WO2021157667A1 - 予測装置、予測方法及びプログラム - Google Patents
予測装置、予測方法及びプログラム Download PDFInfo
- Publication number
- WO2021157667A1 WO2021157667A1 PCT/JP2021/004168 JP2021004168W WO2021157667A1 WO 2021157667 A1 WO2021157667 A1 WO 2021157667A1 JP 2021004168 W JP2021004168 W JP 2021004168W WO 2021157667 A1 WO2021157667 A1 WO 2021157667A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- process data
- value
- prediction
- prediction model
- processing
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 339
- 230000008569 process Effects 0.000 claims abstract description 317
- 238000012545 processing Methods 0.000 claims abstract description 119
- 239000000126 substance Substances 0.000 claims abstract description 32
- 238000006243 chemical reaction Methods 0.000 claims abstract description 31
- 230000001364 causal effect Effects 0.000 claims abstract description 16
- 238000010923 batch production Methods 0.000 claims description 50
- 238000010924 continuous production Methods 0.000 claims description 49
- 238000005070 sampling Methods 0.000 claims description 18
- 238000004364 calculation method Methods 0.000 claims description 9
- 230000009467 reduction Effects 0.000 claims description 5
- 230000004913 activation Effects 0.000 claims description 3
- 238000010586 diagram Methods 0.000 description 46
- 238000007689 inspection Methods 0.000 description 21
- 239000000047 product Substances 0.000 description 20
- 238000003860 storage Methods 0.000 description 20
- 238000004519 manufacturing process Methods 0.000 description 16
- 238000005457 optimization Methods 0.000 description 16
- 230000006870 function Effects 0.000 description 12
- 238000004458 analytical method Methods 0.000 description 9
- 238000004891 communication Methods 0.000 description 9
- 238000009499 grossing Methods 0.000 description 8
- 238000012544 monitoring process Methods 0.000 description 8
- 230000008859 change Effects 0.000 description 7
- 239000002994 raw material Substances 0.000 description 6
- 230000009471 action Effects 0.000 description 4
- 238000010276 construction Methods 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 238000003672 processing method Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 238000011144 upstream manufacturing Methods 0.000 description 3
- 230000005856 abnormality Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000011058 failure modes and effects analysis Methods 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000000611 regression analysis Methods 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 230000026676 system process Effects 0.000 description 2
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000006196 deacetylation Effects 0.000 description 1
- 238000003381 deacetylation reaction Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 238000007599 discharging Methods 0.000 description 1
- 238000004821 distillation Methods 0.000 description 1
- 238000011143 downstream manufacturing Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 239000013067 intermediate product Substances 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000036632 reaction speed Effects 0.000 description 1
- 238000005096 rolling process Methods 0.000 description 1
- 230000001932 seasonal effect Effects 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
Images





















Classifications
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B23/00—Testing or monitoring of control systems or parts thereof
- G05B23/02—Electric testing or monitoring
- G05B23/0205—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults
- G05B23/0259—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults characterized by the response to fault detection
- G05B23/0264—Control of logging system, e.g. decision on which data to store; time-stamping measurements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/04—Manufacturing
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B13/00—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion
- G05B13/02—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric
- G05B13/04—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric involving the use of models or simulators
- G05B13/041—Adaptive control systems, i.e. systems automatically adjusting themselves to have a performance which is optimum according to some preassigned criterion electric involving the use of models or simulators in which a variable is automatically adjusted to optimise the performance
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B19/00—Programme-control systems
- G05B19/02—Programme-control systems electric
- G05B19/418—Total factory control, i.e. centrally controlling a plurality of machines, e.g. direct or distributed numerical control [DNC], flexible manufacturing systems [FMS], integrated manufacturing systems [IMS] or computer integrated manufacturing [CIM]
- G05B19/41875—Total factory control, i.e. centrally controlling a plurality of machines, e.g. direct or distributed numerical control [DNC], flexible manufacturing systems [FMS], integrated manufacturing systems [IMS] or computer integrated manufacturing [CIM] characterised by quality surveillance of production
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B23/00—Testing or monitoring of control systems or parts thereof
- G05B23/02—Electric testing or monitoring
- G05B23/0205—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults
- G05B23/0218—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults characterised by the fault detection method dealing with either existing or incipient faults
- G05B23/0224—Process history based detection method, e.g. whereby history implies the availability of large amounts of data
- G05B23/024—Quantitative history assessment, e.g. mathematical relationships between available data; Functions therefor; Principal component analysis [PCA]; Partial least square [PLS]; Statistical classifiers, e.g. Bayesian networks, linear regression or correlation analysis; Neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/04—Forecasting or optimisation specially adapted for administrative or management purposes, e.g. linear programming or "cutting stock problem"
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
- G06Q10/063—Operations research, analysis or management
- G06Q10/0639—Performance analysis of employees; Performance analysis of enterprise or organisation operations
- G06Q10/06395—Quality analysis or management
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B2219/00—Program-control systems
- G05B2219/30—Nc systems
- G05B2219/32—Operator till task planning
- G05B2219/32194—Quality prediction
Definitions
- This disclosure relates to prediction devices, prediction methods and programs.
- a technique for predicting the quality of a product in a manufacturing process and controlling the operation based on the prediction has been proposed.
- a prediction system has been proposed in which a characteristic value of a product is predicted during the manufacturing process of the manufacturing process and the control conditions of the manufacturing process in the subsequent process are calculated based on the prediction result (Patent Document 1).
- This system uses a database that stores data measured in the manufacturing process process and / or data that indicates the state of the manufacturing process for each lot, and data stored in the database for the manufacturing process.
- For the formula model creation unit that creates the formula model of, and the lot being manufactured enter the actual value for the processed process and the representative value obtained based on the past lot for the unprocessed process into the formula model.
- the product characteristic prediction unit that predicts the characteristic value of the product and the optimum manufacturing condition calculation unit that calculates the optimum manufacturing condition of the target process to be controlled among the unprocessed processes according to the prediction result by the product characteristic prediction unit. It is provided, and the prediction by the product characteristic prediction unit and the calculation by the optimum manufacturing condition calculation unit are carried out for each predetermined controlled process for the lot being manufactured.
- the purpose of this technique is to improve the prediction accuracy of processes including reactions in chemical plants.
- the prediction device includes a process data processing unit that performs a predetermined processing process on the process data obtained from the chemical plant, and a process data obtained from the chemical plant or a process data processed by the process data processing unit. Obtained from a chemical plant based on causal relationship information that defines a combination of a first process data as an explanatory variable and a second process data as an objective variable or a value corresponding to the second process data. It is equipped with a prediction model creation unit that creates a prediction model that learns the characteristics of process data. In addition, the process data processing unit uses the process data to obtain a value according to the reaction speed of the processing target in a predetermined period.
- the reaction is non-linear due to the influence of temperature, etc., so it was difficult to predict the characteristics of the process data based on, for example, the peak value, difference value, integral value, etc. of the process data.
- the value corresponding to the reaction rate as described above becomes an explanatory variable that correlates with the reaction amount per hour, for example.
- the value corresponding to the reaction rate may be an integrated value of the reaction rate.
- the value according to the reaction rate is calculated using the Arrhenius equation, and even if the frequency factor and activation energy of the reaction rate constant are determined according to the type of chemical reaction and the processing target in the chemical plant. good. Specifically, such a value can be adopted.
- the process data processing unit determines the integral value, differential value, average value, maximum value, or minimum value of the process data in a predetermined period, or the instantaneous value of the process data at a predetermined time point, depending on the type of process data. You may ask for more. By performing such processing on the process data, the prediction accuracy of the prediction model can be improved.
- the prediction model has a hierarchical structure including a plurality of prediction formulas, and may have a second prediction formula including the prediction value calculated by the first prediction formula as an explanatory variable. For example, in this way, a plurality of causal relationships can be expressed by a function.
- the value corresponding to the second process data is a value obtained by sampling a plurality of second process data by the reduction method, and is the range of the acquisition timing of the first process data in the chemical plant and the second.
- the prediction model creation unit may create a prediction model by associating the calculation timing of the value according to the process data with the residence time of the processing target in the chemical plant.
- the chemical plant performs a batch process in which the processing target is sequentially processed for each predetermined processing unit and a continuous process in which the processing target is continuously processed thereafter, and the range of the completion timing of the batch process and the second
- the prediction model creation unit may create a prediction model by associating the calculation timing of the value according to the process data with the residence time of the processing target in the chemical plant. Even when the batch process and the continuous process are continuously performed, the accuracy of prediction can be improved by appropriately associating the process data as the explanatory variable with the process data as the objective variable.
- the contents described in the means for solving the problems can be combined as much as possible without departing from the problems and technical ideas of the present disclosure. Further, the content of the means for solving the problem can be provided as a device such as a computer or a system including a plurality of devices, a method executed by the computer, or a program executed by the computer. A recording medium for holding the program may be provided.
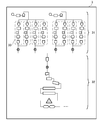
- FIG. 1 is a diagram showing an example of a system according to an embodiment.
- FIG. 2 is a schematic diagram showing an example of a process performed by the equipment provided in the plant.
- FIG. 3 is a diagram for explaining an example of process data in the batch process.
- FIG. 4 is a diagram showing an example of information registered in advance in the knowledge base.
- FIG. 5 is a diagram showing an example of a tag attribute table of a batch process created based on a knowledge base.
- FIG. 6 is a diagram showing an example of a tag binding table created based on the knowledge base.
- FIG. 7 is a diagram showing an example of a logic tree showing the configuration of the prediction model.
- FIG. 8 is a diagram for explaining an example of process data in a continuous process.
- FIG. 1 is a diagram showing an example of a system according to an embodiment.
- FIG. 2 is a schematic diagram showing an example of a process performed by the equipment provided in the plant.
- FIG. 3 is a diagram for explaining an example of
- FIG. 9 is a diagram for explaining the correspondence between the sample in the process inspection of the continuous process and the serial number in the batch process.
- FIG. 10 is a diagram for explaining the residence time from the sensor position in the continuous process to the sampling position in the process inspection.
- FIG. 11 is a diagram showing an example of a tag attribute table of a continuous process created based on a knowledge base.
- FIG. 12 is a diagram showing an example of a logic tree showing the configuration of the prediction model.
- FIG. 13 is a block diagram showing an example of the configuration of the prediction device.
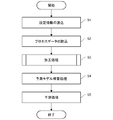
- FIG. 14 is a processing flow diagram showing an example of prediction processing executed by the prediction device.
- FIG. 15 is a diagram showing an example of a writing sequence for a batch process.
- FIG. 16 is a processing flow diagram showing an example of processing.
- FIG. 17 is a diagram showing an example of a batch array.
- FIG. 18 is a diagram for explaining the process data to be substituted into the prediction formula or the predicted value thereof.
- FIG. 19 is a diagram showing another example for explaining the process data to be substituted into the prediction formula or the predicted value thereof.
- FIG. 20 is a diagram showing an example of a writing array holding data of the type “continuous”.
- FIG. 21 is a diagram showing an example of a writing array holding data of the type “batch”.
- FIG. 22 is a diagram showing an example of a combined ID data array that holds process data after processing in a continuous process.
- FIG. 23 is a processing flow diagram showing an example of the control processing executed by the prediction device.
- FIG. 1 is a diagram showing an example of a system according to the present embodiment.
- the system 100 includes a prediction device 1, a control station 2, and a plant 3.
- the system 100 is, for example, a distributed control system (DCS), and includes a plurality of control stations 2. That is, the control system of the plant 3 is divided into a plurality of sections, and each control section is distributed and controlled by the control station 2.
- the control station 2 is an existing facility in the DCS, and receives a status signal output from a sensor or the like provided in the plant 3 or outputs a control signal to the plant 3. Then, based on the control signal, actuators such as valves and other equipment included in the plant 3 are controlled.
- the prediction device 1 acquires the status signal (process data) of the plant 3 via the control station 2.
- the process data includes the temperature, pressure, flow rate, and the like of the raw material and the intermediate product to be processed, and the set values that determine the operating conditions of the equipment provided in the plant 3.
- the prediction device 1 creates a prediction model based on a knowledge base that stores the correspondence between the assumed cause and the influence that appears as an abnormality, for example. For example, using causal relationship information that defines a combination of process data as an explanatory variable (also called a factor system) and process data as an objective variable (also called an influence system) created based on a knowledge base, quality. And create a cost prediction formula.
- the prediction device 1 uses the prediction formula and the process data to predict the characteristic value representing the quality of the product and the characteristic value of the product when the operating conditions of the plant 3 are changed. Can be done. Further, the prediction device 1 may obtain operating conditions in which, for example, quality and cost satisfy predetermined conditions. Further, the prediction device 1 uses the prediction formula and the process data to obtain the operating conditions for shifting to the stable state with respect to the change in the state appearing as an influence, or the product satisfies a predetermined requirement. You may ask for operating conditions. Further, the prediction device 1 may use the analysis value obtained in the predetermined process inspection as the objective variable instead of the process data of the influence system.
- FIG. 2 is a schematic diagram showing an example of the equipment provided in the plant or the process performed by the equipment. That is, the process shall include a production process which is a process and a process device which is an apparatus.
- the process may include a batch process 31 and a continuous process 32.
- the processing target is sequentially processed for each predetermined processing unit, and for example, processing such as receiving, holding, and discharging the raw material to each device is performed in order.
- the continuous step 32 the processing objects to be continuously introduced are continuously processed, and for example, processing such as acceptance, holding, and discharge of raw materials is performed in parallel.
- the process may include a plurality of series 33 that perform the same processing in parallel.
- the equipment that performs each treatment includes, for example, a reactor, a distillation apparatus, a heat exchanger, a compressor, a pump, a tank, etc., and these are connected via piping.
- sensors, valves, and the like are provided at predetermined positions of equipment and piping.
- the sensor may include a thermometer, a flow meter, a pressure gauge, a level gauge, a densitometer, and the like.
- the sensor monitors the operating status of each device and outputs a status signal. Further, it is assumed that the sensor included in the plant 3 is attached with a "tag" which is identification information for identifying each of the sensors. Then, the prediction device 1 and the control station 2 manage the input / output signals to each device based on the tags.
- FIG. 3 is a diagram for explaining an example of process data in the batch process.
- the left column of FIG. 3 shows a part of the process of batch step 31 shown in FIG. Specifically, the process includes a shredder 301, a cyclone 302, a pretreatment 303, a precooler 304, and a reactor 305. Further, these processes are classified into a pretreatment process, a precooling process, and a reaction process.
- the right column of FIG. 3 shows an example of process data acquired in each process.
- time series data is acquired from the sensors whose tags are 001 and 002.
- time series data is acquired from the sensors whose tags are 003 and 004.
- time series data is acquired from the sensors whose tags are 005, 006 and 007.
- the processing target associated with the serial number (also referred to as "manufacturing number") is intermittently processed. That is, the serial number is identification information for identifying the processing targets to be collectively processed in the batch process.
- time-series data relating to the processing target associated with the subsequent serial number is obtained. The time points t 1 and t 2 will be described later.
- FIG. 4 is a diagram showing an example of information registered in advance in the knowledge base.
- the knowledge base shall be stored in advance in the storage device of the prediction device 1.
- the table of FIG. 4 contains a column corresponding to each of the sensors and a row indicating the cause of the change in the output value of each sensor. That is, the values are registered in the columns corresponding to the sensors affected by the causes such as "increased amount of auxiliary raw material A" and "decreased amount of auxiliary raw material A” shown in each row.
- the value is registered with a positive or negative sign corresponding to the fluctuation of the output value of the sensor.
- the combination of cause and effect is not always one-to-one. That is, a plurality of causes may be associated with one influence, or the same cause may be associated with a plurality of influences.
- HAZOP Hazard and Operability Study
- HAZOP is, for example, a detection means at a monitoring point by instrumentation equipment constituting the plant, a control range (upper and lower thresholds and alarm setting points), a deviation from the control range (abnormality, modulation), and a control range.
- the logic for determining which possible cause caused the deviation, the effect of the deviation, the action to be taken when the deviation occurs, and the action for the action.
- This is a method for associating these and enumerating them comprehensively.
- HAZOP HAZOP
- FTA fault Tree Analysis
- FMEA Finction Mode and Effect Analysis
- ETA Event Tree Analysis
- the knowledge base may be created based on the contents, the contents extracted from the work standard document and the technical standard document.
- FIG. 5 is a diagram showing an example of a tag attribute table of a batch process created based on a knowledge base.
- the tag attribute table defines how to process the data obtained from the sensor corresponding to each tag.
- the tag attribute table may be a so-called database table, or may be a file having a predetermined format such as CSV (Comma Separated Values). Further, the tag attribute table is created in advance by the user and read by the prediction device 1.
- the tag attribute table includes each attribute of tag, series, product type, primary processing, smoothing, and operation condition optimization.
- a tag which is sensor identification information, is registered in the tag field. Identification information for identifying the process series is registered in the series field. The type of processing target is registered in the product type field. In the prediction process, the prediction device 1 may set parameters according to, for example, the type of processing target.
- the primary processing field information indicating the processing method of the output value of the sensor is registered.
- the attributes of the primary processing further include the attributes of the batch process, the method, and the data section.
- identification information indicating the subdivided process in the batch process is registered. Information indicating the type of data processing method is registered in the method field.
- Types include "instantaneous value”, “average”, “integral”, “differential”, “difference”, “maximum”, “minimum”, “heat history”, and “none".
- the “instantaneous value” represents a value at the start or end specified in the data interval.
- Average represents the average value obtained by dividing the value of the period specified in the data interval by the number of data.
- Integral represents the sum of the values for the period specified in the data interval.
- “Differentiation” represents the derivative coefficient at the start or end specified in the data interval.
- “Difference” represents the difference between the start and end values specified in the data interval.
- Maximum represents the maximum value within the period specified in the data interval.
- “Minimum” represents the minimum value within the period specified by the data interval.
- the “heat history” is an example of the degree of reaction progress, and represents, for example, the integral value of the reaction rate in the period specified in the data interval.
- "None” is attached to the tag at the end of the batch and indicates that no processing is performed.
- the attributes of the data interval further include the attributes of the start and end, and information indicating the timing of acquiring the output value of the sensor is registered in at least one of the start and end fields. The information indicating the timing may be defined based on a predetermined step predetermined for each subdivided process, for example. In the smoothing field, information indicating whether or not a predetermined smoothing process should be performed on the data is registered.
- the operating condition optimization attributes further include adjustment / monitoring, cost impact, control range, and set range attributes.
- adjustment / monitoring field a type indicating whether to be adjusted or monitored in the optimization process is registered.
- cost impact field the cost per predetermined unit that affects the adjustment in the optimization process is registered.
- the attributes of the control range further include the attributes of the upper limit and the lower limit, and in the fields of the upper limit and the lower limit, information indicating the allowable range of the output value of the sensor is registered.
- the attributes of the setting range further include the attributes of the upper limit and the lower limit, and in the fields of the upper limit and the lower limit, information indicating the target range of the output value of the sensor is registered. According to the information registered in the field of operating condition optimization as described above, the prediction device 1 may perform multi-objective optimization or single-objective optimization.
- FIG. 6 is a diagram showing an example of a tag binding table created based on the knowledge base.
- the tag join table is information representing a causal relationship obtained from the knowledge base, and defines a combination of process data as an explanatory variable and process data as an objective variable.
- the tag join table may also be a so-called database table or a file of a predetermined format such as CSV.
- the tag binding table is also created in advance by the user and read by the prediction device 1.
- the tag join table includes each attribute of join ID, tag, factor / influence, causal relationship, learning period, and dependency relationship.
- Identification information indicating a set of causal relationships is registered in the field of the combination ID.
- a tag which is sensor identification information, is registered in the tag field.
- the factor / influence field a type indicating whether it is a factor system or an influence system in a causal relationship (in other words, whether it is an explanatory variable or an objective variable) is registered.
- the positive or negative type that indicates the sign constraint that the output value of the factor system corresponding to the tag should be changed in order to change the value of the influence system in the positive or negative direction is registered. Will be done.
- the prediction device 1 has a constraint (“sign constraint”) that has a certain correspondence between the positive / negative direction of the fluctuation of the value of the factor system and the positive / negative direction of the fluctuation of the value of the influence system. ”)
- signal constraint a constraint that has a certain correspondence between the positive / negative direction of the fluctuation of the value of the factor system and the positive / negative direction of the fluctuation of the value of the influence system.
- a prediction model is created so that the positive and negative fluctuation directions of the objective variable are determined according to the positive and negative fluctuation directions of the explanatory variables. That is, the code registered in the causal field changes the output value of the sensor corresponding to the tag of the record, either positive or negative, in order to change the value of the influence system in a predetermined direction, positive or negative. It shows whether it should be changed in the direction of.
- information for specifying the period of the process data used for creating the prediction model is registered. The information may be, for example, the number of the most recent serial numbers.
- FIG. 7 is a diagram showing an example of a logic tree showing the configuration of the prediction model. Each rectangle represents the output value or predicted value of the sensor corresponding to the tag.
- the prediction model includes a prediction formula for predicting the output value of the sensor corresponding to the influence system, which is connected by the arrow, based on the output value of the sensor in the upstream process (left side in FIG. 7). Further, the prediction model has a hierarchical structure including a plurality of prediction formulas, and includes other prediction formulas including the prediction value by a certain prediction formula as an explanatory variable.
- the prediction formula is created by combining records with the same join ID in the tag join table shown in FIG.
- the output value of the sensor corresponding to the tag in which "factor" is registered in the factor / impact field or its predicted value is used as an explanatory variable, and the tag in which "impact” is registered in the factor / impact field is supported.
- a predetermined prediction formula is created using the output value of the sensor to be used and the characteristic value of the product, which is an analysis value obtained by, for example, a process inspection, as the objective variable.
- the prediction formula can be expressed by, for example, the following formula (1).
- Y (t) a 1 (t) ⁇ x 1 (t) + a 2 (t) ⁇ x 2 (t) + ⁇ ⁇ ⁇ + a n (t) ⁇ x n (t) + a ar (t) ⁇ Y (t-1) + C
- t is a value according to the serial number
- Y (t) is a predicted value of the influence system
- x (t) is an output value of the sensor of the factor system or its predicted value
- a (t) is a predicted value thereof.
- a ar (t) is the coefficient of the autoregressive term
- C is the constant term.
- the terms corresponding to the factor system are included in the number of output values of the original sensor connected by the arrows in FIG. 7.
- the autoregressive term is a predicted value or an actually measured value related to the past serial number.
- the autoregressive term is not limited to one, and the prediction formula may include the autoregressive term relating to the latest plurality of serial numbers.
- the prediction device 1 performs learning processing for each serial number in the batch process and updates the coefficients of the prediction formula and the like.
- the coefficient is determined by performing regression analysis using, for example, the process data corresponding to the latest predetermined number of serial numbers set in the field of the learning period in FIG. 6 as learning data. At this time, it is assumed that the coefficient is determined so as to satisfy the above-mentioned code constraint.
- FIG. 8 is a diagram for explaining an example of process data in a continuous process.
- the left column of FIG. 8 shows a part of the process of the continuous process 32 shown in FIG. Specifically, the process includes a tank 311 and a pump 312.
- the right column of FIG. 8 shows an example of process data acquired in each process.
- time-series data associated with the tag and not associated with the serial number is continuously acquired from the sensor.
- time series data is acquired from each sensor whose tags are 102 and 103.
- the equipment continuously accepts the processing target and continuously performs the processing.
- Traceability information includes sampling interval and residence time.
- the sampling interval represents an interval for sampling for process inspection by, for example, a reduction method in a continuous process.
- the residence time represents the time during which the processing target stays from the completion of the batch process to the arrival of the process included in the continuous process.
- FIG. 9 is a diagram for explaining the correspondence between the sample in the process inspection of the continuous process and the serial number in the batch process.
- the process inspection is performed at predetermined intervals, and the sample in the process inspection is a reduced sample of the period corresponding to the interval.
- the product of the batch process completed in a predetermined period is introduced as a processing target of the continuous process. Therefore, for the reduced sample of the process data in the continuous process, the serial number group of the corresponding batch process can be specified by tracing back the residence time up to the sampling time and linking it with the range of the completion time of the batch process.
- FIG. 10 is a diagram for explaining the residence time from the sensor position in the continuous process to the sampling position in the process inspection.
- the reduced sample described above is calculated as, for example, an average value of process data obtained in a continuous process for a predetermined period.
- the position of the sensor that outputs the process data in the continuous process and the sampling for the process inspection are performed.
- FIG. 11 is a diagram showing an example of a tag attribute table of a continuous process created based on a knowledge base.
- the tag attribute table of the continuous process may also be a so-called database table or a file of a predetermined format such as CSV. Further, the tag attribute table is created in advance by the user and read by the prediction device 1.
- the tag attribute table for continuous processes includes tags, types, residence times, batch-related tags, and operating condition optimization attributes. The description of the attributes having the same name as the tag attribute table of the batch process shown in FIG. 5 will be omitted.
- a continuous, batch, or quality type is registered in the type field. Of the types, “continuous” indicates that the tag indicated by each record is process data in the continuous process. “Batch” means process data in a batch process. "Quality” indicates that it is an analytical value of a fractionated sample in a process inspection.
- FIG. 12 is a diagram showing an example of a logic tree showing the configuration of the prediction model. Also in FIG. 12, each rectangle represents an output value or a predicted value of the sensor corresponding to the tag.
- the rectangle with the tag 101 indicates the process data of the batch process. In the process data of the batch process, as described with reference to FIG. 9, the corresponding serial number and series are specified based on the residence time, and the average value of these is used as the explanatory variable of the prediction formula.
- the rectangles with tags 102 and 103 indicate the process data of the continuous process. As described with reference to FIG.
- the corresponding period of the process data of the continuous process is specified based on the residence time and the sampling interval, and the average value of the process data within the period is used as an explanatory variable of the prediction formula.
- the rectangle with the tag 104 is an analysis value of a process inspection (also referred to as a quality process), and is a value corresponding to process data obtained by, for example, a reduction method.
- the prediction formula is created by combining the records with the same join ID in the tag join table shown in FIG. Since the prediction formula is the same as that of the batch process, the description thereof will be omitted.
- a prediction model can be created at high speed from the parameters whose causal relationship is clear without requiring a huge parameter of the entire plant.
- a prediction model including an autoregressive term is created, it becomes possible to make a prediction that takes into account changes in the process data over time, which is not reflected by simply performing a simulation from the process data at a certain time point.
- the prediction device 1 uses the created prediction formula and process data to obtain operating conditions for shifting to a stable state with respect to a change in the state that appears as an effect, or such that the product satisfies a predetermined requirement.
- the operating conditions may be obtained and the plant 3 may be controlled based on the operating conditions. For example, target values are set for some characteristic values, tolerances are set for other controllable process data, and favorable operating conditions are obtained. Further, a unit price may be set for at least a part of the process data, and for example, an operating condition that minimizes the cost or an operating condition that satisfies the allowable range of the cost may be obtained.
- the permissible range of each process data is set in the "control range” field of the table shown in FIG.
- the target value of each process data is set in the "setting range” field.
- the cost per predetermined unit amount of each process data is set.
- the process data in which "adjustment” is registered in the “adjustment / monitoring” field represents a value that can be adjusted by controlling an actuator or the like provided in the plant 3.
- the operating conditions of adjustable process data are obtained based on conditions such as a target and an allowable range.
- the cost can be calculated from the sum of the products of the unit price set in the "cost effect (unit price)" field and the value of the process data corresponding to each tag. Then, the controllable process data value (operating condition) is calculated so that the cost, which is the objective function, is minimized.
- the predicted value calculated by the prediction formula is subject to constraints so that it falls within the range registered in the "set range" of FIG.
- These process data are, for example, quality or quality substitution indicators, and the range can be said to be the target value determined by the required specifications.
- controllable process data are limited based on the control range.
- the process data corresponding to the tag in which "adjustment" is registered in the "adjustment / monitoring" field can be adjusted, but constraints are set due to the setting limit determined according to the specifications of the plant 3, for example.
- the prediction model created in the prediction process is also used as a constraint condition. That is, a constraint condition representing a predetermined range is set for at least a part of the objective variable in the prediction formula, and the optimum value of the explanatory variable is searched so that the predicted value is within the range of the constraint condition.
- the calculated optimum solution will be the set value as it is.
- the actuator such as a valve is adjusted so as to approach the calculated optimum solution.
- FIG. 13 is a block diagram showing an example of the configuration of the prediction device 1.
- the prediction device 1 is a general computer, and includes a communication interface (I / F) 11, a storage device 12, an input / output device 13, and a processor 14.
- the communication I / F 11 may be, for example, a network card or a communication module, and communicates with another computer based on a predetermined protocol.
- the storage device 12 includes a main storage device such as a RAM (Random Access Memory) and a ROM (Read Only Memory), and an auxiliary storage device (secondary) such as an HDD (Hard-Disk Drive), an SSD (Solid State Drive), and a flash memory. It may be a storage device).
- the main storage device temporarily stores a program read by the processor 14 and information transmitted to and received from another computer, and secures a work area of the processor 14.
- the auxiliary storage device stores a program executed by the processor 14, information transmitted to and received from another computer, and the like.
- the input / output device 13 is, for example, a user interface such as an input device such as a keyboard and a mouse, an output device such as a monitor, and an input / output device such as a touch panel.
- the processor 14 is an arithmetic processing unit such as a CPU (Central Processing Unit), and executes each process according to the present embodiment by executing a program.
- a functional block is shown in the processor 14. That is, the processor 14 functions as a process data acquisition unit 141, a process data processing unit 142, a prediction model creation unit 143, a quality prediction unit 144, and a plant control unit 145 by executing a predetermined program.
- the process data acquisition unit 141 acquires the process data from the sensor included in the plant 3 via, for example, the communication I / F 11 and the control station 2, and stores the process data in the storage device 12. As mentioned above, the process data is associated with the sensor by the tag.
- the process data processing unit 142 processes the process data based on the tag attribute table of the batch process shown in FIG. 5 or the tag attribute table of the continuous process shown in FIG. That is, the process data processing unit 142 extracts the instantaneous value of the designated timing, calculates the average value of the designated period, and designates based on the information registered in the field of the primary process of the tag attribute table of the batch process. Calculate the integrated value of the period. Further, the process data processing unit 142 has a predetermined tag, based on the information registered in the batch-related tag field of the tag attribute table of the continuous process and, for example, the above-mentioned traceability information stored in the storage device 12 in advance. The average value of the process data corresponding to the system and the serial number may be calculated, or the average value of the period specified based on the traceability information may be calculated for the process data of the continuous process.
- the prediction model creation unit 143 creates a prediction model including the prediction formula as shown in the above formula (1) based on the tag binding table shown in FIG. 6, for example, and stores it in the storage device 12. For example, in the batch process, the prediction model creation unit 143 may update the coefficient of the prediction formula or the like by using the data of the latest predetermined period for each serial number. Further, the prediction model creation unit 143 may update the coefficient of the prediction formula or the like by using the latest data at predetermined intervals, for example, in the continuous process.
- the quality prediction unit 144 predicts the output value of a predetermined sensor and the analysis value of the process inspection by using the process data and the prediction model.
- the quality prediction unit 144 may calculate the predicted value after changing the operating conditions by using the data based on the arbitrary operating conditions and the prediction model.
- the plant control unit 145 controls actuators such as valves and other devices included in the plant 3 via, for example, the communication I / F 11 and the control station 2. Further, the plant control unit 145 may determine operating conditions in which, for example, quality and cost satisfy predetermined conditions, and control the plant 3 based on the operating conditions. Further, the plant control unit 145 may obtain an operating condition for shifting to a predetermined stable state, or may obtain an operating condition for the product to satisfy a predetermined requirement, and control the plant 3 based on the operating condition. ..
- FIG. 14 is a processing flow diagram showing an example of prediction processing executed by the prediction device 1.
- the processor 14 of the prediction device 1 executes a process as shown in FIG. 14 by executing a predetermined program.
- the prediction process is executed for each serial number in the batch process and at a predetermined sampling interval in the continuous process.
- the tag attribute table of the batch process shown in FIG. 5, the tag combination table shown in FIG. 6, the tag attribute table of the continuous process shown in FIG. 11, traceability information, and the like are created by the user and stored in the storage device 12 in advance. It shall be remembered.
- the process data acquisition unit 141 continuously acquires the process data from the sensor included in the plant 3 via, for example, the communication I / F 11 and the control station 2, and temporarily or permanently stores the process data in the storage device 12. It is assumed that it is made to do.
- the process data is described according to a predetermined standard such as OPC.
- the process data acquisition unit 141 of the prediction device 1 reads the setting information (FIG. 14: S1). In this step, the process data acquisition unit 141 reads the tag attribute table, the tag join table, the traceability information, and the like from the storage device 12.
- FIG. 15 is a diagram showing an example of a writing array for a batch process for writing the data read in this step.
- the writing sequence for the batch process may be OPC data, a so-called database table, or a file in a predetermined format such as CSV.
- the table of FIG. 15 includes the date and time, serial number, product type, step, and tag attributes.
- the date and time when the sensor outputs the measured value is registered in the date and time field.
- the serial number is registered in the serial number field.
- the type of processing target is registered in the product type field.
- information indicating a step in the process, which is represented by a predefined step is registered.
- the output value of the sensor corresponding to each tag is registered in the tag field.
- FIG. 16 is a processing flow diagram showing an example of processing.
- the process data processing unit 142 extracts the process data for each prediction formula, each series, and each subdivided process from the writing array shown in FIG. 15, it is added to each record of the writing array.
- the process shown in FIG. 16 is executed.
- the process data processing unit 142 reads a record from the writing array (FIG. 16: S11). In this step, one record is sequentially read from the table as shown in FIG. Further, the process data processing unit 142 processes the data according to the primary processing method (FIG. 16: S12).
- the tag attribute table shown in FIG. 5 is referred to, and based on the type registered in the "method" field of the "primary processing" of the corresponding tag, for example, the instantaneous value, the average value, the integrated value, and the differential value. The coefficient, difference, maximum value, minimum value, thermal history, or process data itself can be obtained.
- FIG. 17 is a diagram showing an example of a batch array for writing the processing result of this step.
- the batch array may also be OPC data, a so-called database table, or a file in a predetermined format such as CSV.
- the table of FIG. 17 includes the serial number, end date and time, and tag attributes.
- the serial number is registered in the serial number field.
- the end date and time field the date and time when the batch process of the production number was completed is registered.
- Process data after processing is registered in the tag field.
- the thermal history is information indicating the degree of progress of a general chemical reaction such as depolymerization, acetylation, or deacetylation.
- the thermal history is obtained as an integral value of the reaction rate for a predetermined period.
- A is a frequency factor.
- E is the activation energy.
- R is a gas constant.
- a (t) and B (t) are concentration terms, and m and n are reaction orders. These values are defined according to the reaction and the object.
- t is a step representing a predetermined section in the process.
- T (t) is the temperature at the step and is obtained as process data.
- the process data processing unit 142 carries out a predetermined data cleansing process (FIG. 16: S13).
- the data cleansing process is a process of eliminating outliers, and various methods can be adopted.
- the moving average value is calculated using the latest data.
- the difference between the moving average value and the measured value is taken to obtain the standard deviation ⁇ (also called error variance) that represents the variation in the difference.
- ⁇ also called error variance
- a value that does not fall within a predetermined confidence interval such as an interval from the average value of the probability distribution -3 ⁇ to the average of the probability distribution + 3 ⁇ (also referred to as a 3 ⁇ interval) is excluded.
- the difference between the measured values before and after may be excluded from the value that does not fall within the 3 ⁇ interval.
- the data cleansing process is performed on, for example, an instantaneous value or process data at the end of a batch.
- the process data processing unit 142 carries out a predetermined smoothing process (FIG. 16: S14).
- the smoothing process is performed on the tag in which "necessary" is registered in the smoothing field in the tag attribute table shown in FIG.
- the smoothing process may be, for example, a process of obtaining the latest moving average of a predetermined number of values after data cleansing, or may be another method capable of smoothing the data.
- the prediction model creation unit 143 of the prediction device 1 performs the prediction model construction process (FIG. 14: S4).
- a prediction formula that constitutes a prediction model is created based on the tag binding table shown in FIG. Specifically, the processed process data of the tags with the same combination ID is read out, and the processed process data is predicted based on the type registered in the factor / influence field (for example, the above-mentioned formula). Applying to (1)), the coefficient and constant term of the prediction formula are determined by regression analysis.
- the processed process data the latest data is targeted for learning according to the value registered in the field of the learning period.
- the prediction model creation unit 143 may also search for a preferable value for the size of the learning period.
- the correlation coefficient is calculated using the created prediction model and the process data, and the learning period is set so that the correlation coefficient is improved.
- the prediction model creation unit 143 stores the created prediction formula in the storage device 12.
- the quality prediction unit 144 of the prediction device 1 performs prediction processing using the prediction model created in the prediction model construction process and the process data or its prediction value (FIG. 14: S5).
- the prediction process is shown in the processing flow of FIG. 14, but the quality prediction unit 144 can perform the prediction process using the prediction model and the process data at an arbitrary time point.
- the quality prediction unit 144 reads out the latest prediction model and process data, substitutes the process data or its prediction value into the prediction formula included in the prediction model, and predicts the value corresponding to an arbitrary influence system. Find the value.
- FIG. 18 is a diagram for explaining the process data to be substituted into the prediction formula or the predicted value thereof.
- predicting the value of the tag 007 illustrated in FIG. 4 at time t 1 in Figure 3, using the measured values or predicted values of the sensors corresponding to each tag, as shown in FIG. 18. That is, when predicting the value of the tag 007 of the serial number 003, the known actually measured values of the tags 001 to 004 of the serial number 003 and the unknown predicted values of the tags 005 and 006 of the serial number 003 are used. , Substitute in the prediction formula of tag 007.
- FIG. 19 is a diagram showing another example for explaining the process data to be substituted into the prediction formula or the predicted value thereof.
- predicting the value of the tag 007 illustrated in FIG. 4 at time t 2 of FIG. 3 uses the measured values or predicted values of the sensors corresponding to each tag, as shown in FIG. 19. That is, when predicting the value of the tag 007 of the serial number 004, the measured values of the tags 001 and 002 of the serial number 004, the actually measured values of the tag 004 of the serial number 003, and the unknown serial number 004 are predicted. The predicted values of the tags 003, 005 and 006 of the above are substituted into the prediction formula of the tag 007.
- the measured value of the latest serial number is used.
- the value to be input to the prediction model is not limited to the process data, and may be data based on arbitrary operating conditions, for example. In this way, the result when the operating conditions of the plant 3 are changed can be predicted.
- the quality prediction unit 144 calculates, for example, the prediction value of predetermined process data by using the prediction model and the output value of the sensor or the prediction value thereof.
- the quality prediction unit 144 obtains a predetermined confidence interval obtained in the above-mentioned data cleansing from the calculated predicted value or the measured value of the process data, and sets the predetermined confidence interval and the predicted value in the input / output device 13 such as a monitor. Alternatively, the measured value may be shown on the graph. In this way, the user can visually grasp the tendency and can use it as a material for determining whether or not the operating conditions of the plant 3 should be changed.
- the plant control unit 145 automatically changes the operating conditions of the plant 3 based on the calculated predicted value, or outputs information suggesting the change of the operating conditions to the user via the input / output device 13. May be good.
- ⁇ Prediction processing (continuous process)> The prediction process shown in FIG. 14 is also performed in the continuous process. Hereinafter, the differences from the batch process will be mainly described. It is assumed that the storage device 12 stores the date and time when the batch process is completed and the transfer (liquid transfer) of the processing target to the continuous process is completed for each series and each serial number.
- FIG. 14 In the process data reading (FIG. 14: S2), in the case of a continuous process, rolling is continuously performed in which new data is written and old data is deleted, not in units of serial numbers. Further, the data structure of the writing array shown in FIG. 15 may be changed based on the information registered in the type field of the tag attribute table shown in FIG.
- FIG. 20 is a diagram showing an example of a writing array holding data of the type “continuous”.
- the writing array holding the data of the type "continuous” can have, for example, a configuration in which the serial number and the step are deleted from the table of FIG.
- FIG. 21 is a diagram showing an example of a writing array holding data of the type “batch”.
- the writing sequence that holds the data of the type "batch" is, for example, a table that holds the serial number and the process data of the serial number, and a table as shown in FIG. 21 is created for each system.
- the data registered in the table of FIG. 21 may be the processed data registered in the batch array of FIG.
- FIG. 14 is a diagram showing an example of a combined ID data array that holds process data after processing in a continuous process.
- the combined ID data array may also be OPC data, a so-called database table, or a file in a predetermined format such as CSV.
- identification information for identifying each process inspection is registered in the field of the process inspection ID including each attribute of the process inspection ID, sampling, and tag.
- the sampling attributes further include the attributes of the start date and time and the end date and time, and the start date and time and the end date and time of sampling of the process inspection by the reduction method are registered in the fields of the start date and time and the end date and time, respectively.
- the analysis value corresponding to each tag is registered in the tag field.
- the tag in which "continuous" is registered in the type field of the tag attribute table shown in FIG. 11 the average value of the process data from the processing time to the time when the sampling interval is traced back in the traceability information is registered.
- NS For the tag in which "batch" is registered in the type field of the tag attribute table shown in FIG. 11, it corresponds to the serial number in which the liquid transfer is completed from the processing time to the time when the sampling interval is traced back in the traceability information.
- the average value of the process data to be processed is registered.
- the prediction model creation unit 143 acquires the analysis value of the process inspection, the prediction model of the analysis value is updated. In this step as well, a prediction formula that constitutes a prediction model is created based on the tag binding table shown in FIG. Further, in the continuous process, as shown in FIG. 9, the prediction model creation unit 143 uses the factor system process data and the influence system process based on the completion timing of the batch process and the predetermined residence time. The data may be associated with each other so that the characteristics of the process data obtained from the plant 3 can be learned. Further, as shown in FIG.
- the prediction model creation unit 143 determines the factor-based process data and the influence based on the difference between the factor-based process data acquisition timing and the influence-based process data acquisition timing.
- the characteristics of the process data obtained from the plant 3 may be learned by associating with the process data of the system.
- the quality prediction unit 144 of the prediction device 1 performs prediction processing using the prediction model created in the prediction model construction process and the process data or its prediction value (FIG. 14: S5). In this step, the quality prediction unit 144 reads out the latest prediction model and process data, substitutes the process data or its prediction value into the prediction formula included in the prediction model, and predicts the value corresponding to an arbitrary influence system. Find the value.
- FIG. 23 is a processing flow diagram showing an example of the control processing executed by the prediction device 1.
- the processor 14 of the prediction device 1 executes a process as shown in FIG. 23 by executing a predetermined program.
- the control process is executed at an arbitrary timing, for example, after the prediction model is updated.
- the tag attribute table of the batch process shown in FIG. 5, the tag binding table shown in FIG. 6, the tag attribute table of the continuous process shown in FIG. 11, the traceability information, and the like are stored in the storage device 12 in advance.
- the process data acquisition unit 141 continuously acquires the process data from the sensor included in the plant 3 via, for example, the communication I / F 11 and the control station 2, and temporarily or permanently stores the process data in the storage device 12. It is assumed that it is made to do.
- the plant control unit 145 of the prediction device 1 reads the setting information (FIG. 23: S21). In this step, the plant control unit 145 reads the tag attribute table, the tag join table, the traceability information, and the like from the storage device 12.
- the information to be read includes, for example, a control goal represented as an objective function of an optimization problem, and a permissible area of control represented as a constraint condition of an optimization problem, for example.
- the objective function is to minimize the cost calculated by using the unit price registered in the cost influence field of FIG.
- the values registered in the control range and setting range fields shall be the constraint conditions.
- the process data acquisition unit 141 reads the process data (FIG. 23: S22).
- the processing in this step is the same as in S2 of FIG.
- the process data corresponding to the tag used in the prediction formula is extracted, for example, for each prediction formula, for each series, and for each subdivided process. Further, the output value of the sensor is registered in the writing array shown in FIG. 15 or FIG.
- process data processing unit 142 performs a predetermined processing process on the process data (FIG. 23: S23). The processing in this step is the same as in S3 of FIG.
- the plant control unit 145 performs arithmetic processing of the optimization problem (FIG. 23: S24).
- the prediction model created in the prediction process is also used as a constraint condition.
- the downstream process data is based on the upstream process data based on the prediction formula constructed in the prediction process. Is calculated.
- the process data corresponding to the tag located at the upstream end and in which "monitoring" is registered in the "adjustment / monitoring" field of FIG. 5 is acquired in S22 and processed in S23. The value given is used.
- the above optimization problems can be solved by existing solutions.
- the process data corresponding to the tag in which "adjustment" is registered in the "adjustment / monitoring" field of FIG. 5 is the adjustment target. That is, the process data whose tags are 001, 003, 004, 006 is the adjustment target, and the target tag does not necessarily match the constraint condition.
- the plant control unit 145 controls the plant 3 according to the operating conditions (FIG. 23: S25). In this step, the plant control unit 145 outputs data indicating operating conditions to the control station 2 via the communication I / F 11. Then, the operation of the plant 3 is controlled according to the control signal from the control station 2. For example, when the multi-objective optimization problem is solved in S24, a plurality of candidates for operating conditions may be presented to the user via the input / output device 13, and the plant 3 may be controlled based on the operating conditions selected by the user. good.
- a chemical plant has been described as an example, but it can be applied to a manufacturing process in a general production facility.
- the lot number can be used as the processing unit, and the processing according to the batch process in the embodiment can be applied.
- At least a part of the functions of the prediction device 1 may be distributed to a plurality of devices to be realized, or the same function may be provided by a plurality of devices in parallel.
- the model creation device that creates a prediction model, the prediction device that makes a prediction using the created prediction model, and the control device that controls the production equipment using the created prediction model may be different. ..
- at least a part of the functions of the prediction device 3 may be provided on the so-called cloud.
- the above-mentioned equation (1) is a linear model including an autoregressive term, but is not limited to such an example.
- a model that does not include an autoregressive term can be adopted.
- the model may be linear or non-linear. Further, it may be a single equation, or a state space model incorporating periodic fluctuations such as seasonal fluctuations may be adopted.
- the model satisfies the code constraint. That is, the coefficients of the prediction formula and the like are determined under the constraint that there is a certain correspondence between the direction of fluctuation of the value of the factor system and the direction of fluctuation of the value of the influence system.
- the present disclosure also includes a method for executing the above-mentioned processing, a computer program, and a computer-readable recording medium on which the program is recorded.
- the recording medium on which the program is recorded can perform the above-mentioned processing by causing the computer to execute the program.
- the computer-readable recording medium means a recording medium in which information such as data and programs is stored by electrical, magnetic, optical, mechanical, or chemical action and can be read from a computer.
- recording media those that can be removed from the computer include flexible disks, magneto-optical disks, optical disks, magnetic tapes, memory cards, and the like.
- HDD High Density Digital
- SSD Solid State Drive
- ROM Read Only Memory
- Predictor 11 Communication I / F 12: Storage device 13: Input / output device 14: Processor 141: Process data acquisition unit 142: Process data processing unit 143: Prediction model creation unit 144: Quality prediction unit 145: Plant control unit 2: Control station 3: Plant
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Physics & Mathematics (AREA)
- Human Resources & Organizations (AREA)
- General Physics & Mathematics (AREA)
- Strategic Management (AREA)
- Economics (AREA)
- Automation & Control Theory (AREA)
- Theoretical Computer Science (AREA)
- Entrepreneurship & Innovation (AREA)
- Tourism & Hospitality (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Development Economics (AREA)
- Quality & Reliability (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Operations Research (AREA)
- Health & Medical Sciences (AREA)
- Educational Administration (AREA)
- Game Theory and Decision Science (AREA)
- Manufacturing & Machinery (AREA)
- Mathematical Physics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Primary Health Care (AREA)
- Testing And Monitoring For Control Systems (AREA)
- Feedback Control In General (AREA)
Abstract
化学プラントにおける反応を含むプロセスについて、予測精度を向上させる。予測装置は、化学プラントから得られるプロセスデータに対し所定の加工処理を行うプロセスデータ加工部と、化学プラントから得られるプロセスデータ又はプロセスデータ加工部によって加工されたプロセスデータのうち、説明変数とする第1のプロセスデータと、目的変数とする第2のプロセスデータ又は当該第2のプロセスデータに応じた値との組合せを定義する因果関係情報に基づいて、化学プラントから得られたプロセスデータの特徴を学習した予測モデルを作成する予測モデル作成部とを備える。また、プロセスデータ加工部は、プロセスデータを用いて、所定の期間における処理対象の反応速度に応じた値を求める。
Description
本開示は、予測装置、予測方法及びプログラムに関する。
従来、製造プロセスにおいて生産物の品質を予測したり、予測に基づいて動作の制御を行う技術が提案されている。例えば、製造プロセスの製造途中において製品の特性値を予測し、その予測結果に基づいて後工程の製造プロセスの制御条件を計算する予測システムが提案されている(特許文献1)。本システムは、ロット毎に、製造プロセスの工程で測定されるデータ、および/または、製造プロセスの状態を示すデータとが格納されるデータベースと、データベースに格納されているデータを用いて、製造プロセスの数式モデルを作成する数式モデル作成部と、製造中のロットに対して、処理済み工程に関しては実績値を、未処理工程に関しては過去のロットに基づいて得られる代表値を数式モデルに入力して製品の特性値を予測する製品特性予測部と、製品特性予測部による予測結果に応じて、未処理工程のうちの制御する対象の工程の最適製造条件を計算する最適製造条件計算部とを備えており、製品特性予測部による予測および最適製造条件計算部による計算を、製造中のロットに対して所定の制御対象工程毎に実施する。
しかしながら、特に化学プラントにおける反応を含むプロセスにおいては、予測精度を向上させることが難しいという問題があった。そこで、本技術は、化学プラントにおける反応を含むプロセスについて、予測精度を向上させることを目的とする。
本開示に係る予測装置は、化学プラントから得られるプロセスデータに対し所定の加工処理を行うプロセスデータ加工部と、化学プラントから得られるプロセスデータ又はプロセスデータ加工部によって加工されたプロセスデータのうち、説明変数とする第1のプロセスデータと、目的変数とする第2のプロセスデータ又は当該第2のプロセスデータに応じた値との組合せを定義する因果関係情報に基づいて、化学プラントから得られたプロセスデータの特徴を学習した予測モデルを作成する予測モデル作成部とを備える。また、プロセスデータ加工部は、プロセスデータを用いて、所定の期間における処理対象の反応速度に応じた値を求める。
一般的に反応は温度等の影響を受け非線形であるため、例えばプロセスデータのピーク値や差分値、積分値等に基づいてプロセスデータの特徴を予測することは困難であった。上記のような反応速度に応じた値は、例えば時間当たりの反応量と相関する説明変数になる。反応速度に応じた値を用いて予測モデルを作成することで、化学プラントにおける反応を含むプロセスについて、予測精度を向上させることができる。
また、反応速度に応じた値は、反応速度の積分値であってもよい。また、反応速度に応じた値は、アレニウスの式を用いて算出され、化学反応の種別と化学プラントにおける処理対象とに応じて反応速度定数の頻度因子及び活性化エネルギーが定められるようにしてもよい。具体的には、このような値を採用することができる。
また、プロセスデータ加工部は、プロセスデータの種別に応じて、所定の期間におけるプロセスデータの積分値、微分値、平均値、最大値、若しくは最小値、又は所定の時点におけるプロセスデータの瞬時値をさらに求めるようにしてもよい。プロセスデータに対しこのような加工を行うことにより、予測モデルの予測精度を向上し得る。
また、予測モデルは、複数の予測式を含む階層構造であり、第1の予測式で算出する予測値を説明変数に含む第2の予測式を有するものであってもよい。例えばこのようにして複数の因果関係を関数で表すことができる。
また、第2のプロセスデータに応じた値は、縮分法により複数の第2のプロセスデータをサンプリングした値であり、化学プラントにおける、第1のプロセスデータの取得タイミングの範囲と、第2のプロセスデータに応じた値の算出タイミングとを、化学プラント内における処理対象の滞留時間に基づいて対応付け、予測モデル作成部は予測モデルを作成するようにしてもよい。化学プラントにおいて処理対象が継続的に処理される場合、説明変数とするプロセスデータの取得タイミングと、目的変数とするプロセスデータの取得タイミングとを適切に対応付けることにより、予測の精度を向上させることができる。
また、化学プラントは、所定の処理単位ごとに処理対象を逐次処理するバッチ工程と、その後に処理対象を連続的に処理する連続工程とを行い、バッチ工程の完了タイミングの範囲と、第2のプロセスデータに応じた値の算出タイミングとを、化学プラント内における処理対象の滞留時間に基づいて対応付け、予測モデル作成部は予測モデルを作成するようにしてもよい。バッチ工程と連続工程とが続けて行われる場合も、説明変数とするプロセスデータと、目的変数とするプロセスデータとを適切に対応付けることで、予測の精度を向上させることができる。
なお、課題を解決するための手段に記載の内容は、本開示の課題や技術的思想を逸脱しない範囲で可能な限り組み合わせることができる。また、課題を解決するための手段の内容は、コンピュータ等の装置若しくは複数の装置を含むシステム、コンピュータが実行する方法、又はコンピュータに実行させるプログラムとして提供することができる。なお、プログラムを保持する記録媒体を提供するようにしてもよい。
開示の技術によれば、生産物の特性値の予測精度を向上させることができる。
以下、図面を参照しつつ予測装置の実施形態について説明する。
<実施形態>
図1は、本実施形態に係るシステムの一例を表す図である。システム100は、予測装置1と、制御ステーション2と、プラント3とを含む。システム100は、例えば分散型制御システム(DCS:Distributed Control System)であり、複数の制御ステーション2を含む。すなわち、プラント3の制御系は複数の区画に分割され、各制御区画が制御ステーション2によって分散制御される。制御ステーション2は、DCSにおける既存の設備であり、プラント3が備えるセンサ等から出力される状態信号を受信したり、プラント3に対して制御信号を出力する。そして、制御信号に基づいて、プラント3が備えるバルブ等のアクチュエータやその他の機器が制御される。
図1は、本実施形態に係るシステムの一例を表す図である。システム100は、予測装置1と、制御ステーション2と、プラント3とを含む。システム100は、例えば分散型制御システム(DCS:Distributed Control System)であり、複数の制御ステーション2を含む。すなわち、プラント3の制御系は複数の区画に分割され、各制御区画が制御ステーション2によって分散制御される。制御ステーション2は、DCSにおける既存の設備であり、プラント3が備えるセンサ等から出力される状態信号を受信したり、プラント3に対して制御信号を出力する。そして、制御信号に基づいて、プラント3が備えるバルブ等のアクチュエータやその他の機器が制御される。
予測装置1は、制御ステーション2を介してプラント3の状態信号(プロセスデータ)を取得する。プロセスデータは、原料や中間的な生産物である処理対象の温度、圧力、流量等や、プラント3が備える機器の運転条件を定める設定値等を含む。また、予測装置1は、想定される原因と、例えば異常として現れる影響との対応関係を記憶する知識ベースに基づく予測モデルを作成する。例えば、知識ベースに基づいて作成された、説明変数とするプロセスデータ(要因系とも呼ぶ)と目的変数とするプロセスデータ(影響系とも呼ぶ)との組合せを定義する因果関係情報を用いて、品質やコストの予測式を作成する。そして、予測装置1は、予測式とプロセスデータとを用いて、生産物の品質等を表す特性値を予測したり、プラント3の運転条件を変更した場合の生産物の特性値を予測することができる。また、予測装置1は、例えば品質とコストとが所定の条件を満たす運転条件を求めるようにしてもよい。また、予測装置1は、予測式とプロセスデータとを用いて、影響として現れた状態の変化に対して安定状態に移行させるための運転条件を求めたり、生産物が所定の要求を満たすような運転条件を求めたりしてもよい。また、予測装置1は、影響系のプロセスデータに代えて、所定の工程検査において得られた分析値を目的変数としてもよい。
図2は、プラントが備える機器又は当該機器によって行われるプロセスの一例を示す模式的な図である。すなわち、プロセスは、処理である生産プロセスと装置であるプロセス機器とを含むものとする。本実施形態では、プロセスは、バッチ工程31と連続工程32とを含み得る。バッチ工程31においては、所定の処理単位ごとに処理対象が逐次処理され、例えば各機器への原料の受入れ、保持、排出といった処理が順に行われる。連続工程32においては、継続して導入される処理対象が連続的に処理され、例えば、原料の受入れ、保持、排出といった処理が並行して行われる。また、プロセスは、並列に同一の処理を行う複数の系列33を含み得る。
各処理を行う機器は、例えば反応器、蒸留装置、熱交換器、圧縮機、ポンプ、タンク等を含み、これらが配管を介して接続されている。また、機器や配管の所定の位置には、センサやバルブ等が設けられる。センサは、温度計、流量計、圧力計、レベル計、濃度計等を含み得る。また、センサは、各機器の運転状態を監視し、状態信号を出力する。また、プラント3が備えるセンサは、センサの各々を特定するための識別情報である「タグ」が付されているものとする。そして、予測装置1及び制御ステーション2は、各機器への入出力信号を、タグに基づいて管理する。
<バッチ工程>
図3は、バッチ工程におけるプロセスデータの一例を説明するための図である。図3の左側の列は、図2に示したバッチ工程31のプロセスの一部を示す。具体的には、プロセスは、シュレッダー301と、サイクロン302と、前処理303と、予冷機304と、反応機305とを含む。また、これらのプロセスは、前処理工程、予冷工程、反応工程に分類されている。図3の右側の列は、各プロセスにおいて取得されるプロセスデータの一例を示す。前処理工程においては、タグが001及び002であるセンサから時系列のデータが取得される。予冷工程においては、タグが003及び004であるセンサから時系列のデータが取得される。反応工程においては、タグが005、006及び007であるセンサから時系列のデータが取得される。また、バッチ工程においては、製造番号(「製番」とも呼ぶ)と対応付けられた処理対象を、断続的に処理する。すなわち、製造番号は、バッチ工程においてまとめて処理される処理対象を識別するための識別情報である。図3に示すように、時間の経過と共に、後続の製造番号と対応付けられた処理対象に関する時系列のデータが得られる。なお、時点t1及びt2については後述する。
図3は、バッチ工程におけるプロセスデータの一例を説明するための図である。図3の左側の列は、図2に示したバッチ工程31のプロセスの一部を示す。具体的には、プロセスは、シュレッダー301と、サイクロン302と、前処理303と、予冷機304と、反応機305とを含む。また、これらのプロセスは、前処理工程、予冷工程、反応工程に分類されている。図3の右側の列は、各プロセスにおいて取得されるプロセスデータの一例を示す。前処理工程においては、タグが001及び002であるセンサから時系列のデータが取得される。予冷工程においては、タグが003及び004であるセンサから時系列のデータが取得される。反応工程においては、タグが005、006及び007であるセンサから時系列のデータが取得される。また、バッチ工程においては、製造番号(「製番」とも呼ぶ)と対応付けられた処理対象を、断続的に処理する。すなわち、製造番号は、バッチ工程においてまとめて処理される処理対象を識別するための識別情報である。図3に示すように、時間の経過と共に、後続の製造番号と対応付けられた処理対象に関する時系列のデータが得られる。なお、時点t1及びt2については後述する。
図4は、知識ベースに予め登録される情報の一例を示す図である。知識ベースは、予測装置1の記憶装置に予め記憶されるものとする。図4のテーブルは、センサの各々に対応する列と、各センサの出力値の変化の原因を示す行とを含む。すなわち、各行に示す「副原料A量上昇」、「副原料A量低下」等の原因によって影響を受けるセンサに対応する列に値が登録されている。値は、センサの出力値の変動と対応する正又は負の符号付きで登録される。なお、原因と影響の組み合わせは1対1とは限らない。すなわち、1つの影響について、複数の原因が対応付けられることもあるし、同一の原因が複数の影響に関連付けられることもある。
知識ベースは、例えばHAZOP(Hazard and Operability Study)に基づいてユーザが予め作成するものとする。HAZOPは、例えば、プラントを構成する計装機器による監視ポイントでの検知手段、管理範囲(上下限の閾値でありアラームの設定点)、管理範囲からのずれ(異常、変調)、管理範囲からのずれが発生する想定原因の列挙、いずれの想定原因によりずれが発生したかを判断するロジック(検知手段)、ずれが発生したことによる影響、ずれが発生した場合にとる処置、その処置に対するアクションに関し、これらを関連付けて網羅的に列挙するための手法である。なお、HAZOPに限らず、FTA(Fault Tree Analysis)、FMEA(Failure Mode and Effect Analysis)、ETA(Event Tree Analysis)又はこれらを応用した手法や、これらに類する手法、オペレータへのヒアリング結果から抽出された内容、作業標準書や技術標準書から抽出された内容に基づいて知識ベースを作成するようにしてもよい。
図5は、知識ベースに基づいて作成される、バッチ工程のタグ属性テーブルの一例を示す図である。タグ属性テーブルは、各タグに対応するセンサから得られるデータの処理方法を定義する。なお、タグ属性テーブルは、いわゆるデータベースのテーブルであってもよいし、CSV(Comma Separated Values)のような所定の形式のファイルであってもよい。また、タグ属性テーブルは、予めユーザによって作成され、予測装置1によって読み出される。
タグ属性テーブルは、タグ、系列、品種、一次加工、平滑化、運転条件最適化の各属性を含む。タグのフィールドには、センサの識別情報であるタグが登録される。系列のフィールドには、プロセスの系列を特定するための識別情報が登録される。品種のフィールドには、処理対象の種別が登録される。予測装置1は、予測処理において、例えば処理対象の品種に応じたパラメータを設定するようにしてもよい。一次加工のフィールドには、センサの出力値の加工方法を示す情報が登録される。また、一次加工の属性は、バッチ工程、方法、データ区間の各属性をさらに含む。バッチ工程のフィールドには、バッチ工程における細分化された工程を示す識別情報が登録される。方法のフィールドには、データの加工方法の種別を示す情報が登録される。種別は、「瞬時値」、「平均」、「積分」、「微分」、「差分」、「最大」、「最小」、「熱履歴」、「なし」を含む。「瞬時値」は、データ区間で指定される開始時又は終了時の値を表す。「平均」は、データ区間で指定される期間の値をデータの個数で除した平均値を表す。「積分」は、データ区間で指定される期間の値の合計値を表す。「微分」は、データ区間で指定される開始時又は終了時の微分係数を表す。「差分」は、データ区間で指定される開始時及び終了時の値の差分を表す。「最大」は、データ区間で指定される期間内の最大値を表す。「最小」は、データ区間で指定される期間内の最小値を表す。「熱履歴」は、反応の進行の程度の一例であり、例えば、データ区間で指定される期間における反応速度の積分値を表す。「なし」は、バッチ終了時のタグに付され、加工処理を行わないことを表す。データ区間の属性は、開始及び終了の属性をさらに含み、開始及び終了のフィールドの少なくとも一方には、センサの出力値を取得するタイミングを示す情報が登録される。タイミングを示す情報は、例えば細分化された工程ごとに予め定められる所定のステップに基づいて定義されるようにしてもよい。平滑化のフィールドには、データに対する所定の平滑化処理の実施の要否を示す情報が登録される。運転条件最適化の属性は、調整/監視、コスト影響、管理範囲、設定範囲の各属性をさらに含む。調整/監視のフィールドには、最適化処理において調整の対象とするか監視の対象とするかを示す種別が登録される。コスト影響のフィールドには、最適化処理において調整した場合に影響する所定の単位当たりのコストが登録される。管理範囲の属性は、上限及び下限の属性をさらに含み、上限及び下限のフィールドには、センサの出力値の許容範囲を示す情報が登録される。設定範囲の属性は、上限及び下限の属性をさらに含み、上限及び下限のフィールドには、センサの出力値の目標とする範囲を示す情報が登録される。以上のような運転条件最適化のフィールドに登録される情報に従い、予測装置1は多目的最適化または単目的最適化を行うようにしてもよい。
図6は、知識ベースに基づいて作成されるタグ結合テーブルの一例を示す図である。タグ結合テーブルは、知識ベースから得られる因果関係を表す情報であって、説明変数とするプロセスデータと、目的変数とするプロセスデータとの組合せを定義する。タグ結合テーブルも、いわゆるデータベースのテーブルであってもよいし、CSVのような所定の形式のファイルであってもよい。また、タグ結合テーブルも、予めユーザによって作成され、予測装置1によって読み出される。
タグ結合テーブルは、結合ID、タグ、要因/影響、因果関係、学習期間、従属関係の各属性を含む。結合IDのフィールドには、因果関係のまとまりを示す識別情報が登録される。タグのフィールドには、センサの識別情報であるタグが登録される。要因/影響のフィールドには、因果関係における要因系であるか影響系であるか(換言すれば、説明変数であるか目的変数であるか)を示す種別が登録される。因果関係のフィールドには、影響系の値を正又は負の方向に変動させるために、当該タグに対応する要因系の出力値を変動させるべき符号の制約を示す、正又は負の種別が登録される。従って、要因/影響のフィールドに「要因」が登録されたレコードに、因果関係の値が登録される。本実施形態では、予測装置1は、要因系の値の変動の正負の方向と、影響系の値の変動の正負の方向との間に、一定の対応関係を有するような制約(「符号制約」と呼ぶ)を課して予測モデルを作成する。例えば、説明変数の正負の変動方向に応じて、目的変数の正負の変動方向が定まるように予測モデルが作成される。すなわち、因果関係のフィールドに登録される符号は、影響系の値を正又は負のうち所定の方向に変動させるために、当該レコードのタグに対応するセンサの出力値を正又は負のうちいずれの方向に変動させればよいかを示している。また、学習期間のフィールドには、予測モデルを作成するために用いるプロセスデータの期間を特定するための情報が登録される。当該情報は、例えば直近の製造番号の個数であってもよい。
以上のようなタグ属性テーブル及びタグ結合テーブルに基づいて、予測装置1は、予測モデルを作成する。図7は、予測モデルの構成を示すロジックツリーの一例を示す図である。各矩形は、タグに対応するセンサの出力値又は予測値を表す。予測モデルは、上流(図7では左側)の工程におけるセンサの出力値に基づいて、矢印で接続された先の、影響系に当たるセンサの出力値を予測するための予測式を含む。また、予測モデルは、複数の予測式を含む階層構造であり、ある予測式による予測値を説明変数に含む他の予測式が含まれる。予測式は、図6に示したタグ結合テーブルにおいて、同一の結合IDが付されたレコードを組み合わせて作成される。例えば、要因/影響のフィールドに「要因」が登録されているタグに対応するセンサの出力値又はその予測値を説明変数とし、要因/影響のフィールドに「影響」が登録されているタグに対応するセンサの出力値や、例えば工程検査によって得られる分析値である、生産物の特性値を目的変数として所定の予測式を作成する。
具体的には、予測式は、例えば次のような式(1)で表すことができる。
Y(t) = a1(t)・x1(t)+a2(t)・x2(t)+・・・+an(t)・xn(t)+aar(t)・Y(t-1)+C (1)
なお、tは製造番号に応じた値であり、Y(t)は影響系の予測値であり、x(t)は要因系のセンサの出力値又はその予測値であり、a(t)は要因系の係数であり、aar(t)は自己回帰項の係数であり、Cは定数項である。要因系に対応する項は、図7において矢印で接続された元のセンサの出力値の数だけ含まれる。また、自己回帰項は、過去の製造番号に係る予測値又は実測値である。自己回帰項は1つには限定されず、予測式は、直近の複数の製造番号に係る自己回帰項を含むものであってもよい。
Y(t) = a1(t)・x1(t)+a2(t)・x2(t)+・・・+an(t)・xn(t)+aar(t)・Y(t-1)+C (1)
なお、tは製造番号に応じた値であり、Y(t)は影響系の予測値であり、x(t)は要因系のセンサの出力値又はその予測値であり、a(t)は要因系の係数であり、aar(t)は自己回帰項の係数であり、Cは定数項である。要因系に対応する項は、図7において矢印で接続された元のセンサの出力値の数だけ含まれる。また、自己回帰項は、過去の製造番号に係る予測値又は実測値である。自己回帰項は1つには限定されず、予測式は、直近の複数の製造番号に係る自己回帰項を含むものであってもよい。
また、予測装置1は、バッチ工程においては製造番号ごとに学習処理を行い予測式の係数等を更新する。係数は、例えば、図6の学習期間のフィールドに設定された、直近の所定数の製造番号に対応するプロセスデータを学習データとして、回帰分析を行い決定される。このとき、上述した符号制約を満たすように、係数が決定されるものとする。
<連続工程>
図8は、連続工程におけるプロセスデータの一例を説明するための図である。図8の左側の列は、図2に示した連続工程32のプロセスの一部を示す。具体的には、プロセスは、タンク311と、ポンプ312とを含む。図8の右側の列は、各プロセスにおいて取得されるプロセスデータの一例を示す。連続工程32においては、タグと対応付けられ、製造番号とは対応付けられていない時系列のデータが、センサから継続して取得される。図8の例においては、タグが102及び103である各センサから時系列のデータが取得される。連続工程においては、機器が連続的に処理対象を受け入れ、継続的に処理を行う。バッチ工程の後に連続工程を行う場合、バッチ工程における処理対象と、連続工程における処理対象とを紐づけるために、本実施形態では予めユーザによって設定されるトレーサビリティ情報を用いる。トレーサビリティ情報は、サンプリング間隔と滞留時間とを含む。サンプリング間隔は、連続工程において例えば縮分法による工程検査のためのサンプリングを行う間隔を表す。滞留時間は、バッチ工程の完了から、連続工程に含まれるプロセスに到達するまでに処理対象が滞留する時間を表す。
図8は、連続工程におけるプロセスデータの一例を説明するための図である。図8の左側の列は、図2に示した連続工程32のプロセスの一部を示す。具体的には、プロセスは、タンク311と、ポンプ312とを含む。図8の右側の列は、各プロセスにおいて取得されるプロセスデータの一例を示す。連続工程32においては、タグと対応付けられ、製造番号とは対応付けられていない時系列のデータが、センサから継続して取得される。図8の例においては、タグが102及び103である各センサから時系列のデータが取得される。連続工程においては、機器が連続的に処理対象を受け入れ、継続的に処理を行う。バッチ工程の後に連続工程を行う場合、バッチ工程における処理対象と、連続工程における処理対象とを紐づけるために、本実施形態では予めユーザによって設定されるトレーサビリティ情報を用いる。トレーサビリティ情報は、サンプリング間隔と滞留時間とを含む。サンプリング間隔は、連続工程において例えば縮分法による工程検査のためのサンプリングを行う間隔を表す。滞留時間は、バッチ工程の完了から、連続工程に含まれるプロセスに到達するまでに処理対象が滞留する時間を表す。
図9は、連続工程の工程検査におけるサンプルとバッチ工程における製造番号との対応付けを説明するための図である。例えば、工程検査は所定の間隔で行われ、工程検査におけるサンプルは当該間隔に相当する期間の縮分サンプルとする。また、バッチ工程の後に連続工程を行う場合、所定の期間に完了したバッチ工程による生成物が、連続工程の処理対象として導入される。したがって、連続工程におけるプロセスデータの縮分サンプルは、サンプリング時点までの滞留時間を遡り、バッチ工程の完了時刻の範囲と紐付けることにより、対応するバッチ工程の製造番号群を特定することができる。このような紐づけにより、バッチ工程と連続工程とが続けて実施される場合において、バッチ工程におけるプロセスデータを利用する予測式の精度を向上させることができる。
図10は、連続工程におけるセンサ位置から工程検査でのサンプリング位置までの滞留時間を説明するための図である。上述した縮分サンプルは、例えば、連続工程において得られるプロセスデータの所定期間の平均値として算出される。この演算を行うサンプリング時点と、当該時点において平均するプロセスデータの取得時点の範囲とを対応付けるため、本実施形態では、連続工程においてプロセスデータを出力するセンサの位置と、工程検査のためのサンプリングを行う位置との間隔について、当該区間の滞留時間を設定する。これにより、連続工程におけるプロセスデータと工程検査の縮分サンプルとを紐づけることができる。このような紐づけにより、連続工程におけるプロセスデータを利用する予測式の精度を向上させることができる。
図11は、知識ベースに基づいて作成される、連続工程のタグ属性テーブルの一例を示す図である。連続工程のタグ属性テーブルも、いわゆるデータベースのテーブルであってもよいし、CSVのような所定の形式のファイルであってもよい。また、タグ属性テーブルは、予めユーザによって作成され、予測装置1によって読み出される。
連続工程のタグ属性テーブルは、タグ、種別、滞留時間、バッチ関連タグ、運転条件最適化の各属性を含む。なお、図5に示したバッチ工程のタグ属性テーブルと名称が同一の属性については説明を省略する。種別のフィールドには、連続、バッチ又は品質の種別が登録される。種別のうち「連続」は、各レコードが示すタグが連続工程におけるプロセスデータであることを表す。「バッチ」は、バッチ工程におけるプロセスデータであることを表す。「品質」は、工程検査における縮分サンプルの分析値であることを表す。
また、連続工程においても、図6に示したようなタグ結合テーブルを利用し、タグ属性テーブル及びタグ結合テーブルに基づいて、予測装置1は、予測モデルを作成する。図12は、予測モデルの構成を示すロジックツリーの一例を示す図である。図12においても、各矩形は、タグに対応するセンサの出力値又は予測値を表す。タグが101の矩形は、バッチ工程のプロセスデータを示す。バッチ工程のプロセスデータは、図9を用いて説明したように、滞留時間に基づいて対応する製造番号及び系列が特定され、これらの平均値を予測式の説明変数として用いる。タグが102及び103の矩形は、連続工程のプロセスデータを示す。連続工程のプロセスデータは、図10を用いて説明したように、滞留時間とサンプリング間隔に基づいて対応する期間が特定され、期間内のプロセスデータの平均値を予測式の説明変数として用いる。タグが104の矩形は、工程検査(品質工程とも呼ぶ)の分析値であり、例えば縮分法により求められるプロセスデータに応じた値である。連続工程においても、予測式は、図6に示したタグ結合テーブルにおいて、同一の結合IDが付されたレコードを組み合わせて作成される。予測式はバッチ工程と同様であるため説明を省略する。
本実施形態では、知識ベースに基づいて選択されたプロセスデータを用いるため、プラント全体の膨大なパラメータを必要とせず、因果関係が明らかなパラメータから予測モデルを高速に作成することができる。また、自己回帰項を含む予測モデルを作成すれば、単にある時点のプロセスデータからシミュレーションを行うのみでは反映されない、プロセスデータの経時的な変化を加味した予測ができるようになる。
また、上述のような符号制約がない場合、予測モデルを用いて逆問題を解く場合に、適切な結果が得られない場合があった。すなわち、要求する品質を指定してこれに応じた運転条件を求める場合に、プロセスの原理原則に反した結果を出力するような予測モデルが作成されてしまうおそれがあった。上述のような符号制約を課すことで、プロセスの原理原則に従った予測モデルを作成することができる。すなわち、符号制約を満足する予測式を用いることにより、生産物の品質の代替指標となる影響系の値を予測できるだけでなく、品質を改善するためにプラントの運転条件をどのように変更すればよいかが容易にわかるようになる。
<制御>
予測装置1は、作成した予測式とプロセスデータとを用いて、影響として現れた状態の変化に対して安定状態に移行させるための運転条件を求めたり、生産物が所定の要求を満たすような運転条件を求め、運転条件に基づいてプラント3を制御するようにしてもよい。例えば、一部の特性値に対して目標値を定め、他の制御可能なプロセスデータに対して許容範囲を定め、好ましい運転条件を求める。また、さらに、少なくとも一部のプロセスデータに対して単価を設定しておき、例えばコストが最小になる運転条件や、コストの許容範囲を満たすような運転条件を求めるようにしてもよい。
予測装置1は、作成した予測式とプロセスデータとを用いて、影響として現れた状態の変化に対して安定状態に移行させるための運転条件を求めたり、生産物が所定の要求を満たすような運転条件を求め、運転条件に基づいてプラント3を制御するようにしてもよい。例えば、一部の特性値に対して目標値を定め、他の制御可能なプロセスデータに対して許容範囲を定め、好ましい運転条件を求める。また、さらに、少なくとも一部のプロセスデータに対して単価を設定しておき、例えばコストが最小になる運転条件や、コストの許容範囲を満たすような運転条件を求めるようにしてもよい。
上述したように、図5に示したテーブルの「管理範囲」のフィールドには、各プロセスデータの許容範囲が設定される。「設定範囲」のフィールドには、各プロセスデータの目標値が設定される。また、「コスト影響(単価)」のフィールドには、各プロセスデータの所定の単位量当たりのコストが設定される。なお、「調整/監視」のフィールドに「調整」が登録されているプロセスデータは、プラント3が備えるアクチュエータ等を制御することにより、調整が可能な値を表している。制御時においては、例えば目標や許容範囲等の条件に基づいて、調整可能なプロセスデータの運転条件を求める。
図5の例では、「コスト影響(単価)」のフィールドに設定された単価と、各タグに対応するプロセスデータの値との積の総和により、コストを求めることができる。そして、目的関数であるコストが最小になるように、制御可能なプロセスデータの値(運転条件)を算出する。
また、設定範囲に基づき、予測式によって算出される予測値は、図5の「設定範囲」に登録される範囲に収まるよう制約条件が課される。これらのプロセスデータは例えば品質又は品質代替指標であり、範囲は要求されるスペックにより定められる狙い値といえる。
さらに、管理範囲に基づき、制御可能なプロセスデータの取り得る値は制限される。「調整/監視」のフィールドに「調整」が登録されているタグに対応するプロセスデータは調整可能であるが、例えばプラント3の仕様等に応じて定まる設定の限界により制約条件が設けられる。
また、本実施形態では、予測処理において作成した予測モデルも制約条件に利用される。すなわち、予測式における目的変数の少なくとも一部に対して所定の範囲を表す制約条件を設け、予測値が当該制約条件の範囲内になるような説明変数の最適値を探索する。
制約条件となる1次不等式や1次等式を満たす変数の中で、目的関数を最小化する値を求める場合は、いわゆる線形計画法により最適化することができる。なお、コストでなく、任意のプロセスデータの予測値を目的変数としてもよい。このとき、コストについて許容範囲を定めるようにしてもよい。また、制約条件や目的関数の一部に非線形であっても、既存の非線形計画法により解くことができる。また、目的関数を複数設定し、多目的最適化を行うようにしてもよい。以上のように、最適化問題を解くことにより運転条件を求めることができる。
例えば調整対象のプロセスデータが副原料の投入量であれば、算出された最適解がそのまま設定値となる。例えば調整対象のプロセスデータが処理対象の温度の積分値であれば、算出された最適解に近づくように、バルブ等のアクチュエータを調整する。
<装置構成>
図13は、予測装置1の構成の一例を示すブロック図である。予測装置1は、一般的なコンピュータであり、通信インターフェース(I/F)11と、記憶装置12と、入出力装置13と、プロセッサ14とを備えている。通信I/F11は、例えばネットワークカードや通信モジュールであってもよく、所定のプロトコルに基づき、他のコンピュータと通信を行う。記憶装置12は、RAM(Random Access Memory)やROM(Read Only Memory)等の主記憶装置、及びHDD(Hard-Disk Drive)やSSD(Solid State Drive)、フラッシュメモリ等の補助記憶装置(二次記憶装置)であってもよい。主記憶装置は、プロセッサ14が読み出すプログラムや他のコンピュータとの間で送受信する情報を一時的に記憶したり、プロセッサ14の作業領域を確保したりする。補助記憶装置は、プロセッサ14が実行するプログラムや他のコンピュータとの間で送受信する情報等を記憶する。入出力装置13は、例えば、キーボード、マウス等の入力装置、モニタ等の出力装置、タッチパネルのような入出力装置等のユーザインターフェースである。プロセッサ14は、CPU(Central Processing Unit)等の演算処理装置であり、プログラムを実行することにより本実施形態に係る各処理を行う。図13の例では、プロセッサ14内に機能ブロックを示している。すなわち、プロセッサ14は、所定のプログラムを実行することにより、プロセスデータ取得部141、プロセスデータ加工部142、予測モデル作成部143、品質予測部144及びプラント制御部145として機能する。
図13は、予測装置1の構成の一例を示すブロック図である。予測装置1は、一般的なコンピュータであり、通信インターフェース(I/F)11と、記憶装置12と、入出力装置13と、プロセッサ14とを備えている。通信I/F11は、例えばネットワークカードや通信モジュールであってもよく、所定のプロトコルに基づき、他のコンピュータと通信を行う。記憶装置12は、RAM(Random Access Memory)やROM(Read Only Memory)等の主記憶装置、及びHDD(Hard-Disk Drive)やSSD(Solid State Drive)、フラッシュメモリ等の補助記憶装置(二次記憶装置)であってもよい。主記憶装置は、プロセッサ14が読み出すプログラムや他のコンピュータとの間で送受信する情報を一時的に記憶したり、プロセッサ14の作業領域を確保したりする。補助記憶装置は、プロセッサ14が実行するプログラムや他のコンピュータとの間で送受信する情報等を記憶する。入出力装置13は、例えば、キーボード、マウス等の入力装置、モニタ等の出力装置、タッチパネルのような入出力装置等のユーザインターフェースである。プロセッサ14は、CPU(Central Processing Unit)等の演算処理装置であり、プログラムを実行することにより本実施形態に係る各処理を行う。図13の例では、プロセッサ14内に機能ブロックを示している。すなわち、プロセッサ14は、所定のプログラムを実行することにより、プロセスデータ取得部141、プロセスデータ加工部142、予測モデル作成部143、品質予測部144及びプラント制御部145として機能する。
プロセスデータ取得部141は、例えば通信I/F11及び制御ステーション2を介して、プラント3が備えるセンサからプロセスデータを取得し、記憶装置12に記憶させる。上述したように、プロセスデータは、タグによってセンサと対応付けられている。
プロセスデータ加工部142は、予測モデルの作成に際し、図5に示したバッチ工程のタグ属性テーブル又は図11に示した連続工程のタグ属性テーブルに基づいて、プロセスデータを加工する。すなわち、プロセスデータ加工部142は、バッチ工程のタグ属性テーブルの一次工程のフィールドに登録された情報に基づいて、指定タイミングの瞬時値を抽出したり、指定期間の平均値を算出したり、指定期間の積分値を算出したりする。また、プロセスデータ加工部142は、連続工程のタグ属性テーブルのバッチ関連タグのフィールドに登録された情報、及び例えば予め記憶装置12に保持されている上述のトレーサビリティ情報に基づいて、所定のタグ、系統及び製造番号に該当するプロセスデータの平均値を算出したり、連続工程のプロセスデータについて、トレーサビリティ情報に基づいて特定される期間の平均値を算出したりしてもよい。
予測モデル作成部143は、例えば図6に示したタグ結合テーブルに基づいて、上述した式(1)に示すような予測式を含む予測モデルを作成し、記憶装置12に記憶させる。予測モデル作成部143は、例えば、バッチ工程においては製造番号ごとに直近の所定期間のデータを用いて予測式の係数等を更新してもよい。また、予測モデル作成部143は、例えば、連続工程においては所定期間ごとに直近のデータを用いて予測式の係数等を更新してもよい。
品質予測部144は、プロセスデータと予測モデルとを用いて、所定のセンサの出力値や、工程検査の分析値を予測する。なお、品質予測部144は、任意の運転条件に基づくデータと予測モデルとを用いて、運転条件変更後の予測値を算出してもよい。
プラント制御部145は、例えば通信I/F11及び制御ステーション2を介して、プラント3が備えるバルブ等のアクチュエータやその他の機器を制御する。また、プラント制御部145は、例えば品質とコストとが所定の条件を満たす運転条件を求め、これに基づいてプラント3を制御してもよい。また、プラント制御部145は、所定の安定状態に移行させるための運転条件を求めたり、生産物が所定の要求を満たすような運転条件を求め、これに基づいてプラント3を制御してもよい。
以上のような構成要素が、バス15を介して接続されている。
<予測処理(バッチ工程)>
図14は、予測装置1が実行する予測処理の一例を示す処理フロー図である。予測装置1のプロセッサ14は、所定のプログラムを実行することにより、図14に示すような処理を実行する。予測処理は、バッチ工程においては製造番号ごとに、連続工程においては所定のサンプリング間隔で、実行される。なお、図5に示したバッチ工程のタグ属性テーブル、図6に示したタグ結合テーブル、図11に示した連続工程のタグ属性テーブル、トレーサビリティ情報等が、ユーザによって作成され、予め記憶装置12に記憶されているものとする。また、プロセスデータ取得部141は、例えば通信I/F11及び制御ステーション2を介して、プラント3が備えるセンサからプロセスデータを継続的に取得し、一時的に又は永続的に、記憶装置12に記憶させているものとする。プロセスデータは、例えばOPCのような所定の規格に従って記述される。
図14は、予測装置1が実行する予測処理の一例を示す処理フロー図である。予測装置1のプロセッサ14は、所定のプログラムを実行することにより、図14に示すような処理を実行する。予測処理は、バッチ工程においては製造番号ごとに、連続工程においては所定のサンプリング間隔で、実行される。なお、図5に示したバッチ工程のタグ属性テーブル、図6に示したタグ結合テーブル、図11に示した連続工程のタグ属性テーブル、トレーサビリティ情報等が、ユーザによって作成され、予め記憶装置12に記憶されているものとする。また、プロセスデータ取得部141は、例えば通信I/F11及び制御ステーション2を介して、プラント3が備えるセンサからプロセスデータを継続的に取得し、一時的に又は永続的に、記憶装置12に記憶させているものとする。プロセスデータは、例えばOPCのような所定の規格に従って記述される。
予測装置1のプロセスデータ取得部141は、設定情報を読み込む(図14:S1)。本ステップでは、プロセスデータ取得部141は、記憶装置12から、タグ属性テーブル、タグ結合テーブル、トレーサビリティ情報等を読み出す。
また、プロセスデータ取得部141は、プロセスデータを読み込む(図14:S2)。本ステップでは、予測式に用いられるタグに対応するプロセスデータが、例えば、予測式ごと、且つ系列ごと、且つ細分化された工程ごとに抽出される。図15は、本ステップにおいて読み出されたデータを書き込むためのバッチ工程用の書込用配列の一例を示す図である。バッチ工程用の書込用配列は、OPCデータであってもよいし、いわゆるデータベースのテーブルであってもよいし、CSVのような所定の形式のファイルであってもよい。図15のテーブルは、日時、製番、品種、ステップ、タグの各属性を含む。日時のフィールドには、センサが測定値を出力した日時が登録される。製番のフィールドには、製造番号が登録される。品種のフィールドには、処理対象の種別が登録される。ステップのフィールドには、予め定義されたステップで表される、当該工程における段階を示す情報が登録される。タグのフィールドには、各タグに対応するセンサの出力値が登録される。
また、予測装置1のプロセスデータ加工部142は、プロセスデータに対し所定の加工処理を行う(図14:S3)。本ステップの詳細は、図16を用いて説明する。図16は、加工処理の一例を示す処理フロー図である。プロセスデータ加工部142は、図15に示した書込用配列に、予測式ごと、且つ系列ごと、且つ細分化された工程ごとのプロセスデータが抽出されると、書込用配列の各レコードに対して図16に示すような処理が実行される。
プロセスデータ加工部142は、書込用配列からレコードを読み出す(図16:S11)。本ステップでは、図15に示したようなテーブルから1レコードが順に読み出される。また、プロセスデータ加工部142は、一次加工方法に応じてデータの加工を行う(図16:S12)。本ステップでは、図5に示したタグ属性テーブルを参照し、対応するタグの「一次加工」の「方法」のフィールドに登録された種別に基づいて、例えば瞬時値、平均値、積分値、微分係数、差分、最大値、最小値、熱履歴、又はプロセスデータそのものが求められる。図17は、本ステップの処理結果を書き込むバッチ配列の一例を示す図である。バッチ配列も、OPCデータであってもよいし、いわゆるデータベースのテーブルであってもよいし、CSVのような所定の形式のファイルであってもよい。図17のテーブルは、製番、終了日時、タグの各属性を含む。製番のフィールドには、製造番号が登録される。終了日時のフィールドには、当該製番のバッチ工程が終了した日時が登録される。タグのフィールドには、加工処理後のプロセスデータが登録される。
ここで、熱履歴の算出について説明する。熱履歴は、例えば解重合やアセチル化、脱アセチル化等の一般的な化学反応について、反応の進行の程度を表す情報である。本実施形態では、熱履歴を、所定の期間の反応速度の積分値として求める。例えば、次の式(2)に示すように、アレニウスの式を用いた反応速度式の積分値により算出する。

ここで、Aは、頻度因子である。Eは、活性化エネルギーである。Rは、気体定数である。また、A(t)、B(t)は濃度項であり、m、nは、反応次数である。これらの値は、反応や対象物に応じて定義される。また、tは、工程における所定の区間を表すステップである。T(t)は、当該ステップにおける温度であり、プロセスデータとして得られる。このような加工により、所定期間に処理対象が受けた熱量を、品質予測に用いることができるようになる。
ここで、Aは、頻度因子である。Eは、活性化エネルギーである。Rは、気体定数である。また、A(t)、B(t)は濃度項であり、m、nは、反応次数である。これらの値は、反応や対象物に応じて定義される。また、tは、工程における所定の区間を表すステップである。T(t)は、当該ステップにおける温度であり、プロセスデータとして得られる。このような加工により、所定期間に処理対象が受けた熱量を、品質予測に用いることができるようになる。
また、プロセスデータ加工部142は、所定のデータクレンジング処理を実施する(図16:S13)。データクレンジング処理は、外れ値を排除する処理であり、様々な手法を採用することができる。例えば、直近のデータを用いて移動平均値を算出する。また、移動平均値と実測値との差をとり、差分のばらつきを表す標準偏差σ(誤差分散とも呼ぶ)を求める。そして、例えば確率分布の平均値-3σから確率分布の平均+3σまでの区間(3σ区間とも呼ぶ)のような所定の信頼区間に入らない値を除外する。同様に、前後の実測値の差について、3σ区間に入らない値を除外するようにしてもよい。データクレンジング処理は、例えば瞬時値や、バッチ終了時のプロセスデータに対して行われる。
また、プロセスデータ加工部142は、所定の平滑化処理を実施する(図16:S14)。平滑化処理は、図5に示したタグ属性テーブルにおいて、平滑化のフィールドに「要」が登録されたタグについて行われる。また、平滑化処理は、例えば、データクレンジング後の値について、直近の所定数の移動平均を求める処理であってもよいし、データを平滑化することができる他の手法であってもよい。以上で、図16の加工処理を終了し、図14の処理に戻る。
その後、予測装置1の予測モデル作成部143は、予測モデル構築処理を行う(図14:S4)。本ステップでは、図6に示したタグ結合テーブルに基づいて、予測モデルを構成する予測式を作成する。具体的には、同一の結合IDが付されたタグの加工後のプロセスデータを読み出し、要因/影響のフィールドに登録された種別に基づいて加工後のプロセスデータを予測式(例えば、上述した式(1))に当てはめ、回帰分析により予測式の係数及び定数項を決定する。このとき、加工後のプロセスデータは、学習期間のフィールドに登録された値に応じて直近のデータを学習対象とする。なお、予測モデル作成部143は、学習期間の大きさについても好ましい値を探索するようにしてもよい。例えば、作成した予測モデルとプロセスデータとを用いて相関係数を算出し、相関係数が向上するように学習期間を設定する。また、因果関係のフィールドに登録された符号に基づいて、要因系の値の変動の方向と、影響系の値の変動の方向との間に、一定の対応関係を有するような制約の下で、予測式の係数等を決定する。そして、予測モデル作成部143は作成した予測式を記憶装置12に記憶させる。
予測装置1の品質予測部144は、予測モデル構築処理において作成された予測モデルと、プロセスデータ又はその予測値とを用いて、予測処理を行う(図14:S5)。便宜上、図14の処理フローの中に予測処理を示すが、品質予測部144は、任意の時点に予測モデルとプロセスデータを用いて予測処理を行うことができる。本ステップでは、品質予測部144は、直近の予測モデルとプロセスデータとを読み出し、予測モデルに含まれる予測式にプロセスデータ又はその予測値を代入して、任意の影響系に相当する値の予測値を求める。
図18は、予測式に代入するプロセスデータ又はその予測値を説明するための図である。図4に示したタグ007の値を予測する場合、図3の時点t1においては、図18に示すように各タグに対応するセンサの実測値又は予測値を用いる。すなわち、製造番号003のタグ007の値を予測する場合、既知である、製造番号003のタグ001から004までの実測値と、未知である、製造番号003のタグ005及び006の予測値とを、タグ007の予測式に代入する。
図19は、予測式に代入するプロセスデータ又はその予測値を説明するための他の例を示す図である。図4に示したタグ007の値を予測する場合、図3の時点t2においては、図19に示すように各タグに対応するセンサの実測値又は予測値を用いる。すなわち、製造番号004のタグ007の値を予測する場合、既知である、製造番号004のタグ001及び002の実測値と、製造番号003のタグ004の実測値と、未知である、製造番号004のタグ003、005及び006の予測値とを、タグ007の予測式に代入する。ここで、図4に示したように、タグ004の値には予測式がないため、直近の製造番号の実測値が用いられる。
また、予測モデルに入力する値は、プロセスデータには限られず、たとえば任意の運転条件に基づくデータであってもよい。このようにすれば、プラント3の運転条件を変更した場合の結果を予測できる。以上のように、品質予測部144は、予測モデルと、センサの出力値又はその予測値を用いて、例えば所定のプロセスデータの予測値を算出する。
また、品質予測部144は、算出された予測値又はプロセスデータの実測値について、上述したデータクレンジングにおいて求めた所定の信頼区間を求め、モニタ等の入出力装置13に所定の信頼区間と予測値又は実測値とをグラフ上に図示するようにしてもよい。このようにすれば、ユーザは視覚的に傾向を把握でき、プラント3の運転条件を変更すべきか否かの判断材料とすることができる。
また、プラント制御部145は、算出された予測値に基づいてプラント3の運転条件を自動的に変更したり、入出力装置13を介してユーザに運転条件の変更を提案する情報を出力してもよい。
<予測処理(連続工程)>
連続工程においても、図14に示した予測処理を行う。以下、バッチ工程との相違点を中心に説明する。なお、系列ごと且つ製造番号ごとに、バッチ工程が終了し、連続工程への処理対象の移送(移液)が完了した日時が、記憶装置12に記憶されているものとする。
連続工程においても、図14に示した予測処理を行う。以下、バッチ工程との相違点を中心に説明する。なお、系列ごと且つ製造番号ごとに、バッチ工程が終了し、連続工程への処理対象の移送(移液)が完了した日時が、記憶装置12に記憶されているものとする。
プロセスデータの読み込み(図14:S2)においては、連続工程の場合、製造番号単位でなく、新しいデータを書き込むと共に古いデータを削除するローリングが継続的に行われる。また、図11に示したタグ属性テーブルの種別のフィールドに登録された情報に基づいて、図15に示した書込用配列のデータ構造を変更してもよい。図20は、種別が「連続」のデータを保持する書込用配列の一例を示す図である。種別が「連続」のデータを保持する書込用配列は、例えば、図15のテーブルから製番及びステップを削除した構成とすることができる。また、図21は、種別が「バッチ」のデータを保持する書込用配列の一例を示す図である。種別が「バッチ」のデータを保持する書込用配列は、例えば、製造番号と当該製造番号のプロセスデータとを保持するテーブルであり、図21のようなテーブルが系統ごとに作成される。図21のテーブルに登録されるデータは、図17のバッチ配列に登録された加工後のデータであってもよい。
また、プロセスデータの加工(図14:S3)は、例えば、工程検査のタイミングを基準として実行される。工程検査のタイミングは、トレーサビリティ情報においてサンプリング間隔として定義されている。図22は、連続工程における加工後のプロセスデータを保持する結合IDデータ配列の一例を示す図である。結合IDデータ配列も、OPCデータであってもよいし、いわゆるデータベースのテーブルであってもよいし、CSVのような所定の形式のファイルであってもよい。図22のテーブルは、工程検査ID、サンプリング、タグの各属性を含む工程検査IDのフィールドには、各工程検査を特定するための識別情報が登録される。サンプリングの属性は、開始日時及び終了日時の属性をさらに含み、開始日時及び終了日時のフィールドにはそれぞれ縮分法による工程検査のサンプリングの開始日時及び終了日時が登録される。タグのフィールドには、各タグに対応する分析値が登録される。ここで、図11に示したタグ属性テーブルの種別のフィールドに「連続」が登録されているタグについては、処理時点からトレーサビリティ情報においてサンプリング間隔を遡った時点までのプロセスデータの平均値が登録される。また、図11に示したタグ属性テーブルの種別のフィールドに「バッチ」が登録されているタグについては、処理時点からトレーサビリティ情報においてサンプリング間隔を遡った時点までに移液が完了した製造番号に対応するプロセスデータの平均値が登録される。
また、予測モデル構築処理(図14:S4)は、例えば、予測モデル作成部143が工程検査の分析値を取得すると、当該分析値の予測モデルを更新する。本ステップでも、図6に示したタグ結合テーブルに基づいて、予測モデルを構成する予測式を作成する。また、連続工程においては、図9に示したように、予測モデル作成部143は、バッチ工程の完了タイミングと、予め定められた滞留時間とに基づいて、要因系のプロセスデータと影響系のプロセスデータとを対応付け、プラント3から得られたプロセスデータの特徴を学習させるようにしてもよい。また、図10に示したように、予測モデル作成部143は、要因系のプロセスデータの取得タイミングと、影響系のプロセスデータの取得タイミングとの差に基づいて、要因系のプロセスデータと、影響系のプロセスデータとを対応付け、プラント3から得られたプロセスデータの特徴を学習させるようにしてもよい。
予測装置1の品質予測部144は、予測モデル構築処理において作成された予測モデルと、プロセスデータ又はその予測値とを用いて、予測処理を行う(図14:S5)。本ステップでは、品質予測部144は、直近の予測モデルとプロセスデータとを読み出し、予測モデルに含まれる予測式にプロセスデータ又はその予測値を代入して、任意の影響系に相当する値の予測値を求める。
<制御処理>
図23は、予測装置1が実行する制御処理の一例を示す処理フロー図である。予測装置1のプロセッサ14は、所定のプログラムを実行することにより、図23に示すような処理を実行する。制御処理は、例えば予測モデルが更新された後など、任意のタイミングで実行される。制御処理においても、図5に示したバッチ工程のタグ属性テーブル、図6に示したタグ結合テーブル、図11に示した連続工程のタグ属性テーブル、トレーサビリティ情報等は、予め記憶装置12に記憶されているものとする。また、プロセスデータ取得部141は、例えば通信I/F11及び制御ステーション2を介して、プラント3が備えるセンサからプロセスデータを継続的に取得し、一時的に又は永続的に、記憶装置12に記憶させているものとする。
図23は、予測装置1が実行する制御処理の一例を示す処理フロー図である。予測装置1のプロセッサ14は、所定のプログラムを実行することにより、図23に示すような処理を実行する。制御処理は、例えば予測モデルが更新された後など、任意のタイミングで実行される。制御処理においても、図5に示したバッチ工程のタグ属性テーブル、図6に示したタグ結合テーブル、図11に示した連続工程のタグ属性テーブル、トレーサビリティ情報等は、予め記憶装置12に記憶されているものとする。また、プロセスデータ取得部141は、例えば通信I/F11及び制御ステーション2を介して、プラント3が備えるセンサからプロセスデータを継続的に取得し、一時的に又は永続的に、記憶装置12に記憶させているものとする。
予測装置1のプラント制御部145は、設定情報を読み込む(図23:S21)。本ステップでは、プラント制御部145は、記憶装置12から、タグ属性テーブル、タグ結合テーブル、トレーサビリティ情報等を読み出す。制御処理においては、読み出される情報は、例えば最適化問題の目的関数として表される制御の目標や、例えば最適化問題の制約条件として表される制御の許容領域を含む。ここでは、図5のコスト影響のフィールドに登録された単価を用いて算出されるコストが最小になることを目的関数とするものとする。また、管理範囲及び設定範囲のフィールドに登録された値が、制約条件になるものとする。
また、プロセスデータ取得部141は、プロセスデータを読み込む(図23:S22)。本ステップの処理は、図14のS2と同様である。本ステップでは、予測式に用いられるタグに対応するプロセスデータが、例えば、予測式ごと、且つ系列ごと、且つ細分化された工程ごとにプロセスデータが抽出される。また、図15又は図20に示した書込用配列に、センサの出力値が登録される。
また、プロセスデータ加工部142は、プロセスデータに対し所定の加工処理を行う(図23:S23)。本ステップの処理は、図14のS3と同様である。
そして、プラント制御部145は、最適化問題の演算処理を行う(図23:S24)。本ステップでは、読み出された制約条件の下で目的関数を最小化又は最大化する運転条件を求める。例えば、図5に示した設定に基づいてコストを最小化する場合、コストは次の式(3)で求められる。
コスト=(タグ001のプロセスデータ×単価)+(タグ002のプロセスデータ×単価)+(タグ004のプロセスデータ×単価) (3)
コスト=(タグ001のプロセスデータ×単価)+(タグ002のプロセスデータ×単価)+(タグ004のプロセスデータ×単価) (3)
また、制約条件として、図5の「設定範囲」に登録される情報を利用する。具体的には、次のような条件が設定される。
タグ005の下限 ≦ タグ005の予測値 ≦ タグ005の上限
タグ007の下限 ≦ タグ007の予測値 ≦ タグ007の上限
タグ005の下限 ≦ タグ005の予測値 ≦ タグ005の上限
タグ007の下限 ≦ タグ007の予測値 ≦ タグ007の上限
また、他の制約条件として、図5の「管理範囲」に登録される情報を利用する。具体的には、次のような条件が設定される。
タグ001の下限 ≦ タグ001の値 ≦ タグ001の上限
タグ002の下限 ≦ タグ002の値 ≦ タグ002の上限
タグ003の下限 ≦ タグ003の値 ≦ タグ003の上限
タグ005の下限 ≦ タグ005の値 ≦ タグ005の上限
タグ001の下限 ≦ タグ001の値 ≦ タグ001の上限
タグ002の下限 ≦ タグ002の値 ≦ タグ002の上限
タグ003の下限 ≦ タグ003の値 ≦ タグ003の上限
タグ005の下限 ≦ タグ005の値 ≦ タグ005の上限
また、本実施形態では、予測処理において作成した予測モデルも制約条件に利用される。例えば、図7及び図12に示したようなロジックツリーにおいてプロセスデータ間に予測式が定義されている場合、予測処理において構築された予測式に基づいて上流のプロセスデータに基づいて下流のプロセスデータが算出される。また、上流側の端部に位置するプロセスであって、図5の「調整/監視」のフィールドに「監視」が登録されているタグに対応するプロセスデータは、S22において取得され、S23において加工された値が用いられる。そして、各予測式における目的変数に対し上述の設定範囲や管理範囲が設定されている場合、これらの範囲を表す制約条件を設け、予測値が当該制約条件の範囲に収まるような説明変数の最適値を探索する。
以上のような最適化問題は、既存の解法により解くことができる。なお、図5の「調整/監視」のフィールドに「調整」が登録されているタグに対応するプロセスデータを調整対象とする。すなわち、タグが001、003、004、006のプロセスデータが調整対象であり、対象のタグは制約条件とは必ずしも一致しない。
最適化問題が解かれ、調整対象のプロセスデータの設定値を含む運転条件が求められると、プラント制御部145は、運転条件に従ってプラント3を制御する(図23:S25)。本ステップでは、プラント制御部145は、通信I/F11を介して制御ステーション2へ、運転条件を示すデータを出力する。そして、制御ステーション2からの制御信号に従って、プラント3の動作が制御される。なお、例えばS24において多目的最適化問題を解いた場合は、運転条件の複数の候補を入出力装置13を介してユーザへ提示し、ユーザが選択した運転条件に基づいてプラント3を制御してもよい。
<変形例>
各実施形態における各構成及びそれらの組み合わせ等は、一例であって、本発明の主旨から逸脱しない範囲内で、適宜、構成の付加、省略、置換、及びその他の変更が可能である。本開示は、実施形態によって限定されることはなく、クレームの範囲によってのみ限定される。また、本明細書に開示された各々の態様は、本明細書に開示された他のいかなる特徴とも組み合わせることができる。
各実施形態における各構成及びそれらの組み合わせ等は、一例であって、本発明の主旨から逸脱しない範囲内で、適宜、構成の付加、省略、置換、及びその他の変更が可能である。本開示は、実施形態によって限定されることはなく、クレームの範囲によってのみ限定される。また、本明細書に開示された各々の態様は、本明細書に開示された他のいかなる特徴とも組み合わせることができる。
また、上述した実施形態では化学プラントを例に説明したが、一般的な生産設備における製造プロセスに適用することができる。例えば、実施形態におけるバッチ工程の製造番号に代えてロット番号を処理単位として、実施形態におけるバッチ工程に準じた処理を適用することができる。
予測装置1の機能の少なくとも一部は、複数の装置に分散して実現するようにしてもよいし、同一の機能を複数の装置が並列に提供するようにしてもよい。例えば、予測モデルを作成するモデル作成装置と、作成された予測モデルを用いて予測を行う予測装置と、作成された予測モデルを用いて生産設備の制御を行う制御装置とが異なっていてもよい。また、予測装置3の機能の少なくとも一部は、いわゆるクラウド上に設けるようにしてもよい。
また、上述した式(1)は、自己回帰項を含む線形モデルであるが、このような例には限定されない。例えば、自己回帰項を含まないモデルを採用することもできる。また、モデルは線形でも非線形でもよい。また、単一の式であってもよいし、例えば季節変動のような周期的な変動を取り入れた状態空間モデルを採用してもよい。ただし、符号制約を満たすモデルであることが好ましい。すなわち、要因系の値の変動の方向と、影響系の値の変動の方向との間に、一定の対応関係を有するような制約の下で、予測式の係数等を決定する。
また、本開示は、上述した処理を実行する方法やコンピュータプログラム、当該プログラムを記録した、コンピュータ読み取り可能な記録媒体を含む。当該プログラムが記録された記録媒体は、プログラムをコンピュータに実行させることにより、上述の処理が可能となる。
ここで、コンピュータ読み取り可能な記録媒体とは、データやプログラム等の情報を電気的、磁気的、光学的、機械的、または化学的作用によって蓄積し、コンピュータから読み取ることができる記録媒体をいう。このような記録媒体のうちコンピュータから取り外し可能なものとしては、フレキシブルディスク、光磁気ディスク、光ディスク、磁気テープ、メモリカード等がある。また、コンピュータに固定された記録媒体としては、HDDやSSD(Solid State Drive)、ROM等がある。
1: 予測装置
11: 通信I/F
12: 記憶装置
13: 入出力装置
14: プロセッサ
141: プロセスデータ取得部
142: プロセスデータ加工部
143: 予測モデル作成部
144: 品質予測部
145: プラント制御部
2: 制御ステーション
3: プラント
11: 通信I/F
12: 記憶装置
13: 入出力装置
14: プロセッサ
141: プロセスデータ取得部
142: プロセスデータ加工部
143: 予測モデル作成部
144: 品質予測部
145: プラント制御部
2: 制御ステーション
3: プラント
Claims (9)
- 化学プラントから得られるプロセスデータに対し所定の加工処理を行うプロセスデータ加工部と、
前記化学プラントから得られるプロセスデータ又は前記プロセスデータ加工部によって加工された前記プロセスデータのうち、説明変数とする第1のプロセスデータと、目的変数とする第2のプロセスデータ又は当該第2のプロセスデータに応じた値との組合せを定義する因果関係情報に基づいて、前記化学プラントから得られた前記プロセスデータの特徴を学習した予測モデルを作成する予測モデル作成部と、
を備え、
前記プロセスデータ加工部は、前記プロセスデータを用いて、所定の期間における処理対象の反応速度に応じた値を求める
予測装置。 - 前記反応速度に応じた値は、反応速度の積分値である
請求項1に記載の予測装置。 - 前記反応速度に応じた値は、アレニウスの式を用いて算出され、化学反応の種別と前記化学プラントにおける処理対象とに応じて反応速度定数の頻度因子及び活性化エネルギーが定められる
請求項2に記載の予測装置。 - 前記プロセスデータ加工部は、前記プロセスデータの種別に応じて、所定の期間における前記プロセスデータの積分値、微分値、平均値、最大値、若しくは最小値、又は所定の時点における前記プロセスデータの瞬時値をさらに求める
請求項1から3のいずれか一項に記載の予測装置。 - 前記予測モデルは、複数の予測式を含む階層構造であり、第1の予測式で算出する予測値を説明変数に含む第2の予測式を有する
請求項1から4のいずれか一項に記載の予測装置。 - 前記第2のプロセスデータに応じた値は、縮分法により複数の第2のプロセスデータをサンプリングした値であり、
前記化学プラントにおける、前記第1のプロセスデータの取得タイミングの範囲と、前記第2のプロセスデータに応じた値の算出タイミングとを、前記化学プラント内における前記処理対象の滞留時間に基づいて対応付け、前記予測モデル作成部は前記予測モデルを作成する
請求項1から5のいずれか一項に記載の予測装置。 - 前記化学プラントは、所定の処理単位ごとに処理対象を逐次処理するバッチ工程と、その後に前記処理対象を連続的に処理する連続工程とを行い、
前記バッチ工程の完了タイミングの範囲と、前記第2のプロセスデータに応じた値の算出タイミングとを、前記化学プラント内における前記処理対象の滞留時間に基づいて対応付け、前記予測モデル作成部は前記予測モデルを作成する
請求項1から6のいずれか一項に記載の予測装置。 - 化学プラントから得られるプロセスデータに対し所定の加工処理を行うプロセスデータ加工ステップと、
前記化学プラントから得られるプロセスデータ又は前記プロセスデータ加工ステップにおいて加工された前記プロセスデータのうち、説明変数とする第1のプロセスデータと、目的変数とする第2のプロセスデータ又は当該第2のプロセスデータに応じた値との組合せを定義する因果関係情報に基づいて、前記化学プラントから得られた前記プロセスデータの特徴を学習した予測モデルを作成する予測モデル作成ステップと、
を予測装置が実行し、
前記プロセスデータ加工ステップにおいて、前記プロセスデータを用いて、所定の期間における処理対象の反応速度に応じた値を求める
予測方法。 - 化学プラントから得られるプロセスデータに対し所定の加工処理を行うプロセスデータ加工ステップと、
前記化学プラントから得られるプロセスデータ又は前記プロセスデータ加工ステップにおいて加工された前記プロセスデータのうち、説明変数とする第1のプロセスデータと、目的変数とする第2のプロセスデータ又は当該第2のプロセスデータに応じた値との組合せを定義する因果関係情報に基づいて、前記化学プラントから得られた前記プロセスデータの特徴を学習した予測モデルを作成する予測モデル作成ステップと、
をコンピュータに実行させ、
前記プロセスデータ加工ステップにおいて、前記プロセスデータを用いて、所定の期間における処理対象の反応速度に応じた値を求める
プログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21751321.7A EP4102322A4 (en) | 2020-02-04 | 2021-02-04 | PREDICTION DEVICE AND METHOD, AND PROGRAM |
| JP2021575866A JPWO2021157667A1 (ja) | 2020-02-04 | 2021-02-04 | |
| CN202180012779.7A CN115053189A (zh) | 2020-02-04 | 2021-02-04 | 预测装置、预测方法以及程序 |
| US17/797,348 US20230057943A1 (en) | 2020-02-04 | 2021-02-04 | Prediction apparatus, prediction method, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020017475 | 2020-02-04 | ||
| JP2020-017475 | 2020-02-04 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021157667A1 true WO2021157667A1 (ja) | 2021-08-12 |
Family
ID=77199332
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/004168 WO2021157667A1 (ja) | 2020-02-04 | 2021-02-04 | 予測装置、予測方法及びプログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20230057943A1 (ja) |
| EP (1) | EP4102322A4 (ja) |
| JP (1) | JPWO2021157667A1 (ja) |
| CN (1) | CN115053189A (ja) |
| WO (1) | WO2021157667A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7354477B1 (ja) * | 2021-12-23 | 2023-10-02 | 千代田化工建設株式会社 | プログラム、情報処理装置、及び方法 |
| JP7552238B2 (ja) | 2020-10-14 | 2024-09-18 | 株式会社レゾナック | 物性予測方法 |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001106703A (ja) | 1999-10-06 | 2001-04-17 | Mitsubishi Rayon Co Ltd | 品質予測反応制御システム |
| JP2001325582A (ja) * | 2000-05-17 | 2001-11-22 | Chugoku Electric Power Co Inc:The | 時系列データ学習・予測装置 |
| JP2003526856A (ja) * | 2000-03-10 | 2003-09-09 | ボレアリス テクノロジー オイ | プロセス制御システム |
| JP2011058102A (ja) * | 2009-09-07 | 2011-03-24 | Nippon Electric Glass Co Ltd | ガラスチョップドストランドマットの製造方法、ガラスチョップドストランドマット、及びルーフライナ |
| JP5751045B2 (ja) | 2010-08-31 | 2015-07-22 | 富士電機株式会社 | プラントの運転条件最適化システム、プラントの運転条件最適化方法、プラントの運転条件最適化プログラム |
| JP2018120343A (ja) | 2017-01-24 | 2018-08-02 | 株式会社東芝 | プロセス診断装置、プロセス診断方法及びプロセス診断システム |
| JP6477423B2 (ja) | 2015-11-02 | 2019-03-06 | オムロン株式会社 | 製造プロセスの予測システムおよび予測制御システム |
| JP2019074969A (ja) * | 2017-10-17 | 2019-05-16 | 新日鐵住金株式会社 | 品質予測装置及び品質予測方法 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5062066A (en) * | 1989-08-17 | 1991-10-29 | Nabisco Brands, Inc. | Model referenced control of a food treatment device |
| KR101827108B1 (ko) * | 2016-05-04 | 2018-02-07 | 두산중공업 주식회사 | 플랜트 이상 감지 학습 시스템 및 방법 |
| EP3482354A1 (en) * | 2016-07-07 | 2019-05-15 | Aspen Technology Inc. | Computer systems and methods for performing root cause analysis and building a predictive model for rare event occurrences in plant-wide operations |
| US11348018B2 (en) * | 2017-12-19 | 2022-05-31 | Aspen Technology, Inc. | Computer system and method for building and deploying models predicting plant asset failure |
-
2021
- 2021-02-04 CN CN202180012779.7A patent/CN115053189A/zh active Pending
- 2021-02-04 WO PCT/JP2021/004168 patent/WO2021157667A1/ja unknown
- 2021-02-04 JP JP2021575866A patent/JPWO2021157667A1/ja active Pending
- 2021-02-04 US US17/797,348 patent/US20230057943A1/en active Pending
- 2021-02-04 EP EP21751321.7A patent/EP4102322A4/en active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001106703A (ja) | 1999-10-06 | 2001-04-17 | Mitsubishi Rayon Co Ltd | 品質予測反応制御システム |
| JP2003526856A (ja) * | 2000-03-10 | 2003-09-09 | ボレアリス テクノロジー オイ | プロセス制御システム |
| JP2001325582A (ja) * | 2000-05-17 | 2001-11-22 | Chugoku Electric Power Co Inc:The | 時系列データ学習・予測装置 |
| JP2011058102A (ja) * | 2009-09-07 | 2011-03-24 | Nippon Electric Glass Co Ltd | ガラスチョップドストランドマットの製造方法、ガラスチョップドストランドマット、及びルーフライナ |
| JP5751045B2 (ja) | 2010-08-31 | 2015-07-22 | 富士電機株式会社 | プラントの運転条件最適化システム、プラントの運転条件最適化方法、プラントの運転条件最適化プログラム |
| JP6477423B2 (ja) | 2015-11-02 | 2019-03-06 | オムロン株式会社 | 製造プロセスの予測システムおよび予測制御システム |
| JP2018120343A (ja) | 2017-01-24 | 2018-08-02 | 株式会社東芝 | プロセス診断装置、プロセス診断方法及びプロセス診断システム |
| JP2019074969A (ja) * | 2017-10-17 | 2019-05-16 | 新日鐵住金株式会社 | 品質予測装置及び品質予測方法 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4102322A4 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7552238B2 (ja) | 2020-10-14 | 2024-09-18 | 株式会社レゾナック | 物性予測方法 |
| JP7354477B1 (ja) * | 2021-12-23 | 2023-10-02 | 千代田化工建設株式会社 | プログラム、情報処理装置、及び方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115053189A (zh) | 2022-09-13 |
| US20230057943A1 (en) | 2023-02-23 |
| JPWO2021157667A1 (ja) | 2021-08-12 |
| EP4102322A1 (en) | 2022-12-14 |
| EP4102322A4 (en) | 2024-03-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3289420B1 (en) | Computer system and method for causality analysis using hybrid first-principles and inferential model | |
| WO2021157667A1 (ja) | 予測装置、予測方法及びプログラム | |
| WO2021241576A1 (ja) | 異常変調原因特定装置、異常変調原因特定方法及び異常変調原因特定プログラム | |
| Liu et al. | Operating optimality assessment and nonoptimal cause identification for non-Gaussian multimode processes with transitions | |
| Pani et al. | A survey of data treatment techniques for soft sensor design | |
| Naderkhani et al. | Economic design of multivariate Bayesian control chart with two sampling intervals | |
| WO2021241580A1 (ja) | 異常変調原因特定装置、異常変調原因特定方法及び異常変調原因特定プログラム | |
| JP7081728B1 (ja) | 運転支援装置、運転支援方法及びプログラム | |
| KR20220137931A (ko) | 산업 플랜트 모니터링 | |
| Wu et al. | Integrated soft sensing of coke-oven temperature | |
| Zhou et al. | Aero-engine prognosis strategy based on multi-scale feature fusion and multi-task parallel learning | |
| Li et al. | A hybrid remaining useful life prediction method for cutting tool considering the wear state | |
| Arakelian et al. | Creation of predictive analytics system for power energy objects | |
| WO2021241578A1 (ja) | 異常変調原因特定装置、異常変調原因特定方法及び異常変調原因特定プログラム | |
| Zhu | System identification for process control: recent experience and outlook | |
| KR20230066093A (ko) | 이상 진단 모델의 구축 방법, 이상 진단 방법, 이상 진단 모델의 구축 장치 및 이상 진단 장치 | |
| Liu et al. | Graph attention network with Granger causality map for fault detection and root cause diagnosis | |
| WO2021157666A1 (ja) | 制御装置、制御方法及びプログラム | |
| WO2021157670A1 (ja) | 予測装置、予測方法及びプログラム | |
| WO2021241579A1 (ja) | 異常変調原因特定装置、異常変調原因特定方法及び異常変調原因特定プログラム | |
| WO2021241577A1 (ja) | 異常変調原因表示装置、異常変調原因表示方法及び異常変調原因表示プログラム | |
| Zhu | System identification for process control: Recent experience and outlook | |
| WO2024214676A1 (ja) | 情報処理装置、プロセスデータ処理方法及びプログラム | |
| Seider et al. | Introduction to dynamic risk analyses | |
| Orantes et al. | A new support methodology for the placement of sensors used for fault detection and diagnosis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21751321 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021575866 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021751321 Country of ref document: EP Effective date: 20220905 |