JP2007122609A - 構造化文書、コンテンツ配信サーバ装置及びコンテンツ配信システム - Google Patents
構造化文書、コンテンツ配信サーバ装置及びコンテンツ配信システム Download PDFInfo
- Publication number
- JP2007122609A JP2007122609A JP2005316897A JP2005316897A JP2007122609A JP 2007122609 A JP2007122609 A JP 2007122609A JP 2005316897 A JP2005316897 A JP 2005316897A JP 2005316897 A JP2005316897 A JP 2005316897A JP 2007122609 A JP2007122609 A JP 2007122609A
- Authority
- JP
- Japan
- Prior art keywords
- document
- content
- external resource
- content distribution
- distribution server
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/10—Office automation; Time management
- G06Q10/107—Computer-aided management of electronic mailing [e-mailing]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
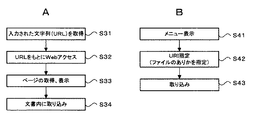
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
Abstract
【解決手段】インターネット100にはWebサーバ1と端末装置2が接続され、この端末装置2に情報蓄積型文書21が設けられる。またインターネット100にはLAN200が接続され、このLAN200に、ファイルサーバ3と端末装置4、5が接続され、これらの端末装置4、5にも情報蓄積型文書41、51が設けられる。このシステムにおいて、文書中のプログラムファイル(外部リース取得プログラム)が、インターネット100上のWebサーバ(サイト)1にアクセスして情報を取得したり、LAN200上のファイルサーバ3からファイルを取得したりして文書内に取り込んでいくものである。この場合に、情報蓄積型文書21、41、51は通常の文書と同様に端末装置2、4、5上で起動され、外部リソースを取得する。
【選択図】図4
Description
インターネット上では日々様々な情報が提供され続けており、ユーザは、自分に有益な情報を提供してくれるサイトをブックマークしたり、RSS(Rich Site Summary)フィードを利用したりして最新の情報を取得できるようにしている。しかしながら、インターネット上の情報は、各個人が非営利で個人の趣味的に提供している場合が多く、突然閉鎖されてしまったり、突然コンテンツの内容が変わってしまったりといったことが少なくない。
企業などではLAN(Local Area Network)が構築されているのが当たり前であり、ファイルサーバなどがいくつかあって、ファイルを共有したりしている。このような環境下において、知らないうちにファイルが追加されていたり、フォルダの階層が深くなっていたりして閲覧が面倒であることもある。また、LAN上においてもWebサーバがあって日々情報が更新されているが、インターネット上と同様に、ある時点でどんな情報が掲載されていたかは後になっては確認することが不可能である。
必要な情報を取得するためにメールマガジンを購読しているユーザも少なくない。個人の好みの情報を定期的に配信してくれるメールマガジンは、いちいちURLを入力してアクティブに情報にアクセスしにいかずに済むため、便利な仕組みではある。
また、近年、テレビ会議などで文書を共有することにより、リモート環境でのコラボレーションの質の向上が図られている。現状での文書の共有の仕方は以下が挙げられる。
(1)フォルダを同期
(2)共有フォルダを利用
(3)文書を画像化して画像を共有
(4)ある地点の文書を映像化し、他の地点に送信
(5)特定フォーマットの文書表示の同期
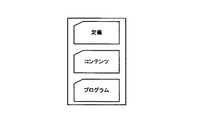
以下の説明では、情報蓄積型文書(カプセル化文書)の実現手段の一つとして、Jar(Java ARchive)ファイルを用いた例を述べる。Jarファイルは、現在広く普及している書庫(ZIP)ファイル形式に基づくファイル形式で、複数のファイルを一つにまとめたプラットフォーム非依存のファイル形式の代表である。そこで、最初に、本発明の前提部分であるカプセル化文書の構造、生成方法などについて述べる。
カプセル化文書(Jar)ファイルの構造は図1に示したとおりである。定義(JarでいうところのMETA−INF)フォルダには、メインプログラム定義ファイル(マニフェストファイル)が格納されており、起動されたときに最初にロードするプログラム情報が記述されている。
<encapsulateddoc>
<programs>
<prog1/>
<prog2/>
<prog3/>
</programs>
<contents>
<page1>
<index.html/>
</page1>
</contents>
</encapsulateddoc>
カプセル化文書(Jar)ファイル自体はZIPと同じ書庫ファイルである。図2に示したものを一つのファイルにパッケージ化する。カプセル化文書ファイルとして必要なメインプログラム定義ファイルの記述例を以下に示す。
Manifest-Version: 1.0
Main-Class: AppMain
Created-By: 1.3.1 (Ricoh Company, LTD.)
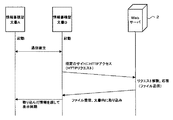
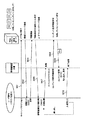
本発明における外部リソース取得プログラムを含むカプセル化(情報蓄積型)文書と外部リソースの位置などを図4に示した。すなわち図4において、インターネット100にはWebサーバ1と端末装置2が接続され、この端末装置2に情報蓄積型文書21が設けられる。またインターネット100にはLAN200が接続され、このLAN200に、ファイルサーバ3と端末装置4、5が接続され、これらの端末装置4、5にも情報蓄積型文書41、51が設けられる。
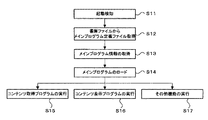
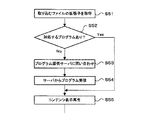
ここでは、図5を参照して外部リソース取得機能を有する文書の起動までの流れを説明する。図5においてステップS11で起動が検知されると、ステップS12でメインプログラム定義ファイルが取得され、ステップS13でメインプログラム情報が取得され、ステップS14でメインプログラムがロードされる。このプログラムはいわばメインルーチン的な役割を果たし、これによりステップS15〜ステップS17で必要な各種プログラムファイルの実行などの指示が行われる。
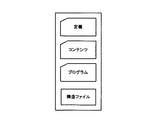
・構造ファイル:プログラムのロード順や、コンテンツの表示順など、文書ファイル内にあるコンテンツやプログラムを管理する。
・メインプログラム定義ファイル(マニフェストファイル):文書を起動する際に最初にロードするプログラム(クラスファイル)の名前が記述されている。
・コンテンツ(最初は無い場合もある):ここでは、プログラムによってロード、表示されるコンテンツを指す。テキスト、画像、動画、音声ファイルその他の各種ファイル。
すなわち、端末装置2、4、5では、ダブルクリックもしくはコマンドラインからの命令(ステップS11)によって、情報蓄積型文書21、41、51のメインプログラム定義ファイルに記述されているプログラムファイルがロード(ステップS14)される。このプログラムはいわばメインルーチン的な役割を果たし、必要な各種プログラムファイルの実行や、構造ファイル(XML)を読み込んで解釈し、必要なプログラムのロード、実行などの指示を行う。
最も単純な例として、情報蓄積型文書がWebにアクセスし情報を取得して表示する例を述べる。ここで必要となるプログラム、つまり文書に最初に格納しておくべきプログラムは、WebサーバにアクセスしてHTMLなどのコンテンツを取得するプログラムと、HTMLなどのコンテンツを表示するためのプログラムである。ここに出てくるWebサーバは通常のインターネット上のサーバである。なおここでは、予めアクセスするWebサーバはプログラム内で指定してあるとするが、ユーザに指定させてももちろん良い。
GET /index.html HTTP/1.0[CR LF(改行)]
のような命令をWebサーバ2に対して送信する(行の末尾は改行コード)。GETコマンドの後には様々な付加情報が続くが、ここでは、触れない。
GET http://webserver/index.html HTTP/1.0[CR LF]
一方、コンテンツを文書内に取り込むためには、ファイル自体を作り直す必要がある。そこで図2に示したコンテンツフォルダ内にコンテンツを配置し、書庫化し直すことによって外部ファイルを取り込むことができる。この際、取得したコンテンツが過去に取得したコンテンツと名前が競合する場合があるので、時間ごとにフォルダを生成したり、ファイル名を振り直したりする必要がある。ここで書庫化しなおすには、以下の点で注意が必要である。
<page2>
<newpage.html/>
</page2>
を加えたりする。このようにして、構造ファイルを更新した上で書庫化を行うことができる。なお、書庫化の方法については先に述べた通りである。
なお上記例は、HTMLを単純に取得しているだけであるが、特定ファイルのみ取得することもできる。ここで画像であれば、HTMLのソースをチェックするとIMGタグで
<IMG SRC="/images/sampl.jpg" HEIGHT="100" WIDTH="100">
のような記述があるので、それを取得することができる。動画ファイルやMP3ファイルなど、他のフォーマットに関しても同様である。
例えばスキャナで取得したデータやデジタルカメラの画像をPC(Personal Computer)に保存する際には通常決まった場所に保存する場合が多い、このフォルダを予め指定しておくことにより、このフォルダを監視し、新しいコンテンツが追加されたらファイルを文書に取り込むことも可能である。
また上記の例では、定期的にWebサーバから情報を取得しているが、場合によっては全く更新がなく、更新があったときのみ取得をする場合や、更新された部分のみを取得したい場合もある。この場合にはRSS(RDF Site SummaryまたはRich Site Summary)を利用する。RSSは、Webサイトの概要をメタデータとして簡潔に記述するXMLフォーマットである。
<?xml version="1.0" encoding="utf-8" ?>
<rdf:RDF
xmlns="http://purl.org/rss/1.0/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xml:lang="ja">
<channel rdf:about="http://machine.ricoh.co.jp/rss.rdf">
<title>Ricohカメラ</title>
<link>http://machine.ricoh.co.jp</link>
<description>Ricoh製のカメラについての情報を提供しています。</description>
<dc:date>2005-09-06T14:21:08+09:00</dc:date>
<items>
<rdf:Seq>
<rdf:lirdf:resource="http://machine.ricoh.co.jp/camera/"/>
<rdf:lirdf:resource="http://machine.ricoh.co.jp/docs/manual.html"/>
</rdf:Seq>
</items>
</channel>
</rdf:RDF>
さらに、単にWebの情報を取得するのではなく、Web上のサービスを利用した結果を文書内に取り込む場合の動作について述べる。ここでは、Google APIの利用に関して述べる。Google APIは、プログラムから検索サービスなどを利用できるように提供されているものであり、以下に示したような処理をプログラミングすれば、プログラムからGoogleの検索サービスを利用することができる。(Proxy関係のセットはProxyを利用する場合にセットする)
s.setProxyHost("proxy server name"); //proxyサーバのセット
s.setProxyPort(port Number); //ポート番号のセット
s.setProxyUserName("name"); //proxyユーザ名のセット
s.setProxyPassword("password"); //proxy パスワードのセット
s.setQueryString(“検索語”); //検索語のセット
GoogleSearchResult r = s.doSearch(); //検索、検索結果の取得
文書間で表示を同期する例はすでにいくつかの従来技術にあるが、コミュニケーション中にコンテンツを追加する例はない。これまで述べてきたように何らかの方法でデータを取り込んだ場合、取り込んだ情報を他文書と同期できるとコミュニケーション上都合がよい。つまり、起動したときに通信を確立し、文書の表示を同期させるような場合に、ある文書がコンテンツを新たに追加しても、円滑にコミュニケーションが継続できるように、他文書に対して取得したコンテンツを提供する必要がある。
起動していない文書がある場合に問題になるのは、文書内のコンテンツの同一性を保持できないことである。例えば図10において、文書Aとは通信確立したものの、文書Bがコンテンツを取得したときには既に文書Aが閉じられていたり、また、文書A、Bで表示の同期を取るようにプログラムされているのにも関わらず、文書Bだけ起動して、単独でコンテンツを追加したときなどである。
例えば文書A、文書Bでほぼ同時に、それぞれ別の何らかのコンテンツを取り込む場合がある。ここでコンテンツを取り込んだ時点では、AとBの両文書に異なるコンテンツが入っていることになる。この状態で文書AとBが同期するとなると、コンテンツの順番などの問題がある。この場合、コンテンツを取り込んだ際の時刻を記録しておき、早いコンテンツの方を順番的に早くする。
ここでは特定メールのアーカイブについて述べる。これは、例えば文書中に特定メールマガジンのメールを蓄積していくことによって、そのメールマガジンを一つのファイルに収めていくのに用いることができる。一つの例として、これまで述べてきたコンテンツを取得するプログラムの変わりに、メールサーバにアクセスし特定サブジェクトのメールのコピーを取得するプログラムを文書に入れる。
これまでの説明は、サーバ側は通常あるWebサーバやメールサーバを指していたが、ここからは「情報蓄積型文書」配信サーバなど、発明に関するサーバの動作、利用について述べる。
文書に何らかのコンテンツを取り込む場合に、先の例では予め文書にそれらのコンテンツを閲覧するためのプログラム(classファイル)を入れておくとしたが、文書を作成した時点では想定していない形式のコンテンツを取り込む場合がある。コンテンツとそれを閲覧するためのプログラムは、コンテンツのファイルの拡張子で関連づけられる。Jpg, gif, pngなどであれば画像ビューワであるし、HtmlであればHTMLビューワであるし、MP3であれば、それに対応した音楽再生プログラムであるといったように、ファイル拡張子から使用するプログラムが決定される。
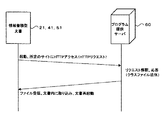
情報蓄積型文書配信サーバは、サーバ上で情報蓄積型文書を作成し、それを端末に配信するものである。ここでは、Webマガジン配信サーバとして説明する。なお、図14は、ユーザのWebブラウザを介しての操作、情報蓄積型文書(Webマガジン)、Webマガジン配信サーバの動作や対応関係を示したものである。この図14を参照して、以下にユーザの操作、文書およびサーバの動作について時系列に述べる。
Claims (18)
- 少なくともプログラム部とコンテンツ部を含む構造化文書であって、
前記プログラム部に設けられるプログラムには、
任意のコンテンツ配信サーバ装置にアクセスして前記コンテンツ配信サーバ装置に用意されたコンテンツを外部リソースとして取り込む機能と、
前記取り込まれた外部リソースを再構成して前記コンテンツ部へ単一の文書として保存する機能と
を有することを特徴とする構造化文書。 - 前記取り込まれる外部リソースは、電子メールのコンテンツ、若しくは指定のURLにおけるコンテンツであることを特徴とする請求項1記載の構造化文書。
- 前記外部リソースを取り込むごとに課金を発生させる機能をさらに有することを特徴とする請求項1記載の構造化文書。
- 前記取り込まれた外部リソースから再構成された文書を外部の文書と同期させる機能をさらに有することを特徴とする請求項1記載の構造化文書。
- 前記プログラム部に設けられるプログラムには識別符号が付加され、前記コンテンツ配信サーバ装置から前記外部リソースを取り込む回数が前記識別符号により制限されることを特徴とする請求項1記載の構造化文書。
- 前記コンテンツ配信サーバ装置に用意されたコンテンツを外部リソースとして取り込む機能は、前記外部リソースに含まれる更新情報を判断して更新が行われたときのみ実行されることを特徴とする請求項1記載の構造化文書。
- 少なくとも外部リソースを取り込む機能と前記取り込まれた外部リソースを再構成して単一の文書として保存する機能とが設けられた構造化文書を保存する手段と、
任意の端末装置からのアクセスに応じて前記構造化文書を送信する手段と、
前記二つの手段とは一体または別体に設けられて、前記端末装置からのアクセスに応じて用意されたコンテンツを前記外部リソースとして送信する手段と
を有することを特徴とするコンテンツ配信サーバ装置。 - 前記送信される外部リソースは、電子メールのコンテンツ、若しくは指定のURLにおけるコンテンツであることを特徴とする請求項7記載のコンテンツ配信サーバ装置。
- 前記外部リソースの送信ごとに前記端末装置に対する課金を発生させる手段をさらに有することを特徴とする請求項7記載のコンテンツ配信サーバ装置。
- 前記保存される構造化文書には、前記取り込まれた外部リソースから再構成された文書を外部の文書と同期させる機能をさらに有することを特徴とする請求項7記載のコンテンツ配信サーバ装置。
- 前記保存される構造化文書の外部リソースを取り込む機能には識別符号が付加され、前記端末装置が前記外部リソースを取り込む回数を前記識別符号により制限することを特徴とする請求項7記載のコンテンツ配信サーバ装置。
- 前記外部リソースには更新情報を含めることを特徴とする請求項7記載のコンテンツ配信サーバ装置。
- 少なくとも外部リソースを取り込む機能及び前記取り込まれた外部リソースを再構成して単一の文書として保存する機能を有する構造化文書が保存されたコンテンツ配信サーバ装置と、端末装置とが情報ネットワークを通じて接続され、
前記コンテンツ配信サーバ装置は、前記端末装置からのアクセスに応じて前記コンテンツ配信サーバ装置に保存された前記構造化文書を送信する手段を有すると共に、
前記端末装置からのアクセスに応じて用意されたコンテンツを前記外部リソースとして送信する手段が、前記コンテンツ配信サーバ装置と一体または別体に設けられる
ことを特徴とするコンテンツ配信システム。 - 前記端末装置からのアクセスに応じて前記コンテンツ配信サーバ装置から送信される外部リソースは、電子メールのコンテンツ、若しくは指定のURLにおけるコンテンツであることを特徴とする請求項13記載のコンテンツ配信システム。
- 前記端末装置からのアクセスに応じて前記コンテンツ配信サーバ装置から前記外部リソースが送信されるごとに前記端末装置に対する課金を発生させる手段がさらに設けられることを特徴とする請求項13記載のコンテンツ配信システム。
- 前記構造化文書には、前記取り込まれた外部リソースから再構成された文書を他の端末装置の文書と同期させる機能をさらに有することを特徴とする請求項13記載のコンテンツ配信システム。
- 前記構造化文書の外部リソースを取り込む機能には識別符号が付加され、前記端末装置が前記コンテンツ配信サーバ装置から前記外部リソースを取り込む回数が前記識別符号により制限されることを特徴とする請求項13記載のコンテンツ配信システム。
- 前記外部リソースには更新情報を含め、前記コンテンツ配信サーバ装置に用意されたコンテンツを外部リソースとして取り込む機能は、前記外部リソースに含まれる更新情報を判断して更新が行われたときのみ実行されることを特徴とする請求項13記載のコンテンツ配信システム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005316897A JP2007122609A (ja) | 2005-10-31 | 2005-10-31 | 構造化文書、コンテンツ配信サーバ装置及びコンテンツ配信システム |
| US11/550,214 US20070106694A1 (en) | 2005-10-31 | 2006-10-17 | Structuralized document, contents delivery server apparatus, and contents delivery system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005316897A JP2007122609A (ja) | 2005-10-31 | 2005-10-31 | 構造化文書、コンテンツ配信サーバ装置及びコンテンツ配信システム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007122609A true JP2007122609A (ja) | 2007-05-17 |
| JP2007122609A5 JP2007122609A5 (ja) | 2008-10-02 |
Family
ID=38005052
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005316897A Pending JP2007122609A (ja) | 2005-10-31 | 2005-10-31 | 構造化文書、コンテンツ配信サーバ装置及びコンテンツ配信システム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20070106694A1 (ja) |
| JP (1) | JP2007122609A (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008047067A (ja) * | 2006-08-21 | 2008-02-28 | Ricoh Co Ltd | カプセル化文書管理装置、カプセル化文書管理方法及びカプセル化文書管理プログラム |
| US8273182B2 (en) * | 2008-07-15 | 2012-09-25 | WLR Enterprises, LLC | Devices and methods for cleaning and drying ice skate blades |
| US20120124175A1 (en) * | 2010-11-17 | 2012-05-17 | Jin Hong Yang | Atom-based really simple syndication (rss) content reader system and method, and atom-based rss content providing system and method |
| US9979774B2 (en) * | 2014-09-23 | 2018-05-22 | Flipboard, Inc. | Debugging and formatting feeds for presentation based on elements and content items |
| US20190180484A1 (en) * | 2017-12-11 | 2019-06-13 | Capital One Services, Llc | Systems and methods for digital content delivery over a network |
| CN109726021A (zh) * | 2018-11-29 | 2019-05-07 | 国云科技股份有限公司 | 一种微服务接口定义类自发现的实现方法 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002183116A (ja) * | 2000-12-18 | 2002-06-28 | Toshiba Corp | 文書合成方法および文書合成装置 |
| WO2005013158A1 (en) * | 2003-07-28 | 2005-02-10 | Limelight Networks, Inc. | Multiple object download |
| JP2005092714A (ja) * | 2003-09-19 | 2005-04-07 | Ricoh Co Ltd | 文書のデータ構造、カプセル化文書生成方法、カプセル化文書生成プログラム、及びカプセル化文書生成装置 |
| WO2005039717A1 (en) * | 2003-10-29 | 2005-05-06 | Matsushita Electric Industrial Co., Ltd. | Game system, game execution apparatus, and portable storage medium |
Family Cites Families (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6633877B1 (en) * | 1991-11-04 | 2003-10-14 | Digeo, Inc. | Method and apparatus for delivery of selected electronic works and for controlling reproduction of the same |
| US5694546A (en) * | 1994-05-31 | 1997-12-02 | Reisman; Richard R. | System for automatic unattended electronic information transport between a server and a client by a vendor provided transport software with a manifest list |
| US5862325A (en) * | 1996-02-29 | 1999-01-19 | Intermind Corporation | Computer-based communication system and method using metadata defining a control structure |
| DE69724947T2 (de) * | 1997-07-31 | 2004-05-19 | Siemens Ag | Rechnersystem und Verfahren zur Sicherung einer Datei |
| US6219788B1 (en) * | 1998-05-14 | 2001-04-17 | International Business Machines Corporation | Watchdog for trusted electronic content distributions |
| EP0993163A1 (en) * | 1998-10-05 | 2000-04-12 | Backweb Technologies Ltd. | Distributed client-based data caching system and method |
| JP3280330B2 (ja) * | 1998-12-16 | 2002-05-13 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 通信方法、クライアント端末、サーバ、通信システム、通信を制御するためのソフトウエア・プロダクトを格納した記録媒体 |
| US6986134B1 (en) * | 1999-03-16 | 2006-01-10 | Sun Microsystems, Inc. | Lightweight global distribution mechanism |
| US6654746B1 (en) * | 1999-05-03 | 2003-11-25 | Symantec Corporation | Methods and apparatuses for single-connection file synchronization workgroup file update |
| GB2361330A (en) * | 2000-04-13 | 2001-10-17 | Int Computers Ltd | Template mechanism for document generation |
| US6854016B1 (en) * | 2000-06-19 | 2005-02-08 | International Business Machines Corporation | System and method for a web based trust model governing delivery of services and programs |
| US6574617B1 (en) * | 2000-06-19 | 2003-06-03 | International Business Machines Corporation | System and method for selective replication of databases within a workflow, enterprise, and mail-enabled web application server and platform |
| WO2002003189A1 (en) * | 2000-06-30 | 2002-01-10 | Zinio Systems, Inc. | System and method for encrypting, distributing and viewing electronic documents |
| US7343324B2 (en) * | 2000-11-03 | 2008-03-11 | Contentguard Holdings Inc. | Method, system, and computer readable medium for automatically publishing content |
| AR027901A1 (es) * | 2000-12-13 | 2003-04-16 | Krolovetzky Miguel Horacio | Metodo para la transmision y sincronizacion de datos multimedia sobre redes de computadoras |
| US7036072B1 (en) * | 2001-12-18 | 2006-04-25 | Jgr Acquisition, Inc. | Method and apparatus for declarative updating of self-describing, structured documents |
| US7353252B1 (en) * | 2001-05-16 | 2008-04-01 | Sigma Design | System for electronic file collaboration among multiple users using peer-to-peer network topology |
| US20030014441A1 (en) * | 2001-06-29 | 2003-01-16 | Akira Suzuki | Document data structure, information recording medium, information processing apparatus, information processing system and information processing method |
| US7496841B2 (en) * | 2001-12-17 | 2009-02-24 | Workshare Technology, Ltd. | Method and system for document collaboration |
| JP2003208343A (ja) * | 2002-01-10 | 2003-07-25 | Ricoh Co Ltd | ファイル作成・閲覧方法、ファイル作成方法、ファイル閲覧方法、ファイル構造及びプログラム |
| JP3920675B2 (ja) * | 2002-03-22 | 2007-05-30 | 株式会社リコー | データ通信方法、コンピュータ、プログラム及び記憶媒体 |
| US7346668B2 (en) * | 2002-05-17 | 2008-03-18 | Sap Aktiengesellschaft | Dynamic presentation of personalized content |
| US7320010B2 (en) * | 2002-11-18 | 2008-01-15 | Innopath Software, Inc. | Controlling updates of electronic files |
| US20040194027A1 (en) * | 2002-12-27 | 2004-09-30 | Akira Suzuki | Computerized electronic document producing, editing and accessing system for maintaining high-security |
| US7389336B2 (en) * | 2003-01-24 | 2008-06-17 | Microsoft Corporation | Pacing network packet transmission using at least partially uncorrelated network events |
| US7849401B2 (en) * | 2003-05-16 | 2010-12-07 | Justsystems Canada Inc. | Method and system for enabling collaborative authoring of hierarchical documents with locking |
| US7810028B2 (en) * | 2003-12-23 | 2010-10-05 | Xerox Corporation | Method and system for copying, moving, replacing and deleting content in group-editable electronic documents |
| JP2005267021A (ja) * | 2004-03-17 | 2005-09-29 | Ricoh Co Ltd | 文書作成方法、文書作成装置、プログラム、記憶媒体および文書のデータ構造 |
| US7818679B2 (en) * | 2004-04-20 | 2010-10-19 | Microsoft Corporation | Method, system, and apparatus for enabling near real time collaboration on an electronic document through a plurality of computer systems |
| JP2006018430A (ja) * | 2004-06-30 | 2006-01-19 | Ricoh Co Ltd | 情報処理装置、ネットワークシステム、プログラム、データ構造及び記憶媒体 |
| JP2006059319A (ja) * | 2004-07-21 | 2006-03-02 | Ricoh Co Ltd | 情報処理装置、プログラムおよび記憶媒体 |
| US20060026502A1 (en) * | 2004-07-28 | 2006-02-02 | Koushik Dutta | Document collaboration system |
| US7593943B2 (en) * | 2005-01-14 | 2009-09-22 | Microsoft Corporation | Method and system for synchronizing multiple user revisions to a shared object |
| US20060230349A1 (en) * | 2005-04-06 | 2006-10-12 | Microsoft Corporation | Coalesced per-file device synchronization status |
| US7512943B2 (en) * | 2005-08-30 | 2009-03-31 | Microsoft Corporation | Distributed caching of files in a network |
-
2005
- 2005-10-31 JP JP2005316897A patent/JP2007122609A/ja active Pending
-
2006
- 2006-10-17 US US11/550,214 patent/US20070106694A1/en not_active Abandoned
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002183116A (ja) * | 2000-12-18 | 2002-06-28 | Toshiba Corp | 文書合成方法および文書合成装置 |
| WO2005013158A1 (en) * | 2003-07-28 | 2005-02-10 | Limelight Networks, Inc. | Multiple object download |
| JP2007525738A (ja) * | 2003-07-28 | 2007-09-06 | ライムライト・ネットワークス・インク | 複数オブジェクトのダウンロード |
| JP2005092714A (ja) * | 2003-09-19 | 2005-04-07 | Ricoh Co Ltd | 文書のデータ構造、カプセル化文書生成方法、カプセル化文書生成プログラム、及びカプセル化文書生成装置 |
| WO2005039717A1 (en) * | 2003-10-29 | 2005-05-06 | Matsushita Electric Industrial Co., Ltd. | Game system, game execution apparatus, and portable storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| US20070106694A1 (en) | 2007-05-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8533199B2 (en) | Intelligent bookmarks and information management system based on the same | |
| US11741057B2 (en) | Unified data object management system and the method | |
| US7899829B1 (en) | Intelligent bookmarks and information management system based on same | |
| JP3719825B2 (ja) | 情報処理装置及び情報処理方法 | |
| US7315848B2 (en) | Web snippets capture, storage and retrieval system and method | |
| US9594759B2 (en) | Backup and archival of selected items as a composite object | |
| JP4812747B2 (ja) | 情報を取り込み抽出する方法及びシステム | |
| JP6482602B2 (ja) | 予測ストレージサービス | |
| US8533238B2 (en) | Sharing information about a document across a private computer network | |
| US7617190B2 (en) | Data feeds for management systems | |
| US7912933B2 (en) | Tags for management systems | |
| US7945535B2 (en) | Automatic publishing of digital content | |
| US20140173417A1 (en) | Method and Apparatus for Archiving and Displaying historical Web Contents | |
| US20080032739A1 (en) | Management of digital media using portable wireless devices in a client-server network | |
| US20090240698A1 (en) | Computing environment platform | |
| US8615477B2 (en) | Monitoring relationships between digital items on a computing apparatus | |
| MX2008011058A (es) | Objeto de procesamiento de datos de sindicacion realmente simple (rss). | |
| US20020133628A1 (en) | Data caching and annotation system with application to document annotation | |
| JP2007122609A (ja) | 構造化文書、コンテンツ配信サーバ装置及びコンテンツ配信システム | |
| US7657585B2 (en) | Automated process for identifying and delivering domain specific unstructured content for advanced business analysis | |
| JP2009075908A (ja) | ウェブ・ページ閲覧履歴管理システム及びウェブ・ページ閲覧履歴管理方法、並びにコンピュータ・プログラム | |
| US11023418B2 (en) | Keyword-based data management system and method | |
| AU2002246646B2 (en) | Web snippets capture, storage and retrieval system and method | |
| US20070288549A1 (en) | Information Processing System, Server Device, Client Device, and Program | |
| AU2002246646A1 (en) | Web snippets capture, storage and retrieval system and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080818 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080818 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20100302 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20100311 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20101014 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101026 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101221 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110208 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110705 |