WO2020261479A1 - 関連文書を検索して表示する方法およびシステム - Google Patents
関連文書を検索して表示する方法およびシステム Download PDFInfo
- Publication number
- WO2020261479A1 WO2020261479A1 PCT/JP2019/025571 JP2019025571W WO2020261479A1 WO 2020261479 A1 WO2020261479 A1 WO 2020261479A1 JP 2019025571 W JP2019025571 W JP 2019025571W WO 2020261479 A1 WO2020261479 A1 WO 2020261479A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- search
- search query
- vector representation
- unit
- vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/338—Presentation of query results
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/38—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/383—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
Definitions
- the present invention relates to a method and a system for searching and displaying related documents.
- Patent Document 1 uses a set (correct answer information) of a set of a search query and a set of correct answer documents that are search target documents conceptually suitable for the search query.
- Patent Document 1 A document concept search method for searching for a search target document that conceptually matches a search query entered by a user is disclosed. According to the document concept search method, the search accuracy can be improved by using the correct answer information.
- the distance between the vectors of two language units that have similar meanings is relatively short.
- the document retrieval method based on the vector representation the document containing more linguistic units having a meaning close to the search query is ranked high. Therefore, according to the document search method, even a document that does not contain any character string that matches the search query may be ranked high in the search results. In such cases, the user may not be able to understand the rationale for the document being searched.
- Patent Document 1 a search target document in which the similarity between the search query concept vector and the concept vector of the search target document is ranked in descending order is displayed as a search result.
- search result no consideration is given to showing the user the rationale for the search results.
- the present invention has been made to solve such a problem, and an object of the present invention is to search and display at least one related document related to a search query from a database in which a plurality of documents are stored.
- the purpose is to show the user the basis of the search result.
- the method of searching and displaying the related document according to the first aspect of the present invention is to search and display at least one related document related to the search query from the database including a plurality of documents.
- the method includes a search step and a display step.
- the search process calculates the distance between the vector representation of each of a plurality of documents and the vector representation of the search query using a vector space that transforms any language unit into a vector representation, and at least one related document depending on the distance.
- the display process displays each of at least one related document.
- the display step includes a step of displaying the language unit in a display mode according to the magnitude of the relationship between the vector representation of each of the plurality of language units included in the related document and the vector representation of the search query.
- the system for searching and displaying related documents searches for and displays at least one related document related to a search query from a plurality of documents.
- the system includes a database and a search processing unit. Multiple documents are stored in the database.
- the search processing unit calculates the distance between the vector representation of each of a plurality of documents and the vector representation of the search query using a vector space that converts any language unit into a vector representation, and at least one association according to the distance.
- Search for documents displays each of at least one related document.
- the search processing unit displays the language unit in a display mode according to the magnitude of the relationship between the vector representation of each of the plurality of language units included in the related document and the vector representation of the search query.
- the language unit and the search query are based on the vector representation of each of the plurality of language units included in the related document and the vector representation of the search query.
- analysis case search system is an example of the system which searches and displays the related document which concerns on embodiment. It is a functional block diagram which shows the structure of the analysis case search system of FIG. It is a figure which shows an example of an analysis report. It is a flowchart for demonstrating the flow of the learning process performed by the learning processing section of FIG. It is a flowchart for demonstrating the flow of the search processing performed by the search processing unit of FIG. It is a figure which shows an example of the search result window displayed on the display by the display control part of FIG. It is a figure which shows the content of the related document displayed in the search result window when the related document of FIG. 6 is selected.
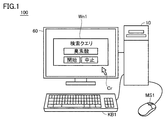
- FIG. 1 is an external view of an analysis case search system 100, which is an example of a system for searching and displaying related documents according to an embodiment.
- the analysis case search system 100 includes a computer 10, a display 60, a keyboard KB1, and a mouse MS1.
- the display 60, the keyboard KB1, and the mouse MS1 are connected to the computer 10.
- the search window Wn1 and the cursor Cr are displayed on the display 60.
- the user operates the cursor by operating the mouse MS1.
- the user inputs a search query into the search window Wn1 by operating the keyboard KB1.
- a user inputs the character string "bromic acid" into the search window Wn1 as a search query in order to search for a document in which an analyzer suitable for bromic acid analysis, an analysis method, analysis conditions, etc. are described. The case is shown.
- FIG. 2 is a functional block diagram showing the configuration of the analysis case search system 100 of FIG. As shown in FIG. 2, the analysis case search system 100 includes a learning processing unit 20 and a search processing unit 40.
- the analysis case search system 100 searches a plurality of documents included in the database 30 based on the search query entered by the user, and searches for related documents related to the search query.
- the database 30 contains document data in the field of analysis cases.
- Document data in the field of analysis cases include, for example, analysis reports, analysis-related articles, and analysis-related patent documents.
- the analysis report is, for example, a document relating to compound analysis as shown in FIG. 3, and includes information regarding an analysis method of a compound to be analyzed, information regarding an analyzer, information regarding analysis conditions, and the like.
- the learning processing unit 20 includes a morphological analysis unit 21, a vector generation unit 23, a relevance learning unit 25, a corpus 27, and a database 30.
- the corpus 27 is a linguistic material in which a large amount of document data related to the field of analysis cases is systematized and accumulated for machine learning using natural language processing.
- the morphological analysis unit 21 subdivides all the document data stored in the corpus 27 into the smallest meaningful linguistic units (morphemes or words) by morphological analysis.
- the vector generation unit 23 generates a vector space that converts a word into a vector expression by machine learning on the result of the morphological analysis by the morphological analysis unit 21.
- the vector space is generated in the process of machine learning for the model formed by the neural network.
- the model for example, a CBOW (Continuous Bag-of-Words) model that infers a central word (target) from a peripheral word (context), or a skip-gram model that infers a peripheral word from a central word. Can be mentioned.
- the vector generation unit 23 generates a word vector which is a semantic expression of a word.
- the vector generation unit 23 generates a sentence vector representing a sentence feature and a document vector representing a document feature from the sum of the feature amounts of words contained in the document and the like.
- the document data may be subdivided in any language unit.
- the type of arbitrary language unit may include letters, morphemes, words, sentences, or paragraphs.
- a sentence is the smallest unit of a meaningful sentence, and a document is composed of multiple sentences. Japanese sentences are separated by punctuation marks, and sentences written in languages such as English are separated by periods (ends).
- the document is divided into sentences by punctuation or period by the above morphological analysis, and a sentence vector is generated based on the above machine learning for the result of the morphological analysis.
- the document may be divided into paragraphs and a sentence vector may be generated for each paragraph.
- the word vector, sentence vector, and document vector generated by the vector generation unit 23 are transmitted to the relevance learning unit 25.
- the relevance learning unit 25 includes a word vector learning unit 25a, a word-sentence learning unit 25b, and a word-document learning unit 25c.
- the word vector learning unit 25a calculates the semantic relevance between words in the vector space and the vector distance between words. To do. Similarly, the word-to-sentence learning unit 25b calculates the degree of association between words and sentences in the vector space and the vector distance, and the word-to-document learning unit 25c calculates the degree of association between words and documents in the vector space and the degree of association between documents. Calculate the vector distance. As the distance between the two vector representations, for example, the cosine distance (cosine similarity) can be mentioned. The smaller the cosine distance between the two vector representations, the closer the meaning of the two linguistic units represented by the two vectors, respectively.
- the calculation results in the word vector learning unit 25a, the word-sentence learning unit 25b, and the word-document learning unit 25c are learned in a database 30 having a multidimensional vector space with each word, sentence, and document as coordinate axes. It is stored with the data as a word vector, a word-sentence vector, and a word-document vector.
- the corpus 27 by accumulating data centered on a specific field such as an analysis example, a vector representation more suitable for that field can be obtained. As a result, it is possible to improve the search accuracy of sentences in a specific field.
- the corpus 27 is composed of an internal corpus that stores in-house reports, technical reports, application news, etc., and an external corpus that collects data published to the outside on the Web such as Wikipedia (registered trademark). You may. Since the external corpus aims to improve the learning of vector representation, it is possible to prevent a decrease in the search speed by excluding the external corpus from the search target.
- FIG. 4 is a flowchart for explaining the flow of learning processing performed by the learning processing unit 20 of FIG. In the following, the step is simply referred to as S.
- the morphological analysis unit 21 divides the document data (learning data) stored in the corpus 27 into a plurality of words by morphological analysis using an existing dictionary in S11.
- the vector generation unit 23 generates a word vector, which is a semantic expression of a word, by machine learning based on the result of morphological analysis in S11, and also generates a sentence vector representing a sentence feature and a sentence.
- a document vector which is a feature vector, is generated from the sum of the features of words contained in the document.
- the word-sentence learning unit 25b calculates the degree of relevance between a word and a sentence in the vector space and the vector distance in S15 following S13.
- the word-document learning unit 25c calculates the degree of relevance between words and documents in the vector space and the vector distance in S17 following S15.
- the relevance learning unit 25 uses the document data of the corpus 27 used as the learning data in S19 following S17, and the calculation results in S13, S15, and S17 as word vectors, word-sentence vectors, and word-document vectors. Store in database 30.
- the search processing unit 40 includes an input unit 1, an analysis unit 11, a feature extraction unit 13, a search unit 15, a display control unit 17, and an output unit 5.
- a search query is input by the user to the input unit 1.
- the search query includes, for example, an analysis-related search keyword, an analysis-related compound name, and an analysis-related analysis object name.
- the input unit 1 includes a keyboard KB1 and a mouse MS1.
- the output unit 5 includes a display 60.
- the analysis unit 11 performs morphological analysis on the search query input to the input unit 1 based on a predefined search dictionary, and divides the search query into words.
- the feature extraction unit 13 calculates the vector representation of the search query using the vector space generated by the learning processing unit 20.
- the search unit 15 searches the database 30 for related documents related to the search query by using the vector representation of the search query acquired from the feature extraction unit 13.
- the search unit 15 searches the database 30 for related documents whose distance from the vector representation of the search query is smaller than the threshold value.
- the search unit 15 outputs to the display control unit 17 the search result in which the related document is ranked higher as the distance between the vector expression of the search query and the vector expression for each of the plurality of searched related documents is shorter. ..
- the display control unit 17 controls the output unit 5 so that related documents are displayed in the order of ranking by the search unit 15.
- the output unit 5 displays information on the display 60 according to the control result of the display control unit 17.
- FIG. 5 is a flowchart for explaining the flow of the search process performed by the search process unit 40 of FIG.
- the input unit 1 accepts a search query input by the user in S21.
- the analysis unit 11 performs morphological analysis on the search query and divides the search query into the smallest unit of morphemes (words).
- the feature extraction unit 13 calculates the vector representation of the search query using the result of the morphological analysis of the search query and the vector space generated by the learning processing unit.
- the search unit 15 searches for related documents related to the search query from the database 30 in which learning data and the like vectorized by learning for the corpus 27 are accumulated.
- a document related to or highly related to the search query is searched.
- a document highly related to a search query is a document obtained by calculating the relationship between a word and a document in advance and having a high degree of relationship between the word and the document in the vector space and a short vector distance.
- the search unit 15 ranks a plurality of searched related documents in ascending order of vector distance.
- the display control unit 17 displays a plurality of searched related documents in the output unit 5 based on the ranking of the search unit 15 in S29 following S27.
- the user can determine the related documents to be browsed according to the order of relevance of each of at least one related documents searched and the search query.
- FIG. 6 is a diagram showing an example of the search result window Wn2 displayed on the display 60 by the display control unit 17 of FIG. As shown in FIG. 6, related documents D1 to D4 are displayed in order along with ranks 1 to 4 in the search result window Wn2. Hyperlinks are set in each of the related documents D1 to D4. In FIG. 6, among the plurality of related documents searched from the database 30, the related document most related to the search query "bromic acid" is D1.
- FIG. 7 is a diagram showing the contents of the related document D1 displayed in the search result window Wn2 when the related document D1 of FIG. 6 is selected.
- the display control unit 17 corresponds to the distance between the vector representation of the search query and the vector representation of the word and the vector representation of the search query for each of the plurality of words included in the related document D1. Then, the word is highlighted by changing the color of the peripheral area of the word in the search result window Wn2.
- the distance between the vector representation of the word contained in the related document D1 and the vector representation of the search query is from the range R1 larger than the distance Ds3, the range R2 larger than the distance Ds2 ( ⁇ Ds3) and less than the distance Ds3, and the distance Ds1 ( ⁇ Ds2). It is roughly divided into four stages: a range R3 having a distance Ds2 or less and a range R4 having a distance Ds1 or less.
- different colors CL1 to CL4 are assigned to the ranges R1 to R4.
- the relationship between each word and the search query may be displayed as a continuous color change (gradation) in the color map CM1.
- the relationship between the word WD5 highlighted in color CL2 and the search query is greater than the relationship between the word highlighted in color CL1 (not shown) and the search query.
- the association between the words WD2, WD4, WD7 highlighted by the color CL3 and the search query is greater than the association between the word WD5 and the search query.
- the association between the words WD1, WD3, WD6, WD8 highlighted by the color CL4 and the search query is greater than the association between the words WD2, WD4, WD7 and the search query.
- the display control unit 17 determines whether or not a selection operation (for example, double-clicking by mouse operation) has been performed on the language unit highlighted in the search result window in S33 following S31. judge.
- a selection operation for example, double-clicking by mouse operation
- the display control unit 17 sets the selected language unit in the search query in S35 and returns the process to S23.
- the user double-clicks the mouse MS1 while the cursor Cr overlaps the peripheral area of the word WD2 in FIG. 7, the word WD2 is set in the search query and the search process from S23 in FIG. 5 starts. Will be done.
- the user can decide a new search query by paying attention to the relevance to the current search query.
- the display control unit 17 determines whether or not the search result window has been closed in S37.
- the search result window is not closed (for example, the button Bn3 in FIG. 7 is pressed) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37) (NO in S37), the display control unit 17 returns the process to S33. When the search result window is closed (YES in S37), the display control unit 17 ends the process.
- the user can confirm the relevance of each of the plurality of words included in the related document D1 to the search query as a difference in highlight color. Even if the related document D1 does not contain a character string that matches the search query, the user can visually grasp the basis for searching the related document D1. In addition, by changing the highlight color of the word according to the distance between the vector representation of each of the plurality of words and the vector representation of the search query, each of the plurality of words included in the searched related document and the search query can be obtained. The relationship with can be shown to the user as a direct relationship independent of other words other than the word.
- Article W i stored in the database 30 can be expressed word wd i, as a set of k by the following equation (1).
- the natural number i is any natural number from 1 to the natural number D (> 1).
- Each of the natural numbers k and t is any natural number from 1 to the natural number N (> 1).
- a plurality of documents stored in the database 30 are expressed as a sentence set W as shown in the following equation (2).
- the distance Ds i between the document Wi and the search query Q is expressed by the following equation (3).
- the function f in equation (3) is a function that returns a vector representation of the arguments.
- Examples of the function f include a Doc2Vec, a K-hot vector, a linear combination of One-hot vectors, a vector representation by counting words, and a topic model.
- Word wd i included in the document W i of Equation (1) in order to determine the contribution to the distance Ds i of t, word wd i from the document W i, the document W i which delete the t, below / t It is defined as in equation (4).
- the distance Ds i, / t between the document Wi, / t and the search query Q is expressed by the following equation (5).
- the contributions Cni , n of the words wd i, t are expressed by the following equation (6).
- FIG. 8 is a diagram showing how each of a plurality of words included in the related document D1 is highlighted by using the contribution of the word as the relationship between the word contained in the related document D1 and the search query.
- the content of the search result window Wn2 of FIG. 8 is the content in which the color map CM1 of the search result window Wn2 of FIG. 7 is replaced with the color map CM2. Other than this, the explanation is not repeated because it is the same.
- the display control unit 17 changes the color of the peripheral area of the word in the search result window Wn2 according to the contribution of the word for each of the plurality of words included in the related document D1. And highlight the word.
- the contributions of the words included in the related document D1 are a range R11 smaller than the contribution Cn1, a range R12 having a contribution Cn1 or more and smaller than the contribution Cn2 (> Cn1), and a contribution Cn3 (contribution Cn2 or more). It is divided into four stages: a range R13 smaller than> Cn2) and a range R14 having a contribution degree Cn3 or more.
- different colors CL1 to CL4 are assigned to the ranges R11 to R14.
- the degree of contribution of a word may be displayed as a continuous color change (gradation) in the color map CM2.
- the highlighted linguistic unit may be something other than a word.
- FIG. 9 is a diagram showing the contents of the related document D1 displayed in the search result window Wn2 when the highlighted language unit is a sentence.
- the color map CM2 shown in FIG. 9 shows the distribution of the contribution of the text.
- the relationship between the sentence ST4 highlighted in color CL2 and the search query is larger than the relationship between the sentence highlighted in color CL1 (not shown) and the search query.
- the relationship between the sentences ST3 and ST6 highlighted by the color CL3 and the search query is larger than the relationship between the sentences ST4 and the search query.
- the relationship between the sentences ST1, ST2, ST5, and ST7 highlighted by the color CL4 and the search query is larger than the relationship between the sentences ST3 and ST6 and the search query.
- FIG. 10 is a diagram showing the contents of the related document D1 displayed in the search result window Wn2 when the highlighted language unit is a paragraph.
- the color map CM2 shown in FIG. 10 shows the distribution of the contribution of paragraphs.
- the association between the paragraph PR3 highlighted in color CL2 and the search query is greater than the association between the paragraph highlighted in color CL1 (not shown) and the search query.
- the association between the paragraph PR1 highlighted in color CL3 and the search query is greater than the association between the paragraph PR3 and the search query.
- the association between paragraph PR2 highlighted in color CL4 and the search query is greater than the association between paragraph PR1 and the search query.
- the language unit highlighted in the search result window Wn2 does not have to be one type, and may be selected from a group consisting of characters, morphemes, words, sentences, paragraphs, and any combination thereof. For example, letters and morphemes may be highlighted linguistic units, or words, sentences, and paragraphs may be highlighted linguistic units.
- FIG. 11 shows an analysis case search when the analysis case search system 100A, which is an example of a system for searching and displaying related documents according to the embodiment, is connected to a plurality of client terminals 80a to 80n via a network 70. It is a functional block diagram which shows the structure of the system 100A.
- the analysis case search system 100A enables a search of an analysis case in response to a request from a user or the like in, for example, an Internet environment, and provides the search result to the user or the like.
- the analysis case search system 100A and a plurality of client terminals 80a to 80n are connected to each other so as to be able to communicate with each other via a network 70 for information communication such as the Internet.
- the analysis case search system 100A and the plurality of client terminals 80a to 80n constitute the client server system 1000.
- the communication unit 61 in the analysis case search system 100A is an interface with the network 70.
- the control unit 65 includes a CPU (Central Processing Unit) and controls the entire analysis case search system 100A including the learning processing unit 20 and the search processing unit 40.
- the memory 67 stores the learning processing program in the learning processing unit 20 described above, the search processing program by the search processing unit 40, and the like.
- the control unit 65 reads these programs from the memory 67 and executes predetermined processing and the like shown in FIGS. 4 and 5.
- the analysis case search system 100A can also be positioned as a server device connected to the network 70. That is, in the analysis case search system 100A, the display process (display process) by the search processing unit 40 is performed on the server side. By connecting an existing client terminal to the server device, it is possible to show the user the grounds for searching the related document through the client terminal.
- the display processing by the search processing unit 40 may be performed on a plurality of client terminals 80a to 80n (client side). By connecting the client terminal to the existing server device, it is possible to show the user the grounds for searching the related document through the client terminal.
- the basis of the search result can be shown to the user.
- the method of searching and displaying the related document is to search and display at least one related document related to the search query from the database including a plurality of documents.
- the method includes a search step and a display step.
- the search process calculates the distance between the vector representation of each of a plurality of documents and the vector representation of the search query using a vector space that transforms any language unit into a vector representation, and at least one related document depending on the distance.
- the display process displays each of at least one related document.
- the display step is a display mode according to the magnitude of the relationship between the language unit and the search query based on the vector representation of each of the plurality of language units included in the related document and the vector representation of the search query. Includes the step of displaying the unit.
- the display mode of the language unit includes the color of the peripheral region of the language unit.
- the relationship between each of the plurality of language units included in the searched related document and the search query is visually grasped as the difference in the color of the peripheral area of the language unit. be able to.
- the magnitude of the relationship between the language unit and the search query is determined by the vector representation of each of the plurality of language units and the vector representation of the search query. The distance.
- the association between each of the plurality of language units contained in the searched related document and the search query is a direct association that does not depend on other language units other than the language unit. It can be shown to the user as a gender.
- the magnitude of the relationship between the language unit and the search query is the degree of contribution of each of the plurality of language units. Contribution is the value obtained by subtracting the distance between the vector representation of the related document and the vector representation of the search query from the distance between the vector representation of the related document and the vector representation of the search query, excluding the language unit from each of at least one related document. Is.
- the relationship between each of the plurality of language units included in the searched related document and the search query is determined by the relationship between the search query and other language units other than the language unit. Can be shown to the user as a comprehensive relevance that reflects.
- the search step is a step of ranking the document higher as the distance between the vector representation of the search query and the vector representation for each of at least one related document is shorter.
- the display step includes displaying at least one related document according to the ranking by the search step.
- the user can determine the related document to be browsed according to the order of relevance of each of at least one related document searched and the search query.
- the type of a plurality of language units is selected from a group consisting of letters, morphemes, words, sentences, paragraphs, and any combination thereof.
- the search step uses at least one language unit as a search query. Includes the process of searching for two related documents.
- the user can determine a new search query by paying attention to the relevance to the current search query.
- the vector space is generated by machine learning that performs natural language processing on the corpus including the database.
- the system for searching and displaying the related document described in paragraph 11 searches and displays at least one related document related to the search query from a plurality of documents.
- the system includes a database and a search processing unit.
- the database contains multiple documents.
- the search processing unit calculates the distance between the vector representation of each of a plurality of documents and the vector representation of the search query using a vector space that converts any language unit into a vector representation, and at least one association according to the distance. Search for documents.
- the search processing unit displays each of at least one related document.
- the search processing unit has a display mode based on the vector representation of each of the plurality of language units included in the related document and the vector representation of the search query according to the magnitude of the relationship between the language unit and the search query. Display language units.
- the degree of relevance between the linguistic unit and the search query based on the vector representation of each of the plurality of linguistic units contained in the related document and the vector representation of the search query is determined.
- the basis of the search result can be shown to the user.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Library & Information Science (AREA)
- Business, Economics & Management (AREA)
- General Business, Economics & Management (AREA)
- Computational Linguistics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/025571 WO2020261479A1 (ja) | 2019-06-27 | 2019-06-27 | 関連文書を検索して表示する方法およびシステム |
| JP2021528777A JP7251625B2 (ja) | 2019-06-27 | 2019-06-27 | 関連文書を検索して表示する方法およびシステム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/025571 WO2020261479A1 (ja) | 2019-06-27 | 2019-06-27 | 関連文書を検索して表示する方法およびシステム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020261479A1 true WO2020261479A1 (ja) | 2020-12-30 |
Family
ID=74060500
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/025571 Ceased WO2020261479A1 (ja) | 2019-06-27 | 2019-06-27 | 関連文書を検索して表示する方法およびシステム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7251625B2 (https=) |
| WO (1) | WO2020261479A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210200948A1 (en) * | 2019-12-27 | 2021-07-01 | Ubtech Robotics Corp Ltd | Corpus cleaning method and corpus entry system |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1145254A (ja) * | 1997-07-25 | 1999-02-16 | Just Syst Corp | 文書検索装置およびその装置としてコンピュータを機能させるためのプログラムを記録したコンピュータ読み取り可能な記録媒体 |
| JP2002222210A (ja) * | 2001-01-25 | 2002-08-09 | Hitachi Ltd | 文書検索システム、文書検索方法及び検索サーバ |
| JP2004334341A (ja) * | 2003-04-30 | 2004-11-25 | Canon Inc | 文書検索装置、文書検索方法及び記録媒体 |
| JP2005092253A (ja) * | 2003-09-11 | 2005-04-07 | Fuji Xerox Co Ltd | 機械学習用データ生成システム及び機械学習用データ生成方法、類似文書対生成システム及び類似文書対生成方法、並びにコンピュータ・プログラム |
| JP2014211870A (ja) * | 2013-04-19 | 2014-11-13 | パロ・アルト・リサーチ・センター・インコーポレーテッドPaloAlto ResearchCenterIncorporated | ビジュアル検索の構築、文書のトリアージおよびカバレッジの追跡 |
| JP2017201478A (ja) * | 2016-05-06 | 2017-11-09 | 日本電信電話株式会社 | キーワード評価装置、類似度評価装置、検索装置、評価方法、検索方法、及びプログラム |
-
2019
- 2019-06-27 WO PCT/JP2019/025571 patent/WO2020261479A1/ja not_active Ceased
- 2019-06-27 JP JP2021528777A patent/JP7251625B2/ja active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1145254A (ja) * | 1997-07-25 | 1999-02-16 | Just Syst Corp | 文書検索装置およびその装置としてコンピュータを機能させるためのプログラムを記録したコンピュータ読み取り可能な記録媒体 |
| JP2002222210A (ja) * | 2001-01-25 | 2002-08-09 | Hitachi Ltd | 文書検索システム、文書検索方法及び検索サーバ |
| JP2004334341A (ja) * | 2003-04-30 | 2004-11-25 | Canon Inc | 文書検索装置、文書検索方法及び記録媒体 |
| JP2005092253A (ja) * | 2003-09-11 | 2005-04-07 | Fuji Xerox Co Ltd | 機械学習用データ生成システム及び機械学習用データ生成方法、類似文書対生成システム及び類似文書対生成方法、並びにコンピュータ・プログラム |
| JP2014211870A (ja) * | 2013-04-19 | 2014-11-13 | パロ・アルト・リサーチ・センター・インコーポレーテッドPaloAlto ResearchCenterIncorporated | ビジュアル検索の構築、文書のトリアージおよびカバレッジの追跡 |
| JP2017201478A (ja) * | 2016-05-06 | 2017-11-09 | 日本電信電話株式会社 | キーワード評価装置、類似度評価装置、検索装置、評価方法、検索方法、及びプログラム |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210200948A1 (en) * | 2019-12-27 | 2021-07-01 | Ubtech Robotics Corp Ltd | Corpus cleaning method and corpus entry system |
| US11580299B2 (en) * | 2019-12-27 | 2023-02-14 | Ubtech Robotics Corp Ltd | Corpus cleaning method and corpus entry system |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7251625B2 (ja) | 2023-04-04 |
| JPWO2020261479A1 (https=) | 2020-12-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3810463B2 (ja) | 情報フィルタリング装置 | |
| US9659084B1 (en) | System, methods, and user interface for presenting information from unstructured data | |
| US20140280314A1 (en) | Dimensional Articulation and Cognium Organization for Information Retrieval Systems | |
| CN120873195A (zh) | 用于基于图谱的动态信息检索及合成的系统和方法 | |
| US20090077056A1 (en) | Customization of search results | |
| Bechhofer et al. | Thesaurus construction through knowledge representation | |
| KR20020075378A (ko) | 개인별 맞춤형 결과 세트를 구축하는 방법 및 시스템 | |
| AU2014205024A1 (en) | Methods and apparatus for identifying concepts corresponding to input information | |
| CN101308498A (zh) | 文本集合可视化系统 | |
| WO2020079752A1 (ja) | 文献検索方法および文献検索システム | |
| Winters et al. | Automatic joke generation: Learning humor from examples | |
| JP5146108B2 (ja) | 文書重要度算出システム、文書重要度算出方法およびプログラム | |
| JP7251625B2 (ja) | 関連文書を検索して表示する方法およびシステム | |
| Rogushina | Use of Semantic Similarity Estimates for Unstructured Data Analysis. | |
| Dipper et al. | ANNIS | |
| Suresh | Natural language processing for internal link optimisation: Automating content relationships for better search engine optimisation | |
| Umber et al. | A Step Towards Ambiguity Less Natural Language Software Requirements Specifications. | |
| CN115827829B (zh) | 一种基于本体的搜索意图优化方法及系统 | |
| Saravanan et al. | Extraction of Core Web Content from Web Pages using Noise Elimination. | |
| Pannu et al. | Explicit user profiles in web search personalisation | |
| Al Masum et al. | Making topic-specific report and multimodal presentation automatically by mining the web resources | |
| Jiang et al. | Personalized recommendation method of E-commerce based on fusion technology of smart ontology and big data mining | |
| JP2017208047A (ja) | 情報検索方法、情報検索装置、及びプログラム | |
| JP2000105769A (ja) | 文書表示方法 | |
| Ibekwe-SanJuan | How thematic maps can assist collection management: A qualitative assessment of Journals' thematic focus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19935587 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021528777 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19935587 Country of ref document: EP Kind code of ref document: A1 |