CN1663188A - Efficient packet processing pipeline apparatus and method - Google Patents
Efficient packet processing pipeline apparatus and method Download PDFInfo
- Publication number
- CN1663188A CN1663188A CN03814522.7A CN03814522A CN1663188A CN 1663188 A CN1663188 A CN 1663188A CN 03814522 A CN03814522 A CN 03814522A CN 1663188 A CN1663188 A CN 1663188A
- Authority
- CN
- China
- Prior art keywords
- processing unit
- packet
- data portion
- data
- packet processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/30—Peripheral units, e.g. input or output ports
- H04L49/3072—Packet splitting
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/30—Peripheral units, e.g. input or output ports
- H04L49/3063—Pipelined operation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/30—Peripheral units, e.g. input or output ports
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
A packet processing device for processing data packets in a packet switched network, comprising: means for receiving a packet; means for adding management information to a first data portion of a packet, the management information comprising at least an indication of at least one procedure to be applied to said first data portion; and a plurality of parallel pipelines, each pipeline including at least one processing unit, characterized by: the processing unit performs the process indicated by the management information on the first data portion to provide a modified first data portion. According to the method, the tasks executed by each processing unit are organized into a plurality of functions, so that there are actually only function calls and no inter-function calls, and the only context at which each function called by said function call of one processing unit terminates is the first data portion.
Description
Invention field
The present invention relates to communication network, specifically, relate to packet-switched telecommunication network, more particularly, relate to wherein used network element and communication module, and the method that for example described network element of operation and communication module are divided into groups with processing on network node.
Prior art
To determine that processing arrives for example grouping of nodes of telecommunication network with two-forty with flexible way, preferred such architecture: when considering flexible processing unit such as processor cores, include consideration in handling the particularity of dividing into groups.The desirable attributes of packet transaction is to handle the minimum cycle budget that concurrency, datum plane and control plane (single processing threads can stop) intrinsic in the grouping process high I/O (I/O) among both requires and needs be used as far as possible effectively thereon.Parallel processing is favourable for the packet transaction in the packet-switched telecommunication network of high-throughput, can improve disposal ability.
But though handle executed in parallel, some needs accessed resources not without backup.This causes a more than processing unit to wish to visit this type of resource.For example shared resource such as database is can be by a resource of a plurality of processing units visits.Each processing unit can be carried out independent task, and this task is different from the task that any other processing unit is carried out.As the part of task, access shared resources may be essential, for example, and the inline data of accessing database to obtain to be correlated with.When trial made throughput maximum, the shared resource of access process unit had the long stand-by period usually.If processing unit is replied preceding pausing operation receiving from shared resource, then efficient becomes very low.And generally not on chip, therefore, visit and retrieval time are quite big for the resource of the big memory space of needs.
Traditionally, processing on the processing unit with processor cores for example is optimized relates to context and switch, promptly, suspend a thread, and all current datas that will be stored in the register are saved in the memory, can create identical context again when replying receiving like this, later on from shared resource.Yet context switches and to take a large amount of processor resources, perhaps only for this reason Task Distribution take a large amount of time during a small amount of processor resource.
The purpose of this invention is to provide a kind of packet processing unit and with a kind of method of the efficient operating said unit that improves.
Another purpose of the present invention provides a kind of method of a kind of packet processing unit and operating said unit, and by the present invention, the context switching has reduction process time overhead and/or reduction process resource allocation.
Another purpose of the present invention provides a kind of packet processing unit efficiently and uses the method for parallel processing operating said unit.
Summary of the invention
The invention solves this problem, and when keeping simple programming model, obtained very high efficient, can not adjust processing unit to adapt to certain specific function and on processing unit, do not need the very high multithreading of cost to handle also simultaneously.The present invention partly depends on the following fact: switch for context, when initiating the shared resource request in the network element of packet-switched telecommunication network, usually there is purposes context seldom, perhaps can drops to useful context minimum by the task programming of wisdom.Switching is to handle the good working condition that another grouping might not require to preserve processing unit.Wise programming can comprise that the program organization that will move is the function call sequence on each processing unit, be invoked at when moving on the processing unit to have context at every turn, but except the data in grouping itself, do not need to call between function.
Therefore, the invention provides a kind of in the used packet handling facilities of packet switching network the method for process data packets, described packet handling facilities comprises many parallel pipelines, and every streamline comprises at least one processing unit of a part that is used to handle a data grouping; Described method also comprises: the described task groups that each processing unit is carried out is made into a plurality of functions, like this, in fact only there is function call and do not have and call between function, and when each function that the described function call of a processing unit is called stopped, unique context was first data division.
The invention provides the packet handling facilities that uses in packet switching network, described packet handling facilities comprises: the device that is used for receiving at described packet handling facilities grouping; Be used for management information is added to the device of at least the first data division of described grouping, described management information comprises the indication that will be applied at least one process on described first data division at least; Many parallel pipelines, every streamline comprises at least one processing unit, and described at least one processing unit carries out the described process of described management information indication to described first data division, so that first data division of modification to be provided.
The present invention also provides the communication module of using in packet handling facilities, described communication module comprises: the device that is used for receiving in described communication module grouping; Be used for management information is added to the device of at least the first data division of described grouping, described management information comprises the indication that will be applied at least one process on described first data division at least; Many parallel communications streamlines, every communication pipelines uses with at least one processing unit; And the storage device that is used to store described first data division.
The present invention also provides the method for process data packets in the used packet handling facilities of packet switching network, and described packet handling facilities comprises many parallel pipelines, and every streamline comprises at least one processing unit; Described method comprises: management information is added at least the first data division of described grouping, described management information comprises the indication that will be applied at least one process on described first data division at least; And described at least one processing unit carries out the described process of described management information indication to described first data division, so that first data division of modification to be provided.
The present invention also provides the packet handling facilities that uses in packet switching network, described packet handling facilities comprises: the device that is used for receiving at described packet handling facilities grouping; Be used for each packet fragmentation that described packet handling facilities receives is become the module of first data division and second data division; Be used to handle the device of described at least the first data division; And the device that reconfigures described first and second data divisions.
The present invention also provides the method for process data packets in the used packet handling facilities of packet switching network, described comprising: each packet fragmentation that described packet handling facilities is received becomes first data division and second data division; Handle described at least the first data division; And reconfigure described first and second data divisions.
The present invention also provides the packet handling facilities that uses in packet switching network, described packet handling facilities comprises: the device that is used for receiving at described packet handling facilities grouping; Many parallel pipelines, every streamline comprises at least one processing unit, is linked to the communication engines of described at least one processing unit by dual port memory unit, one of them port is connected to described communication engines, and the another port is connected to described processing unit.
The present invention also provides the communication module of using in packet handling facilities, described communication module comprises: the device that is used for receiving in described communication module grouping; Many parallel communications streamlines, every communication pipelines comprises with processing unit communicates by letter so that handle at least one communication engines and the dual port memory unit of grouping, and a port of described dual port memory unit is connected to described communication engines.
The present invention also provides the packet processing unit that uses in packet switching network, described packet processing unit comprises: the device that is used for receiving at described packet processing unit packet; Many parallel pipelines, every streamline comprises that at least a portion that is used for the data grouping carries out at least one processing unit of certain process, the communication engines that is connected to described processing unit and at least one shared resource, wherein: described communication engines is suitable for receiving the shared resource request from described processing unit, and it is sent to described shared resource.Described communication engines also is suitable for replying from described shared resource reception.
The present invention also provides the communication module that cooperates packet processing unit to use, and described communication module comprises: the device that is used for receiving in described communication module packet; Many parallel pipelines, every streamline comprises at least one communication engines and at least one shared resource, described communication engines has the device that is used to be connected to processing unit, wherein: described communication engines is suitable for receiving the shared resource request, and it is sent to described shared resource, and receive from described shared resource and to reply and it is sent to described jockey so that be connected to described processing unit.
Now with reference to following accompanying drawing the present invention is described.
The accompanying drawing summary
Fig. 1 a and 1b have shown the packet transaction path according to the embodiment of the invention;
Fig. 2 a and 2b have shown the packet scheduling operation according to the embodiment of the invention;
Fig. 3 has shown according to the present invention a streamline details of truth example;
The position of header in the FIFO memory that Fig. 4 a has shown with processing unit according to the embodiment of the invention is associated;
Fig. 4 b has shown the header according to the embodiment of the invention;
Fig. 5 has shown the processing unit according to the embodiment of the invention;
Fig. 6 has shown according to the embodiment of the invention and how to have divided into groups by pipeline processes;
Fig. 7 has shown that according to the embodiment of the invention grouping during the transmission is alignd again;
Fig. 8 has shown the communication engines according to the embodiment of the invention;
Fig. 9 has shown according to the embodiment of the invention, is used for controlling the pointer arrangement of buffering area header queue;
Figure 10 has shown the shared resource layout according to further embodiment of this invention;
Figure 11 has shown the flow chart of handling packet header (packet head) according to the present invention.
The detailed description of illustrative embodiment
Describe the present invention with reference to some embodiment and accompanying drawing below, but the present invention is not limited to this.Person of skill in the art will appreciate that the present invention has extensive use in the packet transaction of parallel processing field and/or communication network, particularly packet-switched telecommunication network.
One aspect of the present invention is to be used for the packet transaction communication module that packet header is handled in packet handling facilities.Packet handling facilities is made up of many processing streamlines, and every streamline is made up of some processing units.Processing unit comprises processing unit, for example processor and the memory that is associated.Processor can be a microprocessor, perhaps can be the programmable digital logic unit, for example programmable logic array (PAL), programmable logic array (PLA), programmable gate array, particularly field programmable logic array.The packet transaction communication module comprises the continuous-flow type communication engines, and this communication engines provides the non-local communication function that is applicable to processing unit.In order to form complete packet handling facilities, processor cores and optional other function blocks are installed on the packet transaction communication module.Processor cores need not to have built-in local hardware context handoff functionality.
In following content, with being primarily aimed at complete packet handling facilities the present invention is described, but should understand, processor cores type and the size used with packet transaction communication module according to the present invention not necessarily limit the present invention, and communication module (non-processor) also is an independent aspects of the present invention.
One aspect of the present invention is that the software/hardware of optimizing is divided.For example, processing unit is preferably communicated by letter with responsible non-this locality, and the hardware block that is called communication engines is combined.This hardware block can be realized in a usual manner, for example, is embodied as logic array such as gate array.Yet, the present invention also can realize by replacement device, for example, communication engines can be embodied as configurable, as passing through to use the programmable digital logic unit, as compiling array logic (PAL), programmable logic array (PLA), programmable gate array, particularly configurable of the field programmable logic array acquisition.Specifically, for product is provided as soon as possible, present invention includes the intelligent design strategy in two generations or more generations, the programmable device that uses in the first generation is substituted by hardware blocks in suceeding generation thus.
Hardware block is preferably used in the function of protocol-independent.For protocol-dependent function, allow the software block that reconfigures and redesign when preferably adopting protocol changes.For example, microprocessor is favourable to this type of application.
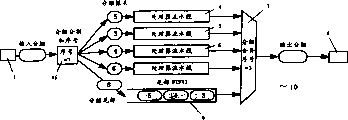
Complete packet treatment facility 10 according to the embodiment of the invention comprises the packet transaction communication module that processor is installed.Treatment facility 10 has as shown in Figure 1a, the packet transaction path of being made up of many parallel processing streamlines 4,5,6.The quantity of streamline depends on the disposal ability that will realize.Shown in Fig. 1 b, the processing path comprises and being used for from for example communication network 1 reception grouping and with the scheduling unit 2 of packet distribution to one or more parallel processing streamline 4,5,6.Communication network 1 can be any packet switching network, for example, and land line or mobile radio communication network.Each receives grouping and comprises title and Payload.Every streamline 4,5,6 comprises a plurality of processing unit 4b...e, 5b...e, 6b...e.These processing units are suitable for handling the title of grouping at least.Packet processing unit 4b...e, 5b...r, 6b...e can with can't connect for some other circuit blocks that each processing unit (for example, routing table) duplicates such as database etc. too big (or expensive).Similarly, some informational needs are upgraded or sampling (for example, statistical information or control information) by many streamlines.Therefore, can add a plurality of so-called shared resource SR1-SR4 that processing unit can communicate with.According to an aspect of the present invention, provide particular communication foundation structure so that processing unit is communicated by letter with shared resource.Because shared resource can be away from processing unit, and because they handle the request of a plurality of processors, therefore, ask and reply between stand-by period can be very long.Specifically, one or more shared resources can be visited through single bus 8a, 8b, 8c, 8d, 8e and 8f at least one unit among processing unit 4b...e, 5b...e, the 6b...e, for example, processing unit 4b, 5b, 6b are through bus 8a visit SR1, and processing unit 4b, 5b, 6b and 4c, 5c, 6c and 4e, 5e, 6e are respectively through bus 8b, 8c and 8d visit SR2.Bus 8 can be any suitable bus, and the form of this bus is not considered as limitation of the present invention. Inlet packet buffer 4a, 5a, 6a and/or outlet packet buffer 4f, 5f, 6f can be located at respectively and handle before the streamline and/or afterwards.A function of packet buffer can be to adapt to the data path bandwidth.The main task of packet buffer is that the primary data path communication bandwidth is transformed into the streamline communication bandwidth from network 1.In addition, can provide some other functions in the packet buffer, search as expense insertion/removal and task.Packet buffer preferably can cushion single header (it comprises packet header at least).It guarantee receive and transmitter side on to the linear speed data transmission of the same big burst with header.
As shown in Fig. 1 a, for example the input of transmitting from communication network 1 divides into groups to be cut apart with the sequence number distributor to be divided into header and afterbody, and this device is preferably in the scheduling unit 2 and implements.Header comprises packet header, and afterbody comprises to small part grouping Payload.One of header feed-in streamline 4-6, and Payload storage (buffering) to suitable storage device 9 as among the FIFO.After processing, header and Payload reconfigure (grouping merges) in recomposition unit 3, and output for example, before sending to another node by network 1, can cushion therein then.
Usually, one or more shared resource SR1-4 can be used for handling the path, are the specific task of the processing unit processes in the streamline.For example, these shared resources can be to use the special use of the data structure of storing in the outer resource of chip to search engine, or are used for the specialized hardware that the special function of information is shared in the needs visit.The present invention in following situation for raising the efficiency advantageous particularly: respond until relevant shared resource if each processing unit suspends, and these stand-by period of shared resource engine response request that will be used for treatment system are very long, and this stand-by period causes the pipeline processes unit efficiencies to descend.Can be used for typical shared resource of the present invention and be that IP transmits, MPLS transmits, control database, statistical information data storehouse.For example, the function of carrying out by the auxiliary pipeline organization of shared resource can for:
IPv4/IPv6 title analysis and forwarding
The classification of multiword section
The MPLS label is analyzed and exchange
IPinIP or gre tunneling termination
MPLS tunnel termination
IPinIP or gre tunneling encapsulation
The MPLS tunnel encapsulation
Metering is collected with statistical information
ECMP and relaying support
The QoS model supports
For this reason, pipeline organization can be auxiliary by following shared resource:
32 or 128 longest prefix match unit
The TCAM sorter
SRAM on the outer DRAM of chip, the outer SRAM of chip, the chip
The accurate matching unit of 6B or 18B
32 or 128 potential source filters (longest prefix match unit)
Metering units
An aspect using shared resource is the dwell time of processing unit when waiting for the replying of the request that sends to shared resource.For making processing unit abandon a current pending task, switch to another task, return first task then, normally provide context to switch, i.e. the content of storage of processor location register.One aspect of the present invention is to adopt hardware-accelerated context to switch.This also allows processor cores to be used for self not being equipped with the processing unit of hardware handoff functionality.This hardware is preferably in each processing node and provides, and for example, provides with the form of communication engines.Each processing unit is safeguarded grouping to be processed pond.When sending the shared resource request, the processing unit of relevant treatment unit switches to another grouping with context, until receiving replying of this request.One aspect of the present invention is to utilize the packet transaction concurrency, and like this, efficient that can be high is as far as possible used processing unit, carries out useful processing, thereby avoids waiting for that I/O (output/output) operates finishes.For example, these I/O operation is that request shared resource or grouping information copied in the processing unit or therefrom copies out.The present invention partly depends on the following fact: when initiating the shared resource request in the network element of packet-switched telecommunication network, have purposes context seldom usually, perhaps can drop to useful context minimum by the task programming of wisdom.Switching is to handle the good working condition that another grouping might not require to preserve processing unit.Wise programming can comprise that the program organization that will move is the function call sequence on each processing unit, be invoked at when moving on the processing unit to have context at every turn, but do not need to call between function.Exception is the context that provides of data in the part of grouping itself or grouping.
Get back to Fig. 1 a and 1b and segmenting device 15, the size of header is through selecting, so that it comprises all related headings that receive with grouping.For example, this can finish (behind the maximum sized title of being supported) by cutting apart at the fixing point of grouping.This can cause some Payloads to be split in the header.Owing to do not handle Payload usually, so this does not generally have problem.Yet, present invention includes the possibility of handling Payload, for example, be used for network rate control.Grouped data comprise can multiple decomposition data the time, under situation about allowing, decide on the forwarded bandwidth of node, network can be with data truncation, thereby has lower resolution.For handling this type of situation, the present invention has comprised more accurate grouping assessment in its scope, with identification title and Payload, and neatly they is cut apart in its junction.Streamline is handled in header (or title) feed-in that separates, and afterbody (or Payload) is then cushioned (and adopting other processing unit that does not show to handle arbitrarily) and append to (modification) header again after processing.
After cutting apart, then header is offered a processing streamline, and afterbody is stored in the memory such as FIFO9.Each grouping is best to distribute a sequence number by sequence number distribution module 15.Subsequently this sequence number is copied in the afterbody of header and each grouping and stored.Described sequence number has following three purposes:
Ressemble (revising the back) header and afterbody at the streamline end
Deletion header and corresponding afterbody thereof when needing
The particular order that keeps grouping when needing
Sequence number can be generated by the counter that comprises in packet fragmentation and the sequence number distributor 15.The preface counter increases progressively with each input grouping.Like this, sequence number is used in the streamline end and places grouping with particular order.
The expense maker is arranged in the packet scheduler 2, perhaps is preferably disposed among packet buffer 4a, 5a, the 6a, so that the new/additional expense that is that each header and/or afterbody generate.After generating complete header, header can be sent to one of streamline 4-6 with available buffer space.Afterbody sends to afterbody FIFO9.
According to embodiments of the invention, the expense of increase is included in the management data in header and/or the afterbody.Schematically shown handling process among Fig. 2 a.At afterbody, new expense preferably comprises sequence number and length, i.e. the length of Payload, and comprise quoting alternatively to the streamline that is used to handle corresponding header.In header, the expense of increase preferably includes header management fields (HAF) and stores by the result of packet transaction streamline generation and the zone of state.Therefore, header can comprise storage as a result, state storage and management data storage.HAF can comprise header length, skew, sequence number and execution FIFO maintenance and header is selected necessary a plurality of field.
Fig. 2 b has shown another group operation that the grouping in the treatment facility is carried out.Can add the interim working area that can be used for storing intermediate object program in each header front by pipeline processes.It also can be used for making up packet descriptor, and packet descriptor can be used by the downstream device of packet processing unit.Shown in Fig. 2 b, packet buffer 4a, 5a, 6a that every streamline begins to locate can add this interim working area in the packet header to.Packet buffer 4f, 5f endways, 6f can delete its (to small part deletion).When grouping entered packet processing unit, title comprised some link layer informations that define packet oriented protocol.This will be converted to the pointer of first task that sensing will carry out grouping by packet processing unit.This search operation can be carried out by inlet packet buffer 4a, 5a, 6a.
One aspect of the present invention is, header comprises and will be quoted by task current and/or that next processing unit is carried out in streamline the time.Like this, the contextual part of processor unit is stored in the header.That is to say that the current version of HAF is equivalent to treatment state in the header, comprise the indication of next process that will carry out this header.Header itself also can be stored inline data, and for example, the median of variable can be stored in the interim working area.For providing necessary all information of its context, processing unit therefore is stored in the header.When header longshore current waterline moved down, context is to be stored in the header relevant portion, and was mobile with header as the form of the data in HAF, the interim working area.Therefore, an innovation aspect of the present invention is that context moves with grouping, rather than context is motionless with respect to certain processor.
Grouping recombination module 3 reconfigures from handling packet header that streamline 4-6 transmits and the corresponding afterbody that transmits from afterbody FIFO9.Packet network can divide be slit into can the network (datagram network) that on each node each grouping is carried out independent route and wherein set up virtual circuit and source and destination between grouping use the network of one of these virtual circuits.Therefore, view network and deciding has different requirements to packet sequencing.Recombination module 3 guarantees that the arrival of dividing into groups with them leaves in proper order, or leaves in proper order with required any other.The device that grouping recombination module 3 has the sequence number of following the tracks of the last grouping that sends.The output of its search different disposal streamline has the header that can send sequence number to search, and the end of search FIFO9 to be to check the afterbody that can be used for transmitting, for example, and next sequence number.For simplifying the operation, preferably strict the processing according to sequence number divided into groups in streamline, and like this, header and corresponding afterbody thereof are simultaneously available in recombination module 3.Therefore, it is strict with the sequence number operation that provides preferably to be used for handling the device that streamline divides into groups.Subsequently, after suitable header propagates into streamline output, can in recombination module 3 it be added in the corresponding afterbody, this afterbody is first clauses and subclauses among the afterbody FIFO9 at that time preferably.Recomposition unit 3 or outlet packet buffer 4f, 5f, 6f delete remaining HAF and other field from header.
When grouping must abandon, processing unit had the device that is used for will abandoning header setting the indication of header, and for example, it can be provided with in packet overhead and abandon sign.Recombination module 3 is responsible for abandoning this header and corresponding afterbody subsequently.
Fig. 3 has schematically shown a streamline 4 according to the embodiment of the invention.Packet header is preferably under the situation that is subjected to the processing unit minimum of interference, handles level along multiple bus from one and is delivered to another processing level.In addition, processing unit needs can continue to handle grouping during transmitting.Each processing unit 4b...4d preferably includes processing unit 14b-14d and communication engines 11b-11d.Communication engines available hardware such as configurable Digital Logic unit realize, and processing unit can comprise processing kernel able to programme, but the invention is not restricted to this.For each processing unit 4b-4d has distributed certain private memory respectively.For example, the partial data memory of each processing unit is dual-ported memory preferably, for example, and two-port RAM 7b...7d or similar memory.An one port is used by communication engines 11b...11d, and the another port is connected to this processing unit of handling the unit.According to one embodiment of present invention, the header that communication engines 11b...11d stores among the operational store 7b...7d in some cases, to be woven to FIFO the same for this memory set seemingly.For this reason, header can be as storing with the logic OR physics mode in FIFO.In this way, the arrival order according to header is pressed into this memory and therefrom ejection with header.Yet, to decide on using, communication engines is not limited to use in this way memory 7b...7d, but can utilize all functions of this memory, for example, it is used as two-port RAM.The advantage that keeps first-in first-out relation between the header when handling header is that the grouping input sequence will keep automatically, thereby produces identical output order of packets.Yet the present invention is not limited to this, but comprise can be by the data storage of communication engines with random fashion visit.
Communication engines communicates each other to transmit header.Therefore, when each communication engines is prepared to receive new data, ready signal is sent to last communication engines or the circuit block before other.
According to the embodiment of the invention shown in Fig. 4 a, from the input port of RAM 7b...7d to output port, be provided with three memory areas: one comprises the header of handling and be ready for sending next stage, another comprises the header of handling, and the 3rd zone comprises the header that partly receives but prepare as yet to handle.RAM 7b...7d is divided into a plurality of equal-sized buffering area 37a-h.Each buffering area 37a-h only comprises a header.Shown in Fig. 4 b, each header comprises:
Header management fields (HAF): HAF comprises all required information of grouping management.It generally is 64 word lengths.Each buffering area 37a-h all has the device of storage HAF data.
Interim working area: but as the favored area of scratchpad, between processor, transmit Packet State, or make up the packet descriptor of the system of will leaving.Each buffering area 37a-h preferably all has the device in interim working area storage data.
Packet overhead: maybe will add the expense the grouping (encapsulation) to from sending out group deletion (going encapsulation).Each buffering area 37a-h preferably all has the device of stores packets expense.
Header packet data: the real header data of grouping.Each buffering area 37a-h preferably all has the device of storage header packet data.
The shared resource request: except that grouping, each buffering area provides certain space at the buffering area end for the shared resource request.Each buffering area 37a-h preferably all has the device of storage shared resource request.
HAF comprises grouping information (length) and treatment state and comprises the partial information of " layer 2 " (when existing) (for example, being at least code and " layer 3 " protocol number of indication physical interface type).
Communication module according to the embodiment of the invention can comprise scheduling unit 2, grouping recomposition unit 3, memory 9, communication engines 11b...d, two-port RAM 7b-d, optional packet buffer and arrive the suitable tie point of handling unit and shared resource.When communication module has been equipped with corresponding processing unit, just formed effective packet handling facilities.
Fig. 5 has schematically shown the processing unit according to the embodiment of the invention.Processing unit 4b comprises processing unit 14b, preferably is embodied as header buffer storage 7b, program storage 12b and the communication engines 11b of two-port RAM.Can be provided for the local storage 13b of processing unit.Program storage 12b is connected to processing unit 14b through instruction bus, and is used to be stored in the program that processing unit 14b goes up operation.Buffer storage 7b is connected to processing unit 14b by data/address bus 17b.Communication engines 11b is through controlling bus 18b monitor data bus, with the write-access of the arbitrary HAF in one of detecting from the processing unit to the buffering area.This allows communication engines 11b to monitor and upgrade the state of each buffering area in its internal register.Communication engines 11b is connected to buffer storage 7b by data ram bus 19b.Alternatively, one or more processing block (not shown)s can be included in processing unit 14b, for example, are included in the association's processing unit such as cryptographic block, so that reduce the load of processing unit 14b, in order to carry out the data-intensive task of repeatability.
Use the Xtensa kernel of handling kernel such as santa clara Tensilica, can realize treatment in accordance with the present invention parts 14b effectively.Have special hardware instructions to quicken the to be mapped to processor cores that this handles the function on the parts, between flexibility and performance, obtained well compromise.In addition, can add required processing unit hardware supports in the sort processor kernel, that is, processor cores does not need context to switch hardware supports.Processing unit 14b is connected to communication engines 11b-by system bus 20b and resets and interrupt and can transmit (preferably as shown in Figure 8) by independent control bus.From the angle of processing unit, data storage 7b is not FIFO, and the pond of just dividing into groups can adopt multiple different selection algorithm therefrom to select grouping to handle.
According to an aspect of the present invention, processing unit is synchronous, makes that buffering area 37a-h can overflow or underflow.Processing to header is finished on processing unit in good time.Grouping is removed once arriving from system, and therefore, processing will never can produce the needs to extra cushion space.Therefore, processing unit should be unable to produce buffering area and overflows.But handling grouping begins in enough data times spent only.When no header was fit to handle, hardware (communication engines) suspended processing unit.RAM 7b...7d provides the buffer-stored space, and allows the processing step of processing unit and streamline not have coupling.
Each processing unit can determine to abandon the part of grouping or strip header or some content is added in the header.For abandoning header, processing unit only needs will abandon flag set in HAF.This will produce two kinds of effects: header will no longer be fit to handle, and have only this HAF will be sent to next stage.Grouping reformer 3 receives and abandons bit during the header of set that it can abandon corresponding afterbody.
HAF has the offset field of the indication first associated byte position.In the input grouping, this will equal zero all the time.Be the part of strip header from the beginning, processing unit is pointed to drift marker to want first byte after the released part.Communication engines will be deleted the part that will peel off, and data are alignd with word boundary again, upgrade the length field among the HAF, and to make offset field be zero.Shown this situation among Fig. 7.The advantage of this process is the determining section that NextState that communication engines will read is positioned at HAF all the time, and therefore, communication engines (and processing unit) can be configured to same position among the visit HAF to obtain essential state information.And, can in HAF, insert the spaces with negative deviant more.The HAF front end is inserted in this space.
The addressable a plurality of shared resources of each processing unit, for example, be used for such as search, the shared resource of multiple-task such as control and statistical information.This visit is to be undertaken by the communication engines that is associated with each processing unit.Provide multiple bus 8a-f, so that communication engines is connected to shared resource.Identical bus 8a-f is used for the request of transmitting and replys.For example, each communication engines 11b is connected to a such bus 8 through shared resource bus interface 24b (SRBI-is referring to Fig. 8).Communication engines and data storage 7b can be configured bus 21 configurations.
Communication engines 11b is the unique channel that communicates of processing unit and resource except that its local storage 13b preferably.Communication engines 11b is controlled through control interface by main processing block 14b.The main task of communication engines 11b is that grouping is sent to next pipeline stages from a pipeline stages.In addition, it is implemented the context switching and communicates by letter with shared resource with main processing block 14b.
Communication engines 11b has the receiving interface 22b (Rx) of the last circuit block that is connected to streamline and is connected to the transmission interface 23b (Tx) of next circuit block in the streamline.Header to be processed is sent to another processing unit from a processing unit through communication engines and TX and RX interface 22b, 23b.If can be at specific processing unit for processing header, then can be for it is equipped with the tunnel field, the processing units quantity that this Field Definition will be ignored.
Each transmission/receiving interface 22b, 23b of the communication engines 11b that receives simultaneously and send is only with accesses data memory 7 in less than 50% clock cycle.This means that two are handled effective bandwidths between the level less than half of bus bandwidth.As long as streamline quantity is greater than 2, then this is enough.Yet first-class pipeline stage must receive burst with National Federation of Trade Unions's linear velocity when new packet header enters streamline.Similarly, last pipeline stages must produce grouping with National Federation of Trade Unions's linear velocity. Inlet packet buffer 4a, 5a, 6a are responsible for balanced these bursts.The inlet packet buffer receives a packet header with bus speed, with its oneself speed it is sent to first processor level then.During this period, can not receive new packet header. Outlet packet buffer 4f, 5f, 6f receive packet header from last processor level.After the reception, it sends to grouping recomposition unit 3 with bus speed with header.The inlet packet buffer can also have two special dutys:
Add packet overhead.
Interface type/protocol code in the packet header that receives is converted to the pointer that points to first task.Grouping " layer 2 " encapsulation comprises protocol fields, identification " layer 3 " agreement.Yet the meaning of this field depends on " layer 2 " agreement.Protocol fields need convert pointer to (" layer 2 " agreement, " layer 3 " agreement), and this pointed will be to the first task of this grouping execution.
The outlet packet buffer also has a special duty:
Deletion packet overhead (a part).
According to the present invention, comprised that a plurality of hardware expanding are to assist the FIFO management.
The fifo address skew.After knowing the FIFO position of the current header of handling, processing unit can be revised read/write address, grouping is seemed be positioned at fixed address.
Automatically header is selected.After receiving the simple request of processing engine, select accessible header by specialized hardware.
When communication engines had been selected new header, processing unit can use the single read access to obtain essential information.This information will be divided into different destination register (FIFO position, header length, agreement etc.).
As mentioned above, in one aspect of the invention, can provide hardware, to support very simple multitask scheme such as communication engines.The process that " context switching " moves on processing unit for example must be waited for replying of shared resource, finishes when perhaps header is prepared to be delivered to next stage.Hardware is responsible for selecting to prepare header to be processed based on HAF.Grouping is sent to another level through simply ready/allowed protocol or any other suitable agreement from one-level.Only transmit the buffering area part that comprises related data.For this reason, header is revised as comprises the guiding header and handle information necessary.According to embodiments of the invention, packet transaction is divided into a plurality of tasks.Each task is handled request responding usually and is generated new request.The pointer of next task is stored in the header.Each task is calculated earlier, stores the pointer of next task then.Each grouping has a state by represented Done (finishing) of two bits in the various combination and Ready (ready) definition.They have following connotation:
Done=0, Ready=0: the current response of waiting for shared resource of dividing into groups.Can't select it to be used for handling, also can not send it to the processing unit of next processing unit.
Done=0, Ready=1: grouping can be selected to be used for managing on the unit herein handling.
Done=1, Ready=0: this processing of handling on the parts is finished.Grouping can send to the processing unit of next processing unit.
Done=1, Ready=1: do not use
The angle of the station management of postponing sees that the buffering area that comprises grouping can be under three kinds of different states:
Be ready to forward to next stage (Ready4Next)
Be ready to processed (Ready4Processing)
The wait shared resource is replied (Waiting)
Communication engines maintenance packets state, for example, by storing correlation behavior in register, and the grouping that will be under the Ready4Processing state offers the processor that is associated with it.Be in Ready4Next or Waiting state after being grouped in processing.When being in the Ready4Next state, communication engines sends to next stage with grouping.When being in the Waiting state, this state will become Ready4Processing or Ready4Next state by communication engines automatically when shared resource is replied arrival.
Communication engines is used to select new packet header.The selection of new packet header is triggered by processing unit, for example, is triggered by the processor read operation on the system bus.Current buffer pointer remains in the register, the current group that indication is just being handled by processing unit.
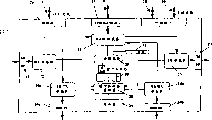
Fig. 8 has shown communication engines schematic diagram according to an embodiment of the invention.5 main tasks of communication engines can be summarized as follows:
Buffer management:
1) receiving terminal 22 (Rx): receive grouping and be pushed on the two-port RAM 7 from last processing node
2) transmitting terminal 23 (Tx): eject ready grouping and send to next unit from two-port RAM 7.
Multitask (context switching))
3) select the suitable new grouping of handling based on buffer state
The shared resource visit:
4) transmitting terminal 24a (Tx): according to the request of request mark tabulation assembling shared resource
5) receiving terminal 24b (Rx): handle and return replying of shared resource request.
Above-mentioned 5 functions have been expressed as 4 limited state machines (FSM32,33,34a, 34b) and Buffer Manager 28 in Fig. 8.Should be understood that this is the functional description of communication engines piece and not necessarily relevant with the actual physical unit.The limited state machine of communication engines shown in Fig. 8 is represented and can be realized in hardware block by standard process techniques.For example, this expression is convertible into such as hardware description languages such as Verilog or VHDL, and can generate the net table such as the gate array of hardware block subsequently from the VHDL source code automatically.
The master data structure of being handled by communication engines (be listed in relate to maximum tasks after) is:
-buffer management: the data structure of class FIFO in the buffering area of two-port RAM
-reception header: the write pointer of storing in the write pointer register
-transmit head: the read pointer of storing in the read pointer register
-multitask: have following state: empty (sky), transmit ready (Ready for transfer), handle ready (Ready for processing), transmit ready hang-up (Ready for tranfer pending), handle ready hang-up (Readyfor processing pending) and add the buffer status vector of waiting for one of level (waiting for level), all states all are stored in the buffer state register
Current buffering area in the current buffer register,
New grouping register: preparation will be by the HAF and the buffering zone position of next grouping of processor processing.
-SR (shared resource) visit: during handling, request is lined up in packet buffer RAM
-transmitting terminal (23a): safeguard shared resource request FIFO, promptly when the assembling request, allow the buffering area of other processing
The other parts of communication engines are:
The moderator 25 of-RAM: many functional units of communication engines share to the bus 19 of RAM7
The configuration field figure of communication engines and buffering area among-configuration interface 26 and the RAM7.Control interface 26 can be used for the configuration communication engine, for example, and register and random access memory size.
A port of data storage 7 is connected to communication engines 11 through data storage (DM) RAM interface 27 and bus 19.During normal running, this bus 19 is used for filling with the data of the RX interface 22 that arrives communication engines 11 the packet buffer 37a-h of memory 7, perhaps it is emptied TX interface 23, and these two kinds of operations are all undertaken by RAM moderator 25.25 pairs of functional units of moderator (FSM): SR RX 34b, SR TX 34a, next divides group selection 29, receive 32, organized and be ranked priority treatment in proper order to the visit of DM RAM7 between sending 33.
Each processor unit 14 is addressable to be used to search, a plurality of shared resources of control and statistical information.Provide multiple bus 8, so that processing unit 14 is connected to shared resource.Same bus 8 can be used for the request of transmitting and replys.Each communication engines 11b is connected to this type of bus through shared resource bus interface 24b (SRBI).
Each communication engines 11 is safeguarded a plurality of packet buffer 37a-h.Each buffering area can comprise a grouping,, has the device of a grouping of storage that is.At minute group of received and transmission, buffering area is handled as FIFO, therefore, order of packets remains unchanged.Grouping enters from RX interface 22, and leaves by TX interface 23.The starting point of the quantity of buffering area, buffer size and buffering area is by control interface 26 configurations in the data storage 7.Buffer size is 2 power all the time, and the buffering area starting point is always the multiple of buffer size.Like this, each storage address can easily resolve into the skew in buffering area numbering and the buffering area.Each buffering area can comprise the data of a grouping.The write access of 14 pairs of buffering areas of processing unit is monitored through controlling bus 18 by communication engines 11, and correspondingly upgrades buffer state in the buffer state register.Buffer Manager 28 is safeguarded 4 pointers in register 35, two pointed buffering areas wherein, and two other points to the specific word in buffering area:
Receive write pointer: point to next word that will write when receiving data.After resetting, it points to first word of first buffering area.
Send write pointer: point to next word that will read when sending data.After resetting, it points to first word of first buffering area.
Send buffer pointer at last: point to the last buffering area that sends, perhaps point to the buffering area that is sending, promptly first word that reads certain buffering area just upgrades it to point to this buffering area.After resetting, it points to last buffering area.
Current buffer pointer: point to the buffering area that current processor is using.Whether the current buffering area effective marker that is associated indicates the content of current buffering area effective.When handling any grouping, current buffering area effectively can not be eliminated processing unit.
Fig. 9 has schematically shown various pointers.
In buffer state register 30, safeguard the state of corresponding each buffering area.Each buffering area is in one of following 5 kinds of states:
Empty: buffering area does not comprise grouping.
Transmit ready: the grouping in the buffering area can be sent to next processor level.
Handle ready: the grouping in the buffering area can be handled by processor selection.
ReadyForTransferWSRPending: when all shared resource requests all had been sent out, grouping must forward the transmission ready state to.
ReadyForProcessingWSRPending: when all shared resource requests all had been sent out, grouping must forward the transmission ready state to.
Except that state, in register 35, safeguard that for each buffering area is waited for a level.Wait for that level is not equal to null representation and is grouped in a certain incident of wait, neither should transfer processor, also should not send.Usually, wait for the quantity of the ongoing shared resource request of level expression.After resetting, all buffering areas all are in dummy status.After packet integrity received, the grouping that needs are handled the buffer state of stores packets is updated to the processing ready state, and for the grouping that does not need to handle (for example, the grouping that abandons), this buffering area then was updated to the transmission ready state.For arbitrary input grouping, the wait level of buffering area is made as zero.
After handling grouping, processor 14 writes HAF by transmitting with shared resource request bit, promptly in the associated buffer of two-port RAM 7, thereby upgrades the buffer state of this grouping.This write operation is monitored through controlling bus 18 by communication engines 11.Processor 14 can not place the ready or transmission ready state of processing with buffering area when having the shared resource request to send, perhaps place ReadyForTransferWSRPending or ReadyForProcessingWSRPending state when having request to send.All requests one send, and buffer state is just at once from ReadyForTransferWSRPending or the echo-plex of ReadyForProcessingWSRPending state is ready or handle ready state.Read pointer arrive new buffering area begin to locate the time, its can wait for before reading and send grouping, enters until this buffering area and transmits ready state and wait for and grade equalling zero.Send at the beginning, buffer state is made as sky immediately.This assurance can't be selected grouping (because write pointer will never be crossed read pointer, therefore, even if buffering area is in dummy status, also can cover and not send data) again.
As long as there is buffer empty, just can receive the input data from the RX interface.When write pointer arrived read pointer, buffering area was full (because read pointer is equal to write pointer under two states, it is full up and empty therefore to need extra mark to distinguish).
When read pointer sensing buffering area, and this buffering area enters the transmission ready state and wait for that level can trigger the transmission of dividing into groups when being zero.At first, buffer state is made as sky, subsequently, and from RAM reading and sending HAF and interim working area.Only comprising the word that will peel off expense is left in the basket.Subsequently, before transmission, read and the remainder of the grouped data of aliging again, to delete the residue overhead byte in first word.Yet, if being provided with it, grouping abandons sign, do not read this grouped data.After grouping sent, read pointer jumped to the place that begins of next buffering area.
Communication engines is safeguarded current buffer pointer, and it points to the packet buffer of processing unit when pre-treatment.The effective marker that is associated indicates the content of current buffering area effective.If processor is not being handled grouping, then effective marker is made as vacation.Have 5 kinds of different algorithms to can be used for selecting new grouping:
First grouping (0): return the buffering area that comprises the oldest grouping.
Next grouping (1): return current buffering area first buffering area afterwards that comprises grouping.If there is not current buffering area, then as first grouping algorithm, work.
First can handle grouping (2): return to comprise and be in the buffering area of handling the oldest grouping under the ready state.
Next can handle grouping (3): return current buffering area first buffering area afterwards that comprises the grouping that is under the processing ready state.If there is not current buffering area, then can handles grouping algorithm and work as first.
Next buffering area (4): return current buffering area first buffering area afterwards.If there is not current buffering area, then return first buffering area.
When processor was finished the processing of a buffering area, it is specified will be to next task of this grouping execution.This finishes by write following field in grouping HAF:
Task: the pointer that points to next task.
Tunnel:, this field is set then if next task is not managed on device or next processor herein.
Grouping abandons: if need be dropped then this field is set.Make task and tunnel field invalid.
Transmit: if next task on another processor, then is provided with this field; If next task is on same processor then with this field zero clearing.
Shared resource request:, this field is set then if before switching to next task, must finish the shared resource visit.
Transmit and shared resource request bit write memory not only, also by communication engines through the XLMI interface monitoring.This is used to upgrade buffer state:
Shared resource request=0, and transmit=0: handle ready
Shared resource request=0, and transmit=1: transmit ready
Shared resource request=1, and transmission=0:ReadyForProcessingWSRPending
Shared resource request=1, and transmission=1:ReadyForTransferWSRPending
Immediately: the data that send are the parts of request mark.This is applicable to the request that only comprises low volume data.Be stored in the position (skew) or the acquiescence skew (acquiescence) of offset field indication in the request mark at replying of request.
Memory: the storage that send is in memory.Request mark comprises the position and the size of data.Two kinds of request types are provided: in one type, data are arranged in packet buffer (relatively); And in another kind of type, absolute memory address (definitely) is pointed in the position.The position that must be stored in the buffering area is replied in the offset field indication.
Sequencer: little sequencer is collected data from all groupings, and makes up request.Request mark comprises the pointer that sensing sequencer program begins.The position that must be stored in the buffering area is replied in the offset field indication.
The shared resource request mark can comprise following field:
Request type: the type of determining request as mentioned above.
Resource: the resource identification of addressing
Success bit: the index of the successful bit that use (vide infra)
Order: if set, then expression need not this request made and replys.If zero clearing expects to have and replys.
Indicate at last: for the last-minute plea sign of grouping is established.For the then zero clearing of other request mark.
Skew: that asks in the buffering area replys the position that must deposit.Skew is unit with the byte, from the section start of buffering area.
Ending skew (EndOffset): if be provided with, the position that must locate of the indication ending of replying then.Being offset from is first byte of pointing to after replying.If zero clearing, then the position that first byte reply must be deposited is pointed in skew.
Data: the data that will send in the request are used for instant request.
The address: the residing position of the data that send (absolute address` or the relative address that begins to locate with respect to packet buffer) is used for memory requests.
Length: the number of words that send is used for memory requests.
Program: the start address of the program that sequencer will be carried out.
After request mark was placed buffer storage 7, processor indicated to have these signs (this finishes usually) when upgrading HAF for next task by with the shared resource request bit set among the HAF.
Can check the shared resource request bit among the HAF during processor buffer release district (by the buffering area that please look for novelty).This can finish by the assessment buffer state.If be provided with, then the buffering area numbering with this grouping is pressed into little FIFO, i.e. among the shared resource request FIFO.When this FIFO when full, when new grouping request is arranged, can return idle task, overflow avoiding.SR TX state machine 34a (Fig. 8) ejects the buffering area numbering from shared resource request FIFO.It begins to resolve the request mark the buffering area subsequently from location superlatively, up to running into the request mark that its Last bit is set.Subsequently, from FIFO, eject next buffering area numbering, till not having clauses and subclauses again and can using.During each analysis request sign, the request of correspondence can be put together and send to SRBI bus 24a.When being provided with the shared resource request bit of HAF, the value according to transmitting bit is made as ReadyForTransferWSRPending or ReadyForProcessingWSRPending with the corresponding buffer region state.As long as buffering area is in one of these states, it just is unsuitable for sending or handling.
No matter when send non-command request, wait for that the level field value can add 1.Receive when replying that it can subtract 1.After all requests sent, buffer state was made as and transmits ready (when from the ReadyForTransferWSRPending state) or handle ready (when from the ReadyForProcessingWSRPending state).This mechanism guarantees be no earlier than following moment transmission or handling grouping (adopt next can handle grouping algorithm/first and can handle grouping algorithm) only:
All requests all send
All that have sent request are replied all and are arrived.
The destination address of replying is by shared resource bus socket (bus socket) decoding.Replying by communication engines of local address of coupling receives through SRBI RX interface 24b.Response header comprises must store the buffering area numbering and the skew of replying.Based on this, communication engines can calculate absolute memory address.The data division of replying receives from SRBI bus 8, and stores in the data storage 7.When all data have all been stored, can read-revise-write operation by the HAF in the addressable buffering area is carried out, thereby upgrade successful bit (vide infra), last, make the wait level field value of this buffering area subtract 1.
Some shared resource requests can success or status of fail finish that (for example, accurately mating resource compares an address and address list.Coupling is returned identifier, does not match and returns status of fail).Adding set is to propagate into this HAF of related grouping.Be provided with a plurality of bits in HAF, for example 5 bits are used to catch the result of different requests.Therefore, request mark must appointment will use which bit in described 5 bits.Shared resource can also place chain, and promptly the result of first shared resource is the request of second shared resource, and by that analogy.Therefore each shared resource in these shared resources can have success or status of fail, may need its oneself successful bit.Be noted that importantly that when resource stops with status of fail the request chain can interrupt.In this case, the resource of failure is directly replied it and is sent to the communication engines that starts.
When handling grouping, the processing unit 14 that is associated with communication engines 11 can be sent one or more requests to shared resource by making communication engines 11 in the buffering area that essential request mark is write associated packets.For example, each request mark is for example single 64 bit words, and will impel the shared resource request that generates.Assembling request and the process that sends it to shared resource are preferably in when processor is no longer handled grouping and begin.Grouping only just can be selected to be handled after all that transmit from shared resource are replied arrival once more.This has guaranteed that processor and communication engines will never revise single buffering area simultaneously.
The shared resource request is called by solicited message is sent to the communication engines that is associated together with the information of next operation from processing unit.Next operation information is to discern the pointer of next operation that need carry out in this grouping and the option that indication need transmit the packet to next processing unit for this operation.Then, processing unit reads the pointer that needs the operation carried out subsequently.This selection is finished by same specialized hardware such as communication engines, this specialized hardware for the processing unit relevant with processing unit control with header copy into or copy out buffer storage 7.Thus, communication engines is also handled replying from shared resource.The shared resource request preferably includes sending quoting of processing of request parts.Comprise that when replying when shared resource returns, replying this quotes.This permission received communication engine will be replied and be write in the tram, promptly write in the relevant headers in its buffering area.Subsequently, processing unit jumps to the operation that identifies.Like this, the single-threaded model of transaction module for carrying out.Needs are not preserved the high cost context switching of all processing unit states, and promptly not needing may the high operation of cost on time or hardware.In addition, it has reduced the number of options of selecting this type of processing unit.The single-threaded model of carrying out is actually Infinite Cyclic as follows:
1. read operation information
2. jump to this operation
3. will will divide into groups to transfer next stage to the request format or the indication of shared resource
4. return step 1.
This programming model strict difinition like this subsequent operation that will carry out single grouping and will carry out these operations grade.The order of its undefined (operation, grouping) tuple of on single processing unit, carrying out.This is in proper order by shared resource timing and stand-by period decision, and so definite behavior is transparent to this programming model.
The strict difinition of this programming model allows that checking will be to the program code of the operation of grouping execution regularly and on the level of the details of stand-by period numeral not needing to comprise these.
How another embodiment of the present invention relates to access shared resources.Processing unit is connected through multiple bus with shared resource, for example, connects through two 64 bit wide buses.Each node (being assumed to be processing unit or shared resource) has the connection of one or more bus in these buses.The quantity of bus is determined by bandwidth requirement with the number of nodes that is connected to every bus.Each node preferably locks bus, connects to avoid long.This can realize at a high speed, but bring simultaneously the higher stand-by period.All nodes have identical priority, and arbitration is finished with distribution mode in each node.As long as detect end of packet on bus, each node just can insert grouping.When inserting grouping, incoming traffic is stopped.Suppose when actual bandwidth not too approaches available bandwidth this simple arbitration just enough and the stand-by period not too important.The latter is correct for packet handler, and the former can realize by suitable selection bus topology.
Shared resource can be connected to 2 bit wide buses as shown in figure 10.Processing unit P1 is arranged on the bus to P8, and can access shared resources SR1 and SR2; Processing unit P9 is arranged on the second bus to P16, and only with visit SR2; Processing unit P17, P19, P21, P23 are arranged on the three-bus to P24, and only with visit SR3; And processing unit P18, P20, P22, P24 be arranged on the 4th bus, and only with visit SR3.Processing node sends message mutually and communicates with shared resource by other node on shared bus.Each node on the bus has unique address.Idle whenever bus, each node just can insert grouping on bus.The destination node of grouping is taken grouping away from bus.Provide contention mechanism to avoid a conflict on the bus.Each is selected also to be handled by relevant shared resource along the request of bus transmission, and then response is placed on the bus.
Bus can adopt the bus of annular form but not bus type shown in Figure 10, and response can travel through along loop, until arriving relevant treatment unit/shared resource, at this moment, is received by this processing unit/shared resource.
Those skilled in the art is appreciated that by foregoing entering the meeting in group of handling streamline 4-6 triggers a series of operations of carrying out on the processing streamline of this grouping.Operation is defined as a bit of program (supposition is in hardware or software) code, and this section code was carried out on processing unit during some clock cycle, did not communicate by letter with next processing unit in the streamline alternately or not with any shared resource simultaneously.One is finished when operating in the request of receiving shared resource, perhaps finishes by grouping is handed over to next stage.Fig. 6 schematically illustrates this operation, shared resource request in a flowchart and shows the sequence that grouping is transferred.Earlier transmit packet header from scheduling unit.The processing unit of streamline first order processing unit is to this header executable operations.Subsequently, request shared resource SR1.In the time of wait acknowledge, header remains in the FIFO memory that is associated.Receiving when replying, carrying out second operation by same processing unit.Therefore, in a processing unit, can to same grouping carry out these the operation in several operations.When a processing unit finishes the processing of a header, the header of revising is sent to next stage, it is carried out further the operation.
Figure 11 has schematically shown the flow chart of the processing that processing unit in the streamline carries out grouping.As previously mentioned, in buffer storage 7, each buffering area may be in one of following possible buffer state:
Empty
R4P: handle ready
R4T: transmit ready
R4PwSRPending: it is ready that the shared resource request sends reprocessing
R4TwSRPending: the shared resource request sends the back and transmits ready
Wait for level: unsettled shared resource request quantity
Related bits among the HAF:
Transmit
The shared resource request
In step 100, new packet header appears at the receiving port of communication engines, if there is available (sky) buffer location in the memory, then receives packet header, and the state of available buffer is visited by Buffer Manager.If there is available buffer, then header data sends to memory in step 102, and is stored in step 104 in the suitable buffering area, promptly is stored on the suitable memory location.In step 106, if header is handled, then the buffer state in the buffer state register is updated to R4P (perhaps, for the packet header that does not need to handle from dummy status by communication engines, for example to abandon and carry out the packet header of tunnel processing, be updated to R4T).The longshore current waterline sends downwards along with packet header older in the buffering area obtains handling also further, and through after a while, present R4P packet header is just available.
In step 108, processing unit finishes the processing to last packet header, and to next packet header of communication engines request.Next divides group selection is to decide according to the buffer state that comprises in the buffer state register in step 110.If there is not the R4P packet header to use, then communication engines returns the free time to processor and replys.Processing unit will be carried out identical request once more, until obtaining busy replying.
In step 114, communication engines is visited next grouping register, and sends next packet header position, and the task pointer that is associated is also sent to processing unit.For allowing processing unit start immediately, next packet header position not only is provided in replying, and has given the task pointer that is associated.These data are parts of the HAF of next packet header to be processed, thereby need be to the read cycle of memory.Therefore, communication engines adds task pointer two tuples with the packet header position and upgrades new grouping register continuously in step 112, so that this HAF read operation is carried out outside the processing unit cycle budget.
In step 116, processing unit is handled packet header and is upgraded HAF field " transmission " and " shared resource request ".Communication engines monitoring data bus also monitors that according to this bus between processing unit and the memory notice buffer state manager upgrades buffer state in step 118.For example, if do not send the shared resource request, then the packet header state can be changed into R4P or R4T, if send the shared resource request, then can be changed into R4PwSRPending or R4TwSRPending.
In step 120, shared resource request co-pending the processing stage after trigger SR transmit status machine so that assembling and send the shared resource request that is listed in the buffering area end, i.e. request mark tabulation.In step 122, processed in sequence request ID.The indirect type request need be read from memory.In step 124, for opposite with order, each request of expectation echo reply, corresponding making waits for that the level counter increases progressively.
In step 126, SR accepting state machine result when receiving that SR replys, and in step 128 write memory, more particularly, write the buffer location that is associated with the respective packets header.In step 130, make and wait for that the level counter successively decreases.
Finally, when all the request all sent and all reply all received after, in step 132, the packet header state is made as R4P or R4T.In buffering area, packet header data stream has been adopted the processing method of first-in first-out.In step 134, when the oldest current packet header state became " R4T ", the transmit status machine can output to transmit port with this packet header subsequently.
The treatment in accordance with the present invention streamline satisfies following the requirement:
Communication overhead is very low, to satisfy very limited cycle budget
Can support will not the to divide into groups option of rearrangement
Remain unchanged, therefrom peel off information in the packet header size or add therein under the situation of information, the header by streamline correspondingly keeps identical size, dwindles or increases; Streamline makes next related heading align again with processor word boundary all the time.This appears on the fixed position among the FIFO memory 7b...7d title of winning, and this has simplified software.
Processing unit can read, peels off and revise header; The uninterested project of processing unit can be sent to next stage and need not the processing unit intervention.Therefore, can not damage the Payload part of carrying in the title, and just with its forwarding.
Processing unit can abandon grouping.
Processing unit is synchronous.
Claims (44)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB0209670.9A GB0209670D0 (en) | 2002-04-26 | 2002-04-26 | Efficient packet processing pipelining device and method |
| GB0209670.9 | 2002-04-26 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1663188A true CN1663188A (en) | 2005-08-31 |
| CN100450050C CN100450050C (en) | 2009-01-07 |
Family
ID=9935632
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB038145227A Expired - Fee Related CN100450050C (en) | 2002-04-26 | 2003-04-25 | Efficient packet processing pipeline apparatus and method |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP1523829A4 (en) |
| CN (1) | CN100450050C (en) |
| AU (1) | AU2003228900A1 (en) |
| GB (1) | GB0209670D0 (en) |
| WO (1) | WO2003091857A2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103026679A (en) * | 2010-07-26 | 2013-04-03 | 惠普发展公司,有限责任合伙企业 | Mitigation of detected patterns in a network device |
| CN113364685A (en) * | 2021-05-17 | 2021-09-07 | 中国人民解放军国防科技大学 | Distributed MAC table item processing device and method |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018188738A1 (en) * | 2017-04-11 | 2018-10-18 | NEC Laboratories Europe GmbH | Packet handling method and apparatus for network service functions |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0771111B2 (en) * | 1985-09-13 | 1995-07-31 | 日本電気株式会社 | Packet exchange processor |
| US4899333A (en) * | 1988-03-31 | 1990-02-06 | American Telephone And Telegraph Company At&T Bell Laboratories | Architecture of the control of a high performance packet switching distribution network |
| US5341369A (en) * | 1992-02-11 | 1994-08-23 | Vitesse Semiconductor Corp. | Multichannel self-routing packet switching network architecture |
| US6182210B1 (en) * | 1997-12-16 | 2001-01-30 | Intel Corporation | Processor having multiple program counters and trace buffers outside an execution pipeline |
| US6286027B1 (en) * | 1998-11-30 | 2001-09-04 | Lucent Technologies Inc. | Two step thread creation with register renaming |
| US6341347B1 (en) * | 1999-05-11 | 2002-01-22 | Sun Microsystems, Inc. | Thread switch logic in a multiple-thread processor |
| US6625654B1 (en) * | 1999-12-28 | 2003-09-23 | Intel Corporation | Thread signaling in multi-threaded network processor |
| WO2002005499A1 (en) * | 2000-01-30 | 2002-01-17 | Celox Networks, Inc. | Device and method for packet formatting |
| US20020069402A1 (en) * | 2000-10-05 | 2002-06-06 | Nevill Edward Colles | Scheduling control within a system having mixed hardware and software based instruction execution |
-
2002
- 2002-04-26 GB GBGB0209670.9A patent/GB0209670D0/en not_active Ceased
-
2003
- 2003-04-25 WO PCT/US2003/014259 patent/WO2003091857A2/en not_active Ceased
- 2003-04-25 CN CNB038145227A patent/CN100450050C/en not_active Expired - Fee Related
- 2003-04-25 EP EP03726675A patent/EP1523829A4/en not_active Withdrawn
- 2003-04-25 AU AU2003228900A patent/AU2003228900A1/en not_active Abandoned
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103026679A (en) * | 2010-07-26 | 2013-04-03 | 惠普发展公司,有限责任合伙企业 | Mitigation of detected patterns in a network device |
| CN113364685A (en) * | 2021-05-17 | 2021-09-07 | 中国人民解放军国防科技大学 | Distributed MAC table item processing device and method |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1523829A2 (en) | 2005-04-20 |
| WO2003091857A3 (en) | 2003-12-11 |
| CN100450050C (en) | 2009-01-07 |
| AU2003228900A1 (en) | 2003-11-10 |
| WO2003091857A2 (en) | 2003-11-06 |
| WO2003091857A9 (en) | 2007-12-13 |
| AU2003228900A8 (en) | 2003-11-10 |
| GB0209670D0 (en) | 2002-06-05 |
| EP1523829A4 (en) | 2007-12-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11709702B2 (en) | Work conserving, load balancing, and scheduling | |
| CN1025518C (en) | Device and method for asynchronously transmitting control elements using pipeline interface | |
| CN1192314C (en) | SRAM controller for parallel processor architecture | |
| CN87106124A (en) | Multi-central processing unit interlocking device | |
| CN1249963C (en) | Equipment and method for fast and self adapting processing block by using block digest information | |
| CN1199109C (en) | Memory controller that improves bus utilization by reordering memory requests | |
| CN1910869A (en) | TCP/IP offload device with reduced sequential processing | |
| US20050232303A1 (en) | Efficient packet processing pipeline device and method | |
| US20060129699A1 (en) | Network interface adapter with shared data send resources | |
| CN1252144A (en) | Method for self-synchronizing configurable elements of programmable component | |
| US20050198410A1 (en) | Method, system and protocol that enable unrestricted user-level access to a network interface adapter | |
| CN101034469A (en) | Graphics processing unit pipeline synchronization and control system and method | |
| CN112084136A (en) | Queue cache management method, system, storage medium, computer device and application | |
| CN1285064A (en) | System for ordering load and store instructions that performs out-of-order multithread execution | |
| CN1348564A (en) | Method and apparatus for prioritization of access to extenal device | |
| CN1245922A (en) | Context controller with time slice task switching capability and its application processor | |
| CN1254058C (en) | Nod device and packing transmitting control method | |
| CN106878203B (en) | Fast forwarding circuit and method for FC switch chip | |
| CN1229954C (en) | Data distribution management device and data distribution management method | |
| CN1770110A (en) | Method, system and storage medium for lockless infinibandtm poll for I/O completion | |
| US20050147038A1 (en) | Method for optimizing queuing performance | |
| CN1677952A (en) | Method and apparatus for wire speed parallel forwarding of packets | |
| CN1638357A (en) | Memory management system having a linked list processor | |
| US9176912B2 (en) | Processor to message-based network interface using speculative techniques | |
| CN1663188A (en) | Efficient packet processing pipeline apparatus and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20090107 Termination date: 20100425 |