CN105917407B - 识别码簿以在对声场的空间分量译码时使用 - Google Patents
识别码簿以在对声场的空间分量译码时使用 Download PDFInfo
- Publication number
- CN105917407B CN105917407B CN201480031272.6A CN201480031272A CN105917407B CN 105917407 B CN105917407 B CN 105917407B CN 201480031272 A CN201480031272 A CN 201480031272A CN 105917407 B CN105917407 B CN 105917407B
- Authority
- CN
- China
- Prior art keywords
- spatial component
- vector
- spherical harmonic
- spatial
- audio
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 claims abstract description 462
- 238000000354 decomposition reaction Methods 0.000 claims description 371
- 238000013139 quantization Methods 0.000 claims description 188
- 238000007906 compression Methods 0.000 claims description 172
- 230000006835 compression Effects 0.000 claims description 170
- 230000006870 function Effects 0.000 claims description 149
- 238000000605 extraction Methods 0.000 claims description 106
- 238000003860 storage Methods 0.000 claims description 53
- 239000000758 substrate Substances 0.000 claims 3
- 239000013598 vector Substances 0.000 abstract description 2233
- 230000015572 biosynthetic process Effects 0.000 abstract description 93
- 238000003786 synthesis reaction Methods 0.000 abstract description 93
- 239000011159 matrix material Substances 0.000 description 1118
- 238000004458 analytical method Methods 0.000 description 339
- 230000002829 reductive effect Effects 0.000 description 237
- 238000010586 diagram Methods 0.000 description 158
- 230000000875 corresponding effect Effects 0.000 description 152
- 230000009467 reduction Effects 0.000 description 132
- 208000001970 congenital sucrase-isomaltase deficiency Diseases 0.000 description 92
- 230000002123 temporal effect Effects 0.000 description 62
- 230000005540 biological transmission Effects 0.000 description 46
- 230000008569 process Effects 0.000 description 38
- 230000006837 decompression Effects 0.000 description 33
- 238000009792 diffusion process Methods 0.000 description 32
- 239000000284 extract Substances 0.000 description 31
- 230000001427 coherent effect Effects 0.000 description 26
- 238000004422 calculation algorithm Methods 0.000 description 25
- 239000000203 mixture Substances 0.000 description 24
- 238000012732 spatial analysis Methods 0.000 description 24
- 238000009472 formulation Methods 0.000 description 22
- 230000009466 transformation Effects 0.000 description 21
- 238000000513 principal component analysis Methods 0.000 description 20
- 238000004364 calculation method Methods 0.000 description 19
- 230000003595 spectral effect Effects 0.000 description 19
- 230000002441 reversible effect Effects 0.000 description 18
- 238000009877 rendering Methods 0.000 description 17
- 230000003321 amplification Effects 0.000 description 13
- 238000003199 nucleic acid amplification method Methods 0.000 description 13
- 238000012545 processing Methods 0.000 description 13
- 230000007704 transition Effects 0.000 description 11
- 230000002596 correlated effect Effects 0.000 description 10
- 230000000694 effects Effects 0.000 description 10
- 238000004321 preservation Methods 0.000 description 9
- 230000011664 signaling Effects 0.000 description 9
- 238000001308 synthesis method Methods 0.000 description 9
- 238000005516 engineering process Methods 0.000 description 8
- 238000007667 floating Methods 0.000 description 8
- 230000010076 replication Effects 0.000 description 8
- 238000013461 design Methods 0.000 description 7
- 238000004134 energy conservation Methods 0.000 description 7
- 238000009499 grossing Methods 0.000 description 7
- 230000000873 masking effect Effects 0.000 description 7
- 238000011946 reduction process Methods 0.000 description 7
- 230000001413 cellular effect Effects 0.000 description 6
- 238000000926 separation method Methods 0.000 description 6
- 238000004891 communication Methods 0.000 description 5
- 238000004091 panning Methods 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 230000006978 adaptation Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000013500 data storage Methods 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 238000002156 mixing Methods 0.000 description 4
- 238000004088 simulation Methods 0.000 description 4
- 230000005236 sound signal Effects 0.000 description 4
- 230000001131 transforming effect Effects 0.000 description 4
- 230000003044 adaptive effect Effects 0.000 description 3
- 238000003491 array Methods 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 238000009795 derivation Methods 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 230000033001 locomotion Effects 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- ZAKOWWREFLAJOT-CEFNRUSXSA-N D-alpha-tocopherylacetate Chemical compound CC(=O)OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C ZAKOWWREFLAJOT-CEFNRUSXSA-N 0.000 description 2
- 208000037170 Delayed Emergence from Anesthesia Diseases 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 239000002131 composite material Substances 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- 238000012880 independent component analysis Methods 0.000 description 2
- 238000003032 molecular docking Methods 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 230000003334 potential effect Effects 0.000 description 2
- 230000011218 segmentation Effects 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 1
- 208000032041 Hearing impaired Diseases 0.000 description 1
- 241000257303 Hymenoptera Species 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 235000000332 black box Nutrition 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000009432 framing Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000002250 progressing effect Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000011524 similarity measure Methods 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000017105 transposition Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images







































































































































































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S5/00—Pseudo-stereo systems, e.g. in which additional channel signals are derived from monophonic signals by means of phase shifting, time delay or reverberation
- H04S5/005—Pseudo-stereo systems, e.g. in which additional channel signals are derived from monophonic signals by means of phase shifting, time delay or reverberation of the pseudo five- or more-channel type, e.g. virtual surround
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/002—Dynamic bit allocation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0204—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using subband decomposition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
- G10L19/038—Vector quantisation, e.g. TwinVQ audio
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/167—Audio streaming, i.e. formatting and decoding of an encoded audio signal representation into a data stream for transmission or storage purposes
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/20—Vocoders using multiple modes using sound class specific coding, hybrid encoders or object based coding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/18—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being spectral information of each sub-band
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/302—Electronic adaptation of stereophonic sound system to listener position or orientation
- H04S7/303—Tracking of listener position or orientation
- H04S7/304—For headphones
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/40—Visual indication of stereophonic sound image
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0004—Design or structure of the codebook
- G10L2019/0005—Multi-stage vector quantisation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2205/00—Details of stereophonic arrangements covered by H04R5/00 but not provided for in any of its subgroups
- H04R2205/021—Aspects relating to docking-station type assemblies to obtain an acoustical effect, e.g. the type of connection to external loudspeakers or housings, frequency improvement
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/01—Multi-channel, i.e. more than two input channels, sound reproduction with two speakers wherein the multi-channel information is substantially preserved
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/15—Aspects of sound capture and related signal processing for recording or reproduction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/01—Enhancing the perception of the sound image or of the spatial distribution using head related transfer functions [HRTF's] or equivalents thereof, e.g. interaural time difference [ITD] or interaural level difference [ILD]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/03—Application of parametric coding in stereophonic audio systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/11—Application of ambisonics in stereophonic audio systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Mathematical Physics (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Analysis (AREA)
- Pure & Applied Mathematics (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Stereophonic System (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- General Health & Medical Sciences (AREA)
- Otolaryngology (AREA)
- Complex Calculations (AREA)
Abstract
大体来说,本发明描述用于识别码簿以在压缩声场的空间分量时使用的技术。一种包括一或多个处理器的装置可经配置以执行所述技术。所述一或多个处理器可经配置以基于多个空间分量中的空间分量相对于所述多个空间分量中的其余者的阶数识别霍夫曼码簿以在对所述空间分量进行压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
Description
本申请案主张以下美国临时申请案的权益:2013年5月29日申请的第61/828,445号美国临时申请案、2013年5月31日申请的第61/829,791号美国临时申请案、2013年11月1日申请的第61/899,034号美国临时申请案、2013年11月1日申请的第61/899,041号美国临时申请案、2013年5月30日申请的第61/829,182号美国临时申请案、2013年5月30日申请的第61/829,174号美国临时申请案、2013年5月30日申请的第61/829,155号美国临时申请案、2014年1月30日申请的第61/933,706号美国临时申请案、2013年5月31日申请的第61/829,846号美国临时申请案、2013年10月3日申请的第61/886,605号美国临时申请案、2013年10月3日申请的第61/886,617号美国临时申请案、2014年1月8日申请的第61/925,158号美国临时申请案、2014年1月30日申请的第61/933,721号美国临时申请案、2014年1月8日申请的第61/925,074号美国临时申请案、2014年1月8日申请的第61/925,112号美国临时申请案、2014年1月8日申请的第61/925,126号美国临时申请案、2014年5月27日申请的第62/003,515号美国临时申请案,以及2013年5月29日申请的第61/828,615号美国临时申请案,以上美国临时申请案中的每一者的全部内容以引用的方式并入本文中。
技术领域
本发明涉及音频数据,并且更具体来说涉及音频数据的压缩。
背景技术
高阶立体混响(HOA)信号(常由多个球谐系数(SHC)或其它阶层式元素表示)是声场的三维表示。此HOA或SHC表示可以独立于用以重放从此SHC信号再现的多通道音频信号的局部扬声器几何布置的方式来表示此声场。此SHC信号还可促进向后兼容性,因为可将此SHC信号再现为众所周知的且被广泛采用的多通道格式(例如,5.1音频通道格式或7.1音频通道格式)。SHC表示因此可实现对声场的更好表示,其也适应向后兼容性。
发明内容
一般来说,描述了用于较高阶立体混响音频数据的压缩及解压缩的技术。
在一个方面中,一种方法包括获得描述声场的相异分量的一或多个第一向量及描述所述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者是至少通过相对于多个球谐系数执行变换而产生。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以确定描述声场的相异分量的一或多个第一向量及描述所述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者是至少通过相对于多个球谐系数执行变换而产生。
在另一方面中,一种装置包括:用于获得描述声场的相异分量的一或多个第一向量及描述所述声场的背景分量的一或多个第二向量的装置,所述一或多个第一向量及所述一或多个第二向量都是至少通过相对于多个球谐系数执行变换而产生;及用于存储所述一或多个第一向量的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器获得描述声场的相异分量的一或多个第一向量及描述所述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者是至少通过相对于多个球谐系数执行变换而产生。
在另一方面中,一种方法包括:基于表示声场的球谐系数的经压缩版本是否是从合成音频对象产生的指示而选择多个解压缩方案中的一者;及使用所述多个解压缩方案中的选定者解压缩所述球谐系数的经压缩版本。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以基于表示声场的球谐系数的经压缩版本是否是从合成音频对象产生的指示而选择多个解压缩方案中的一者,及使用所述多个解压缩方案中的选定者解压缩所述球谐系数的经压缩版本。
在另一方面中,一种装置包括:用于基于表示声场的球谐系数的经压缩版本是否是从合成音频对象产生的指示而选择多个解压缩方案中的一者的装置;及用于使用所述多个解压缩方案中的选定者解压缩所述球谐系数的经压缩版本的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使集成解码装置的一或多个处理器基于表示声场的球谐系数的经压缩版本是否是从合成音频对象产生的指示而选择多个解压缩方案中的一者,且使用所述多个解压缩方案中的选定者解压缩所述球谐系数的经压缩版本。
在另一方面中,一种方法包括获得表示声场的球谐系数是否是从合成音频对象产生的指示。
在另一方面中,一种装置包括经配置以获得表示声场的球谐系数是否是从合成音频对象产生的指示的一或多个处理器。
在另一方面中,一种装置包括:用于存储表示声场的球谐系数的装置;及用于获得所述球谐系数是否是从合成音频对象产生的指示的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器获得表示声场的球谐系数是否是从合成音频对象产生的指示。
在另一方面中,一种方法包括:量化表示声场的一或多个分量的一或多个第一向量;及补偿归因于所述一或多个第一向量的量化而在也表示所述声场的相同一或多个分量的一或多个第二向量中引入的误差。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以量化表示声场的一或多个分量的一或多个第一向量,且补偿归因于所述一或多个第一向量的量化而在也表示所述声场的相同一或多个分量的一或多个第二向量中引入的误差。
在另一方面中,一种装置包括:用于量化表示声场的一或多个分量的一或多个第一向量的装置;及用于补偿归因于所述一或多个第一向量的量化而在也表示所述声场的相同一或多个分量的一或多个第二向量中引入的误差的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器量化表示声场的一或多个分量的一或多个第一向量,且补偿归因于所述一或多个第一向量的量化而在也表示所述声场的相同一或多个分量的一或多个第二向量中引入的误差。
在另一方面中,一种方法包括基于目标位速率相对于多个球谐系数或其分解执行阶数缩减以产生经缩减球谐系数或其经缩减分解,其中所述多个球谐系数表示声场。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以基于目标位速率相对于多个球谐系数或其分解执行阶数缩减以产生经缩减球谐系数或其经缩减分解,其中所述多个球谐系数表示声场。
在另一方面中,一种装置包括:用于存储多个球谐系数或其分解的装置;及用于基于目标位速率相对于所述多个球谐系数或其分解执行阶数缩减以产生经缩减球谐系数或其经缩减分解的装置,其中所述多个球谐系数表示声场。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器基于目标位速率相对于多个球谐系数或其分解执行阶数缩减以产生经缩减球谐系数或其经缩减分解,其中所述多个球谐系数表示声场。
在另一方面中,一种方法包括获得表示声场的相异分量的向量的系数的第一非零集合,所述向量已从描述声场的多个球谐系数分解。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以获得表示声场的相异分量的向量的系数的第一非零集合,所述向量已从描述所述声场的多个球谐系数分解。
在另一方面中,一种装置包括:用于获得表示声场的相异分量的向量的系数的第一非零集合的装置,所述向量已从描述所述声场的多个球谐系数分解;及用于存储系数的所述第一非零集合的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器确定表示声场的异分量的向量的系数的第一非零集合,所述向量已从描述所述声场的多个球谐系数分解。
在另一方面中,一种方法包括从位流获得从与背景球谐系数重组的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中所述背景球谐系数描述相同声场的一或多个背景分量。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以从位流确定从与背景球谐系数重组的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中所述背景球谐系数描述相同声场的一或多个背景分量。
在另一方面中,一种装置包括用于从位流获得从与背景球谐系数重组的球谐系数分解的一或多个向量中的至少一者的装置,其中所述球谐系数描述声场,且其中所述背景球谐系数描述相同声场的一或多个背景分量。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器从位流获得从与背景球谐系数重组的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中所述背景球谐系数描述相同声场的一或多个背景分量。
在另一方面中,一种方法包括基于针对音频对象中的一或多者确定的方向性从与所述音频对象相关联的一或多个球谐系数(SHC)识别一或多个相异音频对象。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以基于针对音频对象中的一或多者确定的方向性从与所述音频对象相关联的一或多个球谐系数(SHC)识别一或多个相异音频对象。
在另一方面中,一种装置包括:用于存储一或多个球谐系数(SHC)的装置;及用于基于针对音频对象中的一或多者确定的方向性从与所述音频对象相关联的所述一或多个球谐系数(SHC)识别一或多个相异音频对象的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器基于针对音频对象中的一或多者确定的方向性从与所述音频对象相关联的一或多个球谐系数(SHC)识别一或多个相异音频对象。
在另一方面中,一种方法包括:相对于多个球谐系数执行基于向量的合成以产生表示一或多个音频对象及对应方向信息的所述多个球谐系数的经分解表示,其中所述球谐系数与一阶数相关联且描述声场;从所述方向信息确定相异和背景方向信息;缩减与所述背景音频对象相关联的方向信息的阶数以产生经变换背景方向信息;应用补偿以增加经变换方向信息的值以节省所述声场的总能量。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以:相对于多个球谐系数执行基于向量的合成以产生表示一或多个音频对象及对应方向信息的所述多个球谐系数的经分解表示,其中所述球谐系数与一阶数相关联且描述声场;从所述方向信息确定相异和背景方向信息;缩减与所述背景音频对象相关联的方向信息的阶数以产生经变换背景方向信息;应用补偿以增加经变换方向信息的值以节省所述声场的总能量。
在另一方面中,一种装置包括:用于相对于多个球谐系数执行基于向量的合成以产生表示一或多个音频对象及对应方向信息的所述多个球谐系数的经分解表示的装置,其中所述球谐系数与一阶数相关联且描述声场;用于从所述方向信息确定相异和背景方向信息的装置;用于缩减与所述背景音频对象相关联的方向信息的阶数以产生经变换背景方向信息的装置;及用于应用补偿以增加经变换方向信息的值以节省所述声场的总能量的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器:相对于多个球谐系数执行基于向量的合成以产生表示一或多个音频对象及对应方向信息的所述多个球谐系数的经分解表示,其中所述球谐系数与一阶数相关联且描述声场;从所述方向信息确定相异和背景方向信息;缩减与所述背景音频对象相关联的方向信息的阶数以产生经变换背景方向信息;且应用补偿以增加经变换方向信息的值以节省所述声场的总能量。
在另一方面,一种方法包括至少部分通过相对于第一多个球谐系数的第一分解及第二多个球谐系数的第二分解执行内插而获得一时间片段的经分解的经内插球谐系数。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以至少部分通过相对于第一多个球谐系数的第一分解及第二多个球谐系数的第二分解执行内插而获得一时间片段的经分解的经内插球谐系数。
在另一方面中,一种装置包括:用于存储第一多个球谐系数及第二多个球谐系数的装置;及用于至少部分通过相对于所述第一多个球谐系数的第一分解及第二多个球谐系数的第二分解执行内插而获得一时间片段的经分解的经内插球谐系数的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器至少部分通过相对于第一多个球谐系数的第一分解及第二多个球谐系数的第二分解执行内插而获得一时间片段的经分解的经内插球谐系数。
在另一方面中,一种方法包括获得包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以获得包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括:用于获得包括声场的空间分量的经压缩版本的位流的装置,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生;及用于存储所述位流的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器获得包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种方法包括产生包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以产生包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括:用于产生包括声场的空间分量的经压缩版本的位流的装置,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生;及用于存储所述位流的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有指令,所述指令在执行时致使一或多个处理器产生包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种方法包括基于多个经压缩空间分量中的空间分量的经压缩版本相对于所述多个经压缩空间分量中的其余者的阶数识别霍夫曼(Huffman)码簿以在对所述空间分量的经压缩版本进行解压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以基于多个经压缩空间分量中的空间分量的经压缩版本相对于所述多个经压缩空间分量中的其余者的阶数识别霍夫曼(Huffman)码簿以在对所述空间分量的经压缩版本进行解压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括:用于基于多个经压缩空间分量中的空间分量的的经压缩版本相对于所述多个经压缩空间分量中的其余者的阶数识别霍夫曼(Huffman)码簿以在对所述空间分量的经压缩版本进行解压缩时使用的装置,所述空间分量是通过相对于多个球谐系统执行基于向量的合成而产生;及用于存储所述多个经压缩空间分量的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器基于多个经压缩空间分量中的空间分量的经压缩版本相对于所述多个经压缩空间分量中的其余者的阶数识别霍夫曼码簿以在对所述空间分量的经压缩版本进行解压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种方法包括基于多个空间分量中的空间分量相对于所述多个空间分量中的其余者的阶数识别霍夫曼码簿以在对所述空间分量进行压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以基于多个空间分量中的空间分量相对于所述多个空间分量中的其余者的阶数识别霍夫曼码簿以在对所述空间分量进行压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括:用于存储霍夫曼码簿的装置;及用于基于多个空间分量中的空间分量相对于所述多个空间分量中的其余者的阶数识别所述霍夫曼码簿以在对所述空间分量进行压缩时使用的装置,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器基于多个空间分量中的空间分量相对于所述多个空间分量中的其余者的阶数识别霍夫曼码簿以在对所述空间分量进行压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种方法包括确定在对声场的空间分量进行压缩时将使用的量化步长,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括一或多个处理器,所述一或多个处理器经配置以确定在对声场的空间分量进行压缩时将使用的量化步长,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在另一方面中,一种装置包括:用于确定在对声场的空间分量进行压缩时将使用的量化步长的装置,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生;及用于存储所述量化步长的装置。
在另一方面中,一种非暂时性计算机可读存储媒体具有存储于其上的指令,所述指令在执行时致使一或多个处理器确定在对声场的空间分量进行压缩时将使用的量化步长,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在附图和以下描述中阐述所述技术的一或多个方面的细节。这些技术的其它特征、目标和优点将从所述描述和图式以及从权利要求书而显而易见。
附图说明
图1和2是说明具有各种阶数及子阶数的球谐基底函数的图。
图3是说明可执行本发明中所描述的技术的各种方面的系统的图。
图4是更详细说明可执行本发明中描述的技术的各种方面的图3的实例中所示的音频编码装置的一个实例的框图。
图5是更详细说明图3的音频解码装置的框图。
图6是说明音频编码装置的内容分析单元执行本发明中所描述的技术的各种方面的示范性操作的流程图。
图7是说明音频编码装置执行本发明中所描述的基于向量的合成技术的各种方面的示范性操作的流程图。
图8是说明音频解码装置在执行本发明中描述的技术的各种方面中的示范性操作的流程图。
图9A到9L是更详细地说明图4的实例的音频编码装置的各种方面的框图。
图10A到10O(ii)是更详细地说明可指定经压缩空间分量的位流或旁侧通道信息的一部分的图。
图11A到11G是更详细地说明图5的实例中所示的音频解码装置的各种单元的框图。
图12是说明可执行本发明中描述的技术的各种方面的实例音频生态系统的图。
图13是更详细说明图12的音频生态系统的一个实例的图。
图14是更详细说明图12的音频生态系统的一个实例的图。
图15A和15B是更详细说明图12的音频生态系统的其它实例的图。
图16是说明可执行本发明中描述的技术的各种方面的实例音频编码装置的图。
图17是更详细说明图16的音频编码装置的一个实例的图。
图18是说明可执行本发明中描述的技术的各种方面的实例音频解码装置的图。
图19是更详细说明图18的音频解码装置的一个实例的图。
图20A到20G是说明可执行本发明中所描述的技术的各种方面的实例音频获取装置的图。
图21A到21E是说明可执行本发明中所描述的技术的各种方面的实例音频重放装置的图。
图22A到22H是说明根据本发明中所描述的一或多个技术的实例音频重放环境的图。
图23是说明根据本发明中所描述的一或多个技术的实例使用情况的图,其中用户可在佩戴头戴受话器的同时体验到体育赛事的3D声场。
图24是说明在其处可根据本发明中所描述的一或多个技术记录3D声场的体育场的图。
图25是说明根据本发明中所描述的一或多个技术的用于基于局部音频地景(landscape)再现3D声场的技术的流程图。
图26是说明根据本发明中所描述的一或多个技术的实例游戏工作室的图。
图27是说明根据本发明中所描述的一或多个技术的包含再现引擎的多个游戏系统的图。
图28是说明根据本发明中所描述的一或多个技术的可由头戴受话器模拟的扬声器配置的图。
图29是说明根据本发明中所描述的一或多个技术的可用以获取及/或编辑3D声场的多个移动装置的图。
图30是说明与可根据本发明中所描述的一或多个技术加以处理的3D声场相关联的视频帧的图。
图31A到31M为说明展示根据本发明中所描述的技术的各种方面执行声场的合成或记录分类的各种模拟结果的曲线图的图。
图32是说明来自根据本发明中所描述的技术从较高阶立体混响系数分解的S矩阵的奇异值的曲线图的图。
图33A和33B是说明展示在根据本发明中所描述的技术对描述声场的前景分量的向量进行编码时重排序所具有的潜在影响的相应曲线图的图。
图34及35是说明根据本发明的对相异音频对象的单独基于能量的识别与基于方向性的识别之间的差异的概念图。
图36A到36G是说明根据本发明中所描述的技术的各种方面的球谐系数的经分解版本的至少一部分向空间域中投影以便执行内插的图。
图37说明用于获得如本文所描述的空间-时间内插的技术的表示。
图38是说明根据本文所述的技术的用于多维信号的依序SVD块的人工US矩阵(US1及US2)的框图。
图39是说明根据本发明中所描述的技术使用奇异值分解及空间时间分量的平滑来分解较高阶立体混响(HOA)信号的后续帧的框图。
图40A到40J各自为说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置的框图。
图41A到41D是各自说明可执行本发明中所描述的技术的各种方面以对描述二维或三维声场的球谐系数进行解码的实例音频解码装置的框图。
图42A到42C各自为更详细地说明图40B到40J的实例中所展示的阶数缩减单元的框图。
图43更详细说明图40I中所示的V压缩单元的图。
图44是说明根据本发明中所描述的技术的各种方面的由音频编码装置执行以补偿量化误差的示范性操作的图。
图45A及45B是说明根据本发明中所描述的技术的各种方面的从两个帧的若干部分内插子帧的图。
图46A到46E是说明已根据本发明中所描述的技术内插的多个球谐系数的经分解版本的一或多个向量的投影的横截面的图。
图47是更详细地说明图41A到41D的实例中所示的音频解码装置的提取单元的框图。
图48是更详细地说明图41A到41D的实例中所示的音频解码装置的音频再现单元的框图。
图49A到49E(ii)是说明可实施本发明中所描述的技术的各种方面的相应音频译码系统的图。
图50A及50B是各自说明根据本发明中所描述的技术潜在地减小背景内容的阶数的两个不同方法中的一者的框图。
图51是说明可实施本发明中所描述的技术的各种方面以压缩球谐系数的音频编码装置的相异分量压缩路径的实例的框图。
图52是说明可实施本发明中所描述的技术的各种方面以重建或近似地重建球谐系数(SHC)的音频解码装置的另一实例的框图。
图53是说明可执行本发明中所描述的技术的各种方面的音频编码装置的另一实例的框图。
图54是更详细地说明图53的实例中所示的音频编码装置的实例实施方案的框图。
图55A及55B是说明执行本发明中所描述的技术的各种方面以旋转声场的实例的图。
图56是说明根据第一参考系俘获的实例声场的图,所述第一参考系接着根据本发明中所描述的技术旋转以依据第二参考系表达声场。
图57A到57E各自为说明根据本发明中所描述的技术形成的位流的图。
图58是说明图53的实例中所示的音频编码装置实施本发明中所描述的技术的旋转方面的实例操作的流程图。
图59是说明图53的实例中所示的音频编码装置执行本发明中所描述的技术的变换方面的实例操作的流程图。
具体实施方式
环绕声音的演进现今已使得许多输出格式可用于娱乐。此等消费型环绕声格式的实例大部分为“通道”式的,这是因为其以某些几何坐标隐含地指定到扩音器的馈入。这些包含流行的5.1格式(其包含以下六个通道:左前(FL)、右前(FR)、中央或前方中央、左后或环绕左边、右后或环绕右边及低频效果(LFE)),发展的7.1格式、包含例如7.1.4格式和22.2格式(例如,用于与超高清电视标准一起使用)等高度扬声器的各种格式。非消费型格式可涵括任何数目的扬声器(成对称和非对称几何布置),其常常称为“环绕阵列”。此类阵列的一个实例包含定位在截二十面体(truncated icosohedron)的拐角上的坐标处的32个扩音器。
到未来MPEG编码器的输入视情况为三个可能格式中的一者:(i)传统的基于通道的音频(如上文所论述),其意图由处于预先指定的位置处的扩音器播放;(ii)基于对象的音频,其涉及用于单个音频对象的具有含有其位置坐标(以及其它信息)的相关联元数据的离散脉码调制(PCM)数据;及(iii)基于场景的音频,其涉及使用球谐基底函数的系数(也称为“球谐系数”或SHC、“高阶立体混响”或HOA及“HOA系数”)来表示声场。此未来MPEG编码器更详细地描述于国际标准化组织/国际电工委员会(ISO)/(IEC)JTC1/SC29/WG11/N13411的标题为“要求对于3D音频的提议(Call for Proposals for 3D Audio)”的文献中,所述文献于2013年1月在瑞士日内瓦发布,且可在http://mpeg.chiariglione.org/sites/ default/files/files/standards/parts/docs/w13411.zip获得。
在市场中存在各种“环绕声”基于通道的格式。它们的范围(例如)是从5.1家庭影院系统(其在使起居室享有立体声方面已获得最大成功)到NHK(日本广播协会或日本广播公司)所开发的22.2系统。内容创建者(例如,好莱坞工作室)将希望产生电影的音轨一次,而不花费精力来针对每一扬声器配置对其进行重混(remix)。近来,标准开发组织(Standards Developing Organizations)一直在考虑如下方式:将编码及后续解码(适合于且不知晓重放位置(涉及再现器)处的扬声器几何布置(及数目)和声学条件)提供于标准化位流中。
为向内容创建者提供此种灵活性,可使用分层要素集合来表示声场。所述分层要素集合可指其中元素经排序以使得较低阶元素的基础集合提供模型化声场的完整表示的一组元素。在所述集合扩展以包含高阶元素时,表示变得更详细,从而增加分辨率。
分层要素集合的一个实例为一组球谐系数(SHC)。以下表达式示范使用SHC对声场的描述或表示:

此表达式展示可由SHC 唯一地表示在时间t声场在任何点
唯一地表示在时间t声场在任何点 处的压力Pi。此处,
处的压力Pi。此处, c为声速(约343m/s),
c为声速(约343m/s), 为参考点(或观测点),jn(·)为具有阶数n的球面贝塞耳函数(spherical Bessel function),且
为参考点(或观测点),jn(·)为具有阶数n的球面贝塞耳函数(spherical Bessel function),且 为具有阶数n和子阶数m的球谐基底函数。
为具有阶数n和子阶数m的球谐基底函数。
可认识到,方括号中的项为信号的频域表示(即, ),其可通过各种时间-频率变换(例如,离散傅里叶变换(DFT)、离散余弦变换(DCT)或小波变换)来近似。分层集合的其它实例包含小波变换系数的集合和其它多分辨率基底函数系数集合。
),其可通过各种时间-频率变换(例如,离散傅里叶变换(DFT)、离散余弦变换(DCT)或小波变换)来近似。分层集合的其它实例包含小波变换系数的集合和其它多分辨率基底函数系数集合。
图1为说明从零阶(n=0)到第四阶(n=4)的球谐基底函数的图。如可看出,对于每一阶,存在m子阶的扩展,出于易于说明的目的,在图1的实例中展示所述子阶但未明确注释。
图2为说明从零阶(n=0)到四阶(n=4)的球谐基底函数的另一图。在图2中,在三维坐标空间中展示球谐基底函数,其中展示了阶与子阶两者。
可由各种麦克风阵列配置物理上获取(例如,记录)SHC 或者,SHC
或者,SHC 可从声场的基于通道或基于对象的描述导出。SHC表示基于场景的音频,其中SHC可输入到音频编码器以获得经编码SHC,所述经编码SHC可促成更有效的发射或存储。举例来说,可使用涉及(1+4)2个(25,且因此为第四阶)系数的四阶表示。
可从声场的基于通道或基于对象的描述导出。SHC表示基于场景的音频,其中SHC可输入到音频编码器以获得经编码SHC,所述经编码SHC可促成更有效的发射或存储。举例来说,可使用涉及(1+4)2个(25,且因此为第四阶)系数的四阶表示。
如上文所指出,可使用麦克风从麦克风记录导出SHC。可如何从麦克风阵列导出SHC的各种实例描述于Poletti,M.的“基于球谐的三维环绕声系统(Three-DimensionalSurround Sound Systems Based on Spherical Harmonics)”(听觉工程学协会会刊(J.Audio Eng.Soc.),第53卷,第11期,2005年11月,第1004-1025页)中。
为说明可如何从基于对象的描述导出这些SHC,考虑以下等式。可将对应于个别音频对象的声场的系数 表达为:
表达为:

其中i为
 为具有阶n的球面汉克(Hankel)函数(第二种类),且
为具有阶n的球面汉克(Hankel)函数(第二种类),且 为对象的位置。知晓随频率而变的源能量g(ω)(例如,使用时间-频率分析技术,例如对PCM流执行快速傅里叶变换)允许我们将每一PCM对象及其位置转换为SHC
为对象的位置。知晓随频率而变的源能量g(ω)(例如,使用时间-频率分析技术,例如对PCM流执行快速傅里叶变换)允许我们将每一PCM对象及其位置转换为SHC 另外,可展示(由于上式为线性和正交分解):每一对象的
另外,可展示(由于上式为线性和正交分解):每一对象的 系数具相加性。以此方式,许多PCM对象可由
系数具相加性。以此方式,许多PCM对象可由 系数(例如,作为个别对象的系数向量的总和)来表示。实质上,这些系数含有关于声场的信息(随3D坐标而变的压力),且以上情形表示在观测点
系数(例如,作为个别对象的系数向量的总和)来表示。实质上,这些系数含有关于声场的信息(随3D坐标而变的压力),且以上情形表示在观测点
 附近的从个别对象到整体声场的表示的变换。下文在基于对象和基于SHC的音频译码的上下文中描述其余各图。
附近的从个别对象到整体声场的表示的变换。下文在基于对象和基于SHC的音频译码的上下文中描述其余各图。
图3为说明可执行本发明中所描述的技术的各个方面的系统10的图。如图3的实例中所示,系统10包含内容创建者12和内容消费者14。尽管在内容创建者12和内容消费者14的上下文中描述,但可在其中声场的SHC(其也可称为HOA系数)或任何其它阶层表示经编码以形成表示音频数据的位流的任何上下文中实施所述技术。此外,内容创建者12可表示能够实施本发明中所描述的技术的任何形式的计算装置,包含手机(或蜂窝式电话)、平板计算机、智能电话或台式计算机(提供几个实例)。同样,内容消费者14可表示能够实施本发明中所描述的技术的任何形式的计算装置,包含手持机(或蜂窝式电话)、平板计算机、智能电话、机顶盒,或台式计算机(提供几个实例)。
内容创建者12可表示电影演播室或可产生多声道音频内容以供由例如内容消费者14等内容消费者消费的其它实体。在一些实例中,内容创建者12可表示将希望压缩HOA系数11的个别用户。常常,此内容创建者产生音频内容连同视频内容。内容消费者14表示拥有或具有对音频重放系统的存取权的个体,所述音频重放系统可指能够再现SHC以作为多声道音频内容重放的任何形式的音频重放系统。在图3的实例中,内容消费者14包含音频重放系统16。
内容创建者12包含音频编辑系统18。内容创建者12获得各种格式(包含直接作为HOA系数)的实况记录7和音频对象9,内容创建者12可使用音频编辑系统18对其进行编辑。内容创建者可在编辑过程期间再现来自音频对象9的HOA系数11,从而收听所再现的扬声器馈送以试图识别需要进一步编辑的声场的各个方面。内容创建者12可接着编辑HOA系数11(可能经由操纵可供以上文所描述的方式导出源HOA系数的音频对象9中的不同者而间接地编辑)。内容创建者12可采用音频编辑系统18以产生HOA系数11。音频编辑系统18表示能够编辑音频数据且输出此音频数据作为一或多个源球谐系数的任何系统。
当编辑过程完成时,内容创建者12可基于HOA系数11产生位流21。也就是说,内容创建者12包含音频编码装置20,其表示经配置以根据本发明中描述的技术的各个方面编码或以其它方式压缩HOA系数11以产生位流21的装置。音频编码装置20可产生位流21以供(作为一个实例)跨越发射通道发射,所述传输通道可为有线或无线通道、数据存储装置等。位流21可表示HOA系数11的经编码版本,且可包含主要位流和另一旁侧位流(其可称为旁侧通道信息)。
尽管下文更详细地加以描述,但音频编码装置20可经配置以基于基于向量的合成或基于方向的合成编码HOA系数11。以确定是执行基于向量的合成方法还是基于方向的合成方法,音频编码装置20可至少部分基于HOA系数11确定HOA系数11经由声场的自然记录(例如,实况记录7)还是从(作为一个实例)例如PCM对象等音频对象9人工地(即,合成地)产生。当HOA系数11从音频对象9产生时,音频编码装置20可使用基于方向的合成方法编码HOA系数11。当HOA系数11使用例如本征麦克风(eigenmike)实况地俘获时,音频编码装置20可基于基于向量的合成方法编码HOA系数11。上述区别表示其中可部署基于向量或基于方向的合成方法的一个实例。可能存在其它情况:其中所述合成方法中的任一者或两者可用于自然记录、人工产生的内容或两种内容的混合(混合内容)。此外,也有可能同时使用两种方法用于对HOA系数的单一时间帧译码。
出于说明的目的假定:音频编码装置20确定HOA系数11实况地俘获或以其它方式表示实况记录(例如,实况记录7),音频编码装置20可经配置以使用涉及线性可逆变换(LIT)的应用的基于向量的合成方法编码HOA系数11。线性可逆变换的一实例被称作“奇异值分解”(或“SVD”)。在此实例中,音频编码装置20可将SVD应用于HOA系数11以确定HOA系数11之经分解版本。音频编码装置20可接着分析HOA系数11的经分解版本以识别可促进进行HOA系数11的经分解版本的重排序的各种参数。音频编码装置20可接着基于所识别的参数将HOA系数11的经分解版本重排序,其中如下文进一步详细描述,在给定以下情形的情况下,此重排序可改进译码效率:变换可将HOA系数跨越HOA系数的帧重排序(其中一帧通常包含HOA系数11的M个样本且在一些实例中,M经设定为1024)。在将HOA系数11的经分解版本重排序之后,音频编码装置20可HOA系数11的选择表示声场的前景(或,换句话说,相异的、占优势的或突出的)分量的经分解版本。音频编码装置20可将HOA系数11的表示前景分量的经分解版本指定为音频对象和相关联方向信息。
音频编码装置20还可对于HOA系数11执行声场分析以便至少部分识别HOA系数11中表示声场的一或多个背景(或,换句话说,环境)分量的那些HOA系数。假定在一些实例中,背景分量可仅包含HOA系数11的任何给定样本的子集(例如,例如对应于零阶和一阶球面基底函数的那些样本而非对应于二阶或更高阶球面基底函数的那些样本,那么音频编码装置20可对于背景分量执行能量补偿。换句话说,当执行阶数缩减时,音频编码装置20可扩增(例如,添加能量到/从中减去能量)HOA系数11中的剩余背景HOA系数以补偿由于执行阶数缩减而导致的总体能量的改变。
音频编码装置20接下来可相对于表示背景分量的HOA系数11中的每一者和前景音频对象中的每一者执行一种形式的心理声学编码(例如,MPEG环绕、MPEG-AAC、MPEG-USAC或其它已知形式的心理声学编码)。音频编码装置20可相对于前景方向信息执行一种形式的内插,且接着关于经内插前景方向信息执行阶数缩减以产生经阶数缩减的前景方向信息。在一些实例中,音频编码装置20可进一步关于经阶数缩减的前景方向信息执行量化,从而输出经译码前景方向信息。在一些情况下,此量化可包括标量/熵量化。音频编码装置20可接着形成位流21以包含经编码背景分量、经编码前景音频对象和经量化的方向信息。音频编码装置20可接着传输或以其它方式将位流21输出到内容消费者14。
虽然图3中展示为直接发射到内容消费者14,但内容创建者12可将位流21输出到定位在内容创建者12与内容消费者14之间的中间装置。此中间装置可存储位流21以供稍后递送到可请求此位流的内容消费者14。所述中间装置可包括文件服务器、网络服务器、台式计算机、膝上型计算机、平板计算机、移动电话、智能电话,或能够存储位流21以供音频解码器稍后检索的任何其它装置。此中间装置可驻留在能够将位流21(且可能结合发射对应视频数据位流)串流到请求位流21的订户(例如内容消费者14)的内容递送网络中。
或者,内容创建者12可将位流21存储到存储媒体,例如压缩光盘、数字视频光盘、高清视频光盘或其它存储媒体,其中大多数能够由计算机读取且因此可称为计算机可读存储媒体或非暂时性计算机可读存储媒体。在此上下文中,发射通道可指代借以发射存储到这些媒体的内容的那些通道(且可包含零售商店和其它基于商店的递送机制)。在任何情况下,本发明的技术因此就此而言不应限于图3的实例。
如图3的实例中进一步展示,内容消费者14包含音频重放系统16。音频重放系统16可表示能够重放多声道音频数据的任何音频重放系统。音频重放系统16可包含若干不同再现器22。再现器22可各自提供不同形式的再现,其中所述不同形式的再现可包含执行基于向量的振幅平移(VBAP)的各种方式中的一或多者,和/或执行声场合成的各种方式中的一或多者。如本文所使用,“A和/或B”意味着“A或B”,或“A和B”两者。
音频重放系统16可进一步包含音频解码装置24。音频解码装置24可表示经配置以解码来自位流21的HOA系数11'的装置,其中HOA系数11'可类似于HOA系数11但归因于有损操作(例如,量化)和/或经由发射通道的发射而不同。也就是说,音频解码装置24可对位流21中指定的前景方向信息进行解量化,同时还对于位流21中指定的前景音频对象和表示背景分量的经编码HOA系数执行心理声学解码。音频解码装置24可进一步相对于经解码前景方向信息执行内插,且接着基于经解码前景音频对象和经内插前景方向信息确定表示前景分量的HOA系数。音频解码装置24可接着基于表示前景分量的所确定的HOA系数和表示背景分量的经解码HOA系数确定HOA系数11'。
音频重放系统16可随后解码位流21以获得HOA系数11'且再现HOA系数11'以输出扩音器馈送25。扩音器馈送25可驱动一或多个扩音器(其为便于说明的目的在图3的实例中未图示)。
为选择适当再现器,或在一些情况下为产生适当再现器,音频重放系统16可获得指示扩音器的数目和/或扩音器的空间几何布置的扩音器信息13。在一些情况下,音频重放系统16可使用参考麦克风获得扬声器信息13且以动态地确定扬声器信息13的方式驱动所述扩音器。在其它情况下或结合动态确定扬声器信息13,音频重放系统16可提示用户与音频重放系统16介接并输入扬声器信息16。
音频重放系统16可随后基于扬声器信息13选择音频再现器22中的一者。在一些情况下,音频重放系统16可在音频再现器22均不在扬声器信息13中指定的量度的某一阈值类似性量度(依据扬声器几何布置)内时,音频重放系统16可基于扬声器信息13产生音频再现器22中的所述一者。音频重放系统16可在一些情况下基于扬声器信息13产生音频再现器22中的所述一者,而不首先尝试选择音频再现器22中的现有一者。
图4为更详细地说明可执行本发明中所描述的技术的各个方面的图3的实例中所展示的音频编码装置20的一个实例的框图。音频编码装置20包含内容分析单元26、基于向量的合成方法单元27和基于方向的合成方法单元28。
内容分析单元26表示经配置以分析HOA系数11的内容以识别HOA系数11表示从实况记录产生的内容还是从音频对象产生的内容的单元。内容分析单元26可确定HOA系数11是从实际声场的记录产生还是从人工音频对象产生。内容分析单元26可以各种方式进行此确定。举例来说,内容分析单元26可对(N+1)2-1个通道进行译码且预测最后的剩余通道(其可表示为向量)。内容分析单元26可将标量施加到(N+l)2-l个通道中的至少一些且将所产生的值相加以确定最后剩余通道。此外,在此实例中,内容分析单元26可确定经预测通道的准确性。在此实例中,如果所预测通道的准确度相对较高(例如,准确度超过特定阈值),那么HOA系数11可能是从合成音频对象产生。相比之下,如果所预测通道的准确度相对较低(例如,准确度低于特定阈值),那么HOA系数11更可能表示所记录的声场。举例来说,在此实例中,如果经预测通道的信噪比(SNR)超过100分贝(dbs),那么HOA系数11较可能表示从合成音频对象产生的声场。相比之下,使用本征麦克风记录的声场的SNR可为5db到20db。因而,在由从实际直接记录产生与从合成音频对象产生的HOA系数11表示的声场之间的SNR比率中可存在明显分界。
更确切地说,在确定表示声场的HOA系数11是否是从合成音频对象产生时,内容分析单元26可获得HOA系数的帧,其对于四阶表示(即,N=4)可为大小25乘1024。在获得帧式HOA系数(其也可在本文表示为帧式SHC矩阵11,且后续帧式SHC矩阵可表示为帧式SHC矩阵27B、27C等)之后。内容分析单元26可随后排除帧式HOA系数的第一向量以产生缩减的帧式HOA系数。在一些实例中,从帧式HOA系数11排除的此第一向量可对应于HOA系数11中的与零阶、零子阶球谐基底函数相关联的那些HOA系数。
内容分析单元26可接着从减小帧式HOA系数的剩余向量预测减小帧式HOA系数的第一非零向量。所述第一非零向量可指代从一阶(且考虑阶数相依性子阶中的每一者)达到四阶(且考虑阶数相依性子阶中的每一者)且值不同于零的第一向量。在一些实例中,减小帧式HOA系数的第一非零向量指代HOA系数11中的与一阶、零子阶球谐基底函数相关联的那些HOA系数。尽管关于第一非零向量进行描述,但所述技术可从减小帧式HOA系数的剩余向量预测减小帧式HOA系数的其它向量。举例来说,内容分析单元26可预测减小帧式HOA系数中的与一阶、第一子阶球谐基底函数或一阶、负一阶球谐基底函数相关联的那些HOA系数。作为另外其它实例,内容分析单元26可预测减小帧式HOA系数中的与二阶、零阶球谐基底函数相关联的那些HOA系数。
为预测第一非零向量,内容分析单元26可根据以下等式而操作:

其中i为从1到(N+1)2-2,其对于四阶表示为23,αi表示用于第i向量的某一常数,且vi指第ⅰ向量。在预测第一非零向量之后,内容分析单元26可基于预测的第一非零向量和实际非零向量而获得一误差。在一些实例中,内容分析单元26从实际第一非零向量减去经预测第一非零向量以导出所述误差。内容分析单元26可将误差计算为经预测第一非零向量与实际第一非零向量中的每一条目之间的差的绝对值的总和。
一旦获得所述误差,内容分析单元26就可基于实际第一非零向量和所述误差的能量计算比率。内容分析单元26可通过对第一非零向量的每一条目求平方并将经求平方的条目彼此相加来确定此能量。内容分析单元26可接着比较此比率与一阈值。当所述比率不超出阈值时,内容分析单元26可确定帧式HOA系数11是从记录产生,且在位流中指示HOA系数11的对应经译码表示是从记录产生。当所述比率超过阈值时,内容分析单元26可确定帧式HOA系数11是从合成音频对象产生,且在位流中指示帧式HOA系数11的对应经译码表示是从合成音频对象产生。
帧式HOA系数11是从记录还是合成音频对象产生的指示对于每一帧可包括单一位。所述单一位可指示不同编码用于每一帧,从而有效地在借以对对应帧进行编码的不同方式之间双态触发。在一些情况下,当帧式HOA系数11是从记录产生时,内容分析单元26将HOA系数11传递到基于向量的合成单元27。在一些情况下,当帧式HOA系数11是从合成音频对象产生时,内容分析单元26将HOA系数11传递到基于方向的合成单元28。基于方向的合成单元28可表示经配置以执行HOA系数11的基于方向的合成以产生基于方向的位流21的单元。
换句话说,所述技术基于使用前端分类器对HOA系数译码。所述分类器可如下工作:
以帧式SH矩阵(比方说4阶,帧大小1024,其也可被称作帧式HOA系数或HOA系数)开始-其中获得大小25×1024的矩阵。
排除第1向量(0阶SH)-因此存在大小为24×1024的矩阵。
预测矩阵中的第一非零向量(1×1024大小的向量)-从矩阵中的其余向量(大小为1×1024的23个向量)。
预测如下:经预测向量=总和-i[α-i x向量-I](其中总和I经由23个索引进行,i=1...23)
随后检查误差:实际向量-经预测向量=误差。
如果向量/误差的能量比率大(即,误差小),那么基础声场(在所述帧处)为稀疏/合成的。否则,基础声场为所记录(比如,使用麦克风阵列)的声场。
取决于所记录对合成决策,以不同方式进行编码/解码(其可涉及带宽压缩)。决策为针对每一帧经由位流发送的1位决策。
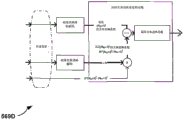
如图4的实例中所示,基于向量的合成单元27可包含线性可逆变换(LIT)单元30、参数计算单元32、重排序单元34、前景选择单元36、能量补偿单元38、心理声学音频译码器单元40、位流产生单元42、声场分析单元44、系数减少单元46、背景(BG)选择单元48、空间-时间内插单元50,和量化单元52。
线性可逆变换(LIT)单元30接收呈HOA通道形式的HOA系数11,每一通道表示与球面基底函数的给定阶数、子阶数相关联的系数的块或帧(其可表示为HOA[k],其中k可表示样本的当前帧或块)。HOA系数11的矩阵可具有尺寸D:M×(N+1)2。
即,LIT单元30可表示经配置以执行被称作奇异值分解的形式的分析的单元。虽然相对于SVD加以描述,但可相对于提供数组线性不相关的能量密集输出的任何类似变换或分解执行本发明中所描述的技术。并且,在本发明中对“集合”的参考希望指代“非零”集合(除非特定地相反陈述),且并不希望指代包含所谓的“空集合”的集合的经典数学定义。
替代变换可包括常常被称作“PCA”的主分量分析。PCA指代使用正交变换将一组可能相关变量的观测结果转换成被称作主分量的一组线性不相关变量的数学程序。线性不相关变量表示彼此并不具有线性统计关系(或相依性)的变量。可将这些主分量描述为彼此具有小程度的统计相关性。在任何情况下,所谓的主分量的数目小于或等于原始变量的数目。在一些实例中,以如下方式定义变换:第一主分量具有最大可能方差(或,换句话说,尽可能多地解释数据中的可变性),且每一随后分量又具有可能的最高方差(在以下约束下:此连续分量正交于(可重新表述为不相关于)前述分量)。PCA可执行一形式的,其依据HOA系数11可产生HOA系数11的压缩。取决于上下文,PCA可由若干不同名称指代,例如离散卡亨南-洛维变换、霍特林变换、恰当正交分解(POD)和本征值分解(EVD),仅举几例。有利于压缩音频数据的基本目标的此种操作的特性为多声道音频数据的“能量压缩”和“去相关”。
在任何情况下,LIT单元30执行奇异值分解(其再次可称为“SVD”)以将HOA系数11变换为经变换HOA系数的两个或两个以上集合。经变换HOA系数的此等“集合”可包含经变换HOA系数的向量。在图4的实例中,LIT单元30可相对于HOA系数11执行SVD以产生所谓的V矩阵、S矩阵和U矩阵。在线性代数中,SVD可按如下形式表示y乘z实数或复数矩阵X(其中X可表示多声道音频数据,例如HOA系数11)的因子分解:
x=USV*
U可表示y乘y实数或复数单位矩阵,其中U的y列通常被称为多声道音频数据的左奇异向量。S可表示在对角线上具有非负实数数字的y乘z矩形对角线矩阵,其中S的对角线值通常被称为多声道音频数据的奇异值。V*(其可表示V的共轭转置)可表示z乘z实数或复数单位矩阵,其中V*的z列通常被称为多声道音频数据的右奇异向量。
尽管本发明中描述为应用于包含HOA系数11的多声道音频数据,但所述技术可应用于任何形式的多声道音频数据。以此方式,音频编码装置20可相对于表示声场的至少一部分的多声道音频数据执行奇异值分解,以产生表示多声道音频数据的左奇异向量的U矩阵、表示多声道音频数据的奇异值的S矩阵和表示多声道音频数据的右奇异向量的V矩阵,且将多声道音频数据表示为U矩阵、S矩阵和V矩阵中的一或多者的至少一部分的函数。
在一些实例中,以上提及的SVD数学表达式中的V*矩阵表示为V矩阵的共轭转置以反映SVD可应用于包括复数的矩阵。当应用于仅包括实数的矩阵时,V矩阵的复数共轭(或换句话说,V*矩阵)可被视为V矩阵的转置。下文中为容易说明的目的,假定HOA系数11包括实数,结果是经由SVD而非V*矩阵输出V矩阵。此外,尽管在本发明中表示为V矩阵,但对V矩阵的提及应理解为在适当的情况下涉及V矩阵的转置。尽管假定为V矩阵,但所述技术可以类似方式应用于具有复数系数的HOA系数11,其中SVD的输出为V*矩阵。因此,就此而言,所述技术不应限于仅提供应用SVD以产生V矩阵,而是可包含将SVD应用于具有复数分量的HOA系数11以产生V*矩阵。
在任何情况下,LIT单元30可相对于高阶立体混响(HOA)音频数据(其中此立体混响音频数据包含HOA系数11或任何其它形式的多声道音频数据的块或样本)的每一块(其可称作帧)执行逐块形式的SVD。如上文所注释,变数M可用以表示音频帧的长度(以样本数计)。举例来说,当音频帧包含1024个音频样本时,M等于1024。尽管相对于M的此典型值加以描述,但本发明的技术不应限于M的此典型值。LIT单元30可因此相对于具有M乘(N+1)2个HOA系数的HOA系数11的块执行逐区块SVD,其中N再次表示HOA音频数据的阶数。LIT单元30可经由执行此SVD而产生V矩阵、S矩阵和U矩阵,其中矩阵中的每一者可表示上文所描述的相应V、S和U矩阵。以此方式,线性可逆变换单元30可相对于HOA系数11执行SVD以输出具有维度D:M×(N+1)2的US[k]向量33(其可表示S向量和U向量的组合版本),和具有维度D:(N+1)2×(N+1)2的V[k]向量35。US[k]矩阵中的个别向量元素也可被称为XPS(k),而V[k]矩阵中的个别向量也可被称为v(k)。
U、S和V矩阵的分析可显示,这些矩阵携载或表示上文由X表示的基本声场的空间和时间特性。U(长度为M个样本)中的N个向量中的每一者可表示依据时间(对于由M个样本表示的时间周期)的经正规化的分离音频信号,其彼此正交且已与任何空间特性(其也可被称作方向信息)解耦。表示空间形状和位置 宽度的空间特性可改为由V矩阵中的个别第i向量v(i)(k)(每一者具有长度(N+1)2)表示。U矩阵和V矩阵中的向量均经正规化而使得其均方根能量等于单位。U中的音频信号的能量因而由S中的对角线元素表示。将U与S相乘以形成US[k](具有个别向量元素XPS(k)),因而表示具有真正能量的音频信号。SVD分解使音频时间信号(U中)、其能量(S中)与其空间特性(V中)解耦的能力可支持本发明中所描述的技术的各个方面。另外,通过US[k]与V[k]的向量乘法合成基本HOA[k]系数X的此模型给出贯穿此文献使用的术语术语“基于向量的合成方法”。
宽度的空间特性可改为由V矩阵中的个别第i向量v(i)(k)(每一者具有长度(N+1)2)表示。U矩阵和V矩阵中的向量均经正规化而使得其均方根能量等于单位。U中的音频信号的能量因而由S中的对角线元素表示。将U与S相乘以形成US[k](具有个别向量元素XPS(k)),因而表示具有真正能量的音频信号。SVD分解使音频时间信号(U中)、其能量(S中)与其空间特性(V中)解耦的能力可支持本发明中所描述的技术的各个方面。另外,通过US[k]与V[k]的向量乘法合成基本HOA[k]系数X的此模型给出贯穿此文献使用的术语术语“基于向量的合成方法”。
尽管描述为直接相对于HOA系数11执行,但LIT单元30可将线性可逆变换应用到HOA系数11的导出项。举例来说,LIT单元30可相对于从HOA系数11导出的功率谱密度矩阵应用SVD。功率谱密度矩阵可表示为PSD且经由hoaFrame到hoaFrame的转置的矩阵乘法而获得,如下文的伪码中概述。hoaFrame记法是指HOA系数11的帧。
LIT单元30可在将SVD(svd)应用于PSD之后可获得S[k]2矩阵(S_squared)和V[k]矩阵。S[k]2矩阵可表示S[k]矩阵的平方,因此LIT单元30可将平方根运算应用于S[k]2矩阵以获得S[k]矩阵。在一些情况下,LIT单元30可相对于V[k]矩阵执行量化以获得经量化V[k]矩阵(其可表示为V[k]'矩阵)。LIT单元30可通过首先将S[k]矩阵乘以经量化V[k]'矩阵以获得SV[k]'矩阵而获得U[k]矩阵。LIT单元30接下来可获得SV[k]'矩阵的伪倒数(pinv)且接着将HOA系数11乘以SV[k]'矩阵的伪倒数以获得U[k]矩阵。可由以下伪码表示前述情况:
PSD=hoaFrame'*hoaFrame;
[V,S_squared]=svd(PSD,'econ');
S=sqrt(S_squared);
U=hoaFrame*pinv(S*V');
通过相对于HOA系数的功率谱密度(PSD)而非系数自身执行SVD,LIT单元30可在处理器循环和存储空间的之一或多者方面可能地降低执行SVD的计算复杂性,同时实现相同的源音频编码效率,如同SVD是直接应用于HOA系数一般。即,上述PSD型SVD可潜在地需求较少计算,因为SVD是在F*F矩阵(其中F为HOA系数的数目)上完成。与M*F矩阵相比,其中M为帧长度,即1024或更多个样本。经由应用于PSD而非HOA系数11,与应用于HOA系数11时的O(M*L2)相比较,SVD的复杂性现可为约O(L3)(其中O(*)表示计算机科学技术中常见的计算复杂性的大O记法)。
参数计算单元32表示经配置以计算各种参数的单元,所述参数例如相关性参数(R)、方向特性参数 和能量特性(e)。用于当前帧的这些参数中的每一者可表示为R[k]、θ[k]、
和能量特性(e)。用于当前帧的这些参数中的每一者可表示为R[k]、θ[k]、 r[k]和e[k]。参数计算单元32可相对于US[k]向量33执行能量分析和/或相关(或所谓的交叉相关)以识别这些参数。参数计算单元32还可确定先前帧的这些参数,其中先前帧参数可基于具有US[k-1]向量和V[k-1]向量的先前帧表示为R[k-1]、θ[k-1]、
r[k]和e[k]。参数计算单元32可相对于US[k]向量33执行能量分析和/或相关(或所谓的交叉相关)以识别这些参数。参数计算单元32还可确定先前帧的这些参数,其中先前帧参数可基于具有US[k-1]向量和V[k-1]向量的先前帧表示为R[k-1]、θ[k-1]、 r[k-1]和e[k-1]。参数计算单元32可将当前参数37和先前参数39输出到重排序单元34。
r[k-1]和e[k-1]。参数计算单元32可将当前参数37和先前参数39输出到重排序单元34。
即,参数计算单元32可相对于对应于第一时间的L个第一US[k]向量33中的每一者和对应于第二时间的第二US[k-1]向量33中的每一者执行能量分析,从而计算第一音频帧的至少一部分(但常常为整个)及第二音频帧的一部分(但常常为整个)的均方根能量且借此产生2L能量,一个用于第一音频帧的L个第一US[k]向量33中的每一者,且一个用于第二音频帧的第二US[k-1]向量33中的每一者。
在其它实例中,,参数计算单元32可执行第一US[k]向量33中的每一者的与第二US[k-1]向量33中的每一者的样本集合的某一部分(如果非整个)之间的交叉相关。交叉相关可指代如信号处理技术中理解的交叉相关。换句话说,交叉相关可涉及测量两个波形(在此情况下,其被定义为M个样本的离散集合)之间的相似度,其随应用于其中的一者的时间滞后而变。在一些实例中,为执行交叉相关,参数计算单元32逐轮比较每一第一US[k]向量27的最后L个样本与第二US[k-1]向量33中的剩余者中的每一者的前L个样本以确定相关参数。如本文所使用,“逐轮”运算是指相对于第一元素集合和第二元素集合进行的逐元素运算,其中所述运算根据集合的排序而“依次”从第一和第二元素集合中的每一者取出一个元素。
参数计算单元32还可分析V[k]和/或V[k-1]向量35以确定方向特性参数。这些方向特性参数可提供由对应US[k]和/或US[k-l]向量33表示的音频对象的移动和位置的指示。参数计算单元32可将以上当前参数37的任何组合(相对于US[k]向量33和/或V[k]向量35确定)和先前参数39的任何组合(相对于US[k-1]向量33和/或V[k-1]向量35确定)提供到重排序单元34。
SVD分解不保证由US[k-1]向量33中的第p向量(其可表示为US[k-1][p]向量(或替代地表示为XPS (p)(k-1)))表示的音频信号/对象将与由US[k]向量33中的第p向量(其也可表示为US[k][p]向量33(或替代地表示为XPS (p)(k)))表示的音频信号/对象(随时间而进展)相同。由参数计算单元32计算的参数可供重排序单元34用以将音频对象重排序以表示其自然评估或随时间推移的连续性。
也就是说,重排序单元34可随后将来自第一US[k]向量33的参数37中的每一者依次与第二US[k-1]向量33的参数39中的每一者比较。重排序单元34可基于当前参数37和先前参数39对US[k]矩阵33和V[k]矩阵35内的各个向量重排序(作为一个实例,使用Hungarian算法)以将经重排序的US[k]矩阵33'(其可数学上表示为US[k])和经重排序的V[k]矩阵35'(其可数学表示为V[k])输出到前景声音(或占优势的声音-PS)选择单元36(“前景选择单元36”)和能量补偿单元38。
换句话说,重排序单元34可表示经配置以对US[k]矩阵33内的向量重排序以产生经重排序的US[k]矩阵33'的单元。重排序单元34可对US[k]矩阵33重排序,因为US[k]向量33(其中,再次,US[k]向量33中的每一向量,其可再次替代地表示为XPS (p)(k),可表示存在于声场中的一或多个相异(或换句话说,占优势的)单声道音频对象)的阶数可在音频数据的各部分之间不同。也就是说,在一些实例中,假定音频编码装置12对音频数据的通常称为音频帧的这些部分操作,那么对应于这些相异单声道音频对象的向量的位置(如在所导出的US[k]矩阵33中所表示)可归因于将SVD应用于帧和帧间每一音频对象形式的不同突出性而在音频帧间不同。
将US[k]矩阵33内的向量直接传递到心理声学音频译码器单元40而不逐音频帧地对US[k]矩阵33内的向量重排序可能减小一些压缩方案(例如旧版压缩方案,其在单声道音频对象跨越音频帧为连续(逐通道的,其在此实例中由US[k]矩阵33内的向量相对于彼此的位置次序而定义)时性能更好)可实现的压缩程度。此外,当不重排序时,US[k]矩阵33内的向量的编码可能在解码时降低音频数据的质量。举例来说,与逐帧地直接编码US[k]矩阵33内的向量时所实现的压缩相比,在图3的实例中可由心理声学音频译码器单元40表示的AAC编码器可更有效地逐帧压缩US[k]矩阵33'内的经重排序的一或多个向量。尽管上文相对于AAC编码器予以描述,但可相对于跨越处于特定阶数或位置的帧指定单声道音频对象(逐通道地)时提供更好压缩的任何编码器执行所述技术。
以此方式,所述技术的各个方面可使得音频编码装置12能够对一或多个向量重排序(例如,US[k]矩阵33内的向量,以产生经重排序US[k]矩阵33'内的经重排序的一或多个向量且借此促进旧版音频编码器(例如心理声学音频译码器单元40)对US[k]矩阵33内的向量的压缩)。
举例来说,重排序单元34可基于当前参数37和先前参数39对来自第一音频帧的US[k]矩阵33内的一或多个向量重排序,所述第一音频帧在时间上在US[k-1]矩阵33内的一或多个第二向量对应于的第二帧之后。尽管于在时间上在第二音频帧之后的第一音频帧的上下文中予以描述,但第一音频帧可在时间上先于第二音频帧。因此,所述技术不应限于本发明中描述的实例。
为进行说明,考虑下表1,其中US[k]矩阵33内的p个向量中的每一者表示为US[k][p],其中k表示对应向量是来自第k帧还是先前第(k-1)帧,且p表示所述向量相对于相同音频帧(其中US[k]矩阵具有(N+1)2个此种向量)的向量的行。如上文所指出,假定N确定为1,那么p可表示向量一(1)到(4)。
表1
| 相关能量 | 与以下各者相比 |
| US[k-1][1] | US[k][1],US[k][2],US[k][3],US[k][4] |
| US[k-1][2] | US[k][1],US[k][2],US[k][3],US[k][4] |
| US[k-1][3] | US[k][1],US[k][2],US[k][3],US[k][4] |
| US[k-1][4] | US[k][1],US[k][2],US[k][3],US[k][4] |
在上文表1中,重排序单元34将针对US[k-l][1]计算的能量与针对US[k][1]、US[k][2]、US[k][3]、US[k][4]中的每一者计算的能量比较,将针对US[k-1][2]计算的能量与针对US[k][1]、US[k][2]、US[k][3]、US[k][4]中的每一者计算的能量比较,等等。重排序单元34可随后丢弃先前第二音频帧(依据时间)的第二US[k-1]向量33中的一或多者。为进行说明,考虑展示剩余第二US[k-1]向量33的下表2:
表2
| 相关向量 | 相关剩余向量 |
| US[k-1][1] | US[k][1],US[k][2] |
| US[k-1][2] | US[k][1],US[k][2] |
| US[k-1][3] | US[k][3],US[k][4] |
| US[k-1][4] | US[k][3],US[k][4] |
在以上表2中,重排序单元34可基于能量比较确定针对US[k-1][1]计算的能量类似于针对US[k][1]和US[k][2]中的每一者计算的能量,针对US[k-1][2]计算的能量类似于针对US[k][1]和US[k][2]中的每一者计算的能量,针对US[k-1][3]计算的能量类似于针对US[k][3]和US[k][4]中的每一者计算的能量,且针对US[k-1][4]计算的能量类似于针对US[k][3]和US[k][4]中的每一者计算的能量在一些实例中,重排序单元34可执行进一步能量分析以识别US[k]矩阵33的第一向量中的每一者与US[k-1]矩阵33的第二向量中的每一者之间的相似度。
在其它实例中,重排序单元32可基于与交叉相关有关的当前参数37和先前参数39对向量重排序。在这些实例中,返回参考以上表2,重排序单元34可基于这些交叉相关参数确定表3中表达的以下示范性相关:
表3
| 相关向量 | 与以下各者相关 |
| US[k-1][1] | US[k][2] |
| US[k-1][2] | US[k][1] |
| US[k-1][3] | US[k][3] |
| US[k-1][4] | US[k][4] |
从以上表3,作为一个实例,重排序单元34确定US[k-1][1]向量与位置不同的US[k][2]向量相关,US[k-1][2]向量与位置不同的US[k][1]向量相关,US[k-1][3]向量与位置类似的US[k][3]向量相关,且US[k-1][4]向量与位置类似的US[k][4]向量相关。换句话说,重排序单元34确定描述以下情况的重排序信息:如何重排序US[k]矩阵33的第一向量使得US[k][2]向量再定位在US[k]矩阵33的第一向量的第一行中且US[k][1]向量再定位在第一US[k]向量33的第二行中。重排序单元34可随后基于此重排序信息对US[k]矩阵33的第一向量重排序以产生经重排序的US[k]矩阵33'。
此外,尽管未在图4的实例中展示,但重排序单元34可将此重排序信息提供至位流产生装置42,位流产生装置42可产生位流21以包含此重排序信息,以使得音频解码装置(例如图3和5的实例中所示的音频解码装置24)可确定如何对US[k]矩阵33'的经重排序向量重排序以便恢复US[k]矩阵33的向量。
虽然上文描述为执行涉及基于分析的首先能量特定参数和随后交叉相关参数的两步法,但重排序单元32可仅相对于能量参数仅执行此分析以确定重排序信息,仅相对于交叉相关参数执行此分析以确定重排序信息,或相对于能量参数和交叉相关参数两者执行所述分析(以上文所描述的方式)。此外,所述技术可使用并不涉及执行能量比较和/或交叉相关中的一或两者的其它类型的过程用于确定相关。因此,就此而言,所述技术不应限于以上阐述的实例。此外,从参数计算单元32获得的其它参数(例如从V向量导出的空间位置参数或V[k]和V[k-1]中的向量的相关性)也可与从US[k]和US[k-1]获得的能量和交叉相关参数一起使用(同时/联合地或连续地)以正确US中的向量的正确排序。
作为使用V矩阵中的向量的相关性的一个实例,参数计算单元34可确定V[k]矩阵35的向量为相关的,如在以下表4中所指定:
表4
| 相关向量 | 与以下各者相关 |
| V[k-1][1] | V[k][2] |
| V[k-1][2] | V[k][1] |
| V[k-1][3] | V[k][3] |
| V[k-1][4] | V[k][4] |
从以上表4,作为一个实例,重排序单元34确定V[k-1][1]向量与位置不同的V[k][2]向量相关,V[k-1][2]向量与位置不同的V[k][1]向量相关,V[k-1][3]向量与位置类似的V[k][3]向量相关,且V[k-1][4]向量与位置类似的V[k][4]向量相关。重排序单元34可输出V[k]矩阵35的向量的经重排序版本作为经重排序的V[k]矩阵35'。
在一些实例中,应用于US矩阵中的向量的相同的重排序也适用于V矩阵中的向量。换句话说,用于对V向量重排序的任何分析可与用以对US向量重排序的任何分析结合使用。为了说明其中重排序信息并不仅仅相对于US[k]向量35相对于能量参数和/或交叉相关参数确定的实例,重排序单元34还可以类似于上文相对于V[k]向量35描述的方式基于交叉相关参数和能量参数相对于V[k]向量35执行此分析。此外,虽然US[k]向量33并不具有任何方向特性,但V[k]向量35可提供关于对应US[k]向量33的方向性的信息。在此意义上,重排序单元34可基于对应方向特性参数的分析识别V[k]向量35与V[k-1]向量35之间的相关。也就是说,在一些实例中,音频对象在移动时以连续方式在声场内移动或保持处于相对稳定的位置。由此,重排序单元34可将V[k]矩阵35和V[k-1]矩阵35的展现一些已知实体实际运动或在声场内保持固定的那些向量识别为相关的,从而基于此方向特性相关而对US[k]向量33和V[k]向量35重排序。在任何情况下,重排序单元34可将经重排序的US[k]向量33'和经重排序的V[k]向量35'输出到前景选择单元36。
此外,所述技术可使用并不涉及执行能量比较和/或交叉相关中的一或两者的其它类型的过程用于确定正确次序。因此,就此而言,所述技术不应限于以上阐述的实例。
尽管上文描述为对V矩阵的向量重排序以镜射US矩阵的向量的重排序,但在某些情况下,V向量可以不同于US向量的方式重排序,其中可产生单独语法元素以指示US向量的重排序和V向量的重排序。在一些情况下,假定V向量可不进行心理声学编码,则可不对V向量重排序而可仅对US向量重排序。
其中V矩阵的向量与US矩阵的向量的重排序不同的实施例为当意图调换空间中的音频对象时--即,将其移开原始记录位置(当基本声场为自然记录时)或艺术意图位置(当基本声场为对象的人工混合时)。作为一实例,假设存在两个音频源A和B,A可为出自声场“左”部分的猫的声音“喵喵”,且B可为出自声场“右”部分的狗的声音“汪汪”。当V与US的重排序不同时,调换两个声源的位置。在调换之后,A(“喵喵”)出自于声场的右部,且B(“汪汪”)出自于声场的左部。
声场分析单元44可表示经配置以相对于HOA系数11执行声场分析以便有可能实现目标位速率41的单元。声场分析单元44可基于此分析和/或基于所接收目标位速率41,确定心理声学译码器执行个体的总数目(其可为环境或背景通道的总数目(BGTOT)的函数)和前景通道(或换句话说,优势通道)的数目。心理声学译码器执行个体的总数可表示为numHOATransportChannels。再次为了潜在地实现目标位速率41,声场分析单元44还可确定前景通道的总数(nFG)45、背景(或换句话说,环境)声场的最小阶数(NBG或替代地,MinAmbHoaOrder)、表示背景声场的最小阶数的实际通道的对应数目(nBGa=(MinAmbHoaOrder+1)2),和要发送的额外BG HOA通道的索引(i)(其在图4的实例中可共同地表示为背景通道信息43)。背景通道信息42也可被称作环境通道信息43。保持来自numHOATransportChannels-nBGa的通道中的每一者可为“额外背景/环境通道”、“活动的基于向量的优势通道”、“活动的基于方向的优势信号”或“完全非活动”。在一个实施例中,这些通道类型可为由两个位指示(为“ChannelType”)的语法元素(例如,00:额外背景通道;01:基于向量的优势信号;10:不活动信号;11:基于方向的信号)。可由(MinAmbHoaOrder+1)2+呈现为用于所述帧的位流中的通道类型的索引00(在以上实例中)的倍数给出背景或环境信号的总数nBGa。
在任何情况下,声场分析单元44可基于目标位速率41选择背景(或换句话说,环境)通道的数目和前景(或换句话说,占优势)通道的数目,从而在目标位速率41相对较高时(例如,在目标位速率41等于或大于512Kbps时)选择更多背景和/或前景通道。在一个实施例中,在位流的标头区段中,numHOATransportChannels可设定为8,且MinAmbHoaOrder可设定为1(其相对于图10到10O(ii)予以更详细地描述)。在此情境下,在每个帧处,四个通道可专用于表示声场的背景或环境部分,而其它4个通道可逐帧地在通道类型上变化--例如,用作额外背景/环境通道或前景/占优势通道。前景/优势信号可为基于向量或基于方向的信号中的一者,如上文所描述。
在一些情况下,可通过在一帧的位流中的ChannelType索引为01(在以上实例中)的倍数给出用于所述帧的基于向量的优势信号的总数。在以上实施例中,对于每一额外背景/环境通道(例如,对应于ChannelType 00),其可能HOA系数(超出前四个)的对应信息可表示于所述通道中。用于四阶HOA内容的此信息可为指示于5到25之间的索引(在minAmbHoaOrder设定为1时,可始终发送前四个1到4,因此仅需要指示5到25之间的一者)。因而可使用5位语法元素(对于四阶内容)发送此信息,其可表示为“CodedAmbCoeffIdx”。
在第二实施例中,所有前景/优势信号为基于向量的信号。在此第二实施例中,可由nFG=numHOATransportChannels-[(MinAmbHoaOrder+1)2+索引00的倍数]给出前景/优势信号的总数。
声场分析单元44将背景通道信息43和HOA系数11输出到背景(BG)选择单元46,将背景通道信息43输出到系数减少单元46和位流产生单元42,且将nFG 45输出到前景选择单元36。
在一些实例中,声场分析单元44可基于US[k]矩阵33和目标位速率41的向量的分析选择具有最大值的这些分量的可变nFG数目。换句话说,声场分析单元44可通过分析由S[k]矩阵33的向量的递减对角线值产生的曲线的斜率而确定分隔两个子空间的变数A(其可类似或实质上类似于NBG)的值,其中大奇异值表示前景或相异声音,且低奇异值表示声场的背景分量。也就是说,变数A可将总体声场分段成前景子空间和背景子空间。
在一些实例中,声场分析单元44可使用奇异值曲线的一阶和二阶导数。声场分析单元44还可将变数A的值限制在一与五之间。作为另一实例,声场分析单元44可将变数A的值限制在一与(N+l)2之间。或者,声场分析单元44可将变数A的值预先界定为例如值四。在任何情况下,基于A的值,声场分析单元44确定前景通道的总数(nFG)45、背景声场的阶数(NBG)和要发送的额外BG HOA通道的数目(nBGa)及索引(i)。
此外,声场分析单元44可每向量地确定V[k]矩阵35中的向量的能量。声场分析单元44可确定V[k]矩阵35中的向量中的每一者的能量,且将具有高能量的那些向量识别为前景分量。
此外,声场分析单元44可对于HOA系数11执行各种其它分析,包括空间能量分析、空间掩蔽分析、扩散分析或其它形式的听觉分析。声场分析单元44可经由将HOA系数11变换到空间域来执行空间能量分析,且识别表示应保存的声场的方向分量的高能量区域。声场分析单元44可以类似于空间能量分析的方式执行感知空间掩蔽分析,只是声场分析单元44可识别由空间上接近的较高能量声音掩蔽的空间区域。在一些情况下,声场分析单元44可接着基于感知掩蔽区域识别较少前景分量。声场分析单元44可进一步对于HOA系数11执行扩散分析以识别可表示声场的背景分量的扩散能量区域。
声场分析单元44还可表示经配置以使用与音频数据相关联的基于方向性的信息确定表示声场的音频数据的突出性、相异性或优势性的单元。虽然基于能量的确定可改进由SVD分解的声场的再现以识别声场的相异音频分量,但在背景音频分量展现高能级的情况下,基于能量的确定也可使装置错误地将背景音频分量识别为相异音频分量。即,相异和背景音频分量的基于仅能量的分离可能不稳健,因为高能(例如,较响)背景音频分量可能经不正确地识别为相异音频分量。为了更稳健地在声场的相异背景音频分量之间区分,本发明中所描述的技术的各个方面可使声场分析单元44能够执行HOA系数11的基于方向性的分析以将前景和环境音频分量与HOA系数11的经分解版本分离。
在这方面中,声场分析单元44可表示经配置或以其它方式可操作以识别来自US[k]矩阵33中的向量和V[k]矩阵35中的向量中的一或多者中包含的背景元素的相异(或前景)元素的单元。根据一些基于SVD的技术,能量最高的分量(例如,US[k]矩阵33和V[k]矩阵35中的一或多者的前面几个向量或自其导出的向量)可处理为相异分量。然而,US[k]矩阵33中的向量和V[k]矩阵35中的向量中的一或多者的能量最高的分量(其由向量表示)并非在所有情形中均可表示最具方向性的分量/信号。
声场分析单元44可实施本文中所描述的技术的一或多个方面以基于US[k]矩阵33中的向量和V[k]矩阵35中的向量或自其导出的向量中的一或多者的向量的方向性而识别前景/直接/优势元素。在一些实例中,声场分析单元44可基于能量的向量的方向性两者识别或选择一或多个向量作为相异音频分量(其中所述分量也可被称作“对象”)。举例来说,声场分析单元44可将US[k]矩阵33中的向量和V[k]矩阵35中的向量(或自其导出的向量)中的一或多者中的显示高能量和高方向性(例如,表示为方向性商)两者的那些向量识别为相异音频分量。结果,如果声场分析单元44确定特定向量与US[k]矩阵33中的向量和V[k]矩阵35中的向量(或自其导出的向量)中的一或多者中的其它向量相比具有相对较少的方向性,那么不管与所述特定向量相关联的能量级如何,声场分析单元44可确定所述特定向量表示由HOA系数11表示的声场的背景(或环境)音频分量。
在一些实例中,声场分析单元44可通过执行以下操作基于方向性识别相异音频对象(如上文所指出,其也可称为“分量”)。声场分析单元44可将S[k]矩阵(其可从US[k]向量33导出或(尽管图4的实例中未单独图示)由LIT单元30输出)中的向量乘以(例如,使用一或多个矩阵乘法过程)V[k]矩阵35中的向量。通过使V[k]矩阵35与S[k]向量相乘,声场分析单元44可获得VS[k]矩阵。此外,声场分析单元44可对VS[k]矩阵中的向量中的每一者的条目中的至少一些求平方(即,幂次为二的取幂)。在一些情况下,声场分析单元44可对每一向量的与大于1的阶数相关联的那些经求平方的条目进行求和。
作为一个实例,如果VS[k]矩阵的每一向量包含25个条目,那么声场分析单元44可相对于每一向量对在第五条目处开始且在第二十五条目处结束的每一向量的条目求平方,对经求平方的条目求和以确定方向性商(或方向性指示符)。每一求和运算可导致对应的向量的方向性商。在此实例中,声场分析单元44可确定每一行的与小于或等于1的阶数相关联的那些条目(即,第一到第四条目),更通常是针对能量的量,且较少针对那些条目的方向性。也就是说,与阶数零或一相关联的较低阶立体混响对应于图1和图2中所说明的球面基底函数,在压力波的方向方面并不提供许多,而是实际上提供某一音量(其表示能量)。
以上实例中描述的操作也可以根据以下伪码而表达。以下伪码包含标注,呈包含在字符串“/*”和“*/”(无引号)的连续实例内的注释语句的形式。
[U,S,V]=svd(audioframe,'ecom');
VS=V*S;
/*下一排针对独立地分析每一行,且将从第五条目到第二十五条目的第一(作为一实例)行中的值求和以确定一对应的向量的商或方向性量度。在求和前将所述条目自乘。每一行中与大于1的阶相关联的条目与较高阶立体混响相关联,且因此更有可能为方向性的。*/
sumVS=sum(VS(5:end,:).^2,1);
/*下一排是针对将产生的VS矩阵的平方的总和排序,且选择最大值的集合(例如,最大值中的三个或四个)*/
[~,idxVS]=sort(sumVS,'descend');
U=U(:,idxVS);
V=V(:,idxVS);
S=S(idxVS,idxVS);
换句话说,根据以上伪码,声场分析单元44可选择从HOA系数11中的对应于具有大于一的阶数的球形基底函数的那些HOA系数分解的VS[k]矩阵的每一向量的条目。声场分析单44可接着将VS[k]矩阵的每一向量的这些条目自乘,将经平方条目求和以识别、计算或以其它方式确定VS[k]矩阵的每一向量的方向性量度或商。接下来,声场分析单元44可基于向量中的每一者的相应方向性量度将VS[k]矩阵的向量排序。声场分析单元44可将这些向量以方向性量度的降序排序,使得具有最高对应方向性的那些向量是最先的,且具有最低对应方向性的那些向量是最后的。声场分析单元44可随后选择向量的具有最高相对方向性量度的非零子集。
声场分析单元44可执行先前分析的任何组合以确定心理声学译码器执行个体的总数(其可为环境或背景通道的总数(BGTOT)和前景通道的数目的函数。声场分析单元44可基于先前分析的任何组合确定前景通道的总数(nFG)45、背景声场的阶数(NBG)和要发送的额外BG HOA通道的数目(nBGa)及索引(i)(其在图4的实例中可共同地表示为背景通道信息43)。
在一些实例中,声场分析单元44可每M个样本(其可重新表述为逐帧地)执行此分析。在这方面中,A的值可在帧间不同。其中每M个样本进行决策的位流的例子展示于图10到10O(ii)中。在其它实例中,声场分析单元44可每帧执行此分析一次以上,从而分析帧的两个或两个以上部分。因此,所述技术在这方面不应限于本发明中描述的实例。
背景选择单元48可表示经配置以基于背景通道信息(例如,背景声场(NBG)以及待发送的额外BG HOA通道的数目(nBGa)及索引(i))确定背景或环境HOA系数47的单元。举例来说,当NBG等于一时,背景选择单元48可选择具有等于或小于一的阶数的音频帧的每一样本的HOA系数11。在此实例中,背景选择单元48可接着选择具有由索引(i)中的一者识别的索引的HOA系数11作为额外BG HOA系数,其中将待于位流21中指定的nBGa提供到位产生单元42以便使得音频解码装置(例如,图3的实例中所展示的音频解码装置24)能够从位流21解析BG HOA系数47。背景选择单元48可接着将环境HOA系数47输出到能量补偿单元38。环境HOA系数47可具有尺寸D:M×[(NBG+1)2+nBGa]。
前景选择单元36可表示经配置以基于nFG 45(其可表示识别这些前景向量的一或多个索引)选择经重排序的US[k]矩阵33'和经重排序的V[k]矩阵35'中的表示声场的前景或相异分量的那些的单元。前景选择单元36可将nFG信号49(其可表示为经重排序的US[k]1,…,nFG 49、FG1,…,nfG[k]49,或 输出到心理声学音频译码器单元40,其中nFG信号49可具有尺寸D:M×nFG,且每一者表示单声道音频对象。前景选择单元36还可将对应于声场的前景分量的经重排序的V[k]矩阵35'(或v(1..nFG)(k)35')输出到空间-时间内插单元50,其中经重排序的V[k]矩阵35'中的对应于前景分量的那些可表示为具有尺寸D:((N+1)2×nFG)的前景V[k]矩阵51k(其可在数学上表示为
输出到心理声学音频译码器单元40,其中nFG信号49可具有尺寸D:M×nFG,且每一者表示单声道音频对象。前景选择单元36还可将对应于声场的前景分量的经重排序的V[k]矩阵35'(或v(1..nFG)(k)35')输出到空间-时间内插单元50,其中经重排序的V[k]矩阵35'中的对应于前景分量的那些可表示为具有尺寸D:((N+1)2×nFG)的前景V[k]矩阵51k(其可在数学上表示为
能量补偿单元38可表示经配置以相对于环境HOA系数47执行能量补偿以补偿归因于由背景选择单元48移除HOA通道中的各者而产生的能量损失的单元。能量补偿单元38可相对于经重排序的US[k]矩阵33'、经重排序的V[k]矩阵35'、nFG信号49、前景V[k]向量51k和环境HOA系数47中的一或多者执行能量分析,且接着基于此能量分析执行能量补偿以产生经能量补偿的环境HOA系数47'。能量补偿单元38可将经能量补偿的环境HOA系数47'输出到心理声学音频译码器元40。
有效地,能量补偿单元38可用于补偿由于减小HOA系数11描述的声场的环境分量的阶数以产生阶数缩减的环境HOA系数47(其在一些实例中具有小于N的阶数,依据对应于具有以下阶数/子阶数的球面基底函数的唯一包含系数:[(NBG+1)2+nBGa])所导致的声场的背景声音分量的总体能量的可能降低。在一些实例中,能量补偿单元38通过以下操作补偿此能量损耗:确定适用于环境HOA系数47的[(NBG+1)2+nBGa]列中的每一者的呈放大值的形式的补偿增益以便将环境HOA系数47能量的均方根(RMS)增加到等于或至少更接近地近似HOA系数11的RMS(如经由经重排序的US[k]矩阵33'、经重排序的V[k]矩阵35'、nFG信号49、前景V[k]向量51k和阶数缩减的环境HOA系数47中的一或多者的总计能量分析而确定),随后将环境HOA系数47输出到心理声学音频译码器单元40。
在一些情况下,能量补偿单元38可识别经重排序的US[k]矩阵33'和经重排序的V[k]矩阵35'中的一或多者上的每一行和/或列的RMS。能量补偿单元38还可识别选定前景通道中的一或多者(其可包含nFG信号49和前景V[k]向量51k,以及阶数缩减的环境HOA系数47)的每一行和/或列的RMS。经重排序的US[k]矩阵33'和经重排序的V[k]矩阵35'中的所述一或多者的每一行和/或列的RMS可存储为表示为RMSFULL的向量,而nFG信号49、前景V[k]向量51k和阶数缩减的环境HOA系数47中的一或多者的每一行和/或列的RMS可存储为表示为RMSREDUCED的向量。能量补偿单元38可随后根据以下等式计算放大值向量Z:Z=RMSFULL/RMSREDUCED。能量补偿单元38可随后将此放大值向量Z或其各部分应用到nFG信号49、前景V[k]向量51k和阶数缩减的环境HOA系数47中的一或多者。在一些情况下,放大值向量Z依据以下等式HOABG_RED'=HOABG_REDZT施加到仅阶数缩减的环境HOA系数47,其中HOABG_RED指示阶数缩减的环境HOA系数47,HOABG_RED'指示经能量补偿的阶数缩减的HOA系数47',且ZT指示Z向量的转置。
在一些实例中,为确定经重排序的US[k]矩阵33'、经重排序的V[k]矩阵35'、nFG信号49、前景V[k]向量51k和阶数缩减的环境HOA系数47中的一或多者的相应行和/或列的每一RMS,能量补偿单元38可首先将参考球谐系数(SHC)再现器应用到所述列。由能量补偿单元38应用参考SHC再现器允许确定SHC域中的RMS以确定经重排序的US[k]矩阵33'、经重排序的V[k]矩阵35'、nFG信号49、前景V[k]向量51k和阶数缩减的环境HOA系数47中的一或多者的行和/或列表示的帧的每一行和/或列所描述的总体声场的能量,如下文更详细地描述。
空间-时间内插单元50可表示经配置以接收第k帧的前景V[k]向量51k和前一帧(因此为k-1记法)的前景V[k-1]向量51k-1且执行空间-时间内插以产生经内插前景V[k]向量的单元。空间-时间内插单元50可将nFG信号49与前景V[k]向量51k重新组合以恢复经重排序的前景HOA系数。空间-时间内插单元50可接着将经重排序的前景HOA系数除以经内插的V[k]向量以产生经内插的nFG信号49'。空间-时间内插单元50还可输出前景V[k]向量51k的用于产生经内插前景V[k]向量的那些前景V[k]向量51k使得例如音频解码装置24等音频解码装置可产生经内插前景V[k]向量且借此恢复前景V[k]向量51k。将前景V[k]向量51k的用以产生经内插的前景V[k]向量的那些前景V[k]向量51k表示为剩余前景V[k]向量53。为了确保在编码器和解码器处使用相同的V[k]和V[k-1](以创建经内插的向量V[k]),可在编码器和解码器处使用这些的经量化/经解量化的版本。
就此而言,空间-时间内插单元50可表示从第一音频帧的一些其它部分和第二时间上在后或在前的音频帧内插第一音频帧的第一部分的单元。在一些实例中,所述部分可表示为子帧,其中下文关于图45到46E更详细地描述如相对于子帧执行的内插。在其它实例中,空间-时间内插单元50可相对于前一帧的某一最后数目的样本和后续帧的某一第一数目的样本操作,如相对于图37到39更详细描述。空间-时间内插单元50可在执行此内插时减小位流21中需要指定的前景V[k]向量51k的样本的数目,因为前景V[k]向量51k的仅那些用于产生经内插V[k]向量的前景V[k]向量51k表示前景V[k]向量51k的子集。也就是说,为了潜在地使HOA系数11的压缩更有效(通过减小在位流21中指定的前景V[k]向量51k的数目),本发明中所描述的技术的各个方面可提供第一音频帧的一或多个部分的内插,其中所述部分中的每一者可表示HOA系数11的经分解版本。
空间-时间内插可导致数个益处。首先,归因于执行SVD或其它LIT的逐区块性质,nFG信号49可不从帧到帧为连续的。换句话说,在LIT单元30逐帧应用SVD的条件下,所产生的经变换HOA系数中可存在特定不连续性,如例如US[k]矩阵33和V[k]矩阵35的无序性质所证明。通过执行此内插,在内插可具有潜在地减少归因于帧边界(或换句话说,HOA系数11分段为帧)而引入的任何假影的平滑效果的条件下可减小不连续。使用前景V[k]向量51k执行此内插且接着基于经内插前景V[k]向量51k从所恢复的经重排序HOA系数产生经内插nFG信号49'可使归因于逐帧运算以及归因于对nFG信号49重排序的至少一些效果平滑化。
在操作中,空间-时间内插单元50可内插来自包含于第一帧中的第一多个HOA系数11的一部分的第一分解(例如,前景V[k]向量51k)和包含于第二帧中的第二多个HOA系数11的一部分的第二分解(例如,前景V[k]向量51k-1)的第一音频帧的一或多个子帧以产生用于所述一或多个子帧的经分解的经内插球谐系数。
在一些实例中,第一分解包括表示HOA系数11的所述部分的右奇异向量的第一前景V[k]向量51k。同样,在一些实例中,第二分解包括表示HOA系数11的所述部分的右奇异向量的第二前景V[k]向量51k。
换句话说,就球面上的正交基底函数而言,基于球谐的3D音频可为3D压力场的参数表示。所述表示的阶数N越高,空间分辨率可能地越高,且常常球谐(SH)系数的数目越大(总共(N+1)2个系数)。对于许多应用,可能需要系数的带宽压缩能够有效地发射且存储所述系数。在本发明中所针对的此技术可提供使用奇异值分解(SVD)的基于帧的维度减少过程。SVD分析可将系数的每一帧分解成三个矩阵U、S和V。在一些实例中,所述技术可将US[k]矩阵中的向量中的一些作为基础声场的方向分量处置。然而,当以此方式处置时,这些向量(在U S[k]矩阵中)在帧间是不连续的-即使其表示同一相异音频分量。当通过变换音频译码器馈入所述分量时,这些不连续性可导致显著假影。
本发明中所描述的技术可解决此不连续性。即,所述技术可基于以下观测结果:V矩阵可经解译为球谐域中的正交空间轴。U[k]矩阵可表示球谐(HOA)数据根据那些基底函数的投影,其中不连续性可归因于正交的空间轴(V[k]),所述空间轴线每帧改变且因此自身为不连续的。这不同于例如傅立叶变换等类似分解,其中基底函数在一些实例中在帧间将为常数。在这些术语中,SVD可认为是匹配追求算法。本发明中所描述的技术可使内插单元50能够通过在其间进行内插而在帧间维持基底函数(V[k])之间的连续性。
如上文所指出,可相对于样本执行内插。当子帧包括样本的单个集合时,此情况在以上描述中得以一般化。在经由样本和经由子帧的内插的两个情况中,内插运算可呈以下等式的形式:

在此上述等式中,内插可从单一V-向量v(k-1)相对于单一V-向量v(k)执行,其在一个实施例中可表示来自邻近帧k和k-1的V-向量。在上述等式中,l表示执行内插所针对的分辨率,其中l可指示整数样本且l=1,…,T(其中T为样本的长度,在所述长度内执行内插且在所述长度内需要输出的经内插的向量 且所述长度还指示此过程的输出产生这些向量的l)。替代地,l可指示由多个样本组成的子帧。当(例如)将帧划分成四个子帧时,l可包括用于所述子帧中的每一者的值1、2、3和4。可经由位流将l的值作为被称为“CodedSpatialInterpolationTime”的字段用信号发出,使得可在解码器中重复内插运算。w(l)可包括内插权重的值。当内插为线性的时,w(l)可作为l的函数而线性地且单调地在0与1之间变化。在其它情况下,w(l)可作为l的函数以非线性但单调的方式(例如升余弦的四分之一循环)在0与1之间变化。可将函数w(l)在几个不同函数可能性之间编索引且将函数w(l)在位流中作为被称为“SpatialInterpolationMethod”的字段用信号发出,使得可由解码器重复相同的内插运算。当w(l)为接近0的值时,输出
且所述长度还指示此过程的输出产生这些向量的l)。替代地,l可指示由多个样本组成的子帧。当(例如)将帧划分成四个子帧时,l可包括用于所述子帧中的每一者的值1、2、3和4。可经由位流将l的值作为被称为“CodedSpatialInterpolationTime”的字段用信号发出,使得可在解码器中重复内插运算。w(l)可包括内插权重的值。当内插为线性的时,w(l)可作为l的函数而线性地且单调地在0与1之间变化。在其它情况下,w(l)可作为l的函数以非线性但单调的方式(例如升余弦的四分之一循环)在0与1之间变化。可将函数w(l)在几个不同函数可能性之间编索引且将函数w(l)在位流中作为被称为“SpatialInterpolationMethod”的字段用信号发出,使得可由解码器重复相同的内插运算。当w(l)为接近0的值时,输出 可被很大程度加权或受v(k-1)影响。而当w(l)为接近于1的值时,其确保输出
可被很大程度加权或受v(k-1)影响。而当w(l)为接近于1的值时,其确保输出 被很大程度加权或受v(k-1)影响。
被很大程度加权或受v(k-1)影响。
系数减少单元46可表示经配置以基于背景通道信息43相对于剩余前景V[k]向量53执行系数减少以将经缩减的前景V[k]向量55输出到量化单元52的单元。经缩减的前景V[k]向量55可具有维度D:[(N+1)2-(NBG+1)2-nBGa]×nFG。
系数减少单元46可在这方面中表示经配置以减少剩余前景V[k]向量53的系数的数目的单元。换句话说,系数减少单元46可表示经配置以消除(形成剩余前景V[k]向量53的)前景V[k]向量的具有极少到零方向信息的那些系数的单元。如上文所描述,在一些实例中,相异或(换句话说)前景V[k]向量的对应于一阶和零阶基底函数的那些系数(其可表示为NBG)提供极少方向信息,且因此可从前景V向量移除(经由可被称作“系数减少”的过程)。在此实例中,可提供较大灵活性以不仅从集合[(NBG+1)2+1,(N+1)2]识别对应于NBG的这些系数而且识别额外HOA通道(其可由变量TotalOfAddAmbHOAChan表示)。声场分析单元44可分析HOA系数11以确定BGTOT,其可不仅识别(NBG+1)2而且识别TotalOfAddAmbHOAChan(其可统称为背景通道信息43)。系数减少单元46可随后从剩余前景V[k]向量53移除对应于(NBG+12和TotalOfAddAmbHOAChan的那些系数以产生大小为((N+12-(BGTOT)x nFG的较小维度V[k]矩阵55,其也可被称作缩减的前景V[k]向量55。
量化单元52可表示经配置以执行任何形式的量化以压缩缩减的前景V[k]向量55以产生经译码前景V[k]向量57从而将这些经译码前景V[k]向量57输出到位流产生单元42的单元。在操作中,量化单元52可表示经配置以压缩声场的空间分量(即,在此实例中,缩减的前景V[k]向量55中的一或多者)的单元。出于实例的目的,假定缩减的前景V[k]向量55包含两行向量,由于系数减少,每一行具有小于25个元素(其暗示声场的四阶HOA表示)。尽管相对于两个行向量来描述,但任何数目个向量可包含在缩减的前景V[k]量55中,至多为(n+1)2个,其中n表示声场的HOA表示的阶数。此外,尽管下文描述为执行标量和/或熵量化,但量化单元52可执行导致缩减的前景V[k]向量55的压缩的任何形式的量化。
量化单元52可接收缩减的前景V[k]向量55且执行压缩方案以产生经译码前景V[k]向量57。此压缩方案通常可涉及用于压缩向量或数据的元素的任何可设想压缩方案,且不应限于以下更详细描述的实例。作为一实例,量化单元52可执行包含以下各者中的一或多者的压缩方案:将缩减的前景V[k]向量55的每一元素的浮点表示变换成缩减的前景V[k]向量55的每一元素的整数表示、缩减的前景V[k]向量55的整数表示的均匀量化,以及剩余前景V[k]向量55的经量化的整数表示的分类和译码。
在一些实例中,可由参数动态地控制此压缩方案的一或多个过程中的各者以实现或几乎实现用于所得位流21的目标位速率(作为一个实例)。在缩减的前景V[k]向量55中的每一者彼此正交的条件下,缩减的前景V[k]向量55中的每一者可独立译码。在一些实例中,如下文更详细地所描述,可使用相同译码模式(由各种子模式界定)译码每一缩减的前景V[k]向量55的每一元素。
在任何情况下,如上文所指出,此译码方案可首先涉及将缩减的前景V[k]向量55中的每一者的每一元素的浮点表示(其在一些实例中为32位浮点数)变换为16位整数表示。量化单元52可通过将缩减的前景V[k]向量55中的给定者的每一元素乘以215(在一些实例中,其通过右移15而执行)而执行此浮点到整数变换。
量化单元52可随后相对于缩减的前景V[k]向量55中的给定者的所有元素执行均一量化。量化单元52可基于可表示为nbits参数的值识别量化步长。量化单元52可基于目标位速率41动态地确定此nbits参数。量化单元52可依据此nbits参数确定量化步长。作为一个实例,量化单元52可将量化步长(在本发明中表示为“差量”或“Δ”)确定为等于216-nbits。在此实例中,如果nbits等于六,那么差量等于210,且存在26个量化层级。在这方面中,对于向量元素v,经量化向量元素vq等于[v/Δ],且-2nbits-1<vq<2nbits-1。
量化单元52可接着执行经量化向量元素的分类和残余译码。作为一个实例,量化单元52可使用以下等式对于一给定经量化向量元素vq识别此元素所对应的类别(通过确定类别识别符cid):

量化单元52可接着对此类别索引cid进行霍夫曼译码,同时也识别指示vq为正值还是负值的正负号位。
量化单元52接下来可识别此类别中的残余。作为一个实例,量化单元52可根据以下等式确定此残余:
残余=|vq|-2cid-1
量化单元52可接着用cid-1个位对此残余进行块译码。
以下实例说明此分类和残余译码过程的简化实例。首先,假定nbits等于6使得vq∈[-31,31]。接下来,假定以下:
| cid | vq | 用于cid的霍夫曼码 |
| 0 | 0 | ‘1’ |
| 1 | -1,1 | ‘01’ |
| 2 | -3,-2,2,3 | ‘000’ |
| 3 | -7,-6,-5,-4,4,5,6,7 | ‘0010’ |
| 4 | -15,-14,...,-8,8,...,14,15 | ‘00110’ |
| 5 | -31,-30,...,-16,16,...,30,31 | ‘00111’ |
并且,假定以下:
| cid | 用于残余的块码 |
| 0 | 不可用 |
| 1 | 0,1 |
| 2 | 01,00,10,11 |
| 3 | 011,010,001,000,100,101,110,111 |
| 4 | 0111,0110...,0000,1000,...,1110,1111 |
| 5 | 01111,...,00000,10000,...,11111 |
因而,对于vq=[6,-17,0,0,3],可确定以下:
>>cid=3,5,0,0,2
>>正负号=l,0,x,x,l
>>残余=2,1,x,x,1
>>针对6的位=‘0010’+‘1’+‘10’
>>针对-17的位=‘00111’+‘0’+‘0001’
>>针对0的位=‘0’
>>针对0的位=‘0’
>>针对3的位=‘000’+‘1’+‘1’
>>总位=7+10+1+1+5=24
>>平均位=24/5=4.8
尽管未展示于先前简化实例中,但量化单元52可在对cid进行译码时针对nbits的不同值选择不同霍夫曼码簿。在一些实例中,量化单元52可针对nbits值6,…,15提供不同霍夫曼译码表。此外,量化单元52可包含针对范围为6,…,15的不同nbits值中的每一者的五个不同霍夫曼码簿,总共50个霍夫曼码簿。就此而言,量化单元52可包括多个不同霍夫曼码簿以适应数个不同统计情境中的cid的译码。
为了说明,量化单元52可针对nbits值中的每一者包含用于对向量元素一到四译码的第一霍夫曼码簿、用于对向量元素五到九译码的第二霍夫曼码簿、用于对向量元素九及以上译码的第三霍夫曼码簿。当出现以下情形时,可使用这前三个霍夫曼码簿:缩减的前景V[k]向量55中待压缩的前景V[k]向量55并非从缩减的前景V[k]向量55中在时间上后续的对应前景V[k]向量预测而来且并非表示合成音频对象((例如)最初由经脉码调制(PCM)音频对象界定的音频对象)的空间信息。量化单元52可另外针对nbits值中的每一者包含用于对缩减的前景V[k]向量55中的所述一者译码的第四霍夫曼码簿(当缩减的前景V[k]向量55中的此一者是从缩减的前景V[k]向量55中在时间上后续的对应前景V[k]向量预测而来时)。量化单元52还可针对nbits值中的每一者包含用于对缩减的前景V[k]向量55中的所述一者译码的第五霍夫曼码簿(当缩减的前景V[k]向量55中的此一者表示合成音频对象时)。可针对这些不同统计情境(即,在此实例中,非预测和非合成情境、预测情境及合成情境)中的每一者开发各种霍夫曼码簿。
下表说明霍夫曼表选择和待于位流中指定以使得解压缩单元能够选择适当霍夫曼表的位:


在前表中,预测模式(“Pred模式”)指示是否针对当前向量执行了预测,而霍夫曼表(“HT信息”)指示用以选择霍夫曼表一到五中的一者的额外霍夫曼码簿(或表)信息。
下表进一步说明此霍夫曼表选择过程(假定各种统计情境或情形)。
| 记录 | 合成 | |
| 无Pred | HT{1,2,3} | HT5 |
| 有Pred | HT4 | HT5 |
在前表中,“记录”列指示向量表示所记录的音频对象时的译码情境,而“合成”列指示向量表示合成音频对象时的译码情境。“无Pred”行指示并不相对于向量元素执行预测时的译码情境,而“有Pred”行指示相对于向量元素执行预测时的译码情境。如此表中所示,量化单元52在向量表示所记录音频对象且不相对于向量元素执行预测时选择HT{1,2,3}。量化单元52在音频对象表示合成音频对象且不相对于向量元素执行预测时选择HT5。量化单元52在向量表示所记录音频对象且相对于向量元素执行预测时选择HT4。量化单元52在音频对象表示合成音频对象且相对于向量元素执行预测时选择HT5。
在这方面中,量化单元52可执行上文所述的标量量化和/或霍夫曼编码以压缩缩减的前景V[k]向量55,从而输出经译码前景V[k]向量57(其可被称为旁侧通道信息57)。此旁侧通道信息57可包含用以对剩余前景V[k]向量55译码的语法元素。量化单元52可以类似于图10B和10C中的一者的实例中展示的方式的方式输出旁侧通道信息57。
如上所述,量化单元52可产生旁侧通道信息57的语法元素。举例来说,量化单元52可指定存取单元(其可包含一或多个帧)的标头中的表示选择所述多个配置模式中的哪一配置模式的语法元素。尽管描述为在每存取单元基础上予以指定,但量化单元52可在每帧基础或任何其它周期性基础或非周期性基础(例如整个位流一次)上指定此语法元素。在任何情况下,此语法元素可包括指示选择了四个配置模式中的哪一者用于指定缩减的前景V[k]向量55的非零系数集合以表示此相异分量的方向方面的两个位。所述语法元素可表示为“codedVVecLength”。以此方式,量化单元52可在位流中用信号通知或以其它方式指定使用四个配置模式中的哪一者来在位流中指定经译码前景V[k]向量57。尽管相对于四个配置模式予以描述,但所述技术不应限于四个配置模式,而应限于任何数目的配置模式,包含单个配置模式或多个配置模式。标量/熵量化单元53还可将旗标63指定为旁侧通道信息57中的另一语法元素。
音频编码装置20内包含的心理声学音频译码器单元40可表示心理声学音频译码器的多个例子,其每一者用于编码经能量补偿环境HOA系数47'和经内插nFG信号49'中的每一者的不同音频对象或HOA通道以产生经编码环境HOA系数59和经编码nFG信号61。心理声学音频译码器单元40可将经编码环境HOA系数59和经编码nFG信号61输出到位流产生单元42。
在一些情况下,此心理声学音频译码器40可表示高级音频译码(AAC)编码单元的一或多个实例。心理声学音频译码器单元40可对经能量补偿的环境HOA系数47'和经内插nFG信号49'的每一列或行进行编码。常常,心理声学音频译码器单元40可针对经能量补偿的环境HOA系数47'和经内插nFG信号49'中剩余的阶/子阶组合中的每一者调用AAC编码单元的例项。关于可如何使用AAC编码单元对背景球谐系数31进行编码的更多信息可见于埃里克·赫卢德(Eric Hellerud)等人的标题为“以AAC编码较高阶立体混响(EncodingHigher Order Ambisonics with AAC)”的大会论文中,其在第124次大会(2008年5月17日至20日)上提交且可在下处获得:http://ro.uow.edu.au/cgi/viewcontent.cgi?article =:8025&context=engpapers。在一些情况下,音频编码单元14可使用比用于编码经内插nFG信号49'低的目标位速率对经能量补偿的环境HOA系数47'进行音频编码,借此与经内插nFG信号49'相比潜在地更多地压缩经能量补偿的环境HOA系数47'。
包括于音频编码装置20内的位流产生单元42表示将数据格式化以符合已知格式(其可指代解码装置已知的格式)借此产生基于向量的位流21的单元。位流产生单元42在一些实例中可表示多路复用器,其可接收经译码前景V[k]向量57、经编码环境HOA系数59、经编码nFG信号61,和背景通道信息43。位流产生单元42可接着基于经译码前景V[k]向量57、经编码环境HOA系数59、经编码nFG信号61和背景通道信息43产生位流21。位流21可包含主要或主位流和一或多个旁侧通道位流。
尽管在图4的实例中未展示,但音频编码装置20还可包含位流输出单元,所述位流输出单元基于当前帧将使用基于方向的合成还是基于向量的合成编码而切换从音频编码装置20输出的位流(例如,在基于方向的位流21与基于向量的位流21之间切换)。此位流输出单元可基于由内容分析单元26输出的指示执行基于方向的合成(作为检测到HOA系数11是从合成音频对象产生的结果)还是执行基于向量的合成(作为检测到HOA系数经记录的结果)的语法元素执行此切换。位流输出单元可指定正确的标头语法以指示用于当前帧以及位流21中的相应一者的此切换或当前编码。
在一些情况下,所述技术的各个方面还可使音频编码装置20能够确定HOA系数11是否是从合成音频对象产生。所述技术的这些方面可使音频编码装置20能够经配置以获得表示声场的球谐系数是否是从合成音频对象产生的指示。
在这些和其它情况下,音频编码装置20进一步经配置以确定球谐系数是否是从合成音频对象产生。
在这些和其它情况下,音频编码装置20经配置以从存储表示声场的球谐系数的至少一部分的帧式球谐系数矩阵排除第一向量以获得缩减的帧式球谐系数矩阵。
在这些和其它情况下,音频编码装置20经配置以从存储表示声场的球谐系数的至少一部分的帧式球谐系数矩阵排除第一向量以获得缩减的帧式球谐系数矩阵,且基于所述缩减的帧式球谐系数矩阵的剩余向量预测所述缩减的帧式球谐系数矩阵的向量。
在这些和其它情况下,音频编码装置20经配置以从存储表示声场的球谐系数的至少一部分的帧式球谐系数矩阵排除第一向量以获得经缩减帧式球谐系数矩阵,且至少部分基于所述经缩减帧式球谐系数矩阵的剩余向量的总和预测所述经缩减帧式球谐系数矩阵的向量。
在这些和其它情况下,音频编码装置20经配置以至少部分基于帧式球谐系数矩阵的剩余向量的总和预测存储球谐系数的至少一部分的帧式球谐系数矩阵的向量。
在这些和其它情况下,音频编码装置20经配置以至少部分基于帧式球谐系数矩阵的剩余向量的总和预测存储球谐系数的至少一部分的帧式球谐系数矩阵的向量,且基于所预测的向量计算误差。
在这些和其它情况下,音频编码装置20经配置以至少部分基于帧式球谐系数矩阵的剩余向量的总和预测存储球谐系数的至少一部分的帧式球谐系数矩阵的向量,且基于所预测的向量和帧式球谐系数矩阵的对应向量计算误差。
在这些和其它情况下,音频编码装置20经配置以至少部分基于帧式球谐系数矩阵的剩余向量的总和预测存储球谐系数的至少一部分的帧式球谐系数矩阵的向量,且将误差计算为所预测向量与帧式球谐系数矩阵的对应向量的差的绝对值的总和。
在这些和其它情况下,音频编码装置20经配置以至少部分基于帧式球谐系数矩阵的剩余向量的总和预测存储球谐系数的至少一部分的帧式球谐系数矩阵的向量,基于所预测向量和帧式球谐系数矩阵的对应向量计算误差,基于帧式球谐系数矩阵的对应向量与所述误差的能量计算比率,且比较所述比率与阈值以确定表示声场的球谐系数是否是从合成音频对象产生。
在这些和其它情况下,音频编码装置20经配置以在存储球谐系数的经压缩版本的位流21中指定所述指示。
在一些情况下,各种技术可使音频编码装置20能够相对于HOA系数11执行变换。在这些和其它情况下,音频编码装置20可经配置以获得描述声场的相异分量的一或多个第一向量和描述声场的背景分量的一或多个第二向量,所述一或多个第一向量和所述一或多个第二向量两者至少通过相对于所述多个球谐系数11执行变换而产生。
在这些和其它情况下,音频编码装置20,其中变换包括奇异值分解,所述奇异值分解产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵和表示所述多个球谐系数11的右奇异向量的V矩阵。
在这些和其它情况下,音频编码装置20,其中所述一或多个第一向量包括一或多个经音频编码的UDIST*SDIST向量,其是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,且其中U矩阵和S矩阵是至少通过对于相对于所述多个球谐系数执行奇异值分解而产生。
在这些和其它情况下,音频编码装置20,其中所述一或多个第一向量包括一或多个经音频编码的UDIST*SDIST向量和具有V矩阵的转置的一或多个VT DIST向量,所述UDIST*SDIST向量是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,且其中U矩阵和S矩阵以及V矩阵是至少通过相对于所述多个球谐系数11执行奇异值分解而产生。
在这些和其它情况下,音频编码装置20,其中所述一或多个第一向量包括一或多个UDIST*SDIST向量和具有V矩阵的转置的一或多个VT DIST向量,所述UDIST*SDIST向量是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,其中U矩阵、S矩阵和V矩阵是至少通过对于相对于所述多个球谐系数执行奇异值分解而产生,且其中音频编码装置20进一步经配置以获得指示将从位流提取以形成所述一或多个UDIST*SDIST向量和所述一或多个VT DIST向量的向量数目的值D。
在这些和其它情况下,音频编码装置20,其中所述一或多个第一向量包括一或多个UDIST*SDIST向量和具有V矩阵的转置的一或多个VT DIST向量,所述UDIST*SDIST向量是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,其中U矩阵、S矩阵和V矩阵是至少通过对于相对于所述多个球谐系数执行奇异值分解而产生,且其中音频编码装置20进一步经配置以基于逐个音频帧获得值D,所述值D指示待从位流提取以形成所述一或多个UDIST*SDIST向量和所述一或多个VT DIST向量的向量的数目。
在这些和其它情况下,音频编码装置20,其中所述变换包括主分量分析以识别声场的相异分量和声场的背景分量。
本发明中所描述的技术的各个方面可提供经配置以补偿量化误差的音频编码装置20。
在一些情况下,音频编码装置20可经配置以量化表示声场的一或多个分量的一或多个第一向量,且补偿归因于所述一或多个第一向量的量化而在也表示所述声场的相同一或多个分量的一或多个第二向量中引入的误差。
在这些和其它情况下,音频编码装置经配置以量化来自至少部分通过相对于描述声场的多个球谐系数执行奇异值分解而产生的V矩阵的转置的一或多个向量。
在这些和其它情况下,音频编码装置进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵,和表示所述多个球谐系数的右奇异向量的V矩阵,且经配置以量化来自V矩阵的转置的一或多个向量。
在这些和其它情况下,音频编码装置进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵,和表示所述多个球谐系数的右奇异向量的V矩阵,经配置以量化来自V矩阵的转置的一或多个向量,且经配置以补偿归因于通过将U矩阵的一或多个U向量乘以S矩阵的一或多个S向量而计算出的一或多个U*S向量的量化而引入的误差。
在这些和其它情况下,音频编码装置进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵,和表示所述多个球谐系数的右奇异向量的V矩阵;确定U矩阵的一或多个UDIST向量,其每一者对应于声场的相异分量;确定S矩阵的一或多个SDIST向量,其每一者对应于声场的相同的相异分量;且确定V矩阵的转置的一或多个VT DIST向量,其每一者对应于声场的相同的相异分量;经配置以量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量;且经配置以补偿归因于通过将U矩阵的所述一或多个UDIST向量乘以S矩阵的一或多个SDIST向量以便产生一或多个经误差补偿的UDIST*SDIST向量而计算出的一或多个UDIST*SDIST向量的量化而引入的误差。
在这些和其它情况下,音频编码装置经配置以基于所述一或多个UDIST向量、所述一或多个SDIST向量和所述一或多个VT DIST向量确定相异球谐系数,且相对于所述VT Q_DIST向量执行伪逆以将所述相异球谐系数除以所述一或多个VT Q_DIST向量且进而产生至少部分补偿通过VT DIST向量的量化而引入的误差的经误差补偿的一或多个UC_DIST*SC_DIST向量。
在这些和其它情况下,音频编码装置进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵和表示所述多个球谐系数的右奇异向量的V矩阵,确定描述声场的一或多个背景分量的U矩阵的一或多个UBG向量和描述声场的一或多个相异分量的U矩阵的一或多个UDIST向量,确定描述声场的所述一或多个背景分量的S矩阵的一或多个SBG向量和描述声场的所述一或多个相异分量的S矩阵的一或多个SDIST向量,且确定V矩阵的转置的一或多个VT DIST向量和一或多个VT BG向量,其中VT DIST向量描述声场的所述一或多个相异分量且VT BG描述声场的所述一或多个背景分量,经配置以量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量,且经配置以补偿归因于通过将所述一或多个UBG向量乘以所述一或多个SBG向量且随后乘以所述一或多个VT BG向量以便产生经误差补偿的背景球谐系数而形成的背景球谐系数中的量化而引入的误差。
在这些和其它情况下,音频编码装置经配置以基于VT DIST向量和通过将所述UDIST向量乘以SDIST向量而形成的一或多个UDIST*SDIST向量确定所述误差,且将所确定的误差相加到背景球谐系数以产生经误差补偿的背景球谐系数。
在这些和其它情况下,音频编码装置经配置以补偿归因于所述一或多个第一向量的量化而在也表示声场的相同的一或多个分量的一或多个第二向量中引入的误差以产生一或多个经误差补偿的第二向量,且进一步经配置以产生位流以包含所述一或多个经误差补偿的第二向量和所述经量化的一或多个第一向量。
在这些和其它情况下,音频编码装置经配置以补偿归因于所述一或多个第一向量的量化而在也表示声场的相同的一或多个分量的一或多个第二向量中引入的误差以产生一或多个经误差补偿的第二向量,且进一步经配置以对所述一或多个经误差补偿的第二向量进行音频编码,且产生位流以包含经音频编码的一或多个经误差补偿的第二向量和所述经量化的一或多个第一向量。
所述技术的各个方面可进一步使得音频编码装置20能够产生经缩减球谐系数或其分解。在一些情况下,音频编码装置20可经配置以基于目标位速率相对于多个球谐系数或其分解执行阶数缩减以产生经缩减球谐系数或其经缩减分解,其中所述多个球谐系数表示声场。
在这些和其它情况下,音频编码装置20进一步经配置以在执行阶数缩减之前相对于所述多个球谐系数执行奇异值分解以识别描述声场的相异分量的一或多个第一向量和识别声场的背景分量的一或多个第二向量,且经配置以相对于所述一或多个第一向量、所述一或多个第二向量或所述一或多个第一向量和所述一或多个第二向量两者执行阶数缩减。
在这些和其它情况下,音频编码装置20进一步经配置以相对于所述多个球谐系数或其分解执行内容分析,且经配置以基于目标位速率和所述内容分析相对于所述多个球谐系数或其分解执行阶数缩减以产生经缩减球谐系数或其经缩减分解。
在这些和其它情况下,音频编码装置20经配置以相对于所述多个球谐系数或其分解执行空间分析。
在这些和其它情况下,音频编码装置20经配置以相对于所述多个球谐系数或其分解执行扩散分析。
在这些和其它情况下,音频编码装置20为经配置以相对于所述多个球谐系数或其分解执行空间分析和扩散分析的一或多个处理器。
在这些和其它情况下,音频编码装置20进一步经配置以在包含经缩减球谐系数或其经缩减分解的位流中指定经缩减球谐系数或其经缩减分解所对应的球面基底函数的一或多个阶数和/或一或多个子阶。
在这些和其它情况下,经缩减球谐系数或其经缩减分解比所述多个球谐系数或其分解具有较小的值。
在这些和其它情况下,音频编码装置20经配置以移除所述多个球谐系数或其分解的向量中的具有指定阶数和/或子阶的那些球谐系数或向量以产生经缩减球谐系数或其经缩减分解。
在这些和其它情况下,音频编码装置20经配置以零化所述多个球谐系数或其分解的那些向量中的具有指定阶数和/或子阶的那些球谐系数或向量以产生经缩减球谐系数或其经缩减分解。
所述技术的各个方面还可允许音频编码装置20经配置以表示声场的相异分量。在这些和其它情况下,音频编码装置20经配置以获得待用以表示声场的相异分量的向量的系数的第一非零集合,其中所述向量是从描述声场的多个球谐系数分解。
在这些和其它情况下,音频编码装置20经配置以确定所述向量的所述系数的所述第一非零集合以包含所有所述系数。
在这些和其它情况下,音频编码装置20经配置以将系数的所述第一非零集合确定为所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数。
在这些和其它情况下,音频编码装置20经配置以确定系数的第一非零集合以包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数,且排除所述系数中的对应于大于所述多个球谐系数中的所述一或多者所对应的所述基底函数的阶数的阶数的至少一者。
在这些和其它情况下,音频编码装置20经配置以确定系数的所述第一非零集合以包含所有所述系数,但对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的所述系数中的至少一者除外。
在这些和其它情况下,音频编码装置20进一步经配置以在旁侧通道信息中指定所述向量的所述系数的所述第一非零集合。
在这些和其它情况下,音频编码装置20进一步经配置以在旁侧通道信息中指定所述向量的所述系数的所述第一非零集合,而不对所述向量的所述系数的所述第一非零集合进行音频编码。
在这些和其它情况下,所述向量包括使用基于向量的合成从所述多个球谐系数分解的向量。
在这些和其它情况下,所述基于向量的合成包括奇异值分解。
在这些和其它情况下,所述向量包括使用奇异值分解从所述多个球谐系数分解的V向量。
在这些和其它情况下,音频编码装置20进一步经配置以选择多个配置模式中借以指定所述向量的系数的所述非零集合的一个配置模式,且基于所述多个配置模式中的所述选定者指定所述向量的系数的所述非零集合。
在这些和其它情况下,所述多个配置模式中的所述一者指示所述系数的所述非零集合包含所有所述系数。
在这些和其它情况下,所述多个配置模式中的所述一者指示系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数。
在这些和其它情况下,所述多个配置模式中的所述一者指示所述系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数,且排除所述系数中的对应于大于所述多个球谐系数中的所述一或多者所对应的所述基底函数的所述阶数的阶数的至少一个系数。
在这些和其它情况下,所述多个配置模式中的所述一者指示系数的所述非零集合包含所有所述系数,但所述系数中的至少一者除外。
在这些和其它情况下,音频编码装置20进一步经配置以在位流中指定所述多个配置模式中的所述选定一者。
本发明中所描述的技术的各个方面还可允许音频编码装置20经配置而以各种方式表示声场的相异分量。在这些和其它情况下,音频编码装置20经配置以获得待用以表示声场的相异分量的向量的系数的第一非零集合,其中所述向量已从描述声场的多个球谐系数分解。
在这些和其它情况下,系数的所述第一非零集合包含向量的所有系数。
在这些和其它情况下,系数的所述第一非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数。
在这些和其它情况下,所述系数的所述第一非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数,且排除所述系数中的对应于大于所述多个球谐系数中的所述一或多者所对应的所述基底函数的所述阶数的阶数的至少一个系数。
在这些和其它情况下,系数的所述第一非零集合包含所有所述系数,但所述系数中的识别为不具有足够方向信息的至少一个系数除外。
在这些和其它情况下,音频编码装置20进一步经配置以将系数的所述第一非零集合提取为向量的第一部分。
在这些和其它情况下,音频编码装置20进一步经配置以从旁侧通道信息提取向量的第一非零集合,且基于所述向量的系数的所述第一非零集合获得所述多个球谐系数的重组版本。
在这些和其它情况下,所述向量包括使用基于向量的合成从所述多个球谐系数分解的向量。
在这些和其它情况下,所述基于向量的合成包括奇异值分解。
在这些和其它情况下,音频编码装置20进一步经配置以确定借以根据多个配置模式中的一者提取所述向量的系数的非零集合的所述多个配置模式中的所述一者,且基于所述多个配置模式中的所获得者提取所述向量的系数的所述非零集合。
在这些和其它情况下,所述多个配置模式中的所述一者指示所述系数的所述非零集合包含所有所述系数。
在这些和其它情况下,所述多个配置模式中的所述一者指示系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数。
在这些和其它情况下,所述多个配置模式中的所述一者指示所述系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数,且排除所述系数中的对应于大于所述多个球谐系数中的所述一或多者所对应的所述基底函数的所述阶数的阶数的至少一个系数。
在这些和其它情况下,所述多个配置模式中的所述一者指示系数的所述非零集合包含所有所述系数,但所述系数中的至少一者除外。
在这些和其它情况下,音频编码装置20经配置以基于在位流中用信号通知的值确定所述多个配置模式中的所述一者。
在一些情况下,所述技术的各个方面还可使得音频编码装置20能够识别一或多个相异音频对象(或,换句话说,优势音频对象)。在一些情况下,音频编码装置20可经配置以基于针对音频对象中的一或多者确定的方向性从与所述音频对象相关联的一或多个球谐系数(SHC)识别一或多个相异音频对象。
在这些和其它情况下,音频编码装置20进一步经配置以基于与音频对象相关联的球谐系数确定所述一或多个音频对象的方向性。
在这些和其它情况下,音频编码装置20进一步经配置以相对于球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵和表示所述多个球谐系数的右奇异向量的V矩阵,且将所述多个球谐系数表示为U矩阵、S矩阵和V矩阵中的一或多者的至少一部分的函数,其中音频编码装置20经配置以至少部分基于所述V矩阵确定所述一或多个音频对象的相应方向性。
在这些和其它情况下,音频编码装置20进一步经配置以对V矩阵的一或多个向量重排序,使得具有较大方向性商的向量在经重排序的V矩阵中定位在具有较小方向性商的向量之上。
在这些和其它情况下,音频编码装置20进一步经配置以确定具有较大方向性商的向量比具有较小方向性商的向量包含更多的方向信息。
在这些和其它情况下,音频编码装置20进一步经配置以将V矩阵乘以S矩阵以产生VS矩阵,所述VS矩阵包含一或多个向量。
在这些和其它情况下,音频编码装置20进一步经配置以选择VS矩阵的每一行的与大于14的阶数相关联的条目,对所选条目中的每一者求平方以形成对应求平方条目,且对于VS矩阵的每一行,对所有求平方条目进行求和以确定对应向量的方向性商。
在这些和其它情况下,音频编码装置20经配置以选择VS矩阵的每一行的与大于14的阶数相关联的条目包括选择在VS矩阵的每一行的第18条目处开始且在VS矩阵的每一行的第38条目处结束的所有条目。
在这些和其它情况下,音频编码装置20进一步经配置以选择VS矩阵的向量的子集来表示相异音频对象。在这些和其它情况下,音频编码装置20经配置以选择VS矩阵的四个向量,且其中选定的四个向量具有VS矩阵的所有向量中的四个最大方向性商。
在这些和其它情况下,音频编码装置20经配置以确定表示相异音频对象的向量的选定子集是基于每一向量的方向性和能量两者。
在这些和其它情况下,音频编码装置20进一步经配置以在表示相异音频对象的一或多个第一向量与一或多个第二向量之间执行能量比较以确定经重排序的一或多个第一向量,其中所述一或多个第一向量描述音频数据的第一部分中的相异音频对象,且所述一或多个第二向量描述音频数据的第二部分中的相异音频对象。
在这些和其它情况下,音频编码装置20进一步经配置以在表示相异音频对象的一或多个第一向量与一或多个第二向量之间执行交叉相关以确定经重排序的一或多个第一向量,其中所述一或多个第一向量描述音频数据的第一部分中的相异音频对象,且所述一或多个第二向量描述音频数据的第二部分中的相异音频对象。
在一些情况下,所述技术的各个方面还可使得音频编码装置20能够经配置以相对于HOA系数11的分解执行能量补偿。在这些和其它情况下,音频编码装置20可经配置以:相对于多个球谐系数执行基于向量的合成以产生表示一或多个音频对象和对应方向信息的所述多个球谐系数的经分解表示,其中所述球谐系数与一阶数相关联且描述声场;从所述方向信息确定相异和背景方向信息;缩减与所述背景音频对象相关联的方向信息的阶数以产生经变换背景方向信息;应用补偿以增加经变换方向信息的值以节省所述声场的总能量。
在这些和其它情况下,音频编码装置20可经配置以:相对于多个球谐系数执行奇异值分解以产生表示音频对象的U矩阵和S矩阵以及表示方向信息的V矩阵;确定V矩阵的相异列向量和V矩阵的背景列向量;缩减V矩阵的背景列向量的阶数以产生V矩阵的经变换背景列向量;及应用补偿以增加V矩阵的经变换背景列向量的值以节省声场的总体能量。
在这些和其它情况下,音频编码装置20进一步经配置以确定S矩阵的突出奇异值的数目,其中V矩阵的相异列向量的数目为S矩阵的突出奇异值的数目。
在这些和其它情况下,音频编码装置20经配置以确定球谐系数的经缩减阶数,且零化与大于所述经缩减阶数的阶数相关联的V矩阵的背景列向量的行的值。
在这些和其它情况下,音频编码装置20进一步经配置以组合U矩阵的背景列、S矩阵的背景列和V矩阵的经变换背景列的转置以产生经修改球谐系数。
在这些和其它情况下,所述经修改球谐系数描述声场的一或多个背景分量。
在这些和其它情况下,音频编码装置20经配置以确定V矩阵的背景列向量的向量的第一能量和V矩阵的经变换背景列向量的向量的第二能量,且将放大值应用到V矩阵的经变换背景列向量的所述向量的每一元素,其中所述放大值包括第一能量与第二能量的比率。
在这些和其它情况下,音频编码装置20经配置以确定V矩阵的背景列向量的向量的第一均方根能量和V矩阵的经变换背景列向量的向量的第二均方根能量,且将放大值应用于V矩阵的经变换背景列向量的向量的每一元素,其中所述放大值包括第一能量与第二能量的比率。
本发明中所描述的技术的各个方面还可使得音频编码装置20能够相对于HOA系数11的经分解版本执行内插。在一些情况下,音频编码装置20可经配置以至少部分通过相对于第一多个球谐系数的第一分解和第二多个球谐系数的第二分解执行内插而获得一时间片段的分解式经内插球谐系数。
在这些和其它情况下,所述第一分解包括表示所述第一多个球谐系数的右奇异向量的第一V矩阵。
在这些和其它实例中,所述第二分解包括表示所述第二多个球谐系数的右奇异向量的第二V矩阵。
在这些和其它情况下,所述第一分解包括表示所述第一多个球谐系数的右奇异向量的第一V矩阵,且所述第二分解包括表示所述第二多个球谐系数的右奇异向量的第二V矩阵。
在这些和其它情况下,所述时间片段包括音频帧的子帧。
在这些和其它情况下,所述时间片段包括音频帧的时间样本。
在这些和其它情况下,音频编码装置20经配置以获得第一多个球谐系数中的球谐系数的第一分解和第二分解的经内插分解。
在这些和其它情况下,音频编码装置20经配置以获得用于包含在第一帧中的所述第一多个球谐系数的第一部分的第一分解和用于包含在第二帧中的所述第二多个球谐系数的第二部分的第二分解的经内插分解,且音频编码装置20进一步经配置以将所述经内插分解应用于包含在第一帧中的所述第一多个球谐系数的第一部分的第一时间分量以产生所述第一多个球谐系数的第一人工时间分量,且将相应经内插分解应用于包含在第二帧中的所述第二多个球谐系数的第二部分的第二时间分量以产生所包含的所述第二多个球谐系数的第二人工时间分量。
在这些和其它情况下,所述第一时间分量是通过相对于所述第一多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,所述第二时间分量是通过相对于所述第二多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,音频编码装置20进一步经配置以:接收所述第一人工时间分量和所述第二人工时间分量;计算用于所述第一多个球谐系数的第一部分的第一分解和用于所述第二多个球谐系数的第二部分的第二分解的经内插分解;及将所述经内插分解的逆应用于所述第一人工时间分量以恢复所述第一时间分量且应用于所述第二人工时间分量以恢复所述第二时间分量。
在这些和其它情况下,音频编码装置20经配置以内插所述第一多个球谐系数的第一空间分量和所述第二多个球谐系数的第二空间分量。
在这些和其它情况下,所述第一空间分量包括表示所述第一多个球谐系数的左奇异向量的第一U矩阵。
在这些和其它情况下,所述第二空间分量包括表示所述第二多个球谐系数的左奇异向量的第二U矩阵。
在这些和其它情况下,所述第一空间分量表示用于所述第一多个球谐系数的球谐系数的M个时间片段,且所述第二空间分量表示用于所述第二多个球谐系数的球谐系数的M个时间片段。
在这些和其它情况下,所述第一空间分量表示用于第一多个球谐系数的球谐系数的M个时间片段且所述第二空间分量表示用于所述第二多个球谐系数的球谐系数的M个时间片段,且音频编码装置20经配置以内插所述第一空间分量的最后N个元素和所述第二空间分量的前N个元素。
在这些和其它情况下,所述第二多个球谐系数在时域中在所述第一多个球谐系数之后。
在这些和其它情况下,音频编码装置20进一步经配置以分解所述第一多个球谐系数以产生所述第一多个球谐系数的第一分解。
在这些和其它情况下,音频编码装置20进一步经配置以分解所述第二多个球谐系数以产生所述第二多个球谐系数的第二分解。
在这些和其它情况下,音频编码装置20进一步经配置以相对于所述第一多个球谐系数执行奇异值分解以产生表示所述第一多个球谐系数的左奇异向量的U矩阵、表示所述第一多个球谐系数的奇异值的S矩阵和表示所述第一多个球谐系数的右奇异向量的V矩阵。
在这些和其它情况下,音频编码装置20进一步经配置以相对于所述第二多个球谐系数执行奇异值分解以产生表示所述第二多个球谐系数的左奇异向量的U矩阵、表示所述第二多个球谐系数的奇异值的S矩阵和表示所述第二多个球谐系数的右奇异向量的V矩阵。
在这些和其它情况下,所述第一和第二多个球谐系数各表示声场的平面波表示。
在这些和其它情况下,所述第一和第二多个球谐系数各表示混合在一起的一或多个单声道音频对象。
在这些和其它情况下,所述第一和第二多个球谐系数各包括表示三维声场的相应第一和第二球谐系数。
在这些和其它情况下,所述第一和第二多个球谐系数各与具有大于一的阶数的至少一球形基底函数相关联。
在这些和其它情况下,所述第一和第二多个球谐系数各与具有等于四的阶数的至少一球形基底函数相关联。
在这些和其它情况下,所述内插为所述第一分解和第二分解的经加权内插,其中应用于所述第一分解的经加权内插的权重与由所述第一和第二分解的向量表示的时间成反比,且其中应用于所述第二分解的经加权内插的权重与由所述第一和第二分解的向量表示的时间成比例。
在这些和其它情况下,分解式经内插球谐系数平滑化所述第一多个球谐系数和所述第二多个球谐系数的空间分量和时间分量中的至少一者。
在这些和其它情况下,音频编码装置20经配置以计算Us[n]=HOA(n)*(V_vec[n])-1以获得一标量。
在这些和其它情况下,内插包括线性内插。在这些和其它情况下,内插包括非线性内插。在这些和其它情况下,所述内插包括余弦内插。在这些和其它情况下,内插包括经加权余弦内插。在这些和其它情况下,内插包括立方内插。在这些和其它情况下,内插包括自适应性样条内插。在这些和其它情况下,内插包括最小曲率内插。
在这些和其它情况下,音频编码装置20进一步经配置以产生包含用于时间片段的分解式经内插球谐系数的表示和内插的类型的指示的位流。
在这些和其它情况下,所述指示包括映射到内插的类型的一或多个位。
以此方式,本发明中所描述的技术的各个方面可使得音频编码装置20能够经配置以获得包含用于时间片段的分解式经内插球谐系数的表示和内插的类型的指示的位流。
在这些和其它情况下,所述指示包括映射到内插的类型的一或多个位。
就此而言,音频编码装置20可表示所述技术的一个实施例,这是由于在一些情况下,音频编码装置20可经配置以产生包括声场的空间分量的经压缩版本、通过相对于多个球谐系数执行基于向量的合成而产生的空间分量的位流。
在这些和其它情况下,音频编码装置20进一步经配置以产生位流以包含指定在压缩空间分量时使用的预测模式的字段。
在这些和其它情况下,音频编码装置20经配置以产生位流以包含指定在压缩空间分量时使用的霍夫曼表的霍夫曼表信息。
在这些和其它情况下,音频编码装置20经配置以产生位流以包含指示表达在压缩空间分量时使用的量化步长或其变数的值的字段。
在这些和其它情况下,所述值包括nbits值。
在这些和其它情况下,音频编码装置20经配置以产生位流以包含声场(包含其空间分量的经压缩版本)的多个空间分量的经压缩版本,其中所述值表达当压缩所述多个空间分量时使用的量化步长或其变数。
在这些和其它情况下,音频编码装置20进一步经配置以产生位流以包含霍夫曼码以表示识别空间分量所对应的压缩类别的类别识别符。
在这些和其它情况下,音频编码装置20经配置以产生位流以包含识别空间分量为正值还是负值的正负号位。
在这些和其它情况下,音频编码装置20经配置以产生位流以包含霍夫曼码以表示空间分量的残余值。
在这些和其它情况下,所述基于向量的合成包括奇异值分解。
就此而言,音频编码装置20可进一步实施所述技术的各个方面,这是因为在一些情况下,音频编码装置20可经配置以基于多个经压缩空间分量中的一空间分量相对于所述多个空间分量中的剩余者的阶数识别霍夫曼码簿以在压缩所述空间分量时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,音频编码装置20经配置以基于压缩所述空间分量时使用的预测模式识别霍夫曼码簿。
在这些和其它情况下,空间分量的经压缩版本至少部分使用识别霍夫曼码簿的霍夫曼表信息而表示于位流中。
在这些和其它情况下,空间分量的经压缩版本至少部分使用指示表达压缩所述空间分量时使用的量化步长或其变数的值的字段而表示于位流中。
在这些和其它情况下,所述值包括nbits值。
在这些和其它情况下,位流包括声场(包括其空间分量的经压缩版本)的多个空间分量的经压缩版本,且所述值表达当压缩所述多个空间分量时使用的量化步长或其变数。
在这些和其它情况下,空间分量的经压缩版本至少部分使用霍夫曼码选定形式而表示于位流中,所识别的霍夫曼码簿用以表示识别空间分量所对应的压缩类别的类别识别符。
在这些和其它情况下,空间分量的经压缩版本至少部分使用识别空间分量为正值还是负值的正负号位而表示于位流中。
在这些和其它情况下,空间分量的经压缩版本至少部分使用霍夫曼码选定形式而表示于位流中,所识别的霍夫曼码簿用以表示空间分量的残余值。
在这些和其它情况下,音频编码装置20进一步经配置以基于所识别的霍夫曼码簿压缩空间分量以产生空间分量的经压缩版本,且产生位流以包含空间分量的经压缩版本。
此外,在一些情况下,音频编码装置20可实施所述技术的各个方面,这是由于音频编码装置20可经配置以确定在压缩声场的空间分量(通过相对于多个球谐系数执行基于向量的合成而产生的空间分量)时将使用的量化步长。
在这些和其它情况下,音频编码装置20进一步经配置以基于目标位速率确定量化步长。
在这些和其它情况下,音频编码装置20经配置以确定用以表示空间分量的位的数目的估计,且基于所述估计与目标位速率之间的差确定所述量化步长。
在这些和其它情况下,音频编码装置20经配置以确定用以表示空间分量的位的数目的估计,判定所述估计与目标位速率之间的差,且通过将所述差相加到目标位速率而确定所述量化步长。
在这些和其它情况下,音频编码装置20经配置以计算将针对空间分量产生的位的数目估计(给定对应于目标位速率的码簿)。
在这些和其它情况下,音音频编码装置20经配置以计算将针对空间分量产生的位的数目的估计(给定在压缩空间分量时使用的译码模式)。
在这些和其它情况下,音频编码装置20经配置以:计算将针对空间分量产生的位的数目的第一估计(给定在压缩空间分量时将使用的第一译码模式);计算将针对空间分量产生的位的数目的第二估计(给定在压缩空间分量时将使用的第二译码模式);选择第一估计和第二估计中具有最少数目的位将用作位数目的所确定的估计的估计。
在这些和其它情况下,音频编码装置20经配置以:识别识别空间分量所对应的类别的类别识别符;识别在压缩对应于所述类别的空间分量时将导致的空间分量的残余值的位长度;且至少部分通过将用以表示类别识别符的位数目相加到残余值的位长度来确定位数目的估计。
在这些和其它情况下,音频编码装置20进一步经配置以选择在压缩空间分量时将使用的多个码簿中的一者。
在这些和其它情况下,音频编码装置20进一步经配置以使用所述多个码簿中的每一者确定用以表示空间分量的位的数目的估计,且选择所述多个码簿中导致具有最少数目的位的所确定的估计的一个码簿。
在这些和其它情况下,音频编码装置20进一步经配置以使用所述多个码簿中的一或多者确定用以表示空间分量的位的数目的估计,所述多个码簿中的所述一或多者是基于将相对于空间分量的其它元素压缩的空间分量的元素的阶数而加以选择。
在这些和其它情况下,音频编码装置20进一步经配置以使用所述多个码簿中的经设计以在空间分量并非从后续空间分量预测时使用的一个码簿确定用以表示所述空间分量的位的数目的估计。
在这些和其它情况下,音频编码装置20进一步经配置以使用所述多个码簿中的经设计以在空间分量是从后续空间分量预测时使用的一个码簿确定用以表示所述空间分量的位的数目的估计。
在这些和其它情况下,音频编码装置20进一步经配置以使用所述多个码簿中的经设计以在空间分量表示声场中的合成音频对象时使用的一个码簿确定用以表示所述空间分量的位的数目的估计。
在这些和其它情况下,合成音频对象包括经脉码调制(PCM)音频对象。
在这些和其它情况下,音频编码装置20进一步经配置以使用所述多个码簿中的经设计以在空间分量表示声场中的所记录音频对象时使用的一个码簿确定用以表示所述空间分量的位的数目的估计。
在上述各种实例中的每一者中,应理解,音频编码装置20可执行方法,或另外包括执行音频编码装置20经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频编码装置20已经配置以执行的方法。
图5是更详细说明图3的音频解码装置24的框图。如图5的实例中所展示,音频解码装置24可包含提取单元72、基于方向性的重建单元90和基于向量的重建单元92。
提取单元72可表示经配置以接收位流21和提取HOA系数11的各种经编码版本(例如,基于方向的经编码版本或基于向量的经编码版本)的单元。提取单元72可从上文标注的语法元素(例如,图10E和10H(i)到10O(ii)的实例中展示的ChannelType语法元素)确定HOA系数11是否经由所述各种版本而编码。当执行基于方向的编码时,提取单元72可提取HOA系数11之基于方向的版本和与此经编码版本相关联的语法元素(其在图5的实例中表示为基于方向的信息91),将此基于方向的信息91传递到基于方向的重建单元90。此基于方向的重建单元90可表示经配置以基于所述基于方向的信息91重建呈HOA系数11'的形式的HOA系数的单元。位流和位流内语法元素的布置在下文相对于图10至10O(ii)和11的实例更详细描述。
当语法元素指示使用基于向量的合成对HOA系数11编码时,提取单元72可提取经译码前景V[k]向量57、经编码环境HOA系数59和经编码nFG信号59。提取单元72可将经译码前景V[k]向量57传递到量化单元74,且将经编码环境HOA系数59连同经编码nFG信号61提供到心理声学解码单元80。
为提取经译码前景V[k]向量57、经编码环境HOA系数59和经编码nFG信号59,提取单元72可获得包含表示为codedVVecLength的语法元素的旁侧通道信息57。提取单元72可从旁侧通道信息57解析codedVVecLength。提取单元72可经配置以在上文所描述的配置模式中的任一者中基于codedVVecLength语法元素操作。
提取单元72随后根据配置模式中的任一者操作以从旁侧通道信息57解析经压缩形式的经缩减前景V[k]向量55k。提取单元72可根据以下伪码中呈现的switch叙述以及以下VVectorData的语法表中呈现的语法而操作:




在前述语法表中,具有四种情况(情况0到3)的第一switch叙述提供借以依据系数的数目(VVecLength)和索引(VVecCoeffId)确定VT DIST向量长度的方式。第一情况(情况0)指示用于VT DIST向量的所有系数(NumOfHoaCoeffs)经指定。第二情况,情况1,指示仅VT DIST向量的对应于大于MinNumOfCoeffsForAmbHOA的阶数的那些系数被指定,其可表示上文被称作(NDIST+1)2-(NBG+1)2的情况。另外,ContAddAmbHoaChan中识别的那些NumOfContAddAmbHoaChan系数被减去。列表ContAddAmbHoaChan指定对应于超过阶数MinAmbHoaOrder的阶数的额外通道(其中“通道”是指对应于某一阶数、子阶组合的特定系数)。第三情况,情况2,指示VT DIST向量的对应于大于MinNumOfCoeffsForAmbHOA的阶数的那些系数被指定,其可表示上文被称作(NDIST+1)2-(NBG+1)2的情况。第四情况,情况3,指示VT DIST向量的在移除由NumOfAddAmbHoaChan识别的系数之后所剩余的那些系数被指定。VVecLength以及VVecCoeffId列表两者对于HOAFrame上的所有VVector均是有效的。
在此switch叙述之后,可由NbitsQ(或,如上文所表示,nbits)控制是否执行均匀解量化的决策,如果NbitsQ等于5,那么执行均匀的8位标量解量化。与此对比,大于或等于6的NbitsQ值可导致霍夫曼解码的应用。上文提及的cid值可等于NbitsQ值的两个最低有效位。上文所论述的预测模式在以上语法表中表示为PFlag,而HT信息位在以上语法表中表示为CbFlag。剩余语法指定解码如何以实质上类似于上文所描述的方式的方式发生。下文关于图10H(i)到10O(ii)更详细地描述符合以上指出的各种情况中的每一者的位流21的各种实例。
基于向量的重建构单元92表示经配置以执行与上文关于基于向量的合成单元27所描述的操作互逆的操作以便重建HOA系数11'的单元。基于向量的重建单元92可包含量化单元74、空间-时间内插单元76、前景制订单元78、心理声学解码单元80、HOA系数制订单元82和重排序单元84。
量化单元74可表示经配置而以与图4的实例中所示的量化单元52互逆的方式操作以便对经译码前景V[k]向量57解量化且借此产生经缩减前景V[k]向量55k的单元。解量化单元74可在一些实例中以与上文相对于量化单元52描述的方式互逆的方式执行一种形式的熵解码和标量解量化。解量化单元74可将经缩减前景V[k]向量55k转发到重排序单元84。
心理声学解码单元80可以与图4的实例中展示的心理声学音频译码单元40互逆的方式操作以便解码经编码环境HOA系数59和经编码nFG信号61且借此产生经能量补偿的环境HOA系数47'和经内插nFG信号49'(其也可被称作经内插nFG音频对象49')。心理声学解码单元80可将经能量补偿的环境HOA系数47'传递到HOA系数制订单元82且将nFG信号49'传递到重排序器84。
重排序单元84可表示经配置而以与上文相对于重排序单元34所描述的方式大体互逆的方式操作的单元。重排序单元84可接收指示HOA系数11的前景分量的原始次序的语法元素。重排序单元84可基于这些重排序语法元素对经内插nFG信号49'和经缩减前景V[k]向量55k重排序以产生经重排序的nFG信号49"和经重排序的前景V[k]向量55k'。重排序单元84可将经重排序的nFG信号49"输出到前景制订单元78,且将经重排序的前景V[k]向量55k'输出到空间-时间内插单元76。
空间-时间内插单元76可以类似于上文相对于空间-时间内插单元50所描述方式的方式操作。空间-时间内插单元76可接收经重排序的前景V[k]向量55k'且对于经重排序的前景V[k]向量55k'和经重排序的前景V[k-1]向量55k-1'执行空间-时间内插以产生经内插前景V[k]向量55k"。空间-时间内插单元76可将经内插前景V[k]向量55k"转发到前景制订单元78。
前景制订单元78可表示经配置以关于经内插的前景V[k]向量55k"和经重排序的nFG信号49"执行矩阵乘法以产生前景HOA系数65的单元。前景制订单元78可执行经重排序的nFG信号49"乘以经内插前景V[k]向量55k"的矩阵乘法。
HOA系数制订单元82可表示经配置以将前景HOA系数65相加到环境HOA通道47'以便获得HOA系数11'的单元,其中撇号记法反映这些HOA系数11'可类似于HOA系数11但非与其相同。HOA系数11与11'之间的差可起因于归因于有损发射媒体上的发射、量化或其它有损操作产生的损失。
以此方式,所述技术可使得例如音频解码装置24等音频解码装置能够:从位流确定经量化方向信息、经编码前景音频对象及经编码环境高阶立体混响(HOA)系数,其中经量化方向信息及经编码前景音频对象表示描述声场的前景分量的前景HOA系数,且其中经编码环境HOA系数描述声场的环境分量;对经量化方向信息进行解量化以产生方向信息;相对于所述方向信息执行空间-时间内插以产生经内插方向信息;对经编码前景音频对象进行音频解码以产生前景音频对象及经编码环境HOA系数从而产生环境HOA系数;作为经内插方向信息及前景音频对象的函数确定前景HOA系数;及作为前景HOA系数及环境HOA系数的函数确定HOA系数。
以此方式,所述技术的各个方面可使得统一音频解码装置24能够在两个不同解压缩方案之间切换。在一些情况下,音频解码装置24可经配置以基于表示声场的球谐系数的经压缩版本是否是从合成音频对象产生的指示而选择多个解压缩方案中的一者,且使用所述多个解压缩方案中的所述选定者解压缩所述球谐系数的所述经压缩版本。在这些和其它情况下,所述音频解码装置24包括集成式解码器。
在一些情况下,音频解码装置24可经配置以获得表示声场的球谐系数是否是从合成音频对象产生的指示。
在这些和其它情况下,音频解码装置24经配置以从存储球谐系数的经压缩版本的位流获得所述指示。
以此方式,所述技术的各个方面可使得音频解码装置24能够获得描述声场的相异分量和背景分量的向量。在一些情况下,音频解码装置24可经配置以确定描述声场的相异分量的一或多个第一向量及描述所述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者是至少通过相对于所述多个球谐系数执行变换而产生。
在这些和其它情况下,音频解码装置24,其中变换包括奇异值分解,所述奇异值分解产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵。
在这些和其它情况下,音频解码装置24,其中所述一或多个第一向量包括一或多个经音频编码的UDIST*SDIST向量,其是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,且其中U矩阵及S矩阵是至少通过相对于所述多个球谐系数执行奇异值分解而产生。
在这些和其它情况下,音频解码装置24进一步经配置以对所述一或多个经音频编码的UDIST*SDIST向量进行音频解码以产生一或多个经音频编码UDIST*SDIST向量的经音频解码版本。
在这些和其它情况下,音频编码装置24,其中所述一或多个第一向量包括一或多个经音频编码的UDIST*SDIST向量和具有V矩阵的转置的一或多个VT DIST向量,所述UDIST*SDIST向量是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,且其中U矩阵和S矩阵以及V矩阵是至少通过相对于所述多个球谐系数执行奇异值分解而产生。
在这些和其它情况下,音频解码装置24进一步经配置以对所述一或多个经音频编码的UDIST*SDIST向量进行音频解码以产生一或多个经音频编码UDIST*SDIST向量的经音频解码版本。
在这些和其它情况下,音频解码装置24进一步经配置以将UDIST*SDIST向量乘以VT DIST向量以恢复所述多个球谐中表示声场的相异分量的球谐。
在这些和其它情况下,音频解码装置24,其中所述一或多个第二向量包括一或多个经音频编码的UBG*SBG*VT BG向量,所述UBG*SBG*VT BG向量是在音频编码之前通过将包含于U矩阵内的UBG向量乘以包含于S矩阵内的SBG向量且接着乘以包含于V矩阵的转置内的VT BG向量而产生,且其中U矩阵、S矩阵以及V矩阵各自是至少通过相对于所述多个球谐系数执行奇异值分解而产生。
在这些和其它情况下,音频解码装置24,其中所述一或多个第二向量包括一或多个经音频编码的UBG*SBG*VT BG向量,所述UBG*SBG*VT BG向量是在音频编码之前通过将包含于U矩阵内的UBG向量乘以包含于S矩阵内的SBG向量且接着乘以包含于V矩阵的转置内的VT BG向量而产生,其中S矩阵、U矩阵及V矩阵是至少通过相对于所述多个球谐系数执行奇异值分解而产生,且其中音频解码装置24进一步经配置以对所述一或多个经音频编码的UBG*SBG*VT BG向量进行音频解码以产生一或多个经音频解码的UBG*SBG*VT BG向量。
在这些和其它情况下,音频解码装置24,其中所述一或多个第一向量包括在音频编码前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量及V矩阵的转置的一或多个VT DIST向量而产生的一或多个经音频编码的UDIST*SDIST向量,其中U矩阵、S矩阵及V矩阵至少通过执行相对于所述多个球谐系数的奇异值分解而产生,且其中音频解码装置24进一步经配置以音频解码所述一或多个经音频编码的UDIST*SDIST向量以产生所述一或多个UDIST*SDIST向量,且将UDIST*SDIST向量乘以VT DIST向量以恢复所述多个球谐系数中描述声场的相异分量的那些球谐系数,其中所述一或多个第二向量包括在音频编码前正通过将包含于U矩阵内的UBG向量乘以包含于S矩阵内的SBG向量且接着乘以包含于V矩阵的转置内的VT BG向量而产生的一或多个经音频编码的UBG*SBG*VT BG向量,且其中音频解码装置24进一步经配置以音频解码所述一或多个经音频编码的UBG*SBG*VT BG向量以恢复描述声场的背景分量的所述多个球谐系数的至少一部分,且将描述声场的相异分量的所述多个球谐系数与描述声场的背景分量的所述多个球谐系数的所述至少一部分相加以产生所述多个球谐系数的经重建版本。
在这些和其它情况下,音频解码装置24,其中所述一或多个第一向量包括一或多个UDIST*SDIST向量和具有V矩阵的转置的一或多个VT DIST向量,所述UDIST*SDIST向量是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,其中U矩阵、S矩阵和V矩阵是至少通过对于相对于所述多个球谐系数执行奇异值分解而产生,且其中音频解码装置20进一步经配置以获得指示将从位流提取以形成所述一或多个UDIST*SDIST向量和所述一或多个VT DIST向量的向量数目的值D。
在这些和其它情况下,音频解码装置24,其中所述一或多个第一向量包括一或多个UDIST*SDIST向量和具有V矩阵的转置的一或多个VT DIST向量,所述UDIST*SDIST向量是在音频编码之前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生,其中U矩阵、S矩阵和V矩阵是至少通过对于相对于所述多个球谐系数执行奇异值分解而产生,且其中音频解码装置24进一步经配置以基于逐个音频帧获得值D,所述值D指示待从位流提取以形成所述一或多个UDIST*SDIST向量和所述一或多个VT DIST向量的向量的数目。
在这些和其它情况下,音频解码装置24,其中所述变换包括主分量分析以识别声场的相异分量和声场的背景分量。
本发明中所描述的技术的各个方面还可使得音频编码装置24能够相对于HOA系数的经分解版本执行内插。在一些情况下,音频解码装置24可经配置以至少部分通过相对于第一多个球谐系数的第一分解和第二多个球谐系数的第二分解执行内插而获得一时间片段的分解式经内插球谐系数。
在这些和其它情况下,所述第一分解包括表示所述第一多个球谐系数的右奇异向量的第一V矩阵。
在这些和其它实例中,所述第二分解包括表示所述第二多个球谐系数的右奇异向量的第二V矩阵。
在这些和其它情况下,所述第一分解包括表示所述第一多个球谐系数的右奇异向量的第一V矩阵,且所述第二分解包括表示所述第二多个球谐系数的右奇异向量的第二V矩阵。
在这些和其它情况下,所述时间片段包括音频帧的子帧。
在这些和其它情况下,所述时间片段包括音频帧的时间样本。
在这些和其它情况下,音频解码装置24经配置以获得第一多个球谐系数中的球谐系数的第一分解和第二分解的经内插分解。
在这些和其它情况下,音频解码装置24经配置以获得用于包含在第一帧中的所述第一多个球谐系数的第一部分的第一分解和用于包含在第二帧中的所述第二多个球谐系数的第二部分的第二分解的经内插分解,且音频解码装置24进一步经配置以将所述经内插分解应用于包含在第一帧中的所述第一多个球谐系数的第一部分的第一时间分量以产生所述第一多个球谐系数的第一人工时间分量,且将相应经内插分解应用于包含在第二帧中的所述第二多个球谐系数的第二部分的第二时间分量以产生所包含的所述第二多个球谐系数的第二人工时间分量。
在这些和其它情况下,所述第一时间分量是通过相对于所述第一多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,所述第二时间分量是通过相对于所述第二多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,音频解码装置24进一步经配置以:接收所述第一人工时间分量和所述第二人工时间分量;计算用于所述第一多个球谐系数的第一部分的第一分解和用于所述第二多个球谐系数的第二部分的第二分解的经内插分解;及将所述经内插分解的逆应用于所述第一人工时间分量以恢复所述第一时间分量且应用于所述第二人工时间分量以恢复所述第二时间分量。
在这些和其它情况下,音频解码装置24经配置以内插所述第一多个球谐系数的第一空间分量和所述第二多个球谐系数的第二空间分量。
在这些和其它情况下,所述第一空间分量包括表示所述第一多个球谐系数的左奇异向量的第一U矩阵。
在这些和其它情况下,所述第二空间分量包括表示所述第二多个球谐系数的左奇异向量的第二U矩阵。
在这些和其它情况下,所述第一空间分量表示用于所述第一多个球谐系数的球谐系数的M个时间片段,且所述第二空间分量表示用于所述第二多个球谐系数的球谐系数的M个时间片段。
在这些和其它情况下,所述第一空间分量表示用于所述第一多个球谐系数的球谐系数的M个时间片段且所述第二空间分量表示用于所述第二多个球谐系数的球谐系数的M个时间片段,且音频解码装置24经配置以内插所述第一空间分量的最后N个元素和所述第二空间分量的前N个元素。
在这些和其它情况下,所述第二多个球谐系数在时域中在所述第一多个球谐系数之后。
在这些和其它情况下,音频解码装置24进一步经配置以分解所述第一多个球谐系数以产生所述第一多个球谐系数的第一分解。
在这些和其它情况下,音频解码装置24进一步经配置以分解所述第二多个球谐系数以产生所述第二多个球谐系数的第二分解。
在这些和其它情况下,音频解码装置24进一步经配置以相对于所述第一多个球谐系数执行奇异值分解以产生表示所述第一多个球谐系数的左奇异向量的U矩阵、表示所述第一多个球谐系数的奇异值的S矩阵及表示所述第一多个球谐系数的右奇异向量的V矩阵。
在这些和其它情况下,音频解码装置24进一步经配置以相对于所述第二多个球谐系数执行奇异值分解以产生表示所述第二多个球谐系数的左奇异向量的U矩阵、表示所述第二多个球谐系数的奇异值的S矩阵及表示所述第二多个球谐系数的右奇异向量的V矩阵。
在这些和其它情况下,所述第一和第二多个球谐系数各表示声场的平面波表示。
在这些和其它情况下,所述第一和第二多个球谐系数各表示混合在一起的一或多个单声道音频对象。
在这些和其它情况下,所述第一和第二多个球谐系数各包括表示三维声场的相应第一和第二球谐系数。
在这些和其它情况下,所述第一和第二多个球谐系数各与具有大于一的阶数的至少一个球形基底函数相关联。
在这些和其它情况下,所述第一和第二多个球谐系数各与具有等于四的阶数的至少一个球形基底函数相关联。
在这些和其它情况下,所述内插为所述第一分解和第二分解的经加权内插,其中应用于所述第一分解的经加权内插的权重与由所述第一和第二分解的向量表示的时间成反比,且其中应用于所述第二分解的经加权内插的权重与由所述第一和第二分解的向量表示的时间成比例。
在这些和其它情况下,分解式经内插球谐系数平滑化所述第一多个球谐系数和所述第二多个球谐系数的空间分量和时间分量中的至少一者。
在这些和其它情况下,音频解码装置24经配置以计算Us[n]=HOA(n)*(V_vec[n])-1以获得一标量。
在这些和其它情况下,内插包括线性内插。在这些和其它情况下,内插包括非线性内插。在这些和其它情况下,所述内插包括余弦内插。在这些和其它情况下,内插包括经加权余弦内插。在这些和其它情况下,内插包括立方内插。在这些和其它情况下,内插包括自适应性样条内插。在这些和其它情况下,内插包括最小曲率内插。
在这些和其它情况下,音频解码装置24进一步经配置以产生包含用于时间片段的分解式经内插球谐系数的表示和内插的类型的指示的位流。
在这些和其它情况下,所述指示包括映射到内插的类型的一或多个位。
在这些和其它情况下,音频解码装置24进一步经配置以获得包含用于时间片段的分解式经内插球谐系数的表示和内插的类型的指示的位流。
在这些和其它情况下,所述指示包括映射到内插的类型的一或多个位。
在一些情况下,所述技术的各个方面可进一步使得音频解码装置24能够经配置以获得包含声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,空间分量的经压缩版本是至少部分使用指定当压缩空间分量时使用的预测模式的字段表示于位流中。
在这些和其它情况下,空间分量的经压缩版本是至少部分使用霍夫曼表信息而表示于位流中,所述霍夫曼表信息指定在压缩空间分量时使用的霍夫曼表。
在这些和其它情况下,空间分量的经压缩版本至少部分使用指示表达压缩所述空间分量时使用的量化步长或其变数的值的字段而表示于位流中。
在这些和其它情况下,所述值包括nbits值。
在这些和其它情况下,位流包括声场(包括其空间分量的经压缩版本)的多个空间分量的经压缩版本,且所述值表达当压缩所述多个空间分量时使用的量化步长或其变数。
在这些和其它情况下,空间分量的经压缩版本至少部分使用霍夫曼码而表示于位流中,从而表示识别空间分量所对应的压缩类别的类别识别符。
在这些和其它情况下,空间分量的经压缩版本至少部分使用识别空间分量为正值还是负值的正负号位而表示于位流中。
在这些和其它情况下,空间分量的经压缩版本是至少部分使用用以表示空间分量的残余值的霍夫曼码而表示于位流中。
在这些和其它情况下,所述装置包括音频解码装置。
所述技术的各个方面还可使得音频解码装置24能够基于多个经压缩空间分量中的一空间分量的经压缩版本相对于所述多个经压缩空间分量中的其余者的阶数识别霍夫曼码簿以在对所述空间分量的所述经压缩版本进行解压缩时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
在这些和其它情况下,音频解码装置24经配置以获得包含声场的空间分量的经压缩版本的位流,且至少部分使用所识别霍夫曼码簿解压缩空间分量的经压缩版本以获得空间分量。
在这些和其它情况下,空间分量的经压缩版本至少部分使用指定在压缩空间分量时使用的预测模式的字段而表示于位流中,且音频解码装置24经配置以至少部分基于所述预测模式解压缩空间分量的经压缩版本以获得空间分量。
在这些和其它情况下,空间分量的经压缩版本至少部分使用指定在压缩空间分量时使用的霍夫曼表的霍夫曼表信息而表示于位流中,且音频解码装置24经配置以至少部分基于所述霍夫曼表信息解压缩空间分量的经压缩版本。
在这些和其它情况下,空间分量的经压缩版本至少部分使用指示表达在压缩空间分量时使用的量化步长或其变数的值的字段而表示于位流中,且音频解码装置24经配置以至少部分基于所述值解压缩空间分量的经压缩版本。
在这些和其它情况下,所述值包括nbits值。
在这些和其它情况下,位流包含声场(包括其空间分量的经压缩版本)的多个空间分量的经压缩版本,所述值表达当压缩所述多个空间分量时使用的量化步长或其变数,且音频解码装置24经配置以至少部分基于所述值解压缩空间分量的所述多个经压缩版本。
在这些和其它情况下,空间分量的经压缩版本至少部分使用用以表示识别空间分量所对应的压缩类别的类别识别符的霍夫曼码而表示于位流中,且音频解码装置24经配置以至少部分基于所述霍夫曼码解压缩空间分量的经压缩版本。
在这些和其它情况下,空间分量的经压缩版本至少部分使用识别空间分量为正值还是负值的正负号位而表示于位流中,且音频解码装置24经配置以至少部分基于所述正负号位解压缩空间分量的经压缩版本。
在这些和其它情况下,空间分量的经压缩版本至少部分使用用以表示空间分量的残余值的霍夫曼码而表示于位流中,且音频解码装置24经配置以至少部分基于包含于所识别的霍夫曼码簿中的霍夫曼码解压缩空间分量的经压缩版本。
在上文所描述的各种实例中的每一者中,应理解,音频解码装置24可执行方法或另外包括执行音频解码装置24经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频解码装置24已经配置以执行的方法。
图6为说明音频编码装置的内容分析单元(例如图4的实例中所示的内容分析单元26)执行本发明中所描述的技术的各个方面的示范性操作的流程图。
在确定表示声场的HOA系数11是否是从合成音频对象产生时,内容分析单元26可获得HOA系数的帧(93),其对于四阶表示(即,N=4)可为大小25乘1024。在获得帧式HOA系数(其也可在本文中表示为帧式SHC矩阵11,且后续帧式SHC矩阵可表示为帧式SHC矩阵27B、27C,等)之后,内容分析单元26可接着排除帧式HOA系数11的第一向量以产生经缩减帧式HOA系数(94)。
内容分析单元26可接着从经缩减帧式HOA系数的剩余向量预测经缩减帧式HOA系数的第一非零向量(95)。在预测第一非零向量之后,内容分析单元26可基于预测的第一非零向量和实际非零向量而获得一误差(96)。一旦获得所述误差,内容分析单元26就可基于实际第一非零向量和所述误差的能量计算比率(97)。内容分析单元26可接着比较此比率与一阈值(98)。当所述比率不超出阈值(“否”98)时,内容分析单元26可确定帧式SHC矩阵11是从记录产生,且在位流中指示SHC矩阵11的对应经译码表示是从记录产生(100,101)。当所述比率超过阈值(“是”98)时,内容分析单元26可确定帧式SHC矩阵11是从合成音频对象产生,且在位流中指示SHC矩阵11的对应经译码表示是从合成音频对象产生(102、103)。在一些情况下,当帧式SHC矩阵11是从记录产生时,内容分析单元26将帧式SHC矩阵11传递到基于向量的合成单元27(101)。在一些情况下,当帧式SHC矩阵11是从合成音频对象产生时,内容分析单元26将帧式SHC矩阵11传递到基于方向的合成单元28(104)。
图7为说明音频编码装置(例如图4的实例中所示的音频编码装置20)执行本发明中所描述的基于向量的合成技术的各个方面的示范性操作的流程图。最初,音频编码装置20接收HOA系数11(106)。音频编码装置20可调用LIT单元30,其可相对于HOA系数应用LIT以输出经变换HOA系数(例如,在SVD的情况下,经变换HOA系数可包括US[k]向量33和V[k]向量35)(107)。
音频编码装置20接下来可调用参数计算单元32以按上文所描述的方式相对于US[k]向量33、US[k-1]向量33、V[k]和/或V[k-1]向量35的任何组合执行上文所描述的分析以识别各种参数。也就是说,参数计算单元32可基于经变换的HOA系数33/35的分析确定至少一个参数(108)。
音频编码装置20可接着调用重排序单元34,重排序单元34基于参数将经变换的HOA系数(再次在SVD的上下文中,其可指US[k]向量33及V[k]向量35)重排序以产生经重排序的经变换的HOA系数33'/35'(或,换句话说,US[k]向量33'及V[k]向量35'),如上文所描述(109)。音频编码装置20可在以上操作或后续操作中的任一者期间还调用声场分析单元44。声场分析单元44可如上文所描述相对于HOA系数11和/或经变换HOA系数33/35执行声场分析以确定前景通道(nFG)45的总数、背景声场(NBG)的次序以及待发送的额外BG HOA通道的数目(nBGa)和索引(i)(其可在图4的实例中统一表示为背景通道信息43)(110)。
音频编码装置20还可调用背景选择单元48。背景选择单元48可基于背景通道信息43确定背景或环境HOA系数47(112)。音频编码装置20可进一步调用前景选择单元36,前景选择单元36可基于nFG 45(其可表示识别这些前景向量的一或多个索引)选择经重排序的US[k]向量33'及经重排序的V[k]向量35'中表示声场的前景或相异分量的那些向量(114)。
音频编码装置20可调用能量补偿单元38。能量补偿单元38可相对于环境HOA系数47执行能量补偿以补偿归因于由背景选择单元48(114)移除HOA通道的各者而导致的能量损耗,且借此产生经能量补偿的环境HOA系数47'。
音频编码装置20还随后调用空间-时间内插单元50。空间-时间内插单元50可相对于经重排序的经变换HOA系数33'/35'执行空间-时间内插以获得经内插前景信号49'(其也可被称作“经内插nFG信号49'”和剩余前景方向信息53其也可被称作“V[k]向量53”)(116)。音频编码装置20可随后调用系数减少单元46。系数减少单元46可基于背景通道信息43相对于剩余前景V[k]向量53执行系数减少以获得经缩减前景方向信息55(其也可被称作经缩减前景V[k]向量55)(118)。
音频编码装置20可接着调用量化单元52以按上文所描述的方式压缩经缩减前景V[k]向量55且产生经译码前景V[k]向量57(120)。
音频编码装置20还可调用心理声学音频译码器单元40。心理声学音频译码器单元40可对经能量补偿的环境HOA系数47'和经内插nFG信号49'的每一向量进行心理声学译码以产生经编码环境HOA系数59和经编码nFG信号61。音频编码装置可随后调用位流产生单元42。位流产生单元42可基于经译码前景方向信息57、经译码环境HOA系数59、经译码nFG信号61和背景通道信息43产生位流21。
图8为说明音频解码装置(例如图5中所示的音频解码装置24)执行本发明中所描述的技术的各个方面的示范性操作的流程图。最初,音频解码装置24可接收位流21(130)。在接收到位流后,音频解码装置24可调用提取单元72。出于论述的目的假定位流21指示将执行基于向量的重建,提取装置72可解析此位流以检索上文所提及的信息,将此信息传递到基于向量的重建单元92。
换句话说,提取单元72可按上文所描述的方式从位流21中提取经译码前景方向信息57(再次,其也可被称作经译码前景V[k]向量57)、经译码环境HOA系数59和经译码前景信号(其也可被称作经译码前景nFG信号59或经译码前景音频对象59)(132)。
音频解码装置24可进一步调用量化单元74。量化单元74可对经译码前景方向信息57进行熵解码及解量化以获得缩减的前景方向信息55k(136)。音频解码装置24还可调用心理声学解码单元80。心理声学音频译码单元80可解码经编码环境HOA系数59及经编码前景信号61以获得经能量补偿的环境HOA系数47'及经内插的前景信号49'(138)。心理声学解码单元80可将经能量补偿的环境HOA系数47'传递到HOA系数制订单元82且将nFG信号49'传递到重排序单元84。
重排序单元84可接收指示HOA系数11的前景分量的原始次序的语法元素。重排序单元84可基于这些重排序语法元素对经内插nFG信号49'和经缩减前景V[k]向量55k重排序以产生经重排序的nFG信号49"和经重排序的前景V[k]向量55k'(140)。重排序单元84可将经重排序的nFG信号49"输出到前景制订单元78,且将经重排序的前景V[k]向量55k'输出到空间-时间内插单元76。
音频解码装置24接下来可调用空间-时间内插单元76。空间-时间内插单元76可接收经重排序的前景方向信息55k'且关于缩减的前景方向信息55k/55k-1执行空间-时间内插以产生经内插的前景方向信息55k"(142)。空间-时间内插单元76可将经内插前景V[k]向量55k"转发到前景制订单元718。
音频解码装置24可调用前景制订单元78。前景制订单元78可执行经内插前景信号49"与经内插前景方向信息55k"的矩阵乘法以获得前景HOA系数65(144)。音频解码装置24还可调用HOA系数制订单元82。HOA系数制订单元82可将前景HOA系数65相加到环境HOA通道47'以便获得HOA系数11'(146)。
图9A到9L是更详细地说明图4的实例的音频编码装置20的各个方面的框图。图9A为更详细地说明音频编码装置20的LIT单元30的框图。如图9A的实例中所示,LIT单元30可包含多个不同的线性可逆变换200至200N。LIT单元30可包含(提供几个实例)奇异值分解(SVD)变换200A(“SVD 200A”)、主分量分析(PCA)变换200B(“PCA200B”)、Karhunen-Loève变换(KLT)200C(“KLT 200C”)、快速傅里叶变换(FFT)200D(“FFT 200D”)和离散余弦变换(DCT)200N(“DCT 200N”)。LIT单元30可调用这些线性可逆变换200中的任一者以相对于HOA系数11应用相应变换且产生相应经变换HOA系数33/35。
尽管描述为直接相对于HOA系数11执行,但LIT单元30可将线性可逆变换200应用到HOA系数11的导出项。举例来说,LIT单元30可相对于从HOA系数11导出的功率谱密度矩阵应用SVD 200。功率谱密度矩阵可表示为PSD且经由hoaFrame到hoaFrame的转置的矩阵乘法而获得,如下文的伪码中概述。hoaFrame记法是指HOA系数11的帧。
LIT单元30可在将SVD 200(svd)应用于PSD之后可获得S[k]2矩阵(S_squared)和V[k]矩阵。S[k]2矩阵可指代平方S[k]矩阵,因此LIT单元30(或替代地,SVD单元200,作为一个实例)可将平方根运算应用到S[k]2矩阵以获得S[k]矩阵。在一些情况下,SVD单元200可相对于V[k]矩阵执行量化以获得经量化V[k]矩阵(其可表示为V[k]'矩阵)。LIT单元30可通过首先将S[k]矩阵乘以经量化V[k]'矩阵以获得SV[k]'矩阵而获得U[k]矩阵。LIT单元30接下来可获得SV[k]'矩阵的伪倒数(pinv)且接着将HOA系数11乘以SV[k]'矩阵的伪倒数以获得U[k]矩阵。
可由以下伪码表示前述情况:
PSD=hoaFrame'*hoaFrame;
[V,S_squared]=svd(PSD,'econ');
S=sqrt(S_squared);
U=hoaFrame*pinv(S*V');
通过相对于HOA系数的功率谱密度(PSD)而非系数自身执行SVD,LIT单元30可在处理器循环和存储空间的一或多者方面可能地降低执行SVD的计算复杂性,同时实现相同的源音频编码效率,如同SVD是直接应用于HOA系数一般。即,上述PSD型SVD可潜在地需求较少计算,因为SVD是在F*F矩阵(其中F为HOA系数的数目)上完成。与M*F矩阵相比,其中M为帧长度,即1024或更多个样本。经由应用于PSD而非HOA系数11,与应用于HOA系数11时的O(M*L2)相比较,SVD的复杂性现可为约O(L3)(其中O(*)表示计算机科学技术中常见的计算复杂性的大O记法)。
图9B为更详细地说明音频编码装置20的参数计算单元32的框图。参数计算单元32可包含能量分析单元202及交叉相关单元204。能量分析单元202可相对于US[k]向量33和V[k]向量35中的一或多者执行上述能量分析以产生用于当前帧(k)或前一帧(k-1)中的一或多者的相关参数(R)、方向特性参数 及能量特性(e)中的一或多者。同样,交叉相关单元204可对于US[k]向量33和V[k]向量35中的一或多者执行上述交叉相关以产生用于当前帧(k)或前一帧(k-1)中的一或多者的相关参数(R)、方向特性参数
及能量特性(e)中的一或多者。同样,交叉相关单元204可对于US[k]向量33和V[k]向量35中的一或多者执行上述交叉相关以产生用于当前帧(k)或前一帧(k-1)中的一或多者的相关参数(R)、方向特性参数
 和能量特性(e)中的一或多者。参数计算单元32可输出当前帧参数37和前一帧参数39。
和能量特性(e)中的一或多者。参数计算单元32可输出当前帧参数37和前一帧参数39。
图9C为更详细地说明音频编码装置20的重排序单元34的框图。重排序单元34包含参数评估单元206和向量重排序单元208。参数评估单元206表示经配置以以上文所描述的方式评估前一帧参数39和当前帧参数37以产生重排序索引205的单元。重排序索引205包含识别US[k]向量33的向量和V[k]向量35的向量将如何经重排序的索引(例如,通过具有识别当前向量位置的索引的对的第一索引和识别所述向量的经重排序位置的所述对的第二索引的索引对)。向量重排序单元208表示经配置以根据重排序索引205对US[k]向量33和V[k]向量35重排序的单元。重排序单元34可输出经重排序的US[k]向量33'和经重排序的V[k]向量35',同时还将重排序索引205作为一或多个语法元素传递到位流产生单元42。
图9D为更详细地说明音频编码装置20的声场分析单元44的框图。如图9D的实例中所示,声场分析单元44可包含奇异值分析单元210A、能量分析单元210B、空间分析单元210C、空间掩蔽分析单元210D、扩散分析单元210E及方向分析单元210F。奇异值分析单元210A可表示经配置以分析通过使S向量的对角线值(形成US[k]向量33的部分)递减而产生的曲线的斜率的单元,其中大奇异值表示前景或相异声音,且低奇异值表示声场的背景分量,如上文所描述。能量分析单元210B可表示经配置以每向量地确定V[k]矩阵35的能量的单元。
空间分析单元210C可表示经配置以经由将HOA系数11变换到空间域且识别表示应保留的声场的方向分量的高能量区域而执行上文所描述的空间能量分析的单元。空间掩蔽分析单元210D可表示经配置而以类似于空间能量分析(只是空间掩蔽分析单元210D可识别通过空间上接近的较高能量声音掩蔽的空间区域)的方式执行空间掩蔽分析的单元。扩散分析单元210E可表示经配置以相对于HOA系数11执行上述扩散分析以识别可表示声场的背景分量的扩散能量区域的单元。方向分析单元210F可表示经配置以执行以上指出的方向分析的单元,所述方向分析涉及计算VS[k]向量,以及对这些VS[k]向量中的每一者的每一条目进行求平方及求和以识别方向性商。方向分析单元210F可将VS[k]向量中的每一者的此方向性商提供到背景/前景(BG/FG)识别(ID)单元212。
声场分析单元44还可包含BG/FG ID单元212,所述BG/FG ID单元212可表示经配置以基于由分析单元210至210F的任何组合输出的分析的任何组合确定前景通道的总数(nFG)45、背景声场的阶数(NBG)以及要发送的额外BG HOA通道的数目(nBGa)及索引(i)(其在图4的实例中可共同地表示为背景通道信息43)的单元。BG/FG ID单元212可确定nFG 45和背景通道信息43以便实现目标位速率41。
图9E为更详细地说明音频编码装置20的前景选择单元36的框图。前景选择单元36包含向量剖析单元214,该所述向量剖析单元214可剖析或以其他方式从经重排序的US[k]向量33'及经重排序的V[k]向量35'提取由nFG语法元素45识别的前景US[k]向量49及前景V[k]向量51k。向量剖析单元214可剖析表示由声场分析单元44识别且由nFG语法元素45(其也可被称作前景通道信息45)指定的声场的前景分量的各种向量。如图9E的实例中所示,在一些情况下,向量剖析单元214可选择前景US[k]向量49及前景V[k]向量51k内的非连续向量来表示声场的前景分量。此外,在一些情况下,向量剖析单元214可选择前景US[k]向量49及前景V[k]向量51k的相同向量(逐位置)来表示声场的前景分量。
图9F为更详细地说明音频编码装置20的背景选择单元48的框图。背景选择单元48可基于背景通道信息(例如,背景声场(NBG)以及要发送的额外BG HOA通道的数目(nBGa)及索引(i))确定背景或环境HOA系数47。举例来说,当NBG等于一时,背景选择单元48可选择具有等于或小于一的阶数的音频帧的每一样本的HOA系数11。在此实例中,背景选择单元48可接着选择具有由索引(i)中的一者识别的索引的HOA系数11作为额外BG HOA系数,其中将待于位流21中指定的nBGa提供到位产生单元42以便使得音频解码装置(例如,图5的实例中所展示的音频解码装置24)能够从位流21解析BG HOA系数47。背景选择单元48可接着将环境HOA系数47输出到能量补偿单元38。环境HOA系数47可具有尺寸D:M×[(NBG+1)2+nBGa]。
图9G为更详细地说明音频编码装置20的能量补偿单元38的框图。能量补偿单元38可表示经配置以相对于环境HOA系数47执行能量补偿以补偿归因于由背景选择单元48移除HOA通道中的各者而产生的能量损失的单元。能量补偿单元38可包含能量确定单元218、能量分析单元220及能量放大单元222。
能量确定单元218可表示经配置以识别经重排序的US[k]矩阵33'及经重排序的V[k]矩阵35'中的一或多者上的每一行和/或列的RMS的单元。能量确定单元38还可识别选定前景通道中的一或多者(其可包含nFG信号49和前景V[k]向量51k,以及阶数缩减的环境HOA系数47)的每一行和/或列的RMS。经重排序的US[k]矩阵33'和经重排序的V[k]矩阵35'中的所述一或多者的每一行和/或列的RMS可存储为表示为RMSFULL的向量,而nFG信号49、前景V[k]向量51k和阶数缩减的环境HOA系数47中的一或多者的每一行和/或列的RMS可存储为表示为RMSREDUCED的向量。
在一些实例中,为确定经重排序的US[k]矩阵33'、经重排序的V[k]矩阵35'、nFG信号49、前景V[k]向量51k及阶数缩减的环境HOA系数47中的一或多者的相应行和/或列的每一RMS,能量确定单元218可首先将参考球谐系数(SHC)再现器应用于所述列。由能量确定单元218应用参考SHC再现器允许确定SHC域中的RMS以确定经重排序的US[k]矩阵33'、经重排序的V[k]矩阵35'、nFG信号49、前景V[k]向量51k和经阶数缩减的环境HOA系数47中的一或多者的行和/或列表示的帧的每一行和/或列所描述的总体声场的能量。能量确定单元38可将此RMSFULL和RMSREDUCED向量传递到能量分析单元220。
能量分析单元220可表示经配置以根据以下等式计算放大值向量Z的单元:Z=RMSFULL/RMSREDUCED。能量分析单元220可随后将此放大值向量Z传递到能量放大单元222。能量放大单元222可表示经配置以将此放大值向量Z或其各种部分应用到nFG信号49、前景V[k]向量51k和经阶数缩减的环境HOA系数47中的一或多者的单元。在一些情况下,放大值向量Z依据以下等式HOABG-RED'=HOABG-REDZT施加到仅阶数缩减的环境HOA系数47,其中HOABG-RED指示阶数缩减的环境HOA系数47,HOABG-RED'指示经能量补偿的阶数缩减的HOA系数47',且ZT指示Z向量的转置。
图9H为更详细地说明图4的实例中所示的音频编码装置20的空间-时间内插单元50的框图。空间-时间内插单元50可表示经配置以接收第k帧的前景V[k]向量51k和前一帧(因此为k-1记法)的前景V[k-1]向量51k-1且执行空间-时间内插以产生经内插前景V[k]向量的单元。空间-时间内插单元50可包含V内插单元224及前景调适单元226。
V内插单元224可基于当前前景V[k]向量51k及先前前景V[k-1]向量51k-1的剩余部分选择当前前景V[k]向量51k的要内插的部分。V内插单元224可将所述部分选择为以上指出的子帧中的一或多者或仅为可能逐帧变化的单一不确定部分。在一些情况下,V内插单元224可选择当前前景V[k]向量51k的1024个样本的单一128个样本部分以内插。V内插单元224可接着通过将当前前景V[k]向量51k及先前前景V[k-1]向量51k-1中的向量投影到球面上(使用例如T设计矩阵的投影矩阵)来将所述向量中的每一者转换为单独空间点阵图。V内插单元224可接着将V中的向量解译为球面上的形状。为内插256样本部分的V矩阵,V内插单元224可接着内插这些空间形状,且且接着经由投影矩阵的逆将其变换回到球谐域向量。以此方式,本发明的技术可提供V矩阵之间的平滑转变。V内插单元224可接着产生剩余V[k]向量53,其表示经修改以移除前景V[k]向量51k的经内插部分之后的前景V[k]向量51k。V内插单元224可接着将经内插前景V[k]向量51k'传递到nFG调适单元226。
当选择单一部分进行内插时,V内插单元224可产生表示为CodedSpatialInterpolationTime 254的语法元素,其识别持续时间或换句话说,内插的时间(例如,根据样本的数目)。当选择单一部分执行子帧内插时,V内插单元224还可产生表示为SpatialInterpolationMethod 255的另一语法元素,其可识别所执行的内插的类型(或在一些情况下,是否执行内插)。空间-时间内插单元50可将这些语法元素254和255输出到位流产生单元42。
nFG调适单元226可表示经配置以产生经调适nFG信号49'的单元。nFG调适单元226可通过首先经由nFG信号49与前景V[k]向量51k的乘法获得前景HOA系数而产生经调适nFG信号49'。在获得前景HOA系数之后,nFG调适单元226可将前景HOA系数除以经内插前景V[k]向量53以获得经调适nFG信号49'(其可被称作经内插nFG信号49',假定这些信号是从经内插前景V[k]向量51k'导出)。
图9I为更详细地说明图4的实例中所示的音频编码装置20的系数缩减单元46的框图。系数减少单元46可表示经配置以基于背景通道信息43相对于剩余前景V[k]向量53执行系数减少以将经缩减的前景V[k]向量55输出到量化单元52的单元。经缩减的前景V[k]向量55可具有维度D:[(N+1)2-(NBG+1)2-nBGa]×nFG。
系数缩减单元46可包括系数最小化单元228,系数最小化单元228可表示经配置以通过移除在背景HOA系数47(如由背景通道信息43所识别)中考量的任何系数而缩减或以其它方式最小化剩余前景V[k]向量53中的每一者的大小的单元。系数最小化单元228可移除由背景通道信息43识别的那些系数以获得经缩减前景V[k]向量55。
图9J为更详细地说明图4的实例中所示的音频编码装置20的心理声学音频译码器单元40的框图。心理声学音频译码器单元40可表示经配置以相对于经能量补偿的背景HOA系数47'及经内插nFG信号49'执行心理声学编码的单元。如图9H的实例中所示,心理声学音频译码器单元40可调用心理声学音频编码器40A至40N的多个例项以对经能量补偿的背景HOA系数47'的通道(其中在此上下文中,通道是指对应于特定阶数/子阶球面基底函数的帧中的所有样本)中的每一者及经内插nFG信号49'的每一信号进行音频编码。在一些实例中,心理声学音频译码器单元40执行个体化或以其它方式包含(当以硬件实施时)足够数目的音频编码器40A到40N以对经能量补偿的背景HOA系数47'的每一通道(或nBGa加索引(i)的总数)及经内插nFG信号49'(或nFG)的每一信号进行单独地编码(对于总共nBGa加额外环境HOA通道的索引(i)的总数加nFG)。音频编码器40A到40N可输出经编码背景HOA系数59及经编码nFG信号61。
图9K为更详细地说明图4的实例中所示的音频编码装置20的量化单元52的框图。在图9K的实例中,量化单元52包含均一量化单元230、nbits单元232、预测单元234、预测模式单元236(“Pred模式单元236”)、类别和残余译码单元238以及霍夫曼表选择单元240。均一量化单元230表示经配置以相对于空间分量中的一者(其可表示经缩减前景V[k]向量55中的任一者)执行上文描述的均一量化的单元。nbits单元232表示经配置以确定nbits参数或值的单元。
预测单元234表示经配置以相对于经量化空间分量执行预测的单元。预测单元234可通过用经缩减前景V[k]向量55中的时间上在后的一对应者(其可表示为经缩减前景V[k-1]向量55)逐元素地减去经缩减前景V[k]向量55中的一当前者而执行预测。此预测的结果可被称作所预测空间分量。
预测模式单元236可表示经配置以选择预测模式的单元。霍夫曼表选择单元240可表示经配置以选择适当霍夫曼表用于cid的译码的单元。作为一个实例,预测模式单元236及霍夫曼表选择单元240可根据以下伪码操作:


类别及残余译码单元238可表示经配置以按以上更详细地描述的方式执行经预测的空间分量或经量化的空间分量(当预测停用时)的分类及残余译码的单元。
如图9K的实例中所示,量化单元52可输出各种参数或值用于包含于位流21或旁侧信息(其可自身为与位流21分开的位流)中。假定信息在旁侧通道信息中指定,那么标量/熵量化单元50可将nbits值(作为nbits值233)、预测模式(作为预测模式237)及霍夫曼表信息(作为霍夫曼表信息241)连同空间分量的经压缩版本(在图4的实例中展示为经译码前景V[k]向量57)(在此实例中,其可指经选择以对cid、正负号位及块译码残余进行编码的霍夫曼码)输出到位流产生单元42。nbits值可对于所有经译码前景V[k]向量57在旁侧通道信息中指定一次,而预测模式及霍夫曼表信息可针对经译码前景V[k]向量57中的每一者予以指定。在图10B及/或10C的实例中更详细地展示位流的指定空间分量的经压缩版本的部分。
图9L为更详细地说明图4的实例中所示的音频编码装置20的位流产生单元42的框图。位流产生单元42可包含主通道信息产生单元242及旁侧通道信息产生单元244。主通道信息产生单元242可产生包含重排序索引205、CodedSpatialInterpolationTime语法元素254、SpatialInterpolationMethod语法元素255、经编码背景HOA系数59及经编码nFG信号61中的一或多者(如果并非全部)的主位流21。旁侧通道信息产生单元244可表示经配置以产生可包含nbits值233、预测模式237、霍夫曼表信息241及经译码前景V[k]向量57中的一或多者(如果并非全部)的旁侧通道位流21B的单元。位流21及21B可统称为位流21。在一些上下文中,位流21可仅指主通道位流21,而位流21B可被称作旁侧通道信息21B。
图10A至10O(ii)为更详细地说明可指定经压缩空间分量的位流或旁侧通道信息的部分的图。在图10A的实例中,部分250包括转译器识别符(“转译器ID”)字段251及HOADecoderConfig字段252。转译器ID字段251可表示存储已用于HOA内容的混音的转译器的ID的字段。HOADecoderConfig字段252可表示经配置以存储用以初始化HOA空间解码器的信息的字段。
HOADecoderConfig字段252进一步包含方向信息(“方向信息”)字段253、CodedSpatialInterpolationTime字段254、SpatialInterpolationMethod字段255、CodedVVecLength字段256及增益信息字段257。方向信息字段253可表示存储用于配置基于方向的合成解码器的信息的字段。CodedSpatialInterpolationTime字段254可表示存储基于向量的信号的空间-时间内插的时间的字段。SpatialInterpolationMethod字段255可表示存储在基于向量的信号的空间-时间内插期间应用的内插类型的指示的字段。CodedVVecLength字段256可表示存储用以合成基于向量的信号的所发射数据向量的长度的字段。增益信息字段257表示存储指示应用于信号的增益校正的信息的字段。
在图10B的实例中,部分258A表示旁侧信息通道的一部分,其中部分258A包含帧标头259,帧标头259包含字节数目字段260及nbits字段261。字节数目字段260可表示用以表达包含于用于指定空间分量v1到vn的帧中的字节数目(包含用于字节对准字段264的零)的字段。nbits字段261表示可指定经识别供用于解压缩空间分量v1到vn的nbits值的字段。
如图10B的实例中进一步所示,部分258A可包含用于v1到vn的子位流,其中的每一者包含预测模式字段262、霍夫曼表信息字段263及经压缩空间分量v1到vn中的一对应者。预测模式字段262可表示用以存储是否对于经压缩空间分量v1到vn中的所述对应者执行预测的指示的字段。霍夫曼表信息字段263表示用以至少部分指示应使用哪一霍夫曼表来对经压缩空间分量v1到vn中的所述对应者的各种方面进行解码的字段。
就此而言,所述技术可使得音频编码装置20能够获得包含声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
图10C为更详细地说明可指定经压缩空间分量的旁侧通道信息的部分258B的替代实例的图。在图10C的实例中,部分258B包括包含Nbits字段261的帧标头259。Nbits字段261表示可指定经识别供用于解压缩空间分量v1到vn的nbits值的字段。
如图10C的实例中进一步所示,部分258B可包含用于v1到vn的子位流,其中的每一者包含预测模式字段262、霍夫曼表信息字段263及经压缩空间分量v1到vn中的一对应者。预测模式字段262可表示用以存储是否对于经压缩空间分量v1到vn中的所述对应者执行预测的指示的字段。霍夫曼表信息字段263表示用以至少部分指示应使用哪一霍夫曼表来对经压缩空间分量v1到vn中的所述对应者的各种方面进行解码的字段。
在所说明的实例中,Nbits字段261包含子字段A 265、B 266及C 267。在此实例中,A 265及B 266各自为1位子字段,而C 267为2位子字段。其它实例可包含大小不同的子字段265、266及267。A字段265及B字段266可表示存储Nbits字段261的第一及第二最高有效位的字段,而C字段267可表示存储Nbits字段261的最低有效位的字段。
部分258B还可包含AddAmbHoaInfoChannel字段268。AddAmbHoaInfoChannel字段268可表示存储用于额外环境HOA系数的信息的字段。如图10C的实例中所示,AddAmbHoaInfoChannel 268包含CodedAmbCoeffIdx字段246、AmbCoeffIdxTransition字段247。CodedAmbCoeffIdx字段246可表示存储额外环境HOA系数的索引的字段。AmbCoeffIdxTransition字段247可表示经配置以存储指示在此帧中是否有额外环境HOA系数被淡入或淡出的数据的字段。
图10C(i)为更详细地说明可指定经压缩空间分量的旁侧通道信息的部分258B'的替代实例的图。在图10C(i)的实例中,部分258B'包括包含Nbits字段261的帧标头259。Nbits字段261表示可指定经识别供用于解压缩空间分量v1到vn的nbits值的字段。
如图10C(i)的实例中进一步所示,部分258B'可包含用于v1到vn的子位流,其中的每一者包括霍夫曼表信息字段263及经压缩方向分量v1到vn中的一对应者,而不包含预测模式字段262。在所有其它方面,部分258B'可类似于部分258B。
图10D为更详细地说明位流21的部分258C的图。部分258C类似于部分258,但以下情况除外:帧标头259及零字节对准264已被移除,同时Nbits 261字段已添加在用于v1到vn的位流中的每一者之前,如图10D的实例中所示。
图10D(i)为更详细地说明位流21的部分258C'的图。部分258C'类似于部分258C,但部分258C'不包含用于V向量v1到vn中的每一者的预测模式字段262除外。
图10E为更详细地说明位流21的部分258D的图。部分258D类似于部分258B,但以下情况除外:帧标头259及零字节对准264已被移除,同时Nbits 261字段已添加在用于v1到vn的位流中的每一者之前,如图10E的实例中所示。
图10E(i)为更详细地说明位流21的部分258D'的图。部分258D'类似于部分258D,但部分258D'不包含用于V向量v1到vn中的每一者的预测模式字段262除外。就此而言,音频编码装置20可产生不包含用于每一经压缩V向量的预测模式字段262的位流21,如关于图10C(i)、10D(i)及10E(i)的实例所表明。
图10F为以不同方式说明图10A的实例中所示的位流21的部分250的图。图10D的实例中所示的部分250包含HOAOrder字段(其为容易说明的目的而未在图10F的实例中展示)、MinAmbHoaOrder字段(其再次为容易说明的目的而未在图10F的实例中展示)、方向信息字段253、CodedSpatialInterpolationTime字段254、SpatialInterpolationMethod字段255、CodedVVecLength字段256及增益信息字段257。如图10F的实例中所示,CodedSpatialInterpolationTime字段254可包含三位字段,SpatialInterpolationMethod字段255可包含一位字段,且CodedVVecLength字段256可包含二位字段。
图10G为更详细地说明位流21的部分248的图。部分248表示统一话音/音频译码器(USAC)三维(3D)有效负载,其包含HOAframe字段249(其还可表示为旁带信息、旁侧通道信息,或旁侧通道位流)。如图10E的实例中所示,HOAFrame字段249的展开图可类似于图10C的实例中所示的位流21的部分258B。“ChannelSideInfoData”包含ChannelType字段269(其出于容易说明的目的而未在图10C的实例中展示)、在图10E的实例中表示为“ba”的A字段265、在图10E的实例中表示为“bb”的B字段266及在图10E的实例中表示为“unitC”的C字段267。ChannelType字段指示通道为基于方向的信号、基于向量的信号还是额外环境HOA系数。在不同ChannelSideInfoData之间,存在AddAmbHoaInfoChannel字段268,其中不同V向量位流用灰色表示(例如,“用于v1的位流”及“用于v2的位流”)。
图10H到10O(ii)为更详细地说明位流21的另一各种实例部分248H到248O连同伴随的HOAconfig部分250H到250O的图。图10H(i)及10H(ii)说明已产生第一实例位流248H及伴随的HOA config部分250H以与以上伪码中的情况0相对应。在图10H(i)的实例中,HOAconfig部分250H包含CodedVVecLength语法元素256,其经设定以指示V向量的所有元素经译码,例如,所有16个V向量元素。HOAconfig部分250H还包含SpatialInterpolationMethod语法元素255,其经设定以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250H包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。HOAconfig部分250H进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。HOAconfig部分250H包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10H(i)的实例中进一步所示,部分248H包括统一话音及音频译码(USAC)三维(USAC-3D)音频帧,其中两个HOA帧249A及249B存储在一USAC有效负载中,假定在启用频谱带复制(SBR)时所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例中,其是假定numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10H(ii)更详细地说明帧249A及249B。如图10H(ii)的实例中所示,帧249A包括ChannelSideInfoData(CSID)字段154到154C、HOAGainCorrectionData(HOAGCD)字段、VVectorData字段156及156B以及HOAPredictionInfo字段。CSID字段154包含unitC267、bb266及ba265连同ChannelType 269,其中的每一者设定到图10H(i)的实例中所示的对应值01、1、0及01。CSID字段154B包含unitC 267、bb 266及ba 265连同ChannelType 269,其中的每一者设定到图10H(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。CSID字段154到154C中的每一者对应于传输通道1、2及3中的一相应者。在效果上,每一CSID字段154到154C指示对应有效负载156及156B为基于方向的信号(当对应ChannelType等于零时)、基于向量的信号(当对应ChannelType等于一时)、额外环境HOA系数(当对应ChannelType等于二时),还是为空(当ChannelType等于三时)。
在图10H(ii)的实例中,帧249A包含两个基于向量的信号(假定ChannelType 269在CSID字段154及154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250H,音频解码装置24可确定所有16个V向量元素经编码。因此,VVectorData 156及156B各自包含所有16个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由单星号(*)所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249B中,CSID字段154及154B与帧249中的CSID字段154及154B相同,而帧249B的CSID字段154C切换到为一的ChannelType。因此,帧249B的CSID字段154C包含Cbflag267、Pflag 267(指示霍夫曼编码)及Nbits 261(等于12)。结果,帧249B包含第三VVectorData字段156C,其包含16个V向量元素,其中的每一者通过12个位均匀量化且经霍夫曼译码。如上文所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定,而霍夫曼译码方案通过NbitsQ=12、CbFlag=0及Pflag=0在用于此特定传输通道(例如,第3传输通道)的CSID字段154C中用信号通知。
图10I(i)及10I(ii)的实例说明已产生第二实例位流248I及伴随的HOA config部分250I以与以上伪码中的以上情况0相对应。在图10I(i)的实例中,HOAconfig部分250I包含CodedVVecLength语法元素256,其经设定以指示V向量的所有元素经译码,例如,所有16个V向量元素。HOAconfig部分250I还包含SpatialInterpolationMethod语法元素255,其经设定以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250I包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。
HOAconfig部分250I进一步包含MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。音频解码装置24还可导出MaxNoOfAddActiveAmbCoeffs语法元素,如设定到NumOfHoaCoeff语法元素与MinNumOfCoeffsForAmbHOA之间的差,在此实例中假定其等于16-4或12。音频解码装置24还可导出AmbAsignmBits语法元素,如设定到ceil(log2(MaxNoOfAddActiveAmbCoeffs))=ceil(log2(12))=4。HOAconfig部分250H包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10I(i)的实例中进一步所示,部分248H包含USAC-3D音频帧,其中两个HOA帧249C及249D存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例中,假设numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10I(ii)更详细地说明帧249C及249D。如图10I(ii)的实例中所示,帧249C包含CSID字段154到154C及VVectorData字段156。CSID字段154包含CodedAmbCoeffIdx246、AmbCoeffIdxTransition 247(其中双星号(**)指示对于第1灵活传输通道,此处假定解码器的内部状态为AmbCoeffIdxTransitionState=2,其导致CodedAmbCoeffIdx位字段在位流中用信号通知或以其它方式指定)及ChannelType 269(其等于二,从而用信号通知对应有效负载为额外环境HOA系数)。在此实例中,音频解码装置24可将AmbCoeffIdx导出为等于CodedAmbCoeffIdx+1+MinNumOfCoeffsForAmbHOA或5。CSID字段154B包含unitC 267、bb266及ba 265连同ChannelType 269,其中的每一者设定到图10I(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。
在图10I(ii)的实例中,帧249C包含单一基于向量的信号(假定ChannelType 269在CSID字段154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250I,音频解码装置24可确定所有16个V向量元素经编码。因此,VVectorData 156包括所有16个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由脚注2所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249D中,CSID字段154包含指示无转变已发生的AmbCoeffIdxTransition247,且因此可从前一帧暗示而无需用信号通知或以其它方式再次指定CodedAmbCoeffIdx246。帧249D的CSID字段154B及154C与用于帧249C的CSID字段相同,且因而,如同帧249C,帧249D包含单一VVectorData字段156,其包含所有16个向量元素,其中的每一者通过8个位均匀量化。
图10J(i)及10J(ii)说明已产生第一实例位流248J及伴随的HOA config部分250J以与以上伪码中的情况1相对应。在图10J(i)的实例中,HOAconfig部分250J包含CodedVVecLength语法元素256,其经设定以指示除了元素1到MinNumOfCoeffsForAmbHOA及在ContAddAmbHoaChan语法元素(在此实例中假定为零)中指定的那些元素,V向量的所有元素经译码。HOAconfig部分250J还包含SpatialInterpolationMethod语法元素255集合以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250J包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。HOAconfig部分250J进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。HOAconfig部分250J包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10J(i)的实例中进一步所示,部分248J包含USAC-3D音频帧,其中两个HOA帧249E及249F存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例中,假设numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10J(ii)更详细地说明帧249E及249F。如图10J(ii)的实例中所示,帧249E包含CSID字段154到154C以及VVectorData字段156及156B。CSID字段154包含unitC 267、bb 266及ba 265连同ChannelType 269,其中的每一者设定到图10J(i)的实例中所示的对应值01、1、0及01。CSID字段154B包括unitC 267、bb 266及ba 265连同ChannelType269,其中的每一者设定到图10J(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。CSID字段154到154C中的每一者对应于传输通道1、2及3中的一相应者。
在图10J(ii)的实例中,帧249E包含两个基于向量的信号(假定ChannelType 269在CSID字段154及154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250H,音频解码装置24可确定所有12个V向量元素经编码(其中12是导出为(HOAOrder+1)2-(MinNumOfCoeffsForAmbHOA)-(ContAddAmbHoaChan)=16-4-0=12)。因此,VVectorData 156及156B各自包含所有12个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由单星号(*)所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249F中,CSID字段154及154B与帧249E中的CSID字段154及154B相同,而帧249F的CSID字段154C切换到为一的ChannelType。因此,帧249B的CSID字段154C包含Cbflag267、Pflag 267(指示霍夫曼编码)及Nbits 261(等于12)。结果,帧249F包含第三VVectorData字段156C,其包含12个V向量元素,其中的每一者通过12个位均匀量化且经霍夫曼译码。如上文所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定,而霍夫曼译码方案通过NbitsQ=12、CbFlag=0及Pflag=0在用于此特定传输通道(例如,第3传输通道)的CSID字段154C中用信号通知。
图10K(i)及10K(ii)的实例说明已产生第二实例位流248K及伴随的HOA config部分250K以与以上伪码中的以上情况1相对应。在图10K(i)的实例中,HOAconfig部分250K包含CodedVVecLength语法元素256,其经设定以指示除了元素1到MinNumOfCoeffsForAmbHOA及在ContAddAmbHoaChan语法元素(在此实例中假定为一)中指定的那些元素,V向量的所有元素经译码。HOAconfig部分250K还包含SpatialInterpolationMethod语法元素255,其经设定以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250K包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。
HOAconfig部分250K进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。音频解码装置24还可导出MaxNoOfAddActiveAmbCoeffs语法元素,如设定到NumOfHoaCoeff语法元素与MinNumOfCoeffsForAmbHOA之间的差,在此实例中假定其等于16-4或12。音频解码装置24还可导出AmbAsignmBits语法元素,如设定到ceil(log2(MaxNoOfAddActiveAmbCoeffs))=ceil(log2(12))=4。HOAconfig部分250K包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10K(i)的实例中进一步所示,部分248K包含USAC-3D音频帧,其中两个HOA帧249G及249H存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例中,假设numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10K(ii)更详细地说明帧249G及249H。如图10K(ii)的实例中所示,帧249G包含CSID字段154到154C以及VVectorData字段156。CSID字段154包含CodedAmbCoeffIdx246、AmbCoeffIdxTransition 247(其中双星号(**)指示对于第1灵活传输通道,此处假定解码器的内部状态为AmbCoeffIdxTransitionState=2,其导致CodedAmbCoeffIdx位字段在位流中用信号通知或以其它方式指定)及ChannelType 269(其等于二,从而用信号通知对应有效负载为额外环境HOA系数)。在此实例中,音频解码装置24可将AmbCoeffIdx导出为等于CodedAmbCoeffIdx+1+MinNumOfCoeffsForAmbHOA或5。CSID字段154B包含unitC 267、bb266及ba 265连同ChannelType 269,其中的每一者设定到图10K(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。
在图10K(ii)的实例中,帧249G包含单一基于向量的信号(假定ChannelType 269在CSID字段154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250K,音频解码装置24可确定11个V向量元素经编码(其中12导出为(HOAOrder+1)2-(MinNumOfCoeffsForAmbHOA)-(ContAddAmbHoaChan)=16-4-1=11)。因此,VVectorData 156包含所有11个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由脚注2所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249H中,CSID字段154包含指示无转变已发生的AmbCoeffIdxTransition247,且因此可从前一帧暗示而无需用信号通知或以其它方式再次指定CodedAmbCoeffIdx246。帧249H的CSID字段154B及154C与用于帧249G的CSID字段相同,且因而,如同帧249G,帧249H包含单一VVectorData字段156,其包含11个向量元素,其中的每一者通过8个位均匀量化。
图10L(i)及10L(ii)说明已产生第一实例位流248L及伴随的HOA config部分250L以与以上伪码中的情况2相对应。在图10L(i)的实例中,HOAconfig部分250L包含CodedVVecLength语法元素256,其经设定以指示除了0阶直至由MinAmbHoaOrder语法元素150(其在此实例中等于(HoaOrder+1)2-(MinAmbHoaOrder+1)2=16-4=12)指定的阶数的元素,V向量的所有元素经译码。HOAconfig部分250L还包含SpatialInterpolationMethod语法元素255,其经设定以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250L包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。HOAconfig部分250L进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。HOAconfig部分250L包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10L(i)的实例中进一步所示,部分248L包含USAC-3D音频帧,其中两个HOA帧249I及249J存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例,假定numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10L(ii)更详细地说明帧249I及249J。如图10L(ii)的实例中所示,帧249I包含CSID字段154到154C以及VVectorData字段156及156B。CSID字段154包含unitC 267、bb 266及ba 265连同ChannelType 269,其中的每一者设定到图10J(i)的实例中所示的对应值01、1、0及01。CSID字段154B包含unitC 267、bb 266及ba 265连同ChannelType269,其中的每一者设定到图10L(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。CSID字段154到154C中的每一者对应于传输通道1、2及3中的一相应者。
在图10L(ii)的实例中,帧249I包含两个基于向量的信号(假定ChannelType 269在CSID字段154及154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250H,音频解码装置24可确定12个V向量元素经编码。因此,VVectorData 156及156B各自包含12个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由单星号(*)所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249J中,CSID字段154及154B与帧249I中的CSID字段154及154B相同,而帧249F的CSID字段154C切换到为一的ChannelType。因此,帧249B的CSID字段154C包含Cbflag267、Pflag 267(指示霍夫曼编码)及Nbits 261(等于12)。结果,帧249F包含第三VVectorData字段156C,其包含12个V向量元素,其中的每一者通过12个位均匀量化且经霍夫曼译码。如上文所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定,而霍夫曼译码方案通过NbitsQ=12、CbFlag=0及Pflag=0在用于此特定传输通道(例如,第3传输通道)的CSID字段154C中用信号通知。
图10M(i)及10M(ii)的实例说明已产生第二实例位流248M及伴随的HOA config部分250M以与以上伪码中的以上情况2相对应。在图10M(i)的实例中,HOAconfig部分250M包含CodedVVecLength语法元素256,其经设定以指示除了0阶直至由MinAmbHoaOrder语法元素150(其在此实例中等于(HoaOrder+1)2-(MinAmbHoaOrder+1)2=16-4=12)指定的阶数的元素,V向量的所有元素经译码。HOAconfig部分250M还包含SpatialInterpolationMethod语法元素255集合以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250M包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。
HOAconfig部分250M进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。音频解码装置24还可导出MaxNoofAddActiveAmbCoeffs语法元素,如设定到NumOfHoaCoeff语法元素与MinNumOfCoeffsForAmbHOA之间的差,在此实例中假定其等于16-4或12。音频解码装置24还可导出AmbAsignmBits语法元素,如设定到ceil(log2(MaxNoOfAddActiveAmbCoeffs))=ceil(log2(12))=4。HOAconfig部分250M包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10M(i)的实例中进一步所示,部分248M包含USAC-3D音频帧,其中两个HOA帧249K及249L存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例中,假设numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10M(ii)更详细地说明帧249K及249L。如图10M(ii)的实例中所示,帧249K包含CSID字段154到154C以及VVectorData字段156。CSID字段154包含CodedAmbCoeffIdx 246、AmbCoeffIdxTransition 247(其中双星号(**)指示对于第1灵活传输通道,此处假定解码器的内部状态为AmbCoeffIdxTransitionState=2,其导致CodedAmbCoeffIdx位字段在位流中用信号通知或以其它方式指定)及ChannelType269(其等于二,从而用信号通知对应有效负载为额外环境HOA系数)。在此实例中,音频解码装置24可将AmbCoeffIdx导出为等于CodedAmbCoeffIdx+1+MinNumOfCoeffsForAmbHOA或5。CSID字段154B包含unitC267、bb 266及ba 265连同ChannelType 269,其中的每一者设定到图10M(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。
在图10M(ii)的实例中,帧249K包含单一基于向量的信号(假定ChannelType 269在CSID字段154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250M,音频解码装置24可确定12个V向量元素经编码。因此,VVectorData 156包含12个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由脚注2所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249L中,CSID字段154包含指示无转变已发生的AmbCoeffIdxTransition247,且因此可从前一帧暗示而无需用信号通知或以其它方式再次指定CodedAmbCoeffIdx246。帧249L的CSID字段154B及154C与用于帧249K的CSID字段相同,且因而,如同帧249K,帧249L包含单一VVectorData字段156,其包含所有12个向量元素,其中的每一者通过8个位均匀量化。
图10N(i)及10N(ii)说明已产生第一实例位流248N及伴随的HOA config部分250N以与以上伪码中的情况3相对应。在图10N(i)的实例中,HOAconfig部分250N包含CodedVVecLength语法元素256,其经设定以指示除了在ContAddAmbHoaChan语法元素(其在此实例中假定为零)中指定的那些元素,V向量的所有元素经译码。HOAconfig部分250N包含SpatialInterpolationMethod语法元素255集合以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250N包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。HOAconfig部分250N进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。HOAconfig部分250N包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10N(i)的实例中进一步所示,部分248N包含USAC-3D音频帧,其中两个HOA帧249M及249N存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例,假定numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10N(ii)更详细地说明帧249M及249N。如图10N(ii)的实例中所示,帧249M包含CSID字段154到154C以及VVectorData字段156及156B。CSID字段154包含unitC267、bb 266及ba 265连同ChannelType 269,其中的每一者设定到图10J(i)的实例中所示的对应值01、1、0及01。CSID字段154B包含unitC 267、bb 266及ba 265连同ChannelType 269,其中的每一者设定到图10N(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。CSID字段154到154C中的每一者对应于传输通道1、2及3中的一相应者。
在图10N(ii)的实例中,帧249M包含两个基于向量的信号(假定ChannelType 269在CSID字段154及154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250M,音频解码装置24可确定16个V向量元素经编码。因此,VVectorData 156及156B各自包含16个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由单星号(*)所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249N中,CSID字段154及154B与帧249M中的CSID字段154及154B相同,而帧249F的CSID字段154C切换到为一的ChannelType。因此,帧249B的CSID字段154C包含Cbflag267、Pflag 267(指示霍夫曼编码)及Nbits 261(等于12)。结果,帧249F包含第三VVectorData字段156C,其包含16个V向量元素,其中的每一者通过12个位均匀量化且经霍夫曼译码。如上文所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定,而霍夫曼译码方案通过NbitsQ=12、CbFlag=0及Pflag=0在用于此特定传输通道(例如,第3传输通道)的CSID字段154C中用信号通知。
图10O(i)及10O(ii)的实例说明已产生第二实例位流248O及伴随的HOA config部分250O以与以上伪码中的以上情况3相对应。在图10O(i)的实例中,HOAconfig部分250O包含CodedVVecLength语法元素256,其经设定以指示除了在ContAddAmbHoaChan语法元素(其在此实例中假定为一)中指定的那些元素,V向量的所有元素经译码。HOAconfig部分250O还包含SpatialInterpolationMethod语法元素255集合以指示空间-时间内插的内插函数为升余弦。此外,HOAconfig部分250O包含CodedSpatialInterpolationTime 254,其经设定以指示为256的经内插样本持续时间。
HOAconfig部分250O进一步包括MinAmbHoaOrder语法元素150,其经设定以指示环境HOA内容的MinimumHOA阶数为一,其中音频解码装置24可导出MinNumofCoeffsForAmbHOA语法元素等于(1+1)2或四。音频解码装置24还可导出MaxNoOfAddActiveAmbCoeffs语法元素,如设定到NumOfHoaCoeff语法元素与MinNumOfCoeffsForAmbHOA之间的差,在此实例中假定其等于16-4或12。音频解码装置24还可导出AmbAsignmBits语法元素,如设定到ceil(log2(MaxNoOfAddActiveAmbCoeffs))=ceil(log2(12))=4。HOAconfig部分250O包含HoaOrder语法元素152,其经设定以指示内容的HOA阶数等于三(或换句话说,N=3),其中音频解码装置24可导出NumOfHoaCoeffs等于(N+1)2或16。
如图10O(i)的实例中进一步所示,部分248O包含USAC-3D音频帧,其中两个HOA帧249O及249P存储于USAC扩展有效负载中,假定在启用频谱带复制(SBR)时,所述两个音频帧存储在一个USAC-3D帧内。音频解码装置24可导出作为numHOATransportChannels语法元素及MinNumOfCoeffsForAmbHOA语法元素的函数的数个灵活传输通道。在以下实例,假定numHOATransportChannels语法元素等于7且MinNumOfCoeffsForAmbHOA语法元素等于四,其中灵活传输通道的数目等于numHOATransportChannels语法元素减MinNumOfCoeffsForAmbHOA语法元素(或三)。
图10O(ii)更详细地说明帧249O及249P。如图10O(ii)的实例中所示,帧249O包含CSID字段154到154C以及VVectorData字段156。CSID字段154包括CodedAmbCoeffIdx246、AmbCoeffIdxTransition 247(其中双星号(**)指示对于第1灵活传输通道,此处假定解码器的内部状态为AmbCoeffIdxTransitionState=2,其导致CodedAmbCoeffIdx位字段在位流中用信号通知或以其它方式指定)及ChannelType 269(其等于二,从而用信号通知对应有效负载为额外环境HOA系数)。在此实例中,音频解码装置24可将AmbCoeffIdx导出为等于CodedAmbCoeffIdx+1+MinNumOfCoeffsForAmbHOA或5。CSID字段154B包含unitC 267、bb266及ba 265连同ChannelType 269,其中的每一者设定到图10O(ii)的实例中所示的对应值01、1、0及01。CSID字段154C包含具有值3的ChannelType字段269。
在图10O(ii)的实例中,帧249O包含单一基于向量的信号(假定ChannelType 269在CSID字段154B中等于1)及一空信号(假定ChannelType 269在CSID字段154C中等于3)。给定前述HOAconfig部分250O,音频解码装置24可确定16减去由ContAddAmbHoaChan语法元素(例如,其中与索引6相关联的向量元素被指定为ContAddAmbHoaChan语法元素)指定的一,或15个V向量元素经编码。因此,VVectorData156包含15个向量元素,其中的每一者通过8个位均匀量化。如脚注1所指出,经译码VVectorData元素的数目及索引由参数CodedVVecLength=0指定。此外,如由脚注2所指出,译码方案通过NbitsQ=5在用于对应传输通道的CSID字段中用信号通知。
在帧249P中,CSID字段154包含指示无转变已发生的AmbCoeffIdxTransition247,且因此可从前一帧暗示而无需用信号通知或以其它方式再次指定CodedAmbCoeffIdx246。帧249P的CSID字段154B及154C与用于帧249O的CSID字段相同,且因而,如同帧249O,帧249P包含单一VVectorData字段156,其包含15个向量元素,其中的每一者通过8个位均匀量化。
图11A到11G是更详细说明图5的实例中所示的音频解码装置24的各种单元的框图。图11A是更详细说明音频解码装置24的提取单元72的框图。如图11A的实例中所示,提取单元72可包含模式剖析单元270、模式配置单元272(“模式配置单元272”)以及可配置提取单元274。
模式剖析单元270可表示经配置以剖析指示用以对HOA系数11进行编码以便形式位流21的译码模式的上文指出的语法元素(例如,图10E的实例中所示的ChannelType语法元素)的单元。模式剖析单元270可将确定语法元素传递到模式配置单元272。模式配置单元272可表示经配置以基于经剖析语法元素配置可配置提取单元274的单元。模式配置单元272可配置可配置提取单元274以从位流21提取HOA系数11的基于方向的经译码表示或基于经剖析语法元素从位流21提取HOA系数11的基于向量的经译码表示。
当执行基于方向的编码时,可配置提取单元274可提取HOA系数11的基于方向的版本以及与此经编码版本相关联的语法元素(其在图11A的实例中表示为基于方向的信息91)。此基于方向的信息91可包含图10D的实例中所示的方向性信息253以及图10E的实例中所示的基于方向的SideChannelInfoData,如由等于零的ChannelType界定。
当语法元素指示HOA系数11是使用基于向量的合成经编码时(例如,当ChannelType语法元素等于一时),可配置提取单元274可提取经译码前景V[k]向量57、经编码周围HOA系数59以及经编码nFG信号59。可配置提取单元274还可在确定语法元素指示HOA系数11是使用基于向量的合成经编码之后即刻从位流21提取CodedSpatialInterpolationTime语法元素254和SpatialInterpolationMethod语法元素255,将这些语法元素254和255传递到空间-时间内插单元76。
图11B是更详细说明图5的实例中所示的音频解码装置24的量化单元74的框图。量化单元74可表示经配置而以与图4的实例中所示的量化单元52互逆的方式操作以便对经译码前景V[k]向量57进行熵解码并解量化且进而产生经缩减前景V[k]向量55k的单元。标量/熵解量化单元984可包含类别/残余解码单元276、预测单元278及均匀解量化单元280。
类别/残余解码单元276可表示经配置以使用通过霍夫曼表信息241(如上文所指出,其表示为位流21中的语法元素)识别的霍夫曼表相对于经译码前景V[k]向量57执行霍夫曼解码的单元。类别/残余解码单元276可将经量化前景V[k]向量输出到预测单元278。预测单元278可表示经配置以基于预测模式237相对于经量化前景V[k]向量执行预测从而将经增强经量化前景V[k]向量输出到均匀解量化单元280的单元。均匀解量化单元280可表示经配置以基于nbits值233相对于经增强经量化前景V[k]向量执行解量化从而输出经缩减前景V[k]向量55k的单元。
图11C是更详细说明图5的实例中所示的音频解码装置24的心理声学解码单元80的框图。如上文所指出,心理声学解码单元80可以与图4的实例中所示的心理声学音频译码单元40互逆的方式操作以便对经编码周围HOA系数59及经编码nFG信号61进行解码且进而产生能量经补偿的周围HOA系数47'及经内插nFG信号49'(其也可被称作经内插nFG音频对象49')。心理声学解码单元80可将能量经补偿的周围HOA系数47'传递到HOA系数制订单元82且将nFG信号49'传递到重排序器84。心理声学解码单元80可包含类似于心理声学音频译码单元40的多个音频解码器80到80N。音频解码器80到80N可以足够数量通过心理声学音频译码单元40执行个体化或以其它方式包含于心理声学音频译码单元40内以如上文所指出支持对背景HOA系数47'的每一通道及nFG信号49'的每一信号的同时解码。
图11D是更详细说明图5的实例中所示的音频解码装置24的重排序单元84的框图。重排序单元84可表示经配置而以与上文相对于重排序单元34所描述的方式大体互逆的方式操作的单元。重排序单元84可包含向量重排序单元282,其可表示经配置以接收指示HOA系数11的前景分量的原始次序的语法元素205的单元。提取单元72可剖析来自位流21的这些语法元素205,且将语法元素205传递到重排序单元84。向量重排序单元282可基于这些重排序语法元素205对经内插nFG信号49'及经缩减前景V[k]向量55k重排序以产生经重排序的nFG信号49"及经重排序的前景V[k]向量55k'。重排序单元84可将经重排序的nFG信号49"输出到前景制订单元78,且将经重排序的前景V[k]向量55k'输出到空间-时间内插单元76。
图11E是更详细说明图5的实例中所示的音频解码装置24的空间-时间内插单元76的框图。空间-时间内插单元76可以类似于上文相对于空间-时间内插单元50所描述方式的方式操作。空间-时间内插单元76可包含V内插单元284,其可表示经配置以接收经重排序的前景V[k]向量55k'且相对于经重排序的前景V[k]向量55k'及经重排序的前景V[k-1]向量55k-1'执行空间-时间内插以产生经内插前景V[k]向量55k"的单元。V内插单元284可基于CodedSpatialInterpolationTime语法元素254及SpatialInterpolationMethod语法元素255执行内插。在一些实例中,V内插单元285可使用由SpatialInterpolationMethod语法元素255识别的内插类型在由CodedSpatialInterpolationTime语法元素254指定的持续时间内内插V向量。空间-时间内插单元76可将经内插前景V[k]向量55k"转发到前景制订单元78。
图11F是更详细说明图5的实例中所示的音频解码装置24的前景制订单元78的框图。前景制订单元78可包含乘法单元286,其可表示经配置以相对于经内插前景V[k]向量55k"及经重排序nFG信号49"执行矩阵乘法以产生前景HOA系数65的单元。
图11G是更详细说明图5的实例中所示的音频解码装置24的HOA系数制订单元82的框图。HOA系数制订单元82可包含加法单元288,其可表示经配置以将前景HOA系数65相加到周围HOA通道47'以便获得HOA系数11'的单元。
图12是说明可执行本发明中描述的技术的各种方面的实例音频生态系统的图。如图12中所示,音频生态系统300可包含获取301、编辑302、译码303、发射304,及重放305。
获取301可表示音频生态系统300的获取音频内容的技术。获取301的实例包含(但不限于)记录声音(例如,实况声音)、音频产生(例如,音频对象、歌舞剧制作、声音合成、模拟),等等。在一些实例中,声音可在音乐会、体育事件及在进行监督时记录。在一些实例中,可在执行模拟时产生及制作/混合(例如,电影、游戏)音频。音频对象可用于好莱坞(例如,IMAX工作室)中。在一些实例中,获取301可由内容创建者(例如图3的内容创建者12)执行。
编辑302可表示音频生态系统300的编辑和/或修改音频内容的技术。作为一个实例,可通过将音频内容的多个单元组合为音频内容的单个单元而编辑音频内容。作为另一实例,可通过调整实际音频内容(例如,调整音频内容的一或多个频率分量的电平)来编辑音频内容。在一些实例中,编辑302可由音频编辑系统(例如图3的音频编辑系统18)执行。在一些实例中,可在移动装置(例如图29中所说明的移动装置中的一或多者)上执行编辑302。
译码303可表示音频生态系统300的将音频内容译码为音频内容的表示的技术。在一些实例中,音频内容的表示可为位流,例如图3的位流21。在一些实例中,译码302可由例如图3的音频编码装置20等音频编码装置执行。
发射304可表示音频生态系统300的将音频内容从内容创建者传送到内容消费者的元件。在一些实例中,可实时或接近实时地输送音频内容。例如,音频内容可串流传输到内容消费者。在一些实例中,音频内容可通过将音频内容译码于媒体(例如计算机可读存储媒体)上而予以输送。例如,音频内容可存储在光盘、驱动器及类似物(例如,蓝光光盘、存储器卡、硬盘驱动器等)上。
重放305可表示音频生态系统300的将音频内容再现且重放给内容消费者的技术。在一些实例中,重放305可包含基于重放环境的一或多个方面再现3D声场。换句话说,重放305可基于局部声学地景。
图13是更详细说明图12的音频生态系统的一个实例的图。如图13中所说明,音频生态系统300可包含音频内容308、电影工作室310、音乐工作室311、游戏音频工作室312、基于通道的音频内容313、译码引擎314、游戏音频原声315、游戏音频译码/再现引擎316,及递送系统317。图26中说明实例游戏音频工作室312。图27中说明一些实例游戏音频译码/再现引擎316。
如图13所说明,电影工作室310、音乐工作室311和游戏音频工作室312可接收音频内容308。在某一实例中,音频内容308可表示图12的获取301的输出。电影工作室310可例如通过使用数字音频工作站(DAW)输出基于通道的音频内容313(例如,在2.0、5.1和7.1中)。音乐工作室310可例如通过使用DAW而输出基于通道的音频内容313(例如,在2.0及5.1中)。在任一情况下,译码引擎314可接收基于通道的音频内容313且基于一或多个编解码器(例如,AAC、AC3、杜比真实HD、杜比数字加以及DTS主音频)对基于通道的音频内容313进行编码以用于由递送系统317输出。以此方式,译码引擎314可为图12的译码303的实例。游戏音频工作室312可例如通过使用DAW输出一或多个游戏音频原声315。游戏音频译码/再现引擎316可将音频原声315译码和或再现为基于通道的音频内容以用于由递送系统317输出。在一些实例中,电影工作室310、音乐工作室311和游戏音频工作室312的输出可表示图12的编辑302的输出。在一些实例中,译码引擎314和/或游戏音频译码/再现引擎316的输出可经由图12的发射304的技术输送到递送系统317。
图14是更详细说明图12的音频生态系统的另一实例的图。如图14中所说明,音频生态系统300B可包含广播记录音频对象319、专业音频系统320、消费者装置上俘获322、HOA音频格式323、装置上再现324、消费者音频、TV及附件325,及汽车音频系统326。
如图14中所说明,广播记录音频对象319、专业音频系统320和消费者装置上俘获322可全部使用HOA音频格式323对其输出进行译码。以此方式,音频内容可使用HOA音频格式323译码为可使用装置上再现324、消费者音频、TV和附件325以及汽车音频系统326重放的单个表示。换句话说,音频内容的单个表示可在通用音频重放系统处重放(即,与要求例如5.1、7.1等特定配置相反)。
图15A和15B是更详细说明图12的音频生态系统的其它实例的图。如图15A中所说明,音频生态系统300C可包含获取元件331和重放元件336。获取元件331可包含有线和/或无线获取装置332(例如,本征麦克风)、装置上环绕声俘获334以及移动装置335(例如,智能电话和平板计算机)。在一些实例中,有线和/或无线获取装置332可经由有线和/或无线通信通道333耦合到移动装置335。
根据本发明的一或多个技术,移动装置335可用以获取声场。例如,移动装置335可经由有线和/或无线获取装置332及/或装置上环绕声俘获334(例如,集成到移动装置335中的多个麦克风)获取声场。移动装置335可接着将所获取声场译码成HOA 337以供由重放元件336中的一或多者重放。例如,移动装置335的用户可记录实况事件(例如,会面、会议、剧、音乐会等)(获取其声场),且将所述记录译码成HOA。
移动装置335还可利用重放元件336中的一或多者来重放HOA经译码声场。例如,移动装置335可对HOA经译码声场进行解码,且将使得重放元件336中的一或多者重建声场的信号输出到重放元件336中的一或多者。作为一个实例,移动装置335可利用无线及/或无线通信通道338将信号输出到一或多个扬声器(例如,扬声器阵列、声棒(sound bar),等)。作为另一实例,移动装置335可利用对接解决方案339将信号输出到一或多个对接台和/或一或多个对接的扬声器(例如,智能汽车和/或家庭中的声音系统)。作为另一实例,移动装置335可利用头戴受话器再现340来将信号输出到一组头戴受话器(例如)以产生实际的双耳声音。
在一些实例中,特定移动装置335可获取3D声场并且在稍后时间重放同一3D声场。在一些实例中,移动装置335可获取3D声场,将3D声场编码为HOA,且将经编码3D声场发射到一或多个其它装置(例如,其它移动装置及/或其它非移动装置)用于重放。
如图15B中所说明,音频生态系统300D可包含音频内容343、游戏工作室344、经译码音频内容345、再现引擎346,及递送系统347。在一些实例中,游戏工作室344可包含可支持对HOA信号的编辑的一或多个DAW。举例来说,所述一或多个DAW可包含可经配置以与一或多个游戏音频系统一起操作(例如,工作)的HOA插件及/或工具。在一些实例中,游戏工作室344可输出支持HOA的新原声格式。在任何情况下,游戏工作室344可将经译码音频内容345输出到再现引擎346,再现引擎346可再现声场以供由递送系统347重放。
图16是说明可执行本发明中描述的技术的各种方面的实例音频编码装置的图。如图16中所说明,音频生态系统300E可包含原始3D音频内容351、编码器352、位流353、解码器354、再现器355和重放元件356。如图16进一步说明,编码器352可包含声场分析和分解357、背景提取358、背景突出性确定359、音频译码360、前景/相异音频提取361和音频译码362。在一些实例中,编码器352可经配置以执行类似于图3和4的音频编码装置20的操作。在一些实例中,声场分析和分解357可经配置以执行类似于图4的声场分析单元44的操作。在一些实例中,背景提取358和背景突出性确定359可经配置以执行类似于图4的BG选择单元48的操作。在一些实例中,音频译码360和音频译码362可经配置以执行类似于图4的心理声学音频译码器单元40的操作。在一些实例中,前景/相异音频提取361可经配置以执行类似于图4的前景选择单元36的操作。
在一些实例中,前景/相异音频提取361可对应于图33的视频帧390分析音频内容。举例来说,前景/相异音频提取361可确定对应于区391A至391C的音频内容是前景音频。
如图16中所说明,编码器352可经配置以将可具有25至75Mbps的位速率的原始内容351编码为可具有256kbps至1.2Mbps的位速率的位流353。图17是更详细说明图16的音频编码装置的一个实例的图。
图18是说明可执行本发明中描述的技术的各种方面的实例音频解码装置的图。如图18中所说明,音频生态系统300E可包含原始3D音频内容351、编码器352、位流353、解码器354、再现器355和重放元件356。如图16进一步说明,解码器354可包含音频解码器363、音频解码器364、前景重建365和混合366。在一些实例中,解码器354可经配置以执行类似于图3和5的音频解码装置24的操作。在一些实例中,音频解码器363、音频解码器364可经配置以执行类似于图5的心理声学解码单元80的操作。在一些实例中,前景重建365可经配置以执行类似于图5的前景制订单元78的操作。
如图16中所说明,解码器354可经配置以接收且解码位流353且将所得经重建3D声场输出到再现器355,所述再现器355可随后致使重放元件356中的一或多者输出原始3D内容351的表示。图19是更详细说明图18的音频解码装置的一个实例的图。
图20A到20G是说明可执行本发明中所描述的技术的各种方面的实例音频获取装置的图。图20A说明可包含共同地经配置以记录3D声场的多个麦克风的本征麦克风370。在一些实例中,本征麦克风370的所述多个麦克风可位于具有大约4cm的半径的实质上球面球的表面上。在一些实例中,音频编码装置20可集成到本征麦克风中以便直接从麦克风370输出位流17。
图20B说明可经配置以从例如一或多个本征麦克风370等一或多个麦克风接收信号的制作车372。制作车372还可包含音频编码器,例如图3的音频编码器20。
图20C到20E说明可包含共同地经配置以记录3D声场的多个麦克风的移动装置374。换句话说,所述多个麦克风可具有X、Y、Z分集。在一些实例中,移动装置374可包含麦克风376,其可相对于移动装置374的一或多个其它麦克风旋转以提供X、Y、Z分集。移动装置374还可包含音频编码器,例如图3的音频编码器20。
图20F说明可经配置以记录3D声场的加固型视频俘获装置378。在一些实例中,加固型视频俘获装置378可附接到参与活动的用户的头盔。举例来说,加固型视频俘获装置378可在用户泛舟时附接到用户的头盔。以此方式,加固型视频俘获装置378可俘获表示用户周围的动作(例如,水在用户身后的撞击、另一泛舟者在用户前方说话等)的3D声场。
图20G说明可经配置以记录3D声场的附件增强型移动装置380。在一些实例中,移动装置380可类似于图15的移动装置335,其中添加一或多个附件。举例来说,本征麦克风可附接到图15的移动装置335以形成附件增强型移动装置380。以此方式,附件增强型移动装置380可俘获比仅使用集成到附件增强型移动装置380的声音俘获组件更高质量的3D声场版本。
图21A到21E是说明可执行本发明中所描述的技术的各种方面的实例音频重放装置的图。图21A和21B说明多个扬声器382及声棒384。根据本发明的一或多个技术,扬声器382及/或声棒384可布置成任何任意配置同时仍重放3D声场。图21C到21E说明多个头戴受话器重放装置386到386C。头戴受话器重放装置386到386C可经由有线或无线连接耦合到解码器。根据本发明的一或多个技术,可利用声场的单一通用表示来在扬声器382、声棒384及头戴受话器重放装置386到386C的任何组合上再现声场。
图22A到22H是说明根据本发明中所描述的一或多个技术的实例音频重放环境的图。举例来说,图22A说明5.1扬声器重放环境,图22B说明2.0(例如,立体声)扬声器重放环境,图22C说明具有全高度前方扬声器的9.1扬声器重放环境,图22D和22E各自说明22.2扬声器重放环境,图22F说明16.0扬声器重放环境,图22G说明汽车扬声器重放环境,且图22H说明具有耳塞重放环境的移动装置。
根据本发明的一或多个技术,可利用声场的单一通用表示来在图22A到22H中所说明的重放环境中的任一者上再现声场。此外,本发明的技术使得再现器能够从通用表示再现声场以供在不同于图22A到22H中所说明的环境的重放环境上重放。举例来说,如果设计考虑禁止扬声器根据7.1扬声器重放环境的恰当置放(例如,如果不可能置放右环绕扬声器),那么本发明的技术使得再现器能够以其它6个扬声器进行补偿,使得可在6.1扬声器重放环境上实现重放。
如图23中所说明,用户可在佩戴头戴受话器386时观看体育比赛。根据本发明的一或多个技术,可获取体育比赛的3D声场(例如,一或多个本征麦克风可放在图24中说明的棒球体育场中和/或周围),可获得对应于3D声场的HOA系数且传输到解码器,解码器可基于HOA系数确定重建3D声场且将经重建3D声场输出到再现器,再现器可获得关于重放环境的类型(例如,头戴受话器)的指示,且将经重建3D声场再现为致使头戴受话器输出体育比赛的3D声场的表示的信号。在一些实例中,再现器可根据图25的技术获得关于重放环境的类型的指示。以此方式,再现器可针对各种扬声器位置、数目、类型、大小而“适配”,并且还理想地针对局部环境而均衡。
图28是说明根据本发明中所描述的一或多个技术的可由头戴受话器模拟的扬声器配置的图。如图28所说明,本发明的技术可使得佩戴头戴受话器389的用户能够体验到声场,如同所述声场是由扬声器388重放一般。以此方式,用户可收听3D声场而无需将声音输出到大的区域。
图30是说明与可根据本发明中所描述的一或多个技术加以处理的3D声场相关联的视频帧的图。
图31A到31M为说明展示根据本发明中所描述的技术的各种方面执行声场的合成或记录分类的各种模拟结果的曲线图400A到400M的图。在图31A到31M的实例中,曲线图400A到400M中的每一者包含由点线表示的阈值402及由虚线表示的相应音频对象404A到404M(统称“音频对象404”)。
当通过上文相对于内容分析单元26描述的分析而确定音频对象404低于阈值402时,内容分析单元26确定音频对象404中的对应一者表示已记录的音频对象。如图31B、31D到31H及31J到31L的实例中所示,内容分析单元26确定音频对象404B、404D到404H、404J到404L低于阈值402(至少+90%的时间,且常常100%的时间),且因此表示所记录的音频对象。如图31A、31C及31I的实例中所示,内容分析单元26确定音频对象404A、404C及404I超出阈值402且因此表示合成音频对象。
在图31M的实例中,音频对象404M表示混合的合成/记录音频对象,其具有一些合成部分(例如,高于阈值402)及一些合成部分(例如,低于阈值402)。在此情况下,内容分析单元26识别音频对象404M的合成及记录部分,结果,音频编码装置20产生位流21以包含基于方向性的经编码音频数据及基于向量的经编码音频数据两者。
图32是说明来自根据本发明中所描述的技术从高阶立体混响系数分解的S矩阵的奇异值的曲线图406的图。如图32中所示,具有大值的非零奇异值较少。图4之声场分析单元44可分析这些奇异值以确定经重排序的US[k]向量33'及经重排序的V[k]向量35'的nFG前景(或换句话说,优势)分量(常常由向量表示)。
图33A及33B为说明展示在根据本发明中所描述的技术对描述声场的前景分量的向量进行编码时重排序所具有的潜在影响的相应曲线图410A及410B的图。曲线图410A展示对无序(或换句话说,原始)US[k]向量33中的至少一些进行编码的结果,而曲线图410B展示对有序US[k]向量33'中的对应者进行编码的结果。曲线图410A和410B中的每一者中的顶部绘图展示编码中的错误,其中可能在曲线图410B中仅在帧边界处存在明显错误。因此,本发明中所描述的重排序技术可促进或以其它方式促成使用旧版音频译码器对单声道音频对象的译码。
图34及35是说明根据本发明的对相异音频对象的单独基于能量的识别与基于方向性的识别之间的差异的概念图。在图34的实例中,展现较大能量的向量识别为相异音频对象,而不管方向性如何。如图34中所示,根据较高能量值定位(标绘在y轴上)的音频对象确定为“在前景中”,而不管方向性(例如,由标绘在x轴上的方向性商表示)如何。
图35说明例如根据由图4的声场分析单元44实施的技术基于方向性和能量两者的相异音频对象的识别。如图35中所示,较大方向性商是朝向x轴的左边标绘,且较大能级是朝向y轴的上方标绘。在此实例中,声场分析单元44可确定相异音频对象(例如,“在前景中”的音频对象)与标绘为相对朝向曲线图的左上方的向量数据相关联。作为一个实例,声场分析单元44可确定标绘在曲线图的左上象限中的那些向量与相异音频对象相关联。
图36A到36F是说明根据本发明中所描述的技术的各种方面的球谐系数的经分解版本的至少一部分向空间域中投影以便执行内插的图。图36A是说明V[k]向量35中的一或多者向球面412上的投影的图。在图36A的实例中,每一数字识别投影到球面上的不同球谐系数(可能与V矩阵19'的一个行和/或列相关联)。不同颜色暗示相异音频分量的方向,其中较淡(且逐渐变深)的颜色表示相异分量的主要方向。图4的实例中所示的音频编码装置20的空间-时间内插单元50可在红点中的每一者之间执行空间-时间内插以产生图36A的实例中所示的球面。
图36B是说明V[k]向量35中的一或多者到横杆上的投影的图。空间-时间内插单元50可投影V[k]向量35的一个行及/或列或V[k]向量35的多个行及/或列以产生图36B的实例中所示的横杆414。
图36C是说明V[k]向量35中的一或多者的一或多个向量到球面(例如图36的实例中所示的球面412)上的投影的横截面的图。
图36D到36G中展示在不同声源(蜜蜂、直升机、电子音乐,及体育场中的人)可说明于三维空间中时的时间(在约20毫秒的1个帧内)的快照的实例。
本发明中描述的技术允许使用单个US[k]向量和单个V[k]向量识别和表示这些不同声音源的表示。声音源的时间变化是以US[k]向量表示,而每一声音源的空间分布是由单个V[k]向量表示。一个V[k]向量可表示声音源的宽度、位置和大小。此外,单个V[k]向量可表示为球谐基底函数的线性组合。在图36D到36G的绘图中,声音源的表示是基于将单个V向量变换到空间坐标系中。图36到36C中使用说明声音源的类似方法。
图37说明用于获得如本文所描述的空间-时间内插的技术的表示。图4的实例中所示的音频编码装置20的空间-时间内插单元50可执行下文更详细地描述的空间-时间内插。空间-时间内插可包含在空间和时间维度两者中获得较高分辨率空间分量。空间分量可基于由较高阶立体混响(HOA)系数(或HOA系数也可以称为“球谐系数”)构成的多维信号的正交分解。
在所说明的曲线图中,向量V1和V2表示多维信号的两个不同空间分量的对应向量。空间分量可通过多维信号的逐块分解而获得。在一些实例中,空间分量是通过相对于较高阶立体混响(HOA)音频数据(其中此立体混响音频数据包含块、样本或任何其它形式的多通道音频数据)的每一块(其可指代帧)执行逐块形式的SVD而得到。变量M可用以表示音频帧的长度(以样本数计)。
因此,V1和V2可表示HOA系数11的顺序块的前景V[k]向量51k和前景V[k-1]向量51k-1的对应向量。V1可例如表示用于第一帧(k-1)的前景V[k-1]向量51k-1的第一向量,而V2可表示用于第二且后续帧(k)的前景V[k]向量51k的第一向量。V1及V2可表示包含在多维信号中的单个音频对象的空间分量。
用于每一x的经内插向量Vx是通过根据多维信号(经内插向量Vx可应用于所述多维信号以平滑化时间(且因此,在一些情况下,空间)分量)的时间分量的时间片段或“时间样本”的数目x对V1及V2进行加权而获得。如上文所描述,采用SVD组成,可通过对每一时间样本向量(例如,HOA系数11的样本)与对应经内插Vx进行向量除法来获得nFG信号49的平滑。即,US[n]=HOA[n]*Vx[n]-1,其中此表示行向量乘以列向量,因而产生US的标量元素。Vx[n]-1可作为Vx[n]的伪逆而获得。
相对于V1及V2的加权,归因于在时间上在V1之后出现的V2,V1的权重沿着时间维度按比例较低。即,尽管前景V[k-1]向量51k-1为分解的空间分量,但时间上连续的前景V[k]向量51k随时间推移表示空间分量的不同值。因此,V1的权重减小,而V2的权重随着x沿着t增大而增长。此处,d1及d2表示权重。
图38是说明根据本文所述的技术的用于多维信号的依序SVD块的人工US矩阵(US1及US2)的框图。经内插V向量可应用于人工US矩阵的行向量以恢复原始多维信号。更具体来说,空间-时间内插单元50可将经内插前景V[k]向量53的伪逆乘以nFG信号49与前景V[k]向量51k(其可表示为前景HOA系数)的相乘结果以获得K/2经内插样本,其可代替nFG信号的K/2样本用作第一K/2样本,如U2矩阵的图38的实例中所示。
图39是说明根据本发明中所描述的技术使用奇异值分解及空间时间分量的平滑来分解较高阶立体混响(HOA)信号的后续帧的框图。帧n-1及帧n(其也可以表示为帧n及帧n+1)表示时间上连续的帧,其中每一帧包括1024个时间片段且具有HOA阶数4,从而得出(4+1)2=25个系数。可通过如所说明应用经内插V向量而获得为帧n-1及帧n处的经人工平滑的U矩阵的US矩阵。每一灰色行或列向量表示一个音频对象。
计算作用中基于向量的信号的HOA表示
通过取表示于XVECk中的基于向量的信号中的每一者且将其与其对应(经解量化)空间向量VVECk相乘而产生瞬时CVECk。每一VVECk表示于MVECk中。因而,对于L阶HOA信号及M个基于向量的信号,将存在M个基于向量的信号,其中的每一者将具有由帧长度P给出的维度。这些信号可因此表示为:XVECkmn,n=0,..P-1;m=0,..M-1。对应地,将存在M个空间向量,维度(L+1)2的VVECk。这些可表示为MVECkml,l=0,..,(L+1)2-l;m=0,..,M-1。每一基于向量的信号的HOA表示CVECkm是如下给出的矩阵向量乘法:
CVECkm=(XVECkm(MVECkm)T)T
其产生矩阵(L+1)2乘P。通过如下对每一基于向量的信号的贡献求和而给出完整HOA表示:
CVECk=m=0M-1CVECk[m]
V向量的空间-时间内插
然而,为了维持平滑的空间-时间连续性,仅对于帧长度的部分P-B进行以上计算。改为通过使用从当前MVECkm及先前值MVECk-1m导出的经内插集合MVECkml(m=0,..,M-1;l=0,..,(L+1)2)进行HOA矩阵的前B个样本。此导致较高时间密度空间向量,因为我们如下对于每一时间样本p导出一向量:
MVECkmp=pB-1MVECkm+B-1-pB-1MVECk-1m,p=0,..,B-1。
对于每一时间样本p,具有(L+1)2个维度的新HOA向量计算为:
CVECkp=(XVECkmp)MVECkmp,p=0,..,B-1
通过先前区段的P-B样本增强这些前B个样本以导致第m基于向量的信号的完整HOA表示CVECkm。
在解码器(例如,图5的实例中所示的音频解码装置24)处,对于某些相异、前景或基于向量的优势声音,可使用线性(或非线性)内插来内插来自前一帧的V向量及来自当前帧的V向量以产生特定时间片段内的较高分辨率(在时间上)经内插V向量。空间时间内插单元76可执行此内插,其中空间-时间内插单元76可接着将当前帧中的US向量与较高分辨率经内插V向量相乘以产生所述特定时间片段内的HOA矩阵。
或者,空间-时间内插单元76可将US向量与当前帧的V向量相乘以产生第一HOA矩阵。此外,解码器可将US向量与来自前一帧的V向量相乘以产生第二HOA矩阵。空间-时间内插单元76可接着将线性(或非线性)内插应用于特定时间片段内的第一HOA矩阵及第二HOA矩阵。假定共同输入矩阵/向量,此内插的输出可匹配US向量与经内插V向量的乘法的输出。
在这方面中,所述技术可使得音频编码装置20及/或音频解码装置24能够经配置以根据以下条款操作。
条款135054-1C。一种装置,例如音频编码装置20或音频解码装置24,其包括:一或多个处理器,其经配置以在空间及时间两者中获得多个较高分辨率空间分量,其中所述空间分量是基于由球谐系数构成的多维信号的正交分解。
条款135054-1D。一种装置,例如音频编码装置20或音频解码装置24,其包括:一或多个处理器,其经配置以平滑第一多个球谐系数及第二多个球谐系数的空间分量及时间分量中的至少一者。
条款135054-1E。一种装置,例如音频编码装置20或音频解码装置24,其包括:一或多个处理器,其经配置以在空间及时间两者中获得多个较高分辨率空间分量,其中所述空间分量是基于由球谐系数构成的多维信号的正交分解。
条款135054-1G。一种装置,例如音频编码装置20或音频解码装置24,其包括:一或多个处理器,其经配置以至少部分通过相对于第一多个球谐系数的第一分解及第二多个球谐系数的第二分解增加分辨率而获得用于一时间片段的经分解增加分辨率的球谐系数。
条款135054-2G。条款135054-1G的装置,其中所述第一分解包括表示所述第一多个球谐系数的右奇异向量的第一V矩阵。
条款135054-3G。条款135054-1G的装置,其中所述第二分解包括表示所述第二多个球谐系数的右奇异向量的第二V矩阵。
条款135054-4G。条款135054-1G的装置,其中所述第一分解包括表示所述第一多个球谐系数的右奇异向量的第一V矩阵,且其中所述第二分解包括表示所述第二多个球谐系数的右奇异向量的第二V矩阵。
条款135054-5G。条款135054-1G的装置,其中所述时间片段包括音频帧的子帧。
条款135054-6G。条款135054-1G的装置,其中所述时间片段包括音频帧的时间样本。
条款135054-7G。条款135054-1G的装置,其中所述一或多个处理器经配置以获得所述第一多个球谐系数中的球谐系数的第一分解及第二分解的经内插分解。
条款135054-8G。条款135054-1G的装置,其中所述一或多个处理器经配置以获得用于包含在第一帧中的所述第一多个球谐系数的第一部分的第一分解及用于包含在第二帧中的所述第二多个球谐系数的第二部分的第二分解的经内插分解,其中所述一或多个处理器进一步经配置以将所述经内插分解应用于包含在第一帧中的所述第一多个球谐系数的第一部分的第一时间分量以产生所述第一多个球谐系数的第一人工时间分量,且将相应经内插分解应用于包含在第二帧中的所述第二多个球谐系数的第二部分的第二时间分量以产生所包含的所述第二多个球谐系数的第二人工时间分量。
条款135054-9G。条款135054-8G的装置,其中所述第一时间分量是通过相对于所述第一多个球谐系数执行基于向量的合成而产生。
条款135054-10G。条款135054-8G的装置,其中所述第二时间分量是通过相对于所述第二多个球谐系数执行基于向量的合成而产生。
条款135054-11G。条款135054-8G的装置,其中所述一或多个处理器进一步经配置以:接收所述第一人工时间分量及所述第二人工时间分量;计算用于所述第一多个球谐系数的第一部分的第一分解及用于所述第二多个球谐系数的第二部分的第二分解的经内插分解;及将所述经内插分解的逆应用于所述第一人工时间分量以恢复所述第一时间分量且应用于所述第二人工时间分量以恢复所述第二时间分量。
条款135054-12G。条款135054-1G的装置,其中所述一或多个处理器经配置以内插所述第一多个球谐系数的第一空间分量及所述第二多个球谐系数的第二空间分量。
条款135054-13G。条款135054-12G的装置,其中所述第一空间分量包含表示所述第一多个球谐系数的左奇异向量的第一U矩阵。
条款135054-14G。条款135054-12G的装置,其中所述第二空间分量包含表示所述第二多个球谐系数的左奇异向量的第二U矩阵。
条款135054-15G。条款135054-12G的装置,其中所述第一空间分量表示用于所述第一多个球谐系数的球谐系数的M个时间片段,且所述第二空间分量表示用于所述第二多个球谐系数的球谐系数的M个时间片段。
条款135054-16G。条款135054-12G的装置,其中所述第一空间分量表示用于所述第一多个球谐系数的球谐系数的M个时间片段,且所述第二空间分量表示用于所述第二多个球谐系数的球谐系数的M个时间片段,且其中所述一或多个处理器经配置以获得用于所述时间片段的经分解经内插球谐系数包括内插所述第一空间分量的最后N个元素及所述第二空间分量的前N个元素。
条款135054-17G。条款135054-1G的装置,其中所述第二多个球谐系数在时域中在所述第一多个球谐系数之后。
条款135054-18G。条款135054-1G的装置,其中所述一或多个处理器进一步经配置以分解所述第一多个球谐系数以产生所述第一多个球谐系数的所述第一分解。
条款135054-19G。条款135054-1G的装置,其中所述一或多个处理器进一步经配置以分解所述第二多个球谐系数以产生所述第二多个球谐系数的所述第二分解。
条款135054-20G。条款135054-1G的装置,其中所述一或多个处理器进一步经配置以相对于所述第一多个球谐系数执行奇异值分解以产生表示所述第一多个球谐系数的左奇异向量的U矩阵、表示所述第一多个球谐系数奇异值的S矩阵及表示所述第一多个球谐系数的右奇异向量的V矩阵。
条款135054-21G。条款135054-1G的装置,其中所述一或多个处理器进一步经配置以相对于所述第二多个球谐系数执行奇异值分解以产生表示所述第二多个球谐系数的左奇异向量的U矩阵、表示所述第二多个球谐系数的奇异值的S矩阵及表示所述第二多个球谐系数的右奇异向量的V矩阵。
条款135054-22G。条款135054-1G的装置,其中所述第一及第二多个球谐系数各自表示声场的平面波表示。
条款135054-23G。条款135054-1G的装置,其中所述第一及第二多个球谐系数各自表示混合在一起的一或多个单声道音频对象。
条款135054-24G。条款135054-1G的装置,其中所述第一及第二多个球谐系数各自包含表示三维声场的相应第一及第二球谐系数。
条款135054-25G。条款135054-1G的装置,其中所述第一及第二多个球谐系数各自与具有大于一的阶数的至少一个球面基底函数相关联。
条款135054-26G。条款135054-1G的装置,其中所述第一及第二多个球谐系数各自与具有等于四的阶数的至少一个球面基底函数相关联。
条款135054-27G。条款135054-1G的装置,其中所述内插为所述第一分解及第二分解的经加权内插,其中应用于所述第一分解的经加权内插的权重与由所述第一及第二分解的向量表示的时间成反比,且其中应用于所述第二分解的经加权内插的权重与由所述第一及第二分解的向量表示的的时间成比例。
条款135054-28G。条款135054-1G的装置,其中所述经分解经内插球谐系数平滑所述第一多个球谐系数及所述第二多个球谐系数的空间分量及时间分量中的至少一者。
图40A到40J各自为说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510A到510J的框图。在图40A到40J的实例中的每一者中,在一些实例中,音频编码装置510A及510B各自表示能够对音频数据进行编码的任何装置,例如桌上型计算机、膝上型计算机、工作站、平板(tablet,slate)计算机、专用音频记录装置、蜂窝式电话(包含所谓的“智能电话”)、个人媒体播放器装置、个人游戏装置,或能够对音频数据进行编码的任何其它类型的装置。
尽管展示为单个装置,即,图40A到40J的实例中的装置510A到510J,但下文称为包含于装置510A到510J内的各种组件或单元可实际上形成在装置510A到510J外部的单独装置。换句话说,虽然本发明中描述为由单个装置(即,在图40A到40J的实例中的装置510A到510J)执行,但所述技术可由包括多个装置的系统实施或另外执行,其中这些装置中的每一者可各自包含以下更详细地描述的各种组件或单元中的一或多者。因此,所述技术不应限于图40A到40J的实例。
在一些实例中,音频编码装置510A到510J表示上文相对于图3及4的实例所描述的音频编码装置的替代。贯穿对音频编码装置510A到510J的以下论述,对于上文相对于图4所描述的音频编码装置20的各种单元30到52指出在操作方面的各种相似性。在许多方面,如下所述,音频编码装置510A到510J可以实质上类似于音频编码装置20的方式操作,但具有轻微偏差或修改。
如图40A的实例中所示,音频编码装置510A包括音频压缩单元512、音频编码单元514及位流产生单元516。音频压缩单元512可表示压缩球谐系数(SHC)511(“SHC511”)的单元,SHC 511也可以表示为较高阶立体混响(HOA)系数511。音频压缩单元512可在一些情况下,音频压缩单元512表示可无损地压缩SHC 511或相对于SHC 511执行有损压缩的单元。SHC 511可表示多个SHC,其中所述多个SHC中的至少一者对应于阶数大于一的球面基底函数(其中具有此多样性的SHC被称作较高阶立体混响(HOA)以便与较低阶立体混响相区分,较低阶立体混响的一个实例为所谓的“B格式”),如上文更详细地描述。尽管音频压缩单元512可无损地压缩SHC 511,但在一些实例中,音频压缩单元512移除SHC 511的在描述声场(在再生时)时不突出或不相关的那些SHC(因为一些SHC可能不能够由人听觉系统听到)。在此意义上,此压缩的有损性质可能不会在从SHC 511的经压缩版本再生时过度影响声场的感知质量。
在图40A的实例中,音频压缩单元包含分解单元518和声场分量提取单元520。分解单元518可类似于音频编码装置20的线性可逆变换单元30。即,分解单元518可表示经配置以执行称为奇异值分解的形式的分析的单元。尽管相对于SVD描述,但可相对于提供线性不相关数据的集合的任何类似变换或分解执行所述技术。并且,在本发明中对“集合”的参考既定指代“非零”集合(除非特定地相反陈述),且并不既定指代包含所谓的“空集合”的集合的经典数学定义。
在任何情况下,分解单元518执行奇异值分解(其再次可由其首字母缩略词“SVD”表示)以将球谐系数511变换成经变换球谐系数的两个或两个以上集合。在图40的实例中,分解单元518可相对于SHC 511执行SVD以产生所谓的V矩阵519、S矩阵519B及U矩阵519C。在图40的实例中,分解单元518单独地输出矩阵中的每一者而非如上文相对于线性可逆变换单元30所论述以组合形式输出US[k]向量。
如上文所指出,以上提及的SVD数学表达式中的V*矩阵表示为V矩阵的共轭转置以反映SVD可应用于包括复数的矩阵。当应用于仅包括实数的矩阵时,V矩阵的复数共轭(或换句话说,V*矩阵)可认为等于V矩阵。下文中为容易说明的目的,假定SHC 511包括实数,结果经由SVD而非V*矩阵输出V矩阵。尽管假定为V矩阵,但所述技术可以类似方式应用于具有复数系数的SHC 511,其中SVD的输出为V*矩阵。因此,就此而言,所述技术不应限于仅提供应用SVD以产生V矩阵,而可包含将SVD应用于具有复数分量的SHC 511以产生V*矩阵。
在任何情况下,分解单元518可相对于较高阶立体混响(HOA)音频数据(其中此立体混响音频数据包含SHC 511或任何其它形式的多通道音频数据的块或样本)的每一块(其可称作帧)执行逐块形式的SVD。变量M可用以表示音频帧的长度(以样本数计)。举例来说,当音频帧包含1024个音频样本时,M等于1024。分解单元518可因此相对于具有M乘(N+1)2个SHC的SHC 511的块执行逐块SVD,其中N再次表示HOA音频数据的阶数。分解单元518可通过执行此SVD而产生V矩阵519、S矩阵519B及U矩阵519C,其中矩阵519到519C(“矩阵519”)中的每一者可表示上文更详细描述的相应V、S及U矩阵。分解单元518可将这些矩阵519A传递或输出到声场分量提取单元520。V矩阵519A可具有大小(N+1)2乘(N+1)2,S矩阵519B可具有大小(N+1)2乘(N+1)2,且U矩阵可具有大小M乘(N+1)2,其中M指音频帧中的样本的数目。M的典型值为1024,但本发明的技术不应限于M的此典型值。
声场分量提取单元520可表示经配置以确定且接着提取声场的相异分量及声场的背景分量从而有效地将声场的相异分量与声场的背景分量分离的单元。在这方面中,声场分量提取单元520可执行上文相对于图4的实例中所示的音频编码装置20的声场分析单元44、背景选择单元48及前景选择单元36所描述的操作中的许多者。假定在一些实例中,声场的相异分量需要较高阶(相对于声场的背景分量)基底函数(且因此需要更多SHC)来准确地表示这些分量的相异性质,将相异分量与背景分量分离可使得能够将较多位分配给相异分量且将较少位(相对而言)分配给背景分量。因此,通过应用此变换(以SVD的形式或任何其它变换形式,包含PCA),本发明中所描述的技术可促进将位分配给各种SHC,且进而压缩SHC511。
此外,如下文相对于图40B所更详细地描述,所述技术还可实现声场的背景分量的阶数缩减,假定在一些实例中不需要较高阶基底函数来表示声场的这些背景部分(给定这些分量的扩散或背景性质)。因此,所述技术可实现声场的扩散或背景方面的压缩,同时通过将SVD应用于SHC 511而保留声场的突出的相异分量或方面。
如图40的实例中进一步所示,声场分量提取单元520包含转置单元522、突出分量分析单元524及数学单元526。转置单元522表示经配置以转置V矩阵519A以产生V矩阵519的转置(其表示为“VT矩阵523”)的单元。转置单元522可将此VT矩阵523输出到数学单元526。VT矩阵523可具有大小(N+1)2乘(N+1)2。
突出分量分析单元524表示经配置以相对于S矩阵519B执行突出性分析的单元。在这方面中,突出分量分析单元524可执行类似于上文相对于图4的实例中所示的音频编码装置20的声场分析单元44所描述的操作的操作。突出分量分析单元524可分析S矩阵519B的对角线值,从而选择可变D数目个具有最大值的这些分量。换句话说,突出分量分析单元524可通过分析由S的递减对角线值产生的曲线的斜率而确定分隔两个子空间(例如,前景或优势子空间及背景或环境子空间)的值D,其中大奇异值表示前景或相异声音,且低奇异值表示声场的背景分量。在一些实例中,突出分量分析单元524可使用奇异值曲线的一阶及二阶导数。突出分量分析单元524还可将数目D限制在一与五之间。作为另一实例,突出分量分析单元524可将数目D限制在一与(N+1)2之间。或者,突出分量分析单元524可预定义数目D,以便达到值四。在任何情况下,一旦估计出数目D,突出分量分析单元24便从矩阵U、V及S提取前景及背景子空间。
在一些实例中,突出分量分析单元524可每M个样本(其可重新表述为逐帧地)执行此分析。在这方面中,D可在帧间不同。在其它实例中,突出分量分析单元24可每帧执行此分析一次以上,从而分析帧的两个或两个以上部分。因此,所述技术在这方面不应限于本发明中描述的实例。
实际上,突出分量分析单元524可分析对角线矩阵(其在图40的实例中表示为S矩阵519B)的奇异值,识别相对值大于对角线S矩阵519B的其它值的那些值。突出分量分析单元524可识别D值,提取这些值以产生SDIST矩阵525A及SBG矩阵525B。SDIST矩阵525A可表示包括具有原始S矩阵519B的(N+1)2的D列的对角线矩阵。在一些情况下,SBG矩阵525B可表示具有(N+1)2-D列的矩阵,其中的每一者包含原始S矩阵519B的(N+1)2个经变换球谐系数。尽管描述为表示包括原始S矩阵519B的D列(具有(N+1)2个值)的矩阵,但突出分量分析单元524可截断此矩阵以产生具有原始S矩阵519B的D列(具有D个值)的SDIST矩阵,假定S矩阵519B为对角线矩阵且在每一列中的第D值之后的D列的(N+1)2值常常为零值。尽管相对于完整SDIST矩阵525A及完整SBG矩阵525B描述,但可相对于这些SDIST矩阵525A的截断版本及此SBG矩阵525B的截断版本实施所述技术。因此,就此而言,本发明的技术不应受到限制。
换句话说,SDIST矩阵525A可具有大小D乘(N+1)2,而SBG矩阵525B可具有大小(N+1)2-D乘(N+1)2。SDIST矩阵525A可包含在为声场的相异(DIST)音频分量方面被确定为突出的那些主分量或(换句话说)奇异值,而SBG矩阵525B可包含被确定为声场的背景(BG)或(换句话说)环境或非相异音频分量的那些奇异值。尽管在图40的实例中展示为单独矩阵525A及525B,但矩阵525A与525B可指定为单个矩阵,使用变量D来表示此表示SDIST矩阵525的单个矩阵的列(从左到右)的数目。在一些实例中,变量D可设定为四。
突出分量分析单元524还可分析U矩阵519C以产生UDIST矩阵525C及UBG矩阵525D。常常,突出分量分析单元524可分析S矩阵519B以识别变量D,从而基于变量D产生UDIST矩阵525C及UBG矩阵525B。即,在识别出S矩阵519B的突出的D列之后,突出分量分析单元524可基于此确定的变量D分裂U矩阵519C。在此情况下,突出分量分析单元524可产生UDIST矩阵525C以包含原始U矩阵519C的(N+1)2个经变换球谐系数的D列(从左到右),且产生UBG矩阵525D以包含原始U矩阵519C的(N+1)2个经变换球谐系数的剩余(N+1)2-D列。UDIST矩阵525C可具有大小M乘D,而UBG矩阵525D可具有大小M乘(N+1)2-D。尽管在图40的实例中展示为单独矩阵525C及525D,但矩阵525C与525D可指定为单个矩阵,使用变量D来表示此表示UDIST矩阵525B的单个矩阵的列(从左到右)的数目。
突出分量分析单元524还可分析VT矩阵523以产生VT DIST矩阵525E及VT BG矩阵525F。常常,突出分量分析单元524可分析S矩阵519B以识别变量D,从而基于变量D产生VT DIST矩阵525E及VBG矩阵525F。即,在识别出S矩阵519B的突出的D列之后,突出分量分析单元524可基于此确定的变量D分裂V矩阵519A。在此情况下,突出分量分析单元524可产生VT DIST矩阵525E以包含原始VT矩阵523的为D值的(N+1)2行(从上到下),且产生VT BG矩阵525F以包含原始VT矩阵523的为(N+1)2-D值的剩余(N+1)2行。VT DIST矩阵525E可具有大小(N+1)2乘D,而VT BG矩阵525D可具有大小(N+1)2乘(N+1)2-D。尽管在图40的实例中展示为单独矩阵525E及525F,但矩阵525E与525F可指定为单个矩阵,使用变量D来表示此表示VDIST矩阵525E的单个矩阵的列(从左到右)的数目。突出分量分析单元524可将SDIST矩阵525、SBG矩阵525B、UDIST矩阵525C、UBG矩阵525D及VT BG矩阵525F输出到数学单元526,同时也将VT DIST矩阵525E输出到位流产生单元516。
数学单元526可表示经配置以执行能够相对于一或多个矩阵(或向量)执行的矩阵乘法或任何其它数学运算的单元。更具体来说,如图40的实例中所示,数学单元526可表示经配置以执行矩阵乘法以将UDIST矩阵525C乘以SDIST矩阵525A以产生具有大小M乘D的UDIST*SDIST向量527的单元。矩阵数学单元526还可表示经配置以执行矩阵乘法以将UBG矩阵525D乘以SBG矩阵525B且接着乘以VT BG矩阵525F以产生UBG*SBG*VT BG矩阵525F以产生大小为大小M乘(N+1)2的背景球谐系数531(其可表示球谐系数511的表示声场的背景分量的那些球谐系数)的单元。数学单元526可将UDIST*SDIST向量527及背景球谐系数531输出到音频编码单元514。
因此,音频编码装置510不同于音频编码装置20,不同之处在于音频编码装置510包含经配置以通过编码过程结束时的矩阵乘法而产生UDIST*SDIST向量527及背景球谐系数531的此数学单元526。音频编码装置20的线性可逆变换单元30执行U与S矩阵的乘法以在编码过程的相对开始处输出US[k]向量33,其可促进未在图40的实例中展示的稍后操作,例如重排序。此外,音频编码装置20并非在编码过程结束时恢复背景SHC531,而是直接从HOA系数11选择背景HOA系数47,进而潜在地避免矩阵乘法以恢复背景SHC 531。
音频编码单元514可表示执行某形式的编码以进一步压缩UDIST*SDIST向量527及背景球谐系数531的单元。音频编码单元514可以实质上类似于图4的实例中所示的音频编码装置20的心理声学音频译码器单元40的方式操作。在一些情况下,此音频编码单元514可表示高级音频编码(AAC)编码单元的一或多个实例。音频编码单元514可对UDIST*SDIST向量527的每一列或行进行编码。常常,音频编码单元514可对于背景球谐系数531中剩余的阶数/子阶组合中的每一者调用AAC编码单元的实例。关于可如何使用AAC编码单元对背景球谐系数531进行编码的更多信息可见于埃里克·赫卢德(Eric Hellerud)等人的标题为“以AAC编码较高阶立体混响(Encoding Higher Order Ambisonics with AAC)”的大会论文中,其在第124次大会(2008年5月17日至20日)上提交且可在下处获得:http://ro.uow.edu.au/ cgi/viewcontent.cgi?article=8025&context=engpapers。音频编码单元14可将UDIST*SDIST向量527的经编码版本(表示为“经编码UDIST*SDIST向量515”)及背景球谐系数531的经编码版本(表示为“经编码背景球谐系数515B”)输出到位流产生单元516。在一些情况下,音频编码单元514可使用比用以对UDIST*SDIST向量527进行编码的位速率低的位速率对背景球谐系数531进行音频编码,进而潜在地与UDIST*SDIST向量527相比更多地压缩背景球谐系数531。
位流产生单元516表示格式化数据以符合已知格式(其可指解码装置已知的格式)进而产生位流517的单元。位流产生单元42可以实质上类似于上文相对于图4的实例中所示的音频编码器件24的位流产生单元42所描述的方式操作。位流产生单元516可包含对经编码UDIST*SDIST向量515、经编码背景球谐系数515B及VT DIST矩阵525E进行多路复用的多路复用器。
图40B是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510B的框图。音频编码装置510B可类似于音频编码装置510,类似之处在于音频编码装置510B包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510B的音频压缩单元512可类似于音频编码装置510的音频压缩单元,类似之处在于音频压缩单元512包含分解单元518。音频编码装置510B的音频压缩单元512可不同于音频编码装置510的音频压缩单元512,其不同之处在于声场分量提取单元520包含表示为阶数缩减单元528A(“阶数缩减单元528”)的额外单元。出于此原因,音频编码装置510B的声场分量提取单元520表示为“声场分量提取单元520B”。
阶数缩减单元528A表示经配置以执行背景球谐系数531的额外阶数缩减的单元。在一些情况下,阶数缩减单元528A可旋转背景球谐系数531所表示的声场以缩减表示声场所必要的背景球谐系数531的数目。在一些情况下,假定背景球谐系数531表示声场的背景分量,阶数缩减单元528A可移除、消除或以其它方式删除(常常通过零化)背景球谐系数531中对应于较高阶球面基底函数的那些球谐系数。在这方面中,阶数缩减单元528A可执行类似于图4的实例中所示的音频编码装置20的背景选择单元48的操作。阶数缩减单元528A可将背景球谐系数531的经缩减版本(表示为“经缩减背景球谐系数529”)输出到音频编码单元514,音频编码单元514可以上文所描述的方式执行音频编码以对经缩减背景球谐系数529进行编码且进而产生经编码经缩减背景球谐系数515B。
以下列出的各种条款可呈现本发明中所描述的技术的各种方面。
条款132567-1。一种装置,例如音频编码装置510或音频编码装置510B,其包括一或多个处理器,所述一或多个处理器经配置以执行以下操作:相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;及将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数。
条款132567-2。条款132567-1的装置,其中所述一或多个处理器进一步经配置以产生位流以将所述多个球谐系数的表示包含为U矩阵、S矩阵及V矩阵的一或多个向量,包含其组合或其导出项。
条款132567-3。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时确定包含于所述U矩阵内的描述声场的相异分量的一或多个UDIST向量。
条款132567-4。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时确定包含于所述U矩阵内的描述声场的相异分量的一或多个UDIST向量,确定包含于所述S矩阵内的也描述声场的相异分量的一或多个SDIST向量,且将所述一或多个UDIST向量与所述一或多个一或多个SDIST向量相乘以产生UDIST*SDIST向量。
条款132567-5。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时确定包含于所述U矩阵内的描述声场的相异分量的一或多个UDIST向量,确定包含于所述S矩阵内的也描述声场的相异分量的一或多个SDIST向量,且将所述一或多个UDIST向量与所述一或多个一或多个SDIST向量相乘以产生UDIST*SDIST向量,且其中所述一或多个处理器进一步经配置以对所述一或多个UDIST*SDIST向量进行音频编码以产生所述一或多个UDIST*SDIST向量的音频编码版本。
条款132567-6。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时确定包含于所述U矩阵内的一或多个UBG向量。
条款132567-7。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时分析所述S矩阵以识别声场的相异分量及背景分量。
条款132567-8。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时分析所述S矩阵以识别声场的相异分量及背景分量,且基于对S矩阵的分析确定所述U矩阵的描述声场的相异分量的一或多个UDIST向量及所述U矩阵的描述声场的背景分量的一或多个UBG向量。
条款132567-9。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时分析所述S矩阵以逐音频帧地识别声场的相异分量及背景分量,且基于对所述S矩阵的逐音频帧分析确定U矩阵的描述声场的相异分量的一或多个UDIST向量及U矩阵的描述声场的背景分量的一或多个UBG向量。
条款132567-10。条款132567-1的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时分析所述S矩阵以识别声场的相异分量及背景分量,且基于对S矩阵的分析确定U矩阵的描述声场的相异分量的一或多个UDIST向量及U矩阵的描述声场的背景分量的一或多个UBG向量,基于对S矩阵的分析确定S矩阵的对应于所述一或多个UDIST向量及所述一或多个UBG向量的一或多个SDIST向量及一或多个SBG向量,且基于对S矩阵的分析确定V矩阵的转置的对应于所述一或多个UDIST向量及所述一或多个UBG向量的一或多个VT DIST向量及一或多个VT BG向量。
条款132567-11。条款132567-10的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时进一步将所述一或多个UBG向量乘以所述一或多个SBG向量且接着乘以一或多个VT BG向量以产生一或多个UBG*SBG*VT BG向量,且其中所述一或多个处理器进一步经配置以对所述UBG*SBG*VT BG向量进行音频编码以产生所述UBG*SBG*VT BG向量的音频编码版本。
条款132567-12。条款132567-10的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时将所述一或多个UBG向量乘以所述一或多个SBG向量且接着乘以一或多个VT BG向量以产生一或多个UBG*SBG*VT BG向量,且执行阶数缩减过程以消除所述一或多个UBG*SBG*VT BG向量的系数中的与球谐基底函数的一或多个阶数相关联的那些系数且进而产生所述一或多个UBG*SBG*VT BG向量的阶数经缩减版本。
条款132567-13。条款132567-10的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时将所述一或多个UBG向量乘以所述一或多个SBG向量且接着乘以一或多个VT BG向量以产生一或多个UBG*SBG*VT BG向量,且执行阶数缩减过程以消除所述一或多个UBG*SBG*VT BG向量的系数中的与球谐基底函数的一或多个阶数相关联的那些系数且进而产生所述一或多个UBG*SBG*VT BG向量的阶数经缩减版本,且其中所述一或多个处理器进一步经配置以对所述一或多个UBG*SBG*VT BG向量的阶数经缩减版本进行音频编码以产生阶数经缩减一或多个UBG*SBG*VT BG向量的音频编码版本。
条款132567-14。条款132567-10的装置,其中所述一或多个处理器进一步经配置以当表示所述多个球谐系数时将所述一或多个UBG向量乘以所述一或多个SBG向量且接着乘以一或多个VT BG向量以产生一或多个UBG*SBG*VT BG向量,执行阶数缩减过程以消除所述一或多个UBG*SBG*VT BG向量的系数中的与大于球谐基底函数中的一者的一或多个阶数相关联的那些系数且进而产生所述一或多个UBG*SBG*VT BG向量的阶数经缩减版本,且对所述一或多个UBG*SBG*VT BG向量的阶数经缩减版本进行音频编码以产生阶数经缩减一或多个UBG*SBG*VT BG向量的音频编码版本。
条款132567-15。条款132567-10的装置,其中所述一或多个处理器进一步经配置以产生位流以包含所述一或多个VT DIST向量。
条款132567-16。条款132567-10的装置,其中所述一或多个处理器进一步经配置以产生位流以包含所述一或多个VT DIST向量而不对所述一或多个VT DIST向量进行音频编码。
条款132567-1F。一种装置,例如音频编码装置510或510B,包括一或多个处理器以相对于表示声场的至少一部分的多通道音频数据执行奇异值分解以产生表示所述多通道音频数据的左奇异向量的U矩阵、表示所述多通道音频数据的奇异值的S矩阵以及表示所述多通道音频数据的右奇异向量的V矩阵,且将所述多通道音频数据表示为所述U矩阵、所述S矩阵和所述V矩阵中的一或多者的至少一部分的函数。
条款132567-2F。条款132567-1F的装置,其中所述多通道音频数据包含多个球谐系数。
条款132567-3F。条款132567-2F的装置,其中所述一或多个处理器进一步经配置以如条款132567-2到132567-16的任何组合所述而执行。
从上述各种条款中的每一者,应理解,音频编码装置510A到510J中的任一者可执行方法,或另外包括执行音频编码装置510A到510J经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频编码装置510A到510J已经配置以执行的方法。
举例来说,条款132567-17可从先前条款132567-1导出而为一种方法,所述方法包括:相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;及将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数。
作为另一实例,条款132567-18可从先前条款132567-1导出而为一种装置,例如音频编码装置510B,其包括:用于相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵的装置;及用于将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数的装置。
作为又一实例,条款132567-18可从先前条款132567-1导出而为一种上面存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使一或多个处理器相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,且将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数。
对于如上文所举例说明而导出的各种装置、方法及非暂时性计算机可读存储媒体,各种条款可同样地从条款132567-2到132567-16导出。可针对贯穿本发明列出的各种其它条款执行同样的操作。
图40C是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510C的框图。音频编码装置510C可类似于音频编码装置510B,类似之处在于音频编码装置510C包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510C的音频压缩单元512可类似于音频编码装置510B的音频压缩单元,类似之处在于音频压缩单元512包含分解单元518。
然而,音频编码装置510C的音频压缩单元512可不同于音频编码装置510B的音频压缩单元512,其不同之处在于声场分量提取单元520包含表示为向量重排序单元532的额外单元。出于此原因,音频编码装置510C的声场分量提取单元520表示为“声场分量提取单元520C”。
向量重排序单元532可表示经配置以对UDIST*SDIST向量527重排序以产生经重排序的一或多个UDIST*SDIST向量533的单元。在这方面中,向量重排序单元532可以类似于上文相对于图4的实例中所示的音频编码装置20的重排序单元34所描述的方式操作。声场分量提取单元520C可调用向量重排序单元532以对UDIST*SDIST向量527重排序,因为UDIST*SDIST向量527的阶数(其中UDIST*SDIST向量527的每一向量可表示存在于声场中的一或多个相异单声道音频对象)可能由于上文指出的原因而对于音频数据的各部分不同。即,在一些实例中,假定音频压缩单元512对通常被称作音频帧的音频数据的这些部分(其可具有球谐系数511的M个样本,其中M在一些实例中设定为1024)操作,对应于这些相异单声道音频对象的向量的位置(如表示于导出UDIST*SDIST向量527的U矩阵519C中)可在音频帧间不同。
将这些UDIST*SDIST向量527直接传递到音频编码单元514而不对这些UDIST*SDIST向量527逐音频帧地重排序可能减小一些压缩方案(例如旧版压缩方案,其在单声道音频对象跨越音频帧相关(逐通道,其在此实例中由UDIST*SDIST向量527相对于彼此的阶数来界定)时执行地更好)可实现的压缩程度。此外,当不重排序时,UDIST*SDIST向量527的编码可能在恢复时降低音频数据的质量。举例来说,与直接逐帧地对UDIST*SDIST向量527进行编码时实现的压缩相比,在图40C的实例中可由音频编码单元514表示的AAC编码器可更有效地逐帧地压缩经重排序的一或多个UDIST*SDIST向量533。尽管上文相对于AAC编码器予以描述,但可相对于跨越处于特定阶数或位置的帧指定单声道音频对象(逐通道地)时提供更好压缩的任何编码器执行所述技术。
如下文更详细地描述,所述技术可使得音频编码装置510C能够重排序一或多个向量(即,UDIST*SDIST向量527以产生经重排序一或多个向量UDIST*SDIST向量533且进而促进通过例如音频编码单元514等旧版音频编码器对UDIST*SDIST向量527的压缩。音频编码装置510C可进一步执行本发明中所描述的技术以使用音频编码单元514对经重排序的一或多个UDIST*SDIST向量533进行音频编码以产生经重排序的一或多个UDIST*SDIST向量533的经编码版本515A。
举例来说,声场分量提取单元520C可调用向量重排序单元532以对来自在时间上在一或多个第二UDIST*SDIST向量527所对应的第二帧之后的第一音频帧的一或多个第一UDIST*SDIST向量527重排序。尽管于在时间上在第二音频帧之后的第一音频帧的上下文中予以描述,但第一音频帧可在时间上先于第二音频帧。因此,所述技术不应限于本发明中描述的实例。
向量重排序单元532可首先相对于第一UDIST*SDIST向量527及第二UDIST*SDIST向量527中的每一者执行能量分析,计算第一音频帧的至少一部分(但常常为整个)及第二音频帧的一部分(但常常为整个)的均方根能量且进而产生(假定D为四)八个能量,针对第一音频帧的第一UDIST*SDIST向量527中的每一者产生一个且针对第二音频帧的第二UDIST*SDIST向量527中的每一者产生一个。向量重排序单元532可接着逐轮比较来自第一UDIST*SDIST向量527的每一能量与第二UDIST*SDIST向量527中的每一者,如上文相对于表1到4所描述。
换句话说,当对HoA信号使用基于帧的SVD(或相关方法,例如KLT及PCA)分解时,可能不保证向量的排序在帧间一致。举例来说,如果在基础声场中存在两个对象,则分解(其在恰当地执行时可被称作“理想分解”)可导致所述两个对象的分离,使得一个向量将表示U矩阵中的一个对象。然而,即使当分解可表示为“理想分解”时,向量在U矩阵中(且对应地在S及V矩阵中)的位置也可能在帧间交替。另外,可存在相位差异,其中向量重排序单元532可使用相位反转(通过将经反相向量的每一元素点乘负一)来使相位反转。为了逐帧地将这些向量馈送到同一“AAC/音频译码引擎”,可能需要识别阶数(或换句话说,匹配信号)、矫正相位且在帧边界处应用谨慎的内插。无此条件的情况下,底层音频编解码器可产生极端恶劣的假象,包含被称为‘时间拖尾’或‘预回波’的那些假象。
根据本发明中所描述的技术的各种方面,音频编码装置510C可应用多个方法来使用向量的帧边界处的能量及交叉相关来识别/匹配向量。音频编码装置510C还可确保常常在帧边界处出现的180度的相位改变得以校正。向量重排序单元532可在向量之间应用某形式的淡入/淡出内插窗来确保帧之间的平滑转变。
以此方式,音频编码装置530C可对一或多个向量重排序以产生经重排序的一或多个第一向量且进而促进旧版音频编码器的编码,其中所述一或多个向量描述表示声场的相异分量,且使用旧版音频编码器对经重排序的一或多个向量进行音频编码以产生经重排序的一或多个向量的经编码版本。
本发明中所描述的技术的各种方面可使得音频编码装置510C能够根据以下条款而操作。
条款133143-1A。一种装置,例如音频编码装置510C,其包括:一或多个处理器,所述一或多个处理器经配置以在一或多个第一向量与一或多个第二向量之间执行能量比较以确定经重排序的一或多个第一向量且促进所述一或多个第一向量及所述一或多个第二向量中的一或两者的提取,其中所述一或多个第一向量描述音频数据的第一部分中的声场的相异分量,且所述一或多个第二向量描述音频数据的第二部分中的声场的相异分量。
条款133143-2A。条款133143-1A的装置,其中所述一或多个第一向量不表示音频数据的第一部分中的声场的背景分量,且其中所述一或多个第二向量不表示音频数据的第二部分中的声场的背景分量。
条款133143-3A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以在执行所述能量比较之后在所述一或多个第一向量与所述一或多个第二向量之间执行交叉相关以识别与所述一或多个第二向量相关的所述一或多个第一向量。
条款133143-4A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以进行以下操作:基于所述能量比较舍弃所述第二向量中的一或多者以产生比所述一或多个第二向量具有较少向量的经缩减一或多个第二向量;在所述一或多个第一向量中的至少一者与所述经缩减一或多个第二向量之间执行交叉相关以识别所述经缩减一或多个第二向量中的与所述一或多个第一向量中的所述至少一者相关的第二向量;及基于所述交叉相关对所述一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量。
条款133143-5A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以进行以下操作:基于所述能量比较舍弃第二向量中的一或多者以产生比所述一或多个第二向量具有较少向量的经缩减一或多个第二向量;在所述一或多个第一向量中的至少一者与经缩减一或多个第二向量之间执行交叉相关以识别经缩减一或多个第二向量中的与所述一或多个第一向量中的至少一者相关的第二向量;基于所述交叉相关对所述一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量;及对经重排序的一或多个第一向量进行编码以产生经重排序的一或多个第一向量的音频编码版本。
条款133143-6A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以进行以下操作:基于所述能量比较舍弃第二向量中的一或多者以产生比所述一或多个第二向量具有较少向量的经缩减一或多个第二向量;在所述一或多个第一向量中的至少一者与经缩减一或多个第二向量之间执行交叉相关以识别经缩减一或多个第二向量中的与所述一或多个第一向量中的至少一者相关的一个第二向量;基于所述交叉相关对一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量;对经重排序的一或多个第一向量进行编码以产生经重排序的一或多个第一向量的音频编码版本;及产生位流以包含经重排序的一或多个第一向量的经编码版本。
条款133143-7A。技术方案3A到6A的装置,其中所述音频数据的第一部分包括具有M个样本的第一音频帧,其中所述音频数据的第二部分包括具有相同数目M个样本的第二音频帧,其中所述一或多个处理器进一步经配置以在执行交叉相关时相对于一或多个第一向量中的至少一者的最后M-Z个值及经缩减一或多个第二向量中的每一者的前M-Z个值执行交叉相关以识别经缩减一或多个第二向量中的与一或多个第一向量中的所述至少一者相关的一个第二向量,且其中Z小于M。
条款133143-8A。技术方案3A到6A的装置,其中所述音频数据的第一部分包括具有M个样本的第一音频帧,其中所述音频数据的第二部分包括具有相同数目M个样本的第二音频帧,其中所述一或多个处理器进一步经配置以在执行交叉相关时相对于一或多个第一向量中的至少一者的最后M-Y个值及经缩减一或多个第二向量中的每一者的前M-Z个值执行交叉相关以识别经缩减一或多个第二向量中的与一或多个第一向量中的所述至少一者相关的一个第二向量,且其中Z和Y两者小于M。
条款133143-9A。技术方案3A到6A的装置,其中所述一或多个处理器进一步经配置以当执行交叉相关时使一或多个第一向量及一或多个第二向量中的至少一者反转。
条款133143-10A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生一或多个第一向量及一或多个第二向量。
条款133143-11A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵以及表示所述多个球谐系数的右奇异向量的Y矩阵,且产生所述一或多个第一向量和所述一或多个第二向量作为所述U矩阵、S矩阵和V矩阵中的一或多者的函数。
条款133143-12A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,相对于所述S矩阵执行突出性分析以识别U矩阵的一或多个UDIST向量及S矩阵的一或多个SDIST向量,且通过至少部分将所述一或多个UDIST向量乘以所述一或多个SDIST向量而确定所述一或多个第一向量及所述一或多个第二向量。
条款133143-13A。条款133143-1A的装置,其中所述音频数据的第一部分在时间上出现于所述音频数据的第二部分之前。
条款133143-14A。条款133143-1A的装置,其中所述音频数据的第一部分在时间上出现于所述音频数据的第二部分之后。
条款133143-15A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以当执行能量比较时计算一或多个第一向量及一或多个第二向量中的每一者的均方根能量,且比较针对所述一或多个第一向量中的至少一者计算的均方根能量与针对所述一或多个第二向量中的每一者计算的均方根能量。
条款133143-16A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以基于所述能量比较对一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量,且其中所述一或多个处理器进一步经配置以在对第一向量重排序时在所述一或多个第一向量之间应用淡入/淡出内插窗以确保在产生经重排序的一或多个第一向量时的平滑转变。
条款133143-17A。条款133143-1A的装置,其中所述一或多个处理器进一步经配置以至少基于所述能量比较对一或多个第一向量重排序以产生经重排序的一或多个第一向量,产生位流以包含经重排序的一或多个第一向量或经重排序的一或多个第一向量的经编码版本,且在所述位流中指定描述如何对所述一或多个第一向量重排序的重排序信息。
条款133143-18A。条款133143-1A的装置,其中所述能量比较促进一或多个第一向量及一或多个第二向量中的一或两者的提取以便促成一或多个第一向量及一或多个第二向量中的所述一或两者的音频编码。
条款133143-1B。一种装置,例如音频编码装置510C,其包括:一或多个处理器,所述一或多个处理器经配置以相对于一或多个第一向量与一或多个第二向量执行交叉相关以确定经重排序的一或多个第一向量且促进所述一或多个第一向量及所述一或多个第二向量中的一或两者的提取,其中所述一或多个第一向量描述音频数据的第一部分中的声场的相异分量,且所述一或多个第二向量描述音频数据的第二部分中的声场的相异分量。
条款133143-2B。条款133143-1B的装置,其中所述一或多个第一向量不表示音频数据的第一部分中的声场的背景分量,且其中所述一或多个第二向量不表示音频数据的第二部分中的声场的背景分量。
条款133143-3B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以在执行所述交叉相关之前在一或多个第一向量与一或多个第二向量之间执行能量比较以产生比所述一或多个第二向量具有较少向量的经缩减一或多个第二向量,且其中所述一或多个处理器进一步经配置以当执行所述交叉相关时在一或多个第一向量与经缩减一或多个第二向量之间执行交叉相关以促进对一或多个第一向量及一或多个第二向量中的一或两者的音频编码。
条款133143-4B。条款133143-3B的装置,其中所述一或多个处理器进一步经配置以当执行能量比较时计算一或多个第一向量及一或多个第二向量中的每一者的均方根能量,且比较针对所述一或多个第一向量中的至少一者计算的均方根能量与针对所述一或多个第二向量中的每一者计算的均方根能量。
条款133143-5B。条款133143-3B的装置,其中所述一或多个处理器进一步经配置以进行以下操作:基于所述能量比较舍弃第二向量中的一或多者以产生比所述一或多个第二向量具有较少向量的经缩减一或多个第二向量;其中所述一或多个处理器进一步经配置以当执行所述交叉相关时在所述一或多个第一向量中的至少一者与经缩减一或多个第二向量之间执行交叉相关以识别经缩减一或多个第二向量中的与所述一或多个第一向量中的至少一者相关的一个第二向量;且其中所述一或多个处理器进一步经配置以基于所述交叉相关对所述一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量。
条款133143-6B。条款133143-3B的装置,其中所述一或多个处理器进一步经配置以基于所述能量比较舍弃第二向量中的一或多者以产生比一或多个第二向量具有较少向量的经缩减一或多个第二向量,其中所述一或多个处理器进一步经配置以在执行交叉相关时在一或多个第一向量中的至少一者与经缩减一或多个第二向量之间执行交叉相关以识别经缩减一或多个第二向量中的与一或多个第一向量中的至少一者相关的一个第二向量,且其中所述一或多个处理器进一步经配置以基于所述交叉相关对一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量,且对经重排序的一或多个第一向量进行编码以产生经重排序的一或多个第一向量的音频编码版本。
条款133143-7B。条款133143-3B的装置,其中所述一或多个处理器进一步经配置以基于所述能量比较舍弃第二向量中的一或多者以产生比一或多个第二向量具有较少向量的经缩减一或多个第二向量,其中所述一或多个处理器进一步经配置以在执行交叉相关时在一或多个第一向量中的至少一者与经缩减一或多个第二向量之间执行交叉相关以识别经缩减一或多个第二向量中的与一或多个第一向量中的至少一者相关的一个第二向量,且其中所述一或多个处理器进一步经配置以基于所述交叉相关对一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量,对经重排序的一或多个第一向量进行编码以产生经重排序的一或多个第一向量的音频编码版本,且产生位流以包含经重排序的一或多个第一向量的经编码版本。
条款133143-8B。技术方案3B到7B的装置,其中所述音频数据的第一部分包括具有M个样本的第一音频帧,其中所述音频数据的第二部分包括具有相同数目M个样本的第二音频帧,其中所述一或多个处理器进一步经配置以在执行交叉相关时相对于一或多个第一向量中的至少一者的最后M-Z个值及经缩减一或多个第二向量中的每一者的前M-Z个值执行交叉相关以识别经缩减一或多个第二向量中的与一或多个第一向量中的所述至少一者相关的一个第二向量,且其中Z小于M。
条款133143-9B。技术方案3B到7B的装置,其中所述音频数据的第一部分包括具有M个样本的第一音频帧,其中所述音频数据的第二部分包括具有相同数目M个样本的第二音频帧,其中所述一或多个处理器进一步经配置以在执行交叉相关时相对于一或多个第一向量中的至少一者的最后M-Y个值及经缩减一或多个第二向量中的每一者的前M-Z个值执行交叉相关以识别经缩减一或多个第二向量中的与一或多个第一向量中的所述至少一者相关的一个第二向量,且其中Z和Y两者小于M。
条款133143-10B。技术方案1B的装置,其中所述一或多个处理器进一步经配置以当执行交叉相关时使一或多个第一向量及一或多个第二向量中的至少一者反转。
条款133143-11B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生一或多个第一向量及一或多个第二向量。
条款133143-12B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵以及表示所述多个球谐系数的右奇异向量的V矩阵,且产生所述一或多个第一向量和所述一或多个第二向量作为所述U矩阵、S矩阵和V矩阵中的一或多者的函数。
条款133143-13B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,相对于所述S矩阵执行突出性分析以识别U矩阵的一或多个UDIST向量及S矩阵的一或多个SDIST向量,且通过至少部分将所述一或多个UDIST向量乘以所述一或多个SDIST向量而确定所述一或多个第一向量及所述一或多个第二向量。
条款133143-14B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,且在确定一或多个第一向量及一或多个第二向量时相对于所述S矩阵执行突出性分析以将V矩阵的一或多个VDIST向量识别为所述一或多个第一向量及所述一或多个第二向量中的至少一者。
条款133143-15B。条款133143-1B的装置,其中所述音频数据的第一部分在时间上出现于所述音频数据的第二部分之前。
条款133143-16B。条款133143-1B的装置,其中所述音频数据的第一部分在时间上出现于所述音频数据的第二部分之后。
条款133143-17B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以基于所述交叉相关对一或多个第一向量中的至少一者重排序以产生经重排序的一或多个第一向量,且在对第一向量重排序时在一或多个第一向量之间应用淡入/淡出内插窗以确保在产生经重排序的一或多个第一向量时的平滑转变。
条款133143-18B。条款133143-1B的装置,其中所述一或多个处理器进一步经配置以至少基于所述交叉相关对一或多个第一向量重排序以产生经重排序的一或多个第一向量,产生位流以包含经重排序的一或多个第一向量或经重排序的一或多个第一向量的经编码版本,且在所述位流中指定如何对所述一或多个第一向量重排序。
条款133143-19B。条款133143-1B的装置,其中所述交叉相关促进一或多个第一向量及一或多个第二向量中的一或两者的提取以便促成一或多个第一向量及一或多个第二向量中的所述一或两者的音频编码。
图40D是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510D的框图。音频编码装置510D可类似于音频编码装置510C,类似之处在于音频编码装置510D包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510D的音频压缩单元512可类似于音频编码装置510C的音频压缩单元,类似之处在于音频压缩单元512包含分解单元518。
然而,音频编码装置510D的音频压缩单元512可不同于音频编码装置510C的音频压缩单元512,其不同之处在于声场分量提取单元520包含表示为量化单元534(“量化单元534”)的额外单元。出于此原因,音频编码装置510D的声场分量提取单元520表示为“声场分量提取单元520D”。
量化单元534表示经配置以量化一或多个VT DIST向量525E及/或一或多个VT BG向量525F以产生对应的一或多个VT Q_DIST向量525G及/或一或多个VT Q_BG向量525H的单元。量化单元534可量化(其为用于通过消除用以表示值的位而进行的数学舍入的信号处理术语)一或多个VT DIST向量525E以便减少用以在位流517中表示一或多个VT DIST向量525E的位的数目。在一些实例中,量化单元534可量化一或多个VT DIST向量525E的32位值,用经舍入16位值替换这些32位值以产生一或多个VT Q_DIST向量525G。在这方面中,量化单元534可以类似于上文相对于图4的实例中所示的音频编码装置20的量化单元52所描述的方式操作。
此性质的量化可将误差引入于声场的表示中,所述误差根据量化的粗糙度而变化。换句话说,用以表示一或多个VT DIST向量525E的位越多,可能导致的量化误差越少。可通过从一或多个VT Q_DIST向量525G减去一或多个VT DIST向量525E而确定归因于VT DIST向量525E的量化而造成的量化误差(其可表示为“EDIST”)。
根据本发明中所描述的技术,音频编码装置510D可通过将EDIST误差投影到通过将一或多个UBG向量525D乘以一或多个SBG向量525B且接着乘以一或多个VT BG向量525F而产生的UDIST*SDIST向量527或背景球谐系数531中的一或多者或以其他其它方式修改所述UDIST*SDIST向量527或背景球谐系数531中的一或多者而补偿EDIST量化误差中的一或多者。在一些实例中,音频编码装置510D可仅补偿UDIST*SDIST向量527中的EDIST误差。在其它实例中,音频编码装置510D可仅补偿背景球谐系数中的EBG误差。在又其它实例中,音频编码装置510D可补偿UDIST*SDIST向量527及背景球谐系数两者中的EDIST误差。
在操作中,突出分量分析单元524可经配置以将一或多个SDIST向量525、一或多个SBG向量525B、一或多个UDIST向量525C、一或多个UBG向量525D、一或多个VT DIST向量525E及一或多个VT BG向量525F输出到数学单元526。突出分量分析单元524还可将一或多个VT DIST向量525E输出到量化单元534。量化单元534可量化一或多个VT DIST向量525E以产生一或多个VT Q_DIST向量525G。量化单元534可将一或多个VT Q_DIST向量525G提供到数学单元526,同时也将一或多个VT Q_DIST向量525G提供到向量重排序单元532(如上文所描述)。向量重排序单元532可以类似于上文相对于VT DIST向量525E所描述的方式相对于所述一或多个VT Q_DIST向量525G操作。
在接收到这些向量525到525G(“向量525”)之后,数学单元526可即刻首先确定描述声场的相异分量的相异球谐系数及描述声场的背景分量的背景球谐系数。矩阵数学单元526可经配置以通过将一或多个UDIST 525C向量乘以一或多个SDIST向量525A且接着乘以一或多个VT DIST向量525E而确定相异球谐系数。数学单元526可经配置以通过将一或多个UBG525D向量乘以一或多个SBG向量525A且接着乘以一或多个VT BG向量525E而确定背景球谐系数。
数学单元526可接着通过相对于一或多个VT Q_DIST向量525G执行伪逆操作且接着将相异球谐乘以一或多个VT Q_DIST向量525G的伪逆而确定一或多个经补偿的UDIST*SDIST向量527'(其可类似于UDIST*SDIST向量527,但这些向量包含用以补偿EDIST误差的值)。向量重排序单元532可以上文所描述的方式操作以产生经重排序的向量527',所述经重排序的向量527'接着由音频编码单元515A进行音频编码以产生音频编码经重排序的向量515',再次如上文所描述。
数学单元526可接下来将EDIST误差投影到背景球谐系数。为执行此投影,数学单元526可通过将相异球谐系数相加到背景球谐系数而确定或以其它方式恢复原始球谐系数511。数学单元526可接着从球谐系数511减去经量化相异球谐系数(其可通过将UDIST向量525C乘以SDIST向量525A且接着乘以VT Q_DIST向量525G而产生)及背景球谐系数以确定归因于VT DIST向量519的量化而造成的剩余误差。数学单元526可接着将此误差相加到经量化背景球谐系数以产生经补偿的经量化背景球谐系数531'。
在任何情况下,阶数缩减单元528A可如上文所描述而执行以将经补偿的经量化背景球谐系数531'缩减为经缩减背景球谐系数529',经缩减背景球谐系数529'可由音频编码单元514以上文所描述的方式进行音频编码以产生音频编码的经缩减背景球谐系数515B'。
以此方式,所述技术可使得音频编码装置510D能够量化表示声场的一或多个分量的一或多个第一向量(例如VT DIST向量525E),且补偿归因于一或多个第一向量的量化而引入于也表示声场的相同的一或多个分量的一或多个第二向量(例如UDIST*SDIST向量527及/或背景球谐系数531的向量)中的误差。
此外,所述技术可根据以下条款提供此量化误差补偿。
条款133146-1B。一种装置,例如音频编码装置510D,其包括:一或多个处理器,所述一或多个处理器经配置以量化表示声场的一或多个相异分量的一或多个第一向量,且补偿归因于一或多个第一向量的量化而引入于也表示声场的相同的一或多个相异分量的一或多个第二向量中的误差。
条款133146-2B。条款133146-1B的装置,其中所述一或多个处理器经配置以量化来自至少部分通过相对于描述声场的多个球谐系数执行奇异值分解而产生的V矩阵的转置的一或多个向量。
条款133146-3B。条款133146-1B的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,且其中所述一或多个处理器经配置以量化来自V矩阵的转置的一或多个向量。
条款133146-4B。条款133146-1B的装置,其中所述一或多个处理器经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,其中所述一或多个处理器经配置以量化来自V矩阵的转置的一或多个向量,且其中所述一或多个处理器经配置以补偿归因于量化而引入于通过将U矩阵的一或多个U向量乘以S矩阵的一或多个S向量而计算出的一或多个U*S向量中的误差。
条款133146-5B。条款133146-1B的装置,其中所述一或多个处理器进一步经配置以进行以下操作:相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;确定U矩阵的一或多个UDIST向量,其中的每一者对应于声场的相异分量中的一者;确定S矩阵的一或多个SDIST向量,其中的每一者对应于声场的相异分量中的相同一者;及确定V矩阵的转置的一或多个VT DIST向量,其中的每一者对应于声场的相异分量中的相同一者,
其中所述一或多个处理器经配置以量化一或多个VT DIST向量以产生一或多个VT Q_DIST向量,且其中所述一或多个处理器经配置以补偿归因于量化而引入于通过将U矩阵的一或多个UDIST向量乘以S矩阵的一或多个SDIST向量而计算出的一或多个UDIST*SDIST向量中的误差以便产生一或多个经误差补偿的UDIST*SDIST向量。
条款133146-6B。条款133146-5B的装置,其中所述一或多个处理器经配置以基于所述一或多个UDIST向量、所述一或多个SDIST向量及所述一或多个VT DIST向量确定相异球谐系数,且相对于所述VT Q_DIST向量执行伪逆以将所述相异球谐系数除以所述一或多个VT Q_DIST向量且进而产生至少部分补偿通过VT DIST向量的量化而引入的误差的经误差补偿的一或多个UC_DIST*SC_DIST向量。
条款133146-7B。条款133146-5B的装置,其中所述一或多个处理器进一步经配置以对一或多个经误差补偿的UDIST*SDIST向量进行音频编码。
条款133146-8B。条款133146-1B的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵以及表示所述多个球谐系数的右奇异向量的V矩阵,确定所述U矩阵的描述声场的一或多个背景分量的一或多个UBG向量以及所述U矩阵的描述声场的一或多个相异分量的一或多个UDIST向量,确定所述S矩阵的描述声场的一或多个背景分量的一或多个SBG向量以及所述S矩阵的描述声场的一或多个相异分量的一或多个SDIST向量,且确定所述V矩阵的转置的一或多个VT DIST向量和一或多个VT BG向量,其中所述VT DIST向量描述声场的一或多个相异分量且所述VT BG描述声场的一或多个背景分量,其中所述一或多个处理器经配置以量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量,且其中所述一或多个处理器进一步经配置以补偿归因于量化而引入于通过将一或多个UBG向量乘以一或多个SBG向量且接着乘以一或多个VT BG向量而形成的背景球谐系数中的误差的至少一部分以便产生经误差补偿的背景球谐系数。
条款133146-9B。条款133146-8B的装置,其中所述一或多个处理器经配置以基于VT DIST向量及通过将所述UDIST向量乘以SDIST向量而形成的一或多个UDIST*SDIST向量确定所述误差,且将所述所确定的误差相加到背景球谐系数以产生经误差补偿的背景球谐系数。
条款133146-10B。条款133146-8B的装置,其中所述一或多个处理器进一步经配置以对经误差补偿的背景球谐系数进行音频编码。
条款133146-11B。条款133146-1B的装置,
其中所述一或多个处理器经配置以补偿归因于一或多个第一向量的量化而引入于也表示声场的相同的一或多个分量的一或多个第二向量中的误差以产生一或多个经误差补偿的第二向量,且其中所述一或多个处理器进一步经配置以产生位流以包含一或多个经误差补偿的第二向量及经量化的一或多个第一向量。
条款133146-12B。条款133146-1B的装置,其中所述一或多个处理器经配置以补偿归因于一或多个第一向量的量化而引入于也表示声场的相同的一或多个分量的一或多个第二向量中的误差以产生一或多个经误差补偿的第二向量,且其中所述一或多个处理器进一步经配置以对一或多个经误差补偿的第二向量进行音频编码,且产生位流以包含音频编码的一或多个经误差补偿的第二向量及经量化的一或多个第一向量。
条款133146-1C。一种装置,例如音频编码装置510D,其包括:一或多个处理器,所述一或多个处理器经配置以量化表示声场的一或多个相异分量的一或多个第一向量,且补偿归因于一或多个第一向量的量化而引入于表示声场的一或多个背景分量的一或多个第二向量中的误差。
条款133146-2C。条款133146-1C的装置,其中所述一或多个处理器经配置以量化来自至少部分通过相对于描述声场的多个球谐系数执行奇异值分解而产生的V矩阵的转置的一或多个向量。
条款133146-3C。条款133146-1C的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,且其中所述一或多个处理器经配置以量化来自V矩阵的转置的一或多个向量。
条款133146-4C。条款133146-1C的装置,其中所述一或多个处理器进一步经配置以相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵以及表示所述多个球谐系数奇异向量右奇异向量的V矩阵;确定所述U矩阵的一或多个UDIST向量,其中的每一者对应于声场的相异分量中的一者;确定所述S矩阵的一或多个向量,其中的每一者对应于声场的相异分量中的同一一者;且确定V矩阵的转置的一或多个VT DIST向量,其中的每一者对应于声场的相异分量中的同一一者,其中所述一或多个处理器经配置以量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量,且补偿归因于量化而引入于通过将U矩阵的一或多个UDIST向量乘以S矩阵的一或多个SDIST向量而计算出的一或多个UDIST*SDIST向量中的误差以便产生一或多个经误差补偿的UDIST*SDIST向量。
条款133146-5C。条款133146-4C的装置,其中所述一或多个处理器经配置以基于所述一或多个UDIST向量、所述一或多个SDIST向量及所述一或多个VT DIST向量确定相异球谐系数,且相对于所述VT Q_DIST向量执行伪逆以将所述相异球谐系数除以所述一或多个VT Q_DIST向量且进而产生至少部分补偿通过VT DIST向量的量化而引入的误差的一或多个UC_DIST*SC_DIST向量。
条款133146-6C。条款133146-4C的装置,其中所述一或多个处理器进一步经配置以对一或多个经误差补偿的UDIST*SDIST向量进行音频编码。
条款133146-7C。条款133146-1C的装置,其中所述一或多个处理器进一步经配置以进行以下操作:相对于表示声场的多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;确定U矩阵的描述声场的一或多个背景分量的一或多个UBG向量及U矩阵的描述声场的一或多个相异分量的一或多个UDIST向量;确定S矩阵的描述声场的一或多个背景分量的一或多个SBG向量及S矩阵的描述声场的一或多个相异分量的一或多个SDIST向量;及确定V矩阵的转置的一或多个VT DIST向量及一或多个VT BG向量,其中所述VT DIST向量描述声场的所述一或多个相异分量且所述VT BG描述声场的所述一或多个背景分量,其中所述一或多个处理器经配置以量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量,且其中所述一或多个处理器经配置以补偿归因于量化而引入于通过将所述一或多个UBG向量乘以所述一或多个SBG向量且接着乘以所述一或多个VT BG向量而形成的背景球谐系数中的误差以便产生经误差补偿的背景球谐系数。
条款133146-8C。条款133146-7C的装置,其中所述一或多个处理器经配置以基于VT DIST向量及通过将所述UDIST向量乘以SDIST向量而形成的一或多个UDIST*SDIST向量确定所述误差,且将所述所确定的误差相加到背景球谐系数以产生经误差补偿的背景球谐系数。
条款133146-9C。条款133146-7C的装置,其中所述一或多个处理器进一步经配置以对经误差补偿的背景球谐系数进行音频编码。
条款133146-10C。条款133146-1C的装置,其中所述一或多个处理器经配置以补偿归因于一或多个第一向量的量化而引入于也表示声场的相同的一或多个分量的一或多个第二向量中的误差以产生一或多个经误差补偿的第二向量,且产生位流以包含一或多个经误差补偿的第二向量及经量化的一或多个第一向量。
条款133146-11C。条款133146-1C的装置,其中所述一或多个处理器进一步经配置以补偿归因于所述一或多个第一向量的量化而引入于也表示声场的相同的一或多个分量的一或多个第二向量中的误差以产生一或多个经误差补偿的第二向量,对所述一或多个经误差补偿的第二向量进行音频编码,且产生位流以包含经音频编码的一或多个经误差补偿的第二向量及所述经量化的一或多个第一向量。
换句话说,当出于带宽减小的目的而对HoA信号使用基于帧的SVD(或相关方法,例如KLT及PCA)分解时,本发明中所描述的技术可使音频编码装置10D能够量化U矩阵的前几个向量(乘以S矩阵的对应奇异值)以及V向量的对应向量。这将包括声场的‘前景’或‘相异’分量。所述技术可接着使音频编码装置510D能够使用例如AAC编码器等‘黑箱’音频译码引擎对U*S向量进行译码。V向量可经标量量化或向量量化。
此外,U矩阵中的剩余向量中的一些可乘以S矩阵及V矩阵的对应奇异值且还使用‘黑箱’音频译码引擎进行译码。这些将包括声场的‘背景’分量。V向量的简单16位标量量化对于四阶(25个系数)可导致约80kbps额外开销且对于6阶(49个系数)可导致160kbps。越粗略的量化可导致越大的量化误差。本发明中所描述的技术可通过将V向量的量化误差‘投影’到前景及背景分量上而补偿V向量的量化误差。
本发明中的技术可包含计算实际V向量的经量化版本。此经量化V向量可称为V'(其中V'=V+e)。所述技术试图重建的用于前景分量的基础HoA信号是由H_f=USV给出,其中U、S及V仅含有前景元素。出于此论述的目的,US将被向量U的单个集合代替。因而,H_f=UV。假定我们具有有误差的V',则所述技术试图尽可能接近地重建H_f。因而,所述技术可使音频编码装置10D能够找出使得H_f=U'V'的U'。音频编码装置10D可使用允许U'=H_f[V']^(-1)的伪逆方法。使用所谓的‘黑箱’音频译码引擎来对U'进行译码,所述技术可最小化由于可被称为有误差的V'向量而造成的H中的误差。
以类似方式,所述技术还可使音频编码装置能够将归因于量化V而造成的误差投影到背景元素中。音频编码装置510D可经配置以重建总HoA信号,其为前景和背景HoA信号的组合,即,H=H_f+H_b。由于V'中的量化误差,这可再次建模为H=H_f+e+H_b。以此方式,替代于使H_b通过‘黑箱音频译码器’,我们使(e+H_b)通过音频译码器,从而实际上补偿V'中的误差。实际上,这补偿仅高达由音频编码装置510D确定以为背景元素发送的阶数的误差。
图40E是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510E的框图。音频编码装置510E可类似于音频编码装置510D,类似之处在于音频编码装置510E包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510E的音频压缩单元512可类似于音频编码装置510D的音频压缩单元,类似之处在于音频压缩单元512包含分解单元518。
然而,音频编码装置510E的音频压缩单元512可不同于音频编码装置510D的音频压缩单元512,不同之处在于声场分量提取单元520的数学单元526执行本发明中所描述的技术的额外方面以在将V矩阵519A的转置的经缩减版本包含在位流517中之前进一步缩减V矩阵519A。出于此原因,音频编码装置510E的声场分量提取单元520表示为“声场分量提取单元520E”。
在图40E的实例中,并非将经缩减背景球谐系数529'转发到音频编码单元514,阶数缩减单元528将经缩减背景球谐系数529'返回到数学单元526。如上文所指出,这些经缩减背景球谐系数529'可能已通过移除系数中的对应于具有一或多个所识别阶数及/或子阶数的球面基底函数的那些系数而得以缩减。经缩减背景球谐系数529'的经缩减阶数可由变量NBG表示。
假定声场分量提取单元520E不可相对于经重排序的一或多个UDIST*SDIST向量533'执行阶数缩减,则描述声场的相异分量的球谐系数的此分解的阶数(其可由变量NDIST表示)可大于背景阶数NBG。换句话说,NBG可能通常小于NDIST。NBG可能小于NDIST的一个可能原因是假定背景分量不具有许多方向性,使得不需要较高阶球面基底函数,进而实现阶数缩减且导致NBG小于NDIST。
假定先前公开地发送经重排序的一或多个VT Q_DIST向量539而不将这些向量539音频编码于位流517中,如图40A到40D的实例中所示,则经重排序的一或多个VT Q_DIST向量539可能消耗相当大的带宽。作为一个实例,经重排序的一或多个VT Q_DIST向量539中的每一者当经量化到16位标量值时可针对第四阶立体混响音频数据(其中每一向量具有25个系数)消耗近似20Kbps且针对第六阶立体混响音频数据(其中每一向量具有49个系数)消耗近似40Kbps。
根据本发明中所描述的技术的各种方面,声场分量提取单元520E可减小需要针对球谐系数或其分解(例如经重排序的一或多个VT Q_DIST向量539)指定的位的量。在一些实例中,数学单元526可基于阶数经缩减的球谐系数529'确定经重排序的VT Q_DIST向量539中将被移除且与阶数经缩减的球谐系数529'重组的那些向量及经重排序的VT Q_DIST向量539中的将形成VT SMALL向量521的那些向量。即,数学单元526可确定阶数经缩减的球谐系数529'的阶数,其中此阶数可表示为NBG。经重排序的VT Q_DIST向量539可具有由变量NDIST表示的阶数,其中NDIST大于阶数NBG。
数学单元526可接着剖析经重排序的VT Q_DIST向量539的第一NBG阶数,移除指定对应于阶数小于或等于NBG的球面基底函数的经分解球谐系数的那些向量。这些经移除的经重排序的VT Q_DIST向量539可接着用以形成中间球谐系数,其是通过将经重排序的UDIST*SDIST向量533'中的表示对应于阶数小于或等于NBG的球面基底函数的球谐系数511的经分解版本的那些向量乘以经移除的经重排序的VT Q_DIST向量539以形成中间相异球谐系数。数学单元526可通过将所述中间相异球谐系数相加到阶数经缩减的球谐系数529'而产生经修改的背景球谐系数537。数学单元526可接着将此经修改的背景球谐系数537传递到音频编码单元514,音频编码单元514对这些系数537进行音频编码以形成音频编码的经修改的背景球谐系数515B'。
数学单元526可接着传递所述一或多个VT SMALL向量521,其可表示表示对应于阶数大于NBG且小于或等于NDIST的球面基底函数的球谐系数511的分解形式的那些向量539。在这方面中,数学单元526可执行类似于图4的实例中所示的音频编码装置20的系数缩减单元46的操作。数学单元526可将所述一或多个VT SMALL向量521传递到位流产生单元516,位流产生单元516可产生位流517以包含VT SMALL向量521(常常呈其原始非经音频编码形式)。假定VT SMALL向量521包含比经重排序的VT Q_DIST向量539少的向量,则所述技术可通过仅在位流517中指定VT SMALL向量521而促进将较少位分配到经重排序的VT Q_DIST向量539。
尽管展示为未经量化,但在一些情况下,音频编码装置510E可量化VT BG向量525F。在一些情况下,例如当音频编码单元514不用以压缩背景球谐系数时,音频编码装置510E可量化VT BG向量525F。
以此方式,所述技术可使音频编码装置510E能够确定从将与背景球谐系数重组以减少需要在位流中分配给一或多个向量的位的量的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中所述背景球谐系数描述相同声场的一或多个背景分量。
即,所述技术可使音频编码装置510E能够以由以下条款指示的方式加以配置。
条款133149-1A。一种装置,例如音频编码装置510E,其包括:一或多个处理器,所述一或多个处理器经配置以确定从将与背景球谐系数重组以减少需要在位流中分配到一或多个向量的位的量的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中背景球谐系数描述相同声场的一或多个背景分量。
条款133149-2A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以通过从所述一或多个向量移除所述一或多个向量中的所确定的至少一者而产生所述一或多个向量的经缩减集合。
条款133149-3A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以哦那个过从所述一或多个向量移除所述一或多个向量中的所确定的至少一者而产生所述一或多个向量的经缩减集合,重组所述一或多个向量中的经移除的至少一者与背景球谐系数以产生经修改的背景球谐系数,且产生位流以包含所述一或多个向量的经缩减集合及所述经修改的背景球谐系数。
条款133149-4A。条款133149-3A的装置,其中所述一或多个向量的经缩减集合包含在所述位流中而不首先经音频编码。
条款133149-5A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以通过从所述一或多个向量移除所述一或多个向量中的所确定的至少一者而产生所述一或多个向量的经缩减集合,重组所述一或多个向量中的经移除的至少一者与背景球谐系数以产生经修改的背景球谐系数,对经修改的背景球谐系数进行音频编码,且产生位流以包含所述一或多个向量的经缩减集合及所述音频编码的经修改的背景球谐系数。
条款133149-6A。条款133149-1A的装置,其中所述一或多个向量包括表示声场的一或多个相异分量的至少某一方面的向量。
条款133149-7A。条款133149-1A的装置,其中所述一或多个向量包括来自至少部分通过相对于描述声场的所述多个球谐系数执行奇异值分解而产生的V矩阵的转置的一或多个向量。
条款133149-8A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以相对于所述多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,且其中所述一或多个向量包括来自所述V矩阵的转置的一或多个向量。
条款133149-9A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以相对于背景球谐系数执行阶数缩减以便移除背景球谐系数中的对应于具有所识别阶数及/或子阶数的球面基底函数的那些背景球谐系数,其中所述背景球谐系数对应于阶数NBG。
条款133149-10A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以相对于背景球谐系数执行阶数缩减以便移除背景球谐系数中的对应于具有所识别阶数及/或子阶数的球面基底函数的那些背景球谐系数,其中所述背景球谐系数对应于小于相异球谐系数的阶数NDIST的阶数NBG,且其中所述相异球谐系数表示声场的相异分量。
条款133149-11A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以相对于背景球谐系数执行阶数缩减以便移除背景球谐系数中的对应于具有所识别阶数及/或子阶数的球面基底函数的那些背景球谐系数,其中所述背景球谐系数对应于小于相异球谐系数的阶数NDIST的阶数NBG,且其中所述相异球谐系数表示声场的相异分量且不经受阶数缩减。
条款133149-12A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以相对于所述多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,且确定V矩阵的转置的一或多个VT DIST向量及一或多个VT BG向量,所述一或多个VT DIST向量描述声场的一或多个相异分量,且所述一或多个VT BG向量描述声场的一或多个背景分量,且其中所述一或多个向量包含所述一或多个VT DIST向量。
条款133149-13A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以相对于所述多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,确定V矩阵的转置的一或多个VT DIST向量及一或多个VT BG向量,所述一或多个VDIST向量描述声场的一或多个相异分量,且所述一或多个VBG向量描述声场的一或多个背景分量,且量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量,且其中所述一或多个向量包含所述一或多个VT Q_DIST向量。
条款133149-14A。条款133149-12A或条款133149-13A中的任一者的装置,其中所述一或多个处理器进一步经配置以进行以下操作:确定U矩阵的一或多个UDIST向量及一或多个UBG向量,所述一或多个UDIST向量描述声场的一或多个相异分量,且所述一或多个UBG向量描述声场的一或多个背景分量;及确定S矩阵的一或多个SDIST向量及一或多个SBG向量,所述一或多个SDIST向量描述声场的一或多个相异分量,且所述一或多个SBG向量描述声场的一或多个背景分量。
条款133149-15A。条款133149-14A的装置,其中所述一或多个处理器进一步经配置以进行以下操作:依据一或多个UBG向量、一或多个SBG向量及一或多个VT BG确定背景球谐系数;相对于背景球谐系数执行阶数缩减以产生阶数等于NBG的经缩减背景球谐系数;将一或多个UDIST乘以一或多个SDIST向量以产生一或多个UDIST*SDIST向量;从所述一或多个向量移除所述一或多个向量中的所确定的至少一者以产生所述一或多个向量的经缩减集合;将一或多个UDIST*SDIST向量乘以所述一或多个VT DIST向量或所述一或多个VT Q_DIST向量中的所移除的至少一者以产生中间相异球谐系数;及将中间相异球谐系数相加到背景球谐系数以重组所述一或多个VT DIST向量或所述一或多个VT Q_DIST向量中的所移除的至少一者与背景球谐系数。
条款133149-16A。条款133149-14A的装置,其中所述一或多个处理器进一步经配置以进行以下操作:依据一或多个UBG向量、一或多个SBG向量及一或多个VT BG确定背景球谐系数;相对于背景球谐系数执行阶数缩减以产生阶数等于NBG的经缩减背景球谐系数;将一或多个UDIST乘以一或多个SDIST向量以产生一或多个UDIST*SDIST向量;重排序所述一或多个UDIST*SDIST向量以产生经重排序的一或多个UDIST*SDIST向量;从所述一或多个向量移除所述一或多个向量中的所确定的至少一者以产生所述一或多个向量的经缩减集合;将经重排序的一或多个UDIST*SDIST向量乘以所述一或多个VT DIST向量或所述一或多个VT Q_DIST向量中的所移除的至少一者以产生中间相异球谐系数;及将中间相异球谐系数相加到背景球谐系数以重组所述一或多个VT DIST向量或所述一或多个VT Q_DIST向量中的所移除的至少一者与背景球谐系数。
条款133149-17A。条款133149-15A或条款133149-16A中的任一者的装置,其中所述一或多个处理器进一步经配置以在将中间相异球谐系数相加到背景球谐系数之后对背景球谐系数进行音频编码,且产生位流以包含音频编码的背景球谐系数。
条款133149-18A。条款133149-1A的装置,其中所述一或多个处理器进一步经配置以进行以下操作:相对于所述多个球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;确定V矩阵的转置的一或多个VT DIST向量及一或多个VT BG向量,所述一或多个VDIST向量描述声场的一或多个相异分量,且所述一或多个VBG向量描述声场的一或多个背景分量;量化所述一或多个VT DIST向量以产生一或多个VT Q_DIST向量;及对所述一或多个VT Q_DIST向量重排序以产生经重排序的一或多个VT Q_DIST向量,且其中所述一或多个向量包含经重排序的一或多个VT Q_DIST向量。
图40F是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510F的框图。音频编码装置510F可类似于音频编码装置510C,其中音频编码装置510F包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510F的音频压缩单元512可类似于音频编码装置510C的音频压缩单元,其中音频压缩单元512包含分解单元518及向量重排序单元532,所述单元可类似于音频编码装置510C的同样单元操作。在一些实例中,音频编码装置510F可包含量化单元534(如相对于图40D和40E所描述)以量化UDIST向量525C、UBG向量525D、VT DIST向量525E及VT BG向量525J中的任一者的一或多个向量。
然而,音频编码装置510F的音频压缩单元512可不同于音频编码装置510C的音频压缩单元512,不同之处在于声场分量提取单元520的突出分量分析单元524可执行内容分析以选择前景分量的数目(在图40A到40J的上下文中表示为D)。换句话说,突出分量分析单元524可以上文所描述的方式相对于U、S及V矩阵519操作以识别球谐系数的经分解版本是从合成音频对象还是从利用麦克风的自然记录产生。突出分量分析单元524可接着基于此合成确定而确定D。
此外,音频编码装置510F的音频压缩单元512可不同于音频编码装置510C的音频压缩单元512,不同之处在于声场分量提取单元520可包含额外单元,即阶数缩减及能量保留单元528F(说明为“阶数缩减及能量保留单元528F”)。出于此原因,音频编码装置510F的声场分量提取单元520表示为“声场分量提取单元520F”。
阶数缩减及能量保留单元528F表示经配置以对表示所述多个球谐系数511的右奇异向量的VBG矩阵525H的背景分量执行阶数缩减同时保留部分地由完整VBG矩阵525H描述的声场的总体能量(及伴随的声压)的单元。在这方面中,阶数缩减及能量保留单元528F可执行上文相对于图4的实例中所示的音频编码装置20的背景选择单元48及能量补偿单元38所描述的操作。
完整VBG矩阵525H具有维度(N+1)2×(N+1)2-D,其中D表示确定为在为声场的相异音频分量方面突出的主分量或(换句话说)奇异值的数目。即,完整VBG矩阵525H包含经确定为声场的背景(BG)或(换句话说)环境或非相异音频分量的那些奇异值。
如上文相对于例如图40B到40E的阶数缩减单元524所描述,阶数缩减及能量保留单元528F可移除、消除或以其它方式删除(常常通过零化)VBG矩阵525H的背景奇异值中的对应于较高阶球形基底函数的那些背景奇异值。阶数缩减及能量保留单元528F可将VBG矩阵525H的经缩减版本(表示为“VBG'矩阵525I”,且在下文中称作“经缩减VBG'矩阵525I”)输出到转置单元522。经缩减VBG'矩阵525I可具有维度(η+1)2×(N+1)2-D,其中η<N。转置单元522将转置操作应用于经缩减VBG'矩阵525I以产生经转置经缩减VT BG'矩阵525J且将其输出到数学单元526,数学单元526可操作以通过使用UBG矩阵525D、SBG矩阵525B及经转置的经缩减VT BG'矩阵525J计算UBG*SBG*VT BG而重建声场的背景声音分量。
根据本文所述的技术,阶数缩减及能量保留单元528F进一步经配置以补偿声场的背景声音分量的总体能量的可能降低,所述可能降低是由缩减完整VBG矩阵525H的阶数以产生经缩减VBG'矩阵525I而造成。在一些实例中,阶数缩减及能量保留单元528F通过确定呈放大值形式的补偿增益而进行补偿,所述补偿增益将应用于经缩减VBG'矩阵525I的(N+1)2-D列中的每一者以便将经缩减VBG'矩阵525I的均方根(RMS)能量增加到等于或至少更接近于完整VBG矩阵525H的RMS,随后将经缩减VBG'矩阵525I输出到转置单元522。
在一些情况下,阶数缩减及能量保留单元528F可确定完整VBG矩阵525H的每一列的RMS能量及经缩减VBG'矩阵525I的每一列的RMS能量,接着将所述列的放大值确定为前者与后者的比率,如以下方程式中所指示:
∝=vBG/vBG',
其中∝为用于一列的放大值,vBG表示VBG矩阵525H的单一列,且vBG'表示VBG'矩阵525I的对应单个列。这可按矩阵记法表示为:
A=VBG RMS/VBG'RMS,

其中VBG RMS是具有表示VBG矩阵525H的每一列的RMS的元素的RMS向量,VBG' RMS是具有表示经缩减VBG'矩阵525I的每一列的RMS的元素的RMS向量,且A是具有用于VBG矩阵525H的每一列的元素的放大值向量。阶数缩减及能量保留单元528F使用对应放大值∝或以向量形式将标量乘法应用于经缩减VBG矩阵525I的每一列:
V”BG=VBG'AT,
其中VB”G表示包含能量补偿的经缩减VBG'矩阵525I。阶数缩减及能量保留单元528F可将包含能量补偿的经缩减VBG'矩阵525I输出到转置单元522以使经缩减VBG'矩阵525I的RMS与完整VBG矩阵525H的RMS均衡(或几乎均衡)。包含能量补偿的经缩减VBG'矩阵525I的输出维度可为(η+1)2×(N+1)2-D。
在一些实例中,为确定经缩减VBG'矩阵525I及完整VBG矩阵525H的相应列的每一RMS,阶数缩减及能量保留单元528F可首先将参考球谐系数(SHC)再现器应用于所述列。通过阶数缩减及能量保留单元528F应用参考SHC再现器允许在SHC域中确定RMS以确定由经缩减VBG'矩阵525I及完整VBG矩阵525H所表示的帧的每一列描述的总体声场的能量。因而,在此些实例中,阶数缩减及能量保留单元528F可将参考SHC再现器应用于完整VBG矩阵525H的每一列且应用于经缩减VBG'矩阵525I的每一经缩减列,确定所述列及经缩减列的相应RMS值,且将用于所述列的放大值确定为所述列的RMS值与所述经缩减列的RMS值的比率。在一些实例中,达到经缩减VBG'矩阵525I的阶数缩减与能量保留一致地逐列进行。此可表达于如下伪码中:

在以上伪码中,numChannels可表示(N+1)2-D,numBG可表示(η+1)2,V可表示VBG矩阵525H,且V_out可表示经缩减VBG'矩阵525I,且R可表示阶数缩减及能量保留单元528F的参考SHC再现器。V的维度可为(N+1)2×(N+1)2-D,且V_out的维度可为(η+1)2×(N+1)2-D。
结果,当表示所述多个球谐系数511时,音频编码装置510F可使用包含由于阶数缩减过程而可能损失的能量的补偿的阶数经缩减的VBG'矩阵525I重建背景声音分量。
图40G是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510G的框图。在图40G的实例中,音频编码装置510G包含声场分量提取单元520F。又,声场分量提取单元520F包含突出分量分析单元524G。
然而,音频编码装置510G的音频压缩单元512可不同于音频编码装置10F的音频压缩单元512,其不同之处在于音频编码装置510G的音频压缩单元512包含突出分量分析单元524G。突出分量分析单元524G可表示经配置以使用与音频数据相关联的基于方向性的信息表示声场的音频数据的突出性性或相异性的单元。
虽然基于能量的确定可改善由SVD分解的声场的再现以识别声场的相异音频分量,但在背景音频分量展现高能级的情况下,基于能量的确定也可使装置错误地将背景音频分量识别为相异音频分量。即,相异和背景音频分量的基于仅能量的分离可不稳健,因为高能(例如,扬声器)背景音频分量可能经不正确地识别为相异音频分量。为了更稳健地在声场的相异和背景音频分量之间区分,本发明中所描述的技术的各种方面可使突出分量分析单元524G能够执行SHC 511的基于方向性的分析以将相异和背景音频分量与SHC 511的经分解版本分离。
在图40H的实例中,突出分量分析单元524G可表示经配置或另外可操作以将相异(或前景)元素与包含在V矩阵519、S矩阵519B及U矩阵519C中的一或多者中的背景元素分离的单元,类似于先前所描述的音频编码装置510到510F的突出分量分析单元524。根据一些基于SVD的技术,可将最高能分量(例如,V、S和U矩阵519到519C或从其导出的矩阵中的一或多者的前少数向量)处理为相异分量。然而,矩阵519到519C中的一或多者的最高能分量(其由向量表示)可不在所有情境中表示最有方向性的分量/信号。
不同于先前所描述的突出分量分析单元524,突出分量分析单元524G可实施本文中所描述的技术的一或多个方面以基于矩阵519到519C或从其导出的矩阵中的一或多者的向量的方向性识别前景元素。在一些实例中,突出分量分析单元524G可基于能量及向量的方向性识别或选择一或多个向量作为相异音频分量(其中分量也可被称作“对象”)。举例来说,突出分量分析单元524G可将矩阵519到519C(或从其导出的矩阵)中的一或多者的显示高能量及高方向性(例如,表示为方向性商)的那些向量识别为相异音频分量。结果,如果突出分量分析单元524G确定当与矩阵519到519C(或从其导出的矩阵)中的一或多者的其它向量比较时一特定向量相对较小,则不管与所述特定向量相关联的能级,突出分量分析单元524G可确定所述特定向量表示由SHC 511表示的声场的背景(或环境)音频分量。在这方面中,突出分量分析单元524G可执行类似于以上相对于图4的实例中展示的音频编码装置20的声场分析单元44描述的操作的操作。
在一些实施方案中,突出分量分析单元524G可通过执行下列操作基于方向性识别相异音频对象(如上所指出,其也可被称作“分量”)。突出分量分析单元524G可(例如,使用一或多个矩阵乘法过程)将V矩阵519A乘以S矩阵519B。通过将V矩阵519A与S矩阵519B相乘,突出分量分析单元524G可获得VS矩阵。另外,突出分量分析单元524G可将VS矩阵的向量(其可为行)中的每一者的条目中的至少一些自乘(即,按二次方求幂)。在一些情况下,突出分量分析单元524G可将每一向量的与大于1的阶数相关联的那些平方条目求和。作为一个实例,如果矩阵的每一向量包含25个条目,则突出分量分析单元524G可相对于每一向量将开始于第五条目且结束于第二十五条目的每一向量的条目自乘,将平方条目求和以确定方向性商(或方向性指示符)。每一求和运算可导致对应的向量的方向性商。在此实例中,突出分量分析单元524G可确定每一行的与小于或等于1的阶数相关联的那些条目(即,第一到第四条目)更通常是针对能量的量,且较少针对那些条目的方向性。即,与零或一的阶数相关联的较低阶立体混响对应于球面基底函数,如在图1及图2中所说明,就压力波的方向而言球面基底函数并不提供许多,而是提供某个体积(其表示能量)。
以上实例中描述的操作也可以根据以下伪码而表达。以下伪码包含标注,呈包含在字符串“/*”和“*/”(无引号)的连续实例内的注释语句的形式。
[U,S,V]=svd(audioframe,'ecom');
VS=V*S;
/*下一行是针对独立地分析每一行,及从第五条目到第二十五条目对第一(作为一个实例)行中的值求和以确定对应向量的方向性商或方向性度量。在求和之前对所述条目求平方。每一行中的与大于1的阶数相关联的条目与较高阶立体混响相关联,且因而更可能具有方向性。*/
sumVS=sum(VS(5:end,:).^2,1);
/*下一行是针对将产生的VS矩阵的平方的总和分类,且选择最大值的集合(例如,最大值中的三个或四个)*/
[~,idxVS]=sort(sumVS,'descend');
U=U(:,idxVS);
V=V(:,idxVS);
S=S(idxVS,idxVS);
换句话说,根据以上伪码,突出分量分析单元524G可选择从对应于具有大于一的阶数的球面基底函数的SHC 511的那些分解的VS矩阵的每一向量的条目。突出分量分析单元524G可接着将VS矩阵的每一向量的这些条目自乘,将经平方条目求和以识别、计算或另外确定VS矩阵的每一向量的方向性量度或商。接下来,突出分量分析单元524G可基于向量中的每一者的相应方向性量度将VS矩阵的向量分类。突出分量分析单元524G可按方向性量度的降序将这些向量分类,使得具有最高对应的方向性的那些向量为第一,且具有最低对应的方向性的那些向量为最后。突出分量分析单元524G可接着选择向量的具有最高相对方向性量度的非零子集。
根据本文中所描述的技术的一些方面,音频编码装置510G或其一或多个组件可将VS矩阵的预定数目个向量识别为或另外用作相异音频分量。举例来说,在选择了VS矩阵的每一行的条目5到25且将选定条目求和以确定每一相应向量的相对方向性量度之后,突出分量分析单元524G可实施所述向量间的进一步选择以识别表示相异音频分量的向量。在一些实例中,突出分量分析单元524G可通过比较向量的方向性商来选择VS矩阵的预定数目个向量。作为一个实例,突出分量分析单元524G可选择具有四个最高方向性商(且为经分类的VS矩阵的首先四个向量)的在VS矩阵中表示的四个向量。又,突出分量分析单元524G可确定四个选定向量表示与声场的对应SHC表示相关联的四个最相异音频对象。
在一些实例中,突出分量分析单元524G可重排序从VS矩阵导出的向量,以反映四个选定向量的相异性,如上所述。在一个实例中,突出分量分析单元524G可重排序所述向量,使得四个选定条目经重新定位到VS矩阵的顶部。举例来说,突出分量分析单元524G可修改VS矩阵,使得所有四个选定条目定位于所得经重排序的VS矩阵的第一(或最高)行中。虽然本文中相对于突出分量分析单元524G描述,但在各种实施方案中,音频编码装置510G的其它组件(例如,向量重排序单元532)可执行所述重排序。
突出分量分析单元524G可将所得矩阵(即,经重排序或未经重排序的VS矩阵)传送到位流产生单元516。又,位流产生单元516可使用VS矩阵525K以产生位流517。举例来说,如果突出分量分析单元524G已重排序VS矩阵525K,则位流产生单元516可将VS矩阵525K的经重排序版本的顶部行用作相异音频对象,例如通过量化或丢弃VS矩阵525K的经重排序版本的剩余向量。通过量化VS矩阵525K的经重排序版本的剩余向量,位流产生单元16可将剩余向量作为环境或背景音频数据处理。
在其中突出分量分析单元524G尚未重排序VS矩阵525K的实例中,位流产生单元516可基于如由突出分量分析单元524G选择的VS矩阵525K的每一行的特定条目(例如,第5到25条目)而区分相异音频数据与背景音频数据。举例来说,位流产生单元516可通过量化或丢弃VS矩阵525K的每一行的前四个条目来产生位流517。
以此方式,音频编码装置510G及/或其组件(例如,突出分量分析单元524G)可实施本发明的技术以确定或另外利用音频数据的较高及较低系数的能量的比率,以便在相异音频对象与表示声场的背景音频数据之间区分。举例来说,如所描述,突出分量分析单元524G可利用基于由突出分量分析单元524H产生的VS矩阵525K的各种条目的值的能量比。通过组合由V矩阵519A及S矩阵519B提供的数据,突出分量分析单元524G可产生VS矩阵525K以提供关于音频数据的各种分量的方向性及总能量的信息,其呈向量及有关数据(例如,方向性商)的形式。更具体来说,V矩阵519A可提供与方向性确定有关的信息,而S矩阵519B可提供与针对音频数据的分量的总能量确定有关的信息。
在其它实例中,突出分量分析单元524G可使用重排序的VT DIST向量539产生VS矩阵525K。在这些实例中,突出分量分析单元524G可在基于S矩阵519B的任何修改前基于V矩阵519确定相异性。换句话说,根据这些实例,突出分量分析单元524G可使用仅V矩阵519确定方向性,而不执行产生VS矩阵525K的步骤。更具体来说,V矩阵519A可提供关于混合音频数据的分量(例如,V矩阵519的向量)的方式的信息,及潜在地,关于由向量传达的数据的各种协同效果的信息。举例来说,V矩阵519A可提供如由 中继到音频编码装置510G的关于由向量表示的各种音频分量的“到达方向”的信息,例如每一音频分量的到达方向。如本文中所使用,术语“音频数据的分量”可与矩阵519或从其导出的任何矩阵中的任一者的“条目”互换使用。
中继到音频编码装置510G的关于由向量表示的各种音频分量的“到达方向”的信息,例如每一音频分量的到达方向。如本文中所使用,术语“音频数据的分量”可与矩阵519或从其导出的任何矩阵中的任一者的“条目”互换使用。
根据本发明的技术的一些实施方案,突出分量分析单元524G可对SHC表示进行补充或增强外来信息以进行本文中描述的各种确定。作为一个实例,突出分量分析单元524G可对SHC增强外来信息以便确定在矩阵519到519C中表示的各种音频分量的突出性。作为另一实例,突出分量分析单元524G及/或向量重排序单元532可对HOA增强外来数据以在相异音频对象与背景音频数据之间区分。
在一些实例中,突出分量分析单元524G可检测音频数据的部分(例如,相异音频对象)显示凯因斯(Keynesian)能量。此些相异对象的实例可与调制的人类话音相关联。在调制的基于话音的音频数据的情况下,突出分量分析单元524G可确定作为与剩余分量的能量的比率的调制数据的能量随时间过去保持大致恒定(例如,在一阈值范围内恒定)或大致固定。传统地,如果具有凯因斯能量的相异音频分量的能量特性(例如,与调制话音相关联的那些能量特性)在音频帧之间改变,则装置可能不能够将一系列音频分量识别为单个信号。然而,突出分量分析单元524G可实施本发明的技术以确定表示为各种矩阵中的向量的距离对象的方向性或孔径。
更具体来说,突出分量分析单元524G可确定例如方向性及/或孔径等特性不大可能跨音频帧实质上改变。如本文所使用,孔径表示在音频数据内的较高阶系数对较低阶系数的比率。V矩阵519A的每一行可包含对应于特定SHC的向量。突出分量分析单元524G可确定较低阶SHC(例如,与小于或等于1的阶数相关联)倾向于表示环境数据,而较高阶条目倾向于表示相异数据。另外,突出分量分析单元524G可确定在许多情况下,较高阶SHC(例如,与大于1的阶数相关联)显示较大能量,且在音频帧间,较高阶SHC与较低阶SHC的能量比率保持实质上类似(或大致恒定)。
突出分量分析单元524G的一或多个组件可使用V矩阵519确定音频数据的特性,例如方向性及孔径。以此方式,音频编码装置510G的组件(例如,突出分量分析单元524G)可实施本文中所描述的技术以使用基于方向性的信息确定突出性及/或将相异音频对象与背景音频区分开。通过使用方向性确定突出性及/或相异性,突出分量分析单元524G可比经配置以使用仅基于能量的数据确定突出性及/或相异性的装置实现更稳健的确定。虽然以上相对于方向性及/或相异性的基于方向性的确定描述,但突出分量分析单元524G可实施本发明的技术以除了其它特性(例如,能量)之外还使用方向性来确定音频数据的特定分量的突出性及/或相异性,如由矩阵519到519C(或从其导出的任何矩阵)中的一或多者的向量表示。
在一些实例中,一种方法包含基于针对音频对象中的一或多者确定的方向性从与所述音频对象相关联的一或多个球谐系数(SHC)识别一或多个相异音频对象。在一个实例中,所述方法进一步包含基于与音频对象相关联的球谐系数确定所述一或多个音频对象的方向性。在一些实例中,所述方法进一步包含执行相对于球谐系数的奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;及将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数,其中确定所述一或多个音频对象的相应方向性是至少部分基于V矩阵。
在一个实例中,所述方法进一步包含将V矩阵的一或多个向量重排序使得在经重排序的V矩阵中,具有较大方向性商的向量定位于具有较小方向性商的向量上方。在一个实例中,所述方法进一步包含确定具有较大方向性商的向量包含比具有较小方向性商的向量大的方向信息。在一个实例中,所述方法进一步包含将V矩阵乘以S矩阵以产生VS矩阵,所述VS矩阵包含一或多个向量。在一个实例中,所述方法进一步包含选择VS矩阵的每一行的与大于1的阶数相关联的条目,将选定条目中的每一者自乘以形成对应的平方条目,且针对VS矩阵的每一行,将所有平方条目求和以确定对应向量的方向性商。
在一些实例中,VS矩阵的每一行包含25个条目。在一个实例中,选择VS矩阵的每一行的与大于1的阶数相关联的条目包含选择开始于VS矩阵的每一行的第5条目且结束于VS矩阵的每一行的第25条目的所有条目。在一个实例中,所述方法进一步包含选择VS矩阵的向量的子集来表示相异音频对象。在一些实例中,选择所述子集包含选择VS矩阵的四个向量,且选定四个向量具有VS矩阵的所有向量的四个最大方向性商。在一个实例中,确定向量的选定子集表示相异音频对象是基于每一向量的方向性及能量两者。
在一些实例中,一种方法包含基于针对音频对象中的一或多者确定的方向性及能量从与所述音频对象相关联的一或多个球谐系数识别一或多个相异音频对象。在一个实例中,所述方法进一步包含基于与音频对象相关联的球谐系数确定所述一或多个音频对象的方向性及能量中的一或两者。在一些实例中,所述方法进一步包含执行相对于表示声场的球谐系数的奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵;及将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数,其中确定所述一或多个音频对象的相应方向性是至少部分基于V矩阵,且其中确定所述一或多个音频对象的相应能量是至少部分基于S矩阵。
在一个实例中,所述方法进一步包含将V矩阵乘以S矩阵以产生VS矩阵,所述VS矩阵包含一或多个向量。在一些实例中,所述方法进一步包含选择VS矩阵的每一行的与大于1的阶数相关联的条目,将选定条目中的每一者自乘以形成对应的平方条目,且针对VS矩阵的每一行,将所有平方条目求和以产生VS矩阵的对应向量的方向性商。在一些实例中,VS矩阵的每一行包含25个条目。在一个实例中,选择VS矩阵的每一行的与大于1的阶数相关联的条目包括选择开始于VS矩阵的每一行的第5条目且结束于VS矩阵的每一行的第25条目的所有条目。在一些实例中,所述方法进一步包含选择向量的子集来表示相异音频对象。在一个实例中,选择所述子集包括选择VS矩阵的四个向量,且选定四个向量具有VS矩阵的所有向量的四个最大方向性商。在一些实例中,确定向量的选定子集表示相异音频对象是基于每一向量的方向性及能量两者。
在一些实例中,一种方法包含使用基于方向性的信息确定描述所述声场的相异分量的一或多个第一向量及描述所述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者是至少通过执行相对于所述多个球谐系数的变换而产生。在一个实例中,所述变换包括奇异值分解,奇异值分解产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵。在一个实例中,变换包括主分量分析以识别声场的相异分量及声场的背景分量。
在一些实例中,一种装置经配置或另外可操作以执行本文所描述的技术中的任一者或所述技术的任一组合。在一些实例中,一种计算机可读存储媒体经编码有指令,所述指令当执行时致使一或多个处理器执行本文所描述的技术中的任一者或所述技术的任一组合。在一些实例中,一种装置包含用以执行本文中所描述的技术中的任一者或所述技术的任一组合的装置。
即,所述技术的前述方面可使音频编码装置510G能够经配置以根据以下条款操作。
条款134954-1B。一种装置,例如音频编码装置510G,其包括:一或多个处理器,其经配置以基于针对音频对象中的一或多者确定的方向性及能量识别来自与音频对象相关联的一或多个球谐系数的一或多个相异音频对象。
条款134954-2B。条款134954-1B的装置,其中所述一或多个处理器进一步经配置以基于与音频对象相关联的球谐系数确定所述一或多个音频对象的方向性及能量中的一或两者。
条款134954-3B。如技术方案1B或2B中任一项或其组合的装置,其中所述一或多个处理器进一步经配置以执行相对于表示声场的球谐系数的奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵,及将所述多个球谐系数表示为U矩阵、S矩阵及V矩阵中的一或多者的至少一部分的函数,其中所述一或多个处理器经配置以至少部分基于V矩阵确定所述一或多个音频对象的相应方向性,且其中所述一或多个处理器经配置以确定所述一或多个音频对象的相应能量是至少部分基于S矩阵。
条款134954-4B。条款134954-3B的装置,其中所述一或多个处理器进一步经配置以将V矩阵乘以S矩阵以产生VS矩阵,所述VS矩阵包含一或多个向量。
条款134954-5B。条款134954-4B的装置,其中所述一或多个处理器进一步经配置以选择VS矩阵的每一行的与大于1的阶数相关联的条目,将选定条目中的每一者自乘以形成对应的平方条目,且针对VS矩阵的每一行,将所有平方条目求和以产生VS矩阵的对应向量的方向性商。
条款134954-6B。如技术方案5B及6B中任一项或其组合的装置,其中VS矩阵的每一行包含25个条目。
条款134954-7B。条款134954-6B的装置,其中所述一或多个处理器经配置以选择开始于VS矩阵的每一行的第5条目且结束于VS矩阵的每一行的第25条目的所有条目。
条款134954-8B。条款134954-6B及条款134954-7B中任一项或其组合的装置,其中所述一或多个处理器进一步经配置以选择向量的子集来表示相异音频对象。
条款134954-9B。条款134954-8B的装置,其中所述一或多个处理器经配置以选择VS矩阵的四个向量,且其中选定四个向量具有VS矩阵的所有向量的四个最大方向性商。
条款134954-10B。条款134954-8B及条款134954-9B中任一项或其组合的装置,其中所述一或多个处理器进一步经配置以确定向量的选定子集表示相异音频对象是基于每一向量的方向性及能量两者。
条款134954-1C。一种装置,例如音频编码装置510G,其包括:一或多个处理器,所述一或多个处理器经配置以使用基于方向性的信息确定描述声场的相异分量的一或多个第一向量及描述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者至少通过执行相对于所述多个球谐系数的变换而产生。
条款134954-2C。条款134954-1C的方法,其中所述变换包括奇异值分解,所述奇异值分解产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数的奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵。
条款134954-3C。条款134954-2C的方法,其进一步包括由条款134954-1A到条款134954-12A及条款134954-1B到134954-9B的任一组合叙述的操作。
条款134954-4C。条款134954-1C的方法,其中所述变换包括主分量分析以识别声场的相异分量及声场的背景分量。
图40H是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510H的框图。音频编码装置510H可类似于音频编码装置510G,因为音频编码装置510H包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510H的音频压缩单元512可类似于音频编码装置510G的音频压缩单元,因为音频压缩单元512包含分解单元518及声场分量提取单元520G,所述单元可类似于音频编码装置510G的同样单元操作。在一些实例中,音频编码装置510H可包含量化单元534(如相对于图40D到40E所描述)以量化UDIST向量525C、UBG向量525D、VT DIST向量525E及VT BG向量525J中的任一者的一或多个向量。
然而,音频编码装置510H的音频压缩单元512可不同于音频编码装置510G的音频压缩单元512,其不同之处在于,音频编码装置510H的音频压缩单元512包含表示为内插单元550的额外单元。内插单元550可表示内插来自第一音频帧的子帧的第一音频帧的子帧及第二时间上后续或先前的音频帧,如以下相对于图45及45B更详细地描述。内插单元550可在执行此内插过程中通过潜在地减小需要分解单元518分解SHC 511的程度来降低计算复杂度(就处理循环及/或存储器消耗而言)。在这方面中,内插单元550可执行类似于以上相对于在图4的实例中展示的音频编码装置24的空间-时间内插单元50描述的操作的操作。
即,由分解单元518执行的奇异值分解潜在地非常具有处理器及/或存储器集中性,同时又在一些实例中,花费大量时间来分解SHC 511,尤其随着SHC 511的阶数增大。为了减少时间量且使SHC 511的压缩更有效率(就处理循环及/或存储器消耗而言),本发明中所描述的技术可提供第一音频帧的一或多个子帧的内插,其中子帧中的每一者可表示SHC511的经分解版本。并不相对于整个帧执行SVD,所述技术可使分解单元518能够分解第一音频帧的第一子帧,从而产生V矩阵519'。
分解单元518还可分解第二音频帧的第二子帧,其中此第二音频帧可时间上在第一音频帧之后或时间上在第一音频帧之前。分解单元518可针对第二音频帧的此子帧输出V矩阵519'。内插单元550可接着基于从第一及第二子帧分解的V矩阵519'内插第一音频帧的剩余子帧,输出V矩阵519、S矩阵519B及U矩阵519C,其中可基于SHC 511、第一音频帧的V矩阵519A及用于第一音频帧的剩余子帧的经内插V矩阵519计算针对剩余子帧的分解。内插可因此避免针对第一音频帧的剩余子帧的分解的计算。
此外,如上所指出,U矩阵519C可不在帧间为连续的,其中可在与从SHC 511的第二音频帧分解的U矩阵519C中不同的行及/或列中指定从SHC 511的第一音频帧分解的U矩阵519C的相异分量。通过执行此内插,如果线性内插可具有可减少归因于帧边界(或换句话说,SHC 511到帧的分段)而引入的任何假象的平滑效应,则可减少不连续性。使用V矩阵519'执行此内插且接着基于经内插V矩阵519'从SHC 511恢复U矩阵519C可使来自重排序U矩阵519C的任何效应平滑。
在操作中,内插单元550可内插来自包含在第一帧中的第一多个球谐系数511的一部分的第一分解(例如,V矩阵519')及包含在第二帧中的第二多个球谐系数511的一部分的第二分解(例如,V矩阵519')的第一音频帧的一或多个子帧以产生用于所述一或多个子帧的经分解的经内插球谐系数。
在一些实例中,第一分解包括表示所述第一多个球谐系数511的部分的右奇异向量的第一V矩阵519'。同样地,在一些实例中,第二分解包含表示所述第二多个球谐系数的部分的右奇异向量的第二V矩阵519'。
内插单元550可基于第一V矩阵519'及第二V矩阵519'相对于所述一或多个子帧执行时间内插。即,内插单元550可基于从第一音频帧的第一子帧分解的V矩阵519'及从第二音频帧的第一子帧分解的V矩阵519'在时间上内插例如来自第一音频帧的四个全部子帧的第二、第三及第四子帧。在一些实例中,此时间内插为线性时间内插,其中当内插第一音频帧的第二子帧时从第一音频帧的第一子帧分解的V矩阵519'比当内插第一音频帧的第四子帧时加权得更重。当内插第三子帧时,可均匀地加权V矩阵519'。当内插第四子帧时,从第二音频帧的第一子帧分解的V矩阵519'可比从第一音频帧的第一子帧分解的V矩阵519'重地加权。
换句话说,给定待内插的第一音频帧的子帧中的一者的接近性,则线性时间内插可加权V矩阵519'。对于待内插的第二子帧,给定从第一音频帧的第一子帧分解的V矩阵519'与待内插的第二子帧的接近性,则可对所述V矩阵519'比对从第二音频帧的第一子帧分解的V矩阵519'重地加权。出于此原因,当基于V矩阵519'内插第三子帧时,权重可等效。给定待内插的第四子帧与接近第一音频帧的第一子帧相比更接近第二音频帧的第一子帧,则应用于从第二音频帧的第一子帧分解的V矩阵519'的权重可大于应用于从第一音频帧的第一子帧分解的V矩阵519'的权重。
虽然在一些实例中,仅使用每一音频帧的第一子帧执行内插,但所述第一多个球谐系数的部分可包括所述第一多个球谐系数511的四个子帧中的两个。在这些及其它实例中,所述第二多个球谐系数511的部分包括所述第二多个球谐系数511的四个子帧中的两个。
如上所指出,单个装置(例如,音频编码装置510H)可在还分解所述第一多个球谐系数的部分的同时执行内插以产生所述第一多个球谐系数的所述部分的第一分解。在这些及其它实例中,分解单元518可分解所述第二多个球谐系数的部分以产生所述第二多个球谐系数的部分的第二分解。虽然相对于单个装置描述,但两个或两个以上装置可执行本发明中所描述的技术,其中所述两个装置中的一者执行分解,且所述装置中的另一者根据本发明中所描述的技术执行内插。
换句话说,就球面上的正交基底函数而言,基于球谐的3D音频可为3D压力场的参数表示。所述表示的阶数N越高,空间分辨率可能地越高,且常常球谐(SH)系数的数目越大(总共(N+1)2个系数)。对于许多应用,可能需要系数的带宽压缩能够有效地传输且存储所述系数。在本发明中所针对的此技术可提供使用奇异值分解(SVD)的基于帧的维度减少过程。SVD分析可将系数的每一帧分解成三个矩阵U、S及V。在一些实例中,所述技术可将U中的向量中的一些作为基础声场的方向分量处置。然而,当以此方式处置时,这些向量(在U中)在帧间是不连续的--即使其表示同一相异音频分量。当通过变换音频译码器馈入所述分量时,这些不连续性可导致显著假象。
本发明中所描述的技术可解决此不连续性。即,所述技术可基于以下观测结果:V矩阵可经解译为球谐域中的正交空间轴。U矩阵可表示球谐(HOA)数据根据那些基底函数的投影,其中不连续性可归因于基底函数(V),所述基底函数(V)改变每一帧且因此自身为不连续的。这不同于例如傅立叶变换的类似分解,其中基底函数在一些实例中在帧间将为常数。在这些术语中,SVD可认为是匹配追求算法。本发明中所描述的技术可使内插单元550能够通过在其间进行内插而在帧间维持基底函数(V)之间的连续性。
在一些实例中,所述技术使内插单元550能够将SH数据的帧划分成四个子帧,如上所述且以下相对于图45及45B进一步描述。内插单元550可接着计算第一子帧的SVD。类似地,我们计算第二帧的第一子帧的SVD。对于第一帧及第二帧中的每一者,内插单元550可通过将向量投影到球面上(使用例如T设计矩阵的投影矩阵)将V中的向量转换到空间映射。内插单元550可接着将V中的向量解译为球面上的形状。为了在第一帧的第一子帧与下一个帧的第一子帧之间内插三个子帧的V矩阵,内插单元550可接着内插这些空间形状,且接着经由投影矩阵的逆将其变换回到SH向量。以此方式,本发明的技术可提供V矩阵之间的平滑转变。
以此方式,音频编码装置510H可经配置以执行以下相对于下列条款阐明的技术的各种方面。
条款135054-1A。一种装置,例如音频编码装置510H,其包括:一或多个处理器,所述一或多个处理器经配置以内插来自包含在第一帧中的第一多个球谐系数的一部分的第一分解及包含在第二帧中的第二多个球谐系数的一部分的第二分解的第一帧的一或多个子帧以产生用于所述一或多个子帧的经分解的经内插球谐系数。
条款135054-2A。条款135054-1A的装置,其中所述第一分解包括表示所述第一多个球谐系数的部分的右奇异向量的第一V矩阵。
条款135054-3A。条款135054-1A的装置,其中所述第二分解包括表示所述第二多个球谐系数的部分的右奇异向量的第二V矩阵。
条款135054-4A。条款135054-1A的装置,其中第一分解包括表示所述第一多个球谐系数的部分的右奇异向量的第一V矩阵,且其中第二分解包含表示所述第二多个球谐系数的部分的右奇异向量的第二V矩阵。
条款135054-5A。条款135054-1A的装置,其中所述一或多个处理器进一步经配置以当内插一或多个子帧时,基于第一分解及第二分解在时间上内插所述一或多个子帧。
条款135054-6A。条款135054-1A的装置,其中所述一或多个处理器进一步经配置以当内插一或多个子帧时,将第一分解投影到空间域中以产生第一投影分解,将第二分解投影到空间域中以产生第二投影分解,空间上内插第一投影分解及第二投影分解以产生第一空间内插的投影分解及第二空间内插的投影分解,及基于第一空间内插的投影分解及第二空间内插的投影分解在时间上内插所述一或多个子帧。
条款135054-7A。条款135054-6A的装置,其中所述一或多个处理器进一步经配置以将从内插所述一或多个子帧产生的时间上内插的球谐系数投影回到球谐域。
条款135054-8A。条款135054-1A的装置,其中所述第一多个球谐系数的所述部分包括所述第一多个球谐系数的单个子帧。
条款135054-9A。条款135054-1A的装置,其中所述第二多个球谐系数的所述部分包括所述第二多个球谐系数的单个子帧。
条款135054-10A。条款135054-1A的装置,
其中所述第一帧经划分成四个子帧,且
其中所述第一多个球谐系数的所述部分仅包括所述第一多个球谐系数的所述第一子帧。
条款135054-11A。条款135054-1A的装置,
其中所述第二帧经划分成四个子帧,且
其中所述第二多个球谐系数的所述部分仅包括所述第二多个球谐系数的所述第一子帧。
条款135054-12A。条款135054-1A的装置,其中所述第一多个球谐系数的所述部分包括所述第一多个球谐系数的四个子帧中的两个。
条款135054-13A。条款135054-1A的装置,其中所述第二多个球谐系数的所述部分包括所述第二多个球谐系数的四个子帧中的两个。
条款135054-14A。条款135054-1A的装置,其中所述一或多个处理器进一步经配置以分解所述第一多个球谐系数的所述部分以产生所述第一多个球谐系数的所述部分的第一分解。
条款135054-15A。条款135054-1A的装置,其中所述一或多个处理器进一步经配置以分解所述第二多个球谐系数的所述部分以产生所述第二多个球谐系数的所述部分的第二分解。
条款135054-16A。条款135054-1A的装置,其中所述一或多个处理器进一步经配置以执行相对于所述第一多个球谐系数的所述部分的奇异值分解以产生表示所述第一多个球谐系数的左奇异向量的U矩阵、表示所述第一多个球谐系数的奇异值的S矩阵及表示所述第一多个球谐系数的右奇异向量的V矩阵。
条款135054-17A。条款135054-1A的装置,其中所述一或多个处理器进一步经配置以执行相对于所述第二多个球谐系数的所述部分的奇异值分解以产生表示所述第二多个球谐系数的左奇异向量的U矩阵、表示所述第二多个球谐系数的奇异值的S矩阵及表示所述第二多个球谐系数的右奇异向量的V矩阵。
条款135054-18A。条款135054-1A的装置,其中所述第一及第二多个球谐系数各自表示声场的平面波表示。
条款135054-19A。条款135054-1A的装置,其中所述第一及第二多个球谐系数各自表示混合在一起的一或多个单声道音频对象。
条款135054-20A。条款135054-1A的装置,其中所述第一及第二多个球谐系数各自包含表示三维声场的相应第一及第二球谐系数。
条款135054-21A。条款135054-1A的装置,其中所述第一及第二多个球谐系数各自与具有大于一的阶数的至少一个球面基底函数相关联。
条款135054-22A。条款135054-1A的装置,其中所述第一及第二多个球谐系数各自与具有等于四的阶数的至少一个球面基底函数相关联。
虽然以上描述为由音频编码装置510H执行,但各种音频解码装置24及540也可执行以上相对于条款135054-1A到135054-22A阐明的技术的各种方面中的任一者。
图40I是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510I的框图。音频编码装置510I可类似于音频编码装置510H,因为音频编码装置510I包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510I的音频压缩单元512可类似于音频编码装置510H的音频压缩单元,因为音频压缩单元512包含分解单元518及声场分量提取单元520,所述单元可类似于音频编码装置510H的同样单元操作。在一些实例中,音频编码装置10I可包含量化单元34(如相对于图3D到3E所描述)以量化UDIST 25C、UBG 25D、VT DIST25E及VT BG 25J中的任一者的一或多个向量。
然而,虽然音频编码装置510I的音频压缩单元512及音频编码装置10H的音频压缩单元512两者包含声场分量提取单元,但音频编码装置510I的声场分量提取单元520I可包含被称作V压缩单元552的额外模块。V压缩单元552可表示经配置以压缩声场的空间分量(即,在此实例中为VT DIST向量539中的一或多者)的单元。即,相对于SHC执行的奇异值分解可将SHC(其表示声场)分解成由S矩阵的向量表示的能量分量、由U矩阵表示的时间分量及由V矩阵表示的空间分量。V压缩单元552可执行类似于以上相对于量化单元52所描述的操作的操作。
出于实例的目的,假定VT DIST向量539包括各具有25个元素的两个行向量(其暗示声场的四阶HOA表示)。尽管相对于两个行向量来描述,但任何数目个向量可包含在VT DIST向量539中,至多为(n+1)2个,其中n表示声场的HOA表示的阶数。
V压缩单元552可接收VT DIST向量539,且执行压缩方案以产生经压缩的VT DIST向量表示539'。此压缩方案通常可涉及用于压缩向量或数据的元素的任何可设想压缩方案,且不应限于以下更详细描述的实例。
作为一实例,V压缩单元552可执行包含下列中的一或多者的压缩方案:将VT DIST向量539的每一元素的浮点表示变换到VT DIST向量539的每一元素的整数表示、VT DIST向量539的整数表示的均匀量化以及VT DIST向量539的经量化整数表示的分类及译码。此压缩方案的一或多个过程中的各者可由参数动态控制以实现或几乎实现(作为一个实例)针对所得位流517的目标位速率。
假定VT DIST向量539中的每一者相互正交,则VT DIST向量539中的每一者可独立地译码。在一些实例中,如下文更详细地所描述,可使用同一译码模式(由各种子模式定义)译码每一VT DIST向量539的每一元素。
在任何情况下,如上文所指出,此译码方案可首先涉及将VT DIST向量539中的每一者的每一元素的浮点表示(其在一些实例中为32位浮点数)变换为16位整数表示。V压缩单元552可通过将VT DIST向量539中的给定一者的每一元素乘以215(在一些实例中,其通过右移15而执行)来执行此浮点到整数变换。
V压缩单元552可接着执行相对于VT DIST向量539中的所述给定一者的所有元素的均匀量化。V压缩单元552可基于可表示为nbits参数的值而识别量化步长。V压缩单元552可基于目标位速率动态确定此nbits参数。V压缩单元552可确定作为此nbits参数的函数的量化步长。作为一个实例,V压缩单元552可将量化步长(在本发明中表示为“差量”或“Δ”)确定为等于216-nbits。在此实例中,如果nbits等于六,则差量等于210,且存在26个量化层级。在这方面中,对于向量元素v,经量化向量元素vq等于[v/Δ],且-2nbits-1<vq<2nbits-1。
V压缩单元552可接着执行经量化向量元素的分类及残余译码。作为一个实例,V压缩单元552可使用以下方程式对于一给定经量化向量元素vq识别此元素所对应的类别(通过确定类别识别符cid):

V压缩单元552可接着对此类别索引cid进行霍夫曼译码,同时也识别指示vq为正值还是负值的正负号位。V压缩单元552接下来可识别此类别中的残余。作为一个实例,V压缩单元552可根据以下方程式确定此残余:
残余=|vq|-2cid-1
V压缩单元552可接着用cid-1个位对此残余进行块译码。
以下实例说明此分类及残余译码过程的简化实例过程。首先,假定nbits等于六以使得vq∈[-31,31]。接下来,假定以下:


又,假定以下:
| cid | 用于残余的块码 |
| 0 | 不可用 |
| 1 | 0,1 |
| 2 | 01,00,10,11 |
| 3 | 011,010,001,000,100,101,110,111 |
| 4 | 0111,0110...,0000,1000,...,1110,1111 |
| 5 | 01111,...,00000,10000,...,11111 |
因而,对于vq=[6,-17,0,0,3],可确定以下:
>>cid=3,5,0,0,2
>>sign=l,0,x,x,l
>>残余=2,1,x,x,1
>>用于6的位=‘0010’+‘1’+‘10’
>>用于-17的位=‘00111’+‘0’+‘0001’
>>用于0的位=‘0’
>>用于0的位=‘0’
>>用于3的位=‘000’+‘l’+‘l’
>>总共位=7+10+1+1+5=24
>>平均位=24/5=4.8
尽管未展示于先前简化实例中,但V压缩单元552可在对cid进行译码时针对nbits的不同值选择不同霍夫曼码簿。在一些实例中,V压缩单元552可提供针对nbits值6、……、15的不同霍夫曼译码表。此外,V压缩单元552可包含用于范围从6、……、15的不同nbits值中的每一者的五个不同霍夫曼码簿,一共50个霍夫曼码簿。在这方面中,V压缩单元552可包含多个不同霍夫曼码簿以适应在许多不同统计情境中的cid的译码。
为了说明,V压缩单元552可针对nbits值中的每一者包含用于译码向量元素一到四的第一霍夫曼码簿、用于译码向量元素五到九的第二霍夫曼码簿、用于译码向量元素九及以上的第三霍夫曼码簿。当待压缩的VT DIST向量539中的一者未从VT DIST向量539中的时间上后续对应一者预测且不表示合成音频对象(例如,原先由脉码调制(PCM)音频对象定义的一个合成音频对象)的空间信息时,可使用这前三个霍夫曼码簿。V压缩单元552可另外对于nbits值中的每一者包含用于译码VT DIST向量539中的所述一者的第四霍夫曼码簿(当VT DIST向量539中的此一者是从VT DIST向量539的时间上后续的对应一者预测时)。V压缩单元552对于nbits值中的每一者还可包含用于译码VT DIST向量539中的所述一者的第五霍夫曼码簿(当VT DIST向量539中的此一者表示合成音频对象时)。可针对这些不同统计情境(即,在此实例中,非预测及非合成情境、预测情境及合成情境)中的每一者开发各种霍夫曼码簿。
下表说明霍夫曼表选择及待于位流中指定以使得解压缩单元能够选择适当霍夫曼表的位:
| 预测模式 | HT信息 | HT表 |
| 0 | 0 | HT5 |
| 0 | 1 | HT{1,2,3} |
| 1 | 0 | HT4 |
| 1 | 1 | HT5 |
在前表中,预测模式(“Pred模式”)指示是否针对当前向量执行了预测,而霍夫曼表(“HT信息”)指示用以选择霍夫曼表一到五中的一者的额外霍夫曼码簿(或表)信息。
下表进一步说明此霍夫曼表选择过程(假定各种统计情景或情形)。
| 记录 | 合成 | |
| 无预测 | HT{1,2,3} | HT5 |
| 有预测 | HT4 | HT5 |
在前表中,“记录”列指示向量表示所记录的音频对象时的译码情境,而“合成”列指示向量表示合成音频对象时的译码情境。“无预测”行指示并不相对于向量元素执行预测时的写译码情境,而“有预测”行指示相对于向量元素执行预测时的译码情境。如此表中所示,V压缩单元552在向量表示所记录音频对象且不相对于向量元素执行预测时选择HT{1,2,3}。V压缩单元552在音频对象表示合成音频对象且不相对于向量元素执行预测时选择HT5。V压缩单元552在向量表示所记录音频对象且相对于向量元素执行预测时选择HT4。V压缩单元552在音频对象表示合成音频对象且相对于向量元素执行预测时选择HT5。
以此方式,所述技术可使音频压缩装置能够压缩声场的空间分量,其中空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
图43是更详细地说明图40I中所示的V压缩单元552的图。在图43的实例中,V压缩单元552包含均匀量化单元600、nbits单元602、预测单元604、预测模式单元606(“预测模式单元606”)、类别及残余译码单元608及霍夫曼表选择单元610。均匀量化单元600表示经配置以执行以上相对于在图43的实例中表示为v的空间分量中的一者(其可表示VT DIST向量539中的任一者)所描述的均匀量化的单元。nbits单元602表示经配置以确定nbits参数或值的单元。
预测单元604表示经配置以执行相对于在图43的实例中表示为vq的经量化空间分量的预测的单元。预测单元604可通过执行将VT DIST向量539的当前一者逐个元素减去VT DIST向量539的时间上后续对应一者来执行预测。此预测的结果可被称作预测空间分量。
预测模式单元606可表示经配置以选择预测模式的单元。霍夫曼表选择单元610可表示经配置以选择适当霍夫曼表用于cid的译码的单元。作为一个实例,预测模式单元606及霍夫曼表选择单元610可根据以下伪码操作:


类别及残余译码单元608可表示经配置以按以上更详细地描述的方式执行经预测空间分量或经量化空间分量(当预测停用时)的分类及残余译码的单元。
如图43的实例中所示,V压缩单元552可输出各种参数或值用于包含于位流517或辅助信息(其可自身为与位流517分开的位流)中。假定在位流517中指定所述信息,则V压缩单元单元可将nbits值、预测模式及霍夫曼表信息连同空间分量(在图40I的实例中展示为经压缩空间分量539')的经压缩版本输出到位流产生单元516,在此实例中,所述空间分量可指经选择以编码cid、正负号位及经块译码残余的霍夫曼码。可针对所有VT DIST向量539在位流517中指定nbits值一次,但可针对向量539中的每一者指定预测模式及霍夫曼表信息。指定空间分量的经压缩版本的位流的部分展示于图10B及10C的实例中。
以此方式,音频编码装置510H可执行以下相对于下列条款阐明的技术的各种方面。
条款141541-1A。一种装置,例如音频编码装置510H,其包括:一或多个处理器,所述一或多个处理器经配置以获得包含声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2A。条款141541-1A的装置,其中空间分量的经压缩版本是至少部分使用指定当压缩空间分量时使用的预测模式的字段表示于位流中。
条款141541-3A。条款141541-1A及条款141541-2A的任一组合的装置,其中空间分量的经压缩版本是至少部分使用指定当压缩空间分量时使用的霍夫曼表的霍夫曼表信息表示于位流中。
条款141541-4A。条款141541-1A到条款141541-3A的任一组合的装置,其中空间分量的经压缩版本是至少部分使用指示表达当压缩空间分量时使用的量化步长或其变量的值的字段表示于位流中。
条款141541-5A。条款141541-4A的装置,其中所述值包括nbits值。
条款141541-6A。条款141541-4A及条款141541-5A的任一组合的装置,其中所述位流包括声场(包含其空间分量的经压缩版本)的多个空间分量的经压缩版本,且其中所述值表达当压缩所述多个空间分量时使用的量化步长或其变量。
条款141541-7A。条款141541-1A到条款141541-6A的任一组合的装置,其中空间分量的经压缩版本是至少部分使用霍夫曼码以表示识别空间分量对应于的压缩类别的类别识别符来表示于位流中。
条款141541-8A。条款141541-1A到条款141541-7A的任一组合的装置,其中空间分量的经压缩版本是至少部分使用识别空间分量为正值或是负值的正负号位元表示于位流中。
条款141541-9A。条款141541-1A到条款141541-8A的任一组合的装置,其中空间分量的经压缩版本是至少部分使用霍夫曼码以表示空间分量的残余值来表示于位流中。
条款141541-10A。条款141541-1A到条款141541-9A的任一组合的装置,其中所述装置包括音频编码装置位流产生装置。
条款141541-12A。条款141541-1A到条款141541-11A的任一组合的装置,其中基于向量的合成包括奇异值分解。
虽然描述为由音频编码装置510H执行,但所述技术也可以由音频解码装置24及/或540中的任一者执行。
以此方式,音频编码装置510H可另外执行以下相对于下列条款阐明的技术的各种方面。
条款141541-1D。一种装置,例如音频编码装置510H,其包括:一或多个处理器,所述一或多个处理器经配置以产生包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2D。条款141541-1D的装置,其中所述一或多个处理器进一步经配置以当产生位流时产生包含指定当压缩空间分量时使用的预测模式的字段的位流。
条款141541-3D。条款141541-1D及条款141541-2D的任一组合的装置,其中所述一或多个处理器进一步经配置以当产生位流时,产生包含指定当压缩空间分量时使用的霍夫曼表的霍夫曼表信息的位流。
条款141541-4D。条款141541-1D到条款141541-3D的任一组合的装置,其中所述一或多个处理器进一步经配置以当产生位流时,产生包含指示表达当压缩空间分量时使用的量化步长或其变量的值的字段的位流。
条款141541-5D。条款141541-4D的装置,其中所述值包括nbits值。
条款141541-6D。条款141541-4D及条款141541-5D的任一组合的装置,其中所述一或多个处理器进一步经配置以当产生位流时,产生包含声场(包含其空间分量的经压缩版本)的多个空间分量的经压缩版本的位流,且其中所述值表达当压缩所述多个空间分量时使用的量化步长或其变量。
条款141541-7D。条款141541-1D到条款141541-6D的任一组合的装置,其中所述一或多个处理器进一步经配置以当产生位流时,产生包含表示识别空间分量对应于的压缩类别的类别识别符的霍夫曼码的位流。
条款141541-8D。条款141541-1D到条款141541-7D的任一组合的装置,其中所述一或多个处理器进一步经配置以当产生位流时,产生包含识别空间分量为正值或是负值的正负号位的位流。
条款141541-9D。条款141541-1D到条款141541-8D的任一组合的装置,其中所述一或多个处理器进一步经配置以当产生位流时,产生包含表示空间分量的残余值的霍夫曼码的位流。
条款141541-10D。条款141541-1D到条款141541-10D的任一组合的装置,其中基于向量的合成包括奇异值分解。
音频编码装置510H可进一步经配置以实施如在下列条款中阐明的技术的各种方面。
条款141541-1E。一种装置,例如音频编码装置510H,其包括:一或多个处理器,所述一或多个处理器经配置以压缩声场的空间分量,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2E。条款141541-1E的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,将空间分量从浮点表示转换到整数表示。
条款141541-3E。条款141541-1E及条款141541-2E的任一组合的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,动态确定指示量化步长的值,且基于所述值量化空间分量以产生经量化空间分量。
条款141541-4E。如技术方案1E到3E的任一组合的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,识别空间分量对应于的类别。
条款141541-5E。条款141541-1E及条款141541-4E的任一组合的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,识别所述空间分量的残余值。
条款141541-6E。条款141541-1E到条款141541-5E的任一组合的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,执行相对于空间分量及后续空间分量的预测以产生经预测空间分量。
条款141541-7E。条款141541-1E的任一组合的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,将空间分量从浮点表示转换到整数表示,动态确定指示量化步长的值,且基于所述值量化空间分量的整数表示以产生经量化空间分量,基于经量化空间分量识别所述空间分量对应于的类别以产生类别识别符,确定所述空间分量的正负号,基于经量化空间分量及类别识别符识别所述空间分量的残余值,及基于类别识别符、正负号及残余值产生空间分量的经压缩版本。
条款141541-8E。条款141541-1E的任一组合的装置,其中所述一或多个处理器进一步经配置以当压缩空间分量时,将空间分量从浮点表示转换到整数表示,动态确定指示量化步长的值,基于所述值量化空间分量的整数表示以产生经量化空间分量,执行相对于空间分量及后续空间分量的预测以产生经预测空间分量,基于经量化空间分量识别经预测空间分量对应于的类别以产生类别识别符,确定所述空间分量的正负号,基于经量化空间分量及类别识别符识别所述空间分量的残余值,及基于类别识别符、正负号及残余值产生空间分量的经压缩版本。
条款141541-9E。条款141541-1E到条款141541-8E的任一组合的装置,其中基于向量的合成包括奇异值分解。
所述技术的各种方面可此外使音频编码装置510H能够经配置以如在下列条款中所阐明而操作。
条款141541-1F。一种装置,例如音频编码装置510H,其包括:一或多个处理器,所述一或多个处理器经配置以基于多个空间分量中当前空间分量相对于所述多个空间分量中的其余者的阶数识别霍夫曼码簿以当压缩所述当前空间分量时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2F。条款141541-3F的装置,其中所述一或多个处理器进一步经配置以执行条款141541-1A到条款141541-12A、条款141541-1B到条款141541-10B及条款141541-1C到条款141541-9C中叙述的步骤的任一组合。
所述技术的各种方面可此外使音频编码装置510H能够经配置以如在下列条款中所阐明而操作。
条款141541-1H。一种装置,例如音频编码装置510H,其包括:一或多个处理器,所述一或多个处理器经配置以确定待在压缩声场的空间分量时使用的量化步长,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2H。条款141541-1H的装置,其中所述一或多个处理器进一步经配置以当确定量化步长时,基于目标位速率确定量化步长。
条款141541-3H。条款141541-1H的装置,其中所述一或多个处理器进一步经配置以当选择多个量化步长中的一者时,确定用以表示空间分量的位的数目的估计,及基于估计与目标位速率之间的差确定量化步长。
条款141541-4H。条款141541-1H的装置,其中所述一或多个处理器进一步经配置以当选择多个量化步长中的一者时,确定用以表示空间分量的位的数目的估计,确定估计与目标位速率之间的差,及通过将所述差与目标位速率相加来确定量化步长。
条款141541-5H。条款141541-3H或条款141541-4H的装置,其中所述一或多个处理器进一步经配置以当确定位数目的估计时,计算待针对空间分量产生的位数目的估计(给定对应于目标位速率的码簿)。
条款141541-6H。条款141541-3H或条款141541-4H的装置,其中所述一或多个处理器进一步经配置以当确定位数目的估计时,计算待针对空间分量产生的位数目的估计(给定当压缩空间分量时使用的译码模式)。
条款141541-7H。条款141541-3H或条款141541-4H的装置,其中所述一或多个处理器进一步经配置以当确定位数目的估计时,计算待针对空间分量产生的位数目的第一估计(给定待在压缩空间分量时使用的第一译码模式),计算待针对空间分量产生的位数目的第二估计(给定待在压缩空间分量时使用的第二译码模式),选择第一估计及第二估计中具有待用作位数目的经确定估计的最小位数目的一者。
条款141541-8H。条款141541-3H或条款141541-4H的装置,其中所述一或多个处理器进一步经配置以当确定位数目的估计时,识别识别空间分量对应于的类别的类别识别符,识别当压缩对应于类别的空间分量时将产生的用于空间分量的残余值的位长度,及通过至少部分将用以表示类别识别符的位数目与残余值的位长度相加来确定位数目的估计。
条款141541-9H。条款141541-1H到条款141541-8H的任一组合的装置,其中基于向量的合成包括奇异值分解。
虽然描述为由音频编码装置510H执行,但以上条款条款141541-1H到条款141541-9H中阐明的技术也可由音频解码装置540D执行。
另外,所述技术的各种方面可使音频编码装置510H能够经配置以如在下列条款中所阐明而操作。
条款141541-1J。一种装置,例如音频编码装置510J,其包括:一或多个处理器,所述一或多个处理器经配置以选择待在压缩声场的空间分量时使用的多个码簿中的一者,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2J。条款141541-1J的装置,其中所述一或多个处理器进一步经配置以当选择多个码簿中的一者时,使用所述多个码簿中的每一者确定用以表示空间分量的位数目的估计,及选择所述多个码簿中导致具有最小位数目的经确定估计的一者。
条款141541-3J。条款141541-1J的装置,其中所述一或多个处理器进一步经配置以当选择多个码簿中的一者时,使用多个码簿中的一或多者确定用以表示空间分量的位数目的估计,所述多个码簿中的所述一或多者是基于待压缩的空间分量的元素相对于空间分量的其它元素的阶数而选择。
条款141541-4J。条款141541-1J的装置,其中所述一或多个处理器进一步经配置以当选择多个码簿中的一者时,使用经设计以当不从后续空间分量预测所述空间分量时使用的多个码簿中的一者确定用以表示空间分量的位数目的估计。
条款141541-5J。条款141541-1J的装置,其中所述一或多个处理器进一步经配置以当选择多个码簿中的一者时,使用经设计以当从后续空间分量预测所述空间分量时使用的多个码簿中的一者确定用以表示空间分量的位数目的估计。
条款141541-6J。条款141541-1J的装置,其中所述一或多个处理器进一步经配置以当选择多个码簿中的一者时,使用经设计以当空间分量表示声场中的合成音频对象时使用的多个码簿中的一者确定用以表示空间分量的位数目的估计。
条款141541-7J。条款141541-1J的装置,其中所述合成音频对象包括经脉码调制(PCM)的音频对象。
条款141541-8J。条款141541-1J的装置,其中所述一或多个处理器进一步经配置以当选择多个码簿中的一者时,使用经设计以当空间分量表示声场中的经记录音频对象时使用的多个码簿中的一者确定用以表示空间分量的位数目的估计。
条款141541-9J。技术方案1J到8J的任一组合的装置,其中基于向量的合成包括奇异值分解。
在上述各种实例中的每一者中,应理解,音频编码装置510可执行方法,或另外包括执行音频编码装置510经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频编码装置510已经配置以执行的方法。
图40J是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频编码装置510J的框图。音频编码装置510J可类似于音频编码装置510G,因为音频编码装置510J包含音频压缩单元512、音频编码单元514及位流产生单元516。此外,音频编码装置510J的音频压缩单元512可类似于音频编码装置510G的音频压缩单元,因为音频压缩单元512包含分解单元518及声场分量提取单元520,所述单元可类似于音频编码装置510I的同样单元操作。在一些实例中,音频编码装置510J可包含量化单元534(如相对于图40D到40E所描述)以量化UDIST向量525C、UBG向量525D、VT DIST向量525E及VT BG向量525J中的任一者的一或多个向量。
然而,音频编码装置510J的音频压缩单元512可不同于音频编码装置510G的音频压缩单元512,其不同之处在于,音频编码装置510J的音频压缩单元512包含表示为内插单元550的额外单元。内插单元550可表示内插来自第一音频帧的子帧的第一音频帧的子帧及第二时间上后续或先前的音频帧,如以下相对于图45及45B更详细地描述。内插单元550可在执行此内插过程中通过潜在地减小需要分解单元518分解SHC 511的程度来降低计算复杂度(就处理循环及/或存储器消耗而言)。内插单元550可按类似于以上相对于在图40H及40I的实例中展示的音频编码装置510H及510I的内插单元550描述的方式的方式操作。
在操作中,内插单元200可内插来自包含在第一帧中的第一多个球谐系数11的一部分的第一分解(例如,V矩阵19')及包含在第二帧中的第二多个球谐系数11的一部分的第二分解(例如,V矩阵19')的第一音频帧的一或多个子帧以产生用于所述一或多个子帧的经分解的经内插球谐系数。
内插单元550可至少部分通过相对于第一多个球谐系数的第一分解及第二多个球谐系数的第二分解执行内插而获得一时间片段的经分解的经内插球谐系数。平滑单元554可应用经分解的经内插球谐系数以使所述第一多个球谐系数及所述第二多个球谐系数的空间分量及时间分量中的至少一者平滑。平滑单元554可产生经平滑的UDIST矩阵525C',如上相对于图37到39所描述。第一及第二分解可参照图40J中的V1 T556、V2 T556B。
在一些情况下,VT或其它V向量或V矩阵可以经量化版本输出以用于内插。以此方式,用于内插的V向量可与解码器处的V向量相同,解码器也可执行V向量内插,例如以恢复多维信号。
在一些实例中,第一分解包括表示所述第一多个球谐系数511的部分的右奇异向量的第一V矩阵519'。同样地,在一些实例中,第二分解包含表示所述第二多个球谐系数的部分的右奇异向量的第二V矩阵519'。
内插单元550可基于第一V矩阵519'及第二V矩阵19'相对于所述一或多个子帧执行时间内插。即,内插单元550可基于从第一音频帧的第一子帧分解的V矩阵519'及从第二音频帧的第一子帧分解的V矩阵519'在时间上内插例如来自第一音频帧的四个全部子帧的第二、第三及第四子帧。在一些实例中,此时间内插为线性时间内插,其中当内插第一音频帧的第二子帧时从第一音频帧的第一子帧分解的V矩阵519'比当内插第一音频帧的第四子帧时加权得更重。当内插第三子帧时,可均匀地加权V矩阵519'。当内插第四子帧时,从第二音频帧的第一子帧分解的V矩阵519'可比从第一音频帧的第一子帧分解的V矩阵519'重地加权。
换句话说,给定待内插的第一音频帧的子帧中的一者的接近性,则线性时间内插可加权V矩阵519'。对于待内插的第二子帧,给定从第一音频帧的第一子帧分解的V矩阵519'与待内插的第二子帧的接近性,则可对所述V矩阵519'比对从第二音频帧的第一子帧分解的V矩阵519'重地加权。出于此原因,当基于V矩阵519'内插第三子帧时,权重可等效。给定待内插的第四子帧与接近第一音频帧的第一子帧相比更接近第二音频帧的第一子帧,则应用于从第二音频帧的第一子帧分解的V矩阵519'的权重可大于应用于从第一音频帧的第一子帧分解的V矩阵519'的权重。
在一些实例中,内插单元550可将从第一音频帧的第一子帧分解的第一V矩阵519'投影到空间域中以产生第一经投影分解。在一些实例中,此投影包含到球面中的投影(例如,使用投影矩阵,例如T设计矩阵)。内插单元550可接着将从第二音频帧的第一子帧分解的第二V矩阵519'投影到空间域中以产生第二经投影分解。内插单元550可接着空间内插(其再次可为线性内插)第一经投影分解及第二经投影分解以产生第一空间内插的经投影分解及第二空间内插的经投影分解。内插单元550可接着基于第一空间内插的经投影分解及第二空间内插的经投影分解在时间上内插所述一或多个子帧。
在内插单元550空间且接着时间投影V矩阵519'的那些实例中,内插单元550可将从内插所述一或多个子帧产生的时间内插球谐系数投影回到球谐域,进而产生V矩阵519、S矩阵519B及U矩阵519C。
在一些实例中,所述第一多个球谐系数的部分包含所述第一多个球谐系数511的单个子帧。在一些实例中,所述第二多个球谐系数的部分包括所述第二多个球谐系数511的单个子帧。在一些实例中,V矩阵19'分解自的此单个子帧为第一子帧。
在一些实例中,第一帧经划分成四个子帧。在这些和其它实例中,所述第一多个球谐系数的部分仅包括所述多个球谐系数511的第一子帧。在这些和其它实例中,第二帧经划分成四个子帧,且所述第二多个球谐系数511的部分仅包括所述第二多个球谐系数511的第一子帧。
虽然在一些实例中,仅使用每一音频帧的第一子帧执行内插,但所述第一多个球谐系数的部分可包括所述第一多个球谐系数511的四个子帧中的两个。在这些及其它实例中,所述第二多个球谐系数511的部分包括所述第二多个球谐系数511的四个子帧中的两个。
如上所指出,单个装置(例如,音频编码装置510J)可在还分解所述第一多个球谐系数的部分的同时执行内插以产生所述第一多个球谐系数的所述部分的第一分解。在这些及其它实例中,分解单元518可分解所述第二多个球谐系数的部分以产生所述第二多个球谐系数的部分的第二分解。虽然相对于单个装置描述,但两个或两个以上装置可执行本发明中所描述的技术,其中所述两个装置中的一者执行分解,且所述装置中的另一者根据本发明中所描述的技术执行内插。
在一些实例中,分解单元518可相对于所述第一多个球谐系数511的部分执行奇异值分解以产生表示所述第一多个球谐系数511的右奇异向量的V矩阵519'(以及S矩阵519B'及U矩阵519C',为了易于说明的目的其未展示)。在这些和其它实例中,分解单元518可相对于所述第二多个球谐系数511的部分执行奇异值分解以产生表示所述第二多个球谐系数511的右奇异向量的V矩阵519'(以及S矩阵519B'及U矩阵519C',为了易于说明的目的其未展示)。
在一些实例中,如上所指出,所述第一及第二多个球谐系数各自表示声场的平面波表示。在这些和其它实例中,所述第一及第二多个球谐系数511各自表示混合在一起的一或多个单声道音频对象。
换句话说,就球面上的正交基底函数而言,基于球谐的3D音频可为3D压力场的参数表示。所述表示的阶数N越高,空间分辨率可能地越高,且常常球谐(SH)系数的数目越大(总共(N+1)2个系数)。对于许多应用,可能需要系数的带宽压缩能够有效地传输且存储所述系数。在本发明中所针对的此技术可提供使用奇异值分解(SVD)的基于帧的维度减少过程。SVD分析可将系数的每一帧分解成三个矩阵U、S及V。在一些实例中,所述技术可将U中的向量中的一些作为基础声场的方向分量处置。然而,当以此方式处置时,这些向量(在U中)在帧间是不连续的--即使其表示同一相异音频分量。当通过变换音频译码器馈入所述分量时,这些不连续性可导致显著假象。
本发明中所描述的技术可解决此不连续性。即,所述技术可基于以下观测结果:V矩阵可经解译为球谐域中的正交空间轴。U矩阵可表示球谐(HOA)数据根据那些基底函数的投影,其中不连续性可归因于基底函数(V),所述基底函数(V)改变每一帧且因此自身为不连续的。这不同于例如傅立叶变换的类似分解,其中基底函数在一些实例中在帧间将为常数。在这些术语中,SVD可认为是匹配追求算法。本发明中所描述的技术可使内插单元550能够通过在其间进行内插而在帧间维持基底函数(V)之间的连续性。
在一些实例中,所述技术使内插单元550能够将SH数据的帧划分成四个子帧,如上所述且以下相对于图45及45B进一步描述。内插单元550可接着计算第一子帧的SVD。类似地,我们计算第二帧的第一子帧的SVD。对于第一帧及第二帧中的每一者,内插单元550可通过将向量投影到球面上(使用例如T设计矩阵的投影矩阵)将V中的向量转换到空间映射。内插单元550可接着将V中的向量解译为球面上的形状。为了在第一帧的第一子帧与下一个帧的第一子帧之间内插三个子帧的V矩阵,内插单元550可接着内插这些空间形状,且接着经由投影矩阵的逆将其变换回到SH向量。以此方式,本发明的技术可提供V矩阵之间的平滑转变。
图41到41D是各自说明可执行本发明中所描述的技术的各种方面以对描述二维或三维声场的球谐系数进行解码的实例音频解码装置540A到540D的框图。音频解码装置540A可表示能够解码音频数据的任何装置,例如桌上型计算机、膝上型计算机、工作站、平板计算机、专用音频记录装置、蜂窝式电话(包含所谓的“智能电话”)、个人媒体播放机装置、个人游戏装置或能够解码音频数据的任何其它类型的装置。
在一些实例中,音频解码装置540A执行与由音频编码装置510或510B中的任一者执行的音频编码过程互逆的音频解码过程,例外情况为执行阶数缩减(如上相对于图40B到40J的实例所描述),在一些实例中,所述音频解码过程由音频编码装置510B到510J用以有助于外来不相关数据的移除。
虽然展示为单个装置,即,在图41的实例中的装置540A,但以下提及为包含于装置540A内的各种组件或单元可形成在装置540外部的单独装置。换句话说,虽然本发明中描述为由单个装置(即,在图41的实例中的装置540A)执行,但所述技术可由包括多个装置的系统实施或另外执行,其中这些装置中的每一者可各自包含以下更详细地描述的各种组件或单元中的一或多者。因此,所述技术在这方面不应限于图41的实例。
如图41的实例中所示,音频解码装置540A包括提取单元542、音频解码单元544、数学单元546和音频再现单元548。提取单元542表示经配置以从位流517提取经编码缩减背景球谐系数515B、经编码UDIST*SDIST向量515A和VT DIST向量525E的单元。提取单元542将经编码缩减背景球谐系数515B和经编码UDIST*SDIST向量515A输出到音频解码单元544,同时也将VT DIST矩阵525E输出到数学单元546。在这方面中,提取单元542可以类似于图5的实例中所示的音频解码装置24的提取单元72的方式操作。
音频解码单元544表示用以解码经编码音频数据(常根据互逆音频解码方案,例如AAC解码方案)以便恢复UDIST*SDIST向量527及减小背景球谐系数529的单元。音频解码单元544将UDIST*SDIST向量527及减小的背景球谐系数529输出到数学单元546。在这方面中,音频解码单元544可按类似于在图5的实例中展示的音频解码装置24的心理声学解码单元80的方式操作。
数学单元546可表示经配置以执行矩阵乘法及加法(以及,在一些实例中,任何其它矩阵数学运算)的单元。数学单元546可首先执行UDIST*SDIST向量527与VT DIST矩阵525E的矩阵乘法。数学单元546可接着将UDIST*SDIST向量527与VT DIST矩阵525E与减小的背景球谐系数529的相乘的结果(再次,其可指代UBG矩阵525D与SBG矩阵525B及接着与VT BG矩阵525F的相乘的结果)与UDIST*SDIST向量527与VT DIST矩阵525E的矩阵乘法的结果相加以产生原始球谐系数11的减小版本(其表示为恢复的球谐系数547)。数学单元546可将恢复的球谐系数547输出到音频再现单元548。在这方面中,数学单元546可按类似于在图5的实例中展示的音频解码装置24的前景制订单元78及HOA系数制订单元82的方式操作。
音频再现单元548表示经配置以再现通道549A到549N(“通道549”,其也可以大体被称作“多通道音频数据549”或称作“扬声器馈送549”)的单元。音频再现单元548可将变换(常按矩阵的形式表达)应用于恢复的球谐系数547。因为恢复的球谐系数547描述三维中的声场,所以恢复的球谐系数547表示有助于以能够适应多数解码器-局部扬声器几何布置(其可指将重放多通道音频数据549的扬声器的几何布置)的方式再现多通道音频数据549A的音频格式。以上相对于图48描述关于多通道音频数据549A的再现的更多信息。
虽然在多通道音频数据549A为环绕声多通道音频数据549的情境中描述,但音频再现单元48还可执行双声化的形式以使恢复的球谐系数549A双声化,且进而产生两个双声再现的通道549。因此,所述技术不应限于多通道音频数据的环绕声形式,而可包含双声化的多通道音频数据。
以下列出的各种条款可呈现本发明中所描述的技术的各种方面。
条款132567-1B。一种装置,例如音频解码装置540,其包括:一或多个处理器,所述一或多个处理器经配置以确定描述声场的相异分量的一或多个第一向量及描述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者至少通过执行相对于所述多个球谐系数的奇异值分解而产生。
条款132567-2B。条款132567-1B的装置,其中所述一或多个第一向量包括在音频编码前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量而产生的一或多个经音频编码的UDIST*SDIST向量,其中U矩阵及S矩阵至少通过执行相对于所述多个球谐系数的奇异值分解而产生,且其中所述一或多个处理器进一步经配置以音频解码所述一或多个经音频编码的UDIST*SDIST向量以产生所述一或多个经音频编码的UDIST*SDIST向量的经音频解码版本。
条款132567-3B。条款132567-1B的装置,其中所述一或多个第一向量包括在音频编码前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量及V矩阵的转置的一或多个VT DIST向量而产生的一或多个经音频编码的UDIST*SDIST向量,其中U矩阵及S矩阵及V矩阵至少通过执行相对于所述多个球谐系数的奇异值分解而产生,且其中所述一或多个处理器进一步经配置以音频解码所述一或多个经音频编码的UDIST*SDIST向量以产生所述一或多个经音频编码的UDIST*SDIST向量的经音频解码版本。
条款132567-4B。条款132567-3B的装置,其中所述一或多个处理器进一步经配置以将UDIST*SDIST向量乘以VT DIST向量以恢复所述多个球谐中表示声场的相异分量的那些球谐。
条款132567-5B。条款132567-1B的装置,其中所述一或多个第二向量包括在音频编码前通过将包含在U矩阵内的UBG向量乘以包含在S矩阵内的SBG向量及接着乘以包含在V矩阵的转置内的VT BG向量而产生的一或多个经音频编码的UBG*SBG*VT BG向量,其中S矩阵、U矩阵及V矩阵各自至少通过执行相对于所述多个球谐系数的奇异值分解而产生。
条款132567-6B。条款132567-1B的装置,其中所述一或多个第二向量包括在音频编码前通过将包含在U矩阵内的UBG向量乘以包含在S矩阵内的SBG向量且接着乘以包含在V矩阵的转置内的VT BG向量而产生的一或多个经音频编码的UBG*SBG*VT BG向量,且其中S矩阵、U矩阵及V矩阵至少通过执行相对于所述多个球谐系数的奇异值分解而产生,且其中所述一或多个处理器进一步经配置以音频解码所述一或多个经音频编码的UBG*SBG*VT BG向量以产生一或多个经音频解码的UBG*SBG*VT BG向量。
条款132567-7B。条款132567-1B的装置,其中所述一或多个第一向量包括在音频编码前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量及V矩阵的转置的一或多个VT DIST向量而产生的一或多个经音频编码的UDIST*SDIST向量,其中U矩阵、S矩阵及V矩阵至少通过执行相对于所述多个球谐系数的奇异值分解而产生,且其中所述一或多个处理器进一步经配置以音频解码所述一或多个经音频编码的UDIST*SDIST向量以产生一或多个UDIST*SDIST向量,且将UDIST*SDIST向量乘以VT DIST向量以恢复所述多个球谐系数中描述声场的相异分量的那些球谐系数,其中所述一或多个第二向量包括在音频编码前正通过将包含于U矩阵内的UBG向量乘以包含于S矩阵内的SBG向量且接着乘以包含于V矩阵的转置内的VT BG向量而产生的一或多个经音频编码的UBG*SBG*VT BG向量,且其中所述一或多个处理器进一步经配置以音频解码所述一或多个经音频编码的UBG*SBG*VT BG向量以恢复描述声场的背景分量的所述多个球谐系数的至少一部分,且将描述声场的相异分量的所述多个球谐系数与描述声场的背景分量的所述多个球谐系数的至少一部分相加以产生所述多个球谐系数的经重建版本。
条款132567-8B。条款132567-1B的装置,其中所述一或多个第一向量包括在音频编码前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量及V矩阵的转置的一或多个VT DIST向量而产生的一或多个UDIST*SDIST向量,其中U矩阵、S矩阵及V矩阵至少通过执行相对于所述多个球谐系数的奇异值分解而产生,且其中所述一或多个处理器进一步经配置以确定指示将从位流提取以形成所述一或多个UDIST*SDIST向量和所述一或多个VT DIST向量的向量数目的值D。
条款132567-9B。条款132567-10B的装置,其中所述一或多个第一向量包括在音频编码前通过将U矩阵的一或多个经音频编码的UDIST向量乘以S矩阵的一或多个SDIST向量及V矩阵的转置的一或多个VT DIST向量而产生的一或多个UDIST*SDIST向量,其中U矩阵、S矩阵及V矩阵是至少通过相对于所述多个球谐系数执行奇异值分解而产生,且其中所述一或多个处理器进一步经配置以基于逐个音频帧确定值D,所述值D指示待从位流提取以形成所述一或多个UDIST*SDIST向量及所述一或多个VT DIST向量的向量的数目。
条款132567-1G。一种装置,例如音频解码装置540,其包括:一或多个处理器,所述或多个处理器经配置以确定描述声场的相异分量的一或多个第一向量及描述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者至少通过执行相对于表示声场的至少一部分的多通道音频数据的奇异值分解而产生。
条款132567-2G。条款132567-1G的装置,其中所述多通道音频数据包含多个球谐系数。
条款132567-3G。条款132567-2G的装置,其中所述一或多个处理器进一步经配置以执行条款132567-2B到条款132567-9B的任一组合。
从上述各种条款中的每一者,应理解,音频解码装置540A到540D中的任一者可执行方法,或另外包括执行音频解码装置540A到540D经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频解码装置540A到540D已经配置以执行的方法。
举例来说,条款132567-10B可从前述条款132567-1B导出为包括以下步骤的方法:确定描述声场的相异分量的一或多个第一向量及描述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者至少通过执行相对于表示声场的多个球谐系数的奇异值分解而产生。
作为另一实例,条款132567-11B可从前述条款132567-1B导出为一种装置,例如音频解码装置540,其包括用于确定描述声场的相异分量的一或多个第一向量及描述声场的背景分量的一或多个第二向量的装置,所述一或多个第一向量及所述一或多个第二向量两者至少通过执行相对于所述多个球谐系数的奇异值分解而产生;及用于存储所述一或多个第一向量及所述一或多个第二向量的装置。
作为又一实例,条款132567-12B可从条款132567-1B导出为一种具有存储于其上的指令的非暂时性计算机可读存储媒体,所述指令在执行时致使一或多个处理器确定描述声场的相异分量的一或多个第一向量及描述声场的背景分量的一或多个第二向量,所述一或多个第一向量及所述一或多个第二向量两者至少通过执行相对于包含于描述声场的较高阶立体混响音频数据内的多个球谐系数的奇异值分解而产生。
对于如上文所举例说明而导出的各种装置、方法及非暂时性计算机可读存储媒体,各种条款可同样地从条款132567-2B到132567-9B导出。可针对贯穿本发明列出的各种其它条款执行同样的操作。
图41B是说明可执行本发明中所描述的技术的各种方面以压缩描述二维或三维声场的球谐系数的实例音频解码装置540B的框图。音频解码装置540B可类似于音频解码装置540,例外情况为,在一些实例中,提取单元542可提取经重排序的VT DIST向量539,而不是VT DIST向量525E。在其它实例中,提取单元542可提取VT DIST向量525E,且接着基于在位流中指定或经推断(通过其它向量的分析)以确定经重排序的VT DIST向量539的重排序信息重排序这些VT DIST向量525E。在这方面中,提取单元542可按类似于图5的实例中展示的音频解码装置24的提取单元72的方式操作。在任何情况下,提取单元542可将经重排序的VT DIST向量539输出到数学单元546,其中可相对于这些经重排序的VT DIST向量539执行以上相对于恢复球谐系数描述的过程。
以此方式,所述技术可使音频解码装置540B能够音频解码表示声场的相异分量的经重排序的一或多个向量,所述经重排序的一或多个向量已经重排序以有助于压缩所述一或多个向量。在这些和其它实例中,音频解码装置540B可将经重排序的一或多个向量与经重排序的一或多个额外向量重组以恢复表示声场的相异分量的球谐系数。在这些和其它实例中,音频解码装置540B可接着基于表示声场的相异分量的球谐系数及基于表示声场的背景分量的球谐系数恢复多个球谐系数。
即,所述技术的各种方面可提供待经配置以根据下列条款解码经重排序的一或多个向量的音频解码装置540B。
条款133146-1F。一种装置,例如音频编码装置540B,其包括:一或多个处理器,所述一或多个处理器经配置以确定对应于声场中的分量的向量的数目。
条款133146-2F。条款133146-1F的装置,其中所述一或多个处理器经配置以在根据上述实例的任一组合执行阶数缩减之后确定向量的数目。
条款133146-3F。条款133146-1F的装置,其中所述一或多个处理器进一步经配置以根据上述实例的任一组合执行阶数缩减。
条款133146-4F。条款133146-1F的装置,其中所述一或多个处理器经配置以从位流中指定的值确定向量的数目,且其中所述一或多个处理器进一步经配置以基于所确定的向量数目剖析位流以识别位流中表示声场的相异分量的一或多个向量。
条款133146-5F。条款133146-1F的装置,其中所述一或多个处理器经配置以从位流中指定的值确定向量的数目,且其中所述一或多个处理器进一步经配置以基于所确定的向量数目剖析位流以识别位流中表示声场的背景分量的一或多个向量。
条款133143-1C。一种装置,例如音频解码装置540B,其包括:一或多个处理器,所述一或多个处理器经配置以重排序表示声场的相异分量的经重排序的一或多个向量。
条款133143-2C。条款133143-1C的装置,其中所述一或多个处理器进一步经配置以确定经重排序的一或多个向量,及确定描述重排序所述经重排序的一或多个向量的方式的重排序信息,其中所述一或多个处理器进一步经配置以当重排序所述经重排序的一或多个向量时,基于所确定的重排序信息重排序所述经重排序的一或多个向量。
条款133143-3C。1C的装置,其中所述经重排序的一或多个向量包括由技术方案1A到18A的任一组合或技术方案1B到19B的任一组合叙述的所述一或多个经重排序的第一向量,且其中所述一或多个第一向量是根据由技术方案1A到18A的任一组合或技术方案1B到19B的任一组合叙述的方法确定。
条款133143-4D。一种装置,例如音频解码装置540B,其包括:一或多个处理器,所述一或多个处理器经配置以音频解码表示声场的相异分量的经重排序的一或多个向量,所述经重排序的一或多个向量已经重排序以有助于压缩所述一或多个向量。
条款133143-5D。条款133143-4D的装置,其中所述一或多个处理器进一步经配置以重组所述经重排序的一或多个向量与经重排序的一或多个额外向量以恢复表示声场的相异分量的球谐系数。
条款133143-6D。条款133143-5D的装置,其中所述一或多个处理器进一步经配置以基于表示声场的相异分量的球谐系数及表示声场的背景分量的球谐系数恢复多个球谐系数。
条款133143-1E。一种装置,例如音频解码装置540B,其包括:一或多个处理器,所述一或多个处理器经配置以重排序一或多个向量以产生经重排序的一或多个第一向量,且进而有助于由旧版音频编码器进行的编码,其中所述一或多个向量描述表示声场的相异分量,且使用旧版音频编码器音频编码经重排序的一或多个向量以产生经重排序的一或多个向量的经编码版本。
条款133143-2E。1E的装置,其中所述经重排序的一或多个向量包括由技术方案1A到18A的任一组合或技术方案1B到19B的任一组合叙述的所述一或多个经重排序的第一向量,且其中所述一或多个第一向量是根据由技术方案1A到18A的任一组合或技术方案1B到19B的任一组合叙述的方法确定。
图41C是说明另一示范性音频编码装置540C的框图。音频解码装置540C可表示能够解码音频数据的任一装置,例如桌上型计算机、膝上型计算机、工作站、平板计算机、专用音频记录装置、蜂窝式电话(包含所谓的“智能电话”)、个人媒体播放器装置、个人游戏装置或能够解码音频数据的任何其它类型的装置。
在图41C的实例中,音频解码装置540C执行与由音频编码装置510B到510E中的任一者执行的音频编码过程互逆的音频解码过程,例外情况为执行阶数降低(如上相对于图40B到40J的实例所描述),在一些实例中,所述音频解码过程由音频编码装置510B到510J用以有助于外来不相关数据的移除。
虽然展示为单个装置,即,在图41C的实例中的装置540C,但以下提及为包含于装置540C内的各种组件或单元可形成在装置540C外部的单独装置。换句话说,虽然本发明中描述为由单个装置(即,在图41C的实例中的装置540C)执行,但所述技术可由包括多个装置的系统实施或另外执行,其中这些装置中的每一者可各自包含以下更详细地描述的各种组件或单元中的一或多者。因此,所述技术在这方面不应限于图41C的实例。
此外,音频编码装置540C可类似于音频编码装置540B。然而,提取单元542可从位流517而非经重排序的VT Q_DIST向量539或VT DIST向量525E(如相对于图40的音频编码装置510所描述的情况)确定所述一或多个VT SMALL向量521。结果,提取单元542可将VT SMALL向量521传递到数学单元546。
另外,提取单元542可从位流517确定经音频编码的经修改背景球谐系数515B',将这些系数515B'传递到音频解码单元544,音频解码单元544可音频解码经编码的经修改背景球谐系数515B以恢复经修改背景球谐系数537。音频解码单元544可将这些经修改背景球谐系数537传递到数学单元546。
数学单元546可接着将经音频解码的(且可能无序)UDIST*SDIST向量527'乘以所述一或多个VT SMALL向量521以恢复较高阶相异球谐系数。数学单元546可接着将较高阶相异球谐系数与经修改背景球谐系数537相加以恢复所述多个球谐系数511或其某一导出(其可为归因于在编码器单元510E处执行的阶数缩减的导出)。
以此方式,所述技术可使音频解码装置540C能够确定从与背景球谐系数重组以减少需要在位流中分配给一或多个向量的位的量的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中所述背景球谐系数描述相同声场的一或多个背景分量。
在这方面,所述技术的各种方面可使音频解码装置540C能够在一些情况下经配置以从位流确定从与背景球谐系数重组的球谐系数分解的一或多个向量中的至少一者,其中所述球谐系数描述声场,且其中所述背景球谐系数描述同一声场的一或多个背景分量。
在这些和其它实例中,音频解码装置540C经配置以从位流获得球谐系数的具有等于NBG的阶数的第一部分。
在这些和其它实例中,音频解码装置540C进一步经配置以从位流获得球谐系数的具有等于NBG的阶数的第一经音频编码的部分,且音频解码球谐系数的经音频编码的第一部分以产生球谐系数的第一部分。
在这些和其它实例中,所述一或多个向量中的所述至少一者包括一或多个VT SMALL向量,所述一或多个VT SMALL向量已从通过执行相对于所述多个球谐系数的奇异值分解产生的V矩阵的转置确定。
在这些和其它实例中,所述一或多个向量中的所述至少一者包括一或多个VT SMALL向量,所述一或多个VT SMALL向量已经从通过执行相对于所述多个球谐系数的奇异值分解而产生的V矩阵的转置确定,且音频解码装置540C进一步经配置以从位流获得已从U矩阵及S矩阵导出的一或多个UDIST*SDIST向量,所述两个矩阵都是通过执行相对于所述多个球谐系数的奇异值分解而产生,且将UDIST*SDIST向量乘以VT SMALL向量。
在这些和其它实例中,所述一或多个向量中的所述至少一者包括一或多个VT SMALL向量,所述一或多个VT SMALL向量已经从通过执行相对于所述多个球谐系数的奇异值分解而产生的V矩阵的转置确定,且音频解码装置540C进一步经配置以从位流获得已从U矩阵及S矩阵导出的一或多个UDIST*SDIST向量,所述两个矩阵都是通过执行相对于所述多个球谐系数的奇异值分解而产生,且将UDIST*SDIST向量乘以VT SMALL向量以恢复较高阶相异背景球谐系数,且将包含较低阶相异背景球谐系数的背景球谐系数与较高阶相异背景球谐系数相加以至少部分恢复所述多个球谐系数。
在这些和其它实例中,所述一或多个向量中的所述至少一者包括一或多个VT SMALL向量,所述一或多个VT SMALL向量已经从通过执行相对于所述多个球谐系数的奇异值分解而产生的V矩阵的转置确定,且音频解码装置540C进一步经配置以从位流获得已从U矩阵及S矩阵导出的一或多个UDIST*SDIST向量,所述两个矩阵都是通过执行相对于所述多个球谐系数的奇异值分解而产生,将UDIST*SDIST向量乘以VT SMALL向量以恢复较高阶相异背景球谐系数,将包含较低阶相异背景球谐系数的背景球谐系数与较高阶相异背景球谐系数相加以至少部分恢复所述多个球谐系数,且再现恢复的多个球谐系数。
图41D是说明另一示范性音频编码装置540D的框图。音频解码装置540D可表示能够解码音频数据的任一装置,例如桌上型计算机、膝上型计算机、工作站、平板计算机、专用音频记录装置、蜂窝式电话(包含所谓的“智能电话”)、个人媒体播放器装置、个人游戏装置或能够解码音频数据的任何其它类型的装置。
在图41D的实例中,音频解码装置540D执行与由音频编码装置510B到510J中的任一者执行的音频编码过程互逆的音频解码过程,例外情况为执行阶数缩减(如上相对于图40B到40J的实例所描述),在一些实例中,所述音频解码过程由音频编码装置510B到510J用以有助于外来不相关数据的移除。
虽然展示为单个装置,即,在图41D的实例中的装置540D,但以下提及为包含于装置540D内的各种组件或单元可形成在装置540D外部的单独装置。换句话说,虽然本发明中描述为由单个装置(即,在图41D的实例中的装置540D)执行,但所述技术可由包括多个装置的系统实施或另外执行,其中这些装置中的每一者可各自包含以下更详细地描述的各种组件或单元中的一或多者。因此,所述技术在这方面不应限于图41D的实例。
此外,音频解码装置540D可类似于音频解码装置540B,不同的是音频解码装置540D执行与由以上相对于图40I描述的V压缩单元552执行的压缩大体互逆的额外V解压缩。在图41D的实例中,提取单元542包含V解压缩单元555,其执行包含在位流517中(且大体根据在图10B及10C中的一者中展示的实例指定)的经压缩空间分量539'的此V解压缩。V解压缩单元555可基于以下方程式解压缩VT DIST向量539:

换句话说,V解压缩单元555可首先剖析来自位流517的nbits值,且识别五个霍夫曼码表的适当集合以当解码cid的霍夫曼码时使用。基于预测模式及在位流517中指定的霍夫曼译码信息及可能空间分量的元素相对于空间分量的其它元素的阶数,V解压缩单元555可识别针对经剖析的nbits值定义的五个霍夫曼表中的正确者。使用此霍夫曼表,V解压缩单元555可从霍夫曼码解码cid值。V解压缩单元555可随后剖析正负号位和残余块码,对残余块码进行解码以识别残余。根据以上方程式,V解压缩单元555可解码VT DIST向量539中的一者。
前述内容可总结于以下语法表中:
表—经解码向量


在前述语法表中,具有四种情况(情况0到3)的第一切换语句提供就系数的数目而言确定VT DIST向量长度的方式。第一情况,情况0,指示用于VT DIST向量的所有系数被指定。第二情况,情况1,指示仅VT DIST向量的对应于大于MinNumOfCoeffsForAmbHOA的阶数的那些系数被指定,其可表示上文被称作(NDIST+1)-(NBG+1)的情况。第三情况,情况2,类似于第二情况,但进一步将识别的系数减去NumOfAddAmbHoaChan,其表示用于指定对应于超过阶数NBG的阶数的额外通道(其中“通道”指对应于某一阶数、子阶数组合的特定系数)的变量。第四情况,情况3,指示仅VT DIST向量的在移除由NumOfAddAmbHoaChan识别的系数之后所剩余的那些系数被指定。
在此切换语句后,是否执行统一解量化的决策由NbitsQ(或如上所表示,nbits)控制,NbitsQ如果不等于5,则导致应用霍夫曼解码。上文提及的cid值等于NbitsQ值的两个最低有效位。上文所论述的预测模式在以上语法表中表示为PFlag,而HT信息位在以上语法表中表示为CbFlag。剩余语法指定解码如何以实质上类似于上文所描述的方式的方式发生。
以此方式,本发明的技术可使音频解码装置540D能够获得包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生,且解压缩空间分量的经压缩版本以获得空间分量。
此外,所述技术可使得音频解码装置540D能够解压缩声场的空间分量的经压缩版本,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
以此方式,音频编码装置540D可执行以下相对于下列条款阐明的技术的各种方面。
条款141541-1B。一种装置,其包括:
一或多个处理器,所述一或多个处理器经配置以获得包括声场的空间分量的经压缩版本的位流,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生,及解压缩空间分量的经压缩版本以获得空间分量。
条款141541-2B。条款141541-1B的装置,其中空间分量的经压缩版本至少部分使用指定当压缩空间分量时使用的预测模式的字段表示于位流中,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于所述预测模式解压缩空间分量的经压缩版本以获得空间分量。
条款141541-3B。条款141541-1B及条款141541-2B的任一组合的装置,其中空间分量的经压缩版本至少部分使用指定当压缩空间分量时使用的霍夫曼表的霍夫曼表信息表示于位流中,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于霍夫曼表信息解压缩空间分量的经压缩版本。
条款141541-4B。条款141541-1B到条款141541-3B的任一组合的装置,其中空间分量的经压缩版本至少部分使用指示表达当压缩空间分量时使用的量化步长或其变量的值的字段表示于位流中,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于所述值解压缩空间分量的经压缩版本。
条款141541-5B。条款141541-4B的装置,其中所述值包括nbits值。
条款141541-6B。条款141541-4B及条款141541-5B的任一组合的装置,其中所述位流包括声场(包含其空间分量的经压缩版本)的多个空间分量的经压缩版本,且其中所述值表达当压缩所述多个空间分量时使用的量化步长或其变量,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于所述值解压缩所述空间分量的所述多个经压缩版本。
条款141541-7B。条款141541-1B到条款141541-6B的任一组合的装置,其中空间分量的经压缩版本至少部分使用霍夫曼码表示识别空间分量对应于的压缩类别的类别识别符来表示于位流中,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于霍夫曼码解压缩空间分量的经压缩版本。
条款141541-8B。条款141541-1B到条款141541-7B的任一组合的装置,其中空间分量的经压缩版本至少部分使用识别空间分量为正值或是负值的正负号位表示于位流中,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于所述正负号位解压缩空间分量的经压缩版本。
条款141541-9B。条款141541-1B至到款141541-8B的任一组合的装置,其中空间分量的经压缩版本至少部分使用霍夫曼码表示空间分量的残余值来表示于位流中,且其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,至少部分基于霍夫曼码解压缩空间分量的经压缩版本。
条款141541-10B。条款141541-1B到条款141541-10B的任一组合的装置,其中基于向量的合成包括奇异值分解。
此外,音频解码装置540D可经配置以执行以下关于下列条款阐明的技术的各种方面。
条款141541-1C。一种装置,例如音频解码装置540D,其包括:一或多个处理器,所述一或多个处理器经配置以解压缩声场的空间分量的经压缩版本,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2C。条款141541-1C及条款141541-2C的任一组合的装置,其中所述一或多个处理器进一步经配置以当解压缩空间分量的经压缩版本时,获得识别空间分量当经压缩时分类到的类别的类别识别符,获得识别空间分量是否为正值或是负值的正负号,获得与空间分量的经压缩版本相关联的残余值,及基于类别识别符、正负号及残余值解压缩空间分量的经压缩版本。
条款141541-3C。条款141541-2C的装置,其中所述一或多个处理器经进一步经配置以当获得类别识别符时,获得表示类别识别符的霍夫曼码,及解码所述霍夫曼码以获得类别识别符。
条款141541-4C。条款141541-3C的装置,其中所述一或多个处理器进一步经配置以当解码霍夫曼码时,至少部分基于空间分量在指定多个空间分量的向量中的相对位置来识别用以解码霍夫曼码的霍夫曼表。
条款141541-5C。条款141541-3C及条款141541-4C的任一组合的装置,其中所述一或多个处理器经进一步经配置以当解码霍夫曼码时,至少部分基于当压缩空间分量时使用的预测模式识别用以解码霍夫曼码的霍夫曼表。
条款141541-6C。条款141541-3C到条款141541-5C的任一组合的装置,其中所述一或多个处理器进一步经配置以当解码霍夫曼码时,至少部分基于与空间分量的经压缩版本相关联的霍夫曼表信息识别用以解码霍夫曼码的霍夫曼表。
条款141541-7C。条款141541-3C的装置,其中所述一或多个处理器进一步经配置以当解码霍夫曼码时,至少部分基于空间分量在指定多个空间分量的向量中的相对位置、当压缩空间分量时使用的预测模式及与空间分量的经压缩版本相关联的霍夫曼表信息识别用以解码霍夫曼码的霍夫曼表。
条款141541-8C。条款141541-2C的装置,其中所述一或多个处理器进一步经配置以当获得残余值时,解码表示残余值的块码以获得残余值。
条款141541-9C。条款141541-1C到条款141541-8C的任一组合的装置,其中基于向量的合成包括奇异值分解。
此外,音频解码装置540D可经配置以执行以下关于下列条款阐明的技术的各种方面。
条款141541-1G。一种装置,例如音频解码装置540D,其包括:一或多个处理器,所述一或多个处理器经配置以基于多个经压缩空间分量中的当前空间分量的经压缩版本相对于所述多个经压缩空间分量中的其余者的阶数识别霍夫曼码簿以在解压缩所述当前空间分量的经压缩版本时使用,所述空间分量是通过相对于多个球谐系数执行基于向量的合成而产生。
条款141541-2G。条款141541-1G的装置,其中所述一或多个处理器进一步经配置以执行在条款141541-1D到条款141541-10D及条款141541-1E到条款141541-9E中叙述的步骤的任一组合。
图42到42C各自为更详细地说明图40B到40J的实例中所展示的阶数缩减单元528A的框图。图42是说明阶数缩减单元528的框图,其可表示图40B到40J的阶数缩减单元528A的一个实例。阶数缩减单元528A可接收或另外确定目标位速率535,且仅基于此目标位速率535执行相对于背景球谐系数531的阶数缩减。在一些实例中,阶数缩减单元528A可使用目标位速率535存取表或其它数据结构以识别待从背景球谐系数531移除的那些阶数及/或子阶数以产生缩减的背景球谐系数529。
以此方式,所述技术可使音频编码装置(例如音频编码装置510B到410J)能够基于目标位速率535执行相对于多个球谐系数或其分解(例如,背景球谐系数531)的阶数缩减,以产生缩减的球谐系数529或其缩减的分解,其中所述多个球谐系数表示声场。
在上文所描述的各种实例中的每一者中,应理解,音频解码装置540可执行方法或另外包括执行音频解码装置540经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频解码装置540已经配置以执行的方法。
图42B是说明阶数缩减单元528B的框图,其可表示图40B到40J的阶数缩减单元528A的一个实例。在图42B的实例中,并非基于仅目标位速率535执行阶数缩减,阶数缩减单元528B可基于背景球谐系数531的内容分析执行阶数缩减。阶数缩减单元528B可包含执行此内容分析的内容分析单元536A。
在一些实例中,内容分析单元536A可包含执行参考空间分析的形式的内容分析的空间分析单元536A。空间分析可涉及分析背景球谐系数531以识别描述声场的背景分量的形状或其它空间性质的空间信息。基于此空间信息,阶数缩减单元528B可识别待从背景球谐系数531移除的那些阶数及/或子阶数以产生缩减的背景球谐系数529。
在一些实例中,内容分析单元536A可包含执行称为扩散分析的形式的内容分析的扩散分析单元536B。扩散分析可涉及分析背景球谐系数531以识别描述声场的背景分量的扩散性的扩散信息。基于此扩散信息,阶数缩减单元528B可识别待从背景球谐系数531移除的那些阶数及/或子阶数以产生缩减的背景球谐系数529。
虽然展示为包含空间分析单元536A及扩散分析单元36B两者,但内容分析单元536A可包含仅空间分析单元536、仅扩散分析单元536B或空间分析单元536A及扩散分析单元536B两者。在一些实例中,除了空间分析及扩散分析中的一或两者之外,或替代空间分析及扩散分析中的一或两者,内容分析单元536A可执行其它形式的内容分析。因此,在此方面中本发明中描述的技术不应受到限制。
以此方式,所述技术可使音频编码装置(例如音频编码装置510B到510J)能够基于描述声场的多个球谐系数或其分解的内容分析执行相对于所述多个球谐系数或其分解的阶数缩减以产生缩减的球谐系数或其缩减的分解。
换句话说,所述技术可使装置(例如音频编码装置510B到510J)能够根据下列条款配置。
条款133146-1E。一种装置,例如音频编码装置510B到510J中的任一者,其包括一或多个处理器,所述一或多个处理器经配置以基于描述声场的多个球谐系数或其分解的内容分析执行相对于所述多个球谐系数或其分解的阶数缩减以产生缩减的球谐系数或其缩减的分解。
条款133146-2E。条款133146-1E的装置,其中所述一或多个处理器进一步经配置以在执行阶数缩减前,执行相对于所述多个球谐系数的奇异值分解以识别描述声场的相异分量的一或多个第一向量及识别声场的背景分量的一或多个第二向量,且其中所述一或多个处理器经配置以执行相对于所述一或多个第一向量、所述一或多个第二向量或所述一或多个第一向量及所述一或多个第二向量两者的阶数缩减。
条款133146-3E。条款133146-1E的装置,其中所述一或多个处理器进一步经配置以执行相对于所述多个球谐系数或其分解的内容分析。
条款133146-4E。条款133146-3E的装置,其中所述一或多个处理器经配置以执行相对于所述多个球谐系数或其分解的空间分析。
条款133146-5E。条款133146-3E的装置,其中执行内容分析包括执行相对于所述多个球谐系数或其分解的扩散分析。
条款133146-6E。条款133146-3E的装置,其中所述一或多个处理器经配置以执行相对于所述多个球谐系数或其分解的空间分析及扩散分析。
条款133146-7E。技术方案1的装置,其中所述一或多个处理器经配置以基于所述多个球谐系数或其分解的内容分析及目标位速率执行相对于所述多个球谐系数或其分解的阶数缩减以产生缩减的球谐系数或其缩减的分解。
条款133146-8E。条款133146-1E的装置,其中所述一或多个处理器进一步经配置以音频编码缩减的球谐系数或其分解。
条款133146-9E。条款133146-1E的装置,其中所述一或多个处理器进一步经配置以音频编码缩减的球谐系数或其缩减的分解,且产生位流以包含缩减的球谐系数或其缩减的分解。
条款133146-10E。条款133146-1E的装置,其中所述一或多个处理器进一步经配置以指定在位流中那些缩减的球谐系数或其缩减的分解对应于的球面基底函数的一或多个阶数和/或一或多个子阶数,所述位流包含所述缩减的球谐系数或其缩减的分解。
条款133146-11E。条款133146-1E的装置,其中经缩减球谐系数或其经缩减分解具有比所述多个球谐系数或其分解少的值。
条款133146-12E。条款133146-1E的装置,其中所述一或多个处理器进一步经配置以移除所述多个球谐系数或其分解的向量中的具有指定阶数及/或子阶数的那些球谐系数或向量以产生经缩减球谐系数或其经缩减分解。
条款133146-13E。条款133146-1E的装置,其中所述一或多个处理器经配置以将所述多个球谐系数或其分解的那些向量中的具有指定阶数及/或子阶数的那些球谐系数或向量零化以产生经缩减球谐系数或其经缩减分解。
图42C是说明阶数缩减单元528C的框图,其可表示图40B到40J的阶数缩减单元528A的一个实例。图42B的阶数缩减单元528C实质上与阶数缩减单元528B相同,但可按以上相对于图42的阶数缩减单元528A描述的方式接收或另外确定目标位速率535,同时也按以上相对于图42B的阶数缩减单元528B描述的方式执行内容分析。阶数缩减单元528C可接着基于此目标位速率535及内容分析执行相对于背景球谐系数531的阶数缩减。
以此方式,所述技术可使音频编码装置(例如音频编码装置510B到510J)能够执行相对于所述多个球谐系数或其分解的内容分析。当执行阶数缩减时,音频编码装置510B到510J可基于目标位速率535及内容分析执行相对于所述多个球谐系数或其分解的阶数缩减以产生经缩减球谐系数或其经缩减分解。
假定移除了一或多个向量,则音频编码装置510B到510J可在位流中将向量的数目指定为控制数据。音频编码装置510B到510J可在位流中指定此向量数目以有助于由音频解码装置从位流提取向量。
图44是说明根据本发明中所描述的技术的各种方面的由音频编码装置410D执行以补偿量化误差的示范性操作的图。在图44的实例中,音频编码装置510D的数学单元526展示为虚线块以表示数学运算可由音频解码装置510D的数学单元526执行。
如图44的实例中所展示,数学单元526可首先将UDIST*SDIST向量527乘以VT DIST向量525E以产生相异球谐系数(表示为“HDIST向量630”)。数学单元526可接着将HDIST向量630除以VT DIST向量525E的经量化版本(其再次表示为“VT Q_DIST向量525G”)。数学单元526可通过确定VT Q_DIST向量525G的伪逆且接着将HDIST向量乘以VT Q_DIST向量525G的伪逆来执行此除法,从而输出UDIST*SDIST(其可被缩写为“USDIST”或“USDIST向量”)的经误差补偿的版本。在图44的实例中,USDIST的经误差补偿的版本可表示为US* DIST向量527'。以此方式,所述技术可有效地至少部分将量化误差投影到USDIST向量527,从而产生US* DIST向量527'。
数学单元526可接着从UDIST*SDIST向量527减去US* DIST向量527'以确定USERR向量634(其可表示归因于投影到UDIST*SDIST向量527中的量化的误差的至少一部分)。数学单元526可接着将USERR向量634乘以VT Q_DIST向量525G以确定HERR向量636。在数学上,HERR向量636可等效于USDIST向量527-US* DIST向量527',其结果接着与VT DIST向量525E相乘。数学单元526可接着将HERR向量636通过将UBG向量525D乘以SBG向量525B且接着乘以VT BG向量525F计算的背景球谐系数531(在图44的实例中,表示为HBG向量531)相加。数学单元526可将HERR向量636与HBG向量531相加,从而有效地将量化误差的至少一部分投影到HBG向量531中以产生经补偿的HBG向量531'。以此方式,所述技术可将量化误差的至少一部分投影到HBG向量531中。
图45及45B是说明根据本发明中所描述的技术的各种方面的从两个帧的若干部分内插子帧的图。在图45的实例中,展示第一帧650及第二帧652。第一帧650可包含可经分解为U[1]、S[1]和V'[1]矩阵的球谐系数(“SH[1]”)。第二帧652可包含球谐系数(“SH[2]”)。这些SH[1]及SH[2]可识别以上描述的SHC 511的不同帧。
在图45B的实例中,在图40H的实例中展示的音频编码装置510H的分解单元518可将帧650及652中的每一者分成四个相应子帧651A到651D及653A到653D。分解单元518可接着将帧650的第一子帧651A(表示为“SH[1,1]”)分解成U[1,1]、S[1,1]及V[1,1]矩阵,从而将V[1,1]矩阵519'输出到内插单元550。分解单元518可接着将帧652的第二子帧653A(表示为“SH[2,1]”)分解成U[1,1]、S[1,1]及V[1,1]矩阵,从而将V[2,1]矩阵519'输出到内插单元550。分解单元518还可将SHC 11的SH[1,1]、SH[1,2]、SH[1,3]及SH[1,4]及SHC 511的SH[2,1]、SH[2,2]、SH[2,3]及SH[2,4]输出到内插单元550。
内插单元550可接着执行在于图45B的实例中展示的图示的底部处识别的内插。即,内插单元550可基于V'[1,1]和V'[2,1]内插V'[l,2]。内插单元550还可基于V'[1,1]及V'[2,1]内插V'[1,3]。另外,内插单元550还可基于V'[1,1]及V'[2,1]内插V'[1,4]。这些内插可涉及V'[1,1]及V'[2,1]到空间域中的投影,如在图46到46E的实例中所展示,接着为时间内插,接着投影回到球谐域中。
内插单元550可接下来通过将SH[1,2]乘以(V'[1,2])-1导出U[1,2]S[1,2],通过将SH[1,3]乘以(V'[1,3])-1导出U[1,3]S[1,3],且将SH[1,4]乘以(V'[1,4])-1导出U[1,4]S[1,4]。内插单元550可接着按经分解的形式重整帧,从而输出V矩阵519、S矩阵519B及U矩阵519C。
图46A到46E是说明已根据本发明中所描述的技术内插的多个球谐系数的经分解版本的一或多个向量的投影的横截面的图。图46A说明已经通过SVD过程从来自第一帧的第一子帧的SHC 511分解的第一V矩阵19'的一或多个第一向量的投影的横截面。图46B说明已经通过SVD过程从来自第二帧的第一子帧的SHC 511分解的第二V矩阵519'的一或多个第二向量的投影的横截面。
图46C说明表示来自第一帧的第二子帧的V矩阵519A的一或多个经内插向量的投影的横截面,这些向量已经根据本发明中描述的技术从V矩阵519'内插,所述V矩阵519'是从SHC 511的第一帧的第一子帧(即,在此实例中图46的实例中所示的V矩阵519'的一或多个向量)和SHC 511的第二帧的第一子帧(即,在此实例中图46B的实例中所示的V矩阵519'的一或多个向量)分解。
图46D说明表示来自第一帧的第三子帧的V矩阵519A的一或多个经内插向量的投影的横截面,这些向量已经根据本发明中描述的技术从V矩阵519'内插,所述V矩阵519'是从SHC 511的第一帧的第一子帧(即,在此实例中图46的实例中所示的V矩阵519'的一或多个向量)和SHC 511的第二帧的第一子帧(即,在此实例中图46B的实例中所示的V矩阵519'的一或多个向量)分解。
图46E说明表示来自第一帧的第四子帧的V矩阵519A的一或多个经内插向量的投影的横截面,这些向量已经根据本发明中描述的技术从V矩阵519'内插,所述V矩阵519'是从SHC 511的第一帧的第一子帧(即,在此实例中图46的实例中所示的V矩阵519'的一或多个向量)和SHC 511的第二帧的第一子帧(即,在此实例中图46B的实例中所示的V矩阵519'的一或多个向量)分解。
图47是更详细地说明图41A到41D的实例中展示的音频解码装置540A到540D的提取单元542的框图。在一些实例中,提取单元542可表示可被称作“集成解码器”的前端,其可执行两个或两个以上解码方案(其中通过执行这两个或两个以上方案,可认为解码器“集成”所述两个或两个以上方案)。如在图44的实例中所展示,提取单元542包含多路复用器620及提取子单元622A及622B(“提取子单元622”)。多路复用器620基于相关联的经编码帧式SHC矩阵547到547N从合成音频对象还是从记录产生的对应指示识别经编码帧式SHC矩阵547到547N中待发送到提取子单元622A及提取子单元622B的那些矩阵。提取子单元622A中的每一者可执行不同的解码(其可被称作“解压缩”)方案,在一些实例中,所述方案适应于从合成音频对象产生的SHC或从记录产生的SHC。提取子单元622A中的每一者可执行这些解压缩方案中的相应一者,以便产生待输出到SHC 547的SHC 547的帧。
举例来说,提取单元622A可执行解压缩方案以使用下列方程式从主要信号(PS)重建SA:
HOA=DirV×PS,
其中DirV为方向向量(表示各种方向及宽度),其可经由旁侧通道传输。在此实例中,提取单元622B可执行使用下列方程式从PS重建HOA矩阵的解压缩方案:

其中Ynm为球谐函数,且θ及 信息可经由旁侧通道发送。
信息可经由旁侧通道发送。
在这方面中,所述技术使提取单元538能够基于表示声场的球谐系数的经压缩版本是否从合成音频对象产生的指示而选择多个解压缩方案中的一者,且使用所述多个解压缩方案中的选定者解压缩所述球谐系数的所述经压缩版本。在一些实例中,所述装置包括集成解码器。
图48是更详细地说明图41A到41D的实例中所示的音频解码装置540A到540D的音频再现单元48的框图。图48说明从所恢复球谐系数547到与解码器局部扬声器几何布置兼容的多通道音频数据549A的转换。对于一些局部扬声器几何布置(其可再次指代在解码器处的扬声器几何布置),确保可逆性的一些变换可导致不太合乎需要的音频图像质量。也就是说,当与所俘获的音频相比较时,声音再生可并不总是导致声音的正确定位。为了对此不大合意的图像质量进行校正,可进一步增强技术以引入可被称作“虚拟扬声器”的概念。
可修改以上框架以包含某一形式的平移,例如向量基础振幅平移(VBAP)、基于距离的振幅平移或其它形式的平移,而不是需要将一或多个扬声器再定位或定位于具有由例如上述的ITU-R BS.775-1等标准指定的特定角度公差的空间的特定或所定义的区中。出于说明的目的而聚焦于VBAP上,VBAP实际上可引入可被表征为“虚拟扬声器”的东西。VBAP可修改到一或多个扩音器的馈送以使得这些一或多个扩音器实际上输出显得源自虚拟扬声器的声音,所述虚拟扬声器处于不同于支持所述虚拟扬声器的一或多个扩音器的位置及/或角度中的至少一者的位置及角度中的一或多者处。
为进行说明,用于根据SHC确定扩音器馈送的以下方程式可如下:

在上文方程式中,VBAP矩阵具有M行乘N列的大小,其中M表示扬声器的数目(且在以上方程式中将等于五),且N表示虚拟扬声器的数目。可依据从收听者的经定义位置到扬声器的位置中的每一者的向量及从收听者的经定义位置到虚拟扬声器的位置中的每一者的向量来计算VBAP矩阵。以上方程式中的D矩阵可具有N行乘(阶数+1)2列的大小,其中阶数可指代SH函数的阶数。D矩阵可表示以下方程式
矩阵:
g矩阵(或考虑到仅存在单一列,向量)可表示布置于解码器局部几何布置中的扬声器的扬声器馈送的增益。在方程式中,g矩阵具有大小M。A矩阵(或考虑到仅存在单一列,向量)可表示SHC 520,且具有大小(阶数+1)(阶数+1),其也可以表示为(阶数+1)2。
实际上,VBAP矩阵为MxN矩阵,其提供可被称作“增益调整”的调整,所述调整将扬声器的位置及虚拟扬声器的位置考虑在内。以此方式引入平移可导致多通道音频的较好重现,这导致在由局部扬声器几何布置再生时的较好质量图像。此外,通过将VBAP并入到此方程式中,技术可克服不与各种标准中所指定的几何条件对准的不佳扬声器几何布置。
实际上,可反转及使用所述方程式以将SHC变换回到用于扩音器的特定几何布置或配置的多通道馈送,所述特定几何布置或配置在本发明中可再次被称作解码器局部几何布置。也就是说,可反转方程式以求解g矩阵。经反转的方程式可如下:

g矩阵可表示在此实例中用于5.1扬声器配置中的五个扩音器中的每一者的扬声器增益。此配置中所使用的虚拟扬声器位置可对应于5.1多声道格式规格或标准中所定义的位置。可使用任何数目的已知音频定位技术来确定可支持这些虚拟扬声器中的每一者的扩音器的位置,所述技术中的许多技术涉及播放具有特定频率的音调以确定每一扩音器相对于头端单元(例如音频/视频接收器(A/V接收器)、电视、游戏系统、数字视频光盘系统或其它类型的头端系统)的位置。或者,头端单元的用户可手动地指定扩音器中的每一者的位置。在任何情况下,在给定这些已知位置及可能角度的情况下,假定虚拟扩音器的通过VBAP的理想配置,可求解头端单元的增益。
在这方面中,装置或设备可对所述多个虚拟通道执行向量基础振幅平移或其它形式的平移,以产生驱使解码器局部几何布置中的扬声器发射呈现为起源于经配置成不同局部几何布置的虚拟扬声器的声音的多个通道。所述技术因此可使得音频解码装置40能够对所述多个球谐系数(例如所恢复球谐系数47)执行变换以产生多个通道。所述多个通道中的每一者可与空间的对应不同区相关联。此外,所述多个通道中的每一者可包括多个虚拟通道,其中所述多个虚拟通道可与空间的对应不同区相关联。装置因此可对虚拟通道执行向量基础振幅平移以产生多通道音频数据49的所述多个通道。
图49A到49E(ii)是说明可实施本发明中所描述的技术的各种方面的相应音频译码系统560A到560C、567D、569D、571E及573E的图。如图49A的实例中所示,音频译码系统560A可包含音频编码装置562及音频解码装置564。音频编码装置562可类似于分别在图4及40A到40D的实例中所示的音频编码装置20及510A到510D中的任一者。音频解码装置564可类似于图5及41的实例中所示的音频解码装置24及40。
如上文所描述,较高阶立体混响(HOA)是描述基于空间傅立叶变换的声场的所有方向信息的方式。在一些实例中,立体混响阶数N越高,空间空间分辨率就越高,且球谐(SH)系数的数目(N+1)2就越大。因此,在一些实例中,立体混响阶数N越高,就会导致用于传输及存储系数的带宽要求越大。因为与例如5.1或7.1环绕声音频数据相比较,HOA的带宽要求相当高,所以对于许多应用而言可期望带宽减少。
根据本发明中所描述的技术,音频译码系统560A可执行基于在空间声声场景中将相异(前景)与非相异(背景或环境)元素分离的方法。此分离可允许音频译码系统560A彼此独立地处理前景及背景元素。在此实例中,音频译码系统560A利用前景元素可吸引更多注意(由听者)的性质,且与背景元素相比较可较容易定位(再次由听者)。因此,音频译码系统560A可更有效地存储或传输HOA内容。
在一些实例中,音频译码系统560A可通过使用奇异值分解(SVD)过程而实现此分离。SVD过程可将HOA系数的帧分离成3个矩阵(U,S,V)。矩阵U含有左奇异向量,且V矩阵含有右奇异向量。对角线矩阵S在其对角线中含有非负经分类奇异值。HOA系数的通常良好(或在一些情况下,完美假定表示HOA系数中的无限精度)重建将由U*S*V'给出。仅通过用D最大奇异值重建子空间:U(:,1:D)*S(1:D,:)*V',音频译码系统560A可从此HOA帧提取大部分突出空间信息,即前景声音元素(且可为一些强早期室内反射)。其余部分U(:,D+1:end)*S(D+1:end,:)*V'可从所述内容重建背景元素和混响。
音频译码系统560A可通过分析由S的递减对角线值产生的曲线的斜率确定使两个子空间分离的值D:大奇异值表示前景声音,低奇异值表示背景值。音频译码系统560A可使用奇异值曲线的一阶及二阶导数。音频译码系统560A还可将数目D限制在一与五之间。或者,音频译码系统560A可将数目D预定义为例如值四。在任何情况下,一旦估计出数目D,音频译码系统560A即从矩阵U及S提取前景及背景子空间。
音频译码系统560A接着可经由U(:,D+1:end)*S(D+1:end,:)*V'重建背景场景的HOA系数,从而导致HOA系数的(N+1)2通道。因为已知背景元素在一些实例中并非同样突出的且并非同样可相对于前景元素定位,所以音频译码系统560A可截断HOA通道的阶数。此外,音频译码系统560A可用有损或无损音频编解码器(例如AAC)压缩这些通道,或任选地用与用以压缩突出前景元素的编解码器相比更积极的音频编解码器来进行压缩。在一些情况下,为了节省带宽,音频译码系统560A可不同地传输前景元素。即,音频译码系统可在用有损或无损音频编解码器(例如AAC)进行压缩之后传输左奇异向量U(:,1:D),及连同重建矩阵R=S(1:D,:)*V'一起传输这些经压缩左奇异值。R可表示D×(N+1)2矩阵,所述矩阵可跨帧而不同。
在音频译码系统560的接收器侧处,音频译码系统可使这两个矩阵相乘以重建(N+1)2个HOA通道的帧。一旦将背景及前景HOA通道一起求和,音频译码系统560A即可使用任何适当立体混响再现器向任何扬声器设置进行再现。因为所述技术提供前景元素(直接或相异声音)与元素的分离,所以听觉受损的人可控制前景到背景元素的混合以增加可懂度。又,其它音频效果也可为适用的,例如仅对前景元素的动态压缩器。
图49B是更详细地说明音频编码系统560B的框图。如图49B的实例中所示,音频译码系统560B可包含音频编码装置566及音频解码装置568。音频编码装置566可类似于图4及40E的实例中所示的音频编码装置24及510E。音频解码装置568可类似于图5及41B的实例中所示的音频解码装置24及540B。
根据本发明中所描述的技术,当出于带宽减小的目的而对HoA信号使用基于帧的SVD(或相关方法,例如KLT及PCA)分解时,音频编码装置66可量化U矩阵的前几个向量(乘以S矩阵的对应奇异值)以及VT向量的对应向量。此将包括声场的‘前景’分量。所述技术可使音频编码装置566能够使用‘黑箱’音频译码引擎对UDIST*SDIST向量进行译码。V向量可经标量量化或向量量化。此外,U矩阵中的剩余向量中的一些或全部可乘以S矩阵及V矩阵的对应奇异值且还使用‘黑箱’音频译码引擎进行译码。这些将包括声场的‘背景’分量。
因为将最响听觉分量分解成‘前景分量’,所以音频编码装置566可在使用‘黑箱’音频译码引擎之前减少‘背景’分量的立体混响阶数,因为(我们假定)背景并不含有重要的可定位内容。取决于前景分量的立体混响阶数,音频编码单元566可传输对应V向量,对应V向量可相当大。举例来说,V向量的简单16位标量量化将产生每一前景分量大约用于第4阶的20kbps开销(25个系数)及用于第6阶的40kbps(49个系数)。本发明中所描述的技术可提供用以减少V向量的此开销的方法。
为进行说明,假定前景元素的立体混响阶数为NDIST,且背景元素的立体混响阶数为NBG,如上文所描述。因为音频编码装置566可如上文所描述减少背景元素的立体混响阶数,所以NBG可小于NDIST。需要经传输以在接收器侧处重建前景元素的前景V向量的长度具有每一前景元素(NDIST+1)2的长度,而第一((NDIST+1)2)-((NBG+1)2)系数可用以重建最高为阶数NBG的前景或相异分量。使用本发明中所描述的技术,音频编码装置566可重建至多为阶数NBG的前景且将所得(NBG+1)2个通道与背景通道合并,从而导致至多为阶数NBG的完整声场。音频编码装置566接着可将V向量减少到具有高于(NBG+1)2的索引以用于传输的那些系数(其中这些向量可被称作“VT SMALL”)。在接收器侧处,音频解码单元568可通过将前景元素与VT SMALL向量相乘来重建用于大于NBG的立体混响阶数的前景音频通道。
图49C是更详细地说明音频编码系统560C的框图。如图49C的实例中所示,音频译码系统560B可包含音频编码装置567及音频解码装置569。音频编码装置567可类似于图4及40F的实例中所示的音频编码装置20及510F。音频解码装置569可类似于图5及41B的实例中所示的音频解码装置24及540B。
根据本发明中所描述的技术,当出于带宽减小的目的而对HoA信号使用基于帧的SVD(或相关方法,例如KLT及PCA)分解时,音频编码装置567可量化U矩阵的前几个向量(乘以S矩阵的对应奇异值)以及VT向量的对应向量。此将包括声场的‘前景’分量。所述技术可使音频编码装置567能够使用‘黑箱’音频译码引擎对UDIST*SDIST向量进行译码。V向量可经标量量化或向量量化。此外,U矩阵中的剩余向量中的一些或全部可乘以S矩阵及V矩阵的对应奇异值且还使用‘黑箱’音频译码引擎进行译码。这些将包括声场的‘背景’分量。
因为将最响听觉分量分解成‘前景分量’,所以音频编码装置567可在使用‘黑箱’音频译码引擎之前减少‘背景’分量的立体混响阶数,因为(我们假定)背景并不含有重要的可定位内容。音频编码装置567可以使得保留根据本文中所描述的技术的声场的总能量的方式减少阶数。取决于前景分量的立体混响阶数,音频编码单元567可传输对应V向量,对应V向量可相当大。举例来说,V向量的简单16位标量量化将产生每一前景分量大约用于第4阶的20kbps开销(25个系数)及用于第6阶的40kbps(49个系数)。本发明中所描述的技术可提供用以减少V向量的此开销的方法。
为进行说明,假定前景元素及背景元素的立体混响阶数为N。音频编码装置567可使V向量的背景元素的立体混响阶数从N减少到η,以使得η<N。音频编码装置67进一步应用补偿以增加V向量的背景元素的值,从而保留由SHC描述的声场的总能量。上文相对于图40F描述用于应用补偿的实例技术。在接收器侧处,音频解码单元569可重建用于立体混响阶数的背景音频通道。
图49D(i)及49D(ii)分别说明音频编码装置567D及音频解码装置569D。音频编码装置567D及音频解码装置569D可可经配置以执行根据本发明的方面的一或多个基于方向性的相异性确定。较高阶立体混响(HOA)是描述基于空间傅立叶变换的声场的所有方向信息的方法。通常,立体混响阶数N越高,空间分辨率就越高,球谐(SH)系数的数目(N+1)^2越大,用于发射和存储数据所需要的带宽就越大。因为HOA的带宽要求相当高,所以对于许多应用而言,期望带宽减少。
先前描述已描述了SVD(奇异值分解)或相关过程可如何用于空间音频压缩。本文中所描述的技术呈现用于选择突出元素(也称为前景元素)的改进算法。在将HOA音频帧基于SVD分解成其U、S及V矩阵之后,所述技术使K个突出元素的选择排他性地基于U矩阵的前K个通道[U(:,1:K)*S(1:K,1:K)]。这导致选择具有最高能量的音频元素。然而,并不保证那些元素也是方向性的。因此,所述技术是针对发现具有高能量及也为方向性的声音元素。这通过对V矩阵以及S矩阵进行加权而潜在地实现。接着,对于此所得矩阵的每一行,对较高索引元素(其与较高阶HOA系数相关联)求平方及求和,从而导致每一行一个值[在相对于图40H描述的伪码中的sumVS]。根据伪码中表示的工作流程,考虑在第5索引处开始的较高阶立体混响系数。这些值根据其大小来分类,且分类索引用以相应地重新布置原始U、S及V矩阵。接着可应用在本发明中较早所描述的基于SVD的压缩算法而无进一步修改。
图49E(i)及49E(ii)为分别说明音频编码装置571E及音频解码装置573E的框图。音频编码装置571E及音频解码装置573E可执行上文相对于图49到49D(ii)的实例所描述的技术的各种方面,除了音频编码装置571E可执行相对于HOA系数的功率谱密度矩阵(PDS)的奇异值分解以产生S2矩阵及V矩阵之外。S2矩阵可表示求平方的S矩阵,因此S2矩阵可经历平方根操作以获得S矩阵。在一些情况下,音频编码装置571E可相对于V矩阵执行量化以获得经量化V矩阵(其可表示为V'矩阵)。
音频编码装置571E可通过首先将S矩阵与经量化V'矩阵相乘以产生SV'矩阵来获得U矩阵。音频编码装置571E接下来可获得SV'矩阵的伪逆且接着将HOA系数乘以SV'矩阵的伪逆以获得U矩阵。通过相对于HOA系数的功率谱密度而非系数自身执行SVD,音频编码装置571E可在处理器循环及存储空间中的一或多者的方面潜在地减小执行SVD的计算复杂度,同时实现如同SVD直接应用于HOA系数的相同的源音频编码效率。
音频解码装置573E可类似于上文所描述的那些音频解码装置,除了音频解码装置573可从通过将SVD应用于HOA系数的功率谱密度实现的HOA系数的分解而不是直接从HOA系数来重建HOA系数之外。
图50A及50B是各自说明根据本发明中所描述的技术潜在地减小背景内容的阶数的两个不同方法中的一者的框图。如图50的实例中所示,第一方法可使用相对于UBG*SBG*VT向量的阶数缩减将阶数从N缩减到η,其中η小于(<)N。即,图40B到40J的实例中所示的阶数缩减单元528A可执行阶数缩减以进行截断,或以其它方式将UBG*SBG*VT向量的阶数N缩减到η,其中η小于(<)N。
作为一替代方法,阶数缩减单元528A可如图50B的实例中所示相对于VT执行此截断从而将行消除为(η+1)2,其出于说明目的而未在图40B的实例中说明。换句话说,阶数缩减单元528A可移除VT矩阵的一或多个阶数以有效地产生VBG矩阵。此VBG矩阵的大小是(η+1)2x(N+1)2-D,其中此VBG矩阵随后当产生UBG*SBG*VT向量时代替VT矩阵使用,从而有效地执行截断以产生大小M×(η+l)2的UBG*SBG*VT向量。
图51是说明可实施本发明中所描述的技术的各种方面以压缩球谐系数701的音频编码装置700A的相异分量压缩路径的实例的框图。在图51的实例中,相异分量压缩路径可指代压缩由SHC 701表示的声场的相异分量的音频编码装置700A的处理路径。可被称作背景分量压缩路径的另一路径可表示压缩SHC 701的背景分量的音频编码装置700A的处理路径。
尽管出于易于说明的目的而未图示,背景分量压缩路径可直接相对于SHC 701而不是SHC 701的分解进行操作。这类似于上文相对于图49到49C所描述的情形,除了背景分量处理路径可直接相对于SHC 701操作(如上文相对于图4的实例中所示的音频编码装置20所描述),使用心理声学编码器来压缩这些背景分量,而不是从UBG、SBG及VBG矩阵重组背景分量且接着执行这些重组背景分量的某一形式的心理声学编码(例如,使用AAC编码器)。通过执行直接相对于SHC 701的心理声学编码,与执行相对于重组背景分量的心理声学编码相比较,可减少不连续性,同时也减少计算复杂度(在压缩背景分量所需要的操作方面)。尽管涉及相异及背景方面,但在本发明中,可使用术语“显著”代替“相异”,且可使用术语“环境”代替“背景”。
在任一情况下,球谐系数701(“SHC 701”)可包括具有M×(N+1)2的大小的系数矩阵,其中M表示音频帧中的样本的数目(及在一些实例中,1024),且N表示系数所对应的基底函数的最高阶数。如上文所注明,对于总共1024×25个系数,N通常设定为四(4)。对应于特定阶数子阶数组合的SHC 701中的每一者可被称作通道。举例来说,对应于一阶零子阶基底函数的所有M个样本系数可表示通道,而对应于零阶零子阶基底函数的系数可表示另一通道等。SHC 701在本发明中也可被称作较高阶立体混响(HOA)内容701或SH信号701。
如图51的实例中所示,音频编码装置700A包含分析单元702、基于向量的合成单元704、向量缩减单元706、心理声学编码单元708、系数缩减单元710及压缩单元712(“压缩单元712”)。分析单元702可表示经配置以执行相对于SHC 701的分析以便识别声场(D)703的相异分量及背景分量(BGTOT)705的总数的单元。与上文所描述的音频编码装置相比较,音频编码装置700A并不执行相对于SHC 701的分解的此确定,但执行直接相对于SHC 701的确定。
基于向量的合成单元704表示经配置以执行相对于SHC 701的某一形式的基于向量的合成(例如SVD、KLT、PCA或任何其它基于向量的合成)以在SVD的实例中产生具有M×(N+1)2的大小的[US]矩阵707及具有(N+1)2×(N+1)2的大小的[V]矩阵709的单元。[US]矩阵707可表示由通过将SVD应用于SHC 701产生的[U]矩阵与[S]矩阵的矩阵相乘产生的矩阵。
向量缩减单元706可表示经配置以缩减[US]矩阵707及[V]矩阵709的向量数目以使得[US]矩阵707及[V]矩阵709的剩余向量中的每一者识别声场的相异或显著分量的单元。向量缩减单元706可执行基于相异分量D 703的数目的此缩减。相异分量D 703的数目可实际上表示数目阵列,其中每一数目识别矩阵707及709的不同相异向量。向量缩减单元706可输出大小M×D的缩减[US]矩阵711及大小(N+1)2x D的缩减[V]矩阵713。
尽管为容易说明的目的未图示,[V]矩阵709的内插可以类似于上文更详细地描述的方式的方式在[V]矩阵709的缩减之前发生。此外,尽管为容易说明的目的未图示,但以上文更详细地描述的方式重排序缩减[US]矩阵711及/或缩减[V]矩阵712。因此,所述技术不应在这些和其它方面受到限制(例如误差投影或上文所描述但在图51的实例中并未图示的前述技术的任何其它方面)。
心理声学编码单元708表示经配置以执行相对于[US]矩阵711的心理声学编码以产生位流715的单元。系数缩减单元710可表示经配置以缩减经缩减[V]矩阵713的通道的数目的单元。换句话说,系数缩减单元710可表示经配置以消除具有极少方向信息的相异V向量(其形成经缩减[V]矩阵713)的那些系数的单元。如上文所描述,在一些实例中,对应于一阶及零阶基底函数的相异V向量的那些系数(上文表示为NBG)提供极少方向信息且因此可从相异V向量移除(通过上文被称作“阶数缩减”的缩减)。在此实例中,可提供较大灵活性以不仅从集合[(NBG+1)2+1,(N+1)2]识别对应于NBG的此这些系数而且识别额外HOA通道(其可由变量TotalOfAddAmbHOAChan表示)。分析单元702可分析SHC 701以确定BGTOT,其不仅可识别(NBG+1)2而且识别TotalOfAddAmbHOAChan。系数缩减单元710接着可从经缩减[V]矩阵713移除对应于(NBG+1)2及TotalOfAddAmbHOAChan的那些系数,以产生大小为((N+1)2-(BGTOT)×D的小[V]矩阵717。
压缩单元712接着可执行上文所注明的标量量化及/或霍夫曼编码以压缩小[V]矩阵717,输出经压缩小[V]矩阵717作为旁侧通道信息719(“旁侧通道信息719”)。压缩单元712可以类似于图10到10O(ii)的实例中所示的方式的方式输出旁侧通道信息719。在一些实例中,类似于上文所描述的单元的位流产生单元可将旁侧通道信息719并入到位流715中。此外,在被称作位流715时,如上文所指出,音频编码装置700A可包含产生另一位流的背景分量处理路径,其中类似于上文所描述的单元的位流产生单元可产生类似于上文所描述的位流17的位流,所述位流包含位流715及由背景分量处理路径输出的位流。
根据本发明中描述的技术,分析单元702可经配置以确定向量的系数的第一非零集合,即在此实例中经缩减[V]矩阵713的向量,以用以表示声场的相异分量。在一些实例中,分析单元702可确定形成经缩减[V]矩阵713的每一向量的所有系数将包含在旁侧通道信息719中。分析单元702因此可设定BGTOT等于零。
音频编码装置700A因此可有效地以与上文相对于表示为“经解码向量”的表所描述的方式互逆的方式起作用。另外,音频编码装置700A可在存取单元的标头(其可包含一或多个帧)中指定选择所述多个配置模式中的哪一者的语法元素。尽管描述为在每存取单元基础上予以指定,但分析单元702可在每帧基础或任何其它周期性基础或非周期性基础(例如整个位流一次)上指定此语法元素。在任何情况下,此语法元素可包括指示选择了四个配置模式中的哪一者用于指定经缩减[V]矩阵713的非零系数集合以表示此相异分量的方向方面的两个位。所述语法元素可表示为“codedVVecLength”。以此方式,音频编码装置700A可在位流中用信号表示或以其它方式指定使用四个配置模式中的哪一者来在位流中指定小[V]矩阵717。尽管相对于四个配置模式予以描述,但所述技术不应限于四个配置模式,而应限于任何数目的配置模式,包含单个配置模式或多个配置模式。
因此,所述技术的各种方面可使音频编码装置700A能够经配置以根据以下条款操作。
条款133149-1F。一种装置,其包括:一或多个处理器,所述一或多个处理器经配置以选择用以指定向量的系数的非零集合的多个配置模式中的一者,所述向量已从描述声场且表示声场的相异分量的多个球谐系数分解,且基于所述多个配置模式中的选定者指定所述向量的系数的所述非零集合。
条款133149-2F。条款133149-1F的装置,其中所述多个配置模式中的所述一者指示所述系数的所述非零集合包含所有所述系数。
条款133149-3F。条款133149-1F的装置,其中所述多个配置模式中的所述一者指示系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数。
条款133149-4F。条款133149-1F的装置,其中所述多个配置模式中的所述一者指示系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数,且排除所述系数中的对应于大于所述多个球谐系数中的所述一或多者对应的所述基底函数的阶数的阶数的至少一个系数。
条款133149-5F。条款133149-1F的装置,其中所述多个配置模式中的所述一者指示系数的所述非零集合包含所有所述系数,所述系数中的至少一者除外。
条款133149-6F。条款133149-1F的装置,其中所述一或多个处理器进一步经配置以在位流中指定所述多个配置模式中的选定一者。
条款133149-1G。一种装置,其包括:一或多个处理器,所述一或多个处理器经配置以确定多个配置模式中的一者,将根据多个配置模式中的所述一者提取向量的系数的非零集合,所述向量已从描述声场且表示声场的相异分量的的多个球谐系数分解,且基于所述多个配置模式中的所述获得者指定所述向量的系数的所述非零集合。
条款133149-2G。条款133149-1G的装置,其中所述多个配置模式中的所述一者指示所述系数的所述非零集合包含所有所述系数。
条款133149-3G。条款133149-1G的装置,其中所述多个配置模式中的所述一者指示系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数。
条款133149-4G。条款133149-1G的装置,其中所述多个配置模式中的所述一者指示系数的所述非零集合包含所述系数中的对应于大于所述多个球谐系数中的一或多者所对应的基底函数的阶数的阶数的那些系数,且排除所述系数中的对应于大于所述多个球谐系数中的所述一或多者对应的所述基底函数的阶数的阶数的至少一个系数。
条款133149-5G。条款133149-1G的装置,其中所述多个配置模式中的所述一者指示系数的所述非零集合包含所有所述系数,所述系数中的至少一者除外。
条款133149-6G。条款133149-1G的装置,其中所述一或多个处理器进一步经配置以当确定所述多个配置模式中的所述一者时基于在位流中用信号表示的值确定所述多个配置模式中的所述一者。
图52是说明可实施本发明中所描述的技术的各种方面以重建或接近重建SHC 701的音频解码装置750A的另一实例的框图。在图52的实例中,音频解码装置750A类似于图41D的实例中所示的音频解码装置540D,提取单元542接收位流715'(其类似于上文相对于图51的实例所描述的位流715,位流715'还包含SHCBG 752的经音频编码版本除外)及旁侧通道信息719除外。出于此原因,所述提取单元表示为“提取单元542'”。
此外,提取单元542'不同于提取单元542之处在于提取单元542'包含V解压缩单元555的经修改形式(其在图52的实例中展示为“V解压缩单元555'”)。V解压缩单元555'接收旁侧通道信息719及表示为codedVVecLength 754的语法元素。提取单元542'从位流715'(及在一个实例中,从包含于位流715'内的存取单元标头)剖析codedVVecLength754。V解压缩单元555'包含模式配置单元756(“模式配置单元756”)及可配置以根据前描配置模式760中的任一者操作的剖析单元758。
模式配置单元756接收语法元素754及选择配置模式760中的一者。模式配置单元756接着用配置模式760中的所述选定者配置剖析单元758。剖析单元758表示经配置以根据配置模式760中的任一者操作以从旁侧通道信息719剖析小[V]向量717的压缩形式的单元。剖析单元758可根据以下表中所呈现的切换语句来操作。
表—经解码向量


在先前语法表中,具有四种情况(情况0到3)的第一切换语句提供用以根据系数的数目确定小[V]矩阵717的每一向量的长度的方式。第一情况,情况0,指示用于VT DIST向量的所有系数被指定。第二情况,情况1,指示仅VT DIST向量的对应于大于MinNumOfCoeffsForAmbHOA的阶数的那些系数被指定,其可表示上文被称作(NDIST+1)-(NBG+1)的情况。第三情况,情况2,类似于第二情况,但进一步将识别的系数减去NumOfAddAmbHoaChan,其表示用于指定对应于超过阶数NBG的阶数的额外通道(其中“通道”指对应于某一阶数、子阶数组合的特定系数)的变量。第四情况,情况3,指示仅VT DIST向量的在移除由NumOfAddAmbHoaChan识别的系数之后所剩余的那些系数被指定。
在这方面中,音频解码装置750A可根据本发明中所描述的技术操作以确定表示声场的相异分量的向量的系数的第一非零集合,所述向量已从描述声场的多个球谐系数分解。
此外,音频解码装置750A可经配置以根据本发明中所描述的技术操作以确定多个配置模式中的一者,将根据多个配置模式中的所述一者提取向量的系数的非零集合,所述向量已从描述声场且表示声场的相异分量的多个球谐系数分解,且基于所述多个配置模式中的所述获得者提取所述向量的系数的所述非零集合。
图53是说明可执行本发明中所描述的技术的各种方面的音频编码装置570的另一实例的框图。在图53的实例中,音频编码装置570可类似于音频编码装置510A到510J中的一或多者(其中假定阶数缩减单元528A包含在声场分量提取单元20内但为容易说明的目的未图示)。然而,音频编码装置570可包含更一般变换单元572,所述变换单元在一些实例中可包括分解单元518。
图54是更详细地说明图53的实例中所示的音频编码装置570的实例实施方案的框图。如图54的实例中所说明,音频编码装置570的变换单元572包含旋转单元654。音频编码装置570的声场分量提取单元520包含空间分析单元650、内容特性分析单元652、提取相干分量单元656及提取扩散分量单元658。音频编码装置570的音频编码单元514包含AAC译码引擎660及AAC译码引擎162。音频编码装置570的位流产生单元516包含多路复用器(MUX)164。
表示呈SHC的形式的3D音频数据所需要的根据位/秒的带宽可使其在消费者使用方面是过高的。举例来说,当使用48kHz的取样速率时,且在32位/相同分辨率的情况下,四阶SHC表示是表示36Mbits/秒的带宽(25×48000×32bps)。当与用于立体声信号的当前技术水平音频译码(其通常约为100kbits/秒)相比较时,此为较大的数字。图54的实例中所实施的技术可缩减3D音频表示的带宽。
空间分析单元650、内容特性分析单元652及旋转单元654可接收SHC 511。如在本发明中其它地方所描述,SHC 511可表示声场。在图54的实例中,空间分析单元650、内容特性分析单元652及旋转单元654可接收用于声场的四阶(n=4)表示的二十五个SHC。
空间分析单元650可分析由SHC 511表示的声场以识别声场的相异分量和声场的扩散分量。声场的相异分量是经感知为来自可识别方向或以其它方式不同于声场的背景或扩散分量的声音。举例来说,由个别乐器产生的声音可感知为来自可识别的方向。相比之下,声场的扩散或背景分量未被感知为来自可识别的方向。举例来说,风穿过森林的声音可为声场的扩散分量。
空间分析单元650可识别试图识别最佳角度的一或多个相异分量,以所述最佳角度旋转声场以使具有大部分能量的相异分量的那些分量与垂直及/或水平轴(相对于记录此声场的假定麦克风)对准。空间分析单元650可识别此最佳角度以使得声场可旋转,使得这些相异分量与图1及2的实例中所示的基础球面基底函数较好地对准。
在一些实例中,空间分析单元650可表示经配置以执行某一形式的扩散分析以识别包含扩散声音的由SHC 511表示的声场的百分比(扩散声音可指代具有低层级方向或低阶SHC的声音,意味着具有小于或等于一的阶数的那些SHC 511)。作为一个实例,空间分析单元650可以类似于威利·帕吉(Ville Pulkki)的标题为“以方向性音频译码的空间声音再生(Spatial Sound Reproduction with Directional Audio Coding)”的论文(公布于听觉工程学协会会刊第55卷第6期,日期为2007年6月)中所描述的方式的方式执行扩散分析。在一些情况下,空间分析单元650在执行扩散分析以确定扩散百分比时可仅分析HOA系数的非零子集,例如SHC 511的零阶及一阶SHC。
内容特性分析单元652可至少部分基于SHC 511确定所述SHC 511是经由声场的自然记录产生还是由(作为一个实例)例如PCM对象的音频对象人工地(即,合成地)产生。此外,内容特性分析单元652接着可至少部分基于SHC 511是经由声场的实际记录产生还是由人工音频对象产生确定位流517中包含的通道的总数。举例来说,内容特性分析单元652可至少部分基于SHC 511是由实际声场的记录产生还是由人工音频对象产生来确定位流517将包含十六个通道。通道中的每一者可为单声道通道。内容特性分析单元652可基于位流517的输出位速率(例如,1.2Mbps)进一步执行对位流517中所包含的通道的总数的确定。
另外,内容特性分析单元652可至少部分基于SHC 511是由实际声场的记录产生还是由人工音频对象产生来确定有多少通道分配给声场的相干或(换句话说)相异分量,及有多少通道分配给声场的扩散或(换句话说)背景分量。举例来说,当SHC 511是由使用(作为一个实例)Eigenmic记录实际声场产生的时,内容特性分析单元652可将通道中的三个通道分配给声场的相干分量,且可将剩余通道分配给声场的扩散分量。在此实例中,当由人工音频对象产生SHC 511时,内容特性分析单元652可将通道中的五个通道分配给声场的相干分量,且可将剩余通道分配给声场的扩散分量。以此方式,内容分析块(即,内容特性分析单元652)可确定声场的类型(例如,扩散/方向等),且又确定提取的相干/扩散分量的数目。
目标位速率可影响个别AAC译码引擎(例如,AAC译码引擎660,662)的组件的数目及位速率。换句话说,内容特性分析单元652可进一步执行基于位流517的输出位速率(例如1.2Mbps)确定分配给相干分量的通道数目及分配给扩散分量的通道数目。
在一些实例中,分配给声场的相干分量的通道的位速率可大于分配给声场的扩散分量的通道的位速率。举例来说,位流517的最大位速率可为1.2Mb/秒。在此实例中,可存在分配给相干分量的四个通道及分配给扩散分量的16个通道。此外,在此实例中,分配给相干分量的通道中的每一者可具有64kb/秒的最大位速率。在此实例中,分配给扩散分量的通道中的每一者可具有48kb/秒的最大位速率。
如上文所指示,内容特性分析单元652可确定SHC 511是从实际声场的记录还是从人工音频对象产生。内容特性分析单元652可以各种方式进行此确定。举例来说,音频编码装置570可使用4阶SHC。在此实例中,内容特性分析单元652可译码24个通道且预测第25个通道(其可表示为向量)。内容特性分析单元652可将标量应用于所述24个通道中的至少一些且将所得值相加以确定第25向量。此外,在此实例中,内容特性分析单元652可确定所预测第25个通道的准确度。在此实例中,如果所预测第25通道的准确度相对较高(例如,准确度超过特定阈值),则SHC 511可能是从合成音频对象产生。相比之下,如果所预测第25通道的准确度相对较低(例如,准确度低于特定阈值),则SHC 511更可能表示所记录的声场。举例来说,在此实例中,如果第25通道的信噪比(SNR)超过100分贝(db),则SHC 511更可能表示从合成音频对象产生的声场。相比之下,使用本征麦克风记录的声场的SNR可为5db到20db。因而,在由从实际直接记录产生与从合成音频对象产生的SHC 511表示的声场之间的SNR比率中可存在明显分界。
此外,内容特性分析单元652可至少部分基于SHC 511是从实际声场的记录还是从人工音频对象产生而选择用于量化V向量的码簿。换句话说,取决于由HOA系数表示的声场是记录的还是合成的,内容特性分析单元652可选择不同码簿供用于量化V向量。
在一些实例中,内容特性分析单元652可重复地确定SHC 511是从实际声场的记录还是从人工音频对象产生。在一些此些实例中,重复基础可为每个帧。在其它实例中,内容特性分析单元652可执行此确定一次。此外,内容特性分析单元652可重复地确定相干分量通道及扩散分量通道的通道总数及分配。在一些此些实例中,重复基础可为每个帧。在其它实例中,内容特性分析单元652可执行此确定一次。在一些实例中,内容特性分析单元652可重复地选择供用于量化V向量的码簿。在一些此些实例中,重复基础可为每个帧。在其它实例中,内容特性分析单元652可执行此确定一次。
旋转单元654可执行HOA系数的旋转操作。如在本发明中在别处所论述(例如,相对于图55及55B),执行旋转操作可减少表示SHC 511所需的位数目。在一些实例中,由旋转单元652执行的旋转分析为奇异值分解(“SVD”)分析的实例。主分量分析(“PCA”)、独立分量分析(“ICA”)及卡忽南-拉维变换(“KLT”)为可能适用的相关技术。
在图54的实例中,提取相干分量单元656从旋转单元654接收经旋转SHC 511。此外,提取相干分量单元656从经旋转SHC 511提取与声场的相干分量相关联的那些经旋转SHC 511。
此外,提取相干分量单元656产生一或多个相干分量通道。相干分量通道中的每一者可包含与声场的相干系数相关联的经旋转SHC 511的不同子集。在图54的实例中,提取相干分量单元656可产生1到16个相干分量通道。由提取相干分量单元656产生的相干分量通道的数目可通过由内容特性分析单元652分配给声场的相干分量的通道数目来确定。由提取相干分量单元656产生的相干分量通道的位速率可由内容特性分析单元652确定。
类似地,在图54的实例中,提取扩散分量单元658从旋转单元654接收经旋转SHC511。此外,提取扩散分量单元658从经旋转SHC 511提取与声场的扩散分量相关联的那些经旋转SHC 511。
此外,提取扩散分量单元658产生一或多个扩散分量通道。扩散分量通道中的每一者可包含与声场的扩散系数相关联的经旋转SHC 511的不同子集。在图54的实例中,提取扩散分量单元658可产生1到9个扩散分量通道。由提取扩散分量单元658产生的扩散分量通道的数目可通过由内容特性分析单元652分配给声场的扩散分量的通道数目来确定。由提取扩散分量单元658产生的扩散分量通道的位速率可由内容特性分析单元652确定。
在图54的实例中,AAC译码单元660可使用AAC编解码器来对由提取相干分量单元656产生的相干分量通道进行编码。类似地,AAC译码单元662可使用AAC编解码器来对由提取扩散分量单元658产生的扩散分量通道进行编码。多路复用器664(“多路复用器664”)可对经编码相干分量通道及经编码扩散分量通道连同旁侧数据(例如,由空间分析单元650确定的最佳角度)进行多路复用以产生位流517。
以此方式,所述技术可使音频编码装置570能够确定表示声场的球谐系数是否是从合成音频对象产生。
在一些实例中,音频编码装置570可基于球谐系数是否是从合成音频对象产生而确定表示声场的相异分量的球谐系数的子集。在这些和其它实例中,音频编码装置570可产生位流以包含球谐系数的子集。在一些情况下,音频编码装置570可对球谐系数的所述子集进行音频编码,且产生位流以包含球谐系数的经音频编码子集。
在一些实例中,音频编码装置570可基于球谐系数是否是从合成音频对象产生而确定表示声场的背景分量的球谐系数的子集。在这些和其它实例中,音频编码装置570可产生位流以包含球谐系数的所述子集。在这些和其它实例中,音频编码装置570可对球谐系数的所述子集进行音频编码,且产生位流以包含球谐系数的经音频编码子集。
在一些实例中,音频编码装置570可相对于球谐系数执行空间分析以识别要旋转由球谐系数表示的声场的角度,且执行旋转操作以将声场旋转所识别角度以产生经旋转球谐系数。
在一些实例中,音频编码装置570可基于球谐系数是否是从合成音频对象产生而确定表示声场的相异分量的球谐系数的第一子集,且基于球谐系数是否是从合成音频对象产生而确定表示声场的背景分量的球谐系数的第二子集。在这些和其它实例中,音频编码装置570可按比用以对球谐系数的第二主体进行音频编码的目标位速率高的目标位速率对球谐系数的第一子集进行音频编码。
以此方式,所述技术的各种方面可使音频编码装置570能够根据以下条款确定SCH511是否是从合成音频对象产生。
条款132512-1。一种装置,例如音频编码装置570,其包括:其中所述一或多个处理器进一步经配置以确定表示声场的球谐系数是否是从合成音频对象产生。
条款132512-2。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时从存储表示声场的球谐系数的至少一部分的帧式球谐系数矩阵排除第一向量以获得经缩减帧式球谐系数矩阵。
条款132512-3。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时从存储表示声场的球谐系数的至少一部分的帧式球谐系数矩阵排除第一向量以获得经缩减帧式球谐系数矩阵,且基于所述经缩减帧式球谐系数矩阵的剩余向量预测所述经缩减帧式球谐系数矩阵的向量。
条款132512-4。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时从存储表示声场的球谐系数的至少一部分的帧式球谐系数矩阵排除第一向量以获得经缩减帧式球谐系数矩阵,且至少部分基于所述经缩减帧式球谐系数矩阵的剩余向量的总和预测所述经缩减帧式球谐系数矩阵的向量。
条款132512-5。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时至少部分基于存储球谐系数的至少一部分的帧式球谐系数矩阵的剩余向量的总和预测所述帧式球谐系数矩阵的向量。
条款132512-6。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时至少部分基于存储球谐系数的至少一部分的帧式球谐系数矩阵的剩余向量的总和预测所述帧式球谐系数矩阵的向量,且基于所述所预测向量计算误差。
条款132512-7。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时至少部分基于存储球谐系数的至少一部分的帧式球谐系数矩阵的剩余向量的总和预测所述帧式球谐系数矩阵的向量,且基于所述所预测向量及所述帧式球谐系数矩阵的对应向量计算误差。
条款132512-8。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时至少部分基于存储球谐系数的至少一部分的帧式球谐系数矩阵的剩余向量的总和预测所述帧式球谐系数矩阵的向量,且将误差计算为所预测向量与所述帧式球谐系数矩阵的对应向量的差的绝对值的总和。
条款132512-9。条款132512-1的装置,其中所述一或多个处理器进一步经配置以当确定表示声场的球谐系数是否是从合成音频对象产生时至少部分基于存储球谐系数的至少一部分的帧式球谐系数矩阵的剩余向量的总和预测所述帧式球谐系数矩阵的向量,基于所预测向量及所述帧式球谐系数矩阵的对应向量计算误差,基于所述帧式球谐系数矩阵的对应向量的能量与所述误差计算一比率,且比较所述比率与阈值以确定表示声场的球谐系数是否是从合成音频对象产生。
条款132512-10。技术方案4到9中任一项的装置,其中所述一或多个处理器进一步经配置以当预测所述向量时预测存储所述球谐系数的至少所述部分的帧式球谐系数矩阵的第一非零向量。
条款132512-11。技术方案1到10中任一项的装置,其中所述一或多个处理器进一步经配置以在存储球谐系数的经压缩版本的位流中指定球谐系数是否是从合成音频对象产生的指示。
条款132512-12。条款132512-11的装置,其中所述指示为单个位。
条款132512-13。条款132512-1的装置,其中所述一或多个处理器进一步经配置以基于球谐系数是否是从合成音频对象产生而确定表示声场的相异分量的球谐系数的子集。
条款132512-14。条款132512-13的装置,其中所述一或多个处理器进一步经配置以产生位流以包含球谐系数的所述子集。
条款132512-15。条款132512-13的装置,其中所述一或多个处理器进一步经配置以对球谐系数的所述子集进行音频编码,且产生位流以包含所述球谐系数的经音频编码子集。
条款132512-16。条款132512-1的装置,其中所述一或多个处理器进一步经配置以基于球谐系数是否是从合成音频对象产生而确定表示声场的背景分量的球谐系数的子集。
条款132512-17。条款132512-16的装置,其中所述一或多个处理器进一步经配置以产生位流以包含球谐系数的所述子集。
条款132512-18。条款132512-15的装置,其中所述一或多个处理器进一步经配置以对球谐系数的所述子集进行音频编码,且产生位流以包含所述球谐系数的经音频编码子集。
条款132512-18。条款132512-1的装置,其中所述一或多个处理器进一步经配置以相对于球谐系数执行空间分析以识别需旋转由球谐系数表示的声场的角度,且执行旋转操作以将所述声场旋转所识别角度以产生经旋转球谐系数。
条款132512-20。条款132512-1的装置,其中所述一或多个处理器进一步经配置以基于球谐系数是否是从合成音频对象产生而确定表示声场的相异分量的球谐系数的第一子集,且基于球谐系数是否是从合成音频对象产生而确定表示声场的背景分量的球谐系数的第二子集。
条款132512-21。条款132512-20的装置,其中所述一或多个处理器进一步经配置以按比用以对球谐系数的第二主体进行音频编码的目标位速率高的目标位速率对球谐系数的第一子集进行音频编码。
条款132512-22。条款132512-1的装置,其中所述一或多个处理器进一步经配置以相对于所述球谐系数执行奇异值分解以产生表示所述多个球谐系数的左奇异向量的U矩阵、表示所述多个球谐系数奇异值的S矩阵及表示所述多个球谐系数的右奇异向量的V矩阵。
条款132512-23。条款132512-22的装置,其中所述一或多个处理器进一步经配置以基于球谐系数是否是从合成音频对象产生而确定U矩阵、S矩阵及V矩阵中的一或多者的表示声场的相异分量的那些部分。
条款132512-24。条款132512-22的装置,其中所述一或多个处理器进一步经配置以基于球谐系数是否是从合成音频对象产生而确定U矩阵、S矩阵及V矩阵中的一或多者的表示声场的背景分量的那些部分。
条款132512-1C。一种装置,例如音频编码装置570,其包括:一或多个处理器,所述一或多个处理器经配置以基于至少依据球谐系数的向量的能量与基于球谐系数的向量的预测版本及球谐系数的向量而导出的误差而计算出的比率确定表示声场的球谐系数是否是从合成音频对象产生。
在上述各种实例中的每一者中,应理解,音频编码装置570可执行方法,或另外包括执行音频编码装置570经配置以执行的方法的每一步骤的装置。在一些情况下,这些装置可包括一或多个处理器。在一些情况下,所述一或多个处理器可表示借助于存储到非暂时性计算机可读存储媒体的指令配置的专用处理器。换句话说,编码实例的集合中的每一者中的技术的各种方面可提供其上存储有指令的非暂时性计算机可读存储媒体,所述指令在执行时致使所述一或多个处理器执行音频编码装置570已经配置以执行的方法。
图55及55B是说明执行本发明中所描述的技术的各种方面以旋转声场640的实例的图。图55是根据本发明中所描述的技术的各种方面的说明在旋转前的声场640的图。在图55的实例中,声场640包含两个高压力位置(表示为位置642A及642B)。这些位置642A及642B(“位置642”)位于具有非零斜率(其为参考非水平线的另一方式,因为水平线具有零的斜率)的线644上。假定位置642除x及y坐标之外还具有z坐标,可能需要较高阶球面基底函数来正确地表示此声场640(因为这些较高阶球面基底函数描述声场的上部及下部或非水平部分)。音频编码装置570可旋转声场640直到连接位置642的线644水平为止,而非直接将声场640缩减到SHC 511。
图55B为说明声场640在被旋转直到连接位置642的线644水平之后的图。由于以此方式旋转声场640,所以可导出SHC 511使得SHC 511中的较高阶SHC被指定为零(假定经旋转声场640对于z坐标不再具有任何压力(或能量)位置)。以此方式,音频编码装置570可旋转、平移或更大体而言调整声场640以减少具有非零值的SHC 511的数目。结合所述技术的各种其它方面,音频编码装置570可接着在位流517的字段中用信号表示未用信号表示SHC511的这些较高阶SHC,而非用信号表示识别SHC 511的这些较高阶SHC具有零值的32位带正负号数。音频编码装置570还可常通过以上文所描述的方式来表达方位角及高度角而在位流517中指定指示如何旋转声场640的旋转信息。例如音频编码装置等提取装置可接着暗示SHC 511的这些未用信号表示的SHC具有零值,且当基于SHC 511再生声场640时,执行旋转以旋转声场640以使得声场640类似于图55的实例中所示的声场640。以此方式,音频编码装置570可根据本发明中所描述的技术减少需要在位流517中指定的SHC 511的数目。
可使用‘空间压缩’算法来确定声场的最佳旋转。在一个实施例中,音频编码装置570可执行所述算法以迭代通过所有可能的方位角及仰角组合(即,在以上实例中为1024×512个组合),从而针对每一组合旋转声场且计算高于阈值的SHC 511的数目。可将产生最小数目的高于阈值的SHC 511的方位角/仰角候选者组合视为可称作“最佳旋转”的组合。在此经旋转形式中,声场可能需要最小数目的SHC 511以用于表示声场且可因而被视为压缩的。在一些情况下,调整可包括此最佳旋转且上文所描述的调整信息可包含此旋转(其可称为“最佳旋转”)信息(就方位角及仰角而言)。
在一些情况下,音频编码装置570可以(作为一个实例)欧拉角的形式来指定额外角,而非仅指定方位角及仰角。欧拉角指定关于z轴、以前的x轴及以前的z轴的旋转角度。虽然在本发明中相对于方位角及仰角的组合加以描述,但本发明的技术不应受限于仅指定方位角及仰角,而是可包含指定任何数目的角度(包括上文所提及的三个欧拉角)。在此意义上,音频编码装置570可旋转声场以减少提供与描述声场相关的信息的多个阶层元素的数目且在位流中将欧拉角指定为旋转信息。如上文所提及,欧拉角可描述如何旋转声场。当使用欧拉角时,位流提取装置可剖析位流以确定包含欧拉角的旋转信息,且当基于提供与描述声场相关的信息的那些多个阶层元素来再生声场时基于欧拉角来旋转声场。
此外,在一些情况下,音频编码装置570可指定与指定旋转的一或多个角度的预定义组合相关联的索引(其可称作“旋转索引”),而非在位流517中显式地指定这些角。换句话说,在一些情况下,旋转信息可包含旋转索引。在这些情况下,旋转索引的给定值(例如,零值)可指示未执行旋转。可关于旋转表来使用此旋转索引。即,音频编码装置570可包含旋转表,所述旋转表包括针对方位角及仰角的组合中的每一者的条目。
或者,旋转表可包含针对表示方位角及仰角的每一组合的每一矩阵变换的条目。即,音频编码装置570可存储旋转表,所述旋转表具有针对用于将声场旋转方位角及仰角的组合中的每一组合的每一矩阵变换的条目。通常,音频编码装置570接收SHC 511且当执行旋转时根据以下方程式来导出SHC 511':

在以上方程式中,将SHC 511'计算为以下三者的函数:用于依据第二参考系来编码声场的编码矩阵(EncMat2);用于将SHC 511恢复回到依据第一参考系的声场的逆矩阵(InvMat1);及SHC 511。EncMat2具有大小25x32,而InvMat2具有大小32x25。SHC 511'与SHC511两者均具有大小25,其中SHC 511'可归因于移除了不指定突出音频信息的那些SHC而得以进一步缩减。EncMat2可针对每一方位角及仰角组合而变化,而InvMat1可相对于每一方位角及仰角组合而保持不变。旋转表可包含存储将每一不同EncMat2与InvMat1相乘的结果的条目。
图56是说明根据第一参考系俘获的实例声场的图,所述第一参考系接着根据本发明中所描述的技术旋转以依据第二参考系表达声场。在图56的实例中,在假定第一参考系的情况下俘获包围本征麦克风646的声场,所述第一参考系在图56的实例中由X1、Y1及Z1轴表示。SHC 511依据此第一参考系来描述声场。InvMat1将SHC 511变换回到声场,从而在图56的实例中使得能够将声场旋转到由X2、Y2及Z2轴所表示的第二参考系。上文所描述的EncMat2可旋转声场并产生依据第二参考系来描述此经旋转声场的SHC 511'。
在任何情况下,可如下导出以上方程式。假定用某一坐标系来记录声场,使得前方被视为x轴的方向,从此参考坐标系来定义本征麦克风(或其它麦克风配置)的32个麦克风位置。可接着将声场的旋转视为此参考系的旋转。对于所假定的参考系,可如下计算SHC511:

在以上方程式中, 表示第i麦克风(其中在此实例中i可为1到32)的位置(Posi)处的球面基底函数。mici向量表示时间t的第i麦克风的麦克风信号。位置(Posi)指麦克风在第一参考系(即,在此实例中为在旋转前的参考系)中的位置。
表示第i麦克风(其中在此实例中i可为1到32)的位置(Posi)处的球面基底函数。mici向量表示时间t的第i麦克风的麦克风信号。位置(Posi)指麦克风在第一参考系(即,在此实例中为在旋转前的参考系)中的位置。
可替代地依据上文所表示的数学表示式来将以上方程式表达为:

为了旋转声场(或在第二参考系中),将在第二参考系中计算位置(Posi)。只要原始麦克风信号存在,便可任意地旋转声场。然而,原始麦克风信号(mici(t))常不可获得。问题接着可为如何从SHC 511检索麦克风信号(mici(t))。如果使用T设计(如在32麦克风本征麦克风中),则可通过求解以下方程式来实现此问题的解决方案:

此InvMat1可指定根据麦克风的位置(如相对于第一参考系所指定)所计算的球谐基底函数。此方程式也可以表达为 如上所述。
如上所述。
一旦根据以上方程式检索麦克风信号(mici(t)),便可旋转描述声场的所述麦克风信号(mici(t))以计算对应于第二参考系的SHC 511',从而产生以下方程式:

EncMat2指定来自旋转位置(Posi')的球谐基底函数。以此方式,EncMat2可有效地指定方位角及仰角的组合。因此,当旋转表存储方位角和仰角的每一组合的 的结果时,旋转表有效地指定方位角和仰角的每一组合。以上方程式还可表达为:
的结果时,旋转表有效地指定方位角和仰角的每一组合。以上方程式还可表达为:

其中θ2, 表示不同于由θ1,
表示不同于由θ1, 表示的第一方位角及仰角的第二方位角及第二仰角。θ1,
表示的第一方位角及仰角的第二方位角及第二仰角。θ1, 对应于第一参考系,而θ2,
对应于第一参考系,而θ2, 对应于第二参考系。InvMat1可因此对应于
对应于第二参考系。InvMat1可因此对应于 而EncMat2可对应于
而EncMat2可对应于
以上可表示不考虑滤波操作(上文在表示在频域中导出SHC 511的各种方程式中由jn(·)函数表示,该jn(·)函数指n阶球面贝塞耳函数)的计算的更简化版本。在时域中,此jn(·)函数表示特定针对特定阶数n的滤波操作。在进行滤波的情况下,可按阶数执行旋转。为进行说明,考虑以下方程式:


从这些方程式,分开地完成数个阶数的经旋转SHC 511',因为对于每一阶来说bn(t)是不同的。结果,可如下更改以上方程式以用于计算经旋转SHC 511'中的一阶者:

假定存在三个一阶SHC 511,在以上方程式中SHC 511'及SHC 511向量中的每一者的大小为三。同样地,对于二阶来说,可应用以下方程式:

再次,假定存在五个二阶SHC 511,在以上方程式中SHC 511'及SHC 511向量中的每一者的大小为五。对于其它阶(即,三阶及四阶)来说,剩余方程式可类似于上文所描述的方程式,其关于矩阵的大小遵循相同模式(因为EncMat2的行数、InvMat1的列数以及三阶SHC511及SHC 511'向量与四阶SHC 511及SHC 511'向量的大小等于三阶球谐基底函数及四阶球谐基底函数中的每一者的子阶的数目(m乘二加1))。
音频编码装置570可因此相对于方位角及仰角的每一组合来执行此旋转操作以尝试识别所谓的最佳旋转。在执行此旋转操作之后,音频编码装置570可计算高于阈值的SHC511'的数目。在一些情况下,音频编码装置570可在一持续时间(例如,音频帧)内执行此旋转以导出表示声场的一系列SHC 511'。通过在此持续时间内执行此旋转以导出表示声场的一系列SHC 511',音频编码装置570可在小于一帧或其它长度的持续时间中减少不得不执行的旋转操作的数目(与针对描述声场的SHC 511的每一集合完成此旋转操作相比)。在任何情况下,音频编码装置570可贯穿此过程节省那些SHC 511',从而具有最小数目的大于阈值的SHC 511'。
然而,相对于方位角及仰角的每一组合来执行此旋转操作可为处理器密集的或耗时的。结果,音频编码装置570可不执行可被表征为旋转算法的此“蛮力”实施方案的过程。替代地,音频编码装置570可相对于提供大体良好压缩的方位角及仰角的可能已知(按统计方式)组合的子集来执行旋转,关于此子集中的组合周围的组合来执行进一步旋转,从而与子集中的其它组合相比提供更好的压缩。
作为另一替代例,音频编码装置570可仅相对于组合的已知子集来执行此旋转。作为另一替代例,音频编码装置570可遵循组合的轨迹(空间上),相对于组合的此轨迹来执行旋转。作为另一替代例,音频编码装置570可指定压缩阈值,所述压缩阈值界定具有高于阈值的非零值的SHC 511'的最大数目。此压缩阈值可有效地设定搜索的停止点,使得当音频编码装置570执行旋转且确定具有高于所设定阈值的值的SHC 511'的数目小于或等于(或在一些情况下小于)压缩阈值时,音频编码装置570停止相对于剩余组合来执行任何额外旋转操作。作为又一替代例,音频编码装置570可遍历组合的阶层式布置树(或其它数据结构),关相对于当前组合来执行旋转操作且取决于具有大于阈值的非零值的SHC 511'的数目而遍历所述树到右边或左边(例如,对于二进制树而言)。
在此意义上,这些替代例中的每一者涉及执行第一及第二旋转操作且比较执行第一及第二旋转操作的结果以识别产生最小数目的具有大于阈值的非零值的SHC 511'的第一及第二旋转操作中的一者。因此,音频编码装置570可对声场执行第一旋转操作以根据第一方位角及第一仰角来旋转声场,且确定提供与描述声场相关的信息的所述多个阶层式元素的第一数目,所述多个阶层元素表示根据第一方位角及第一仰角所旋转的声场。音频编码装置570还可对声场执行第二旋转操作以根据第二方位角及第二仰角来旋转声场,且确定提供与描述声场相关的信息的多个阶层式元素的第二数目,所述多个阶层式元素表示根据第二方位角及第二仰角所旋转的声场。此外,音频编码装置570可基于所述多个阶层式元素的第一数目与所述多个阶层式元素的第二数目的比较来选择第一旋转操作或第二旋转操作。
在一些实例中,可相对于持续时间来执行旋转算法,其中对旋转算法的后续调用可基于对旋转算法的过去调用来执行旋转操作。换句话说,旋转算法可基于在旋转声场历时先前持续时间时所确定的过去旋转信息而为自适应的。举例来说,音频编码装置570可旋转声场历时第一持续时间(例如,音频帧)以识别针对此第一持续时间的SHC 511'。音频编码装置570可以上文所描述的方式中的任一者而在位流517中指定旋转信息及SHC 511'。可将此旋转信息称作第一旋转信息,因为其描述声场在第一持续时间中的旋转。音频编码装置570可接着基于此第一旋转信息来旋转声场历时第二持续时间(例如,第二音频帧)以识别针对此第二持续时间的SHC 511'。当在第二持续时间内执行第二旋转操作时,音频编码装置570可利用此第一旋转信息以初始化对方位角及仰角的“最佳”组合的搜索(作为一个实例)。音频编码装置570可接着在位流517中指定SHC 511'及针对第二持续时间的对应旋转信息(其可称作“第二旋转信息”)。
虽然上文是相对于实施旋转算法以减少处理时间及/或消耗的若干不同方式加以描述,但所述技术可相对于可减少或以其它方式加速对可称作“最佳旋转”的旋转的识别的任何算法加以执行。此外,可相对于识别非最佳旋转但可在其它方面中改善性能(常依据速度或处理器或其它资源利用率来测量)的任何算法来执行所述技术。
图57到57E各自为说明根据本发明中所描述的技术形成的位流517A到517E的图。在图57A的实例中,位流517A可表示上图53中所示的位流517的一个实例。位流517A包含SHC存在字段670和存储SHC 511'的字段(其中所述字段表示为“SHC 511'”)。SHC存在字段670可包含对应于SHC 511中的每一者的位。SHC 511'可表示SHC 511的在位流中指定的那些SHC,其可在数目上少于SHC 511的数目。通常,SHC 511'中的每一者是SHC 511的具有非零值的那些SHC。如上所述,对于任何给定声场的四阶表示,需要(1+4)2或25个SHC。消除这些SHC中的一或多者且以单个位替换这些零值SHC可节省31位,其可经分配以更详细表达声场的其它部分或另外移除以促进高效的带宽利用。
在图57B的实例中,位流517B可表示上图53中所示的位流517的一个实例。位流517B包含变换信息字段672(“变换信息672”)和存储SHC 511'的字段(其中所述字段表示为“SHC 511'”)。如上所述,变换信息672可包括转译信息、旋转信息和/或表示对声场的调整的任何其它形式的信息。在一些情况下,变换信息672还可指定在位流517B中指定为SHC511'的SHC 511的最高阶数。即,变换信息672可指示三的阶数,提取装置可理解为指示SHC511'包含高达且包含具有三的阶数的那些SHC 511的那些SHC511。提取装置可接着经配置以将具有四或更高阶数的SHC 511设定到零,进而潜在地在位流中移除阶数为四或更高的SHC 511的显式信令。
在图57C的实例中,位流517C可表示上图53中所示的位流517的一个实例。位流517C包含变换信息字段672(“变换信息672”)、SHC存在字段670以及存储SHC 511'的字段(其中所述字段表示为“SHC 511'”)。并非经配置以理解如上文相对于图57B所描述不用信号表示SHC 511的哪一阶数,SHC存在字段670可显式地用信号表示SHC511的哪一者在位流517C中指定为SHC 511'。
在图57D的实例中,位流517D可表示上图53中所示的位流517的一个实例。位流517D包含阶数字段674(“阶数60”)、SHC存在字段670、方位角旗标676(“AZF676”)、仰角旗标678(“ELF 678”)、方位角字段680(“方位角680”)、仰角字段682(“仰角682”)以及存储SHC511'的字段(其中再次所述字段表示为“SHC 511'”)。阶数字段674指定SHC 511'的阶数,即,上文对于用以表示声场的球面基底函数的最高阶数由n表示的阶数。阶数字段674经展示为8位字段,但可具有其它各种位大小,例如三(其为指定四阶所需的位的数目)。SHC存在字段670展示为25位字段。然而,再次SHC存在字段670可具有其它各种位大小。SHC存在字段670展示为25位以指示SHC存在字段670可包含用于对应于声场的四阶表示的球谐系数中的每一者的一个位。
方位角旗标676表示1位旗标,其指定方位角字段680是否存在于位流517D中。当方位角旗标676设定成一时,SHC 511'的方位角字段680存在于位流517D中。当方位角旗标676设定成零时,SHC 511'的方位角字段680不存在或另外在位流517D中指定。同样,仰角旗标678表示一位旗标,其指定仰角字段682是否存在于位流517D中。当仰角旗标678设定成一时,SHC 511'的仰角字段682存在于位流517D中。当仰角旗标678设定成零时,SHC 511'的仰角字段682不存在或另外在位流517D中指定。虽然描述为对应字段存在的一信令和对应字段不存在的零信令,但惯例可逆转以使得零指定对应字段在位流517D中指定且一指定对应字段未在位流517D中指定。本发明中描述的技术因此不应在此方面中受限制。
方位角字段680表示10位字段,其当在位流517D中存在时指定方位角。虽然展示为10位字段,但方位角字段680可具有其它位大小。仰角字段682表示9位字段,其当在位流517D中存在时指定仰角。分别在字段680和682中指定的方位角和仰角可与旗标676和678结合表示上述旋转信息。此旋转信息可用以旋转声场以便恢复原始参考系中的SHC 511。
SHC 511'字段经展示为具有大小X的可变字段。SHC 511'字段可归因于在位流中被指定的SHC 511'的数目(如由SHC存在字段670所表示)而变化。可将大小X导出作为SHC存在字段670中的一的数目乘32位(其为每一SHC 511'的大小)的函数。
在图57E的实例中,位流517E可表示上图53中所示的位流517的另一实例。位流517E包含阶数字段674(“阶数60”)、SHC存在字段670和旋转索引字段684,以及存储SHC511'的字段(其中再次所述字段表示为“SHC 511'”)。阶数字段674、SHC存在字段670和SHC511'字段可大体上类似于上述的那些字段。旋转索引字段684可表示用以指定仰角和方位角的1024×512(或换句话说,524288)个组合中的一者的20位字段。在一些情况下,仅19位可用以指定此旋转索引字段684,且音频编码装置570可在位流中指定额外旗标以指示旋转操作是否执行(并且因此,旋转索引字段684是否存在于位流中)。此旋转索引字段684指定上文提到的旋转索引,其可指代旋转表中对音频编码装置570和位流提取装置两者共同的条目。此旋转表在一些情况下可存储方位角和仰角的不同组合。替代地,旋转表可存储上述矩阵,其有效地以矩阵形式存储方位角和仰角的不同组合。
图58是说明图53的实例中所示的音频编码装置570实施本发明中所描述的技术的旋转方面的实例操作的流程图。初始地,音频编码装置570可根据上述各种旋转算法中的一或多者选择方位角和仰角组合(800)。音频编码装置570可随后根据选定方位角和仰角旋转声场(802)。如上文所描述,音频编码装置570可首先使用上文提到的InvMat1从SHC 511导出声场。音频编码装置570还可确定表示经旋转声场的SHC 511'(804)。虽然描述为单独的步骤或操作,但音频编码装置570可应用表示方位角和仰角组合的选择的变换(其可表示[EncMat2][InvMat1]的结果),从SHC 511导出声场,旋转所述声场且确定表示经旋转声场的SHC 511'。
在任何情况下,音频编码装置570可接着计算大于阈值的所确定的SHC 511'的数目,将此数目与针对相对于先前方位角及仰角组合的先前迭代所计算的数目相比较(806、808)。在相对于第一方位角和仰角组合的第一迭代中,此比较可为与预定义先前数目(其可设定成零)的比较。在任何情况下,如果SHC 511'的所确定的数目小于先前数目(“是”808),那么音频编码装置570存储SHC 511'、方位角和仰角,常常替换从旋转算法的先前迭代存储的先前SHC 511'、方位角和仰角(810)。
如果SHC 511'的所确定的数目不小于先前数目(“否”808)或在存储代替先前所存储的SHC 511'、方位角及仰角的SHC 511'、方位角及仰角之后,音频编码装置570可确定旋转算法是否已完成(812)。即,音频编码装置570作为一个实例可确定是否已经评估方位角和仰角的全部可用组合。在其它实例中,音频编码装置570可确定是否满足其它准则(例如已经执行组合的全部经界定子集、是否已遍历给定轨迹、是否已遍历阶层式树到叶节点等)以使得音频编码装置570完成执行旋转算法。如果未完成(“否”812),那么音频编码装置570可相对于另一选定组合执行以上过程(800到812)。如果完成(“是”812),那么音频编码装置570可以上述各种方式中的一者在位流517中指定所存储的SHC 511'、方位角和仰角(814)。
图59是说明图53的实例中所示的音频编码装置570执行本发明中所描述的技术的变换方面的实例操作的流程图。初始地,音频编码装置570可选择表示线性可逆变换的矩阵(820)。表示线性可逆变换的矩阵的一个实例可为上方展示的矩阵,即[EncMat1][IncMat1]的结果。音频编码装置570可随后将所述矩阵应用于声场以变换所述声场(822)。音频编码装置570还可确定表示经旋转声场的SHC 511'(824)。虽然描述为单独的步骤或操作,但音频编码装置570可应用变换(其可表示[EncMat2][InvMat1]的结果),从SHC 511导出声场,变换所述声场且确定表示变换声场的SHC 511'。
在任何情况下,音频编码装置570可接着计算大于阈值的所确定的SHC 511'的数目,从而将此数目与针对相对于变换矩阵的前应用的先前迭代所计算的数目相比较(826,828)。如果SHC 511'的所确定的数目小于先前数目(“是”828),那么音频编码装置570存储SHC 511'及矩阵(或其某一衍生物,例如与矩阵相关联的索引),常替换从旋转算法的先前迭代所存储的先前SHC 511'及矩阵(或其衍生物)(830)。
如果SHC 511'的所确定的数目不小于先前数目(“否”828)或在存储SHC 511'和矩阵代替先前所存储的SHC 511'和矩阵之后,音频编码装置570可确定变换算法是否已完成(832)。即,音频编码装置570作为一个实例可确定是否已经评估全部可用变换矩阵。在其它实例中,音频编码装置570可确定是否满足其它准则(例如已经执行可用变换矩阵的全部经界定子集、是否已遍历给定轨迹、是否已遍历阶层式树到叶节点等)以使得音频编码装置570完成执行变换算法。如果未完成(“否”832),那么音频编码装置570可相对于另一选定变换矩阵执行以上过程(820到832)。如果完成(“是”832),那么音频编码装置570可以上述各种方式中的一者在位流517中指定所存储的SHC 511'和矩阵(834)。
在一些实例中,变换算法可执行单个迭代,评估单个变换矩阵。即,变换矩阵可包括表示线性可逆变换的任何矩阵。在一些情况下,线性可逆变换可将声场从空间域变换到频域。此线性可逆变换的实例可包含离散傅立叶变换(DFT)。DFT的应用可仅涉及单个迭代,并且因此将不一定包含确定变换算法是否完成的步骤。因此,所述技术不应限于图59的实例。
换句话说,线性可逆变换的一个实例是离散傅立叶变换(DFT)。可通过DFT对二十五个SHC 511'操作以形成二十五个复合系数的集合。音频编码装置570还可将所述二十五个SHC 511'填零为2的整数倍数,以便潜在地增加DFT的区间大小的分辨率,且潜在地具有DFT的更有效实施方案,例如通过应用快速傅立叶变换(FFT)。在一些情况下,增加DFT的分辨率超出25点不一定是需要的。在变换域中,音频编码装置570可应用阈值以确定在特定区间中是否存在任何谱能量。音频编码装置570在此上下文中可随后丢弃或零化低于此阈值的谱系数能量,且音频编码装置570可应用逆变换以恢复已丢弃或零化SHC 511'中的一或多者的SHC 511'。即,在应用逆变换之后,低于阈值的系数不存在,且因此,可使用较少位来对声场进行编码。
在一或多个实例中,所描述功能可以用硬件、软件、固件或其任何组合来实施。如果以软件来实施,那么所述功能可以作为一或多个指令或代码存储在计算机可读媒体上或经由计算机可读媒体予以传输,并且由基于硬件的处理单元执行。计算机可读媒体可包含计算机可读存储媒体,其对应于有形媒体,例如数据存储媒体,或包含任何促进将计算机程序从一处传送到另一处的媒体(例如,根据通信协议)的通信媒体。以此方式,计算机可读媒体大体上可对应于(1)有形计算机可读存储媒体,其是非暂时形的,或(2)通信媒体,例如信号或载波。数据存储媒体可为可由一或多个计算机或一或多个处理器存取以检索用于实施本发明中所描述的技术指令、代码及/或数据结构的任何可用的媒体。计算机程序产品可包含计算机可读媒体。
借助于实例而非限制,此类计算机可读存储媒体可包括RAM、ROM、EEPROM、CD-ROM或其它光盘存储装置、磁盘存储装置或其它磁性存储装置、快闪存储器或任何其它可用来存储指令或数据结构的形式的期望程序代码并且可由计算机存取的媒体。同样,任何连接可恰当地称为计算机可读媒体。举例来说,如果使用同轴电缆、光纤缆线、双绞线、数字订户线(DSL)或例如红外线、无线电及微波等无线技术从网站、服务器或其它远程源传输指令,那么将同轴电缆、光纤缆线、双绞线、DSL或例如红外线、无线电及微波等无线技术包含在媒体的定义中。但是,应理解,计算机可读存储媒体及数据存储媒体并不包含连接、载波、信号或其它暂时性媒体,而是实际上针对非暂时性的有形存储媒体。如本文所使用,磁盘和光盘包含压缩光盘(CD)、激光光盘、光学光盘、数字多功能光盘(DVD)、软性磁盘和蓝光光盘,其中磁盘通常以磁性方式再现数据,而光盘用激光以光学方式再现数据。上述各项的组合也应该包含在计算机可读媒体的范围内。
指令可由一或多个处理器执行,所述一或多个处理器例如是一或多个数字信号处理器(DSP)、通用微处理器、专用集成电路(ASIC)、现场可编程逻辑阵列(FPGA)、或其它等效的集成或离散逻辑电路。因此,如本文中所使用的术语“处理器”可指前述结构或适合于实施本文中所描述的技术的任何其它结构中的任一者。另外,在一些方面中,本文所描述的功能性可以提供于经配置用于编码及解码的专用硬件及/或软件模块内,或者并入于组合编解码器中。并且,可将所述技术完全实施于一或多个电路或逻辑元件中。
本发明的技术可以在广泛多种装置或设备中实施,包含无线手持机、集成电路(IC)或一组IC(例如,芯片组)。本发明中描述各种组件、模块或单元是为了强调经配置以执行所揭示技术的装置的功能方面,但未必需要通过不同硬件单元实现。实际上,如上文所描述,各种单元可以配合合适的软件及/或固件组合在一个编解码器硬件单元中,或者通过互操作硬件单元的集合来提供,所述硬件单元包括如上文所描述的一或多个处理器。
已描述所述技术的各种实施例。所述技术的这些和其它方面在所附权利要求书的范围内。
Claims (42)
1.一种用于解压缩空间分量的方法,所述方法包括:
由包括提取单元的音频解码装置的处理器获得包括多个经压缩空间分量的空间分量的经压缩版本的位流,所述空间分量在球谐域中界定,并且其中所述空间分量的所述经压缩版本至少部分使用霍夫曼码以表示识别所述空间分量所对应的压缩类别的类别识别符而表示于所述位流中;
由所述处理器识别多个霍夫曼码簿的霍夫曼码簿以在解压缩所述空间分量的所述经压缩版本时使用;
由所述音频解码装置中的提取单元从所述位流中提取所述霍夫曼码;
基于所述霍夫曼码分配所述类别识别符;
将所述类别识别符与固定值进行比较;
由所述处理器中的去量化单元至少部分基于识别的霍夫曼码簿和所述霍夫曼码解压缩所述空间分量的所述经压缩版本以获得所述空间分量,其中所述空间分量基于所述类别识别符与所述至少一个固定值的比较;以及
由所述处理器基于解压缩的空间分量重建三维声场。
2.根据权利要求1所述的方法,
其中解压缩所述空间分量的所述经压缩版本包括至少部分地基于所述识别的霍夫曼码簿、所述霍夫曼码和预测模式解压缩所述空间分量的所述经压缩版本以获得所述空间分量。
3.根据权利要求1所述的方法,
其中解压缩所述空间分量的所述经压缩版本包括至少部分地基于所述识别的霍夫曼码簿和指定当压缩所述空间分量时使用的霍夫曼表的霍夫曼表信息解压缩所述空间分量的所述经压缩版本。
4.根据权利要求1所述的方法,
其中解压缩所述空间分量的所述经压缩版本包括至少部分地基于所述识别的霍夫曼码簿、所述霍夫曼码和识别所述空间分量为正值还是负值的正负号位解压缩所述空间分量的所述经压缩版本。
5.根据权利要求1所述的方法,还包括:
由所述处理器再现到一个或多个扬声器馈送的球谐系数;以及
由耦合到所述音频解码装置的一个或多个扬声器基于所述一个或多个扬声器馈送再生所述声场。
6.根据权利要求1所述的方法,其中重建多个球谐系数包括:基于所述空间分量重建所述多个球谐系数的高阶立体混响HOA帧。
7.根据权利要求1所述的方法,其中所述固定值是零或一。
8.一种解压缩空间分量的装置,所述装置包括:
一或多个处理器,其经配置以:
获得包括多个经压缩空间分量的空间分量的经压缩版本的位流,所述空间分量在球谐域中界定,并且所述空间分量的所述经压缩版本至少部分使用霍夫曼码以表示识别所述空间分量所对应的压缩类别的类别识别符而表示于所述位流中;
识别多个霍夫曼码簿的霍夫曼码簿以在解压缩所述空间分量的所述经压缩版本时使用;
由所述装置中的提取单元从所述位流中提取所述霍夫曼码;
基于所述霍夫曼码分配所述类别识别符;
将所述类别识别符与固定值进行比较;
至少部分基于识别的霍夫曼码簿和所述霍夫曼码解压缩所述空间分量的所述经压缩版本以获得所述空间分量,其中所述空间分量基于所述类别识别符与所述固定值的比较;
基于解压缩的空间分量重建三维声场;以及
存储器,耦合到所述一个或多个处理器,并且经配置以存储所述霍夫曼码簿。
9.根据权利要求8所述的装置,
其中所述一或多个处理器经配置以至少部分地基于所述识别的霍夫曼码簿、所述霍夫曼码和预测模式解压缩所述空间分量的所述经压缩版本以获得所述空间分量。
10.根据权利要求8所述的装置,
其中所述一或多个处理器经配置以至少部分地基于所述识别的霍夫曼码簿、所述霍夫曼码和指定当压缩所述空间分量时使用的霍夫曼表的霍夫曼表信息解压缩所述空间分量的所述经压缩版本。
11.根据权利要求8所述的装置,
其中所述一或多个处理器经配置以至少部分地基于所述识别的霍夫曼码簿、所述霍夫曼码和识别所述空间分量为正值还是负值的正负号位解压缩所述空间分量的所述经压缩版本。
12.根据权利要求8所述的装置,其中所述一或多个处理器进一步经配置以再现到一个或多个扬声器馈送的球谐系数,并且其中所述装置还包括耦合到所述一或多个处理器的一个或多个扬声器,并且所述一或多个处理器经配置以基于所述一个或多个扬声器馈送再生所述声场。
13.根据权利要求8所述的装置,其中所述一或多个处理器进一步经配置以基于所述空间分量重建所述多个球谐系数的高阶立体混响HOA帧。
14.根据权利要求8所述的装置,其中所述固定值是零或一。
15.一种装置,其包括:
用于获得包括多个经压缩空间分量的空间分量的经压缩版本的位流的装置,所述空间分量在球谐域中界定,并且其中所述空间分量的所述经压缩版本至少部分使用霍夫曼码以表示识别所述空间分量所对应的压缩类别的类别识别符而表示于所述位流中;
用于识别多个霍夫曼码簿的霍夫曼码簿以在解压缩空间分量的经压缩版本时使用的装置;
用于从所述位流中提取所述霍夫曼码的装置;
用于基于所述霍夫曼码分配所述类别识别符的装置;
用于将所述类别识别符与固定值进行比较的装置;
用于至少部分使用识别的霍夫曼码簿和所述霍夫曼码解压缩所述空间分量的所述经压缩版本以获得所述空间分量的装置,其中所述空间分量基于用于将所述类别识别符与固定值进行比较的装置;以及
用于基于解压缩的空间分量重建三维声场的装置。
16.一种非暂时性计算机可读存储媒体,其具有存储于其上的指令,所述指令在被执行时致使一或多个处理器:
获得包括多个经压缩空间分量的空间分量的经压缩版本的位流,所述空间分量在球谐域中界定,并且其中所述空间分量的所述经压缩版本至少部分使用霍夫曼码以表示识别所述空间分量所对应的压缩类别的类别识别符而表示于所述位流中;
识别多个霍夫曼码簿的霍夫曼码簿以在解压缩所述空间分量的所述经压缩版本时使用;
从所述位流中提取所述霍夫曼码;
基于所述霍夫曼码分配所述类别识别符;
将所述类别识别符与固定值进行比较;
至少部分使用识别的霍夫曼码簿和所述霍夫曼码解压缩所述空间分量的所述经压缩版本以获得所述空间分量,其中所述空间分量基于所述类别识别符与所述固定值的比较;以及
基于解压缩的空间分量重建三维声场。
17.一种当压缩空间分量时的方法,所述方法包括:
由处理器对于多个球谐系数执行分解,以从对应于音频对象的多个空间分量中解耦由所述多个球谐系数表示的音频对象,所述多个球谐系数表示声场,并且所述空间分量在球谐域中界定;
在处理器中通过类别识别符和残余单元识别所述多个空间分量中的空间分量所对应的压缩类别的类别识别符;
当所述空间分量为非零时,将非零值分配到类别识别符;
由所述处理器识别多个霍夫曼码簿的霍夫曼码簿以在压缩所述空间分量时使用;
由所述处理器中的量化单元至少部分地使用所述类别识别符和所识别的霍夫曼码簿来压缩所述空间分量,以获得所述空间分量的经压缩版本;以及
由所述处理器生成包括所述空间分量的经压缩版本的位流。
18.根据权利要求17所述的方法,其中识别所述霍夫曼码簿包括基于在压缩所述空间分量时使用的预测模式识别所述霍夫曼码簿。
19.根据权利要求17所述的方法,其中生成所述位流包括至少部分使用识别所述霍夫曼码簿的霍夫曼表信息而将所述空间分量的经压缩版本表示于所述位流中。
20.根据权利要求17所述的方法,其中生成所述位流包括至少部分使用指示表达压缩所述空间分量时使用的量化步长或其变数的值的字段而将所述空间分量的经压缩版本表示于所述位流中。
21.根据权利要求20所述的方法,其中所述值包括nbits值。
22.根据权利要求20所述的方法,
其中所述值表达在压缩所述多个空间分量时使用的所述量化步长或其变数。
23.根据权利要求17所述的方法,其中生成所述位流包括至少部分使用从经识别霍夫曼码簿选定的霍夫曼码以表示识别所述空间分量所对应的压缩类别的类别识别符,而将所述空间分量的经压缩版本表示于所述位流中。
24.根据权利要求17所述的方法,其中生成所述位流包括至少部分使用识别所述空间分量为正值还是负值的正负号位而将所述空间分量的经压缩版本表示于位流中。
25.根据权利要求17所述的方法,其中生成所述位流包括至少部分使用从经识别霍夫曼码簿选定的霍夫曼码以表示所述空间分量的残余值,而将所述空间分量的经压缩版本表示于所述位流中。
26.根据权利要求17所述的方法,还包括由麦克风捕获表示所述多个球谐系数的音频数据。
27.根据权利要求17所述的方法,其中当所述空间分量为非零时将所述非零值分配到所述类别识别符是基于应用于所述空间分量的对数函数。
28.根据权利要求27所述的方法,其中当所述空间分量为非零时将所述非零值分配到所述类别识别符是基于在将所述对数函数应用于所述空间分量之前获取所述空间分量的绝对值。
29.一种压缩空间分量的装置,其包括:
一或多个处理器,其经配置以
对于多个球谐系数执行分解,以从对应于音频对象的多个空间分量中解耦由所述多个球谐系数表示的音频对象,所述多个球谐系数表示声场,并且所述空间分量在球谐域中界定;
识别所述多个空间分量中的空间分量所对应的压缩类别的类别识别符;
当所述空间分量为非零时,将非零值分配到类别识别符;
识别多个霍夫曼码簿的霍夫曼码簿以在压缩所述空间分量时使用;
至少部分地使用所述类别识别符和所识别的霍夫曼码簿来压缩所述空间分量,以获得所述空间分量的经压缩版本;
生成包括所述空间分量的经压缩版本的位流;以及
存储器,耦合到所述处理器,并且经配置以存储所述霍夫曼码簿。
30.根据权利要求29所述的装置,其中所述一或多个处理器经配置以基于在压缩所述空间分量时使用的预测模式识别所述霍夫曼码簿。
31.根据权利要求29所述的装置,其中所述一或多个处理器经配置以至少部分使用识别所述霍夫曼码簿的霍夫曼表信息而将所述空间分量的经压缩版本表示于位流中。
32.根据权利要求29所述的装置,其中所述一或多个处理器经配置以至少部分使用指示表达压缩所述空间分量时使用的量化步长或其变数的值的字段而将所述空间分量的经压缩版本表示于位流中。
33.根据权利要求32所述的装置,其中所述值包括nbits值。
34.根据权利要求32所述的装置,
其中所述值表达在压缩所述多个空间分量时使用的所述量化步长或其变数。
35.根据权利要求29所述的装置,其中所述一或多个处理器经配置以至少部分使用从经识别霍夫曼码簿选定的霍夫曼码以表示识别所述空间分量所对应的压缩类别的类别识别符,而将所述空间分量的经压缩版本表示于位流中。
36.根据权利要求29所述的装置,其中所述一或多个处理器经配置以至少部分使用识别所述空间分量为正值还是负值的正负号位而将所述空间分量的经压缩版本表示于位流中。
37.根据权利要求29所述的装置,其中所述一或多个处理器经配置以至少部分使用从经识别霍夫曼码簿选定的霍夫曼码以表示所述空间分量的残余值,而将所述空间分量的经压缩版本表示于位流中。
38.根据权利要求29所述的装置,还包括一或多个麦克风经配置以捕获表示所述多个球谐系数的音频数据。
39.根据权利要求29所述的装置,其中所述一或多个处理器经配置以当所述空间分量为非零时将所述非零值分配到所述类别识别符是基于应用于所述空间分量的对数函数。
40.根据权利要求39所述的装置,其中所述一或多个处理器经配置以当所述空间分量为非零时将所述非零值分配到所述类别识别符是基于在将所述对数函数应用于所述空间分量之前获取所述空间分量的绝对值。
41.一种装置,其包括:
用于对于多个球谐系数执行分解的装置,以从对应于音频对象的多个空间分量中解耦由所述多个球谐系数表示的音频对象,所述多个球谐系数表示声场,并且所述空间分量在球谐域中界定;
用于识别所述多个空间分量中的空间分量所对应的压缩类别的类别识别符的装置;
用于当所述空间分量为非零时将非零值分配到类别识别符的装置;
用于至少部分地使用所述类别识别符和所识别的霍夫曼码簿来压缩所述空间分量,以获得所述空间分量的经压缩版本的装置;以及
用于生成包括所述空间分量的经压缩版本的位流的装置。
42.一种非暂时性计算机可读存储媒体,其具有存储在其上的指令,所述指令在被执行时致使一或多个处理器:
对于多个球谐系数执行分解,以从对应于音频对象的多个空间分量中解耦由所述多个球谐系数表示的音频对象,所述多个球谐系数表示声场,并且所述空间分量在球谐域中界定;
识别所述多个空间分量中的空间分量所对应的压缩类别的类别识别符;
当所述空间分量为非零时,将非零值分配到类别识别符;
识别多个霍夫曼码簿的霍夫曼码簿以在压缩所述空间分量时使用;
至少部分地使用所述类别识别符和所识别的霍夫曼码簿来压缩所述空间分量,以获得所述空间分量的经压缩版本;以及
生成包括所述空间分量的经压缩版本的位流。
Applications Claiming Priority (39)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361828615P | 2013-05-29 | 2013-05-29 | |
| US201361828445P | 2013-05-29 | 2013-05-29 | |
| US61/828,615 | 2013-05-29 | ||
| US61/828,445 | 2013-05-29 | ||
| US201361829155P | 2013-05-30 | 2013-05-30 | |
| US201361829174P | 2013-05-30 | 2013-05-30 | |
| US201361829182P | 2013-05-30 | 2013-05-30 | |
| US61/829,182 | 2013-05-30 | ||
| US61/829,155 | 2013-05-30 | ||
| US61/829,174 | 2013-05-30 | ||
| US201361829791P | 2013-05-31 | 2013-05-31 | |
| US201361829846P | 2013-05-31 | 2013-05-31 | |
| US61/829,791 | 2013-05-31 | ||
| US61/829,846 | 2013-05-31 | ||
| US201361886617P | 2013-10-03 | 2013-10-03 | |
| US201361886605P | 2013-10-03 | 2013-10-03 | |
| US61/886,617 | 2013-10-03 | ||
| US61/886,605 | 2013-10-03 | ||
| US201361899041P | 2013-11-01 | 2013-11-01 | |
| US201361899034P | 2013-11-01 | 2013-11-01 | |
| US61/899,041 | 2013-11-01 | ||
| US61/899,034 | 2013-11-01 | ||
| US201461925126P | 2014-01-08 | 2014-01-08 | |
| US201461925158P | 2014-01-08 | 2014-01-08 | |
| US201461925112P | 2014-01-08 | 2014-01-08 | |
| US201461925074P | 2014-01-08 | 2014-01-08 | |
| US61/925,126 | 2014-01-08 | ||
| US61/925,112 | 2014-01-08 | ||
| US61/925,158 | 2014-01-08 | ||
| US61/925,074 | 2014-01-08 | ||
| US201461933706P | 2014-01-30 | 2014-01-30 | |
| US201461933721P | 2014-01-30 | 2014-01-30 | |
| US61/933,706 | 2014-01-30 | ||
| US61/933,721 | 2014-01-30 | ||
| US201462003515P | 2014-05-27 | 2014-05-27 | |
| US62/003,515 | 2014-05-27 | ||
| US14/289,440 | 2014-05-28 | ||
| US14/289,440 US10499176B2 (en) | 2013-05-29 | 2014-05-28 | Identifying codebooks to use when coding spatial components of a sound field |
| PCT/US2014/040061 WO2014194116A1 (en) | 2013-05-29 | 2014-05-29 | Identifying codebooks to use when coding spatial components of a sound field |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN105917407A CN105917407A (zh) | 2016-08-31 |
| CN105917407B true CN105917407B (zh) | 2020-04-24 |
Family
ID=51985123
Family Applications (7)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201480031271.1A Active CN105580072B (zh) | 2013-05-29 | 2014-05-29 | 用于音频数据的压缩的方法、装置及计算机可读存储媒体 |
| CN201480032630.5A Active CN105284132B (zh) | 2013-05-29 | 2014-05-29 | 经变换高阶立体混响音频数据的方法及装置 |
| CN201480032616.5A Active CN105284131B (zh) | 2013-05-29 | 2014-05-29 | 用于声场的经分解表示的内插 |
| CN201480031031.1A Active CN105264598B (zh) | 2013-05-29 | 2014-05-29 | 声场的经分解表示中的误差的补偿 |
| CN201480031272.6A Active CN105917407B (zh) | 2013-05-29 | 2014-05-29 | 识别码簿以在对声场的空间分量译码时使用 |
| CN201910693832.9A Active CN110767242B (zh) | 2013-05-29 | 2014-05-29 | 声场的经分解表示的压缩 |
| CN201480031114.0A Active CN105340009B (zh) | 2013-05-29 | 2014-05-29 | 声场的经分解表示的压缩 |
Family Applications Before (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201480031271.1A Active CN105580072B (zh) | 2013-05-29 | 2014-05-29 | 用于音频数据的压缩的方法、装置及计算机可读存储媒体 |
| CN201480032630.5A Active CN105284132B (zh) | 2013-05-29 | 2014-05-29 | 经变换高阶立体混响音频数据的方法及装置 |
| CN201480032616.5A Active CN105284131B (zh) | 2013-05-29 | 2014-05-29 | 用于声场的经分解表示的内插 |
| CN201480031031.1A Active CN105264598B (zh) | 2013-05-29 | 2014-05-29 | 声场的经分解表示中的误差的补偿 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910693832.9A Active CN110767242B (zh) | 2013-05-29 | 2014-05-29 | 声场的经分解表示的压缩 |
| CN201480031114.0A Active CN105340009B (zh) | 2013-05-29 | 2014-05-29 | 声场的经分解表示的压缩 |
Country Status (20)
| Country | Link |
|---|---|
| US (16) | US20140355769A1 (zh) |
| EP (8) | EP3005358B1 (zh) |
| JP (6) | JP6121625B2 (zh) |
| KR (11) | KR20160016885A (zh) |
| CN (7) | CN105580072B (zh) |
| AU (1) | AU2014274076B2 (zh) |
| BR (1) | BR112015030102B1 (zh) |
| CA (1) | CA2912810C (zh) |
| ES (4) | ES2689566T3 (zh) |
| HK (1) | HK1215752A1 (zh) |
| HU (3) | HUE046520T2 (zh) |
| IL (1) | IL242648B (zh) |
| MY (1) | MY174865A (zh) |
| PH (1) | PH12015502634B1 (zh) |
| RU (1) | RU2668059C2 (zh) |
| SG (1) | SG11201509462VA (zh) |
| TW (2) | TWI645723B (zh) |
| UA (1) | UA116140C2 (zh) |
| WO (12) | WO2014194105A1 (zh) |
| ZA (1) | ZA201509227B (zh) |
Families Citing this family (122)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2665208A1 (en) | 2012-05-14 | 2013-11-20 | Thomson Licensing | Method and apparatus for compressing and decompressing a Higher Order Ambisonics signal representation |
| EP2743922A1 (en) | 2012-12-12 | 2014-06-18 | Thomson Licensing | Method and apparatus for compressing and decompressing a higher order ambisonics representation for a sound field |
| US9736609B2 (en) | 2013-02-07 | 2017-08-15 | Qualcomm Incorporated | Determining renderers for spherical harmonic coefficients |
| US9883310B2 (en) | 2013-02-08 | 2018-01-30 | Qualcomm Incorporated | Obtaining symmetry information for higher order ambisonic audio renderers |
| US10178489B2 (en) | 2013-02-08 | 2019-01-08 | Qualcomm Incorporated | Signaling audio rendering information in a bitstream |
| US9609452B2 (en) | 2013-02-08 | 2017-03-28 | Qualcomm Incorporated | Obtaining sparseness information for higher order ambisonic audio renderers |
| US20140355769A1 (en) | 2013-05-29 | 2014-12-04 | Qualcomm Incorporated | Energy preservation for decomposed representations of a sound field |
| US9466305B2 (en) | 2013-05-29 | 2016-10-11 | Qualcomm Incorporated | Performing positional analysis to code spherical harmonic coefficients |
| WO2014195190A1 (en) * | 2013-06-05 | 2014-12-11 | Thomson Licensing | Method for encoding audio signals, apparatus for encoding audio signals, method for decoding audio signals and apparatus for decoding audio signals |
| US9922656B2 (en) * | 2014-01-30 | 2018-03-20 | Qualcomm Incorporated | Transitioning of ambient higher-order ambisonic coefficients |
| US9502045B2 (en) | 2014-01-30 | 2016-11-22 | Qualcomm Incorporated | Coding independent frames of ambient higher-order ambisonic coefficients |
| US20150243292A1 (en) | 2014-02-25 | 2015-08-27 | Qualcomm Incorporated | Order format signaling for higher-order ambisonic audio data |
| US10412522B2 (en) | 2014-03-21 | 2019-09-10 | Qualcomm Incorporated | Inserting audio channels into descriptions of soundfields |
| EP2922057A1 (en) | 2014-03-21 | 2015-09-23 | Thomson Licensing | Method for compressing a Higher Order Ambisonics (HOA) signal, method for decompressing a compressed HOA signal, apparatus for compressing a HOA signal, and apparatus for decompressing a compressed HOA signal |
| US9847087B2 (en) | 2014-05-16 | 2017-12-19 | Qualcomm Incorporated | Higher order ambisonics signal compression |
| US10770087B2 (en) | 2014-05-16 | 2020-09-08 | Qualcomm Incorporated | Selecting codebooks for coding vectors decomposed from higher-order ambisonic audio signals |
| US9959876B2 (en) | 2014-05-16 | 2018-05-01 | Qualcomm Incorporated | Closed loop quantization of higher order ambisonic coefficients |
| US20150332682A1 (en) | 2014-05-16 | 2015-11-19 | Qualcomm Incorporated | Spatial relation coding for higher order ambisonic coefficients |
| US9620137B2 (en) | 2014-05-16 | 2017-04-11 | Qualcomm Incorporated | Determining between scalar and vector quantization in higher order ambisonic coefficients |
| US9852737B2 (en) | 2014-05-16 | 2017-12-26 | Qualcomm Incorporated | Coding vectors decomposed from higher-order ambisonics audio signals |
| US10134403B2 (en) * | 2014-05-16 | 2018-11-20 | Qualcomm Incorporated | Crossfading between higher order ambisonic signals |
| US20150347392A1 (en) * | 2014-05-29 | 2015-12-03 | International Business Machines Corporation | Real-time filtering of massive time series sets for social media trends |
| JP6423009B2 (ja) | 2014-05-30 | 2018-11-14 | クゥアルコム・インコーポレイテッドQualcomm Incorporated | 高次アンビソニックオーディオレンダラのためのシンメトリ情報を取得すること |
| EP2960903A1 (en) * | 2014-06-27 | 2015-12-30 | Thomson Licensing | Method and apparatus for determining for the compression of an HOA data frame representation a lowest integer number of bits required for representing non-differential gain values |
| US9838819B2 (en) | 2014-07-02 | 2017-12-05 | Qualcomm Incorporated | Reducing correlation between higher order ambisonic (HOA) background channels |
| US9536531B2 (en) * | 2014-08-01 | 2017-01-03 | Qualcomm Incorporated | Editing of higher-order ambisonic audio data |
| US9847088B2 (en) | 2014-08-29 | 2017-12-19 | Qualcomm Incorporated | Intermediate compression for higher order ambisonic audio data |
| US9747910B2 (en) | 2014-09-26 | 2017-08-29 | Qualcomm Incorporated | Switching between predictive and non-predictive quantization techniques in a higher order ambisonics (HOA) framework |
| US20160093308A1 (en) | 2014-09-26 | 2016-03-31 | Qualcomm Incorporated | Predictive vector quantization techniques in a higher order ambisonics (hoa) framework |
| US9875745B2 (en) | 2014-10-07 | 2018-01-23 | Qualcomm Incorporated | Normalization of ambient higher order ambisonic audio data |
| US9984693B2 (en) | 2014-10-10 | 2018-05-29 | Qualcomm Incorporated | Signaling channels for scalable coding of higher order ambisonic audio data |
| US9940937B2 (en) | 2014-10-10 | 2018-04-10 | Qualcomm Incorporated | Screen related adaptation of HOA content |
| US10140996B2 (en) | 2014-10-10 | 2018-11-27 | Qualcomm Incorporated | Signaling layers for scalable coding of higher order ambisonic audio data |
| CN106303897A (zh) | 2015-06-01 | 2017-01-04 | 杜比实验室特许公司 | 处理基于对象的音频信号 |
| US11223857B2 (en) * | 2015-06-02 | 2022-01-11 | Sony Corporation | Transmission device, transmission method, media processing device, media processing method, and reception device |
| EP3329486B1 (en) * | 2015-07-30 | 2020-07-29 | Dolby International AB | Method and apparatus for generating from an hoa signal representation a mezzanine hoa signal representation |
| US12087311B2 (en) | 2015-07-30 | 2024-09-10 | Dolby Laboratories Licensing Corporation | Method and apparatus for encoding and decoding an HOA representation |
| JP6501259B2 (ja) * | 2015-08-04 | 2019-04-17 | 本田技研工業株式会社 | 音声処理装置及び音声処理方法 |
| US10693936B2 (en) * | 2015-08-25 | 2020-06-23 | Qualcomm Incorporated | Transporting coded audio data |
| US20170098452A1 (en) * | 2015-10-02 | 2017-04-06 | Dts, Inc. | Method and system for audio processing of dialog, music, effect and height objects |
| US9961475B2 (en) | 2015-10-08 | 2018-05-01 | Qualcomm Incorporated | Conversion from object-based audio to HOA |
| US9961467B2 (en) | 2015-10-08 | 2018-05-01 | Qualcomm Incorporated | Conversion from channel-based audio to HOA |
| IL302588B1 (en) * | 2015-10-08 | 2024-10-01 | Dolby Int Ab | Layered coding and data structure for compressed high-order sound or surround sound field representations |
| MX2020011754A (es) | 2015-10-08 | 2022-05-19 | Dolby Int Ab | Codificacion en capas para representaciones de sonido o campo de sonido comprimidas. |
| US10249312B2 (en) * | 2015-10-08 | 2019-04-02 | Qualcomm Incorporated | Quantization of spatial vectors |
| US10070094B2 (en) | 2015-10-14 | 2018-09-04 | Qualcomm Incorporated | Screen related adaptation of higher order ambisonic (HOA) content |
| US9959880B2 (en) | 2015-10-14 | 2018-05-01 | Qualcomm Incorporated | Coding higher-order ambisonic coefficients during multiple transitions |
| WO2017085140A1 (en) * | 2015-11-17 | 2017-05-26 | Dolby International Ab | Method and apparatus for converting a channel-based 3d audio signal to an hoa audio signal |
| EP3174316B1 (en) * | 2015-11-27 | 2020-02-26 | Nokia Technologies Oy | Intelligent audio rendering |
| EP3188504B1 (en) | 2016-01-04 | 2020-07-29 | Harman Becker Automotive Systems GmbH | Multi-media reproduction for a multiplicity of recipients |
| BR112018013526A2 (pt) * | 2016-01-08 | 2018-12-04 | Sony Corporation | aparelho e método para processamento de áudio, e, programa |
| PL3338462T3 (pl) | 2016-03-15 | 2020-03-31 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Urządzenie, sposób lub program komputerowy do generowania opisu pola dźwięku |
| WO2018001500A1 (en) * | 2016-06-30 | 2018-01-04 | Huawei Technologies Duesseldorf Gmbh | Apparatuses and methods for encoding and decoding a multichannel audio signal |
| KR102561371B1 (ko) * | 2016-07-11 | 2023-08-01 | 삼성전자주식회사 | 디스플레이장치와, 기록매체 |
| US11032663B2 (en) | 2016-09-29 | 2021-06-08 | The Trustees Of Princeton University | System and method for virtual navigation of sound fields through interpolation of signals from an array of microphone assemblies |
| CN107945810B (zh) * | 2016-10-13 | 2021-12-14 | 杭州米谟科技有限公司 | 用于编码和解码hoa或多声道数据的方法和装置 |
| US20180107926A1 (en) * | 2016-10-19 | 2018-04-19 | Samsung Electronics Co., Ltd. | Method and apparatus for neural network quantization |
| US11321609B2 (en) | 2016-10-19 | 2022-05-03 | Samsung Electronics Co., Ltd | Method and apparatus for neural network quantization |
| EP3497944A1 (en) * | 2016-10-31 | 2019-06-19 | Google LLC | Projection-based audio coding |
| CN108206021B (zh) * | 2016-12-16 | 2020-12-18 | 南京青衿信息科技有限公司 | 一种后向兼容式三维声编码器、解码器及其编解码方法 |
| KR20190118212A (ko) * | 2017-01-24 | 2019-10-18 | 주식회사 알티스트 | 차량 상태 모니터링 시스템 및 방법 |
| US10455321B2 (en) | 2017-04-28 | 2019-10-22 | Qualcomm Incorporated | Microphone configurations |
| US9820073B1 (en) | 2017-05-10 | 2017-11-14 | Tls Corp. | Extracting a common signal from multiple audio signals |
| CN110771181B (zh) * | 2017-05-15 | 2021-09-28 | 杜比实验室特许公司 | 用于将空间音频格式转换为扬声器信号的方法、系统和设备 |
| US10390166B2 (en) * | 2017-05-31 | 2019-08-20 | Qualcomm Incorporated | System and method for mixing and adjusting multi-input ambisonics |
| US10405126B2 (en) | 2017-06-30 | 2019-09-03 | Qualcomm Incorporated | Mixed-order ambisonics (MOA) audio data for computer-mediated reality systems |
| RU2736274C1 (ru) | 2017-07-14 | 2020-11-13 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Принцип формирования улучшенного описания звукового поля или модифицированного описания звукового поля с использованием dirac-технологии с расширением глубины или других технологий |
| RU2740703C1 (ru) | 2017-07-14 | 2021-01-20 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Принцип формирования улучшенного описания звукового поля или модифицированного описания звукового поля с использованием многослойного описания |
| RU2736418C1 (ru) | 2017-07-14 | 2020-11-17 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Принцип формирования улучшенного описания звукового поля или модифицированного описания звукового поля с использованием многоточечного описания звукового поля |
| US10075802B1 (en) | 2017-08-08 | 2018-09-11 | Qualcomm Incorporated | Bitrate allocation for higher order ambisonic audio data |
| US10674301B2 (en) * | 2017-08-25 | 2020-06-02 | Google Llc | Fast and memory efficient encoding of sound objects using spherical harmonic symmetries |
| US10764684B1 (en) | 2017-09-29 | 2020-09-01 | Katherine A. Franco | Binaural audio using an arbitrarily shaped microphone array |
| CN111164679B (zh) | 2017-10-05 | 2024-04-09 | 索尼公司 | 编码装置和方法、解码装置和方法以及程序 |
| US10972851B2 (en) * | 2017-10-05 | 2021-04-06 | Qualcomm Incorporated | Spatial relation coding of higher order ambisonic coefficients |
| CN111656441B (zh) | 2017-11-17 | 2023-10-03 | 弗劳恩霍夫应用研究促进协会 | 编码或解码定向音频编码参数的装置和方法 |
| US10595146B2 (en) | 2017-12-21 | 2020-03-17 | Verizon Patent And Licensing Inc. | Methods and systems for extracting location-diffused ambient sound from a real-world scene |
| EP3506080B1 (en) * | 2017-12-27 | 2023-06-07 | Nokia Technologies Oy | Audio scene processing |
| US11409923B1 (en) * | 2018-01-22 | 2022-08-09 | Ansys, Inc | Systems and methods for generating reduced order models |
| FR3079706B1 (fr) | 2018-03-29 | 2021-06-04 | Inst Mines Telecom | Procede et systeme de diffusion d'un flux audio multicanal a des terminaux de spectateurs assistant a un evenement sportif |
| GB2572650A (en) * | 2018-04-06 | 2019-10-09 | Nokia Technologies Oy | Spatial audio parameters and associated spatial audio playback |
| US10672405B2 (en) * | 2018-05-07 | 2020-06-02 | Google Llc | Objective quality metrics for ambisonic spatial audio |
| CN108831494B (zh) * | 2018-05-29 | 2022-07-19 | 平安科技(深圳)有限公司 | 语音增强方法、装置、计算机设备及存储介质 |
| GB2574873A (en) * | 2018-06-21 | 2019-12-25 | Nokia Technologies Oy | Determination of spatial audio parameter encoding and associated decoding |
| US10999693B2 (en) | 2018-06-25 | 2021-05-04 | Qualcomm Incorporated | Rendering different portions of audio data using different renderers |
| US12056594B2 (en) * | 2018-06-27 | 2024-08-06 | International Business Machines Corporation | Low precision deep neural network enabled by compensation instructions |
| US11798569B2 (en) | 2018-10-02 | 2023-10-24 | Qualcomm Incorporated | Flexible rendering of audio data |
| WO2020084170A1 (en) * | 2018-10-26 | 2020-04-30 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Directional loudness map based audio processing |
| FI3874492T3 (fi) * | 2018-10-31 | 2024-01-08 | Nokia Technologies Oy | Spatiaalisten äänten parametrikoodauksen ja siihen liittyvän dekoodauksen määrittäminen |
| GB2578625A (en) | 2018-11-01 | 2020-05-20 | Nokia Technologies Oy | Apparatus, methods and computer programs for encoding spatial metadata |
| KR102599744B1 (ko) | 2018-12-07 | 2023-11-08 | 프라운호퍼-게젤샤프트 추르 푀르데룽 데어 안제반텐 포르슝 에 파우 | 방향 컴포넌트 보상을 사용하는 DirAC 기반 공간 오디오 코딩과 관련된 인코딩, 디코딩, 장면 처리 및 기타 절차를 위한 장치, 방법 및 컴퓨터 프로그램 |
| FR3090179B1 (fr) * | 2018-12-14 | 2021-04-09 | Fond B Com | Procédé d’interpolation d’un champ sonore, produit programme d’ordinateur et dispositif correspondants. |
| CN113316943B (zh) * | 2018-12-19 | 2023-06-06 | 弗劳恩霍夫应用研究促进协会 | 再现空间扩展声源的设备与方法、或从空间扩展声源生成比特流的设备与方法 |
| KR102277952B1 (ko) * | 2019-01-11 | 2021-07-19 | 브레인소프트주식회사 | 디제이 변환에 의한 주파수 추출 방법 |
| EP3706119A1 (fr) * | 2019-03-05 | 2020-09-09 | Orange | Codage audio spatialisé avec interpolation et quantification de rotations |
| GB2582748A (en) * | 2019-03-27 | 2020-10-07 | Nokia Technologies Oy | Sound field related rendering |
| RU2722223C1 (ru) * | 2019-04-16 | 2020-05-28 | Вадим Иванович Филиппов | Способ сжатия многомерных образов путем приближения элементов пространств Lp{ (0, 1]m} , p больше или равно 1 и меньше бесконечности, по системам сжатий и сдвигов одной функции рядами типа Фурье с целыми коэффциентами и целочисленное разложение элементов многомодулярных пространств |
| US11538489B2 (en) * | 2019-06-24 | 2022-12-27 | Qualcomm Incorporated | Correlating scene-based audio data for psychoacoustic audio coding |
| US12073842B2 (en) * | 2019-06-24 | 2024-08-27 | Qualcomm Incorporated | Psychoacoustic audio coding of ambisonic audio data |
| GB2586214A (en) * | 2019-07-31 | 2021-02-17 | Nokia Technologies Oy | Quantization of spatial audio direction parameters |
| JP7270836B2 (ja) * | 2019-08-08 | 2023-05-10 | ブームクラウド 360 インコーポレイテッド | 音響心理学的周波数範囲拡張のための非線形適応フィルタバンク |
| WO2021041623A1 (en) * | 2019-08-30 | 2021-03-04 | Dolby Laboratories Licensing Corporation | Channel identification of multi-channel audio signals |
| GB2587196A (en) | 2019-09-13 | 2021-03-24 | Nokia Technologies Oy | Determination of spatial audio parameter encoding and associated decoding |
| US11430451B2 (en) * | 2019-09-26 | 2022-08-30 | Apple Inc. | Layered coding of audio with discrete objects |
| CN110708647B (zh) * | 2019-10-29 | 2020-12-25 | 扆亮海 | 一种球面分配引导的数据匹配立体声场重构方法 |
| GB2590906A (en) * | 2019-12-19 | 2021-07-14 | Nomono As | Wireless microphone with local storage |
| US11636866B2 (en) | 2020-03-24 | 2023-04-25 | Qualcomm Incorporated | Transform ambisonic coefficients using an adaptive network |
| CN113593585A (zh) * | 2020-04-30 | 2021-11-02 | 华为技术有限公司 | 音频信号的比特分配方法和装置 |
| GB2595871A (en) * | 2020-06-09 | 2021-12-15 | Nokia Technologies Oy | The reduction of spatial audio parameters |
| WO2022046155A1 (en) * | 2020-08-28 | 2022-03-03 | Google Llc | Maintaining invariance of sensory dissonance and sound localization cues in audio codecs |
| FR3113993B1 (fr) * | 2020-09-09 | 2023-02-24 | Arkamys | Procédé de spatialisation sonore |
| CN116391365A (zh) * | 2020-09-25 | 2023-07-04 | 苹果公司 | 高阶环境立体声编码和解码 |
| CN112327398B (zh) * | 2020-11-20 | 2022-03-08 | 中国科学院上海光学精密机械研究所 | 一种矢量补偿体布拉格光栅角度偏转器的制备方法 |
| US11743670B2 (en) | 2020-12-18 | 2023-08-29 | Qualcomm Incorporated | Correlation-based rendering with multiple distributed streams accounting for an occlusion for six degree of freedom applications |
| US11521623B2 (en) | 2021-01-11 | 2022-12-06 | Bank Of America Corporation | System and method for single-speaker identification in a multi-speaker environment on a low-frequency audio recording |
| CN113518299B (zh) * | 2021-04-30 | 2022-06-03 | 电子科技大学 | 一种改进的源分量及环境分量提取方法、设备及计算机可读存储介质 |
| CN113345448B (zh) * | 2021-05-12 | 2022-08-05 | 北京大学 | 一种基于独立成分分析的hoa信号压缩方法 |
| CN115376527A (zh) * | 2021-05-17 | 2022-11-22 | 华为技术有限公司 | 三维音频信号编码方法、装置和编码器 |
| CN115497485B (zh) * | 2021-06-18 | 2024-10-18 | 华为技术有限公司 | 三维音频信号编码方法、装置、编码器和系统 |
| CN113378063B (zh) * | 2021-07-09 | 2023-07-28 | 小红书科技有限公司 | 一种基于滑动谱分解确定内容多样性的方法和内容排序方法 |
| WO2023008831A1 (ko) * | 2021-07-27 | 2023-02-02 | 브레인소프트 주식회사 | 해석적 방법에 기반한 디제이 변환 주파수 추출 방법 |
| US20230051841A1 (en) * | 2021-07-30 | 2023-02-16 | Qualcomm Incorporated | Xr rendering for 3d audio content and audio codec |
| CN113647978B (zh) * | 2021-08-18 | 2023-11-21 | 重庆大学 | 一种带有截断因子的高鲁棒性符号相干系数超声成像方法 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8379868B2 (en) * | 2006-05-17 | 2013-02-19 | Creative Technology Ltd | Spatial audio coding based on universal spatial cues |
Family Cites Families (208)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IT1159034B (it) | 1983-06-10 | 1987-02-25 | Cselt Centro Studi Lab Telecom | Sintetizzatore vocale |
| US4972344A (en) | 1986-05-30 | 1990-11-20 | Finial Technology, Inc. | Dual beam optical turntable |
| US5012518A (en) | 1989-07-26 | 1991-04-30 | Itt Corporation | Low-bit-rate speech coder using LPC data reduction processing |
| US5363050A (en) | 1990-08-31 | 1994-11-08 | Guo Wendy W | Quantitative dielectric imaging system |
| SG49883A1 (en) | 1991-01-08 | 1998-06-15 | Dolby Lab Licensing Corp | Encoder/decoder for multidimensional sound fields |
| US5757927A (en) | 1992-03-02 | 1998-05-26 | Trifield Productions Ltd. | Surround sound apparatus |
| JP2626492B2 (ja) | 1993-09-13 | 1997-07-02 | 日本電気株式会社 | ベクトル量子化装置 |
| US5790759A (en) | 1995-09-19 | 1998-08-04 | Lucent Technologies Inc. | Perceptual noise masking measure based on synthesis filter frequency response |
| US5819215A (en) | 1995-10-13 | 1998-10-06 | Dobson; Kurt | Method and apparatus for wavelet based data compression having adaptive bit rate control for compression of digital audio or other sensory data |
| JP3707116B2 (ja) | 1995-10-26 | 2005-10-19 | ソニー株式会社 | 音声復号化方法及び装置 |
| US5956674A (en) | 1995-12-01 | 1999-09-21 | Digital Theater Systems, Inc. | Multi-channel predictive subband audio coder using psychoacoustic adaptive bit allocation in frequency, time and over the multiple channels |
| JP3849210B2 (ja) | 1996-09-24 | 2006-11-22 | ヤマハ株式会社 | 音声符号化復号方式 |
| US5821887A (en) * | 1996-11-12 | 1998-10-13 | Intel Corporation | Method and apparatus for decoding variable length codes |
| US6167375A (en) | 1997-03-17 | 2000-12-26 | Kabushiki Kaisha Toshiba | Method for encoding and decoding a speech signal including background noise |
| US6072878A (en) | 1997-09-24 | 2000-06-06 | Sonic Solutions | Multi-channel surround sound mastering and reproduction techniques that preserve spatial harmonics |
| US6263312B1 (en) | 1997-10-03 | 2001-07-17 | Alaris, Inc. | Audio compression and decompression employing subband decomposition of residual signal and distortion reduction |
| JP3211762B2 (ja) | 1997-12-12 | 2001-09-25 | 日本電気株式会社 | 音声及び音楽符号化方式 |
| AUPP272698A0 (en) | 1998-03-31 | 1998-04-23 | Lake Dsp Pty Limited | Soundfield playback from a single speaker system |
| EP1018840A3 (en) | 1998-12-08 | 2005-12-21 | Canon Kabushiki Kaisha | Digital receiving apparatus and method |
| WO2000060575A1 (en) | 1999-04-05 | 2000-10-12 | Hughes Electronics Corporation | A voicing measure as an estimate of signal periodicity for a frequency domain interpolative speech codec system |
| US6370502B1 (en) | 1999-05-27 | 2002-04-09 | America Online, Inc. | Method and system for reduction of quantization-induced block-discontinuities and general purpose audio codec |
| US6782360B1 (en) | 1999-09-22 | 2004-08-24 | Mindspeed Technologies, Inc. | Gain quantization for a CELP speech coder |
| US20020049586A1 (en) | 2000-09-11 | 2002-04-25 | Kousuke Nishio | Audio encoder, audio decoder, and broadcasting system |
| JP2002094989A (ja) | 2000-09-14 | 2002-03-29 | Pioneer Electronic Corp | ビデオ信号符号化装置及びビデオ信号符号化方法 |
| US7660424B2 (en) | 2001-02-07 | 2010-02-09 | Dolby Laboratories Licensing Corporation | Audio channel spatial translation |
| US20020169735A1 (en) | 2001-03-07 | 2002-11-14 | David Kil | Automatic mapping from data to preprocessing algorithms |
| GB2379147B (en) | 2001-04-18 | 2003-10-22 | Univ York | Sound processing |
| US20030147539A1 (en) * | 2002-01-11 | 2003-08-07 | Mh Acoustics, Llc, A Delaware Corporation | Audio system based on at least second-order eigenbeams |
| US7031894B2 (en) * | 2002-01-16 | 2006-04-18 | Timbre Technologies, Inc. | Generating a library of simulated-diffraction signals and hypothetical profiles of periodic gratings |
| US7262770B2 (en) | 2002-03-21 | 2007-08-28 | Microsoft Corporation | Graphics image rendering with radiance self-transfer for low-frequency lighting environments |
| US20030223603A1 (en) * | 2002-05-28 | 2003-12-04 | Beckman Kenneth Oren | Sound space replication |
| US8160269B2 (en) | 2003-08-27 | 2012-04-17 | Sony Computer Entertainment Inc. | Methods and apparatuses for adjusting a listening area for capturing sounds |
| ES2297083T3 (es) | 2002-09-04 | 2008-05-01 | Microsoft Corporation | Codificacion entropica por adaptacion de la codificacion entre modos por longitud de ejecucion y por nivel. |
| FR2844894B1 (fr) | 2002-09-23 | 2004-12-17 | Remy Henri Denis Bruno | Procede et systeme de traitement d'une representation d'un champ acoustique |
| US7330812B2 (en) | 2002-10-04 | 2008-02-12 | National Research Council Of Canada | Method and apparatus for transmitting an audio stream having additional payload in a hidden sub-channel |
| FR2847376B1 (fr) | 2002-11-19 | 2005-02-04 | France Telecom | Procede de traitement de donnees sonores et dispositif d'acquisition sonore mettant en oeuvre ce procede |
| US6961696B2 (en) | 2003-02-07 | 2005-11-01 | Motorola, Inc. | Class quantization for distributed speech recognition |
| FI115324B (fi) | 2003-03-14 | 2005-04-15 | Elekta Neuromag Oy | Menetelmä ja järjestelmä monikanavaisen mittaussignaalin käsittelemiseksi |
| US7558393B2 (en) | 2003-03-18 | 2009-07-07 | Miller Iii Robert E | System and method for compatible 2D/3D (full sphere with height) surround sound reproduction |
| US7920709B1 (en) | 2003-03-25 | 2011-04-05 | Robert Hickling | Vector sound-intensity probes operating in a half-space |
| JP2005086486A (ja) | 2003-09-09 | 2005-03-31 | Alpine Electronics Inc | オーディオ装置およびオーディオ処理方法 |
| US7433815B2 (en) | 2003-09-10 | 2008-10-07 | Dilithium Networks Pty Ltd. | Method and apparatus for voice transcoding between variable rate coders |
| US7447317B2 (en) | 2003-10-02 | 2008-11-04 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V | Compatible multi-channel coding/decoding by weighting the downmix channel |
| KR100556911B1 (ko) | 2003-12-05 | 2006-03-03 | 엘지전자 주식회사 | 무선 동영상 스트리밍 서비스를 위한 동영상 데이터의 구조 |
| KR100629997B1 (ko) | 2004-02-26 | 2006-09-27 | 엘지전자 주식회사 | 오디오 신호의 인코딩 방법 |
| US7283634B2 (en) | 2004-08-31 | 2007-10-16 | Dts, Inc. | Method of mixing audio channels using correlated outputs |
| US7630902B2 (en) | 2004-09-17 | 2009-12-08 | Digital Rise Technology Co., Ltd. | Apparatus and methods for digital audio coding using codebook application ranges |
| FR2880755A1 (fr) | 2005-01-10 | 2006-07-14 | France Telecom | Procede et dispositif d'individualisation de hrtfs par modelisation |
| KR100636229B1 (ko) | 2005-01-14 | 2006-10-19 | 학교법인 성균관대학 | 신축형 부호화를 위한 적응적 엔트로피 부호화 및 복호화방법과 그 장치 |
| JP5012504B2 (ja) | 2005-03-30 | 2012-08-29 | アイシン・エィ・ダブリュ株式会社 | 車両用ナビゲーションシステム |
| WO2006122146A2 (en) | 2005-05-10 | 2006-11-16 | William Marsh Rice University | Method and apparatus for distributed compressed sensing |
| EP1905004A2 (en) * | 2005-05-26 | 2008-04-02 | LG Electronics Inc. | Method of encoding and decoding an audio signal |
| ATE378793T1 (de) | 2005-06-23 | 2007-11-15 | Akg Acoustics Gmbh | Methode zur modellierung eines mikrofons |
| US7599840B2 (en) * | 2005-07-15 | 2009-10-06 | Microsoft Corporation | Selectively using multiple entropy models in adaptive coding and decoding |
| WO2007037613A1 (en) | 2005-09-27 | 2007-04-05 | Lg Electronics Inc. | Method and apparatus for encoding/decoding multi-channel audio signal |
| US8510105B2 (en) | 2005-10-21 | 2013-08-13 | Nokia Corporation | Compression and decompression of data vectors |
| WO2007048900A1 (fr) | 2005-10-27 | 2007-05-03 | France Telecom | Individualisation de hrtfs utilisant une modelisation par elements finis couplee a un modele correctif |
| US8190425B2 (en) | 2006-01-20 | 2012-05-29 | Microsoft Corporation | Complex cross-correlation parameters for multi-channel audio |
| CN101379553B (zh) | 2006-02-07 | 2012-02-29 | Lg电子株式会社 | 用于编码/解码信号的装置和方法 |
| EP1853092B1 (en) | 2006-05-04 | 2011-10-05 | LG Electronics, Inc. | Enhancing stereo audio with remix capability |
| US8712061B2 (en) | 2006-05-17 | 2014-04-29 | Creative Technology Ltd | Phase-amplitude 3-D stereo encoder and decoder |
| US8345899B2 (en) | 2006-05-17 | 2013-01-01 | Creative Technology Ltd | Phase-amplitude matrixed surround decoder |
| US20080004729A1 (en) | 2006-06-30 | 2008-01-03 | Nokia Corporation | Direct encoding into a directional audio coding format |
| US7877253B2 (en) | 2006-10-06 | 2011-01-25 | Qualcomm Incorporated | Systems, methods, and apparatus for frame erasure recovery |
| DE102006053919A1 (de) | 2006-10-11 | 2008-04-17 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum Erzeugen einer Anzahl von Lautsprechersignalen für ein Lautsprecher-Array, das einen Wiedergaberaum definiert |
| US7966175B2 (en) | 2006-10-18 | 2011-06-21 | Polycom, Inc. | Fast lattice vector quantization |
| AU2007322488B2 (en) | 2006-11-24 | 2010-04-29 | Lg Electronics Inc. | Method for encoding and decoding object-based audio signal and apparatus thereof |
| JP5450085B2 (ja) * | 2006-12-07 | 2014-03-26 | エルジー エレクトロニクス インコーポレイティド | オーディオ処理方法及び装置 |
| US7663623B2 (en) | 2006-12-18 | 2010-02-16 | Microsoft Corporation | Spherical harmonics scaling |
| JP2008227946A (ja) | 2007-03-13 | 2008-09-25 | Toshiba Corp | 画像復号装置 |
| US8290167B2 (en) | 2007-03-21 | 2012-10-16 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Method and apparatus for conversion between multi-channel audio formats |
| US9015051B2 (en) | 2007-03-21 | 2015-04-21 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Reconstruction of audio channels with direction parameters indicating direction of origin |
| US8908873B2 (en) | 2007-03-21 | 2014-12-09 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Method and apparatus for conversion between multi-channel audio formats |
| EP2137973B1 (en) | 2007-04-12 | 2019-05-01 | InterDigital VC Holdings, Inc. | Methods and apparatus for video usability information (vui) for scalable video coding (svc) |
| US20080298610A1 (en) * | 2007-05-30 | 2008-12-04 | Nokia Corporation | Parameter Space Re-Panning for Spatial Audio |
| US8180062B2 (en) | 2007-05-30 | 2012-05-15 | Nokia Corporation | Spatial sound zooming |
| EP2278582B1 (en) * | 2007-06-08 | 2016-08-10 | LG Electronics Inc. | A method and an apparatus for processing an audio signal |
| US7885819B2 (en) | 2007-06-29 | 2011-02-08 | Microsoft Corporation | Bitstream syntax for multi-process audio decoding |
| WO2009007639A1 (fr) | 2007-07-03 | 2009-01-15 | France Telecom | Quantification apres transformation lineaire combinant les signaux audio d'une scene sonore, codeur associe |
| DE602007008717D1 (de) | 2007-07-30 | 2010-10-07 | Global Ip Solutions Inc | Audiodekoder mit geringer Verzögerung |
| US8463615B2 (en) * | 2007-07-30 | 2013-06-11 | Google Inc. | Low-delay audio coder |
| US8566106B2 (en) | 2007-09-11 | 2013-10-22 | Voiceage Corporation | Method and device for fast algebraic codebook search in speech and audio coding |
| CN101884065B (zh) | 2007-10-03 | 2013-07-10 | 创新科技有限公司 | 用于双耳再现和格式转换的空间音频分析和合成的方法 |
| US8509454B2 (en) * | 2007-11-01 | 2013-08-13 | Nokia Corporation | Focusing on a portion of an audio scene for an audio signal |
| WO2009067741A1 (en) | 2007-11-27 | 2009-06-04 | Acouity Pty Ltd | Bandwidth compression of parametric soundfield representations for transmission and storage |
| EP2234104B1 (en) | 2008-01-16 | 2017-06-14 | III Holdings 12, LLC | Vector quantizer, vector inverse quantizer, and methods therefor |
| EP2094032A1 (en) | 2008-02-19 | 2009-08-26 | Deutsche Thomson OHG | Audio signal, method and apparatus for encoding or transmitting the same and method and apparatus for processing the same |
| JP5266341B2 (ja) | 2008-03-03 | 2013-08-21 | エルジー エレクトロニクス インコーポレイティド | オーディオ信号処理方法及び装置 |
| KR101230479B1 (ko) | 2008-03-10 | 2013-02-06 | 프라운호퍼 게젤샤프트 쭈르 푀르데룽 데어 안겐반텐 포르슝 에. 베. | 트랜지언트 이벤트를 갖는 오디오 신호를 조작하기 위한 장치 및 방법 |
| US8219409B2 (en) | 2008-03-31 | 2012-07-10 | Ecole Polytechnique Federale De Lausanne | Audio wave field encoding |
| US8781197B2 (en) * | 2008-04-28 | 2014-07-15 | Cornell University | Tool for accurate quantification in molecular MRI |
| US8184298B2 (en) | 2008-05-21 | 2012-05-22 | The Board Of Trustees Of The University Of Illinois | Spatial light interference microscopy and fourier transform light scattering for cell and tissue characterization |
| JP5383676B2 (ja) | 2008-05-30 | 2014-01-08 | パナソニック株式会社 | 符号化装置、復号装置およびこれらの方法 |
| EP2297557B1 (en) | 2008-07-08 | 2013-10-30 | Brüel & Kjaer Sound & Vibration Measurement A/S | Reconstructing an acoustic field |
| EP2144230A1 (en) | 2008-07-11 | 2010-01-13 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Low bitrate audio encoding/decoding scheme having cascaded switches |
| GB0817950D0 (en) | 2008-10-01 | 2008-11-05 | Univ Southampton | Apparatus and method for sound reproduction |
| JP5697301B2 (ja) | 2008-10-01 | 2015-04-08 | 株式会社Nttドコモ | 動画像符号化装置、動画像復号装置、動画像符号化方法、動画像復号方法、動画像符号化プログラム、動画像復号プログラム、及び動画像符号化・復号システム |
| US8207890B2 (en) * | 2008-10-08 | 2012-06-26 | Qualcomm Atheros, Inc. | Providing ephemeris data and clock corrections to a satellite navigation system receiver |
| US8391500B2 (en) | 2008-10-17 | 2013-03-05 | University Of Kentucky Research Foundation | Method and system for creating three-dimensional spatial audio |
| FR2938688A1 (fr) | 2008-11-18 | 2010-05-21 | France Telecom | Codage avec mise en forme du bruit dans un codeur hierarchique |
| US8964994B2 (en) * | 2008-12-15 | 2015-02-24 | Orange | Encoding of multichannel digital audio signals |
| US8817991B2 (en) | 2008-12-15 | 2014-08-26 | Orange | Advanced encoding of multi-channel digital audio signals |
| US8332229B2 (en) | 2008-12-30 | 2012-12-11 | Stmicroelectronics Asia Pacific Pte. Ltd. | Low complexity MPEG encoding for surround sound recordings |
| EP2205007B1 (en) | 2008-12-30 | 2019-01-09 | Dolby International AB | Method and apparatus for three-dimensional acoustic field encoding and optimal reconstruction |
| WO2010086342A1 (en) | 2009-01-28 | 2010-08-05 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoder, audio decoder, method for encoding an input audio information, method for decoding an input audio information and computer program using improved coding tables |
| GB2476747B (en) | 2009-02-04 | 2011-12-21 | Richard Furse | Sound system |
| JP5163545B2 (ja) | 2009-03-05 | 2013-03-13 | 富士通株式会社 | オーディオ復号装置及びオーディオ復号方法 |
| EP2237270B1 (en) | 2009-03-30 | 2012-07-04 | Nuance Communications, Inc. | A method for determining a noise reference signal for noise compensation and/or noise reduction |
| GB0906269D0 (en) | 2009-04-09 | 2009-05-20 | Ntnu Technology Transfer As | Optimal modal beamformer for sensor arrays |
| US8629600B2 (en) * | 2009-05-08 | 2014-01-14 | University Of Utah Research Foundation | Annular thermoacoustic energy converter |
| JP4778591B2 (ja) | 2009-05-21 | 2011-09-21 | パナソニック株式会社 | 触感処理装置 |
| JP5678048B2 (ja) * | 2009-06-24 | 2015-02-25 | フラウンホッファー−ゲゼルシャフト ツァ フェルダールング デァ アンゲヴァンテン フォアシュンク エー.ファオ | カスケード化されたオーディオオブジェクト処理ステージを用いたオーディオ信号デコーダ、オーディオ信号を復号化する方法、およびコンピュータプログラム |
| ES2690164T3 (es) | 2009-06-25 | 2018-11-19 | Dts Licensing Limited | Dispositivo y método para convertir una señal de audio espacial |
| WO2011041834A1 (en) | 2009-10-07 | 2011-04-14 | The University Of Sydney | Reconstruction of a recorded sound field |
| AU2009353896B2 (en) | 2009-10-15 | 2013-05-23 | Widex A/S | Hearing aid with audio codec and method |
| JP5746974B2 (ja) | 2009-11-13 | 2015-07-08 | パナソニック インテレクチュアル プロパティ コーポレーション オブアメリカPanasonic Intellectual Property Corporation of America | 符号化装置、復号装置およびこれらの方法 |
| JP5427565B2 (ja) * | 2009-11-24 | 2014-02-26 | 株式会社日立製作所 | Mri装置用磁場調整 |
| SI2510515T1 (sl) | 2009-12-07 | 2014-06-30 | Dolby Laboratories Licensing Corporation | Dekodiranje večkanalnih avdio kodiranih bitnih prenosov s pomočjo adaptivne hibridne transformacije |
| EP2346028A1 (en) * | 2009-12-17 | 2011-07-20 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | An apparatus and a method for converting a first parametric spatial audio signal into a second parametric spatial audio signal |
| CN102104452B (zh) | 2009-12-22 | 2013-09-11 | 华为技术有限公司 | 信道状态信息反馈方法、信道状态信息获得方法及设备 |
| TWI443646B (zh) | 2010-02-18 | 2014-07-01 | Dolby Lab Licensing Corp | 音訊解碼器及使用有效降混之解碼方法 |
| EP2539892B1 (fr) | 2010-02-26 | 2014-04-02 | Orange | Compression de flux audio multicanal |
| RU2586848C2 (ru) | 2010-03-10 | 2016-06-10 | Долби Интернейшнл АБ | Декодер звукового сигнала, кодирующее устройство звукового сигнала, способы и компьютерная программа, использующие зависящее от частоты выборки кодирование контура деформации времени |
| WO2011117399A1 (en) | 2010-03-26 | 2011-09-29 | Thomson Licensing | Method and device for decoding an audio soundfield representation for audio playback |
| ES2656815T3 (es) * | 2010-03-29 | 2018-02-28 | Fraunhofer-Gesellschaft Zur Förderung Der Angewandten Forschung | Procesador de audio espacial y procedimiento para proporcionar parámetros espaciales en base a una señal de entrada acústica |
| JP5850216B2 (ja) | 2010-04-13 | 2016-02-03 | ソニー株式会社 | 信号処理装置および方法、符号化装置および方法、復号装置および方法、並びにプログラム |
| TW201214415A (en) | 2010-05-28 | 2012-04-01 | Fraunhofer Ges Forschung | Low-delay unified speech and audio codec |
| US9053697B2 (en) | 2010-06-01 | 2015-06-09 | Qualcomm Incorporated | Systems, methods, devices, apparatus, and computer program products for audio equalization |
| US9398308B2 (en) | 2010-07-28 | 2016-07-19 | Qualcomm Incorporated | Coding motion prediction direction in video coding |
| US9208792B2 (en) | 2010-08-17 | 2015-12-08 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for noise injection |
| NZ587483A (en) | 2010-08-20 | 2012-12-21 | Ind Res Ltd | Holophonic speaker system with filters that are pre-configured based on acoustic transfer functions |
| US9271081B2 (en) | 2010-08-27 | 2016-02-23 | Sonicemotion Ag | Method and device for enhanced sound field reproduction of spatially encoded audio input signals |
| CN101977349A (zh) | 2010-09-29 | 2011-02-16 | 华南理工大学 | Ambisonic声重发系统解码的优化改进方法 |
| US9084049B2 (en) | 2010-10-14 | 2015-07-14 | Dolby Laboratories Licensing Corporation | Automatic equalization using adaptive frequency-domain filtering and dynamic fast convolution |
| US20120093323A1 (en) | 2010-10-14 | 2012-04-19 | Samsung Electronics Co., Ltd. | Audio system and method of down mixing audio signals using the same |
| US9552840B2 (en) | 2010-10-25 | 2017-01-24 | Qualcomm Incorporated | Three-dimensional sound capturing and reproducing with multi-microphones |
| EP2450880A1 (en) | 2010-11-05 | 2012-05-09 | Thomson Licensing | Data structure for Higher Order Ambisonics audio data |
| EP2451196A1 (en) | 2010-11-05 | 2012-05-09 | Thomson Licensing | Method and apparatus for generating and for decoding sound field data including ambisonics sound field data of an order higher than three |
| KR101401775B1 (ko) | 2010-11-10 | 2014-05-30 | 한국전자통신연구원 | 스피커 어레이 기반 음장 합성을 이용한 음장 재생 장치 및 방법 |
| US9448289B2 (en) * | 2010-11-23 | 2016-09-20 | Cornell University | Background field removal method for MRI using projection onto dipole fields |
| CN103460285B (zh) | 2010-12-03 | 2018-01-12 | 弗劳恩霍夫应用研究促进协会 | 用于以几何为基础的空间音频编码的装置及方法 |
| EP2464146A1 (en) * | 2010-12-10 | 2012-06-13 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for decomposing an input signal using a pre-calculated reference curve |
| EP2469741A1 (en) | 2010-12-21 | 2012-06-27 | Thomson Licensing | Method and apparatus for encoding and decoding successive frames of an ambisonics representation of a 2- or 3-dimensional sound field |
| US20120163622A1 (en) | 2010-12-28 | 2012-06-28 | Stmicroelectronics Asia Pacific Pte Ltd | Noise detection and reduction in audio devices |
| US8809663B2 (en) | 2011-01-06 | 2014-08-19 | Hank Risan | Synthetic simulation of a media recording |
| US9008176B2 (en) | 2011-01-22 | 2015-04-14 | Qualcomm Incorporated | Combined reference picture list construction for video coding |
| US20120189052A1 (en) | 2011-01-24 | 2012-07-26 | Qualcomm Incorporated | Signaling quantization parameter changes for coded units in high efficiency video coding (hevc) |
| EP2671221B1 (en) * | 2011-02-03 | 2017-02-01 | Telefonaktiebolaget LM Ericsson (publ) | Determining the inter-channel time difference of a multi-channel audio signal |
| WO2012122397A1 (en) | 2011-03-09 | 2012-09-13 | Srs Labs, Inc. | System for dynamically creating and rendering audio objects |
| CN105244034B (zh) | 2011-04-21 | 2019-08-13 | 三星电子株式会社 | 针对语音信号或音频信号的量化方法以及解码方法和设备 |
| EP2541547A1 (en) | 2011-06-30 | 2013-01-02 | Thomson Licensing | Method and apparatus for changing the relative positions of sound objects contained within a higher-order ambisonics representation |
| EP2727383B1 (en) * | 2011-07-01 | 2021-04-28 | Dolby Laboratories Licensing Corporation | System and method for adaptive audio signal generation, coding and rendering |
| US8548803B2 (en) * | 2011-08-08 | 2013-10-01 | The Intellisis Corporation | System and method of processing a sound signal including transforming the sound signal into a frequency-chirp domain |
| US9641951B2 (en) | 2011-08-10 | 2017-05-02 | The Johns Hopkins University | System and method for fast binaural rendering of complex acoustic scenes |
| EP2560161A1 (en) | 2011-08-17 | 2013-02-20 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Optimal mixing matrices and usage of decorrelators in spatial audio processing |
| EP2592846A1 (en) | 2011-11-11 | 2013-05-15 | Thomson Licensing | Method and apparatus for processing signals of a spherical microphone array on a rigid sphere used for generating an Ambisonics representation of the sound field |
| EP2592845A1 (en) | 2011-11-11 | 2013-05-15 | Thomson Licensing | Method and Apparatus for processing signals of a spherical microphone array on a rigid sphere used for generating an Ambisonics representation of the sound field |
| EP2600343A1 (en) | 2011-12-02 | 2013-06-05 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for merging geometry - based spatial audio coding streams |
| KR101590332B1 (ko) | 2012-01-09 | 2016-02-18 | 삼성전자주식회사 | 영상장치 및 그 제어방법 |
| US9584912B2 (en) | 2012-01-19 | 2017-02-28 | Koninklijke Philips N.V. | Spatial audio rendering and encoding |
| EP2637427A1 (en) | 2012-03-06 | 2013-09-11 | Thomson Licensing | Method and apparatus for playback of a higher-order ambisonics audio signal |
| EP2645748A1 (en) | 2012-03-28 | 2013-10-02 | Thomson Licensing | Method and apparatus for decoding stereo loudspeaker signals from a higher-order Ambisonics audio signal |
| US9955280B2 (en) * | 2012-04-19 | 2018-04-24 | Nokia Technologies Oy | Audio scene apparatus |
| EP2665208A1 (en) | 2012-05-14 | 2013-11-20 | Thomson Licensing | Method and apparatus for compressing and decompressing a Higher Order Ambisonics signal representation |
| US9190065B2 (en) | 2012-07-15 | 2015-11-17 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for three-dimensional audio coding using basis function coefficients |
| US20140086416A1 (en) | 2012-07-15 | 2014-03-27 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for three-dimensional audio coding using basis function coefficients |
| US9288603B2 (en) | 2012-07-15 | 2016-03-15 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for backward-compatible audio coding |
| EP2688066A1 (en) | 2012-07-16 | 2014-01-22 | Thomson Licensing | Method and apparatus for encoding multi-channel HOA audio signals for noise reduction, and method and apparatus for decoding multi-channel HOA audio signals for noise reduction |
| CN107071687B (zh) | 2012-07-16 | 2020-02-14 | 杜比国际公司 | 用于渲染音频声场表示以供音频回放的方法和设备 |
| US9473870B2 (en) | 2012-07-16 | 2016-10-18 | Qualcomm Incorporated | Loudspeaker position compensation with 3D-audio hierarchical coding |
| EP2875511B1 (en) | 2012-07-19 | 2018-02-21 | Dolby International AB | Audio coding for improving the rendering of multi-channel audio signals |
| US9761229B2 (en) * | 2012-07-20 | 2017-09-12 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for audio object clustering |
| US9479886B2 (en) | 2012-07-20 | 2016-10-25 | Qualcomm Incorporated | Scalable downmix design with feedback for object-based surround codec |
| JP5967571B2 (ja) | 2012-07-26 | 2016-08-10 | 本田技研工業株式会社 | 音響信号処理装置、音響信号処理方法、及び音響信号処理プログラム |
| WO2014068167A1 (en) * | 2012-10-30 | 2014-05-08 | Nokia Corporation | A method and apparatus for resilient vector quantization |
| US9336771B2 (en) | 2012-11-01 | 2016-05-10 | Google Inc. | Speech recognition using non-parametric models |
| EP2743922A1 (en) | 2012-12-12 | 2014-06-18 | Thomson Licensing | Method and apparatus for compressing and decompressing a higher order ambisonics representation for a sound field |
| US9736609B2 (en) | 2013-02-07 | 2017-08-15 | Qualcomm Incorporated | Determining renderers for spherical harmonic coefficients |
| US9883310B2 (en) | 2013-02-08 | 2018-01-30 | Qualcomm Incorporated | Obtaining symmetry information for higher order ambisonic audio renderers |
| EP2765791A1 (en) | 2013-02-08 | 2014-08-13 | Thomson Licensing | Method and apparatus for determining directions of uncorrelated sound sources in a higher order ambisonics representation of a sound field |
| US10178489B2 (en) | 2013-02-08 | 2019-01-08 | Qualcomm Incorporated | Signaling audio rendering information in a bitstream |
| US9609452B2 (en) | 2013-02-08 | 2017-03-28 | Qualcomm Incorporated | Obtaining sparseness information for higher order ambisonic audio renderers |
| US9338420B2 (en) | 2013-02-15 | 2016-05-10 | Qualcomm Incorporated | Video analysis assisted generation of multi-channel audio data |
| CN104010265A (zh) * | 2013-02-22 | 2014-08-27 | 杜比实验室特许公司 | 音频空间渲染设备及方法 |
| US9685163B2 (en) | 2013-03-01 | 2017-06-20 | Qualcomm Incorporated | Transforming spherical harmonic coefficients |
| SG11201507066PA (en) * | 2013-03-05 | 2015-10-29 | Fraunhofer Ges Forschung | Apparatus and method for multichannel direct-ambient decomposition for audio signal processing |
| US9197962B2 (en) | 2013-03-15 | 2015-11-24 | Mh Acoustics Llc | Polyhedral audio system based on at least second-order eigenbeams |
| EP2800401A1 (en) | 2013-04-29 | 2014-11-05 | Thomson Licensing | Method and Apparatus for compressing and decompressing a Higher Order Ambisonics representation |
| RU2667630C2 (ru) | 2013-05-16 | 2018-09-21 | Конинклейке Филипс Н.В. | Устройство аудиообработки и способ для этого |
| US9466305B2 (en) | 2013-05-29 | 2016-10-11 | Qualcomm Incorporated | Performing positional analysis to code spherical harmonic coefficients |
| US9384741B2 (en) | 2013-05-29 | 2016-07-05 | Qualcomm Incorporated | Binauralization of rotated higher order ambisonics |
| US20140355769A1 (en) | 2013-05-29 | 2014-12-04 | Qualcomm Incorporated | Energy preservation for decomposed representations of a sound field |
| WO2014195190A1 (en) | 2013-06-05 | 2014-12-11 | Thomson Licensing | Method for encoding audio signals, apparatus for encoding audio signals, method for decoding audio signals and apparatus for decoding audio signals |
| EP3933834B1 (en) | 2013-07-05 | 2024-07-24 | Dolby International AB | Enhanced soundfield coding using parametric component generation |
| TWI631553B (zh) | 2013-07-19 | 2018-08-01 | 瑞典商杜比國際公司 | 將以<i>L</i><sub>1</sub>個頻道為基礎之輸入聲音訊號產生至<i>L</i><sub>2</sub>個揚聲器頻道之方法及裝置,以及得到一能量保留混音矩陣之方法及裝置,用以將以輸入頻道為基礎之聲音訊號混音以用於<i>L</i><sub>1</sub>個聲音頻道至<i>L</i><sub>2</sub>個揚聲器頻道 |
| US20150127354A1 (en) | 2013-10-03 | 2015-05-07 | Qualcomm Incorporated | Near field compensation for decomposed representations of a sound field |
| US9922656B2 (en) | 2014-01-30 | 2018-03-20 | Qualcomm Incorporated | Transitioning of ambient higher-order ambisonic coefficients |
| US9502045B2 (en) | 2014-01-30 | 2016-11-22 | Qualcomm Incorporated | Coding independent frames of ambient higher-order ambisonic coefficients |
| US20150243292A1 (en) * | 2014-02-25 | 2015-08-27 | Qualcomm Incorporated | Order format signaling for higher-order ambisonic audio data |
| US20150264483A1 (en) | 2014-03-14 | 2015-09-17 | Qualcomm Incorporated | Low frequency rendering of higher-order ambisonic audio data |
| US9852737B2 (en) | 2014-05-16 | 2017-12-26 | Qualcomm Incorporated | Coding vectors decomposed from higher-order ambisonics audio signals |
| US10770087B2 (en) | 2014-05-16 | 2020-09-08 | Qualcomm Incorporated | Selecting codebooks for coding vectors decomposed from higher-order ambisonic audio signals |
| US9959876B2 (en) * | 2014-05-16 | 2018-05-01 | Qualcomm Incorporated | Closed loop quantization of higher order ambisonic coefficients |
| US20150332682A1 (en) * | 2014-05-16 | 2015-11-19 | Qualcomm Incorporated | Spatial relation coding for higher order ambisonic coefficients |
| US9620137B2 (en) | 2014-05-16 | 2017-04-11 | Qualcomm Incorporated | Determining between scalar and vector quantization in higher order ambisonic coefficients |
| US10142642B2 (en) | 2014-06-04 | 2018-11-27 | Qualcomm Incorporated | Block adaptive color-space conversion coding |
| US20160093308A1 (en) | 2014-09-26 | 2016-03-31 | Qualcomm Incorporated | Predictive vector quantization techniques in a higher order ambisonics (hoa) framework |
| US9747910B2 (en) | 2014-09-26 | 2017-08-29 | Qualcomm Incorporated | Switching between predictive and non-predictive quantization techniques in a higher order ambisonics (HOA) framework |
-
2014
- 2014-05-28 US US14/289,323 patent/US20140355769A1/en not_active Abandoned
- 2014-05-28 US US14/289,588 patent/US20140358565A1/en not_active Abandoned
- 2014-05-28 US US14/289,549 patent/US9883312B2/en active Active
- 2014-05-28 US US14/289,551 patent/US9502044B2/en active Active
- 2014-05-28 US US14/289,234 patent/US9763019B2/en active Active
- 2014-05-28 US US14/289,539 patent/US9854377B2/en active Active
- 2014-05-28 US US14/289,174 patent/US9495968B2/en not_active Expired - Fee Related
- 2014-05-28 US US14/289,522 patent/US11146903B2/en active Active
- 2014-05-28 US US14/289,396 patent/US9769586B2/en active Active
- 2014-05-28 US US14/289,440 patent/US10499176B2/en active Active
- 2014-05-28 US US14/289,477 patent/US9980074B2/en active Active
- 2014-05-28 US US14/289,265 patent/US9716959B2/en active Active
- 2014-05-29 EP EP14733462.7A patent/EP3005358B1/en active Active
- 2014-05-29 TW TW103118935A patent/TWI645723B/zh active
- 2014-05-29 HU HUE16183136A patent/HUE046520T2/hu unknown
- 2014-05-29 EP EP14733873.5A patent/EP3005359B1/en active Active
- 2014-05-29 ES ES16183135.9T patent/ES2689566T3/es active Active
- 2014-05-29 RU RU2015151021A patent/RU2668059C2/ru active
- 2014-05-29 KR KR1020157036271A patent/KR20160016885A/ko not_active Application Discontinuation
- 2014-05-29 KR KR1020157036262A patent/KR101877605B1/ko active IP Right Grant
- 2014-05-29 CN CN201480031271.1A patent/CN105580072B/zh active Active
- 2014-05-29 WO PCT/US2014/040041 patent/WO2014194105A1/en active Application Filing
- 2014-05-29 CN CN201480032630.5A patent/CN105284132B/zh active Active
- 2014-05-29 KR KR1020157036263A patent/KR101795900B1/ko active IP Right Grant
- 2014-05-29 JP JP2016516821A patent/JP6121625B2/ja active Active
- 2014-05-29 KR KR1020157036261A patent/KR102190201B1/ko active IP Right Grant
- 2014-05-29 WO PCT/US2014/040048 patent/WO2014194110A1/en active Application Filing
- 2014-05-29 BR BR112015030102-9A patent/BR112015030102B1/pt active IP Right Grant
- 2014-05-29 EP EP14736510.0A patent/EP3005361B1/en active Active
- 2014-05-29 CN CN201480032616.5A patent/CN105284131B/zh active Active
- 2014-05-29 WO PCT/US2014/040008 patent/WO2014194080A1/en active Application Filing
- 2014-05-29 JP JP2016516824A patent/JP6449256B2/ja active Active
- 2014-05-29 KR KR1020157036200A patent/KR101929092B1/ko active IP Right Grant
- 2014-05-29 CA CA2912810A patent/CA2912810C/en active Active
- 2014-05-29 WO PCT/US2014/040042 patent/WO2014194106A1/en active Application Filing
- 2014-05-29 KR KR1020157036244A patent/KR20160016879A/ko active IP Right Grant
- 2014-05-29 CN CN201480031031.1A patent/CN105264598B/zh active Active
- 2014-05-29 KR KR1020157036246A patent/KR20160016881A/ko not_active Application Discontinuation
- 2014-05-29 JP JP2016516813A patent/JP6185159B2/ja active Active
- 2014-05-29 CN CN201480031272.6A patent/CN105917407B/zh active Active
- 2014-05-29 TW TW103118931A patent/TW201509200A/zh unknown
- 2014-05-29 WO PCT/US2014/039999 patent/WO2014194075A1/en active Application Filing
- 2014-05-29 KR KR1020157036199A patent/KR20160013125A/ko active Application Filing
- 2014-05-29 KR KR1020157036241A patent/KR101961986B1/ko active IP Right Grant
- 2014-05-29 KR KR1020157036243A patent/KR20160016878A/ko not_active Application Discontinuation
- 2014-05-29 EP EP16183136.7A patent/EP3107095B1/en active Active
- 2014-05-29 SG SG11201509462VA patent/SG11201509462VA/en unknown
- 2014-05-29 WO PCT/US2014/040013 patent/WO2014194084A1/en active Application Filing
- 2014-05-29 ES ES14733873.5T patent/ES2635327T3/es active Active
- 2014-05-29 HU HUE14736510A patent/HUE033545T2/hu unknown
- 2014-05-29 WO PCT/US2014/040061 patent/WO2014194116A1/en active Application Filing
- 2014-05-29 ES ES16183136T patent/ES2764384T3/es active Active
- 2014-05-29 WO PCT/US2014/040044 patent/WO2014194107A1/en active Application Filing
- 2014-05-29 HU HUE16183135A patent/HUE039457T2/hu unknown
- 2014-05-29 EP EP14734328.9A patent/EP3005360B1/en active Active
- 2014-05-29 KR KR1020217022743A patent/KR102407554B1/ko active IP Right Grant
- 2014-05-29 WO PCT/US2014/040047 patent/WO2014194109A1/en active Application Filing
- 2014-05-29 WO PCT/US2014/040025 patent/WO2014194090A1/en active Application Filing
- 2014-05-29 MY MYPI2015704125A patent/MY174865A/en unknown
- 2014-05-29 ES ES14736510.0T patent/ES2641175T3/es active Active
- 2014-05-29 EP EP17177230.4A patent/EP3282448A3/en not_active Ceased
- 2014-05-29 WO PCT/US2014/040057 patent/WO2014194115A1/en active Application Filing
- 2014-05-29 AU AU2014274076A patent/AU2014274076B2/en active Active
- 2014-05-29 EP EP16183119.3A patent/EP3107093A1/en not_active Withdrawn
- 2014-05-29 EP EP16183135.9A patent/EP3107094B1/en active Active
- 2014-05-29 UA UAA201511755A patent/UA116140C2/uk unknown
- 2014-05-29 JP JP2016516823A patent/JP6345771B2/ja active Active
- 2014-05-29 CN CN201910693832.9A patent/CN110767242B/zh active Active
- 2014-05-29 WO PCT/US2014/040035 patent/WO2014194099A1/en active Application Filing
- 2014-05-29 CN CN201480031114.0A patent/CN105340009B/zh active Active
-
2015
- 2015-11-17 IL IL242648A patent/IL242648B/en active IP Right Grant
- 2015-11-26 PH PH12015502634A patent/PH12015502634B1/en unknown
- 2015-12-18 ZA ZA2015/09227A patent/ZA201509227B/en unknown
-
2016
- 2016-03-30 HK HK16103671.2A patent/HK1215752A1/zh unknown
- 2016-08-25 US US15/247,244 patent/US9749768B2/en active Active
- 2016-08-25 US US15/247,364 patent/US9774977B2/en active Active
-
2017
- 2017-03-29 JP JP2017065537A patent/JP6199519B2/ja active Active
- 2017-06-19 JP JP2017119791A patent/JP6290498B2/ja active Active
-
2021
- 2021-10-11 US US17/498,707 patent/US11962990B2/en active Active
-
2024
- 2024-04-12 US US18/634,501 patent/US20240276166A1/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8379868B2 (en) * | 2006-05-17 | 2013-02-19 | Creative Technology Ltd | Spatial audio coding based on universal spatial cues |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11962990B2 (en) | Reordering of foreground audio objects in the ambisonics domain | |
| US20150127354A1 (en) | Near field compensation for decomposed representations of a sound field | |
| CN105340008B (zh) | 声场的经分解表示的压缩 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |