JP4164458B2 - 情報処理装置及び方法、並びに、コンピュータプログラム及びコンピュータ可読記憶媒体 - Google Patents
情報処理装置及び方法、並びに、コンピュータプログラム及びコンピュータ可読記憶媒体 Download PDFInfo
- Publication number
- JP4164458B2 JP4164458B2 JP2004064492A JP2004064492A JP4164458B2 JP 4164458 B2 JP4164458 B2 JP 4164458B2 JP 2004064492 A JP2004064492 A JP 2004064492A JP 2004064492 A JP2004064492 A JP 2004064492A JP 4164458 B2 JP4164458 B2 JP 4164458B2
- Authority
- JP
- Japan
- Prior art keywords
- character
- image
- information
- character image
- embedding
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images












Description
Techniques for data hiding W. Bender, D. Gruhl, N. Morimoto, A. Lu IBM Systems Journal, vol.35, nos.3&4, 1996. King Mongkut大学による"Electronic document data hiding technique using inter-character space", The 1998 IEEE Asia-Pacific Conf. On Circuits and Systems,1998,pp.419-422.) "和文書へのシール画像による電子透かし"(中村康弘,松井甲子雄),情報処理学会論文誌 Vol.38 No.11 Nov. 1997.
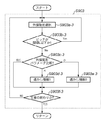
文書画像に情報を埋め込む情報処理装置であって、
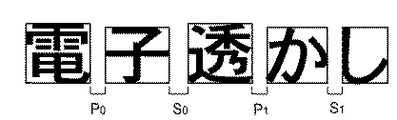
入力した文書画像中の各文字画像の外接矩形の位置とサイズに関する情報を抽出する抽出手段と、
抽出した各文字画像の位置と外接矩形のサイズを示す情報を、文字の並び方向である行を単位に記憶する記憶手段と、
該記憶手段に記憶された情報に基づき、前記文書画像中の各文字画像の位置を、行を単位に正規化する正規化手段と、
該正規化手段の正規化後の文書画像中の着目行中の着目文字画像を挟む両隣の文字画像の位置を固定にし、前記着目文字画像の位置を行頭若しくは行末の方向に移動することで、前記着目文字画像に1ビットの透かし情報を埋め込む埋め込み手段と、
該埋め込み手段による埋め込み後の文字画像で構成される出力用の文書画像を生成する画像生成手段とを備え、
前記正規化手段は、
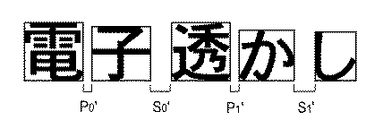
前記記憶手段に記憶された情報を参照して、着目行の各文字画像間の総空白長を算出し、前記着目行の平均文字間隔を算出する算出手段と、
前記着目行の各文字画像間の空白長が前記算出手段で算出した前記平均空白長となるように、前記記憶手段に記憶された前記着目行の各文字画像の位置の情報を更新すると共に、前記更新後の各文字画像の位置情報に従って前記文書画像中の着目行の各文字画像の位置を更新する手段とを備える。
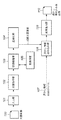
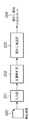
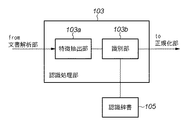
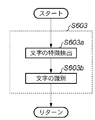
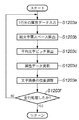
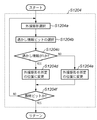
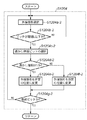
図1は、第1の実施形態における電子透かし埋め込み装置の構成概念図である。なお、本第1の実施形態では、各文字の回転によって情報を埋め込む技術を例にして説明することとする。
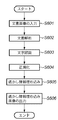
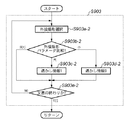
まず、透かし情報の抽出対象となる検証画像200が図23のスキャナ2317に代表される画像入力手段201を介して、文書解析手段202に入力される(ステップS901)。なお、この検証画像は印刷物を2317のスキャナに限らない。例えば、ネットワーク上からダウンロードしてもよいし、CDROM等の記憶媒体に格納されているのであれば、そこから読み出すようにしてもよい。
上記実施形態では、正規化部104では、1行の文字画像群の文字間隔を等間隔にすることで、埋め込み可能とする箇所を増やすものであったが、無条件に文字間を等間隔にすると不自然なものとなる場合がある。例えば、1行中に全角文字列と半角文字列が混在している場合、上記処理によると、半角文字、全角文字を問わず、各文字間が平均化してしまい、結果的に、全角文字で構成される文字間隔は狭く、半角文字で構成される文字間隔は広くなってしまう。これは、固定ピッチの文字と、プロポーショナル文字についても言えることである。
上記実施形態では、文字画像の回転により、付加情報を埋め込む例であるが、文字間を変更すること埋め込む例を第2の実施形態として説明する。
上記第1、第2の実施形態での正規化処理は、行中の文字画像の全空白長を等分、もしくは、半角・全角、固定ピッチ・プロポーショナル文字の2種類に分けてそれぞれの空白帳を等分にするものであった。すなわち、文字ピッチを入力した文書画像に依存して決定した。
上記各実施形態では、文字間空白長、回転に適合する例を説明した。また、対象となる文書画像は、横書きを前提にして説明した。縦書きの場合には、文字画像の並び方向が横書きに対して90度回転したものとなり、外接矩形の高さと幅の関係も入れ代わる。また、文字間の空白長を調整する場合には、文字画像の上下移動となるだけであるので、同様に適用できるのは明らかである。
Claims (6)
- 文書画像に情報を埋め込む情報処理装置であって、
入力した文書画像中の各文字画像の外接矩形の位置とサイズに関する情報を抽出する抽出手段と、
抽出した各文字画像の位置と外接矩形のサイズを示す情報を、文字の並び方向である行を単位に記憶する記憶手段と、
該記憶手段に記憶された情報に基づき、前記文書画像中の各文字画像の位置を、行を単位に正規化する正規化手段と、
該正規化手段の正規化後の文書画像中の着目行中の着目文字画像を挟む両隣の文字画像の位置を固定にし、前記着目文字画像の位置を行頭若しくは行末の方向に移動することで、前記着目文字画像に1ビットの透かし情報を埋め込む埋め込み手段と、
該埋め込み手段による埋め込み後の文字画像で構成される出力用の文書画像を生成する画像生成手段とを備え、
前記正規化手段は、
前記記憶手段に記憶された情報を参照して、着目行の各文字画像間の総空白長を算出し、前記着目行の平均文字間隔を算出する算出手段と、
前記着目行の各文字画像間の空白長が前記算出手段で算出した前記平均空白長となるように、前記記憶手段に記憶された前記着目行の各文字画像の位置の情報を更新すると共に、前記更新後の各文字画像の位置情報に従って前記文書画像中の着目行の各文字画像の位置を更新する手段とを備える
ことを特徴とする情報処理装置。 - 前記正規化手段は、行に含まれる文字画像の半角/全角、或いは、固定ピッチ/プロポーショナル文字で外接矩形を分類し、分類された外接矩形毎に平均文字間隔間隔を設定することを特徴とする請求項1に記載の情報処理装置。
- 前記正規化手段は、前記記憶手段に記憶された情報に基づき、行中の着目する文字画像とその左隣の文字画像の間の空白長が所定長より大きい場合、前記着目文字を正規化対象外とし、且つ、前記着目文字は前記透かし情報の埋め込み対象外とすることを特徴とする請求項1に記載の情報処理装置。
- 文書画像に情報を埋め込む情報処理方法であって、
入力した文書画像中の各文字画像の外接矩形の位置とサイズに関する情報を抽出する抽出工程と、
抽出した各文字画像の位置と外接矩形のサイズを示す情報を、文字の並び方向である行を単位に記憶手段に格納する格納工程と、
該記憶手段に記憶された情報に基づき、前記文書画像中の各文字画像の位置を、行を単位に正規化する正規化工程と、
該正規化工程の正規化後の文書画像中の着目行中の着目文字画像を挟む両隣の文字画像の位置を固定にし、前記着目文字画像の位置を行頭若しくは行末の方向に移動することで、前記着目文字画像に1ビットの透かし情報を埋め込む埋め込み工程と、
該埋め込み工程による埋め込み後の文字画像で構成される出力用の文書画像を生成する画像生成工程とを備え、
前記正規化工程は、
前記記憶手段に記憶された情報を参照して、着目行の各文字画像間の総空白長を算出し、前記着目行の平均文字間隔を算出する算出工程と、
前記着目行の各文字画像間の空白長が前記算出工程で算出した前記平均空白長となるように、前記記憶手段に記憶された前記着目行の各文字画像の位置の情報を更新すると共に、前記更新後の各文字画像の位置情報に従って前記文書画像中の着目行の各文字画像の位置を更新する工程とを備える
ことを特徴とする情報処理方法。 - 請求項1乃至3のいずれか1項に記載の情報処理装置の機能をコンピュータに実行させるためのコンピュータプログラム。
- 請求項5に記載のコンピュータプログラムを格納したことを特徴とするコンピュータ可読記憶媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004064492A JP4164458B2 (ja) | 2004-03-08 | 2004-03-08 | 情報処理装置及び方法、並びに、コンピュータプログラム及びコンピュータ可読記憶媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004064492A JP4164458B2 (ja) | 2004-03-08 | 2004-03-08 | 情報処理装置及び方法、並びに、コンピュータプログラム及びコンピュータ可読記憶媒体 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005253004A JP2005253004A (ja) | 2005-09-15 |
| JP2005253004A5 JP2005253004A5 (ja) | 2007-03-01 |
| JP4164458B2 true JP4164458B2 (ja) | 2008-10-15 |
Family
ID=35033025
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004064492A Expired - Fee Related JP4164458B2 (ja) | 2004-03-08 | 2004-03-08 | 情報処理装置及び方法、並びに、コンピュータプログラム及びコンピュータ可読記憶媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4164458B2 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7505180B2 (en) * | 2005-11-15 | 2009-03-17 | Xerox Corporation | Optical character recognition using digital information from encoded text embedded in the document |
| JP4719717B2 (ja) | 2006-06-27 | 2011-07-06 | 株式会社リコー | 画像処理装置、画像処理方法及び画像処理プログラム |
| JP5173690B2 (ja) * | 2007-10-11 | 2013-04-03 | キヤノン株式会社 | 情報処理装置及び情報処理方法、並びに、コンピュータプログラム及びコンピュータ可読記録媒体 |
| US8125691B2 (en) | 2007-10-11 | 2012-02-28 | Canon Kabushiki Kaisha | Information processing apparatus and method, computer program and computer-readable recording medium for embedding watermark information |
| JP4956366B2 (ja) * | 2007-10-16 | 2012-06-20 | キヤノン株式会社 | 画像処理装置 |
-
2004
- 2004-03-08 JP JP2004064492A patent/JP4164458B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005253004A (ja) | 2005-09-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4310288B2 (ja) | 画像処理装置及びその方法、プログラム並びに記憶媒体 | |
| JP4854491B2 (ja) | 画像処理装置及びその制御方法 | |
| JP4393161B2 (ja) | 画像処理装置及び画像処理方法 | |
| JP2003230001A (ja) | 文書用電子透かし埋め込み装置及び文書用電子透かし抽出装置並びにそれらの制御方法 | |
| JP4194462B2 (ja) | 電子透かし埋め込み方法、電子透かし埋め込み装置、及びそれらを実現するプログラム並びにコンピュータ可読記憶媒体 | |
| JP2008109394A (ja) | 画像処理装置及びその方法、プログラム | |
| JP2004265384A (ja) | 画像処理システム及び情報処理装置、並びに制御方法及びコンピュータプログラム及びコンピュータ可読記憶媒体 | |
| JP4164463B2 (ja) | 情報処理装置及びその制御方法 | |
| JP4208780B2 (ja) | 画像処理システム及び画像処理装置の制御方法並びにプログラム | |
| JP2006050551A (ja) | 画像処理装置及びその方法、並びにプログラム及び記憶媒体 | |
| JP4673200B2 (ja) | 印刷処理システムおよび印刷処理方法 | |
| KR100905857B1 (ko) | 정보 처리 장치 및 정보 처리 장치의 제어 방법 | |
| JP4338189B2 (ja) | 画像処理システム及び画像処理方法 | |
| JP2006025129A (ja) | 画像処理システム及び画像処理方法 | |
| JP2004246577A (ja) | 画像処理方法 | |
| JP4164458B2 (ja) | 情報処理装置及び方法、並びに、コンピュータプログラム及びコンピュータ可読記憶媒体 | |
| JP2006023944A (ja) | 画像処理システム及び画像処理方法 | |
| JP3728209B2 (ja) | 画像処理方法及び装置及びコンピュータプログラム及び記憶媒体 | |
| JP2007129557A (ja) | 画像処理システム | |
| JP4179977B2 (ja) | スタンプ処理装置、電子承認システム、プログラム、及び記録媒体 | |
| JP2005149097A (ja) | 画像処理システム及び画像処理方法 | |
| JP2009278181A (ja) | 電子透かし情報埋め込み装置及び方法、並びに、電子透かし情報抽出装置及び方法 | |
| JP4324058B2 (ja) | 画像処理装置及びその方法 | |
| JP2010108296A (ja) | 情報処理装置、情報処理方法 | |
| JP4310176B2 (ja) | 画像処理装置、画像処理方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070117 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070117 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20080417 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080425 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080623 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20080722 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20080728 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110801 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120801 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120801 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130801 Year of fee payment: 5 |
|
| LAPS | Cancellation because of no payment of annual fees |