以下に、図を用いて本発明の実施の形態を説明する。なお、本発明はこれら実施の形態に何ら限定されるものではなく、その要旨を逸脱しない範囲において、種々なる態様で実施しうる。
なお実施例1および実施例2は、主に請求項1、6、11などについて説明する。また実施例3は、主に請求項2、7、12などについて説明する。また実施例4は、主に請求項3、8、13などについて説明する。また実施例5は、主に請求項4、9、14などについて説明する。また実施例6は、主に請求項5、10、15などについて説明する。
≪実施例1≫
<概要>
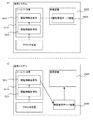
図1は、本実施例の検索システムにおける閲覧情報収集の一例を説明するための概念図である。この図にあるように、クライアント端末1にてブラウザが起動されている。また、このブラウザにはツールバーが組み込まれており、ブラウザの起動に合わせてツールバーもブラウザ上の所定領域(0101)に表示されている。
ここで、本実施例では、ユーザーがブラウザやツールバーに入力した検索キーやURLを、ツールバーのプログラムによって収集する。またブラウザでのWebページの表示時間や、移動先や移動元などWebページの遷移経路を示す情報も、ツールバーによって取得される。そして、このようにしてネットワーク上の各クライアント端末1,2,3、・・・にて取得された情報が、閲覧管理サーバ装置を含む検索装置(0102)に送信される。
図2は、このようにクライアント端末のツールバーにて取得され、閲覧管理サーバ装置を介して検索装置に収集される閲覧情報の一例を表す図である。この図にあるように、ツールバーは閲覧情報として、ユーザーIDやブラウザにてアクセスしたWebページのURL、そのWebページの閲覧開始時刻(アクセス時刻)、閲覧時間(Webページなどの表示時間)、あるいは図示しない移動先や移動元で示されるWebページの遷移経路を示す情報などを取得する、という具合である。
そして検索装置では、各クライアント端末から閲覧管理サーバ装置を介して収集した上記のような閲覧情報を利用して、例えばユーザーのWebブラウジング行動を解析したり、その解析結果からユーザーにとって人気の高いサイトなどを迅速に把握したりすることができる。そして、例えばいわゆる「クローラ」によって検索用インデックス情報を収集する際には、その人気サイトをクロールする頻度を上げて当該人気サイトの最新の情報が検索によって提供されるよう構成する、など様々に活用することができる、という具合である。
<機能的構成>
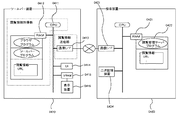
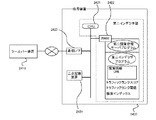
図3は、本実施例の検索システムにおける機能ブロックの一例を表す図である。この図にあるように、本実施例の「検索システム」(0300)は、「ツールバー装置」(0310)と、「検索装置」(0320)と、からなる。
なお、「ツールバー装置」(0310)とは、クライアント端末上のブラウザの機能を補助、拡張、代替などするため、ブラウザとともに動作するよう構成されたアプリケーションが組み込まれた装置をいう。またツールバー装置の一般的な機能としては、例えば、検索窓に入力されたキーワードによるWeb上のリソースの検索機能、RSS文書データの収集や表示機能、ショートカットアイコンによるランチャー機能などが挙げられる。そして、本実施例の検索システムにおいては、後述する構成によってブラウザにて閲覧されたURLを含む閲覧情報を取得し、閲覧管理サーバ装置に送信するというさらなる機能を有していることを特徴とする。
また、「検索装置」(0320)とは、前述のように「クローラ」が収集したWeb上のリソースの情報を利用して所定の検索エンジンの処理によってインデックス情報を生成し、ユーザーからの検索キーワードなどに応じてインデックス情報の検索処理を実行するサーバ装置をいう。そして本実施例の検索システムにおいては、クライアント端末のツールバー装置にて取得され閲覧管理サーバ装置に送信された閲覧情報を収集し、その検索処理やインデックス情報の生成処理などに活用することを特徴とする。
なお本実施例では、図3(a)に示すように閲覧管理サーバ装置がこの検索装置に含まれる構成を例に挙げ説明するが、もちろん本実施例の検索システムの構成はそれに限定されるものではない。例えば図3(b)に示すように閲覧管理サーバ装置が検索装置とは別個のサーバ装置としてネットワーク上に設けられ、検索装置は当該閲覧管理サーバ装置にて管理されている閲覧情報を取得する、といった構成であっても良い。
ここで、まず検索装置とともに本実施例の検索システムを構成する「ツールバー装置」(0301)の機能的構成について以下に説明する。図3にあるように「ツールバー装置」は、「閲覧情報送信部」(0303)と、「閲覧情報取得部」(0304)とを有する。
なお、以下に記載する本システムのツールバー装置や検索装置の各機能ブロックは、ハードウェア、ソフトウェア、又はハードウェア及びソフトウェアの両方として実現され得る。具体的には、コンピュータを利用するものであれば、CPUや主メモリ、バス、あるいは二次記憶装置(ハードディスクや不揮発性メモリ、CDやDVDどの記憶メディアとそれらメディアの読取ドライブなど)、印刷機器や表示装置、その他の外部周辺装置などのハードウェア構成部、またその外部周辺装置用のI/Oポート、それらハードウェアを制御するためのドライバプログラムやその他アプリケーションプログラム、情報入力に利用されるユーザーインターフェースなどが挙げられる。
そして主メモリ上に展開したプログラムに従ったCPUの演算処理によって、インターフェースを介して入力されメモリやハードディスク上に保持されているデータなどが加工、蓄積されたり、上記各ハードウェアやソフトウェアを制御するための命令が生成されたりする。また、この発明はシステムとして実現できるのみでなく、方法としても実現可能である。また、このような発明の一部をソフトウェアとして構成することができる。さらに、そのようなソフトウェアをコンピュータに実行させるために用いるソフトウェア製品、及び同製品を記録媒体に固定した記録媒体も、当然にこの発明の技術的な範囲に含まれる(本明細書の全体を通じて同様である)。
「閲覧情報取得部」(0311)は、ブラウザから少なくとも閲覧URL含む閲覧情報を取得する機能を有する。「閲覧URL」とは、このツールバー装置が組み込まれたクライアント端末のブラウザにて表示されているリソースのWeb上での所在を示す情報をいい、例えば「http://・・・/001.bmp」等の情報が挙げられる。
そして本実施例の検索システムでは、ネットワーク上の各クライアント端末のツールバーにて取得され、閲覧管理サーバ装置を介して検索装置にて収集されるこの閲覧URLを利用した各種処理、例えば「クローラ」の巡回対象を決定するなどの処理を行うことを特徴とする。
また閲覧情報には、上記閲覧URL以外にもブラウザでの閲覧に係る各種情報が含まれていて良い。例えば、ユーザーID、ブラウザIDやツールバーID、閲覧開始時刻情報、閲覧時間情報、あるいはWeb上の2以上のリソースを連続で閲覧した際の「移動元リソース」や「移動先リソース」などの遷移情報などが挙げられる。
ここでユーザーIDとはユーザーを識別するための情報をいい、例えばクライアント端末へのログイン時のIDやサービス単位で割当てられるIDなどが挙げられる。また、ブラウザIDやツールバーIDも同様に当該ブラウザやツールバーを識別するための情報をいい、例えば予めブラウザプログラムやツールバープログラムに記録されている製品IDなどを利用すると良い。そして、これら識別情報を利用することでクライアント端末を識別することができるので、クライアント端末(ユーザー)単位での閲覧情報の管理、分析を行うことができる。なお、これらID情報の保持は、例えばツールバー装置自身が保持する方法や、ブラウザ装置が有するcookie機能を利用する方法などが挙げられる。
また、閲覧開始時刻情報とは、ブラウザにてWeb上のリソースにアクセスされた時刻、あるいはそのアクセスによってブラウザにリソースが取得された時刻や表示された時刻などをいう。具体的に当該時刻は、例えばブラウザにてアクセスリクエストしたリソースのロード完了を検出した時刻や、Webサーバが「200:OK」などのHTTPステータスコードを応答した時刻等が挙げられる。
また閲覧時間情報とは、ブラウザにてWeb上のリソースが表示されている時間をいい、例えば、ブラウザのUIウィンドウが、オープンしていた時間や、当該ウィンドウがアクティブとなっている時間、またウィンドウ領域にマウスポインタが存在する時間などが挙げられる。またさらに、一定時間の操作がないためクライアント端末のOSが自動的にログオフ処理を行ったり、スクリーンセーバ等が起動したりした場合には、ログオフされている時間やスクリーンセーバが起動している時間を除いた後の時間としてもよい。また閲覧時間情報は、前記閲覧開始時刻と閲覧終了時刻との差分を算出することで取得されても良い。
また遷移情報とは、Web上の2以上のリソースを連続で閲覧した際の「移動元リソース」と「移動先リソース」とを示す情報をいい、例えばハイパーリンクのクリックによる遷移のほか、ブラウザやツールバーのURL入力欄に連続で入力された2以上のURLを「移動先」「移動元」とする遷移情報などが挙げられる。
そしてツールバー装置は上記閲覧情報を、例えばAPI(Application Program Interface)やDDE(Dynamic Data Exchange)やファイルシステム等を用いてクライアント端末のブラウザから取得する、という具合である。
「閲覧情報送信部」(0312)は、取得した閲覧情報を所定の閲覧管理サーバ装置に送信する機能を有する。具体的には、上記のように取得した閲覧情報を、クライアント端末の通信I/Fを使用し通信回線等を介して、所定の閲覧管理サーバ装置に送信する機能を有する。なお、閲覧情報の送信先となる所定の閲覧管理サーバ装置の送信先アドレスは、例えばツールバー装置のプログラム内に予め記述されることで特定する方法などが挙げられる。また、この閲覧情報送信部から閲覧情報が送信されるタイミングはブラウザにて表示されているリソースが切換わるごとに送信するといったタイミングや、一定の時間、又は時刻が到来した際にバッチ処理で送信するタイミング、あるいはツールバー起動時または終了時に送信するタイミングなどが挙げられる。
そして、このように各クライアント端末上ブラウザでの閲覧に応じてツールバー装置にて取得された閲覧情報が閲覧管理サーバ装置に送信される。そして後述するように閲覧管理サーバ装置を介して検索装置にて当該閲覧情報が収集されることで、検索装置ではクライアント端末の閲覧リソースの特定などブラウジング(閲覧)履歴を容易に把握することができる、という具合である。
続いて、上記ツールバー装置とともに本実施例の検索システムを構成する「検索装置」(0320)の機能的構成について、同様に図3を用いて以下に説明する。図3にあるように「検索装置」は、「閲覧管理サーバ装置」(0330)を備える。
「閲覧管理サーバ装置」(0330)は、閲覧情報送信部(0312)から送信される閲覧情報を受信、管理する機能を有する。そして、閲覧管理サーバ装置では閲覧情報を利用して、例えばユーザーのWebブラウジング行動を解析したり、その解析結果からユーザーにとって人気の高いサイトなどを迅速に把握したりすることができる。そして、検索装置での「クローラ」による検索用インデックス情報収集の際には、その人気サイトについてクロールする頻度を上げて当該人気サイトの最新の情報が検索によって提供されるようにする、など様々な処理を行うことができる。
またその他にも、詳細は実施例2にて後述するように、例えば、閲覧情報に含まれる閲覧URLのうち自身が管理していないURLを他のページにハイパーリンクされていないリソースのURLとして「クローラ」の巡回先として新規に指定する処理を行っても良い。あるいは詳細は実施例3にて後述するように、閲覧情報に含まれる閲覧時間などの情報から、誤アクセスなどを排除して集計したリソースの実効的なアクセス指標(視聴度指数)であるトラフィックランクを算出し、「クローラ」の巡回スケジュールに利用する処理を行っても良い。
なお閲覧管理サーバ装置は前述のように、ネットワーク上にて検索装置とは別個のサーバ装置として存在しても良い。その場合、図3(b)に示すように閲覧管理サーバ装置にて管理されている閲覧情報を、「検索装置」が収集し、上記のような各種処理を行うよう構成されていても良い。
<ハードウェア的構成>
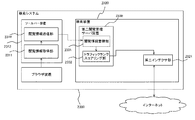
図4は、上記機能的な各構成要件をハードウェアとして実現した際の、検索システムにおける構成の一例を表す概略図である。この図を利用して本実施例の検索システムにおけるそれぞれのハードウェア構成部の働きについて説明する。この図にあるように、本実施例の検索システムのハードウェア構成は、クライアント端末に組み込まれた「ツールバー装置」(0410)と、サーバ装置としてネットワーク上に配置されている「検索装置」(0420)と、により構成される。なお本例では、閲覧管理サーバ装置を実現するための「閲覧管理サーバプログラム」が検索装置において実行される構成、すなわち検索装置が閲覧管理サーバ装置を含む構成を例に挙げて説明する。
そしてツールバー装置と検索装置は電気通信回線を介して相互に接続され、情報の送受信を行う。なお、電気通信回線はインターネットを含む。
また「ツールバー装置」においては、閲覧情報取得部を実現し、またその他各種演算処理を行う「CPU(中央演算装置)」(0411)と、「RAM」(0412)や、閲覧情報送信部である「通信I/F」(0413)を備える。またキーボード、マウス等の入力装置である「UI」(ユーザーインターフェース)(0414)や、ブラウザプログラムにて処理されたリソースを表示するための「VRAM」(0415)や、ディスプレイなどの「表示装置」(0416)も備える。そしてそれらが「システムバス」などのデータ通信経路によって相互に接続され、情報の送受信や処理を行う。
またツールバー装置の「RAM」上には、ブラウザプログラムと、ツールバープログラムとが格納されており、これらプログラムに従い閲覧情報の取得や送信処理やその他処理に係る「CPU」の各種演算処理が実行される。また上記ツールバープログラムによって、RAM上の所定のアドレスには閲覧URLを格納する領域が確保されている。
一方「検索装置」においては、各種演算処理を行う「CPU」(0421)と、「RAM」(0422)と、「通信I/F」(0423)と、大量の閲覧情報などを蓄積するためのハードディスクなどの「二次記憶装置」(0424)とを有している。そしてそれらが「システムバス」などのデータ通信経路によって相互に接続され、情報の送受信や処理を行う。
また検索装置の「RAM」上には、閲覧管理サーバプログラムが格納されており、当該プログラムに従い閲覧情報の管理処理やその他処理に係る「CPU」の各種演算処理が実行される。
ここで、「ツールバー装置」においてユーザーの「UI」を介した操作入力を受付け、「RAM」上のブラウザプログラムおよびツールバープログラムに従い以下のような処理が実行される。すなわち「UI」を介したブラウザ操作によってWeb上のリソースへのアクセス指示が入力されると、そのアクセス指示で指定されたリソースのURLが「RAM」の所定アドレスに格納される。するとブラウザプログラムに従い指定されたURLに対してHTTPリクエストが送信される。そしてそのHTTPリクエストに対するレスポンスをアクセスリソースのコンテンツとして「通信I/F」にて受信する。つづいて受信したコンテンツに含まれるHTMLファイル、イメージファイルなどを、ブラウザプログラムが有するHTMLレンダリングエンジンなどに従った「CPU」の演算処理よってレンダリング処理する。そしてその処理結果が「VRAM」に転送され「表示装置」上にWebコンテンツが表示される。そしてユーザーは表示された当該WWW上のWebページなどのリソースを閲覧する。
また、それとともに前記ブラウザでのアクセス指示入力に応じてツールバープログラムは以下の処理を実行する。すなわち「RAM」の所定アドレスに格納されたURLを閲覧情報として、前述のような所定の各タイミングで「通信I/F」から「検索装置」に送信する、という具合である。
また、ツールバープログラムは、その他に以下のようにしてユーザーIDや閲覧時間情報などを取得して、上記URLと同様に閲覧情報として送信しても良い。まず、ツールバープログラムが起動すると、インターネットキャッシュなどからユーザーIDを取得し、「RAM」上の所定のアドレスに格納する。また、ブラウザプログラムによりHTTPレスポンスの取得が完了するとOSのタイマ関数などより現在時刻を取得し「RAM」上の所定のアドレスに格納する。あるいは、ブラウザにおいて一のURLに関してウィンドウがアクティブ状態である時間を監視し、その時間を閲覧時間として「RAM」上の所定のアドレスに格納する。そして、上記「RAM」に格納した各情報を前述のような所定の各タイミングで「通信I/F」から「検索装置」に送信する、という具合である。
そして、「検索装置」では、「通信I/F」にて各ツールバー装置から送信されてきた閲覧情報を受信し「RAM」の所定アドレスに格納する。そして、閲覧管理サーバプログラムにしたがって、例えば閲覧情報に含まれるURLやユーザーIDなどパラメータとする閲覧履歴データベースなどを「CPU」の演算処理によって生成し、HDDなどの「二次記憶装置」に格納する、という具合である。
そして、そのデータベースを利用して、例えば閲覧URLごとのアクセス数を「CPU」の演算処理によって集計する。そして「アクセス数−巡回頻度テーブル」などを参照し、集計結果の高い順にクローラの巡回頻度を決定する処理を行う、という具合である。
<処理の流れ>
図5は、本実施例の検索システムにおける処理の流れの一例を表すフローチャートである。なお、以下に示すステップは、媒体に記録され計算機を制御するためのプログラムを構成する処理ステップであっても構わない。
この図にあるように、ツールバー装置にてツールバーが起動されると、まずURLを含む閲覧情報を取得する(ステップS0501)。次にユーザーのブラウザの操作により閲覧URLが更新(変更)されたか否かを判断する(ステップS0502)。更新されたと判断された場合には、閲覧URLを含む情報を閲覧情報として閲覧管理サーバ装置を含む検索装置に送信する(ステップS0503)。
またツールバー装置では、閲覧情報の送信(ステップS0503)後、閲覧が終了したか否かの判断がなされる(ステップS0504)。ブラウザが終了されるなど、閲覧が終了したと判断されると処理は終了する。終了していないと判断された場合には、URLを含む閲覧情報を取得する(ステップS0501)処理に戻る。
検索装置では、ステップS0503にてツールバー装置により送信されたURLを含む閲覧情報を受信し(ステップS0511)、記録媒体等に格納する(ステップS0512)。そして各ツールバー装置から取得した閲覧情報を利用してデータベースを生成、蓄積し、各種処理に利用する。
もちろん、前述のようにステップS0503では、検索装置とは別個の閲覧管理サーバ装置に閲覧情報を送信しても良い。そして、その場合には、検索措置にて閲覧管理サーバ装置で受信した閲覧情報を収集するステップが追加されると良い。
<効果の簡単な説明>
以上のように本実施例の検索システムによってクライアント端末のツールバー装置を利用してユーザーの閲覧情報を取得し、その閲覧情報を閲覧管理サーバ装置を介して検索装置に送信することが可能となる。そして検索装置では、ネットワーク上の複数のツールバー装置から送信される閲覧情報を幅広く収集しデータベースなどを構築することが容易に可能である。
そしてその構築したデータベースを利用して、例えば閲覧URLごとのアクセス数を集計し、集計結果の高い順にクローラの巡回頻度を決定する処理を行ったりすることができる。
≪実施例2≫
<概要>
図6は、本実施例の検索システムにおける処理の一例を説明するための概念図である。この図にあるように、あるユーザーAが、ツールバー装置を備えたクライアント端末(0601)を利用して、友人が新規に開設したWebサイトA(0602)にアクセスしている。ここで、新規WebサイトAは新規開設されたばかりであるため、他のWeb上のリソースからのハイパーリンクなどが無い状態である。そのため「クローラ」の巡回対象にはなっておらず、未だ検索装置(0603)の検索サービス用インデックスファイル(0604)には存在していない。
しかし、本実施例の検索システムにおいては、上記クライアント端末によるWebサイトAへのアクセスによって、検索装置に対して当該URLを含む閲覧情報が送信される構成となっている。そこで、検索装置では送信されてきた当該URLと、検索サービス用インデックスファイルに含まれるURLとの比較処理を行う。そしてインデックスファイルに含まれていなければコンテンツを取得しインデックスファイルに追加格納する。またそれに加えて「クローラ」によるハイパーリンク以外の直接巡回対象URLとして設定する、という具合である。
<機能的構成>
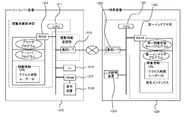
図7は、本実施例の閲覧管理サーバ装置における機能ブロックの一例を表す図である。この図にあるように、本実施例の「検索システム」(0700)は、実施例1の構成を基本として、「ツールバー装置」(0710)と、「検索装置」(0720)とを有する。そして「ツールバー装置」は、実施例1同様に「閲覧情報取得部」(0711)と、「閲覧情報送信部」(0712)とを有する。なお、上記ツールバー装置と検索装置の機能的構成を含む詳細な説明は、実施例1にて記載済みであるので省略する。
そして本実施例の特徴点は、「検索装置」が「第一閲覧管理サーバ装置」(0730)を有し、その第一閲覧管理サーバ装置がさらに「第一インデクサ部」(0731)を有する点である。
「第一インデクサ部」(0731)は、収集した閲覧情報に基づいて新規検索対象URLを抽出するとともに、抽出したURLのコンテンツをインデクシングする機能を有する。
「新規検索対象URL」とは、検索エンジンにて新規に検索対象として利用するURLをいう。具体的には、検索装置は「クローラ」が巡回して収集したWWW上のリソースに関する情報をまとめてインデックスファイルを生成、保持している。そして検索エンジンによる検索の際には、その保持しているインデックスファイルを参照し検索を行うよう構成されている。つまりインデックスファイルに含まれていないURLは検索対象とならない構成となっている。そこで、閲覧情報に含まれるURLとインデックスファイルに格納されているURLと差分情報を取得し、その差分であるURLを新規検索対象URLとして抽出する、という具合である。
そして、このように抽出された新規検索対象のURL、および当該URLにあるリソースのコンテンツなどが検索装置にてインデクシング(インデックスファイルへの追加処理)されることで、本実施例の検索システムでは新規開設Webページなど本来検索対象となっていなかったようなWWW上のリソースについても検索対象とすることができる、という具合である。また、ここで「インデクシング」処理とは、詳細には検索エンジンがターゲットとなるキーワードを高速に検索しやすいようなデータ構造や、ファイル構造に再構成することである。例えば、抽出したキーワードをキーとし、これをハッシュテーブル化したインデックスを新たに付与するといった方法などが挙げられる。
また、本実施例の検索装置は上記インデクシング処理に加え、さらに抽出した新規検索対象URLを「クローラ」がハイパーリンクを辿らずに直接巡回する対象として追加する処理を行い、更新情報を取得するよう構成しても良い。
<ハードウェア的構成>
図8は、上記機能的な各構成要件をハードウェアとして実現した際の、検索システムにおける構成の一例を表す概略図である。この図を利用して本実施例の検索システムにおけるそれぞれのハードウェア構成部の働きについて説明する。この図にあるように、本実施例の検索システムのハードウェア構成は、ツールバー装置(0810)と検索装置(0820)より構成される。そして両者はインターネットを含む電気通信回線を介して、相互に接続可能となっている。
また、「ツールバー装置」(0810)は、実施例1と同様に「CPU」(0811)と「RAM」(0812)、「通信I/F」(0813)、「UI」(0814)、「VRAM」(0815)と「表示装置(ディスプレイなど)」(0816)と、を備える。
そして「検索装置」(0820)も実施例1と同様に、「CPU」(0821)と「RAM」(0822)、「通信I/F」(0823)と、「二次記憶装置」(0824)と、を有する。
ここで実施例1にて説明したように、ネットワーク上の複数のツールバー装置のツールバープログラムの処理によって、閲覧URLを含む閲覧情報が検索装置に送信され、「RAM」の所定アドレスに格納される。
検索装置では、第一閲覧管理サーバプログラムに含まれる第一インデクサプログラムに従い、以下のような処理を実行する。まず、予め「二次記憶装置」にて格納されている検索サービス用のインデックスファイルを参照し、「RAM」の所定アドレスに格納された閲覧URLをキーとした検索処理が「CPU」の演算によって実行される。そして、その検索処理の結果、インデックスファイルに当該URLが含まれていないとの判断結果が出力されれば、そのURLは新規検索対象のURLである判断する。すると第一インデクサプログラムに従い、「CPU」は「RAM」に格納されたそのURLに対して通信I/F(0913)を介してアクセスし、リソースコンテンツを取得する命令を出力する。そして取得したコンテンツに関し、「CPU」の処理によってインデクシング処理が実行され、新規のインデックス情報として「二次記憶装置」に保持されているインデックスファイルに記録される、という具合である。
また、第一インデクサプログラムに従って、「RAM」に格納された当該URLを、次回以降のクローラの巡回対象としてスケジュールに組み込む処理を実行しても良い。またさらに、当該URLに関しては情報鮮度の高いリソースであると仮定して、クローラの巡回頻度を上げたスケジュールを生成するよう処理しても良い。
<処理の流れ>
図9は、本実施例の検索システムにおける処理の流れの一例を表すフローチャートである。なお、以下に示すステップは、媒体に記録され計算機を制御するためのプログラムを構成する処理ステップであっても構わない。
ここで、ツールバー装置にてツールバーが起動されると、まずURLを含む閲覧情報を取得する(ステップS0901)。次にユーザーのブラウザの操作により閲覧URLが更新(変更)されたか否かを判断する(ステップS0902)。そして更新されたと判断された場合には、閲覧URLを含む情報を閲覧情報として第一閲覧管理サーバ装置を含む検索装置に送信する(ステップS0903)。
つづいて検索装置において、ネットワーク上の各クライアント端末から送信されてきたn個のURLを含む閲覧情報を受信、収集する(ステップS0911)。次に、閲覧情報を記録媒体等に格納する(ステップS0912)。次にループ1に入り、格納されているn個のURLのそれぞれについて検索装置のインデックスファイル(データベース)を参照し、同一のURLが存在するか否かの判定を行う(ステップS0914)。
そしてその判定処理の結果、インデックスファイルに存在しないと判定されたURLについては、新規検索対象URLとしてリソースコンテンツを取得しインデクシングする(ステップS0915)。一方、同一のURLが存在すると判定されたURLについては、インデクシングの処理はスキップする。そして、閲覧情報で示される全てのURLに対して上記判定処理が完了すると、処理を終了する。
<効果の簡単な説明>
以上のように本実施例の検索システムでは、新規開設Webページなどハイパーリンクが張られていないため従来のクローラでは検索対象となっていなかったようなWWW上のリソースについても検索用のインデックスファイルとしてインデックス化することができる。
≪実施例3≫
<概要>
本実施例は、上記実施例1の検索システムを基本として、ネットワーク上の各クライアント端末のツールバー装置から閲覧情報を収集する。そしてWWW上のリソースの視聴度合いに関して、その閲覧情報を利用して従来よりも精度の高い視聴度指数である「トラフィックランク」を算出することを特徴とする検索システムである。
図10は、本実施例の検索装置における処理の一例を説明するための図である。この図にあるように、ツールバー装置を備えるクライアント端末にて、サイトBを経由したサイトAへのアクセスが実行された。ここで、サイトBへのアクセス時間は単なるリンクの経由であったため短い。一方、閲覧を目的としたサイトAへのアクセス時間は長いものとなっている。
そして、そのようなアクセス(閲覧)時間を含む閲覧情報が検索装置に送信されると、検索装置ではそのアクセス時間や閲覧情報に含まれるその他情報を利用して「トラフィックランク」を算出する。そして、このトラフィックランクは、後述するように上記リンク経由によるアクセスや誤アクセスを排除した閲覧実体に即した指数となっているため、従来のサイト(WWW上のリソース)視聴度指数よりも精度の高い指数を算出することができる、という具合である。
<機能的構成>
図11は、本実施例の検索装置における機能ブロックの一例を表す図である。この図にあるように、本実施例の「検索システム」(1100)は、実施例1の構成を基本として、「ツールバー装置」(1110)と、「検索装置」(1120)とを有する。また「ツールバー装置」(1110)は、実施例1と同様に「閲覧情報送信部」(1111)と、「閲覧情報取得部」(1112)とを有する。なお、上記各構成は、実施例1にて既に記載済みであるのでその説明は省略する。
そして本実施例の特徴は、「検索装置」(1120)が、「第二閲覧管理サーバ装置」(1130)を有し、その第二閲覧管理サーバ装置がさらに「閲覧情報蓄積部」(1131)と、「トラフィックランクスコアリング部」(1132)とを有する点である。
「閲覧情報蓄積部」(1131)は、収集した閲覧情報を蓄積する機能を有する。具体的にはツールバー装置において取得され、閲覧管理サーバ装置を介するなどして検索装置にて収集された閲覧情報を入力として受け取り、HDDや不揮発性メモリなどの記憶媒体に格納する機能を有する。なお、ここで蓄積される閲覧情報は、後述するトラフィックランクスコアリング部におけるトラフィックランクの算出のため、例えばリソースごとの閲覧(アクセス)時間やユーザーID(クライアント端末ID、ツールバー装置ID)、リソースの遷移情報などが含まれていることが望ましい。
「トラフィックランクスコアリング部」(1132)は、閲覧情報蓄積部(1131)に蓄積されている閲覧情報に基づいてURL毎にトラフィックランクを算出する機能を有する。「トラフィックランク」とは、WWW上のリソースの視聴度指数をいい、例えば以下のようにして算出する方法が挙げられる。
すなわち、トラフィックランクの算出方法の一例としては、例えば1日における全ウェッブページの合計表示時間に対するウェッブページAの合計表示時間のパーセンテージをウェッブページのランクとして算出する方法などが挙げられる。このようにウェッブページのランクを算出することで、クリックミスなどの表示時間が短いアクセスに関しては、そのランクを低いものとして算出することができる。したがって単純なアクセス数などでは推定することが困難な、クリックミスなどを排除して実体に即した広告効果などを示す指標としてウェッブページのトラフィックランクを算出することができる。
なお、上記ウェッブページのランクの算出処理として、主に以下のような3つのパターンによる算出処理が考えられる。第一に、例えば一日を単位とし、集計された全端末あるいは一部端末からのブラウジング情報に含まれる表示時間を利用して、いわゆるウェッブページごとの「全国ランク」を算出する処理が挙げられる。
また第二に、閲覧情報に含まれるユーザーIDなどから「ユーザーID−属性情報テーブル」などを参照して特定されるユーザーの属性情報を利用して、年齢別、男女別、居住地別、職業別などの各種セグメントごとにウェッブページの「属性別ランク」を算出するように構成しても良い。
なお上記「ユーザーID−属性情報テーブル」は、一例として以下のようにして構築することができる。例えば、クライアント端末にツールバー装置をインストールする際には、上記ユーザーの属性情報の登録を必須とする。そして、登録された属性情報をCookieなどのユーザーIDと紐付けて検索装置にて管理することで、クライアント端末のツールバー装置から送信されたユーザー(属性情報)の特定を実行する、という具合である。
また第三に、ユーザーIDなどを利用して閲覧情報をユーザー単位で分類し、「ユーザーαにおけるサイトAのランク」、「ユーザーαにおけるサイトBのランク」といった具合に、いわゆる「ユーザー別ランク」を算出するよう構成しても良い。
具体的に、この第三の算出処理を行うための構成としては、本実施例の検索システムのツールバー装置と検索装置が以下のような構成を備えていると良い。例えば、このツールバー装置は、その閲覧情報送信部にて送信する閲覧情報に、例えばCookieやその他ユーザーを識別するための情報であるユーザー識別情報を含み検索装置に送信するよう構成されている。
そして、ここで送信されたユーザー識別情報を利用して、検索装置の以下の構成によって「ユーザー別ランク」が算出されることになる。すなわち検索装置は、そのトラフィックランクスコアリング部がさらに「ユーザー別トラフィックランク算出手段」をさらに含むことを特徴とする。
「ユーザー別トラフィックランク算出手段」は、ユーザー別にトラフィックランクを算出する機能を有する。このユーザー別のトラフィックランクは、例えば前述の表示時間に応じたウェッブページのトラフィックランク算出時に、ユーザー識別情報を利用してユーザー単位で算出される、という具合である。
また、上記ウェッブページのランクの算出に際しては、同一ユーザーによる不正なども含めた同一リソースへの重複アクセスを排除してトラフィックランクを算出するよう構成しても良い。具体的には、閲覧情報に含まれるCookieなどを利用して、同一ユーザーが同一ページへアクセスしたことを判断する。そして、そのように判断された表示時間に関しては、合計値ではなくその平均値などを利用してトラフィックランクを算出する、という具合である。
また、上記のように集計されたトラフィックランクについて、前日のアクセス数からの増減率(バースト度)を算出し、その増減率をウェッブページのランクに反映するような計算式を用いるよう構成しても良い。このような増減率を反映させることで、ウェッブページの一日ごとの盛り上がりを反映させることもできる。
図12は、上記のようにして算出されたWebページ(リソース)ごとのトラフィックランクの一例を表す図である。この図にあるように、例えばその視聴回数やバースト度(前日のアクセス数からの増減率)を用いて、所定の関数によりリソースごとにトラフィックランクが「140」、「120」、「60」、「89」といった具合に算出される。そして、このようにして算出されたトラフィックランクに関して、本実施例の検索装置は当該リソースのURLと関連付けて図に示すようにテーブルデータなどとして保持する、という具合である。そしてそのトラフィックランクを利用して実施例4や5にて後述するよう「クローラ」の巡回頻度のスケジュール調整や検索結果の順位ソートなど様々な処理を実行することができる。
なお、例えばあるWebサイトの「トップページ」と「ページ1」「ページ2」、という具合に、通常は複数のリソースで一のWebコンテンツが構成されることが多い。したがってトラフィックランクスコアリング部で算出されるトラフィックランクは、URLごとでなくても構わない。例えば、同一Webサイトを構成するWebページであれば、IPアドレスやURLのドメインなどを比較することでそのことを判断し、URLは異なっていても一のトラフィックランクが算出されるよう構成しても良い。
<ハードウェア的構成>
図13は、上記機能的な各構成要件をハードウェアとして実現した際の、検索システムにおける構成の一例を表す概略図である。この図を利用して本実施例の検索システムにおけるそれぞれのハードウェア構成部の働きについて説明する。
この図にあるように、本実施例の検索システムのハードウェア構成は、ツールバー装置(1310)と検索装置(1320)とにより構成され、両者はインターネットを含む電気通信回線を介して、相互に接続可能となっている。
また、「ツールバー装置」(1310)は、実施例1と同様に「CPU」(1311)と「RAM」(1312)、「通信I/F」(1313)、「UI」(1314)、「VRAM」(1315)と「表示装置(ディスプレイなど)」(1316)と、を備える。
そして「検索装置」(1320)も実施例1と同様に、「CPU」(1321)と「RAM」(1322)、「通信I/F」(1323)と、「二次記憶装置」(1324)と、を有する。
ここで実施例1にて説明したように、ツールバー装置のツールバープログラムの処理によって、閲覧URLがツールバー装置の「RAM」の所定アドレスに格納される。また、本実施例では、さらに以下のようにして取得された閲覧URLごとのアクセス時刻や閲覧(アクセス)時間などの情報が同様に「RAM」の所定アドレスに格納される。
具体的に、例えば「UI」の操作入力に応じてブラウザプログラムが当該URLのリソース(ここではWebページ)のコンテンツを「通信I/F」にて受信した時刻を内蔵時計などで取得し、アクセス時刻として「RAM」に格納する。またブラウザプログラムによる処理を監視することで、当該URLで示されるウェッブページが例えばディスプレイ上の最前面に表示されるよう制御されている時間や、ポインティングデバイスが当該ウェッブページのウィンドウ上にあるよう制御されている時間を図示しないカウンタや内蔵時計などで計測し、閲覧時間として「RAM」に格納する、という具合である。
そしてツールバー装置ではツールバープログラムに従って、このように取得された閲覧URLや、当該URLで示されるリソースへのアクセス時刻や閲覧時間に、例えばCookieなどで示されるユーザーIDを加えて図2に示すようにテーブル化する。そしてそれら情報を閲覧情報として「通信I/F」から検索装置に対して送信する。
検索装置では、ツールバー装置のツールバープログラムにしたがった処理により送信されてきた閲覧情報を「通信I/F」にて受信し「RAM」の所定アドレスに格納する。また閲覧情報は必要に応じて「二次記憶装置」に記録、蓄積されてもよい。
そして検索装置にて閲覧情報が格納されると、トラフィックランク算出プログラムに従い、以下のような処理が実行される。すなわち「RAM」上などに格納されている上記閲覧情報を参照し、例えば以下のような関数を利用した演算処理を「CPU」において実行しトラフィックランクを算出する。
ここで、例えばウェッブページaのトラフィックランクRaは数1のような関数を用いて算出される。taは全ユーザーIDによるページaの視聴時間の合算値である。Tは、全ユーザーIDによる全URLの視聴時間合算値である。Baは次の数2で示された、バースト値である。なおバースト値については後述する。NIは、総閲覧ID数である。また、naは全ユーザーIDによるページaの閲覧回数の合算値である。Nは全ユーザーによる全ウェッブページの閲覧回数合算値である。そして、rxはページaの関連ページxのトラフィックランクである。
このように数1では、全ページの視聴時間(T)のうちのページaの視聴時間(t
a)の割合(t
a/T)を算出する。この数値によってクリックミスなどの表示時間が短いアクセスに関しては、そのトラフィックランクを低いものとして算出することができる。したがって前述のように、単純なアクセス数などでは推定することが困難なクリックミスなどを排除して、実体に即した指標としてリソースの視聴度指数を算出することができる。
また、WebページaのURLのバースト度Baは、例えば数2で示す関数式で求めると良い。ratは、Webページaの本日の閲覧数である。またrayは、Webページaの昨日の閲覧数である。つまり数1で算出されるバースト度は、昨日の閲覧数を基準とした本日の閲覧数の増減率となる。したがって、通常時のアクセス数に比べて急激な伸びが認められる場合にはこの値が高くなる。つまり、そのページの注目度の高まりをバースト度によって表し、当該Webページ(リソース)のトラフィックランクに反映させることができる。
また、その他にも総閲覧ID数(NI)を関数の変数として利用することで以下のような効果が期待できる。すなわち、例えばあるサイトのトラフィックランクを不正に上げようとして、一ユーザーがあるサイトへ複数アクセスを実行した。しかし、そのような場合でも変数NIを利用することで、一ユーザーによる複数アクセスよりも複数ユーザーによる複数アクセスの方がトラフィックランクを高く算出することができる、という具合である。
また、トラフィックランクの算出対象であるWebページaのリンク先などの関連ページx1、x2、・・・のトラフィックランク(rx)を、上記関数の変数として利用しても良い。
また、ここで利用される関連ページのトラフィックランクrxは、例えば算出の対象となっているURLからハイパーリンクが設けられているページについてのみ、加重平均等でトラフィックランクを算出するものでもよい。また、あるURLから遷移する確率が一定値以上であるURLを取り出し、各URLが有するトラフィックランクを加重平均により算出したものを関連URLのトラフィックランクとしてもよい。
また上記算出されるランクは、いわゆる「全国ランク」以外にも、前述のように「属性別ランク」や「個人ランク」であっても良い。具体的には、受信した閲覧情報に含まれるCookieなどを「RAM」に格納する。そしてそのCookieをキーとして、予め保持しているユーザー登録情報などからその閲覧情報で示される表示時間に関してセグメントや個人を特定する処理を「CPU」の演算処理によって実行する。そして、上記例えばURLaおよび全URLの表示時間の合算処理において、特定された個人やセグメント別にその合算値を算出し、その表示時間の割合を「CPU」の演算処理によって算出する、という具合である。
そして、このようにして閲覧URLごとに算出したトラフィックランクを、「二次記憶装置」にトラフィックランクデータベースとして記録、保持する。そして実施例4や5で後述するように、「クローラ」の巡回頻度のスケジュール調整や検索結果の順位ソートなど際に当該トラフィックランクデータベースを参照する、という具合である。
<処理の流れ>
図14は、本実施例の検索システムにおける処理の流れの一例を表すフローチャートである。なお、以下に示すステップは、媒体に記録され計算機を制御するためのプログラムを構成する処理ステップであっても構わない。
この図にあるように、ツールバー装置にてツールバーが起動されると、まず閲覧URLなどを取得する(ステップS1401)。次にユーザーのブラウザの操作により閲覧URLが更新(変更)されたか否かを判断する(ステップS1402)。更新されたと判断された場合には当該URLのアクセス時間を取得する(ステップS1403)。そして取得した閲覧URLやアクセス時間を含む情報を閲覧情報として閲覧管理サーバ装置を含む検索装置に送信する(ステップS1404)。
次に検索装置において、この図にあるように、n個のURLと、当該URLに関連付けたユーザーIDや閲覧時間などの情報を含む閲覧情報をツールバー装置より受信する(ステップS1411)。次に受信した閲覧情報を主メモリなどに格納する(ステップS1412)。その後、ループ1(ステップS1413)を開始とする以下の処理を実行する。まず蓄積されたn個の閲覧情報を関数の変数として利用し、トラフィックランクを算出する(ステップS1414)。そして、n個のURLごとに算出したトラフィックランクを、例えばHDDなどにデータベースとして記録する。そして例えば当該データベースを参照し「クローラ」の巡回頻度のスケジュール調整を実行したり、検索結果の順位ソートを実行したりする。
<効果の簡単な説明>
このように本実施例の検索システムによって、誤アクセスなどを排除して集計した実効的なリソースのアクセス指標(視聴度指数)であるトラフィックランクを算出することができる。また、上記のような関数を利用すれば、さらに単にWebページのURL毎のアクセス数や、ユニークユーザー数などだけではなく、注目度の高まりなどを含めた総合的な評価指標によりWebページを評価することができるトラフィックランクを算出することができる。
≪実施例4≫
<概要>
本実施例は、上記実施例3を基本として、算出したトラフィックランクをリソースの人気度の指標として利用し、クローラの巡回優先度の決定に利用することを特徴とする検索システムである。
図15は、本実施例の検索システムにおける処理の一例を説明するための概念図である。この図にあるように、検索装置は上記実施例3で記載した構成、処理によって、トラフィックランクを算出し、データベースとして保持している。そしてさらに、本実施例の検索装置では、例えば「TR(トラフィックランク):60」のサイトCに対しては「巡回優先度:12」、一方「TR:20」のサイトDであれば「巡回優先度:4」という具合に、トラフィックランクに応じて巡回優先度を算出していることを特徴とする。
そして、このトラフィックランクに応じた優先度を利用して、本実施例の検索装置では、クローラの巡回スケジュールを、例えばサイトCであれば「3回/週」としてスケジューリングし、一方優先度(トラフィックランク)の低いサイトDは「1回/週」としてスケジューリングする、という具合である。
つまり、前述のようにインターネットユーザーは更新頻度が高いWebページを中心的に検索しアクセスする傾向がある。これは逆に言えば、アクセス頻度の高いリソースは頻繁に更新などされている可能性が高い、ということである。そして、上記実施例3で説明したように「トラフィックランク」は、ユーザーの実効的なアクセス数を示す指標である。したがって、このトラフィックランクによってユーザーの実効的なアクセス数に応じてクローラの巡回優先度の決定することができる、ということである。
<機能的構成>
図16は、本実施例の検索システムにおける機能ブロックの一例を表す図である。この図にあるように、本実施例の「検索システム」(1600)は、実施例3を基本として「ツールバー装置」(1610)と、「検索装置」(1620)とを有する。また「ツールバー装置」(1610)は、実施例3と同様に「閲覧情報送信部」(1611)と、「閲覧情報取得部」(1612)とを有する。
また「検索装置」(1620)も、実施例3を基本として「第二閲覧管理サーバ装置」(1630)を有し、その第二閲覧管理サーバ装置が「閲覧情報蓄積部」(1631)と、「トラフィックランクスコアリング部」(1632)とを有する。なお、上記ツールバー装置及び検索装置の各構成は、実施例1や3にて既に記載済みであるのでその説明は省略する。
そして、本実施例の特徴点は、検索装置が、さらに「クローラ部」(1621)と、「スケジュール決定部」(1622)と、を有する点である。
「クローラ部」(1621)は、インターネット上のリソース間に張られたハイパーリンクをたどりWWW上を巡回することで各リソースにアクセスしコンテンツを収集するいわゆる「クローラ」プログラムによって実現することができる。
また、このクローラプログラムは、通常その巡回対象となるリソースのURLやその巡回開始時刻などを予め定めたスケジュールに従ってコンテンツを収集する機能を有する。そして、本実施例では、下記の構成によってそのスケジューリングにおける巡回頻度を、トラフィックランクに応じて立案することを特徴とする。
「スケジュール決定部」(1622)は、トラフィックランクスコアリング部(1632)で算出されたトラフィックランクに基づいてクローラ部(1621)のクローリングスケジュールを決定する機能を有する。
具体的には、例えばトラフィックランクを変数とする比例関数y=f(TR)を利用したCPUの演算処理によって当該URLに対するクローラプログラム実行の巡回優先度yを算出する。そして算出した巡回優先度に基づいて、例えば「3回/週(巡回優先度12)」、「1回/週(巡回優先度4)」といった具合にクローラプログラムの巡回頻度を含むスケジュールを決定する、という具合である。
このようにして、ユーザーの実効的なアクセス数を示すトラフィックランクによってクローラの巡回優先度の決定し、更新頻度が高く情報鮮度が高いと思われるWWW上のリソースの情報を検索装置にて好適なタイミングで更新取得することができる。
<ハードウェア的構成>
図17は、上記機能的な各構成要件をハードウェアとして実現した際の、検索システムにおける構成の一例を表す概略図である。この図を利用して本実施例の検索システムにおけるそれぞれのハードウェア構成部の働きについて説明する。
この図にあるように、本実施例の検索システムのハードウェア構成は、ツールバー装置(1710)と検索装置(1720)より構成され、両者はインターネットを含む電気通信回線を介して、相互に接続可能となっている。
なお「ツールバー装置」(1710)は、実施例3のツールバー装置と同様の構成、及び処理を行うため、ここでの説明は省略する。そして「検索装置」(1720)の構成は、上記実施例と同様に、「CPU」(1721)と「RAM」(1722)、「通信I/F」(1723)と、「二次記憶装置」(1724)と、を有し、以下のような処理を実行する。
すなわちツールバー装置から上記実施例3にて説明したような処理によって送信されてきた、閲覧URL、及びその閲覧URLごとのアクセス時刻や閲覧(アクセス)時間などの情報を含む閲覧情報を、検索装置は「通信I/F」にて受信し、「RAM」の所定アドレスに格納する。
そして、同じく上記実施例3にて記載したような処理を実行し、「RAM」上に格納されている上記閲覧情報を利用してURLごとのトラフィックランクを算出し、トラフィックランクデータベースとして「二次記憶装置」に記録、保持する。
つづいてスケジュール決定プログラムに従い以下のような処理が実行される。すなわちクローラの巡回スケジュールを立てるべきURLをキーとして「二次記憶装置」に保持されているトラフィックランクデータベースを参照し、当該URLのトラフィックランクの値TRを取得する。そして例えばy=f(TR)といった関数を利用した演算処理を「CPU」において実行し、当該トラフィックランクに係るURLを対象としたクローラプログラムの巡回優先度yを算出する。そして、「二次記憶装置」に保持されている「巡回優先度−巡回頻度テーブル」を参照し、算出された巡回優先度yと対応付けられた、例えば「3回/週」といった巡回頻度を決定する。
そして決定された「3回/週」といった巡回頻度に応じてタスクスケジューラなどでクローラプログラムの実効日時を予約し、決定された頻度でのクローラプログラムによるリソース巡回、コンテンツ取得処理が実行される、という具合である。
<処理の流れ>
図18は、本実施例の検索システムにおける処理の流れの一例を表すフローチャートである。なお、以下に示すステップは、媒体に記録され計算機を制御するためのプログラムを構成する処理ステップであっても構わない。
まず、ツールバー装置における処理の流れについては、図14を用い実施例3で述べた処理(S1401〜S1404)と同様であるためその説明は省略する。
次に検索装置において、この図にあるように、n個のURLと、当該URLに関連付けたユーザーIDや閲覧時間などの情報を含む閲覧情報をツールバー装置より受信する(ステップS1811)。次に受信した閲覧情報を主メモリなどに格納する(ステップS1812)。その後、ループ1(ステップS1813)を開始とする以下の処理を実行する。まず蓄積されたn個の閲覧情報を、例えば前述の関数の変数として利用しトラフィックランクを算出する(ステップS1814)。そして、算出したトラフィックランクに基づいて当該URLに対するクローラ部のクローリングスケジュールを決定する(ステップS1815)。そして上記処理をn個のURLに関して繰り返して実行する(ステップS1816)。
<効果の簡単な説明>
このように本実施例の検索システムによって、ユーザーの実効的なアクセス数を示すトラフィックランクによってクローラの巡回優先度の決定することができる。したがって、更新頻度が高く情報鮮度が高いと思われるWWW上のリソースの情報を検索装置にて好適なタイミングで更新取得することができる。
≪実施例5≫
<概要>
本実施例は、上記実施例3や4を基本として、算出したトラフィックランクを利用して、ツールバー装置からの検索リクエストに対する検索結果をソートすることを特徴とする検索システムである。
図19は、本実施例の検索システムにおける検索処理の一例を説明するための概念図である。この図にあるように、クライアント端末が当該検索システムにおける検索用Webページにアクセスし、検索クエリの入力、送信を行う。すると検索装置は従来の検索システム同様に検索クエリを含むリソースを検索用のインデックスファイルから抽出する。そして、抽出されたリソースをリスト化などし、検索結果用画面を生成する。
ここで、本実施例の検索装置は従来と異なる以下のような処理をさらに実行する。すなわち、検索結果で示されるURL(のリスト)に係るトラフィックランク値の大小に応じて、例えばサイトBを検索結果(リスト)の1番上位にソートし、サイトAを2番目にソートする、といった検索結果の並び替えを実行する、という具合である。
このようにして、本実施例の検索システムではユーザーの実効的なアクセス数を示すトラフィックランクに応じた検索結果をクライアント端末に返信することができる。
<機能的構成>
図20は、本実施例の検索システムにおける機能ブロックの一例を表す図である。この図にあるように、本実施例の「検索システム」(2000)は、実施例3を基本として「ツールバー装置」(2010)と、「検索装置」(2020)とを有する。また「ツールバー装置」(2010)は、実施例3と同様に「閲覧情報送信部」(2011)と、「閲覧情報取得部」(2012)とを有する。
また「検索装置」(2020)も、実施例3を基本として「第二閲覧管理サーバ装置」(2030)を有し、その第二閲覧管理サーバ装置が「閲覧情報蓄積部」(2031)と、「トラフィックランクスコアリング部」(2032)とを有する。また、上記実施例4を基本として、検索装置が図示しない「クローラ部」や「スケジュール決定部」を有していても良い。なお、上記ツールバー装置及び検索装置の各構成は、上記各実施例にて既に記載済みであるのでその説明は省略する。
そして、本実施例の特徴点は、検索装置が、「ランクソート出力部」(2021)をさらに有する点である。
「ランクソート出力部」(2021)は、トラフィックランクスコアリング部(2032)で算出されたトラフィックランクに基づいて検索結果をソートしてクライアントに対して出力する機能を有する。
具体的に「ランクソート出力部」による前記ソートの前に、本実施例の検索システムでは従来の検索システム同様の検索処理が実行される。すなわち、クライアント端末にて送信された検索クエリをキーとして、検索用インデックスファイルを検索する。そして検索クエリを含むリソースをインデックスファイルから抽出する。
続いて、その抽出したリソースを並び替えて例えば箇条形式(リスト形式)などの検索結果としてクライアントに返信することになる。ここで通常の検索システムでは、検索結果の並び替えを、例えばデータ生成や取得の古い順/新しい順、アクセス数順、あいうえお順、あるいはリンクを利用して付されるリソースの再帰的な格付け、などに応じて実行する。しかし、本実施例の検索システムでは、実施例3で算出したユーザーの実体的なアクセス数を示すトラフィックランクを利用する事を特徴とする。すなわち、検索によって抽出されたリソースのトラフィックランクを、上記実施例3にて記載したトラフィックランクデータベースなどから取得する。そしてトラフィックランクの大小比較をCPUの演算処理によって実行し、例えばトラフィックランクの大きい順にリソースを並び替え(ソートして)検索結果とする、という具合である。
このようにして、ユーザーの実効的なアクセス数、すなわち実体的なアクセス人気度を示すトラフィックランクに応じた検索結果をクライアント端末に返信することができる。
<ハードウェア的構成>
図21は、上記機能的な各構成要件をハードウェアとして実現した際の、検索システムにおける構成の一例を表す概略図である。この図を利用して本実施例の検索システムにおけるそれぞれのハードウェア構成部の働きについて説明する。
この図にあるように、本実施例の検索システムのハードウェア構成は、ツールバー装置(2110)と検索装置(2120)より構成され、両者はインターネットを含む電気通信回線を介して、相互に接続可能となっている。
なお「ツールバー装置」(2110)は、実施例3や4のツールバー装置と同様の構成、及び処理を行うため、ここでの説明は省略する。そして「検索装置」(2120)の構成は、上記実施例と同様に、「CPU」(2121)と「RAM」(2122)、「通信I/F」(2123)と、「二次記憶装置」(2124)と、を有し、以下のような処理を実行する。
すなわちツールバー装置から送信された閲覧URL、及びその閲覧URLごとのアクセス時刻や閲覧(アクセス)時間などの情報を含む閲覧情報を利用して、検索装置にてトラフィックランクが算出され「二次記憶装置」に記録、保持される。
その後、ネットワーク上のツールバー装置が検索用Webページにアクセスし、検索クエリの入力、送信を行うと、検索装置は「通信I/F」にてその検索クエリを含むHTTPリクエストを受信し、「RAM」の所定アドレスに格納する。すると、検索装置では検索サーバプログラムに従い以下の処理を実行する。すなわち「RAM」に格納されている検索クエリをキーとして、「二次記憶装置」に保持されている検索用のインデックスファイルを参照し、検索クエリを含むリソースを抽出する。
つづいて、同じく「二次記憶装置」に保持されているトラフィックランクデータベースを参照し、抽出したリソースのトラフィックランクを取得する。そして、「CPU」の比較演算処理によってトラフィックランクの大小比較を実行し、例えばトラフィックランクの大きい(ランクが高い)順に検索結果の並び順を決定する。そして決定された並び順に従って抽出したリソースを並べて箇条形式とした検索結果を「CPU」の演算処理によって生成し、「通信I/F」より検索クエリの送信元のツールバー装置に対して返信する、という具合である。
<処理の流れ>
図22は、本実施例の検索システムにおける処理の流れの一例を表すフローチャートである。なお、以下に示すステップは、媒体に記録され計算機を制御するためのプログラムを構成する処理ステップであっても構わない。
まず、ツールバー装置が組み込まれるなどしたクライアント端末における処理の流れについては、図14を用い実施例3で述べた処理(S1401〜S1404)と同様であるためその説明は省略する。また検索装置におけるトラフィックランクの算出(ステップS2211)までの処理も実施例3で述べた処理(S1411〜S1414)までと同様であるのでその説明は省略する。
そして、この図にあるように、検索装置ではネットワーク上のクライアント端末(ツールバー装置が組み込まれていなくとも構わない)から送信された検索クエリを受信する(ステップS2212)と、検索クエリをキーとして検索用インデックスファイルの検索処理を実行する(ステップS2213)。そして検索クエリをコンテンツに含むリソースを抽出し検索結果として取得する(ステップS2214)。
つづいて、抽出したリソースのトラフィックランクを取得し(ステップS2215)、そのトラフィックランクの例えば大小順に応じて検索結果のリソースを並び替える(ステップS2216)。そして並び替えた検索結果を、検索クエリの送信元のクライアント端末に対して返信する(ステップS2217)。
<効果の簡単な説明>
このように本実施例の検索システムによって、ユーザーの実効的なアクセス数、すなわち実体的なアクセス人気度を示すトラフィックランクに応じた検索結果をクライアント端末に返信することができる。
≪実施例6≫
<概要>
本実施例は、実施例2と同様に新規の検索対象を抽出し、抽出した新規検索対象URLを利用して検索用のインデックスファイルを追加更新する機能を備える。そして、実施例2との相違点は、その新規検索対象URLの抽出において、実施例3などにて説明したトラフィックランクを利用する点である。
具体的には、検索装置において、クライアント端末のツールバー装置にて閲覧情報を取得し、上記実施例で記載したようにURLごとにトラフィックランクを算出する。ここで、実施例2と同じようにそのURLが検索用のインデックスファイルに含まれるかを判断する。そして、インデックスファイルに含まれておらず、かつ例えばトラフィックランクが所定値以上であれば、新規にインデックスファイルに追加するに相応しいリソースであるとして、クローラの新規巡回検索対象として、実施例2同様にインデクシング処理を実行する、という具合である。
<機能的構成>
図23は、本実施例の検索システムにおける機能ブロックの一例を表す図である。この図にあるように、本実施例の「検索システム」(2300)は、実施例3を基本として「ツールバー装置」(2310)と、「検索装置」(2320)とを有する。また「ツールバー装置」(2310)は、実施例3と同様に「閲覧情報送信部」(2311)と、「閲覧情報取得部」(2312)とを有する。
また「検索装置」(2320)も、実施例3を基本として「第二閲覧管理サーバ装置」(2330)を有し、その第二閲覧管理サーバ装置が「閲覧情報蓄積部」(2331)と、「トラフィックランクスコアリング部」(2332)とを有する。また、上記実施例4や5を基本として、検索装置が図示しない「クローラ部」や「スケジュール決定部」、「ランクソート出力部」を有していても良い。なお、上記ツールバー装置及び検索装置の各構成は、上記各実施例にて既に記載済みであるのでその説明は省略する。
そして、本実施例の特徴点は、検索装置が、「第二インデクサ部」(2321)をさらに有する点である。
「第二インデクサ部」(2321)は、トラフィックランクスコアリング部で算出されたトラフィックランクに基づいて検索エンジンにて新規に検索対象として利用するURLである新規検索対象URLを抽出するとともに、抽出したURLのコンテンツをインデクシングする機能を有する。
なお、算出されたトラフィックランクに係るURLを、クローラの新規巡回検索の対象とするための処理については、実施例2にて記載したものと同様であるのでその説明は省略する。また、本実施例においては、インデックスファイル中のURLとトラフィックランクに係るURLの差分のみならず、そのURLで示されるリソースの視聴度指数であるトラフィックランクを利用するため、実施例2で記載した処理に加えさらに以下のような処理を実行しても良い。
すなわち、トラフィックランクが所定値以上であるか否かの比較判断処理を実行し、所定値以上であればクローラの新規巡回検索対象として相応しいリソースである、と判断する。一方、トラフィックランクが所定値以下であると判断された場合には、クローラの新規巡回検索対象としてインデックスファイルには追加しない、という具合である。
<ハードウェア的構成>
図24は、上記機能的な各構成要件をハードウェアとして実現した際の、検索システムにおける構成の一例を表す概略図である。この図を利用して本実施例の検索システムにおけるそれぞれのハードウェア構成部の働きについて説明する。
この図にあるように、本実施例の検索システムのハードウェア構成は、ツールバー装置(2410)と検索装置(2420)より構成され、両者はインターネットを含む電気通信回線を介して、相互に接続可能となっている。
なお「ツールバー装置」(2410)は、実施例3や4、5のツールバー装置と同様の構成、及び処理を行うため、ここでの説明は省略する。そして「検索装置」(2420)の構成は、上記実施例と同様に、「CPU」(2421)と「RAM」(2422)、「通信I/F」(2423)と、「二次記憶装置」(2424)と、を有し、以下のような処理を実行する。
まず、上記実施例と同様の処理により、ツールバー装置から送信された閲覧URL、及びその閲覧URLごとのアクセス時刻や閲覧(アクセス)時間などの情報を含む閲覧情報を利用して、検索装置にてトラフィックランクが算出され「二次記憶装置」に記録、保持される。
つづいて、予め「二次記憶装置」にて格納されている検索サービス用のインデックスファイルを参照し、「二次記憶装置」の保持されたトラフィックランクに係るURLをキーとした検索処理を実行する。そして、その検索処理の結果、インデックスファイルに当該URLが含まれていないとの判断結果が出力されれば、そのURLは新規検索対象のURL候補であると判断する。
つづいて、第二インデクサプログラムに従い、「CPU」は前記候補URLに係るトラフィックランクを「RAM」に格納し、予め「二次記憶装置」に保持されている所定値との大小比較処理を実行する。そしてその大小比較処理の結果トラフィックランクが所定値以上であると判断されれば、当該URLは新規検索対象のURLとしてインデクシング処理(二次記憶装置に保持されているインデックスファイルへの追加更新処理)が実行される、という具合である。
<処理の流れ>
図25は、本実施例の検索システムにおける処理の流れの一例を表すフローチャートである。なお、以下に示すステップは、媒体に記録され計算機を制御するためのプログラムを構成する処理ステップであっても構わない。
まず、ツールバー装置における処理の流れについては、図14を用い実施例3で述べた処理(S1401〜S1404)と同様であるためその説明は省略する。
次に検索装置において、この図にあるように、n個のURLと、当該URLに関連付けたユーザーIDや閲覧時間などの情報を含む閲覧情報をツールバー装置より受信する(ステップS2511)。次に受信した閲覧情報を主メモリなどに格納する(ステップS2512)。その後、ループ1(ステップS2513)を開始とする以下の処理を実行する。まず蓄積されたn個の閲覧情報を関数の変数として利用し、トラフィックランクを算出する(ステップS2514)。
つづいて検索装置のインデックスファイルに当該URLが存在するか否かの第一の判断処理を行う(ステップS2515)。そして第一の判断処理の結果、インデックスファイルに当該URLが存在しないとの判断結果が出力された場合、当該URLに係るトラフィックランクが所定値以上であるか否かの判断処理を実行する(ステップS2516)。
そして第二の判断処理の結果、トラフィックランクが所定値以上であるとの判断結果が出力されれば、クローラの新規巡回検索対象として相応しいリソースである、として抽出したURLを、クローラの新規検索対象URLとしてインデクシング処理を実行する(ステップS2517)。
<効果の簡単な説明>
このように本実施例の検索システムによって、インデックスファイルへの追加(インデクサ)を行うに相応しいリソースであるかを判断した上で、新規開設Webページなどハイパーリンクが張られていないため従来のクローラでは検索対象となっていなかったようなWWW上のリソースについてもインデクサを実行することができる。