JP2009043276A - Fifo記憶方法 - Google Patents
Fifo記憶方法 Download PDFInfo
- Publication number
- JP2009043276A JP2009043276A JP2008249116A JP2008249116A JP2009043276A JP 2009043276 A JP2009043276 A JP 2009043276A JP 2008249116 A JP2008249116 A JP 2008249116A JP 2008249116 A JP2008249116 A JP 2008249116A JP 2009043276 A JP2009043276 A JP 2009043276A
- Authority
- JP
- Japan
- Prior art keywords
- data
- bus
- fifo
- pae
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images















Abstract
【課題】FIFOの出し過程を、以前にデータ語が読出・書込みされている場合には再び開始することができるFIFO記憶方法を提供する。
【解決手段】データ流を複数の独立した分岐路に分配し、続いて個々の分岐路を1つのデータ流に統合する。このとき個々のデータ流は時間的に正しい順序で再び統合される。このデータ流の相互の同期のために、FIFOの書き込み読み出しに関するフロー制御を、コンフィギュレーション可能なプロトコルにより提供する。
【選択図】図1
【解決手段】データ流を複数の独立した分岐路に分配し、続いて個々の分岐路を1つのデータ流に統合する。このとき個々のデータ流は時間的に正しい順序で再び統合される。このデータ流の相互の同期のために、FIFOの書き込み読み出しに関するフロー制御を、コンフィギュレーション可能なプロトコルにより提供する。
【選択図】図1
Description
本発明は、送信器および受信器が多次元構成されている中でデータを管理および伝送する方法に関する。
データ流を複数の独立した分岐路に分配し、続いて個々の分岐路を1つのデータ流に統合することは簡単に実行できるべきであり、このとき個々のデータ流は時間的に正しい順序で再び統合される。とりわけ再入可能なコードを処理するにはこの方法が重要である。本発明の方法はとりわけコンフィギュレーション可能なアーキテクチャに適し、コンフィギュレーションおよび再コンフィギュレーションの効率的な制御に重点が置かれる。
本発明の課題は、産業的使用のために新たなものを提供することである。
この課題は、読出し過程を、以前にデータ語が読出されている場合には再び開始することができる、ことを特徴とするFIFO記憶方法および書込み過程を、以前にデータ語が書き込まれている場合には再び開始することができる、ことを特徴とするFIFO記憶方法により解決される。有利な実施形態は従属請求項に記載されている。
再コンフィギュレーション可能なアーキテクチャとは、コンフィギュレーション可能な機能および/またはネットワークを備える既存の構成ユニット(VPU)であると理解されたい。これはとりわけ1次元または多次元配置された算術的及び/または論理的および/またはアナログおよび/または記憶可能および/または内部/外部でネットワーク化された複数の構成群であり、これらは直接またはバスシステムを介して相互に接続されている。
この構成ユニットにはとりわけシストリック・アレイ、ニューラルネットワーク、マルチプロセッサシステム、複数の計算機構および/または論理セルおよび/または通信/端末セル(IO)を備えるプロセッサ、ネットワーク構成ユニット、例えばクラスバースイッチ、および公知のFPGA、DPGA、Chameleon, XPUTER等の構成素子である。 上記のアーキテクチャは例として明確化のために使用され、以下、VPUと称する。このアーキテクチャは、任意の算術的、論理的セル(メモリも)および/またはメモリセルおよび/またはネットワークセルおよび/または通信/端末(IO)セル(PAE)からなり、これらは一次元または多次元マトリクス(PA)に配置することができる。ここでこのマトリクスは種々異なって任意に構成されたセルを有することができ、ここではバスシステムもセルとして理解されたい。このマトリクスには全体としてまたはその一部としてコンフィギュレーションユニット(CT)が配属されており、これらはPAのネットワークおよび機能に影響を与える。
発明の説明
VPUのコンフィギュレーション可能なセルはデータを正しく処理するために相互に同期していなければならない。このために2つの異なるプロトコルが使用される。1つはデータトラフィックの同期化のためであり、もう一つはデータ処理のフロー制御のためである。データは有利には複数のコンフィギュレーション可能なバスシステムを介して伝送される。コンフィギュレーション可能なバスシステムとはここで、任意のPAEがデータを送信し、受信器PAEへの接続、並びに受信器PAEが任意にコンフィギュレーション可能であることを意味する。
VPUのコンフィギュレーション可能なセルはデータを正しく処理するために相互に同期していなければならない。このために2つの異なるプロトコルが使用される。1つはデータトラフィックの同期化のためであり、もう一つはデータ処理のフロー制御のためである。データは有利には複数のコンフィギュレーション可能なバスシステムを介して伝送される。コンフィギュレーション可能なバスシステムとはここで、任意のPAEがデータを送信し、受信器PAEへの接続、並びに受信器PAEが任意にコンフィギュレーション可能であることを意味する。
データトラフィックの同期化は有利にはハンドシェークプロトコルにより行われ、これはデータと共に伝送される。以下、簡単なハンドシェーク並びに複雑な方法を説明する。これらの有利な適用はそれぞれ実行すべきアプリケーションまたはアプリケーション量に依存する。
フロー制御は、PAEの状態を指示する信号(トリガ)により行われる。トリガはデータに依存せずに任意のコンフィギュレーション可能なバスシステムを介して実行することができる。すなわち種々異なる送信器および/または受信器を有することができ、同様にハンドシェークプロトコルを有する。トリガは送信側PAEの状態により発生される(例えばゼロフラグ、オーバフローフラグ、ネガティブフラグ)。これは個々の状態または組合せを転送することにより行われる。
VPU内でデータ処理するセル(PAE)は種々異なる処理状態を取ることができる。これはセルおよび/または到来するトリガ、または到来したトリガに依存する:
"not configured":
データ処理なし
"configured":
GO 到来するすべてのデータを計算する。
"not configured":
データ処理なし
"configured":
GO 到来するすべてのデータを計算する。
STOP 到来するデータが計算されない。
STEP 正確に1つの計算が実行される。
GO、STOPおよびSTEPは次に説明するトリガによりトリガされる。
GO、STOPおよびSTEPは次に説明するトリガによりトリガされる。
ハンドシェーク同期
とりわけ簡単で、それでもなお高性能なハンドシェークプロトコルを次に説明する。このハンドシェークプロトコルは有利にはデータおよびトリガの伝送の際に使用される。ハンドシェークプロトコルの制御は有利には固定的のハードウエアに設定されており、VPUのデータ処理パラダイムの重要な構成部である。
とりわけ簡単で、それでもなお高性能なハンドシェークプロトコルを次に説明する。このハンドシェークプロトコルは有利にはデータおよびトリガの伝送の際に使用される。ハンドシェークプロトコルの制御は有利には固定的のハードウエアに設定されており、VPUのデータ処理パラダイムの重要な構成部である。
送信器から任意のバスを介して送信された各情報と共にRDY信号も送信される。この信号は情報の有効性を指示する。
受信器はRDY信号の付された情報だけを処理し、他の情報はすべて無視する。
情報が送信器により処理され、受信器が新たな情報を受け取ると直ちに、受信器は受領信号(ACK)を送信器に送信することにより、送信器が新たに情報を送信しても良いことを指示する。送信器は常に、これが新たなデータを送信する前にACKの到来を待機する。
2つの動作形式が区別される:
a)"depended":情報を受け取らなければならないすべての入力側は、情報を処理する前に有効なRDYを有する。その後に初めてACKが発生される。
b)"independent":情報を受け取る入力側が有効なRDYを有すると直ちに、この入力側がデータを受け取ることができる場合、すなわち先行のデータが処理された場合、この所定の入力側に対してACKが発生される;それ以外の場合は、データの処理が待機される。
a)"depended":情報を受け取らなければならないすべての入力側は、情報を処理する前に有効なRDYを有する。その後に初めてACKが発生される。
b)"independent":情報を受け取る入力側が有効なRDYを有すると直ちに、この入力側がデータを受け取ることができる場合、すなわち先行のデータが処理された場合、この所定の入力側に対してACKが発生される;それ以外の場合は、データの処理が待機される。
同期の実行およびデータ処理の制御は従来技術によれば固定的に実現されたステートマシン、微細顆粒状にコンフィギュレートされた状態マシン、または有利にはプログラミング可能なシーケンサにより実行できる。プログラミング可能なステートマシンは実行すべきフローに相応してコンフィギュレートされる。Alteraの構成素子EPS448は例えばこの種のプログラミング可能なシーケンサを実現する。
VPUに対するハンドシェークプロトコルのタスクは、パイプライン形式のデータ処理の実行である。このデータ処理ではとりわけ各クロックサイクルでデータを各PAEで処理することができる。この要求はハンドシェークへの特別の負荷となる。RDY/ACKプロトコルの例でこのタスクの問題と解決を示す:
図1aはVPU内のパイプラインの構造を示す。データは、有利にはコンフィギュレート可能なバスシステム0107,0108,0109を介してレジスタ0101,0104に供給される。レジスタには場合によりデータ処理論理回路0102,0105が後置接続されている。このデータ処理論理回路には出力段0103,0106が配属されており、出力段は有利にはレジスタを有しており、結果を再びバスに接続する。バスシステム0107,0108,0109を介しても、データ処理論理回路によっても0102,0105、RDY/ACKプロトコルが同期化のために伝送される。
図1aはVPU内のパイプラインの構造を示す。データは、有利にはコンフィギュレート可能なバスシステム0107,0108,0109を介してレジスタ0101,0104に供給される。レジスタには場合によりデータ処理論理回路0102,0105が後置接続されている。このデータ処理論理回路には出力段0103,0106が配属されており、出力段は有利にはレジスタを有しており、結果を再びバスに接続する。バスシステム0107,0108,0109を介しても、データ処理論理回路によっても0102,0105、RDY/ACKプロトコルが同期化のために伝送される。
2つの意味(セマンティック)がRDY/ACKプロトコルに対して重要である:
a)ACKは「受信器がデータを引き受ける」を意味する。この効果によりパイプラインは各クロックで動作する。しかしハードウエア技術的実現により、パイプラインストールの場合にはACKがパイプラインの停止されたすべての段を介して非同期に経過するという問題がある。このことにより甚だしい問題が時間特性に、とりわけVPUが大きくおよび/またはクロック周波数が高い場合に生じる。
b)ACKは「受信器がデータを引き受ける」を意味する。この効果により、ACKは常にそれぞれ次の段までだけ経過し、そこにはレジスタが存在している。このことにより発生する問題は、パイプラインがハードウエア技術的実現で必要なレジスタの遅延により各2つのクロックでしか動作しないことである。
a)ACKは「受信器がデータを引き受ける」を意味する。この効果によりパイプラインは各クロックで動作する。しかしハードウエア技術的実現により、パイプラインストールの場合にはACKがパイプラインの停止されたすべての段を介して非同期に経過するという問題がある。このことにより甚だしい問題が時間特性に、とりわけVPUが大きくおよび/またはクロック周波数が高い場合に生じる。
b)ACKは「受信器がデータを引き受ける」を意味する。この効果により、ACKは常にそれぞれ次の段までだけ経過し、そこにはレジスタが存在している。このことにより発生する問題は、パイプラインがハードウエア技術的実現で必要なレジスタの遅延により各2つのクロックでしか動作しないことである。
この問題の解決は、2つの意味(セマンティック)を図1bのように組み合わせることである。図1bは段0101から0103を抜粋して示す。バスシステム0107,0108,0109にはプロトコルb)が使用される。これによりレジスタ10110は到来シアタRDYを伝送されたデータの記録により入力レジスタへACKより1クロックだけ遅れて再びバスに送出する。この段0110はほぼバスプロトコルとプロトコルとの間のプロトコルコンバータとしてデータ処理論理回路内で動作する。
データ処理論理回路はプロトコルa)を使用する。このプロトコルは後置接続されたプロトコルコンバータ0111により形成される。とりわけ0111では到来するデータがデータ処理論理回路により実際にバスシステムから取り出されたものであるか否かを予測しなければならない。このことは、付加的バッファレジスタ0112を、バスシステム上で伝送すべきデータに対する出力段0103,0106に挿入することにより解決される。データ処理論理回路により発生されたデータはバスシステムとバッファレジスタに同時に書き込まれる。バスがデータを取り出すことが出来なければ、すなわちバスシステムのACKがオフであれば、データはバッファレジスタに存在し、バスシステムが待機状態になると直ちにマルチプレクサ0113を介してバスシステムに切り替えられる。バスシステムが直ちにデータを取り出す準備が出来ていれば、データはマルチプレクサ0113を介してバスに直接転送される。バッファレジスタにより意味(セマンティック)a)による受領確認が可能である。なぜならバッファレジスタが空であれば、「受信器がデータを引き受ける」により受領確認することができるからである。なぜならバッファレジスタへの書込みによって、データの失われないことが保証されるからである。
トリガ
VPU構成素子では簡単な情報の伝送のためにいわゆるトリガが使用される。トリガはセグメントに分割された一次元または多次元バスシステムによって伝送される。個々のセグメントにはドライバを、信号品質の改善のために装備することができる。複数のセグメントの接続を介して実現されるそれぞれのトリガ接続はユーザによりプログラミングすることができ、CTを介してコンフィギュレートされる。
VPU構成素子では簡単な情報の伝送のためにいわゆるトリガが使用される。トリガはセグメントに分割された一次元または多次元バスシステムによって伝送される。個々のセグメントにはドライバを、信号品質の改善のために装備することができる。複数のセグメントの接続を介して実現されるそれぞれのトリガ接続はユーザによりプログラミングすることができ、CTを介してコンフィギュレートされる。
トリガは後続の情報またはこれらの任意の組合せを主に伝送するが、それだけを伝送するわけではない。
*計算機構(ALU)の状態情報、例えば
−キャリー
−ゼロによる割算
−否定
−アンダーフロー/オーバフロー
*比較および/またはループの結果
*nビット情報(小さなnに対して)
*内部または外部で発生される割込み要求
トリガは任意のセルにより発生され、任意のイベントにより個々のセルで制御される。とりわけトリガはCT、またはセルアレイまたは構成素子の外部にある外部ユニットにより発生される。
−キャリー
−ゼロによる割算
−否定
−アンダーフロー/オーバフロー
*比較および/またはループの結果
*nビット情報(小さなnに対して)
*内部または外部で発生される割込み要求
トリガは任意のセルにより発生され、任意のイベントにより個々のセルで制御される。とりわけトリガはCT、またはセルアレイまたは構成素子の外部にある外部ユニットにより発生される。
トリガは主にVPU内でのフロー制御に、例えば比較および/またはループに対して用いられる。データ経路および/または分岐はトリガによりイネーブルまたはディスエーブルされる。トリガの別の重要な使用領域はシーケンスの同期化および制御、並びにそれらの情報交換;同様にセル内でのデータ処理の制御である。
トリガの管理およびデータ処理の制御は従来技術によれば、固定的に実現されたステートマシン、微細顆粒状にコンフィギュレートされた状態マシンまたは有利にはプログラミング可能なステートマシンにより実行される。プログラミング可能なステートマシンは実行すべきフローに相応してコンフィギュレートされる。Alteraの構成素子EPS448は例えばこの種のプログラミング可能なシーケンサを実現する。
基本方法
RDY/ACKプロトコルによる単純な同期化方法は複雑なデータ流の処理を困難にする。なぜなら正しい順序を維持するためのコストが非常に高いからである。正しい実現はプログラマのタスクである。さらに実現のために付加的リソースが必要である。
RDY/ACKプロトコルによる単純な同期化方法は複雑なデータ流の処理を困難にする。なぜなら正しい順序を維持するためのコストが非常に高いからである。正しい実現はプログラマのタスクである。さらに実現のために付加的リソースが必要である。
以下、この課題を解決する簡単な方法を説明する。
伝送 1:n
これは通常のありきたりな場合である:送信器はデータをバスに書き込む。データは、受領確認としてのACKがすべての受信器から到来するまでバスに安定して存在する(データが「立っている」)。RDYはパルスである。すなわち正確に1クロックの間だけ存在する。これによりデータが誤って多重に読み出されることがない。RDYが実現例に依存してマルチプレクサおよび/またはゲートおよび/または別の適切な伝送素子を制御し、これらがデータ伝送を制御する場合、この制御はこのデータ伝送の時間の間、記憶される(RdyHold)。これによりゲートの位置および/またはマルチプレクサおよび/または別の適切な伝送素子がRFYパルスの後も有効に留まり、これによりさらに有効なデータがバスに供給される。
これは通常のありきたりな場合である:送信器はデータをバスに書き込む。データは、受領確認としてのACKがすべての受信器から到来するまでバスに安定して存在する(データが「立っている」)。RDYはパルスである。すなわち正確に1クロックの間だけ存在する。これによりデータが誤って多重に読み出されることがない。RDYが実現例に依存してマルチプレクサおよび/またはゲートおよび/または別の適切な伝送素子を制御し、これらがデータ伝送を制御する場合、この制御はこのデータ伝送の時間の間、記憶される(RdyHold)。これによりゲートの位置および/またはマルチプレクサおよび/または別の適切な伝送素子がRFYパルスの後も有効に留まり、これによりさらに有効なデータがバスに供給される。
受信器がデータを引き受けると直ちに、受信器はACKにより受領確認する。正しいデータは受信器による取り出しまでバスに存在することを再度述べておく。ACKは同様に有利にはパルスとして伝送される。RDYが以前に制御の記憶のために用いられたマルチプレクサおよび/またはゲートおよび/または別の適切な伝送素子(RdyHold参照)をACKが通過すると、この制御は消去される。
1:nの伝送のために有利にはACKを、新たなRDYが到来するまで保持する。複数の入力側への分岐路である各バスノードでは、到来するACKが相互に丸められる(AND)。ACKが持続しているので、最終的に持続するACKが送信器に生じ、これはすべての受信器のACKを代表する。ANDゲートによるACKチェーンの伝搬時間をできるだけ小さく維持するため、ツリー状のバス構造を選択すること、ないしは処理すべきプログラムのルーティング中に形成することが推奨される。
ACKが持続することは実現形態に依存して問題となることがある。すなわちRDYが信号geACTになり、この信号に対して本来のACKが存在しないことが生じ得る。なぜなら古いACKが過度に長く存在するからである。これに対する解決手段は、ACKを基本的にパルスとし、分岐路で到来する各経路のACKを記憶するのである。すべての経路のACKが到来して初めて、ACKパルスを送信器の方向に転送し、同時に、記憶されているすべてのACK(AckHold)および場合によりRdyHoldを消去するのである。
図1cはこの方法の基本を示す。送信器0120はデータをバスシステム0121を介して、RDY0122と共に送出する。複数の受信器0123,0124,0125,0126がデータおよびこれに所属するRDY0122を受け取る。各受信器はACK0127,0128,0129,0130を発生し、これらはそれぞれ適切なブール論理回路0131,0132,0133、例えば論理AND機能を介して結合され、送信器に導かれる0134。
図1dは、2つの受信器a,bを有する有利な構成を示す。出力段0103がデータと、これに所属するこの実施例ではパルス状のRDY0131を送出する。RdyHold段0130は目標PAEの前方でパルス状RDYを定常的RDYに変換する。定常的RDYはこの例ではブール値b’1を有する。全RdyHold段の内容は論理OR機能0133のチェーンを介して0103にフィードバックされる。目標PAEがデータの受け取りを確認すると、それぞれ到来したACK0133によってだけそれぞれ相応するRdyHold段がリセットされる。フィードバックされた信号の意味(セマンティック)は、b’1="いずれかのPAEがデータを取り出さなかった"である。すべてのRdyHold段がリセットされると直ちに、ORチェーン0133を介して情報b’0="すべてのPAEがデータを取り出した"が0103に到達する。このことはACKとして評価される。RdyHold段の出力側0132はすでに説明したように、バススイッチの制御のために共に使用することができる。
ORチェーンの最後の入力側には論理b’0が印加され、これによりチェーンは正常に機能する。
伝送 n:1
これは比較的複雑な場合である。(F1)一方では複数の送信器が1つの受信器でマルチプレクスされなければならない。(F2)他方では通常は、送信器の時間的順序を維持しなければならない。以下、この課題を解決するための複数の方法を説明する。ここでは基本的に有利な方法は存在しない。むしろシステムおよび実行すべきアルゴリズムに応じて、それぞれプログラミング、面倒さ、およびコストの観点から最適のものを選択すべきである。
これは比較的複雑な場合である。(F1)一方では複数の送信器が1つの受信器でマルチプレクスされなければならない。(F2)他方では通常は、送信器の時間的順序を維持しなければならない。以下、この課題を解決するための複数の方法を説明する。ここでは基本的に有利な方法は存在しない。むしろシステムおよび実行すべきアルゴリズムに応じて、それぞれプログラミング、面倒さ、およびコストの観点から最適のものを選択すべきである。
単純なn:1伝送は、それぞれ複数のデータ経路をPAEの入力側に導くことによって実現される。PAEはマルチプレクサ段としてコンフィギュレートされる。到来するトリガはマルチプレクサを制御し、多数のデータ経路からそれぞれ1つを選択する。必要であれば、マルチプレクサとしてコンフィギュレートされたPAEからなるツリー構造を形成し、複数のデータ流をまとめることができる。この方法では、種々異なるデータ流を時間的に正確に分類するためにプログラミングに特別の注意を払わなければならない。とりわけすべてのデータ経路が同じ長さおよび/または同じ遅延を有し、これによりデータの正しい順序を保証しなければならない。
高性能の統合方法は次のとおりである:
まずF1は後置接続されたマルチプレクサを備える任意のアービタにより簡単に解決されると思われるので、考察をF2からはじめる。
まずF1は後置接続されたマルチプレクサを備える任意のアービタにより簡単に解決されると思われるので、考察をF2からはじめる。
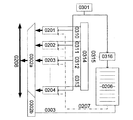
時間的順序の維持は単純なアービタでは不可能である。図2は第1の可能な実現例を示す。FIFO0206が、伝送要求の時間的順序をバスシステム0208へ正しく配分し処理するために使用される。このために各送信器0201,0202,0203,0204には一義的な番号が割り当てられ、この番号がアドレスを表わす。各送信器はバスシステム0208へのデータ伝送を、自分のアドレスをバス0209,0210,0211,0212に指示することにより要求する。それぞれのアドレスはマルチプレクサ0205を介し、FIFOで送信要求の順序に相応して記憶される。FIFOはステップごとに処理され、それぞれのFIFOエントリーのアドレスは別のバス0207に指示される。このバスは送信器をアドレシングし、相応に適合するアドレスを有する送信器はバス0208へアクセスする。この種の方法のためには、VPU技術の内部メモリをFIFOとして使用することができる。
しかし詳細に考察すると次の問題が発生する:複数の送信器が同時にバスへアクセスしようとすると直ちに、そのアドレスがFIFOに記憶される送信器を選択しなければならない。そして次のクロックでは次の送信器が選択される。この選択はアービタ0205により行うことができる。これにより同時性が解決され、このことは通常は問題とならない。リアルタイム適用に対しては優先付けられたアービタを使用することができる。しかしこの方法は簡単な例で失敗する:時点tで3つの送信器S1,S2,S3が受信器Eを要求すると、tでS1が、t+1でS2が、そしてt+2でS3が記憶される。しかしt+1でS4とS5が、t+2でさらにS6とS1が再び受信器を要求する。今や9つの要求が重なるので、処理は非常に急速に極端に複雑となり、甚だしい付加的ハードウエアコストを必要とする。
従って図2に示した方法は有利には単純なn:1伝送に対して使用すべきであり、この伝送では同時のバス要求は発生しない。
この考察によれば、1つの送信器を各クロック毎に記憶するのではなく、すべての送信器の集合が所定の時点で伝送を要求するのが有利であると思われる。それぞれ連続するクロックでそれぞれ新たな集合を記憶するのである。複数の送信器が同じクロックで伝送を要求する限り、これらはメモリの処理の際に仲裁される。
しかし複数の送信器アドレスの記憶は同様に非常に面倒である。以下の構成による簡単な実現が図3に示されている:
・付加的カウンタ(REQCNT,0301)はクロックTを計数する。クロックtで伝送を要求する各送信器0201,0202,0203,0204は、クロックtにおけるREQCNTの値(REQCNT(t))を自分のアドレスとして記憶する。
・・・・
・クロックt+nで伝送を要求する各送信器は、クロックt+nにおけるREQCNTの値(REQCNT(t+n))を自分のアドレスとして記憶する。
・付加的カウンタ(REQCNT,0301)はクロックTを計数する。クロックtで伝送を要求する各送信器0201,0202,0203,0204は、クロックtにおけるREQCNTの値(REQCNT(t))を自分のアドレスとして記憶する。
・・・・
・クロックt+nで伝送を要求する各送信器は、クロックt+nにおけるREQCNTの値(REQCNT(t+n))を自分のアドレスとして記憶する。
FIFO0206は次にREQCNTの値(tb)を所定のクロックtbにおいて記憶する。
FIFOは記憶したREQCNTの値を送信要求として別個のバス0207に指示する。各送信器はこの値を、自分の記憶した値と比較する。値が同じであれば、送信器はデータを送出する。複数の送信器が同じ値を有する場合、すなわち同時にデータを伝送しようとする場合、伝送は適切なアービタ(CHNARB,0302b)により仲裁され、アービタにより制御されるマルチプレクサ(0302a)によってバスに切り替えられる。アービタの例として可能な構成を以下に説明する。
送信器がREQCNTに応答しなくなると、すなわちアービタに仲裁のためのバス要求が存在しなくなると(0303)直ちに、FIFOは次の値までさらに切り替わる。FIFOが有効なエントリーを含まなくなると(empty)、値は無効としてマークされ、これにより間違ったバスアクセスが発生しなくなる。
有利な構成では、送信器0201,0202,0203,0204のバス要求が存在したREQCNTの値だけがFIFO0206に記憶される。このために各送信器は自分のバス要求0310,0311,0312,0313を通知する。これらは例えばOR機能により論理的に結合される0314。発生したすべての送信器の送信要求0315はゲート0316に供給される。このゲートは実際にバス要求が存在していたREQCNTの値だけをFIFO0206に送出する。
前記の方法は図4の有利な実施例に相応して次のように最適化することができる:
REQCNT0410により値(REQCNT(tb))の線形シーケンスが発生される。これは、すべてのクロックtではなく、送信器0315のバス要求が存在しているクロックが計数される場合である。REQCNTから発生し、空隙のない線形シーケンスによって、FIFOを簡単なカウンタ(SNDCNT、0402)により置換することができる。この簡単なカウンタも同様に線形に計数し、その値0403は0207に相応してそれぞれの送信器を解除接続する。ここでSNDCNTは、送信器がSNDCNTの値に応答しなくなるまでさらに計数する。REQCNTの値がSNDCNTの値と等しくなると直ちに、SNDCNTは計数をストップする。なぜなら最後の値に達したからである。
REQCNT0410により値(REQCNT(tb))の線形シーケンスが発生される。これは、すべてのクロックtではなく、送信器0315のバス要求が存在しているクロックが計数される場合である。REQCNTから発生し、空隙のない線形シーケンスによって、FIFOを簡単なカウンタ(SNDCNT、0402)により置換することができる。この簡単なカウンタも同様に線形に計数し、その値0403は0207に相応してそれぞれの送信器を解除接続する。ここでSNDCNTは、送信器がSNDCNTの値に応答しなくなるまでさらに計数する。REQCNTの値がSNDCNTの値と等しくなると直ちに、SNDCNTは計数をストップする。なぜなら最後の値に達したからである。
全体的実現に対しては、最大で必要なREQCNTの幅がlog2(送信器の数)であることが当てはまる。最大可能値を上回る場合、REQCNTとSNDCNTは再び最小値(通常は0)からカウントする。
アービタ
複数のアービタを従来技術によりCHNARBとして使用することができる。適用に応じて優先付けられたアービタまたは優先付けられないアービタがより適する。ここで優先付けられたアービタでは、リアルタイムタスクの際に所定のタスクを優先することができる。
複数のアービタを従来技術によりCHNARBとして使用することができる。適用に応じて優先付けられたアービタまたは優先付けられないアービタがより適する。ここで優先付けられたアービタでは、リアルタイムタスクの際に所定のタスクを優先することができる。
以下、シリアル・アービタについて説明する。シリアル・アービタはVPU技術において特に簡単に、リソースを節約して実現することができる。とりわけこのアービタは、優先度を以て動作するという利点を有し、これにより所定の伝送を優先的に処理することができる。
まずバスシステムの可能な基本構造を図5で説明する。VPUの構成素子は複数のデータバスシステム0502からなるネットワークを有し、ここで各PAEはデータ伝送のために少なくとも1つの端子をデータバスに有する。通常のように、ネットワークは複数の平行なデータバス0502から構成されており、これらのデータバスの各々は1つのデータ伝送のためにコンフィギュレートすることができる。残りのデータバスは別のデータ伝送のために自由に使用することができる。
さらにデータバスはセグメント化することができることを述べておく。すなわちコンフィギュレーション0521によりバスセグメント0502を、ゲートGを介して隣接するバスセグメント0522へ接続することができる。ゲートGはトランスミッションゲートから構成することができ、有利には信号増幅器および/またはレジスタを有する。
PAE0501は有利にはマルチプレクサ0503を介してまたは同等の回路を介してデータをバス0502の1つから取り出す。マルチプレクサ構成の解除接続はコンフィギュレート可能である0504。
有利にはPAE0510から発生されたデータ(結果)が同様に依存せずにコンフィギュレート可能0505なマルチプレクサ回路を介してバス0502に接続される。
図5に示した回路はバスノードにより特徴付けられる。
バスノードに対する簡単なアービタは、図6に示すように実現することができる:
2つのANDゲート0601,0602により、簡単なシリアル・アービタの基本素子0610が形成される、図6a参照。この基本素子は入力側RDY、0603を有し、この入力側によって、これがデータを伝送し、受信器バスへの解除接続を要求する入力バスを指示する。別の入力側(ACTIVATE,0604)はこの実施例では論理1レベルによって、先行の基本素子のいずれもが瞬時にバスを仲裁しておらず、従ってこの基本素子による仲裁が許容されることを指示する。出力側RDY_OUT0605は例えば後置接続されたバスノードに、基本素子がバスアクセスを解除接続することを指示し(バス要求RDYが存在する場合)、ACTIVATE_OUT0606は、基本素子が瞬時には解除接続を実行していないことを指示する。これは、バス要求(RDY)が存在していないか、および/または先行のアービタ段が受信器バス(ACTIVE)を占有していないからである。
2つのANDゲート0601,0602により、簡単なシリアル・アービタの基本素子0610が形成される、図6a参照。この基本素子は入力側RDY、0603を有し、この入力側によって、これがデータを伝送し、受信器バスへの解除接続を要求する入力バスを指示する。別の入力側(ACTIVATE,0604)はこの実施例では論理1レベルによって、先行の基本素子のいずれもが瞬時にバスを仲裁しておらず、従ってこの基本素子による仲裁が許容されることを指示する。出力側RDY_OUT0605は例えば後置接続されたバスノードに、基本素子がバスアクセスを解除接続することを指示し(バス要求RDYが存在する場合)、ACTIVATE_OUT0606は、基本素子が瞬時には解除接続を実行していないことを指示する。これは、バス要求(RDY)が存在していないか、および/または先行のアービタ段が受信器バス(ACTIVE)を占有していないからである。
図6bに相応して、ACTIVATEとACTIVATE_OUTとを基本素子0610を介してシリアルにチェーン接続することにより、優先付けられたシリアル・アービタが発生する。ここで第1の基本素子は最上位の優先度を有し、そのACTIVATE入力側は常にアクティベートされている。
すでに説明したプロトコルにより、同じSNDCNT値内では各PAEが1つのデータ伝送だけを実行することが保証される。なぜなら後続のデータ伝送は別のSNDCNT値を有することとなるからである。この条件はシリアル・アービタの障害のない機能に対して必要である。なぜならこれにより、優先付けに対して必要な解除接続要請(RDY)の仲裁順序が保証されるからである。言い替えると、解除要求(RDY)は仲裁中に後から、すでにACTIVATE_OUTによりバスアクセスの解除接続が不可能であることを指示する基本素子に発生することはできない。
局所性および伝搬時間
基本的に本発明の方法は長い区間を越えて使用することができる。システム周波数に依存する長さを越えると、データの伝送およびプロトコルの実行を1つのクロックで行うのは不可能である。
基本的に本発明の方法は長い区間を越えて使用することができる。システム周波数に依存する長さを越えると、データの伝送およびプロトコルの実行を1つのクロックで行うのは不可能である。
解決手段はデータ経路を正確に同じ長さに設定することと、統合を正確に1つの個所で実行することである。これによりプロトコルに対する全体的制御信号がローカルとなり、これによりシステム周波数を上昇することができる。データ経路を平衡化するためには、FIFO段が提案される。このFIFO段はコンフィギュレート可能な遅延を有する遅延段(遅延線)として動作し、以下、詳細に説明する。
データ経路をツリー状に統合することのできる十分に理想的な解決手段は次のように構成することができる:
変更されたプロトコル、タイムスタンプ
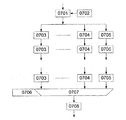
前提条件は、1つのデータ経路が複数の分岐に分割され、後で再び統合されることである。このことは通常は、プログラム構造の「IF」または「CASE」の場合のような分岐で行われる。図7aにはCASEに類似する構造が例として示されている。遅くとも分岐0701の前の最後のPAEにREQCNT0702が配属され、このREQCNTは各データ語に値(タイムスタンプ)を割り当てる。この値は以降常にデータ語と共に伝送される。REGCNTは線形に各データ語を計数する。これにより一義的な値によってデータ語のデータ流内での位置を検出することができる。データ語は以降、複数の異なるデータ経路0703,0704,0705に分岐する。各データ語にと共に、これに配属された値(タイムスタンプ)がデータ経路を通って導かれる。
変更されたプロトコル、タイムスタンプ
前提条件は、1つのデータ経路が複数の分岐に分割され、後で再び統合されることである。このことは通常は、プログラム構造の「IF」または「CASE」の場合のような分岐で行われる。図7aにはCASEに類似する構造が例として示されている。遅くとも分岐0701の前の最後のPAEにREQCNT0702が配属され、このREQCNTは各データ語に値(タイムスタンプ)を割り当てる。この値は以降常にデータ語と共に伝送される。REGCNTは線形に各データ語を計数する。これにより一義的な値によってデータ語のデータ流内での位置を検出することができる。データ語は以降、複数の異なるデータ経路0703,0704,0705に分岐する。各データ語にと共に、これに配属された値(タイムスタンプ)がデータ経路を通って導かれる。
合流されたデータ経路をさらに処理するPAE0708の前方で、マルチプレクサ0707がデータ語を再び正しい順序にソートする。このためにマルチプレクサには線形に計数するSNDCNT0706が配属されている。各データ語に割り当てられた値(タイムスタンプ)はSNDCNTの値と比較される。それぞれ通過するデータ語はマルチプレクサにより選択される。所定の時点でデータ語が通過しなければ、選択は実行されない。SNDCNTは、通過したデータ語が選択された場合だけさらに計数する。
できるだけ高いクロック周波数を達成するために、データ経路の統合は非常に局所的に実行すべきである。これにより線路長は最小になり、これと結び付いた伝搬時間も小さく維持される。
場合によりデータ経路の長さはレジスタ段(パイプライン)により、データ経路全体が共通の点で統合できるまで調整される。このとき、パイプラインの長さがほぼ同じであり、データ語環で大きな時間差が生じないように注意しなければならない。
マルチプレクサへのタイムスタンプの使用
1つのPAE(PAE−S)の出力は複数のPAE(PAE−E)にさらに導かれる。これらPAEのうちの1つだけがデータを各クロックサイクルで処理する。PAE−Eはそれぞれ異なってコンフィギュレートされた固定のアドレスを有し、このアドレスはそれぞれタイムスタンプバスと比較される。PAE−Sは受信側PAEを次のようにして選択する。すなわちPAE−Sが、受信側PAEのアドレスをタイムスタンプバスに出力することにより選択する。このことによりデータがそれぞれ定められたPAEがアドレシングされる。
1つのPAE(PAE−S)の出力は複数のPAE(PAE−E)にさらに導かれる。これらPAEのうちの1つだけがデータを各クロックサイクルで処理する。PAE−Eはそれぞれ異なってコンフィギュレートされた固定のアドレスを有し、このアドレスはそれぞれタイムスタンプバスと比較される。PAE−Sは受信側PAEを次のようにして選択する。すなわちPAE−Sが、受信側PAEのアドレスをタイムスタンプバスに出力することにより選択する。このことによりデータがそれぞれ定められたPAEがアドレシングされる。
推測実行とタスクスイッチ
古典的マイクロプロセッサにより推測実行の問題が公知である。この問題は、先行のデータ処理の結果に依存するデータを処理する場合に生じる。しかし依存データの処理はパフォーマンスの理由から前もって、所要の結果が存在する前に開始されるからである。結果が前もって仮定したものと異なると、間違った仮定に基づくデータの処理を新たに実行しなければならない(エラー推測)。一般的にこのことはVPUで発生する。
古典的マイクロプロセッサにより推測実行の問題が公知である。この問題は、先行のデータ処理の結果に依存するデータを処理する場合に生じる。しかし依存データの処理はパフォーマンスの理由から前もって、所要の結果が存在する前に開始されるからである。結果が前もって仮定したものと異なると、間違った仮定に基づくデータの処理を新たに実行しなければならない(エラー推測)。一般的にこのことはVPUで発生する。
再ソートおよび類似の方法によってこの問題を最小にすることができる。しかしその発生を除外することはできない。
類似の問題が、データ処理においてPA内で上位のユニット(例えばオペレーティングシステムのタスクスケジューラ、リアルタイム要求等)によりデータ処理が、これが完全に実行される前に中断された場合にも発生する。この場合、パイプラインの状態を次のように確保しなければならない。すなわち、データ処理が再び、最後に生じた結果の計算のためのオペランドの個所の後から開始されるように確保しなければならない。
パイプライン内では2つの関連する状態が発生する:
RD パイプラインの開始部では、新たなデータが仮定された、または要求されたことが指示される。
DONE パイプラインの終端部では、エラー推測の発生しなかったデータの正しい処理が指示される。
RD パイプラインの開始部では、新たなデータが仮定された、または要求されたことが指示される。
DONE パイプラインの終端部では、エラー推測の発生しなかったデータの正しい処理が指示される。
さらに状態MISS_PREDICTを使用することができる。この状態は、エラー推測が発生したことを指示する。補助的にこの状態は、状態DONEを適切な時点で反転することにより発生することもできる。
特殊なFIFO
データがメモリに保持され、このメモリから処理のために読み出され、ないしは結果がこれに格納される方法が公知である。このために複数の独立したメモリが使用される。メモリは種々の動作形式で動作することができ、とりわけランダムアクセス、スタック動作モードまたはFIFO動作モードを使用することができる。データはVPUで線形処理され、これによりFIFO動作モードが頻繁に優先的に使用される。例としてメモリのFIFO動作モードに対する特別の拡張を紹介する。この拡張FIFO動作モードは推測を直接サポートし、エラー推測の場合はエラー推測されたデータの再処理が可能である。さらにFIFOはラスクスイッチを任意の時点でサポートする。
データがメモリに保持され、このメモリから処理のために読み出され、ないしは結果がこれに格納される方法が公知である。このために複数の独立したメモリが使用される。メモリは種々の動作形式で動作することができ、とりわけランダムアクセス、スタック動作モードまたはFIFO動作モードを使用することができる。データはVPUで線形処理され、これによりFIFO動作モードが頻繁に優先的に使用される。例としてメモリのFIFO動作モードに対する特別の拡張を紹介する。この拡張FIFO動作モードは推測を直接サポートし、エラー推測の場合はエラー推測されたデータの再処理が可能である。さらにFIFOはラスクスイッチを任意の時点でサポートする。
まず拡張FIFO動作モードはメモリの例で実行される。このメモリへは所定のデータ処理の枠内で読み出しアクセスされる。例としてのFIFOが図8に示されている。書込み回路の構造は通常の書込みポインタWR_PTR,0801に相応し、従来技術では各書込みアクセス0810によりさらに移動する。読み出し回路は例えば通常のカウンタRD_PTR、0802を有し、このカウンタは各読み出されたワードの読み出し信号0811に相応して計数し、相応にメモリ0803の読み出しアドレスを変更する。従来技術に対して新規なのは付加的回路DONE_PTR0804であり、この付加的回路は読み出されたデータを文書化せずに、読み出し、正しく処理する。言い替えると、エラーが発生詩なかったデータを処理し、それらの結果を計算の最後に出力し、正しい計算終了は信号0812により指示される。可能な回路を以下に説明する。
(従来技術による)FULLフラグ0805はFIFOが一杯であり、それ以上のデータを記憶することができないことを指示する。このFULLフラグはDONE_PTRとWR_WTRとの比較0806により発生される。このことにより、生じ得るエラー推測によりバックアクセスが必要となるデータが上書きされないことが保証される。
EMPTYフラグ0807は通常の構造に相応して、RD_PRTとWR_PTRの比較0808により発生する。エラー推測MISS_PREDICT、0809が発生すると、読み出しポインタには値DONE_PTR+1がロードされる。これによりデータ処理が再度、エラー推測をトリガした値から開始される。
DONE_PTRの2つの可能な構成を例として詳細に説明する:
a)カウンタによる実現
DONE_PTRはカウンタとして実現される。カウンタは回路のリセット時、またはデータ処理の開始時にRD_PTRに等しくセットされる。到来する信号(DONE)によりデータが必要であることが指示される。すなわちエラー推測なしで処理さえたことが指示される。これによりDONE_PRTは、処理中の次のデータ語を指示するように変更される。
b)減算器による実現
データ処理するパイプラインの長さが常に正確に既知であり、長さが一定であること(すなわち長さの異なるパイプラインへの分岐が生じない)が保証されれば、減算器を使用することができる。配属されたレジスタでは、メモリの端子から生じ得るエラー推測を識別するまでのパイプラインの長さが記憶される。このことによりデータ処理はエラー推測後に、差により計算することのできるデータ語において再開されなければならない。
a)カウンタによる実現
DONE_PTRはカウンタとして実現される。カウンタは回路のリセット時、またはデータ処理の開始時にRD_PTRに等しくセットされる。到来する信号(DONE)によりデータが必要であることが指示される。すなわちエラー推測なしで処理さえたことが指示される。これによりDONE_PRTは、処理中の次のデータ語を指示するように変更される。
b)減算器による実現
データ処理するパイプラインの長さが常に正確に既知であり、長さが一定であること(すなわち長さの異なるパイプラインへの分岐が生じない)が保証されれば、減算器を使用することができる。配属されたレジスタでは、メモリの端子から生じ得るエラー推測を識別するまでのパイプラインの長さが記憶される。このことによりデータ処理はエラー推測後に、差により計算することのできるデータ語において再開されなければならない。
書込み側では、コンフィギュレーションのデータ処理の結果を確保するために相応に構成されたメモリが必要であり、ここで書込みポインタに対するDONE_PRTの機能が実現される。これによりすでに(エラー)計算された結果をデータ処理の新たな実行の際に上書きすることができる。言い替えると、書込みポインタと読み出しポインタの機能が図面に示されたアドレスに相応して交換される。
データの処理が他のソース(例えばオペレーティングシステムのタスクスイッチ)により中断されると、DONE_PTRが十分に確保され、データ処理は後の時点でDONE_PTR+1から再開される。
入力/出力段に対するFIFO、例えば0101,0103
データ経路および/またはグラフの種々異なるエッジの状態、ないしデータ処理の種々の分岐を平衡化するため、コンフィギュレート可能なFIFOをPAEの出力端または入力端で使用するのが有利である。FIFOは調整可能な待機時間を有しており、種々異なるエッジ/分岐の遅延、すなわちデータが少なくとも平行で長さの異なるデータ経路を介して伝搬する伝搬時間を相互に調整することができる。
データ経路および/またはグラフの種々異なるエッジの状態、ないしデータ処理の種々の分岐を平衡化するため、コンフィギュレート可能なFIFOをPAEの出力端または入力端で使用するのが有利である。FIFOは調整可能な待機時間を有しており、種々異なるエッジ/分岐の遅延、すなわちデータが少なくとも平行で長さの異なるデータ経路を介して伝搬する伝搬時間を相互に調整することができる。
VPU内では発生するデータまたは発生するトリガに基づいてパイプラインが停止することがあるから、FIFOも同様に遅延を調整すると有利である。以下に説明するFIFOは2つの課題を解決する:
FIFO段は例えば図9に示されており、次のように構成することができる:レジスタ0901にはマルチプレクサ0902が後置接続されている。レジスタはデータ0903と、その正確な存在、すなわち所属のRDY0904を記憶する。レジスタへの書込みは、FIFOの出力端0920の近くに示された隣接するFIFO段が一杯であり0905、RDY0904がデータに対して印加されるときに行われる。マルチプレクサは到来するデータ0903を、データがレジスタに書き込まれ、FIFOの入力端0921の近くに示された隣接するFIFO段がこれにより一杯になるまで出力端へ直接伝送する0906。データのFIFO段への取り込みは入力確認(IACK)0908により確認される。データのFIFOからの取り出しは、出力確認(OACK)0909により確認される。OACKは同時にすべてのFIFO段に到達し、データをFIFOでそれぞれ1段だけさらに書き込ませる。
FIFO段は例えば図9に示されており、次のように構成することができる:レジスタ0901にはマルチプレクサ0902が後置接続されている。レジスタはデータ0903と、その正確な存在、すなわち所属のRDY0904を記憶する。レジスタへの書込みは、FIFOの出力端0920の近くに示された隣接するFIFO段が一杯であり0905、RDY0904がデータに対して印加されるときに行われる。マルチプレクサは到来するデータ0903を、データがレジスタに書き込まれ、FIFOの入力端0921の近くに示された隣接するFIFO段がこれにより一杯になるまで出力端へ直接伝送する0906。データのFIFO段への取り込みは入力確認(IACK)0908により確認される。データのFIFOからの取り出しは、出力確認(OACK)0909により確認される。OACKは同時にすべてのFIFO段に到達し、データをFIFOでそれぞれ1段だけさらに書き込ませる。
個々のFIFO段は任意の長さのFIFOを構成するために図9aに示すようにカスケード接続することができる。このためにすべてのIACK出力端は例えばOR機能0910相互に論理結合される。
この機能は図10a,bの例で説明する:
データ語の挿入
新たなデータ語が個々のFIFO段のマルチプレクサを介してレジスタに導かれる。第1の一杯になったFIFO段1001はその前の段1002に、記憶されたRDYに基づいて、これ以上データを取り込むことができないことを通知する。その前の段1002はRDYを記憶していない。しかし後続の段1001の満杯状態を識別する。従ってこの段はデータとRDY1003を記憶する;そして送信器へのACKにより記憶を確認する。FIFO段のマルチプレクサ1004は、これがデータ経路を後続の段に接続せず、レジスタの内容を伝送するように切り替わる。
データ語の挿入
新たなデータ語が個々のFIFO段のマルチプレクサを介してレジスタに導かれる。第1の一杯になったFIFO段1001はその前の段1002に、記憶されたRDYに基づいて、これ以上データを取り込むことができないことを通知する。その前の段1002はRDYを記憶していない。しかし後続の段1001の満杯状態を識別する。従ってこの段はデータとRDY1003を記憶する;そして送信器へのACKにより記憶を確認する。FIFO段のマルチプレクサ1004は、これがデータ経路を後続の段に接続せず、レジスタの内容を伝送するように切り替わる。
データ語の除去
ACK1011が最後のFIFO段に到来すると、各先行の段のデータがそれぞれ後続の段に伝送される1010。このことは、グローバル書込みクロックを各段に印加することにより行われる。マルチプレクサ全体はすでにレジスタ占有に相応して調整されているから、FIFOのすべてのデータは1つのセルだけ下方に移動する。
ACK1011が最後のFIFO段に到来すると、各先行の段のデータがそれぞれ後続の段に伝送される1010。このことは、グローバル書込みクロックを各段に印加することにより行われる。マルチプレクサ全体はすでにレジスタ占有に相応して調整されているから、FIFOのすべてのデータは1つのセルだけ下方に移動する。
データ語の除去と同時の挿入
グローバル書込みクロックが印加されると、最初に空きになった段にはデータ語が記憶されない。この段のマルチプレクサはデータをさらに後続の段に転送するから、最初に一杯になった段1012はデータを記憶する。そのデータは前に述べたように同じくロックで後続の段に記憶される。言い替えると:新たに書き込むべきデータは自動的に最初に空きになったFIFO段1012に移動する。すなわちかつては最後に一杯であったFIFO段であり、ACKの除去により空になったFIFO段に移動する。
グローバル書込みクロックが印加されると、最初に空きになった段にはデータ語が記憶されない。この段のマルチプレクサはデータをさらに後続の段に転送するから、最初に一杯になった段1012はデータを記憶する。そのデータは前に述べたように同じくロックで後続の段に記憶される。言い替えると:新たに書き込むべきデータは自動的に最初に空きになったFIFO段1012に移動する。すなわちかつては最後に一杯であったFIFO段であり、ACKの除去により空になったFIFO段に移動する。
コンフィギュレート可能なパイプライン
所定の適用に対しては、図9の例に示されたFIFO段にあるスイッチ0930によってFIFOの個々のマルチプレクサを切り替え、基本的に相応するレジスタがスイッチオンされるようにすると有利である。これにより固定の待機時間ないし遅延時間をデータ伝送の際にスイッチを介して調整可能にコンフィギュレートすることができる。
所定の適用に対しては、図9の例に示されたFIFO段にあるスイッチ0930によってFIFOの個々のマルチプレクサを切り替え、基本的に相応するレジスタがスイッチオンされるようにすると有利である。これにより固定の待機時間ないし遅延時間をデータ伝送の際にスイッチを介して調整可能にコンフィギュレートすることができる。
データ流の統合(マージ)
データ流を統合するために全体で3つの方法が使用される。これらの方法は適用に応じてそれぞれ適切に使用される:
a)ローカルマージ
b)ツリーマージ
c)メモリマージ
ローカル統合(ローカルマージ)
もっとも単純な変形はローカルマージである。ここではすべてのデータ流が有利にはただ1つのポイントまたは比較的ローカルに統合され、場合により直ちに分離される。ローカルSNDCNTはマルチプレクサを介して、そのタイムスタンプがSNDCNTの値に相応し、従って瞬時に予期されるデータ語を正確に選択する。2つの手段を図7aと図7bに基づいて詳細に説明する。
a)カウンタSNDCNT、0706はデータパケットが到来するたびにさらに計数する。各データ経路には比較器が後置接続されている。比較器は計数器状態をデータ経路のタイムスタンプとそれぞれ比較する。計数器状態とタイプスタンプの値が一致すると、データパケットがマルチプレクサを介して後続のPAEに転送される。
b)解決手段a)を次のように拡張する。すなわち将来のデータ経路としてそれぞれアクティブなデータ経路を選択した後に、この経路に例えばCTコンフィギュレート可能なルックアップテーブル07010を介して、目標データ経路を配属するのである。将来のデータ経路は、データと共に到来したタイムスタンプを方法a)に相応してSNDCNT、0711と比較し0712、一致したデータ経路をアドレシングし0714、マルチプレクサ0713を介して選択することにより求められる。アドレス0714はルックアップテーブル0710によって目標データ経路アドレス0715に割り当てられる。この目標データ経路アドレスはデマルチプレクサ0716を介して目標経路を選択する。前記構造がバスノードにおいて同様に実現されていれば、ルックアップテーブル0710を介してデータ接続を、バスノードに配属されたPAE0718でも形成することができる。これはPAEの入力端へのゲート機能(透過ゲート)0717を介して行われる。
データ流を統合するために全体で3つの方法が使用される。これらの方法は適用に応じてそれぞれ適切に使用される:
a)ローカルマージ
b)ツリーマージ
c)メモリマージ
ローカル統合(ローカルマージ)
もっとも単純な変形はローカルマージである。ここではすべてのデータ流が有利にはただ1つのポイントまたは比較的ローカルに統合され、場合により直ちに分離される。ローカルSNDCNTはマルチプレクサを介して、そのタイムスタンプがSNDCNTの値に相応し、従って瞬時に予期されるデータ語を正確に選択する。2つの手段を図7aと図7bに基づいて詳細に説明する。
a)カウンタSNDCNT、0706はデータパケットが到来するたびにさらに計数する。各データ経路には比較器が後置接続されている。比較器は計数器状態をデータ経路のタイムスタンプとそれぞれ比較する。計数器状態とタイプスタンプの値が一致すると、データパケットがマルチプレクサを介して後続のPAEに転送される。
b)解決手段a)を次のように拡張する。すなわち将来のデータ経路としてそれぞれアクティブなデータ経路を選択した後に、この経路に例えばCTコンフィギュレート可能なルックアップテーブル07010を介して、目標データ経路を配属するのである。将来のデータ経路は、データと共に到来したタイムスタンプを方法a)に相応してSNDCNT、0711と比較し0712、一致したデータ経路をアドレシングし0714、マルチプレクサ0713を介して選択することにより求められる。アドレス0714はルックアップテーブル0710によって目標データ経路アドレス0715に割り当てられる。この目標データ経路アドレスはデマルチプレクサ0716を介して目標経路を選択する。前記構造がバスノードにおいて同様に実現されていれば、ルックアップテーブル0710を介してデータ接続を、バスノードに配属されたPAE0718でも形成することができる。これはPAEの入力端へのゲート機能(透過ゲート)0717を介して行われる。
特に高性能な回路例が図7cに示されている。PAE0720は3つのデータ入力端A,B,Cを有し、例えばXPU128ESにある。バスシステム0733はコンフィギュレート可能および/またはマルチプレクス可能であり、各クロックサイクルで選択可能にデータ入力端へ切り替えることができる。各バスシステムはデータ、ハンドシェークおよび所属のタイムスタンプ0721を伝送する。PAE0720の入力端AとCは、データチャネルのタイムスタンプをPAEに転送する0722,0723ために使用される。個々のタイムスタンプは後で説明するSIMDバスシステムにより束ねられる。束ねられたタイムスタンプはPAEで再び分離され、各タイムスタンプはそれぞれ個別に0725,0726,0727、PAEで実現された/コンフィギュレートされたSNDCNT0724と比較される0728。比較結果は、入力側マルチプレクサ0730を制御するために使用される。これにより入力側マルチプレクサは、正しいタイムスタンプを有するバスシステムを集合レール0731に接続する。集合レールは有利には入力端Bと接続されており、データをPAEに0717,0718に相応して転送することを可能にする。出力側デマルチプレクサ0732はデータを種々異なるバスシステムへさらに転送する。この出力側マルチプレクサも同様に結果により制御される。ここで有利には結果の再配列はフレキシブルな翻訳により、例えばルックアップテーブル0729により行われる。その結果、結果を自由にデマルチプレクサ0732を介して、選択されたバスシステムに割り当てることができる。
ツリー状の統合(ツリーマージ)
多くのアプリケーションでは、複数のポイントでデータ流の一部をマージすることが所望される。そこからツリー状の構造が生じる。このとき、データ語を選択するのに中央での決定が行われず、決定が複数のノードに分散されているという問題が生じる。従ってすべてのノードにSNDCNTのそれぞれの値を伝送する必要がある。しかしクロック周波数が高い場合、このことは複数のレジスタ段により伝送の際に発生する待機時間を伴う。そのためこの解決手段は有意な性能を示さない。しかし能力を改善するために、各ノードでのローカル決定をSNDCNTの値に依存しないで行うようにする。例えば単純なアプローチでは、それぞれもっとも小さなタイムスタンプを有するデータ語をノードで選択する。しかしこのアプローチは、データ経路がノードで1つのクロックごとにデータ語を送出しない場合に問題となる。この場合、どのデータ経路を優先すべきかの判断ができない。
多くのアプリケーションでは、複数のポイントでデータ流の一部をマージすることが所望される。そこからツリー状の構造が生じる。このとき、データ語を選択するのに中央での決定が行われず、決定が複数のノードに分散されているという問題が生じる。従ってすべてのノードにSNDCNTのそれぞれの値を伝送する必要がある。しかしクロック周波数が高い場合、このことは複数のレジスタ段により伝送の際に発生する待機時間を伴う。そのためこの解決手段は有意な性能を示さない。しかし能力を改善するために、各ノードでのローカル決定をSNDCNTの値に依存しないで行うようにする。例えば単純なアプローチでは、それぞれもっとも小さなタイムスタンプを有するデータ語をノードで選択する。しかしこのアプローチは、データ経路がノードで1つのクロックごとにデータ語を送出しない場合に問題となる。この場合、どのデータ経路を優先すべきかの判断ができない。
以下のアルゴリズムはこの特性を改善する:
a)各ノードは固有のSNDCNTカウンタSNDCNTKを有している。
b)各ノードは入力データ経路(P0...Pn)を有するべきである。
c)各ノードは複数の出力データ経路を有することができ、これらは変換方法、例えば上位のコンフィギュレートCTによりコンフィギュレート可能なルックアップテーブルによって入力データ経路に依存して選択される。
d)ルートノードはメインSNDCNTを有し、このメインSNDCNTにすべてのSNDCNTKが同期化される。
a)各ノードは固有のSNDCNTカウンタSNDCNTKを有している。
b)各ノードは入力データ経路(P0...Pn)を有するべきである。
c)各ノードは複数の出力データ経路を有することができ、これらは変換方法、例えば上位のコンフィギュレートCTによりコンフィギュレート可能なルックアップテーブルによって入力データ経路に依存して選択される。
d)ルートノードはメインSNDCNTを有し、このメインSNDCNTにすべてのSNDCNTKが同期化される。
正しいデータ経路を選択するために、次のアルゴリズムが使用される:
I.データがすべてのPn入力側データ経路で行列していれば次のことが当てはまる:
a)最小のタイムスタンプTsを有するデータ経路P(Ts)が選択される。
b)K:=Ts+1;SNDCNT>Ts+1が割り当てられ、SNDCNTK:=SNDCNTが成り立つ。
II.すべてのPn入力側データ経路にデータが発生していなければ、次のことが当てはまる:
a)タイムスタンプTs==SNDCNTKの場合だけデータ経路を選択する。
b)SNDCNTK:=SNDCNT+1
c)SNDCNT:=SNDCNT+1
III.1つのクロックで割り当てが実行されない場合には次のことが当てはまる:
a)SNDCNTK:=SNDCNT
IV.ルートノードはSNDCNTを有する。このSNDCNTは、有効なデータ語を選択するたびにさらに増分計数し、ツリーのルートにおいてデータ語の正しい順序を保証する必要であれば(1から3参照)他のすべてのノードがSNDCNTの値に同期される。このとき待機時間が発生し、この待機時間はSNDCNTの区間をSNDCNTKの後にブリッジオーバするために挿入すべきレジスタの数に相応する。
I.データがすべてのPn入力側データ経路で行列していれば次のことが当てはまる:
a)最小のタイムスタンプTsを有するデータ経路P(Ts)が選択される。
b)K:=Ts+1;SNDCNT>Ts+1が割り当てられ、SNDCNTK:=SNDCNTが成り立つ。
II.すべてのPn入力側データ経路にデータが発生していなければ、次のことが当てはまる:
a)タイムスタンプTs==SNDCNTKの場合だけデータ経路を選択する。
b)SNDCNTK:=SNDCNT+1
c)SNDCNT:=SNDCNT+1
III.1つのクロックで割り当てが実行されない場合には次のことが当てはまる:
a)SNDCNTK:=SNDCNT
IV.ルートノードはSNDCNTを有する。このSNDCNTは、有効なデータ語を選択するたびにさらに増分計数し、ツリーのルートにおいてデータ語の正しい順序を保証する必要であれば(1から3参照)他のすべてのノードがSNDCNTの値に同期される。このとき待機時間が発生し、この待機時間はSNDCNTの区間をSNDCNTKの後にブリッジオーバするために挿入すべきレジスタの数に相応する。
図11は可能なツリーを示す。このツリーは例えばPAE上でVPU XPU128ESのツリーと同じように構成される。ルートノード1101は累積SNDCNTを有し、その値は出力端H、1102で得られる。入力端AとCのデータ語は記述の方法に相応して選択され、それぞれデータ語が正しい順序で出力端Lに導かれる。
次の階層段1103のPAEと、さらに上位の各階層段1104,1105も相応して動作する。しかし以下の相違がある:累積SNDCNTKはローカルであり、それぞれの値は転送されない。SNDCNTKは、その値が入力端Bに印加されるSNDCNTによる記述の方法に相応して同期化される。
SNDCNTはすべてのノード間で、とりわけ個々の階層段の間で、レジスタを介してパイプラインされる。
メモリによる統合(メモリマージ)
この方法では、データ流の統合のためにメモリが使用される。ここでタイムスタンプの各値にはメモリスペースが割り当てられる。データはそのタイムスタンプの値に相応してメモリにファイルされる。言い替えると、タイムスタンプは割り当てられたデータに対するメモリセルのアドレスとして使用される。これによりタイムスタンプに対して線形なデータ空間が発生する。すなわちこのデータ空間はタイムスタンプに相応してソートされている。データ空間が完全になって初めて、すなわちすべてのデータが記憶されて初めて、メモリはさらなる処理のためにイネーブルされるか、または線形に読出される。このことは次のようにして簡単に検出される。すなわち、幾つのデータがメモリに書き込まれたかを計数することにより検出される。メモリが有しているデータ登録と同じだけのデータが書き込まれれば、メモリは一杯である。
この方法では、データ流の統合のためにメモリが使用される。ここでタイムスタンプの各値にはメモリスペースが割り当てられる。データはそのタイムスタンプの値に相応してメモリにファイルされる。言い替えると、タイムスタンプは割り当てられたデータに対するメモリセルのアドレスとして使用される。これによりタイムスタンプに対して線形なデータ空間が発生する。すなわちこのデータ空間はタイムスタンプに相応してソートされている。データ空間が完全になって初めて、すなわちすべてのデータが記憶されて初めて、メモリはさらなる処理のためにイネーブルされるか、または線形に読出される。このことは次のようにして簡単に検出される。すなわち、幾つのデータがメモリに書き込まれたかを計数することにより検出される。メモリが有しているデータ登録と同じだけのデータが書き込まれれば、メモリは一杯である。
基本原理の実施の際には次の問題が発生する:メモリが隙間なしに満たされる前に、タイムスタンプのオーバフローが発生することがある。オーバフローは次のように定義される:タイムスタンプが有限線形数値空間(TSR)からの数である。タイムスタンプの設定は厳しく単調に行われる。これにより数値空間内で各設定されたタイムスタンプが一義的である。タイムスタンプの設定の際に数値空間の終了に達すれば、設定はTSRの始めから継続される。このことにより不連続な個所が発生する。そうするとタイムスタンプの設定は先行のものに対してもはや一義的ではなくなる。基本的にはこの不連続個所が処理の際に考慮されることを保証すべきである。従って数値空間TSRは、最悪の場合でも同じタイムスタンプがデータ処理内で2つ発生することによる多義性が発生しないような大きさに選択すべきである。言い替えるとTSRは、後続の処理パイプラインおよび/またはメモリ内で発生し得る最悪の場合でも、同じタイムスタンプが処理パイプラインおよび/またはメモリ内に存在しないような大きさでなければならない。
タイムスタンプのオーバフローが発生すると、メモリはいずれの場合でもこれに応答できなければならない。オーバフロー後には、一部ではオーバフロー前のタイムスタンプを有するデータ(古いデータ)と、一部ではオーバフロー後のタイムスタンプを有するデータ(新しいデータ)とがメモリに含まれていることを前提にしなければならない。新しいデータを古いデータのメモリ個所に書き込んではならない。なぜなら古いデータが未だ読出されていないからである。従って複数の(少なくとの2つの)独立したメモリブロックを設ける必要がある。これにより古いデータと新た恣意データを別個に書き込むことができる。
メモリブロックを管理するために任意の方法を使用することができる。2つの手段を詳細に説明する:
a)所定のタイムスタンプの古いデータがこのタイムスタンプの新たなデータよりも前に到来することが常に保証されるならば、古いデータに対するメモリセルが未だ空きであるか否かが検査される。未だ空きであるなら古いデータが存在し、メモリセルは書き込まれ、空きがなければ新しいデータが存在し、メモリセルは新しいデータに対して書き込まれる。
b)所定のタイムスタンプ値の古いデータがこのタイムスタンプ値の新しいデータより前に到来することが保証されなければ、このタイムスタンプに識別子が付され、新しいデータと古いデータとが区別される。この識別子は1または複数のビットとすることができる。タイムスタンプがオーバフローする場合、識別子は線形に変化する。このことにより古いデータと新しいデータに一義的なタイムスタンプが付される。識別子に相応して、データは複数のメモリブロックの1つに割り当てられる。
a)所定のタイムスタンプの古いデータがこのタイムスタンプの新たなデータよりも前に到来することが常に保証されるならば、古いデータに対するメモリセルが未だ空きであるか否かが検査される。未だ空きであるなら古いデータが存在し、メモリセルは書き込まれ、空きがなければ新しいデータが存在し、メモリセルは新しいデータに対して書き込まれる。
b)所定のタイムスタンプ値の古いデータがこのタイムスタンプ値の新しいデータより前に到来することが保証されなければ、このタイムスタンプに識別子が付され、新しいデータと古いデータとが区別される。この識別子は1または複数のビットとすることができる。タイムスタンプがオーバフローする場合、識別子は線形に変化する。このことにより古いデータと新しいデータに一義的なタイムスタンプが付される。識別子に相応して、データは複数のメモリブロックの1つに割り当てられる。
従って有利には、その最大数値がタイムスタンプの最大数値よりも格段に小さい識別子が使用される。有利な関係は次のとおりである:
識別子(最大)<(最大タイムスタンプ/2)
幅広のグラフをパーティショニングするためのメモリの使用
公知にように、大きなアルゴリズムをパーティショニングする必要がある。すなわち複数の部分アルゴリズムに分割する必要がある。これによりアルゴリズムがVPUのPAEの所定の要求および量に適合することができる。パーティショニングは一方では性能効率の点から、他方ではもちろんアルゴリズムの正当性を維持するように実行すべきである。ここで重要な側面は、それぞれのデータ経路のデータと状態(トリガ)の管理である。以下に、管理を改善し、簡素化するための方法を紹介する。
識別子(最大)<(最大タイムスタンプ/2)
幅広のグラフをパーティショニングするためのメモリの使用
公知にように、大きなアルゴリズムをパーティショニングする必要がある。すなわち複数の部分アルゴリズムに分割する必要がある。これによりアルゴリズムがVPUのPAEの所定の要求および量に適合することができる。パーティショニングは一方では性能効率の点から、他方ではもちろんアルゴリズムの正当性を維持するように実行すべきである。ここで重要な側面は、それぞれのデータ経路のデータと状態(トリガ)の管理である。以下に、管理を改善し、簡素化するための方法を紹介する。
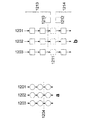
多くの場合、データ流グラフを1つのエッジでだけ切断する(図2a参照)ことは不可能である。なぜならグラフが例えば広すぎるか、または多数のエッジ1201,1202,1203が切断個所1204に存在するからである。
パーティショニングは本発明によれば、図12bに相応してすべてのエッジに沿って切断することにより実行される。第1のコンフィギュレーション1213の各エッジのデータは別個のメモリ1211に書き込まれる。
データと共に(または別個に)データ処理の関連する状態情報全体もエッジを介して(例えば図12b)伝搬し、メモリに書き込まれることを述べておく。状態情報はVPUテクノロジーに例えばトリガによって表わされる。
再コンフィギュレーション後に、データおよび/または状態情報は後続のコンフィギュレーション1214によりメモリから読出され、このコンフィギュレーションによりさらに処理される。
メモリは第1のコンフィギュレーションのデータ経路として(もっぱら書込み動作で)動作し、また後続のコンフィギュレーションのデータ送信器として(もっぱら読出し動作で)動作する。メモリ1211自体は2つのコンフィギュレーションの一部/リソースである。
データを正しく処理するために、データがメモリに書き込まれた時間順序を正しく識別することが必要である。基本的にこのことは次のようにして保証される。すなわちデータ流を、
a)メモリへの書込みの際にソートするか、および/または
b)メモリから読み出しの際にソートするか、および/または
c)ソート順序をデータと共に記憶し、後続のデータ処理の際に使用するのである。
a)メモリへの書込みの際にソートするか、および/または
b)メモリから読み出しの際にソートするか、および/または
c)ソート順序をデータと共に記憶し、後続のデータ処理の際に使用するのである。
このためにメモリには制御ユニットが配属され、制御ユニットはデータ1210のメモリ1211への書込みの際とデータのメモリ1212からの読出しの際に、データ順序およびデータ依存性の管理を行う。構成に応じて種々異なる管理形式および相応の制御メカニズムを使用することができる。
2つの可能な相応する方法を図13に基づき詳細に説明する。メモリは、PAEからのアレイ1310,1320に配属されている:
a)図13aで、メモリはそのアドレスを例えば共通のアドレス発生器により同期して発生する。言い替えると、書込みアドレス1301はサイクルごとにさらに計数されるが、この計数はメモリに実際に有効なデータが記憶されるか否かには依存しない。これにより多くのメモリ1303,1304は同じタイムベース、ないし書込み/読出しアドレスを有する。個々のフラグVOID,1302はメモリ中の各データメモリ個所ごとに、有効データがメモリアドレスに書き込まれたか否かを指示する。フラグVOIDは、データに配属されたRDY1305により発生することができる。相応してメモリの読み出しの際にデータRDY1306はフラグVOIDから発生される。データを後続のコンフィギュレーションにより読出すために、データの書込みに相応して共通の読出しアドレス1307が発生され、この読出しアドレスはサイクルごとにさらに転送される。
b)より効率的なのは、図13bの実施例に示すように、タイムスタンプを各データ語にすでに述べた方法に相応して割り当てることである。データ1317は所属のタイムスタンプ1311と共にそれぞれのメモリ個所に記憶される。このことによりメモリ中に隙間が発生せず、メモリは効率的に活用される。各メモリは独立の書込みポインタ1313,1314をデータ書込みコンフィギュレーションのために有し、読出しポインタ1315,1316を後続のデータ読出しコンフィギュレーションのために有する。公知の方法(例えば図7aまたは図11)に相応して、データ語の読出しの際に時間的に正しいデータ語が、配属され、共に記憶されたタイムスタンプ1312に基づいて選択される。
a)図13aで、メモリはそのアドレスを例えば共通のアドレス発生器により同期して発生する。言い替えると、書込みアドレス1301はサイクルごとにさらに計数されるが、この計数はメモリに実際に有効なデータが記憶されるか否かには依存しない。これにより多くのメモリ1303,1304は同じタイムベース、ないし書込み/読出しアドレスを有する。個々のフラグVOID,1302はメモリ中の各データメモリ個所ごとに、有効データがメモリアドレスに書き込まれたか否かを指示する。フラグVOIDは、データに配属されたRDY1305により発生することができる。相応してメモリの読み出しの際にデータRDY1306はフラグVOIDから発生される。データを後続のコンフィギュレーションにより読出すために、データの書込みに相応して共通の読出しアドレス1307が発生され、この読出しアドレスはサイクルごとにさらに転送される。
b)より効率的なのは、図13bの実施例に示すように、タイムスタンプを各データ語にすでに述べた方法に相応して割り当てることである。データ1317は所属のタイムスタンプ1311と共にそれぞれのメモリ個所に記憶される。このことによりメモリ中に隙間が発生せず、メモリは効率的に活用される。各メモリは独立の書込みポインタ1313,1314をデータ書込みコンフィギュレーションのために有し、読出しポインタ1315,1316を後続のデータ読出しコンフィギュレーションのために有する。公知の方法(例えば図7aまたは図11)に相応して、データ語の読出しの際に時間的に正しいデータ語が、配属され、共に記憶されたタイムスタンプ1312に基づいて選択される。
データのメモリへのソート/メモリからのソートは、種々のそれぞれ適切な方法に従って例えば次のようにして行われる。
a)メモリスペースをタイムスタンプにより割り当てる。
b)タイムスタンプに従ってデータ流へソートする。
c)各クロックをVALIDフラグと共に記憶する。
d)タイムスタンプを記憶し、これをメモリの読み出しの際に後続のアルゴリズムへさらに転送する。
a)メモリスペースをタイムスタンプにより割り当てる。
b)タイムスタンプに従ってデータ流へソートする。
c)各クロックをVALIDフラグと共に記憶する。
d)タイムスタンプを記憶し、これをメモリの読み出しの際に後続のアルゴリズムへさらに転送する。
アプリケーションに独立して、複数の(またはすべての)データ経路を記憶の前でも本発明のマージ方法を介して統合することができる。これを実行するか否かは実質的に、使用されるリソースに依存する。少数のメモリしか使用できなければ、記憶前での統合が必要であり、所望される。少数のPAEしか使用できなければ、有利にはそれ以上のPAEが統合のために使用されない。
タイムスタンプによる端末インタフェース(IO)の拡張
以下に、IOチャネルに端末構成素子および/または外部メモリタイムについてのイムスタンプを割り当てる方法を説明する。割り当ては種々の目的を満たすことができ、例えばデータ流を送信器と受信器との間で正しくソートするため、および/またはデータ流のソースおよび/または宛先を一義的に選択するために行われる。
以下に、IOチャネルに端末構成素子および/または外部メモリタイムについてのイムスタンプを割り当てる方法を説明する。割り当ては種々の目的を満たすことができ、例えばデータ流を送信器と受信器との間で正しくソートするため、および/またはデータ流のソースおよび/または宛先を一義的に選択するために行われる。
次の実施例を、インタフェースセルの例で説明する。ここではVPU内部バスの収束、および種々のVPU間またはVPUと端末(IO)との間のデータ交換方法を記述する。
この方法の欠点は、データソースが受信器においてもはや同定不能であり、正しい時間的順序も保証されないことである。以下の新しい方法はこの問題を解決し、それぞれ適用固有の複数の方法を使用され、場合により組み合わされる。
a)データソースの同定
図14は例として、2つのVPU1410,1420のコンフィギュレート可能なエレメントPAEからのアレイPA、1408間の同定を示す。アービタ1401がデータ送信側構成素子VPU、1410において可能なデータソース1405の1つを選択し、これをマルチプレクサ1402を介してIOに接続する。データソース1403のアドレスはデータ1404と共にIOに送信される。データ受信側構成素子VPU、1411は、データソースのアドレス1403に相応して相応の受信器1406をデマルチプレクサ1407を介して選択する。有利には変換方法、例えばルックアップテーブルを使用して、伝送されるアドレス1403と受信器1406とをフレキシブルに割り当てることができる。ルックアップテーブルは上位のコンフィギュレーションユニットCTによりコンフィギュレートすることができる。マルチプレクサ1402に前置接続されたおよび/またはデマルチプレクサ1407に後置接続されたインタフェース構成群を、バスシステムのコンフィギュレート可能な接続のために使用することができることを述べておく。
b)時間的順序の維持
b1)最も簡単な方法は、タイムスタンプをIOに送信し、タイムスタンプを受理した受信器に評価を任せることである。
b2)別のバージョンでは、タイムスタンプがアービタによりデコードされる。アービタは正しいタイムスタンプを有する送信器だけを選択し、IOに送信する。受信器はデータを正しい順序で受け取る。
a)データソースの同定
図14は例として、2つのVPU1410,1420のコンフィギュレート可能なエレメントPAEからのアレイPA、1408間の同定を示す。アービタ1401がデータ送信側構成素子VPU、1410において可能なデータソース1405の1つを選択し、これをマルチプレクサ1402を介してIOに接続する。データソース1403のアドレスはデータ1404と共にIOに送信される。データ受信側構成素子VPU、1411は、データソースのアドレス1403に相応して相応の受信器1406をデマルチプレクサ1407を介して選択する。有利には変換方法、例えばルックアップテーブルを使用して、伝送されるアドレス1403と受信器1406とをフレキシブルに割り当てることができる。ルックアップテーブルは上位のコンフィギュレーションユニットCTによりコンフィギュレートすることができる。マルチプレクサ1402に前置接続されたおよび/またはデマルチプレクサ1407に後置接続されたインタフェース構成群を、バスシステムのコンフィギュレート可能な接続のために使用することができることを述べておく。
b)時間的順序の維持
b1)最も簡単な方法は、タイムスタンプをIOに送信し、タイムスタンプを受理した受信器に評価を任せることである。
b2)別のバージョンでは、タイムスタンプがアービタによりデコードされる。アービタは正しいタイムスタンプを有する送信器だけを選択し、IOに送信する。受信器はデータを正しい順序で受け取る。
a)およびb)による方法は、それぞれのアプリケーションの要求に相応して共通して、または個別に適用することができる。
さらにこの方法はチャネル番号の設定および同定により拡張することができる。チャネル番号は所定の送信領域を表わす。例えばチャネル番号は、構成素子内のバス、構成素子、構成群の記述のような複数の同定から成ることができる。このことにより多数のPAEおよび/または多数の構成素子の合同を使用する場合には簡単な同定が得られる。
有利にはチャネル番号を使用する際にそれぞれ個々のデータ語を伝送せずに、複数のデータ語をデータパケットにまとめ、チャネル番号の記載の下で伝送する。個々のデータ語をまとめることは、例えば適切なメモリを使用して行うことができる。
伝送されたアドレスおよび/またはタイムスタンプは有利に識別子または識別子の一部としてバスシステムで使用できることを述べておく。
シークエンサの構造
タイムスタンプまたは同等の方法を使用することにより、PAEの群からの簡単なシークエンサ構造が可能となる。回路のバスおよび基本機能はコンフィギュレートされ、詳細機能およびデータアドレスはオペコードによって伝搬時間にフレキシブルに調整される。
タイムスタンプまたは同等の方法を使用することにより、PAEの群からの簡単なシークエンサ構造が可能となる。回路のバスおよび基本機能はコンフィギュレートされ、詳細機能およびデータアドレスはオペコードによって伝搬時間にフレキシブルに調整される。
複数のこのシークエンサは同時にPA(PAEからのアレイ)内で構成され、駆動される。
VPU内のシークエンサはアルゴリズムに相応して形成され、複数に分割された本発明のステップですでに与えられている。ここでは複数のPAEからのシーケンサの構造が記載されている。このことは以下の説明に対する基礎的例として用いる。
以下のシーケンサの構成は自由に適合される:
・IO/メモリの形式および量
・割込みの形式および量(例えばトリガを介して)
・命令セット
・レジスタの数および形式
簡単なシーケンサは例えば次の例から形成される:
1.算術機能および論理機能を実行するためのALU
2.データを擬似的にレジスタセットとして記憶するためのメモリ
3.プログラムに対するコードソースとしてのメモリ
場合によりシーケンサはIOエレメントだけ拡張される。とりわけさらなるPAEがデータソースまたはデータ受信器として接続される。
・IO/メモリの形式および量
・割込みの形式および量(例えばトリガを介して)
・命令セット
・レジスタの数および形式
簡単なシーケンサは例えば次の例から形成される:
1.算術機能および論理機能を実行するためのALU
2.データを擬似的にレジスタセットとして記憶するためのメモリ
3.プログラムに対するコードソースとしてのメモリ
場合によりシーケンサはIOエレメントだけ拡張される。とりわけさらなるPAEがデータソースまたはデータ受信器として接続される。
使用されるコードソースに応じて、PAEのオペコードをデータバスを介して直接セットすることができ、データソース/データ宛先を指示することができる。
データソース/データ宛先のアドレスは例えばタイムスタンプ方法で伝送される。さらにバスをオペコードの伝送のために使用することができる。
例としてのタイムスタンピングが図14に示されており、シーケンサはプログラムを記憶するためのRAM、データ(ALU)を計算するためのPAE1502、プログラムポインタ1503を計算するためのPAE、レジスタセットとしてのメモリ、および外部機器1505に対するIOから成る。
配線によって2つのバスシステム、すなわちALU IBUS1506への入力バス、およびALU OBUS1507からの出力バスが発生する。バスにはそれぞれ4ビット幅のタイムスタンプが配属されており、このタイムスタンプがソースIBUS−ADR1508ないし宛先OBUS−ADR1509をアドレシングする。
1504からプログラムポインタ1510が1501に供給される。1501はオペコードをフィードバックする。オペコードは、ALU1512およびプログラムポインタ1513に対するコマンド中にあり、データアドレス1508,1509を分割する。バスを分割するために次のSIMD方法およびバスシステムを使用することができる。
1502はアキュムレータマシンとして構成されており、例えば次の機能をサポートする:
ld<reg> レジスタからアキュムレータ1520にロード
add_sub<reg> 加算/減算レジスタからアキュムレータへ
sl_sr アキュムレータシフト
rl_rr アキュムレータ回転
st<reg> アキュムレータをレジスタに書込み
コマンドに対しては3ビットが必要である。第4のビットがオペレーションの形式を指示する:加算または減算、右または左シフト。1502はALU状態キャリーをトリガポート0に、ゼロをトリガポート1に送出する。
ld<reg> レジスタからアキュムレータ1520にロード
add_sub<reg> 加算/減算レジスタからアキュムレータへ
sl_sr アキュムレータシフト
rl_rr アキュムレータ回転
st<reg> アキュムレータをレジスタに書込み
コマンドに対しては3ビットが必要である。第4のビットがオペレーションの形式を指示する:加算または減算、右または左シフト。1502はALU状態キャリーをトリガポート0に、ゼロをトリガポート1に送出する。
<reg>は次のように符号化される:
0..7 1504のデータレジスタ
8 入力レジスタ1521 プログラムポインタ計算
9 IOデータ
10 IOアドレス
アドレスに対しては4ビットが必要である。
0..7 1504のデータレジスタ
8 入力レジスタ1521 プログラムポインタ計算
9 IOデータ
10 IOアドレス
アドレスに対しては4ビットが必要である。
1503は次のオペレーションをプログラムポインタを介してサポートする:
jmp 入力レジスタ2321のアドレスへジャンプ
jt0 トリガ0がセットされているとき入力レジスタのアドレスへジャンプ
jt1 トリガ1がセットされているとき入力レジスタのアドレスへジャンプ
jt2 トリガ2がセットされているときに入力レジスタのアドレスへジャンプ
jmpr 入力レジツタのアドレスプラスPPにジャンプ
コマンドに対しては3ビットが必要である。第4のビットはオペレーションの形式を維持する:加算または減算。
jmp 入力レジスタ2321のアドレスへジャンプ
jt0 トリガ0がセットされているとき入力レジスタのアドレスへジャンプ
jt1 トリガ1がセットされているとき入力レジスタのアドレスへジャンプ
jt2 トリガ2がセットされているときに入力レジスタのアドレスへジャンプ
jmpr 入力レジツタのアドレスプラスPPにジャンプ
コマンドに対しては3ビットが必要である。第4のビットはオペレーションの形式を維持する:加算または減算。
オペコード1511は3つの群でそれぞれ4ビットごとに分割される:(1508,1509)、1512,1513,1508と1509は所定のインストラクションセットでは同じとすることができる。1512,1513は例えばPAEのCレジスタに供給され、PAE内で命令としてデコードされる。
シーケンサは複合構造に形成することができる。例えば<reg>=11,12,13,14,15によりさらなるデータソースをアドレシング可能であり、このデータソースは他のPAEから発することもできる。同様にさらなるデータ経路がアドレシングされる。データソースおよびデータ受信器は任意であり、PAEとすることができる。
図示された回路はオペコード1511の12ビットしか必要としないことを述べておく。従って32ビットアーキテクチャでは、20ビットが基本回路の拡張のためのオプションとして使用される。
SIMD計算機構とSIMDバスシステム
アルゴリズムを処理するために再コンフィギュレーション可能な技術を使用する場合、重大なパラドクスが発生する:一方ではできるだけ高い計算能力を得るために複合ALUが必要であり、その際に再コンフィギュレーションに対するコストは最小でなければならない。他方ではALUはできるだけ簡単にビットレベルでの効率的な処理を可能にしなければならない。さらに再コンフィギュレーションとデータ管理は、これが効率的かつ簡単にプログラミングされるよう、インテリジェントで高速に実行されなければならない。
アルゴリズムを処理するために再コンフィギュレーション可能な技術を使用する場合、重大なパラドクスが発生する:一方ではできるだけ高い計算能力を得るために複合ALUが必要であり、その際に再コンフィギュレーションに対するコストは最小でなければならない。他方ではALUはできるだけ簡単にビットレベルでの効率的な処理を可能にしなければならない。さらに再コンフィギュレーションとデータ管理は、これが効率的かつ簡単にプログラミングされるよう、インテリジェントで高速に実行されなければならない。
これまでの技術は、
a)再コンフィギュレーションサポート(FPGA)の少ない小さなALUを使用し、別途レベルでは効率であるか、
b)再コンフィギュレーションサポートの少ない大きなALU(Cameleon)を使用するか、
c)再コンフィギュレーションサポートとデータ管理(VPU)を行う大きなALUと小さなALUを混合して使用していた。
a)再コンフィギュレーションサポート(FPGA)の少ない小さなALUを使用し、別途レベルでは効率であるか、
b)再コンフィギュレーションサポートの少ない大きなALU(Cameleon)を使用するか、
c)再コンフィギュレーションサポートとデータ管理(VPU)を行う大きなALUと小さなALUを混合して使用していた。
VPU技術は高性能な技術であるから、これに基づく最適な方法を見出すべきである。この方法は同様に他のアーキテクチャに対しても使用できることを述べておく。
再コンフィギュレーションを効率的に制御するための面積コストはPAE当たりで約10000から40000ゲート量であり比較的高い。このゲート量以下では簡単な伝搬制御しか実現されず、VPUのプログラミング性が非常に制限され、汎用プロセッサとしての使用が除外される。特別に高速なコンフィギュレーションを目的とするならば、付加的なメモリを設けなければならないが、これにより所要のゲート量はさらに上昇する。
再コンフィギュレーションコストと計算能力との間で適切な関係を得るためには、大きなALU(多数の機能性および/または大きなビット幅)を必然的に使用しなければならない。しかしALUが過度に大きくなると、チップ当たりの使用可能な平行計算能力が低下する。ALUが過度に小さいと(例えば4ビット)、面倒な機能(例えば32ビット乗算)をコンフィギュレートするためのコストが過度に大きくなる。とりわけ配線コストが商品的に意味のない領域まで上昇する。
11.1 SIMD計算機構の使用
小さなビット幅の処理と、配線コストと、面倒な機能のコンフィギュレーションとの間で理想的な関係を得るために、SIMD計算機構の使用が提案される。ここでは幅mの計算機構が分割され、幅がb=m/nの個々のn個のブロックが発生する。コンフィギュレーションにより各計算機構は、計算機構を分割しないか、または複数のブロックに分割し、それぞれ同じ幅または異なる幅を有するようにするかが設定される。言い替えると、計算機構は、1つの計算機構内で異なるワード幅が同時にコンフィギュレートされるように(例えば32nビット幅を1×16ビット、1×8ビットそして2×4ビットに)分割することができる。データは次のようにPAE間で伝送される。すなわち分割されたデータ語(SIMD語)がビット幅mのデータ語にまとめられ、パケットとしてネットワークを介して伝送される。ネットワークは常に完全なパケットを伝送する。すなわちすべてのデータ語は1パケット内で有効であり、公知のハンドシェーク法に従って伝送される。
小さなビット幅の処理と、配線コストと、面倒な機能のコンフィギュレーションとの間で理想的な関係を得るために、SIMD計算機構の使用が提案される。ここでは幅mの計算機構が分割され、幅がb=m/nの個々のn個のブロックが発生する。コンフィギュレーションにより各計算機構は、計算機構を分割しないか、または複数のブロックに分割し、それぞれ同じ幅または異なる幅を有するようにするかが設定される。言い替えると、計算機構は、1つの計算機構内で異なるワード幅が同時にコンフィギュレートされるように(例えば32nビット幅を1×16ビット、1×8ビットそして2×4ビットに)分割することができる。データは次のようにPAE間で伝送される。すなわち分割されたデータ語(SIMD語)がビット幅mのデータ語にまとめられ、パケットとしてネットワークを介して伝送される。ネットワークは常に完全なパケットを伝送する。すなわちすべてのデータ語は1パケット内で有効であり、公知のハンドシェーク法に従って伝送される。
11.1.1 SIMD語の再ソート
SIMD計算機構を効率的に使用するためには、SIMD語を相互にバス内または種々異なるバス間でフレキシブルかつ効率的に再ソートする必要がある。
SIMD計算機構を効率的に使用するためには、SIMD語を相互にバス内または種々異なるバス間でフレキシブルかつ効率的に再ソートする必要がある。
図5ないし図7b、cのバススイッチは次のように変更することができる。すなわち個々のSIMD語のフレキシブルなネットワーキングが可能であるように変更することができる。このためにマルチプレクサは計算機構に相応して、コンフィギュレーションにより分割を定めることができるように構成される。言い替えると、ビット幅mのマルチプレクサをバスごとに使用するのではなく、ビット幅b=m/nのn個の個々のマルチプレクサを使用するのである。これによりデータバスをbビット幅に対してコンフィギュレートすることができる。バスのマトリクス構造(図5)によって、データを簡単に再ソートすることができる。これは図16cに示されている。第1のPAEはデータを第2のバス1601,1602を介して送信する。これらのバスはそれぞれ4つの部分バスに分割されている。バスシステム1603は個々の部分バスを、付加的にバスに存在する部分バスと接続する。第2のPAEは、種々異なってソートされた部分バスをその2つの入力バス1604,1605で受け取る。
例えば2重SIMD計算機構1614,1615を有する2つのPAE間でのバスのハンドシェークは図16aで論理的に結合され、新たに配列されたバス1611に対する共通のハンドシェーク1610が元のバスのハンドシェークから発生される。例えば新たにソートされたバスに対するRDYは、このバスに対してデータを送出するバスのすべてのRDYを論理AND結合することにより発生される。同様にデータを送出するバスのACKは、データをさらに処理するすべてのバスのACKをAND結合することにより発生できる。
共通のハンドシェークは、PAE1612を管理するための制御ユニット1613を制御する。バス1611はPAEを内部で2つの計算機構1614,1615に分割する。
第1の変形実施例では、ハンドシェークの結合が各バスノード内で実行される。このことにより、ビット幅bのn個の部分バスから成るビット幅mのバスシステムにハンドシェークプロトコルを割り当てることが可能になる。
別の有利な実施形態では、バスシステム全体が幅bに構成され、この幅bはSIMD語の最小実現可能入/出力データ幅bに相当する。PAEデータ経路(m)の幅に相応して、入/出力バスは幅bのm/b=n個の部分バスからなる。例えば3つの32ビット入力バスと、2つの32ビット出力バスを備えるPAEは、8の最小SIMD語幅の場合に実際には3×4の8ビット入力バスと、2×4の8ビット出力バスを有する。
部分バスの各々には、ハンドシェーク信号と制御信号全体が配属される。
PAEの出力端は、n個の部分バス全体に対して同じ制御信号を送信する。到来するすべての部分バスの受領信号は相互に論理的にAND機能により結合される。バスシステムは各部分バスを自由に接続することができ、これはルートに依存しない。バスシステムとバスノードは、個々のバスのハンドシェーク信号をそれらのルーティング、構成およびソートに依存しないで処理し、結合する。PAEにデータが到来する場合、n個の部分バス全体の制御信号が相互に結合され、一般的に有効な制御信号がデータ経路に対するバス制御信号として発生される。
例えば定義に従い「依存性の」動作形式でRdyHold段を各個々のデータ経路に対して使用することができ、全RdyHold段が発生したデータをシグナリングして初めて、これらはPAEにより引き取られる。
定義による「独立性の」動作形式では、各部分バスのデータが個別にPAEの入力レジスタに書き込まれ、受領される。これにより部分バスは直ちに次のデータ伝送に対して空きとなる。すべての部分バスのすべての所要データが入力レジスタに存在することは、PAE内において、各部分バスに対し入力レジスタに記憶されたRDY信号を適切に論理結合することにより検知される。これに基づきおPAEはデータ処理を開始する。
ここから得られるこの方法の利点は、PAEのSIMD特性が使用されるバスシステムに何ら影響を及ぼさないことである。図16bに示したように、幅bの小さな複数のバス1620と所属のハンドシェーク1621が必要なだけである。配線回路自体は変化しない。PAEは制御線路をローカルに結合し、管理する。このことにより、制御線路を管理および/または結合するためのバスシステムでの付加的ハードウエアコストが省略される。
0107,0108,0109 バスシステム、 0101,0104 レジスタ、 0102,0105 データ処理論理回路、 0103,0106 出力段
Claims (5)
- 読出し過程を、以前にデータ語が読出されている場合には再び開始することができる、
ことを特徴とするFIFO記憶方法。 - 書込み過程を、以前にデータ語が書き込まれている場合には再び開始することができる、ことを特徴とするFIFO記憶方法。
- 保安レジスタがデータ語のアドレス位置を確保し、当該アドレスで過程を繰り替えることができる、請求項1または2記載の方法。
- FIFOの空き状態または満杯状態は、保安レジスタとの比較によって検査される、請求項1から3までのいずれか1項記載の方法。
- 保安レジスタは、各アドレスに任意にセットすることができる、請求項1から4までのいずれか1項記載の方法。
Applications Claiming Priority (36)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE10110530 | 2001-03-05 | ||
| DE10111014 | 2001-03-07 | ||
| PCT/EP2001/006703 WO2002013000A2 (de) | 2000-06-13 | 2001-06-13 | Pipeline ct-protokolle und -kommunikation |
| EP01115021 | 2001-06-20 | ||
| DE10135211 | 2001-07-24 | ||
| PCT/EP2001/008534 WO2002008964A2 (de) | 2000-07-24 | 2001-07-24 | Integrierter schaltkreis |
| DE10135210 | 2001-07-24 | ||
| DE10139170 | 2001-08-16 | ||
| DE10142231 | 2001-08-29 | ||
| DE10142904 | 2001-09-03 | ||
| DE10142903 | 2001-09-03 | ||
| DE10142894 | 2001-09-03 | ||
| US31787601P | 2001-09-07 | 2001-09-07 | |
| DE10144732 | 2001-09-11 | ||
| DE10144733 | 2001-09-11 | ||
| DE10145795 | 2001-09-17 | ||
| DE10145792 | 2001-09-17 | ||
| DE10146132 | 2001-09-19 | ||
| US09/967,847 US7210129B2 (en) | 2001-08-16 | 2001-09-28 | Method for translating programs for reconfigurable architectures |
| EP0111299 | 2001-09-30 | ||
| PCT/EP2001/011593 WO2002029600A2 (de) | 2000-10-06 | 2001-10-08 | Zellenarordnung mit segmentierterwischenzellstruktur |
| DE10154260 | 2001-11-05 | ||
| DE10154259 | 2001-11-05 | ||
| EP01129923 | 2001-12-14 | ||
| EP02001331 | 2002-01-18 | ||
| DE10202044 | 2002-01-19 | ||
| DE10202175 | 2002-01-20 | ||
| DE10206653 | 2002-02-15 | ||
| DE10206856 | 2002-02-18 | ||
| DE10206857 | 2002-02-18 | ||
| DE10207224 | 2002-02-21 | ||
| DE10207226 | 2002-02-21 | ||
| DE10207225 | 2002-02-21 | ||
| DE10208434 | 2002-02-27 | ||
| DE10208435 | 2002-02-27 | ||
| DE10129237A DE10129237A1 (de) | 2000-10-09 | 2002-06-20 | Verfahren zur Bearbeitung von Daten |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002570104A Division JP2004536373A (ja) | 2001-03-05 | 2002-03-05 | データ処理方法およびデータ処理装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009043276A true JP2009043276A (ja) | 2009-02-26 |
Family
ID=40360440
Family Applications (5)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008249106A Pending JP2009054170A (ja) | 2001-03-05 | 2008-09-26 | データ流の管理方法 |
| JP2008249099A Pending JP2009032281A (ja) | 2001-03-05 | 2008-09-26 | データ伝送方法 |
| JP2008249112A Pending JP2009020909A (ja) | 2001-03-05 | 2008-09-26 | グラフのパーティショニング方法 |
| JP2008249116A Pending JP2009043276A (ja) | 2001-03-05 | 2008-09-26 | Fifo記憶方法 |
| JP2008249115A Pending JP2009043275A (ja) | 2001-03-05 | 2008-09-26 | シーケンスの形成方法 |
Family Applications Before (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008249106A Pending JP2009054170A (ja) | 2001-03-05 | 2008-09-26 | データ流の管理方法 |
| JP2008249099A Pending JP2009032281A (ja) | 2001-03-05 | 2008-09-26 | データ伝送方法 |
| JP2008249112A Pending JP2009020909A (ja) | 2001-03-05 | 2008-09-26 | グラフのパーティショニング方法 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008249115A Pending JP2009043275A (ja) | 2001-03-05 | 2008-09-26 | シーケンスの形成方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (5) | JP2009054170A (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9176912B2 (en) * | 2011-09-07 | 2015-11-03 | Altera Corporation | Processor to message-based network interface using speculative techniques |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04121891A (ja) * | 1990-09-12 | 1992-04-22 | Sharp Corp | Fifoメモリ装置 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH03156545A (ja) * | 1989-11-14 | 1991-07-04 | Fujitsu Ltd | Cpuシステム |
| DE69221338T2 (de) * | 1991-01-18 | 1998-03-19 | Nat Semiconductor Corp | Steuervorrichtung für Wiederholerschnittstelle |
| JPH0535669A (ja) * | 1991-07-29 | 1993-02-12 | Nippon Telegr & Teleph Corp <Ntt> | データ転送方式 |
| US5701514A (en) * | 1994-04-01 | 1997-12-23 | International Business Machines Corporation | System providing user definable selection of different data transmission modes of drivers of an I/O controller transmitting to peripherals with different data transmission rate |
| JPH08106443A (ja) * | 1994-10-05 | 1996-04-23 | Hitachi Ltd | データ処理システム及び並列コンピュータ |
| JPH09190390A (ja) * | 1996-01-11 | 1997-07-22 | Toshiba Corp | サイクリック伝送システム |
| JP2845794B2 (ja) * | 1996-02-29 | 1999-01-13 | 日本電気株式会社 | 論理回路分割方式 |
| DE19651075A1 (de) * | 1996-12-09 | 1998-06-10 | Pact Inf Tech Gmbh | Einheit zur Verarbeitung von numerischen und logischen Operationen, zum Einsatz in Prozessoren (CPU's), Mehrrechnersystemen, Datenflußprozessoren (DFP's), digitalen Signal Prozessoren (DSP's) oder dergleichen |
| JP3859345B2 (ja) * | 1997-05-27 | 2006-12-20 | ユニデン株式会社 | データ伝送方法及びデータ伝送装置 |
| US6438108B1 (en) * | 1999-03-11 | 2002-08-20 | Telefonaktiebolaget L M Ericsson (Publ) | System for improved transmission of acknowledgements within a packet data network |
| JP2000286856A (ja) * | 1999-03-30 | 2000-10-13 | Kokusai Electric Co Ltd | 無線lanシステム |
| WO2000077652A2 (de) * | 1999-06-10 | 2000-12-21 | Pact Informationstechnologie Gmbh | Sequenz-partitionierung auf zellstrukturen |
-
2008
- 2008-09-26 JP JP2008249106A patent/JP2009054170A/ja active Pending
- 2008-09-26 JP JP2008249099A patent/JP2009032281A/ja active Pending
- 2008-09-26 JP JP2008249112A patent/JP2009020909A/ja active Pending
- 2008-09-26 JP JP2008249116A patent/JP2009043276A/ja active Pending
- 2008-09-26 JP JP2008249115A patent/JP2009043275A/ja active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04121891A (ja) * | 1990-09-12 | 1992-04-22 | Sharp Corp | Fifoメモリ装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2009054170A (ja) | 2009-03-12 |
| JP2009020909A (ja) | 2009-01-29 |
| JP2009043275A (ja) | 2009-02-26 |
| JP2009032281A (ja) | 2009-02-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10152320B2 (en) | Method of transferring data between external devices and an array processor | |
| US8468329B2 (en) | Pipeline configuration protocol and configuration unit communication | |
| US8194690B1 (en) | Packet processing in a parallel processing environment | |
| JP3894957B2 (ja) | 大きな網目状接続コストを伴う大容量データを管理するための、2次元または多次元プログラマブルセル構造を有するモジュール並びにdfpに対する内部バスシステム | |
| US6594713B1 (en) | Hub interface unit and application unit interfaces for expanded direct memory access processor | |
| US5524250A (en) | Central processing unit for processing a plurality of threads using dedicated general purpose registers and masque register for providing access to the registers | |
| JP2004536373A (ja) | データ処理方法およびデータ処理装置 | |
| JP4672305B2 (ja) | デジタル・メディア・ストリームを処理するための方法及び装置 | |
| CN100451949C (zh) | 带有共享内容的异构型并行多线程处理器(hpmt) | |
| EP3776231A1 (en) | Arbitrating portions of transactions over virtual channels associated with an interconnect | |
| US20140310466A1 (en) | Multi-processor bus and cache interconnection system | |
| EP0991999A1 (en) | Method and apparatus for arbitrating access to a shared memory by network ports operating at different data rates | |
| US6982976B2 (en) | Datapipe routing bridge | |
| US20020188885A1 (en) | DMA port sharing bandwidth balancing logic | |
| US6694385B1 (en) | Configuration bus reconfigurable/reprogrammable interface for expanded direct memory access processor | |
| US20150033000A1 (en) | Parallel Processing Array of Arithmetic Unit having a Barrier Instruction | |
| US9141390B2 (en) | Method of processing data with an array of data processors according to application ID | |
| US20070299993A1 (en) | Method and Device for Treating and Processing Data | |
| US20090210653A1 (en) | Method and device for treating and processing data | |
| JP2009043276A (ja) | Fifo記憶方法 | |
| US8055809B2 (en) | System and method for distributing signal with efficiency over microprocessor | |
| US7653765B2 (en) | Information communication controller interface apparatus and method | |
| WO2023016910A2 (en) | Interconnecting reconfigurable regions in an field programmable gate array | |
| Heath et al. | Design and performance of a modular hardware process mapper (scheduler) for a real-time token controlled data driven multiprocessor architecture | |
| WO2007092747A2 (en) | Multi-core architecture with hardware messaging |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110121 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110706 |