JP2014149713A - 画像評価装置 - Google Patents
画像評価装置 Download PDFInfo
- Publication number
- JP2014149713A JP2014149713A JP2013018446A JP2013018446A JP2014149713A JP 2014149713 A JP2014149713 A JP 2014149713A JP 2013018446 A JP2013018446 A JP 2013018446A JP 2013018446 A JP2013018446 A JP 2013018446A JP 2014149713 A JP2014149713 A JP 2014149713A
- Authority
- JP
- Japan
- Prior art keywords
- image
- feature amount
- information
- information indicating
- text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000011156 evaluation Methods 0.000 title claims abstract description 247
- 238000004364 calculation method Methods 0.000 claims abstract description 37
- 230000008921 facial expression Effects 0.000 claims description 18
- 238000010801 machine learning Methods 0.000 claims description 11
- 238000003860 storage Methods 0.000 description 85
- 238000000034 method Methods 0.000 description 34
- 239000013598 vector Substances 0.000 description 14
- 238000012545 processing Methods 0.000 description 9
- 238000004220 aggregation Methods 0.000 description 8
- 230000002776 aggregation Effects 0.000 description 8
- 238000010586 diagram Methods 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 5
- 101100082911 Schizosaccharomyces pombe (strain 972 / ATCC 24843) ppp1 gene Proteins 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 238000012706 support-vector machine Methods 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
Images














Abstract
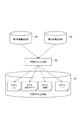
【解決手段】画像評価装置1は、第1の画像に対するテキストを入力して、当該テキストの数を集計する集計部31と、第1の画像の特徴量を示す情報を取得する第1特徴量取得部34と、第1特徴量取得部34によって取得された特徴量を説明変数に対応する情報、及び集計部31によって集計された数に基づく情報を目的変数に対応する情報とした学習用データを用いて機械学習を実行して、任意の画像の特徴量を入力としてスコアを出力する学習モデルを生成する学習モデル生成部36と、第2の画像の特徴量を示す情報を取得する第2特徴量取得部52と、学習モデル生成部36によって生成された学習モデルに、第2特徴量取得部52によって取得された特徴量を説明変数として入力して、当該学習モデルの出力から第2の画像のスコアを算出するスコア算出部54と、を備える。
【選択図】図1
Description
Claims (10)
- 第1の画像に対するテキストを入力して、当該テキストの数を集計する第1の集計手段と、
前記第1の画像の特徴量を示す情報を取得する第1の特徴量取得手段と、
前記第1の特徴量取得手段によって取得された特徴量を説明変数に対応する情報、及び前記第1の集計手段によって集計された数に基づく情報を目的変数に対応する情報とした学習用データを用いて機械学習を実行して、任意の画像の特徴量を入力としてスコアを出力する学習モデルを生成する学習モデル生成手段と、
第2の画像の特徴量を示す情報を取得する第2の特徴量取得手段と、
前記学習モデル生成手段によって生成された学習モデルに、前記第2の特徴量取得手段によって取得された特徴量を説明変数として入力して、当該学習モデルの出力から前記第2の画像のスコアを算出するスコア算出手段と、
を備える画像評価装置。 - 前記第1の画像の分類を示す情報を取得する第1の分類情報取得手段と、
前記第2の画像の分類を示す情報を取得する第2の分類情報取得手段と、を更に備え、
前記学習モデル生成手段は、第1の分類情報取得手段によって取得された情報によって示される前記第1の画像の分類に応じて学習モデルを生成し、
前記スコア算出手段は、第2の分類情報取得手段によって取得された情報によって示される前記第2の画像の分類に応じた学習モデルを用いて前記第2の画像のスコアを算出する、請求項1に記載の画像評価装置。 - 前記第1の特徴量取得手段は、前記第1の画像を入力して、入力した第1の画像から特徴量を算出して、当該特徴量を示す情報を取得し、
前記第2の特徴量取得手段は、前記第2の画像を入力して、入力した第2の画像から特徴量を算出して、当該特徴量を示す情報を取得する、請求項1又は2に記載の画像評価装置。 - 前記第1の特徴量取得手段は、前記第1の画像の解像度を示す情報を取得し、当該画像の解像度を示す情報に基づいて前記第1の画像の特徴量を示す情報を生成し、
前記第2の特徴量取得手段は、前記第2の画像の解像度を示す情報を取得し、当該画像の解像度を示す情報に基づいて前記第2の画像の特徴量を示す情報を生成する、請求項1〜3の何れか一項に記載の画像評価装置。 - 前記第1の特徴量取得手段は、前記第1の画像に写っている物体の数を示す情報を取得し、当該物体の数を示す情報に基づいて前記第1の画像の特徴量を示す情報を生成し、
前記第2の特徴量取得手段は、前記第2の画像に写っている物体の数を示す情報を取得し、当該物体の数を示す情報に基づいて前記第2の画像の特徴量を示す情報を生成する、請求項1〜4の何れか一項に記載の画像評価装置。 - 前記第1の特徴量取得手段は、前記第1の画像に写っている人の表情を示す情報を取得し、当該人の表情を示す情報に基づいて前記第1の画像の特徴量を示す情報を生成し、
前記第2の特徴量取得手段は、前記第2の画像に写っている人の表情を示す情報を取得し、当該人の表情を示す情報に基づいて前記第2の画像の特徴量を示す情報を生成する、請求項1〜5の何れか一項に記載の画像評価装置。 - 前記第1の特徴量取得手段は、前記第1の画像に対するテキストを入力して、当該テキストに基づいて前記第1の画像の特徴量を示す情報を生成し、
前記第2の特徴量取得手段は、前記第2の画像に対するテキストを入力して、当該テキストに基づいて前記第2の画像の特徴量を示す情報を生成する、請求項1〜6の何れか一項に記載の画像評価装置。 - 前記第1の特徴量取得手段は、前記第1の画像に対するテキストの内容がネガティブなものか、ポジティブなものかを判定し、当該判定結果に基づいて前記第1の画像の特徴量を示す情報を生成し、
前記第2の特徴量取得手段は、前記第2の画像に対するテキストの内容がネガティブなものか、ポジティブなものかを判定し、当該判定結果に基づいて前記第2の画像の特徴量を示す情報を生成する、請求項7に記載の画像評価装置。 - 第2の画像に対するテキストを入力して、当該第2の画像毎のテキストの数を集計する第2の集計手段と、
前記スコア算出手段によって算出された前記第2の画像のスコア、及び前記第2の集計手段によって集計された数に基づいて、前記第2の画像の総合スコアを算出する総合スコア算出手段と、を更に備える、請求項1〜8の何れか一項に記載の画像評価装置。 - 第2の画像を複数取得する画像取得手段と、
前記画像取得手段によって取得された第2の画像に対するテキストを取得するテキスト取得手段と、
前記画像取得手段によって取得された第2の画像と、前記テキスト取得手段によって取得されたテキストとに基づいて、前記第2の画像同士が類似するか否かを判定する類似判定手段と、
前記類似判定手段によって類似すると判定された複数の第2の画像について、前記スコア算出手段によって算出されたスコアに基づいて、当該複数の第2の画像を代表する代表画像を決定する代表画像決定手段と、
を更に備える請求項1〜9の何れか一項に記載の画像評価装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013018446A JP6033697B2 (ja) | 2013-02-01 | 2013-02-01 | 画像評価装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013018446A JP6033697B2 (ja) | 2013-02-01 | 2013-02-01 | 画像評価装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014149713A true JP2014149713A (ja) | 2014-08-21 |
| JP6033697B2 JP6033697B2 (ja) | 2016-11-30 |
Family
ID=51572628
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013018446A Active JP6033697B2 (ja) | 2013-02-01 | 2013-02-01 | 画像評価装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6033697B2 (ja) |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016151640A1 (ja) * | 2015-03-26 | 2016-09-29 | 日本電気株式会社 | 学習システム、方法およびプログラム |
| JP2017135505A (ja) * | 2016-01-26 | 2017-08-03 | ヤフー株式会社 | 生成装置、生成方法、及び生成プログラム |
| KR101831821B1 (ko) * | 2016-10-04 | 2018-02-23 | 한국과학기술원 | 삼차원 모델의 대표 이미지 생성 장치 및 방법 |
| JP2019053409A (ja) * | 2017-09-13 | 2019-04-04 | ヤフー株式会社 | 付与装置、付与方法、付与プログラム、及びモデル |
| JP2019531783A (ja) * | 2016-08-26 | 2019-11-07 | エレクタ、インク.Elekta, Inc. | 畳み込みニューラルネットワークを用いた画像セグメンテーションのためのシステムおよび方法 |
| JP2019219945A (ja) * | 2018-06-20 | 2019-12-26 | Zホールディングス株式会社 | データ抽出装置、データ抽出方法、及びプログラム |
| WO2020039476A1 (ja) * | 2018-08-20 | 2020-02-27 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、学習装置、メッセージ出力方法、学習方法及びプログラム |
| CN113226153A (zh) * | 2018-12-26 | 2021-08-06 | 佳能株式会社 | 图像处理装置、图像处理方法和程序 |
| JP2021128723A (ja) * | 2020-02-17 | 2021-09-02 | ヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
| JP2022048237A (ja) * | 2018-08-20 | 2022-03-25 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、メッセージ出力方法及びプログラム |
| JP7475405B2 (ja) | 2022-09-20 | 2024-04-26 | Lineヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007279930A (ja) * | 2006-04-05 | 2007-10-25 | Hitachi Ltd | 画像処理プログラム、画像処理装置 |
| JP2009282824A (ja) * | 2008-05-23 | 2009-12-03 | Toyota Central R&D Labs Inc | 感情推定装置及びプログラム |
-
2013
- 2013-02-01 JP JP2013018446A patent/JP6033697B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007279930A (ja) * | 2006-04-05 | 2007-10-25 | Hitachi Ltd | 画像処理プログラム、画像処理装置 |
| JP2009282824A (ja) * | 2008-05-23 | 2009-12-03 | Toyota Central R&D Labs Inc | 感情推定装置及びプログラム |
Non-Patent Citations (2)
| Title |
|---|
| JPN6016026624; 石原のぞみ、外4名: 'ウェブ上の類似画像に付加されたメタ情報に基づく画像スコアリング' インタラクション2011予稿集[online] , 20110311, 一般社団法人情報処理学会 * |
| JPN7016001926; Pedro, Jose San. et al.: 'Ranking and Classifying Attractiveness of Photos in Folksonomies' Proceedings of the 18th international conference on World Wide Web , 20090420, pp.771-780, ACM * |
Cited By (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016151640A1 (ja) * | 2015-03-26 | 2016-09-29 | 日本電気株式会社 | 学習システム、方法およびプログラム |
| JPWO2016151640A1 (ja) * | 2015-03-26 | 2017-10-26 | 日本電気株式会社 | 学習システム、方法およびプログラム |
| JP2017135505A (ja) * | 2016-01-26 | 2017-08-03 | ヤフー株式会社 | 生成装置、生成方法、及び生成プログラム |
| JP2019531783A (ja) * | 2016-08-26 | 2019-11-07 | エレクタ、インク.Elekta, Inc. | 畳み込みニューラルネットワークを用いた画像セグメンテーションのためのシステムおよび方法 |
| KR101831821B1 (ko) * | 2016-10-04 | 2018-02-23 | 한국과학기술원 | 삼차원 모델의 대표 이미지 생성 장치 및 방법 |
| JP2019053409A (ja) * | 2017-09-13 | 2019-04-04 | ヤフー株式会社 | 付与装置、付与方法、付与プログラム、及びモデル |
| JP2019219945A (ja) * | 2018-06-20 | 2019-12-26 | Zホールディングス株式会社 | データ抽出装置、データ抽出方法、及びプログラム |
| JP7181014B2 (ja) | 2018-06-20 | 2022-11-30 | ヤフー株式会社 | データ抽出装置、データ抽出方法、及びプログラム |
| JPWO2020039476A1 (ja) * | 2018-08-20 | 2021-05-13 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、学習装置、メッセージ出力方法、学習方法及びプログラム |
| JP7014913B2 (ja) | 2018-08-20 | 2022-02-01 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、学習装置、メッセージ出力方法、学習方法及びプログラム |
| JP2022048237A (ja) * | 2018-08-20 | 2022-03-25 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、メッセージ出力方法及びプログラム |
| WO2020039476A1 (ja) * | 2018-08-20 | 2020-02-27 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、学習装置、メッセージ出力方法、学習方法及びプログラム |
| JP7285349B2 (ja) | 2018-08-20 | 2023-06-01 | 株式会社ソニー・インタラクティブエンタテインメント | メッセージ出力装置、メッセージ出力方法及びプログラム |
| US11711328B2 (en) | 2018-08-20 | 2023-07-25 | Sony Interactive Entertainment Inc. | Message output apparatus, learning apparatus, message output method, learning method, and program |
| CN113226153A (zh) * | 2018-12-26 | 2021-08-06 | 佳能株式会社 | 图像处理装置、图像处理方法和程序 |
| JP2021128723A (ja) * | 2020-02-17 | 2021-09-02 | ヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
| JP7144468B2 (ja) | 2020-02-17 | 2022-09-29 | ヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
| JP7475405B2 (ja) | 2022-09-20 | 2024-04-26 | Lineヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6033697B2 (ja) | 2016-11-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6033697B2 (ja) | 画像評価装置 | |
| KR102092691B1 (ko) | 웹페이지 트레이닝 방법 및 기기, 그리고 검색 의도 식별 방법 및 기기 | |
| JP6240916B2 (ja) | 視覚的クエリーに応答したテキスト用語の識別 | |
| Cappallo et al. | New modality: Emoji challenges in prediction, anticipation, and retrieval | |
| JP6381775B2 (ja) | 情報処理システム及び情報処理方法 | |
| JP6506439B1 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| WO2021019831A1 (ja) | 管理システム及び管理方法 | |
| US9483740B1 (en) | Automated data classification | |
| JP6767342B2 (ja) | 検索装置、検索方法および検索プログラム | |
| WO2013080214A1 (en) | Topic extraction and video association | |
| JP6529133B2 (ja) | 複数地域でのトピックの評価を分析する装置、プログラム及び方法 | |
| WO2016114790A1 (en) | Reading difficulty level based resource recommendation | |
| CN114238573B (zh) | 基于文本对抗样例的信息推送方法及装置 | |
| US10289624B2 (en) | Topic and term search analytics | |
| JP5048852B2 (ja) | 検索装置、検索方法、検索プログラム、及びそのプログラムを記憶するコンピュータ読取可能な記録媒体 | |
| US9516089B1 (en) | Identifying and processing a number of features identified in a document to determine a type of the document | |
| JP5952756B2 (ja) | 予測対象コンテンツにおける将来的なコメント数を予測する予測サーバ、プログラム及び方法 | |
| CN110647504B (zh) | 司法文书的检索方法及装置 | |
| JP5138621B2 (ja) | 情報処理装置及び不満解決商品発見方法及びプログラム | |
| JP2016076115A (ja) | 情報処理装置、情報処理方法及びプログラム | |
| EP3731108A1 (en) | Search system, search method, and program | |
| JP6696270B2 (ja) | 情報提供サーバ装置、プログラム及び情報提供方法 | |
| KR101318843B1 (ko) | 시간 정보를 활용한 블로그 카테고리 분류 방법 및 장치 | |
| JP6696344B2 (ja) | 情報処理装置及びプログラム | |
| JP2017068862A (ja) | 情報処理装置、情報処理方法、及び情報処理プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150814 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160627 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160712 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160909 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20161004 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20161026 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6033697 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |