WO2022239178A1 - インセンティブ最適化方法、インセンティブ最適化装置、及びプログラム - Google Patents
インセンティブ最適化方法、インセンティブ最適化装置、及びプログラム Download PDFInfo
- Publication number
- WO2022239178A1 WO2022239178A1 PCT/JP2021/018182 JP2021018182W WO2022239178A1 WO 2022239178 A1 WO2022239178 A1 WO 2022239178A1 JP 2021018182 W JP2021018182 W JP 2021018182W WO 2022239178 A1 WO2022239178 A1 WO 2022239178A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- incentive
- optimization
- giving
- incentives
- achievement
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 72
- 238000005457 optimization Methods 0.000 title claims abstract description 63
- 230000006399 behavior Effects 0.000 description 30
- 238000012545 processing Methods 0.000 description 8
- 230000003542 behavioural effect Effects 0.000 description 7
- 238000004891 communication Methods 0.000 description 6
- 230000006870 function Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000013178 mathematical model Methods 0.000 description 2
- 230000004075 alteration Effects 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000037081 physical activity Effects 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 230000000276 sedentary effect Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/04—Forecasting or optimisation specially adapted for administrative or management purposes, e.g. linear programming or "cutting stock problem"
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
Definitions
- the present invention relates to an incentive optimization method, an incentive optimization device, and a program.
- Non-Patent Document 1 discloses that, for the purpose of forming exercise habits, the provision of incentives (money) according to the amount of exercise promotes the formation of exercise habits.
- the magnitude of the effect of an incentive is thought to differ from individual to individual, even if the amount, number of times, and timing of the incentive are the same.
- the incentive may become less attractive due to the longer period until the incentive is obtained due to the achievement of the goal, and as a result, the effect of the incentive may be reduced.
- Non-Patent Document 1 the method of giving incentives is not optimized for each individual, and the influence of the period until incentives are obtained is not considered. It may not have been utilized.
- An embodiment of the present invention has been made in view of the above points, and aims to optimize the method of giving incentives for each individual, taking into consideration the period until incentives are obtained.
- an incentive optimization method for optimizing a method of giving an incentive to an individual's behavior, wherein the behavior sequence and the incentive for the sequence are optimized.
- a parameter estimation procedure for estimating, for each individual, the parameters of a model having the input and output of the incentive provision method and the degree of achievement of the target behavior, respectively, using the observation data of the provision method, and the parameters estimated by the parameter estimation procedure.
- a computer executes an optimization procedure for calculating a method of giving incentives that maximizes the degree of achievement, using the model in which the parameters are set.
- FIG. 10 is a diagram showing an output example of estimated parameter values; It is a figure which shows the output example of a maximum achievement degree and an optimal incentive.
- an incentive optimization device 10 capable of optimizing the incentive giving method for each individual in consideration of the period until the incentive is obtained will be described.
- the incentive optimization device 10 optimizes the incentive giving method for each individual, taking into consideration the period until the incentive is obtained, according to the following (1) and (2).
- a mathematical model (hereinafter also referred to as "behavioral model") is prepared for each individual, in which the method of giving incentives is input and the degree of achievement of target behavior is output, and incentives are given based on each individual's behavioral model. Optimize the method.
- the method of giving incentives is composed of the number of times incentives are given, the timing of each time, and the magnitude (amount) of incentives.
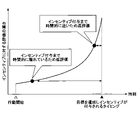
- time discounting means that, as shown in Fig. 1, the incentive is evaluated low when the incentive is given away in time, and the incentive is evaluated highly when the incentive is given close in time. be.
- FIG. 2 is a diagram showing an example of the hardware configuration of the incentive optimization device 10 according to this embodiment.
- the incentive optimization device 10 is realized by the hardware configuration of a general computer or computer system, and includes an input device 101, a display device 102, an external I/F 103, a communication It has an I/F 104 , a processor 105 and a memory device 106 . Each of these pieces of hardware is communicably connected via a bus 107 .
- the input device 101 is, for example, a keyboard, mouse, touch panel, or the like.
- the display device 102 is, for example, a display. Note that the incentive optimization device 10 may not have at least one of the input device 101 and the display device 102, for example.
- the external I/F 103 is an interface with an external device such as the recording medium 103a.
- the incentive optimization device 10 can perform reading, writing, etc. of the recording medium 103 a via the external I/F 103 .
- Examples of the recording medium 103a include CD (Compact Disc), DVD (Digital Versatile Disk), SD memory card (Secure Digital memory card), USB (Universal Serial Bus) memory card, and the like.
- the communication I/F 104 is an interface for connecting the incentive optimization device 10 to a communication network.
- the processor 105 is, for example, various arithmetic units such as a CPU (Central Processing Unit) and a GPU (Graphics Processing Unit).
- the memory device 106 is, for example, various storage devices such as HDD (Hard Disk Drive), SSD (Solid State Drive), RAM (Random Access Memory), ROM (Read Only Memory), and flash memory.
- the incentive optimization device 10 can implement the incentive optimization processing described later.
- the hardware configuration shown in FIG. 2 is an example, and the incentive optimization device 10 may have multiple processors 105 and may have multiple memory devices 106 .
- FIG. 3 is a diagram showing an example of the functional configuration of the incentive optimization device 10 according to this embodiment.
- the incentive optimization device 10 has a parameter estimation section 201 and an incentive optimization section 202 . These units are implemented by, for example, processing that one or more programs installed in the incentive optimization device 10 cause the processor 105 to execute.
- the parameter estimating unit 201 receives the action history data of each individual as input, estimates the parameters of each individual's action model, and outputs estimated parameter values as the estimation results.
- the incentive optimization unit 202 inputs the estimated parameter values and the optimization conditions, which are the conditions regarding the method of giving incentives. , and outputs the optimum incentive and the degree of achievement at that time (maximum degree of achievement).
- one incentive optimization device 10 has the parameter estimation unit 201 and the incentive optimization unit 202, but this is an example, and for example, the parameter estimation unit 201 and Different devices may each have the incentive optimization unit 202 .
- FIG. 4 is a flowchart showing an example of incentive optimization processing according to this embodiment.
- Steps S101 to S103 are parameter estimation phases for estimating the parameters of the behavioral model
- steps S104 to S106 are incentive optimization phases for obtaining maximum achievement and optimal incentives from the behavioral model for which the estimated parameter values are set. is.
- each individual's action history data is provided to the incentive optimization device 10
- estimated parameter values and optimization conditions are provided to the incentive optimization device 10.
- Step S101 First, the parameter estimation unit 201 inputs action history data of each individual.
- the action history data is observation data relating to the actions of each individual (hereinafter also referred to as a user), the number of incentives for the actions, the time (or the date and time, etc.), and the amount.
- u be an ID or the like that identifies a user
- U be the total number of users
- Tu be the length of the target action period of the user u
- N u be the number of incentives observed for the user u.
- the action history data includes the action sequence ⁇ y t u ⁇ at each observation time of the user u, the incentive provision time sequence ⁇ s n u ⁇ observed by the user u, and the incentive given to the user u and a series of incentive amounts ⁇ m n u ⁇ .
- the observed value ⁇ y t u ⁇ of the behavior is assumed to be a numerical value obtained by quantitatively evaluating the goodness of the target behavior.
- the observed value of behavior may be the number of steps per day or the like.
- examples of the incentive amount include money, points, and the like.
- Step S102 Next, the parameter estimation unit 201 estimates the parameters of each individual's behavior model using the behavior history data input in step S101.
- a behavior model is a mathematical model that inputs the method of giving incentives and outputs the degree of achievement of a target behavior. In this step, the parameters of this behavior model are estimated for each user u.
- m i is the i-th incentive amount
- ⁇ is a parameter
- s i ⁇ 1 , s i , ⁇ ) represents the degree of influence of the i-th given incentive on behavior per unit incentive amount.
- s i ⁇ 1 , s i , ⁇ ) is designed to be a monotonically increasing function with respect to time t. It is also assumed that xt represents an internal state and is converted to observed behavior yt through a function ⁇ ( x ).
- s i ⁇ 1 , s i , ⁇ ) on behavior per unit incentive amount is, for example, a function h(t
- s i ⁇ 1 , s i , ⁇ ) 1/(1+ ⁇ (s i ⁇ t)).
- an evaluation function G ( ⁇ y t ⁇ ) for calculating the degree of achievement of the target action from the series of actions ⁇ y t ⁇ (y 1 , y 2 , . . . , y T ) in a period of length T is Define.
- Achievement level of target behavior G( ⁇ y t ⁇ ) (2)
- a behavior model is defined by the above equations (1) and (2).
- the evaluation function G ( ⁇ y t ⁇ ) is arbitrarily designed according to the target behavior. The further away from the goal, the lower the degree of achievement.
- the parameter estimation unit 201 estimates the parameter ⁇ so as to minimize the difference ⁇ y between the behavior predicted from the behavior model and the behavior history data. However, parameter estimation is performed for each user u.
- parameter estimating section 201 estimates parameter ⁇ u of user u using the following equation (3).
- ⁇ is assumed to be a non-negative value.
- Step S103 Then, the parameter estimator 201 outputs the parameter ⁇ u estimated in step S102 as an estimated parameter value.
- FIG. 5 shows an output example of estimated parameter values.
- the output destination of the estimated parameter values can be arbitrarily set, and examples thereof include the display device 102, the memory device 106, and other devices connected via a communication network.
- Step S104 Subsequently, the incentive optimization unit 202 inputs estimated parameter values and optimization conditions.
- Z u denote an incentive giving method for user u.
- the incentive giving method Z u consists of the number of times N of incentives, the time sequence ⁇ s n ⁇ (s 1 , s 2 , . . . , s N ) of giving incentives, and the amount A sequence ⁇ m n ⁇ (m 1 , m 2 , . . . , m N ). That is, Z u ⁇ (N, ⁇ s n ⁇ , ⁇ m n ⁇ ).
- C Z u be a condition (optimization condition) to be considered for the incentive giving method.
- the optimization condition G Z u is specifically a set of various incentive giving methods for user u. For example, it is a set such as ⁇ Z
- the purpose is to search for the optimum incentive giving method (that is, the giving method that maximizes the effect of the incentive (the degree of achievement of the target behavior)) from among the incentive giving methods that satisfy such a certain condition.
- the optimization condition G Z u is the search space for the incentive provision method for user u. It is to be noted that the incentive designer or the like determines what kind of condition the set of incentive giving methods that satisfies G Z u .
- Step S105 Next, the incentive optimization unit 202 uses the estimated parameter values and the optimization conditions input in step S104 to calculate the optimum incentive provision method Zu . That is, the incentive optimization unit 202 searches for the optimal incentive giving method Z u for the user u using the following equation (4).
- the optimum incentive giving method Z u for the user u may be searched by a known algorithm (for example, a brute-force method).
- Step S106 Then, the incentive optimization unit 202 outputs the maximum achievement level and the optimum incentive obtained in the above step S105.
- optimum number of incentives N 3, optimum incentive giving time (3, 5, 10)
- optimum incentive at each time It shows an example when amounts (2,000 yen, 5,000 yen, and 3,000 yen) are output.
- the output destination of the maximum achievement level and optimal incentive can be arbitrarily set, but examples thereof include the display device 102, the memory device 106, and other devices connected via a communication network.
- the incentive optimization device 10 creates, for each user, a behavior model that also considers the period until the incentive is given, and uses this behavior model to provide an optimal incentive method, that is, Search for an incentive giving method that maximizes the degree of achievement of target behavior for each user.
- an optimal incentive method that is, Search for an incentive giving method that maximizes the degree of achievement of target behavior for each user.
Abstract
一実施形態に係るインセンティブ最適化方法は、個人の行動に対するインセンティブの付与方法を最適化するためのインセンティブ最適化方法であって、前記行動の系列と前記系列に対するインセンティブの付与方法の観測データを用いて、前記インセンティブの付与方法と目標行動に対する達成度をそれぞれ入力と出力に持つモデルのパラメータを前記個人毎に推定するパラメータ推定手順と、前記パラメータ推定手順で推定されたパラメータを設定した前記モデルを用いて、前記達成度を最大化するインセンティブの付与方法を算出する最適化手順と、をコンピュータが実行する。
Description
本発明は、インセンティブ最適化方法、インセンティブ最適化装置、及びプログラムに関する。
インセンティブによる目標行動の達成、あるいは目標習慣の形成に関する従来技術として、非特許文献1に記載されている技術が知られている。非特許文献1には、運動習慣の形成を目的として、運動量に応じたインセンティブ(金銭)の付与によって人の運動習慣の形成が促進されることが開示されている。
Finkelstein, Eric. A., et al., "A Randomized Study of Financial Incentives to Increase Physical Activity among Sedentary Older Adults", Preventive medicine, 47(2), pp.182-187.
ところで、或る目標行動の達成において、インセンティブによる効果の大きさは同じ量や回数、タイミングのインセンティブであっても個人毎に異なると考えられる。また、行動の開始から目標達成までの期間が長い場合、目標の達成によりインセンティブが得られるまでの期間が長くなることでインセンティブの魅力が小さくなり、結果としてインセンティブの効果が小さくなる可能性がある。
しかしながら、非特許文献1に記載されている技術では、インセンティブの付与方法が個人毎に最適化されておらず、またインセンティブが得られるまでの期間の影響が考慮されていないため、インセンティブを有効に活用できていない可能性がある。
本発明の一実施形態は、上記の点に鑑みてなされたもので、インセンティブが得られるまでの期間も考慮して、インセンティブの付与方法を個人毎に最適化することを目的とする。
上記目的を達成するため、一実施形態に係るインセンティブ最適化方法は、個人の行動に対するインセンティブの付与方法を最適化するためのインセンティブ最適化方法であって、前記行動の系列と前記系列に対するインセンティブの付与方法の観測データを用いて、前記インセンティブの付与方法と目標行動に対する達成度をそれぞれ入力と出力に持つモデルのパラメータを前記個人毎に推定するパラメータ推定手順と、前記パラメータ推定手順で推定されたパラメータを設定した前記モデルを用いて、前記達成度を最大化するインセンティブの付与方法を算出する最適化手順と、をコンピュータが実行する。
インセンティブが得られるまでの期間も考慮して、インセンティブの付与方法を個人毎に最適化することができる。
以下、本発明の一実施形態について説明する。本実施形態では、インセンティブが得られるまでの期間も考慮して、インセンティブの付与方法を個人毎に最適化することができるインセンティブ最適化装置10について説明する。
ここで、本実施形態に係るインセンティブ最適化装置10は、以下の(1)及び(2)により、インセンティブが得られるまでの期間も考慮して、インセンティブの付与方法を個人毎に最適化する。
(1)インセンティブの付与方法を入力、目標行動に対する達成度を出力とする数理モデル(以下、「行動モデル」ともいう。)を個人毎に用意し、各個人の行動モデルに基づいてインセンティブの付与方法を最適化する。ここで、インセンティブの付与方法は、インセンティブの回数と、各回のタイミング及びインセンティブの大きさ(量)とで構成されるものとする。
(2)行動モデルにおいて、遠い将来に得られるインセンティブを近い将来に得られるインセンティブに対して低く評価する行動経済学現象、すなわち時間割引を考慮する。ここで、時間割引とは、図1に示すように、インセンティブの付与まで時間的に離れている場合はインセンティブを低く評価し、インセンティブの付与まで時間的に近い場合はインセンティブを高く評価することである。
<ハードウェア構成>
まず、本実施形態に係るインセンティブ最適化装置10のハードウェア構成について、図2を参照しながら説明する。図2は、本実施形態に係るインセンティブ最適化装置10のハードウェア構成の一例を示す図である。
まず、本実施形態に係るインセンティブ最適化装置10のハードウェア構成について、図2を参照しながら説明する。図2は、本実施形態に係るインセンティブ最適化装置10のハードウェア構成の一例を示す図である。
図2に示すように、本実施形態に係るインセンティブ最適化装置10は一般的なコンピュータ又はコンピュータシステムのハードウェア構成で実現され、入力装置101と、表示装置102と、外部I/F103と、通信I/F104と、プロセッサ105と、メモリ装置106とを有する。これらの各ハードウェアは、それぞれがバス107により通信可能に接続される。
入力装置101は、例えば、キーボードやマウス、タッチパネル等である。表示装置102は、例えば、ディスプレイ等である。なお、インセンティブ最適化装置10は、例えば、入力装置101及び表示装置102のうちの少なくとも一方を有していなくてもよい。
外部I/F103は、記録媒体103a等の外部装置とのインタフェースである。インセンティブ最適化装置10は、外部I/F103を介して、記録媒体103aの読み取りや書き込み等を行うことができる。なお、記録媒体103aとしては、例えば、CD(Compact Disc)、DVD(Digital Versatile Disk)、SDメモリカード(Secure Digital memory card)、USB(Universal Serial Bus)メモリカード等が挙げられる。
通信I/F104は、インセンティブ最適化装置10を通信ネットワークに接続するためのインタフェースである。プロセッサ105は、例えば、CPU(Central Processing Unit)やGPU(Graphics Processing Unit)等の各種演算装置である。メモリ装置106は、例えば、HDD(Hard Disk Drive)やSSD(Solid State Drive)、RAM(Random Access Memory)、ROM(Read Only Memory)、フラッシュメモリ等の各種記憶装置である。
本実施形態に係るインセンティブ最適化装置10は、図2に示すハードウェア構成を有することにより、後述するインセンティブ最適化処理を実現することができる。なお、図2に示すハードウェア構成は一例であって、インセンティブ最適化装置10は、複数のプロセッサ105を有していてもよいし、複数のメモリ装置106を有していてもよい。
<機能構成>
次に、本実施形態に係るインセンティブ最適化装置10の機能構成について、図3を参照しながら説明する。図3は、本実施形態に係るインセンティブ最適化装置10の機能構成の一例を示す図である。
次に、本実施形態に係るインセンティブ最適化装置10の機能構成について、図3を参照しながら説明する。図3は、本実施形態に係るインセンティブ最適化装置10の機能構成の一例を示す図である。
図3に示すように、本実施形態に係るインセンティブ最適化装置10は、パラメータ推定部201と、インセンティブ最適化部202とを有する。これら各部は、例えば、インセンティブ最適化装置10にインストールされた1以上のプログラムが、プロセッサ105に実行させる処理により実現される。
パラメータ推定部201は、各個人の行動履歴データを入力として各個人の行動モデルのパラメータを推定し、その推定結果として推定パラメータ値を出力する。
インセンティブ最適化部202は、推定パラメータ値とインセンティブの付与方法に関する条件である最適化条件とを入力として、各個人の行動モデルにより、目標行動の達成度を最大化するインセンティブ付与方法を表す最適インセンティブを探索し、その最適インセンティブとそのときの達成度(最大達成度)とを出力する。
なお、図1に示す例では、1台のインセンティブ最適化装置10がパラメータ推定部201とインセンティブ最適化部202とを有しているが、これは一例であって、例えば、パラメータ推定部201とインセンティブ最適化部202とをそれぞれ異なる装置が有していてもよい。
<インセンティブ最適化処理>
次に、本実施形態に係るインセンティブ最適化処理について、図4を参照しながら説明する。図4は、本実施形態に係るインセンティブ最適化処理の一例を示すフローチャートである。ステップS101~ステップS103は行動モデルのパラメータを推定するためのパラメータ推定フェーズであり、ステップS104~ステップS106は推定パラメータ値を設定した行動モデルにより最大達成度及び最適インセンティブを得るためのインセンティブ最適化フェーズである。なお、パラメータ推定フェーズでは各個人の行動履歴データがインセンティブ最適化装置10に与えられ、インセンティブ最適化フェーズでは推定パラメータ値と最適化条件がインセンティブ最適化装置10に与えられる。
次に、本実施形態に係るインセンティブ最適化処理について、図4を参照しながら説明する。図4は、本実施形態に係るインセンティブ最適化処理の一例を示すフローチャートである。ステップS101~ステップS103は行動モデルのパラメータを推定するためのパラメータ推定フェーズであり、ステップS104~ステップS106は推定パラメータ値を設定した行動モデルにより最大達成度及び最適インセンティブを得るためのインセンティブ最適化フェーズである。なお、パラメータ推定フェーズでは各個人の行動履歴データがインセンティブ最適化装置10に与えられ、インセンティブ最適化フェーズでは推定パラメータ値と最適化条件がインセンティブ最適化装置10に与えられる。
ステップS101:まず、パラメータ推定部201は、各個人の行動履歴データを入力する。
行動履歴データとは、各個人(以下、ユーザともいう。)の行動とそれに対するインセンティブの回数、時刻(又は、年月日や日時等でもよい。)、量に関する観測データのことである。ユーザを識別するID等をu、ユーザの総数をU、ユーザuの目標とする行動の期間の長さをTu、ユーザuで観測されたインセンティブ付与の回数をNuとする。このとき、行動履歴データは、ユーザuの各観測時刻における行動の系列{yt
u}と、ユーザuで観測されたインセンティブ付与の時刻の系列{sn
u}と、ユーザuに付与されたインセンティブ量の系列{mn
u}とで構成される。ここで、

ただし、行動の観測値{yt
u}は、目標とする行動の良さを定量的に評価した数値であるものとする。例えば、ウォーキング習慣の形成を目的とする場合、行動の観測値を1日の歩数等とすることが挙げられる。また、インセンティブ量の例としては、金銭やポイント等が挙げられる。
ステップS102:次に、パラメータ推定部201は、上記のステップS101で入力した行動履歴データを用いて、各個人の行動モデルのパラメータを推定する。
行動モデルとは、インセンティブの付与方法を入力、目標行動に対する達成度を出力とする数理モデルであり、本ステップでは、この行動モデルのパラメータをユーザu毎に推定する。
まず、各ユーザの時刻tにおける行動ytが以下の式(1)で与えられる状況を考える。

なお、単位インセンティブ量あたりの行動への影響度h(t|si-1,si,θ)は、例えば、双曲割引を考慮した関数h(t|si-1,si,θ)=1/(1+θ(si-t))等で与えられる。
次に、長さTの期間における行動の系列{yt}≡(y1,y2,・・・,yT)から目標行動の達成度を算出する評価関数G({yt})を定義する。
目標行動の達成度=G({yt}) (2)
上記の式(1)及び式(2)により行動モデルが定義される。
上記の式(1)及び式(2)により行動モデルが定義される。
なお、評価関数G({yt})としては、目標行動に応じて任意に設計されるが、行動の系列{yt}が目標に近付くほど達成度が高く、行動の系列{yt}が目標から遠ざかるほど達成度が低くなるものとする。
したがって、パラメータ推定部201は、行動モデルから予測される行動と、行動履歴データとの差分Δyを最小化するようにパラメータθを推定する。ただし、パラメータの推定はユーザu毎に行われる。
すなわち、パラメータ推定部201は、以下の式(3)によりユーザuのパラメータθuを推定する。

ステップS103:そして、パラメータ推定部201は、上記のステップS102で推定されたパラメータθuを推定パラメータ値として出力する。ここで、推定パラメータ値の出力例を図5に示す。図5に示す例では、ユーザu=1のパラメータθu=0.3、ユーザu=2のパラメータθu=0.1、及びユーザu=3のパラメータθu=2.1等が推定パラメータ値として出力された場合の例を示している。なお、推定パラメータ値の出力先は任意に設定することが可能であるが、例えば、表示装置102、メモリ装置106、通信ネットワークを介して接続される他の装置等が挙げられる。
ステップS104:続いて、インセンティブ最適化部202は、推定パラメータ値と最適化条件とを入力する。
ここで、ユーザuに関するインセンティブの付与方法をZuとする。インセンティブの付与方法Zuは、インセンティブの回数Nと、インセンティブ付与の時刻の系列{sn}≡(s1,s2,・・・,sN)と、ユーザuに付与されるインセンティブ量の系列{mn}≡(m1,m2,・・・,mN)とで構成される。つまり、Zu≡(N,{sn},{mn})とする。また、このとき、インセンティブの付与方法を最適化するにあたり、インセンティブの付与方法に関して考慮すべき条件(最適化条件)をCZ
uとする。
最適化条件GZ
uは、具体的には、ユーザuに関する様々なインセンティブ付与方法の集合のことである。例えば、インセンティブ付与方法をZとして、{Z|N=3,インセンティブ量の合計=10000}といった集合等のことである。これは、インセンティブ付与回数が3回で、インセンティブ量の合計が10000であるインセンティブ付与方法Zの集合を表している。このような或る条件を満たすインセンティブ付与方法の中から最適なインセンティブ付与方法(つまり、インセンティブの効果(目標行動の達成度)を最大化する付与方法)を探索することが目的である。この意味で最適化条件GZ
uは、ユーザuに関するインセンティブ付与方法の探索空間のことである。なお、どのような条件を満たすインセンティブ付与方法の集合をGZ
uとするかは、インセンティブの設計者等によって決定される。
ステップS105:次に、インセンティブ最適化部202は、上記のステップS104で入力した推定パラメータ値と最適化条件とを用いて、最適なインセンティブの付与方法Zuを算出する。すなわち、インセンティブ最適化部202は、以下の式(4)によりユーザuの最適なインセンティブ付与方法Zuを探索する。

上記の最適なインセンティブ付与方法Zuは、各ユーザu∈{1,2.・・・,U}に対して探索される。これにより、ユーザ毎に最適インセンティブと最大達成度とが得られる。
ステップS106:そして、インセンティブ最適化部202は、上記のステップS105で得られた最大達成度及び最適インセンティブを出力する。ここで、最大達成度G*及び最適インセンティブZu*=(N,{sn},{mn})の出力例を図6に示す。図6に示す例では、ユーザu=1の最大達成度G*=10.5、最適なインセンティブ回数N=3、最適なインセンティブ付与時刻(3,5,10)、各時刻での最適なインセンティブ量(2千円、5千円、3千円)が出力された場合の例を示している。同様に、ユーザu=2の最大達成度G*=20.3、最適なインセンティブ回数N=1、最適なインセンティブ付与時刻(10)、各時刻での最適なインセンティブ量(1万)が出力された場合の例を示している。同様に、ユーザu=3の最大達成度G*=12.4、最適なインセンティブ回数N=3、最適なインセンティブ付与時刻(1,2,10)、各時刻での最適なインセンティブ量(1千円、1千円、8千円)が出力された場合の例を示している。この図6に示す例では、各ユーザuの金銭的インセンティブの予算(つまり、各ユーザuのインセンティブ量の合計)が1万円であることを条件としている。なお、最大達成度及び最適インセンティブの出力先は任意に設定することが可能であるが、例えば、表示装置102、メモリ装置106、通信ネットワークを介して接続される他の装置等が挙げられる。
<まとめ>
以上のように、本実施形態に係るインセンティブ最適化装置10は、インセンティブが付与されるまでの期間も考慮した行動モデルをユーザ毎に作成し、この行動モデルを用いて最適なインセンティブ付与方法、すなわち目標行動の達成度を最大化するインセンティブ付与方法をユーザ毎に探索する。これにより、各個人のインセンティブに対する行動原理に基づいて、その個人が目標とする行動を達成するために最も効果的なインセンティブの付与方法を個人毎に特定することができるようになる。
以上のように、本実施形態に係るインセンティブ最適化装置10は、インセンティブが付与されるまでの期間も考慮した行動モデルをユーザ毎に作成し、この行動モデルを用いて最適なインセンティブ付与方法、すなわち目標行動の達成度を最大化するインセンティブ付与方法をユーザ毎に探索する。これにより、各個人のインセンティブに対する行動原理に基づいて、その個人が目標とする行動を達成するために最も効果的なインセンティブの付与方法を個人毎に特定することができるようになる。
本発明は、具体的に開示された上記の実施形態に限定されるものではなく、請求の範囲の記載から逸脱することなく、種々の変形や変更、既知の技術との組み合わせ等が可能である。
10 インセンティブ最適化装置
101 入力装置
102 表示装置
103 外部I/F
103a 記録媒体
104 通信I/F
105 プロセッサ
106 メモリ装置
107 バス
201 パラメータ推定部
202 インセンティブ最適化部
101 入力装置
102 表示装置
103 外部I/F
103a 記録媒体
104 通信I/F
105 プロセッサ
106 メモリ装置
107 バス
201 パラメータ推定部
202 インセンティブ最適化部
Claims (6)
- 個人の行動に対するインセンティブの付与方法を最適化するためのインセンティブ最適化方法であって、
前記行動の系列と前記系列に対するインセンティブの付与方法の観測データを用いて、前記インセンティブの付与方法と目標行動に対する達成度をそれぞれ入力と出力に持つモデルのパラメータを前記個人毎に推定するパラメータ推定手順と、
前記パラメータ推定手順で推定されたパラメータを設定した前記モデルを用いて、前記達成度を最大化するインセンティブの付与方法を算出する最適化手順と、
をコンピュータが実行するインセンティブ最適化方法。 - 前記モデルは、遠い将来に得られるインセンティブを近い将来に得られるインセンティブよりも低く評価する時間割引を考慮して、前記達成度を出力する、請求項1に記載のインセンティブ最適化方法。
- 前記インセンティブの付与方法には、インセンティブ付与の回数と、インセンティブの付与日時と、インセンティブの付与量とが含まれる、請求項1又は2に記載のインセンティブ最適化方法。
- 前記最適化手順は、
前記付与量の合計が一定との条件の下で、前記インセンティブの付与方法を算出する、請求項3に記載のインセンティブ最適化方法。 - 個人の行動に対するインセンティブの付与方法を最適化するためのインセンティブ最適化装置であって、
前記行動の系列と前記系列に対するインセンティブの付与方法の観測データを用いて、前記インセンティブの付与方法と目標行動に対する達成度をそれぞれ入力と出力に持つモデルのパラメータを前記個人毎に推定するパラメータ推定部と、
前記パラメータ推定部で推定されたパラメータを設定した前記モデルを用いて、前記達成度を最大化するインセンティブの付与方法を算出する最適化部と、
を有するインセンティブ最適化装置。 - コンピュータに、請求項1乃至4の何れか一項に記載のインセンティブ最適化方法を実行させるプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023520676A JPWO2022239178A1 (ja) | 2021-05-13 | 2021-05-13 | |
| PCT/JP2021/018182 WO2022239178A1 (ja) | 2021-05-13 | 2021-05-13 | インセンティブ最適化方法、インセンティブ最適化装置、及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/018182 WO2022239178A1 (ja) | 2021-05-13 | 2021-05-13 | インセンティブ最適化方法、インセンティブ最適化装置、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022239178A1 true WO2022239178A1 (ja) | 2022-11-17 |
Family
ID=84028069
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/018182 WO2022239178A1 (ja) | 2021-05-13 | 2021-05-13 | インセンティブ最適化方法、インセンティブ最適化装置、及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2022239178A1 (ja) |
| WO (1) | WO2022239178A1 (ja) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003248724A (ja) * | 2002-02-26 | 2003-09-05 | Matsushita Electric Ind Co Ltd | 健康サービス継続支援システムのセンタ装置 |
| JP2010516004A (ja) * | 2007-01-12 | 2010-05-13 | ヘルスオーナーズ コーポレイション | 断続性報酬を用いた行動修正 |
| JP2013020587A (ja) * | 2011-07-14 | 2013-01-31 | Nec Corp | 情報処理システム、ユーザの行動促進方法、情報処理装置及びその制御方法と制御プログラム |
| JP2018028889A (ja) * | 2017-02-02 | 2018-02-22 | 株式会社FiNC | 健康管理装置 |
| JP2019046173A (ja) * | 2017-09-01 | 2019-03-22 | ヤフー株式会社 | 情報解析装置、情報解析方法、およびプログラム |
| JP2020107132A (ja) * | 2018-12-27 | 2020-07-09 | 楽天株式会社 | 価額設定装置、価額設定方法、及び価額設定プログラム |
-
2021
- 2021-05-13 WO PCT/JP2021/018182 patent/WO2022239178A1/ja active Application Filing
- 2021-05-13 JP JP2023520676A patent/JPWO2022239178A1/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003248724A (ja) * | 2002-02-26 | 2003-09-05 | Matsushita Electric Ind Co Ltd | 健康サービス継続支援システムのセンタ装置 |
| JP2010516004A (ja) * | 2007-01-12 | 2010-05-13 | ヘルスオーナーズ コーポレイション | 断続性報酬を用いた行動修正 |
| JP2013020587A (ja) * | 2011-07-14 | 2013-01-31 | Nec Corp | 情報処理システム、ユーザの行動促進方法、情報処理装置及びその制御方法と制御プログラム |
| JP2018028889A (ja) * | 2017-02-02 | 2018-02-22 | 株式会社FiNC | 健康管理装置 |
| JP2019046173A (ja) * | 2017-09-01 | 2019-03-22 | ヤフー株式会社 | 情報解析装置、情報解析方法、およびプログラム |
| JP2020107132A (ja) * | 2018-12-27 | 2020-07-09 | 楽天株式会社 | 価額設定装置、価額設定方法、及び価額設定プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022239178A1 (ja) | 2022-11-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Wang et al. | Collaborative filtering with social exposure: A modular approach to social recommendation | |
| Takács et al. | Alternating least squares for personalized ranking | |
| Mohri et al. | Learning theory and algorithms for revenue optimization in second price auctions with reserve | |
| EP3179434A1 (en) | Designing context-aware recommendation systems, based on latent contexts | |
| JP6414363B2 (ja) | 予測システム、方法およびプログラム | |
| JP2011096255A (ja) | ランキング指向の協調フィルタリング推薦方法および装置 | |
| JP7040319B2 (ja) | 運用管理装置、移動先推奨方法及び移動先推奨プログラム | |
| Su et al. | Modeling left-truncated and right-censored survival data with longitudinal covariates | |
| KR101955244B1 (ko) | 논문 평가 방법 및 전문가 추천 방법 | |
| Wang et al. | Predicting new workload or CPU performance by analyzing public datasets | |
| JP7139932B2 (ja) | 需要予測方法、需要予測プログラムおよび需要予測装置 | |
| Li et al. | Hierarchical functional data with mixed continuous and binary measurements | |
| JP5481295B2 (ja) | オブジェクト推薦装置、オブジェクト推薦方法、オブジェクト推薦プログラムおよびオブジェクト推薦システム | |
| WO2022239178A1 (ja) | インセンティブ最適化方法、インセンティブ最適化装置、及びプログラム | |
| JP6870467B2 (ja) | 広告効果推定装置、広告効果推定方法及び広告効果推定プログラム | |
| KR102262118B1 (ko) | 사용자 맞춤형 추천정보 제공장치 및 제공방법, 이를 실행시키기 위한 프로그램을 기록한 컴퓨터 해독 가능한 기록 매체 | |
| US20170046726A1 (en) | Information processing device, information processing method, and program | |
| Watanabe et al. | Kl-ucb-based policy for budgeted multi-armed bandits with stochastic action costs | |
| JP6810184B2 (ja) | 算出装置、算出方法及び算出プログラム | |
| JP7235960B2 (ja) | ジョブ電力予測プログラム、ジョブ電力予測方法、およびジョブ電力予測装置 | |
| CN109636432B (zh) | 计算机执行的项目选择方法和装置 | |
| US8086626B2 (en) | Rare pattern extracting device and rare pattern extracting method | |
| Olaleke et al. | Dynamic modeling of user preferences for stable recommendations | |
| JP7001380B2 (ja) | 情報処理システム、情報処理方法、およびプログラム | |
| JP6025796B2 (ja) | 行動予測装置、行動予測方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21941912 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023520676 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18558717 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |