WO2020040007A1 - 学習装置、学習方法及び学習プログラム - Google Patents
学習装置、学習方法及び学習プログラム Download PDFInfo
- Publication number
- WO2020040007A1 WO2020040007A1 PCT/JP2019/031874 JP2019031874W WO2020040007A1 WO 2020040007 A1 WO2020040007 A1 WO 2020040007A1 JP 2019031874 W JP2019031874 W JP 2019031874W WO 2020040007 A1 WO2020040007 A1 WO 2020040007A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- average
- variance
- generation unit
- data
- Prior art date
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/213—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods
- G06F18/2134—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods based on separation criteria, e.g. independent component analysis
- G06F18/21342—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods based on separation criteria, e.g. independent component analysis using statistical independence, i.e. minimising mutual information or maximising non-gaussianity
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
Definitions
- the present invention relates to a learning device, a learning method, and a learning program.
- Deep learning that is, deep neural networks have achieved great success in image recognition, voice recognition, and the like (see Non-Patent Document 1).
- Generative Adversarial Network GAN
- the GAN is a model including a generator that generates an image or the like by performing a non-linear conversion or the like by using a random number as an input, and a classifier that identifies whether the data is generated data or true data.
- a large amount of data and a long learning time are required. Therefore, in deep learning, Curriculum @ Learning (see Non-Patent Document 2) and pre-training that improve learning efficiency by learning simple tasks in advance have been proposed.
- Non-Patent Document 3 A method using likelihood for series data has been proposed (see Non-Patent Document 3).
- Unscented @ transform (UT) has been used for estimating the state of a nonlinear dynamic system (see Non-Patent Document 4).
- UT is a technique for estimating the average and variance of the output when a random variable whose covariance matrix and average are known is input to a nonlinear function.
- Non-Patent Document 3 requires complicated processing of setting a likelihood function by assuming a probability model, and it may be difficult to perform deep learning efficiently. Therefore, in order to generate complicated image data with high accuracy, a large amount of data and a long learning time are still required.
- the present invention has been made in view of the above, and an object of the present invention is to provide a learning device, a learning method, and a learning program capable of efficiently performing deep learning.
- a learning device includes a generation unit having a mathematical model for generating data by inputting random numbers used for deep learning to a nonlinear function,
- a pre-learning unit for executing pre-learning of variance and average using Unscented transform.
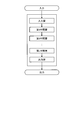
- FIG. 1 is a schematic diagram illustrating a schematic configuration of a learning device according to an embodiment.
- FIG. 2 is a diagram illustrating a deep learning model.
- FIG. 3 is a diagram illustrating GAN learning.
- FIG. 4 is a diagram illustrating the application of the UT to the generation unit illustrated in FIG.
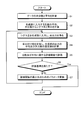
- FIG. 5 is a flowchart showing the procedure of the pre-learning process according to the present embodiment.
- FIG. 6 is a diagram illustrating an example of a computer on which a learning device is realized by executing a program.
- FIG. 1 is a schematic diagram illustrating a schematic configuration of a learning device according to an embodiment.
- FIG. 2 is a diagram illustrating a deep learning model.
- FIG. 3 is a diagram illustrating GAN learning.
- a predetermined program is read into a computer including a ROM (Read Only Memory), a RAM (Random Access Memory), a CPU (Central Processing Unit), and the like, and the CPU executes the predetermined program. It is realized by executing.
- the learning device 10 has an NIC (Network Interface Card) or the like, and can perform communication with another device via an electric communication line such as a LAN (Local Area Network) or the Internet.
- the learning device 10 performs learning using GAN.
- the learning device 10 includes a generation unit 11, an identification unit 12, and a pre-learning unit 13.
- the generation unit 11 and the identification unit 12 have deep learning models 14 and 15.
- the generation unit 11 has a mathematical model (deep learning model 14 (see FIG. 2)) for generating data by inputting random numbers used for deep learning to a nonlinear function.
- the generation unit 11 uses the deep learning model 14 and generates pseudo data by inputting random numbers as shown in FIG.
- the random number input to the generation unit 11 is a random number generated value, and is a random number used for image generation by deep learning.
- the generation unit 11 inputs the random number into a non-linear function to generate data.
- the deep learning model includes an input layer into which a signal enters, one or a plurality of intermediate layers for variously converting a signal from the input layer, and an output for converting a signal of the intermediate layer into an output such as a probability.
- layers With layers.
- ⁇ ⁇ Input data is input to the input layer. Also, from the output layer, for example, in the case of a generator in image generation using GAN, the pixel value of the generated pseudo image is output. On the other hand, the output of the GAN discriminator outputs, for example, a score indicating whether the input is true data or pseudo data in the range of 0 to 1.
- the identification unit 12 receives data to be learned and data generated by the generation unit 11 and uses the deep learning model 15 (see FIG. 3) to identify whether the generated data is true data. Then, the identification unit 12 adjusts the parameters of the deep learning model 14 of the identification unit 12 so that the generated data approaches the true data.
- the pre-learning unit 13 causes the generation unit 11 to execute variance and average pre-learning using the UT.
- the pre-learning unit 13 causes the generation unit 11 to perform pre-learning using the variance and the average after the non-linear conversion by the UT.
- the pre-learning unit 13 estimates the variance and the average of the pseudo data generated from the generation unit 11 using the UT before learning the GAN.
- the pre-learning unit 13 updates the parameter ⁇ of the generation unit 11 so as to minimize the evaluation function for evaluating the similarity between the estimated variance and average and the variance and average of the true data calculated in advance.
- the pre-learning unit 13 estimates the variance and average of the data (pseudo data) generated by the generation unit 11, calculates the variance and average of the true data, and minimizes the norm of these squares.
- the parameter ⁇ of the generation unit 11 is updated.
- the learning device 10 uses the data variance and the average in the pre-learning, unlike the method based on the likelihood, it is not necessary to set the likelihood function by assuming a probability model. Therefore, the learning device 10 can improve the learning efficiency by learning the statistics of the data in advance with a simple and low calculation amount.
- the probability distribution of the data x that is a column vector is optimized using a random number z that is a column vector according to a probability distribution p z (z) such as a normal distribution, as shown in Expression (1).
- D and G are called a classifier (classification unit 12) and a generator (generation unit 11), respectively, and are modeled by a neural network. This optimization is performed by learning D and G alternately. It is conceivable that D is learned in advance, but if D becomes a complete discriminator, the gradient becomes 0 and learning fails, so D and G must be learned in a well-balanced manner.
- D (referred to as critic, not a discriminator) is K Lipschitz in order to obtain Wasserstein distance, and W indicates a parameter set satisfying this condition.
- W indicates a parameter set satisfying this condition.
- D referred to as critic, not a discriminator
- W indicates a parameter set satisfying this condition.
- WGAN there is no problem even if D is maximized more than G is learned.
- W needs to be a compact set, and WGAN achieves this by constraining the magnitude of the parameters in an appropriate way.
- GAN derivatives such as LSGAN.
- G can be applied as long as G is a model that receives random numbers and generates data regardless of these methods.
- W (l) is a weight coefficient, and satisfies the expression (5).
- the UT can estimate the mean and covariance of the random variable after the nonlinear transformation.
- a method of selecting a sigma point required for the calculation will be described.
- W (0) m and W (0) c are weights for calculating an average and a covariance, respectively, and ⁇ , ⁇ , and ⁇ are hyperparameters.
- the input of the generation unit 11 is assumed to be a normal distribution with mean 0 and variance I, and a square norm is used as a criterion for variance and mean.
- the implementation method is not limited to this.
- u l is orthogonal vectors, for example, utilize such singular vectors obtained by performing SVD (Singular Value Decomposition) to a suitable matrix.
- SVD Single Value Decomposition
- ⁇ may be selected from 0 ⁇ ⁇ ⁇ 1. As for ⁇ , it is said that a smaller value should be selected as the nonlinearity of the nonlinear function becomes stronger. However, in the case of a higher dimension, there is a result that a larger value is better.
- the generation unit 11 is a data generation model
- the statistics of the output of the generation unit 11 match the statistics of the data. Therefore, under the control of the pre-learning unit 13, generator 11, from the data, the average value mu xdata of x, the dispersion sigma xdata was calculated, and this mean and variance mu ⁇ x generation unit 11, estimated sigma Prior learning is performed so that ⁇ ⁇ x matches.
- an evaluation function for evaluating each similarity is prepared, and the parameter ⁇ of the generation unit 11 is updated so as to minimize the evaluation function.
- This evaluation function is set, for example, as shown in equation (16) using a square norm.
- the pre-learning unit 13 terminates the pre-learning by the generation unit 11 on the basis of a small value of the evaluation function, learning for a certain period of time, and the like. Then, the generation unit 11 and the identification unit 12 perform the original GAN learning using the parameters of the generation unit 11 obtained by the pre-learning as initial values.
- This pre-learning is a simple task as compared with learning of the distribution of generation of actual data, and can be learned with 2n sigma points which are smaller than the number of data. Further, in the pre-learning, since the identification unit 12 is not used, learning can be performed with a much smaller amount of calculation than in GAN learning. For example, assuming that the number of data is N, the calculation order of the average value ⁇ xdata and the variance x xdata of the data is O (Np) and O (Np 2 ). For example, the calculation order of the average value ⁇ xdata and the variance x xdata of the data is smaller than the calculation amount of the back error propagation per epoch of the perceptron of n units and one layer is O (Nn 2 ). Then, the generation unit 11 generates a sample close to the true generation distribution by pre-learning, and has an effect such that a gradient is easily obtained. Therefore, the learning time can be reduced.
- FIG. 5 is a flowchart showing the procedure of the pre-learning process according to the present embodiment.
- the pre-learning unit 13 calculates the covariance and the average of the data (Step S1). Subsequently, the pre-learning unit 13 calculates a sigma point and a weight from the average and covariance of the random numbers input to the generation unit 11 (Step S2). The pre-learning unit 13 inputs the sigma points to the generation unit 11 and obtains each output (Step S3). Then, the pre-learning unit 13 calculates the weighted sum, and calculates the average of the output of the generation unit 11 and the estimated value of the covariance (Step S4).
- the pre-learning unit 13 evaluates with an evaluation function regarding the average and the variance (step S5).
- the pre-learning unit 13 uses the norm of the square of the average and variance of the pseudo data generated by the generation unit 11 and the mean and variance of the true data as an evaluation function, and calculates the estimated variance and average. Evaluate the variance and average similarity of the pre-calculated true data.
- the pre-learning unit 13 determines whether the evaluation result satisfies the evaluation criteria (Step S6). For example, the preliminary learning unit 13 determines whether or not the square norm is equal to or less than a predetermined reference value.
- Step S6 determines that the evaluation result does not satisfy the evaluation criteria
- the pre-learning unit 13 updates the parameters of the generation unit 11 to minimize the evaluation function (Step S7). ), And execute the processing after step S3.
- the pre-learning unit 13 determines that the evaluation result satisfies the evaluation criterion (Step S6: Yes)
- the pre-learning process ends.
- the learning device 10 provides a generator having a mathematical model for generating data by inputting a random number used for deep learning to a nonlinear function, and calculating a variance and an average using a UT.
- Perform pre-learning Specifically, in the embodiment, in the pre-learning, the variance and the average of the data generated from the generation unit are estimated using the UT, and the estimated variance and the average are compared with the true data calculated in advance.
- the parameters of the generation unit 11 are updated so as to minimize the evaluation function for evaluating the degree of similarity with the variance and the average.
- the learning can be made more efficient by learning the statistics of the data in advance with a simple and low calculation amount.
- Each component of the learning device 10 illustrated in FIG. 1 is a functional concept and does not necessarily need to be physically configured as illustrated. That is, the specific form of distribution and integration of the functions of the learning device 10 is not limited to the illustrated one, and all or a part of the functions may be divided into functional units or physical units in arbitrary units according to various loads and usage conditions. Can be distributed or integrated.
- each process performed by the learning device 10 may be realized by a CPU and a program analyzed and executed by the CPU. Further, each process performed in the learning device 10 may be realized as hardware by wired logic.
- all or a part of the processes described as being performed automatically may be manually performed.
- all or part of the processing described as being performed manually can be automatically performed by a known method.
- the above-described and illustrated processing procedures, control procedures, specific names, and information including various data and parameters can be appropriately changed unless otherwise specified.
- FIG. 6 is a diagram illustrating an example of a computer in which the learning device 10 is realized by executing a program.
- the computer 1000 has, for example, a memory 1010 and a CPU 1020.
- the computer 1000 has a hard disk drive interface 1030, a disk drive interface 1040, a serial port interface 1050, a video adapter 1060, and a network interface 1070. These components are connected by a bus 1080.
- the memory 1010 includes a ROM 1011 and a RAM 1012.
- the ROM 1011 stores, for example, a boot program such as a BIOS (Basic Input Output System).
- BIOS Basic Input Output System
- the hard disk drive interface 1030 is connected to the hard disk drive 1090.
- the disk drive interface 1040 is connected to the disk drive 1100.
- a removable storage medium such as a magnetic disk or an optical disk is inserted into the disk drive 1100.
- the serial port interface 1050 is connected to, for example, a mouse 1110 and a keyboard 1120.
- the video adapter 1060 is connected to the display 1130, for example.
- the hard disk drive 1090 stores, for example, an operating system (OS) 1091, an application program 1092, a program module 1093, and program data 1094. That is, a program that defines each process of the learning device 10 is implemented as a program module 1093 in which codes executable by the computer 1000 are described.
- the program module 1093 is stored in, for example, the hard disk drive 1090.
- a program module 1093 for executing the same processing as the functional configuration of the learning device 10 is stored in the hard disk drive 1090.
- the hard disk drive 1090 may be replaced by an SSD (Solid State Drive).
- the setting data used in the processing of the above-described embodiment is stored as the program data 1094 in, for example, the memory 1010 or the hard disk drive 1090. Then, the CPU 1020 reads out the program module 1093 and the program data 1094 stored in the memory 1010 and the hard disk drive 1090 to the RAM 1012 as needed, and executes them.
- the program module 1093 and the program data 1094 are not limited to being stored in the hard disk drive 1090, but may be stored in, for example, a removable storage medium and read out by the CPU 1020 via the disk drive 1100 or the like. Alternatively, the program module 1093 and the program data 1094 may be stored in another computer connected via a network (LAN, Wide Area Network (WAN), or the like). Then, the program module 1093 and the program data 1094 may be read from another computer by the CPU 1020 via the network interface 1070.
- LAN Local Area Network
- WAN Wide Area Network
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Databases & Information Systems (AREA)
- Multimedia (AREA)
- Medical Informatics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
- Complex Calculations (AREA)
Abstract
学習装置(10)は、深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデルを有する生成部(11)と、生成部(11)に対して、Unscented transform(UT)を用いた分散及び平均の事前学習を実行させる事前学習部(13)と、を有する。事前学習部(13)は、UTを用いて、生成部(11)から生成されるデータの分散及び平均を推定し、推定した分散及び平均と、事前に計算した真のデータの分散及び平均との類似度を評価する評価関数を最小化するように生成部(11)のパラメータを更新する。
Description
本発明は、学習装置、学習方法及び学習プログラムに関する。
深層学習、すなち、ディープニューラルネットワークは、画像認識や音声認識などで大きな成功を収めている(非特許文献1参照)。特に、画像などのデータを新たに生成する生成モデルというタスクにおいては、Generative Adversarial Network(GAN)が用いられる。GANは、乱数を入力とし非線形変換などを行って画像などを生成する生成器と、生成されたデータか、真のデータかを識別する識別器からなるモデルである。複雑な画像データを高精度に生成するためには、大量のデータと長時間の学習が必要である。そこで深層学習ではあらかじめ簡単なタスクを学習させることで学習を効率化するCurriculum Learning(非特許文献2参照)やプレトレーニングが提案されている。
例えば、GANのプレトレーニングでは。系列データに対し尤度を使う手法などが提案されている(非特許文献3参照)。また、Unscented transform(UT)は、非線形な動的システムの状態推定に用いられてきた(非特許文献4参照)。UTは、共分散行列と平均とが既知の確率変数が、非線形関数に入力されたときに、その出力の平均と分散を推定する技術である。
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
Yoshua Bengio, et al. "Curriculum Learning" Proceedings of the 26th annual international conference on machine learning. ACM, 2009.
Lantao Yu,et al. "SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient". AAAI.2017.
片山徹. 非線形カルマンフィルタ. 朝倉書店, 2011.
しかしながら、非特許文献3記載の手法では、確率モデルを仮定して尤度関数を設定するという複雑な処理が必要であり、深層学習を効率的に行なうことが難しい場合があった。このため、複雑な画像データを高精度に生成するためには、依然、大量のデータと長時間の学習が必要である。
本発明は、上記に鑑みてなされたものであって、深層学習を効率的に行なうことができる学習装置、学習方法及び学習プログラムを提供することを目的とする。
上述した課題を解決し、目的を達成するために、本発明に係る学習装置は、深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデルを有する生成部と、生成部に対して、Unscented transformを用いた分散及び平均の事前学習を実行させる事前学習部と、を有することを特徴とする。
本発明によれば、深層学習を効率的に行なうことができる。
以下、図面を参照して、本発明の一実施形態を詳細に説明する。なお、この実施の形態により本発明が限定されるものではない。また、図面の記載において、同一部分には同一の符号を付して示している。また、以下では、ベクトル、行列又はスカラーであるAに対し、“^A”と記載する場合は「“A”の直上に“^”が記された記号」と同等であるとする。
[実施の形態]
まず、実施の形態に係る学習装置について、概略構成、評価処理の流れ及び具体例を説明する。図1は、実施の形態に係る学習装置の概略構成を示す模式図である。図2は、深層学習モデルを説明する図である。図3は、GANの学習を説明する図である。
まず、実施の形態に係る学習装置について、概略構成、評価処理の流れ及び具体例を説明する。図1は、実施の形態に係る学習装置の概略構成を示す模式図である。図2は、深層学習モデルを説明する図である。図3は、GANの学習を説明する図である。
実施の形態に係る学習装置10は、ROM(Read Only Memory)、RAM(Random Access Memory)、CPU(Central Processing Unit)等を含むコンピュータ等に所定のプログラムが読み込まれて、CPUが所定のプログラムを実行することで実現される。また、学習装置10は、NIC(Network Interface Card)等を有し、LAN(Local Area Network)やインターネットなどの電気通信回線を介した他の装置との間の通信を行うことも可能である。学習装置10は、GANを用いた学習を行う。図1に示すように、学習装置10は、生成部11と識別部12と事前学習部13とを有する。生成部11と識別部12とは、深層学習モデル14,15を有する。
生成部11は、深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデル(深層学習モデル14(図2参照))を有する。生成部11は、深層学習モデル14を用い、図3に示すように、乱数を入力とし擬似データを生成する。生成部11に入力される乱数は、乱数生成された値であり、深層学習による画像生成に用いられる乱数である。生成部11は、この乱数を非線形関数に入力してデータを生成する。
図2に示すように、深層学習のモデルは、信号の入る入力層、入力層からの信号を様々に変換する1層または複数の中間層、中間層の信号を確率などの出力に変換する出力層を有する。
入力層には入力データが入力される。また、出力層からは、例えばGANを使った画像生成における生成器の場合、生成された擬似画像の画素値が出力される。一方、GANの識別器の出力は、例えば、入力が真のデータか擬似データかのスコアを0から1の範囲で出力する。
識別部12は、学習したいデータと生成部11が生成したデータとを入力として、深層学習モデル15(図3参照)を用い、生成したデータが真のデータかどうかを識別する。そして、識別部12では、生成したデータがより真のデータに近づくように、識別部12の深層学習モデル14のパラメータを調整する。
事前学習部13は、生成部11に対して、UTを用いた分散及び平均の事前学習を実行させる。事前学習部13は、UTにより非線形変換後の分散及び平均を用いて生成部11に事前学習を行わせる。具体的には、事前学習部13は、GANの学習を行う前に、UTを用いて、生成部11から生成される擬似データの分散及び平均を推定する。事前学習部13は、推定した分散及び平均と、事前に計算した真のデータの分散及び平均との類似度を評価する評価関数を最小化するように生成部11のパラメータθを更新する。すなわち、事前学習部13は、生成部11において生成されるデータ(疑似データ)の分散及び平均を推定するとともに、真のデータの分散及び平均を計算し、これらの二乗のノルムを最小化するように生成部11のパラメータθを更新する。
このように、学習装置10は、事前学習において、データの分散と平均を用いるため、尤度に基づく手法と異なり確率モデルを仮定して尤度関数を設定する必要がない。したがって、学習装置10は、簡単かつ低計算量でデータの統計量を事前に学習することによって、学習を効率化できる。
[GANの概要]
GANでは、列ベクトルであるデータxの確率分布を、正規分布などの確率分布pz(z)に従う列ベクトルである乱数zを使って(1)式に示すような最適化を行う。
GANでは、列ベクトルであるデータxの確率分布を、正規分布などの確率分布pz(z)に従う列ベクトルである乱数zを使って(1)式に示すような最適化を行う。

ここでDとGは、それぞれ識別器(識別部12)、生成器(生成部11)と呼ばれ、ニューラルネットワークでモデル化する。この最適化はDとGを交互に学習させることで行う。Dは事前に学習させることも考えられるが、Dが完全な識別器になってしまうと勾配が0となり学習が失敗するため、DとGとはバランスよく学習させなければならない。
また、GANの学習では、G(z)の分布とデータの分布pdata(x)の分布が離れすぎると、Gの勾配がほぼ0となり学習が進まない。GANの派生技術としてWasserstein distance(earth mover distance)に基づくWGANが提案されている。WGANでは、(2)式に示すWasserstein distanceが、最小となるようにθを学習する。
ここで、D(識別器ではなくcriticと呼ぶ)はWasserstein distanceを求めるためにKリプシッツであるという条件があり、Wはこの条件を満たすパラメータ集合をさす。WGANであれば、Dの最大化をGの学習より進めても問題がない。KリプシッツであるためにWをコンパクト集合にする必要があり、WGANではパラメータの大きさを適切な方法で制約することによって、これを実現する。その他にLSGANなどのGANの派生技術があるが、本実施の形態では、これらの手法に依らずGが乱数を入力としデータを生成するモデルであれば適用可能である。
[UTの概要]
ある確率変数z∈Rn平均をμzとし、共分散行列をΣzzとする。そして、列ベクトルx=f(z)を、任意の非線形要素f:Rn→Rpとする。このとき、xの平均μxと、分散行列Σxxと、共分散行列Σzxとを近似計算によって求める。まず、(3)式及び(4)式を満たす2n+1個の代表点(シグマ点){z(l),l=0,・・・,2n}を考える。
ある確率変数z∈Rn平均をμzとし、共分散行列をΣzzとする。そして、列ベクトルx=f(z)を、任意の非線形要素f:Rn→Rpとする。このとき、xの平均μxと、分散行列Σxxと、共分散行列Σzxとを近似計算によって求める。まず、(3)式及び(4)式を満たす2n+1個の代表点(シグマ点){z(l),l=0,・・・,2n}を考える。


ただしW(l)は、重み係数であり、(5)式を満たす。

次に、シグマ点に対して、非線形変換を計算し、x(l)=s(z(l))を得る。この変換した2n+1個の点の重みつき平均値を計算し(6)式を得る。

最後に共分散行列Σzxを以下の(7)式を用いて計算する。

以上の方法によって、UTは、非線形変換後の確率変数の平均と共分散とを推定することができる。次に、その計算に必要なシグマ点の選択方法について説明する。
[シグマ点の選択]
まず、Σzzの平方根行列B∈Rn×nを(8)式とする。
まず、Σzzの平方根行列B∈Rn×nを(8)式とする。
このとき、シグマ点と重み係数とを(9)~(12)式とする。



ここで、W(0)
mとW(0)
cは、それぞれ平均、共分散を求めるときの重みであり、κ、β、αは、ハイパーパラメータであるが、後述の通り設定の指針がある
[本実施の形態の手法]
以下に、本実施の形態明細書における手法について述べる。本実施の形態の学習方法の実現方法の一例として、生成部11の入力を、平均0、分散Iの正規分布と仮定し、分散と平均の評価基準として、二乗ノルムを使用して説明するが、実現方法はこれに限らない。
以下に、本実施の形態明細書における手法について述べる。本実施の形態の学習方法の実現方法の一例として、生成部11の入力を、平均0、分散Iの正規分布と仮定し、分散と平均の評価基準として、二乗ノルムを使用して説明するが、実現方法はこれに限らない。
[UTを使ったGANの事前学習]
GANにおいて、モデルに印加する前の確率変数zは平均0、分散Iの正規分布から求めることが多い。このとき、シグマ点は、(13)式~(15)式により得られる
GANにおいて、モデルに印加する前の確率変数zは平均0、分散Iの正規分布から求めることが多い。このとき、シグマ点は、(13)式~(15)式により得られる
ただし、ulは直交ベクトルであり、例えば、適当な行列にSVD(Singular Value Decomposition)を施して得られる特異ベクトルなどを利用する。UTを使用する際に、非線形関数にかけられるzの分布が正規分布である場合、β=2が最適であるとされる。また、κの値は重要ではないため、通常、=0とすればよい。最後に、αは、0≦α≦1から選べばよい。αについては、非線形関数の非線形度が強いほど小さな値を選べばよいとされるが、高次元の場合は、大きな値がよいという結果もある。
図4は、図1に示す生成部11へのUTの適用を説明する図である。図4に示すように、以上のUTを施すことでGANの生成部11から得られる^x=G(z)の平均値と分散との近似値を求めることができる。
この際、^xの分布の形は仮定していない。生成部11がデータの生成モデルとなっている場合、生成部11の出力の統計量(平均や分散など)とデータの統計量とは一致する。そこで、事前学習部13の制御にしたがい、生成部11は、データから、xの平均値μxdata、分散Σxdataを計算し、これと、推定された生成部11の平均μ^xと分散Σ^xとが一致するように事前学習を行う。
具体的には、それぞれの類似度を評価する評価関数を用意し、これを最小化するように生成部11のパラメータθを更新する。この評価関数には、例えば、二乗ノルムを使って(16)式のように設定する。
事前学習部13は、生成部11による事前学習を、評価関数の値が小さい、一定時間学習を行った、などを基準に終了させる。そして、生成部11及び識別部12は、この事前学習によって得られた生成部11のパラメータを初期値として、元々のGANの学習を行う。
この事前学習は、実際のデータの生成分布の学習と比較して簡単なタスクであり、また、データの数と比較して少ない2n個のシグマ点で学習できる。さらに事前学習では、識別部12を使用しないため、GANの学習よりも非常に少ない計算量で学習可能である。例えば、データ数をNとすると、データの平均値μxdata、分散Σxdataの計算オーダーは、O(Np)、O(Np2)である。例えば、例えば、nユニット1層のパーセプトロンの1エポックあたりの逆誤差伝搬の計算量がO(Nn2)であることと比べると、データの平均値μxdata、分散Σxdataの計算オーダーは小さい。そして、事前学習によって生成部11が真の生成分布と近いサンプルを生成し、勾配が得られやすくなる等の効果があるため、学習時間を短縮できる。
[事前学習処理]
次に、学習装置10による事前学習処理の処理手順について説明する。図5は、本実施の形態に係る事前学習処理の処理手順を示すフローチャートである。
次に、学習装置10による事前学習処理の処理手順について説明する。図5は、本実施の形態に係る事前学習処理の処理手順を示すフローチャートである。
図5に示すように、事前学習部13は、データの共分散及び平均を計算する(ステップS1)。続いて、事前学習部13は、生成部11に入力する乱数の平均、共分散からシグマ点と重みとを計算する(ステップS2)。事前学習部13は、シグマ点を生成部11に入力し、各出力を得る(ステップS3)。そして、事前学習部13は、重み付け和を計算し、生成部11の出力の平均と共分散の推定値を計算する(ステップS4)。
続いて、事前学習部13は、平均と分散に関する評価関数で評価する(ステップS5)。例えば、事前学習部13は、生成部11において生成される疑似データの平均、分散の推定値と、真のデータの平均、分散との二乗のノルムを評価関数として使用し、推定した分散及び平均、事前に計算した真のデータの分散及び平均の類似度を評価する。
そして、事前学習部13は、評価結果が評価基準を満たすか否かを判定する(ステップS6)。例えば、事前学習部13は、二乗のノルムが所定の基準値以下となるか否かを判定する。
事前学習部13は、評価結果が評価基準を満たさないと判定した場合(ステップS6:No)、事前学習部13は、評価関数の最小化のために生成部11のパラメータ更新を行い(ステップS7)、ステップS3以降の処理を実行する。一方、事前学習部13は、評価結果が評価基準を満たすと判定した場合(ステップS6:Yes)、事前学習処理を終了する。
[実施の形態の効果]
上記のように、実施の形態に係る学習装置10は、深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデルを有する生成部に対して、UTを用いた分散及び平均の事前学習を実行させる。具体的には、実施の形態では、事前学習において、UTを用いて、前記生成部から生成されるデータの分散及び平均を推定し、推定した分散及び平均と、事前に計算した真のデータの分散及び平均との類似度を評価する評価関数を最小化するように前記生成部11のパラメータを更新する。
上記のように、実施の形態に係る学習装置10は、深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデルを有する生成部に対して、UTを用いた分散及び平均の事前学習を実行させる。具体的には、実施の形態では、事前学習において、UTを用いて、前記生成部から生成されるデータの分散及び平均を推定し、推定した分散及び平均と、事前に計算した真のデータの分散及び平均との類似度を評価する評価関数を最小化するように前記生成部11のパラメータを更新する。
このように、実施の形態によれば、事前学習において、データの分散と平均を用いるため、尤度に基づく手法と異なり確率モデルを仮定して尤度関数を設定する必要がない。したがって、実施の形態によれば、簡単かつ低計算量でデータの統計量を事前に学習することによって、学習を効率化できる。
[実施の形態のシステム構成について]
図1に示した学習装置10の各構成要素は機能概念的なものであり、必ずしも物理的に図示のように構成されていることを要しない。すなわち、学習装置10の機能の分散及び統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散または統合して構成することができる。
図1に示した学習装置10の各構成要素は機能概念的なものであり、必ずしも物理的に図示のように構成されていることを要しない。すなわち、学習装置10の機能の分散及び統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散または統合して構成することができる。
また、学習装置10において行われる各処理は、全部または任意の一部が、CPU及びCPUにより解析実行されるプログラムにて実現されてもよい。また、学習装置10において行われる各処理は、ワイヤードロジックによるハードウェアとして実現されてもよい。
また、実施の形態において説明した各処理のうち、自動的におこなわれるものとして説明した処理の全部または一部を手動的に行うこともできる。もしくは、手動的におこなわれるものとして説明した処理の全部または一部を公知の方法で自動的に行うこともできる。この他、上述及び図示の処理手順、制御手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて適宜変更することができる。
[プログラム]
図6は、プログラムが実行されることにより、学習装置10が実現されるコンピュータの一例を示す図である。コンピュータ1000は、例えば、メモリ1010、CPU1020を有する。また、コンピュータ1000は、ハードディスクドライブインタフェース1030、ディスクドライブインタフェース1040、シリアルポートインタフェース1050、ビデオアダプタ1060、ネットワークインタフェース1070を有する。これらの各部は、バス1080によって接続される。
図6は、プログラムが実行されることにより、学習装置10が実現されるコンピュータの一例を示す図である。コンピュータ1000は、例えば、メモリ1010、CPU1020を有する。また、コンピュータ1000は、ハードディスクドライブインタフェース1030、ディスクドライブインタフェース1040、シリアルポートインタフェース1050、ビデオアダプタ1060、ネットワークインタフェース1070を有する。これらの各部は、バス1080によって接続される。
メモリ1010は、ROM1011及びRAM1012を含む。ROM1011は、例えば、BIOS(Basic Input Output System)等のブートプログラムを記憶する。ハードディスクドライブインタフェース1030は、ハードディスクドライブ1090に接続される。ディスクドライブインタフェース1040は、ディスクドライブ1100に接続される。例えば磁気ディスクや光ディスク等の着脱可能な記憶媒体が、ディスクドライブ1100に挿入される。シリアルポートインタフェース1050は、例えばマウス1110、キーボード1120に接続される。ビデオアダプタ1060は、例えばディスプレイ1130に接続される。
ハードディスクドライブ1090は、例えば、OS(Operating System)1091、アプリケーションプログラム1092、プログラムモジュール1093、プログラムデータ1094を記憶する。すなわち、学習装置10の各処理を規定するプログラムは、コンピュータ1000により実行可能なコードが記述されたプログラムモジュール1093として実装される。プログラムモジュール1093は、例えばハードディスクドライブ1090に記憶される。例えば、学習装置10における機能構成と同様の処理を実行するためのプログラムモジュール1093が、ハードディスクドライブ1090に記憶される。なお、ハードディスクドライブ1090は、SSD(Solid State Drive)により代替されてもよい。
また、上述した実施の形態の処理で用いられる設定データは、プログラムデータ1094として、例えばメモリ1010やハードディスクドライブ1090に記憶される。そして、CPU1020が、メモリ1010やハードディスクドライブ1090に記憶されたプログラムモジュール1093やプログラムデータ1094を必要に応じてRAM1012に読み出して実行する。
なお、プログラムモジュール1093やプログラムデータ1094は、ハードディスクドライブ1090に記憶される場合に限らず、例えば着脱可能な記憶媒体に記憶され、ディスクドライブ1100等を介してCPU1020によって読み出されてもよい。或いは、プログラムモジュール1093及びプログラムデータ1094は、ネットワーク(LAN、WAN(Wide Area Network)等)を介して接続された他のコンピュータに記憶されてもよい。そして、プログラムモジュール1093及びプログラムデータ1094は、他のコンピュータから、ネットワークインタフェース1070を介してCPU1020によって読み出されてもよい。
以上、本発明者によってなされた発明を適用した実施の形態について説明したが、本実施の形態による本発明の開示の一部をなす記述及び図面により本発明は限定されることはない。すなわち、本実施の形態に基づいて当業者等によりなされる他の実施の形態、実施例及び運用技術等は全て本発明の範疇に含まれる。
10 学習装置
11 生成部
12 識別部
13 事前学習部
14,15 深層学習モデル
11 生成部
12 識別部
13 事前学習部
14,15 深層学習モデル
Claims (5)
- 深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデルを有する生成部と、
前記生成部に対して、Unscented transformを用いた分散及び平均の事前学習を実行させる事前学習部と、
を有することを特徴とする学習装置。 - 前記事前学習部は、前記Unscented transformを用いて、前記生成部から生成されるデータの分散及び平均を推定し、推定した分散及び平均と、事前に計算した真のデータの分散及び平均との類似度を評価する評価関数を最小化するように前記生成部のパラメータを更新することを特徴とする請求項1に記載の学習装置。
- 前記事前学習部は、前記推定した分散及び平均と、前記事前に計算した真のデータの分散及び平均との二乗のノルムを最小化するように前記生成部のパラメータを更新することを特徴とする請求項2に記載の学習装置。
- 学習装置が実行する学習方法であって、
前記学習装置は、深層学習に用いられる乱数を非線形関数に入力してデータを生成する数理モデルを有する生成部を有し、
前記生成部に対して、Unscented transformを用いた分散及び平均の事前学習を実行させる事前学習工程
を含んだことを特徴とした学習方法。 - コンピュータを請求項1~3のいずれか一つに記載の学習装置として機能させるための学習プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/270,056 US20210326705A1 (en) | 2018-08-23 | 2019-08-13 | Learning device, learning method, and learning program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018156733A JP7047665B2 (ja) | 2018-08-23 | 2018-08-23 | 学習装置、学習方法及び学習プログラム |
| JP2018-156733 | 2018-08-23 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020040007A1 true WO2020040007A1 (ja) | 2020-02-27 |
Family
ID=69592627
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/031874 WO2020040007A1 (ja) | 2018-08-23 | 2019-08-13 | 学習装置、学習方法及び学習プログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20210326705A1 (ja) |
| JP (1) | JP7047665B2 (ja) |
| WO (1) | WO2020040007A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112738092A (zh) * | 2020-12-29 | 2021-04-30 | 北京天融信网络安全技术有限公司 | 一种日志数据增强方法、分类检测方法及系统 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025134586A1 (ja) * | 2023-12-20 | 2025-06-26 | パナソニックIpマネジメント株式会社 | 情報処理装置および情報処理方法 |
-
2018
- 2018-08-23 JP JP2018156733A patent/JP7047665B2/ja active Active
-
2019
- 2019-08-13 WO PCT/JP2019/031874 patent/WO2020040007A1/ja active Application Filing
- 2019-08-13 US US17/270,056 patent/US20210326705A1/en active Pending
Non-Patent Citations (2)
| Title |
|---|
| 20 September 2019 (2019-09-20), pages 651 - 654, XP055688138, Retrieved from the Internet <URL:https://www.jstage.jst.go.jp/article/oukan/2005/0/2005_0_200/_pdf> * |
| UNSCENTED TRANSFORM GAN (CVIM, 13 September 2018 (2018-09-13), Retrieved from the Internet <URL:https://ipsj.ixsq.nii.ac.jp/ej/index.php?active_action=repository_view_main_item_detail&page_id=13&block_id=8&item_id=191372&item_no=l> * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112738092A (zh) * | 2020-12-29 | 2021-04-30 | 北京天融信网络安全技术有限公司 | 一种日志数据增强方法、分类检测方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20210326705A1 (en) | 2021-10-21 |
| JP7047665B2 (ja) | 2022-04-05 |
| JP2020030702A (ja) | 2020-02-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210174264A1 (en) | Training tree-based machine-learning modeling algorithms for predicting outputs and generating explanatory data | |
| EP3572985A1 (en) | System and method for generating explainable latent features of machine learning models | |
| CN108399383B (zh) | 表情迁移方法、装置存储介质及程序 | |
| Chan et al. | Bayesian poisson regression for crowd counting | |
| CN111695415A (zh) | 图像识别模型的构建方法、识别方法及相关设备 | |
| US20230222326A1 (en) | Method and system for training a neural network model using gradual knowledge distillation | |
| Murtaza et al. | Face recognition using adaptive margin fisher’s criterion and linear discriminant analysis | |
| WO2021059388A1 (ja) | 学習装置、画像処理装置、学習方法及び学習プログラム | |
| WO2017092022A1 (zh) | 一种张量模式下的有监督学习优化方法及系统 | |
| WO2022105108A1 (zh) | 一种网络数据分类方法、装置、设备及可读存储介质 | |
| JP6673226B2 (ja) | 特徴変換装置、認識装置、特徴変換方法及びコンピュータ読み取り可能記録媒体 | |
| CN110781970A (zh) | 分类器的生成方法、装置、设备及存储介质 | |
| CN114830137A (zh) | 用于生成预测模型的方法和系统 | |
| WO2017188048A1 (ja) | 作成装置、作成プログラム、および作成方法 | |
| WO2020223850A1 (en) | System and method for quantum circuit simulation | |
| WO2020040007A1 (ja) | 学習装置、学習方法及び学習プログラム | |
| JP2018081493A (ja) | パターン識別装置、パターン識別方法およびプログラム | |
| US10546246B2 (en) | Enhanced kernel representation for processing multimodal data | |
| Ibragimovich et al. | Effective recognition of pollen grains based on parametric adaptation of the image identification model | |
| US20190156182A1 (en) | Data inference apparatus, data inference method and non-transitory computer readable medium | |
| CN114299304A (zh) | 一种图像处理方法及相关设备 | |
| WO2019234156A1 (en) | Training spectral inference neural networks using bilevel optimization | |
| CN111160487B (zh) | 人脸图像数据集的扩充方法和装置 | |
| JP7477859B2 (ja) | 計算機、計算方法及びプログラム | |
| JP2019113962A (ja) | 解析装置、解析方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19851666 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19851666 Country of ref document: EP Kind code of ref document: A1 |