EP0782128B1 - Procédé d'analyse par prédiction linéaire d'un signal audiofréquence, et procédés de codage et de décodage d'un signal audiofréquence en comportant application - Google Patents
Procédé d'analyse par prédiction linéaire d'un signal audiofréquence, et procédés de codage et de décodage d'un signal audiofréquence en comportant application Download PDFInfo
- Publication number
- EP0782128B1 EP0782128B1 EP96402715A EP96402715A EP0782128B1 EP 0782128 B1 EP0782128 B1 EP 0782128B1 EP 96402715 A EP96402715 A EP 96402715A EP 96402715 A EP96402715 A EP 96402715A EP 0782128 B1 EP0782128 B1 EP 0782128B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- signal
- stage
- transfer function
- coefficients
- parameters
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 238000000034 method Methods 0.000 title claims description 74
- 238000004458 analytical method Methods 0.000 claims description 88
- 230000005284 excitation Effects 0.000 claims description 87
- 230000015572 biosynthetic process Effects 0.000 claims description 86
- 238000003786 synthesis reaction Methods 0.000 claims description 86
- 238000012546 transfer Methods 0.000 claims description 79
- 230000008569 process Effects 0.000 claims description 35
- 230000003595 spectral effect Effects 0.000 claims description 29
- 238000013139 quantization Methods 0.000 claims description 24
- 238000001914 filtration Methods 0.000 claims description 20
- 238000001228 spectrum Methods 0.000 claims description 20
- 238000004519 manufacturing process Methods 0.000 claims description 9
- 230000001419 dependent effect Effects 0.000 claims description 3
- 230000006870 function Effects 0.000 description 53
- 241000897276 Termes Species 0.000 description 27
- 238000011002 quantification Methods 0.000 description 14
- 230000005236 sound signal Effects 0.000 description 11
- 235000021183 entrée Nutrition 0.000 description 9
- 230000004044 response Effects 0.000 description 9
- 241000135309 Processus Species 0.000 description 8
- 230000006978 adaptation Effects 0.000 description 8
- 238000010586 diagram Methods 0.000 description 7
- 230000007774 longterm Effects 0.000 description 7
- 238000012545 processing Methods 0.000 description 6
- 230000001934 delay Effects 0.000 description 4
- 230000003044 adaptive effect Effects 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 230000000873 masking effect Effects 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 238000007493 shaping process Methods 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
Definitions
- the present invention relates to a method of analysis by linear prediction of an audio signal.
- This process finds a particular, but not exclusive, application in prediction audio coders, especially in coders with analysis by synthesis, the most common type of which is the coder CELP ("Code-Excited Linear Prediction").
- Predictive coding techniques with analysis by synthesis are currently widely used for coding the speech in the telephone band (300-3400 Hz) at rates that can down to 8 kbit / s, while maintaining quality telephone.
- the transform coding techniques are used for voice signal broadcasting and storage applications and musical.
- these techniques involve delays in relatively large coding (larger than 100 ms), which produces in particular difficulties in participating in group communications where interactivity is very important.
- Predictive techniques delay lower, essentially depending on the length of the frames linear prediction analysis (typically 10 to 20 ms), and therefore find applications even for coding voice and / or music signals having bandwidth greater than the telephone band.
- the predictive coders used for bit rate compression perform modeling of the spectral envelope of the signal. This modeling results from an analysis by linear prediction of order M (M-10 typically in narrow band), consisting in determining M coefficients a i of linear prediction of the input signal. These coefficients characterize a synthesis filter used at the decoder, whose transfer function is of the form 1 / A (z) with
- Linear prediction analysis has a domain of broader application than that of coding the speech.
- the order M of the prediction is one of the variables that predictive analysis linear aims to obtain, this variable being influenced by the number of peaks present in the spectrum of the signal analyzed (see US-A-5,142,581).
- the filter calculated by the linear prediction analysis can have various structures, leading to different choices of parameters for the representation of the coefficients (the coefficients a i themselves, the parameters LAR, LSF, LSP, the reflection coefficients or PARCOR. ..).
- DSP digital signal processors
- it was common to use recursive structures for the calculated filter for example structures using PARCOR coefficients of the type described in the article by F. ITAKURA and S. SAITO "Digital Filtering Techniques for Speech Analysis and Synthesis", Proc. of the 7th International Congress on Acoustics, Budapest 1971, pages 261-264 (see FR-A-2 284 946 or US-A-3 975 587).
- the coefficients a i are also used to construct a perceptual weighting filter used by the coder to determine the excitation signal to be applied to the short-term synthesis filter to obtain a synthetic signal representative of the signal of speech.
- This perceptual weighting accentuates the portions of the spectrum where the coding errors are the most perceptible, that is to say the interformant areas.
- the linear prediction coefficients a i are also used to define a post-filter used to attenuate the frequency zones between the formants and the harmonics of the speech signal, without modifying the slope of the spectrum of the signal.
- G P is a gain factor compensating for the attenuation of the filters
- ⁇ 1 and ⁇ 2 are coefficients such that 0 ⁇ 1 ⁇ 2 ⁇ 1, ⁇ is a positive constant
- r 1 denotes the first dependent reflection coefficient coefficients a i .
- Modeling the spectral envelope of the signal by the coefficients a i therefore constitutes an essential element of the coding and decoding process, in the sense that it must represent the spectral content of the signal to be reconstructed at the decoder and that it also controls masking quantization noise as well as post-filtering at the decoder.
- linear prediction analysis usually practiced fails to faithfully model the envelope of the spectrum. Often the speech signals are noticeably more energetic at low frequencies than at frequencies so that the linear prediction analysis certainly leads to precise bass modeling frequencies but at the expense of spectrum modeling at higher frequencies. This drawback becomes particularly troublesome in the case of wideband coding.
- US Patent 5,142,581 describes a filter for multistage linear prediction, in which the order prediction used in each stage is a variable parameter.
- An object of the present invention is to improve the modeling of the spectrum of an audiofrequency signal in a system using a prediction analysis method linear. Another goal is to make the performance of a such more homogeneous system for different input signals (speech, music, sinusoids, DTMF signals %), different bandwidths (telephone band, band enlarged, hifi band %), different recording conditions (directive microphone, acoustic antenna %) and filtering.
- the invention thus proposes a method of analysis by linear prediction of order M of an audiofrequency signal, to determine spectral parameters dependent on a short-term spectrum of the audiofrequency signal, divided into q successive prediction stages, q being an integer greater than 1.
- parameters are determined representing a predefined number Mp of coefficients a 1 P , ..., a Mp p of linear prediction of an input signal from said stage , the audio signal analyzed constituting the input signal of the first stage, and the input signal of a stage p + 1 being constituted by the input signal of stage p filtered by a transfer function filter the prediction order M being such that
- the number Mp of linear prediction coefficients can notably increase from one floor to the next. So the first floor will be able to fairly accurately reflect the general slope of the spectrum or signal, while the stages following will refine the representation of the signal formants. This avoids, in the case of high dynamic signals, too much focus on the most energetic areas at risk poor modeling of other frequency zones which may be perceptually important.
- the transfer function A (z) thus obtained can also be used to define according to formula (2) the transfer function of the perceptual weighting filter when the coder is a coder for analysis by synthesis with closed loop determination of the signal of excitation.
- Another interesting possibility is to adopt coefficients of spectral expansion ⁇ 1 and ⁇ 2 which can vary from one stage to the next, that is to say to give the perceptual weighting filter a function of transfer of the form.
- ⁇ 1 p , ⁇ 2 p denote pairs of spectral expansion coefficients such that 0 ⁇ 2 p ⁇ 1 p ⁇ 1 for 1 ⁇ p ⁇ q.
- This transfer function A (z) can also be used to define a post-filter whose transfer function comprises, as in formula (3) above, a term of the form A (z / ⁇ 1 ) / A (z / ⁇ 2 ), where ⁇ 1 and ⁇ 2 denote coefficients such as 0 ⁇ 1 ⁇ 2 ⁇ 1.
- stepwise linear prediction analysis method multiple proposed according to the invention has many other applications in audio signal processing, for example example in transform predictive coders, in speech recognition systems in systems speech enhancement ...
- the audiofrequency signal to be analyzed in the method illustrated in FIG. 1 is denoted s 0 (n). It is assumed to be available in the form of digital samples, the integer n denoting the successive sampling instants.
- the linear prediction analysis method comprises q successive stages 5 1 , ..., 5 p , ..., 5 q . At each prediction stage 5 p (1 p p q q), a linear order Mp prediction of an input signal s p-1 (n) is carried out.
- the input signal of the first stage 5 1 is constituted by the audio frequency signal to be analyzed s 0 (n), while the input signal of a stage 5 p + 1 (1 ⁇ p ⁇ q) is constituted by the signal s p (n), obtained in a step denoted 6 p by applying to the input signal s p-1 (n) of the p-th stage 5 p a filtering by means of a transfer function filter where the coefficients a i p (1 ⁇ i ⁇ Mp) are the linear prediction coefficients obtained on stage 5 p .
- the quantity E (Mp) is the energy of the residual prediction error of stage p.
- the quantification can relate to the normalized frequencies ⁇ i p or to their cosines.
- the analysis can be performed at each 5 p prediction stage according to the classic Levinson-Durbin algorithm mentioned above.
- Other algorithms providing the same results, developed more recently, can be used advantageously, in particular the exploded Levinson algorithm (see “A new Efficient Algorithm to Compute the LSP Parameters for Speech Coding", by S. Saoudi, JM Boucher and A. Le Guyader, Signal Processing, Vol.28, 1992, pages 201-212), or the use of Chebyshev polynomials (see “The Computation of Line Spectrum Frequencies Using Chebyshev Polynomials, by P. Kabal and RP Ramachandran, IEEE Trans. On Acoustics, Speech, and Signal Processing, Vol. ASSP-34, n ° 6, pages 1419-1426, December 1986).
- the orders Mp of the linear predictions carried out preferably increase from one stage to the following: M1 ⁇ M2 ⁇ ... ⁇ Mq.
- M1 2 for example
- M1 2 for example
- the signal sampling frequency Fe was 16 kHz.
- the signal spectrum (modulus of its Fourier transform) is represented by curve I. This spectrum is representative of audio frequency signals which have, on average, more energy at low frequencies than at high frequencies. The spectral dynamics are sometimes higher than that of Figure 2 (60 dB).
- Curves (II) and (III) correspond to the modeled spectral envelopes
- the invention is described below in its application to a CELP type speech coder.
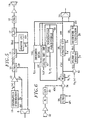
- FIG. 3 The speech synthesis process implemented in a CELP coder and decoder is illustrated in FIG. 3.
- An excitation generator 10 delivers an excitation code c k belonging to a predetermined repertoire in response to an index k.
- An amplifier 12 multiplies this excitation code by an excitation gain ⁇ , and the resulting signal is subjected to a long-term synthesis filter 14.
- the output signal u of the filter 14 is in turn subjected to a short-term synthesis filter 16, the output of which constitutes what is considered here as the synthetic speech signal.
- This synthetic signal is applied to a post-filter 17 intended to improve the subjective quality of the reconstructed speech.
- Post-filtering techniques are well known in the field of speech coding (see JH Chen and A.
- the coefficients of the post-filter 17 are obtained from the LPC parameters characterizing the short-term synthesis filter 16. It will be understood that, as in certain current CELP decoders, the post-filter 17 could also include a long-term post-filtering component.
- the aforementioned signals are digital signals represented for example by words of 16 bits at a sampling rate Fe equal for example to 16 kHz for an encoder in wide band (50-7000 Hz).
- the synthesis filters 14, 16 are generally purely recursive filters.
- the delay T and the gain G constitute long-term prediction parameters (LTP) which are determined adaptively by the coder.
- the LPC parameters defining the short-term synthesis filter 16 are determined at the coder by a method of analysis by linear prediction of the speech signal.
- the transfer function of the filter 16 is generally of the form 1 / A (z) with A (z) of the form (1).
- the present invention proposes to adopt a similar form of the transfer function, in which A (z) is broken down according to (7) as indicated above.
- excitation signal designates here the signal u (n) applied to the short-term synthesis filter 14.
- This excitation signal comprises an LTP Gu (nT) component and a residual component, or innovation sequence, ⁇ c k (n).
- the parameters characterizing the residual component and, optionally, the LTP component are evaluated in a closed loop, using a perceptual weighting filter.
- FIG 4 shows the diagram of a CELP coder.
- the speech signal s (n) is a digital signal, for example supplied by an analog-to-digital converter 20 processing the amplified and filtered output signal from a microphone 22.
- LPC, LTP and EXC parameters index k and gain excitation ⁇
- LPC, LTP and EXC parameters index k and gain excitation ⁇
- These parameters are then quantified in a known manner for transmission efficient digital and then subjected to a multiplexer 30 which forms the encoder output signal.
- These parameters are also supplied to a module 32 for calculating initial states some encoder filters.
- This module 32 essentially comprises a decoding chain such as that shown in FIG. 3. Like the decoder, the module 32 operates on the basis of quantified LPC, LTP and EXC parameters. If one interpolation of LPC parameters is performed at the decoder, as is common, the same interpolation is performed by the module 32.
- the module 32 makes it possible to know at the level of the coder the previous states of the synthesis filters 14, 16 of the decoder, determined according to the synthesis parameters and excitation prior to the sub-frame considered.
- the next step in coding is determining LTP long term prediction parameters. These are for example determined once per L subframe samples.
- the signal outlet of the subtractor 34 is subjected to a filter 38 of perceptual weighting whose role is to accentuate portions of the spectrum where errors are most noticeable, that is to say the inter-forming zones.
- the respective coefficients b i and c i (1 i i M M) of the functions AN (z) and AP (z) are calculated for each frame by a module 39 for evaluating the perceptual weighting which supplies them to the filter 38.
- AN (z) A (z / ⁇ 1 )
- AP (z) A (z / ⁇ 2 ) with 0 ⁇ 2 ⁇ 1 ⁇ 1, which comes back to the usual form (2 ) with A (z) of the form (7).
- the invention however allows, with a very low computational overload, to have greater flexibility as regards the shaping of the quantization noise, by adopting the form (6) for W (z), that is:
- the closed loop LTP analysis performed by the module 26 consists, in a conventional manner, in selecting for each subframe the delay T which maximizes the normalized correlation: where x '(n) denotes the output signal of the filter 38 during the sub-frame considered, and y T (n) denotes the convolution product u (nT) * h' (n).
- h '(0), h' (1) ..., h '(L-1) denotes the impulse response of the weighted synthesis filter, with transfer function W (z) / A (z).
- This impulse response h ′ is obtained by a module 40 for calculating impulse responses, as a function of the coefficients b i and c i provided by the module 39 and of the LPC parameters which have been determined for the sub-frame, if appropriate after quantification. and interpolation.
- the samples u (nT) are the previous states of the long-term synthesis filter 14, provided by the module 32.
- the missing samples u (nT) are obtained by interpolation on the basis of previous samples, or from the speech signal.
- the delays T, whole or fractional, are selected in a specific window.
- the signal Gy T (n) which has been calculated by the module 26 for the optimal delay T, is first subtracted from the signal x '(n) by the subtractor 42.
- the resulting signal x (n) is subjected to a reverse filter 44 which provides a signal D (n) given by: where h (0), h (1), ..., h (L-1) designates the impulse response of the filter composed of the synthesis filters and the perceptual weighting filter, calculated by the module 40.
- the compound filter has the transfer function W (z) / [A (z) .B (z)].
- the vector D constitutes a target vector for the module 28 for searching for the excitation.
- the CELP decoder includes a demultiplexer 8 receiving the bit stream from the coder.
- the quantized values of the excitation parameters EXC and LTP and LPC synthesis parameters are provided to the generator 10, amplifier 12 and filters 14, 16 to reconstruct the synthetic signal s and, which is subjected to post-filter 17 then converted to analog by the converter 18 before being amplified and then applied to a loudspeaker 19 to restore the original speech.
- the LPC parameters are for example constituted by quantization indexes of the reflection coefficients r i p (also called partial correlation coefficients or PARCOR) relating to the different linear prediction stages.
- a module 15 recovers the quantized values of the r i p from the quantization indexes, and converts them to provide the q sets of linear prediction coefficients. This conversion is for example carried out by the same recursive method as in the Levinson-Durbin algorithm.
- the sets of coefficients a i p are supplied to the short-term synthesis filter 16 constituted by a succession of q filters / stages of transfer functions 1 / A 1 (z), ..., 1 / A q (z) given by relation (4).
- the filter 16 could also be in a single stage of transfer function 1 / A (z) given by the relation (1) in which the coefficients a i have been calculated according to the relations (9) to (13).
- the reflection coefficient r 1 can be that associated with the coefficients a i of the composite synthesis filter, which it is then necessary to calculate.
- the invention makes it possible to adopt coefficients ⁇ 1 and ⁇ 2 different from one stage to the next (formula (8)), namely:
- the invention has been described above in its application to a predictive coder with forward adaptation, that is to say in which the audio signal subject to linear prediction analysis is the input signal of the coder.
- the invention also applies to predictive coders / decoders with backward adaptation, in which synthetic signal is subject to prediction analysis linear to the coder and the decoder (see J.H. Chen et al: "A Low-Delay CELP Coder for the CCITT 16 kbit / s Speech Coding Standard ", IEEE J.SAC, Vol.10, n ° 5, pages 830-848, June 1992).
- Figures 5 and 6 respectively show a decoder CELP and a "backward" adaptation CELP coder implements the present invention. Numerical references identical to those of FIGS. 3 and 4 were used to designate similar elements.
- the "backward" adaptation decoder receives only the quantization values of the parameters defining the excitation signal u (n) to apply to the synthesis filter in the short term 16.
- these parameters are the index k and the associated gain ⁇ as well as the parameters LTP.
- the synthetic signal s and (n) is processed by a module 124 analysis by linear multistage prediction identical to module 24 of FIG. 3.
- Module 124 provides the LPC parameters at filter 16 for one or more frames following of the excitation signal, and to the post-filter 17 of which the coefficients are obtained as described above.
- the corresponding encoder performs multi-stage linear prediction analysis on the synthetic signal generated locally and not on the signal audio s (n). It thus includes a local decoder 132 consisting essentially of the elements marked 10, 12, 14, 16 and 124 of the decoder in Figure 5. Besides the samples u from the adaptive dictionary and the initial states s and du filter 36, the local decoder 132 provides the LPC parameters obtained by synthetic signal analysis, which are used by module 39 for evaluating perceptual weighting and the module 40 for calculating the impulse responses h and h '. For the rest, the operation of the encoder is identical to that of the encoder described with reference to FIG. 4, except that the LPC 24 analysis module is no longer necessary. Only the EXC and LTP parameters are sent to the decoder.
- Figures 7 and 8 are block diagrams of a CELP decoder and a CELP coder with mixed adaptation.
- the linear prediction coefficients of the first stage (s) result from a forward analysis of the audio signal performed by the encoder, while the coefficients of linear prediction of the last stage (s) result from a "backward" analysis of the synthetic signal performed by the decoder (and by a local decoder provided in the coder).
- the coefficients of linear prediction of the last stage result from a "backward" analysis of the synthetic signal performed by the decoder (and by a local decoder provided in the coder).
- the mixed decoder illustrated in FIG. 7 receives the quantization values of the parameters EXC, LTP defining the excitation signal u (n) to be applied to the short-term synthesis filter 16, and the quantization values of the determined LPC / F parameters by the "forward" analysis performed by the coder.
- These LPC / F parameters represent q F sets of linear prediction coefficients a 1 F, p , ..., a MFp F, p for 1 ⁇ p ⁇ q F , and define a first component 1 / A F (z) of the transfer function 1 / A (z) of filter 16:
- the mixed decoder comprises an inverse filter 200 of transfer function A F (z) which filters the synthetic signal s and (n) produced by the short-term synthesis filter 16 to produce a filtered synthetic signal s and 0 (n).
- the LPC / B coefficients thus obtained are supplied to the synthesis filter 16 to define its second component for the next frame.
- the local decoder 232 provided in the mixed encoder consists essentially of the elements noted 10, 12, 14, 16, 200 and 224 / B of the decoder of Figure 7.
- the local decoder 232 provides the LPC / B parameters that are used, with LPC / F parameters provided by analysis module 224 / F, by module 39 Perception Weighting Assessment and Module 40 for calculating the impulse responses h and h '.
- the operation of the mixed encoder is identical to that of the encoder described with reference to the figure 4. Only EXC, LTP and LPC / F parameters are sent to the decoder.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Description



- analyse par prédiction linéaire d'un signal audiofréquence numérisé en trames successives pour déterminer des paramètres définissant un filtre de synthèse à court terme ;
- détermination de paramètres d'excitation définissant un signal d'excitation à appliquer au filtre de synthèse à court terme pour produire un signal synthétique représentatif du signal audiofréquence ; et
- production de valeurs de quantification des paramètres définissant le filtre de synthèse à court terme et des paramètres d'excitation,


- on reçoit des valeurs de quantification de paramètres définissant un filtre de synthèse à court terme et des paramètres d'excitation, les paramètres définissant le filtre de synthèse à court terme comprenant un nombre q>1 de jeux de coefficients de prédiction linéaire, chaque jeu comportant un nombre prédéfini de coefficients ;
- on produit un signal d'excitation sur la base des valeurs de quantification des paramètres d'excitation ;
- on produit un signal audiofréquence synthétique en
filtrant le signal d'excitation par un filtre de synthèse
ayant une fonction de transfert de la forme 1/A(z) avec
où les coefficients a1 p,...,aMp p correspondent au p-ième jeu de coefficients de prédiction linéaire pour 1≤p≤q.


- analyse par prédiction linéaire d'un second signal audiofréquence pour déterminer des paramètres définissant un filtre de synthèse à court terme ;
- détermination de paramètres d'excitation définissant un signal d'excitation à appliquer au filtre de synthèse à court terme pour produire un signal synthétique représentatif du premier signal audiofréquence, ce signal synthétique constituant ledit second signal audiofréquence pour au moins une trame suivante ; et
- production de valeurs de quantification des paramètres d'excitation,

- on reçoit des valeurs de quantification de paramètres d'excitation ;
- on produit un signal d'excitation sur la base des valeurs de quantification des paramètres d'excitation ;
- on produit un signal audiofréquence synthétique en filtrant le signal d'excitation par un filtre de synthèse à court terme ;
- on effectue une analyse par prédiction linéaire du signal synthétique pour obtenir des coefficients du filtre de synthèse à court terme pour au moins une trame suivante,

- analyse par prédiction linéaire du premier signal audiofréquence pour déterminer des paramètres définissant une première composante d'un filtre de synthèse à court terme ;
- détermination de paramètres d'excitation définissant un signal d'excitation à appliquer au filtre de synthèse à court terme pour produire un signal synthétique représentatif du premier signal audio-fréquence ;
- production de valeurs de quantification des paramètres définissant la première composante du filtre de synthèse à court terme et des paramètres d'excitation ;
- filtrage du signal synthétique par un filtre de fonction de transfert correspondant à l'inverse de la fonction de transfert de la première composante du filtre de synthèse à court terme ; et
- analyse par prédiction linéaire du signal synthétique filtré pour obtenir des coefficients d'une seconde composante du filtre de synthèse à court terme pour au moins une trame suivante,




- on reçoit des valeurs de quantification de
paramètres définissant une première composante d'un filtre
de synthèse à court terme et de paramètres d'excitation, les
paramètres définissant la première composante du filtre de
synthèse à court terme représentant un nombre qF au moins
égal à 1 de jeux de coefficients de prédiction linéaire
a1 F,p ,...,aMFp F,p pour 1≤p≤qF, chaque jeu p comportant un
nombre prédéfini MFp de coefficients, la première composante
du filtre de synthèse à court terme ayant une fonction de
transfert de la forme 1/AF(z) avec

- on produit un signal d'excitation sur la base des valeurs de quantification des paramètres d'excitation ;
- on produit un signal audiofréquence synthétique en filtrant le signal d'excitation par un filtre de synthèse à court terme de fonction de transfert 1/A(z) avec A(z)=AF(z).AB(z), 1/AB(z) représentant la fonction de transfert d'une seconde composante du filtre de synthèse à court terme ;
- on filtre le signal synthétique par un filtre de fonction de transfert AF(z) ; et
- on effectue une analyse par prédiction linéaire du signal synthétique filtré pour obtenir des coefficients de la seconde composante du filtre de synthèse à court terme pour au moins une trame suivante,

- la figure 1 est un organigramme d'un procédé d'analyse par prédiction linéaire selon l'invention ;
- la figure 2 est un diagramme spectral comparant les résultats d'un procédé selon l'invention avec ceux d'un procédé conventionnel d'analyse par prédiction linéaire ;
- les figures 3 et 4 sont des schémas synoptiques d'un décodeur et d'un codeur CELP pouvant mettre en oeuvre l'invention ;
- les figures 5 et 6 sont des schémas synoptiques de variantes de décodeur et de codeur CELP pouvant mettre en oeuvre l'invention ; et
- les figures 7 et 8 sont des schémas synoptiques d'autres variantes de décodeur et de codeur CELP pouvant mettre en oeuvre d'invention.

- évaluation de Mp autocorrélations R(i) (0≤i≤Mp) du
signal d'entrée sp-1(n) de l'étage sur une fenêtre d'analyse
de Q échantillons :
avec s*(n)=sp-1(n).f(n), f(n) désignant une fonction de fenêtrage de longueur Q, par exemple une fonction rectangulaire ou une fonction de Hamming ;

- évaluation récursive des coefficients ai p:















Claims (22)
- Procédé d'analyse par prédiction linéaire d'ordre M d'un signal audiofréquence (s0(n)), pour déterminer des paramètres spectraux dépendant d'un spectre à court terme du signal audiofréquence, caractérisé en ce que le procédé est divisé en q étages de prédiction successifs (5p), q étant un entier supérieur à 1, et en ce qu'à chaque étage de prédiction p (1≤p≤q), on détermine des paramètres représentant un nombre Mp, prédéfini pour chaque étage p, de coefficients a1 P ,..., aMp p de prédiction linéaire d'un signal d'entrée dudit étage, le signal audiofréquence à analyser constituant le signal d'entrée (s0(n)) du premier étage, et le signal d'entrée (sp(n)) d'un étage p+1 étant constitué par le signal d'entrée (sp-1(n)) de l'étage p filtré par un filtre de fonction de transfertl'ordre de prédiction M étant tel que


- Procédé d'analyse selon la revendication 1, caractérisé en ce que le nombre Mp de coefficients de prédiction linéaire augmente d'un étage au suivant.
- Procédé de codage d'un signal audiofréquence, comprenant les étapes suivantes :caractérisé en ce que l'analyse par prédiction linéaire est un processus à q étages successifs (5p), q étant un entier supérieur à 1, ledit processus comportant, à chaque étage de prédiction p (1≤p≤q), la détermination de paramètres représentant un nombre Mp, prédéfini pour chaque étage p, de coefficients a1 p ,..., aMp p de prédiction linéaire d'un signal d'entrée dudit étage, le signal audiofréquence à coder (s(n)) constituant le signal d'entrée (s0(n)) du premier étage, et le signal d'entrée (sp(n)) d'un étage p+1 étant constitué par le signal d'entrée (sp-1(n)) de l'étage p filtré par un filtre de fonction de transfertanalyse par prédiction linéaire du signal audiofréquence (s(n)) numérisé en trames successives pour déterminer des paramètres (LPC) définissant un filtre de synthèse à court terme (16) ;détermination de paramètres d'excitation (k,β,LTP) définissant un signal d'excitation (u(n)) à appliquer au filtre de synthèse à court terme (16) pour produire un signal synthétique (s and(n)) représentatif du signal audiofréquence ; etproduction de valeurs de quantification des paramètres définissant le filtre de synthèse à court terme et des paramètres d'excitation,le filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/A(z) avec


- Procédé de codage selon la revendication 3, caractérisé en ce que le nombre Mp de coefficients de prédiction linéaire augmente d'un étage au suivant.
- Procédé de codage selon la revendication 3 ou 4, caractérisé en ce que certains au moins des paramètres d'excitation sont déterminés en minimisant l'énergie d'un signal d'erreur résultant du filtrage de la différence entre le signal audiofréquence (s(n)) et le signal synthétique (s and(n)) par au moins un filtre de pondération perceptuelle (38) dont la fonction de transfert est de la forme W(z)=A(z/γ1)/A(z/γ2) où γ1 et γ2 désignent des coefficients d'expansion spectrale tels que 0≤γ2≤γ1≤ 1.
- Procédé de codage selon la revendication 3 ou 4, caractérisé en ce que certains au moins des paramètres d'excitation sont déterminés en minimisant l'énergie d'un signal d'erreur résultant du filtrage de la différence entre le signal audiofréquence (s(n)) et le signal synthétique (s and(n)) par au moins un filtre de pondération perceptuelle (38) dont la fonction de transfert est de la formeoù γ 1 p , γ 2 p désignent des paires de coefficients d'expansion spectrale tels que 0≤ γ 2 p ≤ γ 1 p ≤ 1 pour 1≤p≤q.

- Procédé de décodage d'un flux binaire pour construire un signal audiofréquence codé par ledit flux binaire, caractérisé en ce que :on reçoit des valeurs de quantification de paramètres (LPC) définissant un filtre de synthèse à court terme (16) et de paramètres d'excitation (k,β,LTP), les paramètres définissant le filtre de synthèse représentant un nombre q plus grand que 1 de jeux de coefficients de prédiction linéaire (ai p ), chaque jeu p comportant un nombre prédéfini Mp de coefficients ;on produit un signal d'excitation (u(n)) sur la base des valeurs de quantification des paramètres d'excitation ; eton produit un signal audiofréquence synthétique (s and(n)) en filtrant le signal d'excitation par un filtre de synthèse (16) ayant une fonction de transfert de la forme 1/A(z) avecoù les coefficients a1 p,...,aMp p correspondent au p-ième jeu de coefficients de prédiction linéaire pour 1≤p≤q.

- Procédé de décodage selon la revendication 7, caractérisé en ce que ledit signal audiofréquence synthétique (s and(n)) est appliqué à un post-filtre (17) dont la fonction de transfert (HPF(z)) comporte un terme de la forme A(z/β1)/A(z/β2), où β1 et β2 désignent des coefficients tels que 0≤β1≤β2≤1.
- Procédé de décodage selon la revendication 7, caractérisé en ce que ledit signal audiofréquence synthétique (s and(n)) est appliqué à un post-filtre (17) dont la fonction de transfert (HPF(z)) comporte un terme de la formeoù β 1 p , β 2 p désignent des paires de coefficients tels que 0≤β 1 p ≤β 2 p ≤1 pour 1≤p≤q, et Ap(z) représente, pour le p-ième jeu de coefficients de prédiction linéaire, la fonction


- Procédé de codage d'un premier signal audiofréquence numérisé en trames successives, comprenant les étapes suivantes :caractérisé en ce que l'analyse par prédiction linéaire est un processus à q étages successifs (5p), q étant un entier supérieur à 1, ledit processus comportant, à chaque étage de prédiction p (1≤p≤q), la détermination de paramètres représentant un nombre Mp, prédéfini pour chaque étage p, de coefficients a1 p,...,aMp P de prédiction linéaire d'un signal d'entrée dudit étage, le second signal audiofréquence (s and(n)) constituant le signal d'entrée (s0(n)) du premier étage, et le signal d'entrée (sp(n)) d'un étage p+1 étant constitué par le signal d'entrée (sp-1(n)) de l'étage p filtré par un filtre de fonction de transfertanalyse par prédiction linéaire d'un second signal audiofréquence (s and(n)) pour déterminer des paramètres (LPC) définissant un filtre de synthèse à court terme (16) ;détermination de paramètres d'excitation (k,β,LTP) définissant un signal d'excitation (u(n)) à appliquer au filtre de synthèse à court terme (16) pour produire un signal synthétique (s and(n)) représentatif du premier signal audiofréquence, ce signal synthétique constituant ledit second signal audiofréquence pour au moins une trame suivante ; etproduction de valeurs de quantification des paramètres d'excitation,le filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/A(z) avec


- Procédé de codage selon la revendication 10, caractérisé en ce que le nombre Mp de coefficients de prédiction linéaire augmente d'un étage au suivant.
- Procédé de codage selon la revendication 10 ou 11, caractérisé en ce que certains au moins des paramètres d'excitation sont déterminés en minimisant l'énergie d'un signal d'erreur résultant du filtrage de la différence entre le premier signal audiofréquence (s(n)) et le signal synthétique (s and(n)) par au moins un filtre de pondération perceptuelle (38) dont la fonction de transfert est de la forme W(z)=A(z/γ1)/A(z/γ2) où γ1 et γ2 désignent des coefficients d'expansion spectrale tels que 0≤γ2≤γ1≤ 1.
- Procédé de codage selon la revendication 10 ou 11, caractérisé en ce que certains au moins des paramètres d'excitation sont déterminés en minimisant l'énergie d'un signal d'erreur résultant du filtrage de la différence entre le premier signal audiofréquence (s(n)) et le signal synthétique (s and(n)) par au moins un filtre de pondération perceptuelle (38) dont la fonction de transfert est de la formeoù γ 1 p , γ 2 p désignent des paires de coefficients d'expansion spectrale tels que 0≤ γ 2 p ≤ γ 1 p ≤ 1 pour 1≤p≤q.

- Procédé de décodage d'un flux binaire pour construire en trames successives un signal audiofréquence codé par ledit flux binaire, caractérisé en ce que :et en ce que l'analyse par prédiction linéaire est un processus à q étages successifs (5p), q étant un entier supérieur à 1, ledit processus comportant, à chaque étage de prédiction p (1≤p≤q), la détermination de paramètres représentant un nombre Mp, prédéfini pour chaque étage p, de coefficients a1 p,...,aMp p de prédiction linéaire d'un signal d'entrée dudit étage, le signal synthétique (s and(n)) constituant le signal d'entrée (s0(n)) du premier étage, et le signal d'entrée (sp(n)) d'un étage p+1 étant constitué par le signal d'entrée (sp-1(n)) de l'étage p filtré par un filtre de fonction de transferton reçoit des valeurs de quantification de paramètres d'excitation (k,β,LTP) ;on produit un signal d'excitation (u(n)) sur la base des valeurs de quantification des paramètres d'excitation ;on produit un signal audiofréquence synthétique (s and(n)) en filtrant le signal d'excitation par un filtre de synthèse à court terme (16) ;on effectue une analyse par prédiction linéaire du signal synthétique (s and(n)) pour obtenir des coefficients du filtre de synthèse à court terme (16) pour au moins une trame suivante,le filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/A(z) avec


- Procédé de décodage selon la revendication 14, caractérisé en ce que ledit signal audiofréquence synthétique (s and(n)) est appliqué à un post-filtre (17) dont la fonction de transfert (HPF(z)) comporte un terme de la forme A(z/β1)/A(z/β2), où β1 et β2 désignent des coefficients tels que 0≤β1≤β2≤1.
- Procédé de décodage selon la revendication 14, caractérisé en ce que ledit signal audiofréquence synthétique (s and(n)) est appliqué à un post-filtre (17) dont la fonction de transfert (HPF(z)) comporte un terme de la formeoù β 1 p , β 2 p désignent des paires de coefficients tels que 0≤ β 1 p ≤ β 2 p ≤1 pour 1≤p≤q.

- Procédé de codage d'un premier signal audiofréquence numérisé en trames successives, caractérisé en ce qu'il comprend les étapes suivantes :en ce que l'analyse par prédiction linéaire du premier signal audiofréquence (s(n)) est un processus à qF étages successifs (5p), qF étant un entier au moins égal à 1, ledit processus à qF étages comportant, à chaque étage de prédiction p (1≤p≤qF), la détermination de paramètres représentant un nombre MFp, prédéfini pour chaque étage p, de coefficients a1 F,p ,...,aMFp F , p de prédiction linéaire d'un signal d'entrée dudit étage, le premier signal audiofréquence (s(n)) constituant le signal d'entrée (s0(n)) du premier étage du processus à qF étages, et le signal d'entrée (sp(n)) d'un étage p+1 du processus à qF étages étant constitué par le signal d'entrée (sp-1(n)) de l'étage p du processus à qF étages filtré par un filtre de fonction de transfertanalyse par prédiction linéaire du premier signal audiofréquence (s(n)) pour déterminer des paramètres (LPC/F) définissant une première composante d'un filtre de synthèse à court terme (16) ;détermination de paramètres d'excitation (k,β,LTP) définissant un signal d'excitation (u(n)) à appliquer au filtre de synthèse à court terme (16) pour produire un signal synthétique (s and(n)) représentatif du premier signal audiofréquence ;production de valeurs de quantification des paramètres définissant la première composante du filtre de synthèse à court terme et des paramètres d'excitation ;filtrage du signal synthétique (s and(n)) par un filtre de fonction de transfert correspondant à l'inverse de la fonction de transfert de la première composante du filtre de synthèse à court terme ; etanalyse par prédiction linéaire du signal synthétique filtré ((s and0(n)) pour obtenir des coefficients d'une seconde composante du filtre de synthèse à court terme pour au moins une trame suivante,la première composante du filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/AF(z) avec
 et en ce que l'analyse par prédiction linéaire du signal synthétique filtré est un processus à qB étages successifs (5p), qB étant un entier au moins égal à 1, ledit processus à qB étages comportant, à chaque étage de prédiction p (1≤p≤qB), la détermination de paramètres représentant un nombre MBp, prédéfini pour chaque étage p, de coefficients a1 B,p,...,aMBp B , p de prédiction linéaire d'un signal d'entrée dudit étage, le signal synthétique filtré (s and0(n)) constituant le signal d'entrée (s0(n)) du premier étage du processus à qB étages, et le signal d'entrée (sp(n)) d'un étage p+1 du processus à qB étages étant constitué par le signal d'entrée (sp-1(n)) de l'étage p du processus à qB étages filtré par un filtre de fonction de transfert
et en ce que l'analyse par prédiction linéaire du signal synthétique filtré est un processus à qB étages successifs (5p), qB étant un entier au moins égal à 1, ledit processus à qB étages comportant, à chaque étage de prédiction p (1≤p≤qB), la détermination de paramètres représentant un nombre MBp, prédéfini pour chaque étage p, de coefficients a1 B,p,...,aMBp B , p de prédiction linéaire d'un signal d'entrée dudit étage, le signal synthétique filtré (s and0(n)) constituant le signal d'entrée (s0(n)) du premier étage du processus à qB étages, et le signal d'entrée (sp(n)) d'un étage p+1 du processus à qB étages étant constitué par le signal d'entrée (sp-1(n)) de l'étage p du processus à qB étages filtré par un filtre de fonction de transfert la seconde composante du filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/AB(z) avec
la seconde composante du filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/AB(z) avec et le filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/A(z) avec A(z)=AF(z).AB(z).
et le filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/A(z) avec A(z)=AF(z).AB(z).
- Procédé de codage selon la revendication 17, caractérisé en ce que certains au moins des paramètres d'excitation sont déterminés en minimisant l'énergie d'un signal d'erreur résultant du filtrage de la différence entre le premier signal audiofréquence (s(n)) et le signal synthétique (s and(n)) par au moins un filtre de pondération perceptuelle (38) dont la fonction de transfert est de la forme W(z)=A(z/γ1)/A(z/γ2) où γ1 et γ2 désignent des coefficients d'expansion spectrale tels que 0≤γ2≤γ1≤ 1.
- Procédé de codage selon la revendication 17, caractérisé en ce que certains au moins des paramètres d'excitation sont déterminés en minimisant l'énergie d'un signal d'erreur résultant du filtrage de la différence entre le premier signal audiofréquence (s(n)) et le signal synthétique (s and(n)) par au moins un filtre de pondération perceptuelle (38) dont la fonction de transfert est de la formeoù γ 1 F,p , γ 2 F,p désignent des paires de coefficients d'expansion spectrale tels que 0≤ γ2 F,p ≤ γ 1 F,p ≤ 1 pour 1≤p≤qF, et γ 1 B,p , γ 2 B,p désignent des paires de coefficients d'expansion spectrale tels que 0≤ γ 2 B,p ≤ γ 1 B,p ≤ 1 pour 1≤p≤qB.

- Procédé de décodage d'un flux binaire pour construire en trames successives un signal audiofréquence codé par ledit flux binaire, caractérisé en ce que :et en ce que l'analyse par prédiction linéaire du signal synthétique filtré est un processus à qB étages successifs (5p), qB étant un entier au moins égal à 1, ledit processus comportant, à chaque étage de prédiction p (1≤p≤qB), la détermination de paramètres représentant un nombre MBp, prédéfini pour chaque étage p, de coefficients a1 B,p,...,aMBp B,p de prédiction linéaire d'un signal d'entrée dudit étage, le signal synthétique filtré (s and0(n)) constituant le signal d'entrée (s0(n)) du premier étage, et le signal d'entrée (sp(n)) d'un étage p+1 étant constitué par le signal d'entrée (sp-1(n)) de l'étage p filtré par un filtre de fonction de transferton reçoit des valeurs de quantification de paramètres (LPC/F) définissant une première composante d'un filtre de synthèse à court terme (16) et de paramètres d'excitation (k,β,LTP), les paramètres définissant la première composante du filtre de synthèse à court terme représentant un nombre qF au moins égal à 1 de jeux de coefficients de prédiction linéaire a1 F,p,...,aMFp F,p pour 1≤p≤qF, chaque jeu p comportant un nombre prédéfini MFp de coefficients, la première composante du filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/AF(z) avec
 on produit un signal d'excitation (u(n)) sur la base des valeurs de quantification des paramètres d'excitation ;on produit un signal audiofréquence synthétique (s and(n)) en filtrant le signal d'excitation par un filtre de synthèse à court terme (16) de fonction de transfert 1/A(z) avec A(z)=AF(z).AB(z), 1/AB(z) représentant la fonction de transfert d'une seconde composante du filtre de synthèse à court terme (16) ;on filtre le signal synthetique (s and(n)) par un filtre de fonction de transfert AF(z) ; eton effectue une analyse par prédiction linéaire du signal synthétique filtré (s and0(n)) pour obtenir des coefficients de la seconde composante du filtre de synthèse à court terme (16) pour au moins une trame suivante,la seconde composante du filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/AB(z) avec
on produit un signal d'excitation (u(n)) sur la base des valeurs de quantification des paramètres d'excitation ;on produit un signal audiofréquence synthétique (s and(n)) en filtrant le signal d'excitation par un filtre de synthèse à court terme (16) de fonction de transfert 1/A(z) avec A(z)=AF(z).AB(z), 1/AB(z) représentant la fonction de transfert d'une seconde composante du filtre de synthèse à court terme (16) ;on filtre le signal synthetique (s and(n)) par un filtre de fonction de transfert AF(z) ; eton effectue une analyse par prédiction linéaire du signal synthétique filtré (s and0(n)) pour obtenir des coefficients de la seconde composante du filtre de synthèse à court terme (16) pour au moins une trame suivante,la seconde composante du filtre de synthèse à court terme (16) ayant une fonction de transfert de la forme 1/AB(z) avec

- Procédé de décodage selon la revendication 20, caractérisé en ce que ledit signal audiofréquence synthétique (s and(n)) est appliqué à un post-filtre (17) dont la fonction de transfert (HPF(z)) comporte un terme de la forme A(z/β1)/A(z/β2), où β1 et β2 désignent des coefficients tels que 0≤β1≤β2≤1.
- Procédé de décodage selon la revendication 20, caractérisé en ce que ledit signal audiofréquence synthétique (s and(n)) est appliqué à un post-filtre (17) dont la fonction de transfert (HPF(z)) comporte un terme de la formeoù β 1 F,p, β 2 F,p désignent des paires de coefficients tels que 0≤β 1 F,p ≤β 2 F,p ≤1 pour 1≤p≤qF, et β 1 B,p , β 2 B,p désignent des paires de coefficients tels que 0≤β 1 B,p ≤β 2 B,p ≤1 pour 1≤p≤qB.

Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9514925A FR2742568B1 (fr) | 1995-12-15 | 1995-12-15 | Procede d'analyse par prediction lineaire d'un signal audiofrequence, et procedes de codage et de decodage d'un signal audiofrequence en comportant application |
| FR9514925 | 1995-12-15 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP0782128A1 EP0782128A1 (fr) | 1997-07-02 |
| EP0782128B1 true EP0782128B1 (fr) | 2000-06-21 |
Family
ID=9485565
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP96402715A Expired - Lifetime EP0782128B1 (fr) | 1995-12-15 | 1996-12-12 | Procédé d'analyse par prédiction linéaire d'un signal audiofréquence, et procédés de codage et de décodage d'un signal audiofréquence en comportant application |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US5787390A (fr) |
| EP (1) | EP0782128B1 (fr) |
| JP (1) | JP3678519B2 (fr) |
| KR (1) | KR100421226B1 (fr) |
| CN (1) | CN1159691A (fr) |
| DE (1) | DE69608947T2 (fr) |
| FR (1) | FR2742568B1 (fr) |
Families Citing this family (46)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5621852A (en) | 1993-12-14 | 1997-04-15 | Interdigital Technology Corporation | Efficient codebook structure for code excited linear prediction coding |
| FR2729247A1 (fr) * | 1995-01-06 | 1996-07-12 | Matra Communication | Procede de codage de parole a analyse par synthese |
| FR2729246A1 (fr) * | 1995-01-06 | 1996-07-12 | Matra Communication | Procede de codage de parole a analyse par synthese |
| JPH10124088A (ja) * | 1996-10-24 | 1998-05-15 | Sony Corp | 音声帯域幅拡張装置及び方法 |
| JP3064947B2 (ja) | 1997-03-26 | 2000-07-12 | 日本電気株式会社 | 音声・楽音符号化及び復号化装置 |
| FI973873A (fi) * | 1997-10-02 | 1999-04-03 | Nokia Mobile Phones Ltd | Puhekoodaus |
| FR2774827B1 (fr) | 1998-02-06 | 2000-04-14 | France Telecom | Procede de decodage d'un flux binaire representatif d'un signal audio |
| US6223157B1 (en) * | 1998-05-07 | 2001-04-24 | Dsc Telecom, L.P. | Method for direct recognition of encoded speech data |
| US6148283A (en) * | 1998-09-23 | 2000-11-14 | Qualcomm Inc. | Method and apparatus using multi-path multi-stage vector quantizer |
| US6778953B1 (en) * | 2000-06-02 | 2004-08-17 | Agere Systems Inc. | Method and apparatus for representing masked thresholds in a perceptual audio coder |
| WO2002039430A1 (fr) * | 2000-11-09 | 2002-05-16 | Koninklijke Philips Electronics N.V. | Extension large bande de conversations telephoniques permettant d'augmenter la qualite perceptuelle |
| CN1270291C (zh) * | 2000-12-06 | 2006-08-16 | 皇家菲利浦电子有限公司 | 滤波设备和方法 |
| WO2002067246A1 (fr) * | 2001-02-16 | 2002-08-29 | Centre For Signal Processing, Nanyang Technological University | Procede de determination des coefficients de prediction lineaire optimale |
| US6590972B1 (en) * | 2001-03-15 | 2003-07-08 | 3Com Corporation | DTMF detection based on LPC coefficients |
| US7062429B2 (en) * | 2001-09-07 | 2006-06-13 | Agere Systems Inc. | Distortion-based method and apparatus for buffer control in a communication system |
| US6934677B2 (en) | 2001-12-14 | 2005-08-23 | Microsoft Corporation | Quantization matrices based on critical band pattern information for digital audio wherein quantization bands differ from critical bands |
| US7240001B2 (en) * | 2001-12-14 | 2007-07-03 | Microsoft Corporation | Quality improvement techniques in an audio encoder |
| US20030216921A1 (en) * | 2002-05-16 | 2003-11-20 | Jianghua Bao | Method and system for limited domain text to speech (TTS) processing |
| EP1383109A1 (fr) * | 2002-07-17 | 2004-01-21 | STMicroelectronics N.V. | Procédé et dispositif d'encodage de la parole à bande élargie |
| US7502743B2 (en) * | 2002-09-04 | 2009-03-10 | Microsoft Corporation | Multi-channel audio encoding and decoding with multi-channel transform selection |
| US7299190B2 (en) * | 2002-09-04 | 2007-11-20 | Microsoft Corporation | Quantization and inverse quantization for audio |
| JP4676140B2 (ja) * | 2002-09-04 | 2011-04-27 | マイクロソフト コーポレーション | オーディオの量子化および逆量子化 |
| US7254533B1 (en) * | 2002-10-17 | 2007-08-07 | Dilithium Networks Pty Ltd. | Method and apparatus for a thin CELP voice codec |
| US20040260540A1 (en) * | 2003-06-20 | 2004-12-23 | Tong Zhang | System and method for spectrogram analysis of an audio signal |
| US7539612B2 (en) * | 2005-07-15 | 2009-05-26 | Microsoft Corporation | Coding and decoding scale factor information |
| US8027242B2 (en) | 2005-10-21 | 2011-09-27 | Qualcomm Incorporated | Signal coding and decoding based on spectral dynamics |
| US8417185B2 (en) * | 2005-12-16 | 2013-04-09 | Vocollect, Inc. | Wireless headset and method for robust voice data communication |
| US7885419B2 (en) * | 2006-02-06 | 2011-02-08 | Vocollect, Inc. | Headset terminal with speech functionality |
| US7773767B2 (en) | 2006-02-06 | 2010-08-10 | Vocollect, Inc. | Headset terminal with rear stability strap |
| US8392176B2 (en) | 2006-04-10 | 2013-03-05 | Qualcomm Incorporated | Processing of excitation in audio coding and decoding |
| CN101114415B (zh) * | 2006-07-25 | 2011-01-12 | 元太科技工业股份有限公司 | 双稳态显示器的驱动装置及其方法 |
| US8239191B2 (en) * | 2006-09-15 | 2012-08-07 | Panasonic Corporation | Speech encoding apparatus and speech encoding method |
| US8330745B2 (en) | 2007-01-25 | 2012-12-11 | Sharp Kabushiki Kaisha | Pulse output circuit, and display device, drive circuit, display device, and pulse output method using same circuit |
| US8428957B2 (en) | 2007-08-24 | 2013-04-23 | Qualcomm Incorporated | Spectral noise shaping in audio coding based on spectral dynamics in frequency sub-bands |
| TWI346465B (en) * | 2007-09-04 | 2011-08-01 | Univ Nat Central | Configurable common filterbank processor applicable for various audio video standards and processing method thereof |
| USD605629S1 (en) | 2008-09-29 | 2009-12-08 | Vocollect, Inc. | Headset |
| FR2938688A1 (fr) | 2008-11-18 | 2010-05-21 | France Telecom | Codage avec mise en forme du bruit dans un codeur hierarchique |
| EP2407963B1 (fr) | 2009-03-11 | 2015-05-13 | Huawei Technologies Co., Ltd. | Procédé, dispositif et système d'analyse par prédiction linéaire |
| US8160287B2 (en) | 2009-05-22 | 2012-04-17 | Vocollect, Inc. | Headset with adjustable headband |
| US8438659B2 (en) | 2009-11-05 | 2013-05-07 | Vocollect, Inc. | Portable computing device and headset interface |
| CN102812512B (zh) * | 2010-03-23 | 2014-06-25 | Lg电子株式会社 | 处理音频信号的方法和装置 |
| KR101257776B1 (ko) * | 2011-10-06 | 2013-04-24 | 단국대학교 산학협력단 | 상태-체크 코드를 이용한 부호화 방법 및 부호화 장치 |
| CN102638846B (zh) * | 2012-03-28 | 2015-08-19 | 浙江大学 | 一种基于最优量化策略的wsn通信负载降低方法 |
| ES2703565T3 (es) * | 2014-01-24 | 2019-03-11 | Nippon Telegraph & Telephone | Aparato, método, programa y soporte de registro de análisis predictivo lineal |
| KR101883800B1 (ko) * | 2014-01-24 | 2018-07-31 | 니폰 덴신 덴와 가부시끼가이샤 | 선형 예측 분석 장치, 방법, 프로그램 및 기록 매체 |
| US9626983B2 (en) * | 2014-06-26 | 2017-04-18 | Qualcomm Incorporated | Temporal gain adjustment based on high-band signal characteristic |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3975587A (en) * | 1974-09-13 | 1976-08-17 | International Telephone And Telegraph Corporation | Digital vocoder |
| US4398262A (en) * | 1981-12-22 | 1983-08-09 | Motorola, Inc. | Time multiplexed n-ordered digital filter |
| CA1245363A (fr) * | 1985-03-20 | 1988-11-22 | Tetsu Taguchi | Vocodeur a reconnaissance de formes |
| US4868867A (en) * | 1987-04-06 | 1989-09-19 | Voicecraft Inc. | Vector excitation speech or audio coder for transmission or storage |
| JP2625998B2 (ja) * | 1988-12-09 | 1997-07-02 | 沖電気工業株式会社 | 特徴抽出方式 |
| GB2235354A (en) * | 1989-08-16 | 1991-02-27 | Philips Electronic Associated | Speech coding/encoding using celp |
| US5307441A (en) * | 1989-11-29 | 1994-04-26 | Comsat Corporation | Wear-toll quality 4.8 kbps speech codec |
| FI98104C (fi) * | 1991-05-20 | 1997-04-10 | Nokia Mobile Phones Ltd | Menetelmä herätevektorin generoimiseksi ja digitaalinen puhekooderi |
| IT1257065B (it) * | 1992-07-31 | 1996-01-05 | Sip | Codificatore a basso ritardo per segnali audio, utilizzante tecniche di analisi per sintesi. |
| US5706395A (en) * | 1995-04-19 | 1998-01-06 | Texas Instruments Incorporated | Adaptive weiner filtering using a dynamic suppression factor |
| US5692101A (en) * | 1995-11-20 | 1997-11-25 | Motorola, Inc. | Speech coding method and apparatus using mean squared error modifier for selected speech coder parameters using VSELP techniques |
-
1995
- 1995-12-15 FR FR9514925A patent/FR2742568B1/fr not_active Expired - Lifetime
-
1996
- 1996-12-11 US US08/763,457 patent/US5787390A/en not_active Expired - Lifetime
- 1996-12-12 EP EP96402715A patent/EP0782128B1/fr not_active Expired - Lifetime
- 1996-12-12 DE DE69608947T patent/DE69608947T2/de not_active Expired - Lifetime
- 1996-12-13 CN CN96121556A patent/CN1159691A/zh active Pending
- 1996-12-14 KR KR1019960065696A patent/KR100421226B1/ko active IP Right Grant
- 1996-12-16 JP JP33614096A patent/JP3678519B2/ja not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| FR2742568A1 (fr) | 1997-06-20 |
| DE69608947T2 (de) | 2001-02-01 |
| CN1159691A (zh) | 1997-09-17 |
| US5787390A (en) | 1998-07-28 |
| EP0782128A1 (fr) | 1997-07-02 |
| KR100421226B1 (ko) | 2004-07-19 |
| KR970050107A (ko) | 1997-07-29 |
| JPH09212199A (ja) | 1997-08-15 |
| FR2742568B1 (fr) | 1998-02-13 |
| JP3678519B2 (ja) | 2005-08-03 |
| DE69608947D1 (de) | 2000-07-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP0782128B1 (fr) | Procédé d'analyse par prédiction linéaire d'un signal audiofréquence, et procédés de codage et de décodage d'un signal audiofréquence en comportant application | |
| EP0801790B1 (fr) | Procede de codage de parole a analyse par synthese | |
| FR2734389A1 (fr) | Procede d'adaptation du niveau de masquage du bruit dans un codeur de parole a analyse par synthese utilisant un filtre de ponderation perceptuelle a court terme | |
| EP1692689B1 (fr) | Procede de codage multiple optimise | |
| EP0721180B1 (fr) | Procédé de codage de parole à analyse par synthèse | |
| WO1996021218A1 (fr) | Procede de codage de parole a analyse par synthese | |
| JP3357795B2 (ja) | 音声符号化方法および装置 | |
| EP0616315A1 (fr) | Dispositif de codage et de décodage numérique de la parole, procédé d'exploration d'un dictionnaire pseudo-logarithmique de délais LTP, et procédé d'analyse LTP | |
| EP2171713B1 (fr) | Codage de signaux audionumériques | |
| FR2783651A1 (fr) | Dispositif et procede de filtrage d'un signal de parole, recepteur et systeme de communications telephonique | |
| EP1192619B1 (fr) | Codage et decodage audio par interpolation | |
| EP1192618B1 (fr) | Codage audio avec liftrage adaptif | |
| EP1192621B1 (fr) | Codage audio avec composants harmoniques | |
| EP1194923B1 (fr) | Procedes et dispositifs d'analyse et de synthese audio | |
| WO2001003121A1 (fr) | Codage et decodage audio avec composants harmoniques et phase minimale | |
| WO2013135997A1 (fr) | Modification des caractéristiques spectrales d'un filtre de prédiction linéaire d'un signal audionumérique représenté par ses coefficients lsf ou isf | |
| WO2001003119A1 (fr) | Codage et decodage audio incluant des composantes non harmoniques du signal | |
| WO2002029786A1 (fr) | Procede et dispositif de codage segmental d'un signal audio | |
| FR2980620A1 (fr) | Traitement d'amelioration de la qualite des signaux audiofrequences decodes | |
| FR2773653A1 (fr) | Dispositifs de codage/decodage de donnees, et supports d'enregistrement memorisant un programme de codage/decodage de donnees au moyen d'un filtre de ponderation frequentielle | |
| FR2737360A1 (fr) | Procedes de codage et de decodage de signaux audiofrequence, codeur et decodeur pour la mise en oeuvre de tels procedes |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): DE GB IT |
|
| 17P | Request for examination filed |
Effective date: 19970726 |
|
| 17Q | First examination report despatched |
Effective date: 19990511 |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| RIC1 | Information provided on ipc code assigned before grant |
Free format text: 7G 10L 19/06 A |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): DE GB IT |
|
| REF | Corresponds to: |
Ref document number: 69608947 Country of ref document: DE Date of ref document: 20000727 |
|
| ITF | It: translation for a ep patent filed |
Owner name: BARZANO' E ZANARDO MILANO S.P.A. |
|
| GBT | Gb: translation of ep patent filed (gb section 77(6)(a)/1977) |
Effective date: 20000821 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: IF02 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: IT Payment date: 20151120 Year of fee payment: 20 Ref country code: DE Payment date: 20151119 Year of fee payment: 20 Ref country code: GB Payment date: 20151125 Year of fee payment: 20 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R082 Ref document number: 69608947 Country of ref document: DE Representative=s name: WEICKMANN & WEICKMANN PATENTANWAELTE - RECHTSA, DE Ref country code: DE Ref legal event code: R081 Ref document number: 69608947 Country of ref document: DE Owner name: 3G LICENSING S.A., LU Free format text: FORMER OWNER: FRANCE TELECOM, S.A., PARIS, FR Ref country code: DE Ref legal event code: R081 Ref document number: 69608947 Country of ref document: DE Owner name: ORANGE, FR Free format text: FORMER OWNER: FRANCE TELECOM, S.A., PARIS, FR |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R082 Ref document number: 69608947 Country of ref document: DE Representative=s name: WEICKMANN & WEICKMANN PATENTANWAELTE - RECHTSA, DE Ref country code: DE Ref legal event code: R081 Ref document number: 69608947 Country of ref document: DE Owner name: 3G LICENSING S.A., LU Free format text: FORMER OWNER: ORANGE, PARIS, FR |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R071 Ref document number: 69608947 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: PE20 Expiry date: 20161211 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF EXPIRATION OF PROTECTION Effective date: 20161211 |