WO2023144926A1 - Offload server, offload control method, and offload program - Google Patents
Offload server, offload control method, and offload program Download PDFInfo
- Publication number
- WO2023144926A1 WO2023144926A1 PCT/JP2022/002880 JP2022002880W WO2023144926A1 WO 2023144926 A1 WO2023144926 A1 WO 2023144926A1 JP 2022002880 W JP2022002880 W JP 2022002880W WO 2023144926 A1 WO2023144926 A1 WO 2023144926A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- processing
- offload
- loop
- unit
- application program
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 82
- 238000012545 processing Methods 0.000 claims abstract description 497
- 238000005259 measurement Methods 0.000 claims abstract description 147
- 238000012795 verification Methods 0.000 claims abstract description 75
- 230000004044 response Effects 0.000 claims abstract description 69
- 238000004364 calculation method Methods 0.000 claims abstract description 40
- 238000012546 transfer Methods 0.000 claims description 72
- 238000004458 analytical method Methods 0.000 claims description 51
- 230000008569 process Effects 0.000 abstract description 27
- 230000006870 function Effects 0.000 description 95
- 108090000623 proteins and genes Proteins 0.000 description 64
- 238000012360 testing method Methods 0.000 description 57
- 230000015654 memory Effects 0.000 description 32
- 238000010586 diagram Methods 0.000 description 25
- 238000011156 evaluation Methods 0.000 description 24
- 238000004519 manufacturing process Methods 0.000 description 24
- 238000006243 chemical reaction Methods 0.000 description 23
- 238000000605 extraction Methods 0.000 description 23
- 230000035772 mutation Effects 0.000 description 23
- 238000011056 performance test Methods 0.000 description 22
- 239000000284 extract Substances 0.000 description 21
- 238000005516 engineering process Methods 0.000 description 14
- 238000004891 communication Methods 0.000 description 12
- 230000010354 integration Effects 0.000 description 9
- 238000003860 storage Methods 0.000 description 9
- 238000004422 calculation algorithm Methods 0.000 description 7
- 230000000694 effects Effects 0.000 description 7
- 238000005457 optimization Methods 0.000 description 7
- 230000008859 change Effects 0.000 description 6
- 230000000052 comparative effect Effects 0.000 description 6
- 238000002595 magnetic resonance imaging Methods 0.000 description 6
- 238000011161 development Methods 0.000 description 5
- 230000018109 developmental process Effects 0.000 description 5
- 230000002068 genetic effect Effects 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 230000003044 adaptive effect Effects 0.000 description 4
- 238000012790 confirmation Methods 0.000 description 4
- 241000220317 Rosa Species 0.000 description 3
- 230000006978 adaptation Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 230000003252 repetitive effect Effects 0.000 description 3
- 238000004088 simulation Methods 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 238000009826 distribution Methods 0.000 description 2
- 238000003500 gene array Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000003672 processing method Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 238000010187 selection method Methods 0.000 description 2
- 230000001133 acceleration Effects 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 238000004378 air conditioning Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000036760 body temperature Effects 0.000 description 1
- 239000004020 conductor Substances 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 230000005611 electricity Effects 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000010429 evolutionary process Effects 0.000 description 1
- 238000007667 floating Methods 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 230000033772 system development Effects 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/60—Software deployment
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
Definitions
- the present invention automatically offloads functional processing to an accelerator such as a GPU (Graphics Processing Unit) or FPGA (Field Programmable Gate Array), and places the converted application program (hereinafter referred to as an application as appropriate) in an appropriate location.
- an accelerator such as a GPU (Graphics Processing Unit) or FPGA (Field Programmable Gate Array)
- the present invention relates to a server, an offload control method, and an offload program.
- AWS Amazon Web Services
- Azure registered trademark
- Azure provides GPU instances and FPGA instances, and these resources can be used on demand.
- Microsoft uses FPGAs to streamline searches.
- OpenCL is an open API (Application Programming Interface) that can handle all computational resources (not limited to CPUs and GPUs) in a unified manner without being tied to specific hardware.
- GPUs and FPGAs can be easily used in user applications. That is, when deploying general-purpose applications such as image processing and cryptographic processing to be operated in an environment, it is desired that the platform analyzes the application logic and automatically offloads the processing to the GPU and FPGA.
- CUDA General Purpose GPUs
- OpenCL has also emerged as a standard for handling heterogeneous hardware such as GPUs, FPGAs, and many-core CPUs in a unified manner.
- a portion to be processed in parallel such as a loop statement
- a compiler converts it into device-oriented code according to the directive.
- Technical specifications include OpenACC (Open Accelerator) and the like
- compilers include PGI Compiler (registered trademark) and the like.
- OpenACC Open Accelerator
- PGI Compiler registered trademark
- the user specifies parallel processing in code written in C/C++/Fortran using OpenACC directives.
- the PGI compiler checks the parallelism of the code, generates executable binaries for GPU and CPU, and converts them into executable modules.
- the IBM JDK (registered trademark) supports a function of offloading parallel processing specification according to the lambda format of Java (registered trademark) to the GPU.
- the programmer does not need to be aware of data allocation to the GPU memory.
- techniques such as OpenCL, CUDA, and OpenACC enable offload processing to GPUs and FPGAs.
- Non-Patent Literature 1 the optimum arrangement of VNs is determined in consideration of communication traffic.
- it is intended for single-resource virtual networks, with the goal of reducing carrier equipment costs and overall response time, taking into account conditions such as the processing time of different applications and the cost and response time requirements of individual users. It has not been.
- Non-Patent Document 2 can be cited as an approach to automate the trial-and-error process for parallel processing.
- Non-Patent Literature 2 describes how once written code can use GPUs, FPGAs, many-core CPUs, etc. that exist in the deployment destination environment, automatic conversion, resource settings, etc. are performed, and applications are operated at high performance.
- Non-Patent Document 2 proposes a system for automatically offloading loop statements of application code to the GPU as an element of environment-adaptive software, and evaluates performance improvement.
- Non-Patent Document 3 proposes a system for automatically offloading loop statements of application code to FPGA as an element of environment adaptive software, and evaluates performance improvement.
- Non-Patent Document 4 evaluates a method of optimizing the amount of resources (such as the number of virtual machine cores) for executing an application after automatic conversion for a GPU or the like as an element of environment-adaptive software.
- Non-Patent Documents 1 to 4 focus on shortening the processing time during automatic offloading. There is a problem that when processing is offloaded to heterogeneous devices such as GPUs and FPGAs, there is no proposal to operate the converted application while satisfying user demands (price, response time).
- an offload server for offloading specific processing of an application program to an accelerator, comprising: an application code analysis unit for analyzing the source code of the application program; A data transfer specification section that analyzes the reference relationships of variables used and, for data that may be transferred outside the loop, specifies data transfer using an explicit specification line that explicitly specifies data transfer outside the loop and a parallel processing designation unit that identifies loop statements of the application program, compiles each identified loop statement by designating a parallel processing designation statement in the accelerator, and a loop statement that causes a compilation error.
- a parallel processing pattern creation unit for creating a parallel processing pattern for specifying whether or not to perform parallel processing for a loop statement that is not to be offloaded and that does not generate a compilation error; and the application of the parallel processing pattern.
- a performance measurement unit that compiles a program, places it in an accelerator verification device, and executes performance measurement processing when offloaded to the accelerator; Depending on the conditions, when deploying on a cloud server, carrier edge server, or user edge server on the network, device and link costs, computational resource limits, and bandwidth limits are constraints, and computational resource costs or and a placement setting unit that calculates and sets a placement location of an application program based on a linear programming formula with response time as an objective function.
- the converted application when an application is automatically converted so that it can be placed on an offload device such as a GPU or FPGA, the converted application can be optimally placed to meet the user's cost or response time requirements.
- FIG. 1 is a functional block diagram showing a configuration example of an offload server according to the first embodiment of the present invention
- FIG. FIG. 4 is a diagram showing automatic offload processing using the offload server according to the first embodiment
- FIG. 4 is a diagram showing a search image of a control unit (automatic offload function unit) by Simple GA of the offload server according to the first embodiment
- FIG. 10 is a diagram showing an example of a normal CPU program of a comparative example
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from a CPU to a GPU using a simple CPU program of a comparative example
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the offload server according to the first embodiment is nested and integrated;
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the transfer integration of the offload server according to the first embodiment is performed;
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the transfer integration of the offload server according to the first embodiment is performed;
- FIG. 10 is a diagram showing an example of a loop statement when data is transferred from the CPU to the GPU when the offload server according to the first embodiment transfers data together and a temporary area is used; 4 is a flow chart for explaining an overview of the operation of implementing the offload server according to the first embodiment; 4 is a flow chart for explaining an overview of the operation of implementing the offload server according to the first embodiment; 7 is a flow chart illustrating setting of the resource ratio and amount of resources to be added after the offload server's GPU offload attempt and placement of a new application according to the first embodiment; FIG.
- FIG. 2 is a diagram illustrating an example topology of computation nodes of the offload server according to the first embodiment; 8 is a graph showing changes in the average response time of the offload server according to the first embodiment and the number of deployed applications;
- FIG. 8 is a functional block diagram showing a configuration example of an offload server according to the second embodiment of the present invention;
- FIG. 11 is a flow chart for explaining an operation outline of implementation of the offload server according to the second embodiment;
- FIG. FIG. 11 is a flow chart showing performance measurement processing of the performance measurement unit of the offload server according to the second embodiment;
- FIG. FIG. 12 is a diagram showing a search image of the PLD processing pattern creation unit of the offload server according to the second embodiment;
- FIG. 12 is a diagram illustrating the flow from the C code of the offload server to the search for the OpenCL final solution according to the second embodiment;
- 3 is a hardware configuration diagram showing an example of a computer that implements the functions of an offload server according to each embodiment of the present invention;
- this embodiment an offload server in a mode for carrying out the present invention (hereinafter referred to as "this embodiment") will be described with reference to the drawings.
- this embodiment Basic concept of automatic offloading of the present invention
- the present inventor has so far proposed methods for GPU automatic offloading of program loop statements, FPGA automatic offloading, and optimization of conversion application execution resources ( See Non-Patent Documents 2, 3, and 4).
- the basic concept of the present invention will be described based on the examination of the elemental technologies of these Non-Patent Documents 2, 3, and 4 as well.
- Non-Patent Document 2 can automatically offload a normal program to an offload device such as a GPU or FPGA.
- an offload device such as a GPU or FPGA.
- multi-core CPUs and many-core CPUs can flexibly allocate a percentage of all cores through virtualization using virtual machines and containers.
- GPUs have been virtualized in the same way as CPUs, and operations such as allocating a percentage of all cores of GPUs are becoming possible.
- FPGA resource usage is often represented by a set number of Look Up Tables and Flip Flops, and unused gates can be used for other purposes.
- Non-Patent Document 2 it is possible to convert the application into code for CPU and GPU processing using the method described in Non-Patent Document 2.
- the code itself is good, it will not perform well if the amount of CPU and GPU resources is not properly balanced. For example, when performing a certain process, if the CPU processing time is 1000 seconds and the GPU processing time is 1 second, even if the processing that can be offloaded is speeded up by the GPU to some extent, the CPU as a whole becomes a bottleneck.
- Non-Patent Document 5 "K. Shirahata, H. Sato and S. Matsuoka, "Hybrid Map Task Scheduling for GPU-Based Heterogeneous Clusters," IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), pp.733 -740, Dec. 2010.”, by distributing Map tasks so that the CPU and GPU execution times are the same when processing tasks with the MapReduce (registered trademark) framework using the CPU and GPU. , to improve overall performance.
- MapReduce registered trademark
- the inventor came up with the idea of determining the resource ratio between the CPU and the offload device as follows. In other words, in order to avoid the processing in any device becoming a bottleneck, refer to the above non-patent documents, etc., so that the processing time of the CPU and the offload device are of the same order from the processing time of the test case. , the resource ratio between the CPU and the offload device (hereinafter referred to as "resource ratio").
- the inventor adopts a method of gradually increasing the speed based on the performance measurement results in the verification environment during automatic offloading, like the method of Non-Patent Document 2.
- the reason is that the performance varies greatly depending on not only the code structure but also the actual processing details such as hardware specifications, data size, loop count, and the like. Also, performance is difficult to predict statically and requires dynamic measurements. Therefore, at the time of code conversion, since there are already performance measurement results in the verification environment, resource ratios are determined using those results.
- test case processing time in the verification environment is CPU processing: 10 seconds and GPU processing: 5 seconds
- the resource on the CPU side is doubled, and the processing time is considered to be about the same. Therefore, the resource ratio is 2:1.
- a test case that includes that process and speed up the test case using the method described in Non-Patent Document 2 or the like. is reflected.
- resource amount determination and automatic verification of the amount of resources of the CPU and the offload device (hereinafter referred to as "resource amount")
- the resource ratio is determined by ⁇ Optimizing the resource ratio between the CPU and the offload device>
- the application is placed in the commercial environment.
- the resource amount is determined while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user. For example, with respect to CPU, it is assumed that 1 VM is 1000 yen/month, GPU is 4000 yen/month, and the resource ratio is 2:1. It is also assumed that the user's budget is within 10,000 yen per month.
- the resource ratio is set to 2:1
- the budget is within the user's budget of 10,000 yen per month. "1" is secured and placed in the commercial environment. Also, if the user's budget is within 5000 yen per month, the appropriate resource ratio of 2:1 cannot be maintained. In this case, as the resource amount, "1" is secured for the CPU and "1" for the GPU.
- Automatic verification After securing resources and deploying the program in the commercial environment, automatic verification is performed to confirm that it will work before the user uses it.
- Automatic verification runs performance verification test cases and regression test cases.
- a performance verification test case is performed by using an automatic test execution tool such as Jenkins (registered trademark) for a hypothetical test case specified by the user, and the processing time, throughput, and the like are measured.
- a regression test case obtains information about software such as middleware and OS installed in the system, and executes a regression test corresponding to the information using Jenkins or the like.
- a study to perform these automatic verifications with a small number of test case preparations is in Non-Patent Document 6 (Y.
- the performance verification test cases check whether the calculation results are correct even if offloading is performed. Also, in the performance verification test case, the difference between the calculation result and the case without offloading is checked.
- the PGI compiler that processes the GPU uses the PCAST (registered trademark) function PGI_compare (registered trademark) and acc_compare (registered trademark) API (Application Programming Interface) to calculate the difference between calculation results when the GPU is used and when it is not used. I can confirm. Note that even if parallel processing or the like is correctly offloaded, there are cases where the calculation results do not match completely, such as when the GPU and CPU have different rounding errors. Therefore, for example, confirmation according to the IEEE 754 specification is performed, and whether the difference is acceptable is presented to the user for confirmation by the user.
- the user is presented with information on the processing time and throughput of performance verification test cases, differences in calculation results, and regression test execution results.
- the user is also presented with the secured resources (the number of VMs, specifications, etc.) and their prices, and the user refers to this information to determine the start of operation.
- the resource ratio is the ratio of the number of instances of CPU, GPU, and FPGA. If the number of instances is 1, 2, or 3, the resource ratio is 1:2:3.
- Test Case Processing Time This embodiment searches for and discovers an offload pattern that speeds up a test case specified by the user.
- the test case is the number of transaction processing such as TPC-C (registered trademark) in the case of DB (database), and execution of Fourier transform processing in sample data in the case of FFT.
- the processing time is the execution time when the sample processing is executed. For example, the processing time of process A is 10 seconds before offloading, but it becomes 2 seconds after offloading. Each time is obtained.
- ⁇ Loop statement found> Currently, it is difficult for a compiler to find a match that this loop statement is suitable for GPU parallel processing. It is difficult to predict how much performance and power consumption will be achieved by offloading to the GPU without actually measuring it. Therefore, an instruction to offload this loop statement to the GPU is manually performed, and trial and error measurements are performed.
- the present invention automatically finds appropriate loop statements to offload to the GPU using a genetic algorithm (GA), which is an evolutionary computation technique. That is, for a group of parallelizable loop statements, 1 is set for GPU execution and 0 is set for CPU execution to generate a gene, and an appropriate pattern is searched for by repeated measurement in a verification environment.
- GA genetic algorithm
- this embodiment Next, the offload server 1 and the like in the mode for carrying out the present invention (hereinafter referred to as “this embodiment”) will be described.
- FIG. 1 is a functional block diagram showing a configuration example of an offload server 1 according to the first embodiment of the present invention.
- the offload server 1 is a device that automatically offloads specific processing of an application to an accelerator.
- the offload server 1 includes a control unit 11, an input/output unit 12, a storage unit 13, and a verification machine 14 (accelerator verification device). be.
- the input/output unit 12 includes a communication interface for transmitting/receiving information to/from each device, etc., an input device for transmitting/receiving information to/from an input device such as a touch panel or a keyboard, or an output device such as a monitor. It consists of an output interface.
- the storage unit 13 is composed of a hard disk, flash memory, RAM (Random Access Memory), etc., and stores a program (offload program) for executing each function of the control unit 11 and information necessary for processing of the control unit 11 (for example, an intermediate language file (Intermediate file) 133) is temporarily stored.
- a program offload program for executing each function of the control unit 11 and information necessary for processing of the control unit 11 ( For example, an intermediate language file (Intermediate file) 133) is temporarily stored.
- the storage unit 13 includes a test case DB (Test case database) 131, an equipment resource DB 132, and an intermediate language file (Intermediate file) 133.
- Test case database Test case database
- equipment resource DB equipment resource DB
- intermediate language file Intermediate file
- the test case DB 131 stores test item data corresponding to the software to be verified.
- the test item data is, for example, transaction test data such as TPC-C in the case of a database system such as MySQL.
- the facility resource DB 132 holds resources such as servers held by the business operator, information prepared in advance such as prices, and information on how much they are used. For example, there are 10 servers that can accommodate 3 GPU instances, and 1 GPU instance costs 5000 yen per month. It is information that is only used. This information is used to determine the amount of resources to be secured when the user specifies operating conditions (conditions such as cost and performance).
- the user operating conditions are the cost conditions specified by the user at the time of the offload request (for example, budget within 10,000 yen per month) and performance conditions (for example, transaction throughput such as TPC-C is above or above, sample Fourier transform processing is 1 thread) within how many seconds, etc.).
- the intermediate language file 133 temporarily stores information necessary for the processing of the control unit 11 in the form of a programming language interposed between the high-level language and the machine language.
- the verification machine 14 is equipped with a CPU, GPU, and FPGA as a verification environment for environment-adaptive software.
- the control unit 11 is an automatic offloading function that controls the offload server 1 as a whole.
- the control unit 11 is implemented, for example, by a CPU (Central Processing Unit) (not shown) expanding an application program (offload program) stored in the storage unit 13 into a RAM and executing the application program.
- a CPU Central Processing Unit
- application program offload program
- the control unit 11 includes an application code specifying unit (Specify application code) 111, an application code analyzing unit (Analyze application code) 112, a data transfer specifying unit 113, a parallel processing specifying unit 114, a resource ratio determining unit 115, A resource amount setting unit 116, a placement setting unit 170, a parallel processing pattern creation unit 117, a performance measurement unit 118, an execution file creation unit 119, a production environment placement unit (Deploy final binary files to production environment) 120, It has a performance measurement test extract execution unit (Extract performance test cases and run automatically) 121 and a user provision unit (Provide price and performance to a user to judge) 122 .
- the application code designation unit 111 designates an input application code. Specifically, the application code designation unit 111 passes the application code described in the received file to the application code analysis unit 112 .
- the application code analysis unit 112 analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
- the data transfer specification unit 113 analyzes the reference relationships of variables used in loop statements of the application program, and explicitly specifies data transfer outside the loop for data that may be transferred outside the loop. using target specification lines (#pragma acc kernels, #pragma acc data copyin(a, b), #pragma acc data copyout(a, b), #prama acc parallel loop, #prama acc parallel loop vector, etc.) Specify data transfer.
- the parallel processing designation unit 114 specifies loop statements (repetition statements) of the application program, and compiles each loop statement by designating a parallel processing designation statement in the accelerator.
- the parallel processing designation unit 114 includes an extract offload able area 114a and an output intermediate file 114b.
- the offload range extraction unit 114a identifies processing that can be offloaded to the GPU/FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
- the intermediate language file output unit 114b outputs the extracted intermediate language file 133.
- FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- the resource ratio determination unit 115 determines the processing time of the CPU and the offload device (test case CPU processing time and offload device processing time) as the resource ratio based on the performance measurement result (described later). Specifically, the resource ratio determination unit 115 determines the resource ratio so that the processing times of the CPU and the offload device are of the same order. Further, when the difference between the processing times of the CPU and the offload device is equal to or greater than a predetermined threshold value, the resource ratio determination unit 115 sets the resource ratio to a predetermined upper limit value.
- the resource amount setting unit 116 Based on the determined resource ratio, the resource amount setting unit 116 sets the resource amount of the CPU and the offload device so as to satisfy a predetermined cost condition (described later). Specifically, the resource amount setting unit 116 maintains the determined resource ratio and sets the maximum resource amount that satisfies a predetermined cost condition. In addition, if the predetermined cost condition is not satisfied by setting the minimum resource amount while maintaining the determined resource ratio, the resource amount setting unit 116 breaks the resource ratio and sets the resource amounts of the CPU and the offload device to satisfy the cost condition. Set with a smaller value (e.g. minimum).
- the placement setting unit 170 when placing the converted application on any of the cloud server, the carrier edge server, and the user edge server on the network, according to the cost or response time conditions specified by the user, determines the devices and links. , the computational resource upper limit, and the bandwidth upper limit as constraints, and the cost of the computational resource or the response time as the objective function, the application location is calculated and set. Specifically, the placement setting unit 170 calculates the placement location of the new application (the placement location of the APL) by a linear programming method based on the server of the equipment resource DB 132, the specification information of the link, and the placement information of the existing application. to set.
- the linear programming method uses, for example, the objective function and constraint conditions of the linear programming formulas shown in [Equation 1] and [Equation 2] below.
- the linear programming formulas shown in [Equation 1] and [Equation 2] below are stored in the equipment resource DB 132, and are read out from the equipment resource DB 132 by the layout setting unit 170, and expanded on the memory processed by the layout setting unit 170. .
- the parallel processing pattern creation unit 117 excludes loop statements (repeated statements) that cause compilation errors from being offloaded, and designates whether or not to execute parallel processing for repetitive statements that do not cause compilation errors. Create a parallel processing pattern to do.
- the performance measurement unit 118 compiles the parallel processing pattern application program, places it in the verification machine 14, and executes performance measurement processing when offloaded to the accelerator.
- the performance measurement unit 118 includes a Deploy binary files unit 118a.
- the binary file placement unit 118a deploys (places) an execution file derived from the intermediate language to the verification machine 14 having a GPU or FPGA.
- the performance measurement unit 118 executes the arranged binary file, measures the performance when offloading, and returns the performance measurement result to the offload range extraction unit 114a.
- the offload range extraction unit 114a extracts another parallel processing pattern, and the intermediate language file output unit 114b attempts performance measurement based on the extracted intermediate language (marked a in FIG. 2 described later). reference).
- the execution file creation unit 119 selects a plurality of parallel processing patterns with high processing performance from among a plurality of parallel processing patterns based on the performance measurement results repeated a predetermined number of times, crosses the parallel processing patterns with high processing performance, and suddenly Mutation processing creates different parallel processing patterns. Then, the executable file creation unit 119 newly performs performance measurement, and after performing the performance measurement for the specified number of times, selects the parallel processing pattern with the highest processing performance from among a plurality of parallel processing patterns based on the performance measurement result, and selects the parallel processing pattern with the highest processing performance. Compile the parallel processing pattern of processing performance and create an executable file.
- the production environment placement unit 120 places the created executable file in the production environment for the user (“place final binary file in production environment”).
- the production environment placement unit 120 determines a pattern specifying the final offload area, and deploys it in the production environment for users.
- the performance measurement test extraction execution unit 121 After arranging the execution files, the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and executes the performance test (“arrangement of the final binary file to the production environment”). After arranging the executable file, the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user.
- the user providing unit 122 presents information such as price/performance to the user based on the performance test results (“Provision of information such as price/performance to the user”).
- the test case DB 131 stores performance test items.
- the user provision unit 122 presents data such as price and performance to the user along with the performance test results based on the performance test results corresponding to the test items stored in the test case DB 131 . Based on the presented information such as price and performance, the user decides to start using the service for a fee.
- non-patent document 7 Y. Yamato, M. Muroi, K. Tanaka and M.
- the offload server 1 can use GA (Genetic Algorithms) for offload optimization.
- GA Genetic Algorithms
- the configuration of the offload server 1 when using GA is as follows. That is, the parallel processing specifying unit 114 sets the gene length to the number of loop statements (repeated statements) that do not cause compilation errors based on the genetic algorithm.
- the parallel processing pattern creation unit 117 maps the availability of accelerator processing to the gene pattern by assigning either 1 or 0 when accelerator processing is to be performed, and the other 0 or 1 when not performing accelerator processing.
- the parallel processing pattern creation unit 117 prepares a gene pattern for a specified number of individuals in which each value of the gene is randomly created to be 1 or 0.
- the performance measurement unit 118 compiles the application code specifying the parallel processing specifying statement in the accelerator according to each individual, and places it in the verification machine 14 .
- the performance measurement unit 118 executes performance measurement processing in the verification machine 14 .
- the performance measurement unit 118 does not compile and measure the performance of the application code corresponding to the parallel processing pattern. Use the same value.
- the performance measurement unit 118 sets the performance measurement value to a predetermined time (long time) as a time-out for an application code that causes a compile error and an application code whose performance measurement does not end within a predetermined time.
- the executable file creation unit 119 performs performance measurement on all individuals, and evaluates individuals with shorter processing times so that the degree of fitness is higher.
- the execution file creation unit 119 selects individuals whose fitness is higher than a predetermined value (for example, the top n% of all individuals, or the top m of all individuals, where n and m are natural numbers) as individuals with high performance. , the selected individual is crossover and mutated to create the next generation individual.
- the execution file creating unit 119 selects the parallel processing pattern with the highest performance as a solution after the specified number of generations have been processed.
- FIG. 2 is a diagram showing automatic offload processing using the offload server 1.
- the offload server 1 is applied to elemental technology of environment adaptive software.
- the offload server 1 has a control unit (automatic offload function unit) 11 , a test case DB 131 , an equipment resource DB 132 , an intermediate language file 133 and a verification machine 14 .
- the offload server 1 acquires an application code 125 used by the user.
- the user is, for example, a person who has made a contract to use various devices (Device 151, device 152 having CPU-GPU, device 153 having CPU-FPGA, device 154 having CPU).
- the offload server 1 automatically offloads functional processing to the accelerators of the device 152 with CPU-GPU and the device 153 with CPU-FPGA.
- step S11 Specify application code>
- the application code designation unit 111 passes the application code written in the received file to the application code analysis unit 112 .
- Step S12 Analyze application code>
- the application code analysis unit 112 analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
- Step S13 Extract offloadable area>
- the parallel processing designation unit 114 identifies loop statements (repetition statements) of the application, and compiles each repetition statement by designating a parallel processing designation statement in the accelerator.
- the offload range extraction unit 114a identifies processing that can be offloaded to the GPU/FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
- Step S14 Output intermediate file>
- the intermediate language file output unit 114b (see FIG. 1) outputs the intermediate language file 133.
- FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- Step S15 Compile error>
- the parallel processing pattern creation unit 117 excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors are processed in parallel. Create a parallel processing pattern that specifies whether or not.
- Step S21 Deploy binary files>
- the binary file placement unit 118a (see FIG. 1) deploys the execution file derived from the intermediate language to the verification machine 14 equipped with GPU/FPGA.
- Step S22 Measure performance>
- the performance measurement unit 118 executes the placed file and measures the performance when offloading. In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offload range extraction unit 114a, and the offload range extraction unit 114a extracts another pattern. Then, the intermediate language file output unit 114b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2).
- the control unit 11 repeatedly executes steps S12 to S22.
- the automatic offload function of the control unit 11 is summarized below. That is, the parallel processing specification unit 114 specifies loop statements (repetition statements) of the application program, specifies a parallel processing specification statement in the GPU for each repetition statement, and compiles it. Then, the parallel processing pattern creation unit 117 creates a parallel processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to perform parallel processing for loop statements that do not cause compilation errors. do. Then, the binary file placement unit 118a compiles the application program of the parallel processing pattern and places it on the verification machine 14, and the performance measurement unit 118 executes the performance measurement processing on the verification machine 14. FIG.
- the execution file creation unit 119 selects a pattern with the highest processing performance from a plurality of parallel processing patterns based on the performance measurement results repeated a predetermined number of times, compiles the selected patterns, and creates an execution file.
- Step S23 Resource amount setting according to user operating conditions>
- the control unit 11 performs resource amount setting according to user operating conditions. That is, the resource ratio determination unit 115 of the control unit 11 determines the resource ratio between the CPU and the offload device. Based on the determined resource ratio, the resource amount setting unit 116 then refers to the information in the facility resource DB 132 and sets the resource amounts of the CPU and the offload device so as to satisfy the user operating conditions (see FIG. 10). described later).
- Step S24 Deploy final binary files to production environment>
- the production environment placement unit 120 determines a pattern specifying the final offload area, and deploys it to the production environment for the user.
- Step S25 Extract performance test cases and run automatically>
- the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user after the execution file is arranged.
- Step S26 Provide price and performance to a user to judge>
- the user providing unit 122 presents information such as price and performance to the user based on the performance test results. Based on the presented information such as price and performance, the user decides to start using the service for a fee.
- steps S11 to S26 are performed, for example, in the background when the user uses the service, and are assumed to be performed, for example, during the first day of provisional use.
- control unit 11 of the offload server 1 when applied to the element technology of the environment-adaptive software, for offloading the function processing, the source code of the application program used by the user , the offloaded area is extracted and the intermediate language is output (steps S11 to S15).
- the control unit 11 arranges and executes the execution file derived from the intermediate language on the verification machine 14, and verifies the offload effect (steps S21 to S22). After repeating verification and determining an appropriate offload area, the control unit 11 deploys the executable file in the production environment that is actually provided to the user and provides it as a service (steps S23 to S26).
- GPU automatic offload using GA GPU automatic offloading is a process for repeating steps S12 to S22 in FIG. 2 for the GPU and finally obtaining the offload code to be deployed in step S23.
- GPUs generally do not guarantee latency, but they are devices suitable for increasing throughput through parallel processing. Encryption processing, image processing for camera video analysis, and machine learning processing for analyzing a large amount of sensor data are typical examples, and these are often repetitive processes. Therefore, we aim to increase the speed by automatically offloading repeated statements of the application to the GPU.
- an appropriate offload area is automatically extracted from a general-purpose program that is not intended for parallelization. For this reason, the parallelizable for statement is checked first, and then the performance verification trial is repeated in the verification environment using the GA for the parallelizable for statement group to search for an appropriate area. After narrowing down to parallelizable for statements, by retaining and recombining parallel processing patterns that can be accelerated in the form of genes, patterns that can be efficiently accelerated from a huge number of possible parallel processing patterns can be explored.
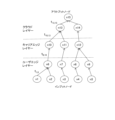
- FIG. 3 is a diagram showing a search image of the control unit (automatic offload function unit) 11 by Simple GA.
- FIG. 3 shows a search image of processing and gene sequence mapping of the for statement.
- GA is one of combinatorial optimization methods that imitate the evolutionary process of organisms.
- the flow chart of GA consists of initialization ⁇ evaluation ⁇ selection ⁇ crossover ⁇ mutation ⁇ end determination.
- Simple GA with simplified processing is used among GAs.
- Simple GA is a simplified GA in which only genes are 1 and 0, and roulette selection, one-point crossover, and mutation reverse the value of one gene.
- the for statements that can be parallelized are mapped to the gene array. It is set to 1 when GPU processing is performed, and set to 0 when GPU processing is not performed.
- a gene prepares a specified number of individuals M, and randomly assigns 1 and 0 to one for statement.
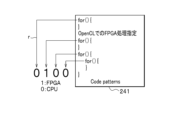
- the control unit (automatic offload function unit) 11 acquires an application code 130 (see FIG. 2) used by the user and, as shown in FIG. From the code patterns 141 of the code 130, the parallel propriety of the for statement is checked. As shown in FIG. 3, when five for statements are found from code pattern 141 (see symbol b in FIG.
- one digit for each for statement here five digits for five for statements, or 0 is randomly assigned. For example, it is set to 0 when processed by the CPU, and set to 1 when output to the GPU. However, 1 or 0 is randomly assigned at this stage.
- circle marks ( ⁇ marks) in the code pattern 141 are shown as code images.
- ⁇ select> high performance code patterns are selected based on goodness of fit (see symbol d in FIG. 3). Based on the fitness, the performance measurement unit 118 (see FIG. 1) selects genes with high fitness in a specified number of individuals. In this embodiment, roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed.
- FIG. 3 shows a search image in which the number of circles (o) in the selected code patterns 142 is reduced to three.
- ⁇ Crossover> In crossover, at a constant crossover rate Pc, some genes are exchanged between selected individuals at one point to create offspring individuals. Roulette-selected patterns (parallel processing patterns) and genes of other patterns are crossed. The position of the one-point crossover is arbitrary. For example, crossover is performed at the third digit of the five-digit code.
- Mutation changes each value of an individual's gene from 0 to 1 or 1 to 0 at a constant mutation rate Pm. Also, in order to avoid local minima, mutations are introduced. It should be noted that a mode in which no mutation is performed is also possible in order to reduce the amount of calculation.
- next generation code patterns after crossover & mutation see symbol e in FIG. 3
- the processing is terminated after repeating T times for the designated number of generations, and the gene with the highest degree of fitness is taken as the solution. For example, take performance measurements and choose the fastest three: 10010, 01001, 00101.
- the next generation recombines these three by GA, for example, crosses the first and second, and creates a new pattern (parallel processing pattern) 11011 .
- a mutation such as changing 0 to 1 is arbitrarily inserted into the recombined pattern. Repeat the above to find the fastest pattern.
- a designated generation (for example, the 20th generation) is determined, and the pattern remaining in the final generation is taken as the final solution.
- ⁇ deploy (deployment)> Deploy again to the production environment with the parallel processing pattern with the highest processing performance that corresponds to the gene with the highest fitness and provide it to users.
- OpenACC has a compiler that can be specified with the directive #pragma acc kernels to extract bytecodes for GPUs and execute them for GPU offloading. By writing a for statement command in this #pragma, it is possible to determine whether or not the for statement runs on the GPU.
- the length (gene length) is defined as the length without error. If there are 5 error-free for statements, the gene length is 5, and if there are 10 error-free for statements, the gene length is 10. Parallel processing is not possible when there is a dependence on data such that the previous processing is used for the next processing. The above is the preparation stage. Next, GA processing is performed.
- a code pattern with a gene length corresponding to the number of for statements is obtained.
- parallel processing patterns 10010, 01001, 00101, . . . are randomly assigned.
- an error may occur even though it is a for statement that can be offloaded. That is when the for statement is hierarchical (if one is specified, the GPU can process it). In this case, you can leave the for statement that caused the error.
- the image processing is benchmarked.
- the -1/2 power of the processing time is 1 if it takes 1 second, 0.1 if it takes 100 seconds, and 10 if it takes 0.01 seconds.
- Those with high adaptability are selected, for example, 3 to 5 out of 10 are selected and rearranged to create a new code pattern.
- the same thing as before may be created in the middle of creation. In that case, we don't need to do the same benchmark, so we use the same data as before.
- the code pattern and its processing time are stored in the storage unit 13 .
- the search image of the control unit (automatic offload function unit) 11 by Simple GA has been described above. Next, a batch processing technique for data transfer will be described.
- Comparative examples are a normal CPU program (see FIG. 4), simple GPU use (see FIG. 5), and nest integration (Non-Patent Document 2) (see FIG. 6).
- ⁇ 1> to ⁇ 4>, etc. at the beginning of loop statements in the following descriptions and figures are added for convenience of explanation (the same applies to other figures and their explanations).
- FIG. 5 is a diagram showing a loop statement when the normal CPU program shown in FIG. 4 uses a simple GPU to transfer data from the CPU to the GPU.
- Data transfer types include data transfer from the CPU to the GPU and data transfer from the GPU to the CPU. Data transfer from the CPU to the GPU will be taken as an example below.
- a processing unit capable of parallel processing such as a for statement by the PGI compiler is specified by the OpenACC directive #pragma acc kernels (parallel processing specifying statement). Data is transferred from the CPU to the GPU by #pragma acc kernels, as shown in the dashed box surrounding the symbol i in FIG. Here, since a and b are transferred at this timing, they are transferred 10 times.
- FIG. 6 is a diagram showing a loop statement when data is transferred from the CPU to the GPU and from the GPU to the CPU by nest integration (Non-Patent Document 2).
- a data transfer instruction line from the CPU to the GPU here #pragma acc data copyin(a, b) of the copyin clause of variables a and b, is inserted at the position indicated by symbol k in FIG. do.
- parentheses ( ) are attached to copyin(a,b) for notational reasons. Copyout(a, b) and datacopyin(a, b, c, d) described later also use the same notation method.
- FIG. 7 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment.
- FIG. 7 corresponds to the nest integration in FIG. 6 of the comparative example.
- a data transfer instruction line from the CPU to the GPU is placed at the position indicated by symbol m in FIG. , c, d).
- the GPU processing and the CPU processing are not nested, and for the variables for which the CPU processing and the GPU processing are separated, specify the data copy statement #pragma of OpenACC to collectively transfer the variables.
- the data copy statement #pragma of OpenACC to collectively transfer the variables.
- acc data copyin(a, b, c, d) Since a, b, c, and d are transferred at the timing indicated by the dashed-dotted frame surrounding the symbol m in FIG. 7, one transfer occurs.
- Variables that are collectively transferred using the above #pragma acc data copyin(a, b, c, d) and that do not need to be transferred at that timing are indicated by the two-dot chain frame surrounding the symbol o in FIG.
- a data present statement #pragma acc data present (c, d) is used to specify that the GPU already has a variable.
- the data transfer instruction line from the GPU to the CPU here #pragma acc datacopyout( a, b, c, d) are inserted at position p where ⁇ 3> loop of FIG. 7 ends.
- variables that can be transferred in batches are transferred in a batch, and variables that have already been transferred and do not need to be transferred are specified using data present, thereby reducing transfers and further improving the efficiency of offloading methods. can be achieved.
- the compiler may automatically determine and transfer.
- the automatic transfer by the compiler is a phenomenon in which the transfer between the CPU and the GPU is originally unnecessary but is automatically transferred depending on the compiler, unlike the instructions of OpenACC.
- FIG. 8 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment.
- FIG. 8 corresponds to nested collation and transfer-free variable explicitness of FIG.
- a declare create statement #pragma acc declare create of OpenACC for creating a temporary area during CPU-GPU data transfer is specified at the position indicated by symbol q in FIG.
- a temporary area is created (#pragma acc declare create) when data is transferred between the CPU and GPU, and the data is stored in the temporary area.
- the OpenACC declare create statement #pragma acc update for synchronizing the temporary area is specified to instruct the transfer.
- the number of loops is investigated using a profiling tool as a preliminary step to searching for full-scale offload processing.
- a profiling tool makes it possible to investigate the number of times each line is executed. Therefore, for example, programs with loops of 50 million times or more can be sorted in advance, such as targeting offload processing searches. A specific description will be given below (partially overlaps with the content described in FIG. 2).
- the application code analysis unit 112 (FIG. 1) analyzes the application and grasps loop statements such as for, do, and while. Next, execute the sample processing, use the profiling tool to investigate the number of loops in each loop statement, and determine whether or not to perform full-scale search based on whether there is a loop that exceeds a certain value. conduct.
- the process of GA is entered (see Figure 2).
- the initialization step after checking whether or not all loop statements of the application code can be parallelized, the loop statements that can be parallelized are mapped to the gene array as 1 if GPU processing is to be performed, and as 0 if not. A specified number of individuals are prepared for the gene, and 1 and 0 are randomly assigned to each value of the gene.
- an explicit instruction for data transfer (#pragma acc data copyin/copyout/copy) is added from the variable data reference relationship within the loop statement specified to be processed by the GPU.
- the code corresponding to the gene is compiled, deployed and executed on the verification machine, and benchmark performance is measured. Then, the goodness of fit of a gene with a good performance pattern is increased.
- the code corresponding to the gene includes a parallel processing instruction line (for example, reference symbol f in FIG. 4) and a data transfer instruction line (for example, reference symbol h in FIG. 4, reference symbol i in FIG. 5, and ) is inserted.
- genes with high fitness are selected for the specified number of individuals based on the fitness.
- roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed.
- the crossover step at a constant crossover rate Pc, some genes are exchanged between the selected individuals at one point to create offspring individuals.
- each value of an individual's gene is changed from 0 to 1 or 1 to 0 at a constant mutation rate Pm.
- the process is terminated after repeating the specified number of generations, and the gene with the highest fitness is taken as the solution. Re-deploy to the production environment with the highest performing code pattern that corresponds to the best-fitting gene and provide it to the user.
- the implementation of the offload server 1 will be described below. This implementation is for confirming the effectiveness of this embodiment.
- An implementation of automatic offloading of C/C++ applications using a general-purpose PGI compiler is described. Since the purpose of this implementation is to confirm the validity of automatic GPU offloading, the target application is a C/C++ language application, and the GPU processing itself is explained using a conventional PGI compiler.
- the C/C++ language boasts top popularity in the development of OSS (Open Source Software) and proprietary software, and many applications are being developed in the C/C++ language.
- OSS Open Source Software
- applications are being developed in the C/C++ language.
- OSS general-purpose applications such as encryption processing and image processing are used.
- the GPU processing is performed by the PGI compiler.
- the PGI compiler is a C/C++/Fortran compiler that understands OpenACC.
- a parallel-capable processing unit such as a for statement is specified by an OpenACC directive #pragma acc kernels (parallel processing specifying statement).
- #pragma acc kernels parallel processing specifying statement
- This enables GPU offloading by extracting bytecodes for GPUs and executing them.
- an error is generated when the data in the for statement is dependent on each other and cannot be processed in parallel, or when multiple layers of nested for statements are specified.
- directives such as #pragma acc data copyin/copyout/copy can be used to explicitly instruct data transfer.
- the code of the C/C++ application is first analyzed to find for statements, and to understand the program structure such as variable data used in the for statements.
- LLVM/Clang syntax analysis library is used for syntax analysis.
- GNU coverage gcov etc. is used to grasp the number of loops.
- GNU Profiler (gprof) and “GNU Coverage (gcov)” are known as profiling tools. Either can be used because both can examine the execution count of each line. The number of executions can, for example, target only applications with loop counts of 10 million or more, but this value can be changed.
- a is the gene length. 1 of the gene corresponds to presence of parallel processing directive, 0 corresponds to no parallel processing directive, and the application code is mapped to the gene of length a.
- the C/C++ code with parallel processing and data transfer directives inserted is compiled with the PGI compiler on a machine equipped with a GPU. Deploy compiled executables and measure performance and power usage with benchmarking tools.
- Directive insertion, compilation, performance measurement, fitness setting, selection, crossover, and mutation processing are performed on the next-generation individuals.
- the individual is not compiled and the performance measurement is not performed, and the same measured value as before is used.
- the solution is the C/C++ code with directives that corresponds to the gene sequence with the highest performance.
- the number of individuals, the number of generations, the crossover rate, the mutation rate, the fitness setting, and the selection method are parameters of the GA and are specified separately.
- FIGS. 9A-B are flow charts outlining the operation of the implementation described above, and FIGS. 9A and 9B are connected by a connector. The following processing is performed using the OpenACC compiler for C/C++.
- step S101 the application code analysis unit 112 (see FIG. 1) performs code analysis of the C/C++ application.
- step S102 the parallel processing designation unit 114 (see FIG. 1) identifies loop statements and reference relationships of the C/C++ application.
- step S103 the parallel processing designation unit 114 checks the GPU processability of each loop statement (#pragma acc kernels).
- the control unit (automatic offload function unit) 11 repeats the processing of steps S105 to S116 by the number of loop statements between the loop start end of step S104 and the loop end of step S117.
- the control unit (automatic offload function unit) 11 repeats the processing of steps S106 and S107 by the number of loop statements between the loop start end of step S105 and the loop end end of step S108.
- the parallel processing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc kernels) with OpenACC.
- the parallel processing designation unit 114 checks the GPU processing possibility with the following directive (#pragma acc parallel loop) when an error occurs.
- the control unit (automatic offload function unit) 11 repeats the processing of steps S110 to S111 by the number of loop statements between the loop start point of step S109 and the loop end point of step S112.
- the parallel processing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc parallel loop) with OpenACC.
- the parallel processing designation unit 114 checks the GPU processability with the following directive (#pragma acc parallel loop vector) when an error occurs.
- the control unit (automatic offload function unit) 11 repeats the processing of steps S114 to S115 by the number of loop statements between the loop start point of step S113 and the loop end point of step S116.
- the parallel processing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc parallel loop vector) with OpenACC.
- the parallel processing specifying unit 114 removes the GPU processing directive phrase from the loop statement when an error occurs.
- step S118 the parallel processing designating unit 114 counts the number of loop statements (here, for statements) in which no compilation error occurs, and sets the number as the gene length.
- the parallel processing designation unit 114 prepares gene sequences for the designated number of individuals. Here, 0 and 1 are randomly assigned and created.
- the parallel processing designating unit 114 maps the C/C++ application code to genes and prepares a designated population pattern. Depending on the prepared gene sequence, a directive specifying parallel processing is inserted into the C/C++ code when the value of the gene is 1 (see, for example, the #pragma directive in FIG. 3).
- the control unit (automatic offload function unit) 11 repeats the processing of steps S121 to S130 for a specified number of generations between the loop start end of step S120 and the loop end of step S131 in FIG. 9B. Further, in the repetition of the designated number of generations, the processing of steps S122 to S125 is repeated for the designated number of individuals between the loop start end of step S121 and the loop end of step S126. That is, repetitions of the specified number of individuals are processed in a nested state within the repetition of the specified number of generations.
- step S122 the data transfer designation unit 113 transfers data using explicit instruction lines (#pragma acc data copy/copyin/copyout/present and #pragma acc declarecreate, #pragma acc update) based on the variable reference relationship. Specify transfer.
- step S123 the parallel processing pattern creating unit 117 (see FIG. 1) compiles the C/C++ code specified by the directive according to the gene pattern using the PGI compiler. That is, the parallel processing pattern creation unit 117 compiles the created C/C++ code with the PGI compiler on the verification machine 14 having a GPU.
- a compilation error may occur when multiple nested for statements are specified in parallel. This case is handled in the same way as when the processing time times out during performance measurement.
- step S124 the performance measurement unit 118 (see FIG. 1) deploys the execution file to the verification machine 14 equipped with the CPU-GPU.
- step S125 the performance measurement unit 118 executes the arranged binary file and measures the benchmark performance when offloading.
- genes with the same pattern as before are not measured, and the same values are used.
- the same measured values as before are used without compiling or performance measurement for that individual.
- the performance measurement unit 118 measures the processing time.
- the performance measurement unit 118 sets an evaluation value based on the measured processing time.
- step S129 the execution file creation unit 119 (see FIG. 1) evaluates individuals with shorter processing times so that their fitness levels are higher, and selects individuals with higher performance.
- the execution file creating unit 119 selects a pattern of short time and low power consumption as a solution from among the plurality of measured patterns.
- step S130 the execution file creation unit 119 performs crossover and mutation processing on the selected individuals to create next-generation individuals.
- the executable file creation unit 119 performs compilation, performance measurement, fitness setting, selection, crossover, and mutation processing for the next-generation individuals. That is, after benchmark performance is measured for all individuals, the degree of fitness of each gene sequence is set according to the benchmark processing time. Individuals to be left are selected according to the set degree of fitness.
- the execution file creation unit 119 performs GA processing such as crossover processing, mutation processing, and copy processing as it is on the selected individuals to create a group of individuals for the next generation.
- step S132 the executable file creation unit 119 takes the C/C++ code corresponding to the highest performance gene sequence (highest performance parallel processing pattern) as a solution after the GA processing for the designated number of generations is completed.
- GA parameters The number of individuals, number of generations, crossover rate, mutation rate, fitness setting, and selection method are parameters of the GA.
- GA parameters may be set as follows, for example.
- Parameters and conditions of Simple GA to be executed can be set as follows, for example.
- Gene length Number of loop statements that can be parallelized Number of individuals M: Less than gene length Number of generations T: Less than gene length Goodness of fit: (Processing time) (-1/2)
- the degree of fitness to include the (-1/2) power of the processing time, it is possible to prevent the search range from narrowing due to the degree of fitness of a specific individual whose processing time is short becoming too high. can. If the performance measurement does not end within a certain period of time, it is timed out, and the suitability is calculated assuming that the processing time is 1000 seconds (long time). This timeout period may be changed according to performance measurement characteristics. Selection: Roulette selection However, we also perform elite preservation in which the gene with the highest fitness in the generation is preserved in the next generation without crossover or mutation. Crossover rate Pc: 0.9 Mutation rate Pm: 0.05
- gcov, gprof, etc. are used to identify in advance an application that has many loops and takes a long time to execute, and offloading is attempted. This allows you to find applications that can be efficiently accelerated.
- ⁇ Time to start using the actual service> Describe the time until the start of use of the actual service. Assuming that it takes about 3 minutes from compilation to performance measurement, it takes about 20 hours at maximum with GA of 20 individuals and 20 generations. Finish in 8 hours or less. The reality is that it takes about half a day to start using many cloud, hosting, and network services. In this embodiment, for example, automatic offloading within half a day is possible. For this reason, as long as the automatic offload is within half a day, if trial use is possible at first, it can be expected that user satisfaction will be sufficiently increased.
- the GA is performed with a small number of individuals and a small number of generations, but by setting the crossover rate Pc to a high value of 0.9 and searching a wide range, a solution with a certain level of performance can be found quickly. ing.
- the directives are expanded in order to increase the number of applicable applications.
- directives specifying GPU processing in addition to kernels directives, parallel loop directives and parallel loop vector directives are expanded.
- kernels are used for single loops and tightly nested loops.
- parallel loops are used for loops including non-tightly nested loops.
- parallel loop vector is used for loops that cannot be parallelized but can be vectorized.
- a tightly nested loop is a nested loop, for example, when two loops that increment i and j are nested, the lower loop uses i and j, and the upper loop does not A simple loop like Also, in the implementation of the PGI compiler, etc., there is a difference in that the compiler makes decisions about parallelization for kernels, and the programmer makes decisions about parallelization for parallels.
- kernels are used for single and tightly nested loops
- parallel loops are used for non-tightly nested loops.
- the parallel directive may reduce the reliability of the results compared to kernels.
- the final offload program will be subjected to a sample test, the difference between the result and the CPU will be checked, and the result will be shown to the user for confirmation by the user.
- the CPU and GPU have different hardware, there are differences in the number of significant digits and rounding errors, and it is necessary to check the result difference between the kernels and the CPU.
- FIG. 10 is a flow chart illustrating setting the resource ratio and amount of resources added after a GPU offload attempt and placing a new application. The flow chart shown in FIG. 10 is executed after the GPU offload attempts shown in FIGS. 9A-B.
- step S51 the resource ratio determination unit 115 acquires user operating conditions, test case CPU processing time, and offload device processing time.
- the user operating conditions are specified by the user when the user specifies the code to be offloaded.
- the user operating conditions are used when the resource amount setting unit 116 refers to the information in the equipment resource DB 132 and determines the resource amount.
- the resource ratio determination unit 115 determines the ratio of the CPU and offload device processing times (test case CPU processing time and offload device processing time) as the resource ratio based on the performance measurement result.
- the resource ratio determination unit 115 determines the resource ratio so that the processing times of the CPU and the offload device are of the same order. By determining the resource ratio so that the processing time of the CPU and the offload device are of the same order, the processing time of the CPU and the offload device can be aligned, and the CPU and accelerator can be used in mixed environments such as GPUs, FPGAs, and many-core CPUs. Even if there is, the amount of resources can be appropriately set.
- the resource ratio determination unit 115 sets the resource ratio to a predetermined upper limit when the difference between the processing times of the CPU and the offload device is equal to or greater than a predetermined threshold. That is, if the processing time between the CPU and the offload device in the verification environment has a difference of, for example, 10 times or more, increasing the resource ratio to 10 times or more leads to deterioration in cost performance.
- a resource ratio such as 5:1 is set as the upper limit (the upper limit is a resource ratio of 5:1 of the processing time).
- step S53 the resource amount setting unit 116 sets the resource amount based on the user operating conditions and the appropriate resource ratio. That is, the resource amount setting unit 116 determines the resource amount while maintaining the resource ratio as much as possible so as to satisfy the cost condition specified by the user.
- the resource amount setting unit 116 maintains an appropriate resource ratio and sets the maximum resource amount that satisfies the user operating conditions.
- the CPU1VM is 1,000 yen/month
- the GPU is 4,000 yen/month
- the resource ratio is 2:1
- the user's budget is within 10,000 yen per month.
- 2 CPUs and 1 GPU are secured and placed in the commercial environment.
- the resource amount setting unit 116 sets the resource amount of the CPU and the offload device to the minimum so as to satisfy the cost condition by breaking the resource ratio.
- the CPU1VM is 1,000 yen/month
- the GPU is 4,000 yen/month
- the resource ratio is 2:1
- the user's budget is within 5,000 yen per month.
- the resource amounts of the CPU and the offload device are set smaller, that is, 1 is secured for the CPU and 1 is allocated for the GPU.
- step S53 above After the processing of step S53 above is completed and the resources are secured and allocated in the commercial environment, the automatic verification described in FIG. 2 is executed in order to confirm the performance and cost before use by the user. As a result, resources can be reserved in a commercial environment, and performance and cost can be presented to the user after automatic verification.
- Performance measurements are used in solving offload patterns to optimize resource ratios.
- the implementation determines the resource ratio so that the CPU and GPU processing times are of the same order from the test case processing time. For example, if the test case processing time is 10 seconds for CPU processing and 5 seconds for GPU processing, the resources on the CPU side are doubled and the processing time is considered to be about the same, so the resource ratio is 2:1. . Since the number of virtual machines and the like is an integer, when calculating the resource ratio from the processing time, the resource ratio is rounded to an integer ratio.
- the next step is to set the resource amount when deploying the application to the commercial environment.
- the implementation determines the number of VMs, etc. while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user at the time of the offload request. Specifically, the maximum number of VMs is selected while maintaining the resource ratio within the cost range.
- 1 VM is 1000 yen/month
- GPU is 4000 yen/month
- the resource ratio is 2:1. Secure 1.
- the resource amount is set so that the resource ratio is as close to an appropriate one as possible, starting from one CPU unit and one GPU unit. For example, if the budget is within 5000 yen per month, the resource ratio cannot be maintained, but 1 CPU and 1 GPU are secured.
- the implementation uses, for example, the virtualization function of Xen Server to allocate CPU and GPU resources.
- step S54 the placement setting unit 170 calculates the new application placement location (APL placement location) using a linear programming method based on the server of the equipment resource DB 132, the link specification information, and the existing application placement information. to set.
- the offload server 1 of the present embodiment when offloading a program for a CPU to a device such as a GPU, selects a location where the application is placed so as to meet the user's requirements such as cost and operate with a short response time. rationalize.
- FIG. 11 is a diagram showing an example of the topology of computation nodes.
- data is sent from an IoT device that collects data in the user environment, such as an IoT system, to the user edge, and the data is sent to the cloud via the network edge, and the analysis results are viewed by company executives. This is the topology used in
- the topology for arranging applications consists of three layers, the number of bases in the cloud layer (eg, data center) is "2" (n13, n14), and the carrier edge layer (eg, office) is "3", the user edge layer (eg, user environment) is "4" (n6-n9), and the input node is "5" (n1-n5).
- applications such as IoT, IoT data (pollen sensors, body temperature sensors, etc., which are one of IoT devices) is collected from the input node to the user edge, and depending on the characteristics of the application (response time requirements, etc.), Analysis processing is performed at the user edge and carrier edge, and analysis processing is performed after data is uploaded to the cloud.
- the output node is "1" (n15), and the analysis results are viewed by company executives.
- the input node is IoT data (pollen sensor)
- the person in charge of the Japan Meteorological Agency confirms the statistics and analysis results of the output node.
- the arrangement topology of three layers shown in FIG. 11 is an example, and may be, for example, five layers. Also, the number of user edges and carrier edges may actually be several tens to several hundred.
- Computing nodes are divided into three types: CPU, GPU, and FPGA. Nodes equipped with GPUs and FPGAs are also equipped with CPUs, but virtualization technology (for example, NVIDIA vGPU) provides separate GPU instances and FPGA instances that also include CPU resources.
- virtualization technology for example, NVIDIA vGPU
- an application converted for GPU or FPGA is arranged, and the user can issue two types of requests when arranging the application.
- the first is a cost request, which specifies the permissible cost of computing resources for operating the application, for example, within 5000 yen per month.
- the second is a response time request, which specifies an allowable response time for operating an application, such as returning a response within 10 seconds.
- locations for arranging servers that accommodate virtual networks are systematically designed in consideration of long-term trends such as traffic increases.
- This embodiment has the following features (1) and (2).
- Applications to be placed are not statically determined, but are automatically converted for GPUs and FPGAs, and patterns suitable for usage forms are extracted through actual measurements through GA and the like. Because of this, application code and performance can change dynamically.
- Application placement policies can also change dynamically.
- the application placement of this embodiment is such that when there is a request for placement from the user, conversion is performed, and the converted applications are sequentially placed on appropriate servers at that time. Iku form. If converting the application does not improve the cost performance, the application should be placed before the conversion. For example, when a GPU instance costs twice as much as a CPU instance, and the conversion does not improve the performance by more than two times, it is better to allocate before the conversion. Also, if the computational resources and bandwidth have already been used up to the upper limit, it may not be possible to allocate to that server.
- Linear programming formula for appropriate placement of applications we formulate a linear programming method for calculating appropriate placement locations of applications.
- the linear programming method is represented by [Formula 1] (Formulas (1) to (4) below) and [Formula 2] (Formulas (3) to (6) below). parameters are used.
- device and link costs, computational resource upper limits, band upper limits, etc. depend on the servers and networks prepared by the business operator. Therefore, those parameter values are set in advance by the operator.
- the calculation resource amount, bandwidth, data capacity, and processing time used by the application when offloading are determined by the measurement values of the offload pattern that was finally selected in the test in the verification environment before automatic conversion. Automatically set by the environment adaptation function.
- the objective function and constraints on the parameters of the linear programming formula change depending on whether the user request is a cost request for computational resources or a response time request.
- the objective function is minimization of the response time of formula (1).
- One of the constraints is how much the computational resource cost of Equation (2) is within.
- a constraint condition is added as to whether or not the resource upper limit of the server in formulas (3) and (4) is exceeded.
- the objective function is to minimize the computational resource cost of Equation (5) corresponding to Equation (2).
- One of the constraints is how many seconds the response time of Equation (6) corresponding to Equation (1) is within. Furthermore, the constraints of equations (3) and (4) are added.
- Formulas (1) and (6) are formulas for calculating the response time of application k.
- Rk is the objective function
- Rk is a constraint that sets a user-specified upper bound.
- Equations (2) and (5) are equations for calculating the cost (price) Pk of operating application k.
- Pk is the objective function.
- Formulas (3) and (4) are constraints that set the upper limit of computational resources and communication bandwidth, are calculated including applications deployed by others, and prevent the resource upper limit from being exceeded due to the placement of applications by new users.
- the linear programming formulas (1) to (4) and (3) to (6) are calculated based on the network topology, conversion application type (increase in cost and performance for CPU, etc.), user requirements, and existing applications. Appropriate application placement can be calculated for different conditions by deriving solutions with linear programming solvers such as GLPK (Gnu Linear Programming Kit) and CPLEX (IBM Decision Optimization). By sequentially performing actual placement for a plurality of users after appropriate placement calculation, a plurality of applications are placed based on each user's request.
- linear programming solvers such as GLPK (Gnu Linear Programming Kit) and CPLEX (IBM Decision Optimization).
- ⁇ Evaluation condition> ⁇ Target application The application to be placed performs image processing by Fourier transform, which is assumed to be used by many users.
- Fourier transform processing is used in various aspects of IoT monitoring, such as vibration frequency analysis.
- NAS.FT https://www.nas.nasa.gov/publications/npb.html
- FFT Fourier transform processing
- NAS.FT https://www.nas.nasa.gov/publications/npb.html
- MRI-Q http://impact.crhc.illinois.edu/parboil/) (registered trademark) uses the matrix Q to represent the scanner configuration for calibration used in non-Cartesian spatial three-dimensional MRI reconstruction algorithms. calculate.
- image processing is often required for automatic surveillance from camera video, and there is a need for automatic offloading of image processing.
- MRI-Q is a C-language application that performs 3D MRI image processing during performance measurement and measures processing time using Large 64 ⁇ 64 ⁇ 64 size sample data.
- CPU processing is based on C language
- FPGA processing is based on OpenCL (registered trademark).
- NAS.FT can be speeded up by GPU
- MRI-Q can be speeded up by FPGA, which are five times and seven times faster than CPU, respectively.
- the topology for deploying applications consists of three layers as shown in Fig. 11.
- the number of bases in the cloud layer is "5"
- the carrier edge layer is "20”
- the user edge layer is "60”
- the input node. is "300”.
- IoT data is collected from the input node to the user edge, and depending on the characteristics of the application (requirements for response time, etc.), analysis processing is performed at the user edge and carrier edge, and it is delivered to the cloud. After the data is given, it is analyzed and processed.
- 1000 applications are arranged based on user requirements based on the parameters of the linear programming formulas shown in [Formula 1] and [Formula 2].
- an upper limit of 7,000 yen per month, an upper limit of 8,500 yen, or an upper limit of 10,000 yen is selected for the price, and an upper limit of 6 seconds, a condition of 7 seconds, or an upper limit of 10 seconds is selected for the response time.
- an upper limit of 12,500 yen or 20,000 yen per month is selected for the price, and an upper limit of 4 seconds or 8 seconds is selected for the response time.
- Pattern 1 Select 1/6 of 6 types of requests for NAS.FT, and 1/4 of 4 types of requests for MRI-Q.
- Pattern 2 The request selects the condition with the lowest price as the upper limit (first 7,000 yen, 12,500 yen), and if there are no vacancies, the next lowest price condition.
- Pattern 3 The request selects the condition with the minimum response time as the upper limit (first 6 seconds, 4 seconds), and if there is no free space, the next fastest response time condition.
- - Placement simulation Placement is performed by a simulation experiment using solver GLPK5.0 (registered trademark) as an evaluation tool.
- solver GLPK5.0 registered trademark
- an application offload request is received, an offload pattern is created through repeated performance tests using the verification environment, and the appropriate amount of resources is determined based on the performance test results in the verification environment (Fig. 10).
- an appropriate layout is determined using GLPK, etc., normality confirmation tests and performance tests are automatically performed when actually deployed, the results and prices are presented to the user, and use is made after the user decides. to start.
- FIG. 12 is a graph showing changes in the number of applications deployed in the average response time.
- FIG. 12 shows the average response time and the number of applications deployed for the above three patterns. It was confirmed that pattern 2 was filled in order from the cloud, and pattern 3 was filled in order from the edge. In pattern 1, when various requests are received, they are arranged by satisfying the user requirements. As shown in FIG. 12, in pattern 2, all up to the 400th placement position are placed in the cloud and the average response time remains the slowest, but when the cloud is filled, it gradually decreases. In pattern 3, NAS.FT is placed from the user edge and MRI-Q is placed from the carrier edge. Therefore, the average response time is the shortest. However, as the number increases, it is also deployed in the cloud, slowing the average response time. In pattern 2, the average response time is intermediate between patterns 1 and 3, and is arranged according to user requests. Thus, in pattern 2, the average response time is appropriately reduced compared to pattern 1, which initially enters the cloud entirely.
- the software is automatically adapted according to the deployment environment, and when automatically offloaded to the GPU, etc., it meets the user's cost and response time requirements. That is, the program is converted so that it can be processed by a device such as a GPU, and after the amount of resources to be assigned is determined, the converted application is optimally arranged.
- the appropriate allocation is calculated by changing the price conditions, response time conditions, and the number of applications requested by the user. This enables arrangement according to the user's request.
- the second embodiment is an example applied to FPGA automatic offloading of loop statements.
- a PLD Programmable Logic Device
- FPGA Field Programmable Gate Array
- OpenCL conversion is performed for loop statements with high arithmetic intensity and loop count as candidates.
- the CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to OpenCL syntax.
- FPGA kernel
- CPU host
- For candidate loop statements precompile your OpenCL to find resource-efficient loop statements. Since resources to be created can be known during compilation, loop statements that use a sufficiently small amount of resources are further narrowed down. Since some candidate loop statements remain, we use them to measure performance and power consumption.
- the selected single-loop statement is compiled and measured, and for the single-loop statement whose speed has been further improved, a combination pattern is created and the second measurement is performed. A pattern of short time and low power consumption is selected as a solution from among the measured patterns.
- FIG. 13 is a functional block diagram showing a configuration example of the offload server 1A according to the second embodiment of the invention.
- the offload server 1A is a device that automatically offloads specific processing of an application to an accelerator.
- the offload server 1A can be connected to an emulator.
- the offload server 1A includes a control unit 21, an input/output unit 12, a storage unit 13, and a verification machine 14 (accelerator verification device). be.
- the control unit 21 is an automatic offloading function that controls the entire offload server 1A.
- the control unit 21 is implemented, for example, by a CPU (not shown) expanding a program (offload program) stored in the storage unit 13 into a RAM and executing the program.
- the control unit 21 includes an application code specification unit (Specify application code) 111, an application code analysis unit (Analyze application code) 112, a PLD processing specification unit 213, an arithmetic intensity calculation unit 214, an arrangement setting unit 170, and a PLD A processing pattern creation unit 215, a performance measurement unit 118, an execution file creation unit 119, a production environment deployment unit (Deploy final binary files to production environment) 120, and a performance measurement test extraction execution unit (Extract performance test cases and run automatically ) 121 and a user provision unit (Provide price and performance to a user to judge) 122 .
- the PLD processing designation unit 213 identifies loop statements (repetition statements) of the application, and creates a plurality of offload processing patterns in which pipeline processing and parallel processing in the PLD are designated by OpenCL for each of the identified loop statements. to compile.
- the PLD processing designation unit 213 includes an extract offload able area 213a and an output intermediate file 213b.
- the offload range extracting unit 213a identifies processing that can be offloaded to the FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
- the intermediate language file output unit 213b outputs the extracted intermediate language file 133.
- Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- the arithmetic intensity calculation unit 214 calculates the arithmetic intensity of the loop statement of the application using an arithmetic intensity analysis tool such as the ROSE framework (registered trademark).
- Arithmetic intensity is the number of floating point numbers (FN) executed during program execution divided by the number of bytes accessed to main memory (FN operations/memory access).
- Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of the loop statement.
- the PLD processing pattern creation unit 215 narrows down loop statements with high arithmetic intensity to offload candidates.
- the PLD processing pattern creation unit 215 Based on the arithmetic intensity calculated by the arithmetic intensity calculation unit 214, the PLD processing pattern creation unit 215 narrows down loop statements whose arithmetic intensity is higher than a predetermined threshold (hereinafter referred to as high arithmetic intensity as appropriate) as offload candidates, Create a PLD processing pattern. As a basic operation, the PLD processing pattern creation unit 215 excludes loop statements (repeated statements) that cause compilation errors from being offloaded, and performs PLD processing on repetitive statements that do not cause compilation errors. Create a PLD processing pattern that specifies whether or not
- the PLD processing pattern creation unit 215 measures the loop count of the loop statements of the application using a profiling tool. Narrow down loop statements that are more than the number of times (hereinafter referred to as a high number of loops as appropriate). GNU coverage gcov etc. is used to grasp the number of loops. "GNU Profiler (gprof)” and “GNU Coverage (gcov)” are known as profiling tools. Either can be used because both can examine the number of executions of each loop.
- a profiling tool is used to measure the number of loops in order to detect loops with a large number of loops and high load.
- the level of arithmetic intensity indicates whether the processing is suitable for offloading to the FPGA, and the number of loops ⁇ arithmetic intensity indicates whether the load associated with offloading to the FPGA is high.
- the PLD processing pattern creation unit 215 creates OpenCL (OpenCL conversion) for offloading each narrowed loop statement to the FPGA as an OpenCL creation function. That is, the PLD processing pattern creation unit 215 compiles OpenCL that offloads the narrowed loop statements. In addition, the PLD processing pattern creation unit 215 lists loop statements whose performance is improved compared to the CPU among the measured performance, and creates OpenCL for offloading by combining the loop statements in the list.
- OpenCL OpenCL conversion
- the PLD processing pattern creation unit 215 converts the loop statement into a high-level language such as OpenCL.
- a CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to the grammar of a high-level language such as OpenCL.
- FPGA kernel
- CPU host
- OpenCL high-level language
- a kernel created according to the OpenCL C language grammar is executed on a device (eg FPGA) by a created host (eg CPU) side program using the OpenCL C language run-time API.
- the part that calls the kernel function hello() from the host side is to call clEnqueueTask(), which is one of the OpenCL runtime APIs.
- the basic flow of initialization, execution, and termination of OpenCL written in host code is steps 1 to 13 below. Among these steps 1 to 13, steps 1 to 10 are procedures (preparations) until the kernel function hello() is called from the host side, and step 11 is execution of the kernel.
- Create Command Queue Create a command queue ready to control the device using the function clCreateCommandQueue( ) that provides the command queue creation functionality defined in the OpenCL runtime API.
- the host issues commands to the device (issues a kernel execution command or a memory copy command between the host and the device) through the command queue.
- Memory object creation Using the function clCreateBuffer(), which provides a function to allocate memory on the device defined in the OpenCL runtime API, create a memory object that allows the host to refer to the memory object.
- Kernel file loading The kernel running on the device is controlled by the host program. Therefore, the host program must first load the kernel program.
- the kernel program includes binary data created by the OpenCL compiler and source code written in the OpenCL C language. Read this kernel file (description omitted). Note that the OpenCL runtime API is not used for kernel file reading.
- Program Object Creation recognizes a kernel program as a program project. This procedure is program object creation. Using the function clCreateProgramWithSource( ) that provides the program object creation function defined in the OpenCL runtime API, create a program object that allows the host to refer to the memory object. Use clCreateProgramWithBinary() when creating from a compiled binary string of a kernel program.
- Kernel Object Creation A kernel object is created using the function clCreateKernel( ) that provides the kernel object creation function defined in the OpenCL runtime API.
- One kernel object corresponds to one kernel function, so the kernel function name (hello) is specified when the kernel object is created. Also, when a plurality of kernel functions are described as one program object, one kernel object corresponds to one kernel function, so clCreateKernel( ) is called multiple times.
- Kernel Argument Setting Kernel arguments are set using the function clSetKernel() that provides the function of giving arguments to the kernel defined in the OpenCL runtime API (passing values to the arguments of kernel functions). After steps 1 to 10 complete preparations, step 11 is entered to execute the kernel on the device from the host side.
- Kernel Execution Kernel execution (throwing into the command queue) is a queuing function to the command queue because it acts on the device.
- the function clEnqueueTask( ) which provides kernel execution functionality defined in the OpenCL runtime API, is used to queue a command to execute kernel hello on the device. After the command to execute kernel hello is queued, it will be executed in the executable arithmetic unit on the device.
- Reading from a memory object Using the function clEnqueueReadBuffer(), which provides a function to copy data from device-side memory to host-side memory defined in the OpenCL runtime API, read data from the device-side memory area to the host-side memory area. copy the data to In addition, data is copied from the host-side memory area to the device-side memory area using the function clEnqueueWrightBuffer(), which provides a function to copy data from the host side to the client side memory. Since these functions act on the device, the data copy starts after the copy command is queued in the command queue once.
- Resource Amount Calculation Function As a resource amount calculation function, the PLD processing pattern creation unit 215 precompiles the created OpenCL and calculates the resource amount to be used (“first resource amount calculation”). The PLD processing pattern creation unit 215 calculates resource efficiency based on the calculated arithmetic intensity and resource amount, and based on the calculated resource efficiency, c loops whose resource efficiency is higher than a predetermined value in each loop statement. choose a sentence. The PLD processing pattern creation unit 215 calculates the resource amount to be used by precompiling with the combined offload OpenCL (“second resource amount calculation”). Here, without precompilation, the sum of resource amounts in precompilation before the first measurement may be used.
- the performance measurement unit 118 compiles the created PLD processing pattern application, places it in the verification machine 14, and executes performance measurement processing when offloaded to the PLD.
- the performance measurement unit 118 executes the arranged binary file, measures the performance when offloaded, and returns the performance measurement result to the offload range extraction unit 213a.
- the offload range extraction unit 213a extracts another PLD processing pattern, and the intermediate language file output unit 213b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2). ).
- the performance measurement unit 118 includes a binary file placement unit (Deploy binary files) 118a.
- the binary file placement unit 118a deploys (places) an execution file derived from the intermediate language on the verification machine 14 having a GPU.
- the PLD processing pattern creation unit 215 narrows down loop statements with high resource efficiency, and compiles OpenCL for offloading the loop statements narrowed down by the executable file creation unit 119 .
- the performance measurement unit 118 measures the performance of the compiled program (“first performance measurement”).
- the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance measured.
- the PLD processing pattern creation unit 215 creates OpenCL for offloading by combining the loop statements of the list.
- the PLD processing pattern creation unit 215 precompiles with the combined offload OpenCL and calculates the amount of resources to be used. Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation.
- the executable file creation unit 119 compiles the combined offload OpenCL, and the performance measurement unit 118 measures the performance of the compiled program (“second performance measurement”).
- the execution file creation unit 119 selects the PLD processing pattern with the highest evaluation value from a plurality of PLD processing patterns based on the measurement result of the processing time repeated a predetermined number of times, and compiles the PLD processing pattern with the highest evaluation value. to create an executable file.
- the offload server 1A of the present embodiment is an example in which elemental technology of environment-adaptive software is applied to FPGA automatic offloading of user application logic. Description will be made with reference to the automatic offload processing of the offload server 1A shown in FIG. As shown in FIG. 2, the offload server 1A is applied to elemental technology of environment adaptive software.
- the offload server 1A has a control unit (automatic offload function unit) 11, a test case DB 131, an intermediate language file 133, and a verification machine .
- the offload server 1A acquires an application code 125 used by the user.
- a user uses, for example, various devices (Device) 151, a device 152 having a CPU-GPU, a device 153 having a CPU-FPGA, and a device 154 having a CPU.
- the offload server 1A automatically offloads functional processing to the accelerators of the device 152 having a CPU-GPU and the device 153 having a CPU-FPGA.
- step S21 the application code specifying unit 111 (see FIG. 13) specifies the processing function (image analysis, etc.) of the service provided to the user. Specifically, the application code designation unit 111 designates the input application code.
- Step S12 Analyze application code>
- the application code analysis unit 112 analyzes the source code of the processing function and grasps the structure of specific library usage such as loop statements and FFT library calls.
- Step S13 Extract offloadable area>
- the PLD processing designation unit 213 identifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement, and performs high-level synthesis. Compile with tools.
- the offload range extraction unit 213a identifies processing that can be offloaded to the FPGA, such as a loop statement, and extracts OpenCL as an intermediate language corresponding to the offload processing.
- Step S14 Output intermediate file>
- the intermediate language file output unit 213b (see FIG. 13) outputs the intermediate language file 133.
- FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
- Step S15 Compile error>
- the PLD processing pattern creation unit 215 excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors to be FPGA-processed. Create a PLD processing pattern that specifies whether or not to perform.
- Step S21 Deploy binary files>
- the binary file placement unit 118a (see FIG. 13) deploys the execution file derived from the intermediate language to the verification machine 14 having an FPGA.
- the binary file placement unit 118a activates the placed file, executes an assumed test case, and measures performance when offloading.
- Step S22 Measure performance>
- the performance measurement unit 118 executes the arranged file and measures the performance and power usage when offloading. In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offload range extraction unit 213a, and the offload range extraction unit 213a extracts another pattern. Then, the intermediate language file output unit 213b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2). The performance measurement unit 118 repeats the performance/power consumption measurement in the verification environment and finally determines the code pattern to be deployed.
- the control unit 21 repeatedly executes steps S12 to S22.
- the automatic offload function of the control unit 21 is summarized below. That is, the PLD processing designation unit 213 specifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement in OpenCL (intermediate language), and uses a high-level synthesis tool. Compile with Then, the PLD processing pattern creation unit 215 creates a PLD processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to perform PLD processing on loop statements that do not cause compilation errors. do.
- Step S23 Deploy final binary files to production environment>
- the production-environment placement unit 120 determines a pattern specifying the final offload area, and deploys it to the production environment for the user.
- Step S24 Extract performance test cases and run automatically>
- the performance measurement test extraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user after the execution file is arranged.
- Step S25 Provide price and performance to a user to judge>
- the user providing unit 122 presents information such as price and performance to the user based on the performance test results. Based on the presented information such as price and performance, the user decides to start using the service for a fee.
- steps S21 to S25 are performed in the background when the user uses the service, and are assumed to be performed, for example, during the first day of provisional use. Also, the processing performed in the background for cost reduction may target only GPU/FPGA offload.
- control unit 21 of the offload server 1A when the control unit (automatic offload function unit) 21 of the offload server 1A is applied to the element technology of the environment-adaptive software, the source code of the application used by the user is used to offload the function processing. , the offloading area is extracted and the intermediate language is output (steps S12 to S15). The control unit 21 arranges and executes the execution file derived from the intermediate language on the verification machine 14, and verifies the offload effect (steps S21 to S22). After repeating verification and determining an appropriate offload area, the control unit 21 deploys the executable file in the production environment that is actually provided to the user and provides it as a service (step S26).
- offloading application processing it is necessary to consider the GPU, FPGA, IoT GW, etc. according to the offload destination.
- performance it is difficult to automatically discover the setting that maximizes performance at one time. For this reason, offload patterns are tried by repeating performance measurement several times in a verification environment to find a pattern that can speed up the process.
- FIG. 14 is a flowchart for explaining the outline of the operation of the offload server 1A.
- the application code analysis unit 112 analyzes the source code of the application to be offloaded.
- the application code analysis unit 112 analyzes information on loop statements and variables according to the language of the source code.
- step S202 the PLD processing designation unit 213 identifies loop statements and reference relationships of the application.
- the PLD processing pattern creation unit 215 performs processing for narrowing down candidates for whether to try FPGA offloading for the grasped loop statements.
- Arithmetic strength is one indicator of whether a loop statement has an offload effect.
- the arithmetic strength calculation unit 214 calculates the arithmetic strength of the loop statement of the application using the arithmetic strength analysis tool.
- Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of loop statements and narrows down loop statements with high density to offload candidates. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of loop statements and narrows down loop statements with high density to offload candidates.
- the PLD processing pattern creation unit 215 translates the target loop statement into a high-level language such as OpenCL, and first calculates the resource amount. Also, since the arithmetic intensity and the resource amount when the loop statement is offloaded are determined, the arithmetic intensity/resource amount or arithmetic intensity ⁇ loop count/resource amount is defined as the resource efficiency. Then, loop statements with high resource efficiency are further narrowed down as offload candidates.
- step S204 the PLD processing pattern creation unit 215 measures the number of loops of loop statements of the application using profiling tools such as gcov and gprof.
- step S205 the PLD processing pattern creation unit 215 narrows down the loop statements with high arithmetic strength and high loop count among the loop statements.
- step S206 the PLD processing pattern creation unit 215 creates OpenCL for offloading each narrowed loop statement to the FPGA.
- step S207 the PLD processing pattern creation unit 215 pre-compiles the created OpenCL and calculates the resource amount to be used ("first resource amount calculation").
- step S208 the PLD processing pattern creation unit 215 narrows down loop statements with high resource efficiency.
- step S209 the execution file creation unit 119 compiles OpenCL for offloading the narrowed down loop statements.
- step S210 the performance measurement unit 118 measures the performance of the compiled program ("first performance measurement"). Since some candidate loop statements remain, the performance measurement unit 118 uses them to actually measure the performance (see the subroutine in FIG. 15 for details).
- step S211 the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance-measured ones.
- step S212 the PLD processing pattern creation unit 215 creates OpenCL for offloading by combining the loop statements of the list.
- step S213 the PLD processing pattern creation unit 215 calculates the amount of resources to be used by precompiling with the combined offload OpenCL (“second resource amount calculation”). Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation. By doing so, the number of times of precompilation can be reduced.
- step S214 the execution file creation unit 119 compiles the combined offload OpenCL.
- step S215 the performance measurement unit 118 measures the performance of the compiled program ("second performance measurement").
- the performance measurement unit 118 compiles and measures the selected single-loop statement, creates a combination pattern for the single-loop statement that has been further accelerated, and performs the second performance measurement (for details, see (see subroutine in FIG. 15).
- step S216 the production environment placement unit 120 selects the pattern with the highest performance among the first and second measurements, and terminates the processing of this flow.
- a short-time pattern is selected as a solution from the measured multiple patterns.
- the FPGA automatic offloading of loop statements creates offload patterns by focusing on loop statements with high arithmetic strength, loop counts, and high resource efficiency, and searches for high-speed patterns through actual measurements in a verification environment (Fig. 14).
- FIG. 15 is a flowchart showing performance/power consumption measurement processing of the performance measurement unit 118.
- FIG. This flow is called and executed by a subroutine call in step S210 or step S215 in FIG.
- step S301 the performance measurement unit 118 measures the processing time required for FPGA offloading.
- step S302 the performance measurement unit 118 sets an evaluation value based on the measured processing time.
- step S303 the performance measurement unit 118 measures the performance of patterns with high evaluation values, which are evaluated such that the higher the evaluation value, the higher the fitness, and returns to step S210 or step S215 in FIG.
- FIG. 16 is a diagram showing a search image of the PLD processing pattern generator 215.
- the control unit (automatic offload function unit) 21 analyzes the application code 125 (see FIG. 2) used by the user, and determines the code pattern of the application code 125 as shown in FIG. (Code patterns) 241 checks whether the for statement can be parallelized.
- code patterns code patterns
- FIG. 16 when four for statements are found from the code pattern 241, one digit is assigned to each for statement, here four digits of 1 or 0 are assigned to the four for statements.
- 1 is set when FPGA processing is performed
- 0 is set when FPGA processing is not performed (that is, when processing is performed by the CPU).
- Procedures A to F in FIG. 17 are diagrams for explaining the flow from the C code to the search for the final OpenCL solution.
- the application code analysis unit 112 parses the "C code” shown in procedure A of FIG. ) specifies the “loop statement, variable information” shown in procedure B in FIG. 17 (see symbol t in FIG. 17).
- the arithmetic intensity calculation unit 214 performs arithmetic intensity analysis on the specified "loop statement, variable information" using an arithmetic intensity analysis tool (see symbol u in FIG. 17).
- the PLD processing pattern creation unit 215 narrows down loop statements with high arithmetic intensity to offload candidates. Furthermore, the PLD processing pattern creation unit 215 performs profiling analysis using a profiling tool to further narrow down loop statements with high arithmetic intensity and high loop count.
- the PLD processing pattern creation unit 215 creates OpenCL for offloading each narrowed loop statement to the FPGA (OpenCL conversion) (see symbol v in FIG. 17).
- OpenCL conversion OpenCL conversion
- the PLD processing pattern creation unit 215 compiles ( ⁇ precompiles>) OpenCL for offloading the narrowed loop statements.
- the performance measurement unit 118 measures the performance of the compiled program for the "resource-efficient loop statement" shown in procedure D of FIG. 17 ("first performance measurement"). Then, the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance measured. Similarly, we calculate the amount of resources, offload OpenCL compilation, and measure the performance of the compiled program.
- the executable file creation unit 119 compiles ( ⁇ main compile>) OpenCL for offloading the narrowed loop statements.
- Combination pattern actual measurement shown in procedure E of FIG. 17 refers to measuring a candidate loop statement alone, and then measuring a verification pattern with its combination.
- the performance measurement unit 118 selects ( ⁇ selects>) "0010" with the best maximum speed between the first measurement and the second measurement.
- ⁇ deploy (deployment)> Deploy again to the production environment with the PLD processing pattern of the highest processing performance of the OpenCL final solution and provide it to the user.
- FPGA such as Intel PAC with Intel Arria10 GX FPGA can be used.
- Intel Acceleration Stack (Intel FPGA SDK for OpenCL, Quartus Prime Version) or the like can be used for FPGA processing.
- Intel FPGA SDK for OpenCL is a high-level synthesis tool (HLS) that interprets #pragma for Intel in addition to standard OpenCL.
- HLS high-level synthesis tool
- the implementation example interprets the OpenCL code that describes the kernel processed by the FPGA and the host program processed by the CPU, outputs information such as the amount of resources, and performs the wiring work of the FPGA, etc., so that it can operate on the FPGA.
- LLVM/Clang syntax analysis library can be used for syntax analysis.
- the example implementation then runs the Arithmetic Intensity Analysis tool to get an indication of the arithmetic intensity determined by number of computations, number of accesses, etc., to get a sense of the FPGA offload effect of each loop statement.
- the ROSE framework etc. can be used for arithmetic intensity analysis. Target only loop statements with high arithmetic strength.
- a profiling tool such as gcov is used to obtain the loop count of each loop. Candidates are narrowed down to loop statements with the highest number of arithmetic strength times the number of loops.
- the FPGA offloading OpenCL code is then generated for each loop statement with high arithmetic intensity.
- the OpenCL code is obtained by dividing the corresponding loop statement as the FPGA kernel and the remainder as the CPU host program.
- the expansion processing of the loop statement may be performed by a constant number b. Loop statement expansion processing increases the amount of resources, but is effective in speeding up processing. Therefore, the number of expansions is limited to a certain number b so as not to increase the amount of resources.
- the Intel FPGA SDK for OpenCL is used to precompile the a number of OpenCL codes, and the amount of resources such as Flip Flop and Look Up Table to be used is calculated.
- the used resource amount is displayed as a percentage of the total resource amount.
- a pattern to be measured is created with c loop statements as candidates. For example, if the 1st and 3rd loops are highly resource efficient, create each OpenCL pattern that offloads the 1st and 3rd loops, compiles them, and measures the performance. If you can speed up with offload patterns of multiple single loop statements (for example, if you can speed up both 1st and 3rd), create an OpenCL pattern with that combination, compile and perform Measure (e.g. pattern offloading both #1 and #3).
- the combination pattern is not created.
- performance measurement is performed on a server equipped with an FPGA in the verification environment.
- sample processing specified by the application to be accelerated is performed.
- performance is measured using transform processing with sample data as a benchmark.
- the implementation selects the fast pattern of the multiple measurement patterns as the solution.
- [evaluation] Describe your rating.
- [FPGA automatic offload of loop statement] of the second embodiment can be evaluated in the same manner as [GPU automatic offload of loop statement] of the first embodiment.
- the evaluation target is MRI-Q of MRI (Magnetic Resonance Imaging) image processing.
- MRI-Q computes a matrix Q that represents the scanner configuration used in the non-Cartesian spatial 3D MRI reconstruction algorithm.
- MRI-Q is written in C language, executes three-dimensional MRI image processing during performance measurement, and measures processing time with Large (maximum) 64 ⁇ 64 ⁇ 64 size data.
- CPU processing uses C language, and FPGA processing is based on OpenCL.
- ⁇ Evaluation method> Enter the code of the target application, and try to offload loop statements recognized by Clang or the like to the destination GPU or FPGA to determine the offload pattern. At this time, the processing time and power consumption are measured. For the final offload pattern, obtain the change in power consumption over time and confirm the reduction in power consumption compared to the case where all processing is performed by the CPU.
- GA is not performed, and arithmetic intensity or the like is used to narrow down the measurement patterns to four patterns.
- Offload Eligible Loop Statements MRI-Q 16 Pattern conformity: The lower the processing time, the higher the evaluation value, which is a high degree of conformity. In the MRI-Q of the second embodiment as well, cost and response time can be improved in the manner shown in FIG. 12, compared to simply placing priority on cheapness and response time.
- the offload servers according to the first and second embodiments are implemented by a computer 900, which is a physical device configured as shown in FIG. 18, for example.
- FIG. 18 is a hardware configuration diagram showing an example of a computer that implements the functions of the offload servers 1 and 1A.
- Computer 900 has CPU 901 , RAM 902 , ROM 903 , HDD 904 , accelerator 905 , input/output interface (I/F) 906 , media interface (I/F) 907 , and communication interface (I/F: Interface) 908 .
- the accelerator 905 is an accelerator (device) that processes at least one of data from the communication I/F 908 and data from the RAM 902 at high speed.
- the accelerator 905 is an accelerator for the device 151, the device 152 having a CPU-GPU, the device 153 having a CPU-FPGA, and the device 154 having a CPU in FIG.
- a type look-aside type
- the accelerator 905 a type (look-aside type) that returns the execution result to the CPU 901 or the RAM 902 after executing the processing from the CPU 901 or the RAM 902 may be used.
- a type (in-line type) that performs processing by entering between the communication I/F 908 and the CPU 901 or the RAM 902 may be used.
- Accelerator 905 is connected to external device 915 via communication I/F 908 .
- Input/output I/F 906 is connected to input/output device 916 .
- a media I/F 907 reads and writes data from a recording medium 917 .
- the CPU 901 operates based on programs stored in the ROM 903 or HDD 904, and executes programs (also called applications or apps for short) read into the RAM 902 to operate the offload servers 1 and 1 shown in FIGS. Control is performed by each processing unit of 1A.
- This program can be distributed via a communication line or recorded on a recording medium 917 such as a CD-ROM for distribution.
- the ROM 903 stores a boot program executed by the CPU 901 when the computer 900 is started, a program depending on the hardware of the computer 900, and the like.
- the CPU 901 controls, via the input/output I/F 906, an input/output device 916 comprising an input unit such as a mouse and keyboard, and an output unit such as a display and printer.
- the CPU 901 acquires data from the input/output device 916 via the input/output I/F 906 and outputs the generated data to the input/output device 916 .
- a GPU Graphics Processing Unit
- a GPU may be used together with the CPU 901 as a processor.
- the HDD 904 stores programs executed by the CPU 901 and data used by the programs.
- the communication I/F 908 receives data from other devices via a communication network (for example, NW (Network)) and outputs the data to the CPU 901, and also transmits data generated by the CPU 901 to other devices via the communication network. Send to a communication network (for example, NW (Network)) and outputs the data to the CPU 901, and also transmits data generated by the CPU 901 to other devices via the communication network.
- NW Network
- the media I/F 907 reads programs or data stored in the recording medium 917 and outputs them to the CPU 901 via the RAM 902 .
- the CPU 901 loads a program related to target processing from the recording medium 917 onto the RAM 902 via the media I/F 907, and executes the loaded program.
- the recording medium 917 includes optical recording media such as DVD (Digital Versatile Disc) and PD (Phase change rewritable Disk), magneto-optical recording media such as MO (Magneto Optical disk), magnetic recording media, conductor memory tape media, semiconductor memories, and the like. is.
- the CPU 901 of the computer 900 executes the programs loaded on the RAM 902 to perform the offload servers 1 and 1A. to realize the function of Also, the data in the RAM 902 is stored in the HDD 904 .
- the CPU 901 reads a program related to target processing from the recording medium 912 and executes it.
- the CPU 901 may read a program related to target processing from another device via a communication network.
- the offload server 1 (see FIG. 1) according to the first embodiment is an offload server that offloads specific processing of an application program to an accelerator.
- the code analysis unit 112 analyzes the reference relationships of variables used in the loop statements of the application program, and for data that may be transferred outside the loop, an explicit A data transfer specification unit 113 that specifies data transfer using a specified line, and a parallel processing specification that specifies loop statements of an application program and compiles each specified loop statement by specifying a parallel processing specification statement in the accelerator.
- Parallel processing that creates a parallel processing pattern that designates whether or not to perform parallel processing for loop statements that do not cause a compile error and excludes loop statements that cause a compile error from being offloaded.
- the price conditions and response time conditions requested by the user, the number of applications arranged, etc. can be changed, and the cloud server on the network , a carrier edge server, or a user edge server. This allows the converted application to meet computational resource cost or response time requirements to achieve optimal placement according to user requirements.
- An offload server 1A (see FIG. 13) according to the second embodiment is an offload server that offloads specific processing of an application program to a PLD, and includes an application code analysis unit 112 that analyzes the source code of the application program; a PLD processing designation unit 213 that identifies loop statements of an application program, creates and compiles pipeline processing and parallel processing in PLD by a plurality of offload processing patterns designated by OpenCL for each of the identified loop statements; Based on the arithmetic intensity calculation unit 214 that calculates the arithmetic intensity of the loop statements of the application program and the arithmetic intensity calculated by the arithmetic intensity calculation unit 214, the loop statements whose arithmetic intensity is higher than a predetermined threshold are narrowed down as offload candidates, A PLD processing pattern creation unit 215 that creates a PLD processing pattern and an application program for the created PLD processing pattern are compiled, placed in an accelerator verification device, and performance measurement processing when offloaded to the PLD is executed.
- the device and A placement setting unit 170 that calculates and sets the placement location of an application program based on a linear programming formula with link cost, computational resource upper limit, and bandwidth upper limit as constraint conditions, and with computational resource cost or response time as an objective function. And prepare.
- the placement setting unit 170 minimizes the cost of computational resources or minimizes the response time when the application program is placed on the server. It is characterized by calculating the placement of
- the transformed application can be optimally deployed to meet the computational resource cost or response time requirements.
- the placement setting unit 170 performs a linear It is characterized by calculating according to a planning formula.
- the placement setting unit 170 uses the linear programming formula shown in [Formula 2] for the placement that minimizes the response time when the application program is placed on the server. It is characterized by calculating according to
- the present invention is an offload program for causing a computer to function as the above offload server.
- each function of the offload servers 1 and 1A can be realized using a general computer.
- each of the above embodiments all or part of the processes described as being performed automatically can be performed manually, or the processes described as being performed manually can be performed manually. can also be performed automatically by a known method.
- information including processing procedures, control procedures, specific names, and various data and parameters shown in the above documents and drawings can be arbitrarily changed unless otherwise specified.
- each component of each device illustrated is functionally conceptual, and does not necessarily need to be physically configured as illustrated.
- the specific form of distribution and integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed and integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
- each of the above configurations, functions, processing units, processing means, etc. may be realized in hardware, for example, by designing a part or all of them with an integrated circuit.
- each configuration, function, etc. described above may be realized by software for a processor to interpret and execute a program for realizing each function.
- Information such as programs, tables, files, etc. that realize each function is stored in memory, hard disk, SSD (Solid State Drive) and other recording devices, IC (Integrated Circuit) cards, SD (Secure Digital) cards, optical discs, etc. It can be held on a recording medium.
- a genetic algorithm (GA) technique is used in order to find a solution to a combinatorial optimization problem within a limited optimization period. It can be something like For example, local search, dynamic programming, or a combination thereof may be used.
- the OpenACC compiler for C/C++ is used, but any compiler can be used as long as it can offload GPU processing.
- Java lambda (registered trademark) GPU processing IBM Java 9 SDK (registered trademark) may be used.
- IBM Java 9 SDK registered trademark
- the parallel processing specification statement depends on these development environments. For example, in Java (registered trademark), parallel processing can be described in the lambda format since Java 8. IBM (registered trademark) provides a JIT compiler that offloads lambda-style parallel processing descriptions to the GPU. In Java, similar offloading is possible by using these to perform tuning in GA as to whether or not loop processing should be in the lambda format.
- the for statement is exemplified as the iterative statement (loop statement), but the while statement and the do-while statement other than the for statement are also included.
- the for statement which specifies loop continuation conditions, etc., is more suitable.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Debugging And Monitoring (AREA)
Abstract
This offload server (1) comprises: a performance measurement unit (118) for compiling an application program of a parallel processing pattern, positioning the application program in a device for accelerator verification, and executing a process for performance measurement when offloading to an accelerator has occurred; and a positioning setting unit (170) that, when positioning a converted application program in one of a cloud server, a carrier edge server, and a user edge server on a network in accordance with a condition pertaining to a cost or a response time as designated by a user, calculates and sets the location for positioning of the application program on the basis of a linear planning formula in which device and link costs, a calculation resource upper limit, and a bandwidth upper limit are used as constraint conditions and the cost or response time of the calculation resource is used as an objective function.
Description
本発明は、機能処理をGPU(Graphics Processing Unit)やFPGA(Field Programmable Gate Array)等のアクセラレータに自動オフロードし、変換したアプリケーションプログラム(以下適宜、アプリケーションという)を適切な場所に配置するオフロードサーバ、オフロード制御方法およびオフロードプログラムに関する。
The present invention automatically offloads functional processing to an accelerator such as a GPU (Graphics Processing Unit) or FPGA (Field Programmable Gate Array), and places the converted application program (hereinafter referred to as an application as appropriate) in an appropriate location. The present invention relates to a server, an offload control method, and an offload program.
CPU(Central Processing Unit)以外のヘテロな計算リソースを用いることが増えている。例えば、GPU(アクセラレータ)を強化したサーバで画像処理を行ったり、FPGA(アクセラレータ)で信号処理をアクセラレートすることが始まっている。FPGAは、製造後に設計者等が構成を設定できるプログラム可能なゲートアレイであり、PLD(Programmable Logic Device)の一種である。Amazon Web Services (AWS)(登録商標)では、GPUインスタンス、FPGAインスタンスが提供されており、オンデマンドにそれらリソースを使うこともできる。Microsoft(登録商標)は、FPGAを用いて検索を効率化している。
The use of heterogeneous computational resources other than the CPU (Central Processing Unit) is increasing. For example, it has begun to perform image processing on servers with enhanced GPUs (accelerators), and to accelerate signal processing with FPGAs (accelerators). An FPGA is a programmable gate array whose configuration can be set by a designer or the like after manufacturing, and is a type of PLD (Programmable Logic Device). Amazon Web Services (AWS) (registered trademark) provides GPU instances and FPGA instances, and these resources can be used on demand. Microsoft (registered trademark) uses FPGAs to streamline searches.
サービス連携技術等を用いて、多彩なアプリケーションの創出が期待されるが、更に進歩したハードウェアを生かすことで、動作アプリケーションの高性能化が期待できる。しかし、そのためには、動作させるハードウェアに合わせたプログラミングや設定が必要である。例えば、CUDA(Compute Unified Device Architecture)、OpenCL(Open Computing Language)といった多くの技術知識が求められ、ハードルは高い。OpenCLは、あらゆる計算資源(CPUやGPUに限らない)を特定のハードに縛られず統一的に扱えるオープンなAPI(Application Programming Interface)である。
It is expected that various applications will be created using service linking technology, etc., but by making use of more advanced hardware, the performance of operating applications can be expected to be improved. However, in order to do so, programming and settings that match the hardware to be operated are required. For example, many technical knowledge such as CUDA (Compute Unified Device Architecture) and OpenCL (Open Computing Language) is required, and the hurdles are high. OpenCL is an open API (Application Programming Interface) that can handle all computational resources (not limited to CPUs and GPUs) in a unified manner without being tied to specific hardware.
GPUやFPGAをユーザのアプリケーションで容易に利用できるようにするため下記が求められる。すなわち、動作させる画像処理、暗号処理等の汎用アプリケーションを環境にデプロイする際に、プラットフォームがアプリケーションロジックを分析し、GPU、FPGAに自動で処理をオフロードすることが望まれる。
The following are required so that GPUs and FPGAs can be easily used in user applications. That is, when deploying general-purpose applications such as image processing and cryptographic processing to be operated in an environment, it is desired that the platform analyzes the application logic and automatically offloads the processing to the GPU and FPGA.
GPUの計算能力を画像処理以外にも使うGPGPU(General Purpose GPU)のための開発環境CUDAが発展している。CUDAは、GPGPU向けの開発環境である。また、GPU、FPGA、メニーコアCPU等のヘテロハードウェアを統一的に扱うための標準規格としてOpenCLも登場している。
The development environment CUDA for GPGPUs (General Purpose GPUs), which uses the computing power of GPUs for purposes other than image processing, is being developed. CUDA is a development environment for GPGPUs. OpenCL has also emerged as a standard for handling heterogeneous hardware such as GPUs, FPGAs, and many-core CPUs in a unified manner.
CUDAやOpenCLでは、C言語の拡張によるプログラミングを行う。ただし、GPU等のデバイスとCPUの間のメモリコピー、解放等を記述する必要があり、記述の難度は高い。実際に、CUDAやOpenCLを使いこなせる技術者は数多くはいない。
With CUDA and OpenCL, programming is done by extending the C language. However, it is necessary to describe memory copy, release, etc. between a device such as a GPU and a CPU, which makes the description highly difficult. Actually, there are not many engineers who can master CUDA and OpenCL.
簡易にGPGPUを行うため、ディレクティブベースで、ループ文等の並列処理すべき個所を指定し、ディレクティブに従いコンパイラがデバイス向けコードに変換する技術がある。技術仕様としてOpenACC(Open Accelerator)等、コンパイラとしてPGIコンパイラ(登録商標)等がある。例えば、OpenACCを使った例では、ユーザはC/C++/Fortran言語で書かれたコードに、OpenACCディレクティブで並列処理させる等を指定する。PGIコンパイラは、コードの並列可能性をチェックして、GPU用、CPU用実行バイナリを生成し、実行モジュール化する。IBM JDK(登録商標)は、Java(登録商標)のlambda形式に従った並列処理指定を、GPUにオフロードする機能をサポートしている。これらの技術を用いることで、GPUメモリへのデータ割り当て等を、プログラマは意識する必要がない。
このように、OpenCL、CUDA、OpenACC等の技術により、GPUやFPGAへのオフロード処理が可能になっている。 In order to perform GPGPU easily, there is a technique in which a portion to be processed in parallel, such as a loop statement, is specified on a directive basis, and a compiler converts it into device-oriented code according to the directive. Technical specifications include OpenACC (Open Accelerator) and the like, and compilers include PGI Compiler (registered trademark) and the like. For example, in an example using OpenACC, the user specifies parallel processing in code written in C/C++/Fortran using OpenACC directives. The PGI compiler checks the parallelism of the code, generates executable binaries for GPU and CPU, and converts them into executable modules. The IBM JDK (registered trademark) supports a function of offloading parallel processing specification according to the lambda format of Java (registered trademark) to the GPU. By using these techniques, the programmer does not need to be aware of data allocation to the GPU memory.
In this way, techniques such as OpenCL, CUDA, and OpenACC enable offload processing to GPUs and FPGAs.
このように、OpenCL、CUDA、OpenACC等の技術により、GPUやFPGAへのオフロード処理が可能になっている。 In order to perform GPGPU easily, there is a technique in which a portion to be processed in parallel, such as a loop statement, is specified on a directive basis, and a compiler converts it into device-oriented code according to the directive. Technical specifications include OpenACC (Open Accelerator) and the like, and compilers include PGI Compiler (registered trademark) and the like. For example, in an example using OpenACC, the user specifies parallel processing in code written in C/C++/Fortran using OpenACC directives. The PGI compiler checks the parallelism of the code, generates executable binaries for GPU and CPU, and converts them into executable modules. The IBM JDK (registered trademark) supports a function of offloading parallel processing specification according to the lambda format of Java (registered trademark) to the GPU. By using these techniques, the programmer does not need to be aware of data allocation to the GPU memory.
In this way, techniques such as OpenCL, CUDA, and OpenACC enable offload processing to GPUs and FPGAs.
しかし、オフロード処理自体は行えるようになっても、適切なオフロードには課題が多い。例えば、Intelコンパイラ(登録商標)のように自動並列化機能を持つコンパイラがある。自動並列化する際は、プログラム上のfor文(繰り返し文)等の並列処理部を抽出する。ところが、GPUを用いて並列に動作させる場合は、CPU-GPUメモリ間のデータやり取りによるオーバヘッドのため、性能が出ないことも多い。GPUを用いて高速化する際は、スキル保持者が、OpenCLやCUDAでのチューニングや、PGIコンパイラ等で適切な並列処理部を探索することが必要になっている。
このため、スキルが無いユーザがGPUを使ってアプリケーションを高性能化することは難しいし、自動並列化技術を使う場合も、for文を並列するかしないかの試行錯誤チューニング等により、利用開始までに多くの時間がかかっている。 However, even if offload processing itself can be performed, there are many problems with appropriate offloading. For example, there is a compiler with an automatic parallelization function, such as the Intel compiler (registered trademark). When performing automatic parallelization, parallel processing parts such as for statements (repeated statements) in the program are extracted. However, when GPUs are used to operate in parallel, performance is often poor due to overhead due to data exchange between the CPU and GPU memory. When speeding up by using a GPU, it is necessary for a skilled person to search for an appropriate parallel processing part by tuning with OpenCL or CUDA, or with a PGI compiler or the like.
For this reason, it is difficult for users without skills to improve the performance of applications using GPUs. takes a lot of time.
このため、スキルが無いユーザがGPUを使ってアプリケーションを高性能化することは難しいし、自動並列化技術を使う場合も、for文を並列するかしないかの試行錯誤チューニング等により、利用開始までに多くの時間がかかっている。 However, even if offload processing itself can be performed, there are many problems with appropriate offloading. For example, there is a compiler with an automatic parallelization function, such as the Intel compiler (registered trademark). When performing automatic parallelization, parallel processing parts such as for statements (repeated statements) in the program are extracted. However, when GPUs are used to operate in parallel, performance is often poor due to overhead due to data exchange between the CPU and GPU memory. When speeding up by using a GPU, it is necessary for a skilled person to search for an appropriate parallel processing part by tuning with OpenCL or CUDA, or with a PGI compiler or the like.
For this reason, it is difficult for users without skills to improve the performance of applications using GPUs. takes a lot of time.
配置に関して、ネットワークリソースの最適利用として、ネットワーク上にあるサーバ 群に対してVN(Virtual Network)の埋め込み位置を最適化する研究がある(非特許文献1参照)。非特許文献1では、通信トラヒックを考慮したVNの最適配置を決定する。しかし、単一リソースの仮想ネットワークが対象で、キャリアの設備コストや全体的応答時間の削減が目的で、個々に異なるアプリケーションの処理時間や、個々のユーザのコストや応答時間要求等の条件は考慮されていない。
Regarding placement, there is research to optimize the embedding position of VN (Virtual Network) for a group of servers on the network as an optimal use of network resources (see Non-Patent Document 1). In Non-Patent Literature 1, the optimum arrangement of VNs is determined in consideration of communication traffic. However, it is intended for single-resource virtual networks, with the goal of reducing carrier equipment costs and overall response time, taking into account conditions such as the processing time of different applications and the cost and response time requirements of individual users. It has not been.
並列処理箇所の試行錯誤を自動化する取り組みとして、非特許文献2が挙げられる。
非特許文献2は、一度記述したコードで、配置先の環境に存在するGPUやFPGA、メニーコアCPU等を利用できるように、変換、リソース設定等を自動で行い、アプリケーションを高性能で動作させることを目的とした、環境適応ソフトウェアを提案している。併せて、非特許文献2は、環境適応ソフトウェアの要素として、アプリケーションコードのループ文を、GPUに自動オフロードする方式を提案し性能向上を評価している。 Non-PatentDocument 2 can be cited as an approach to automate the trial-and-error process for parallel processing.
Non-Patent Literature 2 describes how once written code can use GPUs, FPGAs, many-core CPUs, etc. that exist in the deployment destination environment, automatic conversion, resource settings, etc. are performed, and applications are operated at high performance. We propose an environment adaptive software for the purpose of In addition, Non-Patent Document 2 proposes a system for automatically offloading loop statements of application code to the GPU as an element of environment-adaptive software, and evaluates performance improvement.
非特許文献2は、一度記述したコードで、配置先の環境に存在するGPUやFPGA、メニーコアCPU等を利用できるように、変換、リソース設定等を自動で行い、アプリケーションを高性能で動作させることを目的とした、環境適応ソフトウェアを提案している。併せて、非特許文献2は、環境適応ソフトウェアの要素として、アプリケーションコードのループ文を、GPUに自動オフロードする方式を提案し性能向上を評価している。 Non-Patent
Non-Patent Literature 2 describes how once written code can use GPUs, FPGAs, many-core CPUs, etc. that exist in the deployment destination environment, automatic conversion, resource settings, etc. are performed, and applications are operated at high performance. We propose an environment adaptive software for the purpose of In addition, Non-Patent Document 2 proposes a system for automatically offloading loop statements of application code to the GPU as an element of environment-adaptive software, and evaluates performance improvement.
非特許文献3は、環境適応ソフトウェアの要素として、アプリケーションコードのループ文を、FPGAに自動オフロードする方式を提案し性能向上を評価している。
非特許文献4は、環境適応ソフトウェアの要素として、GPU等向けに自動変換した後、アプリケーションを実行するリソース量(仮想マシンコアの数など)を、適正化する手法を評価している。 Non-Patent Document 3 proposes a system for automatically offloading loop statements of application code to FPGA as an element of environment adaptive software, and evaluates performance improvement.
Non-PatentDocument 4 evaluates a method of optimizing the amount of resources (such as the number of virtual machine cores) for executing an application after automatic conversion for a GPU or the like as an element of environment-adaptive software.
非特許文献4は、環境適応ソフトウェアの要素として、GPU等向けに自動変換した後、アプリケーションを実行するリソース量(仮想マシンコアの数など)を、適正化する手法を評価している。 Non-Patent Document 3 proposes a system for automatically offloading loop statements of application code to FPGA as an element of environment adaptive software, and evaluates performance improvement.
Non-Patent
非特許文献1~4では、自動オフロード時の処理時間の短縮を中心に評価している。
GPU、FPGA等のヘテロジニアスなデバイスに処理をオフロードする際に、変換したアプリケーションをユーザ要望(価格、応答時間)を満たして動作させることについては提案されていないという課題がある。Non-Patent Documents 1 to 4 focus on shortening the processing time during automatic offloading.
There is a problem that when processing is offloaded to heterogeneous devices such as GPUs and FPGAs, there is no proposal to operate the converted application while satisfying user demands (price, response time).
GPU、FPGA等のヘテロジニアスなデバイスに処理をオフロードする際に、変換したアプリケーションをユーザ要望(価格、応答時間)を満たして動作させることについては提案されていないという課題がある。
There is a problem that when processing is offloaded to heterogeneous devices such as GPUs and FPGAs, there is no proposal to operate the converted application while satisfying user demands (price, response time).
このような点に鑑みて本発明がなされたのであり、GPUやFPGA等のオフロードデバイスに配置できるよう自動変換した際に、変換したアプリケーションをユーザのコストまたは応答時間の要求を満たして最適に配置することを課題とする。
It is with this in mind that the present invention has been made, which, when automatically converted for placement on an offload device such as a GPU or FPGA, optimizes the converted application to meet the user's cost or response time requirements. The task is to place
前記した課題を解決するため、アプリケーションプログラムの特定処理をアクセラレータにオフロードするオフロードサーバであって、前記アプリケーションプログラムのソースコードを分析するアプリケーションコード分析部と、前記アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行を用いたデータ転送指定を行うデータ転送指定部と、前記アプリケーションプログラムのループ文を特定し、特定した各前記ループ文に対して、前記アクセラレータにおける並列処理指定文を指定してコンパイルする並列処理指定部と、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ないループ文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する並列処理パターン作成部と、前記並列処理パターンの前記アプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、前記アクセラレータにオフロードした際の性能測定用処理を実行する性能測定部と、変換した前記アプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定する配置設定部と、を備えることを特徴とするオフロードサーバとした。
In order to solve the above-described problems, an offload server for offloading specific processing of an application program to an accelerator, comprising: an application code analysis unit for analyzing the source code of the application program; A data transfer specification section that analyzes the reference relationships of variables used and, for data that may be transferred outside the loop, specifies data transfer using an explicit specification line that explicitly specifies data transfer outside the loop and a parallel processing designation unit that identifies loop statements of the application program, compiles each identified loop statement by designating a parallel processing designation statement in the accelerator, and a loop statement that causes a compilation error. , a parallel processing pattern creation unit for creating a parallel processing pattern for specifying whether or not to perform parallel processing for a loop statement that is not to be offloaded and that does not generate a compilation error; and the application of the parallel processing pattern. A performance measurement unit that compiles a program, places it in an accelerator verification device, and executes performance measurement processing when offloaded to the accelerator; Depending on the conditions, when deploying on a cloud server, carrier edge server, or user edge server on the network, device and link costs, computational resource limits, and bandwidth limits are constraints, and computational resource costs or and a placement setting unit that calculates and sets a placement location of an application program based on a linear programming formula with response time as an objective function.
本発明によれば、GPUやFPGA等のオフロードデバイスに配置できるよう自動変換した際に、変換したアプリケーションをユーザのコストまたは応答時間の要求を満たして最適に配置することができる。
According to the present invention, when an application is automatically converted so that it can be placed on an offload device such as a GPU or FPGA, the converted application can be optimally placed to meet the user's cost or response time requirements.
以下、図面を参照して本発明を実施するための形態(以下、「本実施形態」という)におけるオフロードサーバについて説明する。
(本発明の自動オフロードの基本的な考え方)
本発明者は、環境適応ソフトウェアのコンセプトを具体化するために、これまでに、プログラムのループ文のGPU自動オフロード、FPGA自動オフロード、変換アプリケーションの実行リソース適正化の方式を提案してきた(非特許文献2、3、4参照)。これら非特許文献2、3、4の要素技術の検討も踏まえて、本発明の基本的な考え方を述べる。 Hereinafter, an offload server in a mode for carrying out the present invention (hereinafter referred to as "this embodiment") will be described with reference to the drawings.
(Basic concept of automatic offloading of the present invention)
In order to embody the concept of environment-adaptive software, the present inventor has so far proposed methods for GPU automatic offloading of program loop statements, FPGA automatic offloading, and optimization of conversion application execution resources ( See Non-Patent Documents 2, 3, and 4). The basic concept of the present invention will be described based on the examination of the elemental technologies of these Non-Patent Documents 2, 3, and 4 as well.
(本発明の自動オフロードの基本的な考え方)
本発明者は、環境適応ソフトウェアのコンセプトを具体化するために、これまでに、プログラムのループ文のGPU自動オフロード、FPGA自動オフロード、変換アプリケーションの実行リソース適正化の方式を提案してきた(非特許文献2、3、4参照)。これら非特許文献2、3、4の要素技術の検討も踏まえて、本発明の基本的な考え方を述べる。 Hereinafter, an offload server in a mode for carrying out the present invention (hereinafter referred to as "this embodiment") will be described with reference to the drawings.
(Basic concept of automatic offloading of the present invention)
In order to embody the concept of environment-adaptive software, the present inventor has so far proposed methods for GPU automatic offloading of program loop statements, FPGA automatic offloading, and optimization of conversion application execution resources ( See
<CPUとオフロードデバイスのリソース比の適切化>
まず、デバイスにオフロードするプログラム変換ができた後の、CPUとオフロードデバイスのリソース比の適切化について説明する。
非特許文献2等の手法により、GPUやFPGA等のオフロードデバイスに通常のプログラムを自動オフロードすることができる。
現在、マルチコアCPU、メニーコアCPUは、仮想マシンやコンテナによる仮想化により、全コアの何割を割り当てる等が柔軟にできるようになっている。GPUについても、近年CPU同様の仮想化が行われ、GPUの全コアの何割を割り当てる等の運用が可能になりつつある。FPGAに関しては、リソース使用量は、Look Up TableやFlip Flopの設定数で表されることが多く、利用されていないゲートについては別用途に使うことができる。 <Appropriate resource ratio between CPU and offload device>
First, optimization of the resource ratio between the CPU and the offload device after program conversion for offloading to the device is completed will be described.
A method such asNon-Patent Document 2 can automatically offload a normal program to an offload device such as a GPU or FPGA.
Currently, multi-core CPUs and many-core CPUs can flexibly allocate a percentage of all cores through virtualization using virtual machines and containers. In recent years, GPUs have been virtualized in the same way as CPUs, and operations such as allocating a percentage of all cores of GPUs are becoming possible. Regarding FPGA, resource usage is often represented by a set number of Look Up Tables and Flip Flops, and unused gates can be used for other purposes.
まず、デバイスにオフロードするプログラム変換ができた後の、CPUとオフロードデバイスのリソース比の適切化について説明する。
非特許文献2等の手法により、GPUやFPGA等のオフロードデバイスに通常のプログラムを自動オフロードすることができる。
現在、マルチコアCPU、メニーコアCPUは、仮想マシンやコンテナによる仮想化により、全コアの何割を割り当てる等が柔軟にできるようになっている。GPUについても、近年CPU同様の仮想化が行われ、GPUの全コアの何割を割り当てる等の運用が可能になりつつある。FPGAに関しては、リソース使用量は、Look Up TableやFlip Flopの設定数で表されることが多く、利用されていないゲートについては別用途に使うことができる。 <Appropriate resource ratio between CPU and offload device>
First, optimization of the resource ratio between the CPU and the offload device after program conversion for offloading to the device is completed will be described.
A method such as
Currently, multi-core CPUs and many-core CPUs can flexibly allocate a percentage of all cores through virtualization using virtual machines and containers. In recent years, GPUs have been virtualized in the same way as CPUs, and operations such as allocating a percentage of all cores of GPUs are becoming possible. Regarding FPGA, resource usage is often represented by a set number of Look Up Tables and Flip Flops, and unused gates can be used for other purposes.
このように、CPU、GPU、FPGAとも全リソースの一部を使う運用が可能であり、CPUとオフロードデバイスのリソースを用途に応じて適切化することはコストパフォーマンスを高める上で重要である。
In this way, it is possible to operate using a portion of all resources for the CPU, GPU, and FPGA, and optimizing the resources of the CPU and offload devices according to the application is important for improving cost performance.
また、非特許文献2等の手法を用いて、アプリケーションをCPUとGPU処理のコードに変換することはできる。しかし、コード自体は、適切であっても、CPUとGPUとのリソース量が適切なバランスでない場合には、性能が出ない。例えば、ある処理を行う際に、CPUの処理時間が1000秒、GPUの処理時間が1秒では、オフロードできる処理をGPUである程度高速化しても、全体的にはCPUがボトルネックとなっている。
In addition, it is possible to convert the application into code for CPU and GPU processing using the method described in Non-Patent Document 2. However, even if the code itself is good, it will not perform well if the amount of CPU and GPU resources is not properly balanced. For example, when performing a certain process, if the CPU processing time is 1000 seconds and the GPU processing time is 1 second, even if the processing that can be offloaded is speeded up by the GPU to some extent, the CPU as a whole becomes a bottleneck. there is
さらに、非特許文献5の「K. Shirahata, H. Sato and S. Matsuoka, "Hybrid Map Task Scheduling for GPU-Based Heterogeneous Clusters,"IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), pp.733-740, Dec. 2010.」では、CPUとGPUを使ってMapReduce(登録商標)フレームワークでタスク処理している際に、CPUとGPUの実行時間が同じになるようMapタスクを配分することで、全体の高性能化を図っている。
Furthermore, Non-Patent Document 5, "K. Shirahata, H. Sato and S. Matsuoka, "Hybrid Map Task Scheduling for GPU-Based Heterogeneous Clusters," IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), pp.733 -740, Dec. 2010.”, by distributing Map tasks so that the CPU and GPU execution times are the same when processing tasks with the MapReduce (registered trademark) framework using the CPU and GPU. , to improve overall performance.
本発明者は、CPUとオフロードデバイスのリソース比を下記のように決めることを想到した。すなわち、何れかのデバイスでの処理がボトルネックとなることを避けるため、上記非特許文献等も参考に、テストケースの処理時間から、CPUとオフロードデバイスの処理時間が同等オーダになるように、CPUとオフロードデバイスのリソース比(以下、「リソース比」という)を決定する。
The inventor came up with the idea of determining the resource ratio between the CPU and the offload device as follows. In other words, in order to avoid the processing in any device becoming a bottleneck, refer to the above non-patent documents, etc., so that the processing time of the CPU and the offload device are of the same order from the processing time of the test case. , the resource ratio between the CPU and the offload device (hereinafter referred to as "resource ratio").
また、本発明者は、非特許文献2の手法のように、自動オフロードの際、検証環境での性能測定結果に基づいて徐々に高速化していく手法を採る。理由としては、性能に関しては、コード構造だけでなく、実際に処理するハードウェアのスペック、データサイズ、ループ回数等の実際に処理する内容によって大きく変わるためである。また、性能は、静的に予測することが困難であり、動的な測定が必要だからである。そのため、コード変換の際に、既に検証環境での性能測定結果があるので、その結果を用いてリソース比を定める。
In addition, the inventor adopts a method of gradually increasing the speed based on the performance measurement results in the verification environment during automatic offloading, like the method of Non-Patent Document 2. The reason is that the performance varies greatly depending on not only the code structure but also the actual processing details such as hardware specifications, data size, loop count, and the like. Also, performance is difficult to predict statically and requires dynamic measurements. Therefore, at the time of code conversion, since there are already performance measurement results in the verification environment, resource ratios are determined using those results.
性能測定の際には、テストケースを指定して測定を行う。例えば、検証環境でのテストケースの処理時間が、CPU処理:10秒、GPU処理:5秒の場合では、CPU側のリソースは2倍で同等の処理時間程度と考えられる。このため、リソース比は2:1となる。なお、特にある処理をオフロードで高速化したいといったユーザ要望については、その処理を含むテストケースを準備して、そのテストケースに対して非特許文献2等の手法で高速化することでユーザ要望が反映される。
When measuring performance, specify a test case and measure it. For example, if the test case processing time in the verification environment is CPU processing: 10 seconds and GPU processing: 5 seconds, the resource on the CPU side is doubled, and the processing time is considered to be about the same. Therefore, the resource ratio is 2:1. In addition, for a user request to speed up a particular process by offloading, prepare a test case that includes that process and speed up the test case using the method described in Non-Patent Document 2 or the like. is reflected.
<CPUとオフロードデバイスのリソース量の決定と自動検証>
次に、CPUとオフロードデバイスのリソース量(以下、「リソース量」という)の決定と自動検証について説明する。
上記<CPUとオフロードデバイスのリソース比の適切化>により、リソース比が定まった場合、次に商用環境へのアプリケーションの配置を行う。
商用環境への配置の際は、ユーザが指定したコスト要求を満たすように、リソース比は可能な限りキープ(維持)したまま、リソース量を決定する。例えば、CPUに関して、1VMは1000円/月、GPUは4000円/月、リソース比は2:1が適切であるとする。そして、ユーザの予算は、月10000円以内であると想定する。この場合には、リソース比を2:1としても、ユーザの予算内である月10000円以内に収まるので、適切なリソース比2:1をキープしたリソース量、すなわちCPUは「2」、GPUは「1」を確保して商用環境に配置することになる。また、ユーザの予算が、月5000円以内であった場合には、適切なリソース比2:1はキープできない。この場合、リソース量として、CPUは「1」、GPUは「1」を確保して配置する。 <Determining and automatically verifying the amount of CPU and offload device resources>
Next, determination and automatic verification of the amount of resources of the CPU and the offload device (hereinafter referred to as "resource amount") will be described.
When the resource ratio is determined by <Optimizing the resource ratio between the CPU and the offload device>, the application is placed in the commercial environment.
When deploying in a commercial environment, the resource amount is determined while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user. For example, with respect to CPU, it is assumed that 1 VM is 1000 yen/month, GPU is 4000 yen/month, and the resource ratio is 2:1. It is also assumed that the user's budget is within 10,000 yen per month. In this case, even if the resource ratio is set to 2:1, the budget is within the user's budget of 10,000 yen per month. "1" is secured and placed in the commercial environment. Also, if the user's budget is within 5000 yen per month, the appropriate resource ratio of 2:1 cannot be maintained. In this case, as the resource amount, "1" is secured for the CPU and "1" for the GPU.
次に、CPUとオフロードデバイスのリソース量(以下、「リソース量」という)の決定と自動検証について説明する。
上記<CPUとオフロードデバイスのリソース比の適切化>により、リソース比が定まった場合、次に商用環境へのアプリケーションの配置を行う。
商用環境への配置の際は、ユーザが指定したコスト要求を満たすように、リソース比は可能な限りキープ(維持)したまま、リソース量を決定する。例えば、CPUに関して、1VMは1000円/月、GPUは4000円/月、リソース比は2:1が適切であるとする。そして、ユーザの予算は、月10000円以内であると想定する。この場合には、リソース比を2:1としても、ユーザの予算内である月10000円以内に収まるので、適切なリソース比2:1をキープしたリソース量、すなわちCPUは「2」、GPUは「1」を確保して商用環境に配置することになる。また、ユーザの予算が、月5000円以内であった場合には、適切なリソース比2:1はキープできない。この場合、リソース量として、CPUは「1」、GPUは「1」を確保して配置する。 <Determining and automatically verifying the amount of CPU and offload device resources>
Next, determination and automatic verification of the amount of resources of the CPU and the offload device (hereinafter referred to as "resource amount") will be described.
When the resource ratio is determined by <Optimizing the resource ratio between the CPU and the offload device>, the application is placed in the commercial environment.
When deploying in a commercial environment, the resource amount is determined while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user. For example, with respect to CPU, it is assumed that 1 VM is 1000 yen/month, GPU is 4000 yen/month, and the resource ratio is 2:1. It is also assumed that the user's budget is within 10,000 yen per month. In this case, even if the resource ratio is set to 2:1, the budget is within the user's budget of 10,000 yen per month. "1" is secured and placed in the commercial environment. Also, if the user's budget is within 5000 yen per month, the appropriate resource ratio of 2:1 cannot be maintained. In this case, as the resource amount, "1" is secured for the CPU and "1" for the GPU.
商用環境にリソースを確保してプログラムを配置した後は、ユーザが利用する前に動作することを確認するため、自動検証が行われる。自動検証では、性能検証テストケースやリグレッションテストケースが実行される。性能検証テストケースは、ユーザが指定した想定テストケースをJenkins(登録商標)等の試験自動実行ツールを用いて行い、処理時間やスループット等を測定する。リグレッションテストケースは、システムにインストールされるミドルウェアやOS等のソフトウェアの情報を取得して、それらに対応するリグレッションテストをJenkins等を用いて実行する。これらの自動検証を、少ないテストケースの準備で行うための検討は非特許文献6(Y. Yamato, “Automatic verification technology of software patches for user virtual environments on IaaS cloud,” Journal of Cloud Computing, Springer, 2015, 4:4, DOI: 10.1186/s13677-015-0028-6, Feb. 2015.)等でなされており、この非特許文献6の技術を用いる。
After securing resources and deploying the program in the commercial environment, automatic verification is performed to confirm that it will work before the user uses it. Automatic verification runs performance verification test cases and regression test cases. A performance verification test case is performed by using an automatic test execution tool such as Jenkins (registered trademark) for a hypothetical test case specified by the user, and the processing time, throughput, and the like are measured. A regression test case obtains information about software such as middleware and OS installed in the system, and executes a regression test corresponding to the information using Jenkins or the like. A study to perform these automatic verifications with a small number of test case preparations is in Non-Patent Document 6 (Y. Yamato, “Automatic verification technology of software patches for user virtual environments on IaaS cloud,” Journal of Cloud Computing, Springer, 2015 , 4:4, DOI: 10.1186/s13677-015-0028-6, Feb. 2015.), etc., and the technology of this non-patent document 6 is used.
性能検証テストケースでは、オフロードした場合でも計算結果が不正でないかをチェックする。また、性能検証テストケースでは、オフロードしない場合との計算結果差分もチェックする。例えば、GPUを処理するPGIコンパイラは、PCAST(登録商標)という機能のPGI_compare(登録商標)やacc_compare(登録商標)というAPI(Application Programming Interface)で、GPUを使う場合使わない場合の計算結果差分を確認できる。
なお、GPUとCPUでは丸め誤差が異なる等、並列処理等を正しくオフロードしても完全に計算結果が一致しない場合もある。そのため、例えばIEEE 754仕様による確認等を行い、許容できる差分かをユーザに提示し、ユーザに確認をしてもらう。 In the performance verification test cases, check whether the calculation results are correct even if offloading is performed. Also, in the performance verification test case, the difference between the calculation result and the case without offloading is checked. For example, the PGI compiler that processes the GPU uses the PCAST (registered trademark) function PGI_compare (registered trademark) and acc_compare (registered trademark) API (Application Programming Interface) to calculate the difference between calculation results when the GPU is used and when it is not used. I can confirm.
Note that even if parallel processing or the like is correctly offloaded, there are cases where the calculation results do not match completely, such as when the GPU and CPU have different rounding errors. Therefore, for example, confirmation according to the IEEE 754 specification is performed, and whether the difference is acceptable is presented to the user for confirmation by the user.
なお、GPUとCPUでは丸め誤差が異なる等、並列処理等を正しくオフロードしても完全に計算結果が一致しない場合もある。そのため、例えばIEEE 754仕様による確認等を行い、許容できる差分かをユーザに提示し、ユーザに確認をしてもらう。 In the performance verification test cases, check whether the calculation results are correct even if offloading is performed. Also, in the performance verification test case, the difference between the calculation result and the case without offloading is checked. For example, the PGI compiler that processes the GPU uses the PCAST (registered trademark) function PGI_compare (registered trademark) and acc_compare (registered trademark) API (Application Programming Interface) to calculate the difference between calculation results when the GPU is used and when it is not used. I can confirm.
Note that even if parallel processing or the like is correctly offloaded, there are cases where the calculation results do not match completely, such as when the GPU and CPU have different rounding errors. Therefore, for example, confirmation according to the IEEE 754 specification is performed, and whether the difference is acceptable is presented to the user for confirmation by the user.
自動検証の結果として、性能検証テストケースの処理時間やそのスループット、計算結果差分およびリグレッションテストの実行結果の情報が、ユーザに提示される。ユーザには、さらに確保したリソース(VMの数やスペック等)とその価格が提示されており、ユーザはそれら情報を参照して運用開始を判断する。
As a result of automatic verification, the user is presented with information on the processing time and throughput of performance verification test cases, differences in calculation results, and regression test execution results. The user is also presented with the secured resources (the number of VMs, specifications, etc.) and their prices, and the user refers to this information to determine the start of operation.
<リソース、リソース比、テストケース処理時間>
本実施形態におけるリソース、リソース比、テストケース処理時間について述べる。
・リソースについて
CPU、GPU、FPGA等は仮想資源のインスタンスとして提供されるようになってきている。
リソースとして、CPUのコア数、クロック、メモリ量、ディスクサイズ、GPUのコア数、クロック、メモリ量、FPGAのゲート規模(Intel(登録商標)の場合はLE(登録商標)、Xilinx(登録商標)の場合LC(登録商標)が単位となる)がある。クラウド等の事業者は、それらをパッケージ化して、small sizeの仮想マシンやGPUインスタンスといった形で提供している。仮想化する場合は、利用するインスタンスの数が利用するリソース量といえる。 <resource, resource ratio, test case processing time>
The resource, resource ratio, and test case processing time in this embodiment will be described.
- Resources CPUs, GPUs, FPGAs, etc. are now being provided as instances of virtual resources.
As resources, the number of CPU cores, clock, memory amount, disk size, GPU core number, clock, memory amount, FPGA gate size (LE (registered trademark) for Intel (registered trademark), Xilinx (registered trademark) In the case of , the unit is LC (registered trademark)). Cloud service providers package them and provide them in the form of small-sized virtual machines or GPU instances. In the case of virtualization, it can be said that the number of instances to be used is the amount of resources to be used.
本実施形態におけるリソース、リソース比、テストケース処理時間について述べる。
・リソースについて
CPU、GPU、FPGA等は仮想資源のインスタンスとして提供されるようになってきている。
リソースとして、CPUのコア数、クロック、メモリ量、ディスクサイズ、GPUのコア数、クロック、メモリ量、FPGAのゲート規模(Intel(登録商標)の場合はLE(登録商標)、Xilinx(登録商標)の場合LC(登録商標)が単位となる)がある。クラウド等の事業者は、それらをパッケージ化して、small sizeの仮想マシンやGPUインスタンスといった形で提供している。仮想化する場合は、利用するインスタンスの数が利用するリソース量といえる。 <resource, resource ratio, test case processing time>
The resource, resource ratio, and test case processing time in this embodiment will be described.
- Resources CPUs, GPUs, FPGAs, etc. are now being provided as instances of virtual resources.
As resources, the number of CPU cores, clock, memory amount, disk size, GPU core number, clock, memory amount, FPGA gate size (LE (registered trademark) for Intel (registered trademark), Xilinx (registered trademark) In the case of , the unit is LC (registered trademark)). Cloud service providers package them and provide them in the form of small-sized virtual machines or GPU instances. In the case of virtualization, it can be said that the number of instances to be used is the amount of resources to be used.
・リソース比について
CPU、GPU、FPGAのインスタンス数の比がリソース比となる。インスタンス数が1つ、2つ、3つであれば、リソース比は1:2:3である。 ・Resource ratio The resource ratio is the ratio of the number of instances of CPU, GPU, and FPGA. If the number of instances is 1, 2, or 3, the resource ratio is 1:2:3.
CPU、GPU、FPGAのインスタンス数の比がリソース比となる。インスタンス数が1つ、2つ、3つであれば、リソース比は1:2:3である。 ・Resource ratio The resource ratio is the ratio of the number of instances of CPU, GPU, and FPGA. If the number of instances is 1, 2, or 3, the resource ratio is 1:2:3.
・テストケース処理時間について
本実施形態は、ユーザが指定するテストケースを高速化するオフロードパターンを探索して発見する。テストケースは、DB(データベース)であればTPC-C(登録商標)のようなトランザクション処理数であり、FFTであればサンプルデータでのフーリエ変換処理の実行である。処理時間は、そのサンプル処理を実行した際の実行時間である。例えば、処理Aの処理時間は、オフロード前は10秒であったものが、オフロード後は2秒になるといった形で、CPUで実行した場合と、オフロードデバイスで実行した場合との実行時間がそれぞれ取得される。 - Test Case Processing Time This embodiment searches for and discovers an offload pattern that speeds up a test case specified by the user. The test case is the number of transaction processing such as TPC-C (registered trademark) in the case of DB (database), and execution of Fourier transform processing in sample data in the case of FFT. The processing time is the execution time when the sample processing is executed. For example, the processing time of process A is 10 seconds before offloading, but it becomes 2 seconds after offloading. Each time is obtained.
本実施形態は、ユーザが指定するテストケースを高速化するオフロードパターンを探索して発見する。テストケースは、DB(データベース)であればTPC-C(登録商標)のようなトランザクション処理数であり、FFTであればサンプルデータでのフーリエ変換処理の実行である。処理時間は、そのサンプル処理を実行した際の実行時間である。例えば、処理Aの処理時間は、オフロード前は10秒であったものが、オフロード後は2秒になるといった形で、CPUで実行した場合と、オフロードデバイスで実行した場合との実行時間がそれぞれ取得される。 - Test Case Processing Time This embodiment searches for and discovers an offload pattern that speeds up a test case specified by the user. The test case is the number of transaction processing such as TPC-C (registered trademark) in the case of DB (database), and execution of Fourier transform processing in sample data in the case of FFT. The processing time is the execution time when the sample processing is executed. For example, the processing time of process A is 10 seconds before offloading, but it becomes 2 seconds after offloading. Each time is obtained.
<ループ文の発見>
コンパイラが、このループ文はGPUの並列処理に適しているという適合性を見つけることは難しいのが現状である。GPUにオフロードすることでどの程度の性能、電力消費量になるかは、実測してみないと予測は難しい。そのため、このループ文をGPUにオフロードするという指示を手動で行い、測定の試行錯誤が行われている。
本発明は、GPUにオフロードする適切なループ文の発見を、進化計算手法である遺伝的アルゴリズム(GA:Genetic Algorithm)を用いて自動的に行う。すなわち、並列可能ループ文群に対して、GPU実行の際を1、CPU実行の際を0に値を置いて遺伝子化し、検証環境で反復測定し適切なパターンを探索する。 <Loop statement found>
Currently, it is difficult for a compiler to find a match that this loop statement is suitable for GPU parallel processing. It is difficult to predict how much performance and power consumption will be achieved by offloading to the GPU without actually measuring it. Therefore, an instruction to offload this loop statement to the GPU is manually performed, and trial and error measurements are performed.
The present invention automatically finds appropriate loop statements to offload to the GPU using a genetic algorithm (GA), which is an evolutionary computation technique. That is, for a group of parallelizable loop statements, 1 is set for GPU execution and 0 is set for CPU execution to generate a gene, and an appropriate pattern is searched for by repeated measurement in a verification environment.
コンパイラが、このループ文はGPUの並列処理に適しているという適合性を見つけることは難しいのが現状である。GPUにオフロードすることでどの程度の性能、電力消費量になるかは、実測してみないと予測は難しい。そのため、このループ文をGPUにオフロードするという指示を手動で行い、測定の試行錯誤が行われている。
本発明は、GPUにオフロードする適切なループ文の発見を、進化計算手法である遺伝的アルゴリズム(GA:Genetic Algorithm)を用いて自動的に行う。すなわち、並列可能ループ文群に対して、GPU実行の際を1、CPU実行の際を0に値を置いて遺伝子化し、検証環境で反復測定し適切なパターンを探索する。 <Loop statement found>
Currently, it is difficult for a compiler to find a match that this loop statement is suitable for GPU parallel processing. It is difficult to predict how much performance and power consumption will be achieved by offloading to the GPU without actually measuring it. Therefore, an instruction to offload this loop statement to the GPU is manually performed, and trial and error measurements are performed.
The present invention automatically finds appropriate loop statements to offload to the GPU using a genetic algorithm (GA), which is an evolutionary computation technique. That is, for a group of parallelizable loop statements, 1 is set for GPU execution and 0 is set for CPU execution to generate a gene, and an appropriate pattern is searched for by repeated measurement in a verification environment.
(第1の実施形態)
次に、本発明を実施するための形態(以下、「本実施形態」と称する。)における、オフロードサーバ1等について説明する。 (First embodiment)
Next, theoffload server 1 and the like in the mode for carrying out the present invention (hereinafter referred to as "this embodiment") will be described.
次に、本発明を実施するための形態(以下、「本実施形態」と称する。)における、オフロードサーバ1等について説明する。 (First embodiment)
Next, the
[ループ文のGPU自動オフロード]
図1は、本発明の第1の実施形態に係るオフロードサーバ1の構成例を示す機能ブロック図である。
オフロードサーバ1は、アプリケーションの特定処理をアクセラレータに自動的にオフロードする装置である。
図1に示すように、オフロードサーバ1は、制御部11と、入出力部12と、記憶部13と、検証用マシン14(Verification machine)(アクセラレータ検証用装置)と、を含んで構成される。 [GPU automatic offload of loop statement]
FIG. 1 is a functional block diagram showing a configuration example of anoffload server 1 according to the first embodiment of the present invention.
Theoffload server 1 is a device that automatically offloads specific processing of an application to an accelerator.
As shown in FIG. 1, theoffload server 1 includes a control unit 11, an input/output unit 12, a storage unit 13, and a verification machine 14 (accelerator verification device). be.
図1は、本発明の第1の実施形態に係るオフロードサーバ1の構成例を示す機能ブロック図である。
オフロードサーバ1は、アプリケーションの特定処理をアクセラレータに自動的にオフロードする装置である。
図1に示すように、オフロードサーバ1は、制御部11と、入出力部12と、記憶部13と、検証用マシン14(Verification machine)(アクセラレータ検証用装置)と、を含んで構成される。 [GPU automatic offload of loop statement]
FIG. 1 is a functional block diagram showing a configuration example of an
The
As shown in FIG. 1, the
入出力部12は、各デバイス等との間で情報の送受信を行うための通信インターフェイスと、タッチパネルやキーボード等の入力装置や、モニタ等の出力装置との間で情報の送受信を行うための入出力インターフェイスとから構成される。
The input/output unit 12 includes a communication interface for transmitting/receiving information to/from each device, etc., an input device for transmitting/receiving information to/from an input device such as a touch panel or a keyboard, or an output device such as a monitor. It consists of an output interface.
記憶部13は、ハードディスクやフラッシュメモリ、RAM(Random Access Memory)等により構成され、制御部11の各機能を実行させるためのプログラム(オフロードプログラム)や、制御部11の処理に必要な情報(例えば、中間言語ファイル(Intermediate file)133)が一時的に記憶される。
The storage unit 13 is composed of a hard disk, flash memory, RAM (Random Access Memory), etc., and stores a program (offload program) for executing each function of the control unit 11 and information necessary for processing of the control unit 11 ( For example, an intermediate language file (Intermediate file) 133) is temporarily stored.
記憶部13は、テストケースDB(Test case database)131、設備リソースDB132、中間言語ファイル(Intermediate file)133を備える。
The storage unit 13 includes a test case DB (Test case database) 131, an equipment resource DB 132, and an intermediate language file (Intermediate file) 133.
テストケースDB131は、検証対象ソフトに対応した試験項目のデータを格納する。試験項目のデータは、例えばMySQL等のデータベースシステムの場合、TPC-C等のトランザクション試験のデータである。
The test case DB 131 stores test item data corresponding to the software to be verified. The test item data is, for example, transaction test data such as TPC-C in the case of a database system such as MySQL.
設備リソースDB132は、事業者が保持するサーバ等のリソースと価格等の事前に準備された情報と、それらがどの程度使われているかの情報を保持する。例えばGPUインスタンスを3収容できるサーバが10台あり、1GPUインスタンスは月5000円であり、10台のうち、A,Bの2台はフルに使われており、Cの1台はインスタンスが1つだけ使われている等の情報である。この情報は、ユーザが運用条件(コスト、性能等の条件)を指定した際に、確保するリソース量を決定するために利用される。ユーザ運用条件は、ユーザがオフロード依頼時に指定したコスト条件(例えば、月10000円以内の予算等)と性能条件(例えば、TPC-C等のトランザクションスループットが何以上やサンプルフーリエ変換処理が1スレッドで何秒以内等)である。
The facility resource DB 132 holds resources such as servers held by the business operator, information prepared in advance such as prices, and information on how much they are used. For example, there are 10 servers that can accommodate 3 GPU instances, and 1 GPU instance costs 5000 yen per month. It is information that is only used. This information is used to determine the amount of resources to be secured when the user specifies operating conditions (conditions such as cost and performance). The user operating conditions are the cost conditions specified by the user at the time of the offload request (for example, budget within 10,000 yen per month) and performance conditions (for example, transaction throughput such as TPC-C is above or above, sample Fourier transform processing is 1 thread) within how many seconds, etc.).
中間言語ファイル133は、高水準言語と機械語の中間に介在するプログラミング言語の形で制御部11の処理に必要な情報を一時的に記憶する。
The intermediate language file 133 temporarily stores information necessary for the processing of the control unit 11 in the form of a programming language interposed between the high-level language and the machine language.
検証用マシン14は、環境適応ソフトウェアの検証用環境として、CPU、GPU、FPGAを備える。
The verification machine 14 is equipped with a CPU, GPU, and FPGA as a verification environment for environment-adaptive software.
制御部11は、オフロードサーバ1全体の制御を司る自動オフロード機能部(Automatic Offloading function)である。制御部11は、例えば、記憶部13に格納されたアプリケーションプログラム(オフロードプログラム)を不図示のCPU(Central Processing Unit)が、RAMに展開し実行することにより実現される。
The control unit 11 is an automatic offloading function that controls the offload server 1 as a whole. The control unit 11 is implemented, for example, by a CPU (Central Processing Unit) (not shown) expanding an application program (offload program) stored in the storage unit 13 into a RAM and executing the application program.
制御部11は、アプリケーションコード指定部(Specify application code)111と、アプリケーションコード分析部(Analyze application code)112と、データ転送指定部113と、並列処理指定部114と、リソース比決定部115と、リソース量設定部116と、配置設定部170と、並列処理パターン作成部117と、性能測定部118と、実行ファイル作成部119と、本番環境配置部(Deploy final binary files to production environment)120と、性能測定テスト抽出実行部(Extract performance test cases and run automatically)121と、ユーザ提供部(Provide price and performance to a user to judge)122と、を備える。
The control unit 11 includes an application code specifying unit (Specify application code) 111, an application code analyzing unit (Analyze application code) 112, a data transfer specifying unit 113, a parallel processing specifying unit 114, a resource ratio determining unit 115, A resource amount setting unit 116, a placement setting unit 170, a parallel processing pattern creation unit 117, a performance measurement unit 118, an execution file creation unit 119, a production environment placement unit (Deploy final binary files to production environment) 120, It has a performance measurement test extract execution unit (Extract performance test cases and run automatically) 121 and a user provision unit (Provide price and performance to a user to judge) 122 .
<アプリケーションコード指定部111>
アプリケーションコード指定部111は、入力されたアプリケーションコードの指定を行う。具体的には、アプリケーションコード指定部111は、受信したファイルに記載されたアプリケーションコードを、アプリケーションコード分析部112に渡す。 <Applicationcode designation unit 111>
The applicationcode designation unit 111 designates an input application code. Specifically, the application code designation unit 111 passes the application code described in the received file to the application code analysis unit 112 .
アプリケーションコード指定部111は、入力されたアプリケーションコードの指定を行う。具体的には、アプリケーションコード指定部111は、受信したファイルに記載されたアプリケーションコードを、アプリケーションコード分析部112に渡す。 <Application
The application
<アプリケーションコード分析部112>
アプリケーションコード分析部112は、処理機能のソースコードを分析し、ループ文やFFTライブラリ呼び出し等の構造を把握する。 <Applicationcode analysis unit 112>
The applicationcode analysis unit 112 analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
アプリケーションコード分析部112は、処理機能のソースコードを分析し、ループ文やFFTライブラリ呼び出し等の構造を把握する。 <Application
The application
<データ転送指定部113>
データ転送指定部113は、アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行(後記する#pragma acc kernels、#pragma acc data copyin(a,b)、#pragma acc data copyout(a,b)、#prama acc parallel loop、#prama acc parallel loop vectorなど)を用いたデータ転送指定を行う。 <Datatransfer designation unit 113>
The datatransfer specification unit 113 analyzes the reference relationships of variables used in loop statements of the application program, and explicitly specifies data transfer outside the loop for data that may be transferred outside the loop. using target specification lines (#pragma acc kernels, #pragma acc data copyin(a, b), #pragma acc data copyout(a, b), #prama acc parallel loop, #prama acc parallel loop vector, etc.) Specify data transfer.
データ転送指定部113は、アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行(後記する#pragma acc kernels、#pragma acc data copyin(a,b)、#pragma acc data copyout(a,b)、#prama acc parallel loop、#prama acc parallel loop vectorなど)を用いたデータ転送指定を行う。 <Data
The data
<並列処理指定部114>
並列処理指定部114は、アプリケーションプログラムのループ文(繰り返し文)を特定し、各ループ文に対して、アクセラレータにおける並列処理指定文を指定してコンパイルする。
並列処理指定部114は、オフロード範囲抽出部(Extract offload able area)114aと、中間言語ファイル出力部(Output intermediate file)114bと、を備える。 <Parallelprocessing designation unit 114>
The parallelprocessing designation unit 114 specifies loop statements (repetition statements) of the application program, and compiles each loop statement by designating a parallel processing designation statement in the accelerator.
The parallelprocessing designation unit 114 includes an extract offload able area 114a and an output intermediate file 114b.
並列処理指定部114は、アプリケーションプログラムのループ文(繰り返し文)を特定し、各ループ文に対して、アクセラレータにおける並列処理指定文を指定してコンパイルする。
並列処理指定部114は、オフロード範囲抽出部(Extract offload able area)114aと、中間言語ファイル出力部(Output intermediate file)114bと、を備える。 <Parallel
The parallel
The parallel
オフロード範囲抽出部114aは、ループ文やFFT等、GPU・FPGAにオフロード可能な処理を特定し、オフロード処理に応じた中間言語を抽出する。
中間言語ファイル出力部114bは、抽出した中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。 The offloadrange extraction unit 114a identifies processing that can be offloaded to the GPU/FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
The intermediate languagefile output unit 114b outputs the extracted intermediate language file 133. FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
中間言語ファイル出力部114bは、抽出した中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。 The offload
The intermediate language
<リソース比決定部115>
リソース比決定部115は、性能測定結果をもとに、CPUとオフロードデバイスの処理時間(テストケースCPU処理時間とオフロードデバイス処理時間)を、リソース比として決定する(後記)。具体的には、リソース比決定部115は、CPUとオフロードデバイスの処理時間が同等オーダになるように、リソース比を決定する。また、リソース比決定部115は、CPUとオフロードデバイスの処理時間の差分が所定閾値以上の場合、リソース比を所定の上限値に設定する。 <Resourceratio determination unit 115>
The resourceratio determination unit 115 determines the processing time of the CPU and the offload device (test case CPU processing time and offload device processing time) as the resource ratio based on the performance measurement result (described later). Specifically, the resource ratio determination unit 115 determines the resource ratio so that the processing times of the CPU and the offload device are of the same order. Further, when the difference between the processing times of the CPU and the offload device is equal to or greater than a predetermined threshold value, the resource ratio determination unit 115 sets the resource ratio to a predetermined upper limit value.
リソース比決定部115は、性能測定結果をもとに、CPUとオフロードデバイスの処理時間(テストケースCPU処理時間とオフロードデバイス処理時間)を、リソース比として決定する(後記)。具体的には、リソース比決定部115は、CPUとオフロードデバイスの処理時間が同等オーダになるように、リソース比を決定する。また、リソース比決定部115は、CPUとオフロードデバイスの処理時間の差分が所定閾値以上の場合、リソース比を所定の上限値に設定する。 <Resource
The resource
<リソース量設定部116>
リソース量設定部116は、決定したリソース比をもとに、所定のコスト条件を満たすように、CPUおよびオフロードデバイスのリソース量を設定する(後記)。具体的には、リソース量設定部116は、決定したリソース比を維持して、所定のコスト条件を満たす最大のリソース量を設定する。また、リソース量設定部116は、決定したリソース比を維持した最小リソース量の設定で所定のコスト条件を満たさない場合は、リソース比を崩してCPUとオフロードデバイスのリソース量をコスト条件を満たすより小さい値(例えば、最小)で設定する。 <Resourceamount setting unit 116>
Based on the determined resource ratio, the resourceamount setting unit 116 sets the resource amount of the CPU and the offload device so as to satisfy a predetermined cost condition (described later). Specifically, the resource amount setting unit 116 maintains the determined resource ratio and sets the maximum resource amount that satisfies a predetermined cost condition. In addition, if the predetermined cost condition is not satisfied by setting the minimum resource amount while maintaining the determined resource ratio, the resource amount setting unit 116 breaks the resource ratio and sets the resource amounts of the CPU and the offload device to satisfy the cost condition. Set with a smaller value (e.g. minimum).
リソース量設定部116は、決定したリソース比をもとに、所定のコスト条件を満たすように、CPUおよびオフロードデバイスのリソース量を設定する(後記)。具体的には、リソース量設定部116は、決定したリソース比を維持して、所定のコスト条件を満たす最大のリソース量を設定する。また、リソース量設定部116は、決定したリソース比を維持した最小リソース量の設定で所定のコスト条件を満たさない場合は、リソース比を崩してCPUとオフロードデバイスのリソース量をコスト条件を満たすより小さい値(例えば、最小)で設定する。 <Resource
Based on the determined resource ratio, the resource
<配置設定部170>
配置設定部170は、変換したアプリケーションを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションの配置場所を計算して設定する。具体的には、配置設定部170は、設備リソースDB132のサーバ、リンクのスペック情報、既存アプリケーションの配置情報に基づいて、線形計画手法で、新規アプリケーションの配置先(APLの配置場所)を計算して設定する。線形計画手法では、例えば、後記[数1][数2]に示す線形計画式の目的関数および制約条件を用いる。後記[数1][数2]に示す線形計画式は、設備リソースDB132に保存されており、配置設定部170が、設備リソースDB132から読み出し、配置設定部170が処理するメモリ上で展開される。 <Placement setting unit 170>
Theplacement setting unit 170, when placing the converted application on any of the cloud server, the carrier edge server, and the user edge server on the network, according to the cost or response time conditions specified by the user, determines the devices and links. , the computational resource upper limit, and the bandwidth upper limit as constraints, and the cost of the computational resource or the response time as the objective function, the application location is calculated and set. Specifically, the placement setting unit 170 calculates the placement location of the new application (the placement location of the APL) by a linear programming method based on the server of the equipment resource DB 132, the specification information of the link, and the placement information of the existing application. to set. The linear programming method uses, for example, the objective function and constraint conditions of the linear programming formulas shown in [Equation 1] and [Equation 2] below. The linear programming formulas shown in [Equation 1] and [Equation 2] below are stored in the equipment resource DB 132, and are read out from the equipment resource DB 132 by the layout setting unit 170, and expanded on the memory processed by the layout setting unit 170. .
配置設定部170は、変換したアプリケーションを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションの配置場所を計算して設定する。具体的には、配置設定部170は、設備リソースDB132のサーバ、リンクのスペック情報、既存アプリケーションの配置情報に基づいて、線形計画手法で、新規アプリケーションの配置先(APLの配置場所)を計算して設定する。線形計画手法では、例えば、後記[数1][数2]に示す線形計画式の目的関数および制約条件を用いる。後記[数1][数2]に示す線形計画式は、設備リソースDB132に保存されており、配置設定部170が、設備リソースDB132から読み出し、配置設定部170が処理するメモリ上で展開される。 <
The
<並列処理パターン作成部117>
並列処理パターン作成部117は、コンパイルエラーが出るループ文(繰り返し文)に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する。 <Parallel processingpattern creation unit 117>
The parallel processingpattern creation unit 117 excludes loop statements (repeated statements) that cause compilation errors from being offloaded, and designates whether or not to execute parallel processing for repetitive statements that do not cause compilation errors. Create a parallel processing pattern to do.
並列処理パターン作成部117は、コンパイルエラーが出るループ文(繰り返し文)に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する。 <Parallel processing
The parallel processing
<性能測定部118>
性能測定部118は、並列処理パターンのアプリケーションプログラムをコンパイルして、検証用マシン14に配置し、アクセラレータにオフロードした際の性能測定用処理を実行する。
性能測定部118は、バイナリファイル配置部(Deploy binary files)118aを備える。バイナリファイル配置部118aは、GPUやFPGAを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイ(配置)する。 <Performance measurement unit 118>
Theperformance measurement unit 118 compiles the parallel processing pattern application program, places it in the verification machine 14, and executes performance measurement processing when offloaded to the accelerator.
Theperformance measurement unit 118 includes a Deploy binary files unit 118a. The binary file placement unit 118a deploys (places) an execution file derived from the intermediate language to the verification machine 14 having a GPU or FPGA.
性能測定部118は、並列処理パターンのアプリケーションプログラムをコンパイルして、検証用マシン14に配置し、アクセラレータにオフロードした際の性能測定用処理を実行する。
性能測定部118は、バイナリファイル配置部(Deploy binary files)118aを備える。バイナリファイル配置部118aは、GPUやFPGAを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイ(配置)する。 <
The
The
性能測定部118は、配置したバイナリファイルを実行し、オフロードした際の性能を測定するとともに、性能測定結果を、オフロード範囲抽出部114aに戻す。この場合、オフロード範囲抽出部114aは、別の並列処理パターン抽出を行い、中間言語ファイル出力部114bは、抽出された中間言語をもとに、性能測定を試行する(後記図2の符号a参照)。
The performance measurement unit 118 executes the arranged binary file, measures the performance when offloading, and returns the performance measurement result to the offload range extraction unit 114a. In this case, the offload range extraction unit 114a extracts another parallel processing pattern, and the intermediate language file output unit 114b attempts performance measurement based on the extracted intermediate language (marked a in FIG. 2 described later). reference).
<実行ファイル作成部119>
実行ファイル作成部119は、所定回数繰り返された、性能測定結果をもとに、複数の並列処理パターンから高処理性能の並列処理パターンを複数選択し、高処理性能の並列処理パターンを交叉、突然変異処理により別の複数の並列処理パターンを作成する。そして、実行ファイル作成部119は、新たに性能測定までを行い、指定回数の性能測定後に、性能測定結果をもとに、複数の並列処理パターンから最高処理性能の並列処理パターンを選択し、最高処理性能の並列処理パターンをコンパイルして実行ファイルを作成する。 <ExecutableFile Creation Unit 119>
The executionfile creation unit 119 selects a plurality of parallel processing patterns with high processing performance from among a plurality of parallel processing patterns based on the performance measurement results repeated a predetermined number of times, crosses the parallel processing patterns with high processing performance, and suddenly Mutation processing creates different parallel processing patterns. Then, the executable file creation unit 119 newly performs performance measurement, and after performing the performance measurement for the specified number of times, selects the parallel processing pattern with the highest processing performance from among a plurality of parallel processing patterns based on the performance measurement result, and selects the parallel processing pattern with the highest processing performance. Compile the parallel processing pattern of processing performance and create an executable file.
実行ファイル作成部119は、所定回数繰り返された、性能測定結果をもとに、複数の並列処理パターンから高処理性能の並列処理パターンを複数選択し、高処理性能の並列処理パターンを交叉、突然変異処理により別の複数の並列処理パターンを作成する。そして、実行ファイル作成部119は、新たに性能測定までを行い、指定回数の性能測定後に、性能測定結果をもとに、複数の並列処理パターンから最高処理性能の並列処理パターンを選択し、最高処理性能の並列処理パターンをコンパイルして実行ファイルを作成する。 <Executable
The execution
<本番環境配置部120>
本番環境配置部120は、作成した実行ファイルを、ユーザ向けの本番環境に配置する(「最終バイナリファイルの本番環境への配置」)。本番環境配置部120は、最終的なオフロード領域を指定したパターンを決定し、ユーザ向けの本番環境にデプロイする。 <Productionenvironment placement unit 120>
The productionenvironment placement unit 120 places the created executable file in the production environment for the user (“place final binary file in production environment”). The production environment placement unit 120 determines a pattern specifying the final offload area, and deploys it in the production environment for users.
本番環境配置部120は、作成した実行ファイルを、ユーザ向けの本番環境に配置する(「最終バイナリファイルの本番環境への配置」)。本番環境配置部120は、最終的なオフロード領域を指定したパターンを決定し、ユーザ向けの本番環境にデプロイする。 <Production
The production
<性能測定テスト抽出実行部121>
性能測定テスト抽出実行部121は、実行ファイル配置後、テストケースDB131から性能試験項目を抽出し、性能試験を実行する(「最終バイナリファイルの本番環境への配置」)。
性能測定テスト抽出実行部121は、実行ファイル配置後、ユーザに性能を示すため、性能試験項目をテストケースDB131から抽出し、抽出した性能試験を自動実行する。 <Performance measurement testextraction execution unit 121>
After arranging the execution files, the performance measurement testextraction execution unit 121 extracts performance test items from the test case DB 131 and executes the performance test (“arrangement of the final binary file to the production environment”).
After arranging the executable file, the performance measurement testextraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user.
性能測定テスト抽出実行部121は、実行ファイル配置後、テストケースDB131から性能試験項目を抽出し、性能試験を実行する(「最終バイナリファイルの本番環境への配置」)。
性能測定テスト抽出実行部121は、実行ファイル配置後、ユーザに性能を示すため、性能試験項目をテストケースDB131から抽出し、抽出した性能試験を自動実行する。 <Performance measurement test
After arranging the execution files, the performance measurement test
After arranging the executable file, the performance measurement test
<ユーザ提供部122>
ユーザ提供部122は、性能試験結果を踏まえた、価格・性能等の情報をユーザに提示する(「価格・性能等の情報のユーザへの提供」)。テストケースDB131には、性能試験項目が格納されている。ユーザ提供部122は、テストケースDB131に格納された試験項目に対応した性能試験の実施結果に基づいて、価格、性能等のデータを、上記性能試験結果と共にユーザに提示する。ユーザは、提示された価格・性能等の情報をもとに、サービスの課金利用開始を判断する。ここで、本番環境への一括デプロイには、非特許文献7(Y. Yamato, M. Muroi, K. Tanaka and M. Uchimura, “Development of Template Management Technology for Easy Deployment of Virtual Resources on OpenStack,” Journal of Cloud Computing, Springer, 2014, 3:7, DOI: 10.1206/s13677-014-0007-3, 12 pages, June 2014.)の技術を、また、性能自動試験には、前述の非特許文献6の技術を用いればよい。 <User provision unit 122>
Theuser providing unit 122 presents information such as price/performance to the user based on the performance test results (“Provision of information such as price/performance to the user”). The test case DB 131 stores performance test items. The user provision unit 122 presents data such as price and performance to the user along with the performance test results based on the performance test results corresponding to the test items stored in the test case DB 131 . Based on the presented information such as price and performance, the user decides to start using the service for a fee. Here, non-patent document 7 (Y. Yamato, M. Muroi, K. Tanaka and M. Uchimura, “Development of Template Management Technology for Easy Deployment of Virtual Resources on OpenStack,” Journal of Cloud Computing, Springer, 2014, 3:7, DOI: 10.1206/s13677-014-0007-3, 12 pages, June 2014.). 6 technique may be used.
ユーザ提供部122は、性能試験結果を踏まえた、価格・性能等の情報をユーザに提示する(「価格・性能等の情報のユーザへの提供」)。テストケースDB131には、性能試験項目が格納されている。ユーザ提供部122は、テストケースDB131に格納された試験項目に対応した性能試験の実施結果に基づいて、価格、性能等のデータを、上記性能試験結果と共にユーザに提示する。ユーザは、提示された価格・性能等の情報をもとに、サービスの課金利用開始を判断する。ここで、本番環境への一括デプロイには、非特許文献7(Y. Yamato, M. Muroi, K. Tanaka and M. Uchimura, “Development of Template Management Technology for Easy Deployment of Virtual Resources on OpenStack,” Journal of Cloud Computing, Springer, 2014, 3:7, DOI: 10.1206/s13677-014-0007-3, 12 pages, June 2014.)の技術を、また、性能自動試験には、前述の非特許文献6の技術を用いればよい。 <
The
[遺伝的アルゴリズムの適用]
オフロードサーバ1は、オフロードの最適化にGA(Genetic Algorithms)を用いることができる。GAを用いた場合のオフロードサーバ1の構成は下記の通りである。
すなわち、並列処理指定部114は、遺伝的アルゴリズムに基づき、コンパイルエラーが出ないループ文(繰り返し文)の数を遺伝子長とする。並列処理パターン作成部117は、アクセラレータ処理をする場合を1または0のいずれか一方、しない場合を他方の0または1として、アクセラレータ処理可否を遺伝子パターンにマッピングする。 [Application of genetic algorithm]
Theoffload server 1 can use GA (Genetic Algorithms) for offload optimization. The configuration of the offload server 1 when using GA is as follows.
That is, the parallelprocessing specifying unit 114 sets the gene length to the number of loop statements (repeated statements) that do not cause compilation errors based on the genetic algorithm. The parallel processing pattern creation unit 117 maps the availability of accelerator processing to the gene pattern by assigning either 1 or 0 when accelerator processing is to be performed, and the other 0 or 1 when not performing accelerator processing.
オフロードサーバ1は、オフロードの最適化にGA(Genetic Algorithms)を用いることができる。GAを用いた場合のオフロードサーバ1の構成は下記の通りである。
すなわち、並列処理指定部114は、遺伝的アルゴリズムに基づき、コンパイルエラーが出ないループ文(繰り返し文)の数を遺伝子長とする。並列処理パターン作成部117は、アクセラレータ処理をする場合を1または0のいずれか一方、しない場合を他方の0または1として、アクセラレータ処理可否を遺伝子パターンにマッピングする。 [Application of genetic algorithm]
The
That is, the parallel
並列処理パターン作成部117は、遺伝子の各値を1か0にランダムに作成した指定個体数の遺伝子パターンを準備する。性能測定部118は、各個体に応じて、アクセラレータにおける並列処理指定文を指定したアプリケーションコードをコンパイルして、検証用マシン14に配置する。性能測定部118は、検証用マシン14において性能測定用処理を実行する。
The parallel processing pattern creation unit 117 prepares a gene pattern for a specified number of individuals in which each value of the gene is randomly created to be 1 or 0. The performance measurement unit 118 compiles the application code specifying the parallel processing specifying statement in the accelerator according to each individual, and places it in the verification machine 14 . The performance measurement unit 118 executes performance measurement processing in the verification machine 14 .
ここで、性能測定部118は、途中世代で、以前と同じ並列処理パターンの遺伝子が生じた場合は、当該並列処理パターンに該当するアプリケーションコードのコンパイル、および、性能測定はせずに、性能測定値としては同じ値を使う。
また、性能測定部118は、コンパイルエラーが生じるアプリケーションコード、および、性能測定が所定時間で終了しないアプリケーションコードについては、タイムアウトの扱いとして、性能測定値を所定の時間(長時間)に設定する。 Here, if a gene with the same parallel processing pattern as before occurs in an intermediate generation, theperformance measurement unit 118 does not compile and measure the performance of the application code corresponding to the parallel processing pattern. Use the same value.
In addition, theperformance measurement unit 118 sets the performance measurement value to a predetermined time (long time) as a time-out for an application code that causes a compile error and an application code whose performance measurement does not end within a predetermined time.
また、性能測定部118は、コンパイルエラーが生じるアプリケーションコード、および、性能測定が所定時間で終了しないアプリケーションコードについては、タイムアウトの扱いとして、性能測定値を所定の時間(長時間)に設定する。 Here, if a gene with the same parallel processing pattern as before occurs in an intermediate generation, the
In addition, the
実行ファイル作成部119は、全個体に対して、性能測定を行い、処理時間の短い個体ほど適合度が高くなるように評価する。実行ファイル作成部119は、全個体から、適合度が所定値(例えば、全個数の上位n%、または全個数の上位m個 n,mは自然数)より高いものを性能の高い個体として選択し、選択された個体に対して、交叉、突然変異の処理を行い、次世代の個体を作成する。実行ファイル作成部119は、指定世代数の処理終了後、最高性能の並列処理パターンを解として選択する。
The executable file creation unit 119 performs performance measurement on all individuals, and evaluates individuals with shorter processing times so that the degree of fitness is higher. The execution file creation unit 119 selects individuals whose fitness is higher than a predetermined value (for example, the top n% of all individuals, or the top m of all individuals, where n and m are natural numbers) as individuals with high performance. , the selected individual is crossover and mutated to create the next generation individual. The execution file creating unit 119 selects the parallel processing pattern with the highest performance as a solution after the specified number of generations have been processed.
以下、上述のように構成されたオフロードサーバ1の自動オフロード動作について説明する。
[自動オフロード動作]
図2は、オフロードサーバ1を用いた自動オフロード処理を示す図である。
図2に示すように、オフロードサーバ1は、環境適応ソフトウェアの要素技術に適用される。オフロードサーバ1は、制御部(自動オフロード機能部)11と、テストケースDB131と、設備リソースDB132と、中間言語ファイル133と、検証用マシン14と、を有している。
オフロードサーバ1は、ユーザが利用するアプリケーションコード(Application code)125を取得する。 The automatic offload operation of theoffload server 1 configured as described above will be described below.
[Auto Offload Operation]
FIG. 2 is a diagram showing automatic offload processing using theoffload server 1. As shown in FIG.
As shown in FIG. 2, theoffload server 1 is applied to elemental technology of environment adaptive software. The offload server 1 has a control unit (automatic offload function unit) 11 , a test case DB 131 , an equipment resource DB 132 , an intermediate language file 133 and a verification machine 14 .
Theoffload server 1 acquires an application code 125 used by the user.
[自動オフロード動作]
図2は、オフロードサーバ1を用いた自動オフロード処理を示す図である。
図2に示すように、オフロードサーバ1は、環境適応ソフトウェアの要素技術に適用される。オフロードサーバ1は、制御部(自動オフロード機能部)11と、テストケースDB131と、設備リソースDB132と、中間言語ファイル133と、検証用マシン14と、を有している。
オフロードサーバ1は、ユーザが利用するアプリケーションコード(Application code)125を取得する。 The automatic offload operation of the
[Auto Offload Operation]
FIG. 2 is a diagram showing automatic offload processing using the
As shown in FIG. 2, the
The
ユーザは、例えば、各種デバイス(Device151、CPU-GPUを有する装置152、CPU-FPGAを有する装置153、CPUを有する装置154)の利用を契約した人である。
オフロードサーバ1は、機能処理をCPU-GPUを有する装置152、CPU-FPGAを有する装置153のアクセラレータに自動オフロードする。 The user is, for example, a person who has made a contract to use various devices (Device 151, device 152 having CPU-GPU, device 153 having CPU-FPGA, device 154 having CPU).
Theoffload server 1 automatically offloads functional processing to the accelerators of the device 152 with CPU-GPU and the device 153 with CPU-FPGA.
オフロードサーバ1は、機能処理をCPU-GPUを有する装置152、CPU-FPGAを有する装置153のアクセラレータに自動オフロードする。 The user is, for example, a person who has made a contract to use various devices (
The
以下、図2のステップ番号を参照して各部の動作を説明する。
<ステップS11:Specify application code>
ステップS11において、アプリケーションコード指定部111(図1参照)は、受信したファイルに記載されたアプリケーションコードを、アプリケーションコード分析部112に渡す。 The operation of each part will be described below with reference to the step numbers in FIG.
<Step S11: Specify application code>
In step S<b>11 , the application code designation unit 111 (see FIG. 1 ) passes the application code written in the received file to the applicationcode analysis unit 112 .
<ステップS11:Specify application code>
ステップS11において、アプリケーションコード指定部111(図1参照)は、受信したファイルに記載されたアプリケーションコードを、アプリケーションコード分析部112に渡す。 The operation of each part will be described below with reference to the step numbers in FIG.
<Step S11: Specify application code>
In step S<b>11 , the application code designation unit 111 (see FIG. 1 ) passes the application code written in the received file to the application
<ステップS12:Analyze application code>
ステップS12において、アプリケーションコード分析部112(図1参照)は、処理機能のソースコードを分析し、ループ文やFFTライブラリ呼び出し等の構造を把握する。 <Step S12: Analyze application code>
In step S12, the application code analysis unit 112 (see FIG. 1) analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
ステップS12において、アプリケーションコード分析部112(図1参照)は、処理機能のソースコードを分析し、ループ文やFFTライブラリ呼び出し等の構造を把握する。 <Step S12: Analyze application code>
In step S12, the application code analysis unit 112 (see FIG. 1) analyzes the source code of the processing function and grasps structures such as loop statements and FFT library calls.
<ステップS13:Extract offloadable area>
ステップS13において、並列処理指定部114(図1参照)は、アプリケーションのループ文(繰り返し文)を特定し、各繰り返し文に対して、アクセラレータにおける並列処理指定文を指定してコンパイルする。具体的には、オフロード範囲抽出部114a(図1参照)は、ループ文やFFT等、GPU・FPGAにオフロード可能な処理を特定し、オフロード処理に応じた中間言語を抽出する。 <Step S13: Extract offloadable area>
In step S13, the parallel processing designation unit 114 (see FIG. 1) identifies loop statements (repetition statements) of the application, and compiles each repetition statement by designating a parallel processing designation statement in the accelerator. Specifically, the offloadrange extraction unit 114a (see FIG. 1) identifies processing that can be offloaded to the GPU/FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
ステップS13において、並列処理指定部114(図1参照)は、アプリケーションのループ文(繰り返し文)を特定し、各繰り返し文に対して、アクセラレータにおける並列処理指定文を指定してコンパイルする。具体的には、オフロード範囲抽出部114a(図1参照)は、ループ文やFFT等、GPU・FPGAにオフロード可能な処理を特定し、オフロード処理に応じた中間言語を抽出する。 <Step S13: Extract offloadable area>
In step S13, the parallel processing designation unit 114 (see FIG. 1) identifies loop statements (repetition statements) of the application, and compiles each repetition statement by designating a parallel processing designation statement in the accelerator. Specifically, the offload
<ステップS14:Output intermediate file>
ステップS14において、中間言語ファイル出力部114b(図1参照)は、中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。 <Step S14: Output intermediate file>
In step S14, the intermediate languagefile output unit 114b (see FIG. 1) outputs the intermediate language file 133. FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
ステップS14において、中間言語ファイル出力部114b(図1参照)は、中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。 <Step S14: Output intermediate file>
In step S14, the intermediate language
<ステップS15:Compile error>
ステップS15において、並列処理パターン作成部117(図1参照)は、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する。 <Step S15: Compile error>
In step S15, the parallel processing pattern creation unit 117 (see FIG. 1) excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors are processed in parallel. Create a parallel processing pattern that specifies whether or not.
ステップS15において、並列処理パターン作成部117(図1参照)は、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する。 <Step S15: Compile error>
In step S15, the parallel processing pattern creation unit 117 (see FIG. 1) excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors are processed in parallel. Create a parallel processing pattern that specifies whether or not.
<ステップS21:Deploy binary files>
ステップS21において、バイナリファイル配置部118a(図1参照)は、GPU・FPGAを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイする。 <Step S21: Deploy binary files>
In step S21, the binaryfile placement unit 118a (see FIG. 1) deploys the execution file derived from the intermediate language to the verification machine 14 equipped with GPU/FPGA.
ステップS21において、バイナリファイル配置部118a(図1参照)は、GPU・FPGAを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイする。 <Step S21: Deploy binary files>
In step S21, the binary
<ステップS22:Measure performances>
ステップS22において、性能測定部118(図1参照)は、配置したファイルを実行し、オフロードした際の性能を測定する。
オフロードする領域をより適切にするため、この性能測定結果は、オフロード範囲抽出部114aに戻され、オフロード範囲抽出部114aが、別パターンの抽出を行う。そして、中間言語ファイル出力部114bは、抽出された中間言語をもとに、性能測定を試行する(図2の符号a参照)。 <Step S22: Measure performance>
In step S22, the performance measurement unit 118 (see FIG. 1) executes the placed file and measures the performance when offloading.
In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offloadrange extraction unit 114a, and the offload range extraction unit 114a extracts another pattern. Then, the intermediate language file output unit 114b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2).
ステップS22において、性能測定部118(図1参照)は、配置したファイルを実行し、オフロードした際の性能を測定する。
オフロードする領域をより適切にするため、この性能測定結果は、オフロード範囲抽出部114aに戻され、オフロード範囲抽出部114aが、別パターンの抽出を行う。そして、中間言語ファイル出力部114bは、抽出された中間言語をもとに、性能測定を試行する(図2の符号a参照)。 <Step S22: Measure performance>
In step S22, the performance measurement unit 118 (see FIG. 1) executes the placed file and measures the performance when offloading.
In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offload
図2の符号aに示すように、制御部11は、上記ステップS12乃至ステップS22を繰り返し実行する。制御部11の自動オフロード機能をまとめると、下記である。すなわち、並列処理指定部114は、アプリケーションプログラムのループ文(繰り返し文)を特定し、各繰返し文に対して、GPUでの並列処理指定文を指定して、コンパイルする。そして、並列処理パターン作成部117は、コンパイルエラーが出るループ文を、オフロード対象外とし、コンパイルエラーが出ないループ文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する。そして、バイナリファイル配置部118aは、該当並列処理パターンのアプリケーションプログラムをコンパイルして、検証用マシン14に配置し、性能測定部118が、検証用マシン14で性能測定用処理を実行する。実行ファイル作成部119は、所定回数繰り返された、性能測定結果をもとに、複数の並列処理パターンから最高処理性能のパターンを選択し、選択パターンをコンパイルして実行ファイルを作成する。
As indicated by symbol a in FIG. 2, the control unit 11 repeatedly executes steps S12 to S22. The automatic offload function of the control unit 11 is summarized below. That is, the parallel processing specification unit 114 specifies loop statements (repetition statements) of the application program, specifies a parallel processing specification statement in the GPU for each repetition statement, and compiles it. Then, the parallel processing pattern creation unit 117 creates a parallel processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to perform parallel processing for loop statements that do not cause compilation errors. do. Then, the binary file placement unit 118a compiles the application program of the parallel processing pattern and places it on the verification machine 14, and the performance measurement unit 118 executes the performance measurement processing on the verification machine 14. FIG. The execution file creation unit 119 selects a pattern with the highest processing performance from a plurality of parallel processing patterns based on the performance measurement results repeated a predetermined number of times, compiles the selected patterns, and creates an execution file.
<ステップS23:ユーザ運用条件によるリソース量設定>
ステップS23において、制御部11は、ユーザ運用条件によるリソース量設定を行う。すなわち、制御部11のリソース比決定部115は、CPUとオフロードデバイスのリソース比を決定する。そして、リソース量設定部116は、決定したリソース比をもとに、設備リソースDB132の情報を参照し、ユーザ運用条件を満たすように、CPUおよびオフロードデバイスのリソース量を設定する(図10により後記する)。 <Step S23: Resource amount setting according to user operating conditions>
In step S23, thecontrol unit 11 performs resource amount setting according to user operating conditions. That is, the resource ratio determination unit 115 of the control unit 11 determines the resource ratio between the CPU and the offload device. Based on the determined resource ratio, the resource amount setting unit 116 then refers to the information in the facility resource DB 132 and sets the resource amounts of the CPU and the offload device so as to satisfy the user operating conditions (see FIG. 10). described later).
ステップS23において、制御部11は、ユーザ運用条件によるリソース量設定を行う。すなわち、制御部11のリソース比決定部115は、CPUとオフロードデバイスのリソース比を決定する。そして、リソース量設定部116は、決定したリソース比をもとに、設備リソースDB132の情報を参照し、ユーザ運用条件を満たすように、CPUおよびオフロードデバイスのリソース量を設定する(図10により後記する)。 <Step S23: Resource amount setting according to user operating conditions>
In step S23, the
<ステップS24:Deploy final binary files to production environment>
ステップS24において、本番環境配置部120は、最終的なオフロード領域を指定したパターンを決定し、ユーザ向けの本番環境にデプロイする。 <Step S24: Deploy final binary files to production environment>
In step S<b>24 , the productionenvironment placement unit 120 determines a pattern specifying the final offload area, and deploys it to the production environment for the user.
ステップS24において、本番環境配置部120は、最終的なオフロード領域を指定したパターンを決定し、ユーザ向けの本番環境にデプロイする。 <Step S24: Deploy final binary files to production environment>
In step S<b>24 , the production
<ステップS25:Extract performance test cases and run automatically>
ステップS25において、性能測定テスト抽出実行部121は、実行ファイル配置後、ユーザに性能を示すため、性能試験項目をテストケースDB131から抽出し、抽出した性能試験を自動実行する。 <Step S25: Extract performance test cases and run automatically>
In step S25, the performance measurement testextraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user after the execution file is arranged.
ステップS25において、性能測定テスト抽出実行部121は、実行ファイル配置後、ユーザに性能を示すため、性能試験項目をテストケースDB131から抽出し、抽出した性能試験を自動実行する。 <Step S25: Extract performance test cases and run automatically>
In step S25, the performance measurement test
<ステップS26:Provide price and performance to a user to judge>
ステップS26において、ユーザ提供部122は、性能試験結果を踏まえた、価格・性能等の情報をユーザに提示する。ユーザは、提示された価格・性能等の情報をもとに、サービスの課金利用開始を判断する。 <Step S26: Provide price and performance to a user to judge>
In step S26, theuser providing unit 122 presents information such as price and performance to the user based on the performance test results. Based on the presented information such as price and performance, the user decides to start using the service for a fee.
ステップS26において、ユーザ提供部122は、性能試験結果を踏まえた、価格・性能等の情報をユーザに提示する。ユーザは、提示された価格・性能等の情報をもとに、サービスの課金利用開始を判断する。 <Step S26: Provide price and performance to a user to judge>
In step S26, the
上記ステップS11~ステップS26は、例えばユーザのサービス利用のバックグラウンドで行われ、例えば、仮利用の初日の間に行う等を想定している。
The above steps S11 to S26 are performed, for example, in the background when the user uses the service, and are assumed to be performed, for example, during the first day of provisional use.
上記したように、オフロードサーバ1の制御部(自動オフロード機能部)11は、環境適応ソフトウェアの要素技術に適用した場合、機能処理のオフロードのため、ユーザが利用するアプリケーションプログラムのソースコードから、オフロードする領域を抽出して中間言語を出力する(ステップS11~ステップS15)。制御部11は、中間言語から導かれる実行ファイルを、検証用マシン14に配置実行し、オフロード効果を検証する(ステップS21~ステップS22)。検証を繰り返し、適切なオフロード領域を定めたのち、制御部11は、実際にユーザに提供する本番環境に、実行ファイルをデプロイし、サービスとして提供する(ステップS23~ステップS26)。
As described above, the control unit (automatic offload function unit) 11 of the offload server 1, when applied to the element technology of the environment-adaptive software, for offloading the function processing, the source code of the application program used by the user , the offloaded area is extracted and the intermediate language is output (steps S11 to S15). The control unit 11 arranges and executes the execution file derived from the intermediate language on the verification machine 14, and verifies the offload effect (steps S21 to S22). After repeating verification and determining an appropriate offload area, the control unit 11 deploys the executable file in the production environment that is actually provided to the user and provides it as a service (steps S23 to S26).
[GAを用いたGPU自動オフロード]
GPU自動オフロードは、GPUに対して、図2のステップS12~ステップS22を繰り返し、最終的にステップS23でデプロイするオフロードコードを得るための処理である。 [GPU automatic offload using GA]
GPU automatic offloading is a process for repeating steps S12 to S22 in FIG. 2 for the GPU and finally obtaining the offload code to be deployed in step S23.
GPU自動オフロードは、GPUに対して、図2のステップS12~ステップS22を繰り返し、最終的にステップS23でデプロイするオフロードコードを得るための処理である。 [GPU automatic offload using GA]
GPU automatic offloading is a process for repeating steps S12 to S22 in FIG. 2 for the GPU and finally obtaining the offload code to be deployed in step S23.
GPUは、一般的にレイテンシーは保証しないが、並列処理によりスループットを高めることに向いたデバイスである。暗号化処理や、カメラ映像分析のための画像処理、大量センサデータ分析のための機械学習処理等が代表的であり、それらは、繰り返し処理が多い。そこで、アプリケーションの繰り返し文をGPUに自動でオフロードすることでの高速化を狙う。
GPUs generally do not guarantee latency, but they are devices suitable for increasing throughput through parallel processing. Encryption processing, image processing for camera video analysis, and machine learning processing for analyzing a large amount of sensor data are typical examples, and these are often repetitive processes. Therefore, we aim to increase the speed by automatically offloading repeated statements of the application to the GPU.
しかし、従来技術で記載の通り、高速化には適切な並列処理が必要である。特に、GPUを使う場合は、CPUとGPU間のメモリ転送のため、データサイズやループ回数が多くないと性能が出ないことが多い。また、メモリデータ転送のタイミング等により、並列高速化できる個々のループ文(繰り返し文)の組み合わせが、最速とならない場合等がある。例えば、10個のfor文(繰り返し文)で、1番、5番、10番の3つがCPUに比べて高速化できる場合に、1番、5番、10番の3つの組み合わせが最速になるとは限らない等である。
However, as described in the prior art, appropriate parallel processing is required for speeding up. In particular, when a GPU is used, performance often cannot be obtained unless the data size and the number of loops are large due to memory transfer between the CPU and the GPU. Also, depending on the timing of memory data transfer, etc., the combination of individual loop statements (repetition statements) that can be speeded up in parallel may not be the fastest. For example, if there are 10 for statements (repeated statements), and if the 1st, 5th, and 10th can be faster than the CPU, the combination of the 1st, 5th, and 10th will be the fastest. and so on.
適切な並列領域指定のため、PGIコンパイラを用いて、for文の並列可否を試行錯誤して最適化する試みがある。しかし、試行錯誤には多くの稼働がかかり、サービスとして提供する際に、ユーザの利用開始が遅くなり、コストも上がってしまう問題がある。
In order to specify the appropriate parallel area, there is an attempt to use the PGI compiler to optimize the parallelization of for statements through trial and error. However, trial and error requires a lot of operations, and when the service is provided, there is a problem that it delays the user's start of use and increases the cost.
そこで、本実施形態では、並列化を想定していない汎用プログラムから、自動で適切なオフロード領域を抽出する。このため、最初に並列可能for文のチェックを行い、次に並列可能for文群に対してGAを用いて検証環境で性能検証試行を反復し適切な領域を探索すること、を実現する。並列可能for文に絞った上で、遺伝子の部分の形で、高速化可能な並列処理パターンを保持し組み換えていくことで、取り得る膨大な並列処理パターンから、効率的に高速化可能なパターンを探索できる。
Therefore, in this embodiment, an appropriate offload area is automatically extracted from a general-purpose program that is not intended for parallelization. For this reason, the parallelizable for statement is checked first, and then the performance verification trial is repeated in the verification environment using the GA for the parallelizable for statement group to search for an appropriate area. After narrowing down to parallelizable for statements, by retaining and recombining parallel processing patterns that can be accelerated in the form of genes, patterns that can be efficiently accelerated from a huge number of possible parallel processing patterns can be explored.
[Simple GAによる制御部(自動オフロード機能部)11の探索イメージ]
図3は、Simple GAによる制御部(自動オフロード機能部)11の探索イメージを示す図である。図3は、処理の探索イメージと、for文の遺伝子配列マッピングを示す。
GAは、生物の進化過程を模倣した組合せ最適化手法の一つである。GAのフローチャートは、初期化→評価→選択→交叉→突然変異→終了判定となっている。
本実施形態では、GAの中で、処理を単純にしたSimple GAを用いる。Simple GAは、遺伝子は1、0のみとし、ルーレット選択、一点交叉、突然変異は1箇所の遺伝子の値を逆にする等、単純化されたGAである。 [Search image of control unit (automatic offload function unit) 11 by Simple GA]
FIG. 3 is a diagram showing a search image of the control unit (automatic offload function unit) 11 by Simple GA. FIG. 3 shows a search image of processing and gene sequence mapping of the for statement.
GA is one of combinatorial optimization methods that imitate the evolutionary process of organisms. The flow chart of GA consists of initialization→evaluation→selection→crossover→mutation→end determination.
In the present embodiment, Simple GA with simplified processing is used among GAs. Simple GA is a simplified GA in which only genes are 1 and 0, and roulette selection, one-point crossover, and mutation reverse the value of one gene.
図3は、Simple GAによる制御部(自動オフロード機能部)11の探索イメージを示す図である。図3は、処理の探索イメージと、for文の遺伝子配列マッピングを示す。
GAは、生物の進化過程を模倣した組合せ最適化手法の一つである。GAのフローチャートは、初期化→評価→選択→交叉→突然変異→終了判定となっている。
本実施形態では、GAの中で、処理を単純にしたSimple GAを用いる。Simple GAは、遺伝子は1、0のみとし、ルーレット選択、一点交叉、突然変異は1箇所の遺伝子の値を逆にする等、単純化されたGAである。 [Search image of control unit (automatic offload function unit) 11 by Simple GA]
FIG. 3 is a diagram showing a search image of the control unit (automatic offload function unit) 11 by Simple GA. FIG. 3 shows a search image of processing and gene sequence mapping of the for statement.
GA is one of combinatorial optimization methods that imitate the evolutionary process of organisms. The flow chart of GA consists of initialization→evaluation→selection→crossover→mutation→end determination.
In the present embodiment, Simple GA with simplified processing is used among GAs. Simple GA is a simplified GA in which only genes are 1 and 0, and roulette selection, one-point crossover, and mutation reverse the value of one gene.
<初期化>
初期化では、アプリケーションコードの全for文の並列可否をチェック後、並列可能for文を遺伝子配列にマッピングする。GPU処理する場合は1、GPU処理しない場合は0とする。遺伝子は、指定の個体数Mを準備し、1つのfor文にランダムに1、0の割り当てを行う。
具体的には、制御部(自動オフロード機能部)11(図1参照)は、ユーザが利用するアプリケーションコード(Application code)130(図2参照)を取得し、図3に示すように、アプリケーションコード130のコードパターン(Code patterns)141からfor文の並列可否をチェックする。図3に示すように、コードパターン141から5つのfor文が見つかった場合(図3の符号b参照)、各for文に対して1桁、ここでは5つのfor文に対し5桁の1または0をランダムに割り当てる。例えば、CPUで処理する場合0、GPUに出す場合1とする。ただし、この段階では1または0をランダムに割り当てる。
遺伝子長に該当するコードが5桁であり、5桁の遺伝子長のコードは25=32パターン、例えば10001、10010、…となる。なお、図3では、コードパターン141中の丸印(○印)をコードのイメージとして示している。 <initialization>
In the initialization, after checking whether all the for statements in the application code can be parallelized, the for statements that can be parallelized are mapped to the gene array. It is set to 1 when GPU processing is performed, and set to 0 when GPU processing is not performed. A gene prepares a specified number of individuals M, and randomly assigns 1 and 0 to one for statement.
Specifically, the control unit (automatic offload function unit) 11 (see FIG. 1) acquires an application code 130 (see FIG. 2) used by the user and, as shown in FIG. From thecode patterns 141 of the code 130, the parallel propriety of the for statement is checked. As shown in FIG. 3, when five for statements are found from code pattern 141 (see symbol b in FIG. 3), one digit for each for statement, here five digits for five for statements, or 0 is randomly assigned. For example, it is set to 0 when processed by the CPU, and set to 1 when output to the GPU. However, 1 or 0 is randomly assigned at this stage.
The code corresponding to the gene length is 5 digits, and the 5-digit gene length code is 2 5 =32 patterns, eg, 10001, 10010, . In FIG. 3, circle marks (○ marks) in thecode pattern 141 are shown as code images.
初期化では、アプリケーションコードの全for文の並列可否をチェック後、並列可能for文を遺伝子配列にマッピングする。GPU処理する場合は1、GPU処理しない場合は0とする。遺伝子は、指定の個体数Mを準備し、1つのfor文にランダムに1、0の割り当てを行う。
具体的には、制御部(自動オフロード機能部)11(図1参照)は、ユーザが利用するアプリケーションコード(Application code)130(図2参照)を取得し、図3に示すように、アプリケーションコード130のコードパターン(Code patterns)141からfor文の並列可否をチェックする。図3に示すように、コードパターン141から5つのfor文が見つかった場合(図3の符号b参照)、各for文に対して1桁、ここでは5つのfor文に対し5桁の1または0をランダムに割り当てる。例えば、CPUで処理する場合0、GPUに出す場合1とする。ただし、この段階では1または0をランダムに割り当てる。
遺伝子長に該当するコードが5桁であり、5桁の遺伝子長のコードは25=32パターン、例えば10001、10010、…となる。なお、図3では、コードパターン141中の丸印(○印)をコードのイメージとして示している。 <initialization>
In the initialization, after checking whether all the for statements in the application code can be parallelized, the for statements that can be parallelized are mapped to the gene array. It is set to 1 when GPU processing is performed, and set to 0 when GPU processing is not performed. A gene prepares a specified number of individuals M, and randomly assigns 1 and 0 to one for statement.
Specifically, the control unit (automatic offload function unit) 11 (see FIG. 1) acquires an application code 130 (see FIG. 2) used by the user and, as shown in FIG. From the
The code corresponding to the gene length is 5 digits, and the 5-digit gene length code is 2 5 =32 patterns, eg, 10001, 10010, . In FIG. 3, circle marks (○ marks) in the
<評価>
評価では、デプロイ(配置)とパフォーマンスの測定(Deploy & performance measurement)を行う(図3の符号c参照)。すなわち、性能測定部118(図1参照)は、遺伝子に該当するコードをコンパイルして検証用マシン14にデプロイして実行する。性能測定部118は、ベンチマーク性能測定を行う。性能が良いパターン(並列処理パターン)の遺伝子の適合度を高くする。 <evaluation>
In the evaluation, deployment (arrangement) and performance measurement (Deploy & performance measurement) are performed (see symbol c in FIG. 3). That is, the performance measurement unit 118 (see FIG. 1) compiles the code corresponding to the gene, deploys it to theverification machine 14, and executes it. The performance measurement unit 118 performs benchmark performance measurement. The goodness of fit of the gene of the pattern with good performance (parallel processing pattern) is increased.
評価では、デプロイ(配置)とパフォーマンスの測定(Deploy & performance measurement)を行う(図3の符号c参照)。すなわち、性能測定部118(図1参照)は、遺伝子に該当するコードをコンパイルして検証用マシン14にデプロイして実行する。性能測定部118は、ベンチマーク性能測定を行う。性能が良いパターン(並列処理パターン)の遺伝子の適合度を高くする。 <evaluation>
In the evaluation, deployment (arrangement) and performance measurement (Deploy & performance measurement) are performed (see symbol c in FIG. 3). That is, the performance measurement unit 118 (see FIG. 1) compiles the code corresponding to the gene, deploys it to the
<選択>
選択では、適合度に基づいて、高性能コードパターンを選択(Select high performance code patterns)する(図3の符号d参照)。性能測定部118(図1参照)は、適合度に基づいて、高適合度の遺伝子を、指定の個体数で選択する。本実施形態では、適合度に応じたルーレット選択および最高適合度遺伝子のエリート選択を行う。
図3では、選択されたコードパターン(Select code patterns)142の中の丸印(○印)が、3つに減ったことを探索イメージとして示している。 <select>
In the selection, high performance code patterns are selected based on goodness of fit (see symbol d in FIG. 3). Based on the fitness, the performance measurement unit 118 (see FIG. 1) selects genes with high fitness in a specified number of individuals. In this embodiment, roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed.
FIG. 3 shows a search image in which the number of circles (o) in the selectedcode patterns 142 is reduced to three.
選択では、適合度に基づいて、高性能コードパターンを選択(Select high performance code patterns)する(図3の符号d参照)。性能測定部118(図1参照)は、適合度に基づいて、高適合度の遺伝子を、指定の個体数で選択する。本実施形態では、適合度に応じたルーレット選択および最高適合度遺伝子のエリート選択を行う。
図3では、選択されたコードパターン(Select code patterns)142の中の丸印(○印)が、3つに減ったことを探索イメージとして示している。 <select>
In the selection, high performance code patterns are selected based on goodness of fit (see symbol d in FIG. 3). Based on the fitness, the performance measurement unit 118 (see FIG. 1) selects genes with high fitness in a specified number of individuals. In this embodiment, roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed.
FIG. 3 shows a search image in which the number of circles (o) in the selected
<交叉>
交叉では、一定の交叉率Pcで、選択された個体間で一部の遺伝子をある一点で交換し、子の個体を作成する。
ルーレット選択された、あるパターン(並列処理パターン)と他のパターンとの遺伝子を交叉させる。一点交叉の位置は任意であり、例えば上記5桁のコードのうち3桁目で交叉させる。 <Crossover>
In crossover, at a constant crossover rate Pc, some genes are exchanged between selected individuals at one point to create offspring individuals.
Roulette-selected patterns (parallel processing patterns) and genes of other patterns are crossed. The position of the one-point crossover is arbitrary. For example, crossover is performed at the third digit of the five-digit code.
交叉では、一定の交叉率Pcで、選択された個体間で一部の遺伝子をある一点で交換し、子の個体を作成する。
ルーレット選択された、あるパターン(並列処理パターン)と他のパターンとの遺伝子を交叉させる。一点交叉の位置は任意であり、例えば上記5桁のコードのうち3桁目で交叉させる。 <Crossover>
In crossover, at a constant crossover rate Pc, some genes are exchanged between selected individuals at one point to create offspring individuals.
Roulette-selected patterns (parallel processing patterns) and genes of other patterns are crossed. The position of the one-point crossover is arbitrary. For example, crossover is performed at the third digit of the five-digit code.
<突然変異>
突然変異では、一定の突然変異率Pmで、個体の遺伝子の各値を0から1または1から0に変更する。
また、局所解を避けるため、突然変異を導入する。なお、演算量を削減するために突然変異を行わない態様でもよい。 <mutation>
Mutation changes each value of an individual's gene from 0 to 1 or 1 to 0 at a constant mutation rate Pm.
Also, in order to avoid local minima, mutations are introduced. It should be noted that a mode in which no mutation is performed is also possible in order to reduce the amount of calculation.
突然変異では、一定の突然変異率Pmで、個体の遺伝子の各値を0から1または1から0に変更する。
また、局所解を避けるため、突然変異を導入する。なお、演算量を削減するために突然変異を行わない態様でもよい。 <mutation>
Mutation changes each value of an individual's gene from 0 to 1 or 1 to 0 at a constant mutation rate Pm.
Also, in order to avoid local minima, mutations are introduced. It should be noted that a mode in which no mutation is performed is also possible in order to reduce the amount of calculation.
<終了判定>
図3に示すように、クロスオーバーと突然変異後の次世代コードパターンの生成(Generate next generation code patterns after crossover & mutation)を行う(図3の符号e参照)。
終了判定では、指定の世代数T回、繰り返しを行った後に処理を終了し、最高適合度の遺伝子を解とする。
例えば、性能測定して、速い3つ10010、01001、00101を選ぶ。この3つをGAにより、次の世代は、組み換えをして、例えば1番目と2番目を交叉させて新しいパターン(並列処理パターン)11011を作っていく。このとき、組み換えをしたパターンに、勝手に0を1にするなどの突然変異を入れる。上記を繰り返して、一番早いパターンを見付ける。指定世代(例えば、20世代)などを決めて、最終世代で残ったパターンを、最後の解とする。 <end judgment>
As shown in FIG. 3, generate next generation code patterns after crossover & mutation (see symbol e in FIG. 3).
In the termination determination, the processing is terminated after repeating T times for the designated number of generations, and the gene with the highest degree of fitness is taken as the solution.
For example, take performance measurements and choose the fastest three: 10010, 01001, 00101. The next generation recombines these three by GA, for example, crosses the first and second, and creates a new pattern (parallel processing pattern) 11011 . At this time, a mutation such as changing 0 to 1 is arbitrarily inserted into the recombined pattern. Repeat the above to find the fastest pattern. A designated generation (for example, the 20th generation) is determined, and the pattern remaining in the final generation is taken as the final solution.
図3に示すように、クロスオーバーと突然変異後の次世代コードパターンの生成(Generate next generation code patterns after crossover & mutation)を行う(図3の符号e参照)。
終了判定では、指定の世代数T回、繰り返しを行った後に処理を終了し、最高適合度の遺伝子を解とする。
例えば、性能測定して、速い3つ10010、01001、00101を選ぶ。この3つをGAにより、次の世代は、組み換えをして、例えば1番目と2番目を交叉させて新しいパターン(並列処理パターン)11011を作っていく。このとき、組み換えをしたパターンに、勝手に0を1にするなどの突然変異を入れる。上記を繰り返して、一番早いパターンを見付ける。指定世代(例えば、20世代)などを決めて、最終世代で残ったパターンを、最後の解とする。 <end judgment>
As shown in FIG. 3, generate next generation code patterns after crossover & mutation (see symbol e in FIG. 3).
In the termination determination, the processing is terminated after repeating T times for the designated number of generations, and the gene with the highest degree of fitness is taken as the solution.
For example, take performance measurements and choose the fastest three: 10010, 01001, 00101. The next generation recombines these three by GA, for example, crosses the first and second, and creates a new pattern (parallel processing pattern) 11011 . At this time, a mutation such as changing 0 to 1 is arbitrarily inserted into the recombined pattern. Repeat the above to find the fastest pattern. A designated generation (for example, the 20th generation) is determined, and the pattern remaining in the final generation is taken as the final solution.
<デプロイ(配置)>
最高適合度の遺伝子に該当する、最高処理性能の並列処理パターンで、本番環境に改めてデプロイして、ユーザに提供する。 <deploy (deployment)>
Deploy again to the production environment with the parallel processing pattern with the highest processing performance that corresponds to the gene with the highest fitness and provide it to users.
最高適合度の遺伝子に該当する、最高処理性能の並列処理パターンで、本番環境に改めてデプロイして、ユーザに提供する。 <deploy (deployment)>
Deploy again to the production environment with the parallel processing pattern with the highest processing performance that corresponds to the gene with the highest fitness and provide it to users.
<補足説明>
GPUにオフロードできないfor文(ループ文;繰り返し文)が相当数存在する場合について説明する。例えば、for文が200個あっても、GPUにオフロードできるものは30個くらいである。ここでは、エラーになるものを除外し、この30個について、GAを行う。 <Supplementary explanation>
A case where there are a considerable number of for statements (loop statements; repetition statements) that cannot be offloaded to the GPU will be described. For example, even if there are 200 for statements, only about 30 can be offloaded to the GPU. Here, GA is performed on these 30 items by excluding those that cause errors.
GPUにオフロードできないfor文(ループ文;繰り返し文)が相当数存在する場合について説明する。例えば、for文が200個あっても、GPUにオフロードできるものは30個くらいである。ここでは、エラーになるものを除外し、この30個について、GAを行う。 <Supplementary explanation>
A case where there are a considerable number of for statements (loop statements; repetition statements) that cannot be offloaded to the GPU will be described. For example, even if there are 200 for statements, only about 30 can be offloaded to the GPU. Here, GA is performed on these 30 items by excluding those that cause errors.
OpenACCには、ディレクティブ #pragma acc kernelsで指定して、GPU向けバイトコードを抽出し、実行によりGPUオフロードを可能とするコンパイラがある。この#pragmaに、for文のコマンドを書くことにより、そのfor文がGPUで動くか否かを判定することができる。
OpenACC has a compiler that can be specified with the directive #pragma acc kernels to extract bytecodes for GPUs and execute them for GPU offloading. By writing a for statement command in this #pragma, it is possible to determine whether or not the for statement runs on the GPU.
例えばC/C++を使った場合、C/C++のコードを分析し、for文を見付ける。for文を見付けると、OpenACCで並列処理の文法である#pragma acc kernels、#prama acc parallel loopや#prama acc parallel loop vectorを使ってfor文に対して書き込む。詳細には、#pragma acc kernels、#prama acc parallel loopや#prama acc parallel loop vectorに、一つ一つfor文を入れてコンパイルして、エラーであれば、そのfor文はそもそも、GPU処理できないので、除外する。
For example, when using C/C++, analyze the C/C++ code and find the for statement. When a for statement is found, OpenACC writes to the for statement using #pragma acc kernels, #prama acc parallel loop, and #prama acc parallel loop vector, which are parallel processing grammars. In detail, put the for statement into #pragma acc kernels, #prama acc parallel loop and #prama acc parallel loop vector one by one and compile. If an error occurs, the for statement cannot be processed by GPU in the first place. so exclude.
このようにして、残るfor文を見付ける。そして、エラーが出ないものを、長さ(遺伝子長)とする。エラーのないfor文が5つであれば、遺伝子長は5であり、エラーのないfor文が10であれば、遺伝子長は10である。なお、並列処理できないものは、前の処理を次の処理に使うようなデータに依存がある場合である。
以上が準備段階である。次にGA処理を行う。 In this way, we find the remaining for statements. Then, the length (gene length) is defined as the length without error. If there are 5 error-free for statements, the gene length is 5, and if there are 10 error-free for statements, the gene length is 10. Parallel processing is not possible when there is a dependence on data such that the previous processing is used for the next processing.
The above is the preparation stage. Next, GA processing is performed.
以上が準備段階である。次にGA処理を行う。 In this way, we find the remaining for statements. Then, the length (gene length) is defined as the length without error. If there are 5 error-free for statements, the gene length is 5, and if there are 10 error-free for statements, the gene length is 10. Parallel processing is not possible when there is a dependence on data such that the previous processing is used for the next processing.
The above is the preparation stage. Next, GA processing is performed.
for文の数に対応する遺伝子長を有するコードパターンが得られている。始めはランダムに並列処理パターン10010、01001、00101、…を割り当てる。GA処理を行い、コンパイルする。その時に、オフロードできるfor文であるにもかかわらず、エラーがでることがある。それは、for文が階層になっている(どちらか指定すればGPU処理できる)場合である。この場合は、エラーとなったfor文は、残してもよい。具体的には、処理時間が多くなった形にして、タイムアウトさせる方法がある。
A code pattern with a gene length corresponding to the number of for statements is obtained. At the beginning, parallel processing patterns 10010, 01001, 00101, . . . are randomly assigned. Perform GA processing and compile. At that time, an error may occur even though it is a for statement that can be offloaded. That is when the for statement is hierarchical (if one is specified, the GPU can process it). In this case, you can leave the for statement that caused the error. Specifically, there is a method of increasing the processing time and causing timeout.
検証用マシン14でデプロイして、ベンチマーク、例えば画像処理であればその画像処理でベンチマークする、その処理時間が短い程、適応度が高いと評価する。例えば、処理時間の-1/2乗で、処理時間1秒かかるものは1、100秒かかるものは0.1、0.01秒かかるものは10とする。
適応度が高いものを選択して、例えば10個のなかから、3~5個を選択して、それを組み替えて新しいコードパターンを作る。このとき、作成途中で、前と同じものができる場合がある。その場合、同じベンチマークを行う必要はないので、前と同じデータを使う。本実施形態では、コードパターンと、その処理時間は記憶部13に保存しておく。
以上で、Simple GAによる制御部(自動オフロード機能部)11の探索イメージについて説明した。次に、データ転送の一括処理手法について述べる。 It is deployed on theverification machine 14 and benchmarked, for example, in the case of image processing, the image processing is benchmarked. The shorter the processing time, the higher the adaptability is evaluated. For example, the -1/2 power of the processing time is 1 if it takes 1 second, 0.1 if it takes 100 seconds, and 10 if it takes 0.01 seconds.
Those with high adaptability are selected, for example, 3 to 5 out of 10 are selected and rearranged to create a new code pattern. At this time, the same thing as before may be created in the middle of creation. In that case, we don't need to do the same benchmark, so we use the same data as before. In this embodiment, the code pattern and its processing time are stored in thestorage unit 13 .
The search image of the control unit (automatic offload function unit) 11 by Simple GA has been described above. Next, a batch processing technique for data transfer will be described.
適応度が高いものを選択して、例えば10個のなかから、3~5個を選択して、それを組み替えて新しいコードパターンを作る。このとき、作成途中で、前と同じものができる場合がある。その場合、同じベンチマークを行う必要はないので、前と同じデータを使う。本実施形態では、コードパターンと、その処理時間は記憶部13に保存しておく。
以上で、Simple GAによる制御部(自動オフロード機能部)11の探索イメージについて説明した。次に、データ転送の一括処理手法について述べる。 It is deployed on the
Those with high adaptability are selected, for example, 3 to 5 out of 10 are selected and rearranged to create a new code pattern. At this time, the same thing as before may be created in the middle of creation. In that case, we don't need to do the same benchmark, so we use the same data as before. In this embodiment, the code pattern and its processing time are stored in the
The search image of the control unit (automatic offload function unit) 11 by Simple GA has been described above. Next, a batch processing technique for data transfer will be described.
[データ転送の一括処理手法]
<基本的な考え方>
CPU-GPU転送の削減のため、ネストループの変数をできるだけ上位で転送することに加え、本発明は、多数の変数転送タイミングを一括化し、さらにコンパイラが自動転送してしまう転送を削減する。
転送の削減にあたり、ネスト単位だけでなく、GPUに転送するタイミングがまとめられる変数については一括化して転送する。例えば、GPUの処理結果をCPUで加工してGPUで再度処理させるなどの変数でなければ、複数のループ文で使われるCPUで定義された変数を、GPU処理が始まる前に一括してGPUに送り、全GPU処理が終わってからCPUに戻すなどの対応も可能である。 [Batch processing method for data transfer]
<Basic concept>
In order to reduce CPU-GPU transfers, in addition to transferring nested loop variables as high as possible, the present invention unifies the transfer timing of many variables and reduces transfers automatically transferred by the compiler.
In order to reduce the number of transfers, not only the nest units but also the variables for which the transfer timings to the GPU can be grouped are collectively transferred. For example, if the GPU processing result is not processed by the CPU and processed again by the GPU, the variables defined by the CPU that are used in multiple loop statements are collectively transferred to the GPU before the GPU processing starts. It is also possible to send the data and return it to the CPU after all GPU processing is completed.
<基本的な考え方>
CPU-GPU転送の削減のため、ネストループの変数をできるだけ上位で転送することに加え、本発明は、多数の変数転送タイミングを一括化し、さらにコンパイラが自動転送してしまう転送を削減する。
転送の削減にあたり、ネスト単位だけでなく、GPUに転送するタイミングがまとめられる変数については一括化して転送する。例えば、GPUの処理結果をCPUで加工してGPUで再度処理させるなどの変数でなければ、複数のループ文で使われるCPUで定義された変数を、GPU処理が始まる前に一括してGPUに送り、全GPU処理が終わってからCPUに戻すなどの対応も可能である。 [Batch processing method for data transfer]
<Basic concept>
In order to reduce CPU-GPU transfers, in addition to transferring nested loop variables as high as possible, the present invention unifies the transfer timing of many variables and reduces transfers automatically transferred by the compiler.
In order to reduce the number of transfers, not only the nest units but also the variables for which the transfer timings to the GPU can be grouped are collectively transferred. For example, if the GPU processing result is not processed by the CPU and processed again by the GPU, the variables defined by the CPU that are used in multiple loop statements are collectively transferred to the GPU before the GPU processing starts. It is also possible to send the data and return it to the CPU after all GPU processing is completed.
コード分析時にループおよび変数の参照関係を把握するため、その結果から複数ファイルで定義された変数について、GPU処理とCPU処理が入れ子にならず、CPU処理とGPU処理が分けられる変数については、一括化して転送する指定をOpenACCのdata copy文を用いて指定する。
GPU処理の始まる前に一括化して転送され、ループ文処理のタイミングで転送が不要な変数はdata presentを用いて転送不要であることを明示する。
CPU-GPUのデータ転送時は、一時領域を作成し(#pragma acc declare create)、データは一時領域に格納後、一時領域を同期(#pragma acc update)することで転送を指示する。 In order to understand the reference relationship between loops and variables during code analysis, for variables defined in multiple files, GPU processing and CPU processing are not nested, and CPU processing and GPU processing are separated. Use the data copy statement of OpenACC to specify the data to be converted and transferred.
Variables that are collectively transferred before the start of GPU processing and that do not need to be transferred at the timing of loop statement processing use data present to clearly indicate that they do not need to be transferred.
When transferring data between the CPU and GPU, a temporary area is created (#pragma acc declare create), data is stored in the temporary area, and then the temporary area is synchronized (#pragma acc update) to instruct the transfer.
GPU処理の始まる前に一括化して転送され、ループ文処理のタイミングで転送が不要な変数はdata presentを用いて転送不要であることを明示する。
CPU-GPUのデータ転送時は、一時領域を作成し(#pragma acc declare create)、データは一時領域に格納後、一時領域を同期(#pragma acc update)することで転送を指示する。 In order to understand the reference relationship between loops and variables during code analysis, for variables defined in multiple files, GPU processing and CPU processing are not nested, and CPU processing and GPU processing are separated. Use the data copy statement of OpenACC to specify the data to be converted and transferred.
Variables that are collectively transferred before the start of GPU processing and that do not need to be transferred at the timing of loop statement processing use data present to clearly indicate that they do not need to be transferred.
When transferring data between the CPU and GPU, a temporary area is created (#pragma acc declare create), data is stored in the temporary area, and then the temporary area is synchronized (#pragma acc update) to instruct the transfer.
<比較例>
まず、比較例について述べる。
比較例は、通常CPUプログラム(図4参照)、単純GPU利用(図5参照)、ネスト一括化(非特許文献2)(図6参照)である。なお、以下の記載および図中のループ文の文頭の<1>~<4>等は、説明の便宜上で付したものである(他図およびその説明においても同様)。
図4に示す通常CPUプログラムのループ文は、CPUプログラム側で記述され、
<1> ループ〔for(i=0; i<10; i++)〕{
}
の中に、
<2> ループ〔for(j=0; j<20; j++〕 {
がある。図4の符号fは、上記 <2>ループにおける、変数a,bの設定である。
また、
<3> ループ〔for(k=0; k<30; k++)〕{
}
と、
<4> ループ〔for(l=0; l<40; l++)〕{
}
と、が続く。図4の符号gは、上記<3>ループにおける変数c,dの設定であり、図4の符号hは、上記<4>ループにおける変数e,fの設定である。
図4に示す通常CPUプログラムは、CPUで実行される(GPU利用しない)。 <Comparative example>
First, a comparative example will be described.
Comparative examples are a normal CPU program (see FIG. 4), simple GPU use (see FIG. 5), and nest integration (Non-Patent Document 2) (see FIG. 6). Note that <1> to <4>, etc. at the beginning of loop statements in the following descriptions and figures are added for convenience of explanation (the same applies to other figures and their explanations).
The loop statement of the normal CPU program shown in FIG. 4 is written on the CPU program side,
<1> Loop [for(i=0; i<10; i++)] {
}
in the
<2> Loop [for(j=0; j<20; j++] {
There is Symbol f in FIG. 4 is the setting of variables a and b in the <2> loop.
again,
<3> Loop [for(k=0; k<30; k++)] {
}
and,
<4> Loop [for(l=0; l<40; l++)] {
}
and continues. Symbol g in FIG. 4 is the setting of variables c and d in the <3> loop, and symbol h in FIG. 4 is the setting of variables e and f in the <4> loop.
The normal CPU program shown in FIG. 4 is executed by the CPU (not using the GPU).
まず、比較例について述べる。
比較例は、通常CPUプログラム(図4参照)、単純GPU利用(図5参照)、ネスト一括化(非特許文献2)(図6参照)である。なお、以下の記載および図中のループ文の文頭の<1>~<4>等は、説明の便宜上で付したものである(他図およびその説明においても同様)。
図4に示す通常CPUプログラムのループ文は、CPUプログラム側で記述され、
<1> ループ〔for(i=0; i<10; i++)〕{
}
の中に、
<2> ループ〔for(j=0; j<20; j++〕 {
がある。図4の符号fは、上記 <2>ループにおける、変数a,bの設定である。
また、
<3> ループ〔for(k=0; k<30; k++)〕{
}
と、
<4> ループ〔for(l=0; l<40; l++)〕{
}
と、が続く。図4の符号gは、上記<3>ループにおける変数c,dの設定であり、図4の符号hは、上記<4>ループにおける変数e,fの設定である。
図4に示す通常CPUプログラムは、CPUで実行される(GPU利用しない)。 <Comparative example>
First, a comparative example will be described.
Comparative examples are a normal CPU program (see FIG. 4), simple GPU use (see FIG. 5), and nest integration (Non-Patent Document 2) (see FIG. 6). Note that <1> to <4>, etc. at the beginning of loop statements in the following descriptions and figures are added for convenience of explanation (the same applies to other figures and their explanations).
The loop statement of the normal CPU program shown in FIG. 4 is written on the CPU program side,
<1> Loop [for(i=0; i<10; i++)] {
}
in the
<2> Loop [for(j=0; j<20; j++] {
There is Symbol f in FIG. 4 is the setting of variables a and b in the <2> loop.
again,
<3> Loop [for(k=0; k<30; k++)] {
}
and,
<4> Loop [for(l=0; l<40; l++)] {
}
and continues. Symbol g in FIG. 4 is the setting of variables c and d in the <3> loop, and symbol h in FIG. 4 is the setting of variables e and f in the <4> loop.
The normal CPU program shown in FIG. 4 is executed by the CPU (not using the GPU).
図5は、図4に示す通常CPUプログラムを、単純GPU利用して、CPUからGPUへのデータ転送する場合のループ文を示す図である。データ転送の種類は、CPUからGPUへのデータ転送、および、GPUからCPUへのデータ転送がある。以下、CPUからGPUへのデータ転送を例にとる。
図5に示す単純GPU利用のループ文は、CPUプログラム側で記述され、
<1> ループ〔for(i=0; i<10; i++)〕{
}
の中に、
<2> ループ〔for(j=0; j<20; j++〕 {
がある。
さらに、図5の符号iに示すように、 <1> ループ〔for(i=0; i<10; i++)〕{
}の上部に、PGIコンパイラによるfor文等の並列処理可能処理部を、OpenACCのディレクティブ #pragma acc kernels(並列処理指定文)で指定している。
図5の符号iを含む破線枠囲みに示すように、#pragma acc kernelsによって、CPUからGPUへデータ転送される。ここでは、このタイミングでa,bが転送されるため10回転送される。 FIG. 5 is a diagram showing a loop statement when the normal CPU program shown in FIG. 4 uses a simple GPU to transfer data from the CPU to the GPU. Data transfer types include data transfer from the CPU to the GPU and data transfer from the GPU to the CPU. Data transfer from the CPU to the GPU will be taken as an example below.
The simple GPU utilization loop statement shown in FIG. 5 is described on the CPU program side,
<1> Loop [for(i=0; i<10; i++)] {
}
in the
<2> Loop [for(j=0; j<20; j++] {
There is
Furthermore, as indicated by symbol i in FIG. 5, <1> loop [for(i=0; i<10; i++)] {
} above, a processing unit capable of parallel processing such as a for statement by the PGI compiler is specified by the OpenACC directive #pragma acc kernels (parallel processing specifying statement).
Data is transferred from the CPU to the GPU by #pragma acc kernels, as shown in the dashed box surrounding the symbol i in FIG. Here, since a and b are transferred at this timing, they are transferred 10 times.
図5に示す単純GPU利用のループ文は、CPUプログラム側で記述され、
<1> ループ〔for(i=0; i<10; i++)〕{
}
の中に、
<2> ループ〔for(j=0; j<20; j++〕 {
がある。
さらに、図5の符号iに示すように、 <1> ループ〔for(i=0; i<10; i++)〕{
}の上部に、PGIコンパイラによるfor文等の並列処理可能処理部を、OpenACCのディレクティブ #pragma acc kernels(並列処理指定文)で指定している。
図5の符号iを含む破線枠囲みに示すように、#pragma acc kernelsによって、CPUからGPUへデータ転送される。ここでは、このタイミングでa,bが転送されるため10回転送される。 FIG. 5 is a diagram showing a loop statement when the normal CPU program shown in FIG. 4 uses a simple GPU to transfer data from the CPU to the GPU. Data transfer types include data transfer from the CPU to the GPU and data transfer from the GPU to the CPU. Data transfer from the CPU to the GPU will be taken as an example below.
The simple GPU utilization loop statement shown in FIG. 5 is described on the CPU program side,
<1> Loop [for(i=0; i<10; i++)] {
}
in the
<2> Loop [for(j=0; j<20; j++] {
There is
Furthermore, as indicated by symbol i in FIG. 5, <1> loop [for(i=0; i<10; i++)] {
} above, a processing unit capable of parallel processing such as a for statement by the PGI compiler is specified by the OpenACC directive #pragma acc kernels (parallel processing specifying statement).
Data is transferred from the CPU to the GPU by #pragma acc kernels, as shown in the dashed box surrounding the symbol i in FIG. Here, since a and b are transferred at this timing, they are transferred 10 times.
また、図5の符号jに示すように、 <3> ループ〔for(k=0; k<30; k++)〕{
}の上部に、PGIコンパイラによるfor文等の並列処理可能処理部を、OpenACCのディレクティブ #pragma acc kernelsで指定している。
図5の符号jを含む破線枠囲みに示すように、#pragma acc kernelsによって、このタイミングでc,dが転送される。 Also, as indicated by symbol j in FIG. 5, <3> loop [for(k=0; k<30; k++)] {
}, the parallel processing part such as the for statement by the PGI compiler is specified by the directive #pragma acc kernels of OpenACC.
As shown in the dashed frame surrounding the symbol j in FIG. 5, c and d are transferred at this timing by #pragma acc kernels.
}の上部に、PGIコンパイラによるfor文等の並列処理可能処理部を、OpenACCのディレクティブ #pragma acc kernelsで指定している。
図5の符号jを含む破線枠囲みに示すように、#pragma acc kernelsによって、このタイミングでc,dが転送される。 Also, as indicated by symbol j in FIG. 5, <3> loop [for(k=0; k<30; k++)] {
}, the parallel processing part such as the for statement by the PGI compiler is specified by the directive #pragma acc kernels of OpenACC.
As shown in the dashed frame surrounding the symbol j in FIG. 5, c and d are transferred at this timing by #pragma acc kernels.
ここで、 <4> ループ〔for(l=0; l<40; l++)〕{
}の上部には、#pragma acc kernelsを指定しない。このループは、GPU処理しても効率が悪いのでGPU処理しない。 where <4> loop [for(l=0; l<40; l++)] {
Do not specify #pragma acc kernels above }. This loop is not GPU-processed because it is inefficient even if GPU-processed.
}の上部には、#pragma acc kernelsを指定しない。このループは、GPU処理しても効率が悪いのでGPU処理しない。 where <4> loop [for(l=0; l<40; l++)] {
Do not specify #pragma acc kernels above }. This loop is not GPU-processed because it is inefficient even if GPU-processed.
図6は、ネスト一括化(非特許文献2)による、CPUからGPUおよびGPUからCPUへのデータ転送する場合のループ文を示す図である。
図6に示すループ文では、図6の符号kに示す位置に、CPUからGPUへのデータ転送指示行、ここでは変数a,bの copyin 節の #pragma acc data copyin(a,b)を挿入する。なお、本明細書では表記の関係でcopyin(a,b)について、括弧()を付している。後記copyout(a,b)、datacopyin(a,b,c,d)についても同様の表記方法を採る。
上記 #pragma acc data copyin(a,b)は、変数aの設定、定義を含まない最上位のループ(ここでは、 <1> ループ〔for(i=0; i<10; i++)〕{
}の上部)に指定される。
図6の符号kを含む一点鎖線枠囲みに示すタイミングでa,bが転送されるため1回転送が発生する。 FIG. 6 is a diagram showing a loop statement when data is transferred from the CPU to the GPU and from the GPU to the CPU by nest integration (Non-Patent Document 2).
In the loop statement shown in FIG. 6, a data transfer instruction line from the CPU to the GPU, here #pragma acc data copyin(a, b) of the copyin clause of variables a and b, is inserted at the position indicated by symbol k in FIG. do. In this specification, parentheses ( ) are attached to copyin(a,b) for notational reasons. Copyout(a, b) and datacopyin(a, b, c, d) described later also use the same notation method.
The above #pragma acc data copyin(a, b) is the top-level loop that does not include the setting and definition of variable a (here, the <1> loop [for(i=0; i<10; i++)] {
})).
Since a and b are transferred at the timing shown in the frame enclosed by the dashed line including the symbol k in FIG. 6, one transfer occurs.
図6に示すループ文では、図6の符号kに示す位置に、CPUからGPUへのデータ転送指示行、ここでは変数a,bの copyin 節の #pragma acc data copyin(a,b)を挿入する。なお、本明細書では表記の関係でcopyin(a,b)について、括弧()を付している。後記copyout(a,b)、datacopyin(a,b,c,d)についても同様の表記方法を採る。
上記 #pragma acc data copyin(a,b)は、変数aの設定、定義を含まない最上位のループ(ここでは、 <1> ループ〔for(i=0; i<10; i++)〕{
}の上部)に指定される。
図6の符号kを含む一点鎖線枠囲みに示すタイミングでa,bが転送されるため1回転送が発生する。 FIG. 6 is a diagram showing a loop statement when data is transferred from the CPU to the GPU and from the GPU to the CPU by nest integration (Non-Patent Document 2).
In the loop statement shown in FIG. 6, a data transfer instruction line from the CPU to the GPU, here #pragma acc data copyin(a, b) of the copyin clause of variables a and b, is inserted at the position indicated by symbol k in FIG. do. In this specification, parentheses ( ) are attached to copyin(a,b) for notational reasons. Copyout(a, b) and datacopyin(a, b, c, d) described later also use the same notation method.
The above #pragma acc data copyin(a, b) is the top-level loop that does not include the setting and definition of variable a (here, the <1> loop [for(i=0; i<10; i++)] {
})).
Since a and b are transferred at the timing shown in the frame enclosed by the dashed line including the symbol k in FIG. 6, one transfer occurs.
また、図6に示すループ文では、図6の符号lに示す位置に、GPUからCPUへのデータ転送指示行、ここでは変数a,bの copyout 節の #pragma acc data copyout(a,b)を挿入する。
上記 #pragma acc data copyout(a,b)は、 <1> ループ〔for(i=0; i<10; i++)〕{
}の下部に指定される。 In the loop statement shown in FIG. 6, a data transfer instruction line from the GPU to the CPU is placed at the position indicated by symbol l in FIG. insert
The above #pragma acc data copyout(a, b) is <1> loop [for(i=0; i<10; i++)] {
It is specified at the bottom of }.
上記 #pragma acc data copyout(a,b)は、 <1> ループ〔for(i=0; i<10; i++)〕{
}の下部に指定される。 In the loop statement shown in FIG. 6, a data transfer instruction line from the GPU to the CPU is placed at the position indicated by symbol l in FIG. insert
The above #pragma acc data copyout(a, b) is <1> loop [for(i=0; i<10; i++)] {
It is specified at the bottom of }.
このように、CPUからGPUへのデータ転送において、変数aの copyin 節の #pragma acc data copyin(a,b)を、上述した位置に挿入することによりデータ転送を明示的に指示する。これにより、できるだけ上位のループでデータ転送を一括して行うことができ、図5に示す単純GPU利用のループ文のようにループ毎に毎回データを転送する非効率な転送を避けることができる。
In this way, in data transfer from the CPU to the GPU, data transfer is explicitly instructed by inserting #pragma acc data copyin(a, b) in the copyin clause of variable a at the above-mentioned position. As a result, data can be transferred collectively in a loop as high as possible, and it is possible to avoid inefficient transfer in which data is transferred in each loop, as in the simple GPU-using loop statement shown in FIG.
<実施形態>
次に、本実施形態について述べる。
《転送不要な変数をdata presentを用いて明示》
本実施形態では、複数ファイルで定義された変数について、GPU処理とCPU処理が入れ子にならず、CPU処理とGPU処理が分けられる変数については、一括化して転送する指定をOpenACCのdata copy文を用いて指定する。併せて、一括化して転送され、そのタイミングで転送が不要な変数はdata presentを用いて明示する。 <Embodiment>
Next, this embodiment will be described.
《Variables that do not need to be transferred are specified using data present》
In this embodiment, for variables defined in multiple files, GPU processing and CPU processing are not nested, and for variables for which CPU processing and GPU processing are separated, OpenACC's data copy statement is used to specify that they are collectively transferred. specified using At the same time, variables that are collectively transferred and that do not need to be transferred at that timing are specified using data present.
次に、本実施形態について述べる。
《転送不要な変数をdata presentを用いて明示》
本実施形態では、複数ファイルで定義された変数について、GPU処理とCPU処理が入れ子にならず、CPU処理とGPU処理が分けられる変数については、一括化して転送する指定をOpenACCのdata copy文を用いて指定する。併せて、一括化して転送され、そのタイミングで転送が不要な変数はdata presentを用いて明示する。 <Embodiment>
Next, this embodiment will be described.
《Variables that do not need to be transferred are specified using data present》
In this embodiment, for variables defined in multiple files, GPU processing and CPU processing are not nested, and for variables for which CPU processing and GPU processing are separated, OpenACC's data copy statement is used to specify that they are collectively transferred. specified using At the same time, variables that are collectively transferred and that do not need to be transferred at that timing are specified using data present.
図7は、本実施形態のCPU-GPUのデータ転送時の転送一括化によるループ文を示す図である。図7は、比較例の図6のネスト一括化に対応する。
図7に示すループ文では、図7の符号mに示す位置に、CPUからGPUへのデータ転送指示行、ここでは変数a,b,c,dの copyin 節の #pragma acc datacopyin(a,b,c,d)を挿入する。
上記 #pragma acc data copyin(a,b,c,d)は、変数aの設定、定義を含まない最上位のループ(ここでは、 <1> ループ〔for(i=0; i<10; i++)〕{
}の上部)に指定される。 FIG. 7 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment. FIG. 7 corresponds to the nest integration in FIG. 6 of the comparative example.
In the loop statement shown in FIG. 7, a data transfer instruction line from the CPU to the GPU is placed at the position indicated by symbol m in FIG. , c, d).
The above #pragma acc data copyin(a, b, c, d) is the top-level loop that does not include the setting and definition of variable a (here, the <1> loop [for(i=0; i<10; i++ )] {
})).
図7に示すループ文では、図7の符号mに示す位置に、CPUからGPUへのデータ転送指示行、ここでは変数a,b,c,dの copyin 節の #pragma acc datacopyin(a,b,c,d)を挿入する。
上記 #pragma acc data copyin(a,b,c,d)は、変数aの設定、定義を含まない最上位のループ(ここでは、 <1> ループ〔for(i=0; i<10; i++)〕{
}の上部)に指定される。 FIG. 7 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment. FIG. 7 corresponds to the nest integration in FIG. 6 of the comparative example.
In the loop statement shown in FIG. 7, a data transfer instruction line from the CPU to the GPU is placed at the position indicated by symbol m in FIG. , c, d).
The above #pragma acc data copyin(a, b, c, d) is the top-level loop that does not include the setting and definition of variable a (here, the <1> loop [for(i=0; i<10; i++ )] {
})).
このように、複数ファイルで定義された変数について、GPU処理とCPU処理が入れ子にならず、CPU処理とGPU処理が分けられる変数については、一括化して転送する指定をOpenACCのdata copy文#pragma acc data copyin(a,b,c,d)を用いて指定する。
図7の符号mを含む一点鎖線枠囲みに示すタイミングでa,b,c,dが転送されるため1回転送が発生する。 In this way, for variables defined in multiple files, the GPU processing and the CPU processing are not nested, and for the variables for which the CPU processing and the GPU processing are separated, specify the data copy statement #pragma of OpenACC to collectively transfer the variables. Specify using acc data copyin(a, b, c, d).
Since a, b, c, and d are transferred at the timing indicated by the dashed-dotted frame surrounding the symbol m in FIG. 7, one transfer occurs.
図7の符号mを含む一点鎖線枠囲みに示すタイミングでa,b,c,dが転送されるため1回転送が発生する。 In this way, for variables defined in multiple files, the GPU processing and the CPU processing are not nested, and for the variables for which the CPU processing and the GPU processing are separated, specify the data copy statement #pragma of OpenACC to collectively transfer the variables. Specify using acc data copyin(a, b, c, d).
Since a, b, c, and d are transferred at the timing indicated by the dashed-dotted frame surrounding the symbol m in FIG. 7, one transfer occurs.
そして、上記#pragma acc data copyin(a,b,c,d)を用いて一括化して転送され、そのタイミングで転送が不要な変数は、図7の符号nを含む二点鎖線枠囲みに示すタイミングで既にGPUに変数があることを明示するdata present文#pragma acc data present (a,b)を用いて指定する。
Then, the variables that are collectively transferred using the above #pragma acc data copyin(a, b, c, d) and that do not need to be transferred at that timing are indicated by the two-dot chain line frame surrounding the code n in FIG. It is specified using the data present statement #pragma acc data present (a, b) that clearly indicates that the GPU already has a variable at the timing.
上記#pragma acc data copyin(a,b,c,d)を用いて一括化して転送され、そのタイミングで転送が不要な変数は、図7の符号oを含む二点鎖線枠囲みに示すタイミングで既にGPUに変数があることを明示するdata present文#pragma acc data present(c,d)を用いて指定する。
<1>、<3>のループがGPU処理されGPU処理が終了したタイミングで、GPUからCPUへのデータ転送指示行、ここでは変数a,b,c,dの copyout 節の #pragma acc datacopyout(a,b, c, d)を、図7の<3>ループが終了した位置pに挿入する。 Variables that are collectively transferred using the above #pragma acc data copyin(a, b, c, d) and that do not need to be transferred at that timing are indicated by the two-dot chain frame surrounding the symbol o in FIG. A data present statement #pragma acc data present (c, d) is used to specify that the GPU already has a variable.
At the timing when the loops <1> and <3> are processed by the GPU and the GPU processing is completed, the data transfer instruction line from the GPU to the CPU, here #pragma acc datacopyout( a, b, c, d) are inserted at position p where <3> loop of FIG. 7 ends.
<1>、<3>のループがGPU処理されGPU処理が終了したタイミングで、GPUからCPUへのデータ転送指示行、ここでは変数a,b,c,dの copyout 節の #pragma acc datacopyout(a,b, c, d)を、図7の<3>ループが終了した位置pに挿入する。 Variables that are collectively transferred using the above #pragma acc data copyin(a, b, c, d) and that do not need to be transferred at that timing are indicated by the two-dot chain frame surrounding the symbol o in FIG. A data present statement #pragma acc data present (c, d) is used to specify that the GPU already has a variable.
At the timing when the loops <1> and <3> are processed by the GPU and the GPU processing is completed, the data transfer instruction line from the GPU to the CPU, here #pragma acc datacopyout( a, b, c, d) are inserted at position p where <3> loop of FIG. 7 ends.
一括化して転送する指定により一括化して転送できる変数は一括転送し、既に転送され転送が不要な変数はdata presentを用いて明示することで、転送を削減して、オフロード手段のさらなる効率化を図ることができる。しかし、OpenACCで転送を指示してもコンパイラによっては、コンパイラが自動判断して転送してしまう場合がある。コンパイラによる自動転送とは、OpenACCの指示と異なり、本来はCPU-GPU間の転送が不要であるにもかかわらずコンパイラ依存で自動転送されてしまう事象のことである。
By specifying batch transfer, variables that can be transferred in batches are transferred in a batch, and variables that have already been transferred and do not need to be transferred are specified using data present, thereby reducing transfers and further improving the efficiency of offloading methods. can be achieved. However, depending on the compiler, even if OpenACC is instructed to transfer, the compiler may automatically determine and transfer. The automatic transfer by the compiler is a phenomenon in which the transfer between the CPU and the GPU is originally unnecessary but is automatically transferred depending on the compiler, unlike the instructions of OpenACC.
《データの一時領域格納》
図8は、本実施形態のCPU-GPUのデータ転送時の転送一括化によるループ文を示す図である。図8は、図7のネスト一括化および転送不要な変数明示に対応する。
図8に示すループ文では、図8の符号qに示す位置に、CPU-GPUのデータ転送時、一時領域を作成するOpenACCのdeclare create文#pragma acc declare createを指定する。これにより、CPU-GPUのデータ転送時は、一時領域を作成し(#pragma acc declare create)、データは一時領域に格納される。 <<Temporary storage of data>>
FIG. 8 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment. FIG. 8 corresponds to nested collation and transfer-free variable explicitness of FIG.
In the loop statement shown in FIG. 8, a declare create statement #pragma acc declare create of OpenACC for creating a temporary area during CPU-GPU data transfer is specified at the position indicated by symbol q in FIG. As a result, a temporary area is created (#pragma acc declare create) when data is transferred between the CPU and GPU, and the data is stored in the temporary area.
図8は、本実施形態のCPU-GPUのデータ転送時の転送一括化によるループ文を示す図である。図8は、図7のネスト一括化および転送不要な変数明示に対応する。
図8に示すループ文では、図8の符号qに示す位置に、CPU-GPUのデータ転送時、一時領域を作成するOpenACCのdeclare create文#pragma acc declare createを指定する。これにより、CPU-GPUのデータ転送時は、一時領域を作成し(#pragma acc declare create)、データは一時領域に格納される。 <<Temporary storage of data>>
FIG. 8 is a diagram showing a loop statement by transfer integration at the time of data transfer between the CPU and GPU of this embodiment. FIG. 8 corresponds to nested collation and transfer-free variable explicitness of FIG.
In the loop statement shown in FIG. 8, a declare create statement #pragma acc declare create of OpenACC for creating a temporary area during CPU-GPU data transfer is specified at the position indicated by symbol q in FIG. As a result, a temporary area is created (#pragma acc declare create) when data is transferred between the CPU and GPU, and the data is stored in the temporary area.
また、図8の符号rに示す位置に、一時領域を同期するためのOpenACCのdeclare create文#pragma acc updateを指定することで転送を指示する。
Also, at the position indicated by symbol r in FIG. 8, the OpenACC declare create statement #pragma acc update for synchronizing the temporary area is specified to instruct the transfer.
このように、一時領域を作成し、一時領域でパラメータを初期化して、CPU-GPU転送に用いることで、不要なCPU-GPU転送を遮断する。OpenACCの指示では意図しないが性能を劣化する転送を削減することができる。
In this way, unnecessary CPU-GPU transfers are blocked by creating a temporary area, initializing parameters in the temporary area, and using it for CPU-GPU transfers. The OpenACC instructions can reduce transfers that unintentionally degrade performance.
[GPUオフロード処理]
上述したデータ転送の一括処理手法により、オフロードに適切なループ文を抽出し、非効率なデータ転送を避けることができる。
ただし、上記データ転送の一括処理手法を用いても、GPUオフロードに向いていないプログラムも存在する。効果的なGPUオフロードには、オフロードする処理のループ回数が多いことが必要である。 [GPU offload processing]
The batch processing technique for data transfer described above makes it possible to extract loop statements suitable for offloading and avoid inefficient data transfer.
However, there are programs that are not suitable for GPU offload even if the batch processing method of data transfer is used. Effective GPU offloading requires a large number of loops in the processing to be offloaded.
上述したデータ転送の一括処理手法により、オフロードに適切なループ文を抽出し、非効率なデータ転送を避けることができる。
ただし、上記データ転送の一括処理手法を用いても、GPUオフロードに向いていないプログラムも存在する。効果的なGPUオフロードには、オフロードする処理のループ回数が多いことが必要である。 [GPU offload processing]
The batch processing technique for data transfer described above makes it possible to extract loop statements suitable for offloading and avoid inefficient data transfer.
However, there are programs that are not suitable for GPU offload even if the batch processing method of data transfer is used. Effective GPU offloading requires a large number of loops in the processing to be offloaded.
そこで、本実施形態では、本格的なオフロード処理探索の前段階として、プロファイリングツールを用いて、ループ回数を調査する。プロファイリングツールを用いると、各行の実行回数を調査できるため、例えば、5000万回以上のループを持つプログラムをオフロード処理探索の対象とする等、事前に振り分けることができる。以下、具体的に説明する(図2で述べた内容と一部重複する)。
Therefore, in this embodiment, the number of loops is investigated using a profiling tool as a preliminary step to searching for full-scale offload processing. Using a profiling tool makes it possible to investigate the number of times each line is executed. Therefore, for example, programs with loops of 50 million times or more can be sorted in advance, such as targeting offload processing searches. A specific description will be given below (partially overlaps with the content described in FIG. 2).
本実施形態では、まず、アプリケーションコード分析部112(図1)がアプリケーションを分析し、for,do,while等のループ文を把握する。次に、サンプル処理を実行し、プロファイリングツールを用いて、各ループ文のループ回数を調査し、一定の値以上のループがあるか否かで、探索を本格的に行うか否かの判定を行う。
In this embodiment, first, the application code analysis unit 112 (FIG. 1) analyzes the application and grasps loop statements such as for, do, and while. Next, execute the sample processing, use the profiling tool to investigate the number of loops in each loop statement, and determine whether or not to perform full-scale search based on whether there is a loop that exceeds a certain value. conduct.
探索を本格的に行うと決まった場合は、GAの処理に入る(図2参照)。初期化ステップでは、アプリケーションコードの全ループ文の並列可否をチェックした後、並列可能ループ文をGPU処理する場合は1、しない場合は0として遺伝子配列にマッピングする。遺伝子は、指定の個体数が準備されるが、遺伝子の各値にはランダムに1,0の割り当てをする。
When it is decided to carry out full-scale search, the process of GA is entered (see Figure 2). In the initialization step, after checking whether or not all loop statements of the application code can be parallelized, the loop statements that can be parallelized are mapped to the gene array as 1 if GPU processing is to be performed, and as 0 if not. A specified number of individuals are prepared for the gene, and 1 and 0 are randomly assigned to each value of the gene.
ここで、遺伝子に該当するコードでは、GPU処理すると指定されたループ文内の変数データ参照関係から、データ転送の明示的指示(#pragma acc data copyin/copyout/copy)を追加する。
Here, in the code corresponding to the gene, an explicit instruction for data transfer (#pragma acc data copyin/copyout/copy) is added from the variable data reference relationship within the loop statement specified to be processed by the GPU.
評価ステップでは、遺伝子に該当するコードをコンパイルして検証用マシンにデプロイして実行し、ベンチマーク性能測定を行う。そして、性能が良いパターンの遺伝子の適合度を高くする。遺伝子に該当するコードは、上述のように、並列処理指示行(例えば、図4の符号f参照)とデータ転送指示行(例えば、図4の符号h参照、図5の符号i参照、図6の符号k参照)が挿入されている。
In the evaluation step, the code corresponding to the gene is compiled, deployed and executed on the verification machine, and benchmark performance is measured. Then, the goodness of fit of a gene with a good performance pattern is increased. As described above, the code corresponding to the gene includes a parallel processing instruction line (for example, reference symbol f in FIG. 4) and a data transfer instruction line (for example, reference symbol h in FIG. 4, reference symbol i in FIG. 5, and ) is inserted.
選択ステップでは、適合度に基づいて、高適合度の遺伝子を、指定の個体数分選択する。本実施形態では、適合度に応じたルーレット選択および最高適合度遺伝子のエリート選択を行う。交叉ステップでは、一定の交叉率Pcで、選択された個体間で一部の遺伝子をある一点で交換し、子の個体を作成する。突然変異ステップでは、一定の突然変異率Pmで、個体の遺伝子の各値を0から1または1から0に変更する。
In the selection step, genes with high fitness are selected for the specified number of individuals based on the fitness. In this embodiment, roulette selection according to goodness of fit and elite selection of genes with the highest goodness of fit are performed. In the crossover step, at a constant crossover rate Pc, some genes are exchanged between the selected individuals at one point to create offspring individuals. In the mutation step, each value of an individual's gene is changed from 0 to 1 or 1 to 0 at a constant mutation rate Pm.
突然変異ステップまで終わり、次の世代の遺伝子が指定個体数作成されると、初期化ステップと同様に、データ転送の明示的指示を追加し、評価、選択、交叉、突然変異ステップを繰り返す。
When the mutation step is completed and the specified number of genes for the next generation is created, an explicit instruction for data transfer is added, and the evaluation, selection, crossover, and mutation steps are repeated in the same way as the initialization step.
最後に、終了判定ステップでは、指定の世代数、繰り返しを行った後に処理を終了し、最高適合度の遺伝子を解とする。最高適合度の遺伝子に該当する、最高性能のコードパターンで、本番環境に改めてデプロイして、ユーザに提供する。
Finally, in the termination determination step, the process is terminated after repeating the specified number of generations, and the gene with the highest fitness is taken as the solution. Re-deploy to the production environment with the highest performing code pattern that corresponds to the best-fitting gene and provide it to the user.
以下、オフロードサーバ1の実装を説明する。本実装は、本実施形態の有効性を確認するためのものである。
[実装]
C/C++アプリケーションを汎用のPGIコンパイラを用いて自動オフロードする実装を説明する。
本実装では、GPU自動オフロードの有効性確認が目的であるため、対象アプリケーションはC/C++言語のアプリケーションとし、GPU処理自体は、従来のPGIコンパイラを説明に用いる。 The implementation of theoffload server 1 will be described below. This implementation is for confirming the effectiveness of this embodiment.
[implementation]
An implementation of automatic offloading of C/C++ applications using a general-purpose PGI compiler is described.
Since the purpose of this implementation is to confirm the validity of automatic GPU offloading, the target application is a C/C++ language application, and the GPU processing itself is explained using a conventional PGI compiler.
[実装]
C/C++アプリケーションを汎用のPGIコンパイラを用いて自動オフロードする実装を説明する。
本実装では、GPU自動オフロードの有効性確認が目的であるため、対象アプリケーションはC/C++言語のアプリケーションとし、GPU処理自体は、従来のPGIコンパイラを説明に用いる。 The implementation of the
[implementation]
An implementation of automatic offloading of C/C++ applications using a general-purpose PGI compiler is described.
Since the purpose of this implementation is to confirm the validity of automatic GPU offloading, the target application is a C/C++ language application, and the GPU processing itself is explained using a conventional PGI compiler.
C/C++言語は、OSS(Open Source Software)およびproprietaryソフトウェアの開発で、上位の人気を誇り、数多くのアプリケーションがC/C++言語で開発されている。一般ユーザが用いるアプリケーションのオフロードを確認するため、暗号処理や画像処理等のOSSの汎用アプリケーションを利用する。
The C/C++ language boasts top popularity in the development of OSS (Open Source Software) and proprietary software, and many applications are being developed in the C/C++ language. In order to check the offloading of applications used by general users, OSS general-purpose applications such as encryption processing and image processing are used.
GPU処理は、PGIコンパイラにより行う。PGIコンパイラは、OpenACCを解釈するC/C++/Fortran向けコンパイラである。本実施形態では、for文等の並列可能処理部を、OpenACCのディレクティブ #pragma acc kernels(並列処理指定文)で指定する。これにより、GPU向けバイトコードを抽出し、その実行によりGPUオフロードを可能としている。さらに、for文内のデータ同士に依存性があり並列処理できない処理やネストのfor文の異なる複数の階層を指定されている場合等の際に、エラーを出す。併せて、#pragma acc data copyin/copyout/copy 等のディレクティブにより、明示的なデータ転送の指示が可能とする。
GPU processing is performed by the PGI compiler. The PGI compiler is a C/C++/Fortran compiler that understands OpenACC. In this embodiment, a parallel-capable processing unit such as a for statement is specified by an OpenACC directive #pragma acc kernels (parallel processing specifying statement). This enables GPU offloading by extracting bytecodes for GPUs and executing them. In addition, an error is generated when the data in the for statement is dependent on each other and cannot be processed in parallel, or when multiple layers of nested for statements are specified. In addition, directives such as #pragma acc data copyin/copyout/copy can be used to explicitly instruct data transfer.
上記 #pragma acc kernels(並列処理指定文)での指定に合わせて、OpenACCのcopyin 節の#pragma acc data copyout(a[…])の、上述した位置への挿入により、明示的なデータ転送の指示を行う。
By inserting #pragma acc data copyout(a[...]) in OpenACC's copyin clause at the above-mentioned position according to the specification in the above #pragma acc kernels (parallel processing specification statement), explicit data transfer give instructions.
<実装の動作概要>
実装の動作概要を説明する。
実装は、以下の処理を行う。
下記図9A-Bのフローの処理を開始する前に、高速化するC/C++アプリケーションとそれを性能測定するベンチマークツールを準備する。 <Overview of implementation behavior>
Describe the operation overview of the implementation.
The implementation performs the following processing.
Before starting the processing of the flow shown in FIGS. 9A and 9B below, prepare a C/C++ application to be accelerated and a benchmark tool for measuring its performance.
実装の動作概要を説明する。
実装は、以下の処理を行う。
下記図9A-Bのフローの処理を開始する前に、高速化するC/C++アプリケーションとそれを性能測定するベンチマークツールを準備する。 <Overview of implementation behavior>
Describe the operation overview of the implementation.
The implementation performs the following processing.
Before starting the processing of the flow shown in FIGS. 9A and 9B below, prepare a C/C++ application to be accelerated and a benchmark tool for measuring its performance.
実装では、C/C++アプリケーションの利用依頼があると、まず、C/C++アプリケーションのコードを解析して、for文を発見するとともに、for文内で使われる変数データ等の、プログラム構造を把握する。構文解析には、LLVM/Clangの構文解析ライブラリ等を使用する。
In the implementation, when there is a request to use a C/C++ application, the code of the C/C++ application is first analyzed to find for statements, and to understand the program structure such as variable data used in the for statements. . LLVM/Clang syntax analysis library is used for syntax analysis.
実装では、最初に、そのアプリケーションがGPUオフロード効果があるかの見込みを得るため、ベンチマークを実行し、上記構文解析で把握したfor文のループ回数を把握する。ループ回数把握には、GNUカバレッジのgcov等を用いる。プロファイリングツールとしては、「GNUプロファイラ(gprof)」、「GNUカバレッジ(gcov)」が知られている。双方とも各行の実行回数を調査できるため、どちらを用いてもよい。実行回数は、例えば、1000万回以上のループ回数を持つアプリケーションのみ対象とするようにできるが、この値は変更可能である。
In the implementation, first, in order to get a sense of whether the application has a GPU offload effect, a benchmark is run and the number of loops of the for statement ascertained in the above parsing is ascertained. GNU coverage gcov etc. is used to grasp the number of loops. "GNU Profiler (gprof)" and "GNU Coverage (gcov)" are known as profiling tools. Either can be used because both can examine the execution count of each line. The number of executions can, for example, target only applications with loop counts of 10 million or more, but this value can be changed.
CPU向け汎用アプリケーションは、並列化を想定して実装されているわけではない。そのため、まず、GPU処理自体が不可なfor文は排除する必要がある。そこで、各for文一つずつに対して、GPU処理の#pragma acc kernelsや#prama acc parallel loopや#prama acc parallel loop vectorディレクティブ挿入を試行し、コンパイル時にエラーが出るかの判定を行う。コンパイルエラーに関しては、幾つかの種類がある。for文の中で外部ルーチンが呼ばれている場合、ネストfor文で異なる階層が重複指定されている場合、break等でfor文を途中で抜ける処理がある場合、for文のデータにデータ依存性がある場合等がある。アプリケーションによって、コンパイル時エラーの種類は多彩であり、これ以外の場合もあるが、コンパイルエラーは処理対象外とし、#pragmaディレクティブは挿入しない。
General-purpose CPU applications are not implemented with parallelization in mind. Therefore, first of all, it is necessary to eliminate for statements that cannot be processed by the GPU. Therefore, #pragma acc kernels, #prama acc parallel loop, and #prama acc parallel loop vector directives for GPU processing are tried to be inserted for each for statement, and it is determined whether an error occurs during compilation. There are several types of compilation errors. If an external routine is called in a for statement, if a different hierarchy is specified repeatedly in a nested for statement, or if there is a process to exit the for statement with a break, etc., the data in the for statement is subject to data dependency. There are cases where there is Depending on the application, there are various types of compile-time errors, and there are other cases, but compile errors are excluded from processing and #pragma directives are not inserted.
コンパイルエラーは自動対処が難しく、また対処しても効果が出ないことも多い。外部ルーチンコールの場合は、#pragma acc routineにより回避できる場合があるが、多くの外部コールはライブラリであり、それを含めてGPU処理してもそのコールがネックとなり性能が出ない。for文一つずつを試行するため、ネストのエラーに関しては、コンパイルエラーは生じない。また、break等により途中で抜ける場合は、並列処理にはループ回数を固定化する必要があり、プログラム改造が必要となる。データ依存が有る場合はそもそも並列処理自体ができない。
It is difficult to automatically deal with compile errors, and there are many cases where dealing with them is ineffective. In the case of external routine calls, #pragma acc routine can sometimes be avoided, but many external calls are libraries, and even if they are included in GPU processing, the call becomes a bottleneck and performance is not good. Since each for statement is tried one by one, no compile error occurs regarding nesting errors. In addition, when exiting in the middle due to a break or the like, it is necessary to fix the number of loops for parallel processing, and program modification is required. Parallel processing itself cannot be performed in the first place when there is data dependence.
ここで、並列処理してもエラーが出ないループ文の数がaの場合、aが遺伝子長となる。遺伝子の1は並列処理ディレクティブ有、0は無に対応させ、長さaの遺伝子に、アプリケーションコードをマッピングする。
Here, if the number of loop statements in which no error occurs even if parallel processing is a, then a is the gene length. 1 of the gene corresponds to presence of parallel processing directive, 0 corresponds to no parallel processing directive, and the application code is mapped to the gene of length a.
次に、初期値として,指定個体数の遺伝子配列を準備する。遺伝子の各値は、図3で説明したように、0と1をランダムに割当てて作成する。準備された遺伝子配列に応じて、遺伝子の値が1の場合はGPU処理を指定するディレクティブ \#pragma acc kernels,\#pragma acc parallel loop,\#pragma acc parallel loop vectorをC/C++コードに挿入する。single loop等はparallelにしない理由としては、同じ処理であればkernelsの方が、PGIコンパイラとしては性能が良いためである。この段階で、ある遺伝子に該当するコードの中で、GPUで処理させる部分が決まる。
Next, as an initial value, prepare gene sequences for the specified number of individuals. Each value of the gene is created by randomly assigning 0 and 1 as described in FIG. Insert directives \#pragma acc kernels,\#pragma acc parallel loop,\#pragma acc parallel loop vector into the C/C++ code to specify GPU processing when the gene value is 1 according to the prepared gene sequence do. The reason why single loops and the like are not parallel is that if the same processing is performed, kernels has better performance as a PGI compiler. At this stage, the part of the code corresponding to a certain gene that is to be processed by the GPU is determined.
並列処理およびデータ転送のディレクティブを挿入されたC/C++コードを、GPUを備えたマシン上のPGIコンパイラでコンパイルを行う。コンパイルした実行ファイルをデプロイし、ベンチマークツールで性能と電力使用量を測定する。
The C/C++ code with parallel processing and data transfer directives inserted is compiled with the PGI compiler on a machine equipped with a GPU. Deploy compiled executables and measure performance and power usage with benchmarking tools.
全個体数に対して、ベンチマーク性能測定後、ベンチマーク処理時間と電力使用量に応じて、各遺伝子配列の適合度を設定する。設定された適合度に応じて、残す個体の選択を行う。選択された個体に対して、交叉処理、突然変異処理、そのままコピー処理のGA処理を行い、次世代の個体群を作成する。
After measuring the benchmark performance for all populations, set the fitness of each gene sequence according to the benchmark processing time and power consumption. Individuals to be left are selected according to the set degree of fitness. The selected individuals are subjected to GA processing such as crossover processing, mutation processing, and copy processing as they are to create a population of the next generation.
次世代の個体に対して、ディレクティブ挿入、コンパイル、性能測定、適合度設定、選択、交叉、突然変異処理を行う。ここで、GA処理の中で、以前と同じパターンの遺伝子が生じた場合は、その個体についてはコンパイル、性能測定をせず、以前と同じ測定値を用いる。
Directive insertion, compilation, performance measurement, fitness setting, selection, crossover, and mutation processing are performed on the next-generation individuals. Here, in the GA processing, if the gene with the same pattern as before occurs, the individual is not compiled and the performance measurement is not performed, and the same measured value as before is used.
指定世代数のGA処理終了後、最高性能の遺伝子配列に該当する、ディレクティブ付きC/C++コードを解とする。
After completing GA processing for the specified number of generations, the solution is the C/C++ code with directives that corresponds to the gene sequence with the highest performance.
この中で、個体数、世代数、交叉率、突然変異率、適合度設定、選択方法は、GAのパラメータであり、別途指定する。提案技術は、上記処理を自動化することで、従来、専門技術者の時間とスキルが必要だった、GPUオフロードの自動化を可能にする。
Among these, the number of individuals, the number of generations, the crossover rate, the mutation rate, the fitness setting, and the selection method are parameters of the GA and are specified separately. By automating the above processing, the proposed technology makes it possible to automate GPU offloading, which conventionally required the time and skills of a specialized engineer.
図9A-Bは、上述した実装の動作概要を説明するフローチャートであり、図9Aと図9Bは、結合子で繋がれる。
C/C++向けOpenACCコンパイラを用いて以下の処理を行う。 FIGS. 9A-B are flow charts outlining the operation of the implementation described above, and FIGS. 9A and 9B are connected by a connector.
The following processing is performed using the OpenACC compiler for C/C++.
C/C++向けOpenACCコンパイラを用いて以下の処理を行う。 FIGS. 9A-B are flow charts outlining the operation of the implementation described above, and FIGS. 9A and 9B are connected by a connector.
The following processing is performed using the OpenACC compiler for C/C++.
<コード解析>
ステップS101で、アプリケーションコード分析部112(図1参照)は、C/C++アプリのコード解析を行う。 <Code Analysis>
In step S101, the application code analysis unit 112 (see FIG. 1) performs code analysis of the C/C++ application.
ステップS101で、アプリケーションコード分析部112(図1参照)は、C/C++アプリのコード解析を行う。 <Code Analysis>
In step S101, the application code analysis unit 112 (see FIG. 1) performs code analysis of the C/C++ application.
<ループ文特定>
ステップS102で、並列処理指定部114(図1参照)は、C/C++アプリのループ文、参照関係を特定する。 <Specify loop statement>
In step S102, the parallel processing designation unit 114 (see FIG. 1) identifies loop statements and reference relationships of the C/C++ application.
ステップS102で、並列処理指定部114(図1参照)は、C/C++アプリのループ文、参照関係を特定する。 <Specify loop statement>
In step S102, the parallel processing designation unit 114 (see FIG. 1) identifies loop statements and reference relationships of the C/C++ application.
<ループ文の並列処理可能性>
ステップS103で、並列処理指定部114は、各ループ文のGPU処理可能性をチェックする(#pragma acc kernels)。 <Possibility of parallel processing of loop statements>
In step S103, the parallelprocessing designation unit 114 checks the GPU processability of each loop statement (#pragma acc kernels).
ステップS103で、並列処理指定部114は、各ループ文のGPU処理可能性をチェックする(#pragma acc kernels)。 <Possibility of parallel processing of loop statements>
In step S103, the parallel
<ループ文の繰り返し>
制御部(自動オフロード機能部)11は、ステップS104のループ始端とステップS117のループ終端間で、ステップS105-S116の処理についてループ文の数だけ繰り返す。 <Repeat loop statement>
The control unit (automatic offload function unit) 11 repeats the processing of steps S105 to S116 by the number of loop statements between the loop start end of step S104 and the loop end of step S117.
制御部(自動オフロード機能部)11は、ステップS104のループ始端とステップS117のループ終端間で、ステップS105-S116の処理についてループ文の数だけ繰り返す。 <Repeat loop statement>
The control unit (automatic offload function unit) 11 repeats the processing of steps S105 to S116 by the number of loop statements between the loop start end of step S104 and the loop end of step S117.
<ループの数の繰り返し(その1)>
制御部(自動オフロード機能部)11は、ステップS105のループ始端とステップS108のループ終端間で、ステップS106-S107の処理についてループ文の数だけ繰り返す。
ステップS106で、並列処理指定部114は、各ループ文に対して、OpenACCでGPU処理(#pragma acc kernels)を指定してコンパイルする。
ステップS107で、並列処理指定部114は、エラー時は、次の指示句でGPU処理可能性をチェックする(#pragma acc parallel loop)。 <Repetition of number of loops (Part 1)>
The control unit (automatic offload function unit) 11 repeats the processing of steps S106 and S107 by the number of loop statements between the loop start end of step S105 and the loop end end of step S108.
In step S106, the parallelprocessing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc kernels) with OpenACC.
In step S107, the parallelprocessing designation unit 114 checks the GPU processing possibility with the following directive (#pragma acc parallel loop) when an error occurs.
制御部(自動オフロード機能部)11は、ステップS105のループ始端とステップS108のループ終端間で、ステップS106-S107の処理についてループ文の数だけ繰り返す。
ステップS106で、並列処理指定部114は、各ループ文に対して、OpenACCでGPU処理(#pragma acc kernels)を指定してコンパイルする。
ステップS107で、並列処理指定部114は、エラー時は、次の指示句でGPU処理可能性をチェックする(#pragma acc parallel loop)。 <Repetition of number of loops (Part 1)>
The control unit (automatic offload function unit) 11 repeats the processing of steps S106 and S107 by the number of loop statements between the loop start end of step S105 and the loop end end of step S108.
In step S106, the parallel
In step S107, the parallel
<ループの数の繰り返し(その2)>
制御部(自動オフロード機能部)11は、ステップS109のループ始端とステップS112のループ終端間で、ステップS110-S111の処理についてループ文の数だけ繰り返す。
ステップS110で、並列処理指定部114は、各ループ文に対して、OpenACCでGPU処理(#pragma acc parallel loop)を指定してコンパイルする。
ステップS111で、並列処理指定部114は、エラー時は、次の指示句でGPU処理可能性をチェックする(#pragma acc parallel loop vector)。 <Repetition of number of loops (Part 2)>
The control unit (automatic offload function unit) 11 repeats the processing of steps S110 to S111 by the number of loop statements between the loop start point of step S109 and the loop end point of step S112.
In step S110, the parallelprocessing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc parallel loop) with OpenACC.
In step S111, the parallelprocessing designation unit 114 checks the GPU processability with the following directive (#pragma acc parallel loop vector) when an error occurs.
制御部(自動オフロード機能部)11は、ステップS109のループ始端とステップS112のループ終端間で、ステップS110-S111の処理についてループ文の数だけ繰り返す。
ステップS110で、並列処理指定部114は、各ループ文に対して、OpenACCでGPU処理(#pragma acc parallel loop)を指定してコンパイルする。
ステップS111で、並列処理指定部114は、エラー時は、次の指示句でGPU処理可能性をチェックする(#pragma acc parallel loop vector)。 <Repetition of number of loops (Part 2)>
The control unit (automatic offload function unit) 11 repeats the processing of steps S110 to S111 by the number of loop statements between the loop start point of step S109 and the loop end point of step S112.
In step S110, the parallel
In step S111, the parallel
<ループの数の繰り返し(その3)>
制御部(自動オフロード機能部)11は、ステップS113のループ始端とステップS116のループ終端間で、ステップS114-S115の処理についてループ文の数だけ繰り返す。
ステップS114で、並列処理指定部114は、各ループ文に対して、OpenACCでGPU処理(#pragma acc parallel loop vector)を指定してコンパイルする。
ステップS115で、並列処理指定部114は、エラー時は、当該ループ文からはGPU処理指示句を除去する。 <Repetition of number of loops (Part 3)>
The control unit (automatic offload function unit) 11 repeats the processing of steps S114 to S115 by the number of loop statements between the loop start point of step S113 and the loop end point of step S116.
In step S114, the parallelprocessing designation unit 114 compiles each loop statement by designating GPU processing (#pragma acc parallel loop vector) with OpenACC.
In step S115, the parallelprocessing specifying unit 114 removes the GPU processing directive phrase from the loop statement when an error occurs.
制御部(自動オフロード機能部)11は、ステップS113のループ始端とステップS116のループ終端間で、ステップS114-S115の処理についてループ文の数だけ繰り返す。
ステップS114で、並列処理指定部114は、各ループ文に対して、OpenACCでGPU処理(#pragma acc parallel loop vector)を指定してコンパイルする。
ステップS115で、並列処理指定部114は、エラー時は、当該ループ文からはGPU処理指示句を除去する。 <Repetition of number of loops (Part 3)>
The control unit (automatic offload function unit) 11 repeats the processing of steps S114 to S115 by the number of loop statements between the loop start point of step S113 and the loop end point of step S116.
In step S114, the parallel
In step S115, the parallel
<for文の数カウント>
ステップS118で、並列処理指定部114は、コンパイルエラーが出ないループ文(ここではfor文)の数をカウントし、遺伝子長とする。 <count the number of for statements>
In step S118, the parallelprocessing designating unit 114 counts the number of loop statements (here, for statements) in which no compilation error occurs, and sets the number as the gene length.
ステップS118で、並列処理指定部114は、コンパイルエラーが出ないループ文(ここではfor文)の数をカウントし、遺伝子長とする。 <count the number of for statements>
In step S118, the parallel
<指定個体数パターン準備>
次に、初期値として、並列処理指定部114は、指定個体数の遺伝子配列を準備する。ここでは、0と1をランダムに割当てて作成する。
ステップS119で、並列処理指定部114は、C/C++アプリコードを、遺伝子にマッピングし、指定個体数パターン準備を行う。
準備された遺伝子配列に応じて、遺伝子の値が1の場合は並列処理を指定するディレクティブをC/C++コードに挿入する(例えば図3の#pragmaディレクティブ参照)。 <Specified population pattern preparation>
Next, as an initial value, the parallelprocessing designation unit 114 prepares gene sequences for the designated number of individuals. Here, 0 and 1 are randomly assigned and created.
In step S119, the parallelprocessing designating unit 114 maps the C/C++ application code to genes and prepares a designated population pattern.
Depending on the prepared gene sequence, a directive specifying parallel processing is inserted into the C/C++ code when the value of the gene is 1 (see, for example, the #pragma directive in FIG. 3).
次に、初期値として、並列処理指定部114は、指定個体数の遺伝子配列を準備する。ここでは、0と1をランダムに割当てて作成する。
ステップS119で、並列処理指定部114は、C/C++アプリコードを、遺伝子にマッピングし、指定個体数パターン準備を行う。
準備された遺伝子配列に応じて、遺伝子の値が1の場合は並列処理を指定するディレクティブをC/C++コードに挿入する(例えば図3の#pragmaディレクティブ参照)。 <Specified population pattern preparation>
Next, as an initial value, the parallel
In step S119, the parallel
Depending on the prepared gene sequence, a directive specifying parallel processing is inserted into the C/C++ code when the value of the gene is 1 (see, for example, the #pragma directive in FIG. 3).
制御部(自動オフロード機能部)11は、図9BのステップS120のループ始端とステップS131のループ終端間で、ステップS121-S130の処理について指定世代数繰り返す。
また、上記指定世代数繰り返しにおいて、さらにステップS121のループ始端とステップS126のループ終端間で、ステップS122-S125の処理について指定個体数繰り返す。すなわち、指定世代数繰り返しの中で、指定個体数の繰り返しが入れ子状態で処理される。 The control unit (automatic offload function unit) 11 repeats the processing of steps S121 to S130 for a specified number of generations between the loop start end of step S120 and the loop end of step S131 in FIG. 9B.
Further, in the repetition of the designated number of generations, the processing of steps S122 to S125 is repeated for the designated number of individuals between the loop start end of step S121 and the loop end of step S126. That is, repetitions of the specified number of individuals are processed in a nested state within the repetition of the specified number of generations.
また、上記指定世代数繰り返しにおいて、さらにステップS121のループ始端とステップS126のループ終端間で、ステップS122-S125の処理について指定個体数繰り返す。すなわち、指定世代数繰り返しの中で、指定個体数の繰り返しが入れ子状態で処理される。 The control unit (automatic offload function unit) 11 repeats the processing of steps S121 to S130 for a specified number of generations between the loop start end of step S120 and the loop end of step S131 in FIG. 9B.
Further, in the repetition of the designated number of generations, the processing of steps S122 to S125 is repeated for the designated number of individuals between the loop start end of step S121 and the loop end of step S126. That is, repetitions of the specified number of individuals are processed in a nested state within the repetition of the specified number of generations.
<データ転送指定>
ステップS122で、データ転送指定部113は、変数参照関係をもとに、明示的指示行(#pragma acc data copy/copyin/copyout/presentおよび#pragam acc declarecreate, #pragma acc update)を用いたデータ転送指定を行う。 <Data transfer specification>
In step S122, the datatransfer designation unit 113 transfers data using explicit instruction lines (#pragma acc data copy/copyin/copyout/present and #pragma acc declarecreate, #pragma acc update) based on the variable reference relationship. Specify transfer.
ステップS122で、データ転送指定部113は、変数参照関係をもとに、明示的指示行(#pragma acc data copy/copyin/copyout/presentおよび#pragam acc declarecreate, #pragma acc update)を用いたデータ転送指定を行う。 <Data transfer specification>
In step S122, the data
<コンパイル>
ステップS123で、並列処理パターン作成部117(図1参照)は、遺伝子パターンに応じてディレクティブ指定したC/C++コードをPGIコンパイラでコンパイルする。すなわち、並列処理パターン作成部117は、作成したC/C++コードを、GPUを備えた検証用マシン14上のPGIコンパイラでコンパイルを行う。
ここで、ネストfor文を複数並列指定する場合等でコンパイルエラーとなることがある。この場合は、性能測定時の処理時間がタイムアウトした場合と同様に扱う。 <compile>
In step S123, the parallel processing pattern creating unit 117 (see FIG. 1) compiles the C/C++ code specified by the directive according to the gene pattern using the PGI compiler. That is, the parallel processingpattern creation unit 117 compiles the created C/C++ code with the PGI compiler on the verification machine 14 having a GPU.
Here, a compilation error may occur when multiple nested for statements are specified in parallel. This case is handled in the same way as when the processing time times out during performance measurement.
ステップS123で、並列処理パターン作成部117(図1参照)は、遺伝子パターンに応じてディレクティブ指定したC/C++コードをPGIコンパイラでコンパイルする。すなわち、並列処理パターン作成部117は、作成したC/C++コードを、GPUを備えた検証用マシン14上のPGIコンパイラでコンパイルを行う。
ここで、ネストfor文を複数並列指定する場合等でコンパイルエラーとなることがある。この場合は、性能測定時の処理時間がタイムアウトした場合と同様に扱う。 <compile>
In step S123, the parallel processing pattern creating unit 117 (see FIG. 1) compiles the C/C++ code specified by the directive according to the gene pattern using the PGI compiler. That is, the parallel processing
Here, a compilation error may occur when multiple nested for statements are specified in parallel. This case is handled in the same way as when the processing time times out during performance measurement.
ステップS124で、性能測定部118(図1参照)は、CPU-GPU搭載の検証用マシン14に、実行ファイルをデプロイする。
ステップS125で、性能測定部118は、配置したバイナリファイルを実行し、オフロードした際のベンチマーク性能を測定する。 In step S124, the performance measurement unit 118 (see FIG. 1) deploys the execution file to theverification machine 14 equipped with the CPU-GPU.
In step S125, theperformance measurement unit 118 executes the arranged binary file and measures the benchmark performance when offloading.
ステップS125で、性能測定部118は、配置したバイナリファイルを実行し、オフロードした際のベンチマーク性能を測定する。 In step S124, the performance measurement unit 118 (see FIG. 1) deploys the execution file to the
In step S125, the
ここで、途中世代で、以前と同じパターンの遺伝子については測定せず、同じ値を使う。つまり、GA処理の中で、以前と同じパターンの遺伝子が生じた場合は、その個体についてはコンパイルや性能測定をせず、以前と同じ測定値を用いる。
Here, in the middle generation, genes with the same pattern as before are not measured, and the same values are used. In other words, when the same pattern of genes as before occurs during GA processing, the same measured values as before are used without compiling or performance measurement for that individual.
ステップS127で、性能測定部118(図1参照)は、処理時間を測定する。
At step S127, the performance measurement unit 118 (see FIG. 1) measures the processing time.
ステップS128で、性能測定部118は、測定した処理時間をもとに評価値を設定する。
At step S128, the performance measurement unit 118 sets an evaluation value based on the measured processing time.
ステップS129で、実行ファイル作成部119(図1参照)は、処理時間の短い個体ほど適合度が高くなるように評価し、性能の高い個体を選択する。実行ファイル作成部119は、測定された複数パターンの中で、短時間かつ低電力使用量のパターンを解として選択する。
In step S129, the execution file creation unit 119 (see FIG. 1) evaluates individuals with shorter processing times so that their fitness levels are higher, and selects individuals with higher performance. The execution file creating unit 119 selects a pattern of short time and low power consumption as a solution from among the plurality of measured patterns.
ステップS130で、実行ファイル作成部119は、選択された個体に対して、交叉、突然変異の処理を行い、次世代の個体を作成する。実行ファイル作成部119は、次世代の個体に対して、コンパイル、性能測定、適合度設定、選択、交叉、突然変異処理を行う。
すなわち、全個体に対して、ベンチマーク性能測定後、ベンチマーク処理時間に応じて、各遺伝子配列の適合度を設定する。設定された適合度に応じて、残す個体の選択を行う。実行ファイル作成部119は、選択された個体に対して、交叉処理、突然変異処理、そのままコピー処理のGA処理を行い、次世代の個体群を作成する。 In step S130, the executionfile creation unit 119 performs crossover and mutation processing on the selected individuals to create next-generation individuals. The executable file creation unit 119 performs compilation, performance measurement, fitness setting, selection, crossover, and mutation processing for the next-generation individuals.
That is, after benchmark performance is measured for all individuals, the degree of fitness of each gene sequence is set according to the benchmark processing time. Individuals to be left are selected according to the set degree of fitness. The executionfile creation unit 119 performs GA processing such as crossover processing, mutation processing, and copy processing as it is on the selected individuals to create a group of individuals for the next generation.
すなわち、全個体に対して、ベンチマーク性能測定後、ベンチマーク処理時間に応じて、各遺伝子配列の適合度を設定する。設定された適合度に応じて、残す個体の選択を行う。実行ファイル作成部119は、選択された個体に対して、交叉処理、突然変異処理、そのままコピー処理のGA処理を行い、次世代の個体群を作成する。 In step S130, the execution
That is, after benchmark performance is measured for all individuals, the degree of fitness of each gene sequence is set according to the benchmark processing time. Individuals to be left are selected according to the set degree of fitness. The execution
ステップS132で、実行ファイル作成部119は、指定世代数のGA処理終了後、最高性能の遺伝子配列に該当するC/C++コード(最高性能の並列処理パターン)を解とする。
In step S132, the executable file creation unit 119 takes the C/C++ code corresponding to the highest performance gene sequence (highest performance parallel processing pattern) as a solution after the GA processing for the designated number of generations is completed.
<GAのパラメータ>
上記、個体数、世代数、交叉率、突然変異率、適合度設定、選択方法は、GAのパラメータである。GAのパラメータは、例えば、以下のように設定してもよい。
実行するSimple GAの、パラメータ、条件は例えば以下のようにできる。
遺伝子長:並列可能ループ文数
個体数M:遺伝子長以下
世代数T:遺伝子長以下
適合度:(処理時間)(-1/2) <GA parameters>
The number of individuals, number of generations, crossover rate, mutation rate, fitness setting, and selection method are parameters of the GA. GA parameters may be set as follows, for example.
Parameters and conditions of Simple GA to be executed can be set as follows, for example.
Gene length: Number of loop statements that can be parallelized Number of individuals M: Less than gene length Number of generations T: Less than gene length Goodness of fit: (Processing time) (-1/2)
上記、個体数、世代数、交叉率、突然変異率、適合度設定、選択方法は、GAのパラメータである。GAのパラメータは、例えば、以下のように設定してもよい。
実行するSimple GAの、パラメータ、条件は例えば以下のようにできる。
遺伝子長:並列可能ループ文数
個体数M:遺伝子長以下
世代数T:遺伝子長以下
適合度:(処理時間)(-1/2) <GA parameters>
The number of individuals, number of generations, crossover rate, mutation rate, fitness setting, and selection method are parameters of the GA. GA parameters may be set as follows, for example.
Parameters and conditions of Simple GA to be executed can be set as follows, for example.
Gene length: Number of loop statements that can be parallelized Number of individuals M: Less than gene length Number of generations T: Less than gene length Goodness of fit: (Processing time) (-1/2)
この設定により、ベンチマーク処理時間が短い程、高適合度になる。また、適合度を、処理時間の(-1/2)乗を含む形とすることで、処理時間が短い特定の個体の適合度が高くなり過ぎて、探索範囲が狭くなるのを防ぐことができる。また、性能測定が一定時間で終わらない場合は、タイムアウトさせ、処理時間1000秒等の時間(長時間)であるとして、適合度を計算する。このタイムアウト時間は、性能測定特性に応じて変更させればよい。
選択:ルーレット選択
ただし、世代での最高適合度遺伝子は交叉も突然変異もせず次世代に保存するエリート保存も合わせて行う。
交叉率Pc:0.9
突然変異率Pm:0.05 With this setting, the shorter the benchmark processing time, the higher the compatibility. In addition, by setting the degree of fitness to include the (-1/2) power of the processing time, it is possible to prevent the search range from narrowing due to the degree of fitness of a specific individual whose processing time is short becoming too high. can. If the performance measurement does not end within a certain period of time, it is timed out, and the suitability is calculated assuming that the processing time is 1000 seconds (long time). This timeout period may be changed according to performance measurement characteristics.
Selection: Roulette selection However, we also perform elite preservation in which the gene with the highest fitness in the generation is preserved in the next generation without crossover or mutation.
Crossover rate Pc: 0.9
Mutation rate Pm: 0.05
選択:ルーレット選択
ただし、世代での最高適合度遺伝子は交叉も突然変異もせず次世代に保存するエリート保存も合わせて行う。
交叉率Pc:0.9
突然変異率Pm:0.05 With this setting, the shorter the benchmark processing time, the higher the compatibility. In addition, by setting the degree of fitness to include the (-1/2) power of the processing time, it is possible to prevent the search range from narrowing due to the degree of fitness of a specific individual whose processing time is short becoming too high. can. If the performance measurement does not end within a certain period of time, it is timed out, and the suitability is calculated assuming that the processing time is 1000 seconds (long time). This timeout period may be changed according to performance measurement characteristics.
Selection: Roulette selection However, we also perform elite preservation in which the gene with the highest fitness in the generation is preserved in the next generation without crossover or mutation.
Crossover rate Pc: 0.9
Mutation rate Pm: 0.05
<コストパフォーマンス>
自動オフロード機能のコストパフォーマンスについて述べる。
NVIDIA Tesla等の、GPUボードのハードウェアの価格だけを見ると、GPUを搭載したマシンの価格は、通常のCPUのみのマシンの約2倍となる。しかし、一般にデータセンタ等のコストでは、ハードウェアやシステム開発のコストが1/3以下であり、電気代や保守・運用体制等の運用費が1/3超であり、サービスオーダ等のその他費用が1/3程度である。本実施形態では、暗号処理や画像処理等動作させるアプリケーションで時間がかかる処理を2倍以上高性能化できる。このため、サーバハードウェア価格自体は2倍となっても、コスト効果が十分に期待できる。 <Cost performance>
The cost performance of the automatic offload function is described.
Looking only at the hardware price of GPU boards, such as NVIDIA Tesla, the price of a machine with a GPU is about double that of a normal CPU-only machine. However, in general, in the cost of data centers, hardware and system development costs are less than 1/3, operating costs such as electricity costs and maintenance and operation systems are more than 1/3, and other costs such as service orders. is about 1/3. In this embodiment, it is possible to double or more increase the performance of processing that takes a long time in applications such as encryption processing and image processing. Therefore, even if the price of the server hardware itself doubles, the cost effect can be fully expected.
自動オフロード機能のコストパフォーマンスについて述べる。
NVIDIA Tesla等の、GPUボードのハードウェアの価格だけを見ると、GPUを搭載したマシンの価格は、通常のCPUのみのマシンの約2倍となる。しかし、一般にデータセンタ等のコストでは、ハードウェアやシステム開発のコストが1/3以下であり、電気代や保守・運用体制等の運用費が1/3超であり、サービスオーダ等のその他費用が1/3程度である。本実施形態では、暗号処理や画像処理等動作させるアプリケーションで時間がかかる処理を2倍以上高性能化できる。このため、サーバハードウェア価格自体は2倍となっても、コスト効果が十分に期待できる。 <Cost performance>
The cost performance of the automatic offload function is described.
Looking only at the hardware price of GPU boards, such as NVIDIA Tesla, the price of a machine with a GPU is about double that of a normal CPU-only machine. However, in general, in the cost of data centers, hardware and system development costs are less than 1/3, operating costs such as electricity costs and maintenance and operation systems are more than 1/3, and other costs such as service orders. is about 1/3. In this embodiment, it is possible to double or more increase the performance of processing that takes a long time in applications such as encryption processing and image processing. Therefore, even if the price of the server hardware itself doubles, the cost effect can be fully expected.
本実施形態では、gcov,gprof等を用いて、ループが多く実行時間がかかっているアプリケーションを事前に特定して、オフロード試行をする。これにより、効率的に高速化できるアプリケーションを見つけることができる。
In this embodiment, gcov, gprof, etc. are used to identify in advance an application that has many loops and takes a long time to execute, and offloading is attempted. This allows you to find applications that can be efficiently accelerated.
<本番サービス利用開始までの時間>
本番サービス利用開始までの時間について述べる。
コンパイルから性能測定1回は3分程度とすると、20の個体数、20の世代数のGAで最大20時間程度解探索にかかるが、以前と同じ遺伝子パターンのコンパイル、測定は省略されるため、8時間以下で終了する。多くのクラウドやホスティング、ネットワークサービスではサービス利用開始に半日程度かかるのが実情である。本実施形態では、例えば半日以内の自動オフロードが可能である。このため、半日以内の自動オフロードであれば、最初は試し利用ができるとすれば、ユーザ満足度を十分に高めることが期待できる。 <Time to start using the actual service>
Describe the time until the start of use of the actual service.
Assuming that it takes about 3 minutes from compilation to performance measurement, it takes about 20 hours at maximum with GA of 20 individuals and 20 generations. Finish in 8 hours or less. The reality is that it takes about half a day to start using many cloud, hosting, and network services. In this embodiment, for example, automatic offloading within half a day is possible. For this reason, as long as the automatic offload is within half a day, if trial use is possible at first, it can be expected that user satisfaction will be sufficiently increased.
本番サービス利用開始までの時間について述べる。
コンパイルから性能測定1回は3分程度とすると、20の個体数、20の世代数のGAで最大20時間程度解探索にかかるが、以前と同じ遺伝子パターンのコンパイル、測定は省略されるため、8時間以下で終了する。多くのクラウドやホスティング、ネットワークサービスではサービス利用開始に半日程度かかるのが実情である。本実施形態では、例えば半日以内の自動オフロードが可能である。このため、半日以内の自動オフロードであれば、最初は試し利用ができるとすれば、ユーザ満足度を十分に高めることが期待できる。 <Time to start using the actual service>
Describe the time until the start of use of the actual service.
Assuming that it takes about 3 minutes from compilation to performance measurement, it takes about 20 hours at maximum with GA of 20 individuals and 20 generations. Finish in 8 hours or less. The reality is that it takes about half a day to start using many cloud, hosting, and network services. In this embodiment, for example, automatic offloading within half a day is possible. For this reason, as long as the automatic offload is within half a day, if trial use is possible at first, it can be expected that user satisfaction will be sufficiently increased.
より短時間でオフロード部分を探索するためには、複数の検証用マシンにより個体数分並列で性能測定することが考えられる。アプリケーションに応じて、タイムアウト時間を調整することも短時間化に繋がる。例えば、オフロード処理がCPUでの実行時間の2倍かかる場合はタイムアウトとする等である。また、個体数、世代数が多い方が、高性能な解を発見できる可能性が高まる。しかし、各パラメータを最大にする場合、個体数×世代数だけコンパイル、および性能ベンチマークを行う必要がある。このため、本番サービス利用開始までの時間がかかる。本実施形態では、GAとしては少ない個体数、世代数で行っているが、交叉率Pcを0.9と高い値にして広範囲を探索することで、ある程度の性能の解を早く発見するようにしている。
In order to search for the offload part in a shorter time, it is conceivable to measure the performance in parallel for the number of individuals using multiple verification machines. Adjusting the timeout time according to the application also leads to shortening. For example, if the offload processing takes twice as long as the execution time in the CPU, it is timed out. Also, the larger the number of individuals and the number of generations, the higher the possibility of discovering a high-performance solution. However, when maximizing each parameter, it is necessary to compile and perform performance benchmarks for the number of individuals times the number of generations. Therefore, it takes time to start using the actual service. In this embodiment, the GA is performed with a small number of individuals and a small number of generations, but by setting the crossover rate Pc to a high value of 0.9 and searching a wide range, a solution with a certain level of performance can be found quickly. ing.
[指示句の拡大]
本実施形態では、適用できるアプリケーション増加のため、指示句の拡大を行う。具体的には、GPU処理を指定する指示句として、kernels指示句に加えて,parallel loop指示句、parallel loop vector指示句にも拡大する。
OpenACC標準では、kernelsは、single loopやtightly nested loopに使われる。また、parallel loopは、non-tightly nested loopも含めたループに使われる。parallel loop vectorは、parallelizeはできないがvectorizeはできるループに使われる。ここで、tightly nested loopとは、ネストループにて、例えば、iとjをインクリメントする二つのループが入れ子になっている時、下位のループでiとjを使った処理がされ、上位ではされないような単純なループである。また、PGIコンパイラ等の実装においては、kernelsは、並列化の判断はコンパイラが行い、parallelは並列化の判断はプログラマが行うという違いがある。 [Expansion of directives]
In this embodiment, the directives are expanded in order to increase the number of applicable applications. Specifically, as directives specifying GPU processing, in addition to kernels directives, parallel loop directives and parallel loop vector directives are expanded.
In the OpenACC standard, kernels are used for single loops and tightly nested loops. Also, parallel loops are used for loops including non-tightly nested loops. parallel loop vector is used for loops that cannot be parallelized but can be vectorized. Here, a tightly nested loop is a nested loop, for example, when two loops that increment i and j are nested, the lower loop uses i and j, and the upper loop does not A simple loop like Also, in the implementation of the PGI compiler, etc., there is a difference in that the compiler makes decisions about parallelization for kernels, and the programmer makes decisions about parallelization for parallels.
本実施形態では、適用できるアプリケーション増加のため、指示句の拡大を行う。具体的には、GPU処理を指定する指示句として、kernels指示句に加えて,parallel loop指示句、parallel loop vector指示句にも拡大する。
OpenACC標準では、kernelsは、single loopやtightly nested loopに使われる。また、parallel loopは、non-tightly nested loopも含めたループに使われる。parallel loop vectorは、parallelizeはできないがvectorizeはできるループに使われる。ここで、tightly nested loopとは、ネストループにて、例えば、iとjをインクリメントする二つのループが入れ子になっている時、下位のループでiとjを使った処理がされ、上位ではされないような単純なループである。また、PGIコンパイラ等の実装においては、kernelsは、並列化の判断はコンパイラが行い、parallelは並列化の判断はプログラマが行うという違いがある。 [Expansion of directives]
In this embodiment, the directives are expanded in order to increase the number of applicable applications. Specifically, as directives specifying GPU processing, in addition to kernels directives, parallel loop directives and parallel loop vector directives are expanded.
In the OpenACC standard, kernels are used for single loops and tightly nested loops. Also, parallel loops are used for loops including non-tightly nested loops. parallel loop vector is used for loops that cannot be parallelized but can be vectorized. Here, a tightly nested loop is a nested loop, for example, when two loops that increment i and j are nested, the lower loop uses i and j, and the upper loop does not A simple loop like Also, in the implementation of the PGI compiler, etc., there is a difference in that the compiler makes decisions about parallelization for kernels, and the programmer makes decisions about parallelization for parallels.
そこで、本実施形態では、single、tightly nested loopにはkernelsを使い、non-tightly nested loopにはparallel loopを使う。また、parallelizeできないがvectorizeできるループにはparallel loop vectorを使う。
ここで、parallel指示句にすることで、結果がkernelsの場合より信頼度が下がる懸念がある。しかし、最終的なオフロードプログラムに対して、サンプルテストを行い、CPUとの結果差分をチェックしその結果をユーザに見せて、ユーザに確認してもらうことを想定している。そもそも、CPUとGPUではハードが異なるため,有効数字桁数や丸め誤差の違い等があり、kernelsだけでもCPUとの結果差分のチェックは必要である。 Therefore, in this embodiment, kernels are used for single and tightly nested loops, and parallel loops are used for non-tightly nested loops. Also, use parallel loop vector for loops that cannot be parallelized but can be vectorized.
Here, there is a concern that using the parallel directive may reduce the reliability of the results compared to kernels. However, it is assumed that the final offload program will be subjected to a sample test, the difference between the result and the CPU will be checked, and the result will be shown to the user for confirmation by the user. In the first place, since the CPU and GPU have different hardware, there are differences in the number of significant digits and rounding errors, and it is necessary to check the result difference between the kernels and the CPU.
ここで、parallel指示句にすることで、結果がkernelsの場合より信頼度が下がる懸念がある。しかし、最終的なオフロードプログラムに対して、サンプルテストを行い、CPUとの結果差分をチェックしその結果をユーザに見せて、ユーザに確認してもらうことを想定している。そもそも、CPUとGPUではハードが異なるため,有効数字桁数や丸め誤差の違い等があり、kernelsだけでもCPUとの結果差分のチェックは必要である。 Therefore, in this embodiment, kernels are used for single and tightly nested loops, and parallel loops are used for non-tightly nested loops. Also, use parallel loop vector for loops that cannot be parallelized but can be vectorized.
Here, there is a concern that using the parallel directive may reduce the reliability of the results compared to kernels. However, it is assumed that the final offload program will be subjected to a sample test, the difference between the result and the CPU will be checked, and the result will be shown to the user for confirmation by the user. In the first place, since the CPU and GPU have different hardware, there are differences in the number of significant digits and rounding errors, and it is necessary to check the result difference between the kernels and the CPU.
[リソース比とリソース量の設定、および新規アプリケーションの配置フローチャート]
図10は、GPUオフロード試行の後に追加されるリソース比とリソース量の設定および新規アプリケーションの配置を説明するフローチャートである。図10に示すフローチャートは、図9A-Bに示すGPUオフロード試行後に実行される。 [Resource ratio and resource amount settings, and new application allocation flow chart]
FIG. 10 is a flow chart illustrating setting the resource ratio and amount of resources added after a GPU offload attempt and placing a new application. The flow chart shown in FIG. 10 is executed after the GPU offload attempts shown in FIGS. 9A-B.
図10は、GPUオフロード試行の後に追加されるリソース比とリソース量の設定および新規アプリケーションの配置を説明するフローチャートである。図10に示すフローチャートは、図9A-Bに示すGPUオフロード試行後に実行される。 [Resource ratio and resource amount settings, and new application allocation flow chart]
FIG. 10 is a flow chart illustrating setting the resource ratio and amount of resources added after a GPU offload attempt and placing a new application. The flow chart shown in FIG. 10 is executed after the GPU offload attempts shown in FIGS. 9A-B.
ステップS51でリソース比決定部115は、ユーザ運用条件、テストケースCPU処理時間、オフロードデバイス処理時間を取得する。ユーザ運用条件は、ユーザがオフロードしたいコードを指定する際に合わせてユーザに指定してもらう。ユーザ運用条件は、リソース量設定部116が、設備リソースDB132の情報を参照してリソース量を決定する際に利用する。
In step S51, the resource ratio determination unit 115 acquires user operating conditions, test case CPU processing time, and offload device processing time. The user operating conditions are specified by the user when the user specifies the code to be offloaded. The user operating conditions are used when the resource amount setting unit 116 refers to the information in the equipment resource DB 132 and determines the resource amount.
<リソース比決定部115の処理>
ステップS52でリソース比決定部115は、性能測定結果をもとに、CPUとオフロードデバイスの処理時間(テストケースCPU処理時間とオフロードデバイス処理時間)の比を、リソース比として決定する。 <Processing of ResourceRatio Determining Unit 115>
In step S52, the resourceratio determination unit 115 determines the ratio of the CPU and offload device processing times (test case CPU processing time and offload device processing time) as the resource ratio based on the performance measurement result.
ステップS52でリソース比決定部115は、性能測定結果をもとに、CPUとオフロードデバイスの処理時間(テストケースCPU処理時間とオフロードデバイス処理時間)の比を、リソース比として決定する。 <Processing of Resource
In step S52, the resource
本自動オフロードによって、コード変換の際には、既に検証環境での性能測定結果が得られている。この性能測定結果を用いて、リソース比決定部115は、CPUとオフロードデバイスのリソース比を決定する。具体的には、検証環境でのCPUとオフロードデバイスの処理時間の比に対して、適正なリソース比を決定する。例えば、検証環境でのテストケース処理時間が、CPU処理:10秒、GPU処理:5秒の場合は、リソース比は、CPU:GPU=2:1となる。
With this automatic offload, the performance measurement results in the verification environment have already been obtained at the time of code conversion. Using this performance measurement result, the resource ratio determination unit 115 determines the resource ratio between the CPU and the offload device. Specifically, an appropriate resource ratio is determined with respect to the ratio of the processing time of the CPU and the offload device in the verification environment. For example, if the test case processing time in the verification environment is CPU processing: 10 seconds and GPU processing: 5 seconds, the resource ratio is CPU:GPU=2:1.
リソース比決定部115は、CPUとオフロードデバイスの処理時間が同等オーダになるように、リソース比を決定する。CPUとオフロードデバイスの処理時間が同等オーダになるように、リソース比を決定することで、CPUとオフロードデバイスの処理時間を揃え、CPUとアクセラレータがGPU、FPGA、メニーコアCPU等の混在環境であってもリソース量を適切に設定することができる。
The resource ratio determination unit 115 determines the resource ratio so that the processing times of the CPU and the offload device are of the same order. By determining the resource ratio so that the processing time of the CPU and the offload device are of the same order, the processing time of the CPU and the offload device can be aligned, and the CPU and accelerator can be used in mixed environments such as GPUs, FPGAs, and many-core CPUs. Even if there is, the amount of resources can be appropriately set.
リソース比決定部115は、CPUとオフロードデバイスの処理時間の差分が所定閾値以上の場合、リソース比を所定の上限値に設定する。すなわち、検証環境でのCPUとオフロードデバイスの処理時間が、例えば10倍以上差分がある場合にリソース比を10倍以上にしてしまうと、コストパフォーマンス悪化につながる。この場合は、例えば、5:1等のリソース比を上限にする(上限値は、処理時間の5:1のリソース比)。リソース比に上限を設けることで、VM数の大幅増加を防ぐことができる。
The resource ratio determination unit 115 sets the resource ratio to a predetermined upper limit when the difference between the processing times of the CPU and the offload device is equal to or greater than a predetermined threshold. That is, if the processing time between the CPU and the offload device in the verification environment has a difference of, for example, 10 times or more, increasing the resource ratio to 10 times or more leads to deterioration in cost performance. In this case, for example, a resource ratio such as 5:1 is set as the upper limit (the upper limit is a resource ratio of 5:1 of the processing time). By setting an upper limit on the resource ratio, it is possible to prevent a large increase in the number of VMs.
<リソース量設定部116の処理>
ステップS53でリソース量設定部116は、ユーザ運用条件と適切リソース比をもとに、リソース量を設定する。すなわち、リソース量設定部116は、ユーザが指定したコスト条件を満たすように、リソース比はできるだけキープして、リソース量を決定する。 <Processing of resourceamount setting unit 116>
In step S53, the resourceamount setting unit 116 sets the resource amount based on the user operating conditions and the appropriate resource ratio. That is, the resource amount setting unit 116 determines the resource amount while maintaining the resource ratio as much as possible so as to satisfy the cost condition specified by the user.
ステップS53でリソース量設定部116は、ユーザ運用条件と適切リソース比をもとに、リソース量を設定する。すなわち、リソース量設定部116は、ユーザが指定したコスト条件を満たすように、リソース比はできるだけキープして、リソース量を決定する。 <Processing of resource
In step S53, the resource
リソース量設定部116は、適切リソース比を維持して、ユーザ運用条件を満たす最大のリソース量を設定する。具体例を挙げると、CPU1VMは1000円/月、GPUは4000円/月、リソース比は2:1が適切であるとし、ユーザは月10000円以内の予算であるとする。この場合には、CPUは2、GPUは1を確保して商用環境に配置する。
The resource amount setting unit 116 maintains an appropriate resource ratio and sets the maximum resource amount that satisfies the user operating conditions. As a specific example, it is assumed that the CPU1VM is 1,000 yen/month, the GPU is 4,000 yen/month, the resource ratio is 2:1, and the user's budget is within 10,000 yen per month. In this case, 2 CPUs and 1 GPU are secured and placed in the commercial environment.
リソース量設定部116は、リソース比を維持した最小リソース量でもユーザ運用条件を満たさない場合は、リソース比を崩してCPUとオフロードデバイスのリソース量をコスト条件を満たすよう最小で設定する。具体例を挙げると、CPU1VMは1000円/月、GPUは4000円/月、リソース比は2:1が適切であるとし、ユーザは月5000円以内の予算であるとする。この場合には、ユーザ予算が足りないため、リソース比はキープできないが、CPUとオフロードデバイスのリソース量をより小さく設定、すなわちCPUは1、GPUは1を確保して配置する。
If the user operation condition is not satisfied even with the minimum resource amount maintaining the resource ratio, the resource amount setting unit 116 sets the resource amount of the CPU and the offload device to the minimum so as to satisfy the cost condition by breaking the resource ratio. To give a specific example, it is assumed that the CPU1VM is 1,000 yen/month, the GPU is 4,000 yen/month, the resource ratio is 2:1, and the user's budget is within 5,000 yen per month. In this case, since the user budget is insufficient, the resource ratio cannot be maintained, but the resource amounts of the CPU and the offload device are set smaller, that is, 1 is secured for the CPU and 1 is allocated for the GPU.
上記ステップS53の処理を終え、商用環境にリソースを確保して配置した後は、ユーザが利用する前に、性能およびコストを確認するため、図2で述べた自動検証を実行する。これにより、商用環境でリソースを確保して、自動検証後、性能とコストをユーザに提示することができる。
After the processing of step S53 above is completed and the resources are secured and allocated in the commercial environment, the automatic verification described in FIG. 2 is executed in order to confirm the performance and cost before use by the user. As a result, resources can be reserved in a commercial environment, and performance and cost can be presented to the user after automatic verification.
<リソース比とリソース量の設定のまとめ>
リソース比を適切化するため、オフロードパターンの解を決める際の性能測定結果を用いる。実装は、テストケースの処理時間から、CPUとGPUの処理時間が同等オーダになるようリソース比を定める。例えば、テストケースの処理時間が、CPU処理:10秒、GPU処理:5秒の場合では、CPU側のリソースは2倍で同等の処理時間程度と考えられるため、リソース比は2:1となる。なお、仮想マシン等の数は整数となるため、リソース比は処理時間から計算する際に、整数比となるように四捨五入する。 <Summary of resource ratio and resource amount settings>
Performance measurements are used in solving offload patterns to optimize resource ratios. The implementation determines the resource ratio so that the CPU and GPU processing times are of the same order from the test case processing time. For example, if the test case processing time is 10 seconds for CPU processing and 5 seconds for GPU processing, the resources on the CPU side are doubled and the processing time is considered to be about the same, so the resource ratio is 2:1. . Since the number of virtual machines and the like is an integer, when calculating the resource ratio from the processing time, the resource ratio is rounded to an integer ratio.
リソース比を適切化するため、オフロードパターンの解を決める際の性能測定結果を用いる。実装は、テストケースの処理時間から、CPUとGPUの処理時間が同等オーダになるようリソース比を定める。例えば、テストケースの処理時間が、CPU処理:10秒、GPU処理:5秒の場合では、CPU側のリソースは2倍で同等の処理時間程度と考えられるため、リソース比は2:1となる。なお、仮想マシン等の数は整数となるため、リソース比は処理時間から計算する際に、整数比となるように四捨五入する。 <Summary of resource ratio and resource amount settings>
Performance measurements are used in solving offload patterns to optimize resource ratios. The implementation determines the resource ratio so that the CPU and GPU processing times are of the same order from the test case processing time. For example, if the test case processing time is 10 seconds for CPU processing and 5 seconds for GPU processing, the resources on the CPU side are doubled and the processing time is considered to be about the same, so the resource ratio is 2:1. . Since the number of virtual machines and the like is an integer, when calculating the resource ratio from the processing time, the resource ratio is rounded to an integer ratio.
リソース比が決定されると、次に、商用環境へのアプリケーション配置を行う際のリソース量の設定を行う。実装は、リソース量決定には、ユーザがオフロード依頼時に指定したコスト要求を満たすように、リソース比はできるだけキープして、VM等の数を定める。具体的には、コスト範囲内で、リソース比をキープする中では、VM等の数は最大値を選択する。
Once the resource ratio has been determined, the next step is to set the resource amount when deploying the application to the commercial environment. For resource amount determination, the implementation determines the number of VMs, etc. while keeping the resource ratio as much as possible so as to satisfy the cost request specified by the user at the time of the offload request. Specifically, the maximum number of VMs is selected while maintaining the resource ratio within the cost range.
例えば、CPUに関して1VMは1000円/月、GPUは4000円/月、リソース比は2:1が適切であり、ユーザは月10000円以内の予算であった場合には、CPUは2、GPUは1を確保する。また、コスト範囲内で、リソース比をキープできない場合は、CPU1単位、GPU1単位から始めてできるだけ適切なリソース比に近くなるよう、リソース量を設定する。例えば、月5000円以内の予算であった場合には、リソース比はキープできないが、CPUは1、GPUは1を確保する。
リソース量を設定すると、実装では、例えばXen Serverの仮想化機能を用いて、CPUやGPUのリソースを割り当てる。 For example, for CPU, 1 VM is 1000 yen/month, GPU is 4000 yen/month, and the resource ratio is 2:1. Secure 1. Also, if the resource ratio cannot be maintained within the cost range, the resource amount is set so that the resource ratio is as close to an appropriate one as possible, starting from one CPU unit and one GPU unit. For example, if the budget is within 5000 yen per month, the resource ratio cannot be maintained, but 1 CPU and 1 GPU are secured.
Once the amount of resources is set, the implementation uses, for example, the virtualization function of Xen Server to allocate CPU and GPU resources.
リソース量を設定すると、実装では、例えばXen Serverの仮想化機能を用いて、CPUやGPUのリソースを割り当てる。 For example, for CPU, 1 VM is 1000 yen/month, GPU is 4000 yen/month, and the resource ratio is 2:1. Secure 1. Also, if the resource ratio cannot be maintained within the cost range, the resource amount is set so that the resource ratio is as close to an appropriate one as possible, starting from one CPU unit and one GPU unit. For example, if the budget is within 5000 yen per month, the resource ratio cannot be maintained, but 1 CPU and 1 GPU are secured.
Once the amount of resources is set, the implementation uses, for example, the virtualization function of Xen Server to allocate CPU and GPU resources.
ステップS54で配置設定部170は、設備リソースDB132のサーバ、リンクのスペック情報、既存アプリケーションの配置情報に基づいて、線形計画手法を用いて、新規アプリケーションの配置先(APLの配置場所)を計算して設定する。
In step S54, the placement setting unit 170 calculates the new application placement location (APL placement location) using a linear programming method based on the server of the equipment resource DB 132, the link specification information, and the existing application placement information. to set.
[変換したアプリケーションの最適配置]
本実施形態のオフロードサーバ1は、CPU向けプログラムを、GPU等のデバイスにオフロードした際に、アプリケーションをユーザのコスト等要求を満たして、応答時間等を短く動作するように、配置先を適正化する。 [Optimal Placement of Converted Applications]
Theoffload server 1 of the present embodiment, when offloading a program for a CPU to a device such as a GPU, selects a location where the application is placed so as to meet the user's requirements such as cost and operate with a short response time. rationalize.
本実施形態のオフロードサーバ1は、CPU向けプログラムを、GPU等のデバイスにオフロードした際に、アプリケーションをユーザのコスト等要求を満たして、応答時間等を短く動作するように、配置先を適正化する。 [Optimal Placement of Converted Applications]
The
<アプリケーション配置場所の適切化>
本実施形態では、アプリケーションはクラウドだけでなく、ネットワークエッジやユーザエッジに配置できることを前提とする。ただし、ネットワークエッジやユーザエッジは、クラウドに比べサーバの集約度が低く分散している。このため、計算リソースのコストは、クラウドに比べ割高となる。すなわち、一般にCPUやGPU等のハードウェアの価格は配置場所によらず一定であるものの、クラウドを運用するデータセンタでは集約されたサーバをまとめて監視や空調制御等できるため、運用費が割安となる。
例えば、計算ノードリンクの簡単なトポロジーとしては、図11が挙げられる。 <Appropriate placement of applications>
In this embodiment, it is assumed that applications can be placed not only in the cloud but also in network edges and user edges. However, the network edge and user edge are distributed with a lower concentration of servers compared to the cloud. Therefore, the cost of computing resources is relatively high compared to the cloud. In other words, although the price of hardware such as CPUs and GPUs is generally the same regardless of where they are located, in a data center that operates a cloud, the centralized servers can be collectively monitored and air conditioning controlled, so operation costs are relatively low. Become.
For example, a simple topology of computation node links is shown in FIG.
本実施形態では、アプリケーションはクラウドだけでなく、ネットワークエッジやユーザエッジに配置できることを前提とする。ただし、ネットワークエッジやユーザエッジは、クラウドに比べサーバの集約度が低く分散している。このため、計算リソースのコストは、クラウドに比べ割高となる。すなわち、一般にCPUやGPU等のハードウェアの価格は配置場所によらず一定であるものの、クラウドを運用するデータセンタでは集約されたサーバをまとめて監視や空調制御等できるため、運用費が割安となる。
例えば、計算ノードリンクの簡単なトポロジーとしては、図11が挙げられる。 <Appropriate placement of applications>
In this embodiment, it is assumed that applications can be placed not only in the cloud but also in network edges and user edges. However, the network edge and user edge are distributed with a lower concentration of servers compared to the cloud. Therefore, the cost of computing resources is relatively high compared to the cloud. In other words, although the price of hardware such as CPUs and GPUs is generally the same regardless of where they are located, in a data center that operates a cloud, the centralized servers can be collectively monitored and air conditioning controlled, so operation costs are relatively low. Become.
For example, a simple topology of computation node links is shown in FIG.
図11は、計算ノードのトポロジーの一例を示す図である。図11は、IoTシステムのように、ユーザ環境でデータを収集するIoTデバイス等から、ユーザエッジにデータが送られ、ネットワークエッジを介してクラウドにデータが送られ、分析結果を会社の幹部が見る等で使われるトポロジーである。
FIG. 11 is a diagram showing an example of the topology of computation nodes. In FIG. 11, data is sent from an IoT device that collects data in the user environment, such as an IoT system, to the user edge, and the data is sent to the cloud via the network edge, and the analysis results are viewed by company executives. This is the topology used in
図11に示すように、アプリケーションを配置するトポロジーは、3層で構成され、クラウドレイヤー(例えば、データセンタ)の拠点数は「2」(n13,n14)、キャリアエッジレイヤー(例えば、局舎)は「3」、ユーザエッジレイヤー(例えば、ユーザ環境)は「4」(n6-n9)、インプットノードは「5」(n1-n5)とする。
IoT等のアプリケーションを想定してインプットノードからIoTデータ(IoTデバイスの一つである花粉センサや体温センサ等)がユーザエッジに収集され、アプリケーションの特性(応答時間の要求条件等)に応じて、ユーザエッジ、キャリアエッジで分析処理がされたり、クラウドまでデータをあげてから分析処理されたりされる。アウトプットノードは「1」(n15)であり、分析結果を会社の幹部が見る。例えば、インプットノードがIoTデータ(花粉センサ)の場合は、アウトプットノードの統計・分析結果は気象庁の責任者が確認する。
図11に示す配置トポロジー3層は、一例であり、例えば5層であってもよい。また、ユーザエッジ、キャリアエッジの数は、実際には数十~数百の場合もある。 As shown in FIG. 11, the topology for arranging applications consists of three layers, the number of bases in the cloud layer (eg, data center) is "2" (n13, n14), and the carrier edge layer (eg, office) is "3", the user edge layer (eg, user environment) is "4" (n6-n9), and the input node is "5" (n1-n5).
Assuming applications such as IoT, IoT data (pollen sensors, body temperature sensors, etc., which are one of IoT devices) is collected from the input node to the user edge, and depending on the characteristics of the application (response time requirements, etc.), Analysis processing is performed at the user edge and carrier edge, and analysis processing is performed after data is uploaded to the cloud. The output node is "1" (n15), and the analysis results are viewed by company executives. For example, when the input node is IoT data (pollen sensor), the person in charge of the Japan Meteorological Agency confirms the statistics and analysis results of the output node.
The arrangement topology of three layers shown in FIG. 11 is an example, and may be, for example, five layers. Also, the number of user edges and carrier edges may actually be several tens to several hundred.
IoT等のアプリケーションを想定してインプットノードからIoTデータ(IoTデバイスの一つである花粉センサや体温センサ等)がユーザエッジに収集され、アプリケーションの特性(応答時間の要求条件等)に応じて、ユーザエッジ、キャリアエッジで分析処理がされたり、クラウドまでデータをあげてから分析処理されたりされる。アウトプットノードは「1」(n15)であり、分析結果を会社の幹部が見る。例えば、インプットノードがIoTデータ(花粉センサ)の場合は、アウトプットノードの統計・分析結果は気象庁の責任者が確認する。
図11に示す配置トポロジー3層は、一例であり、例えば5層であってもよい。また、ユーザエッジ、キャリアエッジの数は、実際には数十~数百の場合もある。 As shown in FIG. 11, the topology for arranging applications consists of three layers, the number of bases in the cloud layer (eg, data center) is "2" (n13, n14), and the carrier edge layer (eg, office) is "3", the user edge layer (eg, user environment) is "4" (n6-n9), and the input node is "5" (n1-n5).
Assuming applications such as IoT, IoT data (pollen sensors, body temperature sensors, etc., which are one of IoT devices) is collected from the input node to the user edge, and depending on the characteristics of the application (response time requirements, etc.), Analysis processing is performed at the user edge and carrier edge, and analysis processing is performed after data is uploaded to the cloud. The output node is "1" (n15), and the analysis results are viewed by company executives. For example, when the input node is IoT data (pollen sensor), the person in charge of the Japan Meteorological Agency confirms the statistics and analysis results of the output node.
The arrangement topology of three layers shown in FIG. 11 is an example, and may be, for example, five layers. Also, the number of user edges and carrier edges may actually be several tens to several hundred.
計算ノードは、CPU、GPU、FPGAの3種に分けられる。GPUやFPGAを備えるノードには、CPUも搭載されているが、仮想化技術(例えば、NVIDIA vGPU)により、GPUインスタンス、FPGAインスタンスとして、CPUリソースも含む形で分割して提供される。
Computing nodes are divided into three types: CPU, GPU, and FPGA. Nodes equipped with GPUs and FPGAs are also equipped with CPUs, but virtualization technology (for example, NVIDIA vGPU) provides separate GPU instances and FPGA instances that also include CPU resources.
アプリケーションは、クラウド、キャリアエッジ、ユーザエッジに配置され、ユーザ環境に近い側程、応答時間を低減することが可能になる代わりに、計算リソースのコストが高くなる。本実施形態では、GPUやFPGA向けに変換したアプリケーションを配置することになるが、配置する際に、ユーザは2種類のリクエストを発出できる。
一つ目は、コスト要求であり、アプリケーションを動作させるために許容できる計算リソースのコストを指定する形で、例えば月5000円以内で動作させる等である。二つ目は、応答時間要求であり、アプリケーションを動作させる際の許容応答時間を指定する形で、例えば10秒以内に応答を返す等である。従来から行われている設備設計では、例えば仮想ネットワークを収容するサーバを配置する場所を、トラフィック増加量等の長期的傾向を見て、計画的に設計している。 Applications are deployed in the cloud, carrier edge, and user edge, and the closer to the user environment, the lower the response time, but the higher the cost of computing resources. In this embodiment, an application converted for GPU or FPGA is arranged, and the user can issue two types of requests when arranging the application.
The first is a cost request, which specifies the permissible cost of computing resources for operating the application, for example, within 5000 yen per month. The second is a response time request, which specifies an allowable response time for operating an application, such as returning a response within 10 seconds. In the conventional equipment design, for example, locations for arranging servers that accommodate virtual networks are systematically designed in consideration of long-term trends such as traffic increases.
一つ目は、コスト要求であり、アプリケーションを動作させるために許容できる計算リソースのコストを指定する形で、例えば月5000円以内で動作させる等である。二つ目は、応答時間要求であり、アプリケーションを動作させる際の許容応答時間を指定する形で、例えば10秒以内に応答を返す等である。従来から行われている設備設計では、例えば仮想ネットワークを収容するサーバを配置する場所を、トラフィック増加量等の長期的傾向を見て、計画的に設計している。 Applications are deployed in the cloud, carrier edge, and user edge, and the closer to the user environment, the lower the response time, but the higher the cost of computing resources. In this embodiment, an application converted for GPU or FPGA is arranged, and the user can issue two types of requests when arranging the application.
The first is a cost request, which specifies the permissible cost of computing resources for operating the application, for example, within 5000 yen per month. The second is a response time request, which specifies an allowable response time for operating an application, such as returning a response within 10 seconds. In the conventional equipment design, for example, locations for arranging servers that accommodate virtual networks are systematically designed in consideration of long-term trends such as traffic increases.
本実施形態では、下記(1),(2)の特徴がある。(1)配置されるアプリケーションは静的に定まっているのではなく、GPUやFPGA向けに自動変換され、GA等を通じて利用形態に適したパターンが実測を通じて抽出される。このため、アプリケーションのコードや性能は動的に変わり得る。
(2)キャリアの設備コストや全体的応答時間だけを低減すればよいのではなく、計算リソースのコストや応答時間に対する個々のユーザ要求を満たす必要がある。また、アプリケーションの配置ポリシーも動的に変わり得る。 This embodiment has the following features (1) and (2). (1) Applications to be placed are not statically determined, but are automatically converted for GPUs and FPGAs, and patterns suitable for usage forms are extracted through actual measurements through GA and the like. Because of this, application code and performance can change dynamically.
(2) It is not enough to reduce only the carrier's equipment cost and overall response time, but it is necessary to meet individual user requirements for computational resource cost and response time. Application placement policies can also change dynamically.
(2)キャリアの設備コストや全体的応答時間だけを低減すればよいのではなく、計算リソースのコストや応答時間に対する個々のユーザ要求を満たす必要がある。また、アプリケーションの配置ポリシーも動的に変わり得る。 This embodiment has the following features (1) and (2). (1) Applications to be placed are not statically determined, but are automatically converted for GPUs and FPGAs, and patterns suitable for usage forms are extracted through actual measurements through GA and the like. Because of this, application code and performance can change dynamically.
(2) It is not enough to reduce only the carrier's equipment cost and overall response time, but it is necessary to meet individual user requirements for computational resource cost and response time. Application placement policies can also change dynamically.
上記(1),(2)の特徴も踏まえ、本実施形態のアプリケーション配置は、ユーザからの配置依頼があった場合、変換を行い、変換したアプリケーションをその時点で適切なサーバに順次配置していく形とする。アプリケーションを変換しても、コストパフォーマンスが向上しない場合は、変換前のアプリケーション配置とする。例えば、GPUインスタンスはCPUインスタンスの2倍のコストがかかる際に、変換しても2倍以上性能が改善されないならば、変換前を配置した方がよい。また、既に上限まで計算リソースや帯域が使われてしまっている場合はそのサーバには配置はできないことがある。
In consideration of the features (1) and (2) above, the application placement of this embodiment is such that when there is a request for placement from the user, conversion is performed, and the converted applications are sequentially placed on appropriate servers at that time. Iku form. If converting the application does not improve the cost performance, the application should be placed before the conversion. For example, when a GPU instance costs twice as much as a CPU instance, and the conversion does not improve the performance by more than two times, it is better to allocate before the conversion. Also, if the computational resources and bandwidth have already been used up to the upper limit, it may not be possible to allocate to that server.
<アプリケーション適切配置のための線形計画式>
本実施形態では、アプリケーションの適切な配置場所を計算するための、線形計画手法の定式化を行う。線形計画手法は、具体的には、[式1](以下の式(1)~式(4))、[式2](以下の式(3)~式(6))に示す線形計画式のパラメータを用いる。 <Linear programming formula for appropriate placement of applications>
In this embodiment, we formulate a linear programming method for calculating appropriate placement locations of applications. Specifically, the linear programming method is represented by [Formula 1] (Formulas (1) to (4) below) and [Formula 2] (Formulas (3) to (6) below). parameters are used.
本実施形態では、アプリケーションの適切な配置場所を計算するための、線形計画手法の定式化を行う。線形計画手法は、具体的には、[式1](以下の式(1)~式(4))、[式2](以下の式(3)~式(6))に示す線形計画式のパラメータを用いる。 <Linear programming formula for appropriate placement of applications>
In this embodiment, we formulate a linear programming method for calculating appropriate placement locations of applications. Specifically, the linear programming method is represented by [Formula 1] (Formulas (1) to (4) below) and [Formula 2] (Formulas (3) to (6) below). parameters are used.
ここで、デバイスやリンクのコストや計算リソース上限、帯域上限等は、事業者が準備するサーバやネットワークに依存する。このため、それらのパラメータ値は事業者が事前に設定する。オフロードした際にアプリケーションが使用する計算リソース量、帯域、データ容量、処理時間は、自動変換する前の検証環境での試験での最終的に選択されたオフロードパターンでの計測値により決まり、環境適応機能により自動設定される。
ユーザ要求が計算リソースのコスト要求であるかまたは応答時間要求であるかで、線形計画式のパラメータにおける、目的関数と制約条件が変わる。 Here, device and link costs, computational resource upper limits, band upper limits, etc., depend on the servers and networks prepared by the business operator. Therefore, those parameter values are set in advance by the operator. The calculation resource amount, bandwidth, data capacity, and processing time used by the application when offloading are determined by the measurement values of the offload pattern that was finally selected in the test in the verification environment before automatic conversion. Automatically set by the environment adaptation function.
The objective function and constraints on the parameters of the linear programming formula change depending on whether the user request is a cost request for computational resources or a response time request.
ユーザ要求が計算リソースのコスト要求であるかまたは応答時間要求であるかで、線形計画式のパラメータにおける、目的関数と制約条件が変わる。 Here, device and link costs, computational resource upper limits, band upper limits, etc., depend on the servers and networks prepared by the business operator. Therefore, those parameter values are set in advance by the operator. The calculation resource amount, bandwidth, data capacity, and processing time used by the application when offloading are determined by the measurement values of the offload pattern that was finally selected in the test in the verification environment before automatic conversion. Automatically set by the environment adaptation function.
The objective function and constraints on the parameters of the linear programming formula change depending on whether the user request is a cost request for computational resources or a response time request.
・コスト要求による、線形計画式のパラメータ
コスト要求により、一月幾ら以内での配置が必要な要求の場合は、下記[式1]に示す線形計画式のパラメータを用いる。 • Parameter of linear programming formula according to cost request If the request requires allocation within one month due to cost request, the parameters of the linear programming formula shown in [Equation 1] below are used.
コスト要求により、一月幾ら以内での配置が必要な要求の場合は、下記[式1]に示す線形計画式のパラメータを用いる。 • Parameter of linear programming formula according to cost request If the request requires allocation within one month due to cost request, the parameters of the linear programming formula shown in [Equation 1] below are used.

式(1)の応答時間の最小化が目的関数である。式(2)の計算リソースのコストがいくら以内であるかは、制約条件の一つである。さらに、式(3)(4)のサーバのリソース上限を超えていないかの制約条件も加わる。
The objective function is minimization of the response time of formula (1). One of the constraints is how much the computational resource cost of Equation (2) is within. Furthermore, a constraint condition is added as to whether or not the resource upper limit of the server in formulas (3) and (4) is exceeded.
・応答時間要求による、線形計画式のパラメータ
応答時間要求により、アプリケーションの応答時間が何秒以内での配置が必要な要求の場合は、下記[式2]に示す線形計画式のパラメータを用いる。 • Parameter of linear programming formula according to response time request If the response time request requires placement within seconds of the application response time, use the parameters of the linear programming formula shown in [Formula 2] below.
応答時間要求により、アプリケーションの応答時間が何秒以内での配置が必要な要求の場合は、下記[式2]に示す線形計画式のパラメータを用いる。 • Parameter of linear programming formula according to response time request If the response time request requires placement within seconds of the application response time, use the parameters of the linear programming formula shown in [Formula 2] below.

式(2)に対応する式(5)の計算リソースのコストの最小化が目的関数である。式(1)に対応する式(6)の応答時間が何秒以内であるかは、制約条件の一つである。さらに、式(3)(4)の制約条件も加わる。
The objective function is to minimize the computational resource cost of Equation (5) corresponding to Equation (2). One of the constraints is how many seconds the response time of Equation (6) corresponding to Equation (1) is within. Furthermore, the constraints of equations (3) and (4) are added.
・線形計画式のパラメータの説明
式(1)および式(6)は、アプリケーションkの応答時間を計算するための式であり、式(1)の場合はRkが目的関数、式(6)の場合はRkがユーザが指定した上限を設定する制約条件である。 ・Explanation of parameters of linear programming formula Formulas (1) and (6) are formulas for calculating the response time of application k. In the case of formula (1), Rk is the objective function, and If Rk is a constraint that sets a user-specified upper bound.
式(1)および式(6)は、アプリケーションkの応答時間を計算するための式であり、式(1)の場合はRkが目的関数、式(6)の場合はRkがユーザが指定した上限を設定する制約条件である。 ・Explanation of parameters of linear programming formula Formulas (1) and (6) are formulas for calculating the response time of application k. In the case of formula (1), Rk is the objective function, and If Rk is a constraint that sets a user-specified upper bound.
式(2)および式(5)は、アプリケーションkを動作させるコスト(価格)Pkを計算するための式であり、式(2)の場合はPkがユーザが指定した上限を設定する制約条件、式(5)の場合はPkが目的関数である。
Equations (2) and (5) are equations for calculating the cost (price) Pk of operating application k. In the case of equation (5), Pk is the objective function.
式(3)および式(4)は、計算リソースおよび通信帯域の上限を設定する制約条件であり、他者が配置したアプリケーション含めて計算され、新規ユーザのアプリケーション配置によるリソース上限の超過を防ぐ。
Formulas (3) and (4) are constraints that set the upper limit of computational resources and communication bandwidth, are calculated including applications deployed by others, and prevent the resource upper limit from being exceeded due to the placement of applications by new users.
式(1)乃至式(4)および、式(3)乃至式(6)の線形計画式を、ネットワークトポロジーや変換アプリケーションタイプ(CPUに対するコスト増と性能増等)、ユーザ要求、既配置アプリケーションの異なる条件に対して、GLPK(Gnu Linear Programming Kit)やCPLEX(IBM Decision Optimization)等の線形計画ソルバで解を導出することで、適切なアプリケーション配置を計算できる。適切配置計算後に実際の配置を、複数のユーザに対して、順次行っていくことで、複数のアプリケーションが各ユーザの要求に基づいて配置される。
The linear programming formulas (1) to (4) and (3) to (6) are calculated based on the network topology, conversion application type (increase in cost and performance for CPU, etc.), user requirements, and existing applications. Appropriate application placement can be calculated for different conditions by deriving solutions with linear programming solvers such as GLPK (Gnu Linear Programming Kit) and CPLEX (IBM Decision Optimization). By sequentially performing actual placement for a plurality of users after appropriate placement calculation, a plurality of applications are placed based on each user's request.
以上のように、線形計画式に基づいて、新規にアプリケーションの配置依頼があった場合に計算し、順に配置することで、ユーザ要望を満たした配置が可能である。
ここで、アプリケーションプログラムの配置は、順次行われるため早い者勝ちと言えるが、アプリケーション100個毎等、定期的に、既に配置済みのアプリケーションプログラム群の適正配置を再計算する。そして、ユーザの指定するコスト、応答時間に応じて、目的関数が極小化される配置を計算し、計算で定まった位置に、アプリケーションを再配置してもよい。 As described above, when there is a new application placement request, calculations are made based on the linear programming formula, and the applications are placed in order.
Since the application programs are arranged sequentially, it can be said that the first come, first served. Then, an arrangement that minimizes the objective function may be calculated according to the cost and response time specified by the user, and the application may be rearranged at the position determined by the calculation.
ここで、アプリケーションプログラムの配置は、順次行われるため早い者勝ちと言えるが、アプリケーション100個毎等、定期的に、既に配置済みのアプリケーションプログラム群の適正配置を再計算する。そして、ユーザの指定するコスト、応答時間に応じて、目的関数が極小化される配置を計算し、計算で定まった位置に、アプリケーションを再配置してもよい。 As described above, when there is a new application placement request, calculations are made based on the linear programming formula, and the applications are placed in order.
Since the application programs are arranged sequentially, it can be said that the first come, first served. Then, an arrangement that minimizes the objective function may be calculated according to the cost and response time specified by the user, and the application may be rearranged at the position determined by the calculation.
[評価]
線形計画手法の一態様である線形計画式に基づき、無償ソルバのGLPK(登録商標)を用いて、複数のアプリケーションが適切に配置されていくことを、いくつかの条件を変更して確認した。 [evaluation]
Based on a linear programming formula, which is one aspect of the linear programming method, it was confirmed that multiple applications were appropriately arranged using the free solver GLPK (registered trademark) by changing some conditions.
線形計画手法の一態様である線形計画式に基づき、無償ソルバのGLPK(登録商標)を用いて、複数のアプリケーションが適切に配置されていくことを、いくつかの条件を変更して確認した。 [evaluation]
Based on a linear programming formula, which is one aspect of the linear programming method, it was confirmed that multiple applications were appropriately arranged using the free solver GLPK (registered trademark) by changing some conditions.
<評価条件>
・対象アプリケーション
配置対象のアプリケーションは、多くのユーザが利用すると想定されるフーリエ変換による画像処理をする。フーリエ変換処理(FFT)は、振動周波数の分析等、IoTでのモニタリングの様々な場面で利用されている。
NAS.FT(https://www.nas.nasa.gov/publications/npb.html)(登録商標)は、FFT処理のオープンソースアプリケーションの一つである。備え付けのサンプルテストの2048×2048サイズの計算を行う。IoTで、デバイスからデータをネットワーク転送するアプリケーションについて想定した際に、ネットワークコストを下げるため、デバイス側でFFT 処理等の一次分析をして送ることが想定される。 <Evaluation condition>
・Target application The application to be placed performs image processing by Fourier transform, which is assumed to be used by many users. Fourier transform processing (FFT) is used in various aspects of IoT monitoring, such as vibration frequency analysis.
NAS.FT (https://www.nas.nasa.gov/publications/npb.html) (registered trademark) is one of the open source applications for FFT processing. Perform 2048×2048 size calculations of the provided sample test. When considering an IoT application that transfers data from a device to a network, it is assumed that primary analysis such as FFT processing is performed on the device side before transmission in order to reduce network costs.
・対象アプリケーション
配置対象のアプリケーションは、多くのユーザが利用すると想定されるフーリエ変換による画像処理をする。フーリエ変換処理(FFT)は、振動周波数の分析等、IoTでのモニタリングの様々な場面で利用されている。
NAS.FT(https://www.nas.nasa.gov/publications/npb.html)(登録商標)は、FFT処理のオープンソースアプリケーションの一つである。備え付けのサンプルテストの2048×2048サイズの計算を行う。IoTで、デバイスからデータをネットワーク転送するアプリケーションについて想定した際に、ネットワークコストを下げるため、デバイス側でFFT 処理等の一次分析をして送ることが想定される。 <Evaluation condition>
・Target application The application to be placed performs image processing by Fourier transform, which is assumed to be used by many users. Fourier transform processing (FFT) is used in various aspects of IoT monitoring, such as vibration frequency analysis.
NAS.FT (https://www.nas.nasa.gov/publications/npb.html) (registered trademark) is one of the open source applications for FFT processing. Perform 2048×2048 size calculations of the provided sample test. When considering an IoT application that transfers data from a device to a network, it is assumed that primary analysis such as FFT processing is performed on the device side before transmission in order to reduce network costs.
MRI-Q(http://impact.crhc.illinois.edu/parboil/)(登録商標)は、非デカルト空間の3次元MRI再構成アルゴリズムで使用されるキャリブレーション用のスキャナー構成を表す行列Qを計算する。IoT環境では、カメラビデオからの自動監視のために画像処理が必要になることが多く、画像処理の自動オフロードへのニーズはある。MRI-QはC言語アプリケーションで、パフォーマンス測定中に3次元MRI画像処理を実行し、Large の64×64×64サイズのサンプルデータを使用して処理時間を測定する。CPU処理はC言語で、FPGA処理はOpenCL(登録商標)に基づき処理される。
本実施形態のGPU、FPGA自動オフロード技術により、NAS.FTはGPUで高速化でき、MRI-QはFPGAで高速化でき、それぞれ、CPUに比べて5倍、7倍の高速化ができる。 MRI-Q (http://impact.crhc.illinois.edu/parboil/) (registered trademark) uses the matrix Q to represent the scanner configuration for calibration used in non-Cartesian spatial three-dimensional MRI reconstruction algorithms. calculate. In the IoT environment, image processing is often required for automatic surveillance from camera video, and there is a need for automatic offloading of image processing. MRI-Q is a C-language application that performs 3D MRI image processing during performance measurement and measures processing time using Large 64×64×64 size sample data. CPU processing is based on C language, and FPGA processing is based on OpenCL (registered trademark).
With the GPU and FPGA automatic offload technology of this embodiment, NAS.FT can be speeded up by GPU, and MRI-Q can be speeded up by FPGA, which are five times and seven times faster than CPU, respectively.
本実施形態のGPU、FPGA自動オフロード技術により、NAS.FTはGPUで高速化でき、MRI-QはFPGAで高速化でき、それぞれ、CPUに比べて5倍、7倍の高速化ができる。 MRI-Q (http://impact.crhc.illinois.edu/parboil/) (registered trademark) uses the matrix Q to represent the scanner configuration for calibration used in non-Cartesian spatial three-dimensional MRI reconstruction algorithms. calculate. In the IoT environment, image processing is often required for automatic surveillance from camera video, and there is a need for automatic offloading of image processing. MRI-Q is a C-language application that performs 3D MRI image processing during performance measurement and measures processing time using Large 64×64×64 size sample data. CPU processing is based on C language, and FPGA processing is based on OpenCL (registered trademark).
With the GPU and FPGA automatic offload technology of this embodiment, NAS.FT can be speeded up by GPU, and MRI-Q can be speeded up by FPGA, which are five times and seven times faster than CPU, respectively.
・評価手法
アプリケーションを配置するトポロジーは、図11に示すように3層で構成され、クラウドレイヤーの拠点数は「5」、キャリアエッジレイヤーは「20」、ユーザエッジレイヤーは「60」、インプットノードは「300」とする。IoT等のアプリケーションを想定してインプットノードからIoTデータ等がユーザエッジに収集され、アプリケーションの特性(応答時間の要求条件等)に応じて、ユーザエッジ、キャリアエッジで分析処理がされたり、クラウドまでデータをあげてから分析処理されたりされる。 ・Evaluation method The topology for deploying applications consists of three layers as shown in Fig. 11. The number of bases in the cloud layer is "5", the carrier edge layer is "20", the user edge layer is "60", and the input node. is "300". Assuming applications such as IoT, IoT data is collected from the input node to the user edge, and depending on the characteristics of the application (requirements for response time, etc.), analysis processing is performed at the user edge and carrier edge, and it is delivered to the cloud. After the data is given, it is analyzed and processed.
アプリケーションを配置するトポロジーは、図11に示すように3層で構成され、クラウドレイヤーの拠点数は「5」、キャリアエッジレイヤーは「20」、ユーザエッジレイヤーは「60」、インプットノードは「300」とする。IoT等のアプリケーションを想定してインプットノードからIoTデータ等がユーザエッジに収集され、アプリケーションの特性(応答時間の要求条件等)に応じて、ユーザエッジ、キャリアエッジで分析処理がされたり、クラウドまでデータをあげてから分析処理されたりされる。 ・Evaluation method The topology for deploying applications consists of three layers as shown in Fig. 11. The number of bases in the cloud layer is "5", the carrier edge layer is "20", the user edge layer is "60", and the input node. is "300". Assuming applications such as IoT, IoT data is collected from the input node to the user edge, and depending on the characteristics of the application (requirements for response time, etc.), analysis processing is performed at the user edge and carrier edge, and it is delivered to the cloud. After the data is given, it is analyzed and processed.
[式1][式2]に示す線形計画式のパラメータを元に、ユーザ要求条件に基づいて、例えば1000個のアプリケーションを配置する。アプリケーションは、IoTアプリケーションで、インプットノードから生じるデータを分析する想定である。インプットノード(「300」あるとする)から配置依頼をランダムに生じさせる。
例えば、配置依頼数として、NAS.FT:MRI-Q=3:1の割合で1000回アプリを配置依頼する。また、ユーザ要求として、配置依頼する際にアプリ毎に価格条件か応答時間条件が選ばれる。NAS.FTの場合、価格に関しては月7000円上限か8500円上限か10000円上限、応答時間に関しては6秒上限か7秒条件か10秒上限が選択される。MRI-Qの場合、価格に関しては月12500円上限か20000円上限、応答時間に関しては、4秒上限か8秒上限が選択される。 For example, 1000 applications are arranged based on user requirements based on the parameters of the linear programming formulas shown in [Formula 1] and [Formula 2]. The application is an IoT application and is supposed to analyze the data coming from the input node. Placement requests are generated randomly from input nodes (assuming there are "300").
For example, as the number of placement requests, the application placement is requested 1000 times at a ratio of NAS.FT:MRI-Q=3:1. Also, as a user request, a price condition or a response time condition is selected for each application when requesting placement. In the case of NAS.FT, an upper limit of 7,000 yen per month, an upper limit of 8,500 yen, or an upper limit of 10,000 yen is selected for the price, and an upper limit of 6 seconds, a condition of 7 seconds, or an upper limit of 10 seconds is selected for the response time. In the case of MRI-Q, an upper limit of 12,500 yen or 20,000 yen per month is selected for the price, and an upper limit of 4 seconds or 8 seconds is selected for the response time.
例えば、配置依頼数として、NAS.FT:MRI-Q=3:1の割合で1000回アプリを配置依頼する。また、ユーザ要求として、配置依頼する際にアプリ毎に価格条件か応答時間条件が選ばれる。NAS.FTの場合、価格に関しては月7000円上限か8500円上限か10000円上限、応答時間に関しては6秒上限か7秒条件か10秒上限が選択される。MRI-Qの場合、価格に関しては月12500円上限か20000円上限、応答時間に関しては、4秒上限か8秒上限が選択される。 For example, 1000 applications are arranged based on user requirements based on the parameters of the linear programming formulas shown in [Formula 1] and [Formula 2]. The application is an IoT application and is supposed to analyze the data coming from the input node. Placement requests are generated randomly from input nodes (assuming there are "300").
For example, as the number of placement requests, the application placement is requested 1000 times at a ratio of NAS.FT:MRI-Q=3:1. Also, as a user request, a price condition or a response time condition is selected for each application when requesting placement. In the case of NAS.FT, an upper limit of 7,000 yen per month, an upper limit of 8,500 yen, or an upper limit of 10,000 yen is selected for the price, and an upper limit of 6 seconds, a condition of 7 seconds, or an upper limit of 10 seconds is selected for the response time. In the case of MRI-Q, an upper limit of 12,500 yen or 20,000 yen per month is selected for the price, and an upper limit of 4 seconds or 8 seconds is selected for the response time.
ユーザ要求のバリエーションとして、3パターンがある。
パターン1:NAS.FTでは6種のリクエストを1/6ずつ、MRI-Qでは4種のリクエストを1/4ずつ選択する。
パターン2:リクエストは最低価格が上限の条件を選択(最初は7000円、12500円)し、空きがない場合は次に安い価格条件とする。
パターン3:リクエストは最低応答時間が上限の条件を選択(最初は6秒、4秒)し、空きがない場合は次に速い応答時間条件とする。 There are three patterns of user request variations.
Pattern 1:Select 1/6 of 6 types of requests for NAS.FT, and 1/4 of 4 types of requests for MRI-Q.
Pattern 2: The request selects the condition with the lowest price as the upper limit (first 7,000 yen, 12,500 yen), and if there are no vacancies, the next lowest price condition.
Pattern 3: The request selects the condition with the minimum response time as the upper limit (first 6 seconds, 4 seconds), and if there is no free space, the next fastest response time condition.
パターン1:NAS.FTでは6種のリクエストを1/6ずつ、MRI-Qでは4種のリクエストを1/4ずつ選択する。
パターン2:リクエストは最低価格が上限の条件を選択(最初は7000円、12500円)し、空きがない場合は次に安い価格条件とする。
パターン3:リクエストは最低応答時間が上限の条件を選択(最初は6秒、4秒)し、空きがない場合は次に速い応答時間条件とする。 There are three patterns of user request variations.
Pattern 1:
Pattern 2: The request selects the condition with the lowest price as the upper limit (first 7,000 yen, 12,500 yen), and if there are no vacancies, the next lowest price condition.
Pattern 3: The request selects the condition with the minimum response time as the upper limit (first 6 seconds, 4 seconds), and if there is no free space, the next fastest response time condition.
・配置のシミュレーション
配置は、評価ツールとしてソルバGLPK5.0(登録商標)を用いてシミュレーション実験により行う。規模のあるネットワーク配置の模擬のため、評価ツールを用いたシミュレーションになる。実利用の際は、アプリケーションのオフロード依頼が来た場合、検証環境を用いた繰返し性能試験でオフロードパターンを作成し、検証環境での性能試験結果に基づいて適切なリソース量を決める(図10参照)。そして、ユーザ要望に応じてGLPK等を用いて適切な配置を定め、実際にデプロイした際の正常確認試験や性能試験を自動で行い、その結果と価格をユーザに提示して、ユーザ判断後利用を開始する。 - Placement simulation Placement is performed by a simulation experiment using solver GLPK5.0 (registered trademark) as an evaluation tool. In order to simulate a large-scale network layout, it becomes a simulation using an evaluation tool. In actual use, when an application offload request is received, an offload pattern is created through repeated performance tests using the verification environment, and the appropriate amount of resources is determined based on the performance test results in the verification environment (Fig. 10). Then, according to the user's request, an appropriate layout is determined using GLPK, etc., normality confirmation tests and performance tests are automatically performed when actually deployed, the results and prices are presented to the user, and use is made after the user decides. to start.
配置は、評価ツールとしてソルバGLPK5.0(登録商標)を用いてシミュレーション実験により行う。規模のあるネットワーク配置の模擬のため、評価ツールを用いたシミュレーションになる。実利用の際は、アプリケーションのオフロード依頼が来た場合、検証環境を用いた繰返し性能試験でオフロードパターンを作成し、検証環境での性能試験結果に基づいて適切なリソース量を決める(図10参照)。そして、ユーザ要望に応じてGLPK等を用いて適切な配置を定め、実際にデプロイした際の正常確認試験や性能試験を自動で行い、その結果と価格をユーザに提示して、ユーザ判断後利用を開始する。 - Placement simulation Placement is performed by a simulation experiment using solver GLPK5.0 (registered trademark) as an evaluation tool. In order to simulate a large-scale network layout, it becomes a simulation using an evaluation tool. In actual use, when an application offload request is received, an offload pattern is created through repeated performance tests using the verification environment, and the appropriate amount of resources is determined based on the performance test results in the verification environment (Fig. 10). Then, according to the user's request, an appropriate layout is determined using GLPK, etc., normality confirmation tests and performance tests are automatically performed when actually deployed, the results and prices are presented to the user, and use is made after the user decides. to start.
図12は、平均応答時間のアプリケーション配置数変化を示すグラフである。図12は、平均応答時間とアプリケーション配置数を、上記3パターンに対して取る。
パターン2ではクラウドから順に、パターン3ではエッジから順に埋まっていくことが確認できた。パターン1では、多様な依頼が来た場合に、ユーザ要求条件を満たして配置される。
図12に示すように、パターン2では、400配置位までは全てクラウドに配置され平均応答時間は最遅のままであるが、クラウドが埋まると段々下がっていくことが分かる。
パターン3では、NAS.FTはユーザエッジから、またMRI-Qはキャリアエッジから配置される。このため、平均応答時間については最短となる。しかし、数が増えるとクラウドにも配置されるため平均応答時間は遅くなる。パターン2では、平均応答時間は、パターン1やパターン3の中間であり、ユーザ要求に応じて配置される。このため、パターン2では、最初はクラウドに全て入るパターン1に比べて平均応答時間は適切に低減されている。 FIG. 12 is a graph showing changes in the number of applications deployed in the average response time. FIG. 12 shows the average response time and the number of applications deployed for the above three patterns.
It was confirmed thatpattern 2 was filled in order from the cloud, and pattern 3 was filled in order from the edge. In pattern 1, when various requests are received, they are arranged by satisfying the user requirements.
As shown in FIG. 12, inpattern 2, all up to the 400th placement position are placed in the cloud and the average response time remains the slowest, but when the cloud is filled, it gradually decreases.
Inpattern 3, NAS.FT is placed from the user edge and MRI-Q is placed from the carrier edge. Therefore, the average response time is the shortest. However, as the number increases, it is also deployed in the cloud, slowing the average response time. In pattern 2, the average response time is intermediate between patterns 1 and 3, and is arranged according to user requests. Thus, in pattern 2, the average response time is appropriately reduced compared to pattern 1, which initially enters the cloud entirely.
パターン2ではクラウドから順に、パターン3ではエッジから順に埋まっていくことが確認できた。パターン1では、多様な依頼が来た場合に、ユーザ要求条件を満たして配置される。
図12に示すように、パターン2では、400配置位までは全てクラウドに配置され平均応答時間は最遅のままであるが、クラウドが埋まると段々下がっていくことが分かる。
パターン3では、NAS.FTはユーザエッジから、またMRI-Qはキャリアエッジから配置される。このため、平均応答時間については最短となる。しかし、数が増えるとクラウドにも配置されるため平均応答時間は遅くなる。パターン2では、平均応答時間は、パターン1やパターン3の中間であり、ユーザ要求に応じて配置される。このため、パターン2では、最初はクラウドに全て入るパターン1に比べて平均応答時間は適切に低減されている。 FIG. 12 is a graph showing changes in the number of applications deployed in the average response time. FIG. 12 shows the average response time and the number of applications deployed for the above three patterns.
It was confirmed that
As shown in FIG. 12, in
In
このように、ソフトウェアを配置先環境に合わせて自動適応させ、GPU等に自動オフロードした際に、ユーザのコスト要求、応答時間要求に応える。すなわち、GPU等のデバイスで処理できるよう、プログラムを変換し、アサインするリソース量が定まった後に変換したアプリケーションの最適配置を行う。
In this way, the software is automatically adapted according to the deployment environment, and when automatically offloaded to the GPU, etc., it meets the user's cost and response time requirements. That is, the program is converted so that it can be processed by a device such as a GPU, and after the amount of resources to be assigned is determined, the converted application is optimally arranged.
まとめると、まず、プログラム変換する際に検証環境で行った性能試験のデータから、アプリケーションの利用データ容量、計算リソース量、帯域、処理時間を設定する。変換アプリケーション毎に設定される値と、事前に設定されるサーバやリンクのコスト等の値から、線形計画式に基づき、アプリケーションの適切な配置が計算される。アプリケーション配置の際は、ユーザが指定する価格や応答時間のリクエストに基づき、一方が制約条件にもう一方が目的関数となる。線形計画ソルバにより適切な配置が計算され、提案方式は計算された場所にリソースを配置した際の、価格等をユーザに提示し、ユーザ承諾後に利用が開始される。
To summarize, first, set the data capacity used by the application, the amount of computational resources, the bandwidth, and the processing time based on the performance test data that was conducted in the verification environment when converting the program. Appropriate placement of applications is calculated based on a linear programming formula from values set for each conversion application and values such as server and link costs set in advance. When deploying an application, one is the constraint and the other is the objective function, based on user-specified price and response time requirements. Appropriate placement is calculated by the linear programming solver, and the proposed method presents the price etc. to the user when the resource is placed in the calculated place, and the use is started after the user's consent.
GPU、FPGAに自動オフロードしたアプリケーションに対して、ユーザのリクエストする価格条件や応答時間条件、アプリケーションの配置数等を変更して、適正配置を計算する。これにより、ユーザ要望に従った配置が可能になる。
For applications that are automatically offloaded to GPUs and FPGAs, the appropriate allocation is calculated by changing the price conditions, response time conditions, and the number of applications requested by the user. This enables arrangement according to the user's request.
(第2実施形態)
次に、本発明の第2実施形態における、オフロードサーバ1A等について説明する。
第2実施形態は、ループ文のFPGA自動オフロードに適用した例である。
本実施形態は、PLD(Programmable Logic Device)として、FPGA(Field Programmable Gate Array)に適用した例について説明する。本発明は、プログラマブルロジックデバイス全般に適用可能である。 (Second embodiment)
Next, theoffload server 1A etc. in the second embodiment of the present invention will be described.
The second embodiment is an example applied to FPGA automatic offloading of loop statements.
In the present embodiment, an example in which a PLD (Programmable Logic Device) is applied to an FPGA (Field Programmable Gate Array) will be described. The present invention is applicable to programmable logic devices in general.
次に、本発明の第2実施形態における、オフロードサーバ1A等について説明する。
第2実施形態は、ループ文のFPGA自動オフロードに適用した例である。
本実施形態は、PLD(Programmable Logic Device)として、FPGA(Field Programmable Gate Array)に適用した例について説明する。本発明は、プログラマブルロジックデバイス全般に適用可能である。 (Second embodiment)
Next, the
The second embodiment is an example applied to FPGA automatic offloading of loop statements.
In the present embodiment, an example in which a PLD (Programmable Logic Device) is applied to an FPGA (Field Programmable Gate Array) will be described. The present invention is applicable to programmable logic devices in general.
(原理説明)
FPGAで、どのループをオフロードすれば高速になるかの予測は難しいため、GPU同様検証環境で自動測定することを提案している。しかし、FPGAは、OpenCLをコンパイルして実機で動作させるまで数時間以上かかるため、GPU自動オフロードでのGAを用いて何回も反復して測定することは、処理時間が膨大となり行うことはできない。そこで、FPGAにオフロードする候補のループ文を絞ってから、測定を行う形をとる。具体的には、発見されたループ文に対して、ROSE(登録商標)等の算術強度分析ツールを用いて算術強度が高いループ文を抽出する。更に、gcov(登録商標)等のプロファイリングツールを用いてループ回数が多いループ文も抽出する。 (Explanation of principle)
Since it is difficult to predict which loops should be offloaded to increase speed with FPGA, we propose automatic measurement in a verification environment similar to GPU. However, FPGA takes more than several hours to compile OpenCL and run it on the actual machine. Can not. Therefore, after narrowing down candidate loop statements to be offloaded to the FPGA, measurement is performed. Specifically, for the found loop statements, a loop statement with high arithmetic strength is extracted using an arithmetic strength analysis tool such as ROSE (registered trademark). Furthermore, a profiling tool such as gcov (registered trademark) is used to extract loop statements with a large number of loops.
FPGAで、どのループをオフロードすれば高速になるかの予測は難しいため、GPU同様検証環境で自動測定することを提案している。しかし、FPGAは、OpenCLをコンパイルして実機で動作させるまで数時間以上かかるため、GPU自動オフロードでのGAを用いて何回も反復して測定することは、処理時間が膨大となり行うことはできない。そこで、FPGAにオフロードする候補のループ文を絞ってから、測定を行う形をとる。具体的には、発見されたループ文に対して、ROSE(登録商標)等の算術強度分析ツールを用いて算術強度が高いループ文を抽出する。更に、gcov(登録商標)等のプロファイリングツールを用いてループ回数が多いループ文も抽出する。 (Explanation of principle)
Since it is difficult to predict which loops should be offloaded to increase speed with FPGA, we propose automatic measurement in a verification environment similar to GPU. However, FPGA takes more than several hours to compile OpenCL and run it on the actual machine. Can not. Therefore, after narrowing down candidate loop statements to be offloaded to the FPGA, measurement is performed. Specifically, for the found loop statements, a loop statement with high arithmetic strength is extracted using an arithmetic strength analysis tool such as ROSE (registered trademark). Furthermore, a profiling tool such as gcov (registered trademark) is used to extract loop statements with a large number of loops.
算術強度やループ回数が多いループ文を候補として、OpenCL 化を行う。OpenCL 化時には、CPU処理プログラムを、カーネル(FPGA)とホスト(CPU)に、OpenCL の文法に従って分割する。候補ループ文に対して、作成したOpenCL をプレコンパイルして、リソース効率が高いループ文を見つける。これは、コンパイルの途中で、作成するリソースは分かるため、利用するリソース量が十分少ないループ文に更に絞り込む。
候補ループ文が幾つか残るため、それらを用いて性能や電力使用量を実測する。選択された単ループ文に対してコンパイルして測定し、更に高速化できた単ループ文に対してはその組み合わせパターンも作り2回目の測定をする。測定された複数パターンの中で、短時間かつ低電力使用量のパターンを解として選択する。 OpenCL conversion is performed for loop statements with high arithmetic intensity and loop count as candidates. When converted to OpenCL, the CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to OpenCL syntax. For candidate loop statements, precompile your OpenCL to find resource-efficient loop statements. Since resources to be created can be known during compilation, loop statements that use a sufficiently small amount of resources are further narrowed down.
Since some candidate loop statements remain, we use them to measure performance and power consumption. The selected single-loop statement is compiled and measured, and for the single-loop statement whose speed has been further improved, a combination pattern is created and the second measurement is performed. A pattern of short time and low power consumption is selected as a solution from among the measured patterns.
候補ループ文が幾つか残るため、それらを用いて性能や電力使用量を実測する。選択された単ループ文に対してコンパイルして測定し、更に高速化できた単ループ文に対してはその組み合わせパターンも作り2回目の測定をする。測定された複数パターンの中で、短時間かつ低電力使用量のパターンを解として選択する。 OpenCL conversion is performed for loop statements with high arithmetic intensity and loop count as candidates. When converted to OpenCL, the CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to OpenCL syntax. For candidate loop statements, precompile your OpenCL to find resource-efficient loop statements. Since resources to be created can be known during compilation, loop statements that use a sufficiently small amount of resources are further narrowed down.
Since some candidate loop statements remain, we use them to measure performance and power consumption. The selected single-loop statement is compiled and measured, and for the single-loop statement whose speed has been further improved, a combination pattern is created and the second measurement is performed. A pattern of short time and low power consumption is selected as a solution from among the measured patterns.
ループ文のFPGA オフロードについては、算術強度等を用いて絞り込んでから、測定を行い、低電力パターンの評価値を高めることで、自動での高速化、低電力化を行う。
For FPGA offloading of loop statements, after narrowing down using arithmetic strength, etc., measurement is performed and the evaluation value of the low power pattern is increased to automatically speed up and reduce power consumption.
図13は、本発明の第2実施形態に係るオフロードサーバ1Aの構成例を示す機能ブロック図である。本実施形態の説明に当たり、図1と同一構成部分には同一符号を付して重複箇所の説明を省略する。
オフロードサーバ1Aは、アプリケーションの特定処理をアクセラレータに自動的にオフロードする装置である。
また、オフロードサーバ1Aは、エミュレータに接続可能である。
図13に示すように、オフロードサーバ1Aは、制御部21と、入出力部12と、記憶部13と、検証用マシン14(Verification machine)(アクセラレータ検証用装置)と、を含んで構成される。 FIG. 13 is a functional block diagram showing a configuration example of theoffload server 1A according to the second embodiment of the invention. In describing this embodiment, the same components as those in FIG.
Theoffload server 1A is a device that automatically offloads specific processing of an application to an accelerator.
Also, theoffload server 1A can be connected to an emulator.
As shown in FIG. 13, theoffload server 1A includes a control unit 21, an input/output unit 12, a storage unit 13, and a verification machine 14 (accelerator verification device). be.
オフロードサーバ1Aは、アプリケーションの特定処理をアクセラレータに自動的にオフロードする装置である。
また、オフロードサーバ1Aは、エミュレータに接続可能である。
図13に示すように、オフロードサーバ1Aは、制御部21と、入出力部12と、記憶部13と、検証用マシン14(Verification machine)(アクセラレータ検証用装置)と、を含んで構成される。 FIG. 13 is a functional block diagram showing a configuration example of the
The
Also, the
As shown in FIG. 13, the
制御部21は、オフロードサーバ1A全体の制御を司る自動オフロード機能部(Automatic Offloading function)である。制御部21は、例えば、記憶部13に格納されたプログラム(オフロードプログラム)を不図示のCPUが、RAMに展開し実行することにより実現される。
The control unit 21 is an automatic offloading function that controls the entire offload server 1A. The control unit 21 is implemented, for example, by a CPU (not shown) expanding a program (offload program) stored in the storage unit 13 into a RAM and executing the program.
制御部21は、アプリケーションコード指定部(Specify application code)111と、アプリケーションコード分析部(Analyze application code)112と、PLD処理指定部213と、算術強度算出部214と、配置設定部170と、PLD処理パターン作成部215と、性能測定部118と、実行ファイル作成部119と、本番環境配置部(Deploy final binary files to production environment)120と、性能測定テスト抽出実行部(Extract performance test cases and run automatically)121と、ユーザ提供部(Provide price and performance to a user to judge)122と、を備える。
The control unit 21 includes an application code specification unit (Specify application code) 111, an application code analysis unit (Analyze application code) 112, a PLD processing specification unit 213, an arithmetic intensity calculation unit 214, an arrangement setting unit 170, and a PLD A processing pattern creation unit 215, a performance measurement unit 118, an execution file creation unit 119, a production environment deployment unit (Deploy final binary files to production environment) 120, and a performance measurement test extraction execution unit (Extract performance test cases and run automatically ) 121 and a user provision unit (Provide price and performance to a user to judge) 122 .
<PLD処理指定部213>
PLD処理指定部213は、アプリケーションのループ文(繰り返し文)を特定し、特定した各ループ文に対して、PLDにおけるパイプライン処理、並列処理をOpenCLで指定した複数のオフロード処理パターンを作成してコンパイルする。
PLD処理指定部213は、オフロード範囲抽出部(Extract offload able area)213aと、中間言語ファイル出力部(Output intermediate file)213bと、を備える。 <PLDprocessing designation unit 213>
The PLDprocessing designation unit 213 identifies loop statements (repetition statements) of the application, and creates a plurality of offload processing patterns in which pipeline processing and parallel processing in the PLD are designated by OpenCL for each of the identified loop statements. to compile.
The PLDprocessing designation unit 213 includes an extract offload able area 213a and an output intermediate file 213b.
PLD処理指定部213は、アプリケーションのループ文(繰り返し文)を特定し、特定した各ループ文に対して、PLDにおけるパイプライン処理、並列処理をOpenCLで指定した複数のオフロード処理パターンを作成してコンパイルする。
PLD処理指定部213は、オフロード範囲抽出部(Extract offload able area)213aと、中間言語ファイル出力部(Output intermediate file)213bと、を備える。 <PLD
The PLD
The PLD
オフロード範囲抽出部213aは、ループ文やFFT等、FPGAにオフロード可能な処理を特定し、オフロード処理に応じた中間言語を抽出する。
The offload range extracting unit 213a identifies processing that can be offloaded to the FPGA, such as loop statements and FFT, and extracts an intermediate language corresponding to the offload processing.
中間言語ファイル出力部213bは、抽出した中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。
The intermediate language file output unit 213b outputs the extracted intermediate language file 133. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
<算術強度算出部214>
算術強度算出部214は、例えばROSEフレームワーク(登録商標)等の算術強度(Arithmetic Intensity)分析ツールを用いて、アプリケーションのループ文の算術強度を算出する。算術強度は、プログラムの稼働中に実行した浮動小数点演算(floating point number,FN)の数を、主メモリへのアクセスしたbyte数で割った値(FN演算/メモリアクセス)である。
算術強度は、計算回数が多いと増加し、アクセス数が多いと減少する指標であり、算術強度が高い処理はプロセッサにとって重い処理となる。そこで、算術強度分析ツールで、ループ文の算術強度を分析する。PLD処理パターン作成部215は、算術強度が高いループ文をオフロード候補に絞る。 <Arithmetic intensity calculator 214>
The arithmeticintensity calculation unit 214 calculates the arithmetic intensity of the loop statement of the application using an arithmetic intensity analysis tool such as the ROSE framework (registered trademark). Arithmetic intensity is the number of floating point numbers (FN) executed during program execution divided by the number of bytes accessed to main memory (FN operations/memory access).
Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of the loop statement. The PLD processingpattern creation unit 215 narrows down loop statements with high arithmetic intensity to offload candidates.
算術強度算出部214は、例えばROSEフレームワーク(登録商標)等の算術強度(Arithmetic Intensity)分析ツールを用いて、アプリケーションのループ文の算術強度を算出する。算術強度は、プログラムの稼働中に実行した浮動小数点演算(floating point number,FN)の数を、主メモリへのアクセスしたbyte数で割った値(FN演算/メモリアクセス)である。
算術強度は、計算回数が多いと増加し、アクセス数が多いと減少する指標であり、算術強度が高い処理はプロセッサにとって重い処理となる。そこで、算術強度分析ツールで、ループ文の算術強度を分析する。PLD処理パターン作成部215は、算術強度が高いループ文をオフロード候補に絞る。 <
The arithmetic
Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of the loop statement. The PLD processing
算術強度の計算例について述べる。
1回のループの中での浮動小数点計算処理が10回(10FLOP)行われ、ループの中で使われるデータが2byteであるとする。ループ毎に同じサイズのデータが使われる際は、10/2=5 [FLOP/byte]が算術強度となる。
なお、算術強度では、ループ回数が考慮されないため、本実施形態では、算術強度に加えて、ループ回数も考慮して絞り込む。 A calculation example of the arithmetic strength is described.
Assume that floating-point calculation processing is performed 10 times (10 FLOPs) in one loop and the data used in the loop is 2 bytes. When the same size data is used for each loop, the arithmetic intensity is 10/2=5 [FLOP/byte].
Since the arithmetic strength does not consider the number of loops, in the present embodiment, the number of loops is also considered in addition to the arithmetic strength to narrow down.
1回のループの中での浮動小数点計算処理が10回(10FLOP)行われ、ループの中で使われるデータが2byteであるとする。ループ毎に同じサイズのデータが使われる際は、10/2=5 [FLOP/byte]が算術強度となる。
なお、算術強度では、ループ回数が考慮されないため、本実施形態では、算術強度に加えて、ループ回数も考慮して絞り込む。 A calculation example of the arithmetic strength is described.
Assume that floating-point calculation processing is performed 10 times (10 FLOPs) in one loop and the data used in the loop is 2 bytes. When the same size data is used for each loop, the arithmetic intensity is 10/2=5 [FLOP/byte].
Since the arithmetic strength does not consider the number of loops, in the present embodiment, the number of loops is also considered in addition to the arithmetic strength to narrow down.
<PLD処理パターン作成部215>
PLD処理パターン作成部215は、算術強度算出部214が算出した算術強度をもとに、算術強度が所定の閾値より高い(以下、適宜、高算術強度という)ループ文をオフロード候補として絞り込み、PLD処理パターンを作成する。
また、PLD処理パターン作成部215は、基本動作として、コンパイルエラーが出るループ文(繰り返し文)に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、PLD処理するかしないかの指定を行うPLD処理パターンを作成する。 <PLDprocessing pattern generator 215>
Based on the arithmetic intensity calculated by the arithmeticintensity calculation unit 214, the PLD processing pattern creation unit 215 narrows down loop statements whose arithmetic intensity is higher than a predetermined threshold (hereinafter referred to as high arithmetic intensity as appropriate) as offload candidates, Create a PLD processing pattern.
As a basic operation, the PLD processingpattern creation unit 215 excludes loop statements (repeated statements) that cause compilation errors from being offloaded, and performs PLD processing on repetitive statements that do not cause compilation errors. Create a PLD processing pattern that specifies whether or not
PLD処理パターン作成部215は、算術強度算出部214が算出した算術強度をもとに、算術強度が所定の閾値より高い(以下、適宜、高算術強度という)ループ文をオフロード候補として絞り込み、PLD処理パターンを作成する。
また、PLD処理パターン作成部215は、基本動作として、コンパイルエラーが出るループ文(繰り返し文)に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、PLD処理するかしないかの指定を行うPLD処理パターンを作成する。 <PLD
Based on the arithmetic intensity calculated by the arithmetic
As a basic operation, the PLD processing
・ループ回数測定機能
PLD処理パターン作成部215は、ループ回数測定機能として、プロファイリングツールを用いてアプリケーションのループ文のループ回数を測定し、ループ文のうち、高算術強度で、ループ回数が所定の回数より多い(以下、適宜、高ループ回数という)ループ文を絞り込む。ループ回数把握には、GNUカバレッジのgcov等を用いる。プロファイリングツールとしては、「GNUプロファイラ(gprof)」、「GNUカバレッジ(gcov)」が知られている。双方とも各ループの実行回数を調査できるため、どちらを用いてもよい。 ・Loop count measurement function As a loop count measurement function, the PLD processingpattern creation unit 215 measures the loop count of the loop statements of the application using a profiling tool. Narrow down loop statements that are more than the number of times (hereinafter referred to as a high number of loops as appropriate). GNU coverage gcov etc. is used to grasp the number of loops. "GNU Profiler (gprof)" and "GNU Coverage (gcov)" are known as profiling tools. Either can be used because both can examine the number of executions of each loop.
PLD処理パターン作成部215は、ループ回数測定機能として、プロファイリングツールを用いてアプリケーションのループ文のループ回数を測定し、ループ文のうち、高算術強度で、ループ回数が所定の回数より多い(以下、適宜、高ループ回数という)ループ文を絞り込む。ループ回数把握には、GNUカバレッジのgcov等を用いる。プロファイリングツールとしては、「GNUプロファイラ(gprof)」、「GNUカバレッジ(gcov)」が知られている。双方とも各ループの実行回数を調査できるため、どちらを用いてもよい。 ・Loop count measurement function As a loop count measurement function, the PLD processing
また、算術強度分析では、ループ回数は特に見えないため、ループ回数が多く負荷が高いループを検出するため、プロファイリングツールを用いて、ループ回数を測定する。ここで、算術強度の高さは、FPGAへのオフロードに向いた処理かどうかを表わし、ループ回数×算術強度は、FPGAへのオフロードに関連する負荷が高いかどうかを表わす。
In addition, since the number of loops is not particularly visible in arithmetic intensity analysis, a profiling tool is used to measure the number of loops in order to detect loops with a large number of loops and high load. Here, the level of arithmetic intensity indicates whether the processing is suitable for offloading to the FPGA, and the number of loops×arithmetic intensity indicates whether the load associated with offloading to the FPGA is high.
・OpenCL(中間言語)作成機能
PLD処理パターン作成部215は、OpenCL作成機能として、絞り込まれた各ループ文をFPGAにオフロードするためのOpenCLを作成(OpenCL化)する。すなわち、PLD処理パターン作成部215は、絞り込んだループ文をオフロードするOpenCLをコンパイルする。また、PLD処理パターン作成部215は、性能測定された中でCPUに比べ高性能化されたループ文をリスト化し、リストのループ文を組み合わせてオフロードするOpenCLを作成する。 - OpenCL (intermediate language) creation function The PLD processingpattern creation unit 215 creates OpenCL (OpenCL conversion) for offloading each narrowed loop statement to the FPGA as an OpenCL creation function. That is, the PLD processing pattern creation unit 215 compiles OpenCL that offloads the narrowed loop statements. In addition, the PLD processing pattern creation unit 215 lists loop statements whose performance is improved compared to the CPU among the measured performance, and creates OpenCL for offloading by combining the loop statements in the list.
PLD処理パターン作成部215は、OpenCL作成機能として、絞り込まれた各ループ文をFPGAにオフロードするためのOpenCLを作成(OpenCL化)する。すなわち、PLD処理パターン作成部215は、絞り込んだループ文をオフロードするOpenCLをコンパイルする。また、PLD処理パターン作成部215は、性能測定された中でCPUに比べ高性能化されたループ文をリスト化し、リストのループ文を組み合わせてオフロードするOpenCLを作成する。 - OpenCL (intermediate language) creation function The PLD processing
OpenCL化について述べる。
PLD処理パターン作成部215は、ループ文をOpenCL等の高位言語化する。まず、CPU処理のプログラムを、カーネル(FPGA)とホスト(CPU)に、OpenCL等の高位言語の文法に従って分割する。例えば、10個のfor文の内一つのfor文をFPGAで処理する場合は、その一つをカーネルプログラムとして切り出し、OpenCLの文法に従って記述する。OpenCLの文法例については、後記する。 Describe OpenCL conversion.
The PLD processingpattern creation unit 215 converts the loop statement into a high-level language such as OpenCL. First, a CPU processing program is divided into a kernel (FPGA) and a host (CPU) according to the grammar of a high-level language such as OpenCL. For example, when one of ten for statements is to be processed by the FPGA, one of the for statements is cut out as a kernel program and described according to the OpenCL grammar. A grammar example of OpenCL will be described later.
PLD処理パターン作成部215は、ループ文をOpenCL等の高位言語化する。まず、CPU処理のプログラムを、カーネル(FPGA)とホスト(CPU)に、OpenCL等の高位言語の文法に従って分割する。例えば、10個のfor文の内一つのfor文をFPGAで処理する場合は、その一つをカーネルプログラムとして切り出し、OpenCLの文法に従って記述する。OpenCLの文法例については、後記する。 Describe OpenCL conversion.
The PLD processing
さらに、分割する際、より高速化するための技法を盛り込むこともできる。一般に、FPGAを用いて高速化するためには、ローカルメモリキャッシュ、ストリーム処理、複数インスタンス化、ループ文の展開処理、ネストループ文の統合、メモリインターリーブ等がある。これらは、ループ文によっては、絶対効果があるわけではないが、高速化するための手法として、よく利用されている。
In addition, it is possible to incorporate techniques to speed up the division. In general, there are local memory cache, stream processing, multiple instantiation, unrolling processing of loop statements, integration of nested loop statements, memory interleaving, etc. in order to speed up using FPGA. Although these methods are not absolutely effective depending on the loop statement, they are often used as a technique for speeding up.
OpenCLのC言語の文法に沿って作成したカーネルは、OpenCLのC言語のランタイムAPIを利用して、作成するホスト(例えば、CPU)側のプログラムによりデバイス(例えば、FPGA)で実行される。カーネル関数hello()をホスト側から呼び出す部分は、OpenCLランタイムAPIの一つであるclEnqueueTask()を呼び出すことである。
ホストコードで記述するOpenCLの初期化、実行、終了の基本フローは、下記ステップ1~13である。このステップ1~13のうち、ステップ1~10がカーネル関数hello()をホスト側から呼び出すまでの手続(準備)であり、ステップ11でカーネルの実行となる。 A kernel created according to the OpenCL C language grammar is executed on a device (eg FPGA) by a created host (eg CPU) side program using the OpenCL C language run-time API. The part that calls the kernel function hello() from the host side is to call clEnqueueTask(), which is one of the OpenCL runtime APIs.
The basic flow of initialization, execution, and termination of OpenCL written in host code issteps 1 to 13 below. Among these steps 1 to 13, steps 1 to 10 are procedures (preparations) until the kernel function hello() is called from the host side, and step 11 is execution of the kernel.
ホストコードで記述するOpenCLの初期化、実行、終了の基本フローは、下記ステップ1~13である。このステップ1~13のうち、ステップ1~10がカーネル関数hello()をホスト側から呼び出すまでの手続(準備)であり、ステップ11でカーネルの実行となる。 A kernel created according to the OpenCL C language grammar is executed on a device (eg FPGA) by a created host (eg CPU) side program using the OpenCL C language run-time API. The part that calls the kernel function hello() from the host side is to call clEnqueueTask(), which is one of the OpenCL runtime APIs.
The basic flow of initialization, execution, and termination of OpenCL written in host code is
1.プラットフォーム特定
OpenCLランタイムAPIで定義されているプラットフォーム特定機能を提供する関数clGetPlatformIDs()を用いて、OpenCLが動作するプラットフォームを特定する。 1. Platform Specific Identify the platform on which OpenCL is running using the function clGetPlatformIDs( ) which provides the platform specific functionality defined in the OpenCL runtime API.
OpenCLランタイムAPIで定義されているプラットフォーム特定機能を提供する関数clGetPlatformIDs()を用いて、OpenCLが動作するプラットフォームを特定する。 1. Platform Specific Identify the platform on which OpenCL is running using the function clGetPlatformIDs( ) which provides the platform specific functionality defined in the OpenCL runtime API.
2.デバイス特定
OpenCLランタイムAPIで定義されているデバイス特定機能を提供する関数clGetDeviceIDs()を用いて、プラットフォームで使用するGPU等のデバイスを特定する。 2. Device identification Use the function clGetDeviceIDs( ), which provides device identification functions defined in the OpenCL runtime API, to identify devices such as GPUs used in the platform.
OpenCLランタイムAPIで定義されているデバイス特定機能を提供する関数clGetDeviceIDs()を用いて、プラットフォームで使用するGPU等のデバイスを特定する。 2. Device identification Use the function clGetDeviceIDs( ), which provides device identification functions defined in the OpenCL runtime API, to identify devices such as GPUs used in the platform.
3.コンテキスト作成
OpenCLランタイムAPIで定義されているコンテキスト作成機能を提供する関数clCreateContext()を用いて、OpenCLを動作させる実行環境となるOpenCLコンテキストを作成する。 3. Context Creation Using the function clCreateContext( ) that provides the context creation function defined in the OpenCL runtime API, an OpenCL context that serves as an execution environment for operating OpenCL is created.
OpenCLランタイムAPIで定義されているコンテキスト作成機能を提供する関数clCreateContext()を用いて、OpenCLを動作させる実行環境となるOpenCLコンテキストを作成する。 3. Context Creation Using the function clCreateContext( ) that provides the context creation function defined in the OpenCL runtime API, an OpenCL context that serves as an execution environment for operating OpenCL is created.
4.コマンドキュー作成
OpenCLランタイムAPIで定義されているコマンドキュー作成機能を提供する関数clCreateCommandQueue()を用いて、デバイスを制御する準備であるコマンドキューを作成する。OpenCLでは、コマンドキューを通して、ホストからデバイスに対する働きかけ(カーネル実行コマンドやホスト-デバイス間のメモリコピーコマンドの発行)を実行する。 4. Create Command Queue Create a command queue ready to control the device using the function clCreateCommandQueue( ) that provides the command queue creation functionality defined in the OpenCL runtime API. In OpenCL, the host issues commands to the device (issues a kernel execution command or a memory copy command between the host and the device) through the command queue.
OpenCLランタイムAPIで定義されているコマンドキュー作成機能を提供する関数clCreateCommandQueue()を用いて、デバイスを制御する準備であるコマンドキューを作成する。OpenCLでは、コマンドキューを通して、ホストからデバイスに対する働きかけ(カーネル実行コマンドやホスト-デバイス間のメモリコピーコマンドの発行)を実行する。 4. Create Command Queue Create a command queue ready to control the device using the function clCreateCommandQueue( ) that provides the command queue creation functionality defined in the OpenCL runtime API. In OpenCL, the host issues commands to the device (issues a kernel execution command or a memory copy command between the host and the device) through the command queue.
5.メモリオブジェクト作成
OpenCLランタイムAPIで定義されているデバイス上にメモリを確保する機能を提供する関数clCreateBuffer()を用いて、ホスト側からメモリオブジェクトを参照できるようにするメモリオブジェクトを作成する。 5. Memory object creation Using the function clCreateBuffer(), which provides a function to allocate memory on the device defined in the OpenCL runtime API, create a memory object that allows the host to refer to the memory object.
OpenCLランタイムAPIで定義されているデバイス上にメモリを確保する機能を提供する関数clCreateBuffer()を用いて、ホスト側からメモリオブジェクトを参照できるようにするメモリオブジェクトを作成する。 5. Memory object creation Using the function clCreateBuffer(), which provides a function to allocate memory on the device defined in the OpenCL runtime API, create a memory object that allows the host to refer to the memory object.
6.カーネルファイル読み込み
デバイスで実行するカーネルは、その実行自体をホスト側のプログラムで制御する。このため、ホストプログラムは、まずカーネルプログラムを読み込む必要がある。カーネルプログラムには、OpenCLコンパイラで作成したバイナリデータや、OpenCL C言語で記述されたソースコードがある。このカーネルファイルを読み込む(記述省略)。なお、カーネルファイル読み込みでは、OpenCLランタイムAPIは使用しない。 6. Kernel file loading The kernel running on the device is controlled by the host program. Therefore, the host program must first load the kernel program. The kernel program includes binary data created by the OpenCL compiler and source code written in the OpenCL C language. Read this kernel file (description omitted). Note that the OpenCL runtime API is not used for kernel file reading.
デバイスで実行するカーネルは、その実行自体をホスト側のプログラムで制御する。このため、ホストプログラムは、まずカーネルプログラムを読み込む必要がある。カーネルプログラムには、OpenCLコンパイラで作成したバイナリデータや、OpenCL C言語で記述されたソースコードがある。このカーネルファイルを読み込む(記述省略)。なお、カーネルファイル読み込みでは、OpenCLランタイムAPIは使用しない。 6. Kernel file loading The kernel running on the device is controlled by the host program. Therefore, the host program must first load the kernel program. The kernel program includes binary data created by the OpenCL compiler and source code written in the OpenCL C language. Read this kernel file (description omitted). Note that the OpenCL runtime API is not used for kernel file reading.
7.プログラムオブジェクト作成
OpenCLでは、カーネルプログラムをプログラムプロジェクトとして認識する。この手続きがプログラムオブジェクト作成である。
OpenCLランタイムAPIで定義されているプログラムオブジェクト作成機能を提供する関数clCreateProgramWithSource()を用いて、ホスト側からメモリオブジェクトを参照できるようにするプログラムオブジェクトを作成する。カーネルプログラムのコンパイル済みバイナリ列から作成する場合は、clCreateProgramWithBinary()を使用する。 7. Program Object Creation OpenCL recognizes a kernel program as a program project. This procedure is program object creation.
Using the function clCreateProgramWithSource( ) that provides the program object creation function defined in the OpenCL runtime API, create a program object that allows the host to refer to the memory object. Use clCreateProgramWithBinary() when creating from a compiled binary string of a kernel program.
OpenCLでは、カーネルプログラムをプログラムプロジェクトとして認識する。この手続きがプログラムオブジェクト作成である。
OpenCLランタイムAPIで定義されているプログラムオブジェクト作成機能を提供する関数clCreateProgramWithSource()を用いて、ホスト側からメモリオブジェクトを参照できるようにするプログラムオブジェクトを作成する。カーネルプログラムのコンパイル済みバイナリ列から作成する場合は、clCreateProgramWithBinary()を使用する。 7. Program Object Creation OpenCL recognizes a kernel program as a program project. This procedure is program object creation.
Using the function clCreateProgramWithSource( ) that provides the program object creation function defined in the OpenCL runtime API, create a program object that allows the host to refer to the memory object. Use clCreateProgramWithBinary() when creating from a compiled binary string of a kernel program.
8.ビルド
ソースコードとして登録したプログラムオブジェクトを OpenCL Cコンパイラ・リンカを使いビルドする。
OpenCLランタイムAPIで定義されているOpenCL Cコンパイラ・リンカによるビルドを実行する関数clBuildProgram()を用いて、プログラムオブジェクトをビルドする。なお、clCreateProgramWithBinary()でコンパイル済みのバイナリ列からプログラムオブジェクトを生成した場合、このコンパイル手続は不要である。 8. Build Build the program object registered as the source code using the OpenCL C compiler/linker.
A program object is built using the function clBuildProgram(), which performs a build with the OpenCL C compiler and linker defined in the OpenCL runtime API. Note that this compilation procedure is not required if a program object is created from a compiled binary string using clCreateProgramWithBinary().
ソースコードとして登録したプログラムオブジェクトを OpenCL Cコンパイラ・リンカを使いビルドする。
OpenCLランタイムAPIで定義されているOpenCL Cコンパイラ・リンカによるビルドを実行する関数clBuildProgram()を用いて、プログラムオブジェクトをビルドする。なお、clCreateProgramWithBinary()でコンパイル済みのバイナリ列からプログラムオブジェクトを生成した場合、このコンパイル手続は不要である。 8. Build Build the program object registered as the source code using the OpenCL C compiler/linker.
A program object is built using the function clBuildProgram(), which performs a build with the OpenCL C compiler and linker defined in the OpenCL runtime API. Note that this compilation procedure is not required if a program object is created from a compiled binary string using clCreateProgramWithBinary().
9.カーネルオブジェクト作成
OpenCLランタイムAPIで定義されているカーネルオブジェクト作成機能を提供する関数clCreateKernel()を用いて、カーネルオブジェクトを作成する。1つのカーネルオブジェクトは、1つのカーネル関数に対応するので、カーネルオブジェクト作成時には、カーネル関数の名前(hello)を指定する。また、複数のカーネル関数を1つのプログラムオブジェクトとして記述した場合、1つのカーネルオブジェクトは、1つのカーネル関数に1対1で対応するので、clCreateKernel()を複数回呼び出す。 9. Kernel Object Creation A kernel object is created using the function clCreateKernel( ) that provides the kernel object creation function defined in the OpenCL runtime API. One kernel object corresponds to one kernel function, so the kernel function name (hello) is specified when the kernel object is created. Also, when a plurality of kernel functions are described as one program object, one kernel object corresponds to one kernel function, so clCreateKernel( ) is called multiple times.
OpenCLランタイムAPIで定義されているカーネルオブジェクト作成機能を提供する関数clCreateKernel()を用いて、カーネルオブジェクトを作成する。1つのカーネルオブジェクトは、1つのカーネル関数に対応するので、カーネルオブジェクト作成時には、カーネル関数の名前(hello)を指定する。また、複数のカーネル関数を1つのプログラムオブジェクトとして記述した場合、1つのカーネルオブジェクトは、1つのカーネル関数に1対1で対応するので、clCreateKernel()を複数回呼び出す。 9. Kernel Object Creation A kernel object is created using the function clCreateKernel( ) that provides the kernel object creation function defined in the OpenCL runtime API. One kernel object corresponds to one kernel function, so the kernel function name (hello) is specified when the kernel object is created. Also, when a plurality of kernel functions are described as one program object, one kernel object corresponds to one kernel function, so clCreateKernel( ) is called multiple times.
10.カーネル引数設定
OpenCLランタイムAPIで定義されているカーネルへ引数を与える(カーネル関数が持つ引数へ値を渡す)機能を提供する関数clSetKernel()を用いて、カーネル引数を設定する。
以上、上記ステップ1~10で準備が整い、ホスト側からデバイスでカーネルを実行するステップ11に入る。 10. Kernel Argument Setting Kernel arguments are set using the function clSetKernel() that provides the function of giving arguments to the kernel defined in the OpenCL runtime API (passing values to the arguments of kernel functions).
Aftersteps 1 to 10 complete preparations, step 11 is entered to execute the kernel on the device from the host side.
OpenCLランタイムAPIで定義されているカーネルへ引数を与える(カーネル関数が持つ引数へ値を渡す)機能を提供する関数clSetKernel()を用いて、カーネル引数を設定する。
以上、上記ステップ1~10で準備が整い、ホスト側からデバイスでカーネルを実行するステップ11に入る。 10. Kernel Argument Setting Kernel arguments are set using the function clSetKernel() that provides the function of giving arguments to the kernel defined in the OpenCL runtime API (passing values to the arguments of kernel functions).
After
11.カーネル実行
カーネル実行(コマンドキューへ投入)は、デバイスに対する働きかけとなるので、コマンドキューへのキューイング関数となる。
OpenCLランタイムAPIで定義されているカーネル実行機能を提供する関数clEnqueueTask()を用いて、カーネルhelloをデバイスで実行するコマンドをキューイングする。カーネルhelloを実行するコマンドがキューイングされた後、デバイス上の実行可能な演算ユニットで実行されることになる。 11. Kernel Execution Kernel execution (throwing into the command queue) is a queuing function to the command queue because it acts on the device.
The function clEnqueueTask( ), which provides kernel execution functionality defined in the OpenCL runtime API, is used to queue a command to execute kernel hello on the device. After the command to execute kernel hello is queued, it will be executed in the executable arithmetic unit on the device.
カーネル実行(コマンドキューへ投入)は、デバイスに対する働きかけとなるので、コマンドキューへのキューイング関数となる。
OpenCLランタイムAPIで定義されているカーネル実行機能を提供する関数clEnqueueTask()を用いて、カーネルhelloをデバイスで実行するコマンドをキューイングする。カーネルhelloを実行するコマンドがキューイングされた後、デバイス上の実行可能な演算ユニットで実行されることになる。 11. Kernel Execution Kernel execution (throwing into the command queue) is a queuing function to the command queue because it acts on the device.
The function clEnqueueTask( ), which provides kernel execution functionality defined in the OpenCL runtime API, is used to queue a command to execute kernel hello on the device. After the command to execute kernel hello is queued, it will be executed in the executable arithmetic unit on the device.
12.メモリオブジェクトからの読み込み
OpenCLランタイムAPIで定義されているデバイス側のメモリからホスト側のメモリへデータをコピーする機能を提供する関数clEnqueueReadBuffer()を用いて、デバイス側のメモリ領域からホスト側のメモリ領域にデータをコピーする。また、ホスト側からクライアント側のメモリへデータをコピーする機能を提供する関数clEnqueueWrightBuffer()を用いて、ホスト側のメモリ領域からデバイス側のメモリ領域にデータをコピーする。なお、これらの関数は、デバイスに対する働きかけとなるので、一度コマンドキューへコピーコマンドがキューイングされてからデータコピーが始まることになる。 12. Reading from a memory object Using the function clEnqueueReadBuffer(), which provides a function to copy data from device-side memory to host-side memory defined in the OpenCL runtime API, read data from the device-side memory area to the host-side memory area. copy the data to In addition, data is copied from the host-side memory area to the device-side memory area using the function clEnqueueWrightBuffer(), which provides a function to copy data from the host side to the client side memory. Since these functions act on the device, the data copy starts after the copy command is queued in the command queue once.
OpenCLランタイムAPIで定義されているデバイス側のメモリからホスト側のメモリへデータをコピーする機能を提供する関数clEnqueueReadBuffer()を用いて、デバイス側のメモリ領域からホスト側のメモリ領域にデータをコピーする。また、ホスト側からクライアント側のメモリへデータをコピーする機能を提供する関数clEnqueueWrightBuffer()を用いて、ホスト側のメモリ領域からデバイス側のメモリ領域にデータをコピーする。なお、これらの関数は、デバイスに対する働きかけとなるので、一度コマンドキューへコピーコマンドがキューイングされてからデータコピーが始まることになる。 12. Reading from a memory object Using the function clEnqueueReadBuffer(), which provides a function to copy data from device-side memory to host-side memory defined in the OpenCL runtime API, read data from the device-side memory area to the host-side memory area. copy the data to In addition, data is copied from the host-side memory area to the device-side memory area using the function clEnqueueWrightBuffer(), which provides a function to copy data from the host side to the client side memory. Since these functions act on the device, the data copy starts after the copy command is queued in the command queue once.
13.オブジェクト解放
最後に、ここまでに作成してきた各種オブジェクトを解放する。
以上、OpenCL C言語に沿って作成されたカーネルの、デバイス実行について説明した。 13. Releasing Objects Finally, release the various objects created so far.
The device execution of the kernel created according to the OpenCL C language has been described above.
最後に、ここまでに作成してきた各種オブジェクトを解放する。
以上、OpenCL C言語に沿って作成されたカーネルの、デバイス実行について説明した。 13. Releasing Objects Finally, release the various objects created so far.
The device execution of the kernel created according to the OpenCL C language has been described above.
・リソース量算出機能
PLD処理パターン作成部215は、リソース量算出機能として、作成したOpenCLをプレコンパイルして利用するリソース量を算出する(「1回目のリソース量算出」)。PLD処理パターン作成部215は、算出した算術強度およびリソース量に基づいてリソース効率を算出し、算出したリソース効率をもとに、各ループ文で、リソース効率が所定の値より高いc個のループ文を選ぶ。
PLD処理パターン作成部215は、組み合わせたオフロードOpenCLでプレコンパイルして利用するリソース量を算出する(「2回目のリソース量算出」)。ここで、プレコンパイルせず、1回目測定前のプレコンパイルでのリソース量の和でもよい。 • Resource Amount Calculation Function As a resource amount calculation function, the PLD processingpattern creation unit 215 precompiles the created OpenCL and calculates the resource amount to be used (“first resource amount calculation”). The PLD processing pattern creation unit 215 calculates resource efficiency based on the calculated arithmetic intensity and resource amount, and based on the calculated resource efficiency, c loops whose resource efficiency is higher than a predetermined value in each loop statement. choose a sentence.
The PLD processingpattern creation unit 215 calculates the resource amount to be used by precompiling with the combined offload OpenCL (“second resource amount calculation”). Here, without precompilation, the sum of resource amounts in precompilation before the first measurement may be used.
PLD処理パターン作成部215は、リソース量算出機能として、作成したOpenCLをプレコンパイルして利用するリソース量を算出する(「1回目のリソース量算出」)。PLD処理パターン作成部215は、算出した算術強度およびリソース量に基づいてリソース効率を算出し、算出したリソース効率をもとに、各ループ文で、リソース効率が所定の値より高いc個のループ文を選ぶ。
PLD処理パターン作成部215は、組み合わせたオフロードOpenCLでプレコンパイルして利用するリソース量を算出する(「2回目のリソース量算出」)。ここで、プレコンパイルせず、1回目測定前のプレコンパイルでのリソース量の和でもよい。 • Resource Amount Calculation Function As a resource amount calculation function, the PLD processing
The PLD processing
<性能測定部118>
性能測定部118は、作成されたPLD処理パターンのアプリケーションをコンパイルして、検証用マシン14に配置し、PLDにオフロードした際の性能測定用処理を実行する。 <Performance measurement unit 118>
Theperformance measurement unit 118 compiles the created PLD processing pattern application, places it in the verification machine 14, and executes performance measurement processing when offloaded to the PLD.
性能測定部118は、作成されたPLD処理パターンのアプリケーションをコンパイルして、検証用マシン14に配置し、PLDにオフロードした際の性能測定用処理を実行する。 <
The
性能測定部118は、配置したバイナリファイルを実行し、オフロードした際の性能を測定するとともに、性能測定結果を、オフロード範囲抽出部213aに戻す。この場合、オフロード範囲抽出部213aは、別のPLD処理パターン抽出を行い、中間言語ファイル出力部213bは、抽出された中間言語をもとに、性能測定を試行する(図2の符号a参照)。
The performance measurement unit 118 executes the arranged binary file, measures the performance when offloaded, and returns the performance measurement result to the offload range extraction unit 213a. In this case, the offload range extraction unit 213a extracts another PLD processing pattern, and the intermediate language file output unit 213b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2). ).
性能測定部118は、バイナリファイル配置部(Deploy binary files)118aを備える。バイナリファイル配置部118aは、GPUを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイ(配置)する。
The performance measurement unit 118 includes a binary file placement unit (Deploy binary files) 118a. The binary file placement unit 118a deploys (places) an execution file derived from the intermediate language on the verification machine 14 having a GPU.
性能測定の具体例について述べる。
PLD処理パターン作成部215は、高リソース効率のループ文を絞り込み、実行ファイル作成部119が絞り込んだループ文をオフロードするOpenCLをコンパイルする。性能測定部118は、コンパイルされたプログラムの性能を測定する(「1回目の性能測定」)。 A specific example of performance measurement will be described.
The PLD processingpattern creation unit 215 narrows down loop statements with high resource efficiency, and compiles OpenCL for offloading the loop statements narrowed down by the executable file creation unit 119 . The performance measurement unit 118 measures the performance of the compiled program (“first performance measurement”).
PLD処理パターン作成部215は、高リソース効率のループ文を絞り込み、実行ファイル作成部119が絞り込んだループ文をオフロードするOpenCLをコンパイルする。性能測定部118は、コンパイルされたプログラムの性能を測定する(「1回目の性能測定」)。 A specific example of performance measurement will be described.
The PLD processing
そして、PLD処理パターン作成部215は、性能測定された中でCPUに比べ高性能化されたループ文をリスト化する。PLD処理パターン作成部215は、リストのループ文を組み合わせてオフロードするOpenCLを作成する。PLD処理パターン作成部215は、組み合わせたオフロードOpenCLでプレコンパイルして利用するリソース量を算出する。
なお、プレコンパイルせず、1回目測定前のプレコンパイルでのリソース量の和でもよい。実行ファイル作成部119は、組み合わせたオフロードOpenCLをコンパイルし、性能測定部118は、コンパイルされたプログラムの性能を測定する(「2回目の性能測定」)。 Then, the PLD processingpattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance measured. The PLD processing pattern creation unit 215 creates OpenCL for offloading by combining the loop statements of the list. The PLD processing pattern creation unit 215 precompiles with the combined offload OpenCL and calculates the amount of resources to be used.
Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation. The executablefile creation unit 119 compiles the combined offload OpenCL, and the performance measurement unit 118 measures the performance of the compiled program (“second performance measurement”).
なお、プレコンパイルせず、1回目測定前のプレコンパイルでのリソース量の和でもよい。実行ファイル作成部119は、組み合わせたオフロードOpenCLをコンパイルし、性能測定部118は、コンパイルされたプログラムの性能を測定する(「2回目の性能測定」)。 Then, the PLD processing
Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation. The executable
<実行ファイル作成部119>
実行ファイル作成部119は、所定回数繰り返された、処理時間の測定結果をもとに、複数のPLD処理パターンから最高評価値のPLD処理パターンを選択し、最高評価値のPLD処理パターンをコンパイルして実行ファイルを作成する。 <ExecutableFile Creation Unit 119>
The executionfile creation unit 119 selects the PLD processing pattern with the highest evaluation value from a plurality of PLD processing patterns based on the measurement result of the processing time repeated a predetermined number of times, and compiles the PLD processing pattern with the highest evaluation value. to create an executable file.
実行ファイル作成部119は、所定回数繰り返された、処理時間の測定結果をもとに、複数のPLD処理パターンから最高評価値のPLD処理パターンを選択し、最高評価値のPLD処理パターンをコンパイルして実行ファイルを作成する。 <Executable
The execution
以下、上述のように構成されたオフロードサーバ1Aの自動オフロード動作について説明する。
[自動オフロード動作]
本実施形態のオフロードサーバ1Aは、環境適応ソフトウェアの要素技術としてユーザアプリケーションロジックのFPGA自動オフロードに適用した例である。
図2に示すオフロードサーバ1Aの自動オフロード処理を参照して説明する。
図2に示すように、オフロードサーバ1Aは、環境適応ソフトウェアの要素技術に適用される。オフロードサーバ1Aは、制御部(自動オフロード機能部)11と、テストケースDB131と、中間言語ファイル133と、検証用マシン14と、を有している。
オフロードサーバ1Aは、ユーザが利用するアプリケーションコード(Application code)125を取得する。 The automatic offload operation of theoffload server 1A configured as described above will be described below.
[Auto Offload Operation]
Theoffload server 1A of the present embodiment is an example in which elemental technology of environment-adaptive software is applied to FPGA automatic offloading of user application logic.
Description will be made with reference to the automatic offload processing of theoffload server 1A shown in FIG.
As shown in FIG. 2, theoffload server 1A is applied to elemental technology of environment adaptive software. The offload server 1A has a control unit (automatic offload function unit) 11, a test case DB 131, an intermediate language file 133, and a verification machine .
Theoffload server 1A acquires an application code 125 used by the user.
[自動オフロード動作]
本実施形態のオフロードサーバ1Aは、環境適応ソフトウェアの要素技術としてユーザアプリケーションロジックのFPGA自動オフロードに適用した例である。
図2に示すオフロードサーバ1Aの自動オフロード処理を参照して説明する。
図2に示すように、オフロードサーバ1Aは、環境適応ソフトウェアの要素技術に適用される。オフロードサーバ1Aは、制御部(自動オフロード機能部)11と、テストケースDB131と、中間言語ファイル133と、検証用マシン14と、を有している。
オフロードサーバ1Aは、ユーザが利用するアプリケーションコード(Application code)125を取得する。 The automatic offload operation of the
[Auto Offload Operation]
The
Description will be made with reference to the automatic offload processing of the
As shown in FIG. 2, the
The
ユーザは、例えば、各種デバイス(Device)151、CPU-GPUを有する装置152、CPU-FPGAを有する装置153、CPUを有する装置154を利用する。オフロードサーバ1Aは、機能処理をCPU-GPUを有する装置152、CPU-FPGAを有する装置153のアクセラレータに自動オフロードする。
A user uses, for example, various devices (Device) 151, a device 152 having a CPU-GPU, a device 153 having a CPU-FPGA, and a device 154 having a CPU. The offload server 1A automatically offloads functional processing to the accelerators of the device 152 having a CPU-GPU and the device 153 having a CPU-FPGA.
以下、図2のステップ番号を参照して各部の動作を説明する。
<ステップS21:Specify application code>
ステップS21において、アプリケーションコード指定部111(図13参照)は、ユーザに提供しているサービスの処理機能(画像分析等)を特定する。具体的には、アプリケーションコード指定部111は、入力されたアプリケーションコードの指定を行う。 The operation of each part will be described below with reference to the step numbers in FIG.
<Step S21: Specify application code>
In step S21, the application code specifying unit 111 (see FIG. 13) specifies the processing function (image analysis, etc.) of the service provided to the user. Specifically, the applicationcode designation unit 111 designates the input application code.
<ステップS21:Specify application code>
ステップS21において、アプリケーションコード指定部111(図13参照)は、ユーザに提供しているサービスの処理機能(画像分析等)を特定する。具体的には、アプリケーションコード指定部111は、入力されたアプリケーションコードの指定を行う。 The operation of each part will be described below with reference to the step numbers in FIG.
<Step S21: Specify application code>
In step S21, the application code specifying unit 111 (see FIG. 13) specifies the processing function (image analysis, etc.) of the service provided to the user. Specifically, the application
<ステップS12:Analyze application code>
ステップS12において、アプリケーションコード分析部112(図13参照)は、処理機能のソースコードを分析し、ループ文やFFTライブラリ呼び出し等の特定ライブラリ利用の構造を把握する。 <Step S12: Analyze application code>
In step S12, the application code analysis unit 112 (see FIG. 13) analyzes the source code of the processing function and grasps the structure of specific library usage such as loop statements and FFT library calls.
ステップS12において、アプリケーションコード分析部112(図13参照)は、処理機能のソースコードを分析し、ループ文やFFTライブラリ呼び出し等の特定ライブラリ利用の構造を把握する。 <Step S12: Analyze application code>
In step S12, the application code analysis unit 112 (see FIG. 13) analyzes the source code of the processing function and grasps the structure of specific library usage such as loop statements and FFT library calls.
<ステップS13:Extract offload able area>
ステップS13において、PLD処理指定部213(図13参照)は、アプリケーションのループ文(繰り返し文)を特定し、各繰り返し文に対して、FPGAにおける並列処理またはパイプライン処理を指定して、高位合成ツールでコンパイルする。具体的には、オフロード範囲抽出部213a(図13参照)は、ループ文等、FPGAにオフロード可能な処理を特定し、オフロード処理に応じた中間言語としてOpenCLを抽出する。 <Step S13: Extract offloadable area>
In step S13, the PLD processing designation unit 213 (see FIG. 13) identifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement, and performs high-level synthesis. Compile with tools. Specifically, the offloadrange extraction unit 213a (see FIG. 13) identifies processing that can be offloaded to the FPGA, such as a loop statement, and extracts OpenCL as an intermediate language corresponding to the offload processing.
ステップS13において、PLD処理指定部213(図13参照)は、アプリケーションのループ文(繰り返し文)を特定し、各繰り返し文に対して、FPGAにおける並列処理またはパイプライン処理を指定して、高位合成ツールでコンパイルする。具体的には、オフロード範囲抽出部213a(図13参照)は、ループ文等、FPGAにオフロード可能な処理を特定し、オフロード処理に応じた中間言語としてOpenCLを抽出する。 <Step S13: Extract offloadable area>
In step S13, the PLD processing designation unit 213 (see FIG. 13) identifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement, and performs high-level synthesis. Compile with tools. Specifically, the offload
<ステップS14:Output intermediate file>
ステップS14において、中間言語ファイル出力部213b(図13参照)は、中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。 <Step S14: Output intermediate file>
In step S14, the intermediate languagefile output unit 213b (see FIG. 13) outputs the intermediate language file 133. FIG. Intermediate language extraction is not a one-time process, but iterates to try and optimize executions for suitable offload region searches.
ステップS14において、中間言語ファイル出力部213b(図13参照)は、中間言語ファイル133を出力する。中間言語抽出は、一度で終わりでなく、適切なオフロード領域探索のため、実行を試行して最適化するため反復される。 <Step S14: Output intermediate file>
In step S14, the intermediate language
<ステップS15:Compile error>
ステップS15において、PLD処理パターン作成部215(図13参照)は、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、FPGA処理するかしないかの指定を行うPLD処理パターンを作成する。 <Step S15: Compile error>
In step S15, the PLD processing pattern creation unit 215 (see FIG. 13) excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors to be FPGA-processed. Create a PLD processing pattern that specifies whether or not to perform.
ステップS15において、PLD処理パターン作成部215(図13参照)は、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ない繰り返し文に対して、FPGA処理するかしないかの指定を行うPLD処理パターンを作成する。 <Step S15: Compile error>
In step S15, the PLD processing pattern creation unit 215 (see FIG. 13) excludes loop statements that cause compilation errors from being offloaded, and repeat statements that do not cause compilation errors to be FPGA-processed. Create a PLD processing pattern that specifies whether or not to perform.
<ステップS21:Deploy binary files>
ステップS21において、バイナリファイル配置部118a(図13参照)は、FPGAを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイする。バイナリファイル配置部118aは、配置したファイルを起動し、想定するテストケースを実行して、オフロードした際の性能を測定する。 <Step S21: Deploy binary files>
In step S21, the binaryfile placement unit 118a (see FIG. 13) deploys the execution file derived from the intermediate language to the verification machine 14 having an FPGA. The binary file placement unit 118a activates the placed file, executes an assumed test case, and measures performance when offloading.
ステップS21において、バイナリファイル配置部118a(図13参照)は、FPGAを備えた検証用マシン14に、中間言語から導かれる実行ファイルをデプロイする。バイナリファイル配置部118aは、配置したファイルを起動し、想定するテストケースを実行して、オフロードした際の性能を測定する。 <Step S21: Deploy binary files>
In step S21, the binary
<ステップS22:Measure performances>
ステップS22において、性能測定部118(図13参照)は、配置したファイルを実行し、オフロードした際の性能と電力使用量を測定する。
オフロードする領域をより適切にするため、この性能測定結果は、オフロード範囲抽出部213aに戻され、オフロード範囲抽出部213aが、別パターンの抽出を行う。そして、中間言語ファイル出力部213bは、抽出された中間言語をもとに、性能測定を試行する(図2の符号a参照)。性能測定部118は、検証環境での性能・電力使用量測定を繰り返し、最終的にデプロイするコードパターンを決定する。 <Step S22: Measure performance>
In step S22, the performance measurement unit 118 (see FIG. 13) executes the arranged file and measures the performance and power usage when offloading.
In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offloadrange extraction unit 213a, and the offload range extraction unit 213a extracts another pattern. Then, the intermediate language file output unit 213b attempts performance measurement based on the extracted intermediate language (see symbol a in FIG. 2). The performance measurement unit 118 repeats the performance/power consumption measurement in the verification environment and finally determines the code pattern to be deployed.
ステップS22において、性能測定部118(図13参照)は、配置したファイルを実行し、オフロードした際の性能と電力使用量を測定する。
オフロードする領域をより適切にするため、この性能測定結果は、オフロード範囲抽出部213aに戻され、オフロード範囲抽出部213aが、別パターンの抽出を行う。そして、中間言語ファイル出力部213bは、抽出された中間言語をもとに、性能測定を試行する(図2の符号a参照)。性能測定部118は、検証環境での性能・電力使用量測定を繰り返し、最終的にデプロイするコードパターンを決定する。 <Step S22: Measure performance>
In step S22, the performance measurement unit 118 (see FIG. 13) executes the arranged file and measures the performance and power usage when offloading.
In order to make the area to be offloaded more appropriate, this performance measurement result is returned to the offload
図2の符号aに示すように、制御部21は、上記ステップS12乃至ステップS22を繰り返し実行する。制御部21の自動オフロード機能をまとめると、下記である。すなわち、PLD処理指定部213は、アプリケーションのループ文(繰り返し文)を特定し、各繰返し文に対して、FPGAにおける並列処理またはパイプライン処理をOpenCL(中間言語)で指定して、高位合成ツールでコンパイルする。そして、PLD処理パターン作成部215は、コンパイルエラーが出るループ文を、オフロード対象外とし、コンパイルエラーが出ないループ文に対して、PLD処理するかしないかの指定を行うPLD処理パターンを作成する。そして、バイナリファイル配置部118aは、該当PLD処理パターンのアプリケーションをコンパイルして、検証用マシン14に配置し、性能測定部118が、検証用マシン14で性能測定用処理を実行する。実行ファイル作成部119は、所定回数繰り返された、性能測定結果をもとに、複数のPLD処理パターンから最高評価値(例えば、評価値=(処理時間)-1/2が最も高いもの)のパターンを選択し、選択パターンをコンパイルして実行ファイルを作成する。
As indicated by symbol a in FIG. 2, the control unit 21 repeatedly executes steps S12 to S22. The automatic offload function of the control unit 21 is summarized below. That is, the PLD processing designation unit 213 specifies loop statements (repetition statements) of the application, designates parallel processing or pipeline processing in the FPGA for each repetition statement in OpenCL (intermediate language), and uses a high-level synthesis tool. Compile with Then, the PLD processing pattern creation unit 215 creates a PLD processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to perform PLD processing on loop statements that do not cause compilation errors. do. Then, the binary file placement unit 118a compiles the application of the PLD processing pattern and places it on the verification machine 14, and the performance measurement unit 118 executes the performance measurement processing on the verification machine 14. FIG. The execution file creation unit 119 selects the highest evaluation value (for example, the highest evaluation value = (processing time) - 1/2 ) from a plurality of PLD processing patterns based on the performance measurement results repeated a predetermined number of times. Select a pattern and compile the selected pattern to create an executable.
<ステップS23:Deploy final binary files to production environment>
ステップS23において、本番環境配置部120は、最終的なオフロード領域を指定したパターンを決定し、ユーザ向けの本番環境にデプロイする。 <Step S23: Deploy final binary files to production environment>
In step S23, the production-environment placement unit 120 determines a pattern specifying the final offload area, and deploys it to the production environment for the user.
ステップS23において、本番環境配置部120は、最終的なオフロード領域を指定したパターンを決定し、ユーザ向けの本番環境にデプロイする。 <Step S23: Deploy final binary files to production environment>
In step S23, the production-
<ステップS24:Extract performance test cases and run automatically>
ステップS24において、性能測定テスト抽出実行部121は、実行ファイル配置後、ユーザに性能を示すため、性能試験項目をテストケースDB131から抽出し、抽出した性能試験を自動実行する。 <Step S24: Extract performance test cases and run automatically>
In step S24, the performance measurement testextraction execution unit 121 extracts performance test items from the test case DB 131 and automatically executes the extracted performance test in order to show the performance to the user after the execution file is arranged.
ステップS24において、性能測定テスト抽出実行部121は、実行ファイル配置後、ユーザに性能を示すため、性能試験項目をテストケースDB131から抽出し、抽出した性能試験を自動実行する。 <Step S24: Extract performance test cases and run automatically>
In step S24, the performance measurement test
<ステップS25:Provide price and performance to a user to judge>
ステップS25において、ユーザ提供部122は、性能試験結果を踏まえた、価格・性能等の情報をユーザに提示する。ユーザは、提示された価格・性能等の情報をもとに、サービスの課金利用開始を判断する。 <Step S25: Provide price and performance to a user to judge>
In step S25, theuser providing unit 122 presents information such as price and performance to the user based on the performance test results. Based on the presented information such as price and performance, the user decides to start using the service for a fee.
ステップS25において、ユーザ提供部122は、性能試験結果を踏まえた、価格・性能等の情報をユーザに提示する。ユーザは、提示された価格・性能等の情報をもとに、サービスの課金利用開始を判断する。 <Step S25: Provide price and performance to a user to judge>
In step S25, the
上記ステップS21~ステップS25は、ユーザのサービス利用のバックグラウンドで行われ、例えば、仮利用の初日の間に行う等を想定している。また、コスト低減のためにバックグラウンドで行う処理は、GPU・FPGAオフロードのみを対象としてもよい。
The above steps S21 to S25 are performed in the background when the user uses the service, and are assumed to be performed, for example, during the first day of provisional use. Also, the processing performed in the background for cost reduction may target only GPU/FPGA offload.
上記したように、オフロードサーバ1Aの制御部(自動オフロード機能部)21は、環境適応ソフトウェアの要素技術に適用した場合、機能処理のオフロードのため、ユーザが利用するアプリケーションのソースコードから、オフロードする領域を抽出して中間言語を出力する(ステップS12~ステップS15)。制御部21は、中間言語から導かれる実行ファイルを、検証用マシン14に配置実行し、オフロード効果を検証する(ステップS21~ステップS22)。検証を繰り返し、適切なオフロード領域を定めたのち、制御部21は、実際にユーザに提供する本番環境に、実行ファイルをデプロイし、サービスとして提供する(ステップS26)。
As described above, when the control unit (automatic offload function unit) 21 of the offload server 1A is applied to the element technology of the environment-adaptive software, the source code of the application used by the user is used to offload the function processing. , the offloading area is extracted and the intermediate language is output (steps S12 to S15). The control unit 21 arranges and executes the execution file derived from the intermediate language on the verification machine 14, and verifies the offload effect (steps S21 to S22). After repeating verification and determining an appropriate offload area, the control unit 21 deploys the executable file in the production environment that is actually provided to the user and provides it as a service (step S26).
なお、上記では、環境適応に必要な、コード変換、リソース量調整、配置場所調整を一括して行う処理フローを説明したが、これに限らず、行いたい処理だけ切出すことも可能である。例えば、FPGA向けにコード変換だけ行いたい場合は、上記ステップS21~ステップS25の、環境適応機能や検証環境等必要な部分だけ利用すればよい。
In the above, the process flow for collectively performing code conversion, resource amount adjustment, and placement location adjustment required for environmental adaptation was explained, but it is not limited to this, and it is also possible to extract only the desired process. For example, when only code conversion for FPGA is desired, only necessary parts such as the environment adaptation function and verification environment in steps S21 to S25 may be used.
[FPGA自動オフロード]
上述したコード分析は、Clang等の構文解析ツールを用いて、アプリケーションコードの分析を行う。コード分析は、オフロードするデバイスを想定した分析が必要になるため、一般化は難しい。ただし、ループ文や変数の参照関係等のコードの構造を把握したり、機能ブロックとしてFFT処理を行う機能ブロックであることや、FFT処理を行うライブラリを呼び出している等を把握することは可能である。機能ブロックの判断は、オフロードサーバが自動判断することは難しい。これもDeckard等の類似コード検出ツールを用いて類似度判定等で把握することは可能である。ここで、Clangは、C/C++向けツールであるが、解析する言語に合わせたツールを選ぶ必要がある。 [FPGA automatic offload]
The code analysis described above analyzes the application code using a syntax analysis tool such as Clang. Code analysis is difficult to generalize because it requires analysis assuming the device to be offloaded. However, it is possible to understand the structure of the code such as loop statements and reference relationships of variables, whether it is a function block that performs FFT processing as a function block, or whether it is calling a library that performs FFT processing. be. It is difficult for the offload server to automatically determine the function block. This can also be grasped by similarity determination using a similar code detection tool such as Deckard. Here, Clang is a tool for C/C++, but it is necessary to select a tool suitable for the language to be analyzed.
上述したコード分析は、Clang等の構文解析ツールを用いて、アプリケーションコードの分析を行う。コード分析は、オフロードするデバイスを想定した分析が必要になるため、一般化は難しい。ただし、ループ文や変数の参照関係等のコードの構造を把握したり、機能ブロックとしてFFT処理を行う機能ブロックであることや、FFT処理を行うライブラリを呼び出している等を把握することは可能である。機能ブロックの判断は、オフロードサーバが自動判断することは難しい。これもDeckard等の類似コード検出ツールを用いて類似度判定等で把握することは可能である。ここで、Clangは、C/C++向けツールであるが、解析する言語に合わせたツールを選ぶ必要がある。 [FPGA automatic offload]
The code analysis described above analyzes the application code using a syntax analysis tool such as Clang. Code analysis is difficult to generalize because it requires analysis assuming the device to be offloaded. However, it is possible to understand the structure of the code such as loop statements and reference relationships of variables, whether it is a function block that performs FFT processing as a function block, or whether it is calling a library that performs FFT processing. be. It is difficult for the offload server to automatically determine the function block. This can also be grasped by similarity determination using a similar code detection tool such as Deckard. Here, Clang is a tool for C/C++, but it is necessary to select a tool suitable for the language to be analyzed.
また、アプリケーションの処理をオフロードする場合には、GPU、FPGA、IoT GW等それぞれにおいて、オフロード先に合わせた検討が必要となる。一般に、性能に関しては、最大性能になる設定を一回で自動発見するのは難しい。このため、オフロードパターンを、性能測定を検証環境で何度か繰り返すことにより試行し、高速化できるパターンを見つけることを行う。
Also, when offloading application processing, it is necessary to consider the GPU, FPGA, IoT GW, etc. according to the offload destination. In general, with regard to performance, it is difficult to automatically discover the setting that maximizes performance at one time. For this reason, offload patterns are tried by repeating performance measurement several times in a verification environment to find a pattern that can speed up the process.
以下、アプリケーションソフトウェアのループ文のFPGA向けオフロード手法について説明する。
[フローチャート]
図14は、オフロードサーバ1Aの動作概要を説明するフローチャートである。
ステップS201でアプリケーションコード分析部112は、アプリケーションのオフロードしたいソースコードの分析を行う。アプリケーションコード分析部112は、ソースコードの言語に合わせて、ループ文や変数の情報を分析する。 An FPGA-oriented offload technique for application software loop statements will now be described.
[flowchart]
FIG. 14 is a flowchart for explaining the outline of the operation of theoffload server 1A.
In step S201, the applicationcode analysis unit 112 analyzes the source code of the application to be offloaded. The application code analysis unit 112 analyzes information on loop statements and variables according to the language of the source code.
[フローチャート]
図14は、オフロードサーバ1Aの動作概要を説明するフローチャートである。
ステップS201でアプリケーションコード分析部112は、アプリケーションのオフロードしたいソースコードの分析を行う。アプリケーションコード分析部112は、ソースコードの言語に合わせて、ループ文や変数の情報を分析する。 An FPGA-oriented offload technique for application software loop statements will now be described.
[flowchart]
FIG. 14 is a flowchart for explaining the outline of the operation of the
In step S201, the application
ステップS202でPLD処理指定部213は、アプリケーションのループ文および参照関係を特定する。
In step S202, the PLD processing designation unit 213 identifies loop statements and reference relationships of the application.
次に、PLD処理パターン作成部215は、把握したループ文に対して、FPGAオフロードを試行するかどうか候補を絞っていく処理を行う。ループ文に対してオフロード効果があるかどうかは、算術強度が一つの指標となる。
ステップS203で算術強度算出部214は、算術強度分析ツールを用いてアプリケーションのループ文の算術強度を算出する。算術強度は、計算数が多いと増加し、アクセス数が多いと減少する指標であり、算術強度が高い処理はプロセッサにとって重い処理となる。そこで、算術強度分析ツールで、ループ文の算術強度を分析し、密度が高いループ文をオフロード候補に絞る。そこで、算術強度分析ツールで、ループ文の算術強度を分析し、密度が高いループ文をオフロード候補に絞る。 Next, the PLD processingpattern creation unit 215 performs processing for narrowing down candidates for whether to try FPGA offloading for the grasped loop statements. Arithmetic strength is one indicator of whether a loop statement has an offload effect.
In step S203, the arithmeticstrength calculation unit 214 calculates the arithmetic strength of the loop statement of the application using the arithmetic strength analysis tool. Arithmetic intensity is an index that increases as the number of calculations increases and decreases as the number of accesses increases, and processing with high arithmetic intensity is heavy processing for the processor. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of loop statements and narrows down loop statements with high density to offload candidates. Therefore, the arithmetic strength analysis tool analyzes the arithmetic strength of loop statements and narrows down loop statements with high density to offload candidates.
ステップS203で算術強度算出部214は、算術強度分析ツールを用いてアプリケーションのループ文の算術強度を算出する。算術強度は、計算数が多いと増加し、アクセス数が多いと減少する指標であり、算術強度が高い処理はプロセッサにとって重い処理となる。そこで、算術強度分析ツールで、ループ文の算術強度を分析し、密度が高いループ文をオフロード候補に絞る。そこで、算術強度分析ツールで、ループ文の算術強度を分析し、密度が高いループ文をオフロード候補に絞る。 Next, the PLD processing
In step S203, the arithmetic
高算術強度のループ文であっても、それをFPGAで処理する際に、FPGAリソースを過度に消費してしまうのは問題である。そこで、高算術強度ループ文をFPGA処理する際のリソース量の算出について述べる。
FPGAにコンパイルする際の処理としては、OpenCL等の高位言語からハードウェア記述のHDL等のレベルに変換され、それに基づき実際の配線処理等がされる。この時、配線処理等は多大な時間がかかるが、HDL等の途中状態の段階までは時間は分単位でしかかからない。HDL等の途中状態の段階であっても、FPGAで利用するFlip FlopやLook Up Table等のリソースは分かる。このため、HDL等の途中状態の段階をみれば、利用するリソース量はコンパイルが終わらずとも短時間でわかる。 Even high-arithmetic-intensive loop statements can be problematic when processing them in an FPGA, consuming too much FPGA resources. Therefore, calculation of the amount of resources when FPGA processing a high arithmetic intensity loop statement will be described.
When compiling to FPGA, a high-level language such as OpenCL is converted to a hardware description level such as HDL, and based on this, actual wiring processing and the like are performed. At this time, wiring processing and the like take a lot of time, but the time up to the stage of the intermediate state such as HDL takes only minutes. Resources such as Flip Flop and Look Up Table used in FPGA can be known even at the stage of intermediate state such as HDL. Therefore, the amount of resources to be used can be known in a short time by looking at the intermediate state of HDL or the like, even if the compilation is not finished.
FPGAにコンパイルする際の処理としては、OpenCL等の高位言語からハードウェア記述のHDL等のレベルに変換され、それに基づき実際の配線処理等がされる。この時、配線処理等は多大な時間がかかるが、HDL等の途中状態の段階までは時間は分単位でしかかからない。HDL等の途中状態の段階であっても、FPGAで利用するFlip FlopやLook Up Table等のリソースは分かる。このため、HDL等の途中状態の段階をみれば、利用するリソース量はコンパイルが終わらずとも短時間でわかる。 Even high-arithmetic-intensive loop statements can be problematic when processing them in an FPGA, consuming too much FPGA resources. Therefore, calculation of the amount of resources when FPGA processing a high arithmetic intensity loop statement will be described.
When compiling to FPGA, a high-level language such as OpenCL is converted to a hardware description level such as HDL, and based on this, actual wiring processing and the like are performed. At this time, wiring processing and the like take a lot of time, but the time up to the stage of the intermediate state such as HDL takes only minutes. Resources such as Flip Flop and Look Up Table used in FPGA can be known even at the stage of intermediate state such as HDL. Therefore, the amount of resources to be used can be known in a short time by looking at the intermediate state of HDL or the like, even if the compilation is not finished.
そこで、本実施形態では、PLD処理パターン作成部215は、対象のループ文をOpenCL等の高位言語化し、まずリソース量を算出する。また、ループ文をオフロードした際の算術強度とリソース量が決まるため、算術強度/リソース量または算術強度×ループ回数/リソース量をリソース効率とする。そして、高リソース効率のループ文をオフロード候補として更に絞り込む。
Therefore, in this embodiment, the PLD processing pattern creation unit 215 translates the target loop statement into a high-level language such as OpenCL, and first calculates the resource amount. Also, since the arithmetic intensity and the resource amount when the loop statement is offloaded are determined, the arithmetic intensity/resource amount or arithmetic intensity×loop count/resource amount is defined as the resource efficiency. Then, loop statements with high resource efficiency are further narrowed down as offload candidates.
図14のフローに戻って、ステップS204でPLD処理パターン作成部215は、gcov、gprof等のプロファイリングツールを用いてアプリケーションのループ文のループ回数を測定する。
ステップS205でPLD処理パターン作成部215は、ループ文のうち、高算術強度で高ループ回数のループ文を絞り込む。 Returning to the flow of FIG. 14, in step S204, the PLD processingpattern creation unit 215 measures the number of loops of loop statements of the application using profiling tools such as gcov and gprof.
In step S205, the PLD processingpattern creation unit 215 narrows down the loop statements with high arithmetic strength and high loop count among the loop statements.
ステップS205でPLD処理パターン作成部215は、ループ文のうち、高算術強度で高ループ回数のループ文を絞り込む。 Returning to the flow of FIG. 14, in step S204, the PLD processing
In step S205, the PLD processing
ステップS206でPLD処理パターン作成部215は、絞り込まれた各ループ文をFPGAにオフロードするためのOpenCLを作成する。
In step S206, the PLD processing pattern creation unit 215 creates OpenCL for offloading each narrowed loop statement to the FPGA.
ここで、ループ文のOpenCL化(OpenCLの作成)について、補足して説明する。すなわち、ループ文をOpenCL等によって、高位言語化する際には、2つの処理が必要である。一つは、CPU処理のプログラムを、カーネル(FPGA)とホスト(CPU)に、OpenCL等の高位言語の文法に従って分割することである。もう一つは、分割する際に、高速化するための技法を盛り込むことである。一般に、FPGAを用いて高速化するためには、ローカルメモリキャッシュ、ストリーム処理、複数インスタンス化、ループ文の展開処理、ネストループ文の統合、メモリインターリーブ等がある。これらは、ループ文によっては、絶対効果があるわけではないが、高速化するための手法として、よく利用されている。
Here, I will provide a supplementary explanation of converting loop statements into OpenCL (creating OpenCL). That is, two processes are required when converting a loop statement into a high-level language using OpenCL or the like. One is to divide the CPU processing program into a kernel (FPGA) and a host (CPU) according to the grammar of a high-level language such as OpenCL. Another is to include techniques for speeding up the division. In general, there are local memory cache, stream processing, multiple instantiation, unrolling processing of loop statements, integration of nested loop statements, memory interleaving, etc. in order to speed up using FPGA. Although these methods are not absolutely effective depending on the loop statement, they are often used as a technique for speeding up.
次に、高リソース効率のループ文が幾つか選択されたので、それらを用いて性能を実測するオフロードパターンを実測する数だけ作成する。FPGAでの高速化は、1個の処理だけFPGAリソース量を集中的にかけて高速化する形もあれば、複数の処理にFPGAリソースを分散して高速化する形もある。選択された単ループ文のパターンを一定数作り、FPGA実機で動作する前段階としてプレコンパイルする。
Next, since several loop statements with high resource efficiency have been selected, we will use them to create the number of offload patterns to measure performance. There are two ways to increase the speed of an FPGA: by concentrating the FPGA resources on a single process, and by distributing the FPGA resources to a plurality of processes. A certain number of selected single-loop statement patterns are created and pre-compiled as a pre-stage before operating on the actual FPGA.
ステップS207でPLD処理パターン作成部215は、作成したOpenCLをプレコンパイルして利用するリソース量を算出する(「1回目のリソース量算出」)。
In step S207, the PLD processing pattern creation unit 215 pre-compiles the created OpenCL and calculates the resource amount to be used ("first resource amount calculation").
ステップS208でPLD処理パターン作成部215は、高リソース効率のループ文を絞り込む。
In step S208, the PLD processing pattern creation unit 215 narrows down loop statements with high resource efficiency.
ステップS209で実行ファイル作成部119は、絞り込んだループ文をオフロードするOpenCLをコンパイルする。
In step S209, the execution file creation unit 119 compiles OpenCL for offloading the narrowed down loop statements.
ステップS210で性能測定部118は、コンパイルされたプログラムの性能を測定する(「1回目の性能測定」)。候補ループ文が幾つか残るため、性能測定部118は、それらを用いて性能を実測する(詳細については、図15のサブルーチン参照)。
In step S210, the performance measurement unit 118 measures the performance of the compiled program ("first performance measurement"). Since some candidate loop statements remain, the performance measurement unit 118 uses them to actually measure the performance (see the subroutine in FIG. 15 for details).
ステップS211でPLD処理パターン作成部215は、性能測定された中でCPUに比べ高性能化されたループ文をリスト化する。
In step S211, the PLD processing pattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance-measured ones.
ステップS212でPLD処理パターン作成部215は、リストのループ文を組み合わせてオフロードするOpenCLを作成する。
ステップS213でPLD処理パターン作成部215は、組み合わせたオフロードOpenCLでプレコンパイルして利用するリソース量を算出する(「2回目のリソース量算出」)。なお、プレコンパイルせず、1回目測定前のプレコンパイルでのリソース量の和でもよい。このようにすれば、プレコンパイル回数を削減することができる。 In step S212, the PLD processingpattern creation unit 215 creates OpenCL for offloading by combining the loop statements of the list.
In step S213, the PLD processingpattern creation unit 215 calculates the amount of resources to be used by precompiling with the combined offload OpenCL (“second resource amount calculation”). Note that the sum of resource amounts in precompilation before the first measurement may be used without precompilation. By doing so, the number of times of precompilation can be reduced.
ステップS213でPLD処理パターン作成部215は、組み合わせたオフロードOpenCLでプレコンパイルして利用するリソース量を算出する(「2回目のリソース量算出」)。なお、プレコンパイルせず、1回目測定前のプレコンパイルでのリソース量の和でもよい。このようにすれば、プレコンパイル回数を削減することができる。 In step S212, the PLD processing
In step S213, the PLD processing
ステップS214で実行ファイル作成部119は、組み合わせたオフロードOpenCLをコンパイルする。
In step S214, the execution file creation unit 119 compiles the combined offload OpenCL.
ステップS215で性能測定部118は、コンパイルされたプログラムの性能を測定する(「2回目の性能測定」)。性能測定部118は、選択された単ループ文に対してコンパイルして測定し、更に高速化できた単ループ文に対してはその組み合わせパターンも作り2回目の性能測定を行う(詳細については、図15のサブルーチン参照)。
In step S215, the performance measurement unit 118 measures the performance of the compiled program ("second performance measurement"). The performance measurement unit 118 compiles and measures the selected single-loop statement, creates a combination pattern for the single-loop statement that has been further accelerated, and performs the second performance measurement (for details, see (see subroutine in FIG. 15).
ステップS216で本番環境配置部120は、1回目と2回目の測定の中で最高性能のパターンを選択して本フローの処理を終了する。測定された複数パターンの中で、短時間のパターンを解として選択する。
In step S216, the production environment placement unit 120 selects the pattern with the highest performance among the first and second measurements, and terminates the processing of this flow. A short-time pattern is selected as a solution from the measured multiple patterns.
このように、ループ文のFPGA自動オフロードは、算術強度とループ回数が高くリソース効率が高いループ文に絞って、オフロードパターンを作り、検証環境で実測を通じて高速なパターンの探索を行う(図14参照)。
In this way, the FPGA automatic offloading of loop statements creates offload patterns by focusing on loop statements with high arithmetic strength, loop counts, and high resource efficiency, and searches for high-speed patterns through actual measurements in a verification environment (Fig. 14).
図15は、性能測定部118の性能・電力使用量測定処理を示すフローチャートである。本フローは、図14のステップS210またはステップS215のサブルーチンコールにより呼び出され、実行される。
FIG. 15 is a flowchart showing performance/power consumption measurement processing of the performance measurement unit 118. FIG. This flow is called and executed by a subroutine call in step S210 or step S215 in FIG.
ステップS301で、性能測定部118は、FPGAオフロード時に必要となる処理時間を測定する。
In step S301, the performance measurement unit 118 measures the processing time required for FPGA offloading.
ステップS302で、性能測定部118は、測定した処理時間をもとに評価値を設定する。
In step S302, the performance measurement unit 118 sets an evaluation value based on the measured processing time.
ステップS303で、性能測定部118は、評価値が高い個体ほど適合度が高くなるように評価された評価値の高いパターンの性能を測定し、図14のステップS210またはステップS215に戻る。
In step S303, the performance measurement unit 118 measures the performance of patterns with high evaluation values, which are evaluated such that the higher the evaluation value, the higher the fitness, and returns to step S210 or step S215 in FIG.
[オフロードパターンの作成例]
図16は、PLD処理パターン作成部215の探索イメージを示す図である。
制御部(自動オフロード機能部)21(図13参照)は、ユーザが利用するアプリケーションコード(Application code)125(図2参照)を分析し、図16に示すように、アプリケーションコード125のコードパターン(Code patterns)241からfor文の並列可否をチェックする。図16の符号rに示すように、コードパターン241から4つのfor文が見つかった場合、各for文に対してそれぞれ1桁、ここでは4つのfor文に対し4桁の1または0を割り当てる。ここでは、FPGA処理する場合は1、FPGA処理しない場合(すなわちCPUで処理する場合)は0とする。 [Example of offload pattern creation]
FIG. 16 is a diagram showing a search image of the PLDprocessing pattern generator 215. As shown in FIG.
The control unit (automatic offload function unit) 21 (see FIG. 13) analyzes the application code 125 (see FIG. 2) used by the user, and determines the code pattern of theapplication code 125 as shown in FIG. (Code patterns) 241 checks whether the for statement can be parallelized. As indicated by symbol r in FIG. 16, when four for statements are found from the code pattern 241, one digit is assigned to each for statement, here four digits of 1 or 0 are assigned to the four for statements. Here, 1 is set when FPGA processing is performed, and 0 is set when FPGA processing is not performed (that is, when processing is performed by the CPU).
図16は、PLD処理パターン作成部215の探索イメージを示す図である。
制御部(自動オフロード機能部)21(図13参照)は、ユーザが利用するアプリケーションコード(Application code)125(図2参照)を分析し、図16に示すように、アプリケーションコード125のコードパターン(Code patterns)241からfor文の並列可否をチェックする。図16の符号rに示すように、コードパターン241から4つのfor文が見つかった場合、各for文に対してそれぞれ1桁、ここでは4つのfor文に対し4桁の1または0を割り当てる。ここでは、FPGA処理する場合は1、FPGA処理しない場合(すなわちCPUで処理する場合)は0とする。 [Example of offload pattern creation]
FIG. 16 is a diagram showing a search image of the PLD
The control unit (automatic offload function unit) 21 (see FIG. 13) analyzes the application code 125 (see FIG. 2) used by the user, and determines the code pattern of the
[CコードからOpenCL最終解の探索までの流れ]
図17の手順A-Fは、CコードからOpenCL最終解の探索までの流れを説明する図である。
アプリケーションコード分析部112(図13参照)は、図17の手順Aに示す「Cコード」を構文解析し(<構文解析>:図17の符号s参照)、PLD処理指定部213(図13参照)は、図17の手順Bに示す「ループ文、変数情報」を特定する(図17の符号t参照)。 [Flow from C code to search for OpenCL final solution]
Procedures A to F in FIG. 17 are diagrams for explaining the flow from the C code to the search for the final OpenCL solution.
The application code analysis unit 112 (see FIG. 13) parses the "C code" shown in procedure A of FIG. ) specifies the “loop statement, variable information” shown in procedure B in FIG. 17 (see symbol t in FIG. 17).
図17の手順A-Fは、CコードからOpenCL最終解の探索までの流れを説明する図である。
アプリケーションコード分析部112(図13参照)は、図17の手順Aに示す「Cコード」を構文解析し(<構文解析>:図17の符号s参照)、PLD処理指定部213(図13参照)は、図17の手順Bに示す「ループ文、変数情報」を特定する(図17の符号t参照)。 [Flow from C code to search for OpenCL final solution]
Procedures A to F in FIG. 17 are diagrams for explaining the flow from the C code to the search for the final OpenCL solution.
The application code analysis unit 112 (see FIG. 13) parses the "C code" shown in procedure A of FIG. ) specifies the “loop statement, variable information” shown in procedure B in FIG. 17 (see symbol t in FIG. 17).
算術強度算出部214(図13参照)は、特定した「ループ文、変数情報」に対して、算術強度分析ツールを用いて算術強度分析(Arithmetic Intensity analysis)する(図17の符号u参照)。PLD処理パターン作成部215は、算術強度が高いループ文をオフロード候補に絞る。さらに、PLD処理パターン作成部215は、プロファイリングツールを用いてプロファイリング分析(Profiling analysis)を行って、高算術強度で高ループ回数のループ文をさらに絞り込む。
The arithmetic intensity calculation unit 214 (see FIG. 13) performs arithmetic intensity analysis on the specified "loop statement, variable information" using an arithmetic intensity analysis tool (see symbol u in FIG. 17). The PLD processing pattern creation unit 215 narrows down loop statements with high arithmetic intensity to offload candidates. Furthermore, the PLD processing pattern creation unit 215 performs profiling analysis using a profiling tool to further narrow down loop statements with high arithmetic intensity and high loop count.
そして、PLD処理パターン作成部215は、絞り込まれた各ループ文をFPGAにオフロードするためのOpenCLを作成(OpenCL化)する(図17の符号v参照)。
さらに、OpenCL化時にコード分割と共に展開等の高速化手法を導入する(後記)。 Then, the PLD processingpattern creation unit 215 creates OpenCL for offloading each narrowed loop statement to the FPGA (OpenCL conversion) (see symbol v in FIG. 17).
In addition, we will introduce speed-up techniques such as decompression along with code division when converting to OpenCL (described later).
さらに、OpenCL化時にコード分割と共に展開等の高速化手法を導入する(後記)。 Then, the PLD processing
In addition, we will introduce speed-up techniques such as decompression along with code division when converting to OpenCL (described later).
<「高算術強度,OpenCL化」具体例(その1):手順C>
例えば、アプリケーションコード130のコードパターン241(図16参照)から4つのfor文(4桁の1または0の割り当て)が見つかった場合、算術強度分析で3つが絞り込まれる(選ばれる)。すなわち、図17の符号uに示すように、4つのfor文から、3つのfor文のオフロードパターン「1000」「0010」「0001」が絞り込まれる。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 1): Procedure C>
For example, if 4 for statements (assignment of 4digits 1 or 0) are found from the code pattern 241 (see FIG. 16) of the application code 130, the arithmetic intensity analysis narrows down (chooses) 3 of them. That is, as indicated by symbol u in FIG. 17, the offload patterns "1000", "0010", and "0001" of the three for statements are narrowed down from the four for statements.
例えば、アプリケーションコード130のコードパターン241(図16参照)から4つのfor文(4桁の1または0の割り当て)が見つかった場合、算術強度分析で3つが絞り込まれる(選ばれる)。すなわち、図17の符号uに示すように、4つのfor文から、3つのfor文のオフロードパターン「1000」「0010」「0001」が絞り込まれる。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 1): Procedure C>
For example, if 4 for statements (assignment of 4
<OpenCL化時にコード分割と共に実行する「展開」例>
FPGAからCPUへのデータ転送する場合の、CPUプログラム側で記述されるループ文〔k=0; k<10; k++〕 {
}
において、このループ文の上部に、\pragma unrollを指示する。すなわち、
\pragma unroll
for(k=0; k<10; k++){
}
と記述する。 <Example of "expansion" executed with code division when converting to OpenCL>
A loop statement [k=0; k<10; k++] written on the CPU program side when data is transferred from the FPGA to the CPU
}
, specify \pragma unroll above this loop statement. i.e.
\pragma unroll
for(k=0; k<10; k++){
}
described as
FPGAからCPUへのデータ転送する場合の、CPUプログラム側で記述されるループ文〔k=0; k<10; k++〕 {
}
において、このループ文の上部に、\pragma unrollを指示する。すなわち、
\pragma unroll
for(k=0; k<10; k++){
}
と記述する。 <Example of "expansion" executed with code division when converting to OpenCL>
A loop statement [k=0; k<10; k++] written on the CPU program side when data is transferred from the FPGA to the CPU
}
, specify \pragma unroll above this loop statement. i.e.
\pragma unroll
for(k=0; k<10; k++){
}
described as
\pragma unroll等のIntelやXilinx(登録商標)のツールに合った文法でunrollを指示すると、上記展開例であれば、i=0,i=1,i=2と展開してパイプライン実行することができる。このため、リソース量は10倍使うことになるが、高速になる場合がある。
また、unrollで展開する数は全ループ回数個でなく5個に展開等の指定もでき、その場合は、ループ2回ずつが、5つに展開される。
以上で、「展開」例についての説明を終える。 If you specify unroll with a syntax suitable for Intel or Xilinx (registered trademark) tools such as \pragma unroll, in the above expansion example, i = 0, i = 1, i = 2 and pipeline execution be able to. For this reason, the amount of resources will be used ten times, but the speed may be increased.
In addition, the number to be unrolled by unroll can be specified to be 5 instead of the total number of loops.
This completes the description of the "deployment" example.
また、unrollで展開する数は全ループ回数個でなく5個に展開等の指定もでき、その場合は、ループ2回ずつが、5つに展開される。
以上で、「展開」例についての説明を終える。 If you specify unroll with a syntax suitable for Intel or Xilinx (registered trademark) tools such as \pragma unroll, in the above expansion example, i = 0, i = 1, i = 2 and pipeline execution be able to. For this reason, the amount of resources will be used ten times, but the speed may be increased.
In addition, the number to be unrolled by unroll can be specified to be 5 instead of the total number of loops.
This completes the description of the "deployment" example.
次に、PLD処理パターン作成部215は、オフロード候補として絞り込まれた高算術強度のループ文を、リソース量を用いてさらに絞り込む。すなわち、PLD処理パターン作成部215は、リソース量を算出し、PLD処理パターン作成部215は、高算術強度のループ文のオフロード候補の中から、リソース効率(=算術強度/FPGA処理時のリソース量、または、算術強度×ループ回数/FPGA処理時のリソース量)分析して、リソース効率の高いループ文を抽出する。
Next, the PLD processing pattern creation unit 215 further narrows down the high arithmetic intensity loop sentences narrowed down as offload candidates by using the resource amount. That is, the PLD processing pattern creation unit 215 calculates the resource amount, and the PLD processing pattern creation unit 215 selects the resource efficiency (=arithmetic intensity/resource at the time of FPGA processing) from the offload candidates for the loop statement with high arithmetic intensity. amount, or (arithmetic intensity×number of loops/resource amount during FPGA processing)) is analyzed to extract loop statements with high resource efficiency.
図17の符号vでは、PLD処理パターン作成部215は、絞り込んだループ文をオフロードするためのOpenCLをコンパイル(<プレコンパイル>)する。
At symbol v in FIG. 17, the PLD processing pattern creation unit 215 compiles (<precompiles>) OpenCL for offloading the narrowed loop statements.
<「高算術強度,OpenCL化」具体例(その2)>
図17の符号uに示すように、算術強度分析で絞り込まれた4つのオフロードパターン「1000」「0100」「0010」「0001」の中から、上記リソース効率分析により3つのオフロードパターン「1000」「0010」「0001」に絞り込む。
以上、図17の手順Cに示す「高算術強度,OpenCL化」について説明した。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 2)>
As indicated by symbol u in FIG. , 0010, and 0001.
In the above, "High arithmetic strength, OpenCL conversion" shown in the procedure C of FIG. 17 has been described.
図17の符号uに示すように、算術強度分析で絞り込まれた4つのオフロードパターン「1000」「0100」「0010」「0001」の中から、上記リソース効率分析により3つのオフロードパターン「1000」「0010」「0001」に絞り込む。
以上、図17の手順Cに示す「高算術強度,OpenCL化」について説明した。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 2)>
As indicated by symbol u in FIG. , 0010, and 0001.
In the above, "High arithmetic strength, OpenCL conversion" shown in the procedure C of FIG. 17 has been described.
図17の手順Dに示す「リソース効率の高いループ文」に対して、性能測定部118は、コンパイルされたプログラムの性能を測定する(「1回目の性能測定」)。
そして、PLD処理パターン作成部215は、性能測定された中でCPUに比べ高性能化されたループ文をリスト化する。以下、同様に、リソース量を算出、オフロードOpenCLコンパイル、コンパイルされたプログラムの性能を測定する。 Theperformance measurement unit 118 measures the performance of the compiled program for the "resource-efficient loop statement" shown in procedure D of FIG. 17 ("first performance measurement").
Then, the PLD processingpattern creation unit 215 lists the loop statements whose performance is improved compared to the CPU among the performance measured. Similarly, we calculate the amount of resources, offload OpenCL compilation, and measure the performance of the compiled program.
そして、PLD処理パターン作成部215は、性能測定された中でCPUに比べ高性能化されたループ文をリスト化する。以下、同様に、リソース量を算出、オフロードOpenCLコンパイル、コンパイルされたプログラムの性能を測定する。 The
Then, the PLD processing
<「高算術強度,OpenCL化」具体例(その3)>
図17の符号wに示すように、3つのオフロードパターン「1000」「0010」「0001」について1回目測定を行う。その3つの測定の中で、「1000」「0010」の2つの性能が高くなったとすると、「1000」と「0010」の組合せについて2回目測定を行う。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 3)>
As indicated by symbol w in FIG. 17, the first measurement is performed for three offload patterns "1000", "0010", and "0001". If two performances of "1000" and "0010" are high among the three measurements, the second measurement is performed for the combination of "1000" and "0010".
図17の符号wに示すように、3つのオフロードパターン「1000」「0010」「0001」について1回目測定を行う。その3つの測定の中で、「1000」「0010」の2つの性能が高くなったとすると、「1000」と「0010」の組合せについて2回目測定を行う。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 3)>
As indicated by symbol w in FIG. 17, the first measurement is performed for three offload patterns "1000", "0010", and "0001". If two performances of "1000" and "0010" are high among the three measurements, the second measurement is performed for the combination of "1000" and "0010".
図17の符号xでは、実行ファイル作成部119は、絞り込んだループ文をオフロードするためのOpenCLをコンパイル(<本コンパイル>)する。
At symbol x in FIG. 17, the executable file creation unit 119 compiles (<main compile>) OpenCL for offloading the narrowed loop statements.
図17の手順Eに示す「組合せパターン実測」は、候補ループ文単体、その後、その組合せで検証パターン測定することをいう。
"Combination pattern actual measurement" shown in procedure E of FIG. 17 refers to measuring a candidate loop statement alone, and then measuring a verification pattern with its combination.
<「高算術強度,OpenCL化」具体例(その4)>
図17の符号yに示すように、「1000」と「0010」の組合せである「1010」について2回目測定する。2回測定し、その結果、1回目測定と2回目測定の中で最高速度の「0010」が選択された。このような場合、「0010」が最終の解となる。ここで、組合せパターンがリソース量制限のため測定できない場合がある。この場合、組合せについてはスキップして、単体の結果から最高速度のものを選ぶだけでもよい。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 4)>
As indicated by symbol y in FIG. 17, the second measurement is performed for "1010" which is a combination of "1000" and "0010". Two measurements were made, and as a result, the highest speed "0010" was selected between the first and second measurements. In such a case, "0010" is the final solution. Here, there are cases where the combination pattern cannot be measured due to resource limitations. In this case, it is possible to skip the combinations and just select the single result with the highest speed.
図17の符号yに示すように、「1000」と「0010」の組合せである「1010」について2回目測定する。2回測定し、その結果、1回目測定と2回目測定の中で最高速度の「0010」が選択された。このような場合、「0010」が最終の解となる。ここで、組合せパターンがリソース量制限のため測定できない場合がある。この場合、組合せについてはスキップして、単体の結果から最高速度のものを選ぶだけでもよい。 <Concrete example of “High arithmetic intensity, OpenCL conversion” (Part 4)>
As indicated by symbol y in FIG. 17, the second measurement is performed for "1010" which is a combination of "1000" and "0010". Two measurements were made, and as a result, the highest speed "0010" was selected between the first and second measurements. In such a case, "0010" is the final solution. Here, there are cases where the combination pattern cannot be measured due to resource limitations. In this case, it is possible to skip the combinations and just select the single result with the highest speed.
図17の符号zでは、性能測定部118は、1回目測定と2回目測定の中で最高速度の良い「0010」を選択(<選択>)する。
At symbol z in FIG. 17, the performance measurement unit 118 selects (<selects>) "0010" with the best maximum speed between the first measurement and the second measurement.
以上により、図17の手順Fに示す「OpenCL最終解」の「0010」(図17の符号aa参照)が選択された。
As a result, "0010" (see symbol aa in FIG. 17) of the "OpenCL final solution" shown in procedure F of FIG. 17 was selected.
<デプロイ(配置)>
OpenCL最終解の、最高処理性能のPLD処理パターンで、本番環境に改めてデプロイして、ユーザに提供する。 <deploy (deployment)>
Deploy again to the production environment with the PLD processing pattern of the highest processing performance of the OpenCL final solution and provide it to the user.
OpenCL最終解の、最高処理性能のPLD処理パターンで、本番環境に改めてデプロイして、ユーザに提供する。 <deploy (deployment)>
Deploy again to the production environment with the PLD processing pattern of the highest processing performance of the OpenCL final solution and provide it to the user.
[実装例]
実装例を説明する。
FPGAはIntel PAC with Intel Arria10 GX FPGA等が利用できる。
FPGA処理は、Intel Acceleration Stack(Intel FPGA SDK for OpenCL、Quartus Prime Version)等が利用できる。
Intel FPGA SDK for OpenCLは、標準OpenCLに加え、Intel向けの#pragma等を解釈する高位合成ツール(HLS)である。
実装例では、FPGAで処理するカーネルとCPUで処理するホストプログラムを記述したOpenCLコードを解釈し、リソース量等の情報を出力し、FPGAの配線作業等を行い、FPGAで動作できるようにする。FPGA実機で動作できるようにするには、100行程度の小プログラムでも3時間程の長時間がかかる。ただし、リソース量オーバーの際は、早めにエラーとなる。また、FPGAで処理できないOpenCLコードの際は、数時間後にエラーを出力する。 [Example of implementation]
An implementation example is explained.
FPGA such as Intel PAC with Intel Arria10 GX FPGA can be used.
Intel Acceleration Stack (Intel FPGA SDK for OpenCL, Quartus Prime Version) or the like can be used for FPGA processing.
Intel FPGA SDK for OpenCL is a high-level synthesis tool (HLS) that interprets #pragma for Intel in addition to standard OpenCL.
The implementation example interprets the OpenCL code that describes the kernel processed by the FPGA and the host program processed by the CPU, outputs information such as the amount of resources, and performs the wiring work of the FPGA, etc., so that it can operate on the FPGA. Even a small program of about 100 lines takes a long time of about 3 hours to be able to operate on an actual FPGA. However, when the amount of resources is exceeded, an error occurs early. Also, when the OpenCL code cannot be processed by the FPGA, an error is output after several hours.
実装例を説明する。
FPGAはIntel PAC with Intel Arria10 GX FPGA等が利用できる。
FPGA処理は、Intel Acceleration Stack(Intel FPGA SDK for OpenCL、Quartus Prime Version)等が利用できる。
Intel FPGA SDK for OpenCLは、標準OpenCLに加え、Intel向けの#pragma等を解釈する高位合成ツール(HLS)である。
実装例では、FPGAで処理するカーネルとCPUで処理するホストプログラムを記述したOpenCLコードを解釈し、リソース量等の情報を出力し、FPGAの配線作業等を行い、FPGAで動作できるようにする。FPGA実機で動作できるようにするには、100行程度の小プログラムでも3時間程の長時間がかかる。ただし、リソース量オーバーの際は、早めにエラーとなる。また、FPGAで処理できないOpenCLコードの際は、数時間後にエラーを出力する。 [Example of implementation]
An implementation example is explained.
FPGA such as Intel PAC with Intel Arria10 GX FPGA can be used.
Intel Acceleration Stack (Intel FPGA SDK for OpenCL, Quartus Prime Version) or the like can be used for FPGA processing.
Intel FPGA SDK for OpenCL is a high-level synthesis tool (HLS) that interprets #pragma for Intel in addition to standard OpenCL.
The implementation example interprets the OpenCL code that describes the kernel processed by the FPGA and the host program processed by the CPU, outputs information such as the amount of resources, and performs the wiring work of the FPGA, etc., so that it can operate on the FPGA. Even a small program of about 100 lines takes a long time of about 3 hours to be able to operate on an actual FPGA. However, when the amount of resources is exceeded, an error occurs early. Also, when the OpenCL code cannot be processed by the FPGA, an error is output after several hours.
実装例では、C/C++アプリケーションの利用依頼があると、まず、C/C++アプリケーションのコードを解析して、for文を発見するとともに、for文内で使われる変数データ等のプログラム構造を把握する。構文解析には、LLVM/Clangの構文解析ライブラリ等が利用できる。
In the implementation example, when there is a request to use a C/C++ application, the code of the C/C++ application is first analyzed, the for statement is discovered, and the program structure such as variable data used in the for statement is understood. . LLVM/Clang syntax analysis library can be used for syntax analysis.
実装例では、次に、各ループ文のFPGAオフロード効果があるかの見込みを得るため、算術強度分析ツールを実行し、計算数、アクセス数等で定まる算術強度の指標を取得する。算術強度分析には、ROSEフレームワーク等が利用できる。算術強度上位個のループ文のみ対象とするようにする。
次に、gcov等のプロファイリングツールを用いて、各ループのループ回数を取得する。算術強度×ループ回数が上位a個のループ文を候補に絞る。 The example implementation then runs the Arithmetic Intensity Analysis tool to get an indication of the arithmetic intensity determined by number of computations, number of accesses, etc., to get a sense of the FPGA offload effect of each loop statement. The ROSE framework etc. can be used for arithmetic intensity analysis. Target only loop statements with high arithmetic strength.
Next, a profiling tool such as gcov is used to obtain the loop count of each loop. Candidates are narrowed down to loop statements with the highest number of arithmetic strength times the number of loops.
次に、gcov等のプロファイリングツールを用いて、各ループのループ回数を取得する。算術強度×ループ回数が上位a個のループ文を候補に絞る。 The example implementation then runs the Arithmetic Intensity Analysis tool to get an indication of the arithmetic intensity determined by number of computations, number of accesses, etc., to get a sense of the FPGA offload effect of each loop statement. The ROSE framework etc. can be used for arithmetic intensity analysis. Target only loop statements with high arithmetic strength.
Next, a profiling tool such as gcov is used to obtain the loop count of each loop. Candidates are narrowed down to loop statements with the highest number of arithmetic strength times the number of loops.
実装例では、次に、高算術強度の個々のループ文に対して、FPGAオフロードするOpenCLコードを生成する。OpenCLコードは、該当ループ文をFPGAカーネルとして、残りをCPUホストプログラムとして分割したものである。FPGAカーネルコードとする際に、高速化の技法としてループ文の展開処理を一定数bだけ行ってもよい。ループ文展開処理は、リソース量は増えるが、高速化に効果がある。そこで、展開する数は、一定数bに制限してリソース量が膨大にならない範囲で行う。
In the implementation example, the FPGA offloading OpenCL code is then generated for each loop statement with high arithmetic intensity. The OpenCL code is obtained by dividing the corresponding loop statement as the FPGA kernel and the remainder as the CPU host program. When the FPGA kernel code is used, as a technique for speeding up, the expansion processing of the loop statement may be performed by a constant number b. Loop statement expansion processing increases the amount of resources, but is effective in speeding up processing. Therefore, the number of expansions is limited to a certain number b so as not to increase the amount of resources.
実装例では、次に、a個のOpenCLコードに対して、Intel FPGA SDK for OpenCLを用いて、プレコンパイルをして、利用するFlip Flop、Look Up Table等のリソース量を算出する。使用リソース量は、全体リソース量の割合で表示される。ここで、算術強度とリソース量または算術強度とループ回数とリソース量から、各ループ文のリソース効率を計算する。例えば、算術強度が10、リソース量が0.5のループ文は、10/0.5=20、算術強度が3、リソース量が0.3のループ文は3/0.3=10がリソース効率となり、前者が高い。また、ループ回数をかけた値をリソース効率としてもよい。各ループ文で、リソース効率が高いc個を選定する。
In the implementation example, the Intel FPGA SDK for OpenCL is used to precompile the a number of OpenCL codes, and the amount of resources such as Flip Flop and Look Up Table to be used is calculated. The used resource amount is displayed as a percentage of the total resource amount. Here, the resource efficiency of each loop statement is calculated from the arithmetic strength and the resource amount or from the arithmetic strength, the number of loops and the resource amount. For example, a loop statement with an arithmetic strength of 10 and a resource amount of 0.5 has 10/0.5=20 resources, and a loop statement with an arithmetic strength of 3 and a resource amount of 0.3 has 3/0.3=10 resources. Efficiency is high, and the former is high. Alternatively, a value obtained by multiplying the number of loops may be used as the resource efficiency. In each loop statement, select c with high resource efficiency.
実装例では、次に、c個のループ文を候補に、実測するパターンを作る。例えば、1番目と3番目のループが高リソース効率であった場合、1番をオフロード、3番をオフロードする各OpenCLパターンを作成して、コンパイルして性能測定する。複数の単ループ文のオフロードパターンで高速化できている場合(例えば、1番と3番両方が高速化できている場合)は、その組合せでのOpenCLパターンを作成して、コンパイルして性能測定する(例えば1番と3番両方をオフロードするパターン)。
In the implementation example, next, a pattern to be measured is created with c loop statements as candidates. For example, if the 1st and 3rd loops are highly resource efficient, create each OpenCL pattern that offloads the 1st and 3rd loops, compiles them, and measures the performance. If you can speed up with offload patterns of multiple single loop statements (for example, if you can speed up both 1st and 3rd), create an OpenCL pattern with that combination, compile and perform Measure (e.g. pattern offloading both #1 and #3).
なお、単ループの組み合わせを作る際は、利用リソース量も組み合わせになる。このため、上限値に納まらない場合は、その組合せパターンは作らない。組合せも含めてd個のパターンを作成した場合、検証環境のFPGAを備えたサーバで性能測定を行う。性能測定には、高速化したいアプリケーションで指定されたサンプル処理を行う。例えば、フーリエ変換のアプリケーションであれば、サンプルデータでの変換処理をベンチマークに性能測定をする。
実装例では、最後に、複数の測定パターンの高速なパターンを解として選択する。 Note that when creating a combination of single loops, the amount of resources used is also a combination. Therefore, if it does not fit within the upper limit, the combination pattern is not created. When d patterns including combinations are created, performance measurement is performed on a server equipped with an FPGA in the verification environment. For performance measurement, sample processing specified by the application to be accelerated is performed. For example, in the case of a Fourier transform application, performance is measured using transform processing with sample data as a benchmark.
Finally, the implementation selects the fast pattern of the multiple measurement patterns as the solution.
実装例では、最後に、複数の測定パターンの高速なパターンを解として選択する。 Note that when creating a combination of single loops, the amount of resources used is also a combination. Therefore, if it does not fit within the upper limit, the combination pattern is not created. When d patterns including combinations are created, performance measurement is performed on a server equipped with an FPGA in the verification environment. For performance measurement, sample processing specified by the application to be accelerated is performed. For example, in the case of a Fourier transform application, performance is measured using transform processing with sample data as a benchmark.
Finally, the implementation selects the fast pattern of the multiple measurement patterns as the solution.
第2実施形態でも第1実施形態で述べたと同様の「リソース量決定と配置決定」を実行する(説明省略)。
In the second embodiment, the same "resource amount determination and allocation determination" as described in the first embodiment are executed (description omitted).
[評価]
評価を説明する。
第2実施形態の[ループ文のFPGA自動オフロード]では、第1実施形態の[ループ文のGPU自動オフロード]と同様に評価できる。 [evaluation]
Describe your rating.
[FPGA automatic offload of loop statement] of the second embodiment can be evaluated in the same manner as [GPU automatic offload of loop statement] of the first embodiment.
評価を説明する。
第2実施形態の[ループ文のFPGA自動オフロード]では、第1実施形態の[ループ文のGPU自動オフロード]と同様に評価できる。 [evaluation]
Describe your rating.
[FPGA automatic offload of loop statement] of the second embodiment can be evaluated in the same manner as [GPU automatic offload of loop statement] of the first embodiment.
<評価対象>
評価対象は、第2実施形態の[ループ文のFPGA自動オフロード]では、MRI(Magnetic Resonance Imaging)画像処理のMRI-Qとする。
MRI-Qは、非デカルト空間の3次元MRI再構成アルゴリズムで使用されるスキャナー構成を表す行列Qを計算する。MRI-Qは、C言語で記述されており、性能測定中に3次元MRI画像処理を実行し、Large(最大)の64×64×64サイズのデータで処理時間を測定する。CPU処理は、C言語を用い、FPGA処理はOpenCL に基づき処理される。 <Evaluation target>
In [FPGA automatic offloading of loop statement] of the second embodiment, the evaluation target is MRI-Q of MRI (Magnetic Resonance Imaging) image processing.
MRI-Q computes a matrix Q that represents the scanner configuration used in the non-Cartesian spatial 3D MRI reconstruction algorithm. MRI-Q is written in C language, executes three-dimensional MRI image processing during performance measurement, and measures processing time with Large (maximum) 64×64×64 size data. CPU processing uses C language, and FPGA processing is based on OpenCL.
評価対象は、第2実施形態の[ループ文のFPGA自動オフロード]では、MRI(Magnetic Resonance Imaging)画像処理のMRI-Qとする。
MRI-Qは、非デカルト空間の3次元MRI再構成アルゴリズムで使用されるスキャナー構成を表す行列Qを計算する。MRI-Qは、C言語で記述されており、性能測定中に3次元MRI画像処理を実行し、Large(最大)の64×64×64サイズのデータで処理時間を測定する。CPU処理は、C言語を用い、FPGA処理はOpenCL に基づき処理される。 <Evaluation target>
In [FPGA automatic offloading of loop statement] of the second embodiment, the evaluation target is MRI-Q of MRI (Magnetic Resonance Imaging) image processing.
MRI-Q computes a matrix Q that represents the scanner configuration used in the non-Cartesian spatial 3D MRI reconstruction algorithm. MRI-Q is written in C language, executes three-dimensional MRI image processing during performance measurement, and measures processing time with Large (maximum) 64×64×64 size data. CPU processing uses C language, and FPGA processing is based on OpenCL.
<評価手法>
対象となるアプリケーションのコードを入力し、移行先のGPUやFPGAに対して、Clang等で認識されたループ文オフロードを試行してオフロードパターンを決める。この際に、処理時間と電力使用量を測定する。最終オフロードパターンについて、電力使用量の時間変化を取得し、全てCPUで処理する場合に比べた低電力化を確認する。
第2実施形態の[ループ文のFPGA自動オフロード]では、GAは行わず、算術強度等を用いて、測定パターンが4パターンとなるまで絞り込む。
オフロード対象ループ文: MRI-Q 16
パターン適合度:処理時間が低い程、評価値が高くなり、高適合度になる。第2の実施形態のMRI-Qでも前述の図12のような形で、単純に安さ優先や応答時間優先の配置に比べて、コストや応答時間が改善できる。 <Evaluation method>
Enter the code of the target application, and try to offload loop statements recognized by Clang or the like to the destination GPU or FPGA to determine the offload pattern. At this time, the processing time and power consumption are measured. For the final offload pattern, obtain the change in power consumption over time and confirm the reduction in power consumption compared to the case where all processing is performed by the CPU.
In the [FPGA automatic offloading of loop statement] of the second embodiment, GA is not performed, and arithmetic intensity or the like is used to narrow down the measurement patterns to four patterns.
Offload Eligible Loop Statements: MRI-Q 16
Pattern conformity: The lower the processing time, the higher the evaluation value, which is a high degree of conformity. In the MRI-Q of the second embodiment as well, cost and response time can be improved in the manner shown in FIG. 12, compared to simply placing priority on cheapness and response time.
対象となるアプリケーションのコードを入力し、移行先のGPUやFPGAに対して、Clang等で認識されたループ文オフロードを試行してオフロードパターンを決める。この際に、処理時間と電力使用量を測定する。最終オフロードパターンについて、電力使用量の時間変化を取得し、全てCPUで処理する場合に比べた低電力化を確認する。
第2実施形態の[ループ文のFPGA自動オフロード]では、GAは行わず、算術強度等を用いて、測定パターンが4パターンとなるまで絞り込む。
オフロード対象ループ文: MRI-Q 16
パターン適合度:処理時間が低い程、評価値が高くなり、高適合度になる。第2の実施形態のMRI-Qでも前述の図12のような形で、単純に安さ優先や応答時間優先の配置に比べて、コストや応答時間が改善できる。 <Evaluation method>
Enter the code of the target application, and try to offload loop statements recognized by Clang or the like to the destination GPU or FPGA to determine the offload pattern. At this time, the processing time and power consumption are measured. For the final offload pattern, obtain the change in power consumption over time and confirm the reduction in power consumption compared to the case where all processing is performed by the CPU.
In the [FPGA automatic offloading of loop statement] of the second embodiment, GA is not performed, and arithmetic intensity or the like is used to narrow down the measurement patterns to four patterns.
Offload Eligible Loop Statements: MRI-Q 16
Pattern conformity: The lower the processing time, the higher the evaluation value, which is a high degree of conformity. In the MRI-Q of the second embodiment as well, cost and response time can be improved in the manner shown in FIG. 12, compared to simply placing priority on cheapness and response time.
[ハードウェア構成]
第1および第2の実施形態に係るオフロードサーバは、例えば図18に示すような構成の物理装置であるコンピュータ900によって実現される。
図18は、オフロードサーバ1,1Aの機能を実現するコンピュータの一例を示すハードウェア構成図である。コンピュータ900は、CPU901、RAM902、ROM903、HDD904、アクセラレータ905、入出力インターフェイス(I/F)906、メディアインターフェイス(I/F)907、および通信インターフェイス(I/F:Interface)908を有する。 [Hardware configuration]
The offload servers according to the first and second embodiments are implemented by acomputer 900, which is a physical device configured as shown in FIG. 18, for example.
FIG. 18 is a hardware configuration diagram showing an example of a computer that implements the functions of the offload servers 1 and 1A. Computer 900 has CPU 901 , RAM 902 , ROM 903 , HDD 904 , accelerator 905 , input/output interface (I/F) 906 , media interface (I/F) 907 , and communication interface (I/F: Interface) 908 .
第1および第2の実施形態に係るオフロードサーバは、例えば図18に示すような構成の物理装置であるコンピュータ900によって実現される。
図18は、オフロードサーバ1,1Aの機能を実現するコンピュータの一例を示すハードウェア構成図である。コンピュータ900は、CPU901、RAM902、ROM903、HDD904、アクセラレータ905、入出力インターフェイス(I/F)906、メディアインターフェイス(I/F)907、および通信インターフェイス(I/F:Interface)908を有する。 [Hardware configuration]
The offload servers according to the first and second embodiments are implemented by a
FIG. 18 is a hardware configuration diagram showing an example of a computer that implements the functions of the
アクセラレータ905は、通信I/F908からのデータ、または、RAM902からのデータの少なくとも一方のデータを高速に処理するアクセラレータ(デバイス)である。例えば、アクセラレータ905は、図2の各種デバイス(Device)151、CPU-GPUを有する装置152、CPU-FPGAを有する装置153、CPUを有する装置154のアクセラレータである。
なお、アクセラレータ905として、CPU901またはRAM902からの処理を実行した後にCPU901またはRAM902に実行結果を戻すタイプ(look-aside型)を用いてもよい。一方、アクセラレータ905として、通信I/F908とCPU901またはRAM902との間に入って、処理を行うタイプ(in-line型)を用いてもよい。 Theaccelerator 905 is an accelerator (device) that processes at least one of data from the communication I/F 908 and data from the RAM 902 at high speed. For example, the accelerator 905 is an accelerator for the device 151, the device 152 having a CPU-GPU, the device 153 having a CPU-FPGA, and the device 154 having a CPU in FIG.
As theaccelerator 905, a type (look-aside type) that returns the execution result to the CPU 901 or the RAM 902 after executing the processing from the CPU 901 or the RAM 902 may be used. On the other hand, as the accelerator 905, a type (in-line type) that performs processing by entering between the communication I/F 908 and the CPU 901 or the RAM 902 may be used.
なお、アクセラレータ905として、CPU901またはRAM902からの処理を実行した後にCPU901またはRAM902に実行結果を戻すタイプ(look-aside型)を用いてもよい。一方、アクセラレータ905として、通信I/F908とCPU901またはRAM902との間に入って、処理を行うタイプ(in-line型)を用いてもよい。 The
As the
アクセラレータ905は、通信I/F908を介して外部装置915と接続される。入出力I/F906は、入出力装置916と接続される。メディアI/F907は、記録媒体917からデータを読み書きする。
Accelerator 905 is connected to external device 915 via communication I/F 908 . Input/output I/F 906 is connected to input/output device 916 . A media I/F 907 reads and writes data from a recording medium 917 .
CPU901は、ROM903またはHDD904に記憶されたプログラムに基づき作動し、RAM902に読み込んだプログラム(アプリケーションや、その略のアプリとも呼ばれる)を実行することにより、図1、図13に示すオフロードサーバ1,1Aの各処理部による制御を行う。そして、このプログラムは、通信回線を介して配布したり、CD-ROM等の記録媒体917に記録して配布したりすることも可能である。
ROM903は、コンピュータ900の起動時にCPU901によって実行されるブートプログラムや、コンピュータ900のハードウェアに依存するプログラム等を格納する。 TheCPU 901 operates based on programs stored in the ROM 903 or HDD 904, and executes programs (also called applications or apps for short) read into the RAM 902 to operate the offload servers 1 and 1 shown in FIGS. Control is performed by each processing unit of 1A. This program can be distributed via a communication line or recorded on a recording medium 917 such as a CD-ROM for distribution.
TheROM 903 stores a boot program executed by the CPU 901 when the computer 900 is started, a program depending on the hardware of the computer 900, and the like.
ROM903は、コンピュータ900の起動時にCPU901によって実行されるブートプログラムや、コンピュータ900のハードウェアに依存するプログラム等を格納する。 The
The
CPU901は、入出力I/F906を介して、マウスやキーボード等の入力部、および、ディスプレイやプリンタ等の出力部からなる入出力装置916を制御する。CPU901は、入出力I/F906を介して、入出力装置916からデータを取得するともに、生成したデータを入出力装置916へ出力する。なお、プロセッサとしてCPU901とともに、GPU(Graphics Processing Unit)等を用いてもよい。
The CPU 901 controls, via the input/output I/F 906, an input/output device 916 comprising an input unit such as a mouse and keyboard, and an output unit such as a display and printer. The CPU 901 acquires data from the input/output device 916 via the input/output I/F 906 and outputs the generated data to the input/output device 916 . A GPU (Graphics Processing Unit) or the like may be used together with the CPU 901 as a processor.
HDD904は、CPU901により実行されるプログラムおよび当該プログラムによって使用されるデータ等を記憶する。通信I/F908は、通信網(例えば、NW(Network))を介して他の装置からデータを受信してCPU901へ出力し、また、CPU901が生成したデータを、通信網を介して他の装置へ送信する。
The HDD 904 stores programs executed by the CPU 901 and data used by the programs. The communication I/F 908 receives data from other devices via a communication network (for example, NW (Network)) and outputs the data to the CPU 901, and also transmits data generated by the CPU 901 to other devices via the communication network. Send to
メディアI/F907は、記録媒体917に格納されたプログラムまたはデータを読み取り、RAM902を介してCPU901へ出力する。CPU901は、目的の処理に係るプログラムを、メディアI/F907を介して記録媒体917からRAM902上にロードし、ロードしたプログラムを実行する。記録媒体917は、DVD(Digital Versatile Disc)、PD(Phase change rewritable Disk)等の光学記録媒体、MO(Magneto Optical disk)等の光磁気記録媒体、磁気記録媒体、導体メモリテープ媒体又は半導体メモリ等である。
The media I/F 907 reads programs or data stored in the recording medium 917 and outputs them to the CPU 901 via the RAM 902 . The CPU 901 loads a program related to target processing from the recording medium 917 onto the RAM 902 via the media I/F 907, and executes the loaded program. The recording medium 917 includes optical recording media such as DVD (Digital Versatile Disc) and PD (Phase change rewritable Disk), magneto-optical recording media such as MO (Magneto Optical disk), magnetic recording media, conductor memory tape media, semiconductor memories, and the like. is.
例えば、コンピュータ900が第1および第2の実施形態に係るオフロードサーバ1,1Aとして機能する場合、コンピュータ900のCPU901は、RAM902上にロードされたプログラムを実行することによりオフロードサーバ1,1Aの機能を実現する。また、HDD904には、RAM902内のデータが記憶される。CPU901は、目的の処理に係るプログラムを記録媒体912から読み取って実行する。この他、CPU901は、他の装置から通信網を介して目的の処理に係るプログラムを読み込んでもよい。
For example, when the computer 900 functions as the offload servers 1 and 1A according to the first and second embodiments, the CPU 901 of the computer 900 executes the programs loaded on the RAM 902 to perform the offload servers 1 and 1A. to realize the function of Also, the data in the RAM 902 is stored in the HDD 904 . The CPU 901 reads a program related to target processing from the recording medium 912 and executes it. In addition, the CPU 901 may read a program related to target processing from another device via a communication network.
[効果]
以上説明したように、第1実施形態に係るオフロードサーバ1(図1参照)は、アプリケーションプログラムの特定処理をアクセラレータにオフロードするオフロードサーバであって、アプリケーションプログラムのソースコードを分析するアプリケーションコード分析部112と、アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行を用いたデータ転送指定を行うデータ転送指定部113と、アプリケーションプログラムのループ文を特定し、特定した各ループ文に対して、アクセラレータにおける並列処理指定文を指定してコンパイルする並列処理指定部114と、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ないループ文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する並列処理パターン作成部117と、並列処理パターンのアプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、アクセラレータにオフロードした際の性能測定用処理を実行する性能測定部118と、変換したアプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定する配置設定部170と、を備える。 [effect]
As described above, the offload server 1 (see FIG. 1) according to the first embodiment is an offload server that offloads specific processing of an application program to an accelerator. Thecode analysis unit 112 analyzes the reference relationships of variables used in the loop statements of the application program, and for data that may be transferred outside the loop, an explicit A data transfer specification unit 113 that specifies data transfer using a specified line, and a parallel processing specification that specifies loop statements of an application program and compiles each specified loop statement by specifying a parallel processing specification statement in the accelerator. Parallel processing that creates a parallel processing pattern that designates whether or not to perform parallel processing for loop statements that do not cause a compile error and excludes loop statements that cause a compile error from being offloaded. A processing pattern creation unit 117, a performance measurement unit 118 that compiles an application program for a parallel processing pattern, places it in an accelerator verification device, and executes performance measurement processing when offloaded to the accelerator, and a converted application program. is placed on a cloud server, carrier edge server, or user edge server on the network, depending on the cost or response time conditions specified by the user, device and link costs, computational resource limits, and bandwidth limits and a placement setting unit 170 that calculates and sets the placement location of the application program based on a linear programming formula with the cost of the computational resource or the response time as the objective function.
以上説明したように、第1実施形態に係るオフロードサーバ1(図1参照)は、アプリケーションプログラムの特定処理をアクセラレータにオフロードするオフロードサーバであって、アプリケーションプログラムのソースコードを分析するアプリケーションコード分析部112と、アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行を用いたデータ転送指定を行うデータ転送指定部113と、アプリケーションプログラムのループ文を特定し、特定した各ループ文に対して、アクセラレータにおける並列処理指定文を指定してコンパイルする並列処理指定部114と、コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ないループ文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する並列処理パターン作成部117と、並列処理パターンのアプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、アクセラレータにオフロードした際の性能測定用処理を実行する性能測定部118と、変換したアプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定する配置設定部170と、を備える。 [effect]
As described above, the offload server 1 (see FIG. 1) according to the first embodiment is an offload server that offloads specific processing of an application program to an accelerator. The
このようにすることにより、GPU、FPGA等のアクセラレータに自動オフロードしたアプリケーションに対して、ユーザのリクエストする価格条件や応答時間条件、アプリケーションの配置数等を変更して、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する適正配置を計算する。これにより、変換したアプリケーションを計算リソースのコストまたは応答時間の要求を満たして、ユーザ要望に従った最適配置を実現することができる。
By doing so, for applications automatically offloaded to accelerators such as GPUs and FPGAs, the price conditions and response time conditions requested by the user, the number of applications arranged, etc. can be changed, and the cloud server on the network , a carrier edge server, or a user edge server. This allows the converted application to meet computational resource cost or response time requirements to achieve optimal placement according to user requirements.
第2実施形態に係るオフロードサーバ1A(図13参照)は、アプリケーションプログラムの特定処理をPLDにオフロードするオフロードサーバであって、アプリケーションプログラムのソースコードを分析するアプリケーションコード分析部112と、アプリケーションプログラムのループ文を特定し、特定した各ループ文に対して、PLDにおけるパイプライン処理および並列処理をOpenCLで指定した複数のオフロード処理パターンにより作成してコンパイルするPLD処理指定部213と、アプリケーションプログラムのループ文の算術強度を算出する算術強度算出部214と、算術強度算出部214が算出した算術強度をもとに、算術強度が所定の閾値より高いループ文をオフロード候補として絞り込み、PLD処理パターンを作成するPLD処理パターン作成部215と、作成されたPLD処理パターンのアプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、PLDにオフロードした際の性能測定用処理を実行する性能測定部118と、変換したアプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定する配置設定部170と、を備える。
An offload server 1A (see FIG. 13) according to the second embodiment is an offload server that offloads specific processing of an application program to a PLD, and includes an application code analysis unit 112 that analyzes the source code of the application program; a PLD processing designation unit 213 that identifies loop statements of an application program, creates and compiles pipeline processing and parallel processing in PLD by a plurality of offload processing patterns designated by OpenCL for each of the identified loop statements; Based on the arithmetic intensity calculation unit 214 that calculates the arithmetic intensity of the loop statements of the application program and the arithmetic intensity calculated by the arithmetic intensity calculation unit 214, the loop statements whose arithmetic intensity is higher than a predetermined threshold are narrowed down as offload candidates, A PLD processing pattern creation unit 215 that creates a PLD processing pattern and an application program for the created PLD processing pattern are compiled, placed in an accelerator verification device, and performance measurement processing when offloaded to the PLD is executed. When arranging the performance measurement unit 118 and the converted application program to either a cloud server, a carrier edge server, or a user edge server on the network according to the cost or response time conditions specified by the user, the device and A placement setting unit 170 that calculates and sets the placement location of an application program based on a linear programming formula with link cost, computational resource upper limit, and bandwidth upper limit as constraint conditions, and with computational resource cost or response time as an objective function. And prepare.
このようにすることにより、実際に性能測定するパターンを絞ってから検証環境に配置し、コンパイルしてPLD(例えば、FPGA)実機で性能測定することで、性能測定する回数を減らすことができる。これにより、PLDへの自動オフロードにおいて、アプリケーションのループ文の自動オフロードを高速で行うことができる。そして、変換したアプリケーションに対して、ユーザのリクエストする価格条件や応答時間条件、アプリケーションの配置数等を変更して、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する適正配置を計算する。これにより、変換したアプリケーションについて、計算リソースのコストまたは応答時間の要求を満たして、ユーザ要望に従った最適配置を実現することができる。
By doing this, it is possible to reduce the number of performance measurements by narrowing down the patterns to be actually measured, placing them in the verification environment, compiling them, and measuring the performance on the actual PLD (for example, FPGA). This allows automatic offloading of application loop statements at high speed in automatic offloading to the PLD. Then, for the converted application, change the price conditions and response time conditions requested by the user, the number of applications to be deployed, etc., and deploy them to either the cloud server, carrier edge server, or user edge server on the network. Calculate proper placement. This allows the converted application to meet the computational resource cost or response time requirements to achieve optimal placement according to the user's wishes.
第1および第2実施形態に係るオフロードサーバ1,1Aにおいて、配置設定部170は、サーバにアプリケーションプログラムを配置した際に、計算リソースのコストを極小化する配置、または、応答時間を極小化する配置を計算することを特徴とする。
In the offload servers 1 and 1A according to the first and second embodiments, the placement setting unit 170 minimizes the cost of computational resources or minimizes the response time when the application program is placed on the server. It is characterized by calculating the placement of
このようにすることにより、変換したアプリケーションを計算リソースのコストまたは応答時間の要求を満たして最適に配置することができる。
By doing so, the transformed application can be optimally deployed to meet the computational resource cost or response time requirements.
第1および第2実施形態に係るオフロードサーバ1,1Aにおいて、配置設定部170は、サーバにアプリケーションプログラムを配置した際に、計算リソースのコストを極小化する配置を[数1]に示す線形計画式に従って計算することを特徴とする。
In the offload servers 1 and 1A according to the first and second embodiments, the placement setting unit 170 performs a linear It is characterized by calculating according to a planning formula.
このようにすることにより、例えば、一月いくら以内での配置が必要な要求の場合は、[数1]の式(1)の応答時間の最小化が目的関数となり、[数1]の式(2)の計算リソースのコストがいくら以内であるかが制約条件の一つとなる。よって、変換したアプリケーションを計算リソースのコストの要求を満たして最適に配置することができる。
By doing so, for example, in the case of a request that needs to be placed within a month, the minimization of the response time in expression (1) of [Equation 1] becomes the objective function, and the expression of [Equation 1] One of the constraints is how much the cost of the computational resources of (2) is within. Thus, the transformed application can be optimally placed to meet the computational resource cost requirements.
第1および第2実施形態に係るオフロードサーバ1,1Aにおいて、配置設定部170は、サーバにアプリケーションプログラムを配置した際に、応答時間を極小化する配置を[数2]に示す線形計画式に従って計算することを特徴とする。
In the offload servers 1 and 1A according to the first and second embodiments, the placement setting unit 170 uses the linear programming formula shown in [Formula 2] for the placement that minimizes the response time when the application program is placed on the server. It is characterized by calculating according to
このようにすることにより、例えば、アプリケーションの応答時間が何秒以内での配置が必要な要求の場合は、[数2]の式(5)のコストの最小化が目的関数となり、[数2]の式(6)の応答時間が何秒以内であるかが制約条件の一つとなる。よって、変換したアプリケーションをユーザの応答時間の要求を満たして最適に配置することができる。
By doing so, for example, in the case of a request that needs to be placed within seconds of the application response time, the minimization of the cost in the expression (5) of [Equation 2] becomes the objective function, and [Equation 2 One of the constraints is how many seconds the response time of expression (6) of ] is within. Thus, the converted application can be optimally placed to meet the user's response time requirements.
本発明は、コンピュータを、上記オフロードサーバとして機能させるためのオフロードプログラムとした。
The present invention is an offload program for causing a computer to function as the above offload server.
このようにすることにより、一般的なコンピュータを用いて、上記オフロードサーバ1,1Aの各機能を実現させることができる。
By doing so, each function of the offload servers 1 and 1A can be realized using a general computer.
また、上記各実施形態において説明した各処理のうち、自動的に行われるものとして説明した処理の全部又は一部を手作業で行うこともでき、あるいは、手作業で行われるものとして説明した処理の全部又は一部を公知の方法で自動的に行うこともできる。この他、上述文書中や図面中に示した処理手順、制御手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更することができる。
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部又は一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的又は物理的に分散・統合して構成することができる。 Further, among the processes described in each of the above embodiments, all or part of the processes described as being performed automatically can be performed manually, or the processes described as being performed manually can be performed manually. can also be performed automatically by a known method. In addition, information including processing procedures, control procedures, specific names, and various data and parameters shown in the above documents and drawings can be arbitrarily changed unless otherwise specified.
Also, each component of each device illustrated is functionally conceptual, and does not necessarily need to be physically configured as illustrated. In other words, the specific form of distribution and integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed and integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部又は一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的又は物理的に分散・統合して構成することができる。 Further, among the processes described in each of the above embodiments, all or part of the processes described as being performed automatically can be performed manually, or the processes described as being performed manually can be performed manually. can also be performed automatically by a known method. In addition, information including processing procedures, control procedures, specific names, and various data and parameters shown in the above documents and drawings can be arbitrarily changed unless otherwise specified.
Also, each component of each device illustrated is functionally conceptual, and does not necessarily need to be physically configured as illustrated. In other words, the specific form of distribution and integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed and integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
また、上記の各構成、機能、処理部、処理手段等は、それらの一部又は全部を、例えば集積回路で設計する等によりハードウェアで実現してもよい。また、上記の各構成、機能等は、プロセッサがそれぞれの機能を実現するプログラムを解釈し、実行するためのソフトウェアで実現してもよい。各機能を実現するプログラム、テーブル、ファイル等の情報は、メモリや、ハードディスク、SSD(Solid State Drive)等の記録装置、又は、IC(Integrated Circuit)カード、SD(Secure Digital)カード、光ディスク等の記録媒体に保持することができる。
In addition, each of the above configurations, functions, processing units, processing means, etc. may be realized in hardware, for example, by designing a part or all of them with an integrated circuit. Further, each configuration, function, etc. described above may be realized by software for a processor to interpret and execute a program for realizing each function. Information such as programs, tables, files, etc. that realize each function is stored in memory, hard disk, SSD (Solid State Drive) and other recording devices, IC (Integrated Circuit) cards, SD (Secure Digital) cards, optical discs, etc. It can be held on a recording medium.
また、本実施形態では、組合せ最適化問題を、限られた最適化期間中に解を発見できるようにするため、遺伝的アルゴリズム(GA)の手法を用いているが、最適化の手法はどのようなものでもよい。例えば、local search(局所探索法)、Dynamic Programming(動的計画法)、これらの組み合わせでもよい。
In addition, in the present embodiment, a genetic algorithm (GA) technique is used in order to find a solution to a combinatorial optimization problem within a limited optimization period. It can be something like For example, local search, dynamic programming, or a combination thereof may be used.
また、本実施形態では、C/C++向けOpenACCコンパイラを用いているが、GPU処理をオフロードできるものであればどのようなものでもよい。例えば、Java lambda(登録商標) GPU処理、IBM Java 9 SDK(登録商標)でもよい。なお、並列処理指定文は、これらの開発環境に依存する。
例えば、Java(登録商標)では、Java 8よりlambda形式での並列処理記述が可能である。IBM(登録商標)は、lambda形式の並列処理記述を、GPUにオフロードするJITコンパイラを提供している。Javaでは、これらを用いて、ループ処理をlambda形式にするか否かのチューニングをGAで行うことで、同様のオフロードが可能である。 Also, in this embodiment, the OpenACC compiler for C/C++ is used, but any compiler can be used as long as it can offload GPU processing. For example, Java lambda (registered trademark) GPU processing, IBM Java 9 SDK (registered trademark) may be used. Note that the parallel processing specification statement depends on these development environments.
For example, in Java (registered trademark), parallel processing can be described in the lambda format since Java 8. IBM (registered trademark) provides a JIT compiler that offloads lambda-style parallel processing descriptions to the GPU. In Java, similar offloading is possible by using these to perform tuning in GA as to whether or not loop processing should be in the lambda format.
例えば、Java(登録商標)では、Java 8よりlambda形式での並列処理記述が可能である。IBM(登録商標)は、lambda形式の並列処理記述を、GPUにオフロードするJITコンパイラを提供している。Javaでは、これらを用いて、ループ処理をlambda形式にするか否かのチューニングをGAで行うことで、同様のオフロードが可能である。 Also, in this embodiment, the OpenACC compiler for C/C++ is used, but any compiler can be used as long as it can offload GPU processing. For example, Java lambda (registered trademark) GPU processing, IBM Java 9 SDK (registered trademark) may be used. Note that the parallel processing specification statement depends on these development environments.
For example, in Java (registered trademark), parallel processing can be described in the lambda format since Java 8. IBM (registered trademark) provides a JIT compiler that offloads lambda-style parallel processing descriptions to the GPU. In Java, similar offloading is possible by using these to perform tuning in GA as to whether or not loop processing should be in the lambda format.
また、本実施形態では、繰り返し文(ループ文)として、for文を例示したが、for文以外のwhile文やdo-while文も含まれる。ただし、ループの継続条件等を指定するfor文がより適している。
Also, in the present embodiment, the for statement is exemplified as the iterative statement (loop statement), but the while statement and the do-while statement other than the for statement are also included. However, the for statement, which specifies loop continuation conditions, etc., is more suitable.
1,1A オフロードサーバ
11,21 制御部
12 入出力部
13 記憶部
14 検証用マシン (アクセラレータ検証用装置)
111 アプリケーションコード指定部
112 アプリケーションコード分析部
113 データ転送指定部
114 並列処理指定部
114a,213a オフロード範囲抽出部
114b,213b 中間言語ファイル出力部
115 リソース比決定部
116 リソース量設定部
117 並列処理パターン作成部
118 性能測定部
118a バイナリファイル配置部
119 実行ファイル作成部
120 本番環境配置部
121 性能測定テスト抽出実行部
122 ユーザ提供部
125 アプリケーションコード
131 テストケースDB
132 設備リソースDB
133 中間言語ファイル
151 各種デバイス
152 CPU-GPUを有する装置
153 CPU-FPGAを有する装置
154 CPUを有する装置
170 配置設定部
213 PLD処理指定部
214 算術強度算出部
215 PLD処理パターン作成部
905 アクセラレータ 1, 1A offload server 11, 21 control unit 12 input/output unit 13 storage unit 14 verification machine (accelerator verification device)
111 applicationcode specification unit 112 application code analysis unit 113 data transfer specification unit 114 parallel processing specification unit 114a, 213a offload range extraction unit 114b, 213b intermediate language file output unit 115 resource ratio determination unit 116 resource amount setting unit 117 parallel processing pattern Creation unit 118 Performance measurement unit 118a Binary file placement unit 119 Execution file creation unit 120 Production environment placement unit 121 Performance measurement test extraction execution unit 122 User provision unit 125 Application code 131 Test case DB
132 equipment resource DB
133Intermediate language file 151 Various devices 152 Device having CPU-GPU 153 Device having CPU-FPGA 154 Device having CPU 170 Placement setting unit 213 PLD processing designation unit 214 Arithmetic intensity calculation unit 215 PLD processing pattern creation unit 905 Accelerator
11,21 制御部
12 入出力部
13 記憶部
14 検証用マシン (アクセラレータ検証用装置)
111 アプリケーションコード指定部
112 アプリケーションコード分析部
113 データ転送指定部
114 並列処理指定部
114a,213a オフロード範囲抽出部
114b,213b 中間言語ファイル出力部
115 リソース比決定部
116 リソース量設定部
117 並列処理パターン作成部
118 性能測定部
118a バイナリファイル配置部
119 実行ファイル作成部
120 本番環境配置部
121 性能測定テスト抽出実行部
122 ユーザ提供部
125 アプリケーションコード
131 テストケースDB
132 設備リソースDB
133 中間言語ファイル
151 各種デバイス
152 CPU-GPUを有する装置
153 CPU-FPGAを有する装置
154 CPUを有する装置
170 配置設定部
213 PLD処理指定部
214 算術強度算出部
215 PLD処理パターン作成部
905 アクセラレータ 1,
111 application
132 equipment resource DB
133
Claims (8)
- アプリケーションプログラムの特定処理をアクセラレータにオフロードするオフロードサーバであって、
前記アプリケーションプログラムのソースコードを分析するアプリケーションコード分析部と、
前記アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行を用いたデータ転送指定を行うデータ転送指定部と、
前記アプリケーションプログラムのループ文を特定し、特定した各前記ループ文に対して、前記アクセラレータにおける並列処理指定文を指定してコンパイルする並列処理指定部と、
コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ないループ文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成する並列処理パターン作成部と、
前記並列処理パターンの前記アプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、前記アクセラレータにオフロードした際の性能測定用処理を実行する性能測定部と、
変換した前記アプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定する配置設定部と、
を備えることを特徴とするオフロードサーバ。 An offload server that offloads specific processing of an application program to an accelerator,
an application code analysis unit that analyzes the source code of the application program;
Analyzing the reference relationship of variables used in the loop statement of the application program, and using an explicit specification line that explicitly specifies data transfer outside the loop for data that may be transferred outside the loop a data transfer designation unit for designating data transfer;
a parallel processing specifying unit that specifies loop statements of the application program, specifies a parallel processing specifying statement in the accelerator for each of the specified loop statements, and compiles them;
A parallel processing pattern creation module that creates a parallel processing pattern that excludes loop statements that cause compilation errors from being offloaded, and specifies whether or not to execute parallel processing for loop statements that do not cause compilation errors. and,
a performance measurement unit that compiles the application program of the parallel processing pattern, places it in an accelerator verification device, and executes performance measurement processing when offloaded to the accelerator;
When the converted application program is placed on any of the cloud server, carrier edge server, and user edge server on the network according to the cost or response time conditions specified by the user, device and link costs, calculation a placement setting unit that calculates and sets a placement location of an application program based on a linear programming formula with resource upper limit and bandwidth upper limit as constraint conditions and with computational resource cost or response time as an objective function;
An offload server comprising: - アプリケーションプログラムの特定処理をPLD(Programmable Logic Device)にオフロードするオフロードサーバであって、
前記アプリケーションプログラムのソースコードを分析するアプリケーションコード分析部と、
前記アプリケーションプログラムのループ文を特定し、特定した各前記ループ文に対して、前記PLDにおけるパイプライン処理および並列処理をOpenCLで指定した複数のオフロード処理パターンにより作成してコンパイルするPLD処理指定部と、
前記アプリケーションプログラムのループ文の算術強度を算出する算術強度算出部と、
前記算術強度算出部が算出した算術強度をもとに、前記算術強度が所定の閾値より高いループ文をオフロード候補として絞り込み、PLD処理パターンを作成するPLD処理パターン作成部と、
作成された前記PLD処理パターンの前記アプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、前記PLDにオフロードした際の性能測定用処理を実行する性能測定部と、
変換した前記アプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定する配置設定部と、
を備えることを特徴とするオフロードサーバ。 An offload server that offloads specific processing of an application program to a PLD (Programmable Logic Device),
an application code analysis unit that analyzes the source code of the application program;
A PLD processing designation unit that identifies loop statements of the application program, and creates and compiles pipeline processing and parallel processing in the PLD by a plurality of offload processing patterns designated by OpenCL for each of the identified loop statements. and,
an arithmetic strength calculation unit that calculates the arithmetic strength of the loop statement of the application program;
a PLD processing pattern creation unit configured to create a PLD processing pattern by narrowing down, as offload candidates, loop statements whose arithmetic strength is higher than a predetermined threshold based on the arithmetic strength calculated by the arithmetic strength calculation unit;
a performance measurement unit that compiles the application program of the created PLD processing pattern, places it in an accelerator verification device, and executes performance measurement processing when offloaded to the PLD;
When the converted application program is placed on any of the cloud server, carrier edge server, and user edge server on the network according to the cost or response time conditions specified by the user, device and link costs, calculation a placement setting unit that calculates and sets a placement location of an application program based on a linear programming formula with resource upper limit and bandwidth upper limit as constraint conditions and with computational resource cost or response time as an objective function;
An offload server comprising: - 前記配置設定部は、サーバにアプリケーションプログラムを配置した際に、計算リソースのコストを極小化する配置、または、応答時間を極小化する配置を計算する
ことを特徴とする請求項1または請求項2に記載のオフロードサーバ。 3. The arrangement setting unit calculates the arrangement that minimizes the cost of computational resources or the arrangement that minimizes the response time when arranging the application programs on the server. offload server as described in . - 前記配置設定部は、サーバにアプリケーションプログラムを配置した際に、応答時間を極小化する配置を次式に示す線形計画式に従って計算する

- 前記配置設定部は、サーバにアプリケーションプログラムを配置した際に、計算リソースのコストを極小化する配置を次式に示す線形計画式に従って計算する

- アプリケーションプログラムの特定処理をアクセラレータにオフロードするオフロードサーバのオフロード制御方法であって、
前記オフロードサーバは、
前記アプリケーションプログラムのソースコードを分析するステップと、
前記アプリケーションプログラムのループ文の中で用いられる変数の参照関係を分析し、ループ外でデータ転送してよいデータについては、ループ外でのデータ転送を明示的に指定する明示的指定行を用いたデータ転送指定を行うステップと、
前記アプリケーションプログラムのループ文を特定し、特定した各前記ループ文に対して、前記アクセラレータにおける並列処理指定文を指定してコンパイルするステップと、
コンパイルエラーが出るループ文に対して、オフロード対象外とするとともに、コンパイルエラーが出ないループ文に対して、並列処理するかしないかの指定を行う並列処理パターンを作成するステップと、
前記並列処理パターンの前記アプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、前記アクセラレータにオフロードした際の性能測定用処理を実行するステップと、
変換した前記アプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定するステップと、を実行する
ことを特徴とするオフロード制御方法。 An offload control method for an offload server that offloads specific processing of an application program to an accelerator, comprising:
The offload server is
analyzing the source code of the application program;
Analyzing the reference relationship of variables used in the loop statement of the application program, and using an explicit specification line that explicitly specifies data transfer outside the loop for data that may be transferred outside the loop specifying data transfer;
a step of identifying loop statements of the application program, designating a parallel processing designation statement in the accelerator for each of the identified loop statements, and compiling the program;
a step of creating a parallel processing pattern for excluding loop statements that cause compilation errors from being offloaded and specifying whether or not to perform parallel processing for loop statements that do not cause compilation errors;
Compiling the application program of the parallel processing pattern, placing it in an accelerator verification device, and executing performance measurement processing when offloaded to the accelerator;
When the converted application program is placed on any of the cloud server, carrier edge server, and user edge server on the network according to the cost or response time conditions specified by the user, device and link costs, calculation calculating and setting the placement location of the application program based on a linear programming formula with the resource upper limit and the bandwidth upper limit as the constraint conditions, and with the computational resource cost or the response time as the objective function. off-road control method. - アプリケーションプログラムの特定処理をPLD(Programmable Logic Device)にオフロードするオフロードサーバのオフロード制御方法であって、
前記オフロードサーバは、
前記アプリケーションプログラムのソースコードを分析するステップと、
前記アプリケーションプログラムのループ文を特定し、特定した各前記ループ文に対して、前記PLDにおけるパイプライン処理および並列処理をOpenCLで指定した複数のオフロード処理パターンにより作成してコンパイルするステップと、
前記アプリケーションプログラムのループ文の算術強度を算出する算術強度算出部と、
前記算術強度算出部が算出した算術強度をもとに、前記算術強度が所定の閾値より高いループ文をオフロード候補として絞り込み、PLD処理パターンを作成するステップと、
作成された前記PLD処理パターンの前記アプリケーションプログラムをコンパイルして、アクセラレータ検証用装置に配置し、前記PLDにオフロードした際の性能測定用処理を実行するステップと、
変換した前記アプリケーションプログラムを、ユーザの指定するコストまたは応答時間の条件に応じて、ネットワーク上の、クラウドサーバ、キャリアエッジサーバ、ユーザエッジサーバのいずれかに配置する際、デバイスおよびリンクのコスト、計算リソース上限、帯域上限を制約条件とし、かつ計算リソースのコストまたは応答時間を目的関数とした線形計画式に基づいて、アプリケーションプログラムの配置場所を計算して設定するステップと、を実行する
ことを特徴とするオフロード制御方法。 An offload control method for an offload server that offloads specific processing of an application program to a PLD (Programmable Logic Device),
The offload server is
analyzing the source code of the application program;
identifying loop statements of the application program, creating and compiling pipeline processing and parallel processing in the PLD for each of the identified loop statements by a plurality of offload processing patterns specified in OpenCL;
an arithmetic strength calculation unit that calculates the arithmetic strength of the loop statement of the application program;
creating a PLD processing pattern by narrowing down loop statements whose arithmetic strength is higher than a predetermined threshold as offload candidates based on the arithmetic strength calculated by the arithmetic strength calculation unit;
Compiling the application program of the created PLD processing pattern, placing it in an accelerator verification device, and executing performance measurement processing when offloaded to the PLD;
When the converted application program is placed on any of the cloud server, carrier edge server, and user edge server on the network according to the cost or response time conditions specified by the user, device and link costs, calculation calculating and setting the placement location of the application program based on a linear programming formula with the resource upper limit and the bandwidth upper limit as the constraint conditions, and with the computational resource cost or the response time as the objective function. off-road control method. - コンピュータを、請求項1乃至請求項5のいずれか一項に記載のオフロードサーバとして機能させるためのオフロードプログラム。 An offload program for causing a computer to function as the offload server according to any one of claims 1 to 5.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023576454A JPWO2023144926A1 (en) | 2022-01-26 | 2022-01-26 | |
| PCT/JP2022/002880 WO2023144926A1 (en) | 2022-01-26 | 2022-01-26 | Offload server, offload control method, and offload program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/002880 WO2023144926A1 (en) | 2022-01-26 | 2022-01-26 | Offload server, offload control method, and offload program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023144926A1 true WO2023144926A1 (en) | 2023-08-03 |
Family
ID=87471201
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/002880 WO2023144926A1 (en) | 2022-01-26 | 2022-01-26 | Offload server, offload control method, and offload program |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2023144926A1 (en) |
| WO (1) | WO2023144926A1 (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111405569A (en) * | 2020-03-19 | 2020-07-10 | 三峡大学 | Calculation unloading and resource allocation method and device based on deep reinforcement learning |
| WO2020175411A1 (en) * | 2019-02-25 | 2020-09-03 | 日本電信電話株式会社 | Application disposition device, and application disposition program |
| WO2021156956A1 (en) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | Offload server, offload control method, and offload program |
| WO2021156955A1 (en) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | Offload server, offload control method, and offload program |
-
2022
- 2022-01-26 JP JP2023576454A patent/JPWO2023144926A1/ja active Pending
- 2022-01-26 WO PCT/JP2022/002880 patent/WO2023144926A1/en unknown
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020175411A1 (en) * | 2019-02-25 | 2020-09-03 | 日本電信電話株式会社 | Application disposition device, and application disposition program |
| WO2021156956A1 (en) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | Offload server, offload control method, and offload program |
| WO2021156955A1 (en) * | 2020-02-04 | 2021-08-12 | 日本電信電話株式会社 | Offload server, offload control method, and offload program |
| CN111405569A (en) * | 2020-03-19 | 2020-07-10 | 三峡大学 | Calculation unloading and resource allocation method and device based on deep reinforcement learning |
Non-Patent Citations (1)
| Title |
|---|
| YAMATO YOJI: "Initial study of environment-adaptive application placement optimization ", ENGRXIV ARCHIVE, 11 July 2021 (2021-07-11), pages 1, XP093081816, DOI: 10.31224/osf.io/vdn8z * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2023144926A1 (en) | 2023-08-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7063289B2 (en) | Optimal software placement method and program for offload servers | |
| Pérez et al. | Simplifying programming and load balancing of data parallel applications on heterogeneous systems | |
| JP6927424B2 (en) | Offload server and offload program | |
| JP7322978B2 (en) | Offload server, offload control method and offload program | |
| JP6992911B2 (en) | Offload server and offload program | |
| Angelelli et al. | Towards a multi-objective scheduling policy for serverless-based edge-cloud continuum | |
| Yamato | Proposal and evaluation of GPU offloading parts reconfiguration during applications operations for environment adaptation | |
| Boiński et al. | Optimization of data assignment for parallel processing in a hybrid heterogeneous environment using integer linear programming | |
| WO2023144926A1 (en) | Offload server, offload control method, and offload program | |
| WO2022102071A1 (en) | Offload server, offload control method, and offload program | |
| US12033235B2 (en) | Offload server, offload control method, and offload program | |
| US12056475B2 (en) | Offload server, offload control method, and offload program | |
| US20220222177A1 (en) | Systems, apparatus, articles of manufacture, and methods for improved data transfer for heterogeneous programs | |
| JP7521597B2 (en) | OFFLOAD SERVER, OFFLOAD CONTROL METHOD, AND OFFLOAD PROGRAM | |
| WO2023228369A1 (en) | Offload server, offload control method, and offload program | |
| WO2023002546A1 (en) | Offload server, offload control method, and offload program | |
| US11947975B2 (en) | Offload server, offload control method, and offload program | |
| WO2024147197A1 (en) | Offload server, offload control method, and offload program | |
| JP7184180B2 (en) | offload server and offload program | |
| WO2024079886A1 (en) | Offload server, offload control method, and offload program | |
| JP7473003B2 (en) | OFFLOAD SERVER, OFFLOAD CONTROL METHOD, AND OFFLOAD PROGRAM | |
| Zaki | Scalable techniques for scheduling and mapping DSP applications onto embedded multicore platforms |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22923794 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2023576454 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |