CN101452571B - 积和熔加功能单元 - Google Patents
积和熔加功能单元 Download PDFInfo
- Publication number
- CN101452571B CN101452571B CN2008101825044A CN200810182504A CN101452571B CN 101452571 B CN101452571 B CN 101452571B CN 2008101825044 A CN2008101825044 A CN 2008101825044A CN 200810182504 A CN200810182504 A CN 200810182504A CN 101452571 B CN101452571 B CN 101452571B
- Authority
- CN
- China
- Prior art keywords
- precision
- operand
- double
- dfma
- functional unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000009877 rendering Methods 0.000 claims abstract description 25
- YEORLXJBCPPSOC-UHFFFAOYSA-N 2-amino-5-(diaminomethylideneazaniumyl)-2-(difluoromethyl)pentanoate Chemical group NC(N)=NCCCC(N)(C(F)F)C(O)=O YEORLXJBCPPSOC-UHFFFAOYSA-N 0.000 claims description 125
- 238000012360 testing method Methods 0.000 claims description 59
- 238000000034 method Methods 0.000 claims description 53
- 238000012545 processing Methods 0.000 claims description 46
- 230000008569 process Effects 0.000 claims description 45
- 238000006243 chemical reaction Methods 0.000 claims description 23
- 230000004087 circulation Effects 0.000 claims description 21
- 238000007792 addition Methods 0.000 claims description 7
- 239000000654 additive Substances 0.000 claims description 7
- 230000000996 additive effect Effects 0.000 claims description 7
- 239000000155 melt Substances 0.000 claims 1
- 230000000694 effects Effects 0.000 abstract description 2
- 238000003860 storage Methods 0.000 description 25
- 238000010586 diagram Methods 0.000 description 22
- 239000000284 extract Substances 0.000 description 21
- 238000004364 calculation method Methods 0.000 description 16
- 238000010606 normalization Methods 0.000 description 16
- 238000007667 floating Methods 0.000 description 12
- 238000005516 engineering process Methods 0.000 description 11
- 230000004044 response Effects 0.000 description 10
- 238000013461 design Methods 0.000 description 9
- 238000000605 extraction Methods 0.000 description 9
- 238000006073 displacement reaction Methods 0.000 description 7
- 230000008676 import Effects 0.000 description 7
- 230000004048 modification Effects 0.000 description 7
- 238000012986 modification Methods 0.000 description 7
- 230000008859 change Effects 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 239000000047 product Substances 0.000 description 6
- 238000004891 communication Methods 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 230000000712 assembly Effects 0.000 description 3
- 238000000429 assembly Methods 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 3
- 239000007795 chemical reaction product Substances 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 230000006399 behavior Effects 0.000 description 2
- 238000004422 calculation algorithm Methods 0.000 description 2
- 230000003750 conditioning effect Effects 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- 230000000087 stabilizing effect Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000009471 action Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000005574 cross-species transmission Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/14—Digital output to display device ; Cooperation and interconnection of the display device with other functional units
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/50—Adding; Subtracting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
- G06F9/30112—Register structure comprising data of variable length
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/3012—Organisation of register space, e.g. banked or distributed register file
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/3012—Organisation of register space, e.g. banked or distributed register file
- G06F9/30123—Organisation of register space, e.g. banked or distributed register file according to context, e.g. thread buffers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
- G06F9/3851—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution from multiple instruction streams, e.g. multistreaming
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
- G06F9/3888—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple threads [SIMT] in parallel
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
- G06F9/3893—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units controlled in tandem, e.g. multiplier-accumulator
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Multimedia (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Optimization (AREA)
- Computing Systems (AREA)
- Human Computer Interaction (AREA)
- Image Processing (AREA)
- Image Generation (AREA)
- Complex Calculations (AREA)
Abstract
除了用于绘制的单精度功能单元外,还将一功能单元添加到图形处理器以提供对双精度算术的直接支持。所述双精度功能单元可使用至少为双精度宽度的数据路径和/或逻辑电路对双精度输入执行若干不同运算,包括积和熔加。所述双精度和单精度功能单元可由共享的指令发布电路控制,且核心中包含的所述双精度功能单元的副本的数目可小于所述单精度功能单元的副本的数目,借此减小添加针对双精度的支持对芯片面积的影响。
Description
技术领域
本发明大体涉及图形处理器,且明确地说涉及一种用于图形处理器的双精度积和熔加功能单元。
背景技术
图形处理器普遍用于计算机系统中以加速从二维或三维几何数据的图像的绘制。此类处理器通常经设计而具有高度并行性和高处理量,从而允许并行处理数千个图元以实时绘制复杂、逼真的动画图像。高端图形处理器提供比典型中央处理单元(CPU)多的计算能力。
更近一些,已关注于影响图形处理器的功率以加速与图像绘制无关的各种计算。“通用”图形处理器可用于在科学、经济、商业和其它领域中执行计算。
对图形处理器进行调适以用于通用计算的一个困难是,图形处理器通常经设计以实现相对较低数值精度。可使用32位(“单精度”)或甚至16位(“半精度”)浮点值来绘制高质量图像,且功能单元和内部管线经配置以支持这些数据宽度。相比之下,许多通用计算需要较高数值精度,例如64位(“双精度”)。
为了支持较高精度,一些图形处理器使用软件技术来使用机器指令序列和32位或16位功能单元执行双精度计算。此方法减缓了处理量;例如,可能需要一百个或一百个以上机器指令来完成单一64位乘法运算。此类较长序列可显著减少图形处理器的双精度处理量。在一个代表性情况下,估计图形处理器将以高端双核心CPU芯片可能的处理量的约1/5完成双精度计算。(通过比较,相同图形处理器可以双核心CPU的处理量的约15-20倍完成单精度计算。)因为基于软件的解决方案慢得如此多,所以现有图形处理器很少用于双精度计算。
另一解决方案只是使图形处理器的所有算术电路足够宽以处理双精度操作数。这将增加图形处理器对于双精度运算的处理量以与单速处理量匹配。然而,图形处理器通常具有每一算术电路的许多副本以支持并行运算,且增加每一此电路的大小将实质上增加芯片面积、成本和功率消耗。
如2006年2月21日申请的共同拥有共同待决的第11/359,353号美国专利申请案中描述的另一解决方案是,影响单精度算术电路以执行双精度运算。在此方法中,单精度功能单元中包含的特殊硬件用于迭代地执行双精度运算。此方法显著快于基于软件的解决方案(处理量可能相对于单精度处理量减小例如4倍,而不是约100倍),但其可使芯片设计明显复杂。另外,如果太多指令需要同一功能单元,那么在单精度与双精度运算之间共享同一功能单元可导致所述单元变成管线中的瓶颈。
发明内容
本发明的实施例直接支持图形处理器中的双精度算术。除了用于绘制的单精度功能单元外,还提供多用途双精度功能单元。双精度功能单元可使用至少双精度宽度的数据路径和/或逻辑电路对双精度输入执行若干不同运算,包括积和熔加。双精度和单精度功能单元可由共享的指令发布电路控制,且核心中包含的双精度功能单元的副本的数目可小于单精度功能单元的副本的数目,借此减小添加针对双精度的支持对芯片面积的影响。
根据本发明的一个方面,一种图形处理器具有适于产生图像数据的绘制管线。对单精度操作数操作的所述绘制管线包含适于执行若干同时线程的处理核心。处理核心包含适于对一组双精度输入操作数选择性地执行若干双精度运算中的一者的多用途双精度功能单元。多用途双精度功能单元包含至少一个算术逻辑电路,且双精度功能单元的所有算术逻辑电路足够宽以在双精度下操作。在一些实施例中,双精度功能单元经调适使得双精度运算的每一者在相同数目的时钟循环中完成,且所述单元也可经调适使得完成双精度运算的任一者所需的时间(例如,时钟循环的数目)不受下溢或溢出条件影响。
可支持双精度运算的各种操作和组合。在一个实施例中,双精度运算包含将两个双精度操作数相加的加法运算;将两个双精度操作数相乘的乘法运算;以及计算第一双精度操作数与第二双精度操作数的乘积,接着将第三双精度操作数添加到所述乘积的积和熔加运算。可支持的其它双精度运算包含:双精度比较(DSET)运算,其对第一操作数和第二操作数执行比较测试并产生指示是否满足所述比较测试的布尔结果;双精度最大化(DMAX)运算,其传回两个双精度输入操作数中的较大一者;或双精度最小化(DMAX)运算,其传回两个双精度输入操作数中的较小一者。另外,还可支持将操作数从双精度格式转换为非双精度格式(或反之亦然)的格式转换操作。
根据本发明的另一方面,一种图形处理器包含适于产生图像数据的绘制管线。所述绘制管线包含适于执行多个同时线程的处理核心。处理核心包含适于对一个或一个以上单精度操作数执行算术运算的单精度功能单元,以及适于对一组双精度输入操作数执行积和熔加运算并提供双精度结果的双精度积和熔加(DFMA)功能单元。DFMA功能单元有利地包含DFMA管线,其具有足够宽以在单次通过DFMA管线的过程中执行积和熔加运算的数据路径。举例来说,DFMA功能单元可包含适于在单一迭代中计算两个双精度尾数的乘积的乘法器,和适于在单一迭代中计算两个双精度尾数的和的加法器。
DFMA功能单元还可经配置以执行其它运算。举例来说,在一些实施例中,DFMA经配置以对一对双精度输入操作数执行乘法运算,并提供双精度结果。在一些实施例中,乘法运算和积和熔加运算每一者在相同数目的时钟循环中完成。类似地,DFMA功能单元可经配置以对一对双精度输入操作数执行加法运算,并提供双精度结果。在一个实施例中,加法运算和积和熔加运算每一者在相同数目的时钟循环中完成。
在一些实施例中,处理核心包含适于并行操作的第一功能单元的若干(P)副本以及DFMA功能单元的若干(N)副本,数目P大于数目N。在一个实施例中,数目N为一。
处理核心可包含输入管理器电路,其适于收集用于DFMA功能单元的P组双精度输入操作数,且在不同(例如,连续)时钟循环上将所述P组双精度操作数中的不同者传递到DFMA功能单元。输入管理器电路还可适于收集用于第一功能单元的P组单精度输入操作数,且并行地将所述P组单精度操作数中的不同者传递到第一功能单元的P个副本中的每一者。
以下具体实施方式连同附图一起将提供对本发明的性质和优点的较好理解。
附图说明
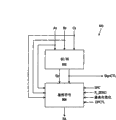
图1是根据本发明一实施例的计算机系统的框图;
图2是根据本发明一实施例可在图形处理单元中实施的绘制管线的框图;
图3是根据本发明一实施例的执行核心的框图;
图4列举根据本发明一实施例可由双精度功能单元执行的双精度算术、比较运算和格式转换操作;
图5是根据本发明一实施例的双精度功能单元的简化框图;
图6是图5的双精度功能单元的操作数准备区块的框图;
图7是图5的双精度功能单元的指数路径的框图;
图8是图5的双精度功能单元的尾数路径的框图;
图9是图5的双精度功能单元的符号路径的框图;
图10是图5的双精度功能单元的输出区段的框图;
图11是根据本发明一实施例的执行核心的框图;以及
图12是展示根据本发明一实施例双精度功能单元的操作数定序的框图。
具体实施方式
本发明实施例提供包含专用双精度(例如,64位)功能单元的图形处理器。在一个实施例中,双精度功能单元能够执行加法、乘法和积和熔加运算,以及双精度比较和向双精度格式及从双精度格式的格式转换。
I.系统概述
A.计算机系统概述
图1是根据本发明一实施例的计算机系统100的框图。计算机系统100包含经由包含存储器桥105的总线路径通信的中央处理单元(CPU)102和系统存储器104。存储器桥105(其可以是例如常规北桥芯片)经由总线或其它通信路径106(例如,超传送链接)连接到I/O(输入/输出)桥107。I/O桥107(其可以是例如常规南桥芯片)从一个或一个以上用户输入装置108(例如,键盘、鼠标)接收用户输入并将所述输入经由总线106和存储器桥105转发到CPU 102。视觉输出提供于基于像素的显示装置110(例如,常规基于CRT或LCD的监视器)上,所述基于像素的显示装置110在经由总线或其它通信路径113(例如,PCI Express(PCI-E),或加速图形端口(AGP)链接)耦合到存储器桥105的图形子系统112的控制下操作。系统盘114也连接到I/O桥107。开关116在I/O桥107与例如网络适配器118和各种内插式卡120、121等其它组件之间提供连接。其它组件(未明确展示),包含USB或其它端口连接、CD驱动器、DVD驱动器等也可连接到I/O桥107。各种组件间的总线连接可使用总线协议来实施,所述总线协议例如PCI(外围组件互连)、PCI-E、AGP、超传送,或任何其它总线或点到点通信协议,且不同装置之间的连接可使用此项技术中已知的不同协议。
图形处理子系统112包含图形处理单元(GPU)122和图形存储器124,其可例如使用比如可编程处理器、专用集成电路(ASIC)和存储器装置等一个或一个以上集成电路装置来实施。GPU 122可经配置以执行与从由CPU 102和/或系统存储器104经由存储器桥105和总线113供应的图形数据产生像素数据、与图形存储器124交互以存储和更新像素数据等有关的各种任务。举例来说,GPU 122可从在CPU 102上执行的各种程序所提供的2-D或3-D场景数据产生像素数据。GPU 122还可在进行或不进行进一步处理的情况下将经由存储器桥105接收的像素数据存储到图形存储器124。GPU 122还包含经配置以将像素数据从图形存储器124递送到显示装置110的扫描输出模块。
GPU 122还可经配置以针对数据处理任务执行通用计算,所述数据处理任务包含与图形应用有关的任务(例如,对于视频游戏等的物理建模)以及与图形应用无关的任务。对于通用计算,GPU 122有利地读取来自系统存储器104或图形存储器124的输入数据,执行一个或一个以上程序以处理所述数据,并将输出数据写回到系统存储器104或图形存储器124。除了在绘制操作期间使用的其它单精度功能单元外,GPU 122有利地还包含用于通用计算中的一个或一个以上双精度积和熔加单元(图1未图示)。
CPU 102作为系统100的主处理器操作,其控制并协调其它系统组件的操作。明确地说,CPU 102发布控制GPU 122的操作的命令。在一些实施例中,CPU 102将针对GPU 122的命令流写入到命令缓冲器,所述命令缓冲器可在系统存储器104、图形存储器124,或CPU 102和GPU 122两者可存取的另一存储位置中。GPU 122从命令缓冲器读取命令流并与CPU 102的操作异步地执行命令。所述命令可包含用于产生图像的常规绘制命令,以及使在CPU 102上执行的应用程序能够影响GPU 122的用于可能与图像产生无关的数据处理的计算能力的通用计算命令。
将了解,本文展示的系统是说明性的,且可能作出变化和修改。可视需要修改包含桥的数目和布置的总线拓扑。举例来说,在一些实施例中,系统存储器104直接而不是通过桥连接到CPU 102,且其它装置经由存储器桥105和CPU 102与系统存储器104通信。在其它替代拓扑中,图形子系统112连接到I/O桥107而不是连接到存储器桥105。在另外其它实施例中,I/O桥107和存储器桥105可能并入到单一芯片中。本文展示的特定组件是任选的;例如,可能支持任何数目的内插式卡或外围装置。在一些实施例中,消除开关116,且网络适配器118和内插式卡120、121直接连接到I/O桥107。
还可改变GPU 122到系统100的其余部分的连接。在一些实施例中,将图形系统112实施为可插入到系统100的扩展槽中的内插式卡。在其它实施例中,GPU与总线桥(例如,存储器桥105或I/O桥107)集成在单一芯片上。在另外其它实施例中,GPU 122的一些或所有元件可与CPU 102集成。
GPU可具备任何量的局部图形存储器,包含无局部存储器,且可使用处于任何组合中的局部存储器和系统存储器。举例来说,在统一存储器结构(UMA)实施例中,不提供专用图形存储器装置,且GPU专门地或几乎专门地使用系统存储器。在UMA实施例中,GPU可集成到总线桥芯片中或提供为具有将GPU连接到桥芯片和系统存储器的高速总线(例如,PCI-E)的离散芯片。
还应了解,可例如通过将多个GPU包含在单一图形卡上或通过将多个图形卡连接到总线113,而将任何数目的GPU包含在系统中。多个GPU可并行操作以针对相同显示装置或针对不同显示装置产生图像,且一个GPU可经操作以产生图像,同时另一GPU执行通用计算,包含如下文所描述的双精度计算。
另外,体现本发明多个方面的GPU可并入到多种装置中,包含通用计算机系统、视频游戏控制台和其它特殊用途计算机系统、DVD播放器、手持式装置(例如,移动电话或个人数字助理)等。
B.绘制管线概述
图2是根据本发明一实施例可在图1的GPU 122中实施的绘制管线200的框图。在此实施例中,使用一结构来实施绘制管线200,在所述结构中,使用相同并行处理硬件(下文中称为“多线程核心阵列”202)来执行任何可应用的图形相关程序(例如,顶点遮影器、几何遮影器和/或像素遮影器)和通用计算程序。
除了多线程核心阵列202外,绘制管线200还包含前端204和数据汇编器206、设置模块208、光栅化器210、颜色汇编模块212和光栅操作模块(ROP)214,其每一者可使用常规集成电路技术或其它技术实施。
对于绘制操作,前端204例如从图1的CPU 102接收状态信息(STATE)、命令(CMD)和几何数据(GDATA)。在一些实施例中,并不是直接提供几何数据,而是CPU 102提供对系统存储器104中存储几何数据的位置的参考;数据汇编器206从系统存储器104检索所述数据。对于绘制操作,状态信息、命令和几何数据可以具有一般常规性质,且可用于界定所需绘制的图像,包含场景的几何形状、照明、阴影、纹理、运动和/或相机参数。
状态信息和绘制命令界定绘制管线200的各个级的处理参数和动作。前端204将状态信息和绘制命令经由控制路径(未明确展示)导向绘制管线200的其它组件。如此项技术中已知,这些组件可通过在各种控制寄存器中存储或更新在处理期间存取的值来响应于所接收的状态信息,且可通过处理管线中接收的数据而响应于绘制命令。
前端204将几何数据导向数据汇编器206。数据汇编器206将几何数据格式化并准备将其递送到多线程核心阵列202中的几何模块218。
几何模块218引导多线程核心阵列202中的可编程处理引擎(未明确展示)以对顶点数据执行顶点和/或几何遮影器程序,其中所述程序是响应于由前端204提供的状态信息而选择。顶点和/或几何遮影器程序可通过如此项技术中已知的绘制应用程序指定,且不同的遮影器程序可应用于不同顶点和/或图元。在一些实施例中,顶点遮影器程序和几何遮影器程序是使用多线程核心阵列202中的相同可编程处理核心来执行。因此,在某些时间,给定处理核心可作为顶点遮影器操作,其接收并执行顶点程序指令,且在其它时间,同一处理核心可作为几何遮影器操作,其接收并执行几何程序指令。处理核心可多线程化,且执行不同类型的遮影器程序的不同线程可在多线程核心阵列202中同时处于运行中。
在已执行顶点和/或几何遮影器程序之后,几何模块218将经处理的几何数据(GDATA′)传递到设置模块208。设置模块208(其可以是一般常规设计)从每一图元的剪辑空间或屏幕空间坐标产生边缘等式;所述边缘等式可有利地用于确定屏幕空间中的一点在图元内部还是外部。
设置模块208将每一图元(PRIM)提供到光栅化器210。光栅化器210(其可以是一般常规设计)例如使用常规扫描转换算法确定哪些(如果有的话)像素被图元覆盖。如本文所使用,“像素”(或“片段”)一般是指2-D屏幕空间中将针对其确定单一颜色值的区域;像素的数目和布置可以是绘制管线200的可配置参数,且可能或可能不与特定显示装置的屏幕分辨率相关。
在确定哪些像素被图元覆盖之后,光栅化器210将图元(PRIM)连同被图元覆盖的像素的屏幕坐标(X,Y)的列表一起提供到颜色汇编模块212。颜色汇编模块212使从光栅化器210接收的图元和覆盖信息与图元的顶点的属性(例如,颜色分量、纹理坐标、表面法线)相关联,且产生将一些或所有所述属性界定为屏幕坐标空间中的位置的函数的平面等式(或其它适宜的等式)。
这些属性等式可有利地用于像素遮影器程序中以计算属性在图元内的任何位置处的值;常规技术可用于产生所述等式。举例来说,在一个实施例中,颜色汇编模块212针对每一属性U产生平面等式的系数A、B和C,其形式为U=Ax+By+C。
颜色汇编模块212将覆盖像素的至少一个取样位置的每一图元的属性等式(EQS,其可包含(例如)平面等式系数A、B和C)和被覆盖像素的屏幕坐标(X,Y)的列表提供到多线程核心阵列202中的像素模块224。像素模块224引导多线程核心阵列202中的可编程处理引擎(未明确展示)以对由图元覆盖的每一像素执行一个或一个以上像素遮影器程序,其中所述程序是响应于由前端204提供的状态信息而选择。与顶点遮影器程序和几何遮影器程序一样,绘制应用程序可指定待用于任何给定组像素的像素遮影器程序。
像素遮影器程序有利地使用也执行顶点和/或几何遮影器程序的相同可编程处理引擎在多线程核心阵列202中执行。因此,在某些时间,给定处理引擎可作为顶点遮影器操作,其接收并执行顶点程序指令;在其它时间,同一处理引擎可作为几何遮影器操作,其接收并执行几何程序指令;且在另外其它时间,同一处理引擎可作为像素遮影器操作,其接收并执行像素遮影器程序指令。
一旦对于像素或像素群组的处理完成,像素模块224就将经处理的像素(PDATA)提供到ROP 214。ROP 214(其可以是一般常规设计)在可位于(例如)图形存储器124中的帧缓冲器226的构造下将从像素模块224接收的像素值与图像的像素集成。在一些实施例中,ROP 214可遮蔽像素或将新的像素与先前写入到所绘制的图像的像素混合。深度缓冲器、α缓冲器和模板缓冲器也可用于确定每一传入像素对所绘制的图像的贡献(如果有的话)。将对应于每一传入像素值与任一先前存储的像素值的适当组合的像素数据PDATA′写回到帧缓冲器226。一旦图像完成,帧缓冲器226就扫描输出到显示装置和/或经受进一步处理。
对于通用计算,多线程核心阵列可由像素模块224(或由几何模块218)控制。前端204例如从图1的CPU 102接收状态信息(STATE)和处理命令(CMD),并将状态信息和命令经由控制路径(未明确展示)递送到工作分布单元,所述工作分布单元可并入(例如)到颜色汇编器212或像素模块224中。工作分布单元在组成多线程核心阵列202的处理核心之间分布处理任务。可使用各种工作分布算法。
每一处理任务有利地包含执行若干处理线程,其中每一线程执行相同程序。所述程序有利地包含以下指令:从“全局存储器”(例如,系统存储器104、图形存储器124,或GPU 122和CPU 102两者可存取的任何其它存储器)读取输入数据,对输入数据执行包含至少一些双精度运算的各种运算以产生输出数据,并将输出数据写入到全局存储器。特定处理任务对于本发明并不关键。
将了解,本文描述的绘制管线是说明性的,且可能作出变化和修改。管线可包含与所展示的那些单元不同的单元,且处理事件的顺序可不同于本文描述的顺序。此外,本文描述的一些或所有模块的多个实例可并行操作。在一个此类实施例中,多线程核心阵列202包含两个或两个以上几何模块218和并行操作的相等数目的像素模块224。每一几何模块和像素模块联合控制多线程核心阵列202中的不同子组的处理引擎。
C.核心概述
多线程核心阵列202有利地包含适于并行执行大量处理线程的一个或一个以上处理核心,其中术语“线程”是指对一组特定输入数据执行的特定程序的实例。举例来说,线程可以是对单一顶点的属性执行的顶点遮影器程序的实例、对给定图元和像素执行的像素遮影器程序,或通用计算程序的实例。
图3是根据本发明一实施例的执行核心300的框图。可例如在上述多线程核心阵列202中实施的执行核心300经配置以执行用于执行各种计算的任意指令序列。在一些实施例中,相同执行核心300可用于在图形绘制的所有阶段执行遮影器程序,包含顶点遮影器、几何遮影器和/或像素遮影器程序,以及通用计算程序。
执行核心300包含取得与分派单元302、发布单元304、双精度积和熔加(DFMA)单元320、若干(N)其它功能单元(FU)322和寄存器堆324。每一功能单元320、322经配置以执行指定操作。在一个实施例中,DFMA单元320除了如下文描述的其它双精度运算外还有利地实施双精度积和熔加运算。应了解,任何数目的DFMA单元320可包含在核心300中。
其它功能单元322可以是一般常规设计且可支持例如单精度加法、乘法、逐位逻辑运算、比较运算、格式转换操作、纹理过滤、存储器存取(例如,加载和存储操作)、超越函数的近似、内插等多种操作。功能单元320、322可管线化,从而允许在已完成先前指令之前发布新的指令,如此项技术中已知。可提供功能单元的任何组合。
在执行核心300的操作期间,取得与分派单元302从指令存储库(未图示)获得指令,对其进行解码并将其作为具有相关联操作数参考或操作数数据的操作码分派到发布单元304。对于每一指令,发布单元304例如从寄存器堆324获得任何所参考操作数。当指令的所有操作数准备就绪时,发布单元304通过将操作码和操作数发送到DFMA单元320或另一功能单元322而发布指令。发布单元304有利地使用操作码来选择适当功能单元执行给定指令。取得与分派单元302和发布单元304可使用常规微处理器结构和技术来实施,且省略详细描述,因为对理解本发明并不关键。
DFMA单元320和其它功能单元322接收操作码和相关联操作数并对操作数执行指定运算。以结果值的形式提供结果数据,所述结果值可经由数据传递路径326转发到寄存器堆324(或另一目的地)。在一些实施例中,寄存器堆324包含具有分配到特定线程的区段的局部寄存器堆和允许在线程之间共享数据的全局寄存器堆。寄存器堆324可用于存储在程序执行期间的输入数据、中间结果等。寄存器堆324的特定实施方案对本发明并不关键。
在一个实施例中,核心300多线程化且可(例如)通过维持与每一线程相关联的当前状态信息而同时执行至多达最大数目(例如,384、768)的线程。核心300有利地经设计以从一个线程快速切换到另一线程,使得(例如)来自顶点线程的程序指令可在一个时钟循环上发布,之后是来自不同顶点线程或来自不同类型的线程(例如,几何线程或像素线程等)的程序指令。
将了解,图3的执行核心是说明性的,且可能作出变化和修改。任何数目的核心可包含在处理器中,且任何数目的功能单元可包含在一核心中。取得与分派单元302和发布单元304可实施任何所需微结构,(视需要)包含具有按序或无序指令发布的标量、超标量或向量结构;推测性执行模式;单指令多数据(SIMD)指令发布等。在一些结构中,发布单元可接收和/或发布长指令字,其包含用于多个功能单元的操作码和操作数,或用于一个功能单元的多个操作码和/或操作数。在一些结构中,执行核心可包含可并行操作(例如)以执行SIMD指令的每一功能单元的多个实例。执行核心还可包含管线功能单元序列,其中来自一个级中的功能单元的结果转发到稍后级中的功能单元而不是直接转发到寄存器堆;此配置中的功能单元可由单一长指令字或单独指令控制。
另外,能够使用本发明教示的所属领域的一般技术人员将认识到,DFMA单元320可实施为任何微处理器中的功能单元,不限于图形处理器或任何特定处理器或执行核心结构。举例来说,DFMA单元320可实施在通用并行处理单元或CPU中。
C.DFMA单元概述
根据本发明一个实施例,执行核心300包含执行三类操作的DFMA单元320:双精度算术、比较运算,和双精度与其它格式之间的格式转换。
DFMA单元320有利地处理呈双精度浮点格式(且对于转换操作,呈其它浮点和定点格式)的输入和输出;用于不同运算的操作数可呈不同格式。在描述DFMA单元320的实施例之前,将定义代表性格式。
如本文所使用,“fp32”是指标准IEEE 754单精度浮点格式,其中正规浮点数由符号位、八个指数位和23个有效数位表示。指数向上偏置127使得处于2-126到2127范围内的指数使用从1到254的整数来表示。对于“正规”数,23个有效数位解译为一24位尾数的小数部分,其中所隐含的1是整数部分。(本文中当隐含前导1时使用术语“有效数”,而“尾数”用于表示(如果适用的话)已使前导1为显式。)
如本文所使用,“fp64”是指标准IEEE 754双精度浮点格式,其中正规浮点数由符号位、11个指数位和52个有效数位表示。指数向上偏置1023使得处于2-1022到21023范围内的指数使用从1到2046的整数来表示。对于“正规”数,52个有效数位解译为一53位尾数的小数部分,其中所隐含的1是整数部分。
如本文所使用,“fp16”是指普遍用于图形中的“半精度”浮点格式,其中正规浮点数由符号位、5个指数位和10个有效数位表示。指数向上偏置15使得处于2-14到215范围内的指数使用从1到30的整数来表示。对于“正规”数,10个有效数位解译为一11位尾数的小数部分,其中所隐含的1是整数部分。
在fp16、fp32和fp64格式中,指数位中全部为零的数字称为非正规化数字(或“非正规化数(denorm)”),且被解译为尾数中不具有所隐含前导1;此类数字可表示(例如)计算中的下溢。指数位中全部为一且有效数位中全部为零的数字(正或负)称为(正或负)INF;此数字可表示(例如)计算中的溢出。指数位中全部为一且有效数位中为非零数字的数字称为不是一个数字(Not a Number,NaN),且可用于(例如)表示未定义的值。零也被认为是特殊数字且由所有指数和有效数位均设定为零来表示。零可具有任一符号;因此正和负零两者均是允许的。
本文中通过指示格式为带符号还是不带符号的初始“s”或“u”和表示位的总数的数字(例如,16、32、64)来指定固定点格式;因此,s32表示带符号32位格式,u64表示不带符号64位格式等等。对于带符号格式,有利地使用二的补码表示形式。在本文使用的所有格式中,最高有效位(MSB)在位字段中的左侧,且最低有效位(LSB)在右侧。
应了解,在本文中出于说明的目的界定并参考这些格式,且DFMA单元可能支持这些格式或不同格式的任何组合,而不脱离本发明的范围。明确地说,应了解,“单精度”和“双精度”可表示任何两种不同浮点格式,不限于当前定义的标准;双精度格式(例如,fp64)是指使用比相关单精度格式(例如,fp32)大的数目的位来表示较大范围的浮点数和/或以较高精度表示浮点值的任何格式。类似地,“半精度”可通常表示使用比相关单精度格式少的位来表示较小范围的浮点数和/或以较低精度表示浮点数的格式。
现将描述根据本发明的DFMA单元320的实施例。图4是列举可由DFMA单元320的此实施例执行的双精度算术、比较运算和格式转换操作的表400。
部分402列举算术运算。加法(DADD)将两个fp64输入A和C相加并返回fp64和A+C。乘法(DMUL)将两个fp64输入A和B相乘并返回fp64积A*B。积和熔加(DFMA)接收三个fp64输入A、B和C并计算A*B+C。运算为“熔加”,因为积A*B在加上C之前不舍入;使用准确值A*B改进了准确性且遵守浮点算术的即将出现的IEEE 754R标准。
部分404列举比较运算。最大化运算(DMAX)返回fp64操作数A和B中的较大者,且最小化运算(DMIN)返回两者中的较小者。二元测试运算(DSET)对双精度操作数A和B执行若干二元关系测试中的一者并返回指示是否满足所述测试的布尔值。在此实施例中,可测试的二元关系包含大于(A>B)、小于(A<B)、等于(A=B),和无序(A?B,如果A或B任一者为NaN,那么其为真),以及否定(例如,A≠B),和各种组合测试(例如,A≥B、A<>B、A?=B等)。
部分406列举格式转换和舍入运算。在此实施例中,DFMA单元320可将fb64格式数字转换为呈其它64位或32位格式的数字,或反之亦然。D2F运算将操作数A从fp64转换为fp32;F2D将操作数A从fp32转换为fp64。D2I运算将操作数A从fp64转换为s64、u64、s32和u32格式中的任一者;应了解,不同操作码可用于识别目标格式。I2D运算将整数操作数C从s64、u64、s32和u32格式中的任一者转换为fp64格式;再次应了解,不同操作码可用于识别源格式。在此实施例中,DFMA单元320支持到或从双精度格式的所有转换;其它功能单元可执行其它格式转换(例如,fp32与fp16之间,fp32与整数格式之间等)。
D2D运算用于将舍入运算,例如IEEE舍入模式应用于fp64操作数。这些运算将fp64操作数舍入到以fp64格式表示的整数值。在一个实施例中,所支持的D2D运算包含舍位(向零舍入)、最高限度(向+INF舍入)、最低限度(向-INF舍入)和最近(向上或向下至最近整数舍入)。
在此实施例中,DFMA单元320不提供对于例如除法、余数或平方根等较高级数学函数的直接硬件支持。然而,DFMA单元320可用于加速这些运算的基于软件的实施。举例来说,一种常用除法方法估计商q=a/b,接着使用t=q*b-a来测试所述估计值。如果t为零,那么已正确确定商q。如果t不是零,那么使用t的大小来修改所估计的商q,且重复测试直到t变为零为止。可使用单一DFMA运算(其中,A=q,B=b,C=-a)准确地计算每一迭代的测试结果t。类似地,对于平方根,一种常用方法是估计r=a1/2,接着计算t=r*r-a以测试所述估计值并在t不是零的情况下修改r。再次,可使用单一DFMA运算(其中,A=B=r,C=-a)准确地计算每一迭代的测试结果t。
部分II和III描述可执行图4所示的所有运算的DFMA单元320。部分II描述DFMA单元320的电路结构,且部分III描述可如何使用所述电路结构来执行图4中列举的运算。应了解,本文描述的DFMA单元320是说明性的,且可能使用电路区块的适当组合支持其它或不同的功能组合。
II.DFMA单元结构
图5是根据本发明一实施例支持图4所示的所有运算的DFMA单元320的简化框图。在此实施例中,DFMA单元320实施用于所有运算的多级管线。在每一处理器循环上,DFMA单元320可经由操作数输入路径502、504、506接收(例如,从图3的发布单元304)三个新操作数(A0、B0、C0),并经由操作码路径508接收指示待执行的运算的操作码。在此实施例中,运算可以是图4所示的任何运算。除了运算外,操作码还有利地指示操作数的输入格式以及用于结果的输出格式,其可能或可能不与输入格式相同。应注意,图4所示的运算可具有与其相关联的多个操作码;例如,对于具有s64输出的D2I可存在一个操作码,且对于具有s32输出的D2I可存在不同的操作码等。
DFMA单元320穿过其所有管线级处理每一运算,并在信号路径510上产生64位(或对于某些格式转换操作为32位)结果值(OUT)且在信号路径512上产生相应条件码(COND)。这些信号可传播(例如)到如图3所示的寄存器堆324,传播到发布单元304,或传播到处理器核心的其它元件,这取决于结构。在一个实施例中,一个管线级对应于一个处理器循环;在其它实施例中,一级可包含多个处理器循环。另外,管线内的不同路径有利地并行操作。
部分II.A提供DFMA管线的概述,且部分II.B-I详细描述每一部分的电路区块。
A.DFMA管线
可参考DFMA运算期间如何使用电路区块来获得对管线的初始理解。操作数准备区块514执行操作数格式化(对于尚未呈fp64格式的操作数)和特殊数字检测;操作数准备区块514还从输入fp64操作数中提取尾数(Am、Bm、Cm)、指数(Ae、Be、Ce)和符号位(As、Bs、Cs)。在一个实施例中,不存在非法操作数组合;可简单地忽略特定运算中未使用的任何操作数。
尾数路径516计算尾数Am和Bm的积。并行地,指数路径518使用指数Ae和Be来确定积A*B与操作数C之间的相对对准,并将操作数C的对准的尾数(C_align)供应到尾数路径516。尾数路径516将C_align加上积Am*Bm,接着正规化结果。基于正规化,尾数路径516提供对准信号(ALIGN_NORM)回到指数路径518,指数路径518使用ALIGN_NORM信号连同指数Ae、Be和Ce一起来确定最后结果的指数。
符号路径520从操作数准备区块514接收符号位As、Bs和Cs,并确定结果的符号。尾数路径516检测结果为零的情况并将零结果(R_ZERO)以信号通知符号路径520。
输出区段522从尾数路径516接收结果尾数Rm,从指数路径518接收结果指数Re,并从符号路径520接收结果符号Rs。输出区段522还从操作数准备区块514接收特殊数字信号(SPC)。基于此信息,输出区段522格式化最后结果(OUT)以递送到输出路径510上,并在输出路径512上产生条件码(COND)。条件码(其有利地包含比结果少的位)载运关于结果的性质的一般信息。举例来说,条件码可包含指示结果是否为正、负、零、NaN、INF、非正规化数等的位。如此项技术中已知,在随结果提供条件码的情况下,所述结果的后续消费者有时可使用条件码而不是结果本身来进行其处理。在一些实施例中,条件码可用于指示运算的执行期间异常或其它事件的发生。在其它实施例中,可完全省略条件码。
应了解,虽然例如“尾数路径”和“指数路径”等名称可暗示每一路径的各种电路区块在某些运算(例如,DFMA)期间执行的功能,但可以随运算而定的方式针对多种用途影响沿着内部数据路径的任一者的电路区块。下文描述实例。
除了数据路径外,DFMA单元320还提供控制路径,图5中由控制区块530表示。控制区块530接收操作码并产生本文一般表示为“OPCTL”的各种随操作码而定的控制信号,其可与穿过管线的数据传播同步而传播到每一电路区块。(图5中未展示OPCTL信号到各种电路区块中的连接。)如下文所描述,OPCTL信号可用于响应于操作码而启用、停用和以另外方式控制DFMA单元3220的各种电路区块的操作,使得可使用相同管线元件执行不同操作。本文提及的各种OPCTL信号可包含操作码本身或(例如)通过控制区块530中实施的组合逻辑从操作码导出的某一其它信号。在一些实施例中,可在若干管线级中使用多个电路区块来实施控制区块530。应了解,在给定操作期间提供到不同区块的OPCTL信号可以是相同信号或不同信号。鉴于本揭示内容,所属领域的一般技术人员将能够构造适宜的OPCTL信号。
应注意,给定级的电路区块可能需要不同量的处理时间,且特定级处所需的时间可能依据操作的不同而变化。因此,DFMA单元320还可包含各种定时和同步电路(图5中未展示)以控制不同路径上数据从一个管线级到下一管线级的传播。可使用任何适当的定时电路(例如,锁存器、传输门等)。
A.操作数准备
图6是根据本发明一实施例的操作数准备区块514的框图。操作数准备区块514接收输入操作数A、B和C并将尾数部分(Am、Bm、Cm)提供到尾数路径516,将指数部分(Ae、Be、Ce)提供到指数路径518,并将符号位(As、Bs、Cs)提供到符号路径520。
操作数A、B和C在各自NaN检测区块612、614、616和各自绝对值/负值区块618、620、622处被接收。每一NaN检测区块612、614、616确定所接收的操作数是否为NaN(指数位中全部为一,且有效数位中为非零数字)并产生相应控制信号。
绝对值/负值区块618、620、622可用于响应于OPCTL信号(未明确展示)反转操作数的符号位。举例来说,图4中列举的运算的任一者可能指定将使用操作数的负值或操作数的绝对值。区块618、620、622可反转符号位以将操作数取负值或迫使符号位变为非负状态(对于IEEE 754格式为零)。如果输入操作数为NaN,那么适当绝对值/负值区块618、620、622还“安定”NaN(例如,通过将有效数的前导位设定为1),从而保持符号位。绝对值/负值区块618、620、622将其各自输出提供到操作数选择多路复用器632、634、636。
对于双精度算术,可直接使用由绝对值/负值区块618产生的操作数A、B和C。对于比较运算,A/B比较电路624将操作数A与B进行比较。在一个实施例中,绝对值/负值电路620将操作数B取负值,且A/B比较电路624计算A与-B的和,如同其是定点数一样。如果结果为正,那么A大于B;如果结果为负,那么A小于B;如果结果为零,那么A等于B。A/B比较电路624还可从NaN检测电路612和614接收NaN信息(这些路径在图6中未明确展示)。如果A或B(或两者)是NaN,那么A和B“无序”。将结果信息提供到控制逻辑630。控制逻辑630将结果信息作为信号R_TEST提供到输出区段522,并且还将控制信号提供到操作数选择多路复用器632、634、636。
对于格式转换操作数,输入可能不呈fp64格式。fp32提取电路626在F2D运算期间有效。fp32提取电路626接收操作数A并对于非正规fp32输入执行所有测试。fp32提取电路626还将所接收操作数的有效数字段从23位扩展到52位(例如,通过加上尾随零)。fp32提取电路626将8位fp32指数扩展到11位,且将指数偏置从127增加到1023(例如,通过将896加上fp32指数)。
不带符号/带符号(U/S)提取电路628在I2D运算期间有效。U/S提取电路628接收呈u32、s32、u64或s64格式中的任一者的固定点操作数C,并将其准备好以转换为fp64。U/S提取电路628将固定点操作数从1的补码(或2的补码)形式转换为符号-量值形式,并预备或附加零以对准有效数字段中的操作数。U/S提取电路628将其输出作为I2D输入信号提供到操作数选择多路复用器636,且还提供到指数路径518。
操作数选择多路复用器632、634、636响应于来自控制逻辑630的信号以选择操作数A、B和C。操作数选择多路复用器632在来自绝对值/负值电路618的操作数A与常数值0.0和1.0(以fp64格式表达)之间进行选择。对于DMUL和DFMA运算,选择操作数A。对于DMIN(DMAX)运算,如果A<B(A>B),那么选择操作数A;否则,选择1.0。对于DADD和I2D运算,选择0.0。
操作数选择多路复用器634在来自绝对值/负值电路620的操作数B与常数值0.0和1.0(以fp64格式表达)之间进行选择。对于DMUL和DFMA运算,选择操作数B。对于DMIN(DMAX)运算,如果B<A(B>A),那么选择操作数B;否则,选择1.0。对于DADD和I2D运算,选择0.0。
操作数选择多路复用器636在来自绝对值/负值电路622的操作数C、来自fp32提取电路626的所提取fp32值、来自U/S提取电路628的所提取不带符号或带符号整数值与常数值0.0(以fp64格式表达)之间进行选择。对于DADD和DFMA运算,选择操作数C。对于DMUL和比较运算,选择常数0.0。对于F2D运算,选择来自fp32提取电路626的所提取fp32值,且对于I2D运算,选择来自U/S提取电路628的所提取u/s值。
将由选择多路复用器632、634、636选择的操作数A、B和C提供到特殊数字检测电路638、640、642。对于fp64操作数,特殊数字检测电路638、640、642检测所有特殊数字条件,包含非正规化数、NaN、INF和零。对于F2D运算,特殊数字检测电路642经由路径644从fp32提取电路626接收fp32特殊数字信息。每一特殊数字检测电路638、640、642产生特殊数字信号(SPC),其指示操作数是否为特殊数字,且如果是,那么为何种类型。特殊数字信号SPC在信号路径524上提供到输出区段522,如图5所示。可使用一般常规设计的特殊数字检测逻辑。在一个替代实施例中,不在电路638、640、642中重复NaN检测(由电路612、614和616执行);事实上,每一特殊数字检测电路638、640、642从NaN检测电路612、614和616的相应一者接收NaN信号,并使用所述信号来确定操作数是否为NaN。
不管是否检测到任何特殊数字,特殊数字检测电路638、640和642将操作数分离为尾数、指数和符号位。特殊数字检测电路638将操作数A的尾数部分(Am)提供到尾数路径516(图5),将操作数A的指数部分(Ae)提供到指数路径518,并将符号位(As)提供到符号路径520。特殊数字检测电路640将操作数B的尾数部分(Bm)提供到尾数路径516,将操作数B的指数部分(Be)提供到指数路径518,并将符号位(Bs)提供到符号路径520。特殊数字检测电路642将操作数C的尾数部分(Cm)和指数部分(Ce)提供到指数路径518,并将符号位(Cs)提供到符号路径520。在一些实施例中,特殊数字检测电路638、640、642将前导1附加到尾数Am、Bm、Cm(数字为非正规化数的情况除外)。
B.指数路径
图7是根据本发明一实施例的指数路径518的框图。
指数计算电路702从操作数准备区块514(图5)接收指数位Ae、Be和Ce,并计算DFMA结果A*B+C的区块指数。可使用常规指数计算电路。在一个实施例中,如果所有操作数均为正规数字,那么指数计算电路将Ae与Be相加并减去fp64指数偏置(1023)以确定积A*B的指数,接着选择积指数和指数Ce中的较大者作为DFMA结果的区块指数(BLE)。将此区块指数BLE提供到下游最终指数计算电路704。如果一个或一个以上操作数为非正规的(如由特殊数字信号SPC指示),那么可使用适当逻辑来确定区块指数BLE。在其它实施例中,在输出区段522中处理涉及特殊数字的运算的指数确定,如下文所描述。
另外,指数计算区块702确定为了使Cm与积Am*Bm对准操作数C的尾数将有效左移或右移的量。此量作为Sh_C控制信号提供到移位电路706。此控制信号有利地说明Cm的额外填充以使得有效左移或右移可始终通过右移Cm来实现。
尾数Cm提供到负值电路708,所述负值电路708在C与积A*B之间存在相对减号的情况下有条件地将Cm取负值(例如,使用1的补码负值)。相对减号在如下文所描述的符号路径520上检测到,且符号控制信号SignCTL指示是否存在相对减号。负值电路708的输出(Cm或~Cm)提供到移位电路706。
在一个实施例中,移位电路706是可将54位尾数Cm右移至多达157位的217位桶形移位器;Sh_C信号决定右移Cm的量。尾数Cm有利地以对准进入移位器,使得可如同所需那样远地右移Cm。选择217位大小以允许有足够的空间将53位尾数Cm(加上保护位和舍入位)完全对准到106位积A*B(加上积的保护位和舍入位)的左侧或完全对准到其右侧,所述106位积A*B将以55位对准到217位字段的MSB的右侧。可丢弃右移离开桶形移位器的任何位。在其它实施例中,使用旗标位跟踪是否所有右移离开桶形移位器的位均为“1”,且此信息可用于下文描述的舍入运算中。
在替代实施例中,常规交换多路复用器可用于在积Am*Bm与Cm之间选择较大操作数,接着将较小操作数右移。
对于D2D运算,尾数Cm还被提供到D2D逻辑电路710。D2D逻辑电路710接收尾数Cm、指数Ce和符号Cs并应用整数舍入规则。在一个实施例中,D2D逻辑电路710基于指数Ce确定二元点的位置,接着基于OPCTL信号(未明确展示)应用选定的舍入规则。可使用用于实施舍入模式的常规逻辑,且可支持舍入模式的任何组合,包含(但不限于)舍位、最高限度、最低限度和最近模式。
选择多路复用器712从U/S提取电路628(图6)接收经移位尾数C_Shift、D2D逻辑电路输出和I2D输入,并基于OPCTL信号选择这些输入中的一者作为待供应到尾数路径516的经对准尾数C_align。对于双精度算术和比较运算,选择操作数C_Shift。对于格式转换D2D或I2D,选择适当的替代输入。
下溢逻辑713经配置以检测fp64和fp32结果中的潜在下溢。对于除D2F运算以外的运算,下溢逻辑713确定11位fp64区块指数BLE是否为零或足够接近零以使得可能实现非正规化结果。基于区块指数,下溢逻辑713确定尾数在指数达到零之前可左移的位的最大数目。将此数字作为8位下溢信号U_fp64提供到尾数路径516(见图8)。对于D2F运算,将指数视为8位fp32指数,且下溢逻辑713确定所允许的最大左移。将此数字作为8位下溢信号U_fp32提供到尾数路径516。
指数路径518还包含最终指数计算逻辑电路704。区块指数BLE提供到减法电路720。还提供到减法电路720的是来自尾数路径516的区块移位信号(BL_Sh)。如下文所描述,BL_Sh信号反映当积Am*Bm加上操作数C_align时MSB的消去效果。减法电路720从BLE减去BL_Sh以确定差EDIF。下溢/溢出电路722检测减法结果EDIF中的下溢或溢出。加1电路724将1加上结果EDIF,且基于下溢/溢出条件,多路复用器720在EDIF与EDIF+1信号之间选择作为结果指数Re。结果Re和下溢/溢出信号(U/O)提供到输出区段522。
C.尾数路径
图8是根据本发明一实施例的尾数路径516的框图。尾数路径516对操作数A、B和C的尾数执行积与和运算。
53x53乘法器802从操作数准备区块514(上文所描述)接收尾数Am和Bm,并计算106位积Am*Bm。积提供到168位加法器804,所述168位加法器804还接收经对准尾数C_align。由桶形移位器706使用的217位字段的尾随位可丢弃,或可保留指示尾随位为非零还是全部为1的旗标位。加法器804产生和与~和(和的2的补码)输出。多路复用器806基于和的MSB(符号位)在和与~和之间进行选择。选定的和(S)提供到零检测电路814并提供到左移电路816。零检测电路814确定选定的和S是否为零并将相应R_ZERO信号提供到符号路径520。
尾数路径516还正规化和S。使用前导零检测(LZD)电路808、810并行地对和与~和两者执行前导零检测。每一LZD电路808、810产生指示其输入中的前导零的数目的LZD信号(Z1、Z2)。LZD多路复用器812基于和的MSB(符号位)选择相关LZD信号(Z1或Z2)。如果多路复用器806选择和,那么选择Z2,且如果多路复用器806选择~和,那么选择Z1。选定的LZD信号作为区块移位信号BL_Sh提供到指数路径518,在指数路径518处其被用于如上所述调节结果指数。
正规化逻辑818选择确定和S的正规化移位的左移量Lshift。对于正规数结果,左移量有利地足够大以将前导1移出尾数字段,从而留下52位有效数(加上保护和舍入位)。然而,在一些情况下,结果是应表达为fp64或fp32非正规化数的下溢。在一个实施例中,对于除D2F以外的运算,除非BL_Sh大于下溢信号U_fp64,否则正规化逻辑818从LZD多路复用器812选择输出BL_Sh,在BL_Sh大于下溢信号U_fp64的情况下,正规化逻辑818选择U_fp64作为左移量。对于D2F运算,正规化逻辑818使用fp32下溢信号U_fp32来限制左移量Lshift。
左移电路816将和S左移所述量Lshift。结果Sn提供到舍入逻辑820,提供到加1加法器822并提供到尾数选择多路复用器824。舍入逻辑820有利地实施针对IEEE标准算术界定的四个舍入模式(最近、最低限度、最高限度和舍位),其中不同模式可能选择不同结果。OPCTL信号或另一控制信号(未图示)可用于指定舍入模式中的一者。基于舍入模式和经正规化和Sn,舍入逻辑820确定选择结果Sn还是由加1加法器822计算的Sn+1。选择多路复用器824通过选择适当结果(Sn或Sn+1)来响应于来自舍入逻辑820的控制信号。
多路复用器824选择的结果传递到格式化区块826。对于具有浮点输出的运算,区块826将尾数Rm提供到输出区段522。和S有利地为至少64位宽(以支持整数运算),且还可通过格式化区块826来去除无关的位。对于D2I运算(其具有整数输出),格式化区块826将结果分离为含有LSB的52位int_L字段以及含有MSB的11位int_M字段。将Rm、int_L和int_M递送到输出区段522。
D.符号路径
图9是根据本发明一实施例的符号路径520的框图。符号路径520从操作数准备区块514(图5)接收操作数的符号As、Bs和Cs。符号路径520还从尾数路径516接收零结果信号R_Zero,并接收指示进行中的运算的类型的OPCTL信号,以及从操作数准备区块514接收特殊数字信号SPC。基于此信息,符号路径520确定结果的符号并产生符号位Rs。
更明确地说,符号路径520包含积/和电路902和最终符号电路904。积/和电路902从操作数准备区块514接收操作数A、B和C的符号位As、Bs和Cs。积/和电路902使用符号位As和Bs以及常规符号逻辑规则确定积A*B的符号(Sp),接着将积的符号与符号位Cs进行比较以确定积与操作数C具有相同符号还是相反符号。基于此确定,积/和电路904对SignCTL信号进行断言或解除断言,所述SignCTL信号被递送到最终符号电路904并递送到指数路径518(图7)中的负值区块708。此外,如果积与操作数C具有相同符号,那么最后结果也将具有所述符号;如果积与操作数C具有相反符号,那么结果将取决于哪一个更大。
最终符号电路904接收确定最终符号所需的所有信息。明确地说,最终符号电路904从积/和电路902接收符号信息,包含积的符号Sp和SignCTL信号,以及接收符号位As、Bs和Cs。最终符号电路904还从尾数路径516接收零检测信号R_ZERO,并从操作数准备区块514接收特殊数字信号SPC。最终符号电路904还从尾数路径516上的加法器804接收和的MSB,其指示和为正还是负。
基于此信息,最终符号电路904可使用常规符号逻辑来确定结果的符号位Rs。举例来说,对于DFMA运算,如果符号位Sp与Cs相同,那么结果也将具有所述符号。如果Sp与Cs为相反符号,那么尾数路径516中的加法器804计算(Am*Bm)-C_align。如果Am*Bm大于C_align,那么加法器804将计算正结果和,且应选择积符号Sp;如果Am*Bm小于Calign,那么加法器804将计算负结果和,且应选择符号Cs。加法器804的和输出的MSB指示结果的符号且可用于驱动选择。如果结果和为零,那么断言R_ZERO信号,且最终符号电路904可视需要选择任一符号(零在fp64格式中可为正或负)。对于其它运算,最终符号电路904可通过一个或另一操作数的符号作为最终符号。
E.输出区段
图10是根据本发明一实施例的DFMA单元320的输出区段522的框图。
输出多路复用器控制逻辑1002从指数路径518(图7)接收下溢/溢出(U/O)信号,从操作数准备区块514(图6)接收R_test和SPC信号,以及指示进行中的运算的类型的OPCTL信号。基于此信息,输出多路复用器控制逻辑1002产生针对有效数选择多路复用器1004和指数选择多路复用器1006的选择控制信号。输出多路复用器控制逻辑1002还产生可指示(例如)溢出或下溢、NaN或其它条件的条件码信号COND。在一些实施例中,条件码还用于在DSET运算期间以信号通知布尔结果。
有效数选择多路复用器1004从尾数路径516接收结果有效数Rm和一整数输出的多达52位(在D2I运算期间使用),以及若干特殊值。在一个实施例中,特殊值包含:一的52位字段(用于表达D2I运算的最大64位整数);零的52位字段(在0.0或1.0为结果的情况下使用);52位字段0x0_0000_8000_0000(用于表达D2I运算的最小32位整数);具有前导1的52位字段(用于表示内部产生的安定NaN);max_int32值,例如0x7fff_ffff_ffff_ffff(用于表达D2I运算的最大32位整数);安定的NaN值(用于通过来自操作数准备区块514的为NaN的输入操作数);以及min_denorm值,例如最后位位置中的1(用于下溢)。依据运算以及操作数或结果的任一者是否为特殊数字,可选择输入中的任一者。
指数选择多路复用器1006从指数路径518接收结果指数Re和多达11整数位(整数格式输出的MSB),以及若干特殊值。在一个实施例中,特殊值包含:0x3ff(fp64中1.0的指数)、0x000(非正规化数和0.0的指数)、0x7fe(正规化数字的最大fp64指数)以及0x7ff(用于fp64 NaN或INF结果)。依据运算以及操作数或结果的任一者是否为特殊数字,可选择输入中的任一者。
串联区块1008接收符号位Rs、由多路复用器1004选择的有效数位和由多路复用器1006选择的指数位。串联区块1008将结果格式化(例如,依据IEEE 754标准,按符号、指数、有效数的次序)并提供64位输出信号OUT。
F.操作数绕过或通过路径
在一些实施例中,DFMA单元320提供允许操作数在未修改的情况下传播穿过各种电路区块的绕过或通过路径。举例来说,在一些运算期间,乘法器802将输入(例如,Am)乘以1.0,从而有效地通过输入Am。不同于将Am乘以1.0,可提供围绕乘法器802的用于输入Am的绕过路径。绕过路径有利地消耗与乘法器802相同数目的时钟循环,使得Am在正确时间到达到加法器804的输入。但乘法器802当其被绕过时可设定为无效或低功率状态,借此减少功率消耗以换取电路面积的较小增加。同样,在一些运算期间,加法器804用于将零加上输入(例如,C_align),从而有效地通过输入C_align。不同于将零加上C_align,可提供围绕加法器804的用于输入C_align的绕过路径,尤其对于事先知道多路复用器806应选择加法器804的和与~和输出中的哪一者的运算;输入C_align可被绕到和与~和路径中的正确一者上。再次,绕过路径有利地消耗与加法器804相同数目的时钟循环,使得定时不受影响,但功率消耗可减少,因为加法器804可针对绕过其的运算置于无效或低功率状态。
因此,部分III(下文)中的运算描述可参考被绕过或通过到达特定电路区块的各种操作数;应了解,这可通过以下方式实现:控制任何介入电路区块以执行不影响操作数的运算(例如,加上零或乘以1.0),使得到区块的输入作为输出或借助使用绕过路径而被通过。此外,遵循围绕某些电路区块的绕过或通过路径不一定需要在后续电路区块处继续遵循绕过路径。另外,在一个电路区块中修改的值可遵循围绕后续电路区块的绕过路径。在运算期间绕过特定电路区块的情况下,所述电路区块可设定为无效状态以减少功率消耗,或允许例如通过使用选择多路复用器或其它电路元件使其输出被忽略的情况下正常操作。
将了解,本文描述的DFMA单元是说明性的,且可能作出变化和修改。本文描述的许多电路区块提供常规功能,且可使用此项技术中已知的技术实施;因此,已省略对这些区块的详细描述。可修改运算电路至区块的划分,且可组合或改变区块。另外,还可修改或改变管线级的数目和特定电路区块或运算到特定管线级的指派。针对特定实施方案的电路区块的选择和指派将取决于所支持的运算组,且所属领域的技术人员将认识到,并非每个可能的运算组合都需要本文描述的所有区块。
III.DFMA单元运算
DFMA单元320有利地影响上述电路区块而以区域有效方式支持图4中列举的所有运算。因此,DFMA单元320的运算在至少一些方面取决于正执行哪一运算。以下部分描述使用DFMA单元320执行图4中列举的运算的每一者。
应注意,在DFMA单元320内处理浮点异常(包含,例如溢出或下溢情形),而不需要额外处理循环。举例来说,在图5的操作数准备区块514中检测到其中输入操作数为NaN或其它特殊数字的运算,且在输出区段522中选择适当的特殊数字输出。当在运算过程中发生NaN、下溢、溢出或其它特殊数字的情况下,检测所述情形且在输出区段522中选择适当的特殊数字输出。
A.积和熔加(DFMA)
对于DFMA运算,DFMA单元320接收呈fp64格式的操作数A0、B0和C0,以及指示将执行DFMA运算的操作码。NaN电路612、614、616确定选定操作数中的任一者是否为NaN。绝对值/负值电路618、620、622视需要针对每一操作数将符号位取负值(或不这样做)。操作数选择多路复用器632、634和636选择绝对值/负值电路618、620、622的各自输出并将那些输出提供到特殊数字检测电路638、640、642。特殊数字检测电路638、640和642确定每一操作数是否为特殊数字且在路径524上产生适当的特殊数字SPC信号。特殊数字检测电路638、640和642将尾数Am、Bm和Cm(对于正规数字附加有前导1,且对于非正规化数附加有前导零)提供到尾数路径516,将指数Ae、Be和Ce提供到指数路径518,并将符号位As、Bs和Cs提供到符号路径520。
A/B比较电路624、fp32提取电路626和U/S整数提取电路628不用于DFMA运算,且这些电路可视需要设定为无效或低功率状态。
在信号路径520上,积/和电路902从符号位As和Bs确定积A*B为正还是负,且将积的符号Sp与符号位Cs进行比较。如果积与Cs具有相反符号,那么断言SignCTL信号以指示相反符号;如果积与Cs具有相同符号,那么将SignCTL信号解除断言。
在指数路径518(图7)上,指数计算区块702接收指数Ae、Be和Ce。指数计算区块702将指数Ae和Be相加以确定积A*B的区块指数,接着选择积区块指数和指数Ce中的较大者作为结果区块指数BLE。指数计算区块702还从积区块指数和指数Ce中的较大者减去两者中的较小者并产生相应移位控制信号Sh_C。下溢逻辑713检测区块指数BLE是否对应于下溢或潜在下溢并产生下溢信号U_fp64。(U_fp32信号在DFMA运算期间不使用。)
负值区块708从操作数准备区块514接收尾数Cm,并从信号路径520接收SignCTL信号。如果SignCTL信号经断言,那么负值区块708反转尾数Cm以说明相对减号,并将经反转Cm提供到移位电路706。否则,负值区块708将Cm在不修改的情况下提供到移位电路706。
移位电路706将由负值区块708提供的尾数Cm右移对应于移位控制信号Sh_C的量,并将经移位C_Shift尾数提供到选择多路复用器712。选择多路复用器712选择经移位尾数C_Shift并将经移位尾数作为操作数C_align提供到尾数路径516。
在尾数路径516(图8)中,乘法器802计算106位积Am*Bm并将积提供到168位加法器804。乘法器802的运算可与指数计算区块702的运算并行发生。
加法器804从指数路径518的选择多路复用器712接收操作数C_align,并将输入Am*Bm和C_align相加以确定和与~和。基于和的MSB,多路复用器806选择输出中的一者作为最终和。如果和为正(MSB零),那么选择和,而如果和为负(MSB一),那么选择~和。LZD电路808和810分别确定~和与和中的前导零的数目;多路复用器812选择LZD输出中的一者作为所述前导零数目,并将前导零信号BL_Sh提供到指数路径518且提供到正规化逻辑818。
多路复用器806选择的最终和S还提供到零检测电路814。如果最终和为零,那么零检测电路814向符号路径520断言R_ZERO信号;否则,不断言R_ZERO信号。
除非U_fp64信号指示下溢,否则正规化逻辑818选择前导零信号作为正规化信号Lshift;在U_fp64信号指示下溢的情况下,尾数仅移位到对应于指数1的点,使得以非正规化形式表达结果。移位电路816响应于Lshift信号将选定的和S左移以产生正规化和Sn。加1加法器822将1加上正规化和Sn。舍入逻辑820使用舍入模式(由OPCTL信号指定)和正规化和Sn的LSB(路径821上)来确定是否应上舍入所述正规化和。如果是,那么舍入逻辑820控制选择多路复用器824从加法器822选择输出Sn+1;否则,选择多路复用器824选择正规化和Sn。选择多路复用器824将选定结果Rm提供到输出区段522。在一些实施例中,选择多路复用器824从结果尾数丢弃前导位(对于正规数字为1)。
与舍入运算并行,指数路径518(图7)计算结果指数Re。明确地说,减法区块720从指数计算区块702接收区块指数BLE,并从尾数路径516接收区块移位信号BL_Sh。减法区块720将其两个输入相减并将结果EDIF提供到下溢/溢出逻辑722、加1加法器724和选择多路复用器726。下溢/溢出逻辑722使用结果的MSB确定是否已发生下溢或溢出,并产生反映下溢或溢出的存在或不存在的U/O信号。基于U/O信号,选择多路复用器726在减法结果EDIF与加1加法器724的输出之间进行选择。将选定值作为结果指数Re并连同U/O信号一起提供到输出区段522。
与舍入运算并行,符号路径520(图9)中的最终符号电路904基于由积/和电路902确定的符号、从尾数路径516接收的R_ZERO信号及和的MSB,以及从操作数准备区块514接收的特殊数字SPC信号而确定最终符号Rs。
输出区段522(图10)从尾数路径516接收结果尾数Rm,从指数路径518接收结果指数Re,并从符号路径520接收结果符号Rs,以及从操作数准备区块514接收特殊数字SPC信号,和从指数路径518接收U/O信号。基于SPC和U/O信号,输出多路复用器控制逻辑1002产生用于有效数多路复用器1004的控制信号和用于指数多路复用器1006的控制信号。输出多路复用器控制逻辑1002还产生例如指示结果为溢出、下溢还是NaN的各种条件码COND。
有效数多路复用器1004选择有效数Rm用于正规数和非正规化数。对于下溢,选择零或min_denorm有效数,这取决于舍入模式。对于溢出(INF),选择有效数0x0_0000_0000_0000。在任何输入操作数为NaN的情况下,选择安定的NaN有效数。如果在运算期间产生NaN,那么选择内部(安定)NaN尾数0x8_0000_0000。
指数多路复用器1006选择结果指数Re用于正规数。对于非正规化数和下溢,选择指数0x000。对于INF或NaN,选择最大指数0x7ff。
串联区块1008接收选定有效数和指数及符号Rs并产生最终fp64结果OUT。可视需要设定条件码。
应注意,DFMA单元320在相同数目的循环中完成所有DFMA运算,而不管溢出还是下溢。DFMA单元320还根据IEEE 754标准针对浮点算术实施预期默认溢出/下溢行为:返回适当的结果OUT,且设定状态旗标(在条件码COND中)以指示溢出/下溢条件。在一些实施例中,可实施用户定义的陷阱以处理这些情形;条件码COND可用于确定是否应发生陷阱。
B.乘法
乘法(DMUL)可与上述DFMA运算相同地实施,其中操作数C设定为零;DFMA单元320接着计算A*B+0.0。在一个实施例中,当操作码指示DMUL运算时,选择多路复用器636(图6)可用于以fp64零值代替输入操作数C。
C.加法
加法(DADD)可与上述DFMA运算相同地实施,其中操作数B设定为1.0;DFMA单元320接着计算A*1.0+C。在一个实施例中,当操作码指示DADD运算时,选择多路复用器634(图6)可用于以fp64 1.0值代替输入操作数B。
D.DMAX和DMIN
对于DMAX或DMIN运算,操作数准备区块514(图6)接收操作数A和B。NaN电路612和614确定选定操作数的任一者或两者是否为NaN。绝对值/负值电路618、620视需要将符号位取负值(或不这样做)。
A/B比较电路624从绝对值/负值电路618、620接收操作数A和B并例如通过从A中减去B(如同操作数是整数那样)来执行比较。基于减法,A/B比较电路624产生指示A大于、小于还是等于B的COMP信号。COMP信号提供到控制逻辑630,其产生相应R_Test信号且还产生用于选择多路复用器632、634和636的选择信号。
明确地说,对于DMAX运算,操作数A多路复用器632在A大于B的情况下选择操作数A,且在A小于B的情况下选择操作数1.0,而操作数B多路复用器634在B大于A的情况下选择操作数B,且在B小于A的情况下选择操作数1.0。对于DMIN运算,操作数A多路复用器632在A小于B的情况下选择操作数A,且在A大于B的情况下选择操作数1.0,而操作数B多路复用器634在B小于A的情况下选择操作数B,且在B大于A的情况下选择操作数1.0。对于DMAX和DMIN两者,可通过控制多路复用器632选择操作数A同时多路复用器634选择操作数1.0或通过控制多路复用器632选择操作数1.0同时多路复用器634选择操作数B来处理A=B的特殊情况。在任何情况下,操作数C多路复用器636有利地操作以选择操作数0.0。
特殊数字检测电路638、640和642确定操作数是否为特殊数字并在路径524上产生适当的特殊数字SPC信号。特殊数字检测电路638、640和642将尾数Am、Bm和Cm(对于正规数附加有前导1,且对于非正规化数附加有前导零)提供到尾数路径516;将指数Ae、Be和Ce提供到指数路径518,并将符号位As、Bs和Cs提供到符号路径520。
fp32提取电路626和不带符号/带符号整数提取电路628不用于DMAX或DMIN运算,且这些电路可视需要设定为无效或低功率状态。
尾数路径516、指数路径518和符号路径520如上文针对DFMA运算所描述而操作。对于DMAX运算,尾数路径516、指数路径518和符号路径520计算max(A,B)*1.0+0.0;对于DMIN运算,尾数路径516、指数路径518和符号路径520计算min(A,B)*1.0+0.0。因此,对于正规数,Rm、Re和Rs对应于所需结果的尾数,指数和符号。
输出区段522(图10)处理特殊数字。明确地说,DMAX和DMIN运算的结果针对NaN操作数未定义,且结果可设定为NaN值。输出多路复用器控制逻辑1002使用特殊数字SPC信号来确定结果是否应为NaN;如果是,那么有效数多路复用器1004选择安定的NaN输入,同时指数多路复用器选择0x7ff。否则,选择结果Rm和Re。可视需要设定条件码。
在替代实施例中,可绕过尾数路径516、指数路径518和符号路径520的一些或所有组件;被绕过的组件可置于低功率状态。绕过路径可包含各种延迟电路(锁存器等)使得所述路径占据与尾数路径516、指数路径518和符号路径520中的最长者相同数目的管线级。这确保DFMA单元320中的所有运算需要完成相同数目的循环,其简化了指令发布逻辑。
E.DSET
与DMAX和DMIN一样,DSET运算使用操作数准备区块514(图6)中的A/B比较电路624。不同于DMAX和DMIN,DSET不返回输入操作数的一者,而是返回指示是否满足所测试条件的布尔值。
对于DSET运算,操作数准备区块514(图6)接收操作数A和B。NaN电路612和614确定选定操作数中的任一者或两者是否为NaN。绝对值/负值电路618、620视需要将符号位取负值。
A/B比较电路624从绝对值/负值电路618、620接收操作数A和B并例如通过从A中减去B(如同操作数是整数那样)来执行比较并考虑其各自符号位。基于减法,A/B比较电路624产生指示A大于、小于还是等于B的COMP信号。COMP信号提供到控制逻辑630,其产生相应R_Test信号且还产生用于A-多路复用器632、B-多路复用器634和C-多路复用器636的选择信号。在一个实施例中,由于DSET运算的结果为布尔值,所以所有三个多路复用器632、634和636选择零操作数。在另一实施例中,多路复用器632和634选择操作数A和B;特殊数字检测电路638和640确定操作数是否为特殊数字并在路径524上产生适当的特殊数字SPC信号。
fp32提取电路626和不带符号/带符号整数提取电路628不用于DSET运算,且这些电路可视需要设定为无效或低功率状态。
尾数路径516、指数路径518和符号路径520如上文针对DFMA运算所描述而操作,或者可部分或完全被绕过。任何被绕过的组件可置于低功率状态。如上所述,绕过路径可包含各种延迟电路(锁存器等)使得所述路径占据与尾数路径516、指数路径518和符号路径520中的最长者相同数目的管线级。这确保DFMA单元320中的所有运算需要完成相同数目的循环,其简化了指令发布逻辑。
输出区段522(图10)处理特殊数字。明确地说,在IEEE 754标准下,如果A或B(或两者)为NaN,那么A和B为无序的。输出多路复用器控制逻辑1002接收指示A大于、小于还是等于B的R_Test信号、指示A或B是否为NaN的特殊数字SPC信号、以及指示所请求的特定测试运算的OPCTL信号。输出多路复用器控制逻辑1002使用R_Test和SPC信号来确定是否满足所请求的测试。在一个实施例中,DSET运算的结果提供为条件码,且忽略结果OUT;在所述情况下,输出多路复用器控制逻辑1002设定条件码COND以指示结果且可任意选择输出OUT的有效数和指数。在另一实施例中,可设定输出OUT以反映测试结果,在所述情况下,输出多路复用器控制逻辑1002操作有效数多路复用器1004和指数多路复用器1006以选择对应于逻辑真的64位值(如果满足测试)或对应于逻辑假的64位值(如果不满足测试)。
F.格式转换
在一些实施例中,DFMA单元320还支持到和从双精度格式的格式转换操作。现将描述实例。
1.fp32到fp64(F2D)
对于F2D运算,将fp32输入操作数A转换为相应fp64数字。适当处理特殊数字输入;例如将fp32 INF或NaN转换为fp64 INF或NaN。所有fp32非正规化数可转换为fp64正规化数。
操作数准备区块514(图6)接收fp32操作数A。绝对值/负值电路618将操作数A在不修改的情况下传递到fp32提取区块626。fp32提取区块626执行操作数A到fp64格式的初始向上转换。明确地说,fp32提取区块626提取8位指数并加上1023-127=896以产生对于fp64格式具有正确偏置的11位指数。用尾随零填充23位尾数。fp32提取区块626还确定操作数A是否为fp32特殊数字(例如,INF、NaN、零或非正规化数),并将所述信息经由路径644提供到特殊数字检测电路642。fp32提取区块626还可将操作数取负值或对操作数应用绝对值。
操作数C多路复用器636选择由fp32提取区块626提供的经向上转换操作数;操作数A多路复用器632和操作数B多路复用器634选择零操作数。除非操作数为fp32非正规化数,否则特殊数字检测电路642将前导1预备到尾数。特殊数字检测电路642还使用由fp32提取区块626提供的特殊数字信息作为其特殊数字SPC信号,只是fp32非正规化数被识别为正规化数(由于在fp64中,所有fp32非正规化数均可表达为正规化数)。
尾数路径516和指数路径518如上文针对DFMA运算所描述而操作以在fp64格式中计算0.0*0.0+C。尾数路径516和指数路径518中的正规化元件使经向上转换的fp64操作数正规化。在替代实施例中,参看图8,来自指数路径518的经对准尾数C_align可围绕尾数路径516中的加法器804被绕到多路复用器806的和输入;乘法器802和加法器804可置于低功率状态。符号路径520有利地通过符号位Cs。
在输出区段522(图10)中,除非特殊数字SPC信号指示输入操作数为fp32 INF、NaN或零,否则选择经正规化fp64结果(Rm、Rs、Re)。如果输入操作数为fp32 INF,那么输出多路复用器控制逻辑1002操作有效数多路复用器1004选择fp64 INF有效数(0x0_0000_0000_0000)且操作指数多路复用器1006选择fp64 INF指数(0x7ff)。如果输入操作数为fp32 NaN,那么输出多路复用器控制逻辑1002操作有效数多路复用器1004选择fp64安定NaN有效数且操作指数多路复用器1006选择fp64 NaN指数(0x7ff)。如果输入操作数为fp32零,那么输出多路复用器控制逻辑1002操作有效数多路复用器1004选择fp64零有效数(0x0_0000_0000_0000)且操作指数多路复用器1006选择fp64零指数(0x000)。可视需要设定条件码。
2.整数到fp64(I2D)
对于I2D运算,将整数(u64、s64、u32或s32格式)转换为fp64格式。操作数准备区块514(图6)接收64位整数操作数C。对于32位整数格式,可预备32个前导零。绝对值/负值电路622将操作数C在不修改的情况下传递到U/S提取区块628。U/S提取区块628执行操作数C到fp64格式的初始向上转换。明确地说,提取区块628确定操作数C中前导1的位置(例如,使用优先编码器)。通过将指数字段初始化为1086(对应于263)来确定11位指数。对于32位输入格式,丢弃前导1,且用尾随零填充尾数以产生52位有效数。对于64位输入格式,尾数视需要舍位到53位,且丢弃前导1。可视需要保留保护位和舍入位。
U/S提取区块628还确定输入操作数是否为零,并产生用于特殊数字检测电路642的相应控制信号。其它特殊数字(非正规化数、INF和NaN)在I2D运算期间不发生且不需要检测。
操作数C多路复用器636选择由U/S提取区块628提供的经向上转换操作数;操作数A多路复用器632和操作数B多路复用器634每一者选择零操作数。特殊数字检测电路642使用由U/S提取区块628提供的零信息以产生指示输入操作数是否为零的特殊数字SPC信号。
尾数路径516和指数路径518如上文针对DFMA运算所描述而操作以计算0.0*0.0+C。尾数路径516和指数路径518中的正规化元件使经向上转换的fp64操作数正规化。在替代实施例中,来自指数路径518的经对准尾数C_align可围绕尾数路径516中的加法器804被绕到多路复用器806的和输入;乘法器802和加法器804可置于低功率状态。符号路径520有利地通过符号位Cs。
在输出区段522(图10)中,除非特殊数字SPC信号指示输入操作数为整数零,否则选择经正规化fp64结果(Rm、Rs、Re)。如果输入操作数为整数零,那么输出多路复用器控制逻辑1002操作有效数多路复用器1004选择fp64零有效数(0x0_0000_0000_0000)且操作指数多路复用器1006选择fp64零指数(0x000)。可视需要设定条件码。
3.fp64到fp32(D2F)
由于fp64比fp32覆盖更大范围的浮点值,所以从fp64转换为fp32(D2F)需要检测fp32值中的溢出和下溢。
对于D2F运算,将操作数C提供到操作数准备区块514(图6)。绝对值/负值电路622视需要执行绝对值或操作数负值并将操作数C传递到操作数C多路复用器636,操作数C多路复用器636选择待提供到特殊数字检测电路642的操作数C。特殊数字检测电路642检测fp64非正规化数、零、INF或NaN并将相应SPC信号提供到输出区段522。选择多路复用器632和634选择0.0操作数。
在指数路径518(图7)中,指数计算区块702使fp64指数向下偏置897以确定相应fp32指数。如果fp32指数下溢,那么指数计算区块702产生Sh_C信号,其将使C的尾数右移以消除下溢(如果需要大于217位的移位,那么C的尾数将变为零)。移位电路706根据Sh_C信号使C的尾数右移。结果由多路复用器712选择并作为经对准尾数C_align提供到尾数路径516。下溢逻辑713检测fp32下溢并产生U_fp32信号。
在尾数路径516(图8)中,乘法器802计算积0.0*0.0(或被绕过)。加法器804将积(零)加上尾数C_align。多路复用器806选择和结果(由于输入呈符号/量值形式)。电路814检测零结果;如上文在DFMA运算的上下文中所描述正规化非零结果。舍入逻辑820可用于确定是否上舍入;应注意,加1加法器822将需要将1加上第24位位置(而不是第53),因为结果将是23位fp32尾数。
输出区段522(图10)汇编结果。在52位字段Rm中提供23位fp32有效数。除非结果不是fp32正规化数,否则输出多路复用器控制逻辑1002控制有效数多路复用器1004选择Rm。对于fp32零或INF,选择零尾数0x0_0000_0000_0000;对于fp32 NaN,选择安定的fp32 NaN尾数。对于fp32非正规化数,可使用Rm。
在11位指数字段中提供8位fp32指数。除非结果不是fp32正规化数,否则输出多路复用器控制逻辑1002控制指数多路复用器1004选择Re。对于fp32非正规化数或零,选择零指数0x000。对于fp32 INF或NaN,选择最大fp32指数0x7ff。
串联区块1008将Rm和Re装填到64位输出字段的31位中并附加符号位Rs。丢弃11位指数中的3个MSB,如同52位有效数中的29个LSB一样。fp32结果可视需要例如在64位字段的MSB或LSB中对准。可视需要设定条件码。
4.fp64到整数(D2I)
对于D2I运算,检测溢出和下溢。溢出设定为最大整数值,且下溢设定为零。
以fp64格式将待转换的操作数提供为操作数C。绝对值/负值电路622视需要执行绝对值或操作数负值并将操作数C传递到操作数C多路复用器636,操作数C多路复用器636选择待提供到特殊数字检测电路642的操作数C。特殊数字检测电路642检测fp64非正规化数、零、INF或NaN并将相应SPC信号提供到输出区段522。选择多路复用器632和634选择0.0操作数。
在指数路径518(图7)中,指数计算区块702使用指数Ce确定为了使二元点在整数位置处对准时Cm应移位的量并产生相应Sh_C信号。在一个实施例中,指数计算区块702去除指数偏置并说明有效数的宽度、待使用的整数格式,以及32位格式的结果在64位字段中将如何表示(例如,使用32个MSB或32个LSB)。指数Ce还用于确定结果在目标整数格式中是否将溢出或下溢;如果是,那么有利地将相应的溢出或下溢信号(未明确展示)发送到输出区段522(图10)中的输出多路复用器控制逻辑1002。
移位电路706将Cm移位量C_Shift,且多路复用器712选择C_Shift信号作为C_align信号。
在尾数路径516(图8)中,乘法器802将0.0结果提供到加法器804。加法器804将0.0加上C_align,并依据C为正还是负而选择和或~和。移位器816有利地不使结果移位。整数格式区块826将结果分离为11位MSB字段int_M和53位LSB字段int_L。
在输出区段522(图10)中,输出多路复用器控制逻辑1002分别控制有效数多路复用器1004和指数多路复用器1006选择int_L和int_M结果,在溢出、下溢或特殊数字操作数的情况下除外。对于溢出,选择输出格式(u32、s32、u64或s64)中的最大整数;对于下溢,选择零。可视需要设定条件码。
IV.另外的实施例
虽然已相对于特定实施例描述本发明,但所属领域的技术人员将认识到,大量修改是可能的。举例来说,DFMA单元可经实施以支持更多、更少或不同功能组合,并支持呈任何格式或格式组合的操作数和结果。
本文描述的各种绕过路径和通过路径也可变化。一般来说,在描述围绕任何电路区块的绕过路径的情况下,可由所述区块中的识别运算(即,对其操作数没有影响的运算,例如加上零)替换所述路径。在给定运算期间绕过的电路区块可置于闲置状态(例如,减少功率状态)或在其结果被下游区块忽略(例如,通过选择多路复用器或其它电路的操作)的情况下正常操作。
DFMA管线可划分为任何数目的级,且可视需要改变每一级处组件的组合。本文中归因于特定电路区块的功能性也可在管线级上分离;举例来说,乘法器树可能占据多个级。还可修改各种区块的功能性。举例来说,在一些实施例中,可使用不同加法器电路或乘法器电路。
另外,已依据电路区块描述DFMA单元以促进理解;所属领域的技术人员将认识到,可使用多种电路组件和布局实施所述区块,且本文描述的区块不限于一组特定组件或物理布局。区块可视需要在物理上组合或分离。
处理器可包含执行核心中的一个或一个以上DFMA单元。举例来说,在需要超标量指令发布(即,每循环发布一个以上指令)或SIMD指令发布的情况下,可实施多个DFMA单元,且不同的DFMA单元可支持不同功能组合。处理器还可包含多个执行核心,且每一核心可具有其自身的DFMA单元。
在其中执行核心支持SIMD指令发布的一些实施例中,单一DFMA单元可与适当输入定序和输出收集逻辑组合使用以允许在单一DFMA管线中依序处理多个数据集。
图11是根据本发明一实施例包含DFMA功能单元1102的执行核心1100的框图。DFMA单元1102可与上文描述的DFMA单元320类似或相同。核心1100发布SIMD指令,意味着具有P组不同单精度操作数的相同指令可并行发布到一组P个单精度SIMD单元1104。每一SIMD单元1104接收相同操作码和一组不同操作数;P个SIMD单元1104并行操作以产生P个结果。P路SIMD指令作为一系列P个单精度、单数据(SISD)指令发布到DFMA单元1102。
输入管理器1106(其可以是指令发布单元的一部分)收集SIMD指令的操作数,且当已收集SIMD指令的所有P组操作数时,将操作数和适用的操作码递送到P个SIMD单元1104或递送到DFMA单元1102。输出收集器1008从SIMD单元1104或DFMA单元1102收集结果并将结果经由结果总线1110递送到寄存器堆(图11中未明确展示)。在一些实施例中,结果总线1110还提供到达输入管理器1106的绕过路径使得结果可与向寄存器堆的递送并行而递送到输入管理器1106以与后续指令一起使用。为了使用一个DFMA单元1102提供SIMD行为的表现,输入管理器1106可例如通过在P个连续时钟循环的每一者上发布相同操作码与一组不同操作数而有利地使向DFMA单元1102的指令的发布串行化。
图12是展示根据本发明一实施例DFMA单元1102的串行化指令发布的框图。输入操作数收集单元1202(其可包含在图11的输入管理器1106中)包含两个收集器1204、1206。每一收集器1204、1206是为P个单精度操作数三元组A、B和C提供充足空间的32位寄存器的布置;换句话说,每一收集器1204、1206可存储用于单一SIMD指令的所有操作数。输入操作数收集单元1202例如从图3的寄存器堆324和/或从图11的结果总线1110获得操作数;可使用标记或其它常规技术来确定将对于给定指令收集哪些操作数。提供足够的收集器1206以允许用于给定指令的操作数在所述指令将被发布的时间之前若干时钟循环被收集到。
对于单精度指令,一个收集器(例如,收集器1204)载有P个SIMD单元1104执行一个指令所需的所有操作数。当指令发布到P个SIMD单元1104时,有利地并行地读取整个收集器1204,其中向SIMD单元1104的每一者递送不同的A、B、C操作数三元组。
对于到达DFMA单元1102的指令,操作数为双精度(例如,64位)。每一操作数可使用收集器1204、1206两者中的相应寄存器来存储;举例来说,收集器1204中的寄存器1208可存储操作数A的一个实例的32个MSB(例如,符号位、11个指数位和有效数的20个MSB),而收集器1206中的寄存器1210存储同一操作数的32个LSB(例如,有效数的剩余32位)。因此可使用两个单精度收集器1204、1206收集P路双精度SIMD指令所需的所有操作数三元组A、B、C。
核心1100仅具有一个DFMA单元1102,且有利地使用输出多路复用器(多路复用器)1212、1214依序递送P组操作数,所述输出多路复用器1212、1214两者由计数器1216控制。多路复用器1212和1214响应于计数器1216从各自收集器1204和1206中选择操作数三元组的MSB和LSB。举例来说,在所示的数据路径中,多路复用器1212可从收集器1204中的寄存器1208中选择操作数A的32个MSB,而多路复用器1214从收集器1206中的寄存器1210中选择相同操作数A的32个LSB。64位在双精度宽路径上递送到DFMA单元1102。类似地,可使用由相同计数器1216控制的相应多路复用器(未明确展示)将操作数B(来自寄存器1220和1222)和C(来自寄存器1224和1226)递送到DFMA单元1102。在下一时钟循环上,来自收集器1204和1206中的下一组寄存器的操作数A、B和C可递送到DFMA单元1102等等,直到已递送所有P组操作数为止。
多路复用器1212和1214连同收集器1204和1206一起为DFMA单元1102提供SIMD执行的表现(虽然具有减少的处理量)。因此,核心1100的编程模型可假定P路SIMD执行可用于所有指令,包含双精度指令。
将了解,本文描述的操作数收集和定序逻辑是说明性的,且可能作出变化和修改。在启用SIMD的核心中,可提供任何数目的DFMA单元,且指令可并行发布到任何数目的DFMA单元。在一些实施例中,双精度运算相对于单精度运算的处理量随着DFMA单元的数目缩放。举例来说,如果存在P个SIMD单元和N个DFMA单元,那么双精度处理量将是单精度处理量的N/P。在一些实施例中,N最佳等于P;在其它实施例中,其它因素(例如,寄存器堆与功能单元之间的内部数据路径的宽度)可将双精度处理量限制为小于单精度处理量,而不管存在的DFMA单元的数目如何。在所述情况下,N最佳不大于所允许的其它限制因素。
还应注意,由于DFMA单元与单精度功能单元分离,所以其当不在使用时,例如当图形处理器或核心正专门用于绘制过程或不需要双精度的其它计算时,可断电。此外,可从集成电路设计中去除DFMA单元而不影响其它电路组件的操作。这促进了其中不同芯片提供对双精度运算的不同等级的支持的产品系列的设计。举例来说,GPU系列可能包含具有许多核心的高端GPU(每一核心包含至少一个DFMA单元),以及不具有基于硬件的双精度支持且不具有DFMA单元的低端GPU。
此外,虽然已参考图形处理器描述本发明,但所属领域的技术人员将了解,也可在例如数学协处理器、向量处理器或通用处理器等其它处理器中使用本发明的各方面。
因此,尽管已相对于特定实施例描述本发明,但将了解,本发明希望涵盖在所附权利要求书范围内的所有修改和等效物。
Claims (17)
1.一种图形处理器,其包括:
适于产生图像数据的绘制管线,所述绘制管线包含适于执行多个同时线程的处理核心,其中所述绘制管线对单精度操作数操作,
所述处理核心进一步包含适于对一组双精度输入操作数选择性地执行多个双精度运算中的一者的多用途双精度功能单元,所述多用途双精度功能单元包含至少一个算术逻辑电路,所述多个双精度运算包含将两个双精度操作数相加的加法运算、将两个双精度操作数相乘的乘法运算以及计算第一双精度操作数与第二双精度操作数的乘积,接着将第三双精度操作数加到所述乘积的积和熔加运算,
其中所述多用途双精度功能单元足够宽以在单次通过中执行所述多个双精度运算的每一者,使得所述多个双精度运算的每一者在相同数目的时钟循环中完成,以及
其中所述双精度功能单元的所有所述算术逻辑电路足够宽以在双精度下操作。
2.根据权利要求1所述的图形处理器,其中所述双精度功能单元进一步经调适使得所述多个双精度运算的每一者在相同数目的时钟循环中完成而不管是否发生溢出或下溢条件。
3.根据权利要求2所述的图形处理器,其中所述双精度功能单元进一步适于在确实发生溢出或下溢条件的情况下产生符合浮点算术标准的溢出或下溢结果,并设定输出状态旗标以指示是否发生了所述溢出或下溢条件。
4.根据权利要求1所述的图形处理器,其中所述双精度功能单元进一步经调适使得完成所述多个双精度运算的任一者所需的时间不受浮点异常的影响。
5.根据权利要求1所述的图形处理器,其中所述多个双精度运算进一步包含双精度比较(DSET)运算,其对第一操作数和第二操作数执行比较测试并产生指示是否满足所述比较测试的布尔结果。
6.根据权利要求1所述的图形处理器,其中所述多个双精度运算进一步包含:
双精度最大化(DMAX)运算,其传回两个双精度输入操作数中的较大一者;以及
双精度最小化(DMIN)运算,其传回两个双精度输入操作数中的较小一者。
7.根据权利要求1所述的图形处理器,其中所述多个双精度运算进一步包含将操作数从双精度格式转换为非双精度格式的至少一个格式转换操作。
8.根据权利要求1所述的图形处理器,其中所述多个双精度运算进一步包含将操作数从非双精度格式转换为双精度格式的至少一个格式转换操作。
9.一种图形处理器,其包括:
适于产生图像数据的绘制管线,所述绘制管线包含适于执行多个同时线程的处理核心,
所述处理核心包含适于对一个或一个以上单精度操作数执行算术运算的单精度功能单元,
所述处理核心进一步包含适于对一组双精度输入操作数执行积和熔加运算并提供双精度结果、对一对双精度输入操作数执行加法运算并提供双精度结果以及对一对双精度输入操作数执行乘法运算并提供双精度结果的双精度积和熔加(DFMA)功能单元,
其中所述DFMA功能单元包含DFMA管线,所述DFMA管线具有足够宽的数据路径以在单次通过所述DFMA管线的过程中执行所述积和熔加运算、所述加法运算或所述乘法运算,使得所述积和熔加运算、所述加法运算和所述乘法运算每一者在相同数目的时钟循环中完成。
10.根据权利要求9所述的图形处理器,其中所述DFMA功能单元包含:
适于在单一迭代中计算两个双精度尾数的乘积的乘法器;以及
适于在单一迭代中计算两个双精度尾数的和的加法器。
11.根据权利要求9所述的图形处理器,其中:
所述积和熔加运算、所述加法运算和所述乘法运算每一者在相同数目的时钟循环中完成,而不管是否发生溢出或下溢条件。
12.根据权利要求11所述的图形处理器,其中所述DFMA功能单元进一步经配置以在发生溢出或下溢条件的情况下产生符合浮点算术标准的溢出或下溢结果,并设定输出状态旗标以指示是否发生了所述溢出或下溢条件。
13.根据权利要求9所述的图形处理器,其中所述处理核心包含适于并行操作的单精度功能单元的若干(P)副本以及所述DFMA功能单元的若干(N)副本。
14.根据权利要求13所述的图形处理器,其中所述数目P大于所述数目N。
15.根据权利要求14所述的图形处理器,其中所述数目N为一。
16.根据权利要求15所述的图形处理器,其中所述处理核心进一步包含输入管理器电路,其适于收集用于所述DFMA功能单元的N组双精度输入操作数,且在不同时钟循环上向所述DFMA功能单元递送所述N组双精度操作数中的不同者。
17.根据权利要求16所述的图形处理器,其中所述输入管理器电路进一步适于收集用于所述单精度功能单元的P组单精度输入操作数,且并行地向所述单精度功能单元的所述P个副本中的每一者递送所述P组单精度操作数中的一不同者。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/952,858 | 2007-12-07 | ||
| US11/952,858 US8106914B2 (en) | 2007-12-07 | 2007-12-07 | Fused multiply-add functional unit |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101452571A CN101452571A (zh) | 2009-06-10 |
| CN101452571B true CN101452571B (zh) | 2012-04-25 |
Family
ID=40230776
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2008101825044A Active CN101452571B (zh) | 2007-12-07 | 2008-12-04 | 积和熔加功能单元 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US8106914B2 (zh) |
| JP (2) | JP2009140491A (zh) |
| KR (1) | KR101009095B1 (zh) |
| CN (1) | CN101452571B (zh) |
| DE (1) | DE102008059371B9 (zh) |
| GB (1) | GB2455401B (zh) |
| TW (1) | TWI402766B (zh) |
Families Citing this family (63)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8190669B1 (en) | 2004-10-20 | 2012-05-29 | Nvidia Corporation | Multipurpose arithmetic functional unit |
| US8037119B1 (en) | 2006-02-21 | 2011-10-11 | Nvidia Corporation | Multipurpose functional unit with single-precision and double-precision operations |
| US8051123B1 (en) | 2006-12-15 | 2011-11-01 | Nvidia Corporation | Multipurpose functional unit with double-precision and filtering operations |
| US8106914B2 (en) | 2007-12-07 | 2012-01-31 | Nvidia Corporation | Fused multiply-add functional unit |
| US8477143B2 (en) | 2008-03-04 | 2013-07-02 | Apple Inc. | Buffers for display acceleration |
| US8289333B2 (en) * | 2008-03-04 | 2012-10-16 | Apple Inc. | Multi-context graphics processing |
| US8633936B2 (en) * | 2008-04-21 | 2014-01-21 | Qualcomm Incorporated | Programmable streaming processor with mixed precision instruction execution |
| US8239441B2 (en) * | 2008-05-15 | 2012-08-07 | Oracle America, Inc. | Leading zero estimation modification for unfused rounding catastrophic cancellation |
| US20100125621A1 (en) * | 2008-11-20 | 2010-05-20 | Advanced Micro Devices, Inc. | Arithmetic processing device and methods thereof |
| US8495121B2 (en) * | 2008-11-20 | 2013-07-23 | Advanced Micro Devices, Inc. | Arithmetic processing device and methods thereof |
| KR101511273B1 (ko) * | 2008-12-29 | 2015-04-10 | 삼성전자주식회사 | 멀티 코어 프로세서를 이용한 3차원 그래픽 렌더링 방법 및시스템 |
| US8803897B2 (en) * | 2009-09-03 | 2014-08-12 | Advanced Micro Devices, Inc. | Internal, processing-unit memory for general-purpose use |
| US8990282B2 (en) * | 2009-09-21 | 2015-03-24 | Arm Limited | Apparatus and method for performing fused multiply add floating point operation |
| US8745111B2 (en) | 2010-11-16 | 2014-06-03 | Apple Inc. | Methods and apparatuses for converting floating point representations |
| KR101735677B1 (ko) | 2010-11-17 | 2017-05-16 | 삼성전자주식회사 | 부동 소수점의 복합 연산장치 및 그 연산방법 |
| US8752064B2 (en) * | 2010-12-14 | 2014-06-10 | Advanced Micro Devices, Inc. | Optimizing communication of system call requests |
| US8965945B2 (en) * | 2011-02-17 | 2015-02-24 | Arm Limited | Apparatus and method for performing floating point addition |
| DE102011108754A1 (de) * | 2011-07-28 | 2013-01-31 | Khs Gmbh | Inspektionseinheit |
| CN102750663A (zh) * | 2011-08-26 | 2012-10-24 | 新奥特(北京)视频技术有限公司 | 一种基于gpu的地理信息数据处理的方法、设备和系统 |
| US9792087B2 (en) * | 2012-04-20 | 2017-10-17 | Futurewei Technologies, Inc. | System and method for a floating-point format for digital signal processors |
| US9110713B2 (en) | 2012-08-30 | 2015-08-18 | Qualcomm Incorporated | Microarchitecture for floating point fused multiply-add with exponent scaling |
| US9152382B2 (en) | 2012-10-31 | 2015-10-06 | Intel Corporation | Reducing power consumption in a fused multiply-add (FMA) unit responsive to input data values |
| US9665973B2 (en) * | 2012-11-20 | 2017-05-30 | Intel Corporation | Depth buffering |
| US9019284B2 (en) | 2012-12-20 | 2015-04-28 | Nvidia Corporation | Input output connector for accessing graphics fixed function units in a software-defined pipeline and a method of operating a pipeline |
| US9123128B2 (en) | 2012-12-21 | 2015-09-01 | Nvidia Corporation | Graphics processing unit employing a standard processing unit and a method of constructing a graphics processing unit |
| US9317251B2 (en) | 2012-12-31 | 2016-04-19 | Nvidia Corporation | Efficient correction of normalizer shift amount errors in fused multiply add operations |
| GB2511314A (en) | 2013-02-27 | 2014-09-03 | Ibm | Fast fused-multiply-add pipeline |
| US9389871B2 (en) | 2013-03-15 | 2016-07-12 | Intel Corporation | Combined floating point multiplier adder with intermediate rounding logic |
| US9465578B2 (en) * | 2013-12-13 | 2016-10-11 | Nvidia Corporation | Logic circuitry configurable to perform 32-bit or dual 16-bit floating-point operations |
| US10297001B2 (en) * | 2014-12-26 | 2019-05-21 | Intel Corporation | Reduced power implementation of computer instructions |
| KR102276910B1 (ko) | 2015-01-06 | 2021-07-13 | 삼성전자주식회사 | 테셀레이션 장치 및 방법 |
| US9817791B2 (en) | 2015-04-04 | 2017-11-14 | Texas Instruments Incorporated | Low energy accelerator processor architecture with short parallel instruction word |
| US11847427B2 (en) | 2015-04-04 | 2023-12-19 | Texas Instruments Incorporated | Load store circuit with dedicated single or dual bit shift circuit and opcodes for low power accelerator processor |
| US9952865B2 (en) | 2015-04-04 | 2018-04-24 | Texas Instruments Incorporated | Low energy accelerator processor architecture with short parallel instruction word and non-orthogonal register data file |
| US10152310B2 (en) * | 2015-05-27 | 2018-12-11 | Nvidia Corporation | Fusing a sequence of operations through subdividing |
| US10503474B2 (en) | 2015-12-31 | 2019-12-10 | Texas Instruments Incorporated | Methods and instructions for 32-bit arithmetic support using 16-bit multiply and 32-bit addition |
| US10387988B2 (en) * | 2016-02-26 | 2019-08-20 | Google Llc | Compiler techniques for mapping program code to a high performance, power efficient, programmable image processing hardware platform |
| US10282169B2 (en) | 2016-04-06 | 2019-05-07 | Apple Inc. | Floating-point multiply-add with down-conversion |
| US10157059B2 (en) * | 2016-09-29 | 2018-12-18 | Intel Corporation | Instruction and logic for early underflow detection and rounder bypass |
| US10401412B2 (en) | 2016-12-16 | 2019-09-03 | Texas Instruments Incorporated | Line fault signature analysis |
| US10275391B2 (en) | 2017-01-23 | 2019-04-30 | International Business Machines Corporation | Combining of several execution units to compute a single wide scalar result |
| GB2560766B (en) * | 2017-03-24 | 2019-04-03 | Imagination Tech Ltd | Floating point to fixed point conversion |
| US10409614B2 (en) | 2017-04-24 | 2019-09-10 | Intel Corporation | Instructions having support for floating point and integer data types in the same register |
| US10417734B2 (en) | 2017-04-24 | 2019-09-17 | Intel Corporation | Compute optimization mechanism for deep neural networks |
| US10417731B2 (en) | 2017-04-24 | 2019-09-17 | Intel Corporation | Compute optimization mechanism for deep neural networks |
| US10489877B2 (en) | 2017-04-24 | 2019-11-26 | Intel Corporation | Compute optimization mechanism |
| US10474458B2 (en) * | 2017-04-28 | 2019-11-12 | Intel Corporation | Instructions and logic to perform floating-point and integer operations for machine learning |
| US10726514B2 (en) * | 2017-04-28 | 2020-07-28 | Intel Corporation | Compute optimizations for low precision machine learning operations |
| CN108595369B (zh) * | 2018-04-28 | 2020-08-25 | 天津芯海创科技有限公司 | 算式并行计算装置及方法 |
| US10635439B2 (en) * | 2018-06-13 | 2020-04-28 | Samsung Electronics Co., Ltd. | Efficient interface and transport mechanism for binding bindless shader programs to run-time specified graphics pipeline configurations and objects |
| CN108958705B (zh) * | 2018-06-26 | 2021-11-12 | 飞腾信息技术有限公司 | 一种支持混合数据类型的浮点融合乘加器及其应用方法 |
| US11093579B2 (en) * | 2018-09-05 | 2021-08-17 | Intel Corporation | FP16-S7E8 mixed precision for deep learning and other algorithms |
| US11455766B2 (en) * | 2018-09-18 | 2022-09-27 | Advanced Micro Devices, Inc. | Variable precision computing system |
| JP7115211B2 (ja) * | 2018-10-18 | 2022-08-09 | 富士通株式会社 | 演算処理装置および演算処理装置の制御方法 |
| WO2020190809A1 (en) | 2019-03-15 | 2020-09-24 | Intel Corporation | Architecture for block sparse operations on a systolic array |
| US20220114108A1 (en) | 2019-03-15 | 2022-04-14 | Intel Corporation | Systems and methods for cache optimization |
| WO2020190801A1 (en) | 2019-03-15 | 2020-09-24 | Intel Corporation | Graphics processor operation scheduling for deterministic latency |
| US11934342B2 (en) | 2019-03-15 | 2024-03-19 | Intel Corporation | Assistance for hardware prefetch in cache access |
| US10990389B2 (en) * | 2019-04-29 | 2021-04-27 | Micron Technology, Inc. | Bit string operations using a computing tile |
| US11016765B2 (en) * | 2019-04-29 | 2021-05-25 | Micron Technology, Inc. | Bit string operations using a computing tile |
| US11907713B2 (en) * | 2019-12-28 | 2024-02-20 | Intel Corporation | Apparatuses, methods, and systems for fused operations using sign modification in a processing element of a configurable spatial accelerator |
| US12020349B2 (en) * | 2020-05-01 | 2024-06-25 | Samsung Electronics Co., Ltd. | Methods and apparatus for efficient blending in a graphics pipeline |
| CN111610955B (zh) * | 2020-06-28 | 2022-06-03 | 中国人民解放军国防科技大学 | 一种数据饱和加打包处理部件、芯片及设备 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5487022A (en) * | 1994-03-08 | 1996-01-23 | Texas Instruments Incorporated | Normalization method for floating point numbers |
| US6061781A (en) * | 1998-07-01 | 2000-05-09 | Ip First Llc | Concurrent execution of divide microinstructions in floating point unit and overflow detection microinstructions in integer unit for integer divide |
Family Cites Families (55)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5241638A (en) * | 1985-08-12 | 1993-08-31 | Ceridian Corporation | Dual cache memory |
| JPS6297060A (ja) | 1985-10-23 | 1987-05-06 | Mitsubishi Electric Corp | デイジタルシグナルプロセツサ |
| US4893268A (en) | 1988-04-15 | 1990-01-09 | Motorola, Inc. | Circuit and method for accumulating partial products of a single, double or mixed precision multiplication |
| US4972362A (en) * | 1988-06-17 | 1990-11-20 | Bipolar Integrated Technology, Inc. | Method and apparatus for implementing binary multiplication using booth type multiplication |
| US5287511A (en) * | 1988-07-11 | 1994-02-15 | Star Semiconductor Corporation | Architectures and methods for dividing processing tasks into tasks for a programmable real time signal processor and tasks for a decision making microprocessor interfacing therewith |
| US4969118A (en) | 1989-01-13 | 1990-11-06 | International Business Machines Corporation | Floating point unit for calculating A=XY+Z having simultaneous multiply and add |
| JPH0378083A (ja) * | 1989-08-21 | 1991-04-03 | Hitachi Ltd | 倍精度演算方式及び積和演算装置 |
| JPH03100723A (ja) * | 1989-09-13 | 1991-04-25 | Fujitsu Ltd | 精度変換命令の処理方式 |
| US5241636A (en) | 1990-02-14 | 1993-08-31 | Intel Corporation | Method for parallel instruction execution in a computer |
| US5068816A (en) | 1990-02-16 | 1991-11-26 | Noetzel Andrew S | Interplating memory function evaluation |
| DE69129569T2 (de) * | 1990-09-05 | 1999-02-04 | Philips Electronics N.V., Eindhoven | Maschine mit sehr langem Befehlswort für leistungsfähige Durchführung von Programmen mit bedingten Verzweigungen |
| JPH0612229A (ja) | 1992-06-10 | 1994-01-21 | Nec Corp | 乗累算回路 |
| EP0576262B1 (en) | 1992-06-25 | 2000-08-23 | Canon Kabushiki Kaisha | Apparatus for multiplying integers of many figures |
| JPH0659862A (ja) * | 1992-08-05 | 1994-03-04 | Fujitsu Ltd | 乗算器 |
| US5581778A (en) * | 1992-08-05 | 1996-12-03 | David Sarnoff Researach Center | Advanced massively parallel computer using a field of the instruction to selectively enable the profiling counter to increase its value in response to the system clock |
| EP0622727A1 (en) | 1993-04-29 | 1994-11-02 | International Business Machines Corporation | System for optimizing argument reduction |
| EP0645699A1 (en) * | 1993-09-29 | 1995-03-29 | International Business Machines Corporation | Fast multiply-add instruction sequence in a pipeline floating-point processor |
| US5673407A (en) * | 1994-03-08 | 1997-09-30 | Texas Instruments Incorporated | Data processor having capability to perform both floating point operations and memory access in response to a single instruction |
| US5553015A (en) | 1994-04-15 | 1996-09-03 | International Business Machines Corporation | Efficient floating point overflow and underflow detection system |
| US5734874A (en) | 1994-04-29 | 1998-03-31 | Sun Microsystems, Inc. | Central processing unit with integrated graphics functions |
| JP3493064B2 (ja) | 1994-09-14 | 2004-02-03 | 株式会社東芝 | バレルシフタ |
| US5548545A (en) * | 1995-01-19 | 1996-08-20 | Exponential Technology, Inc. | Floating point exception prediction for compound operations and variable precision using an intermediate exponent bus |
| US5701405A (en) | 1995-06-21 | 1997-12-23 | Apple Computer, Inc. | Method and apparatus for directly evaluating a parameter interpolation function used in rendering images in a graphics system that uses screen partitioning |
| US5778247A (en) | 1996-03-06 | 1998-07-07 | Sun Microsystems, Inc. | Multi-pipeline microprocessor with data precision mode indicator |
| JP3790307B2 (ja) | 1996-10-16 | 2006-06-28 | 株式会社ルネサステクノロジ | データプロセッサ及びデータ処理システム |
| US6490607B1 (en) | 1998-01-28 | 2002-12-03 | Advanced Micro Devices, Inc. | Shared FP and SIMD 3D multiplier |
| JP2000081966A (ja) * | 1998-07-09 | 2000-03-21 | Matsushita Electric Ind Co Ltd | 演算装置 |
| JP3600026B2 (ja) | 1998-08-12 | 2004-12-08 | 株式会社東芝 | 浮動小数点演算器 |
| US6317133B1 (en) | 1998-09-18 | 2001-11-13 | Ati Technologies, Inc. | Graphics processor with variable performance characteristics |
| US6480872B1 (en) | 1999-01-21 | 2002-11-12 | Sandcraft, Inc. | Floating-point and integer multiply-add and multiply-accumulate |
| JP2000293494A (ja) * | 1999-04-09 | 2000-10-20 | Fuji Xerox Co Ltd | 並列計算装置および並列計算方法 |
| JP2001236206A (ja) * | 1999-10-01 | 2001-08-31 | Hitachi Ltd | データのロード方法及びその記憶方法、データワードのロード方法及びその記憶方法、並びに、浮動小数点数の比較方法 |
| US6198488B1 (en) * | 1999-12-06 | 2001-03-06 | Nvidia | Transform, lighting and rasterization system embodied on a single semiconductor platform |
| US6807620B1 (en) * | 2000-02-11 | 2004-10-19 | Sony Computer Entertainment Inc. | Game system with graphics processor |
| US6557022B1 (en) | 2000-02-26 | 2003-04-29 | Qualcomm, Incorporated | Digital signal processor with coupled multiply-accumulate units |
| US6912557B1 (en) | 2000-06-09 | 2005-06-28 | Cirrus Logic, Inc. | Math coprocessor |
| JP2002008060A (ja) * | 2000-06-23 | 2002-01-11 | Hitachi Ltd | データ処理方法、記録媒体及びデータ処理装置 |
| US6976043B2 (en) | 2001-07-30 | 2005-12-13 | Ati Technologies Inc. | Technique for approximating functions based on lagrange polynomials |
| JP3845009B2 (ja) | 2001-12-28 | 2006-11-15 | 富士通株式会社 | 積和演算装置、及び積和演算方法 |
| JP2003223316A (ja) | 2002-01-31 | 2003-08-08 | Matsushita Electric Ind Co Ltd | 演算処理装置 |
| EP1543418B1 (en) * | 2002-08-07 | 2016-03-16 | MMagix Technology Limited | Apparatus, method and system for a synchronicity independent, resource delegating, power and instruction optimizing processor |
| US8549501B2 (en) * | 2004-06-07 | 2013-10-01 | International Business Machines Corporation | Framework for generating mixed-mode operations in loop-level simdization |
| US7437538B1 (en) * | 2004-06-30 | 2008-10-14 | Sun Microsystems, Inc. | Apparatus and method for reducing execution latency of floating point operations having special case operands |
| US7640285B1 (en) | 2004-10-20 | 2009-12-29 | Nvidia Corporation | Multipurpose arithmetic functional unit |
| WO2006053173A2 (en) * | 2004-11-10 | 2006-05-18 | Nvidia Corporation | Multipurpose multiply-add functional unit |
| KR20060044124A (ko) * | 2004-11-11 | 2006-05-16 | 삼성전자주식회사 | 3차원 그래픽 가속을 위한 그래픽 시스템 및 메모리 장치 |
| JP4571903B2 (ja) * | 2005-12-02 | 2010-10-27 | 富士通株式会社 | 演算処理装置,情報処理装置,及び演算処理方法 |
| US7747842B1 (en) * | 2005-12-19 | 2010-06-29 | Nvidia Corporation | Configurable output buffer ganging for a parallel processor |
| US7728841B1 (en) | 2005-12-19 | 2010-06-01 | Nvidia Corporation | Coherent shader output for multiple targets |
| JP4482052B2 (ja) * | 2006-02-14 | 2010-06-16 | 富士通株式会社 | 演算装置および演算方法 |
| US7484076B1 (en) * | 2006-09-18 | 2009-01-27 | Nvidia Corporation | Executing an SIMD instruction requiring P operations on an execution unit that performs Q operations at a time (Q<P) |
| US7617384B1 (en) * | 2006-11-06 | 2009-11-10 | Nvidia Corporation | Structured programming control flow using a disable mask in a SIMD architecture |
| JP4954799B2 (ja) | 2007-06-05 | 2012-06-20 | 日本発條株式会社 | 衝撃吸収装置 |
| US8775777B2 (en) * | 2007-08-15 | 2014-07-08 | Nvidia Corporation | Techniques for sourcing immediate values from a VLIW |
| US8106914B2 (en) | 2007-12-07 | 2012-01-31 | Nvidia Corporation | Fused multiply-add functional unit |
-
2007
- 2007-12-07 US US11/952,858 patent/US8106914B2/en active Active
-
2008
- 2008-11-25 GB GB0821495A patent/GB2455401B/en active Active
- 2008-11-27 JP JP2008302713A patent/JP2009140491A/ja active Pending
- 2008-11-28 DE DE102008059371A patent/DE102008059371B9/de active Active
- 2008-12-04 CN CN2008101825044A patent/CN101452571B/zh active Active
- 2008-12-05 TW TW097147390A patent/TWI402766B/zh active
- 2008-12-08 KR KR1020080124099A patent/KR101009095B1/ko active IP Right Grant
-
2011
- 2011-09-30 JP JP2011217575A patent/JP2012084142A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5487022A (en) * | 1994-03-08 | 1996-01-23 | Texas Instruments Incorporated | Normalization method for floating point numbers |
| US6061781A (en) * | 1998-07-01 | 2000-05-09 | Ip First Llc | Concurrent execution of divide microinstructions in floating point unit and overflow detection microinstructions in integer unit for integer divide |
Also Published As
| Publication number | Publication date |
|---|---|
| DE102008059371B9 (de) | 2012-06-06 |
| US8106914B2 (en) | 2012-01-31 |
| TW200937341A (en) | 2009-09-01 |
| GB2455401A (en) | 2009-06-10 |
| TWI402766B (zh) | 2013-07-21 |
| JP2012084142A (ja) | 2012-04-26 |
| DE102008059371A1 (de) | 2009-06-25 |
| KR20090060207A (ko) | 2009-06-11 |
| CN101452571A (zh) | 2009-06-10 |
| US20090150654A1 (en) | 2009-06-11 |
| GB2455401B (en) | 2010-05-05 |
| GB0821495D0 (en) | 2008-12-31 |
| DE102008059371B4 (de) | 2012-03-08 |
| JP2009140491A (ja) | 2009-06-25 |
| KR101009095B1 (ko) | 2011-01-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101452571B (zh) | 积和熔加功能单元 | |
| CN101133389B (zh) | 多用途乘法-加法功能单元 | |
| US10884734B2 (en) | Generalized acceleration of matrix multiply accumulate operations | |
| EP3575952B1 (en) | Arithmetic processing device, information processing device, method and program | |
| US11816481B2 (en) | Generalized acceleration of matrix multiply accumulate operations | |
| CN101615173B (zh) | 处理任何数个不同格式数据的串流处理器及其方法及模块 | |
| CN101847087B (zh) | 一种支持定浮点可重构的横向求和网络结构 | |
| KR20240011204A (ko) | 행렬 연산 가속기의 명령어들을 위한 장치들, 방법들, 및 시스템들 | |
| TWI389028B (zh) | 多用途之乘加法功能單元 | |
| CN101907987A (zh) | 执行范围检测的指令和逻辑 | |
| CN102520903A (zh) | 支持定浮点可重构的长度可配置的向量最大/最小值网络 | |
| CN107851010B (zh) | 针对宽数据元素使用寄存器对的具有偶数元素和奇数元素运算的混合宽度simd运算 | |
| KR20180052721A (ko) | 이미지 프로세서용 다기능 실행 레인 | |
| US7769981B2 (en) | Row of floating point accumulators coupled to respective PEs in uppermost row of PE array for performing addition operation | |
| CN117561501A (zh) | 一种多线程数据处理方法及装置 | |
| Hsiao et al. | Design of a low-cost floating-point programmable vertex processor for mobile graphics applications based on hybrid number system | |
| EP2600241B1 (en) | VLIW processor, instruction structure, and instruction execution method | |
| US20150067298A1 (en) | Splitable and scalable normalizer for vector data | |
| Zendegani et al. | AMCAL: Approximate Multiplier with the Configurable Accuracy Levels for Image Processing and Convolutional Neural Network |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant |