞれ実現する。当該プログラムは、例えば、CD(Compact Disc)、メモリカード等のような可搬型記録媒体やネットワーク上の他のコンピュータから入出力I/F14を介してインストールされ、メモリに格納される。
a1+a2*p+a3*n+a4*p*n=f(p,n) (式1)
PCD=D/(W*tM) (式3)
PMDは(D/p)<Memを満たす最小のpである。 (式4)
図3は、分散実行パターンと各マシンの負担との関係の一例を示す図である。図3の例では、クラスタ内のマシン数Mが20であり、処理数Cが40であり、データサイズDが40GBである場合が示されている。この場合、図3に示されるように、6個の分散実行パターンが存在し得る。
以下、第1実施形態における分散処理システム1の動作例について図9を用いて説明する。図9は、第1実施形態における分散処理システム1の動作例を示すフローチャートである。
第1実施形態では、パラメータの異なる複数の処理を実現する分散プログラムのトータル実行時間が最小となる分散実行パターンが選択され、選択された分散実行パターンに基づいて当該分散プログラムが実行される。よって、第1実施形態によれば、実行すべき分散プログラムのトータル実行時間を短縮させることができる。
以下、第2実施形態における分散処理システム1について、第1実施形態と異なる内容を中心に説明し、第1実施形態と同じ内容については適宜省略する。
図10は、第2実施形態におけるマスタ装置10の構成例を概念的に示す図である。図10に示されるように、第2実施形態におけるマスタ装置10は、第1実施形態の構成に加えて、予測モデル格納部110及びモデル選択部111を更に有する。これら各処理部についても、例えば、メモリに格納されるプログラムがCPU11により実行されることにより実現される。
a1+a2*p+a3*n=f1(p,n) (式8−1)
a1+a2*p+a3*n+a4*p^2=f2(p,n) (式8−2)
a1+a2*p+a3*n+a4*n^2=f3(p,n) (式8−3)
a1+a2*p+a3*n+a4*n*p=f4(p,n) (式8−4)
上述のように、第2実施形態では、複数の予測モデル式の候補の中から、最良の予測モデル式が選択されて、この選択された予測モデル式を用いて、各分散実行パターンに対応するユーザReduceの処理時間が推定される。従って、第2実施形態によれば、ユーザReduceの処理時間を一層正確に推定することができ、ひいては、トータル実行時間を最小化する最良の分散実行パターンを選択することができる。
なお、上述の実施形態では、分散実行パターンを特定する情報としてグループあたりのマシン数pを用いることにより、上記(式2)の値が最小となるpが決定された。分散実行パターンを特定する情報としてはグループ数gが用いられてもよい。この場合、上記(式2)のpをM/gで置き換えた式を利用して、その式の値が最小となるgが決定されればよい。
tM=D/(p・W)
この場合、ユーザReduce計測部104と基準Reduce計測部105、回帰分析部106は不要である。
を備えることを特徴とする分散処理管理装置。
前記選択部は、前記Mapフェーズの処理時間の推定式により得られる、又は、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる、前記各分散実行パターンに依存する推定式を用いて、前記トータル実行時間を推定する、
ことを特徴とする付記1に記載の分散処理管理装置。
を更に備え、
前記選択部は、前記各分散実行パターンに対応する1コンピュータ当たりのデータ読み取り時間、及び、前記Mapフェーズ計測部により計測された前記Mapフェーズの前記計算時間を取得し、取得されたいずれか一方の時間を、前記トータル実行時間に含まれる前記Mapフェーズの処理時間として用いる、
ことを特徴とする付記2に記載の分散処理管理装置。
を更に備え、
前記選択部は、処理されるデータ量と前記各分散実行パターンとに応じて前記Reduceフェーズの処理の基準とされる基準処理の処理時間を予測する予測モデル式を取得し、該予測モデル式に基づいて前記第1分散実行パターンに対応する基準処理の処理時間を推定し、前記第1分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間と前記第1分散実行パターンに対応する基準処理の処理時間との比を用いて該予測モデル式を補正することにより、前記各分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間を推定し、該推定されたReduceフェーズの処理時間を用いて、前記トータル実行時間に含まれる前記Reduceフェーズの実行時間を推定する、
ことを特徴とする付記2又は3に記載の分散処理管理装置。
前記基準処理計測部により取得された、担当するコンピュータの数、処理されるデータ量及び前記基準処理の実行時間の複数の組み合わせデータを用いて回帰分析を行うことにより、前記予測モデル式を推定する回帰分析部と、
を更に備えることを特徴とする付記4に記載の分散処理管理装置。
前記回帰分析部による各予測モデル式に対する回帰分析の結果に基づいて情報量基準により前記複数の予測モデル式を評価することにより、前記複数の予測モデル式の中の1つを選択する予測モデル選択部と、
を更に備え、
前記選択部は、前記予測モデル選択部により選択された予測モデル式を取得する、
ことを特徴とする付記5に記載の分散処理管理装置。
前記分散処理管理装置は、
前記複数のコンピュータの少なくとも1つに前記複数の処理の中の1つを実行させることにより、1処理あたりのSetupフェーズの処理時間を計測するSetupフェーズ計測部、を更に備え、
前記選択部は、前記各分散実行パターンに対応する1コンピュータ当たりの処理数を取得し、前記1処理あたりのSetupフェーズの処理時間に、該1コンピュータ当たりの処理数を掛け合わせることにより、前記Setupフェーズの処理時間の推定式を推定し、前記Mapフェーズの処理時間の推定式及び前記Reduceフェーズの処理時間の推定式に加えて、前記Setupフェーズの処理時間の推定式を更に合わせることにより得られる、前記各分散実行パターンに依存する推定式を用いて、前記トータル実行時間を推定する、
ことを特徴とする付記2から6のいずれか1つに記載の分散処理管理装置。
を更に備える付記1から7のいずれか1つに記載の分散処理管理装置。
複数のコンピュータが複数のフェーズでパラメータの異なる複数の処理を分散実行するのにかかるトータル実行時間を、該複数のコンピュータのグループ分け形態を示しかつ各処理を担当するコンピュータの数に対応する分散実行パターンに応じて推定することにより、複数の分散実行パターンの中から、該トータル実行時間が最小となる分散実行パターンを選択する、
ことを含む分散処理管理方法。
前記分散実行パターンの選択は、前記Mapフェーズの処理時間の推定式により得られる、又は、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる、前記各分散実行パターンに依存する推定式を用いて、前記トータル実行時間を推定する、
付記9に記載の分散処理管理方法。
前記複数のコンピュータの少なくとも1つに前記Mapフェーズを実行させることにより、前記Mapフェーズの計算時間を計測する、
ことを更に含み、
前記分散実行パターンの選択は、前記各分散実行パターンに対応する1コンピュータ当たりのデータ読み取り時間、及び、計測された前記Mapフェーズの前記計算時間を取得し、取得されたいずれか一方の時間を、前記トータル実行時間に含まれる前記Mapフェーズの処理時間として用いる、
付記10に記載の分散処理管理方法。
前記複数の分散実行パターンの中の第1分散実行パターンで前記複数の処理の中の1つを実行させることにより、該第1分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間を計測する、
ことを更に含み、
前記分散実行パターンの選択は、
処理されるデータ量と前記各分散実行パターンとに応じて前記Reduceフェーズの処理の基準とされる基準処理の処理時間を予測する予測モデル式を取得し、
前記予測モデル式に基づいて前記第1分散実行パターンに対応する基準処理の処理時間を推定し、
前記第1分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間と前記第1分散実行パターンに対応する基準処理の処理時間との比を用いて該予測モデル式を補正することにより、前記各分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間を推定する、
ことを含み、
前記推定されたReduceフェーズの処理時間を用いて、前記トータル実行時間に含まれる前記Reduceフェーズの実行時間を推定する、
ことを特徴とする付記10又は11に記載の分散処理管理方法。
担当するコンピュータの数及び処理されるデータ量を変えながら、前記基準処理を実際に実行することにより、前記基準処理の実行時間を計測し、
前記担当するコンピュータの数、前記処理されるデータ量及び前記基準処理の実行時間の複数の組み合わせデータを用いて回帰分析を行うことにより、前記予測モデル式を推定する、
ことを更に含む付記12に記載の分散処理管理方法。
前記基準処理の処理時間を予測する複数の予測モデル式に対して回帰分析をそれぞれ行い、
前記各予測モデル式に対する回帰分析の結果に基づいて情報量基準により前記複数の予測モデル式を評価することにより、前記複数の予測モデル式の中の1つを選択する、
ことを更に含み、
前記分散実行パターンの選択は、前記選択された予測モデル式を取得する、
付記13に記載の分散処理管理方法。
前記コンピュータが、
前記複数のコンピュータの少なくとも1つに前記複数の処理の中の1つを実行させることにより、1処理あたりのSetupフェーズの処理時間を計測する、
ことを更に含み、
前記分散実行パターンの選択は、前記各分散実行パターンに対応する1コンピュータ当たりの処理数を取得し、前記1処理あたりのSetupフェーズの処理時間に、該1コンピュータ当たりの処理数を掛け合わせることにより、前記Setupフェーズの処理時間の推定式を推定し、前記Mapフェーズの処理時間の推定式及び前記Reduceフェーズの処理時間の推定式に加えて、前記Setupフェーズの処理時間の推定式を更に合わせることにより得られる、前記各分散実行パターンに依存する推定式を用いて、前記トータル実行時間を推定する、
付記10から14のいずれか1つに記載の分散処理管理方法。
前記選択された分散実行パターンにより示されるグループ分け形態に基づいて、各グループに対して各パラメータをそれぞれ割り当て、
前記複数の処理を分散実行するように前記各グループに指示する、
ことを更に含む付記9から15のいずれか1つに記載の分散処理管理方法。
複数のコンピュータが複数のフェーズでパラメータの異なる複数の処理を分散実行するのにかかるトータル実行時間を、該複数のコンピュータのグループ分け形態を示しかつ各処理を担当するコンピュータの数に対応する分散実行パターンに応じて推定することにより、複数の分散実行パターンの中から、該トータル実行時間が最小となる分散実行パターンを選択する選択部、
を実現させることを特徴とするプログラム。
前記選択部は、前記Mapフェーズの処理時間の推定式により得られる、又は、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる、前記各分散実行パターンに依存する推定式を用いて、前記トータル実行時間を推定する、
ことを特徴とする付記17に記載のプログラム。
前記複数のコンピュータの少なくとも1つに前記Mapフェーズを実行させることにより、前記Mapフェーズの計算時間を計測するMapフェーズ計測部、
を更に実現させ、
前記選択部は、前記各分散実行パターンに対応する1コンピュータ当たりのデータ読み取り時間、及び、前記Mapフェーズ計測部により計測された前記Mapフェーズの前記計算時間を取得し、取得されたいずれか一方の時間を、前記トータル実行時間に含まれる前記Mapフェーズの処理時間として用いる、
ことを特徴とする付記18に記載のプログラム。
前記複数の分散実行パターンの中の第1分散実行パターンで前記複数の処理の中の1つを実行させることにより、該第1分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間を計測するReduceフェーズ計測部、
を更に実現させ、
前記選択部は、処理されるデータ量と前記各分散実行パターンとに応じて前記Reduceフェーズの処理の基準とされる基準処理の処理時間を予測する予測モデル式を取得し、該予測モデル式に基づいて前記第1分散実行パターンに対応する基準処理の処理時間を推定し、前記第1分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間と前記第1分散実行パターンに対応する基準処理の処理時間との比を用いて該予測モデル式を補正することにより、前記各分散実行パターンに対応する1処理あたりのReduceフェーズの処理時間を推定し、該推定されたReduceフェーズの処理時間を用いて、前記トータル実行時間に含まれる前記Reduceフェーズの実行時間を推定する、
ことを特徴とする付記18又は19に記載のプログラム。
担当するコンピュータの数及び処理されるデータ量を変えながら、前記基準処理を実際に実行することにより、前記基準処理の実行時間を計測する基準処理計測部と、
前記基準処理計測部により取得された、担当するコンピュータの数、処理されるデータ量及び前記基準処理の実行時間の複数の組み合わせデータを用いて回帰分析を行うことにより、前記予測モデル式を推定する回帰分析部と、
を更に実現させることを特徴とする付記20に記載のプログラム。
前記基準処理の処理時間を予測する複数の予測モデル式を格納する予測モデル格納部と、
前記回帰分析部による各予測モデル式に対する回帰分析の結果に基づいて情報量基準により前記複数の予測モデル式を評価することにより、前記複数の予測モデル式の中の1つを選択する予測モデル選択部と、
を更に実現させ、
前記選択部は、前記予測モデル選択部により選択された予測モデル式を取得する、
ことを特徴とする付記21に記載のプログラム。
前記コンピュータに、
前記複数のコンピュータの少なくとも1つに前記複数の処理の中の1つを実行させることにより、1処理あたりのSetupフェーズの処理時間を計測するSetupフェーズ計測部、
を更に実現させ、
前記選択部は、前記各分散実行パターンに対応する1コンピュータ当たりの処理数を取得し、前記1処理あたりのSetupフェーズの処理時間に、該1コンピュータ当たりの処理数を掛け合わせることにより、前記Setupフェーズの処理時間の推定式を推定し、前記Mapフェーズの処理時間の推定式及び前記Reduceフェーズの処理時間の推定式に加えて、前記Setupフェーズの処理時間の推定式を更に合わせることにより得られる、前記各分散実行パターンに依存する推定式を用いて、前記トータル実行時間を推定する、
ことを特徴とする付記18から22のいずれか1つに記載のプログラム。
前記選択部により選択された分散実行パターンにより示されるグループ分け形態に基づいて、各グループに対して各パラメータをそれぞれ割り当て、前記複数の処理を分散実行するように該各グループに指示する分散処理実行部、
を更に実現させる付記17から23のいずれか1つに記載のプログラム。
Claims (10)
- 複数の処理をグループ分けされた複数のコンピュータの各グループに割り当てて分散実行するのにかかるトータル実行時間が最小となるグループ形態を、各処理を担当するグループ当たりのコンピュータの数に対応する複数の情報の中から、選択する選択部、
を備え、
前記複数の処理は、複数のフェーズで実行され、
該複数のフェーズは、前記各処理のための入力データを読み込み、該入力データに第1の処理を施すことにより得られる出力データを後段のフェーズに送るMapフェーズと、当該出力データに対して第2の処理を行うReduceフェーズと、を少なくとも含み、
前記選択部は、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する、分散処理管理装置。 - 前記複数のコンピュータの少なくとも1つに前記Mapフェーズを実行させることにより、前記Mapフェーズの計算時間を計測するMapフェーズ計測部、
を備え、
前記選択部は、前記複数の情報で示される各グループ形態に対応する1コンピュータ当たりのデータ読み取り時間、及び、前記Mapフェーズ計測部により計測された前記Mapフェーズの前記計算時間、のいずれかを、前記トータル実行時間に含まれる前記Mapフェーズの処理時間として用いる、
請求項1に記載の分散処理管理装置。 - 前記複数の情報の中の第1の情報で示されるグループ形態であらわされるグループの1つに前記複数の処理の中の1つを実行させることにより、該第1の情報で示されるグループ形態に対応する1処理あたりのReduceフェーズの処理時間を計測するReduceフェーズ計測部、
を備え、
前記選択部は、処理されるデータ量と前記複数の情報で示される各グループ形態とに応じて前記Reduceフェーズの処理の基準とされる基準処理の処理時間を予測する予測モデル式を取得し、該予測モデル式に基づいて前記第1の情報で示されるグループ形態に対応する基準処理の処理時間を推定し、前記第1の情報で示されるグループ形態に対応する1処理あたりのReduceフェーズの処理時間と前記第1の情報で示されるグループ形態に対応する前記基準処理の処理時間との比を用いて該予測モデル式を補正することにより、前記複数の情報で示される各グループ形態に対応する1処理あたりのReduceフェーズの処理時間を推定し、該推定されたReduceフェーズの処理時間を用いて、前記トータル実行時間に含まれる前記Reduceフェーズの実行時間を推定する、
請求項1又は2に記載の分散処理管理装置。 - 担当するコンピュータの数及び処理されるデータ量を変えながら、前記基準処理を実際に実行することにより、前記基準処理の実行時間を計測する基準処理計測部と、
前記基準処理計測部により取得された、担当するコンピュータの数、処理されるデータ量及び前記基準処理の実行時間の複数の組み合わせデータを用いて回帰分析を行うことにより、前記予測モデル式を推定する回帰分析部と、
を備える請求項3に記載の分散処理管理装置。 - 前記基準処理の処理時間を予測する複数の予測モデル式を格納する予測モデル格納部と、
前記回帰分析部による各予測モデル式に対する回帰分析の結果に基づいて情報量基準により前記複数の予測モデル式を評価することにより、前記複数の予測モデル式の中の1つを選択する予測モデル選択部と、
を備え、
前記選択部は、前記予測モデル選択部により選択された予測モデル式を取得する、
請求項4に記載の分散処理管理装置。 - 前記複数のフェーズは、後段のフェーズのための初期化処理を行うSetupフェーズを含み、
前記分散処理管理装置は、
前記複数のコンピュータの少なくとも1つに前記複数の処理の中の1つを実行させることにより、1処理あたりのSetupフェーズの処理時間を計測するSetupフェーズ計測部、
を備え、
前記選択部は、前記複数の情報で示される各グループ形態に対応する1コンピュータ当たりの処理数を取得し、前記1処理あたりのSetupフェーズの処理時間に、該1コンピュータ当たりの処理数を掛け合わせることにより、前記Setupフェーズの処理時間の推定式を推定し、前記Mapフェーズの処理時間の推定式及び前記Reduceフェーズの処理時間の推定式に、前記Setupフェーズの処理時間の推定式を合わせることにより得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する、
請求項1から5のいずれか1項に記載の分散処理管理装置。 - 前記選択部により選択されたグループ形態に対応するグループ分けをされた、複数のコンピュータの各グループに、前記複数の処理を割り当てて分散実行するように該各グループに指示する分散処理実行部、
を備える請求項1から6のいずれか1項に記載の分散処理管理装置。 - 前記複数の処理は、複数のフェーズで実行され、
該複数のフェーズは、前記各処理のための入力データを読み込み、該入力データに第1の処理を施すことにより得られる出力データを後段のフェーズに送るMapフェーズと、当該出力データに対して第2の処理を行うReduceフェーズと、を少なくとも含み、
前記選択部は、前記Mapフェーズの処理時間の推定式により得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する、
請求項1に記載の分散処理管理装置。 - コンピュータが、
複数の処理をグループ分けされた複数のコンピュータの各グループに割り当てて分散実行するのにかかるトータル実行時間が最小となるグループ形態を、各処理を担当するグループ当たりのコンピュータの数に対応する複数の情報の中から、選択し、
前記複数の処理は、複数のフェーズで実行され、
該複数のフェーズは、前記各処理のための入力データを読み込み、該入力データに第1の処理を施すことにより得られる出力データを後段のフェーズに送るMapフェーズと、当該出力データに対して第2の処理を行うReduceフェーズと、を少なくとも含み、
前記コンピュータが、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する、分散処理管理方法。 - コンピュータに、
複数の処理をグループ分けされた複数のコンピュータの各グループに割り当てて分散実行するのにかかるトータル実行時間が最小となるグループ形態を、各処理を担当するグループ当たりのコンピュータの数に対応する複数の情報の中から、選択する選択部、
を実現させ、
前記複数の処理は、複数のフェーズで実行され、
該複数のフェーズは、前記各処理のための入力データを読み込み、該入力データに第1の処理を施すことにより得られる出力データを後段のフェーズに送るMapフェーズと、当該出力データに対して第2の処理を行うReduceフェーズと、を少なくとも含み、
前記選択部は、前記Mapフェーズの処理時間の推定式と前記Reduceフェーズの処理時間の推定式とを合わせることにより得られる推定式であって、前記複数の情報で示される各グループ形態に依存する推定式を用いて、前記トータル実行時間を推定する、プログラム。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011177753 | 2011-08-15 | ||
| JP2011177753 | 2011-08-15 | ||
| JP2011244517 | 2011-11-08 | ||
| JP2011244517 | 2011-11-08 | ||
| PCT/JP2012/005163 WO2013024597A1 (ja) | 2011-08-15 | 2012-08-15 | 分散処理管理装置及び分散処理管理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2013024597A1 JPWO2013024597A1 (ja) | 2015-03-05 |
| JP6176111B2 true JP6176111B2 (ja) | 2017-08-09 |
Family
ID=47714931
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013528921A Active JP6176111B2 (ja) | 2011-08-15 | 2012-08-15 | 分散処理管理装置及び分散処理管理方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20140201114A1 (ja) |
| EP (1) | EP2746942A4 (ja) |
| JP (1) | JP6176111B2 (ja) |
| WO (1) | WO2013024597A1 (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6357807B2 (ja) * | 2014-03-05 | 2018-07-18 | 富士通株式会社 | タスク割当プログラム、タスク実行プログラム、マスタサーバ、スレーブサーバおよびタスク割当方法 |
| US9910888B2 (en) * | 2014-10-01 | 2018-03-06 | Red Hat, Inc. | Map-reduce job virtualization |
| WO2017113278A1 (zh) * | 2015-12-31 | 2017-07-06 | 华为技术有限公司 | 数据处理方法、装置和系统 |
| US10878318B2 (en) | 2016-03-28 | 2020-12-29 | Google Llc | Adaptive artificial neural network selection techniques |
| JP6766495B2 (ja) * | 2016-07-21 | 2020-10-14 | 富士通株式会社 | プログラム、コンピュータ及び情報処理方法 |
| JP6411562B2 (ja) * | 2017-02-24 | 2018-10-24 | 株式会社三菱総合研究所 | 情報処理装置、情報処理方法及びプログラム |
| JP6917732B2 (ja) * | 2017-03-01 | 2021-08-11 | 株式会社日立製作所 | プログラム導入支援システム、プログラム導入支援方法、及びプログラム導入支援プログラム |
| JP2018160258A (ja) * | 2018-05-24 | 2018-10-11 | 株式会社三菱総合研究所 | 情報処理装置、情報処理方法及びプログラム |
| CN109375873B (zh) * | 2018-09-27 | 2022-02-18 | 郑州云海信息技术有限公司 | 一种分布式存储集群中数据处理守护进程的初始化方法 |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1139271A (ja) * | 1997-07-15 | 1999-02-12 | Toshiba Corp | ライブラリシステムおよびライブラリの割り当て方法 |
| JP3792879B2 (ja) | 1998-03-09 | 2006-07-05 | 富士通株式会社 | 並列実行システム |
| JP4739472B2 (ja) * | 1998-12-04 | 2011-08-03 | 新日鉄ソリューションズ株式会社 | 性能予測装置および方法、記録媒体 |
| JP3671759B2 (ja) * | 1999-08-26 | 2005-07-13 | 株式会社日立製作所 | ソフトウェア配布方法およびシステム |
| JP2001184222A (ja) * | 1999-12-27 | 2001-07-06 | Nec Ic Microcomput Syst Ltd | 分散処理装置、分散処理方法および記録媒体 |
| US7395250B1 (en) * | 2000-10-11 | 2008-07-01 | International Business Machines Corporation | Methods and apparatus for outlier detection for high dimensional data sets |
| US6704687B2 (en) * | 2001-01-31 | 2004-03-09 | Hewlett-Packard Development Company, L.P. | Historical results based method for automatically improving computer system performance |
| JP3683216B2 (ja) * | 2001-12-28 | 2005-08-17 | 新日鉄ソリューションズ株式会社 | 性能評価装置、情報処理方法およびプログラム |
| US7805392B1 (en) * | 2005-11-29 | 2010-09-28 | Tilera Corporation | Pattern matching in a multiprocessor environment with finite state automaton transitions based on an order of vectors in a state transition table |
| US8244747B2 (en) * | 2006-12-05 | 2012-08-14 | International Business Machines Corporation | Middleware for query processing across a network of RFID databases |
| JP4405520B2 (ja) * | 2007-01-22 | 2010-01-27 | インターナショナル・ビジネス・マシーンズ・コーポレーション | プロジェクトの進行スケジュールを調整するためのコンピュータプログラム、コンピュータ装置及び方法 |
| WO2009059377A1 (en) * | 2007-11-09 | 2009-05-14 | Manjrosoft Pty Ltd | Software platform and system for grid computing |
| JP2010079622A (ja) * | 2008-09-26 | 2010-04-08 | Hitachi Ltd | マルチコアプロセッサシステム、および、そのタスク制御方法 |
| JP2010218307A (ja) * | 2009-03-17 | 2010-09-30 | Hitachi Ltd | 分散計算制御装置及び方法 |
| US8239847B2 (en) * | 2009-03-18 | 2012-08-07 | Microsoft Corporation | General distributed reduction for data parallel computing |
| US8229868B2 (en) * | 2009-04-13 | 2012-07-24 | Tokyo Institute Of Technology | Data converting apparatus and medium having data converting program |
| US9250625B2 (en) * | 2011-07-19 | 2016-02-02 | Ge Intelligent Platforms, Inc. | System of sequential kernel regression modeling for forecasting and prognostics |
-
2012
- 2012-08-15 JP JP2013528921A patent/JP6176111B2/ja active Active
- 2012-08-15 US US14/238,708 patent/US20140201114A1/en not_active Abandoned
- 2012-08-15 WO PCT/JP2012/005163 patent/WO2013024597A1/ja active Application Filing
- 2012-08-15 EP EP12823546.2A patent/EP2746942A4/en not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| EP2746942A1 (en) | 2014-06-25 |
| US20140201114A1 (en) | 2014-07-17 |
| JPWO2013024597A1 (ja) | 2015-03-05 |
| WO2013024597A1 (ja) | 2013-02-21 |
| EP2746942A4 (en) | 2015-09-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6176111B2 (ja) | 分散処理管理装置及び分散処理管理方法 | |
| JP7413580B2 (ja) | ニューラルネットワークを使用した集積回路フロアプランの生成 | |
| US10318874B1 (en) | Selecting forecasting models for time series using state space representations | |
| JP6638030B2 (ja) | Paradigm薬剤反応ネットワーク | |
| Rasooli et al. | COSHH: A classification and optimization based scheduler for heterogeneous Hadoop systems | |
| CN103136039B (zh) | 用于平衡能量消耗和调度性能的作业调度方法和系统 | |
| US20180004751A1 (en) | Methods and apparatus for subgraph matching in big data analysis | |
| JP5983728B2 (ja) | 仮想マシン管理装置及び仮想マシン管理方法 | |
| US10120717B2 (en) | Method for optimizing the size of a data subset of a processing space for improved execution performance | |
| JP6953800B2 (ja) | シミュレーションジョブを実行するためのシステム、コントローラ、方法、及びプログラム | |
| US9916283B2 (en) | Method and system for solving a problem involving a hypergraph partitioning | |
| JP2016042284A (ja) | 並列計算機システム、管理装置、並列計算機システムの制御方法及び管理装置の制御プログラム | |
| KR20170092707A (ko) | 최적화된 브라우저 렌더링 프로세스 | |
| US20150012629A1 (en) | Producing a benchmark describing characteristics of map and reduce tasks | |
| CN109033439A (zh) | 流式数据的处理方法和装置 | |
| JP5803469B2 (ja) | 予測方法及び予測プログラム | |
| Rosas et al. | Improving performance on data-intensive applications using a load balancing methodology based on divisible load theory | |
| US20220076121A1 (en) | Method and apparatus with neural architecture search based on hardware performance | |
| US20190101911A1 (en) | Optimization of virtual sensing in a multi-device environment | |
| JP2012221254A (ja) | 並列処理最適化装置及びシミュレーションプログラム | |
| Shichkina et al. | Applying the list method to the transformation of parallel algorithms into account temporal characteristics of operations | |
| WO2020218246A1 (ja) | 最適化装置、最適化方法、及びプログラム | |
| CN109684094B (zh) | 云平台环境下海量文献并行挖掘的负载分配方法及系统 | |
| CN108228323A (zh) | 基于数据本地性的Hadoop任务调度方法及装置 | |
| CN111527734B (zh) | 节点流量占比预测方法及装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150702 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160712 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160908 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20170207 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170426 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20170509 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170613 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170626 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6176111 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |