JP5145751B2 - 医療用の情報処理システム - Google Patents
医療用の情報処理システム Download PDFInfo
- Publication number
- JP5145751B2 JP5145751B2 JP2007100546A JP2007100546A JP5145751B2 JP 5145751 B2 JP5145751 B2 JP 5145751B2 JP 2007100546 A JP2007100546 A JP 2007100546A JP 2007100546 A JP2007100546 A JP 2007100546A JP 5145751 B2 JP5145751 B2 JP 5145751B2
- Authority
- JP
- Japan
- Prior art keywords
- information
- terminal
- report
- processing system
- information processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 230000010365 information processing Effects 0.000 title claims description 51
- 201000010099 disease Diseases 0.000 claims description 26
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 26
- 238000010801 machine learning Methods 0.000 claims description 23
- 238000012545 processing Methods 0.000 claims description 19
- 238000009826 distribution Methods 0.000 claims description 16
- 230000004044 response Effects 0.000 claims description 10
- 230000006870 function Effects 0.000 description 71
- 238000007726 management method Methods 0.000 description 41
- 238000000034 method Methods 0.000 description 31
- 238000003860 storage Methods 0.000 description 29
- 230000005540 biological transmission Effects 0.000 description 26
- 230000008569 process Effects 0.000 description 23
- 208000003174 Brain Neoplasms Diseases 0.000 description 22
- 238000000605 extraction Methods 0.000 description 20
- 238000004458 analytical method Methods 0.000 description 17
- 238000010276 construction Methods 0.000 description 17
- 208000026106 cerebrovascular disease Diseases 0.000 description 16
- 238000010586 diagram Methods 0.000 description 13
- 238000005315 distribution function Methods 0.000 description 13
- 238000003384 imaging method Methods 0.000 description 13
- 230000001364 causal effect Effects 0.000 description 9
- 238000007689 inspection Methods 0.000 description 8
- 210000001652 frontal lobe Anatomy 0.000 description 7
- 230000014509 gene expression Effects 0.000 description 7
- 206010061216 Infarction Diseases 0.000 description 6
- 206010028980 Neoplasm Diseases 0.000 description 6
- 230000007574 infarction Effects 0.000 description 6
- 239000000284 extract Substances 0.000 description 4
- 238000000926 separation method Methods 0.000 description 4
- 238000012706 support-vector machine Methods 0.000 description 4
- 230000000007 visual effect Effects 0.000 description 4
- 102100022441 Sperm surface protein Sp17 Human genes 0.000 description 3
- 230000002490 cerebral effect Effects 0.000 description 3
- 239000000470 constituent Substances 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 235000012054 meals Nutrition 0.000 description 3
- 208000019553 vascular disease Diseases 0.000 description 3
- 206010059245 Angiopathy Diseases 0.000 description 2
- 206010062767 Hypophysitis Diseases 0.000 description 2
- 206010008118 cerebral infarction Diseases 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000000302 ischemic effect Effects 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 210000003635 pituitary gland Anatomy 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 210000003625 skull Anatomy 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 210000004885 white matter Anatomy 0.000 description 2
- 101100365087 Arabidopsis thaliana SCRA gene Proteins 0.000 description 1
- 235000006481 Colocasia esculenta Nutrition 0.000 description 1
- 240000004270 Colocasia esculenta var. antiquorum Species 0.000 description 1
- 208000009798 Craniopharyngioma Diseases 0.000 description 1
- 208000021309 Germ cell tumor Diseases 0.000 description 1
- 241001484259 Lacuna Species 0.000 description 1
- 208000000172 Medulloblastoma Diseases 0.000 description 1
- 101001067830 Mus musculus Peptidyl-prolyl cis-trans isomerase A Proteins 0.000 description 1
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 210000002551 anterior cerebral artery Anatomy 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 235000013372 meat Nutrition 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000000474 nursing effect Effects 0.000 description 1
- 235000012046 side dish Nutrition 0.000 description 1
Images








Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Medical Treatment And Welfare Office Work (AREA)
- Measuring And Recording Apparatus For Diagnosis (AREA)
- Processing Or Creating Images (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
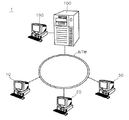
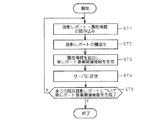
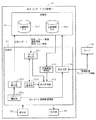
図1は、本発明の実施形態に係る情報処理システム1の概略構成を示す図である。
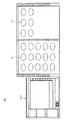
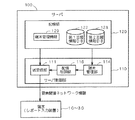
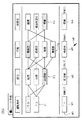
図3は、主に端末30で実現される関連情報生成機能に係る機能構成を示すブロック図である。
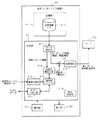
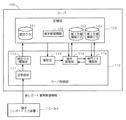
図6は、主にサーバ100で実現される支援情報生成機能に係る機能構成を示すブロック図である。
図9は、主にサーバ100で実現される情報配信機能に係る機能構成を示すブロック図である。ここでは、サーバ100が、記憶部120に格納されているプログラムをCPUで読み込んで実行することで、情報配信機能に係る各種機能構成を実現する。
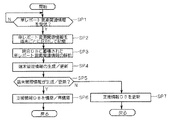
図11は、主に端末30で実現される入力支援機能に係る機能構成を示すブロック図である。ここでは、端末30が、記憶部34に格納されているプログラムをCPUで読み込んで実行することで、入力支援機能に係る各種機能構成を実現する。
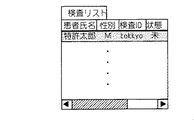
データ読込部311は、診療情報DB341から検査リストの情報(検査リスト情報)を読み込み、タスク管理部318に転送する。
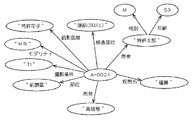
入力支援動作では、上述した支援情報生成機能によって生成されたネットワーク情報を、レポート作成領域A4においてテンプレート表示の形態で可視的に出力し、当該テンプレート表示における語句の選択肢が適宜指定されることで、新規な読影レポートの入力を行う。
以上、この発明の実施形態について説明したが、この発明は上記説明した内容のものに限定されるものではない。
端末10〜30が各家庭に設置され、サーバ100に送られる複数の要素が関連付けられた情報(要素関連情報)が、食事のメニューに係る項目「主食」「主莱」「副菜」に属する要素を関連付けたものである。そして、サーバ100側で判定する「特定の条件」を「一定期間内に主菜が肉料理である割合が所定割合以上」などといったものとすれば、特定の条件に沿って切り分けられて生成されるデータベースを用いて、家庭ごとの嗜好を反映したメニューの提案などが可能となる。
端末10〜30がパソコン販売店にそれぞれ配置され、サーバ100に送られる複数の要素が関連付けられた情報(要素関連情報)が、売れたパソコンセットの内容、例えば、「メーカー」「OSの種類」「CPUの種類」「メモリの容量」「ハードディスクの容量」「ディスプレイのサイズ」「プリンタの種類」といった項目に属する要素を関連付けたものである。そして、サーバ100側で判定する「特定の条件」が「一定期間にハードディスクの容量が100GB以上である割合が所定割合以上」などといったものとすれば、特定の条件に沿って切り分けられて生成されるデータベースを用いて、店舗ごとに異なるユーザー層の特徴(所謂ライトユーザーが多いのか、所謂ヘビーユーザーが多いのか等)を反映して、おすすめ商品の提案などが可能となる。
10〜30 端末
31 制御部
32 操作部
33 表示部
34 記憶部
100 サーバ
110 サーバ制御部
111 送受信部
112 統合DB構築部
113 解析部
114 端末管理部
115 専門DB構築部
116 配信制御部
120 記憶部
121 統合DB
122 第1支援情報DB
123 第2支援情報DB
129 端末管理情報
311 データ読込部
312 自然文構造化部
313 機械学習部
315 識別部
316 送受信部
317 支援情報検索部
318 タスク管理部
319 表示制御部
320 レポート構成部
321 データ書込部
341 診療情報DB
342 支援情報DB
Claims (9)
- 医療用の情報処理システムであって、
サーバと、複数の端末とを備え、
各前記端末が、
複数の分類項目に属する医療に関する複数の語句を関連付けることで該複数の語句を含む要素関連情報を生成する取得手段と、
前記要素関連情報を前記サーバに送信する送信手段と、
を有し、
前記サーバが、
各前記端末から前記要素関連情報を受信する受信手段と、
各前記端末から前記サーバに送信された複数の要素関連情報に基づいて、各前記端末が特定の条件を満たすことを認識する認識手段と、
前記複数の端末に含まれる1以上の端末が前記特定の条件を満たす場合に、該1以上の端末から受信した複数の要素関連情報に基づいて、前記複数の分類項目間で該各分類項目に属する複数の語句をネットワーク状に関連付けることでネットワーク情報を生成するネットワーク情報生成手段と、
を有することを特徴とする医療用の情報処理システム。 - 請求項1に記載の医療用の情報処理システムであって、
前記サーバが、
前記ネットワーク情報を各前記端末に対して配信する配信手段、
を更に有し、
各前記端末が、
前記ネットワーク情報に含まれる全体ネットワーク情報または一部ネットワーク情報に基づいて、複数の分類項目に含まれる各分類項目間で該各分類項目にそれぞれ属する各語句が相互に関連付けられた情報の一覧表示を表示部において表示するように制御する表示制御手段、
を更に有することを特徴とする医療用の情報処理システム。 - 請求項2に記載の医療用の情報処理システムであって、
各前記端末が、
前記表示部に前記一覧表示が表示された状態で、ユーザーによる操作に応答して、前記一覧表示に含まれる各分類項目に対し、それぞれ1以上の語句を所定のレポートモデルに沿ったレポート情報を構成するレポート構成要素として指定する要素指定手段と、
前記レポート構成要素に基づいて、前記所定のレポートモデルに沿った新規なレポート情報を生成するレポート生成手段と、
を更に有することを特徴とする医療用の情報処理システム。 - 請求項3に記載の医療用の情報処理システムであって、
前記レポート情報が、読影レポート情報を含み、
前記複数の分類項目が、部位、所見、疾患名を含むことを特徴とする医療用の情報処理システム。 - 請求項1から請求項4のいずれかに記載の医療用の情報処理システムであって、
前記認識手段が、
前記複数の端末に含まれる1つの端末から前記サーバに送信された要素関連情報の数が、所定の値域範囲に含まれれば、該1つの端末が前記特定の条件を満たすと認識することを特徴とする医療用の情報処理システム。 - 請求項1から請求項4のいずれかに記載の医療用の情報処理システムであって、
前記認識手段が、
前記複数の端末に含まれる1つの端末から前記サーバに送信された複数の要素関連情報のうち、所定の語句を含む要素関連情報が占める割合が、所定の値域範囲に含まれれば、該1つの端末が前記特定の条件を満たすと認識することを特徴とする医療用の情報処理システム。 - 請求項1から請求項6のいずれかに記載の医療用の情報処理システムであって、
前記サーバが、
前記複数の端末のうちの前記特定の条件を満たす端末に対して、前記ネットワーク情報を送信することを特徴とする医療用の情報処理システム。 - 請求項1から請求項7のいずれかに記載の医療用の情報処理システムであって、
前記取得手段が、
文章情報に対して言語処理を含む所定の情報処理を施すことで、前記文章情報から各前記分類項目に属する1以上の語句を抽出し、関連付けることで、前記要素関連情報を生成することを特徴とする医療用の情報処理システム。 - 請求項8に記載の医療用の情報処理システムであって、
前記言語処理が、
機械学習によって得られた情報に基づいた処理であることを特徴とする医療用の情報処理システム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007100546A JP5145751B2 (ja) | 2007-04-06 | 2007-04-06 | 医療用の情報処理システム |
| US12/080,533 US8135826B2 (en) | 2007-04-06 | 2008-04-03 | Information processing system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007100546A JP5145751B2 (ja) | 2007-04-06 | 2007-04-06 | 医療用の情報処理システム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008257569A JP2008257569A (ja) | 2008-10-23 |
| JP5145751B2 true JP5145751B2 (ja) | 2013-02-20 |
Family
ID=39827923
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007100546A Expired - Fee Related JP5145751B2 (ja) | 2007-04-06 | 2007-04-06 | 医療用の情報処理システム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US8135826B2 (ja) |
| JP (1) | JP5145751B2 (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2011004622A1 (ja) * | 2009-07-10 | 2012-12-20 | コニカミノルタエムジー株式会社 | 医療情報システムおよびそのためのプログラム |
| CN102125423B (zh) * | 2010-10-13 | 2012-09-19 | 深圳市理邦精密仪器股份有限公司 | 一种集成中央监护功能的医用监护方法及装置 |
| JP5672183B2 (ja) * | 2011-07-15 | 2015-02-18 | 富士通株式会社 | 情報処理装置、情報処理方法、および情報処理プログラム |
| CN104365184B (zh) * | 2012-06-11 | 2016-09-21 | 皇家飞利浦有限公司 | 用于存储、建议和/或利用照明设置的方法 |
| CN112352243B (zh) * | 2018-05-15 | 2025-02-14 | 英德科斯控股私人有限公司 | 专家报告编辑器 |
| WO2020241857A1 (ja) | 2019-05-31 | 2020-12-03 | 富士フイルム株式会社 | 医療文書作成装置、方法およびプログラム、学習装置、方法およびプログラム、並びに学習済みモデル |
| JP7321959B2 (ja) * | 2020-03-25 | 2023-08-07 | 株式会社日立製作所 | 報告書執筆支援システム、報告書執筆支援方法 |
| WO2024034232A1 (ja) * | 2022-08-09 | 2024-02-15 | コニカミノルタ株式会社 | 情報処理装置、情報処理方法及びプログラム |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5146439A (en) * | 1989-01-04 | 1992-09-08 | Pitney Bowes Inc. | Records management system having dictation/transcription capability |
| US5715174A (en) * | 1994-11-15 | 1998-02-03 | Absolute Software Corporation | Security apparatus and method |
| US7000015B2 (en) * | 2000-04-24 | 2006-02-14 | Microsoft Corporation | System and methods for providing physical location information and a location method used in discovering the physical location information to an application on a computing device |
| US8538770B2 (en) * | 2000-08-01 | 2013-09-17 | Logical Images, Inc. | System and method to aid diagnoses using cross-referenced knowledge and image databases |
| JP2002230426A (ja) * | 2001-01-31 | 2002-08-16 | Matsushita Electric Ind Co Ltd | ライセンスを受けて製造等される記録媒体等の課金システムおよび課金方法 |
| JP2003085086A (ja) * | 2001-09-12 | 2003-03-20 | Sony Corp | サービス提供システム、サービス提供方法 |
| US20030135393A1 (en) * | 2002-01-11 | 2003-07-17 | Laboratory Corporation Of America Holdings | System, method and computer program product for improving treatment of medical patients |
| JP2004030128A (ja) * | 2002-06-25 | 2004-01-29 | Nec Software Kyushu Ltd | 健康医療情報共有システム,健康医療情報共有方法および健康医療情報共有プログラム |
| WO2004032019A2 (en) * | 2002-09-27 | 2004-04-15 | Hill-Rom Services, Inc. | Universal communications, monitoring, tracking, and control system for a healthcare facility |
| US7353179B2 (en) * | 2002-11-13 | 2008-04-01 | Biomedical Systems | System and method for handling the acquisition and analysis of medical data over a network |
| US20040122705A1 (en) * | 2002-12-18 | 2004-06-24 | Sabol John M. | Multilevel integrated medical knowledge base system and method |
| JP2004355412A (ja) * | 2003-05-29 | 2004-12-16 | Hitachi Medical Corp | 診断支援システム |
| US8200775B2 (en) * | 2005-02-01 | 2012-06-12 | Newsilike Media Group, Inc | Enhanced syndication |
| US7793217B1 (en) * | 2004-07-07 | 2010-09-07 | Young Kim | System and method for automated report generation of ophthalmic examinations from digital drawings |
| US7584103B2 (en) * | 2004-08-20 | 2009-09-01 | Multimodal Technologies, Inc. | Automated extraction of semantic content and generation of a structured document from speech |
| JP2006268405A (ja) * | 2005-03-24 | 2006-10-05 | Hitachi Ltd | 顧客価値生成シナリオ作成支援装置、システムおよび方法 |
| US7617093B2 (en) * | 2005-06-02 | 2009-11-10 | Microsoft Corporation | Authoring speech grammars |
-
2007
- 2007-04-06 JP JP2007100546A patent/JP5145751B2/ja not_active Expired - Fee Related
-
2008
- 2008-04-03 US US12/080,533 patent/US8135826B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US8135826B2 (en) | 2012-03-13 |
| JP2008257569A (ja) | 2008-10-23 |
| US20080250102A1 (en) | 2008-10-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8521561B2 (en) | Database system, program, image retrieving method, and report retrieving method | |
| JP5145751B2 (ja) | 医療用の情報処理システム | |
| Khatib et al. | The Challenge and Potential Solutions of Reading Voluminous Electronic Medical Records (EMR): A Case Study from UAE | |
| JP2024515534A (ja) | 人工知能支援の画像解析のためのシステムおよび方法 | |
| US20050114283A1 (en) | System and method for generating a report using a knowledge base | |
| JP6291872B2 (ja) | 情報処理システム、およびプログラム | |
| JP4402033B2 (ja) | 情報処理システム | |
| US20060136830A1 (en) | System and user interface for creating and presenting forms | |
| US20180330820A1 (en) | Content-driven problem list ranking in electronic medical records | |
| WO2021104324A1 (zh) | 医疗信息的处理方法、获取方法以及交互方法 | |
| McGrath et al. | Optimizing radiologist productivity and efficiency: work smarter, not harder | |
| JP5392086B2 (ja) | データベースシステム、およびプログラム | |
| JP2011018111A (ja) | 情報処理システム、およびプログラム | |
| JP2009110485A (ja) | 情報処理システム、及びプログラム | |
| JP4967317B2 (ja) | 情報処理システム | |
| JPWO2010001792A1 (ja) | データベースシステム | |
| JP2008269041A (ja) | データベースシステムおよびプログラム | |
| JP7127370B2 (ja) | 読影レポート作成装置 | |
| JP2008276364A (ja) | 情報処理システム、及びプログラム | |
| JP2010160590A (ja) | 医療用レポート作成端末、医療用レポート作成方法、およびプログラム | |
| JP4992297B2 (ja) | データベースシステム、およびプログラム | |
| JP2008117239A (ja) | 医療情報処理システム、所見データ編集装置、所見データ編集方法及びプログラム | |
| Khairat et al. | Virtual Nursing and the Future of Workforce Sustainability | |
| Wee | Providing personal health records in Malaysia: a portable prototype | |
| US20190198164A1 (en) | Patient-centric timeline for medical studies |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20091020 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100301 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120229 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120306 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120424 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20121030 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121112 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5145751 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151207 Year of fee payment: 3 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |