JP2015507255A - ステートマシンにおけるデータ解析用の方法およびシステム - Google Patents
ステートマシンにおけるデータ解析用の方法およびシステム Download PDFInfo
- Publication number
- JP2015507255A JP2015507255A JP2014547290A JP2014547290A JP2015507255A JP 2015507255 A JP2015507255 A JP 2015507255A JP 2014547290 A JP2014547290 A JP 2014547290A JP 2014547290 A JP2014547290 A JP 2014547290A JP 2015507255 A JP2015507255 A JP 2015507255A
- Authority
- JP
- Japan
- Prior art keywords
- result
- output
- data
- input
- match
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims description 35
- 238000007405 data analysis Methods 0.000 title description 2
- 238000004458 analytical method Methods 0.000 claims abstract description 30
- 238000013479 data entry Methods 0.000 claims 3
- 230000015654 memory Effects 0.000 description 63
- 239000000872 buffer Substances 0.000 description 46
- 210000004027 cell Anatomy 0.000 description 45
- 230000000875 corresponding effect Effects 0.000 description 26
- 238000001514 detection method Methods 0.000 description 25
- 239000004020 conductor Substances 0.000 description 19
- 239000013598 vector Substances 0.000 description 18
- 230000008569 process Effects 0.000 description 16
- 230000006870 function Effects 0.000 description 14
- 238000003909 pattern recognition Methods 0.000 description 14
- 238000012545 processing Methods 0.000 description 10
- 238000011144 upstream manufacturing Methods 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 6
- 210000004556 brain Anatomy 0.000 description 6
- 230000007704 transition Effects 0.000 description 6
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 4
- 230000004913 activation Effects 0.000 description 4
- 230000014509 gene expression Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 229910052710 silicon Inorganic materials 0.000 description 4
- 239000010703 silicon Substances 0.000 description 4
- 210000002569 neuron Anatomy 0.000 description 3
- 238000012856 packing Methods 0.000 description 3
- 230000003139 buffering effect Effects 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 210000000478 neocortex Anatomy 0.000 description 2
- 150000004767 nitrides Chemical class 0.000 description 2
- 241000282412 Homo Species 0.000 description 1
- 206010048669 Terminal state Diseases 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 210000003061 neural cell Anatomy 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 229910021420 polycrystalline silicon Inorganic materials 0.000 description 1
- 208000003580 polydactyly Diseases 0.000 description 1
- 229920005591 polysilicon Polymers 0.000 description 1
- 108090000623 proteins and genes Proteins 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000008672 reprogramming Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 210000001044 sensory neuron Anatomy 0.000 description 1
- 210000000697 sensory organ Anatomy 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/94—Hardware or software architectures specially adapted for image or video understanding
- G06V10/955—Hardware or software architectures specially adapted for image or video understanding using specific electronic processors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- General Physics & Mathematics (AREA)
- Biophysics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Multimedia (AREA)
- Neurology (AREA)
- Logic Circuits (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Mobile Radio Communication Systems (AREA)
Abstract
Description
Claims (29)
- 第一の結果を受信するように構成された第一のデータ入力であって、前記第一の結果は、ステートマシンの素子によってデータストリームの少なくとも一部上で実施される解析の結果である、第一のデータ入力と、
第二の結果を受信するように構成された第二のデータ入力であって、前記第二の結果は、前記ステートマシンの別の素子によって前記データストリームの少なくとも一部上で実施される解析の結果である、第二のデータ入力と、
前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された出力と、
を含むマッチ素子を含む、
ことを特徴とするデバイス。 - 前記マッチ素子は、
第一の制御信号を受信するように構成された第一の制御入力と、
第二の制御信号を受信するように構成された第二の制御入力と、
を含む、
ことを特徴とする請求項1に記載のデバイス。 - 前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された前記出力は、前記第一および第二の制御信号に基づいて、前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された前記出力を含む、
ことを特徴とする請求項2に記載のデバイス。 - 前記マッチ素子は、出力イネーブル信号を受信するように構成された第三の制御入力を含む、
ことを特徴とする請求項3に記載のデバイス。 - 前記第一および第二の制御信号に基づいて、前記第一の結果もしくは前記第二の結果を提供するように構成された前記出力は、前記第一および第二の制御信号と前記出力イネーブル信号とに基づいて、前記第一の結果もしくは前記第二の結果を提供するように構成された前記マッチ素子を含む、
ことを特徴とする請求項4に記載のデバイス。 - 前記マッチ素子は、前記第一のデータ入力、前記第二のデータ入力、前記第一の制御入力、前記第二の制御入力、前記第三の制御入力、前記出力に結合された2:1マルチプレクサを含む、
ことを特徴とする請求項4に記載のデバイス。 - 前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された前記出力は、出力を提供しないか、前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された前記出力を含む、
ことを特徴とする請求項1に記載のデバイス。 - 前記マッチ素子は、
第三の結果を受信するように構成された第三のデータ入力であって、前記第三の結果は、前記ステートマシンの第三の素子によって前記データストリームの少なくとも一部上で実施された解析の結果である、第三のデータ入力と、
第四の結果を受信するように構成された第四のデータ入力であって、前記第四の結果は、前記ステートマシンの専用素子によって検出された複数の結果の組み合わせを含む、第四のデータ入力と、
前記第三の結果もしくは前記第四の結果を選択的に提供するように構成された第二の出力と、
を含む、
ことを特徴とする請求項2に記載のデバイス。 - 前記マッチ素子は、
第三の制御信号を受信するように構成された第三の制御入力と、
第四の制御信号を受信するように構成された第四の制御入力と、
を含む、
ことを特徴とする請求項8に記載のデバイス。 - 前記第三の結果もしくは前記第四の結果を選択的に提供するように構成された前記第二の出力は、前記第三および第四の制御信号に基づいて、前記第三の結果もしくは前記第四の結果を選択的に提供するように構成された前記第二の出力を含む、
ことを特徴とする請求項9に記載のデバイス。 - 前記マッチ素子は、出力イネーブル信号を受信するように構成された第五の制御入力を含む、
ことを特徴とする請求項10に記載のデバイス。 - 前記第三および第四の制御信号に基づいて、前記第三の結果もしくは前記第四の結果を提供するように構成された前記マッチ素子は、前記第三および第四の制御信号ならびに前記出力イネーブル信号に基づいて、前記第三の結果もしくは前記第四の結果を提供するように構成された前記マッチ素子を含む、
ことを特徴とする請求項11に記載のデバイス。 - 前記マッチ素子は、前記第三のデータ入力、前記第四のデータ入力、前記第三の制御入力、前記第四の制御入力、前記第五の制御入力、前記第二の出力に結合された2:1マルチプレクサを含む、
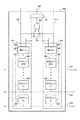
ことを特徴とする請求項11に記載のデバイス。 - データストリームの少なくとも一部上で実施される解析の第一の結果を提供するように構成された第一の素子と、
前記データストリームの少なくとも一部上で実施される解析の第二の結果を提供するように構成された第二の素子と、
マッチ素子であって、
前記第一の結果を受信するように構成された第一の入力と、
前記第二の結果を受信するように構成された第二の入力と、
前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された出力と、
を含むマッチ素子と、
を各々含む複数の行、
を各々含む複数のブロック、
を含むステートマシン、
を含む、
ことを特徴とするデバイス。 - 前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された前記出力は、出力を提供しないか、前記第一の結果もしくは前記第二の結果を選択的に提供するように構成された前記出力を含む、
ことを特徴とする請求項1に記載のデバイス。 - 前記複数の行の各々は、前記第一の素子および前記第二の素子に選択的に結合されるように構成された複数の行ルーティングラインを含む、
ことを特徴とする請求項14に記載のデバイス。 - 前記複数の行の各々は、前記第一の素子および前記第二の素子の各々に、選択された複数の行ルーティングラインを選択的に結合するように構成された複数の接合点を含む、
ことを特徴とする請求項16に記載のデバイス。 - 前記複数の接合点のうちの少なくとも一つは、前記マッチ素子へ、前記行ルーティングラインのうちの少なくとも一つを選択的に結合するように構成される、
ことを特徴とする請求項17に記載のデバイス。 - 前記複数の行の各々は、専用結果を提供するように構成された専用素子を含み、前記専用結果は、前記データストリームの少なくとも一部上で実施された解析からの複数の結果の組み合わせに基づく、
ことを特徴とする請求項14に記載のデバイス。 - 前記複数の行の各々は、前記データストリームの少なくとも一部上で実施された解析の第三の結果を提供するように構成された第三の素子を含む、
ことを特徴とする請求項19に記載のデバイス。 - 前記マッチ素子は、
前記第三の結果を受信するように構成された第三の入力と、
前記専用結果を受信するように構成された第四の入力と、
前記第三の結果もしくは前記専用結果を選択的に提供するように構成された第二の出力と、
をさらに含む、
ことを特徴とする請求項20に記載のデバイス。 - ステートマシンの第一の素子によって、データストリームの少なくとも一部上で実施された解析の第一の結果を、マッチ素子の第一のデータ入力で受信することと、
前記ステートマシンの第二の素子によって、前記データストリームの少なくとも一部上で実施された解析の第二の結果を、前記マッチ素子の第二のデータ入力で受信することと、
前記第一の結果もしくは前記第二の結果を前記マッチ素子から選択的に出力することと、
を含む、
ことを特徴とする方法。 - 前記マッチ素子で第一の制御信号を受信することと、
前記マッチ素子で第二の制御信号を受信することと、
を含む、
ことを特徴とする請求項22に記載の方法。 - 前記第一の結果もしくは前記第二の結果を前記マッチ素子から選択的に出力することは、前記第一および第二の制御信号に基づいて、前記マッチ素子から出力を出力しないか、前記第一の結果もしくは前記第二の結果を前記マッチ素子から選択的に出力することを含む、
ことを特徴とする請求項23に記載の方法。 - 前記マッチ素子で出力イネーブル信号を受信することをさらに含み、前記第一および第二の制御信号に基づいて、前記マッチ素子から出力を出力しないか、前記第一の結果もしくは前記第二の結果を前記マッチ素子から選択的に出力することは、前記第一および第二の制御信号と前記出力イネーブル信号とに基づいて、前記マッチ素子から出力を出力しないか、前記第一の結果もしくは前記第二の結果を前記マッチ素子から選択的に出力することを含む、
ことを特徴とする請求項24に記載の方法。 - 前記ステートマシンの第三の素子によって前記データストリームの少なくとも一部上で実施された解析の第三の結果を前記マッチ素子で受信することと、
前記マッチ素子で第四の結果を受信することであって、前記第四の結果は前記ステートマシンの専用素子によって検出された複数の結果の組み合わせを含む、ことと、
前記第三の結果もしくは前記第四の結果を、前記マッチ素子から選択的に出力することと、
を含む、
ことを特徴とする請求項26に記載の方法。 - 前記マッチ素子で第三の制御信号を受信することと、
前記マッチ素子で第四の制御信号を受信することと、
を含み、
前記第三の結果もしくは前記第四の結果を前記マッチ素子から選択的に出力することは、前記第三および第四の制御信号に基づいて、前記第三の結果もしくは前記第四の結果を前記マッチ素子から選択的に出力することを含む、
ことを特徴とする請求項27に記載の方法。 - 前記マッチ素子において出力イネーブル信号を受信することをさらに含み、前記第三および第四の制御信号に基づいて、前記第三の結果もしくは前記第四の結果を前記マッチ素子から選択的に出力することは、前記第三および第四の制御信号と、前記出力イネーブル信号とに基づいて、前記第三の結果もしくは前記第四の結果を前記マッチ素子から選択的に出力することを含む、
ことを特徴とする請求項28に記載の方法。 - データストリームの解析の複数の結果が一つ以上の複数のステートマシン素子で検出された複数の指示を受信するように構成された複数のデータ入力を含むマッチ素子を含む、
ことを特徴とするデバイス。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/327,591 US9443156B2 (en) | 2011-12-15 | 2011-12-15 | Methods and systems for data analysis in a state machine |
| US13/327,591 | 2011-12-15 | ||
| PCT/US2012/067999 WO2013090094A1 (en) | 2011-12-15 | 2012-12-05 | Methods and systems for data analysis in a state machine |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015507255A true JP2015507255A (ja) | 2015-03-05 |
| JP6082753B2 JP6082753B2 (ja) | 2017-02-15 |
Family
ID=47561803
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014547290A Active JP6082753B2 (ja) | 2011-12-15 | 2012-12-05 | ステートマシンにおけるデータ解析用の方法およびシステム |
Country Status (7)
| Country | Link |
|---|---|
| US (4) | US9443156B2 (ja) |
| EP (1) | EP2791781B1 (ja) |
| JP (1) | JP6082753B2 (ja) |
| KR (1) | KR101996961B1 (ja) |
| CN (2) | CN103999035B (ja) |
| TW (1) | TWI515669B (ja) |
| WO (1) | WO2013090094A1 (ja) |
Families Citing this family (38)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100138575A1 (en) | 2008-12-01 | 2010-06-03 | Micron Technology, Inc. | Devices, systems, and methods to synchronize simultaneous dma parallel processing of a single data stream by multiple devices |
| US20100174887A1 (en) | 2009-01-07 | 2010-07-08 | Micron Technology Inc. | Buses for Pattern-Recognition Processors |
| US9323994B2 (en) | 2009-12-15 | 2016-04-26 | Micron Technology, Inc. | Multi-level hierarchical routing matrices for pattern-recognition processors |
| US8489534B2 (en) * | 2009-12-15 | 2013-07-16 | Paul D. Dlugosch | Adaptive content inspection |
| US8782624B2 (en) | 2011-12-15 | 2014-07-15 | Micron Technology, Inc. | Methods and systems for detection in a state machine |
| US8593175B2 (en) | 2011-12-15 | 2013-11-26 | Micron Technology, Inc. | Boolean logic in a state machine lattice |
| US8648621B2 (en) | 2011-12-15 | 2014-02-11 | Micron Technology, Inc. | Counter operation in a state machine lattice |
| US9443156B2 (en) | 2011-12-15 | 2016-09-13 | Micron Technology, Inc. | Methods and systems for data analysis in a state machine |
| US8680888B2 (en) | 2011-12-15 | 2014-03-25 | Micron Technologies, Inc. | Methods and systems for routing in a state machine |
| US20130275709A1 (en) | 2012-04-12 | 2013-10-17 | Micron Technology, Inc. | Methods for reading data from a storage buffer including delaying activation of a column select |
| US9524248B2 (en) | 2012-07-18 | 2016-12-20 | Micron Technology, Inc. | Memory management for a hierarchical memory system |
| US9235798B2 (en) | 2012-07-18 | 2016-01-12 | Micron Technology, Inc. | Methods and systems for handling data received by a state machine engine |
| US9389841B2 (en) * | 2012-07-18 | 2016-07-12 | Micron Technology, Inc. | Methods and systems for using state vector data in a state machine engine |
| US9075428B2 (en) | 2012-08-31 | 2015-07-07 | Micron Technology, Inc. | Results generation for state machine engines |
| US9063532B2 (en) | 2012-08-31 | 2015-06-23 | Micron Technology, Inc. | Instruction insertion in state machine engines |
| US9501131B2 (en) | 2012-08-31 | 2016-11-22 | Micron Technology, Inc. | Methods and systems for power management in a pattern recognition processing system |
| US9448965B2 (en) | 2013-03-15 | 2016-09-20 | Micron Technology, Inc. | Receiving data streams in parallel and providing a first portion of data to a first state machine engine and a second portion to a second state machine |
| US9703574B2 (en) | 2013-03-15 | 2017-07-11 | Micron Technology, Inc. | Overflow detection and correction in state machine engines |
| FR3011659B1 (fr) * | 2013-10-04 | 2015-10-16 | Commissariat Energie Atomique | Circuit electronique, notamment apte a l'implementation d'un reseau de neurones, et systeme neuronal |
| US11366675B2 (en) | 2014-12-30 | 2022-06-21 | Micron Technology, Inc. | Systems and devices for accessing a state machine |
| WO2016109571A1 (en) | 2014-12-30 | 2016-07-07 | Micron Technology, Inc | Devices for time division multiplexing of state machine engine signals |
| US10430210B2 (en) | 2014-12-30 | 2019-10-01 | Micron Technology, Inc. | Systems and devices for accessing a state machine |
| CN104516820B (zh) * | 2015-01-16 | 2017-10-27 | 浪潮(北京)电子信息产业有限公司 | 一种独热码检测方法和独热码检测器 |
| US10977309B2 (en) | 2015-10-06 | 2021-04-13 | Micron Technology, Inc. | Methods and systems for creating networks |
| US10846103B2 (en) | 2015-10-06 | 2020-11-24 | Micron Technology, Inc. | Methods and systems for representing processing resources |
| US10691964B2 (en) | 2015-10-06 | 2020-06-23 | Micron Technology, Inc. | Methods and systems for event reporting |
| US10146555B2 (en) | 2016-07-21 | 2018-12-04 | Micron Technology, Inc. | Adaptive routing to avoid non-repairable memory and logic defects on automata processor |
| US10019311B2 (en) | 2016-09-29 | 2018-07-10 | Micron Technology, Inc. | Validation of a symbol response memory |
| US10268602B2 (en) | 2016-09-29 | 2019-04-23 | Micron Technology, Inc. | System and method for individual addressing |
| US10929764B2 (en) | 2016-10-20 | 2021-02-23 | Micron Technology, Inc. | Boolean satisfiability |
| US10592450B2 (en) | 2016-10-20 | 2020-03-17 | Micron Technology, Inc. | Custom compute cores in integrated circuit devices |
| US9996328B1 (en) * | 2017-06-22 | 2018-06-12 | Archeo Futurus, Inc. | Compiling and optimizing a computer code by minimizing a number of states in a finite machine corresponding to the computer code |
| US10481881B2 (en) * | 2017-06-22 | 2019-11-19 | Archeo Futurus, Inc. | Mapping a computer code to wires and gates |
| US10514914B2 (en) * | 2017-08-29 | 2019-12-24 | Gsi Technology Inc. | Method for min-max computation in associative memory |
| US10826801B1 (en) | 2019-07-31 | 2020-11-03 | Bank Of America Corporation | Multi-level data channel and inspection architectures |
| US11115310B2 (en) | 2019-08-06 | 2021-09-07 | Bank Of America Corporation | Multi-level data channel and inspection architectures having data pipes in parallel connections |
| US11470046B2 (en) | 2019-08-26 | 2022-10-11 | Bank Of America Corporation | Multi-level data channel and inspection architecture including security-level-based filters for diverting network traffic |
| CN113379047B (zh) * | 2021-05-25 | 2024-04-05 | 北京微芯智通科技合伙企业(有限合伙) | 一种实现卷积神经网络处理的系统及方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04116475A (ja) * | 1990-09-06 | 1992-04-16 | Hitachi Ltd | 半導体集積回路 |
| US20110145544A1 (en) * | 2009-12-15 | 2011-06-16 | Micron Technology, Inc. | Multi-level hierarchical routing matrices for pattern-recognition processors |
Family Cites Families (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5357512A (en) * | 1992-12-30 | 1994-10-18 | Intel Corporation | Conditional carry scheduler for round robin scheduling |
| US5790531A (en) * | 1994-12-23 | 1998-08-04 | Applied Digital Access, Inc. | Method and apparatus for determining the origin of a remote alarm indication signal |
| US6097212A (en) * | 1997-10-09 | 2000-08-01 | Lattice Semiconductor Corporation | Variable grain architecture for FPGA integrated circuits |
| US20020069379A1 (en) * | 2000-12-05 | 2002-06-06 | Cirrus Logic, Inc. | Servo data detection with improved phase shift tolerance |
| WO2003039001A1 (en) | 2001-10-29 | 2003-05-08 | Leopard Logic, Inc. | Programmable interface for field programmable gate array cores |
| US7333580B2 (en) * | 2002-01-28 | 2008-02-19 | Broadcom Corporation | Pipelined parallel processing of feedback loops in a digital circuit |
| US6880146B2 (en) * | 2003-01-31 | 2005-04-12 | Hewlett-Packard Development Company, L.P. | Molecular-wire-based restorative multiplexer, and method for constructing a multiplexer based on a configurable, molecular-junction-nanowire crossbar |
| US7305047B1 (en) * | 2003-03-12 | 2007-12-04 | Lattice Semiconductor Corporation | Automatic lane assignment for a receiver |
| US7366352B2 (en) | 2003-03-20 | 2008-04-29 | International Business Machines Corporation | Method and apparatus for performing fast closest match in pattern recognition |
| DE102004045527B4 (de) * | 2003-10-08 | 2009-12-03 | Siemens Ag | Konfigurierbare Logikschaltungsanordnung |
| US7487542B2 (en) * | 2004-01-14 | 2009-02-03 | International Business Machines Corporation | Intrusion detection using a network processor and a parallel pattern detection engine |
| US7176717B2 (en) * | 2005-01-14 | 2007-02-13 | Velogix, Inc. | Programmable logic and routing blocks with dedicated lines |
| US7358761B1 (en) * | 2005-01-21 | 2008-04-15 | Csitch Corporation | Versatile multiplexer-structures in programmable logic using serial chaining and novel selection schemes |
| US7392229B2 (en) | 2005-02-12 | 2008-06-24 | Curtis L. Harris | General purpose set theoretic processor |
| US7804719B1 (en) * | 2005-06-14 | 2010-09-28 | Xilinx, Inc. | Programmable logic block having reduced output delay during RAM write processes when programmed to function in RAM mode |
| US7276934B1 (en) * | 2005-06-14 | 2007-10-02 | Xilinx, Inc. | Integrated circuit with programmable routing structure including diagonal interconnect lines |
| US8065249B1 (en) * | 2006-10-13 | 2011-11-22 | Harris Curtis L | GPSTP with enhanced aggregation functionality |
| US7774286B1 (en) | 2006-10-24 | 2010-08-10 | Harris Curtis L | GPSTP with multiple thread functionality |
| US7735045B1 (en) * | 2008-03-12 | 2010-06-08 | Xilinx, Inc. | Method and apparatus for mapping flip-flop logic onto shift register logic |
| US8015530B1 (en) * | 2008-08-05 | 2011-09-06 | Xilinx, Inc. | Method of enabling the generation of reset signals in an integrated circuit |
| US8209521B2 (en) | 2008-10-18 | 2012-06-26 | Micron Technology, Inc. | Methods of indirect register access including automatic modification of a directly accessible address register |
| US8938590B2 (en) | 2008-10-18 | 2015-01-20 | Micron Technology, Inc. | Indirect register access method and system |
| US7970964B2 (en) | 2008-11-05 | 2011-06-28 | Micron Technology, Inc. | Methods and systems to accomplish variable width data input |
| US9639493B2 (en) | 2008-11-05 | 2017-05-02 | Micron Technology, Inc. | Pattern-recognition processor with results buffer |
| US7917684B2 (en) | 2008-11-05 | 2011-03-29 | Micron Technology, Inc. | Bus translator |
| US20100118425A1 (en) | 2008-11-11 | 2010-05-13 | Menachem Rafaelof | Disturbance rejection in a servo control loop using pressure-based disc mode sensor |
| US9348784B2 (en) | 2008-12-01 | 2016-05-24 | Micron Technology, Inc. | Systems and methods for managing endian mode of a device |
| US9164945B2 (en) | 2008-12-01 | 2015-10-20 | Micron Technology, Inc. | Devices, systems, and methods to synchronize parallel processing of a single data stream |
| US10007486B2 (en) * | 2008-12-01 | 2018-06-26 | Micron Technology, Inc. | Systems and methods to enable identification of different data sets |
| US20100138575A1 (en) | 2008-12-01 | 2010-06-03 | Micron Technology, Inc. | Devices, systems, and methods to synchronize simultaneous dma parallel processing of a single data stream by multiple devices |
| US8140780B2 (en) | 2008-12-31 | 2012-03-20 | Micron Technology, Inc. | Systems, methods, and devices for configuring a device |
| US20100174887A1 (en) | 2009-01-07 | 2010-07-08 | Micron Technology Inc. | Buses for Pattern-Recognition Processors |
| US8281395B2 (en) * | 2009-01-07 | 2012-10-02 | Micron Technology, Inc. | Pattern-recognition processor with matching-data reporting module |
| US8214672B2 (en) | 2009-01-07 | 2012-07-03 | Micron Technology, Inc. | Method and systems for power consumption management of a pattern-recognition processor |
| US8843523B2 (en) | 2009-01-12 | 2014-09-23 | Micron Technology, Inc. | Devices, systems, and methods for communicating pattern matching results of a parallel pattern search engine |
| US8146040B1 (en) * | 2009-06-11 | 2012-03-27 | Xilinx, Inc. | Method of evaluating an architecture for an integrated circuit device |
| US9836555B2 (en) | 2009-06-26 | 2017-12-05 | Micron Technology, Inc. | Methods and devices for saving and/or restoring a state of a pattern-recognition processor |
| US8489534B2 (en) | 2009-12-15 | 2013-07-16 | Paul D. Dlugosch | Adaptive content inspection |
| US9501705B2 (en) | 2009-12-15 | 2016-11-22 | Micron Technology, Inc. | Methods and apparatuses for reducing power consumption in a pattern recognition processor |
| US8601013B2 (en) * | 2010-06-10 | 2013-12-03 | Micron Technology, Inc. | Analyzing data using a hierarchical structure |
| US8766666B2 (en) * | 2010-06-10 | 2014-07-01 | Micron Technology, Inc. | Programmable device, hierarchical parallel machines, and methods for providing state information |
| US8294490B1 (en) * | 2010-10-01 | 2012-10-23 | Xilinx, Inc. | Integrated circuit and method of asynchronously routing data in an integrated circuit |
| US8726256B2 (en) | 2011-01-25 | 2014-05-13 | Micron Technology, Inc. | Unrolling quantifications to control in-degree and/or out-degree of automaton |
| JP5763784B2 (ja) * | 2011-01-25 | 2015-08-12 | マイクロン テクノロジー, インク. | 要素利用のための状態のグループ化 |
| CN103547999B (zh) | 2011-01-25 | 2017-05-17 | 美光科技公司 | 利用专用元件实施有限状态机 |
| JP5763783B2 (ja) * | 2011-01-25 | 2015-08-12 | マイクロン テクノロジー, インク. | 正規表現をコンパイルするための方法および装置 |
| US8782624B2 (en) | 2011-12-15 | 2014-07-15 | Micron Technology, Inc. | Methods and systems for detection in a state machine |
| US8648621B2 (en) | 2011-12-15 | 2014-02-11 | Micron Technology, Inc. | Counter operation in a state machine lattice |
| US9443156B2 (en) | 2011-12-15 | 2016-09-13 | Micron Technology, Inc. | Methods and systems for data analysis in a state machine |
| US8593175B2 (en) | 2011-12-15 | 2013-11-26 | Micron Technology, Inc. | Boolean logic in a state machine lattice |
| US8680888B2 (en) * | 2011-12-15 | 2014-03-25 | Micron Technologies, Inc. | Methods and systems for routing in a state machine |
| US8536896B1 (en) * | 2012-05-31 | 2013-09-17 | Xilinx, Inc. | Programmable interconnect element and method of implementing a programmable interconnect element |
-
2011
- 2011-12-15 US US13/327,591 patent/US9443156B2/en active Active
-
2012
- 2012-12-05 CN CN201280062293.5A patent/CN103999035B/zh active Active
- 2012-12-05 EP EP12816168.4A patent/EP2791781B1/en active Active
- 2012-12-05 KR KR1020147018494A patent/KR101996961B1/ko active IP Right Grant
- 2012-12-05 CN CN201710652791.XA patent/CN107609644B/zh active Active
- 2012-12-05 JP JP2014547290A patent/JP6082753B2/ja active Active
- 2012-12-05 WO PCT/US2012/067999 patent/WO2013090094A1/en active Application Filing
- 2012-12-14 TW TW101147678A patent/TWI515669B/zh active
-
2016
- 2016-09-12 US US15/262,958 patent/US9870530B2/en active Active
-
2018
- 2018-01-15 US US15/871,660 patent/US10733508B2/en active Active
-
2020
- 2020-06-30 US US16/917,221 patent/US11977977B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04116475A (ja) * | 1990-09-06 | 1992-04-16 | Hitachi Ltd | 半導体集積回路 |
| US20110145544A1 (en) * | 2009-12-15 | 2011-06-16 | Micron Technology, Inc. | Multi-level hierarchical routing matrices for pattern-recognition processors |
Also Published As
| Publication number | Publication date |
|---|---|
| US10733508B2 (en) | 2020-08-04 |
| TW201333838A (zh) | 2013-08-16 |
| KR20140104991A (ko) | 2014-08-29 |
| CN103999035A (zh) | 2014-08-20 |
| EP2791781B1 (en) | 2021-07-14 |
| US9870530B2 (en) | 2018-01-16 |
| CN107609644A (zh) | 2018-01-19 |
| KR101996961B1 (ko) | 2019-07-05 |
| WO2013090094A1 (en) | 2013-06-20 |
| CN103999035B (zh) | 2017-09-22 |
| CN107609644B (zh) | 2021-03-16 |
| US9443156B2 (en) | 2016-09-13 |
| TWI515669B (zh) | 2016-01-01 |
| US20200334533A1 (en) | 2020-10-22 |
| US20160379114A1 (en) | 2016-12-29 |
| US20130159239A1 (en) | 2013-06-20 |
| US20180137416A1 (en) | 2018-05-17 |
| JP6082753B2 (ja) | 2017-02-15 |
| EP2791781A1 (en) | 2014-10-22 |
| US11977977B2 (en) | 2024-05-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11977977B2 (en) | Methods and systems for data analysis in a state machine | |
| JP6126127B2 (ja) | ステートマシンにおけるルーティング用の方法およびシステム | |
| US9817678B2 (en) | Methods and systems for detection in a state machine | |
| JP6154824B2 (ja) | ステートマシンラチスにおけるブール型論理 | |
| JP6207605B2 (ja) | 状態機械エンジンをプログラミングするための方法およびデバイス | |
| JP6109186B2 (ja) | 状態機械格子におけるカウンタ動作 | |
| JP6041987B2 (ja) | 状態機械エンジンにおいて状態ベクトルデータを使用するための方法およびシステム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150903 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160727 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160802 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161006 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161101 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161214 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170117 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170123 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6082753 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |