JP2011123740A - 閲覧システム、サーバ、テキスト抽出方法及びプログラム - Google Patents
閲覧システム、サーバ、テキスト抽出方法及びプログラム Download PDFInfo
- Publication number
- JP2011123740A JP2011123740A JP2009281880A JP2009281880A JP2011123740A JP 2011123740 A JP2011123740 A JP 2011123740A JP 2009281880 A JP2009281880 A JP 2009281880A JP 2009281880 A JP2009281880 A JP 2009281880A JP 2011123740 A JP2011123740 A JP 2011123740A
- Authority
- JP
- Japan
- Prior art keywords
- server
- text
- image
- predetermined area
- web page
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/94—Hardware or software architectures specially adapted for image or video understanding
- G06V10/95—Hardware or software architectures specially adapted for image or video understanding structured as a network, e.g. client-server architectures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/1444—Selective acquisition, locating or processing of specific regions, e.g. highlighted text, fiducial marks or predetermined fields
- G06V30/1456—Selective acquisition, locating or processing of specific regions, e.g. highlighted text, fiducial marks or predetermined fields based on user interactions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/26—Techniques for post-processing, e.g. correcting the recognition result
- G06V30/262—Techniques for post-processing, e.g. correcting the recognition result using context analysis, e.g. lexical, syntactic or semantic context
- G06V30/268—Lexical context
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Human Computer Interaction (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Information Transfer Between Computers (AREA)
- Character Discrimination (AREA)
Abstract
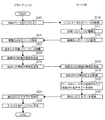
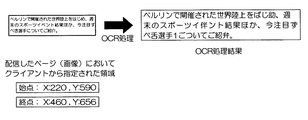
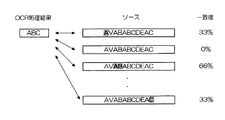
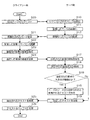
【解決手段】サーバ10は、インターネットからウェブページを取得し(ステップS10)、取得したウェブページから画像を生成し(ステップS11)、画像をクライアント端末20へ送信する(ステップS12)。クライアント端末20は、画像を受信し(ステップS21)、表示部23へ表示し(ステップS22)、矩形領域を指定し(ステップS23)、その情報をサーバ10へ送信する(ステップS24)。サーバ10は、画像から矩形領域の画像を切り出し、OCR処理によりテキストを認識し(ステップS14)、Htmlファイルのソースから認識されたテキストと最も一致度の高いテキストを抽出し(ステップS15)、クライアント端末20へ送信する(ステップS16)。
【選択図】 図4
Description
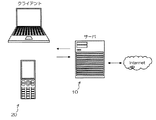
閲覧システム1は、主として、サーバ10と、クライアント端末20とで構成される。サーバ10と接続されるクライアント端末20は1台でも良いし、複数でもよい。
第1の実施の形態は、OCR処理のミスにより間違ったテキストが認識された場合においても、そのミスを補完し、正しいテキストを抽出するため、ソースに含まれるテキストの中からテキストを抽出する処理を行なったが、必ずしもソースからのテキスト抽出処理が必要とは限らない。例えば、単語等テキストの長さが短い場合には、OCR処理の制度が高いため、処理結果が正しい場合も多い。
Claims (8)
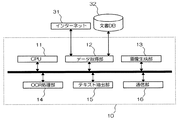
- 表示手段が設けられた端末装置と、前記端末装置と接続されたサーバとで構成された閲覧システムであって、
前記端末装置は、
前記サーバから送信された画像データを受信する端末側受信手段と、
前記受信された画像データに基づいて前記表示手段に画像を表示させる表示制御手段と、
前記表示手段に表示された画像の中の所定の領域を選択する選択手段と、
前記選択された所定の領域の情報を前記サーバへ送信する端末側送信手段と、を備え、
前記サーバは、
ウェブページのソースを取得する取得手段と、
前記取得されたウェブページのソースに基づいて当該ウェブページの画像データを生成する画像生成手段と、
前記生成された画像データを前記端末装置に送信するサーバ側送信手段と、
前記端末装置から送信された所定の領域の情報を受信するサーバ側受信手段と、
前記受信された所定の領域の情報と前記生成された画像データとに基づいて、前記所定の領域の画像からOCR処理により文字を認識する文字認識手段と、
前記OCR処理により認識された文字と推定される文字列を前記取得されたウェブページのソースから抽出する文字列抽出手段と、を備え、
前記サーバ側送信手段は、前記抽出された文字列を前記端末装置に送信し、
前記端末側受信手段は、前記送信された文字列を受信することを特徴とする閲覧システム。 - 前記サーバは、前記所定の領域が閾値以上であるか否かを判断する判断手段を備え、
前記所定の領域が閾値以上であると判断されなかった場合には、前記サーバ側送信手段は、前記OCR処理により認識された文字列を送信することを特徴とする請求項1に記載の閲覧システム。 - 前記端末側送信手段は、前記所定の領域の情報として当該所定の領域の座標の情報を前記サーバへ送信し、
前記文字認識手段は、前記生成された画像データと、前記所定の領域の座標の情報とから前記所定の領域の画像を切り出し、当該切り出された所定の領域の画像から文字を認識することを特徴とする請求項1又は2に記載の閲覧システム。 - 前記文字列抽出手段は、前記OCR処理により認識された文字をキーと前記取得されたソースに含まれるテキストとを比較し、前記OCR処理により認識された文字と最も一致度の高い文字列を抽出することを特徴とする請求項1、2又は3に記載の閲覧システム。
- 前記端末装置は、前記受信した文字列を記憶する記憶手段を備えたことを特徴とする請求項1から4のいずれかに記載の閲覧システム。
- 請求項1から5のいずれかに記載の閲覧システムを構成するサーバ。
- 携帯端末からウェブページの閲覧要求を受け付けるステップと、
前記受け付けられた閲覧要求に基づいてウェブページのソースを取得するステップと、
前記取得されたウェブページのソースに基づいて当該ウェブページの画像データを生成するステップと、
前記端末装置から所定の領域の情報を受信するステップと、
前記受信した所定の領域の情報と前記生成された画像データとに基づいて、前記所定の領域の画像からOCR処理により文字を認識するステップと、
前記取得されたソースから前記OCR処理により認識された文字と推定される文字列を抽出するステップと、
前記抽出された文字列を前記端末装置に送信するステップと、
を含むことを特徴とするテキスト抽出方法。 - 請求項7に記載のテキスト抽出方法を演算装置に実行させることを特徴とするプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009281880A JP2011123740A (ja) | 2009-12-11 | 2009-12-11 | 閲覧システム、サーバ、テキスト抽出方法及びプログラム |
| US12/962,512 US20110142344A1 (en) | 2009-12-11 | 2010-12-07 | Browsing system, server, and text extracting method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009281880A JP2011123740A (ja) | 2009-12-11 | 2009-12-11 | 閲覧システム、サーバ、テキスト抽出方法及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011123740A true JP2011123740A (ja) | 2011-06-23 |
| JP2011123740A5 JP2011123740A5 (ja) | 2012-12-20 |
Family
ID=44142983
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009281880A Abandoned JP2011123740A (ja) | 2009-12-11 | 2009-12-11 | 閲覧システム、サーバ、テキスト抽出方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20110142344A1 (ja) |
| JP (1) | JP2011123740A (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015118590A (ja) * | 2013-12-19 | 2015-06-25 | 富士通株式会社 | 情報提供プログラム、情報提供方法および情報提供装置 |
| JP2016513298A (ja) * | 2013-01-09 | 2016-05-12 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | 電子文書の提供方法、システム、親本サーバ及び子本クライアント |
| WO2020101479A1 (en) * | 2018-11-14 | 2020-05-22 | Mimos Berhad | System and method to detect and generate relevant content from uniform resource locator (url) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5832432B2 (ja) * | 2010-06-15 | 2015-12-16 | 株式会社ナビタイムジャパン | ナビゲーションシステム、ナビゲーション方法、および、プログラム |
| US20130230248A1 (en) * | 2012-03-02 | 2013-09-05 | International Business Machines Corporation | Ensuring validity of the bookmark reference in a collaborative bookmarking system |
| US20140075393A1 (en) * | 2012-09-11 | 2014-03-13 | Microsoft Corporation | Gesture-Based Search Queries |
| US10153995B2 (en) | 2013-07-01 | 2018-12-11 | [24]7.ai, Inc. | Method and apparatus for effecting web page access in a plurality of media applications |
| US9576070B2 (en) * | 2014-04-23 | 2017-02-21 | Akamai Technologies, Inc. | Creation and delivery of pre-rendered web pages for accelerated browsing |
| US10909306B2 (en) | 2018-03-16 | 2021-02-02 | Canva Pty Ltd. | Systems and methods of publishing a design |
| US10963723B2 (en) * | 2018-12-23 | 2021-03-30 | Microsoft Technology Licensing, Llc | Digital image transcription and manipulation |
| CN110059688B (zh) * | 2019-03-19 | 2024-05-28 | 平安科技(深圳)有限公司 | 图片信息识别方法、装置、计算机设备和存储介质 |
| JP7274322B2 (ja) * | 2019-03-25 | 2023-05-16 | 東芝テック株式会社 | プログラム及び文字認識方法 |
| US10798089B1 (en) | 2019-06-11 | 2020-10-06 | Capital One Services, Llc | System and method for capturing information |
| US11805138B2 (en) * | 2020-04-21 | 2023-10-31 | Zscaler, Inc. | Data loss prevention on images |
| CN115796145B (zh) * | 2022-11-16 | 2023-09-08 | 珠海横琴指数动力科技有限公司 | 一种网页文本的采集方法、系统、服务器及可读存储介质 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202935A (ja) * | 2000-10-31 | 2002-07-19 | Mishou Kk | サーバ装置 |
| JP2007199983A (ja) * | 2006-01-26 | 2007-08-09 | Nec Corp | 文書ファイル閲覧システム、文書ファイル閲覧方法、及び、文書閲覧プログラム |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3334025B2 (ja) * | 1995-11-13 | 2002-10-15 | ミノルタ株式会社 | 画像形成装置 |
| US6343290B1 (en) * | 1999-12-22 | 2002-01-29 | Celeritas Technologies, L.L.C. | Geographic network management system |
| JP2004334339A (ja) * | 2003-04-30 | 2004-11-25 | Canon Inc | 情報処理装置及び情報処理方法ならびに記憶媒体、プログラム |
| CN100419785C (zh) * | 2004-04-08 | 2008-09-17 | 佳能株式会社 | 基于网络服务应用的光学字符识别系统和方法 |
| JP4695388B2 (ja) * | 2004-12-27 | 2011-06-08 | 株式会社リコー | セキュリティ情報推定装置、セキュリティ情報推定方法、セキュリティ情報推定プログラム及び記録媒体 |
| WO2007063588A1 (ja) * | 2005-11-30 | 2007-06-07 | Fujitsu Limited | 情報処理装置、電子機器、およびプログラム |
| JP5162896B2 (ja) * | 2006-12-26 | 2013-03-13 | 富士ゼロックス株式会社 | 設置場所管理システム及びプログラム |
| JP5194566B2 (ja) * | 2007-05-30 | 2013-05-08 | 富士ゼロックス株式会社 | 画像処理装置、画像処理システム及び制御プログラム |
-
2009
- 2009-12-11 JP JP2009281880A patent/JP2011123740A/ja not_active Abandoned
-
2010
- 2010-12-07 US US12/962,512 patent/US20110142344A1/en not_active Abandoned
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202935A (ja) * | 2000-10-31 | 2002-07-19 | Mishou Kk | サーバ装置 |
| JP2007199983A (ja) * | 2006-01-26 | 2007-08-09 | Nec Corp | 文書ファイル閲覧システム、文書ファイル閲覧方法、及び、文書閲覧プログラム |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016513298A (ja) * | 2013-01-09 | 2016-05-12 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | 電子文書の提供方法、システム、親本サーバ及び子本クライアント |
| US10587731B2 (en) | 2013-01-09 | 2020-03-10 | Baidu Online Network Technology (Beijing) Co., Ltd. | Method and system for providing electronic document, mother book server and child book client |
| JP2015118590A (ja) * | 2013-12-19 | 2015-06-25 | 富士通株式会社 | 情報提供プログラム、情報提供方法および情報提供装置 |
| WO2020101479A1 (en) * | 2018-11-14 | 2020-05-22 | Mimos Berhad | System and method to detect and generate relevant content from uniform resource locator (url) |
Also Published As
| Publication number | Publication date |
|---|---|
| US20110142344A1 (en) | 2011-06-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2011123740A (ja) | 閲覧システム、サーバ、テキスト抽出方法及びプログラム | |
| US8121413B2 (en) | Method and system for controlling browser by using image | |
| US9128596B2 (en) | Method and device for selecting and displaying a region of interest in an electronic document | |
| US9268987B2 (en) | Method of recognizing QR code in image data and apparatus and method for converting QR code in content data into touchable object | |
| JP5335632B2 (ja) | ウェブページ閲覧システム、サーバ、ウェブページ閲覧方法及びプログラム | |
| US20120163664A1 (en) | Method and system for inputting contact information | |
| WO2023155712A1 (zh) | 页面生成方法、显示方法、装置、电子设备和存储介质 | |
| CN112685671A (zh) | 页面显示方法、装置、设备及存储介质 | |
| EP2146291A1 (en) | Method and system for providing interface of web page | |
| WO2015035897A1 (en) | Search methods, servers, and systems | |
| CN117349519A (zh) | 网页数据采集方法、装置、终端及存储介质 | |
| CN109933805A (zh) | 文本解析方法、系统及计算机可读存储介质 | |
| JP2020021455A (ja) | 特許評価判定方法、特許評価判定装置、および特許評価判定プログラム | |
| KR101377385B1 (ko) | 정보 처리 장치 | |
| US10895962B2 (en) | Apparatus and method for facilitating browser navigation | |
| CN104142925A (zh) | 一种浏览器地址栏输入内容的联想方法及装置 | |
| JP2009211278A (ja) | 携帯端末を利用した検索システムおよびその検索方法 | |
| CN112765445A (zh) | 生僻字识别方法及装置 | |
| JP2012181693A (ja) | ウェブページ表示制御装置およびスクロール制御方法 | |
| CN113867584A (zh) | 触控事件响应方法及其装置 | |
| KR101592725B1 (ko) | 스마트 기기를 기반으로 하는 이미지 링크 어플리케이션 장치 | |
| JP5913774B2 (ja) | Webサイトを共有する方法、電子機器およびコンピュータ・プログラム | |
| JP2004110698A (ja) | インターネット端末装置 | |
| JP5632905B2 (ja) | 情報入力装置及び入力切替制御方法 | |
| EP4404084A1 (en) | Information processing apparatus and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20120828 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20121009 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20121106 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130509 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130517 |
|
| A762 | Written abandonment of application |
Free format text: JAPANESE INTERMEDIATE CODE: A762 Effective date: 20130611 |