JP4315016B2 - コンピュータシステムの系切替方法 - Google Patents
コンピュータシステムの系切替方法 Download PDFInfo
- Publication number
- JP4315016B2 JP4315016B2 JP2004047177A JP2004047177A JP4315016B2 JP 4315016 B2 JP4315016 B2 JP 4315016B2 JP 2004047177 A JP2004047177 A JP 2004047177A JP 2004047177 A JP2004047177 A JP 2004047177A JP 4315016 B2 JP4315016 B2 JP 4315016B2
- Authority
- JP
- Japan
- Prior art keywords
- computer
- standby
- active
- failure
- processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims description 96
- 230000008569 process Effects 0.000 claims description 66
- 238000012545 processing Methods 0.000 claims description 64
- 238000012544 monitoring process Methods 0.000 claims description 33
- 238000002360 preparation method Methods 0.000 claims description 23
- 238000001514 detection method Methods 0.000 claims description 8
- 230000005856 abnormality Effects 0.000 claims description 5
- 238000010586 diagram Methods 0.000 description 10
- 238000004891 communication Methods 0.000 description 7
- 230000006870 function Effects 0.000 description 5
- 238000011084 recovery Methods 0.000 description 4
- 238000001994 activation Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000004913 activation Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2046—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant where the redundant components share persistent storage
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/203—Failover techniques using migration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2041—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant with more than one idle spare processing component
Description
本発明では、現用系コンピュータで障害が発生した場合に、現用系以外のクラスタ内のコンピュータから、現用系の行なっていた処理を引き継ぐ待機系コンピュータを決定する。障害発生の検出は、現用系以外のコンピュータが現用系を監視する方式でもよいし、現用系が自立的に、エラー率、メモリ余裕度などから異常を検知する方式でもよい。また、待機系コンピュータの決定は、現用系の障害発生を検出した前述のコンピュータが行なう方式でもよいし、この検出したコンピュータが、別のコンピュータに通知を行い、そのコンピュータが行なう方式でもよい。
図1では、説明を分かりやすくするため、二桁の番号を用いている。さらに、以降の図2、図3、図7において同様の番号を用いているものがあるが、それらについては特に説明がない場合、図1の説明と同様である。
前記の系切替において、系切替を高速化するホットスタンバイ技術を適用するためには、現用系の障害確定(図中(3))時には、待機系決定(図中(4))前であるため、任意のコンピュータのアプリケーションに対してホットスタンバイを行なっておく必要があるが、計算機資源を消費し、本来実行すべきアプリケーションの動作を圧迫してしまうため、実用的でない、という問題がある。
図2では、現用系コンピュータ10で障害が発生すると(図中(1))、監視系コンピュータ20上のクラスタソフト21が障害を検知する(図中(2))。クラスタソフト21は、障害を検知すると、すぐに現用系の処理を引き継ぐ待機系コンピュータ30を決定し(図中(3))、待機系のクラスタソフト31に対して、アプリケーションをホットスタンバイ状態にするように指示を行なう(図中(4))。指示を受けたクラスタソフト31は、アプリケーションのホットスタンバイ起動を行なう(図中(5))。ここれにより、ディスク装置40からアプリケーションのプログラム41が読み込まれ(図中(6))、アプリケーションがホットスタンバイ切替可能な状態まで起動された状態となる(図中(7))。
図3では、現用系コンピュータ10で障害が発生したが(図中(1))、その後障害が回復した場合(図中(7))のシステムモデルをあらわしている。
図3において、現用系障害の発生(図中(1))から待機系コンピュータ30でアプリケーション32がホットスタンバイ状態になる(図中(7))までの処理は、図2と同様の処理で行なわれる。現用系の障害が回復すると(図中(8))、クラスタソフト21は障害回復を検知する(図中(9))。検知後、クラスタソフト21は、待機系コンピュータ30のクラスタソフト31に対して、ホットスタンバイ状態を解除するように指示し(図中(10))、すでに決定されていた待機系の状態を破棄する(図中(11))。
以上の手段を持つ第二の実施例により、図2において現用系障害が確定しないで障害が回復した場合に、ホットスタンバイ化した待機系を解除し、障害が発生する前の状態、すなわち、待機系が任意のシステムに対して可能であるクラスタシステムに戻すことが可能となる。
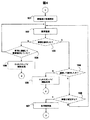
図4は、監視系コンピュータ20のクラスタソフト21の動作を表している。クラスタソフトは、障害検出処理101を開始し、現用系コンピュータ10の障害監視処理102を行ない、障害を検知したかどうかについて判断処理103を行なう。
判断処理106の結果、障害が確定した場合には、処理105でホットスタンバイ状態にある待機系に系切替を行なう処理107を行なう。障害が確定しなかった場合には、再び障害監視処理102に戻り、障害が確定するまで障害の監視を続ける。
図6で、待機系のクラスタソフト31は、ホットスタンバイ状態で待機しており(図5の処理506)、監視系のクラスタソフト21が現用系コンピュータ10の障害を判断した結果が通信されるのを待つ(処理601)。通信結果を受けると、クラスタソフト31は、指示の結果から障害が確定したか/回復したかを判断する(処理602)。
図7は図中の処理(5)、処理(6−A)は、図2における処理(5)、処理(6)と同様の手続きであり、待機系コンピュータがホットスタンバイ状態を完了するまでの処理を示している。
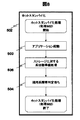
図7では、ディスク装置40は、ディスクコントローラ43、ディスクキャッシュ44、アプリケーションデータ先読み設定ファイル45を含む。ディスクコントローラ43は、例えば、ディスク装置40内のデータをディスクキャッシュ44に読み込む機能をもつ。また、アプリケーションデータ先読み設定ファイル45は、図2で行われる処理(11)のアプリケーションデータの読み込みで必要とされるデータを定義している。
処理(6−A)の実行後、クラスタソフトウェア31はアプリケーションデータ先読み設定ファイル45を読み込み(図中(6−B))、ファイル45に定義されたデータをディスクキャッシュ44に読み込むように、ディスクコントローラ43に指示を出す(図中(6−C))。指示を受けたコントローラ43は、指定されたデータをディスクキャッシュに読み込む(図中(6−D))。
図8は、図5におけるホットスタンバイ化処理502に対応する処理フローを記している。処理503、処理504は、図5と同様の処理である。処理503の終了後、ストレージに対して系切替準備処理を行なうように指示し(処理505)、処理504を行なうことでホットスタンバイ化処理502が終了する。たとえば、この処理505としては、図7における処理(6−B)、処理(6−C)、処理(6−D)からなる一連の処理であっても良い。
以上、第三の実施例では、待機系をホットスタンバイ状態にする処理の中に、ディスク装置の系切替準備処理を含めることにより、系切替の際にディスク装置に対して行なわれる処理を高速に実行する系切替を実現することのできる機能を有するシステムが実現される。
また、本実施例では、監視系コンピュータ20とは異なる待機系コンピュータ30が系切替によって処理を引き継ぐ構成とした。この他に、監視系コンピュータと待機系コンピュータが同一のコンピュータである構成としてもよい。
加えて、本実施例では、説明を容易にするためにホットスタンバイによる系切替の方法として、アプリケーションのプログラムを予めロードしておく方法を用いているが、ホットスタンバイの方法、アプリケーションの種類を制限するものではない。
まず、クラスタ構成の高可用性コンピュータシステムにおいて、現用系に障害が発生したことを検知したことを契機として、系切替先となる待機系を決定し、この待機系が系切替準備処理をしておき、現用系の障害が確定した時に、系切替準備完了状態にある待機系に系切替を行なうことで、高速な系切替を実現することが可能となる。
さらに、系切替準備処理において、ディスク装置が系切替準備を行なう処理を含むことで、高速な系切替を実現することが可能となる。
さらに、ディスクキャッシュに系切替時に利用するデータを充填する方法により、前記のディスク装置の系切替準備処理を実現することが可能となる。
さらに、待機系が引継準備処理をした後に、現用系の障害が回復した場合には、引継準備状態から待機系を回復させることで、障害が回復した場合には、障害発生前と同じ状態に戻る系切替を実現することが可能となる。
20:監視コンピュータ
30:待機系コンピュータ
11、21、31:クラスタソフト
12、32:アプリケーション
40:ディスク装置
41:アプリケーションのプログラム
42:アプリケーションのデータ
43 :ディスクコントローラ
44 :ディスクキャッシュ
45 :アプリケーション先読み設定ファイル
90:ネットワーク。
Claims (8)
- 現用系のコンピュータと、該現用系のコンピュータの処理を引き継ぐべき待機系となりうる複数のコンピュータと、これらコンピュータに接続されたディスク装置であって、該現用系のコンピュータの処理を行なうアプリケーションに必要なデータを保持するディスク装置を含むコンピュータシステムにおける系切替方法であって、
前記現用系のコンピュータの障害発生を検出したことを第1の契機に、処理を引き継ぐ待機系のコンピュータを決定し、決定したコンピュータに通知するステップ、
通知をうけたコンピュータが引継準備処理を行なうステップ、
前記現用系の障害により系切替が必要となったことを第2の契機に、前記引継準備処理をおこなったコンピュータが、前記現用系が実行していた処理を、引き継ぐステップ、及び
前記現用系の障害が回復し、系切替が不要となったことを第3の契機に、前記待機系のコンピュータの引継準備処理を解消するステップ、
を含む系切替方法。 - 前記引継準備とは前記現用系のコンピュータで稼動していたアプリケーションプログラム
を前記ディスク装置から読み込む処理であることを特徴とする請求項1の系切替方法。 - 前記第1の契機により、前記ディスク装置は系切替準備処理を行うこと特徴とする請求項
1記載の系切替方法。 - 前記ディスク装置が行う系切替準備処理は、系切替でアクセスするデータをディスクから
キャッシュにプリフェッチする処理を含む請求項3記載の系切替方法。 - 現用系のコンピュータと、該現用系のコンピュータの処理を引き継ぐべき待機系となりう
るコンピュータと、を含むコンピュータシステムにおける系切替方法であって、
前記現用系のコンピュータの障害発生を検出したことを契機に、処理を引き継ぐ待機系の
コンピュータを決定し、該待機系のコンピュータが引継準備処理を行なうステップ、
前記現用系の障害が回復し、系切替が不要となったことを契機に、前記待機系のコンピュ
ータの引継準備処理を解消するステップ、
を含む系切替方法。 - 前記現用系のコンピュータの障害発生の検出は、前記現用系以外のコンピュータによる監
視あるいは前記現用系のコンピュータによる異常の検知によって行なわれることを特徴と
する請求項1又は5記載の系切替方法。 - 前記現用系のコンピュータによる異常の検知は、前記現用系のコンピュータのエラー率又
はメモリ余裕度に基づくことを特徴とする請求項6記載の系切替方法。 - 現用系のコンピュータと、該現用系のコンピュータの処理を引き継ぐべき待機系となりう
るコンピュータとに接続される監視用計算機であって、
前記現用系のコンピュータの障害発生を検出したことを契機に、処理を引き継ぐ待機系の
コンピュータを決定し、該待機系のコンピュータにホットスタンバイ処理を指示する手段と、
前記現用系の障害が回復し、系切替が不要となったことを契機に、前記待機系のコンピュ
ータにホットスタンバイを解除する指示を行う手段、とを
を有することを特徴とする監視用計算機。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004047177A JP4315016B2 (ja) | 2004-02-24 | 2004-02-24 | コンピュータシステムの系切替方法 |
| US10/942,873 US7305578B2 (en) | 2004-02-24 | 2004-09-17 | Failover method in a clustered computer system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004047177A JP4315016B2 (ja) | 2004-02-24 | 2004-02-24 | コンピュータシステムの系切替方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005242404A JP2005242404A (ja) | 2005-09-08 |
| JP2005242404A5 JP2005242404A5 (ja) | 2007-01-25 |
| JP4315016B2 true JP4315016B2 (ja) | 2009-08-19 |
Family
ID=34908488
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004047177A Expired - Fee Related JP4315016B2 (ja) | 2004-02-24 | 2004-02-24 | コンピュータシステムの系切替方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US7305578B2 (ja) |
| JP (1) | JP4315016B2 (ja) |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2843209B1 (fr) * | 2002-08-02 | 2006-01-06 | Cimai Technology | Procede de replication d'une application logicielle dans une architecture multi-ordinateurs, procede pour realiser une continuite de fonctionnement mettant en oeuvre ce procede de replication, et systeme multi-ordinateurs ainsi equipe. |
| JP4392343B2 (ja) * | 2004-12-28 | 2009-12-24 | 株式会社日立製作所 | メッセージ配布方法、待機系ノード装置およびプログラム |
| JP4249719B2 (ja) * | 2005-03-29 | 2009-04-08 | 株式会社日立製作所 | バックアップシステム、プログラム及びバックアップ方法 |
| US7434104B1 (en) * | 2005-03-31 | 2008-10-07 | Unisys Corporation | Method and system for efficiently testing core functionality of clustered configurations |
| JP4920391B2 (ja) * | 2006-01-06 | 2012-04-18 | 株式会社日立製作所 | 計算機システムの管理方法、管理サーバ、計算機システム及びプログラム |
| JP4757669B2 (ja) * | 2006-03-15 | 2011-08-24 | 日本電気通信システム株式会社 | エコーキャンセラ装置及び切替制御方法 |
| US8977252B1 (en) * | 2006-07-06 | 2015-03-10 | Gryphonet Ltd. | System and method for automatic detection and recovery of malfunction in mobile devices |
| JP5526784B2 (ja) | 2007-12-26 | 2014-06-18 | 日本電気株式会社 | 縮退構成設計システムおよび方法 |
| WO2009081736A1 (ja) | 2007-12-26 | 2009-07-02 | Nec Corporation | 冗長構成管理システムおよび方法 |
| US8688642B2 (en) * | 2010-02-26 | 2014-04-01 | Symantec Corporation | Systems and methods for managing application availability |
| US8738961B2 (en) | 2010-08-17 | 2014-05-27 | International Business Machines Corporation | High-availability computer cluster with failover support based on a resource map |
| JP5618792B2 (ja) * | 2010-11-30 | 2014-11-05 | 三菱電機株式会社 | エラー検出修復装置 |
| JP6096423B2 (ja) * | 2012-05-23 | 2017-03-15 | 日本電気通信システム株式会社 | 通信システム及び通信システムの冗長切替方法 |
| JP5876780B2 (ja) * | 2012-07-06 | 2016-03-02 | 株式会社Nttドコモ | 加入者データベース切替制御装置、加入者データベースシステム、加入者データベース切替制御装置の制御プログラム、および加入者データベース切替制御装置の制御方法 |
| JP6007988B2 (ja) * | 2012-09-27 | 2016-10-19 | 日本電気株式会社 | 予備系装置、運用系装置、冗長構成システム、及び負荷分散方法 |
| CN103425553B (zh) * | 2013-09-06 | 2015-01-28 | 哈尔滨工业大学 | 一种双机热备份系统及该系统的故障检测方法 |
| CN105579981B (zh) | 2013-09-26 | 2017-08-25 | 三菱电机株式会社 | 通信系统、备用装置以及通信方法 |
| JP2015194971A (ja) * | 2014-03-31 | 2015-11-05 | 日本信号株式会社 | 冗長系制御装置 |
| US9846624B2 (en) * | 2014-09-26 | 2017-12-19 | Microsoft Technology Licensing, Llc | Fast single-master failover |
| CN105404287B (zh) * | 2015-12-27 | 2018-02-06 | 彭晔 | 基于心跳协议的数据采集与监控系统的控制切换方法 |
| JP7149313B2 (ja) | 2020-09-28 | 2022-10-06 | 株式会社日立製作所 | 記憶システム及びその制御方法 |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5408649A (en) * | 1993-04-30 | 1995-04-18 | Quotron Systems, Inc. | Distributed data access system including a plurality of database access processors with one-for-N redundancy |
| JPH08221287A (ja) | 1995-02-10 | 1996-08-30 | Hitachi Ltd | 系切り替え制御方法 |
| JP3062155B2 (ja) | 1998-07-31 | 2000-07-10 | 三菱電機株式会社 | 計算機システム |
| US6393485B1 (en) * | 1998-10-27 | 2002-05-21 | International Business Machines Corporation | Method and apparatus for managing clustered computer systems |
| US6438705B1 (en) * | 1999-01-29 | 2002-08-20 | International Business Machines Corporation | Method and apparatus for building and managing multi-clustered computer systems |
| US6918051B2 (en) * | 2001-04-06 | 2005-07-12 | International Business Machines Corporation | Node shutdown in clustered computer system |
| US7526549B2 (en) * | 2003-07-24 | 2009-04-28 | International Business Machines Corporation | Cluster data port services for clustered computer system |
-
2004
- 2004-02-24 JP JP2004047177A patent/JP4315016B2/ja not_active Expired - Fee Related
- 2004-09-17 US US10/942,873 patent/US7305578B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US20050198552A1 (en) | 2005-09-08 |
| US7305578B2 (en) | 2007-12-04 |
| JP2005242404A (ja) | 2005-09-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4315016B2 (ja) | コンピュータシステムの系切替方法 | |
| JP4529767B2 (ja) | クラスタ構成コンピュータシステム及びその系リセット方法 | |
| US20060089975A1 (en) | Online system recovery system, method and program | |
| JP2001022709A (ja) | クラスタシステム及びプログラムを記憶したコンピュータ読み取り可能な記憶媒体 | |
| JPH01224846A (ja) | プロセス空間切り換え制御方式 | |
| JP3025732B2 (ja) | 多重化コンピュータシステムの制御方式 | |
| JP2002049509A (ja) | データ処理システム | |
| JP6109404B2 (ja) | 計算機装置及び計算機機構 | |
| JP4788516B2 (ja) | 動的置き換えシステム、動的置き換え方法およびプログラム | |
| JP2785992B2 (ja) | サーバプログラムの管理処理方式 | |
| JP3470454B2 (ja) | マルチプロセッサシステムの通信制御方法 | |
| JP2629415B2 (ja) | 相互スタンバイシステムにおける業務処理系切り替え方法 | |
| JP2730209B2 (ja) | 入出力制御方式 | |
| JPH02188863A (ja) | マルチプロセッサシステム | |
| JPH08235133A (ja) | 多重処理システム | |
| JPS597982B2 (ja) | 計算機システムのシステム障害時の再開始方式 | |
| JPH07271611A (ja) | プロセス自動再起動処理方式 | |
| JPH04291628A (ja) | 複合サブシステム形オンラインシステムの障害回復方式 | |
| JP2513122B2 (ja) | ホットスタンバイ切り替えシステム | |
| JP2815730B2 (ja) | アダプタ及びコンピュータシステム | |
| JP2013140491A (ja) | Os動作装置及びos動作プログラム | |
| JPH01261742A (ja) | システム管理装置のエラー処理方法 | |
| JPS6341943A (ja) | 論理装置のエラ−回復方式 | |
| JP2006178552A (ja) | 仮想計算機システム | |
| JPS62296264A (ja) | デ−タ処理システムの構成制御方式 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20060424 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061130 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061130 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090123 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090203 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090406 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090428 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090511 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120529 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120529 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130529 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130529 Year of fee payment: 4 |
|
| LAPS | Cancellation because of no payment of annual fees |