WO2022145214A1 - 情報処理装置および方法 - Google Patents
情報処理装置および方法 Download PDFInfo
- Publication number
- WO2022145214A1 WO2022145214A1 PCT/JP2021/045929 JP2021045929W WO2022145214A1 WO 2022145214 A1 WO2022145214 A1 WO 2022145214A1 JP 2021045929 W JP2021045929 W JP 2021045929W WO 2022145214 A1 WO2022145214 A1 WO 2022145214A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- node
- attribute data
- data
- unit
- decoding
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 76
- 238000000034 method Methods 0.000 title abstract description 164
- 238000012545 processing Methods 0.000 claims abstract description 332
- 238000003672 processing method Methods 0.000 claims abstract description 12
- 238000002910 structure generation Methods 0.000 description 26
- 238000005516 engineering process Methods 0.000 description 19
- 230000008685 targeting Effects 0.000 description 15
- 238000013507 mapping Methods 0.000 description 14
- 238000013139 quantization Methods 0.000 description 12
- 238000013075 data extraction Methods 0.000 description 11
- 238000010586 diagram Methods 0.000 description 10
- 239000003086 colorant Substances 0.000 description 4
- 238000004891 communication Methods 0.000 description 4
- 230000015654 memory Effects 0.000 description 4
- 230000006870 function Effects 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- 101000801040 Homo sapiens Transmembrane channel-like protein 1 Proteins 0.000 description 1
- 102100033690 Transmembrane channel-like protein 1 Human genes 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000003796 beauty Effects 0.000 description 1
- FFBHFFJDDLITSX-UHFFFAOYSA-N benzyl N-[2-hydroxy-4-(3-oxomorpholin-4-yl)phenyl]carbamate Chemical compound OC1=C(NC(=O)OCC2=CC=CC=C2)C=CC(=C1)N1CCOCC1=O FFBHFFJDDLITSX-UHFFFAOYSA-N 0.000 description 1
- 230000010267 cellular communication Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 238000005065 mining Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000007430 reference method Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images




















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T9/00—Image coding
- G06T9/40—Tree coding, e.g. quadtree, octree
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T17/00—Three dimensional [3D] modelling, e.g. data description of 3D objects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/60—Analysis of geometric attributes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T9/00—Image coding
- G06T9/001—Model-based coding, e.g. wire frame
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/96—Tree coding, e.g. quad-tree coding
Definitions
- the present disclosure relates to an information processing device and a method, and more particularly to an information processing device and a method capable of more reliably decoding attribute data.
- Non-Patent Document 1 a method for encoding 3D data representing a three-dimensional structure such as a point cloud has been considered (see, for example, Non-Patent Document 1).
- a method of realizing parallelization of decoding by signaling a flag that divides Octree into node groups (node group), and decoding of some node groups See, for example, Non-Patent Document 2).
- the predicted value of the point to be processed is derived using the attribute data of the surrounding points, and the difference value between the attribute data of the point to be processed and the predicted value is coded.
- a coding method for example, a method called Lifting has been considered (see, for example, Non-Patent Document 3).
- a neighborhood point search is performed to set a point that refers to the attribute data in order to derive the predicted value.
- Non-Patent Document 3 does not limit the points to be searched. Therefore, for example, when a node group is formed in a tree structure of attribute data, there is a possibility that a node belonging to the node group that is not decoded may also be searched. As a result, there is a risk that the decoding of the attribute data will fail.
- This disclosure has been made in view of such a situation, and is intended to enable more reliable decoding of attribute data.
- the information processing device uses the attribute data of each point in the point cloud, which expresses a three-dimensional object as a set of points, as a node, and forms a slice that is a node group that can be encoded independently of each other.
- the neighborhood point search unit that executes the neighborhood point search for setting, the attribute data of the processing target node, and the attribute data of the reference point set by the neighborhood point search by the neighborhood point search unit.
- This is an information processing apparatus including a coding unit that encodes a difference value from the predicted value derived from the above.
- the attribute data of each point of the point cloud that expresses a three-dimensional object as a set of points is used as a node, and slices that are node groups that can be encoded independently of each other are formed.
- the difference value between the attribute data of the processing target node and the predicted value derived by using the attribute data of the reference point set by the neighborhood point search. Is an information processing method that encodes.
- the information processing device on the other side of the present technology uses the attribute data of each point of the point cloud, which expresses a three-dimensional object as a set of points, as a node, and forms a slice, which is a node group that can be encoded independently of each other.
- a decoding unit that decodes the coded data in which the difference value between the attribute data and the predicted value of the attribute data of the processing target node of the tree structure is encoded and derives the difference value of the processing target node.
- a reference point to be referred to when deriving the predicted value of the processing target node is targeted only to the node decoded by the decoding unit before the processing target node among the nodes of the tree structure.
- the neighborhood point search unit that executes the neighborhood point search for setting, the difference value derived by the decoding unit, and the attribute data of the reference point set by the neighborhood point search by the neighborhood point search unit.
- a restoration unit that restores the attribute data of the processing target node by adding the predicted value derived using the data, the attribute data of the point of the decoding target area restored by the restoration unit, and the attribute data. It is an information processing device provided with a matching unit that associates point geometry data with each other.
- the information processing method of the other aspect of this technology uses the attribute data of each point of the point cloud that expresses a three-dimensional object as a set of points as a node, and forms a slice that is a node group that can be encoded independently of each other.
- the coded data in which the difference value between the attribute data and the predicted value of the attribute data of the processing target node of the tree structure to be processed is encoded is decoded, the difference value of the processing target node is derived, and the tree is described. Neighboring point search for setting a reference point to be referred to when deriving the predicted value of the processing target node, targeting only the node decoded before the processing target node among the nodes of the structure.
- the attribute data of each point of the point cloud that expresses a three-dimensional object as a set of points is used as a node, and the slice is a node group that can be encoded independently of each other.
- the slice is a node group that can be encoded independently of each other.
- the attribute data of each point of the point cloud that expresses a three-dimensional object as a set of points is used as a node, and is a node group that can be encoded independently of each other.
- Encoded data in which the difference between the attribute data and the predicted value of the attribute data of the processing target node of the tree structure in which the slice is formed is encoded is decoded, and the difference value of the processing target node is derived, and the difference value is derived.
- the neighborhood point search is executed to set the reference point to be referred to when deriving the predicted value of the processing target node, targeting only the nodes decoded before the processing target node.
- the attribute data of the processing target node is restored and restored.
- the attribute data of the point in the decoding target area is associated with the geometry data of that point.
- Non-Patent Document 1 (above)
- Non-Patent Document 2 (above)
- Non-Patent Document 3 (above)
- Point cloud data (also referred to as point cloud data) is composed of position information (also referred to as geometry) and attribute information (also referred to as attributes) at each point.
- the attribute can contain any information. For example, it may include color information, reflectance information, normal information, etc. of each point.
- the point cloud has a relatively simple data structure and can express an arbitrary three-dimensional structure with sufficient accuracy by using a sufficiently large number of points.
- a voxel is a three-dimensional region for quantizing geometry (position information).
- the three-dimensional area containing the point cloud (also referred to as a bounding box) is divided into a small three-dimensional area called a voxel, and each voxel indicates whether or not the point is included.
- the position of each point is quantized in voxel units. Therefore, it is possible to suppress an increase in the amount of information (typically, reduce the amount of information).
- the resolution of the geometry depends on the size of this voxel (in other words, the number of voxels).
- the geometry was considered to make the geometry a tree structure by making it possible to recursively divide voxels by utilizing such characteristics.
- the resolution of the geometry can be made variable. That is, the geometry can be expressed not only at the highest resolution corresponding to the lowest layer of the tree structure but also at the low resolution corresponding to the middle layer of the tree structure.
- a method of encoding and decoding point cloud data was considered. For example, when transmitting point cloud data, the transmitting side encodes the point cloud data to generate a bit stream, the bit stream is transmitted, and the receiving side decodes the bit stream to generate the point cloud data. By doing so, the amount of data at the time of transmission can be reduced, and an increase in load can be suppressed. The same applies when storing point cloud data.
- the point cloud is composed of geometry and attributes. That is, the geometry and attribute data are encoded and decoded respectively.
- the geometry data (also referred to as geometry data) can be decoded in a scalable manner with respect to the resolution by encoding according to the above-mentioned tree structure. That is, it is possible to realize the scalability of the resolution in the decoding process. For example, partial decoding is possible, such as decoding only the nodes from the top layer of the tree structure to an arbitrary layer (do not decode the nodes in the lower layers). That is, it is possible to obtain a geometry having a desired resolution by decoding only a necessary part without decoding all the coded data of the geometry.
- Non-Patent Document 2 discloses a method of signaling a flag for dividing this point cloud tree structure (Octree) into node groups.
- decoding becomes possible independently for each node group. Therefore, for example, the decoding process can be divided into node groups and parallelized. It is also possible to decode only some node groups. For example, by dividing the node group for each partial area of the three-dimensional area, it is possible to decode only the geometry of a part of the area. That is, in the decoding process, it is possible to realize scalability for the area. That is, it is possible to obtain the geometry of a desired region by decoding only the necessary part without decoding all the coded data of the geometry.
- This node group is also called a slice. That is, a slice is a grouping of nodes in a tree structure of geometry.
- the geometry data can be independently encoded for each slice.
- the coded data of the geometry data can be independently decoded for each slice.
- the tree structure of the geometry may be any tree structure. For example, it may be Octree or KD Tree, or it may be other than that.
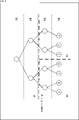
- Figure 1 shows another example of the slice structure set in the geometry data.
- the solid line of the thin line shows the tree structure, and the branch point of the practice shows the node.
- the node group surrounded by the thick line forms one slice.
- LoD indicates the hierarchy of the tree structure.
- all the nodes of LoD0 to LoD4 belong to slice 1.
- the node of the area 1 (gray area) of LoD5 to LoD7 belongs to the slice 2.
- the nodes in region 2 (white background region) of LoD5 to LoD7 belong to slice 3.
- the nodes in region 3 (gray area) of LoD5 to LoD7 belong to slice 4.
- the nodes in region 4 (white background region) of LoD5 to LoD7 belong to slice 5.
- each node of LoD0 to LoD4 is encoded layer by layer in the order from the upper layer to the lower layer for the entire region.
- Each node of LoD5 to LoD7 is encoded layer by layer in the order from the upper layer to the lower layer for each region of region 1 to region 4.
- the decoding order is the same.
- the attribute data of each point is encoded as a difference value from the predicted value derived by referring to the attribute data of other points.
- the attribute data of each point For example, it will be described as two-dimensional.
- each circle indicates a point. It is assumed that the points are in such a positional relationship.
- the attribute data of each point is encoded or decoded as a difference value from the predicted value derived by referring to the attribute data of other points as shown by the arrow shown in B of FIG.
- the attribute data of each point may be hierarchized using geometry.
- the predicted point is selected so that the attribute information remains in the voxel of the next higher hierarchy (LoD) to which the voxel in which the point exists belongs.
- a square indicates a voxel and a circle indicates a point.
- the voxel 20 is divided into four to form one lower layer voxel, and the lower right voxel is divided into four to further form one lower layer voxel. Leave the voxel point (gray point) of any one of the four points (three white points and one gray point) of the voxel in the lowest hierarchy in the voxel in the next higher hierarchy. ..
- ⁇ Neighborhood point search> As shown in B of FIG. 2, in order to derive the predicted value of the attribute of the processing target point by referring to the attribute data of another point (neighborhood point), the search of the neighborhood point referring to the attribute data (also referred to as the neighborhood point search). ) Is executed.
- an interreference also referred to as an inter-LoD reference
- an intra-reference also called an in-LoD reference
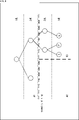
- FIG. 3 shows an example of the slice structure.
- the entire area is sliced into one (slice # 1).
- the lower 2LoD is divided into two regions, and each region is sliced (slice # 2, slice # 3).
- the lowest layer nodes A to D belong to slice # 2
- nodes E to G belong to slice # 3.
- FIG. 4 shows an example of the slice structure of the attribute data in that case.
- node A to node G correspond to FIG. 3, respectively.
- the entire region of the upper 2LoD is sliced into one (slice # 4).
- the lower 2LoD is divided into two regions, and each region is sliced (slice # 5, slice # 6).
- Non-Patent Document 2 did not correspond to such a slice structure.
- the attribute data of each node is decoded for each LoD, and the target of the neighborhood point search is not limited, so the attribute data of the points in the entire area is the target of the neighborhood point search. Therefore, there is a possibility that the attribute data of the point in the area that is not the decoding target (that is, the node belonging to the slice that is not decoded) is referred to.
- the target of the neighborhood point search at the time of interreference is the node within the frame of the alternate long and short dash line. That is, among the nodes A to G, the node A, the node D, the node E, and the node G are the search targets. Further, the target of the neighborhood point search at the time of intra-reference is a node within the frame of the two-dot chain line. That is, in the node A to the node G, the node B and the node C are the search targets.
- the neighborhood point search is performed only for the decoded nodes.
- the decoded node is a node that is decoded before the processing target node at the time of decoding.
- searching for neighborhood points only for decoded nodes means that "nodes that have been decoded” are targeted for neighborhood point search among the nodes of the tree structure, and other nodes (nodes that have not been decoded). Is not the target of the neighborhood point search.
- the search is executed, and the difference value between the attribute data of the processing target node and the predicted value derived using the attribute data of the reference point set by the neighborhood point search is encoded.
- a neighborhood point search is executed to set a reference point to be referred to when deriving the predicted value of the processed node, and the derived difference value is executed only for the node decoded before the processed node.
- the predicted value derived using the attribute data of the reference point set by the neighborhood point search are added to restore the attribute data of the processing target node.
- the decoding unit that decodes the coded data in which the difference value between the attribute data and the predicted value of the attribute data of the processing target node is encoded and derives the difference value of the processing target node, and the node of the tree structure.
- Processing by adding the difference value derived by the point search unit and its decoding unit and the predicted value derived using the attribute data of the reference point set by the neighborhood point search unit by the neighborhood point search unit. It is provided with a restore unit that restores the attribute data of the target node.
- the tree structure of the attribute data may use the attribute data of each point layered based on the geometry data as a node.
- the tree structure of the attribute data is based on the geometry data, and the attribute data of each point layered so that the voxel in the next higher hierarchy to which the voxel in which the point in the processing target hierarchy belongs also has a point. It may be a node.
- the geometry data may form a hierarchical tree structure based on the resolution of the geometry, and each node of the attribute data tree structure may correspond to each node of the geometry data tree structure.
- slices which are node groups that can be encoded independently of each other, are formed in the tree structure of geometry data, and the structure of slices formed in the tree structure of attribute data is formed in the tree structure of the geometry data. It may correspond to the structure of.
- the tree structure of attribute data corresponds to the tree structure of geometry data in this way, it is possible to realize scalable decoding of point cloud data. Further, by making the slice structure of the attribute data correspond to the slice structure of the geometry data, the point cloud data can be restored independently for each slice.
- the neighborhood point search for the LoD-to-LoD reference may be executed for the decoded node (method 1-1). ).
- the neighborhood point search unit targets only the nodes in the tree structure of the attribute data, which are higher than the processing target node and are decoded before the processing target node by the decoding unit. Therefore, the neighborhood point search may be executed.
- the attribute data to which the interreference is applied at the time of decoding can be independently decoded for each slice, and the attribute data can be decoded more reliably.
- the neighborhood point search may be executed for the nodes belonging to the decoded slice (method). 1-1-1).
- the decoded slice is a slice (node) that is decoded before the processing target node at the time of decoding.
- the neighborhood point search unit belongs to the same slice as the processing target node among the nodes of the attribute data tree structure, and is decoded before the processing target node at the time of decoding.
- the neighborhood point search may be executed only for the nodes in the hierarchy higher than the processing target node and the nodes belonging to the slice to be decoded before the slice to which the processing target node belongs at the time of decoding.
- the neighborhood point search unit belongs to the same slice as the processing target node among the nodes of the attribute data tree structure, and is decoded before the processing target node by the decoding unit.
- the neighborhood point search may be executed only for the nodes higher than the target node and the nodes belonging to the slice to which the processing target node belongs by the decoding unit.
- the neighborhood point search for interreference is executed for the node within the frame of the one-dot chain line shown in FIG. That is, among the nodes A to G, the node A, the node E, and the node G are the search targets.
- node B to node D that is, the node belonging to slice # 5 is excluded from the neighborhood point search (it is made not set to the node that refers to the attribute data).
- the attribute data can be independently decoded for each slice, and the attribute data can be decoded more reliably.
- the neighborhood point search may be executed for the ancestor node of the tree structure of the attribute data as shown in the fourth row from the top of the table in FIG. (Method 1-1-2).
- the ancestor node is a node of the upper LoD to which the processing target node directly or indirectly belongs in the attribute data tree structure.
- the straight lines between the nodes indicate the parent-child relationship between the nodes.
- a node that is directly or indirectly connected to the processing target node by this straight line in the direction from a certain node (reference node) toward a higher LoD is called an ancestor node of the reference node.
- a node that is directly connected means a node that is connected to a certain node by the straight line without going through another node.
- node E is a node directly connected to node F.
- An indirectly connected node means a node connected to a certain node via another node by the straight line.
- node G is a node indirectly connected to node F (connected via node E or the like). That is, the node E and the node G are the ancestor nodes of the node F.
- the nodes A to D and the like are also indirectly connected to the node F (connected via the node G and the like), but these nodes belong to the lower LoD with respect to the node G. .. That is, since it is not a node connected (indirectly) in the direction toward the upper LoD when viewed from the node F, it is not an ancestor node of the node F.
- the neighborhood point search unit may execute the neighborhood point search only for the ancestor node of the processing target node among the nodes of the tree structure of the attribute data.
- the neighborhood point search for interreference is executed for the node within the frame of the one-dot chain line shown in FIG. That is, among the nodes A to G, the node E and the node G are the search targets. In other words, node A to node D are excluded from the neighborhood point search (they are not set to the node that refers to the attribute data). That is, in this case as well, the node belonging to slice # 5 is excluded from the neighborhood point search.
- the neighborhood point search for interreference is executed for the node within the frame of the two-dot chain line shown in FIG. 7. That is, in the node A to the node G, the node A, the node D, and the node G are the search targets. In other words, node B, node E, and node F are excluded from the neighborhood point search (they are not set to the node that refers to the attribute data). That is, in this case, the node belonging to slice # 6 is excluded from the neighborhood point search.
- the attribute data can be independently decoded for each slice, and the attribute data can be decoded more reliably.
- the neighborhood point search for the LoD intra-reference may be executed for the decoded node (method 1-2). ).
- the neighborhood point search unit targets only the nodes in the attribute data tree structure that are in the same layer as the processing target node and are decoded before the processing target node at the time of decoding. Therefore, the neighborhood point search may be executed.
- the neighborhood point search unit targets only the nodes in the tree structure of the attribute data, which are in the same layer as the processing target node and are decoded before the processing target node by the decoding unit. , The neighborhood point search may be executed.
- the attribute data to which the intra reference is applied at the time of decoding can be independently decoded for each slice, and the attribute data can be decoded more reliably.
- the neighborhood point search may be executed for the decoded node in the processing target LoD of the processing target slice.
- the processing target slice is a slice to which the processing target node belongs.
- the processing target LoD is the LoD to which the processing target node belongs.
- the decoded node is a node that is decoded before the processing target node at the time of decoding.
- the neighborhood point search unit belongs to the same slice as the processing target node in the node of the attribute data tree structure, and is decoded before the processing target node at the time of decoding.
- the neighborhood point search may be executed only for the nodes in the same layer as the processing target node.
- the neighborhood point search unit belongs to the same slice as the processing target node among the nodes of the attribute data tree structure, and is decoded before the processing target node by the decoding unit.
- the neighborhood point search may be executed only for the nodes in the same layer as the target node.
- the neighborhood point search for intra-reference is executed for the node within the frame of the two-dot chain line shown in FIG. That is, in this case, the node of the lowest LoD in slice # 6 is searched. In other words, node B and node C, that is, the node belonging to slice # 5, are excluded from the neighborhood point search (the node that refers to the attribute data is not set).
- the attribute data can be independently decoded for each slice, and the attribute data can be decoded more reliably.
- slice # 1 and slice # 3 of the geometry data are decoded, and slice # 2 is not decoded.
- the number of the geometry data to be decoded is 1 point, 2 points, 2 points, and 3 points from the upper LoD to the lower LoD.
- the number of decoded attribute data is one color, two colors, three colors, and four colors from the upper LoD to the lower LoD. That is, in the lower 2 LoDs, the number of decoded geometry data and the number of attribute data do not match. Therefore, for the lower 2 LoDs, the geometry data and the attribute data cannot be associated with each other, and there is a possibility that the point cloud data cannot be generated.
- the decoding target area is an area corresponding to the slice to be decoded (the area where the point corresponding to the node belonging to the slice is located).
- a neighborhood point search is executed to set a reference point to be referred to when deriving the predicted value of the processed node, and the derived difference value is executed only for the node decoded before the processed node.
- the attribute data of the processing target node is restored, and the point of the restored decoding target area is restored. Associate the attribute data with the geometry data at that point.
- the decoding unit that decodes the coded data in which the difference value between the attribute data and the predicted value of the attribute data of the processing target node is encoded and derives the difference value of the processing target node, and the node of the tree structure.
- Processing by adding the difference value derived by the point search unit and its decoding unit and the predicted value derived using the attribute data of the reference point set by the neighborhood point search unit by the neighborhood point search unit. It is provided with a restoration unit that restores the attribute data of the target node, and a matching unit that associates the attribute data of the point of the decoding target area restored by the restoration unit with the geometry data of the point.
- the geometry data of the non-decoding target area may be included in the correspondence, and then the points of the non-decoding target area may be removed based on the geometry.
- the non-decoding target area indicates an area in which a point corresponding to a node belonging to a slice that is not a decoding target is located.
- the non-decoding target area indicates an area in which the point corresponding to the node belonging to the decoding target slice is not located.
- the area where the points corresponding to the nodes belonging to the slice to be decoded are located is referred to as the decoding target area.
- the undecrypted target area is used using the decoded geometry. You may try to remove the point of (Method 2-1-1).
- the mapping unit associates the attribute data and the geometry data of all the points restored by the restoration unit, and among the points to which the attribute data and the geometry data are associated, non-decoding. You may try to remove the points in the target area.
- the geometry data including the node A is associated with the attribute data obtained by decoding slices # 4 and # 6.
- the node A can be removed by removing the points in the non-decoding target area based on the geometry data.
- mapping between the geometry data and the attribute data can be executed more reliably, and the point cloud data can be generated more reliably.
- the attribute data in the non-decoding target area may be removed, and then the geometry data and the attribute data may be associated with each other (method 2-2).
- the geometry data associated with the node at the time of LoD Generation is used to remove the attribute data in the non-decoding target area, and then the geometry data and the attribute data are associated with each other.
- the mapping unit may remove the attribute data of the points in the non-decoding target area restored by the restoration unit and associate the attribute data of the points in the decoding target area with the geometry data. good.
- the geometry is associated with each node of the attribute data.
- Each node of the lowest LoD is associated with intermediate resolution geometry data (that is, geometry data of the same LoD).
- the attribute data of the points in the non-decoding target area is removed by using the geometry of each node as shown in FIG.
- the node A since the geometry of the node A is located in the decoding target area, the node A is removed.
- the lowest layer has three colors, and the numbers of geometry data and attribute data match.
- the geometry data and the attribute data can be associated with each other. That is, by doing so, it is possible to more reliably execute the correspondence between the geometry data and the attribute data, and it is possible to generate the point cloud data more reliably.
- FIG. 14 is a block diagram showing an example of a configuration of a coding device, which is an aspect of an information processing device to which the present technology is applied.
- the coding device 100 shown in FIG. 14 is a device that encodes a point cloud (3D data).
- the present technique (for example, various methods described with reference to FIGS. 1 to 13) can be applied to the coding apparatus 100.
- FIG. 14 shows the main things such as the processing unit and the data flow, and not all of them are shown in FIG. That is, in the coding apparatus 100, there may be a processing unit that is not shown as a block in FIG. 14, or there may be a processing or data flow that is not shown as an arrow or the like in FIG.
- the coding device 100 includes a geometry data coding unit 101, a geometry data decoding unit 102, a point cloud generation unit 103, an attribute data coding unit 104, and a bitstream generation unit 105.
- the geometry data coding unit 101 encodes the position information of the point cloud (3D data) input to the coding device 100, and generates the coding data of the geometry data.
- This coding method is arbitrary. For example, processing such as filtering and quantization for noise suppression (denoise) may be performed.
- the geometry data coding unit 101 supplies the generated coded data to the geometry data decoding unit 102 and the bitstream generation unit 105.
- the geometry data decoding unit 102 acquires the coded data supplied from the geometry data coding unit 101.
- the geometry data decoding unit 102 decodes the coded data and generates the geometry data.
- This decoding method is arbitrary as long as it corresponds to the coding by the geometry data coding unit 101. For example, processing such as filtering for denoise and dequantization may be performed.
- the geometry data decoding unit 102 supplies the generated geometry data (decoding result) to the point cloud generation unit 103.
- the point cloud generation unit 103 acquires the attribute data of the point cloud input to the coding device 100 and the geometry data (decoding result) supplied from the geometry data decoding unit 102.
- the point cloud generation unit 103 performs a process (recolor process) of matching the attribute data with the geometry data (decoding result).
- the point cloud generation unit 103 supplies the attribute data corresponding to the geometry data (decoding result) to the attribute data coding unit 104.
- the attribute data coding unit 104 acquires point cloud data (geometry data (decoding result) and attribute data) supplied from the point cloud generation unit 103.
- the attribute data coding unit 104 encodes the attribute data using the geometry data (decoding result) and generates the coded data of the attribute data.
- the attribute data coding unit 104 supplies the generated coded data to the bitstream generation unit 105.
- the bitstream generation unit 105 acquires the coded data of the geometry data supplied from the geometry data coding unit 101. Further, the bitstream generation unit 105 acquires the coded data of the attribute data supplied from the attribute data coding unit 104. The bitstream generation unit 105 multiplexes these coded data and generates a bitstream including these coded data. The bitstream generation unit 105 outputs the generated bitstream to the outside of the encoding device 100. This bit stream is supplied to a decoding side device (for example, a decoding device described later) via an arbitrary communication medium or an arbitrary storage medium, for example.
- a decoding side device for example, a decoding device described later
- the attribute data coding unit 104 has ⁇ 1.
- the above-mentioned technique can be applied in the limitation of neighborhood point search>. That is, in that case, the attribute data coding unit 104 has ⁇ 1.
- Attribute data is encoded by the method to which the present technique described above is applied in Restriction of neighborhood point search>.
- the coding device 100 can encode the attribute data so that it can be independently decoded for each slice. Therefore, the attribute data can be decoded more reliably.
- each processing unit may be configured by a logic circuit that realizes the above-mentioned processing.
- each processing unit has, for example, a CPU (Central Processing Unit), a ROM (Read Only Memory), a RAM (Random Access Memory), and the like, and the above-mentioned processing is realized by executing a program using them. You may do so.
- each processing unit may have both configurations, and a part of the above-mentioned processing may be realized by a logic circuit, and the other may be realized by executing a program.
- the configurations of the respective processing units may be independent of each other.
- some processing units realize a part of the above-mentioned processing by a logic circuit, and some other processing units execute a program.
- the above processing may be realized, and another processing unit may realize the above-mentioned processing by both the logic circuit and the execution of the program.
- FIG. 15 is a block diagram showing a main configuration example of the attribute data coding unit 104 (FIG. 14). It should be noted that FIG. 15 shows the main things such as the processing unit and the flow of data, and not all of them are shown in FIG. That is, in the attribute data coding unit 104, there may be a processing unit that is not shown as a block in FIG. 15, or there may be a processing or data flow that is not shown as an arrow or the like in FIG.
- the attribute data coding unit 104 includes a layering unit 131, a slice structure generation unit 132, a neighborhood point search unit 133, a prediction processing unit 134, a quantization unit 135, and a coding unit 136.
- the layering unit 131 executes a process related to layering (LoD Generation) of attribute data. For example, the layering unit 131 acquires the attribute data and the geometry data (decoding result) supplied from the point cloud generation unit 103. The layering unit 131 uses the geometry data to layer the attribute data. For example, the layering unit 131 layered the attribute data so as to generate a tree structure similar to the geometry data. The layered unit 131 supplies the layered attribute data to the slice structure generation unit 132 together with the geometry data.
- Layering unit 131 executes a process related to layering (LoD Generation) of attribute data. For example, the layering unit 131 acquires the attribute data and the geometry data (decoding result) supplied from the point cloud generation unit 103. The layering unit 131 uses the geometry data to layer the attribute data. For example, the layering unit 131 layered the attribute data so as to generate a tree structure similar to the geometry data. The layered unit 131 supplies the layered attribute data to the slice structure generation unit 132 together with the
- the slice structure generation unit 132 executes a process related to the generation of the slice structure. For example, the slice structure generation unit 132 acquires the attribute data and the geometry data supplied from the layering unit 131. The slice structure generation unit 132 executes slice division on the attribute data and generates a slice structure. That is, the slice structure generation unit 132 groups the nodes of the tree structure of the attribute data to form a node group. At that time, the slice structure generation unit 132 uses the geometry data (that is, based on the geometry of the point) to perform slice division so as to divide each node into each region. For example, the slice structure generation unit 132 generates a slice structure of attribute data so as to have a slice structure similar to that of geometry data. The slice structure generation unit 132 supplies the attribute data for which the slice structure is generated to the neighborhood point search unit 133 together with the geometry data.
- the neighborhood point search unit 133 executes the process related to the search for the neighborhood point that refers to the attribute data in order to derive the predicted value of the processing target point. For example, the neighborhood point search unit 133 acquires the attribute data and the geometry data supplied from the slice structure generation unit 132. Further, the neighborhood point search unit 133 executes the neighborhood point search based on the geometry data.
- the neighborhood point search unit 133 is ⁇ 1. Restriction of neighborhood point search> The above-mentioned technique is applied to execute neighborhood point search. For example, as described above in ⁇ Node grouping of attributes>, the neighborhood point search unit 133 uses the attribute data of each point of the point cloud as a node, and forms a slice which is a node group that can be encoded independently of each other. To set the reference point to be referred to when deriving the predicted value of the attribute data of the processing target node, targeting only the node that is decoded before the processing target node at the time of decoding among the nodes of the tree structure. You may perform a neighborhood point search for.
- the tree structure of the attribute data may use the attribute data of each point layered based on the geometry data as a node.
- the tree structure of the attribute data is based on the geometry data, and the attribute data of each point layered so that the voxel in the next higher hierarchy to which the voxel in which the point in the processing target hierarchy belongs also has a point. It may be a node.
- the geometry data may form a hierarchical tree structure based on the resolution of the geometry, and each node of the attribute data tree structure may correspond to each node of the geometry data tree structure.
- slices, which are node groups that can be encoded independently of each other, are formed in the tree structure of geometry data, and the structure of slices formed in the tree structure of attribute data is formed in the tree structure of the geometry data. It may correspond to the structure of.
- the neighborhood point search unit 133 among the nodes of the attribute data tree structure higher than the processing target node, before the processing target node at the time of decoding.
- the neighborhood point search may be executed only for the node to be decoded.
- the neighborhood point search unit 133 has described the neighborhood point search target restriction for the interreference based on the slice structure in the node of the tree structure of the attribute data.
- the neighborhood point search may be executed only for the nodes belonging to the slice to be decoded first.
- the neighborhood point search unit 133 uses the tree structure node of the attribute data as described above in ⁇ Restriction of the neighborhood point search target for the interreference based on the tree structure>. Of these, the neighborhood point search may be executed only for the ancestor node of the processing target node.
- the neighborhood point search unit 133 decodes the attribute data tree structure of the nodes in the same layer as the processing target node before the processing target node at the time of decoding. Peripheral point search may be executed only for the nodes to be used.
- the neighborhood point search unit 133 has described the neighborhood point search target restriction for the intrareference based on the slice structure in the node of the tree structure of the attribute data.
- the neighborhood point search may be executed only for the nodes belonging to the same slice as the processing target node and being decoded before the processing target node at the time of decoding, in the same layer as the processing target node.
- the neighborhood point search unit 133 supplies the search result to the prediction processing unit 134 together with the attribute data and the geometry data.
- the prediction processing unit 134 executes processing related to prediction of attribute data. For example, the prediction processing unit 134 acquires the search result, attribute data, and geometry data of the neighborhood point search supplied from the neighborhood point search unit 133. The prediction processing unit 134 uses the information to derive the predicted value of the attribute data of the processing target node. For example, the prediction processing unit 134 sets the searched neighborhood points to the parent node or the grandparent node, and derives the predicted value of the attribute data of the processing target node using the attribute data of those nodes.
- the prediction processing unit 134 derives the difference value between the attribute data and the derived predicted value for the processing target node. Then, the prediction processing unit 134 supplies the derived difference value to the quantization unit 135.
- the quantization unit 135 is supplied from the prediction processing unit 134 and acquires a difference value.
- the quantization unit 135 quantizes the difference value.
- the quantized unit 135 supplies the quantized difference value to the coding unit 136.
- the coding unit 136 acquires the quantized difference value supplied from the quantizing unit 135.
- the coding unit 136 encodes the quantized difference value and generates the coded data of the attribute data (difference value). This coding method is arbitrary.
- the coding unit 136 supplies the generated coded data to the bitstream generation unit 105 (FIG. 14).
- the neighborhood point search unit 133 applies the present technique to execute the neighborhood point search, so that the coding device 100 (attribute data coding unit 104) independently obtains the attribute data for each slice. It can be encoded so that it can be decoded. Therefore, the attribute data can be decoded more reliably.
- each processing unit may be configured by a logic circuit that realizes the above-mentioned processing.
- each processing unit may have, for example, a CPU, ROM, RAM, etc., and execute a program using them to realize the above-mentioned processing.
- each processing unit may have both configurations, and a part of the above-mentioned processing may be realized by a logic circuit, and the other may be realized by executing a program.
- the configurations of the respective processing units may be independent of each other. For example, some processing units realize a part of the above-mentioned processing by a logic circuit, and some other processing units execute a program.
- the above-mentioned processing may be realized by the other processing unit by both the logic circuit and the execution of the program.
- the coding device 100 encodes the data in the point cloud by executing the coding process. An example of the flow of this coding process will be described with reference to the flowchart of FIG.
- the geometry data coding unit 101 of the coding device 100 encodes the input point cloud geometry data in step S101 and generates the coding data of the geometry data.
- step S102 the geometry data decoding unit 102 decodes the coded data generated in step S101 and generates geometry data.
- step S103 the point cloud generation unit 103 performs recolor processing using the input point cloud attribute data and the geometry data (decoding result) generated in step S102, and corresponds the attribute data to the geometry data. Let me.
- step S104 the attribute data coding unit 104 encodes the attribute data recolored in step S103 by executing the attribute data coding process, and generates the coded data of the attribute data.
- step S105 the bitstream generation unit 105 generates and outputs a bitstream including the coded data of the geometry data generated in step S101 and the coded data of the attribute data generated in step S104.
- step S105 When the process of step S105 is completed, the coding process is completed.
- the attribute data coding process executed in step S104 of such a coding process includes ⁇ 1.
- the above-mentioned technique can be applied in the limitation of neighborhood point search>. That is, in that case, the attribute data coding unit 104 has ⁇ 1.
- the attribute data coding process is executed by the method to which the present technique is applied in the restriction of neighborhood point search>, and the attribute data is encoded.
- the coding apparatus 100 can encode the attribute data so that it can be independently decoded for each slice. Therefore, the attribute data can be decoded more reliably.
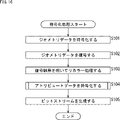
- the layering unit 131 of the attribute data coding unit 104 layers the attribute data so as to correspond to the hierarchical structure of the geometry data in step S131.
- step S132 the slice structure generation unit 132 generates a slice structure of attribute data.
- step S133 the neighborhood point search unit 133 searches for a neighborhood point that refers to the attribute data in order to derive a predicted value of the processing target point based on the geometry data.
- the neighborhood point search unit 133 is ⁇ 1. Restriction of neighborhood point search>
- the above-mentioned technique is applied to execute neighborhood point search.
- the neighborhood point search unit 133 uses the attribute data of each point of the point cloud as a node, and forms a slice which is a node group that can be encoded independently of each other.
- the reference point to be referred to when deriving the predicted value of the attribute data of the processing target node, targeting only the node that is decoded before the processing target node at the time of decoding among the nodes of the tree structure. You may perform a neighborhood point search for.
- the tree structure of the attribute data may use the attribute data of each point layered based on the geometry data as a node.
- the tree structure of the attribute data is based on the geometry data, and the attribute data of each point layered so that the voxel in the next higher hierarchy to which the voxel in which the point in the processing target hierarchy belongs also has a point. It may be a node.
- the geometry data may form a hierarchical tree structure based on the resolution of the geometry, and each node of the attribute data tree structure may correspond to each node of the geometry data tree structure.
- slices, which are node groups that can be encoded independently of each other, are formed in the tree structure of geometry data, and the structure of slices formed in the tree structure of attribute data is formed in the tree structure of the geometry data. It may correspond to the structure of.
- the neighborhood point search unit 133 among the nodes of the attribute data tree structure higher than the processing target node, before the processing target node at the time of decoding.
- the neighborhood point search may be executed only for the node to be decoded.
- the neighborhood point search unit 133 has described the neighborhood point search target restriction for the interreference based on the slice structure in the node of the tree structure of the attribute data.
- the neighborhood point search may be executed only for the nodes belonging to the slice to be decoded first.
- the neighborhood point search unit 133 uses the tree structure node of the attribute data as described above in ⁇ Restriction of the neighborhood point search target for the interreference based on the tree structure>. Of these, the neighborhood point search may be executed only for the ancestor node of the processing target node.
- the neighborhood point search unit 133 decodes the attribute data tree structure of the nodes in the same layer as the processing target node before the processing target node at the time of decoding. Peripheral point search may be executed only for the nodes to be used.
- the neighborhood point search unit 133 has described the neighborhood point search target restriction for the intrareference based on the slice structure in the node of the tree structure of the attribute data.
- the neighborhood point search may be executed only for the nodes belonging to the same slice as the processing target node and being decoded before the processing target node at the time of decoding, in the same layer as the processing target node.
- step S134 the prediction processing unit 134 derives a predicted value of the attribute data of the node to be processed based on the reference structure between the nodes corresponding to the result of the neighborhood point search in step S133, and the attribute data and the predicted value are combined with each other. Derive the difference value.
- step S135 the quantizing unit 135 quantizes the difference value derived in step S134.
- step S136 the coding unit 136 encodes the difference value quantized in step S135.
- step S136 When the process of step S136 is completed, the attribute data coding process is completed.
- the coding device 100 (attribute data coding unit 104) can encode the attribute data so that it can be independently decoded for each slice. Therefore, the attribute data can be decoded more reliably.
- FIG. 18 is a block diagram showing an example of a configuration of a decoding device, which is an aspect of an information processing device to which the present technology is applied.
- the decoding device 200 shown in FIG. 18 is a device that decodes the coded data of the point cloud (3D data).
- the present technique (for example, various methods described with reference to FIGS. 1 to 13) can be applied to the decoding device 200.
- FIG. 18 shows the main things such as the processing unit and the data flow, and not all of them are shown in FIG. That is, in the decoding device 200, there may be a processing unit that is not shown as a block in FIG. 18, or there may be a processing or data flow that is not shown as an arrow or the like in FIG.
- the decoding device 200 has a decoding target setting unit 201, a coded data extraction unit 202, a geometry data decoding unit 203, an attribute data decoding unit 204, and a point cloud generation unit 205.
- the decoding target setting unit 201 performs processing related to setting the hierarchy (LoD) and slice (node group) to be decoded.
- the decoding target setting unit 201 has a layer or area to be decoded, such as to which layer the coded data of the point cloud held in the coded data extraction unit 202 is to be decoded, which slice is to be decoded, and the like. Set about.
- the method of setting the hierarchy and slice to be decoded is arbitrary.
- the decryption target setting unit 201 may be set based on an instruction regarding a hierarchy or slice supplied from the outside such as a user or an application. Further, the decoding target setting unit 201 may obtain and set the layer or slice to be decoded based on arbitrary information such as an output image.
- the data unit of this decoding target setting is arbitrary.
- the decryption target setting unit 201 can also set a hierarchy or a slice for the entire point cloud. Further, the decoding target setting unit 201 can also set a hierarchy or a slice for each object. Further, the decoding target setting unit 201 can also set a hierarchy or a slice for each partial area in the object. Of course, it is also possible to set hierarchies and slices in data units other than these examples.
- the coded data extraction unit 202 acquires and holds a bit stream input to the decoding device 200.
- the coded data extraction unit 202 extracts the coded data of the geometry data and the attribute data corresponding to the decoding target range specified by the decoding target setting unit 201 from the bit stream held therein.
- the coded data extraction unit 202 supplies the coded data of the extracted geometry data to the geometry data decoding unit 203.
- the coded data extraction unit 202 supplies the coded data of the extracted attribute data to the attribute data decoding unit 204.
- the geometry data decoding unit 203 acquires the coded data of the geometry data supplied from the coded data extraction unit 202.
- the geometry data decoding unit 203 decodes the coded data and generates geometry data (decoding result).
- This decoding method is arbitrary as long as it is the same method as in the case of the geometry data decoding unit 102 of the coding apparatus 100.
- the geometry data decoding unit 203 supplies the generated geometry data (decoding result) to the attribute data decoding unit 204 and the point cloud generation unit 205.
- the attribute data decoding unit 204 acquires the coded data of the attribute data supplied from the coded data extraction unit 202.
- the attribute data decoding unit 204 acquires the geometry data (decoding result) supplied from the geometry data decoding unit 203.
- the attribute data decoding unit 204 decodes the coded data using the geometry data (decoding result) and generates the attribute data (decoding result).
- the attribute data decoding unit 204 supplies the generated attribute data (decoding result) to the point cloud generation unit 205.
- the point cloud generation unit 205 acquires the geometry data (decoding result) supplied from the geometry data decoding unit 203.
- the point cloud generation unit 205 acquires the attribute data (decoding result) supplied from the attribute data decoding unit 204.
- the point cloud generation unit 205 associates the geometry data (decoding result) with the attribute data (decoding result) and generates the point cloud data (decoding result).
- the point cloud generation unit 205 outputs the generated point cloud data (decoding result) to the outside of the decoding device 200.
- the attribute data decoding unit 204 has ⁇ 1.
- the above-mentioned technique can be applied in the limitation of neighborhood point search>. That is, in that case, the attribute data decoding unit 204 has ⁇ 1.
- the coded data of the attribute data is decoded by the method to which the present technique described above is applied in the restriction of the neighborhood point search>.
- the decoding device 200 can encode the attribute data so that it can be independently decoded for each slice. Therefore, the attribute data can be decoded more reliably.
- the point cloud generation unit 205 has ⁇ 2.
- the above-mentioned technique can be applied in the restriction of association>. That is, in that case, the point cloud generation unit 205 is set to ⁇ 2.
- Point cloud data is generated by the method to which the present technique described above is applied in the restriction of association>.
- the point cloud generation unit 205 determines the attribute data of the points in the decoding target area restored by the attribute data decoding unit 204 (restoration unit 236 described later). It may be associated with the geometry data of the point.
- the point cloud generation unit 205 associates the attribute data and the geometry data of all the points restored by the attribute data decoding unit 204 (restoration unit 236 described later) with the attribute data decoding unit 204 (recovery unit 236 described later) as described above in ⁇ Remove after mapping>. , Of the points to which the attribute data and the geometry data are associated, the points in the non-decoding target area may be removed.
- the point cloud generation unit 205 removes the attribute data of the points in the non-decoding target area restored by the attribute data decoding unit 204 (restoration unit 236 described later) as described above in ⁇ Remove before mapping>.
- the attribute data of the point in the decoding target area and the geometry data may be associated with each other.
- the decoding device 200 can associate the geometry data with the attribute data. That is, by doing so, it is possible to more reliably execute the correspondence between the geometry data and the attribute data, and it is possible to generate the point cloud data more reliably.
- each processing unit may be configured by a logic circuit that realizes the above-mentioned processing.
- each processing unit may have, for example, a CPU, ROM, RAM, etc., and execute a program using them to realize the above-mentioned processing.
- each processing unit may have both configurations, and a part of the above-mentioned processing may be realized by a logic circuit, and the other may be realized by executing a program.
- the configurations of the respective processing units may be independent of each other. For example, some processing units realize a part of the above-mentioned processing by a logic circuit, and some other processing units execute a program.
- the above-mentioned processing may be realized by the other processing unit by both the logic circuit and the execution of the program.
- FIG. 19 is a block diagram showing a main configuration example of the attribute data decoding unit 204 (FIG. 18). It should be noted that FIG. 19 shows the main things such as the processing unit and the flow of data, and not all of them are shown in FIG. That is, in the attribute data decoding unit 204, there may be a processing unit that is not shown as a block in FIG. 19, or there may be a processing or data flow that is not shown as an arrow or the like in FIG.
- the attribute data decoding unit 204 has a decoding unit 231, an inverse quantization unit 232, a layering unit 233, a slice structure generation unit 234, a neighborhood point search unit 235, and a restoration unit 236.
- Decoding unit 231 executes processing related to decoding. For example, the decoding unit 231 acquires the coded data of the attribute data supplied from the coded data extraction unit 202 (FIG. 18). The decoding unit 231 decodes the coded data. By this decoding, the difference value between the attribute data and the predicted value is obtained. It should be noted that this difference value is quantized. Further, this decoding method is arbitrary as long as it corresponds to the coding method by the coding unit 136 (FIG. 15) of the coding device 100. The decoding unit 231 supplies the generated difference value (quantized difference value) to the inverse quantization unit 232.
- the inverse quantization unit 232 acquires the quantized difference value supplied from the decoding unit 231.
- the dequantization unit 232 dequantizes the quantized difference value and derives the difference value.
- the inverse quantization unit 232 supplies the difference value to the layering unit 233.
- the layering unit 233 acquires the difference value supplied from the inverse quantization unit 232.
- the layering unit 233 stratifies (tree-structures) the attribute data based on the geometry data supplied from the geometry data decoding unit 203. As a result, the layering unit 233 forms a tree structure similar to that in the case of the coding device 100 for the attribute data.
- the layered unit 233 supplies the layered difference value to the slice structure generation unit 234.
- the slice structure generation unit 234 acquires the layered difference value (attribute data) supplied from the layered unit 233.
- the slice structure generation unit 234 executes slice division on the layered difference value (attribute data) in the same manner as the slice structure generation unit 132, and generates a slice structure.
- the slice structure generation unit 234 uses the geometry data (that is, based on the geometry of the point) to perform slice division so as to divide each node into each region.
- the slice structure generation unit 234 generates a slice structure of a difference value (attribute data) so that the slice structure is similar to the geometry data.
- the slice structure generation unit 234 supplies the difference value (attribute data) that generated the slice structure to the neighborhood point search unit 235 together with the geometry data.
- the neighborhood point search unit 235 executes the process related to the search for the neighborhood point that refers to the attribute data in order to derive the predicted value of the processing target point. For example, the neighborhood point search unit 235 acquires the difference value (attribute data) supplied from the slice structure generation unit 234 and the geometry data. Further, the neighborhood point search unit 235 executes the neighborhood point search based on the geometry data.
- the neighborhood point search unit 235 has ⁇ 1. Restriction of neighborhood point search> The above-mentioned technique is applied to execute neighborhood point search. For example, as described above in ⁇ Node grouping of attributes>, the neighborhood point search unit 235 uses the attribute data of each point of the point cloud as a node, and forms a slice which is a node group that can be encoded independently of each other. Neighboring point search for setting a reference point to be referred to when deriving the predicted value of the processing target node, targeting only the node decoded before the processing target point by the decoding unit 231 in the node of the tree structure. May be executed.
- the tree structure of the attribute data may use the attribute data of each point layered based on the geometry data as a node.
- the tree structure of the attribute data is based on the geometry data, and the attribute data of each point layered so that the voxel in the next higher hierarchy to which the voxel in which the point in the processing target hierarchy belongs also has a point. It may be a node.
- the geometry data may form a hierarchical tree structure based on the resolution of the geometry, and each node of the attribute data tree structure may correspond to each node of the geometry data tree structure.
- slices, which are node groups that can be encoded independently of each other, are formed in the tree structure of geometry data, and the structure of slices formed in the tree structure of attribute data is formed in the tree structure of the geometry data. It may correspond to the structure of.
- the tree structure of attribute data corresponds to the tree structure of geometry data in this way, it is possible to realize scalable decoding of point cloud data. Further, by making the slice structure of the attribute data correspond to the slice structure of the geometry data, the point cloud data can be restored independently for each slice.
- the neighborhood point search unit 235 is higher than the processing target node among the nodes of the attribute data tree structure, and the decoding unit 231 precedes the processing target node.
- the neighborhood point search may be executed only for the decoded node.
- the neighborhood point search unit 235 has the neighborhood point search unit 235 in the node of the tree structure of the attribute data as described above in ⁇ Restriction of the neighborhood point search target for the interreference based on the slice structure>. From the slice that belongs to the same slice as the processing target node and is decoded before the processing target node by the decoding unit 231 and higher than the processing target node, and the slice to which the processing target node belongs by the decoding unit 231. You may also perform a neighborhood point search only for the nodes that belong to the slice that was decoded earlier.
- the neighborhood point search unit 235 uses the tree structure node of the attribute data as described above in ⁇ Restriction of the neighborhood point search target for the interreference based on the tree structure>. Of these, the neighborhood point search may be executed only for the ancestor node of the processing target node.
- the neighborhood point search unit 235 decodes the attribute data tree structure before the processing target node by the decoding unit 231 among the nodes in the same layer as the processing target node.
- the neighborhood point search may be executed only for the nodes that have been created.
- the neighborhood point search unit 235 As a neighborhood point search for the inter-reference, the neighborhood point search unit 235, as described above in ⁇ Restriction of neighborhood point search target for intra-reference based on slice structure>, among the nodes of the tree structure of the attribute data, The neighborhood point search may be executed only for the nodes belonging to the same slice as the processing target node and decoded by the decoding unit 231 before the processing target node in the same layer as the processing target node.
- the neighborhood point search unit 235 supplies the search result to the restoration unit 236 together with the attribute data and the geometry data.
- the restoration unit 236 executes a process related to restoration of attribute data. For example, the restoration unit 236 acquires the search result, the difference value (attribute data), and the geometry data of the neighborhood point search supplied from the neighborhood point search unit 235. The restoration unit 236 uses the information to derive the predicted value of the attribute data of the processing target node. For example, the restoration unit 236 sets the searched neighborhood points to the parent node or the grandparent node, and derives the predicted value of the attribute data of the processing target node using the attribute data of those nodes.
- the restoration unit 236 restores the attribute data by adding the derived predicted value to the difference value for the processing target node. Then, the restoration unit 236 supplies the derived attribute data to the point cloud generation unit 205.
- the neighborhood point search unit 235 applies the present technique to execute the neighborhood point search, so that the decoding device 200 (attribute data decoding unit 204) independently decodes the attribute data for each slice. be able to. Therefore, the attribute data can be decoded more reliably.
- each processing unit may be configured by a logic circuit that realizes the above-mentioned processing.
- each processing unit may have, for example, a CPU, ROM, RAM, etc., and execute a program using them to realize the above-mentioned processing.
- each processing unit may have both configurations, and a part of the above-mentioned processing may be realized by a logic circuit, and the other may be realized by executing a program.
- the configurations of the respective processing units may be independent of each other. For example, some processing units realize a part of the above-mentioned processing by a logic circuit, and some other processing units execute a program.
- the above-mentioned processing may be realized by the other processing unit by both the logic circuit and the execution of the program.
- the decoding device 200 decodes the coded data of the point cloud by executing the decoding process. An example of the flow of this decoding process will be described with reference to the flowchart of FIG.
- the decoding target setting unit 201 of the decoding device 200 sets the LoD or slice to be decoded in step S201.
- step S202 the coded data extraction unit 202 acquires and holds the bit stream, and obtains the coded data of the LoD or slice (that is, the decoding target) geometry data and the attribute data (difference value) set in step S201. Extract.
- step S203 the geometry data decoding unit 203 decodes the coded data extracted in step S202 and generates geometry data (decoding result).
- step S204 the attribute data decoding unit 204 decodes the coded data extracted in step S202 by executing the attribute data decoding process, and generates a difference value (attribute data).
- step S205 the point cloud generation unit 205 executes the point cloud generation process, and by associating the geometry data generated in step S203 with the difference value (attribute data) generated in step S204, the point cloud ( Decryption result) is generated.
- step S205 When the process of step S205 is completed, the decryption process is completed.
- the attribute data decoding process executed in step S204 of such a decoding process includes ⁇ 1.
- the above-mentioned technique can be applied in the limitation of neighborhood point search>. That is, in that case, the attribute data decoding unit 204 has ⁇ 1.
- the attribute data decoding process is executed by the method to which the present technique is applied in the restriction of neighborhood point search>, and the coded data of the difference value (attribute data) is decoded.
- the point cloud generation process executed in step S205 includes ⁇ 2.
- the above-mentioned technique can be applied in the restriction of association>. That is, in that case, the point cloud generation unit 205 has ⁇ 1.
- Point cloud generation processing is executed by the method to which this technique is applied in Restriction of neighborhood point search>, and the attribute data of the restored point of the decoding target area is associated with the geometry data of that point, and the point cloud data To generate.
- the decoding device 200 can independently decode the attribute data for each slice. Further, the decoding device 200 can associate the geometry data with the attribute data. Therefore, the attribute data can be decoded more reliably.
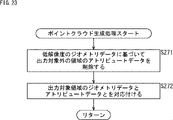
- the decoding unit 231 of the attribute data decoding unit 204 decodes the coded data of the attribute data (difference value) in step S231 and generates the difference value. This difference value is quantized.
- step S232 the dequantization unit 232 dequantizes the quantized difference value obtained in step S231 to obtain the difference value.
- step S233 the layering unit 233 stratifies the difference value (attribute data) obtained in step S232. For example, the layering unit 233 layers the difference values so as to correspond to the hierarchical structure of the geometry data.
- step S234 the slice structure generation unit 234 executes slice division on the layered difference value (attribute data) in step S233 in the same manner as the slice structure generation unit 132, and generates a slice structure.
- the slice structure generation unit 234 uses the geometry data (that is, based on the geometry of the point) to perform slice division so as to divide each node into each region.
- the slice structure generation unit 234 generates a slice structure of a difference value (attribute data) so that the slice structure is similar to the geometry data.
- step S235 the neighborhood point search unit 235 executes a search for a neighborhood point that refers to the attribute data in order to derive a predicted value of the processing target point.
- the neighborhood point search unit 235 is ⁇ 1. Restriction of neighborhood point search>
- the above-mentioned technique is applied to execute neighborhood point search.
- the neighborhood point search unit 235 uses the attribute data of each point of the point cloud as a node, and forms a slice which is a node group that can be encoded independently of each other.
- Neighboring point search for setting a reference point to be referred to when deriving the predicted value of the processing target node, targeting only the node decoded before the processing target node by the decoding unit 231 in the node of the tree structure. May be executed.
- the tree structure of the attribute data may use the attribute data of each point layered based on the geometry data as a node.
- the tree structure of the attribute data is based on the geometry data, and the attribute data of each point layered so that the voxel in the next higher hierarchy to which the voxel in which the point in the processing target hierarchy belongs also has a point. It may be a node.
- the geometry data may form a hierarchical tree structure based on the resolution of the geometry, and each node of the attribute data tree structure may correspond to each node of the geometry data tree structure.
- slices, which are node groups that can be encoded independently of each other, are formed in the tree structure of geometry data, and the structure of slices formed in the tree structure of attribute data is formed in the tree structure of the geometry data. It may correspond to the structure of.
- the neighborhood point search unit 235 uses the decoding unit 231 to precede the processing target node among the nodes in the hierarchy higher than the processing target node in the attribute data tree structure.
- the neighborhood point search may be executed only for the decoded node.
- the neighborhood point search unit 235 has the neighborhood point search unit 235 in the node of the tree structure of the attribute data as described above in ⁇ Restriction of the neighborhood point search target for the interreference based on the slice structure>. From the slice that belongs to the same slice as the processing target node and is decoded before the processing target node by the decoding unit 231 and higher than the processing target node, and the slice to which the processing target node belongs by the decoding unit 231. You may also perform a neighborhood point search only for the nodes that belong to the slice that was decoded earlier.
- the neighborhood point search unit 235 uses the tree structure node of the attribute data as described above in ⁇ Restriction of the neighborhood point search target for the interreference based on the tree structure>. Of these, the neighborhood point search may be executed only for the ancestor node of the processing target node.
- the neighborhood point search unit 235 decodes the attribute data tree structure before the processing target node by the decoding unit 231 among the nodes in the same layer as the processing target node.
- the neighborhood point search may be executed only for the nodes that have been created.
- the neighborhood point search unit 235 As a neighborhood point search for the inter-reference, the neighborhood point search unit 235, as described above in ⁇ Restriction of neighborhood point search target for intra-reference based on slice structure>, among the nodes of the tree structure of the attribute data, The neighborhood point search may be executed only for the nodes belonging to the same slice as the processing target node and decoded by the decoding unit 231 before the processing target node in the same layer as the processing target node.
- step S236 the restoration unit 236 uses the search result of the neighborhood point search executed in step S235, the difference value (attribute data) obtained in step S232, and the geometry data to predict the attribute data of the node to be processed. Is derived. For example, the restoration unit 236 sets the searched neighborhood points to the parent node or the grandparent node, and derives the predicted value of the attribute data of the processing target node using the attribute data of those nodes. Further, the restoration unit 236 restores the attribute data by adding the derived predicted value to the difference value for the processing target node.
- step S236 When the process of step S236 is completed, the attribute data decoding process is completed.
- the decoding device 200 (attribute data decoding unit 204) can independently decode the attribute data for each slice. Therefore, the attribute data can be decoded more reliably.
- the point cloud generation unit 205 associates the geometry data with the attribute data including the area not to be output in step S251.
- step S252 the point cloud generation unit 205 deletes the points in the region not to be output based on the geometry data.
- step S252 When the process of step S252 is completed, the process returns to FIG. 20.
- the point cloud generation unit 205 can remove the points in the non-decoding target area and leave the points in the decoding target area as described above in ⁇ Remove after mapping>. Therefore, the decoding device 200 (point cloud generation unit 205) can more reliably execute the correspondence between the geometry data and the attribute data, and can more reliably generate the point cloud data.
- the point cloud generation unit 205 deletes the attribute data of the area not to be output based on the low resolution geometry data in step S271.
- step S272 the point cloud generation unit 205 associates the geometry data of the output target area with the attribute data.
- step S272 When the process of step S272 is completed, the process returns to FIG. 20.
- the point cloud generation unit 205 can associate the geometry data with the attribute data as described above in ⁇ Remove before association>. That is, by doing so, the decoding device 200 (point cloud generation unit 205) can more reliably execute the correspondence between the geometry data and the attribute data, and can more reliably generate the point cloud data. can.
- Addendum> ⁇ Computer> The series of processes described above can be executed by hardware or software.
- the programs constituting the software are installed in the computer.
- the computer includes a computer embedded in dedicated hardware and, for example, a general-purpose personal computer capable of executing various functions by installing various programs.
- FIG. 24 is a block diagram showing a configuration example of computer hardware that executes the above-mentioned series of processes programmatically.
- the CPU Central Processing Unit
- ROM ReadOnly Memory
- RAM RandomAccessMemory
- the input / output interface 910 is also connected to the bus 904.
- An input unit 911, an output unit 912, a storage unit 913, a communication unit 914, and a drive 915 are connected to the input / output interface 910.
- the input unit 911 includes, for example, a keyboard, a mouse, a microphone, a touch panel, an input terminal, and the like.
- the output unit 912 includes, for example, a display, a speaker, an output terminal, and the like.
- the storage unit 913 is composed of, for example, a hard disk, a RAM disk, a non-volatile memory, or the like.
- the communication unit 914 is composed of, for example, a network interface.
- the drive 915 drives a removable medium 921 such as a magnetic disk, an optical disk, a magneto-optical disk, or a semiconductor memory.
- the CPU 901 loads the program stored in the storage unit 913 into the RAM 903 via the input / output interface 910 and the bus 904 and executes the above-mentioned series. Is processed.
- the RAM 903 also appropriately stores data and the like necessary for the CPU 901 to execute various processes.
- the program executed by the computer can be recorded and applied to the removable media 921 as a package media or the like, for example.
- the program can be installed in the storage unit 913 via the input / output interface 910 by mounting the removable media 921 in the drive 915.
- This program can also be provided via wired or wireless transmission media such as local area networks, the Internet, and digital satellite broadcasting. In that case, the program can be received by the communication unit 914 and installed in the storage unit 913.
- this program can also be installed in advance in ROM 902 or storage unit 913.
- this technology can be applied to any configuration.
- this technology is a transmitter or receiver (for example, a television receiver or mobile phone) in satellite broadcasting, wired broadcasting such as cable TV, distribution on the Internet, and distribution to terminals by cellular communication, or It can be applied to various electronic devices such as devices (for example, hard disk recorders and cameras) that record images on media such as optical disks, magnetic disks, and flash memories, and reproduce images from these storage media.
- devices for example, hard disk recorders and cameras
- the present technology includes a processor as a system LSI (Large Scale Integration) (for example, a video processor), a module using a plurality of processors (for example, a video module), and a unit using a plurality of modules (for example, a video unit).
- a processor as a system LSI (Large Scale Integration) (for example, a video processor), a module using a plurality of processors (for example, a video module), and a unit using a plurality of modules (for example, a video unit).
- a processor as a system LSI (Large Scale Integration) (for example, a video processor), a module using a plurality of processors (for example, a video module), and a unit using a plurality of modules (for example, a video unit).
- a processor as a system LSI (Large Scale Integration) (for example, a video processor), a module using a plurality of processors (for example,
- this technique can be applied to a network system composed of a plurality of devices.
- the present technology may be implemented as cloud computing that is shared and jointly processed by a plurality of devices via a network.
- this technology is implemented in a cloud service that provides services related to images (video) to any terminal such as computers, AV (AudioVisual) devices, portable information processing terminals, and IoT (Internet of Things) devices. You may try to do it.
- the system means a set of a plurality of components (devices, modules (parts), etc.), and it does not matter whether all the components are in the same housing. Therefore, a plurality of devices housed in separate housings and connected via a network, and a device in which a plurality of modules are housed in one housing are both systems. ..
- Systems, devices, processing units, etc. to which this technology is applied can be used in any field such as transportation, medical care, crime prevention, agriculture, livestock industry, mining, beauty, factories, home appliances, weather, nature monitoring, etc. .. The use is also arbitrary.
- the configuration described as one device (or processing unit) may be divided and configured as a plurality of devices (or processing units).
- the configurations described above as a plurality of devices (or processing units) may be collectively configured as one device (or processing unit).
- a configuration other than the above may be added to the configuration of each device (or each processing unit).
- a part of the configuration of one device (or processing unit) may be included in the configuration of another device (or other processing unit). ..
- the above-mentioned program may be executed in any device.
- the device may have necessary functions (functional blocks, etc.) so that necessary information can be obtained.
- each step of one flowchart may be executed by one device, or may be shared and executed by a plurality of devices.
- one device may execute the plurality of processes, or the plurality of devices may share and execute the plurality of processes.
- a plurality of processes included in one step can be executed as processes of a plurality of steps.
- the processes described as a plurality of steps can be collectively executed as one step.
- the processing of the steps for writing the program may be executed in chronological order in the order described in the present specification, and may be executed in parallel or in a row. It may be executed individually at the required timing such as when it is broken. That is, as long as there is no contradiction, the processes of each step may be executed in an order different from the above-mentioned order. Further, the processing of the step for describing this program may be executed in parallel with the processing of another program, or may be executed in combination with the processing of another program.
- a plurality of techniques related to this technique can be independently implemented independently as long as there is no contradiction.
- any plurality of the present techniques can be used in combination.
- some or all of the techniques described in any of the embodiments may be combined with some or all of the techniques described in other embodiments.
- a part or all of any of the above-mentioned techniques may be carried out in combination with other techniques not described above.
- the present technology can also have the following configurations.
- Neighbor point search for setting a reference point to be referred to when deriving the predicted value of the attribute data of the processing target node, targeting only the node to be decoded before the processing target node at the time of decoding.
- the neighborhood point searcher that executes Coding that encodes the difference value between the attribute data of the processing target node and the predicted value derived using the attribute data of the reference point set by the neighborhood point search unit.
- the neighborhood point search unit targets only the node of the tree structure that is higher than the processing target node and is decoded before the processing target node at the time of decoding.
- the information processing apparatus according to (1) which executes the neighborhood point search.
- the neighborhood point search unit is located in the node of the tree structure. The node that belongs to the same slice as the processing target node, is decoded before the processing target node at the time of decoding, and is higher than the processing target node.
- the information processing apparatus according to (2), wherein the neighborhood point search is executed only for the node belonging to the slice to be decoded before the slice to which the processing target node belongs at the time of decoding.
- the information processing apparatus executes the neighborhood point search only for the ancestor node of the processing target node among the nodes of the tree structure.
- the neighborhood point search unit targets only the node of the tree structure in the same layer as the processing target node, which is decoded before the processing target node at the time of decoding.
- the information processing apparatus which executes the neighborhood point search.
- the near point search unit belongs to the same slice as the processing target node among the nodes of the tree structure, and is decoded before the processing target node at the time of the decoding.
- the information processing apparatus according to (5), which executes the neighborhood point search only for the node in the same layer as the target node.
- the information processing apparatus has the attribute data of each point layered based on the geometry data as the node.
- the tree structure is based on the geometry data, and the point is layered so that the point also exists in the voxel in the one higher layer to which the voxel in which the point exists in the processing target layer belongs.
- the information processing apparatus according to (7), wherein the attribute data is the node.
- the geometry data forms a hierarchical tree structure based on the resolution of the geometry. Each node of the tree structure of the attribute data corresponds to each node of the tree structure of the geometry data.
- Slices which are node groups that can be encoded independently of each other, are formed in the tree structure of the geometry data.
- the information processing apparatus according to (8), wherein the structure of the slice formed in the tree structure of the attribute data corresponds to the structure of the slice formed in the tree structure of the geometry data.
- (10) Within the node of the tree structure in which slices, which are node groups that can be encoded independently of each other, are used as nodes, with the attribute data of each point in the point cloud that expresses a three-dimensional object as a set of points.
- Neighbor point search for setting a reference point to be referred to when deriving the predicted value of the attribute data of the processing target node, targeting only the node to be decoded before the processing target node at the time of decoding. And execute An information processing method for encoding a difference value between the attribute data of the processing target node and the predicted value derived by using the attribute data of the reference point set by the neighborhood point search.
- a tree structure processing target node in which slices are formed which is a node group that can be encoded independently of each other, with the attribute data of each point in the point cloud that expresses a three-dimensional object as a set of points as a node.
- a decoding unit that decodes the coded data in which the difference value between the attribute data and the predicted value of the attribute data is encoded, and derives the difference value of the processing target node.
- the nodes of the tree structure only the node decoded before the processing target node by the decoding unit is targeted, and a reference point to be referred to when deriving the predicted value of the processing target node is set.
- a neighborhood point search unit that executes a neighborhood point search for By adding the difference value derived by the decoding unit and the predicted value derived using the attribute data of the reference point set by the neighborhood point search unit, the neighborhood point search unit is used.
- a restore unit that restores the attribute data of the processing target node, An information processing device including an association unit that associates the attribute data of the point in the decoding target area restored by the restoration unit with the geometry data of the point. (12)
- the neighborhood point search unit is located in the node of the tree structure. The node that belongs to the same slice as the processing target node and is decoded before the processing target node by the decoding unit, and is higher than the processing target node.
- the information processing apparatus wherein the neighborhood point search is executed only for the node belonging to the slice decoded earlier than the slice to which the processing target node belongs by the decoding unit.
- the information processing apparatus wherein the neighborhood point search unit executes the neighborhood point search only for the ancestor node of the processing target node among the nodes of the tree structure.
- the processing target belongs to the same slice as the processing target node among the nodes of the tree structure, and is decoded before the processing target node by the decoding unit.
- the information processing apparatus which executes the neighborhood point search only for the node in the same layer as the node.
- the information processing apparatus according to any one of (11) to (14), wherein the tree structure has the attribute data of each point layered based on the geometry data as a node.
- the tree structure is based on the geometry data, and the point is layered so that the point also exists in the voxel in the one higher layer to which the voxel in which the point exists in the processing target layer belongs.
- the information processing apparatus according to (15), wherein the attribute data is the node.
- the geometry data forms a hierarchical tree structure based on the resolution of the geometry. Each node of the tree structure of the attribute data corresponds to each node of the tree structure of the geometry data.
- Slices which are node groups that can be encoded independently of each other, are formed in the tree structure of the geometry data.
- the corresponding unit is The attribute data of all the points restored by the restoration unit and the geometry data are associated with each other.
- the corresponding unit is The attribute data of the point of the non-decoding target area restored by the restoration unit is removed.
- a tree structure processing target node in which slices are formed which is a node group that can be encoded independently of each other, with the attribute data of each point in the point cloud that expresses a three-dimensional object as a set of points as a node.
- the nodes of the tree structure only the node decoded before the processing target node is targeted, and the vicinity for setting the reference point to be referred to when deriving the predicted value of the processing target node.
- 100 coding device 101 geometry data coding unit, 102 geometry data decoding unit, 103 point cloud generation unit, 104 attribute data coding unit, 105 bit stream generation unit, 131 layering unit, 132 slice structure generation unit, 133 neighborhood Point search unit, 134 prediction processing unit, 135 quantization unit, 136 coding unit, 200 decoding device, 201 decoding target setting unit, 202 coding data extraction unit, 203 geometry data decoding unit, 204 attribute data decoding unit, 205 points Cloud generation unit, 231 decoding unit, 232 inverse quantization unit, 233 layering unit, 234 slice structure generation unit, 235 neighborhood point search unit, 236 restoration unit, 900 computer
Abstract
Description
1.近傍点探索の制限
2.対応付けの制限
3.第1の実施の形態(符号化装置)
4.第2の実施の形態(復号装置)
5.付記
<技術内容と技術用語をサポートする文献等>
本技術で開示される範囲は、実施の形態に記載されている内容だけではなく、出願当時において公知となっている以下の非特許文献に記載されている内容も含まれる。
非特許文献2:(上述)
非特許文献3:(上述)
従来、3Dデータとして、立体構造物(3次元形状のオブジェクト)を多数のポイントの集合として表現するポイントクラウドが存在した。ポイントクラウドのデータ(ポイントクラウドデータとも称する)は、各点の位置情報(ジオメトリとも称する)と属性情報(アトリビュートとも称する)とにより構成される。アトリビュートは任意の情報を含みうる。例えば、各ポイントの色情報、反射率情報、法線情報等を含み得る。このようにポイントクラウドは、データ構造が比較的単純であるとともに、十分に多くの点を用いることにより任意の立体構造物を十分な精度で表現することができる。
ところで、非特許文献2において、このポイントクラウドの木構造(Octree)をノードグループ(node group)に分割するフラグをシグナルする方法が開示された。この方法により、ノードグループ毎に独立に復号が可能になる。したがって、例えば、デコード処理をノードグループ毎に分けて並列化することができる。また、一部のノードグループのみをデコードすることもできる。例えば、3次元領域の部分領域毎にノードグループを分けることにより、一部の領域のジオメトリのみを復号することができる。つまり、復号処理において、領域についてのスケーラビリティを実現することができる。つまり、ジオメトリの全ての符号化データを復号しなくても、必要な部分のみを復号することにより、所望の領域のジオメトリを得ることができる。
これに対してアトリビュートについて、符号化による劣化を含めジオメトリを既知であるものとして、点間の位置関係を利用して符号化したり、復号したりする方法が考えられた。このようなアトリビュートの符号化方法として、RAHT(Region Adaptive Hierarchical Transform)や、非特許文献2に記載のようなLiftingと称する変換を用いる方法が考えられた。これらの技術を適用することにより、ジオメトリのOctreeのように、アトリビュートを階層化することもできる。
図2のBのように他のポイント(近傍点)のアトリビュートデータを参照して処理対象ポイントのアトリビュートの予測値を導出するために、アトリビュートデータを参照する近傍点の探索(近傍点探索とも称する)が実行される。なお、この予測値導出のための参照の仕方として、処理対象ポイントが属するLoDと異なるLoDに属するポイントを参照するインター参照(LoD間参照とも称する)と、処理対象ポイントと同一のLoDに属するポイントを参照するイントラ参照(LoD内参照とも称する)とがある。
ところで、上述したように、ジオメトリデータは木構造をノードグループ化(スライス分割)することができる。図3にそのスライス構造の例を示す。図3の例の場合、上位の2LoDは、全領域が1つにスライス化されている(スライス#1)。これに対して下位の2LoDは、2領域に分割され、各領域がスライス化されている(スライス#2、スライス#3)。例えば、最下位層のノードA乃至ノードDは、スライス#2に属し、ノードE乃至ノードGは、スライス#3に属している。
図5の表の上から2段目に示されるように、LoD間参照(インター参照)のための近傍点探索を、復号済みのノードを対象として実行するようにしてもよい(方法1-1)。例えば、情報処理装置において、近傍点探索部が、アトリビュートデータの木構造のノードの内、処理対象ノードよりも上位階層の、復号の際にその処理対象ノードよりも先に復号されるノードのみを対象として、近傍点探索を実行するようにしてもよい。または、情報処理装置において、近傍点探索部が、アトリビュートデータの木構造のノードの内、処理対象ノードよりも上位階層の、復号部によりその処理対象ノードよりも先に復号されたノードのみを対象として、近傍点探索を実行するようにしてもよい。
そのインター参照のための近傍点探索として、図5の表の上から3段目に示されるように、復号済みのスライスに属するノードを対象として近傍点探索を実行するようにしてもよい(方法1-1-1)。この復号済みのスライスとは、復号の際に処理対象ノードよりも先に復号されるスライス(のノード)のことである。
また、インター参照のための近傍点探索として、図5の表の上から4段目に示されるように、アトリビュートデータの木構造の先祖ノードを対象として近傍点探索を実行するようにしてもよい(方法1-1-2)。ここで先祖ノードとは、アトリビュートデータの木構造において、処理対象ノードが直接的または間接的に属する上位LoDのノードである。例えば、図7に示される木構造の場合、ノード間の直線がノード同士の親子関係を示している。あるノード(基準ノード)からより上位LoDに向かう方向に、この直線により直接的または間接的に処理対象ノードに接続されるノードを、基準ノードの先祖ノードと称する。
図5の表の上から5段目に示されるように、LoD内参照(イントラ参照)のための近傍点探索を、復号済みのノードを対象として実行するようにしてもよい(方法1-2)。例えば、情報処理装置において、近傍点探索部が、アトリビュートデータの木構造の、処理対象ノードと同一階層のノードの内、復号の際にその処理対象ノードよりも先に復号されるノードのみを対象として、近傍点探索を実行するようにしてもよい。または、情報処理装置において、近傍点探索部が、アトリビュートデータの木構造のノードの内、処理対象ノードと同一階層の、復号部によりその処理対象ノードよりも先に復号されたノードのみを対象として、近傍点探索を実行するようにしてもよい。
そのイントラ参照のための近傍点探索として、図5の表の最下段に示されるように、処理対象スライスの処理対象LoD内の復号済みノードを対象として近傍点探索を実行するようにしてもよい(方法1-2-1)。処理対象スライスとは、処理対象ノードが属するスライスのことである。処理対象LoDとは、処理対象ノードが属するLoDのことである。復号済みノードとは、復号の際に処理対象ノードよりも先に復号されるノードのことである。
<ジオメトリとアトリビュートの対応付け>
ところで、ジオメトリデータが復号され、アトリビュートデータが復号されると、そのジオメトリデータとアトリビュートデータの対応付けが実行される。つまり、ポイント毎にジオメトリとアトリビュートがまとめられ(紐付けされ)、ポイントクラウドデータが生成される。
そこで、図11の表の最上段に示されるように、ジオメトリデータとアトリビュートデータとの対応付け(つまり、ポイントクラウドデータの生成)において、復号対象領域のアトリビュートをジオメトリと対応付けるようにする(方法2)。復号対象領域とは、復号対象のスライスに対応する領域(そのスライスに属するノードに対応するポイントが位置する領域)のことである。
図11の表の上から2段目に示されるように、非復号対象領域のジオメトリデータも含めて対応付けし、その後、ジオメトリに基づいて非復号対象領域のポイントを除去するようにしてもよい(方法2-1)。ここで、非復号対象領域とは、復号対象でないスライスに属するノードに対応するポイントが位置する領域のことを示す。換言するに、非復号対象領域とは、復号対象のスライスに属するノードに対応するポイントが位置しない領域のことを示す。なお、復号対象のスライスに属するノードに対応するポイントが位置する領域は、復号対象領域と称する。
図11の表の上から4段目に示されるように、非復号対象領域のアトリビュートデータを除去してから、ジオメトリデータとアトリビュートデータとを対応付けるようにしてもよい(方法2-2)。例えば、図11の表の最下段に示されるように、LoD Generation時にノードと対応付けたジオメトリを用いて、非復号対象領域のアトリビュートデータを除去してから、ジオメトリデータとアトリビュートデータとを対応付けるようにしてもよい(方法2-2-1)。
<符号化装置>
図14は、本技術を適用した情報処理装置の一態様である符号化装置の構成の一例を示すブロック図である。図14に示される符号化装置100は、ポイントクラウド(3Dデータ)を符号化する装置である。符号化装置100には、本技術(例えば図1乃至図13を参照して説明した各種方法等)を適用し得る。
図15は、アトリビュートデータ符号化部104(図14)の主な構成例を示すブロック図である。なお、図15においては、処理部やデータの流れ等の主なものを示しており、図15に示されるものが全てとは限らない。つまり、アトリビュートデータ符号化部104において、図15においてブロックとして示されていない処理部が存在したり、図15において矢印等として示されていない処理やデータの流れが存在したりしてもよい。
次に、この符号化装置100により実行される処理について説明する。符号化装置100は、符号化処理を実行することによりポイントクラウドのデータを符号化する。この符号化処理の流れの例を、図16のフローチャートを参照して説明する。
次に、図16のステップS104において実行されるアトリビュートデータ符号化処理の流れの例を、図17のフローチャートを参照して説明する。
<復号装置>
図18は、本技術を適用した情報処理装置の一態様である復号装置の構成の一例を示すブロック図である。図18に示される復号装置200は、ポイントクラウド(3Dデータ)の符号化データを復号する装置である。復号装置200には、本技術(例えば図1乃至図13を参照して説明した各種方法等)を適用し得る。
図19は、アトリビュートデータ復号部204(図18)の主な構成例を示すブロック図である。なお、図19においては、処理部やデータの流れ等の主なものを示しており、図19に示されるものが全てとは限らない。つまり、アトリビュートデータ復号部204において、図19においてブロックとして示されていない処理部が存在したり、図19において矢印等として示されていない処理やデータの流れが存在したりしてもよい。
次に、この復号装置200により実行される処理について説明する。復号装置200は、復号処理を実行することによりポイントクラウドの符号化データを復号する。この復号処理の流れの例を、図20のフローチャートを参照して説明する。
次に、図20のステップS204において実行されるアトリビュートデータ復号処理の流れの例を、図21のフローチャートを参照して説明する。
次に、図20のステップS205において実行されるポイントクラウド生成処理の流れの例を、図22のフローチャートを参照して説明する。なお、このフローチャートは、<2.対応付けの制限>の<対応付け後に除去>において説明した例に対応する。
次に、図20のステップS205において実行されるポイントクラウド生成処理の流れの他の例を、図23のフローチャートを参照して説明する。なお、このフローチャートは、<2.対応付けの制限>の<対応付け前に除去>において説明した例に対応する。
<コンピュータ>
上述した一連の処理は、ハードウエアにより実行させることもできるし、ソフトウエアにより実行させることもできる。一連の処理をソフトウエアにより実行する場合には、そのソフトウエアを構成するプログラムが、コンピュータにインストールされる。ここでコンピュータには、専用のハードウエアに組み込まれているコンピュータや、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータ等が含まれる。
以上においては、ポイントクラウドデータの符号化や復号に本技術を適用する場合について説明したが、本技術は、これらの例に限らず、任意の規格の3Dデータの符号化や復号に対して適用することができる。例えば、メッシュ(Mesh)データの符号化や復号において、メッシュデータをポイントクラウドデータに変換し、本技術を適用して符号化・復号を行うようにしてもよい。つまり、上述した本技術と矛盾しない限り、符号化や復号方式等の各種処理、並びに、3Dデータやメタデータ等の各種データの仕様は任意である。また、本技術と矛盾しない限り、上述した一部の処理や仕様を省略してもよい。
本技術を適用したシステム、装置、処理部等は、例えば、交通、医療、防犯、農業、畜産業、鉱業、美容、工場、家電、気象、自然監視等、任意の分野に利用することができる。また、その用途も任意である。
本技術の実施の形態は、上述した実施の形態に限定されるものではなく、本技術の要旨を逸脱しない範囲において種々の変更が可能である。
(1) 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の前記ノードの内、復号の際に処理対象ノードよりも先に復号される前記ノードのみを対象として、前記処理対象ノードの前記アトリビュートデータの予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行する近傍点探索部と、
前記処理対象ノードの前記アトリビュートデータと、前記近傍点探索部による前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値との差分値を符号化する符号化部と
を備える情報処理装置。
(2) 前記近傍点探索部は、前記木構造の、前記処理対象ノードよりも上位階層の前記ノードの内、前記復号の際に前記処理対象ノードよりも先に復号される前記ノードのみを対象として、前記近傍点探索を実行する
(1)に記載の情報処理装置。
(3) 前記近傍点探索部は、前記木構造の前記ノードの内、
前記処理対象ノードと同一の前記スライスに属し、前記復号の際に前記処理対象ノードよりも先に復号される、前記処理対象ノードよりも上位階層の前記ノードと、
前記復号の際に前記処理対象ノードが属する前記スライスよりも先に復号される前記スライスに属する前記ノードと
のみを対象として、前記近傍点探索を実行する
(2)に記載の情報処理装置。
(4) 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードの先祖ノードのみを対象として、前記近傍点探索を実行する
(2)に記載の情報処理装置。
(5) 前記近傍点探索部は、前記木構造の、前記処理対象ノードと同一階層の前記ノードの内、前記復号の際に前記処理対象ノードよりも先に復号される前記ノードのみを対象として、前記近傍点探索を実行する
(1)に記載の情報処理装置。
(6) 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードと同一の前記スライスに属し、前記復号の際に前記処理対象ノードよりも先に復号される、前記処理対象ノードと同一階層の前記ノードのみを対象として、前記近傍点探索を実行する
(5)に記載の情報処理装置。
(7) 前記木構造は、ジオメトリデータに基づいて階層化された各ポイントの前記アトリビュートデータを前記ノードとする
(1)乃至(6)のいずれかに記載の情報処理装置。
(8) 前記木構造は、前記ジオメトリデータに基づいて、処理対象階層の前記ポイントが存在するボクセルが属する1つ上位階層の前記ボクセルにも前記ポイントが存在するように階層化された各ポイントの前記アトリビュートデータを前記ノードとする
(7)に記載の情報処理装置。
(9) 前記ジオメトリデータは、ジオメトリの解像度に基づいて階層化された木構造を形成し、
前記アトリビュートデータの前記木構造の各ノードは、前記ジオメトリデータの前記木構造の各ノードに対応し、
前記ジオメトリデータの前記木構造には、互いに独立に符号化可能なノードグループであるスライスが形成され、
前記アトリビュートデータの前記木構造に形成される前記スライスの構造は、前記ジオメトリデータの前記木構造に形成される前記スライスの構造に対応する
(8)に記載の情報処理装置。
(10) 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の前記ノードの内、復号の際に処理対象ノードよりも先に復号される前記ノードのみを対象として、前記処理対象ノードの前記アトリビュートデータの予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行し、
前記処理対象ノードの前記アトリビュートデータと、前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値との差分値を符号化する
情報処理方法。
前記木構造の前記ノードの内、前記復号部により前記処理対象ノードよりも先に復号された前記ノードのみを対象として、前記処理対象ノードの前記予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行する近傍点探索部と、
前記復号部により導出された前記差分値と、前記近傍点探索部による前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値とを加算することにより、前記処理対象ノードの前記アトリビュートデータを復元する復元部と、
前記復元部により復元された復号対象領域の前記ポイントの前記アトリビュートデータと、前記ポイントのジオメトリデータとを対応付ける対応付け部と
を備える情報処理装置。
(12) 前記近傍点探索部は、前記木構造の前記ノードの内、
前記処理対象ノードと同一の前記スライスに属し、前記復号部により前記処理対象ノードよりも先に復号された、前記処理対象ノードよりも上位階層の前記ノードと、
前記復号部により前記処理対象ノードが属する前記スライスよりも先に復号された前記スライスに属する前記ノードと
のみを対象として、前記近傍点探索を実行する
(11)に記載の情報処理装置。
(13) 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードの先祖ノードのみを対象として、前記近傍点探索を実行する
(11)に記載の情報処理装置。
(14) 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードと同一の前記スライスに属し、前記復号部により前記処理対象ノードよりも先に復号された、前記処理対象ノードと同一階層の前記ノードのみを対象として、前記近傍点探索を実行する
(11)に記載の情報処理装置。
(15) 前記木構造は、ジオメトリデータに基づいて階層化された各ポイントの前記アトリビュートデータをノードとする
(11)乃至(14)のいずれかに記載の情報処理装置。
(16) 前記木構造は、前記ジオメトリデータに基づいて、処理対象階層の前記ポイントが存在するボクセルが属する1つ上位階層の前記ボクセルにも前記ポイントが存在するように階層化された各ポイントの前記アトリビュートデータを前記ノードとする
(15)に記載の情報処理装置。
(17) 前記ジオメトリデータは、ジオメトリの解像度に基づいて階層化された木構造を形成し、
前記アトリビュートデータの前記木構造の各ノードは、前記ジオメトリデータの前記木構造の各ノードに対応し、
前記ジオメトリデータの前記木構造には、互いに独立に符号化可能なノードグループであるスライスが形成され、
前記アトリビュートデータの前記木構造に形成される前記スライスの構造は、前記ジオメトリデータの前記木構造に形成される前記スライスの構造に対応する
(16)に記載の情報処理装置。
(18) 前記対応付け部は、
前記復元部により復元された全ての前記ポイントの前記アトリビュートデータと前記ジオメトリデータとを対応付け、
前記アトリビュートデータと前記ジオメトリデータとが対応付けられた非復号対象領域の前記ポイントを除去する
(17)に記載の情報処理装置。
(19) 前記対応付け部は、
前記復元部により復元された非復号対象領域の前記ポイントの前記アトリビュートデータを除去し、
前記復号対象領域のポイントの前記アトリビュートデータと前記ジオメトリデータとを対応付ける
(17)に記載の情報処理装置。
(20) 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の処理対象ノードの、前記アトリビュートデータと前記アトリビュートデータの予測値との差分値が符号化された符号化データを復号し、前記処理対象ノードの前記差分値を導出し、
前記木構造の前記ノードの内、前記処理対象ノードよりも先に復号された前記ノードのみを対象として、前記処理対象ノードの前記予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行し、
導出された前記差分値と、前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値とを加算することにより、前記処理対象ノードの前記アトリビュートデータを復元し、
復元された復号対象領域の前記ポイントの前記アトリビュートデータと、前記ポイントのジオメトリデータとを対応付ける
情報処理方法。
Claims (20)
- 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の前記ノードの内、復号の際に処理対象ノードよりも先に復号される前記ノードのみを対象として、前記処理対象ノードの前記アトリビュートデータの予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行する近傍点探索部と、
前記処理対象ノードの前記アトリビュートデータと、前記近傍点探索部による前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値との差分値を符号化する符号化部と
を備える情報処理装置。 - 前記近傍点探索部は、前記木構造の、前記処理対象ノードよりも上位階層の前記ノードの内、前記復号の際に前記処理対象ノードよりも先に復号される前記ノードのみを対象として、前記近傍点探索を実行する
請求項1に記載の情報処理装置。 - 前記近傍点探索部は、前記木構造の前記ノードの内、
前記処理対象ノードと同一の前記スライスに属し、前記復号の際に前記処理対象ノードよりも先に復号される、前記処理対象ノードよりも上位階層の前記ノードと、
前記復号の際に前記処理対象ノードが属する前記スライスよりも先に復号される前記スライスに属する前記ノードと
のみを対象として、前記近傍点探索を実行する
請求項2に記載の情報処理装置。 - 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードの先祖ノードのみを対象として、前記近傍点探索を実行する
請求項2に記載の情報処理装置。 - 前記近傍点探索部は、前記木構造の、前記処理対象ノードと同一階層の前記ノードの内、前記復号の際に前記処理対象ノードよりも先に復号される前記ノードのみを対象として、前記近傍点探索を実行する
請求項1に記載の情報処理装置。 - 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードと同一の前記スライスに属し、前記復号の際に前記処理対象ノードよりも先に復号される、前記処理対象ノードと同一階層の前記ノードのみを対象として、前記近傍点探索を実行する
請求項5に記載の情報処理装置。 - 前記木構造は、ジオメトリデータに基づいて階層化された各ポイントの前記アトリビュートデータを前記ノードとする
請求項1に記載の情報処理装置。 - 前記木構造は、前記ジオメトリデータに基づいて、処理対象階層の前記ポイントが存在するボクセルが属する1つ上位階層の前記ボクセルにも前記ポイントが存在するように階層化された各ポイントの前記アトリビュートデータを前記ノードとする
請求項7に記載の情報処理装置。 - 前記ジオメトリデータは、ジオメトリの解像度に基づいて階層化された木構造を形成し、
前記アトリビュートデータの前記木構造の各ノードは、前記ジオメトリデータの前記木構造の各ノードに対応し、
前記ジオメトリデータの前記木構造には、互いに独立に符号化可能なノードグループであるスライスが形成され、
前記アトリビュートデータの前記木構造に形成される前記スライスの構造は、前記ジオメトリデータの前記木構造に形成される前記スライスの構造に対応する
請求項8に記載の情報処理装置。 - 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の前記ノードの内、復号の際に処理対象ノードよりも先に復号される前記ノードのみを対象として、前記処理対象ノードの前記アトリビュートデータの予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行し、
前記処理対象ノードの前記アトリビュートデータと、前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値との差分値を符号化する
情報処理方法。 - 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の処理対象ノードの、前記アトリビュートデータと前記アトリビュートデータの予測値との差分値が符号化された符号化データを復号し、前記処理対象ノードの前記差分値を導出する復号部と、
前記木構造の前記ノードの内、前記復号部により前記処理対象ノードよりも先に復号された前記ノードのみを対象として、前記処理対象ノードの前記予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行する近傍点探索部と、
前記復号部により導出された前記差分値と、前記近傍点探索部による前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値とを加算することにより、前記処理対象ノードの前記アトリビュートデータを復元する復元部と、
前記復元部により復元された復号対象領域の前記ポイントの前記アトリビュートデータと、前記ポイントのジオメトリデータとを対応付ける対応付け部と
を備える情報処理装置。 - 前記近傍点探索部は、前記木構造の前記ノードの内、
前記処理対象ノードと同一の前記スライスに属し、前記復号部により前記処理対象ノードよりも先に復号された、前記処理対象ノードよりも上位階層の前記ノードと、
前記復号部により前記処理対象ノードが属する前記スライスよりも先に復号された前記スライスに属する前記ノードと
のみを対象として、前記近傍点探索を実行する
請求項11に記載の情報処理装置。 - 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードの先祖ノードのみを対象として、前記近傍点探索を実行する
請求項11に記載の情報処理装置。 - 前記近傍点探索部は、前記木構造の前記ノードの内、前記処理対象ノードと同一の前記スライスに属し、前記復号部により前記処理対象ノードよりも先に復号された、前記処理対象ノードと同一階層の前記ノードのみを対象として、前記近傍点探索を実行する
請求項11に記載の情報処理装置。 - 前記木構造は、ジオメトリデータに基づいて階層化された各ポイントの前記アトリビュートデータをノードとする
請求項11に記載の情報処理装置。 - 前記木構造は、前記ジオメトリデータに基づいて、処理対象階層の前記ポイントが存在するボクセルが属する1つ上位階層の前記ボクセルにも前記ポイントが存在するように階層化された各ポイントの前記アトリビュートデータを前記ノードとする
請求項15に記載の情報処理装置。 - 前記ジオメトリデータは、ジオメトリの解像度に基づいて階層化された木構造を形成し、
前記アトリビュートデータの前記木構造の各ノードは、前記ジオメトリデータの前記木構造の各ノードに対応し、
前記ジオメトリデータの前記木構造には、互いに独立に符号化可能なノードグループであるスライスが形成され、
前記アトリビュートデータの前記木構造に形成される前記スライスの構造は、前記ジオメトリデータの前記木構造に形成される前記スライスの構造に対応する
請求項16に記載の情報処理装置。 - 前記対応付け部は、
前記復元部により復元された全ての前記ポイントの前記アトリビュートデータと前記ジオメトリデータとを対応付け、
前記アトリビュートデータと前記ジオメトリデータとが対応付けられた非復号対象領域の前記ポイントを除去する
請求項17に記載の情報処理装置。 - 前記対応付け部は、
前記復元部により復元された非復号対象領域の前記ポイントの前記アトリビュートデータを除去し、
前記復号対象領域のポイントの前記アトリビュートデータと前記ジオメトリデータとを対応付ける
請求項17に記載の情報処理装置。 - 3次元形状のオブジェクトをポイントの集合として表現するポイントクラウドの各ポイントのアトリビュートデータをノードとし、互いに独立に符号化可能なノードグループであるスライスが形成される木構造の処理対象ノードの、前記アトリビュートデータと前記アトリビュートデータの予測値との差分値が符号化された符号化データを復号し、前記処理対象ノードの前記差分値を導出し、
前記木構造の前記ノードの内、前記処理対象ノードよりも先に復号された前記ノードのみを対象として、前記処理対象ノードの前記予測値を導出する際に参照する参照ポイントを設定するための近傍点探索を実行し、
導出された前記差分値と、前記近傍点探索によって設定された前記参照ポイントの前記アトリビュートデータを用いて導出された前記予測値とを加算することにより、前記処理対象ノードの前記アトリビュートデータを復元し、
復元された復号対象領域の前記ポイントの前記アトリビュートデータと、前記ポイントのジオメトリデータとを対応付ける
情報処理方法。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21915075.2A EP4270323A1 (en) | 2020-12-28 | 2021-12-14 | Information processing device and method |
| KR1020237019457A KR20230125186A (ko) | 2020-12-28 | 2021-12-14 | 정보 처리 장치 및 방법 |
| JP2022572979A JPWO2022145214A1 (ja) | 2020-12-28 | 2021-12-14 | |
| US18/265,387 US20240056604A1 (en) | 2020-12-28 | 2021-12-14 | Information processing apparatus and method |
| CN202180086127.8A CN116670721A (zh) | 2020-12-28 | 2021-12-14 | 信息处理装置和方法 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-218500 | 2020-12-28 | ||
| JP2020218500 | 2020-12-28 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022145214A1 true WO2022145214A1 (ja) | 2022-07-07 |
Family
ID=82260464
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/045929 WO2022145214A1 (ja) | 2020-12-28 | 2021-12-14 | 情報処理装置および方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20240056604A1 (ja) |
| EP (1) | EP4270323A1 (ja) |
| JP (1) | JPWO2022145214A1 (ja) |
| KR (1) | KR20230125186A (ja) |
| CN (1) | CN116670721A (ja) |
| WO (1) | WO2022145214A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117213725A (zh) * | 2023-09-12 | 2023-12-12 | 国能龙源环保有限公司 | 火电厂脱硫设备密封检测方法、系统、终端及存储介质 |
| CN117213725B (zh) * | 2023-09-12 | 2024-05-14 | 国能龙源环保有限公司 | 火电厂脱硫设备密封检测方法、系统、终端及存储介质 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017104115A1 (ja) * | 2015-12-14 | 2017-06-22 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 三次元データ符号化方法、三次元データ復号方法、三次元データ符号化装置及び三次元データ復号装置 |
| WO2020189296A1 (ja) * | 2019-03-19 | 2020-09-24 | ソニー株式会社 | 情報処理装置および方法 |
| WO2020189709A1 (ja) * | 2019-03-18 | 2020-09-24 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 三次元データ符号化方法、三次元データ復号方法、三次元データ符号化装置、及び三次元データ復号装置 |
-
2021
- 2021-12-14 US US18/265,387 patent/US20240056604A1/en active Pending
- 2021-12-14 CN CN202180086127.8A patent/CN116670721A/zh active Pending
- 2021-12-14 JP JP2022572979A patent/JPWO2022145214A1/ja active Pending
- 2021-12-14 WO PCT/JP2021/045929 patent/WO2022145214A1/ja active Application Filing
- 2021-12-14 KR KR1020237019457A patent/KR20230125186A/ko unknown
- 2021-12-14 EP EP21915075.2A patent/EP4270323A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017104115A1 (ja) * | 2015-12-14 | 2017-06-22 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 三次元データ符号化方法、三次元データ復号方法、三次元データ符号化装置及び三次元データ復号装置 |
| WO2020189709A1 (ja) * | 2019-03-18 | 2020-09-24 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 三次元データ符号化方法、三次元データ復号方法、三次元データ符号化装置、及び三次元データ復号装置 |
| WO2020189296A1 (ja) * | 2019-03-19 | 2020-09-24 | ソニー株式会社 | 情報処理装置および方法 |
Non-Patent Citations (3)
| Title |
|---|
| DAVID FLYNNKHALED MAMMOU: "G-PCC: A hierarchical geometry slice structure", ISO/IEC JCTC1/SC29/WG11 MPEG/M54677, April 2020 (2020-04-01) |
| KHALED MAMMOUALEXIS TOURAPISJUNGSUN KIMFABRICE ROBINETVALERY VALENTINYEPING SU: "Lifting Scheme for Lossy Attribute Encoding in TMC 1", ISO/IEC JTC1/SC29/WG11 MPEG2018/M42640, April 2018 (2018-04-01) |
| R. MEKURIAK. BLOMP. CESAR., DESIGN, IMPLEMENTATION AND EVALUATION OF A POINT CLOUD CODEC FOR TELE-IMMERSIVE VIDEO |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117213725A (zh) * | 2023-09-12 | 2023-12-12 | 国能龙源环保有限公司 | 火电厂脱硫设备密封检测方法、系统、终端及存储介质 |
| CN117213725B (zh) * | 2023-09-12 | 2024-05-14 | 国能龙源环保有限公司 | 火电厂脱硫设备密封检测方法、系统、终端及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN116670721A (zh) | 2023-08-29 |
| US20240056604A1 (en) | 2024-02-15 |
| EP4270323A1 (en) | 2023-11-01 |
| JPWO2022145214A1 (ja) | 2022-07-07 |
| KR20230125186A (ko) | 2023-08-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7384159B2 (ja) | 画像処理装置および方法 | |
| WO2019198523A1 (ja) | 画像処理装置および方法 | |
| JP7327166B2 (ja) | 画像処理装置および方法 | |
| US11943457B2 (en) | Information processing apparatus and method | |
| WO2020188932A1 (ja) | 情報処理装置および情報生成方法 | |
| WO2021140930A1 (ja) | 情報処理装置および方法 | |
| WO2020262019A1 (ja) | 情報処理装置および方法 | |
| JP7396302B2 (ja) | 画像処理装置および方法 | |
| WO2020145143A1 (ja) | 情報処理装置および方法 | |
| WO2020071115A1 (ja) | 画像処理装置および方法 | |
| WO2021002214A1 (ja) | 情報処理装置および方法 | |
| WO2022145214A1 (ja) | 情報処理装置および方法 | |
| WO2021010200A1 (ja) | 情報処理装置および方法 | |
| WO2021010134A1 (ja) | 情報処理装置および方法 | |
| WO2021140928A1 (ja) | 情報処理装置および方法 | |
| WO2021261237A1 (ja) | 情報処理装置および方法 | |
| WO2020262020A1 (ja) | 情報処理装置および方法 | |
| WO2021095565A1 (ja) | 画像処理装置および方法 | |
| JP2022036353A (ja) | 画像処理装置および方法 | |
| JP2022051968A (ja) | 情報処理装置および方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21915075 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022572979 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18265387 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202180086127.8 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2021915075 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021915075 Country of ref document: EP Effective date: 20230728 |