WO2020203067A1 - 情報処理装置、情報処理方法、およびプログラム - Google Patents
情報処理装置、情報処理方法、およびプログラム Download PDFInfo
- Publication number
- WO2020203067A1 WO2020203067A1 PCT/JP2020/009948 JP2020009948W WO2020203067A1 WO 2020203067 A1 WO2020203067 A1 WO 2020203067A1 JP 2020009948 W JP2020009948 W JP 2020009948W WO 2020203067 A1 WO2020203067 A1 WO 2020203067A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- operating body
- voice recognition
- result
- information processing
- control unit
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 133
- 238000003672 processing method Methods 0.000 title claims description 12
- 238000000034 method Methods 0.000 claims abstract description 83
- 230000008569 process Effects 0.000 claims abstract description 80
- 230000033001 locomotion Effects 0.000 claims abstract description 24
- 238000012545 processing Methods 0.000 claims description 70
- 230000009471 action Effects 0.000 claims description 38
- 239000000284 extract Substances 0.000 claims description 5
- 230000000875 corresponding effect Effects 0.000 description 31
- 238000004891 communication Methods 0.000 description 28
- 230000006870 function Effects 0.000 description 20
- 238000010586 diagram Methods 0.000 description 17
- 230000004044 response Effects 0.000 description 13
- 230000010354 integration Effects 0.000 description 8
- 238000001514 detection method Methods 0.000 description 7
- 230000006399 behavior Effects 0.000 description 6
- 230000005540 biological transmission Effects 0.000 description 6
- 238000011156 evaluation Methods 0.000 description 6
- 230000002596 correlated effect Effects 0.000 description 5
- 238000003058 natural language processing Methods 0.000 description 5
- 230000003287 optical effect Effects 0.000 description 5
- 230000000694 effects Effects 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 3
- 230000001276 controlling effect Effects 0.000 description 3
- 230000007613 environmental effect Effects 0.000 description 3
- 230000001932 seasonal effect Effects 0.000 description 3
- 239000004065 semiconductor Substances 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- 101150012579 ADSL gene Proteins 0.000 description 1
- 102100020775 Adenylosuccinate lyase Human genes 0.000 description 1
- 108700040193 Adenylosuccinate lyases Proteins 0.000 description 1
- 235000006481 Colocasia esculenta Nutrition 0.000 description 1
- 240000004270 Colocasia esculenta var. antiquorum Species 0.000 description 1
- 206010011469 Crying Diseases 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 206010039740 Screaming Diseases 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 238000005452 bending Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 235000019219 chocolate Nutrition 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 230000008921 facial expression Effects 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 210000004705 lumbosacral region Anatomy 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001151 other effect Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000008092 positive effect Effects 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
Images
























Classifications
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B25—HAND TOOLS; PORTABLE POWER-DRIVEN TOOLS; MANIPULATORS
- B25J—MANIPULATORS; CHAMBERS PROVIDED WITH MANIPULATION DEVICES
- B25J11/00—Manipulators not otherwise provided for
- B25J11/0005—Manipulators having means for high-level communication with users, e.g. speech generator, face recognition means
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/0011—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots associated with a remote control arrangement
- G05D1/0016—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots associated with a remote control arrangement characterised by the operator's input device
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/20—Control system inputs
- G05D1/22—Command input arrangements
- G05D1/221—Remote-control arrangements
- G05D1/222—Remote-control arrangements operated by humans
- G05D1/223—Command input arrangements on the remote controller, e.g. joysticks or touch screens
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/30—Distributed recognition, e.g. in client-server systems, for mobile phones or network applications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/32—Multiple recognisers used in sequence or in parallel; Score combination systems therefor, e.g. voting systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/84—Detection of presence or absence of voice signals for discriminating voice from noise
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
- G10L2015/0635—Training updating or merging of old and new templates; Mean values; Weighting
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/226—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics
- G10L2015/228—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics of application context
Definitions
- This disclosure relates to information processing devices, information processing methods, and programs.
- Patent Document 1 discloses a technique for improving speech recognition accuracy by lowering the volume level of another device that can be a sound source of noise.
- a control unit that controls the operation of the moving body based on the result of the voice recognition processing is provided, and the control unit is the result of the voice recognition processing based on the voice collected by one of the moving bodies, or An information processing device that controls the operation of the other operating body is provided based on the voice recognition environment recognized based on the sensor information collected by the operating body.
- the processor controls the operation of the operating body based on the result of the voice recognition processing, and the control includes voice recognition based on the voice collected by one of the moving bodies.
- An information processing method is provided that further comprises controlling the movement of the other moving body based on the result of processing or a speech recognition environment recognized based on the sensor information collected by one said moving body.
- the computer includes a control unit that controls the operation of the operating body based on the result of the voice recognition process, and the control unit is voice recognition based on the voice collected by one of the moving bodies.
- various devices have been developed that recognize a user's utterance and execute an operation based on the recognition result. Examples of the above-mentioned devices include a voice agent device that provides various functions through voice dialogue with a user, and an autonomous operating body that changes its behavior according to the recognized user's utterance and surrounding environment. Be done.
- the above-mentioned devices are equipped with a device that transmits the collected voice data to the server via the network and operates based on the result of the voice recognition process executed on the server side, and a device that is mounted on the housing (client). There are some that execute voice recognition processing on a computer.
- a device that collects voice performs an operation accompanied by a relatively loud operation sound
- its own operation sound may interfere with voice collection and the accuracy of voice recognition may decrease.
- each moving body is more suitable for the situation in an environment where there are a plurality of moving bodies that perform actions based on voice recognition processing. It makes it possible to realize the operation.
- the information processing method includes that the processor controls the operation of the operating body based on the result of the voice recognition process.
- the above control is based on the result of voice recognition processing based on the voice collected by one moving body, or the voice recognition environment recognized based on the sensor information collected by one moving body. It further includes controlling the body.
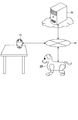
- FIG. 1 is a diagram showing a configuration example of an information processing system according to an embodiment of the present disclosure.
- the information processing server 30 according to the present embodiment may include a plurality of operating bodies that perform operations based on voice recognition processing.
- the information processing system according to the present embodiment includes a first operating body 10, a second operating body 20, and an information processing server 30. Further, the configurations are connected so as to be able to communicate with each other via the network 40.
- the first operating body 10 is an example of an operating body (information processing device) that operates based on voice recognition processing.
- the first operating body 10 according to the present embodiment transmits the collected voice to the information processing server 30, and operates based on the result of the voice recognition process by the information processing server 30.
- the first operating body 10 according to the present embodiment makes a response utterance to the user's utterance based on the result of the above-mentioned voice recognition process, actively speaks to the user based on the recognized environment, and the like. Can be done.
- the first moving body 10 according to the present embodiment may be, for example, an autonomous moving body capable of traveling or rotating by means of wheels provided on the bottom.
- the first operating body 10 according to the present embodiment may have a size and shape that can be installed on a table, for example.
- the first operating body 10 according to the present embodiment executes various operations including utterance while autonomously moving based on the result of voice recognition processing by the information processing server 30 and various recognition results. ..
- the second operating body 20 is an example of an operating body (information processing device) that operates based on the voice recognition process, similarly to the first operating body 10.
- the second operating body 20 according to the present embodiment executes the voice recognition process by itself, that is, on the local side.
- the second moving body 20 according to the present embodiment may be, for example, as shown in the figure, a quadrupedal walking type autonomous moving body imitating an animal such as a dog.
- the second operating body 20 according to the present embodiment executes a response to the user by an operation, a bark, or the like, based on the result of the voice recognition process executed on the local side.
- the information processing server 30 is an information processing device that performs voice recognition processing and natural language understanding processing based on the voice collected by the first operating body 10. Further, the information processing server 30 according to the present embodiment is based on the result of voice recognition processing based on the voice collected by one moving body and the voice recognition environment recognized based on the sensor information collected by one moving body. , The operation of other operating bodies may be controlled.
- the network 40 has a function of connecting each of the above configurations.
- the network 40 may include a public network such as the Internet, a telephone line network, a satellite communication network, various LANs (Local Area Network) including Ethernet (registered trademark), and a WAN (Wide Area Network). Further, the network 40 may include a dedicated network such as IP-VPN (Internet Protocol-Virtual Private Network). Further, the network 40 may include a wireless communication network such as Wi-Fi (registered trademark) and Bluetooth (registered trademark).
- the configuration example of the information processing system according to this embodiment has been described above.
- the above configuration described with reference to FIG. 1 is merely an example, and the configuration of the information processing system according to the present embodiment is not limited to such an example.
- the information processing system according to the present embodiment may include three or more types of operating bodies.
- a part of the moving body is not limited to the autonomous moving body, and may be a stationary type or an indoor embedded type agent device.
- the configuration of the information processing system according to the present embodiment can be flexibly modified according to specifications and operations.
- FIG. 2 is a block diagram showing a functional configuration example of the first operating body 10 according to the present embodiment.
- the first operating body 10 according to the present embodiment includes a sound input unit 110, a photographing unit 120, a sensor unit 130, a trigger detection unit 140, a control unit 150, a drive unit 160, and a sound output unit 170. , Display unit 180, and communication unit 190.
- the sound input unit 110 collects various sounds including the voice spoken by the user.
- the sound input unit 110 according to the present embodiment includes one or more microphones.
- the photographing unit 120 captures an image of the user and the surrounding environment.
- the photographing unit 120 according to the present embodiment includes an image sensor.
- the sensor unit 130 collects sensor information related to the user, the surrounding environment, and the first operating body 10 by various sensor devices.
- the sensor unit 130 according to the present embodiment includes, for example, a ToF sensor, an inertial sensor, an infrared sensor, an illuminance sensor, a millimeter wave radar, a touch sensor, a GNSS (Global Navigation Satellite System) signal receiver, and the like.
- a ToF sensor an inertial sensor
- an infrared sensor an illuminance sensor
- a millimeter wave radar a touch sensor
- GNSS Global Navigation Satellite System
- the trigger detection unit 140 detects various triggers related to the start of the voice recognition process based on various information collected by the sound input unit 110, the photographing unit 120, and the sensor unit 130.
- the trigger detection unit 140 may detect a specific word (activation word) based on the utterance voice collected by the sound input unit 110 and the specific utterance expression freely registered by the user. Good.
- the trigger detection unit 140 may detect the user's face or body or detect a specific gesture based on the image captured by the photographing unit 120.
- the trigger detection unit 140 may detect the lifting or standing of the first moving body 10 by the user based on the acceleration information collected by the sensor unit 130.
- Control unit 150 The control unit 150 according to the present embodiment controls each configuration included in the first operating body 10. Further, as will be described later, the control unit 150 according to the present embodiment transmits the result of the voice recognition process by the information processing server 30 to the second operating body 20, and indirectly or directly the second operating body. The operation of 20 may be controlled.
- the drive unit 160 performs various operations based on the control by the control unit 150.
- the drive unit 160 according to the present embodiment may include, for example, a plurality of actuators (motors and the like), wheels and the like.
- the sound output unit 170 outputs system voice or the like based on the control by the control unit 150.
- the sound output unit 170 according to the present embodiment includes an amplifier and a speaker.
- Display unit 180 The display unit 180 according to the present embodiment presents visual information based on the control by the control unit 150.
- the display unit 180 according to the present embodiment includes, for example, an LED or an OLED corresponding to an eye.
- the communication unit 190 performs information communication with the second operating body 20 and the information processing server 30 via the network 40.
- the communication unit 190 according to the present embodiment transmits the user's uttered voice collected by the sound input unit 110 to the information processing server 30, and receives the voice recognition result and the response information corresponding to the uttered voice.
- the functional configuration example of the first operating body 10 according to the present embodiment has been described above.
- the above configuration described with reference to FIG. 2 is merely an example, and the functional configuration of the first operating body 10 according to the present embodiment is not limited to such an example.
- the functional configuration of the first operating body 10 according to the present embodiment can be flexibly modified according to specifications and operations.
- FIG. 3 is a block diagram showing a functional configuration example of the second operating body 20 according to the present embodiment.
- the second operating body 20 according to the present embodiment includes a sound input unit 210, a photographing unit 220, a sensor unit 230, a recognition unit 240, a control unit 250, a drive unit 260, and a sound output unit 270. It includes a display unit 280 and a communication unit 290.
- the sound input unit 210 collects various sounds including the voice spoken by the user.
- the sound input unit 210 according to the present embodiment includes one or more microphones.
- the photographing unit 220 captures an image of the user and the surrounding environment.
- the photographing unit 220 according to the present embodiment includes an image sensor.
- the photographing unit 220 may be provided with two wide-angle cameras, for example, at the tip of the nose and the waist of the second moving body 20.
- the wide-angle camera arranged at the tip of the nose captures an image corresponding to the front field of view (that is, the field of view of the dog) of the second moving body 20, and the wide-angle camera at the waist is the peripheral area centered on the upper side.
- SLAM Simultaneus Localization and Mapping
- the sensor unit 230 collects sensor information related to the user, the surrounding environment, and the second operating body 20 by various sensor devices.
- the sensor unit 230 according to the present embodiment includes, for example, a distance measuring sensor, an inertial sensor, an infrared sensor, an illuminance sensor, a touch sensor, a grounding sensor, and the like.
- the recognition unit 240 executes various recognition processes based on the information collected by the sound input unit 210, the photographing unit 220, and the sensor unit 230.
- the recognition unit 240 executes the voice recognition process based on the user's uttered voice collected by the sound input unit 210 on the local side.
- the recognition unit 240 performs speaker identification, facial expression and line-of-sight recognition, object recognition, motion recognition, spatial area recognition, color recognition, shape recognition, marker recognition, obstacle recognition, step recognition, brightness recognition, and the like. Good.
- Control unit 250 The control unit 250 according to the present embodiment controls each configuration included in the second operating body 20 based on the results of various recognition processes by the recognition unit 240. Further, the control unit 250 according to the present embodiment transmits the results of various recognition processes by the recognition unit 240 to another operating body (for example, a first operating body or a second operating body), and the other operation. You may control the movement of the body indirectly or directly.
- another operating body for example, a first operating body or a second operating body
- the drive unit 260 has a function of bending and stretching a plurality of joint portions of the second operating body 20 based on the control of the control unit 250. More specifically, the drive unit 260 drives an actuator included in each joint unit based on control by the control unit 250.
- the sound output unit 270 outputs a sound or the like imitating a dog's bark based on the control by the control unit 250.
- the sound output unit 170 according to the present embodiment includes an amplifier and a speaker.
- the display unit 280 presents visual information based on the control by the control unit 250.
- the display unit 280 according to the present embodiment includes, for example, an LED or an OLED corresponding to the eye.
- the communication unit 290 performs information communication with the first operating body 10 and the information processing server 30 via the network 40.
- the communication unit 290 according to the present embodiment receives the result of the voice recognition process based on the voice collected by the other operating body from the first operating body 10 or the information processing server 30.
- the functional configuration example of the second operating body 20 according to the present embodiment has been described above.
- the above configuration described with reference to FIG. 3 is merely an example, and the functional configuration of the second operating body 20 according to the present embodiment is not limited to such an example.
- the functional configuration of the second operating body 20 according to the present embodiment can be flexibly modified according to specifications and operations.
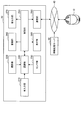
- FIG. 4 is a block diagram showing a functional configuration example of the information processing server 30 according to the present embodiment.
- the information processing server 30 according to the present embodiment includes a voice recognition unit 310, a natural language processing unit 320, a control unit 330, a response generation unit 340, and a communication unit 350.
- the voice recognition unit 310 performs voice recognition processing to return to the spoken voice received from the first operating body 10, and converts the spoken voice into a character string.
- the natural language processing unit 320 performs natural language understanding processing based on the character string generated by the voice recognition unit 310, and extracts the intention of the user's utterance.
- Control unit 330 The control unit 330 according to the present embodiment performs one operation based on the result of voice recognition processing based on the voice collected by one moving body and the environment recognized based on the sensor information collected by one moving body. Controls the movement of the body and other moving bodies. Details of the functions of the control unit 330 according to this embodiment will be described later.
- the response generation unit 340 generates response information corresponding to the user's utterance intention extracted by the natural language processing unit 320 based on the control by the control unit 330.
- the response generation unit 340 generates, for example, a response voice to the user's utterance.
- the communication unit 350 performs information communication with the first operating body 10 and the second operating body 20 via the network 40. For example, the communication unit 350 receives the uttered voice from the first operating body 10. In addition, the communication unit 350 transmits information related to the results of the voice recognition process and the natural language understanding process based on the spoken voice to the second operating body 20.
- the functional configuration example of the information processing server 30 according to the present embodiment has been described above.
- the above configuration described with reference to FIG. 4 is merely an example, and the functional configuration of the information processing server 30 according to the present embodiment is not limited to such an example.
- the functional configuration of the information processing server 30 according to the present embodiment can be flexibly modified according to specifications and operations.
- the information processing method according to the present embodiment shares the information recognized from the information collected by each operating body in an environment in which a plurality of moving bodies operating based on the voice recognition processing exist. It is intended to realize that each moving body performs a more appropriate movement.
- the information processing system according to the present embodiment may be provided with a plurality of types of operating bodies having different functions and characteristics.
- the information processing system according to the present embodiment may include the first operating body 10 and the second operating body 20 described above.
- the first operating body 10 is a voice recognition process (hereinafter, also referred to as a first voice recognition) using a cloud dictionary (hereinafter, also referred to as a first dictionary) having a large number of vocabularies by the information processing server 30. It is possible to operate based on the result of processing) and natural language understanding processing, and it recognizes a wider vocabulary and speech intention with high accuracy and performs a response operation as compared with the second operating body 20. It is possible.
- a voice recognition process hereinafter, also referred to as a first voice recognition
- a cloud dictionary hereinafter, also referred to as a first dictionary
- the moving sound (operation) is compared with the walking movement of the second operating body 20 having a large servo sound and grounding noise.
- One of the features is that the sound) is quiet.
- the first moving body 10 since the first moving body 10 according to the present embodiment is assumed to be arranged on the table, it has a higher viewpoint than the second moving body 20 and has a second moving body. It is possible to recognize a user, an object, or the like with a field of view wider than 20.
- the first operating body 10 can interact with the user using a language, and can more reliably convey the recognized user's utterance, environment, and the like to the user.
- the second operating body 20 uses a local dictionary (hereinafter, also referred to as a second dictionary) having a smaller number of vocabularies than the cloud dictionary on the local side for voice recognition processing (hereinafter, also referred to as a second dictionary). , Also referred to as a second voice recognition process), and operates based on the result of the voice recognition process. Therefore, the second operating body 20 according to the present embodiment can recognize only the vocabulary registered in advance, while suppressing the number of vocabularies effectively reduces the amount of calculation and performs a quick response. Is possible.
- the second moving body 20 since the second moving body 20 according to the present embodiment walks and moves on the floor, it has a wider range of action as compared with the first moving body 10 and can move between a plurality of rooms. .. Further, the second operating body 20 according to the present embodiment can generate an environmental map by SLAM, and the name of the space (for example, living room, kitchen, etc.) and the environmental map are given by the instruction from the user. It is also possible to associate with.
- the first operating body 10 and the second operating body 20 according to the present embodiment each have an advantage over each other.
- the information linkage between the first operating body 10 and the second operating body 20 having the above-mentioned characteristics will be described with reference to specific examples.
- the control unit 330 of the information processing server 30 transfers an operation corresponding to the result of the voice recognition process to another operating body based on the result of the voice recognition processing based on the voice collected by one operating body. You may let it run.
- the control unit 330 transmits the result of the first voice recognition process based on the voice collected by the first operating body 10 to the second operating body 20, and indirectly performs the operation of the second operating body 20. Alternatively, it can be controlled directly.
- FIG. 5 is a diagram for explaining sharing of the voice recognition result according to the present embodiment.
- the user U is performing the utterance UO1 having the intention (goodFB) of complimenting the second moving body 20, which is "That's my boy".
- the information processing server 30 recognizes the utterance UO1 with high accuracy by the first voice recognition process. Also, the recognition result can be transmitted to the first moving body 10.
- the control unit 330 of the information processing server 30 is collected by the first operating body 10. Based on the resulting voice and the result of the first voice recognition process based on the first dictionary 322, the second operating body 20 may execute the operation corresponding to the repentance.
- control unit 330 extracts the vocabulary corresponding to the vocabulary category obtained as a result of the first speech recognition process from the second dictionary 242, and extracts the vocabulary from the second dictionary 242. May be transmitted to the moving body 20 of.
- the control unit 330 uses the vocabulary “Good boy” corresponding to the category: good FB of the vocabulary “That's my boy” obtained by the first voice recognition process as a second dictionary. It is extracted from 242 and the vocabulary "Good boy” is transmitted to the second moving body 20. According to the control, the second moving body 20 pseudo-understands the vocabulary "That's my boy” that cannot be recognized by itself, and executes an appropriate action according to the utterance intention of the user U. It becomes possible. In addition to or instead of the vocabulary obtained by the first voice recognition process, the control unit 330 may transmit information related to the category of the vocabulary to the second operating body 20.
- control unit 330 when sharing the voice recognition result as described above, transmits the result of the voice recognition processing based on the voice collected by one moving body to another moving body.
- the operation shown may be executed by the one operating body.
- control unit 330 performs an operation indicating that the result of the first voice recognition process based on the voice collected by the first operating body 10 is transmitted to the second operating body 20.
- the operating body 10 may execute the operation.
- the control unit 330 causes the first operating body 10 to output the system utterance SO1 called "He privileged you" toward the second operating body 20.
- control unit 330 may use, for example, system utterances such as "I taught you", or the first operating body 10 may send the user U's utterance UO1 to the second operating body 20.
- the first operating body 10 may be made to execute a system utterance (for example, a utterance using a sound imitating a dog's bark) as if it were an interpreter.
- control unit 330 may also cause the second operating body, which is the sharing destination of the voice recognition result, to execute an operation indicating that the sharing has been performed.
- the control unit 330 may cause the second operating body 20 to perform a voice or movement larger than that in the normal state, for example.
- the control unit 330 may cause the second operating body 20 to perform behaviors that make it embarrassing that it could not be understood by itself, or behavior that shows gratitude to the first operating body 10.
- control subject related to sharing is the control unit 330 of the information processing server 30
- control subject related to sharing the voice recognition result is the control unit 150 of the first operating body 10. It may be.
- the control unit 150 After receiving the result of the first voice recognition process from the information processing server 30, the control unit 150 can transmit the result to the second operating body 20 by short-range wireless communication or the like.
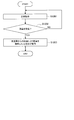
- FIG. 6A is a flowchart showing an operation flow of the first operating body 10 and the information processing server 30 in sharing the voice recognition result according to the present embodiment.
- the first operating body 10 first performs an autonomous operation based on the recognized environment (S1101).
- control unit 150 or the control unit 330 which is the control subject, has a vocabulary of the category corresponding to the vocabulary recognized by the first voice recognition process in the second dictionary 242 included in the second operating body 20. Whether or not it is determined (S1102).
- the control subject subsequently determines whether or not the utterance is for the second action body 20 (S1103).
- the control unit 150 and the control unit 330 have detected that the trigger detection unit 140 of the first operation body 10 faces the user's face toward the second operation body 20, and the second operation body 20 depends on the user.
- the above determination can be made based on the fact that the contact is detected, that the immediately preceding utterance includes the name of the second moving body, and the like.
- the control subject transmits the corresponding vocabulary to the second moving body 20 (S1104).
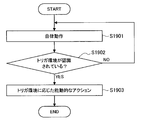
- FIG. 6B is a flowchart showing the operation flow of the second operating body 20 in sharing the voice recognition result according to the present embodiment.
- the second operating body 20 first performs an autonomous operation based on the recognized environment (S1201).
- control unit 250 of the second operating body 20 determines whether or not the vocabulary has been received from the first operating body 10 or the information processing server 30 (S1202).
- control unit 250 causes the first operating body 10 to execute an operation indicating that the vocabulary is understood by transmission from another device (S1203).
- the second operating body 20 can reduce the amount of calculation and realize a fast response by suppressing the number of vocabularies registered in the second dictionary 242.
- the recognition accuracy may decrease and the user experience may be impaired. Therefore, the information processing system according to the present embodiment may have a mechanism for regularly or irregularly replacing the vocabulary set registered in the second dictionary 242.
- FIG. 7 is a diagram for explaining the replacement of the vocabulary set registered in the second dictionary 242 according to the present embodiment. Note that FIG. 7 is a block diagram created by paying attention to the vocabulary set replacement function among the configurations provided in the information processing system, and some configurations are omitted.
- the second operating body 20 is separate from the evaluation unit 735, the dictionary update unit 740, and the second dictionary 242.
- Candidate dictionary 745 may be provided.
- the evaluation unit 735 evaluates the user's utterance performance based on the accumulated independent knowledge.
- the above-mentioned independent knowledge refers to knowledge based on the unique experience of the second operating body 20.
- the independent knowledge according to the present embodiment includes the utterance log 720 recognized by the recognition unit 240 and the utterance status log 730 that records the status at the time of utterance.
- the evaluation unit 735 may evaluate that the vocabulary that has been recognized more frequently has a higher utterance record.
- the evaluation unit 735 may comprehensively evaluate the utterance performance based on the utterance status and the like in order to deal with erroneous recognition by the recognition unit 240 and the rushing out.
- the erroneous recognition means that the recognition unit 240 outputs a recognition result other than "good morning” to the actual utterance "good morning” of the user, for example, "good night”.
- "springing out” means that the recognition result is output for sounds other than the user's utterance such as daily life sounds, for example, the recognition result of "ban” is output for the sound of closing the door. To do.
- the dictionary update unit 740 updates the second dictionary 242 and the candidate dictionary 745 according to the utterance record evaluated by the evaluation unit 735 based on the control by the control unit 250.
- the candidate dictionary 745 according to the present embodiment is a dictionary in which a vocabulary to be added or replaced with the second dictionary 242 is registered.
- the dictionary update unit 740 deletes a vocabulary having a low utterance record from the second dictionary 242 or shifts to the candidate dictionary 745, and replaces the high priority vocabulary registered in the candidate dictionary 745 with the second dictionary 242. You can register with.
- the dictionary update unit 740 may have a function of acquiring an unregistered vocabulary from the information processing server 30 and additionally registering the vocabulary in the second dictionary 242 or the candidate dictionary 745.
- the dictionary update unit 740 may acquire the correlated vocabulary 931, the trend vocabulary 932, the seasonal vocabulary 933, the generational vocabulary 934, the dialect 935, and the like, and additionally register them in the second dictionary 242 and the candidate dictionary 745.
- the dictionary update unit 740 may delete vocabularies having a low utterance record from the second dictionary 242 and the candidate dictionary 745.
- the above-mentioned correlated vocabulary 931 refers to a vocabulary that is highly correlated with other vocabularies and functions, such as another vocabulary uttered after one vocabulary.
- the correlated vocabulary 931 may be acquired, for example, based on the analysis of the collective intelligence 915 in which the utterance log 720 and the utterance status log 730 recorded by the plurality of second moving bodies 20 are accumulated in an integrated manner.
- trend vocabulary 932 refers to vocabulary that is trending in the world
- seasonal vocabulary 933 refers to vocabulary according to the season
- generational vocabulary 934 refers to vocabulary that is frequently used for each generation.
- the second dictionary 242 can be appropriately updated based on the user's utterance record, and the vocabulary set used by the user and the vocabulary set registered in the second dictionary 242 can be effectively separated from each other. Can be suppressed to.
- Japanese Patent Application No. 2018-124856 filed in the past by the applicant of the present disclosure.
- the control unit 250 sends a dictionary update to the dictionary update unit 740 using the recognition log 324 related to the result of the first voice recognition process based on the voice collected by the first operating body 10. You may let it run. That is, the control unit 250 according to the present embodiment can control the replacement of the second dictionary 242 and the candidate dictionary 745 based on the recognition log 324.
- the user's utterance record can be evaluated more accurately based on the vocabulary recognized with high accuracy by the first speech recognition process and the number of times, and the accuracy of dictionary update can be improved. It is possible to minimize the accumulation of logs required for evaluation.
- FIG. 8 is a flowchart showing a flow of accumulating recognition logs by the information processing server 30 according to the present embodiment.
- the voice recognition unit 310 performs the first voice recognition process based on the voice data received from the first operating body 10 (S1301).
- the voice recognition unit 310 determines whether or not there is a vocabulary recognized a plurality of times by the first voice recognition process in step S1301 (S1302).
- the voice recognition unit 310 stores the recognized vocabulary and the number of times in the recognition log 324 (S1303).
- FIG. 9 is a flowchart showing the flow of dictionary update by the second operating body 20 according to the present embodiment.
- control unit 250 causes the dictionary update unit 740 to execute the replacement algorithm related to the dictionary update (S1401).
- control unit 250 determines whether or not the vocabulary exists in the recognition log 324 stored in the information processing server 30 (S1402).
- the control unit 250 causes the dictionary update unit 740 to additionally select another vocabulary related to the vocabulary (S1403).
- the dictionary update unit 740 selects additional vocabulary to be registered from correlated vocabulary 931, trend vocabulary 932, seasonal vocabulary 933, generational vocabulary 934, dialect 935, etc., based on the vocabulary profile registered in the recognition log 324. You can.
- control unit 250 controls the dictionary update unit 740 to add the vocabulary acquired from the recognition log 324 and the related vocabulary to the second dictionary 242 and the candidate dictionary 745 (S1404).
- control unit 250 of the second operating body 20 is the control body for the dictionary update
- control body for the dictionary update according to the present embodiment is the control of the information processing server 30. It may be part 330.
- the operation control based on the sharing of the recognition environment according to the present embodiment will be described.
- the environment recognized based on the collected information of each moving body is shared among a plurality of moving bodies, and is used for the movement control of the moving body. You may be able to.
- control unit 330 may improve the voice recognition environment related to another moving body when the voice recognition environment related to one moving body is an environment that may cause a decrease in the voice recognition processing accuracy.
- the movement of the moving body may be controlled.
- the above-mentioned voice recognition environment refers to various environments that affect the voice recognition accuracy, and may include, for example, the operating state of the moving body.
- the operating body is performing an operation accompanied by a relatively loud operation sound such as a servo sound or a grounding sound, it is assumed that the operation sound interferes with the collection of the user's uttered sound and the voice recognition accuracy is lowered.
- a relatively loud operation sound such as a servo sound or a grounding sound
- control unit 330 may control the operation of another operating body based on the operating state of one operating body. More specifically, the control unit 330 according to the present embodiment controls so that when one operating body is performing an operation accompanied by a relatively loud operating sound, the operating sound of the other operating body is further reduced. ..
- FIG. 10 is a diagram for explaining operation control of another operating body based on the operating state of one moving body according to the present embodiment.
- the user U is performing the utterance UO2 in the situation where the second operating body 20 is playing with the ball.
- the second operating body 20 may not be able to collect the voice related to the utterance UO2 with high accuracy because of its own operating sound.
- the control unit 330 of the information processing server 30 receives the second voice by the second operating body 20 based on the operation status (2nd_MOVING: TRUE) uploaded from the second operating body 20. It may be possible to predict a decrease in the accuracy of the recognition process. Further, the control unit 330 controls so that the operation sound of the first operation body 10 becomes smaller so that the first operation body 10 can collect the voice related to the utterance UO2 with high accuracy. The control unit 330 may, for example, stop the first operating body 10.
- the first operating body 10 can collect the voice related to the utterance UO2 of the user U instead of the second operating body 20 in operation, and further, the first voice recognition. By transmitting the result of the process to the second operating body 20, it is possible to perform the operation corresponding to the utterance UO2 even while the second operating body 20 is operating.
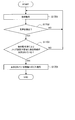
- FIG. 11 is a flowchart showing a flow of operation control of another operating body based on the operating state of one moving body according to the present embodiment.
- the control unit 330 determines whether or not the second operating body 20 is operating (S1502). ). As described above, the control unit 330 can make the above determination based on the operation status uploaded from the second operating body 20.
- control unit 330 controls so that the operating sound of the first operating body 10 becomes smaller (S1503).
- control unit 330 determines whether or not the vocabulary of the category corresponding to the vocabulary recognized by the first voice recognition process exists in the second dictionary 242 included in the second operating body 20 (S1504). ).
- the control unit 330 transmits the corresponding vocabulary to the second operating body 20 (S1505).
- the control unit 330 may transmit the corresponding vocabulary to the second moving body 20 only when the utterance is for the second moving body 20, as in the case shown in FIG. 6A.
- the second operating body 20 may execute the subsequent processing according to the flow shown in FIG. 6B.
- the control subject is the control unit 330 of the information processing server 30 has been described as an example, but the control subject may be the control unit 150 of the first operating body 10.
- the voice recognition environment according to the present embodiment includes the operating state of the operating body, but the voice recognition environment according to the present embodiment includes an environment related to springing and speaker identification, that is, a noise sound source and the like.
- the recognition (identification) result of the speaker may be included.
- FIG. 12A is a diagram for explaining sharing of the recognition result of the noise sound source according to the present embodiment.
- the noise source NS which is a television device. It shows the situation of recognizing that it is being output.
- the first operating body 10b and the second operating body 20 may mistake the voice output by the noise sound source NS as the spoken voice of the user and execute the voice recognition process.
- the first operating body 10a may upload the information related to the recognized noise sound source NS to the information processing server 30. Further, the control unit 330 of the information processing server 30 transmits the information related to the noise sound source NS uploaded by the first operating body 10a to the first operating body 10b and the second operating body 20, and the voice recognition process is performed. It may be controlled indirectly or directly so that it is not executed.
- FIG. 12B is a diagram for explaining sharing of the result of speaker recognition according to the present embodiment.
- the first operating bodies 10a and 10b and the second operating body 20 are in the same room, only the first operating body 10a identifies the user U, and the television. It shows a situation in which it is recognized that no sound is output from the noise source NS, which is a John device.
- the voice is likely to be the spoken voice of the user U.
- control unit 330 of the information processing server 30 transmits the information related to the user U and the noise sound source NS uploaded by the first operating body 10a to the first operating body 10b and the second operating body 20.
- voice When voice is detected, it may be indirectly or directly controlled to execute the voice recognition process.
- control unit 330 transmits the noise sound source recognized based on the sensor information collected by one moving body and the information related to the speaker to the other moving body, and the other. It is possible to control whether or not the voice recognition process related to the moving body is executed.
- control unit 330 does not necessarily have to be the control subject for sharing information related to the noise sound source and the speaker.
- the sharing control subject may be a sharing source operating body (first operating body 10 or a second operating body), and information is directly sent to the sharing destination operating body without going through the information processing server 30. You may communicate.
- FIG. 13A is a flowchart showing the operation flow of the sharing source in the information sharing related to the noise sound source and the speaker according to the present embodiment.
- the sharing source operating body performs an autonomous operation (S1601).
- the sharing source operating body recognizes the noise sound source or the speaker (S1602: YES)
- the sharing source operating body transmits the recognized noise sound source or information related to the speaker to another operating body (S1602: YES). S1603).
- FIG. 13B is a flowchart showing a flow of operation of the sharing destination in information sharing related to the noise sound source and the speaker according to the present embodiment.
- the sharing destination operating body performs an autonomous operation (S1701).
- the sharing destination operating body subsequently determines whether or not information related to the noise sound source and the speaker is shared by other operating bodies (S1703). ..
- the sharing destination operating body when information related to the noise sound source and the speaker is shared by another operating body (S1703: YES), the sharing destination operating body performs an operation according to the shared information (S1704). For example, in an environment where there are many noise sound sources, the sharing destination operating body may increase the possibility of identifying the user by making an utterance such as "Somehow noisy, show your face".
- the shared moving body by transmitting the environment recognized by one moving body to another moving body, the shared moving body operates more appropriately according to the environment. Can be done.
- the sharing of the environment as described above may be used for active actions for the user by the operating body.
- one of the features of the first operating body 10 according to the present embodiment is that it not only responds to the user's utterance but also actively speaks to the user to actively engage in dialogue.
- the second moving body 20 according to the present embodiment is also characterized in that it realizes positive interaction by actively behaving with respect to the user.
- the frequency of active action execution may be effectively increased by sharing the recognized environment with a plurality of operating bodies.
- FIG. 14 is a diagram for explaining sharing of an environment that triggers an active action according to the present embodiment.
- FIG. 14 shows a situation in which the user U in the kitchen is identified by the second operating body 20a also in the kitchen.
- the second operating body 20a uploads information indicating that the user U has been identified in the kitchen to the information processing server 30. Further, the control unit 330 of the information processing server 30 transmits the information uploaded by the second operating body 20a to the first operating body 10 and the second operating body 20b in the living room, and is active for the user. It may be indirectly or directly controlled to perform the action.
- control unit 330 may cause the first operating body 10 to perform a system utterance SO3 such that the user U knows that the user U is in the kitchen. Further, for example, the control unit 330 may perform control such as moving the second operating body 20b to the kitchen.
- control unit 330 causes another moving body to execute an active action for the user based on the environment recognized based on the sensor information collected by one moving body. You can. Further, when the sharing destination moving body can speak, the sharing destination moving body may be made to execute an active utterance according to the above environment.
- control subject may be an operating body (first operating body 10 or second operating body) as a sharing source, and the information processing server 30 Information may be directly transmitted to the sharing destination operating body without going through.
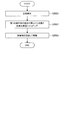
- FIG. 15A is a flowchart showing the flow of the operation of the sharing source in sharing the environment that triggers the active action according to the present embodiment.
- the sharing source operating body performs an autonomous operation (S1801).
- the sharing source operating body when the sharing source operating body recognizes an environment (also referred to as a trigger environment) that triggers an active action (S1802: YES), the sharing source operating body transfers information related to the recognized environment to other information. It is transmitted to the moving body (S1803).
- the environment include the location and behavior of a user or another person, recognition of weather and environmental sounds, and the like.
- FIG. 15B is a flowchart showing the flow of the operation of the sharing destination in sharing the environment that triggers the active action according to the present embodiment.
- the sharing destination operating body performs an autonomous operation (S1901).
- the shared operating body performs an active action according to the shared environment (S1903).
- the sharing destination moving body by transmitting the environment recognized by one moving body to another moving body, the sharing destination moving body is active according to the environment. It becomes possible to execute an action.
- the first operating body 10 can switch a plurality of dialogue engines according to the recognized environment or the shared environment to perform a dialogue with the user.
- FIG. 16 is a diagram for explaining switching of the dialogue engine according to the present embodiment.
- FIG. 16 shows the types of engines used for each environment.
- the first operating body 10 according to the present embodiment can realize richer dialogue by switching four different engines related to scenario dialogue, situation dialogue, knowledge dialogue, and chat dialogue according to the environment, for example. It is possible.
- the above-mentioned scenario dialogue may be a dialogue that generates utterances corresponding to an environment that matches the conditions, based on a scenario consisting of a set of preset conditions and standard utterances.
- the situation dialogue may be a dialogue that uses a knowledge database to generate utterances that explain the recognized situation (environment).
- the above-mentioned knowledge dialogue may be a dialogue in which other necessary vocabularies are extracted from the knowledge database based on the vocabulary included in the user's utterance and the vocabulary estimated from the environment to generate the utterance.
- chat dialogue is to generate utterances by using a machine learning method or the like for free utterances whose domain is not fixed, or to extract appropriate fixed phrases from the utterance sentence database and generate utterances. It may be a dialogue.
- the engine with high priority may be used.
- an attempt may be made to generate an utterance by an engine having a higher priority and an appropriate utterance cannot be generated, an attempt may be made to generate an utterance by an engine having the next highest priority.
- the first moving body 10 can make utterances such as "Hey” and "Long time” by using an engine related to a scenario dialogue or a situation dialogue. ..
- the first operating body 10 can make utterances such as "that? Where is Taro?" By using the engine related to the situation dialogue.
- the first moving body 10 can make an utterance such as "Oh, it's a ball" by using the engine related to the situation dialogue.
- the first moving body 10 can make an utterance such as "By the way, what do you like?" By using the engine related to the scenario dialogue. Is.
- the first moving body 10 uses an engine related to a situation dialogue or a knowledge dialogue, so that "it's raining, I have to bring an umbrella” or “during a meeting?" It is possible to make utterances such as "Let's be quiet.”
- the first operating body 10 can make an utterance such as "a delay occurs at an ABC station" by using an engine related to knowledge dialogue. Is.
- the first moving body 10 uses an engine related to knowledge dialogue or chat dialogue, such as "I heard a cake. I like chocolate cake.” It is possible to speak.
- the switching of the dialogue engine according to this embodiment has been described above. By switching the dialogue engine as described above, it is possible to realize an appropriate and richer dialogue according to the environment.
- FIG. 17A and 17B are diagrams for explaining the integration of the voice recognition processing results according to the present embodiment.
- FIG. 17A shows a situation in which the user U makes an utterance UO4 in an environment in which the first moving bodies 10a to 10c and the second moving body 20 are present together.
- the first moving bodies 10a and 10b accurately collect the voices related to the utterance UO4 and obtain an accurate vocabulary by the first voice recognition process, while the first moving bodies 10a Is far from the user U, so that the voice related to the utterance UO4 cannot be collected with high accuracy, and an erroneous vocabulary is obtained by the first voice recognition process.
- the second operating body 20 is performing an operation of playing with a ball, and cannot collect sufficient voice for the second voice recognition processing.
- control unit 330 of the information processing server 30 integrates (aggregates) the results of the voice recognition process based on the voice collected by each operating body. If the voice data or the voice recognition result is not uploaded from the moving body, the control unit 330 may consider that the moving body has failed to collect the voice because it exists in the same environment.
- control unit 330 may transmit the integrated recognition result obtained as a result of the integration to each operating body and indirectly or directly control the operation of each operating body.
- control unit 330 determines the vocabulary “Good morning”, which has the largest number from the obtained results of the plurality of speech recognition processes, as the integrated recognition result, and the first moving bodies 10a to It is transmitted to 10c.
- control unit 330 applies the above-mentioned to the first operating body 10b and the first operating body 10c that collect the voices for which the same voice recognition processing result as the integrated recognition result is obtained.
- the words and actions related to the first moving body 10a and the second moving body 20 for which the same voice recognition processing result could not be obtained may be executed.
- control unit 330 causes the first operating body 10b to perform the system utterance SO3 that conveys the correct user's intention to the first operating body 10a. Further, the control unit 330 causes the first operating body 10c to perform system utterance SO5 to the effect that the second operating body 20 cannot understand the utterance UO4.
- control unit obtains the same voice recognition processing result in the first operating body 10a that collects the voices for which the same voice recognition processing result as the integrated recognition result was not obtained. You may make them perform words and actions that indicate that they were not able to do so.
- control unit 330 causes the first operating body 10a to perform the system utterance SO4 indicating that the erroneous vocabulary has been recognized.
- the user's utterance can be recognized with high accuracy based on the result of the voice recognition processing based on the voice collected by each of the plurality of moving bodies, and the moving bodies discuss the recognition result. It is possible to express the appearance of doing the above, and it is expected to have the effect of further attracting the user's interest.
- FIG. 18 is a flowchart showing a flow of integration of voice recognition results by the information processing server 30 according to the present embodiment.
- the communication unit 350 receives voice data or the result of the second voice recognition process from a plurality of operating bodies (S2001).
- control unit 330 integrates the result of the first voice recognition process based on the voice data received in step S2001 and the result of the second voice recognition process received in step S2001 (S2002).
- control unit 330 determines the integrated recognition result based on the number of recognition results and the state of the operating body at the time of voice collection (S2003).
- the control unit 330 may determine the integrated recognition result by weighting not only the number of recognition results but also the distance between the moving body and the user at the time of voice acquisition and the operating state of the moving body.
- control unit 330 transmits the integrated recognition result determined in step S2003 to each operating body via the communication unit 350 (S2004).
- FIG. 19 is a flowchart showing a flow of operation control based on the integrated recognition result according to the present embodiment.
- the control unit of the moving body rejects the recognition result corresponding to the voice collected by itself, that is, itself. Determines whether or not the recognition result corresponding to the voice collected by is different from the integrated recognition result (S2101).
- the operating body obtains the same voice recognition processing result as the integrated recognition result, that is, the behavior corresponding to the rejection.
- the words and actions indicating that the failure was not performed are executed (S2102).
- the control of the operating body subsequently determines whether or not another moving body whose recognition result is rejected exists within a predetermined distance (for example, a visually recognizable distance) (S2103).
- the information processing system according to the present embodiment may have a function related to cooperation of a plurality of operating bodies.
- the first moving body 10 may transmit the state of the second moving body 20 to the user instead of the second moving body 20 having no function of communicating using a language. It is possible.
- FIG. 20 is a flowchart showing a flow of transmission of the state of the second operating body by the first operating body 10 according to the present embodiment.
- the first operating body 10 first performs an autonomous operation (S2201).
- the first operating body 10 when a request related to the state transmission of the second operating body is detected from a user's utterance or an application operated by the user (S2202), the first operating body 10 is in the state of the second operating body 20. (S2203). At this time, the first operating body 10 may directly inquire the state of the second operating body 20, and when the second operating body 20 uploads the state to the information processing server 30, information is provided. You may make an inquiry to the processing server 30.
- the first operating body 10 transmits the state of the second operating body 20 acquired by the inquiry in step S2203 to the user (S2204).
- the state of the second moving body 20 includes, for example, dynamic states such as emotions, currently created SLAM maps, recognized objects, and remaining battery power, and static information such as individual identification numbers. May be included.
- first operating body 10 may give various operation instructions to the second operating body 20.
- the second moving body 20 has a wider moving range than the first moving body 10. Therefore, for example, when the first operating body 10 that cannot move from the desktop cannot recognize the user, the first operating body 10 may instruct another room or the like to search for the user.
- FIG. 21 is a flowchart showing a flow of user search by the second operating body 20 based on the instruction of the first operating body 10 according to the present embodiment.
- the second operating body 20 first performs an autonomous operation (S2301).
- the second operating body 20 searches for a user by walking around the house (S2303).
- the second operating body 20 transmits the place or situation in which the user is recognized to the first operating body 10 (S2305).
- the first moving body 10 may perform words and actions based on the transmitted information. For example, when the user is informed that he / she is in the kitchen, the first operating body 10 may make an utterance such as "Mike told me, are you making rice?".
- the second operating body 20 transmits to the first operating body 10 that the user could not be found (S2306).
- the second moving body 20 may express the search result by crying, behavior, or the like. ..
- the second moving body 20 may behave like eating an object while shaking its tail, or when the user cannot be found. May perform actions such as screaming arguably while shaking its head.
- the first operating body 10 can give an instruction to the second operating body 20 based on the information acquired from an external service such as an SNS or a message application.
- an external service such as an SNS or a message application.
- FIG. 22 is a flowchart showing an example of a flow of instructions to the second operating body 20 based on the information acquired from the external service according to the present embodiment.
- the first operating body 10 first performs an autonomous operation (S2401).
- the first operating body 10 may instruct the second operating body 20 to wait at the entrance (S2402). S2403). In this case, the second operating body 20 waits at the entrance based on the instruction from the first operating body 10. Further, when the first operating body 10 recognizes the user who has returned home, he / she may make an utterance such as "Mike, did you wait properly at the entrance?".
- the first operating body 10 may have a function of communicating with the user via a message application or SNS. According to such a function, the user can enjoy the dialogue with the first moving body 10 and can grasp the situation of the second moving body 20 and the house even while going out.
- the first moving body 10 according to the present embodiment can give a movement instruction related to obstacle avoidance to the second moving body 20 by utilizing a high viewpoint.
- the first moving body 10 according to the present embodiment since the first moving body 10 according to the present embodiment is assumed to be arranged on the table, it has a higher viewpoint than the second moving body 20 that walks and moves on the floor. Have.
- FIG. 23A is a flowchart showing a flow of a movement instruction to the second operating body 20 by the first operating body 10 according to the present embodiment.
- the first operating body 10 performs an autonomous operation (S2401).
- the first operating body 10 transmits the image around the second operating body 20 to the second operating body (S2402).
- the first moving body 10 may transmit the above-mentioned video based on the request from the second moving body 20, or recognizes a situation in which the second moving body 20 is likely to collide with an obstacle.
- the above video may be transmitted based on the above.
- the first operating body 10 may perform an expression related to a movement instruction for the second operating body 20 (S2403).
- the first moving body 10 can make an utterance such as "Dangerous! Migi, Migi!.
- FIG. 23B is a flowchart showing the flow of operation of the second operating body 20 based on the movement instruction from the first operating body 10 according to the present embodiment.
- the second operating body 20 performs an autonomous operation (S2501).
- the second operating body 20 maps the image obtained from the viewpoint of the first operating body 10 to its surroundings (S2502).
- the second moving body 20 moves while avoiding obstacles based on the mapping of the image in step S2502 (S2503).
- FIG. 24 is a block diagram showing a hardware configuration example of the information processing server 30 according to the embodiment of the present disclosure.
- the information processing server 30 includes, for example, a processor 871, a ROM 872, a RAM 873, a host bus 874, a bridge 875, an external bus 876, an interface 877, an input device 878, and an output device. It has 879, a storage 880, a drive 881, a connection port 882, and a communication device 883.
- the hardware configuration shown here is an example, and some of the components may be omitted. Further, components other than the components shown here may be further included.
- the processor 871 functions as, for example, an arithmetic processing unit or a control device, and controls all or a part of the operation of each component based on various programs recorded in the ROM 872, the RAM 873, the storage 880, or the removable recording medium 901. ..
- the ROM 872 is a means for storing a program read into the processor 871 and data used for calculation.
- a program read into the processor 871 and various parameters that change as appropriate when the program is executed are temporarily or permanently stored.
- the processors 871, ROM 872, and RAM 873 are connected to each other via, for example, a host bus 874 capable of high-speed data transmission.
- the host bus 874 is connected to the external bus 876, which has a relatively low data transmission speed, via, for example, the bridge 875.
- the external bus 876 is connected to various components via the interface 877.
- Input device 8708 For the input device 878, for example, a mouse, a keyboard, a touch panel, buttons, switches, levers, and the like are used. Further, as the input device 878, a remote controller (hereinafter, remote controller) capable of transmitting a control signal using infrared rays or other radio waves may be used. Further, the input device 878 includes a voice input device such as a microphone.
- the output device 879 provides the user with acquired information such as a display device such as a CRT (Cathode Ray Tube), an LCD, or an organic EL, an audio output device such as a speaker or headphones, a printer, a mobile phone, or a facsimile. It is a device that can notify visually or audibly. Further, the output device 879 according to the present disclosure includes various vibration devices capable of outputting tactile stimuli.
- the storage 880 is a device for storing various types of data.
- a magnetic storage device such as a hard disk drive (HDD), a semiconductor storage device, an optical storage device, an optical magnetic storage device, or the like is used.
- the drive 881 is a device that reads information recorded on a removable recording medium 901 such as a magnetic disk, an optical disk, a magneto-optical disk, or a semiconductor memory, or writes information on the removable recording medium 901.
- a removable recording medium 901 such as a magnetic disk, an optical disk, a magneto-optical disk, or a semiconductor memory
- the removable recording medium 901 is, for example, a DVD media, a Blu-ray (registered trademark) media, an HD DVD media, various semiconductor storage media, and the like.
- the removable recording medium 901 may be, for example, an IC card equipped with a non-contact type IC chip, an electronic device, or the like.
- connection port 882 is a port for connecting an external connection device 902 such as a USB (Universal Serial Bus) port, an IEEE1394 port, a SCSI (SCSI Computer System Interface), an RS-232C port, or an optical audio terminal. is there.
- an external connection device 902 such as a USB (Universal Serial Bus) port, an IEEE1394 port, a SCSI (SCSI Computer System Interface), an RS-232C port, or an optical audio terminal.
- the externally connected device 902 is, for example, a printer, a portable music player, a digital camera, a digital video camera, an IC recorder, or the like.
- the communication device 883 is a communication device for connecting to a network, and is, for example, a communication card for wired or wireless LAN, Wireless (registered trademark), or WUSB (Wireless USB), a router for optical communication, and ADSL (Asymmetric Digital). A router for Subscriber Line), a modem for various communications, and the like.
- the information processing server 30 includes a control unit 330 that controls the operation of the operating body based on the result of the voice recognition process.
- the control unit 330 according to the embodiment of the present disclosure is a voice recognition environment recognized based on the result of voice recognition processing based on the voice collected by one moving body or the sensor information collected by one moving body.
- One of the features is to control the movements of other moving bodies based on the above. According to this configuration, in an environment where there are a plurality of operating bodies that perform operations based on voice recognition processing, it is possible for each operating body to realize an operation more suitable for the situation.
- a program for causing hardware such as a CPU, ROM, and RAM built in a computer to exhibit a function equivalent to that of the first operating body 10, the second operating body 20, or the information processing server 30.
- a computer-readable non-transient recording medium on which the program is recorded may also be provided.
- each step related to the processing of the information processing system of the present specification does not necessarily have to be processed in chronological order in the order described in the flowchart.
- each step related to the processing of the information processing system may be processed in an order different from the order described in the flowchart, or may be processed in parallel.
- a control unit that controls the operation of the operating body based on the result of voice recognition processing, With The control unit performs the other operation based on the result of the voice recognition process based on the voice collected by the one operating body or the voice recognition environment recognized based on the sensor information collected by the one operating body. Control body movements, Information processing device.
- the control unit causes another operating body to perform an operation corresponding to the result of the voice recognition processing based on the result of the voice recognition processing based on the voice collected by one of the moving bodies.
- the information processing device according to (1) above.
- the control unit causes the one operating body to perform an operation indicating that the result of the voice recognition process based on the voice collected by the one operating body is transmitted to the other operating body.
- the information processing device according to (2) above.
- a first action body that performs an action based on the result of the first voice recognition process using the first dictionary and a second dictionary having a smaller vocabulary than the first dictionary were used.
- the control unit performs an operation corresponding to the result of the first voice recognition process based on the voice collected by the first operating body and the result of the first voice recognition process based on the first dictionary. Let the second operating body execute The information processing device according to (2) or (3) above.
- the control unit extracts the vocabulary corresponding to the vocabulary category obtained as a result of the first speech recognition process from the second dictionary, and transmits the vocabulary to the second operating body.
- the information processing device controls the replacement of vocabulary in the second dictionary based on the log related to the result of the first voice recognition process.
- the second operating body locally executes the second voice recognition process using the second dictionary.
- the information processing device according to any one of (4) to (6) above.
- the moving body is an autonomous mobile body.
- the information processing device according to any one of (1) to (7) above. (9)
- the control unit of the other operating body can improve the voice recognition environment of the other operating body. Control the operation, The information processing device according to (8) above.
- the voice recognition environment includes the operating status of the operating body.
- the control unit controls the operation of the other operating body based on the operating state of one of the operating bodies.
- (11) When one of the operating bodies is performing an operation accompanied by an operating sound, the control unit controls so that the operating sound of the other operating body is further reduced.
- (12) The speech recognition environment includes a noise source or a speaker's recognition result.
- the control unit transmits information related to a noise sound source or a speaker recognized based on the sensor information collected by one of the operating bodies to the other operating body.
- the information processing device according to any one of (1) to (11).
- the control unit controls whether or not to execute the voice recognition process related to the other moving body based on the noise sound source recognized based on the sensor information collected by the moving body or the information related to the speaker.
- the information processing device according to (12) above.
- the control unit causes the other operating body to perform an active action on the user based on the environment recognized based on the sensor information collected by the one operating body.
- the information processing device according to any one of (1) to (13).
- the control unit causes the other operating body to execute an active utterance according to the environment based on the environment recognized based on the sensor information collected by the one operating body.
- the control unit controls the operation of the operating body based on the integrated recognition result determined from the results of a plurality of voice recognition processes based on the voices collected by the plurality of operating bodies.
- the information processing device according to any one of (1) to (15).
- the control unit has not obtained the same voice recognition processing result as the integrated recognition result on the operating body that has collected the voices for which the same voice recognition processing result as the integrated recognition result has been obtained.
- the information processing device according to (16) above.
- the control unit indicates that the same voice recognition processing result as the integrated recognition result was not obtained for the operating body that collected the voices for which the same voice recognition processing result as the integrated recognition result was not obtained. Make the words and actions shown The information processing device according to (16) or (17).
- the processor controls the operation of the operating body based on the result of the speech recognition process. Including The control is based on the result of voice recognition processing based on the voice collected by one of the moving bodies, or the voice recognition environment recognized based on the sensor information collected by one of the moving bodies. Controlling the movement of the moving body, Including, Information processing method. (20) Computer, A control unit that controls the operation of the operating body based on the result of voice recognition processing, With The control unit performs the other operation based on the result of the voice recognition process based on the voice collected by the one operating body or the voice recognition environment recognized based on the sensor information collected by the one operating body. Control body movements, Information processing device, A program to function as.
- First operating unit 140 Trigger detection unit 150 Control unit 20 Second operating unit 240 Recognition unit 242 Second dictionary 250 Control unit 30 Information processing server 310 Voice recognition unit 320 Natural language processing unit 322 First dictionary 330 Control Department 40 Network
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Multimedia (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- Aviation & Aerospace Engineering (AREA)
- Automation & Control Theory (AREA)
- Remote Sensing (AREA)
- Radar, Positioning & Navigation (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Signal Processing (AREA)
- Mathematical Physics (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Robotics (AREA)
- Mechanical Engineering (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
音声認識処理の結果に基づいて動作体の動作を制御する制御部、を備え、前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、情報処理装置が提供される。
Description
本開示は、情報処理装置、情報処理方法、およびプログラムに関する。
近年、音声認識処理に基づく動作を行う種々の装置が普及されている。また、音声認識処理の精度を向上させるための技術も多く開発されている。例えば、特許文献1には、雑音の音源と成り得る他の装置の音量レベルを低下させることで、音声認識精度を向上させる技術が開示されている。
ところで、環境中において、音声認識処理に基づく動作を行う動作体が複数存在する場合、各動作体が収集した情報に基づく認識結果を共有することで、より状況に適した動作を実現できる可能性がある。
本開示によれば、音声認識処理の結果に基づいて動作体の動作を制御する制御部、を備え、前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、情報処理装置が提供される。
また、本開示によれば、プロセッサが、音声認識処理の結果に基づいて動作体の動作を制御すること、を含み、前記制御することは、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御すること、をさらに含む、情報処理方法が提供される。
また、本開示によれば、コンピュータを、音声認識処理の結果に基づいて動作体の動作を制御する制御部、を備え、前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、情報処理装置、として機能させるためのプログラムが提供される。
以下に添付図面を参照しながら、本開示の好適な実施の形態について詳細に説明する。なお、本明細書及び図面において、実質的に同一の機能構成を有する構成要素については、同一の符号を付することにより重複説明を省略する。
なお、説明は以下の順序で行うものとする。
1.実施形態
1.1.概要
1.2.システム構成例
1.3.第1の動作体10の機能構成例
1.4.第2の動作体20の機能構成例
1.5.情報処理サーバ30の機能構成例
1.6.機能の詳細
2.情報処理サーバ30のハードウェア構成例
3.まとめ
1.実施形態
1.1.概要
1.2.システム構成例
1.3.第1の動作体10の機能構成例
1.4.第2の動作体20の機能構成例
1.5.情報処理サーバ30の機能構成例
1.6.機能の詳細
2.情報処理サーバ30のハードウェア構成例
3.まとめ
<1.実施形態>
<<1.1.概要>>
近年、ユーザの発話などを認識し、認識結果に基づく動作を実行する種々の装置が開発されている。上記のような装置には、例えば、ユーザとの音声対話を介して種々の機能提供を行う音声エージェント装置や、認識したユーザの発話や周囲環境などに応じて振る舞いを変化させる自律動作体が挙げられる。
<<1.1.概要>>
近年、ユーザの発話などを認識し、認識結果に基づく動作を実行する種々の装置が開発されている。上記のような装置には、例えば、ユーザとの音声対話を介して種々の機能提供を行う音声エージェント装置や、認識したユーザの発話や周囲環境などに応じて振る舞いを変化させる自律動作体が挙げられる。
上記のような装置には、収集した音声データをネットワークを介してサーバに送信し、サーバ側で実行された音声認識処理の結果に基づいて動作を行うものと、筐体(クライアント)に搭載した演算機で音声認識処理を実行するものとが存在する。
サーバ側で音声認識処理を実行する場合、演算資源を豊富に用意することが比較的容易なことから、一般的に高い認識精度が期待される。一方、クライアント側で音声認識処理を実行する場合、演算資源が限定される場合が多いものの、認識可能な語彙数を抑えることなどにより、演算量の低減と認識精度の向上を図りながら、速いレスポンスを実現することが可能である。
しかし、クライアント側で音声認識処理を実行する場合において、ユーザが発する語彙のセットと、予め用意された音声認識辞書の語彙のセットとに乖離がある場合、ユーザの発話を正確に認識することが困難である。
また、例えば、音声を収集する装置が比較的大きな動作音を伴う動作を行う場合、動作状況によっては、自身の動作音が音声収集の妨げとなり、音声認識の精度が低下する可能性がある。
本開示に係る技術思想は上記のような点に着目して発想されたものであり、音声認識処理に基づく動作を行う複数の動作体が存在する環境において、各動作体がより状況に適した動作を実現することを可能とする。
このために、本開示の一実施形態に係る情報処理方法は、プロセッサが、音声認識処理の結果に基づいて動作体の動作を制御すること、を含む。また、上記制御することは、一の動作体が収集した音声に基づく音声認識処理の結果、または一の動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の動作体を制御すること、をさらに含む。
<<1.2.システム構成例>>
図1は、本開示の一実施形態に係る情報処理システムの構成例を示す図である。本実施形態に係る情報処理サーバ30は、音声認識処理に基づく動作を行う複数の動作体を備えてよい。図1に示す一例の場合、本実施形態に係る情報処理システムは、第1の動作体10、第2の動作体20、および情報処理サーバ30を備えている。また、各構成は、ネットワーク40を介して互いに通信が可能なように接続される。
図1は、本開示の一実施形態に係る情報処理システムの構成例を示す図である。本実施形態に係る情報処理サーバ30は、音声認識処理に基づく動作を行う複数の動作体を備えてよい。図1に示す一例の場合、本実施形態に係る情報処理システムは、第1の動作体10、第2の動作体20、および情報処理サーバ30を備えている。また、各構成は、ネットワーク40を介して互いに通信が可能なように接続される。
(第1の動作体10)
本実施形態に係る第1の動作体10は、音声認識処理に基づいて動作する動作体(情報処理装置)の一例である。本実施形態に係る第1の動作体10は、収集した音声を情報処理サーバ30に送信し、情報処理サーバ30による音声認識処理の結果に基づいて動作する。本実施形態に係る第1の動作体10は、上記の音声認識処理の結果に基づいて、ユーザの発話に対するレスポンス発話を行うことや、認識した環境などに基づいて能動的にユーザに語りかけることなどができてよい。
本実施形態に係る第1の動作体10は、音声認識処理に基づいて動作する動作体(情報処理装置)の一例である。本実施形態に係る第1の動作体10は、収集した音声を情報処理サーバ30に送信し、情報処理サーバ30による音声認識処理の結果に基づいて動作する。本実施形態に係る第1の動作体10は、上記の音声認識処理の結果に基づいて、ユーザの発話に対するレスポンス発話を行うことや、認識した環境などに基づいて能動的にユーザに語りかけることなどができてよい。
また、本実施形態に係る第1の動作体10は、例えば、底部に備える車輪により走行や回転などが可能な自律移動体であってもよい。本実施形態に係る第1の動作体10は、例えば、卓上に設置が可能な程度の大きさと形状を有してもよい。本実施形態に係る第1の動作体10は、情報処理サーバ30による音声認識処理の結果や、各種の認識結果に基づいて、自律的に移動を行いながら、発話を含む各種の動作を実行する。
(第2の動作体20)
本実施形態に係る第2の動作体20は、第1の動作体10と同様に、音声認識処理に基づいて動作する動作体(情報処理装置)の一例である。一方、本実施形態に係る第2の動作体20は、第1の動作体10とは異なり、自身、すなわちローカル側で音声認識処理を実行する。
本実施形態に係る第2の動作体20は、第1の動作体10と同様に、音声認識処理に基づいて動作する動作体(情報処理装置)の一例である。一方、本実施形態に係る第2の動作体20は、第1の動作体10とは異なり、自身、すなわちローカル側で音声認識処理を実行する。
本実施形態に係る第2の動作体20は、例えば、図示するように、イヌなどの動物を模した四足歩行型の自律移動体であってもよい。本実施形態に係る第2の動作体20は、ローカル側で実行した音声認識処理の結果などに基づいて、ユーザに対する応答を動作や鳴き声などにより実行する。
(情報処理サーバ30)
本実施形態に係る情報処理サーバ30は、第1の動作体10が収集した音声に基づく音声認識処理や自然言語理解処理を行う情報処理装置である。また、本実施形態に係る情報処理サーバ30は、一の動作体が収集した音声に基づく音声認識処理の結果や一の動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の動作体の動作を制御してもよい。
本実施形態に係る情報処理サーバ30は、第1の動作体10が収集した音声に基づく音声認識処理や自然言語理解処理を行う情報処理装置である。また、本実施形態に係る情報処理サーバ30は、一の動作体が収集した音声に基づく音声認識処理の結果や一の動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の動作体の動作を制御してもよい。
(ネットワーク40)
ネットワーク40は、上記の各構成を接続する機能を有する。ネットワーク40は、インターネット、電話回線網、衛星通信網などの公衆回線網や、Ethernet(登録商標)を含む各種のLAN(Local Area Network)、WAN(Wide Area Network)などを含んでもよい。また、ネットワーク40は、IP-VPN(Internet Protocol-Virtual Private Network)などの専用回線網を含んでもよい。また、ネットワーク40は、Wi-Fi(登録商標)、Bluetooth(登録商標)など無線通信網を含んでもよい。
ネットワーク40は、上記の各構成を接続する機能を有する。ネットワーク40は、インターネット、電話回線網、衛星通信網などの公衆回線網や、Ethernet(登録商標)を含む各種のLAN(Local Area Network)、WAN(Wide Area Network)などを含んでもよい。また、ネットワーク40は、IP-VPN(Internet Protocol-Virtual Private Network)などの専用回線網を含んでもよい。また、ネットワーク40は、Wi-Fi(登録商標)、Bluetooth(登録商標)など無線通信網を含んでもよい。
以上、本実施形態に係る情報処理システムの構成例について述べた。なお、図1を用いて説明した上記の構成はあくまで一例であり、本実施形態に係る情報処理システムの構成は係る例に限定されない。例えば、本実施形態に係る情報処理システムは、3種以上の動作体を備えてもよい。また、動作体の一部は自律移動体に限定されず、据え置き型や屋内埋め込み型のエージェント装置であってもよい。本実施形態に係る情報処理システムの構成は、仕様や運用に応じて柔軟に変形可能である。
<<1.3.第1の動作体10の機能構成例>>
次に、本実施形態に係る第1の動作体10の機能構成例について述べる。図2は、本実施形態に係る第1の動作体10の機能構成例を示すブロック図である。図2に示すように、本実施形態に係る第1の動作体10は、音入力部110、撮影部120、センサ部130、トリガ検出部140、制御部150、駆動部160、音出力部170、表示部180、および通信部190を備える。
次に、本実施形態に係る第1の動作体10の機能構成例について述べる。図2は、本実施形態に係る第1の動作体10の機能構成例を示すブロック図である。図2に示すように、本実施形態に係る第1の動作体10は、音入力部110、撮影部120、センサ部130、トリガ検出部140、制御部150、駆動部160、音出力部170、表示部180、および通信部190を備える。
(音入力部110)
本実施形態に係る音入力部110は、ユーザの発話音声を含む各種の音を収集する。このために、本実施形態に係る音入力部110は、1つ以上のマイクロフォンを備える。
本実施形態に係る音入力部110は、ユーザの発話音声を含む各種の音を収集する。このために、本実施形態に係る音入力部110は、1つ以上のマイクロフォンを備える。
(撮影部120)
本実施形態に係る撮影部120は、ユーザや周囲環境の画像を撮影する。このために、本実施形態に係る撮影部120は、撮像素子を備える。
本実施形態に係る撮影部120は、ユーザや周囲環境の画像を撮影する。このために、本実施形態に係る撮影部120は、撮像素子を備える。
本実施形態に係るセンサ部130は、各種のセンサデバイスによりユーザや周囲環境、また第1の動作体10に係るセンサ情報を収集する。本実施形態に係るセンサ部130は、例えば、ToFセンサ、慣性センサ、赤外線センサ、照度センサ、ミリ波レーダ、タッチセンサ、GNSS(Global Navigation Satellite System)信号受信機などを備える。
(トリガ検出部140)
本実施形態に係るトリガ検出部140は、音入力部110、撮影部120、およびセンサ部130が収集した各種の情報に基づいて、音声認識処理の開始に係る各種のトリガを検出する。
本実施形態に係るトリガ検出部140は、音入力部110、撮影部120、およびセンサ部130が収集した各種の情報に基づいて、音声認識処理の開始に係る各種のトリガを検出する。
例えば、本実施形態に係るトリガ検出部140は、音入力部110が収集した発話音声と、ユーザにより自由に登録された特定発話表現とに基づいて、特定ワード(起動ワード)を検出してもよい。
また、例えば、本実施形態に係るトリガ検出部140は、撮影部120が撮影した画像に基づいて、ユーザの顔や体の検出や、特定ジェスチャの検出を行ってもよい。
また、例えば、本実施形態に係るトリガ検出部140は、センサ部130が収集した加速度情報に基づいて、ユーザによる第1の動作体10の持ち上げや静置を検出してもよい。
(制御部150)
本実施形態に係る制御部150は、第1の動作体10が備える各構成を制御する。また、本実施形態に係る制御部150は、後述するように、情報処理サーバ30による音声認識処理の結果などを第2の動作体20に伝達し、間接的あるいは直接的に第2の動作体20の動作を制御してもよい。
本実施形態に係る制御部150は、第1の動作体10が備える各構成を制御する。また、本実施形態に係る制御部150は、後述するように、情報処理サーバ30による音声認識処理の結果などを第2の動作体20に伝達し、間接的あるいは直接的に第2の動作体20の動作を制御してもよい。
(駆動部160)
本実施形態に係る駆動部160は、制御部150による制御に基づいて、各種の動作を行う。本実施形態に係る駆動部160は、例えば、複数のアクチュエータ(モータ等)や車輪等を備えてもよい。
本実施形態に係る駆動部160は、制御部150による制御に基づいて、各種の動作を行う。本実施形態に係る駆動部160は、例えば、複数のアクチュエータ(モータ等)や車輪等を備えてもよい。
(音出力部170)
本実施形態に係る音出力部170は、制御部150による制御に基づいてシステム音声等の出力を行う。このために、本実施形態に係る音出力部170は、アンプやスピーカを備える。
本実施形態に係る音出力部170は、制御部150による制御に基づいてシステム音声等の出力を行う。このために、本実施形態に係る音出力部170は、アンプやスピーカを備える。
(表示部180)
本実施形態に係る表示部180は、制御部150による制御に基づいて、視覚情報の提示を行う。本実施形態に係る表示部180は、例えば、眼に対応するLEDやOLED等を備える。
本実施形態に係る表示部180は、制御部150による制御に基づいて、視覚情報の提示を行う。本実施形態に係る表示部180は、例えば、眼に対応するLEDやOLED等を備える。
(通信部190)
本実施形態に係る通信部190は、ネットワーク40を介して第2の動作体20や情報処理サーバ30との情報通信を行う。例えば、本実施形態に係る通信部190は、音入力部110が収集したユーザの発話音声を情報処理サーバ30に送信し、当該発話音声に対応する音声認識結果や応答情報を受信する。
本実施形態に係る通信部190は、ネットワーク40を介して第2の動作体20や情報処理サーバ30との情報通信を行う。例えば、本実施形態に係る通信部190は、音入力部110が収集したユーザの発話音声を情報処理サーバ30に送信し、当該発話音声に対応する音声認識結果や応答情報を受信する。
以上、本実施形態に係る第1の動作体10の機能構成例について説明した。なお、図2を用いて説明した上記の構成はあくまで一例であり、本実施形態に係る第1の動作体10の機能構成は係る例に限定されない。本実施形態に係る第1の動作体10の機能構成は、仕様や運用に応じて柔軟に変形可能である。
<<1.4.第2の動作体20の機能構成例>>
次に、本実施形態に係る第2の動作体20の機能構成例について述べる。図3は、本実施形態に係る第2の動作体20の機能構成例を示すブロック図である。図3に示すように、本実施形態に係る第2の動作体20は、音入力部210、撮影部220、センサ部230、認識部240、制御部250、駆動部260、音出力部270、表示部280、および通信部290を備える。
次に、本実施形態に係る第2の動作体20の機能構成例について述べる。図3は、本実施形態に係る第2の動作体20の機能構成例を示すブロック図である。図3に示すように、本実施形態に係る第2の動作体20は、音入力部210、撮影部220、センサ部230、認識部240、制御部250、駆動部260、音出力部270、表示部280、および通信部290を備える。
(音入力部210)
本実施形態に係る音入力部210は、ユーザの発話音声を含む各種の音を収集する。このために、本実施形態に係る音入力部210は、1つ以上のマイクロフォンを備える。
本実施形態に係る音入力部210は、ユーザの発話音声を含む各種の音を収集する。このために、本実施形態に係る音入力部210は、1つ以上のマイクロフォンを備える。
(撮影部220)
本実施形態に係る撮影部220は、ユーザや周囲環境の画像を撮影する。このために、本実施形態に係る撮影部220は、撮像素子を備える。撮影部220は、例えば、第2の動作体20の鼻先と腰部に2つの広角カメラを備えてもよい。この場合、鼻先に配置される広角カメラは、第2の動作体20の前方視野(すなわち、イヌの視野)に対応した画像を撮像し、腰部の広角カメラは、上方を中心とする周囲領域の画像を撮像する。第2の動作体20は、例えば、腰部に配置される広角カメラにより撮像された画像に基づいて、天井の特徴点などを抽出し、SLAM(Simultaneous Localization and Mapping)を実現することができる。
本実施形態に係る撮影部220は、ユーザや周囲環境の画像を撮影する。このために、本実施形態に係る撮影部220は、撮像素子を備える。撮影部220は、例えば、第2の動作体20の鼻先と腰部に2つの広角カメラを備えてもよい。この場合、鼻先に配置される広角カメラは、第2の動作体20の前方視野(すなわち、イヌの視野)に対応した画像を撮像し、腰部の広角カメラは、上方を中心とする周囲領域の画像を撮像する。第2の動作体20は、例えば、腰部に配置される広角カメラにより撮像された画像に基づいて、天井の特徴点などを抽出し、SLAM(Simultaneous Localization and Mapping)を実現することができる。
本実施形態に係るセンサ部230は、各種のセンサデバイスによりユーザや周囲環境、また第2の動作体20に係るセンサ情報を収集する。本実施形態に係るセンサ部230は、例えば、測距センサ、慣性センサ、赤外線センサ、照度センサ、タッチセンサ、接地センサなどを備える。
(認識部240)
本実施形態に係る認識部240は、音入力部210、撮影部220、およびセンサ部230が収集した情報に基づいて、各種の認識処理を実行する。例えば、本実施形態に係る認識部240は、音入力部210が収集したユーザの発話音声に基づく音声認識処理をローカル側で実行する。また、認識部240は、話者識別、表情や視線の認識、物体認識、動作認識、空間領域認識、色認識、形認識、マーカー認識、障害物認識、段差認識、明るさ認識などを行ってよい。
本実施形態に係る認識部240は、音入力部210、撮影部220、およびセンサ部230が収集した情報に基づいて、各種の認識処理を実行する。例えば、本実施形態に係る認識部240は、音入力部210が収集したユーザの発話音声に基づく音声認識処理をローカル側で実行する。また、認識部240は、話者識別、表情や視線の認識、物体認識、動作認識、空間領域認識、色認識、形認識、マーカー認識、障害物認識、段差認識、明るさ認識などを行ってよい。
(制御部250)
本実施形態に係る制御部250は、認識部240による各種の認識処理の結果に基づいて、第2の動作体20が備える各構成を制御する。また、本実施形態に係る制御部250は、認識部240による各種の認識処理の結果を他の動作体(例えば、第1の動作体または第2の動作体)に伝達し、当該他の動作体の動作を間接的あるいは直接的に制御してもよい。
本実施形態に係る制御部250は、認識部240による各種の認識処理の結果に基づいて、第2の動作体20が備える各構成を制御する。また、本実施形態に係る制御部250は、認識部240による各種の認識処理の結果を他の動作体(例えば、第1の動作体または第2の動作体)に伝達し、当該他の動作体の動作を間接的あるいは直接的に制御してもよい。
(駆動部260)
駆動部260は、制御部250による制御に基づいて、第2の動作体20が有する複数の関節部を屈伸させる機能を有する。より具体的には、駆動部260は、制御部250による制御に基づき、各関節部が備えるアクチュエータを駆動させる。
駆動部260は、制御部250による制御に基づいて、第2の動作体20が有する複数の関節部を屈伸させる機能を有する。より具体的には、駆動部260は、制御部250による制御に基づき、各関節部が備えるアクチュエータを駆動させる。
(音出力部270)
本実施形態に係る音出力部270は、制御部250による制御に基づいてイヌの鳴き声を模した音等の出力を行う。このために、本実施形態に係る音出力部170は、アンプやスピーカを備える。
本実施形態に係る音出力部270は、制御部250による制御に基づいてイヌの鳴き声を模した音等の出力を行う。このために、本実施形態に係る音出力部170は、アンプやスピーカを備える。
(表示部280)
本実施形態に係る表示部280は、制御部250による制御に基づいて、視覚情報の提示を行う。本実施形態に係る表示部280は、例えば、眼に対応するLEDやOLED等を備える。
本実施形態に係る表示部280は、制御部250による制御に基づいて、視覚情報の提示を行う。本実施形態に係る表示部280は、例えば、眼に対応するLEDやOLED等を備える。
(通信部290)
本実施形態に係る通信部290は、ネットワーク40を介して第1の動作体10や情報処理サーバ30との情報通信を行う。例えば、本実施形態に係る通信部290は、第1の動作体10または情報処理サーバ30から、他の動作体が収集した音声に基づく音声認識処理の結果を受信する。
本実施形態に係る通信部290は、ネットワーク40を介して第1の動作体10や情報処理サーバ30との情報通信を行う。例えば、本実施形態に係る通信部290は、第1の動作体10または情報処理サーバ30から、他の動作体が収集した音声に基づく音声認識処理の結果を受信する。
以上、本実施形態に係る第2の動作体20の機能構成例について説明した。なお、図3を用いて説明した上記の構成はあくまで一例であり、本実施形態に係る第2の動作体20の機能構成は係る例に限定されない。本実施形態に係る第2の動作体20の機能構成は、仕様や運用に応じて柔軟に変形可能である。
<<1.5.情報処理サーバ30の機能構成例>>
次に、本実施形態に係る情報処理サーバ30の機能構成例について述べる。図4は、本実施形態に係る情報処理サーバ30の機能構成例を示すブロック図である。図4に示すように、本実施形態に係る情報処理サーバ30は、音声認識部310、自然言語処理部320、制御部330、応答生成部340、通信部350を備える。
次に、本実施形態に係る情報処理サーバ30の機能構成例について述べる。図4は、本実施形態に係る情報処理サーバ30の機能構成例を示すブロック図である。図4に示すように、本実施形態に係る情報処理サーバ30は、音声認識部310、自然言語処理部320、制御部330、応答生成部340、通信部350を備える。
(音声認識部310)
本実施形態に係る音声認識部310は、第1の動作体10から受信した発話音声に戻づく音声認識処理を行い、当該発話音声を文字列に変換する。
本実施形態に係る音声認識部310は、第1の動作体10から受信した発話音声に戻づく音声認識処理を行い、当該発話音声を文字列に変換する。
(自然言語処理部320)
本実施形態に係る自然言語処理部320は、音声認識部310が生成した文字列に基づく自然言語理解処理を行い、ユーザの発話の意図を抽出する。
本実施形態に係る自然言語処理部320は、音声認識部310が生成した文字列に基づく自然言語理解処理を行い、ユーザの発話の意図を抽出する。
(制御部330)
本実施形態に係る制御部330は、一の動作体が収集した音声に基づく音声認識処理の結果や、一の動作体が収集したセンサ情報に基づいて認識された環境に基づいて、一の動作体や他の動作体の動作を制御する。本実施形態に係る制御部330が有する機能の詳細については、別途後述する。
本実施形態に係る制御部330は、一の動作体が収集した音声に基づく音声認識処理の結果や、一の動作体が収集したセンサ情報に基づいて認識された環境に基づいて、一の動作体や他の動作体の動作を制御する。本実施形態に係る制御部330が有する機能の詳細については、別途後述する。
(応答生成部340)
本実施形態に係る応答生成部340は、制御部330による制御に基づいて、自然言語処理部320が抽出したユーザの発話意図に対応する応答情報を生成する。応答生成部340は、例えば、ユーザの発話に対する応答音声等を生成する。
本実施形態に係る応答生成部340は、制御部330による制御に基づいて、自然言語処理部320が抽出したユーザの発話意図に対応する応答情報を生成する。応答生成部340は、例えば、ユーザの発話に対する応答音声等を生成する。
(通信部350)
本実施形態に係る通信部350は、ネットワーク40を介して第1の動作体10や第2の動作体20との情報通信を行う。例えば、通信部350は、第1の動作体10から発話音声を受信する。また、通信部350は、上記発話音声に基づく音声認識処理および自然言語理解処理の結果に係る情報を第2の動作体20に送信する。
本実施形態に係る通信部350は、ネットワーク40を介して第1の動作体10や第2の動作体20との情報通信を行う。例えば、通信部350は、第1の動作体10から発話音声を受信する。また、通信部350は、上記発話音声に基づく音声認識処理および自然言語理解処理の結果に係る情報を第2の動作体20に送信する。
以上、本実施形態に係る情報処理サーバ30の機能構成例について説明した。なお、図4を用いて説明した上記の構成はあくまで一例であり、本実施形態に係る情報処理サーバ30の機能構成は係る例に限定されない。本実施形態に係る情報処理サーバ30の機能構成は、仕様や運用に応じて柔軟に変形可能である。
<<1.6.機能の詳細>>
次に、本実施形態に係る情報処理システムが有する機能について詳細に説明する。上述したように、本実施形態に係る情報処理方法は、音声認識処理に基づき動作する複数の動作体が存在する環境において、各動作体が収集した情報から認識された情報を共有することにより、各動作体がより適切な動作を行うことを実現するものである。
次に、本実施形態に係る情報処理システムが有する機能について詳細に説明する。上述したように、本実施形態に係る情報処理方法は、音声認識処理に基づき動作する複数の動作体が存在する環境において、各動作体が収集した情報から認識された情報を共有することにより、各動作体がより適切な動作を行うことを実現するものである。
このために、本実施形態に係る情報処理システムでは、機能や特性が異なる複数種類の動作体を備えてもよい。例えば、本実施形態に係る情報処理システムは、上述した第1の動作体10と第2の動作体20とを備え得る。
本実施形態に係る第1の動作体10は、情報処理サーバ30による語彙数が豊富なクラウド辞書(以下、第1の辞書、とも称する)を用いた音声認識処理(以下、第1の音声認識処理、とも称する)、および自然言語理解処理の結果に基づいて動作することが可能であり、第2の動作体20と比較して、より広い語彙および発話意図を精度高く認識し応答動作を行うことが可能である。
また、本実施形態に係る第1の動作体10は、底部に備える車輪により移動することから、サーボ音や接地ノイズが大きい第2の動作体20の歩行移動と比較して、移動音(動作音)が静かであることが特徴の一つである。
また、本実施形態に係る第1の動作体10は、卓上に配置されることを想定していることから、第2の動作体20と比較して高い視点を有し、第2の動作体20よりも広い視野でユーザや物体などを認識することが可能である。
さらには、本実施形態に係る第1の動作体10は、言語を用いてユーザとの対話が可能であり、認識したユーザの発話や環境などについて、より確実にユーザに伝達することができる。
上記に対し、本実施形態に係る第2の動作体20は、ローカル側において、クラウド辞書よりも語彙数が少ないローカル辞書(以下、第2の辞書、とも称する)を用いて音声認識処理(以下、第2の音声認識処理、とも称する)を行い、当該音声認識処理の結果に基づいて動作する。このため、本実施形態に係る第2の動作体20は、予め登録された語彙のみを認識可能である一方、語彙数を抑えることで、演算量を効果的に低減し、速いレスポンスを行うことが可能である。
また、本実施形態に係る第2の動作体20は、床上を歩行移動することから、第1の動作体10と比較して広い行動範囲を有し、複数の部屋間を移動することができる。さらには、本実施形態に係る第2の動作体20は、SLAMにより環境地図を生成することができ、また、ユーザからの教示などにより空間の名称(例えば、リビングルームやキッチンなど)と環境地図とを対応付けることも可能である。
このように、本実施形態に係る第1の動作体10および第2の動作体20は、互いに対し優位な点をそれぞれに有する。以下、上記のような特徴を有する第1の動作体10と第2の動作体20との情報連携について、具体例を挙げながら説明する。
まず、本実施形態に係る音声認識結果の共有について説明する。本実施形態に係る情報処理サーバ30の制御部330は、一の動作体が収集した音声に基づく音声認識処理の結果に基づいて、当該音声認識処理の結果に対応する動作を他の動作体に実行させてよい。例えば、制御部330は、ある第1の動作体10が収集した音声に基づく第1の音声認識処理の結果を第2の動作体20に伝達し、第2の動作体20の動作を間接的あるいは直接的に制御することが可能である。
図5は、本実施形態に係る音声認識結果の共有について説明するための図である。図5の上段に示す一例では、ユーザUが“That‘s my boy”という、第2の動作体20を褒める意図(goodFB)を有する発話UO1を行っている。
しかし、図5に示す一例の場合、第2の動作体20が備える第2の辞書242には、カテゴリ:goodFBに対応する語彙が、“Good boy”のみしか登録されていないため、第2の動作体20は、ユーザUの発話UO1を正確に認識することが困難である。
一方、情報処理サーバ30が備える第1の辞書322には、“That‘s my boy”が登録されているため、情報処理サーバ30は、第1の音声認識処理により発話UO1を精度高く認識し、また認識結果を第1の動作体10に伝達することができる。
このように、第2の動作体20が備える第2の辞書242にユーザの発話に対応する語彙が登録されていない場合、情報処理サーバ30の制御部330は、第1の動作体10が収集した音声と第1の辞書322に基づく第1の音声認識処理の結果に基づいて、当該悔過に対応する動作を第2の動作体20に実行させてもよい。
より具体的には、本実施形態に係る制御部330は、第1の音声認識処理の結果として得られた語彙のカテゴリに対応する語彙を第2の辞書242から抽出し、当該語彙を第2の動作体20に伝達してよい。
図5の下段に示す一例の場合、制御部330は、第1の音声認識処理により得られた語彙“That‘s my boy”のカテゴリ:goodFBに対応する語彙“Good boy”を第2の辞書242から抽出し、語彙“Good boy”を第2の動作体20に伝達している。係る制御によれば、第2の動作体20が、自力では認識することができない語彙“That‘s my boy”を疑似的に理解し、ユーザUの発話意図に応じた適切な動作を実行することが可能となる。なお、制御部330は、第1の音声認識処理により得られた語彙に加えて、あるいは代えて、当該語彙のカテゴリに係る情報を第2の動作体20に伝達してもよい。
また、上記のような音声認識結果の共有を行う場合、本実施形態に係る制御部330は、一の動作体が収集した音声に基づく音声認識処理の結果を他の動作体に伝達したことを示す動作を当該一の動作体に実行させてもよい。
例えば、本実施形態に係る制御部330は、第1の動作体10が収集した音声に基づく第1の音声認識処理の結果を第2の動作体20に伝達したことを示す動作を第1の動作体10に実行させてもよい。図5の下段に示す一例の場合、制御部330は、第1の動作体10に、“He praised you”というシステム発話SO1を第2の動作体20に向けて出力させている。
上記の例の他、制御部330は、例えば、「僕が教えてあげたんだ」などのシステム発話や、第1の動作体10がユーザUの発話UO1を第2の動作体20に対して通訳しているようなシステム発話(例えば、犬の鳴き声を模した音を用いた発話)を第1の動作体10に実行させてもよい。
また、制御部330は、音声認識結果の共有先である第2の動作体にも、共有が行われたことを示す動作を実行させてもよい。上記のような第1の音声認識結果の伝達を行った場合、制御部330は、例えば、通常時よりも大きな音声や動きを第2の動作体20に行わせてもよい。また、制御部330は、自力で理解できなかったことを恥ずかしそうにする振る舞いや、第1の動作体10に対して感謝を示す振る舞いなどを第2の動作体20に実行させてもよい。
上記のような制御によれば、第1の動作体10と第2の動作体20とが実際の生物のようにコミュニケーションを行っているような表現を実現することができ、ユーザの興味をさらに引き付けることが期待される。
以上、本実施形態に係る音声認識結果の共有について説明した。なお、上記では、共有に係る制御主体が情報処理サーバ30の制御部330である場合を例に述べたが、音声認識結果の共有に係る制御主体は、第1の動作体10の制御部150であってもよい。制御部150は、情報処理サーバ30から第1の音声認識処理の結果を受信した後、当該結果を近距離無線通信などにより第2の動作体20に伝達することが可能である。
続いて、本実施形態に係る音声認識結果の共有の処理の流れについて説明する。図6Aは、本実施形態に係る音声認識結果の共有における第1の動作体10および情報処理サーバ30の動作の流れを示すフローチャートである。
図6Aを参照すると、第1の動作体10は、まず、認識した環境に基づいて自律動作を行う(S1101)。
次に、制御主体となる制御部150または制御部330は、第1の音声認識処理により認識された語彙に対応するカテゴリの語彙が第2の動作体20が備える第2の辞書242に存在するか否かを判定する(S1102)。
ここで、対応する語彙が第2の辞書242に存在する場合(S1102:YES)、制御主体は、続いて、発話が第2の動作体20に対するものか否かを判定する(S1103)。制御部150や制御部330は、第1の動作体10のトリガ検出部140がユーザの顔が第2の動作体20に向いていることを検出したこと、第2の動作体20がユーザによる接触を検出したこと、直前の発話が第2の動作体の名前を含んでいたこと、などに基づいて、上記の判定を行うことができる。
ここで、発話が第2の動作体20に対するものである場合(S1103:YES)、制御主体は、対応する語彙を第2の動作体20に伝達する(S1104)。
一方、第2の辞書242に対応する語彙が存在しない場合(S1102:NO)や、発話が第2の動作体20に対するものではない場合(S1103:NO)、第1の動作体10は、ステップS1101に復帰する。
図6Bは、本実施形態に係る音声認識結果の共有における第2の動作体20の動作の流れを示すフローチャートである。
図6Bを参照すると、第2の動作体20は、まず、認識した環境に基づいて自律動作を行う(S1201)。
次に、第2の動作体20の制御部250は、第1の動作体10または情報処理サーバ30から、語彙を受信したか否かを判定する(S1202)。
ここで、語彙が受信されている場合(S1202:YES)、制御部250は、他装置からの伝達により語彙を理解したことを示す動作を第1の動作体10に実行させる(S1203)。
一方、語彙が受信されていない場合(S1202:NO)、第2の動作体20は、ステップS1201に復帰する。
以上、本実施形態に係る音声認識結果の共有の処理の流れについて説明した。続いて、本実施形態に係る第1の音声認識処理の結果のログに基づく第2の辞書の更新について述べる。
上述したように、本実施形態に係る第2の動作体20は、第2の辞書242に登録する語彙数を抑えることで、演算量を抑え速いレスポンスを実現することができる。一方、ユーザが日常的に使用する語彙セットと第2の辞書242に登録されている語彙セットとの間に乖離がある場合、認識精度が低下しユーザ体験を損なう可能性が生じる。このために、本実施形態に係る情報処理システムは、第2の辞書242に登録される語彙セットを定期または非定期に入れ替える仕組みを有してよい。
図7は、本実施形態に係る第2の辞書242に登録される語彙セットの入れ替えについて説明するための図である。なお、図7では、情報処理システムが備える構成のうち、語彙セットの入れ替え機能に着目して作成されたブロック図であり、一部の構成が省略されている。
第2の辞書242に登録される語彙の入れ替えを実現するために、本実施形態に係る第2の動作体20は、評価部735、辞書更新部740、および、第2の辞書242とは別途の候補辞書745を備えてよい。
本実施形態に係る評価部735は、蓄積された単独知に基づいて、ユーザの発話実績を評価する。ここで、上記の単独知とは、第2の動作体20の独自の経験に基づく知識を指す。具体的には、本実施形態に係る単独知には、認識部240が認識した発話ログ720や発話時におけるステータスを記録した発話時ステータスログ730が含まれる。
この際、本実施形態に係る評価部735は、認識された回数が多い語彙ほど発話実績が高いと評価してもよい。一方、認識部240による誤認識や、湧き出しなどへの対応のため、評価部735は、発話時ステータスなどに基づいて発話実績を総合的に評価してよい。ここで、誤認識とは、ユーザの実際の発話「おはよう」に対して認識部240が「おはよう」以外の認識結果を出力すること、例えば、「おやすみ」と出力してしまうことを意味する。また、湧き出しとは、生活音などユーザの発話以外の音に対して認識結果を出力すること、例えば、ドアを閉めた音に対して「ばん」という認識結果を出力してしまうことを意味する。
また、本実施形態に係る辞書更新部740は、制御部250による制御に基づき、評価部735が評価した発話実績に応じた第2の辞書242および候補辞書745の更新を実行する。ここで、本実施形態に係る候補辞書745は、第2の辞書242への追加または入れ替え対象となる語彙が登録される辞書である。辞書更新部740は、例えば、発話実績が低い語彙を第2の辞書242から削除、または候補辞書745に移行し、候補辞書745に登録される優先度の高い語彙を代わりに第2の辞書242に登録することなどができる。
また、本実施形態に係る辞書更新部740は、情報処理サーバ30から未登録の語彙を取得し、当該語彙を第2の辞書242や候補辞書745に追加登録する機能を有してよい。辞書更新部740は、例えば、相関語彙931、トレンド語彙932、季節語彙933、世代別語彙934、方言935などを取得し、第2の辞書242や候補辞書745に追加登録してもよい。この際、語彙数を一定以下に保つため、辞書更新部740は、第2の辞書242や候補辞書745から、発話実績が低い語彙を削除してもよい。
なお、上記の相関語彙931とは、ある語彙に続けて発話される別の語彙など、他の語彙や機能との相関性の高い語彙を指す。相関語彙931は、例えば、複数の第2の動作体20が記録した発話ログ720や発話時ステータスログ730を統合的に蓄積した集合知915の分析に基づき取得されてもよい。
また、上記のトレンド語彙932とは世間においてトレンドとなっている語彙を、季節語彙933とは季節に応じた語彙を、世代別語彙934とは世代ごとに多用される語彙を、それぞれ指す。
以上、第2の辞書242の更新に係る第2の動作体20の構成について述べた。上述した構成によれば、ユーザの発話実績に基づいて第2の辞書242を適宜更新することができ、ユーザが用いる語彙セットと第2の辞書242に登録される語彙セットとの乖離を効果的に抑えることができる。なお、上記で説明した辞書更新の詳細については、本開示の出願人が過去に出願を行った特願2018-124856を参照されたい。
一方、ユーザの発話実績を第2の動作体20が蓄積する発話ログ720や発話時ステータスログ730のみに基づいて評価する場合、分析を行うために必要な情報の蓄積には時間を要する場合も想定される。このため、本実施形態に係る制御部250は、第1の動作体10が収集した音声に基づく第1の音声認識処理の結果に係る認識ログ324をさらに用いた辞書更新を辞書更新部740に実行させてもよい。すなわち、本実施形態に係る制御部250は、認識ログ324に基づいて、第2の辞書242や候補辞書745の入れ替えを制御することができる。
上記の制御によれば、第1の音声認識処理により精度高く認識された語彙とその回数に基づいて、ユーザの発話実績をさらに正確に評価することができ、辞書更新の精度を向上させるとともに、評価に必要なログの蓄積を最小化することが可能となる。
図8は、本実施形態に係る情報処理サーバ30による認識ログの蓄積の流れを示すフローチャートである。
図8を参照すると、まず、音声認識部310が第1の動作体10から受信した音声データに基づいて第1の音声認識処理を行う(S1301)。
続いて、音声認識部310は、ステップS1301における第1の音声認識処理により複数回認識した語彙があるか否かを判定する(S1302)。
ここで、複数回認識した語彙がある場合(S1302:YES)、音声認識部310は、認識した語彙とその回数を認識ログ324に保存する(S1303)。
一方、複数認識した語彙がない場合(S1302:NO)、情報処理サーバ30は、ステップS1301に復帰する。
図9は、本実施形態に係る第2の動作体20による辞書更新の流れを示すフローチャートである。
図9を参照すると、まず、制御部250が、辞書の更新に係る入れ替えアルゴリズムを辞書更新部740に実行させる(S1401)。
次に、制御部250は、情報処理サーバ30に蓄積される認識ログ324に語彙が存在するか否かを判定する(S1402)。
ここで、認識ログ324に語彙が存在する場合(S1402:YES)、制御部250は、辞書更新部740に当該語彙と関連する他の語彙を追加で選定させる(S1403)。辞書更新部740は、認識ログ324に登録されている語彙のプロファイルに基づいて、相関語彙931、トレンド語彙932、季節語彙933、世代別語彙934、方言935などから追加で登録する語彙を選定してよい。
次に、制御部250は、辞書更新部740を制御し、認識ログ324から取得された語彙と関連する語彙とを第2の辞書242や候補辞書745に追加させる(S1404)。
以上、本実施形態に係る辞書更新について説明した。なお、上記では、第2の動作体20の制御部250が、辞書更新の制御主体となる場合を例に説明したが、本実施形態に係る辞書更新の制御主体は、情報処理サーバ30の制御部330であってもよい。
次に、本実施形態に係る認識環境の共有に基づく動作制御について説明する。本実施形態に係る情報処理方法では、音声認識結果の他、各動作体が収集された情報に基づいて認識された環境を複数の動作体の間で共有し、また動作体の動作制御に利用することができてよい。
例えば、本実施形態に係る制御部330は、一の動作体に係る音声認識環境が音声認識処理精度の低下要因となり得る環境である場合、他の動作体に係る音声認識環境が向上するよう他の動作体の動作を制御してもよい。
ここで、上記の音声認識環境とは、音声認識精度に影響を及ぼす各種の環境を指し、例えば、動作体の動作状況を含んでよい。例えば、動作体がサーボ音や接地音などの比較的大きな動作音を伴う動作を行っている場合、当該動作音がユーザの発話音声の収集を妨害し、音声認識精度が低下する場合が想定される。
このため、本実施形態に係る制御部330は、一の動作体の動作状況に基づいて、他の動作体の動作を制御してもよい。より詳細には、本実施形態に係る制御部330は、一の動作体が比較的大きな動作音を伴う動作を実行している場合、他の動作体の動作音がより低下するよう制御を行う。
図10は、本実施形態に係る一の動作体の動作状況に基づく他の動作体の動作制御について説明するための図である。図10に示す一例の場合、第2の動作体20がボールで遊ぶ動作を行っている状況において、ユーザUが、発話UO2を行っている。この場合、第2の動作体20は、自身の動作音に妨げられ発話UO2に係る音声を精度高く収集できない可能性がある。
この際、本実施形態に係る情報処理サーバ30の制御部330は、第2の動作体20からアップロードされる動作ステータス(2nd_MOVING:TRUE)に基づいて、第2の動作体20による第2の音声認識処理の精度低下を予測することができてよい。また、制御部330は、第1の動作体10が発話UO2に係る音声を精度高く収集することができるように、第1の動作体10の動作音がより小さくなるよう制御を行う。制御部330は、例えば、第1の動作体10を静止させてもよい。
上記の制御によれば、動作中である第2の動作体20に代わり、第1の動作体10がユーザUの発話UO2に係る音声を収集することができ、さらには、第1の音声認識処理の結果を第2の動作体20に伝達することにより、第2の動作体20が動作中であっても発話UO2に対応する動作を行うことが可能となる。
図11は、本実施形態に係る一の動作体の動作状況に基づく他の動作体の動作制御の流れを示すフローチャートである。
図11を参照すると、まず、第1の動作体10が自律動作を行っている状況(S1501)において、制御部330が第2の動作体20が動作中であるか否かを判定する(S1502)。上述したように、制御部330は、第2の動作体20からアップロードされる動作ステータスに基づいて上記の判定を行うことができる。
ここで、第2の動作体20が動作中である場合(S1502:YES)、制御部330は、第1の動作体10の動作音がより小さくなるように制御を行う(S1503)。
次に、制御部330は、第1の音声認識処理により認識された語彙に対応するカテゴリの語彙が第2の動作体20が備える第2の辞書242に存在するか否かを判定する(S1504)。
ここで、対応する語彙が第2の辞書242に存在する場合(S1504:YES)、制御部330は、対応する語彙を第2の動作体20に伝達する(S1505)。なお、制御部330は、図6Aに示した場合と同様に、発話が第2の動作体20に対するものである場合にのみ、対応する語彙を第2の動作体20に伝達してもよい。また、第2の動作体20は、図6Bに示す流れに従って後続の処理を実行してよい。また、上記では、制御主体が情報処理サーバ30の制御部330である場合を例に述べたが、当該制御主体は、第1の動作体10の制御部150であってもよい。
次に、本実施形態に係る他の音声認識環境の共有と動作体の動作制御について述べる。上記では、本実施形態に係る音声認識環境が動作体の動作状況を含むことを述べたが、本実施形態に係る音声認識環境には、湧き出しや話者識別に係る環境、すなわちノイズ音源や話者の認識(識別)結果が含まれてもよい。
図12Aは、本実施形態に係るノイズ音源の認識結果の共有について説明するための図である。図12Aには、第1の動作体10aおよび10b、第2の動作体20が同じ部屋の中にいる場合において、第1の動作体10aのみが、テレビジョン装置であるノイズ源NSから音声が出力されていることを認識している状況を示している。
この場合、第1の動作体10bおよび第2の動作体20は、ノイズ音源NSが出力する音声をユーザの発話音声と誤認し、音声認識処理を実行する可能性がある。
上記のような事態を回避するため、第1の動作体10aは、認識したノイズ音源NSに係る情報を情報処理サーバ30にアップロードしてよい。また、情報処理サーバ30の制御部330は、第1の動作体10aによりアップロードされたノイズ音源NSに係る情報を第1の動作体10bおよび第2の動作体20に伝達し、音声認識処理が実行されないよう間接的あるいは直接的に制御してもよい。
図12Bは、本実施形態に係る話者認識の結果の共有について説明するための図である。図12Bには、第1の動作体10aおよび10b、第2の動作体20が同じ部屋の中にいる場合において、第1の動作体10aのみが、ユーザUを識別しており、また、テレビジョン装置であるノイズ源NSから音声が出力されていないことを認識している状況を示している。
この場合において、第1の動作体10bおよび第2の動作体20が音声を検出した場合、当該音声は、ユーザUの発話音声である可能性が高いといえる。
このため、情報処理サーバ30の制御部330は、第1の動作体10aによりアップロードされたユーザUおよびノイズ音源NSに係る情報を第1の動作体10bおよび第2の動作体20に伝達し、音声を検出した場合、音声認識処理を実行するよう間接的あるいは直接的に制御してもよい。
以上説明したように、本実施形態に係る制御部330は、一の動作体が収集したセンサ情報に基づいて認識されたノイズ音源や話者に係る情報を他の動作体に伝達し、また他の動作体に係る音声認識処理の実行有無を制御することができる。
なお、ノイズ音源や話者に係る情報の共有は、必ずしも制御部330が制御主体でなくてもよい。上記共有の制御主体は、共有元となる動作体(第1の動作体10または第2の動作体)であってもよく、情報処理サーバ30を介さずに直接共有先の動作体に情報を伝達してもよい。
図13Aは、本実施形態に係るノイズ音源や話者に係る情報共有における共有元の動作の流れを示すフローチャートである。
図13Aを参照すると、まず、共有元の動作体が自律動作を行う(S1601)。
ここで、共有元の動作体がノイズ音源や話者を認識した場合(S1602:YES)、共有元の動作体は、認識したノイズ音源や話者に係る情報を他の動作体に伝達する(S1603)。
一方、図13Bは、本実施形態に係るノイズ音源や話者に係る情報共有における共有先の動作の流れを示すフローチャートである。
図13Bを参照すると、まず、共有先の動作体が自律動作を行う(S1701)。
ここで、音声を検出した場合(S1702:YES)、共有先の動作体は、続いて、他の動作体によりノイズ音源や話者に係る情報が共有されているか否かを判定する(S1703)。
ここで、他の動作体によりノイズ音源や話者に係る情報が共有されている場合(S1703:YES)、共有先の動作体は、共有されている情報に応じた動作を行う(S1704)。共有先の動作体は、例えば、ノイズ音源が多い環境では、「なんだかうるさいなぁ、顔みせてよ」などの発話を行うことで、ユーザを識別することができる可能性を高めてもよい。
以上説明したように、本実施形態に係る情報処理方法によれば、ある動作体が認識した環境を他の動作体に伝達することで、共有先の動作体が当該環境に応じたより適切な動作を行うことが可能となる。
なお、上記のような環境の共有は、動作体によるユーザに対する能動的なアクションに用いられてもよい。例えば、本実施形態に係る第1の動作体10は、ユーザの発話に対する応答のみではなく、ユーザに対し能動的に語り掛けることで、積極的な対話を行うことを特徴の一つする。また、本実施形態に係る第2の動作体20も同様にユーザに対する能動的な振る舞いを行うことで積極的なインタラクションを実現することを特徴の一つとする。
このために、本実施形態に係る情報処理方法では、認識された環境を複数の動作体で共有することで、能動的なアクションの実行頻度を効果的に高めることができてよい。
図14は、本実施形態に係る能動的なアクションのトリガとなる環境の共有について説明するための図である。図14には、キッチンに居るユーザUを同じくキッチンに居る第2の動作体20aが識別している状況が示されている。
この際、第2の動作体20aは、ユーザUをキッチンにおいて識別したことを示す情報を情報処理サーバ30にアップロードする。また、情報処理サーバ30の制御部330は、第2の動作体20aによりアップロードされた情報をリビングルームにいる第1の動作体10および第2の動作体20bに伝達し、ユーザに対する能動的なアクションを実行するよう間接的あるいは直接的に制御してもよい。
例えば、制御部330は、第1の動作体10に、ユーザUがキッチンにいることを把握しているようなシステム発話SO3を行わせてもよい。また、例えば、制御部330は、第2の動作体20bをキッチンに移動させるなどの制御を行ってもよい。
以上説明したように、本実施形態に係る制御部330は、一の動作体が収集したセンサ情報に基づいて認識された環境に基づいて、ユーザに対する能動的なアクションを他の動作体に実行させてよい。また、共有先の動作体が発話が可能な場合、上記環境に応じた能動的な発話を共有先の動作体に実行させてよい。
上記のような制御によれば、各動作体が自身が収集するセンサ情報に基づき認識する環境以上に多くの事象を認識することができ、ユーザに対しより積極的なアクションを行うことで、ユーザ体験を向上させることが可能となる。
なお、ノイズ音源や話者に係る情報の共有と同様に、制御主体は、共有元となる動作体(第1の動作体10または第2の動作体)であってもよく、情報処理サーバ30を介さずに直接共有先の動作体に情報を伝達してもよい。
図15Aは、本実施形態に係る能動的アクションのトリガとなる環境の共有における共有元の動作の流れを示すフローチャートである。
図15Aを参照すると、まず、共有元の動作体が自律動作を行う(S1801)。
ここで、共有元の動作体が能動的アクションのトリガとなる環境(トリガ環境、とも称する)を認識した場合(S1802:YES)、共有元の動作体は、認識した環境に係る情報を他の動作体に伝達する(S1803)。上記環境には、例えば、ユーザや他の人物の所在や行動、天気や環境音の認識などが挙げられる。
一方、図15Bは、本実施形態に係る能動的アクションのトリガとなる環境の共有における共有先の動作の流れを示すフローチャートである。
図15Bを参照すると、まず、共有先の動作体が自律動作を行う(S1901)。
ここで、他の動作体により上記トリガとなる環境が共有されている場合(S1902:YES)、共有先の動作体は、共有されている環境に応じた能動的なアクションを行う(S1903)。
以上説明したように、本実施形態に係る情報処理方法によれば、ある動作体が認識した環境を他の動作体に伝達することで、共有先の動作体が当該環境に応じた能動的なアクションを実行することが可能となる。
なお、本実施形態に係る第1の動作体10は、認識した環境あるいは共有された環境に応じて複数の対話エンジンを切り替えてユーザとの対話を行うことが可能である。
図16は、本実施形態に係る対話エンジンの切り替えについて説明するための図である。図16には、環境ごとに使用されるエンジンの種別がそれぞれ示されている。本実施形態に係る第1の動作体10は、例えば、シナリオ対話、状況対話、知識対話、雑談対話に係る4つの異なるエンジンを環境に応じて切り替えることで、より豊かな対話を実現することが可能である。
なお、上記のシナリオ対話とは、予め設定された条件と定型発話分の組から成るシナリオに基づき、条件と一致した環境に対応する発話生成を行う対話であってよい。
また、状況対話とは、知識データベースを用いて、認識した状況(環境)を説明するような発話の生成を行う対話であってよい。
また、上記の知識対話とは、ユーザの発話に含まれる語彙や環境中から推定される語彙を基に知識データベースから必要な他の語彙を抽出して発話生成を行う対話であってよい。
また、上記の雑談対話とは、ドメインの定まらない自由な発話に対して、機械学習手法などを用いて発話生成を行ったり、あるいは発話文データベースから適切な定型文を抽出して発話生成を行う対話であってよい。
なお、図中において複数のエンジンが対応している場合、優先度の高いエンジンが使用されてもよい。一方、優先度の高いエンジンによる発話生成を試みて、適切な発話が生成できなかった場合には、次に優先度の高いエンジンによる発話生成を試みてもよい。
例えば、人を見つけて話しかける場合、第1の動作体10は、シナリオ対話または状況対話に係るエンジンを使用することで、「ねぇねぇ」や「ひさしぶり」などの発話を行うことが可能である。
また、人がいなくなった場合、第1の動作体10は、状況対話に係るエンジンを使用することで、「あれ?タロウどこ?」などの発話を行うことが可能である。
また、特定の物体を見つけた場合、第1の動作体10は、状況対話に係るエンジンを使用することで、「あ、ボールだ」などの発話を行うことが可能である。
また、その場にいる人に質問する場合、第1の動作体10は、シナリオ対話に係るエンジンを使用することで、「そういえば、好きなものは何?」などの発話を行うことが可能である。
また、知識のある環境を認識した場合、第1の動作体10は、状況対話または知識対話に係るエンジンを使用することで、「雨だなぁ、傘持っていかなくちゃ」や「会議中かぁ、静かにしよう」などの発話を行うことが可能である。
また、時事ニュースなど外部から新たな情報を入手した場合、第1の動作体10は、知識対話に係るエンジンを使用することで、「ABC駅で遅延発生だって」などの発話を行うことが可能である。
また、人の会話を漏れ聞いた場合、第1の動作体10は、知識対話または雑談対話に係るエンジンを使用することで、「ケーキって聞こえたよ。僕はチョコレートケーキが好きだなぁ」などの発話を行うことが可能である。
以上、本実施形態に係る対話エンジンの切り替えについて説明した。上記のような対話エンジンの切り替えによれば、環境に応じた適切かつより豊かな対話を実現することが可能となる。
次に、本実施形態に係る音声認識結果の統合について説明する。上記では、ある動作体により収集された音声に基づく音声認識処理の結果を他の動作体に共有することについて述べたが、本実施形態に係る情報処理方法では、複数の動作体が収集した音声のそれぞれに基づく複数の音声認識処理の結果を統合的に判断し、単一の統合認識結果を決定してもよい。
図17Aおよび図17Bは、本実施形態に係る音声認識処理結果の統合について説明するための図である。図17Aには、第1の動作体10a~10c、および第2の動作体20が共に居る環境において、ユーザUが発話UO4を行った状況が示されている。
図17Aに示す一例では、第1の動作体10aおよび10bは、発話UO4に係る音声を精度高く収集し、第1の音声認識処理により正確な語彙を得ている一方、第1の動作体10aはユーザUとの距離が離れているため、発話UO4に係る音声を精度高く収集することができず、第1の音声認識処理により誤った語彙を得ている。また、第2の動作体20は、ボールで遊ぶ動作を行っており、第2の音声認識処理に十分な音声を収集できていない。
この際、情報処理サーバ30の制御部330は、各動作体が収集した音声に基づく音声認識処理の結果を統合(集計)する。なお、制御部330は、同一環境中に存在することを動作体から音声データまたは音声認識結果がアップロードされない場合には、当該動作体が音声の収集に失敗したと見做してもよい。
また、本実施形態に係る制御部330は、統合の結果得られた統合認識結果を各動作体に伝達し、各動作体の動作を間接的あるいは直接的に制御してよい。
例えば、図17Bに示す一例の場合、制御部330は、得られた複数の音声認識処理の結果から最も数が多い語彙“Good morning”を統合認識結果として決定し、第1の動作体10a~10cに伝達している。
また、この際、本実施形態に係る制御部330は、統合認識結果と同一の音声認識処理の結果が得られた音声を収集した第1の動作体10bや第1の動作体10cに、上記同一の音声認識処理の結果が得られなかった第1の動作体10aや第2の動作体20に関する言動を実行させてもよい。
図17Bに示す一例の場合、制御部330は、第1の動作体10bに、第1の動作体10aに対し、正しいユーザの意図を伝えるシステム発話SO3を行わせている。また、制御部330は、第1の動作体10cに、第2の動作体20が発話UO4を理解できなかった旨のシステム発話SO5を行わせている。
一方、本実施形態に係る制御部は、統合認識結果と同一の音声認識処理の結果が得られなかった音声を収集した第1の動作体10aには、上記同一の音声認識処理の結果が得られなかったことを示す言動を実行させてもよい。
図17Bに示す一例の場合、制御部330は、第1の動作体10aに、誤った語彙を認識した旨のシステム発話SO4を行わせている。
上記のような制御によれば、複数の動作体がそれぞれ収集した音声に基づく音声認識処理の結果に基づいて、精度高くユーザの発話を認識することができると共に、動作体同士が認識結果について協議を行っているような様子を表現することが可能となり、ユーザの興味をさらに引き付ける効果が期待される。
続いて、本実施形態に係る音声認識処理結果の統合と動作制御の流れについて説明する。図18は、本実施形態に係る情報処理サーバ30による音声認識結果の統合の流れを示すフローチャートである。
図18を参照すると、まず、通信部350が複数の動作体から音声データまたは第2の音声認識処理の結果を受信する(S2001)。
次に、制御部330は、ステップS2001において受信した音声データに基づく第1の音声認識処理の結果やステップS2001で受信した第2の音声認識処理の結果を統合する(S2002)。
次に、制御部330は、認識結果数や音声収集時の動作体の状態に基づいて、統合認識結果を決定する(S2003)。制御部330は、例えば、認識結果の数のみではなく、音声収集時における動作体とユーザの距離や、動作体の動作状況に基づいて重み付けを行い、統合認識結果を決定してもよい。
次に、制御部330は、通信部350を介して、ステップS2003において決定した統合認識結果を各動作体に伝達する(S2004)。
また、図19は、本実施形態に係る統合認識結果に基づく動作制御の流れを示すフローチャートである。
図19を参照すると、まず、動作体(第1の動作体10または第2の動作体20)の制御部は、自身が収集した音声に対応する認識結果が棄却されたか否か、すなわち、自身が収集した音声に対応する認識結果が統合認識結果と異なっているか否か、を判定する(S2101)。
ここで、自身が収集した音声に対応する認識結果が棄却されている場合(S2101:YES)、動作体は、上記棄却に対応する言動、すなわち統合認識結果と同一の音声認識処理の結果が得られなかったことを示す言動を実行する(S2102)。
一方、自身が収集した音声に対応する認識結果が棄却されていない場合、すなわち自身が収集した音声に対応する認識結果が統合認識結果と同一であった場合(S2101:NO)、動作体の制御部は、続いて、認識結果が却下された他の動作体が所定の距離(例えば、視認が可能な距離)内に存在するか否かを判定する(S2103)。
ここで、認識結果が却下された他の動作体が所定の距離内に存在する場合(S2103:YES)、動作体は、当該他の動作体に関する言動を実行する(S2104)。
一方、認識結果が却下された他の動作体が所定の距離内に存在しない場合(S2103:NO)、動作体は、統合認識結果に対応する言動を実行する(S2105)。
以上、本実施形態に係る情報処理システムが有する機能の一例について説明した。なお、本実施形態に係る情報処理システムは、上記で示した例以外にも複数の動作体の連携に係る機能を有してよい。
例えば、本実施形態に係る第1の動作体10は、言語を用いたコミュニケーションを行う機能を有しない第2の動作体20に代わり、第2の動作体20の状態をユーザに伝達することも可能である。
図20は、本実施形態に係る第1の動作体10による第2の動作体の状態の伝達の流れを示すフローチャートである。
図20を参照すると、第1の動作体10は、まず、自律動作を行う(S2201)。
ここで、ユーザの発話やユーザが操作するアプリケーションなどからの、第2の動作体の状態伝達に係る要求を検出すると(S2202)、第1の動作体10は、第2の動作体20の状態に係る問い合わせを実行する(S2203)。この際、第1の動作体10は、第2の動作体20に直接状態を問い合わせてもよいし、第2の動作体20が状態を情報処理サーバ30にアップロードしている場合には、情報処理サーバ30に問い合わせを行ってもよい。
次に、第1の動作体10は、ステップS2203における問い合わせにより取得した第2の動作体20の状態をユーザに伝達する(S2204)。なお、第2の動作体20の状態には、例えば、感情、現在作成されているSLAM地図、認識した物体、バッテリー残量などの動的な状態や、個体識別番号などの静的な情報が含まれてもよい。
また、本実施形態に係る第1の動作体10は、第2の動作体20に対する各種の動作指示を行ってもよい。
上述したように、本実施形態に係る第2の動作体20は、第1の動作体10と比較して広い移動範囲を有する。このため、例えば、卓上から動けない第1の動作体10がユーザを認識できない場合、第1の動作体10は、他の部屋などにユーザを探索しに行くよう指示を行ってもよい。
図21は、本実施形態に係る第1の動作体10の指示に基づく第2の動作体20によるユーザ探索の流れを示すフローチャートである。
図21を参照すると、第2の動作体20は、まず、自律動作を行う(S2301)。
ここで、第1の動作体10からのユーザ探索要求を受信した場合(S2302)、第2の動作体20は、家の中を歩き回るなどしてユーザの探索を行う(S2303)。
ここで、所定時間内にユーザを認識できた場合(S2304:YES)、第2の動作体20は、ユーザを認識した場所や状況を第1の動作体10に伝達する(S2305)。この場合、第1の動作体10は、伝達された情報に基づく言動を行ってもよい。例えば、ユーザがキッチンにいることを伝達された場合、第1の動作体10は、「Mikeに教えてもらったよ、ご飯作ってるの?」などの発話を行ってもよい。
一方、所定時間内にユーザを認識できなかった場合(S2304:NO)、第2の動作体20は、ユーザを見つけられなかったことを第1の動作体10に伝達する(S2306)。
なお、ステップS2305やS2306における情報の伝達時に、周囲に探索対象であるユーザ以外の人物がいる場合には、第2の動作体20は、鳴き声や振る舞いなどにより探索の結果を表現してもよい。例えば、探索対象のユーザをキッチンで認識した場合には、第2の動作体20は、しっぽを振りながら物を食べるような振る舞いを行ってもよいし、ユーザを見つけることができなかった場合には、首を横に振りながら悲しそうに鳴くなどの動作を行ってもよい。
また、例えば、本実施形態に係る第1の動作体10は、SNSやメッセージアプリケーションなどの外部サービスから取得した情報に基づいて、第2の動作体20に指示を行うことも可能である。
図22は、本実施形態に係る外部サービスから取得した情報に基づく第2の動作体20への指示の流れの一例を示すフローチャートである。
図22を参照すると、第1の動作体10は、まず、自律動作を行う(S2401)。
ここで、メッセージアプリケーションやSNSからユーザの帰宅を示す情報を抽出すると(S2402)、第1の動作体10は、第2の動作体20に対し、玄関で待機するように指示を行ってよい(S2403)。この場合、第2の動作体20は、第1の動作体10からの指示に基づいて、玄関で待機する。また、第1の動作体10は、帰宅したユーザを認識した際、「Mike、玄関でちゃんと待ってた?」などの発話を行ってもよい。
このために、本実施形態に係る第1の動作体10は、メッセージアプリケーションやSNSを介してユーザとのコミュニケーションを図る機能を有してもよい。係る機能によれば、外出中であっても、ユーザが第1の動作体10との対話を楽しむことができ、また第2の動作体20や家の状況を把握することができる。
また、例えば、本実施形態に係る第1の動作体10は、高い視点を活かして第2の動作体20に障害物回避などに係る移動指示を行うことも可能である。上述したように、本実施形態に係る第1の動作体10は、卓上に配置されることを想定していることから、床上を歩行移動する第2の動作体20と比較して高い視点を有する。
図23Aは、本実施形態に係る第1の動作体10による第2の動作体20への移動指示の流れを示すフローチャートである。
図23Aを参照すると、まず、第1の動作体10は、自律動作を行う(S2401)。
次に、第1の動作体10は、第2の動作体20の周辺の映像を第2の動作体に送信する(S2402)。第1の動作体10は、第2の動作体20からの要求に基づいて上記映像の送信を行ってもよいし、第2の動作体20が障害物に衝突しそうな状況を認識したことなどに基づいて上記映像の送信を行ってもよい。
また、第1の動作体10は、第2の動作体20に対する移動指示に係る表出を行ってよい(S2403)。第1の動作体10は、例えば、「危ないよ!みぎ、みぎ!」などの発話を行うことができる。
また、図23Bは、本実施形態に係る第1の動作体10からの移動指示に基づく第2の動作体20の動作の流れを示すフローチャートである。
図23Bを参照すると、まず、第2の動作体20は、自律動作を行う(S2501)。
ここで、第1の動作体10から映像を受信すると、第2の動作体20は、第1の動作体10の視点で得られた映像を自身の周囲にマッピングする(S2502)。
続いて、第2の動作体20は、ステップS2502における映像のマッピングに基づいて、障害物を回避して移動する(S2503)。
<2.情報処理サーバ30のハードウェア構成例>
次に、本開示の一実施形態に係る情報処理サーバ30のハードウェア構成例について説明する。図24は、本開示の一実施形態に係る情報処理サーバ30のハードウェア構成例を示すブロック図である。図24に示すように、情報処理サーバ30は、例えば、プロセッサ871と、ROM872と、RAM873と、ホストバス874と、ブリッジ875と、外部バス876と、インタフェース877と、入力装置878と、出力装置879と、ストレージ880と、ドライブ881と、接続ポート882と、通信装置883と、を有する。なお、ここで示すハードウェア構成は一例であり、構成要素の一部が省略されてもよい。また、ここで示される構成要素以外の構成要素をさらに含んでもよい。
次に、本開示の一実施形態に係る情報処理サーバ30のハードウェア構成例について説明する。図24は、本開示の一実施形態に係る情報処理サーバ30のハードウェア構成例を示すブロック図である。図24に示すように、情報処理サーバ30は、例えば、プロセッサ871と、ROM872と、RAM873と、ホストバス874と、ブリッジ875と、外部バス876と、インタフェース877と、入力装置878と、出力装置879と、ストレージ880と、ドライブ881と、接続ポート882と、通信装置883と、を有する。なお、ここで示すハードウェア構成は一例であり、構成要素の一部が省略されてもよい。また、ここで示される構成要素以外の構成要素をさらに含んでもよい。
(プロセッサ871)
プロセッサ871は、例えば、演算処理装置又は制御装置として機能し、ROM872、RAM873、ストレージ880、又はリムーバブル記録媒体901に記録された各種プログラムに基づいて各構成要素の動作全般又はその一部を制御する。
プロセッサ871は、例えば、演算処理装置又は制御装置として機能し、ROM872、RAM873、ストレージ880、又はリムーバブル記録媒体901に記録された各種プログラムに基づいて各構成要素の動作全般又はその一部を制御する。
(ROM872、RAM873)
ROM872は、プロセッサ871に読み込まれるプログラムや演算に用いるデータ等を格納する手段である。RAM873には、例えば、プロセッサ871に読み込まれるプログラムや、そのプログラムを実行する際に適宜変化する各種パラメータ等が一時的又は永続的に格納される。
ROM872は、プロセッサ871に読み込まれるプログラムや演算に用いるデータ等を格納する手段である。RAM873には、例えば、プロセッサ871に読み込まれるプログラムや、そのプログラムを実行する際に適宜変化する各種パラメータ等が一時的又は永続的に格納される。
(ホストバス874、ブリッジ875、外部バス876、インタフェース877)
プロセッサ871、ROM872、RAM873は、例えば、高速なデータ伝送が可能なホストバス874を介して相互に接続される。一方、ホストバス874は、例えば、ブリッジ875を介して比較的データ伝送速度が低速な外部バス876に接続される。また、外部バス876は、インタフェース877を介して種々の構成要素と接続される。
プロセッサ871、ROM872、RAM873は、例えば、高速なデータ伝送が可能なホストバス874を介して相互に接続される。一方、ホストバス874は、例えば、ブリッジ875を介して比較的データ伝送速度が低速な外部バス876に接続される。また、外部バス876は、インタフェース877を介して種々の構成要素と接続される。
(入力装置878)
入力装置878には、例えば、マウス、キーボード、タッチパネル、ボタン、スイッチ、及びレバー等が用いられる。さらに、入力装置878としては、赤外線やその他の電波を利用して制御信号を送信することが可能なリモートコントローラ(以下、リモコン)が用いられることもある。また、入力装置878には、マイクロフォンなどの音声入力装置が含まれる。
入力装置878には、例えば、マウス、キーボード、タッチパネル、ボタン、スイッチ、及びレバー等が用いられる。さらに、入力装置878としては、赤外線やその他の電波を利用して制御信号を送信することが可能なリモートコントローラ(以下、リモコン)が用いられることもある。また、入力装置878には、マイクロフォンなどの音声入力装置が含まれる。
(出力装置879)
出力装置879は、例えば、CRT(Cathode Ray Tube)、LCD、又は有機EL等のディスプレイ装置、スピーカ、ヘッドホン等のオーディオ出力装置、プリンタ、携帯電話、又はファクシミリ等、取得した情報を利用者に対して視覚的又は聴覚的に通知することが可能な装置である。また、本開示に係る出力装置879は、触覚刺激を出力することが可能な種々の振動デバイスを含む。
出力装置879は、例えば、CRT(Cathode Ray Tube)、LCD、又は有機EL等のディスプレイ装置、スピーカ、ヘッドホン等のオーディオ出力装置、プリンタ、携帯電話、又はファクシミリ等、取得した情報を利用者に対して視覚的又は聴覚的に通知することが可能な装置である。また、本開示に係る出力装置879は、触覚刺激を出力することが可能な種々の振動デバイスを含む。
(ストレージ880)
ストレージ880は、各種のデータを格納するための装置である。ストレージ880としては、例えば、ハードディスクドライブ(HDD)等の磁気記憶デバイス、半導体記憶デバイス、光記憶デバイス、又は光磁気記憶デバイス等が用いられる。
ストレージ880は、各種のデータを格納するための装置である。ストレージ880としては、例えば、ハードディスクドライブ(HDD)等の磁気記憶デバイス、半導体記憶デバイス、光記憶デバイス、又は光磁気記憶デバイス等が用いられる。
(ドライブ881)
ドライブ881は、例えば、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリ等のリムーバブル記録媒体901に記録された情報を読み出し、又はリムーバブル記録媒体901に情報を書き込む装置である。
ドライブ881は、例えば、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリ等のリムーバブル記録媒体901に記録された情報を読み出し、又はリムーバブル記録媒体901に情報を書き込む装置である。
(リムーバブル記録媒体901)
リムーバブル記録媒体901は、例えば、DVDメディア、Blu-ray(登録商標)メディア、HD DVDメディア、各種の半導体記憶メディア等である。もちろん、リムーバブル記録媒体901は、例えば、非接触型ICチップを搭載したICカード、又は電子機器等であってもよい。
リムーバブル記録媒体901は、例えば、DVDメディア、Blu-ray(登録商標)メディア、HD DVDメディア、各種の半導体記憶メディア等である。もちろん、リムーバブル記録媒体901は、例えば、非接触型ICチップを搭載したICカード、又は電子機器等であってもよい。
(接続ポート882)
接続ポート882は、例えば、USB(Universal Serial Bus)ポート、IEEE1394ポート、SCSI(Small Computer System Interface)、RS-232Cポート、又は光オーディオ端子等のような外部接続機器902を接続するためのポートである。
接続ポート882は、例えば、USB(Universal Serial Bus)ポート、IEEE1394ポート、SCSI(Small Computer System Interface)、RS-232Cポート、又は光オーディオ端子等のような外部接続機器902を接続するためのポートである。
(外部接続機器902)
外部接続機器902は、例えば、プリンタ、携帯音楽プレーヤ、デジタルカメラ、デジタルビデオカメラ、又はICレコーダ等である。
外部接続機器902は、例えば、プリンタ、携帯音楽プレーヤ、デジタルカメラ、デジタルビデオカメラ、又はICレコーダ等である。
(通信装置883)
通信装置883は、ネットワークに接続するための通信デバイスであり、例えば、有線又は無線LAN、Bluetooth(登録商標)、又はWUSB(Wireless USB)用の通信カード、光通信用のルータ、ADSL(Asymmetric Digital Subscriber Line)用のルータ、又は各種通信用のモデム等である。
通信装置883は、ネットワークに接続するための通信デバイスであり、例えば、有線又は無線LAN、Bluetooth(登録商標)、又はWUSB(Wireless USB)用の通信カード、光通信用のルータ、ADSL(Asymmetric Digital Subscriber Line)用のルータ、又は各種通信用のモデム等である。
<3.まとめ>
以上説明したように、本開示の一実施形態に係る情報処理サーバ30は、音声認識処理の結果に基づいて動作体の動作を制御する制御部330を備える。また、本開示の一実施形態に係る制御部330は、一の動作体が収集した音声に基づく音声認識処理の結果、または一の動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の動作体の動作を制御すること、を特徴の一つとする。係る構成によれば、音声認識処理に基づく動作を行う複数の動作体が存在する環境において、各動作体がより状況に適した動作を実現することを可能とする。
以上説明したように、本開示の一実施形態に係る情報処理サーバ30は、音声認識処理の結果に基づいて動作体の動作を制御する制御部330を備える。また、本開示の一実施形態に係る制御部330は、一の動作体が収集した音声に基づく音声認識処理の結果、または一の動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の動作体の動作を制御すること、を特徴の一つとする。係る構成によれば、音声認識処理に基づく動作を行う複数の動作体が存在する環境において、各動作体がより状況に適した動作を実現することを可能とする。
以上、添付図面を参照しながら本開示の好適な実施形態について詳細に説明したが、本開示の技術的範囲はかかる例に限定されない。本開示の技術分野における通常の知識を有する者であれば、請求の範囲に記載された技術的思想の範疇内において、各種の変更例または修正例に想到し得ることは明らかであり、これらについても、当然に本開示の技術的範囲に属するものと了解される。
また、本明細書に記載された効果は、あくまで説明的または例示的なものであって限定的ではない。つまり、本開示に係る技術は、上記の効果とともに、または上記の効果に代えて、本明細書の記載から当業者には明らかな他の効果を奏しうる。
また、コンピュータに内蔵されるCPU、ROMおよびRAMなどのハードウェアに、第1の動作体10、第2の動作体20、または情報処理サーバ30が有する構成と同等の機能を発揮させるためのプログラムも作成可能であり、当該プログラムを記録した、コンピュータに読み取り可能な非一過性の記録媒体も提供され得る。
また、本明細書の情報処理システムの処理に係る各ステップは、必ずしもフローチャートに記載された順序に沿って時系列に処理される必要はない。例えば、情報処理システムの処理に係る各ステップは、フローチャートに記載された順序と異なる順序で処理されても、並列的に処理されてもよい。
なお、以下のような構成も本開示の技術的範囲に属する。
(1)
音声認識処理の結果に基づいて動作体の動作を制御する制御部、
を備え、
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、
情報処理装置。
(2)
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果に基づいて、当該音声認識処理の結果に対応する動作を他の前記動作体に実行させる、
前記(1)に記載の情報処理装置。
(3)
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果を他の前記動作体に伝達したことを示す動作を当該一の前記動作体に実行させる、
前記(2)に記載の情報処理装置。
(4)
前記動作体は、第1の辞書を用いた第1の音声認識処理の結果に基づく動作を行う第1の動作体と、前記第1の辞書よりも語彙数の少ない第2の辞書を用いた第2の音声認識処理の結果に基づく動作を行う第2の動作体を含み、
前記制御部は、前記第1の動作体が収集した音声と前記第1の辞書に基づく前記第1の音声認識処理の結果に基づいて、前記第1の音声認識処理の結果に対応する動作を前記第2の動作体に実行させる、
前記(2)または(3)に記載の情報処理装置。
(5)
前記制御部は、前記第1の音声認識処理の結果として得られた語彙のカテゴリに対応する語彙を前記第2の辞書から抽出し、当該語彙を前記第2の動作体に伝達する、
前記(4)に記載の情報処理装置。
(6)
前記制御部は、前記第1の音声認識処理の結果に係るログに基づいて、前記第2の辞書の語彙の入れ替えを制御する、
前記(4)または(5)に記載の情報処理装置。
(7)
前記第2の動作体は、前記第2の辞書を用いた前記第2の音声認識処理をローカルで実行する、
前記(4)~(6)のいずれかに記載の情報処理装置。
(8)
前記動作体は、自律移動体である、
前記(1)~(7)のいずれかに記載の情報処理装置。
(9)
前記制御部は、一の前記動作体に係る音声認識環境が音声認識処理精度の低下要因となり得る環境である場合、他の前記動作体に係る音声認識環境が向上するよう他の前記動作体の動作を制御する、
前記(8)に記載の情報処理装置。
(10)
前記音声認識環境は、前記動作体の動作状況を含み、
前記制御部は、一の前記動作体の動作状況に基づいて、他の前記動作体の動作を制御する、
前記(9)に記載の情報処理装置。
(11)
前記制御部は、一の前記動作体が動作音を伴う動作を実行している場合、他の前記動作体の動作音がより低下するよう制御する、
前記(10)に記載の情報処理装置。
(12)
前記音声認識環境は、ノイズ音源または話者の認識結果を含み、
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識されたノイズ音源または話者に係る情報を他の前記動作体に伝達する、
前記(1)~(11)のいずれかに記載の情報処理装置。
(13)
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識されたノイズ音源または話者に係る情報に基づいて、他の前記動作体に係る音声認識処理の実行有無を制御する、
前記(12)に記載の情報処理装置。
(14)
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識された環境に基づいて、ユーザに対する能動的なアクションを他の前記動作体に実行させる、
前記(1)~(13)のいずれかに記載の情報処理装置。
(15)
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識された環境に基づいて、当該環境に応じた能動的な発話を他の前記動作体に実行させる、
前記(14)に記載の情報処理装置。
(16)
前記制御部は、複数の前記動作体が収集した音声のそれぞれに基づく複数の音声認識処理の結果から決定される統合認識結果に基づいて、前記動作体の動作を制御する、
前記(1)~(15)のいずれかに記載の情報処理装置。
(17)
前記制御部は、前記統合認識結果と同一の音声認識処理の結果が得られた音声を収集した前記動作体に、前記統合認識結果と同一の音声認識処理の結果が得られなかった他の前記動作体に関する言動を実行させる、
前記(16)に記載の情報処理装置。
(18)
前記制御部は、前記統合認識結果と同一の音声認識処理の結果が得られなかった音声を収集した前記動作体に、前記統合認識結果と同一の音声認識処理の結果が得られなかったことを示す言動を実行させる、
前記(16)または(17)に記載の情報処理装置。
(19)
プロセッサが、音声認識処理の結果に基づいて動作体の動作を制御すること、
を含み、
前記制御することは、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御すること、
をさらに含む、
情報処理方法。
(20)
コンピュータを、
音声認識処理の結果に基づいて動作体の動作を制御する制御部、
を備え、
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、
情報処理装置、
として機能させるためのプログラム。
(1)
音声認識処理の結果に基づいて動作体の動作を制御する制御部、
を備え、
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、
情報処理装置。
(2)
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果に基づいて、当該音声認識処理の結果に対応する動作を他の前記動作体に実行させる、
前記(1)に記載の情報処理装置。
(3)
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果を他の前記動作体に伝達したことを示す動作を当該一の前記動作体に実行させる、
前記(2)に記載の情報処理装置。
(4)
前記動作体は、第1の辞書を用いた第1の音声認識処理の結果に基づく動作を行う第1の動作体と、前記第1の辞書よりも語彙数の少ない第2の辞書を用いた第2の音声認識処理の結果に基づく動作を行う第2の動作体を含み、
前記制御部は、前記第1の動作体が収集した音声と前記第1の辞書に基づく前記第1の音声認識処理の結果に基づいて、前記第1の音声認識処理の結果に対応する動作を前記第2の動作体に実行させる、
前記(2)または(3)に記載の情報処理装置。
(5)
前記制御部は、前記第1の音声認識処理の結果として得られた語彙のカテゴリに対応する語彙を前記第2の辞書から抽出し、当該語彙を前記第2の動作体に伝達する、
前記(4)に記載の情報処理装置。
(6)
前記制御部は、前記第1の音声認識処理の結果に係るログに基づいて、前記第2の辞書の語彙の入れ替えを制御する、
前記(4)または(5)に記載の情報処理装置。
(7)
前記第2の動作体は、前記第2の辞書を用いた前記第2の音声認識処理をローカルで実行する、
前記(4)~(6)のいずれかに記載の情報処理装置。
(8)
前記動作体は、自律移動体である、
前記(1)~(7)のいずれかに記載の情報処理装置。
(9)
前記制御部は、一の前記動作体に係る音声認識環境が音声認識処理精度の低下要因となり得る環境である場合、他の前記動作体に係る音声認識環境が向上するよう他の前記動作体の動作を制御する、
前記(8)に記載の情報処理装置。
(10)
前記音声認識環境は、前記動作体の動作状況を含み、
前記制御部は、一の前記動作体の動作状況に基づいて、他の前記動作体の動作を制御する、
前記(9)に記載の情報処理装置。
(11)
前記制御部は、一の前記動作体が動作音を伴う動作を実行している場合、他の前記動作体の動作音がより低下するよう制御する、
前記(10)に記載の情報処理装置。
(12)
前記音声認識環境は、ノイズ音源または話者の認識結果を含み、
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識されたノイズ音源または話者に係る情報を他の前記動作体に伝達する、
前記(1)~(11)のいずれかに記載の情報処理装置。
(13)
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識されたノイズ音源または話者に係る情報に基づいて、他の前記動作体に係る音声認識処理の実行有無を制御する、
前記(12)に記載の情報処理装置。
(14)
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識された環境に基づいて、ユーザに対する能動的なアクションを他の前記動作体に実行させる、
前記(1)~(13)のいずれかに記載の情報処理装置。
(15)
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識された環境に基づいて、当該環境に応じた能動的な発話を他の前記動作体に実行させる、
前記(14)に記載の情報処理装置。
(16)
前記制御部は、複数の前記動作体が収集した音声のそれぞれに基づく複数の音声認識処理の結果から決定される統合認識結果に基づいて、前記動作体の動作を制御する、
前記(1)~(15)のいずれかに記載の情報処理装置。
(17)
前記制御部は、前記統合認識結果と同一の音声認識処理の結果が得られた音声を収集した前記動作体に、前記統合認識結果と同一の音声認識処理の結果が得られなかった他の前記動作体に関する言動を実行させる、
前記(16)に記載の情報処理装置。
(18)
前記制御部は、前記統合認識結果と同一の音声認識処理の結果が得られなかった音声を収集した前記動作体に、前記統合認識結果と同一の音声認識処理の結果が得られなかったことを示す言動を実行させる、
前記(16)または(17)に記載の情報処理装置。
(19)
プロセッサが、音声認識処理の結果に基づいて動作体の動作を制御すること、
を含み、
前記制御することは、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御すること、
をさらに含む、
情報処理方法。
(20)
コンピュータを、
音声認識処理の結果に基づいて動作体の動作を制御する制御部、
を備え、
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、
情報処理装置、
として機能させるためのプログラム。
10 第1の動作体
140 トリガ検出部
150 制御部
20 第2の動作体
240 認識部
242 第2の辞書
250 制御部
30 情報処理サーバ
310 音声認識部
320 自然言語処理部
322 第1の辞書
330 制御部
40 ネットワーク
140 トリガ検出部
150 制御部
20 第2の動作体
240 認識部
242 第2の辞書
250 制御部
30 情報処理サーバ
310 音声認識部
320 自然言語処理部
322 第1の辞書
330 制御部
40 ネットワーク
Claims (20)
- 音声認識処理の結果に基づいて動作体の動作を制御する制御部、
を備え、
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、
情報処理装置。 - 前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果に基づいて、当該音声認識処理の結果に対応する動作を他の前記動作体に実行させる、
請求項1に記載の情報処理装置。 - 前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果を他の前記動作体に伝達したことを示す動作を当該一の前記動作体に実行させる、
請求項2に記載の情報処理装置。 - 前記動作体は、第1の辞書を用いた第1の音声認識処理の結果に基づく動作を行う第1の動作体と、前記第1の辞書よりも語彙数の少ない第2の辞書を用いた第2の音声認識処理の結果に基づく動作を行う第2の動作体を含み、
前記制御部は、前記第1の動作体が収集した音声と前記第1の辞書に基づく前記第1の音声認識処理の結果に基づいて、前記第1の音声認識処理の結果に対応する動作を前記第2の動作体に実行させる、
請求項2に記載の情報処理装置。 - 前記制御部は、前記第1の音声認識処理の結果として得られた語彙のカテゴリに対応する語彙を前記第2の辞書から抽出し、当該語彙を前記第2の動作体に伝達する、
請求項4に記載の情報処理装置。 - 前記制御部は、前記第1の音声認識処理の結果に係るログに基づいて、前記第2の辞書の語彙の入れ替えを制御する、
請求項4に記載の情報処理装置。 - 前記第2の動作体は、前記第2の辞書を用いた前記第2の音声認識処理をローカルで実行する、
請求項4に記載の情報処理装置。 - 前記動作体は、自律移動体である、
請求項1に記載の情報処理装置。 - 前記制御部は、一の前記動作体に係る音声認識環境が音声認識処理精度の低下要因となり得る環境である場合、他の前記動作体に係る音声認識環境が向上するよう他の前記動作体の動作を制御する、
請求項8に記載の情報処理装置。 - 前記音声認識環境は、前記動作体の動作状況を含み、
前記制御部は、一の前記動作体の動作状況に基づいて、他の前記動作体の動作を制御する、
請求項9に記載の情報処理装置。 - 前記制御部は、一の前記動作体が動作音を伴う動作を実行している場合、他の前記動作体の動作音がより低下するよう制御する、
請求項10に記載の情報処理装置。 - 前記音声認識環境は、ノイズ音源または話者の認識結果を含み、
前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識されたノイズ音源または話者に係る情報を他の前記動作体に伝達する、
請求項1に記載の情報処理装置。 - 前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識されたノイズ音源または話者に係る情報に基づいて、他の前記動作体に係る音声認識処理の実行有無を制御する、
請求項12に記載の情報処理装置。 - 前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識された環境に基づいて、ユーザに対する能動的なアクションを他の前記動作体に実行させる、
請求項1に記載の情報処理装置。 - 前記制御部は、一の前記動作体が収集したセンサ情報に基づいて認識された環境に基づいて、当該環境に応じた能動的な発話を他の前記動作体に実行させる、
請求項14に記載の情報処理装置。 - 前記制御部は、複数の前記動作体が収集した音声のそれぞれに基づく複数の音声認識処理の結果から決定される統合認識結果に基づいて、前記動作体の動作を制御する、
請求項1に記載の情報処理装置。 - 前記制御部は、前記統合認識結果と同一の音声認識処理の結果が得られた音声を収集した前記動作体に、前記統合認識結果と同一の音声認識処理の結果が得られなかった他の前記動作体に関する言動を実行させる、
請求項16に記載の情報処理装置。 - 前記制御部は、前記統合認識結果と同一の音声認識処理の結果が得られなかった音声を収集した前記動作体に、前記統合認識結果と同一の音声認識処理の結果が得られなかったことを示す言動を実行させる、
請求項16に記載の情報処理装置。 - プロセッサが、音声認識処理の結果に基づいて動作体の動作を制御すること、
を含み、
前記制御することは、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御すること、
をさらに含む、
情報処理方法。 - コンピュータを、
音声認識処理の結果に基づいて動作体の動作を制御する制御部、
を備え、
前記制御部は、一の前記動作体が収集した音声に基づく音声認識処理の結果、または一の前記動作体が収集したセンサ情報に基づいて認識された音声認識環境に基づいて、他の前記動作体の動作を制御する、
情報処理装置、
として機能させるためのプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20784973.8A EP3950236A4 (en) | 2019-03-29 | 2020-03-09 | INFORMATION PROCESSING DEVICE, INFORMATION PROCESSING METHOD AND PROGRAM |
| US17/441,009 US12057118B2 (en) | 2019-03-29 | 2020-03-09 | Information processing apparatus and information processing method |
| JP2021511308A JP7501523B2 (ja) | 2019-03-29 | 2020-03-09 | 情報処理装置、情報処理方法、およびプログラム |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019-065746 | 2019-03-29 | ||
| JP2019065746 | 2019-03-29 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020203067A1 true WO2020203067A1 (ja) | 2020-10-08 |
Family
ID=72668580
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/009948 WO2020203067A1 (ja) | 2019-03-29 | 2020-03-09 | 情報処理装置、情報処理方法、およびプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12057118B2 (ja) |
| EP (1) | EP3950236A4 (ja) |
| JP (1) | JP7501523B2 (ja) |
| WO (1) | WO2020203067A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102022103305A1 (de) | 2022-02-11 | 2023-08-17 | Einhell Germany Ag | Projektunterstützung bei der Nutzung eines Elektrogeräts mit einem Akkupack |
| WO2024025244A1 (ko) * | 2022-07-27 | 2024-02-01 | 삼성전자주식회사 | 로봇 장치의 위치에 대응되는 모드로 동작하는 로봇 장치 및 그 제어 방법 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002337079A (ja) * | 2001-05-11 | 2002-11-26 | Sony Corp | 情報処理装置および方法、記録媒体、並びにプログラム |
| JP2016130800A (ja) * | 2015-01-14 | 2016-07-21 | シャープ株式会社 | システム、サーバ、電子機器、サーバの制御方法、およびプログラム |
| JP2017138476A (ja) | 2016-02-03 | 2017-08-10 | ソニー株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2018081233A (ja) * | 2016-11-17 | 2018-05-24 | シャープ株式会社 | 電子機器、制御方法、およびプログラム |
| JP2018124856A (ja) | 2017-02-02 | 2018-08-09 | 株式会社デンソー | 電子制御装置 |
| JP2020046478A (ja) * | 2018-09-14 | 2020-03-26 | 株式会社フュートレック | ロボットシステム |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2737624B2 (ja) * | 1993-12-27 | 1998-04-08 | 日本電気株式会社 | 音声認識装置 |
| KR100682897B1 (ko) * | 2004-11-09 | 2007-02-15 | 삼성전자주식회사 | 사전 업데이트 방법 및 그 장치 |
| US9070367B1 (en) | 2012-11-26 | 2015-06-30 | Amazon Technologies, Inc. | Local speech recognition of frequent utterances |
| JP6448971B2 (ja) | 2014-09-30 | 2019-01-09 | シャープ株式会社 | 対話装置 |
| JP2017191531A (ja) | 2016-04-15 | 2017-10-19 | ロボットスタート株式会社 | コミュニケーションシステム、サーバ及びコミュニケーション方法 |
| WO2018107389A1 (zh) * | 2016-12-14 | 2018-06-21 | 深圳前海达闼云端智能科技有限公司 | 语音联合协助的实现方法、装置及机器人 |
| CN109119078A (zh) | 2018-10-26 | 2019-01-01 | 北京石头世纪科技有限公司 | 自动机器人控制方法、装置、自动机器人和介质 |
-
2020
- 2020-03-09 EP EP20784973.8A patent/EP3950236A4/en active Pending
- 2020-03-09 US US17/441,009 patent/US12057118B2/en active Active
- 2020-03-09 WO PCT/JP2020/009948 patent/WO2020203067A1/ja unknown
- 2020-03-09 JP JP2021511308A patent/JP7501523B2/ja active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002337079A (ja) * | 2001-05-11 | 2002-11-26 | Sony Corp | 情報処理装置および方法、記録媒体、並びにプログラム |
| JP2016130800A (ja) * | 2015-01-14 | 2016-07-21 | シャープ株式会社 | システム、サーバ、電子機器、サーバの制御方法、およびプログラム |
| JP2017138476A (ja) | 2016-02-03 | 2017-08-10 | ソニー株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2018081233A (ja) * | 2016-11-17 | 2018-05-24 | シャープ株式会社 | 電子機器、制御方法、およびプログラム |
| JP2018124856A (ja) | 2017-02-02 | 2018-08-09 | 株式会社デンソー | 電子制御装置 |
| JP2020046478A (ja) * | 2018-09-14 | 2020-03-26 | 株式会社フュートレック | ロボットシステム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3950236A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2020203067A1 (ja) | 2020-10-08 |
| US20220157305A1 (en) | 2022-05-19 |
| JP7501523B2 (ja) | 2024-06-18 |
| EP3950236A1 (en) | 2022-02-09 |
| EP3950236A4 (en) | 2022-07-06 |
| US12057118B2 (en) | 2024-08-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10628714B2 (en) | Entity-tracking computing system | |
| JP7317529B2 (ja) | サウンドデータを処理するシステム、及びシステムの制御方法 | |
| KR102541718B1 (ko) | 키 문구 사용자 인식의 증강 | |
| US20200042832A1 (en) | Artificial intelligence apparatus and method for updating artificial intelligence model | |
| US11551684B1 (en) | State detection and responses for electronic devices | |
| CN111432989A (zh) | 人工增强基于云的机器人智能框架及相关方法 | |
| KR102490916B1 (ko) | 전자 장치, 이의 제어 방법 및 비일시적인 컴퓨터 판독가능 기록매체 | |
| CN110427462A (zh) | 与用户互动的方法、装置、存储介质及服务机器人 | |
| KR20210039049A (ko) | 음성 인식을 수행하는 인공 지능 장치 및 그 방법 | |
| WO2020203067A1 (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| KR20210047173A (ko) | 오인식된 단어를 바로잡아 음성을 인식하는 인공 지능 장치 및 그 방법 | |
| KR20190104490A (ko) | 사용자의 발화 음성을 인식하는 인공 지능 장치 및 그 방법 | |
| KR20190113693A (ko) | 단어 사용 빈도를 고려하여 사용자의 음성을 인식하는 인공 지능 장치 및 그 방법 | |
| KR102339085B1 (ko) | 사용자의 어플리케이션 사용 기록을 고려하여 사용자의 음성을 인식하는 인공 지능 장치 및 그 방법 | |
| KR20200074690A (ko) | 전자 장치 및 이의 제어 방법 | |
| KR20190096308A (ko) | 전자기기 | |
| US20220338281A1 (en) | Artificial intelligence device for providing device control function based on interworking between devices and method therefor | |
| KR20210055347A (ko) | 인공 지능 장치 | |
| Kim et al. | Beginning of a new standard: Internet of Media Things | |
| KR20230095585A (ko) | 안내 로봇 및 그것의 동작 방법 | |
| CN110517702A (zh) | 信号生成的方法、基于人工智能的语音识别方法及装置 | |
| KR102573461B1 (ko) | 스마트 인공지능 다기능 비상벨 시스템 및 이의 제어방법 | |
| CN113168835B (zh) | 信息处理设备、信息处理方法和程序 | |
| JP7400364B2 (ja) | 音声認識システム及び情報処理方法 | |
| WO2020022122A1 (ja) | 情報処理装置、行動決定方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20784973 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021511308 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020784973 Country of ref document: EP Effective date: 20211029 |