図1は、本発明に係る再生装置の一実施例の概略構成ブロック図を示す。再生装置10の記録媒体12には、音声付きの映像信号が記録されている。記録媒体12は、DVD(Digital Versatile Disk)に代表される光ディスク、磁気テープ、ハードディスク、又は、フラッシュメモリを内蔵したメモリカードなどからなる。記録媒体駆動装置14は、記録媒体12を駆動して、記録媒体12に信号を読み書きする装置である。
データベース16には、複数人の個人情報データが登録可能であり、現に登録されている。各個人情報データは、顔画像照合機能に使用する顔画像データとその特徴量を示す顔画像特徴量データ、人声照合機能に使用する声データとその特徴量を示す声特徴量データ、並びに、その他の種々のデータを含む。
画像処理部18は、記録媒体12から読み出された圧縮画像データを復号化し、種々の加工を施して、再生画像データを生成する。顔画像認識部20は、画像処理部18で処理された画像データから人物の顔に該当する領域の有無を判別する。顔画像照合部22は、顔画像認識部20で顔画像があると判別された領域を、データベース16に登録された顔画像データと比較する。これにより、再生画像中に含まれる人物が、データベース16に登録済みか否か、そして登録された誰であるかを特定できる。
付加画像生成部24は、記録媒体12から再生された再生画像信号にスーパーインポーズされるべき付加画像データを生成する。表示画像生成部26は画像処理部18から出力させる再生画像データに付加画像生成部24から出力される付加画像データを合成する。表示画像生成部26により、再生画像に付加画像がスーパーインポーズされた合成画像が生成される。但し、表示画像生成部26の出力画像は、合成画像以外に、再生画像のみからなる場合、又は付加画像のみからなる場合もありうる。
表示部28は、表示画像生成部26で生成された画像データを使用者が視認できるように画像として表示する。表示部28は、例えば、該再生装置に組み込まれている。表示部28は、液晶ディスプレイ(LCD)や有機ELディスプレイなどのディスプレイ装置とその駆動回路からなる。
音声処理部30は、記録媒体12から読み出された圧縮音声データを復号化し、種々の加工を施す。人声認識部32は、音声処理部30で得られた再生音声信号から、人間の発声に該当する音声の有無を判別する。人声照合部34は、人声認識部32で人間の声と判別された部分に対し、データベース16に登録された声データと比較する。音量検出部36は、人声認識部32で人物の声であると判断された場合に、その音量の大きさを検出する。音声出力装置38は、音声処理部30で生成された再生音声を音響出力する装置である。音声出力装置38は、例えば、再生装置10に組み込まれたスピーカとその駆動回路からなる。
付加画像表示判定部40は、顔画像照合部22の照合結果と人声照合部34の照合結果を基に、付加画像生成部24により生成させる付加画像の内容を決定する。
外部出力部42は、表示画像生成部26により生成された画像信号及び音声処理部30による再生音声信号を外部に出力する手段であり、例えば、外部出力用の駆動回路と、接続端子又は送信アンテナとからなる。
CPU44は、付加画像生成部24及び表示画像生成部26を制御するだけでなく、画像処理および音声処理が同期動作するように再生装置10の全体を制御する中央演算装置である。
入力装置46は、使用者が再生装置10に動作モードや動作条件等を入力するための装置であり、種々のスイッチ又はボタン、若しくは、メニュー画面上に表示される操作可能な要素などからなる。
本実施例の特徴的な動作を理解するために、次のような状況を想定する。すなわち、A氏とB氏の2人が会話を交わしている状況でA氏にカメラを向けた結果として、図2に示すように撮影画角内にはA氏だけが収まり、B氏は音声だけが記録されたとする。
図3は、そのような状況で記録された映像の、従来の方法による再生画面の表示例を示す。人物Aを含む再生画像が画面上に表示され、再生音声が、画面横のスピーカから出力される。画面の右隅とスピーカに付記した記号群は、B氏の声を図示化したものである。
これに対し、図4は、本実施例による再生画面例を示す。再生画像が表示部28の画面上に表示され、再生音声が、画面横のスピーカ(音声出力装置38)から出力される。画面の右隅とスピーカに付記した記号群は、B氏の声を図示化したものである。図3とは異なり、画面内に、人物Bを示す付加画像が重畳表示される。人物Bを示す付加画像により、視聴者は,発言者がB氏であることを認識又は推測することができる。
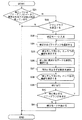
本実施例により撮影画角内に入っていない話者を特定し、当該話者を示す付加画像を合成する動作を説明する。図5は、その動作のフローチャートを示す。なお、ここでは、記録媒体12がDVDであるとする。
まず、データベース16に、必要な人物の個人情報データを事前に登録する(S1)。先に説明したように、各人の個人情報データは、顔画像データとその特徴量を示す顔画像特徴量データ、声データとその特徴量を示す声特徴量データ、及び、その他の種々の属性データからなる。属性データは、例えば、氏名、ニックネーム、性別」、年齢、生年月日及び似顔絵などからなる。
音声処理部30は、記録媒体12から読み出された圧縮音声データを伸長し、再生音声信号を人声認識部32、音声出力装置38及び外部出力部42に供給する。人声認識部32は、再生音声信号から人声を抽出して解析し、人声が含まれているかどうかを判別する(S2)。人声が含まれている場合、人声認識部32は、抽出した人声データを人声照合部34に供給する。
人声照合部34は、人声認識部32からの人声データからその特徴量を抽出し、データベース16の声特徴量データに照合して、一定以上の高い相関を有する特徴量を持つ人物を探索する(S3)。人声照合部34は、一定値以上の相関度を有する声特徴量データが存在した場合、これらの声特徴量データを有する人物を付加画像表示の候補として付加画像表示判定部40に通知する(S4)。
他方、画像処理部18は、記録媒体12から再生された圧縮画像データを伸長して再生画像データを生成する。顔画像認識部20は、再生画像から人の顔画像を抽出し、抽出した顔画像データを顔画像照合部22に供給する(S5)。顔画像照合部22は、顔画像認識部20からの顔画像データからその特徴量を抽出し、データベース16の顔画像特徴量データに照合して、一定以上の高い相関を有する顔画像特徴量を持つ人物を探索する(S6)。顔画像照合部22は、一定値以上の相関度を有する顔画像特徴量データが存在した場合、その顔画像特徴量データを有する人物を、付加画像表示の除外候補として付加画像表示判定部40に通知する(S7)。
付加画像表示判定部40は、再生音声から抽出された候補(人声照合部34からの通知情報)から、再生画像から抽出された除外候補(顔画像照合部22からの除外候補)を除外する(S8)。これにより、話者の可能性の高い人物候補(S4)から、画面内に入っている人物(S7)を除外できる。即ち,撮影画面内には入っていないが,音声が記録されている人物を特定できる。複数人が存在する場合には、人声特徴量の相関度が最も高い人物を話者と決定する。付加画像表示判定部40は、最終的に決定した人物を付加画像生成部24に通知する。
付加画像生成部24は、付加画像表示判定部40から通知された人物の顔画像データをデータベース16から読み出し、この顔画像を含む所定サイズの付加画像を生成する(S9)。付加画像生成部24は、生成した付加画像を表示画像生成部26に供給する。
表示画像生成部26は、画像処理部18からの再生画像データに、付加画像生成部24からの付加画像をスーパーインポーズして、合成画像データを生成する(S10)。合成画像データは、表示部28に印加され、図4に示すように表示される。もちろん、外部出力部42から外部に出力されることもある。表示画像は、記録媒体12に記録された画像の上にピクトグラフが重ね描きされた見掛けになる。このため、再生画像にスーパーインポーズする付加画像を以降ではピクトグラフとも表現する。
データベース16を説明する。データベース16は、記録媒体12に格納されても、再生装置10に内蔵されても良い。再生装置10がネットワーク対応の場合には、データベース16を、ネッットワークを介して接続するサーバ上に用意しても良い。記録媒体12が再生装置10から着脱自在である場合、記録媒体12のデータベースを再生装置10の記憶領域にロードして利用する方式でも、記録媒体12上のデータベースを直接参照する方式の何れであってもよい。また、前者の場合、データベースのみを記録した着脱可能な記録媒体を用意してもよい。
データベース16に登録される各人の個人情報データは、顔画像照合とピクトグラフ表示に使用するための顔画像データと、音声照合に使用するための声データを必ず有する。これに加えて、氏名、ニックネーム、性別、年齢、生年月日、及び似顔絵などデータを付加的な属性情報として保持する。これらの付加的な属性情報を、顔画像データと同時に、または置き換えてピクトグラフ表示に使用してもよい。
データベース16に登録される人数が増加してくると、ピクトグラフとして表示を出したい人物と出したくない人物の区分が生じてくる。この区分に対応するために、各々の個人情報データ毎にピクトグラフ表示の可否を設定する項目を設けるのが好ましい。新規登録された個人情報データの新規登録時にデフォルトでどちらを設定するかは、使用状況に応じて決定すればよい。CPU44は、付加画像を表示すべき人物が、データベース16において、合成表示を許すように設定されている場合に、表示画像生成部26に前記再生画像信号に前記付加画像を合成させる。
データベース16は、他の機器で作成されたものも読み込んで使えるような汎用性のあるものであるのが好ましい。
本実施例のピクトグラフ表示について説明する。声だけが聞こえる人物に関する情報をピクトグラフで表示することは、視認性を付加できるので有用ではある。そして、表示方法を工夫することで、その効果を更に増すことができる。
ピクトグラフ表示機能の有効/無効、即ち、要否を使用者が設定できると、本来の記録画像だけを見たいという要求にも対応できる。これは、画像に映っていない人物が誰であるのかを気にしない場合や、既知の声だが聞こえている場合などに有効である。たとえば、使用者によりピクトグラフ表示機能が無効に設定されている場合、CPU44は、画面外の発声者の声が録音されていても、付加画像生成部24に付加画像を生成させない。
ピクトグラフとして表示される情報はデータベース16が有する項目の中から1つ以上である。どの項目を表示させるかを選択できると、使用者の知りたい情報に連動することができる。例えば、顔画像と同時に「氏名」を表示させれば、顔画像だけでは誰であるのかを判別しづらいときでも、人物を特定しやすくなる。もちろん、「氏名」だけを表示することでも、同様の効果を得ることができる。
ピクトグラフ表示対象者の全人物に対し表示をするデータ項目を統一した場合、幾人かの人物では該当項目が未登録である可能性も考えられる。このような状況に対応するために、ピクトグラフ表示データの各項目に優先順位を持たせ、上位項目が未登録な場合には次点項目を表示するようにすると良い。例えば、第1優先順位に「ニックネーム」を、第2優先順位に「氏名」を設定したとする。この場合、「ニックネーム」の項目が登録されている人物に関しては「ニックネーム」が表示され、「ニックネーム」の項目が登録されていない人物に関しては「氏名」が表示されるようにする。すなわち、データベース16の各人物の項目中に、付加画像の生成に利用できる複数の項目がある場合に、使用者が、これら複数の項目の全部又は一部に優先順位を設定する手段を設ける。
このような優先順位を設定する作業は、データベース16に登録できる各人の個人情報データの項目が多数になるほど、煩雑なものとなる。これに対しては、有限個の上位順位までを使用者が設定できるようにしておき、それ以下の順位の項目については再生装置10が自動的に割り振るようにすればよい。これにより、使用者の負担が軽減する。尚、使用者がデータベース16の個人情報データ内の項目に一切のデータを追加したかった場合でも、登録必須項目である顔画像データが何れかの優先順位に割り当てられるので、ピクトグラフに表示するデータは確保される。
画面上でのピクトグラフは、再生画像中の注目度の高い部分を出来るだけ遮らないが望ましい。一般的に、画像の注目度は周辺部よりも中心部の方が高い傾向にあるので、ピクトグラフの表示場所は基本的に再生画像の周辺部に配置されることになる。しかし、被写体が動いているシーンなどでは、その被写体の移動に伴って周辺部の注目度が高くなる場合もあり得る。このとき、注目度が高くなる場所と、ピクトグラフが表示される場所とが重なり合うことは望ましくない。ピクトグラフの表示場所を使用者が設定できると、このような事態を回避できる。
ピクトグラフの大きさについても使用者が設定できると便利である。例えば、大きさを、「大」、「中」、「小」やドット数で表現された規定段階の中から選択できる形式や、同様の表現が付記された図表を用いて選択する形式が考えられる。これは、再生装置10に備えつけられている比較的小型の表示画面で見る場合と、外部接続機能を介してテレビなどの比較的大型の画面で見る場合のように、表示画面の画素数が大きく異なる場合に、有用である。視認性を満足するために求められるピクトグラフの大きさに無視できない差があるからである。
また、形状についても、四角形や丸形などの選択肢を設けると、使用者の嗜好性を活かすことができる。ただし、設定された形状に従って表示可能なデータに制限を設ける必要も生じる。例えば、小さな外形寸法内部で視認性を満足しながら表現できるデータは、限られる。実際の制限の設け方は、それぞれの再生装置に適したもので良い。ピクトグラフの形状として、このような制限が働く形状が設定された場合、表示可能なデータ候補の中の優先順位が上位のものから表示される。大きさ及び形状の何れについても、設定変更操作と同時に実際のピクトグラフの大きさ及び形状が変更するのが好ましい。
再生音声信号とデータベース16にある声データをそれぞれの特徴量で照合して、正しい人物を選択できなかった場合、ピクトグラフに誤ったデータが使用されることになる。使用者が表示されたピクトグラフを見て誤りに気付いたとき、本実施例では、正しい内容に修正できる。図6は、その修正動作のフローチャートを示す。
使用者は、再生表示画像を見て、聞こえてくる声とピクトグラフに表示される人物情報の正誤を確認する(S21)。ここで誤りを発見し、修正を行う場合は修正機能を使用する(S22)。表示部28の画面を見ながら、スイッチやタッチパネルなどの入力装置46を用いて、正しい情報がヒストグラムとして表示されるように修正する(S23〜S31)。
具体的に説明する。使用者が修正を選択すると(S22)、修正モードに入り、画面上のピクトグラフを選択する画面になる(S23)。このピクトグラフ選択の際に、データベース16には該当する人物がいないとして表示対象から外されていた声に対して、「該当人物なし」を示すピクトグラフを表示して、それを選択できるようにすることが望ましい。これにより、人声照合部34が再生音声信号とデータベース16の声データとを同定できなかった誤りに対する修正が可能になる。
ピクトグラフ選択画面上で選択されているピクトグラフは、形状や色や縁取りなどが変化をして何らかの強調表示をする。使用者は入力装置46によって修正対象のピクトグラフを選択する(S24)。選択の直後に、「本当に修正をして良いか」という、修正の意思を確認するダイアログを表示する(S25)。続いて、修正後に使用するデータを検索し選択する(S26)。
また、同時に修正するピクトグラフの対象範囲を選択する(S27)。このような選択ステップを設けることで、誤選択の可能性を低減できる。たとえば、第1の選択肢として、「選択したもののみ」に限定する。第2の選択肢として、「選択したピクトグラフと同一人物が認識されているもの全て」に限定する。第3の選択肢として、「選択したピクトグラフと同一人物が認識されているものの中で、選択したシーンと比較して人声照合の相関率が低いもの」に限定する。これらの選択肢の表現方法は、それぞれの再生装置に適した方法が選択される。
修正実行可否を確認する(S28)。使用者の修正実行の決定に従い、実際のピクトグラフ表示データの差替え処理が行われる(S29)。このとき、対象となったピクトグラフと同時修正を行った範囲をデータベース16に反映すると、次回以降の人声照合の精度が向上する。
他にも修正すべきピクトグラフがある場合(S30)、同様の手順によって修正を行う。その他の修正すべきピクトグラフが無い場合(S30)、修正モードから抜け(S231)、一連の修正作業を終える。
以上の構成および動作によって、画像信号と音声信号を再生した際に、画像に映っておらずに声だけが聞こえる人物に関する情報を視認できるようになる。
図9は、本発明の第3実施例の概略構成ブロック図を示す。再生装置110の記録媒体112には、音声付きの映像信号が記録されている。記録媒体112は、DVDに代表される光ディスク、磁気テープ、ハードディスク、又は、フラッシュメモリを内蔵したメモリカードなどからなる。記録媒体駆動装置114は、記録媒体112を駆動して、記録媒体112に信号を読み書きする装置である。
データベース116にはデータベース16と同様に、複数人の個人情報データが登録可能であり、現に登録されている。各個人情報データは、顔画像照合機能に使用する顔画像データとその特徴量を示す顔画像特徴量データ、人声照合機能に使用する声データとその特徴量を示す声特徴量データ、並びに、その他の種々のデータを含む。
画像処理部118は、記録媒体112から読み出された圧縮画像データを復号化し、種々の加工を施して、再生画像データを生成する。顔画像認識部120は、画像処理部118で処理された画像データから人物の顔に該当する領域の有無を判別する。顔画像照合部122は、顔画像認識部120で顔画像があると判別された領域を、データベース116に登録された顔画像データと比較する。これにより、再生画像中に含まれる人物が、データベース116に登録済みか否か、そして登録された誰であるかを特定できる。
付加画像生成部124は、記録媒体112から再生された再生画像信号にスーパーインポーズされるべき付加画像データを生成する。表示画像生成部126は画像処理部118から出力させる再生画像データに付加画像生成部124から出力される付加画像データを合成する。表示画像生成部126により、再生画像に付加画像がスーパーインポーズされた合成画像が生成される。但し、表示画像生成部126の出力画像は、合成画像以外に、再生画像のみからなる場合、又は付加画像のみからなる場合もありうる。
表示部128は、表示画像生成部126で生成された画像データを使用者が視認できるように画像として表示する。表示部128は、例えば、該再生装置に組み込まれている。表示部128は、液晶ディスプレイ(LCD)や有機ELディスプレイなどのディスプレイ装置とその駆動回路からなる。
音声処理部130は、記録媒体112から読み出された圧縮音声データを復号化し、種々の加工を施す。人声認識部132は、音声処理部130で得られた再生音声信号から、人間の発声に該当する音声の有無を判別する。人声照合部134は、人声認識部132で人間の声と判別された部分に対し、データベース116に登録された声データと比較する。音量検出部136は、人声認識部132で人物の声であると判断された場合に、その音量の大きさを検出する。音声出力装置138は、音声処理部130で生成された再生音声を音響出力する装置である。音声出力装置138は、例えば、再生装置110に組み込まれたスピーカとその駆動回路からなる。
付加画像表示判定部140は、顔画像照合部122の照合結果と人声照合部134の照合結果を基に、付加画像生成部124により生成させる付加画像の内容を決定する。
外部出力部142は、表示画像生成部126により生成された画像信号及び音声処理部130による再生音声信号を外部に出力する手段であり、例えば、外部出力用の駆動回路と、接続端子又は送信アンテナとからなる。
カメラ部150はレンズ及び撮像センサから成り、データベース116に登録する顔画像データを取り込むのに利用できる。すなわち、画像処理部118は、カメラ部150で撮影された画像信号に色バランス及びガンマ補正を施し、サイズ等を調整し、データベース116に顔画像データとして登録する。画像処理部118はまた、カメラ部150からの撮影画像の特徴量を抽出し、抽出した特徴量を顔画像特徴量データとしてデータベース116に登録する。
マイクロホン152は、データベース116の声データの基になる人声を収音するのに使用可能である。音声処理部130は、マイクロホン152で収音された音声信号に必要な処理を施した後、データベース116に音データとして登録する。その処理のために、音声処理部130は、マイクロホン52の出力を増幅するプリアンプ、及び、プリアンプのアナログ出力をデジタル化するA/D変換器を具備する。音声処理部130はまた、収音された音データの特徴量を抽出し、声特徴量データとしてデータベース116に登録する。
CPU144は、付加画像生成部124及び表示画像生成部126を制御するだけでなく、画像処理および音声処理が同期動作するように再生装置110の全体を制御する中央演算装置である。
入力装置146は、使用者が再生装置110に動作モードや動作条件等を入力するための装置であり、種々のスイッチ又はボタン、若しくは、メニュー画面上に表示される操作可能な要素などからなる。
オーサリング処理部160は画像処理部118と音声処理部130の出力信号に、付加画像生成部124で生成された付加画像をサブピクチャとして付加したものを、規定のフォーマットに則したデータに変換する。オーサリング処理部160は、その処理結果を、記録媒体駆動装置162を介して記録媒体164に記録する。記録媒体164は、オーサリング処理部160で生成されたデータの記録保存先である。記録媒体駆動装置162は、記録媒体164に応じた制御方式で記録媒体164を駆動し、記録媒体164に信号を読み書きする。
記録媒体112をオーサリング処理部160の処理結果の記録先にしてもよいことは明らかである。この場合、勿論、記録媒体112は読み出し専用記録媒体ではなく、記録可能な媒体である。図9に示す実施例では、各データの保存場所を理解しやすいように、記録媒体112と記録媒体164を別々に図示しているに過ぎない。
図10は、本実施例の特徴的な動作を示すフローチャートである。図10を参照して、本実施例の特徴的な動作を説明する。
まず、データベース116に、必要な人物の個人情報データを事前に登録する(S101)。先に説明したように、各人の個人情報データは、顔画像データとその特徴量を示す顔画像特徴量データ、声データとその特徴量を示す声特徴量データ、及び、その他の種々の属性データからなる。属性データは、例えば、氏名、ニックネーム、性別」、年齢、生年月日及び似顔絵などからなる。
データベース116のデータの内、顔画像データ、声データ及びこれらの特徴量を示すデータは、カメラ部150、マイクロホン152、画像処理部118及び音声処理部130を使って、データベース116に登録できる。具体的な方法は後述する。
音声処理部130は、記録媒体112から読み出された圧縮音声データを伸長し、再生音声信号を人声認識部132、音声出力装置138、外部出力部142及びオーサリング処理部160に供給する。人声認識部132は、再生音声信号から人声を抽出して解析し、人声が含まれているかどうかを判別する(S102)。人声が含まれている場合、人声認識部132は、抽出した人声データを人声照合部134に供給する。
人声照合部134は、人声認識部132からの人声データからその特徴量を抽出し、データベース116の声特徴量データに照合して、一定以上の高い相関を有する特徴量を持つ人物を探索する(S103)。人声照合部134は、一定値以上の相関度を有する声特徴量データが存在した場合、これらの声特徴量データを有する人物を付加画像表示の候補として付加画像表示判定部140に通知する(S104)。
他方、画像処理部118は、記録媒体112から再生された圧縮画像データを伸長して再生画像データを生成する。顔画像認識部120は、再生画像から人の顔画像を抽出し、抽出した顔画像データを顔画像照合部122に供給する(S105)。顔画像照合部122は、顔画像認識部120からの顔画像データからその特徴量を抽出し、データベース116の顔画像特徴量データと照合して、一定以上の高い相関を有する顔画像特徴量を持つ人物を探索する(S106)。顔画像照合部122は、一定値以上の相関度を有する顔画像特徴量データが存在した場合、その顔画像特徴量データを有する人物を、付加画像表示の除外候補として付加画像表示判定部140に通知する(S107)。
付加画像表示判定部140は、再生音声から抽出された候補(人声照合部134からの通知情報)から、再生画像から抽出された除外候補(顔画像照合部122からの除外候補)を除外する(S108)。これにより、同一シーン中で、話者の可能性の高い人物候補(S104)から、画面内に入っている人物(S107)を除外できる。即ち,撮影画面内には入っていないが,音声が記録されている人物を特定できる。付加画像表示判定部140は、このように特定された人物を付加画像生成部124に通知する。
付加画像生成部124は、付加画像表示判定部140から通知された人物の顔画像データをデータベース116から取得し(S109)、この顔画像を含む所定サイズの付加画像を生成する(S110)。付加画像生成部124は、生成した付加画像を表示画像生成部126とオーサリング処理部160に供給する。
表示画像生成部126は、画像処理部118からの再生画像データに、付加画像生成部124からの付加画像をスーパーインポーズして、合成画像データを生成する。合成画像データは、表示部128に印加され、図4に示すように表示される。もちろん、外部出力部142から外部に出力されることもある。
また、オーサリング処理部160は、画像処理部118からの再生画像信号と、音声処理部130からの再生音声信号と、付加画像生成部124からの付加画像を多重して1つの映像コンテンツを生成する。その際、付加画像をピクトグラム様のサブピクチャとして再生画像信号に重畳した映像信号を生成する(S111)。オーサリング処理部160は、このように生成した映像コンテンツを記録媒体駆動装置162により記録媒体164に記録する(S112)。例えば、DVD−VIDEO形式のDVDを作成する。DVD−VIDEO形式の場合、「字幕」機能をオンにすることによって、画角外で発声する人物の情報を主たる映像の上に重ね描き表示させながら、視聴できる。
データベース116を説明する。データベース116は、データベース16と同様に、記録媒体112に格納されても、再生装置110に内蔵されても良い。再生装置110がネットワーク対応の場合には、データベース116を、ネットワークを介して接続するサーバ上に用意しても良い。記録媒体112が再生装置110から着脱自在である場合、記録媒体112に記録されるデータベースを再生装置110の記憶領域にロードして利用する方式でも、記録媒体112上のデータベースを直接参照する方式の何れであってもよい。また、前者の場合、データベースのみを記録した着脱可能な記録媒体を用意してもよい。
データベース116の構造は、データベース16の構造と同様である。データベース116に登録される各人の個人情報データは、顔画像照合とピクトグラフ表示に使用するための顔画像データと、音声照合に使用するための声データを必ず有する。これに加えて、氏名、ニックネーム、性別、年齢、生年月日、及び似顔絵などデータを付加的な属性情報として保持する。これらの付加的な属性情報を、顔画像データと同時に、または置き換えてピクトグラフ表示に使用してもよい。
データベース116に登録される人数が増加してくると、ピクトグラフとして表示を出したい人物と出したくない人物の区分が生じてくる。この区分に対応するために、各々の個人情報データ毎にピクトグラフ表示の可否を設定する項目を設けるのが好ましい。新規登録された個人情報データの新規登録時にデフォルトでどちらを設定するかは、使用状況に応じて決定すればよい。
データベース116も、データベース16と同様に、他の機器で作成されたものも読み込んで使えるような汎用性のあるものであるのが好ましい。
本実施例のピクトグラフ表示について説明する。声だけが聞こえる人物に関する情報をピクトグラフで表示することは、視認性を付加できるので有用ではある。そして、表示方法を工夫することで、その効果を更に増すことができる。
ピクトグラフ表示機能の有効/無効を使用者が設定できると、本来の記録画像だけを見たいという要求にも対応できる。これは、画像に映っていない人物が誰であるのかを気にしない場合や、既知の声だが聞こえている場合などに有効である。
ピクトグラフとして表示される情報はデータベース116が有する項目の中から1つ以上である。どの項目を表示させるかを選択できると、使用者の知りたい情報に連動することができる。例えば、顔画像と同時に「氏名」を表示させれば、顔画像だけでは誰であるのかを判別しづらいときでも、人物を特定しやすくなる。もちろん、「氏名」だけを表示することでも、同様の効果を得ることができる。
ピクトグラフ表示対象者の全人物に対し表示をするデータ項目を統一した場合、幾人かの人物では該当項目が未登録である可能性も考えられる。このような状況に対応するために、ピクトグラフ表示データの各項目に優先順位を持たせ、上位項目が未登録な場合には次点項目を表示するようにすると良い。例えば、第1優先順位に「ニックネーム」を、第2優先順位に「氏名」を設定したとする。この場合、「ニックネーム」の項目が登録されている人物に関しては「ニックネーム」が表示され、「ニックネーム」の項目が登録されていない人物に関しては「氏名」が表示される。このような優先順位を設定する作業は、データベース116に登録できる各人の個人情報データの項目が多数になるほど、煩雑なものとなる。これに対しては、有限個の上位順位までを使用者が設定できるようにしておき、それ以下の順位の項目については再生装置110が自動的に割り振るようにすればよい。これにより、使用者の負担が軽減する。尚、使用者がデータベース116の個人情報データ内の項目に一切のデータを追加したかった場合でも、登録必須項目である顔画像データが何れかの優先順位に割り当てられるので、ピクトグラフに表示するデータは確保される。
画面上でのピクトグラフは、再生画像中の注目度の高い部分を出来るだけ遮らないが望ましい。一般的に、画像の注目度は周辺部よりも中心部の方が高い傾向にあるので、ピクトグラフの表示場所は基本的に再生画像の周辺部に配置されることになる。しかし、被写体が動いているシーンなどでは、その被写体の移動に伴って周辺部の注目度が高くなる場合もあり得る。このとき、注目度が高くなる場所と、ピクトグラフが表示される場所とが重なり合うことは望ましくない。ピクトグラフの表示場所を使用者が設定できると、このような事態を回避できる。
ピクトグラフの大きさについても使用者が設定できると便利である。例えば、大きさを、「大」、「中」、「小」やドット数で表現された規定段階の中から選択できる形式や、同様の表現が付記された図表を用いて選択する形式が考えられる。これは、再生装置10に備えつけられている比較的小型の表示画面で見る場合と、外部接続機能を介してテレビなどの比較的大型の画面で見る場合のように、表示画面の画素数が大きく異なる場合に、有用である。視認性を満足するために求められるピクトグラフの大きさに無視できない差があるからである。
また、形状についても、四角形や丸形などの選択肢を設けると、使用者の嗜好性を活かすことができる。ただし、設定された形状に従って表示可能なデータに制限を設ける必要も生じる。例えば、小さな外形寸法内部で視認性を満足しながら表現できるデータは、限られる。実際の制限の設け方は、それぞれの再生装置に適したもので良い。ピクトグラフの形状として、このような制限が働く形状が設定された場合、表示可能なデータ候補の中の優先順位が上位のものから表示される。大きさ及び形状の何れについても、設定変更操作と同時に実際のピクトグラフの大きさ及び形状が変更するのが好ましい。
画面上に同時に表示されるピクトグラフの数に上限を設けると、多数のピクトグラフが現れてしまうことで主映像や他のピクトグラフを覆い隠してしまうことを防止できる。一画面上または同一シーンに対して表示されるピクトグラフの上限数又は最大数を使用者が設定できると、再生するテレビモニタのサイズや視認能力に応じて適切な変更が可能となる。このように表示数に制限がある場合、どのようなピクトグラフを優先して表示をするかが重要になってくる。最もシンプルな方法は、発声者を認識した時点で次々とピクトグラフを更新していく方法である。時系列の発声順序に注目した、所謂「後着優先型」である。常に最新の発声者からピクトグラフの表示上限に等しい数だけ遡る時点での発言者までが表示対象となる。同じ人物が連続的に発声を続ける限りは表示の更新が行われないが、他の者の発言が挿入された時点で更新が行われる。
他には、発声音量に連動する方法が考えられる。音量検出部136を用いて人物の発声音量を測定し、この結果からピクトグラフの表示優先順位を決定する。音量の大きな順番に優先順位が高くなれば、より耳に届きやすい人物のピクトグラフが優先表示される。逆に音量の小さな順番に優先順位が高くなれば、より耳に届きにくく聞き逃しやすい人物のピクトグラフが優先表示される。
また、もともと優先的に表示をしたい人物を決めておくことも有効である。これはデータベース116の登録項目中にピクトグラフ表示優先度設定値を持たせ、付加画像表示判定部140がこの設定値に応じた処理を行うことで実現できる。
例えば,映像ソースがホームビデオで撮影されたものである場合、撮影者が最も近距離から頻繁に発声していることが考えられる。このとき、前述のような優先順位を与えると、撮影者のピクトグラフが断然高頻度で表示されることになる。撮影者が映像に映らないことが多いのは確かではあるが、それが誰であったのかは比較的分かり易いものである。そこで、撮影者が誰であるのかを入力できるようにして、その人物のピクトグラフだけを他とは違う表現方法にしたり、あるいは表示しないようにすることで、ピクトグラフ表示の煩雑さを軽減できる。
視認性の向上とあわせて娯楽性のあるインターフェイスも考えられる。1つ目の方法では、発声音声の音量に応じてピクトグラフの大きさを変化させる。音量検出部136で検出された音量データとピクトグラフの外形寸法の二者に相関性を持たせる。例えば、大きさを3段階で変化させる場合、音量データに2つの閾値レベルを設け、低い側の閾値レベル以下であれば小さく、2つの閾値レベル間であれば中程度に、高い側の閾値レベル以上であれば大きくする。
2つ目の方法では、発声音声の指向角に応じてピクトグラフの表示位置を変化させる。音量検出部136が再生音声を解析し、スピーカ出力に対して視聴者のがどの方向からの音声と認識するかを調べる。再生音声が2チャンネルモードの場合には、音声の指向角に合わせてピクトグラフを左右方向に変化させて表示する。サラウンドモードの場合には、音声の左右方向を左右に、前後方向を上下に見立ててピクトグラフを配置する。例えば、右前方から聞こえる音声に対応するピクトグラフを再生画像の右上方に表示する。
発声音量や指向角は常時変化するものであるから、ピクトグラフ表示もその変化に追随すべきである。適当な時間間隔でピクトグラフ表示を更新することで、音声の変化動向を可視的に表すことができる。
また他にも、データベース116に登録されたデータを基に、性別や年齢などに応じた色分けをすることなども考えられる。
表示タイミングにも配慮をすると、より見やすくすることができる。例えば、驚いた拍子に発する「あっ」という短い発声を検出した場合を考える。このような音声の検出結果に対して敏速な反応をすると、ピクトグラフが表示されるのは一瞬の出来事となる。これではピクトグラフで表示された人物が誰であったのかを確認するのは、非常に困難になる。そこで、オーサリング処理部160が、ある音声に対応するピクトグラフを一定時間先行して表示開始するように設定する。また、発声終了時には、一定時間表示を保持した後に消すという設定にする。すなわち、オーサリング処理部160は、発声開始よりも時間的に先行してサブピクチャの表示を開始し、発声終了より時間的に遅れてサブピクチャの表示を終了するようにオーサリングを行う。こうすることで、実際の発声時間の前後にピクトグラフを確認できる時間的余裕が生まれ、短い発声に対する視認性が改善される。あるいは、事前に発声時間を検出できるようであれば、ある規定時間以下の発声に対してだけ、前記のタイミング調整を行うのも良い。
前述した様々なピクトグラフ表示方法を組み合わせてサブピクチャの設定を行う際に次のようにする。すなわち、複数のサブピクチャチャネルを生成するオーサリング処理が可能であるならば、組合せ方法を変えた複数のチャネルを持ち合わせるようにする。例えば、あるチャネルは後着優先表示で、別のチャネルは音量優先表示で、更に別のチャネルでは指向角と性別による色分けで、という手法が可能である。これがDVDVIDEO形式でオーサリングされたものであれば、「字幕」を切り替えることで色々な表示を楽しむことができる。図11は、同時に表示されるピクトグラフの上限数が3で、発声音量と発声指向角に連動するピクトグラフ表示例を示す。
このように、本実施例では、再生画像に映らずに再生声だけが聞こえる人物に関する情報を示すピクトグラフをサブピクチャとして表示可能な情報媒体を作成できる。
再生音声信号とデータベース116にある声データをそれぞれの特徴量で照合して、正しい人物を選択できなかった場合、ピクトグラフに誤ったデータが使用されることになる。使用者が表示されたピクトグラフを見て誤りに気付いたとき、本実施例では、正しい内容に修正できる。図12は、その修正動作のフローチャートを示す。
使用者は、再生表示画像を見て、聞こえてくる声とピクトグラフに表示される人物情報の正誤を確認する(S121)。ここで誤りを発見し、修正を行う場合は修正機能を使用する(S122)。表示部128の画面を見ながら、スイッチやタッチパネルなどの入力装置146を用いて、正しい情報がヒストグラムとして表示されるように修正する(S123〜S131)。
具体的に説明する。使用者が修正を選択すると(S122)、修正モードに入り、画面上のピクトグラフを選択する画面になる(S123)。このピクトグラフ選択の際に、データベース116には該当する人物がいないとして表示対象から外されていた声に対して、「該当人物なし」を示すピクトグラフを表示して、それを選択できるようにすることが望ましい。これにより、人声照合部134が再生音声信号とデータベース116の声データとを同定できなかった誤りに対する修正が可能になる。
ピクトグラフ選択画面上で選択されているピクトグラフは、形状や色や縁取りなどが変化をして何らかの強調表示をする。使用者は入力装置146によって修正対象のピクトグラフを選択する(S124)。選択の直後に、「本当に修正をして良いか」という、修正の意思を確認するダイアログを表示する(S125)。続いて、修正後に使用するデータを検索し選択する(S126)。
また、同時に修正するピクトグラフの対象範囲を選択する(S127)。このような選択ステップを設けることで、誤選択の可能性を低減できる。たとえば、第1の選択肢として、「選択したもののみ」に限定する。第2の選択肢として、「選択したピクトグラフと同一人物が認識されているもの全て」に限定する。第3の選択肢として、「選択したピクトグラフと同一人物が認識されているものの中で、選択したシーンと比較して人声照合の相関率が低いもの」に限定する。これらの選択肢の表現方法は、それぞれの再生装置に適した方法が選択される。
修正実行可否を確認する(S128)。使用者の修正実行の決定に従い、実際のピクトグラフ表示データの差替え処理が行われる(S129)。このとき、対象となったピクトグラフと同時修正を行った範囲をデータベース116に反映すると、次回以降の人声照合の精度が向上する。
他にも修正すべきピクトグラフがある場合(S130)、同様の手順によって修正を行う。その他の修正すべきピクトグラフが無い場合(S130)、修正モードから抜け(S131)、一連の修正作業を終える。
以上の構成および動作によって、画像信号と音声信号を再生した際に、画像に映っておらずに声だけが聞こえる人物に関する情報を視認できるようになる。
本実施例では、カメラ部150及びマイクロホン152をデータベース116に顔画像データ及び声データを登録するのに使用できる。図13を参照して、取り込んだ画像データ及び音声データのデータベース116への登録方法を説明する。
使用者は再生装置110の機能メニュからデータベース登録機能を選択し(S141)、データベース116に新しい個人情報を作成する(S142)。
まず、顔画像データを登録する(S143)。具体的には、カメラ部150が起動し、撮影が可能な状態になる(S144)。登録したい人物を被写体とし、その顔を含んだ画像を撮影する(S145)。このとき、表示部128にカメラ部150が捉えている画像が表示される。被写体となった人物自身が、表示部128の表示画像を見ながら、カメラ部150と自分の顔の位置関係を確認できるようにすると、効率的な撮影が行える。撮影画角内に被写体が的確に捉えられたら、入力装置146のスイッチを押して撮影を実行し、被写体の顔画像を取り込む(S146)。画像処理部118は、カメラ部150からの画像データをデータベース116への登録に適した形式とサイズに処理する。このとき、画像処理部118は、撮影した顔画像データから顔画像特徴量を算出し(S147)、顔画像データとともにデータベース116に登録する(S148)。ここでの顔画像特徴量算出処理には、再生画像から検出された人物の顔画像特徴量を算出する機能を利用できる。
次に、声データを登録する(S149)。音声処理部130は、マイクロホン152が収音する音声信号を処理する機能を起動する(S150)。収音準備が整い収音可能な状態になったら、表示部128に声を入力することを促す表示をする。登録に適したフレーズを表示し、それを登録者に発声させるようにすれば、登録者が発言すべきフレーズに迷うことがないので好ましい。声を記録する際、入力装置146のスイッチを記録開始時と終了時に押すようにするか、押されている最中を記録期間とする。
音声処理部130は、マイクロホン152からの音声を一旦保持する(S151)。そして、表示とともにこの音声を再生して、登録して良いかどうかを使用者に確認する(S152)。使用者が登録を拒否すれば、音声の取り込みをやり直す。使用者が登録を承認すると、音声処理部130は、取り込んだ音声をデータベース116への登録に適した形式及びサイズに処理し、声特徴量を算出し(S153)、声データと声特徴量をデータベース116に登録する(S154)。ここでの声特徴量算出処理には、再生音声から声特徴量を算出する機能を利用できる。
続いて、データベース116に、例えば、氏名等の、その他の項目を入力する(S155)。
図13に示す登録順序は一例であり、例えば最初に「氏名」を入力してから顔画像データを登録してもよいことは明らかである。