WO2017179912A1 - Apparatus and method for three-dimensional information augmented video see-through display, and rectification apparatus - Google Patents
Apparatus and method for three-dimensional information augmented video see-through display, and rectification apparatus Download PDFInfo
- Publication number
- WO2017179912A1 WO2017179912A1 PCT/KR2017/003973 KR2017003973W WO2017179912A1 WO 2017179912 A1 WO2017179912 A1 WO 2017179912A1 KR 2017003973 W KR2017003973 W KR 2017003973W WO 2017179912 A1 WO2017179912 A1 WO 2017179912A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- module
- current
- information
- difference value
- images
- Prior art date
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T19/00—Manipulating 3D models or images for computer graphics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/20—Image signal generators
Definitions
- Embodiments of the present invention relate to a three-dimensional information augmented video see-through display apparatus and method and a rectification apparatus for the same.
- a head mounted display (HMD) device is an image display device that can be worn on a head, such as glasses, to view an image, and is a next generation image display device that is used for viewing a large screen and performing surgery or diagnosis while carrying.
- Conventional HMDs have been used for special purposes such as military and training purposes, but as HMDs become smaller and lighter due to the development of display technology, low-priced HMDs are commercially available. These low-cost HMDs have been used mainly for 3D movie watching until recently, but are actively researching and developing them as visualization devices for virtual reality and augmented reality by doubling the technical characteristics that can provide high immersion.
- HMD Video See-Through Head Mounted Display
- the real world image (real image) acquired through the camera is converted into a digital signal and visualized by HMD. In this way, the user sees the real world in front as a digital image.
- Video see-through HMDs have several benefits. Firstly, information that cannot be seen with the naked eye, such as infrared, ultraviolet, ultrasonic, and electromagnetic waves, can be visually identified using a special camera. In addition, by using the zoom-in function of the camera, a far object can be magnified from several times to several tens of times. In addition, when the fisheye lens is mounted on the camera, the viewing angle may be greatly widened to provide an omnidirectional view.
- the video see-through HMD can store the front view as seen by the user as a stereoscopic image.
- the saved video information can be shared with others through the network, and the user can view it again in the future. This storage of visual experiences allows users to play / share experiences beyond time and space constraints.
- video see-through HMDs provide the ability to protect the user's eyes from the risk of damaging vision, such as sunlight, lasers, dirt, and hazardous materials.
- network means including video see-through HMD, wireless video communications and the Internet
- a visual experience sharing system that can be put to practical use in the near future will be possible. Accordingly, there is a need for a technology development of a smooth information service that enables sharing of visual experiences among these various benefits that can be obtained when using a video see-through HMD.
- An object of the present invention is to generate a three-dimensional image for virtual reality or augmented reality in a video see-through method by processing the three-dimensional image in a module implemented by a hardware chip without the help of a PC from the plurality of camera modules.
- the present invention provides a three-dimensional information enhancement video see-through display device and method.
- an object of the present invention is to reduce the storage space of the breakpoint lookup table by sequentially storing a plurality of breakpoint information for rectification, the empty space on the breakpoint lookup table.
- an object of the present invention is to store the difference value between the next target coordinate and the current target coordinate, which are coordinates to be transformed, in advance in the current coordinate transformation information for rectification, in the breakpoint lookup table. This is to perform redirection by minimizing access.
- the three-dimensional information augmented video see-through display device is a camera interface module for obtaining at least two real images from at least two camera modules, A rectification module that performs rectification, combining the virtual image into each of the at least two real images based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens for the at least two real images Lens distortion compensation module correcting at least two composite images and side by side image processing on at least two composite images to generate a three-dimensional image for virtual reality (VR) or augmented reality (AR). It includes an image generation module for generating.
- VR virtual reality
- AR augmented reality
- the rectification module may be configured to perform coordinate transformation equal to each other among a plurality of pixels included in each of the at least two real images based on the current reference target break point information on a previously stored break point lookup table.
- a current coordinate transformation target pixel group consisting of at least one consecutive pixel required, each of which is determined, and each coordinate coordinate transformation target pixel group includes a current coordinate value including a current difference value that is a difference value from a current target coordinate that is a coordinate to be converted Based on the conversion information, coordinates of each pixel group of the current coordinate conversion target are converted.
- the pre-stored breakpoint lookup table may sequentially store a plurality of breakpoint information in an empty space on the memory, and at least one memory of at least one breakpoint information among the plurality of sequentially stored breakpoint information. More storage address information.
- the current coordinate transformation information may be a next difference that is a difference value with a next target coordinate that is a coordinate to be transformed, respectively, based on the next reference target breakpoint information on the previously stored breakpoint lookup table.
- the difference value between the value and the current difference value is stored in advance.
- the rectification module converts the coordinates of each of the next coordinate conversion target pixel groups based on the difference between the next difference value and the current difference value.
- a differential field which is a field indicating a current difference value, includes at least four bits.
- the three-dimensional information augmented video see-through display device improves image processing reliability for at least two camera modules for taking at least two real images, an infrared camera module for taking infrared images and at least two real images.
- the apparatus may further include a camera calibration module that performs camera calibration on at least two camera modules based on the infrared image.
- the three-dimensional information augmentation video see-through display device is a light detection module for detecting a light position within a certain radius of the current position based on the current position and the direction data for each light based on the current position based on the detected light position.
- the apparatus further includes a spatial generating module for generating a virtual image, wherein the virtual image is input from a computer that is interoperable with the three-dimensional information augmentation video see-through display device and combined with each of at least two real images. Gives an object a shadow effect.
- the light detection module further detects illuminance of each light for each light position, and the computer adjusts a shadow depth of an object in the virtual image based on the detected illuminance when applying a shadow effect.
- the three-dimensional information augmented video see-through display apparatus further includes a microphone module for detecting a sound generated within a predetermined radius based on the current position and a communication module for transmitting the detected sound to a preset sound transmission target.
- the module when there are a plurality of microphone modules, based on azimuth azimuth of each of the plurality of microphone modules, further comprising a sense of space generating module for generating the direction data of the sound sensed by each of the plurality of microphone modules, communication The module further transmits the generated direction data to the sound transmission object.
- the 3D information enhancement video see-through display device further includes a lens distortion compensation lookup table that stores lens distortion compensation values matched for each of the plurality of display devices, and the lens distortion compensation module uses at least two lens distortion compensation lookup tables. The two composite images.
- At least one of the camera interface module, the rectification module, the lens distortion compensation module, and the image generating module is implemented as a hardware chip.
- the three-dimensional information augmented video see-through display method is to obtain at least two real images from at least two camera modules, rectification for at least two real images performing a rectification, based on a lens distortion compensation value representing a value for compensating for distortion of the wide-angle lens for at least two real images, at least two composite images combining the virtual image into each of the at least two real images Correcting and generating a 3D image for virtual reality (VR) or augmented reality (AR) by performing side by side image processing on the at least two composite images.
- VR virtual reality
- AR augmented reality
- the step of performing rectification may include transforming coordinates identical to each other among a plurality of pixels included in each of the at least two real images based on the current reference target break point information on a pre-stored break point lookup table. Determining a current coordinate transformation target pixel group composed of at least one continuous pixel required, and each current coordinate transformation target pixel group including a current difference value that is a difference value from a current target coordinate that is a coordinate to be converted. And converting the coordinates of each pixel group of the current coordinate transformation target based on the current coordinate transformation information.
- the current coordinate transformation information is a difference value from a next target coordinate, which is a coordinate to which each of the next coordinate transformation target pixel groups predetermined based on the next reference target breakpoint information on the pre-stored breakpoint lookup table is converted.
- the difference between the next difference and the current difference is stored in advance.
- the three-dimensional information augmentation video see-through display method detects an illumination position within a predetermined radius based on the current position, and generates directional data for each illumination based on the current position based on the detected illumination position. And applying a shading effect to the object in the virtual image based on the generated direction data.
- the 3D information enhancement video see-through display method may further include storing lens distortion compensation values matched for each of the plurality of display apparatuses in a lens distortion compensation lookup table, and correcting the lens distortion compensation lookup table. And correcting the at least two composite images using.
- a rectification apparatus is a rectification (rectification) for at least two real images and a camera interface module for obtaining at least two real images from at least two camera modules
- a repetition module for performing a) wherein the repetition module includes a plurality of pixels included in each of the at least two actual images based on current reference target break point information on a pre-stored break point lookup table.
- each pixel group of the current coordinate conversion target It converts the coordinates.
- a three-dimensional image for virtual reality or augmented reality in a video see-through method can be generated.
- the processing reliability can be improved.
- rectification may be performed on images captured from a plurality of camera modules to change the plurality of captured images as if they were captured from a camera arranged on the same column. This can provide high quality images.
- the image quality can be improved by adding an opposite distortion to the image incident through the wide-angle lens.
- a virtual image to be combined with a photographed image by detecting a surrounding light position and illumination of each light position through a light sensing module such as a CDS, and using the detection result.
- a light sensing module such as a CDS
- the other party by sensing the surrounding sound and the azimuth angle to which the sound is directed through the microphone module, and using the result of the detection to transmit the sound having a directionality to the other party, the other party to see the atmosphere of the field Make it feel vivid.
- the mounting base may be detachably installed on various display devices through fastening of the mounting base and the cover.
- the storage space of the breakpoint lookup table may be reduced by sequentially storing empty spaces on the breakpoint lookup table for the plurality of breakpoint information for rectification.
- the break point lookup table by previously storing a difference value between a next target coordinate and a current target coordinate, which are coordinates to be transformed, in the current coordinate transformation information for rectification, respectively. This can be done by minimizing access to.
- FIG. 1 is a block diagram illustrating a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
- FIG. 2 is a diagram illustrating an operation of a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
- FIG. 3 is a PCB block diagram illustrating a connection state between a control unit and a peripheral device of a 3D information enhanced video see-through display device according to an embodiment of the present invention.
- 4 to 6 are flowcharts illustrating a three-dimensional information augmentation video seed display method according to an embodiment of the present invention.
- FIG. 7 is a diagram illustrating a structure in which a three-dimensional information augmentation video seed display device according to an embodiment of the present invention is detachably coupled to a display device.
- FIG. 8 is a flowchart illustrating a step of performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
- 9A and 9B are diagrams for explaining a breakpoint lookup table utilized in a conventional rectification algorithm.
- FIGS. 10A and 10B are diagrams for explaining a breakpoint lookup table used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
- 11A and 11B are diagrams for explaining current coordinate transformation information utilized in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
- FIG. 12 is a diagram for explaining a double target field of current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. to be.
- FIG. 13 is a diagram illustrating a differential field of current coordinate transformation information used in performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
- FIG. 14 is a view illustrating a continuous information field defining a next target coordinate among current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. It is a figure shown for description.
- FIG. 1 is a block diagram illustrating a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
- a three-dimensional information augmentation video seed display device 100 may include a camera module 110, a camera interface module 120, a rectification module 130, Lens Distortion Compensation Module 140, Image Generation Module 150, Display Module 160, Camera Calibration Module 170, Light Detection Module 180, Microphone Module 185, Space Creation Module 190 , And the controller 195.
- the camera module 110 may include two camera modules for capturing two actual images. That is, the camera module 110 may include a stereoscopic camera for capturing two actual images, which are images corresponding to the right eye and the left eye of the user. Therefore, the two actual images may be divided into left and right images (some regions overlap) on the basis of the photographing target.
- the actual image may mean a captured image of the visible light region photographed by the two camera modules.
- the camera module 110 may include three camera modules. In this case, two camera modules may be used as the stereo camera, and the other camera module may be used to detect a depth of an image.
- the camera module 110 may include an infrared camera module for capturing infrared images.
- Infrared images can be used to enhance the image processing reliability of two real images when the surroundings are dark. That is, the infrared camera module may be driven together with the stereo camera when the surroundings become dark.
- the camera interface module 120 obtains an image from the camera module 110. That is, the camera interface module 120 obtains two actual images from the stereo camera module consisting of two camera modules. In addition, the camera interface module 120 may obtain three real images from three camera modules, or alternatively, two real images and infrared images from a stereo camera module and an infrared camera module.
- the camera interface module 120 may include an interface selection module (see “210" in FIG. 2) and a color space conversion module (see “220" in FIG. 2).
- the interface selection module selects an interface suitable for the camera in consideration of different interfaces for each camera.
- the color space conversion module converts color signals into other colors, such as converting YUV analog video to digital RGB (red, green, blue) video, converting RGB to CMYK (cyan, magenta, yellow, black), and so on. Do it. That is, the color space conversion module converts an image input through the interface selection module into a format for image processing.
- the rectification module 130 performs rectification on two actual images. That is, the rectification module 130 can change the two actual images as if they were taken from a camera arranged on the same column. For example, the rectification module 130 may make the optical axis and the reference point parallel and intersect at infinity. Accordingly, scene overlap can be maximized, and distortion can be minimized.
- the rectification module 130 may extract a reference point from a chess board or a 3D object.
- the rectification module 130 may perform rectification using epipolar geometry. In this way, the reticulation module 130 may provide a high quality image by correcting the error of the instrument (alignment error of two cameras) with software.
- the rectification module 130 may coordinate the same among the plurality of pixels included in each of the at least two real images based on the current reference target break point information on the prestored break point lookup table.
- the coordinates of each pixel group of the current coordinate transformation target may be converted based on the current coordinate transformation information.
- the lens distortion compensation module 140 combines two composite images by combining virtual images with each of the two real images based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens with respect to the two actual images. Correct the image.
- the lens distortion compensation module 140 is based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens for the two rectified real image, the virtual image in each of the two actual image You can also correct two composite images combining.
- the spectacle display device such as a head mount display (HMD) uses a wide-angle lens to widen the field of view because the gap between the user's eyes and the lens is narrow. At this time, an image incident through the wide-angle lens is distorted (distorted). This will occur. Therefore, in the present exemplary embodiment, the lens distortion compensation module 140 may apply lens distortion compensation values to two composite images to compensate for distortion of the wide-angle lens by applying opposite distortion to an image incident through the wide-angle lens.
- HMD head mount display
- the virtual image may be input from a computer linked with the three-dimensional information augmentation video see-through display device 100 and combined with each of two real images.
- the virtual image refers to a graphic image for providing a virtual reality (VR) or augmented reality (AV).
- the spectacle display device may have a different lens distortion compensation value for each type or model.
- the HMD of the A product may have a greater distortion of the wide-angle lens than the HMD of the B product. That is, corresponding lens distortion compensation values may be different for each of the plurality of video see-through based display devices. Therefore, in the present embodiment, the lens distortion compensation value matched for each of the plurality of video seed-based display devices may be stored in the lens distortion compensation look-up table.
- the lens distortion compensation module 140 may correct two composite images using the lens distortion compensation lookup table.
- the lens distortion compensation module 140 extracts a lens distortion compensation value matched with the corresponding display device from the lens distortion compensation lookup table, and uses the extracted lens distortion compensation value to have two composite images having opposite distortions. You can correct it.
- the image generation module 150 performs side by side image processing on the two composite images to generate a 3D image for the virtual reality (VR) or the augmented reality (AR). That is, the image generating module 150 may generate a 3D image for virtual reality or augmented reality by performing an image processing operation of converting two composite images divided into left and right into one image having the same size.
- VR virtual reality
- AR augmented reality
- the side-by-side image processing is an algorithm for generating a 3D image and may refer to image processing for setting two images to be arranged left and right, and a detailed description thereof will be omitted.
- the display module 160 displays the generated 3D image on the screen. Accordingly, the user can view the 3D image through the screen.
- the display module 160 may not be included in the three-dimensional information augmented video seed display device 100, and may be implemented as an external display device.
- the camera calibration module 170 may perform camera calibration on the two camera modules based on the infrared image in order to improve image processing reliability on the two actual images.
- the image processing reliability of two real images may be improved through the camera calibration module 170.
- the camera calibration module 170 performs camera calibration for two camera modules, that is, stereo cameras, by using an infrared image captured by the infrared camera module when the surroundings become dark, thereby increasing the sharpness of two actual images.
- the image processing reliability thereof can be improved.
- the light detection module 180 may detect a light position within a predetermined radius based on the current position. In addition, the light detection module 180 may further detect the illuminance of each light for each lighting position. That is, the light detection module 180 may detect the illumination position around the user and the illumination intensity of each illumination position. The sensed illumination position and illuminance can be used to add a shadow effect to the virtual image.
- the microphone module 185 may detect a sound generated within a predetermined radius based on the current position. That is, the microphone module 185 may detect sound generated around the user. In this case, a plurality of microphone modules 185 may be provided. In this case, the plurality of microphone modules 185 may have direct azimuth angles. The detected sound may be transmitted to the other party (a preset sound transmission target, for example, the HMD of the other party in a video conference) through a communication module (not shown).
- a preset sound transmission target for example, the HMD of the other party in a video conference
- the sense of space generation module 190 may generate direction data for each illumination based on the current position based on the detected illumination position. Accordingly, the computer may give a shadow effect (shadow) to the object in the virtual image based on the generated direction data. In addition, the computer may adjust the shadow depth of the object in the virtual image based on the sensed illuminance when applying the shadow effect.
- shadow shadow
- the spatial feeling generating module 190 generates direction data of sound detected by each of the plurality of microphone modules 185 based on the direction of azimuth of each of the plurality of microphone modules 185 when there are a plurality of microphone modules 185. can do.
- the generated direction data may be transmitted to the sound transmission target together with the detected sound.
- the controller 195 is a three-dimensional information augmented video seed display device 100 according to an embodiment of the present invention, that is, a camera module 110, a camera interface module 120, a rectification module 130, Lens Distortion Compensation Module 140, Image Generation Module 150, Display Module 160, Camera Calibration Module 170, Light Detection Module 180, Microphone Module 185, Space Creation Module 190 Etc., the overall operation can be controlled.
- the controller 195 may include at least one of the camera interface module 120, the rectification module 130, the lens distortion compensation module 140, and the image generating module 150. It may be implemented as a hardware chip.
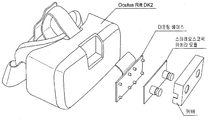
- the 3D information enhancement video seed display device 100 may be combined with a plurality of various display devices.
- the display device may include all of the various video see-through based display devices including the eyeglass display device. Therefore, the 3D information enhancement video seed display device 100 may be detachably coupled to the display device.
- the three-dimensional information augmentation video see-through display device (Stereoscopic Camera Module) 100 is mounted with a mounting base (Mounting base) and a cover (Back), respectively, in a state where the mounting base ( The mounting base may be detachably coupled to various display devices through a method in which the mounting base is detachably attached to the oculus.
- FIG. 2 is a diagram illustrating an operation of a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
- the camera interface module 120 selects an interface suitable for two left and right camera modules 110, CAM CON (L) and CAM CON (R), through the interface selection module 210, and a color space.
- the conversion module 220 converts two actual images captured by the CAM CON (L) and the CAM CON (R) into an image processing format.
- the camera interface module 120 selects an interface suitable for one central camera module 110 CAM CON (C) through the interface selection module 210, and selects the CAM CON () through the color space conversion module 220.
- the image captured by C) can be converted into an image processing format.
- the CAM CON (C) may be an infrared camera module for capturing an infrared image
- the camera calibration module 170 may improve image processing reliability of two actual images by performing a camera calibration using the infrared image. .
- the image passed through the camera interface module 120 is input to the rectification module 130, and the rectification module 130 performs rectification on two actual images.
- the rectified image 230 passed through the rectification module 130 is transmitted to the PC 250 (240), the PC 250 generates a virtual image that is a graphic image to be combined with the Rectified Image (230) .
- the Rectified Image 230 is combined with the Rendered Image 260 from the PC 250 and input to the lens distortion compensation module 140.
- an image combining the Rectified Image 230 and the Rendered Image 260 is defined as a composite image. Therefore, two composite images are input to the lens distortion compensation module 140.
- the two composite images are applied to the image generating module 150 after the opposite distortion is applied through the lens distortion compensation module 140 to be corrected to the same or similar to the actual image.
- the two composite images are image-processed in a side by side manner through the image generating module 150 and converted into one 3D image.
- the three-dimensional image is displayed on the screen through the display module (Oculus Lift / HMD Display) 160, so that the user can display the three-dimensional image for virtual reality (VR) or augmented reality (AV) through the screen of the Oculus Lift or HMD. You will be able to see the image.
- VR virtual reality
- AV augmented reality
- the PC 250 may receive the illumination and direction data for each of the surrounding light through the light detection module 180 and the sense of space generation module 190 to give a shadow effect (shadow) to the object in the virtual image, You can also adjust the shadow depth.
- the virtual image 260 to which the shadow effect is applied may be combined with the Rectified Image 230 and input to the lens distortion compensation module 140.
- the PC 250 may receive the surrounding sound through the microphone module 185 and the space generating module 190 and transmit the ambient sound to the counterpart through a network.
- the PC 250 may receive the direction data of the sound detected by each of the plurality of microphone modules 185 through the sense of space generating module 190 and transmit the received direction data to the counterpart through the network.
- the other party can directly hear the sound around the user, and can also feel the liveliness through the direction of the sound.
- FIG. 3 is a PCB block diagram illustrating a connection state between a control unit and a peripheral device of a 3D information enhanced video see-through display device according to an embodiment of the present invention.
- the controller 195 may be implemented as a field programmable gate array (FPGA).
- Three camera modules 110 may be connected to the controller 195, of which two camera modules (Connector (L) and Connector (R)) 310 and 320 are stereo camera modules and the other one camera module.
- IR sensor (C) 330 is an infrared camera module.
- the control unit 195 is connected to two main memories (main memory, for example, DDR3) 340, which are memory for image processing, and booting memory, which is an OS processing memory in which data for initializing the FPGA is stored.
- Main memory for example, DDR3
- booting memory which is an OS processing memory in which data for initializing the FPGA is stored.
- Memory 350 may be connected.
- the boot memory 350 may be implemented as an SD card.
- the controller 195 may be connected to an HDMI 360 that is an input / output interface for transmitting an actual image to the PC 250 or receiving a virtual image from the PC 250.
- the HDMI 360 may also function as an input / output interface for transmitting the 3D image to the Oculus Rift / HMD for displaying the 3D image.
- the HDMI 360 may be replaced by a wireless module that transmits high resolution video and audio in real time at a short range.
- the control unit 195 may be connected to an ADC 170 that performs analog-to-digital conversion of sensing data sensed by the CDS 180 as a light sensing module and the MIC 185 as a microphone module.
- the controller 195 may be connected to the serial communication module 380 for data initialization (input at the time of setting the keyboard, etc.).
- the control unit 195 may be connected to a GPIO (General Purpose Input / Output) 390 and a SOM Cont. 395 as selectable options.
- GPIO General Purpose Input / Output
- 4 to 6 are flowcharts illustrating a three-dimensional information augmentation video seed display method according to an embodiment of the present invention.
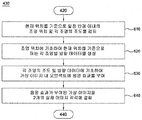
- step 410 the 3D information augmentation video see-through display device obtains two actual images from two camera modules.
- the three-dimensional information augmented video see-through display device obtains two real images from two camera modules (510), then obtains an infrared image from an infrared camera module (520), and then processes the two real images.
- camera calibration may be performed for two camera modules based on the infrared image.
- step 420 the 3D information enhancement video seed display device performs rectification on the two real images.
- step 420 a more detailed description of the step 420 will be described later with reference to FIGS. 8 to 14, and overlapping descriptions are omitted.
- step 430 the three-dimensional information augmented video see-through display device combines the virtual image to each of the two real images to generate two composite images.
- the three-dimensional information augmented video see-through display device detects the illumination position within a predetermined radius and the illumination of each light based on the current position (610), and then each of the illumination based on the current position based on the detected illumination position After generating the directional data (620), a shadow effect may be applied to the object in the virtual image based on the illumination of each light and the directional data for each light (630). Subsequently, the three-dimensional information augmented video see-through display device may combine the virtual image with the shadow effect to each of the two real images (640).
- the 3D video enhancement video see-through display device corrects the two composite images based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens for the two actual images.
- the 3D information augmented video see-through display device performs side by side image processing on the two composite images to perform virtual reality (VR) or augmented reality (AR). Create a three-dimensional image.
- VR virtual reality
- AR augmented reality
- step 460 the display device to which the 3D information-separation video see-through display device is detached and displays the generated 3D image.
- FIGS. 8-14 a step 420 of the redirection module 130 and the three-dimensional information augmentation video seed display method of the three-dimensional information augmentation video seed display device 100 will be described.
- FIG. 8 is a flowchart illustrating a step of performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
- step 420 which is a step of performing rectification on two actual images, is a step of determining a current coordinate transformation target pixel group 810 and a current coordinate transformation, respectively.
- the coordinates of each target pixel group may be converted.
- the rectification module 130 transforms coordinates identical to each other among a plurality of pixels included in each of the at least two real images based on the current reference target break point information on the previously stored break point lookup table. This may mean a step of determining a current coordinate transformation target pixel group including at least one continuous pixel required.
- some of the pixels consecutive to each other in each of the two real images may require the same coordinate transformation.
- the 1st to 3rd pixels may refer to the current coordinate transformation target pixel group, which is a continuous pixel requiring the same coordinate transformation.
- the fourth to eighth pixels may refer to a next coordinate transformation target pixel group that is a continuous pixel requiring the same coordinate transformation.
- break point information information that stores which pixels among consecutive pixels are required to have the same coordinate transformation
- break point information for determining a current coordinate transformation target pixel group may be defined as a break point for the current reference object. Defined as point information.
- a plurality of break point information for distinguishing consecutive pixels requiring the same coordinate transformation among the plurality of pixels included in each of the two actual images may be stored on the break point lookup table.
- 9A and 9B are diagrams for explaining a breakpoint lookup table utilized in a conventional rectification algorithm.
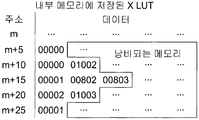
- the conventional break point lookup table may be separately stored for each of the X and Y axis directions.
- the breakpoint information corresponding to the breakpoint information corresponding to each address previously allocated on the internal memory exists. If the corresponding breakpoint information does not exist, the table sets the corresponding address to an empty state.
- break point information is shown in “00000”, “00000”, “01002”, “00001”, “00802”, “00803", “00002”, “01003", “00001” and FIG. 9B shown in FIG. 9A. It may mean “00000”, “00004", "04001”, “04802”, “01803", and "00004" shown.
- the conventional breakpoint lookup table has a problem in that wasted memory occurs when there is no breakpoint information corresponding to a pre-assigned address.
- FIGS. 10A and 10B a breakpoint lookup table used in the step of performing rectification of the 3D information augmentation video seed display method according to an embodiment of the present invention will be described.
- FIGS. 10A and 10B are diagrams for explaining a breakpoint lookup table used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
- the breakpoint lookup table utilized in performing the redirection of the 3D information augmented video see-through display method according to an embodiment of the present invention is similar to the conventional breakpoint lookup table. It may be stored separately for each of the X-axis direction and Y-axis direction.
- the breakpoint lookup table utilized in the step 420 of the present invention sequentially stores a plurality of breakpoint information in an empty space on an internal memory. As shown in each of the boxes of FIGS. 10A and 10B, it may refer to a table that separately stores storage address information on at least one memory for at least one break point information among the plurality of break point information.
- the breakpoint lookup table utilized in the step 420 of the present invention stores the breakpoint information without wasting memory on the internal memory, thereby effectively utilizing the storage space of the internal memory.
- the conventional break point lookup table is compared with the break point lookup table utilized in step 420 of the present invention.
- the storage address information of "00000” which is the break point information of the m + 5th column of FIG. 9A is "0", and the storage address information of "00000” which is the first breakpoint information of the m + 10th column is "1", m
- the storage address information of "01002”, which is the second breakpoint information of the + 10th column, is "2”, and the storage address information of "00001”, which is the first breakpoint information of the m + 15th column, is "3", m + 15
- the storage address information of "00802", the second break point information of the first column, is "4", the storage address information of "00803", the third break point information of the m + 15th column, is "5", and the storage address information of the m + 20th column is "5".
- the storage address information of the first breakpoint information "00002" is “6"
- the storage address information of "01003" which is the second breakpoint information of the m + 20th column is "7”
- the breakpoint of the m + 25th column is defined as "8”, respectively.
- the storage address information of "00000” which is breakpoint information of the n + 5th column shown in FIG. 9B is "0"
- the storage address information of "00004" which is first breakpoint information of the n + 10th column is "1”. If the storage address information of “00004”, which is the first breakpoint information of the n + 15 th column, is defined as “5”, each breakpoint is used in the breakpoint lookup table utilized in the step 420 of the present invention shown in FIG. 10B. After storing the point information "00000”, “00004", “04001”, “04802”, “01803", and "00004" sequentially, the first break point for each row shown in Fig. 9B. The storage address information "0", "1", and "5" corresponding to the information may be separately stored.
- the pre-stored breakpoint lookup table sequentially stores a plurality of breakpoint information in an empty space in the memory, and stores at least one breakpoint information of at least one breakpoint information among the plurality of sequentially stored breakpoint information. You can save more storage address information.
- step 820 which is a step of transforming coordinates of each pixel group of the current coordinate transformation target, is described.
- the rectification module 130 may convert the current coordinate transformation object based on the current coordinate transformation information including a current difference value that is a difference value between the current coordinate transformation target pixel group and the current target coordinate that is a coordinate to be converted. It may mean a step of converting coordinates of each pixel group.
- step 820 the coordinates of the first pixel included in the current coordinate transformation target pixel group are (1,0), the coordinates of the second pixel are (2,0), and the coordinates of the third pixel are (3 , 0), and the current difference value included in the current coordinate transformation information when the first target coordinate is (1,1), the second pixel is (2,1), and the third pixel is (3,1) May mean as much as +1 in the y-axis direction.
- 11A and 11B are diagrams for explaining current coordinate transformation information utilized in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
- the current coordinate conversion information is data composed of 18 bits for each of the X axis direction and the Y axis direction. It is not limited to data.
- the current coordinate transformation information for the X-axis direction includes a double target field including a predetermined number of bits, a differential field including a predetermined number of bits, and It may include a row number field including a predetermined number of bits.
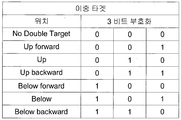
- the dual target field is a field indicating neighboring pixels for interpolating pixel values that are empty when at least two of the pixels included in the current coordinate conversion target pixel group are mapped to the same current target coordinate. It can contain a total of three bits.
- the difference field may mean a field indicating a difference value between a current target coordinate, which is a coordinate to which each of the current coordinate transformation target pixel groups, and a current coordinate transformation target pixel group.
- a differential field which is a field indicating a current difference value, may include at least four bits.
- the difference field includes four bits in total, the difference field is -8 to +7. Since it can be stored, the coordinate transformation of each pixel group of the current coordinate transformation target can be performed in a wider range.
- the horizontal column field is a field for storing coordinate information of pixels included in each pixel group of the current coordinate transformation target, and may include a total of 11 bits.
- the current coordinate transformation information for the Y-axis direction includes a continuous information field including a predetermined number of bits, a differential field including a predetermined number of bits, and It may include a column number field including a preset number of bits.
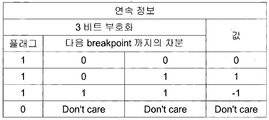
- the continuous information field may include a next difference value and a current coordinate conversion target pixel, which is a difference value from the next target coordinate, which is a coordinate to be transformed, next to the current coordinate conversion target pixel group.
- the continuous information field may store in advance a value of ⁇ 1, which is a difference between a current difference value of +5 and a next difference value of +4.
- information that the next difference value of the next coordinate conversion target pixel group is less than 1 in the X-axis direction than the current difference value of the current coordinate conversion target pixel group may be stored in advance in the current coordinate conversion information.
- the coordinate transformation of the next coordinate transformation target pixel group can be performed based on the difference value between the current difference value of the current coordinate transformation target pixel group and the next difference value of the next coordinate transformation target pixel group without repeatedly accessing the memory. Since it can be, the operation speed is shortened.
- the current coordinate transformation information is a next difference value that is a difference value with a next target coordinate that is a coordinate to which each of the next coordinate transformation target pixel groups determined in advance is based on the next reference target breakpoint information on the previously stored breakpoint lookup table.
- the difference between the current difference and the current difference can be stored in advance.
- the rectification module 130 may convert the coordinates of each of the next coordinate conversion target pixel groups based on the difference between the next difference value and the current difference value.
- FIG. 12 is a diagram for explaining a double target field of current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. to be.
- bit value of 3 bits of the dual target field when the bit value of 3 bits of the dual target field is 0,0,0, this may mean no empty target, and the bit value is 0,0,1. In this case, it may mean that the pixel value of an empty pixel is stored as the pixel value of the Up Forward. If the bit value is 0,1,0, the pixel value of the empty pixel is converted to the pixel value of the Up. If the bit value is 0,1,1, it can mean to save as the pixel value of the upper back. If the bit value is 1,0,0, it is the lower forward. If the bit value is 1,0,1, it means that it is stored as the pixel value of the lower. If the bit value is 1,1,0, it means the lower left. It may mean storing as a pixel value of Backward).
- FIG. 13 is a diagram illustrating a differential field of current coordinate transformation information used in performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
- the difference field when the difference field includes a total of four bits, the difference field is a difference value between a current target coordinate, which is a coordinate at which the current coordinate transformation target pixel group is to be transformed, and a coordinate of a current coordinate transformation target pixel group.
- the current difference value can be stored in the range of -8 to 7.
- each of the plurality of pixels included in the current coordinate conversion pixel group should be coordinate converted in the X axis direction by -2. Can mean.
- -2 corresponding to 1,0,0,1 may mean a current difference value.
- FIG. 14 is a view illustrating a continuous information field defining a next target coordinate among current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. It is a figure shown for description.
- the continuous information field may store in advance a difference value between a current difference value for the current coordinate transformation target pixel group and a next difference value for the next coordinate transformation target pixel group.
- one bit may mean a flag field and the remaining two bits may mean a difference value field.
- the first bit of the difference value field may mean a sign bit and the second bit may mean an absolute value of the difference value.
- the difference between the current difference value and the next difference value may be stored as one of -1, 0, 1, and in this case, the flag field may be set to one value.
- the coordinate conversion of the next coordinate conversion target pixel group can be performed without accessing the memory, and the current difference value and the next difference value If the difference between is less than -1 or greater than 1, the memory must be accessed again to perform coordinate transformation of the next coordinate transformation pixel group.
- the continuous information field includes a total of five bits, a total of three bits remain except for the flag field 1 bit and the sign bit 1 bit, in which case the current information field is presently different.
- the difference between the value and the next difference is 15 in total: -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7.
- the difference value can be stored.
- the difference value between the current difference value and the next difference value is in the range of -7 to 7, the coordinate conversion of the next coordinate transformation target pixel group can be performed without accessing the memory. Only when the difference between the difference value and the next difference value is less than or equal to -7 is greater than 7, the memory is accessed again and the coordinate transformation of the next coordinate transformation target pixel group is performed.
- the lens distortion compensation module 140 may compensate for the lens distortion by using the same algorithm as the rectification module 130 described above.
- the lens distortion compensation module 140 is identical to each other among a plurality of pixels included in each of the at least two actualized images based on the current reference lens distortion compensation breakpoint information on the prestored lens distortion compensation lookup table.
- the coordinates of each pixel group of the current coordinate transformation target may be converted based on the current coordinate transformation information.
- the pre-stored lens distortion compensation lookup table sequentially stores the plurality of lens distortion compensation break point information in an empty space on the memory, and compensates at least one lens distortion of the plurality of sequentially stored lens distortion compensation break point information.
- the storage address information on at least one memory for the break point information may be further stored.
- the current coordinate transformation information may be a difference value from a next target coordinate, which is a coordinate to be transformed with each of the next coordinate transformation target pixel groups determined based on the next reference target lens distortion compensation breakpoint information on the previously stored lens distortion compensation lookup table.
- the difference between the next difference and the current difference can be stored in advance.
- the lens distortion compensation module 140 may convert the coordinates of each of the following coordinate conversion target pixel groups based on the difference between the next difference value and the current difference value.
- the rectification apparatus (not shown) according to an embodiment of the present invention is the camera interface module 120 and the rectification module 130 in the three-dimensional information augmented video see-through display device 100 shown in FIG. ) May mean only a device.
- a rectification apparatus may be directed to a camera interface module 120 that acquires at least two actual images from at least two camera modules and to at least two actual images. It may include a repetition module 130 to perform the application (rectification).
- the rectification module 130 requests the same coordinate transformation among the plurality of pixels included in each of the at least two real images based on the current reference target break point information on the previously stored break point lookup table.
- Embodiments of the invention include a computer readable medium containing program instructions for performing various computer-implemented operations.
- the computer readable medium may include program instructions, local data files, local data structures, or the like, alone or in combination.
- the media may be those specially designed and constructed for the purposes of the present invention, or they may be of the kind well-known and available to those having skill in the computer software arts.
- Examples of computer-readable recording media include magnetic media such as hard disks, floppy disks, and magnetic tape, optical recording media such as CD-ROMs, DVDs, magnetic-optical media such as floppy disks, and ROM, RAM, flash memory, and the like.
- Hardware devices specifically configured to store and execute the same program instructions are included.
- Examples of program instructions include not only machine code generated by a compiler, but also high-level language code that can be executed by a computer using an interpreter or the like.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computer Graphics (AREA)
- Computer Hardware Design (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
- Controls And Circuits For Display Device (AREA)
Abstract
An apparatus for a three-dimensional information augmented video see-through display according to one embodiment of the present invention comprises: a camera interface module for obtaining at least two real images from at least two camera modules; a rectification module for performing rectification for the at least two real images; a lens distortion compensation module for correcting at least two composite images in which a virtual image is combined to each of the at least two real images, on the basis of a lens distortion compensation value representing a value for compensating for the distortion of a wide-angle lens with respect to the at least two real images; and an image generation module for generating a three-dimensional image for a virtual reality (VR) or augmented reality (AR) by performing side-by-side image processing for the at least two composite images.
Description
본 발명의 실시예들은 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치 및 방법과 이를 위한 렉티피케이션 장치에 관한 것이다.Embodiments of the present invention relate to a three-dimensional information augmented video see-through display apparatus and method and a rectification apparatus for the same.
나아가, 본 발명은 2016년 04월 15일 출원된 한국특허출원 제10-2016-0046176호 및 2017년 04월 12일 출원된 한국특허출원 제10-2017-0047277호의 이익을 주장하며, 그 내용 전부는 본 명세서에 포함된다.Furthermore, the present invention claims the benefits of Korean Patent Application No. 10-2016-0046176, filed April 15, 2016 and Korean Patent Application No. 10-2017-0047277, filed April 12, 2017, all of the contents of Is included herein.
헤드 마운티드 디스플레이(Head Mounted Display, 이하 HMD) 장치란, 안경처럼 머리에 쓰고 영상을 볼 수 있는 영상표시 장치로서, 휴대하면서 대형 화면을 보거나 수술이나 진단에 사용하는 차세대 영상표시 장치이다. 종전의 HMD는 군사용, 훈련용 등의 특수한 목적으로 활용되었으나 최근 디스플레이 기술의 발달로 소형화 경량화 되면서 저가의 HMD가 상용화 되고 있는 추세이다. 이러한 저가의 HMD는 최근까지 3D 영화감상 등의 용도로 주로 사용되었으나 고도의 몰입성을 제공할 수 있는 기술적 특성을 배가하여 가상현실, 증강현실의 시각화 장치로 활발한 연구개발이 진행되고 있다.A head mounted display (HMD) device is an image display device that can be worn on a head, such as glasses, to view an image, and is a next generation image display device that is used for viewing a large screen and performing surgery or diagnosis while carrying. Conventional HMDs have been used for special purposes such as military and training purposes, but as HMDs become smaller and lighter due to the development of display technology, low-priced HMDs are commercially available. These low-cost HMDs have been used mainly for 3D movie watching until recently, but are actively researching and developing them as visualization devices for virtual reality and augmented reality by doubling the technical characteristics that can provide high immersion.
비디오 씨쓰루 HMD(Head Mounted Display)는 전방에 카메라가 구비되어 HMD를 통해 실세계를 볼 수 있게 하는 장치이다. 카메라를 통해 취득된 실세계 영상(실제 이미지)을 디지털 신호로 변환하고, 이를 HMD로 가시화하는 것이다. 이렇게 하여 사용자는 전방의 실세계를 디지털 영상으로 보게 된다.Video See-Through Head Mounted Display (HMD) is a device equipped with a camera in front to enable viewing of the real world through the HMD. The real world image (real image) acquired through the camera is converted into a digital signal and visualized by HMD. In this way, the user sees the real world in front as a digital image.
비디오 씨쓰루 HMD는 몇 가지 이익을 가져다 주는데, 첫째로 육안으로 볼 수 없는 정보들 예컨대 적외선, 자외선, 초음파, 전자파 등을 특수 카메라를 이용하여 육안으로 확인할 수 있다. 또한, 카메라의 줌인 기능을 이용하게 되면 원거리의 사물을 수 배에서 수십 배 확대하여 볼 수도 있다. 또한, 카메라에 어안렌즈를 장착하게 되면 시야각을 크게 넓혀 전방위의 시야를 제공할 수도 있다.Video see-through HMDs have several benefits. Firstly, information that cannot be seen with the naked eye, such as infrared, ultraviolet, ultrasonic, and electromagnetic waves, can be visually identified using a special camera. In addition, by using the zoom-in function of the camera, a far object can be magnified from several times to several tens of times. In addition, when the fisheye lens is mounted on the camera, the viewing angle may be greatly widened to provide an omnidirectional view.
둘째로, 비디오 씨쓰루 HMD는 사용자가 보고 있는 전방의 시야를 그대로 입체 영상으로 저장할 수 있다. 이렇게 저장된 영상 정보는 네트워크를 통해 타인과 공유할 수 있고 사용자 본인이 향후에 다시 보기 할 수 있다. 이러한 시각적 경험의 저장을 통해 사용자는 시간과 공간에 제약을 뛰어 넘어 경험을 재생/공유 할 수 있다.Second, the video see-through HMD can store the front view as seen by the user as a stereoscopic image. The saved video information can be shared with others through the network, and the user can view it again in the future. This storage of visual experiences allows users to play / share experiences beyond time and space constraints.
셋째로, 비디오 씨쓰루 HMD는 태양광, 레이저, 오물, 위해 물질 등 시각을 손상시킬 수 있는 위험으로부터 사용자의 눈을 보호하는 기능을 제공하기도 한다. 비디오 씨쓰루 HMD와 무선 영상통신 그리고 인터넷을 포함하는 네트워크 수단을 활용한 새로운 정보 서비스를 제공함으로써 가까운 미래에 실용화 가능한 시각경험 공유 시스템이 가능할 것이다. 따라서, 비디오 씨쓰루 HMD를 이용할 경우에 얻을 수 있는 이러한 다양한 이익들 중에서 시각적 경험의 공유를 가능하게 하는 매끄러운 정보 서비스의 기술 개발이 요구된다.Third, video see-through HMDs provide the ability to protect the user's eyes from the risk of damaging vision, such as sunlight, lasers, dirt, and hazardous materials. By providing new information services using network means, including video see-through HMD, wireless video communications and the Internet, a visual experience sharing system that can be put to practical use in the near future will be possible. Accordingly, there is a need for a technology development of a smooth information service that enables sharing of visual experiences among these various benefits that can be obtained when using a video see-through HMD.
이와 관련하여, 발명의 명칭이 "비드오 씨쓰루 헤드 마운티드 디스플레이 영상 컨텐츠 운용 방법 및 시스템"인 한국 공개특허공보 제10-2015-0044488호가 존재한다.In this regard, there is a Korean Patent Laid-Open Publication No. 10-2015-0044488 entitled "Video O-Through Head Mounted Display Image Content Operation Method and System".
본 발명의 목적은 복수의 카메라 모듈로부터 획득된 영상을 PC의 도움 없이 하드웨어 칩으로 구현된 모듈에서 3차원 영상 처리함으로써, 비디오 씨쓰루 방식으로 가상현실 또는 증강현실을 위한 3차원 영상을 생성할 수 있는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치 및 방법을 제공하기 위함이다.An object of the present invention is to generate a three-dimensional image for virtual reality or augmented reality in a video see-through method by processing the three-dimensional image in a module implemented by a hardware chip without the help of a PC from the plurality of camera modules. The present invention provides a three-dimensional information enhancement video see-through display device and method.
또한, 본 발명의 목적은 렉티피케이션(rectification)을 위한 복수의 브레이크 포인트 정보를 브레이크 포인트 룩업 테이블 상에서 비어있는 공간이 순차적으로 저장함으로써, 브레이크 포인트 룩업 테이블의 저장공간을 감소시키기 위함이다.In addition, an object of the present invention is to reduce the storage space of the breakpoint lookup table by sequentially storing a plurality of breakpoint information for rectification, the empty space on the breakpoint lookup table.
더 나아가, 본 발명의 목적은 렉티피케이션을 위한 현재 좌표 변환 정보에 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와 현재 대상 좌표 간의 차분값을 미리 저장함으로써, 브레이크 포인트 룩업 테이블에 접근을 최소화하여 렉티피케이션을 수행하기 위함이다.Furthermore, an object of the present invention is to store the difference value between the next target coordinate and the current target coordinate, which are coordinates to be transformed, in advance in the current coordinate transformation information for rectification, in the breakpoint lookup table. This is to perform redirection by minimizing access.
본 발명이 해결하고자 하는 과제는 이상에서 언급한 과제(들)로 제한되지 않으며, 언급되지 않은 또 다른 과제(들)은 아래의 기재로부터 당업자에게 명확하게 이해될 수 있을 것이다.The problem to be solved by the present invention is not limited to the problem (s) mentioned above, and other object (s) not mentioned will be clearly understood by those skilled in the art from the following description.
상기한 목적을 달성하기 위하여, 본 발명의 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 카메라 인터페이스 모듈, 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 렉티피케이션 모듈, 적어도 2개의 실제 이미지에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 적어도 2개의 실제 이미지 각각에 가상 이미지를 결합한 적어도 2개의 합성 이미지를 보정하는 렌즈 왜곡 보상 모듈 및 적어도 2개의 합성 이미지에 대해 사이드 바이 사이드(side by side) 영상 처리를 수행하여 가상현실(VR) 또는 증강현실(AR)을 위한 3차원 이미지를 생성하는 이미지 생성 모듈을 포함한다.In order to achieve the above object, the three-dimensional information augmented video see-through display device according to an embodiment of the present invention is a camera interface module for obtaining at least two real images from at least two camera modules, A rectification module that performs rectification, combining the virtual image into each of the at least two real images based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens for the at least two real images Lens distortion compensation module correcting at least two composite images and side by side image processing on at least two composite images to generate a three-dimensional image for virtual reality (VR) or augmented reality (AR). It includes an image generation module for generating.
일 실시예에 따르면, 렉티피케이션 모듈은, 미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고, 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환한다.According to an embodiment of the present disclosure, the rectification module may be configured to perform coordinate transformation equal to each other among a plurality of pixels included in each of the at least two real images based on the current reference target break point information on a previously stored break point lookup table. A current coordinate transformation target pixel group consisting of at least one consecutive pixel required, each of which is determined, and each coordinate coordinate transformation target pixel group includes a current coordinate value including a current difference value that is a difference value from a current target coordinate that is a coordinate to be converted Based on the conversion information, coordinates of each pixel group of the current coordinate conversion target are converted.
예를 들면, 미리 저장된 브레이크 포인트 룩업 테이블은, 복수의 브레이크 포인트 정보를 메모리 상에서 비어있는 공간에 순차적으로 저장하며, 순차적으로 저장된 복수의 브레이크 포인트 정보 중 적어도 하나의 브레이크 포인트 정보에 대한 적어도 하나의 메모리 상의 저장 주소 정보를 더 저장한다.For example, the pre-stored breakpoint lookup table may sequentially store a plurality of breakpoint information in an empty space on the memory, and at least one memory of at least one breakpoint information among the plurality of sequentially stored breakpoint information. More storage address information.
예를 들어, 현재 좌표 변환 정보는, 미리 저장된 브레이크 포인트 룩업 테이블 상의 다음 참조 대상 브레이크 포인트 정보에 기초하여 미리 결정된 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 상기 현재 차분값 간의 차이값을 미리 저장한다.For example, the current coordinate transformation information may be a next difference that is a difference value with a next target coordinate that is a coordinate to be transformed, respectively, based on the next reference target breakpoint information on the previously stored breakpoint lookup table. The difference value between the value and the current difference value is stored in advance.
예컨대, 렉티피케이션 모듈은, 다음 차분값과 현재 차분값 간의 차이값에 기초하여 다음 좌표 변환 대상 픽셀군 각각의 좌표를 변환한다.For example, the rectification module converts the coordinates of each of the next coordinate conversion target pixel groups based on the difference between the next difference value and the current difference value.
일 실시예에 따라, 적어도 2개의 카메라 모듈이 각각 어안렌즈 카메라인 경우, 현재 차분값을 나타내는 필드인 차분 필드(differential field)는 적어도 4개의 비트를 포함한다.According to an embodiment, when the at least two camera modules are each fisheye lens cameras, a differential field, which is a field indicating a current difference value, includes at least four bits.
일 실시예에 따르면, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 적어도 2개의 실제 이미지를 촬영하는 적어도 2개의 카메라 모듈, 적외선 이미지를 촬영하는 적외선 카메라 모듈 및 적어도 2개의 실제 이미지에 대한 영상 처리 신뢰도를 향상시키기 위해, 적외선 이미지에 기초하여 적어도 2개의 카메라 모듈에 대한 카메라 캘리브레이션을 수행하는 카메라 캘리브레이션 모듈을 더 포함한다.According to one embodiment, the three-dimensional information augmented video see-through display device improves image processing reliability for at least two camera modules for taking at least two real images, an infrared camera module for taking infrared images and at least two real images. The apparatus may further include a camera calibration module that performs camera calibration on at least two camera modules based on the infrared image.
예를 들어, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 현재 위치를 기준으로 일정 반경 이내의 조명 위치를 감지하는 조명 감지 모듈 및 감지된 조명 위치에 기초하여 현재 위치를 기준으로 하는 각 조명별 방향 데이터를 생성하는 공간감 생성 모듈을 더 포함하며, 가상 이미지는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치와 연동하는 컴퓨터로부터 입력되어 적어도 2개의 실제 이미지 각각과 결합되며, 컴퓨터는 생성된 방향 데이터에 기초하여 가상 이미지 내 오브젝트에 음영 효과를 부여한다.For example, the three-dimensional information augmentation video see-through display device is a light detection module for detecting a light position within a certain radius of the current position based on the current position and the direction data for each light based on the current position based on the detected light position. The apparatus further includes a spatial generating module for generating a virtual image, wherein the virtual image is input from a computer that is interoperable with the three-dimensional information augmentation video see-through display device and combined with each of at least two real images. Gives an object a shadow effect.
예를 들어, 조명 감지 모듈은 조명 위치별로 각 조명의 조도를 더 감지하고, 컴퓨터는 음영 효과의 부여 시, 감지된 조도에 기초하여 가상 이미지 내 오브젝트의 음영 깊이를 조절한다.For example, the light detection module further detects illuminance of each light for each light position, and the computer adjusts a shadow depth of an object in the virtual image based on the detected illuminance when applying a shadow effect.
예컨대, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 현재 위치를 기준으로 일정 반경 이내에서 발생된 소리를 감지하는 마이크 모듈 및 감지된 소리를 미리 설정된 소리 전송 대상에게 전송하는 통신 모듈을 더 포함한다.For example, the three-dimensional information augmented video see-through display apparatus further includes a microphone module for detecting a sound generated within a predetermined radius based on the current position and a communication module for transmitting the detected sound to a preset sound transmission target.
일 실시예에 따라, 마이크 모듈이 복수개인 경우, 복수개의 마이크 모듈 각각의 지향 방위각에 기초하여, 복수개의 마이크 모듈 각각에 의해 감지된 소리의 방향 데이터를 생성하는 공간감 생성 모듈을 더 포함하고, 통신 모듈은 생성된 방향 데이터를 소리 전송 대상에게 더 전송한다.According to one embodiment, when there are a plurality of microphone modules, based on azimuth azimuth of each of the plurality of microphone modules, further comprising a sense of space generating module for generating the direction data of the sound sensed by each of the plurality of microphone modules, communication The module further transmits the generated direction data to the sound transmission object.
예컨대, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 복수의 디스플레이 장치별로 매칭되는 렌즈 왜곡 보상 값을 저장하는 렌즈 왜곡 보상 룩업 테이블을 더 포함하고, 렌즈 왜곡 보상 모듈은 렌즈 왜곡 보상 룩업 테이블을 이용하여 적어도 2개의 합성 이미지를 보정한다.For example, the 3D information enhancement video see-through display device further includes a lens distortion compensation lookup table that stores lens distortion compensation values matched for each of the plurality of display devices, and the lens distortion compensation module uses at least two lens distortion compensation lookup tables. The two composite images.
일 실시예에 따라, 카메라 인터페이스 모듈, 렉티피케이션 모듈, 렌즈 왜곡 보상 모듈, 및 이미지 생성 모듈 중 적어도 하나는 하드웨어 칩으로 구현된다.According to an embodiment, at least one of the camera interface module, the rectification module, the lens distortion compensation module, and the image generating module is implemented as a hardware chip.
상기한 목적을 달성하기 위하여 본 발명의 실시예에 따른, 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법은 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 단계, 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 단계, 적어도 2개의 실제 이미지에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 적어도 2개의 실제 이미지 각각에 가상 이미지를 결합한 적어도 2개의 합성 이미지를 보정하는 단계 및 적어도 2개의 합성 이미지에 대해 사이드 바이 사이드(side by side) 영상 처리를 수행하여 가상현실(VR) 또는 증강현실(AR)을 위한 3차원 이미지를 생성하는 단계를 포함한다.According to an embodiment of the present invention, in order to achieve the above object, the three-dimensional information augmented video see-through display method is to obtain at least two real images from at least two camera modules, rectification for at least two real images performing a rectification, based on a lens distortion compensation value representing a value for compensating for distortion of the wide-angle lens for at least two real images, at least two composite images combining the virtual image into each of the at least two real images Correcting and generating a 3D image for virtual reality (VR) or augmented reality (AR) by performing side by side image processing on the at least two composite images.
예를 들어, 렉티피케이션을 수행하는 단계는, 미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하는 단계 및 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계를 포함한다.For example, the step of performing rectification may include transforming coordinates identical to each other among a plurality of pixels included in each of the at least two real images based on the current reference target break point information on a pre-stored break point lookup table. Determining a current coordinate transformation target pixel group composed of at least one continuous pixel required, and each current coordinate transformation target pixel group including a current difference value that is a difference value from a current target coordinate that is a coordinate to be converted. And converting the coordinates of each pixel group of the current coordinate transformation target based on the current coordinate transformation information.
일 실시예에 따르면, 현재 좌표 변환 정보는, 미리 저장된 브레이크 포인트 룩업 테이블 상의 다음 참조 대상 브레이크 포인트 정보에 기초하여 미리 결정된 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 현재 차분값 간의 차이값을 미리 저장한다.According to an embodiment, the current coordinate transformation information is a difference value from a next target coordinate, which is a coordinate to which each of the next coordinate transformation target pixel groups predetermined based on the next reference target breakpoint information on the pre-stored breakpoint lookup table is converted. The difference between the next difference and the current difference is stored in advance.
예를 들어, 렉티피케이션(rectification)을 수행하는 단계는, 다음 차분값과 현재 차분값 간의 차이값에 기초하여 다음 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계를 포함한다.For example, the step of performing rectification may include converting coordinates of each of the next coordinate transformation target pixel groups based on a difference value between a next difference value and a current difference value.
예를 들어, 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법은 현재 위치를 기준으로 일정 반경 이내의 조명 위치를 감지하는 단계, 감지된 조명 위치에 기초하여 현재 위치를 기준으로 하는 각 조명별 방향 데이터를 생성하는 단계 및 생성된 방향 데이터에 기초하여 가상 이미지 내 오브젝트에 음영 효과를 부여하는 단계를 더 포함한다.For example, the three-dimensional information augmentation video see-through display method detects an illumination position within a predetermined radius based on the current position, and generates directional data for each illumination based on the current position based on the detected illumination position. And applying a shading effect to the object in the virtual image based on the generated direction data.
일 실시예에 따라, 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법은 복수의 디스플레이 장치별로 매칭되는 렌즈 왜곡 보상 값을 렌즈 왜곡 보상 룩업 테이블에 저장하는 단계를 더 포함하고, 보정하는 단계는 렌즈 왜곡 보상 룩업 테이블을 이용하여 상기 적어도 2개의 합성 이미지를 보정하는 단계를 포함한다.According to an embodiment, the 3D information enhancement video see-through display method may further include storing lens distortion compensation values matched for each of the plurality of display apparatuses in a lens distortion compensation lookup table, and correcting the lens distortion compensation lookup table. And correcting the at least two composite images using.
상기한 목적을 달성하기 위하여, 본 발명의 실시예에 따른 렉티피케이션 장치는 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 카메라 인터페이스 모듈 및 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 렉티피케이션 모듈을 포함하며, 렉티피케이션 모듈은, 미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고, 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환한다.In order to achieve the above object, a rectification apparatus according to an embodiment of the present invention is a rectification (rectification) for at least two real images and a camera interface module for obtaining at least two real images from at least two camera modules A repetition module for performing a), wherein the repetition module includes a plurality of pixels included in each of the at least two actual images based on current reference target break point information on a pre-stored break point lookup table. Determine a current coordinate transformation target pixel group composed of at least one consecutive pixel requiring the same coordinate transformation, and each include a difference value with the current target coordinate that is a coordinate to be converted. Based on the current coordinate conversion information, each pixel group of the current coordinate conversion target It converts the coordinates.
기타 실시예들의 구체적인 사항들은 상세한 설명 및 첨부 도면들에 포함되어 있다.Specific details of other embodiments are included in the detailed description and the accompanying drawings.
본 발명의 일 실시예에 따르면, 복수의 카메라 모듈로부터 획득된 영상을 PC의 도움 없이 하드웨어 칩으로 구현된 모듈에서 3차원 영상 처리함으로써, 비디오 씨쓰루 방식으로 가상현실 또는 증강현실을 위한 3차원 영상을 생성할 수 있다.According to an embodiment of the present invention, by processing a three-dimensional image in a module implemented by a hardware chip without the help of a PC, the image obtained from the plurality of camera modules, a three-dimensional image for virtual reality or augmented reality in a video see-through method Can be generated.
본 발명의 일 실시예에 따르면, 사용자 주변이 어두울 때 적외선 카메라 모듈에 의해 촬영된 적외선 이미지를 이용하여 스테레오 카메라에 대한 카메라 캘리브레이션을 수행함으로써, 스테레오 카메라에 의해 촬영된 이미지의 선명도를 높여 그에 대한 영상 처리 신뢰도를 향상시킬 수 있다.According to an embodiment of the present invention, by performing a camera calibration for the stereo camera using the infrared image captured by the infrared camera module when the user's surroundings are dark, to increase the sharpness of the image taken by the stereo camera image The processing reliability can be improved.
본 발명의 일 실시예에 따르면, 복수의 카메라 모듈로부터 촬영된 이미지에 대해 렉티피케이션(rectification)을 수행하여 복수의 촬영 이미지가 동일한 행(column)상에 정렬된 카메라로부터 촬영된 것처럼 바꿀 수 있으며, 이를 통해 질 높은 영상을 제공할 수 있다.According to an embodiment of the present invention, rectification may be performed on images captured from a plurality of camera modules to change the plurality of captured images as if they were captured from a camera arranged on the same column. This can provide high quality images.
본 발명의 일 실시예에 따르면, 복수의 비디오 씨쓰루 디스플레이 장치별로 광각 렌즈의 왜형 정도가 다른 점을 고려하여, 렌즈 왜곡 보상 룩업 테이블을 이용하여 각 디스플레이 장치별로 광각 렌즈의 렌즈 왜곡을 보정함으로써, 광각 렌즈를 통해 입사된 영상에 반대 왜형을 가한 효과를 주어 영상 품질을 향상시킬 수 있다.According to an embodiment of the present invention, by considering the distortion of the wide-angle lens for each of the plurality of video see-through display device, by correcting the lens distortion of the wide-angle lens for each display device using a lens distortion compensation lookup table, The image quality can be improved by adding an opposite distortion to the image incident through the wide-angle lens.
본 발명의 일 실시예에 따르면, CDS와 같은 조명 감지 모듈을 통해 주변의 조명 위치 및 각 조명 위치별 조명의 조도를 감지하고, 그 감지 결과를 이용하여 촬영 이미지(실제 이미지)와 결합될 가상 이미지에 음영 효과를 부여함으로써 보다 생동감 있는 3차원 이미지를 생성할 수 있다.According to an embodiment of the present invention, a virtual image to be combined with a photographed image (actual image) by detecting a surrounding light position and illumination of each light position through a light sensing module such as a CDS, and using the detection result. You can create a more vibrant three-dimensional image by adding a shading effect to it.
본 발명의 일 실시예에 따르면, 마이크 모듈을 통해 주변의 소리와 그 소리가 지향하는 방위각을 감지하고, 그 감지 결과를 이용하여 방향성을 가지는 소리를 상대방에게 전달함으로써, 상대방이 현장의 분위기를 보다 생생하게 느낄 수 있도록 한다.According to an embodiment of the present invention, by sensing the surrounding sound and the azimuth angle to which the sound is directed through the microphone module, and using the result of the detection to transmit the sound having a directionality to the other party, the other party to see the atmosphere of the field Make it feel vivid.
본 발명의 일 실시예에 따르면, 마운팅 베이스와 커버와의 체결을 통해 다양한 디스플레이 장치에 탈부착 가능하게 설치될 수 있다.According to an embodiment of the present invention, the mounting base may be detachably installed on various display devices through fastening of the mounting base and the cover.
본 발명의 일 실시예에 따르면, 렉티피케이션(rectification)을 위한 복수의 브레이크 포인트 정보를 브레이크 포인트 룩업 테이블 상에서 비어있는 공간이 순차적으로 저장함으로써, 브레이크 포인트 룩업 테이블의 저장공간을 감소시킬 수 있다.According to an embodiment of the present invention, the storage space of the breakpoint lookup table may be reduced by sequentially storing empty spaces on the breakpoint lookup table for the plurality of breakpoint information for rectification.
본 발명의 일 실시예에 따르면, 렉티피케이션을 위한 현재 좌표 변환 정보에 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와 현재 대상 좌표 간의 차분값을 미리 저장함으로써, 브레이크 포인트 룩업 테이블에 접근을 최소화하여 렉티피케이션을 수행할 수 있다.According to one embodiment of the present invention, the break point lookup table by previously storing a difference value between a next target coordinate and a current target coordinate, which are coordinates to be transformed, in the current coordinate transformation information for rectification, respectively. This can be done by minimizing access to.
도 1은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치를 설명하기 위해 도시한 블록도이다.1 is a block diagram illustrating a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
도 2는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치의 동작을 설명하기 위해 도시한 도면이다.2 is a diagram illustrating an operation of a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
도 3은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치의 제어부와 주변 장치 간의 접속 상태를 도시한 PCB 블록도이다.FIG. 3 is a PCB block diagram illustrating a connection state between a control unit and a peripheral device of a 3D information enhanced video see-through display device according to an embodiment of the present invention.
도 4 내지 도 6은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법을 설명하기 위해 도시한 흐름도이다.4 to 6 are flowcharts illustrating a three-dimensional information augmentation video seed display method according to an embodiment of the present invention.
도 7은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치가 디스플레이 장치에 탈부착 가능하게 결합되는 구조를 도시한 도면이다.FIG. 7 is a diagram illustrating a structure in which a three-dimensional information augmentation video seed display device according to an embodiment of the present invention is detachably coupled to a display device.
도 8은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계를 설명하기 위해 도시한 흐름도이다.8 is a flowchart illustrating a step of performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
도 9a 및 도 9b는 종래의 렉티피케이션 알고리즘에서 활용되는 브레이크 포인트 룩업 테이블을 설명하기 위해 도시한 도면이다.9A and 9B are diagrams for explaining a breakpoint lookup table utilized in a conventional rectification algorithm.
도 10a 및 도 10b는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 브레이크 포인트 룩업 테이블을 설명하기 위해 도시한 도면이다.10A and 10B are diagrams for explaining a breakpoint lookup table used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
도 11a 및 도 11b는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보를 설명하기 위해 도시한 도면이다.11A and 11B are diagrams for explaining current coordinate transformation information utilized in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
도 12는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보 중 이중 타겟 필드(double target field)를 설명하기 위해 도시한 도면이다.FIG. 12 is a diagram for explaining a double target field of current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. to be.
도 13은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보 중 차분 필드(differential field)를 설명하기 위해 도시한 도면이다.FIG. 13 is a diagram illustrating a differential field of current coordinate transformation information used in performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
도 14는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보 중 다음 대상 좌표를 정의하는 연속 정보 필드(consecutive information field)를 설명하기 위해 도시한 도면이다.FIG. 14 is a view illustrating a continuous information field defining a next target coordinate among current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. It is a figure shown for description.
본 발명의 이점 및/또는 특징, 그리고 그것들을 달성하는 방법은 첨부되는 도면과 함께 상세하게 후술되어 있는 실시예들을 참조하면 명확해질 것이다. 그러나, 본 발명은 이하에서 개시되는 실시예들에 한정되는 것이 아니라 서로 다른 다양한 형태로 구현될 것이며, 단지 본 실시예들은 본 발명의 개시가 완전하도록 하며, 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 발명의 범주를 완전하게 알려주기 위해 제공되는 것이며, 본 발명은 청구항의 범주에 의해 정의될 뿐이다. 명세서 전체에 걸쳐 동일 참조 부호는 동일 구성요소를 지칭한다.Advantages and / or features of the present invention and methods for achieving them will become apparent with reference to the embodiments described below in detail in conjunction with the accompanying drawings. However, the present invention is not limited to the embodiments disclosed below, but may be implemented in various different forms, only the present embodiments to make the disclosure of the present invention complete, and common knowledge in the art to which the present invention pertains. It is provided to fully inform the person having the scope of the invention, which is defined only by the scope of the claims. Like reference numerals refer to like elements throughout.
이하에서는 첨부된 도면을 참조하여 본 발명의 실시예들을 상세히 설명하기로 한다.Hereinafter, with reference to the accompanying drawings will be described embodiments of the present invention;
도 1은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치를 설명하기 위해 도시한 블록도이다.1 is a block diagram illustrating a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
도 1을 참조하면, 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)는 카메라 모듈(110), 카메라 인터페이스 모듈(120), 렉티피케이션(rectification) 모듈(130), 렌즈 왜곡 보상 모듈(140), 이미지 생성 모듈(150), 디스플레이 모듈(160), 카메라 캘리브레이션(calibration) 모듈(170), 조명 감지 모듈(180), 마이크 모듈(185), 공간감 생성 모듈(190), 및 제어부(195)를 포함할 수 있다.Referring to FIG. 1, a three-dimensional information augmentation video seed display device 100 according to an embodiment of the present invention may include a camera module 110, a camera interface module 120, a rectification module 130, Lens Distortion Compensation Module 140, Image Generation Module 150, Display Module 160, Camera Calibration Module 170, Light Detection Module 180, Microphone Module 185, Space Creation Module 190 , And the controller 195.
카메라 모듈(110)은 2개의 실제 이미지를 촬영하기 위한 2개의 카메라 모듈을 포함할 수 있다. 즉, 카메라 모듈(110)은 사용자의 우안 및 좌안에 대응되는 영상인 2개의 실제 이미지를 촬영하기 위한 스테레오 카메라(stereoscopic camera)를 구비할 수 있다. 따라서, 2개의 실제 이미지는 촬영 대상을 기준으로 각각 좌측 및 우측 이미지(일부 영역은 겹침)로 구분될 수 있다.The camera module 110 may include two camera modules for capturing two actual images. That is, the camera module 110 may include a stereoscopic camera for capturing two actual images, which are images corresponding to the right eye and the left eye of the user. Therefore, the two actual images may be divided into left and right images (some regions overlap) on the basis of the photographing target.
일 실시예에 따르면, 실제 이미지는 2개의 카메라 모듈을 통해 촬영된 가시광선 영역의 촬영 영상을 의미할 수 있다.According to an embodiment, the actual image may mean a captured image of the visible light region photographed by the two camera modules.
카메라 모듈(110)은 3개의 카메라 모듈을 포함할 수도 있는데, 이러한 경우 2개의 카메라 모듈은 상기 스테레오 카메라로서 사용되고, 나머지 1개의 카메라 모듈은 영상의 깊이(Depth)를 검출하기 위해 사용될 수 있다.The camera module 110 may include three camera modules. In this case, two camera modules may be used as the stereo camera, and the other camera module may be used to detect a depth of an image.
또한, 카메라 모듈(110)은 적외선 이미지를 촬영하기 위한 적외선 카메라 모듈을 포함할 수 있다. 적외선 이미지는 주변이 어두워졌을 때 2개의 실제 이미지의 영상 처리 신뢰성을 높이기 위해 이용될 수 있다. 즉, 적외선 카메라 모듈은 주변이 어두워졌을 때 스테레오 카메라와 함께 구동될 수 있다.In addition, the camera module 110 may include an infrared camera module for capturing infrared images. Infrared images can be used to enhance the image processing reliability of two real images when the surroundings are dark. That is, the infrared camera module may be driven together with the stereo camera when the surroundings become dark.
카메라 인터페이스 모듈(120)은 카메라 모듈(110)로부터 영상을 획득한다. 즉, 카메라 인터페이스 모듈(120)은 2개의 카메라 모듈로 구성되는 스테레오 카메라 모듈로부터 2개의 실제 이미지를 획득한다. 또한, 카메라 인터페이스 모듈(120)은 3개의 카메라 모듈로부터 3개의 실제 이미지를 획득할 수 있으며, 또 달리 스테레오 카메라 모듈과 적외선 카메라 모듈로부터 2개의 실제 이미지와 적외선 이미지를 각각 획득할 수도 있다.The camera interface module 120 obtains an image from the camera module 110. That is, the camera interface module 120 obtains two actual images from the stereo camera module consisting of two camera modules. In addition, the camera interface module 120 may obtain three real images from three camera modules, or alternatively, two real images and infrared images from a stereo camera module and an infrared camera module.
이를 위해, 카메라 인터페이스 모듈(120)은 인터페이스 선택 모듈(도 2의 "210" 참조) 및 색상 공간 변환 모듈(도 2의 "220" 참조)을 포함할 수 있다. 인터페이스 선택 모듈은 카메라마다 인터페이스가 다른 것을 고려하여 해당 카메라에 맞는 인터페이스를 선택하는 역할을 한다. 색상 공간 변환 모듈은 YUV 아날로그 비디오를 디지털 RGB(red, green, blue) 비디오로 변환하는 것, RGB를 CMYK(cyan, magenta, yellow, black)로 변환하는 것 등과 같이 색상 신호를 다른 색상으로 바꾸는 역할을 한다. 즉, 색상 공간 변환 모듈은 인터페이스 선택 모듈을 통해 입력된 이미지를 영상 처리용 포맷으로 변환하는 역할을 한다.To this end, the camera interface module 120 may include an interface selection module (see "210" in FIG. 2) and a color space conversion module (see "220" in FIG. 2). The interface selection module selects an interface suitable for the camera in consideration of different interfaces for each camera. The color space conversion module converts color signals into other colors, such as converting YUV analog video to digital RGB (red, green, blue) video, converting RGB to CMYK (cyan, magenta, yellow, black), and so on. Do it. That is, the color space conversion module converts an image input through the interface selection module into a format for image processing.
렉티피케이션 모듈(130)은 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행한다. 즉, 렉티피케이션 모듈(130)은 2개의 실제 이미지가 동일한 행(column)상에 정렬된 카메라로부터 촬영된 것처럼 바꿀 수 있다. 예를 들어, 렉티피케이션 모듈(130)은 광축(optical axis) 및 기준점이 평행하며, 무한대에서 교차하도록 만들 수 있다. 이에 따라, 장면 겹침이 최대가 되며, 왜곡이 최소가 될 수 있다.The rectification module 130 performs rectification on two actual images. That is, the rectification module 130 can change the two actual images as if they were taken from a camera arranged on the same column. For example, the rectification module 130 may make the optical axis and the reference point parallel and intersect at infinity. Accordingly, scene overlap can be maximized, and distortion can be minimized.
이처럼 렉티피케이션을 수행하기 위해서는 기준점이 필요하다. 렉티피케이션 모듈(130)은 체스 보드(chess board) 또는 3D 물체로부터 기준점을 추출할 수 있다. 렉티피케이션 모듈(130)은 에피폴라 기하(epipolar geometry)를 이용하여 렉티피케이션을 수행할 수 있다. 이와 같이, 렉티피케이션 모듈(130)은 기구의 에러(2대의 카메라의 정렬 에러)를 소프트웨어로 정정하여 질 높은 영상을 제공할 수 있다.In order to perform the replication, a reference point is needed. The rectification module 130 may extract a reference point from a chess board or a 3D object. The rectification module 130 may perform rectification using epipolar geometry. In this way, the reticulation module 130 may provide a high quality image by correcting the error of the instrument (alignment error of two cameras) with software.
일 실시예에 따라 렉티피케이션 모듈(130)은, 미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고, 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환할 수 있다.According to an embodiment, the rectification module 130 may coordinate the same among the plurality of pixels included in each of the at least two real images based on the current reference target break point information on the prestored break point lookup table. Determine a current coordinate transformation target pixel group composed of at least one continuous pixel to be transformed, and each current coordinate transformation target pixel group includes a current difference value that is a difference from the current target coordinate that is a coordinate to be transformed The coordinates of each pixel group of the current coordinate transformation target may be converted based on the current coordinate transformation information.
이때, 렉티피케이션 모듈(130)에 대한 보다 구체적인 설명은 이하 도 8 내지 도 14를 참조하여 후술하도록 하며, 중복되는 설명은 생략한다.In this case, a more detailed description of the rectification module 130 will be described later with reference to FIGS. 8 to 14, and overlapping description thereof will be omitted.
렌즈 왜곡 보상 모듈(140)은 2개의 실제 이미지(rectified image)에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 2개의 실제 이미지 각각에 가상 이미지를 결합한 2개의 합성 이미지를 보정한다.The lens distortion compensation module 140 combines two composite images by combining virtual images with each of the two real images based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens with respect to the two actual images. Correct the image.
일 실시예에 따르면, 렌즈 왜곡 보상 모듈(140)는 2개의 렉티파이된 실제 이미지에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 2개의 실제 이미지 각각에 가상 이미지를 결합한 2개의 합성 이미지를 보정할 수도 있다.According to one embodiment, the lens distortion compensation module 140 is based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens for the two rectified real image, the virtual image in each of the two actual image You can also correct two composite images combining.
구체적으로, HMD(Head Mount Display) 등과 같은 안경식 디스플레이 장치는 사용자의 눈과 렌즈 사이의 간격이 좁기 때문에 시야를 넓혀주기 위해서 광각 렌즈를 사용하는데, 이때 광각 렌즈를 통해 입사되는 영상에는 왜형(왜곡)이 발생하게 된다. 따라서, 본 실시예에서는 렌즈 왜곡 보상 모듈(140)을 통해 2개의 합성 이미지에 렌즈 왜곡 보상 값을 적용함으로써, 광각 렌즈를 통해 입사된 영상에 반대 왜형을 가하여 광각 렌즈의 왜곡을 보상할 수 있다.In detail, the spectacle display device such as a head mount display (HMD) uses a wide-angle lens to widen the field of view because the gap between the user's eyes and the lens is narrow. At this time, an image incident through the wide-angle lens is distorted (distorted). This will occur. Therefore, in the present exemplary embodiment, the lens distortion compensation module 140 may apply lens distortion compensation values to two composite images to compensate for distortion of the wide-angle lens by applying opposite distortion to an image incident through the wide-angle lens.
여기서, 가상 이미지는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)와 연동하는 컴퓨터로부터 입력되어 2개의 실제 이미지 각각과 결합될 수 있다. 가상 이미지는 가상현실(VR)이나 증강현실(AV)을 제공하기 위한 그래픽 이미지를 말한다.In this case, the virtual image may be input from a computer linked with the three-dimensional information augmentation video see-through display device 100 and combined with each of two real images. The virtual image refers to a graphic image for providing a virtual reality (VR) or augmented reality (AV).
한편, 안경식 디스플레이 장치는 그 종류나 모델별로 상기 렌즈 왜곡 보상 값이 다를 수 있다. 예를 들어, A 제품의 HMD는 B 제품의 HMD에 비해 광각 렌즈의 왜형 정도가 클 수 있다. 즉, 복수의 비디오 씨쓰루(Video See-Through) 기반 디스플레이 장치별로 해당 렌즈 왜곡 보상 값에 차이가 있을 수 있다. 따라서, 본 실시예에서는 복수의 비디오 씨쓰루 기반 디스플레이 장치별로 매칭되는 렌즈 왜곡 보상 값을 렌즈 왜곡 보상 룩업 테이블(look-up table)에 저장할 수 있다.The spectacle display device may have a different lens distortion compensation value for each type or model. For example, the HMD of the A product may have a greater distortion of the wide-angle lens than the HMD of the B product. That is, corresponding lens distortion compensation values may be different for each of the plurality of video see-through based display devices. Therefore, in the present embodiment, the lens distortion compensation value matched for each of the plurality of video seed-based display devices may be stored in the lens distortion compensation look-up table.
렌즈 왜곡 보상 모듈(140)은 렌즈 왜곡 보상 룩업 테이블을 이용하여 2개의 합성 이미지를 보정할 수 있다. 다시 말해, 렌즈 왜곡 보상 모듈(140)은 렌즈 왜곡 보상 룩업 테이블로부터 해당 디스플레이 장치에 매칭되는 렌즈 왜곡 보상 값을 추출하고, 추출된 렌즈 왜곡 보상 값을 이용하여 2개의 합성 이미지를 반대 왜형을 가지도록 보정할 수 있다.The lens distortion compensation module 140 may correct two composite images using the lens distortion compensation lookup table. In other words, the lens distortion compensation module 140 extracts a lens distortion compensation value matched with the corresponding display device from the lens distortion compensation lookup table, and uses the extracted lens distortion compensation value to have two composite images having opposite distortions. You can correct it.
이미지 생성 모듈(150)은 2개의 합성 이미지에 대해 사이드 바이 사이드(side by side) 영상 처리를 수행하여 가상현실(VR) 또는 증강현실(AR)을 위한 3차원 이미지를 생성한다. 즉, 이미지 생성 모듈(150)은 좌-우로 나눠진 2개의 합성 이미지를 동일한 사이즈를 갖는 하나의 이미지로 변환하는 영상 처리 작업을 수행하여 가상현실 또는 증강현실을 위한 3차원 이미지를 생성할 수 있다.The image generation module 150 performs side by side image processing on the two composite images to generate a 3D image for the virtual reality (VR) or the augmented reality (AR). That is, the image generating module 150 may generate a 3D image for virtual reality or augmented reality by performing an image processing operation of converting two composite images divided into left and right into one image having the same size.
일 실시예에 따르면, 사이드 바이 사이드 영상처리는 3차원 이미지를 생성하기 위한 알고리즘으로, 2 개의 영상이 좌우로 배치되도록 설정하는 영상 처리를 의미할 수 있으며, 이에 대한 구체적인 설명은 생략한다.According to an embodiment, the side-by-side image processing is an algorithm for generating a 3D image and may refer to image processing for setting two images to be arranged left and right, and a detailed description thereof will be omitted.
디스플레이 모듈(160)은 생성된 3차원 이미지를 화면에 디스플레이한다. 이에 따라, 사용자는 화면을 통해 3차원 이미지를 볼 수 있게 된다. 다만, 다른 실시예에서는 디스플레이 모듈(160)은 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)에 포함되지 않을 수 있고, 외부의 디스플레이 장치로서 구현될 수 있다. The display module 160 displays the generated 3D image on the screen. Accordingly, the user can view the 3D image through the screen. However, in another embodiment, the display module 160 may not be included in the three-dimensional information augmented video seed display device 100, and may be implemented as an external display device.
카메라 캘리브레이션 모듈(170)은 2개의 실제 이미지에 대한 영상 처리 신뢰도를 향상시키기 위해, 적외선 이미지에 기초하여 2개의 카메라 모듈에 대한 카메라 캘리브레이션(calibration)을 수행할 수 있다.The camera calibration module 170 may perform camera calibration on the two camera modules based on the infrared image in order to improve image processing reliability on the two actual images.
구체적으로, 주변이 밝을 때는 2개의 실제 이미지가 선명하기 때문에 그에 대한 영상 처리 신뢰도가 높은 편이지만, 주변이 어두울 때는 2개의 실제 이미지가 선명하지 않아 그에 대한 영상 처리 신뢰도가 높지 않은 편이다. 이러한 문제를 해결하기 위하여, 본 실시예에서는 카메라 캘리브레이션 모듈(170)을 통해 2개의 실제 이미지에 대한 영상 처리 신뢰도를 향상시킬 수 있다.In detail, when the surroundings are bright, two actual images are clear, so the image processing reliability is high. However, when the surroundings are dark, the two actual images are not clear and the reliability of the image processing is not high. In order to solve this problem, in this embodiment, the image processing reliability of two real images may be improved through the camera calibration module 170.
즉, 카메라 캘리브레이션 모듈(170)은 주변이 어두워졌을 때 적외선 카메라 모듈에 의해 촬영된 적외선 이미지를 이용하여 2개의 카메라 모듈, 즉 스테레오 카메라에 대한 카메라 캘리브레이션을 수행함으로써, 2개의 실제 이미지의 선명도를 높여 그에 대한 영상 처리 신뢰도를 향상시킬 수 있다.That is, the camera calibration module 170 performs camera calibration for two camera modules, that is, stereo cameras, by using an infrared image captured by the infrared camera module when the surroundings become dark, thereby increasing the sharpness of two actual images. The image processing reliability thereof can be improved.
조명 감지 모듈(180)은 현재 위치를 기준으로 일정 반경 이내의 조명 위치를 감지할 수 있다. 또한, 조명 감지 모듈(180)은 조명 위치별로 각 조명의 조도를 더 감지할 수 있다. 즉, 조명 감지 모듈(180)은 사용자 주변의 조명 위치 및 각 조명 위치별로 조명의 조도를 감지할 수 있다. 감지된 조명 위치 및 조도는 가상 이미지에 음영 효과를 부여하는 데에 사용될 수 있다.The light detection module 180 may detect a light position within a predetermined radius based on the current position. In addition, the light detection module 180 may further detect the illuminance of each light for each lighting position. That is, the light detection module 180 may detect the illumination position around the user and the illumination intensity of each illumination position. The sensed illumination position and illuminance can be used to add a shadow effect to the virtual image.
마이크 모듈(185)은 현재 위치를 기준으로 일정 반경 이내에서 발생된 소리를 감지할 수 있다. 즉, 마이크 모듈(185)은 사용자 주변에서 발생된 소리를 감지할 수 있다. 이때, 마이크 모듈(185)은 복수개가 구비될 수 있는데, 이러한 경우 복수개의 마이크 모듈(185)은 각각 지향 방위각을 가질 수 있다. 감지된 소리는 통신 모듈(미도시)을 통해 상대방(미리 설정된 소리 전송 대상, 예컨대 화상 회의 시 상대방의 HMD)에게 전송될 수 있다.The microphone module 185 may detect a sound generated within a predetermined radius based on the current position. That is, the microphone module 185 may detect sound generated around the user. In this case, a plurality of microphone modules 185 may be provided. In this case, the plurality of microphone modules 185 may have direct azimuth angles. The detected sound may be transmitted to the other party (a preset sound transmission target, for example, the HMD of the other party in a video conference) through a communication module (not shown).
공간감 생성 모듈(190)은 감지된 조명 위치에 기초하여 현재 위치를 기준으로 하는 각 조명별 방향 데이터를 생성할 수 있다. 이에 따라, 컴퓨터는 생성된 방향 데이터에 기초하여 가상 이미지 내 오브젝트에 음영 효과(그림자)를 부여할 수 있다. 또한, 컴퓨터는 음영 효과의 부여 시, 감지된 조도에 기초하여 가상 이미지 내 오브젝트의 음영 깊이를 조절할 수 있다.The sense of space generation module 190 may generate direction data for each illumination based on the current position based on the detected illumination position. Accordingly, the computer may give a shadow effect (shadow) to the object in the virtual image based on the generated direction data. In addition, the computer may adjust the shadow depth of the object in the virtual image based on the sensed illuminance when applying the shadow effect.
공간감 생성 모듈(190)은 마이크 모듈(185)이 복수개인 경우, 복수개의 마이크 모듈(185) 각각의 지향 방위각에 기초하여, 복수개의 마이크 모듈(185) 각각에 의해 감지된 소리의 방향 데이터를 생성할 수 있다. 생성된 방향 데이터는 감지된 소리와 함께 소리 전송 대상에게 전송될 수 있다.The spatial feeling generating module 190 generates direction data of sound detected by each of the plurality of microphone modules 185 based on the direction of azimuth of each of the plurality of microphone modules 185 when there are a plurality of microphone modules 185. can do. The generated direction data may be transmitted to the sound transmission target together with the detected sound.
제어부(195)는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100), 즉 카메라 모듈(110), 카메라 인터페이스 모듈(120), 렉티피케이션(rectification) 모듈(130), 렌즈 왜곡 보상 모듈(140), 이미지 생성 모듈(150), 디스플레이 모듈(160), 카메라 캘리브레이션(calibration) 모듈(170), 조명 감지 모듈(180), 마이크 모듈(185), 공간감 생성 모듈(190) 등의 동작을 전반적으로 제어할 수 있다.The controller 195 is a three-dimensional information augmented video seed display device 100 according to an embodiment of the present invention, that is, a camera module 110, a camera interface module 120, a rectification module 130, Lens Distortion Compensation Module 140, Image Generation Module 150, Display Module 160, Camera Calibration Module 170, Light Detection Module 180, Microphone Module 185, Space Creation Module 190 Etc., the overall operation can be controlled.
제어부(195)는 카메라 인터페이스 모듈(120), 렉티피케이션(rectification) 모듈(130), 렌즈 왜곡 보상 모듈(140), 이미지 생성 모듈(150) 중 적어도 하나를 포함할 수 있으며, 하나 또는 그 이상의 하드웨어 칩(hardware chip)으로 구현될 수 있다.The controller 195 may include at least one of the camera interface module 120, the rectification module 130, the lens distortion compensation module 140, and the image generating module 150. It may be implemented as a hardware chip.
한편, 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)는 복수의 다양한 디스플레이 장치와 결합될 수 있다. 여기서, 디스플레이 장치는 안경식 디스플레이 장치를 포함하여 현존하는 모든 다양한 비디오 씨쓰루 기반 디스플레이 장치를 모두 포함할 수 있다. 따라서, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)는 디스플레이 장치에 탈착 가능하게 결합될 수 있다. 예를 들면, 도 7에 도시된 바와 같이, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(Stereoscopic Camera Module)(100)는 마운팅 베이스(Mounting base) 및 커버(Cover)와 각각 앞뒤로 결합된 상태에서 마운팅 베이스(Mounting base)가 오큘러스(Oculus)와 탈부착 가능하게 체결되는 방식을 통해 다양한 디스플레이 장치에 탈부착 가능하게 결합될 수 있다.Meanwhile, the 3D information enhancement video seed display device 100 according to an embodiment of the present invention may be combined with a plurality of various display devices. Here, the display device may include all of the various video see-through based display devices including the eyeglass display device. Therefore, the 3D information enhancement video seed display device 100 may be detachably coupled to the display device. For example, as shown in FIG. 7, the three-dimensional information augmentation video see-through display device (Stereoscopic Camera Module) 100 is mounted with a mounting base (Mounting base) and a cover (Back), respectively, in a state where the mounting base ( The mounting base may be detachably coupled to various display devices through a method in which the mounting base is detachably attached to the oculus.
도 2는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치의 동작을 설명하기 위해 도시한 도면이다.2 is a diagram illustrating an operation of a three-dimensional information augmentation video see-through display device according to an embodiment of the present invention.
도 2를 참조하면, 카메라 인터페이스 모듈(120)은 인터페이스 선택 모듈(210)을 통해 2개의 좌우측 카메라 모듈(110)인 CAM CON(L)와 CAM CON(R)에 맞는 인터페이스를 선택하고, 색상 공간 변환 모듈(220)을 통해 상기 CAM CON(L)와 CAM CON(R)에 의해 촬영된 2개의 실제 이미지를 영상 처리용 포맷으로 변환한다.Referring to FIG. 2, the camera interface module 120 selects an interface suitable for two left and right camera modules 110, CAM CON (L) and CAM CON (R), through the interface selection module 210, and a color space. The conversion module 220 converts two actual images captured by the CAM CON (L) and the CAM CON (R) into an image processing format.
이때, 카메라 인터페이스 모듈(120)은 인터페이스 선택 모듈(210)을 통해 1개의 중앙 카메라 모듈(110)인 CAM CON(C)에 맞는 인터페이스를 선택하고, 색상 공간 변환 모듈(220)을 통해 CAM CON(C)에 의해 촬영된 이미지를 영상 처리용 포맷으로 변환할 수 있다. 여기서, CAM CON(C)은 적외선 이미지를 촬영하는 적외선 카메라 모듈일 수 있으며, 카메라 캘리브레이션 모듈(170)은 적외선 이미지를 이용하여 카메라 캘리브레이션을 수행함으로써 2개의 실제 이미지의 영상 처리 신뢰도를 향상시킬 수 있다.At this time, the camera interface module 120 selects an interface suitable for one central camera module 110 CAM CON (C) through the interface selection module 210, and selects the CAM CON () through the color space conversion module 220. The image captured by C) can be converted into an image processing format. Here, the CAM CON (C) may be an infrared camera module for capturing an infrared image, and the camera calibration module 170 may improve image processing reliability of two actual images by performing a camera calibration using the infrared image. .
카메라 인터페이스 모듈(120)을 거친 이미지는 렉티피케이션 모듈(130)에 입력되고, 렉티피케이션 모듈(130)은 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행한다. 렉티피케이션 모듈(130)을 거친 이미지(Rectified image)(230)는 PC(250)에 전달되고(240), PC(250)는 Rectified Image(230)와 결합할 그래픽 이미지인 가상 이미지를 생성한다. Rectified Image(230)는 PC(250)로부터의 가상 이미지(Rendered Image)(260)와 결합되어 렌즈 왜곡 보상 모듈(140)로 입력된다. 본 실시예에서는 Rectified Image(230)와 가상 이미지(Rendered Image)(260)를 결합한 이미지를 합성 이미지로 정의한다. 그러므로, 렌즈 왜곡 보상 모듈(140)에는 2개의 합성 이미지가 입력되는 것이 된다.The image passed through the camera interface module 120 is input to the rectification module 130, and the rectification module 130 performs rectification on two actual images. The rectified image 230 passed through the rectification module 130 is transmitted to the PC 250 (240), the PC 250 generates a virtual image that is a graphic image to be combined with the Rectified Image (230) . The Rectified Image 230 is combined with the Rendered Image 260 from the PC 250 and input to the lens distortion compensation module 140. In the present embodiment, an image combining the Rectified Image 230 and the Rendered Image 260 is defined as a composite image. Therefore, two composite images are input to the lens distortion compensation module 140.
2개의 합성 이미지는 렌즈 왜곡 보상 모듈(140)을 통해 반대 왜형이 가해져서 실제와 동일 또는 유사한 이미지로 보정된 후, 이미지 생성 모듈(150)로 입력된다. 2개의 합성 이미지는 이미지 생성 모듈(150)을 통해 사이드 바이 사이드(side by side) 방식으로 영상 처리되어 하나의 3차원 이미지로 변환된다. 3차원 이미지는 디스플레이 모듈(Oculus Lift/HMD Display)(160)을 통해 화면에 디스플레이되며, 이에 따라 사용자는 Oculus Lift나 HMD의 화면을 통해 가상현실(VR) 또는 증강현실(AV)을 위한 3차원 이미지를 볼 수 있게 된다.The two composite images are applied to the image generating module 150 after the opposite distortion is applied through the lens distortion compensation module 140 to be corrected to the same or similar to the actual image. The two composite images are image-processed in a side by side manner through the image generating module 150 and converted into one 3D image. The three-dimensional image is displayed on the screen through the display module (Oculus Lift / HMD Display) 160, so that the user can display the three-dimensional image for virtual reality (VR) or augmented reality (AV) through the screen of the Oculus Lift or HMD. You will be able to see the image.
한편, PC(250)는 조명 감지 모듈(180) 및 공간감 생성 모듈(190)을 통해 주변의 각 조명별 조도와 방향 데이터를 수신하여 가상 이미지 내 오브젝트에 음영 효과(그림자)를 부여할 수 있으며, 이때 음영 깊이도 조절할 수 있다. 음영 효과가 부여된 가상 이미지(260)는 Rectified Image(230)와 결합되어 렌즈 왜곡 보상 모듈(140)에 입력될 수 있다.On the other hand, the PC 250 may receive the illumination and direction data for each of the surrounding light through the light detection module 180 and the sense of space generation module 190 to give a shadow effect (shadow) to the object in the virtual image, You can also adjust the shadow depth. The virtual image 260 to which the shadow effect is applied may be combined with the Rectified Image 230 and input to the lens distortion compensation module 140.
또한, PC(250)는 마이크 모듈(185) 및 공간감 생성 모듈(190)을 통해 주변의 소리를 수신하여 네트워크(Network)를 통해 상대방에게 전송할 수 있다. 이때, PC(250)는 공간감 생성 모듈(190)을 통해 복수개의 마이크 모듈(185) 각각에 의해 감지된 소리의 방향 데이터를 수신하여 네트워크(Network)를 통해 상대방에게 전송할 수 있다. 이로써, 상대방은 사용자 주위의 소리를 직접 들을 수 있으며, 나아가 그 소리의 방향성을 통해 생동감마저도 느낄 수 있게 된다.In addition, the PC 250 may receive the surrounding sound through the microphone module 185 and the space generating module 190 and transmit the ambient sound to the counterpart through a network. In this case, the PC 250 may receive the direction data of the sound detected by each of the plurality of microphone modules 185 through the sense of space generating module 190 and transmit the received direction data to the counterpart through the network. As a result, the other party can directly hear the sound around the user, and can also feel the liveliness through the direction of the sound.
도 3은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치의 제어부와 주변 장치 간의 접속 상태를 도시한 PCB 블록도이다.FIG. 3 is a PCB block diagram illustrating a connection state between a control unit and a peripheral device of a 3D information enhanced video see-through display device according to an embodiment of the present invention.
도 3을 참조하면, 제어부(195)는 FPGA(Field Programmable Gate Array)로 구현될 수 있다. 제어부(195)에는 3개의 카메라 모듈(110)이 접속될 수 있으며, 그 중 2개의 카메라 모듈(Connector(L), Connector(R))(310, 320)은 스테레오 카메라 모듈이고 나머지 1개의 카메라 모듈(IR sensor(C))(330)은 적외선 카메라 모듈이다.Referring to FIG. 3, the controller 195 may be implemented as a field programmable gate array (FPGA). Three camera modules 110 may be connected to the controller 195, of which two camera modules (Connector (L) and Connector (R)) 310 and 320 are stereo camera modules and the other one camera module. IR sensor (C) 330 is an infrared camera module.
제어부(195)에는 영상 처리용 메모리인 메인 메모리(Main memory, 예컨대 DDR3로 구현될 수 있음)(340)가 2개 접속되고, FPGA를 초기화하기 위한 데이터가 저장된 OS 처리용 메모리인 부팅 메모리(Booting Memory)(350)가 접속될 수 있다. 부팅 메모리(350)는 SD 카드로 구현될 수 있다.The control unit 195 is connected to two main memories (main memory, for example, DDR3) 340, which are memory for image processing, and booting memory, which is an OS processing memory in which data for initializing the FPGA is stored. Memory 350 may be connected. The boot memory 350 may be implemented as an SD card.
제어부(195)에는 PC(250)에 실제 이미지를 전송하거나 PC(250)로부터 가상 이미지를 수신하기 위한 입출력 인터페이스인 HDMI(360)가 접속될 수 있다. 이때, HDMI(360)는 3차원 이미지의 디스플레이를 위해 Oculus Rift/HMD 등에 3차원 이미지를 전송하기 위한 입출력 인터페이스로도 기능할 수 있다. 여기서, HDMI(360)는 근거리에서 고해상도 영상과 음성을 실시간으로 전송하는 무선 모듈로 대체될 수 있다.The controller 195 may be connected to an HDMI 360 that is an input / output interface for transmitting an actual image to the PC 250 or receiving a virtual image from the PC 250. In this case, the HDMI 360 may also function as an input / output interface for transmitting the 3D image to the Oculus Rift / HMD for displaying the 3D image. Here, the HDMI 360 may be replaced by a wireless module that transmits high resolution video and audio in real time at a short range.
제어부(195)에는 조명 감지 모듈인 CDS(180) 및 마이크 모듈인 MIC(185)에 의해 감지된 센싱 데이터를 아날로그-디지털 변환하는 역할을 하는 ADC(170)가 접속될 수 있다. 또한, 제어부(195)에는 데이터 초기화(키보드 등 세팅 시 입력)를 위한 시리얼 통신 모듈(380)이 접속될 수 있다. 또한, 제어부(195)에는 GPIO(General Purpose Input/Output)(390) 및 SOM Connt.(395)가 선택 가능한 옵션으로 접속될 수 있다.The control unit 195 may be connected to an ADC 170 that performs analog-to-digital conversion of sensing data sensed by the CDS 180 as a light sensing module and the MIC 185 as a microphone module. In addition, the controller 195 may be connected to the serial communication module 380 for data initialization (input at the time of setting the keyboard, etc.). In addition, the control unit 195 may be connected to a GPIO (General Purpose Input / Output) 390 and a SOM Cont. 395 as selectable options.
도 4 내지 도 6은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법을 설명하기 위해 도시한 흐름도이다.4 to 6 are flowcharts illustrating a three-dimensional information augmentation video seed display method according to an embodiment of the present invention.
도 4 내지 도 6을 참조하면, 단계(410)에서 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 2개의 카메라 모듈로부터 2개의 실제 이미지를 획득한다.4 to 6, in step 410, the 3D information augmentation video see-through display device obtains two actual images from two camera modules.
이때, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 2개의 카메라 모듈로부터 2개의 실제 이미지를 획득한 후(510), 적외선 카메라 모듈로부터 적외선 이미지를 획득하고(520), 이어서 2개의 실제 이미지에 대한 영상 처리 신뢰도를 향상시키기 위해, 적외선 이미지에 기초하여 2개의 카메라 모듈에 대한 카메라 캘리브레이션을 수행할 수 있다.At this time, the three-dimensional information augmented video see-through display device obtains two real images from two camera modules (510), then obtains an infrared image from an infrared camera module (520), and then processes the two real images. To improve reliability, camera calibration may be performed for two camera modules based on the infrared image.
다음으로, 단계(420)에서 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 상기 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행한다.Next, in step 420, the 3D information enhancement video seed display device performs rectification on the two real images.
이때, 단계(420)에 대한 보다 구체적인 설명은 이하 도 8 내지 도 14를 참조하여 후술하도록 하며, 중복되는 설명은 생략한다.At this time, a more detailed description of the step 420 will be described later with reference to FIGS. 8 to 14, and overlapping descriptions are omitted.
다음으로, 단계(430)에서 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 2개의 실제 이미지 각각에 가상 이미지를 결합하여 2개의 합성 이미지를 생성한다.Next, in step 430, the three-dimensional information augmented video see-through display device combines the virtual image to each of the two real images to generate two composite images.
이때, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 현재 위치를 기준으로 일정 반경 이내의 조명 위치 및 각 조명의 조도를 감지한 후(610), 감지된 조명 위치에 기초하여 현재 위치를 기준으로 하는 각 조명별 방향 데이터를 생성한 다음(620), 각 조명의 조도 및 각 조명별 방향 데이터에 기초하여 가상 이미지 내 오브젝트에 음영 효과를 부여할 수 있다(630). 이어서, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 음영 효과가 부여된 가상 이미지를 2개의 실제 이미지 각각에 결합할 수 있다(640).At this time, the three-dimensional information augmented video see-through display device detects the illumination position within a predetermined radius and the illumination of each light based on the current position (610), and then each of the illumination based on the current position based on the detected illumination position After generating the directional data (620), a shadow effect may be applied to the object in the virtual image based on the illumination of each light and the directional data for each light (630). Subsequently, the three-dimensional information augmented video see-through display device may combine the virtual image with the shadow effect to each of the two real images (640).
다음으로, 단계(440)에서 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 2개의 실제 이미지에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 상기 2개의 합성 이미지를 보정한다.Next, in step 440, the 3D video enhancement video see-through display device corrects the two composite images based on a lens distortion compensation value representing a value for compensating for the distortion of the wide-angle lens for the two actual images. .
다음으로, 단계(450)에서 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치는 상기 2개의 합성 이미지에 대해 사이드 바이 사이드(side by side) 영상 처리를 수행하여 가상현실(VR) 또는 증강현실(AR)을 위한 3차원 이미지를 생성한다.Next, in operation 450, the 3D information augmented video see-through display device performs side by side image processing on the two composite images to perform virtual reality (VR) or augmented reality (AR). Create a three-dimensional image.
다음으로, 단계(460)에서 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치가 탈부착 되는 디스플레이 장치는 상기 생성된 3차원 이미지를 디스플레이한다.Next, in step 460, the display device to which the 3D information-separation video see-through display device is detached and displays the generated 3D image.
이제 도 8 내지 도 14를 참조하여, 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)의 렉티피케이션 모듈(130) 및 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 단계(420)을 설명한다.Referring now to FIGS. 8-14, a step 420 of the redirection module 130 and the three-dimensional information augmentation video seed display method of the three-dimensional information augmentation video seed display device 100 will be described.
도 8은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계를 설명하기 위해 도시한 흐름도이다.8 is a flowchart illustrating a step of performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
도 8에 도시된 바와 같이, 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 단계인 단계(420)은 현재 좌표 변환 대상 픽셀군을 각각 결정하는 단계인 단계(810) 및 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계인 단계(820)을 포함할 수 있다.As shown in FIG. 8, step 420, which is a step of performing rectification on two actual images, is a step of determining a current coordinate transformation target pixel group 810 and a current coordinate transformation, respectively. In operation 820, the coordinates of each target pixel group may be converted.
단계(810)는 렉티피케이션 모듈(130)이 미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하는 단계를 의미할 수 있다.In operation 810, the rectification module 130 transforms coordinates identical to each other among a plurality of pixels included in each of the at least two real images based on the current reference target break point information on the previously stored break point lookup table. This may mean a step of determining a current coordinate transformation target pixel group including at least one continuous pixel required.
예를 들어, 단계(810)에서 렉티피케이션을 수행함에 있어서, 2개의 실제 이미지 각각에서 서로 연속된 픽셀 중 일부 픽셀들은 서로 동일한 좌표변환이 요구될 수 있다.For example, in performing the rectification in operation 810, some of the pixels consecutive to each other in each of the two real images may require the same coordinate transformation.
예를 들어, 총 8개의 픽셀이 서로 연속하며 1번째 픽셀, 2번째 픽셀, 3번째 픽셀은 각각 x축 방향으로 +1만큼 좌표변환이 필요하고, 4번째 픽셀, 5번째 픽셀, 6번째 픽셀, 7번째 픽셀, 8번째 픽셀은 x축 방향으로 +3만큼 좌표변환이 필요한 경우라면, 1번째 픽셀 내지 3번째 픽셀은 서로 동일한 좌표 변환이 요구되는 연속된 픽셀인 현재 좌표 변환 대상 픽셀군을 의미할 수 있으며, 4번째 픽셀 내지 8번째 픽셀은 서로 동일한 좌표 변환이 요구되는 연속된 픽셀인 다음 좌표 변환 대상 픽셀군을 의미할 수 있다.For example, a total of eight pixels are continuous with each other, and the first pixel, the second pixel, and the third pixel need to be coordinated by +1 in the x-axis direction, respectively, and the fourth, fifth, sixth, If the 7th pixel and the 8th pixel require coordinate transformation by +3 in the x-axis direction, the 1st to 3rd pixels may refer to the current coordinate transformation target pixel group, which is a continuous pixel requiring the same coordinate transformation. The fourth to eighth pixels may refer to a next coordinate transformation target pixel group that is a continuous pixel requiring the same coordinate transformation.
이때, 서로 연속한 픽셀들 중 어떠한 픽셀들이 서로 동일한 좌표 변환이 요구되는지 저장하는 정보를 브레이크 포인트 정보라 정의할 수 있으며, 특히나 현재 좌표 변환 대상 픽셀군을 결정하기 위한 브레이크 포인트 정보를 현재 참조 대상 브레이크 포인트 정보라 정의하도록 한다.In this case, information that stores which pixels among consecutive pixels are required to have the same coordinate transformation may be defined as break point information, and in particular, break point information for determining a current coordinate transformation target pixel group may be defined as a break point for the current reference object. Defined as point information.
2개의 실제 이미지 각각에 포함된 복수의 픽셀들 중 서로 동일한 좌표 변환이 요구되는 연속된 픽셀을 구분하기 위한 복수의 브레이크 포인트 정보는 브레이크 포인트 룩업 테이블 상에 저장될 수 있다.A plurality of break point information for distinguishing consecutive pixels requiring the same coordinate transformation among the plurality of pixels included in each of the two actual images may be stored on the break point lookup table.
이제 도 9a 및 도 9b를 참조하여, 종래의 브레이크 포인트 룩업 테이블을 활용한 렉티피케이션 알고리즘에서 적용하는 종래의 브레이크 포인트 룩업 테이블을 설명한다.9A and 9B, a conventional breakpoint lookup table applied in a rectification algorithm utilizing a conventional breakpoint lookup table will be described.
도 9a 및 도 9b는 종래의 렉티피케이션 알고리즘에서 활용되는 브레이크 포인트 룩업 테이블을 설명하기 위해 도시한 도면이다.9A and 9B are diagrams for explaining a breakpoint lookup table utilized in a conventional rectification algorithm.
도 9a 및 도 9b에 도시된 바와 같이 종래의 브레이크 포인트 룩업 테이블은 X축 방향과 Y축 방향 각각에 대하여 별도로 저장될 수 있다.As shown in FIGS. 9A and 9B, the conventional break point lookup table may be separately stored for each of the X and Y axis directions.
이때, 도 9a 및 도 9b에 도시된 바와 같이, 종래의 브레이크 포인트 룩업 테이블은 내부 메모리(internal memory) 상에 미리 할당된 주소(address) 별로 해당되는 브레이크 포인트 정보가 존재하는 경우 해당되는 브레이크 포인트 정보를 저장하고, 해당되는 브레이크 포인트 정보가 존재하지 않는 경우 해당되는 주소를 비어있는 상태로 설정하는 테이블을 의미한다.In this case, as shown in FIGS. 9A and 9B, in the conventional breakpoint lookup table, the breakpoint information corresponding to the breakpoint information corresponding to each address previously allocated on the internal memory exists. If the corresponding breakpoint information does not exist, the table sets the corresponding address to an empty state.
이때, 브레이크 포인트 정보는 도 9a에 도시된 "00000", "00000", "01002", "00001", "00802", "00803", "00002", "01003", "00001" 및 도 9b에 도시된 "00000", "00004", "04001", "04802", "01803", "00004"를 의미할 수 있다.At this time, the break point information is shown in "00000", "00000", "01002", "00001", "00802", "00803", "00002", "01003", "00001" and FIG. 9B shown in FIG. 9A. It may mean "00000", "00004", "04001", "04802", "01803", and "00004" shown.
즉, 종래의 브레이크 포인트 룩업 테이블에서는 미리 할당된 주소에 대응되는 브레이크 포인트 정보가 없는 경우 낭비되는 메모리(wasted memory)가 발생하는 문제가 있다.That is, the conventional breakpoint lookup table has a problem in that wasted memory occurs when there is no breakpoint information corresponding to a pre-assigned address.
이제 도 10a 및 도 10b를 참조하여, 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 브레이크 포인트 룩업 테이블을 설명한다.Referring now to FIGS. 10A and 10B, a breakpoint lookup table used in the step of performing rectification of the 3D information augmentation video seed display method according to an embodiment of the present invention will be described.
도 10a 및 도 10b는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 브레이크 포인트 룩업 테이블을 설명하기 위해 도시한 도면이다.10A and 10B are diagrams for explaining a breakpoint lookup table used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
도 10a 및 도 10b에 도시된 바와 같이 본 발명의 일 실시예에 따른 삼차원 정보 증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 브레이크 포인트 룩업 테이블은 종래의 브레이크 포인트 룩업 테이블과 마찬가지로 X축 방향과 Y축 방향 각각에 대하여 별도로 저장될 수 있다.As shown in FIGS. 10A and 10B, the breakpoint lookup table utilized in performing the redirection of the 3D information augmented video see-through display method according to an embodiment of the present invention is similar to the conventional breakpoint lookup table. It may be stored separately for each of the X-axis direction and Y-axis direction.
이때, 도 10a 및 도 10b에 도시된 바와 같이, 본 발명의 단계(420)에서 활용되는 브레이크 포인트 룩업 테이블은 복수의 브레이크 포인트 정보를 내부 메모리(internal memory) 상에서 비어있는 공간에 순차적으로 저장하며, 도 10a 및 도 10b 각각의 박스에 표시된 바와 같이, 복수의 브레이크 포인트 정보 중 적어도 하나의 브레이크 포인트 정보에 대한 적어도 하나의 메모리 상의 저장 주소 정보를 별도로 저장하는 테이블을 의미할 수 있다.10A and 10B, the breakpoint lookup table utilized in the step 420 of the present invention sequentially stores a plurality of breakpoint information in an empty space on an internal memory. As shown in each of the boxes of FIGS. 10A and 10B, it may refer to a table that separately stores storage address information on at least one memory for at least one break point information among the plurality of break point information.
그 결과, 본 발명의 단계(420)에서 활용되는 브레이크 포인트 룩업 테이블은 내부 메모리 상에서 낭비되는 메모리가 없이 브레이크 포인트 정보를 저장함으로써, 내부 메모리의 저장 공간을 효율적으로 활용할 수 있는 효과가 있다.As a result, the breakpoint lookup table utilized in the step 420 of the present invention stores the breakpoint information without wasting memory on the internal memory, thereby effectively utilizing the storage space of the internal memory.
이제, 도 9a 및 도 10a를 동시에 참조하여, 종래의 브레이크 포인트 룩업 테이블과 본 발명의 단계(420)에서 활용되는 브레이크 포인트 룩업 테이블을 서로 비교한다.Now, referring to FIGS. 9A and 10A simultaneously, the conventional break point lookup table is compared with the break point lookup table utilized in step 420 of the present invention.
도 9a의 m+5번째 열의 브레이크 포인트 정보인 "00000"의 저장 주소 정보를 "0"으로, m+10번째 열의 첫 번째 브레이크 포인트 정보인 "00000"의 저장 주소 정보를 "1"로, m+10번째 열의 두 번째 브레이크 포인트 정보인 "01002"의 저장 주소 정보를 "2"로, m+15번째 열의 첫 번째 브레이크 포인트 정보인 "00001"의 저장 주소 정보를 "3"으로, m+15번째 열의 두 번째 브레이크 포인트 정보인 "00802"의 저장 주소 정보를 "4"로, m+15번째 열의 세 번째 브레이크 포인트 정보인 "00803"의 저장 주소 정보를 "5"로, m+20번째 열의 첫 번째 브레이크 포인트 정보인 "00002"의 저장 주소 정보를 "6"으로, m+20번째 열의 두 번째 브레이크 포인트 정보인 "01003"의 저장 주소 정보를 "7"로, m+25번째 열의 브레이크 포인트 정보인 "00001"의 저장 주소 정보를 "8"로 각각 정의한다.The storage address information of "00000" which is the break point information of the m + 5th column of FIG. 9A is "0", and the storage address information of "00000" which is the first breakpoint information of the m + 10th column is "1", m The storage address information of "01002", which is the second breakpoint information of the + 10th column, is "2", and the storage address information of "00001", which is the first breakpoint information of the m + 15th column, is "3", m + 15 The storage address information of "00802", the second break point information of the first column, is "4", the storage address information of "00803", the third break point information of the m + 15th column, is "5", and the storage address information of the m + 20th column is "5". The storage address information of the first breakpoint information "00002" is "6", the storage address information of "01003" which is the second breakpoint information of the m + 20th column is "7", and the breakpoint of the m + 25th column The storage address information of the information "00001" is defined as "8", respectively.
이때, 도 10a에 도시된 본 발명의 단계(420)에서 활용되는 브레이크 포인트 룩업 테이블에서는 각각의 브레이크 포인트 정보인 "00000", "00000", "01002", "00001", "00802", "00803", "00002", "01003", "00001"를 순차적으로 저장한 뒤, 도 9a에 도시된 각각의 열(row)에 대한 최초의 브레이크 포인트 정보에 대응되는 저장 주소 정보인 "0", "1", "3", "6", "8"을 별도로 저장할 수 있다.In this case, in the break point lookup table utilized in the step 420 of the present invention shown in FIG. 10A, the respective break point information "00000", "00000", "01002", "00001", "00802", and "00803" "," 00002 "," 01003 "," 00001 "are sequentially stored, and then" 0 "and" storage address information corresponding to the first break point information for each row shown in FIG. 9A. 1 "," 3 "," 6 ", and" 8 "can be stored separately.
마찬가지로, 도 9b에 도시된 n+5 번째 열의 브레이크 포인트 정보인 "00000"의 저장 주소 정보를 "0", n+10 번째 열의 첫 번째 브레이크 포인트 정보인 "00004"의 저장 주소 정보를 "1", n+15 번째 열의 첫 번째 브레이크 포인트 정보인 "00004"의 저장 주소 정보를 "5"라 정의하면, 도 10b에 도시된 본 발명의 단계(420)에서 활용되는 브레이크 포인트 룩업 테이블에서는 각각의 브레이크 포인트 정보인 "00000", "00004", "04001", "04802", "01803", "00004"를 순차적으로 저장한 뒤, 도 9b에 도시된 각각의 열(row)에 대한 최초의 브레이크 포인트 정보에 대응되는 저장 주소 정보인 "0", "1", "5"를 별도로 저장할 수 있다.Similarly, the storage address information of "00000" which is breakpoint information of the n + 5th column shown in FIG. 9B is "0", and the storage address information of "00004" which is first breakpoint information of the n + 10th column is "1". If the storage address information of “00004”, which is the first breakpoint information of the n + 15 th column, is defined as “5”, each breakpoint is used in the breakpoint lookup table utilized in the step 420 of the present invention shown in FIG. 10B. After storing the point information "00000", "00004", "04001", "04802", "01803", and "00004" sequentially, the first break point for each row shown in Fig. 9B. The storage address information "0", "1", and "5" corresponding to the information may be separately stored.
다시 말해, 미리 저장된 브레이크 포인트 룩업 테이블은, 복수의 브레이크 포인트 정보를 메모리 상에서 비어있는 공간에 순차적으로 저장하며, 순차적으로 저장된 복수의 브레이크 포인트 정보 중 적어도 하나의 브레이크 포인트 정보에 대한 적어도 하나의 메모리 상의 저장 주소 정보를 더 저장할 수 있다.In other words, the pre-stored breakpoint lookup table sequentially stores a plurality of breakpoint information in an empty space in the memory, and stores at least one breakpoint information of at least one breakpoint information among the plurality of sequentially stored breakpoint information. You can save more storage address information.
다시 도 8을 참조하여, 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계인 단계(820)를 설명한다.Referring back to FIG. 8, step 820, which is a step of transforming coordinates of each pixel group of the current coordinate transformation target, is described.
단계(820)는 렉티피케이션 모듈(130)이 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계를 의미할 수 있다.In operation 820, the rectification module 130 may convert the current coordinate transformation object based on the current coordinate transformation information including a current difference value that is a difference value between the current coordinate transformation target pixel group and the current target coordinate that is a coordinate to be converted. It may mean a step of converting coordinates of each pixel group.
예를 들어, 단계(820)에서 현재 좌표 변환 대상 픽셀군에 포함된 제1픽셀의 좌표가 (1,0), 제2 픽셀의 좌표가 (2,0), 제3 픽셀의 좌표가 (3,0)이고, 현재 대상 좌표가 제1 픽셀은 (1,1), 제2 픽셀은 (2,1), 제3 픽셀은 (3,1)인 경우 현재 좌표 변환 정보에 포함된 현재 차분값은 y축 방향으로 +1 만큼을 의미할 수 있다.For example, in step 820, the coordinates of the first pixel included in the current coordinate transformation target pixel group are (1,0), the coordinates of the second pixel are (2,0), and the coordinates of the third pixel are (3 , 0), and the current difference value included in the current coordinate transformation information when the first target coordinate is (1,1), the second pixel is (2,1), and the third pixel is (3,1) May mean as much as +1 in the y-axis direction.
이제 도 11a 및 도 11b를 참조하여, 현재 좌표 변환 정보를 설명한다.Referring now to FIGS. 11A and 11B, current coordinate transformation information will be described.
도 11a 및 도 11b는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보를 설명하기 위해 도시한 도면이다.11A and 11B are diagrams for explaining current coordinate transformation information utilized in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention.
예를 들어, 도 11a 및 도 11b에 도시된 바와 같이, 현재 좌표 변환 정보가 X축 방향 및 Y축 방향 각각에 대하여 18bit로 구성된 데이터인 경우를 설명하나, 본 발명의 현재 좌표 변환 정보는 18bit의 데이터로 한정되지 않는다.For example, as illustrated in FIGS. 11A and 11B, a case in which the current coordinate conversion information is data composed of 18 bits for each of the X axis direction and the Y axis direction will be described. It is not limited to data.
도 11a에 도시된 바와 같이, X축 방향에 대한 현재 좌표 변환 정보는 기설정된 개수의 비트를 포함하는 이중 타겟 필드(double target field), 기설정된 개수의 비트를 포함하는 차분 필드(differential field) 및 기설정된 개수의 비트를 포함하는 가로열 필드(Row number field)를 포함할 수 있다.As shown in FIG. 11A, the current coordinate transformation information for the X-axis direction includes a double target field including a predetermined number of bits, a differential field including a predetermined number of bits, and It may include a row number field including a predetermined number of bits.
일 실시예에 따르면, 이중 타겟 필드는 현재 좌표 변환 대상 픽셀군에 포함된 픽셀들 중 적어도 2개의 픽셀이 서로 동일한 현재 대상 좌표에 매핑되는 경우, 비게 되는 픽셀값을 보간하기 위한 주변 픽셀을 나타내는 필드로 총 3개의 비트를 포함할 수 있다.According to an embodiment, the dual target field is a field indicating neighboring pixels for interpolating pixel values that are empty when at least two of the pixels included in the current coordinate conversion target pixel group are mapped to the same current target coordinate. It can contain a total of three bits.
일 실시예에 따르면, 차분 필드는 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와 현재 좌표 변환 대상 픽셀군 간의 차분값을 나타내는 필드를 의미할 수 있다.According to an embodiment, the difference field may mean a field indicating a difference value between a current target coordinate, which is a coordinate to which each of the current coordinate transformation target pixel groups, and a current coordinate transformation target pixel group.
예를 들어, 적어도 2개의 카메라 모듈이 각각 어안렌즈 카메라인 경우, 현재 차분값을 나타내는 필드인 차분 필드(differential field)는 적어도 4개의 비트를 포함할 수 있다.For example, when at least two camera modules are fisheye lens cameras, a differential field, which is a field indicating a current difference value, may include at least four bits.
이는, 광각렌즈의 일종인 어안렌즈를 활용하는 경우, 렌즈에 의한 왜곡이 일반 렌즈에 비해 더욱 커지기 때문이며, 차분 필드가 총 4개의 비트를 포함한다면 차분필드는 -8 내지 +7 까지의 차분값을 저장할 수 있기 때문에 현재 좌표 변환 대상 픽셀군 각각의 좌표 변환이 보다 넓은 범위에서 이루어질 수 있는 장점이 있다.This is because, when using a fisheye lens, which is a kind of wide-angle lens, the distortion caused by the lens becomes larger than that of a general lens. If the difference field includes four bits in total, the difference field is -8 to +7. Since it can be stored, the coordinate transformation of each pixel group of the current coordinate transformation target can be performed in a wider range.
예를 들어, 가로열 필드는 현재 좌표 변환 대상 픽셀군 각각에 포함된 픽셀들의 좌표 정보를 저장하기 위한 필드로, 총 11개의 비트를 포함할 수 있다.For example, the horizontal column field is a field for storing coordinate information of pixels included in each pixel group of the current coordinate transformation target, and may include a total of 11 bits.
도 11b에 도시된 바와 같이, Y축 방향에 대한 현재 좌표 변환 정보는 기설정된 개수의 비트를 포함하는 연속 정보 필드(consecutive information field), 기설정된 개수의 비트를 포함하는 차분 필드(differential field) 및 기설정된 개수의 비트를 포함하는 세로열 필드(Column number field)를 포함할 수 있다.As shown in FIG. 11B, the current coordinate transformation information for the Y-axis direction includes a continuous information field including a predetermined number of bits, a differential field including a predetermined number of bits, and It may include a column number field including a preset number of bits.
이때, 차분 필드 및 세로열 필드에 대한 설명은, 도 11a에서 설명한 바와 동일하므로 중복되는 설명은 생략한다.In this case, the description of the difference field and the column field is the same as described with reference to FIG. 11A, and thus redundant descriptions thereof will be omitted.
예를 들어, 연속 정보 필드는 현재 좌표 변환 대상 픽셀군 다음으로 좌표 변환이 수행될 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값 간의 차이값을 미리 저장하는 필드이다.For example, the continuous information field may include a next difference value and a current coordinate conversion target pixel, which is a difference value from the next target coordinate, which is a coordinate to be transformed, next to the current coordinate conversion target pixel group. A field that stores in advance a difference between a current difference value that is a difference value from a current target coordinate that is a coordinate to be converted to each group.
예를 들어, 현재 좌표 변환 대상 픽셀군에 대한 현재 차분값이 X축 방향으로 +5만큼을 의미하고, 다음 좌표 변환 대상 픽셀군에 대한 다음 차분값 X축 방향으로 +4만큼을 의미하는 경우, 연속 정보 필드는 현재 차분값인 +5와 다음 차분값인 +4의 차이값인 -1을 미리 저장할 수 있다.For example, if the current difference value for the current group of pixel transformation target coordinates is +5 in the X-axis direction, and the current difference value for the next pixel group of coordinate transformation targets is +4 in the X-axis direction, The continuous information field may store in advance a value of −1, which is a difference between a current difference value of +5 and a next difference value of +4.
즉, 다음 좌표 변환 대상 픽셀군의 다음 차분값은 현재 좌표 변환 대상 픽셀군의 현재 차분값보다 X축 방향으로 1만큼 적다는 정보가 현재 좌표 변환 정보에 미리 저장될 수 있다. That is, information that the next difference value of the next coordinate conversion target pixel group is less than 1 in the X-axis direction than the current difference value of the current coordinate conversion target pixel group may be stored in advance in the current coordinate conversion information.
그 결과, 메모리에 반복적으로 접근하지 않고도, 현재 좌표 변환 대상 픽셀군의 현재 차분값과 다음 좌표 변환 대상 픽셀군의 다음 차분값의 차이값에 기초하여 다음 좌표 변환 대상 픽셀군의 좌표 변환을 수행할 수 있기 때문에, 연산속도가 단축되는 장점이 있다.As a result, the coordinate transformation of the next coordinate transformation target pixel group can be performed based on the difference value between the current difference value of the current coordinate transformation target pixel group and the next difference value of the next coordinate transformation target pixel group without repeatedly accessing the memory. Since it can be, the operation speed is shortened.
다시 말해, 현재 좌표 변환 정보는, 미리 저장된 브레이크 포인트 룩업 테이블 상의 다음 참조 대상 브레이크 포인트 정보에 기초하여 미리 결정된 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 현재 차분값 간의 차이값을 미리 저장할 수 있다.In other words, the current coordinate transformation information is a next difference value that is a difference value with a next target coordinate that is a coordinate to which each of the next coordinate transformation target pixel groups determined in advance is based on the next reference target breakpoint information on the previously stored breakpoint lookup table. The difference between the current difference and the current difference can be stored in advance.
그 결과, 단계(420)에서 렉티피케이션 모듈(130)은, 다음 차분값과 현재 차분값 간의 차이값에 기초하여 다음 좌표 변환 대상 픽셀군 각각의 좌표를 변환할 수 있다.As a result, in step 420, the rectification module 130 may convert the coordinates of each of the next coordinate conversion target pixel groups based on the difference between the next difference value and the current difference value.
이제 도 12를 참조하여, 이중 타겟 필드를 설명한다.Referring now to FIG. 12, a dual target field is described.
도 12는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보 중 이중 타겟 필드(double target field)를 설명하기 위해 도시한 도면이다.FIG. 12 is a diagram for explaining a double target field of current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. to be.
도 12에 도시된 바와 같이, 이중 타겟 필드의 3 비트의 비트값이 0,0,0 인 경우 비어있는 픽셀이 없음(No Double Target)을 의미할 수 있고, 비트값이 0,0,1 인 경우 비어있는 픽셀의 픽셀값을 우측상단(Up Forward)의 픽셀값으로 저장함을 의미할 수 있으며, 비트값이 0,1,0 인 경우 비어있는 픽셀의 픽셀값을 상단(Up)의 픽셀값으로 저장함을 의미할 수 있으며, 비트값이 0,1,1 인 경우 좌측상단(Up Backward)의 픽셀값으로 저장함을 의미할 수 있으며, 비트값이 1,0,0 인 경우 우측하단(Below Forward)의 픽셀값으로 저장함을 의미할 수 있으며, 비트값이 1,0,1 인 경우 하단(Below)의 픽셀값으로 저장함을 의미할 수 있고, 비트값이 1,1,0 인 경우 좌측하단(Below Backward)의 픽셀값으로 저장함을 의미할 수 있다.As shown in FIG. 12, when the bit value of 3 bits of the dual target field is 0,0,0, this may mean no empty target, and the bit value is 0,0,1. In this case, it may mean that the pixel value of an empty pixel is stored as the pixel value of the Up Forward. If the bit value is 0,1,0, the pixel value of the empty pixel is converted to the pixel value of the Up. If the bit value is 0,1,1, it can mean to save as the pixel value of the upper back. If the bit value is 1,0,0, it is the lower forward. If the bit value is 1,0,1, it means that it is stored as the pixel value of the lower. If the bit value is 1,1,0, it means the lower left. It may mean storing as a pixel value of Backward).
이제 도 13을 참조하여, 차분 필드를 설명한다.Referring now to FIG. 13, the difference field is described.
도 13은 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보 중 차분 필드(differential field)를 설명하기 위해 도시한 도면이다.FIG. 13 is a diagram illustrating a differential field of current coordinate transformation information used in performing rectification of the 3D information enhancement video seed display method according to an embodiment of the present invention.
도 13에 도시된 바와 같이, 차분 필드가 총 4개의 비트를 포함하는 경우, 차분 필드는 현재 좌표 변환 대상 픽셀군이 변환될 좌표인 현재 대상 좌표와 현재 좌표 변환 대상 픽셀군의 좌표의 차분값인 현재 차분값을 -8 내지 7의 범위에서 저장할 수 있다.As shown in FIG. 13, when the difference field includes a total of four bits, the difference field is a difference value between a current target coordinate, which is a coordinate at which the current coordinate transformation target pixel group is to be transformed, and a coordinate of a current coordinate transformation target pixel group. The current difference value can be stored in the range of -8 to 7.
예를 들어, X축에 대한 차분 필드의 비트값이 1,0,0,1인 경우 현재 좌표 변환 대상 픽셀군에 포함된 복수의 픽셀 각각은 X축 방향으로 -2만큼 좌표 변환이 되어야 함을 의미할 수 있다.For example, if the bit value of the difference field on the X axis is 1,0,0,1, each of the plurality of pixels included in the current coordinate conversion pixel group should be coordinate converted in the X axis direction by -2. Can mean.
이때, 1,0,0,1에 대응되는 -2는 현재 차분값을 의미할 수 있다.In this case, -2 corresponding to 1,0,0,1 may mean a current difference value.
이제 도 14를 참조하여, 연속 정보 필드를 설명한다.Referring now to FIG. 14, the continuous information field is described.
도 14는 본 발명의 일 실시예에 따른 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법의 렉티피케이션을 수행하는 단계에서 활용되는 현재 좌표 변환 정보 중 다음 대상 좌표를 정의하는 연속 정보 필드(consecutive information field)를 설명하기 위해 도시한 도면이다.FIG. 14 is a view illustrating a continuous information field defining a next target coordinate among current coordinate transformation information used in performing rectification of a 3D information enhancement video seed display method according to an embodiment of the present invention. It is a figure shown for description.
도 14에 도시된 바와 같이, 연속 정보 필드는 현재 좌표 변환 대상 픽셀군에 대한 현재 차분값과 다음 좌표 변환 대상 픽셀군에 대한 다음 차분값의 차이값을 미리 저장할 수 있다.As shown in FIG. 14, the continuous information field may store in advance a difference value between a current difference value for the current coordinate transformation target pixel group and a next difference value for the next coordinate transformation target pixel group.
예를 들어, 연속 정보 필드가 총 3개의 비트를 포함하는 경우, 1개의 비트는 플래그(flag) 필드를 의미하고 나머지 2개의 비트는 차이값 필드를 의미할 수 있다.For example, when the continuous information field includes three bits in total, one bit may mean a flag field and the remaining two bits may mean a difference value field.
이 경우, 차이값 필드 중 첫 번째 비트는 부호 비트를 의미하고 두 번째 비트는 차이값의 절대값을 의미할 수 있다.In this case, the first bit of the difference value field may mean a sign bit and the second bit may mean an absolute value of the difference value.
그 결과, 연속 정보 필드가 총 3개의 비트를 포함하는 경우에, 현재 차분값과 다음 차분값의 차이값은 -1, 0, 1 중 하나로 저장될 수 있으며, 이 경우, 플래그 필드는 1값을 가지게 된다.As a result, when the continuous information field includes a total of three bits, the difference between the current difference value and the next difference value may be stored as one of -1, 0, 1, and in this case, the flag field may be set to one value. Have.
이 경우, 현재 차분값과 다음 차분값의 차이값이 -1, 0, 1 중 하나인 경우 메모리에 접근하지 않고도 다음 좌표 변환 대상 픽셀군의 좌표 변환이 가능하게 되며, 현재 차분값과 다음 차분값의 차이값이 -1보다 작거나 1보다 큰 경우, 메모리에 다시 접근하여 다음 좌표 변환 대상 픽셀군의 좌표 변환을 수행해야 한다.In this case, when the difference between the current difference value and the next difference value is one of -1, 0, 1, the coordinate conversion of the next coordinate conversion target pixel group can be performed without accessing the memory, and the current difference value and the next difference value If the difference between is less than -1 or greater than 1, the memory must be accessed again to perform coordinate transformation of the next coordinate transformation pixel group.
마찬가지로, 도면에 도시되지는 않았으나, 연속 정보 필드가 총 5개의 비트를 포함하는 경우, 플래그 필드 1비트와 부호 비트 1비트를 제외하면 총 3개의 비트가 남게 되며, 이 경우 연속 정보 필드에는 현재 차분값과 다음 차분값의 차이값으로써 -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7 까지의 총 15개의 차이값이 저장될 수 있으며, 그 결과 현재 차분값과 다음 차분값의 차이값이 -7 내지 7 범위인 경우 메모리에 접근하지 않고도 다음 좌표 변환 대상 픽셀군의 좌표 변환이 가능하게 되며, 현재 차분값과 다음 차분값의 차이값이 -7보다 작거나 7보다 큰 경우에만 메모리에 다시 접근하여 다음 좌표 변환 대상 픽셀군의 좌표 변환을 수행하게 된다.Similarly, although not shown in the drawing, when the continuous information field includes a total of five bits, a total of three bits remain except for the flag field 1 bit and the sign bit 1 bit, in which case the current information field is presently different. The difference between the value and the next difference is 15 in total: -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7. The difference value can be stored. As a result, when the difference value between the current difference value and the next difference value is in the range of -7 to 7, the coordinate conversion of the next coordinate transformation target pixel group can be performed without accessing the memory. Only when the difference between the difference value and the next difference value is less than or equal to -7 is greater than 7, the memory is accessed again and the coordinate transformation of the next coordinate transformation target pixel group is performed.
일 실시예에 따르면, 렌즈 왜곡 보상 모듈(140)은 상술한 렉티피케이션 모듈(130)과 동일한 알고리즘을 활용하여 렌즈 왜곡을 보상할 수도 있다.According to an embodiment, the lens distortion compensation module 140 may compensate for the lens distortion by using the same algorithm as the rectification module 130 described above.
이 경우, 렌즈 왜곡 보상 모듈(140)은, 미리 저장된 렌즈 왜곡 보상 룩업 테이블 상의 현재 참조 대상 렌즈 왜곡 보상 브레이크 포인트 정보에 기초하여 적어도 2개의 렉티파이된 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고, 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환할 수 있다.In this case, the lens distortion compensation module 140 is identical to each other among a plurality of pixels included in each of the at least two actualized images based on the current reference lens distortion compensation breakpoint information on the prestored lens distortion compensation lookup table. Determine a current coordinate conversion target pixel group composed of at least one continuous pixel for which coordinate transformation is required, and include a current difference value that is a difference value from the current target coordinate, which is a coordinate to be converted, respectively. The coordinates of each pixel group of the current coordinate transformation target may be converted based on the current coordinate transformation information.
이 경우, 미리 저장된 렌즈 왜곡 보상 룩업 테이블은, 복수의 렌즈 왜곡 보상 브레이크 포인트 정보를 메모리 상에서 비어있는 공간에 순차적으로 저장하며, 순차적으로 저장된 복수의 렌즈 왜곡 보상 브레이크 포인트 정보 중 적어도 하나의 렌즈 왜곡 보상 브레이크 포인트 정보에 대한 적어도 하나의 메모리 상의 저장 주소 정보를 더 저장할 수 있다.In this case, the pre-stored lens distortion compensation lookup table sequentially stores the plurality of lens distortion compensation break point information in an empty space on the memory, and compensates at least one lens distortion of the plurality of sequentially stored lens distortion compensation break point information. The storage address information on at least one memory for the break point information may be further stored.
이때, 현재 좌표 변환 정보는, 미리 저장된 렌즈 왜곡 보상 룩업 테이블 상의 다음 참조 대상 렌즈 왜곡 보상 브레이크 포인트 정보에 기초하여 미리 결정된 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 현재 차분값 간의 차이값을 미리 저장할 수 있다.In this case, the current coordinate transformation information may be a difference value from a next target coordinate, which is a coordinate to be transformed with each of the next coordinate transformation target pixel groups determined based on the next reference target lens distortion compensation breakpoint information on the previously stored lens distortion compensation lookup table. The difference between the next difference and the current difference can be stored in advance.
그 결과, 렌즈 왜곡 보상 모듈(140)은, 다음 차분값과 현재 차분값 간의 차이값에 기초하여 다음 좌표 변환 대상 픽셀군 각각의 좌표를 변환할 수 있다.As a result, the lens distortion compensation module 140 may convert the coordinates of each of the following coordinate conversion target pixel groups based on the difference between the next difference value and the current difference value.
이제 본 발명의 일 실시예에 따른, 렉티피케이션 장치(미도시)를 설명한다.Now, a rectification apparatus (not shown) according to an embodiment of the present invention is described.
여기서, 본 발명의 일 실시예에 따른, 렉티피케이션 장치(미도시)는 도 1에 도시된 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치(100)에서 카메라 인터페이스 모듈(120) 및 렉티피케이션 모듈(130)만을 포함하는 장치를 의미할 수 있다.Here, the rectification apparatus (not shown) according to an embodiment of the present invention is the camera interface module 120 and the rectification module 130 in the three-dimensional information augmented video see-through display device 100 shown in FIG. ) May mean only a device.
예컨대, 본 발명의 일 실시예에 따른, 렉티피케이션 장치(미도시)는 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 카메라 인터페이스 모듈(120) 및 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 렉티피케이션 모듈(130)을 포함할 수 있다.For example, in accordance with one embodiment of the present invention, a rectification apparatus (not shown) may be directed to a camera interface module 120 that acquires at least two actual images from at least two camera modules and to at least two actual images. It may include a repetition module 130 to perform the application (rectification).
이때, 렉티피케이션 모듈(130)은, 미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고, 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환한다.In this case, the rectification module 130 requests the same coordinate transformation among the plurality of pixels included in each of the at least two real images based on the current reference target break point information on the previously stored break point lookup table. Determine a current coordinate transformation target pixel group composed of at least one continuous pixel, and each current coordinate transformation target pixel group is based on current coordinate transformation information including a difference value with a current target coordinate that is a coordinate to be converted. Coordinates of each pixel group of the current coordinate conversion target are converted.
이때, 본 발명의 일 실시예에 따른, 렉티피케이션 장치(미도시)의 각각의 구성들에 대한 설명은 도 1 내지 도 14에서 설명한 바와 동일하므로 중복되는 설명은 생략한다.In this case, the description of each configuration of the rectification apparatus (not shown) according to an embodiment of the present invention is the same as described with reference to FIGS.
본 발명의 실시예들은 다양한 컴퓨터로 구현되는 동작을 수행하기 위한 프로그램 명령을 포함하는 컴퓨터 판독 가능 매체를 포함한다. 상기 컴퓨터 판독 가능 매체는 프로그램 명령, 로컬 데이터 파일, 로컬 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 상기 매체는 본 발명을 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 컴퓨터 판독 가능 기록 매체의 예에는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체, CD-ROM, DVD와 같은 광기록 매체, 플롭티컬 디스크와 같은 자기-광 매체, 및 롬, 램, 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 코드를 포함한다.Embodiments of the invention include a computer readable medium containing program instructions for performing various computer-implemented operations. The computer readable medium may include program instructions, local data files, local data structures, or the like, alone or in combination. The media may be those specially designed and constructed for the purposes of the present invention, or they may be of the kind well-known and available to those having skill in the computer software arts. Examples of computer-readable recording media include magnetic media such as hard disks, floppy disks, and magnetic tape, optical recording media such as CD-ROMs, DVDs, magnetic-optical media such as floppy disks, and ROM, RAM, flash memory, and the like. Hardware devices specifically configured to store and execute the same program instructions are included. Examples of program instructions include not only machine code generated by a compiler, but also high-level language code that can be executed by a computer using an interpreter or the like.
지금까지 본 발명에 따른 구체적인 실시예에 관하여 설명하였으나, 본 발명의 범위에서 벗어나지 않는 한도 내에서는 여러 가지 변형이 가능함은 물론이다. 그러므로, 본 발명의 범위는 설명된 실시예에 국한되어 정해져서는 안 되며, 후술하는 특허 청구의 범위뿐 아니라 이 특허 청구의 범위와 균등한 것들에 의해 정해져야 한다.While specific embodiments of the present invention have been described so far, various modifications are possible without departing from the scope of the present invention. Therefore, the scope of the present invention should not be limited to the described embodiments, but should be determined not only by the claims below, but also by the equivalents of the claims.
이상과 같이 본 발명은 비록 한정된 실시예와 도면에 의해 설명되었으나, 본 발명은 상기의 실시예에 한정되는 것은 아니며, 이는 본 발명이 속하는 분야에서 통상의 지식을 가진 자라면 이러한 기재로부터 다양한 수정 및 변형이 가능하다. 따라서, 본 발명 사상은 아래에 기재된 특허청구범위에 의해서만 파악되어야 하고, 이의 균등 또는 등가적 변형 모두는 본 발명 사상의 범주에 속한다고 할 것이다.As described above, the present invention has been described by way of limited embodiments and drawings, but the present invention is not limited to the above-described embodiments, which can be variously modified and modified by those skilled in the art to which the present invention pertains. Modifications are possible. Accordingly, the spirit of the present invention should be understood only by the claims set forth below, and all equivalent or equivalent modifications thereof will belong to the scope of the present invention.
Claims (20)
- 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 카메라 인터페이스 모듈;A camera interface module for obtaining at least two actual images from at least two camera modules;상기 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 렉티피케이션 모듈;A rectification module that performs rectification on the at least two actual images;상기 적어도 2개의 실제 이미지에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 상기 적어도 2개의 실제 이미지 각각에 가상 이미지를 결합한 적어도 2개의 합성 이미지를 보정하는 렌즈 왜곡 보상 모듈; 및Lens distortion compensation for correcting at least two composite images combining a virtual image with each of the at least two real images based on a lens distortion compensation value representing a value for compensating for distortion of the wide-angle lens for the at least two real images module; And상기 적어도 2개의 합성 이미지에 대해 사이드 바이 사이드(side by side) 영상 처리를 수행하여 가상현실(VR) 또는 증강현실(AR)을 위한 3차원 이미지를 생성하는 이미지 생성 모듈을 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And an image generation module configured to generate a 3D image for virtual reality (VR) or augmented reality by performing side by side image processing on the at least two composite images. 3D information enhancement video see-through display device.
- 제1항에 있어서,The method of claim 1,상기 렉티피케이션 모듈은,The repetition module,미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 상기 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고,Based on the current reference target break point information on a pre-stored break point lookup table, the plurality of pixels included in each of the at least two real images are composed of at least one consecutive pixel requiring the same coordinate transformation. Determine the current coordinate conversion target pixel group,상기 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 상기 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And converting the coordinates of each of the current coordinate transformation target pixel groups based on current coordinate transformation information including a current difference value that is a difference value from each current coordinate transformation target pixel group that is a coordinate to be converted. 3D information enhancement video see-through display device.
- 제2항에 있어서,The method of claim 2,상기 미리 저장된 브레이크 포인트 룩업 테이블은,The pre-stored break point lookup table is복수의 브레이크 포인트 정보를 메모리 상에서 비어있는 공간에 순차적으로 저장하며,A plurality of break point information is sequentially stored in an empty space in the memory,상기 순차적으로 저장된 복수의 브레이크 포인트 정보 중 적어도 하나의 브레이크 포인트 정보에 대한 적어도 하나의 상기 메모리 상의 저장 주소 정보를 더 저장하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And storing at least one storage address information on at least one memory of at least one break point information of the plurality of sequentially stored break point information.
- 제2항에 있어서,The method of claim 2,상기 현재 좌표 변환 정보는,The current coordinate conversion information,상기 미리 저장된 브레이크 포인트 룩업 테이블 상의 다음 참조 대상 브레이크 포인트 정보에 기초하여 미리 결정된 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 상기 현재 차분값 간의 차이값을 미리 저장하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.The difference value between the next difference value and the current difference value, which is a difference value from the next target coordinate, which is a coordinate to be transformed, respectively, according to the next reference target break point information on the previously stored break point lookup table. 3D information augmentation video see-through display device, characterized in that for storing in advance.
- 제4항에 있어서,The method of claim 4, wherein상기 렉티피케이션 모듈은,The repetition module,상기 다음 차분값과 상기 현재 차분값 간의 차이값에 기초하여 상기 다음 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And a coordinate of each of the next coordinate transform target pixel groups based on a difference value between the next difference value and the current difference value.
- 제2항에 있어서,The method of claim 2,상기 적어도 2개의 카메라 모듈이 각각 어안렌즈 카메라인 경우,When the at least two camera modules are each fisheye lens camera,상기 현재 차분값을 나타내는 필드인 차분 필드(differential field)는 적어도 4개의 비트를 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And a differential field, which is a field representing the current difference value, includes at least four bits.
- 제1항에 있어서,The method of claim 1,상기 적어도 2개의 실제 이미지를 촬영하는 상기 적어도 2개의 카메라 모듈;The at least two camera modules for capturing the at least two actual images;적외선 이미지를 촬영하는 적외선 카메라 모듈; 및An infrared camera module for photographing infrared images; And상기 적어도 2개의 실제 이미지에 대한 영상 처리 신뢰도를 향상시키기 위해, 상기 적외선 이미지에 기초하여 상기 적어도 2개의 카메라 모듈에 대한 카메라 캘리브레이션을 수행하는 카메라 캘리브레이션 모듈을 더 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And a camera calibration module configured to perform camera calibration on the at least two camera modules based on the infrared image to improve image processing reliability of the at least two real images. See-through display device.
- 제1항에 있어서,The method of claim 1,현재 위치를 기준으로 일정 반경 이내의 조명 위치를 감지하는 조명 감지 모듈; 및An illumination detection module configured to detect an illumination position within a predetermined radius based on the current position; And상기 감지된 조명 위치에 기초하여 현재 위치를 기준으로 하는 각 조명별 방향 데이터를 생성하는 공간감 생성 모듈을 더 포함하고,Further comprising a sense of space generating module for generating the direction data for each light based on the current position based on the detected light position,상기 가상 이미지는The virtual image is상기 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치와 연동하는 컴퓨터로부터 입력되어 상기 적어도 2개의 실제 이미지 각각과 결합되며,Input from a computer interoperating with the three-dimensional information augmentation video see-through display device and combined with each of the at least two real images,상기 컴퓨터는The computer is상기 생성된 방향 데이터에 기초하여 상기 가상 이미지 내 오브젝트에 음영 효과를 부여하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And a shadow effect is applied to the object in the virtual image based on the generated direction data.
- 제8항에 있어서,The method of claim 8,상기 조명 감지 모듈은The light detection module상기 조명 위치별로 각 조명의 조도를 더 감지하고,Further detect the illuminance of each light for each light position,상기 컴퓨터는The computer is상기 음영 효과의 부여 시, 상기 감지된 조도에 기초하여 상기 가상 이미지 내 오브젝트의 음영 깊이를 조절하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And a shadow depth of the object in the virtual image based on the detected illuminance when the shadow effect is applied.
- 제1항에 있어서,The method of claim 1,현재 위치를 기준으로 일정 반경 이내에서 발생된 소리를 감지하는 마이크 모듈; 및A microphone module detecting a sound generated within a predetermined radius of the current position; And상기 감지된 소리를 미리 설정된 소리 전송 대상에게 전송하는 통신 모듈을 더 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And a communication module configured to transmit the detected sound to a predetermined sound transmission target.
- 제10항에 있어서,The method of claim 10,상기 마이크 모듈이 복수개인 경우,If there are a plurality of microphone modules,상기 복수개의 마이크 모듈 각각의 지향 방위각에 기초하여, 상기 복수개의 마이크 모듈 각각에 의해 감지된 소리의 방향 데이터를 생성하는 공간감 생성 모듈을 더 포함하고,Based on the azimuth angle of each of the plurality of microphone modules, further comprising a sense of space generating module for generating the direction data of the sound sensed by each of the plurality of microphone modules,상기 통신 모듈은The communication module상기 생성된 방향 데이터를 상기 소리 전송 대상에게 더 전송하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And transmitting the generated direction data to the sound transmission target.
- 제1항에 있어서,The method of claim 1,복수의 디스플레이 장치별로 매칭되는 상기 렌즈 왜곡 보상 값을 저장하는 렌즈 왜곡 보상 룩업 테이블을 더 포함하고,The apparatus may further include a lens distortion compensation lookup table configured to store the lens distortion compensation values matched by a plurality of display devices.상기 렌즈 왜곡 보상 모듈은The lens distortion compensation module상기 렌즈 왜곡 보상 룩업 테이블을 이용하여 상기 적어도 2개의 합성 이미지를 보정하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And the at least two composite images are corrected by using the lens distortion compensation lookup table.
- 제1항에 있어서,The method of claim 1,상기 카메라 인터페이스 모듈, 상기 렉티피케이션 모듈, 상기 렌즈 왜곡 보상 모듈, 및 상기 이미지 생성 모듈 중 적어도 하나는 하드웨어 칩으로 구현되는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 장치.And at least one of the camera interface module, the rectification module, the lens distortion compensation module, and the image generation module is implemented as a hardware chip.
- 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 단계;Obtaining at least two actual images from at least two camera modules;상기 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 단계;Performing rectification on the at least two actual images;상기 적어도 2개의 실제 이미지에 대한 광각 렌즈의 왜곡을 보상하기 위한 값을 나타내는 렌즈 왜곡 보상 값에 기초하여, 상기 적어도 2개의 실제 이미지 각각에 가상 이미지를 결합한 적어도 2개의 합성 이미지를 보정하는 단계; 및Correcting at least two composite images combining a virtual image with each of the at least two real images based on a lens distortion compensation value representing a value for compensating for distortion of the wide-angle lens for the at least two real images; And상기 적어도 2개의 합성 이미지에 대해 사이드 바이 사이드(side by side) 영상 처리를 수행하여 가상현실(VR) 또는 증강현실(AR)을 위한 3차원 이미지를 생성하는 단계를 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법.And performing a side by side image processing on the at least two composite images to generate a three-dimensional image for virtual reality (VR) or augmented reality (AR). Augmented Video See-Through Display Method.
- 제14항에 있어서,The method of claim 14,상기 렉티피케이션을 수행하는 단계는,The step of performing the rectification,미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 상기 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하는 단계; 및Based on the current reference target break point information on a pre-stored break point lookup table, the plurality of pixels included in each of the at least two real images are composed of at least one consecutive pixel requiring the same coordinate transformation. Determining a current group of coordinate transformation target pixels; And상기 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값인 현재 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 상기 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계를 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법.Converting coordinates of each of the current coordinate transformation target pixel groups based on current coordinate transformation information including a current difference value that is a difference value from each current coordinate transformation target pixel group that is a coordinate to be converted. 3D information augmentation video see-through display method characterized in that.
- 제15항에 있어서,The method of claim 15,상기 현재 좌표 변환 정보는,The current coordinate conversion information,상기 미리 저장된 브레이크 포인트 룩업 테이블 상의 다음 참조 대상 브레이크 포인트 정보에 기초하여 미리 결정된 다음 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 다음 대상 좌표와의 차분값인 다음 차분값과 상기 현재 차분값 간의 차이값을 미리 저장하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법.The difference value between the next difference value and the current difference value, which is a difference value from the next target coordinate, which is a coordinate to be transformed, respectively, according to the next reference target break point information on the previously stored break point lookup table. 3D information enhancement video see-through display method characterized in that for storing in advance.
- 제16항에 있어서,The method of claim 16,상기 렉티피케이션(rectification)을 수행하는 단계는,The step of performing the rectification,상기 다음 차분값과 상기 현재 차분값 간의 차이값에 기초하여 상기 다음 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 단계를 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법.And converting coordinates of each of the next coordinate transformation target pixel groups based on a difference value between the next difference value and the current difference value.
- 제14항에 있어서,The method of claim 14,현재 위치를 기준으로 일정 반경 이내의 조명 위치를 감지하는 단계;Detecting a lighting position within a predetermined radius of the current position;상기 감지된 조명 위치에 기초하여 현재 위치를 기준으로 하는 각 조명별 방향 데이터를 생성하는 단계; 및Generating directional data for each illumination based on the current position based on the detected illumination position; And상기 생성된 방향 데이터에 기초하여 상기 가상 이미지 내 오브젝트에 음영 효과를 부여하는 단계를 더 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법.And applying a shadow effect to the object in the virtual image based on the generated direction data.
- 제14항에 있어서,The method of claim 14,복수의 디스플레이 장치별로 매칭되는 상기 렌즈 왜곡 보상 값을 렌즈 왜곡 보상 룩업 테이블에 저장하는 단계를 더 포함하고,Storing the lens distortion compensation value matched for each of a plurality of display devices in a lens distortion compensation lookup table,상기 보정하는 단계는The correcting step상기 렌즈 왜곡 보상 룩업 테이블을 이용하여 상기 적어도 2개의 합성 이미지를 보정하는 단계를 포함하는 것을 특징으로 하는 삼차원 정보증강 비디오 씨쓰루 디스플레이 방법.And correcting the at least two composite images by using the lens distortion compensation lookup table.
- 적어도 2개의 카메라 모듈로부터 적어도 2개의 실제 이미지를 획득하는 카메라 인터페이스 모듈; 및A camera interface module for obtaining at least two actual images from at least two camera modules; And상기 적어도 2개의 실제 이미지에 대해 렉티피케이션(rectification)을 수행하는 렉티피케이션 모듈을 포함하며,A rectification module for performing rectification on the at least two actual images,상기 렉티피케이션 모듈은,The repetition module,미리 저장된 브레이크 포인트(break point) 룩업 테이블 상의 현재 참조 대상 브레이크 포인트 정보에 기초하여 상기 적어도 2개의 실제 이미지 각각에 포함된 복수의 픽셀 중 서로 동일한 좌표 변환이 요구되는 적어도 하나의 연속된 픽셀로 구성되는 현재 좌표 변환 대상 픽셀군을 각각 결정하고,Based on the current reference target break point information on a pre-stored break point lookup table, the plurality of pixels included in each of the at least two real images are composed of at least one consecutive pixel requiring the same coordinate transformation. Determine the current coordinate conversion target pixel group,상기 현재 좌표 변환 대상 픽셀군 각각이 변환될 좌표인 현재 대상 좌표와의 차분값을 포함하는 현재 좌표 변환 정보에 기초하여 상기 현재 좌표 변환 대상 픽셀군 각각의 좌표를 변환하는 것을 특징으로 하는 렉티피케이션 장치.Rectification, characterized in that for converting the coordinates of each of the current coordinate conversion target pixel group on the basis of the current coordinate conversion information including a difference value with each current coordinate transformation target pixel group is a coordinate to be converted. Device.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/093,860 US10650602B2 (en) | 2016-04-15 | 2017-04-12 | Apparatus and method for three-dimensional information augmented video see-through display, and rectification apparatus |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2016-0046176 | 2016-04-15 | ||
| KR20160046176 | 2016-04-15 | ||
| KR10-2017-0047277 | 2017-04-12 | ||
| KR1020170047277A KR101870865B1 (en) | 2016-04-15 | 2017-04-12 | Apparatus and method for 3d augmented information video see-through display, rectification apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2017179912A1 true WO2017179912A1 (en) | 2017-10-19 |
Family
ID=60041671
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2017/003973 WO2017179912A1 (en) | 2016-04-15 | 2017-04-12 | Apparatus and method for three-dimensional information augmented video see-through display, and rectification apparatus |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2017179912A1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110166760A (en) * | 2019-05-27 | 2019-08-23 | 浙江开奇科技有限公司 | Image treatment method and terminal device based on panoramic video image |
| CN111556228A (en) * | 2020-05-15 | 2020-08-18 | 展讯通信(上海)有限公司 | Method and system for correcting lens shadow |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060041060A (en) * | 2004-11-08 | 2006-05-11 | 한국전자통신연구원 | Apparatus and method for production multi-view contents |
| US20100260355A1 (en) * | 2006-03-27 | 2010-10-14 | Konami Digital Entertainment Co., Ltd. | Sound Processing Apparatus, Sound Processing Method, Information Recording Medium, and Program |
| US20110234584A1 (en) * | 2010-03-25 | 2011-09-29 | Fujifilm Corporation | Head-mounted display device |
| US20150302648A1 (en) * | 2014-02-18 | 2015-10-22 | Sulon Technologies Inc. | Systems and methods for mapping an environment using structured light |
-
2017
- 2017-04-12 WO PCT/KR2017/003973 patent/WO2017179912A1/en active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060041060A (en) * | 2004-11-08 | 2006-05-11 | 한국전자통신연구원 | Apparatus and method for production multi-view contents |
| US20100260355A1 (en) * | 2006-03-27 | 2010-10-14 | Konami Digital Entertainment Co., Ltd. | Sound Processing Apparatus, Sound Processing Method, Information Recording Medium, and Program |
| US20110234584A1 (en) * | 2010-03-25 | 2011-09-29 | Fujifilm Corporation | Head-mounted display device |
| US20150302648A1 (en) * | 2014-02-18 | 2015-10-22 | Sulon Technologies Inc. | Systems and methods for mapping an environment using structured light |
Non-Patent Citations (1)
| Title |
|---|
| HUNG, SON NGUYEN ET AL.: "Real-time Stereo Rectification Using Compressed Look-up Table with Variable Breakpoint Indexing", IECON 2016-42ND ANNUAL CONFERENCE OF THE IEEE INDUSTRIAL ELECTRONICS SOCIETY, 23 October 2016 (2016-10-23), pages 4814 - 4819, XP033033881 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110166760A (en) * | 2019-05-27 | 2019-08-23 | 浙江开奇科技有限公司 | Image treatment method and terminal device based on panoramic video image |
| CN111556228A (en) * | 2020-05-15 | 2020-08-18 | 展讯通信(上海)有限公司 | Method and system for correcting lens shadow |
| CN111556228B (en) * | 2020-05-15 | 2022-07-22 | 展讯通信(上海)有限公司 | Method and system for correcting lens shadow |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101870865B1 (en) | Apparatus and method for 3d augmented information video see-through display, rectification apparatus | |
| WO2018052251A1 (en) | Method, apparatus, and system for sharing virtual reality viewport | |
| WO2013081429A1 (en) | Image processing apparatus and method for subpixel rendering | |
| WO2016190489A1 (en) | Head mounted display and control method therefor | |
| WO2016017966A1 (en) | Method of displaying image via head mounted display device and head mounted display device therefor | |
| WO2019059562A1 (en) | Electronic device comprising plurality of cameras using rolling shutter mode | |
| WO2017164573A1 (en) | Near-eye display apparatus and near-eye display method | |
| WO2021133025A1 (en) | Electronic device comprising image sensor and method of operation thereof | |
| WO2020101420A1 (en) | Method and apparatus for measuring optical characteristics of augmented reality device | |
| WO2014178509A1 (en) | Multi-projection system for extending visual element of main image | |
| WO2018030567A1 (en) | Hmd and control method therefor | |
| WO2019035582A1 (en) | Display apparatus and server, and control methods thereof | |
| WO2017026705A1 (en) | Electronic device for generating 360 degree three-dimensional image, and method therefor | |
| WO2017179912A1 (en) | Apparatus and method for three-dimensional information augmented video see-through display, and rectification apparatus | |
| WO2019088407A1 (en) | Camera module comprising complementary color filter array and electronic device comprising same | |
| WO2019160237A1 (en) | Electronic device and method for controlling display of images | |
| WO2019164312A1 (en) | Camera module and super resolution image processing method thereof | |
| WO2019059635A1 (en) | Electronic device for providing function by using rgb image and ir image acquired through one image sensor | |
| WO2018070793A1 (en) | Method, apparatus, and recording medium for processing image | |
| WO2020190030A1 (en) | Electronic device for generating composite image and method thereof | |
| WO2020171450A1 (en) | Electronic device and method for generating depth map | |
| WO2020145744A1 (en) | Camera device and electronic device including same | |
| WO2017155365A1 (en) | Electronic apparatus for providing panorama image and control method thereof | |
| WO2024019599A1 (en) | Wearable virtual object visibility improvement display device | |
| WO2018012925A1 (en) | Image producing method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17782667 Country of ref document: EP Kind code of ref document: A1 |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 17782667 Country of ref document: EP Kind code of ref document: A1 |