JP2013025456A - 情報処理装置、情報処理方法、並びにプログラム - Google Patents
情報処理装置、情報処理方法、並びにプログラム Download PDFInfo
- Publication number
- JP2013025456A JP2013025456A JP2011157852A JP2011157852A JP2013025456A JP 2013025456 A JP2013025456 A JP 2013025456A JP 2011157852 A JP2011157852 A JP 2011157852A JP 2011157852 A JP2011157852 A JP 2011157852A JP 2013025456 A JP2013025456 A JP 2013025456A
- Authority
- JP
- Japan
- Prior art keywords
- electronic document
- information
- storage unit
- sentence
- link
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 36
- 238000003672 processing method Methods 0.000 title claims description 10
- 238000000605 extraction Methods 0.000 claims abstract description 21
- 239000000284 extract Substances 0.000 claims abstract description 10
- 238000000034 method Methods 0.000 claims description 113
- 230000008569 process Effects 0.000 claims description 111
- 238000004364 calculation method Methods 0.000 claims description 3
- 238000005516 engineering process Methods 0.000 abstract description 15
- 238000010586 diagram Methods 0.000 description 30
- 230000007704 transition Effects 0.000 description 5
- 238000001514 detection method Methods 0.000 description 4
- 239000003814 drug Substances 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 238000004891 communication Methods 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 2
- 238000012015 optical character recognition Methods 0.000 description 2
- ZYXYTGQFPZEUFX-UHFFFAOYSA-N benzpyrimoxan Chemical compound O1C(OCCC1)C=1C(=NC=NC=1)OCC1=CC=C(C=C1)C(F)(F)F ZYXYTGQFPZEUFX-UHFFFAOYSA-N 0.000 description 1
- 239000004020 conductor Substances 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000010422 painting Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
- G06F16/94—Hypermedia
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/134—Hyperlinking
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Business, Economics & Management (AREA)
- General Business, Economics & Management (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Document Processing Apparatus (AREA)
Abstract
【課題】電子文書内に記載されている参考文献などに対して、その参考文献の記載をクリックするだけでアクセスできるようにする。
【解決手段】電子文書の情報を記憶する記憶部と、記憶部に記憶されている情報を含む文章を、所定の電子文書内から抽出する抽出部と、抽出部により抽出された文章から、記憶部の情報へのリンクを生成する生成部とを備える。電子文書が、スキャンされることで電子文書にされた文書であっても、その電子文書に含まれる文章と、記憶部に記憶されている情報との一致度が高い場合、その文章と情報が関連づけられ、リンクが張られる。本技術は、電子書籍を扱う端末に適用できる。
【選択図】図1
【解決手段】電子文書の情報を記憶する記憶部と、記憶部に記憶されている情報を含む文章を、所定の電子文書内から抽出する抽出部と、抽出部により抽出された文章から、記憶部の情報へのリンクを生成する生成部とを備える。電子文書が、スキャンされることで電子文書にされた文書であっても、その電子文書に含まれる文章と、記憶部に記憶されている情報との一致度が高い場合、その文章と情報が関連づけられ、リンクが張られる。本技術は、電子書籍を扱う端末に適用できる。
【選択図】図1
Description
本技術は、情報処理装置、情報処理方法、並びにプログラムに関する。詳しくは、電子文書内の著作物に関する情報を検出し、検出された情報をユーザに提示し、その著作物のさらなる情報を提示できるようにする情報処理装置、情報処理方法、並びにプログラムに関する。
従来の紙媒体の書籍の代わりに、近年、電子書籍と称される電子機器のディスプレイ上で閲覧できる書籍が普及しつつある。そのような電子書籍においては、紙媒体の書籍に対して提供できなかったサービスを提供できる。例えば、映像や音声を提供する書籍もある。
特許文献1では、ネットワークを介して、ユーザに書籍に関するユニークなコンテンツや情報を提示することが提案されている。また、特許文献2や特許文献3では、電子書籍内のリンクを編集することが提案されている。
上記したように、電子書籍においては、紙媒体の書籍に対して提供できなかったサービスなども提供できるようになるため、サービスの質の向上などが望まれている。
本技術は、このような状況に鑑みてなされたものであり、電子文書内に記載されている著作物の情報を検出し、その情報以外のさらなる情報も、ユーザに提供できるようにするものである。
本技術の一側面の情報処理装置は、電子文書の情報を記憶する記憶部と、前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する抽出部と、前記抽出部により抽出された前記文章から、前記記憶部の情報へのリンクを生成する生成部とを備える。
前記記憶部は、同一端末内に記憶されている電子文書の情報が記憶されている第1の記憶部と、他の端末内に記憶されている電子文書の情報が記憶されている第2の記憶部があり、前記抽出部は、前記第1の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、前記第2の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出するようにすることができる。
前記電子文書は、紙媒体に印刷されていた文書を電子化したものであるようにすることができる。
前記抽出部は、前記電子文書内の所定の文章と、前記記憶部に記憶されている前記情報との第1の類似度を算出し、前記所定の文章の次の文章を結合した文章と、前記記憶部に記憶されている前記情報との第2の類似度を算出し、前記第2の類似度が前記第1の類似度よりも大きいと判断されるまでの間は、文章の結合と類似度の算出を繰り返し行い、前記第2の類似度が前記第1の類似度よりも小さいと判断されたとき、結合前の文章を抽出結果とするようにすることができる。
前記抽出部は、抽出された文章を参照する番号を前記所定の電子文書内からさらに抽出し、前記生成部は、前記抽出部で抽出された前記番号に、前記番号が参照している前記文章に対して生成された前記リンクを付与するようにすることができる。
前記記憶部が更新された場合、更新された情報を含む文章を、前記所定の電子文書内から抽出することで、更新処理を行うようにすることができる。
本技術の一側面の情報処理方法は、電子文書の情報を記憶する記憶部を備える情報処理装置の情報処理方法は、前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、前記抽出された前記文章から、前記記憶部の情報へのリンクを生成するステップを含む。
本技術の一側面のプログラムは、電子文書の情報を記憶する記憶部を備える情報処理装置を制御するコンピュータに、前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、前記抽出された前記文章から、前記記憶部の情報へのリンクを生成するステップを含む処理を実行させるためのコンピュータ読み取り可能なプログラムである。
本技術の一側面の情報処理装置、情報処理方法、並びにプログラムにおいては、電子文書の情報が記憶され、その記憶されている情報を含む文章が、所定の電子文書内から抽出される。電子文書内から文章が抽出された場合、その文章と、その文章に含まれる情報であり、記憶部に記憶されている情報が関連付けられる。関連付けとしては、文章から情報にアクセスできるリンクが張られることで行われる。
本技術の一側面によれば、電子文書内に記載されている著作物の情報を検出することができる。また、検出された情報以外のさらなる情報も、ユーザに提供できるようになり、電子文書に関するサービスの質や使い勝手を向上させることが可能となる。
以下に、本技術の実施の形態について図面を参照して説明する。
[本技術を適用したシステムの構成について]
図1は、本技術を適用したシステムの一実施の形態の構成を示す図である。図1に示したシステムは、ネットワーク11、サーバ21、電子文書閲覧端末31、情報端末41、およびスキャナ51を含む構成とされている。ネットワーク11には、サーバ21、電子文書閲覧端末31、および情報端末41が接続され、データの授受を行えるように構成されている。スキャナ51は、情報端末41に接続され、スキャナ51により読み込まれたデータは、情報端末41に供給されるように構成されている。
図1は、本技術を適用したシステムの一実施の形態の構成を示す図である。図1に示したシステムは、ネットワーク11、サーバ21、電子文書閲覧端末31、情報端末41、およびスキャナ51を含む構成とされている。ネットワーク11には、サーバ21、電子文書閲覧端末31、および情報端末41が接続され、データの授受を行えるように構成されている。スキャナ51は、情報端末41に接続され、スキャナ51により読み込まれたデータは、情報端末41に供給されるように構成されている。
サーバ21は、著作物データベース22と顧客データベース23を備える。サーバ21は、パーソナルコンピュータなどで構成することができる。著作物データベース22は、詳細は後述するが、著作物に関する情報、例えば、作品名、作者名、出版社などの所定の著作物を一意に特定することができる情報を管理するためのデータベースである。
顧客データベース23は、著作物データベース22で管理されているデータを閲覧する際に購入が必要な場合などのために設けられており、個人を特定するための情報を管理するためのデータベースである。
電子文書閲覧端末31は、著作物データベース32と電子文書記憶部33を備える。電子文書閲覧端末31は、電子文書を閲覧できる端末であり、電子文書を閲覧するための専用の端末であってもよいし、携帯電話機などの端末であってもよい。電子文書閲覧端末31が備える著作物データベース32は、サーバ21が備える著作物データベース22と基本的に同様の構成とされる。電子文書記憶部33は、電子文書を記憶する。この電子文書記憶部33は、ネットワーク11を介して他の装置、例えば、サーバ21から購入した電子書籍(電子文書)や、スキャナ51で取り込まれた文書などが記憶されている。
電子文書閲覧端末31に備えられている著作物データベース32は、電子文書閲覧端末31内に記憶されている電子文書に関するデータを管理している。サーバ21の著作物データベース22と、電子文書閲覧端末31の著作物データベース32は、同一のデータ構造を有するが、記憶されているデータの内容は異なる。
情報端末41は、著作物データベース42と電子文書記憶部43を備える。情報端末41は、パーソナルコンピュータなどで構成される。情報端末41が備える著作物データベース42は、サーバ21が備える著作物データベース22と基本的に同様の構成とされる。電子文書記憶部43は、電子文書を記憶する。この電子文書記憶部43は、ネットワーク11を介して他の装置、例えば、サーバ21から購入した電子書籍や、スキャナ51で取り込まれた文書などが記憶されている。ここでは、スキャナ51により取り込まれた文書61が、電子文書として、電子文書記憶部43に記憶されるとして説明を続ける。
情報端末41に備えられている著作物データベース42は、情報端末41内に記憶されている電子文書に関するデータを管理している。サーバ21の著作物データベース22と、情報端末41の著作物データベース42は、同一のデータ構造を有するが、記憶されているデータの内容は異なる。
図1に示したシステムにより、スキャナ51で文書61のイメージが取り込まれ、その取り込まれたデータが、接続されている情報端末41に供給される。情報端末41は、スキャナ51により取り込まれたイメージを元に文書61を電子化した電子文書を作成する。また、情報端末41は、OCR(Optical Character Recognition)などの技術を用い、文書61のイメージから書かれている文字情報を取得し、その文字情報を含む電子文書を作成することも可能とされている。
また情報端末41は、電子文書閲覧端末31とUSBなどを介して接続されたときや、ネットワーク11を介して接続されたときに、電子文書記憶部43に記憶されている電子文書を、電子文書閲覧端末31の電子文書記憶部33にコピーあるいは移動する。電子文書閲覧端末31の電子文書記憶部33には、このようにして取得された電子文書が記憶される。
情報端末41では、文書61だけでなく、CD(Compact Disc)などから得られる音楽データなども取得し、記憶し、電子文書閲覧端末31に供給することも可能な構成とされている。これら電子文書閲覧端末31に転送された電子文書や音楽データなどの著作物の情報は、電子文書閲覧端末31の著作物データベース32と、情報端末41の著作物データベース42のそれぞれで管理される。後述するように、この著作物データベース32(著作物データベース42)に記憶されている情報に基づき、例えば、電子文書内に記載されている著作物名にリンクを張り、そのリンク先からさらなる情報が取得される。
また、電子文書閲覧端末31は、ネットワーク11に接続する機能を有し、ネットワーク11上にあるサーバ21内の著作物データベース22に接続して、ネットワーク11上の他の装置で管理されている著作物を取得し閲覧することができる。著作物データベース22内の著作物を閲覧するのに購入が必要な場合は、サーバ21内で顧客データベース23を管理し、課金処理が行えるようにすることもできる。
[電子文書について]
次に、電子文書閲覧端末31の電子文書記憶部33に記憶され、電子文書閲覧端末31の表示部101(図4)に表示されて、ユーザに閲覧される電子文書について説明する。この電子文書は、例えば、紙媒体の書籍から、スキャナ51で読み込まれ、電子文書記憶部43に記憶された電子文書である。
次に、電子文書閲覧端末31の電子文書記憶部33に記憶され、電子文書閲覧端末31の表示部101(図4)に表示されて、ユーザに閲覧される電子文書について説明する。この電子文書は、例えば、紙媒体の書籍から、スキャナ51で読み込まれ、電子文書記憶部43に記憶された電子文書である。
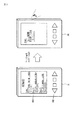
図2に、文書61の一例を示す。図2に示した文書61は、以下の説明においてリンクを張る対象となる文書の一例(ページの一例)である。図2Aは、参考書などの書籍であり、図2Bは、音楽CDなどに添付される音楽冊子(ライナーノーツ)である。図2Aを参照するに、例えば、参考書などの書籍には、参考文献の一覧が記載されたページがある。また、章の最終ページなどに、そのような参考文献が記載されている場合などもある。図2Aに示した文書は、そのようなページの一例を示し、“参考文献”との記載の下に、“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”といった記載がある。
このように、参考文献などとして記載されている文書は、著作者、タイトル、出版社名、発行年度などの情報が記載されている。すなわち、著作物に関する情報が記載されている。後述するように、本実施の形態においては、このような著作物に関する情報が検出され、リンクが張られる。
図2Bを参照するに、例えば、ライナーノーツなどには、そのライナーノーツが添付されていた音楽CDに収録されている収録曲に関する情報が記載されている。図2Bに示した文書は、そのような収録曲に関する情報が記載されているページの一例であり、ページ上部に“収録曲”との記載がある。そして、その記載の下に、“Track 1 「ピアノ協奏曲 第24番 ハ単調」 モーツアルト」”、“Track 2 「ヴァイオリン協奏曲集 <<四季>>」 ヴィヴァルディ”、“Track 3 「ヴァイオリン協奏曲 ニ長調」 チャイコフスキー”といった記載がある。
このように、ライナーノーツなどに記載されている文書は、楽曲名、作曲者名、アーティスト名、指揮者名、オーケストラ名などの情報が記載されている。すなわち、著作物に関する情報が記載されている。後述するように、本実施の形態においては、このような著作物に関する情報が検出され、リンクが張られる。
[データベースの構成について]
次に、著作物データベースについて説明する。サーバ21は、例えば、電子書籍などの著作物をダウンロードさせることで販売するサイトなどである。このような場合、サーバ21の著作物データベース22には、販売対象となる電子書籍(電子文書)などの著作物の情報が記載される。すなわち、サーバ21の著作物データベース22では、サーバ21が管理する著作物に関する情報が記載され、管理されている。
次に、著作物データベースについて説明する。サーバ21は、例えば、電子書籍などの著作物をダウンロードさせることで販売するサイトなどである。このような場合、サーバ21の著作物データベース22には、販売対象となる電子書籍(電子文書)などの著作物の情報が記載される。すなわち、サーバ21の著作物データベース22では、サーバ21が管理する著作物に関する情報が記載され、管理されている。
同様に、電子文書閲覧装置31の著作物データベース32は、電子文書閲覧装置31内の電子文書記憶部33に記憶されている電子文書(著作物)の情報を管理する。また同様に、情報端末41の著作物データベース42は、情報端末41内の電子文書記憶部43に記憶されている電子文書(著作物)の情報を管理する。
このように、著作物データベース22、著作物データベース32、著作物データベース42のそれぞれで管理されている情報は異なるが、その構造は同じであるため、ここでは、著作物データベース32を例に挙げて説明する。図3は、著作物データベース32の構造例を示す図である。図3Aに示した著作物データベース32の構造は、著作物が書籍である場合を示している。また図3Bに示した著作物データベース32の構造は、著作物が音楽である場合を示している。
図3Aに示した著作物データベース32には、著作物を一意に表わすID、タイトル、著作者、出版社、発行年度、ISBNの項目が設けられ、項目毎に対応する情報が記載される。例えば、IDが“1”には、タイトルとして“マーケット原論”が関連付けられ、著作者として“P.コトー”が関連付けられ、出版社として“ダイヤリング社”が関連付けられ、発行年度として“1995“が関連付けられ、IDBNとして”0123456789012“が関連付けられている。
同様に、図3Bに示した著作物データベース32には、音楽に関するデータベースであるため、著作物を一意に表わすID、楽曲名、アーティスト、アルバム名、作曲者、作詞者、編曲者、リリース年、JASRACコードという項目が設けられ、項目毎に対応する情報が記載される。例えば、IDが“3”には、楽曲名として“会えない日々”が関連付けられ、アーティストとして“小島太郎”が関連付けられ、アルバム名として“Kojima Best”が関連付けられ、作曲者として“太田和夫”が関連付けられ、作詞者として“岸川浩司”が関連付けられ、編曲者として“山川隆”が関連付けられ、リリース年として“2011”が関連付けられ、JASRACコードとして“0304059391”が関連付けられている。
このように、著作物データベース32には、書籍や音楽といった管理する著作物に対応する項目が設けられ、それらの項目毎に対応する情報が記載され、その情報が管理される。なおここでは、書籍と音楽を例に挙げて説明したが、他の著作物、例えば、映画、演劇、絵画といった著作物の情報も、それぞれの著作物にあった項目が設けられ、管理されるようにすることも勿論可能である。
[著作物データベースを用いた処理の概略について]
上記したような著作物データベース32が管理されているときの電子文書閲覧端末31の機能について説明する。図2Aに示したような文書61が電子文書記憶部33に記憶され、電子文書閲覧端末31に表示されたときの画面例を図4に示す。また、この場合、図3Aに示した書籍に関するデータベースが、著作物データベース32として構築されている場合とする。
上記したような著作物データベース32が管理されているときの電子文書閲覧端末31の機能について説明する。図2Aに示したような文書61が電子文書記憶部33に記憶され、電子文書閲覧端末31に表示されたときの画面例を図4に示す。また、この場合、図3Aに示した書籍に関するデータベースが、著作物データベース32として構築されている場合とする。
図4の左側の図を参照するに、電子文書閲覧端末31には、電子文書を表示する表示部101と、表示部101に表示されている電子文書のページをめくるときなどに操作される操作部102が設けられている。
図4の左側の図に示した表示部101には、図2Aで示した書籍の1ページが表示されている。また、図4の左側の図に示した表示部101には、“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”(以下、書籍[1]と適宜記載する)、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年” (以下、書籍[2]と適宜記載する)に、それぞれ下線が引いてある。この下線は、リンクが張られていることを示す。下線が引かれることで、ユーザはリンクがあることを認識することができる。このリンクは、情報端末41または電子文書閲覧端末31が、後述する処理を実行することで生成される。
また、図4の左側の図に示した表示部101には、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”上にカーソルが位置している状態であり、 “[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”と区別がつくような表示がされている。このような状態のときに、書籍[2]を選択し、決定したという操作がされると、図4の右側の図のような画面に、表示部101の表示が切り換えられる。
この場合、書籍[2]が、電子文書記憶部33に記憶されていたために、リンク先が、その記憶されていた電子文書とされていた状態である。このように、選択された著作物が記憶されていた場合には、その記憶されている著作物に、表示部101の表示が切り換えられる。
一方で、選択された著作物が記憶されていない場合には、図5に示すように画面に遷移される。まず、図5の左側の図を参照する。この図5の左側の図は、図4の左側の図と同じであるが、カーソルが、“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”上に位置している点が異なる。この書籍[1]が、電子文書閲覧端末31に記憶されていない場合、書籍[1]のリンクが操作されると、図5の中央に示した図のような画面に、表示部101の表示が切り換えられる。
この場合、書籍[1]が、電子文書記憶部33に記憶されていないために、リンク先が、書籍[1]を購入するためのサイトとされ、購入するための画面が表示部101に表示される状態とされる。このように、選択された著作物が記憶されていない場合には、その著作物を購入できる先にアクセスし、購入するための画面に表示部101の表示が切り換えられる。また、このように画面が遷移できるようなリンクが生成されている。このような画面が表示され、購入するためのボタンが操作された場合、図5の右側の図のような画面に、表示部101の画面が切り換えられる。
図5の右側の図のような画面は、購入された書籍[1]の表紙の画面である。このように、購入されたときには、著作物のデータがダウンロードされ、電子文書記憶部33に記憶されると共に、表示部101に著作物の1ページが表示される。
このようなことは、音楽であっても同様に行うことができる。図2Bに示したような文書61が電子文書記憶部33に記憶され、電子文書閲覧端末31に表示されたときの画面例を図6に示す。また、この場合、図3Bに示した音楽に関するデータベースが、著作物データベース22として構築されている場合とする。
図6の左側の図に示した表示部101には、図2Bで示したライナーノーツの1ページが表示されている。また、図6の左側の図に示した表示部101には、“Track 1 「ピアノ協奏曲 第24番 ハ単調」 モーツアルト」”(以下、曲[1]と適宜記載する)、“Track 2 「ヴァイオリン協奏曲集 <<四季>>」 ヴィヴァルディ” (以下、曲[2]と適宜記載する)、“Track 3 「ヴァイオリン協奏曲 ニ長調」 チャイコフスキー” (以下、曲[3]と適宜記載する)に、それぞれ下線が引いてある。この下線は、リンクが張られていることを示し、その下線を見ることで、ユーザはリンクがあることを認識することができる。
また、図6の左側の図に示した表示部101には、“Track 1 「ピアノ協奏曲 第24番 ハ単調」 モーツアルト」”上にカーソルが位置している状態であり、曲[2]や曲[3]と区別がつくような表示がされている。このような状態のときに、曲[1]を選択し、決定したという操作がされると、図6の右側の図のような画面に、表示部101の表示が切り換えられる。
この場合、曲[1]の情報が、電子文書記憶部33に記憶されていたために、リンク先が、その記憶されていた曲[1]の情報の電子文書とされていた状態である。なお、電子文書閲覧端末31が、スピーカなどを備え、音を出力する機能を有する場合など、音楽データも記憶し、その音楽データにもリンクが張られるようにしても良い。
このように、選択された曲に関する情報が記憶されていた場合には、その記憶されている曲の情報に、表示部101の表示が切り換えられる。また、音楽データにもリンクが張られていた場合、その音楽データが再生され、ユーザに提供される。
一方で、選択された曲の情報が記憶されていない場合には、図7に示すように画面が遷移する。まず、図7の左側の図を参照する。この図7の左側の図は、図6の左側の図と同じであるが、カーソルが、“Track 2 「ヴァイオリン協奏曲集 <<四季>>」 ヴィヴァルディ”上に位置している点が異なる。この曲[2]は、電子文書閲覧端末31に記憶されていない場合、図7の中央に示した図のような画面に、表示部101の表示が切り換えられる。
この場合、曲[2]に関する情報(音楽データ)が、電子文書記憶部33に記憶されていないために、リンク先が、曲[2]を購入するためのサイトとされ、購入するための画面が表示部101に表示される状態とされる。このように、選択された曲が記憶されていない場合には、その曲を購入できる先にアクセスし、購入するための画面に表示部101の表示が切り換えられる。このような画面が表示され、購入するためのボタンが操作された場合、図7の右側の図のような画面に、表示部101の画面が切り換えられる。
図7の右側の図のような画面は、購入された曲[2]に関する情報が表示されている画面である。このように、購入されたときには、曲の情報、音楽データなどがダウンロードされ、電子文書記憶部33に記憶されると共に、表示部101に、曲に関する情報(テキストや、ジャケットの画像など)が表示される。
[リンク生成の処理について]
次に、電子文書内に記載されている著作物の情報にリンクを生成するための処理について説明する。電子文書閲覧端末31が、電子文書記憶部33に記憶されている電子文書を対象として処理を実行する場合を例に挙げて説明する。また、情報端末41が電子文書記憶部43に記憶されている電子文書を対象として処理を実行する場合も、基本的に同様に行うことができる。
次に、電子文書内に記載されている著作物の情報にリンクを生成するための処理について説明する。電子文書閲覧端末31が、電子文書記憶部33に記憶されている電子文書を対象として処理を実行する場合を例に挙げて説明する。また、情報端末41が電子文書記憶部43に記憶されている電子文書を対象として処理を実行する場合も、基本的に同様に行うことができる。
また、電子文書閲覧端末31の処理能力と、情報端末41の処理能力を比較したとき、情報端末41の処理能力の方が高い場合、情報端末41が、電子文書閲覧端末31の代わりに処理を実行するようにしても良い。例えば、電子文書閲覧端末31の電子文書記憶部33に記憶されている電子文書を、情報端末41が取得し、その取得された電子文書に対して情報端末41が処理を実行するようにしても良い。
また、情報端末41で以下に説明するリンク生成のための処理が実行され、リンクが埋め込まれた電子文書が生成されるようにし、そのリンクが埋め込まれた電子文書が、電子文書閲覧端末31に供給され、記憶されるようにしても良い。
図8のフローチャートを参照し、電子文書閲覧端末31が、電子文書記憶部33に記憶されている電子文書を対象として、リンクを生成する処理について説明する。ステップS101において、電子文書閲覧端末31内の著作物データベース32に対する著作物検索プロセスが実行される。このステップS101の処理が実行されることで、処理対象とされている電子文書内の文章から、著作物を参照している文章と、その文章で参照される著作物が検出される。このステップS101の著作物検索プロセスについては、図11のフローチャートを参照して後述し、先にステップS102以降の処理について説明を続ける。
ステップS101の処理の結果が用いられ、ステップS102の処理が行われる。すなわち、ステップS102において、電子文書閲覧端末31内の著作物データベース32内に含まれる著作物を参照している文章が見つかったか否かが判断される。著作物データベース32内には、電子文書閲覧端末31自体が記憶している電子文書の情報が記載されているが、その情報と一致する文章が、処理対象とされている電子文書内から検出されたか否かが判断される。処理対象とされている電子文書内の文章が、著作物データベース32で管理されている情報と一致する場合、その文章は、一致した情報で管理され、電子文書記憶部33に記憶されている著作物を参照していることを意味する。
ステップS102において、電子文書閲覧端末31内の著作物データベース32内に含まれる著作物を参照している文章が見つかったと判断された場合、ステップS103に処理が進められる。
ステップS103において、電子文書閲覧端末31内に保存されている該著作物へのリンクを、ステップS101の処理において検出された文章に対して付与する。この場合のリンクは、例えば、図4を参照して説明したようなリンクである。ここで再度図4を参照する。図4の左側の図に示したように、“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年” に、それぞれ下線が引いてあり、この下線は、リンクが張られていることを示している。
この“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”と、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”は、それぞれ、ステップS101またはステップS104(後述)で、“著作物を参照している文章”として検出された文章である。図4を参照して説明したように、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”という著作物は、電子文書閲覧端末31に記憶されているので、ステップS102において、YESと判断され、ステップS103に処理が来る。
換言すれば、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”の情報は、図3を参照して説明したように、著作物データベース32に管理されているため、電子文書内の“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”という文章と、著作物データベース32に管理されている情報とが一致するため、電子文書閲覧端末31内の著作物データベース32内に含まれる著作物を参照している文章が見つかったと判断される。
よってこの場合、電子文書閲覧端末31の電子文書記憶部33に記憶されている“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”の電子文書に対してリンクが生成される。このように、電子文書内から、著作物を参照している文章が検出され、その検出された文章が示す著作物が記憶されていた場合には、その記憶されている著作物にアクセスできるリンクが生成される。このようにして、リンクが生成されると、ステップS108に処理が進められる。
ステップS108において、次の文章があるか否かが判断される。ステップS108において、次の文章があると判断された場合、そのあると判断された文章に対して、ステップS101以降の処理が繰り返される。一方で、ステップS108において、次の文章はないと判断された場合、リンクを生成するためのフローチャートの処理は終了される。
ステップS102において、電子文書閲覧端末31内の著作物データベース32内に含まれる著作物を参照している文章は見つかっていないと判断された場合、ステップS104に処理が進められる。ステップS104において、サーバ21内の著作物データベース22に対する著作物検索プロセスが実行される。このステップS104の処理が実行されることで、著作物を参照している文章と、その著作物が検出される。
このステップS104の著作物検索プロセスは、ステップS101の著作物検索プロセスと同じ処理であり、検索先となるデータベースが、サーバ21の著作物データベース22である点が異なるだけである。よって、このステップS104における著作物検索プロセスについても、図11のフローチャートを参照して後述し、先にステップS105以降の処理について説明を続ける。
ステップS105において、サーバ21内の著作物データベース22内に含まれる著作物を参照している文章が見つかったか否かが判断される。ステップS105において、サーバ21内の著作物データベース22内に含まれる著作物を参照している文章が見つかったと判断された場合、ステップS106に処理が進められる。
ステップS106において、その該著作物のIDが著作物データベース22より取得される。そして、ステップS107において、そのIDで示される著作物を参照するリンクが、ステップS104の処理において検出された文章に対して付与される。この場合のリンクは、例えば、図5を参照して説明したようなリンクである。ここで再度図5を参照する。図5の左側の図に示したように、“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年” に、それぞれ下線が引いてあり、この下線は、リンクが張られていることを示している。
この“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”と、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”は、それぞれ、ステップS101またはステップS104で、“著作物を参照している文章”として検出された文章である。図5を参照して説明したように、“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”という著作物は、電子文書閲覧端末31には記憶されていないので、ステップS102において、NOと判断される。そして、ステップS104を介してステップS105に処理が進められ、ステップS105において、サーバ21では管理されていると判断されて、ステップS106,S107に処理が来る。
よってこの場合、サーバ21では“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”が管理されているので、その管理のために割り当てられているIDが取得される。このIDで、サーバ21で管理されている“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”にアクセスできる。ここでアクセスとは、例えば、図5の中央の図に示したような購入画面を提供するサイトなどにアクセスすることを意味する。そして、このようなアクセスが行えるようなリンクが生成され、検出された文章に付与される。このようにして、リンクが生成されると、ステップS108に処理が進められる。
ステップS108において、次の文章があるか否かが判断され、次の文章があると判断された場合、そのあると判断された文章に対して、ステップS101以降の処理が繰り返される。一方で、ステップS108において、次の文章はないと判断された場合、リンクを生成するためのフローチャートの処理は終了される。
ここで、このような処理が行われることによりリンクが付与された電子文書について説明を加える。図9は、リンクが埋め込まれる前の電子文書の文章データと、リンクが埋め込まれた後の電子文書の文章データの一例を示す図である。また図9に示した例は、図2Aに示した書籍が電子文書にされ、上述した処理の対象とされたときの例である。
図10も、リンクが埋め込まれる前の電子文書の文章データと、リンクが埋め込まれた後の電子文書の文章データの一例を示す図である。また図10に示した例は、図2Bに示したライナーノーツが電子文書にされ、上述した処理の対象とされたときの例である。
図9、図10に示したように、電子文書に含まれる文章データは、例えばXML(Extensible Markup Language)形式で記述される。図9Aと図10Aは、それぞれリンクが埋め込まれる前の文章データである。図9Bと図10Bは、それぞれリンクが埋め込まれた後の文章データである。図中、左側に付した行番号は、説明のために付したものである。
図9Aを参照するに、リンクが埋め込まれる前の文章データは、表示部101に表示されるテキストのデータで構成されている。1行目の<page>からm行目の</page>の間に記載されているデータが、電子文書の1ページとして扱われる。2行目の<text x=50 y=29 w=40 h=20>参考文献</text>とのデータは、“参考文献”という文字列が、x座標が“50”、y座標が“29”の位置から表示が開始され、その表示の大きさは、幅(w)が“40”であり、高さ(h)が“20”であることを示している。
このように、表示開始位置と大きさが規定され、表示される文字列が文章データとして記載されている。図10Aに示した曲に関する文章データも同様の構成である。このような文章データに、リンクが埋め込まれると、図9Bに示したような文章データとなる。図9Bを参照するに、リンクが埋め込まれたことにより、埋め込まれる前の図9Aに示した文章データに対して、3行目の<link type=“document” db=“bookservice.com” id=“1”>、6行目の</link>、7行目の<link type=“document” db=“localhost” id=“1”>、および10行目の</link>が追加されたデータとされている。
3行目の<link type=“document” db=“bookservice.com” id=“1”>から、6行目の</link>までのlink要素で囲まれた部分が、電子文書閲覧端末31で表示される際に、リンクが張られていることを示す下線で表わされる文章の範囲である。このlink要素の属性として、例えばtype, db, idがある。typeはリンク先の著作物の種類を表わし、例えばdocumentは文書、musicは音楽を表わす。dbは、接続するデータベースのURLを表わす。例えばlocalhostは、電子文書閲覧端末31自身、すなわち電子文書閲覧端末31内の著作物データベース32を表わす。idはdbで表わされたデータベース内で、著作物を一意に表わす番号である。
例えば、3行目の<link type=“document” db=“bookservice.com” id=“1”>は、“bookservice.com”というデータベース(サイト)にアクセスし、IDが“1”のデータを参照することを示している。7行目の<link type=“document” db=“localhost” id=“1”>は、“localhost”というデータベース、すなわち、電子文書閲覧端末31内の著作物データベース32にアクセスし、IDが“1”のデータを参照することを示している。
このように、リンクが張られていることを示すための下線を引く範囲や、リンク先のデータベース、参照するデータのIDなどが文章データ内に追加記載される。図10Bに示した曲に関する文章データも同様の構成である。
[著作物検索プロセスについて]
図8のフローチャートのステップS101、ステップS104において実行される著作物検索プロセスについて、図11のフローチャートを参照して説明する。上記したように、ステップS101とステップS104は、異なるデータベースを参照する点が異なるだけで、処理としては基本的に同一なので、ここでは、ステップS101で行われる処理を例に挙げて説明する。
図8のフローチャートのステップS101、ステップS104において実行される著作物検索プロセスについて、図11のフローチャートを参照して説明する。上記したように、ステップS101とステップS104は、異なるデータベースを参照する点が異なるだけで、処理としては基本的に同一なので、ここでは、ステップS101で行われる処理を例に挙げて説明する。
ステップS131において、処理対象とされる電子文書内の文書が、文の要素単位で切り出される。このときの要素単位は、例えば改行の単位にすることができる。または所定の文字数で切り出すこともできる。ステップS132において、切り出された文章と、著作物データベース32内の著作物の情報との類似度が、著作物データベース32内に記憶されている全ての著作物の情報に対して計算される。そして、最高の類似度を持つ著作物が検出される。
類似度の計算は、例えば、処理対象とされている文章に含まれている単語と、著作物データベース32に含まれるタイトル、楽曲名、出版社などの図3を参照して説明した情報が比較され、著作物データベース32に含まれる単語とどれだけ適合するか、または、逆に適合しない単語はどれくらい存在するか、によって算出される。
ステップS133において、文章結合をX回以上繰り返したか否かが判断される。文章結合とは、後段のステップS134の処理で行われるので、まず、ステップS134の処理を説明する。ステップS134において、その時点で処理対象とされている文章に、さらにもう一つ先の文章を結合した文章を生成し、その結合された文章で、再度類似度が計算される。そして、最高の類似度を持つ著作物を検出される。
このような、処理対象とされている文章と、次の文章を結合することを文章結合と称する。この文章結合が、予め設定されるX回以上繰り返されたか否かが、ステップS133において判断される。ステップS133において、文章結合をX回以上繰り返してはいないと判断された場合、ステップS134に処理が進められ、上記したように、文章結合が行われ、再度、類似度の計算が行われる。
そして、ステップS135において、結合前の最高類似度と結合後の最高類似度が比較され、結合後の類似度のほうが高いか否かが判断される。ステップS135において、結合後の類似度のほうが結合前の類似度よりも高いと判断された場合、ステップS133に処理が戻され、それ以降の処理が繰り返される。すなわち、さらに文章結合が行われ、類似度が算出され、比較されるといった処理が繰り返される。
例えば、文章結合前の文章には、作者名が含まれていて、文章結合後の文章には、さらに作品名も含まれるような場合、結合後の類似度のほうが結合前の類似度よりも高いと判断される。このように、文章を結合し、さらなる情報が含まれることで、類似度が高くなると考えられるが、さらなる文章を結合しても、その結合した文章に、さらなる情報が含まれなければ、結合後の類似度のほうが結合前の類似度よりも高くなることはない。
よって、結合後の類似度のほうが結合前の類似度よりも高いと判断されている間は、さらなる情報を含んでいる可能性のある次の文章を結合し、結合後の類似度のほうが結合前の類似度よりも高いと判断されなくなった時点で、結合を中止する。
ステップS135において、結合後の類似度のほうが結合前の類似度よりも高いと判断されなかった場合、ステップS136に処理が進められ、文章結合する直前の文章が候補とされる。
このようにして、候補となる文章が決定されると、ステップS138に処理が進められる。ステップS138の処理には、ステップS133において、文章結合をX回以上繰り返したと判断され、ステップS137の処理を経てくる場合もある。ステップS137においては、ステップS132の処理で使われた結合前の最初の文章が候補とされる。
このようにして候補が決定されると、その候補とされた文章に対してステップS138の処理が行われる。ステップS138において、候補とされた文章を用いて算出された最高類似度は、所定の閾値を超えているか否かが判断される。ステップS138において、候補とされた文章を用いて算出された最高類似度は、所定の閾値を超えていると判断された場合、ステップS139に処理が進められる。
ステップS139において、候補とされた文章と、最高の類似度を持つ著作物データベース22のタイトルを検索結果として後段の処理に出力する。すなわち、候補とされた文章は、“著作物を参照している文章”とされ、著作物データベース22のタイトルは、検出された著作物として扱われる。
一方、ステップS138において、候補とされた文章を用いて算出された最高類似度は、所定の閾値を超えていないと判断された場合、ステップS140に処理が進められる。すなわちこの場合、候補とされた文章は、“著作物を参照している文章”ではない可能性が高いため、検索結果なしとして後段の処理が行われる。
このように、電子文書から著作物を参照している文章と、その文章が参照している著作物が検出される。このような処理が、ステップS101において行われる場合、電子文書閲覧端末31の著作物データベース32が検索先のデータベースとされて処理が行われる。よって、ステップS101における処理は、自己が記憶している著作物であるか否かを判断するための処理である。
一方で、ステップS104において、このような処理が行われる場合、サーバ21の著作物データベース21が検索先のデータベースとされて処理が行われる。よって、ステップS104における処理は、他の装置が管理している著作物であるか否かを判断するための処理である。このように、本実施の形態においては、自己が管理している著作物であるか、他の装置が管理している著作物であるかを異なるデータベースを参照して判断する。
[電子文書の表示の処理について]
次に、電子文書が、電子文書閲覧端末31の表示部101に表示される際の処理について、図12のフローチャートを参照して説明する。ステップS161において、選択されたページが、ユーザが指定した倍率で表示される。そして、ステップS162において、表示範囲内にリンクが存在するか否かが判断される。例えば、図9Aに示したようなリンクが埋め込まれてない文章データの文章が、表示の対象とされていた場合、ステップS162においては、表示範囲内にリンクは存在しないと判断され、図12に示したフローチャートの処理は終了される。
次に、電子文書が、電子文書閲覧端末31の表示部101に表示される際の処理について、図12のフローチャートを参照して説明する。ステップS161において、選択されたページが、ユーザが指定した倍率で表示される。そして、ステップS162において、表示範囲内にリンクが存在するか否かが判断される。例えば、図9Aに示したようなリンクが埋め込まれてない文章データの文章が、表示の対象とされていた場合、ステップS162においては、表示範囲内にリンクは存在しないと判断され、図12に示したフローチャートの処理は終了される。
一方で、図9Bに示したようなリンクが埋め込まれている文章データの文章が、表示の対象とされていた場合、ステップS162においては、表示範囲内にリンクが存在すると判断され、ステップS163に処理が進められる。ステップS163において、リンクに含まれる文章に下線が引かれ、表示が行われる。この下線が引かれる範囲などは、図9Bを参照説明したように、リンク要素に挟まれているデータである。
このようにして、例えば、図4の左側の図に示したような画面が表示部101に表示される。図4の左側の図に示した表示部101に表示されている画面内の文章には、リンクが張られている。このようなリンクが張られている文章が、ユーザにより選択されたときの処理について次に説明する。
[リンクが選択されたときの処理について]
図13は、表示されている文章にリンクが張られ、そのリンクが選択されたときの処理について説明するためのフローチャートである。ステップS191において、ユーザによりリンクが選択されたか否かが判断される。ステップS191において、リンクが選択されたと判断されるまで、リンクが選択されたときの処理は待機状態とされ、リンクが選択されたと判断された場合、リンクが選択されたときの処理が開始される。
図13は、表示されている文章にリンクが張られ、そのリンクが選択されたときの処理について説明するためのフローチャートである。ステップS191において、ユーザによりリンクが選択されたか否かが判断される。ステップS191において、リンクが選択されたと判断されるまで、リンクが選択されたときの処理は待機状態とされ、リンクが選択されたと判断された場合、リンクが選択されたときの処理が開始される。
ステップS192において、選択されたリンクのリンク先は、電子文書閲覧端末31内であるか否かが判断される。選択されたリンクのリンク先は、電子文書閲覧端末31内であるか否かの判断は、処理されている文章データを参照することで行われる。例えば、図9Bに示したような文章データが処理されているときに、リンクが選択されたとき、そのリンクの情報が、3行目に記載がある<link type=“document” db=“bookservice.com” id=“1”>であった場合、db=“bookservice.com”との情報から、ネットワーク11に接続されている他の装置のデータベースがリンク先とされていることがわかる。
同様に、選択されたリンクの情報が、7行目の<link type=“document” db=“localhost” id=“1”>であった場合、db=“localhost”との情報から、電子文書閲覧端末31内のデータベースがリンク先とされていることがわかる。
このようにして、文章データ内のリンク先の情報を参照することで、ステップS192において、選択されたリンクのリンク先は、電子文書閲覧端末31内であると判断された場合、ステップS193に処理が進められる。ステップS193において、リンク先とされている電子文書閲覧端末31内の著作物データベース32内の対応するデータが参照され、著作物のデータが電子文書記憶部33から読み出される。そして、その読み出された著作物のデータに基づく画面が、表示部101に表示される(ステップS199)。
このような流れは、図4を参照して説明したような場合である。図4を再度参照するに、図4の右側の図に示した画面が、表示部101に表示されているとき、“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”が選択されると、この著作物のリンク先は、電子文書閲覧端末31内の著作物データベース32であるため、ステップS193に処理が進められる。そして、ステップS193とステップS199の処理が行われることで、図4の右側の図のような画面に、表示部101の表示が切り換えられ、ユーザが選択した著作物がユーザに提供される。
一方、ステップS192において、選択されたリンクのリンク先は、電子文書閲覧端末31内ではないと判断された場合、ステップS194に処理が進められる。ステップS194において、文章データ内のリンクの情報に含まれるURL上にある著作物データベースに対して、同じくリンクの情報に含まれているIDで問い合わせが行われる。
例えば、図9Bに示したような文章データが処理されているときに、選択されたリンクの情報が、3行目に記載がある<link type=“document” db=“bookservice.com” id=“1”>であった場合、db=“bookservice.com”というサーバの著作物データベースに対して、id=“1”のデータについての問い合わせが行われる。
この問い合わせの結果、購入する必要がある著作物であるか否かが、ステップS195において判断される。ステップS195において、購入する必要がある著作物であると判断された場合、ステップS196に処理が進められる。ステップS196において、購入プロセスが実行される。この購入プロセスは、接続先のサイトにより、購入に至るまでの処理の流れは異なる可能性があるが、基本的な流れは同じである。例えば、図5の中央の図に示したような、購入金額や、表紙の画像などを含み、購入するか否かを決定するためのボタンを含むような購入画面が表示部101に表示される。
そして、“購入”というボタンまたは“取消”というボタンが操作される。ステップS197において、著作物が購入されたか否かが判断される。“購入”というボタンが操作された場合、ステップS197において、購入したと判断され、ステップS198に処理が進められる。一方、“取消”というボタンが操作された場合、ステップS197において、購入していないと判断され、ステップS198に処理が進められる。
“購入”というボタンが操作された場合、接続先のサーバ(ここでは、サーバ21とする)は、課金処理などを、顧客データベース23で管理されている顧客データなどを用いて行うと共に、購入された著作物のデータを、電子文書閲覧端末31に供給する。電子文書閲覧端末31は、供給される著作物のデータを、電子文書記憶部33に記憶すると共に、著作物データベース22に購入された著作物の情報を追加する。
このようにして、電子文書記憶部33内に購入された著作物のデータが記憶された場合、ステップS198において、電子文書記憶部33に記憶された著作物のデータが取得され、その取得された著作物のデータに基づく画面が、表示部101に表示される(ステップS199)。例えば、図5の右側の図に示したように、購入された著作物の表紙が表示部101に表示される。
一方、ステップS195において、購入する必要のない著作物であると判断された場合、購入する必要はないが、他の装置(サーバ21)に記憶されているため、ステップS198において、そのサーバ21にアクセスし、対応する著作物のデータがダウンロードされ、電子文書記憶部33に記憶される。その後の処理は、上記した場合と同じく、ステップS199において、ダウンロードされた著作物のデータに基づく画面が、表示部101に表示される。
一方、ステップS197において、著作物は購入されなかったと判断された場合、図13に示したリンク選択時の処理は終了される。この場合、例えば、図5の中央の図に示したような画面が、表示部101に表示されているときに、“取消”というボタンが操作されたので、例えば、図5の左側の図に示した画面、すなわち、購入画面に切り換えられる前の画面に、表示部101の表示が切り換えられる。
このようにして、リンクが操作されたときには、リンク先にアクセスされ、著作物の表示が行われたり、購入が行われたりする。
スキャナ51などで取り込まれた文書61には、通常リンクなどの情報はない。しかしながら、上記したように、本技術を適用することで、リンクがない電子文書に対してリンクを生成することができる。また、自己が記憶している著作物のデータにアクセスできるリンクや、他の装置が記憶している著作物のデータにアクセスできるリンクを生成することができる。
[他のリンクの生成について]
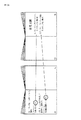
ところで、図2Aに示したように、書籍の1ページとして、参考文献が列挙されているページもあるが、そのようなページの他に、参考文献に番号が付され、その番号が本文中に記載されている場合もある。そのようなページの一例を図14に示す。
ところで、図2Aに示したように、書籍の1ページとして、参考文献が列挙されているページもあるが、そのようなページの他に、参考文献に番号が付され、その番号が本文中に記載されている場合もある。そのようなページの一例を図14に示す。
図14の左側の図に示した書籍の所定のページは、書籍内の本文のページであり、図14の右側の図に示した書籍の所定のページは、本文で参照されていた参照文献のページである。本文中に、参考文献の記載をすると読みづらくなるなどの理由から、図14の左側の図に示したように、参照番号のみが記載されている場合がある。図14の左側の図を参照するに、13ページの“と説いている([1])”といった記載のうち、[1]というのは、図14の右側の図に示した56ページの参照文献一覧内の同一番号で引用される“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”であることを示している。
同様に、図14の左側の図を参照するに、13ページの“と自論を展開している([2])”といった記載のうち、[2]というのは、図14の右側の図に示した56ページの参照文献一覧内の同一番号で引用される“[2]P.コトー 「マーケット原論」 ダイヤリング社 1995年”であることを示している。
紙媒体の書籍においては、例えば、13ページの本文を読んでいたときに、[1]という番号で引用される参照文献は何であるのかを知りたい場合、56ページまでページをめくり、その56ページに記載されている参照文献の記載を読まなくてはならない。さらに、参照文献を認識した後、その参照文献を読みたいと思った時には、その参照文献を、例えば、本棚から探し出してこなくてはならない。
このようなことは、ユーザにとっては煩わしいことである。そこで、電子文書においては、そのような煩わしい処理を行わなくても、参照文献を閲覧できるようにする。図15を参照して説明するに、図15の左側の図は、図14の左側に示した書籍のページを、電子文書として電子文書閲覧端末31の表示部101に表示させた例である。図15の左側の図の表示部101に表示されている文章のうち、“と説いている([1])”といった記載を見るに、この記載のうち、[1]のところには、下線が引かれている。すなわち、[1]にはリンクが張られている。
同様に、[2]という番号にも下線が引かれて表示されており、リンクが張られていることが示されている。ユーザが[1]を選択すると、図15の右側の図のように、表示部101の表示が、番号[1]が割り当てられた参照文献(著作物)の表示に切り換えられる。このように、ユーザは、参照文献に割り当てられた番号を選択するだけで、リンク先の著作物である参照文献を閲覧することが可能となる。
このように、参考文献に対して文書内で一意の番号を付し、それを文書内からその番号を参照する場合、文書内のつながりを解析し、その結果を電子文書に反映させることで、図15のように電子文書閲覧端末31において文書内の参照番号を選択した際に参照先の文書を提示することが可能となる。
このような参照番号に対してリンクを生成する際の処理について、図16のフローチャートを参照して説明する。このような参照番号に対してリンクを生成するには、参照番号を検出することに加え、参照番号で参照されている著作物を検出し、その検出された著作物が、電子文書閲覧端末31に記憶されているか、または他の装置に記憶されているかを検出する必要がある。この後半の著作物を検出し、その検出された著作物が、電子文書閲覧端末31に記憶されているか、または他の装置に記憶されているかを検出するための処理は、上記した場合と同様に行われる。
すなわち、図16に示したフローチャートを参照するに、ステップS221乃至S228の処理は、図8に示したフローチャートのステップS101乃至S108と同様に行われ、電子文書内で著作物を参照している文章が検出され、その文章に著作物にアクセスするためのリンクが生成される。そして、その生成されたリンクのリンク先、または、参照している文章に対して、参照番号からのリンクが張られる。換言すれば、参照番号と、その参照番号が参照している電子文書内の“著作物を参照している文章”に対してリンクが生成されるか、または参照番号から、著作物にアクセスするためのリンクが生成される。
このような処理は、ステップS229において、文書内リンク検出プロセスとして実行される。ステップS229における文書内リンク検出プロセスについて、図17のフローチャートを参照して説明する。
ステップS241において、ステップS223またはステップS227の処理においてリンクが付与された“著作物を参照している文章”を対象とし、その文章の先頭に、文書内参照を示す文字があるか否かが判断される。文書内参照を示す文字とは、例えば、[1]、*1、#1などである。例えば、図14の右側の図に示したように、著作物を参照している文章の先頭部分には、[1]、*1、#1などの参照番号が記載されている。ステップS241においては、そのような参照番号が、“著作物を参照している文章”の先頭部分にあるか否かが判断される。
ステップS241において、著作物を参照している文章の先頭部分に、文書内参照を示す文字がないと判断された場合、その文章は、文書内リンク検出プロセスの対象外の文章であるため、図17に示したフローチャートの処理は終了される。一方、ステップS241において、著作物を参照している文章の先頭部分に、文書内参照を示す文字があると判断された場合、ステップS242に処理が進められる。
ステップS242において、その参照を示す文字が、電子文書内の他の文章内に存在するかが検索される。例えば、[1]という参照を示す文字があったとステップS241において判断された場合には、[1]という文字列が、電子文書内から検出される。このステップS242における検索処理の結果、電子文書内から、参照を示す文字が検出されたか否かが、ステップS243において判断される。
ステップS243において、電子文書の中に、文書内参照を示す文字はないと判断された場合、図17に示したフローチャートの処理は終了される。一方、ステップS243において、電子文書の中に、文書内参照を示す文字があると判断された場合、ステップS244に処理が進められる。ステップS244において、文書内参照を示す文字にリンクが埋め込まれる。すなわち、文書内参照を示す文字があると判断された文章に、ステップS223またはステップS227の処理において付与されたリンクが、その文章内の文書内参照を示す文字に対して付与される。
例えば、図14の右側の図を参照するに、56ページには、文書内参照を示す文字として、[1]がある。この[1]が、ステップS241において検出される。そして、ステップS242,243の処理において、図14の左側の図に示した13ページの“と説いている[1]”という文章が検索され、この文章から、処理対象とされている[1]という文書内参照を示す文字が検出される。
このように検出される、“と説いている[1]”という文章内の「1」に対して、56ページの“[1]P.S.ドラッグ 「マネージャー」 ダイヤリング社 2001年”に対して付与されたリンクが付与される。このようなリンクの付与がされることで、図15を参照して説明したように、ユーザは、[1]という参照番号をクリックするなど所定の操作を行うだけで、その[1]という参照番号で参照されている著作物を閲覧することが可能となる。
このように、文書内に対してもリンクを生成することができ、電子文書の使い勝手の向上をはかることが可能となる。
本技術によれば、スキャナ51などで読み込まれ、電子化された文書を閲覧する際に、そこから参照される著作物をシームレスに利用者が閲覧できるようにすることができる。よって、ユーザに対する利便性を向上させることが可能となる。また、リンク先を、著作物の購入サイトとすることもでき、仮に、私的利用目的で電子化された電子文書からであっても、デジタル著作物の購買につなげることができる。さらに、自分が今までスキャンした書籍間のリンクを自動的に作成することができるので、ユーザがその関連を管理する必要がなくなり、手間が省けるようになる。
[更新処理について]
ところで、上述したようにして電子文書内の文書にリンクが生成されるが、そのリンクを生成する際に参照される著作物データベース22,32,42(図1)に、新たな著作物が追加されたときなど、データベースを更新する必要がある。次に、新たな著作物が追加されるなどして、データベースの更新が行われた場合について説明を加える。
ところで、上述したようにして電子文書内の文書にリンクが生成されるが、そのリンクを生成する際に参照される著作物データベース22,32,42(図1)に、新たな著作物が追加されたときなど、データベースを更新する必要がある。次に、新たな著作物が追加されるなどして、データベースの更新が行われた場合について説明を加える。
図18は、電子文書閲覧端末31で管理されている著作物データベース32が更新されたときの処理について説明するためのフローチャートである。また、ここでは、著作物データベース32が更新されたときの処理として説明を続けるが、情報端末41の著作物データベース42が更新された際も、同様に更新処理を行うことができる。さらに、サーバ21が、電子文書閲覧端末31の著作物データベース32や、情報端末41の著作物データベース42を取得し、サーバ21で更新処理を行うことも可能である。
ステップS261において、更新された分だけを含む仮の著作物データベースが作成される。更新された分とは、例えば、新たに購入され、電子文書閲覧端末31の電子文書記憶部33に記憶された電子文書や、スキャナ51で取り込まれ、電子文書にされた電子文書などの分である。
ステップS262において、電子文書記憶部33に記憶されている複数の電子文書のうちの1つの電子文書が処理対象の電子文書として設定される。そして、その設定された電子文書に対して、ステップS263の処理が実行される。ステップS263において、仮の著作物データベースに対する著作物検索プロセスが実行される。この仮の著作物データベースに対する著作物検索プロセスは、図11に示した著作物検索プロセスのフローチャートの処理に基づいて行われる。
すなわち、図11のフローチャートを参照して上述した説明においては、著作物データベース32に対して行われる場合であったが、ここでは、仮の著作物データベースに対して行われる点が異なるだけであり、基本的な処理は、上述した場合と同様に行われる。よって、説明が重複するので、ここではその説明を省略する。また、ステップS263乃至S266の処理は、図8のステップS101乃至S103,S108の処理と同様に行われるため、ここではその詳細な説明は省略する。
処理対象として設定されている電子文書には、既にリンクが生成されているが、電子文書閲覧端末31に新たに追加された電子文書、すなわち仮の著作物データベースで管理されている電子文書に対しては、リンクが生成されていない。この処理が実行されることで、新たに追加された電子書籍に対してリンクが張られる(リンク先が変更される)ことになる。
ステップS267において、電子文書記憶部33に次の電子文書があるか否かが判断され、あると判断されたときには、ステップS262に処理が戻され、次の電子文書が処理対象とされ、それ以降の処理が繰り返される。一方、ステップS267において、電子文書記憶部33に次の電子文書はないと判断された場合、更新処理は終了される。
このような更新処理は、電子文書が追加されたときに行われるようにしても良いし、複数の電子文書が追加されたときに行われるようにしても良いし、所定の時間間隔で、定期的に行われるようにしても良い。
次に、サーバ21の著作物データベース22が更新されたときの処理について、図19のフローチャートを参照して説明する。サーバ21で更新処理が行われるのは、例えば、ユーザに対して販売する著作物が追加されたときなどである。
サーバ21は、自己が例えば販売などを目的として管理している電子書籍に関する情報を、著作物データベース22で管理すると共に、電子文書閲覧端末31の著作物データベース32で管理されている電子書籍に関する情報も管理している場合を例に挙げて説明する。よって、サーバ21自体に著作物が追加された場合、サーバ21が記憶している電子書籍に対して行う更新処理と、ユーザ側でスキャンなどで電子文書にされた電子文書に対して行う更新処理とがある。
まず、ステップS281において、更新された分だけ含む仮の著作物データベースが作成される。そして、その仮の著作物データベースに対して、ステップS282以降の処理が行われる。
ステップS282乃至S287の処理で、ユーザ側でスキャンなどで電子文書にされた電子文書に対する更新処理が実行される。この処理は、図18に示したフローチャートの処理と同様に行われる。すなわち、図18に示したフローチャートの処理は、電子文書閲覧端末31で行われるとして説明したが、ステップS282乃至287は、サーバ21側で行われる点が異なる。ステップS282乃至287の処理が実行されることで、サーバ21側に新たに追加された電子文書に対して、電子文書閲覧端末31側で管理されている電子書籍からのリンクが新たに生成される。
ステップS288乃至S293の処理は、サーバ21が管理している電子文書に対して、新たに追加された著作物に対してリンクを生成する処理である。この処理も、処理対象とされているのが、サーバ21が管理する電子文書であり、仮の著作物データベースに対して行われる以外は、基本的に上記した場合と同様に行うことができるため、その説明は省略する。
このように、更新処理を実行することで、新たに追加された電子文書に対しても、リンクを生成することが可能となり、ユーザに対する利便性を向上させることが可能となる。
[記録媒体について]
上述した一連の処理は、ハードウエアにより実行することもできるし、ソフトウエアにより実行することもできる。一連の処理をソフトウエアにより実行する場合には、そのソフトウエアを構成するプログラムが、コンピュータにインストールされる。ここで、コンピュータには、専用のハードウエアに組み込まれているコンピュータや、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどが含まれる。
上述した一連の処理は、ハードウエアにより実行することもできるし、ソフトウエアにより実行することもできる。一連の処理をソフトウエアにより実行する場合には、そのソフトウエアを構成するプログラムが、コンピュータにインストールされる。ここで、コンピュータには、専用のハードウエアに組み込まれているコンピュータや、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどが含まれる。
図20は、上述した一連の処理をプログラムにより実行するコンピュータのハードウエアの構成例を示すブロック図である。上述したサーバ21、電子文書閲覧端末31、情報端末41は、図20に示したコンピュータの構成と基本的な構成は同様とすることができる。
コンピュータにおいて、CPU(Central Processing Unit)1001、ROM(Read Only Memory)1002、RAM(Random Access Memory)1003は、バス1004により相互に接続されている。バス1004には、さらに、入出力インタフェース1005が接続されている。入出力インタフェース1005には、入力部1006、出力部1007、記憶部1008、通信部1009、及びドライブ1010が接続されている。
入力部1006は、キーボード、マウス、マイクロフォンなどよりなる。出力部1007は、ディスプレイ、スピーカなどよりなる。記憶部1008は、ハードディスクや不揮発性のメモリなどよりなる。通信部1009は、ネットワークインタフェースなどよりなる。ドライブ1010は、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリなどのリムーバブルメディア1011を駆動する。
以上のように構成されるコンピュータでは、CPU1001が、例えば、記憶部1008に記憶されているプログラムを、入出力インタフェース1005及びバス1004を介して、RAM1003にロードして実行することにより、上述した一連の処理が行われる。
コンピュータ(CPU1001)が実行するプログラムは、例えば、パッケージメディア等としてのリムーバブルメディア1011に記録して提供することができる。また、プログラムは、ローカルエリアネットワーク、インターネット、デジタル衛星放送といった、有線または無線の伝送媒体を介して提供することができる。
コンピュータでは、プログラムは、リムーバブルメディア1011をドライブ1010に装着することにより、入出力インタフェース1005を介して、記憶部1008にインストールすることができる。また、プログラムは、有線または無線の伝送媒体を介して、通信部1009で受信し、記憶部1008にインストールすることができる。その他、プログラムは、ROM1002や記憶部1008に、あらかじめインストールしておくことができる。
例えば、図8に示したフローチャートの処理を、電子文書閲覧端末31が行う場合、かつ、電子文書閲覧端末31が、図20に示した構成を有する場合、CPU1001が実行するプログラムとして実現できる。
なお、コンピュータが実行するプログラムは、本明細書で説明する順序に沿って時系列に処理が行われるプログラムであっても良いし、並列に、あるいは呼び出しが行われたとき等の必要なタイミングで処理が行われるプログラムであっても良い。
また、本明細書において、システムとは、複数の装置により構成される装置全体を表すものである。
なお、本技術の実施の形態は、上述した実施の形態に限定されるものではなく、本技術の要旨を逸脱しない範囲において種々の変更が可能である。
なお、本技術は以下のような構成も取ることができる。
(1)
電子文書の情報を記憶する記憶部と、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する抽出部と、
前記抽出部により抽出された前記文章から、前記記憶部の情報へのリンクを生成する生成部と
を備える情報処理装置。
(2)
前記記憶部は、同一端末内に記憶されている電子文書の情報が記憶されている第1の記憶部と、他の端末内に記憶されている電子文書の情報が記憶されている第2の記憶部があり、
前記抽出部は、前記第1の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、前記第2の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する
前記(1)に記載の情報処理装置。
(3)
前記電子文書は、紙媒体に印刷されていた文書を電子化したものである
前記(1)または前記(2)に記載の情報処理装置。
(4)
前記抽出部は、前記電子文書内の所定の文章と、前記記憶部に記憶されている前記情報との第1の類似度を算出し、
前記所定の文章の次の文章を結合した文章と、前記記憶部に記憶されている前記情報との第2の類似度を算出し、
前記第2の類似度が前記第1の類似度よりも大きいと判断されるまでの間は、文章の結合と類似度の算出を繰り返し行い、
前記第2の類似度が前記第1の類似度よりも小さいと判断されたとき、結合前の文章を抽出結果とする
前記(1)乃至(3)のいずれかに記載の情報処理装置。
(5)
前記抽出部は、抽出された文章を参照する番号を前記所定の電子文書内からさらに抽出し、
前記生成部は、前記抽出部で抽出された前記番号に、前記番号が参照している前記文章に対して生成された前記リンクを付与する
前記(1)乃至(4)のいずれかに記載の情報処理装置。
(6)
前記記憶部が更新された場合、更新された情報を含む文章を、前記所定の電子文書内から抽出することで、更新処理を行う
前記(1)乃至(5)のいずれかに記載の情報処理装置。
(7)
電子文書の情報を記憶する記憶部を備える情報処理装置の情報処理方法は、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、
前記抽出された前記文章から、前記記憶部の情報へのリンクを生成する
ステップを含む情報処理方法。
(8)
電子文書の情報を記憶する記憶部を備える情報処理装置を制御するコンピュータに、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、
前記抽出された前記文章から、前記記憶部の情報へのリンクを生成する
ステップを含む処理を実行させるためのコンピュータ読み取り可能なプログラム。
電子文書の情報を記憶する記憶部と、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する抽出部と、
前記抽出部により抽出された前記文章から、前記記憶部の情報へのリンクを生成する生成部と
を備える情報処理装置。
(2)
前記記憶部は、同一端末内に記憶されている電子文書の情報が記憶されている第1の記憶部と、他の端末内に記憶されている電子文書の情報が記憶されている第2の記憶部があり、
前記抽出部は、前記第1の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、前記第2の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する
前記(1)に記載の情報処理装置。
(3)
前記電子文書は、紙媒体に印刷されていた文書を電子化したものである
前記(1)または前記(2)に記載の情報処理装置。
(4)
前記抽出部は、前記電子文書内の所定の文章と、前記記憶部に記憶されている前記情報との第1の類似度を算出し、
前記所定の文章の次の文章を結合した文章と、前記記憶部に記憶されている前記情報との第2の類似度を算出し、
前記第2の類似度が前記第1の類似度よりも大きいと判断されるまでの間は、文章の結合と類似度の算出を繰り返し行い、
前記第2の類似度が前記第1の類似度よりも小さいと判断されたとき、結合前の文章を抽出結果とする
前記(1)乃至(3)のいずれかに記載の情報処理装置。
(5)
前記抽出部は、抽出された文章を参照する番号を前記所定の電子文書内からさらに抽出し、
前記生成部は、前記抽出部で抽出された前記番号に、前記番号が参照している前記文章に対して生成された前記リンクを付与する
前記(1)乃至(4)のいずれかに記載の情報処理装置。
(6)
前記記憶部が更新された場合、更新された情報を含む文章を、前記所定の電子文書内から抽出することで、更新処理を行う
前記(1)乃至(5)のいずれかに記載の情報処理装置。
(7)
電子文書の情報を記憶する記憶部を備える情報処理装置の情報処理方法は、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、
前記抽出された前記文章から、前記記憶部の情報へのリンクを生成する
ステップを含む情報処理方法。
(8)
電子文書の情報を記憶する記憶部を備える情報処理装置を制御するコンピュータに、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、
前記抽出された前記文章から、前記記憶部の情報へのリンクを生成する
ステップを含む処理を実行させるためのコンピュータ読み取り可能なプログラム。
11 ネットワーク, 21 サーバ, 22 著作物データベース, 23 顧客データベース, 31 電子文書閲覧端末, 32 著作物データベース, 33 電子文書記憶部, 41 情報端末, 42 著作物データベース, 43 電子文書記憶部, 51 スキャナ, 61 文書
Claims (8)
- 電子文書の情報を記憶する記憶部と、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する抽出部と、
前記抽出部により抽出された前記文章から、前記記憶部の情報へのリンクを生成する生成部と
を備える情報処理装置。 - 前記記憶部は、同一端末内に記憶されている電子文書の情報が記憶されている第1の記憶部と、他の端末内に記憶されている電子文書の情報が記憶されている第2の記憶部があり、
前記抽出部は、前記第1の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、前記第2の記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出する
請求項1に記載の情報処理装置。 - 前記電子文書は、紙媒体に印刷されていた文書を電子化したものである
請求項1に記載の情報処理装置。 - 前記抽出部は、前記電子文書内の所定の文章と、前記記憶部に記憶されている前記情報との第1の類似度を算出し、
前記所定の文章の次の文章を結合した文章と、前記記憶部に記憶されている前記情報との第2の類似度を算出し、
前記第2の類似度が前記第1の類似度よりも大きいと判断されるまでの間は、文章の結合と類似度の算出を繰り返し行い、
前記第2の類似度が前記第1の類似度よりも小さいと判断されたとき、結合前の文章を抽出結果とする
請求項1に記載の情報処理装置。 - 前記抽出部は、抽出された文章を参照する番号を前記所定の電子文書内からさらに抽出し、
前記生成部は、前記抽出部で抽出された前記番号に、前記番号が参照している前記文章に対して生成された前記リンクを付与する
請求項1に記載の情報処理装置。 - 前記記憶部が更新された場合、更新された情報を含む文章を、前記所定の電子文書内から抽出することで、更新処理を行う
請求項1に記載の情報処理装置。 - 電子文書の情報を記憶する記憶部を備える情報処理装置の情報処理方法は、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、
前記抽出された前記文章から、前記記憶部の情報へのリンクを生成する
ステップを含む情報処理方法。 - 電子文書の情報を記憶する記憶部を備える情報処理装置を制御するコンピュータに、
前記記憶部に記憶されている前記情報を含む文章を、所定の電子文書内から抽出し、
前記抽出された前記文章から、前記記憶部の情報へのリンクを生成する
ステップを含む処理を実行させるためのコンピュータ読み取り可能なプログラム。
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011157852A JP2013025456A (ja) | 2011-07-19 | 2011-07-19 | 情報処理装置、情報処理方法、並びにプログラム |
| EP12814338.5A EP2713285A1 (en) | 2011-07-19 | 2012-07-11 | Information processing apparatus, information processing method, and program |
| RU2014100875/08A RU2014100875A (ru) | 2011-07-19 | 2012-07-11 | Устройство обработки информации, способ обработки информации и программа |
| CN201280034440.8A CN103688258A (zh) | 2011-07-19 | 2012-07-11 | 信息处理设备、信息处理方法和程序 |
| US14/131,790 US20140156593A1 (en) | 2011-07-19 | 2012-07-11 | Information processing apparatus, information processing method, and program |
| BR112014000662A BR112014000662A2 (pt) | 2011-07-19 | 2012-07-11 | aparelho de processamento de informação, método de processamento de informação, e, programa legível por computador |
| PCT/JP2012/067715 WO2013011896A1 (ja) | 2011-07-19 | 2012-07-11 | 情報処理装置、情報処理方法、並びにプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011157852A JP2013025456A (ja) | 2011-07-19 | 2011-07-19 | 情報処理装置、情報処理方法、並びにプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013025456A true JP2013025456A (ja) | 2013-02-04 |
| JP2013025456A5 JP2013025456A5 (ja) | 2014-08-14 |
Family
ID=47558074
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011157852A Abandoned JP2013025456A (ja) | 2011-07-19 | 2011-07-19 | 情報処理装置、情報処理方法、並びにプログラム |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20140156593A1 (ja) |
| EP (1) | EP2713285A1 (ja) |
| JP (1) | JP2013025456A (ja) |
| CN (1) | CN103688258A (ja) |
| BR (1) | BR112014000662A2 (ja) |
| RU (1) | RU2014100875A (ja) |
| WO (1) | WO2013011896A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022106948A (ja) * | 2021-06-08 | 2022-07-20 | 阿波▲羅▼智▲聯▼(北京)科技有限公司 | 情報表示方法、装置、電子機器、記憶媒体およびコンピュータプログラム |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220058214A1 (en) * | 2018-12-28 | 2022-02-24 | Shenzhen Sekorm Component Network Co., Ltd | Document information extraction method, storage medium and terminal |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3608965B2 (ja) | 1998-12-18 | 2005-01-12 | シャープ株式会社 | 自動オーサリング装置および記録媒体 |
| JP2003280622A (ja) * | 2002-03-25 | 2003-10-02 | Matsushita Electric Ind Co Ltd | 電子表示装置とその表示方法 |
| JP2005190399A (ja) * | 2003-12-26 | 2005-07-14 | Casio Comput Co Ltd | 情報表示制御装置及びプログラム |
| US20060224584A1 (en) * | 2005-03-31 | 2006-10-05 | Content Analyst Company, Llc | Automatic linear text segmentation |
| US20070078814A1 (en) * | 2005-10-04 | 2007-04-05 | Kozoru, Inc. | Novel information retrieval systems and methods |
| US7783644B1 (en) * | 2006-12-13 | 2010-08-24 | Google Inc. | Query-independent entity importance in books |
| JP2009015647A (ja) | 2007-07-05 | 2009-01-22 | Booster Project Inc | 書籍情報送信システムおよび方法 |
| JP4780169B2 (ja) | 2008-09-30 | 2011-09-28 | ブラザー工業株式会社 | データ生成装置、スキャナ、及びコンピュータプログラム |
| JP5071470B2 (ja) * | 2009-12-18 | 2012-11-14 | コニカミノルタビジネステクノロジーズ株式会社 | 電子文書管理装置およびプログラム |
-
2011
- 2011-07-19 JP JP2011157852A patent/JP2013025456A/ja not_active Abandoned
-
2012
- 2012-07-11 RU RU2014100875/08A patent/RU2014100875A/ru not_active Application Discontinuation
- 2012-07-11 US US14/131,790 patent/US20140156593A1/en not_active Abandoned
- 2012-07-11 WO PCT/JP2012/067715 patent/WO2013011896A1/ja active Application Filing
- 2012-07-11 EP EP12814338.5A patent/EP2713285A1/en not_active Withdrawn
- 2012-07-11 CN CN201280034440.8A patent/CN103688258A/zh active Pending
- 2012-07-11 BR BR112014000662A patent/BR112014000662A2/pt not_active IP Right Cessation
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022106948A (ja) * | 2021-06-08 | 2022-07-20 | 阿波▲羅▼智▲聯▼(北京)科技有限公司 | 情報表示方法、装置、電子機器、記憶媒体およびコンピュータプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2013011896A1 (ja) | 2013-01-24 |
| CN103688258A (zh) | 2014-03-26 |
| US20140156593A1 (en) | 2014-06-05 |
| EP2713285A1 (en) | 2014-04-02 |
| BR112014000662A2 (pt) | 2017-02-14 |
| RU2014100875A (ru) | 2015-07-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101443404B1 (ko) | 페이퍼 및 전자 문서내의 주석의 캡처 및 디스플레이 | |
| US10373079B2 (en) | Method and apparatus for generating recommendations from descriptive information | |
| CN103314389B (zh) | 使用旋律标识的媒体权利管理 | |
| CN1272733C (zh) | 提供附加信息的方法 | |
| US20150066999A1 (en) | Information processing device, information processing method, and program | |
| US20070094245A1 (en) | Computer-implemented system and method for obtaining customized information related to media content | |
| US20070136247A1 (en) | Computer-implemented system and method for obtaining customized information related to media content | |
| US20100161620A1 (en) | Method and Apparatus for User-Steerable Recommendations | |
| US20120030230A1 (en) | Method and System for Gathering and Pseudo-Objectively Classifying Copyrightable Material to be Licensed Through a Provider Network | |
| CN101556617A (zh) | 用于将元数据与媒体相关联的系统和方法 | |
| CN103282931A (zh) | 包括旋律识别和选择退出的联合 | |
| US7899808B2 (en) | Text enhancement mechanism | |
| JP2001331724A (ja) | データ処理装置およびデータ処理方法、並びに記録媒体 | |
| JP2002236695A (ja) | マルチメディアデータベースアクセスのメタデータ処理 | |
| WO2001045085A1 (fr) | Procede et appareil pour le traitement de donnees et support de stockage de programme | |
| US9069771B2 (en) | Music recognition method and system based on socialized music server | |
| US20070009234A1 (en) | Using content identifiers to download cd-cover pictures to present audio content items | |
| EP2482210A2 (en) | System and methods for creation and use of a mixed media environment | |
| JP2011028747A (ja) | サーチ・タームを生成するシステムと方法 | |
| KR20130133183A (ko) | 전자서적 생성, 재생, 및 괸리 시스템 | |
| JP2007047959A (ja) | 情報編集表示装置、情報編集表示方法、サーバ、情報処理システムおよび情報編集表示プログラム | |
| CN108292411A (zh) | 使用对象资产生成视频内容项目 | |
| WO2001045084A1 (fr) | Machine de traitement des donnees, procede de traitement des donnees associe et support de stockage de programmes | |
| WO2013011896A1 (ja) | 情報処理装置、情報処理方法、並びにプログラム | |
| KR101108688B1 (ko) | 인터넷을 통해 미디어파일과 관련된 동영상정보 제공 방법, 서버, 및 클라이언트 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140702 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20140702 |
|
| A762 | Written abandonment of application |
Free format text: JAPANESE INTERMEDIATE CODE: A762 Effective date: 20150402 |