WO2019176590A1 - 情報処理装置、情報処理装置およびプログラム - Google Patents
情報処理装置、情報処理装置およびプログラム Download PDFInfo
- Publication number
- WO2019176590A1 WO2019176590A1 PCT/JP2019/008140 JP2019008140W WO2019176590A1 WO 2019176590 A1 WO2019176590 A1 WO 2019176590A1 JP 2019008140 W JP2019008140 W JP 2019008140W WO 2019176590 A1 WO2019176590 A1 WO 2019176590A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information processing
- metadata
- user
- service
- processing apparatus
- Prior art date
Links
Images




















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/431—Generation of visual interfaces for content selection or interaction; Content or additional data rendering
- H04N21/4312—Generation of visual interfaces for content selection or interaction; Content or additional data rendering involving specific graphical features, e.g. screen layout, special fonts or colors, blinking icons, highlights or animations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/048—Interaction techniques based on graphical user interfaces [GUI]
- G06F3/0481—Interaction techniques based on graphical user interfaces [GUI] based on specific properties of the displayed interaction object or a metaphor-based environment, e.g. interaction with desktop elements like windows or icons, or assisted by a cursor's changing behaviour or appearance
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11B—INFORMATION STORAGE BASED ON RELATIVE MOVEMENT BETWEEN RECORD CARRIER AND TRANSDUCER
- G11B27/00—Editing; Indexing; Addressing; Timing or synchronising; Monitoring; Measuring tape travel
- G11B27/005—Reproducing at a different information rate from the information rate of recording
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/41—Structure of client; Structure of client peripherals
- H04N21/422—Input-only peripherals, i.e. input devices connected to specially adapted client devices, e.g. global positioning system [GPS]
- H04N21/42203—Input-only peripherals, i.e. input devices connected to specially adapted client devices, e.g. global positioning system [GPS] sound input device, e.g. microphone
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/4302—Content synchronisation processes, e.g. decoder synchronisation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/4302—Content synchronisation processes, e.g. decoder synchronisation
- H04N21/4307—Synchronising the rendering of multiple content streams or additional data on devices, e.g. synchronisation of audio on a mobile phone with the video output on the TV screen
- H04N21/43074—Synchronising the rendering of multiple content streams or additional data on devices, e.g. synchronisation of audio on a mobile phone with the video output on the TV screen of additional data with content streams on the same device, e.g. of EPG data or interactive icon with a TV program
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/431—Generation of visual interfaces for content selection or interaction; Content or additional data rendering
- H04N21/4312—Generation of visual interfaces for content selection or interaction; Content or additional data rendering involving specific graphical features, e.g. screen layout, special fonts or colors, blinking icons, highlights or animations
- H04N21/4316—Generation of visual interfaces for content selection or interaction; Content or additional data rendering involving specific graphical features, e.g. screen layout, special fonts or colors, blinking icons, highlights or animations for displaying supplemental content in a region of the screen, e.g. an advertisement in a separate window
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/435—Processing of additional data, e.g. decrypting of additional data, reconstructing software from modules extracted from the transport stream
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/488—Data services, e.g. news ticker
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/488—Data services, e.g. news ticker
- H04N21/4882—Data services, e.g. news ticker for displaying messages, e.g. warnings, reminders
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/81—Monomedia components thereof
- H04N21/8126—Monomedia components thereof involving additional data, e.g. news, sports, stocks, weather forecasts
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/81—Monomedia components thereof
- H04N21/8166—Monomedia components thereof involving executable data, e.g. software
- H04N21/8173—End-user applications, e.g. Web browser, game
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/83—Generation or processing of protective or descriptive data associated with content; Content structuring
- H04N21/84—Generation or processing of descriptive data, e.g. content descriptors
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
Definitions
- the present technology relates to an information processing apparatus, an information processing apparatus, and a program that perform information processing for receiving and reproducing moving image content including video, and in particular, the moving image content is an audio-based information service for a user of the information processing device.
- the present invention relates to an information processing apparatus, an information processing method, and a program that are suitable for a case of cooperating with a computer.
- voice AI assistant services have become widespread. This is because the terminal corresponding to the service picks up the voice request issued by the user of the information processing device, recognizes it, analyzes the data, executes the service according to the user's request, This is an information service that responds to the result of execution by voice or the like (for example, see Patent Document 1).
- Alexa registered trademark
- AmazonAEcho registered trademark
- the present inventors have studied a mechanism for using the voice AI assistant service as described above as a means for collecting information on a person or an article appearing in a video in an environment for reproducing moving image content including the video. Yes. For example, if the viewer user wants to know various things such as the role of the person appearing in the video content, the relationship with other characters, and the profile of the actor who plays the person, Information can be provided in real time from the AI assistant service.
- the voice AI assistant service when the voice AI assistant service is actually used as a means for collecting information on a person or an article appearing in the video in an environment where video content including the video is reproduced, the characteristics of the voice AI assistant service are utilized. There are a lot of problems to be solved, such as a suitable usage is not yet established.
- an object of the present technology is to provide an information processing apparatus, an information processing apparatus, and a program that can use the voice AI assistant service by taking advantage of the characteristics when viewing the reproduced video.
- an information processing apparatus includes a media playback unit that acquires and plays back video data including a service target that can use a service that processes a voice request from a user; A control unit for adding an additional image for teaching the user of the service object to the reproduced video.
- the additional image may have a unique visual feature for each service object so that the service object can be uniquely identified by voice recognition in the service.
- the additional image may be presented at a position associated with the service object.
- the control unit may be configured to limit the service object to which the additional image is added according to the user or the attribute of the user.
- the control unit may be configured to skip and reproduce a video during a period in which the service object to which the additional image is added according to the user or the attribute of the user appears.
- the control unit reproduces a video of a period in which the service object to which the additional image is added according to the user or the attribute of the user appears at a first double speed, and a period in which the service object does not appear.
- the video may be configured to be played back at a second speed higher than the first double speed.
- the control unit may be configured to acquire metadata for generating the additional information and add the additional information based on the acquired metadata.
- the control unit obtains an MPD file including the AdaptationSet of the metadata, analyzes the MPD file, obtains the video data and the metadata as MPEG-DASH Media Segments,
- the additional image based on the metadata may be configured to be presented in synchronization with each other.
- the control unit determines whether or not there is a change in the contents of the front side metadata and the rear side metadata that are temporally changed.
- the additional image added to the video based on the data may be added to the video synchronized with the rear metadata as an additional image based on the rear metadata.
- the visual feature of the additional image may be given by any one of a character string, a color, a shape, or an icon related to the service object.
- an information processing method acquires and reproduces video data including a service target that can use a service that processes a voice request from a user, and adds the service target to the reproduced video. This includes a procedure of adding an additional image for teaching an object to the user.
- the program when the program reproduces video data including a service target that can use a service that processes a voice request from a user, the service target is added to the reproduced video.
- the voice AI assistant service can be utilized by taking advantage of its characteristics when viewing the playback video.
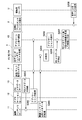
- FIG. 1 is a block diagram illustrating an overall configuration of an information processing system 100 including the information processing apparatus 4 according to the first embodiment of the present technology.
- FIG. 2 is a sequence diagram showing an overall operation flow (part 1) in the information processing system 100 of FIG. 1.
- FIG. 7 is a sequence diagram showing a flow (2) of the overall operation in the information processing system 100 of FIG. 1.
- FIG. 8 is a sequence diagram showing a flow (3) of the overall operation in the information processing system 100 of FIG. 1.
- FIG. 10 is a sequence diagram illustrating an overall operation flow (No. 3) including additional image presentation restriction in the information processing system 100 of FIG. 1. It is a figure explaining trick play reproduction based on POI metadata. It is a figure which shows the example of the application execution environment 43 which processes POI metadata. It is a figure which shows the other example of the application execution environment 43 which processes POI metadata. It is a figure which shows the example of Multi-part MIME format which packages a web application and POI metadata It is a figure which shows the structure of Media Segment in the format of MP4 file. It is a figure which shows the data structure of MPD of MPEG-DASH.
- FIG. 3 is a diagram showing exchanges between the MPEG-DASH server 15 and the information processing apparatus 4 through network communication.
- the information processing apparatus 4 of this embodiment is An AV decoder 41 that acquires and reproduces video data including a service object that can use a voice AI assistant service that processes a voice request from a user; An application execution environment 43 for adding an additional image for teaching the user of the service object to the reproduced video.
- the information processing apparatus 4 of the present embodiment has an effect that the service object of the voice AI assistant service can be discriminated at a glance in the reproduced video, and there is no confusion when selecting the service object.
- FIG. 1 is a block diagram illustrating an overall configuration of an information processing system 100 including the information processing apparatus 4 according to the first embodiment of the present technology.
- the information processing system 100 includes a server group 1, a broadcast / net distribution system 2, a voice AI assistant service terminal 3, and a user information processing device 4.
- the server group 1 includes a moving image content server 11, an application server 12, a POI metadata server 13, and a voice AI assistant service program server 14.
- the video content server 11 stores video content data such as commercials and programs.
- the data of the moving image content may be multimedia data composed of a plurality of types of media data such as video, audio, and subtitles.
- the present technology is particularly applicable to video data, and it does not matter whether there is other media data such as audio and subtitles.
- the POI metadata server 13 directly distributes POI metadata corresponding to the moving image content to the information processing apparatus 4 through the broadcast / net distribution system 2.
- the moving image content server 11 collects at least moving image content data and POI metadata in a predetermined data structure and distributes them to the information processing apparatus 4
- the POI metadata server 13 broadcasts / distributes POI metadata. This is supplied to the moving image content server 11 through the system 2.
- the POI metadata will be described later.
- the application server 12 directly distributes an application for executing processing based on POI metadata in the information processing apparatus 4 to the information processing apparatus 4 through the broadcast / net distribution system 2.
- the application server 12 transmits the application through the broadcast / net distribution system 2. Supplied to the content server 11.
- the voice AI assistant service program server 14 supplies the voice AI assistant service program to the voice AI assistant service terminal 3 through the broadcast / net distribution system 2.
- the voice AI assistant service program is configured to generate a service execution result for a service request given from a user U who is a viewer of the video content for a service target such as a specific person or article appearing in the video content. It is a program.
- the broadcast / net distribution system 2 broadcasts or network communication data of moving image content, a data structure of moving image content data and POI metadata, or a data structure of moving image content data, POI metadata and an application. This is a system that distributes to the information processing apparatus 4.
- the broadcast / net distribution system 2 also transfers data between the video content server 11, the application server 12, and the POI metadata server 13, and further between the voice AI assistant service program server 14 and the voice AI assistant service terminal 3. It is also used for data transfer.
- the information processing apparatus 4 includes, as hardware elements, a CPU (Central Processing Unit), a main memory such as a RAM (Random Access Memory), a storage device such as an HDD (Hard Disk Drive), and an SSD (Solid State Drive).
- a user interface, a broadcast receiving unit such as an antenna and a broadcast tuner, and a communication interface such as a network interface are provided.
- the information processing apparatus 4 may be a personal computer, a smart phone, a tablet terminal, a television, a game machine, a user-mountable information terminal such as an HMD (Head Mounted Display), or the like.
- HMD Head Mounted Display
- the information processing apparatus 4 includes an AV decoder 41, a POI metadata processing module 42, an application execution environment 43, and a renderer 44 as functional elements realized by the hardware elements and software elements described above.
- the information processing apparatus 4 includes a display 45 and a speaker 46 as a user interface. Further, the information processing apparatus 4 may include a user discrimination module 47 as a functional element.
- the AV decoder 41 decodes the multimedia data (video data, audio data, etc.) of the moving image content acquired from the moving image content server 11 through the broadcast / net distribution system 2.
- the POI metadata processing module 42 supplies the POI metadata acquired from the video content server 11 or the POI metadata server 13 to the application execution environment 43 through the broadcast / net distribution system 2.
- POI metadata refers to an additional image that teaches a user U of the information processing apparatus 4 to a video that is being reproduced in the information processing apparatus 4 and a specific service object to which the voice AI assistant service is assigned in the video. This is metadata for adding. POI is an abbreviation for Point of Interest.
- the “specific service object” is a character, an article, or the like that is capable of responding to the service request from the user U by the voice AI assistant service in the video.
- the application execution environment 43 is an environment in which a native application or a web application is executed using a CPU and a main memory.
- the application execution environment 43 generates an additional image to be added to the service object in the video based on the POI metadata given from the POI metadata processing module 42.
- the “additional image” is generated, for example, as a “speech balloon” so that the relationship with the service object in the video can be easily understood.
- the present technology is not limited to this, and may be any image that can easily understand the relationship with the service target in the video.
- the renderer 44 generates a display signal to be output to the display 45 from the video data decoded by the AV decoder 41, and outputs the audio data decoded by the AV decoder 41 to the speaker 46. Further, when an additional image is supplied from the application execution environment 43, the renderer 44 synthesizes the additional image on the program video.
- Display 45 presents video to user U.
- the speaker 46 presents voice to the user U.
- the voice AI assistant service terminal 3 is a terminal that provides a voice assistant service to the user U of the information processing apparatus 4. More specifically, the voice AI assistant service terminal 3 receives a voice service request for an arbitrary service object from the user U in the video, executes the service, and sends the service execution result to the user U. It is a device that can be returned with.
- the service request by voice from the user U is given by words such as a question format, and the execution result of the service is returned to the user U by synthesized voice such as an answer format.
- the voice AI assistant service terminal 3 includes a microphone 31 for assistant service, a voice recognition module 32, a speaker 33 for voice AI assistant service, a voice generation module 34, and a voice AI assistant service program execution environment 35.
- the assistant service microphone 31 captures a voice service request from the user U of the information processing apparatus 4.
- the voice recognition module 32 recognizes the service request voice captured by the assistant service microphone 31 and passes the request data to the voice AI assistant service program execution environment 35.
- the voice AI assistant service program execution environment 35 is an environment in which the voice AI assistant service program acquired from the voice AI assistant service program server 14 is executed.
- the voice AI assistant service program execution environment 35 generates service execution result data for the request data supplied from the voice recognition module 32 and supplies it to the voice generation module 34.
- the voice generation module 34 converts the data of the service execution result supplied from the voice AI assistant service program execution environment 35 into synthesized voice.
- the speaker 33 for the assistant service presents the synthesized voice supplied from the voice generation module 34 to the user U of the information processing apparatus 4.
- FIG. 2 is a sequence diagram showing an overall operation flow (part 1) in the information processing system 100 according to the present embodiment.
- moving image content data, application, and POI metadata are distributed from different servers (moving image content server 11, application server 12, and POI metadata server 13).
- an application is distributed from the application server 12 to the information processing apparatus 4 through the broadcast / net distribution system 2 (step S101). Further, the moving image content data is distributed from the moving image content server 11 to the information processing device 4 through the broadcast / net distribution system 2 (step S102).
- the received video content data is decoded by the AV decoder 41, and the resulting video data and audio data are supplied to the display 45 and the speaker 46 through the renderer 44 (step S103).
- step S104 the application distributed from the application server 12 to the information processing apparatus 4 is introduced into the application execution environment 43, and the application is executed (step S104).
- POI metadata corresponding to the moving image content is distributed from the POI metadata server 13 to the information processing apparatus 4 through the broadcast / net distribution system 2 (step S105).
- the POI metadata is supplied to the application execution environment 43 by the POI metadata processing module 42.
- the application execution environment 43 Based on the POI metadata, the application execution environment 43 generates an additional image that teaches the service object in the video to the user U, and supplies it to the renderer 44.
- a composite image in which the additional image is superimposed on the video of the program is obtained and displayed on the display 45 (step S106).
- the user U gives a voice service request to the voice AI assistant service terminal 3 for the service object on which the additional image is presented in the video displayed on the display 45, and uses the voice AI assistant service (step). S107).
- FIG. 3 is a sequence diagram showing an overall operation flow (part 2) in the information processing system 100 of the present embodiment.
- the moving image content data and the POI metadata are distributed from different servers (moving image content server 11 and POI metadata server 13) to the information processing device 4, so that the information processing device 4, synchronization between the moving image content data and the POI metadata is not guaranteed.
- step S201 the moving image content server 11 collects POI metadata and moving image content data in a predetermined data structure and distributes them to the information processing apparatus 4 through the broadcast / net distribution system 2 (step S203).
- the moving image content data is extracted from the received data structure, the extracted moving image content data is decoded by the AV decoder 41, and the resulting video data and audio data are displayed through the renderer 44. 45 and the speaker 46 (step S204).
- POI metadata is extracted from the received data structure by the POI metadata processing module 42 (step S205) and supplied to the application execution environment 43.
- the application execution environment 43 Based on the POI metadata, the application execution environment 43 generates an additional image that teaches the service object in the video to the user U, and supplies it to the renderer 44. As a result, a composite image in which the additional image is superimposed on the video of the program is obtained and displayed on the display 45 (step S207).
- the user U gives a voice service request to the voice AI assistant service terminal 3 for the service object on which the additional image is presented in the video displayed on the display 45, and uses the voice AI assistant service (step). S208).
- the POI metadata and the moving image content data are collected into a predetermined data structure and distributed from the moving image content server 11 to the information processing device 4, whereby the moving image content data and the POI metadata are Can be processed synchronously with each other. For this reason, a correct additional image can always be added to the service target in the video of the program, and a stable voice AI assistant service can be maintained.
- Step S202 the application is distributed from the application server 12 to the information processing apparatus 4 through the broadcast / net distribution system 2 (step S202), and introduced into the application execution environment 43 to execute the application.
- Step S206 is the same as the above-described operation flow (No. 1).
- FIG. 4 is a sequence diagram showing an overall operation flow (part 3) in the information processing system 100 of the present embodiment. In this flow of operation, it is assumed that moving image content data, POI metadata, and an application for processing the moving image content server 11 are distributed to the information processing apparatus 4 in a predetermined data structure.
- POI metadata is supplied from the POI metadata server 13 to the video content server 11 (step S301). Further, an application is supplied from the application server 12 to the moving image content server 11 (step S302). The order of supply of POI metadata and application may be reversed. Subsequently, the moving image content server 11 collects the moving image content data, the POI metadata, and the application in a predetermined data structure and distributes them to the information processing apparatus 4 through the broadcast / net distribution system 2 (step S303).
- the moving image content data is extracted from the received data structure, the extracted moving image content data is decoded by the AV decoder 41, and the resulting video data and audio data are displayed through the renderer 44. 45 and the speaker 46 (step S304).
- an application is extracted from the received data structure (step S305), introduced into the application execution environment 43 and executed (step S306).
- POI metadata is extracted from the received data structure by the POI metadata processing module 42 (step S307) and supplied to the application execution environment 43.
- the application execution environment 43 Based on the POI metadata, the application execution environment 43 generates an additional image that teaches the service object in the video to the user U, and supplies it to the renderer 44. As a result, a composite image in which the additional image is superimposed on the program video is obtained and displayed on the display 45 (step S308).
- the user U gives a voice service request to the voice AI assistant service terminal 3 for the service object on which the additional image is presented in the video displayed on the display 45, and uses the voice AI assistant service (step). S309).
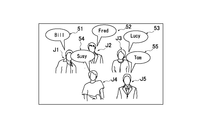
- FIG. 5 is a diagram illustrating an example of a video on which an additional image is superimposed.
- the additional image may be presented, for example, as balloons 51, 52, and 53 associated with service objects J1, J2, and J3 of the voice AI assistant service in the video, respectively.
- the service objects J1, J2, and J3 are voice AI assistant service terminals 3.
- Unique visual features are given to each of the service objects J1, J2, J3 so that they can be uniquely identified by voice recognition. Thereby, the user U can give a service request for the service object to the voice AI assistant service terminal 3 using the voice expressing the characteristics of an arbitrary service object.
- the character strings of the names of the characters that are service objects J1, J2, and J3 such as “Bill”, “Fred”, and “Lucy” in the balloons 51, 52, and 53 are visual features. Is displayed.
- the user U uses a name of an arbitrary service object such as “What is Fred's recent news?” And “How old is Bill?” To make a voice request to the service U for the service object. It can be given to the assistant service terminal 3 by voice.
- the voice AI assistant service terminal 3 can identify the service object from the name recognized by the voice recognition module 32, and the voice AI assistant service program of the voice AI assistant service program execution environment 35 is identified for the identified service object.
- the voice AI assistant service can be executed as follows.
- the visual features unique to each service object placed in the balloons 51, 52, and 53 include various modifications such as a character string of the name of the character, icons, balloon colors, and balloon designs. Conceivable.
- an additional image that teaches the user U that this is a service object is generated on the service object of the voice AI assistant service in the video content video, and the video is displayed on the video content video. Since they are presented in a superimposed manner, the user U can uniquely determine the service object from the video and make a service request for any service object. Thereby, a useless operation of giving a service request for an object other than the service target from the user U to the voice AI assistant service terminal 3 can be avoided, and the voice AI assistant service can be used satisfactorily.
- the service object can be uniquely recognized by voice recognition at the voice AI assistant service terminal 3
- the user U can arbitrarily select the additional image by giving a unique visual feature for each service object.
- a service request for the service object can be given to the voice AI assistant service terminal 3 by voice.
- the user U is not confused as to how to express the service object and notify the voice AI assistant service, and the service object is surely specified in the voice AI assistant service terminal 3.
- Voice AI assistant service is realized.
- FIG. 6 is a block diagram showing the configuration of POI metadata.
- the POI metadata includes a POI icon image, a POI presentation color, a POI presentation position, a POI presentation text, and POI filtering information.
- the POI icon image is an icon file entity or a reference URL (Uniform Resource Locator) used to present an icon as a visual feature of a service target unit in an additional image.
- the XML (Extensible Markup Language) representation of the POI icon image is shown below.
- ⁇ POIIcon iconPng 'true'>... (base64 encoded png file)... ⁇ / POIIcon>
- ⁇ POIIcon iconPngURL 'true'> http: //... (URL of icon png file)... ⁇ / POIIcon>
- the POI presentation color is used when a visual feature by color is given to the additional image.
- CSS CSS
- the XML representation of the POI presentation color is shown below. ⁇ POIColor> ... (CSS color code) ... ⁇ / POIColor>
- the POI presentation position is the URI (Uniform Resource Identifier) of the target content for presenting the additional image, the URI of the application that performs the process of presenting the additional image based on the POI metadata, the presentation time of the additional image, the presentation position of the additional image, etc. Contains information.
- the XML representation of the POI presentation position is shown below.
- ⁇ POITargetContentID URL 'http: //a.com/Program A.MPD'/>
- ⁇ POIApplication URL 'http: //a.com/POI presentation app for program A.html (URL of POI presentation app)'/>
- the POI presentation text is a character string presented on the additional image in order to give a visual feature by characters to the additional image.
- the XML representation of the POI presentation text is shown below. ⁇ POIText>... (Presentation string)... ⁇ / POIText>
- POI filtering information is used when presentation restriction is performed according to the user or user attribute of the additional image.
- the POI filtering information is information for specifying the target user U to present the additional image, and includes the user demographic class identification name and arbitrary user identification information.
- the user demographic class is a class that classifies the user U on the basis of attributes such as the user's gender, age, area of residence, occupation, educational background, family composition, and the like. Uniquely identified.
- the arbitrary user identification information is user identification information such as an account name of a broadcasting station related service, for example.
- An XML representation of arbitrary user identification information is shown below.
- ⁇ POITargetUser privateAccount 'true'> https: //... (Service user account identification URL etc.)... ⁇ / POITargetUser>
- the POI icon image, the POI presentation color, and the POI presentation text may be defined.
- the POI filtering information is defined when introducing additional information presentation restrictions, which will be described later.
- the additional image is presented to the service object of the voice AI assistant service in the video content.
- additional images 51-55 corresponding to the number of service objects J1-J5 are presented. Therefore, a part of the program video may be hidden by these additional images 51-55, and the appearance of the program video may be impaired.
- FIG. 9 is a sequence diagram showing a flow of an operation including the presentation restriction of the additional image.
- the operations in steps S401 to S405 are the same as steps S101 to S105 in the operation flow (part 1) shown in FIG.
- the user determination module 47 of the information processing apparatus 4 determines the user demographic class or the user identification information of the user U (step S406).
- the determined user demographic class or user identification information of the user U is notified to the application execution environment 43 (step S407).
- the user demographic class is a class that classifies users based on various attributes such as the user's gender, age, area of residence, occupation, educational background, and family composition. For example, if you can statistically say that a 20-year-old male is more interested in a recently popular new actress, the user demographic class for a 20-year-old male It matches the user demographic class defined in the POI metadata for the character (service object) to perform.
- a method for determining the user demographic class or the user identification information of the user U by the user determination module 47 is as follows. 1.
- the user determination module 47 estimates attributes such as the sex and age group of the user U from the analysis result of the user U's face image captured by the camera, and determines the user demographic class from the estimated attributes. 2.
- the user discriminating module 47 estimates the attribute of the user U based on information obtained through a voice question from the voice AI assistant service terminal 3 to the user U, and discriminates the user demographic class. 3.
- a user discrimination module can be obtained by previously registering an identification name or user identification information of a user demographic class in association with the user name of each user. 47 can determine the identification name or user identification information of the corresponding user demographic class from the user name confirmed through authentication such as biometric authentication and card authentication.
- the application execution environment 43 of the information processing device 4 identifies the user demographic class identification name or user identification information determined by the user determination module 47 from all the POI metadata for each scene video of the moving image content. Extracts the POI metadata defined as the POI filtering information, generates an additional image for teaching the user U the service object in the video based on the extracted POI metadata, and supplies it to the renderer 44. Thereby, a composite image in which the additional image is superimposed on the video of the program is obtained and displayed on the display 45 (step S408).
- the user U gives a voice service request to the voice AI assistant service terminal 3 for the service object on which the additional image is presented in the video displayed on the display 45, and uses the voice AI assistant service (step). S409).
- the identification name of the user demographic class of the service object J1 in the video is “class1”, and the identification names of the user demographic classes of the other service objects J2-J5 are other than “class1”.
- the user determination module 47 determines that the user demographic class of the user U is “class1”. In this case, since the additional image 51 is presented only to the service object J1, a part of the video of the program is hidden in the additional image 52-55 added to the service object J2-J5 that is not interesting to the user U. To minimize the contamination of the entire image.
- the user demographic class of the user U is determined from attributes such as gender, age, area where he / she lives, occupation, educational background, family attributes, etc. Even if the user U's preference condition is calculated based on U's viewing history and the user demographic class is determined based on this preference condition or taking this preference condition into account. Good.
- trick play reproduction based on POI metadata is the playback at the first double speed for the scene where the additional image is presented based on the POI metadata extracted based on the user demographic class or the user identification information of the user U.
- the other scenes are reproduced at the second double speed higher than the first double speed.
- the first double speed is, for example, a single speed (equal speed) or a double speed lower than the single speed.
- the second double speed is, for example, fast-forward playback that is faster than the single speed.
- the user determination module 47 determines the user demographic class or user identification information of the user U, and supplies it to the application execution environment 43.
- the application execution environment 43 is a POI in which the identification name or user identification information of the user demographic class determined by the user determination module 47 is defined as POI filtering information from all the POI metadata for the video of each scene of the program. Metadata is selected, and trick play playback is performed based on the extracted POI metadata.
- FIG. 10 is a diagram more specifically showing trick play reproduction based on POI metadata.
- the user demographic classes of the service objects “Bill” and “Sam” are “class1”, and the user demographic class of the user U determined by the user determination module 47 is “class1”. .
- the application execution environment 43 Since “Bill” whose user demographic class is “class1” appears in the video of the Ta-Ta ′ period, the application execution environment 43 displays the additional image at the first double speed during the Ta-Ta ′ period. Play the video that contains it. Thereafter, the service execution object whose user demographic class is “class1” does not appear in the video until time Tc, so that the application execution environment 43 performs reproduction at the second double speed higher than the first double speed. Note that the burden on the application execution environment 43 can be reduced by not presenting the additional image during reproduction at the second double speed.
- the application execution environment 43 is a video including an additional image at the first double speed during the Tc-Tc ′ period. Play back. After the time Tc ′, since the service object whose user demographic class is “class1” does not appear in the video, reproduction at the second double speed is performed.
- the scene where the additional image is presented based on the POI metadata extracted based on the user demographic class or the user identification information of the user U is reproduced at the first double speed, and the other scenes are displayed.
- trick play playback focusing on a scene that is useful (interesting) to the user U is realized.
- FIG. 11 is a diagram showing an example of an application execution environment 43 for processing POI metadata.
- the application that processes POI metadata is a native application 49 that operates on the native operating system 48 of the information processing apparatus 4 is shown.
- FIG. 12 is a diagram showing another example of the application execution environment 43 that processes POI metadata.
- This example shows a case where the application that processes POI metadata is a web application 57 that runs on the web browser 56.
- the POI metadata and the web application 57 are distributed to the information processing apparatus 4 simultaneously or substantially simultaneously.
- FIG. 13 is a diagram showing an example of a Multi-part MIME format for packaging the web application and POI metadata.
- a POI metadata file 61 and a web application file 62 are individually stored in each part delimited by the boundary-part.
- the application that processes the POI metadata is a native application that operates using the operating system as an application execution environment, or is distributed separately from the POI metadata
- the POI metadata is converted to the multi-part MIME format. Only the metadata file may be stored and distributed.
- FIG. 14 is a diagram showing the configuration of the Media Segment in the MP4 file format.
- the Media Segment has a plurality of Movie Fragments, and each Movie Fragment is composed of a moof box and an mdat box.
- the mdat box media data is divided into a plurality of Sample boxes in units of time such as frames, and stored in a random accessible manner.
- the moof box stores metadata related to presentation, such as information for generating timing for presenting media data of each Sample box of the mdat box.
- POI metadata is stored in each Sample box of the Media Segment in which the video data is stored in each Sample box in the mdat box, each of the Media Segment in which the audio data is stored in each Sample box in the mdat box, and each of the Sample boxes in the mdat box.
- Media Segment is prepared.
- the MP4 file is a Media Segment of MPEG-DASH (Dynamic Adaptive Streaming over HTTP).
- MPEG-DASH In MPEG-DASH, a plurality of data groups having different encoding speeds and screen sizes are prepared for one moving image content so that streaming reproduction is not interrupted.
- the plurality of data groups are dynamically selected in consideration of the screen size of the information processing apparatus 4 and the state of the network bandwidth. Therefore, in MPEG-DASH, what kind of encoding speed and screen size data group is prepared for one moving picture content as described above is described in metadata called MPD (Media Presentation Description).
- MPD describes information related to the structure of moving image content stored in a server in a hierarchical structure of XML (extensible markup language) format.
- the information processing apparatus 4 acquires an MPD file corresponding to the target moving image content from the MPD file server and analyzes it to acquire a Media Segment necessary for presenting the target moving image content from the server.
- FIG. 15 shows the data structure of MPD.
- the MPD has one period below it, one adaptation set for each type of media below it, and a plurality of subordinate representations below it.
- the MPD hierarchy that is, the highest hierarchy includes information such as MPD starting point, title, streaming type (on-demand / live distribution), and length as management information related to one video content.
- Period is a unit obtained by dividing one video content by time such as a frame.
- a Period defines a start time (start time) and an end time (end time).
- Period is composed of a plurality of AdaptationSets.
- AdaptationSet includes information such as codec information and language related to data for each media type (video, audio, caption, POI metadata) of the moving image content for each period.
- the AdaptationSet has a Representation for each data with different encoding speed and image size.
- Representation includes information such as encoding speed, image size, and storage location (URL) of different segments such as encoding speed and image size, which are respectively stored in the web server.
- information such as encoding speed, image size, and storage location (URL) of different segments such as encoding speed and image size, which are respectively stored in the web server.
- FIG. 16 is a diagram showing an exchange by network communication between the MPEG-DASH server 15 and the information processing apparatus 4.
- the MPEG-DASH server 15 stores an MPD file and a media segment of various media of moving image content.
- the CPU of the information processing apparatus 4 requests the MPD file from the MPEG-DASH server 15 (step S501).
- the MPEG-DASH server 15 transmits an MPD file to the information processing apparatus 4 (step S502).
- the CPU of the information processing device 4 analyzes the received MPD file and confirms what encoding speed and image size Media Segment is prepared (step S503).
- the CPU of the information processing device 4 considers the analysis result of the MPD file, the screen size of the display, the network traffic state of the transmission path, and the like, and sends the media segment having the optimum image size and encoding speed to the MPEG-DASH server 15 A request is made (step S504).
- the MPEG-DASH server 15 transmits a Media Segment to the information processing apparatus 4 (step S505).
- Media Segment has a plurality of Movie Fragments, and each Movie Fragment is composed of a moof box and an mdat box.
- media data is divided into a plurality of Sample boxes in units of time such as frames, and stored in a random accessible manner.
- the moof box stores metadata related to presentation, such as information for generating timing for presenting the media data of each sample in the mdat box.
- BaseMediaDecodeTime is stored as information associated with Sample (1), (2), (3),. (1), (2), (3),..., Sample Duration (1), (2), (3),..., CompositionTimeOffset (1), (2), (3),.
- BaseMediaDecodeTime is information of relative time from the origin of Period to the origin of Movie Fragment.
- SampleCount (1), (2), (3), ... is the number of Samples, SampleDuration (1), (2), (3), ... is the length of Sample (1), (2), (3), ... CompositionTimeOffset (1), (2), (3),... Are adjustment times.
- FIG. 17 is a diagram showing the flow of presentation control of MPEG-DASH moving image content.
- the horizontal axis is a real time (UTC time) axis.
- the CPU of the information processing device 4 generates the starting point of the first period in real time based on the starting time defined as the relative time with respect to the starting point of the MPD based on the starting point of the MPD defined in the MPD file. To do.
- the CPU of the information processing device 4 generates the origin of the Movie Fragment in real time based on the BaseMediaDecodeTime, and further uses the SampleCount, SampleDuration, CompositionTimeOffset to start the presentation of the first Sample (1) of Period. (PresentationTime (1)) is generated, and presentation of the first Sample (1) is started from that time. Subsequently, the CPU of the information processing device 4 similarly generates a presentation start time (PresentationTime (2)) of the next Sample (2), and selects an object to be presented at that time from Sample (1) to Sample (2). Switch to. Thereafter, the switching of Sample presentation is performed in the same manner. In this way, the images of Sample (1), (2),... Are presented without interruption in time.
- the POI is displayed in the lower layer of the MPD Period (T1-T2). Metadata AdaptationSet (T1-T2) is added.
- the POI metadata AdaptationSet (T2-T3) is displayed in a lower hierarchy of the MPD Period (T2-T3). T3) is added.
- FIG. 19 is a diagram illustrating a more specific example of MPD to which an AdaptationSet of POI metadata is added.
- Two Periods are stored in the lower hierarchy. Of the two periods, the first period is defined to start 0 seconds after the start of T0, and the second period is defined to start 100 seconds after the start of T0.
- AdaptationSet for each of video, audio and POI metadata as the second Period AdaptationSet.
- the URL of the first sample of the video is created as “HTTP://a.com/p2/video/512/000001.m4s”.
- the URL of the initialization segment is also generated by connecting the value indicated by “BaseURL” described in each element of the MPD to the path format and adding “IS.mp4” at the end. For example, it is created like “HTTP: //a.com/p2/video/512/IS.mp4”.
- the method for generating the URL indicating the location of the Media Segment of the POI metadata may be the same as the method of generating the URL indicating the location of the Media Segment of the video.
- the method for generating the URL indicating the location of the initialization segment of the POI metadata may be the same as the method for generating the URL indicating the location of the initialization segment of the video.
- the POI metadata initialization segment includes information identifying that the POI metadata is stored as a sample in the media segment.
- the CPU of the information processing apparatus 4 can acquire video, audio, and POI metadata of moving image content in units of Samples based on the URL generated as described above.
- FIG. 20 is a diagram showing a flow of presentation of video and additional images based on MPD.
- the process of presenting each Sample (1), (2), (3) of the video is as described above.
- the CPU of the information processing device 4 performs the presentation start time (PresentationTime) of the first Sample (1) of the video from the presentation start time (PresentationTime) (1) of the first Sample to the next Sample (2).
- additional image presentation processing based on POI metadata (1) is performed.
- the CPU of the information processing device 4 performs the presentation start time (PresentationTime) (3) of the next Sample (3) from the presentation start time (PresentationTime) (2) of the Sample (2) in real time.
- the additional image presentation processing based on the POI metadata (2) is performed, and the actual start time (PresentationTime) (3) of the Sample (2) in real time is updated.
- the additional image presentation processing based on the POI metadata (3) is performed before the presentation start time (PresentationTime) (4).
- the presentation control of the additional image based on the POI metadata is performed for the presentation of other types of media such as video and audio. It can be performed by the same mechanism as the control, and other types of media such as video and audio and the additional image can be accurately synchronized and presented.
- FIG. 21 is a diagram showing POI metadata when the service object in the video moves along the time and the presentation position of the additional image is also moved along with the movement of the service object.
- T1 is an additional image presentation start time based on POI metadata (1)
- T2 is an additional image presentation start time based on POI metadata (2)
- T3 is an additional image presentation time based on POI metadata (3). This is the presentation start time.
- the display position of the additional image is moved in synchronization with the movement of the service object accurately. be able to.
- the POI metadata is associated with each sample video in a one-to-one correspondence control.
- one POI metadata is applied to a plurality of consecutive sample videos. Also good.
- the version information (Version) is added to the value of the identifier (metadataURI) of the POI metadata described in the packages 66, 67, 68 storing the POI metadata files 63, 64, 65. Added.
- this version information is set to the same value as the version information described in the package storing the immediately previous POI metadata. If there is a change in content, it is set to an incremented value.
- the application of the application execution environment 43 performs an operation for presenting an additional image based on POI metadata. If there is no change in the value of each version information, the additional image continues to be presented as it is without performing the calculation for presenting the additional image based on the POI metadata again. Thereby, the calculation load for presentation of an additional image can be reduced.
- the value of the version information added to the identifier (metadataURI) of the POI metadata (1) corresponding to the video of Sample (1) is “1”
- the second Sample (2) The value of the version information added to the identifier (metadataURI) of the POI metadata (2) corresponding to the video is “2”
- the value of the version information added to) is “2”.
- the additional image based on the POI metadata (3) corresponding to the third Sample (3) video is displayed.
- the additional image added to the video of the second Sample (2) is continuously presented to the video of the third Sample (3) without performing any calculation for presentation.
- a media playback unit that acquires and plays back video data including a service object that can use a service that processes a voice request from a user;
- An information processing apparatus comprising: a control unit that adds an additional image for teaching the user of the service object to the reproduced video.
- the additional image has a unique visual feature for each service object so that the service object can be uniquely identified by voice recognition in the service.
- the information processing apparatus configured to limit the service target to which the additional image is added, in accordance with the user or an attribute of the user.
- the information processing apparatus configured to skip and reproduce a video of a period in which the service target object to which the additional image is added appears according to the user or the attribute of the user.
- the information processing apparatus according to any one of (1) to (4), The control unit reproduces a video of a period in which the service object to which the additional image is added according to the user or the attribute of the user appears at a first double speed, and a period in which the service object does not appear.
- An information processing apparatus configured to reproduce a video at a second speed higher than the first double speed.
- the information processing apparatus configured to acquire the metadata for generating the additional information and add the additional information based on the acquired metadata.
- the information processing apparatus configured to acquire the web application for processing the metadata and process the metadata according to the acquired web application.
- the information processing apparatus acquires an MPD file including the AdaptationSet of the metadata, analyzes the MPD file, acquires the video data and the metadata as an MPEG-DASH Media Segment, and the video data, An information processing apparatus configured to present the additional image based on the metadata in synchronization with each other.
- the control unit determines whether there is a change in contents between the front side metadata and the back side metadata that are temporally changed, and if there is no change, the front side metadata
- An information processing apparatus configured to add an additional image added to a video based on data as an additional image based on the rear metadata to a video synchronized with the rear metadata.
- the information processing apparatus according to any one of (1) to (10),
- the visual feature of the additional image is provided by any one of a character string, a color, a shape, or an icon related to the service object.
- the program according to (23), The additional image has a unique visual feature for each service object so that the service object can be uniquely identified by voice recognition in the service.
- the said control part is a program which restrict
- the control unit skips and reproduces a video during a period in which the service object to which the additional image is added according to the user or the attribute of the user appears.
- the program according to any one of (23) to (26), The control unit reproduces a video of a period in which the service object to which the additional image is added according to the user or the attribute of the user appears at a first double speed, and a period in which the service object does not appear.
- the control unit is a program for acquiring metadata for generating the additional information and adding the additional information based on the acquired metadata.
- the control unit determines whether there is a change in contents between the front side metadata and the back side metadata that are temporally changed, and if there is no change, the front side metadata
Abstract
Description
上記付加画像は、上記サービス対象物に付随した位置に提示されてよい。
本実施形態の情報処理装置4は、
ユーザからの音声による要求を処理する音声AIアシスタントサービスを利用可能なサービス対象物を含む映像データを取得して再生するAVデコーダ41と、
前記再生した映像に前記サービス対象物を前記ユーザに教示するための付加画像を付加するアプリケーション実行環境43と、を具備する。
次に、第1の実施形態の情報処理装置4を含む情報処理システム100の構成及びその動作を詳細に説明する。
図1は本技術に係る第1の実施形態の情報処理装置4を含む情報処理システム100の全体構成を示すブロック図である。
同図に示すように、この情報処理システム100は、サーバ群1、放送/ネット配信システム2、音声AIアシスタントサービス端末3、およびユーザの情報処理装置4を含む。
サーバ群1は、動画コンテンツサーバ11、アプリケーションサーバ12、POIメタデータサーバ13、および音声AIアシスタントサービスプログラムサーバ14を含む。
情報処理装置4は、ハードウェア要素として、CPU(Central Processing Unit)と、RAM(Random Access Memory)などのメインメモリと、HDD(Hard Disk Drive)、SSD(Solid State Drive)などのストレージデバイスと、ユーザインタフェースと、アンテナおよび放送チューナなどの放送受信部と、ネットワークインタフェースなどの通信インタフェースとを備える。情報処理装置4は、具体的には、パーソナルコンピュータ、スマートホン、タブレット端末、テレビジョン、ゲーム機、HMD(Head Mounted Display)などのユーザ装着可能形の情報端末などであってよい。
音声AIアシスタントサービス端末3は、情報処理装置4のユーザUに対し、音声によるアシスタントサービスを提供する端末である。音声AIアシスタントサービス端末3は、より具体的には、映像中でユーザUより任意のサービス対象物についての音声によるサービス要求を受け付け、そのサービスを実行し、サービスの実行結果をユーザUに音声などで返すことのできる装置である。ここで、ユーザUからの音声によるサービス要求は例えば質問形式などの言葉により与えられ、サービスの実行結果は例えば回答形式などの合成音声によってユーザUに返される。
図2は、本実施形態の情報処理システム100における全体的動作の流れ(その1)を示すシーケンス図である。
前提として、動画コンテンツのデータ、アプリケーションおよびPOIメタデータがそれぞれ別々のサーバ(動画コンテンツサーバ11、アプリケーションサーバ12、POIメタデータサーバ13)から配信される場合を想定している。
図3は本実施形態の情報処理システム100における全体的動作の流れ(その2)を示すシーケンス図である。
前述の動作の流れ(その1)では、動画コンテンツのデータとPOIメタデータがそれぞれ別々のサーバ(動画コンテンツサーバ11、POIメタデータサーバ13)から情報処理装置4に配信されるため、情報処理装置4において動画コンテンツデータとPOIメタデータとの同期が保証されない。
図4は本実施形態の情報処理システム100における全体的動作の流れ(その3)を示すシーケンス図である。
この動作の流れでは、動画コンテンツサーバ11から情報処理装置4に、動画コンテンツのデータとPOIメタデータとこれを処理するアプリケーションが所定のデータ構造にまとめて配信される場合を想定している。
次に、POIメタデータに基づき生成される付加画像について説明する。
図5は付加画像が重畳された映像の例を示す図である。
同図に示すように、付加画像は、例えば、映像中の音声AIアシスタントサービスのサービス対象物J1、J2、J3にそれぞれ付随した吹き出し51、52、53として提示されてよい。
図6はPOIメタデータの構成を示すブロック図である。
POIメタデータは、POIアイコンイメージ、POI提示色、POI提示位置、POI提示テキスト、POIフィルタリング情報を含む。
<POIIcon iconPng='true'>…(base64エンコードされたpngファイル)…</POIIcon>
<POIIcon iconPngURL='true'>http://…(アイコンpngファイルのURL)…</POIIcon>
<POIColor>...(CSS color code)…</POIColor>
<POITargetContentID URL='http://a.com/番組A.MPD'/>
<POIApplication URL='http://a.com/番組AのためのPOI提示アプリ.html(POI 提示アプリのURL)'/>
<POITimePosition start='P0Y0M0DT1H15M2.000S(開始時刻)'end='P0Y0M0DT1H15M2.500S(終了時刻)'/>
<POISPosition x='345(x 座標ピクセル)'y='567(y 座標ピクセル)'/>
<POIText>…(提示文字列)…</POIText>
<POITargetUser demographicClass='true'>…(ユーザデモグラフィッククラス識別名)…</POITargetUser>
<POITargetUser privateAccount='true'>https://…(サービスのユーザアカウント識別URL等)…</POITargetUser>
上記の実施形態では、動画コンテンツの映像中の音声AIアシスタントサービスのサービス対象物に付加画像を提示することとした。しかしながら、例えば、図7に示すように、一つのシーンに多数のサービス対象物J1-J5が存在する場合にはそれらのサービス対象物J1-J5の数分の付加画像51-55が提示されるため、これらの付加画像51-55によって番組の映像の一部が隠れてしまい、番組映像の見た目が損なわれるおそれがある。
ここで、ステップS401-S405の動作は、図2に示した動作の流れ(その1)のステップS101-S105と同じであるから、説明を省略する。
1.ユーザ判別モジュール47は、カメラで撮像したユーザUの顔画像の解析結果からユーザUの性別や年齢層などの属性を推定し、推定した属性からユーザデモグラフィッククラスを判別する。
2.ユーザ判別モジュール47は、音声AIアシスタントサービス端末3からユーザUへの音声による質問を通して得られた情報を基にユーザUの属性を推定し、ユーザデモグラフィッククラスを判別する。
3.情報処理装置4を使用する複数のユーザが限定されている場合において、各ユーザのユーザ名に対応付けてユーザデモグラフィッククラスの識別名あるいはユーザ識別情報を予め登録しておくことで、ユーザ判別モジュール47は、生体認証、カード認証などの認証を通して確認されたユーザ名から対応するユーザデモグラフィッククラスの識別名あるいはユーザ識別情報を判別することができる。
することができる。
なお、上記の説明では、性別、年齢、住んでいる地域、職業、学歴、家族内属性などの属性からユーザUのユーザデモグラフィッククラスを判別することとしたが、ユーザ判別モジュール47にて、ユーザUの視聴履歴をもとにユーザUの嗜好的な条件を算出し、この嗜好的な条件をもとに、あるいは、この嗜好的な条件を加味して、ユーザデモグラフィッククラスを判別してもよい。
次に、POIメタデータに基づくトリックプレイ再生について説明する。
POIメタデータに基づくトリックプレイ再生とは、ユーザUのユーザデモグラフィッククラスあるいはユーザ識別情報を基に抽出されたPOIメタデータに基づいて付加画像が提示されるシーンについては第1の倍速での再生を行い、その他のシーンについては第1の倍速よりも高速な第2の倍速で再生することを言う。
まず、ユーザ判別モジュール47によってユーザUのユーザデモグラフィッククラスあるいはユーザ識別情報を判別し、アプリケーション実行環境43に供給する。
ここで、サービス対象物である"Bill"と"Sam"のユーザデモグラフィッククラスは"class1"であり、ユーザ判別モジュール47によって判別されたユーザUのユーザデモグラフィッククラスが"class1"であったとする。
図11はPOIメタデータを処理するアプリケーション実行環境43の例を示す図である。
本例では、POIメタデータを処理するアプリケーションが、情報処理装置4のネイティブのオペレーティングシステム48の上で動作するネイティブアプリケーション49である場合を示している。
この例では、POIメタデータを処理するアプリケーションが、ウェブブラウザ56上で動作するウェブアプリケーション57である場合を示している。この場合、POIメタデータとウェブアプリケーション57とが互いに同時あるいは略同時に情報処理装置4に配信される。
情報処理装置4にウェブアプリケーションとPOIメタデータとを同時に配信するために、Multi-part MIME(Multipurpose Internet MAIl Extensions)フォーマットを用いて両者をパッケージングする方法がある。図13はこのウェブアプリケーションとPOIメタデータをパッケージングするMulti-part MIMEフォーマットの例を示す図である。このMulti-part MIMEフォーマットでは、boundary-partによって区切られた各部分にPOIメタデータのファイル61、ウェブアプリケーションのファイル62がそれぞれ個別に格納される。
同図に示すように、Media Segmentは複数のMovie Fragentを有し、各々のMovie Fragentはmoofボックスとmdatボックスで構成される。mdatボックスには、メディアデータが例えばフレームなどの時間の単位で複数のSampleボックスに分割されてランダムアクセス可能に格納される。moofボックスには、mdatボックスの各Sampleボックスのメディアデータを提示するタイミングを生成するための情報など、提示に関するメタデータが格納される。
MPEG-DASHでは、ストリーミング再生が途切れないように、1つの動画コンテンツについて符号化速度と画面サイズが異なる複数のデータ群が用意される。これら複数のデータ群は、情報処理装置4の画面サイズやネットワーク帯域の状態などを考慮して動的に選択される。そのためMPEG-DASHでは、上記のように1つの動画コンテンツについてどのような符号化速度と画面サイズのデータ群が用意されているかがMPD(Media Presentation Description)と呼ばれるメタデータに記述される。
MPDはサーバに格納された動画コンテンツの構成に関する情報をXML(extensible markup language)形式の階層構造で記述したものである。情報処理装置4は、目的の動画コンテンツに対応するMPDファイルをMPDファイルサーバから取得し、解析することによって、サーバから目的の動画コンテンツの提示に必要なMedia Segmentを取得する。
MPDは、その下に1つのPeriodと、その下位に各メディアのタイプごとに一つずつのAdaptationSetと、さらにその下位の複数のRepresentationとを有する。
MPEG-DASHサーバ15には、MPDファイル、および動画コンテンツの各種メディアのMedia Segmentが格納される。
N番目のSampleの提示開始時刻をPresentationTime(N)とすると、PresentationTime(N)は、BaseMediaDecodeTime+(N-1番目までのSample(1),…,(N-1)のSampleDuration(1),…,(N-1)の合計)+(N番目のSampleのCompositionTimeOffset)(N)により算出される。
図17はMPEG-DASH動画コンテンツの提示制御の流れを示す図である。
同図において、横軸は実時間(UTC time)の軸とする。情報処理装置4のCPUは、MPDファイルに定義されたMPDの起点を基準に、PeriodにMPDの起点に対する相対時間として定義された開始時刻をもとに最初のPeriodの実時間上の起点を生成する。
このMPDの最上位階層には@avAIlabilityStartTime=T0と記述されている。これは、動画コンテンツの時間の起点がT0であることを示す。その下位階層には2つのPeriodが格納される。2つのPeriodのうち、最初のPeriodはT0の起点から0sec後に開始され、2番目のPeriodはT0の起点から100sec後に開始されることが定義される。
映像の各Sample(1),(2),(3)を提示する処理は上述したとおりである。
ここで、情報処理装置4のCPUは、映像の最初のSample(1)の実時間上の提示開始時刻(PresentationTime)(1)から次のSample(2)の実時間上の提示開始時刻(PresentationTime)(2)までの間に、POIメタデータ(1)に基づく付加画像の提示処理を行う。この後、情報処理装置4のCPUは、Sample(2)の実時間上の提示開始時刻(PresentationTime)(2)からその次のSample(3)の実時間上の提示開始時刻(PresentationTime)(3)までの間にPOIメタデータ(2)に基づく付加画像の提示処理を行い、さらにSample(2)の実時間上の提示開始時刻(PresentationTime)(3)からその次のSample(3)の実時間上の提示開始時刻(PresentationTime)(4)までの間にPOIメタデータ(3)に基づく付加画像の提示処理を行う。
図21は映像中のサービス対象物が時間に沿って移動する場合にそのサービス対象物の移動に伴って付加画像の提示位置も移動させる場合のPOIメタデータを示す図である。
ここで、T1はPOIメタデータ(1)に基づく付加画像の提示開始時刻、T2はPOIメタデータ(2)に基づく付加画像の提示開始時刻、T3はPOIメタデータ(3)に基づく付加画像の提示開始時刻である。T1-T2はPOIメタデータ(1)に基づく付加画像の提示期間であり、この期間、付加画像は、POIメタデータ(1)中のPOIPosition要素の値(x=x1,y=y1)が示す位置に提示される。T2-T3はPOIメタデータ(2)に基づく付加画像の提示期間であり、この期間、付加画像は、POIメタデータ(2)中のPOIPosition要素の値(x=x2,y=y2)が示す位置に提示される。そしてT3-T4はPOIメタデータ(3)に基づく付加画像の提示期間であり、この期間、付加画像は、POIメタデータ(3)中のPOIPosition要素の値(x=x3,y=y3)が示す位置に提示される。
ここまで、各Sampleの映像にPOIメタデータを1対1に対応付けて付加画像の提示制御が行われる場合を想定したが、1つのPOIメタデータを連続する複数のSampleの映像に適用させてもよい。この場合、図22に示すように、POIメタデータのファイル63、64、65を格納したパッケージ66、67、68に記述されるPOIメタデータの識別子(metadataURI)の値にバージョン情報(Version)が付加される。このバージョン情報は、直前のPOIメタデータに対して内容の変化がない場合には、直前のPOIメタデータを格納したパッケージに記述されるバージョン情報と同じ値とされ、直前のPOIメタデータに対して内容の変化がある場合にはインクリメントされた値に設定される。
(1) ユーザからの音声による要求を処理するサービスを利用可能なサービス対象物を含む映像データを取得して再生するメディア再生部と、
前記再生した映像に前記サービス対象物を前記ユーザに教示するための付加画像を付加する制御部と
を具備する情報処理装置。
前記付加画像は、前記サービス対象物が前記サービスにおいて音声認識によって一意に判別され得るように、前記サービス対象物毎にユニークな視覚的特徴を有する
情報処理装置。
前記付加画像は、前記サービス対象物に付随した位置に提示される
情報処理装置。
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて、前記付加画像が付加される前記サービス対象物を制限するように構成された
情報処理装置。
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像をスキップ再生するように構成された
情報処理装置。
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像を第1の倍速で再生し、前記サービス対象物が登場しない期間の映像を前記第1の倍速よりも高速な第2の速度で再生するように構成された
情報処理装置。
前記制御部は、前記付加情報を生成するためのメタデータを取得し、前記取得したメタデータに基づき前記付加情報を付加するように構成された
情報処理装置。
前記制御部は、前記メタデータを処理するためのウェブアプリケーションを取得し、前記取得したウェブアプリケーションに従って前記メタデータを処理するように構成された
情報処理装置。
前記制御部は、前記メタデータのAdaptationSetを含むMPDファイルを取得し、このMPDファイルを解析して、前記映像データおよび前記メタデータをそれぞれMPEG-DASHのMedia Segmentとして取得し、前記映像データと、前記メタデータに基づく前記付加画像とを互いに同期させて提示するように構成された
情報処理装置。
前記制御部は、前記メタデータのバージョン情報に基づいて、時間的に前後する前側のメタデータと後側のメタデータとの内容の変化の有無を判別し、変化がない場合、前記前側のメタデータに基づき映像に付加した付加画像を、前記後側のメタデータに基づく付加画像として、前記後側のメタデータに同期する映像に付加するように構成された
情報処理装置。
前記付加画像の視覚的特徴が、前記サービス対象物に関する文字列、色、形状、またはアイコンのいずれか1つによって与えられる
情報処理装置。
前記再生した映像に前記サービス対象物を前記ユーザに教示するための付加画像を付加する
情報処理方法。
前記付加画像は、前記サービス対象物が前記サービスにおいて音声認識によって一意に判別され得るように、前記サービス対象物毎にユニークな視覚的特徴を有する
情報処理方法。
前記付加画像は、前記サービス対象物に付随した位置に提示される
情報処理方法。
前記ユーザまたは前記ユーザの属性に応じて、前記付加画像が付加される前記サービス対象物を制限する
情報処理方法。
前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像をスキップ再生する
情報処理方法。
前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像を第1の倍速で再生し、前記サービス対象物が登場しない期間の映像を前記第1の倍速よりも高速な第2の速度で再生する
情報処理方法。
前記付加情報を生成するためのメタデータを取得し、前記取得したメタデータに基づき前記付加情報を付加する
情報処理方法。
前記メタデータを処理するためのウェブアプリケーションを取得し、前記取得したウェブアプリケーションに従って前記メタデータを処理する
情報処理方法。
前記メタデータのAdaptationSetを含むMPDファイルを取得し、このMPDファイルを解析して、前記映像データおよび前記メタデータをそれぞれMPEG-DASHのMedia Segmentとして取得し、前記映像データと、前記メタデータに基づく前記付加画像とを互いに同期させて提示する
情報処理方法。
前記メタデータのバージョン情報に基づいて、時間的に前後する前側のメタデータと後側のメタデータとの内容の変化の有無を判別し、変化がない場合、前記前側のメタデータに基づき映像に付加した付加画像を、前記後側のメタデータに基づく付加画像として、前記後側のメタデータに同期する映像に付加する
情報処理方法。
前記付加画像の視覚的特徴が、前記サービス対象物に関する文字列、色、形状、またはアイコンのいずれか1つによって与えられる
情報処理方法。
前記付加画像は、前記サービス対象物が前記サービスにおいて音声認識によって一意に判別され得るように、前記サービス対象物毎にユニークな視覚的特徴を有する
プログラム。
前記付加画像は、前記サービス対象物に付随した位置に提示される
プログラム。
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて、前記付加画像が付加される前記サービス対象物を制限する
プログラム。
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像をスキップ再生する
プログラム。
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像を第1の倍速で再生し、前記サービス対象物が登場しない期間の映像を前記第1の倍速よりも高速な第2の速度で再生する
プログラム。
前記制御部は、前記付加情報を生成するためのメタデータを取得し、前記取得したメタデータに基づき前記付加情報を付加する
プログラム。
前記制御部は、前記メタデータのバージョン情報に基づいて、時間的に前後する前側のメタデータと後側のメタデータとの内容の変化の有無を判別し、変化がない場合、前記前側のメタデータに基づき映像に付加した付加画像を、前記後側のメタデータに基づく付加画像として、前記後側のメタデータに同期する映像に付加する
プログラム。
前記付加画像の視覚的特徴が、前記サービス対象物に関する文字列、色、形状、またはアイコンのいずれか1つによって与えられる
プログラム。
11…動画コンテンツサーバ
12…アプリケーションサーバ
13…POIメタデータサーバ
41…AVデコーダ
42…POIメタデータ処理モジュール
43…アプリケーション実行環境
44…レンダラ
45…ディスプレイ
46…スピーカ
47…ユーザ判別モジュール
Claims (13)
- ユーザからの音声による要求を処理するサービスを利用可能なサービス対象物を含む映像データを取得して再生するメディア再生部と、
前記再生した映像に前記サービス対象物を前記ユーザに教示するための付加画像を付加する制御部と
を具備する情報処理装置。 - 請求項1に記載の情報処理装置であって、
前記付加画像は、前記サービス対象物が前記サービスにおいて音声認識によって一意に判別され得るように、前記サービス対象物毎にユニークな視覚的特徴を有する
情報処理装置。 - 請求項2に記載の情報処理装置であって、
前記付加画像は、前記サービス対象物に付随した位置に提示される
情報処理装置。 - 請求項3に記載の情報処理装置であって、
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて、前記付加画像が付加される前記サービス対象物を制限するように構成された
情報処理装置。 - 請求項4に記載の情報処理装置であって、
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像をスキップ再生するように構成された
情報処理装置。 - 請求項5に記載の情報処理装置であって、
前記制御部は、前記ユーザまたは前記ユーザの属性に応じて前記付加画像が付加された前記サービス対象物が登場する期間の映像を第1の倍速で再生し、前記サービス対象物が登場しない期間の映像を前記第1の倍速よりも高速な第2の速度で再生するように構成された
情報処理装置。 - 請求項6に記載の情報処理装置であって、
前記制御部は、前記付加情報を生成するためのメタデータを取得し、前記取得したメタデータに基づき前記付加情報を付加するように構成された
情報処理装置。 - 請求項7に記載の情報処理装置であって、
前記制御部は、前記メタデータを処理するためのウェブアプリケーションを取得し、前記取得したウェブアプリケーションに従って前記メタデータを処理するように構成された
情報処理装置。 - 請求項8に記載の情報処理装置であって、
前記制御部は、前記メタデータのAdaptationSetを含むMPDファイルを取得し、このMPDファイルを解析して、前記映像データおよび前記メタデータをそれぞれMPEG-DASHのMedia Segmentとして取得し、前記映像データと、前記メタデータに基づく前記付加画像とを互いに同期させて提示するように構成された
情報処理装置。 - 請求項9に記載の情報処理装置であって、
前記制御部は、前記メタデータのバージョン情報に基づいて、時間的に前後する前側のメタデータと後側のメタデータとの内容の変化の有無を判別し、変化がない場合、前記前側のメタデータに基づき映像に付加した付加画像を、前記後側のメタデータに基づく付加画像として、前記後側のメタデータに同期する映像に付加するように構成された
情報処理装置。 - 請求項2に記載の情報処理装置であって、
前記付加画像の視覚的特徴が、前記サービス対象物に関する文字列、色、形状、またはアイコンのいずれか1つによって与えられる
情報処理装置。 - ユーザからの音声による要求を処理するサービスを利用可能なサービス対象物を含む映像データを取得して再生し、
前記再生した映像に前記サービス対象物を前記ユーザに教示するための付加画像を付加する
情報処理方法。 - ユーザからの音声による要求を処理するサービスを利用可能なサービス対象物を含む映像データを取得して再生するメディア再生部と、
前記再生した映像に前記サービス対象物を前記ユーザに教示するための付加画像を付加する制御部として、
コンピュータを機能させるプログラム。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19767400.5A EP3767964A1 (en) | 2018-03-15 | 2019-03-01 | Information processing device, information processing device, and program |
| CN201980018039.7A CN111837401B (zh) | 2018-03-15 | 2019-03-01 | 信息处理设备、信息处理方法 |
| KR1020207024913A KR102659489B1 (ko) | 2018-03-15 | 2019-03-01 | 정보 처리 장치, 정보 처리 장치 및 프로그램 |
| US16/975,286 US11689776B2 (en) | 2018-03-15 | 2019-03-01 | Information processing apparatus, information processing apparatus, and program |
| JP2020506396A JP7237927B2 (ja) | 2018-03-15 | 2019-03-01 | 情報処理装置、情報処理装置およびプログラム |
| US18/313,259 US20230276105A1 (en) | 2018-03-15 | 2023-05-05 | Information processing apparatus, information processing apparatus, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018048032 | 2018-03-15 | ||
| JP2018-048032 | 2018-03-15 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US16/975,286 A-371-Of-International US11689776B2 (en) | 2018-03-15 | 2019-03-01 | Information processing apparatus, information processing apparatus, and program |
| US18/313,259 Continuation US20230276105A1 (en) | 2018-03-15 | 2023-05-05 | Information processing apparatus, information processing apparatus, and program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019176590A1 true WO2019176590A1 (ja) | 2019-09-19 |
Family
ID=67906666
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/008140 WO2019176590A1 (ja) | 2018-03-15 | 2019-03-01 | 情報処理装置、情報処理装置およびプログラム |
Country Status (6)
| Country | Link |
|---|---|
| US (2) | US11689776B2 (ja) |
| EP (1) | EP3767964A1 (ja) |
| JP (1) | JP7237927B2 (ja) |
| KR (1) | KR102659489B1 (ja) |
| CN (1) | CN111837401B (ja) |
| WO (1) | WO2019176590A1 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002369180A (ja) * | 2001-06-07 | 2002-12-20 | Kyocera Corp | 携帯端末、画像配信サーバ並びに情報表示方法 |
| JP2012249156A (ja) * | 2011-05-30 | 2012-12-13 | Sony Corp | 情報処理装置、情報処理方法、及びプログラム |
| JP2015022310A (ja) | 2013-07-19 | 2015-02-02 | 英奇達資訊股▲ふん▼有限公司 | 音声アシスタントパーソナライズの方法 |
| JP2015154195A (ja) * | 2014-02-13 | 2015-08-24 | Necパーソナルコンピュータ株式会社 | 情報処理装置、情報処理方法、及びプログラム |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0981361A (ja) * | 1995-09-12 | 1997-03-28 | Toshiba Corp | 画像表示方法、データ収集方法及び対象物特定方法 |
| AU2002213071A1 (en) * | 2000-10-11 | 2002-04-22 | United Video Properties, Inc. | Systems and methods for supplementing on-demand media |
| ATE497227T1 (de) * | 2001-08-02 | 2011-02-15 | Intellocity Usa Inc | Nachbereitung von anzeige änderungen |
| US8196168B1 (en) | 2003-12-10 | 2012-06-05 | Time Warner, Inc. | Method and apparatus for exchanging preferences for replaying a program on a personal video recorder |
| JP5331773B2 (ja) * | 2010-10-14 | 2013-10-30 | 株式会社ソニー・コンピュータエンタテインメント | 動画再生装置、情報処理装置および動画再生方法 |
| US20140028780A1 (en) * | 2012-05-31 | 2014-01-30 | Volio, Inc. | Producing content to provide a conversational video experience |
| US8843953B1 (en) * | 2012-06-24 | 2014-09-23 | Time Warner Cable Enterprises Llc | Methods and apparatus for providing parental or guardian control and visualization over communications to various devices in the home |
| US20140089423A1 (en) | 2012-09-27 | 2014-03-27 | United Video Properties, Inc. | Systems and methods for identifying objects displayed in a media asset |
| JP2014230055A (ja) * | 2013-05-22 | 2014-12-08 | ソニー株式会社 | コンテンツ供給装置、コンテンツ供給方法、プログラム、およびコンテンツ供給システム |
| WO2015008538A1 (ja) * | 2013-07-19 | 2015-01-22 | ソニー株式会社 | 情報処理装置および情報処理方法 |
| US9137558B2 (en) * | 2013-11-26 | 2015-09-15 | At&T Intellectual Property I, Lp | Method and system for analysis of sensory information to estimate audience reaction |
| US20160381412A1 (en) * | 2015-06-26 | 2016-12-29 | Thales Avionics, Inc. | User centric adaptation of vehicle entertainment system user interfaces |
| US9883249B2 (en) * | 2015-06-26 | 2018-01-30 | Amazon Technologies, Inc. | Broadcaster tools for interactive shopping interfaces |
| JP6624958B2 (ja) * | 2016-02-03 | 2019-12-25 | キヤノン株式会社 | 通信装置、通信システム、通信制御方法およびコンピュータプログラム |
| US10154293B2 (en) * | 2016-09-30 | 2018-12-11 | Opentv, Inc. | Crowdsourced playback control of media content |
| KR102524180B1 (ko) * | 2017-11-15 | 2023-04-21 | 삼성전자주식회사 | 디스플레이장치 및 그 제어방법 |
-
2019
- 2019-03-01 EP EP19767400.5A patent/EP3767964A1/en active Pending
- 2019-03-01 US US16/975,286 patent/US11689776B2/en active Active
- 2019-03-01 WO PCT/JP2019/008140 patent/WO2019176590A1/ja active Application Filing
- 2019-03-01 CN CN201980018039.7A patent/CN111837401B/zh active Active
- 2019-03-01 JP JP2020506396A patent/JP7237927B2/ja active Active
- 2019-03-01 KR KR1020207024913A patent/KR102659489B1/ko active IP Right Grant
-
2023
- 2023-05-05 US US18/313,259 patent/US20230276105A1/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002369180A (ja) * | 2001-06-07 | 2002-12-20 | Kyocera Corp | 携帯端末、画像配信サーバ並びに情報表示方法 |
| JP2012249156A (ja) * | 2011-05-30 | 2012-12-13 | Sony Corp | 情報処理装置、情報処理方法、及びプログラム |
| JP2015022310A (ja) | 2013-07-19 | 2015-02-02 | 英奇達資訊股▲ふん▼有限公司 | 音声アシスタントパーソナライズの方法 |
| JP2015154195A (ja) * | 2014-02-13 | 2015-08-24 | Necパーソナルコンピュータ株式会社 | 情報処理装置、情報処理方法、及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20200128530A (ko) | 2020-11-13 |
| US11689776B2 (en) | 2023-06-27 |
| US20230276105A1 (en) | 2023-08-31 |
| EP3767964A4 (en) | 2021-01-20 |
| KR102659489B1 (ko) | 2024-04-23 |
| JP7237927B2 (ja) | 2023-03-13 |
| JPWO2019176590A1 (ja) | 2021-03-18 |
| EP3767964A1 (en) | 2021-01-20 |
| CN111837401B (zh) | 2023-10-10 |
| CN111837401A (zh) | 2020-10-27 |
| US20200396516A1 (en) | 2020-12-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11468917B2 (en) | Providing enhanced content | |
| US8776150B2 (en) | Implementation method and system for a media-on-demand frame-spanning playing mode in a peer-to-peer network | |
| US20100169906A1 (en) | User-Annotated Video Markup | |
| JP2018513583A (ja) | オーディオビデオファイルのライブストリーミング方法、システム及びサーバー | |
| CN104065979A (zh) | 一种动态显示和视频内容相关联信息方法及系统 | |
| US20230336842A1 (en) | Information processing apparatus, information processing method, and program for presenting reproduced video including service object and adding additional image indicating the service object | |
| JP2016213709A (ja) | 動画再生システム、クライアント装置、サーバ装置及びプログラム | |
| WO2019176590A1 (ja) | 情報処理装置、情報処理装置およびプログラム | |
| US20090328102A1 (en) | Representative Scene Images | |
| JP2018056811A (ja) | 端末装置、コンテンツ再生システム、コンテンツ再生方法、およびプログラム | |
| US20090307725A1 (en) | Method for providing contents information in vod service and vod system implemented with the same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19767400 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2020506396 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2019767400 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2019767400 Country of ref document: EP Effective date: 20201015 |