WO2019238093A1 - APJ抗体及其与Elabela的融合蛋白质,以及其药物组合物和应用 - Google Patents
APJ抗体及其与Elabela的融合蛋白质,以及其药物组合物和应用 Download PDFInfo
- Publication number
- WO2019238093A1 WO2019238093A1 PCT/CN2019/091090 CN2019091090W WO2019238093A1 WO 2019238093 A1 WO2019238093 A1 WO 2019238093A1 CN 2019091090 W CN2019091090 W CN 2019091090W WO 2019238093 A1 WO2019238093 A1 WO 2019238093A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- amino acid
- antibody
- elabela
- acid sequence
- Prior art date
Links
- 0 C*(C1)C(C(*2)C3S4CC2C3C4)C1=C Chemical compound C*(C1)C(C(*2)C3S4CC2C3C4)C1=C 0.000 description 2
Images






Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2869—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against hormone receptors
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/30—Macromolecular organic or inorganic compounds, e.g. inorganic polyphosphates
- A61K47/42—Proteins; Polypeptides; Degradation products thereof; Derivatives thereof, e.g. albumin, gelatin or zein
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/04—Inotropic agents, i.e. stimulants of cardiac contraction; Drugs for heart failure
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/12—Antihypertensives
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4702—Regulators; Modulating activity
- C07K14/4705—Regulators; Modulating activity stimulating, promoting or activating activity
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
Definitions
- This article provides APJ antibodies and fusion proteins with Elabela. Also provided herein are pharmaceutical compositions of APJ antibodies and Elabela fusion proteins. This article further provides methods for treating, preventing or ameliorating one or more symptoms of pulmonary hypertension, pulmonary hypertension, or heart failure using APJ antibodies and Elabela fusion proteins.
- APJ contains 7 transmembrane units and 308 amino acids, and belongs to the family of G protein coupled receptors (GPCRs).
- GPCRs G protein coupled receptors
- the vasoactive peptide Apelin is the earliest endogenous ligand of the APJ receptor.
- Apelin and APJ are widely distributed in the human central nervous system and various peripheral tissues such as the lung, heart, and breast (Kawamata et al., 2001, Biochem. Biophys. Acta. 1538: 162-71; Medhurst et al., 2003, J. Neurochem. 84: 1162-72), especially in cardiovascular endothelial cells and cardiac tissues (Kleiz et al., 2005, Regul. Pept. 126: 233-40).
- Apelin / APJ signaling system has the effects of enhancing myocardial contractility, reducing blood pressure, promoting new blood vessel formation, regulating the body's immune response and the release of pituitary-related hormones, and regulating insulin secretion. Pathophysiology of atrial fibrillation and ischemia-reperfusion injury.
- Elabela is another endogenous ligand that has attracted much attention in the APJ receptors in recent years (Chng et al., 2013, Dev. Cell 27: 672-680; Pauli et al., 2014, Science 343: 1248636). Elabela is encoded by three exons on human chromosome 4 and was previously considered to be non-coding RNA. However, Elabela contains a conserved ORF that encodes a protein of 54 amino acids, and its mature body consists of only 32 amino acids. . The Elabela / APJ signaling pathway has been shown to play a critical role in the development of the heart and vasculature of the embryo.
- Elabela and Elabela mutants can activate the G ⁇ i1 and ⁇ -arrestin2 signaling pathways of APJ receptors. Further, mutations at the C-terminal end of Elabela polypeptides can cause APJ receptor signaling pathway preferences (Murza et al., 2016, J Med.Chem. 59: 2962-72), and the use of receptor signaling pathways is an important direction for new drug development (Bologna et al., 2017, Biomol. Ther. 25: 12-25).
- Fusion administration of both Elabela and APJ antibodies can significantly extend the half-life of Elabela to retain the biological activity of the Elabela molecule.
- the fusion protein formed by the antibody that Elabela specifically binds to APJ has the molecular targeting provided by the antibody. Helps improve the drugability of the Elabela fusion protein, and plays a role in the treatment of pulmonary hypertension, pulmonary hypertension, type 2 diabetes and its related metabolic syndrome, and one or more diseases in heart failure.
- antibodies that specifically bind to APJ are provided herein.
- an antibody capable of specifically binding to APJ comprising one, two, three, four, five, or six amino acid sequences, wherein each amino acid sequence is independently selected from the following Column amino acid sequence:
- amino acid sequence of heavy chain CDR1 SEQ ID NO: 12, SEQ ID NO: 15 and SEQ ID NO: 18;
- Amino acid sequence of heavy chain CDR2 SEQ ID NO: 13, SEQ ID NO: 16, SEQ ID NO: 19, and SEQ ID NO: 21;
- an Elabela fusion protein comprising an antibody capable of specifically binding to APJ and one, two, three, four, five, six, seven, or eight Elabela fragment peptide linker sequences ( Linker);
- the fusion protein connects the amino terminus of an Elabela fragment with the carboxyl terminus of an APJ antibody light or heavy chain through a peptide linker sequence, wherein each Elabela fragment is independently a forward Elabela fragment or A mutant thereof; or the fusion protein connects the carboxyl end of an Elabela fragment with the amino end of an APJ antibody light or heavy chain through a peptide linker sequence, wherein each Elabela fragment is independently a reverse Elabela Fragments or mutants thereof.
- This article provides an Elabela fusion protein, which contains an antibody that specifically binds to APJ, two Elabela fragments, and two peptide linker sequences (Linker); the fusion protein uses a peptide linker sequence (Linker) to link an Elabela fragment
- the amino terminus is connected to the carboxyl terminus of the light chain of an APJ antibody: N'-R-Linker-Elabela-C '; or the amino terminus of an Elabela fragment is connected to the carboxyl terminus of an APJ antibody heavy chain through a peptide linker sequence Link: N'-R-Linker-Elabela-C '; where: N' represents the amino terminus of the fusion protein polypeptide chain, C 'represents the carboxyl terminus of the fusion protein polypeptide chain, Elabela represents the forward Elabela fragment or its mutant, R Represents the amino acid sequence of the light or heavy chain of the APJ antibody, and Linker represents the peptide linker sequence.
- polynucleotide that encodes an Elabela fusion protein described herein.
- a vector comprising a polynucleotide encoding an Elabela fusion protein described herein.
- a host cell comprising a vector described herein.
- composition comprising an APJ antibody or an Elabela fusion protein as described herein, and a pharmaceutically acceptable carrier.
- an APJ antibody or an Elabela fusion protein described herein in the manufacture of a medicament for the treatment, prevention, or improvement of pulmonary hypertension and conditions associated with pulmonary hypertension.
- an APJ antibody or an Elabela fusion protein described herein in the manufacture of a medicament for the treatment, prevention, or improvement of pulmonary hypertension and conditions associated with pulmonary hypertension.
- an APJ antibody or an Elabela fusion protein described herein for the manufacture of a medicament for the treatment, prevention or amelioration of heart failure and conditions related to heart failure.
- an APJ antibody or an Elabela fusion protein described herein in the manufacture of a medicament for the treatment of type 2 diabetes and its related metabolic syndrome.
- an APJ antibody or an Elabela fusion protein described herein for use in the simultaneous treatment, prevention or improvement of pulmonary hypertension, pulmonary hypertension, type 2 diabetes and its related metabolic syndrome, or two or more disorders of heart failure Use in medicine.
- kits for treating, preventing or ameliorating one or more symptoms of pulmonary hypertension which comprises administering to a subject a therapeutically effective amount of an APJ antibody or an Elabela fusion protein described herein.
- kits for treating, preventing or ameliorating one or more symptoms of pulmonary hypertension comprising administering to a subject a therapeutically effective amount of an APJ antibody or an Elabela fusion protein described herein.
- kits for treating, preventing or ameliorating one or more symptoms of heart failure comprising administering to a subject a therapeutically effective amount of an APJ antibody or an Elabela fusion protein described herein.
- kits for treating one or more symptoms of type 2 diabetes and its related metabolic syndrome which comprise administering to a subject a therapeutically effective amount of an APJ antibody or an Elabela fusion protein described herein
- FIG. 1A to FIG. 1D shows flow cytometry (FACS) detection of recombinantly expressed hAPJ antibody L1H1 (which contains SEQ ID NO: 59 and SEQ ID NO: 64) and L4H4 (which contains SEQ ID NO: 62 and SEQ ID NO: 67)
- L1H1 which contains SEQ ID NO: 59 and SEQ ID NO: 64
- L4H4 which contains SEQ ID NO: 62 and SEQ ID NO: 67
- Figure 2 Shows the detection of recombinantly expressed hAPJ antibodies L5H5 (SEQ ID NO: 63 and SEQ ID NO: 68) and Linker2-Elabela-11 (which contains SEQ ID NO: 123 and SEQ ID NO: 93) by reporter gene experiments.
- the activation curves of the fusion protein, L5H5 and Linker2-EA5 (which contains SEQ ID NO: 123 and SEQ ID NO: 94) activate the Elabela / APJ signaling pathway, with EC 50 of 3.6 and 2.6 nM, respectively.
- Figure 3 Shows reporter gene experiments to detect recombinantly expressed fusion proteins of hAPJ antibody L5H5 and Linker2-EA1 (which contains SEQ ID NO: 123 and SEQ ID NO: 103), L5H5 and Linker2-EA2 (which contains SEQ ID NO: The activation curve of the Elabela / APJ signaling pathway activated by the fusion protein of 123 and SEQ ID NO: 107), EC 50 : 5.0 and 2.2 nM, respectively.
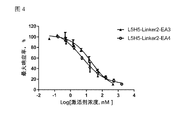
- Figure 4 Shows reporter gene experiments to detect recombinantly expressed hAPJ antibodies L5H5 and Linker2-EA3 (containing SEQ ID NO: 123 and SEQ ID NO: 109) fusion proteins, L5H5 and Linker2-EA4 (containing SEQ ID NO: The activation curve of the Elabela / APJ signaling pathway by the fusion protein of 123 and SEQ ID NO: 116), EC 50 : 20.3 and 5.4 nM, respectively.
- polypeptide sequences are indicated herein using standard one-letter or three-letter abbreviations.
- the first amino acid residue (N ') with an amino group is on the far left and the last amino acid residue (C') with a carboxyl group is on the far right, such as the forward Elabela fragment and
- the mutant sequence SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, SEQ ID NO: 97, SEQ ID NO : 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 101, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106 , SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO:
- a reverse polypeptide sequence refers to a sequence formed by rearranging the amino acid sequence of a polypeptide sequence, such as the reverse Elabela fragment sequence formed by the above-mentioned forward Elabela fragment and its mutant sequence: SEQ ID NO: 125, SEQ ID NO: 126 , SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO : 143, SEQ IDNO: 144, SEQ IDNO: 145, SEQ IDNO: 146, SEQ IDNO: 147, SEQ IDNO: 148, SEQ IDNO: 149
- the 5 'end of the upstream strand of the Elabela single-stranded and double-stranded nucleic acid sequences is on the left and their 3' ends are on the right.
- Particular parts of a polypeptide can be represented by amino acid residue numbers, such as amino acids 67 to 134, or by actual residues at this site, such as Lys67 to Lys134.
- Specific polypeptide or polynucleotide sequences can also be described by explaining their differences from the reference sequence.
- the term "individual” refers to animals including, but not limited to, primates (eg, humans), cattle, pigs, sheep, goats, horses, dogs, cats, rabbits, rats, or mice.
- the terms "individual” and “patient” are used interchangeably, for example, to refer to a mammalian individual, such as a human individual, and in one embodiment, a human.
- treatment includes reducing or eliminating a disorder, disease, or condition, or one or more symptoms associated with the disorder, disease, or condition; or reducing or eliminating the focus of the disorder, disease, or condition.
- prevention includes delaying and / or relieving the onset of a disorder, disease or disorder, and / or its accompanying symptoms; preventing an individual from acquiring the disorder, disease, or disorder; or reducing the risk of an individual acquiring the disorder, disease, or disorder.
- control refers to preventing or slowing the progression, spread, or worsening of a disorder, disorder, or disease, or one or more symptoms thereof (eg, pain). Sometimes individuals benefit from the beneficial effects of prophylactic or therapeutic agents without causing a cure for a disorder, disorder, or disease. In one embodiment, the term control refers to preventing or slowing the progression, spread or worsening of the pain of osteolysis.
- therapeutically effective amount and “effective amount” include an amount of a compound or combination of compounds that, when administered, is sufficient to prevent the development of one or more symptoms of a disorder, disease, or condition being treated or to a certain extent reduce it.
- therapeutically effective amount or “effective amount” also refers to a biological molecule (e.g., protein, enzyme, RNA, or DNA), cell, tissue, system, animal, or human that is sufficient to cause a researcher, veterinarian, doctor, or clinician to seek The amount of biologically or medically responsive compounds.
- each ingredient “pharmaceutically acceptable” means compatible with the other ingredients of the pharmaceutical formulation and suitable for contact with human or animal tissues or organs without excessive toxicity, irritation, allergies Response, immunogenicity, or other problems or complications, equivalent to a reasonable benefit / risk ratio.
- the term “about” or “approximately” refers to an acceptable error determined by those skilled in the art, which depends in part on how the value is measured or determined. In certain embodiments, the term “about” or “about” refers to within 1, 2, 3, or 4 standard deviations. In certain embodiments, the term “about” or “about” refers to 50%, 20%, 15%, 10%, 9%, 8%, 7%, 6%, 5% of a given value or range , 4%, 3%, 2%, 1%, 0.5% or 0.05%.
- peptide each refer to a molecule comprising two or more amino acids linked to each other by a peptide bond.
- proteins encompass, for example, polypeptide analogs of natural and artificial proteins and protein sequences (such as muteins, variants, and fusion proteins) as well as proteins that are co- or non-covalently modified after transcription or otherwise.
- the peptide, polypeptide or protein may be a monomer or a multimer.
- polypeptide fragment refers to a polypeptide having an amino-terminal and / or carboxy-terminal deletion compared to the corresponding full-length protein. Fragment lengths can be, for example, at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 20, 50, 70, 80, 90, 100, 150, or 200 amino acids. The fragment length can be, for example, up to 1000, 750, 500, 250, 200, 175, 150, 125, 100, 90, 80, 70, 60, 50, 40, 30, 20, 15, 14, 13, 12, 11, or 10 amino acids. A fragment may further include one or more additional amino acids at one or both ends, for example, amino acid sequences (eg, Fc or leucine zipper domains) or artificial amino acid sequences (eg, artificial linker sequences) from different natural proteins.
- amino acid sequences eg, Fc or leucine zipper domains
- artificial amino acid sequences eg, artificial linker sequences
- polypeptides herein include polypeptides modified for any reason and by any method, for example, to: (1) reduce the sensitivity to proteolysis, (2) reduce the sensitivity to oxidation, (3) change the affinity for forming a protein complex, ( 4) Change binding affinity, and (5) confer or modify other physicochemical or functional properties.
- Analogs contain mutant proteins of the polypeptide.
- single or multiple amino acid substitutions e.g., conservative amino acid substitutions
- a "conservative amino acid substitution” is one that does not significantly alter the structural characteristics of the parent sequence (e.g., replacement of amino acids should not disrupt the helix that appears in the parent sequence or interfere with other secondary structure types that confers or functions on the parent sequence).
- a "variant" of a polypeptide comprises an amino acid sequence that has one or more amino acid residues inserted, deleted, and / or replaced in the amino acid sequence relative to another polypeptide sequence. Variants herein include fusion proteins.
- a “derivative" of a polypeptide is a chemically modified polypeptide, for example, by binding to other chemical moieties such as polyethylene glycol, albumin (eg, human serum albumin), phosphorylation, and glycosylation.
- antibody includes antibodies other than those comprising two full-length heavy chains and two full-length light chains, as well as derivatives, variants, fragments, and muteins thereof, examples of which are provided below.
- antibody is a protein comprising a portion that binds to an antigen and optionally a scaffold or framework portion that allows the antigen-binding portion to adopt a conformation that promotes the binding of the antibody to the antigen.
- antibodies include whole antibodies, antibody fragments (such as the antigen-binding portion of an antibody), antibody derivatives, and antibody analogs.
- the antibody may comprise, for example, a selectable protein scaffold or an artificial scaffold with grafted CDRs or CDRs derivatives.
- the scaffold includes, but is not limited to, an antibody-derived scaffold comprising, for example, a three-dimensional structure that is introduced to stabilize the antibody, and a fully synthetic scaffold comprising, for example, a biocompatible polymer.
- the antibody may be a mimetic peptide antibody ("PAMs") or a scaffold comprising a mimetic antibody, which uses fibronectin like a scaffold.
- PAMs mimetic peptide antibody
- the antibody may have a structure such as a natural immunoglobulin.
- "Immunoglobulin” is a tetrameric molecule. In natural immunoglobulins, each tetramer is composed of two identical pairs of polypeptide chains, each pair having a "light” chain (about 25 kDa) and a "heavy” chain (about 50-70 kDa). The amino terminus of each chain includes a variable domain of about 100 to 110 amino acids, which is primarily relevant for antigen recognition. The carboxy-terminal portion of each chain defines a constant region mainly related to effector effects. Human antibody light chains are divided into kappa and lambda light chains.
- the heavy chain is divided into ⁇ , ⁇ , ⁇ , or ⁇ , and the isotype of the antigen is determined, such as IgM, IgD, IgG, IgA, and IgE, respectively.
- the variable and constant regions are linked by a "J" region of about 12 or more amino acids, and the heavy chain also includes a "D” region of about 10 amino acids. See, Fundamental Immunology Ch. 7 (ed. Paul, 2nd edition, Raven Press, 1989).
- the variable regions of each light / heavy chain pair form an antibody binding site, such that a complete immunoglobulin has two binding sites.
- Natural immunoglobulin chains show the same basic structure of relatively conserved backbone regions (FRs) connected by three highly variable regions, also known as complementarity determining regions or CDRs. From the N-terminus to the C-terminus, the light and heavy chains each contain the domains FR1, CDR1, FR2, CDR2, FR3, CDR3, and FR4. The assignment of amino acids in each domain is in accordance with the definitions of Kabat et al. In Sequences of Proteins of Immunological Interface, 5th Edition, U.S. Dept. of Health and Human Services, PHS, NIH, NIH, Publication No. 91-3242, 1991.
- antibody refers to an intact immunoglobulin or an antigen-binding portion thereof that can compete with an intact antibody for specific binding.
- Antigen-binding portions can be produced by recombinant DNA technology or by enzymatic or chemical cleavage of whole antibodies.
- Antigen-binding portions include, in particular, Fab, Fab ', F (ab') 2 , Fv, domain antibodies (dAbs), including fragments of complementarity determining regions (CDRs), single chain antibodies (scFv), chimeric antibodies, Diabodies, triabodies, tetrabodies and polypeptides comprising at least a portion of an immunoglobulin sufficient to confer polypeptide-specific antigen binding.
- Fab fragments are monovalent fragments with V L , V H , C L , and C H1 domains; F (ab ') 2 fragments are bivalent fragments with two Fab fragments connected by disulfide bonds in the hinge region; Fv fragment having V H and V L, domains; a dAb fragment having a V H domain, V L domain, or a V H or V L domain antigen binding fragment (U.S. Patent No. US 6,846,634 and US 6,696,245; U.S. Patent application Publication No. (US2005 / 0202512, US 2004/0202995, US 2004/0038291, US 2004/0009507, and US2003 / 0039958; Ward et al., 1989, Nature 341: 544-6.)
- Single-chain antibody is a fusion protein in which the V L and V H region by a linker (e.g., a synthetic amino acid residue sequences) linked to form antibodies continuous protein, wherein the linker is long enough to allow the protein chain folds Back to itself and form a monovalent antigen binding site (see, eg, Bird et al., 1988, Science 242: 423-6; and Huston et al., 1988, Proc. Natl. Acad. Sci. USA 85: 5879-83).
- a linker e.g., a synthetic amino acid residue sequences
- a double-chain antibody is a bivalent antibody comprising two polypeptide chains, where each polypeptide chain contains V H and V L domains connected by a linker that is so short that pairing of the two domains on the same chain is not allowed, Each domain is thus allowed to pair with a complementary domain on another polypeptide chain (see, e.g., Holliger et al., 1993, Proc. Natl. Acad. Sci. USA 90: 6444-8; and Poljak et al., 1994, Structure 2: 1121-3). If the two polypeptide chains of a double-chain antibody are the same, then the double-chain antibody obtained by pairing them will have the same antigen-binding site.
- Polypeptide chains with different sequences can be used to prepare double-chain antibodies with different antigen-binding sites.
- three-chain antibodies and four-chain antibodies are antibodies comprising three and four polypeptide chains, respectively, and form three and four antigen-binding sites, respectively, which may be the same or different.
- CDRs complementarity determining region of a given antibody
- FR framework regions
- One or more CDRs can be covalently or non-covalently incorporated into a molecule to make it an antibody.
- Antibodies can be incorporated into CDR (s) in larger polypeptide chains.
- the CDR (s) can be covalently linked to another native peptide chain, or non-covalently incorporated into the CDR (s).
- CDRs allow antibodies to specifically bind to specific related antigens.
- An antibody may have one or more binding sites. If there is more than one binding site, the binding site may be the same as or different from the other.
- natural human immunoglobulins typically have two identical binding sites, while "bispecific” or “bifunctional” antibodies have two different binding sites.
- murine antibody includes antibodies having one or more variable and constant regions derived from mouse immunoglobulin sequences.
- humanized antibody is an antibody made by transplanting the complementarity determining region sequence of a mouse antibody molecule into the framework of a human antibody variable region.
- antigen-binding domain portions of an antibody that contain amino acid residues that interact with the antigen and contribute to the specificity and affinity of the antibody for the antigen. For an antibody that specifically binds to its antigen, this will include at least a portion of at least one of its CDR domains.
- epitope is the portion of a molecule that binds to an antibody (eg, by an antibody).
- An epitope may comprise a discontinuous portion of a molecule (e.g., in a polypeptide, discontinuous amino acid residues in the primary sequence of the polypeptide are sufficiently close to each other in the tertiary and quaternary structure of the polypeptide to be bound by an antibody) .
- the "percent identity" of two polynucleotides or two polypeptide sequences is determined by comparing sequence using a GAP computer program (GCG Wisconsin Package; version 10.3 (Accelrys, San Diego, CA)) using its default parameters.
- GAP computer program GAP computer program
- nucleic acid molecules e.g., cDNA or genomic DNA
- RNA molecules e.g., mRNA
- Analogs eg, peptide nucleic acids and non-natural nucleotide analogs
- Nucleic acid molecules can be single-stranded or double-stranded.
- a nucleic acid molecule herein comprises a continuous open reading frame encoding an antibody or fragment, derivative, mutein or variant thereof provided herein.
- two single-stranded polynucleotides are "complementary" to each other, such that each nucleotide in one polynucleotide is complementary to the other polynucleotide In contrast, nucleotides do not introduce gaps and there are no unpaired nucleotides at the 5 'or 3' end of each sequence. If two polynucleotides can hybridize to each other under moderately stringent conditions, one polynucleotide is "complementary" to the other. Thus, one polynucleotide may be complementary to another polynucleotide, but not its complementary sequence.
- vector is a nucleic acid that can be used to introduce another nucleic acid linked to it into a cell.
- plasmid refers to a linear or circular double-stranded DNA molecule to which additional nucleic acid segments can be joined.
- viral vector eg, replication defective retroviruses, adenoviruses, and adeno-associated viruses
- viral vectors can autonomously replicate in the host cells into which they are introduced (eg, bacterial vectors containing bacterial origins of replication and episomal mammalian vectors).
- vectors when introduced into a host cell, integrate into the host cell's genome and therefore replicate with the host genome.
- An "expression vector” is a type of vector that directs expression of a selected polynucleotide.
- a nucleotide sequence is "operably linked" to a regulatory sequence if the regulatory sequence affects the expression (e.g., expression level, time, or site) of the nucleotide sequence.
- a "regulatory sequence” is a nucleic acid that can affect the expression (e.g., expression level, time, or site) of a nucleic acid to which it is operatively linked. Regulatory genes, for example, act directly on a regulated nucleic acid or through one or more other molecules (eg, polynucleotides that bind to regulatory sequences and / or nucleic acids). Examples of regulatory sequences include promoters, enhancers and other expression control elements (eg, polyadenylation signals).
- the term "host cell” is a cell used to express a nucleic acid, such as a nucleic acid provided herein.
- the host cell may be a prokaryote, such as E. coli, or it may be a eukaryote, such as a unicellular eukaryote (e.g., yeast or other fungi), a plant cell (e.g., a tobacco or tomato plant cell), an animal cell (e.g., Human cells, monkey cells, hamster cells, rat cells, mouse cells or insect cells) or hybridomas.
- a host cell is a cultured cell that can be transformed or transfected with a polypeptide-encoding nucleic acid, which can then be expressed in the host cell.
- the phrase "recombinant host cell” can be used to describe a host cell transformed or transfected with a nucleic acid that is expected to be expressed.
- a host cell may also be a cell that contains the nucleic acid but is not expressed at a desired level unless a regulatory sequence is introduced into the host cell so that it is operably linked to the nucleic acid.
- the term host cell refers not only to a particular subject cell but also to the progeny or possible progeny of that cell. Due to, for example, mutations or environmental influences that may occur in subsequent generations, the progeny may in fact be different from the mother cell but still fall within the scope of terminology used herein.
- APJ is a 7-pass transmembrane G protein-coupled receptor containing 377 amino acids (O'Dowd et al., 1993, Gene 136: 355-60). Studies so far have found that APJ is widely distributed in the human central nervous system and various peripheral tissues such as the lung, heart, and breast (Kawamata et al., 2001, Biochem. Biophys. Acta. 1538: 162-71; Medhurst et al., 2003, J. Neurochem. 84: 1162-72), especially in cardiovascular endothelial cells and cardiac tissues (Kleiz et al., 2005, Regul. Pept. 126: 233-40).
- APJ is mainly involved in the regulation of the cardiovascular system and has also been reported to be of great significance in insulin regulation and the regulatory mechanisms of diabetes and obesity-related diseases (Boucher et al., 2005, Endocrinology 146: 1764-71; Yue et al., 2010, Am.J. Physiol. Endocrinol. Metab. 298: E59-67).
- Human APJ and “hAPJ” as used herein refer to APJ of human origin and can be used interchangeably.
- rat APJ and “mAPJ” refer to rat-derived APJ, and can also be used interchangeably.
- the antibodies provided herein are antibodies that specifically bind to human APJ.
- the fusion protein provided herein is an Elabela fusion protein that specifically binds to APJ on the cell membrane, and the fusion protein is capable of activating the conduction of Elabela / APJ signals in these cells.
- the fusion protein provided herein is an Elabela fusion protein that binds to human APJ, and the fusion protein can bind to APJ of other species (such as monkeys and mice) and activate Elabela / APJ in these species Signalling.
- amino acid and polynucleotide sequences of APJ are listed below.
- sequence data is derived from the GeneBank database of the National Center for Biotechnology Information and the Uniprot database of the European Bioinformatics Institute:
- Rat (Rattus norvegicus) polynucleotide SEQ ID NO: 57); accession number: AB033170;
- Rat (Rattus norvegicus) amino acid SEQ ID NO: 25); accession number: BAA95002;
- Vasoactive peptide receptor antibody APJ antibody
- APJ antibodies In one embodiment, provided herein are APJ antibodies. In one embodiment, the APJ antibodies provided herein are whole APJ antibodies. In another embodiment, the APJ antibodies provided herein are APJ antibody fragments. In another embodiment, the APJ antibodies provided herein are APJ antibody derivatives. In another embodiment, the APJ antibody provided herein is an APJ antibody mutein. In a further embodiment, the APJ antibodies provided herein are APJ antibody variants.
- an APJ antibody provided herein comprises one, two, three, four, five, or six amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- amino acid sequence of heavy chain CDR1 SEQ ID NO: 12, SEQ ID NO: 15 and SEQ ID NO: 18;
- Amino acid sequence of heavy chain CDR2 SEQ ID NO: 13, SEQ ID NO: 16, SEQ ID NO: 19, and SEQ ID NO: 21;
- Table 1 lists the amino acid sequences of the light chain CDRs of the APJ antibodies provided herein, and their corresponding polynucleotide coding sequences.
- Table 2 lists the amino acid sequences of the heavy chain CDRs of the APJ antibodies provided herein, as well as their corresponding polynucleotide coding sequences.
- an antibody provided herein comprises a sequence that differs from one of the CDR amino acid sequences listed in Tables 1 and 2 by 5, 4, 3, 2, or 1 single amino acid addition, substitution, and / or deletion. . In another embodiment, an antibody provided herein comprises a sequence that differs from one of the CDR amino acid sequences listed in Tables 1 and 2 by 4, 3, 2, or 1 single amino acid addition, substitution, and / or deletion.
- an antibody provided herein comprises a sequence that differs from one of the CDR amino acid sequences listed in Tables 1 and 2 by 3, 2, or 1 single amino acid addition, substitution, and / or deletion.
- the antibodies provided herein comprise sequences that differ from one of the CDR amino acid sequences listed in Tables 1 and 2 by one or one single amino acid addition, substitution, and / or deletion.
- the antibodies provided herein comprise sequences that differ from one of the CDR amino acid sequences listed in Tables 1 and 2 by a single amino acid addition, substitution, and / or deletion.
- an APJ antibody provided herein comprises one or two amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- an APJ antibody provided herein comprises one or two amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- Amino acid sequence of heavy chain CDR2 SEQ ID NO: 13, SEQ ID NO: 16, SEQ ID NO: 19, and SEQ ID NO: 21.
- an APJ antibody provided herein comprises one or two amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- Amino acid sequence of heavy chain CDR3 SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, and SEQ ID NO: 22.
- an APJ antibody provided herein comprises one, two, three, or four amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- Amino acid sequence of heavy chain CDR2 SEQ ID NO: 13, SEQ ID NO: 16, SEQ ID NO: 19, and SEQ ID NO: 21.
- an APJ antibody provided herein comprises one, two, three, or four amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- Heavy chain CDR3 amino acid sequence SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, and SEQ ID NO: 22.
- an APJ antibody provided herein comprises one, two, three, or four amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- Amino acid sequence of heavy chain CDR2 SEQ ID NO: 13, SEQ ID NO: 16, SEQ ID NO: 19, and SEQ ID NO: 21;
- Amino acid sequences of heavy chain CDR3 SEQ ID NO: 14, SEQ ID NO: 17, SEQ ID NO: 20, and SEQ ID NO: 22.
- the APJ antibody provided herein comprises one, two, or three amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below: SEQ ID NO: 1, SEQ ID NO: 2.SEQ IDNO: 3, SEQ IDNO: 4, SEQ IDNO: 5, SEQ IDNO: 6, SEQ IDNO: 7, SEQ IDNO: 8, SEQ IDNO: 9, SEQ IDNO: 10, And SEQ ID NO: 11.
- the APJ antibody provided herein comprises one, two, or three amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below: SEQ ID NO: 12, SEQ ID NO : 13, SEQ ID NO: 14, SEQ ID NO: 15, SEQ ID NO: 16, SEQ ID NO: 17, SEQ ID NO: 18, SEQ ID NO: 19, SEQ ID NO: 20, SEQ ID NO: 21 , And SEQ ID NO: 22.
- an APJ antibody provided herein comprises a combination of light and heavy chain CDR1 amino acid sequences independently selected from the group consisting of SEQ ID NO: 1 and SEQ ID NO: 12, SEQ ID NO: 4 With SEQ ID NO: 15, SEQ ID NO: 7 and SEQ ID NO: 18, and SEQ ID NO: 10 and SEQ ID NO: 18.
- the APJ antibody provided herein comprises a combination of light and heavy chain CDR2 amino acid sequences independently selected from the group consisting of SEQ ID NO: 2 and SEQ ID NO: 13, SEQ ID NO: 13 5 and SEQ ID NO: 16, SEQ ID NO: 8 and SEQ ID NO: 19, and SEQ ID NO: 5 and SEQ ID NO: 21.
- the APJ antibody provided herein comprises a combination of light and heavy chain CDR3 amino acid sequences independently selected from the group consisting of SEQ ID NO: 3 and SEQ ID NO: 14, SEQ ID NO: 14 6 and SEQ ID NO: 17, SEQ ID NO: 9 and SEQ ID NO: 20, and SEQ ID NO: 11 and SEQ ID NO: 22.
- an APJ antibody provided herein comprises:
- a light and heavy chain CDR2 amino acid sequence combination independently selected from the following: SEQ ID NO: 2 and SEQ ID NO: 13, SEQ ID NO: 5 and SEQ ID NO: 16, SEQ ID ID NO : 8 and SEQ ID NO: 19, and SEQ ID NO: 5 and SEQ ID NO: 21.
- an APJ antibody provided herein comprises:
- a light and heavy chain CDR3 amino acid sequence combination independently selected from the following: SEQ ID NO: 3 and SEQ ID NO: 14, SEQ ID NO: 6 and SEQ ID NO: 17, SEQ ID ID NO : 9 and SEQ ID NO: 20, and SEQ ID NO: 11 and SEQ ID NO: 22.
- an APJ antibody provided herein comprises:
- a light and heavy chain CDR3 amino acid sequence combination independently selected from the following: SEQ ID NO: 3 and SEQ ID NO: 14, SEQ ID NO: 6 and SEQ ID NO: 17, SEQ ID ID NO : 9 and SEQ ID NO: 20, and SEQ ID NO: 11 and SEQ ID NO: 22.
- the APJ antibodies provided herein comprise:
- a light and heavy chain CDR2 amino acid sequence combination independently selected from the following: SEQ ID NO: 2 and SEQ ID NO: 13, SEQ ID NO: 5 and SEQ ID NO: 16, SEQ ID ID NO : 8 and SEQ ID NO: 19, and SEQ ID NO: 5 and SEQ ID NO: 21; and
- a light and heavy chain CDR3 amino acid sequence combination independently selected from the following: SEQ ID NO: 3 and SEQ ID NO: 14, SEQ ID NO: 6 and SEQ ID NO: 17, SEQ ID ID NO : 9 and SEQ ID NO: 20, and SEQ ID NO: 11 and SEQ ID NO: 22.
- an antibody described herein comprises:
- Heavy chain CDR1 amino acid sequence SEQ ID NO: 12;
- Heavy chain CDR2 amino acid sequence SEQ ID NO: 13;
- Heavy chain CDR3 amino acid sequence SEQ ID NO: 14;
- Heavy chain CDR1 amino acid sequence SEQ ID NO: 15;
- Heavy chain CDR2 amino acid sequence SEQ ID NO: 16;
- Heavy chain CDR3 amino acid sequence SEQ ID NO: 17;
- Heavy chain CDR1 amino acid sequence SEQ ID NO: 18;
- Heavy chain CDR2 amino acid sequence SEQ ID NO: 19;
- Heavy chain CDR3 amino acid sequence SEQ ID NO: 20;
- Heavy chain CDR1 amino acid sequence SEQ ID NO: 18;
- Heavy chain CDR2 amino acid sequence SEQ ID NO: 21;
- Heavy chain CDR3 amino acid sequence SEQ ID NO: 22.
- an antibody described herein comprises:
- Heavy chain CDR1 amino acid sequence SEQ ID NO: 18;
- Heavy chain CDR2 amino acid sequence SEQ ID NO: 21;
- Heavy chain CDR3 amino acid sequence SEQ ID NO: 22.
- an APJ antibody provided herein comprises one or two amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- Light chain variable domain amino acid sequence SEQ ID NO: 59 (L1), SEQ ID NO: 60 (L2), SEQ ID NO: 61 (L3), SEQ ID NO: 62 (L4), and SEQ ID NO: 63 (L5); and an amino acid sequence that is at least 80%, at least 85%, at least 90%, or at least 95% identical to any of its sequences; and
- Heavy chain variable domain amino acid sequence SEQ ID NO: 64 (H1), SEQ ID NO: 65 (H2), SEQ ID NO: 66 (H3), SEQ ID NO: 67 (H4), and SEQ ID NO: 68 (H5); and an amino acid sequence that is at least 80%, at least 85%, at least 90%, or at least 95% identical to any of its sequences.
- polynucleotide coding sequence of an APJ antibody comprises one or two polynucleotide coding sequences, wherein each polynucleotide coding sequence is independently selected from the following List of polynucleotide coding sequences:
- a light chain variable domain polynucleotide coding sequence SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, and SEQ ID NO: 73; and any of its A sequence has a polynucleotide coding sequence that is at least 80%, at least 85%, at least 90%, or at least 95% identical;
- Heavy chain variable domain polynucleotide coding sequence SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, and SEQ ID NO: 78; A sequence has a polynucleotide coding sequence that is at least 80%, at least 85%, at least 90%, or at least 95% identical.
- the APJ antibody provided herein comprises an amino acid sequence independently selected from the group consisting of SEQ ID NO: 59, SEQ ID NO: 60, SEQ ID NO: 61, SEQ ID NO: 62, and SEQ ID NO: 63.
- the APJ antibody provided herein comprises an amino acid sequence independently selected from the group consisting of SEQ ID NO: 64, SEQ ID NO: 65, SEQ ID NO: 66, SEQ ID NO: 67, And SEQ ID NO: 68.
- the APJ antibody provided herein comprises a light chain and heavy chain variable domain amino acid sequence independently selected from the group consisting of SEQ ID NO: 59 and SEQ ID NO: 64 (L1H1) , SEQ ID NO: 60 and SEQ ID NO: 65 (L2H2), SEQ ID NO: 61 and SEQ ID NO: 66 (L3H3), SEQ ID NO: 62 and SEQ ID NO: 67 (L4H4), and SEQ ID ID NO : 63 and SEQ ID NO: 68 (L5H5).
- L2H2 refers to a complete antibody having a light chain variable region comprising the amino acid sequence of SEQ ID NO: 60 (L2) and a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 65 (H2).
- an APJ antibody provided herein comprises one or two amino acid sequences, wherein each amino acid sequence is independently selected from the amino acid sequences listed below:
- an APJ antibody provided herein comprises a combination of light and heavy chain constant amino acid sequences independently selected from the group consisting of SEQ ID NO: 79 and SEQ ID NO: 82, SEQ ID NO: 82 80 and SEQ ID NO: 83, SEQ ID NO: 80 and SEQ ID NO: 84, SEQ ID NO: 81 and SEQ ID NO: 83, and SEQ ID NO: 81 and SEQ ID NO: 84.
- an APJ antibody provided herein comprises the amino acid sequences of the light and heavy chain CDRs listed herein, as well as FRs (framework).
- the amino acid sequences of FRs are contained in the light chain or heavy chain variable domain amino acid sequences, and are not separately displayed.
- the antibody comprises a light chain CDR1 sequence listed herein.
- the antibody comprises a light chain CDR2 sequence listed herein.
- the antibody comprises a light chain CDR3 sequence listed herein.
- the antibody comprises a heavy chain CDR1 sequence listed herein.
- the antibody comprises a heavy chain CDR2 sequence listed herein.
- the antibody comprises a heavy chain CDR3 sequence listed herein.
- the antibody comprises a light chain FR1 sequence herein. In another embodiment, the antibody comprises a light chain FR2 sequence herein. In another embodiment, the antibody comprises a FR3 sequence of a light chain herein. In another embodiment, the antibody comprises a light chain FR4 sequence herein. In another embodiment, the antibody comprises a heavy chain FR1 sequence herein. In another embodiment, the antibody comprises a FR2 sequence of a heavy chain herein. In another embodiment, the antibody comprises a heavy chain FR3 sequence herein. In a further embodiment, the antibody comprises a heavy chain FR4 sequence herein.
- the light chain CDR3 sequence of the antibody differs from the light chain CDR3 amino acid sequence SEQ ID NO: 11 listed herein by no more than 6, 5, 4, 3, 2, or 1 single amino acid addition, substitution, and / Or missing.
- the heavy chain CDR3 sequence of the antibody differs from the heavy chain CDR3 amino acid sequence SEQ ID NO: 22 listed herein by no more than 6, 5, 4, 3, 2, or 1 single amino acid addition, substitution, and / Or missing.
- the antibody light chain CDR3 sequence differs from the light chain CDR3 amino acid sequence SEQ ID ID NO: 11 listed herein by no more than 6, 5, 4, 3, 2, or 1 single amino acid addition, substitution, and / Or deletion
- the antibody's heavy chain CDR3 sequence differs from the heavy chain CDR3 amino acid sequence SEQ ID ID NO: 22 listed herein by no more than 6, 5, 4, 3, 2, or 1 single amino acid addition, substitution and / or deletion .
- the APJ antibody provided herein comprises a light chain variable domain amino acid sequence, which is the L4 (SEQ ID NO: 62) or L5 (SEQ ID NO: 63) light chain variable listed herein Domain sequence.
- the amino acid sequence of the light chain variable domain of the APJ antibody exists with the light chain variable domain amino acid sequence of L4 (SEQ ID NO: 62) or L5 (SEQ ID NO: 63) 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1 amino acid difference, wherein the difference in each sequence is independently a deletion, insertion or substitution of an amino acid residue.
- the amino acid sequence of the light chain variable domain of the APJ antibody has at least 70% of the amino acid sequence of the light chain variable domain of L4 (SEQ ID NO: 62) or L5 (SEQ ID NO: 63) , At least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 97%, or at least 99% are the same.
- the light chain variable domain polynucleotide coding sequence of the APJ antibody comprises a polynucleotide coding for L4 (SEQ ID NO: 72) or L5 (SEQ ID NO: 73).
- the sequence is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 97%, or at least 99% identical.
- the light chain variable domain polynucleotide coding sequence of the APJ antibody comprises a light chain with L4 (SEQ ID NO: 72) or L5 (SEQ ID NO: 73) under moderate conditions.
- the light chain variable domain polynucleotide coding sequence of the APJ antibody comprises a light chain with L4 (SEQ ID NO: 72) or L5 (SEQ ID NO: 73) under stringent conditions.
- L4 SEQ ID NO: 72
- L5 SEQ ID NO: 73
- the APJ antibody provided herein comprises a heavy chain variable domain amino acid sequence, which sequence is the heavy chain variable structure of H4 (SEQ ID NO: 67) or H5 (SEQ ID NO: 68) listed herein Domain sequence.
- the amino acid sequence of the heavy chain variable domain of the APJ antibody exists with the heavy chain variable domain sequence of H4 (SEQ ID NO: 67) or H5 (SEQ ID NO: 68) 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1 amino acid difference, wherein the difference in each sequence is independently a deletion, insertion or substitution of an amino acid residue.
- the amino acid sequence of the heavy chain variable domain of the APJ antibody has at least 70% of the heavy chain variable domain sequence of H4 (SEQ ID NO: 67) or H5 (SEQ ID NO: 68), At least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 97%, or at least 99% are the same.
- the polynucleotide encoding sequence of the heavy chain variable domain of the APJ antibody is more than the heavy chain variable domain of H4 (SEQ ID NO: 77) or H5 (SEQ ID NO: 78).
- the polynucleotide coding sequence is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 97%, or at least 99% identical.
- the heavy chain variable domain polynucleotide coding sequence of the APJ antibody comprises a heavy chain with H4 (SEQ ID NO: 77) or H5 (SEQ ID NO: 78) under moderately stringent conditions.
- the heavy chain variable domain polynucleotide coding sequence of the APJ antibody comprises a heavy chain of H4 (SEQ ID NO: 77) or H5 (SEQ ID NO: 78) under stringent conditions.
- the antibody provided herein is one comprising L1H1 (SEQ ID NO: 59 and SEQ ID NO: 64), L2H2 (SEQ ID NO: 60 and SEQ ID NO: 65), L3H3 (SEQ ID NO: 61 An antibody in combination with SEQ ID NO: 66), L4H4 (SEQ ID NO: 62 and SEQ ID NO: 67), or L5H5 (SEQ ID NO: 63 and SEQ ID NO: 68), or one of the desired phenotypes ( For example, IgA, IgG1, IgG2a, IgG2b, IgG3, IgM, IgE, or IgD), or a Fab or F (ab ') 2 fragment thereof.
- L1H1 SEQ ID NO: 59 and SEQ ID NO: 64
- L2H2 SEQ ID NO: 60 and SEQ ID NO: 65
- L3H3 SEQ ID NO: 61
- the antibody provided herein is an antibody comprising a combination of L4H4 (SEQ ID NO: 62 and SEQ ID NO: 67) or L5H5 (SEQ ID NO: 63 and SEQ ID NO: 68), or a class thereof Transformed antibodies (eg, IgA, IgG1, IgG2a, IgG2b, IgG3, IgM, IgE, and IgD), or a Fab or F (ab ') 2 fragment thereof.
- the antibodies provided herein may comprise any of the constant regions known in the art.
- the light chain constant region may be, for example, a kappa or lambda type light chain constant region, such as a mouse kappa or lambda type light chain constant region.
- the heavy chain constant region may be, for example, an ⁇ , ⁇ , ⁇ , ⁇ , or ⁇ -type heavy chain constant region, such as a mouse ⁇ , ⁇ , ⁇ , or ⁇ -type heavy chain constant region.
- the light or heavy chain constant region is a fragment, derivative, variant, or mutein of a natural constant region.
- the antibodies provided herein further comprise human constant light chain kappa or a fragment thereof.
- the amino acid sequence of the light chain constant region is as follows:
- the antibodies provided herein further comprise a human heavy chain constant domain or a fragment thereof.
- the amino acid sequence of the constant region of the heavy chain is as follows:
- Human heavy chain constant region amino acid sequence (hIgG2): SEQ ID NO: 83;
- Human heavy chain constant region amino acid sequence (hIgG4): SEQ ID NO: 84.
- amino acid sequences of the heavy and light chains of the APJ antibody provided herein are: SEQ ID NO: 157 and SEQ ID NO: 158, respectively.
- the APJ antibodies provided herein are selected from murine antibodies, humanized antibodies, chimeric antibodies, monoclonal antibodies, polyclonal antibodies, recombinant antibodies, antigen-binding antibody fragments, single-chain antibodies, double-chain antibodies , Three-chain antibodies, four-chain antibodies, Fab fragments, F (ab ') x fragments, domain antibodies, IgD antibodies, IgE antibodies, IgM antibodies, IgGl antibodies, IgG2 antibodies, IgG3 antibodies, or IgG4 antibodies.
- the APJ antibodies provided herein are APJ monoclonal antibodies.
- the APJ antibody provided herein is a monoclonal antibody comprising a combination of amino acid sequences selected from the group consisting of SEQ ID NO: 59 and SEQ ID NO: 64, SEQ ID NO: 60 and SEQ ID NO: 65, SEQ ID NO: 61 and SEQ ID NO: 66, SEQ ID NO: 62 and SEQ ID NO: 67, and SEQ ID NO: 63 and SEQ ID NO: 68.
- the APJ antibody provided herein is a mouse-derived APJ antibody. In another embodiment, the APJ antibody provided herein is a humanized APJ antibody.
- the Kd value of an APJ antibody provided herein is about 1 nM to about 200 nM or about 1 nM to about 100 nM.
- the antibodies provided herein are whole antibodies (including polyclonal, monoclonal, chimeric, humanized, or human antibodies with full-length heavy and / or light chains).
- the antibodies provided herein are antibody fragments, such as F (ab ') 2 , Fab, Fab', Fv, Fc, or Fd fragments, single domain antibodies, single chain antibodies, maxibodies ), Minibodies, intrabodies, two-chain antibodies, three-chain antibodies, four-chain antibodies, v-NAR, or bis-scFv (see, for example, Hollinger and Hudson, 2005, Nature Biotechnology 23: 1126- 36).
- the antibodies provided herein also include antibodies including antibody polypeptides as disclosed in US Patent No. 6703199, including fibronectin polypeptide monoclonal antibodies.
- the antibodies provided herein include a single chain polypeptide as disclosed in US Patent Publication 2005/0238646.
- variable region of a gene of a monoclonal antibody is expressed in a hybridoma using nucleotide primer amplification.
- nucleotide primer amplification can be synthesized by one of ordinary skill in the art or purchased from commercial sources.
- Murine and human variable region primers including V Ha , V Hb , V Hc , V Hd , C H1 , V L , and C L region primers are commercially available. These primers can be used to amplify the heavy or light chain variable regions and then insert them into vectors such as IMMUNOZAP TM H or IMMUNOZAP TM L (Stratagene), respectively. These vectors are then introduced into E. coli, yeast or mammalian-based expression systems. These methods can be used for producing large quantities comprising V H and V L domains of a single chain fusion protein (see Bird et al., 1988, Science 242: 423-6) .
- proteins may undergo various post-transcriptional modifications.
- the type and extent of these modifications depend on the host cell line used to express the protein and the culture conditions.
- modifications include changes in glycosylation, methionine oxidation, diketopiperazine formation, aspartic acid isomerization, and asparagine deamidation.
- the carboxy-terminal basic residues of antibodies may be lost due to frequent modification of carboxypeptidases (see Harris, 1995, Journal of Chromatography 705: 129-34).
- Murine monoclonal antibodies can be produced using commonly used hybridoma cell methods. This monoclonal antibody can be isolated and purified by a variety of established techniques. Such separation techniques include affinity chromatography using protein A-sepharose, molecular exclusion chromatography, and ion-exchange chromatography (see, for example, Coligan on pages 2.7.1-2.7.12 and 2.9.1-2.9. 3 pages; Baines et al., "Purification of Immunoglobulin G (IgG),” Methods in Molecular Biology, Vol. 10, pp. 79-104 (The Humana Press, Inc., 1992)).
- separation techniques include affinity chromatography using protein A-sepharose, molecular exclusion chromatography, and ion-exchange chromatography (see, for example, Coligan on pages 2.7.1-2.7.12 and 2.9.1-2.9. 3 pages; Baines et al., "Purification of Immunoglobulin G (IgG),” Methods in Molecular Biology, Vol. 10,
- the monoclonal antibody can be purified by affinity chromatography using appropriate ligands screened based on the specific properties of the antibody (e.g., heavy or light chain isotype, binding specificity, etc.).
- suitable ligands for affinity chromatography include protein A, protein G, anti-constant region (light or heavy chain) antibodies, anti-idiotypic antibodies, and TGF-binding proteins or fragments or variants thereof.
- Complementary determining regions (CDRs) in the center of the antibody binding site can be used to modify the affinity maturation of the molecule to obtain antibodies with increased affinity, such as antibodies against c-erbB-2 with increased affinity (Schier et al., 1996, J. Mol. Biol. 263: 551-67). Therefore, this type of technology can be used to prepare antibodies to human APJ.
- antibodies against human APJ can be used in in vitro or in vivo assays to detect the presence of human APJ.
- Antibodies can also be made by any conventional technique.
- these antibodies can be purified from cells that naturally express them (e.g., they can be purified from hybridomas that produce antibodies) or produced in recombinant expression systems using any technique known in the art. See, for example, Monoclonal Antibodies, Hybridomas: New Dimensions, Biologicals, Analyses, Kennet et al., Plenum Press (1980); and Antibodies: A Laboratory Manual, Harlow and Land editor, Cold Spring Harbor Laboratory Press (1988). This is discussed in the nucleic acid section below.
- Antibodies can be made by any known technique and screened for the desired properties. Some techniques involve isolating a nucleic acid encoding a polypeptide chain (or a portion thereof) of a related antibody (eg, an anti-APJ antibody) and manipulating the nucleic acid by recombinant DNA technology.
- the nucleic acid can be fused or modified (eg, by mutagenesis or other conventional techniques) with another related nucleic acid to add, delete, or replace one or more amino acid residues.
- affinity maturation protocols can be adopted including maintenance of CDRs (Yang et al., 1995, J. Mol. Biol. 254: 392-403) Strand replacement (Marks et al., 1992, Bio / Technology 10: 779-83), DNA rearrangement using mutant strains of E. coli (Low et al., 1996, J. Mol. Biol. 250: 350-68) (Patten et al., 1997 , Curr. Opin. Biotechnol. 8: 724-33), phage display (Thompson et al., 1996, J. Mol. Biol.
- the antibodies provided herein are anti-APJ fragments.
- the fragment may consist entirely of antibody-derived sequences or may include additional sequences.
- antigen-binding fragments include Fab, F (ab ') 2 , single-chain antibodies, double-chain antibodies, triple-chain antibodies, quad-chain antibodies, and domain antibodies. Other examples are provided in Lunde et al., 2002, Biochem. Soc. Trans. 30: 500-06.
- Single chain antibodies can be formed by linking the heavy and light chain variable domains (Fv regions) via an amino acid bridge (short peptide linker), thereby obtaining a single polypeptide chain. It has DNA encoding a peptide linker between DNAs by fusing two coding variable domain polypeptides (V L and V H) for preparing the single-chain Fvs (scFvs). The resulting polypeptides can fold back to form antigen-binding monomers themselves, or they can form multimers (eg, dimers, trimers, or tetramers), depending on the length of the flexible linker between the two variable domains (Kortt et al., 1997, Prot. Eng. 10: 423; Kortt et al.
- Single chain antibodies derived from the antibodies provided herein include, but are not limited to, scFvs comprising the variable domain combination L1H1, all of which are included herein.
- Antigen-binding fragments derived from antibodies can also be obtained by proteolysis of antibodies, such as by digesting intact antibodies with pepsin or papain according to conventional methods.
- an antibody fragment can be produced using a pepsin-cleaving antibody to provide an SS fragment called F (ab ') 2 .
- F (ab ') 2 This fragment can be further cleaved using a thiol reducing agent to produce a 3.5S Fab 'monovalent fragment.
- the alternative is to use a thiol protecting group to perform the cleavage reaction to obtain the cleavage of disulfide bonds.
- papain can also be used to directly generate two monovalent Fab fragments and one Fc fragment. These methods are described, for example, in Goldenberg, U.S.
- Patent No. 4,331,647 Nisonoff et al., 1960, Arch. Biochem. Biophys. 89: 230; Porter, 1959, Biochem. J. 73: 119; Edelman et al., Methods in Enzymology 1: 422 (Academic Press, 1967); and Andrews and Titus, JA Current Protocols in Immunology (edition by Coligan et al., John Wiley & Sons, 2003), pages 2.8, 1-2.8.10, and pages 2.10A.1-2.10A.5.
- cleaving antibodies such as preparing heavy chains to form monovalent heavy, light chain fragments (Fd), further cleaving fragments, or using other enzyme, chemical or genetic techniques, as long as the fragments bind to an antigen that can be recognized by the intact antibody.
- Fd light chain fragments
- CDRs can be obtained by constructing polypeptides encoding related CDRs.
- Such polypeptides can be prepared, for example, by using a polymerase chain reaction to synthesize variable regions with the mRNA of an antibody-producing cell as a template, see, for example, Larrick et al., 1991, Methods: A Companion to Methods in Enzymology 2: 106; Courtenay-Luck , "Genetic Manipulation of Monoclonal Antibodies,” Monoclonal Antibodies: Production, Engineering and Clinical Application, Ritter et al., 166 (Cambridge University Press, 1995); and Ward et al., "Genetic Manipulation and Expression of Antibodies," Monoclonal Antibodies: Principles and Applications, edited by Birch et al., p.
- the antibody fragment may further comprise at least one variable domain of an antibody described herein.
- the V region domain may be a monomer and is a V H or V L domain, which may independently bind to APJ with an affinity of at least equal to 1 ⁇ 10 ⁇ 7 M or higher, as described below.
- variable region domain may be any natural variable domain or a genetically engineered form thereof.
- Genetically engineered form refers to a variable region domain produced using recombinant DNA engineering techniques.
- the genetically engineered form includes, for example, produced from a specific antibody variable region by insertion, deletion, or alteration of the amino acid sequence of a specific antibody.
- Specific examples include variable region domains that contain only one CDR and optionally one or more framework amino acids from one antibody and the remainder of the variable region domain from another antibody and are genetically assembled.
- variable region domain may be covalently linked to at least one other antibody domain or fragment thereof at the C-terminal amino acid.
- V H region domain may be linked to an immunoglobulin C H1 domain or fragment thereof.
- V L domain can be linked to the C K domain or a fragment thereof.
- the antibody may be a Fab fragment wherein the antigen binding domain comprises a V H and V L, United domains thereof are connected to the C-terminus and C K C Hl domain covalently.
- Other amino acids can be used to extend the C H1 domain, for example to provide a hinge region or as Fab 'portions of the hinge domain fragment or provide other domains, such as an antibody C H2 and C H3 domains.
- the nucleotide sequences encoding the amino acid sequences L1 and H1 can be altered, for example, by random mutagenesis or by site-directed mutagenesis (e.g., oligonucleotide-induced site-directed mutagenesis) to produce a compared to unmutated polynucleotides.
- site-directed mutagenesis e.g., oligonucleotide-induced site-directed mutagenesis
- An altered polynucleotide comprising one or more specific nucleotide substitutions, deletions, or insertions.
- anti-APJ antibody derivatives in the art herein include covalent or aggregated conjugates of anti-APJ antibodies or fragments thereof with other proteins or polypeptides, for example, by expressing a heterologous polypeptide comprising a fusion to the N- or C-terminus of the anti-APJ antibody polypeptide Recombinant fusion protein.
- the binding peptide may be a heterologous signal (or guide) polypeptide, such as a yeast alpha factor leader peptide or a peptide such as an epitope tag.
- Fusion protein-containing antibodies may include peptides (e.g., polyhistidine) added to aid purification or identification of the antibody.
- Antibodies can also be linked to FLAG peptides, as described by Hopp et al., 1988, Bio / Technology 6: 1204, and U.S. Patent 5,011,912.
- FLAG peptides are highly antigenic and provide epitopes that are reversibly bound by specific monoclonal antibodies (mAb), allowing rapid detection and convenient purification of expressed recombinant proteins.
- mAb monoclonal antibodies
- Commercially available Sigma-Aldrich, St. Louis, MO
- oligomers comprising one or more antibodies are available For APJ antagonists or higher oligomers.
- the oligomers may be in the form of covalently linked or non-covalently linked dimers, trimers or higher oligomers. Oligomers containing two or more antibodies can be used, one example of which is a homodimer. Other oligomers include heterodimers, homotrimers, heterotrimers, homotetramers, heterotetramers, and the like.
- One embodiment is directed to oligomers comprising multiple antibodies, which are linked by covalent or non-covalent interactions with the peptide portion fused to the antibody.
- Such peptides can be peptide linkers or peptides with properties that promote oligomerization.
- Leucine zipper and certain antibody-derived polypeptides are peptides that can promote antibody oligomerization, as described in detail below.
- the oligomer comprises two to four antibodies.
- the oligomer antibodies can be in any form, such as any of the forms described above, such as variants or fragments.
- the oligomer comprises an antibody having APJ-binding activity.
- an oligomer is prepared using an immunoglobulin-derived polypeptide.
- the preparation of heterologous polypeptides containing some fusions with different parts of antibody-derived polypeptides (including the Fc domain) has been described, for example, in Ashkenazi et al., 1991, Proc. Natl. Acad. Sci. USA 88: 10535; Byrn et al., 1990, Nature 344: 677; and Hollenbaugh et al., Construction of Immunoglobulin Fusion Proteins, Current Protocols Immunology, Suppl. 4, pp. 10.19.1-10.19.11.
- dimer comprising two fusion proteins produced from a fusion of an Elabela fragment of an anti-APJ antibody or a mutant binding fragment thereof and the Fc region of an antibody.
- Dimers can be prepared by, for example, inserting a gene fusion encoding a fusion protein into an appropriate expression vector, expressing the fusion gene in a host cell transformed with a recombinant expression vector, and allowing the expressed fusion protein to assemble like an antibody molecule, Among them, interchain disulfide bonds between Fc moieties form dimers.
- Fc polypeptide includes polypeptides derived from natural and mutein forms of the Fc region of an antibody. Also included are truncated forms of such polypeptides that include a hinge region that promotes dimerization. Fusion proteins containing Fc portions (and oligomers formed from them) provide the advantage of easy purification by affinity chromatography on a Protein A or Protein G column.
- Fc polypeptide in PCT application WO 93/10151 is a single-chain polypeptide that extends from the N-terminal hinge region to the native C-terminus of the Fc region of a human IgG1 antibody.
- Another useful Fc polypeptide is the Fc mutein described in U.S. Patent 5,457,035 and Baum et al., 1994, EMBO J. 13: 3992-4001.
- the amino acid sequence of this mutant protein is the same as that of the natural Fc sequence shown in WO 93/10151, except that amino acid 19 changes from leucine to alanine, amino acid 20 changes from leucine to glutamine, and amino acid 22 changes from Glycine becomes alanine.
- the mutein exhibits reduced affinity for the Fc receptor.
- the heavy and / or light chain of an anti-APJ antibody may be replaced with a variable portion of the antibody heavy and / or light chain.
- the oligomer is a fusion protein comprising a plurality of antibodies, with or without a spacer peptide.
- linker peptides are described in U.S. Patents 4,751,180 and 4,935,233.
- Leucine zipper domains are peptides that promote the oligomerization of the proteins in which they exist.
- the leucine zipper was originally found in several DNA binding proteins (Landschulz et al., 1988, Science 240: 1759), and has since been found in a variety of different proteins.
- the known leucine zippers are dimerizable or trimerable natural peptides or derivatives thereof.
- leucine zipper domains suitable for the production of soluble oligomeric proteins are described in PCT application WO 94/10308, and leucine zipper derived from lung surfactant protein D (SPD) are described in Hoppe et al., 1994, FEBS Letters 344: 191, incorporated herein by reference.
- SPD lung surfactant protein D
- modified leucine zippers that allow stable trimerization of heterologous proteins fused to them is described in Fanslow et al., 1994, Semin. Immunol. 6: 267-78.
- a recombinant fusion protein comprising an anti-APJ antibody fragment or derivative fused to a leucine zipper peptide is expressed in an appropriate host cell, and a soluble oligomeric anti-APJ antibody fragment is collected from the culture supernatant or Its derivatives.
- the antibody derivative may comprise at least one of the CDRs disclosed herein.
- one or more CDRs can be integrated into known antibody backbone regions (IgG1, IgG2, etc.) or combined with a suitable vector to enhance its half-life.
- Suitable carriers include, but are not limited to, Fc, albumin, transferrin, and the like. These and other suitable vectors are known in the art.
- the CDR-binding peptide may be a monomer, dimer, tetramer, or other form.
- one or more water-soluble polymers are bound at one or more specific sites of the binding agent, such as at the amino terminus.
- the antibody derivative comprises one or more water-soluble polymer attachments including, but not limited to, polyethylene glycol, polyoxyethylene glycol, or polypropylene glycol. See, for example, U.S. Patent Nos. 4640835, 4496689, 4301144, 4670417, 4791192, and 4179337.
- the derivative comprises one or more monomethoxy.
- one or more water-soluble polymers are randomly bound to one or more side chains.
- PEG can enhance the therapeutic effect of binding agents such as antibodies.
- the antibodies provided herein may have at least one amino acid substitution as long as the antibody retains binding specificity. Therefore, modification of antibody structure is included in the scope of this document. These may include amino acid substitutions that do not disrupt the antibody's APJ binding ability, which may be conservative or non-conservative. Conservative amino acid substitutions may include unnatural amino acid residues, which are typically integrated by chemical peptide synthesis rather than by biological systems. These include peptidomimetic and other amino acid moieties in inverted or inverted form. Conservative amino acid substitutions may also involve replacing natural amino acid residues with non-natural residues that have little or no effect on the polarity or charge of the amino acid residues at the site. Non-conservative substitutions may involve the exchange of a member of one class of amino acids or amino acid analogs with a member of another class of amino acids having different physical properties (eg, volume, polarity, hydrophobicity, charge).
- test variants that include amino acid substitutions at each desired amino acid residue.
- Such variants can be screened using activity assays known to those skilled in the art.
- This type of variant can be used to gather information about the appropriate variant. For example, if an amino acid residue is found to cause activity disruption, undesired reduction, or inappropriate activity, variants with such changes can be avoided.
- one skilled in the art can easily determine amino acids that should be avoided further (either alone or in combination with other mutations).
- those skilled in the art can use known techniques to determine appropriate variants of the polypeptides as listed herein.
- those skilled in the art can identify appropriate regions of the molecule that do not disrupt activity if altered by targeting regions that are not important for activity.
- residues or portions of molecules that are conserved among similar polypeptides can be identified.
- even regions that are important for biological activity or structure can be conservatively replaced without disrupting the biological activity or without adversely affecting the polypeptide structure.
- those skilled in the art can investigate structural. Functional studies to identify residues in similar polypeptides that are important for activity or structure. In light of this comparison, the importance of amino acid residues in proteins corresponding to amino acid residues important for activity or structure in similar proteins can be predicted. Those skilled in the art can select chemically similar amino acid substitutions for these predicted important amino acid residues.
- antibody variants include glycosylation variants in which the number and / or type of glycosylation sites is changed compared to the amino acid sequence of the parent polypeptide. In some embodiments, the variant has a greater or lesser number of N-linked glycosylation sites than the native protein. Alternatively, substitutions that remove this sequence can remove existing N-linked sugar chains. Rearrangement of N-linked sugar chains is also provided, in which one or more N-linked sugar chain sites (usually those naturally occurring) are removed and one or more new N-linked sites are created. Other preferred antibody variants include cysteine variants in which one or more cysteine residues are deleted or replaced by another amino acid (eg, serine) compared to the parent amino acid sequence.
- another amino acid eg, serine
- Cysteine variants can be used when the antibody must be folded into a biologically active conformation (e.g., after isolating soluble inclusion bodies). Cysteine variants generally have fewer cysteine residues than natural proteins and often have an even number of cysteine to minimize interactions caused by unpaired cysteine.
- amino acid substitutions can be used to identify important residues of a human APJ antibody or to increase or decrease the affinity of a human APJ antibody described herein.
- the preferred amino acid substitutions are the following: (1) reduced proteolytic sensitivity, (2) reduced oxidation sensitivity, (3) altered binding affinity to form protein complexes, and (4) altered binding affinity and / or (5) Conferring or modifying other physicochemical or functional properties on such polypeptides.
- single or multiple amino acid substitutions may be made in a naturally occurring sequence (in some embodiments, the portion of the polypeptide outside the domain that forms the intermolecular contact) .
- conservative amino acid substitutions generally do not substantially alter the structural characteristics of the parent sequence (eg, replacement amino acids should not break the helix present in the parent sequence or interfere with other types of secondary structures that characterize the parent sequence).
- replacement amino acids should not break the helix present in the parent sequence or interfere with other types of secondary structures that characterize the parent sequence.
- Examples of secondary and tertiary structures of peptides recognized in the art are described in Proteins, Structures, Molecular Principles, Editors, Creighton, WH Freeman, and Company (1984); Introduction to Protein Structure, Branden and Tooze Editor, Garland, Publishing (1991); and Thornton et al., 1991, Nature 354: 105, which is incorporated herein by reference.
- the antibodies provided herein can be chemically bonded to polymers, lipids, or other moieties.
- Antigen-binding reagents can include at least one CDRs described herein that are incorporated into a biocompatible backbone structure.
- the biocompatible backbone structure comprises a polypeptide or portion thereof sufficient to form a conformationally stable structural support or backbone or scaffold, which can display one or more amino acid sequences (e.g., , CDRs, variable regions, etc.).
- Such structures may be naturally occurring polypeptides or polypeptide "folds" (structural motifs), or may have one or more modifications, such as amino acid additions, deletions or substitutions, relative to the natural polypeptide or fold.
- These scaffolds can be derived from polypeptides of any species (or more than one species), for example, humans, other mammals, other vertebrates, invertebrates, bacteria or viruses.
- Biosoluble backbone structures are often based on protein scaffolds or backbones rather than immunoglobulin domains.
- fibronectin-based, ankyrin, lipocalin, neocancer, cytochrome b, CP1 zinc finger protein, PST1, coiled coil, LACI-D1, Z domain and starch can be used Enzyme aprotin domain (see, eg, Nygren and Uhlen, 1997, Current Opinion in Structural Biology 7: 463-9).
- suitable binding agents include portions of these antibodies, such as one or more of the heavy chain CDR1, CDR2, CDR3, light chain CDR1, CDR2, and CDR3, as specifically disclosed herein. At least one of the heavy chain CDR1, CDR2, CDR3, CDR1, CDR2, and CDR3 regions has at least one amino acid substitution as long as the antibody retains the binding specificity of the non-replaced CDRs.
- the non-CDR portion of the antibody may be a non-proteinaceous molecule, wherein the binding agent cross-blocks the binding of the antibodies disclosed herein to human APJ.
- the non-CDR portion of the antibody may be a non-proteinaceous molecule, wherein the antibody shows a binding type to a human Elabela peptide similar to that shown by antibody L4H4 in a competitive binding assay.
- the non-CDR portion of an antibody may consist of amino acids, where the antibody is a recombinant binding protein or a synthetic peptide, and the recombinant binding protein cross-blocks the binding of the antibodies disclosed herein to human APJ.
- the non-CDR portion of the antibody may consist of amino acids, where the antibody is a recombinant antibody, and the recombinant antibody shows a binding type to a human APJ peptide similar to that shown by at least antibody L4H4 in a competitive binding assay.
- APJ antibody and Elabela fusion protein (Elabela fusion protein)
- an Elabela fusion protein comprising an APJ antibody and an Elabela fragment provided herein.
- an Elabela fusion protein comprising an APJ antibody provided herein and one, two, three, four, five, six, seven, or eight Elabela fragments And a peptide linker (Linker); the fusion protein connects the amino terminus of an Elabela fragment with the carboxyl end of an APJ antibody light or heavy chain through a peptide linker sequence, wherein each Elabela fragment is independently a positive To the Elabela fragment or a mutant thereof; or the fusion protein connects the carboxyl end of an Elabela fragment with the amino end of an APJ antibody light or heavy chain through a peptide linker sequence, wherein each Elabela fragment is independently A reverse Elabela fragment or a mutant thereof.
- Linker a peptide linker
- an Elabela fusion protein comprising an APJ antibody provided herein, and one, two, three, or four Elabela fragments and a peptide linker; the fusion protein is passed through an A peptide linker sequence (Linker) connects the amino terminus of an Elabela fragment with the carboxyl terminus of the light or heavy chain of an APJ antibody, wherein each Elabela fragment is independently a forward Elabela fragment or a mutant thereof.
- a peptide linker sequence Linker
- an Elabela fusion protein comprising an APJ antibody provided herein, and one, two, three, or four Elabela fragments and a peptide linker; the fusion protein is passed through an A peptide linker sequence (Linker) connects the carboxy terminus of an Elabela fragment with the amino terminus of the light or heavy chain of an APJ antibody, wherein each Elabela fragment is independently a reverse Elabela fragment or a mutant thereof.
- a peptide linker sequence Linker
- an Elabela fusion protein comprising an APJ antibody provided herein, two Elabela fragments and a peptide linker (Linker); the fusion protein connects an Elabela through a peptide linker sequence (Linker)
- Linker The amino terminus of the fragment is connected to the carboxyl terminus of the light or heavy chain of an APJ antibody, wherein each Elabela fragment is independently a forward Elabela fragment or a mutant thereof.
- an Elabela fusion protein comprising an APJ antibody provided herein, two Elabela fragments and a peptide linker (Linker); the fusion protein connects an Elabela through a peptide linker sequence (Linker)
- the carboxy terminus of the fragment is connected to the amino terminus of the light or heavy chain of an APJ antibody, wherein each Elabela fragment is independently a reverse Elabela fragment or a mutant thereof.
- an Elabela fusion protein which comprises an APJ antibody and two Elabela fragments and a peptide linker (Linker) provided herein; the fusion protein connects an Elabela fragment through a peptide linker sequence (Linker)
- the N-terminus is connected to the carboxyl terminus of the light chain of an APJ antibody: N'-R-Linker-Elabela-C '; or the amino terminus of an Elabela fragment and the carboxyl group of the heavy chain of an APJ antibody are linked by a peptide linker sequence End connection: N'-R-Linker-Elabela-C '; where: N' represents the amino terminus of the fusion protein polypeptide chain, C 'represents the carboxyl terminus of the fusion protein polypeptide chain, and Elabela represents a forward Elabela fragment or a mutant thereof R is the amino acid sequence of the light or heavy chain of an APJ antibody, and Linker represents a peptide linker sequence.
- an Elabela fusion protein comprising an APJ antibody and two Elabela fragments and a peptide linker (Linker) provided herein; the fusion protein connects an Elabela fragment with a peptide linker sequence (Linker).
- N'-Elabela-Linker-R-C ' The carboxy terminus is connected to the amino terminus of the light chain of an APJ antibody: N'-Elabela-Linker-R-C '; or the carboxy terminus of an Elabela fragment is connected to the amino terminus of an APJ antibody heavy chain: N'-Elabela-Linker -R-C '; where: N' represents the amino terminus of the fusion protein polypeptide chain, C 'represents the carboxyl terminus of the fusion protein polypeptide chain, Elabela represents a reverse Elabela fragment or a mutant thereof, and R is the light chain of an APJ antibody Or the amino acid sequence of the heavy chain, and Linker represents a peptide linker sequence.
- an Elabela fusion protein comprising an APJ antibody and two Elabela fragments and a peptide linker (Linker) provided herein; the fusion protein connects an Elabela fragment with a peptide linker sequence (Linker).
- N'-R-Linker-Elabela-C ' The amino terminus is connected to the carboxyl terminus of the light chain of an APJ antibody: N'-R-Linker-Elabela-C '; where: N' represents the amino terminus of the fusion protein polypeptide chain, C 'represents the carboxyl terminus of the fusion protein polypeptide chain, Elabela Represents a forward Elabela fragment or a mutant thereof, R is an amino acid sequence of the light chain of an APJ antibody, and Linker represents a peptide linker sequence.
- an Elabela fusion protein comprising an APJ antibody and two Elabela fragments and a peptide linker (Linker) provided herein; the fusion protein uses an peptide linker sequence (Linker) to bind an Elabela fragment
- the amino terminus is connected to the carboxyl terminus of the heavy chain of an APJ antibody: N'-R-Linker-Elabela-C '; where N' represents the amino terminus of the fusion protein polypeptide chain, and C 'represents the carboxyl terminus of the fusion protein polypeptide chain Elabela represents a forward Elabela fragment or a mutant thereof, R is the amino acid sequence of the heavy chain of an APJ antibody, and Linker represents a peptide linker sequence.
- the forward Elabela fragment or a mutant thereof is independently selected from one of the following amino acid sequences: SEQ ID NO: 91, SEQ ID NO: 92 , SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, SEQ ID NO: 97, SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 101, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO : 109, SEQ IDNO: 110, SEQ IDNO: 111, SEQ IDNO: 112, SEQ IDNO: 113, SEQ IDNO: 114, SEQ IDNO: 115, SEQ IDNO: 116, SEQ IDNO: 117 , SEQ ID NO: 91, SEQ ID NO: 92 ,
- the amino acid sequence of the forward Elabela fragment or a mutant thereof is one of the following amino acid sequences SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 103, SEQ ID NO: 107, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 166, and SEQ ID NO: 167.
- the inverted Elabela fragments or mutants thereof are each independently selected from one of the following amino acid sequences: SEQ ID NO: 125, SEQ ID NO: 126 , SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ IDNO: 144, SEQ IDNO: 145, SEQ IDNO: 146, SEQ IDNO: 147, SEQ IDNO: 148, SEQ IDNO: 149, SEQ IDNO: 150, SEQ IDNO: 151
- the sequence of the peptide linker each independently comprises from 1 to 200 amino acid amines, from 2 to 100 amino acid amines, from 5 to 50 amino acid amines, from 6 to 25 amino acid amines, or from 10 to 20 amino acid amines.
- sequences of the peptide linkers each independently comprise the full length, part, or repeat of one of the following amino acid sequences: SEQ ID NO: 122 , SEQ ID NO: 123, and SEQ ID NO: 124.
- sequences of the peptide linkers are each independently selected from the following amino acid sequences: SEQ ID NO: 122, SEQ ID NO: 123, and SEQ ID NO: 124.
- the light chain amino acid sequence of the Elabela fusion protein provided herein is: SEQ ID NO: 158; and its heavy chain amino acid sequence is one of the following sequences: SEQ ID NO: 156, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, and SEQ ID NO: 165.
- the amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 156, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 159, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 160, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 161, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 162, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 163, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 164, respectively.
- amino acid sequences of the light and heavy chains of the Elabela fusion protein provided herein are: SEQ ID NO: 158 and SEQ ID NO: 165, respectively.
- nucleic acid molecules contains, for example, a polynucleotide encoding all or part of an Elabela fusion protein, such as one or two strands of the Elabela fusion protein herein, or a fragment, derivative, mutein, or variant thereof; sufficient for hybridization probing Needle polynucleotides; PCR primers or sequencing primers used to identify, analyze, mutate or amplify polynucleotides encoding polypeptides; antisense nucleic acids and their complementary sequences for inhibiting polynucleotide expression .
- the nucleic acid can be of any length.
- nucleic acids can be 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 75, 100, 125, 150, 175, 200, 250, 300, 350, 400, 450, 500, 750, 1000, 1500, 3000, 5000 or more nucleotides, and / or comprise one or more additional sequences, such as regulatory sequences, and / or are part of a larger nucleic acid, such as a vector.
- the nucleic acid may be single-stranded or double-stranded and comprises RNA and / or DNA nucleotides and artificial variants thereof (eg, peptide nucleic acids).
- Nucleic acids encoding antibody polypeptides can be isolated from B cells immunized with APJ antigen.
- Nucleic acids of antibodies or Elabela fusion proteins can be isolated by conventional methods such as polymerase chain reaction (PCR).
- Nucleic acid sequences encoding the heavy and light chain variable regions are shown above. The skilled artisan will appreciate that due to the degeneracy of the genetic code, each polypeptide sequence disclosed herein may be encoded by a greater number of other nucleic acid sequences. Provided herein are degenerate nucleotide sequences encoding the antibodies or Elabela fusion proteins provided herein.
- nucleic acids that hybridize to other nucleic acids (eg, nucleic acids comprising the nucleotide sequence of any Elabela fusion protein) under specific hybridization conditions.
- Methods of hybridizing nucleic acids are well known in the art. See, for example, Current Protocols in Molecular Biology, John Wiley & Son (1989), 6.3.1-6.3.6.
- medium stringent conditions use a prewash solution containing 5x sodium chloride / sodium citrate (SSC), 0.5% SDS, 1.0mM EDTA (pH8.0), about 50% formamide hybridization buffer, 6x SSC and 55 ° C hybridization temperature (or other similar hybridization solution, such as those containing 50% formamide, hybridization at 42 ° C), and the elution condition is 60 ° C, using 0.5x SSC, 0.1% SDS.
- Strict hybridization conditions were performed in 6xSSC at 45 ° C, and then washed one or more times at 68 ° C in 0.1xSSC, 0.2% SDS.
- those skilled in the art can manipulate hybridization and / or washing conditions to increase or decrease the stringency of hybridization such that they contain nucleosides that are at least 65, 70, 75, 80, 85, 90, 95, 98, or 99% homologous to each other Nucleic acids of the acid sequence can usually still hybridize to each other.
- Mutations can be introduced using any technique known in the art.
- one or more specific amino acid residues are changed using, for example, a site-directed mutagenesis scheme.
- one or more randomly selected residues are changed using, for example, a random mutagenesis scheme. Regardless of how it is generated, mutant polypeptides can be expressed and screened for desired properties.
- Mutations can be introduced into a nucleic acid without significantly altering the biological activity of its encoded polypeptide.
- nucleotide substitutions can be made that cause amino acid substitutions at non-essential amino acid residues.
- the nucleotide sequence provided herein for the Elabela fusion protein or a fragment, variant or derivative thereof is mutated such that it encodes one or more deletions or substitutions comprising amino acid residues of the Elabela fusion protein shown herein, Become two or more residues that differ in sequence.
- mutagenesis inserts an amino acid near one or more amino acid residues of the Elabela fusion protein shown herein to two or more residues that differ in sequence.
- one or more mutations can be introduced into a nucleic acid to selectively alter the biological activity of its encoded polypeptide (e.g., in combination with APJ).
- the mutation can alter biological activity quantitatively or qualitatively. Examples of quantitative changes include increasing, decreasing, or eliminating the activity. Examples of qualitative changes include altering the binding specificity of an Elabela fusion protein.
- nucleic acid molecules suitable for use as primers or hybridization probes to detect nucleic acid sequences herein can comprise only a portion of a nucleic acid sequence encoding a full-length polypeptide herein, for example, a fragment that can be used as a probe or primer or a fragment encoding an active portion of a polypeptide herein (eg, an APJ binding portion).
- Probes based on the nucleic acid sequences herein can be used to detect the nucleic acid or similar nucleic acids, such as a transcript encoding a polypeptide herein.
- the probe may include a labeling group, such as a radioisotope, a fluorescent compound, an enzyme, or an enzyme cofactor. Such probes can be used to identify cells expressing the polypeptide.
- vectors comprising a nucleic acid encoding a polypeptide or a portion thereof.
- vectors include, but are not limited to, plasmids, viral vectors, non-episomal mammalian vectors, and expression vectors, such as recombinant expression vectors.
- a recombinant expression vector herein may comprise a nucleic acid herein in a form suitable for expression of the nucleic acid in a host cell.
- the recombinant expression vector includes one or more regulatory sequences, and is selected based on the host cell used for expression, and is operably linked to the pre-expressed nucleic acid sequence.
- Regulatory sequences include those that direct constitutive expression of nucleotide sequences in a variety of host cells (e.g., SV40 early gene enhancer, Rolls sarcoma virus promoter, and cytomegalovirus promoter), and direct only in certain hosts Expression of nucleotide sequences in cells (for example, tissue-specific regulatory sequences, see Voss et al., 1986, Trends Biochem.
- inducible expression that directs the nucleotide sequence in response to specific treatments or conditions (e.g., the metal thionin promoter in mammalian cells and the tet-sesponsive response in both prokaryotic and eukaryotic systems) Promoter and / or streptomycin-responsive promoter (ibid.)).
- specific treatments or conditions e.g., the metal thionin promoter in mammalian cells and the tet-sesponsive response in both prokaryotic and eukaryotic systems
- Promoter and / or streptomycin-responsive promoter ibid.
- the host cell can be any prokaryotic or eukaryotic cell.
- Prokaryotic host cells include Gram-negative or Gram-positive organisms, such as E. coli or Bacillus.
- Higher eukaryotic cells include insect cells, yeast cells, and established cell lines of mammalian origin. Examples of suitable mammalian host cell lines include Chinese hamster ovary (CHO) cells or their derivatives such as Veggie CHO and related cell lines grown in serum-free media (see Rasmussen et al., 1998, Cytotechnology 28:31) or CHO Strain DXB-11, which lacks DHFR (see Urlaub et al., 1980, Proc. Natl.
- CHO Chinese hamster ovary
- CHO cell lines include CHO-K1 (ATCC # CCL-61), EM9 (ATCC # CRL-1861), and UV20 (ATCC # CRL-1862).
- Other host cells include the COS-7 line of monkey kidney cells (ATCC # CRL-1651) (see Gluzman et al., 1981, Cell 23: 175), L cells, C127 cells, 3T3 cells (ATCC CCL-163), AM-1 / D cells (described in US Patent Serial No.
- HeLa cells BHK (ATCC CRL-10) cell line derived from the African green monkey kidney cell line CV1 (see McMahan et al., 1991, EMBO J. 10: 2821), human embryonic kidney Cells such as 293, 293, EBNA or MSR 293, human epithelial A431 cells, human C010205 cells, other transformed primate cell lines, normal diploid cells, cell lines derived from in vitro cultures of primary tissues, primary transplants, HL -60, U937, HaK or Jurkat cells. Suitable cloning and expression vectors for bacterial, fungal, yeast, and mammalian cell hosts are described in Pouwels et al. (Cloning Vectors: Laboratory, Manual, Elsevier, 1985).
- Vector DNA can be introduced into prokaryotic or eukaryotic cells by conventional transformation or transfection techniques. For stable mammalian transfection, only a small percentage of cells are known to incorporate foreign DNA into their genome, depending on the expression vector and transfection technology used. To identify and screen these integrants, genes encoding a selection marker (e.g., antibiotic resistance) are usually introduced into a host cell along with the gene of interest. Preferred screening markers include those that can confer resistance to drugs such as G418, hygromycin, and methotrexate. In other methods, drug-screening can be used to identify stably transfected cells containing the introduced nucleic acid (e.g., cells that integrate the screening gene can survive, while other cells die).
- a selection marker e.g., antibiotic resistance
- the transformed cells can be cultured under conditions that increase the expression of the polypeptide, and the polypeptide can be recovered by conventional protein purification methods.
- One such purification method is described in the examples below.
- the polypeptides used herein include a substantially homologous recombinant mammalian Elabela fusion protein polypeptide, which is substantially free of contaminating endogenous materials.
- APJ antibody activity means that the antibodies provided herein have binding activity specific to APJ.
- provided herein is a murine or humanized antibody capable of specifically binding to human APJ.
- the K d of an antibody provided herein when bound to human APJ is about 0.01 nM to about 1000 nM, about 0.1 nM to about 500 nM, about 0.5 nM to about 200 nM, about 1 nM to about 200 nM, or about 10 nM To about 100nM.
- K antibody when binding to human APJ d provided herein is from about 1nM to about 200nM.
- K antibody when binding to human APJ d provided herein is from about 1nM to about 100nM.
- the K d of an antibody provided herein when bound to human APJ is about 1 nM, about 2 nM, about 5 nM, about 10 nM, about 20 nM, about 30 nM, about 40 nM, about 50 nM, about 60 nM, about 70 nM, About 80 nM, about 90 nM, or about 100 nM.
- an APJ antibody described herein is an antibody having one or more of the properties listed below:
- the antibody cross-competitively binds to a reference antibody on human APJ.
- the reference antibody comprises a combination of the light chain variable domain amino acid sequence SEQ ID NO: 62 and the heavy chain variable domain amino acid sequence SEQ ID NO: 67.
- the term "substantially similar” means that the K d of the reference antibody is comparable to or about 200%, about 180%, about 160%, about 150%, about 140%, about 140% of the K d value of the reference antibody, Approximately 120%, approximately 110%, approximately 100%, approximately 99%, approximately 98%, approximately 97%, approximately 95%, approximately 90%, approximately 85%, approximately 80%, approximately 75%, approximately 70%, approximately 65% %, Or about 50%.
- the reference antibody includes, for example, an antibody having a combination of light chain SEQ ID NO: 62 and heavy chain SEQ ID NO: 67.
- the biological activities of the APJ antibody and Elabela fusion protein include the biological activity of Elabela and the APJ antibody activity.
- the activity of the APJ antibody is as described above.
- "Biological activity of Elabela” refers to an Elabela fusion protein that binds in vivo and activates Elabela receptors (such as APJ) and causes a cellular stress response.
- the aforementioned cellular stress response includes, but is not limited to, enhancing myocardial contractility, diastolic blood vessels, lowering blood pressure, diuresis (reducing antidiuretic hormone release), regulating the body's immune response, and the release of pituitary-related hormones.
- the Elabela fusion proteins described herein can be used to treat a variety of diseases and conditions associated with Elabela and APJ.
- the fusion protein exerts its biological effect by acting on Elabela and / or APJ, and thus the Elabela fusion protein described herein can be used to treat subjects with diseases and conditions that respond favorably to "increased Elabela stimulation". These subjects are referred to as "subjects in need of Elabela stimulation therapy.” These subjects include subjects with acute heart failure, chronic heart failure, pulmonary hypertension, and pulmonary hypertension, as well as subjects with diabetic vascular disease, cardiac insufficiency, atrial fibrillation, and ischemia-reperfusion injury.
- the biological activity of the Elabela fusion protein is detected using a reporter gene detection method to quantify the function of the Elabela fusion protein to activate APJ in vitro.
- the antibody fusion proteins provided herein Elabela activation Elabela / APJ signaling pathway EC 50 of from about 0.1nM to about 10OnM, about 0.5nM to about 20 nM, from about 1nM to about 10 nM, or 1nM to about Approximately 5nM.
- a pharmaceutical composition comprising a combination of an Elabela fusion protein provided herein and one or more pharmaceutically acceptable carriers.
- the pharmaceutical composition comprises an Elabela fusion protein provided herein and one or more substances selected from the group consisting of a buffer suitable for the Elabela fusion protein, an antioxidant (e.g., ascorbic acid), a low molecular weight polypeptide (e.g., containing Polypeptides with less than 10 amino acids), proteins, amino acids, sugars (such as dextrin), complexes (such as EDTA), glutathione, stabilizers and excipients.
- the pharmaceutical compositions provided herein may also include a preservative.
- the pharmaceutical compositions provided herein can be formulated as a lyophilized powder using a suitable excipient solution as a diluent.
- suitable excipient solution as a diluent.
- provided herein is a method of treating, preventing, or improving pulmonary hypertension comprising administering to a subject a therapeutically effective amount of an Elabela fusion protein or a pharmaceutical composition thereof provided herein.
- provided herein is a method of treating, preventing, or ameliorating pulmonary hypertension, comprising administering to a subject a therapeutically effective amount of an Elabela fusion protein or a pharmaceutical composition thereof provided herein.
- provided herein is a method of treating, preventing, or ameliorating heart failure, comprising administering to a subject a therapeutically effective amount of an Elabela fusion protein or a pharmaceutical composition thereof provided herein.
- provided herein is a method of treating type 2 diabetes and its related metabolic syndrome, comprising administering to a subject a therapeutically effective amount of an Elabela fusion protein or a pharmaceutical composition thereof provided herein.
- provided herein is a method of treating, preventing, or ameliorating pulmonary hypertension, pulmonary hypertension, type 2 diabetes and its related metabolic syndrome, or two or more conditions of heart failure, comprising administering to an individual An amount of an Elabela fusion protein or a pharmaceutical composition thereof provided herein.
- the pharmaceutical composition is for intravenous or subcutaneous injection.
- Elabela fusion protein pharmaceutical compositions can be administered using any suitable technique including, but not limited to, parenteral, topical, or inhalation.
- the pharmaceutical composition can be administered by rapid injection or continuous infusion, for example, by intra-articular, intravenous, intramuscular, intralesional, intraperitoneal or subcutaneous routes.
- topical administration at the site of the disease or injury such as transdermal administration and continuous release implantation, can be considered.
- Inhalation administration includes, for example, nasal or oral inhalation, use of sprays, inhalation of Elabela fusion protein in the form of an aerosol, and the like.
- Other options include oral formulations including tablets, syrups, or lozenges.
- the dosage and frequency of administration may vary depending on the route of administration, the specific Elabela fusion protein used, the nature and severity of the disease being treated, whether the symptoms are acute or chronic, and the size and overall symptoms of the patient. Appropriate dosages can be determined by methods well known in the art, such as including dose escalation studies in clinical trials.
- the Elabela fusion protein provided herein can be administered, for example, one or more times at regular intervals over a period of time.
- the Elabela fusion protein is administered once at least one month or more, for example one, two or three months or even indeterminate.
- long-term treatment is usually the most effective.
- short-term administration for example, from one week to six weeks is sufficient.
- human Elabela fusion protein is administered until the patient exhibits a medically relevant improvement in selected signs or indicators above baseline levels.
- An example of a treatment regimen provided herein includes subcutaneous injection of Elabela fusion protein at an appropriate dose once a week or longer to treat type 2 diabetes and its related metabolic syndrome, acute heart failure, chronic heart failure, pulmonary hypertension or pulmonary hypertension symptom.
- Elabela fusion protein can be administered weekly or monthly until the desired result is achieved, such as the patient's symptoms subsided. The treatment may be renewed as needed, or alternatively, a maintenance dose may be administered.
- the patient's blood BNP or Pro-BNP concentration, body weight can be monitored before, during, and / or after treatment with the Elabela fusion protein to detect any changes in its pressure.
- changes in BNP or Pro-BNP can vary with factors such as disease progression.
- the BNP or Pro-BNP concentration can be determined by known techniques.
- an Elabela fusion protein and one or more Elabela agonists two or more Elabela fusion proteins provided herein, or an Elabela fusion protein of the invention and one or more other Elabela Agonist.
- the Elabela fusion protein is administered alone or in combination with other agents used to treat the symptoms that are painful to the patient. Examples of these agents include protein as well as non-protein drugs. When multiple drugs are administered in combination, the dosage should be adjusted accordingly as is well known in the art.
- “Combined administration" combination therapy is not limited to simultaneous administration, but also includes a regimen in which the antigen and protein are administered at least once during a course of treatment involving the administration of at least one other therapeutic agent to the patient.
- a method for preparing a medicament for treating heart failure and pulmonary hypertension and related disorders comprising a mixture of an Elabela fusion protein and a pharmaceutically acceptable excipient provided herein for use in treating a related disorder of the above-mentioned diseases.
- the pharmaceutical preparation method is as described above.
- Elabela fusion protein-related compositions, kits, and methods that can specifically bind to human APJ.
- Nucleic acid molecules and derivatives and fragments thereof are also provided that comprise a polynucleotide encoding all or part of a polypeptide that binds to APJ, such as a nucleic acid encoding all or part of an Elabela fusion protein or an Elabela fusion protein derivative.
- vectors and plasmids comprising such nucleic acids and cells and cell lines comprising such nucleic acids and / or vectors and plasmids.
- Provided methods include, for example, a method of preparing, identifying, or isolating an Elabela fusion protein bound to human APJ, a method of determining whether the Elabela fusion protein binds to APJ, and a method of administering an Elabela fusion protein bound to APJ to an animal model.
- CHO-DHFR- cells were seeded into 6-well plates. After culture for 24 hours (hr), the pTM15 plasmid cloned with the hAPJ gene (see SEQ ID NO: 55 for the nucleotide sequence and SEQ ID NO: 23 for the amino acid sequence) was transfected into cells in a 6-well plate. Transfection was performed according to the transfection conditions of Lipofectamine 2000 recommended by Invitrogen. After 48 hours, the culture medium was changed to a complete medium containing 300 ⁇ g / mL hygromycin, and the medium was changed every 3 days (d). After about two weeks of culture, stable growing clones appeared.
- VACS-tagged antibodies (Life Technologies) were used to perform FACS detection on the constructed stable cell lines, and the pressurized cell population was identified based on the FACS detection results. A large amount of hAPJ was expressed on the CHO-DHFR-hAPJ cell membrane after screening. Finally, after subcloning and further identification, three APJ cells were selected as high expression stable cell lines. These hAPJ-expressing cell lines can be used as an immunogen for antibody production (Reference Example 2).
- the fusion protein of the extracellular region of hAPJ and hIgG and Fc can also be used as an immunogen to prepare antibodies.
- the preparation method is as follows: The fusion protein sequence gene of the extracellular region of hAPJ, hIgG2Fc and peptide linker (Linker) is in the pTM5 plasmid. A large number of transient expressions were obtained by suspending HEK293 cells, cell supernatants were obtained, and the APJ extracellular domain fusion protein was purified by affinity chromatography.
- mice The immunogen and aluminum hydroxide adjuvant were mixed, and BALB / c mice (6-8 weeks old) were injected subcutaneously, and the mice were boosted once a week. After a total of 6 immunizations, blood was collected by tail trimming. The serum was separated by centrifugation, and the serum titer was measured by FACS. When the appropriate antibody titer was reached, the mice were sacrificed by neck dissection, and spleen cells were obtained under aseptic conditions. In addition, SP2 / 0 cells in the logarithmic growth phase were collected, the cells were centrifuged, and the precipitated cells were cultured in serum-free until resuspension, centrifuged-resuspended again, and counted.
- the fused hybridoma cells and feeder cells were cultured together in a 96-well plate and subjected to HAT (hypoxanthine, methotrexate, and thymidine) screening to remove non-fused cells. After 10 days, the supernatant of the hybridoma cells in the culture plate was collected for ELISA detection.
- HAT hypoxanthine, methotrexate, and thymidine
- CHO-DHFR-hAPJ cells overexpressing hAPJ and CHO-DHFR- cells not expressing hAPJ were seeded into 96-well plates, respectively. After the cells grew to 90% healing, the cell culture supernatant was removed, washed twice with PBS, and fixed by adding 100% methanol at 4 ° C, and then 100 ⁇ L of prepared H 2 O 2 -PBS was added. The cells were treated at room temperature for 20 minutes and washed twice with PBS. After blocking with BSA (dissolved in PBS), the supernatant of hybridoma cells was added and incubated at 4 ° C for 90 minutes.
- BSA dissolved in PBS
- the positive control was the serum of immunized mice; the negative control was the cell culture supernatant.
- the positive control was the serum of immunized mice; the negative control was the cell culture supernatant.
- several positive hybridoma cell lines that secreted anti-hAPJ antibodies were screened. These hybridoma strains secreting anti-hAPJ antibodies were selected and cloned to obtain cell lines capable of stably secreting anti-hAPJ antibodies.
- the ascites antibodies prepared from the positive hybridoma cells were selected, and the affinity of the hAPJ antibodies contained in them was verified and sorted by the flow cytometry experimental method (refer to Example 9).
- the hybridoma cells secreting the antibodies were collected, and the mRNA of the hybridoma cells was extracted according to the QIAGEN mRNA extraction kit protocol.
- the extracted mRNA is then reverse transcribed into cDNA.
- the reverse transcription primers are specific primers for mouse light and heavy chain constant regions.
- the heavy chain reverse transcription primers are (5'-TTTGGRGGGAAGATGAAGAC-3 ') and the light chain reverse transcription primers. (5'-TTAACACTCTCCCCTGTTGAA-3 ') and (5'-TTAACACTCATTCCTGTTGAA-3').
- the reaction conditions of RT-PCR were: 25 ° C for 5min; 50 ° C for 60min; 70 ° C for 15min.
- an ultrafiltration centrifuge tube Amicon Ultra
- the upstream primers are all OligodT
- the heavy chain downstream primers are (5'-TGGACAGGGATCCAGAGTTCC-3 ') and (5'-TGGACAGGGCTCCATAGTTCC-3')
- the light chain downstream primers are (5'-ACTCGTCCTTGGTCAACGTG-3 ').
- PCR reaction conditions 95 ° C for 5min; 95 ° C for 30s, 56 ° C for 30s, 72 ° C for 1min and 40cycles; 72 ° C for 7min; PCR products were ligated to PMD 18-T vector (Takara Bio) and then sequenced.
- PCR primers were designed based on the DNA sequences of the sequenced antibodies to link the complete light chain, heavy chain signal peptide and variable domain, and the mouse IgG1 constant region to the expression vector pTM5.
- the human gene sequence with the highest homology is used as a template sequence for CDR grafting to obtain a humanized antibody variable region sequence.
- Genes of light and heavy chains of humanized antibodies were synthesized and spliced with human IgG2 or IgG4 constant region sequences to obtain complete recombinant humanized antibody sequences.
- the recombinant antibody was expressed according to Example 8, and the affinity of the recombinant antibody to APJ was verified according to the FACS technology in step 10, and the antibody with the best affinity was selected.
- the variable region sequence was further modified to further improve its affinity for APJ.
- the optimized humanized antibody heavy chain and light chain variable region sequences were outsourced for synthesis, and the complete heavy chain variable region sequence was further linked to the heavy chain constant region expression vector pTM5; similarly, the complete light chain The variable region sequence is linked to the expression vector pTM5 which has been incorporated into the constant region of the light chain.
- the optimized humanized antibody was fused to the Elabela fragment sequence at the C-terminus of the heavy chain to form an Elabela fusion protein.
- the two sequences are linked by a peptide linker sequence (Linker).
- the humanized APJ antibody heavy chain nucleic acid sequence was linked to the "Linker-Elabela fragment” portion by overlapping PCR. Nhe1 and Not1 restriction sites were added to the two ends of the primers, thereby linking the complete fusion protein sequence to the expression vector pTM5.
- Elabela The fusion protein was ligated to an expression vector and sequenced to confirm that it was constructed correctly.
- the collected cell supernatant in Example 8 was centrifuged at a high speed (8000 rpm) to remove the cells and cell debris, and then filtered through a 0.22um filter to clarify.
- the clarified supernatant was used for purification.
- the purification process is performed by a chromatograph.
- the supernatant was first passed through a protein A / G affinity chromatography column.
- the antibody or fusion protein contained in the supernatant was retained in the column after binding with the ligand of the protein A / G affinity chromatography column during this period.
- the column is then washed with a low pH (3.0 or less) elution buffer to dissociate the antibody or fusion protein bound to the column.
- the collected antibody eluate was quickly neutralized with 1M Tris-HCl.
- the obtained antibody or fusion protein eluate is replaced with PBS or other buffer system after dialysis.
- the gray peaks on the left are negative controls for 500nM mouse ascites antibody L1H1 and blank cells CHO-DHFR-binding, and the solid peaks are 500nM ( Figure 1A) and 4nM ( Figure 1B)
- the binding curve of mouse ascites antibody L1H1 and CHO-DHFR-hAPJ has a significant right shift relative to the gray peak negative control, which proves the specific binding of L1H1 and hAPJ.
- the right gray peak is a negative control for 500nM mouse ascites antibody L4H4 and blank cells CHO-DHFR-binding.
- the solid peaks are 500nM (Figure 1C) and 4nM (Figure 1D) mouse ascites antibodies L4H4 and CHO-
- the binding curve of DHFR-hAPJ has a significant right shift relative to the gray peak negative control, which also proves the specific binding of L4H4 and hAPJ.
- CHO-DHFR- cells co-expressing hAPJ-CRE-Luciferase were seeded at 35,000 cells per well to a 96-well cell culture plate and cultured overnight at 37 ° C. The next day, the supernatant of the medium was removed, the cell surface was washed twice with serum-free medium, and the residual liquid was aspirated.
- 50 ⁇ L of forskolin with a concentration of 0.6 ⁇ M was added in advance, and 50 ⁇ L of Elabela fusion protein or Elabela-11 polypeptide was diluted with serum-free medium, and incubated at 37 ° C. for 6 hours. After the stimulation, 100 ⁇ L of Promega's Bright Glo chemiluminescent substrate was added.
- FIG. 1 shows the activation curve of the Elabela / APJ signaling pathway activated by the reporter gene experiment to detect the recombinantly expressed fusion protein of L5H5 and Linker2-Elabela-11, and the fusion protein of L5H5 and Linker2-EA5.
- the EC 50 is 3.61 and 2.55nM, respectively. .
- Figure 3 shows the activation curve of activation of the Elabela / APJ signaling pathway by the recombinant protein L5H5 and Linker2-EA1 fusion protein and the fusion protein of L55H5 and Linker2-EA2 detected by reporter gene experiments, with EC 50 of 4.95 and 2.16nM, respectively.
- Figure 4 shows the activation curve of activation of the Elabela / APJ signaling pathway by the recombinant protein L5H5 and Linker2-EA3 fusion protein and the fusion protein of L5H5 and Linker2-EA4 detected by reporter gene experiments.
- the EC 50 are: 20.27 and 5.43 nM, respectively.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Immunology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Cardiology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Endocrinology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Heart & Thoracic Surgery (AREA)
- Zoology (AREA)
- Gastroenterology & Hepatology (AREA)
- Neurology (AREA)
- Biomedical Technology (AREA)
- Toxicology (AREA)
- Diabetes (AREA)
- Hospice & Palliative Care (AREA)
- Hematology (AREA)
- Obesity (AREA)
- Emergency Medicine (AREA)
- Epidemiology (AREA)
- Inorganic Chemistry (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
Description
图1A至图1D:显示了流式细胞术(FACS)检测重组表达的hAPJ抗体L1H1(其包含SEQ ID NO:59与SEQ ID NO:64)和L4H4(其包含SEQ ID NO:62与SEQ ID NO:67)与hAPJ特异性结合的结果(在500nM或4nM的抗体浓度),其中灰色峰为阴性对照,表示L1H1或L4H4与CHO-DHFR-的结合曲线,实线峰表示L1H1(图1A、图1B)或L4H4(图1C、图1D)与CHO-DHFR-hAPJ的结合曲线。
图2:显示了报告基因实验检测重组表达的hAPJ抗体L5H5(SEQ ID NO:63与SEQ ID NO:68)与Linker2-Elabela-11(其包含SEQ ID NO:123与SEQ ID NO:93)的融合蛋白质、L5H5与Linker2-EA5(其包含SEQ ID NO:123与SEQ ID NO:94)的融合蛋白质激活Elabela/APJ信号通路的激活性曲线,EC 50分别为:3.6和2.6nM。
图3:显示了报告基因实验检测重组表达的hAPJ抗体L5H5与Linker2-EA1(其包含SEQ ID NO:123与SEQ ID NO:103)的融合蛋白质、L5H5与Linker2-EA2(其包含SEQ ID NO:123与SEQ ID NO:107)的融合蛋白质激活Elabela/APJ信号通路的激活性曲线,EC 50分别为:5.0和2.2nM。
图4:显示了报告基因实验检测重组表达的hAPJ抗体L5H5与Linker2-EA3(其包含SEQ ID NO:123与SEQ ID NO:109)的融合蛋白质、L5H5与Linker2-EA4 (其包含SEQ ID NO:123与SEQ ID NO:116)的融合蛋白质激活Elabela/APJ信号通路的激活性曲线,EC 50分别为:20.3和5.4nM。


Claims (50)
- 一个能与人APJ特异性结合的抗体,所述抗体包含一,两,三,四,五,或六个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:a.轻链CDR1氨基酸序列:SEQ ID NO:10、SEQ ID NO:7、SEQ ID NO:4、及SEQ ID NO:1;b.轻链CDR2氨基酸序列:SEQ ID NO:8、SEQ ID NO:5、及SEQ ID NO:2;c.轻链CDR3氨基酸序列:SEQ ID NO:11、SEQ ID NO:9、SEQ ID NO:6、及SEQ ID NO:3;d.重链CDR1氨基酸序列:SEQ ID NO:18、SEQ ID NO:15、及SEQ ID NO:12;e.重链CDR2氨基酸序列:SEQ ID NO:21、SEQ ID NO:19、SEQ ID NO:16、及SEQ ID NO:13;及f.重链CDR3氨基酸序列:SEQ ID NO:22、SEQ ID NO:20、SEQ ID NO:17、及SEQ ID NO:14。
- 根据权利要求1所述的抗体,其中所述抗体包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:a.轻链CDR1氨基酸序列:SEQ ID NO:1、SEQ ID NO:4、SEQ ID NO:7、及SEQ ID NO:10;及b.重链CDR1氨基酸序列:SEQ ID NO:12、SEQ ID NO:15、及SEQ ID NO:18。
- 根据权利要求1或2所述的抗体,其中所述抗体包含或还包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:a.轻链CDR2氨基酸序列:SEQ ID NO:2、SEQ ID NO:5、及SEQ ID NO:8;及b.重链CDR2氨基酸序列:SEQ ID NO:13、SEQ ID NO:16、SEQ ID NO:19、及SEQ ID NO:21。
- 根据权利要求1至3中任一项所述的抗体,其中所述抗体包含或还包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:a.轻链CDR3氨基酸序列:SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、及SEQ ID NO:11;及b.重链CDR3氨基酸序列:SEQ ID NO:14、SEQ ID NO:17、SEQ ID NO:20、及SEQ ID NO:22。
- 根据权利要求1至4中任一项所述的抗体,其中所述抗体包含或还包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、 及SEQ ID NO:11。
- 根据权利要求1至5中任一项所述的抗体,其中所述抗体包含或还包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16、SEQ ID NO:17、SEQ ID NO:18、SEQ ID NO:19、SEQ ID NO:20、SEQ ID NO:21、及SEQ ID NO:22。
- 根据权利要求1至6中任一项所述的抗体,其中所述抗体包含或还包含一个独立地选自于以下所列的轻链和重链CDR1氨基酸序列的组合:SEQ ID NO:1与SEQ ID NO:12、SEQ ID NO:4与SEQ ID NO:15、SEQ ID NO:7与SEQ ID NO:18、及SEQ ID NO:10与SEQ ID NO:18。
- 根据权利要求1至7中任一项所述的抗体,其中所述抗体包含或还包含一个独立地选自于以下所列的轻链和重链CDR2氨基酸序列的组合:SEQ ID NO:2与SEQ ID NO:13、SEQ ID NO:5与SEQ ID NO:16、SEQ ID NO:8与SEQ ID NO:19、及SEQ ID NO:5与SEQ ID NO:21。
- 根据权利要求1至8中任一项所述的抗体,其中所述抗体包含或还包含一个独立地选自于以下所列的轻链和重链CDR3氨基酸序列的组合:SEQ ID NO:3与SEQ ID NO:14、SEQ ID NO:6与SEQ ID NO:17、SEQ ID NO:9与SEQ ID NO:20、及SEQ ID NO:11与SEQ ID NO:22。
- 根据权利要求1至9中任一项所述的抗体,其中所述抗体包含以下所列之一的氨基酸序列的组合:a.SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:12、SEQ ID NO:13、与SEQ ID NO:14的组合;b.SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:15、SEQ ID NO:16、与SEQ ID NO:17的组合;c.SEQ ID NO:5、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:18、SEQ ID NO:21、与SEQ ID NO:22的组合;或d.SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:18、SEQ ID NO:19、与SEQ ID NO:20的组合。
- 权利要求1至9中任一项所述的抗体,其中所述的抗体包含(a)轻链CDR1氨基酸序列:SEQ ID NO:1;轻链CDR2氨基酸序列:SEQ ID NO:2;轻链CDR3氨基酸序列:SEQ ID NO:3;重链CDR1氨基酸序列:SEQ ID NO:12;重链CDR2氨基酸序列:SEQ ID NO:13;及重链CDR3氨基酸序列:SEQ ID NO:14;(b)轻链CDR1氨基酸序列:SEQ ID NO:4;轻链CDR2氨基酸序列:SEQ ID NO:5;轻链CDR3氨基酸序列:SEQ ID NO:6;重链CDR1氨基酸序列:SEQ ID NO:15;重链CDR2氨基酸序列:SEQ ID NO:16;及重链CDR3氨基酸序列:SEQ ID NO:17;(c)轻链CDR1氨基酸序列:SEQ ID NO:7;轻链CDR2氨基酸序列:SEQ ID NO:8;轻链CDR3氨基酸序列:SEQ ID NO:9;重链CDR1氨基酸序列:SEQ ID NO:18;重链CDR2氨基酸序列:SEQ ID NO:19;及重链CDR3氨基酸序列:SEQ ID NO:20;(d)轻链CDR1氨基酸序列:SEQ ID NO:10;轻链CDR2氨基酸序列:SEQ ID NO:5;轻链CDR3氨基酸序列:SEQ ID NO:11;重链CDR1氨基酸序列:SEQ ID NO:18;重链CDR2氨基酸序列:SEQ ID NO:21;及重链CDR3氨基酸序列:SEQ ID NO:22。
- 权利要求11所述的抗体,其中所述的抗体包含轻链CDR1氨基酸序列:SEQ ID NO:10;轻链CDR2氨基酸序列:SEQ ID NO:5;轻链CDR3氨基酸序列:SEQ ID NO:11;重链CDR1氨基酸序列:SEQ ID NO:18;重链CDR2氨基酸序列:SEQ ID NO:21;及重链CDR3氨基酸序列:SEQ ID NO:22。
- 根据权利要求1至12中任一项所述的抗体,其中所述抗体包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:a.轻链可变结构域氨基酸序列:SEQ ID NO:59、SEQ ID NO:60、SEQ ID NO:61、SEQ ID NO:62、及SEQ ID NO:63;及与其任一序列有至少80%、至少85%、至少90%、或至少95%相同的氨基酸序列;及b.重链可变结构域氨基酸序列:SEQ ID NO:64、SEQ ID NO:65、SEQ ID NO:66、SEQ ID NO:67、及SEQ ID NO:68;及与其任一序列有至少80%、至少85%、至少90%、或至少95%相同的氨基酸序列。
- 根据权利要求1至13中任一项所述的抗体,其中所述抗体的多聚核苷酸编码序列包含一或两个多聚核苷酸编码序列,其中每个多聚核苷酸编码序列独立地选自于以下所列多聚核苷酸序列:a.轻链可变结构域多聚核苷酸编码序列:SEQ ID NO:69、SEQ ID NO:70、SEQ ID NO:71、SEQ ID NO:72、及SEQ ID NO:73;及与其任一序列有至少80%、至少85%、至少90%、或至少95%相同的多聚核苷酸编码序列;及b.重链可变结构域多聚核苷酸编码序列:SEQ ID NO:74、SEQ ID NO:75、SEQ ID NO:76、SEQ ID NO:77、及SEQ ID NO:78;及与其任一序列有至少 80%、至少85%、至少90%、或至少95%相同的多聚核苷酸编码序列。
- 根据权利要求1至14中任一项所述的抗体,其中所述抗体包含或还包含一个独立地选自于以下所列的氨基酸序列:SEQ ID NO:59、SEQ ID NO:60、SEQ ID NO:61、SEQ ID NO:62、及SEQ ID NO:63。
- 根据权利要求1至15中任一项所述的抗体,其中所述抗体包含或还包含一个独立地选自于以下所列的氨基酸序列:SEQ ID NO:64、SEQ ID NO:65、SEQ ID NO:66、SEQ ID NO:67、及SEQ ID NO:68。
- 根据权利要求1至16中任一项所述的抗体,其中所述抗体包含一个独立地选自于以下所列的轻链与重链可变结构域氨基酸序列的组合:SEQ ID NO:59与SEQ ID NO:64、SEQ ID NO:60与SEQ ID NO:65、SEQ ID NO:61与SEQ ID NO:66、SEQ ID NO:62与SEQ ID NO:67、及SEQ ID NO:63与SEQ ID NO:68。
- 根据权利要求1至17中任一项所述的抗体,其中所述抗体还包含一或两个氨基酸序列,其中每个氨基酸序列独立地选自于以下所列的氨基酸序列:a.轻链恒定氨基酸序列:SEQ ID NO:79、SEQ ID NO:80、及SEQ ID NO:81;及b.重链恒定氨基酸序列:SEQ ID NO:82、SEQ ID NO:83、及SEQ ID NO:84。
- 一个能与人APJ特异性结合的抗体,所述的抗体具有一个或多个以下所列的性质:a.当与人APJ结合时,其K d与一参比APJ抗体相同或更优;和b.该APJ抗体在人APJ上与一参比APJ抗体交叉竞争结合。
- 权利要求19所述的抗体,其中所述的抗体在人APJ上与所述的参比APJ抗体交叉竞争结合。
- 权利要求19或20所述的抗体,其中所述的参比APJ抗体是权利要求1至18中任一项所述的抗体。
- 权利要求21所述的抗体,其中所述的参比APJ抗体包含轻链可变结构域氨基酸序列SEQ ID NO:62和重链可变结构域氨基酸序列SEQ ID NO:67的组合或轻链可变结构域氨基酸序列SEQ ID NO:63和重链可变结构域氨基酸序列SEQ ID NO:68的组合。
- 根据权利要求1至22中任一项所述的抗体,其特征在于:所述抗体为鼠源抗体、人类抗体、人源化抗体、嵌合抗体、单克隆抗体、多克隆抗体、重组抗体、抗原结合抗体片段、单链抗体、双链抗体、三链抗体、四链抗体、Fab片段、F(ab')x片段、结构域抗体、IgD抗体、IgE抗体、IgM抗体、IgGl抗体、IgG2抗体、IgG3抗体、或IgG4抗体。
- 根据权利要求1至23中任一项所述的抗体,其中所述抗体为鼠源APJ抗体或人源化APJ抗体。
- 根据权利要求1至24中任一项所述的抗体,其中所述抗体为APJ单克隆抗体。
- 根据权利要求1至25中任一项所述的抗体,其中所述抗体的K d值为大约1nM至大约200nM或大约1nM至大约100nM。
- 一个Elabela融合蛋白质,其结构特征在于:所述的融合蛋白质包含权利要求 1至26中任一项所述的一个APJ抗体和一Elabela片段。
- 一个Elabela融合蛋白质,其结构特征在于:所述的融合蛋白质包含权利要求1至26中任一项所述的一个APJ抗体、和一个,二个,三个,四个,五个,六个,七个,或八个Elabela片段和肽接头(Linker);该融合蛋白质通过一肽接头序列(Linker)将一Elabela片段的氨基端与一APJ抗体轻链或重链的羧基端连接,其中每个Elabela片段各自独立地为一正向Elabela片段或其突变体;或者该融合蛋白质通过一肽接头序列(Linker)将一Elabela片段的羧基端与一APJ抗体轻链或重链的氨基端连接,其中每个Elabela片段各自独立地为一反向Elabela片段或其突变体。
- 根据权利要求27或28所述的融合蛋白质,其所述的融合蛋白质包含一个APJ抗体,和一个,二个,三个,或四个Elabela片段和肽接头(Linker);该融合蛋白质通过一个肽接头序列(Linker)将一Elabela片段的氨基端与一APJ抗体轻链或重链的羧基端连接,其中每个Elabela片段各自独立地为一正向Elabela片段或其突变体。
- 权利要求27或28所述的融合蛋白质,其所述的融合蛋白质包含一个APJ抗体,和一个,二个,三个,或四个Elabela片段和肽接头(Linker);该融合蛋白质通过一个肽接头序列(Linker)将一Elabela片段的羧基端与一APJ抗体轻链或重链的氨基端连接,其中每个Elabela片段各自独立地为一反向Elabela片段或其突变体。
- 权利要求27或28所述的融合蛋白质,其所述的融合蛋白质包含一个APJ抗体,和二个Elabela片段和肽接头(Linker);该融合蛋白质通过一个肽接头序列(Linker)将一Elabela片段的氨基端与一APJ抗体轻链或重链的羧基端连接,其中每个Elabela片段各自独立地为一正向Elabela片段或其突变体。
- 权利要求27或28所述的融合蛋白质,其所述的融合蛋白质包含一个APJ抗体,和二个Elabela片段和肽接头(Linker);该融合蛋白质通过一个肽接头序列(Linker)将一Elabela片段的羧基端与一APJ抗体轻链或重链的氨基端连接,其中每个Elabela片段各自独立地为一反向Elabela片段或其突变体。
- 根据权利要求27至32中任一项所述的融合蛋白质,其中所述的APJ抗体、Elabela片段、和肽接头序列(Linker)通过以下所述中一方式融合形成所述的融合蛋白质:通过一个肽接头序列(Linker)将一Elabela片段的氨基端和一APJ抗体轻链的羧基端连接:N'-R-Linker-Elabela-C';及通过一个肽接头序列(Linker)将一Elabela片段的氨基端和一APJ抗体重链的羧基端连接:N'-R-Linker-Elabela-C';其中:N'代表多肽链的氨基端,C'代表多肽链的羧基端,Elabela代表一正向Elabela片段或其突变体,R为权利要求1至26中任一项所述的一APJ抗体的轻链或者重链的氨基酸序列,及Linker代表一肽接头。
- 根据权力要求27至33中任一项所述的Elabela融合蛋白质,所述的肽接头 (Linker)的序列各自独立地包含以下之一的氨基酸序列:SEQ ID NO:122、SEQ ID NO:123、及SEQ ID NO:124。
- 根据权力要求27至34中任一项所述的Elabela融合蛋白质,所述的肽接头(Linker)包含SEQ ID NO:123。
- 根据权力要求27至35中任一项所述的Elabela融合蛋白质,其中所述的Elabela片段包含独立地选自于以下之一的氨基酸序列:SEQ ID NO:91、SEQ ID NO:92、SEQ ID NO:93、SEQ ID NO:94、SEQ ID NO:95、SEQ ID NO:96、SEQ ID NO:97、SEQ ID NO:98、SEQ ID NO:99、SEQ ID NO:100、SEQ ID NO:101、SEQ ID NO:102、SEQ ID NO:103、SEQ ID NO:104、SEQ ID NO:105、SEQ ID NO:106、SEQ ID NO:107、SEQ ID NO:108、SEQ ID NO:109、SEQ ID NO:110、SEQ ID NO:111、SEQ ID NO:112、SEQ ID NO:113、SEQ ID NO:114、SEQ ID NO:115、SEQ ID NO:116、SEQ ID NO:117、SEQ ID NO:118、SEQ ID NO:119、SEQ ID NO:120、SEQ ID NO:121、SEQ ID NO:166、及SEQ ID NO:167。
- 根据权力要求36所述的Elabela融合蛋白质,其中所述的Elabela片段包含独立地选自于以下之一的氨基酸序列:SEQ ID NO:93、SEQ ID NO:94、SEQ ID NO:103、SEQ ID NO:107、SEQ ID NO:109、及SEQ ID NO:116。
- 根据权力要求27至37中任一项所述的Elabela融合蛋白质,其中所述的Elabela片段包含独立地选自于以下之一的氨基酸序列:SEQ ID NO:125、SEQ ID NO:126、SEQ ID NO:127、SEQ ID NO:128、SEQ ID NO:129、SEQ ID NO:130、SEQ ID NO:131、SEQ ID NO:132、SEQ ID NO:133、SEQ ID NO:134、SEQ ID NO:135、SEQ ID NO:136、SEQ ID NO:137、SEQ ID NO:138、SEQ ID NO:139、SEQ ID NO:140、SEQ ID NO:141、SEQ ID NO:142、SEQ ID NO:143、SEQ ID NO:144、SEQ ID NO:145、SEQ ID NO:146、SEQ ID NO:147、SEQ ID NO:148、SEQ ID NO:149、SEQ ID NO:150、SEQ ID NO:151、SEQ ID NO:152、SEQ ID NO:153、SEQ ID NO:154、及SEQ ID NO:155。
- 根据权力要求27至38中任一项所述的Elabela融合蛋白质,其中所述融合蛋白质包含:(i)SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:18、SEQ ID NO:19、与SEQ ID NO:20的组合;(ii)独立地选自于以下之一的氨基酸序列:SEQ ID NO:93、SEQ ID NO:94、SEQ ID NO:103、SEQ ID NO:107、SEQ ID NO:109、及SEQ ID NO:116;(iii)SEQ ID NO:123。
- 一种多核苷酸,其编码权利要求27至39中任一项所述的一Elabela融合蛋白质。
- 一种载体,其包含权利要求40中所述的一多核苷酸。
- 一种宿主细胞,其包含权利要求41中所述的一载体。
- 一种药用组合物,其包含权利要求1至26中任一项所述的抗体和一药用可接受的载体。
- 一种药用组合物,其包含权利要求27至39中任一项所述的一Elabela融合蛋白质和一药用可接受的载体。
- 一种包含权利要求27至39中任一项所述的一Elabela融合蛋白质在制备用于预防或治疗肺动脉高压的药物中的用途。
- 一种包含权利要求27至39中任一项所述的一Elabela融合蛋白质在制备用于预防或治疗肺高压的药物中的用途。
- 一种包含权利要求27至39中任一项所述的一Elabela融合蛋白质在制备用于预防或治疗心力衰竭的药物中的用途。
- 一种包含权利要求27至39中任一项所述的一Elabela融合蛋白质在制备用于治疗二型糖尿病及其相关代谢综合症的药物中的用途。
- 一种包含权利要求27至39中任一项所述的一Elabela融合蛋白质在制备用于预防或治疗肺动脉高压、肺高压、二型糖尿病及其相关代谢综合症或者心力衰竭二种及二种以上病症的药物中的用途。
- 根据权利要求45至49中任一项所述用途,其所述的药物是用于静脉或皮下注射。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020569130A JP2021526833A (ja) | 2018-06-13 | 2019-06-13 | Apj抗体及びelabelaとのその融合タンパク質並びにその医薬組成物及び用途 |
| KR1020217000999A KR20210019535A (ko) | 2018-06-13 | 2019-06-13 | Apj 항체 및 이와 엘라벨라의 융합 단백질, 및 그의 약학 조성물 및 적용 |
| US17/251,663 US20210163614A1 (en) | 2018-06-13 | 2019-06-13 | Apj antibody, fusion protein thereof with elabela, and pharmaceutical compositions and use thereof |
| CA3103585A CA3103585A1 (en) | 2018-06-13 | 2019-06-13 | Apj antibody and its fusion protein with elabela, and pharmaceutical composition and application thereof |
| EP19819592.7A EP3808847A4 (en) | 2018-06-13 | 2019-06-13 | APJ ANTIBODY, FUSION PROTEIN THEREOF WITH ELABELA, AND PHARMACEUTICAL COMPOSITIONS AND USE THEREOF |
| AU2019284320A AU2019284320A1 (en) | 2018-06-13 | 2019-06-13 | APJ antibody, fusion protein thereof with Elabela, and pharmaceutical compositions and use thereof |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810606914.0A CN110655577A (zh) | 2018-06-13 | 2018-06-13 | APJ抗体及其与Elabela的融合蛋白质,以及其药物组合物和应用 |
| CN201810606914.0 | 2018-06-13 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019238093A1 true WO2019238093A1 (zh) | 2019-12-19 |
Family
ID=68842717
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2019/091090 WO2019238093A1 (zh) | 2018-06-13 | 2019-06-13 | APJ抗体及其与Elabela的融合蛋白质,以及其药物组合物和应用 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20210163614A1 (zh) |
| EP (1) | EP3808847A4 (zh) |
| JP (1) | JP2021526833A (zh) |
| KR (1) | KR20210019535A (zh) |
| CN (1) | CN110655577A (zh) |
| AU (1) | AU2019284320A1 (zh) |
| CA (1) | CA3103585A1 (zh) |
| WO (1) | WO2019238093A1 (zh) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112210001A (zh) * | 2020-10-25 | 2021-01-12 | 兰州大学 | 多肽片段ela13及其用途 |
Citations (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4179337A (en) | 1973-07-20 | 1979-12-18 | Davis Frank F | Non-immunogenic polypeptides |
| US4301144A (en) | 1979-07-11 | 1981-11-17 | Ajinomoto Company, Incorporated | Blood substitute containing modified hemoglobin |
| US4331647A (en) | 1980-03-03 | 1982-05-25 | Goldenberg Milton David | Tumor localization and therapy with labeled antibody fragments specific to tumor-associated markers |
| US4496689A (en) | 1983-12-27 | 1985-01-29 | Miles Laboratories, Inc. | Covalently attached complex of alpha-1-proteinase inhibitor with a water soluble polymer |
| US4518584A (en) | 1983-04-15 | 1985-05-21 | Cetus Corporation | Human recombinant interleukin-2 muteins |
| US4640835A (en) | 1981-10-30 | 1987-02-03 | Nippon Chemiphar Company, Ltd. | Plasminogen activator derivatives |
| US4670417A (en) | 1985-06-19 | 1987-06-02 | Ajinomoto Co., Inc. | Hemoglobin combined with a poly(alkylene oxide) |
| US4737462A (en) | 1982-10-19 | 1988-04-12 | Cetus Corporation | Structural genes, plasmids and transformed cells for producing cysteine depleted muteins of interferon-β |
| US4751180A (en) | 1985-03-28 | 1988-06-14 | Chiron Corporation | Expression using fused genes providing for protein product |
| US4791192A (en) | 1986-06-26 | 1988-12-13 | Takeda Chemical Industries, Ltd. | Chemically modified protein with polyethyleneglycol |
| US4935233A (en) | 1985-12-02 | 1990-06-19 | G. D. Searle And Company | Covalently linked polypeptide cell modulators |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US5011912A (en) | 1986-12-19 | 1991-04-30 | Immunex Corporation | Hybridoma and monoclonal antibody for use in an immunoaffinity purification system |
| WO1993010151A1 (en) | 1991-11-22 | 1993-05-27 | Immunex Corporation | Receptor for oncostatin m and leukemia inhibitory factor |
| WO1994010308A1 (en) | 1992-10-23 | 1994-05-11 | Immunex Corporation | Methods of preparing soluble, oligomeric proteins |
| US5457035A (en) | 1993-07-23 | 1995-10-10 | Immunex Corporation | Cytokine which is a ligand for OX40 |
| US6133426A (en) | 1997-02-21 | 2000-10-17 | Genentech, Inc. | Humanized anti-IL-8 monoclonal antibodies |
| CN1283228A (zh) * | 1997-12-24 | 2001-02-07 | 武田药品工业株式会社 | 多肽、其生产方法及应用 |
| US6210924B1 (en) | 1998-08-11 | 2001-04-03 | Amgen Inc. | Overexpressing cyclin D 1 in a eukaryotic cell line |
| US20030039958A1 (en) | 1999-12-03 | 2003-02-27 | Domantis Limited | Direct screening method |
| US20040009507A1 (en) | 2000-10-13 | 2004-01-15 | Domantis, Ltd. | Concatenated nucleic acid sequence |
| US6696245B2 (en) | 1997-10-20 | 2004-02-24 | Domantis Limited | Methods for selecting functional polypeptides |
| US6703199B1 (en) | 1997-06-12 | 2004-03-09 | Research Corporation Technologies, Inc. | Artificial antibody polypeptides |
| US20040202995A1 (en) | 2003-04-09 | 2004-10-14 | Domantis | Nucleic acids, proteins, and screening methods |
| US20050075275A1 (en) * | 2001-08-06 | 2005-04-07 | Bayer Aktiengesellschaft | Regulation of the apj receptor for use in the treatment or prophylaxis of cardiac diseases |
| US20050238646A1 (en) | 2001-01-17 | 2005-10-27 | Trubion Pharmaceuticals, Inc. | Binding domain-immunoglobulin fusion proteins |
| WO2006023893A2 (en) * | 2004-08-23 | 2006-03-02 | Arizona Board Of Regents On Behalf Of The University Of Arizona | Methods for modulating angiogenesis and apoptosis with apelin compositions |
| WO2012102363A1 (ja) * | 2011-01-28 | 2012-08-02 | 国立大学法人大阪大学 | 薬物送達システムおよびその利用 |
| WO2015140296A2 (en) * | 2014-03-20 | 2015-09-24 | Centre National De La Recherche Scientifique (Cnrs) | Use of compounds inhibiting apelin / apj / gp130 signaling for treating cancer |
| WO2016061141A1 (en) * | 2014-10-13 | 2016-04-21 | University Of Maryland, Baltimore | Methods for treating cardiovascular dysfunction and improving fluid homeostasis with a peptide hormone |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005106493A1 (en) * | 2004-04-30 | 2005-11-10 | Bayer Healthcare Ag | Diagnostics and therapeutics for diseases associated with g protein-coupled apelin receptor (apj) |
| WO2013012855A1 (en) * | 2011-07-18 | 2013-01-24 | Amgen Inc. | Apelin antigen-binding proteins and uses thereof |
| JP6317670B2 (ja) * | 2011-08-15 | 2018-04-25 | ザ・ユニバーシティ・オブ・シカゴThe University Of Chicago | ブドウ球菌プロテインaに対する抗体に関連した組成物および方法 |
| AU2014236451B2 (en) * | 2013-03-14 | 2018-08-09 | Regeneron Pharmaceuticals, Inc. | Apelin fusion proteins and uses thereof |
| CN104371019B (zh) * | 2013-08-13 | 2019-09-10 | 鸿运华宁(杭州)生物医药有限公司 | 一种能与glp-1r特异性结合的抗体及其与glp-1的融合蛋白质 |
| CA2931299C (en) * | 2013-11-20 | 2024-03-05 | Regeneron Pharmaceuticals, Inc. | Aplnr modulators and uses thereof |
| CN106659774A (zh) * | 2014-05-16 | 2017-05-10 | 贝勒研究院 | 用于治疗自身免疫和炎性病症的方法和组合物 |
| WO2016156570A1 (en) * | 2015-04-02 | 2016-10-06 | Ablynx N.V. | Bispecific cxcr4-cd-4 polypeptides with potent anti-hiv activity |
| MX2020002042A (es) * | 2017-08-24 | 2020-08-13 | Phanes Therapeutics Inc | Anticuerpos anti-apelin y sus usos. |
-
2018
- 2018-06-13 CN CN201810606914.0A patent/CN110655577A/zh active Pending
-
2019
- 2019-06-13 CA CA3103585A patent/CA3103585A1/en active Pending
- 2019-06-13 KR KR1020217000999A patent/KR20210019535A/ko not_active Application Discontinuation
- 2019-06-13 EP EP19819592.7A patent/EP3808847A4/en active Pending
- 2019-06-13 JP JP2020569130A patent/JP2021526833A/ja active Pending
- 2019-06-13 US US17/251,663 patent/US20210163614A1/en active Pending
- 2019-06-13 AU AU2019284320A patent/AU2019284320A1/en active Pending
- 2019-06-13 WO PCT/CN2019/091090 patent/WO2019238093A1/zh unknown
Patent Citations (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4179337A (en) | 1973-07-20 | 1979-12-18 | Davis Frank F | Non-immunogenic polypeptides |
| US4301144A (en) | 1979-07-11 | 1981-11-17 | Ajinomoto Company, Incorporated | Blood substitute containing modified hemoglobin |
| US4331647A (en) | 1980-03-03 | 1982-05-25 | Goldenberg Milton David | Tumor localization and therapy with labeled antibody fragments specific to tumor-associated markers |
| US4640835A (en) | 1981-10-30 | 1987-02-03 | Nippon Chemiphar Company, Ltd. | Plasminogen activator derivatives |
| US4737462A (en) | 1982-10-19 | 1988-04-12 | Cetus Corporation | Structural genes, plasmids and transformed cells for producing cysteine depleted muteins of interferon-β |
| US4518584A (en) | 1983-04-15 | 1985-05-21 | Cetus Corporation | Human recombinant interleukin-2 muteins |
| US4496689A (en) | 1983-12-27 | 1985-01-29 | Miles Laboratories, Inc. | Covalently attached complex of alpha-1-proteinase inhibitor with a water soluble polymer |
| US4751180A (en) | 1985-03-28 | 1988-06-14 | Chiron Corporation | Expression using fused genes providing for protein product |
| US4670417A (en) | 1985-06-19 | 1987-06-02 | Ajinomoto Co., Inc. | Hemoglobin combined with a poly(alkylene oxide) |
| US4935233A (en) | 1985-12-02 | 1990-06-19 | G. D. Searle And Company | Covalently linked polypeptide cell modulators |
| US4791192A (en) | 1986-06-26 | 1988-12-13 | Takeda Chemical Industries, Ltd. | Chemically modified protein with polyethyleneglycol |
| US5011912A (en) | 1986-12-19 | 1991-04-30 | Immunex Corporation | Hybridoma and monoclonal antibody for use in an immunoaffinity purification system |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| WO1993010151A1 (en) | 1991-11-22 | 1993-05-27 | Immunex Corporation | Receptor for oncostatin m and leukemia inhibitory factor |
| WO1994010308A1 (en) | 1992-10-23 | 1994-05-11 | Immunex Corporation | Methods of preparing soluble, oligomeric proteins |
| US5457035A (en) | 1993-07-23 | 1995-10-10 | Immunex Corporation | Cytokine which is a ligand for OX40 |
| US6133426A (en) | 1997-02-21 | 2000-10-17 | Genentech, Inc. | Humanized anti-IL-8 monoclonal antibodies |
| US6703199B1 (en) | 1997-06-12 | 2004-03-09 | Research Corporation Technologies, Inc. | Artificial antibody polypeptides |
| US6846634B1 (en) | 1997-10-20 | 2005-01-25 | Domantis Limited | Method to screen phage display libraries with different ligands |
| US20050202512A1 (en) | 1997-10-20 | 2005-09-15 | Domantis Limited | Method to screen phage display libraries with different ligands |
| US6696245B2 (en) | 1997-10-20 | 2004-02-24 | Domantis Limited | Methods for selecting functional polypeptides |
| US20040038291A2 (en) | 1997-10-20 | 2004-02-26 | Domantis Limited | Method to screen phage display libraries with different ligands |
| CN1283228A (zh) * | 1997-12-24 | 2001-02-07 | 武田药品工业株式会社 | 多肽、其生产方法及应用 |
| US6210924B1 (en) | 1998-08-11 | 2001-04-03 | Amgen Inc. | Overexpressing cyclin D 1 in a eukaryotic cell line |
| US20030039958A1 (en) | 1999-12-03 | 2003-02-27 | Domantis Limited | Direct screening method |
| US20040009507A1 (en) | 2000-10-13 | 2004-01-15 | Domantis, Ltd. | Concatenated nucleic acid sequence |
| US20050238646A1 (en) | 2001-01-17 | 2005-10-27 | Trubion Pharmaceuticals, Inc. | Binding domain-immunoglobulin fusion proteins |
| US20050075275A1 (en) * | 2001-08-06 | 2005-04-07 | Bayer Aktiengesellschaft | Regulation of the apj receptor for use in the treatment or prophylaxis of cardiac diseases |
| US20040202995A1 (en) | 2003-04-09 | 2004-10-14 | Domantis | Nucleic acids, proteins, and screening methods |
| WO2006023893A2 (en) * | 2004-08-23 | 2006-03-02 | Arizona Board Of Regents On Behalf Of The University Of Arizona | Methods for modulating angiogenesis and apoptosis with apelin compositions |
| WO2012102363A1 (ja) * | 2011-01-28 | 2012-08-02 | 国立大学法人大阪大学 | 薬物送達システムおよびその利用 |
| WO2015140296A2 (en) * | 2014-03-20 | 2015-09-24 | Centre National De La Recherche Scientifique (Cnrs) | Use of compounds inhibiting apelin / apj / gp130 signaling for treating cancer |
| WO2016061141A1 (en) * | 2014-10-13 | 2016-04-21 | University Of Maryland, Baltimore | Methods for treating cardiovascular dysfunction and improving fluid homeostasis with a peptide hormone |
Non-Patent Citations (78)
| Title |
|---|
| "Current Protocols in Molecular Biology", 1995, JOHN WILEY & SONS, INC. |
| "Proteins, Structures and Molecular Principles", 1984, W. H. FREEMAN AND COMPANY |
| "Remington's Pharmaceutical Sciences", 1980, MACK PUBLISHING COMPANY |
| ANDREWS, S. M.TITUS, J. A. ET AL.: "Current Protocols in Immunology", 2003, JOHN WILEY & SONS, pages: 281 - 2810,210A1-210A5 |
| ASHKENAZI ET AL., PNAS USA, vol. 88, 1991, pages 10535 |
| BAINES ET AL.: "Methods in Molecular Biology", vol. 10, 1992, THE HUMANA PRESS, INC., article "Purification of Immunoglobulin G (IgG", pages: 79 - 104 |
| BARON ET AL., NUCLEIC ACIDS RES, vol. 23, 1995, pages 3605 - 06 |
| BAUER ET AL., GENE, vol. 37, 1985, pages 73 |
| BAUM ET AL., EMBO J, vol. 13, 1994, pages 3992 - 4001 |
| BOLOGNA ET AL., BIOMOL. THER., vol. 25, 2017, pages 12 - 25 |
| BOUCHER ET AL., ENDOCRINOLOGY, vol. 146, 2005, pages 1764 - 71 |
| BOWIE ET AL., SCIENCE, vol. 253, 1991, pages 164 - 170 |
| BRENNER, CURR. OP. STRUCT. BIOL., vol. 7, 1997, pages 369 - 376 |
| BYRN ET AL., NATURE, vol. 344, 1990, pages 677 |
| CHNG ET AL., DEV. CELL, vol. 27, 2013, pages 672 - 680 |
| CHOU ET AL., ADV. ENZYMOL. RELAT. AREAS MOL. BIOL., vol. 47, 1978, pages 45 - 148 |
| CHOU ET AL., ANN. REV. BIOCHEM., vol. 47, 1979, pages 251 - 276 |
| CHOU ET AL., BIOCHEMISTRY, vol. 113, 1974, pages 211 - 222 |
| CHOU ET AL., BIOPHYS. J., vol. 26, pages 367 - 384 |
| COURTENAY-LUCK ET AL.: "Monoclonal Antibodies: Production, Engineering and Clinical Application", 1995, CAMBRIDGE UNIVERSITY PRESS, article "Genetic Manipulation of Monoclonal Antibodies", pages: 166 |
| CRAIK, BIOTECHNIQUES, vol. 3, 1985, pages 12 - 19 |
| CRAMERI ET AL., NATURE, vol. 391, 1998, pages 288 - 291 |
| DE GRAAF ET AL., METHODS MOL. BIOL., vol. 178, 2002, pages 379 - 87 |
| EDELMAN ET AL.: "Methods in Enzymology", vol. 1, 1967, ACADEMIC PRESS, pages: 422 |
| FANSLOW ET AL., SEMIN. IMMUNOL., vol. 6, 1994, pages 267 - 78 |
| GLUZMAN ET AL., CELL, vol. 23, 1981, pages 175 |
| GRIBSKOV ET AL., METH. ENZYM., vol. 183, 1990, pages 146 - 159 |
| GRIBSKOV ET AL., PROC. NAT. ACAD. SCI., vol. 84, 1987, pages 4355 - 4358 |
| HARRIS, R. J., JOURNAL OF CHROMATOGRAPHY, vol. 705, 1995, pages 129 - 134 |
| HOLLENBAUGH ET AL.: "Construction of Immunoglobulin Fusion Proteins", CURRENT PROTOCOLS IN IMMUNOLOGY, 1992, pages 10191 - 101911 |
| HOLLIGER ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 90, 1993, pages 6444 - 48 |
| HOLLINGERHUDSON, NATURE BIOTECHNOLOGY, vol. 23, no. 9, 2005, pages 1126 - 1136 |
| HOLM ET AL., NUCL. ACID. RES., vol. 27, 1999, pages 244 - 247 |
| HOPP ET AL., BIO/TECHNOLOGY, vol. 6, 1988, pages 1204 |
| HOPPE ET AL., FEBS LETTERS, vol. 344, 1994, pages 191 |
| HUSTON ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 85, 1988, pages 5879 - 83 |
| HUSTON ET AL., PROC. NATL. ACAD. SCI. USA, vol. 85, 1988, pages 5879 - 83 |
| JONES, CURR. OPIN. STRUCT. BIOL., vol. 7, 1997, pages 377 - 87 |
| KAWAMATA ET AL., BIOCHEM. BIOPHYS. ACTA., vol. 1538, 2001, pages 162 - 71 |
| KLEIZ ET AL., REGUL. PEPT., vol. 126, 2005, pages 233 - 40 |
| KORNDORFER ET AL., PROTEINS, vol. 53, 2003, pages 121 - 129 |
| KORTT ET AL., PROT. ENG., vol. 10, 1997, pages 423 |
| KRIANGKUM ET AL., BIOMOL. ENG., vol. 18, 2001, pages 31 - 108 |
| LANDSCHULZ ET AL., SCIENCE, vol. 240, 1988, pages 1759 - 426 |
| LARRICK ET AL., METHODS: A COMPANION TO METHODS IN ENZYMOLOGY, vol. 2, 1991, pages 106 - 3242 |
| LUNDE ET AL., BIOCHEM. SOC. TRANS., vol. 30, 2002, pages 500 - 06 |
| MANIATIS ET AL., SCIENCE, vol. 236, 1987, pages 1237 |
| MARKS ET AL., BIOLTECHNOLOGY, vol. 10, 1992, pages 779 - 783 |
| MCMAHAN ET AL., EMBO J, vol. 10, 1991, pages 2821 |
| MEDHURST ET AL., J. NEUROCHEM., vol. 84, 2003, pages 1162 - 72 |
| MOULT, CURR. OP. BIOTECH., vol. 7, 1996, pages 422 - 427 |
| MURZA ET AL., J MED. CHEM., vol. 59, 2016, pages 2962 - 72 |
| MURZA ET AL., J. MED. CHEM., vol. 59, 2016, pages 2962 - 72 |
| NISONOFFET ET AL., ARCH. BIOCHEM. BIOPHYS., vol. 89, 1960, pages 230 |
| NYGRENUHLEN, CURRENT OPINION IN STRUCTURAL BIOLOGY, vol. 7, 1997, pages 463 - 469 |
| O'DOWD ET AL., GENE, vol. 136, 1993, pages 355 - 60 |
| PATTEN ET AL., CURR. OPIN. BIOTECHNOL., vol. 8, 1997, pages 724 - 733 |
| PAULI ET AL., SCIENCE, vol. 343, 2014, pages 1248636 |
| POLJAK ET AL., STRUCTURE, vol. 2, 1994, pages 1121 - 23 |
| PORTER: "73", BIOCHEM. J., 1959, pages 119 |
| POUWELS ET AL.: "Cloning Vectors: A Laboratory Manual", 1985, ELSEVIER |
| RASMUSSEN ET AL., CYTOTECHNOLOGY, vol. 28, 1998, pages 31 |
| ROQUE ET AL., BIOTECHNOL. PROG., vol. 20, 2004, pages 639 - 654 |
| SAMBROOKFRITSCHMANIATIS: "Molecular Cloning: A Laboratory Manual", 1989, COLD SPRING HARBOR LABORATORY PRESS, pages: 631 - 636 |
| See also references of EP3808847A4 |
| SIPPL ET AL., STRUCTURE, vol. 4, 1996, pages 15 - 19 |
| THOMPSON ET AL., J. MOL. BIOL., vol. 256, 1996, pages 350 - 368 |
| THORNTON ET AL., NATURE, vol. 354, 1991, pages 105 |
| URLAUB ET AL., PROC. NATL. ACAD. SCI. USA, vol. 77, 1980, pages 4216 - 20 |
| VAUGHAN ET AL., NATURE BIOTECHNOLOGY, vol. 16, 1998, pages 535 - 539 |
| VOSS ET AL., TRENDS BIOCHEM. SCI., vol. 11, 1986, pages 287 |
| WALDER ET AL., GENE, vol. 42, 1986, pages 133 |
| WARD ET AL., NATURE, vol. 334, 1989, pages 544 - 546 |
| WARD ET AL.: "Monoclonal Antibodies: Principles and Applications", 1995, WILEY-LISS, INC., article "Genetic Manipulation and Expression or Antibodies", pages: 137 |
| YANG ET AL., CIRCULATION, vol. 135, 2017, pages 1160 - 1173 |
| YANG ET AL., J. MOL. BIOL., vol. 254, 1995, pages 392 - 403 |
| YUE ET AL., AM. J. PHYSIOL. ENDOCRINOL. METAB., vol. 298, 2010, pages E59 - 67 |
| ZHANG ET AL., CELL PHYSIOL BIOCHEM, vol. 48, 2018, pages 1347 - 1354 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021526833A (ja) | 2021-10-11 |
| AU2019284320A1 (en) | 2021-02-04 |
| EP3808847A1 (en) | 2021-04-21 |
| EP3808847A4 (en) | 2022-08-31 |
| CN110655577A (zh) | 2020-01-07 |
| KR20210019535A (ko) | 2021-02-22 |
| CA3103585A1 (en) | 2019-12-19 |
| US20210163614A1 (en) | 2021-06-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11712470B2 (en) | Human endothelin receptor antibody and use thereof | |
| WO2021052349A1 (zh) | Gipr抗体及其与glp-1的融合蛋白质,以及其药物组合物和应用 | |
| US11780916B2 (en) | GIPR antibody and GLP-1 fusion protein thereof, and pharmaceutical composition and application thereof | |
| WO2021008519A1 (zh) | ETA抗体与TGF-βTrap的融合蛋白质,以及其药物组合物和应用 | |
| US11542336B2 (en) | GCGR antibody and GLP-1 fusion protein thereof, pharmaceutical composition thereof and application thereof | |
| WO2017206840A1 (zh) | Etar抗体,其药物组合物及其应用 | |
| WO2019238093A1 (zh) | APJ抗体及其与Elabela的融合蛋白质,以及其药物组合物和应用 | |
| WO2020248967A1 (zh) | Eta抗体与bnp的融合蛋白质,以及其药物组合物和应用 | |
| WO2024051802A1 (zh) | Gipr抗体及其与fgf21的融合蛋白,以及其药物组合物和应用 | |
| WO2022206857A1 (zh) | 一种能与人内皮素受体特异性结合的抗体及其在糖尿病肾病和慢性肾病治疗中的应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19819592 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 3103585 Country of ref document: CA Ref document number: 2020569130 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 20217000999 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2019819592 Country of ref document: EP Effective date: 20210113 |
|
| ENP | Entry into the national phase |
Ref document number: 2019284320 Country of ref document: AU Date of ref document: 20190613 Kind code of ref document: A |