JP3999771B2 - Translation support program, translation support apparatus, and translation support method - Google Patents
Translation support program, translation support apparatus, and translation support method Download PDFInfo
- Publication number
- JP3999771B2 JP3999771B2 JP2004199606A JP2004199606A JP3999771B2 JP 3999771 B2 JP3999771 B2 JP 3999771B2 JP 2004199606 A JP2004199606 A JP 2004199606A JP 2004199606 A JP2004199606 A JP 2004199606A JP 3999771 B2 JP3999771 B2 JP 3999771B2
- Authority
- JP
- Japan
- Prior art keywords
- translation
- sentence
- original
- editing
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 238000013519 translation Methods 0.000 title claims description 492
- 238000000034 method Methods 0.000 title claims description 99
- 230000015654 memory Effects 0.000 claims description 200
- 230000006870 function Effects 0.000 claims description 16
- 230000014616 translation Effects 0.000 description 424
- 238000012545 processing Methods 0.000 description 78
- 238000012937 correction Methods 0.000 description 8
- 238000006243 chemical reaction Methods 0.000 description 7
- 230000000877 morphologic effect Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000011835 investigation Methods 0.000 description 2
- LFYJSSARVMHQJB-QIXNEVBVSA-N bakuchiol Chemical compound CC(C)=CCC[C@@](C)(C=C)\C=C\C1=CC=C(O)C=C1 LFYJSSARVMHQJB-QIXNEVBVSA-N 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
Images










Landscapes
- Document Processing Apparatus (AREA)
- Machine Translation (AREA)
Description
本発明は、例えばある言語の文章を他の言語の文章に翻訳する翻訳支援プログラム、翻訳支援装置、翻訳支援方法に関する。 The present invention relates to a translation support program, a translation support apparatus, and a translation support method for translating sentences in one language into sentences in another language, for example.
ある言語(原言語)の文書を他の言語(目的言語)の文書に自動的に翻訳する機械翻訳装置がある。 There is a machine translation device that automatically translates a document in one language (source language) into a document in another language (target language).
従来の機械翻訳装置としては、ある言語で書かれている文(原文)と、その文を他の言語で表した文(訳文)とを対で格納したデータベースである翻訳メモリを参照して、翻訳作業を支援する翻訳支援装置が知られている(例えば特許文献1参照)。 As a conventional machine translation device, referring to a translation memory which is a database storing a sentence (original sentence) written in a certain language and a sentence (translation) expressing the sentence in another language, A translation support apparatus that supports translation work is known (see, for example, Patent Document 1).
従来の翻訳支援装置における翻訳処理の流れは以下のようになっている。
1.過去に翻訳済みの対訳文を翻訳メモリに予め登録しておき、翻訳対象文と類似の文が翻訳メモリ中にあれば、それを参照して翻訳に利用する。
2.翻訳対象文と類似の文が翻訳メモリ中にない場合は、機械翻訳を実行させて翻訳文(下訳)を作成し、下訳に人手で適宜修正を加えて訳文を完成する。
3.翻訳対象文と完成した訳文を翻訳メモリに登録して、新たな翻訳対象文書を翻訳する際に再利用する。
1. A previously translated bilingual sentence is registered in the translation memory in advance, and if there is a sentence similar to the translation target sentence in the translation memory, it is referred to and used for translation.
2. If there is no sentence similar to the translation target sentence in the translation memory, machine translation is executed to create a translation sentence (subordinate translation), and the translation is completed by appropriately modifying the subtranslation manually.
3. The translation target sentence and the completed translation are registered in the translation memory and reused when a new translation target document is translated.
従来の翻訳支援装置では、機械翻訳の翻訳結果を人手で修正して翻訳メモリに登録する場合、訳文の修正(後編集)は、簡単に行えても原文の修正(前編集)は簡単には行えないという問題があった。 In the conventional translation support device, when the translation result of machine translation is manually corrected and registered in the translation memory, the correction of the original sentence (pre-editing) is easy even if the correction of the translation (post-editing) can be easily performed. There was a problem that it could not be done.
これは、翻訳メモリに登録する原文がオリジナルの原文から変更されていると、別の文書の翻訳時に再利用され難くなるためである。 This is because if the original text registered in the translation memory is changed from the original original text, it is difficult to reuse it when translating another document.
例えば、ある日本語テキスト文書から、同じ内容のhtml文書、リッチテキスト文書を作ってあったものとする。そして、日本語テキスト文書を基にして英語の翻訳文書を作成し、これらを翻訳メモリに登録したものとする。その際に、翻訳メモリに登録した原文はオリジナルの原文から変更されているものとする。 For example, it is assumed that an html document and a rich text document having the same contents are created from a certain Japanese text document. Then, it is assumed that English translation documents are created based on the Japanese text documents and these are registered in the translation memory. At that time, it is assumed that the original text registered in the translation memory has been changed from the original text.
この翻訳メモリの内容を使って、html文書、リッチテキスト文書を翻訳し、英語版のhtml文書、リッチテキスト文書を作成するものとする。 It is assumed that the contents of the translation memory are used to translate an html document and a rich text document to create an English version html document and a rich text document.
しかし、翻訳メモリには、オリジナルの原文とは異なる原文が登録されているため、翻訳メモリのデータとの類似率は低くなる。また、機械翻訳装置が翻訳し易いように原文を修正すると、実際には存在しない人工的な文になる場合もあり、このような場合は実際の文とマッチしない可能性がさらに高くなる。 However, since the original text different from the original text is registered in the translation memory, the similarity rate with the data in the translation memory is low. Further, when the original sentence is corrected so that it can be easily translated by the machine translation device, it may become an artificial sentence that does not actually exist. In such a case, the possibility of not matching with the actual sentence is further increased.
そこで、原文の修正をあえて行う場合には、修正前の原文を別途保存しておき、翻訳メモリ登録時に修正後の原文と置き換える必要がある。 Therefore, when the original text is corrected, it is necessary to save the original text before correction separately and replace it with the corrected text when registering the translation memory.
しかし、この場合にも、特に原文の分割・結合を行うと、原文との置き換え作業は非常に繁雑になるという問題がある。その上、原文の分割・結合が必要になるケースはまれではない。例えば原文である日本語の1文が「が、」でつながる複数の文からなり、文を分割した方が翻訳結果が良くなる場合や、htmlファイルなどの書式情報付き文書においてレイアウトの都合で1文が分割されており、正しく翻訳するには文を結合する必要がある場合など、枚挙にいとまがない。 However, even in this case, there is a problem that the replacement work with the original text becomes very complicated especially when the original text is divided and combined. In addition, it is not uncommon to need to split and combine text. For example, if the original Japanese sentence is composed of a plurality of sentences connected by “ga”, the result of translation is better if the sentence is divided, or in the case of layout information in a document with format information such as an html file. If the sentences are divided and need to be combined for correct translation, there is no limit.
このように、翻訳メモリに登録することを考えると、原文の修正は簡単にはできないため、現実的には機械翻訳結果の修正は、訳文の修正に頼る場合が大半であった。 In this way, considering the registration in the translation memory, the correction of the original text cannot be easily performed. Therefore, in reality, the correction of the machine translation result is mostly dependent on the correction of the translation.
最初から自分で英文を書き起こせるユーザは、機械翻訳の機能を十分に活用せずに、訳文の上書き編集をして多大な労力を費やし、最初から英文を書き起こすことの難しいユーザは、訳文に問題があることは分かっていても、それをどう直せばよいかを推敲できずに機械翻訳された訳文を容認せざるを得ない場合が多くあった。 Users who can transcribe English by themselves from the beginning do not make full use of the machine translation function, and do a great deal of effort by overwriting and editing the translation. Even though we knew that there was a problem, there were many cases where we had to accept a machine-translated translation without being able to figure out how to fix it.
本発明はこのような課題を解決するためになされたもので、原文を修正しても編集前の状態に戻せるような編集処理が行え、機械翻訳の機能および翻訳メモリ中の翻訳資産を有効に活用できる翻訳支援プログラム、翻訳支援装置、翻訳支援方法を提供することを目的としている。 The present invention has been made to solve such a problem, and can perform editing processing so that even if the original text is corrected, it can be restored to the state before editing, and the machine translation function and the translation assets in the translation memory are effectively used. The purpose is to provide a translation support program, a translation support apparatus, and a translation support method that can be utilized.
上記した目的を達成するために、本発明の翻訳支援プログラムは、翻訳辞書、翻訳結果を記憶する翻訳メモリ、翻訳文及び原文に対する編集履歴を記憶する編集履歴記憶部を備えたコンピュータによって、ある言語の原文を他の言語に翻訳処理する翻訳支援プログラムにおいて、前記コンピュータを、前記原文を、前記翻訳辞書に基づいて機械翻訳することで翻訳文を生成する翻訳手段と、前記翻訳手段により前記原文と前記翻訳文を対応付けて前記翻訳メモリに保存する手段と、前記翻訳メモリに記憶された原文および前記翻訳文のうち少なくとも一つの文にある文字列が編集された場合、その位置に、前記原文の文字列に対して編集部分を示す特殊記号を付加して特殊記号付きの原文を生成する編集手段と、
前記編集手段により生成された特殊記号付きの原文を、元の原文の編集履歴として前記編集履歴記憶部に記憶する手段として機能させることを特徴とする。
上記翻訳支援プログラムにおいて、前記コンピュータを、前記特殊記号付きの原文を、特殊記号に従って再度翻訳して新たな翻訳文を生成する再翻訳手段と、前 記再翻訳手段により生成された新たな翻訳文を翻訳結果の文書として前記特殊記号付きの原文に対応付けて前記翻訳メモリに記憶する手段として機能させるよう にしても良い。
In order to achieve the above-described object, a translation support program according to the present invention includes a translation dictionary, a translation memory for storing a translation result, a computer having an editing history storage unit for storing a translation sentence and an editing history for the original sentence. in the translation support program which processes a textual other language translation, the computer, the original text, the translation means for generating a translation by machine translation on the basis of the translation dictionary, and the original text by said translation means said means in association translations be stored in the translation memory, when said string in at least one sentence of the translation memory stored original and the translated sentence has been edited, in that position, the An editing means for generating a text with a special symbol by adding a special symbol indicating an editing part to the text string of the text,
The original with the generated special symbols by the editing means, characterized in that to function as a means for storing in said edit history storing section as an editing history of the original textual.
In the above-mentioned translation support program, the computer translates the original text with the special symbol again according to the special symbol to generate a new translated text, and a new translated text generated by the re-translating means. May be associated with the original text with the special symbol as a translation result document and stored in the translation memory.
本発明の翻訳支援装置は、ある言語の原文を、予め記憶されている翻訳辞書に基づいて機械翻訳することで他の言語の翻訳文を生成する翻訳手段と、前記翻訳手段による翻訳結果を前記原文と前記翻訳文とを対応付けて保存する翻訳メモリと、前記翻訳手段により翻訳された翻訳文および原文の少なくとも一方を編集した編集履歴が記憶される編集履歴記憶部と、前記原文および前記翻訳文のうち少なくとも一つの文にある文字列が編集された場合、その位置に、前記原文の文字列に対して編集部分を示す特殊記号を付加して特殊記号付きの原文を生成する編集手段と、前記編集手段により生成された特殊記号付きの原文を、元の原文の編集履歴として前記編集履歴記憶部に記憶する手段とを具備したことを特徴とする。
上記翻訳支援装置において、前記特殊記号付きの原文を、特殊記号に従って再度翻訳して新たな翻訳文を生成する再翻訳手段と、前記再翻訳手段により生成された新たな翻訳文を翻訳結果の文書として前記特殊記号付きの原文に対応付けて前記翻訳メモリに記憶する手段とを備えても良い。
Translation supporting apparatus of the present invention, the textual one language, a translation means for generating a translation of the other language by machine translation based on the translation dictionary stored in advance, the translation results by the translation means a translation memory that stores in association with the translation and the original text, and editing history storage unit for editing history editing at least one of the translated translation and original text by said translation means is stored, the original text and the translation Editing means for generating an original sentence with a special symbol by adding a special symbol indicating an editing portion to the original character string at that position when a character string in at least one sentence of the sentence is edited And means for storing the original text with the special symbol generated by the editing means in the editing history storage section as an editing history of the original text.
In the translation support apparatus, a retranslation means for re-translating the original sentence with the special symbol in accordance with the special symbol to generate a new translation sentence, and a new translation sentence generated by the re-translation means as a document of the translation result And means for storing in the translation memory in association with the original text with the special symbol.
本発明の翻訳支援方法は、翻訳手段、翻訳辞書、翻訳メモリ、編集手段、編集履歴記憶部を備えたコンピュータによって、ある言語の原文を他の言語に翻訳処理する翻訳支援方法において、前記翻訳手段が、ある言語の原文を、予め記憶されている前期翻訳辞書に基づいて機械翻訳することで他の言語の翻訳文を生成するステップと、前記翻訳手段が、前記原文と前記翻訳文とを対応付けて翻訳メモリに保存するステップと、前記原文および前記翻訳文のうち少なくとも一つの文にある文字列が編集された場合、その位置に、前記原文の文字列に対して編集部分を示す特殊記号を前記編集手段が付加して特殊記号付きの原文を生成するステップと、生成した特殊記号付きの原文を、前記編集手段が元の原文の編集履歴として編集履歴記憶部に記憶するステップとを有することを特徴とする。 なお、上記翻訳支援方法において、前記特殊記号付きの原文を再翻訳手段が特殊記号に従って再度翻訳して新たな翻訳文を生成するステップと、再度翻訳して生成した新たな翻訳文を前記編集手段が翻訳結果の文書として前記特殊記号付きの原文に対応付けて翻訳メモリに保存するステップとを有してもよい。 The translation support method of the present invention is a translation support method for translating an original sentence of a certain language into another language by a computer having a translation means, a translation dictionary, a translation memory, an editing means, and an edit history storage unit. but the original text of a language, and Luz step to generate a translation in other languages by machine translation based on year translation dictionary stored in advance, said translation means, said translation and the original text and storing in the translation memory in association with, if the string in the at least one sentence of said original and said translation is edited, in that position, the editing portion for strings of the original generating a textual with special symbols added is the editing means of special symbols indicating the original text with the generated special symbols, the edit history storing unit said editing means as the edit history of the original textual Characterized by a step of 憶. In the translation support method, the step of re-translating the original sentence with the special symbol by the re-translation means according to the special symbol to generate a new translation sentence, and the new translation sentence generated by re-translation and the editing means There may have a step of storing the translation memory in association with the original text with the special symbols as a document of the translation result.
本発明では、選択された文字例の分割位置、結合位置、および一文編集のうちの少なくとも一つを行う編集位置に特殊記号を付加した特殊記号付きの原文を生成し、それを原文の編集履歴として編集履歴記憶部に記憶するので、編集履歴記憶部を参照して特殊記号付きの原文から特殊記号を検出することで、特殊記号付きの原文を編集前の原文の形態に戻すことができる。 In the present invention, an original sentence with a special symbol is generated by adding a special symbol to an editing position for performing at least one of a division position, a combining position, and a single sentence editing of the selected character example, and the original editing history is generated. Is stored in the editing history storage unit, and by detecting the special symbol from the original text with the special symbol with reference to the editing history storage unit, the original text with the special symbol can be returned to the original text before editing.
また、特殊記号付きの原文を再度翻訳した新たな翻訳文を翻訳結果の文書として特殊記号付きの原文に対応付けて翻訳メモリに保存するので、高い精度の翻訳結果を再利用できるようになる。 In addition, since a new translation sentence obtained by re-translating the original sentence with the special symbol is stored in the translation memory in association with the original sentence with the special symbol as a translation result document, the translation result with high accuracy can be reused.
以上説明したように本発明によれば、原文を修正しても編集前の状態に戻せるような編集処理が行え、機械翻訳の機能および翻訳メモリ中の翻訳資産を有効に活用できる。 As described above, according to the present invention, it is possible to perform an editing process so that even if the original text is corrected, it is possible to return to the state before editing, and the function of machine translation and the translation assets in the translation memory can be effectively utilized.
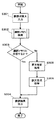
以下、本発明の実施の形態を図面を参照して詳細に説明する。図1は本発明に係る一実施形態の翻訳支援装置全体の構成を示すブロック図である。
この実施形態の翻訳支援装置は、大別して、文分割処理部1、翻訳手段としての翻訳処理部2、編集手段としての原文・訳文編集部3、文書出力部4等の4つの部分からなる。
Hereinafter, embodiments of the present invention will be described in detail with reference to the drawings. FIG. 1 is a block diagram showing the overall configuration of a translation support apparatus according to an embodiment of the present invention.
The translation support apparatus according to this embodiment is roughly divided into four parts: a sentence
文分割処理部1は、翻訳対象の原言語で書かれた原文文書入力部5と、原文文書を所定の文分割規則に従って1文単位に自動的に分割する原文文書自動文分割部6と、自動文分割の際に参照される所定の文分割規則が記憶された文分割規則テーブル7とを有している。原文文書入力部5は、例えばキーボード、マウス、グラフィックユーザインタフェース画面等で構成され、原文および訳文のうち少なくとも一つに対して文字列の編集操作を行う操作手段として機能する。文分割規則テーブル7に記憶されている所定の文分割規則は、例えばメモリにファイルの形態で記憶されていても良く、また、文分割処理部1の処理プログラムの中に予め記述、つまり設定されていても良い。
The sentence
翻訳処理部2は、翻訳処理を制御する翻訳処理制御部8と、翻訳対象のある原言語(例えば日本語等)で書かれた文(翻訳対象文:第1の文書)と、翻訳後の他の言語、つまり目的言語(英語等)で書かれた文(翻訳結果の文書:第2の文書(以下訳文と称す))とが一対(一組)に対応付けられて保存されている翻訳メモリ9と、この翻訳メモリ9の中に、1文単位に分割された原言語からなる原文と類似する文(類似文)があるか否かを検索する翻訳メモリ検索部10と、原文を自動的に目的言語の文に翻訳する機械翻訳処理部11と、この機械翻訳処理部11により参照される翻訳辞書としての翻訳用辞書12を有している。
The
翻訳処理部2は、ある原文を予め記憶されている翻訳用辞書12に基づいて機械翻訳することで目的言語文書である訳語を生成する翻訳手段として機能する。
翻訳用辞書12には、言語翻訳用の辞書情報(日→英辞書、英→日辞書等の辞書データ)と、この他、形態素解析、構文解析、意味解析、言語変換用の解析ルール、変換規則等が記憶されている。
The
The
翻訳メモリ9は、翻訳処理部2による翻訳結果の再利用を目的として翻訳前の文書とこの翻訳前の文書を翻訳した翻訳結果の文書とを対応付けて保存するものである。この翻訳メモリ9は、過去の翻訳実績を再利用するためにデータベースの形態で蓄積し翻訳作業の効率アップを図る機能の一部として用いられる。
The translation memory 9 stores a pre-translation document and a translation result document obtained by translating the pre-translation document in association with each other for the purpose of reusing the translation result by the
機械翻訳処理部11は、形態素解析、構文解析、意味解析、言語変換処理部13、訳文生成部14を有している。
原文・訳文編集部3は、操作手段により原文に対して行われた文字列の編集操作に応じた位置に特殊記号を付加して第3の文書(図6参照)を生成する手段として機能する。
The machine translation processing unit 11 includes a morphological analysis, a syntax analysis, a semantic analysis, a language
The original / translation editing unit 3 functions as a unit that generates a third document (see FIG. 6) by adding a special symbol to a position corresponding to a character string editing operation performed on the original by the operation unit. .
原文・訳文編集部3は、原文、訳文を編集した編集履歴が記憶される編集履歴記憶部15を有している。編集履歴記憶部15は、メモリ、ハードディスク装置に設けられた記憶領域等で実現される。原文・訳文編集部3は、生成した第3の文書を第1の文書の編集履歴として編集履歴記憶部15に記憶する手段として機能する。つまり、編集履歴記憶部15には、原文および訳文のうち、少なくとも一つを編集した編集履歴が記憶される。
原文・訳文編集部3は、操作手段である対訳編集画面によって、原文の中から選択された文字列に対して、編集履歴記憶部15に記憶された特殊記号付きの訳文を基に、分割、結合、および一文編集のうちの少なくとも一つを行う位置を推定し、その位置に特殊記号を付加して特殊記号付きの原文を生成する手段として機能する。原文・訳文編集部3は、生成された特殊記号付きの原文を原文の編集履歴として編集履歴記憶部15に記憶する手段として機能する。
The original sentence / translation editing section 3 has an editing
The original / translation editing unit 3 divides the character string selected from the original using the parallel translation editing screen, which is an operation unit, based on the translation with special symbols stored in the editing
訳文生成部14は、形態素解析、構文解析、意味解析、言語変換処理部13により形態素解析、構文解析、意味解析、言語変換されて意味をなす語句(文字列)となったものを文の形態に並べる処理を行う。
The
文書出力部4は、文の形態の原文・訳文などを文書の形態で出力するものであり、原文、訳文、それぞれの修正文のうち少なくとも一つを出力するプリントドライバ、表示ドライバ等を含むプログラムと、プリンタ、表示装置等のハードウェア等である。 The document output unit 4 outputs an original sentence / translation sentence in the form of a sentence in the form of a document, and includes a print driver, a display driver, etc. that output at least one of the original sentence, the translated sentence, and each corrected sentence. And hardware such as a printer and a display device.
この翻訳支援装置のハードウェアは、CPU、メモリ、ハードディスク装置等を備えたコンピュータと、このコンピュータに接続された表示装置および印刷装置等である。ハードディスク装置にはコンピュータシステム全体を動作させるオペレーティングシステム(以下OSと称す)と、機械翻訳を実行する制御プログラム(以下翻訳支援プログラムと称す)がインストールされており、これら翻訳支援プログラム、OS、CPU、メモリ等が協働して、文分割処理部1、翻訳処理部2、原文・訳文編集部3、文書出力部4等の処理動作を実現する。
The hardware of this translation support apparatus is a computer including a CPU, a memory, a hard disk device, and the like, and a display device and a printing device connected to the computer. An operating system (hereinafter referred to as OS) for operating the entire computer system and a control program (hereinafter referred to as translation support program) for executing machine translation are installed in the hard disk device. These translation support program, OS, CPU, The memory and the like cooperate to realize processing operations of the sentence
以下、図2を参照してこの実施形態の翻訳支援装置の動作を説明する。図2はこの実施形態の翻訳支援装置の処理全体を示すフローチャートである。 The operation of the translation support apparatus according to this embodiment will be described below with reference to FIG. FIG. 2 is a flowchart showing the entire processing of the translation support apparatus of this embodiment.
この翻訳支援装置では、原文文書入力部5に原文文書が入力されると(図2のステップS201)、原文文書自動文分割部6は、原文文書を1文単位に分割する(ステップS202)。この原文文書自動文分割部6では、日本語の文章の場合、1つの文は、読点を区切りとして分割される。また、英語の文章の場合、1つの文は、ピリオド、コロン、セミコロンなどを区切りとして分割される。この他、例えば括弧、改行記号、htmlのような書式情報付き文書では、1つの文は、改行記号、カッコなどを区切りとして分割される。また、英文の場合、“Dr.”などのようにピリオドが付く語があるため、個別に考慮すべき単語を辞書にまとめ、適宜参照する。上記区切り情報は予めメモリあるいはプログラム上に記憶(設定)されている。 In this translation support apparatus, when an original document document is input to the original document input unit 5 (step S201 in FIG. 2), the original document automatic sentence dividing unit 6 divides the original document into units of one sentence (step S202). In the original document automatic sentence dividing unit 6, in the case of a Japanese sentence, one sentence is divided with a punctuation mark as a delimiter. In the case of English sentences, one sentence is divided with a period, a colon, a semicolon, etc. as a delimiter. In addition, for example, in a document with format information such as parentheses, line feed symbols, and html, one sentence is divided with a line feed symbol, parentheses, etc. as a delimiter. In English, there are words with a period, such as “Dr.”, so the words that should be considered individually are compiled into a dictionary and referred to as appropriate. The delimiter information is stored (set) in advance in a memory or program.
原文文書自動文分割部6により1文単位に分割された原文は、1文ずつ、最後の文になるまで(ステップS203)、翻訳処理部2へ送られて、翻訳処理部2によって翻訳処理が行われる(ステップS204)。なお、ステップS204の翻訳処理の詳細な内容は後述する。
The original sentence divided into one sentence unit by the original document automatic sentence dividing unit 6 is sent to the
翻訳処理が行われた訳文は、原文とともに原文・訳文編集部3へ送られる。原文・訳文編集部3では、訳文および/または原文の編集処理が行われる(ステップS205)。このステップS205の編集処理の詳細な内容については後述する。 The translated text that has undergone translation processing is sent to the original text / translated text editing section 3 together with the original text. The original / translation editing unit 3 performs a translation and / or original text editing process (step S205). Details of the editing process in step S205 will be described later.
ステップS205の編集処理が行われた後、編集済みの原文に対する翻訳処理が再度必要な場合、原文・訳文編集部3より翻訳処理部2へ翻訳対象の文が戻される。そして、翻訳処理部2により文書の有無が判定されて(ステップS203)、翻訳処理が行われる(ステップS204)。
なお、翻訳対象の文が複数存在したとしても、ステップS203の判定処理を経ることで、すべての翻訳対象文に対して1文ずつ翻訳処理が実効される。
After the editing process of step S205 is performed, when the edited original sentence needs to be translated again, the original sentence / translation editing part 3 returns the sentence to be translated to the
Even if there are a plurality of sentences to be translated, the translation process is executed one sentence at a time for every sentence to be translated through the determination process in step S203.
翻訳処理が再度必要でない場合(ステップS206のNo)、原文・訳文編集部3は、原文と翻訳結果を文書出力部4へ送り(ステップS207)、原文・訳文編集部3としての処理動作を終了する。 If the translation process is not necessary again (No in step S206), the original / translation editing unit 3 sends the original and the translation result to the document output unit 4 (step S207), and ends the processing operation as the original / translation editing unit 3. To do.
<翻訳処理部2の動作>
ここで、図3を参照して図2のステップ204で示した翻訳処理について説明する。図3は図2のステップ204で示した翻訳処理を示すフローチャートである。
<Operation of
Here, the translation process shown in
文分割処理部1によって1文単位に分割された翻訳対象文が翻訳処理部2に入力されると(ステップS301)、翻訳処理部2では、翻訳メモリ検索部10が、翻訳処理制御部8からの命令により、翻訳対象文をキーにして翻訳メモリ9を検索することで(ステップS302)、翻訳対象文と類似した文が翻訳メモリ9内に存在するか否かを判定する(ステップS303)。なおステップ302の翻訳メモリ検索部10による翻訳メモリ検索処理の詳細な内容について後述する。
When the translation target sentence divided into sentence units by the sentence
検索の結果、翻訳メモリ9内に、翻訳対象文と類似した文が存在した場合(ステップS303のYes)、翻訳メモリ検索部10は、その類似文を翻訳処理による訳文と判定して、翻訳結果を表示装置の表示画面へ出力し(ステップS304)、この翻訳対象文に対する翻訳処理を終了する。
また、翻訳対象文と類似した文が存在しない場合(ステップS303のNo)、翻訳メモリ検索部10は、翻訳対象文を機械翻訳処理部11へ送り、機械翻訳処理を実行させる。
機械翻訳処理部11は、翻訳メモリ検索部10より受けた取った翻訳対象文に対して形態素解析、構文解析、意味解析、言語変換の各種処理からなる原文解析処理(ステップS305)と、訳文生成処理(ステップS306)とを行うことで機械翻訳処理を行う。
機械翻訳処理部11は、機械翻訳処理が終了すると、翻訳結果を原文・訳文編集部3へ出力する(ステップS304)。
As a result of the search, if there is a sentence similar to the translation target sentence in the translation memory 9 (Yes in step S303), the translation
When there is no sentence similar to the translation target sentence (No in step S303), the translation
The machine translation processing unit 11 performs source sentence analysis processing (step S305) including various processes such as morphological analysis, syntax analysis, semantic analysis, and language conversion on the translation target sentence received from the translation
When the machine translation process ends, the machine translation processing unit 11 outputs the translation result to the original / translation editing unit 3 (step S304).
<原文・訳文編集部3の動作>
続いて、図4のフローチャートを参照して、上記図2のステップ205で示した原文・訳文編集部3の処理の詳細について説明する。
<Operation of Original / Translation Editor 3>
Next, the details of the processing of the original / translation editing unit 3 shown in
原文・訳文編集部3に、翻訳処理部2から原文および翻訳処理の結果が送られると、原文・訳文編集部3は、原文・訳文の同じ内容を初期値として編集履歴記憶部15に記憶するとともに、その原文・訳文を表示装置の表示画面に表示する。原文・訳文の編集処理は、表示画面に表示された原文・訳文のうち、ユーザが選択した文に対して実行される。この表示画面は、原文および訳文の対訳編集画面であり、原文および訳文の少なくとも一つに対して編集対象の文字列の選択操作を行う操作手段として機能する。
When the original text and the translation processing result are sent from the
図4には、ユーザが編集したい文を選択してから1回の編集作業が終了するまでの流れを示すものであり、すべての編集作業が終了するまで、必要に応じて図4の処理が繰り返される。 FIG. 4 shows a flow from when a user selects a sentence to be edited to when one editing operation is completed. The processing of FIG. 4 is performed as necessary until all editing operations are completed. Repeated.
ユーザにより選択された編集対象の文字列、つまり編集対象文が原文・訳文編集部3に入力されると(図4のステップS401)、原文・訳文編集部3は、編集対象文が訳文か原文かを判定する(ステップS402)。この判定の仕方としては、入力元(訳文は機械翻訳処理部11から入力、原文は翻訳処理制御部8から入力)がどこであるか、つまりどこから送られてきたかで判定する方法と、ユーザが操作した画面あるいは文自体(原文と訳文を2分割画面に別個に表示しているため)で判定する方法がある。 When the editing target character string selected by the user, that is, the editing target sentence is input to the original / translation editing unit 3 (step S401 in FIG. 4), the original / translation editing unit 3 determines whether the editing target sentence is a translation or an original sentence. Is determined (step S402). As a method of this determination, there is a method of determining where the input source (the translated text is input from the machine translation processing unit 11 and the original text is input from the translation processing control unit 8), that is, from where the input source is sent, and a user operation There is a method of judging on the screen or the sentence itself (because the original sentence and the translated sentence are separately displayed on the two-divided screen).
判定の結果、編集対象文が訳文の場合(ステップS402のYes)、原文・訳文編集部3は、訳文編集を行い(ステップS403)、編集結果を文書出力部4へ出力して(ステップS412)、編集処理を終了する。
また、編集対象文が原文の場合(ステップS402のNo)、原文・訳文編集部3は、編集内容に応じて1文の分割を行うか否か(ステップS404)、複数文の結合を行うか否か(ステップS407)を判定し、この判定結果に応じて処理を行う。
As a result of the determination, if the edit target sentence is a translated sentence (Yes in step S402), the original / translated sentence editing unit 3 performs translation editing (step S403), and outputs the edited result to the document output unit 4 (step S412). The editing process is terminated.
If the edit target sentence is an original sentence (No in step S402), the original sentence / translation sentence editing unit 3 determines whether or not to divide one sentence according to the editing content (step S404) and whether to combine a plurality of sentences. It is determined whether or not (step S407), and processing is performed according to the determination result.
例えば1文の分割を行う場合(ステップS404のYes)、原文・訳文編集部3は、文分割処理を実行し(ステップS405)、複数文の結合を行う場合には、文結合処理を実行し(ステップS408)、これら2つ以外の場合、つまり、編集内容が1文内での変更のみに留まる場合(ステップS404のYes)、原文・訳文編集部3は、1文編集処理を実行する(ステップS409)。これら文分割、文結合、一文編集等の各処理によって、編集文に特殊記号が付される。各処理の内容については、後で図5の例を用いて詳細に説明する。なお、選択入力された文が長い場合、分割と結合を同時に行うことも有り得る。この場合、ステップS405、S408の処理が同時に実行されることになる。また、他の一文編集処理との組み合わせも考えられる。 For example, when dividing a sentence (Yes in step S404), the original / translation editing unit 3 executes a sentence dividing process (step S405), and when combining a plurality of sentences, executes a sentence combining process. (Step S408) In cases other than these two cases, that is, when the editing content is only changed within one sentence (Yes in Step S404), the original / translation editing unit 3 executes single sentence editing processing ( Step S409). A special symbol is attached to the edited sentence by each processing such as sentence division, sentence combination, and single sentence editing. The contents of each process will be described in detail later using the example of FIG. If the selected sentence is long, splitting and combining may be performed at the same time. In this case, the processes of steps S405 and S408 are executed simultaneously. A combination with other single sentence editing processing is also conceivable.
これらの処理の後、原文・訳文編集部3は、編集履歴記憶部15に対して原文編集履歴内容の更新処理を行い(ステップS406)、編集履歴記憶部15に、処理内容が時系列で記憶される。
After these processes, the original / translation editing unit 3 performs an update process of the content of the original text editing history in the editing history storage unit 15 (step S406), and the processing content is stored in the editing
原文の編集作業を終了した後、ユーザは再翻訳が必要か否かを判断する。再翻訳が必要と判断したユーザは、表示画面上の翻訳ボタンを操作し、再翻訳が不要と判断したユーザは、表示画面上の翻訳ボタン以外のボタン、あるいはキー操作を行うので、原文・訳文編集部3は、原文編集後のユーザの操作に応じて処理内容を変える(ステップS410)。 After completing the editing of the original text, the user determines whether retranslation is necessary. The user who determines that retranslation is necessary operates the translation button on the display screen, and the user who determines that retranslation is not necessary operates buttons or key operations other than the translation button on the display screen. The editing unit 3 changes the processing content according to the user's operation after editing the original text (step S410).
例えばユーザにより表示画面上の翻訳ボタンが操作された場合、原文・訳文編集部3は、再翻訳が必要と判定し(ステップS410のYes)、この場合は、編集された原文を翻訳処理部2に渡し、再度の翻訳処理を実行させる(ステップS411)。
For example, when the translation button on the display screen is operated by the user, the original / translation editing unit 3 determines that retranslation is necessary (Yes in step S410). In this case, the edited original is converted into the
また、ユーザにより他の操作が行われた場合、原文・訳文編集部3は、再翻訳を不要と判定し(ステップS410のNo)、翻訳処理(ステップS411)をスキップし、訳文編集が必要か否かの判定処理を行う(ステップS412)。 If the user performs another operation, the original / translation editing unit 3 determines that re-translation is unnecessary (No in step S410), skips the translation process (step S411), and does the translation need to be edited? A determination process of whether or not is performed (step S412).
このステップS412の判定処理では、ユーザにより次の文(原文あるいは訳文)が編集対象として指定された場合に、原文・訳文編集部3は、訳文編集を必要と判定し(ステップS412のYes)、指定された編集対象文に対して訳文編集を実行し(ステップS403)、その後、翻訳結果の文を翻訳メモリ9と文書出力部4へ出力し(ステップS413)、編集処理を終了する。原文・訳文編集部3より出力された翻訳結果の文は、特殊記号が付加された編集後の原文に対応付けられて翻訳メモリ9に保存(登録)される。 In the determination processing in step S412, when the next sentence (original sentence or translation) is designated as an editing target by the user, the original sentence / translation editing section 3 determines that translation editing is necessary (Yes in step S412), The translation editing is executed for the designated editing target sentence (step S403), and then the translation result sentence is output to the translation memory 9 and the document output unit 4 (step S413), and the editing process is terminated. The translation result sentence output from the original sentence / translation sentence editing unit 3 is stored (registered) in the translation memory 9 in association with the edited original sentence to which the special symbol is added.
また、ユーザにより次の文(原文あるいは訳文)が編集対象として指定されず、訳文編集が不要な場合(ステップS412のNo)、原文・訳文編集部3は、訳文編集処理(ステップS403)をスキップして、編集文を出力し(ステップS413)、編集処理を終了する。 If the user does not specify the next sentence (original sentence or translated sentence) as an editing target and the translated sentence is unnecessary (No in step S412), the original sentence / translated sentence editing unit 3 skips the translated sentence editing process (step S403). Then, the edited sentence is output (step S413), and the editing process is terminated.
<原文・訳文編集部3の動作の実例と翻訳メモリ9への登録例>
図5は翻訳処理部2から原文・訳文編集部3に送られてきた、編集処理前の原文・訳文および編集履歴記憶部15の内容を示したものである。これらの例を用いて、具体的な原文・訳文編集部3の動作と翻訳メモリ9への登録内容について説明する。原文・訳文未編集の状態では、編集履歴記憶部15の内容(原文・訳文)は、それぞれの原文・訳文と全く同じ内容になっている。
<Example of operation of original / translation editing unit 3 and registration to translation memory 9>
FIG. 5 shows the contents of the original text / translation text and the editing
これらの例では、翻訳処理から出力された翻訳結果は原文の内容を十分に反映したものとは言えず、修正が必要である。
例えば文51は、ひらがな表記になっているため、「たなか」が人名と認識されていない例である。文52では、「田中ですが、」の「が、」が、日本語では軽い接続の意味で使われているが、翻訳結果では逆接の意味と解釈され、逆接の接続詞”although”が出力されている。文53および文54は、レイアウトの都合で1文が2つに分割されたため、正しく翻訳されていない例である。
In these examples, the translation result output from the translation process cannot be said to sufficiently reflect the contents of the original text and needs to be corrected.
For example,
上記の点を考慮して、ユーザが文の選択操作を行い、この選択操作に応じて原文・訳文編集部3が文分割処理、文結合処理、1文編集処理を行い、原文を修正した結果を図6に示す。 In consideration of the above points, the user performs a sentence selection operation, and the original / translation editing unit 3 performs sentence division processing, sentence combination processing, and one sentence editing processing in accordance with the selection operation, and results of correcting the original sentence Is shown in FIG.
文61は、ひらがな表記を漢字表記に修正したものである。漢字表記にすることで「田中」が人名と解釈され、正しい翻訳結果が出力されている。このように意味が一意に決まるように表記や表現を変更することで、正しい翻訳結果が得られる場合が多い。
文62および文63は、「が、」で接続された原文を2文に分割し、それぞれ文として完結するようにしたものである。これらの文を再度翻訳すると、当然だが、逆接の接続詞althoughは訳文に現れなくなる。このような文の分割処理を行うと、編集履歴記憶部15には、分割した前半文字列の末尾と、後半文字列の先頭に特殊記号”@数字@”が挿入された編集履歴が記憶される。”@”と”@”の間の数字は、この位置に特殊記号を挿入したことを識別するための特殊記号のID番号であり、同じID番号が付いている原文同士は、編集前は繋がっていたことを示す。数字は、通常、文の文節や文の結合部が検出された際に原文・訳文編集部3により連続番号で付与される。
A sentence 62 and a
文64は、文53および文54の2文を結合したものである。結合した文の再翻訳結果は、意味の通るものとなっている。このような文の結合処理を行うと、編集履歴記憶部15には文同士の結合部に”@数字@”が挿入された編集履歴が記憶される。
The
結合処理の場合は同じID番号を持つ複数の原文は存在しないが、同じIDを持つ原文と訳文は存在する。機械翻訳処理部11は、結合した原文を再翻訳するので、訳文中の結合部は、本来は存在しないはずであるが、編集履歴記憶部15(訳文)に保存されている結合前の翻訳結果と再翻訳結果とを比較することで、原文の結合部に対応する訳文の結合部を推定(特定)し翻訳を行う。例えば文64は、”This processing”の後で切れると推定(特定)される。これは、編集履歴記憶部15に記憶された@前の文字列”This processing”と再翻訳結果の”This processing”が完全一致しているので、訳文の切れ目はprocessingの後ろであると推定すると、2つの翻訳結果の一致度がもっとも高くなるためである。
すなわち、翻訳処理制御部8は、編集履歴記憶部15に記憶された訳文(最翻訳結果)に対して、編集履歴記憶部15に記憶された編集記号付き訳文を基にして、文の切れ目を推定する。
In the case of the combining process, there are not a plurality of original sentences having the same ID number, but there are an original sentence and a translated sentence having the same ID. Since the machine translation processing unit 11 re-translates the combined original sentence, the combined part in the translated sentence should not originally exist, but the translation result before combining stored in the editing history storage unit 15 (translated sentence) And the retranslation result are compared to estimate (identify) the translation portion corresponding to the original portion, and perform translation. For example, the
That is, the translation processing control unit 8 applies a sentence break to the translation (the most translated result) stored in the editing
図7は原文を修正して機械翻訳処理部11が再翻訳した訳文に、更に修正を加えた例である。
この例は、文74の「処理」に対する訳語「processing」を「process」に変更する修正を加えた例である。このように、原文の修正を行うことで構文的に正しい翻訳結果が得られると、後は翻訳結果の一部を修正するだけで一定水準の訳文を得ることができる。
FIG. 7 shows an example in which the original sentence is corrected and the translation is re-translated by the machine translation processing unit 11 and further corrected.
This example is an example in which a modification that changes the translated word “processing” to “process” for “processing” in the
したがって、最初から自分で英文を書き起こせるユーザは、訳文を最初から自分で作成する必要が無くなり、翻訳の労力が大幅に軽減できる。
また、最初から英文を自分で作成することが難しいユーザにとっては、わずかな修正で正しい英文が得られるため、機械翻訳の翻訳結果が間違っていても、比較的容易に修正が可能となる。
Therefore, a user who can transcribe himself / herself from the beginning does not need to create a translation from the beginning, and the translation effort can be greatly reduced.
For users who have difficulty in creating English sentences from the beginning, correct English sentences can be obtained with a slight correction, so that even if the translation result of machine translation is wrong, the correction can be made relatively easily.
図8は上記の翻訳結果から、翻訳メモリ9に登録された内容を示した図である。
翻訳メモリ9に登録された原文は、修正を加えた原文ではなく、編集履歴記憶部15の内容であり、オリジナルの原文の文字列に対して文分割部分や文結合部を示す特殊記号を加えたもの(第3の文書の形態)になっている。
FIG. 8 is a diagram showing the contents registered in the translation memory 9 from the above translation result.
The original text registered in the translation memory 9 is not the corrected original text but the contents of the editing
この実施形態の翻訳支援装置では、このような翻訳メモリ9への登録方法を採っているが、原文を分割した場合に限り、分割前の原文に復元したものを翻訳メモリ9に登録する、という方法も可能である。この方法によれば、翻訳メモリ検索部10に特別な機能が無くても、翻訳対象の文が編集前のオリジナルの原文と一致する場合、翻訳メモリ9に登録されたオリジナルの原文と対になっている訳文を出力することができる。
In the translation support apparatus of this embodiment, such a registration method to the translation memory 9 is adopted. However, only when the original text is divided, the restored original text is registered in the translation memory 9. A method is also possible. According to this method, even if the translation
以下、より汎用的な図8に示した内容で翻訳メモリ9に登録する場合について説明する。
<新たな文書翻訳時の翻訳メモリ検索動作>
図8に示した翻訳メモリ9を使って、図9に示す新たな文書を翻訳する場合の、翻訳メモリ検索の動作について説明する。翻訳メモリ検索は、図3のステップS302に示した処理である。
Hereinafter, the case of registering in the translation memory 9 with the more general content shown in FIG. 8 will be described.
<Translation memory search operation during new document translation>
The translation memory search operation when the new document shown in FIG. 9 is translated using the translation memory 9 shown in FIG. 8 will be described. The translation memory search is the process shown in step S302 of FIG.
この場合、翻訳メモリ検索部10は、翻訳対象の1つの文(翻訳文01と呼ぶとする)に対して、翻訳メモリ9内の1つのデータ(メモリデータ01と呼ぶ)と比較処理を行い、比較処理終了後、翻訳メモリ9の次のデータとの比較処理を行う。これを繰り返し翻訳文01と翻訳メモリ9のすべてのデータとの比較処理が終了すると、次の翻訳文02の検索処理を開始する。
In this case, the translation
このような比較方法をとったのは、本実施例の動作を分かりやすく説明するためであり、検査高速化のために、インデックス作成などの他の検索方法をとったとしても、本特許の範囲を逸脱するものではない。なお、比較処理の内容によっては、複数の翻訳文、複数のメモリデータをまとめて比較する場合もある。 The reason why such a comparison method is used is to explain the operation of the present embodiment in an easy-to-understand manner. Even if another search method such as index creation is used for speeding up the inspection, the scope of this patent It does not deviate from. Depending on the contents of the comparison process, a plurality of translated sentences and a plurality of memory data may be compared together.
図10および図11は、翻訳文01と、翻訳メモリデータ1件(メモリデータ01と呼ぶことにする)との比較処理を示すフローチャートであり、図10は完全一致検索処理を示し、図11は類似文検索処理を示す。 10 and 11 are flowcharts showing a comparison process between the translation sentence 01 and one translation memory data item (referred to as memory data 01). FIG. 10 shows an exact match search process, and FIG. A similar sentence search process is shown.
翻訳メモリ検索部10は、まず、図10の完全一致検索処理を実行した後、完全一致するメモリデータ01が検出されなかった翻訳文01に対して、引き続き、図11の類似文検索処理を実行する。
The translation
以下では、まず、図10のフローチャートを用いて検索処理の動作を説明し、図9の例文が当てはまるケースに対して具体例を使った説明を加える。
<翻訳メモリ検索動作−完全一致検索>
翻訳メモリ検索部10に翻訳対象文(翻訳文01)が入力されると(ステップS501)、翻訳メモリ検索部10は、まず、翻訳文01とメモリデータ01とを比較して互いが完全一致するか否かを判定する(ステップS502)。ここで、完全一致とは、翻訳文01とメモリデータ01、つまり翻訳メモリ9に記憶されている翻訳文とが一語一句違わないことを指す。
In the following, first, the operation of the search process will be described using the flowchart of FIG. 10, and a description using a specific example will be added to the case where the example sentence of FIG. 9 applies.
<Translation memory search operation-exact search>
When a translation target sentence (translation sentence 01) is input to the translation memory search unit 10 (step S501), the translation
比較の結果、翻訳文01とメモリデータ01とが完全一致した場合、翻訳メモリ検索部10は、翻訳メモリ9に一致する文が存在するものと判定し(ステップS502のYes)、一致した文をメモリデータ01とする(ステップS503)。
As a result of the comparison, when the translation sentence 01 and the memory data 01 completely match, the translation
このステップS503のような結果になるケースは、翻訳文01が図9の文90の場合に相当する。つまり最初に行った翻訳時に、漢字表記になるよう原文を編集していても、翻訳メモリ9にはオリジナルのひらがな表記の原文である図8の対原文81「わたしはたなかです。」が登録されていたため、オリジナルと同じひらがな表記の翻訳文01にメモリデータ01がマッチして、正しい英文”I am Tanaka.”が翻訳結果とされる。以上は、1文編集処理を行って翻訳メモリ9のデータがマッチするケースの場合である。
The case where the result of step S503 is obtained corresponds to the case where the translated sentence 01 is the
ステップS502の判定処理において、翻訳文01とメモリデータ01が完全一致しない場合(ステップS502のNo)、翻訳メモリ検索部10は、翻訳文01とメモリデータ01の原文中の“@”の前にある文字列とを比較して完全一致するか否かを判定する(ステップS504)。
In the determination process of step S502, when the translation sentence 01 and the memory data 01 do not completely match (No in step S502), the translation
この比較判定の結果、翻訳文01とメモリデータ01の原文中の“@”の前にある文字列とが完全一致しない場合(ステップS504のNo)、翻訳メモリ検索部10は、翻訳文01と一致する文は無しと判定し、検索処理を終了する。
As a result of this comparison and determination, if the translated text 01 and the character string preceding “@” in the original text of the memory data 01 do not completely match (No in step S504), the translation
一方、翻訳文01とメモリデータ01の原文中の“@”の前にある文字列とが完全に一致した場合(ステップS504のYes)、翻訳メモリ検索部10は、“@”がメモリデータ01の文末に存在するか否かを判定する(ステップS505)。
On the other hand, when the translated text 01 and the character string before “@” in the original text of the memory data 01 completely match (Yes in step S504), the translation
この判定の結果、“@”がメモリデータ01の文末に存在した場合(ステップS505のYes)、翻訳メモリ検索部10は、さらに一致しなかった翻訳文中の文字列(この部分を未一致部と呼び、一致している部分を一致部と呼ぶ)が、先頭部分に同じID番号が付いた@記号を持った翻訳メモリ9のデータ(これをメモリデータ02と呼ぶ)と一致するか否かを判定する(ステップS506)。
As a result of this determination, if “@” is present at the end of the sentence of the memory data 01 (Yes in step S505), the translation
この判定の結果、未一致部とメモリデータ02とが完全一致した場合、翻訳メモリ検索部10は、翻訳メモリ9に一致する文が有るものと判定し(ステップS506のYes)、一致した文については、特殊記号“@”を削除すると共にメモリデータ01の後にメモリデータ02を結合し、結合文(メモリデータ01+02)を生成する(S507)。
このS507の結果になるケースは、翻訳文01が図9の文91の場合に相当する。
As a result of this determination, if the unmatched part and the memory data 02 are completely matched, the translation
The case resulting in S507 corresponds to the case where the translated sentence 01 is the sentence 91 in FIG.
翻訳メモリ検索部10は、翻訳メモリ9を検索した場合、まず「私は田中ですが、」の部分がメモリデータの対原文82「私は田中ですが、@1@」の”@1@”の前の部分と一致する(ステップS504)。なお@1@の数字の「1」は新たな文節や結合位置が検出されたときに、機械的に順に付加されている連続番号である。
次のステップS506の調査処理において、「彼は中田です。」の部分がメモリデータの対原文83「@1@彼は中田です。」の@1@より後ろの文字列と一致する。
この調査結果に基づいて、S507の処理では、”I am Tanaka. He is Nakada.”という、逆接の接続詞の入らない英文の翻訳結果が生成される。
When the translation
In the investigation processing in the next step S506, the part “He is Nakata” matches the character string after @ 1 @ of the memory data against the
Based on the result of the investigation, in the process of S507, an English translation result “I am Tanaka. He is Nakada.” That does not include the reverse conjunctive conjunction is generated.
このように、翻訳メモリ9の内容を作成するときに、原文を分割して翻訳メモリ9に登録したときに、分割されたデータに、互いに連結していることを示す特殊記号(@1@等)が付加されているので、オリジナルと同じく分割されていない翻訳文にメモリデータがマッチする。以上は、文分割処理を行って登録した翻訳メモリデータがマッチするケースである。 Thus, when creating the contents of the translation memory 9, when the original text is divided and registered in the translation memory 9, special symbols (@ 1 @, etc.) indicating that the divided data are linked to each other. ) Is added, so that the memory data matches a translation that is not divided as in the original. The above is a case where translation memory data registered by performing sentence division processing matches.
ステップS506の判定処理で「未一致部」がメモリデータ02と完全一致しない場合(ステップS506のYes)、翻訳メモリ検索部10は、予め設定された数式(関数式)を用いてあいまい一致の一致率を計算し、その計算結果の数値と予め設定されていた基準値とを比較して、計算結果の数値が基準値を超えているか否かを判定する(ステップS508)。
すなわち、類似度がある一定の値以上の場合(ステップS508のYes)、翻訳メモリ検索部10は、翻訳文01の「一致部」とメモリデータ01とがマッチ(一致)したものと見なし、翻訳結果にはメモリデータ01の訳文を出力すると共に、「未一致部」についてはメモリデータとマッチしなかったものと判定する(ステップS509)。
類似度がある一定の値に満たない場合(ステップS508のNo)、翻訳メモリ検索部10は、「一致部」、「未一致部」共にメモリデータとマッチしなかったものと判定し、完全一致の検索処理を終了する。
これは、文の一部はマッチしていても、残りの部分の一致度が非常に低い場合は、文全体としての意味を考え直した方が良い場合があるからである。ただしユーザの意志によって、ステップS508の判定処理をスキップする設定に変更し、「一致部」はメモリデータとマッチしたものと判定して、メモリデータの訳文を表示するようなモードを導入するようにしてもよい。
When the “unmatched part” does not completely match the memory data 02 in the determination process of step S506 (Yes in step S506), the translation
That is, when the similarity is equal to or greater than a certain value (Yes in step S508), the translation
If the similarity is less than a certain value (No in step S508), the translation
This is because it may be better to reconsider the meaning of the sentence as a whole when the sentence part matches but the remaining part has a very low degree of coincidence. However, according to the user's will, the setting is changed to skip the determination processing in step S508, and the “matching part” is determined to match the memory data, and a mode for displaying the translation of the memory data is introduced. May be.
ステップS509のような結果になるケースは、翻訳文が図9の文92の場合に相当する。文92の前半「私は田中ですが、」は、メモリデータの対原文82”@”前の部分「私は田中ですが、」と一致するが、後半部の「生まれは千葉です」がメモリデータの対原文83と一致しているのは助詞「は」と助動詞「です」のみで、一致度は非常に低い(8語中3語)。このため、「一致部」は、「未一致部」とともにメモリデータと不一致と判定される。
ステップS505の判定処理において、“@”がメモリデータの文末にない場合(ステップS505のNo)、翻訳メモリ検索部10は、ステップS504の処理での翻訳メモリ9の未一致部が、次の翻訳対象文(翻訳文02と呼ぶ)と完全一致するか否かを判定する(ステップS510)。
未一致部と翻訳文02が一致した場合(ステップS510のYes)、翻訳メモリ検索部10は、一致文ありと判定し、一致文を、翻訳文01に対してはメモリデータ01の”@”前の部分、翻訳文02に対してはメモリデータ01の”@”の後の部分とする結合処理を行い(ステップS511)、訳文を生成する。
The case where the result as in step S509 is obtained corresponds to the case where the translated sentence is the
In the determination process of step S505, when “@” is not at the end of the memory data (No in step S505), the translation
If the unmatched part matches the translated sentence 02 (Yes in step S510), the translation
このステップS511のような結果になるケースは、翻訳文が図9の文93および文94の場合に相当する。
The case where the result as in step S511 is obtained corresponds to the case where the translated sentences are the
すなわち、翻訳メモリ検索部10が翻訳メモリ9を検索したところ、まず図9の文93「この処理は」の部分がメモリデータの対原文84の「この処理は@2@」の”@2@”の前の部分と一致する(ステップS504)。
That is, when the translation
次に、図9の文94「以下のように行います。」の部分が”@2@”の後の部分と一致する(ステップS510)。ステップS511では、この検索結果に基づいて、”This process@2@ is performed as follows.”という訳文(翻訳結果)が生成される。
Next, the portion of the
このように、翻訳メモリ9のデータを作成したときに、原文を結合して翻訳メモリ9に登録しても、結合部に結合の履歴を示す特殊記号(@2@)が挿入されるので、オリジナルと同じく結合されていない翻訳文にメモリデータがマッチする。 As described above, when the data of the translation memory 9 is created, even if the original text is joined and registered in the translation memory 9, a special symbol (@ 2 @) indicating the joining history is inserted into the joining portion. As with the original, the memory data matches the translated text that is not combined.
また、原文の結合部と対応する結合部が訳文においても特殊記号(@2@)が挿入されているので、結合されていない原文の各部分に対して、対応する訳文を出力することができる。以上は、文結合処理を行って登録した翻訳メモリデータがマッチするケースである。 In addition, since a special symbol (@ 2 @) is inserted even in the translation part of the joint part corresponding to the joint part of the original sentence, the corresponding translation sentence can be output for each part of the original sentence that is not joined. . The above is a case where the translation memory data registered by performing sentence combination processing matches.
ステップS510の処理において、翻訳メモリ9の「未一致部」が翻訳文02と完全一致しない場合(ステップS510のNo)、翻訳メモリ検索部10は、あいまい一致の一致率を計算し、ステップS508の判定処理と同様に、類似度がある一定の値を超えているか否かを判定する(ステップS512)。
In the process of step S510, when the “unmatched part” in the translation memory 9 does not completely match the translated sentence 02 (No in step S510), the translation
判定の結果、類似度がある一定の値以上の場合(ステップS512のYes)、翻訳メモリ検索部10は、翻訳メモリ9の「一致部」を翻訳文01とマッチしたものと判定し、翻訳結果としてメモリデータの訳文の“@”前の部分を出力し、「未一致部」についてはメモリデータとマッチしなかったものと判定する(ステップS513)。
As a result of the determination, if the similarity is equal to or higher than a certain value (Yes in step S512), the translation
また、類似度がある一定の値に満たない場合(ステップS512のNo)、翻訳メモリ検索部10は、翻訳文01、02ともにメモリデータとマッチしなかったものと判定し、完全一致の検索処理を終了となる。なお、この他、ステップS508の基準値との比較判定処理の場合と同様に、ステップS512の比較判定を行わずに、「一致部」のメモリデータの訳文を表示するモードを設定してもよい。
ステップS513のような結果になるケースは、翻訳文が図9の文95、文96の場合に相当する。
すなわち、文95は、翻訳メモリデータの対原文84“@”前の文字列と一致するが、文96が“@”後の文字列と一致しているのは動詞「行う」のみである上、活用形が異なり、一致度は非常に低い。このため、翻訳文01は、翻訳文02と共にメモリデータと不一致と判定される。
If the degree of similarity is less than a certain value (No in step S512), the translation
The case where the result as in step S513 is obtained corresponds to the case where the translated sentences are the sentence 95 and the sentence 96 in FIG.
That is, the sentence 95 matches the character string before “@” in the
<翻訳メモリ検索動作−類似文一致検索>
図10の完全一致検索で一致文なしと判定された翻訳対象文に対して、図11の類似文検索を行う。以下では、図11のフローチャートを参照して類似文検索処理について説明する。文分割処理、文結合処理が行われたメモリデータが類似文としてヒットする場合については、図9の具体例を用いて説明する。
翻訳メモリ検索部10は、図10に示した完全一致検索処理で翻訳対象文と一致する文が存在しないものと判定すると、類似文検索処理を行う。
<Translation Memory Search Operation-Similar Sentence Match Search>
The similar sentence search in FIG. 11 is performed on the translation target sentence determined as having no matching sentence in the complete match search in FIG. Hereinafter, the similar sentence search process will be described with reference to the flowchart of FIG. A case where the memory data subjected to sentence division processing and sentence combination processing hit as a similar sentence will be described with reference to a specific example of FIG.
If the translation
この場合、図11に示すように、一致文なしの翻訳対象文が翻訳メモリ検索部10に入力されると(ステップS601)、翻訳メモリ検索部10は、まず、翻訳メモリ9を検索し、翻訳メモリ9に類似文はあるか否かを判定する(ステップS602)。
In this case, as shown in FIG. 11, when a translation target sentence without a matching sentence is input to the translation memory search unit 10 (step S601), the translation
ここでは、翻訳対象文とメモリデータ01との類似度が一定以上の値か否かで類似文の有無を判定する。
類似文検索での一致度は、日本語の場合、文字列の中で一致した文字数がどのくらいあるかといった文字数割合を計算で求める。また、英語の場合は文字列の中で一致した単語数がどのくらいあるかの単語数割合を計算で求める。
Here, the presence or absence of a similar sentence is determined based on whether or not the similarity between the translation target sentence and the memory data 01 is a certain value or more.
In the case of Japanese, the degree of coincidence in the similar sentence search is obtained by calculating the ratio of the number of characters such as how many characters are matched in the character string. In the case of English, the ratio of the number of words indicating how many words are matched in the character string is obtained by calculation.
活用形が異なる単語は、一定の係数をかけた上で「一致」と判定する。計算の結果として得られた類似度が、ユーザが予め設定しておいた値以上の場合(ステップS602のYes)、翻訳メモリ検索部10は、翻訳メモリ9に類似文が存在したものと判定し、類似文をメモリデータ01とする(ステップS603)。
Words with different utilization forms are determined to be “match” after being multiplied by a certain coefficient. If the similarity obtained as a result of the calculation is greater than or equal to the value set in advance by the user (Yes in step S602), the translation
また、類似度が、ユーザが予め設定しておいた値未満の場合(ステップS602のNo)、翻訳メモリ検索部10は、翻訳メモリ9に類似文が存在しないものと判定し、次に翻訳対象文とメモリデータ01の原文中の“@”の前にある文字列との類似度を判定する(ステップS604)。
翻訳対象文と“@”の前にある文字列との類似度を判定した結果でも、類似度が一定の値に満たない場合(ステップS604のNo)、翻訳メモリ検索部10は、類似文なしと判定し、類似文検索処理を終了する。
If the similarity is less than the value preset by the user (No in step S602), the translation
Even when the similarity between the sentence to be translated and the character string preceding “@” is determined, the similarity is less than a certain value (No in step S604), the translation
一方、類似文ありと判定した場合(ステップS604のYes)、翻訳メモリ検索部10は、“@”がメモリデータ01の文末にあるか否かを判定する(ステップSS605)。
On the other hand, if it is determined that there is a similar sentence (Yes in step S604), the translation
この判定の結果、“@”がメモリデータ01の文末にある場合(ステップS605のYes)、翻訳メモリ検索部10は、さらにステップS604の比較判定処理で一致しなかった翻訳文中の未一致部と、メモリデータ02との類似度を判定する(ステップS606)。
As a result of this determination, if “@” is at the end of the sentence of the memory data 01 (Yes in step S605), the translation
この判定の結果、類似度がある一定以上の値に満たない場合(ステップS606のNo)、翻訳メモリ検索部10は、類似文なしと判定し、処理を終了する。
また、類似度がある一定の値以上の場合(ステップS606のYes)、翻訳メモリ検索部10は、類似文ありと判定し、検索された類似文の特殊記号@数字@を削除し、メモリデータ01の後にメモリデータ02を結合した文を生成する(ステップS607)。
As a result of this determination, if the similarity is less than a certain value (No in step S606), the translation
If the degree of similarity is greater than or equal to a certain value (Yes in step S606), the translation
ステップS607の結果となるケースは、翻訳文が図9の文97の場合に相当する。
つまり、図9の文97の「わたしは田中ですが、」および翻訳メモリ9の対原文82「私は田中ですが、」と、文98の「かれは中田です。」および翻訳メモリ9の対原文82「彼は中田です。」とは、「私」および「彼」の表記が異なる以外は一致している。
The case resulting in step S607 corresponds to the case where the translated sentence is the sentence 97 in FIG.
That is, sentence 97 in FIG. 9 “I am Tanaka,” and translation memory 9 vs.
ステップS605の比較判定処理において、“@”がメモリデータ01の文末にない場合(ステップS605のNo)、翻訳メモリ検索部10は、さらにステップS604の比較判定処理での翻訳メモリ9の未一致部と、翻訳文02との類似度を判定する(ステップS608)。
In the comparison determination process in step S605, when “@” is not at the end of the sentence of the memory data 01 (No in step S605), the translation
類似度がある一定以上の値に満たない場合(ステップS608のNo)、翻訳メモリ検索部10は、類似文なしと判定して処理を終了する。
一方、類似度がある一定の値以上の場合(ステップS608のYes)、翻訳メモリ検索部10は、類似文ありと判定し、類似文は、翻訳文01に対してはメモリデータ01の“@”前の部分、翻訳文02に対してはメモリデータ01の“@”の後の部分とした文を生成する(ステップS609)。
ステップS609の結果になるケースは、翻訳文が図9の文98および文99の場合に相当する。
If the similarity is less than a certain value (No in step S608), the translation
On the other hand, if the degree of similarity is equal to or greater than a certain value (Yes in step S608), the translation
The case resulting from step S609 corresponds to the case where the translated sentences are the
つまり図9の文98の「あの処理は」は、メモリデータ対原文84の“@”前部分と指示語が異なるだけであり(「この」と「あの」)、文99はメモリデータの対原文84の“@”後部分と完全一致している。
That is, “that process” in the
このようにこの実施形態の翻訳支援装置によれば、翻訳メモリ9に原文とその翻訳結果を登録する際、原文に対して編集が行われていた場合、編集前の原文の状態を再現できるよう、原文を編集した文字例の位置に特殊記号(@数字@)を付加した文書(第3の文書)を生成し、それを第1の文書の編集履歴として編集履歴記憶部15に記憶する。
また、生成した第3の文書を再翻訳した翻訳結果の文書(第4の文書)を第3の文書と対応付けて翻訳メモリ9に保存(登録)するので、機械翻訳の精度を向上できると共に、編集履歴記憶部15を参照することで機械翻訳が翻訳し易くなる。
さらに、第3の文書に付加されている特殊記号を付加時の規則で削除することで原文の状態に戻せるので、原文自体に対して編集を気軽に行うことができる。さらに原文に対して文分割、文結合、用語の置換、情報の追加などの編集を気軽に行うことができる。
As described above, according to the translation support device of this embodiment, when the original text and the translation result are registered in the translation memory 9, if the original text is edited, the state of the original text before editing can be reproduced. Then, a document (third document) in which a special symbol (@ number @) is added to the position of the character example obtained by editing the original text is generated and stored in the editing
In addition, since the translation result document (fourth document) obtained by retranslating the generated third document is stored (registered) in the translation memory 9 in association with the third document, the accuracy of machine translation can be improved. Referring to the editing
Furthermore, the special text added to the third document can be restored to the original text state by deleting it according to the rules at the time of addition, so that the original text itself can be easily edited. Furthermore, editing such as sentence division, sentence combination, term replacement, and information addition can be easily performed on the original sentence.
この結果、機械翻訳の能力を十分活用し、翻訳作業の効率を高めることができる。 As a result, the ability of machine translation can be fully utilized to improve the efficiency of translation work.
1…文分割処理部、2…翻訳処理部、3…原文・訳文編集部、4…文書出力部、5…原文文書入力部、6…原文文書自動分割部、7…文分割規則テーブル、8…翻訳処理制御部、9…翻訳メモリ、10…翻訳メモリ検索部、11…機械翻訳処理部、12…翻訳用辞書、13…形態素解析、構文解析、意味解析、言語変換処理部、14…訳文生成部、15…編集履歴記憶部。
DESCRIPTION OF
Claims (9)
前記コンピュータを、
前記原文を、前記翻訳辞書に基づいて機械翻訳することで翻訳文を生成する翻訳手段と、
前記翻訳手段により前記原文と前記翻訳文を対応付けて前記翻訳メモリに保存する手段と、
前記翻訳メモリに記憶された原文および前記翻訳文のうち少なくとも一つの文にある文字列が編集された場合、その位置に、前記原文の文字列に対して編集部分を示す特殊記号を付加して特殊記号付きの原文を生成する編集手段と、
前記編集手段により生成された特殊記号付きの原文を、元の原文の編集履歴として前記編集履歴記憶部に記憶する手段
として機能させることを特徴とする翻訳支援プログラム。 In a translation support program for translating an original sentence in one language into another language by a computer having a translation dictionary, a translation memory for storing a translation result, an edit history storage section for storing an edit history for the translated sentence and the original sentence ,
The computer,
The original text, the translation means for generating a translation by the machine translation on the basis of the translation dictionary,
Means for storing in said translation memories in association with the translation and the original text by said translation means,
If the string in at least one sentence of said translation memory stored original and the translated sentence has been edited, in that position, by adding a special symbol indicating the edit portion on a string of the original Editing means for generating original text with special symbols,
A translation support program for causing an original text with a special symbol generated by the editing means to function as means for storing the original text as an editing history in the editing history storage unit.
前記コンピュータを、
前記特殊記号付きの原文を、特殊記号に従って再度翻訳して新たな翻訳文を生成する再翻訳手段と、
前記再翻訳手段により生成された新たな翻訳文を翻訳結果の文書として前記特殊記号付きの原文に対応付けて前記翻訳メモリに記憶する手段
として機能させることを特徴とする翻訳支援プログラム。 The translation support program according to claim 1,
The computer,
Re-translation means for re-translating the original sentence with the special symbol according to the special symbol to generate a new translation sentence;
A translation support program that functions as means for storing a new translated sentence generated by the retranslating means in a translation result document in association with the original sentence with the special symbol in the translation memory.
前記特殊記号は、@と@で挟まれた数字で構成されており、前記数字は、この位置に特殊記号を挿入したことを識別するための特殊記号のID番号であることを特徴とする翻訳支援プログラム。 The translation support program according to claim 1,
The special symbol is composed of a number between @ and @, and the number is an ID number of a special symbol for identifying that the special symbol is inserted at this position. Support program.
前記特殊記号付きの原文のうち、同じID番号が付いている原文同士は、編集前は繋がっていたことを示すことを特徴とする翻訳支援プログラム。 In the translation support program according to claim 3,
A translation support program characterized by showing that originals with the same ID number among originals with special symbols are connected before editing.
前記数字は、文の文節または文の結合部が検出された際に前記編集手段により連続番号で付与されることを特徴とする翻訳支援プログラム。 In the translation support program according to claim 3 or 4,
The translation support program according to claim 1, wherein the number is given by a serial number by the editing means when a sentence clause or sentence combination is detected.
前記翻訳手段による翻訳結果を前記原文と前記翻訳文とを対応付けて保存する翻訳メモリと、
前記翻訳手段により翻訳された翻訳文および原文の少なくとも一方を編集した編集履歴が記憶される編集履歴記憶部と、
前記原文および前記翻訳文のうち少なくとも一つの文にある文字列が編集された場合、その位置に、前記原文の文字列に対して編集部分を示す特殊記号を付加して特殊記号付きの原文を生成する編集手段と、
前記編集手段により生成された特殊記号付きの原文を、元の原文の編集履歴として前記編集履歴記憶部に記憶する手段と
を具備したことを特徴とする翻訳支援装置。 The original of a language, a translation means for generating a translation of the other language by machine translation based on the translation dictionary stored in advance,
A translation memory to store the translation results by the translation means in association with the translation and the original text,
An edit history storage unit for storing an edit history of editing at least one of a translated sentence and an original sentence translated by the translation unit;
If the string in at least one sentence of said original and said translation is edited, in that position, textual with special symbols by adding special symbol indicating the edit portion on a string of the original Editing means for generating
A translation support apparatus, comprising: an original history with a special symbol generated by the editing means; and means for storing the original history as an editing history of the original text in the editing history storage unit.
前記特殊記号付きの原文を、特殊記号に従って再度翻訳して新たな翻訳文を生成する再翻訳手段と、
前記再翻訳手段により生成された新たな翻訳文を翻訳結果の文書として前記特殊記号付きの原文に対応付けて前記翻訳メモリに記憶する手段と
を具備したことを特徴とする翻訳支援装置。 The translation support apparatus according to claim 6,
Re-translation means for re-translating the original sentence with the special symbol according to the special symbol to generate a new translation sentence;
A translation support apparatus, comprising: means for storing a new translated sentence generated by the retranslating means in the translation memory in association with the original sentence with the special symbol as a translation result document.
前記翻訳手段が、ある言語の原文を、予め記憶されている前期翻訳辞書に基づいて機械翻訳することで他の言語の翻訳文を生成するステップと、
前記翻訳手段が、前記原文と前記翻訳文とを対応付けて翻訳メモリに保存するステップと、
前記原文および前記翻訳文のうち少なくとも一つの文にある文字列が編集された場合、その位置に、前記原文の文字列に対して編集部分を示す特殊記号を前記編集手段が付加して特殊記号付きの原文を生成するステップと、
生成した特殊記号付きの原文を、前記編集手段が元の原文の編集履歴として編集履歴記憶部に記憶するステップと
を有することを特徴とする翻訳支援方法。 In a translation support method for translating an original text in one language into another language by a computer having a translation means, a translation dictionary, a translation memory, an editing means, and an editing history storage unit ,
It said translation means, and away step to generate a translation in other languages by machine translation based textual one language, the year translation dictionary stored in advance,
The translation means associates the original sentence with the translated sentence and stores them in a translation memory;
If the string in at least one sentence of said original and said translation is edited, in that position, a special symbol indicating an editing portion for strings of the original special added said editing means Generating a text with a symbol;
A translation support method comprising: a step of storing the generated original text with a special symbol in an editing history storage unit as an editing history of the original text.
前記特殊記号付きの原文を再翻訳手段が特殊記号に従って再度翻訳して新たな翻訳文を生成するステップと、
再度翻訳して生成した新たな翻訳文を前記編集手段が翻訳結果の文書として前記特殊記号付きの原文に対応付けて翻訳メモリに保存するステップと
を有することを特徴とする翻訳支援方法。 9. The translation support method according to claim 8, wherein said computer further comprises re-translation means,
Re-translation means re-translates the original sentence with the special symbol according to the special symbol, and generates a new translation sentence;
A translation support method, comprising: a step of storing, in a translation memory, a new translated sentence generated by re-translating the editing means in association with the original sentence with the special symbol as a translation result document.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004199606A JP3999771B2 (en) | 2004-07-06 | 2004-07-06 | Translation support program, translation support apparatus, and translation support method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004199606A JP3999771B2 (en) | 2004-07-06 | 2004-07-06 | Translation support program, translation support apparatus, and translation support method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006023844A JP2006023844A (en) | 2006-01-26 |
| JP3999771B2 true JP3999771B2 (en) | 2007-10-31 |
Family
ID=35797096
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004199606A Expired - Lifetime JP3999771B2 (en) | 2004-07-06 | 2004-07-06 | Translation support program, translation support apparatus, and translation support method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3999771B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108304388B (en) * | 2017-09-12 | 2020-07-07 | 腾讯科技(深圳)有限公司 | Machine translation method and device |
| CN111753558B (en) | 2020-06-23 | 2022-03-04 | 北京字节跳动网络技术有限公司 | Video translation method and device, storage medium and electronic equipment |
-
2004
- 2004-07-06 JP JP2004199606A patent/JP3999771B2/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006023844A (en) | 2006-01-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US4962452A (en) | Language translator which automatically recognizes, analyzes, translates and reinserts comments in a sentence | |
| EP0370774B1 (en) | Machine translation system | |
| JPS62163173A (en) | Mechanical translating device | |
| JP2007072594A (en) | Translation device, translation method, translation program and medium | |
| JP3999771B2 (en) | Translation support program, translation support apparatus, and translation support method | |
| JPH11328166A (en) | Character input device and computer-readable recording medium where character input processing program is recorded | |
| JP4881399B2 (en) | Bilingual information creation device, machine translation device, and program | |
| JP5909123B2 (en) | Machine translation apparatus, machine translation method and program | |
| JP2003058536A (en) | Translator | |
| JP3692711B2 (en) | Machine translation device | |
| JPS62203274A (en) | Mechanical translation system | |
| JP3197110B2 (en) | Natural language analyzer and machine translator | |
| JP2737160B2 (en) | Sentence processing equipment | |
| JPH087749B2 (en) | Machine translation device | |
| JP2000029882A (en) | Summary preparing device | |
| JP2608384B2 (en) | Machine translation apparatus and method | |
| JP3353873B2 (en) | Machine translation equipment | |
| JPH04259057A (en) | Document processing system | |
| JP2726416B2 (en) | Translation apparatus and translation method | |
| JPH05225232A (en) | Automatic text pre-editor | |
| JPH0773185A (en) | Machine translation system and method therefor | |
| JPH0550778B2 (en) | ||
| JPH10134054A (en) | Document preparation support device | |
| JPH07200588A (en) | Translation device | |
| JPH07122876B2 (en) | Machine translation device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20070522 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070723 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20070807 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20070809 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 3999771 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100817 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100817 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110817 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120817 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120817 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130817 Year of fee payment: 6 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| EXPY | Cancellation because of completion of term |