JP6115220B2 - 情報処理プログラム、情報処理方法及び装置 - Google Patents
情報処理プログラム、情報処理方法及び装置 Download PDFInfo
- Publication number
- JP6115220B2 JP6115220B2 JP2013056542A JP2013056542A JP6115220B2 JP 6115220 B2 JP6115220 B2 JP 6115220B2 JP 2013056542 A JP2013056542 A JP 2013056542A JP 2013056542 A JP2013056542 A JP 2013056542A JP 6115220 B2 JP6115220 B2 JP 6115220B2
- Authority
- JP
- Japan
- Prior art keywords
- book
- reading
- user
- data
- read
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 14
- 238000003672 processing method Methods 0.000 title claims description 9
- 238000012545 processing Methods 0.000 claims description 59
- 238000000034 method Methods 0.000 claims description 43
- 238000013500 data storage Methods 0.000 claims description 18
- 239000000284 extract Substances 0.000 claims description 6
- 238000013075 data extraction Methods 0.000 description 39
- 238000010586 diagram Methods 0.000 description 25
- 230000006870 function Effects 0.000 description 17
- 238000004891 communication Methods 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 6
- 238000013480 data collection Methods 0.000 description 5
- 238000007726 management method Methods 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
Images




















Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Transfer Between Computers (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
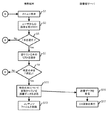
ユーザ毎に、読書速度と、借りた本毎に本を貸出期間内に読了したか否かを表すデータとを格納するデータ格納部から、第1のユーザの第1の読書速度を読み出し、
前記データ格納部から、前記第1のユーザの前記第1の読書速度から所定範囲内の読書速度が格納されており且つ特定の本を借りた他のユーザを抽出し、
抽出された前記他のユーザのうち読了したユーザがいる場合に、前記特定の本の情報を前記第1のユーザが利用する装置に出力する
処理を、コンピュータに実行させるためのプログラム。
前記データ格納部が、ユーザ毎に、第1の読書頻度と、単位時間あたりの第1の読書量に関するデータと、借りた本毎に当該本についての第2の読書頻度及び前記単位時間あたりの第2の読書量に関するデータとをさらに格納しており、
抽出された前記他のユーザのうち読了したユーザを前記第2の読書頻度で分類し、読了したユーザについての第1の分類毎に前記第2の読書量の第1の範囲を特定し、
前記第1のユーザの第1の読書頻度に対応する第1の分類を特定し、
前記第1のユーザの第1の読書量が、特定された前記第1の分類についての第1の範囲の最小値以上となっているか否かを判定し、
当該判定結果に応じた第2のデータを、前記第1のユーザが利用する装置に出力する
処理を、さらに前記コンピュータに実行させるための付記1記載のプログラム。
抽出された前記他のユーザのうち読了しなかったユーザを前記第2の読書頻度で分類し、読了しなかったユーザについての第2の分類毎に前記第2の読書量の第2の範囲を特定し、
前記第1のユーザの読書量が、特定された前記第1の分類についての第1の範囲の最小値未満であれば、特定された前記第1の分類に対応する第2の分類についての第2の範囲の上限を超えているか判定する第2の判定処理をさらに前記コンピュータに実行させ、
前記判定結果が、前記第2の判定処理の結果を含む、付記2記載のプログラム。
前記第1の分類及び前記第1の分類の各々について特定された前記第1の範囲と、前記第2の分類及び前記第2の分類の各々について特定された前記第2の範囲と、前記第1のユーザの第1の読書頻度及び第1の読書量に対応する前記第1の分類又は第2の分類及び前記第1の範囲又は第2の範囲を識別するためのデータとを含む第3のデータを、前記第1のユーザが利用する装置に出力する処理
をさらに前記コンピュータに実行させるための付記1記載のプログラム。
前記第1の読書量に関するデータが、前記単位時間あたりの第1の読書時間のデータを含み、
前記第1の読書量が、前記単位時間あたりの第1の読書時間を前記第1の読書速度で除することによって算出され、
前記第2の読書量に関するデータが、前記本についての第2の読書速度及び前記単位時間あたりの第2の読書時間のデータを含み、
前記第2の読書量が、前記第2の読書時間を前記第2の読書速度で除することによって算出され、
前記第1及び第2の読書速度が、ページ単位の読書速度である
付記1乃至4のいずれか1つ記載のプログラム。
前記第1のデータが、抽出された前記他のユーザの数に対する読了したユーザの数の割合と、抽出された前記他のユーザの数に対する読了しなかったユーザの数の割合とのうち少なくともいずれかを含む
付記1乃至5のいずれか1つ記載のプログラム。
ユーザ毎に、読書速度と、借りた本毎に本を貸出期間内に読了したか否かを表すデータとを格納するデータ格納部から、第1のユーザの第1の読書速度を読み出し、
前記データ格納部から、前記第1のユーザの前記第1の読書速度から所定範囲内の読書速度が格納されており且つ特定の本を借りた他のユーザを抽出し、
抽出された前記他のユーザのうち読了したユーザがいる場合に、前記特定の本の情報を前記第1のユーザが利用する装置に出力する
処理を含み、コンピュータにより実行される情報処理方法。
ユーザ毎に、読書速度と、借りた本毎に本を貸出期間内に読了したか否かを表すデータとを格納するデータ格納部から、第1のユーザの第1の読書速度を読み出し、前記データ格納部から、前記第1のユーザの前記第1の読書速度から所定範囲内の読書速度が格納されており且つ特定の本を借りた他のユーザを抽出する第1の処理部と、
抽出された前記他のユーザのうち読了したユーザがいる場合に、前記特定の本の情報を前記第1のユーザが利用する装置に出力する第2の処理部と、
を有する情報処理装置。
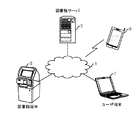
3 図書館サーバ
5 図書館端末
7 ユーザ端末
31 要求処理部
32 データ抽出部
33 ユーザDB
34 ペースDB
35 図書DB
36 コメントDB
37 データ登録部
Claims (12)
- ユーザ毎に、読書速度と、借りた本毎に本を貸出期間内に読了したか否かを表すデータとを格納するデータ格納部から、第1のユーザの第1の読書速度を読み出し、
前記データ格納部から、前記第1のユーザの前記第1の読書速度から所定範囲内の読書速度が格納されており且つ特定の本を借りた他のユーザを抽出し、
抽出された前記他のユーザのうち読了したユーザがいる場合に、前記特定の本の情報を前記第1のユーザが利用する装置に出力する
処理を、コンピュータに実行させるためのプログラム。 - 前記データ格納部が、ユーザ毎に、第1の読書頻度と、単位時間あたりの第1の読書量に関するデータと、借りた本毎に当該本についての第2の読書頻度及び前記単位時間あたりの第2の読書量に関するデータとをさらに格納しており、
抽出された前記他のユーザのうち読了したユーザを前記第2の読書頻度で分類し、読了したユーザについての第1の分類毎に前記第2の読書量の第1の範囲を特定し、
前記第1のユーザの第1の読書頻度に対応する第1の分類を特定し、
前記第1のユーザの第1の読書量が、特定された前記第1の分類についての第1の範囲の最小値以上となっているか否かを判定し、
当該判定結果に応じた第2のデータを、前記第1のユーザが利用する装置に出力する
処理を、さらに前記コンピュータに実行させるための請求項1記載のプログラム。 - 抽出された前記他のユーザのうち読了しなかったユーザを前記第2の読書頻度で分類し、読了しなかったユーザについての第2の分類毎に前記第2の読書量の第2の範囲を特定し、
前記第1のユーザの読書量が、特定された前記第1の分類についての第1の範囲の最小値未満であれば、特定された前記第1の分類に対応する第2の分類についての第2の範囲の最大値を超えているか判定する第2の判定処理をさらに前記コンピュータに実行させ、
前記判定結果が、前記第2の判定処理の結果を含む、請求項2記載のプログラム。 - 前記第1の分類及び前記第1の分類の各々について特定された前記第1の範囲と、前記第2の分類及び前記第2の分類の各々について特定された前記第2の範囲と、前記第1のユーザの第1の読書頻度及び第1の読書量に対応する前記第1の分類又は第2の分類及び前記第1の範囲又は第2の範囲を識別するためのデータとを含む第3のデータを、前記第1のユーザが利用する装置に出力する処理
をさらに前記コンピュータに実行させるための請求項3記載のプログラム。 - ユーザ毎に、読書速度と、借りた本毎に本を貸出期間内に読了したか否かを表すデータとを格納するデータ格納部から、第1のユーザの第1の読書速度を読み出し、
前記データ格納部から、前記第1のユーザの前記第1の読書速度から所定範囲内の読書速度が格納されており且つ特定の本を借りた他のユーザを抽出し、
抽出された前記他のユーザのうち読了したユーザがいる場合に、前記特定の本の情報を前記第1のユーザが利用する装置に出力する
処理を含み、コンピュータにより実行される情報処理方法。 - ユーザ毎に、読書速度と、借りた本毎に本を貸出期間内に読了したか否かを表すデータとを格納するデータ格納部から、第1のユーザの第1の読書速度を読み出し、前記データ格納部から、前記第1のユーザの前記第1の読書速度から所定範囲内の読書速度が格納されており且つ特定の本を借りた他のユーザを抽出する第1の処理部と、
抽出された前記他のユーザのうち読了したユーザがいる場合に、前記特定の本の情報を前記第1のユーザが利用する装置に出力する第2の処理部と、
を有する情報処理装置。 - 本の指定を受け付け、
本の読者を該本に対応付けて記憶する記憶部を参照して、指定された前記本に対応付けられた読者を特定し、
本の読書状況に関する読書情報を、該本の読者に対応付けて記憶する記憶部を参照して、特定した前記読者に対応付けられた読書情報を取得し、
取得した前記読書情報を表示する、
処理をコンピュータに実行させることを特徴とするプログラム。 - 指定された前記本を読了した読者に関する前記本の読書情報を出力する、
ことを特徴とする請求項7に記載のプログラム。 - 前記読書情報は、前記本の読書スピードに関する情報である、
ことを特徴とする請求項7又は8に記載のプログラム。 - 前記本は電子本である、
ことを特徴とする請求項7乃至9のいずれか1つに記載のプログラム。 - 本の指定を受け付け、
本の読者を該本に対応付けて記憶する記憶部を参照して、指定された前記本に対応付けられた読者を特定し、
本の読書状況に関する読書情報を、該本の読者に対応付けて記憶する記憶部を参照して、特定した前記読者に対応付けられた読書情報を取得し、
取得した前記読書情報を表示する、
処理をコンピュータが実行する情報処理方法。 - 本の指定を受け付ける第1の処理部と、
本の読者を該本に対応付けて記憶する記憶部を参照して、指定された前記本に対応付けられた読者を特定する第2の処理部と、
本の読書状況に関する読書情報を、該本の読者に対応付けて記憶する記憶部を参照して、特定した前記読者に対応付けられた読書情報を取得する第3の処理部と、
取得した前記読書情報を表示する第4の処理部と、
を有する情報処理装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013056542A JP6115220B2 (ja) | 2013-03-19 | 2013-03-19 | 情報処理プログラム、情報処理方法及び装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013056542A JP6115220B2 (ja) | 2013-03-19 | 2013-03-19 | 情報処理プログラム、情報処理方法及び装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2014182578A JP2014182578A (ja) | 2014-09-29 |
| JP2014182578A5 JP2014182578A5 (ja) | 2016-09-15 |
| JP6115220B2 true JP6115220B2 (ja) | 2017-04-19 |
Family
ID=51701235
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013056542A Active JP6115220B2 (ja) | 2013-03-19 | 2013-03-19 | 情報処理プログラム、情報処理方法及び装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6115220B2 (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6247727B1 (ja) * | 2016-09-02 | 2017-12-13 | 株式会社 ディー・エヌ・エー | アドバイザによる提案を管理するためのシステム、方法、及びプログラム |
| JP6772723B2 (ja) * | 2016-09-27 | 2020-10-21 | 富士通株式会社 | 貸出プログラム、貸出方法、及び情報処理装置 |
| KR102409598B1 (ko) | 2021-12-14 | 2022-06-22 | 주식회사 밀리의서재 | 전자책 정보를 검색하기 위한 사용자 인터페이스를 제공하는 방법 및 이를 이용한 서버 |
| CN118469095B (zh) * | 2024-07-10 | 2024-09-10 | 北京家音顺达数据技术有限公司 | 一种支持通借通还的共享式图书管理系统 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4463242B2 (ja) * | 2006-06-29 | 2010-05-19 | 日本電気株式会社 | 情報分類装置 |
| JP5588900B2 (ja) * | 2011-03-16 | 2014-09-10 | 株式会社Jsol | 電子書籍装置、サーバ装置、読書情報処理方法、およびプログラム |
-
2013
- 2013-03-19 JP JP2013056542A patent/JP6115220B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014182578A (ja) | 2014-09-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6084123B2 (ja) | サーバ装置、表示制御方法及びプログラム | |
| US11675824B2 (en) | Method and system for entity extraction and disambiguation | |
| US20170097984A1 (en) | Method and system for generating a knowledge representation | |
| KR102139664B1 (ko) | 프로필 이미지 카드를 공유하는 시스템 및 방법 | |
| JP6031535B2 (ja) | 多様な形態のカードを利用してサイトの製作を支援するサイト管理方法およびシステム | |
| US20170098283A1 (en) | Methods, systems and techniques for blending online content from multiple disparate content sources including a personal content source or a semi-personal content source | |
| JP6115220B2 (ja) | 情報処理プログラム、情報処理方法及び装置 | |
| JP6573321B2 (ja) | 情報処理装置、情報処理方法およびプログラム | |
| US20170097933A1 (en) | Methods, systems and techniques for ranking blended content retrieved from multiple disparate content sources | |
| US11836169B2 (en) | Methods, systems and techniques for providing search query suggestions based on non-personal data and user personal data according to availability of user personal data | |
| JP5506104B2 (ja) | 情報処理装置、情報処理方法、及び情報処理プログラム | |
| JP5375642B2 (ja) | 業務時間集計装置、業務時間集計方法及び業務時間集計プログラム | |
| JP2017068547A (ja) | 情報提供装置、プログラム及び情報提供方法 | |
| JP2016053809A (ja) | サーバ装置、プログラム及び情報提供方法 | |
| CN113168354B (zh) | 用于从一个或多个计算机应用中选择并提供可用动作给用户的系统和方法 | |
| KR20130091197A (ko) | 일정 정보 완성 방법과 시스템 및 기록 매체 | |
| KR20110114969A (ko) | 관심 정보 제공 시스템 및 방법 | |
| JP2015018289A (ja) | 情報処理装置、情報処理方法、及び情報処理プログラム | |
| JP5774535B2 (ja) | コンテンツ推薦プログラム、コンテンツ推薦装置及びコンテンツ推薦方法 | |
| JP6235744B1 (ja) | ウェブページ制作支援システム | |
| EP3432154A1 (en) | Method and apparatus for providing search recommendation information | |
| JP7165959B1 (ja) | 情報処理システム及びプログラム | |
| JP6065676B2 (ja) | 情報処理プログラム、情報処理方法及び装置 | |
| JP7003797B2 (ja) | データ推薦装置、方法、プログラム、及びシステム | |
| JP5953248B2 (ja) | インテント分類装置、方法及びプログラム、サービス選択支援装置、方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151007 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160715 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160727 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160816 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170221 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170306 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6115220 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |