JP2013500524A - 周辺相互接続におけるi/o及び計算負荷軽減デバイスのための2レベルのアドレストランスレーションを用いるiommu - Google Patents
周辺相互接続におけるi/o及び計算負荷軽減デバイスのための2レベルのアドレストランスレーションを用いるiommu Download PDFInfo
- Publication number
- JP2013500524A JP2013500524A JP2012521868A JP2012521868A JP2013500524A JP 2013500524 A JP2013500524 A JP 2013500524A JP 2012521868 A JP2012521868 A JP 2012521868A JP 2012521868 A JP2012521868 A JP 2012521868A JP 2013500524 A JP2013500524 A JP 2013500524A
- Authority
- JP
- Japan
- Prior art keywords
- guest
- translation
- request
- control logic
- address
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000013519 translation Methods 0.000 title claims abstract description 154
- 230000002093 peripheral effect Effects 0.000 title claims description 16
- 230000015654 memory Effects 0.000 claims abstract description 178
- 230000014616 translation Effects 0.000 claims abstract description 153
- 238000012545 processing Methods 0.000 claims abstract description 20
- 238000000034 method Methods 0.000 claims description 24
- 230000008569 process Effects 0.000 claims description 17
- 230000006658 host protein synthesis Effects 0.000 claims description 13
- 230000004044 response Effects 0.000 claims description 10
- 238000004519 manufacturing process Methods 0.000 claims 1
- 238000010586 diagram Methods 0.000 description 16
- 238000012986 modification Methods 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 230000006870 function Effects 0.000 description 7
- 230000007246 mechanism Effects 0.000 description 5
- 239000000872 buffer Substances 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000013507 mapping Methods 0.000 description 4
- 230000001427 coherent effect Effects 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 238000013459 approach Methods 0.000 description 1
- 238000013480 data collection Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G06F12/1081—Address translation for peripheral access to main memory, e.g. direct memory access [DMA]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G06F12/1009—Address translation using page tables, e.g. page table structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/0223—User address space allocation, e.g. contiguous or non contiguous base addressing
- G06F12/0292—User address space allocation, e.g. contiguous or non contiguous base addressing using tables or multilevel address translation means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/06—Addressing a physical block of locations, e.g. base addressing, module addressing, memory dedication
- G06F12/0615—Address space extension
- G06F12/063—Address space extension for I/O modules, e.g. memory mapped I/O
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0866—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches for peripheral storage systems, e.g. disk cache
- G06F12/0868—Data transfer between cache memory and other subsystems, e.g. storage devices or host systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0877—Cache access modes
- G06F12/0882—Page mode
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0893—Caches characterised by their organisation or structure
- G06F12/0897—Caches characterised by their organisation or structure with two or more cache hierarchy levels
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0629—Configuration or reconfiguration of storage systems
- G06F3/0631—Configuration or reconfiguration of storage systems by allocating resources to storage systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0638—Organizing or formatting or addressing of data
- G06F3/064—Management of blocks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/067—Distributed or networked storage systems, e.g. storage area networks [SAN], network attached storage [NAS]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/0671—In-line storage system
- G06F3/0683—Plurality of storage devices
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Abstract
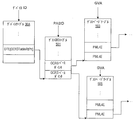
コンピュータシステムのシステムメモリへのI/Oデバイスによる要求を制御するためのIOMMUは、制御論理及びキャッシュメモリを含む。制御論理は、I/Oデバイスからの要求において受信されるアドレスをトランスレートしてよい。要求が処理アドレス空間識別子(PASID)プレフィックスを伴うトランザクション層プロトコル(TLP)パケットを含む場合には、制御論理は2レベルのゲストトランスレーションを実行してよい。従って、制御論理は、ゲストページテーブルのセットにアクセスして、要求において受信されるアドレスをトランスレートしてよい。最後のゲストページテーブル内のポインタは、入れ子にされたページテーブルのセット内の第1のテーブルを指し示す。制御論理は、入れ子にされたページテーブルのセットにアクセスしてシステムメモリ内の物理ページに対応するシステム物理アドレス(SPA)を得るために、最後のゲストページテーブル内のポインタを用いてよい。キャッシュメモリは完了したトランスレーションを記憶する。
【選択図】図5
Description
Claims (21)
- コンピュータシステムのシステムメモリへのI/Oデバイスによる要求を制御するための入力/出力(I/O)メモリ管理ユニット(IOMMU)であって、
前記I/Oデバイスからの要求において受信されるアドレスをトランスレートするように構成される制御論理と、
前記制御論理に結合され完了したトランスレーションを記憶するように構成されるキャッシュメモリとを備え、
処理アドレス空間識別子(PASID)プレフィックスを含むトランザクション層プロトコル(TLP)パケットを前記要求において受信することに応答して、前記制御論理は2レベルのゲストトランスレーションを実行するように構成され、
前記制御論理は前記要求において受信される前記アドレスをトランスレートするためにゲストページテーブルのセットにアクセスするように構成され、最後のゲストページテーブル内のポインタは入れ子にされたページテーブルのセット内の第1のテーブルを指し示し、
前記制御論理は、入れ子にされたページテーブルの前記セットにアクセスして前記システムメモリ内の物理ページに対応するシステム物理アドレス(SPA)を得るために、最後のゲストページテーブル内の前記ポインタを用いるように構成されるIOMMU。 - ゲストページテーブルの前記セットは1つ以上のエントリを有するデバイステーブルを含み、各エントリはゲストテーブルの前記セットの第1のゲストトランスレーションテーブルへのポインタを記憶するように構成され、前記ポインタは前記コンピュータシステムのプロセッサで実行中の仮想メモリモニタ(VMM)によってマッピングされるアドレス空間に対応するSPAを備える請求項1に記載のIOMMU。
- 入れ子にされたページテーブルの前記セット内の第1のテーブルへの前記ポインタは、前記プロセッサ上の仮想マシン(VM)で実行中のゲストオペレーティングシステムによってマッピングされるアドレス空間に対応するゲスト物理アドレス(GPA)を備える請求項2に記載のIOMMU。
- 前記要求において受信される前記アドレスはゲスト仮想アドレス(GVA)を備え、GVAは前記プロセッサ上の仮想マシン(VM)で実行中のゲストアプリケーションによってマッピングされるアドレス空間に対応し、前記制御論理は前記2レベルのゲストトランスレーションを用いて前記GVAをSPAへトランスレートするように構成される請求項2に記載のIOMMU。
- 前記TLPパケットは、プレフィックスフィールド、ヘッダフィールド、データペイロードフィールド、及び随意的なダイジェストフィールドを有するパケットを備え、前記TLPパケットは、周辺コンポーネント相互接続エクスプレス(PCIe)リンク上で前記I/Oデバイスから前記IOMMUへ伝達される請求項1に記載のIOMMU。
- 前記制御論理は前記I/O要求において受信される前記アドレスのビットのサブセットを前記システムメモリ内の物理ページに対応する前記SPAと連結して最終的なトランスレーションアドレスを提供するように更に構成される請求項1に記載のIOMMU。
- 前記TLPパケット内にPASIDプレフィックスを有していないI/Oを受信することに応答して、前記制御論理は1レベルのトランスレーションを実行するように構成され、前記制御論理は所与の要求に対してデバイステーブルエントリ内の別のポインタにアクセスするように構成され、前記別のポインタはホストトランスレーションページテーブルのセットへのポインタを備える請求項2に記載のIOMMU。
- 前記ホストトランスレーションページテーブルの少なくとも幾つかは次の連続的なホストトランスレーションテーブルへのSPAポインタを有するエントリを含む請求項7に記載のIOMMU。
- プロセッサと、
前記プロセッサに結合されトランスレーションデータを記憶するように構成されるシステムメモリと、
前記システムメモリにアクセスするための要求を生成するように構成される少なくとも1つのI/Oデバイスと、
前記I/Oデバイス及び前記システムメモリに結合されるI/Oメモリ管理ユニット(IOMMU)と、
前記制御論理に結合され完了したトランスレーションを記憶するように構成されるキャッシュメモリとを備え、
前記IOMMUは前記I/Oデバイスからの前記要求において受信されるアドレスをトランスレートするように構成される制御論理を含み、
処理アドレス空間識別子(PASID)プレフィックスを含むトランザクション層プロトコル(TLP)パケットを前記要求において受信することに応答して、前記制御論理は2レベルのゲストトランスレーションを実行するように構成され、
前記制御論理は前記要求において受信される前記アドレスをトランスレートするためにゲストページテーブルのセットにアクセスするように構成され、最後のゲストページテーブル内のポインタは入れ子にされたページテーブルのセット内の第1のテーブルを指し示し、
前記制御論理は、入れ子にされたページテーブルの前記セットにアクセスして前記システムメモリ内の物理ページに対応するシステム物理アドレス(SPA)を得るために、最後のゲストページテーブル内の前記ポインタを用いるように構成されるシステム。 - 前記制御論理は任意のトランスレーションを実行する前にトランスレーションのために前記キャッシュメモリを検索するように構成され、ページレベル特権が変化したことを決定することに応答して、前記制御論理は前記トランスレーションを実行して最終的なトランスレーションアドレスを得るように更に構成される請求項9に記載のシステム。
- 前記システムメモリは、前記プロセッサで実行中の仮想メモリモニタ(VMM)によってマッピングされるアドレス空間に対応する前記SPAと、前記プロセッサ上の仮想マシン(VM)で実行中のゲストオペレーティングシステムによってマッピングされるアドレス空間に対応するゲスト物理アドレス(GPA)と、前記プロセッサ上の仮想マシン(VM)で実行中のゲストアプリケーションによってマッピングされるアドレス空間に対応するゲスト仮想アドレス(GVA)とを含む複数のアドレス空間内へマッピングされる請求項9に記載のシステム。
- 前記GVAを含むI/O要求は、TLP_PASIDプレフィックスを含むことによって前記GVAを表示し、前記GPAを含むI/O要求は、TLP_PASIDプレフィックスを省略することによって前記GPAを表示する請求項11に記載のシステム。
- 前記要求において受信される前記アドレスはGVAを備え、前記制御論理は前記2レベルのゲストトランスレーションを用いて前記GVAをSPAへトランスレートするように構成される請求項9に記載のシステム。
- 前記TLPパケットは、プレフィックスフィールド、ヘッダフィールド、データペイロードフィールド、及び随意的なダイジェストフィールドを有するパケットを備え、前記TLPパケットは、周辺コンポーネント相互接続エクスプレス(PCIe)リンク上で前記I/Oデバイスから前記IOMMUへ伝達される請求項9に記載のシステム。
- コンピュータシステムのシステムメモリへのI/Oデバイスによる要求を制御するための入力/出力(I/O)メモリ管理ユニット(IOMMU)であって、
前記I/Oデバイスからの要求において受信されるアドレスをトランスレートするように構成される制御論理と、
前記制御論理に結合され完了したトランスレーションを記憶するように構成されるキャッシュメモリとを備え、
処理アドレス空間識別子(PASID)プレフィックスを含むトランザクション層プロトコル(TLP)パケットを前記要求において受信することに応答して、前記制御論理はシステムメモリ内に記憶されるトランスレーションデータを用いて2レベルのゲストトランスレーションを実行するように構成され、
前記トランスレーションデータは、デバイスデータ構造内の1つ以上のデバイステーブルエントリと、ゲストページデータ構造のセット及び入れ子にされたページデータ構造のセットを含んでいるI/Oページデータ構造の第1のセットとを含み、
前記制御論理は、
所与の要求を生成するI/Oデバイスに対応するデバイス識別子を用いて前記要求に対するデバイスデータ構造エントリを選択し、
選択されたデバイスデータ構造エントリからのポインタを用いてゲストトランスレーションデータ構造のセットにアクセスし、
最後のゲストトランスレーションデータ構造からのポインタを用いて、入れ子にされたページデータ構造の前記セットにアクセスするように更に構成されるIOMMU。 - 入力/出力メモリ管理ユニット(IOMMU)を用いてコンピュータシステムのシステムメモリへの入力/出力I/O要求を制御するための方法であって、
ゲストページテーブルのセット及び入れ子にされたページテーブルのセットを含むトランスレーションデータをコンピュータシステムのシステムメモリ内に記憶することと、
処理アドレス空間識別子(PASID)プレフィックスを含むトランザクション層プロトコル(TLP)パケットをI/Oデバイスからの要求において受信することに応答して2レベルのゲストトランスレーションを実行するように構成される制御論理が、前記要求において受信されるアドレスをトランスレートすることと、
前記制御論理が前記要求において受信される前記アドレスをトランスレートするためにゲストページテーブルの前記セットにアクセスすることと、
完了したトランスレーションを前記制御論理がキャッシュメモリ内に記憶することとを備え、
最後のゲストページテーブル内のポインタは入れ子にされたページテーブルの前記セット内の第1のテーブルを指し示し、
前記制御論理は、入れ子にされたページテーブルの前記セットにアクセスして前記システムメモリ内の物理ページに対応するシステム物理アドレス(SPA)を得るために、最後のゲストページテーブル内の前記ポインタを用いる方法。 - 前記TLPパケットは、プレフィックスフィールド、ヘッダフィールド、データペイロードフィールド、及び随意的なダイジェストフィールドを有するパケットを備え、前記TLPパケットは、周辺コンポーネント相互接続エクスプレス(PCIe)リンク上で前記I/Oデバイスから前記IOMMUへ伝達される請求項16に記載の方法。
- 前記I/O要求において受信される前記アドレスは、前記コンピュータシステムのプロセッサ上の仮想マシン(VM)で実行中のゲストアプリケーションによってマッピングされるアドレス空間に対応するゲスト仮想アドレス(GVA)を備える請求項16に記載の方法。
- 前記制御論理はTLP_PASIDプレフィックスを伴うTLPパケットを含まないI/O要求を受信することに応答して1レベルのトランスレーションを実行する請求項16に記載の方法。
- TLP_PASIDプレフィックスを伴う前記TLPパケットを含まない前記I/O要求において受信されるアドレスは、前記コンピュータシステムのプロセッサ上の仮想マシン(VM)で実行中のゲストオペレーティングシステムによってマッピングされるアドレス空間に対応するゲスト物理アドレス(GPA)を備える請求項19に記載の方法。
- データ構造を備えたコンピュータ可読記憶媒体であって、コンピュータシステム上で実行可能なプログラムによって前記データ構造が動作させられる場合に、前記プログラムが前記データ構造に基づいて動作して前記データ構造によって記述される回路を含む集積回路を製造するための処理の一部を実行し、
前記データ構造において記述される前記回路は、
前記I/Oデバイスからの要求において受信されるアドレスをトランスレートするように構成される制御論理と、
前記制御論理に結合され完了したトランスレーションを記憶するように構成されるキャッシュメモリとを備え、
処理アドレス空間識別子(PASID)プレフィックスを含むトランザクション層プロトコル(TLP)パケットを前記要求において受信することに応答して、前記制御論理は2レベルのゲストトランスレーションを実行するように構成され、
前記制御論理は前記要求において受信される前記アドレスをトランスレートするためにゲストページテーブルのセットにアクセスするように構成され、最後のゲストページテーブル内のポインタは入れ子にされたページテーブルのセット内の第1のテーブルを指し示し、
前記制御論理は、入れ子にされたページテーブルの前記セットにアクセスして前記システムメモリ内の物理ページに対応するシステム物理アドレス(SPA)を得るために、最後のゲストページテーブル内の前記ポインタを用いるように構成されるコンピュータ可読記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/508,890 US9535849B2 (en) | 2009-07-24 | 2009-07-24 | IOMMU using two-level address translation for I/O and computation offload devices on a peripheral interconnect |
| US12/508,890 | 2009-07-24 | ||
| PCT/US2010/043168 WO2011011768A1 (en) | 2009-07-24 | 2010-07-24 | Iommu using two-level address translation for i/o and computation offload devices on a peripheral interconnect |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013500524A true JP2013500524A (ja) | 2013-01-07 |
| JP5680642B2 JP5680642B2 (ja) | 2015-03-04 |
Family
ID=43013181
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012521868A Active JP5680642B2 (ja) | 2009-07-24 | 2010-07-24 | 周辺相互接続におけるi/o及び計算負荷軽減デバイスのための2レベルのアドレストランスレーションを用いるiommu |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9535849B2 (ja) |
| EP (1) | EP2457165B1 (ja) |
| JP (1) | JP5680642B2 (ja) |
| KR (1) | KR101575827B1 (ja) |
| CN (1) | CN102498478B (ja) |
| IN (1) | IN2012DN00935A (ja) |
| WO (1) | WO2011011768A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11754776B2 (en) | 2018-11-01 | 2023-09-12 | Kuraray Co., Ltd. | Light-emitting fiber |
| JP7564830B2 (ja) | 2019-05-27 | 2024-10-09 | アドバンスト・マイクロ・ディバイシズ・インコーポレイテッド | 入出力メモリ管理ユニットレジスタのコピーのゲストオペレーティングシステムへの提供 |
Families Citing this family (72)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8386745B2 (en) * | 2009-07-24 | 2013-02-26 | Advanced Micro Devices, Inc. | I/O memory management unit including multilevel address translation for I/O and computation offload |
| US8327055B2 (en) * | 2010-04-12 | 2012-12-04 | International Business Machines Corporation | Translating a requester identifier to a chip identifier |
| US8341340B2 (en) * | 2010-07-21 | 2012-12-25 | Seagate Technology Llc | Multi-tier address mapping in flash memory |
| US20120246381A1 (en) * | 2010-12-14 | 2012-09-27 | Andy Kegel | Input Output Memory Management Unit (IOMMU) Two-Layer Addressing |
| US9606936B2 (en) * | 2010-12-16 | 2017-03-28 | Advanced Micro Devices, Inc. | Generalized control registers |
| US9916257B2 (en) * | 2011-07-26 | 2018-03-13 | Intel Corporation | Method and apparatus for TLB shoot-down in a heterogeneous computing system supporting shared virtual memory |
| US9164924B2 (en) * | 2011-09-13 | 2015-10-20 | Facebook, Inc. | Software cryptoprocessor |
| US8719464B2 (en) * | 2011-11-30 | 2014-05-06 | Advanced Micro Device, Inc. | Efficient memory and resource management |
| US20130262736A1 (en) * | 2012-03-30 | 2013-10-03 | Ati Technologies Ulc | Memory types for caching policies |
| US9081706B2 (en) * | 2012-05-10 | 2015-07-14 | Oracle International Corporation | Using a shared last-level TLB to reduce address-translation latency |
| US20130318269A1 (en) | 2012-05-22 | 2013-11-28 | Xockets IP, LLC | Processing structured and unstructured data using offload processors |
| US9619406B2 (en) | 2012-05-22 | 2017-04-11 | Xockets, Inc. | Offloading of computation for rack level servers and corresponding methods and systems |
| US20140052899A1 (en) * | 2012-08-18 | 2014-02-20 | Yen Chih Nan | Memory address translation method for flash storage system |
| US9424199B2 (en) * | 2012-08-29 | 2016-08-23 | Advanced Micro Devices, Inc. | Virtual input/output memory management unit within a guest virtual machine |
| US9069690B2 (en) * | 2012-09-13 | 2015-06-30 | Intel Corporation | Concurrent page table walker control for TLB miss handling |
| KR101934519B1 (ko) | 2012-11-26 | 2019-01-02 | 삼성전자주식회사 | 저장 장치 및 그것의 데이터 전송 방법 |
| WO2014113055A1 (en) | 2013-01-17 | 2014-07-24 | Xockets IP, LLC | Offload processor modules for connection to system memory |
| US9378161B1 (en) | 2013-01-17 | 2016-06-28 | Xockets, Inc. | Full bandwidth packet handling with server systems including offload processors |
| US9396011B2 (en) | 2013-03-12 | 2016-07-19 | Qualcomm Incorporated | Algorithm and apparatus to deploy virtual machine monitor on demand |
| US9477603B2 (en) | 2013-09-05 | 2016-10-25 | Facebook, Inc. | System and method for partitioning of memory units into non-conflicting sets |
| US9983894B2 (en) | 2013-09-25 | 2018-05-29 | Facebook, Inc. | Method and system for providing secure system execution on hardware supporting secure application execution |
| US10049048B1 (en) | 2013-10-01 | 2018-08-14 | Facebook, Inc. | Method and system for using processor enclaves and cache partitioning to assist a software cryptoprocessor |
| US9239804B2 (en) * | 2013-10-03 | 2016-01-19 | Advanced Micro Devices, Inc. | Back-off mechanism for a peripheral page request log |
| US9747450B2 (en) | 2014-02-10 | 2017-08-29 | Facebook, Inc. | Attestation using a combined measurement and its constituent measurements |
| US9734092B2 (en) | 2014-03-19 | 2017-08-15 | Facebook, Inc. | Secure support for I/O in software cryptoprocessor |
| EP3159802B1 (en) * | 2014-07-15 | 2018-05-23 | Huawei Technologies Co. Ltd. | Sharing method and device for pcie i/o device and interconnection system |
| US20160077981A1 (en) * | 2014-09-12 | 2016-03-17 | Advanced Micro Devices, Inc. | Method and Apparatus for Efficient User-Level IO in a Virtualized System |
| US9632948B2 (en) | 2014-09-23 | 2017-04-25 | Intel Corporation | Multi-source address translation service (ATS) with a single ATS resource |
| KR102320044B1 (ko) * | 2014-10-02 | 2021-11-01 | 삼성전자주식회사 | Pci 장치, 이를 포함하는 인터페이스 시스템, 및 컴퓨팅 시스템 |
| US10013385B2 (en) * | 2014-11-13 | 2018-07-03 | Cavium, Inc. | Programmable validation of transaction requests |
| JP6070732B2 (ja) * | 2015-01-27 | 2017-02-01 | 日本電気株式会社 | 入出力制御装置、入出力制御システム、入出力制御方法、および、プログラム |
| US9495303B2 (en) | 2015-02-03 | 2016-11-15 | Intel Corporation | Fine grained address remapping for virtualization |
| CN104598298A (zh) * | 2015-02-04 | 2015-05-06 | 上海交通大学 | 基于虚拟机当前工作性质以及任务负载的虚拟机调度算法 |
| CN104698709A (zh) * | 2015-04-01 | 2015-06-10 | 上海天马微电子有限公司 | 一种阵列基板和液晶显示面板 |
| US10089275B2 (en) * | 2015-06-22 | 2018-10-02 | Qualcomm Incorporated | Communicating transaction-specific attributes in a peripheral component interconnect express (PCIe) system |
| WO2016206012A1 (en) | 2015-06-24 | 2016-12-29 | Intel Corporation | Systems and methods for isolating input/output computing resources |
| US10102116B2 (en) | 2015-09-11 | 2018-10-16 | Red Hat Israel, Ltd. | Multi-level page data structure |
| EP3353659A4 (en) * | 2015-09-25 | 2019-05-01 | Intel Corporation | SYSTEMS AND METHODS FOR CONTROLLING INPUT / OUTPUT COMPUTER RESOURCES |
| US9852107B2 (en) * | 2015-12-24 | 2017-12-26 | Intel Corporation | Techniques for scalable endpoint addressing for parallel applications |
| US10509729B2 (en) | 2016-01-13 | 2019-12-17 | Intel Corporation | Address translation for scalable virtualization of input/output devices |
| US10055807B2 (en) | 2016-03-02 | 2018-08-21 | Samsung Electronics Co., Ltd. | Hardware architecture for acceleration of computer vision and imaging processing |
| US10762030B2 (en) | 2016-05-25 | 2020-09-01 | Samsung Electronics Co., Ltd. | Storage system, method, and apparatus for fast IO on PCIE devices |
| CN108139982B (zh) | 2016-05-31 | 2022-04-08 | 安华高科技股份有限公司 | 多信道输入/输出虚拟化 |
| US10048881B2 (en) | 2016-07-11 | 2018-08-14 | Intel Corporation | Restricted address translation to protect against device-TLB vulnerabilities |
| US10241931B2 (en) * | 2016-07-29 | 2019-03-26 | Advanced Micro Devices, Inc. | Controlling access to pages in a memory in a computing device |
| US20180088978A1 (en) * | 2016-09-29 | 2018-03-29 | Intel Corporation | Techniques for Input/Output Access to Memory or Storage by a Virtual Machine or Container |
| US10157277B2 (en) * | 2016-10-01 | 2018-12-18 | Intel Corporation | Technologies for object-oriented memory management with extended segmentation |
| US10417140B2 (en) * | 2017-02-24 | 2019-09-17 | Advanced Micro Devices, Inc. | Streaming translation lookaside buffer |
| US10120813B2 (en) * | 2017-03-08 | 2018-11-06 | Arm Limited | Address translation |
| US10380039B2 (en) * | 2017-04-07 | 2019-08-13 | Intel Corporation | Apparatus and method for memory management in a graphics processing environment |
| US10228981B2 (en) | 2017-05-02 | 2019-03-12 | Intel Corporation | High-performance input-output devices supporting scalable virtualization |
| US10528474B2 (en) * | 2017-09-06 | 2020-01-07 | International Business Machines Corporation | Pre-allocating cache resources for a range of tracks in anticipation of access requests to the range of tracks |
| CN109698845B (zh) * | 2017-10-20 | 2020-10-09 | 华为技术有限公司 | 数据传输的方法、服务器、卸载卡及存储介质 |
| WO2019132976A1 (en) * | 2017-12-29 | 2019-07-04 | Intel Corporation | Unified address translation for virtualization of input/output devices |
| US10990436B2 (en) * | 2018-01-24 | 2021-04-27 | Dell Products L.P. | System and method to handle I/O page faults in an I/O memory management unit |
| US20190227942A1 (en) * | 2018-01-24 | 2019-07-25 | Dell Products, Lp | System and Method to Handle I/O Page Faults in an I/O Memory Management Unit |
| US11157635B2 (en) * | 2018-04-08 | 2021-10-26 | Qualcomm Incorporated | Secure interface disablement |
| US20190114195A1 (en) | 2018-08-22 | 2019-04-18 | Intel Corporation | Virtual device composition in a scalable input/output (i/o) virtualization (s-iov) architecture |
| US10929310B2 (en) * | 2019-03-01 | 2021-02-23 | Cisco Technology, Inc. | Adaptive address translation caches |
| US11036649B2 (en) | 2019-04-04 | 2021-06-15 | Cisco Technology, Inc. | Network interface card resource partitioning |
| US11494211B2 (en) * | 2019-04-22 | 2022-11-08 | Advanced Micro Devices, Inc. | Domain identifier and device identifier translation by an input-output memory management unit |
| US10853263B1 (en) | 2019-07-23 | 2020-12-01 | Ati Technologies Ulc | Unified kernel virtual address space for heterogeneous computing |
| CN111290829B (zh) * | 2020-01-15 | 2023-05-02 | 海光信息技术股份有限公司 | 访问控制模组、虚拟机监视器及访问控制方法 |
| US11422944B2 (en) * | 2020-08-10 | 2022-08-23 | Intel Corporation | Address translation technologies |
| US11321238B2 (en) | 2020-08-11 | 2022-05-03 | Micron Technology, Inc. | User process identifier based address translation |
| US12086082B2 (en) * | 2020-09-21 | 2024-09-10 | Intel Corporation | PASID based routing extension for scalable IOV systems |
| US11775210B2 (en) * | 2020-10-14 | 2023-10-03 | Western Digital Technologies, Inc. | Storage system and method for device-determined, application-specific dynamic command clustering |
| CN112395220B (zh) * | 2020-11-18 | 2023-02-28 | 海光信息技术股份有限公司 | 共享存储控制器的处理方法、装置、系统及存储控制器 |
| US11860792B2 (en) | 2021-05-04 | 2024-01-02 | Red Hat, Inc. | Memory access handling for peripheral component interconnect devices |
| US11900142B2 (en) | 2021-06-16 | 2024-02-13 | Red Hat, Inc. | Improving memory access handling for nested virtual machines |
| US11797178B2 (en) * | 2021-07-16 | 2023-10-24 | Hewlett Packard Enterprise Development Lp | System and method for facilitating efficient management of data structures stored in remote memory |
| CN114201269B (zh) * | 2022-02-18 | 2022-08-26 | 阿里云计算有限公司 | 内存换页方法、系统及存储介质 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04308953A (ja) * | 1991-04-05 | 1992-10-30 | Kyocera Corp | 仮想アドレス計算機装置 |
| JP2002067405A (ja) * | 2000-07-31 | 2002-03-05 | Hewlett Packard Co <Hp> | プリンタ内でデータを転送するシステム |
| US20070168643A1 (en) * | 2006-01-17 | 2007-07-19 | Hummel Mark D | DMA Address Translation in an IOMMU |
| JP2007272885A (ja) * | 2006-03-28 | 2007-10-18 | Internatl Business Mach Corp <Ibm> | 代替ページのプールを使用してdma書込みページ障害をコンピュータにより管理するための方法、装置、及びコンピュータ・プログラム |
| JP2008009982A (ja) * | 2006-06-27 | 2008-01-17 | Internatl Business Mach Corp <Ibm> | メモリ・アドレスの変換およびピン止めのための方法およびシステム |
| US20080120487A1 (en) * | 2006-11-21 | 2008-05-22 | Ramakrishna Saripalli | Address translation performance in virtualized environments |
| US20090187697A1 (en) * | 2008-01-22 | 2009-07-23 | Serebrin Benjamin C | Execute-Only Memory and Mechanism Enabling Execution From Execute-Only Memory for Minivisor |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8041878B2 (en) * | 2003-03-19 | 2011-10-18 | Samsung Electronics Co., Ltd. | Flash file system |
| US7334107B2 (en) * | 2004-09-30 | 2008-02-19 | Intel Corporation | Caching support for direct memory access address translation |
| US7444493B2 (en) | 2004-09-30 | 2008-10-28 | Intel Corporation | Address translation for input/output devices using hierarchical translation tables |
| US7225287B2 (en) | 2005-06-01 | 2007-05-29 | Microsoft Corporation | Scalable DMA remapping on a computer bus |
| US20060288130A1 (en) * | 2005-06-21 | 2006-12-21 | Rajesh Madukkarumukumana | Address window support for direct memory access translation |
| US7793067B2 (en) | 2005-08-12 | 2010-09-07 | Globalfoundries Inc. | Translation data prefetch in an IOMMU |
| US7543131B2 (en) | 2005-08-12 | 2009-06-02 | Advanced Micro Devices, Inc. | Controlling an I/O MMU |
| US7426626B2 (en) * | 2005-08-23 | 2008-09-16 | Qualcomm Incorporated | TLB lock indicator |
| US7548999B2 (en) | 2006-01-17 | 2009-06-16 | Advanced Micro Devices, Inc. | Chained hybrid input/output memory management unit |
| US7849287B2 (en) | 2006-11-13 | 2010-12-07 | Advanced Micro Devices, Inc. | Efficiently controlling special memory mapped system accesses |
| US7873770B2 (en) | 2006-11-13 | 2011-01-18 | Globalfoundries Inc. | Filtering and remapping interrupts |
| US8032897B2 (en) * | 2007-07-31 | 2011-10-04 | Globalfoundries Inc. | Placing virtual machine monitor (VMM) code in guest context to speed memory mapped input/output virtualization |
| US8145876B2 (en) * | 2007-08-06 | 2012-03-27 | Advanced Micro Devices, Inc. | Address translation with multiple translation look aside buffers |
| US8352705B2 (en) * | 2008-01-15 | 2013-01-08 | Vmware, Inc. | Large-page optimization in virtual memory paging systems |
| US8234432B2 (en) * | 2009-01-26 | 2012-07-31 | Advanced Micro Devices, Inc. | Memory structure to store interrupt state for inactive guests |
-
2009
- 2009-07-24 US US12/508,890 patent/US9535849B2/en active Active
-
2010
- 2010-07-24 KR KR1020127004961A patent/KR101575827B1/ko active IP Right Grant
- 2010-07-24 CN CN201080041194.XA patent/CN102498478B/zh active Active
- 2010-07-24 EP EP10738112.1A patent/EP2457165B1/en active Active
- 2010-07-24 IN IN935DEN2012 patent/IN2012DN00935A/en unknown
- 2010-07-24 JP JP2012521868A patent/JP5680642B2/ja active Active
- 2010-07-24 WO PCT/US2010/043168 patent/WO2011011768A1/en active Application Filing
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04308953A (ja) * | 1991-04-05 | 1992-10-30 | Kyocera Corp | 仮想アドレス計算機装置 |
| JP2002067405A (ja) * | 2000-07-31 | 2002-03-05 | Hewlett Packard Co <Hp> | プリンタ内でデータを転送するシステム |
| US20070168643A1 (en) * | 2006-01-17 | 2007-07-19 | Hummel Mark D | DMA Address Translation in an IOMMU |
| JP2007272885A (ja) * | 2006-03-28 | 2007-10-18 | Internatl Business Mach Corp <Ibm> | 代替ページのプールを使用してdma書込みページ障害をコンピュータにより管理するための方法、装置、及びコンピュータ・プログラム |
| JP2008009982A (ja) * | 2006-06-27 | 2008-01-17 | Internatl Business Mach Corp <Ibm> | メモリ・アドレスの変換およびピン止めのための方法およびシステム |
| US20080120487A1 (en) * | 2006-11-21 | 2008-05-22 | Ramakrishna Saripalli | Address translation performance in virtualized environments |
| US20090187697A1 (en) * | 2008-01-22 | 2009-07-23 | Serebrin Benjamin C | Execute-Only Memory and Mechanism Enabling Execution From Execute-Only Memory for Minivisor |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11754776B2 (en) | 2018-11-01 | 2023-09-12 | Kuraray Co., Ltd. | Light-emitting fiber |
| JP7564830B2 (ja) | 2019-05-27 | 2024-10-09 | アドバンスト・マイクロ・ディバイシズ・インコーポレイテッド | 入出力メモリ管理ユニットレジスタのコピーのゲストオペレーティングシステムへの提供 |
Also Published As
| Publication number | Publication date |
|---|---|
| IN2012DN00935A (ja) | 2015-04-03 |
| EP2457165A1 (en) | 2012-05-30 |
| JP5680642B2 (ja) | 2015-03-04 |
| US20110022818A1 (en) | 2011-01-27 |
| US9535849B2 (en) | 2017-01-03 |
| EP2457165B1 (en) | 2018-07-04 |
| CN102498478A (zh) | 2012-06-13 |
| WO2011011768A1 (en) | 2011-01-27 |
| KR101575827B1 (ko) | 2015-12-08 |
| CN102498478B (zh) | 2015-04-29 |
| KR20120044370A (ko) | 2012-05-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5680642B2 (ja) | 周辺相互接続におけるi/o及び計算負荷軽減デバイスのための2レベルのアドレストランスレーションを用いるiommu | |
| EP2457166B1 (en) | I/o memory management unit including multilevel address translation for i/o and computation offload | |
| US7882330B2 (en) | Virtualizing an IOMMU | |
| US7809923B2 (en) | Direct memory access (DMA) address translation in an input/output memory management unit (IOMMU) | |
| US7917726B2 (en) | Using an IOMMU to create memory archetypes | |
| US7543131B2 (en) | Controlling an I/O MMU | |
| US7516247B2 (en) | Avoiding silent data corruption and data leakage in a virtual environment with multiple guests | |
| JP4772795B2 (ja) | 大アドレス容量に及ぶ変換テーブルを用いた、アドレス変換の性能向上 | |
| US7873770B2 (en) | Filtering and remapping interrupts | |
| US7849287B2 (en) | Efficiently controlling special memory mapped system accesses | |
| US7793067B2 (en) | Translation data prefetch in an IOMMU | |
| US11921646B2 (en) | Secure address translation services using a permission table | |
| JP6067928B2 (ja) | 属性フィールドのマルチコアページテーブルセット | |
| US7480784B2 (en) | Ensuring deadlock free operation for peer to peer traffic in an input/output memory management unit (IOMMU) | |
| WO2006039643A1 (en) | Caching support for direct memory access address translation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20130626 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140226 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20140526 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20140602 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140626 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20140730 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20141117 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20141125 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20141216 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150107 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5680642 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |