WO2023181103A1 - 画像処理システム、画像処理方法、及びプログラム - Google Patents
画像処理システム、画像処理方法、及びプログラム Download PDFInfo
- Publication number
- WO2023181103A1 WO2023181103A1 PCT/JP2022/013065 JP2022013065W WO2023181103A1 WO 2023181103 A1 WO2023181103 A1 WO 2023181103A1 JP 2022013065 W JP2022013065 W JP 2022013065W WO 2023181103 A1 WO2023181103 A1 WO 2023181103A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- character string
- area
- region
- regular
- standard
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/412—Layout analysis of documents structured with printed lines or input boxes, e.g. business forms or tables
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G06V30/153—Segmentation of character regions using recognition of characters or words
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/22—Image preprocessing by selection of a specific region containing or referencing a pattern; Locating or processing of specific regions to guide the detection or recognition
- G06V10/225—Image preprocessing by selection of a specific region containing or referencing a pattern; Locating or processing of specific regions to guide the detection or recognition based on a marking or identifier characterising the area
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/60—Type of objects
- G06V20/62—Text, e.g. of license plates, overlay texts or captions on TV images
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Definitions
- the present disclosure relates to an image processing system, an image processing method, and a program.
- Patent Document 1 a group of feature points extracted from an object image related to an identity verification document taken by a user is matched with a group of feature points extracted from a sample image related to a sample identity verification document.
- a technique is described that processes an object image and then identifies an atypical region that includes an atypical character string.
- One of the purposes of the present disclosure is to reliably identify an atypical region including an atypical character string from an object image related to an object including a regular character string and an atypical character string.
- An image processing system includes a detection unit that detects a plurality of character string regions including arbitrary character strings from an object image regarding an object including a regular character string and a non-standard character string; a fixed-form area determination unit that determines whether or not there is a fixed-form region including the fixed-form character string in the column area; and an atypical area specifying unit that specifies the character string area as an atypical area including the atypical character string.
- an atypical region including an atypical character string can be reliably specified from an object image related to an object including a regular character string and an atypical character string.
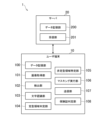
- FIG. 1 is a diagram showing an example of the overall configuration of an image processing system.
- FIG. 3 is a diagram illustrating an example of how a user photographs an insurance card.
- FIG. 2 is a functional block diagram showing an example of functions realized by the image processing system. It is a figure which shows an example of the character string area
- FIG. 3 is a diagram showing an example of a character string area having the same number of characters as a fixed-form character string.
- FIG. 3 is a diagram illustrating an example of the result of character recognition performed on a character string area.
- FIG. 3 is a diagram illustrating an example of a character string area determined to be a fixed-form area.
- FIG. 3 is a diagram illustrating an example of a method for identifying an atypical region.
- FIG. 3 is a diagram illustrating an example of an insurance card image after masking has been performed on an atypical region.
- FIG. 2 is a flow diagram illustrating an example of processing executed by the image processing system.
- FIG. 7 is a functional block diagram in a modified example of the first configuration. It is a functional block diagram in a modification regarding the second configuration.
- FIG. 7 is a diagram illustrating an example of processing for shaping an atypical region.
- FIG. 7 is a diagram illustrating an example of processing for shaping an atypical region.
- FIG. 1 is a diagram showing an example of the overall configuration of an image processing system.
- the image processing system 1 includes a user terminal 10 and a server 20.
- the user terminal 10 and the server 20 can be connected to a network N such as the Internet or a LAN.
- the image processing system 1 may include at least one computer, and is not limited to the example shown in FIG. 1.
- the user terminal 10 is a user's computer.
- the user terminal 10 is a smartphone, a tablet terminal, a personal computer, or a wearable terminal.
- Control unit 11 includes at least one processor.
- the storage unit 12 includes volatile memory such as RAM and nonvolatile memory such as flash memory.
- the communication unit 13 includes at least one of a communication interface for wired communication and a communication interface for wireless communication.
- the operation unit 14 is an input device such as a touch panel.
- the display section 15 is a liquid crystal display or an organic EL display. Photographing unit 16 includes at least one camera.
- the server 20 is a server computer.
- the physical configurations of the control section 21, the storage section 22, and the communication section 23 may be the same as those of the control section 11, the storage section 12, and the communication section 13, respectively.
- the programs stored in the storage units 12 and 22 may be supplied via the network N.
- the user terminal 10 or the server 20 may include a reading section (for example, an optical disk drive or a memory card slot) that reads a computer-readable information storage medium, or an input/output section (for example, , USB port).
- a program stored in an information storage medium may be supplied via a reading section or an input/output section.
- eKYC electronic know your customer
- eKYC identity verification performed online.
- eKYC can be used with any service.
- eKYC can be used in communication services, financial services, electronic payment services, electronic commerce services, insurance services, or government services.
- the user's identity verification document is verified.
- An identity verification document is a document that can prove the identity of the person.
- an insurance card will be explained as an example of an identification document. Therefore, the part that says insurance card can be read as an identity verification document.
- the identity verification document may be of any type and is not limited to an insurance card.
- the identity verification document may be a driver's license, residence card, personal number card, or passport.
- FIG. 2 is a diagram showing an example of how a user photographs an insurance card.
- the user photographs his or her insurance card C using the photographing unit 16.
- Insurance card C in FIG. 2 is fictitious.
- the user terminal 10 generates an insurance card image I in which the insurance card C is shown.
- the insurance card image I is uploaded to the server 20.
- eKYC is performed. eKYC may be performed automatically using image processing, or may be performed visually by a service administrator.
- insurance card C has both information necessary for eKYC and information not necessary for eKYC printed on it.
- the information required for eKYC is the name, date of birth, and gender.
- Information not required for eKYC is assumed to be a business reference number that can identify the business to which the insured person belongs, a personal number that can identify individuals within the same business, and other information.
- "538712110" printed next to "SB” which is an abbreviation for "Symbol” is the business office reference number.
- "123” printed next to "NB” which is an abbreviation for "Number” is the personal number.
- the office reference number and personal number are information that is not necessary for eKYC, so even if masking is performed, there will be no problem with eKYC.
- the image processing system 1 of the present embodiment includes a first configuration for accurately specifying the areas "SB” and "NB” from the insurance card image I, and the areas "SB" and "NB".
- a second configuration for accurately specifying the area of the office reference number and individual number from the information, masking can be performed in an appropriate area.
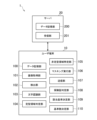
- FIG. 3 is a functional block diagram showing an example of functions realized by the image processing system 1. As shown in FIG. In this embodiment, a case will be exemplified in which main image processing is executed by the user terminal 10.
- the data storage unit 100 is mainly realized by the storage unit 12.
- the image acquisition unit 101, the detection unit 102, the character recognition unit 103, the regular area determination unit 104, the atypical area identification unit 105, the masking execution unit 106, the transmission unit 107, and the insurance card determination unit 108 mainly realize the control unit 11. be done.
- the detection unit 102, the character recognition unit 103, and the regular area determination unit 104 are related to the first configuration.
- Mainly, the detection unit 102, the regular area determination unit 104, and the atypical area identification unit 105 are related to the second configuration.
- the data storage unit 100 stores data necessary for image processing of this embodiment.
- the data storage unit 100 stores an application for using the above-mentioned services.
- image processing may be executed as processing of this application, but image processing may be executed as processing of any program.
- image processing may be performed as processing of a script or other program executed from a browser.
- the data storage unit 100 may also store the insurance card image I.
- the data storage unit 100 may store information indicating a fixed character string, which will be described later.
- the image acquisition unit 101 acquires an insurance card image I.
- the insurance card image I is an image generated by photographing the insurance card C.
- the photographing section 16 is an example of an image generating means.
- the image acquisition unit 101 may acquire the insurance card image I from other image generation means such as a scanner, a copy machine, or a multifunction device.
- the image acquisition unit 101 may acquire the insurance card image I stored in advance in the data storage unit 100, or may acquire the insurance card image I from a computer other than the user terminal 10 or from another information storage medium. Good too.
- the insurance card image I is an example of an object image. Therefore, the portion describing the insurance card image I can be read as the object image.
- the target object image is an image related to the target object.
- the object image shows at least a portion of the object. In this embodiment, a case will be explained where each image (frame) included in a video generated in video mode corresponds to an object image, but a still image generated in still image mode corresponds to an object image. It's okay.
- the object image is not limited to a photograph showing a state of real space, but may be a computer graphic, or an image in which digital information such as a character string is added to a photograph.
- the insurance card C is an example of an object. Therefore, the portion explaining the insurance card C can be read as the object.
- the target object is the object shown in the target object image.
- the target object can also be referred to as an object to be subjected to image processing.
- the object image shows the state of the real space
- the object is a subject in the real space.
- the object image is a computer graphic
- the object is a three-dimensional model or a two-dimensional image in virtual space.
- the object may be an identification document other than the insurance card C. Examples of other identification documents are as described above.
- the object may be an object other than the identification document.
- the object may be any object having a predetermined format.
- the object may be a receipt, invoice, application form, administrative document, financial statement, newspaper, magazine, other book, signboard, poster, or advertisement.
- the target object includes a regular character string and a non-standard character string, but the target object does not need to include only a regular character string and no non-standard character string.
- the object may include a plurality of regular character strings and a plurality of non-standard character strings.
- the object may include only one regular character string and one non-standard character string. The number of regular character strings and non-standard character strings included in the object may be different from each other.
- a fixed string is a string in the format part.
- a fixed string has a fixed arrangement of characters.
- the fixed character string is a character string that does not change depending on the insurance card C.
- the fixed character string is a character string related to information necessary for identity verification. This information is sometimes referred to as personal information.
- personal information is name, date of birth, gender, address, or telephone number.
- the fixed-form character string of one insurance card C and the fixed-form character string of other insurance cards C are the same.
- a character string common to a plurality of insurance cards C corresponds to a fixed character string. That is, in principle, a character string included in any insurance card C corresponds to a fixed character string.
- the fixed character string is not limited to a character string input by a computer, but may be a handwritten character string.
- the fixed string is an item name.
- item names such as "SB” and “NB” both correspond to fixed character strings. Therefore, the parts where "SB” and “NB” are explained can be read as regular character strings.
- “SB” is an example of the first fixed character string.
- “NB” is an example of the second fixed character string.
- the insurance card C may include three or more fixed-form character strings, and may include a third fixed-form character string and subsequent fixed-form character strings.
- Other character strings indicating item names such as "HEALTH INSURANCE ID CARD" and "NAME" printed on the insurance card C also correspond to standard character strings if they also exist on other insurance cards C in principle. However, in this embodiment, these character strings are not specified.
- a non-standard character string is a character string other than the format part.
- a non-standard character string does not have a fixed arrangement of characters.
- the non-standard character string is a character string that can change depending on the insurance card C.
- a non-standard character string is a character string other than a regular character string.
- the non-standard character string is a character string related to information necessary for identity verification. Even if the layouts of each of the plurality of insurance cards C are the same, the non-standard character strings may change. That is, a character string that is common to only a limited number of insurance cards C or a character string that is not the same as any other insurance card C corresponds to an atypical character string.
- a non-standard character string exists for each standard character string. Therefore, the regular character string and the non-standard character string are a set.
- the atypical character string is not limited to a character string input by a computer, but may be a handwritten character string.
- the non-standard string is specific information about the item indicated by the fixed string.
- the office reference number "538712110” and the personal number "123” both correspond to non-standard character strings. Therefore, the parts where these numbers are explained can be read as non-standard character strings.
- Other character strings such as the name and date of birth printed on the insurance card C also correspond to non-standard character strings. However, in this embodiment, since other character strings are not subject to masking, these character strings are not specified.
- the detection unit 102 detects a character string area including an arbitrary character string from the insurance card image I.
- the character string area is an area of the insurance card image I that includes some type of character string.
- a string is a sequence of characters.
- the character string area is assumed to be a rectangle, but the character string area may have any shape.
- the character string shape may be a polygon other than a quadrangle, a circle, or an ellipse.
- the character string area is sometimes called a bounding polygon or a bounding box.
- the character string included in the character string area may be a word or a character string other than a word.
- the detection unit 102 detects, from the insurance card image I, an area in which a shape that is presumed to be some kind of character is continuous, as a character string area. However, the detection unit 102 does not specifically recognize what characters are included. Therefore, the image processing performed by the detection unit 102 is different from the character recognition performed by the character recognition unit 103, which will be described later. For example, the detection unit 102 may detect the character string area by image processing that is simpler than character recognition. In this embodiment, a case will be described in which the detection unit 102 detects a plurality of character string areas from the insurance card image I, but the detection unit 102 may detect only one character string area.
- FIG. 4 is a diagram showing an example of a character string area detected from the insurance card image I.
- the detection unit 102 detects character string regions R1 to R36 from the insurance card image I using a method called Scene Text Detection.
- character string regions R1 to R36 are not distinguished, they will simply be referred to as character string region R.
- the part of the insurance card C such as the two-dimensional code, does not contain any characters, so it is not detected as the character string region R.
- FIG. 4 only the outline of the insurance card C is shown with a dotted line to make the character string region R easier to see, but it is assumed that the insurance card C is not actually deleted from the insurance card image I. This point also applies to other drawings such as FIG. 5.
- Scene Text Detection is a method for detecting text included in scenery.
- the method of "Character Region Awareness for Text Detection" by Youngmin Baek et al. https://arxiv.org/pdf/1904.01941v1.pdf
- Youngmin Baek et al. instead of detecting the character string region R using an object detection method, the method detects a first region that is presumed to be a character and a second region that is presumed to be a blank space between characters. , character string region R is detected.
- the detection unit 102 inputs the insurance card image I to a trained machine learning model that can output two heat maps: a first heat map for each character and a second heat map for characters.
- the first heat map is a map that indicates the high probability that it is a character. For example, in the first heat map, the higher the probability that a certain pixel is a pixel indicating a character, the darker the color of this pixel becomes.
- the second heat map is a map showing the high probability that there is a blank space between characters. For example, in the second heat map, the higher the probability that a certain pixel is a pixel indicating a blank space between characters, the darker the color of this pixel becomes.
- the machine learning model can output the first heat map and the second heat map, it does not specify what characters are included in the insurance card image I.
- the detection unit 102 identifies a first region for each character based on the first heat map.
- the detection unit 102 identifies a second region, which is a blank space between characters, based on the second heat map.
- the second area is specified so as to span between the first area of one character and the first area of the next character.
- the detection unit 102 detects the character string region R by connecting the first region and the second region.
- the detection unit 102 detects a plurality of character string regions R as shown in FIG. Among these character string regions R, there also exist character string regions R of character strings other than "SB" and "NB" that are ultimately desired to be detected. In this embodiment, the purpose is to detect a character string region R of a two-character standard character string such as "SB" and "NB", so the character recognition unit 103 (described later) detects the same number of characters as the standard character string.
- the column area R is targeted for character recognition.
- the detection unit 102 may detect only the character string region R having the same number of characters as the fixed character string.
- FIG. 5 is a diagram showing an example of a character string region R having the same number of characters as a fixed-form character string.
- the number of first regions combined by the second region means the number of characters in the character string included in the character string region R. Therefore, the detection unit 102 obtains the number of first regions specified when detecting a certain character string region R as the number of characters of the character string included in this character string region R.
- a two-character character string region R having the same number of characters as the standard character strings "SB" and "NB” is a character string region R3, R5, R9, They become R11, R24, R29, and R33.
- the detection unit 102 uses “An Efficient and Accurate Scene Text Detector” by Xinyu Zhou et al. (https://arxiv.org/pdf/1704.03155v2.pdf) or “Detecting Text in Natural Image with The character string region R may be detected using other Scene Text Detection methods such as "Connectionist Text Proposal Network” (https://arxiv.org/pdf/1609.03605v1.pdf).
- the detection unit 102 may detect the character string region R using a method other than Scene Text Detection.
- the detection unit 102 may detect the character string region R using an object detection method.
- the detection unit 102 uses an object detection method to detect a bounding box surrounding a highly object-like place from the insurance card image I.
- the detection unit 102 may detect, as the character string region R, an area in which bounding boxes of a size that appear to be characters are lined up at regular intervals.
- the detection unit 102 may detect the character string region R using character recognition. As described above, even if character recognition is performed on the entire insurance card image I, it is difficult to perform character recognition with high accuracy. However, even if the specific characters cannot be identified, it is possible to identify the presence of some characters. For this reason, the detection unit 102 may detect, as the character string region R, a region in the insurance card image I in which regions in which certain characters are specified are lined up at regular intervals.
- the character recognition unit 103 performs character recognition on the character string region R, and calculates a score regarding the result of character recognition for each character included in the character string region R.
- Character recognition is sometimes called optical character recognition (OCR).
- Character recognition is sometimes referred to by other names than optical character recognition, such as intelligent character recognition (ICR) or intelligent word recognition (IWR).
- Various techniques can be used for character recognition itself. For example, a method using a machine learning model (so-called AI OCR), a method using a template image, or a method using the shape characteristics of a line can be used.
- the character recognition result is the content output from the character recognition algorithm.
- each character recognized from the character string region R corresponds to the result of character recognition.
- character recognition is performed on a character string region R of two characters as shown in FIG. Recognize the characters and. The combination of these two characters is the result of character recognition.
- the character recognition unit 103 obtains character recognition results for the number of characters included in the character string region R.
- the score is an index that indicates the correctness of the character recognition results.
- the score is sometimes called probability.
- a case will be described in which the score is expressed by a numerical value, but the score may be expressed by other indicators such as letters or other symbols. A higher score means that the character recognition result is correct.
- the score is expressed in a numerical range of 0 to 100, but the score can be expressed in any other numerical range.
- the score is calculated by the output layer of the machine learning model. This score indicates the correctness of the character labeling performed by the machine learning model. For example, if the method uses a template image, the score is calculated based on the number of pixels that match the template image or the difference in color between each pixel and the template image. For example, if the method uses the shape characteristics of a line, the score is calculated based on the difference from the reference shape. The smaller these differences, the higher the score.
- FIG. 6 is a diagram showing an example of the execution result of character recognition for the character string region R.
- character recognition is capable of recognizing a plurality of recognizable characters.
- the character recognition unit 103 calculates a score for each of the plurality of recognizable characters for each character.
- Recognizable characters are characters that can be recognized by character recognition. For example, in the case of character recognition using a machine learning model, the characters learned by the machine learning model correspond to the recognizable characters. In the case of character recognition using a template image, the characters prepared as the template image correspond to the recognizable characters. In the case of character recognition using the shape of a character, a character for which a reference shape has been prepared corresponds to a recognizable character.
- Recognizable characters can also be referred to as characters that are candidates for character recognition. For example, in English, there are dozens to hundreds of recognizable characters such as alphabets, numbers, and other symbols. Recognizable characters vary depending on the language or character recognition method.
- the character recognition unit 103 is capable of recognizing recognizable characters according to the language targeted for character recognition and the method used for character recognition. For example, in Japanese, about 40,000 characters can be recognized, so the character recognition unit 103 may calculate a score for each of the 40,000 characters. Similarly, in the case of other languages, the character recognition unit 103 calculates a score for each recognizable character in the language.
- the character recognition unit 103 calculates a score for the first character and a score for the second character for each recognizable character.
- an English insurance card C is taken as an example, so the character recognition unit 103 calculates the score of the first character for each of dozens to hundreds of recognizable English characters. , and the score of the second character.
- the top five recognizable characters with the first character score and the top five recognizable characters with the second character score are shown.
- scores are also calculated for other recognizable characters. Therefore, there are also recognizable characters whose scores are 6th or higher.
- the character string area R3 includes the character string "ID".
- the scores of "I” and “D” are not necessarily ranked first.
- "I” has a simple shape and is likely to be mistakenly recognized as another character. Therefore, the first character of the character string region R3 is “1", “l”, “I”, “
- the correct answer for the first letter is "I,” which has the third highest score, but other letters with similar shapes have higher scores.
- the second characters in the character string region R3 are "D", “O”, "B", “R”, and “ ⁇ ” in descending order of score.
- the correct answer for the second letter is "D", which has the highest score. In this way, although both "I” and “D”, which are the correct answers in the character string region R3, are not ranked first, they are both in the top five.
- the character recognition unit 103 also treats the other two-character character string regions R5, R9, R11, R24, R29, and R33 as well as the character string region R3. Identify the recognizable character with the fifth highest score.
- the character string region R9 that includes "SB”, which is a fixed character string that we want to specify in this embodiment "S" and “B” are not both ranked first, but both are within the top five. It's in.
- the character string region R11 that includes "NB” which is a fixed character string that we want to specify in this embodiment, "N" and “B” are not both ranked first, but they are both ranked in the top five. It is within the range.
- the regular region determination unit 104 determines whether the character string region R is a regular region including a regular character string, based on the score calculated for each character. In this embodiment, since a plurality of standard character strings are to be specified, the standard area determination unit 104 determines for each standard character string whether or not the character string area R is a standard area that includes the specified standard character string. do. For example, since there are "SB" and "NB" as standard character strings, the standard area determination unit 104 determines whether the character string area R is a standard area of "SB" and whether the character string area R is a standard area of "NB". It is determined whether the area is a regular area or not.
- the standard area is a character string area R that includes a standard character string.
- the fixed-form region determining unit 104 determines whether a fixed-form character string is included in a certain character string region R, based on the score calculated for each character included in this character string region R. In this embodiment, based on the score of the first character and the score of the second character of a certain character string region R, it is determined whether this character string region R is a regular region.
- the fixed-form area determination unit 104 identifies, for each character, a recognizable character with a relatively high score from among a plurality of recognizable characters as a high-score character. For example, the fixed-form area determination unit 104 identifies, for each character, a recognizable character whose score rank is equal to or higher than a reference rank as a high-score character.
- the standard ranking is a ranking that is a condition for identifying high-scoring characters. In the example of FIG. 6, the standard ranking is 5th place.
- the standard ranking can be set to any ranking, and is not limited to fifth place. For example, the standard ranking may be 1st to 4th or 6th or higher.
- the fixed-form region determination unit 104 determines whether the character string region R is a fixed-form region by determining whether a fixed-form string exists among the combinations of high-scoring characters. In the example of FIG. 6, there are 25 combinations of the top five characters of the first character and the top five characters of the second character. The fixed-form region determining unit 104 judges whether or not there is one among the 25 combinations specified from a certain character string region R that matches the fixed-form character string.
- the method for determining a fixed-form region may be the same even when the number of characters included in the character string region R is not two. Furthermore, the method for determining a typical region may be the same even when the reference ranking is not 5th place. For example, if the character string region R contains n characters (n is an integer greater than or equal to 2), and a character with the highest score of m (m is a natural number) is identified as a high-score character, the fixed region determination unit In step 104, it is only necessary to determine whether or not there is one among the m n combinations that matches the regular character string.
- the fixed-form area determination unit 104 determines whether a character string region R having the same number of characters as the fixed-form character string is a fixed-form region.
- the fixed-form area determination unit 104 excludes character string regions R having a different number of characters from the fixed-form string from the determination target.
- character string regions R1 to R36 are detected, but as shown in FIG. , R5, R9, R11, R24, R29, and R33.
- other character string regions R having a different number of characters from the fixed-form character string are not determined as fixed-form regions. It may be determined whether or not.
- FIG. 7 is a diagram showing an example of a character string region R determined to be a fixed-form region.
- the fixed-form area determination unit 104 determines that the combination of "S", which ranks first in the score of the first character of the character string region R9, and "B", which ranks second in the score of the second character of the character string region R9, is , it is determined that the character string matches "SB", which is the fixed character string that is desired to be specified. Therefore, the regular area determination unit 104 determines that the character string area R9 is a regular area of "SB".
- the fixed area determination unit 104 determines that the combination of "N", which ranks second in the score of the first character of character string region R11, and "B", which ranks first with the score of the second character of character string region R9, is , it is determined that the character string matches "NB", which is the standard character string to be specified. For this reason, the standard area determining unit 104 determines that the character string area R11 is a standard area of "NB". As shown in FIG. 7, the fixed-form region determination unit 104 determines that among the plurality of character string regions R3, R5, R9, R11, R24, R29, and R33 to be determined, character string regions R9 and R11 are fixed-form regions. It is determined that
- the fixed-form region determining unit 104 selects any one of the plurality of character string regions R, and determines whether the selected character string region R is a fixed-form region.
- the regular area determining unit 104 selects character string areas R one by one from the top of the insurance card image I, and determines whether the selected character string area R is a regular area. do.
- the fixed-form area determination unit 104 selects character string areas R3, R5, R9, R11, R24, R29, and R33 one by one in this order.
- the character string regions R may be selected in any order; for example, they may be selected from the bottom, or may be selected from the left or right.
- the regular region determination unit 104 ends the process without selecting the next character string region R.
- the fixed-form area determination unit 104 was able to confirm that both of the two fixed-form character strings existed at the time when the judgment was performed on the character string region R11, so , R33 is not executed and the process ends. That is, when all the fixed-form regions have been identified, the fixed-form region determination unit 104 determines that even if there are still character string regions R that have not yet been determined, the remaining character string regions R are not considered to be determination targets. do not.
- the fixed-form region determining unit 104 selects the next character string region R, and selects the next selected character string. It is determined whether region R is a regular region. In the example of FIG. 5, the fixed-form region determination unit 104 determines that neither the combination of "S" and "B” nor the combination of "N" and "B” exists in the first character string region R3. Since the determination has been made, determination processing for the second character string region R5 is executed. Thereafter, the standard area determination unit 104 selects character string areas R one by one and determines whether or not they are standard areas until all standard areas are identified.
- the non-standard region specifying unit 105 identifies a character string region R that is in a predetermined positional relationship with the regular region as a non-standard region including a non-standard character string.
- the predetermined positional relationship is the positional relationship between the regular character string and the non-standard character string in the insurance card C.
- the predetermined positional relationship is the position where the non-standard character string is placed with respect to the position of the standard character string.
- the positional relationship can also be called relative position.
- the predetermined positional relationship is predetermined in the data storage unit 100.
- a predetermined positional relationship is determined for each fixed-form character string.
- the non-standard area specifying unit 105 specifies other positions in a predetermined positional relationship based on the standard area determined by the regular area determining unit 104.
- the non-standard area identifying unit 105 identifies the character string area R located at the other specified position as the non-standard area corresponding to this standard area.
- the non-standard region identifying unit 105 determines that the character string region R is in a predetermined positional relationship with the regular region.
- the predetermined positional relationship may be within a predetermined distance from the regular area in a predetermined direction.
- the predetermined positional relationship may not be within a predetermined distance, but may be a pinpoint position.
- the atypical area specifying unit 105 specifies a range within a predetermined distance in a predetermined direction from the regular area, and specifies a character string area R within the specified range as an atypical area corresponding to this regular area. do.
- the predetermined direction and predetermined distance corresponding to the predetermined positional relationship may be any predetermined direction and distance.
- the predetermined direction and the predetermined distance may be determined according to the actual positional relationship between the regular character string and the non-standard character string in the insurance card C.
- the predetermined direction is the right direction.
- the predetermined direction may be another direction such as the left direction, the upward direction, or the downward direction, or may be an oblique direction slightly shifted from any of the up, down, left, and right directions.
- the predetermined distance may be any distance that can be assumed as the distance between the regular character string and the non-standard character string in the insurance card C.
- the predetermined distance may be about 1 centimeter to 10 centimeters, more than that, or less than that.
- FIG. 8 is a diagram illustrating an example of a method for specifying an atypical region.
- the non-standard area specifying unit 105 locates the area on or on lines L1 and L2, which are obtained by extending at least one side of the character string area R9, which is a regular area, by a predetermined distance in a predetermined direction. If there is a character string region R nearby, it is determined that the character string region R is in a predetermined positional relationship with the regular pattern region. Nearby means a position within a predetermined distance from the lines L1 and L2.
- the atypical region identifying unit 105 may determine a predetermined positional relationship using only either the side L1 or the side L2.
- the non-standard area specifying unit 105 determines that the character string area R is located on or near two lines obtained by extending two opposing sides L1 and L2 of the standard area by a predetermined distance in a predetermined direction. , it is determined that the character string region R is in a predetermined positional relationship with the fixed-form region.
- the non-standard region specifying unit 105 since the character string regions R10 and R11 are on the lines L1 and L2, the non-standard region specifying unit 105 first determines whether the character string regions R10 and R11 are on the predetermined character string region R9, which is a regular region. It is determined that there is a positional relationship.
- the non-standard area specifying unit 105 similarly creates two lines in which the upper and lower sides are extended by a predetermined distance in a predetermined direction for the character string region R11, which is a regular region. If the character string region R is on or near the line, it is determined that the character string region R is in a predetermined positional relationship with the fixed-form region. Although this line is omitted in the example of FIG. 8, it is assumed that only the character string region R12 exists on this line. The non-standard region specifying unit 105 determines that the character string region R12 is in a predetermined positional relationship with the character string region R11, which is a regular region.
- the non-standard region specifying unit 105 selects the character string region R from among the plurality of character string regions R. Identify as an atypical area.
- the first positional relationship is the predetermined positional relationship in the above description. In the example of FIG. 8, the first positional relationship corresponds to being on or near a line obtained by extending the sides of the regular area. If there are a plurality of character string regions R having a first positional relationship with the regular region, the non-standard region specifying unit 105 selects a character string having a second positional relationship with the regular region from among the plurality of character string regions R. Region R is identified as an atypical region.
- the second positional relationship is a positional relationship determined based on a different criterion than the first positional relationship. For example, when there are a plurality of character string regions R that have a first positional relationship with a regular region, the non-standard region specifying unit 105 determines which of the plurality of character string regions R is the closest (relatively closest) to the regular region. ) The character string region R is specified as the character string region R having a second positional relationship with the regular pattern region. Therefore, being close to the regular area corresponds to the second positional relationship. In the example of FIG.
- the character string region R10 is closest to the character string region R10, which is a fixed-form region, so the character string region R10 is identified as an atypical region.
- the second positional relationship may be another positional relationship. For example, if another regular area exists near the regular area, the second positional relationship may be far from the regular area.
- the non-standard region specifying unit 105 determines that two character string regions R10 and R11 exist on or near lines L1 and L2, which are the extended sides of the character string region R9, which is a regular region. Among these two character string regions R10 and R11, the non-standard region specifying unit 105 identifies the character string region R10 that is closer to the character string region R9 as the first regular region. Since only one character string region R12 exists on or near lines L1 and L2 obtained by extending the sides of the character string region R11, which is a regular region, the non-standard region specifying unit 105 selects the character string region R as the second character string region R12. identified as a typical area. Therefore, the second positional relationship is not determined for the character string region R11.
- FIG. 9 is a diagram showing an example of the insurance card image I after masking has been performed on the atypical region.
- the masking execution unit 106 executes masking on the atypical region.
- Masking is image processing that makes atypical areas invisible.
- the process is a process of filling with a predetermined color, a process of mapping some image or pattern, a process of cutting out an atypical area, or a process of applying a mosaic.
- the character string regions R10 and R12 which are atypical regions, are masked, so the character strings "538712110" and "123" are not known to a third party. is in a state.
- the transmitter 107 transmits the masked insurance card image I to the server 20.
- the transmitter 107 sends the insurance card image I to the server in which the character string regions R10 and R12, which are atypical regions, are masked so that the character strings "538712110" and "123" are not known to a third party.
- Send to 20 when the insurance card determination unit 108 (described later) determines that the insurance card image I includes the insurance card C, masking is performed on the insurance card image I, and the transmission unit 107 transmits the insurance card image Send I. If the insurance card determination unit 108 does not determine that the insurance card C is included in the insurance card image I, the photographing of the insurance card C may be requested again.
- the insurance card determination unit 108 determines that the insurance card C is not included in the insurance card image I when there is a regular character string for which a regular region has not been specified among the plurality of regular character strings. In the present embodiment, the insurance card determination unit 108 determines that the insurance card C is not included in the insurance card image I when a fixed-form region of one or more fixed-form character strings is not specified. Therefore, the insurance card determination unit 108 determines that the insurance card C is included in the insurance card image I when the standard regions of all the standard character strings are identified.
- the insurance card determination unit 108 determines which non-standard region is not identified among the plurality of non-standard character strings. If the fixed character string exists, it is determined that the insurance card C is not included in the insurance card image I. In this embodiment, the insurance card determination unit 108 determines that the insurance card C is not included in the insurance card image I when an atypical region of one or more atypical character strings is not identified. Therefore, the insurance card determination unit 108 determines that the insurance card C is included in the insurance card image I when the atypical regions of all the atypical character strings are identified.
- the data storage section 200 is mainly realized by the storage section 22.
- the receiving section 201 is realized mainly by the control section 21.
- the data storage unit 200 of this embodiment stores data necessary for eKYC.
- the data storage unit 200 stores the insurance card image I received from the user terminal 10.
- the insurance card image I that has been masked is transmitted, so the data storage unit 200 stores the insurance card image I that has been masked.
- the receiving unit 201 receives the masked insurance card image I from the user terminal 10.
- the receiving unit 201 records the received insurance card image I in the data storage unit 200.
- FIG. 10 is a flow diagram illustrating an example of processing executed by the image processing system 1.
- the user terminal 10 acquires an insurance card image I including the insurance card C based on the photographing result by the photographing unit 16 (S1).
- the user terminal 10 detects a plurality of character string regions R from the insurance card image I using the Scene Text Detection method (S2).
- the character string area R detected in S2 is in a state as shown in FIG.
- the user terminal 10 identifies a character string region R having the same number of characters as the regular character string from among the plurality of character string regions R detected in S2 (S3).
- the character string region R specified in S3 is in a state as shown in FIG.
- the user terminal 10 performs character recognition on each of the plurality of character string regions R detected in S3, and calculates a score for each character (S4).
- the score calculated in S4 has contents as shown in FIG.
- the user terminal 10 determines whether each of the plurality of character string regions R is a regular region based on the score for each character calculated in S4 (S5). In S5, as described above, it is determined whether or not a fixed character string is included in the top five combinations of scores.
- the character string area R after the determination is in a state as shown in FIG.
- the user terminal 10 identifies a character string region R that satisfies a predetermined positional relationship with the character string region R determined to be a regular region as an atypical region (S6).
- S6 as shown in FIG. 8, the character string region R on or near the line is specified as an atypical region.
- the user terminal 10 determines whether all the regular regions and atypical regions have been identified (S7). If it is determined that any regular region or non-standard region has not been specified (S7; N), this process ends. In this case, the user terminal 10 may cause the display unit 15 to display an error message indicating that the insurance card C is not captured in the insurance card image I.
- the user terminal 10 performs masking on the non-standard regions (S8).
- the user terminal 10 transmits the masked insurance card image I to the server 20 (S9).
- the server 20 receives the masked insurance card image I and records it in the storage unit 22 (S10), and this process ends. Thereafter, eKYC is performed based on the insurance card image I recorded in the storage unit 22.
- the image processing system 1 includes the first configuration for accurately specifying the "SB" and "NB" areas from the insurance card image I.
- the image processing system 1 performs character recognition on the character string region R detected from the insurance card image I.
- the image processing system 1 determines whether the character string region R is a regular region based on the score calculated for each character included in the character string region R.
- the standard area can be reliably identified from the insurance card image I. For example, if the insurance card C in the insurance card image I is bent or distorted, it is difficult to specifically identify which characters are included, but it is possible to identify whether any characters are included. I can.
- a character string region R that can be detected with high accuracy is first detected.
- the subsequent character recognition cannot be performed with high accuracy, but by using individual scores for each character rather than the score of the entire character string, it is possible to identify standard character strings among the combinations of high-scoring characters. Since it becomes possible to determine that it is only necessary that the area is included, it becomes easier to identify the standard area.
- the image processing system 1 identifies a recognizable character with a relatively high score from among the plurality of recognizable characters as a high-score character.
- the image processing system 1 determines whether the character string region R is a regular region by determining whether a regular character string exists in the combination of high-scoring characters. As a result, even if the score of some characters in the standard character string becomes somewhat low, as long as this character is included in the combination of high-scoring characters, the character string region R can be identified as a standard region. It becomes easier to specify the regular area from the image I.
- a score is calculated using a character string including a plurality of characters as one set.
- the character recognition result is obtained as a set of the entire character string, it is difficult to identify the standard region unless the entire standard character string is recognized as a set.
- the 2-character character string region R9 if a score is calculated for each 2-character string, if the score of the same 2-character string as the standard character string is not high, the standard character string is identified. Can not.
- the standard character string "SB” if the character string "SB" containing both the first character "S” and the second character “B” does not have a high score, the standard character string will be rejected. It can not be identified.
- the score is calculated for each character, so "S” ranks first in the score for the first character, but "B” ranks first in the score for the second character. Even if the character string is ranked second in the eye score, it is only necessary that the fixed character string is included in the combination of high-scoring characters, so that it can be specified that the character string region R9 includes "SB".
- the image processing system 1 specifies, as a high-score character, a recognizable character whose score rank is equal to or higher than the standard rank.
- a high-score character a recognizable character whose score rank is equal to or higher than the standard rank.
- the image processing system 1 determines whether a character string region R having the same number of characters as the fixed-form character string is a fixed-form region. As a result, the character string region R having a different number of characters from the standard character string is excluded from the determination target, and unnecessary processing is not performed, reducing the processing load on the user terminal 10 and the time required to identify the standard region. can be shortened.
- the image processing system 1 selects any one of the plurality of character string regions R, and selects the next character string region R if it is determined that the selected character string region R is a fixed-form region. Terminate processing without doing so. If the selected character string region R is not determined to be a regular region, the image processing system 1 selects the next character string region R, and determines that the selected next character string region R is a regular region. Determine whether it exists or not. As a result, when a regular area is specified, unnecessary processing is not executed thereafter, so that the processing load on the user terminal 10 can be reduced, and the time required to identify the standard area can be shortened.
- the image processing system 1 determines that the insurance card image I does not include the insurance card C. . Thereby, it is possible to reliably identify whether the insurance card C is included in the insurance card image I. For example, if the insurance card C is not included in the insurance card image I, or if the insurance card C in the insurance card image I is unclear, there is a possibility that the eKYC cannot be completed and will have to be redone. By reliably specifying whether or not the insurance card C is included in the insurance card image I, eKYC can be completed reliably. This increases convenience for both the user and the service administrator.
- the image processing system 1 determines whether the character string region R detected from the image generated by photographing an identification document, for example the insurance card C, is a regular region. This makes it possible to reliably identify the standard area from the image of the identity verification document.
- the image processing system 1 includes the second configuration for accurately specifying the business reference number and individual number areas from the "SB" and "NB" areas.
- the image processing system 1 determines whether there is a regular region among the plurality of character string regions R detected from the insurance card image I.
- the image processing system 1 specifies a character string area R that has a predetermined positional relationship with the regular area as an atypical area.
- the atypical area can be identified using the relatively easy-to-identify regular area as a clue, so the atypical area can be reliably identified from the insurance card image I.
- the image processing system 1 determines that the character string region R is in a positional relationship with the regular region. Thereby, when there is an atypical character string within a predetermined distance in a predetermined direction from a regular character string in the insurance card C, it becomes easier to identify the atypical area.
- the image processing system 1 determines that when the character string region R is on or near a line obtained by extending at least one side of the regular region by a distance in the direction, the character string region R is in a positional relationship with the regular region. judge. Thereby, by using the sides of the regular area as a reference, the non-standard area can be specified more reliably. Since the atypical area can be identified through relatively simple processing, the processing load on the user terminal 10 can be reduced and the time required to identify the atypical area can be shortened.
- the image processing system 1 is configured such that when a character string region R is located on or near two lines obtained by extending two mutually opposing sides of a regular region by a distance in the direction, the character string region R is a regular region. It is determined that there is a positional relationship with . Thereby, by using multiple sides of the regular area as a reference, the non-standard area can be specified more reliably. Since the atypical area can be identified through relatively simple processing, the processing load on the user terminal 10 can be reduced and the time required to identify the atypical area can be shortened.
- the image processing system 1 converts the character string region R into a non-standard pattern. Specify as an area.
- the image processing system 1 selects a character string region R having a second positional relationship with the regular pattern region from among the plurality of character string regions R. is identified as an atypical region.
- the image processing system 1 selects a character string region R that is closest to the regular pattern region among the plurality of character string regions R. It is specified as a character string region R having a second positional relationship with the region. This allows the atypical region to be reliably identified. For example, as shown in FIG. 8, even if character string regions R10 and R11 exist on a line obtained by extending the two upper and lower sides of character string region R9, which is a regular region, character string region R10, which is close to character string region R9, can be an atypical region.
- the image processing system 1 determines that the insurance card C is not included in the insurance card image I when there is an atypical character string for which an atypical region has not been identified among the plurality of atypical character strings. It is determined that Thereby, it can be reliably determined that the insurance card C is included in the insurance card image I. For example, it is possible to prevent an insurance card image I with insufficient masking from being transmitted.
- the image processing system 1 also performs masking on the atypical region.
- the insurance card image I can be uploaded after masking information that the user does not want a third party to know.
- the insurance card image I is an image generated by photographing an identification document. This makes it possible to reliably identify atypical areas from an image of an identification document.
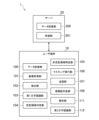
- FIG. 11 is a functional block diagram in a modification of the first configuration.
- an applicable criterion determining section 109 and a criterion number determining section 110 are implemented.
- the applicable criterion determination section 109 and the criterion number determination section 110 are realized mainly by the control section 11.
- the fixed-form area determination unit 104 may specify, for each character, a recognizable character whose score is equal to or higher than a reference score as a high-score character. That is, in the example shown in FIG. 6 of the embodiment, the top five recognizable characters are identified as high-scoring characters, but it is not determined how many characters are recognized as high-scoring characters. Any number of characters may be used as high score characters.
- the standard score is a score that serves as a standard for identifying high-scoring characters.
- the reference score may be any value.
- the reference score may be a fixed value or a variable value.
- the standard score is set to 80.
- the fixed-form region determination unit 104 identifies recognizable characters with a score of 80 or higher as high-score characters. Therefore, the number of high score characters changes depending on the character string region R and the number of characters.
- the fixed-form area determination unit 104 may identify a recognizable character whose score is equal to or higher than a reference score and whose rank is equal to or higher than the reference rank as a high-score character.
- the image processing system 1 of Modification 1-1 specifies, for each character, a recognizable character whose score is equal to or higher than the reference score as a high-score character. As a result, even if the rank of some characters in the standard character string is slightly lower, if the score of this character is equal to or higher than the standard score, it will be classified as a high-scoring character, so the standard region can be identified from the insurance card image I. It becomes easier to do.
- Modification 1-2 For example, depending on the individual characters included in a fixed-form character string, there are some characters that are likely to be misrecognized as other characters. Therefore, the criteria for determining whether a character is a high-score character may be different depending on the character, instead of being the same for all characters.
- the applicable criteria are conditions that a score must satisfy in order to be classified as a high score character. In the example of the embodiment, ranking in the top five corresponds to the applicable criterion. In the example of Modification 1-1, being equal to or higher than the standard score corresponds to the applicable standard.
- the image processing system 1 includes an applicable criterion determination unit 109.
- the applicable criterion determination unit 109 determines an applicable criterion for a recognizable character to correspond to a high-score character based on the fixed character string. It is assumed that the relationship between the fixed character string and the applicable criteria is determined in advance. For example, the applicable criterion determining unit 109 determines the applicable criterion based on the ease with which a fixed character string is misrecognized. The applicable criterion determining unit 109 determines the applicable criterion such that the lower the probability that a fixed character string will be misrecognized, the stricter the applicable criterion. In other words, the applicable criteria determining unit 109 determines the applicable criteria such that the higher the probability that the fixed character string will be misrecognized, the less stringent the applicable criteria.
- Strict applicable standards mean higher applicable standards.
- an increase in the standard ranking corresponds to the fact that the applicable standard is stricter.
- an increase in the standard score corresponds to the corresponding standard becoming stricter.
- the applicable standard is lenient, it means that the applicable standard is lowered.
- a lowering of the standard ranking corresponds to the corresponding standard becoming less strict.
- lowering the standard score corresponds to making the applicable standard less strict.
- the applicable criteria determining unit 109 sets the applicable criteria less harshly as the shape of the fixed character string becomes simpler. Characters with simple shapes are likely to be misrecognized, so by relaxing the criteria, it is possible to prevent characters that you really want to recognize from not being classified as high-scoring characters.
- the fixed area determining unit 104 identifies high-scoring characters based on the applicable criteria determined by the applicable criteria determining unit 109. Although it differs from the embodiment and modification 1-1 in that the applicable criteria determined by the applicable criteria determination unit 109 is used, the process itself of identifying high-scoring characters is the same as that of the embodiment and modified example 1-1. It is similar to
- the image processing system 1 of Modification 1-2 identifies high-scoring characters based on the applicable criteria determined based on the fixed character string.
- high-scoring characters can be specified based on the applicable criteria according to the standard character string, so that the standard area can be specified more reliably. For example, if the standard character string is simple, even if the score of the character you really want to recognize is 6th or higher due to misrecognition with a similar character, you can easily recognize this character by relaxing the criteria. Can be classified as high score characters. Therefore, it becomes easier to specify that the character string area R includes this character.
- the condition for identifying a fixed pattern region is that all characters included in a fixed string are present in a combination of high-scoring characters specified from a certain string region R. explained. If such conditions are set, if the number of characters in the fixed-form character string is large, the conditions may become too strict and it may become impossible to identify the fixed-form region. For example, if the standard character string is 10 characters, even if all 10 characters do not exist in the combination of high score characters, if 8 or more of the 10 characters exist in the combination of high score characters, the character string area R appears to be the typical region.
- the fixed-form area determination unit 104 determines that the fixed-form characters that are equal to or greater than the reference number are in the combination. If the character string region R exists within the specified region, it may be determined that the character string region R is a fixed-form region.
- the reference number is a number used as a reference for determining that the character string region R is a fixed-form region. In Modification 1-3, the reference number is assumed to be a fixed value, but the reference number may be a variable value as in Modification 1-4 described later. In the above example of the fixed string of 10 characters, the standard number is 8 characters. The reference number may be any number. For example, the reference number may be about 70% of the number of characters in the regular character string.
- the number of fixed-form characters included in a fixed-form character string be x (x is an integer of 2 or more).
- the reference number be y (y is an integer smaller than x).
- the fixed-form area determination unit 104 identifies the number of fixed-form characters that are present in the combination of high-scoring characters among the fixed-form characters of x characters. If the specified number is y characters or more, the fixed-form area determining unit 104 determines that the character string region R is a fixed-form region. If the specified number is less than y characters, the fixed-form area determining unit 104 does not determine that the character string region R is a fixed-form region.
- the image processing system 1 of Modified Example 1-3 is configured such that even if there is a fixed character that does not exist in the combination among the plurality of fixed characters included in the fixed character string, a fixed number of fixed characters equal to or greater than the standard number are included in the combination. , it is determined that the character string region R is a fixed-form region. Thereby, when the number of characters in a fixed-form character string is large, it is possible to prevent the conditions for specifying a fixed-form region from becoming too strict and making it impossible to specify a fixed-form region.
- the reference number in Modification 1-3 may be a number corresponding to a fixed character string.
- the image processing system 1 of Modification 1-4 includes a reference number determination unit 110.
- the reference number determination unit 110 determines the reference number based on the fixed character string. It is assumed that the relationship between the standard character string and the reference number is predetermined. For example, the reference number determination unit 110 determines the reference number based on the ease with which a fixed character string is misrecognized.
- the reference number determination unit 110 determines the reference number such that the higher the probability that the fixed character string will be misrecognized, the smaller the reference number becomes. In other words, the reference number determination unit 110 determines the reference number such that the lower the probability that a fixed character string will be misrecognized, the larger the reference number.
- the reference number determining unit 110 may determine the reference number based on the number of characters in the fixed character string.
- the reference number determining unit 110 determines the reference number such that the smaller the number of characters in the fixed character string, the smaller the reference number. In other words, the reference number determining unit 110 determines the reference number such that the larger the number of characters in the fixed character string, the larger the reference number.
- the standard area determining unit 104 determines whether the character string area R is a standard area based on the reference number determined by the standard number determining unit 110. This differs from Modification 1-3 in that the reference number determined by the reference number determination unit 110 is used, but the process itself for determining a regular region is the same as Modification 1-3.
- the image processing system 1 of Modification 1-4 determines whether the character string region R is a regular region based on the reference number determined based on the regular character string. Thereby, when the number of characters in a fixed-form character string is large, it is possible to prevent the conditions for specifying a fixed-form region from becoming too strict and making it impossible to specify a fixed-form region.
- the fixed-form region determination unit 104 of Modification 1-5 determines whether the character string region R is a fixed-form region by determining whether the total score of each of the plurality of fixed-form characters is equal to or greater than the reference total value. Determine whether or not.
- the reference total value is a number that serves as a reference for determining that the character string region R is a fixed-form region. In Modification 1-5, the reference total value is assumed to be a fixed value, but the reference total value may be a variable value as in Modification 1-6 and Modification 1-7 described later. The reference total value may be any number. For example, the reference total value may be about 70% of the maximum value of the total score value.
- the fixed-form area determination unit 104 does not determine that the character string region R is a fixed-form region, and determines that the total value of the scores is equal to or higher than the reference total value. If so, it is determined that the character string region R is a fixed-form region. For example, in the case of a fixed character string "SB", the fixed region determination unit 104 determines that the total value of the score of the first character "S" and the score of the second character "B" is equal to or greater than the reference total value. Determine whether it exists or not. In the example of FIG. 6, the total value of character string regions R3, R5, etc. is extremely low. Since the character string region R9 has a high total value, it is determined to be a regular format region.
- the image processing system 1 of Modification 1-5 determines whether the character string region R is a fixed-form region by determining whether the total value of the scores of each of the plurality of fixed-form characters is equal to or greater than the reference total value. Determine whether As a result, only the fixed characters included in the fixed string can be subject to score calculation, and there is no need to calculate scores for a large number of recognizable characters, reducing the processing load on the user terminal 10, and The time required to identify a typical region can be reduced.
- the reference total value in Modified Example 1-5 may be a value depending on the shape of a regular character.
- the fixed-form region determination unit 104 determines whether the character string region R is a fixed-form region based on a reference total value corresponding to the shape of each of the plurality of fixed-form characters. For example, if a fixed-form character string is complex, there are few characters with similar shapes, so it is thought that misrecognition with other characters is less likely to occur. For this reason, the regular area determination unit 104 sets the reference total value so that the reference total value becomes high. Characters with complex shapes are easy to recognize in the first place, so even if the reference total value is increased, it is unlikely that a typical region will not be identified.
- the regular area determining unit 104 sets the reference total value so that the reference total value is low. Characters with simple shapes are likely to be misrecognized, so by lowering the reference total value, it is possible to prevent difficulty in specifying a fixed-form area.
- this modification differs from Modification 1-5 in that a reference total value is set according to the shape of a regular character, the processing itself for determining a regular format region is the same as Modification 1-5.
- the image processing system 1 of Modification 1-6 determines whether the character string region R is a fixed-form region based on the reference total value according to the shape of each of a plurality of fixed-form characters. Thereby, by using the reference total value according to the shape of the fixed-form characters, the fixed-form region can be specified more reliably. For example, even if the fixed-form character string is simple, it is possible to prevent the fixed-form region from becoming difficult to identify.
- the fixed-form area determining unit 104 may determine whether the character string region R is a fixed-form region based on a reference total value corresponding to the number of fixed-form characters included in the fixed-form character string.
- the fixed-form area determination unit 104 sets the reference total value such that the larger the number of fixed-form characters included in the fixed-form character string, the higher the reference total value.
- the fixed-form area determination unit 104 sets the reference total value such that the smaller the number of regular characters included in the fixed-form character string, the lower the reference total value.
- this modification differs from Modification 1-5 in that a reference total value is set according to the number of regular characters, the process itself for determining a regular format region is the same as Modification 1-5.
- the image processing system 1 of Modification 1-7 determines whether the character string region R is a regular region based on the reference total value according to the number of regular characters included in the regular character string. Thereby, by using the reference total value according to the number of fixed-form characters, the fixed-form region can be specified more reliably.
- the plurality of recognizable characters include the plurality of fixed-form characters included in the fixed-form character string.
- the character recognition unit 103 may perform character recognition on each of a plurality of standard characters in the character string region R, and calculate a score for each standard character.
- the fixed-form region determination unit 104 may determine whether the character string region R is a fixed-form region based on the score calculated for each fixed-form character. In this case, the score is calculated only for fixed characters, as in Modification 1-5.
- the regular region determination unit 104 determines whether the character string region R is a regular region based on other indicators such as the average value of the scores, rather than the total value of the scores as in Modification 1-5. It's okay.
- the image processing system 1 of Modification 1-8 determines whether the character string region R is a fixed-form region based on the score calculated for each fixed-form character. As a result, only the fixed characters included in the fixed string can be subject to score calculation, and there is no need to calculate scores for a large number of recognizable characters, reducing the processing load on the user terminal 10, and The time required to identify a typical region can be reduced.
- the fixed-form area determining unit 104 may determine whether the character string region R having a size corresponding to the fixed-form character string is a fixed-form region. It is assumed that the size corresponding to the fixed character string is predetermined in the data storage unit 100.
- the size is determined to be about two characters.
- the fixed-form region determination unit 104 selects, as a fixed-form region, a character string region R whose size difference from the fixed-form character string is less than a predetermined difference.
- the target is to determine whether or not it exists. Character string regions R that differ greatly in size are not subject to determination.
- the image processing system 1 of Modification 1-9 determines whether a character string region R having a size corresponding to a regular character string is a regular format region. As a result, the character string area R with a size different from the standard character string is excluded from the determination target, and unnecessary processing is not executed, reducing the processing load on the user terminal 10 and the time required to identify the standard area. can be shortened.
- FIG. 12 is a functional block diagram of a modified example of the second configuration.
- the character recognition unit 103 in the embodiment and modifications 1-1 to 1-9 is referred to as a first character recognition unit 103.
- a shaping section 111 and a second character recognition section 112 are implemented.
- the shaping section 111 and the second character recognition section 112 are mainly realized by the control section 11.
- Modification 2-1 For example, in the embodiment, a case has been described in which masking is performed on an atypical region. Image processing other than masking may be performed on the atypical region. In modification 2-1, a case will be described in which character recognition is executed for an atypical area. In the eKYC of the embodiment, a non-standard character string is not used, but in the eKYC of Modification 2-1, a case in which a non-standard character string is used will be exemplified. For example, the office reference number and personal number of insurance card C are used in eKYC.
- the image processing system 1 of Modification 2-1 includes a second character recognition unit 112.
- the second character recognition unit 112 performs character recognition on the non-standard area.
- the character recognition itself may be the same as that of the first character recognition unit 103.
- the second character recognition unit 112 performs character recognition on the non-standard area and recognizes non-standard character strings included in the non-standard area. For example, the second character recognition unit 112 identifies the recognizable character with the highest score for each character included in the atypical region.
- the second character recognition unit 112 recognizes a character string in which recognizable characters with the highest scores are arranged as an atypical character string.
- the transmitting unit 107 transmits the non-standard character string recognized by the second character recognizing unit 112 to the server 20. Upon receiving the non-standard character string, the receiving unit records the non-standard character string in the data storage unit 200 .
- Non-standard character strings are used in eKYC. Note that in Modification 2-1 as well, not only the non-standard character string but also the insurance card image I may be transmitted to the server 20.
- the image processing system 1 of Modification 2-1 performs character recognition on a non-standard area that has a predetermined positional relationship with a regular area. With this, it is possible to reliably specify the atypical region and then perform character recognition on the atypical region, so that the atypical character string can be reliably recognized.
- Modification 2-2 For example, if the insurance card C in the insurance card image I is bent or distorted, individual characters within the atypical area may also be bent or distorted. In this case, even if an attempt is made to perform character recognition on a non-standard region as in Modification 2-1, there is a possibility that the non-standard character string cannot be accurately recognized. For this reason, it is conceivable to reshape the atypical area so that it has a shape that facilitates character recognition.
- FIGS. 13 and 14 are diagrams illustrating an example of processing for shaping an atypical region.
- the image processing system 1 of modification 2-2 includes a shaping section 111.
- the shaping unit 111 shapes a character string region R10, which is a non-standard region, based on a character string region R9, which is a regular region, and a sample region R100.
- the sample area R100 is an area in which a fixed character string appears in an image taken when the insurance card C is photographed from the front.
- a fixed character string "SB" is shown in the sample area R100.
- the character string region R9 corresponds to a regular format region, so hereinafter, when the character string regions R9 and R11 are not distinguished, they will simply be referred to as a regular format region.
- the explanation includes the sample area "NB” instead of the sample area R100 in FIG. 13, the sample area will be explained without the reference numeral R100.
- the regular area and the sample area are rectangular.
- the sample area may have any shape like the regular area.
- the sample area is rectangular or square.
- the regular area may be a rectangle or a square, but if the insurance card C in the insurance card image I is bent or distorted, the regular area may be a quadrilateral whose four corners have angles other than 90 degrees.
- the shaping unit 111 determines a conversion coefficient for converting the non-standard area based on the difference between the regular area and the sample area. For example, the shaping unit 111 determines the conversion coefficient based on the difference between the positional relationship between the four corner points P11 to P14 of the sample area and the positional relationship between the four corner points P21 to P24 of the standard area. The shaping unit 111 obtains the points P31 to P34 of the regular shaped area after shaping by converting the four corner points P41 to P44 of the regular shaped area based on the determined conversion coefficients.
- the shaping unit 111 shapes the atypical region based on the width of the regular region and the width of the sample region.
- the shaping unit 111 determines a conversion coefficient based on the difference between the width of the standard area and the width of the sample area.
- the shaping unit 111 shapes the atypical region based on the determined transformation coefficient. In the example of FIG. 13, a case will be described in which both the vertical width and the horizontal width are used, but the formatting may be performed using only either the vertical width or the horizontal width.
- the shaping unit 111 calculates the width len w1 and the width len h1 of the sample region R100.
- the width len w1 is the distance between the points P11 and P12 or the distance between the points P13 and P14.
- the width len h1 is the distance between the points P11 and P13 or the distance between the points P12 and P14.
- the shaping unit 111 calculates the width len w2 and the width len h2 of the character string region R9, which is a fixed-form region.
- the width len w2 is the distance between the points P21 and P22 or the distance between the points P23 and P24.
- the width len h2 is the distance between the points P21 and P23 or the distance between the points P22 and P24.
- the shaping unit 111 calculates the ratio ⁇ w between the width len w1 and the width len w2 .
- the shaping unit 111 calculates the ratio ⁇ h between the width len h1 and the width len h2 .
- the shaping unit 111 calculates the width len w4 and the width len h4 of the character string region R100, which is an atypical region.
- the shaping unit 111 sets a value obtained by multiplying the ratio ⁇ w by the width len w4 as the width len w3 of the character string region R10r, which is the atypical region after shaping.
- the shaping unit 111 sets a value obtained by multiplying the ratio ⁇ h by the width len h4 as the vertical width len h3 of the character string region R10r.
- the shaping unit 111 calculates a conversion coefficient based on the positional relationship between the four corner points P31 to P34 of the character string region R10r and the four corner points P41 to P44 of the character string region R10. This transformation coefficient may be calculated using a calculation formula used in transformation such as affine transformation.
- the shaping unit 111 shapes the character string region R10 by converting it using the calculated conversion coefficient.
- the shaping unit 111 calculates a conversion coefficient for the character string region R12 using the same procedure, and formats the character string region R12 by converting it.
- the character string regions R10r and R12r after formatting are as shown in FIG. In the state shown in FIG. 14, each character string faces forward, making it easy to recognize characters.
- the insurance card C of Modified Example 2-2 has the first fixed string "SB”, the second fixed string “NB”, the first non-standard string "538712110", as in the embodiment. and a second atypical character string "123".
- the fixed-form area determination unit 104 judges whether or not there is a first fixed-form region including a first fixed-form character string and a second fixed-form region including a second fixed-form character string among the plurality of character string regions R. do. This determination method is as explained in the embodiment.
- the non-standard area specifying unit 105 sets the first non-standard character string to a character string area R that has a predetermined positional relationship with the first regular area. It is specified as the first atypical region containing the first atypical region.
- the non-standard area specifying unit 105 identifies a character string area R in a predetermined positional relationship with the second regular area as a second non-standard area including the second non-standard character string. This identification method is also as explained in the embodiment.
- the shaping unit 111 determines a conversion coefficient for shaping the first non-standard region based on the first regular region and the first sample region regarding the sample of the first regular region.
- the shaping unit 111 shapes the first atypical region based on the determined transformation coefficient.
- the shaping unit 111 also shapes the second atypical region based on the determined transformation coefficient.
- the shaping unit 111 uses the conversion coefficients determined based on the positional relationship between points P31 to P34 and the positional relationship between points P41 to P44 in FIG. It is also used for shaping the column area R12.
- the second character recognition unit 112 performs character recognition on the shaped atypical area. In the example of FIG. 14, the second character recognition unit 112 performs character recognition on each of the character string regions R10r and R12r after shaping.
- the image processing system 1 of Modification 2-2 shapes the atypical area based on the regular area and the sample area. As a result, it is possible to create an atypical area having a shape similar to the area of atypical characters included in a photographed image of the insurance card C in a predetermined state. For example, when character recognition is performed on a non-standard area as in Modification 2-2, the accuracy of character recognition increases because the non-standard area is in a state where character recognition is easy.
- the image processing system 1 also shapes the atypical area based on the width of the regular area and the width of the sample area. By focusing on the width, it becomes possible to perform shaping through simple calculations, and the precision of shaping non-standard areas also increases.
- the image processing system 1 also shapes the second non-standard area based on the transformation coefficient determined based on the first regular area and the first sample area related to the sample of the first regular area. This eliminates the need to calculate the conversion coefficient for the second atypical region, which reduces the processing load on the user terminal 10 and reduces the time required to identify the atypical region.
- the conversion coefficient may be calculated for the character string region R12 as well.
- the conversion coefficient of the character string region R10 will be referred to as a first conversion coefficient.
- the conversion coefficient of the character string area R12 is referred to as a second conversion coefficient.
- the method for calculating the second conversion coefficient differs from the method for calculating the first conversion coefficient in that the character string region R11 corresponds to a fixed-form region and a sample image of this fixed-form region is used, but the calculation method itself is the same. It is. Therefore, the second conversion coefficient is also calculated using the same flow as in FIG.
- the shaping unit 111 determines a first conversion coefficient regarding shaping of the first atypical region based on the first regular region and a first sample region regarding the sample of the first regular region, and The first atypical region is shaped based on the conversion coefficient. This flow is as explained in Modification 2-2.
- the shaping unit 111 determines a second conversion coefficient regarding shaping of the second atypical region based on the second regular region and a second sample region regarding the sample of the second regular region, and The second atypical region is shaped based on the conversion coefficient.
- the shaping unit 111 may determine the second conversion coefficient based on the same flow as in FIG. 13 and may shape the second atypical region.
- the image processing system 1 of Modified Example 2-3 determines the second transformation coefficient regarding shaping of the second atypical region based on the second regular region and the second sample region regarding the sample of the second regular region. , the second atypical region is shaped based on the determined second conversion coefficient. As a result, the conversion coefficient for the second non-standard region is used, so that the accuracy of shaping the second non-standard region is increased.
- the number of characters in an atypical character string may be known in advance. Therefore, character string regions R having too many or too few characters as non-standard character strings may be excluded from the determination of non-standard regions.
- the office reference number for insurance card C is often about 5 to 10 characters.
- the personal number for insurance card C is often about 1 to 5 characters. For this reason, when a character string region R with more than 10 characters is detected, the probability that it is an atypical region is low, so it may not be determined as an atypical region.
- the non-standard region specifying unit 105 identifies a character string region R with the number of characters corresponding to the non-standard character string from among the plurality of character string regions R, and determines the positional relationship between the specified character string region R and the regular region. In some cases, it is identified as an atypical region. It is assumed that the number of characters corresponding to the non-standard character string is stored in the data storage unit 100 in advance.
- the non-standard region specifying unit 105 determines whether the number of characters included in the character string region R is the number of characters corresponding to the non-standard character string.
- the atypical region specifying unit 105 determines whether or not a character string region R having the number of characters corresponding to the atypical character string is an atypical region.
- the non-standard region specifying unit 105 excludes a character string region R whose number of characters does not correspond to the non-standard character string from the determination target of whether or not it is a non-standard region.
- the image processing system 1 of Modified Example 2-4 identifies a character string region R with the number of characters corresponding to the non-standard character string from among the plurality of character string regions R, and the identified character string region R is a regular region. If there is a positional relationship with the area, it is identified as an atypical area. As a result, the character string region R that does not seem to be an atypical character string is excluded from the determination target, and unnecessary processing is not executed, reducing the processing load on the user terminal 10 and until the atypical region is identified. The time required can be reduced.
- the non-standard region specifying unit 105 identifies a character string region R of a size corresponding to the non-standard character string from among the plurality of character string regions R, and the specified character string region R is located in the same position as the regular region. If there is a relationship, it may be specified as an atypical region.
- the character string region R which does not have the number of characters as described in Modification 2-4, but has a size of a character string clearly larger than 10 characters, may not be determined as an atypical region.
- the non-standard region specifying unit 105 determines whether the size of the character string region R is a size corresponding to the non-standard character string.
- the atypical area specifying unit 105 determines whether or not a character string area R having a size corresponding to the atypical character string is an atypical area.
- the non-standard region specifying unit 105 excludes the character string region R whose size does not correspond to the non-standard character string from the determination target of whether or not it is a non-standard region.
- the non-standard region specifying unit 105 identifies a character string region R having a size corresponding to the non-standard character string from among the plurality of character string regions R, and If the character string region R is in a positional relationship with the regular region, it is identified as an atypical region. As a result, the character string region R with a size different from that of the non-standard character string is excluded from the determination target, and unnecessary processing is not executed, reducing the processing load on the user terminal 10 and reducing the time required to identify the non-standard region. The time required can be shortened.
- the image processing system 1 may have the first configuration without having the second configuration. In this case, the image processing system 1 identifies the regular area without identifying the non-standard area. Regular regions can be used for various purposes. For example, the image processing system 1 may use a regular area to determine whether the insurance card C is shown in the insurance card image I. In this case, if the atypical area is not specified and a standard area corresponding to the standard character string area printed on the insurance card C is identified, it is determined that the insurance card C is shown in the insurance card image I. may be done. For example, if the insurance card C in the insurance card image I is bent or distorted, the image processing system 1 may reshape the insurance card image I based on the regular area. In this case, the image processing system 1 shapes the health insurance card image I so that the positional relationship between the plurality of regular areas becomes a predetermined positional relationship.
- the image processing system 1 may have the second configuration without having the first configuration.
- the image processing system 1 specifies the regular area using another method different from the first configuration, and identifies the atypical area based on the specified regular area. Any other method can be used, such as a method using a template image, a method using character recognition, or a method using a machine learning model.
- the image processing system 1 can identify the regular area even without having the first configuration. Therefore, the image processing system does not need to include both the first configuration and the second configuration, and may include only the first configuration or only the second configuration.
- the server 20 may have the first configuration and the second configuration.
- the processing may be shared between the user terminal 10 and the server 20, such that the user terminal 10 has the first configuration and the server 20 has the second configuration.
- processing may be shared between the user terminal 10 and the server 20, such that the user terminal 10 has the second configuration and the server 20 has the first configuration. If the processing is shared, data such as the insurance card image I may be transmitted between the user terminal 10 and the server 20 as appropriate.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Character Input (AREA)
- Character Discrimination (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/687,793 US20240362938A1 (en) | 2022-03-22 | 2022-03-22 | Image processing system, image processing method, and program |
| PCT/JP2022/013065 WO2023181103A1 (ja) | 2022-03-22 | 2022-03-22 | 画像処理システム、画像処理方法、及びプログラム |
| JP2023564176A JP7450131B2 (ja) | 2022-03-22 | 2022-03-22 | 画像処理システム、画像処理方法、及びプログラム |
| EP22933252.3A EP4379678A4 (en) | 2022-03-22 | 2022-03-22 | IMAGE PROCESSING SYSTEM, IMAGE PROCESSING METHOD AND PROGRAM |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/013065 WO2023181103A1 (ja) | 2022-03-22 | 2022-03-22 | 画像処理システム、画像処理方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023181103A1 true WO2023181103A1 (ja) | 2023-09-28 |
Family
ID=88100200
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/013065 Ceased WO2023181103A1 (ja) | 2022-03-22 | 2022-03-22 | 画像処理システム、画像処理方法、及びプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240362938A1 (https=) |
| EP (1) | EP4379678A4 (https=) |
| JP (1) | JP7450131B2 (https=) |
| WO (1) | WO2023181103A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4379677A4 (en) * | 2022-03-22 | 2025-01-08 | Rakuten Group, Inc. | IMAGE PROCESSING SYSTEM, IMAGE PROCESSING METHOD AND PROGRAM |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007233913A (ja) * | 2006-03-03 | 2007-09-13 | Fuji Xerox Co Ltd | 画像処理装置及びプログラム |
| JP2007241442A (ja) * | 2006-03-06 | 2007-09-20 | Oki Electric Ind Co Ltd | 個人情報読取記憶装置及び個人情報読取記憶システム |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8788930B2 (en) * | 2012-03-07 | 2014-07-22 | Ricoh Co., Ltd. | Automatic identification of fields and labels in forms |
| US20150006362A1 (en) * | 2013-06-28 | 2015-01-01 | Google Inc. | Extracting card data using card art |
| US10691884B2 (en) * | 2016-10-25 | 2020-06-23 | Tata Consultancy Services Limited | System and method for cheque image data masking using data file and template cheque image |
| JP6574920B1 (ja) * | 2018-07-06 | 2019-09-11 | 楽天株式会社 | 画像処理システム、画像処理方法、及びプログラム |
| US12039074B2 (en) * | 2018-12-31 | 2024-07-16 | Dathena Science Pte Ltd | Methods, personal data analysis system for sensitive personal information detection, linking and purposes of personal data usage prediction |
| EP3798906B1 (en) * | 2019-09-30 | 2025-01-15 | Tata Consultancy Services Limited | System and method for masking text within images |
-
2022
- 2022-03-22 US US18/687,793 patent/US20240362938A1/en active Pending
- 2022-03-22 EP EP22933252.3A patent/EP4379678A4/en active Pending
- 2022-03-22 WO PCT/JP2022/013065 patent/WO2023181103A1/ja not_active Ceased
- 2022-03-22 JP JP2023564176A patent/JP7450131B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007233913A (ja) * | 2006-03-03 | 2007-09-13 | Fuji Xerox Co Ltd | 画像処理装置及びプログラム |
| JP2007241442A (ja) * | 2006-03-06 | 2007-09-20 | Oki Electric Ind Co Ltd | 個人情報読取記憶装置及び個人情報読取記憶システム |
Non-Patent Citations (3)
| Title |
|---|
| XINYU ZHOU, AN EFFICIENT AND ACCURATE SCENE TEXT DETECTOR, Retrieved from the Internet <URL:https://arxiv.org/pdf/1704.03155v2.pdf> |
| YOUNGMIN BAEK ET AL., CHARACTER REGION AWARENESS FOR TEXT DETECTION, Retrieved from the Internet <URL:https://arxiv.org/pdf/1904.01941v1.pdf> |
| ZHI TIAN ET AL., DETECTING TEXT IN NATURAL IMAGE WITH CONNECTIONIST TEXT PROPOSAL NETWORK, Retrieved from the Internet <URL:https://arxiv.org/pdf/1609.03605v1.pdf> |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7450131B2 (ja) | 2024-03-14 |
| JPWO2023181103A1 (https=) | 2023-09-28 |
| EP4379678A1 (en) | 2024-06-05 |
| US20240362938A1 (en) | 2024-10-31 |
| EP4379678A4 (en) | 2024-12-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6746158B2 (ja) | 2次元コード | |
| US11315353B1 (en) | Systems and methods for spatial-aware information extraction from electronic source documents | |
| US20140036099A1 (en) | Automated Scanning | |
| CN110442744A (zh) | 提取图像中目标信息的方法、装置、电子设备及可读介质 | |
| US20140245120A1 (en) | Creating Tables with Handwriting Images, Symbolic Representations and Media Images from Forms | |
| CN112508011A (zh) | 一种基于神经网络的ocr识别方法及设备 | |
| JP6569532B2 (ja) | 管理システム、リスト作成装置、リスト作成方法、管理方法及び管理用プログラム | |
| JP2019168857A (ja) | 画像処理装置、画像処理方法および画像処理プログラム | |
| CN110909740A (zh) | 信息处理装置以及存储介质 | |
| CN107133615A (zh) | 信息处理设备和信息处理方法 | |
| TW202006597A (zh) | 影像處理系統、影像處理方法及程式產品 | |
| JP7450131B2 (ja) | 画像処理システム、画像処理方法、及びプログラム | |
| JP7316479B1 (ja) | 画像処理システム、画像処理方法、及びプログラム | |
| WO2024088291A1 (zh) | 表单填充方法、装置、电子设备及介质 | |
| CN110781811B (zh) | 异常工单识别方法、装置、可读存储介质和计算机设备 | |
| CN112633279A (zh) | 文本识别方法、装置和系统 | |
| CN115482548A (zh) | 表格识别方法和系统 | |
| JP5998090B2 (ja) | 画像照合装置、画像照合方法、画像照合プログラム | |
| US20240193975A1 (en) | Image processing apparatus, image processing method, and storage medium | |
| CN114730499A (zh) | 图像识别方法及装置、训练方法、电子设备和存储介质 | |
| JP5298830B2 (ja) | 画像処理プログラム、画像処理装置及び画像処理システム | |
| JP7231529B2 (ja) | 情報端末装置、サーバ及びプログラム | |
| CN120564218B (zh) | 票据识别方法、装置、设备及存储介质 | |
| JP7831126B2 (ja) | 文字認識処理システム、文字認識処理方法、及びプログラム | |
| JP7456580B2 (ja) | 情報処理装置、情報処理システム及び情報処理方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023564176 Country of ref document: JP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22933252 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022933252 Country of ref document: EP Effective date: 20240228 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |