WO2023144926A1 - オフロードサーバ、オフロード制御方法およびオフロードプログラム - Google Patents
オフロードサーバ、オフロード制御方法およびオフロードプログラム Download PDFInfo
- Publication number
- WO2023144926A1 WO2023144926A1 PCT/JP2022/002880 JP2022002880W WO2023144926A1 WO 2023144926 A1 WO2023144926 A1 WO 2023144926A1 JP 2022002880 W JP2022002880 W JP 2022002880W WO 2023144926 A1 WO2023144926 A1 WO 2023144926A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- processing
- offload
- loop
- unit
- application program
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/60—Software deployment
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
Definitions
- the present invention automatically offloads functional processing to an accelerator such as a GPU (Graphics Processing Unit) or FPGA (Field Programmable Gate Array), and places the converted application program (hereinafter referred to as an application as appropriate) in an appropriate location.
- an accelerator such as a GPU (Graphics Processing Unit) or FPGA (Field Programmable Gate Array)
- the present invention relates to a server, an offload control method, and an offload program.
- AWS Amazon Web Services
- Azure registered trademark
- Azure provides GPU instances and FPGA instances, and these resources can be used on demand.
- Microsoft uses FPGAs to streamline searches.
- OpenCL is an open API (Application Programming Interface) that can handle all computational resources (not limited to CPUs and GPUs) in a unified manner without being tied to specific hardware.
- GPUs and FPGAs can be easily used in user applications. That is, when deploying general-purpose applications such as image processing and cryptographic processing to be operated in an environment, it is desired that the platform analyzes the application logic and automatically offloads the processing to the GPU and FPGA.
- CUDA General Purpose GPUs
- OpenCL has also emerged as a standard for handling heterogeneous hardware such as GPUs, FPGAs, and many-core CPUs in a unified manner.
- a portion to be processed in parallel such as a loop statement
- a compiler converts it into device-oriented code according to the directive.
- Technical specifications include OpenACC (Open Accelerator) and the like
- compilers include PGI Compiler (registered trademark) and the like.
- OpenACC Open Accelerator
- PGI Compiler registered trademark
- the user specifies parallel processing in code written in C/C++/Fortran using OpenACC directives.
- the PGI compiler checks the parallelism of the code, generates executable binaries for GPU and CPU, and converts them into executable modules.
- the IBM JDK (registered trademark) supports a function of offloading parallel processing specification according to the lambda format of Java (registered trademark) to the GPU.
- the programmer does not need to be aware of data allocation to the GPU memory.
- techniques such as OpenCL, CUDA, and OpenACC enable offload processing to GPUs and FPGAs.
- Non-Patent Literature 1 the optimum arrangement of VNs is determined in consideration of communication traffic.
- it is intended for single-resource virtual networks, with the goal of reducing carrier equipment costs and overall response time, taking into account conditions such as the processing time of different applications and the cost and response time requirements of individual users. It has not been.
- Non-Patent Document 2 can be cited as an approach to automate the trial-and-error process for parallel processing.
- Non-Patent Literature 2 describes how once written code can use GPUs, FPGAs, many-core CPUs, etc. that exist in the deployment destination environment, automatic conversion, resource settings, etc. are performed, and applications are operated at high performance.
- Non-Patent Document 2 proposes a system for automatically offloading loop statements of application code to the GPU as an element of environment-adaptive software, and evaluates performance improvement.
- Non-Patent Document 3 proposes a system for automatically offloading loop statements of application code to FPGA as an element of environment adaptive software, and evaluates performance improvement.
- Non-Patent Document 4 evaluates a method of optimizing the amount of resources (such as the number of virtual machine cores) for executing an application after automatic conversion for a GPU or the like as an element of environment-adaptive software.
- Non-Patent Documents 1 to 4 focus on shortening the processing time during automatic offloading. There is a problem that when processing is offloaded to heterogeneous devices such as GPUs and FPGAs, there is no proposal to operate the converted application while satisfying user demands (price, response time).
- an offload server for offloading specific processing of an application program to an accelerator, comprising: an application code analysis unit for analyzing the source code of the application program; A data transfer specification section that analyzes the reference relationships of variables used and, for data that may be transferred outside the loop, specifies data transfer using an explicit specification line that explicitly specifies data transfer outside the loop and a parallel processing designation unit that identifies loop statements of the application program, compiles each identified loop statement by designating a parallel processing designation statement in the accelerator, and a loop statement that causes a compilation error.
- a parallel processing pattern creation unit for creating a parallel processing pattern for specifying whether or not to perform parallel processing for a loop statement that is not to be offloaded and that does not generate a compilation error; and the application of the parallel processing pattern.
- a performance measurement unit that compiles a program, places it in an accelerator verification device, and executes performance measurement processing when offloaded to the accelerator; Depending on the conditions, when deploying on a cloud server, carrier edge server, or user edge server on the network, device and link costs, computational resource limits, and bandwidth limits are constraints, and computational resource costs or and a placement setting unit that calculates and sets a placement location of an application program based on a linear programming formula with response time as an objective function.
- the converted application when an application is automatically converted so that it can be placed on an offload device such as a GPU or FPGA, the converted application can be optimally placed to meet the user's cost or response time requirements.
- FIG. 1 is a functional block diagram showing a configuration example of an offload server according to the first embodiment of the present invention
- FIG. FIG. 4 is a diagram showing automatic offload processing using the offload server according to the first embodiment
- FIG. 4 is a diagram showing a search image of a control unit (automatic offload function unit) by Simple GA of the offload server according to the first embodiment
- FIG. 10 is a diagram showing an example of a normal CPU program of a comparative example
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from a CPU to a GPU using a simple CPU program of a comparative example
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the offload server according to the first embodiment is nested and integrated;
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the transfer integration of the offload server according to the first embodiment is performed;
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the transfer integration of the offload server according to the first embodiment is performed;
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the offload server according to the first embodiment transfers data together and a temporary area is used; 4 is a flow chart for explaining an overview of the operation of implementing the offload server according to the first embodiment; 4 is a flow chart for explaining an overview of the operation of implementing the offload server according to the first embodiment; 7 is a flow chart illustrating setting of the resource ratio and amount of resources to be added after the offload server's GPU offload attempt and placement of a new application according to the first embodiment; FIG.
- FIG. 2 is a diagram illustrating an example topology of computation nodes of the offload server according to the first embodiment; 8 is a graph showing changes in the average response time of the offload server according to the first embodiment and the number of deployed applications;
- FIG. 8 is a functional block diagram showing a configuration example of an offload server according to the second embodiment of the present invention;
- FIG. 11 is a flow chart for explaining an operation outline of implementation of the offload server according to the second embodiment;
- FIG. FIG. 11 is a flow chart showing performance measurement processing of the performance measurement unit of the offload server according to the second embodiment;
- FIG. FIG. 12 is a diagram showing a search image of the PLD processing pattern creation unit of the offload server according to the second embodiment;
- FIG. 12 is a diagram illustrating the flow from the C code of the offload server to the search for the OpenCL final solution according to the second embodiment;
- 3 is a hardware configuration diagram showing an example of a computer that implements the functions of an offload server according to each embodiment of the present invention;
- this embodiment an offload server in a mode for carrying out the present invention (hereinafter referred to as "this embodiment") will be described with reference to the drawings.
- this embodiment Basic concept of automatic offloading of the present invention
- the present inventor has so far proposed methods for GPU automatic offloading of program loop statements, FPGA automatic offloading, and optimization of conversion application execution resources ( See Non-Patent Documents 2, 3, and 4).
- the basic concept of the present invention will be described based on the examination of the elemental technologies of these Non-Patent Documents 2, 3, and 4 as well.
- Non-Patent Document 2 can automatically offload a normal program to an offload device such as a GPU or FPGA.
- an offload device such as a GPU or FPGA.
- multi-core CPUs and many-core CPUs can flexibly allocate a percentage of all cores through virtualization using virtual machines and containers.
- GPUs have been virtualized in the same way as CPUs, and operations such as allocating a percentage of all cores of GPUs are becoming possible.
- FPGA resource usage is often represented by a set number of Look Up Tables and Flip Flops, and unused gates can be used for other purposes.
- Non-Patent Document 2 it is possible to convert the application into code for CPU and GPU processing using the method described in Non-Patent Document 2.
- the code itself is good, it will not perform well if the amount of CPU and GPU resources is not properly balanced. For example, when performing a certain process, if the CPU processing time is 1000 seconds and the GPU processing time is 1 second, even if the processing that can be offloaded is speeded up by the GPU to some extent, the CPU as a whole becomes a bottleneck.
- Non-Patent Document 5 "K. Shirahata, H. Sato and S. Matsuoka, "Hybrid Map Task Scheduling for GPU-Based Heterogeneous Clusters," IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), pp.733 -740, Dec. 2010.”, by distributing Map tasks so that the CPU and GPU execution times are the same when processing tasks with the MapReduce (registered trademark) framework using the CPU and GPU. , to improve overall performance.
- MapReduce registered trademark
- the inventor came up with the idea of determining the resource ratio between the CPU and the offload device as follows. In other words, in order to avoid the processing in any device becoming a bottleneck, refer to the above non-patent documents, etc., so that the processing time of the CPU and the offload device are of the same order from the processing time of the test case. , the resource ratio between the CPU and the offload device (hereinafter referred to as "resource ratio").
- the inventor adopts a method of gradually increasing the speed based on the performance measurement results in the verification environment during automatic offloading, like the method of Non-Patent Document 2.
- the reason is that the performance varies greatly depending on not only the code structure but also the actual processing details such as hardware specifications, data size, loop count, and the like. Also, performance is difficult to predict statically and requires dynamic measurements. Therefore, at the time of code conversion, since there are already performance measurement results in the verification environment, resource ratios are determined using those results.
- test case processing time in the verification environment is CPU processing: 10 seconds and GPU processing: 5 seconds
- the resource on the CPU side is doubled, and the processing time is considered to be about the same. Therefore, the resource ratio is 2:1.
- a test case that includes that process and speed up the test case using the method described in Non-Patent Document 2 or the like. is reflected.
- resource amount determination and automatic verification of the amount of resources of the CPU and the offload device (hereinafter referred to as "resource amount")
- the resource ratio is determined by ⁇ Optimizing the resource ratio between the CPU and the offload device>
- the application is placed in the commercial environment.
- the resource amount is determined while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user. For example, with respect to CPU, it is assumed that 1 VM is 1000 yen/month, GPU is 4000 yen/month, and the resource ratio is 2:1. It is also assumed that the user's budget is within 10,000 yen per month.
- the resource ratio is set to 2:1
- the budget is within the user's budget of 10,000 yen per month. "1" is secured and placed in the commercial environment. Also, if the user's budget is within 5000 yen per month, the appropriate resource ratio of 2:1 cannot be maintained. In this case, as the resource amount, "1" is secured for the CPU and "1" for the GPU.
- Automatic verification After securing resources and deploying the program in the commercial environment, automatic verification is performed to confirm that it will work before the user uses it.
- Automatic verification runs performance verification test cases and regression test cases.
- a performance verification test case is performed by using an automatic test execution tool such as Jenkins (registered trademark) for a hypothetical test case specified by the user, and the processing time, throughput, and the like are measured.
- a regression test case obtains information about software such as middleware and OS installed in the system, and executes a regression test corresponding to the information using Jenkins or the like.
- a study to perform these automatic verifications with a small number of test case preparations is in Non-Patent Document 6 (Y.
- the performance verification test cases check whether the calculation results are correct even if offloading is performed. Also, in the performance verification test case, the difference between the calculation result and the case without offloading is checked.
- the PGI compiler that processes the GPU uses the PCAST (registered trademark) function PGI_compare (registered trademark) and acc_compare (registered trademark) API (Application Programming Interface) to calculate the difference between calculation results when the GPU is used and when it is not used. I can confirm. Note that even if parallel processing or the like is correctly offloaded, there are cases where the calculation results do not match completely, such as when the GPU and CPU have different rounding errors. Therefore, for example, confirmation according to the IEEE 754 specification is performed, and whether the difference is acceptable is presented to the user for confirmation by the user.
- the user is presented with information on the processing time and throughput of performance verification test cases, differences in calculation results, and regression test execution results.
- the user is also presented with the secured resources (the number of VMs, specifications, etc.) and their prices, and the user refers to this information to determine the start of operation.
- the resource ratio is the ratio of the number of instances of CPU, GPU, and FPGA. If the number of instances is 1, 2, or 3, the resource ratio is 1:2:3.
- Test Case Processing Time This embodiment searches for and discovers an offload pattern that speeds up a test case specified by the user.
- the test case is the number of transaction processing such as TPC-C (registered trademark) in the case of DB (database), and execution of Fourier transform processing in sample data in the case of FFT.
- the processing time is the execution time when the sample processing is executed. For example, the processing time of process A is 10 seconds before offloading, but it becomes 2 seconds after offloading. Each time is obtained.
- ⁇ Loop statement found> Currently, it is difficult for a compiler to find a match that this loop statement is suitable for GPU parallel processing. It is difficult to predict how much performance and power consumption will be achieved by offloading to the GPU without actually measuring it. Therefore, an instruction to offload this loop statement to the GPU is manually performed, and trial and error measurements are performed.
- the present invention automatically finds appropriate loop statements to offload to the GPU using a genetic algorithm (GA), which is an evolutionary computation technique. That is, for a group of parallelizable loop statements, 1 is set for GPU execution and 0 is set for CPU execution to generate a gene, and an appropriate pattern is searched for by repeated measurement in a verification environment.
- GA genetic algorithm
- this embodiment Next, the offload server 1 and the like in the mode for carrying out the present invention (hereinafter referred to as “this embodiment”) will be described.
- FIG. 1 is a functional block diagram showing a configuration example of an offload server 1 according to the first embodiment of the present invention.
- the offload server 1 is a device that automatically offloads specific processing of an application to an accelerator.
- the offload server 1 includes a control unit 11, an input/output unit 12, a storage unit 13, and a verification machine 14 (accelerator verification device). be.
- the input/output unit 12 includes a communication interface for transmitting/receiving information to/from each device, etc., an input device for transmitting/receiving information to/from an input device such as a touch panel or a keyboard, or an output device such as a monitor. It consists of an output interface.
- the storage unit 13 is composed of a hard disk, flash memory, RAM (Random Access Memory), etc., and stores a program (offload program) for executing each function of the control unit 11 and information necessary for processing of the control unit 11 (for example, an intermediate language file (Intermediate file) 133) is temporarily stored.
- a program offload program for executing each function of the control unit 11 and information necessary for processing of the control unit 11 ( For example, an intermediate language file (Intermediate file) 133) is temporarily stored.
- the storage unit 13 includes a test case DB (Test case database) 131, an equipment resource DB 132, and an intermediate language file (Intermediate file) 133.
- Test case database Test case database
- equipment resource DB equipment resource DB
- intermediate language file Intermediate file
- the test case DB 131 stores test item data corresponding to the software to be verified.
- the test item data is, for example, transaction test data such as TPC-C in the case of a database system such as MySQL.
- the facility resource DB 132 holds resources such as servers held by the business operator, information prepared in advance such as prices, and information on how much they are used. For example, there are 10 servers that can accommodate 3 GPU instances, and 1 GPU instance costs 5000 yen per month. It is information that is only used. This information is used to determine the amount of resources to be secured when the user specifies operating conditions (conditions such as cost and performance).
- the user operating conditions are the cost conditions specified by the user at the time of the offload request (for example, budget within 10,000 yen per month) and performance conditions (for example, transaction throughput such as TPC-C is above or above, sample Fourier transform processing is 1 thread) within how many seconds, etc.).
- the intermediate language file 133 temporarily stores information necessary for the processing of the control unit 11 in the form of a programming language interposed between the high-level language and the machine language.
- the verification machine 14 is equipped with a CPU, GPU, and FPGA as a verification environment for environment-adaptive software.
- the control unit 11 is an automatic offloading function that controls the offload server 1 as a whole.
- the control unit 11 is implemented, for example, by a CPU (Central Processing Unit) (not shown) expanding an application program (offload program) stored in the storage unit 13 into a RAM and executing the application program.
- a CPU Central Processing Unit
- application program offload program
- the control unit 11 includes an application code specifying unit (Specify application code) 111, an application code analyzing unit (Analyze application code) 112, a data transfer specifying unit 113, a parallel processing specifying unit 114, a resource ratio determining unit 115, A resource amount setting unit 116, a placement setting unit 170, a parallel processing pattern creation unit 117, a performance measurement unit 118, an execution file creation unit 119, a production environment placement unit (Deploy final binary files to production environment) 120, It has a performance measurement test extract execution unit (Extract performance test cases and run automatically) 121 and a user provision unit (Provide price and performance to a user to judge) 122 .
- the application code designation unit 111 designates an input application code. Specifically, the application code designation unit 111 passes the application code described in the received file to the application code analysis unit 112 .
- the application code analysis unit 112 analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
- the data transfer specification unit 113 analyzes the reference relationships of variables used in loop statements of the application program, and explicitly specifies data transfer outside the loop for data that may be transferred outside the loop. using target specification lines (#pragma acc kernels, #pragma acc data copyin(a, b), #pragma acc data copyout(a, b), #prama acc parallel loop, #prama acc parallel loop vector, etc.) Specify data transfer.
- the parallel processing designation unit 114 specifies loop statements (repetition statements) of the application program, and compiles each loop statement by designating a parallel processing designation statement in the accelerator.
- the parallel processing designation unit 114 includes an extract offload able area 114a and an output intermediate file 114b.
- the offload range extraction unit 114a identifies processing that can be offloaded to the GPU/FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
- the intermediate language file output unit 114b outputs the extracted intermediate language file 133.
- FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- the resource ratio determination unit 115 determines the processing time of the CPU and the offload device (test case CPU processing time and offload device processing time) as the resource ratio based on the performance measurement result (described later). Specifically, the resource ratio determination unit 115 determines the resource ratio so that the processing times of the CPU and the offload device are of the same order. Further, when the difference between the processing times of the CPU and the offload device is equal to or greater than a predetermined threshold value, the resource ratio determination unit 115 sets the resource ratio to a predetermined upper limit value.
- the resource amount setting unit 116 Based on the determined resource ratio, the resource amount setting unit 116 sets the resource amount of the CPU and the offload device so as to satisfy a predetermined cost condition (described later). Specifically, the resource amount setting unit 116 maintains the determined resource ratio and sets the maximum resource amount that satisfies a predetermined cost condition. In addition, if the predetermined cost condition is not satisfied by setting the minimum resource amount while maintaining the determined resource ratio, the resource amount setting unit 116 breaks the resource ratio and sets the resource amounts of the CPU and the offload device to satisfy the cost condition. Set with a smaller value (e.g. minimum).
- the placement setting unit 170 when placing the converted application on any of the cloud server, the carrier edge server, and the user edge server on the network, according to the cost or response time conditions specified by the user, determines the devices and links. , the computational resource upper limit, and the bandwidth upper limit as constraints, and the cost of the computational resource or the response time as the objective function, the application location is calculated and set. Specifically, the placement setting unit 170 calculates the placement location of the new application (the placement location of the APL) by a linear programming method based on the server of the equipment resource DB 132, the specification information of the link, and the placement information of the existing application. to set.
- the linear programming method uses, for example, the objective function and constraint conditions of the linear programming formulas shown in [Equation 1] and [Equation 2] below.
- the linear programming formulas shown in [Equation 1] and [Equation 2] below are stored in the equipment resource DB 132, and are read out from the equipment resource DB 132 by the layout setting unit 170, and expanded on the memory processed by the layout setting unit 170. .
- the parallel processing pattern creation unit 117 excludes loop statements (repeated statements) that cause compilation errors from being offloaded, and designates whether or not to execute parallel processing for repetitive statements that do not cause compilation errors. Create a parallel processing pattern to do.
- the performance measurement unit 118 compiles the parallel processing pattern application program, places it in the verification machine 14, and executes performance measurement processing when offloaded to the accelerator.
- the performance measurement unit 118 includes a Deploy binary files unit 118a.
- the binary file placement unit 118a deploys (places) an execution file derived from the intermediate language to the verification machine 14 having a GPU or FPGA.
- the performance measurement unit 118 executes the arranged binary file, measures the performance when offloading, and returns the performance measurement result to the offload range extraction unit 114a.
- the offload range extraction unit 114a extracts another parallel processing pattern, and the intermediate language file output unit 114b attempts performance measurement based on the extracted intermediate language (marked a in FIG. 2 described later). reference).
- the execution file creation unit 119 selects a plurality of parallel processing patterns with high processing performance from among a plurality of parallel processing patterns based on the performance measurement results repeated a predetermined number of times, crosses the parallel processing patterns with high processing performance, and suddenly Mutation processing creates different parallel processing patterns. Then, the executable file creation unit 119 newly performs performance measurement, and after performing the performance measurement for the specified number of times, selects the parallel processing pattern with the highest processing performance from among a plurality of parallel processing patterns based on the performance measurement result, and selects the parallel processing pattern with the highest processing performance. Compile the parallel processing pattern of processing performance and create an executable file.
- the production environment placement unit 120 places the created executable file in the production environment for the user (“place final binary file in production environment”).
- the production environment placement unit 120 determines a pattern specifying the final offload area, and deploys it in the production environment for users.
- the performance measurement test extraction execution unit 121 After arranging the execution files, the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and executes the performance test (“arrangement of the final binary file to the production environment”). After arranging the executable file, the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user.
- the user providing unit 122 presents information such as price/performance to the user based on the performance test results (“Provision of information such as price/performance to the user”).
- the test case DB 131 stores performance test items.
- the user provision unit 122 presents data such as price and performance to the user along with the performance test results based on the performance test results corresponding to the test items stored in the test case DB 131 . Based on the presented information such as price and performance, the user decides to start using the service for a fee.
- non-patent document 7 Y. Yamato, M. Muroi, K. Tanaka and M.
- the offload server 1 can use GA (Genetic Algorithms) for offload optimization.
- GA Genetic Algorithms
- the configuration of the offload server 1 when using GA is as follows. That is, the parallel processing specifying unit 114 sets the gene length to the number of loop statements (repeated statements) that do not cause compilation errors based on the genetic algorithm.
- the parallel processing pattern creation unit 117 maps the availability of accelerator processing to the gene pattern by assigning either 1 or 0 when accelerator processing is to be performed, and the other 0 or 1 when not performing accelerator processing.
- the parallel processing pattern creation unit 117 prepares a gene pattern for a specified number of individuals in which each value of the gene is randomly created to be 1 or 0.
- the performance measurement unit 118 compiles the application code specifying the parallel processing specifying statement in the accelerator according to each individual, and places it in the verification machine 14 .
- the performance measurement unit 118 executes performance measurement processing in the verification machine 14 .
- the performance measurement unit 118 does not compile and measure the performance of the application code corresponding to the parallel processing pattern. Use the same value.
- the performance measurement unit 118 sets the performance measurement value to a predetermined time (long time) as a time-out for an application code that causes a compile error and an application code whose performance measurement does not end within a predetermined time.
- the executable file creation unit 119 performs performance measurement on all individuals, and evaluates individuals with shorter processing times so that the degree of fitness is higher.
- the execution file creation unit 119 selects individuals whose fitness is higher than a predetermined value (for example, the top n% of all individuals, or the top m of all individuals, where n and m are natural numbers) as individuals with high performance. , the selected individual is crossover and mutated to create the next generation individual.
- the execution file creating unit 119 selects the parallel processing pattern with the highest performance as a solution after the specified number of generations have been processed.
- FIG. 2 is a diagram showing automatic offload processing using the offload server 1.
- the offload server 1 is applied to elemental technology of environment adaptive software.
- the offload server 1 has a control unit (automatic offload function unit) 11 , a test case DB 131 , an equipment resource DB 132 , an intermediate language file 133 and a verification machine 14 .
- the offload server 1 acquires an application code 125 used by the user.
- the user is, for example, a person who has made a contract to use various devices (Device 151, device 152 having CPU-GPU, device 153 having CPU-FPGA, device 154 having CPU).
- the offload server 1 automatically offloads functional processing to the accelerators of the device 152 with CPU-GPU and the device 153 with CPU-FPGA.
- step S11 Specify application code>
- the application code designation unit 111 passes the application code written in the received file to the application code analysis unit 112 .
- Step S12 Analyze application code>
- the application code analysis unit 112 analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
- Step S13 Extract offloadable area>
- the parallel processing designation unit 114 identifies loop statements (repetition statements) of the application, and compiles each repetition statement by designating a parallel processing designation statement in the accelerator.
- the offload range extraction unit 114a identifies processing that can be offloaded to the GPU/FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
- Step S14 Output intermediate file>
- the intermediate language file output unit 114b (see FIG. 1) outputs the intermediate language file 133.
- FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- Step S15 Compile error>
- the parallel processing pattern creation unit 117 excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors are processed in parallel. Create a parallel processing pattern that specifies whether or not.
- Step S21 Deploy binary files>
- the binary file placement unit 118a (see FIG. 1) deploys the execution file derived from the intermediate language to the verification machine 14 equipped with GPU/FPGA.
- Step S22 Measure performance>
- the performance measurement unit 118 executes the placed file and measures the performance when offloading. In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offload range extraction unit 114a, and the offload range extraction unit 114a extracts another pattern. Then, the intermediate language file output unit 114b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2).
- the control unit 11 repeatedly executes steps S12 to S22.
- the automatic offload function of the control unit 11 is summarized below. That is, the parallel processing specification unit 114 specifies loop statements (repetition statements) of the application program, specifies a parallel processing specification statement in the GPU for each repetition statement, and compiles it. Then, the parallel processing pattern creation unit 117 creates a parallel processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to perform parallel processing for loop statements that do not cause compilation errors. do. Then, the binary file placement unit 118a compiles the application program of the parallel processing pattern and places it on the verification machine 14, and the performance measurement unit 118 executes the performance measurement processing on the verification machine 14. FIG.
- the execution file creation unit 119 selects a pattern with the highest processing performance from a plurality of parallel processing patterns based on the performance measurement results repeated a predetermined number of times, compiles the selected patterns, and creates an execution file.
- Step S23 Resource amount setting according to user operating conditions>
- the control unit 11 performs resource amount setting according to user operating conditions. That is, the resource ratio determination unit 115 of the control unit 11 determines the resource ratio between the CPU and the offload device. Based on the determined resource ratio, the resource amount setting unit 116 then refers to the information in the facility resource DB 132 and sets the resource amounts of the CPU and the offload device so as to satisfy the user operating conditions (see FIG. 10). described later).
- Step S24 Deploy final binary files to production environment>
- the production environment placement unit 120 determines a pattern specifying the final offload area, and deploys it to the production environment for the user.
- Step S25 Extract performance test cases and run automatically>
- the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user after the execution file is arranged.
- Step S26 Provide price and performance to a user to judge>
- the user providing unit 122 presents information such as price and performance to the user based on the performance test results. Based on the presented information such as price and performance, the user decides to start using the service for a fee.
- steps S11 to S26 are performed, for example, in the background when the user uses the service, and are assumed to be performed, for example, during the first day of provisional use.
- control unit 11 of the offload server 1 when applied to the element technology of the environment-adaptive software, for offloading the function processing, the source code of the application program used by the user , the offloaded area is extracted and the intermediate language is output (steps S11 to S15).
- the control unit 11 arranges and executes the execution file derived from the intermediate language on the verification machine 14, and verifies the offload effect (steps S21 to S22). After repeating verification and determining an appropriate offload area, the control unit 11 deploys the executable file in the production environment that is actually provided to the user and provides it as a service (steps S23 to S26).
- GPU automatic offload using GA GPU automatic offloading is a process for repeating steps S12 to S22 in FIG. 2 for the GPU and finally obtaining the offload code to be deployed in step S23.
- GPUs generally do not guarantee latency, but they are devices suitable for increasing throughput through parallel processing. Encryption processing, image processing for camera video analysis, and machine learning processing for analyzing a large amount of sensor data are typical examples, and these are often repetitive processes. Therefore, we aim to increase the speed by automatically offloading repeated statements of the application to the GPU.
- an appropriate offload area is automatically extracted from a general-purpose program that is not intended for parallelization. For this reason, the parallelizable for statement is checked first, and then the performance verification trial is repeated in the verification environment using the GA for the parallelizable for statement group to search for an appropriate area. After narrowing down to parallelizable for statements, by retaining and recombining parallel processing patterns that can be accelerated in the form of genes, patterns that can be efficiently accelerated from a huge number of possible parallel processing patterns can be explored.
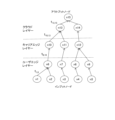
- FIG. 3 is a diagram showing a search image of the control unit (automatic offload function unit) 11 by Simple GA.
- FIG. 3 shows a search image of processing and gene sequence mapping of the for statement.
- GA is one of combinatorial optimization methods that imitate the evolutionary process of organisms.
- the flow chart of GA consists of initialization ⁇ evaluation ⁇ selection ⁇ crossover ⁇ mutation ⁇ end determination.
- Simple GA with simplified processing is used among GAs.
- Simple GA is a simplified GA in which only genes are 1 and 0, and roulette selection, one-point crossover, and mutation reverse the value of one gene.
- the for statements that can be parallelized are mapped to the gene array. It is set to 1 when GPU processing is performed, and set to 0 when GPU processing is not performed.
- a gene prepares a specified number of individuals M, and randomly assigns 1 and 0 to one for statement.
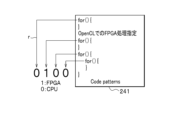
- the control unit (automatic offload function unit) 11 acquires an application code 130 (see FIG. 2) used by the user and, as shown in FIG. From the code patterns 141 of the code 130, the parallel propriety of the for statement is checked. As shown in FIG. 3, when five for statements are found from code pattern 141 (see symbol b in FIG.
- one digit for each for statement here five digits for five for statements, or 0 is randomly assigned. For example, it is set to 0 when processed by the CPU, and set to 1 when output to the GPU. However, 1 or 0 is randomly assigned at this stage.
- circle marks ( ⁇ marks) in the code pattern 141 are shown as code images.
- ⁇ select> high performance code patterns are selected based on goodness of fit (see symbol d in FIG. 3). Based on the fitness, the performance measurement unit 118 (see FIG. 1) selects genes with high fitness in a specified number of individuals. In this embodiment, roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed.
- FIG. 3 shows a search image in which the number of circles (o) in the selected code patterns 142 is reduced to three.
- ⁇ Crossover> In crossover, at a constant crossover rate Pc, some genes are exchanged between selected individuals at one point to create offspring individuals. Roulette-selected patterns (parallel processing patterns) and genes of other patterns are crossed. The position of the one-point crossover is arbitrary. For example, crossover is performed at the third digit of the five-digit code.
- Mutation changes each value of an individual's gene from 0 to 1 or 1 to 0 at a constant mutation rate Pm. Also, in order to avoid local minima, mutations are introduced. It should be noted that a mode in which no mutation is performed is also possible in order to reduce the amount of calculation.
- next generation code patterns after crossover & mutation see symbol e in FIG. 3
- the processing is terminated after repeating T times for the designated number of generations, and the gene with the highest degree of fitness is taken as the solution. For example, take performance measurements and choose the fastest three: 10010, 01001, 00101.
- the next generation recombines these three by GA, for example, crosses the first and second, and creates a new pattern (parallel processing pattern) 11011 .
- a mutation such as changing 0 to 1 is arbitrarily inserted into the recombined pattern. Repeat the above to find the fastest pattern.
- a designated generation (for example, the 20th generation) is determined, and the pattern remaining in the final generation is taken as the final solution.
- ⁇ deploy (deployment)> Deploy again to the production environment with the parallel processing pattern with the highest processing performance that corresponds to the gene with the highest fitness and provide it to users.
- OpenACC has a compiler that can be specified with the directive #pragma acc kernels to extract bytecodes for GPUs and execute them for GPU offloading. By writing a for statement command in this #pragma, it is possible to determine whether or not the for statement runs on the GPU.
- the length (gene length) is defined as the length without error. If there are 5 error-free for statements, the gene length is 5, and if there are 10 error-free for statements, the gene length is 10. Parallel processing is not possible when there is a dependence on data such that the previous processing is used for the next processing. The above is the preparation stage. Next, GA processing is performed.
- a code pattern with a gene length corresponding to the number of for statements is obtained.
- parallel processing patterns 10010, 01001, 00101, . . . are randomly assigned.
- an error may occur even though it is a for statement that can be offloaded. That is when the for statement is hierarchical (if one is specified, the GPU can process it). In this case, you can leave the for statement that caused the error.
- the image processing is benchmarked.
- the -1/2 power of the processing time is 1 if it takes 1 second, 0.1 if it takes 100 seconds, and 10 if it takes 0.01 seconds.
- Those with high adaptability are selected, for example, 3 to 5 out of 10 are selected and rearranged to create a new code pattern.
- the same thing as before may be created in the middle of creation. In that case, we don't need to do the same benchmark, so we use the same data as before.
- the code pattern and its processing time are stored in the storage unit 13 .
- the search image of the control unit (automatic offload function unit) 11 by Simple GA has been described above. Next, a batch processing technique for data transfer will be described.
- Comparative examples are a normal CPU program (see FIG. 4), simple GPU use (see FIG. 5), and nest integration (Non-Patent Document 2) (see FIG. 6).
- ⁇ 1> to ⁇ 4>, etc. at the beginning of loop statements in the following descriptions and figures are added for convenience of explanation (the same applies to other figures and their explanations).
- FIG. 5 is a diagram showing a loop statement when the normal CPU program shown in FIG. 4 uses a simple GPU to transfer data from the CPU to the GPU.
- Data transfer types include data transfer from the CPU to the GPU and data transfer from the GPU to the CPU. Data transfer from the CPU to the GPU will be taken as an example below.
- a processing unit capable of parallel processing such as a for statement by the PGI compiler is specified by the OpenACC directive #pragma acc kernels (parallel processing specifying statement). Data is transferred from the CPU to the GPU by #pragma acc kernels, as shown in the dashed box surrounding the symbol i in FIG. Here, since a and b are transferred at this timing, they are transferred 10 times.
- FIG. 6 is a diagram showing a loop statement when data is transferred from the CPU to the GPU and from the GPU to the CPU by nest integration (Non-Patent Document 2).
- a data transfer instruction line from the CPU to the GPU here #pragma acc data copyin(a, b) of the copyin clause of variables a and b, is inserted at the position indicated by symbol k in FIG. do.
- parentheses ( ) are attached to copyin(a,b) for notational reasons. Copyout(a, b) and datacopyin(a, b, c, d) described later also use the same notation method.
- FIG. 7 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment.
- FIG. 7 corresponds to the nest integration in FIG. 6 of the comparative example.
- a data transfer instruction line from the CPU to the GPU is placed at the position indicated by symbol m in FIG. , c, d).
- the GPU processing and the CPU processing are not nested, and for the variables for which the CPU processing and the GPU processing are separated, specify the data copy statement #pragma of OpenACC to collectively transfer the variables.
- the data copy statement #pragma of OpenACC to collectively transfer the variables.
- acc data copyin(a, b, c, d) Since a, b, c, and d are transferred at the timing indicated by the dashed-dotted frame surrounding the symbol m in FIG. 7, one transfer occurs.
- Variables that are collectively transferred using the above #pragma acc data copyin(a, b, c, d) and that do not need to be transferred at that timing are indicated by the two-dot chain frame surrounding the symbol o in FIG.
- a data present statement #pragma acc data present (c, d) is used to specify that the GPU already has a variable.
- the data transfer instruction line from the GPU to the CPU here #pragma acc datacopyout( a, b, c, d) are inserted at position p where ⁇ 3> loop of FIG. 7 ends.
- variables that can be transferred in batches are transferred in a batch, and variables that have already been transferred and do not need to be transferred are specified using data present, thereby reducing transfers and further improving the efficiency of offloading methods. can be achieved.
- the compiler may automatically determine and transfer.
- the automatic transfer by the compiler is a phenomenon in which the transfer between the CPU and the GPU is originally unnecessary but is automatically transferred depending on the compiler, unlike the instructions of OpenACC.
- FIG. 8 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment.
- FIG. 8 corresponds to nested collation and transfer-free variable explicitness of FIG.
- a declare create statement #pragma acc declare create of OpenACC for creating a temporary area during CPU-GPU data transfer is specified at the position indicated by symbol q in FIG.
- a temporary area is created (#pragma acc declare create) when data is transferred between the CPU and GPU, and the data is stored in the temporary area.
- the OpenACC declare create statement #pragma acc update for synchronizing the temporary area is specified to instruct the transfer.
- the number of loops is investigated using a profiling tool as a preliminary step to searching for full-scale offload processing.
- a profiling tool makes it possible to investigate the number of times each line is executed. Therefore, for example, programs with loops of 50 million times or more can be sorted in advance, such as targeting offload processing searches. A specific description will be given below (partially overlaps with the content described in FIG. 2).
- the application code analysis unit 112 (FIG. 1) analyzes the application and grasps loop statements such as for, do, and while. Next, execute the sample processing, use the profiling tool to investigate the number of loops in each loop statement, and determine whether or not to perform full-scale search based on whether there is a loop that exceeds a certain value. conduct.
- the process of GA is entered (see Figure 2).
- the initialization step after checking whether or not all loop statements of the application code can be parallelized, the loop statements that can be parallelized are mapped to the gene array as 1 if GPU processing is to be performed, and as 0 if not. A specified number of individuals are prepared for the gene, and 1 and 0 are randomly assigned to each value of the gene.
- an explicit instruction for data transfer (#pragma acc data copyin/copyout/copy) is added from the variable data reference relationship within the loop statement specified to be processed by the GPU.
- the code corresponding to the gene is compiled, deployed and executed on the verification machine, and benchmark performance is measured. Then, the goodness of fit of a gene with a good performance pattern is increased.
- the code corresponding to the gene includes a parallel processing instruction line (for example, reference symbol f in FIG. 4) and a data transfer instruction line (for example, reference symbol h in FIG. 4, reference symbol i in FIG. 5, and ) is inserted.
- genes with high fitness are selected for the specified number of individuals based on the fitness.
- roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed.
- the crossover step at a constant crossover rate Pc, some genes are exchanged between the selected individuals at one point to create offspring individuals.
- each value of an individual's gene is changed from 0 to 1 or 1 to 0 at a constant mutation rate Pm.
- the process is terminated after repeating the specified number of generations, and the gene with the highest fitness is taken as the solution. Re-deploy to the production environment with the highest performing code pattern that corresponds to the best-fitting gene and provide it to the user.
- the implementation of the offload server 1 will be described below. This implementation is for confirming the effectiveness of this embodiment.
- An implementation of automatic offloading of C/C++ applications using a general-purpose PGI compiler is described. Since the purpose of this implementation is to confirm the validity of automatic GPU offloading, the target application is a C/C++ language application, and the GPU processing itself is explained using a conventional PGI compiler.
- the C/C++ language boasts top popularity in the development of OSS (Open Source Software) and proprietary software, and many applications are being developed in the C/C++ language.
- OSS Open Source Software
- applications are being developed in the C/C++ language.
- OSS general-purpose applications such as encryption processing and image processing are used.
- the GPU processing is performed by the PGI compiler.
- the PGI compiler is a C/C++/Fortran compiler that understands OpenACC.
- a parallel-capable processing unit such as a for statement is specified by an OpenACC directive #pragma acc kernels (parallel processing specifying statement).
- #pragma acc kernels parallel processing specifying statement
- This enables GPU offloading by extracting bytecodes for GPUs and executing them.
- an error is generated when the data in the for statement is dependent on each other and cannot be processed in parallel, or when multiple layers of nested for statements are specified.
- directives such as #pragma acc data copyin/copyout/copy can be used to explicitly instruct data transfer.
- the code of the C/C++ application is first analyzed to find for statements, and to understand the program structure such as variable data used in the for statements.
- LLVM/Clang syntax analysis library is used for syntax analysis.
- GNU coverage gcov etc. is used to grasp the number of loops.
- GNU Profiler (gprof) and “GNU Coverage (gcov)” are known as profiling tools. Either can be used because both can examine the execution count of each line. The number of executions can, for example, target only applications with loop counts of 10 million or more, but this value can be changed.
- a is the gene length. 1 of the gene corresponds to presence of parallel processing directive, 0 corresponds to no parallel processing directive, and the application code is mapped to the gene of length a.
- the C/C++ code with parallel processing and data transfer directives inserted is compiled with the PGI compiler on a machine equipped with a GPU. Deploy compiled executables and measure performance and power usage with benchmarking tools.
- Directive insertion, compilation, performance measurement, fitness setting, selection, crossover, and mutation processing are performed on the next-generation individuals.
- the individual is not compiled and the performance measurement is not performed, and the same measured value as before is used.
- the solution is the C/C++ code with directives that corresponds to the gene sequence with the highest performance.
- the number of individuals, the number of generations, the crossover rate, the mutation rate, the fitness setting, and the selection method are parameters of the GA and are specified separately.
- FIGS. 9A-B are flow charts outlining the operation of the implementation described above, and FIGS. 9A and 9B are connected by a connector. The following processing is performed using the OpenACC compiler for C/C++.
- step S101 the application code analysis unit 112 (see FIG. 1) performs code analysis of the C/C++ application.
- step S102 the parallel processing designation unit 114 (see FIG. 1) identifies loop statements and reference relationships of the C/C++ application.
- step S103 the parallel processing designation unit 114 checks the GPU processability of each loop statement (#pragma acc kernels).
- the control unit (automatic offload function unit) 11 repeats the processing of steps S105 to S116 by the number of loop statements between the loop start end of step S104 and the loop end of step S117.
- the control unit (automatic offload function unit) 11 repeats the processing of steps S106 and S107 by the number of loop statements between the loop start end of step S105 and the loop end end of step S108.
- the parallel processing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc kernels) with OpenACC.
- the parallel processing designation unit 114 checks the GPU processing possibility with the following directive (#pragma acc parallel loop) when an error occurs.
- the control unit (automatic offload function unit) 11 repeats the processing of steps S110 to S111 by the number of loop statements between the loop start point of step S109 and the loop end point of step S112.
- the parallel processing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc parallel loop) with OpenACC.
- the parallel processing designation unit 114 checks the GPU processability with the following directive (#pragma acc parallel loop vector) when an error occurs.
- the control unit (automatic offload function unit) 11 repeats the processing of steps S114 to S115 by the number of loop statements between the loop start point of step S113 and the loop end point of step S116.
- the parallel processing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc parallel loop vector) with OpenACC.
- the parallel processing specifying unit 114 removes the GPU processing directive phrase from the loop statement when an error occurs.
- step S118 the parallel processing designating unit 114 counts the number of loop statements (here, for statements) in which no compilation error occurs, and sets the number as the gene length.
- the parallel processing designation unit 114 prepares gene sequences for the designated number of individuals. Here, 0 and 1 are randomly assigned and created.
- the parallel processing designating unit 114 maps the C/C++ application code to genes and prepares a designated population pattern. Depending on the prepared gene sequence, a directive specifying parallel processing is inserted into the C/C++ code when the value of the gene is 1 (see, for example, the #pragma directive in FIG. 3).
- the control unit (automatic offload function unit) 11 repeats the processing of steps S121 to S130 for a specified number of generations between the loop start end of step S120 and the loop end of step S131 in FIG. 9B. Further, in the repetition of the designated number of generations, the processing of steps S122 to S125 is repeated for the designated number of individuals between the loop start end of step S121 and the loop end of step S126. That is, repetitions of the specified number of individuals are processed in a nested state within the repetition of the specified number of generations.
- step S122 the data transfer designation unit 113 transfers data using explicit instruction lines (#pragma acc data copy/copyin/copyout/present and #pragma acc declarecreate, #pragma acc update) based on the variable reference relationship. Specify transfer.
- step S123 the parallel processing pattern creating unit 117 (see FIG. 1) compiles the C/C++ code specified by the directive according to the gene pattern using the PGI compiler. That is, the parallel processing pattern creation unit 117 compiles the created C/C++ code with the PGI compiler on the verification machine 14 having a GPU.
- a compilation error may occur when multiple nested for statements are specified in parallel. This case is handled in the same way as when the processing time times out during performance measurement.
- step S124 the performance measurement unit 118 (see FIG. 1) deploys the execution file to the verification machine 14 equipped with the CPU-GPU.
- step S125 the performance measurement unit 118 executes the arranged binary file and measures the benchmark performance when offloading.
- genes with the same pattern as before are not measured, and the same values are used.
- the same measured values as before are used without compiling or performance measurement for that individual.
- the performance measurement unit 118 measures the processing time.
- the performance measurement unit 118 sets an evaluation value based on the measured processing time.
- step S129 the execution file creation unit 119 (see FIG. 1) evaluates individuals with shorter processing times so that their fitness levels are higher, and selects individuals with higher performance.
- the execution file creating unit 119 selects a pattern of short time and low power consumption as a solution from among the plurality of measured patterns.
- step S130 the execution file creation unit 119 performs crossover and mutation processing on the selected individuals to create next-generation individuals.
- the executable file creation unit 119 performs compilation, performance measurement, fitness setting, selection, crossover, and mutation processing for the next-generation individuals. That is, after benchmark performance is measured for all individuals, the degree of fitness of each gene sequence is set according to the benchmark processing time. Individuals to be left are selected according to the set degree of fitness.
- the execution file creation unit 119 performs GA processing such as crossover processing, mutation processing, and copy processing as it is on the selected individuals to create a group of individuals for the next generation.
- step S132 the executable file creation unit 119 takes the C/C++ code corresponding to the highest performance gene sequence (highest performance parallel processing pattern) as a solution after the GA processing for the designated number of generations is completed.
- GA parameters The number of individuals, number of generations, crossover rate, mutation rate, fitness setting, and selection method are parameters of the GA.
- GA parameters may be set as follows, for example.
- Parameters and conditions of Simple GA to be executed can be set as follows, for example.
- Gene length Number of loop statements that can be parallelized Number of individuals M: Less than gene length Number of generations T: Less than gene length Goodness of fit: (Processing time) (-1/2)
- the degree of fitness to include the (-1/2) power of the processing time, it is possible to prevent the search range from narrowing due to the degree of fitness of a specific individual whose processing time is short becoming too high. can. If the performance measurement does not end within a certain period of time, it is timed out, and the suitability is calculated assuming that the processing time is 1000 seconds (long time). This timeout period may be changed according to performance measurement characteristics. Selection: Roulette selection However, we also perform elite preservation in which the gene with the highest fitness in the generation is preserved in the next generation without crossover or mutation. Crossover rate Pc: 0.9 Mutation rate Pm: 0.05
- gcov, gprof, etc. are used to identify in advance an application that has many loops and takes a long time to execute, and offloading is attempted. This allows you to find applications that can be efficiently accelerated.
- ⁇ Time to start using the actual service> Describe the time until the start of use of the actual service. Assuming that it takes about 3 minutes from compilation to performance measurement, it takes about 20 hours at maximum with GA of 20 individuals and 20 generations. Finish in 8 hours or less. The reality is that it takes about half a day to start using many cloud, hosting, and network services. In this embodiment, for example, automatic offloading within half a day is possible. For this reason, as long as the automatic offload is within half a day, if trial use is possible at first, it can be expected that user satisfaction will be sufficiently increased.
- the GA is performed with a small number of individuals and a small number of generations, but by setting the crossover rate Pc to a high value of 0.9 and searching a wide range, a solution with a certain level of performance can be found quickly. ing.
- the directives are expanded in order to increase the number of applicable applications.
- directives specifying GPU processing in addition to kernels directives, parallel loop directives and parallel loop vector directives are expanded.
- kernels are used for single loops and tightly nested loops.
- parallel loops are used for loops including non-tightly nested loops.
- parallel loop vector is used for loops that cannot be parallelized but can be vectorized.
- a tightly nested loop is a nested loop, for example, when two loops that increment i and j are nested, the lower loop uses i and j, and the upper loop does not A simple loop like Also, in the implementation of the PGI compiler, etc., there is a difference in that the compiler makes decisions about parallelization for kernels, and the programmer makes decisions about parallelization for parallels.
- kernels are used for single and tightly nested loops
- parallel loops are used for non-tightly nested loops.
- the parallel directive may reduce the reliability of the results compared to kernels.
- the final offload program will be subjected to a sample test, the difference between the result and the CPU will be checked, and the result will be shown to the user for confirmation by the user.
- the CPU and GPU have different hardware, there are differences in the number of significant digits and rounding errors, and it is necessary to check the result difference between the kernels and the CPU.
- FIG. 10 is a flow chart illustrating setting the resource ratio and amount of resources added after a GPU offload attempt and placing a new application. The flow chart shown in FIG. 10 is executed after the GPU offload attempts shown in FIGS. 9A-B.
- step S51 the resource ratio determination unit 115 acquires user operating conditions, test case CPU processing time, and offload device processing time.
- the user operating conditions are specified by the user when the user specifies the code to be offloaded.
- the user operating conditions are used when the resource amount setting unit 116 refers to the information in the equipment resource DB 132 and determines the resource amount.
- the resource ratio determination unit 115 determines the ratio of the CPU and offload device processing times (test case CPU processing time and offload device processing time) as the resource ratio based on the performance measurement result.
- the resource ratio determination unit 115 determines the resource ratio so that the processing times of the CPU and the offload device are of the same order. By determining the resource ratio so that the processing time of the CPU and the offload device are of the same order, the processing time of the CPU and the offload device can be aligned, and the CPU and accelerator can be used in mixed environments such as GPUs, FPGAs, and many-core CPUs. Even if there is, the amount of resources can be appropriately set.
- the resource ratio determination unit 115 sets the resource ratio to a predetermined upper limit when the difference between the processing times of the CPU and the offload device is equal to or greater than a predetermined threshold. That is, if the processing time between the CPU and the offload device in the verification environment has a difference of, for example, 10 times or more, increasing the resource ratio to 10 times or more leads to deterioration in cost performance.
- a resource ratio such as 5:1 is set as the upper limit (the upper limit is a resource ratio of 5:1 of the processing time).
- step S53 the resource amount setting unit 116 sets the resource amount based on the user operating conditions and the appropriate resource ratio. That is, the resource amount setting unit 116 determines the resource amount while maintaining the resource ratio as much as possible so as to satisfy the cost condition specified by the user.
- the resource amount setting unit 116 maintains an appropriate resource ratio and sets the maximum resource amount that satisfies the user operating conditions.
- the CPU1VM is 1,000 yen/month
- the GPU is 4,000 yen/month
- the resource ratio is 2:1
- the user's budget is within 10,000 yen per month.
- 2 CPUs and 1 GPU are secured and placed in the commercial environment.
- the resource amount setting unit 116 sets the resource amount of the CPU and the offload device to the minimum so as to satisfy the cost condition by breaking the resource ratio.
- the CPU1VM is 1,000 yen/month
- the GPU is 4,000 yen/month
- the resource ratio is 2:1
- the user's budget is within 5,000 yen per month.
- the resource amounts of the CPU and the offload device are set smaller, that is, 1 is secured for the CPU and 1 is allocated for the GPU.
- step S53 above After the processing of step S53 above is completed and the resources are secured and allocated in the commercial environment, the automatic verification described in FIG. 2 is executed in order to confirm the performance and cost before use by the user. As a result, resources can be reserved in a commercial environment, and performance and cost can be presented to the user after automatic verification.
- Performance measurements are used in solving offload patterns to optimize resource ratios.
- the implementation determines the resource ratio so that the CPU and GPU processing times are of the same order from the test case processing time. For example, if the test case processing time is 10 seconds for CPU processing and 5 seconds for GPU processing, the resources on the CPU side are doubled and the processing time is considered to be about the same, so the resource ratio is 2:1. . Since the number of virtual machines and the like is an integer, when calculating the resource ratio from the processing time, the resource ratio is rounded to an integer ratio.
- the next step is to set the resource amount when deploying the application to the commercial environment.
- the implementation determines the number of VMs, etc. while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user at the time of the offload request. Specifically, the maximum number of VMs is selected while maintaining the resource ratio within the cost range.
- 1 VM is 1000 yen/month
- GPU is 4000 yen/month
- the resource ratio is 2:1. Secure 1.
- the resource amount is set so that the resource ratio is as close to an appropriate one as possible, starting from one CPU unit and one GPU unit. For example, if the budget is within 5000 yen per month, the resource ratio cannot be maintained, but 1 CPU and 1 GPU are secured.
- the implementation uses, for example, the virtualization function of Xen Server to allocate CPU and GPU resources.
- step S54 the placement setting unit 170 calculates the new application placement location (APL placement location) using a linear programming method based on the server of the equipment resource DB 132, the link specification information, and the existing application placement information. to set.
- the offload server 1 of the present embodiment when offloading a program for a CPU to a device such as a GPU, selects a location where the application is placed so as to meet the user's requirements such as cost and operate with a short response time. rationalize.
- FIG. 11 is a diagram showing an example of the topology of computation nodes.
- data is sent from an IoT device that collects data in the user environment, such as an IoT system, to the user edge, and the data is sent to the cloud via the network edge, and the analysis results are viewed by company executives. This is the topology used in
- the topology for arranging applications consists of three layers, the number of bases in the cloud layer (eg, data center) is "2" (n13, n14), and the carrier edge layer (eg, office) is "3", the user edge layer (eg, user environment) is "4" (n6-n9), and the input node is "5" (n1-n5).
- applications such as IoT, IoT data (pollen sensors, body temperature sensors, etc., which are one of IoT devices) is collected from the input node to the user edge, and depending on the characteristics of the application (response time requirements, etc.), Analysis processing is performed at the user edge and carrier edge, and analysis processing is performed after data is uploaded to the cloud.
- the output node is "1" (n15), and the analysis results are viewed by company executives.
- the input node is IoT data (pollen sensor)
- the person in charge of the Japan Meteorological Agency confirms the statistics and analysis results of the output node.
- the arrangement topology of three layers shown in FIG. 11 is an example, and may be, for example, five layers. Also, the number of user edges and carrier edges may actually be several tens to several hundred.
- Computing nodes are divided into three types: CPU, GPU, and FPGA. Nodes equipped with GPUs and FPGAs are also equipped with CPUs, but virtualization technology (for example, NVIDIA vGPU) provides separate GPU instances and FPGA instances that also include CPU resources.
- virtualization technology for example, NVIDIA vGPU
- an application converted for GPU or FPGA is arranged, and the user can issue two types of requests when arranging the application.
- the first is a cost request, which specifies the permissible cost of computing resources for operating the application, for example, within 5000 yen per month.
- the second is a response time request, which specifies an allowable response time for operating an application, such as returning a response within 10 seconds.
- locations for arranging servers that accommodate virtual networks are systematically designed in consideration of long-term trends such as traffic increases.
- This embodiment has the following features (1) and (2).
- Applications to be placed are not statically determined, but are automatically converted for GPUs and FPGAs, and patterns suitable for usage forms are extracted through actual measurements through GA and the like. Because of this, application code and performance can change dynamically.
- Application placement policies can also change dynamically.
- the application placement of this embodiment is such that when there is a request for placement from the user, conversion is performed, and the converted applications are sequentially placed on appropriate servers at that time. Iku form. If converting the application does not improve the cost performance, the application should be placed before the conversion. For example, when a GPU instance costs twice as much as a CPU instance, and the conversion does not improve the performance by more than two times, it is better to allocate before the conversion. Also, if the computational resources and bandwidth have already been used up to the upper limit, it may not be possible to allocate to that server.
- Linear programming formula for appropriate placement of applications we formulate a linear programming method for calculating appropriate placement locations of applications.
- the linear programming method is represented by [Formula 1] (Formulas (1) to (4) below) and [Formula 2] (Formulas (3) to (6) below). parameters are used.
- device and link costs, computational resource upper limits, band upper limits, etc. depend on the servers and networks prepared by the business operator. Therefore, those parameter values are set in advance by the operator.
- the calculation resource amount, bandwidth, data capacity, and processing time used by the application when offloading are determined by the measurement values of the offload pattern that was finally selected in the test in the verification environment before automatic conversion. Automatically set by the environment adaptation function.
- the objective function and constraints on the parameters of the linear programming formula change depending on whether the user request is a cost request for computational resources or a response time request.
- the objective function is minimization of the response time of formula (1).
- One of the constraints is how much the computational resource cost of Equation (2) is within.
- a constraint condition is added as to whether or not the resource upper limit of the server in formulas (3) and (4) is exceeded.
- the objective function is to minimize the computational resource cost of Equation (5) corresponding to Equation (2).
- One of the constraints is how many seconds the response time of Equation (6) corresponding to Equation (1) is within. Furthermore, the constraints of equations (3) and (4) are added.
- Formulas (1) and (6) are formulas for calculating the response time of application k.
- Rk is the objective function
- Rk is a constraint that sets a user-specified upper bound.
- Equations (2) and (5) are equations for calculating the cost (price) Pk of operating application k.
- Pk is the objective function.
- Formulas (3) and (4) are constraints that set the upper limit of computational resources and communication bandwidth, are calculated including applications deployed by others, and prevent the resource upper limit from being exceeded due to the placement of applications by new users.
- the linear programming formulas (1) to (4) and (3) to (6) are calculated based on the network topology, conversion application type (increase in cost and performance for CPU, etc.), user requirements, and existing applications. Appropriate application placement can be calculated for different conditions by deriving solutions with linear programming solvers such as GLPK (Gnu Linear Programming Kit) and CPLEX (IBM Decision Optimization). By sequentially performing actual placement for a plurality of users after appropriate placement calculation, a plurality of applications are placed based on each user's request.
- linear programming solvers such as GLPK (Gnu Linear Programming Kit) and CPLEX (IBM Decision Optimization).
- ⁇ Evaluation condition> ⁇ Target application The application to be placed performs image processing by Fourier transform, which is assumed to be used by many users.
- Fourier transform processing is used in various aspects of IoT monitoring, such as vibration frequency analysis.
- NAS.FT https://www.nas.nasa.gov/publications/npb.html
- FFT Fourier transform processing
- NAS.FT https://www.nas.nasa.gov/publications/npb.html
- MRI-Q http://impact.crhc.illinois.edu/parboil/) (registered trademark) uses the matrix Q to represent the scanner configuration for calibration used in non-Cartesian spatial three-dimensional MRI reconstruction algorithms. calculate.
- image processing is often required for automatic surveillance from camera video, and there is a need for automatic offloading of image processing.
- MRI-Q is a C-language application that performs 3D MRI image processing during performance measurement and measures processing time using Large 64 ⁇ 64 ⁇ 64 size sample data.
- CPU processing is based on C language
- FPGA processing is based on OpenCL (registered trademark).
- NAS.FT can be speeded up by GPU
- MRI-Q can be speeded up by FPGA, which are five times and seven times faster than CPU, respectively.
- the topology for deploying applications consists of three layers as shown in Fig. 11.
- the number of bases in the cloud layer is "5"
- the carrier edge layer is "20”
- the user edge layer is "60”
- the input node. is "300”.
- IoT data is collected from the input node to the user edge, and depending on the characteristics of the application (requirements for response time, etc.), analysis processing is performed at the user edge and carrier edge, and it is delivered to the cloud. After the data is given, it is analyzed and processed.
- 1000 applications are arranged based on user requirements based on the parameters of the linear programming formulas shown in [Formula 1] and [Formula 2].
- an upper limit of 7,000 yen per month, an upper limit of 8,500 yen, or an upper limit of 10,000 yen is selected for the price, and an upper limit of 6 seconds, a condition of 7 seconds, or an upper limit of 10 seconds is selected for the response time.
- an upper limit of 12,500 yen or 20,000 yen per month is selected for the price, and an upper limit of 4 seconds or 8 seconds is selected for the response time.
- Pattern 1 Select 1/6 of 6 types of requests for NAS.FT, and 1/4 of 4 types of requests for MRI-Q.
- Pattern 2 The request selects the condition with the lowest price as the upper limit (first 7,000 yen, 12,500 yen), and if there are no vacancies, the next lowest price condition.
- Pattern 3 The request selects the condition with the minimum response time as the upper limit (first 6 seconds, 4 seconds), and if there is no free space, the next fastest response time condition.
- - Placement simulation Placement is performed by a simulation experiment using solver GLPK5.0 (registered trademark) as an evaluation tool.
- solver GLPK5.0 registered trademark
- an application offload request is received, an offload pattern is created through repeated performance tests using the verification environment, and the appropriate amount of resources is determined based on the performance test results in the verification environment (Fig. 10).
- an appropriate layout is determined using GLPK, etc., normality confirmation tests and performance tests are automatically performed when actually deployed, the results and prices are presented to the user, and use is made after the user decides. to start.
- FIG. 12 is a graph showing changes in the number of applications deployed in the average response time.
- FIG. 12 shows the average response time and the number of applications deployed for the above three patterns. It was confirmed that pattern 2 was filled in order from the cloud, and pattern 3 was filled in order from the edge. In pattern 1, when various requests are received, they are arranged by satisfying the user requirements. As shown in FIG. 12, in pattern 2, all up to the 400th placement position are placed in the cloud and the average response time remains the slowest, but when the cloud is filled, it gradually decreases. In pattern 3, NAS.FT is placed from the user edge and MRI-Q is placed from the carrier edge. Therefore, the average response time is the shortest. However, as the number increases, it is also deployed in the cloud, slowing the average response time. In pattern 2, the average response time is intermediate between patterns 1 and 3, and is arranged according to user requests. Thus, in pattern 2, the average response time is appropriately reduced compared to pattern 1, which initially enters the cloud entirely.
- the software is automatically adapted according to the deployment environment, and when automatically offloaded to the GPU, etc., it meets the user's cost and response time requirements. That is, the program is converted so that it can be processed by a device such as a GPU, and after the amount of resources to be assigned is determined, the converted application is optimally arranged.
- the appropriate allocation is calculated by changing the price conditions, response time conditions, and the number of applications requested by the user. This enables arrangement according to the user's request.
- the second embodiment is an example applied to FPGA automatic offloading of loop statements.
- a PLD Programmable Logic Device
- FPGA Field Programmable Gate Array
- OpenCL conversion is performed for loop statements with high arithmetic intensity and loop count as candidates.
- the CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to OpenCL syntax.
- FPGA kernel
- CPU host
- For candidate loop statements precompile your OpenCL to find resource-efficient loop statements. Since resources to be created can be known during compilation, loop statements that use a sufficiently small amount of resources are further narrowed down. Since some candidate loop statements remain, we use them to measure performance and power consumption.
- the selected single-loop statement is compiled and measured, and for the single-loop statement whose speed has been further improved, a combination pattern is created and the second measurement is performed. A pattern of short time and low power consumption is selected as a solution from among the measured patterns.
- FIG. 13 is a functional block diagram showing a configuration example of the offload server 1A according to the second embodiment of the invention.
- the offload server 1A is a device that automatically offloads specific processing of an application to an accelerator.
- the offload server 1A can be connected to an emulator.
- the offload server 1A includes a control unit 21, an input/output unit 12, a storage unit 13, and a verification machine 14 (accelerator verification device). be.
- the control unit 21 is an automatic offloading function that controls the entire offload server 1A.
- the control unit 21 is implemented, for example, by a CPU (not shown) expanding a program (offload program) stored in the storage unit 13 into a RAM and executing the program.
- the control unit 21 includes an application code specification unit (Specify application code) 111, an application code analysis unit (Analyze application code) 112, a PLD processing specification unit 213, an arithmetic intensity calculation unit 214, an arrangement setting unit 170, and a PLD A processing pattern creation unit 215, a performance measurement unit 118, an execution file creation unit 119, a production environment deployment unit (Deploy final binary files to production environment) 120, and a performance measurement test extraction execution unit (Extract performance test cases and run automatically ) 121 and a user provision unit (Provide price and performance to a user to judge) 122 .
- the PLD processing designation unit 213 identifies loop statements (repetition statements) of the application, and creates a plurality of offload processing patterns in which pipeline processing and parallel processing in the PLD are designated by OpenCL for each of the identified loop statements. to compile.
- the PLD processing designation unit 213 includes an extract offload able area 213a and an output intermediate file 213b.
- the offload range extracting unit 213a identifies processing that can be offloaded to the FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
- the intermediate language file output unit 213b outputs the extracted intermediate language file 133.
- Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- the arithmetic intensity calculation unit 214 calculates the arithmetic intensity of the loop statement of the application using an arithmetic intensity analysis tool such as the ROSE framework (registered trademark).
- Arithmetic intensity is the number of floating point numbers (FN) executed during program execution divided by the number of bytes accessed to main memory (FN operations/memory access).
- Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of the loop statement.
- the PLD processing pattern creation unit 215 narrows down loop statements with high arithmetic intensity to offload candidates.
- the PLD processing pattern creation unit 215 Based on the arithmetic intensity calculated by the arithmetic intensity calculation unit 214, the PLD processing pattern creation unit 215 narrows down loop statements whose arithmetic intensity is higher than a predetermined threshold (hereinafter referred to as high arithmetic intensity as appropriate) as offload candidates, Create a PLD processing pattern. As a basic operation, the PLD processing pattern creation unit 215 excludes loop statements (repeated statements) that cause compilation errors from being offloaded, and performs PLD processing on repetitive statements that do not cause compilation errors. Create a PLD processing pattern that specifies whether or not
- the PLD processing pattern creation unit 215 measures the loop count of the loop statements of the application using a profiling tool. Narrow down loop statements that are more than the number of times (hereinafter referred to as a high number of loops as appropriate). GNU coverage gcov etc. is used to grasp the number of loops. "GNU Profiler (gprof)” and “GNU Coverage (gcov)” are known as profiling tools. Either can be used because both can examine the number of executions of each loop.
- a profiling tool is used to measure the number of loops in order to detect loops with a large number of loops and high load.
- the level of arithmetic intensity indicates whether the processing is suitable for offloading to the FPGA, and the number of loops ⁇ arithmetic intensity indicates whether the load associated with offloading to the FPGA is high.
- the PLD processing pattern creation unit 215 creates OpenCL (OpenCL conversion) for offloading each narrowed loop statement to the FPGA as an OpenCL creation function. That is, the PLD processing pattern creation unit 215 compiles OpenCL that offloads the narrowed loop statements. In addition, the PLD processing pattern creation unit 215 lists loop statements whose performance is improved compared to the CPU among the measured performance, and creates OpenCL for offloading by combining the loop statements in the list.
- OpenCL OpenCL conversion
- the PLD processing pattern creation unit 215 converts the loop statement into a high-level language such as OpenCL.
- a CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to the grammar of a high-level language such as OpenCL.
- FPGA kernel
- CPU host
- OpenCL high-level language
- a kernel created according to the OpenCL C language grammar is executed on a device (eg FPGA) by a created host (eg CPU) side program using the OpenCL C language run-time API.
- the part that calls the kernel function hello() from the host side is to call clEnqueueTask(), which is one of the OpenCL runtime APIs.
- the basic flow of initialization, execution, and termination of OpenCL written in host code is steps 1 to 13 below. Among these steps 1 to 13, steps 1 to 10 are procedures (preparations) until the kernel function hello() is called from the host side, and step 11 is execution of the kernel.
- Create Command Queue Create a command queue ready to control the device using the function clCreateCommandQueue( ) that provides the command queue creation functionality defined in the OpenCL runtime API.
- the host issues commands to the device (issues a kernel execution command or a memory copy command between the host and the device) through the command queue.
- Memory object creation Using the function clCreateBuffer(), which provides a function to allocate memory on the device defined in the OpenCL runtime API, create a memory object that allows the host to refer to the memory object.
- Kernel file loading The kernel running on the device is controlled by the host program. Therefore, the host program must first load the kernel program.
- the kernel program includes binary data created by the OpenCL compiler and source code written in the OpenCL C language. Read this kernel file (description omitted). Note that the OpenCL runtime API is not used for kernel file reading.
- Program Object Creation recognizes a kernel program as a program project. This procedure is program object creation. Using the function clCreateProgramWithSource( ) that provides the program object creation function defined in the OpenCL runtime API, create a program object that allows the host to refer to the memory object. Use clCreateProgramWithBinary() when creating from a compiled binary string of a kernel program.
- Kernel Object Creation A kernel object is created using the function clCreateKernel( ) that provides the kernel object creation function defined in the OpenCL runtime API.
- One kernel object corresponds to one kernel function, so the kernel function name (hello) is specified when the kernel object is created. Also, when a plurality of kernel functions are described as one program object, one kernel object corresponds to one kernel function, so clCreateKernel( ) is called multiple times.
- Kernel Argument Setting Kernel arguments are set using the function clSetKernel() that provides the function of giving arguments to the kernel defined in the OpenCL runtime API (passing values to the arguments of kernel functions). After steps 1 to 10 complete preparations, step 11 is entered to execute the kernel on the device from the host side.
- Kernel Execution Kernel execution (throwing into the command queue) is a queuing function to the command queue because it acts on the device.
- the function clEnqueueTask( ) which provides kernel execution functionality defined in the OpenCL runtime API, is used to queue a command to execute kernel hello on the device. After the command to execute kernel hello is queued, it will be executed in the executable arithmetic unit on the device.
- Reading from a memory object Using the function clEnqueueReadBuffer(), which provides a function to copy data from device-side memory to host-side memory defined in the OpenCL runtime API, read data from the device-side memory area to the host-side memory area. copy the data to In addition, data is copied from the host-side memory area to the device-side memory area using the function clEnqueueWrightBuffer(), which provides a function to copy data from the host side to the client side memory. Since these functions act on the device, the data copy starts after the copy command is queued in the command queue once.
- Resource Amount Calculation Function As a resource amount calculation function, the PLD processing pattern creation unit 215 precompiles the created OpenCL and calculates the resource amount to be used (“first resource amount calculation”). The PLD processing pattern creation unit 215 calculates resource efficiency based on the calculated arithmetic intensity and resource amount, and based on the calculated resource efficiency, c loops whose resource efficiency is higher than a predetermined value in each loop statement. choose a sentence. The PLD processing pattern creation unit 215 calculates the resource amount to be used by precompiling with the combined offload OpenCL (“second resource amount calculation”). Here, without precompilation, the sum of resource amounts in precompilation before the first measurement may be used.
- the performance measurement unit 118 compiles the created PLD processing pattern application, places it in the verification machine 14, and executes performance measurement processing when offloaded to the PLD.
- the performance measurement unit 118 executes the arranged binary file, measures the performance when offloaded, and returns the performance measurement result to the offload range extraction unit 213a.
- the offload range extraction unit 213a extracts another PLD processing pattern, and the intermediate language file output unit 213b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2). ).
- the performance measurement unit 118 includes a binary file placement unit (Deploy binary files) 118a.
- the binary file placement unit 118a deploys (places) an execution file derived from the intermediate language on the verification machine 14 having a GPU.
- the PLD processing pattern creation unit 215 narrows down loop statements with high resource efficiency, and compiles OpenCL for offloading the loop statements narrowed down by the executable file creation unit 119 .
- the performance measurement unit 118 measures the performance of the compiled program (“first performance measurement”).
- the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance measured.
- the PLD processing pattern creation unit 215 creates OpenCL for offloading by combining the loop statements of the list.
- the PLD processing pattern creation unit 215 precompiles with the combined offload OpenCL and calculates the amount of resources to be used. Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation.
- the executable file creation unit 119 compiles the combined offload OpenCL, and the performance measurement unit 118 measures the performance of the compiled program (“second performance measurement”).
- the execution file creation unit 119 selects the PLD processing pattern with the highest evaluation value from a plurality of PLD processing patterns based on the measurement result of the processing time repeated a predetermined number of times, and compiles the PLD processing pattern with the highest evaluation value. to create an executable file.
- the offload server 1A of the present embodiment is an example in which elemental technology of environment-adaptive software is applied to FPGA automatic offloading of user application logic. Description will be made with reference to the automatic offload processing of the offload server 1A shown in FIG. As shown in FIG. 2, the offload server 1A is applied to elemental technology of environment adaptive software.
- the offload server 1A has a control unit (automatic offload function unit) 11, a test case DB 131, an intermediate language file 133, and a verification machine .
- the offload server 1A acquires an application code 125 used by the user.
- a user uses, for example, various devices (Device) 151, a device 152 having a CPU-GPU, a device 153 having a CPU-FPGA, and a device 154 having a CPU.
- the offload server 1A automatically offloads functional processing to the accelerators of the device 152 having a CPU-GPU and the device 153 having a CPU-FPGA.
- step S21 the application code specifying unit 111 (see FIG. 13) specifies the processing function (image analysis, etc.) of the service provided to the user. Specifically, the application code designation unit 111 designates the input application code.
- Step S12 Analyze application code>
- the application code analysis unit 112 analyzes the source code of the processing function and grasps the structure of specific library usage such as loop statements and FFT library calls.
- Step S13 Extract offloadable area>
- the PLD processing designation unit 213 identifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement, and performs high-level synthesis. Compile with tools.
- the offload range extraction unit 213a identifies processing that can be offloaded to the FPGA, such as a loop statement, and extracts OpenCL as an intermediate language corresponding to the offload processing.
- Step S14 Output intermediate file>
- the intermediate language file output unit 213b (see FIG. 13) outputs the intermediate language file 133.
- FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- Step S15 Compile error>
- the PLD processing pattern creation unit 215 excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors to be FPGA-processed. Create a PLD processing pattern that specifies whether or not to perform.
- Step S21 Deploy binary files>
- the binary file placement unit 118a (see FIG. 13) deploys the execution file derived from the intermediate language to the verification machine 14 having an FPGA.
- the binary file placement unit 118a activates the placed file, executes an assumed test case, and measures performance when offloading.
- Step S22 Measure performance>
- the performance measurement unit 118 executes the arranged file and measures the performance and power usage when offloading. In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offload range extraction unit 213a, and the offload range extraction unit 213a extracts another pattern. Then, the intermediate language file output unit 213b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2). The performance measurement unit 118 repeats the performance/power consumption measurement in the verification environment and finally determines the code pattern to be deployed.
- the control unit 21 repeatedly executes steps S12 to S22.
- the automatic offload function of the control unit 21 is summarized below. That is, the PLD processing designation unit 213 specifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement in OpenCL (intermediate language), and uses a high-level synthesis tool. Compile with Then, the PLD processing pattern creation unit 215 creates a PLD processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to perform PLD processing on loop statements that do not cause compilation errors. do.
- Step S23 Deploy final binary files to production environment>
- the production-environment placement unit 120 determines a pattern specifying the final offload area, and deploys it to the production environment for the user.
- Step S24 Extract performance test cases and run automatically>
- the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user after the execution file is arranged.
- Step S25 Provide price and performance to a user to judge>
- the user providing unit 122 presents information such as price and performance to the user based on the performance test results. Based on the presented information such as price and performance, the user decides to start using the service for a fee.
- steps S21 to S25 are performed in the background when the user uses the service, and are assumed to be performed, for example, during the first day of provisional use. Also, the processing performed in the background for cost reduction may target only GPU/FPGA offload.
- control unit 21 of the offload server 1A when the control unit (automatic offload function unit) 21 of the offload server 1A is applied to the element technology of the environment-adaptive software, the source code of the application used by the user is used to offload the function processing. , the offloading area is extracted and the intermediate language is output (steps S12 to S15). The control unit 21 arranges and executes the execution file derived from the intermediate language on the verification machine 14, and verifies the offload effect (steps S21 to S22). After repeating verification and determining an appropriate offload area, the control unit 21 deploys the executable file in the production environment that is actually provided to the user and provides it as a service (step S26).
- offloading application processing it is necessary to consider the GPU, FPGA, IoT GW, etc. according to the offload destination.
- performance it is difficult to automatically discover the setting that maximizes performance at one time. For this reason, offload patterns are tried by repeating performance measurement several times in a verification environment to find a pattern that can speed up the process.
- FIG. 14 is a flowchart for explaining the outline of the operation of the offload server 1A.
- the application code analysis unit 112 analyzes the source code of the application to be offloaded.
- the application code analysis unit 112 analyzes information on loop statements and variables according to the language of the source code.
- step S202 the PLD processing designation unit 213 identifies loop statements and reference relationships of the application.
- the PLD processing pattern creation unit 215 performs processing for narrowing down candidates for whether to try FPGA offloading for the grasped loop statements.
- Arithmetic strength is one indicator of whether a loop statement has an offload effect.
- the arithmetic strength calculation unit 214 calculates the arithmetic strength of the loop statement of the application using the arithmetic strength analysis tool.
- Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of loop statements and narrows down loop statements with high density to offload candidates. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of loop statements and narrows down loop statements with high density to offload candidates.
- the PLD processing pattern creation unit 215 translates the target loop statement into a high-level language such as OpenCL, and first calculates the resource amount. Also, since the arithmetic intensity and the resource amount when the loop statement is offloaded are determined, the arithmetic intensity/resource amount or arithmetic intensity ⁇ loop count/resource amount is defined as the resource efficiency. Then, loop statements with high resource efficiency are further narrowed down as offload candidates.
- step S204 the PLD processing pattern creation unit 215 measures the number of loops of loop statements of the application using profiling tools such as gcov and gprof.
- step S205 the PLD processing pattern creation unit 215 narrows down the loop statements with high arithmetic strength and high loop count among the loop statements.
- step S206 the PLD processing pattern creation unit 215 creates OpenCL for offloading each narrowed loop statement to the FPGA.
- step S207 the PLD processing pattern creation unit 215 pre-compiles the created OpenCL and calculates the resource amount to be used ("first resource amount calculation").
- step S208 the PLD processing pattern creation unit 215 narrows down loop statements with high resource efficiency.
- step S209 the execution file creation unit 119 compiles OpenCL for offloading the narrowed down loop statements.
- step S210 the performance measurement unit 118 measures the performance of the compiled program ("first performance measurement"). Since some candidate loop statements remain, the performance measurement unit 118 uses them to actually measure the performance (see the subroutine in FIG. 15 for details).
- step S211 the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance-measured ones.
- step S212 the PLD processing pattern creation unit 215 creates OpenCL for offloading by combining the loop statements of the list.
- step S213 the PLD processing pattern creation unit 215 calculates the amount of resources to be used by precompiling with the combined offload OpenCL (“second resource amount calculation”). Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation. By doing so, the number of times of precompilation can be reduced.
- step S214 the execution file creation unit 119 compiles the combined offload OpenCL.
- step S215 the performance measurement unit 118 measures the performance of the compiled program ("second performance measurement").
- the performance measurement unit 118 compiles and measures the selected single-loop statement, creates a combination pattern for the single-loop statement that has been further accelerated, and performs the second performance measurement (for details, see (see subroutine in FIG. 15).
- step S216 the production environment placement unit 120 selects the pattern with the highest performance among the first and second measurements, and terminates the processing of this flow.
- a short-time pattern is selected as a solution from the measured multiple patterns.
- the FPGA automatic offloading of loop statements creates offload patterns by focusing on loop statements with high arithmetic strength, loop counts, and high resource efficiency, and searches for high-speed patterns through actual measurements in a verification environment (Fig. 14).
- FIG. 15 is a flowchart showing performance/power consumption measurement processing of the performance measurement unit 118.
- FIG. This flow is called and executed by a subroutine call in step S210 or step S215 in FIG.
- step S301 the performance measurement unit 118 measures the processing time required for FPGA offloading.
- step S302 the performance measurement unit 118 sets an evaluation value based on the measured processing time.
- step S303 the performance measurement unit 118 measures the performance of patterns with high evaluation values, which are evaluated such that the higher the evaluation value, the higher the fitness, and returns to step S210 or step S215 in FIG.
- FIG. 16 is a diagram showing a search image of the PLD processing pattern generator 215.
- the control unit (automatic offload function unit) 21 analyzes the application code 125 (see FIG. 2) used by the user, and determines the code pattern of the application code 125 as shown in FIG. (Code patterns) 241 checks whether the for statement can be parallelized.
- code patterns code patterns
- FIG. 16 when four for statements are found from the code pattern 241, one digit is assigned to each for statement, here four digits of 1 or 0 are assigned to the four for statements.
- 1 is set when FPGA processing is performed
- 0 is set when FPGA processing is not performed (that is, when processing is performed by the CPU).
- Procedures A to F in FIG. 17 are diagrams for explaining the flow from the C code to the search for the final OpenCL solution.
- the application code analysis unit 112 parses the "C code” shown in procedure A of FIG. ) specifies the “loop statement, variable information” shown in procedure B in FIG. 17 (see symbol t in FIG. 17).
- the arithmetic intensity calculation unit 214 performs arithmetic intensity analysis on the specified "loop statement, variable information" using an arithmetic intensity analysis tool (see symbol u in FIG. 17).
- the PLD processing pattern creation unit 215 narrows down loop statements with high arithmetic intensity to offload candidates. Furthermore, the PLD processing pattern creation unit 215 performs profiling analysis using a profiling tool to further narrow down loop statements with high arithmetic intensity and high loop count.
- the PLD processing pattern creation unit 215 creates OpenCL for offloading each narrowed loop statement to the FPGA (OpenCL conversion) (see symbol v in FIG. 17).
- OpenCL conversion OpenCL conversion
- the PLD processing pattern creation unit 215 compiles ( ⁇ precompiles>) OpenCL for offloading the narrowed loop statements.
- the performance measurement unit 118 measures the performance of the compiled program for the "resource-efficient loop statement" shown in procedure D of FIG. 17 ("first performance measurement"). Then, the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance measured. Similarly, we calculate the amount of resources, offload OpenCL compilation, and measure the performance of the compiled program.
- the executable file creation unit 119 compiles ( ⁇ main compile>) OpenCL for offloading the narrowed loop statements.
- Combination pattern actual measurement shown in procedure E of FIG. 17 refers to measuring a candidate loop statement alone, and then measuring a verification pattern with its combination.
- the performance measurement unit 118 selects ( ⁇ selects>) "0010" with the best maximum speed between the first measurement and the second measurement.
- ⁇ deploy (deployment)> Deploy again to the production environment with the PLD processing pattern of the highest processing performance of the OpenCL final solution and provide it to the user.
- FPGA such as Intel PAC with Intel Arria10 GX FPGA can be used.
- Intel Acceleration Stack (Intel FPGA SDK for OpenCL, Quartus Prime Version) or the like can be used for FPGA processing.
- Intel FPGA SDK for OpenCL is a high-level synthesis tool (HLS) that interprets #pragma for Intel in addition to standard OpenCL.
- HLS high-level synthesis tool
- the implementation example interprets the OpenCL code that describes the kernel processed by the FPGA and the host program processed by the CPU, outputs information such as the amount of resources, and performs the wiring work of the FPGA, etc., so that it can operate on the FPGA.
- LLVM/Clang syntax analysis library can be used for syntax analysis.
- the example implementation then runs the Arithmetic Intensity Analysis tool to get an indication of the arithmetic intensity determined by number of computations, number of accesses, etc., to get a sense of the FPGA offload effect of each loop statement.
- the ROSE framework etc. can be used for arithmetic intensity analysis. Target only loop statements with high arithmetic strength.
- a profiling tool such as gcov is used to obtain the loop count of each loop. Candidates are narrowed down to loop statements with the highest number of arithmetic strength times the number of loops.
- the FPGA offloading OpenCL code is then generated for each loop statement with high arithmetic intensity.
- the OpenCL code is obtained by dividing the corresponding loop statement as the FPGA kernel and the remainder as the CPU host program.
- the expansion processing of the loop statement may be performed by a constant number b. Loop statement expansion processing increases the amount of resources, but is effective in speeding up processing. Therefore, the number of expansions is limited to a certain number b so as not to increase the amount of resources.
- the Intel FPGA SDK for OpenCL is used to precompile the a number of OpenCL codes, and the amount of resources such as Flip Flop and Look Up Table to be used is calculated.
- the used resource amount is displayed as a percentage of the total resource amount.
- a pattern to be measured is created with c loop statements as candidates. For example, if the 1st and 3rd loops are highly resource efficient, create each OpenCL pattern that offloads the 1st and 3rd loops, compiles them, and measures the performance. If you can speed up with offload patterns of multiple single loop statements (for example, if you can speed up both 1st and 3rd), create an OpenCL pattern with that combination, compile and perform Measure (e.g. pattern offloading both #1 and #3).
- the combination pattern is not created.
- performance measurement is performed on a server equipped with an FPGA in the verification environment.
- sample processing specified by the application to be accelerated is performed.
- performance is measured using transform processing with sample data as a benchmark.
- the implementation selects the fast pattern of the multiple measurement patterns as the solution.
- [evaluation] Describe your rating.
- [FPGA automatic offload of loop statement] of the second embodiment can be evaluated in the same manner as [GPU automatic offload of loop statement] of the first embodiment.
- the evaluation target is MRI-Q of MRI (Magnetic Resonance Imaging) image processing.
- MRI-Q computes a matrix Q that represents the scanner configuration used in the non-Cartesian spatial 3D MRI reconstruction algorithm.
- MRI-Q is written in C language, executes three-dimensional MRI image processing during performance measurement, and measures processing time with Large (maximum) 64 ⁇ 64 ⁇ 64 size data.
- CPU processing uses C language, and FPGA processing is based on OpenCL.
- ⁇ Evaluation method> Enter the code of the target application, and try to offload loop statements recognized by Clang or the like to the destination GPU or FPGA to determine the offload pattern. At this time, the processing time and power consumption are measured. For the final offload pattern, obtain the change in power consumption over time and confirm the reduction in power consumption compared to the case where all processing is performed by the CPU.
- GA is not performed, and arithmetic intensity or the like is used to narrow down the measurement patterns to four patterns.
- Offload Eligible Loop Statements MRI-Q 16 Pattern conformity: The lower the processing time, the higher the evaluation value, which is a high degree of conformity. In the MRI-Q of the second embodiment as well, cost and response time can be improved in the manner shown in FIG. 12, compared to simply placing priority on cheapness and response time.
- the offload servers according to the first and second embodiments are implemented by a computer 900, which is a physical device configured as shown in FIG. 18, for example.
- FIG. 18 is a hardware configuration diagram showing an example of a computer that implements the functions of the offload servers 1 and 1A.
- Computer 900 has CPU 901 , RAM 902 , ROM 903 , HDD 904 , accelerator 905 , input/output interface (I/F) 906 , media interface (I/F) 907 , and communication interface (I/F: Interface) 908 .
- the accelerator 905 is an accelerator (device) that processes at least one of data from the communication I/F 908 and data from the RAM 902 at high speed.
- the accelerator 905 is an accelerator for the device 151, the device 152 having a CPU-GPU, the device 153 having a CPU-FPGA, and the device 154 having a CPU in FIG.
- a type look-aside type
- the accelerator 905 a type (look-aside type) that returns the execution result to the CPU 901 or the RAM 902 after executing the processing from the CPU 901 or the RAM 902 may be used.
- a type (in-line type) that performs processing by entering between the communication I/F 908 and the CPU 901 or the RAM 902 may be used.
- Accelerator 905 is connected to external device 915 via communication I/F 908 .
- Input/output I/F 906 is connected to input/output device 916 .
- a media I/F 907 reads and writes data from a recording medium 917 .
- the CPU 901 operates based on programs stored in the ROM 903 or HDD 904, and executes programs (also called applications or apps for short) read into the RAM 902 to operate the offload servers 1 and 1 shown in FIGS. Control is performed by each processing unit of 1A.
- This program can be distributed via a communication line or recorded on a recording medium 917 such as a CD-ROM for distribution.
- the ROM 903 stores a boot program executed by the CPU 901 when the computer 900 is started, a program depending on the hardware of the computer 900, and the like.
- the CPU 901 controls, via the input/output I/F 906, an input/output device 916 comprising an input unit such as a mouse and keyboard, and an output unit such as a display and printer.
- the CPU 901 acquires data from the input/output device 916 via the input/output I/F 906 and outputs the generated data to the input/output device 916 .
- a GPU Graphics Processing Unit
- a GPU may be used together with the CPU 901 as a processor.
- the HDD 904 stores programs executed by the CPU 901 and data used by the programs.
- the communication I/F 908 receives data from other devices via a communication network (for example, NW (Network)) and outputs the data to the CPU 901, and also transmits data generated by the CPU 901 to other devices via the communication network. Send to a communication network (for example, NW (Network)) and outputs the data to the CPU 901, and also transmits data generated by the CPU 901 to other devices via the communication network.
- NW Network
- the media I/F 907 reads programs or data stored in the recording medium 917 and outputs them to the CPU 901 via the RAM 902 .
- the CPU 901 loads a program related to target processing from the recording medium 917 onto the RAM 902 via the media I/F 907, and executes the loaded program.
- the recording medium 917 includes optical recording media such as DVD (Digital Versatile Disc) and PD (Phase change rewritable Disk), magneto-optical recording media such as MO (Magneto Optical disk), magnetic recording media, conductor memory tape media, semiconductor memories, and the like. is.
- the CPU 901 of the computer 900 executes the programs loaded on the RAM 902 to perform the offload servers 1 and 1A. to realize the function of Also, the data in the RAM 902 is stored in the HDD 904 .
- the CPU 901 reads a program related to target processing from the recording medium 912 and executes it.
- the CPU 901 may read a program related to target processing from another device via a communication network.
- the offload server 1 (see FIG. 1) according to the first embodiment is an offload server that offloads specific processing of an application program to an accelerator.
- the code analysis unit 112 analyzes the reference relationships of variables used in the loop statements of the application program, and for data that may be transferred outside the loop, an explicit A data transfer specification unit 113 that specifies data transfer using a specified line, and a parallel processing specification that specifies loop statements of an application program and compiles each specified loop statement by specifying a parallel processing specification statement in the accelerator.
- Parallel processing that creates a parallel processing pattern that designates whether or not to perform parallel processing for loop statements that do not cause a compile error and excludes loop statements that cause a compile error from being offloaded.
- the price conditions and response time conditions requested by the user, the number of applications arranged, etc. can be changed, and the cloud server on the network , a carrier edge server, or a user edge server. This allows the converted application to meet computational resource cost or response time requirements to achieve optimal placement according to user requirements.
- An offload server 1A (see FIG. 13) according to the second embodiment is an offload server that offloads specific processing of an application program to a PLD, and includes an application code analysis unit 112 that analyzes the source code of the application program; a PLD processing designation unit 213 that identifies loop statements of an application program, creates and compiles pipeline processing and parallel processing in PLD by a plurality of offload processing patterns designated by OpenCL for each of the identified loop statements; Based on the arithmetic intensity calculation unit 214 that calculates the arithmetic intensity of the loop statements of the application program and the arithmetic intensity calculated by the arithmetic intensity calculation unit 214, the loop statements whose arithmetic intensity is higher than a predetermined threshold are narrowed down as offload candidates, A PLD processing pattern creation unit 215 that creates a PLD processing pattern and an application program for the created PLD processing pattern are compiled, placed in an accelerator verification device, and performance measurement processing when offloaded to the PLD is executed.
- the device and A placement setting unit 170 that calculates and sets the placement location of an application program based on a linear programming formula with link cost, computational resource upper limit, and bandwidth upper limit as constraint conditions, and with computational resource cost or response time as an objective function. And prepare.
- the placement setting unit 170 minimizes the cost of computational resources or minimizes the response time when the application program is placed on the server. It is characterized by calculating the placement of
- the transformed application can be optimally deployed to meet the computational resource cost or response time requirements.
- the placement setting unit 170 performs a linear It is characterized by calculating according to a planning formula.
- the placement setting unit 170 uses the linear programming formula shown in [Formula 2] for the placement that minimizes the response time when the application program is placed on the server. It is characterized by calculating according to
- the present invention is an offload program for causing a computer to function as the above offload server.
- each function of the offload servers 1 and 1A can be realized using a general computer.
- each of the above embodiments all or part of the processes described as being performed automatically can be performed manually, or the processes described as being performed manually can be performed manually. can also be performed automatically by a known method.
- information including processing procedures, control procedures, specific names, and various data and parameters shown in the above documents and drawings can be arbitrarily changed unless otherwise specified.
- each component of each device illustrated is functionally conceptual, and does not necessarily need to be physically configured as illustrated.
- the specific form of distribution and integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed and integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
- each of the above configurations, functions, processing units, processing means, etc. may be realized in hardware, for example, by designing a part or all of them with an integrated circuit.
- each configuration, function, etc. described above may be realized by software for a processor to interpret and execute a program for realizing each function.
- Information such as programs, tables, files, etc. that realize each function is stored in memory, hard disk, SSD (Solid State Drive) and other recording devices, IC (Integrated Circuit) cards, SD (Secure Digital) cards, optical discs, etc. It can be held on a recording medium.
- a genetic algorithm (GA) technique is used in order to find a solution to a combinatorial optimization problem within a limited optimization period. It can be something like For example, local search, dynamic programming, or a combination thereof may be used.
- the OpenACC compiler for C/C++ is used, but any compiler can be used as long as it can offload GPU processing.
- Java lambda (registered trademark) GPU processing IBM Java 9 SDK (registered trademark) may be used.
- IBM Java 9 SDK registered trademark
- the parallel processing specification statement depends on these development environments. For example, in Java (registered trademark), parallel processing can be described in the lambda format since Java 8. IBM (registered trademark) provides a JIT compiler that offloads lambda-style parallel processing descriptions to the GPU. In Java, similar offloading is possible by using these to perform tuning in GA as to whether or not loop processing should be in the lambda format.
- the for statement is exemplified as the iterative statement (loop statement), but the while statement and the do-while statement other than the for statement are also included.
- the for statement which specifies loop continuation conditions, etc., is more suitable.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Debugging And Monitoring (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023576454A JP7716632B2 (ja) | 2022-01-26 | 2022-01-26 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
| PCT/JP2022/002880 WO2023144926A1 (ja) | 2022-01-26 | 2022-01-26 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/002880 WO2023144926A1 (ja) | 2022-01-26 | 2022-01-26 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023144926A1 true WO2023144926A1 (ja) | 2023-08-03 |
Family
ID=87471201
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/002880 Ceased WO2023144926A1 (ja) | 2022-01-26 | 2022-01-26 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7716632B2 (https=) |
| WO (1) | WO2023144926A1 (https=) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111405569A (zh) * | 2020-03-19 | 2020-07-10 | 三峡大学 | 基于深度强化学习的计算卸载和资源分配方法及装置 |
| WO2020175411A1 (ja) * | 2019-02-25 | 2020-09-03 | 日本電信電話株式会社 | アプリケーション配置装置及びアプリケーション配置プログラム |
| WO2021156955A1 (ja) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
| WO2021156956A1 (ja) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
-
2022
- 2022-01-26 JP JP2023576454A patent/JP7716632B2/ja active Active
- 2022-01-26 WO PCT/JP2022/002880 patent/WO2023144926A1/ja not_active Ceased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020175411A1 (ja) * | 2019-02-25 | 2020-09-03 | 日本電信電話株式会社 | アプリケーション配置装置及びアプリケーション配置プログラム |
| WO2021156955A1 (ja) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
| WO2021156956A1 (ja) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
| CN111405569A (zh) * | 2020-03-19 | 2020-07-10 | 三峡大学 | 基于深度强化学习的计算卸载和资源分配方法及装置 |
Non-Patent Citations (1)
| Title |
|---|
| YAMATO YOJI: "Initial study of environment-adaptive application placement optimization ", ENGRXIV ARCHIVE, 11 July 2021 (2021-07-11), pages 1, XP093081816, DOI: 10.31224/osf.io/vdn8z * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2023144926A1 (https=) | 2023-08-03 |
| JP7716632B2 (ja) | 2025-08-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7063289B2 (ja) | オフロードサーバのソフトウェア最適配置方法およびプログラム | |
| Pérez et al. | Simplifying programming and load balancing of data parallel applications on heterogeneous systems | |
| JP6927424B2 (ja) | オフロードサーバおよびオフロードプログラム | |
| Yamato | Proposal and evaluation of GPU offloading parts reconfiguration during applications operations for environment adaptation | |
| JP7632712B2 (ja) | オフロードサーバ、および、オフロード制御方法 | |
| US12530296B2 (en) | Systems, apparatus, articles of manufacture, and methods for improved data transfer for heterogeneous programs | |
| JP6992911B2 (ja) | オフロードサーバおよびオフロードプログラム | |
| JP7322978B2 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| US12056475B2 (en) | Offload server, offload control method, and offload program | |
| JP7716632B2 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| JP7806893B2 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| US20230096849A1 (en) | Offload server, offload control method, and offload program | |
| JP7544142B2 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| US12033235B2 (en) | Offload server, offload control method, and offload program | |
| JP7662037B2 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| JP7184180B2 (ja) | オフロードサーバおよびオフロードプログラム | |
| JP7521597B2 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| WO2024147197A1 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム | |
| WO2024079886A1 (ja) | オフロードサーバ、オフロード制御方法およびオフロードプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22923794 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2023576454 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22923794 Country of ref document: EP Kind code of ref document: A1 |