JP2006106972A - 画像処理方法及び画像処理装置 - Google Patents
画像処理方法及び画像処理装置 Download PDFInfo
- Publication number
- JP2006106972A JP2006106972A JP2004290386A JP2004290386A JP2006106972A JP 2006106972 A JP2006106972 A JP 2006106972A JP 2004290386 A JP2004290386 A JP 2004290386A JP 2004290386 A JP2004290386 A JP 2004290386A JP 2006106972 A JP2006106972 A JP 2006106972A
- Authority
- JP
- Japan
- Prior art keywords
- cell
- table frame
- area
- document
- character information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Landscapes
- Character Discrimination (AREA)
Abstract
【解決手段】 原稿上の表領域における表枠の2値データを抽出し、表枠の2値データに基づいて表枠の表構成を認識し、その表枠の中より文字情報を抽出し、表枠を再処理する際に、表枠の表構成の認識結果に応じて文字情報を抽出する領域を選択し、該選択位置における文字情報を再抽出し、その表枠を再処理する。
【選択図】 図7
Description
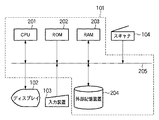
2値化処理302では、入力された文書画像データより輝度情報を抽出し、その輝度値のヒストグラムを作成する。ヒストグラム上より複数の閾値を設定し、各々の閾値で2値化された2値画像上の黒画素の連結等を解析することで最適な閾値を導出し、その閾値による2値画像を得る。
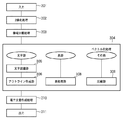
像域分離処理303とは、図4に示す左側の読み取られた1ページのイメージデータをオブジェクト毎の塊(ブロック)として認識し、各々の塊を文字/図画/写真/線/表等の属性に判定し、図4に示す右側のように、異なる属性(TEXT/PICTURE/PHOTE/LINE/TABLE)を持つ領域に分割する処理である。
文字認識部305では、文字単位で切り出された画像に対して、パターンマッチングの一手法を用いて認識を行い、対応する文字コードを得る。この認識処理は、文字画像から得られる特徴を数十次元の数値列に変換した観測特徴ベクトルと、予め字種毎に求められている辞書特徴ベクトルとを比較し、最も距離の近い字種を認識結果とする処理である。この特徴ベクトルの抽出には種々の公知手法があり、例えば文字をメッシュ状に分割し、各メッシュ内の文字線を方向別に線素としてカウントしたメッシュ数次元ベクトルを特徴とする方法がある。
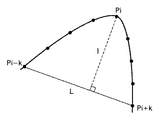
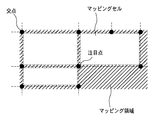
アウトライン作成部306では、像域分離処理303で図画或いは線、表領域とされた領域を対象に、抽出された画素塊の輪郭をベクトルデータに変換する。具体的には、輪郭をなす画素の点列を角と看倣される点で区切って、各区間を部分的な直線或いは曲線で近似する。角とは曲率が極大となる点であり、曲率が極大となる点は、図6に示すように、任意点Piに対して左右k個の離れた点Pi−k,Pi+kの間に弦を引いたとき、この弦とPiの距離が極大となる点として求められる。更に、点Pi−k,Pi+k間の弦の長さ/弧の長さをRとし、Rの値が閾値以下である点を角とみなすことができる。角によって分割された後の各区間は、直線は点列に対する最小二乗法など、曲線は3次スプライン関数などを用いてベクトル化することができる。
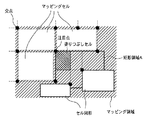
表処理部308では、表中のセル及びその構成を認識し、表枠を罫線により表現する等、セル毎に編集可能な電子データへ変換する。尚、表部は、像域分離処理303により、表枠として表枠中の文字部と分離して抽出されている。
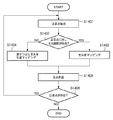
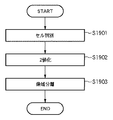
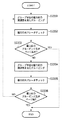
図7に示すステップS703では、表構成認識処理(ステップS702)で抽出された色塗りセルについて再処理を行う。
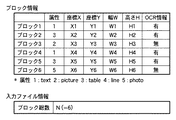
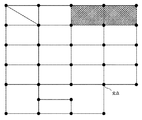
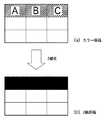
図7に示すステップS704では、ステップS702、S703で作成されたベクトル情報を使用し、表データを作成する。例えば、図18に示す表は図24に示すようになる。図24において、2401〜2403の部位からは、テキスト情報が抽出されている。また、もしテキスト情報がないセルについては、そのまま色塗りセルのままで良いとする。
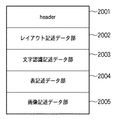
以上の通り、1頁分のイメージデータを像域分離処理303し、ベクトル化処理304した結果は図20に示すような中間データ形式のファイルとして変換される。このようなデータ形式は、ドキュメント・アナリシス・アウトプット・フォーマット(DAOF)と呼ばれる。
Claims (8)
- 原稿上の表領域における表枠の2値データを抽出する工程と、
前記表枠の2値データに基づいて表枠の表構成を認識する工程と、
前記表枠の中より文字情報を抽出し、表枠を再処理する工程とを有し、
前記表枠の表構成の認識結果に応じて文字情報を抽出する領域を選択し、該選択位置における文字情報を再抽出し、前記表枠を再処理することを特徴とする画像処理方法。 - 前記表構成の認識結果は、矩形図形の集合として表を表現し、前記文字情報を抽出する領域は該矩形図形単位で選択されることを特徴とする請求項1記載の画像処理方法。
- 前記再処理は、少なくとも2値化処理か像域分離処理の何れかであることを特徴とする請求項1記載の画像処理方法。
- 前記再処理された表枠を表現するベクトルデータを生成する工程を有することを特徴とする請求項1記載の画像処理方法。
- 原稿上の表領域における表枠の2値データを抽出する抽出手段と、
前記表枠の2値データに基づいて表枠の表構成を認識する認識手段と、
前記表枠の中より文字情報を抽出し、表枠を再処理する再処理手段とを有し、
前記表枠の表構成の認識結果に応じて文字情報を抽出する領域を選択し、該選択位置における文字情報を再抽出し、前記表枠を再処理することを特徴とする画像処理装置。 - 前記再処理手段は、前記表枠でないと想定される領域について、テキスト情報が入っていないと判定した場合は再処理しないことを特徴とする請求項5記載の画像処理装置。
- 請求項1記載の画像処理方法をコンピュータに実行させるためのプログラム。
- 請求項7記載のプログラムを記録したコンピュータ読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004290386A JP4587167B2 (ja) | 2004-10-01 | 2004-10-01 | 画像処理装置及び画像処理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004290386A JP4587167B2 (ja) | 2004-10-01 | 2004-10-01 | 画像処理装置及び画像処理方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2006106972A true JP2006106972A (ja) | 2006-04-20 |
| JP2006106972A5 JP2006106972A5 (ja) | 2007-11-15 |
| JP4587167B2 JP4587167B2 (ja) | 2010-11-24 |
Family
ID=36376667
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004290386A Expired - Fee Related JP4587167B2 (ja) | 2004-10-01 | 2004-10-01 | 画像処理装置及び画像処理方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4587167B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007305034A (ja) * | 2006-05-15 | 2007-11-22 | Canon Inc | 画像処理装置、その制御方法、コンピュータプログラム |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001297303A (ja) * | 2000-02-09 | 2001-10-26 | Ricoh Co Ltd | 文書画像認識方法、装置及びコンピュータ読み取り可能な記録媒体 |
| JP2004127203A (ja) * | 2002-07-30 | 2004-04-22 | Ricoh Co Ltd | 画像処理装置、画像処理方法、及びその方法をコンピュータに実行させるプログラム、並びにそのプログラムを記録したコンピュータ読み取り可能な記録媒体 |
-
2004
- 2004-10-01 JP JP2004290386A patent/JP4587167B2/ja not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001297303A (ja) * | 2000-02-09 | 2001-10-26 | Ricoh Co Ltd | 文書画像認識方法、装置及びコンピュータ読み取り可能な記録媒体 |
| JP2004127203A (ja) * | 2002-07-30 | 2004-04-22 | Ricoh Co Ltd | 画像処理装置、画像処理方法、及びその方法をコンピュータに実行させるプログラム、並びにそのプログラムを記録したコンピュータ読み取り可能な記録媒体 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007305034A (ja) * | 2006-05-15 | 2007-11-22 | Canon Inc | 画像処理装置、その制御方法、コンピュータプログラム |
| US8300946B2 (en) | 2006-05-15 | 2012-10-30 | Canon Kabushiki Kaisha | Image processing apparatus, image processing method, and computer program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4587167B2 (ja) | 2010-11-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7386789B2 (en) | Method for determining logical components of a document | |
| JP5361574B2 (ja) | 画像処理装置、画像処理方法、及びプログラム | |
| JP5302768B2 (ja) | 画像処理装置及び画像処理方法 | |
| JP4366011B2 (ja) | 文書処理装置及び方法 | |
| US6532302B2 (en) | Multiple size reductions for image segmentation | |
| CN105528614B (zh) | 一种漫画图像版面的识别方法和自动识别系统 | |
| US20070230810A1 (en) | Image-processing apparatus, image-processing method, and computer program used therewith | |
| JP4646797B2 (ja) | 画像処理装置及びその制御方法、プログラム | |
| US8965125B2 (en) | Image processing device, method and storage medium for storing and displaying an electronic document | |
| US20120250048A1 (en) | Image processing apparatus and image processing method | |
| US20090274369A1 (en) | Image processing device, image processing method, program, and storage medium | |
| EP1017011A2 (en) | Block selection of table features | |
| CN100568263C (zh) | 布局分析设备和布局分析方法 | |
| JP4371911B2 (ja) | 関数化処理方法及び関数化処理装置 | |
| JP2008176521A (ja) | パターン分離抽出プログラム、パターン分離抽出装置及びパターン分離抽出方法 | |
| JP5049922B2 (ja) | 画像処理装置及び画像処理方法 | |
| JP2000132689A (ja) | カラ―画像の特徴を識別するための方法 | |
| US8181108B2 (en) | Device for editing metadata of divided object | |
| JP5824309B2 (ja) | 画像処理装置、画像処理方法、およびプログラム | |
| JP2006253892A (ja) | 画像処理方法及び画像処理装置 | |
| JP4587167B2 (ja) | 画像処理装置及び画像処理方法 | |
| US20090290797A1 (en) | Image processing for storing objects separated from an image in a storage device | |
| JP5159588B2 (ja) | 画像処理装置、画像処理方法、コンピュータプログラム | |
| JP5767549B2 (ja) | 画像処理装置、画像処理方法、およびプログラム | |
| JP2003046746A (ja) | 画像処理方法及び画像処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071001 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071001 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20071001 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100528 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100726 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100827 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100906 Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100831 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130917 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130917 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130917 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130917 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |