WO2014156400A1 - 遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法、遺伝子情報検索方法及び遺伝子情報検索システム - Google Patents
遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法、遺伝子情報検索方法及び遺伝子情報検索システム Download PDFInfo
- Publication number
- WO2014156400A1 WO2014156400A1 PCT/JP2014/054145 JP2014054145W WO2014156400A1 WO 2014156400 A1 WO2014156400 A1 WO 2014156400A1 JP 2014054145 W JP2014054145 W JP 2014054145W WO 2014156400 A1 WO2014156400 A1 WO 2014156400A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- gene
- encryption
- search
- difference
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/40—Encryption of genetic data
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
- H04L9/08—Key distribution or management, e.g. generation, sharing or updating, of cryptographic keys or passwords
- H04L9/0816—Key establishment, i.e. cryptographic processes or cryptographic protocols whereby a shared secret becomes available to two or more parties, for subsequent use
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09C—CIPHERING OR DECIPHERING APPARATUS FOR CRYPTOGRAPHIC OR OTHER PURPOSES INVOLVING THE NEED FOR SECRECY
- G09C1/00—Apparatus or methods whereby a given sequence of signs, e.g. an intelligible text, is transformed into an unintelligible sequence of signs by transposing the signs or groups of signs or by replacing them by others according to a predetermined system
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L2209/00—Additional information or applications relating to cryptographic mechanisms or cryptographic arrangements for secret or secure communication H04L9/00
- H04L2209/24—Key scheduling, i.e. generating round keys or sub-keys for block encryption
Definitions
- the present invention relates to a storage technique for encrypting and storing in a storage device gene information that is analysis information of a genome or gene obtained as a result of analyzing a DNA sequence.
- the present invention also relates to a technique for searching gene information stored by the storage technique in an encrypted state.
- Non-Patent Document 1 There is a secret search method in which data including a search keyword can be searched from data stored in a database in a state where data stored in the database and a search keyword are encrypted (see Non-Patent Document 1).
- a search keyword assumed to be used when searching for the data is extracted as a tag.
- the data and the tag are respectively encrypted, and the encrypted tag is attached to the encrypted data and stored in the database.
- searching for data including a search keyword from data stored in the database an encrypted search keyword is input.
- an encrypted tag corresponding to the encrypted search keyword is searched.
- the data to which the tag is attached is specified as data including the search keyword.
- An object of the present invention is to enable retrieval of gene information in a state where the gene information is concealed from a third party.
- the genetic information storage device comprises: A genetic information storage device for storing genetic information in a storage device; A reference gene acquisition unit for acquiring a reference gene which is predetermined gene information; A gene input unit for inputting a target gene which is gene information to be stored in the storage device; A difference generation unit that generates difference information by comparing the reference gene acquired by the reference gene acquisition unit and the target gene input by the gene input unit; A data encryption unit that encrypts the target gene to generate an encrypted gene; An encryption tag generator for generating an encryption tag in which the difference information generated by the difference generator is embedded; The data storage unit includes a data storage unit that associates the encrypted gene generated by the data encryption unit with the encryption tag generated by the encryption tag generation unit and stores the data in the storage device.
- the difference information includes a plurality of types of information
- the gene information storage device further includes: For the predetermined type included in the difference information, the value that the type can take is divided into a plurality of blocks, and the value of the type in the difference information generated by the difference generation unit is used to identify the block to which the value belongs A differential information replacement unit that replaces information, The encryption tag generation unit encrypts the difference information replaced by the difference information replacement unit to generate an encryption tag.
- the difference information replacement unit divides the possible values of the type into a plurality of blocks so that some of the values belonging to each block also belong to other blocks, and the type in the difference information generated by the difference generation unit Is replaced with identification information for identifying each block to which the value belongs.
- the encryption tag generation unit is an encryption method in which the encrypted data cannot be decrypted with the secret key when the encryption attribute set in the encrypted data does not correspond to the key attribute set in the secret key.
- the encryption tag is generated by setting attribute information and difference information of a user who can search for the encrypted gene as the encryption attribute, and encrypting a random value.
- attribute information of a user who can decrypt the encrypted gene is set as the encryption attribute, and the target gene is encrypted to generate the encrypted gene.
- the gene information retrieval apparatus comprises: A gene information search device for searching gene information stored in a storage device managed by a data management device; A difference information input unit for inputting difference information between gene information to be searched and reference genes that are predetermined gene information; A search query generation unit that generates a search query in which the difference information input by the difference information input unit is embedded; And a gene information acquisition unit that transmits the search query generated by the search query generation unit to the data management device and acquires gene information including the difference information.
- the difference information includes a plurality of types of information
- the gene information retrieval apparatus further includes: For the predetermined type included in the difference information, a difference information replacement unit that divides the possible value of the type into a plurality of blocks and replaces the value of the type in the difference information with identification information that identifies the block to which the value belongs With
- the search query generation unit generates a search query in which the difference information replaced by the difference information replacement unit is embedded.
- the difference information replacement unit divides the possible values of the type into a plurality of blocks so that some of the values belonging to each block also belong to other blocks, and the value of the type in the difference information It replaces with the identification information which identifies each block to which it belongs, It is characterized by the above-mentioned.
- the gene information retrieval apparatus further includes: When the encryption attribute set in the encrypted data does not correspond to the key attribute set in the secret key, the secret key in the encryption method in which the encrypted data cannot be decrypted with the secret key, A user secret key management unit for managing a secret key in which user attribute information is set as the key attribute; The search query generation unit generates the search query by adding the difference information as a key attribute of a secret key managed by the user secret key management unit.
- the gene information acquisition unit sets decryptable user attribute information as the encryption attribute by the encryption method, and acquires an encrypted gene obtained by encrypting the gene information as gene information including the difference information
- the gene information retrieval apparatus further includes: A decrypting unit for decrypting the encrypted gene with a secret key managed by the user secret key managing unit is provided.
- the gene information storage program includes: A gene information storage program for storing gene information in a storage device; A reference gene acquisition process for acquiring a reference gene as predetermined gene information; Gene input processing for inputting a target gene that is gene information to be stored in the storage device; A difference generation process for generating difference information by comparing the reference gene acquired in the reference gene acquisition process with the target gene input in the gene input process; A data encryption process for encrypting the target gene to generate an encrypted gene; An encryption tag generation process for generating an encryption tag in which the difference information generated in the difference generation process is embedded; The computer is caused to perform data storage processing in which the encrypted gene generated by the data encryption processing is associated with the encryption tag generated by the encryption tag generation processing and stored in the storage device. .
- the difference information includes a plurality of types of information
- the gene information storage program further includes: For a predetermined type included in the difference information, the value that the type can take is divided into a plurality of blocks, and the value of the type in the difference information generated by the difference generation process is used to identify the block to which the value belongs Let the computer execute the difference information replacement process to replace the information, In the encryption tag generation process, the difference information replaced in the difference information replacement process is encrypted to generate an encryption tag.
- the value that the type can take is divided into a plurality of blocks so that some of the values belonging to each block also belong to other blocks, and the type in the difference information generated by the difference generation process Is replaced with identification information for identifying each block to which the value belongs.
- the encryption tag generation process when the encryption attribute set in the encrypted data does not correspond to the key attribute set in the secret key, an encryption method that cannot decrypt the encrypted data with the secret key
- the encryption tag is generated by setting attribute information and difference information of a user who can search for the encrypted gene as the encryption attribute, and encrypting a random value.
- attribute information of a user who can decrypt the encrypted gene is set as the encryption attribute, and the target gene is encrypted to generate the encrypted gene.
- the gene information search program is A gene information search program for searching gene information stored in a storage device managed by a data management device; Difference information input processing for inputting difference information between the gene information to be searched and the reference gene that is the predetermined gene information; A search query generation process for generating a search query in which the difference information input in the difference information input process is embedded; The search query generated in the search query generation process is transmitted to the data management apparatus, and the computer is caused to execute a gene information acquisition process for acquiring gene information including the difference information.
- the difference information includes a plurality of types of information
- the gene information search program further includes: For a predetermined type included in the difference information, a difference information replacement process for dividing a value that the type can take into a plurality of blocks and replacing the value of the type in the difference information with identification information for identifying the block to which the value belongs To the computer, In the search query generation process, a search query in which the difference information replaced in the difference information replacement process is embedded is generated.
- the value that the type can take is divided into a plurality of blocks so that a part of the value that belongs to each block also belongs to another block, and the value of the type in the difference information It replaces with the identification information which identifies each block to which it belongs, It is characterized by the above-mentioned.
- the gene information search program further includes: When the encryption attribute set in the encrypted data does not correspond to the key attribute set in the secret key, the secret key in the encryption method in which the encrypted data cannot be decrypted with the secret key, Causing a computer to execute user secret key management processing for managing a secret key in which user attribute information is set as the key attribute; In the search query generation process, the search query is generated by adding the difference information as a key attribute of a secret key managed in the user secret key management process.
- the user attribute information that can be decrypted is set as the encryption attribute, and the encrypted gene obtained by encrypting the gene information is acquired as the gene information including the difference information.
- the gene information search program further includes: A decryption process for decrypting the encrypted gene is executed by a computer using a secret key managed by the user secret key management process.
- the genetic information storage method comprises: A genetic information storage method for storing genetic information in a storage device, A reference gene acquisition step in which the processing device acquires a reference gene that is predetermined gene information; A gene input step in which the input device inputs a target gene that is gene information to be stored in the storage device; A difference generation step in which the processing device generates difference information by comparing the reference gene acquired in the reference gene acquisition step with the target gene input in the gene input step; A data encryption step in which the processing device encrypts the target gene to generate an encrypted gene; A processing device generates an encryption tag in which the difference information generated in the difference generation step is embedded, and an encryption tag generation step; A processing device comprises a data storage step of associating the encrypted gene generated in the data encryption step with the encryption tag generated in the encryption tag generation step and storing the data in the storage device To do.
- the gene information retrieval method comprises: A gene information search method for searching gene information stored in a storage device managed by a data management device, A difference information input step in which the input device inputs difference information between gene information to be searched and reference genes that are predetermined gene information; A search query generating step for generating a search query in which the processing device embeds the difference information input in the difference information input step; The processing device includes a gene information acquisition step of transmitting the search query generated in the search query generation step to the data management device and acquiring gene information including the difference information.
- the gene information retrieval system comprises: Gene information comprising: a gene information storage device for storing gene information in a storage device managed by the data management device; and a gene information search device for searching for gene information including a search keyword from the gene information stored in the gene information storage device
- the gene information storage device comprises: A reference gene acquisition unit for acquiring a reference gene which is predetermined gene information; A gene input unit for inputting a target gene which is gene information to be stored in the storage device; A difference generation unit that generates difference information by comparing the reference gene acquired by the reference gene acquisition unit and the target gene input by the gene input unit; A data encryption unit that encrypts the target gene to generate an encrypted gene; An encryption tag generator for generating an encryption tag in which the difference information generated by the difference generator is embedded; A data storage unit that associates the encrypted gene generated by the data encryption unit with the encryption tag generated by the encryption tag generation unit, and stores the data in the storage device;
- the gene information retrieval apparatus comprises: A difference information input unit for inputting difference information between gene information to
- gene information including a search keyword is extracted from the database in a state where both the gene information accumulated in the database and the search index tag and the gene information used as the search keyword are encrypted. Can do. Therefore, the genetic information is completely hidden from the third party.
- difference information from the reference gene is used as a search index and a search keyword. For this reason, the number of search indexes is small, and the search can be performed at high speed.
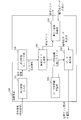
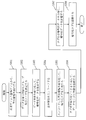
- FIG. 1 is a configuration diagram of a gene search system 10.
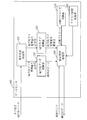
- FIG. 1 is a configuration diagram of a key management server 100.
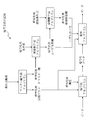
- FIG. 1 is a configuration diagram of an encryption device 200.
- FIG. 1 is a configuration diagram of a search device 300.
- FIG. 1 is a configuration diagram of a data center 400.
- FIG. Explanatory drawing of the encryption system using hierarchical inner product predicate encryption.
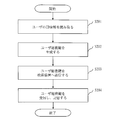
- the flowchart which shows the flow of an initial setting process.
- the block diagram of the encoded SNV information Explanatory drawing of blocking of the positional information in SNV information.
- Explanatory drawing of blocking of CNV gain in SV information The block diagram of encoded NC information.
- Explanatory drawing of the hierarchical structure of tag ID Explanatory drawing of the hierarchical structure of decryption person ID.
- sequence Explanatory drawing of encryption data with a tag.
- Explanatory drawing of an access authority management table. 2 is a diagram illustrating an example of a hardware configuration of a key management server 100, an encryption device 200, a search device 300, and a data center 400.
- FIG. 1 is a configuration diagram of a gene search system 10.
- the gene search system 10 includes a key management server 100, a plurality of encryption devices 200, a plurality of search devices 300, and a data center 400 (data management device).
- the key management server 100, the encryption device 200, the search device 300, and the data center 400 are connected via a network 500.
- the key management server 100 is a server that generates a user secret key such as an encryption user secret key or a secret search user secret key and distributes it to the encryption device 200 or the search device 300.
- the encryption user secret key is a key used for decryption of encrypted data
- the secret search user secret key is a key used for secret search.
- the encryption device 200 is a terminal for encrypting information stored in the data center 400.
- the encryption device 200 is a terminal mainly used by users such as hospital doctors, genome decoding center employees, and patients.
- the search device 300 is a terminal used for searching and acquiring information stored in the data center 400.
- the search device 300 is mainly used by a researcher such as a pharmaceutical company or a user such as a doctor in a hospital.
- the data center 400 is a server that stores genome information collected from patients, an electronic medical record in which a patient's medical history is described, and the like.
- the data center 400 provides a service for searching and browsing genomic information, electronic medical records, and the like according to requests from users such as patients, doctors, and researchers.
- the network 500 is a public line network such as the Internet.
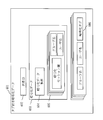
- FIG. 2 is a configuration diagram of the key management server 100.
- the key management server 100 includes a master key generation unit 110, a key storage unit 120, a user secret key generation unit 130, a data transmission / reception unit 140, and a user ID storage unit 150.
- the master key generation unit 110 generates a public parameter shared by all users who use the confidential search by the processing device, and also generates a master key that is a source for generating the user secret key.
- the key storage unit 120 stores the master key and public parameters generated by the master key generation unit 110 in a storage device.
- the user secret key generation unit 130 generates a user secret key from the master key by using the user ID uniquely assigned to the user by the processing device.
- the data transmission / reception unit 140 transmits the public parameters to the encryption device 200, the search device 300, and the data center 400 via the network 500. In addition, the data transmission / reception unit 140 transmits the user secret key to the search device 300 via the network 500. Further, the data transmission / reception unit 140 transmits the user ID to the users of the encryption device 200, the search device 300, and the data center 400 in response to a user request.
- the user ID storage unit 150 stores the user ID of each user in the storage device.
- the user ID is attribute information such as the user's name, affiliation, login ID, and mail address.
- the user ID storage unit 150 may store not only the current attribute information but also past attribute information as a history.
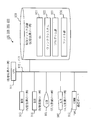
- FIG. 3 is a configuration diagram of the encryption device 200.
- the encryption device 200 includes a reference gene acquisition unit 210, a target gene input unit 220, a public parameter storage unit 230, a difference information generation unit 240, a difference information encoding unit 250, a data encryption unit 260, an encryption tag generation unit 270, a tag An attached encrypted data generation unit 280 is provided.
- the reference gene acquisition unit 210 acquires a predetermined publicly available genome sequence as a reference genome sequence (reference gene).
- the target gene input unit 220 acquires a patient genome sequence (target gene) stored in the data center 400. Further, the target gene input unit 220 acquires a patient ID indicating the patient of the patient genome sequence together with the patient genome sequence.
- the public parameter storage unit 230 receives the public parameter generated by the key management server 100 and stores it in the storage device.
- the difference information generation unit 240 compares the patient genome sequence with the reference genome sequence by the processing device, and generates a plurality of difference information.
- the difference information encoding unit 250 generates encoded difference information by encoding each difference information generated by the difference information generating unit 240 into a form suitable for searching while being encrypted by the processing device. A form suitable for performing a search with encryption will be described later.
- the data encryption unit 260 encrypts the patient genome sequence input by the target gene input unit 220 by the processing device, and generates encrypted data (encrypted gene).
- the encryption tag generation unit 270 encrypts the encoded difference information generated by the difference information encoding unit 250 by the processing device to generate an encryption tag.
- the tagged encrypted data generation unit 280 combines the encrypted data generated by the data encryption unit 260, the plurality of encrypted tags generated by the encryption tag generation unit 270, and the patient ID by the processing device. Generate tagged encrypted data.
- the tagged encrypted data generating unit 280 requests the data center 400 to store the generated tagged encrypted data.
- FIG. 4 is a configuration diagram of the search device 300.
- the search apparatus 300 includes a difference information input unit 310, a user secret key storage unit 320, a difference information encoding unit 330, a search query generation unit 340, a gene information acquisition unit 350, and a data decryption unit 360.
- the difference information input unit 310 inputs a search request including difference information from the reference genome sequence as a search keyword using the input device.
- the user secret key storage unit 320 stores the user secret key issued by the key management server 100 individually to the user and the public parameters in the storage device.
- the difference information encoding unit 330 has the same function as the difference information encoding unit 250.
- the difference information encoding unit 330 generates encoded difference information by encoding the difference information included in the search request input by the difference information input unit 310 into a form suitable for performing the search while being encrypted by the processing device.
- the search query generation unit 340 generates a search query from the user secret key and public parameters stored in the user secret key storage unit 320 and the encoded difference information generated by the difference information encoding unit 330 by the processing device.
- the gene information acquisition unit 350 transmits the search query generated by the search query generation unit 340 to the data center 400 via the network 500. Then, the gene information acquisition unit 350 receives the encrypted data in which the patient genome sequence including the difference information included in the search request (or similar difference information) is encrypted from the data center 400 via the network 500. To do.
- the gene information acquisition part 350 receives patient ID with encryption data.
- the data decryption unit 360 uses the processing device to decrypt the encrypted data received from the data center 400 using the user secret key stored in the user secret key storage unit 320 to obtain a patient genome sequence.
- FIG. 5 is a configuration diagram of the data center 400.
- the data center 400 includes a storage request processing unit 410, an encrypted data storage unit 420, an encryption tag storage unit 430, a search request processing unit 440, a public parameter storage unit 450, and an access authority storage unit 460.
- the storage request processing unit 410 receives the encrypted data with tag from the encryption device 200.
- the storage request processing unit 410 analyzes the received encrypted data with tag and decomposes it into encrypted data, a plurality of encrypted tags, and a patient ID.
- the storage request processing unit 410 allocates a common management number to the decrypted encrypted data and each encryption tag, and transmits the encrypted data together with the patient ID and the management number to the encrypted data storage unit 420, and each encryption tag Is transmitted to the encryption tag storage unit 430 together with the patient ID and the management number.
- the encrypted data storage unit 420 stores the encrypted data received from the storage request processing unit 410 in the storage device in association with the patient ID and the management number.
- the encryption tag storage unit 430 stores the encryption tag received from the storage request processing unit 410 in the storage device in association with the patient ID and the management number.
- the search request processing unit 440 receives a search query from the search device 300.
- the search request processing unit 440 performs a comparison process on the received search query and the encryption tag stored in the encryption tag storage unit 430 by the processing device. By this comparison processing, it is determined whether or not the difference information of the patient genome sequence included in the encryption tag matches the condition specified by the difference information (search request) of the patient genome sequence included in the search query. Thereafter, the search request processing unit 440 acquires the encrypted data associated with the encryption tag hit in the search from the encrypted data storage unit 420 and returns it to the search device 300.
- the encrypted data associated with the encryption tag is encrypted data assigned the same management number as the encryption tag.
- the public parameter storage unit 450 receives the public parameter generated by the key management server 100 and stores it in the storage device.
- the access authority storage unit 460 manages who the patient is allowed to disclose the patient genome sequence.
- the gene search system 10 uses an encryption method called hierarchical inner product predicate encryption described in Non-Patent Document 2 and the like, and a secret search method that enables keyword search with encryption using the same hierarchical inner product predicate encryption. .
- FIG. 6 is an explanatory diagram of an encryption method using hierarchical inner product predicate encryption.
- This encryption method includes a master key generation algorithm, a secret key generation algorithm, a delegation key generation algorithm, an encryption algorithm, and a decryption algorithm.
- an encryption master key and an encryption public parameter are generated using a master key generation algorithm.
- the encryption master key is a secret key used for generating an encryption user secret key for the decryption user.
- the public parameter for encryption is public information used for encryption, and is widely distributed to the user who performs encryption. In this process, it is necessary to determine the configuration of the conditional expression in advance and give the conditional expression as a parameter.
- the existing hierarchical inner product predicate ciphers such as Non-Patent Document 2 do not give the configuration of the conditional expression, but give the number of dimensions when the conditional expression is expressed as a vector. From this point of view, a conditional expression is given here. The same applies hereinafter.
- the encryption user secret key distributed to the decryption user is issued from the encryption conditional expression.
- the encryption conditional expression determines what attributes the decrypting user can decrypt a document, and the condition is described as a conditional expression using AND / OR logical operations.
- the data is encrypted using an encryption algorithm.
- an encryption attribute to be added to the encrypted data is designated and embedded in the encrypted data.
- the encrypted data is decrypted using a decryption algorithm.
- an encryption user private key is designated, but only encrypted data to which an encryption attribute that satisfies the conditional expression embedded in the encryption user private key is assigned can be decrypted. Encrypted data that does not satisfy the conditional expression cannot be decrypted at all.
- the hierarchical inner product predicate encryption also has a feature of key delegation.
- only a part of the conditional expression is set when the encryption user secret key is generated, and a part of the conditional expression is set in an unspecified state.
- a mechanism for setting an additional conditional expression to this unspecified conditional expression is key delegation. Specifically, by using a delegation key generation algorithm, an encryption additional conditional expression that is additionally set with respect to the encryption user secret key is specified, and an encryption delegation secret key is generated.
- This encryption delegation private key can be used for decryption of encrypted data in the same manner as the encryption user private key.
- an encryption user secret key in which the attribute information of the decryption user is set as a key attribute is issued.
- encrypted data in which user attribute information that can be decrypted is set as an encryption attribute is generated.
- encrypted data is encrypted with the encryption user secret key only when the key attribute set in the encryption user secret key and the encryption attribute set in the encryption data correspond to each other. Can be decrypted.
- additional attribute information is added to the encryption user private key, and lower-level encryption that can decrypt only a part of the encrypted data that can be decrypted with the encryption user private key User secret key is generated.
- FIG. 7 is an explanatory diagram of a secret search method using hierarchical inner product predicate encryption.
- This secret search method includes a master key generation algorithm, a secret key generation algorithm, a delegation key generation algorithm, an encryption tag generation algorithm, and a match determination algorithm.
- a secret search master key and a secret search public parameter are generated using a master key generation algorithm.
- the secret search master key is a secret key used to generate a search user secret key for the search user.
- the secret search public parameter is public information used when searching, and is widely distributed to users who search. The description of the conditional expression is the same as that of the encryption method.
- a secret search user secret key to be distributed to the search user from the secret search conditional expression is issued.
- the confidential search conditional expression specifies what attributes the search user can search for documents, and only the framework that specifies the search keyword with which conditional expression can be specified. It is described as a conditional expression using a logical operation of / OR.
- the search keyword itself can be set later by the delegation key generation algorithm.
- an encryption tag used for search processing is generated using an encryption tag generation algorithm.
- an arbitrary random value is generated, attributes are determined to limit users who are allowed to search, and keywords are determined.
- An encryption tag is generated using an encryption tag generation algorithm with a random value, an attribute, and a keyword as input. Specifically, the random number value is encrypted with an encryption algorithm, and a combination of the encrypted random number and the random value is used as an encryption tag.
- a search query is generated using a delegation key generation algorithm. Specifically, a search query is generated by embedding a search keyword in a portion of the secret search user secret key whose value is not specified so that the keyword can be specified later. This search query corresponds to the encryption delegation secret key of the encryption method.
- a match determination is performed using the match determination algorithm to determine whether or not the keywords included in both the received search query and the encrypted tag are the same.
- an encrypted random number is extracted from the encryption tag and decrypted using a search query corresponding to the encryption delegation secret key.
- the decryption result is the same as the random number value included in the encryption tag, that is, when the decryption result can be correctly decrypted, it is determined that the keyword is the same. This is because if the keyword included in the search query (corresponding to the encryption delegation secret key) and the keyword specified when generating the encrypted random number are not the same, the random number value cannot be correctly decrypted.
- the secret key generation algorithm issues a secret search user secret key in which the attribute information of the search user is set as a key attribute.
- encrypted data in which searchable user attribute information and keywords are set as encryption attributes is generated.
- a search query is generated by additionally setting a search keyword as a key attribute to the secret search user secret key.
- the random number value can be decrypted from the encryption tag only when the key attribute information set in the search query corresponds to the attribute information set in the encryption tag.
- the user attribute information set in the search query and the user attribute information set in the encryption tag correspond to each other, and the search keyword set in the search query and the keyword set in the encryption tag
- the random number value can be decrypted from the encryption tag only if and.
- the gene search system 10 executes initial setting processing, user secret key issuance processing, encryption processing, and search processing.
- the encryption process includes an encryption process for the patient genome sequence and an encryption process for the patient's electronic medical record.
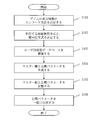
- FIG. 8 is a flowchart showing the flow of the initial setting process.
- the initial setting process is a process executed by the key management server 100 and is executed once before using the gene search system 10.
- the master key generation unit 110 determines a method for encoding the difference information of the patient genome sequence by the processing device. When determining the encoding method, a search expression of how to search is also considered.
- the main difference information includes SNV (Single Nucleotide Variant), SV (Structural Variants), and NC (Novel Config). Therefore, the encoding method and the search method will be described using these three examples.
- FIG. 9 is a configuration diagram of encoded SNV information.
- the SNV information indicates that one base has changed in the genome sequence.
- the SNV information includes a patient ID, a chromosome number, position information, replacement information 1, replacement information 2, and reliability.
- the patient ID is an identification number assigned to be associated with an electronic medical record managed separately. Since the patient ID only needs to be a number associated with the medical chart, not only the identification number assigned to the patient at the hospital, but also a value may be set by randomly assigning a number when storing the medical chart.
- the chromosome number is the number of the chromosome from which SNV was detected. In the case of the human genome, values such as 1, 2,..., 22, X, Y, M, etc. are set.
- the position information is information related to the position where the SNV is detected.
- the position is represented by a numerical value indicating what number in the base sequence, and in the case of the human genome, the value is about 1 to 3 billion.
- numerical information such as a position is searched by specifying a range.
- the range search is difficult to perform in the above-described secret search method, the speed is increased by making blocks.
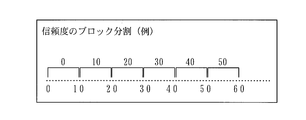
- FIG. 10 shows an encoding method in the case where the range specified at the time of search is generally suppressed to 5000 or less.
- Replacement information 1 and replacement information 2 are information indicating changes in genome information. For example, when a base represented by G is inserted as SNV, “G added” is defined, and when a base represented by A disappears, “A deleted” is represented. Is set. There are two pieces of substitution information. For example, when the base represented by G is changed to the base represented by A, the substitution information 1 is represented as G deletion, the substitution information 2 is represented as A addition, etc. Because.
- the reliability is information representing the reliability of the SNV information, and is represented by a real number from 0 to 100. As with the position information, this is also blocked to speed up the search. For example, as shown in FIG. 11, the reliability is divided in units of 10%, and the corresponding values are set. For example, when the reliability is 7.44%, the value 0 of the corresponding block is set.
- search In the case of search, specify some of the values from the above patient ID to confidence level that you want to specify as conditions, and specify “*” (wild card) that matches any value for unspecified locations. By doing so, difference information (search request) is generated. Then, for each element of the SNV information, a rule is determined such that the search is hit when all of the encryption tags and the search query match.
- each element matches. For example, when a patient ID is designated, those with the same patient ID are regarded as matching. Similarly, the chromosome number to be searched is designated for the chromosome number, and the same one is regarded as a match. In the case of position information, for example, if it is desired to search a range from 7000 to 12000, block 2 is specified as a block including the range, and “2” is designated as the search expression. And when it is the same as any one of the two values set as the position information of the SNV information, it is regarded as a match.
- a value to be searched is set according to the same rule as the value specified in the SNV information, and if both are the same, it is regarded as a match. Similarly, if the same value is specified for the reliability, it is regarded as a match. As described above, the encoding method of SNV information and the method of how the search can be performed are determined.
- FIG. 12 is a configuration diagram of encoded SV information.
- the SNV information indicates that one base is changed, whereas the SV information indicates that a plurality of consecutive base sequences are changed.
- SV information includes patient ID, chromosome number, start position information, end position information, mutation type, CNV gain, recombinant chromosome number, recombinant chromosome start position information, recombinant chromosome end position information, classification ID (insertion sequence), It consists of version (insertion sequence), chromosome number (insertion sequence), start position information (insertion sequence), and end position information (insertion sequence).
- the patient ID and chromosome number are the same as the SNV shown in FIG.
- the start position information is information indicating the position where the change has started.
- the position information is blocked in the same procedure as the position information of the SNV information, and a value indicating the block is set.
- the end position information is information indicating the position where the change has ended.
- the position information is blocked in the same procedure as the position information of the SNV information, and a value indicating the block is set.
- the mutation type is information indicating the type of SV.
- CNV gain and CNV loss indicating the addition / reduction of the number of repetitions of the gene sequence
- Inversion indicating inversion of the base sequence
- Insertion indicating large-scale insertion of the base sequence
- large-scale base sequence Values such as “Delete” indicating a defect and “Recombination” indicating a recombination with another chromosome are set.
- the CNV gain is used when “CNV gain” and “CNV loss” are set as the displacement type.
- CNV gain is set as the mutation type, the CNV gain is set with information indicating how many times the number of repetitions has increased, and when “CNV loss” is set, the number of times the number of repetitions has decreased. Is done.
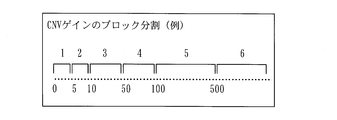
- this value is set by blocking. For example, as shown in FIG. 13, when the rule of blocking is defined and the CNV gain is 15, the corresponding block number “3” is set.
- the recombinant chromosome number is used when “recombination” is designated as the mutation type.
- the number of the recombined other chromosome is set as the recombinant chromosome number.
- the value that can be set is the same as the chromosome number.
- Recombinant chromosome start position information and recombinant chromosome end position information are used when “recombination” is designated as the mutation type.
- Recombinant chromosome start position information and recombinant chromosome end position information are information indicating the start position and end position of recombination in other chromosomes in order to indicate which base sequence of other chromosomes and recombination have occurred.
- the values that can be set are the same as the start position information and the end position information.
- the classification ID (inserted sequence) is used when “Insertion” is designated as the mutation type. As the classification ID (inserted sequence), a number indicating which other organism the inserted base sequence belongs is set.
- the version (inserted sequence) is a numerical value for indicating the version of the genome database used to determine the classification ID.
- Chromosome number (insertion sequence), start position information (insertion sequence), and end position information (insertion sequence) are information indicating which part of the base sequence of other organisms has been inserted. It is encoded by the same method as the position information and end position information. However, since the length of the genome sequence varies depending on the species, it is preferable to prepare a different block separation method for each classification ID.
- search among the values from the above patient ID to the end position information (insertion array), some of the values that are to be specified as conditions are specified, and the unspecified location is considered to match any value “*” Difference information (search request) is generated by designating “(wild card)”, and a search query is generated based on the difference information. Then, for each element of the SV information, a rule is determined such that the search is hit when all of the encryption tags and the search query match.
- Patient ID and chromosome number are the same as in the case of SNV information.
- the start position information, end position information, recombinant chromosome start position information, recombinant chromosome end position information, start position information (insertion sequence), and end position information (insertion sequence) may be handled in the same way as the position information of the SNV information.
- As the mutation type which type of mutation type is to be searched is specified in the search query, and the SV information set with the same value is regarded as a match. For example, when it is desired to search for a CNV gain between 10 and 30, a corresponding block number “3” is designated.
- the recombinant chromosome number and the chromosome number may be handled in the same way as the chromosome number.
- the classification ID and version are regarded as a match if the classification ID and version to be searched are entered in the search query and are the same as the SV information. As described above, the SV information encoding method and the method of how the search can be performed are determined.
- FIG. 14 is a configuration diagram of encoded NC information.
- NC information indicates the base that could not be mapped to the reference genome. In many cases, the base could not be mapped to the reference genome when a special genome was detected due to virus infection or the like. Therefore, the NC information includes a classification ID (insertion sequence), version (insertion sequence), chromosome number (insertion sequence), start position information (insertion sequence), and end position information (insertion sequence) in addition to the patient ID. .
- the method for setting values and the method for searching are the same as those for the SV information, and thus description thereof is omitted.
- the master key generation unit 110 determines a secret search method to be used and an encryption method for encrypting the data body by the processing device.
- a secret search method that can specify a plurality of search keywords is required.
- the secret search method using the above-described hierarchical inner product predicate encryption is used.
- an encryption method using the above-described hierarchical inner product predicate encryption is used as the encryption method.
- the master key generation unit 110 determines how to use the secret search method.
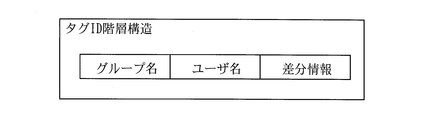
- the hierarchical structure of the tag ID is determined. For example, as shown in FIG.
- the tag ID is composed of three elements, a group name field for storing a group name of a group to which a searchable user belongs, a user name field for storing a name, etc., a difference in patient genome sequence It consists of a difference information column for storing information.
- a rule is considered that the search is hit only when it is determined that the group name, user name, and difference information all match.
- the master key generation unit 110 determines a method of using an encryption method for encrypting the data body.
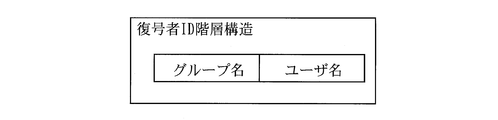
- the hierarchical structure of the decryptor ID is determined. For example, as shown in FIG.
- the decryptor ID is composed of two elements, and is composed of a group name column for storing a group name of a group to which a decryptable user belongs, and a user name column for storing a name and the like. At the time of decryption, it is assumed that only the group name and user name that match all can be decrypted.
- the user ID storage unit 150 constructs a user ID information database that stores user IDs.
- the user ID information database stores information necessary for generating the user secret key and information necessary for specifying the partner group name / user name when the encryption apparatus 200 encrypts the data. It is what is done.
- the user ID information database stores a company name as a group name, a name as a user name, affiliation information, a validity period, and the like.
- the user ID information database may store not only the latest situation but also all past histories.
- the master key generation unit 110 executes a secret search method master key generation algorithm by the processing device to generate a secret search master key and a secret search public parameter. Similarly, the master key generation unit 110 generates an encryption master key and an encryption public parameter by executing an encryption method master key generation algorithm by the processing device.
- the secret search master key and the encryption master key are collectively referred to as a master key
- the secret search disclosure parameter and the encryption disclosure parameter are collectively referred to as a disclosure parameter.
- the key storage unit 120 stores the master key and public parameters generated by the master key generation unit 110 in a storage device.
- the data transmitting / receiving unit 140 publishes the public parameters stored in the key storage unit 120 to the encryption device 200, the search device 300, and the data center 400 via the network 500.
- the disclosed public parameters are stored in the public parameter storage unit 230 in the encryption device 200, stored in the user secret key storage unit 320 in the search device 300, and stored in the public parameter storage unit 450 in the data center 400.
- the setup of the gene search system 10 is completed.
- the contents of the user ID information database generated in S103 are maintained every time a user changes, joins, or leaves the company during system operation.
- FIG. 18 is a flowchart showing the flow of the user secret key issuing process.
- the user secret key issuance process is mainly executed by the key management server 100 and the search device 300, and is executed when a new user is added or when the group name to which the user belongs is changed. .
- the user secret key generation unit 130 acquires the group name and user name of the user who issues the user secret key from the user ID information database held by the user ID storage unit 150.
- the user secret key generation unit 130 generates a secret search user secret key used for generating a search query and an encryption user secret key used for decrypting encrypted data by the processing device.
- the secret search method it is necessary to specify a tag ID hierarchical structure when generating a secret search user secret key.
- the group name acquired in S201 is set in the group name field, the user name is also set as the user name, and the difference information is designated as an element that can be delegated so that a user who searches later can be set.
- a user secret key can be generated.
- the encryption user secret key can be generated by designating the group name acquired in S201 in the group name column and the user name as the user name.
- the secret search user secret key and the encryption user secret key generated above are collectively referred to as a user secret key.
- the data transmission / reception unit 140 transmits the user secret key generated in S202 to the search device 300.
- the user secret key storage unit 320 receives the user secret key transmitted in S203 and stores it in the storage device.
- FIG. 19 is a flowchart showing a flow of encryption processing of a patient genome sequence.
- the patient genome sequence encryption processing is mainly performed by the encryption device 200 and the data center 400, and is performed when the patient genome sequence is encrypted and stored in the data center 400.
- the reference gene acquisition unit 210 acquires a reference genome sequence published on the Internet, for example.
- the target gene input unit 220 inputs a patient genome sequence using an input device.
- the difference information generation unit 240 generates difference information such as SNV, SV, NC, and the like by comparing the patient genome sequence with the reference genome sequence by the processing device.
- the ChIP-seq method, the RNA-seq method, the MeDIP-seq method, the mutation analysis method, the bisulfite method, and the like are known, and their general methods are used.
- the data encryption unit 260 allows a user who operates the encryption device 200 to input a group name and a user name of a user who can decrypt the encrypted data.
- the encryption tag generation unit 270 inputs a group name and a user name of users who can search the encrypted data.
- the group name and the user name input here do not need to be one, and when there are a plurality of users that can be decrypted or searched, a plurality of users can be input.
- the secret search method and encryption method used here can receive a wild card meaning that anyone can be used as a group name or a user name.
- the data encryption unit 260 encrypts the patient genome sequence input in S301 by using the group name and the user name that can be decrypted in S302 by the processing device. Specifically, the data encryption unit 260 randomly generates a session key, encrypts the patient genome sequence with the session key using a common key cipher such as AES or Camellia (registered trademark), and the encrypted data body Is generated. Next, the data encryption unit 260 designates the group name and user name that can be decrypted in S302 as the group name and user name in the decryptor ID hierarchical structure, and uses this as the encryption public key. The session key is encrypted using the encryption method determined in S102, and an encrypted session key is generated.
- the data encryption unit 260 generates encrypted data by combining the above-described two encryption results (encrypted data body and encrypted session key).
- the data structure of the generated encrypted data is indicated by reference numeral 603 in FIG.
- the difference information encoding unit 250 encodes each difference information generated in S301 by the processing device according to the encoding method determined in S101 to generate encoded difference information. Moreover, the difference information encoding part 250 inputs patient ID from a user, and includes it in encoding difference information.
- the encryption tag generation unit 270 encrypts the encode difference information and generates an encryption tag. Specifically, the encryption tag generation unit 270 uses the processing device to specify the searchable group name and user name input in S302 as the group name and user name of the tag ID hierarchical structure, and enter S304 in the difference information column. The encoding difference information encoded in the above is designated, and the random number value is encrypted by the secret search method to generate the encryption tag. Also, the encryption tag generation unit 270 includes the random number value in the encryption tag as plain text. In addition, since the said process is a process with respect to one difference information, this process is implemented with respect to each encoding difference information. For example, this is performed for each encoding difference information of SNV, SV, and NC. If a plurality of combinations of group name and user name are input in S302, an encryption tag is generated for each group name and user name combination.
- the tagged encrypted data generation unit 280 uses the processing device to combine the encrypted data generated in S303, the encrypted tag generated in S305, and the patient ID input in S304 to perform tagged encryption. Data is generated (reference numeral 601 in FIG. 20). Then, the tagged encrypted data generation unit 280 transmits the generated tagged encrypted data to the data center 400 and requests storage. At this time, in order to facilitate storage of the tagged encrypted data in the data center 400, the tagged encrypted data generation unit 280 uses the group name and user name that can be decrypted and the group name that can be searched, input in S302. And user name together. In the configuration of the encrypted data with tag shown in FIG. 20, the group name and user name that can be decrypted, and the group name and user name that can be searched are included in the encrypted data with tag.
- the storage request processing unit 410 uses the processing device to decompose the encrypted data with tag received from the encryption device 200, and extracts the encrypted data, a plurality of encryption tags, and a patient ID. Then, the storage request processing unit 410 causes the encrypted data storage unit 420 to store the encrypted data together with the patient ID.
- the encrypted data storage unit 420 stores the encrypted data separately for each group name and user name included in the tagged encrypted data, and further assigns a management number to the stored encrypted data. Encrypted data can be uniquely identified from the management number. When the encrypted data is associated with a plurality of group names or user names, the encrypted data is stored in association with each group name and user name.
- FIG. 21 is a diagram illustrating an example of storage of encrypted data.
- the storage request processing unit 410 collectively manages the encrypted data, the patient ID, and the management number whose group name is “A pharmaceutical company” and whose user name is “*” (wild card). Further, the encrypted data having the group name “B hospital” and the user name “*”, the patient ID, and the management number are collectively managed.
- the management number 000001 is stored in association with the patient ID and the encrypted data body, and the management number 100002 is encrypted in addition to the patient ID.
- a pointer that refers to the management number 000001 is stored as data.
- the storage request processing unit 410 stores the plurality of encryption tags extracted in S307 in the encryption tag storage unit 430 together with the management number of the corresponding encryption data and the patient ID.
- the encryption tag storage unit 430 stores the encryption tag, the management number, and the patient ID separately for each group name and user name included in the tagged encrypted data.
- FIG. 22 is a flowchart showing a flow of encryption processing of a patient's electronic medical record.
- the encryption process of the patient's electronic medical record is mainly performed by the encryption apparatus 200 and the data center 400, and is executed when the electronic medical record is encrypted and stored in the data center 400.
- the data encryption unit 260 allows a user who operates the encryption device 200 to input a group name and a user name of a user who can decrypt the electronic medical record.
- the group name and the user name input here do not need to be one, and when there are a plurality of users that can be decrypted, a plurality of users can be input.
- the data encryption unit 260 allows the user to input a patient ID and an electronic medical record. Then, the data encryption unit 260 encrypts the electronic medical record using the group name and the user name input in S401 by the processing device. Since the specific encryption method is the same as the flow of encrypting the patient genome sequence in S303, the details are omitted.
- the data encryption unit 260 sends the encrypted data generated in S402 to the data center 400 together with the patient ID indicating the electronic medical record, the group name and user name of the decryptable user, and requests storage. To do.
- the storage request processing unit 410 stores the encrypted data received from the encryption device 200 in the encrypted data storage unit 420 in association with the patient ID.
- FIG. 23 is a flowchart showing the flow of search processing.
- the search process is mainly executed by the search apparatus 300 and the data center 400, and is executed when an encrypted patient genome sequence stored in the data center 400 is acquired.
- the difference information input unit 310 allows a user who operates the search device 300 to input a search request including difference information from the reference genome sequence as a search keyword.
- the difference information input here does not need to specify all the elements as in the difference information extracted from the patient genome.
- the difference information input only includes the chromosome number or the position information. Good.
- the difference information encoding unit 330 encodes the difference information input in S501 by the processing device to generate encoded difference information. Since this process is the same as the process of step S304, the details are omitted. However, it should be noted that elements that are not specified are marked with “*”.
- the search query generation unit 340 generates a search query using the encoding difference information generated in S502 and the user secret key stored in the user secret key storage unit 320 by the processing device. Then, the search query generation unit 340 transmits the generated search query to the data center 400. At this time, the user's own group name and user name are also transmitted. In addition, in order to verify the reliability of the group name and the user name, the user who operates the search terminal is also authenticated.
- the search request processing unit 440 is an encryption that allows the processing device to search from all the encryption tags stored in the encryption tag storage unit 430 using the group name and user name transmitted together with the search query in S503. Get all tags.
- the search request processing unit 440 retrieves a list of patient IDs accessible by the user of the corresponding group name and user name from the access authority storage unit 460, and obtains only the encryption tag corresponding to the patient ID. Narrow down the tags.
- the access authority storage unit 460 has an access authority management table as shown in FIG. 24, specifies a patient ID corresponding to a searchable patient genome sequence using the group name and user name as accessor information, What is necessary is just to output the encryption tag corresponding to the patient ID.
- the search request processing unit 440 performs a confidential search method match determination process on the encrypted tags narrowed down in S504 by the processing device, and the difference information included in the encrypted tags is included in the search query transmitted in S503. It is determined whether or not the condition specified by the difference information is met.
- the secret search method match determination process can only compare one encrypted tag with one search query. Therefore, the matching determination process is performed for all the encryption tags acquired in S504. Then, the management number associated with the encryption tag determined to be coincident as a result of the determination process is specified.
- the search request processing unit 440 acquires all the encrypted data corresponding to the management number specified in S505 from the encrypted data storage unit 420, and transmits it to the search device 300 together with the corresponding patient ID.
- the data decryption unit 360 uses the processing device to decrypt the encrypted data received from the data center 400 in step S506 using the encryption user secret key stored in the user secret key storage unit 320. Decrypt by executing. The data decryption unit 360 performs this process on all received encrypted data.
- the search device 300 can receive the difference information to be searched from the user, obtain the encrypted data that matches the difference information from the data center 400, decrypt it, and browse the patient genome sequence. If necessary, a patient ID corresponding to the encrypted data can be transmitted to the data center 400 to obtain a corresponding electronic medical record.
- the patient genome is encrypted using the secret search method and stored in the data center 400, and the search request is also encrypted using the secret search technique. Asked to search. Therefore, the data center 400 can provide a search service even though the contents of the patient genome cannot be known at all.
- the human genome information is a very large amount of data consisting of 3 billion bases. Therefore, if all the human genome information is used as a tag, the data size may further increase due to encryption, which will cause a pressure on the disk capacity and network capacity.
- the tag since the tag is limited to the difference information with the reference genome sequence that is open to the public, the disk usage and the network capacity can be greatly reduced.
- the gene search system 10 by making numerical information such as SNV position information and reliability into blocks, a range search that is difficult to realize by a secret search is performed using a match search. It was realized. For this reason, it is possible to cope with range search used in genome search.
- the position information of the SNV shown in FIG. That is, the positions 5000 to 10000 overlap in the block 1 and the block 2, and the positions 10000 to 15000 overlap in the block 2 and the block 3.
- the search is performed using all blocks, and when the range specified at the time of search is 10,000 or less, the search is performed only with odd blocks. It becomes possible to process at higher speed.
- the condition match determination is not performed individually, but the inner product predicate encryption is used. It is determined at a time whether all search conditions are satisfied. For this reason, the server does not know that the search was partially hit, and the security is high.
- the patient ID is included together with the encrypted data. Therefore, information such as related electronic medical records can be extracted from the patient ID obtained as a search result. Therefore, if the relevant base mutation has occurred, it is possible to study what kind of disease it is related to.
- the group name and the user name are included in the tag ID hierarchical structure and the decryptor ID hierarchical structure. did. Therefore, it is possible to limit researchers and doctors who can search and decrypt. For example, if “A pharmaceutical company” is designated as the group name and a wild card “*” is designated as the user name, the patient information can be limited to the employees of the A pharmaceutical company. Further, by encrypting the group name and the user name with the wild card “*”, any doctor or researcher registered in the system can use the patient information.
- the data center 400 stores an access authority management table separately from encryption access control, and access control based on this information is also possible. Therefore, according to the request from the patient, “only genome sequence can be browsed” or “the chart can be browsed” can be managed in detail. That is, based on this information, it is determined whether or not a search request from the patient genome sequence is permitted, so fine access control is possible.
- the group name and the user name are included in the searcher's user secret key. Therefore, authentication can be performed by confirming the group name and user name included in the search query generated from the user private key.
- this access control unit is an example.
- a national qualification condition such as a doctor or nurse may be included, or a flag indicating whether or not a participant in a national project may be set. Since these ID hierarchical structures are examples, various elements can be added or deleted.
- the user secret key is stored in the search device 300 so that the search query is generated and the encrypted data is decrypted.
- the user secret key may be managed using a device such as an IC card instead of the search device 300. In this case, since the user secret key is managed safely in the IC card, security can be improved.
- the secret search user secret key used in the search terminal is generated as a key that can be used in common for searching for SNV information, SV information, NC information, and the like.
- the common secret search user secret key is not used, but the SNV information secret search user secret key, the SV information secret search user secret key, and the NC information secret search user.
- a secret search user secret key such as a secret key may be individually generated according to the application. In this case, since the length of the secret search user secret key is optimized to the length of each information, the calculation time is increased.
- character strings such as “A pharmaceutical company” and “Tanaka” are used to indicate group names and user names. This is because priority is given to ease of understanding as an embodiment, and actually, an ID such as a number may be used in addition to a character string. The same applies to other elements such as chromosome numbers.
- hierarchical inner product predicate encryption is used as a secret search method or encryption method.
- the encryption need not be limited to the hierarchical inner product predicate encryption as long as it has the same function. Different methods may be used for the secret search method and the encryption method.
- the user ID storage unit 150 can manage past attribute information of the user. This may be performed only when necessary for management, and only the current attribute information may be managed.
- those that require range search can be determined with complete keyword matching by blocking.
- range to be searched varies depending on the application, it is not always necessary to be able to search with an exact match.
- a plurality of blocks may be specified as a search range like the block 10 or the block 11 at the time of search.
- the hierarchical inner product predicate encryption used as the secret search method or the encryption method can be operated by dividing the key management server 100 into a plurality of layers. For this reason, the key management server 100 can also be operated in multiple hierarchies.
- FIG. 25 is a diagram illustrating an example of a hardware configuration of the key management server 100, the encryption device 200, the search device 300, and the data center 400.
- a key management server 100, an encryption device 200, a search device 300, and a data center 400 include a CPU 911 (Central Processing Unit, a central processing unit, a processing unit, an arithmetic unit, a microprocessor that executes a program. , Also referred to as a microcomputer or a processor).
- the CPU 911 is connected to the ROM 913, the RAM 914, the LCD 901 (Liquid Crystal Display), the keyboard 902 (K / B), the communication board 915, and the magnetic disk device 920 via the bus 912, and controls these hardware devices.
- the magnetic disk device 920 fixed disk device
- a storage device such as an optical disk device or a memory card read / write device may be used.
- the magnetic disk device 920 is connected via a predetermined fixed disk interface.
- the ROM 913 and the magnetic disk device 920 are examples of a nonvolatile memory.
- the RAM 914 is an example of a volatile memory.
- the ROM 913, the RAM 914, and the magnetic disk device 920 are examples of a storage device (memory).
- the keyboard 902 and the communication board 915 are examples of input devices.
- the communication board 915 is an example of a communication device.
- the LCD 901 is an example of a display device.
- an operating system 921 OS
- a window system 922 a program group 923
- a file group 924 are stored in the magnetic disk device 920 or the ROM 913.
- the programs in the program group 923 are executed by the CPU 911, the operating system 921, and the window system 922.
- the program group 923 includes “master key generation unit 110”, “user secret key generation unit 130”, “data transmission / reception unit 140”, “reference gene acquisition unit 210”, “target gene input unit 220”, “Difference information generation unit 240”, “Difference information encoding unit 250”, “Data encryption unit 260”, “Encryption tag generation unit 270”, “Tagged encrypted data generation unit 280”, “Difference information input unit 310” ”,“ Difference information encoding unit 330 ”,“ search query generation unit 340 ”,“ gene information acquisition unit 350 ”,“ data decryption unit 360 ”,“ storage request processing unit 410 ”,“ search request processing unit 440 ”, etc. It stores software, programs and other programs that execute the functions described. The program is read and executed by the CPU 911.
- the file group 924 includes “key storage unit 120”, “user ID storage unit 150”, “public parameter storage unit 230”, “user secret key storage unit 320”, and “encrypted data storage unit 420” in the above description.
- Information, data, signal values, variable values, and parameters stored in “encryption tag storage unit 430”, “public parameter storage unit 450”, “access authority storage unit 460”, etc. are “file” or “database”. It is memorized as each item.
- the “file” and “database” are stored in a storage medium such as a disk or a memory.
- Information, data, signal values, variable values, and parameters stored in a storage medium such as a disk or memory are read out to the main memory or cache memory by the CPU 911 via a read / write circuit, and extracted, searched, referenced, compared, and calculated. Used for the operation of the CPU 911 such as calculation / processing / output / printing / display. Information, data, signal values, variable values, and parameters are temporarily stored in the main memory, cache memory, and buffer memory during the operation of the CPU 911 for extraction, search, reference, comparison, calculation, calculation, processing, output, printing, and display. Is remembered.
- the arrows in the flowcharts in the above description mainly indicate input / output of data and signals, and the data and signal values are recorded in a memory of the RAM 914, other storage media such as an optical disk, and an IC chip.
- Data and signals are transmitted online by a bus 912, signal lines, cables, other transmission media, and radio waves.
- what is described as “to part” in the above description may be “to circuit”, “to device”, “to device”, “to means”, and “to function”. It may be “step”, “ ⁇ procedure”, “ ⁇ processing”.
- ⁇ device may be “ ⁇ circuit”, “ ⁇ equipment”, “ ⁇ means”, “ ⁇ function”, and “ ⁇ step”, “ ⁇ procedure”, “ May be “processing”.
- to process may be “to step”. That is, what is described as “ ⁇ unit” may be realized by firmware stored in the ROM 913. Alternatively, it may be implemented only by software, or only by hardware such as elements, devices, substrates, and wirings, by a combination of software and hardware, or by a combination of firmware.
- Firmware and software are stored in a recording medium such as ROM 913 as a program. The program is read by the CPU 911 and executed by the CPU 911. That is, the program causes a computer or the like to function as the “ ⁇ unit” described above. Alternatively, the procedure or method of “unit” described above is executed by a computer or the like.
- 10 gene search system 100 key management server, 110 master key generation unit, 120 key storage unit, 130 user secret key generation unit, 140 data transmission / reception unit, 150 user ID storage unit, 200 encryption device, 210 reference gene acquisition unit, 220 target gene input unit, 230 public parameter storage unit, 240 differential information generation unit, 250 differential information encoding unit, 260 data encryption unit, 270 encryption tag generation unit, 280 encrypted data generation unit with tag, 300 search device, 310 differential information input unit, 320 user secret key storage unit, 330 differential information encoding unit, 340 search query generation unit, 350 gene information acquisition unit, 360 data decryption unit, 400 data center, 410 storage request processing unit, 420 encrypted data Storage unit, 43 Encrypting the tag memory unit, 440 the search request processing unit, 450 Public parameter storage unit, 460 access the storage unit, 500 network.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Bioethics (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biotechnology (AREA)
- Evolutionary Biology (AREA)
- Medical Informatics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Computer Security & Cryptography (AREA)
- Signal Processing (AREA)
- Computer Networks & Wireless Communication (AREA)
- Databases & Information Systems (AREA)
- Chemical & Material Sciences (AREA)
- Analytical Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Computer Hardware Design (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Genetics & Genomics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Storage Device Security (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201480018404.1A CN105190636A (zh) | 2013-03-28 | 2014-02-21 | 基因信息存储装置、基因信息检索装置、基因信息存储程序、基因信息检索程序、基因信息存储方法、基因信息检索方法以及基因信息检索系统 |
| EP14775361.0A EP2980718A4 (en) | 2013-03-28 | 2014-02-21 | GENETIC INFORMATION STORAGE DEVICE, GENETIC INFORMATION SEARCHING DEVICE, GENETIC INFORMATION STORAGE PROGRAM, GENETIC INFORMATION SEARCHING PROGRAM, GENETIC INFORMATION STORAGE METHOD, METHOD FOR SEARCHING FOR GENETIC INFORMATION, AND SEARCH FOR GENETIC INFORMATION |
| US14/779,527 US10311239B2 (en) | 2013-03-28 | 2014-02-21 | Genetic information storage apparatus, genetic information search apparatus, genetic information storage program, genetic information search program, genetic information storage method, genetic information search method, and genetic information search system |
| HK16107331.5A HK1219324A1 (en) | 2013-03-28 | 2014-02-21 | Genetic information storage device, genetic information search device, genetic information storage program, genetic information search program, genetic information storage method, genetic information search method, and genetic information search system |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013-067770 | 2013-03-28 | ||
| JP2013067770A JP6054790B2 (ja) | 2013-03-28 | 2013-03-28 | 遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法、遺伝子情報検索方法及び遺伝子情報検索システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014156400A1 true WO2014156400A1 (ja) | 2014-10-02 |
Family
ID=51623401
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/054145 Ceased WO2014156400A1 (ja) | 2013-03-28 | 2014-02-21 | 遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法、遺伝子情報検索方法及び遺伝子情報検索システム |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US10311239B2 (enExample) |
| EP (1) | EP2980718A4 (enExample) |
| JP (1) | JP6054790B2 (enExample) |
| CN (1) | CN105190636A (enExample) |
| HK (1) | HK1219324A1 (enExample) |
| TW (1) | TWI510939B (enExample) |
| WO (1) | WO2014156400A1 (enExample) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110506272A (zh) * | 2016-10-11 | 2019-11-26 | 基因组系统公司 | 用于访问以访问单元结构化的生物信息数据的方法和装置 |
| CN111540409A (zh) * | 2020-04-20 | 2020-08-14 | 中南大学 | 基于隐私保护的基因相似度计算方法及基因信息获取方法 |
| WO2024142343A1 (ja) * | 2022-12-28 | 2024-07-04 | 三菱電機株式会社 | 登録要求装置、検索要求装置、データ管理装置、秘匿検索システム、登録要求方法、登録要求プログラム、検索要求方法、検索要求プログラム、データ管理方法及びデータ管理プログラム |
Families Citing this family (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011108540A1 (ja) | 2010-03-03 | 2011-09-09 | 国立大学法人大阪大学 | ヌクレオチドを識別する方法および装置、ならびにポリヌクレオチドのヌクレオチド配列を決定する方法および装置 |
| CN106104274B (zh) | 2013-09-18 | 2018-05-22 | 量子生物有限公司 | 生物分子测序装置、系统和方法 |
| JP2015077652A (ja) | 2013-10-16 | 2015-04-23 | クオンタムバイオシステムズ株式会社 | ナノギャップ電極およびその製造方法 |
| US10438811B1 (en) | 2014-04-15 | 2019-10-08 | Quantum Biosystems Inc. | Methods for forming nano-gap electrodes for use in nanosensors |
| WO2015170782A1 (en) | 2014-05-08 | 2015-11-12 | Osaka University | Devices, systems and methods for linearization of polymers |
| US9875375B2 (en) * | 2015-05-29 | 2018-01-23 | Panasonic Intellectual Property Corporation Of America | Method for performing similar-information search while keeping content confidential by encryption |
| JP6582930B2 (ja) * | 2015-11-30 | 2019-10-02 | コニカミノルタ株式会社 | データ送受信システム、情報処理装置、データ送受信方法およびデータ送受信プログラム |
| JP6742852B2 (ja) * | 2015-12-14 | 2020-08-19 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | 検索方法、検索システム及びプログラム |
| WO2017122326A1 (ja) * | 2016-01-14 | 2017-07-20 | 三菱電機株式会社 | 秘匿検索システム、秘匿検索方法及び秘匿検索プログラム |
| WO2017122352A1 (ja) | 2016-01-15 | 2017-07-20 | 三菱電機株式会社 | 暗号化装置、暗号化方法及び暗号化プログラム |
| EP3414694A4 (en) * | 2016-02-12 | 2019-10-23 | Pegasus Media Security, LLC | SAFETY IMPROVED PORTABLE DATA STORAGE AND PROCESSOR FOR SAFE AND SELECTIVE ACCESS TO GENOMIC DATA |
| US10339325B2 (en) * | 2016-03-03 | 2019-07-02 | JJD Software LLC | Multi-level security model for securing access to encrypted private data |
| CN109937426A (zh) * | 2016-04-11 | 2019-06-25 | 量子生物有限公司 | 用于生物数据管理的系统和方法 |
| CN115595360A (zh) | 2016-04-27 | 2023-01-13 | 因美纳剑桥有限公司(Gb) | 用于生物分子的测量和测序的系统和方法 |
| CN109416932A (zh) * | 2016-06-29 | 2019-03-01 | 皇家飞利浦有限公司 | 面向疾病的基因组匿名化 |
| MX2019004131A (es) * | 2016-10-11 | 2020-01-30 | Genomsys Sa | Metodo y aparato para el acceso a datos bioinformaticos estructurados en unidades de acceso. |
| JP6494893B2 (ja) * | 2017-01-12 | 2019-04-03 | 三菱電機株式会社 | 暗号化タグ生成装置、検索クエリ生成装置及び秘匿検索システム |
| JP6584723B2 (ja) * | 2017-04-25 | 2019-10-02 | 三菱電機株式会社 | 検索装置、検索システム、検索方法及び検索プログラム |
| CN107506615A (zh) * | 2017-08-21 | 2017-12-22 | 为朔医学数据科技(北京)有限公司 | 一种基因组学数据管理方法、服务器和系统 |
| US11899812B2 (en) | 2018-01-03 | 2024-02-13 | JJD Software LLC | Compound platform for maintaining secure data |
| US11038691B2 (en) * | 2018-01-03 | 2021-06-15 | JJD Software LLC | Database platform for maintaining secure data |
| CN108810570A (zh) * | 2018-06-08 | 2018-11-13 | 安磊 | 人工智能视频基因加密方法、装置及设备 |
| US11611539B2 (en) * | 2018-12-16 | 2023-03-21 | Auth9, Inc. | Method, computer program product and apparatus for encrypting and decrypting data using multiple authority keys |
| JP6980155B2 (ja) * | 2019-05-31 | 2021-12-15 | 三菱電機株式会社 | 暗号システム、暗号方法および暗号プログラム |
| WO2020259847A1 (en) | 2019-06-28 | 2020-12-30 | Geneton S.R.O. | A computer implemented method for privacy preserving storage of raw genome data |
| JP6987330B1 (ja) * | 2020-01-14 | 2021-12-22 | 三菱電機株式会社 | 登録装置、検索操作装置、データ管理装置、登録プログラム、検索操作プログラムおよびデータ管理プログラム |
| CN117711501B (zh) * | 2023-10-26 | 2024-06-11 | 安徽溯远分析仪器有限公司 | 一种基因测序数据管理系统 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003177992A (ja) * | 2001-12-10 | 2003-06-27 | Seiko Epson Corp | 差分通信システム、差分通信装置及び差分通信プログラム、並びに差分通信方法 |
| JP2012073693A (ja) * | 2010-09-28 | 2012-04-12 | Mitsubishi Space Software Kk | 遺伝子情報検索システム、遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法及び遺伝子情報検索方法 |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BR9714951A (pt) * | 1997-06-30 | 2000-10-17 | Dow Chemical Co | Processo para preparar um óxido de olefina, composição de catalisador e processo para regenerar um composição. |
| US20080125978A1 (en) * | 2002-10-11 | 2008-05-29 | International Business Machines Corporation | Method and apparatus for deriving the genome of an individual |
| US20040153255A1 (en) * | 2003-02-03 | 2004-08-05 | Ahn Tae-Jin | Apparatus and method for encoding DNA sequence, and computer readable medium |
| JP5154832B2 (ja) * | 2007-04-27 | 2013-02-27 | 株式会社日立製作所 | 文書検索システム及び文書検索方法 |
| JP2011203943A (ja) * | 2010-03-25 | 2011-10-13 | Nippon Telegr & Teleph Corp <Ntt> | メタデータ生成装置およびメタデータ生成方法 |
| WO2012095973A1 (ja) * | 2011-01-13 | 2012-07-19 | 三菱電機株式会社 | データ処理装置及びデータ保管装置 |
| JP2012216114A (ja) * | 2011-04-01 | 2012-11-08 | Life:Kk | 情報処理装置および方法、並びにプログラム |
-
2013
- 2013-03-28 JP JP2013067770A patent/JP6054790B2/ja not_active Expired - Fee Related
-
2014
- 2014-02-21 EP EP14775361.0A patent/EP2980718A4/en not_active Withdrawn
- 2014-02-21 CN CN201480018404.1A patent/CN105190636A/zh active Pending
- 2014-02-21 HK HK16107331.5A patent/HK1219324A1/en unknown
- 2014-02-21 WO PCT/JP2014/054145 patent/WO2014156400A1/ja not_active Ceased
- 2014-02-21 US US14/779,527 patent/US10311239B2/en active Active
- 2014-02-25 TW TW103106205A patent/TWI510939B/zh not_active IP Right Cessation
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003177992A (ja) * | 2001-12-10 | 2003-06-27 | Seiko Epson Corp | 差分通信システム、差分通信装置及び差分通信プログラム、並びに差分通信方法 |
| JP2012073693A (ja) * | 2010-09-28 | 2012-04-12 | Mitsubishi Space Software Kk | 遺伝子情報検索システム、遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法及び遺伝子情報検索方法 |
Non-Patent Citations (5)
| Title |
|---|
| ALLISON LEWKO; TATSUAKI OKAMOTO; AMIT SAHAI; KATSUYUKI TAKASHIMA; BRENT WATERS: "Fully Secure Functional Encryption: Attribute-Based Encryption and (Hierarchical) Inner Product Encryption", EUROCRYPT2010, LECTURE NOTES IN COMPUTER SCIENCE, vol. 6110, 2010 |
| BONEH; DI CRESCENZO; OSTROVSKI; PERSIANO: "Public key encryption with keyword search", EUROCRYPT, 2004, pages 506 - 522 |
| KAZUSHIRO MINEGISHI ET AL.: "Data Outsourcing ni Okeru Privacy Hogo SNP Kensaku System no Jisso", DAI 5 KAI FORUM ON DATA ENGINEERING AND INFORMATION MANAGEMENT (DAI 11 KAI THE DATABASE SOCIETY OF JAPAN NENJI TAIKAI, 31 May 2013 (2013-05-31), XP008180960 * |
| See also references of EP2980718A4 |
| SHOGO SHIMIZU ET AL.: "DAS Model ni Okeru Anzen na Ruiji Mojiretsu Kensaku Hoshiki no Teian", JOURNAL OF THE DBSJ, vol. 7, no. 1, 27 June 2008 (2008-06-27), pages 13 - 18, XP008181036 * |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110506272A (zh) * | 2016-10-11 | 2019-11-26 | 基因组系统公司 | 用于访问以访问单元结构化的生物信息数据的方法和装置 |
| CN110506272B (zh) * | 2016-10-11 | 2023-08-01 | 基因组系统公司 | 用于访问以访问单元结构化的生物信息数据的方法和装置 |
| CN111540409A (zh) * | 2020-04-20 | 2020-08-14 | 中南大学 | 基于隐私保护的基因相似度计算方法及基因信息获取方法 |
| CN111540409B (zh) * | 2020-04-20 | 2023-06-27 | 中南大学 | 基于隐私保护的基因相似度计算方法及基因信息获取方法 |
| WO2024142343A1 (ja) * | 2022-12-28 | 2024-07-04 | 三菱電機株式会社 | 登録要求装置、検索要求装置、データ管理装置、秘匿検索システム、登録要求方法、登録要求プログラム、検索要求方法、検索要求プログラム、データ管理方法及びデータ管理プログラム |
| JP7573797B1 (ja) * | 2022-12-28 | 2024-10-25 | 三菱電機株式会社 | 登録要求装置、検索要求装置、データ管理装置、秘匿検索システム、登録要求方法、登録要求プログラム、検索要求方法、検索要求プログラム、データ管理方法及びデータ管理プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2980718A4 (en) | 2016-11-23 |
| EP2980718A1 (en) | 2016-02-03 |
| HK1219324A1 (en) | 2017-03-31 |
| US20160048690A1 (en) | 2016-02-18 |
| TW201506653A (zh) | 2015-02-16 |
| US10311239B2 (en) | 2019-06-04 |
| JP6054790B2 (ja) | 2016-12-27 |
| TWI510939B (zh) | 2015-12-01 |
| CN105190636A (zh) | 2015-12-23 |
| JP2014191670A (ja) | 2014-10-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6054790B2 (ja) | 遺伝子情報記憶装置、遺伝子情報検索装置、遺伝子情報記憶プログラム、遺伝子情報検索プログラム、遺伝子情報記憶方法、遺伝子情報検索方法及び遺伝子情報検索システム | |
| Akgün et al. | Privacy preserving processing of genomic data: A survey | |
| CN104680076B (zh) | 用于使受保护健康信息匿名化和聚集的系统 | |
| Ayday et al. | Protecting and evaluating genomic privacy in medical tests and personalized medicine | |
| Ayday et al. | Privacy-preserving processing of raw genomic data | |
| JPWO2011086687A1 (ja) | 秘匿検索システム及び暗号処理システム | |
| CN107077469B (zh) | 服务器装置、检索系统、终端装置以及检索方法 | |
| CN114026823A (zh) | 用于处理匿名数据的计算机系统及其操作方法 | |
| CN106169013A (zh) | 用于使受保护信息匿名化和聚集的系统 | |
| KR20140029984A (ko) | 의료정보 데이터베이스 운영 시스템의 의료정보 관리 방법 | |
| WO2012095973A1 (ja) | データ処理装置及びデータ保管装置 | |
| JP6619401B2 (ja) | データ検索システム、データ検索方法およびデータ検索プログラム | |
| Al Sibahee et al. | Efficient encrypted image retrieval in IoT-cloud with multi-user authentication | |
| WO2021048662A1 (en) | Genetic data in transactions | |
| CN104704527A (zh) | 用于记录的加密数据储存器 | |
| EP4250163A1 (en) | Data sharing system, data sharing method, and data sharing program | |
| Funde et al. | Big data privacy and security using abundant data recovery techniques and data obliviousness methodologies | |
| JP6250497B2 (ja) | 情報管理システム | |
| JP2014109826A (ja) | 広域分散医療情報ネットワークの緊急時のためのデータ管理機構 | |
| WO2014141802A1 (ja) | 情報処理装置、情報処理システム、および情報処理方法、並びにプログラム | |
| JP7288194B2 (ja) | 秘密情報管理プログラム、秘密情報管理方法、および秘密情報管理システム | |
| Ayday | Cryptographic solutions for genomic privacy | |
| JP2020109447A (ja) | 秘密情報検索システム、秘密情報検索プログラム、および秘密情報検索方法 | |
| JP7469669B2 (ja) | 秘密情報管理プログラム、秘密情報管理方法、および秘密情報管理システム | |
| Haq et al. | E-healthcare using block Chain technology and cryptographic techniques: A review |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201480018404.1 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14775361 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14779527 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2014775361 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |