WO2023008173A1 - 探索方法、探索システム、プログラム、予測モデル構築方法、及び予測モデル構築装置 - Google Patents
探索方法、探索システム、プログラム、予測モデル構築方法、及び予測モデル構築装置 Download PDFInfo
- Publication number
- WO2023008173A1 WO2023008173A1 PCT/JP2022/027344 JP2022027344W WO2023008173A1 WO 2023008173 A1 WO2023008173 A1 WO 2023008173A1 JP 2022027344 W JP2022027344 W JP 2022027344W WO 2023008173 A1 WO2023008173 A1 WO 2023008173A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- energy
- initial
- atomic arrangement
- structures
- prediction model
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 75
- 238000010276 construction Methods 0.000 title claims description 12
- 238000005457 optimization Methods 0.000 claims abstract description 93
- 239000000463 material Substances 0.000 claims abstract description 81
- 239000000203 mixture Substances 0.000 claims abstract description 70
- 238000003795 desorption Methods 0.000 claims abstract description 36
- 238000004364 calculation method Methods 0.000 claims description 84
- 238000010801 machine learning Methods 0.000 claims description 25
- 230000001747 exhibiting effect Effects 0.000 claims 2
- 125000004429 atom Chemical group 0.000 description 108
- 238000010586 diagram Methods 0.000 description 42
- 238000012795 verification Methods 0.000 description 33
- 230000008569 process Effects 0.000 description 28
- 239000000126 substance Substances 0.000 description 20
- 238000013528 artificial neural network Methods 0.000 description 16
- 238000004590 computer program Methods 0.000 description 14
- 238000012545 processing Methods 0.000 description 13
- PXHVJJICTQNCMI-UHFFFAOYSA-N nickel Substances [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 10
- 239000011572 manganese Substances 0.000 description 9
- 229910052744 lithium Inorganic materials 0.000 description 7
- 230000002093 peripheral effect Effects 0.000 description 7
- 239000000470 constituent Substances 0.000 description 6
- 239000000284 extract Substances 0.000 description 6
- 239000013078 crystal Substances 0.000 description 5
- 239000007774 positive electrode material Substances 0.000 description 5
- HBBGRARXTFLTSG-UHFFFAOYSA-N Lithium ion Chemical compound [Li+] HBBGRARXTFLTSG-UHFFFAOYSA-N 0.000 description 4
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical group [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 229910001416 lithium ion Inorganic materials 0.000 description 4
- 125000004430 oxygen atom Chemical group O* 0.000 description 4
- 238000004891 communication Methods 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 239000004065 semiconductor Substances 0.000 description 3
- 238000012549 training Methods 0.000 description 3
- 238000003775 Density Functional Theory Methods 0.000 description 2
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical group [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 239000007773 negative electrode material Substances 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 230000008707 rearrangement Effects 0.000 description 2
- 238000004088 simulation Methods 0.000 description 2
- PWHULOQIROXLJO-UHFFFAOYSA-N Manganese Chemical group [Mn] PWHULOQIROXLJO-UHFFFAOYSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000013527 convolutional neural network Methods 0.000 description 1
- 239000003792 electrolyte Substances 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000004880 explosion Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 238000005381 potential energy Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 239000013077 target material Substances 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
Images























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/70—Machine learning, data mining or chemometrics
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/30—Prediction of properties of chemical compounds, compositions or mixtures
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C60/00—Computational materials science, i.e. ICT specially adapted for investigating the physical or chemical properties of materials or phenomena associated with their design, synthesis, processing, characterisation or utilisation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/042—Knowledge-based neural networks; Logical representations of neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
Definitions
- the present disclosure relates to a search method and the like for searching for a stable structure of atomic arrangement for the composition of a material after desorption of atoms.
- Non-Patent Document 1 Conventionally, structural optimization techniques have been developed to obtain stable atomic arrangement structures by first-principles calculations (see, for example, Non-Patent Document 1).
- Non-Patent Document 2 discloses a method of estimating characteristic values such as energy using machine learning for input of atomic arrangement structure.
- the present disclosure provides a search method and the like that can efficiently search for a stable structure of atomic arrangement for the composition of a material after desorption of atoms.
- a search method is a search method for searching for a stable structure of atomic arrangement in a three-dimensional space for the composition of a material, wherein a computer desorbs atoms contained in the material to a first step of obtaining a plurality of initial structures, which are structures of atomic arrangements in the three-dimensional space that the composition of the material after separation can take; A second step of performing optimization and calculating a first energy corresponding to a structure with an optimized atomic arrangement, and using a prediction model for other initial structures of the plurality of initial structures, A third step of predicting a second energy corresponding to the structure of the atomic arrangement when the structure optimization is performed on the other initial structure, and a local minimum value based on the first energy and the second energy and a fourth step of extracting a third energy indicating the third energy, a first structure that is a structure of an atomic arrangement corresponding to the third energy, or a third energy and the first structure that are output 5 steps are executed, and the prediction model inputs a structure with
- Computer-readable recording media include non-volatile recording media such as CD-ROMs (Compact Disc-Read Only Memory).
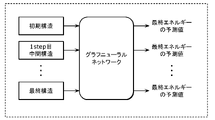
- FIG. 1 is a block diagram showing an overall configuration including a search system according to Embodiment 1.
- FIG. 2 is a diagram illustrating an example of an input structure input to an input unit according to Embodiment 1.
- FIG. 3 is a diagram illustrating an example of a process in which a generation unit according to Embodiment 1 generates an initial structure;
- FIG. 4 is a diagram illustrating an example of a process of generating an initial structure by a generation unit according to Embodiment 1.
- FIG. 5 is a diagram illustrating an example of a process of generating an initial structure by a generation unit according to Embodiment 1.
- FIG. 6 is a diagram depicting an example of data stored in a structure storage unit according to Embodiment 1;
- FIG. 1 is a block diagram showing an overall configuration including a search system according to Embodiment 1.
- FIG. 2 is a diagram illustrating an example of an input structure input to an input unit according to Embodiment 1.
- FIG. 3 is a diagram
- FIG. 7 is a diagram illustrating an example of a process of calculating first energy by a calculating unit according to Embodiment 1.
- FIG. 8 is a diagram showing an example of data stored in a calculation result storage unit according to Embodiment 1.
- FIG. 9 is a diagram illustrating an example of a process of machine learning a prediction model by a learning unit according to Embodiment 1.
- FIG. 10 is a diagram illustrating an example of a process of predicting the second energy by the prediction unit according to Embodiment 1.
- FIG. 11 is a diagram illustrating an example of data generated by a comparing unit according to Embodiment 1;
- FIG. 12 is a diagram illustrating an evaluation example of prediction accuracy of a prediction unit according to Embodiment 1.
- FIG. 13 is a diagram showing a result of verification of prediction accuracy of the prediction unit according to Embodiment 1.
- FIG. 14 is a diagram showing a result of verifying the correlation between the prediction accuracy of the prediction unit and the learning data ratio according to Embodiment 1.
- FIG. 15 is a flowchart showing an operation example of the search system according to Embodiment 1.
- FIG. 16 is a block diagram showing an overall configuration including a search system according to Embodiment 2.
- FIG. 17 is a diagram depicting an example of data stored in a calculation result storage unit according to Embodiment 2;
- FIG. 18 is a diagram illustrating an example of a process of machine-learning a prediction model by a learning unit according to Embodiment 2.
- FIG. 19 is a diagram showing a result of verifying the prediction accuracy of the prediction unit according to Embodiment 2.
- FIG. FIG. 20 is a diagram showing the result of verifying the correlation between the prediction accuracy of the prediction unit and the learning data set ratio according to the second embodiment.
- 21 is a flowchart illustrating an operation example of the search system according to Embodiment 2.
- FIG. 22 is a block diagram showing an overall configuration including a search system according to Embodiment 3.
- FIG. 23 is a diagram depicting an example of data generated by a comparison unit according to Embodiment 3;
- FIG. 24 is a flowchart showing an operation example of the search system according to Embodiment 3.
- FIG. 25 is a block diagram showing an overall configuration including a search system according to Embodiment 4.
- FIG. 26 is a flowchart showing an operation example of the search system according to Embodiment 4.
- Non-Patent Document 1 discloses a structure optimization method based on first-principles calculation.
- a lithium ion battery has a positive electrode active material and a negative electrode active material, and is charged or discharged by moving lithium ions between them.
- lithium ions contained in the positive electrode active material are desorbed, and the desorbed lithium ions move to the negative electrode active material.
- the charging process can be simulated by modeling the atomic arrangement structure of the positive electrode active material and considering a stable atomic arrangement structure in a state where Li (lithium) atoms are sequentially desorbed one by one. .
- the electrode voltage can be calculated from the calculated value of the energy of the stable atomic configuration after the Li atoms are desorbed. Further, by calculating the energy difference from the stable atomic arrangement structure of the substance from which the O (oxygen) atom is detached, the oxygen desorption energy indicating the likelihood of detachment of the O atom can be calculated.
- O atoms are detached from the positive electrode active material, they may bond with the electrolyte and cause an exothermic reaction, so the oxygen desorption energy is an indicator of battery safety.
- the electrical characteristics and safety of the battery can be calculated from the stable atomic arrangement structure after desorption of the elements contained in the substance of the battery.
- the substance before the Li atoms are desorbed is a known substance
- the substance after the Li atoms are desorbed is an unknown new substance.
- structural optimization is performed for the possible candidate atomic arrangement structure of the new substance.
- Candidate atomic configurations are obtained by partially removing atoms contained in the atomic configurations of known substances, here Li atoms. Therefore, a plurality of candidate structures can be obtained depending on which Li atoms are removed.
- one or more structural optimizations are performed for each of the plurality of candidate structures, and the energy of the structurally optimized candidate structure, that is, the total energy is calculated.
- the atomic arrangement structure corresponding to the lowest energy among the calculated energies, that is, the structure-optimized candidate structure is determined to be the thermodynamically most stable atomic arrangement structure in the new substance.
- Non-Patent Document 2 describes a graph neural network model that converts atoms into nodes and bonds into edges in the atomic arrangement structure of the material composition, and predicts characteristic values such as energy from the atomic arrangement structure. Proposed. It has been shown that this method can construct a model that predicts material properties such as energy with high accuracy from the atomic arrangement structure included in the public database.
- Non-Patent Document 1 is a prior art document that discloses the basic technology of structural optimization, and does not disclose learning of a prediction model by machine learning.
- Non-Patent Document 2 merely discloses a technique for predicting material properties from an atomic arrangement structure, and does not disclose a search for a stable atomic arrangement structure.
- the inventors of the present application focused on the fact that the relationship between atomic arrangement structure and energy can be associated with a graph neural network. According to the study of the inventors of the present application, from the atomic arrangement structures that are candidates for the composition of the material after the desorption of the atoms present in a plurality of ways, the atomic arrangement structure that is thermodynamically more stable than the conventional We have found a technique that can efficiently search for As a result, it has become clear that the calculation cost can be reduced, and a stable atomic configuration can be searched with high accuracy.
- a search method is a search method for searching for a stable structure of atomic arrangement in a three-dimensional space for the composition of a material, wherein a computer performs desorption of atoms contained in the material.
- the material contains x atoms (x is an integer of 2 or more) that can be desorbed, and in the first step, z atoms (z is 1 ⁇ z ⁇ x-1) (integer), a plurality of x C z initial structures may be generated for the desorbed system.
- the partial initial structures in the second step are m (m is 1 ⁇ m ⁇ n integer), and the other initial structures in the third step may be (n ⁇ m) initial structures.
- the third energy may be the minimum value of the first energy and the second energy.
- the prediction model may be a model machine-learned using a first learning data set that includes the initial structure as input data and the first energy corresponding to the initial structure as correct data.
- the prediction model is a model machine-learned using a second learning data set that further includes the structure of the optimized atomic arrangement as input data and the first energy corresponding to the structure as correct data. There may be.
- the number of the partial initial structures in the second step may be 90% or less of the number of the plurality of initial structures.
- a search system is a search system for searching for a stable structure of atomic arrangement in a three-dimensional space for the composition of a material, wherein after desorption by desorption of atoms contained in the material
- a generation unit that generates a plurality of initial structures, which are structures of atomic arrangements in the three-dimensional space that the material composition can take, and a structure optimization is performed on some of the plurality of initial structures.
- a calculation unit that calculates a first energy corresponding to a structure of an atomic arrangement whose structure has been optimized;
- a prediction unit that predicts a second energy corresponding to the structure of the atomic arrangement when structural optimization is performed for the prediction model, and an output unit that outputs the first energy and the second energy, and the prediction model is machine-learned so that a structure with an arbitrary atomic arrangement is input, and the energy corresponding to the structure when structural optimization is performed on the structure is output as the second energy.
- the output unit is a third energy indicating a minimum value extracted based on the first energy and the second energy, a first structure that is a structure of an atomic arrangement corresponding to the third energy, or the first 3 energies and the first structure may be output.
- a program is a program for searching for a stable structure of atomic arrangement in a three-dimensional space for the composition of a material, wherein the material after desorption by desorption of atoms contained in the material
- the predictive model is machine-learned so that a structure with an arbitrary atomic arrangement is input, and the energy corresponding to the structure when structural optimization is performed on the structure is output as the second energy.
- the computer further executes a fourth step of extracting a third energy indicating a minimum value based on the first energy and the second energy, and in the sixth step, the third energy, the third
- the first structure which is the structure of the atomic arrangement corresponding to the energy, or the third energy and the first structure may be further output.
- a computer obtains an initial structure, which is an atomic arrangement structure in a three-dimensional space that can be taken by a composition of a material after desorption by desorption of atoms contained in the material.
- a predictive model construction device includes a generation unit that generates an initial structure, which is an atomic arrangement structure in a three-dimensional space that can be taken by a composition of a material after desorption by desorption of atoms contained in the material; , using a learning data set containing the initial structure as input data and the energy corresponding to the structure of the atomic arrangement obtained by performing structural optimization on the initial structure as correct data, any atomic arrangement a learning unit that performs machine learning so as to output energy corresponding to the structure when the structure is structurally optimized with respect to the input of the structure.
- a search method is a search for searching for a stable structure of atomic arrangement in the three-dimensional space for the composition of the material using a prediction model machine-learned by the prediction model construction device.
- a method wherein a computer performs geometry optimization on the initial structures by first obtaining a plurality of the initial structures and using the predictive model for each of the plurality of initial structures.
- the eighth step of predicting the energy corresponding to the structure of the atomic arrangement in the case of and the ninth step of extracting the energy indicating the minimum value from the plurality of predicted energies are executed.
- a search method is a search for searching for a stable structure of atomic arrangement in the three-dimensional space for the composition of the material using a prediction model machine-learned by the prediction model construction device.
- a method wherein a computer performs a first step of obtaining a plurality of said initial structures, performing structure optimization on some initial structures of said plurality of initial structures, and obtaining structure-optimized atoms a second step of calculating a first energy corresponding to a configuration structure; and using the prediction model for at least one initial structure among the partial initial structures to perform structural optimization for the initial structure a tenth step of predicting the second energy corresponding to the structure of the atomic configuration if the transformation were performed; and an eleventh step of verifying prediction accuracy of the prediction model by comparing the first energy and the second energy.
- the computer uses the predictive model for the other initial structure among the plurality of initial structures, thereby for the other initial structure.
- a twelfth step of predicting the second energy corresponding to the structure of the atomic arrangement when the structure optimization is performed, and extracting the third energy indicating the minimum value based on the first energy and the second energy. and a thirteenth step may be further performed.
- Such a computer program can also be realized as a computer program that causes a computer to execute the characteristic processing included in the search method or predictive model construction method of the present disclosure.
- a computer program can be distributed via a computer-readable non-temporary recording medium such as a CD-ROM or a communication network such as the Internet.
- the search system may be configured such that all components are included in one computer, or may be configured as a system in which multiple components are distributed to multiple computers. .
- Search system 100 (search method or program) according to Embodiment 1 of the present disclosure will be described in detail using the drawings.
- Search system 100 (search method or program) according to Embodiment 1 is a system (method or program) for searching for a stable structure of atomic arrangement in three-dimensional space for the composition of a material.
- stable structure refers to a structure in which the force acting on each atom contained in the structure of the atomic arrangement (that is, the crystal structure) is below the threshold, and the energy corresponding to the structure (total energy) is the minimum.
- the threshold can be appropriately set by the user, but may be a value close to zero. This is because the closer the force acting on each atom to zero, the more thermodynamically stable the structure.
- the search system 100 searches for a stable structure as described above and outputs it to the user. It may include a mode of outputting data necessary for performing. In other words, the process of searching for stable structures need not be completed only by the search system 100 (search method or program).
- FIG. 1 is a block diagram showing the overall configuration including a search system 100 according to Embodiment 1.
- the search system 100 is configured as a computer such as a personal computer or a server, for example.
- the search system 100 includes a generator 102 , a calculator 103 , a learner 104 , a predictor 105 , a comparator 106 and an output unit 107 .
- Peripheral configurations of the search system 100 include an input unit 101 , a structure storage unit 108 , a calculation result storage unit 109 , and a prediction model storage unit 110 .
- the peripheral configuration of the search system 100 may be included in the components of the search system 100 .
- the generation unit 102 and the learning unit 104 in the search system 100 are also components of a prediction model construction device.
- the input unit 101 is an input interface that receives a user's input, acquires information about the composition of the material to be searched by user's input, and outputs the information to the generation unit 102 .
- the information about the composition is, for example, the structure of the atomic arrangement in the three-dimensional space of the composition of the material to be searched. Hereinafter, this structure will also be referred to as an "input structure".
- the input unit 101 includes, for example, a keyboard, touch sensor, touch pad, mouse, or the like.
- FIG. 2 is a diagram showing an example of an input structure input to the input unit 101 according to the first embodiment.
- the composition possessed by the material to be searched can be represented by the composition formula as "Li 12 Mn 6 Ni 6 O 24 ". That is, in this case, the composition of the material to be searched is composed of 12 Li (lithium) atoms, 6 Mn (manganese) atoms, 6 Ni (nickel) atoms, and 24 O (oxygen) atoms. indicates that
- the input structure includes, for example, information described in the Crystallographic Information Common Data Format (Crystallographic Information File: CIF).
- CIF Crystallographic Information Common Data Format
- the description format of the information is not limited to the CIF data format, and any description format that enables structural optimization calculations by first-principles calculations such as the composition formula, crystal structure, and lattice vector can be used. can be written in any format.
- the CIF describes the composition formula indicating the composition of the material, the length of the unit cell vector, the angle at which atoms intersect, the arrangement of atoms in the unit cell, and the like.
- FIG. 2(a) shows the atomic arrangement for the composition of the material "Li 12 Mn 6 Ni 6 O 24 ".
- the atomic coordinates (x-coordinate, y-coordinate, z-coordinate) of each atom for example, in the case of Li atoms, a total of 12 atoms from "Li0" to [Li11]) are described. Note that the numbers such as "0" in "Li0" are added only to distinguish elements of the same type.
- the input structure includes, for example, the unit cell of the crystal structure, that is, the atomic arrangement.
- the smallest spheres are O atoms
- the unhatched spheres are Li atoms
- the hatched spheres that are about the same size as the Li atoms are Ni atoms
- the spheres are blacked out.
- the closed spheres represent Mn atoms.
- the generation unit 102 removes atoms from the input structure obtained from the input unit 101, that is, performs atom detachment processing, thereby generating a plurality of initial structures that can be taken by the structure after detachment.
- atoms are removed from the input structure by deleting lines describing the atoms to be removed from the CIF.
- the atoms to be eliminated are Li atoms. That is, the generation unit 102 (in the first step) acquires a plurality of initial structures, which are structures of atomic arrangements in a three-dimensional space that can be taken by the composition of the material after desorption by desorption of atoms contained in the material.
- the “initial structure” referred to here is the composition after one or more atoms are desorbed from the composition of the material to be searched, and is a candidate structure that can become a stable structure of atomic arrangement.
- FIG. 3 to 5 are diagrams each showing an example of the process of generating an initial structure by the generation unit 102 according to Embodiment 1.
- FIG. (a) of FIG. 3 represents the CIF of the input structure
- (b) of FIG. 3 represents the CIF of the structure after one Li atom is eliminated from the input structure
- (c) of FIG. represents the CIF of the structure after two Li atoms are eliminated from the input structure.
- the generation unit 102 generates an initial structure in the case where one Li atom is eliminated by removing "Li4" from the input structure.
- the generation unit 102 generates an initial structure when two Li atoms are desorbed by removing “Li2” and “Li6” from the input structure.
- FIG. 4 shows an example of the initial structure when two Li atoms are eliminated from the input structure.
- the initial structure shown in (a) of FIG. 4 is a structure generated by the generation unit 102 removing “Li2” and “Li6” from the input structure.
- the initial structure shown in (b) of FIG. 4 is a structure generated by the generation unit 102 removing “Li5” and “Li6” from the input structure.
- the initial structure shown in (c) of FIG. 4 is a structure generated by the generation unit 102 removing “Li0” and “Li4” from the input structure.
- the generation unit 102 generates a plurality of initial structures according to the number of Li atoms desorbed from the input structure.
- the leftmost configuration in FIG. 5 represents an example of the initial structure when one Li atom is eliminated from the input structure.
- Generate 12 C 1 12 initial structures, which is the number of combinations that leave one Li atom from .
- the second configuration from the left in FIG. 5 represents an example of the initial structure when two Li atoms are eliminated from the input structure.
- 12 C 2 66 initial structures are generated, which is the number of combinations in which two Li atoms are eliminated from a Li atom.
- the rightmost configuration in FIG. 5 represents an example of the initial structure when eight Li atoms are eliminated from the input structure.
- produces 12 C 8 495 initial structures, the number of combinations that leave 8 Li atoms from .
- a structure corresponding to the formula of the material to be searched includes x atoms represented by the same element symbol, and z atoms can be detached from the x atoms.
- x is an integer of 2 or more
- z is an integer satisfying 1 ⁇ z ⁇ x ⁇ 1.
- the generation unit 102 (at the first step) generates a plurality of x C z initial structures for a system in which z atoms are eliminated. That is, the number of initial structures generated by the generation unit 102 is ( 12 C 1 + . . . + 12 C z ).
- the generator 102 generates a plurality of initial structures for each system.
- the term "system” refers to a set of structures classified by the number of atoms detached from the input structure.
- the generator 102 generates a plurality of initial structures for each (x ⁇ 1) systems.
- the above contents are exemplified below.
- x is an integer of 2 or more
- z is an integer satisfying 1 ⁇ z ⁇ 11.
- the generation unit 102 (in the first step) generates an initial structure of 12 C for a system in which one Li atom has been removed , . Generate structure.
- the number of initial structures generated by the generation unit 102 is ( 12 C 1 + . . . + 12 C 11 ).
- the number of systems is 11.
- the generation unit 102 outputs a plurality of initial structures generated for each system to the structure storage unit 108.
- all the generated initial structures may be output to the structure storage unit 108, or equivalent structures from the viewpoint of symmetry are screened using an existing program or the like, Only the filtered initial structure may be output.
- the structure storage unit 108 is composed of a recording medium such as a hard disk drive or a non-volatile semiconductor memory.
- Structure storage unit 108 stores a plurality of initial structures generated for each system by generation unit 102 .
- the data of each initial structure is stored in a descriptive format such as a composition formula, a crystal structure, and a lattice vector, in which structure optimization calculations such as first-principles calculations can be performed.
- FIG. 6 is a diagram showing an example of data stored in the structure storage unit 108 according to the first embodiment.
- the left column represents the initial structure ID (Identifier) assigned to distinguish each initial structure
- the right column represents the atomic arrangement of the initial structure.
- FIG. 7 is a diagram showing an example of a process of calculating the first energy by calculation section 103 according to Embodiment 1. In FIG.
- the calculation unit 103 (in the second step) performs structure optimization on a part of the initial structures among the plurality of initial structures, and the first energy corresponding to the structure with the optimized atomic arrangement Calculate
- the "first energy” here may indicate the energy corresponding to the final structure obtained by repeating the structure optimization, or may indicate the energy corresponding to the intermediate structure that has not yet reached the final structure. be.
- the calculation unit 103 uses a first-principles calculation package such as VASP (Vienna Abinitio Simulation Package), for example, to execute the process of calculating the first energy corresponding to the structural optimization and the final structure.
- VASP Vehicle Abinitio Simulation Package
- the "final structure” is a structure obtained by performing structural optimization on the initial structure, and is a structure in which the force acting on each atom contained in the structure is equal to or less than the threshold.
- the “intermediate structure” is a structure obtained by performing structure optimization on the initial structure, and the force acting on at least one or more atoms contained in the structure exceeds the threshold value. It is a structure that has not reached the final structure.
- the calculation unit 103 calculates the force F acting on each atom included in the structure to be processed, and the structure (that is, the final structure) in which the magnitude of the force F calculated in each atom is equal to or less than the threshold value. to explore.
- the threshold may be a value close to zero. Specifically, if the magnitude of the force F acting on at least one atom exceeds a threshold in the structure obtained by performing the structure optimization, the calculation unit 103 determines that the force F is applied. Each atom is moved in a direction and the position of each atom is adjusted so that the force F becomes small.
- the calculation unit 103 repeats the above-described process of calculating the force F of each atom and the process of adjusting the position of each atom as one structural optimization, and the magnitude of the force F is equal to or less than the threshold value for all atoms.
- a structure that is, the final structure
- the structure optimization is terminated.
- the calculation unit 103 calculates the energy corresponding to the obtained final structure, that is, the final energy.
- the calculation unit 103 outputs the initial structure, the final structure obtained by repeatedly performing structural optimization on the initial structure, and the final energy corresponding to the calculated final structure to the calculation result storage unit 109 for each system. do.
- the calculation result storage unit 109 stores a set of the final energy calculated by the calculation unit 103 and the corresponding initial structure for each system.
- FIG. 8 is a diagram showing an example of data stored in the calculation result storage unit 109 according to Embodiment 1. As shown in FIG. In FIG. 8, the left column is the initial structure ID, the middle column is the atomic arrangement of the initial structure, and the right column is the final energy corresponding to the final structure obtained by optimizing the initial structure. represents. Thus, the calculation result storage unit 109 may store at least a set of the initial structure and the final energy of the final structure. In Embodiment 1, the calculation result storage unit 109 further stores the atomic arrangement of the final structure.
- the learning unit 104 acquires the initial structure and the final energy of the final structure from the calculation result storage unit 109, and makes the prediction model learn using the acquired initial structure and final energy.
- the set of input and output learned by the prediction model is, for example, the input as the initial structure and the output as the final energy.
- the learning unit 104 uses the learning data set to generate a structure obtained by optimizing the structure (here, the initial structure) with respect to the input structure of an arbitrary atomic arrangement.
- Machine learning is performed on the prediction model so as to output the energy corresponding to (here, the final structure).
- the learning data set includes the initial structure as input data and the energy corresponding to the atomic arrangement structure (here, the final structure) obtained by performing structural optimization on the initial structure as correct data.
- the prediction model is composed of a graph neural network with graph structure as input.
- the graph neural network is, for example, CGCNN (Crystal Graph Convolutional Neural Network) or MEGNet (Material Graph Network).
- the prediction model is constructed by MEGNet.
- MEGNet is a graph neural network that uses not only nodes (nodes/vertices) and edges (branches/sides) as feature quantities, but also global state quantities that represent the features of the entire target system as feature quantities.
- FIG. 9 is a diagram showing an example of a process of machine learning a prediction model by the learning unit 104 according to Embodiment 1.
- the learning unit 104 first converts the atomic coordinates and types of atoms in the initial structure as shown in FIG. 9A into a graph structure as shown in FIG. 9B.
- a node corresponds to each atom of the initial structure and an edge corresponds to a bond between each atom of the initial structure.
- the learning unit 104 inputs the converted graph structure to a graph neural network as shown in FIG. 9(c).
- the learning unit 104 compares the predicted value of the final energy shown in (d) of FIG. 9 output from the graph neural network and the final energy as correct data.
- the learning unit 104 updates the weight of the graph neural network. In this way, the learning unit 104 machine-learns the prediction model by supervised learning using a plurality of learning data sets.
- the learning unit 104 outputs a prediction model for which machine learning has been completed, that is, a learned model to the prediction unit 105 and the prediction model storage unit 110 .
- the prediction model for which this machine learning has been completed takes as input a structure with an arbitrary atomic arrangement (here, the initial structure), and the structure (here, the final structure) when the structure is optimized for the structure. Machine learning is performed so that the corresponding energy is output as second energy, which will be described later.
- This prediction model is machine-learned using a first learning data set that includes an initial structure as input data and a first energy (here, final energy) corresponding to the initial structure as correct data.
- the prediction model storage unit 110 stores the graph neural network structure and weights of the prediction model machine-learned by the learning unit 104 .
- the prediction unit 105 acquires an initial structure whose final energy has not yet been calculated from the structure storage unit 108 . Then, the prediction unit 105 predicts the final energy of the initial structure by inputting the initial structure into the prediction model acquired from the learning unit 104, that is, the learned prediction model.
- the “initial structure whose final energy has not been calculated” means a structure other than a part of the initial structure whose energy has been calculated by the calculation unit 103 among the plurality of initial structures, and other initial structures.
- the prediction unit 105 uses the prediction model for other initial structures among the plurality of initial structures, so as to obtain Predict the second energy corresponding to the structure of the atomic arrangement.
- the second energy is the predicted value of the final energy corresponding to the final structure when geometry optimization is performed on other initial structures.
- FIG. 10 is a diagram showing an example of the process of predicting the second energy by the prediction unit 105 according to Embodiment 1.
- the prediction unit 105 converts the initial structure into a graph structure, and inputs the converted initial structure to the prediction model.
- illustration of the process of converting the initial structure to the graph structure is omitted.
- the predictive model outputs a predicted value of the final energy corresponding to the final structure when structural optimization is performed on the input initial structure, that is, the second energy.
- the prediction model as disclosed in Non-Patent Document 2 outputs a prediction value of the energy corresponding to the input initial structure
- the prediction model according to Embodiment 1 outputs the input initial structure
- the predicted value of the energy output by the prediction model corresponds to the energy corresponding to the structure obtained by the calculation unit 103 actually performing structural optimization on the initial structure. do.
- Embodiment 1 by using a prediction model, a structure optimized for a structure (for example, an intermediate structure or It is possible to obtain the energy corresponding to the final structure). Therefore, in Embodiment 1, calculations for structural optimization can be omitted to some extent, so that calculation costs can be reduced.
- the prediction unit 105 outputs the initial structure and the final energy prediction value corresponding to the initial structure to the comparison unit 106 for each system.
- the comparison unit 106 obtains a set of predicted values of the initial structure and final energy from the prediction unit 105 .
- the comparison unit 106 acquires a set of final structure and final energy from the calculation result storage unit 109 . Then, the comparison unit 106 generates a list in which the set of the initial structure and the predicted value of the final energy and the set of the final structure and the final energy are arranged.
- FIG. 11 is a diagram showing an example of data generated by the comparison unit 106 according to Embodiment 1.
- the left column represents the atomic arrangement of the initial structure or the final structure
- the middle column represents the final energy corresponding to the final structure
- the right column represents the predicted value of the final energy corresponding to the initial structure.
- the comparison unit 106 rearranges the final energies and the predicted values of the final energies in a predetermined order.
- comparison section 106 rearranges the final energy and the predicted value of final energy in order from the lowest energy value.
- Such rearrangement of the final energies and the predicted values of the final energies corresponds to the process of extracting the smallest value, in other words, the minimum value or the minimum value, from the final energies and the predicted values of the final energies.
- the comparison unit 106 extracts the third energy indicating the minimum value based on the first energy and the second energy.
- the first energy is the final energy obtained from the calculation result storage unit 109
- the second energy is the predicted value of the final energy obtained from the prediction unit 105 .
- the minimum value is the minimum value of the first energy and the second energy.
- the third energy is the minimum value of the first energy and the second energy.
- the comparison unit 106 outputs a list in which the final energy and the predicted value of the final energy are rearranged as described above to the output unit 107 for each system.
- the output unit 107 displays the predicted values of the initial structures and final energies, and the final structures and final energies included in the list output by the comparison unit 106, according to the above-described predetermined order, that is, in order from the structure with the lowest energy to the display. indicate. That is, the output unit 107 (in the fifth step) outputs the third energy, the first structure, which is the structure of the atomic arrangement corresponding to the third energy, or the third energy and the first structure.
- the output unit 107 may display only the third energy and the atomic arrangement structure corresponding to the third energy on the display.
- the output unit 107 may display the list before the final energy and the predicted value of the final energy are rearranged by the comparison unit 106 on the display. That is, the output unit 107 (in the sixth step) may output the first energy and the second energy. In this case, the above extraction processing (fourth step) by the comparison unit 106 is unnecessary.
- the output unit 107 displays the above-mentioned output results on the display in a manner in which each system can be distinguished. The display on the display may be performed sequentially for each system, or may be performed collectively for all systems.
- Embodiment 1 Verification of prediction accuracy
- Verification of the prediction accuracy of the prediction unit 105 according to Embodiment 1 will be described below. This verification is based on whether or not the prediction unit 105 can predict a stable structure for each system with respect to the composition of the substance after one or more Li atoms are desorbed from the substance having the composition Li 12 Mn 6 Ni 6 O 24 . The purpose is to ascertain whether
- a total of 4070 sets of initial structures and final energies were prepared for the composition of matter after desorption. That is, for each of a total of 4070 initial structures, structural optimization was performed to obtain the final structure, and the final energy corresponding to the obtained final structure was calculated. Of the total 4070 pairs, 10% of the total, 407 pairs, were used as verification data (test data), and the remaining 90%, 3663 pairs, were used as learning data (train data).
- machine learning of the prediction model was performed by using the initial structure as the input data and the final energy as the correct data as the learning data set.
- the machine-learned prediction model was then used to predict the final energy of the verification data. That is, by inputting the initial structure contained in the verification data into a machine-learned prediction model, a predicted value of the final energy corresponding to the initial structure output from the prediction model was obtained.
- FIG. 12 is a diagram showing an evaluation example of the prediction accuracy of the prediction unit 105 according to the first embodiment.
- the “correct final energy value” referred to here is the final energy corresponding to the final structure obtained by actually performing structural optimization on the initial structure.
- the “predicted value of final energy” referred to here is the predicted value of final energy output from the prediction model by inputting the initial structure into the prediction model.
- the “ranking” referred to here is the ranking when the final structure with the smallest correct value of final energy or the smallest predicted value of final energy is ranked first.
- the structure with the most stable atomic arrangement obtained by actually performing structural optimization is predicted by the prediction unit 105 to be the structure with the second most stable atomic arrangement. become.
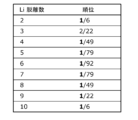
- FIG. 13 is a diagram showing the result of verifying the prediction accuracy of the prediction unit 105 according to Embodiment 1.
- the left column represents the number of Li atoms detached, in other words, the system, and the right column represents the order.
- the number on the left side of the “order” here indicates the order of the most stable atomic arrangement structure predicted by the prediction unit 105 among the verification data in the system.
- the numbers to the right of "Rank” represent the number of validation data in the system. This representation is the same in FIGS. 14, 19, and 20, which will be described later.
- the prediction accuracy of the prediction unit 105 will decrease.
- the structure of the atomic arrangement that is actually considered to be the most stable among the 79 sets of verification data is predicted by the prediction unit 105 to be the most stable structure. was done.
- the structure of the atomic arrangement that is actually considered to be the most stable among the 79 sets of verification data is predicted by the prediction unit 105 to be the 17th most stable structure. .
- the prediction unit 105 determines the structure of the atomic arrangement that is actually considered to be the most stable for any system within 25% of the total verification data for the system. It can be seen that it can be predicted that it has a simple structure. In other words, even if the number of verification data increases, the prediction accuracy of the prediction unit 105 hardly deteriorates.
- the prediction unit 105 determines the structure of the atomic arrangement that is actually considered to be the most stable within 10% of the entire verification data for the system, and further within 5%. It may be possible to predict that it is a structure.
- FIG. 14 is a diagram showing the result of verifying the correlation between the prediction accuracy of prediction section 105 and the ratio of learning data according to the first embodiment. Specifically, FIG. 14 shows the results of the prediction unit 105 while changing the ratio of the learning data for each number of LI atoms detached from the substance having the composition Li 14 Mn 5 Ni 5 O 24 , that is, for each system. It is a figure which shows the result at the time of verifying prediction accuracy.
- the "proportion of learning data” here is the ratio of the number of learning data to the total number of learning data and verification data in the system.
- the ratio of the learning data is 40%
- the structure of the atomic arrangement that is actually considered to be the most stable among 297 sets of verification data in a system in which four Li atoms are detached is determined by the prediction unit 105. was predicted to be the second most stable structure.
- the ratio of the learning data is 40%
- the structure of the atomic arrangement that is actually considered to be the most stable among the 554 sets of verification data in the system in which six Li atoms are desorbed is the prediction unit 105 was predicted to be the 60th most stable structure.
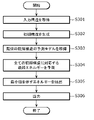
- FIG. 15 is a flowchart showing an operation example of the search system 100 according to Embodiment 1.
- FIG. 15 is a flowchart showing an operation example of the search system 100 according to Embodiment 1.
- Step S101 The input unit 101 acquires an input structure through user input, and outputs the acquired input structure to the generation unit 102 .
- Step S102 The generating unit 102 executes desorption processing on the input structure acquired in step S101. As a result, generation unit 102 generates a plurality of initial structures for each system and outputs them to structure storage unit 108 .
- Step S103 The calculation unit 103 performs structure optimization on some of the initial structures generated in step S102, and calculates the final energy corresponding to the final structure obtained by performing the structure optimization. Calculate Then, the calculation unit 103 outputs the calculation result to the calculation result storage unit 109 for each system.
- n is an integer equal to or greater than 2
- initial structures are obtained in the generating unit 102 (first step)
- m ( m is an initial structure of 1 ⁇ m ⁇ n integer).
- “m” is a number that is 90% or less of "n”.
- “m” may be a number that is 40% or more and 90% or less of “n”. That is, the number of partial initial structures in the calculation unit 103 (second step) is 90% or less of the number of multiple initial structures.
- Step S104 The learning unit 104 performs machine learning of a prediction model configured by a graph neural network using the set of the final energy and the initial structure calculated in step S103 as a learning data set.
- the learning unit 104 then outputs the machine-learned prediction model to the prediction unit 105 and the prediction model storage unit 110 .
- the number of training datasets is the same as the number of some initial structures, which is m.
- Step S105 The prediction unit 105 acquires from the structure storage unit 108 an initial structure for which the final energy has not been calculated, that is, another initial structure among the plurality of initial structures. Then, the prediction unit 105 calculates predicted values of final energies corresponding to other initial structures using the prediction model machine-learned in step S104.
- the number of other initial structures is the number obtained by excluding some initial structures from the plurality of initial structures. That is, the other initial structures in the prediction unit 105 (third step) are (nm) initial structures.
- the prediction model is the prediction model machine-learned in step S104.
- Step S106 The comparison unit 106 generates a list in which the final energy calculated in step S103 and the predicted value of the final energy calculated in step S105 are rearranged in order from the lowest energy value for each system.
- the list is output to the output unit 107 . That is, the comparison unit 106 extracts the energy indicating the minimum value from the final energy and the predicted value of the final energy for each system.
- Step S107 The output unit 107 outputs the predicted values of the initial structures and final energies and the final structures and final energies included in the list generated in step S106 by displaying them on the display in order from the structure with the lowest energy.
- Embodiment 1 instead of performing structural optimization on all initial structures, structural optimization is performed only on some initial structures, and the rest of the initial structures are optimized. On the other hand, by using a predictive model, calculations for structural optimization are omitted. Therefore, in Embodiment 1, it is possible to search for a structure with the most thermodynamically stable atomic arrangement in the new substance, as in the case where structural optimization is performed for all initial structures. Moreover, it is possible to omit the computation required for the search to some extent. That is, in Embodiment 1, compared to the case where structure optimization is performed for all initial structures, the computation cost can be reduced, and the atomic arrangement of the composition of the material after desorption of atoms can be reduced. Stable structures can be searched efficiently.
- the search system 200 (search method or program) according to Embodiment 2 of the present disclosure will be described in detail below with reference to the drawings.
- the search system 200 according to Embodiment 2 differs from the search system 100 according to Embodiment 1 in that it uses not only an initial structure but also an intermediate structure and a final structure when performing machine learning on a prediction model.
- the same reference numerals are given to the same components as in the first embodiment, and the description thereof is omitted.
- FIG. 16 is a block diagram showing the overall configuration including the search system 200 according to the second embodiment.
- the search system 200 includes a generator 102 , a calculator 203 , a learning unit 204 , a predictor 105 , a comparator 106 and an output unit 107 .
- Peripheral configurations of the search system 200 include an input unit 101 , a structure storage unit 108 , a calculation result storage unit 209 , and a prediction model storage unit 210 .
- the peripheral configuration of the search system 200 may be included in the components of the search system 200 .
- the generation unit 102 and the learning unit 204 in the search system 200 are also components of a prediction model construction device.
- the calculation unit 203 acquires part of the initial structure from the structure storage unit 108, and performs structural optimization on the acquired initial structure.
- the calculation unit 103 executes a process of calculating energy (first energy) corresponding to the final structure obtained by repeating the structure optimization.
- the calculation unit 203 outputs the initial structure, the final structure obtained by repeatedly executing structure optimization on the initial structure, and the final energy corresponding to the calculated final structure to the calculation result storage unit 209 for each system. do. In the second embodiment, the calculation unit 203 also outputs to the calculation result storage unit 209 an intermediate structure obtained each time structure optimization is performed on the initial structure.
- the calculation result storage unit 209 stores a set of the final energy calculated by the calculation unit 203, the corresponding initial structure, the corresponding intermediate structure, and the corresponding final structure for each system.
- FIG. 17 shows an example of data stored in the calculation result storage unit 209 according to the second embodiment.
- the left column is the initial structure ID
- the middle column is the atomic arrangement of the intermediate structure and the atomic arrangement of the final structure obtained each time the structure implementation is performed
- the right column is the final energy corresponding to the final structure. represents.
- illustration of the atomic arrangement of the initial structure is omitted.
- the learning unit 204 acquires the initial structure, the intermediate structure, the final structure, and the final energy of the final structure from the calculation result storage unit 209, and uses these to learn the prediction model.
- FIG. 18 is a diagram showing an example of a process of machine learning a prediction model by the learning unit 204 according to the second embodiment.
- the input data included in the training data set includes not only the initial structure but also the intermediate structure and final structure obtained each time structure optimization is performed. .
- the learning unit 204 not only includes the first learning data set including the initial structure as input data and the final energy as correct data, but also the intermediate structure or final structure as input data and the final energy as correct data.
- the prediction model is machine-learned further using a second training data set including as .
- the prediction model further includes, in addition to the first learning data set, the structure of the structure-optimized atomic arrangement, that is, the intermediate structure or the final structure as input data, corresponding to the structure
- This model is machine-learned using a second learning data set that includes the first energy, that is, the final energy as correct data. Note that the details of the prediction model machine learning process by the learning unit 204 are the same as those in the first embodiment, and thus the description thereof is omitted.
- the learning unit 204 outputs a prediction model for which machine learning has been completed, that is, a learned model to the prediction unit 105 and the prediction model storage unit 210 .
- the prediction model storage unit 210 stores the graph neural network structure and weights for the prediction model machine-learned by the learning unit 204 .
- Embodiment 2 Verification of prediction accuracy
- Verification of the prediction accuracy of the prediction unit 105 according to the second embodiment will be described below.
- This verification similar to the verification in Embodiment 1, was carried out for each system with respect to the composition of the substance after one or more Li atoms were desorbed from the substance having the composition Li 12 Mn 6 Ni 6 O 24 .
- the purpose is to confirm whether the predictor 105 can predict a stable structure.
- Verification in Embodiment 2 is that the learning data set used for machine learning of the prediction model further includes not only the above-described first learning data set but also the above-described second learning data set, This is different from the verification in the first embodiment.
- FIG. 19 is a diagram showing the result of verifying the prediction accuracy of the prediction unit 105 according to the second embodiment.
- what each column represents is the same as in FIG. 13 of Embodiment 1, so the description is omitted here.
- the prediction accuracy of the prediction unit 105 will decrease.
- the structure of the atomic arrangement that is actually considered to be the most stable among the 22 sets of verification data is predicted by the prediction unit 105 to be the second most stable structure. was done.
- the prediction unit 105 predicted that the structure with the most stable atomic arrangement among the 92 sets of verification data would be the most stable structure. .
- the prediction unit 105 determines the structure of the atomic arrangement that is actually considered to be the most stable for any system as the first or second most stable among all the verification data for the system. It can be seen that it can be predicted that it has a simple structure. In other words, even if the number of verification data increases, the prediction accuracy of the prediction unit 105 hardly deteriorates.
- FIG. 20 is a diagram showing the result of verifying the correlation between the prediction accuracy of prediction section 105 and the ratio of learning data according to the second embodiment. Specifically, FIG. 20 shows the results of prediction unit 105 while changing the ratio of learning data for each number of LI atoms detached from a substance having the composition Li 14 Mn 5 Ni 5 O 24 , that is, for each system. It is a figure which shows the result at the time of verifying prediction accuracy. In FIG. 20, what each column represents is the same as in FIG. 14 of Embodiment 1, so the description is omitted here.
- the prediction model is machine-learned by further using a learning data set containing the structure of the structurally optimized atomic arrangement, that is, the intermediate structure or the final structure as input data. Even if the ratio is low, it is considered possible to make highly accurate predictions.
- FIG. 21 is a flow chart showing an operation example of the search system 200 according to the second embodiment.
- the processes of steps S201 to S203 and steps S205 to S207 are the same as the processes of steps S101 to S103 and S105 to S107 shown in FIG. 15, respectively, so description thereof will be omitted. That is, the overall flow of the processing of the search system 100 according to Embodiment 1 is the same as that of step S204.
- Step S204 The learning unit 204 uses the set of the final energy and the initial structure calculated in step S203 and the set of the final energy and the optimized structure as learning data sets to create a prediction model configured by a graph neural network. machine learning.
- a "structure optimized structure" as used herein is an intermediate structure or a final structure.
- the learning unit 204 then outputs the machine-learned prediction model to the prediction unit 105 and the prediction model storage unit 210 .
- the prediction model is machine-learned by further using a learning data set containing as input data the structure of the structurally optimized atomic arrangement, that is, the intermediate structure or the final structure. Therefore, in the second embodiment, compared with the first embodiment, it is easier to more accurately predict the energy corresponding to the structure when the structure optimization is performed on the input initial structure.
- Embodiment 3 A search system 300 (search method or program) according to Embodiment 3 of the present disclosure will be described in detail below with reference to the drawings.
- the search system 300 according to Embodiment 3 when predicting the second energy corresponding to the structure of the atomic arrangement when structural optimization is performed on the initial structure, the prediction of a known structure that has been machine-learned in advance is performed. It differs from the search system 100 according to the first embodiment or the search system 200 according to the second embodiment in that a model is used.
- the same reference numerals are assigned to the same constituent elements as those in the first or second embodiment, and the description thereof is omitted.
- FIG. 22 is a block diagram showing the overall configuration including search system 300 according to Embodiment 3.
- the search system 300 includes a generation unit 102, a prediction unit 305, a comparison unit 306, and an output unit 107, and does not include the learning unit 104 or the learning unit 204.
- Peripheral configurations of the search system 300 include an input unit 101 , a structure storage unit 108 , and a prediction model storage unit 310 .
- the peripheral configuration of the search system 300 may be included in the components of the search system 300 .
- the prediction model storage unit 310 stores the structure and weights of the graph neural network for a prediction model that has undergone machine learning in advance.
- the prediction model employed here is, for example, a prediction model relating to a known structure of a known composition similar to the composition of the material after desorption of atoms, or a general-purpose learned prediction model.
- the term "similar” as used herein means, for example, that the composition of the material after desorption of atoms and the composition of the known material differ only in part. "Similar" means that the composition of the known material contains at least one element contained in the composition of the material after atomic desorption.
- the prediction model is the former prediction model, that is, the prediction model for known structures.
- This prediction model uses, for example, a known structure as input data and a learning data set that includes, as correct data, the final energy corresponding to the final structure obtained by performing structural optimization on the known structure. machine-learned.
- the prediction unit 305 acquires the initial structure from the structure storage unit 108. FIG. Then, the prediction unit 305 inputs the initial structure into the trained prediction model acquired from the prediction model storage unit 310, thereby predicting the final energy of the initial structure. In Embodiment 3, the prediction unit 305 predicts the final energy for each of all initial structures using prediction models. That is, the prediction unit 305 (in the eighth step) uses a prediction model for each of a plurality of initial structures to correspond to the structure of the atomic arrangement when the structure optimization is performed for the initial structure. Predict energy. The "energy” here is the predicted value of the final energy corresponding to the final structure when geometry optimization is performed on the initial structure.
- the prediction unit 305 outputs the initial structure and the final energy prediction value corresponding to the initial structure to the comparison unit 306 for each system.
- the comparison unit 306 obtains a set of predicted values of initial structure and final energy from the prediction unit 305 . Then, the comparison unit 306 generates a list in which sets of predicted values of initial structures and final energies are arranged.
- FIG. 23 is a diagram showing an example of data generated by the comparison unit 306 according to the third embodiment.
- the left column represents the atomic arrangement of the initial structure
- the right column represents the predicted value of the final energy corresponding to the initial structure.
- the comparison unit 306 rearranges the final energy prediction values in a predetermined order based on the list.
- the comparison unit 306 rearranges the predicted final energy values in descending order of energy. Such rearrangement of the final energy predicted values corresponds to a process of extracting the smallest value from the final energy predicted values, in other words, the minimum value or minimum value.
- the comparison unit 306 extracts the energy indicating the minimum value from the plurality of predicted energies.
- the "energy” is the predicted value of the final energy corresponding to the final structure when geometry optimization is performed on the initial structure.
- the local minimum is the minimum of the energies.
- the comparison unit 306 outputs a list in which the predicted values of the final energy are rearranged as described above to the output unit 107 for each system.
- FIG. 24 is a flow chart showing an operation example of processing of the search system 300 according to the third embodiment.
- the processing of steps S301 and S302 is the same as the processing of steps S101 and S102 shown in FIG. 15, respectively, so description thereof will be omitted.
- Step S303 The search system 300 obtains a prediction model related to a known structure with a composition similar to that of the material after atom detachment, which has undergone machine learning in advance, and outputs the prediction model to the prediction model storage unit 310 .
- Step S304 The prediction unit 305 acquires the initial structure from the structure storage unit 108. FIG. Then, the prediction unit 305 calculates the predicted value of the final energy corresponding to the initial structure using the prediction model acquired in step S303.
- Step S305 The comparison unit 306 generates a list for each system in which the predicted values of the final energy calculated in step S304 are rearranged in order from the lowest energy value, and outputs the generated list to the output unit 107 .
- the comparison unit 306 extracts the energy indicating the minimum value from the predicted values of the final energy for each system.
- Step S306 The output unit 107 outputs the predicted values of the initial structures and final energies included in the list generated in step S305 by displaying them on the display in order from the structure with the lowest energy.
- Embodiment 3 prediction models that have undergone machine learning in advance are used for all initial structures, so there is no need to perform calculations for structure optimization. Therefore, in Embodiment 3, as in Embodiment 1 or 2, it is possible to search for the structure of the atomic arrangement that is considered to be thermodynamically most stable in the novel substance, and the search It is possible to greatly omit the calculation required for In other words, in Embodiment 3, compared to the case where structural optimization is performed for a part of the initial structure, the calculation cost can be reduced, and the stable structure of the atomic arrangement for the composition of the material can be efficiently obtained. can be explored.
- Search system 400 (search method or program) according to Embodiment 4 of the present disclosure will be described in detail below with reference to the drawings.
- the search system 400 according to Embodiment 4 uses a prediction model for a known structure that has been machine-learned in advance, and verifies whether or not to relearn the prediction model. It differs from system 300 .
- the same reference numerals are given to the same constituent elements as in the first, second, or third embodiment, and the description thereof is omitted.
- FIG. 25 is a block diagram showing the overall configuration including the search system 400 according to the fourth embodiment.
- the search system 400 includes a generator 102, a calculator 103, a learning unit 404, a predictor 405, a comparator 106, and an output unit 107.
- Peripheral configurations of the search system 400 include an input unit 101 , a structure storage unit 108 , a calculation result storage unit 109 , and a prediction model storage unit 310 . Note that the configuration around the search system 400 may be included in the components of the search system 400 .
- the learning unit 404 re-learns the prediction model when the prediction unit 405 determines that the prediction accuracy of the prediction model does not satisfy the conditions. Specifically, the learning unit 404 acquires the final energies of the initial structure and the final structure from the calculation result storage unit 109 and re-learns the prediction model acquired from the prediction model storage unit 310 using these.
- the learning data set used for re-learning the prediction model includes the initial structure as input data and the final energy as correct data.
- the learning unit 404 outputs the re-learned prediction model to the prediction unit 405 and the prediction model storage unit 310 .
- the prediction model storage unit 310 stores the graph neural network structure and weights for the prediction model re-learned by the learning unit 404 . That is, in the prediction model storage unit 310, the already stored prediction model is updated to the re-learned prediction model.
- the prediction unit 405 acquires the final energies of the initial structure and final structure from the calculation result storage unit 109 .
- the prediction unit 405 acquires prediction models from the prediction model storage unit 310 .
- the prediction model acquired by the prediction unit 405 here is a prediction model before being re-learned by the learning unit 404 .
- the prediction unit 405 predicts the final energy of the initial structure by inputting the initial structure into the obtained prediction model. Then, the prediction unit 405 verifies the prediction accuracy of the prediction model by comparing the predicted value of the final energy with the final energy acquired from the calculation result storage unit 109 .
- the prediction unit 405 if the root mean squared error (RMSE) between the final energy and the predicted final energy is below a certain value, the prediction accuracy of the prediction model is sufficient, that is, it satisfies the conditions for prediction accuracy. On the other hand, if the above RMSE exceeds a certain value, the prediction unit 405 determines that the prediction accuracy of the prediction model is insufficient, that is, the prediction accuracy condition is not satisfied. For example, the prediction unit 405 may determine that a structure with an atomic arrangement that is actually considered to be the most stable satisfies the prediction accuracy condition by predicting that the structure is stable within a certain order. Note that the method for verifying the prediction accuracy of the prediction model is not limited to the above method, and other methods may be used.
- RMSE root mean squared error
- the prediction unit 405 uses a prediction model for at least one initial structure out of some of the initial structures, so that when structure optimization is performed on the initial structure Predict the second energy corresponding to the structure of the atomic configuration of .
- the second energy is the predicted value of the final energy corresponding to the final structure when geometry optimization is performed on at least one initial structure.
- the prediction unit 405 verifies the prediction accuracy of the prediction model by comparing the first energy and the second energy.
- the first energy is the final energy of the final structure corresponding to at least one initial structure.
- the prediction unit 405 acquires an initial structure whose final energy has not yet been calculated from the structure storage unit 108.
- the “initial structure for which the final energy has not yet been calculated” as used herein is a structure excluding some of the initial structures, that is, other initial structures. Then, the prediction unit 405 predicts the final energy of the initial structure by inputting the initial structure into the prediction model.
- the prediction unit 405 selects another initial structure among the plurality of initial structures.
- a prediction model is used for the structure to predict the second energy corresponding to the structure of the atomic arrangement if the geometry optimization were performed on the other initial structure.
- the second energy is the predicted value of the final energy corresponding to the final structure when geometry optimization is performed on other initial structures.
- the prediction unit 405 outputs the initial structure and the final energy prediction value corresponding to the initial structure to the comparison unit 106 for each system.
- FIG. 26 is a flow chart showing an operation example of processing of the search system 400 according to the fourth embodiment.
- the processing of steps S401 to S403 is the same as the processing of steps S301 to S303 shown in FIG. 24, respectively, so the description is omitted.
- Step S404 The calculation unit 103 performs structure optimization on some of the initial structures generated in step S403, and calculates the final energy corresponding to the final structure obtained by performing the structure optimization. Calculate Then, the calculation unit 103 outputs the calculation result to the calculation result storage unit 109 for each system.
- Step S405 The prediction unit 405 acquires an initial structure, that is, a partial initial structure, from the calculation result storage unit 109 . Then, the prediction unit 405 calculates a predicted final energy value corresponding to a part of the initial structures using the prediction model acquired in step S403.
- Step S406 The prediction unit 405 verifies the prediction accuracy of the prediction model by comparing the predicted value of the final energy calculated in step S405 and the final energy calculated in step S404. If the prediction result satisfies the prediction accuracy condition (step S406: Yes), the process proceeds to step S408. On the other hand, if the prediction result does not satisfy the prediction accuracy condition (step S406: No), the process proceeds to step S407.
- Step S407 The learning unit 404 performs re-learning of the prediction model configured by the graph neural network using the set of the final energy and the initial structure calculated in step S404 as a learning data set.
- the learning unit 404 then outputs the re-learned prediction model to the prediction unit 405 and the prediction model storage unit 310 .
- a set of an initial structure and a final energy different from the partial initial structure may be used as a learning data set. In this case, the calculation unit 103 needs to separately calculate the final energy corresponding to the different initial structure.
- Step S408 The prediction unit 405 acquires from the structure storage unit 108 an initial structure for which the final energy has not been calculated, that is, another initial structure among the plurality of initial structures. Then, the prediction unit 405 calculates predicted values of final energies corresponding to other initial structures using the prediction model.
- the prediction model if the prediction result satisfies the prediction accuracy condition in step S406, the prediction model acquired in S403 is adopted. On the other hand, if the prediction result does not satisfy the prediction accuracy condition in step S406, the re-learned prediction model is adopted in step S407.
- Step S409 The comparison unit 106 generates a list in which the final energy calculated in step S404 and the predicted value of the final energy calculated in step S408 are rearranged in order from the lowest energy value for each system.
- the list is output to the output unit 107 .
- the comparison unit 106 extracts the energy indicating the minimum value from the final energy and the predicted value of the final energy.
- the comparison unit 106 (at the thirteenth step) extracts the third energy indicating the minimum value based on the first energy and the second energy.
- the first energy is the final energy obtained from the calculation result storage unit 109
- the second energy is the predicted value of the final energy obtained from the prediction unit 405 .
- the third energy is the minimum value of the first energy and the second energy.
- Step S410 The output unit 107 outputs the predicted values of the initial structures and final energies included in the list generated in step S409 by displaying them on the display in order from the structure with the lowest energy.
- Embodiment 4 the prediction accuracy of the prediction model is verified while using the prediction model that has undergone machine learning in advance. Therefore, in Embodiment 4, it becomes easier to realize a prediction model with sufficient prediction accuracy.
- Embodiment 4 by using a prediction model that satisfies the condition of prediction accuracy, that is, a prediction model with relatively high prediction accuracy, it is easier to more efficiently search for a stable structure of atomic arrangement for the material composition.
- the minimum value is the minimum value of the first energy and the second energy, but is not limited to this.
- the first energy is the final energy calculated by the calculator 103
- the second energy is the predicted value of the final energy predicted by the predictors 105, 306, and 406.
- FIG. For example, the smallest value of the first energy and the second energy is the minimum value of the second energy, the second smallest value is the minimum value of the first energy, and these values are approximate. Assume. For example, the difference between the two values is within 1/10000 of the minimum value of the second energy.
- the minimum value may be the minimum value of the first energy instead of the minimum value of the second energy. This is because the actually calculated value is considered to be more accurate than the predicted value.
- the atom detached from the material to be searched is the Li atom, but it is not limited to this.
- the atoms detached from the search target material may be O atoms or other atoms.
- the search systems 100 to 400 acquire a plurality of initial structures by generating a plurality of initial structures by the generation unit 102, but the present invention is not limited to this.
- search systems 100-400 may obtain multiple initial structures generated by other systems.
- the generator 102 is unnecessary. That is, the obtaining step may obtain by generating a plurality of initial structures, or obtain a plurality of initial structures generated by another system.
- each component may be configured with dedicated hardware or implemented by executing a software program suitable for each component.
- Each component may be implemented by a program execution unit such as a CPU (Central Processing Unit) or processor reading and executing a software program recorded in a recording medium such as a hard disk or semiconductor memory.
- a program execution unit such as a CPU (Central Processing Unit) or processor reading and executing a software program recorded in a recording medium such as a hard disk or semiconductor memory.
- the at least one system described above is specifically a computer system composed of a microprocessor, ROM, RAM, hard disk unit, display unit, keyboard, mouse, and the like.
- a computer program is stored in the RAM or hard disk unit.
- At least one of the above systems achieves its functions by a microprocessor operating according to a computer program.
- the computer program is constructed by combining a plurality of instruction codes indicating instructions to the computer in order to achieve a predetermined function.
- a part or all of the components constituting at least one of the above systems may be composed of one system LSI (Large Scale Integration).
- a system LSI is an ultra-multifunctional LSI manufactured by integrating multiple components on a single chip. Specifically, it is a computer system that includes a microprocessor, ROM, RAM, etc. . A computer program is stored in the RAM. The system LSI achieves its functions by the microprocessor operating according to the computer program.
- a part or all of the components that make up at least one of the above systems may be made up of an IC card or a single module that can be attached to and removed from the device.
- An IC card or module is a computer system composed of a microprocessor, ROM, RAM, and the like.
- the IC card or module may include the super multifunctional LSI.
- the IC card or module achieves its function by the microprocessor operating according to the computer program. This IC card or this module may have tamper resistance.
- the present disclosure may be the method shown above. Moreover, it may be a computer program for realizing these methods by a computer, or it may be a digital signal composed of a computer program.
- the present disclosure is a computer-readable recording medium for computer programs or digital signals, such as flexible discs, hard disks, CD (Compact Disc)-ROM, DVD, DVD-ROM, DVD-RAM, BD (Blu-ray (registered trademark) ) Disc), or recorded in a semiconductor memory or the like. It may be a digital signal recorded on these recording media.
- CD Compact Disc
- DVD DVD-ROM
- DVD-RAM DVD-RAM
- BD Blu-ray (registered trademark) ) Disc
- computer programs or digital signals may be transmitted via electric communication lines, wireless or wired communication lines, networks represented by the Internet, data broadcasting, and the like.
- It may be implemented by another independent computer system by recording the program or digital signal on a recording medium and transferring it, or by transferring the program or digital signal via a network or the like.
- the present disclosure makes it possible to search for stable atomic arrangement structures without performing calculations for all atomic arrangement structure candidates, and in situations where large-scale computational resources cannot be prepared, stable atomic arrangement of new materials Useful for searching structures.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Crystallography & Structural Chemistry (AREA)
- Chemical & Material Sciences (AREA)
- Mathematical Physics (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Health & Medical Sciences (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
材料開発において、シミュレーションにより熱力学特性又は安全性等の性質を算出するためには、物質それぞれにおける熱力学的に安定な原子配置構造、つまり安定構造を求める必要がある。ここで、安定な原子配置構造は、構造最適化によって求めることができる。そのため、構造最適化は、物質の解析又は新規物質を開発するためのツールとして利用されている。非特許文献1には、第一原理計算による構造最適化の方法が開示されている。
前記第1エネルギーと前記第2エネルギーとを比較することで前記予測モデルの予測精度を検証する第11ステップと、を実行する。
(実施の形態1:構成の説明)
以下、本開示の実施の形態1に係る探索システム100(探索方法、又はプログラム)について、図面を用いて詳細に説明する。実施の形態1に係る探索システム100(探索方法、又はプログラム)は、材料の組成についての3次元空間における原子配置の安定構造を探索するためのシステム(方法、又はプログラム)である。ここでいう「安定構造」とは、原子配置の構造(つまり、結晶構造)に含まれる各原子に作用する力が閾値以下となるような構造であって、かつ、構造に対応するエネルギー(全エネルギー)が最小となる構造である。なお、閾値は、ユーザが適宜設定可能であるが、零に近似した値であってもよい。各原子に作用する力が零に近ければ近い程、構造が熱力学的に安定するからである。
入力部101は、ユーザの入力を受け付ける入力インタフェースであって、探索対象の材料が有する組成に関する情報をユーザの入力によって取得し、生成部102に出力する。組成に関する情報は、例えば、探索対象の材料が有する組成についての3次元空間における原子配置の構造である。以下、当該構造を「入力構造」とも言う。入力部101は、例えばキーボード、タッチセンサ、タッチパッド又はマウス等を含んで構成される。
生成部102は、入力部101から取得した入力構造に対して原子の除去、つまり原子の脱離処理を実行することにより、脱離後の構造がとり得る複数の初期構造を生成する。ここでは、入力構造からの原子の除去は、CIFから除去対象の原子を記述した行を削除することで実行される。実施の形態1では、脱離する原子はLi原子である。つまり、生成部102は(第1ステップでは)、材料に含まれる原子の脱離による脱離後の材料の組成がとり得る3次元空間における原子配置の構造である複数の初期構造を取得する。ここでいう「初期構造」は、探索対象の材料の組成から1以上の原子が脱離した後の組成であって、原子配置の安定構造となり得る候補の構造である。
算出部103は、図7に示すように、構造記憶部108から初期構造の一部を取得し、取得した初期構造に対して構造最適化を実行する。算出部103は、構造最適化を繰り返すことにより得られた最終構造に対応するエネルギー(第1エネルギー)を算出する処理を実行する。図7は、実施の形態1に係る算出部103による第1エネルギーを算出する過程の一例を示す図である。
学習部104は、算出結果記憶部109から初期構造と、最終構造の最終エネルギーとを取得し、取得した初期構造及び最終エネルギーを用いて予測モデルを学習させる。ここで、予測モデルに学習する入出力の組は、一例として入力が初期構造、出力が最終エネルギーである。
予測部105は、構造記憶部108から最終エネルギーを未算出の初期構造を取得する。そして、予測部105は、学習部104から取得した予測モデル、つまり学習済みの予測モデルに当該初期構造を入力することで、当該初期構造の最終エネルギーを予測する。
比較部106は、予測部105から初期構造及び最終エネルギーの予測値の組を取得する。比較部106は、算出結果記憶部109から最終構造及び最終エネルギーの組を取得する。そして、比較部106は、初期構造及び最終エネルギーの予測値の組と、最終構造及び最終エネルギーの組とを並べたリストを生成する。
出力部107は、比較部106が出力したリストに含まれる初期構造及び最終エネルギーの予測値、並びに最終構造及び最終エネルギーを、上記の所定の順番に従って、つまり最もエネルギーの小さい構造から順番にディスプレイに表示する。つまり、出力部107は(第5ステップでは)、第3エネルギー、第3エネルギーに対応する原子配置の構造である第1構造、または、第3エネルギー及び第1構造を出力する。
以下、実施の形態1に係る予測部105の予測精度の検証について説明する。この検証は、組成Li12Mn6Ni6O24を有する物質から1個以上のLi原子が脱離した脱離後の物質の組成について、系ごとに予測部105が安定構造を予測できるか否かを確かめることを目的とする。
次に、探索システム100の動作について説明する。
図15は、実施の形態1に係る探索システム100の動作例を示すフローチャートである。
入力部101は、入力構造をユーザの入力によって取得し、取得した入力構造を生成部102に出力する。
生成部102は、ステップS101で取得された入力構造に対して脱離処理を実行する。これにより、生成部102は、系ごとに複数の初期構造を生成し、構造記憶部108に出力する。
算出部103は、ステップS102で生成された複数の初期構造のうち一部の初期構造に対して構造最適化を実行し、構造最適化を実施することで得られた最終構造に対応する最終エネルギーを算出する。そして、算出部103は、系ごとに算出結果を算出結果記憶部109に出力する。ここでは、生成部102(第1ステップ)においてn個(nは2以上の整数)の初期構造を取得した場合に、算出部103(第2ステップ)における一部の初期構造は、m個(mは1<m<nの整数)の初期構造である。ここでは、“m”は、“n”の90%以下の数である。“m”は“n”の40%以上90%以下の数であってもよい。つまり、算出部103(第2ステップ)における一部の初期構造の数は、複数の初期構造の数の90%以下である。
学習部104は、ステップS103で算出された最終エネルギーと初期構造との組を学習用データセットとして、グラフニューラルネットワークにより構成される予測モデルの機械学習を行う。そして、学習部104は、機械学習後の予測モデルを予測部105及び予測モデル記憶部110に出力する。ここでは、学習用データセットの数は、一部の初期構造の数と同じであり、m個である。
予測部105は、構造記憶部108から最終エネルギーが算出されていない初期構造、つまり複数の初期構造のうちの他の初期構造を取得する。そして、予測部105は、ステップS104で機械学習された予測モデルにより、他の初期構造に対応する最終エネルギーの予測値を算出する。ここで、他の初期構造の数は、複数の初期構造から一部の初期構造を除いた数である。つまり、予測部105(第3ステップ)における他の初期構造は、(n-m)個の初期構造である。
比較部106は、ステップS103で算出された最終エネルギーと、ステップS105で算出された最終エネルギーの予測値とを、最もエネルギーの小さい値から順番に並び替えたリストを系ごとに生成し、生成したリストを出力部107に出力する。つまり、比較部106は、最終エネルギー及び最終エネルギーの予測値から最小値を示すエネルギーを系ごとに抽出する。
出力部107は、ステップS106で生成されたリストに含まれる初期構造及び最終エネルギーの予測値、並びに最終構造及び最終エネルギーを、最もエネルギーの小さい構造から順番にディスプレイに表示することで出力する。
以下、本開示の実施の形態2に係る探索システム200(探索方法、又はプログラム)について、図面を用いて詳細に説明する。実施の形態2に係る探索システム200は、予測モデルを機械学習させる際に、初期構造だけではなく中間構造及び最終構造を使用する点で、実施の形態1に係る探索システム100と相違する。なお、本実施の形態において、実施の形態1と同一の構成要素には同一の符号を付し、説明を省く。
算出部203は、構造記憶部108から初期構造の一部を取得し、取得した初期構造に対して構造最適化を実行する。算出部103は、構造最適化を繰り返すことにより得られた最終構造に対応するエネルギー(第1エネルギー)を算出する処理を実行する。
学習部204は、算出結果記憶部209から初期構造、中間構造、最終構造、及び最終構造の最終エネルギーを取得し、これらを用いて予測モデルを学習する。
以下、実施の形態2に係る予測部105の予測精度の検証について説明する。この検証は、実施の形態1での検証と同様に、組成Li12Mn6Ni6O24を有する物質から1個以上のLi原子が脱離した脱離後の物質の組成について、系ごとに予測部105が安定構造を予測できるか否かを確かめることを目的とする。
次に、探索システム200の動作について説明する。
図21は、実施の形態2に係る探索システム200の動作例を示すフローチャートである。ステップS201~S203、及びステップS205~S207の処理は、それぞれ図15に示すステップS101~S103、及びS105~S107の処理と同じであるため、説明を省略する。すなわち、ステップS204以外は、実施の形態1に係る探索システム100の処理の全体的な流れと同じである。
学習部204は、ステップS203で算出された最終エネルギーと初期構造との組、及び当該最終エネルギーと構造最適化された構造との組を学習用データセットとして、グラフニューラルネットワークにより構成される予測モデルの機械学習を行う。ここでいう「構造最適化された構造」とは、中間構造又は最終構造である。そして、学習部204は、機械学習後の予測モデルを予測部105及び予測モデル記憶部210に出力する。
以下、本開示の実施の形態3に係る探索システム300(探索方法、又はプログラム)について、図面を用いて詳細に説明する。実施の形態3に係る探索システム300は、初期構造に対して構造最適化が実施された場合の原子配置の構造に対応する第2エネルギーを予測する際に、予め機械学習された既知構造に関する予測モデルを用いる点で、実施の形態1に係る探索システム100又は実施の形態2に係る探索システム200と相違する。なお、本実施の形態において、実施の形態1又は実施の形態2と同一の構成要素には同一の符号を付し、説明を省く。
予測モデル記憶部310は、予め機械学習された学習済みの予測モデルについて、グラフニューラルネットワークの構造及び重みを記憶する。ここで採用される予測モデルは、例えば、原子の脱離後の材料の組成と類似する既知の組成についての既知構造に関する予測モデル、又は汎用的に学習された予測モデルである。ここでいう「類似」とは、例えば原子の脱離後の材料の組成及び既知材料の組成の各々に含まれる元素が一部のみ異なっていることをいう。「類似」とは、既知材料の組成が、原子の脱離後の材料の組成に含まれる少なくとも1つの元素を含むことをいう。
予測部305は、構造記憶部108から初期構造を取得する。そして、予測部305は、予測モデル記憶部310から取得した学習済みの予測モデルに当該初期構造を入力することで、当該初期構造の最終エネルギーを予測する。実施の形態3では、予測部305は、全ての初期構造の各々について、予測モデルを用いて最終エネルギーを予測する。つまり、予測部305は(第8ステップでは)、複数の初期構造それぞれに対して予測モデルを用いることにより、当該初期構造に対して構造最適化が実施された場合の原子配置の構造に対応するエネルギーを予測する。ここでいう「エネルギー」は、初期構造に対して構造最適化が実施された場合の最終構造に対応する最終エネルギーの予測値である。
比較部306は、予測部305から初期構造及び最終エネルギーの予測値の組を取得する。そして、比較部306は、初期構造及び最終エネルギーの予測値の組を並べたリストを生成する。
次に、探索システム300の動作について説明する。
図24は、実施の形態3に係る探索システム300の処理の動作例を示すフローチャートである。ステップS301,S302の処理は、それぞれ図15に示すステップS101,S102の処理と同じであるため、説明を省略する。
探索システム300は、予め機械学習済みであって、原子の脱離後の材料の組成と類似の組成についての既知構造に関する予測モデルを取得し、予測モデル記憶部310に出力する。
予測部305は、構造記憶部108から初期構造を取得する。そして、予測部305は、ステップS303で取得された予測モデルにより、初期構造に対応する最終エネルギーの予測値を算出する。
比較部306は、ステップS304で算出された最終エネルギーの予測値を、最もエネルギーの小さい値から順番に並び替えたリストを系ごとに生成し、生成したリストを出力部107に出力する。つまり、比較部306は、最終エネルギーの予測値から最小値を示すエネルギーを系ごとに抽出する。
出力部107は、ステップS305で生成されたリストに含まれる初期構造及び最終エネルギーの予測値を、最もエネルギーの小さい構造から順番にディスプレイに表示することで出力する。
以下、本開示の実施の形態4に係る探索システム400(探索方法、又はプログラム)について、図面を用いて詳細に説明する。実施の形態4に係る探索システム400は、予め機械学習された既知構造に関する予測モデルを用いており、かつ、予測モデルを再学習するか否かを検証する点で、実施の形態3に係る探索システム300と相違する。なお、本実施の形態において、実施の形態1、実施の形態2、又は実施の形態3と同一の構成要素には同一の符号を付し、説明を省く。
学習部404は、予測部405において予測モデルの予測精度が条件を満たしていないと判定された場合に、予測モデルを再学習する。具体的には、学習部404は、算出結果記憶部109から初期構造及び最終構造の最終エネルギーを取得し、これらを用いて予測モデル記憶部310から取得した予測モデルを再学習する。ここで、予測モデルの再学習に用いる学習用データセットは、初期構造を入力データ、最終エネルギーを正解データとして含む。
予測部405は、算出結果記憶部109から初期構造及び最終構造の最終エネルギーを取得する。予測部405は、予測モデル記憶部310から予測モデルを取得する。ここで予測部405が取得する予測モデルは、学習部404により再学習される前の予測モデルである。予測部405は、取得した予測モデルに当該初期構造を入力することで、当該初期構造の最終エネルギーを予測する。そして、予測部405は、最終エネルギーの予測値と、算出結果記憶部109から取得した最終エネルギーとを比較することにより、予測モデルの予測精度を検証する。具体的には、予測部405は、一例として、最終エネルギーと最終エネルギーの予測値との二乗平均平方根誤差(Root Mean Squared Error:RMSE)が一定の値を下回っていれば、予測モデルの予測精度が十分である、つまり予測精度の条件を満たしている、と判定する。一方、予測部405は、上記のRMSEが一定の値を上回っていれば、予測モデルの予測精度が不十分である、つまり予測精度の条件を満たしていない、と判定する。予測部405は、例えば実際に最も安定と考えられる原子配置の構造を、一定の順位内で安定な構造と予測されていることをもって、予測精度の条件を満たしていると判定してもよい。なお、予測モデルの予測精度の検証手法は、上記の手法に限定されず、他の手法であってもよい。
次に、探索システム400の動作について説明する。
図26は、実施の形態4に係る探索システム400の処理の動作例を示すフローチャートである。ステップS401~S403の処理は、それぞれ図24に示すステップS301~S303の処理と同じであるため、説明を省略する。
算出部103は、ステップS403で生成された複数の初期構造のうち一部の初期構造に対して構造最適化を実行し、構造最適化を実施することで得られた最終構造に対応する最終エネルギーを算出する。そして、算出部103は、算出結果を系ごとに算出結果記憶部109に出力する。
予測部405は、算出結果記憶部109から初期構造、つまり一部の初期構造を取得する。そして、予測部405は、ステップS403で取得された予測モデルにより、一部の初期構造に対応する最終エネルギーの予測値を算出する。
予測部405は、ステップS405で算出された最終エネルギーの予測値と、ステップS404で算出された最終エネルギーとを比較することで、予測モデルの予測精度を検証する。予測結果が予測精度の条件を満たしている場合(ステップS406:Yes)、処理はステップS408に進む。一方、予測結果が予測精度の条件を満たしていない場合(ステップS406:No)、処理はステップS407に進む。
学習部404は、ステップS404で算出された最終エネルギーと初期構造との組を学習用データセットとして、グラフニューラルネットワークにより構成される予測モデルの再学習を行う。そして、学習部404は、再学習後の予測モデルを予測部405及び予測モデル記憶部310に出力する。なお、予測モデルの再学習にあたっては、上記一部の初期構造とは別の初期構造と最終エネルギーとの組を、学習用データセットとして更に用いてもよい。この場合、当該別の初期構造に対応する最終エネルギーを、算出部103で別途算出する必要がある。
予測部405は、構造記憶部108から最終エネルギーが算出されていない初期構造、つまり複数の初期構造のうちの他の初期構造を取得する。そして、予測部405は、予測モデルにより、他の初期構造に対応する最終エネルギーの予測値を算出する。ここで、予測モデルについては、ステップS406で予測結果が予測精度の条件を満たした場合には、S403で取得した予測モデルが採用される。一方、ステップS406で予測結果が予測精度の条件を満たしていない場合には、ステップS407で再学習された予測モデルが採用される。
比較部106は、ステップS404で算出された最終エネルギーと、ステップS408で算出された最終エネルギーの予測値とを、最もエネルギーの小さい値から順番に並び替えたリストを系ごとに生成し、生成したリストを出力部107に出力する。つまり、比較部106は、最終エネルギー及び最終エネルギーの予測値から最小値を示すエネルギーを抽出する。言い換えれば、比較部106は(第13ステップでは)、第1エネルギー及び第2エネルギーに基づいて、極小値を示す第3エネルギーを抽出する。ここでは、第1エネルギーは算出結果記憶部109から取得した最終エネルギー、第2エネルギーは予測部405から取得した最終エネルギーの予測値である。第3エネルギーは、第1エネルギー及び第2エネルギーの最小値である。
出力部107は、ステップS409で生成されたリストに含まれる初期構造及び最終エネルギーの予測値を、最もエネルギーの小さい構造から順番にディスプレイに表示することで出力する。
上記各実施の形態では、極小値は、第1エネルギー及び第2エネルギーのうちの最小値であるが、これに限られない。なお、第1エネルギーは、算出部103で算出された最終エネルギーであり、第2エネルギーは、予測部105、306,406で予測された最終エネルギーの予測値である。例えば、第1エネルギー及び第2エネルギーのうち最も小さい値が第2エネルギーの最小値であって、2番目に小さい値が第1エネルギーの最小値であり、これらの値が近似している、と仮定する。例えば、2つの値の差が第2エネルギーの最小値の10000分の1以内とする。この場合、極小値は、第2エネルギーの最小値ではなく、第1エネルギーの最小値であってもよい。予測された値よりも、実際に算出した値の方が精度が良いと考えられるからである。
101 入力部
102 生成部
103,203 算出部
104,204,404 学習部
105,305,405 予測部
106,306 比較部
107 出力部
108 構造記憶部
109,209 算出結果記憶部
110,210,310 予測モデル記憶部
Claims (16)
- 材料の組成についての3次元空間における原子配置の安定構造を探索するための探索方法であって、
コンピュータが、
前記材料に含まれる原子の脱離によって脱離後の材料の組成がとり得る前記3次元空間における原子配置の構造である複数の初期構造を取得する第1ステップと、
複数の前記初期構造のうちの一部の初期構造に対して構造最適化を実施し、構造最適化された原子配置の構造に対応する第1エネルギーを算出する第2ステップと、
複数の前記初期構造のうちの他の初期構造に対して予測モデルを用いることにより、前記他の初期構造に対して構造最適化が実施された場合の原子配置の構造に対応する第2エネルギーを予測する第3ステップと、
前記第1エネルギー及び前記第2エネルギーに基づいて、極小値を示す第3エネルギーを抽出する第4ステップと、
前記第3エネルギー、前記第3エネルギーに対応する原子配置の構造である第1構造、または、前記第3エネルギー及び前記第1構造を出力する第5ステップと、を実行し、
前記予測モデルは、任意の原子配置の構造を入力として、当該構造に対して構造最適化が実施された場合の構造に対応するエネルギーを前記第2エネルギーとして出力するように機械学習されている、
探索方法。 - 前記材料には、脱離し得る前記原子がx個(xは2以上の整数)含まれており、
前記第1ステップでは、前記原子がz個(zは1≦z≦x-1の整数)脱離した系について、xCz個の複数の前記初期構造を生成する、
請求項1に記載の探索方法。 - 前記第1ステップにおいて、n個(nは2以上の整数)の前記初期構造を取得した場合に、
前記第2ステップにおける前記一部の初期構造は、m個(mは1≦m<nの整数)の前記初期構造であり、
前記第3ステップにおける前記他の初期構造は、(n―m)個の前記初期構造である、
請求項1又は2に記載の探索方法。 - 前記第3エネルギーは、前記第1エネルギー及び前記第2エネルギーの最小値である、
請求項1~3のいずれか一項に記載の探索方法。 - 前記予測モデルは、
前記初期構造を入力データ、当該初期構造に対応する前記第1エネルギーを正解データとして含む第1学習用データセットを用いて機械学習されたモデルである、
請求項1~4のいずれか一項に記載の探索方法。 - 前記予測モデルは、
更に、前記構造最適化された原子配置の構造を入力データ、当該構造に対応する前記第1エネルギーを正解データとして含む第2学習用データセットを用いて機械学習されたモデルである、
請求項5に記載の探索方法。 - 前記第2ステップにおける前記一部の初期構造の数は、複数の前記初期構造の数の90%以下である、
請求項1~6のいずれか一項に記載の探索方法。 - 材料の組成についての3次元空間における原子配置の安定構造を探索するための探索システムであって、
前記材料に含まれる原子の脱離による脱離後の材料の組成がとり得る前記3次元空間における原子配置の構造である複数の初期構造を生成する生成部と、
複数の前記初期構造のうちの一部の初期構造に対して構造最適化を実施し、構造最適化された原子配置の構造に対応する第1エネルギーを算出する算出部と、
複数の前記初期構造のうちの他の初期構造に対して予測モデルを用いることにより、前記他の初期構造に対して構造最適化が実施された場合の原子配置の構造対応する第2エネルギーを予測する予測部と、
前記第1エネルギー及び前記第2エネルギーを出力する出力部と、を備え、
前記予測モデルは、任意の原子配置の構造を入力として、当該構造に対して構造最適化が実施された場合の構造に対応するエネルギーを前記第2エネルギーとして出力するように機械学習されている、
探索システム。 - 前記出力部は、前記第1エネルギー及び前記第2エネルギーに基づいて抽出された、極小値を示す第3エネルギー、前記第3エネルギーに対応する原子配置の構造である第1構造、または、前記第3エネルギー及び前記第1構造を出力する、
請求項8に記載の探索システム。 - 材料の組成についての3次元空間における原子配置の安定構造を探索するためのプログラムであって、
前記材料に含まれる原子の脱離による脱離後の材料の組成がとり得る前記3次元空間における原子配置の構造である複数の初期構造を取得する第1ステップと、
複数の前記初期構造のうちの一部の初期構造に対して構造最適化を実施し、構造最適化された原子配置の構造に対応する第1エネルギーを算出する第2ステップと、
複数の前記初期構造のうちの他の初期構造に対して予測モデルを用いることにより、前記他の初期構造に対して構造最適化が実施された場合の原子配置の構造に対応する第2エネルギーを予測する第3ステップと、
前記第1エネルギー及び前記第2エネルギーを出力する第6ステップと、をコンピュータに実行させ、
前記予測モデルは、任意の原子配置の構造を入力として、当該構造に対して構造最適化が実施された場合の構造に対応するエネルギーを前記第2エネルギーとして出力するように機械学習されている、
プログラム。 - 前記第1エネルギー及び前記第2エネルギーに基づいて、極小値を示す第3エネルギーを抽出する第4ステップを前記コンピュータに更に実行させ、
前記第6ステップでは、前記第3エネルギー、前記第3エネルギーに対応する原子配置の構造である第1構造、または、前記第3エネルギー及び前記第1構造を更に出力する、
請求項10に記載のプログラム。 - コンピュータが、
材料に含まれる原子の脱離による脱離後の材料の組成がとり得る3次元空間における原子配置の構造である初期構造を取得する第1ステップと、
前記初期構造を入力データ、当該初期構造に対して構造最適化を実施して得られた原子配置の構造に対応するエネルギーを正解データとして含む学習用データセットを用いて、任意の原子配置の構造の入力に対して当該構造が構造最適化された場合の構造に対応するエネルギーを出力するように機械学習させる第7ステップと、を実行する、
予測モデル構築方法。 - 材料に含まれる原子の脱離による脱離後の材料の組成がとり得る3次元空間における原子配置の構造である初期構造を生成する生成部と、
前記初期構造を入力データ、当該初期構造に対して構造最適化を実施して得られた原子配置の構造に対応するエネルギーを正解データとして含む学習用データセットを用いて、任意の原子配置の構造の入力に対して当該構造が構造最適化された場合の構造に対応するエネルギーを出力するように機械学習させる学習部と、を備える、
予測モデル構築装置。 - 請求項13に記載の予測モデル構築装置により機械学習された予測モデルを用いて、前記材料の組成についての前記3次元空間における原子配置の安定構造を探索するための探索方法であって、
コンピュータが、
複数の前記初期構造を取得する第1ステップと、
複数の前記初期構造それぞれに対して前記予測モデルを用いることにより、当該初期構造に対して構造最適化が実施された場合の原子配置の構造に対応するエネルギーを予測する第8ステップと、
予測された複数の前記エネルギーから、極小値を示すエネルギーを抽出する第9ステップと、を実行する、
探索方法。 - 請求項13に記載の予測モデル構築装置により機械学習された予測モデルを用いて、前記材料の組成についての前記3次元空間における原子配置の安定構造を探索するための探索方法であって、
コンピュータが、
複数の前記初期構造を取得する第1ステップと、
複数の前記初期構造のうちの一部の初期構造に対して構造最適化を実施し、構造最適化された原子配置の構造に対応する第1エネルギーを算出する第2ステップと、
前記一部の初期構造のうちの少なくとも1つの初期構造に対して前記予測モデルを用いることにより、当該初期構造に対して構造最適化が実施された場合の原子配置の構造に対応する第2エネルギーを予測する第10ステップと、
前記第1エネルギーと前記第2エネルギーとを比較することで前記予測モデルの予測精度を検証する第11ステップと、を実行する、
探索方法。 - 前記第11ステップにおける結果が所定の条件を満たす場合に、
前記コンピュータが、
複数の前記初期構造のうちの他の初期構造に対して前記予測モデルを用いることにより、前記他の初期構造に対して構造最適化が実施された場合の原子配置の構造に対応する前記第2エネルギーを予測する第12ステップと、
前記第1エネルギー及び前記第2エネルギーに基づいて、極小値を示す第3エネルギーを抽出する第13ステップと、を更に実行する、
請求項15に記載の探索方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023538412A JPWO2023008173A1 (ja) | 2021-07-27 | 2022-07-12 | |
| CN202280051390.8A CN117678025A (zh) | 2021-07-27 | 2022-07-12 | 探索方法、探索系统、程序、预测模型构建方法及预测模型构建装置 |
| US18/408,658 US20240144046A1 (en) | 2021-07-27 | 2024-01-10 | Search method, search system, recording medium, prediction model construction method, and prediction model construction device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021122633 | 2021-07-27 | ||
| JP2021-122633 | 2021-07-27 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/408,658 Continuation US20240144046A1 (en) | 2021-07-27 | 2024-01-10 | Search method, search system, recording medium, prediction model construction method, and prediction model construction device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023008173A1 true WO2023008173A1 (ja) | 2023-02-02 |
Family
ID=85086780
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/027344 WO2023008173A1 (ja) | 2021-07-27 | 2022-07-12 | 探索方法、探索システム、プログラム、予測モデル構築方法、及び予測モデル構築装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240144046A1 (ja) |
| JP (1) | JPWO2023008173A1 (ja) |
| CN (1) | CN117678025A (ja) |
| WO (1) | WO2023008173A1 (ja) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020054841A1 (ja) * | 2018-09-14 | 2020-03-19 | 富士フイルム株式会社 | 化合物探索方法、化合物探索プログラム、記録媒体、及び化合物探索装置 |
| JP2020166706A (ja) * | 2019-03-29 | 2020-10-08 | 株式会社クロスアビリティ | 結晶形予測装置、結晶形予測方法、ニューラルネットワークの製造方法、及びプログラム |
-
2022
- 2022-07-12 WO PCT/JP2022/027344 patent/WO2023008173A1/ja active Application Filing
- 2022-07-12 CN CN202280051390.8A patent/CN117678025A/zh active Pending
- 2022-07-12 JP JP2023538412A patent/JPWO2023008173A1/ja active Pending
-
2024
- 2024-01-10 US US18/408,658 patent/US20240144046A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020054841A1 (ja) * | 2018-09-14 | 2020-03-19 | 富士フイルム株式会社 | 化合物探索方法、化合物探索プログラム、記録媒体、及び化合物探索装置 |
| JP2020166706A (ja) * | 2019-03-29 | 2020-10-08 | 株式会社クロスアビリティ | 結晶形予測装置、結晶形予測方法、ニューラルネットワークの製造方法、及びプログラム |
Non-Patent Citations (2)
| Title |
|---|
| HIROYUKI MATSUI, OKADA TOMOHARU: "Machine-Learning-Assisted Design Tool for Semiconducting and Fluorescent Molecules", THE 67TH JSAP SPRING MEETING 2020, 12 March 2020 (2020-03-12), pages 10 - 115, XP055956660, Retrieved from the Internet <URL:https://confit.atlas.jp/guide/event-img/jsap2020s/12p-A405-15/public/pdf?type=in> [retrieved on 20220831] * |
| KIYOHARA, SHIN ET AL.: "Interface Structure Determination and Spectrum Analysis Using Machine Learning", JOURNAL OF JAPANESE SOCIETY FOR ARTIFICIAL INTELLIGENCE, vol. 34, no. 3, 1 May 2019 (2019-05-01), pages 345 - 350, XP009542998, ISSN: 2188-2266, DOI: 10.11517/jjsai.34.3_345 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN117678025A (zh) | 2024-03-08 |
| US20240144046A1 (en) | 2024-05-02 |
| JPWO2023008173A1 (ja) | 2023-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109657805A (zh) | 超参数确定方法、装置、电子设备及计算机可读介质 | |
| CN102087721B (zh) | 信息处理设备和观测值预测方法 | |
| CN111951901A (zh) | 优化设备、优化系统、优化方法及记录介质 | |
| CN117076931A (zh) | 一种基于条件扩散模型的时间序列数据预测方法和系统 | |
| CN117972531B (zh) | 一种多样化的逆合成分析模型评价方法及装置 | |
| Dragomir | Air quality index prediction using K-nearest neighbor technique | |
| CN111783238A (zh) | 涡轮轴结构可靠性分析方法、分析装置及可读存储介质 | |
| CN114660497A (zh) | 一种针对容量再生现象的锂离子电池寿命预测方法 | |
| Feng et al. | Advancing single-cell RNA-seq data analysis through the fusion of multi-layer perceptron and graph neural network | |
| WO2023008172A1 (ja) | 探索方法、探索システム、プログラム、予測モデル構築方法、及び予測モデル構築装置 | |
| Cao et al. | An ensemble learning prognostic method for capacity estimation of lithium-ion batteries based on the V-IOWGA operator | |
| EP4071764A2 (en) | Information processing program, information processing apparatus, and information processing method for determining properties of molecules | |
| Saraswathi et al. | Fast learning optimized prediction methodology (FLOPRED) for protein secondary structure prediction | |
| WO2023008173A1 (ja) | 探索方法、探索システム、プログラム、予測モデル構築方法、及び予測モデル構築装置 | |
| EP1920367A1 (en) | Electronic circuit design | |
| Samadian et al. | Application of data-driven surrogate models in structural engineering: a literature review | |
| CN116964678A (zh) | 使用以蛋白质结构嵌入为条件的生成模型预测蛋白质氨基酸序列 | |
| CN113627513A (zh) | 一种训练数据生成方法、系统、电子设备及存储介质 | |
| Xu | Hybrid adaptive sequential sampling for reliability-based design optimization | |
| Bowman | A tutorial on building markov state models with MSMBuilder and coarse-graining them with BACE | |
| JP7487155B2 (ja) | 情報処理装置、プログラム、及び、情報処理方法 | |
| WO2020018576A1 (en) | Relating complex data | |
| CN117313873A (zh) | 基于量子计算的化学反应路径的生成方法、装置及介质 | |
| JPWO2023008172A5 (ja) | ||
| Fernandez-Zelaia et al. | Self-supervised feature distillation and design of experiments for efficient training of micromechanical deep learning surrogates |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22849237 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023538412 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280051390.8 Country of ref document: CN |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22849237 Country of ref document: EP Kind code of ref document: A1 |