WO2022054124A1 - 画像判定装置、画像判定方法及びプログラム - Google Patents
画像判定装置、画像判定方法及びプログラム Download PDFInfo
- Publication number
- WO2022054124A1 WO2022054124A1 PCT/JP2020/033921 JP2020033921W WO2022054124A1 WO 2022054124 A1 WO2022054124 A1 WO 2022054124A1 JP 2020033921 W JP2020033921 W JP 2020033921W WO 2022054124 A1 WO2022054124 A1 WO 2022054124A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- object data
- training
- learning model
- machine learning
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G06T7/0004—Industrial image inspection
- G06T7/0006—Industrial image inspection using a design-rule based approach
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Definitions
- the present invention relates to an image determination device, an image determination method and a program, and particularly to a technique for determining the substantial identity of a plurality of images.
- a screen image of a computer application is manually designed on the assumption that it will be displayed in one selected execution environment such as a specific smartphone. Objects such as buttons, images, and input forms are placed on these screen images.
- the screen image of substantially the same design is ported to other execution environments.
- the plurality of screen images obtained in this way are often visually confirmed to be substantially identical.
- the number of execution environments for computer applications increases, there is an increasing need to automate such verification tasks.
- the screen size, aspect ratio, and resolution differ depending on the execution environment of the computer application.
- the appearance of objects such as buttons provided by the execution environment such as the operation system and included in each screen image is not a little different. Therefore, even if a plurality of screen images are compared on a pixel-by-pixel basis, it is difficult to confirm their substantial identities. Further, it is conceivable to determine the substantial identity of the screen images by inputting the screen images into the machine learning model, but there is a concern that the learning amount becomes enormous.
- the present invention has been made in view of the above problems, and an object thereof is to provide an image determination device, an image determination method, and a program capable of easily and correctly determining the substantial identity of a plurality of images in which objects are arranged. To do.
- the image determination device uses a first machine learning model in which an image is input and object data indicating the attributes and arrangement of the objects in the image is output.
- the first object data indicating the attribute and arrangement of the object in the first image is acquired from the first image
- the second object data indicating the attribute and arrangement of the object in the second image is acquired from the second image.
- the first object data acquisition means and the second machine learning model in which the first object data and the second object data are input and the substantial identity of the first image and the second image are output are used.
- a determination means for determining the substantial identity of one image and the second image is included.
- the first machine learning model may include R-CNN.
- the first machine learning model may be trained by a training image generated by superimposing a part or all of a plurality of objects on a given base image.
- the second machine learning model may include a fully connected layer.
- the second machine learning model may include a convolution layer and a pooling layer on the upstream side of the fully connected layer, which reduces the number of dimensions of the first object data and the input data based on the second object data.
- the second machine learning model is a first training image and a second trained image generated by superimposing a given object on each of the same or similar first and second base images according to a predetermined placement rule. Learned from the first learning object data showing the attributes and arrangement of the objects in the first training image and the second learning object data showing the attributes and arrangement of the objects in the second training image obtained from the training image. good.
- the step of acquiring the first object data indicating the attributes and arrangement of the objects in the first image from the first image by using the first machine learning model a step of acquiring second object data indicating the attributes and arrangement of objects in the second image from the second image, and using the second machine learning model, A step of determining the substantial identity of the first image and the second image from the first object data and the second object data is included.
- the first machine learning model may include R-CNN.
- the above method may further include a step of performing training of the first machine learning model by a training image generated by superimposing a part or all of a plurality of objects on a given base image.
- the second machine learning model may include a fully connected layer.
- the second machine learning model may include a convolution layer and a pooling layer on the upstream side of the fully connected layer, which reduces the number of dimensions of the first object data and the input data based on the second object data. ..
- the above method includes a step of generating a first training image and a second training image by superimposing a given object on each of the same or similar first and second base images according to a predetermined arrangement rule.
- the first learning object data showing the attributes and arrangement of the objects in the first training image
- the second learning object data By inputting each of the first training image and the second training image into the first machine learning model, the first learning object data showing the attributes and arrangement of the objects in the first training image, and the second learning object data.
- a step of acquiring the second learning object data indicating the attributes and arrangement of the objects in the training image, a step of executing the learning of the second machine learning model by the first learning object data and the second learning object data, and a step of executing the learning. May further be included.
- the program according to still another aspect of the present invention includes a step of acquiring first object data indicating the attributes and arrangement of objects in the first image from the first image by using the first machine learning model. Using the first machine learning model, the step of acquiring the second object data indicating the attributes and arrangement of the objects in the second image from the second image, and the second machine learning model are used. It is a program for causing a computer to execute a step of determining the substantial identity of the first image and the second image from the first object data and the second object data.
- This program may be stored in a computer-readable information storage medium such as a magneto-optical disk or a semiconductor memory.
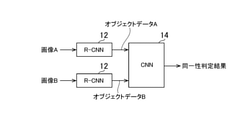
- FIG. 1 is a functional block diagram of an image determination device according to an embodiment of the present invention.
- Each functional block shown in the figure is realized by executing the image determination program according to the embodiment of the present invention on a computer configured mainly by a CPU and a memory.
- the image determination device 10 shown in the figure determines the substantial identity of the two screen images.
- Objects such as buttons are arranged on each screen image as described above.
- the image determination device 10 determines the substantial identity of the two screen images based on the number of objects included in the two screen images, the attributes of each object, and the arrangement of each object in the screen image.
- the attributes of the object are, for example, the type and color information of the object.
- Types of objects include buttons, logo images, trademark images, input forms, and the like.
- As the color information of the object information on one or more representative colors of the object, information on the average color, and the like may be adopted.
- substantially identical to the two images means that the number of object images included in each image, the attributes and arrangement of each image match the predefined regular rules. Further, “there is no substantial identity” between the two images means that the number of object images included in each image, their respective attributes and arrangements meet the predefined negative rule.
- the same is true.
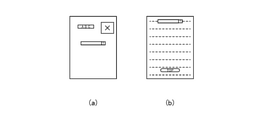
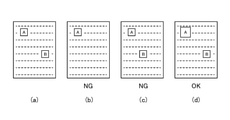
- the screen image in which only the object A is arranged at the same position and the object B is lost is not substantially the same as the screen image shown in the figure (a). Will be done. That is, it is determined that the screen images in which the number of objects does not match are not substantially the same.
- a screen image in which the object A is arranged at the same position but the object B is arranged shifted in the horizontal direction is also a screen image shown in the figure (a). It is judged that there is no substantial identity with. That is, it is determined that the screen image in which the corresponding objects are arranged so as to be displaced in the horizontal direction is not substantially the same as the screen image shown in FIG.
- a screen image having a different size of the object B as shown in the figure (d) and a screen image having a different size of the object A as shown in the figure (e) are shown in the figure (a). It is judged that there is substantial identity with the screen image shown. That is, when comparing two screen images, if the number, attributes, and arrangement of the objects are the same, it is determined that the two screen images are substantially the same even if the sizes of the objects are different.
- the image determination device 10 has a first machine learning model, R-CNN (Regions with Convolutional Neural Networks) 12, and a second machine learning model. It is configured to include CNN (Convolutional Neural Networks) 14 which is a machine learning model.
- CNN Convolutional Neural Networks
- the object data A indicating the attributes and arrangement of the objects included in the screen image A is output.
- the object data B indicating the attributes and arrangement of the objects included in the screen image B is output.
- object data A and object data B are input to CNN14.
- the CNN 14 outputs whether or not the screen image A and the screen image B have substantial identity based on the object data A and the object data B.
- the screen image A and the screen image B are sequentially input to the R-CNN12 so that the object data A and the object data B are sequentially obtained.
- the two R-CNN12s are arranged in parallel.
- the object data B may be generated from the screen image B in parallel with the object data A being generated from the screen image A by providing the object data A in front of the CNN 14.
- the R-CNN12 is a machine learning model for object detection, and is a known machine learning model for object detection such as the original R-CNN, Fast R-CNN, Faster R-CNN, and MASK R-CNN. May be configured by.
- Faster R-CNN is adopted as an example of R-CNN12.
- object data indicating the arrangement in the input image and the attributes of the object is output for each of the objects included in the image.
- the placement of each object in the input image is specified in the object data, for example by an anchor box.
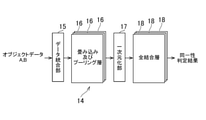
- the CNN 14 includes a data integration unit 15, a multi-stage dimension reduction unit 16, a one-dimensional unit 17, and a multi-stage fully connected layer 18, which are composed of a convolution layer and a pooling layer, respectively. Includes.
- the data integration unit 15 concatenates the object data A and the object data B output from the R-CNN 12 to generate the input data of 1.
- the object data A and the object data B have one dimension indicating the order of the objects (for example, 300 data may be included) and two dimensions indicating the size and arrangement of the objects (for example, four in each dimension). It may be a four-dimensional tensor data consisting of one dimension (for example, 1024 data may be included) indicating the attributes of the object.
- the data integration unit 15 may combine the object data A and the object B to obtain input data by, for example, extending the dimension of the ordinal number of the object to twice the size.
- the objects included in the screen image A are assigned to the ordinal numbers 1 to 300 of the objects
- the objects included in the screen image B are assigned to the ordinal numbers 301 to 600 of the objects.
- the input data generated by the data integration unit 15 is dimensionally reduced by the dimension reduction unit 16 in a plurality of stages, and the two-dimensional intermediate data is output from the dimension reduction unit 16 in the final stage.
- the one-dimensional unit 17 makes the intermediate data one-dimensional, and inputs the one-dimensional intermediate data to the fully connected layer 18 of the first stage.
- the fully connected layer 18 in the final stage outputs a one-dimensional (may include two data) identity determination results from the one-dimensional intermediate data.
- the identity determination result includes data showing the degree of identity of the screen image A and the screen image B to some extent, and data showing the degree to which there is no such identity.
- CNN 14 shown in FIG. 4 it becomes possible to determine whether or not the screen image A and the screen image B are substantially identical from the attributes and arrangements of the objects included in each of the screen image A and the screen image B.
- the object data A and the object data B are combined to obtain the input data, and the dimension reduction of the input data is performed.
- the dimension reduction is performed for each of the object data A and the object data B. You may try to do it. That is, as shown in CNN 14 shown in FIG. 5, the dimension reduction unit 16a having a plurality of stages including the folding layer and the pooling layer reduces the dimension of the object data A, and the dimension reduction unit has the same function as the dimension reduction unit 16a. With 16b, the dimension reduction of the object data B may be performed in parallel with the dimension reduction of the object data A.
- the outputs of the dimension reduction units 16a and 16b are two-dimensional intermediate data, respectively, and the data integration unit 19 converts each intermediate data into one dimension, concatenates them, and outputs one one-dimensional intermediate data.
- the intermediate data output from the data integration unit 19 is input to the fully connected layer 18 of a plurality of stages, and the identity determination result is output from the final stage.
- FIG. 6 is a diagram showing a configuration of a learning device 20 that learns the R-CNN 12.
- Each functional block shown in the figure is realized by executing a program according to an embodiment of the present invention on a computer configured around a CPU and a memory.
- the learning device 20 generates training data for generating training data used for learning of the training unit 21, R-CNN12, which executes learning of R-CNN12 by updating the internal parameters of R-CNN12.
- the unit 22 includes a base image storage unit 24 for storing a base image used when generating training data, and an object image storage unit 26 for storing an object image used when similarly generating training data.
- FIG. 7 shows an example of a base image stored in the base image storage unit 24.
- the base image is image data in raster format which is the basis of the screen image
- FIG. 6A shows a base image in which sentences are represented on the entire surface.
- FIG. 3B shows a plain white base image.
- FIG. C shows a base image consisting of a solid colored page top and a bottom showing the document.
- FIG. 3D shows a base image divided into a plurality of blocks and a document is represented in each block.
- the base image storage unit 24 stores a large number of such raster format base images.
- FIG. 8 shows an example of an object image stored in the object image storage unit 26.
- the object image is image data in raster format which is the basis of the screen image, and shows the appearance of an object such as a button or an input form arranged in the screen image.
- the figure (a) shows a logo image which is a kind of object image. An object number "001" is assigned to the object image shown in the figure.
- FIG. 3B shows an input form image which is a kind of object image.
- An object number "002" is assigned to the object image shown in the figure.
- the figure (c) shows a button image which is a kind of object image. An object number "003" is assigned to the object image shown in the figure.
- the figure (d) shows a trademark image which is a kind of object image. An object number "004" is assigned to the object image shown in the figure.
- the object image storage unit 26 stores a large number of such raster-format object images.
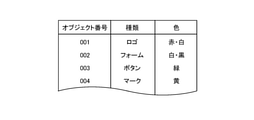
- the object image storage unit 26 stores the object attribute table shown in FIG. 9 in addition to a large number of object images.
- the object attribute table stores the attributes of each object image stored in the object image storage unit 26. Specifically, the object attribute table stores the type and color information of the object image related to each object number in association with each object number. For example, in the object attribute table, the type "logo" of the object image and the color information "red / white” of the object image are stored in association with the object number "001" of the object image shown in FIG. 8 (a). ing.
- the training data generation unit 22 generates a large number of training data based on the data stored in the base image storage unit 24 and the object image storage unit 26.
- the training data includes training images and correct answer data.
- FIG. 10 shows an example of a training image generated by the training data generation unit 22.
- the training image shown in FIG. 7A is the base image shown in FIG. 7B, the object image shown in FIG. 8A, the object image shown in FIG. 8D, and FIG. 8B. ), It is generated by superimposing the object image. Further, in the training image shown in FIG. 10 (b), the object image shown in FIG. 8 (b) and the object image shown in FIG. 8 (c) are superimposed on the base image shown in FIG. 7 (a). It was generated by this.
- the base image used when generating the training image is randomly selected by the training data generation unit 22 from a large number of base images stored in the base image storage unit 24. Further, the object image to be superimposed on the base image is also randomly selected by the training data generation unit 22 from a large number of base images stored in the object image storage unit 24. Further, the arrangement (position and size) of each object image is also randomly determined by the training data generation unit 22.
- FIG. 11 shows an example of correct answer data generated by the training data generation unit 22.
- FIG. 10A shows correct answer data for the training image shown in FIG. 10A.
- This correct answer data includes three object images in the training image, the arrangement of the first object image is "(XA1, YA1)-(XB1, YB1)", and the attribute is "logo, red”. -It is "white", the arrangement of the second object image is "(XA2, YA2)-(XB2, YB2)", the attribute is "mark, yellow”, and the arrangement of the third object image is It is indicated that "(XA3, YA3)-(XB3, YB3)" and the attribute is "form, white / black”. That is, the correct answer data indicates the number of object images included in the training image, and the arrangement and attributes of each object image.
- FIG. 11 (b) shows the correct answer data for the training image shown in FIG. 10 (b).
- the training data generation unit 22 When the training data generation unit 22 generates the training image, the object image to be superimposed on the base image is randomly selected, and the arrangement thereof is also randomly determined.
- the training data generation unit 22 reads the attributes of the selected object image from the object attribute table shown in FIG. 9 and includes them in the correct answer data shown in FIG. 11, and also shows the arrangement of the determined object image in FIG. By including it in the correct answer data, the correct answer data corresponding to the training image is generated.
- the training unit 21 executes the learning process of the R-CNN 12 using the training data generated by the training data generation unit 22. Specifically, the training images included in the training data are sequentially input to the R-CNN12, and the output of the object data is obtained. The difference between this output and the correct answer data included in the training data is calculated, and the internal parameters of R-CNN12 are updated so that this difference becomes small.
- FIG. 12 is an operation flow diagram of the learning device 20.
- the training data generation unit 22 randomly selects an object image stored in the object image storage unit 26 (S101).
- the number of object images to be selected is also randomly determined.
- the training data generation unit 22 randomly selects one base image from the base image storage unit 24 (S102).
- the training data generation unit 22 generates a training image by arranging the selected object image with respect to the selected base image (S103). At this time, the training data generation unit 22 randomly determines the arrangement and size of each object image.
- the training data generation unit 22 further generates the correct answer data exemplified in FIG. 11 according to the processing contents in S101 to S103, and includes it in the training data together with the training image generated in S103 (S104).
- the training unit 21 executes the learning process of R-CNN12 using the generated training data (S106).
- FIG. 13 is a diagram showing a configuration of a learning device 30 that learns the CNN 14.
- the learning device 30 includes a training unit 31 that executes learning of the CNN 14 by updating the internal parameters of the CNN 14, a training data generation unit 32 that generates training data used for learning the CNN 14, and a base image storage.
- a unit 24 and an object image storage unit 26 are included.
- the training data generation unit 32 generates training data related to positive and negative examples by using the base image stored in the base image storage unit 24 and the object image stored in the object image storage unit 26.
- Each training data includes a positive example, that is, a pair of training images that have substantial identity, or a negative example, that is, a pair of training images that do not have substantial identity.
- FIG. 14 is a diagram showing training images related to positive and negative examples used for learning CNN14.
- Figure (a) shows one example of a pair of training images.
- the one training image is generated by arranging a plurality of randomly selected object images at random positions and at random sizes with respect to a randomly selected base image.
- the object images A and B are arranged with respect to the base image in which the document is represented as a whole.
- the figure (b) shows the other training image generated by applying the first negative rule.
- the first negative rule a part of the object image included in one training image is removed.
- the training image of the figure (b) does not include the object image B unlike the training image of the figure (a).
- the figure (c) shows the other training image generated by applying the second negative rule.
- the second negative rule a part of the object image included in one training image is moved horizontally.
- the object image B is shifted to the left as compared with the training image of the figure (a).
- the figure (d) shows the other training image generated by applying the regular rule.
- a part of the object image included in one training image is enlarged or reduced.
- the object image A is enlarged as compared with the training image of the figure (a).
- the training unit 31 executes the learning process of CNN14 using the training data generated in this way. Specifically, the two training images included in the training data are sequentially input to the R-CNN12, and the two object data are acquired. Then, those object data are input to CNN14.
- the training unit 31 acquires the identity determination result output from the CNN 14, and updates the internal parameters of the CNN 14 so that the identity determination result is correct. That is, when the training image according to the positive example is input to the R-CNN12, the internal parameters are updated so that the identity determination results output from the CNN 14 are substantially the same. On the contrary, when the training image according to the negative example is input to the R-CNN12, the internal parameters are updated so that the identity determination results output from the CNN 14 are not substantially the same.
- FIG. 15 is an operation flow diagram of the learning device 30.
- the training data generation unit 32 first randomly selects an object image from the object image storage unit 26 (S201). Further, the training data generation unit 32 randomly selects a base image from the base image storage unit 24 (S202). Then, the training data generation unit 32 generates the training image A by superimposing each object image on the selected base image (S203). At this time, the position and size of each object image are randomly determined.
- the training data generation unit 32 applies the regular rule or the negative rule to superimpose all or a part of the selected object image on the selected base image to obtain the training image B.
- Generate S204.
- the training image B is generated without superimposing a part of the selected object images on the selected base image.
- the training image B is made by moving a part of the selected object image to the right or left and then superimposing it on the selected base image.
- the training image B is generated by enlarging or reducing a part of the selected object image and then superimposing it on the selected base image.
- the training data generation unit 32 generates and stores training data including the generated pair of training images A and B and whether they are positive or negative examples (S205). ..
- the training unit 31 executes the learning process of CNN14 using the generated training data (S207).
- object data indicating the attributes and positions of the object images included in the two screen images to be compared can be obtained from each of the two screen images to be compared. Then, based on the two object data, it is determined whether or not the two screen images are substantially the same.
- the CNN14 is pre-trained with a large number of training image pairs generated according to the regular and negative rules for determining the presence or absence of substantial identity. According to this embodiment, the substantial identity between the two screen images can be suitably determined.
- the present inventors used 500 base images and 33 types of object images to generate 5000 training data for R-CNN12 and 8000 training data for CNN14, and R. -When the learning of CNN12 and CNN14 was carried out, the determination accuracy of the substantial identity of the screen image was about 86%, and it was found that it was sufficiently practical.
- the scope of the present invention is not limited to the above embodiment, and includes various modifications.
- the present invention can be similarly applied not only to screen images but also to various images such as page images of electronic books and web content images.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Multimedia (AREA)
- Medical Informatics (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Quality & Reliability (AREA)
- Image Analysis (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/033921 WO2022054124A1 (ja) | 2020-09-08 | 2020-09-08 | 画像判定装置、画像判定方法及びプログラム |
| US17/419,285 US12067708B2 (en) | 2020-09-08 | 2020-09-08 | Image judgement apparatus, image judgement method and non-transitory computer readable medium |
| JP2022548264A JP7401688B2 (ja) | 2020-09-08 | 2020-09-08 | 画像判定装置、画像判定方法及びプログラム |
| JP2023206941A JP7588203B2 (ja) | 2020-09-08 | 2023-12-07 | 画像判定装置、画像判定方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/033921 WO2022054124A1 (ja) | 2020-09-08 | 2020-09-08 | 画像判定装置、画像判定方法及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022054124A1 true WO2022054124A1 (ja) | 2022-03-17 |
Family
ID=80631391
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/033921 Ceased WO2022054124A1 (ja) | 2020-09-08 | 2020-09-08 | 画像判定装置、画像判定方法及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12067708B2 (https=) |
| JP (2) | JP7401688B2 (https=) |
| WO (1) | WO2022054124A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024039974A (ja) * | 2022-09-12 | 2024-03-25 | 日本電気株式会社 | レイアウト支援システム、レイアウト支援装置、情報蓄積装置、レイアウト支援方法、およびレイアウト支援プログラム |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018169690A (ja) * | 2017-03-29 | 2018-11-01 | 日本電信電話株式会社 | 画像処理装置、画像処理方法及び画像処理プログラム |
| US20190073560A1 (en) * | 2017-09-01 | 2019-03-07 | Sri International | Machine learning system for generating classification data and part localization data for objects depicted in images |
| JP2019219766A (ja) * | 2018-06-15 | 2019-12-26 | 株式会社Lixil | 分析装置、分析システム、及び分析プログラム |
| JP2020088416A (ja) * | 2018-11-15 | 2020-06-04 | シャープ株式会社 | 電子機器および制御装置 |
| JP2020107185A (ja) * | 2018-12-28 | 2020-07-09 | Kddi株式会社 | 画像認識装置、画像認識方法及びプログラム |
Family Cites Families (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TW200746037A (en) * | 2006-02-14 | 2007-12-16 | Sony Corp | Display control device and display control method |
| JP4696099B2 (ja) * | 2007-08-07 | 2011-06-08 | 日立オムロンターミナルソリューションズ株式会社 | 表示画像変換装置 |
| US8315423B1 (en) * | 2007-12-28 | 2012-11-20 | Google Inc. | Providing information in an image-based information retrieval system |
| JP5485781B2 (ja) * | 2010-05-10 | 2014-05-07 | 株式会社ザクティ | 電子カメラ |
| US9002109B2 (en) * | 2012-10-09 | 2015-04-07 | Google Inc. | Color correction based on multiple images |
| JP2016218977A (ja) * | 2015-05-26 | 2016-12-22 | 富士通株式会社 | 比較プログラム、情報処理装置および比較方法 |
| US9767381B2 (en) * | 2015-09-22 | 2017-09-19 | Xerox Corporation | Similarity-based detection of prominent objects using deep CNN pooling layers as features |
| WO2017210908A1 (zh) * | 2016-06-08 | 2017-12-14 | 华为技术有限公司 | 处理方法与终端 |
| JP6832504B2 (ja) * | 2016-08-08 | 2021-02-24 | パナソニックIpマネジメント株式会社 | 物体追跡方法、物体追跡装置およびプログラム |
| US11308350B2 (en) * | 2016-11-07 | 2022-04-19 | Qualcomm Incorporated | Deep cross-correlation learning for object tracking |
| US10210627B1 (en) * | 2017-01-23 | 2019-02-19 | Amazon Technologies, Inc. | Image processing system for determining metrics of objects represented therein |
| US20180268307A1 (en) * | 2017-03-17 | 2018-09-20 | Yahoo Japan Corporation | Analysis device, analysis method, and computer readable storage medium |
| CN107065247A (zh) * | 2017-06-07 | 2017-08-18 | 惠科股份有限公司 | 一种显示面板检测方法、装置及系统 |
| US10794710B1 (en) * | 2017-09-08 | 2020-10-06 | Perceptin Shenzhen Limited | High-precision multi-layer visual and semantic map by autonomous units |
| US10902615B2 (en) * | 2017-11-13 | 2021-01-26 | Qualcomm Incorporated | Hybrid and self-aware long-term object tracking |
| US10885336B1 (en) * | 2018-01-13 | 2021-01-05 | Digimarc Corporation | Object identification and device communication through image and audio signals |
| US10489126B2 (en) * | 2018-02-12 | 2019-11-26 | Oracle International Corporation | Automated code generation |
| US11100400B2 (en) * | 2018-02-15 | 2021-08-24 | Adobe Inc. | Generating visually-aware item recommendations using a personalized preference ranking network |
| CN110580486B (zh) * | 2018-06-07 | 2024-04-12 | 斑马智行网络(香港)有限公司 | 一种数据处理方法、装置、电子设备和可读介质 |
| WO2020070943A1 (ja) * | 2018-10-03 | 2020-04-09 | 株式会社Nttドコモ | パターン認識装置及び学習済みモデル |
| US11354791B2 (en) * | 2018-12-19 | 2022-06-07 | General Electric Company | Methods and system for transforming medical images into different styled images with deep neural networks |
| CN109635141B (zh) * | 2019-01-29 | 2021-04-27 | 京东方科技集团股份有限公司 | 用于检索图像的方法、电子设备和计算机可读存储介质 |
| AU2019200976A1 (en) * | 2019-02-12 | 2020-08-27 | Canon Kabushiki Kaisha | Method, system and apparatus for generating training samples for matching objects in a sequence of images |
| WO2020181066A1 (en) * | 2019-03-06 | 2020-09-10 | Trax Technology Solutions Pte Ltd. | Methods and systems for monitoring products |
| US11551348B2 (en) * | 2019-04-09 | 2023-01-10 | KLA Corp. | Learnable defect detection for semiconductor applications |
| US10607331B1 (en) * | 2019-06-28 | 2020-03-31 | Corning Incorporated | Image segmentation into overlapping tiles |
| US10748650B1 (en) * | 2019-07-17 | 2020-08-18 | Richard Ricci | Machine learning of dental images for E-commerce |
| CN112446832A (zh) * | 2019-08-31 | 2021-03-05 | 华为技术有限公司 | 一种图像处理方法及电子设备 |
| US11513670B2 (en) * | 2020-04-27 | 2022-11-29 | Automation Anywhere, Inc. | Learning user interface controls via incremental data synthesis |
| US20210374947A1 (en) * | 2020-05-26 | 2021-12-02 | Nvidia Corporation | Contextual image translation using neural networks |
| US12111646B2 (en) * | 2020-08-03 | 2024-10-08 | Automation Anywhere, Inc. | Robotic process automation with resilient playback of recordings |
| KR102430029B1 (ko) * | 2020-08-26 | 2022-08-05 | 엔에이치엔클라우드 주식회사 | 딥러닝 기반 유사상품 검색 결과 제공 방법 및 그 시스템 |
-
2020
- 2020-09-08 JP JP2022548264A patent/JP7401688B2/ja active Active
- 2020-09-08 WO PCT/JP2020/033921 patent/WO2022054124A1/ja not_active Ceased
- 2020-09-08 US US17/419,285 patent/US12067708B2/en active Active
-
2023
- 2023-12-07 JP JP2023206941A patent/JP7588203B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018169690A (ja) * | 2017-03-29 | 2018-11-01 | 日本電信電話株式会社 | 画像処理装置、画像処理方法及び画像処理プログラム |
| US20190073560A1 (en) * | 2017-09-01 | 2019-03-07 | Sri International | Machine learning system for generating classification data and part localization data for objects depicted in images |
| JP2019219766A (ja) * | 2018-06-15 | 2019-12-26 | 株式会社Lixil | 分析装置、分析システム、及び分析プログラム |
| JP2020088416A (ja) * | 2018-11-15 | 2020-06-04 | シャープ株式会社 | 電子機器および制御装置 |
| JP2020107185A (ja) * | 2018-12-28 | 2020-07-09 | Kddi株式会社 | 画像認識装置、画像認識方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7588203B2 (ja) | 2024-11-21 |
| JPWO2022054124A1 (https=) | 2022-03-17 |
| US20220309648A1 (en) | 2022-09-29 |
| JP2024015273A (ja) | 2024-02-01 |
| JP7401688B2 (ja) | 2023-12-19 |
| US12067708B2 (en) | 2024-08-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108352083B (zh) | 用于拉伸成3d对象的2d图像处理 | |
| CN106062824B (zh) | 边缘检测装置和边缘检测方法 | |
| GB2559446A (en) | Generating a three-dimensional model from a scanned object | |
| CN112534443A (zh) | 图像处理设备及其操作方法 | |
| JP2018190329A (ja) | 画像処理装置、画像処理プログラム、画像処理システム | |
| JP2015232869A (ja) | 画像処理装置、画像処理方法及び画像処理プログラム | |
| WO2017050083A1 (zh) | 一种元件识别方法及装置 | |
| JP7588203B2 (ja) | 画像判定装置、画像判定方法及びプログラム | |
| CN106778881A (zh) | 数字印花方法及装置 | |
| KR102810293B1 (ko) | 입력 이미지로부터 전력선을 검출하는 인공신경망의 학습 방법 | |
| CN114820834A (zh) | 一种效果处理方法、装置、设备及存储介质 | |
| CN113658280B (zh) | 基于人工智能的数据增广方法、装置、设备和存储介质 | |
| KR20160066511A (ko) | 마커 인식 장치, 마커 인식 방법 및 기록 매체에 저장된 마커 인식용 컴퓨터 프로그램 | |
| CN112927321B (zh) | 基于神经网络的图像智能设计方法、装置、设备及存储介质 | |
| US20240311997A1 (en) | Semiconductor image processing apparatus and semiconductor image processing method | |
| US12277633B2 (en) | Create editable vectorized image from bitmap image | |
| JP7270314B1 (ja) | 検査方法、検査システム、ニューラルネットワーク | |
| WO2023032216A1 (ja) | 点群補完装置、点群補完方法、及び点群補完プログラム | |
| CN114390265B (zh) | 投射区域的设定辅助方法、设定辅助系统以及记录介质 | |
| US20240127507A1 (en) | Image processing method and image processing apparatus | |
| KR20180061496A (ko) | 초해상화 방법 | |
| WO2021182345A1 (ja) | 学習データ作成装置、方法、プログラム、学習データ及び機械学習装置 | |
| CN114820874A (zh) | 一种文字的阴影效果处理方法、装置、设备及存储介质 | |
| Calvo et al. | OpenCV 3. x with Python By Example: Make the most of OpenCV and Python to build applications for object recognition and augmented reality | |
| JP2010108285A (ja) | 画像処理方法およびそのコンピュータプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20953192 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022548264 Country of ref document: JP Kind code of ref document: A |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20953192 Country of ref document: EP Kind code of ref document: A1 |