JP5534007B2 - 特徴点検出システム、特徴点検出方法、及びプログラム - Google Patents
特徴点検出システム、特徴点検出方法、及びプログラム Download PDFInfo
- Publication number
- JP5534007B2 JP5534007B2 JP2012514747A JP2012514747A JP5534007B2 JP 5534007 B2 JP5534007 B2 JP 5534007B2 JP 2012514747 A JP2012514747 A JP 2012514747A JP 2012514747 A JP2012514747 A JP 2012514747A JP 5534007 B2 JP5534007 B2 JP 5534007B2
- Authority
- JP
- Japan
- Prior art keywords
- area
- data
- extracted
- data points
- cluster
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000001514 detection method Methods 0.000 title claims description 65
- 238000000605 extraction Methods 0.000 claims description 17
- 238000009826 distribution Methods 0.000 claims description 13
- 239000000284 extract Substances 0.000 claims description 13
- 230000006870 function Effects 0.000 claims description 3
- 238000000034 method Methods 0.000 description 56
- 230000008569 process Effects 0.000 description 33
- 238000004364 calculation method Methods 0.000 description 26
- 238000012545 processing Methods 0.000 description 14
- 238000005070 sampling Methods 0.000 description 9
- 238000010586 diagram Methods 0.000 description 6
- 238000004590 computer program Methods 0.000 description 5
- 238000007621 cluster analysis Methods 0.000 description 4
- 238000013523 data management Methods 0.000 description 4
- 238000007726 management method Methods 0.000 description 4
- 230000008859 change Effects 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 3
- 230000014759 maintenance of location Effects 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 230000004043 responsiveness Effects 0.000 description 3
- 230000001133 acceleration Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 125000002066 L-histidyl group Chemical group [H]N1C([H])=NC(C([H])([H])[C@](C(=O)[*])([H])N([H])[H])=C1[H] 0.000 description 1
- 241000271496 Lachesis Species 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000008521 reorganization Effects 0.000 description 1
- 238000012958 reprocessing Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000009827 uniform distribution Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images









Classifications
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01C—MEASURING DISTANCES, LEVELS OR BEARINGS; SURVEYING; NAVIGATION; GYROSCOPIC INSTRUMENTS; PHOTOGRAMMETRY OR VIDEOGRAMMETRY
- G01C21/00—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00
- G01C21/26—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00 specially adapted for navigation in a road network
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/29—Geographical information databases
Landscapes
- Engineering & Computer Science (AREA)
- Remote Sensing (AREA)
- Radar, Positioning & Navigation (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Automation & Control Theory (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Traffic Control Systems (AREA)
Description
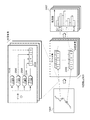
図1は、本発明の実施の形態によるGPSログデータの特徴点検出システム100の構成を示すブロック図である。図1に示すように、特徴点検出システム100は、入力部1002、滞留エリア検出部1003、代表点抽出部1004、及び出力部1005を備えている。入力部1002、滞留エリア検出部1003、代表点抽出部1004、及び出力部1005は、プログラムに従ってコンピュータのプロセッサが行う動作のモジュールを表している。
なお、ここでは緯度、経度、高度からなる3次元空間を考えるが、次元数はこれに限られない。例えば、時間を加えた4次元空間に拡張するなど、その空間における2点間の距離の近さを点の密集度と対応付けられるならば、次元を増やしてもよい。特に、時間的に近いことは滞留という意味では重要であり、時間の差を空間的な距離の差に変換して時間軸を考慮することが可能である。
確率的ヒストグラム化部2001は、GPSログデータ1001の入力に対して、連結ヒストグラム2007を計算する。

前半処理は、クラスター分析処理をhighグループのデータポイントに対して行い、コロニーを形成することを目的としている。ここで、最終的に形成したい滞留エリアの半径を規定するlth、滞留エリア間の最小距離を規定するDthをあらかじめ設定しておく。
後半処理は、前半処理で形成したクラスターセットに対して、lowグループに属する各データポイントが、そのどれか1つのクラスターに属すると判断された場合は該当するクラスターに追加し、どのクラスターにも属しないと判断された場合は新規クラスターを作成し、クラスターセットを更新する処理を行うことで、最終的な滞留エリアを形成する。
図10は本発明による特徴点検出システムをウェイポイント検出部9007に適用したサーバ9004を含む、コンピュータシステムの構成を示す図である。図に示すように、ユーザのGPSログデータを記録する記録デバイス9001と、GPSログデータをアップロードしたり、加工したデータの結果を表示したりするためのコンピュータ9002と、サーバ9004とが、ネットワーク9003を介して接続されている。
(付記1)ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいてそのクラスターにおけるユーザの滞留時間を示す指標を決定し、前記指標に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する滞留エリア検出部であって、前記滞留時間が長いほどそのクラスターが高い確率で抽出される、滞留エリア検出部と、
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を1つずつ抽出すると共に、各々の前記滞留エリア内の前記データポイントの密集度に基づいて、各々の前記代表点のスコアを決定する代表点抽出部と、
前記スコアに基づいて、各々の前記代表点を序列化したリストを出力する代表点序列化部と、を備えた特徴点検出システム。
第1のデータポイントと第2のデータポイントを、2つのデータポイント間の距離が短いほど高い確率で前記第1及び第2のポイントが同一の階級に属するように分類することによりヒストグラムを生成し、前記ヒストグラムの各階級を前記クラスターに対応させて、各階級の頻度を前記滞留時間を示す指標として決定する確率的ヒストグラム化部を備えた付記1に記載の特徴点検出システム。
前記確率的ヒストグラム化部によって生成された前記ヒストグラムの各階級のうち、前記滞留時間の長いクラスターに対応する階級を抽出し、前記抽出した階級に属するデータポイントに対して第2のクラスタリングを行うことにより前記滞留エリアを形成する、付記2に記載の特徴点検出システム。
前記確率的ヒストグラム化部によって生成された前記ヒストグラムの各階級のうち、前記滞留時間の長いクラスターに対応する階級を抽出し、前記抽出した階級を前記滞留時間の長短に基づいて2つのグループに分ける、再構成・グループ化部と、
前記2つのグループのうち、前記滞留時間の長い方のグループの階級に属するデータポイントを用いて滞留エリアを形成した後、他方のグループの階級に属するデータポイントを前記滞留エリアに付加し、または新たな滞留エリアを形成して、滞留エリアを形成するクラスター化部と、を備えた付記2に記載の特徴点検出システム。
各データポイントに対してLSH(Locality Sensitive Hashing)を用いて付与されるラベルを用いて、各々のデータポイントが属する階級を決定する付記2から4のいずれかに記載の特徴点検出システム。
ランドマークに対応する地点に対応するデータポイント、及びユーザの嗜好に合った地点に対応するデータポイントの少なくとも一方に対して前記クラスタリングを行い、そのデータポイントが含まれるクラスターが抽出される確率が高くなるように重み付けをする、付記1から5のいずれかに記載の特徴点検出システム。
前記GPSログデータをランダムにサンプリングしてデータポイント数を削減してから前記滞留エリアの抽出を行う、付記1から6のいずれかに記載の特徴点検出システム。
前記GPSログデータに含まれる全てのデータポイントを含む最小範囲で定義される全体領域を複数の固定領域に分割し、各々の前記固定領域について、前記固定領域に属するデータポイント数が多い固定領域ほど高い確率でデータポイントを抽出し、抽出したデータポイントを用いてクラスタリングを行う請求項1から7のいずれかに記載の特徴点検出システム。
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を1つずつ抽出すると共に、各々の前記滞留エリア内の前記データポイントの密集度に基づいて、各々の前記代表点のスコアを決定する工程と、
前記スコアに基づいて、各々の前記代表点を序列化したリストを出力する工程と、を備えた特徴点検出方法。
ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいてそのクラスターにおけるユーザの滞留時間を示す指標を決定し、前記指標に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する滞留エリア検出部であって、前記滞留時間が長いほどそのクラスターが高い確率で抽出される、滞留エリア検出部と、
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を1つずつ抽出すると共に、各々の前記滞留エリア内の前記データポイントの密集度に基づいて、各々の前記代表点のスコアを決定する代表点抽出部と、
前記スコアに基づいて、各々の前記代表点を序列化したリストを出力する代表点序列化部と、して機能させるプログラム。
Claims (13)
- ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する滞留エリア検出部と、
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を抽出すると共に、各々の前記代表点のスコアを決定する代表点抽出部と、
前記スコアに基づいて前記代表点を出力する出力部と、
を備えた特徴点検出システム。 - ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいてそのクラスターにおけるユーザの滞留時間を示す指標を決定し、前記指標に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する滞留エリア検出部であって、前記滞留時間が長いほどそのクラスターが高い確率で抽出される、滞留エリア検出部と、
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を1つずつ抽出すると共に、各々の前記滞留エリア内の前記データポイントの密集度に基づいて、各々の前記代表点のスコアを決定する代表点抽出部と、
前記スコアに基づいて、各々の前記代表点を序列化したリストを出力する代表点序列化部と、を備えた特徴点検出システム。 - 前記滞留エリア検出部は、
第1のデータポイントと第2のデータポイントを、2つのデータポイント間の距離が短いほど高い確率で前記第1及び第2のポイントが同一の階級に属するように分類することによりヒストグラムを生成し、前記ヒストグラムの各階級を前記クラスターに対応させて、各階級の頻度を前記滞留時間を示す指標として決定する確率的ヒストグラム化部を備えた請求項2に記載の特徴点検出システム。 - 前記滞留エリア検出部は、
前記確率的ヒストグラム化部によって生成された前記ヒストグラムの各階級のうち、前記滞留時間の長いクラスターに対応する階級を抽出し、前記抽出した階級に属するデータポイントに対して第2のクラスタリングを行うことにより前記滞留エリアを形成する、請求項3に記載の特徴点検出システム。 - 前記滞留エリア検出部は、
前記確率的ヒストグラム化部によって生成された前記ヒストグラムの各階級のうち、前記滞留時間の長いクラスターに対応する階級を抽出し、前記抽出した階級を前記滞留時間の長短に基づいて2つのグループに分ける、再構成・グループ化部と、
前記2つのグループのうち、前記滞留時間の長い方のグループの階級に属するデータポイントを用いて滞留エリアを形成した後、他方のグループの階級に属するデータポイントを前記滞留エリアに付加し、または新たな滞留エリアを形成して、滞留エリアを形成するクラスター化部と、を備えた請求項3に記載の特徴点検出システム。 - 前記確率的ヒストグラム化部は、
各データポイントに対してLSH(Locality Sensitive Hashing)を用いて付与されるラベルを用いて、各々のデータポイントが属する階級を決定する請求項3から5のいずれかに記載の特徴点検出システム。 - 前記滞留エリア検出部は、
ランドマークに対応する地点に対応するデータポイント、及びユーザの嗜好に合った地点に対応するデータポイントの少なくとも一方に対して前記クラスタリングを行い、そのデータポイントが含まれるクラスターが抽出される確率が高くなるように重み付けをする、請求項1から6のいずれかに記載の特徴点検出システム。 - 前記滞留エリア検出部は、
前記GPSログデータをランダムにサンプリングしてデータポイント数を削減してから前記滞留エリアの抽出を行う、請求項1から7のいずれかに記載の特徴点検出システム。 - 前記滞留エリア検出部は、
前記GPSログデータに含まれる全てのデータポイントを含む最小範囲で定義される全体領域を複数の固定領域に分割し、各々の前記固定領域について、前記固定領域に属するデータポイント数が多い固定領域ほど高い確率でデータポイントを抽出し、抽出したデータポイントを用いてクラスタリングを行う請求項1から8のいずれかに記載の特徴点検出システム。 - コンピュータの滞留エリア検出部が、ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する工程と、
前記コンピュータの代表点抽出部が、抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を抽出すると共に、各々の前記代表点のスコアを決定する工程と、
前記コンピュータの出力部が、前記スコアに基づいて前記代表点を出力する工程と、
を備えた特徴点検出方法。 - コンピュータの滞留エリア検出部が、ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいてそのクラスターにおけるユーザの滞留時間を示す指標を決定し、前記指標に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成し、前記滞留時間が長いほどそのクラスターが高い確率で抽出される工程と、
前記コンピュータの代表点抽出部が、抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を1つずつ抽出すると共に、各々の前記滞留エリア内の前記データポイントの密集度に基づいて、各々の前記代表点のスコアを決定する工程と、
前記コンピュータの代表点序列化部が、前記スコアに基づいて、各々の前記代表点を序列化したリストを出力する工程と、を備えた特徴点検出方法。
- コンピュータを、
ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する滞留エリア検出部と、
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を抽出すると共に、各々の前記代表点のスコアを決定する代表点抽出部と、
前記スコアに基づいて前記代表点を出力する出力部と、して機能させるプログラム。 - コンピュータを、
ユーザのGPSログデータに含まれるデータポイントの分布に基づいてクラスタリングを行い、各クラスターに含まれるデータポイント数に基づいてそのクラスターにおけるユーザの滞留時間を示す指標を決定し、前記指標に基づいて1以上のクラスターを抽出し、前記抽出したクラスターに基づいてユーザの滞留エリアを形成する滞留エリア検出部であって、前記滞留時間が長いほどそのクラスターが高い確率で抽出される、滞留エリア検出部と、
抽出された各々の前記滞留エリアから、前記滞留エリアの代表点を1つずつ抽出すると共に、各々の前記滞留エリア内の前記データポイントの密集度に基づいて、各々の前記代表点のスコアを決定する代表点抽出部と、
前記スコアに基づいて、各々の前記代表点を序列化したリストを出力する代表点序列化部と、して機能させるプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012514747A JP5534007B2 (ja) | 2010-05-12 | 2011-04-21 | 特徴点検出システム、特徴点検出方法、及びプログラム |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010110361 | 2010-05-12 | ||
| JP2010110361 | 2010-05-12 | ||
| JP2012514747A JP5534007B2 (ja) | 2010-05-12 | 2011-04-21 | 特徴点検出システム、特徴点検出方法、及びプログラム |
| PCT/JP2011/059790 WO2011142225A1 (ja) | 2010-05-12 | 2011-04-21 | 特徴点検出システム、特徴点検出方法、及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2011142225A1 JPWO2011142225A1 (ja) | 2013-07-22 |
| JP5534007B2 true JP5534007B2 (ja) | 2014-06-25 |
Family
ID=44914281
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012514747A Active JP5534007B2 (ja) | 2010-05-12 | 2011-04-21 | 特徴点検出システム、特徴点検出方法、及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US8938357B2 (ja) |
| JP (1) | JP5534007B2 (ja) |
| WO (1) | WO2011142225A1 (ja) |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5886718B2 (ja) * | 2011-11-29 | 2016-03-16 | 株式会社コロプラ | 情報処理方法及び装置 |
| US8955058B2 (en) * | 2012-11-15 | 2015-02-10 | International Business Machines Corporation | Automatically generating challenge questions inferred from user history data for user authentication |
| CN103634829B (zh) * | 2013-12-18 | 2017-03-08 | 中国联合网络通信集团有限公司 | 一种基于路测信息的路段筛选方法和设备 |
| CN103886082B (zh) * | 2014-03-26 | 2017-02-08 | 百度在线网络技术(北京)有限公司 | 对兴趣点的位置信息进行校验的方法和设备 |
| US20150347895A1 (en) * | 2014-06-02 | 2015-12-03 | Qualcomm Incorporated | Deriving relationships from overlapping location data |
| CN105430032A (zh) | 2014-09-17 | 2016-03-23 | 阿里巴巴集团控股有限公司 | 结合终端地理位置推送信息的方法及服务器 |
| JP6546385B2 (ja) * | 2014-10-02 | 2019-07-17 | キヤノン株式会社 | 画像処理装置及びその制御方法、プログラム |
| JP6374842B2 (ja) * | 2015-08-04 | 2018-08-15 | 日本電信電話株式会社 | 滞在確率密度推定装置、方法、及びプログラム |
| CN105307121B (zh) * | 2015-10-16 | 2019-03-26 | 上海晶赞科技发展有限公司 | 一种信息处理方法及装置 |
| CN106897420B (zh) * | 2017-02-24 | 2020-10-02 | 东南大学 | 一种基于手机信令数据的用户出行驻留行为识别方法 |
| WO2019087595A1 (ja) * | 2017-11-06 | 2019-05-09 | 本田技研工業株式会社 | 移動体分布状況予測装置及び移動体分布状況予測方法 |
| CN108388538B (zh) * | 2017-12-29 | 2021-04-27 | 杭州后博科技有限公司 | 一种生成书包减重建议的系统及方法 |
| CN108875032B (zh) * | 2018-06-25 | 2022-02-25 | 讯飞智元信息科技有限公司 | 区域类型确定方法及装置 |
| CN109325082B (zh) * | 2018-08-02 | 2021-04-09 | 武汉中海庭数据技术有限公司 | 基于多源传感器log文件截取的方法 |
| CN111046895B (zh) * | 2018-10-15 | 2023-11-07 | 北京京东振世信息技术有限公司 | 一种确定目标区域的方法和装置 |
| CN110503485B (zh) * | 2019-08-27 | 2020-09-01 | 北京京东智能城市大数据研究院 | 地理区域分类方法及装置、电子设备、存储介质 |
| CN113190696B (zh) * | 2021-05-12 | 2024-12-13 | 百果园技术(新加坡)有限公司 | 一种用户筛选模型的训练、用户推送方法和相关装置 |
| CN113470079B (zh) * | 2021-07-15 | 2024-10-29 | 浙江大华技术股份有限公司 | 一种落脚区域的输出方法、装置及电子设备 |
| CN116738073B (zh) * | 2022-09-21 | 2024-03-22 | 荣耀终端有限公司 | 常驻地的识别方法、设备及存储介质 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003044512A (ja) * | 2001-07-27 | 2003-02-14 | Dainippon Printing Co Ltd | 行動エリア探索サーバおよび情報推薦サーバ |
| JP2006023793A (ja) * | 2004-07-06 | 2006-01-26 | Sony Corp | 情報処理装置,プログラム,プログラム提供サーバ |
| JP2007148517A (ja) * | 2005-11-24 | 2007-06-14 | Fujifilm Corp | 画像処理装置、画像処理方法、および画像処理プログラム |
| JP2009139231A (ja) * | 2007-12-06 | 2009-06-25 | Denso Corp | 位置範囲設定装置、移動物体搭載装置の制御方法および制御装置、ならびに車両用空調装置の制御方法および制御装置 |
| JP2010072828A (ja) * | 2008-09-17 | 2010-04-02 | Olympus Corp | 情報提示システム、情報処理システム、プログラム及び情報記憶媒体 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6400690B1 (en) * | 1998-10-15 | 2002-06-04 | International Business Machines Corporation | Dual map system for navigation and wireless communication |
| US6975939B2 (en) * | 2002-07-29 | 2005-12-13 | The United States Of America As Represented By The Secretary Of The Army | Mapping patterns of movement based on the aggregation of spatial information contained in wireless transmissions |
| US7747625B2 (en) * | 2003-07-31 | 2010-06-29 | Hewlett-Packard Development Company, L.P. | Organizing a collection of objects |
| US7353109B2 (en) * | 2004-02-05 | 2008-04-01 | Alpine Electronics, Inc. | Display method and apparatus for navigation system for performing cluster search of objects |
| JP4034812B2 (ja) | 2004-10-14 | 2008-01-16 | 松下電器産業株式会社 | 移動先予測装置および移動先予測方法 |
| ES2544750T3 (es) * | 2007-03-27 | 2015-09-03 | Telefonaktiebolaget Lm Ericsson (Publ) | Cálculo poligonal adaptable en posicionamiento de identidad celular mejorado adaptable |
| JP2009230514A (ja) * | 2008-03-24 | 2009-10-08 | Nec Corp | 行き先情報推薦システム、行き先情報推薦装置、携帯端末および行き先情報推薦方法 |
| JP5368763B2 (ja) | 2008-10-15 | 2013-12-18 | 株式会社ゼンリン | 電子地図整備システム |
-
2011
- 2011-04-21 WO PCT/JP2011/059790 patent/WO2011142225A1/ja active Application Filing
- 2011-04-21 US US13/696,765 patent/US8938357B2/en active Active
- 2011-04-21 JP JP2012514747A patent/JP5534007B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003044512A (ja) * | 2001-07-27 | 2003-02-14 | Dainippon Printing Co Ltd | 行動エリア探索サーバおよび情報推薦サーバ |
| JP2006023793A (ja) * | 2004-07-06 | 2006-01-26 | Sony Corp | 情報処理装置,プログラム,プログラム提供サーバ |
| JP2007148517A (ja) * | 2005-11-24 | 2007-06-14 | Fujifilm Corp | 画像処理装置、画像処理方法、および画像処理プログラム |
| JP2009139231A (ja) * | 2007-12-06 | 2009-06-25 | Denso Corp | 位置範囲設定装置、移動物体搭載装置の制御方法および制御装置、ならびに車両用空調装置の制御方法および制御装置 |
| JP2010072828A (ja) * | 2008-09-17 | 2010-04-02 | Olympus Corp | 情報提示システム、情報処理システム、プログラム及び情報記憶媒体 |
Non-Patent Citations (4)
| Title |
|---|
| CSNG200501073013; 遠山 緑生 他: 'コンテクスト情報と操作履歴の関連付けによる操作予測システムの提案' 情報処理学会研究報告 2004-UBI-6 ユビキタスコンピューティングシステム 第2004巻 第112号, 20041110, pp.83-90, 社団法人情報処理学会 * |
| CSNJ201010043613; 上坂 大輔 他: '携帯電話の位置履歴に基づく自宅職場推定法' 電子情報通信学会2010年総合大会講演論文集 通信2 , 20100302, p.613, 社団法人電子情報通信学会 * |
| JPN6013056848; 遠山 緑生 他: 'コンテクスト情報と操作履歴の関連付けによる操作予測システムの提案' 情報処理学会研究報告 2004-UBI-6 ユビキタスコンピューティングシステム 第2004巻 第112号, 20041110, pp.83-90, 社団法人情報処理学会 * |
| JPN6013056850; 上坂 大輔 他: '携帯電話の位置履歴に基づく自宅職場推定法' 電子情報通信学会2010年総合大会講演論文集 通信2 , 20100302, p.613, 社団法人電子情報通信学会 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2011142225A1 (ja) | 2013-07-22 |
| WO2011142225A1 (ja) | 2011-11-17 |
| US20130054602A1 (en) | 2013-02-28 |
| US8938357B2 (en) | 2015-01-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5534007B2 (ja) | 特徴点検出システム、特徴点検出方法、及びプログラム | |
| US11216499B2 (en) | Information retrieval apparatus, information retrieval system, and information retrieval method | |
| JP6402653B2 (ja) | 物体認識装置、物体認識方法、およびプログラム | |
| US8037166B2 (en) | System and method of displaying search results based on density | |
| US8938446B2 (en) | System and method of transmitting search results based on arbitrary queries | |
| Sester et al. | Integrating and generalising volunteered geographic information | |
| KR20170007747A (ko) | 자연어 이미지 검색 기법 | |
| JP2019149145A (ja) | 情報検索システム | |
| EP2838034A1 (en) | Device management apparatus and device search method | |
| JP4950508B2 (ja) | 施設情報管理システム、施設情報管理装置、施設情報管理方法および施設情報管理プログラム | |
| JP2010128806A (ja) | 情報分析装置 | |
| JP5389688B2 (ja) | 場所存在確率算出装置及び方法及びプログラム及びトラベルルート推薦装置及び方法及びプログラム | |
| Chow et al. | Geographic disparity of positional errors and matching rate of residential addresses among geocoding solutions | |
| Socharoentum et al. | A comparative analysis of routes generated by Web Mapping APIs | |
| Bruzelius et al. | Satellite images and machine learning can identify remote communities to facilitate access to health services | |
| CN107251049A (zh) | 基于语义指示检测移动装置的位置 | |
| KR20150059208A (ko) | 소셜 웹 미디어의 이벤트 시공간 연관성 분석 장치 및 그 방법 | |
| EP2389625A1 (en) | System and method of displaying search results based on density | |
| JP2017191357A (ja) | 単語判定装置 | |
| KR20170035694A (ko) | 여행성 질의에 대응하는 검색 결과로 코스를 추천하는 방법 및 시스템 | |
| JP7187597B2 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| JP7145247B2 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| JP6489400B2 (ja) | 情報処理システム、情報処理方法及びプログラム | |
| KR20190000061A (ko) | 키워드 속성을 기준으로 관련 있는 키워드를 제공하는 방법 및 시스템 | |
| Deeksha et al. | A spatial clustering approach for efficient landmark discovery using geo-tagged photos |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20131118 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140110 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140401 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5534007 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140414 |