CN103369584A - 终端装置、终端控制方法、程序和信息处理系统 - Google Patents
终端装置、终端控制方法、程序和信息处理系统 Download PDFInfo
- Publication number
- CN103369584A CN103369584A CN2013100953239A CN201310095323A CN103369584A CN 103369584 A CN103369584 A CN 103369584A CN 2013100953239 A CN2013100953239 A CN 2013100953239A CN 201310095323 A CN201310095323 A CN 201310095323A CN 103369584 A CN103369584 A CN 103369584A
- Authority
- CN
- China
- Prior art keywords
- local information
- parameter
- degree
- congestion
- information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Transfer Between Computers (AREA)
- Mobile Radio Communication Systems (AREA)
- Telephonic Communication Services (AREA)
Abstract
公开了一种终端装置、终端控制方法、程序和信息处理系统,该终端装置包括:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;通信单元,将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个便携式终端装置获取的本地信息而学习的统计模型的参数;以及预测单元,使用所接收到的统计模型的参数来预测与任意时间和位置有关的本地信息。
Description
技术领域
本技术涉及一种终端装置、终端控制方法、程序和信息处理系统。具体地,本技术涉及使得每个终端装置可以高效地使用由大量终端装置收集的数据的终端装置、终端控制方法、程序和信息处理系统。
背景技术
近年来,由能够传输大容量数据的便携式无线通信终端(诸如智能电话)的迅速普及而带来的通信线路的拥塞度已成为问题。
本申请人提出了一种通过使用指标b/a来估计线路的拥塞度的方法,其中,指标b/a使用关于基站的扰码的接收信号的关联输出a和关于另一扰码的关联输出的最小值b(例如,参考日本未审查专利申请公布第2011-10267号第[0110]段和日本未审查专利申请公布第2012-9987号第[0062]、[0073]和[0077]段)。另外,本申请人提出了根据线路拥塞度来估计通信速率(例如,参考日本未审查专利申请公布第2012-9987号第[0062]、[0073]和[0077]段).
此外,本申请人提出了一种预测目的地和从用户的当前位置到目的地的移动路线、并且选择时间、地方、通信系统、发送速率等来执行通信的技术(例如,参考日本未审查专利申请公布第2010-211425号第[0121]至[0130]段)。
发明内容
然而,在日本未审查专利申请公布第2010-211425号第[0121]至[0130]段的技术中,公开了使用由服务器从大量客户终端(终端装置)收集的、与目的地和移动路线中的通信环境有关的通信信息,但是不清楚要如何使用该通信信息。当获取由大量客户终端所收集的所有通信信息时,通信线路变得拥塞并且客户终端所需要的存储容量增加。
考虑到诸如这样的情形,本技术使得每个终端装置可以高效地使用由大量终端装置收集的数据。
根据本技术的第一实施例的终端装置包括:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;通信单元,将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个终端装置获取的本地信息而学习的统计模型的参数;以及预测单元,使用所接收到的统计模型的参数来预测与任意时间和位置有关的本地信息。
根据本技术的第一实施例的终端控制方法包括:使得终端装置获取当前时间的当前位置的本地信息;使得终端装置在预定时段内累积所获取的本地信息;使得终端装置将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个终端装置获取的本地信息所学习的统计模型的参数;以及使得终端装置使用所接收到的统计模型的参数来预测与任意时间和位置有关的本地信息。
根据本技术的第一实施例的程序使得计算机用作如下单元:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;通信单元,将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个终端装置获取的本地信息所学习的统计模型的参数;以及预测单元,使用所接收到的统计模型的参数来预测与任意时间和位置有关的本地信息。
根据本技术的第一实施例,获取当前时间的当前位置的本地信息;在预定时段内累积所获取的本地信息;将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个便携式终端获取的本地信息所学习的统计模型的参数;以及使用所接收到的统计模型的参数来预测与任意时间和位置有关的本地信息。
根据本技术的第二实施例的信息处理系统由终端装置和信息处理装置构成,其中,终端装置包括:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;以及通信单元,将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个终端装置获取的本地信息所学习的统计模型的参数;以及其中,信息处理装置包括:通信单元,从终端装置接收在预定时段内向信息处理装置发送的本地信息,并且将统计模型的参数发送到终端装置;以及学习单元,使用从多个终端装置接收到的本地信息来学习统计模型的参数;以及其中,终端装置或信息处理装置中的任一个包括预测单元,该预测单元使用所接收到的统计模型的参数来预测与任意时间和位置有关的本地信息。
根据本技术的第二实施例,在终端装置中,获取当前时间的当前位置的本地信息;在预定时段内累积所获取的本地信息;以及将在预定时段内所累积的本地信息发送到信息处理装置,并且从信息处理装置接收使用由信息处理装置从多个终端装置获取的本地信息所学习的统计模型的参数;以及在信息处理装置中,从终端装置接收在预定时段内向信息处理装置发送的本地信息,并且将统计模型的参数发送到终端装置;以及使用从多个终端装置接收到的本地信息来学习统计模型的参数;以及在终端装置或信息处理装置中的任一个中,使用统计模型的参数来预测与任意时间和位置有关的本地信息。
此外,可以通过经由传输介质传送程序、或者通过将程序记录到记录介质上来提供程序。
终端装置和信息处理装置可以是独立的装置,并且也可以是构成单个装置的内部块。
根据本技术的第一实施例,每个终端装置可以高效地使用由大量终端装置收集的数据。
根据本技术的第二实施例,可以使得每个终端装置高效地使用由大量终端装置收集的数据。
附图说明
图1是示出应用了本技术的信息处理系统的实施例的配置示例的视图;
图2是示出便携式终端和服务器的功能配置示例的框图;
图3是示出拥塞度数据的示例的视图;
图4是在预定时段期间收集的拥塞度的图;
图5是示出作为拥塞度的移动平均值而计算的平均拥塞度的视图;
图6是示出在一个月的时段中的每日平均拥塞度的视图;
图7是示出支持向量回归中的ε可允许误差函数的视图;
图8是使用联立方程的参数计算处理的流程图;
图9是使用梯度方法的参数计算处理的流程图;
图10是示出支持向量回归模型的参数an和an ~的示例的视图;
图11是示出用于执行支持向量回归模型的参数更新的数据更新处理的流程图;
图12是示出对拥塞度进行预测的预测处理的流程图;
图13是示出对支持向量回归模型的参数进行学习的学习处理的流程图;
图14是示出通过使用支持向量回归模型来预测拥塞度而获得的预测结果的视图;
图15是示出通过使用支持向量回归模型来预测拥塞度而获得的预测结果的视图;
图16是示出通过使用支持向量回归模型来预测拥塞度而获得的预测结果的视图;
图17是示出关系向量回归模型的视图;
图18是示出关系向量回归模型的参数m和Σ的示例的视图;
图19是示出通过使用关系向量回归模型来预测拥塞度而获得的预测结果的视图;
图20是示出通过比较支持向量回归模型和关系向量回归模型的预测性能而获得的比较结果的示例的视图;
图21是比较支持向量回归模型和关系向量回归模型的数据项数的视图;
图22是示出预测结果画面的示例的视图;
图23是示出隐马尔科夫模型的图;
图24是示出用户的移动历史的学习结果的视图;
图25是通过预测移动路线和目的地来预测拥塞度的预测处理的流程图;
图26是示出使用预测处理而获得的预测结果的示例的视图;
图27是示出使用预测处理而获得的预测结果的示例的视图;
图28是示出使用预测处理而获得的预测结果的示例的视图;
图29是示出用于输入本地信息的输入画面的示例的视图;
图30是示出预测本地信息的预测结果画面的示例的视图;以及
图31是示出应用了本技术的计算机的实施例的配置示例的框图。
具体实施方式
信息处理系统的实施例
信息处理系统的配置示例
图1示出应用了本技术的信息处理系统的实施例的配置示例。
图1的信息处理系统1包括多个便携式终端(终端装置)11、对由便携式终端11获取的预定数据进行收集和分析的服务器12以及当与服务器12执行数据通信时便携式终端11所连接的基站13。
此外,在图1中,示出了三个便携式终端11-1至11-3和六个基站13-1至13-6,然而便携式终端11和基站13的数量不限于此。
便携式终端11在作为可从用户的当前位置连接的基站13而检测到的多个基站13中,确定例如最近的基站13是要连接的基站13(下文中称为主小区13)。此外,关于如何确定主小区13是任意的。
另外,便携式终端11经由主小区13与服务器12发送和接收预定数据。在本实施例中,便携式终端11以预定间隔测量主小区13的通信线路的拥塞度,累积测量结果作为拥塞度数据项,并且将所累积的拥塞度数据项发送到服务器12。此外,便携式终端11从服务器12接收通过基于服务器12从大量便携式终端11收集的拥塞度数据项进行学习而获得的参数。此外,在这里,线路的拥塞度指的是用于表示多路复用无线通信中的通信带宽的占用程度的指标。
便携式终端11使用从服务器12接收的参数来估计除主小区13之外的预定基站13的拥塞度。通过估计基站13的拥塞度而获得的估计结果可用来确定在当前时间和此后要连接的基站13。例如,便携式终端11预测用户的移动路线和目的地,并且在基于所接收到的参数估计拥塞度之后使用移动路线和目的地来确定要连接的基站13。
在本实施例中,便携式终端11是诸如智能电话的便携式电话。便携式终端11可以是例如平板终端、便携式PC(个人计算机)、便携式音频播放器等。当便携式终端11无法连接到便携式电话通信网络的基站13时,基站13也可以是诸如Wi-Fi的无线通信的接入点。
服务器12使用回归模型来学习(使用统计模型来建模)从多个便携式终端11收集的基站13的拥塞度。在本实施例中,采用内核回归模型(特别地,如下所述的支持向量回归模型或关系向量回归模型)作为回归模型。
此外,服务器12将通过学习而获得的回归模型的参数(模型参数)发送到便携式终端11。例如,便携式终端11累积以一分钟间隔获取的一天的拥塞度的时间序列数据项(拥塞度数据),连接到服务器12并且每天一次将数据发送到服务器12。服务器12基于所收集的拥塞度数据执行学习,并且当下一便携式终端11连接并且发送拥塞度数据时,服务器12将学习模型的更新后的模型参数发送到便携式终端11。当便携式终端11将所累积的拥塞度数据发送到服务器12时,或者在从服务器12接收更新后的模型参数的间隔中,服务器12更新回归模型的模型参数的定时是任意的。
便携式终端和服务器的功能配置示例
图2是示出便携式终端11和服务器12的功能配置示例的框图。
便携式终端11包括拥塞度获取单元41、拥塞度数据累积单元42、服务器通信单元43、参数存储单元44、预测单元45、输入单元46和显示单元47。
便携式终端11的拥塞度获取单元41以预定时间间隔计算主小区13的拥塞度,或者获取由块(未示出)计算的拥塞度,并且将拥塞度提供到拥塞度数据累积单元42。获取拥塞度的定时不必为固定间隔。
拥塞度数据累积单元42在服务器通信单元43连接到服务器12的时段期间累积从拥塞度获取单元41提供的拥塞度,并且发送拥塞度数据。
服务器通信单元43在拥塞度数据项已在拥塞度数据累积单元42中累积到特定程度的预定定时(例如,大约每天一次)连接到服务器12,并且将在拥塞度数据累积单元42中累积的拥塞度数据项发送到服务器12。
另外,在服务器通信单元43连接到服务器12时服务器12中存在回归模型的更新后的参数的情况下,这些参数被接收并且被存储在参数存储单元44中。参数存储单元44存储从服务器12获取的回归模型的参数并且根据需要将参数提供到预测单元45。
预测单元45使用存储在参数存储单元44中的回归模型的参数来预测(估计)除主小区13之外的预定基站13的拥塞度。
输入单元46将用于预测除主小区13之外的预定基站13的拥塞度的条件输入到预测单元45。例如,输入单元46允许用户指定(输入)要预测什么时间和哪个基站13的拥塞度,并且将用于标识所指定的基站13的信息和时间输入到预测单元45。另外,例如,在预测用户的移动路线和目的地并且使用移动路线和目的地来预测要连接的基站13的情况下,输入单元46等同于用于预测用户的移动路线和目的地的块,并且将用于标识位于使用该块所预测的移动路线和目的地周围的基站13的信息提供到预测单元45。这里,作为输入到预测单元45的、用于标识基站13的信息,可以以用于标识基站13的ID为例。
显示单元47例如由LCD(液晶显示器)、有机EL显示器等构成,并且显示预测单元45的预测结果。
服务器12包括拥塞度数据获取单元61、数据预处理单元62、回归模型学习单元63和参数发送单元64。
拥塞度数据获取单元61获取(接收)从多个便携式终端11中的每个在预定定时向其发送的拥塞度数据,并且将拥塞度数据提供到数据预处理单元62。
数据预处理单元62对由大量便携式终端11获取的拥塞度数据项执行预定的预处理,使得它们成为适合于回归模型学习单元63进行学习的数据,然后数据预处理单元62将处理后的数据提供到回归模型学习单元63。例如,作为预处理,数据预处理单元62合并由大量便携式终端11获取的拥塞度数据项,以及按时间序列顺序并且针对每个基站ID对合并后的拥塞度数据项执行重排序。通过使用数据预处理单元62合并由大量便携式终端11获取的拥塞度数据项,可以缓解拥有便携式终端11的用户的隐私问题。
回归模型学习单元63使用预定回归模型,基于由大量便携式终端11收集的拥塞度数据项来学习每个基站13的拥塞度,并且生成模型参数作为学习结果。作为用于学习拥塞度数据的回归模型,采用支持向量模型或关系向量回归模型。以预定定时(例如,每天一次)执行学习处理,并且基于直到该时间点为止所累积的用于学习的数据项来更新回归模型(的参数)。在学习处理中,直到该时间点为止已累积的所有数据项可用于执行再学习,或者仅新累积的用于学习的数据项可用来额外地进行学习。回归模型学习单元63被描述为使用以下的支持向量回归模型进行学习的单元,并且随后,稍后描述关系向量回归模型。
当连接便携式终端11以发送拥塞度数据时,参数发送单元64将学习模型的更新后的模型参数发送到便携式终端11。此外,也可在与拥塞度数据的接收不同的定时执行更新之后的新模型参数的发送。
便携式终端11和服务器12如上所述配置。将进一步分别描述由便携式终端11和服务器12执行的处理的细节。
拥塞度数据的示例
图3示出由便携式终端11获取的并且累积在拥塞度数据累积单元42中的拥塞度数据的示例。
如图3所示,拥塞度数据是获取(计算)拥塞度的日期和时间、主小区13的基站ID和拥塞度的数据集合。
日期和时间从便携式终端11的系统时钟获取。除了日期和时间之外,拥塞度数据还可包括诸如周几以及这一天是工作日还是非工作日(包括国家法定节假日)的信息作为数据项。替选地,还可包括诸如以下的信息:气象信息(温度、湿度、降雨量、降雪量等)、周围环境的状况(亮度、噪声等)或由事件生成的信息。另外,基站ID是用于标识基站13的ID。基站ID是用于估计当前位置的区域的信息。取代基站ID,也可将扰码用作标识数据,或者基站ID和扰码均可被存储作为基站13的标识数据。在智能电话应用等中,提供API,使得可获取主小区13的基站ID。
拥塞度表示主小区13的通信线路的拥塞度。例如,在码分多址(CDMA)方法中,当多路复用的DPCH(专用物理信道)的数量(换言之,与主小区13相关联的用户的数量)或者由多个用户以HSDPA(高速下行链路分组接入)共享的高速下行链路共享信道的数量(HS-DSCH的数量)增加时,每个DPCH或每个HS-DSCH被扩散,然而每个扰码的关联输出显著增加。因此,当最大的扰码关联输出是a并且其它扰码关联输出当中的最小关联输出是b时,认为关联输出b/关联输出a随着用户数量增加和可用容量减小而增加,或者随着干扰增加而增加。因此,拥塞度获取单元41可以使用关联输出a和关联输出b的比率b/a作为拥塞度(指示拥塞度的指标)。此外,计算拥塞度的方法不限于上述示例,并且可根据诸如通信方法的预定条件来适当地确定。
图4是示出以15秒为间隔、在预定时段(大约两个月)内测量特定基站13的拥塞度的数据的图,其中,每天的数据项置于便携式终端11上。该数据通过使用便携式终端11测量一个基站13的拥塞度而获得,然而,即使在由数据预处理单元62对由多个便携式终端11获取的拥塞度进行合并并且对与一个特定基站13相关的拥塞度数据项进行聚合的情况下,也可以获得与图4所示的数据类似的数据。
图4的水平轴表示一天期间的时间(从0:00至24:00),并且垂直轴示出了拥塞度。所表示的是,拥塞度的值越大,越拥塞。
根据图4的拥塞度数据,大致可识别两种状态,即,拥塞度在“0.3”附近的“拥塞状态”和拥塞度在“0.1”附近的“非拥塞状态”。在图4中,认为观察到“拥塞状态”和“非拥塞状态”这两种状态的概率随着时间而改变。预测单元45仅能够预测观察到“拥塞状态”和“非拥塞状态”这两种状态的概率。然而,在图4的状态下,难以直接确定这两种状态的观测概率之间的转变。
图5示出作为图4所示的拥塞度数据前后20分钟的总共40分钟的数据的移动平均值而计算的平均拥塞度数据。
当数据被描绘为如图5中的平均拥塞度时,与图4相比,更容易识别随时间的转变。例如,从大约0:00至8:00的平均拥塞度每天呈现出类似的趋势。同时,从8:00到24:00的平均拥塞度存在两种主要的转变模式。由于获取该数据的基站13的位置是商业区,因此从8:00到24:00的拥塞度的趋势高的数据是工作日的数据,而在该时段的拥塞度的趋势低的数据被预期为非工作日的数据。
因此,例如,在图5所示的数据获取时段中,当根据与11月相关的日期对平均拥塞度进行分类时,这可被表示为如图6所示。
图6中的粗线框示出作为周六、周日和国家法定节假日(11月的第三天和11月的第23天)的日子的平均拥塞度。根据图6,可理解,周末和国家法定节假日的平均拥塞度呈现出与工作日的平均拥塞度不同的趋势。换言之,在图5中,发现在从8:00至24:00的平均拥塞度中所观察到的两种转变模式是工作日与非工作日之间的差别。
根据以上内容,理解拥塞度的趋势在工作日和非工作日是不同的。因此,例如,作为学习模型,可以考虑将数据项划分为工作日和非工作日,并且对数据进行学习(获得参数)。这里,当作为学习模型预测拥塞度时,要使用的模型根据是工作日还是非工作日而改变。
然而,关于通过以此方式基于一些条件逐情况地划分数据项来进行学习,存在一些问题。例如,不确定拥塞度的模式实际上是否仅由是工作日还是非工作日而引起的,并且存在具有不同原因的各种模式存在的可能性。换言之,需要在完全理解所收集的数据的趋势之后执行建模,并且当存在大量要顾及的情况时,要执行的算术处理变得极大。
换言之,如下学习模型是优选的:在该学习模型中,可以输入被认为是必要的条件(诸如周几、非工作日和工作日),并且可以使用一个学习模型来执行学习。作为这样的学习模型,在本实施例中,采用支持向量回归模型,支持向量回归模型是一种内核回归模型。支持向量回归模型可被典型化为:与一般内核回归模型相比,其可以减少参数的数量。以此方式,可减少在参数的发送和接收期间便携式终端11与服务器12之间的通信容量以及便携式终端11的参数存储单元44的存储容量。
支持向量回归模型
以下描述支持向量回归模型。
支持向量回归是一种回归分析:在该回归分析中,对于线性基础的加权参数,使用对成本函数进行优化的参数。作为成本函数,在普通回归模型中通常使用平方误差,然而,在支持向量回归中,使用如图7所示的ε可允许误差函数。
在C.M.Bishop,Springer出版的"Pattern Recognition and MachineLearning"(最后一卷)中详细描述了支持向量回归。
在支持向量回归模型中,关于输入解释变量x,以下面的表达式(1)来表示输出标准变量y(x)。
换言之,标准变量y(x)由M个基础函数φm(x)(m=1,...,M)与加权因子wm的乘积之和来表示。此外,这里,M与数据项数量N没有明确的幅值关系。这里,例如,使用以预定参数的正态分布为基础的高斯基础来提供基础函数φm(x)。表达式(1)中的b是偏置项,并且通过学习获得的参数是表达式(1)的加权因子wm。
在本实施例中,表达式(1)的标准变量y(x)是拥塞度,而图3所示的“日期”、“时间”和“基站ID”是解释变量x。
因此,解释变量x是D维(D≥1)数据,并且当要区分第m个基础函数φm(x)的D维数据时,解释变量x被表示为xm,1:D={xm,1,xm,2,...,xm,D-1,xm,D}(1:D是从1至D中的任一个的缩写)。例如当x是“时间”、“周几”、“工作日或非工作日”以及“基站ID”的集合的拥塞度数据时,则x是4维数据。“时间”信息例如是可使用小数点表示分钟和秒的每小时显示。“周几”信息可通过为一周的每天分配从1至7的数字来表示。“工作日或非工作日”信息例如可通过为工作日分配“0”并且为非工作日分配“1”来表示。
如果存在可输入的任意其它信息,则解释变量x的维数D可以进一步扩大。例如,如果诸如温度、湿度、阳光、降雨量、降雪量、风向和风速的气象状况与拥塞度相关,则可输入诸如此类的气象信息。另外,还可输入被认为与用户移动时的位置相关的交通状况。然而,当输入没有关联的信息作为解释变量x时,存在预测准确度劣化的情况。因此,期望将解释变量x仅设置为预期与标准变量y(x)具有关联的信息。
在服务器12的回归模型学习单元63中,获得上述表达式(1)的加权因子wm作为回归模型的参数。
加权因子wm被获得为如下因子:当传递学习数据集合和基础函数φ时,该因子使下面的误差函数E(w)最小化,其中学习数据集合是解释变量x和标准变量y(x)的观察值t的集合。误差函数E(w)被表示为跨越整个学习数据集合的观察值tn与标准变量y(xn)之间的偏差(y(xn)-tn)的成本函数Ec(y(xn)-tn)之和,其中标准变量y(xn)是根据学习数据集合的解释变量x预测的。
然而,还存在如下情况:其中,当使得误差函数E(w)最小化的加权因子wm是极大值时,与学习数据集合有关的误差函数E(w)减小。然而,在误差函数E(w)由于加权因子wm是极大值而减小的情况下,与未知数据有关的预测性能不好。这样的情形通常称为“过学习(overfitting)”或“非泛化(not generalized)”。
因此,为了避免获得这样的非泛化的加权因子wm,通过使得具有约束(即,关于表达式(2)所应用的正则化)的误差函数E(w)最小化来获得加权因子wm。
表达式(2)的正则化的方法是将加权因子wm的平方和与误差函数相加的方法。平方和往往易于计算,这是采用这样的方法的原因。另外,与成本函数Ec(y(xn)-tn)的和相乘的C(>0)是用于确定正则化的强度的常数。
在支持向量回归中所使用的表达式(2)的成本函数Ec(y(xn)-tn)引入了可允许误差ε,并且当标准变量y(xn)与观察值tn之间的差的绝对值|y(xn)-tn|小于可允许误差ε时由0表示,并且当观察值tn大于可允许误差ε时,由线性成本上升的ε可允许误差函数来表示。
以下表达式(3)是ε可允许误差函数的定义等式,并且图7示出了由表达式(3)表示的ε可允许误差函数Ec(y(xn)-tn)。

当为了处理表达式(3)的绝对值而引入松弛变量ξ和ξ~时(ξ>0,ξ~>0),这可如下表示。
因此,表达式(2)可如下表示。
因此,表达式(2’)成为用于进行最小化的误差函数E(w)。
根据以上内容,回归模型学习单元63执行加权因子wm的获得,该加权因子wm在表达式(4)的约束条件(ξ,ξ~>0)下使得表达式(2’)的误差函数E(w)最小化。回归模型学习单元63使用未定乘数的拉格朗日方法以解决最小化问题。
当使用拉格朗日未定乘数μ、μ~、a、a~时,在表达式(4)的约束条件(ξ,ξ~>0)下的表达式(2’)可被写为表达式(5)。
表达式(5)的第三项对应于ξ,ξ~>0约束,并且第四项和第五项对应于表达式(4)的约束。
当将w,b,ξ,ξ~的偏微分设定为零以使表达式(5)的拉格朗日函数最小化时,当消去这些变量时,最终,未定变量仅仅是拉格朗日未定乘数a和a~,并且表达式(5)使得作为其对偶函数的以下函数(表达式(3’))最小化。
然而,表达式(5)的k(xn,xm)是可使用基础函数向量φ(x)如下地表示的内核函数,其中,基础函数的所有元素垂直地布置,其中k(xn,xm)=k(x,y)。
k(x,y)=φ(X)Tφ(y) (6)
φ(x)T表示φ(x)的转置。
如果基础函数向量φ是已知的,则表达式(6)的内核函数k(x,y)是清楚定义的,然而,即使基础函数向量φ未确定,例如,也可以如表达式(7)中一样来定义内核函数k(x,y)。
表达式(7)的内核函数k(x,y)已知为高斯内核,并且D是输入的解释变量x的维数。对于σ,例如,可按原样使用输入的解释变量x的标准偏差。
当使用表达式(7)的内核函数k(x,y)时,表达式(1)可被重写为以下表达式(8)。
这里,表达式(8)的偏置项b可通过使用以下表达式等预先进行计算来提供。
此外,当以这样的方式使用内核符号时,通过将表达式(1)的M设定为数据项数量N,这变成表达式(1)的等效表达式。
以此方式,取代获得表达式(1)的加权因子wm,支持向量回归返回到获得表达式(8)的参数(拉格朗日未定乘数)an和an ~。
这里,作为获得表达式(8)的参数an和an ~的方法,给出了以下方法的描述:(1)使用联立方程来求解参数的方法;以及(2)使用梯度方法来求解参数的方法。
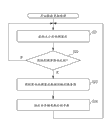
使用联立方程的参数计算处理
图8是示出用于使用联立方程获得回归模型的参数an和an ~的参数计算处理的流程图。
首先,在步骤S1中,回归模型学习单元63使用预定方法确定参数an和an ~(n=1,...,N)的初始值。
在步骤S2中,回归模型学习单元63将学习数据集合的每个拥塞度数据项代入表达式(8),并且计算预测值yi=y(xi)。
在步骤S3中,回归模型学习单元63将标准变量ti比预测值yi大出多于可允许误差ε的拥塞度数据项(换言之,满足(ti-yi)>ε的数据项)设定为组A。另外,回归模型学习单元63将标准变量ti比预测值yi大出少于可允许误差ε的拥塞度数据项(换言之,满足(ti-yi)<ε的数据项)设定为组B。
在步骤S4中,回归模型学习单元63在基于拥塞度数据项属于组A还是组B来分离表达式的同时构成联立方程,并且求解参数ak和ak ~(k=1,...,N)。
换言之,以下表达式(10-1)对于属于组A的拥塞度数据项是有效的,并且以下表达式(10-2)对于属于组B的拥塞度数据项是有效的。因此,回归模型学习单元63构成如下联立方程:其中,基于拥塞度数据项属于组A还是组B而将拥塞度数据项代入表达式(10-1)或表达式(10-2),并且求解参数ak和ak ~(k=1,...,N)。
这里,vk=ak-ak ~。此外,当拥塞度数据项不属于组A或组B时,vk是零(vk=0)并且加和(∑)项被省略。
在步骤S5中,回归模型学习单元63根据通过求解联立方程而获得的vk来确定参数ak和ak ~。换言之,对于属于组A的vk项,参数ak和ak ~是由表达式(11-1)确定的,而对于属于组B的vk项,参数ak和ak ~是由表达式(11-2)确定的。
在步骤S6中,回归模型学习单元63确定所确定的参数ak和ak ~是否满足以下约束。
0≤ak≤C
在步骤S6中,在确定所确定的参数ak和ak ~不满足约束的情况下,处理返回到步骤S2,并且重复从此开始的处理。换言之,使用所确定的参数ak和ak ~再次执行步骤S2至S6的处理。
同时,在步骤S6中,在确定所确定的参数ak和ak ~满足约束的情况下,处理结束。
使用梯度方法的参数计算处理
图9是示出用于使用梯度方法来获得回归模型的参数an和an ~的参数计算处理的流程图。
在该处理中,首先,在步骤S11中,回归模型学习单元63使用预定方法来确定参数an和an ~(n=1,...,N)的初始值。
在步骤S12中,回归模型学习单元63将an和an ~代入以下表达式(12)并更新参数an和an ~,并且获取更新之后的参数an'和an'~。
在步骤S13中,回归模型学习单元63确定参数an和an ~的更新是否已重复了预定次数。
在步骤S13中,在回归模型学习单元63确定参数an和an ~的更新尚未重复预定次数的情况下,处理返回到步骤S12并且重复参数an和an ~的更新。
同时,在步骤S13中,在确定参数an和an ~的更新已重复了预定次数的情况下,回归模型学习单元63结束处理。
此外,取代参数更新的重复次数,步骤S13的结束条件也可通过由参数an和an ~的更新所引起的表达式(3’)的拉格朗日函数的改变是否为预定阈值(收敛宽度)或更小来确定。
图10示出使用任意上述方法计算出的支持向量回归模型的参数an和an ~的示例。
图10所示的参数an和an ~作为回归模型的学习结果而存储在回归模型学习单元63中。此外,由于参数an和an ~对应于解释变量xn,1:D,因此参数an和an ~被存储为解释变量xn,1:D和标准变量tn的集合。
此外,当将回归模型的参数存储到回归模型学习单元63时,在参数an和an ~当中,可以省略an和an ~均为零的参数。支持向量回归可典型化为:出现大量an和an ~均为零的参数,并且可以通过采用支持向量回归模型作为学习模型来减小存储容量。
数据更新处理的描述
参照图11的流程图,给出数据更新处理的描述,在数据更新处理中,便携式终端11执行主小区13的拥塞度的获取、以及支持向量回归模型的参数更新。
首先,在步骤S21中,便携式终端11的拥塞度获取单元41获取(计算)主小区13的拥塞度。可以以预定的固定间隔来获取主小区13的拥塞度,并且例如,也可以不定期地(诸如当用户执行用于测量拥塞度的命令时)获取主小区13的拥塞度。拥塞度获取单元41所获取的拥塞度被提供到拥塞度数据累积单元42,并且连同解释变量“时间”、“周几”、“工作日或非工作日”以及“基站ID”一起被累积。
在步骤S22中,服务器通信单元43确定是否是连接到服务器12的定时。在便携式终端11中,发送拥塞度数据累积单元42中所累积的拥塞度数据的定时是预定的(诸如每天一次),并且服务器通信单元43确定是否是该定时(所设置的时间)。
在步骤S22中,在确定不是连接到服务器12的定时的情况下,处理返回到步骤S21。同时,在步骤S22中确定是连接到服务器12的定时的情况下,处理进行到步骤S23。
在步骤S23中,服务器通信单元43将在拥塞度数据累积单元42中累积的拥塞度数据发送到服务器12。
在步骤S24中,服务器通信单元43从服务器12接收支持向量回归模型的更新参数an和an ~及其解释变量xk,并且将它们存储在参数存储单元44中(n=1,...,N)。在尚未更新参数an和an ~的情况下,跳过步骤S24的处理。
当更新后的参数an和an ~及其解释变量xk被存储在参数存储单元44中时,处理返回到步骤S21并且再次执行从此开始的处理。因此,获取主小区13的拥塞度直至关断便携式终端11的电源为止,并且累积拥塞度数据。
预测处理的描述
图12是描述使用由便携式终端11获取的支持向量回归模型的参数来预测除主小区13之外的预定基站13的拥塞度的预测处理的流程图。
首先,在步骤S41中,便携式终端11的输入单元46允许用户指定预测拥塞度的时间和基站13,并且将所指定的时间和基站13输入到预测单元45。
在步骤S42中,预测单元45使用存储在参数存储单元44中的支持向量回归模型的参数,预测(估计)由用户指定的时间和基站13的拥塞度。
在步骤S43中,预测单元45将预测结果提供到显示单元47并且使得显示单元47显示预测结果。显示单元47显示从预测单元45提供的预测结果并且结束处理。
此外,一般地,用户不知道基站13的位置和基站ID。因此,基站ID和与其覆盖区域对应的基站ID表存储在便携式终端11的内部存储器中,允许用户输入他们想要预测拥塞度的位置(地址)、地名等,并且输入单元46或预测单元45可基于所存储的基站ID表将输入的位置或地名转换成基站ID。
学习处理的描述
接下来,参照图13的流程图描述服务器12学习(更新)支持向量回归模型的参数的学习处理。
首先,在步骤S61中,拥塞度数据获取单元61从每个便携式终端11获取(接收)以预定定时向其传送的拥塞度数据,并且将该拥塞度数据提供到数据预处理单元62。
在步骤S62中,数据预处理单元62合并由每个便携式终端11获取的拥塞度数据项,并且在步骤S63中,按时间序列顺序对合并的拥塞度数据项执行重排序。
此外,在步骤S64中,数据预处理单元62确定是否获得每个基站的支持向量回归模型的参数。例如,使用设置文件预先设定是否获得每个基站的支持向量回归模型的参数。
在步骤S64中,在确定要获得每个基站的参数的情况下,处理进行到步骤S65,并且数据预处理单元62根据基站对已按时间序列顺序重排序后的拥塞度数据进行分类。换言之,数据预处理单元62根据基站ID对已按时间序列顺序重排序后的拥塞度数据进行分类。
此外,在步骤S66中,数据预处理单元62关于每个基站的按时间序列顺序布置的拥塞度数据计算预定持续时间内的拥塞度的移动平均值,并且计算移动平均拥塞度(换言之,平均拥塞度)。将拥塞度数据从数据预处理单元62提供到回归模型学习单元63作为用于学习的新数据,其中,在拥塞度数据中,用平均拥塞度取代拥塞度项(的值)。
在步骤S67中,回归模型学习单元63使用参照图8或图9描述的方法来获得每个基站的支持向量回归模型的参数。换言之,回归模型学习单元63使用从数据预处理单元62提供的用于学习的新数据和至此所累积的用于学习的全部数据作为学习数据集合,来获得用于估计每个基站的拥塞度的支持向量回归模型的参数。
同时,在步骤S64中,在确定要使用用于学习的全部数据来获得支持向量回归模型的参数的情况下,处理进行到步骤S68,并且数据预处理单元62根据基站对已按时间序列顺序重排序后的拥塞度数据进行分类。此外,在步骤S69中,数据预处理单元62关于每个基站的按时间序列顺序布置的拥塞度数据计算预定持续时间内的拥塞度的移动平均值,并且计算平均拥塞度。
此外,在步骤S70中,数据预处理单元62再次针对每个基站将以平均拥塞度替换了拥塞度项(的值)的拥塞度数据与按时间序列顺序布置的拥塞度数据进行合并。
在步骤S71中,回归模型学习单元63使用参照图8或图9所述的方法,以用于学习的新数据和至此的用于学习的数据作为学习数据集合来获得支持向量回归模型的参数。
在步骤S72中,回归模型学习单元63压缩使用学习所获得的支持向量回归模型的参数。例如,如图10所示,在支持向量回归模型的参数中出现大量an和an ~均为零的参数。因此,可以通过移除an和an ~均为零的项并且将an和an ~均不为零的参数作为发送对象来压缩参数。另外,在获得每个基站的参数的情况下,可以通过仅收集用户所使用的基站的参数来压缩参数。
在步骤S73中,参数发送单元64将更新后的参数发送到便携式终端11并且结束处理。
此外,在图13中,将拥塞度数据的接收(步骤S61)、数据预处理和参数学习(步骤S62至S72)以及参数的发送(步骤S73)描述为一系列处理。然而,由于拥塞度数据的接收和参数的发送依赖于便携式终端11进行连接的定时,因此它们实际上是在分开的定时执行的。
在图13的处理中,使得可以选择是获得每个基站的支持向量回归模型的参数,还是获得用于学习的全部数据的参数,然而,也可以仅执行其中的一个或另一个。在仅作为用于学习的全部数据来获得参数的情况下,可以省略作为用于学习的数据而累积的拥塞度数据的项“基站ID”。
另外,可以通过使得便携式终端11或服务器12中的至少之一存储其中存储有每个基站的基站ID和坐标(位置)的表,累积拥塞度数据的解释变量项“基站ID”作为基站的坐标。使用“基站ID”,基站彼此之间的接近程度(距离)不明显,然而,通过使用基站的坐标,可以发现基站彼此之间的接近程度(距离)。因此,例如,在用于估计基站13-4的拥塞度的估计结果是“拥塞”的情况下,接下来,可以进行用于估计相邻的基站13-3或13-5的拥塞度的处理。
预测结果的示例
参照图14至图16给出用于使用支持向量回归模型预测拥塞度的预测结果的描述。
图14和图15分别是将实际测量一天的拥塞度的测量值(真实)与使用支持向量回归模型所预测的预测值(预测)进行叠加和比较的图。图14示出工作日周五的一天的数据,并且图15示出非工作日周日的一天的数据。此外,{“时间”、“周几”、“工作日或非工作日”}包括在支持向量回归模型的解释变量x中。
如根据图14和图15的测量值的比较可以理解,工作日与非工作日之间的拥塞度的模式(趋势)不同,然而,即使当拥塞度的模式以这样的方式不同时,也可以理解通过学习而获得的支持向量回归模型是测量值的良好表示。换言之,预测值是工作日和非工作日的测量值的良好表示。
图16是关于图14的工作日以一小时为单位来计算预测值与测量值的一致度的图。
在图16中,预测值与测量值之间的一致度是通过将测量值与预测值之间的差的最小值除以测量值与预测值之间的差的最大值而获得的值。换言之,一致度被设置为:一致度=MIN(测量值,预测值)/MAX(测量值,预测值)。根据该计算方法,如果测量值与预测值匹配,则一致度是100%,并且当测量值大于预测值时以及当测量值小于预测值时,一致度小于100%。因此,在以一小时为单位、以一天为单位、以一个月为单位等来取平均值的情况下,即使预测值与测量值之间的误差的正负不同,值也不会相互抵消,并且可以评估一致性。
关于图14的工作日,作为一致度的平均值的重叠(overlap)是如图14所示的94.6%,并且作为三个月内的一致度的平均值的累积(accum)是如图14所示的90%。
关于图15的非工作日,作为一致度的平均值的重叠(overlap)是如图15所示的91.6%,并且作为三个月内的一致度的平均值的累积(accum)是如图15所示的90%。
以此方式,即使在工作日和非工作日的拥塞度的模式(趋势)不同的情况下,也可认为支持向量回归模型以良好的准确度来预测拥塞度。
关系向量回归模型
接下来,以下描述关系向量回归模型。
支持向量回归模型可被典型化为:出现大量an和an ~均为零的参数,并且可以减少参数的存储容量。与支持向量回归模型相比,如下所述的关系向量回归模型使得可以更多地减少参数的数量。
在关系向量回归模型中,可使用以下表达式(13)来表示以与支持向量回归相同的方式使标准变量y关于解释变量x回归的表达式。
这里,k(x,xn)是内核函数,并且由表达式(7)来提供。另外,b是偏置项,并且由表达式(9)来提供。以与支持向量回归的情况相同的方式,解释变量x是信息“时间”、“周几”、“工作日或非工作日”以及“基站ID”,而标准变量y(x)是拥塞度。
在支持向量回归中,如上所述,施加约束(即,正则化)来避免加权因子wm变为极大值。相比之下,在关系向量回归中,通过加权因子wm的先前分布来做出加权因子wm是小值的假设,以避免加权因子wm变为极大值。因此,需要统计地处理加权因子wm。
首先,考虑在提供加权因子向量w和解释变量X时出现标准变量t的似然性。学习数据集合的似然性p(t|X,w,β)由以下表达式(14)来提供。
表达式(14)的左侧的X是矩阵,其中布置了学习数据集合当中的D维向量的N行解释变量x。表达式的左侧的w是加权因子wm的向量。β是正的实数,而t是标准变量y(x)的实际值(测量值)。表达式(14)的右侧是这样的表达式,其中假设将根据以预测值y(x)为中心的、对于每个拥塞度数据项独立的、具有相同分散(distribution)的常规分布来生成学习数据集合的实际值t。N(tn|y(Xn,w),β-1)是常规分布。y(Xn,w)是使用表达式(13)来计算的。tn是标准变量。另外,β-1是常规分布噪声的分散(distribution)的倒数。
加权因子wm的值将不会变大的假设被加入到以下的先前分布中。
在表达式(15)中,通过假设加权因子wm是以0为中心、以分散αn -1常规地分布的值,加权因子wm是小值的假设被加入。
使用以上似然性和先前分布,可以表示加权因子向量w的随后分布和常规分布,并且将其表示为如表达式(16)一样。
p(w|t,X,α,β)=N(w|m,Σ) (16)
表达式(16)的加权因子向量w的平均值m和分散Σ由使用学习数据集合以及α和β的以下表达式来提供。
m=βΣφTt
Σ=(diag(α1…αM)+βφTφ)-1 (17)
这里,Φ是内核,Φnm=k(xn,xm)。
因此,如果确定了参数α和β,则加权因子向量w由所提供的学习数据集合和内核Φ(Φnm=k(xn,xm))来毫无疑义地确定。
因此,最终,考虑获得参数α和β。通过关于加权因子向量w对表达式(14)和表达式(15)执行边缘化来获得参数α和β的似然性。
p(t|X,α,β)=∫p(t|X,w,β)p(w|α)dw (18)
参数α和β的值是使用最大似然估计来获得的,然而,由于无法直接获得使表达式(18)的似然性最大化的α和β,因此通过执行诸如以下的序列估计来获得α和β。
表达式(19)的m和Σ是上述表达式(17)的m和Σ。通过重复地执行序列估计直至似然性的改变满足预定收敛条件为止来获得参数α和β的值。
当使用以上述方式使用所获得的α和β时,可如表达式(17)中一样获得加权因子向量w的中心值和分散值。最终,通过用中心值替换加权因子向量w的值,可以执行表达式(13)的回归。
用于获得关系向量回归的参数α和β的值的学习处理与上述图13的处理相同。
图17是关系向量回归的图形模型。
图17的图形模型表示:在关系向量回归中,加权因子wi(i=1,...,K)是随机变量,并且取决于参数αi(i=1,...,K)来确定。另外,图形模型表示:标准变量y(x)的测量值tn(n=1,...,N)由加权因子wi、噪声β、预定基础函数向量φ(未示出)和解释变量x的组合来确定。如前所述,内核函数k(x,xn)也可用作基础函数φ。在这种情况下,K=N。此外,通过经由最大似然性估计来获得α和β,获得加权因子wi的平均值mi和分散Σi,并且使用加权因子wi的平均值mi来获得关于解释变量x的测量值t的预测值y(x)。
在“Uncertainty in artificial intelligence proceedings2000”中由C.M.Bishop和M.E.Tipping发表的“Variation Relevance Vector Machines”等中详细描述了关系向量回归的图形模型。
图18示出通过学习而获得的关系向量回归模型的参数m和Σ的示例。
在关系向量回归模型中,取代表达式(1)的加权因子wm,将表达式(13)的加权因子wn的平均值mn和分散Σn存储在回归模型学习单元63中作为参数。此外,当期望知道预测的范围等的准确度时,需要加权因子wn的分散Σn,并且如上所述,如果仅获得关于解释变量x的测量值t的预测值y(x),则可省略加权因子wn的分散Σn。在图18中,以与图10所示的支持向量回归的情况相同的方式将解释变量xn,1:D和标准变量tn存储为集合。
根据图18,对于关系向量回归模型的参数,需要(3+D)×N个参数,即平均值mn、分散Σn、解释变量xn,1:D(D维)和标准变量tn。然而,在关系向量回归模型中,应理解,在上述参数αn当中存在大量被估计为具有极大值的参数,并且在被估计为具有大值的αn中,平均值mn和分散Σn为零。因此,通过省略与被估计为具有大值的αn对应的平均值mn和分散Σn,可以大大减少关系向量回归模型的参数的数量。
预测结果的示例
图19示出通过使用关系向量回归模型预测拥塞度而获得的预测结果。
图19是以与支持向量回归模型的情况下的图14和图15相同的方式、对使用关系向量回归模型所预测的预测值(预测)和一天的拥塞度的测量值(真实)进行叠加和比较的图。
关于图19的工作日,作为一致度的平均值的重叠(overlap)是如图19所示的94.8%,并且作为三个月内的一致度的平均值的累积(accum)是如图19所示的88%。
支持向量回归模型和关系向量回归模型的比较示例
图20示出通过比较支持向量回归模型和关系向量回归模型的预测性能而获得的比较结果的示例。
图20示出以水平轴为日期并且以垂直轴为重叠,从第一天到第35天测量的支持向量回归模型和关系向量回归模型的各个重叠。在图20中,黑色实心圆的折线示出了支持向量回归模型(SVR)的重叠,而白色实心圆的折线示出了关系向量回归模型的重叠。
根据图20,在开始测量之后,可以看出关系向量回归模型的重叠大致在第七天开始稳定。在支持向量回归模型和关系向量回归模型中,关系向量回归模型的性能稍差,然而,从第10天开始往后,差小于2%,这可以被认为是大致无差别。因此,尽管取决于是否允许小于2%的值,但是在大量应用中,使用关系向量回归模型被认为是足够的。
图21将支持向量回归模型与关系向量回归模型的非零加权数据项的数量进行比较。
图21示出学习数据集合的数量、支持向量回归中加权不为零的数据项的数量以及关系向量回归中权重不为零的数据项的数量的历史。
在图21中,水平轴表示天数,并且示出了从第一天至第35天。另外,垂直轴示出数据项的数量。此外,第35天的数据项的数量越过了边缘,并且存在大约3000个学习数据集合、大约2200个支持向量回归模型以及大约60个关系向量回归模型。
参照图21,在于35天内收集的3000个学习数据集合当中,在支持向量回归模型中,需要存储2200个数据项,然而,在关系向量回归模型中,存储60个数据项就足够了。另外,关系向量回归模型的数据项的数量从第10天往后很少改变。以此方式,即使学习数据集合增加,关系向量回归模型所需的数据项的数量也极低。因此,使用关系向量回归模型来建模适合于将学习数据集合发送到便携式终端11,并且适合于使用具有较少计算资源的便携式终端11来执行预测处理。
在关系向量回归模型中,还可以估计所需要的数据大小。
当要收集的拥塞度数据项的数量是N时,根据解释变量D(维数)×N和标准变量1×N,所需的学习数据集合的数据项的数量大约是(D+1)×N。以下,在D是“时间”、“周几”、“工作日或非工作日”的情况下,D=3。
当对于一个基站来说一天的拥塞度数据项的数量在24小时内是每小时10个(6分钟间隔)时,每天的拥塞度数据项的数量是24×10=240。当在一个月内(30天)以这些条件收集数据时,拥塞度数据项的总数量N是240×30=7200。因此,学习数据集合的数据项的数量是(D+1)×N=(3+1)×7200=28800。当学习数据集合的所有数据的每项以双精度(4字节)的数据格式来存储时,所需的数据大小是28800×4B=115.2kB。换言之,每个基站每个月需要大约100kB。
相比之下,在使用关系向量回归模型执行学习并且使用模型参数的情况下,根据图21的结果,要存储的拥塞度数据项的总数量N是60/3000=1/50,因此7200/50=144项就足够了。此外,每个拥塞度数据项所需要的参数的数量是解释变量D=3、标准变量1和加权平均值1,该数量是D+2,因此要存储144×5=720个数据项。因此,所需的数据大小是720×4B=2.9kB。因此,根据关系向量回归模型,可以将大约100kB的数据量压缩为大约2.9kB。此外,例如,即使要收集1000个基站的数据,在关系向量回归模型中,使用2.9MB的数据库就可以进行预测。
应用示例
周围基站信息应用
在以上描述中,给出了如下示例的描述:在便携式终端11中,用户指定其希望知道拥塞度的基站13,并且预测单元45使用回归模型预测并输出所指定的基站13的拥塞度。
然而,指标“拥塞度”对用户来说不易理解。另外,当主小区13的拥塞度高时,如果可以给出替换基站13,则对用户来说将是方便的。
因此,可考虑如下应用:取代呈现主小区13的指标“拥塞度”,该应用呈现“通信速率”,并且呈现主小区13的周围基站13的“通信速率”和与覆盖区域的距离(或者,直至执行了切换并且基站13变成主小区13为止所预期的距离)。
图22示出使用这样的应用在便携式终端11的显示单元47上显示的预测结果画面的示例。
在图22中,“当前位置”表示用户的便携式终端11的当前位置,并且由[A1,4Mbps]表示的基站13是与当前位置对应的主小区13。[A1,4Mbps]是电信载波A的基站13,并且示出了当前通信速率是4Mbps。
作为与便携式终端11的当前位置相关的、除主小区13之外的基站13,存在三个基站13[B2,10MbpsNW400m]、[B1,2MbpsSW100m]和[A2,13MbpsSE300m]。
由[B2,10MbpsNW400m]表示的基站13是电信载波B的基站13,与其覆盖区域的距离是西北方(NW)400m,并且通信速率是10Mbps。由[B1,2MbpsSW100m]表示的基站13是电信载波B的基站13,与其覆盖区域的距离是西南方(SW)100m,并且通信速率是2Mbps。另外,由[A2,13MbpsSE300m]表示的基站13是电信载波A的基站13,与其覆盖区域的距离是东南方(SE)300m,并且通信速率是13Mbps。
例如可通过保持用于存储每个基站13的周围基站13的表来识别相对于主小区13的周围基站13。另外,在根据坐标(位置)而不是根据基站ID来存储每个基站的情况下,可使用其位置信息。另外,可以通过使用基站13的拥塞度、导频信号的SIR(信号与干扰比)和扩散系数等来估计通信速率。在上述日本未审查专利申请公布第2012-9987号中公开了通信速率的计算方法。
如上所述,根据应用,可以预测和显示通信速率将取决于用户移动的路径和距离而改变的程度。另外,可以基于预测结果来执行诸如在基站13或电信运营商之间进行切换的控制。
此外,提供诸如基站13的通信速率和覆盖区域的信息的方法不限于图22的在地图上显示信息的方法,并且可任意使用仅列出信息的方法、或者使用音频引导来提供信息的方法。另外,这样的应用也可被嵌入为另一应用的一部分。
与移动预测函数链接的应用
以下给出了其它应用示例的描述。
在日本未审查专利申请公布第2011-059924号、日本未审查专利申请公布第2011-252884号等中,本申请人提出了基于通过使用预定学习模型学习用户的移动路线和目的地而获得的学习结果来预测用户的移动路线和目的地的技术。通过将该移动预测功能与在本说明书中提出的关于预定时间和位置的拥塞度预测功能链接起来,可以实现如下应用:该应用使用所预测的移动路线和目的地来预测可连接的基站13的拥塞度,并且适当地选择主小区13。
在日本未审查专利申请公布第2011-059924号、日本未审查专利申请公布第2011-252884号等中所提出的移动预测功能中,采用隐马尔可夫模型作为学习模型来学习用户的移动路线和目的地。因此,给出隐马尔可夫模型的简单描述。
图23示出了隐马尔可夫模型的状态转移图。
隐马尔可夫模型是使用隐藏层中的状态的转移概率和观测概率来对时间序列数据进行建模的概率模型。在学习用户的移动路线和目的地的学习模型的情况下,表示使用GPS传感器等所获得的用户的移动历史的数据是用于学习的时间序列数据。例如在Yoshinori UESAKA和KazuhikoOZEKI,Bun-ichi Co.,Ltd的“Algorithms of Pattern Recognition andLearning”和C.M.Bishop,Springer Japan KK的“Pattern Recognitionand Machine Learning”中详细描述了隐马尔可夫模型。
图23示出了三个状态,即状态S1、状态S2和状态S3,以及九个转移T,即转移T1至T9。每个转移T由三个参数来定义,即,表示转移前的状态的初始状态、表示转移后的状态的结束状态和表示从初始状态到结束状态的转移的概率的转移概率。另外,假设数据预定的离散符号中的任一个将被选择,每个状态具有观测概率,该观测概率将每个符号被选择的概率表示为参数。
图24示出通过使用隐马尔可夫模型来学习用户的移动历史所获得的学习结果。
在图24中,用于学习的数据是用户的过去移动历史,并且是当用户在过去移动时由GPS传感器测量到的时间、纬度和经度的时间序列数据。另外,在图24中,被布置成覆盖移动路线的多个椭圆中的每个表示根据隐马尔可夫模型的状态生成的测量数据的概率分布的轮廓线。另外,在图24中,为了便于理解,使用比椭圆略大的圆来清楚地标记当用于学习的数据被记录时用户的目的地。
与图24所示的多个椭圆中的每个对应的状态的中心值和分散值被学习为隐马尔可夫模型的参数。另外,与图24所示的多个椭圆中的每个对应的状态之间的转移概率也被学习为隐马尔可夫模型的参数。对于目的地,在通过学习获得的隐马尔可夫模型的多个状态当中的、逗留时间长的状态节点被设定为目的节点。
通过预测移动路线和目的地来预测拥塞度的预测处理
图25是由与移动预测功能链接的应用所执行的预测处理的流程图,其中,预测移动路线和目的地,因此根据预测结果来预测拥塞度。在图25中,与移动预测功能链接的应用由便携式终端11的预测单元45来执行,并且预测单元45被描述为具有用于执行移动预测功能的移动预测单元、和用于执行拥塞度的预测的拥塞度预测单元。
首先,在步骤S101中,预测单元45的移动预测单元使用GPS传感器等获取当前位置,并且根据当前位置估计隐马尔可夫模型的状态节点。
在步骤S102中,预测单元45的移动预测单元预测用户将从当前位置移动到的目的地和到该目的地的移动路线。移动预测单元使用通过学习获得的隐马尔可夫模型,对从当前位置的状态节点扩展的状态转移图进行树搜索,以搜索与目的地对应的目的节点。还存在检测到多个目的地和移动路线的情况。例如,移动预测单元按照到目的地的最高到达概率的顺序列出预定数量的目的地,并且将通向目的地的路线当中具有最高发生概率的路线确定为代表路线。
在步骤S103中,预测单元45的移动预测单元将预测目的地的目的地点、和移动路线的地图上作为移动路线点的指定点输入到预测单元45的拥塞度预测单元。目的地点由作为目的节点的状态参数的中心值来提供,并且例如可以根据状态节点的中心值来提供移动路线点,状态节点的中心值表示当以固定时间来分割移动路线或将移动路线分割成固定区间时所形成的每个区间。另外,由于除了目的地和移动路线之外,移动预测单元还可预测到达每个状态节点的到达时间(预定到达时间),因此该时间也连同目的地点和移动路线点一起被输入到拥塞度预测单元。
在步骤S104中,预测单元45的拥塞度预测单元预测输入时间的目的地点和移动路线点。此外,在步骤S105中,拥塞度预测单元在显示单元47上显示预测结果并且结束处理。
可以通过将移动预测功能和拥塞度预测功能链接起来,预测关于所预测的移动路线和目的地可连接的基站13的拥塞度。此外,在图25的处理中,同时获得目的地和移动路线的点,然而,也可获得从当前时间开始的预定时间内可能到达的目的地和移动路线中的至少之一。另外,使用根据移动目的地而预测的拥塞度,自然也可以选择要连接的基站13。本申请人在日本未审查专利申请公布第2011-059924号、日本未审查专利申请公布第2011-252884号等中详细描述了移动预测功能。
图26示出图25所述的预测处理的预测结果的示例。另外,图27示出以通信速率表示的预测结果,该通信速率是根据通过估计获得的拥塞度而获得的。此外,在图26和图27的预测结果之间没有关系。
图26和27是关于一个目的地提取一条移动路线的示例,然而,图28示出关于一个目的地提取多条路线从而显示所提取的每条路线的拥塞度的示例。
除拥塞度之外的信息的应用示例
在上述实施例中,给出了如下示例的描述:通过使用基站13的拥塞度数据利用回归模型进行学习,预测(估计)在时间上或空间上分开的基站13的拥塞度。
然而,本技术不限于诸如拥塞度的信息,并且可以将本技术应用于一般的预测处理,一般的预测处理根据在当前时间点或当前位置获得的本地信息来预测在时间上或空间上分开的位置获得的本地信息。
例如,便携式终端11安装有诸如温度计、湿度计或气压计的传感器,并且获取单元(等同于拥塞度获取单元41)获取由传感器获得的温度、湿度、气压等作为本地信息,将测量结果的时间序列数据发送到服务器12,并且使得服务器12使用回归模型对该时间序列数据进行学习。此外,便携式终端11的预测单元45获取学习结果(回归模型的参数),然后可以预测未来时间或不同位置处的温度、湿度、气压等作为本地信息。
另外,便携式终端11可安装有照度计和麦克风,并且可测量周围的人类活动(人类活动的活动状况,诸如交通状况、噪声状况和城镇的亮度)作为本地信息并且通过回归模型进行学习。
此外,由便携式终端11获取的本地信息不限于使用安装在装置内的传感器等所获取的信息,并且也可通过用户使用GUI等输入本地信息的方法来获取。
图29示出用户输入用户的当前位置周围的拥塞度的示例作为通过用户执行输入的方法所获取的本地信息的示例。
图29示出显示在便携式终端11的显示单元47上的画面的示例,并且用户使用五阶段评估来输入用户的当前位置周围的拥塞度。便携式终端11记录使用五阶段评估所输入的拥塞度连同位置和时间,并且将其发送到服务器12。
图30示出通过使用根据图29所示的本地信息所学习的回归模型来预测预定位置的拥塞度的预测结果的画面的示例。
例如,当用户在画面上显示的地图上触摸他们想知道拥塞度的位置时,如图30所示,以诸如“指定位置的拥塞度是3.2”的方式来显示预测结果。
此外,对于用户输入的本地信息,也可以考虑除拥塞度之外的各种信息。例如,也可输入当前位置(本地区域)中的男女比率、年龄组等作为本地信息。在诸如图29所示的画面中,可以将男女比率呈现为五阶段评估,诸如1.男男男,2.男男女,3.男女,4.女女男,5.女女女等,并且允许用户执行输入。另外,例如,可以通过为用户呈现五阶段评估(诸如:1.70岁以上,2.50至70岁,3.35至50岁,4.20至35岁以及5.0至20岁)来允许用户输入年龄段。另外,也可以考虑城镇的活动度(城镇处于明亮的时段、商店关闭的时段)等、或者道路上的车辆类型的比率(存在更多的卡车、家用汽车、公共汽车或出租车?)等作为可输入的本地信息。这里例示的本地信息仅是示例,并且本地信息不限于此。
这样的本地信息可以是用户的未来动作的动机,并且替选地,对于显示适合于对象的适当广告是重要的。在现有技术中,为了收集这样的本地信息,使用人力执行调查。然而,想到的是,随着期望的信息被细分,这样的调查将变得更困难。通过使用诸如在本说明书中描述的方法,除了容易地收集本地信息之外,还可以预测任意的本地信息。
多个便携式终端11中的每个均获取不同时间的不同本地信息项并且将其发送到服务器12,并且服务器12使用回归模型对由大量便携式终端11作为聚集源知识而收集的本地信息进行学习。接收并使用由服务器12所学习的模型参数的便携式终端11可以预测该便携式终端11本身没有获取的位置的本地信息、或未来时间的本地信息。
另外,服务器12通过使用支持向量回归模型或关系向量回归模型来学习由大量便携式终端11收集的本地信息(的时间序列数据),因此可以减少参数的容量并且将模型参数发送到每个便携式终端11。因此,每个便携式终端11可以高效地使用由大量便携式终端11收集的本地信息。
在上述示例中,便携式终端11接收回归模型的参数并预测本地信息,然而,也可由服务器12来执行本地信息的估计。换言之,可采用这样的配置,使得便携式终端11将要预测的时间和位置发送到服务器12,并且服务器12使用回归模型预测向服务器12发送的时间和位置的本地信息,并且将预测结果发送到便携式终端11。
计算机的配置示例
上述一系列处理可使用硬件来执行,并且也可使用软件来执行。在使用软件执行一系列处理的情况下,构成该软件的程序安装在计算机上。这里,计算机包括嵌入在专用硬件中的计算机、以及由于安装有各种程序而能够执行各种功能的普通个人计算机等。
图31是示出使用程序执行上述一系列处理的计算机的硬件的配置示例的框图。
在计算机中,CPU(中央处理单元)101、ROM(只读存储器)102和RAM(随机访问存储器)103通过总线104相互连接。
输入输出接口105也连接到总线104。输入输出接口105连接到输入单元106、输出单元107、存储单元108、通信单元109和驱动器110。
输入单元106由键盘、鼠标、麦克风等构成。输出单元107由显示器、扬声器等构成。存储单元108由硬盘或易失性存储器等构成。通信单元109由经由因特网、便携式电话网络、无线LAN、卫星广播线等与其它通信装备或基站进行通信的通信模块等构成。传感器112是用于获取本地信息的传感器。驱动器110驱动可移除存储介质111,例如磁盘、光盘、磁光盘或半导体存储器。
在如上所述配置的计算机中,上述一系列处理由CPU101来执行,例如经由输入输出接口105和总线104将存储在存储单元108中的程序加载到RAM103中,并且执行所加载的程序。
在计算机中,可以通过将可移除存储介质111安装到驱动器110中,经由输入输出接口105将程序安装在存储单元108中。另外,可以通过使用通信单元109经由有线或无线传输介质(诸如局域网、因特网或数字卫星广播)接收程序,将程序安装到存储单元108。另外,可以将程序预先安装在ROM102或存储单元108上。
此外,在本说明书中,流程图中描述的步骤可自然地以时间序列方式按所描述的顺序来执行,并且即使步骤不必按时间序列顺序来处理,也可在需要的定时(诸如并行地或当调用步骤时)来执行这些步骤。
此外,在本说明书中,术语“系统”指的是由多个装置构成的装置整体。
本技术的实施例不限于上述实施例,并且可在不偏离本技术的精神的范围内进行各种修改。
此外,本技术可采用诸如下面的配置。
(1)一种终端装置,包括:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;通信单元,将在预定时段内所累积的本地信息发送到信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的本地信息而学习的统计模型的参数;以及预测单元,使用所接收到的所述统计模型的参数来预测与任意时间和位置有关的本地信息。
(2)根据(1)所述的终端装置,其中,所述统计模型是回归模型,在所述回归模型中,至少时间和区域是解释变量,并且本地信息项是标准变量。
(3)根据(2)所述的终端装置,其中,所述通信单元仅接收所述回归模型的加权参数中的加权参数不为零的参数。
(4)根据(1)至(3)中任一项所述的终端装置,其中,所述本地信息是表示基站的拥塞度的信息,所述终端装置连接到所述基站以执行通信。
(5)根据(1)至(4)中任一项所述的终端装置,其中,所述预测单元预测与用户指定的时间和位置有关的本地信息。
(6)根据(1)至(5)中任一项所述的终端装置,其中,所述预测单元包括预测所述终端装置的移动路线的功能、和预测所述移动路线上的至少一个点的位置和到达时间的功能,并且预测与所预测的位置和到达时间有关的本地信息。
(7)根据(1)至(6)中任一项所述的终端装置,还包括:传感器,获取预定数据,其中,所述本地信息是由所述传感器获取的数据。
(8)根据(1)至(7)中任一项所述的终端装置,其中,所述本地信息是与由拥有所述终端装置的用户评估并输入的预定指标有关的评估信息。
(9)一种终端控制方法,包括:使得终端装置获取当前时间的当前位置的本地信息;使得终端装置在预定时段内累积所获取的本地信息;使得终端装置将在预定时段内所累积的本地信息发送到信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的本地信息而学习的统计模型的参数;以及使得终端装置使用所接收到的所述统计模型的参数来预测与任意时间和位置有关的本地信息。
(10)一种使得计算机用作以下单元的程序:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;通信单元,将在预定时段内所累积的本地信息发送到信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的本地信息而学习的统计模型的参数;以及预测单元,使用所接收到的所述统计模型的参数来预测与任意时间和位置有关的本地信息。
(11)一种由终端装置和信息处理装置构成的信息处理系统,其中,所述终端装置包括:获取单元,获取当前时间的当前位置的本地信息;累积单元,在预定时段内累积所获取的本地信息;以及通信单元,将在预定时段内所累积的本地信息发送到所述信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的本地信息而学习的统计模型的参数,以及其中,所述信息处理装置包括:通信单元,接收在预定时段内从所述终端装置向所述信息处理装置传送的本地信息,并且将所述统计模型的参数发送到所述终端装置;以及学习单元,使用从多个终端装置接收到的本地信息来学习所述统计模型的参数,以及其中,所述终端装置或所述信息处理装置中的任一个包括:预测单元,使用所述统计模型的参数来预测与任意时间和位置有关的本地信息。
本公开包含与2012年3月30日在日本专利局提交的日本优先权专利申请JP2012-079034中公开的主题相关的主题,其全部内容通过引用合并于此。
本领域技术人员应理解,在所附权利要求或其等同方案的范围内,根据设计要求和其它因素,可进行各种修改、组合、子组合和变更。
Claims (11)
1.一种终端装置,包括:
获取单元,获取当前时间的当前位置的本地信息;
累积单元,在预定时段内累积所获取的本地信息;
通信单元,将在预定时段内所累积的所述本地信息发送到信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的所述本地信息而学习的统计模型的参数;以及
预测单元,使用所接收到的所述统计模型的参数来预测与任意时间和位置有关的本地信息。
2.根据权利要求1所述的终端装置,
其中,所述统计模型是回归模型,在所述回归模型中,至少时间和区域是解释变量,并且本地信息项是标准变量。
3.根据权利要求2所述的终端装置,
其中,所述通信单元仅接收所述回归模型的加权参数中的所述加权参数不为零的参数。
4.根据权利要求1所述的终端装置,
其中,所述本地信息是表示基站的拥塞度的信息,所述终端装置连接到所述基站以执行通信。
5.根据权利要求1所述的终端装置,
其中,所述预测单元预测与用户指定的时间和位置有关的本地信息。
6.根据权利要求1所述的终端装置,
其中,所述预测单元包括预测所述终端装置的移动路线的功能、和预测所述移动路线上的至少一个点的位置和到达时间的功能,并且预测与所预测的位置和到达时间有关的本地信息。
7.根据权利要求1所述的终端装置,还包括:
传感器,获取预定数据,
其中,所述本地信息是由所述传感器获取的所述数据。
8.根据权利要求1所述的终端装置,
其中,所述本地信息是与由拥有所述终端装置的用户评估并输入的预定指标有关的评估信息。
9.一种终端控制方法,包括:
使得终端装置获取当前时间的当前位置的本地信息;
使得终端装置在预定时段内累积所获取的本地信息;
使得终端装置将在预定时段内所累积的所述本地信息发送到信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的所述本地信息而学习的统计模型的参数;以及
使得终端装置使用所接收到的所述统计模型的参数来预测与任意时间和位置有关的本地信息。
10.一种使得计算机用作以下单元的程序:
获取单元,获取当前时间的当前位置的本地信息;
累积单元,在预定时段内累积所获取的本地信息;
通信单元,将在预定时段内所累积的所述本地信息发送到信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的所述本地信息而学习的统计模型的参数;以及
预测单元,使用所接收到的所述统计模型的参数来预测与任意时间和位置有关的本地信息。
11.一种由终端装置和信息处理装置构成的信息处理系统,
其中,所述终端装置包括:
获取单元,获取当前时间的当前位置的本地信息;
累积单元,在预定时段内累积所获取的本地信息;以及
通信单元,将在预定时段内所累积的所述本地信息发送到所述信息处理装置,并且从所述信息处理装置接收使用由所述信息处理装置从多个终端装置获取的所述本地信息而学习的统计模型的参数,
其中,所述信息处理装置包括:
通信单元,接收在预定时段内从所述终端装置向所述信息处理装置传送的所述本地信息,并且将所述统计模型的参数发送到所述终端装置;以及
学习单元,使用从多个终端装置接收到的所述本地信息来学习所述统计模型的参数,以及
其中,所述终端装置或所述信息处理装置中的任一个包括:
预测单元,使用所述统计模型的所述参数来预测与任意时间和位置有关的本地信息。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012-079034 | 2012-03-30 | ||
| JP2012079034A JP2013211616A (ja) | 2012-03-30 | 2012-03-30 | 端末装置、端末制御方法、プログラム、および情報処理システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN103369584A true CN103369584A (zh) | 2013-10-23 |
Family
ID=49236376
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2013100953239A Pending CN103369584A (zh) | 2012-03-30 | 2013-03-22 | 终端装置、终端控制方法、程序和信息处理系统 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US9547827B2 (zh) |
| JP (1) | JP2013211616A (zh) |
| CN (1) | CN103369584A (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109388841A (zh) * | 2017-08-11 | 2019-02-26 | 株式会社捷太格特 | 生产设备的数据处理装置 |
| CN110784900A (zh) * | 2019-10-15 | 2020-02-11 | 深圳市高德信通信股份有限公司 | 一种运营商网络服务自主监管切换系统 |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104396284B (zh) | 2012-06-22 | 2016-09-07 | 谷歌公司 | 呈现针对当前位置或时间的信息 |
| CN105683716B (zh) | 2012-06-22 | 2018-07-17 | 谷歌有限责任公司 | 场境交通或通行警示 |
| US9811352B1 (en) | 2014-07-11 | 2017-11-07 | Google Inc. | Replaying user input actions using screen capture images |
| US9503516B2 (en) | 2014-08-06 | 2016-11-22 | Google Technology Holdings LLC | Context-based contact notification |
| CN104486773B (zh) * | 2014-12-05 | 2018-09-11 | 中国联合网络通信集团有限公司 | 一种预测基站下终端数的方法及装置 |
| US10264407B2 (en) * | 2015-06-25 | 2019-04-16 | The Board Of Trustees Of The University Of Alabama | Intelligent multi-bean medium access control in ku-band for mission-oriented mobile mesh networks |
| US20180225681A1 (en) * | 2015-08-06 | 2018-08-09 | Nec Corporation | User information estimation system, user information estimation method, and user information estimation program |
| US10970646B2 (en) * | 2015-10-01 | 2021-04-06 | Google Llc | Action suggestions for user-selected content |
| EP3378244B1 (en) * | 2015-11-17 | 2022-03-02 | Sony Group Corporation | Providing location information of a terminal in a communication network |
| JP6752457B2 (ja) * | 2016-06-02 | 2020-09-09 | 株式会社マーズスピリット | 機械学習システム、装置及び情報処理方法 |
| WO2018131311A1 (ja) * | 2017-01-10 | 2018-07-19 | 日本電気株式会社 | センシングシステム、センサノード装置、センサ測定値処理方法及びプログラム |
| JP6838451B2 (ja) * | 2017-03-23 | 2021-03-03 | 日本電気株式会社 | 混雑情報送信端末装置、混雑状況評価システム、混雑状況評価方法、及び、混雑情報送信プログラム |
| US10956787B2 (en) | 2018-05-14 | 2021-03-23 | Quantum-Si Incorporated | Systems and methods for unifying statistical models for different data modalities |
| MX2020012899A (es) * | 2018-05-30 | 2021-02-26 | Quantum Si Inc | Metodos y aparato para la prediccion multimodal utilizando un modelo estadistico entrenado. |
| US11967436B2 (en) | 2018-05-30 | 2024-04-23 | Quantum-Si Incorporated | Methods and apparatus for making biological predictions using a trained multi-modal statistical model |
| GB202001468D0 (en) | 2020-02-04 | 2020-03-18 | Tom Tom Navigation B V | Navigation system |
| US20230130153A1 (en) * | 2020-04-10 | 2023-04-27 | Sony Group Corporation | Information processing apparatus, server, information processing system, and information processing method |
| CN112269930B (zh) * | 2020-10-26 | 2023-10-24 | 北京百度网讯科技有限公司 | 建立区域热度预测模型、区域热度预测的方法及装置 |
| JP7232487B1 (ja) * | 2023-01-10 | 2023-03-03 | 株式会社アドインテ | 推定システム及び推定方法 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101173980A (zh) * | 2007-11-21 | 2008-05-07 | 湖南大学 | 一种基于超宽带的室内节点定位算法 |
| CN102110365A (zh) * | 2009-12-28 | 2011-06-29 | 日电(中国)有限公司 | 基于时空关系的路况预测方法和系统 |
| CN102124504A (zh) * | 2008-08-20 | 2011-07-13 | 日本先锋公司 | 路径决定支持装置和路径决定支持方法 |
| US20110319094A1 (en) * | 2010-06-24 | 2011-12-29 | Sony Corporation | Information processing apparatus, information processing system, information processing method, and program |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3849435B2 (ja) * | 2001-02-23 | 2006-11-22 | 株式会社日立製作所 | プローブ情報を利用した交通状況推定方法及び交通状況推定・提供システム |
| JP4281419B2 (ja) * | 2003-06-02 | 2009-06-17 | 住友電気工業株式会社 | 前置型非線形歪補償器 |
| US20050075905A1 (en) * | 2003-08-22 | 2005-04-07 | Bennett Richard M. | Customizable automatic generation and ordering of a medical report summary |
| US8812526B2 (en) * | 2005-09-14 | 2014-08-19 | Millennial Media, Inc. | Mobile content cross-inventory yield optimization |
| US20070100650A1 (en) * | 2005-09-14 | 2007-05-03 | Jorey Ramer | Action functionality for mobile content search results |
| JP4858380B2 (ja) * | 2007-09-19 | 2012-01-18 | 住友電気工業株式会社 | 交通パラメータ算出システム、算出方法及びコンピュータプログラム |
| JP5515331B2 (ja) | 2009-03-09 | 2014-06-11 | ソニー株式会社 | 情報提供サーバ、情報提供システム、情報提供方法及びプログラム |
| JP5348013B2 (ja) | 2009-05-26 | 2013-11-20 | ソニー株式会社 | 無線通信装置、推定サーバ、無線通信方法および推定方法 |
| US8665724B2 (en) * | 2009-06-12 | 2014-03-04 | Cygnus Broadband, Inc. | Systems and methods for prioritizing and scheduling packets in a communication network |
| US8813124B2 (en) * | 2009-07-15 | 2014-08-19 | Time Warner Cable Enterprises Llc | Methods and apparatus for targeted secondary content insertion |
| JP2012009987A (ja) | 2010-06-23 | 2012-01-12 | Sony Corp | 無線通信装置、プログラム、無線通信方法、および無線通信システム |
| US8391896B2 (en) * | 2010-07-09 | 2013-03-05 | Nokia Corporation | Method and apparatus for providing a geo-predictive streaming service |
| US9832671B2 (en) * | 2010-09-16 | 2017-11-28 | Vassona Networks | Modeling radio access networks |
| US9118593B2 (en) * | 2010-10-07 | 2015-08-25 | Enghouse Networks Limited | System and method for best value routing |
| US10433207B2 (en) * | 2010-10-28 | 2019-10-01 | Verizon Patent And Licensing Inc. | Load balancing to provide a target grade of service (GOS) |
| KR101173382B1 (ko) * | 2010-10-29 | 2012-08-10 | 삼성에스디에스 주식회사 | 데이터 전송 방법 및 장치 |
| US20120170503A1 (en) * | 2010-12-30 | 2012-07-05 | Motorola, Inc. | Method and apparatus for controlling network access in a multi-technology wireless communication system |
| US20120198020A1 (en) * | 2011-02-02 | 2012-08-02 | Verizon Patent And Licensing, Inc. | Content distribution within a service provider network |
| US8812661B2 (en) * | 2011-08-16 | 2014-08-19 | Facebook, Inc. | Server-initiated bandwidth conservation policies |
| US8712389B2 (en) * | 2011-11-22 | 2014-04-29 | T-Mobile Usa, Inc. | User-initiated quality of service modification in a mobile device |
-
2012
- 2012-03-30 JP JP2012079034A patent/JP2013211616A/ja active Pending
-
2013
- 2013-02-26 US US13/777,653 patent/US9547827B2/en active Active
- 2013-03-22 CN CN2013100953239A patent/CN103369584A/zh active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101173980A (zh) * | 2007-11-21 | 2008-05-07 | 湖南大学 | 一种基于超宽带的室内节点定位算法 |
| CN102124504A (zh) * | 2008-08-20 | 2011-07-13 | 日本先锋公司 | 路径决定支持装置和路径决定支持方法 |
| CN102110365A (zh) * | 2009-12-28 | 2011-06-29 | 日电(中国)有限公司 | 基于时空关系的路况预测方法和系统 |
| US20110319094A1 (en) * | 2010-06-24 | 2011-12-29 | Sony Corporation | Information processing apparatus, information processing system, information processing method, and program |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109388841A (zh) * | 2017-08-11 | 2019-02-26 | 株式会社捷太格特 | 生产设备的数据处理装置 |
| CN109388841B (zh) * | 2017-08-11 | 2023-05-09 | 株式会社捷太格特 | 生产设备的数据处理装置 |
| CN110784900A (zh) * | 2019-10-15 | 2020-02-11 | 深圳市高德信通信股份有限公司 | 一种运营商网络服务自主监管切换系统 |
| CN110784900B (zh) * | 2019-10-15 | 2021-11-16 | 深圳市高德信通信股份有限公司 | 一种运营商网络服务自主监管切换系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20130262354A1 (en) | 2013-10-03 |
| JP2013211616A (ja) | 2013-10-10 |
| US9547827B2 (en) | 2017-01-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103369584A (zh) | 终端装置、终端控制方法、程序和信息处理系统 | |
| Gao et al. | Optimize taxi driving strategies based on reinforcement learning | |
| US10419949B2 (en) | Web server and method for hosting a web page for presenting location based user quality data related to a communication network | |
| US9726502B2 (en) | Route planner for transportation systems | |
| US9706411B2 (en) | Small cell planning tool | |
| US7142106B2 (en) | System and method of visualizing network layout and performance characteristics in a wireless network | |
| CN104520881A (zh) | 基于访问可能性对附近目的地排名以及从位置历史来预测对地点的未来访问 | |
| CN106875066A (zh) | 用车出行行为的预测方法、装置、服务器以及存储介质 | |
| CN105893537B (zh) | 地理信息点的确定方法和装置 | |
| Baggio et al. | Strategic visitor flows and destination management organization | |
| CN103636280B (zh) | 基于日历数据的上行带宽和下行带宽的动态优化 | |
| CN115017400B (zh) | 一种应用app推荐方法及电子设备 | |
| Tran et al. | A user equilibrium-based fast-charging location model considering heterogeneous vehicles in urban networks | |
| He et al. | Spatio-temporal capsule-based reinforcement learning for mobility-on-demand coordination | |
| Xiong et al. | An integrated and personalized traveler information and incentive scheme for energy efficient mobility systems | |
| Noursalehi et al. | Predictive decision support platform and its application in crowding prediction and passenger information generation | |
| US10419298B2 (en) | Monitoring device and memory medium for monitoring communication between terminal devices in a group | |
| Song et al. | Potential travel cost saving in urban public-transport networks using smartphone guidance | |
| Roussel et al. | Analyzing Geospatial Key Factors and Predicting Bike Activity in Hamburg | |
| Hüttel et al. | Mind the gap: Modelling difference between censored and uncensored electric vehicle charging demand | |
| Kim et al. | Analysis of variation in demand and performance of urban expressways using dynamic path flow estimation | |
| JP2017077177A (ja) | 供給電力管理装置、車載器、及び電気自動車 | |
| Roosmalen | Forecasting bus ridership with trip planner usage data: A machine learning application | |
| Jiang et al. | A method for private car transportation dispatching based on a passenger demand model | |
| Matias | On improving operational planning and control in public transportation networks using streaming data: A machine learning approach |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20131023 |