以下に添付図面を参照しながら、本発明の好適な実施の形態について詳細に説明する。なお、本明細書及び図面において、実質的に同一の機能構成を有する構成要素については、同一の符号を付することにより重複説明を省略する。
(第1の実施形態)
以下に、本発明の第1の実施形態に係る音声チャットシステムについて、詳細に説明する。
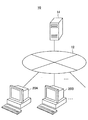
図1は、本実施形態に係る音声チャットシステムを説明するための説明図である。音声チャットシステム10は、例えば、通信網12と、検索サーバ14と、情報処理装置20A、20Bと、を含む。
通信網12は、情報処理装置20および検索サーバ14を双方向通信または一方向通信可能に接続する通信回線網である。この通信網12は、例えば、インターネット、電話回線網、衛星通信網、同報通信路等の公衆回線網や、WAN(Wide Area Network)、LAN(Local Area Network)、IP−VPN(Internet Protocol−Virtual Private Network)、Ethernet(登録商標)、ワイヤレスLAN等の専用回線網等で構成されており、有線/無線を問わない。
検索サーバ14は、インターネット等で公開されている情報についてキーワード等を使って検索できるWebサイトである。本実施形態に係る検索サーバ14は、キーワードによって蓄えられている情報の全文検索を行う全文検索型であってもよく、カテゴリ別に分類されている情報を検索するディレクトリ型であってもよい。
情報処理装置20は、通信網12を介して接続された他の情報処理装置20と、音声によるチャット(音声チャット)を行う。また、情報処理装置20は、通信網12に接続されている検索サーバ14に対して、通信網12を介して情報の検索を要求することができる。また、音声チャットを行う他の情報処理装置20は、図示のように通信網12を介して接続されていてもよく、また、通信網12を介さずに、例えば、USB(Universal Serial Bus)ポートや、i.Link等のIEEE1394ポート、SCSI(Small Computer System Interface)ポート、RS−232Cポート等により直接接続されていてもよい。
なお、図示の例では、情報処理装置20として、デスクトップ型のPCを示しているが、本実施形態に係る情報処理装置20は、デスクトップ型PC、ノート型PCを問わない。また、本実施形態に係る情報処理装置20は、かかる例に限定されず、ネットワークを介した通信機能を有する機器であれば、例えば、テレビジョン受像器や家庭用ゲーム機等の情報家電、携帯電話、PDA(Personal Digital Assistant)等で構成することもできる。また、情報処理装置20は、契約者が持ち運びできるポータブルデバイス(Portabale Device)、例えば、携帯型ゲーム機、PHS、携帯型映像/音声プレーヤなどであってもよい。
さらに、図1では、通信網12に接続されている情報処理装置20は、2つのみであるが、本実施形態は、上記の場合に限定されるわけではなく、情報処理装置20は、通信網12上に複数接続されていてもよい。
(情報処理装置20のハードウェア構成)
次に、本実施形態に係る情報処理装置20のハードウェア構成について、図2を参照しながら簡単に説明する。
図2は、本実施形態にかかる情報処理装置20のハードウェア構成を示した説明図である。情報処理装置20は、主に、CPU(Central Processing Unit)201と、ROM(Read Only Memory)203と、RAM(Random Access Memory)205と、ホストバス207と、ブリッジ209と、外部バス211と、インターフェース213と、入力装置215と、出力装置217と、ストレージ装置219と、ドライブ221と、通信装置223とを備える。
CPU201は、演算処理装置および制御装置として機能し、ROM203、RAM205、ストレージ装置219、またはリムーバブル記録媒体16に記録された各種プログラムに従って情報処理装置20内の動作全般またはその一部を制御する。ROM203は、CPU201が使用するプログラムや演算パラメータ等を記憶する。RAM205は、CPU201の実行において使用するプログラムや、その実行において適宜変化するパラメータ等を一次記憶する。これらはCPUバス等の内部バスにより構成されるホストバス207により相互に接続されている。
ホストバス207は、ブリッジ209を介して、PCI(Peripheral Component Interconnect/Interface)バスなどの外部バス211に接続されている。
入力装置215は、例えば、マウス、キーボード、タッチパネル、ボタン、スイッチおよびレバー等のユーザが操作する操作手段と、マイクロフォンやヘッドセット等の音声入力手段とを備える。また、入力装置215は、例えば、赤外線やその他の電波を利用したリモートコントロール手段(いわゆる、リモコン)であってもよいし、情報処理装置20の操作に対応した携帯電話やPDA等の外部接続機器であってもよい。さらに、入力装置215は、例えば、上記の操作手段や音声入力手段を用いてユーザにより入力された情報に基づいて入力信号を生成し、CPU201に出力する入力制御回路などから構成されている。情報処理装置20のユーザは、この入力装置215を操作することにより、情報処理装置20に対して各種のデータを入力したり処理動作を指示したりすることができる。
出力装置217は、例えば、CRT(Cathode Ray Tube)ディスプレイ装置、液晶ディスプレイ(Liquid Crystal Display:LCD)装置、プラズマディスプレイ(Plasma Display Panel:PDP)装置、EL(Electro−Luminescence)ディスプレイ装置およびランプなどの表示装置や、スピーカおよびヘッドホンなどの音声出力装置や、プリンタ装置、携帯電話、ファクシミリなど、取得した情報をユーザに対して視覚的または聴覚的に通知することが可能な装置で構成される。出力装置217は、例えば、検索サーバを用いて検索した各種情報を出力する。具体的には、表示装置は、検索サーバによる各種情報の検索結果をテキストまたはイメージで表示する。他方、音声出力装置は、再生された音声データ等を音声に変換して出力する。
ストレージ装置219は、本実施形態にかかる情報処理装置20の記憶部の一例として構成されたデータ格納用の装置であり、例えば、HDD(Hard Disk Drive)等の磁気記憶部デバイス、半導体記憶デバイス、光記憶デバイス、または光磁気記憶デバイス等により構成される。このストレージ装置219は、CPU201が実行するプログラムや各種データ、および外部から取得した各種データなどを格納する。
ドライブ221は、記憶媒体用リーダライタであり、情報処理装置20に内蔵、あるいは外付けされる。ドライブ221は、装着されている磁気ディスク、光ディスク、光磁気ディスク、または半導体メモリ等のリムーバブル記録媒体16に記録されている情報を読み出して、RAM205に出力する。また、ドライブ221は、装着されている磁気ディスク、光ディスク、光磁気ディスク、または半導体メモリ等のリムーバブル記録媒体16に記録を書き込むことも可能である。リムーバブル記録媒体16は、例えば、DVDメディア、HD−DVDメディア、Blu−rayメディア、コンパクトフラッシュ(CompactFlash:CF)、メモリースティック、または、SDメモリカード(Secure Digital memory card)等である。また、リムーバブル記録媒体16は、例えば、非接触型ICチップを搭載したICカード(Integrated Circuit card)または電子機器等であってもよい。
通信装置223は、例えば、通信網12に接続するための通信デバイス等で構成された通信インターフェースである。通信装置223は、例えば、有線または無線LAN(Local Area Network)、Bluetooth、またはWUSB(Wireless USB)用の通信カード、光通信用のルータ、ADSL(Asymmetric Digital Subscriber Line)用のルータ、または、各種通信用のモデム等である。この通信装置223は、他の情報処理装置20との間で音声チャットに関する情報を送受信すると共に、例えば、インターネットや他の通信機器との間で各種の情報を送受信することができる。また、通信装置223に接続される通信網12は、有線または無線によって接続されたネットワーク等により構成され、例えば、インターネット、家庭内LAN、赤外線通信、または衛星通信等であってもよい。
以上説明した構成により、情報処理装置20は、当該情報処理装置20に直接接続された他の情報処理装置、または、通信網12に接続された他の情報処理装置と音声チャットを行うことが可能になると同時に、通信網12に接続された検索サーバ14等から、各種の情報を取得することが可能となる。さらに、情報処理装置20は、リムーバブル記録媒体16を用いて、当該情報処理装置20に蓄積されている情報を持ち出すことも可能である。
以上、本実施形態に係る情報処理装置20の機能を実現可能なハードウェア構成の一例を示した。上記の各構成要素は、汎用的な部材を用いて構成されていてもよいし、各構成要素の機能に特化したハードウェアにより構成されていてもよい。従って、本実施形態を実施する時々の技術レベルに応じて、適宜、利用するハードウェア構成を変更することが可能である。また、上記のハードウェア構成は、あくまでも一例であり、これに限定されるものでないことは言うまでもない。また、利用形態によっては、ホストバス207や外部バス211、またはインターフェース213等を省略する構成も可能である。
(情報処理装置20の構成)
続いて、本実施形態に係る情報処理装置20の構成について詳細に説明を行うが、以下の説明においては、音声チャットを行う2つの情報処理装置20について、便宜的に第1情報処理装置20Aおよび第2情報処理装置20Bと称することとする。また、第1情報処理装置20Aおよび第2情報処理装置20Bは、各情報処理装置のユーザの声を音声データ化し、音声チャットの会話相手である他の情報処理装置に対して、音声データを送信するものとする。図3は、本実施形態に係る第1情報処理装置20Aの構成を説明するためのブロック図である。
なお、以下の説明において、単語とは、音声を認識する処理において、1つのまとまりとして扱った方がよい単位のことを言い、言語学的な単語とは必ずしも一致しない。例えば、「タロウ君」は、それ全体を1単語として扱ってもよいし、「タロウ」、「君」という2単語として扱ってもよい。さらに、もっと大きな単位である「こんにちはタロウ君」等を1単語として扱ってもよい。
また、音韻とは、音響的に1つの単位として扱った方が処理上都合のよいもののことを言い、音声学的な音韻や音素とは必ずしも一致しない。例えば、「東京」の「とう」の部分を“t/o/u”という3個の音韻記号で表すことも可能であり、または“o”の長音である“o:”という記号を用意してもよい。さらに、“t/o/o”と表してもよい。他にも、無音を表す記号を用意してもよく、さらに無音を表す記号を「発話前の無音」「発話に挟まれた短い無音区間」「「っ」」の部分の無音」のように細かく分類してもよい。
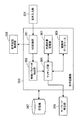
図3に示したように、本実施形態に係る第1情報処理装置20Aは、例えば、音声入力部251と、音声認識部253と、キーワード検出部255と、キーワード管理部257と、音声会話制御部259と、表示部261と、音声出力部263と、通信部265と、記憶部267と、認識単語辞書生成部269と、を備える。
音声入力部251は、第1情報処理装置20Aのユーザが発した音声である音声チャットでの会話を、第1情報処理装置20Aへと取り込むインターフェースであって、例えば、第1情報処理装置20Aに接続された入力装置であるマイクロフォンやヘッドセット等から構成される。マイクロフォンやヘッドセットに向かって発せられたユーザの会話は、自動的かつリアルタイムに第1情報処理装置20Aへと取り込まれて電気信号としての音声信号に変換され、音声入力部251を介して音声認識部253へと伝送される。
音声認識部253は、例えば、CPU、ROM、RAM等で構成され、音声入力部251により自主的に取り込まれリアルタイムに伝送されてくるユーザの会話から音声データを生成して、後述する音声会話制御部259に音声データを伝送するとともに、生成した音声データに基づいて音声認識を行う。音声認識部253は、音声認識の結果として、生成した音声データに対応する単語列を生成して、後述するキーワード検出部255に対して、生成した単語列を伝送する。また、音声認識部253は、生成した単語列を後述する表示部261に伝送してもよい。なお、音声認識部253については、以下で詳細に説明する。
キーワード検出部255は、音声認識部253から伝送された単語列の中に、キーワード管理部257が管理しているキーワードが存在するか否かを判断し、キーワードが存在している場合には、そのキーワードに該当する単語をキーワードとして出力する。キーワード検出部255は、一つの単語列の中に複数のキーワードが存在した場合には、該当する全てのキーワードを同時に検出してもよい。また、キーワード検出部255は、単語列の中から検出したキーワードを、後述する表示部261に伝送してもよい。
例えば、音声認識部253から「最近の構造改革は骨抜きだ」という認識結果が伝送され、キーワード管理部257が管理しているキーワードの中に「構造改革」というキーワードが存在する場合には、キーワード検出部255は、「構造改革」をキーワードとして出力する。
キーワード管理部257は、音声認識部253が生成した単語列の中から抽出されるべきキーワードを管理する。キーワード管理部257は、第1情報処理装置20Aのユーザが検索サーバ14を利用した検索利用履歴情報や、本実施形態に係る音声チャットシステムの利用履歴情報等を記憶部267に記憶しておき、これらの利用履歴情報に含まれる検索キーワードや、検出されたキーワード等に基づいて、管理するキーワードを選択する。キーワード管理部257で管理されているキーワードは、キーワード検出部255が自由に参照することが可能である。また、キーワード管理部257は、管理しているキーワードを音声認識部253に対して提供することも可能であり、音声認識部253は、キーワード管理部257から提供されたキーワードに基づいて、後述する認識用データベースを更新してもよい。
音声会話制御部259は、例えば、CPU、ROM、RAM等で構成され、通信網12を介して接続されている第2情報処理装置20Bとの間で行われる音声チャットを制御する。音声会話制御部259は、音声認識部253で生成された音声データの伝送を受け、通信部265を介して音声データを第2情報処理装置20Bへと送信するとともに、第2情報処理装置20Bから送信される音声データを、通信部265を介して受信し、音声出力部263へと伝送する。また、音声会話制御部259は、音声チャットが行われる毎に、音声チャットの行われた日時、音声チャット自体を識別する識別子および音声チャットの相手を表す識別子を関連付けて、音声チャットの利用履歴情報として記憶部267に記憶してもよい。
なお、音声会話制御部259は、音声会話制御に特化したハードウェアにより構成されていてもよく、音声チャットプログラム等のアプリケーションプログラムとして提供されてもよい。
表示部261は、キーワード検出部255から伝送されたキーワードを、第1情報処理装置20Aのディスプレイ等の表示装置を介して、第1情報処理装置20Aのユーザに対して表示する。また、表示部261は、音声認識部253から伝送された音声認識結果である単語列そのものを、表示してもよい。
音声出力部263は、第2情報処理装置20Bのユーザが発した音声の音声データを受信し、第1情報処理装置20Aへと取り込むインターフェースであって、例えば、第1情報処理装置20Aに接続された出力装置であるスピーカやイヤフォン等から構成される。通信部265を介して受信された第2情報処理装置20Bからの音声データは、音声出力部263を介して、第1情報処理装置20Aのユーザへと出力される。
通信部265は、例えば第1情報処理装置20Aに設けられた通信装置であって、第1情報処理装置20Aの音声認識部253と、キーワード管理部257と、音声会話制御部259と、認識単語辞書生成部269とが、通信網12を介して第1情報処理装置20Aの外部の装置等である検索サーバ14や第2情報処理装置20B等と行う情報の送受信を、仲介する。なお、通信部265は、通信網12を介さずに、第1情報処理装置20Aに直接接続されているその他の情報処理装置等に対して、情報の送受信を行うことも可能である。
記憶部267は、例えば第1情報処理装置20Aに設けられたストレージ装置であって、キーワード検出部255が検出したキーワードやキーワード管理部257が管理しているキーワード情報等のデータを記憶する。また、これらのデータ以外にも、音声認識部253が生成した音声データや単語列等の認識結果や、各種のデータベース等を記憶することも可能である。更に、これらのデータ以外にも、第1情報処理装置20Aが、何らかの処理を行う際に保存する必要が生じた様々なパラメータや処理の途中経過等を、適宜記憶することが可能である。この記憶部267は、音声認識部253や、キーワード検出部255や、キーワード管理部257や、音声会話制御部259や、認識単語辞書生成部269等が、自由に読み書きを行うことが可能である。
認識単語辞書生成部269は、検索サーバ14から取得する検索キーワードリスト等を取得して、取得した検索キーワードリストから適切なキーワードのみを選択し、音声認識に利用する認識単語辞書を生成する。また、認識単語辞書生成部269は、取得した検索キーワードリストからキーワードの選択を行なうだけでなく、選択したキーワードに対して、当該キーワードの属性情報や関連するサブキーワードを付加したり、音声認識に利用する際の認識重み情報を付加したりしてもよい。この認識単語辞書生成部269については、以下で詳細に説明する。
<音声認識部253について>
続いて、図4を参照しながら、本実施形態に係る音声認識部253について、詳細に説明する。図4は、本実施形態に係る音声認識部253を説明するためのブロック図である。
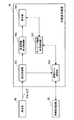
図4に示したように、本実施形態に係る音声認識部253は、例えば、AD変換部301と、特徴パラメータ抽出部303と、マッチング部305と、共通辞書記憶部307と、認識用データベース309と、を備える。
AD変換部301は、音声入力部251から伝送されたアナログ信号である音声信号をサンプリングして量子化し、ディジタル信号である音声データへと変換する。音声データへの変換が終了すると、AD変換部301は、生成した音声データを、音声会話制御部259および特徴パラメータ抽出部303へと伝送する。また、AD変換部301は、生成した音声データを、記憶部267に記憶してもよい。
特徴パラメータ抽出部303は、AD変換部301にて生成された音声データについて、適当なフレームごとに、例えば、メル周波数ケプストラム係数(Mel Frequency Cepstrum Coefficients:MFCC)とその時間差分パラメータ、スペクトル、パワー線形予測係数、ケプストラム係数、線スペクトル対などの特徴パラメータを抽出する。特徴パラメータの抽出が終了すると、特徴パラメータ抽出部303は、抽出した特徴パラメータを、後述するマッチング部305へと伝送する。なお、特徴パラメータ抽出部303は、音声データから抽出した各種の特徴パラメータを、記憶部267に記憶してもよい。
マッチング部305は、特徴パラメータ抽出部303から伝送された各種の特徴パラメータに基づき、後述する共通辞書記憶部307や認識用データベース309等を適宜参照しながら、音声入力部251に入力された音声(すなわち、音声チャットにおける会話内容)に最も近い単語列を、音声認識結果として生成する。単語列の生成方法については、以下で改めて説明する。単語列の生成が終了すると、マッチング部305は、生成した単語列を、キーワード検出部255へと伝送する。また、マッチング部305は、生成した単語列を、記憶部267に記憶してもよい。
なお、上記のマッチング部305は、例えば、ビームサーチに基づくビタビ(Viterbi)デコーダや、A*探索に基づくスタックデコーダなどの手法を用いてマッチングを行なうことも可能であり、例えば、いわゆるキーワードスポッティング等の手法を用いてマッチングを行なうことも可能である。また、マッチング部305が参照する各種の単語辞書に、後述する「認識重み」情報が付加されている場合には、後述する言語スコアに重みをつけた上で認識結果の順位付けを行なうことも可能である。
共通辞書記憶部307は、音声認識で常に使用される単語の辞書である共通辞書を記憶する。共通辞書記憶部307に記憶されている共通辞書には、共通辞書に登録されている全ての単語について、発音情報とカテゴリ情報とがそれぞれ関連付けられて記述されている。例えば、固有名詞である「イチロー(人名)」が共通辞書に登録される場合には、「いちろう」という発音情報(音韻情報)と、“_人名_”というカテゴリとが、「イチロー」という固有名詞にそれぞれ関連付けられて登録される。なお、共通辞書の詳細については、以下で改めて説明する。
認識用データベース309は、マッチング部305が単語列の生成に用いる各種のモデルや規則等を記憶しているデータベースである。この認識用データベース309については、以下で詳述する。
<認識用データベース309について>
続いて、図5を参照しながら、本実施形態に係る認識用データベース309について、詳細に説明する。図5は、本実施形態に係る認識用データベース309を説明するための説明図である。
図5に示したように、本実施形態に係る認識用データベース309は、例えば、認識単語辞書記憶部401と、音響モデル記憶部403と、言語モデル記憶部405と、音韻リスト407と、カナ音韻変換規則409と、を含む。
認識単語辞書記憶部401は、マッチング部305が単語列を生成する際に用いる認識単語辞書を記憶する。認識単語辞書は、例えば、固定単語辞書と、可変単語辞書と、カテゴリテーブルとから構成されている。
固定単語辞書には、単語登録および単語削除の対象外の単語、すなわち、予めシステムに設定されている単語(以下、適宜、固定単語と称する。)についての発音(音韻系列)と、音韻の連鎖関係を記述したモデル等の、各種の情報が記述されている。
また、可変単語辞書には、キーワード単語についての発音や、音韻の連鎖関係を記述したモデル等の、各種の情報が記述されている。キーワード単語の登録・削除や発音の変更といった処理は、主に、この可変単語辞書に登録されている単語に対して行われる。また、可変単語辞書には、何も記憶されていなくともよい。
例えば野球に関連するキーワードを検出したい場合、共通辞書記憶部307には日常会話で通常使われる単語(例えば、国語辞典等の一般的な辞書に記載されているような単語等)を登録し、認識単語辞書記憶部401内の固定単語辞書には野球という分野で一般的で使われる「プレイ」や「ゲッツー」「代打」「ベンチ入り」などの単語を登録する。また、認識単語辞書記憶部401内の可変単語辞書には「イチロー」などの時代とともに変化する固有名詞などを登録しておき、可変単語辞書を随時更新することで、最新の野球の話題のキーワードを含む認識が容易に実行できる。
続いて、図6および図7を参照しながら、本実施形態に係る固定単語辞書について説明する。図6および図7は、本実施形態に係る固定単語辞書の一例を説明するための説明図である。
図6において、「シンボル」は単語を識別するための文字列であり、例えば、カナ表記などを用いて表すことができる。シンボルが同じエントリは、同じ単語のエントリであるとみなされる。また、本実施形態に係る言語モデルは、このシンボルを用いて表されている。また、「トランスクリプション」は、単語の表記を表し、認識結果として出力される文字列はこのトランスクリプションである。「音韻系列」は、単語の発音を音韻系列で表したものである。また、本実施形態に係る固定単語辞書は、図6に示したようなカナ表記のシンボルだけでなく、図7に示したような、漢字やひらがなの混ざった文字列についても記述されている。
なお、図6および図7に記載されている「<先頭>」と「<終端>」とは特殊なシンボルであり、それぞれ「発話前の無音」と「発話後の無音」を表している。従って、トランスクリプションでは対応する表記は存在せず、「[]」(空欄)として表される。
また、図6および図7に記載されている項目以外にも、本実施形態に係る固定単語辞書は、例えば、名詞や動詞といった単語の品詞やジャンル等を記述した「属性」欄や、以下で説明する言語スコアの算出の際に用いられる単語の重み付け情報を記述した「認識重み」欄等を備えても良い。
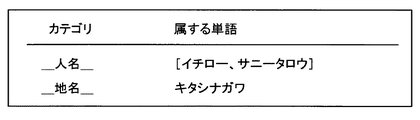
続いて、図8を参照しながら、本実施形態に係る可変単語辞書について、説明する。図8は、本実施形態に係る可変単語辞書の一例を説明するための説明図である。
図8に示したように、本実施形態に係る可変単語辞書には、例えば、「シンボル」欄と「カナ発音」欄が設けられる。また、図8に示した例では、「シンボル」として、カテゴリである“_人名_”と“_地名_”が記述されており、カテゴリ“_人名_”には、二つの単語の発音「イチロー」、「サニータロウ」がカナ発音で記述され、カテゴリ“_地名_”には、一つの単語の発音「キタシナガワ」がカナ発音で記述されている。また、本実施形態に係る可変単語辞書には、図8に示したようなカテゴリだけでなく、具体的な単語についても記述される。可変単語辞書に図示のようなカテゴリではなく具体的な単語が記載される場合には、「シンボル」欄に個々の単語が記載され、それらの単語に対応する「トランスクリプション」や「音韻系列」等の欄が設けられることとなる。
また、本実施形態に係る可変単語辞書には、固定単語辞書の同様に、例えば、名詞や動詞といった単語の品詞やジャンル等を記述した「属性」欄や、以下で説明する言語スコアの算出の際に用いられる単語の重み付け情報を記述した「認識重み」欄等を備えても良い。可変単語辞書に記述される単語は、時代とともに変化する単語が主に記述されるため、「認識重み」欄に記載される値を、固定単語辞書に記載される「認識重み」よりも高い値に設定することが好ましい。このように、可変単語辞書に記載されている単語に高い値の「認識重み」を設定することで、時代に即した話題について会話することが多い音声チャットにおいて、特定のキーワードや当該特定のキーワードに関連した単語を優先的に選択することが可能となり、高い認識率で音声認識を行なうことが可能となる。
なお、本実施形態に係る可変単語辞書の生成・更新処理については、以下で改めて詳細に説明する。
カテゴリテーブルには、以下で説明する言語モデル記憶部405に記憶されている言語モデルに含まれるカテゴリと、そのカテゴリに含まれる単語の情報とが、対応づけて記述される。このカテゴリテーブルは、リスト状であってもよく、テーブルとして記載されていてもよい。なお、カテゴリテーブルは、言語モデルがカテゴリを含まない場合には、何も記憶しなくてもよい。
上記のカテゴリは、意味属性に基づく分類(例えば、“_人名_”、“_ユーザ名_”、“_地名_”、“_店名_”等)だけではなく、品詞に基づく分類(例えば、“_名詞_”、“_動詞_”、“_助詞_”等)であってもよい。なお、以下、“_・・・_”という表記は、カテゴリ名を表すものとする。
図9は、カテゴリテーブルの例を示している。カテゴリテーブルは、以下で説明する言語モデルに使用されているカテゴリの種類と、そのカテゴリに属する単語の情報とが記述されている。例えば、言語モデルに、“_人名_”と“_地名_”の2個のカテゴリが使用されている場合には、カテゴリテーブルには、図9に示すように、“_人名_”と“_地名_”の2つのカテゴリがエントリされる。また、カテゴリテーブルに新たにカテゴリが追加される際には、追加されたカテゴリに属する単語は空欄でもよく、言語モデルの学習や適応化が進むにつれて、属する単語を追加していくことが可能である。なお、図9では、カテゴリ“_人名_”と“_地名_”に属する単語は、「[]」となっているが、この表記は、属する単語が何もないことを表している。
図10は単語の情報がエントリされた認識単語辞書記憶部401のカテゴリテーブルの例を示している。図10において、第1行目のエントリは、カテゴリ“_人名_”に対して、単語「イチロー」および「サニータロウ」が属していることを表している。
音響モデル記憶部403は、音声認識する音声の個々の音韻の音響的な特徴を表す音響モデルを記憶する。ここで、上記の音響モデルとは、母音や子音などの発音記号ごとに、音声の音響的な特徴を表現したモデルであり、入力音声の音声データと認識候補の単語とを、音としての類似性に着目して照合する際に用いられる。音響モデルとしては、例えば、隠れマルコフモデル(Hidden Markov Model:HMM)を用いることが可能であるが、本実施形態に係る音響モデルは、上記のHMMに規定されない。
また、音響モデル記憶部403に記憶される音響モデルとして、例えば、静かな環境用(静かな環境で高い認識率が出る音響モデル)と雑音環境用(騒がしい環境でもそれなりの認識率が出る音響モデル)との2種類を用意し、環境に応じてどちらかを参照するようにすることも可能である。
言語モデル記憶部405は、共通辞書記憶部307や認識単語辞書記憶部401中の各単語辞書に登録されている各単語が、それぞれどのように連鎖する(接続する)かを示す情報(以下、適宜、連鎖情報と称する。)を記述している言語モデルを記憶する。記述方法としては、例えば、統計的な単語連鎖確率(n−gramやclass n−gram)、生成文法、有限状態オートマトン(Finite State Automaton:FSA)等がある。
言語モデル記憶部405に記憶されている言語モデルは、単語についての連鎖情報の他に、単語を特定の観点で分類したカテゴリについての連鎖情報も含んでいる。例えば、「人名を表す単語からなるカテゴリ」を“_人名_”というシンボルで表し、「食品を表す単語からなるカテゴリ」を“_食品_”というシンボルで表す場合、言語モデルは、“_人名_”、“_食品_”についての連鎖情報(すなわち、カテゴリ同士の連鎖、カテゴリと辞書に予め記憶されている単語との連鎖等)も記述している。
したがって、言語モデルに含まれない単語についても、連鎖情報を取得することができる。例えば、「イチロー」と「は(助詞)」の連鎖情報を取得する場合、言語モデルに「イチロー」についての連鎖情報が記述されていなくても、「イチロー」が“_人名_”というシンボルで表されるカテゴリに属していることがわかれば、代わりに“_人名_”と「は」との連鎖情報を取得することによって、「イチロー」と「は」の連鎖情報を取得することができる。
<言語モデルについて>
続いて、図11を参照しながら、本実施形態に係る言語モデルの具体例について説明する。図11は、本実施形態に係る言語モデルの一例を説明するための説明図である。
図11では、言語モデルとして、統計言語モデルが用いられている。統計言語モデルは、単語の連鎖情報を条件付確率で記述したモデルである。図11の言語モデルでは、3つの単語1,2,3の並び、すなわち単語の3連鎖の確率を表すtri−gramが、統計言語モデルとして用いられている。
図11において、「P(単語3|単語1単語2)」は、単語列中に「単語1」、「単語2」という並びがあった場合に、その次に「単語3」が出現する確率を表す。例えば、「<先頭>“_人名_”」という並びがあった場合に、その次に「は」が出現する確率は、「0.012」である。なお、この確率は、大量の雑談を記述したテキストを解析することにより、予め求めることが可能である。また、言語モデルとしては、tri−gramの他に、bi−gram(2連鎖の確率)やuni−gram(単語の出現確率)等も、必要に応じて用いることが可能である。
また、図11の言語モデルにおいて、単語の他に、カテゴリを用いて文法が記述されている。すなわち、図11において、「_人名_」、「_地名_」は、カテゴリ“_人名_”、“_地名_”を意味するが、これらのカテゴリを用いてtri−gramを記述することによって、人名や地名を表す単語が可変単語辞書に登録された場合に、その単語を音声認識部253で認識することが可能となる。
音韻リスト407は、認識用データベース309で使用する音韻記号の一覧である。音韻リスト407は、例えば、図12に示したように、1つの音韻(に相当するもの)を1つの記号で表したものである。例えば、図12の音韻リストにおいて、母音+コロン(例えば、“a:”等)は、長音を表し、“N”は、撥音(「ん」)を表す。また、“sp”、“silB”、“silE”、“q”は、全て無音を表すが、それぞれ「発話の中の無音」、「発話前の無音」、「発話後の無音」、「促音(「っ」)」を表す。
カナ音韻変換規則409は、カナ文字列を音韻系列に変換するための規則である。このように、カナ音韻変換規則409を記憶することによって、共通辞書記憶部307や認識単語辞書記憶部401は、発音情報として、音韻系列とは独立であるカナ文字列を保持することができる。カナ音韻変換規則409は、例えば、図13に示したように、カナによる表記と、この表記に対応づけられた音韻の記号とからなり、存在しうる全てのカナ表記に対応して、音韻への変換規則が記載される。図13のカナ音韻変換規則409によれば、例えば、「イチロー」というカナ文字列は、“i/ch/r/o:”という音韻系列に変換される。
以上、本実施形態に係る第1情報処理装置20Aの機能の一例を示した。上記の各構成要素は、汎用的な部材や回路を用いて構成されていてもよいし、各構成要素の機能に特化したハードウェアにより構成されていてもよい。また、各構成要素の機能を、CPU等が全て行ってもよい。従って、本実施形態を実施する時々の技術レベルに応じて、適宜、利用する構成を変更することが可能である。
なお、第2情報処理装置20Bの構成は、第1情報処理装置20Aの構成と実質的に同一であるので、説明を省略する。
(音声認識部253における音声認識処理について)
続いて、図14を参照しながら、本実施形態に係る音声認識部253における音声認識処理について、詳細に説明する。図14は、本実施形態に係る音声認識処理の一例を説明するための流れ図である。
以下で説明する音声認識処理は、第1情報処理装置20Aのユーザからマイクロフォン等の音声入力部251に音声が入力されたとき、開始される。
音声入力部251で生成された音声信号は、まず、AD変換部301により、ディジタル信号である音声データに変換され、特徴パラメータ抽出部303に伝送される(ステップS101)。この際、AD変換部301は、生成した音声データを、記憶部267に記憶してもよい。次に、音声データが伝送された特徴パラメータ抽出部303は、伝送された音声データからメルケプストラム等の特徴量を抽出する(ステップS103)。特徴パラメータの抽出には、例えば、ケプストラム分析や、線形予測分析や、MFCC係数等を用いた聴覚フィルタに基づく分析等、各種の分析方法を用いることが可能である。また、特徴パラメータ抽出部303は、音声データから抽出した各種の特徴パラメータを、記憶部267に記憶してもよい。
特徴パラメータ抽出部303において特徴量が抽出されると、マッチング部305は、共通辞書記憶部307に記憶されている共通辞書や、認識用データベース309の認識単語辞書記憶部401に記憶されている固定単語辞書と可変単語辞書を参照し、それぞれの辞書においてシンボルで表される単語のいくつかを連結し、単語列を生成する(ステップS105)。その後、マッチング部305は、生成した単語列について、認識用データベース309中の音響モデル記憶部403に記憶されている音響モデルに基づいて、音響スコアを計算する(ステップS105)。ここで、音響スコアとは、音声認識結果の候補である単語列と入力音声とが、音として(音響的に)どれだけ近いかを表すスコアであり、音響スコアが高いほど、生成した単語列が、入力音声に音響的に近いことを意味する。
特徴パラメータに基づいて音響スコアが計算されると、マッチング部305は、得られた音響スコアに基づいて、音響スコアの高い単語列を所定の個数選択する(ステップS107)。なお、マッチング部305は、算出した音響スコアや、選択した単語列等を、記憶部267に記憶してもよい。
音響スコアの算出が終了すると、マッチング部305は、ステップS107で選択した各単語列の言語スコアを、認識用データベース309中の言語モデル記憶部405に記憶されている言語モデルを用いて計算する(ステップS109)。例えば、言語モデル記憶部405に記憶されている各種の言語モデルの中から、文法や有限状態オートマンを使用している場合には、単語列がその言語モデルで受理することができるとき、言語スコアは「1」であり、受理することができないとき、言語スコアは「0」である。
なお、マッチング部305は、生成された単語列を言語モデルが受理することができるとき、ステップS107で選択した単語列を残してもよく、生成された単語列を言語も出るが受理することができないとき、ステップS107で選択した単語列を削除してもよい。
また、言語モデルとして、n−gramやclass n−gramのような統計言語モデルを使用している場合、その単語列の生成確率を言語スコアとする。この言語スコアを求める方法の詳細は、例えば、本出願人が先に提案した特願2001−382579号に開示されている。なお、マッチング部305は、算出した言語スコア等を、記憶部267に記憶してもよい。
なお、本実施形態に係る言語モデルは、共通辞書記憶部307に記憶されている共通辞書や、認識用データベース309内の認識単語辞書記憶部401に記憶されている固定単語辞書や可変単語辞書を用いて言語スコアの算出を行うが、可変単語辞書には、時代とともに変化する固有名詞などが随時更新されながら記述されているために、音声チャット等で話題になることが多い単語についても、言語スコアの算出対象とすることが可能となる。
音響スコアと言語スコアの双方の算出が終了すると、マッチング部305は、ステップS105で計算された音響スコアと、ステップS109で計算された言語スコアを統合して各単語列をソートし、例えば、統合したスコアの一番大きい単語列を認識結果として決定する(ステップS111)。すなわち、マッチング部305は、例えば、音響モデルから得られた音響スコアと言語モデルから得られた言語スコアとの積や、音響スコアの対数と言語スコアの対数との和等を最大とするような単語列を、認識結果として決定する。また、言語モデルで用いた各種の単語辞書に、単語の認識重み情報が付加されている場合には、認識重み情報を加味した言語スコアを利用してもよい。
これにより、音響的にも言語的にも最もふさわしい単語列が認識結果として決定される。最もふさわしい単語列が認識結果として決定されると、マッチング部305は、決定した認識結果を、キーワード検出部255へと伝達する(ステップS113)。また、マッチング部305は、決定した認識結果である単語列を、記憶部267に記憶してもよい。
このように、本実施形態に係る音声認識処理では、言語スコアの算出の際に、ユーザが音声チャットで話題にしやすい最近のトピック(特定のトピック)に関連した語彙を記載した可変単語辞書を参照することで、最近のトピックに関連した語彙を優先的に認識することができ、通常の音声認識処理では認識することが困難な最近のキーワードや当該キーワードに関連する語彙の認識率を向上させることができる。また、認識された結果表示される情報は、最近話題の、すなわちユーザにとっても興味深い可能性の高い情報であることが多いため、仮に提示された情報が音声チャットにおけるユーザの会話と多少離れていても(すなわち、音声認識結果に間違いが生じたとしても)、音声チャットのユーザに会話の広がりを与えることができる。これにより、音声チャットを行っているユーザも、音声認識処理の間違いをある程度許容することが考えられる。
<言語スコアの算出方法について>
続いて、図15を参照しながら、本実施形態に係る言語スコアの算出方法について説明する。図15は、本実施形態に係る言語スコアの計算式の一例を説明するための説明図である。図15では、マッチング部305が、図14のステップS109で、例えば、単語列「<先頭>イチロー は 何時 に 起きた の<終端>」を選択した場合の言語スコアを求める式について、示している。
言語スコア「Score(<先頭>イチロー は 何時 に 起きた の<終端>)」は、式(1)に示すように、単語列「<先頭>イチロー は 何時 に 起きた の<終端>」の生成確率である。
言語スコア「Score(<先頭>イチロー は 何時 に 起きた の<終端>)」の値は、正確には、式(2)に示すように、「P(<先頭>)P(イチロー|<先頭>)P(は|<先頭>イチロー)P(何時|<先頭>イチロー は)P(に|<先頭>イチロー は 何時)P(起きた|<先頭>イチロー は 何時 に)P(の|<先頭>イチロー は 何時 に 起きた)P(<終端>|<先頭>イチロー は 何時 に 起きた の)で求められるが、図16に示すように、言語モデル112は、tri−gramを用いているので、条件部分「<先頭>イチロー は」、「<先頭>イチロー は 何時」、「<先頭>イチロー は 何時 に」、「<先頭>イチロー は 何時 に 起きた」、および「<先頭>イチロー は 何時 に 起きた の」は、直前の最大2単語「イチロー は」、「は 何時」、「何時 に」、「に 起きた」、および「起きた の」にそれぞれ限定した条件付確率で近似する(式(3))。
この条件付確率は、図11に示したような言語モデルを参照することによって求められるが、言語モデルは、シンボル「イチロー」を含んでいないので、マッチング部305は、認識用データベース309中の認識単語辞書記憶部401に記憶されているカテゴリテーブルを参照して、シンボル「イチロー」で表される単語のカテゴリが、“_人名_”であることを認識し、「イチロー」を“_人名_”に変換する。
即ち、式(4)に示すように、「P(イチロー|<先頭>)」は、「P(_人名_|<先頭>)P(イチロー|_人名)」に変更され、「P(_人名_|<先頭>)」/N」で近似される。なお、Nは、カテゴリテーブルの“_人名_”のカテゴリに属している単語の数を表す。
即ち、確率をP(X|Y)という形式で記述した場合、単語XがカテゴリCに属する単語である場合、言語モデルからP(C|Y)を求め、その値に、P(X|C)(カテゴリCから単語Xが生成される確率)を掛ける。カテゴリCに属する単語が全て等確率で生成されると仮定すれば、カテゴリCに属する単語がN個ある場合、P(X|C)は、1/Nと近似できる。
例えば、カテゴリ“_人名_”にシンボル「イチロー」で表される単語のみが属している場合には、上記の「N」は「1」となる。したがって、式(5)に示すように、「P(は|<先頭>イチロー)」は、「P(は|<先頭>_人名_)」となる。また、「P(何時|イチロー は)」は、式(6)に示すように、「P(何時|_人名_ は)となる。
上記のような言語スコアの算出方法を用いることにより、可変単語を含む単語列に対しても、言語スコアを計算することができ、可変単語を認識結果に出現させることが可能となる。
なお、上述の例では、システムの起動時に共通辞書記憶部307の共通辞書には何も記億されていない状態であるとしたが、共通辞書に、いくつかの単語が予め記憶されていてもよい。
図16は、システムの起動時に、キーワード「イチロー」がカテゴリ“_人名_”にエントリされている場合の共通辞書の例を示している。図16において、システムの起動時には、カテゴリ“_人名_”に、カナ発音「イチロー」がエントリされているので、キーワード登録を行わなくても、キーワードを検出できる。
また、上述の例では、固定単語辞書に記憶されている単語は、言語モデルに記述されている単語であり、可変単語辞書に記憶される単語は、カテゴリに属する単語であるとしたが、カテゴリに属する単語の一部を、固定単語辞書に記憶してもよい。
図17は、固定単語辞書の例を示し、図18は、起動時のカテゴリテーブルの例を示している。即ち、図16のカテゴリテーブルには、カテゴリ“_人名_”と、そのカテゴリ“_人名_”に属する単語のシンボル「イチロー」が予め登録されている。また、図17の固定単語辞書131には、シンボル「イチロー」と、そのシンボル「イチロー」で表される単語のトランスクリプション「イチロー」、および音韻系列“i/ch/r/o:”が予め登録されている。
この場合、単語「イチロー」は、カテゴリ“_人名_”に属するものとして音声認識処理が行われる。即ち、単語「イチロー」は、最初から人名として扱われることになる。但し、単語「イチロー」は固定単語辞書に記憶されているため、削除したり、変更したりすることはできない。
このように、想定される単語を予め固定単語辞書に記憶しておくことによって、登録を行わずに、キーワードを認識することができる。
(認識単語辞書生成部269について)
続いて、図19を参照しながら、本実施形態に係る認識単語辞書生成部269について、詳細に説明する。図19は、本実施形態に係る認識単語辞書生成部を説明するためのブロック図である。
本実施形態に係る認識単語辞書生成部269は、図19に示したように、例えば、検索キーワードリスト取得部501と、キーワード選択部503と、サブキーワード取得部505と、キーワード情報付加部507と、を備える。
検索キーワードリスト取得部501は、通信網12を介して接続されている検索サーバ14から、例えば、当該検索サーバで検索された上位検索キーワードのリストを取得する。取得する上位検索キーワードは、検索サーバ14全体の上位検索キーワードであってもよく、特定の分野における上位検索キーワードであってもよい。また、取得する上位検索キーワードは、任意の個数を取得することが可能である。
特定の分野における上位検索キーワードリストを取得する場合には、検索キーワードリスト取得部501は、例えば、記憶部267に記憶されている音声チャットの利用履歴情報や認識したキーワードの履歴情報等を参照して、第1情報処理装置20Aのユーザの嗜好等を判断し、ユーザの嗜好に合致した分野の上位検索キーワードを取得してもよい。例えば、検索キーワードリスト取得部501は、音声チャットの利用履歴情報や認識したキーワードの履歴情報を参照して、PLSA(Probabilistic Latent Semantic Analysis)等により所定の次元を有する話題ベクトルの形に変換しておく一方で、検索サーバの上位検索キーワードに関してもPLSA等により話題ベクトルの形に変換して、履歴情報に基づく話題ベクトルと上位検索キーワードに基づく話題ベクトルとの比較を行い、履歴情報を基にして生成された話題ベクトルに類似したベクトルを有する上位検索キーワードを取得してもよい。
検索キーワードリスト取得部501は、上記のようにして検索サーバ14から取得した検索キーワードリストを、キーワード選択部503へと伝送する。また、検索キーワードリスト取得部501は、取得した検索キーワードリストを、記憶部267に記憶してもよい。
キーワード選択部503は、検索キーワードリスト取得部501が検索サーバ14から取得した検索キーワードリストの中から、第1情報処理装置20Aのユーザの嗜好に基づいて、キーワードの選択を行なう。キーワードの選択は、音声チャットの利用履歴情報や、キーワード検出部255が検出したキーワードの履歴情報等を参照して、PLSA等により所定の次元を有する話題ベクトルの形に変換しておく一方で、取得した検索キーワードリストに関してもPLSA等により話題ベクトルの形に変換して、履歴情報に基づく話題ベクトルと上位検索キーワードに基づく話題ベクトルとの比較を行い、履歴情報を基にして生成された話題ベクトルに類似したベクトルを有する検索キーワードを選択することが可能である。
また、音声チャットの相手である第2情報処理装置20Bから、音声チャットの利用履歴情報や認識したキーワードの履歴情報を取得できる場合には、第2情報処理装置20Bから取得した履歴情報と、第1情報処理装置20Aに記憶されている上記の履歴情報との整合をとり、キーワードの選択を行なってもよい。この場合、両者の履歴情報の整合は、例えば、両者の履歴情報の和集合や積集合やXOR集合をとってもよく、第1情報処理装置20Aのユーザの嗜好に統一をとってもよく、第2情報処理装置20Bにおけるユーザの嗜好に統一をとってもよい。また、取得したキーワードに対して、後述する認識重み情報が付加されている場合には、両者の認識重みの最大値や最小値や平均値を、新たな認識重み情報としてもよい。
また、キーワード選択部503は、検索キーワードリスト取得部501が検索サーバ14から取得した検索キーワードリストの中から、可変単語辞書に加えるのにふさわしくない単語を、適宜削除してもよい。ここで、可変単語辞書に加えるのにふさわしくない単語とは、例えば、i)一般的な単語や、ii)一般常識から鑑みて不適切な単語や、iii)1音韻や2音韻しかないような音声認識が困難な単語、等がある。
キーワード選択部503は、検索サーバ14から取得した検索キーワードリストよりキーワードを選択すると、選択したキーワードを、後述するサブキーワード取得部505と、キーワード情報付加部507とに伝送するとともに、認識単語辞書記憶部401に記憶されている可変単語辞書に、選択したキーワードを記述する。また、キーワード選択部503は、選択したキーワードを、記憶部267に記憶してもよい。
サブキーワード取得部505は、キーワード選択部503が選択したキーワードを、検索サーバ14により検索し、キーワード選択部503が選択したキーワードに関連するサブキーワードを取得する。あるキーワードを検索サーバ14により検索すると、複数の文書が検索結果として得られるが、サブキーワード取得部505は、得られた複数の文書から、例えばTF・IDF(Term Frequency−Inverted Document Frequency)等のような重み付け方法を用いて、サブキーワードを取得する。なお、検索サーバ14による検索結果からサブキーワードを取得する方法は、上記の方法に規制されるわけではなく、公知のあらゆる方法を用いることが可能である。例えば、「サッカー日本代表」という単語がキーワードとしてキーワード選択部503から伝送された場合には、サブキーワード取得部505は「サッカー日本代表」というキーワードにより検索サーバ14にて検索を行い、得られた文書の中から、例えば、「オシム」や「中田」といったキーワードを取得する。
検索サーバ14からのサブキーワードの取得が終了すると、サブキーワード取得部505は、認識単語辞書記憶部401に記憶されている可変単語辞書に、取得したサブキーワードを、検索に利用したキーワードに関連付けて記述する。また、サブキーワード取得部505は、取得したサブキーワードを、後述するキーワード情報付加部507へと伝送する。また、サブキーワード取得部505は、取得したサブキーワードを記憶部267に記憶してもよい。
キーワード情報付加部507は、キーワード選択部503が選択したキーワードに対して、言語スコアの算出の際に用いられる認識重み情報や、キーワードの品詞やジャンル等に関する属性情報を含むキーワード情報を関連づけて付加し、可変単語辞書に記述する。また、キーワードに関連づけられているサブキーワードに対しても、上記のキーワード情報を付加してもよい。
認識重み情報は、言語スコアの算出の際に利用される補正係数(重み付け係数)である認識重みが記載されている情報であって、認識重みが大きい値であるほど言語スコアの補正値は大きな値となり、認識結果として採用されやすくなる。例えば、認識重みが10であるキーワードは、認識重みが1であるキーワード(すなわち、重み付けがなされていないキーワード)よりも10倍高い確率で音声認識される。
認識重みの決定においては、例えば、検索サーバ14から取得した検索キーワードリストでの順位情報や、音声認識結果の出力中に現れるキーワードの頻度等を利用することが可能である。検索キーワードリストは、検索サーバ14における上位いくつかの検索キーワードであるため、例えば、一番検索されているキーワードから順に順位付けを行い、順位付けの上位のものから順に、所定の認識重みを決定することが可能である。具体的には、一番検索されているキーワードから順に所定の係数を付加し、付加した係数に正規化したキーワードの頻度を乗じることで、認識重みとすることが可能である。
また、認識重みの決定において、音声認識結果のキーワードに関して第1情報処理装置20Aのユーザが検索サーバ14を用いて検索を行ったかどうかという情報や、第1情報処理装置20Aのユーザの嗜好等も利用することが可能である。
また、キーワードの品詞やジャンル等に関する情報である属性情報は、例えば、インターネット上に設けられている掲示板やサイトなどの記載内容や、形態素解析ツール等を利用して付加することが可能である。また、インターネット上に設けられている百科事典やWikipediaや国語辞典等を適宜利用することも可能である。
なお、上記の検索キーワードリストの取得、サブキーワードの取得およびキーワード情報の付加においては、検索サーバ14の代わりに、通信網12を介して接続されている任意のサーバ等に記憶されているシソーラス、オントロジーデータベース、百科事典、国語辞書および形態素解析ツール等を利用してもよい。また、検索サーバ14と、上記のシソーラス、オントロジーデータベース、百科事典、国語辞書、形態素解析ツール等とを併用してもよい。
<認識単語辞書の生成・更新処理について>
続いて、図20を参照しながら、本実施形態に係る認識単語辞書生成部の動作について、詳細に説明する。図20は、本実施形態に係る認識単語辞書生成・更新処理を説明するための説明図である。
まず、認識単語辞書生成部269の検索キーワードリスト取得部501は、検索サーバ14から、ユーザの嗜好に沿った上位検索キーワードが記載された検索キーワードリストを取得する。この検索キーワードリストには、例えば図20に記載したように、「サッカー日本代表」、「ワールドベースボールクラシック」、「王監督」、「ジーコ」、「歌詞」、「27」、「ティラミス」、「万座ビーチ」、「飲み会」、「シュート」、「卑猥」といったキーワードが記載されている。検索キーワードリスト取得部501は、取得したキーワードを記憶部267に記憶するとともに、認識単語辞書生成部269のキーワード選択部503へと伝送する。
キーワード選択部503は、伝送された検索キーワードリストを参照して、登録にふさわしくない単語を削除する。上記の例の場合では、一般的な単語である「飲み会」、「シュート」、「歌詞」、「27」と、一般常識から鑑みて不適切な単語である「卑猥」を、検索キーワードリストから削除することとなる。キーワード選択部503は、これらの単語が削除された検索キーワードリストを、可変単語辞書に追加記載する。また、可変単語辞書への追加記載に当たっては、キーワード選択部503は、図20に示した項目以外に、例えば、音韻系列やトランスクリプション等の項目に関しても記載を行う。
続いて、サブキーワード取得部505は、可変単語辞書に追加記載されたこれらのキーワードを取得し、取得したこれらのキーワードに関して、検索サーバ14等により、サブキーワードを取得する。例えば、図20に示したように、「サッカー日本代表」というキーワードを基に検索サーバ14を検索することにより、「オシム」、「中田」、「巻」、「ジーコ」といったサブキーワードを取得して、「サッカー日本代表」というキーワードに関連づけて可変単語辞書に追加記載する。同様に、上記の他のキーワードに関しても、サブキーワードを取得して可変単語辞書に追加記載を行う。
次に、キーワード情報付加部507は、不要な単語が削除された検索キーワードに対して、検索サーバ14での検索順位が上位なものから順にソートし、所定の係数を割り当てる。キーワード情報付加部507は、例えば、検索キーワードリストの一番上に位置しているキーワードから順に、10、9、8・・・と係数を割り当て、当該キーワードの頻度を一般的な頻度の期待値で割った値を、上記の割り当てられた係数にかけることで、認識重みを算出する。また、上記のようにして得られた認識重みに対して、例えばシグモイド関数のようなものを更に掛けてもよい。キーワード情報付加部507は、例えば上記のようにして算出した認識重み情報を、それぞれのキーワードに対して付加して、可変単語辞書に追加記載する。
なお、上記の認識重み情報の算出方法は、あくまでも一例であって、本実施形態に係る認識重み情報の算出方法は、上記の方法に規定されるわけではなく、上記以外の任意の方法を認識重み情報の算出に利用することが可能である。
なお、図20に示したように、固定単語辞書には、一般的な日常会話に用いられるような単語である、「食べる」、「飲む」、「ヒット」、「シュート」、「選手」、「飲み会」といったような単語が、予め登録されている。また、固定単語辞書に予め登録されている単語は、上述のように一般的な単語であり、音声認識において優先的に認識される必要性は低いと考えられるため、認識重み情報は、1として登録される。
また、キーワード情報付加部507は、形態素解析ツールや検索サーバ14上の掲示板等の情報から、それぞれのキーワードの品詞やジャンルといった属性情報を取得して、可変単語辞書に追加記載する。例えば、図20に示した「サッカー日本代表」というキーワードには、属性情報として「名詞:スポーツ」という情報が付加される。
上記のような処理を行うことで、認識単語辞書生成部269は、随時可変単語辞書の生成・更新処理を行うことが可能となる。本実施形態に係る第1情報処理装置20Aを初めて起動する際には、可変単語辞書には何も情報が記載されていない場合がある。そのため、認識単語辞書生成部269は、上記の方法に基づいて、可変単語辞書の生成を行う。また、可変単語辞書の更新処理は、任意に行うことが可能である。例えば、ある期間毎に定期的に可変単語辞書の更新処理を行ってもよく、第1情報処理装置20Aのユーザからの更新命令に基づいて、可変単語辞書の更新処理を行っても良い。
また、可変単語辞書の更新に際して、サブキーワードとして記録されている単語が高頻度で音声認識されている場合には、高頻度で音声認識されているサブキーワードを、新たにキーワードとして可変単語辞書に記憶してもよい。
マッチング部305は、音声認識処理を実行する際に、認識用データベース309中の言語モデル記憶部405に記憶されている、統計言語モデルや文法モデル等に基づいて、各種辞書に記載されている内容を利用して言語モデルの算出を行う。可変単語辞書に記憶されている単語の言語スコアを算出する場合には、マッチング部305は、言語モデルに基づいて通常の方法で言語スコアを算出し、更に、キーワードに付加されている認識重みを算出した言語スコアに掛けることで、実際に音声認識に用いる言語スコアとする。可変単語辞書に記憶されている単語は、図20に示したように1以上の認識重みが付加されているため、共通辞書や固定単語辞書に記憶されている単語に比べて、相対的に高い値の言語スコアが算出されることとなる。そのため、可変単語辞書に記憶されている、最近話題になることが多い特定の単語が、高い確率で認識されることとなる。
なお、上記の方法では、通常の方法で算出された言語スコアに対して認識重みを掛けることとなり、場合によっては、算出される言語スコアが1以上の値を有することとなる。しかしながら、音声認識処理では、言語スコアの絶対値よりも、それぞれのキーワードに関する相対的な言語スコアの順位付けが重要であるため、言語スコアが1以上の値を有してもよい。
上記の認識単語辞書生成部269は、図21Aに示したように、音声チャットを行っている第1情報処理装置20Aおよび第2情報処理装置20Bにそれぞれ実装されていてもよい。また、図21Bに示したように、認識単語辞書生成部は、音声チャットを行っている第1情報処理装置20Aおよび第2情報処理装置20Bには実装されずに、情報処理装置20Aおよび20Bを仲介しているサーバ18内に、実装されてもよい。ここで、図21Bにおけるサーバ図21Bに示したように、サーバ18内に実装される場合には、サーバ18が、検索サーバ14から検索キーワードリストを取得し、取得した検索キーワードリストから上記の方法でキーワードを選択するとともに、選択したキーワードに対して上記の重み付け情報を付加する、認識単語辞書生成装置として機能することとなる。
サーバ18内の認識単語辞書生成部183は、音声会話制御部181から取得した音声会話の内容に基づいて、検索サーバ14から検索キーワードリストを取得し、取得した検索キーワードリスト用いて上記の処理方法で単語の選択と認識重み情報の付加を行なうことで、可変単語辞書を生成する。その後、サーバ18内の認識単語辞書生成部183は、第1情報処理装置20Aおよび第2情報処理装置20Bそれぞれに、作成した可変単語辞書を伝送する。それぞれの情報処理装置は、伝送された可変単語辞書をそれぞれの認識用データベース309に記憶することで、音声認識処理に用いることが可能である。また、第1情報処理装置20Aおよび第2情報処理装置20Bは、サーバ18から認識重み情報が付加された単語のリストを取得し、各情報処理装置において、取得した単語のリストに基づいて可変単語辞書を作成してもよい。
なお、図21Aおよび図21Bに記載されている第1情報処理装置20Aや第2情報処理装置20Bには、それぞれの情報処理装置が備える処理部の一部のみを記載しているが、記載されている処理部以外にも、例えば、図3〜図5に記載されているような処理部を有することは言うまでもない。
以上説明したように、本実施形態に係る音声チャットシステムは、検索サーバ14のデータベースを音声認識に用いられる単語辞書の生成に用いることにより、最近話題にされることが多いキーワードを音声認識の言語知識として利用することができる。また、シソーラスなどを用いて話題のキーワードに関連した単語の出現確率も高く設定することができ、これらの関連キーワードを用いて、音声認識を行うことが出来る。これにより、本実施形態に係る音声チャットシステムは、ユーザが話題にしやすい最近のトピックに関連した語彙を優先的に認識することによって認識率を向上させることができる。また、認識された結果表示される情報は、最近話題の、すなわちユーザにとっても興味深い可能性の高い情報が多いため、仮に提示された情報がユーザの会話と多少離れていても、ユーザには会話の広がりを与えるなどのメリットがある。
(第2の実施形態)
以下に、本発明の第2の実施形態に係るキーワード検出システムについて、詳細に説明する。
図22は、本実施形態に係るキーワード検出システムを説明するための説明図である。図22に示したように、本実施形態に係るキーワード検出システム11は、例えば、通信網12と、情報処理装置20A、20Bと、検索サーバ14と、を含む。また、情報処理装置20Aは、ホームネットワーク19内で、外部表示装置70と接続されている。さらに、情報処理装置20A、20Bと、外部表示装置70とは、放送局80から送信された放送情報を受信することが可能である。
ここで、通信網12、検索サーバ14は、本発明の第1の実施形態に係る通信網12および検索サーバ14と同様の構成を有し、ほぼ同一の効果を奏するため、詳細な説明は省略する。
情報処理装置20は、通信網12を介して接続された他の情報処理装置20と、音声によるチャット(音声チャット)を行う。また、情報処理装置20は、通信網12に接続されている検索サーバ14に対して、通信網12を介してデータベースの参照を要求したり、情報の検索を要求したりすることができる。また、音声チャットを行う他の情報処理装置20は、図示のように通信網12を介して接続されていてもよく、また、通信網12を介さずに、例えば、USBポートや、i.Link等のIEEE1394ポート、SCSIポート、RS−232Cポート等により直接接続されていてもよい。
また、情報処理装置20は、ホームネットワーク19内で、後述する外部表示装置70に接続されており、情報処理装置20と外部表示装置70との間で各種データの送受信を行うことが可能である。情報処理装置20と外部表示装置70との接続は、例えば、HDMI(High−Definition Multimedia Interface)−CEC(Consumer Electronics Control)等の接続ポートを介して行われる。また、情報処理装置20は、後述する放送局80から送信された放送情報を含む放送電波を、内部に設けられた受信機能を用いて受信することも可能である。
なお、図示の例では、情報処理装置20として、デスクトップ型のPCを示しているが、本実施形態に係る情報処理装置20は、デスクトップ型PC、ノート型PCを問わない。また、本実施形態に係る情報処理装置20は、かかる例に限定されず、ネットワークを介した通信機能を有する機器であれば、例えば、テレビジョン受像器や家庭用ゲーム機等の情報家電、携帯電話、PDA等で構成することもできる。また、情報処理装置20は、契約者が持ち運びできるポータブルデバイス、例えば、携帯型ゲーム機、PHS、携帯型映像/音声プレーヤなどであってもよい。
外部表示装置70は、CRTディスプレイ装置、液晶ディスプレイ装置、プラズマディスプレイ装置、ELディスプレイ装置等の表示装置であって、後述する放送局80から送信された放送情報を含む放送電波を受信して、当該表示装置の表示領域に表示する。ここで、放送局から送信された放送情報とは、放送文字情報や放送音声情報や画像情報等のデータを意味しており、放送情報を含む放送電波とは、ワンセグ(ワンセグメント放送)や12セグメントからなるディジタル放送(以下では、フルセグと略称する。)等のディジタル放送の電波を意味する。外部表示装置70は、HDMI−CEC等の接続ポートを介して、受信した放送情報を情報処理装置20に送信することが可能である。また、外部表示装置70は、情報処理装置20から送信された各種データを受信して、当該データに対応した情報を表示することが可能である。
放送局80は、放送文字情報や放送音声情報や画像情報等のデータから構成される放送情報を含む放送電波を送信する。外部表示装置70は、放送局80から送信された放送電波を受信し、放送電波に含まれる放送文字情報に基づいて字幕情報を表示したり、音声を出力したりする。また、情報処理装置20は、放送局80から送信された放送電波を受信して、各種の処理に利用することが可能である。
(情報処理装置20の構成)
次に、本実施形態に係る情報処理装置20の構成について、詳細に説明する。なお、本実施形態に係る情報処理装置20のハードウェア構成は、本発明の第1の実施形態に係るハードウェア構成と実質的に同一であるため、詳細な説明は省略する。
図23は、本実施形態に係る情報処理装置20の構成を説明するためのブロック図である。本実施形態に係る情報処理装置20は、例えば図23に示したように、キーワード管理部257と、表示部261と、通信部265と、記憶部267と、認識単語辞書生成部269と、放送文字情報受信部271と、キーワード検出部273と、外部表示装置接続制御部275と、を主に備える。
キーワード管理部257は、後述する放送文字情報受信部271が受信した放送文字情報に対応した単語列の中から抽出されるべきキーワードを管理する。キーワード管理部257は、情報処理装置20のユーザが検索サーバ14を利用した検索利用履歴情報等を記憶部267に記憶しておき、これらの利用履歴情報に含まれる検索キーワードや、検出されたキーワード等に基づいて、管理するキーワードを選択する。キーワード管理部257で管理されているキーワードは、後述するキーワード検出部273が自由に参照することが可能である。また、キーワード管理部257は、管理しているキーワードを後述する認識単語辞書生成部269に対して提供することも可能であり、認識単語辞書生成部269は、キーワード管理部257から提供されたキーワードと、検索サーバ14から取得した検索キーワードリストと、を利用して、認識単語辞書の生成や更新を行うことができる。
表示部261は、後述するキーワード検出部273から伝送されたキーワードを、情報処理装置20のディスプレイ等の表示装置を介して、情報処理装置20のユーザに対して表示する。また、表示部261は、放送文字情報受信部271が受信した放送文字情報に対応した単語列そのものを、表示してもよい。
通信部265は、情報処理装置20に設けられた通信装置であって、情報処理装置20のキーワード管理部257と、認識単語辞書生成部269とが、通信網12を介して情報処理装置20の外部の装置等である検索サーバ14や他の情報処理装置20等と行う情報の送受信を、仲介する。なお、通信部265は、通信網12を介さずに、情報処理装置20に直接接続されているその他の情報処理装置等に対して、情報の送受信を行うことも可能である。
記憶部267は、例えば情報処理装置20に設けられたストレージ装置であって、後述するキーワード検出部273が検出したキーワードやキーワード管理部257が管理しているキーワード情報等のデータを記憶する。また、これらのデータ以外にも、放送文字情報受信部271が受信した放送文字情報や、各種のデータベース等を記憶することも可能である。更に、これらのデータ以外にも、情報処理装置20が、何らかの処理を行う際に保存する必要が生じた様々なパラメータや処理の途中経過等を、適宜記憶することが可能である。この記憶部267は、キーワード管理部257、表示部261、通信部265、認識単語辞書生成部269、放送文字情報受信部271、キーワード検出部273、外部表示装置接続制御部275等が、自由に読み書きを行うことが可能である。
認識単語辞書生成部269は、検索サーバ14から取得する検索キーワードリスト等を取得して、取得した検索キーワードリストから適切なキーワードのみを選択し、音声認識に利用する認識単語辞書を生成する。また、認識単語辞書生成部269は、取得した検索キーワードリストからキーワードの選択を行なうだけでなく、選択したキーワードに対して、当該キーワードの属性情報や関連するサブキーワードを付加したり、音声認識に利用する際の認識重み情報を付加したりしてもよい。さらに、認識単語辞書生成部269は、キーワード管理部257から伝送されたキーワードや、後述する放送文字情報受信部271が受信した放送文字情報の中からキーワード検出部273が検出したキーワード等を用いて、認識単語辞書の生成や更新を行ってもよい。なお、本実施形態に係る認識単語辞書生成部269の詳細な構成や、認識単語辞書の生成方法等は、本発明の第1の実施形態に係る認識単語辞書生成部269の構成や生成方法と実質的に同一であるため、詳細な説明は省略する。
放送文字情報受信部271は、外部表示装置70が現在受信している放送チャンネルに関する受信チャンネル情報を、外部表示装置70から取得する。ここで、受信チャンネル情報とは、外部表示装置70が現在受信している放送チャンネルが何チャンネルかを表す情報である。放送文字情報受信部271は、この受信チャンネル情報を外部表示装置70から取得することにより、外部表示装置70が受信している放送チャンネルと、放送文字情報受信部271が受信する放送チャンネルとを同期させることができる。
また、放送文字情報受信部271は、取得した受信チャンネル情報に基づいて、外部表示装置70が受信している放送チャンネルに対応した放送電波を、放送局80から直接受信する。この際、放送文字情報受信部271は、放送局80が送信している放送電波のうちワンセグの電波を直接受信し、受信した電波の中から文字情報を取得してもよい。また、放送文字情報受信部271は、放送局80が送信しているフルセグの放送電波を直接受信してもよい。
また、放送文字情報受信部271は、取得した受信チャンネル情報に基づいて、外部表示装置70が受信し外部表示装置70から情報処理装置20に送信された放送文字情報を、受信してもよい。
放送文字情報受信部271が受信した放送文字情報は、後述するキーワード検出部273へと出力される。また、放送文字情報受信部271は、受信した放送文字情報を記憶部267に記録してもよい。
キーワード検出部273は、放送文字情報受信部271から伝送された放送文字情報に対応した単語列の中に、キーワード管理部257が管理しているキーワードが存在するか否かを判断し、キーワードが存在している場合には、そのキーワードに該当する単語をキーワードとして出力する。キーワード検出部273は、一つの単語列の中に複数のキーワードが存在した場合には、該当する全てのキーワードを同時に検出してもよい。また、キーワード検出部273は、単語列の中から検出したキーワードを、表示部261に伝送してもよい。
例えば、放送文字情報受信部271から「最近の構造改革は骨抜きだ」という認識結果が伝送され、キーワード管理部257が管理しているキーワードの中に「構造改革」というキーワードが存在する場合には、キーワード検出部273は、「構造改革」をキーワードとして出力する。
外部表示装置接続制御部275は、情報処理装置20に接続されている外部表示装置70と情報処理装置20との接続制御を行う。また、外部表示装置制御部275は、キーワード検出部273により抽出されたキーワード等を、外部表示装置70に送信する。また、外部表示装置70からある特定のキーワードやキーワードに関する記事について、外部表示装置70のユーザが参照したり選択したりしたことが通知されると、外部表示装置接続制御部267は、その参照履歴や選択履歴を記憶部267に記録するとともに、通信部265を介して検索サーバ14に通知してもよい。検索サーバ14は、これらの参照履歴や選択履歴を、検索サーバ14内で行われる各種の処理に利用することが可能である。なお、外部表示装置接続制御部275は、外部表示装置70に各種情報に対応したデータを送信する際に、送信予定のデータのデータ形式を、外部表示装置70が表示可能なデータ形式へと変換してもよい。
以上、本実施形態に係る情報処理装置20の機能の一例を示した。上記の各構成要素は、汎用的な部材や回路を用いて構成されていてもよいし、各構成要素の機能に特化したハードウェアにより構成されていてもよい。また、各構成要素の機能を、CPU等が全て行ってもよい。従って、本実施形態を実施する時々の技術レベルに応じて、適宜、利用する構成を変更することが可能である。
なお、本実施形態に係る情報処理装置20は、本発明の第1の実施形態に係る情報処理装置20が有する音声認識部や音声会話制御部を更に備えても良い。また、検索サーバ14に記録されている検索キーワードリストの内容を記憶するデータベース記憶部を更に備えてもよい。これにより、検索キーワードリストの内容が情報処理装置20に設けられたデータベース記憶部に格納されることとなり、情報処理装置20が検索サーバ14にアクセスするために要する時間を短縮することができる。また、データベース記憶部の内容を定期的に更新することで、検索サーバ14に記録されている最新の検索キーワードリストの内容を取得することが可能となる。
(外部表示装置70の構成)
続いて、図24および図25を参照しながら、本実施形態に係る外部表示装置70の構成について、詳細に説明する。図24は、本実施形態に係る外部表示装置の構成を説明するためのブロック図であり、図25は、本実施形態に係る外部表示装置の情報表示画面について説明するための説明図である。
本実施形態に係る外部表示装置70のハードウェアは、CRTや、液晶パネル、プラズマディスプレイパネル、ELパネル等の表示素子と、CPU、ROM、RAM等から構成され、これらの表示素子を駆動制御するために用いられる駆動制御回路等から構成される。
また、本実施形態に係る外部表示装置70は、例えば図24に示したように、放送受信部701と、接続ポート制御部703と、放送情報表示制御部705と、キーワード情報表示制御部707と、表示部709と、を主に備える。
放送受信部701は、放送局80から送信された放送電波を受信し、放送電波中に含まれる放送文字情報や放送音声情報や画像情報等のデータを、後述する接続ポート制御部703と、放送情報表示制御部705に出力する。また、放送受信部701は、外部表示装置70に備えられた記憶部(図示せず。)や、外部表示装置70に接続された記憶部(図示せず。)等に、受信した情報を記録してもよい。
接続ポート制御部703は、情報処理装置20とディジタル通信が可能なHDMI−CEC等の接続ポートを制御する。放送ポート制御部703は、放送受信部701が受信している放送チャンネルに関する受信チャンネル情報を、HDMI−CEC等の接続ポートを介して情報処理装置20に送信する。また、放送受信部701が受信した放送文字情報や放送音声情報や画像情報等のデータは、接続ポート制御部703を介して情報処理装置20に出力されてもよい。また、情報処理装置20から送信された各種データは、接続ポート制御部703を介して外部表示装置70に入力される。情報処理装置20から送信された各種データは、後述するキーワード情報表示制御部707に伝送される。
放送情報表示制御部705は、放送受信部701から伝送された放送文字情報、放送音声情報および画像情報を後述する表示部709に表示する際の表示制御を行う。
キーワード情報表示制御部707は、情報処理装置20から送信されたキーワード情報を後述する表示部709に表示する際の表示制御を行う。ここで、情報処理装置20から送信されたキーワード情報とは、情報処理装置20により抽出されたキーワード、抽出されたキーワードの検索結果およびキーワードに関連する記事等の情報である。また、後述する表示部709に表示された情報を、外部表示装置70のユーザがマウスやキーボードやリモコン等の入力装置を用いて選択した場合に、選択された情報の詳細を取得するように表示部709から要請がなされると、キーワード情報表示制御部707は、この詳細情報取得要求を、接続ポート制御部703を介して情報処理装置20に送信する。
表示部709は、放送情報表示制御部705により表示制御される放送文字情報、放送音声情報および画像情報と、キーワード情報表示制御部707により表示制御されるキーワード情報とを、外部表示装置70の情報表示画面に表示する。
外部表示装置70の情報表示画面751は、通常は、放送文字情報、放送音声情報および画像情報等が表示される画像表示領域753が主に存在している。ここで、情報処理装置20からキーワード情報が伝送されると、情報表示画面751は、表示領域が分割され、キーワード情報が表示されるキーワード情報表示領域755が生成される。この画像表示領域753は、例えば放送情報表示制御部705により制御され、キーワード情報表示領域755は、例えばキーワード情報表示制御部707により制御される。
なお、キーワード情報表示領域755の詳細については、本発明の第1の実施形態に係る情報処理装置における検索結果表示画面50と実質的に同一であるため、詳細な説明は省略する。
以上、本実施形態に係る外部表示装置70の機能の一例を示した。上記の各構成要素は、汎用的な部材や回路を用いて構成されていてもよいし、各構成要素の機能に特化したハードウェアにより構成されていてもよい。また、各構成要素の機能を、CPU等が全て行ってもよい。従って、本実施形態を実施する時々の技術レベルに応じて、適宜、利用する構成を変更することが可能である。
(キーワード検出方法)
続いて、図26を参照しながら、本実施形態に係る情報処理装置20で行われるキーワード検出方法の一例について、詳細に説明する。図26は、本実施形態に係るキーワード検出方法について説明するための流れ図である。
まず、情報処理装置20の放送文字情報受信部271は、外部表示装置70から取得した受信チャンネル情報に基づいて、外部表示装置70または放送局80から放送文字情報を受信し、放送字幕の文字列を文字情報データとして取得する(ステップS201)。放送文字情報受信部271は、取得した文字情報データを、キーワード検出部273に出力する。
次に、キーワード検出部273は、伝送された文字情報データを形態素解析して文字列から単語を抽出し、情報処理装置20のメモリ上に記録する(ステップS203)。
次に、キーワード検出部273は、キーワード管理部257の内容を利用して、抽出した単語を検索する(ステップS205)。
続いて、キーワード検出部273は、キーワード管理部257の中に抽出単語が存在しているか否かを判定する(ステップS207)。抽出単語がキーワード管理部257の中に存在している場合には、キーワード検出部273は、存在した抽出単語を、放送キーワードデータとしてメモリ上に記録する(ステップS209)。また、抽出単語がキーワード管理部257の中に存在していない場合には、キーワード検出部273は、後述するステップS211を実行する。
次に、キーワード検出部273は、キーワード管理部257を用いて検索していない抽出単語がメモリ上に存在するか否かを判定する(ステップS211)。メモリ上に未検索の単語が存在する場合には、ステップS205に戻って処理を実行する。また、メモリ上に未検索の単語が存在しない場合には、キーワード検出部273は、メモリ上に存在する放送キーワードデータを、抽出キーワードとして出力する(ステップS213)。
以上説明したような方法で、本実施形態に係る情報処理装置20は、受信した放送文字情報の中からキーワードを抽出することが可能となる。
以上、本実施形態に係る情報処理装置20では、放送局が送信している放送文字情報の中から、キーワード管理部257に存在している単語(キーワード)を自動的に抽出することが可能となり、抽出したキーワードを外部表示装置70に表示させることができる。かかる機能を用いることで、情報処理装置20や外部表示装置70でチャット等の双方向通信を実施しているユーザは、抽出されたキーワードをチャット等の話題として用いることが可能となる。
(本実施形態に係る情報処理装置の第1変形例)
続いて、図27および図28を参照しながら、本実施形態に係る情報処理装置20の第1変形例について、詳細に説明する。図27は、本変形例に係る情報処理装置20の構成を説明するためのブロック図であり、図28は、本変形例に係るキーワード検出方法を説明するための流れ図である。なお、本変形例に係る情報処理装置20のハードウェア構成は、本発明の第2の実施形態に係るハードウェア構成と実質的に同一であるため、詳細な説明は省略する。
本変形例に係る情報処理装置20は、例えば図27に示したように、音声認識部253と、キーワード検出部255と、キーワード管理部257と、表示部261と、通信部265と、記憶部267と、認識単語辞書生成部269と、放送音声情報受信部277と、外部表示装置接続制御部275と、を主に備える。
本実施形態に係るキーワード管理部257、表示部261、通信部265、記憶部267および外部表示装置接続制御部275については、本発明の第2の実施形態に係るキーワード管理部257、表示部261、通信部265、記憶部267および外部表示装置接続制御部275と実質的に同一であり、それぞれ同様の効果を奏するため、詳細な説明は省略する。
音声認識部253は、後述する放送音声情報受信部277が受信した放送音声情報に基づいて、音声認識を行う。音声認識部253は、音声認識の結果として、放送音声情報に対応する単語列を生成し、後述するキーワード検出部255に対して、生成した単語列を伝送する。また、音声認識部253は、生成した単語列を表示部261に伝送してもよい。なお、音声認識部253の詳細な構成および音声認識方法は、本発明の第1の実施形態に係る音声認識部253の構成および音声認識方法と実質的に同一であるため、詳細な説明は省略する。
キーワード検出部255は、音声認識部253から伝送された放送音声情報に対応した単語列の中に、キーワード管理部257が管理しているキーワードが存在するか否かを判断し、キーワードが存在している場合には、そのキーワードに該当する単語をキーワードとして出力する。キーワード検出部255は、一つの単語列の中に複数のキーワードが存在した場合には、該当する全てのキーワードを同時に検出してもよい。また、キーワード検出部255は、単語列の中から検出したキーワードを、表示部261に伝送してもよい。
例えば、音声認識部253から「最近の構造改革は骨抜きだ」という認識結果が伝送され、キーワード管理部257が管理しているキーワードの中に「構造改革」というキーワードが存在する場合には、キーワード検出部255は、「構造改革」をキーワードとして出力する。
認識単語辞書生成部269は、検索サーバ14から取得する検索キーワードリスト等を取得して、取得した検索キーワードリストから適切なキーワードのみを選択し、音声認識に利用する認識単語辞書を生成する。また、認識単語辞書生成部269は、取得した検索キーワードリストからキーワードの選択を行なうだけでなく、選択したキーワードに対して、当該キーワードの属性情報や関連するサブキーワードを付加したり、音声認識に利用する際の認識重み情報を付加したりしてもよい。さらに、認識単語辞書生成部269は、キーワード管理部257から伝送されたキーワードや、後述する放送音声情報受信部277が受信した放送音声情報に対応する単語列の中からキーワード検出部255が検出したキーワード等を用いて、認識単語辞書の生成や更新を行ってもよい。なお、本実施形態に係る認識単語辞書生成部269の詳細な構成や、認識単語辞書の生成方法等は、本発明の第1の実施形態に係る認識単語辞書生成部269の構成や生成方法と実質的に同一であるため、詳細な説明は省略する。
放送音声情報受信部277は、外部表示装置70が現在受信している放送チャンネルに関する受信チャンネル情報を、外部表示装置70から取得する。放送音声情報受信部277は、この受信チャンネル情報を外部表示装置70から取得することにより、外部表示装置70が受信している放送チャンネルと、放送音声情報受信部277が受信する放送チャンネルとを同期させることができる。
また、放送音声情報受信部277は、取得した受信チャンネル情報に基づいて、外部表示装置70が受信している放送チャンネルに対応した放送電波を、放送局80から直接受信する。この際、放送音声情報受信部277は、放送局80が送信している放送電波のうちワンセグの電波を直接受信し、受信した電波の中から音声情報を取得してもよい。また、放送音声情報受信部277は、放送局80が送信しているフルセグの放送電波を直接受信してもよい。
また、放送音声情報受信部277は、取得した受信チャンネル情報に基づいて、外部表示装置70が受信し外部表示装置70から情報処理装置20に送信された放送音声情報を、受信してもよい。
放送音声情報受信部277が受信した放送音声情報は、音声認識部253へと出力される。また、放送音声情報受信部277は、受信した放送音声情報を記憶部267に記録してもよい。
以上、本変形例に係る情報処理装置20の機能の一例を示した。上記の各構成要素は、汎用的な部材や回路を用いて構成されていてもよいし、各構成要素の機能に特化したハードウェアにより構成されていてもよい。また、各構成要素の機能を、CPU等が全て行ってもよい。従って、本実施形態を実施する時々の技術レベルに応じて、適宜、利用する構成を変更することが可能である。
なお、本変形例に係る情報処理装置20は、本発明の第1の実施形態に係る情報処理装置20が有する音声認識部や音声会話制御部を更に備えても良い。また、検索サーバ14に記録されている検索キーワードリストの内容を記憶するデータベース記憶部を更に備えてもよい。これにより、検索キーワードリストの内容が情報処理装置20に設けられたデータベース記憶部に格納されることとなり、情報処理装置20が検索サーバ14にアクセスするために要する時間を短縮することができる。また、データベース記憶部の内容を定期的に更新することで、検索サーバ14に記録されている最新の検索キーワードリストの内容を取得することが可能となる。
(キーワード検出方法)
続いて、図28を参照しながら、本変形例に係る情報処理装置20で行われるキーワード検出方法の一例について、詳細に説明する。
まず、情報処理装置20の放送音声情報受信部277は、外部表示装置70から取得した受信チャンネル情報に基づいて、外部表示装置70または放送局80から放送音声情報を受信し、音声認識部253は、放送音声情報を音声認識し、音声認識結果を決定する(ステップS301)。
次に、キーワード検出部255は、伝送された文字情報データを形態素解析して文字列から単語を抽出し、情報処理装置20のメモリ上に記録する(ステップS303)。
次に、キーワード検出部255は、キーワード管理部257の内容を利用して、抽出した単語を検索する(ステップS305)。
続いて、キーワード検出部255は、キーワード管理部257の中に抽出単語が存在しているか否かを判定する(ステップS307)。抽出単語がキーワード管理部257の中に存在している場合には、キーワード検出部255は、存在した抽出単語を、放送キーワードデータとしてメモリ上に記録する(ステップS309)。また、抽出単語がキーワード管理部257の中に存在していない場合には、キーワード検出部255は、後述するステップS311を実行する。
次に、キーワード検出部255は、キーワード管理部257を用いて検索していない抽出単語がメモリ上に存在するか否かを判定する(ステップS311)。メモリ上に未検索の単語が存在する場合には、ステップS305に戻って処理を実行する。また、メモリ上に未検索の単語が存在しない場合には、キーワード検出部255は、メモリ上に存在する放送キーワードデータを、抽出キーワードとして出力する(ステップS313)。
以上説明したような方法で、本実施形態に係る情報処理装置20は、受信した放送音声情報の中からキーワードを抽出することが可能となる。
以上、本変形例に係る情報処理装置20では、放送局が送信している放送音声情報の中から、キーワード管理部257に存在している単語(キーワード)を自動的に抽出することが可能となり、抽出したキーワードを外部表示装置70に表示させることができる。かかる機能を用いることで、情報処理装置20や外部表示装置70でチャット等の双方向通信を実施しているユーザは、抽出されたキーワードをチャット等の話題として用いることが可能となる。
以上、添付図面を参照しながら本発明の好適な実施形態について説明したが、本発明はかかる例に限定されないことは言うまでもない。当業者であれば、特許請求の範囲に記載された範疇内において、各種の変更例または修正例に想到し得ることは明らかであり、それらについても当然に本発明の技術的範囲に属するものと了解される。
例えば、上述した実施形態においては、音声認識に用いられる各種の単語辞書が、共通辞書記憶部307と、認識用データベース309内の認識単語辞書記憶部401に記憶されている場合について説明したが、音声認識に用いられる各種単語辞書は、ある一つの記憶部内に記憶されていてもよい。
また、上述した実施形態においては、認識単語辞書記憶部401に記憶される固定単語辞書、可変単語辞書、カテゴリテーブルは、それぞれ1つずつである場合について説明しているが、固定単語辞書、可変単語辞書およびカテゴリテーブルは、認識単語辞書記憶部401にそれぞれ複数記憶されていてもよい。認識単語辞書記憶部401にそれぞれ複数の固定単語辞書、可変単語辞書およびカテゴリテーブルを記憶可能とすることで、例えば、ある特定の分野に特化した認識単語辞書を複数生成することが可能となる。また、ある特定のキーワードに関して、当該特定のキーワードに関連の深い単語の出現頻度を高くしたり、N−gramやclass−N−gramの確率を高くしたりすることで、特定のキーワードの認識率を高くしてもよい。
また、本明細書において説明した各種の処理方法は、必ずしも記載された順序に従って時系列的に行われる必要はなく、時系列的に処理されなくとも、または、並列的あるいは個別に実行されてもよい。