WO2021090681A1 - 情報処理装置、情報処理方法及び情報処理プログラム - Google Patents
情報処理装置、情報処理方法及び情報処理プログラム Download PDFInfo
- Publication number
- WO2021090681A1 WO2021090681A1 PCT/JP2020/039499 JP2020039499W WO2021090681A1 WO 2021090681 A1 WO2021090681 A1 WO 2021090681A1 JP 2020039499 W JP2020039499 W JP 2020039499W WO 2021090681 A1 WO2021090681 A1 WO 2021090681A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- utterance
- mask
- data
- information processing
- text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/131—Fragmentation of text files, e.g. creating reusable text-blocks; Linking to fragments, e.g. using XInclude; Namespaces
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/151—Transformation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Definitions
- the present invention relates to an information processing device, an information processing method, and an information processing program.
- cases corresponding to the task domain defined in the system may be collected.
- utterance data is collected as an example assuming various use cases from the aspect of mapping the input of natural language from the user to the semantic symbol defined in the utterance semantic analysis module.
- Such a case is created as an example only by a developer who belongs to the business operator of the system developer and other related parties, and a worker who can include a cloud worker who performs the work on consignment.
- the information processing apparatus of one form according to the present disclosure is obtained by the acquisition unit for acquiring the original data, the mask unit for masking a part of the original data, and the mask processing. It is provided with a restoration reception unit that accepts an input for restoring the mask portion of the masked data.
- Application example 7-1 Partial sharing of utterance cases 7-2. Relay-style utterance case creation 7-3. Providing context 7-4. Efficient data collection support for model learning 7-4-1. Visualization of utterance cases 7-4-2. One side of the effect of visualization 7-5. Linkage with evaluation 7-6. Support for collecting utterance cases that connect excursions 8.
- Modification example 8-1 Transformation example of the case 8-1-1. Dialogue task 8-1-2. Image classification task 8-1--3. Motion classification task 8-1--4. Path search task 8-2. Other modifications 9. Hardware configuration
- Dialogue refers to the act of exchanging information such as utterances between people or machines.
- the dialogue is not limited to one exchange, and may include a case where the dialogue is a plurality of exchanges. When multiple exchanges are performed, it is necessary to select an exchange in consideration of the previous exchanges. Further, the dialogue has a form such as one-to-one, one-to-many, many-to-many, and the like.
- Speech semantic analysis refers to a module that maps a user's input of natural language by text or voice to a semantic symbol defined in advance on the system side. For example, when the text "Show me the weather tomorrow" is input, the text is mapped to a semantic symbol represented by a symbol such as WEATHER-CHECK (tomorrow). Semantic symbols are also called “dialogue actions” in the dialogue system, and the parts corresponding to the arguments are also called “slots". By incorporating various utterance expressions (utterance variations) into specific symbols, the machine becomes easier to handle and individual differences in various user expressions can be absorbed.
- Dialogue system refers to a system capable of exchanging (dialogue) some information with a user.
- natural language using texts and utterances is used for communication, but the communication is not limited to this, and gestures, eye contact, and the like may be used.
- the above-mentioned utterance semantic analysis module may be incorporated into the dialogue system as one module.
- Dialogue agent refers to a service deployed with a dialogue system.
- the dialogue agent may actually have a display device or body, or may be provided as a GUI (Graphical User Interface) like a smartphone application.
- GUI Graphic User Interface
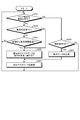
- FIG. 1 is a diagram showing a configuration example of the system 1 according to the embodiment of the present disclosure.
- the system 1 shown in FIG. 1 provides a development support service that supports system development.
- the system 1 also provides a workspace providing service that provides a workspace in which the work of creating the above case is performed.
- utterance cases are collected in system development such as a dialogue system or a dialogue agent, but the present invention is not limited to this. Details will be described later, but it should be added in advance that cases other than utterances may be collected.
- the system 1 may include a development support device 10, worker terminals 30A to 30N, and a work requester terminal 50.
- a development support device 10 worker terminals 30A to 30N
- a work requester terminal 50 work requester terminal 50.
- FIG. 1 shows an example in which one work requester terminal 50 is included in the system 1, a plurality of work requester terminals 50 may be included.
- the development support device 10, the worker terminal 30, and the work requester terminal 50 can be connected via an arbitrary network NW.
- the network NW may be any kind of communication network such as the Internet or LAN (Local Area Network) regardless of whether it is wired or wireless.
- the development support device 10 is a computer that provides the above-mentioned development support service.
- the development support device 10 can correspond to an example of an information processing device.
- the development support device 10 can be implemented as package software or online software by installing a development support program that realizes the above development support service on a desired computer.
- the development support device 10 can be implemented as a server that provides the above-mentioned functions related to the development support service on-premises, for example, a Web server.
- the development support device 10 may be implemented as a SaaS (Software as a Service) type application to provide the above development support service as a cloud service.
- SaaS Software as a Service
- the worker terminal 30 is a computer used by the above-mentioned worker.
- the label "worker terminal” is only a classification from one side of the user, and the type of computer and its hardware configuration are not limited to a specific one, and any computer may be used. ..
- the worker terminal 30 may be a desktop or laptop personal computer or the like. This is merely an example, and the worker terminal 30 may be any computer such as a mobile terminal device or a wearable terminal.
- the work requester terminal 50 is a computer used by the work requester.
- the "work requester” here refers to a person who develops or designs with the intention of generating a corpus of utterance cases, for example, a developer who belongs to the developer of the dialogue system or dialogue agent, and the like. Members of the business concerned may be included. Further, the label "work requester terminal” is also a classification from one side of the user, and the type of computer and its hardware configuration are not limited to a specific one, and is the same as the above-mentioned worker terminal 30. , It can be any computer.
- the development support device 10 of the present disclosure performs "Masked Data Augmentation" that accepts information restoration for information loss of mask data obtained by masking a part of original data.
- Such a problem-solving approach can only be adopted with the technical knowledge that the errors that occur in the process of information loss and information restoration are used to expand the original data.
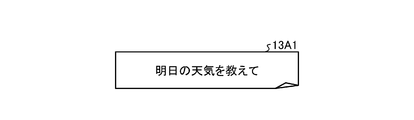
- FIG. 2A is a diagram showing an example of original data.
- FIG. 2A shows, as an example, a case where utterance cases corresponding to the domain of the semantic symbol “WEATHER-CHECK (tomorrow)” are collected.
- the original data 13A1 includes the utterance text "Tell me the weather tomorrow".
- the utterance text created by the above-mentioned work requester or worker can be used.
- FIG. 2B is a diagram showing an example of mask data.
- FIG. 2B illustrates mask data M1 to M3 generated from the utterance text “Tell me the weather tomorrow” of the original data 13A1.
- the utterance text “Teach” is covered with the mask “ ⁇ ” as shown in FIG. 2B.
- Mask data M1 including "Tomorrow's weather ⁇ " can be obtained.
- the word “weather” is masked in the utterance text of the original data 13A1, as shown in FIG. 2B, the utterance text "tomorrow” in which the word "weather” is covered with the mask " ⁇ ".
- Mask data M2 including "Tell me ⁇ " can be obtained. Furthermore, since the phrase “tell me the weather” in the utterance text of the original data 13A1 is masked, as shown in FIG. 2B, the part of the phrase “tell me the weather” is masked by filling the utterance text "Tomorrow”. Mask data M3 including "(fill)" is obtained.
- the mask data M1 to M3 can be displayed on the worker terminal 30.
- the worker inputs to restore the mask portion of the mask data M1 to M3.
- the operator imagines and inputs a word or phrase corresponding to the masked portion from the context of the masked portion and the masked portion in the mask data M1 to M3.
- the development support device 10 receives the restoration of the mask data M1 to M3 from the worker terminal 30.
- the restored data in which the information of the mask portion of the mask data M1 to M3 is restored can be obtained.
- FIG. 2C is a diagram showing an example of restored data.
- FIG. 2C shows the restored data 13B1 restored from the mask data M1 and the restored data 13B2 restored from the mask data M3.
- the utterance text "Show me tomorrow's weather” in the restored data 13B1 does not match the utterance text "Tell me the weather tomorrow" in the original data 13A1.
- a new utterance of the restored data 13B1 that belongs to the domain of the semantic symbol "WEATHER-CHECK (tomorrow)" but uses the word “show” that is different from the word “tell” in the original data 13A1. Can be obtained as an example.
- the utterance text "I wonder if it will rain tomorrow" in the restored data 13B2 does not match the utterance text "Tell me the weather tomorrow" in the original data 13A1.
- the restored data 13B2 which belongs to the domain of the semantic symbol "WEATHER-CHECK (tomorrow)" but uses the phrase “Tell me the weather” of the original data 13A1 and the phrase “Is it raining?" It can be acquired as a new utterance case.
- utterance cases in which words and phrases are different while based on the utterance text of the original data 13A1 but without changing the utterance meaning of the utterance text of the original data 13A1 can be obtained. Can be acquired. Furthermore, if the utterance text of the original data 13A1 contains words and phrases that the worker did not think of, and even an array of them, the range that the worker can think of only from the semantic symbol "WEATHER-CHECK (tomorrow)" is included. You can get more utterance cases.
- the development support device 10 includes a communication interface 11, a storage unit 13, and a control unit 15.
- FIG. 1 only shows an excerpt of the functional parts related to the above-mentioned workspace providing service, and functional parts other than those shown in the figure, for example, functional parts that an existing computer is equipped with by default or as options are shown. It does not prevent the development support device 10 from being provided.
- a functional unit related to the above-mentioned development support service may be provided.
- the communication interface 11 is an interface that controls communication with another device, for example, a worker terminal 30 or a work requester terminal 50.
- a network interface card such as a LAN card can be adopted for the communication interface 11.
- the communication interface 11 receives the setting of the task performed on the workspace from the work requester terminal 50, and accepts the confirmation operation of registering the utterance text of the restored data as an utterance example. Further, the communication interface 11 distributes the mask data allocated to the worker terminals 30A to 30N to the worker terminals 30A to 30N, and receives the restored data in which the mask portion of the mask data is restored.
- the storage unit 13 corresponds to hardware that stores data used in various programs such as an OS (Operating System) executed by the control unit 15 and a workspace providing program corresponding to the above-mentioned workspace providing service.
- OS Operating System
- the storage unit 13 can correspond to the auxiliary storage device in the development support device 10.
- HDD Hard Disk Drive
- optical disk SSD (Solid State Drive), etc.
- flash memory such as EPROM (Erasable Programmable Read Only Memory) can also be used as an auxiliary storage device.
- the storage unit 13 stores the task data 13A, the restoration data 13B, and the corpus data 13C as an example of the data used in the program executed by the control unit 15.
- the storage unit 13 can store various types of data.
- the storage unit 13 can store not only the account information of the worker and the work requester, but also the development support program corresponding to the above-mentioned development support service and the data used by the development support program.
- the task data 13A is data related to a task performed on the above workspace.
- the "task” here refers to the work that the work requester imposes on the worker.
- the task data 13A may be data associated with each task, for example, the number of utterance cases for which collection is requested in the domain of the original data 13A1 or the semantic symbol for each utterance semantic analysis.
- the original data 13A1 is the source data that is the original of the expansion source.
- the utterance text created via the worker terminal 30 or the work requester terminal 50 before the execution of the above "Masked Data Augmentation" can be used for the original data 13A1.
- the original data 13A1 the utterance text recorded in the log of the dialogue system or the dialogue agent can also be used.
- the upper predetermined number of the N-best results obtained by performing voice synthesis on the spoken text of the original data 13A1 and performing voice recognition on the synthesized voice synthesized by voice synthesis is used. be able to.
- the result of translating the utterance text of the original data 13A1 into an arbitrary language different from the language of the utterance text and then retranslating it into the original language can be used.
- the utterance text of the original data 13A1 is input to a paraphrase (sentence with the same meaning but a different expression) language generation model learned in advance by a neural network or the like, and obtained from the language generation model. The output can be used.
- the restored data 13B is data in which the mask portion of the mask data is restored.
- the restoration data 13B is generated as follows when the input for restoring the mask portion of the mask data is received from the worker terminal 30 by the restoration reception unit 15D described later. Specifically, the restoration data is generated by combining the text for which the restoration input is received by the restoration reception unit 15D, which will be described later, with the text other than the mask portion. Further, when the restoration input is accepted, not only the mask portion but also the editing of characters or character strings other than the mask portion may be further accepted.
- the corpus data 13C is data in which utterance examples corresponding to the utterance texts of the restored data 13B are corpus-ized.
- a list of utterance texts of the restored data 13B is displayed on the work requester terminal 50. Confirmation is displayed.
- the registration operation of registering the utterance text of the restored data 13B as the utterance case is accepted via the work requester terminal 50 in which such confirmation display is performed, the utterance case and the meta information accompanying it, for example, the correct answer of the semantic symbol
- the label is additionally registered by the registration unit 15F described later. At the time of the above registration operation, any of the list of utterance texts of the restored data 13B may be edited.
- the control unit 15 is a processing unit that controls the entire development support device 10.
- control unit 15 can be implemented by a hardware processor such as a CPU (Central Processing Unit) or an MPU (Micro Processing Unit).
- a CPU and an MPU are illustrated as an example of a processor, but it can be implemented by any processor regardless of a general-purpose type or a specialized type.
- control unit 15 may be realized by hard-wired logic such as ASIC (Application Specific Integrated Circuit) or FPGA (Field Programmable Gate Array).
- the control unit 15 virtually realizes the following processing unit by deploying the above workspace providing program on the work area of a RAM (Random Access Memory) implemented as a main storage device (not shown).
- FIG. 1 shows a functional unit corresponding to the above-mentioned workspace providing program
- the above-mentioned workspace providing program includes a functional unit corresponding to the packaged software packaged in the above-mentioned development support program. It doesn't matter.
- control unit 15 includes an acquisition unit 15A, a mask unit 15B, an allocation unit 15C, a restoration reception unit 15D, a progress management unit 15E, and a registration unit 15F.
- the acquisition unit 15A is a processing unit that acquires the original data 13A1.
- the acquisition unit 15A when the task data 13A is stored in the storage unit 13, the task execution request is made from the work requester terminal 50, or the time reaches a predetermined regular time, the acquisition unit 15A The original data 13A1 is acquired from the storage unit 13. At this time, the acquisition unit 15A can extract the original data 13A1 stored in the storage unit 13 that satisfies the following conditions. For example, the acquisition unit 15A can extract the original data 13A1 including the content words having a low frequency of appearance among the original data 13A1 stored in the storage unit 13 in the utterance text.
- the acquisition unit 15A obtains the original data 13A1 including the utterance text of the grammatical series whose appearance frequency is low among the original data 13A1 stored in the storage unit 13, for example, "make it ⁇ of ⁇ ". It can also be extracted. Further, the acquisition unit 15A can also extract the original data 13A1 including the sentence length, for example, the utterance text in which the number of characters of the character string constituting the sentence is low, among the original data 13A1 stored in the storage unit 13. ..
- low frequency refers to a case where the frequency is below a predetermined threshold value or the frequency rank is a lower predetermined number.
- the acquisition unit 15A may use the above extraction conditions under the AND condition or the OR condition.
- the mask unit 15B is a processing unit that masks a part of the spoken text of the original data.
- the mask unit 15B masks a part of the utterance text for each utterance text of the original data acquired by the acquisition unit 15A.
- the following methods can be used for the "mask" referred to here.
- the mask unit 15B can mask a predetermined part of speech, a predetermined number of content words, or a predetermined dependency unit in the utterance text of the original data.
- the mask unit 15B can mask a character string corresponding to a predetermined number of characters in the utterance text of the original data.
- the mask unit 15B can randomly mask a predetermined number of characters in the utterance text of the original data.
- the mask unit 15B can mask a prefix, a so-called prefix, or a suffix, a so-called suffix, in the utterance text of the original data.
- the mask methods listed here may be used under the AND condition or under the OR condition.
- the mask portion 15B does not necessarily have to make the mask portion invisible.
- the mask unit 15B can be visually recognized by blurring the characters corresponding to the mask portion, setting a limit on the display time of the mask portion, and moving the utterance text of the original data at a predetermined speed to display it. It may be to reduce the sex.
- the allocation unit 15C is a processing unit that allocates mask data.
- the allocation unit 15C can allocate the mask data generated by the mask unit 15B according to the number of workers corresponding to the worker terminals 30A to 30N. Further, the allocation unit 15C changes the number of master data to be allocated to the worker terminals 30A to 30N according to the skill score and level of the worker when the skill data in which the skill of the worker is indexed can be referred to. be able to. For example, the allocation unit 15C allocates more mask data as the worker's skill score or level increases, while assigns less mask data as the worker's skill score or level decreases. The same mask data may be duplicated and assigned to the plurality of worker terminals 30, or the same mask data may be prohibited from being assigned to the plurality of worker terminals 30.
- the allocation unit 15C starts distribution of the mask data assigned to the worker terminal 30.
- the allocation unit 15C distributes the mask data assigned to the worker terminal 30 one by one according to the instruction of the progress management unit 15E described later.
- the mask data is distributed one by one, but all the mask data assigned to the worker terminal 30 can be distributed at once.
- the restoration reception unit 15D is a processing unit that accepts restoration of the mask portion of the mask data.
- the restoration reception unit 15D accepts the restoration of the mask data from the worker terminal 30 for the mask portion.
- the worker does not necessarily have the skill to restore the masked portion of all the mask data. This is because not only workers who are good at expanding variations but also workers who are not good at expanding variations may be included. Therefore, the restoration reception unit 15D can also accept the input of the restoration NG from the worker terminal 30 from the aspect of suppressing the influence on the progress of other work by stopping the progress in some work.
- the restoration reception unit 15D does not immediately generate the restoration data even if the restoration of the mask portion of the mask data is received from the worker terminal 30. That is, the restoration reception unit 15D generates the restoration data only when the restored text satisfies a predetermined constraint condition.
- the restoration reception unit 15D permits the generation of restoration data when the number of characters in the restored text is different from the number of characters in the text in the mask portion. As a result, the generation of the restored data is prohibited when the number of characters is the same, and as a result, the possibility of acquiring an utterance case different from the utterance text of the original data can be increased.
- the restoration reception unit 15D may allow the restoration data to be generated when the restored text does not contain a predetermined prohibited character. For example, when the mask portion of the mask data M2 shown in FIG. 2B is restored, the use of the Chinese character “Kyo” included in the text of the mask portion is prohibited. This can increase the possibility that a questioning word different from the word "teach" will be restored.
- the restoration reception unit 15D can also allow the restoration data to be generated when the editing distance between the restored text and the text in the mask portion is equal to or greater than the threshold value. As a result, the use of the same word or phrase as the mask portion is prohibited, and as a result, the possibility of obtaining an utterance case different from the utterance text of the original data can be increased.
- the restoration reception unit 15D can also allow the restoration data to be generated when the restored text differs from the text format of the mask portion. For example, when the mask part is colloquial, the use of literary language is permitted at the time of restoration, while the use of colloquialism is prohibited.
- the restoration reception unit 15D may also allow the restoration data to be generated when the restored text is in a predetermined dialect. For example, when the mask part is colloquial, the use of a dialect different from the dialect of the mask part is permitted at the time of restoration, while the use of the same dialect as the mask part is prohibited. This also increases the possibility of acquiring an utterance case different from the utterance text of the original data.
- the constraints listed here may be used under the AND condition or the OR condition.
- the restoration reception unit 15D can also use the error fluctuation of voice recognition by voice input.
- the restored data can be generated by using the voice recognition result obtained by voice recognition by either the worker terminal 30 or the restoration reception unit 15D on the voice of the restored text.
- the restoration reception unit 15D When the restored text satisfies a predetermined constraint condition, the restoration reception unit 15D generates restoration data by combining the text that has received the restoration input and the text other than the mask portion. At the time of restoration, not only the mask portion but also characters or character strings other than the mask portion may be accepted for editing. Further, when the utterance text of the newly generated restored data overlaps with the utterance text of the restored data stored in the storage unit 13, only one of the registrations can be enabled. At this time, from the aspect of managing the number of utterance cases created for each worker, both workers of the restored data may be registered.
- the progress management unit 15E is a processing unit that manages the progress of the task.
- the progress management unit 15E monitors the progress of information restoration for each worker terminal 30 after the distribution of mask data is started by the allocation unit 15C. Specifically, the progress management unit 15E determines whether or not the restoration of the mask portion has been accepted from the worker terminal 30. At this time, if the restoration data of the mask portion is not accepted, the progress management unit 15E further determines whether or not the input of the restoration NG is accepted from the worker terminal 30. At this time, when the input of the restoration NG is received from the worker terminal 30, the progress management unit 15E gives an instruction to the allocation unit 15C to allocate the mask data being restored to the other worker terminal 30.
- the progress management unit 15E gives an instruction to the allocation unit 15C to distribute the next mask data to the worker terminal 30 that has received the input of the restoration NG.
- the progress management unit 15E has passed a predetermined time, for example, 1 minute or 5 minutes since the mask data was delivered to the worker terminal 30. Judge whether or not. Then, when the predetermined time has elapsed, the progress management unit 15E gives an instruction to assign the mask data being restored to the other worker terminal 30 to the allocation unit 15C, and accepts the input of the restoration NG for the next mask data. An instruction to be delivered to the worker terminal 30 is given to the allocation unit 15C.
- the progress management unit 15E monitors the task end condition after the mask data distribution is started by the allocation unit 15C. As an example, the progress management unit 15E determines the end of the task when the variation satisfies a predetermined condition, for example, when the utterance text of the restored data 13B stored in the storage unit 13 reaches a predetermined number. In this case, the progress management unit 15E confirms and displays the list of utterance texts of the restored data 13B stored in the storage unit 13 on the work requester terminal 50.
- the registration unit 15F is a processing unit that registers utterance cases in the storage unit 13.
- the registration unit 15F accepts a registration operation for registering the utterance text of the restored data 13B as an utterance case via the work requester terminal 50
- the utterance case and the meta information associated therewith are stored in the corpus of the storage unit 13. It is additionally registered in the data 13C.
- any of the list of utterance texts of the restored data 13B may be edited.
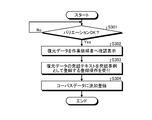
- FIG. 3 is a flowchart showing the procedure of mask processing. This process is performed only as an example when the task data 13A is saved in the storage unit 13, a task execution request is made from the work requester terminal 50, or the time reaches a predetermined regular time. Be told.
- the acquisition unit 15A acquires the original data 13A1 from the storage unit 13 (step S101). Subsequently, the mask unit 15B masks a part of the utterance text for each utterance text of the original data acquired in step S101 (step S102).
- the allocation unit 15C allocates the mask data generated in step S102 to the worker terminal 30 (step S103). Then, the allocation unit 15C starts distribution of the mask data assigned to the worker terminal 30 in step S103 (step S104).
- FIG. 4 is a flowchart showing the procedure of the restoration reception process. As an example, this process is performed in parallel for each worker terminal 30 when the process of step S104 shown in FIG. 3 is executed.
- the restoration reception unit 15D determines whether or not the restored text satisfies a predetermined constraint condition. (Step S202).
- the restoration reception unit 15D combines the text that has received the restoration input and the text other than the mask portion to generate the restoration data. Generate (step S203). Then, the progress management unit 15E gives an instruction to distribute the next mask data to the worker terminal 30 to the allocation unit 15C (step S207), and returns to the process of step S201. If the restored text does not satisfy the predetermined constraint condition (step S202No), the restored data is not generated and the process returns to the process of step S201.
- the progress management unit 15E further determines whether or not the input of the restoration NG is accepted from the worker terminal 30 (step S204). ).
- the progress management unit 15E has a predetermined time, for example, 1 minute or 5 after the mask data is delivered to the worker terminal 30. It is determined whether or not the minutes have passed (step S205).
- step S205 when the predetermined time has elapsed (step S205Yes), the progress management unit 15E gives an instruction to the allocation unit 15C to allocate the mask data being restored to the other worker terminal 30 (step S206). Further, the progress management unit 15E gives an instruction to distribute the next mask data to the worker terminal 30 that has received the input of the restoration NG to the allocation unit 15C (step S207), and shifts to the process of step S201. If the predetermined time has not elapsed (step S205 No), the process returns to step S201.
- step S204 when the input of the restoration NG is received from the worker terminal 30 (step S204Yes), the progress management unit 15E gives an instruction to assign the mask data being restored to the other worker terminal 30 (step S206). ). Further, an instruction to distribute the next mask data to the worker terminal 30 that has received the input of the restoration NG is given to the allocation unit 15C (step S207), and the process proceeds to the process of step S201.
- FIG. 5 is a flowchart showing the procedure of the registration process. This process is performed as an example only when the process of step S104 shown in FIG. 3 is executed. As shown in FIG. 5, the progress management unit 15E determines whether or not the variation satisfies a predetermined condition, for example, whether or not the utterance text of the restored data 13B stored in the storage unit 13 has reached a predetermined number. (Step S301).
- a predetermined condition for example, whether or not the utterance text of the restored data 13B stored in the storage unit 13 has reached a predetermined number.
- the progress management unit 15E confirms and displays the list of utterance texts of the restored data 13B stored in the storage unit 13 on the work requester terminal 50 (step S302).
- the registration unit 15F accepts a registration operation for registering the utterance text of the restored data 13B as an utterance example via the work requester terminal 50 (step S303). After that, the registration unit 15F additionally registers the utterance case and the meta information accompanying the utterance case in the corpus data 13C of the storage unit 13 (step S304), and ends the process shown in FIG.
- step S301Yes If the predetermined condition regarding the variation is satisfied (step S301Yes), or if the process shown in FIG. 5 is completed, the process shown in FIG. 4 can also be completed.
- the development support device 10 accepts "Masked Data” for receiving information restoration for information loss of mask data obtained by masking a part of original data 13A1. Perform "Augmentation”.
- an example in which the utterance case created by each worker is kept private to other workers is given, but in a situation where the bias can be reduced, the utterance case is given. May be disclosed to other workers. For example, when a predetermined time has passed from the time when the utterance case creation work is started, or when the number of utterance cases created by all the workers or the worker with the lowest number of created utterance cases reaches the predetermined number. The utterance text of the restored data can be disclosed to other workers.
- the full text of the utterance text of the restored data does not necessarily have to be published.
- the above publication can be performed by narrowing down the content words that are not included in the restored data of the worker at the publication destination. By exposing a part or all of the utterance text of the restored data to other workers in this way, the imagination of other workers can be stimulated.
- the user simulator refers to a user-like behavior, in this example, a program designed to output the characters or words of the mask part by inputting the mask data.
- the user simulator can be created through the restored data stored in the storage unit 13, the logs of the dialogue system and the dialogue agent, the learned language model, and the like. While the cost of the worker increases in proportion to the amount of work, the virtual worker is realized on the computer, so once the user simulator is generated, the cost is low and the amount of utterance cases that cannot be manually generated is generated. can do.
- FIG. 6 is a diagram showing an example of creating a relay-style utterance case.
- FIG. 6 shows an example in which the relays are in the order of the worker W1, the worker W2, and the worker W3 as an example.
- the mask data "tomorrow " generated from the original data "confirm tomorrow's schedule” is displayed on the worker terminal 30 of the worker W1.
- the restoration data "check tomorrow's calendar” is generated.
- the mask data "tomorrow's calendar " is generated.
- the mask data "Tomorrow's calendar " is delivered to the worker terminal 30 of the worker W2 and the worker terminal 30 of the worker W3.
- the restoration data "Show me the calendar of tomorrow" is generated.
- the restoration data "display tomorrow's calendar” is generated.
- FIG. 6 shows an example in which the mask data “Tomorrow's calendar ...” created from the restored data of the worker W1 is relayed to the worker W2 and the worker W3.
- the exchange of mask data is not limited to one time.
- the mask data "Show me tomorrow's calendar” of the worker W2 is further created to create another worker, for example, a worker other than the workers W1 to W3.
- it can be relayed to the worker W1 or the worker W3.
- the mask data "display tomorrow " is further created from the restored data "display tomorrow's calendar” of the worker W3, and other workers, for example, workers other than workers W1 to W3, or work. It is also possible to relay to the person W1 or the worker W2.
- FIG. 6 shows an example in which only the worker is included, the above virtual worker may be included as a part of the relay. If the utterance case deviates from the domain of the semantic symbol in the middle of this re-relay, it is treated as a negative case and discarded. In particular, in the case of a virtual worker, it is possible to give many negative examples, so some candidates may be output in advance.
- the mask data is presented to the worker terminal 30 when the utterance example is created, but other information can also be presented to the worker terminal 30. For example, thinking of utterances directly from semantic symbols requires strong imagination, so it can be expected to stir the imagination of workers by giving various contexts.
- the dialogue log recorded in the dialogue system or dialogue agent it is also possible to create a context using the dialogue log recorded in the dialogue system or dialogue agent. For example, if there is an utterance case belonging to a semantic symbol, for example, a dialogue log containing an utterance asking the dialogue system or a dialogue agent for the weather, the dialogue log in which the utterance is deleted can be displayed as a context. This makes it possible, for example, to present the dialogue system or dialogue agent with the utterances before and after the utterance asking for the weather to imagine the deleted utterance.
- the development support device 10 of the present disclosure implements an evaluation method of a set of registered utterance cases, for example, utterance cases of corpus data, or utterance cases of corpus data and restored data, and feeds back the evaluation results to the operator. By doing so, high-quality data can be collected.
- the utterance case is encoded by a predetermined method to convert it into a numerical expression such as a vector expression, and the numerical expression is visualized.
- Bag-of-Words using words or characters in the sentence of the utterance case can be mentioned.
- the value of the element corresponding to the vocabulary appearing in the utterance case is set to 1, while appearing in the utterance case.
- Set the value of the element corresponding to the non-vocabulary to 0.
- SWEM Simple Word-Embedding-based Methods
- SWEM Simple Word-Embedding-based Methods
- This makes it possible to map words and sentences to fixed-length vectors using a neural network. Since this neural network is pre-learned based on a large-scale corpus, it is possible to capture features such as words that easily co-occur.
- As a further encoding method it is possible to use the output obtained from a specific layer of the neural network by inputting the utterance example to the input layer of the trained neural network.
- layers composed of neurons are stacked in multiple stages, and a specific layer of these layers, for example, one layer before the final layer, can be used. As a result, the expression according to the task can be acquired.
- FIG. 7 is a diagram showing an example of a visualization map.
- utterance examples included in the corpus data 13C are plotted with cross marks on a two-dimensional visualization map.
- a convex hull including an utterance case having the semantic symbol label “DG-4” is displayed with a solid line
- a convex hull including the utterance case having the semantic symbol label “DG-7” is displayed.
- the hull is displayed as a broken line.
- the visualization map shown in FIG. 7 includes an utterance example in which registration is performed with a multi-label of the semantic symbol label “DG-4” and the semantic symbol label “DG-7”.
- the development support device 10 of the present disclosure inputs the correct answer label of the meaning symbol given to the utterance case and the utterance case into the utterance meaning analysis module for each utterance case included in the corpus data 13C. It is possible to display the collation result with the prediction label of the predicted meaning symbol. As an example, the collation result of the correct label and the predicted label can be displayed as a Confusion Matrix.
- FIG. 8 is a diagram showing an example of Confusion Matrix.
- FIG. 8 shows an example in which four semantic symbols S1 to S4 are defined in the utterance semantic analysis module. Further, the vertical axis of the Confusion Matrix shown in FIG.
- utterance 8 is arranged with the correct label of the semantic symbol, while the horizontal axis is arranged with the predicted label of the semantic symbol predicted by the utterance semantic analysis module. Further, as shown in the legend shown in FIG. 8, in the element of Confusion Matrix, the aggregated value of the utterance cases belonging to the element is displayed, and as the number of utterance cases increases, it is displayed in a darker fill.
- utterance examples in which the correct answer label of the semantic symbol and the predicted label of the semantic symbol match are the 1st row, 1st column, 2nd row, 2nd column, 3rd row, 3rd column, and 4th row, 4th row of the Confusion Matrix.
- the aggregated value is predetermined among the elements of incorrect answers other than the 1st row, 1st column, 2nd row, 2nd column, 3rd row, 3rd column, and 4th row, 4th column, that is, the elements in which the correct answer label and the predicted label do not match. It can be grasped that the prediction accuracy of the utterance meaning analysis module is lowered in the elements that are equal to or more than the threshold value of, for example, the elements in the 1st row and the 4th column displayed by the dark hatching.
- the label of the utterance case in which the correct label of the semantic symbol is S1 is erroneously predicted as S4.
- the utterance case located within a predetermined distance from the boundary between the domain of the semantic symbol "S1" and the domain of the semantic symbol "S4" can be manually or automatically set as the extraction target by the acquisition unit 15A.
- the boundary of the domain of the semantic symbol can be further clarified. That is, for semantic symbols in which domain boundaries overlap or approach each other, by setting utterance cases near the domain boundaries as extraction targets by the acquisition unit 15A, the number of samples for determining the boundary separation surface is increased. Can be made to. As a result, the model used by the utterance semantic analysis module is relearned. By re-visualizing the prediction results of the utterance semantic analysis module in which the model has been relearned in this way, duplication of utterance cases can be reduced, and the possibility of having a distance with a sufficient margin can be increased. ..
- an utterance case that does not belong to any of the semantic symbols and is located within a predetermined distance from the domain boundary of a plurality of semantic symbols can be intentionally registered as a negative utterance case. For example, by adding a case that is similar in notation but has a completely different meaning, the model can be trained to play the negative example from the prediction. Further, for each worker terminal 30, the utterance example corresponding to the restored data generated from the text restored by the worker terminal 30 can be mapped on the domain of the semantic symbol. This makes it easier to understand what kind of utterance data is missing.
- utterance cases within a predetermined distance from the boundary can be detected, and the detected utterance case can be set as an extraction target by the acquisition unit 15A, relabeled, and the domain of the semantic symbol. Will be able to redesign.
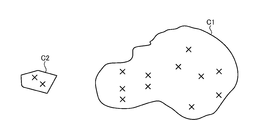
- FIG. 9 is a diagram showing an example of a cluster.
- the result of clustering the utterance cases having the same correct label of the semantic symbol is visualized on the map.
- the utterance case in which the correct label of the semantic symbol is the same is divided into the clusters C1 and the clusters C2 in the excursion, it contributes to lowering the performance of the discriminative model. Therefore, the following processing can be performed from the aspect of filling the gap in the excursion.
- the development support device 10 of the present disclosure can automatically set a pair of utterance cases having the shortest distance between clusters of excursions as extraction targets by the acquisition unit 15A. It is also possible to manually accept the operation of highlighting the pair of utterance cases on the work requester terminal 50 or the like and setting the extraction target by the acquisition unit 15A. Further, the development support device 10 of the present disclosure uses the pre-learning type language model and the already registered corpus data 13C to generate a predetermined number of utterance cases. From the utterance texts generated in this way, utterance cases within a predetermined distance from the boundary of each cluster of excursions can be extracted and displayed on the worker terminal 30 or the work requester terminal 50.
- the extracted utterance case can be set as the extraction target by the acquisition unit 15A, or the work requester terminal 50 can accept the setting of the correct or negative correct label for the utterance case.
- FIG. 10 is a diagram showing a modified example of the case.
- FIG. 10 shows a list of tasks, original data, masks and restored contents.
- the utterance text is used as the original data corresponding to the case.
- the mask data in which the linguistic information of the utterance text of the original data is masked is generated, the linguistic information is restored via the worker terminal 30.
- the dialogue text is used as the original data corresponding to the case.
- the utterance text of a specific turn the utterance text of a specific role, or the mask data in which these substrings are masked is generated among the utterance texts included in the dialogue text of the original data, from the flow of the entire dialogue.
- the utterance of a specific turn or a specific role is restored via the worker terminal 30.
- the task is image classification, the image is used as the original data corresponding to the case.
- the drawing information for interpolating the mask portion via the drawing software or the like executed by the worker terminal 30, for example, the restoration of the line drawing information is performed. Will be done.
- the images or posture positions of a predetermined number of frames included in the motion are used as the original data corresponding to the case.
- the restoration is performed by interpolating the image and the posture motion of the frame corresponding to the mask portion via the worker terminal 30.
- route information including series coordinate data such as sensor data is used as original data corresponding to the case.
- the partial route corresponding to the mask portion is restored via the worker terminal 30.
- FIG. 11 is a diagram showing an example of an extension method of a case in a dialogue task.
- FIG. 11 shows the original data, the mask data, and the restored data in the case of expanding the variation of the case in the dialogue task.
- mask data is generated by masking the utterance texts of a specific turn, for example, the first turn and the third turn among the dialogue texts of the original data.
- the restoration data is generated by accepting the restoration of the first turn and the third turn.
- the example of masking the utterance text of a specific turn is given here, it may be possible to mask a part of the utterance text of a specific turn, for example, a character, a character string, a word or a phrase, or a person or a system. Only one of the rolls can be masked.
- FIG. 12 is a diagram showing an example of an extension method of a case in the image classification task.
- FIG. 12 shows the original data, the mask data, and the restored data in the case of expanding the variation of the case in the image classification task.
- mask data is generated by masking a predetermined region of the dog image of the original data, for example, a partial region including eyes and ears identified from facial feature points.
- restoration data is generated by accepting restoration of the dog's eyes and ears.
- FIG. 13 is a diagram showing an example of an extension method of a case in the motion classification task.
- FIG. 13 shows the original data, the mask data, and the restored data in the case of expanding the variation of the case in the motion classification task.
- the second to fourth frames are passed through the worker terminal 30.
- a restoration is performed that interpolates the image of. Due to these information loss and information recovery errors, the variation of motion images belonging to the common class "punch" can be extended.
- punch is taken as an example, but any motion such as jumping, running, ascending / descending, kicking, dashing, viewing a wristwatch, and taking out a smartphone may be used.
- FIG. 14 is a diagram showing an example of an extension method of a case in the path search task.
- FIG. 14 shows the original data, the mask data, and the restored data in the case of expanding the variation of the case in the path search task.
- mask data is generated by masking a part of the route information of the original data.
- the restoration data is generated by accepting the restoration of the partial route corresponding to the mask portion via the worker terminal 30. Due to these information loss and information restoration errors, variations of common route information can be extended.
- each component of each device shown in the figure is a functional concept, and does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of the device is functionally or physically dispersed / physically distributed in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
- FIG. 15 is a hardware configuration diagram showing an example of a computer 1000 that realizes the functions of the development support device 100.
- the computer 1000 includes a CPU 1100, a RAM 1200, a ROM (Read Only Memory) 1300, an HDD (Hard Disk Drive) 1400, a communication interface 1500, and an input / output interface 1600. Each part of the computer 1000 is connected by a bus 1050.
- the CPU 1100 operates based on the program stored in the ROM 1300 or the HDD 1400, and controls each part. For example, the CPU 1100 expands the program stored in the ROM 1300 or the HDD 1400 into the RAM 1200 and executes processing corresponding to various programs.
- the ROM 1300 stores a boot program such as a BIOS (Basic Input Output System) executed by the CPU 1100 when the computer 1000 is started, a program that depends on the hardware of the computer 1000, and the like.
- BIOS Basic Input Output System
- the HDD 1400 is a computer-readable recording medium that non-temporarily records a program executed by the CPU 1100 and data used by such a program.
- the HDD 1400 is a recording medium for recording the development support program according to the present disclosure, which is an example of the program data 1450.
- the communication interface 1500 is an interface for the computer 1000 to connect to an external network 1550 (for example, the Internet).
- the CPU 1100 receives data from another device or transmits data generated by the CPU 1100 to another device via the communication interface 1500.
- the input / output interface 1600 is an interface for connecting the input / output device 1650 and the computer 1000.
- the CPU 1100 receives data from an input device such as a keyboard or mouse via the input / output interface 1600. Further, the CPU 1100 transmits data to an output device such as a display, a speaker, or a printer via the input / output interface 1600. Further, the input / output interface 1600 may function as a media interface for reading a program or the like recorded on a predetermined recording medium (media).
- the media is, for example, an optical recording medium such as a DVD (Digital Versatile Disc) or PD (Phase change rewritable Disk), a magneto-optical recording medium such as an MO (Magneto-Optical disk), a tape medium, a magnetic recording medium, or a semiconductor memory.
- an optical recording medium such as a DVD (Digital Versatile Disc) or PD (Phase change rewritable Disk)
- a magneto-optical recording medium such as an MO (Magneto-Optical disk)
- a tape medium such as a magnetic tape
- magnetic recording medium such as a magnetic tape
- semiconductor memory for example, an optical recording medium such as a DVD (Digital Versatile Disc) or PD (Phase change rewritable Disk), a magneto-optical recording medium such as an MO (Magneto-Optical disk), a tape medium, a magnetic recording medium, or a semiconductor memory.
- the CPU 1100 of the computer 1000 executes each function unit included in the control unit 15 by executing the development support program loaded on the RAM 1200.
- the HDD 1400 stores the development support program related to the present disclosure and the data in the content storage unit 121.
- the CPU 1100 reads the program data 1450 from the HDD 1400 and executes the program, but as another example, these programs may be acquired from another device via the external network 1550.
- the present technology can also have the following configurations.
- the mask unit performs mask processing on a predetermined part of speech or a predetermined dependency unit in the utterance text of the original data.
- (4) The mask unit performs mask processing on a predetermined number of content words in the spoken text of the original data.
- the mask unit masks a predetermined number of characters in the utterance text of the original data.
- the mask unit masks the prefix or suffix of the utterance text of the original data.
- the restoration reception unit permits the registration of the utterance case based on the input in the corpus when the text restored based on the input satisfies a predetermined constraint condition.
- the restoration reception unit permits the registration of the utterance case based on the input to the corpus.
- the restoration reception unit permits the registration of the utterance case based on the input in the corpus.
- the information processing device according to (7) above. (10) When the editing distance between the text restored based on the input and the text of the mask portion is equal to or greater than the threshold value, the restoration reception unit permits registration of the utterance case based on the input in the corpus. The information processing device according to (7) above. (11) When the colloquial or literary style of the text restored based on the input is different from the style of the mask portion, the restoration reception unit permits the registration of the utterance case based on the input in the corpus. The information processing device according to (7) above.
- a conversion unit that converts utterance cases registered in the corpus into numerical expressions, A visualization unit for visualizing the utterance example by plotting it on a map having a predetermined number of dimensions based on the numerical representation converted by the conversion unit is further provided.
- the visualization unit visualizes the domain of the meaning symbol by displaying the convex hull of the utterance case in which the correct answer label is common based on the correct answer label of the meaning symbol given to the utterance case.
- the visualization unit further visualizes utterance cases located within a predetermined distance from the domain boundary of the semantic symbol.
- the acquisition unit acquires utterance cases located within a predetermined distance from the domain boundary of the semantic symbol as the original data.
- a visualization unit that visualizes the collation result between the predicted label of the semantic symbol predicted by inputting the utterance case registered in the corpus into the utterance semantic analysis module and the correct answer label of the semantic symbol to which the utterance case belongs. Further prepare, The information processing device according to (7) above.
- the collation result is displayed as a Confusion Matrix. The information processing device according to (16) above.
- the acquisition unit selects a combination in which the prediction label and the correct answer label do not match and the aggregated value of the utterance case is equal to or more than a predetermined threshold value.
- Acquire the corresponding utterance case as the original data The information processing device according to (17) above.
- Get the original data Mask processing is performed on a part of the original data. Accepts the input to restore the mask part of the mask data obtained by the mask processing.
- Get the original data Mask processing is performed on a part of the original data. Accepts the input to restore the mask part of the mask data obtained by the mask processing.
- An information processing program that causes a computer to perform processing.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021554871A JPWO2021090681A1 (https=) | 2019-11-07 | 2020-10-21 | |
| US17/767,047 US20220300714A1 (en) | 2019-11-07 | 2020-10-21 | Information processing apparatus, information processing method, and information processing program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019-202727 | 2019-11-07 | ||
| JP2019202727 | 2019-11-07 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021090681A1 true WO2021090681A1 (ja) | 2021-05-14 |
Family
ID=75849761
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/039499 Ceased WO2021090681A1 (ja) | 2019-11-07 | 2020-10-21 | 情報処理装置、情報処理方法及び情報処理プログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220300714A1 (https=) |
| JP (1) | JPWO2021090681A1 (https=) |
| WO (1) | WO2021090681A1 (https=) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018032192A (ja) * | 2016-08-24 | 2018-03-01 | 富士ゼロックス株式会社 | 文書表示装置及びプログラム |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11386354B2 (en) * | 2017-06-16 | 2022-07-12 | Ns Solutions Corporation | Information processing apparatus, information processing method, and program |
| JP7030434B2 (ja) * | 2017-07-14 | 2022-03-07 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 翻訳方法、翻訳装置及び翻訳プログラム |
| JP7124358B2 (ja) * | 2018-03-13 | 2022-08-24 | 富士通株式会社 | 出力プログラム、情報処理装置及び出力制御方法 |
| US11423330B2 (en) * | 2018-07-16 | 2022-08-23 | Invoca, Inc. | Performance score determiner for binary signal classifiers |
| US10607598B1 (en) * | 2019-04-05 | 2020-03-31 | Capital One Services, Llc | Determining input data for speech processing |
| CN112487182B (zh) * | 2019-09-12 | 2024-04-12 | 华为技术有限公司 | 文本处理模型的训练方法、文本处理方法及装置 |
| KR102617753B1 (ko) * | 2020-10-26 | 2023-12-27 | 삼성에스디에스 주식회사 | 텍스트 데이터 증강 장치 및 방법 |
-
2020
- 2020-10-21 WO PCT/JP2020/039499 patent/WO2021090681A1/ja not_active Ceased
- 2020-10-21 JP JP2021554871A patent/JPWO2021090681A1/ja not_active Ceased
- 2020-10-21 US US17/767,047 patent/US20220300714A1/en not_active Abandoned
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018032192A (ja) * | 2016-08-24 | 2018-03-01 | 富士ゼロックス株式会社 | 文書表示装置及びプログラム |
Non-Patent Citations (2)
| Title |
|---|
| KAWANO, SEIYA ET AL.: "Study of Data- Expansion-Type Speech Act Classification Methods that Use Conditional Generative Adversarial Networks", IPSJ SIG TECHNICAL REPORT (SLP)., 3 December 2018 (2018-12-03), pages 1 - 6 * |
| YAMAMURA, SHU ET AL.: "Examination of Effectiveness of Data Expansion in Out-of-Domain Speech Detection Using LOF", PROCEEDINGS OF FORUM ON INFORMATION TECHNOLOGY, 20 August 2019 (2019-08-20), pages 181 - 184 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021090681A1 (https=) | 2021-05-14 |
| US20220300714A1 (en) | 2022-09-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2021257649B2 (en) | Vision-based cell structure recognition using hierarchical neural networks and cell boundaries to structure clustering | |
| US11205143B2 (en) | Utilizing a machine learning model and natural language processing to manage and allocate tasks | |
| Gonçalves et al. | Crowdsourcing dialect characterization through Twitter | |
| Mora et al. | Research methodologies, innovations and philosophies in software systems engineering and information systems | |
| US20180189272A1 (en) | Apparatus and method for sentence abstraction | |
| TW201921267A (zh) | 基於機器翻譯的自動生成重述以產生一對話式代理人的方法及系統 | |
| US10902188B2 (en) | Cognitive clipboard | |
| JP2016024759A (ja) | 言語モデル用の学習テキストを選択する方法及び当該学習テキストを使用して言語モデルを学習する方法、並びに、それらを実行するためのコンピュータ及びコンピュータ・プログラム | |
| KR102092426B1 (ko) | 기존의 단일 언어 프로세스로부터 다수의 언어 프로세스를 구축하는 기법 | |
| JP7029351B2 (ja) | Oos文章を生成する方法及びこれを行う装置 | |
| WO2021172548A1 (ja) | ゲームスクリプトの作成を支援するためのシステム及び方法 | |
| JP6429747B2 (ja) | 情報提供装置、情報提供方法および情報提供プログラム | |
| US20240160413A1 (en) | Application Development Platform, Micro-program Generation Method, and Device and Storage Medium | |
| JP6370281B2 (ja) | 情報提供装置、情報提供方法および情報提供プログラム | |
| WO2021090681A1 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| JP7575983B2 (ja) | 対話制御システム、および対話制御方法 | |
| CN119271433A (zh) | 任务处理方法及设备 | |
| JP2017059077A (ja) | 情報提供装置、情報提供方法および情報提供プログラム | |
| JP5722375B2 (ja) | 文末表現変換装置、方法、及びプログラム | |
| JP7382095B1 (ja) | 人工知能を用いたコード生成方法 | |
| CN118211625A (zh) | 基于机器学习模型的内容生成器 | |
| JP6372577B2 (ja) | プレゼンテーション支援方法、プレゼンテーション支援プログラム及びプレゼンテーション支援装置 | |
| JP2006236037A (ja) | 音声対話コンテンツ作成方法、装置、プログラム、記録媒体 | |
| JP7736359B1 (ja) | 情報処理装置、情報処理方法および情報処理プログラム | |
| KR102898292B1 (ko) | 언어 문제 분석을 통한 학습 자료 생성 시스템과 방법 및 이를 위한 컴퓨터 프로그램 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20885523 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021554871 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20885523 Country of ref document: EP Kind code of ref document: A1 |