CN1282934A - 相似字选取和文件检索的方法和系统 - Google Patents
相似字选取和文件检索的方法和系统 Download PDFInfo
- Publication number
- CN1282934A CN1282934A CN00122279A CN00122279A CN1282934A CN 1282934 A CN1282934 A CN 1282934A CN 00122279 A CN00122279 A CN 00122279A CN 00122279 A CN00122279 A CN 00122279A CN 1282934 A CN1282934 A CN 1282934A
- Authority
- CN
- China
- Prior art keywords
- eigenvector
- word
- inquiry
- document data
- data bank
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



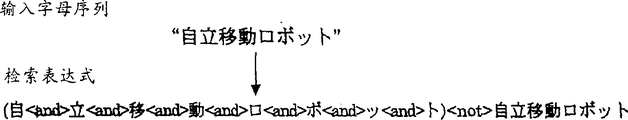

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
提供从文件的文件数据库选取给定字母序列的相似字。相似字的出现模式与给定序列的出现模式相似。准备一个特征矢量表,它包括文件数据库中每个字的第一特征矢量。通过检索相应于给定序列的文件数据库而得到有关给定序列的统计信息。从统计信息,计算相应于给定序列的第二特征矢量。计算第二特征矢量与每个第一特征矢量之间的相似度。选择产生相似度高于预定值的这种字。
Description
本发明一般地涉及文件检索系统,尤其涉及一种出现基于模式的相似字选取器以及其在查询扩展和多语言文件检索的应用。
由于因特网和个人计算机的的扩展,当大量文件已经计算机化和分发时,对文件进行电子搜索变得很普遍。通常,传统的文件检索系统参考用户输入的查询关键字并提供包含关键字的文件作为检索的结果。然而,由于可能存在许多用不同的表达方法描述相同主题事件的文件,对用户来说仅使用用户碰到的关键字来寻找所有这种符合他或她的要求的文件是很困难的。为了这个目的,到目前为止已经提议了各种查询扩展技术,这些技术为扩展检索的给出查询。
由于情况的改善,能通过因特网的扩散而访问世界上的信息,所以以用户母语以外的语言作出检索信息的请求正在日益增加。为了符合这种请求,近来,在多语言文件检索方法方面的研究正在增长。
在日本信息处理协会(IPSJ)的第52届全国会议的刊物中,“具有使用字网的查询扩展的信息检索系统”(1996,pp.4-201-4-202)是由Akamine等人提出的查询扩展技术的一个例子。在该系统中,通过使用固定的同义词词汇寻找查询项的同义名,并用找到的同义名来扩展查询。然而,由于找到的同义名和固定同义词词汇的词汇表有关,它不适用于特殊字段中的检索。
另一个查询扩展技术是由K.Saito等人在IPSJ研究组报告(信息研究基础47-10,1997,pp.67-74)的“基于概念的查询扩展”中提出的。在该系统中,使出现在文件数据库中的待检索的每个字在矢量空间上映射,它的大小相应于构成文件数据库的文件。在矢量空间中的两个字定义的矢量的内积确定两个字之间的相似度。得到与所要求的文件有关的相似字并使用于查询的扩展。
然而,对于未包含在字典词汇表中的字用刚才所述的查询扩展技术不能获得相似程度。为此,该技术不能应用于含有任何未包含在字典中的查询项的查询。
L.Ballesteros等人的“解决交叉语言检索的意义不明确”(ACM-SIGIR98,1998,pp.64-71)描述了多语言文件检索系统。在参考3中,通过使用包含一组文件和它们的一种或多种语言译文的平行文集(corpora),对于所给的源语言查询列出所有可能的目标语言译文。通过使用共同出现统计使列出的译文范围变窄而产生目标语言查询。
因为在这个多语言系统中假设使用一种或多种翻译词典,所选择的翻译和翻译词典的词汇有关,这意味着不能得到未包括在词汇中的项目的翻译。如果将系统用于象日文情况那样字之间未留间隔的一种语言的文件数据库,而且如果所给出的查询包括未包含在词汇表中的字母序列(通常是中文字符),则得不到字母序列的翻译。
本发明试图解决上述的和其它的问题,并使之成为一个目的,提供能够从预定文件数据库选取尚未被广泛接受的给定查询项目的相似字的相似字选取器。
本发明的另一个目的是提供装有相似字选取器的查询扩展技术。
本发明的再一个目的是提供装有相似字选取器的多语言文件检索系统。
根据本发明的一个方面,提供一种方法和一种系统,用于从文件的文件库选取字母的给定序列的相似字。相似字的出现模式与给定序列的出现模式相似。准备了一个特征矢量表,该表包含文件数据库中的每一个字的第一特征矢量。相应于给定序列,通过文件数据库的检索而得到在给定序列上的统计信息。从该统计信息计算相应于给定序列的第二特征矢量。计算第二特征矢量和每个第一特征矢量之间的相似度。选择产生的相似度大于预定值的这种字。
通过产生包括在文件数据库中的字的字组;通过从文件数据库产生索引文件(索引文件是这样的,可以从索引文件得到在文件数据库中使用的每个字的统计信息);以及通过计算每个来自索引文件的第一特征矢量来准备特征矢量表。为了得到统计信息,搜索给定序列的索引文件。
根据本发明的一个方面,提供一种查询扩展方法和系统,在包括第一文件数据库和检索器的文件检索装置中使用。扩展给定查询,馈送至检索器。为了这个目的,利用在给定查询中的查询字的相似字。从文件的第二文件数据库选取查询字的相似字。相似字的出现模式与查询字的出现模式相似。通过准备包含第二文件数据库中每个字的第一特征矢量的特征矢量表;通过相应于查询字的第二文件数据库的检索而得到查询字上的统计信息;通过对相应于来自统计信息的查询字的第二特征矢量的计算;通过计算第二特征矢量和每个第一特征矢量之间的相似度;以及选择产生的相似度大于预定值的这种字作为相似字;而得到相似字的选取。
第一和第二文件数据库最好是相同的东西。
根据本发明的另一个方面,提供一种译文选取方法和系统。对于源语言中的给定字,提供目标语言中的译文,致使如果两个文件数据库中之一是另一个的译文,在源语言文件数据库中的给定字的出现模式和在目标语言文件数据库中的译文的出现模式是一样的。通过准备包含目标语言文件数据库中的每个字的第一特征矢量的特征矢量表;通过相应于查询字的源语言文件数据库的检索而得到查询字上的统计信息;通过对相应于来自统计信息的查询字的第二特征矢量的计算;通过计算第二特征矢量与每个第一特征矢量之间的相似度;以及选择产生的相似度大于预定值的这种目标语言字作为译文;而得到目标语言译文。
通过从目标语言文件数据库产生索引文件(索引文件是这样的,可以从索引文件得到在目标语言文件数据库中使用的每个字的统计信息);以及通过从索引文件计算给定字典(或给定字组)中每个字的第一特征矢量来准备特征矢量表。为了得到统计信息,搜索查询字的索引文件。
根据本发明的再一个方面,提供一种查询扩展方法和系统,在包括第一文件数据库和检索器的文件检索系统中使用。查询扩展手段将源语言查询转换成目标语言查询,馈送至检索器。通过从目标语言文件的第二文件数据库选取源语言查询中每个查询字的译文;以及通过以查询字的译文来代替在源语言查询中的每个查询字而得到查询扩展。译文的出现模式与查询字的出现模式相似。通过准备包含目标语言文件数据库中的每个字的第一特征矢量的特征矢量表;通过相应于查询字的源语言文件数据库的检索而得到查询字上的统计信息;通过对相应于来自统计信息的查询字的第二特征矢量的计算;通过计算第二特征矢量与每个第一特征矢量之间的相似度;以及选择产生的相似度大于预定值的这种目标语言字作为译文;而得到译文的选取。
根据本发明的一个方面,提供一种接收给定字母序列和提供具有足够适当划分的平分字母序列的方法。该方法包括下列步骤:对于包含所有字母序列但不包含字母序列本身的字母的检索文件形成检索表达式;从统计信息对检索表达式产生特征矢量,将该特征矢量称为“掩蔽特征矢量”;将字母序列划分成两个子序列,逐个地移动划分点以得到N-1组平分字母序列;对每个N-1组的平分字母序列的每一个计算特征矢量;用掩蔽特征矢量掩蔽每一个经计算的特征矢量并使经掩蔽经计算的特征矢量归一化;对每个N-1组计算相似度,把相似度定义为每个N-1组的平分字母序列的内积;以及输出相似度大于一个阈值的这种平分字母序列。
根据本发明的另一个方面,对于给定字,通过使用上述译文选取系统至少可以得到一个包括给定字的变量。为了达到这一点,通过使用译文选取系统首先得到关于给定字的译文。通过用含有第一语言文件数据库中每一个字的第三特征矢量的特征矢量表代替特征矢量表以及交换第一语言文件数据库和第二语言文件数据库来配置译文选取系统。通过使用所配置的译文选取系统,得到对于每一个译文的第二译文作为变量。
从下面对本发明的示例实施例和附图的描述,本发明的特征和优点将显而易见,其中:
图1是示意方框图,示出可以实施本发明的文件检索计算机系统的示例布局;
图2是示出本发明的相似字选取器的示例布局的图;
图3是流程图,示出在根据本发明的相似字选取器130的控制下处理器20执行的操作;
图4是示出特征矢量表160的示例结构的图;
图5是流程图,示出使用图3的相似字选取器130的查询扩展器的操作;
图6是示出译文选取系统1300a的布局的图,所述译文选取系统用于交叉语言检索的查询扩展器;
图7是结合选取器130执行的查询扩展程序31b的流程图;
图8是流程图,示出根据本发明的字母序列划分器的示例操作;
图9是示出关于字母序列“自律移动ロボツト”的检索表达式的例子的图;
图10是示出关于字母序列“自律移动ロボツト”的七组划分序列的图;
图11是示出步骤212的处理例子的图
图12是示出判定每个划分序列组的划分是否足以适宜的图;以及
图13是流程图,示出根据本发明的变量寻找器300的示例操作。
对于所有的图纸,当在多张图纸中示出同一个元件时,以同一个参考号来指定。
图1是示意方框图,示出可以实施本发明的文件检索计算机系统的示例布局。文件检索计算机系统1一般包括服务器10、通信媒体12和多个用户14。在系统1中,服务器接收来自(一般是远程的)用户14的查询并响应地将检索结果返回给用户。通信媒体12通常包括诸如因特网、局域网等的各种通信网络。虽然在图1中示出一种用户-服务器配置,但是本发明可以作为独立计算机系统实施,在这种情况下,将从图纸中删除通信媒体12和用户14。
服务器10一般是计算机,具有同时向几个用户提供文件检索服务所必需的容量和速度,它包括:一个或多个作为计算机核心的处理器和存储器20;存储各种程序和数据的海量存储器30;与用户14通信的通信接口40;用户接口50;以及允许管理器对服务器10进行操作的输入和输出装置60。海量存储器30最好包括硬盘(未示出),用于存储文件检索所必需的程序和数据。海量存储器30可以进一步包括,例如一个或多个光盘(未示出),用于存储文件数据库33。上述服务器10和/或元件20、30和40到60可以是任何合适的标准元件。
每个用户14可以是任何合适的终端或带诸如调制解调器或网络接口之类的通信接口(未示出)的个人计算机。
海量存储器30一般存储文件数据库/检索核心程序32和查询扩展器31,用于接收来自用户14的查询并提供根据下面描述的本发明的原理的查询的扩展版本。文件数据库/检索核心程序32和查询扩展器31可以是任何合适的文件数据库和任何合适的检索核心程序的组合,一般包括包含大量文件的文件数据库33、索引产生器34、来自数据库33的由索引产生器34产生的索引文件35以及通过使用索引文件35检索大多数和查询有关的文件的文件检索器36。
在说明下列解说性的实施例之前先定义几个所用的术语,这对较好地理解本发明是有帮助的。
除非另行表明,应把术语“文件”表示为完整的文件或它的任何部分,诸如标题、摘要、或一个或多个从句、句子或段落。
除非另行表明,应把术语“查询”表示为为了从文件数据库33选择文件子集的目的而输入的文本。查询一般包括多个逻辑表达式或自然语言形式的查询项目。每个查询项目是一种支持语言的字母序列,这种序列一般包括支持语言的一个或多个字。即,构成查询的每个字母序列可以是单个的字、复合的字、短语和其它多-字结构。根据所用的语言,单个字之间可以留有间隔也可以不留间隔。
除非另行表明,应把术语“字”包括单个字、复合字、短语和其它多-字结构。此外,术语“字”和“项目”通常可互换地使用。例如,项目和字包括名词、代名词、复合的名词性的词、名词短语、动词、副词、数字表达式和形容词。
下面,我们揭示:
(1)相似字选取器;
(2)使用相似字选取器的查询扩展器(31a);
(3)查询扩展器(31b),它同支持与查询使用不同语言的文件数据库/检索核心程序32相适配(例如,语言交叉语言检索的查询扩展器);
(4)字母序列划分器;
(5)变量(或等效字)寻找器;以及
(6)根据相似字选取器和结合字母序列划分器和变量寻找器的较佳查询扩展器(31c)。
相似字选取器、字母序列划分器和变量寻找器是用于查询扩展器31中的有力工具。从下面的说明可以看到,用相似字选取器来实现字母序列划分器和变量寻找器。
相似字选取器
图2是示出根据本发明的相似字选取器系统1300的示例布局图。在图2中,从源到目的地画出的一路箭头表示目的地的数据是从源得到的,而在表示程序的方框和表示数据结构的方框之间画出的两路箭头表示程序指数据结构。
在相似字选取的实际操作之前,最好从第二文件数据库33a准备在相似字选取操作中使用的第二索引文件134和特征矢量表160。
虽然第二文件数据库33a可能与文件数据库/检索核心程序32的文件数据库33不同,但是强烈地建议第二文件数据库33a应与文件数据库33相同。即使第二文件数据库33a和文件数据库33不同,第二文件数据库33a最好具有与文件数据库33的特征相同的特征,以提高选取字的正确度(即,相关性(relevance))。(为了这个原因,此后把第二文件数据库33a称为“文件数据库33a”或简称为“数据库33a”)。
另一方面,第二索引文件134没有必要和文件数据库/检索核心程序32的索引文件34相同。然而,要注意,最好这样安排第二索引文件134,当文件检索器136为了包含在来自用户14的查询中的查询项目而搜索第二索引文件134时,文件检索器136可以得到诸如在数据库33a中每个文件中的查询项目的出现频率(称之为“基于文件的项目频率”)和包含查询项目的文件数(即使查询项目是任何字母序列,即即使查询项目是字典中找不到的这种字)之类的统计信息。根据日本未审查专利申请第Hei-249354,本申请人可以实现这种索引文件134。
产生特征矢量表160如下。假设在数据库33a中的文件{Di |i=1,2,…,M}数是M;以及给出合适的字组(WORD SET)150,包括项目(或字){TjJ=1,2,…,N},其中N是在数据库33a中的字种类的总数。对于在字组150中的每个字Tj,计算M-维特征矢量tj。定义每个特征矢量tj为
tj=(w(j,1),w(j,2),…,w(j,i),…,w(j,M)) (1)
如从表达式(1)所看到,特征矢量tj的单元w(j,1),w(j,2),…,w(j,i),…,w(j,M)相应于文件D1,D2,…,Di,…,DM。根据本领域所公知的tf(j,i)*idf(j)计算(score)来计算特征矢量tj的第i个单元w(j,i)作为权重。“tf(j,i)”是在给定的文件中项目Tj的出现次数,而且被称为在文件Di中的项目Tj的“项目频率”。把“idf(j)”称为单元Tj的“逆文件频率”,并定义为:
idf(i,j)=log(M/dj)
其中dj是在文件中有项目Tj出现的文件数。(对于tf(j,i)*idf(j)计算的一步说明参考1983年McGraw-Hill出版公司的G.Saltion和M.J.McGilld的“现代信息检索介绍”)。在这种情况中,可以如此地归一化特征矢量tj,使之幅度或长度为1。这样,产生了特征矢量表160,而且现在已准备好相似字选取操作。
图3是流程图,示出处理器20在根据本发明的相似字选取器130的控制下执行的操作。响应于接收到来自远程用户14的查询,调用相似字选取器130。尽管在以下特定的例子中可获得给定查询中每个查询项目的相似字,应当注意,用与以下描述相同的方式可以获得给定查询自身的相似字。
如果收到所接收查询中的第k个查询项目qk,则处理器20根据接收到的查询项目qk搜索第二索引文件134,并在步骤136中输出每个文件Di的查询项目tf(qk,i)的项目频率和查询项目idf(qk)的逆文件频率。在步骤138中,处理器20从逆文件频率idf(qk)计算给定查询项目qk的特征矢量qk以及查询项目的项目频率tf(qk,1),tf(qk,2),…,tf(qk,M)。
步骤40对在特征矢量表160中应经受下列处理的记录作出标志。为了简化该步骤,最好如图4那样配置特征矢量表160的结构。特征矢量表160的每个记录可以包括:包括分类代码、子分类代码等的一个或多个分类字段(CATE1,CATE 2,…)168;以及包括表示对记录作出标志的特殊代码的标志字段166;以及字字段162和特征矢量字段164。如果在下一个步骤中要求仅对一个或多个特殊字段的字计算相似度,则在记录(在所述记录中分类字段168的值落在特殊字段上)的标志字段166中写入特殊代码。还有,如果要求从下面的处理排除查询项目本身,如果项目qk存在于特征矢量表160中,即在字组150中,则只要从查询项目qk的记录的标志字段166中除去特殊代码。
然而,应注意,经常不能在字组150或特征矢量表160中找到查询项目qk,只因为通过文件检索器136已经对于查询项目qk成功地得到逆文件频率和项目频率。这是因为如此地安排第二索引文件134,以致造成对于如上所述的任何查询项目qk得到逆文件频率和项目频率。换句话说,即使对于字组150中找不到的查询项目(或者即使对于查询本身),通过利用第二索引文件134的检索能够获得这种统计信息。
然后,步骤142计算算出的特征矢量qk和在特征矢量表160中的每个带标志的记录特征矢量之间的相似度。计算特征矢量之间的相似度作为特征矢量的内积。例如,查询项目“www”和字“internet”之间的相似度,即,SIM(www,internet)计算如下:
SIM(www,internet)
=1.10*0.15+0.00*0.00+0.12*0.01+…+0.07*0.10
=0.9
另一方面,使用诸如交互信息、t-计算(t-score)等统计信息可以计算矢量之间的相似度。对于交互信息和t-计算(t-score)的进一步的说明参阅K.W.Church和R.L.Mercer的“使用大文集的计算机化语言学的特殊版本的介绍”,(Computational Linguistics,Vol.19,No.1,1993,pp.1-24)。
步骤144将带标志记录字以计算得到的相似度为次序而分级。步骤146将相似性大于预定值的字作为相似字输出,并结束操作。在图2中,对于查询项目“www”,字“internet”和“HTML”作为相似字输出。
在上述实施例中,已经使用了在文件数据库33a中的所有的M个文件。然而,可以通过字段将数据库33a划分成相关字段的文件子集;为每个文件子集准各第二索引文件134和特征矢量表160;以及对于给定的字段,使用和给定字段相关的第二索引文件134和特征矢量表160。另一方面,可以对每个所需字段准备文件数据库33a、第二索引文件134和特征矢量表160。
在上述实施例中,在实际选取相似字之前已经准备了第二索引文件134和特征矢量表160。然而,如果字组150包含极少的字,则在步骤138中,可以在计算特征矢量之后产生第二索引文件134和特征矢量表160。
虽然已经使用字组150来产生特征矢量表160,但是也可以从数据库33a直接产生特征矢量表160。
字组150可以包含所有出现在文件数据库33a中的字或仅在一个或多个特殊字段中的字。通过限制字组150的词汇,相应地可以限制在特征矢量表160中的记录。
使用相似字选取器的查询扩展器
图5是流程图,说明使用图3的相似字选取器130的查询扩展器的操作,查询扩展器31a是图1的查询扩展器31的说明实施例。在图5中,步骤102从给定的查询中选择第一查询项目。步骤104通过使用相似字选取器130寻找所选择查询项目的相似字。步骤106以例如所找到的相似字的逻辑和来代替在查询中的所选择的查询项目。判定步骤108进行测试以观察在查询中的的项目是否已经被提取(或代替)。如果没有,则将控制传到步骤110,在该步骤中选择在给定的查询中的下一个项目并使控制返回步骤104。如果在步骤108中的测试结果是“是”,则将控制进到步骤112,在该步骤中将经扩展的查询传到文件检索器36并使操作终止。
在接收到经扩展的查询时,文件检索器36以传统的方法根据所接收到的经扩展的查询搜索索引文件35。
例如,为了知道有关在WW0W(万维网)上的搜索引擎,在客户处用户输入(www<and>“search engine(搜索引擎)”)作为查询,然后相似字选取器130将提供“internet(因特网)”作为查询项目“www”的相似字以及“retrieval(检索)”作为查询项目“search engine”的相似字,查询扩展器31相应地扩展查询(www<and>“search engine”)以提供经扩展的查询((www<or>internet)<and>(“search engine”<or>retrieval)。这使包含表达式“retrieval serviceson the internet(在因特网上检索服务)”的文件得到检索的结果。
在查询扩展器31a中,已经用相似字选取器130扩展了所有的查询项目。另一方面,只有在字组150中找不到的查询项目的项目才可以用字选取器130扩展。
已经把在步骤104中对所选查询项目找到的相似字代替在步骤106查询中所选的(或原始的)项目。另一方面,可以把所找到的相似字增加到原始项目中。
尽管查询扩展器3la已经扩展了在给定查询中知道的每个查询字,但是可以如此配置查询扩展器31a,即对相似字选取操作测试单个检索条件;将所产生的检索条件传送到相似字选取器130以获得相似字;并把所获得的相似字传送到文件检索器36。
交叉语言检索的查询扩展器
图6示出译文选取系统1300a的布局图,该系统在交叉语言检索的查询扩展器中使用。如从图6所见,译文选取系统1300a与图2的相似字选取系统1300极相似。
除了译文选取系统1300a采用源语言索引文件235而不是第二索引文件134之外,两个选取系统1300a和1300在实际选取操作方面是相同的。从SL文件数据库233传送源语言(SL)索引文件235。由于这个原因,以SL索引文件235代替第二索引文件134,就可以使图3的流程所示的相似字选取器130用于译文选取操作。还有,在该情况下,如果在步骤146中要输出多于一个的译文,则最好以逻辑积的形式来输出译文。
还有,与相似字选取系统1300的不同之处在于,特征矢量表160是由从TL文件数据库333产生的给定目标语言(TL)字组350和TL索引文件335两者产生的。图6的TL文件数据库333最好和图1的文件数据库33相同。然而,然而,文件数据库333可以不同于图1的文件数据库33,如果这样,则两个数据库333和33应具有相同的语言和相同的字段。
SL文件数据库233和TL文件数据库333必须互相作为译文。如果不能获得一个文件数据库的译文文本,通过另一个文件数据库333或233的机器译文分别可以得到一个文件数据库233或333。
图7是程序31b的流程图,当与在译文选取系统1300a中的译文选取器130结合而执行时,该程序作为交叉语言检索的查询扩展器而操作。根据收到的查询而执行查询扩展器程序31b。在图7的步骤122中,处理器20把给定的查询转换成“积的和”的形式。步骤124把在和中的每个积传送到选取器130,以得到结果(在该情况下的译文)。然后,步骤126把结果的逻辑和传送到文件检索器36。
这样,使查询扩展器程序31b适应于文件数据库/检索引擎32,它支持与查询所使用的语言(即源语言)不同的语言(即目标语言)。要注意,可以互换地使用查询扩展器31a和31b并可以被用作单种语言检索的查询扩展和交叉语言检索的查询扩展两种情况。尽管在步骤122中将给定查询转换为积的和的形式,但是可以将给定查询传送给查询扩展器130。
正如从图6可见,如果在客户处用户14输入日文(情报检索<or>情报抽出),它相应于英文的(“information retrieval”<or>“information extraction”),则在译文选取系统1300a中的选取器130对查询项目“情报检索”提供译文“information”和“retrieval”,而对查询项目“情报抽出”提供译文“information”和“extraction”。如果对查询项目选取多于一个的译文,则译文选取系统1300a的选取器130输出如上所述的逻辑积形式的译文。相应地,把检索情况
((information<and>retrieval)<or>(information<and>extraction))传送到文件检索器36。
如从图6可见,一旦已经产生特征矢量表160和SL索引文件235,就不再需要SL和TL数据库233和333、TL字组350和TL索引文件335。通过机器翻译在一种语言中的文件数据库来准备各种语言的特征矢量表160,一种查询扩展器适应于多语言文件检索。
字母序列划分器
图8是流程图,示出根据本发明的字母序列划分器200的示例操作。如果字母序列划分器200接收查询项目,即字母序列(例如,“L1L2L3…Ls,其中s是字母数目),则步骤202形成检索表达式
(L1<and>L2<and>L3…<and>Ls)<not>L1L2L3…Ls。
图9示出对字母序列“自律移动ロボツト”的这种检索表达式的例子。这是一个日文项目,意思是“自主移动机器人”。
步骤204检索满足检索表达式的文件并得到诸如在步骤136中描述的统计信息。步骤206产生用于检索表达式的特征矢量(称之为“掩蔽特征矢量”)。满足检索表达式的文件是诸如包括任何字母序列的字母但不包括字母序列本身之类的文件。例如,选择仅包含一个表达式“自律的に移动するロボツト”的文件,而不选择仅包含一个表达式“自律移动ロボツトにつぃて”的文件。
步骤208把字母序列划分成两部分,逐个地移动划分点以得到s-1组经划分的序列。可以通过词态分析的方法得到划分,如果它产生经划分的子序列。图10示出对于字母序列“自律移动ロボツト”的七组经划分的序列。步骤210对于在每组中每个经划分的序列计算特征矢量。例如对于一组经划分的序列(自、律移动ロボツト),步骤210计算对子序列“自”的特征矢量和对子序列“律移动ロボツ ト”的特征矢量。在相应于包括子序列“自”的文件的大小的元件中,对于子序列“自”的特征矢量具有正值。例如,在仅包含“自由の追求”的文件的大小中,对于子序列“自”的特征矢量具有正值。
然后,步骤212用在步骤206中得到的掩蔽特征矢量掩蔽每个经计算的特征矢量,并使经掩蔽的特征矢量归一化,以致长度为1。用掩蔽特征矢量对特征矢量进行掩蔽意味着留下相应于这种具有正值的特征矢量的元(如它们是的话)的特征矢量元件,而使其它特征矢量元为零。图11是示出步骤212的处理的例子。在图11中,用掩蔽特征矢量掩蔽一组(自、律移动ロボツト)的特征矢量。在图中,具有0值的元件或大小用“o”来表示,而具有正值的元或大小用“x”来表示。在该例子中的组合特征矢量中仅包含“自由の追求”的文件的大小、仅包含“自律移动ロボツト”的文件的大小等具有0值;而只有两个字母子序列“自”和“律移动ロボツト”独立地出现而彼此不连接的文件的大小才具有正值。
通过计算一组特征矢量的内积,步骤214寻找每一组的相似度。图12是示出经划分的序列组的图,由0.35的阈值来判断相应的相似度和相应的划分的适宜性。根据本实施例,如果在文件中更频繁地共同出现字母序列组的经划分的序列,则字母序列组的经划分的序列之间的相似度变成较高。由于在步骤202和212中排除包含如那样的字母序列的文件,经划分的序列频繁独立地出现产生较高的相似度。认为独立出现字母序列是它们自己有意义的那些。
步骤216输出相似度等于或大于阈值的字母序列的经划分的序列。由于在图12的例子中将阈值设置为0.35,判断(自律、移动ロボツト)和(自律移动、ロボツト )两个经划分的序列组有较佳较适宜的划分,并相应地输出。
如上所述,根据本发明的字母序列划分器200尝试对给定字母序列的所有可能的划分,以产生具有足够适宜度的平分字母序列。
在图5和7中具有标为“A”的点的路径上,可以利用字母序列划分器200。例如,在图5中,如果在字组150中没有找到项目,则从使用字母序列划分器200的项目得到平分字母序列,并代替项目而使用。变量寻找器
图13是流程图,示出根据本发明的变量寻找器300的示例操作。在图13中,步骤302把第一语言索引文件和第二语言特征矢量表160a附到图3的译文选取器130上。通过使用译文选取器130,步骤304寻找输入第一语言查询项目的第二语言译文。如果输入第一语言查询项目是,例如日文项目“ギリツャ”,它相应于英文字“Greek”,则假设得到第二语言(假定英文)翻译成“GREECE”作为译文。
然后,在步骤306,分别用译文选取器130中的第二语言索引文件和第一语言特征矢量表代替第一语言索引文件和第二语言特征矢量表。步骤308通过使用译文选取器130寻找每个第二语言译文的第一语言译文。在该步骤中,输入项目“GREECE”将产生三个译文“ギリ ツャ”、“ギリ ツャ”和“ギリツア”输出。在该情况下,对于输入项目“ギリツャ”得到这三个变量。
如果一个字有变量,则在文件中通常使用相同的表达式。由于在单个文件中使用变量较为困难,虽然这些变量彼此极相似,但是相似字选取器130通常不能选取这种变量。
根据本发明的变量寻找器300,可以得到与输入项目的第二语言译文相同的字母序列第二语言译文作为输入项目的变量。换言之,如果一个字有一个或多个第一语言的变量而第二语言只有一个相应于该字的表达式,则作为这种字群的成员,通过使用变量寻找器300可以得到其它的变量。
在图5和7中在标为“B”的点的路径上,可以利用变量寻找器300。特别,对以日文“katakana”字母写的字搜索所得到的查询,这些字趋向于具有变量。对于每个所找到的字,通过使用变量寻找器300来寻找变量,而使用所找到的变量的逻辑和以及原始字来代替原始字。这样做进一步扩展了查询,造成有效地检索文件的结果。
在本申请中提到的所有文章和参考文献(包括专利文献)的揭示内容在此整体地作为参考。
可以构成许多不同的本发明的实施例而不偏离本发明的精神和范围。不用说,本发明不限于本说明描述的特殊实施例,而是由所附的权利要求书所定义。
Claims (10)
1.一种从文件的文件数据库选取给定查询的相似字的方法,相似字的出现模式和给定查询的出现模式相似,所述方法包括下列步骤:
准备特征矢量表,它包含所述文件数据库中每个字的第一特征矢量;
通过检索相应于所述给定查询的所述文件数据库得到有关所述给定查询的统计信息;
从所述统计信息计算相应于所述给定查询的第二特征矢量;
计算所述第二特征矢量与每个所述第一特征矢量之间的相似度;以及
选择产生的相似度高于预定值的这种字。
2.如权利要求1所述的方法,其特征在于,准备特征矢量表的所述步骤包括下列步骤:
从所述文件数据库产生索引文件,所述索引文件是这样的,可以从所述索引文件得到在所述文件数据库中使用的每个字的统计信息;
从所述索引文件计算每个第一特征矢量,以及
其中所述得到统计信息的步骤包括搜索所述给定查询的所述索引文件的步骤。
3.一种从文件的文件数据库选取给定字母序列的相似字的方法,相似字的出现模式和给定序列的出现模式相似,所述方法包括下列步骤:
准备特征矢量表,它包含所述文件数据库中每个字的第一特征矢量;
通过检索相应于所述给定序列的所述文件数据库得到有关所述给定序列的统计信息;
从所述统计信息计算相应于所述给定序列的第二特征矢量;
计算所述第二特征矢量与每个所述第一特征矢量之间的相似度;以及
选择产生的相似度高于预定值的这种字。
4.在包括第一文件数据库和检索器的文件检索系统中,一种扩展给定查询以将经扩展的查询提供给检索器的方法,该方法包括下列步骤:
从文件的第二文件数据库选取所述给定查询的相似字或者所述给定查询中的查询字,所述相似字的出现模式与所述给定查询或所述查询字的出现模式是相似的;及
利用所述给定查询的所述相似字或所述给定查询的所述查询字;
其中选取所述相似字的所述步骤包括下列步骤:
准备特征矢量表,它包含所述第二文件数据库中每个字的第一特征矢量;
通过检索相应于所述查询或所述查询字的所述第二文件数据库得到有关所述查询或所述查询字的统计信息;
从所述统计信息计算相应于所述查询或所述查询字的第二特征矢量;
计算所述第二特征矢量与每个所述第一特征矢量之间的相似度;及
选择产生的相似度高于预定值的这种字作为所述相似字。
5.如权利要求4所述的方法,其特征在于,所述第一和第二文件数据库是相同的东西。
6.一种接收源语言中的任何给定字母序列和提供目标语言中的译文,致使在源语言文件数据库中所述给定序列的出现模式与在目标语言文件数据库中译文的出现模式相同的方法,其中所述两个文件数据库之一是另一个的译文,所述方法包括下列步骤:
准备特征矢量表,它包含所述目标语言文件数据库中每个字的第一特征矢量;
通过检索相应于所述给定序列的所述源语言文件数据库得到有关所述给定序列的统计信息;
从所述统计信息计算相应于所述给定序列的第二特征矢量;
计算所述第二特征矢量与每个所述第一特征矢量之间的相似度;及
选择产生相似度高于预定值的这种目标语言字作为所述译文。
7.如权利要求6所述的方法,其特征在于,准备特征矢量表的所述步骤包括下列步骤:
从所述目标语言文件数据库产生索引文件,所述索引文件是这样的,可以从所述索引文件得到所述目标语言文件数据库中使用的每个字的统计信息;
从所述索引文件计算每个第一特征矢量,以及
其中得到统计信息的所述步骤包括搜索所述给定序列的所述索引文件的步骤。
8.一种在包括第一文件数据库和检索器的文件检索系统中将源语言查询转换成目标语言查询以馈送给检索器的查询扩展方法,该方法包括下列步骤:
从目标语言文件的第二文件数据库选取所述源语言查询中每个查询字的译文,所述译文的出现模式与每个查询字的出现模式相似;
用所述查询字的译文代替所述源语言查询中的每个查询字;及
其中选取所述译文的所述步骤包括下列步骤:
准备特征矢量表,它包含所述目标语言文件数据库中每个字的第一特征矢量;
通过检索相应于所述查询字的所述源语言文件数据库得到有关所述查询字的统计信息;
从所述统计信息计算相应于所述查询字的第二特征矢量;
计算所述第二特征矢量与每个所述第一特征矢量之间的相似度;及
选择产生相似度高于预定值的这种目标语言字作为所述译文。
9.一种接收给定字母序列和提供具有足够划分适宜性的平分字母序列的方法,所述方法包括下列步骤:
形成用于检索文件的检索表达式,所述检索文件包含所述字母序列的所有字母但不包含字母序列本身;
根据所述检索表达式执行检索而得到统计信息;
从所述统计信息产生所述检索表达式的特征矢量,把所述特征矢量称为“掩蔽特征矢量”;
把所述字母序列划分成两个子序列,逐个地移动划分点以得到N-1组平分字母序列,这里N是在所述字母序列中的字母数;
计算每个所述N-1组的每个所述平分字母序列的特征矢量;
用掩蔽特征矢量掩蔽每个所述经计算的特征矢量并使经掩蔽经计算的特征矢量归一化;
计算每个所述N-1组的相似度,定义所述相似度为每个所述N-1组的所述平分字母序列的内积;以及
输出相似度大于阈值的这种平分字母序列。
10.一种配备接收第一语言的给定字和提供第二语言的译文的翻译装置的系统,所述给定字在第一语言文件数据库中的出现模式与译文在第二语言文件数据库中的出现模式相同,其中所述两个文件数据库之一是另一个的译文,其特征在于,所述翻译装置包括特征矢量表,所述特征矢量表包括所述第二语言文件数据库中每个字的第一特征矢量;通过检索相应于所述查询字的所述第一语言文件数据库而得到有关所述查询字的统计信息的装置;由所述统计信息计算相应于所述查询字的第二特征矢量的装置;计算所述第二特征矢量与每个所述第一特征矢量之间的相似度的装置;以及选择产生相似度高于预定值的这种第二语言字作为所述译文的装置,一种对给定字寻找至少一个包括给定字的变量的方法,所述方法包括下列步骤:
利用所述翻译装置得到所述给定字的所述译文;
通过用包含所述第一语言文件数据库中每个字的第三特征矢量的特征矢量表代替所述特征矢量表以及通过交换所述第一语言文件数据库和所述第二语言文件数据库来重新配置所述翻译装置;以及
通过利用重新配置的翻译装置得到每个所述译文的第二译文作为所述至少一个变量。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP11216617A JP2001043236A (ja) | 1999-07-30 | 1999-07-30 | 類似語抽出方法、文書検索方法及びこれらに用いる装置 |
| JP216617/1999 | 1999-07-30 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN1282934A true CN1282934A (zh) | 2001-02-07 |
Family
ID=16691249
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN00122279A Pending CN1282934A (zh) | 1999-07-30 | 2000-07-28 | 相似字选取和文件检索的方法和系统 |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP1072982A3 (zh) |
| JP (1) | JP2001043236A (zh) |
| KR (1) | KR100408637B1 (zh) |
| CN (1) | CN1282934A (zh) |
| TW (1) | TW476034B (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100365628C (zh) * | 2003-12-02 | 2008-01-30 | 索尼株式会社 | 信息处理设备、方法及其程序、信息处理系统及其方法 |
| US9521193B2 (en) | 2009-08-21 | 2016-12-13 | Samsung Electronics Co., Ltd. | Method and apparatus for providing and receiving contents via network, method and apparatus for backing up data via network, backup data providing device, and backup system |
| CN106294639A (zh) * | 2016-08-01 | 2017-01-04 | 金陵科技学院 | 基于语义的跨语言专利新创性预判分析方法 |
Families Citing this family (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100467104B1 (ko) * | 2001-05-11 | 2005-01-24 | 김시환 | 정보 검색 시스템과 그 방법 |
| EP1429258A4 (en) * | 2001-07-26 | 2007-08-29 | Ibm | DATA PROCESSING, DATA PROCESSING SYSTEM AND PROGRAM |
| KR100685023B1 (ko) * | 2001-11-13 | 2007-02-20 | 주식회사 포스코 | 유사성 판단을 위한 예제기반 검색 방법 및 검색 시스템 |
| US6792037B2 (en) | 2002-02-28 | 2004-09-14 | Interdigital Technology Corporation | Apparatus and method of searching for known sequences |
| JP2003288362A (ja) * | 2002-03-27 | 2003-10-10 | Seiko Epson Corp | 特定要素ベクトル生成装置、文字列ベクトル生成装置、類似度算出装置、特定要素ベクトル生成プログラム、文字列ベクトル生成プログラム及び類似度算出プログラム、並びに特定要素ベクトル生成方法、文字列ベクトル生成方法及び類似度算出方法 |
| JP4253483B2 (ja) * | 2002-09-20 | 2009-04-15 | 株式会社リコー | 異表記辞書作成装置および異表記辞書作成方法およびその方法をコンピュータに実行させるためのプログラム |
| US7640232B2 (en) | 2003-10-14 | 2009-12-29 | Aol Llc | Search enhancement system with information from a selected source |
| US7165119B2 (en) | 2003-10-14 | 2007-01-16 | America Online, Inc. | Search enhancement system and method having rankings, explicitly specified by the user, based upon applicability and validity of search parameters in regard to a subject matter |
| JP4622589B2 (ja) * | 2005-03-08 | 2011-02-02 | ソニー株式会社 | 情報処理装置および方法、プログラム、並びに記録媒体 |
| US8600997B2 (en) * | 2005-09-30 | 2013-12-03 | International Business Machines Corporation | Method and framework to support indexing and searching taxonomies in large scale full text indexes |
| JP4995750B2 (ja) * | 2008-02-06 | 2012-08-08 | 日本電信電話株式会社 | Web検索装置、Web検索方法、プログラムおよび記録媒体 |
| KR101126406B1 (ko) * | 2008-11-27 | 2012-04-20 | 엔에이치엔(주) | 유사어 결정 방법 및 시스템 |
| US20100299132A1 (en) * | 2009-05-22 | 2010-11-25 | Microsoft Corporation | Mining phrase pairs from an unstructured resource |
| CA2769222A1 (en) * | 2009-08-21 | 2011-02-24 | Samsung Electronics Co., Ltd. | Method, system and apparatus for providing contents |
| EP2423830A1 (de) * | 2010-08-25 | 2012-02-29 | Omikron Data Quality GmbH | Verfahren zum Suchen in einer Vielzahl von Datensätzen und Suchmaschine |
| KR101272254B1 (ko) * | 2011-08-31 | 2013-06-13 | 주식회사 다음커뮤니케이션 | 검색 서비스 제공 시스템 및 그의 동일의도 검색어 생성 방법 |
| WO2013043146A1 (en) * | 2011-09-19 | 2013-03-28 | Cpa Global Patent Research Limited | Searchable multi-language electronic patent document collection and techniques for searching the same |
| JP5611173B2 (ja) * | 2011-11-10 | 2014-10-22 | 日本電信電話株式会社 | 単語属性推定装置及び方法及びプログラム |
| JP5697256B2 (ja) * | 2011-11-24 | 2015-04-08 | 楽天株式会社 | 検索装置、検索方法、検索プログラム及び記録媒体 |
| EP2693346A1 (en) * | 2012-07-30 | 2014-02-05 | ExB Asset Management GmbH | Resource efficient document search |
| US10789366B2 (en) * | 2013-06-24 | 2020-09-29 | Nippon Telegraph And Telephone Corporation | Security information management system and security information management method |
| US20170206202A1 (en) * | 2014-07-23 | 2017-07-20 | Hewlett Packard Enterprise Development Lp | Proximity of data terms based on walsh-hadamard transforms |
| FR3040808B1 (fr) | 2015-09-07 | 2022-07-15 | Proxem | Procede d'etablissement automatique de requetes inter-langues pour moteur de recherche |
| KR101753768B1 (ko) * | 2015-10-01 | 2017-07-04 | 한국외국어대학교 연구산학협력단 | 가중치에 의한 다수 분야별 검색 기능을 구비한 지식관리 시스템 |
| US10783268B2 (en) | 2015-11-10 | 2020-09-22 | Hewlett Packard Enterprise Development Lp | Data allocation based on secure information retrieval |
| CN105868236A (zh) * | 2015-12-09 | 2016-08-17 | 乐视网信息技术(北京)股份有限公司 | 一种同义词数据挖掘方法和系统 |
| US11080301B2 (en) | 2016-09-28 | 2021-08-03 | Hewlett Packard Enterprise Development Lp | Storage allocation based on secure data comparisons via multiple intermediaries |
| JP7138410B2 (ja) * | 2016-11-08 | 2022-09-16 | 株式会社Nttドコモ | 拠点推定装置 |
| KR102027471B1 (ko) * | 2017-06-20 | 2019-10-01 | 라인 가부시키가이샤 | 소셜 네트워크 컨텐츠를 기반으로 단어 벡터화 기법을 이용하여 일상 언어로 확장하기 위한 방법 및 시스템 |
| JP7016237B2 (ja) * | 2017-10-18 | 2022-02-04 | 三菱重工業株式会社 | 情報検索装置、検索処理方法、およびプログラム |
| CN109165331A (zh) * | 2018-08-20 | 2019-01-08 | 南京师范大学 | 一种英文地名的索引建立方法及其查询方法和装置 |
| JP7388256B2 (ja) * | 2020-03-10 | 2023-11-29 | 富士通株式会社 | 情報処理装置及び情報処理方法 |
| CN116431837B (zh) * | 2023-06-13 | 2023-08-22 | 杭州欧若数网科技有限公司 | 基于大型语言模型和图网络模型的文档检索方法和装置 |
-
1999
- 1999-07-30 JP JP11216617A patent/JP2001043236A/ja not_active Withdrawn
-
2000
- 2000-07-28 EP EP00116441A patent/EP1072982A3/en not_active Withdrawn
- 2000-07-28 CN CN00122279A patent/CN1282934A/zh active Pending
- 2000-07-29 TW TW089115283A patent/TW476034B/zh active
- 2000-07-31 KR KR10-2000-0044283A patent/KR100408637B1/ko not_active IP Right Cessation
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100365628C (zh) * | 2003-12-02 | 2008-01-30 | 索尼株式会社 | 信息处理设备、方法及其程序、信息处理系统及其方法 |
| US9521193B2 (en) | 2009-08-21 | 2016-12-13 | Samsung Electronics Co., Ltd. | Method and apparatus for providing and receiving contents via network, method and apparatus for backing up data via network, backup data providing device, and backup system |
| US10389720B2 (en) | 2009-08-21 | 2019-08-20 | Samsung Electronics Co., Ltd. | Method and apparatus for providing and receiving contents via network, method and apparatus for backing up data via network, backup data providing device, and backup system |
| CN106294639A (zh) * | 2016-08-01 | 2017-01-04 | 金陵科技学院 | 基于语义的跨语言专利新创性预判分析方法 |
| CN106294639B (zh) * | 2016-08-01 | 2020-04-21 | 金陵科技学院 | 基于语义的跨语言专利新创性预判分析方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| TW476034B (en) | 2002-02-11 |
| EP1072982A2 (en) | 2001-01-31 |
| KR100408637B1 (ko) | 2003-12-06 |
| KR20010067045A (ko) | 2001-07-12 |
| JP2001043236A (ja) | 2001-02-16 |
| EP1072982A3 (en) | 2004-05-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1282934A (zh) | 相似字选取和文件检索的方法和系统 | |
| US9378285B2 (en) | Extending keyword searching to syntactically and semantically annotated data | |
| CN102945237B (zh) | 基于原始用户输入建议和细分用户输入的系统和方法 | |
| CN1728142B (zh) | 信息检索系统中的短语识别方法和设备 | |
| KR101195341B1 (ko) | 미등록 단어의 카테고리 결정 방법 및 장치 | |
| CN112035598A (zh) | 一种智能语义检索方法、系统和电子设备 | |
| US20070219986A1 (en) | Method and apparatus for extracting terms based on a displayed text | |
| JP2015523659A (ja) | 多言語混合検索方法およびシステム | |
| EP2499562A1 (en) | Enabling faster full-text searching using a structured data store | |
| US20050278292A1 (en) | Spelling variation dictionary generation system | |
| US20160171052A1 (en) | Method and system for document indexing and data querying | |
| CN1434952A (zh) | 根据有含义中心词检索信息的方法和系统 | |
| CN1687925A (zh) | 一种实现双语网页搜索的方法 | |
| US20090276420A1 (en) | Method and system for extending content | |
| CN101697099A (zh) | 一种字词转换结果的获取方法及系统 | |
| WO2009108587A1 (en) | Conceptual reverse query expander | |
| JPWO2010109594A1 (ja) | 文書検索装置、文書検索システム、文書検索プログラム、および文書検索方法 | |
| JP2001184358A (ja) | カテゴリ因子による情報検索装置,情報検索方法およびそのプログラム記録媒体 | |
| JP4945015B2 (ja) | 文書検索システム、文書検索プログラム、および文書検索方法 | |
| Li et al. | Complex query recognition based on dynamic learning mechanism | |
| Mon et al. | Myanmar language search engine | |
| KR20010107113A (ko) | 자연어 정보 검색 시스템에서 구문 트리를 이용한 자연어질의의 불린 질의 및 벡터 질의 변환 방법 | |
| JPH06274546A (ja) | 情報量一致度計算方式 | |
| Kanlayanawat et al. | Automatic indexing for Thai text with unknown words using trie structure | |
| KR100434718B1 (ko) | 문서 색인 시스템 및 그 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C06 | Publication | ||
| PB01 | Publication | ||
| C12 | Rejection of a patent application after its publication | ||
| RJ01 | Rejection of invention patent application after publication | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: GR Ref document number: 1069652 Country of ref document: HK |