WO2011105003A1 - 信号処理装置及び信号処理方法 - Google Patents
信号処理装置及び信号処理方法 Download PDFInfo
- Publication number
- WO2011105003A1 WO2011105003A1 PCT/JP2011/000358 JP2011000358W WO2011105003A1 WO 2011105003 A1 WO2011105003 A1 WO 2011105003A1 JP 2011000358 W JP2011000358 W JP 2011000358W WO 2011105003 A1 WO2011105003 A1 WO 2011105003A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sound
- conversation
- sound source
- duration
- utterance
- Prior art date
Links
Images


















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Processing of the speech or voice signal to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0272—Voice signal separating
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/40—Arrangements for obtaining a desired directivity characteristic
- H04R25/407—Circuits for combining signals of a plurality of transducers
Abstract
Description
本実施の形態では、発話の重なり又は沈黙の継続長に着目して、会話成立度を算出する。本実施の形態の具体的な構成及び動作を説明する前に、先ず、本発明者らが、発話の重なり又は沈黙の継続長に着目した点について説明する。
・全ての方向のC1,k(t)から、閾値θを超える方向の音源は、すべて会話相手とする。
・全ての方向ではなく、前方(S3~S7など)のみを探索対象とする。
・直前に会話相手が判定されている場合、その方向及び隣り合う方向のみを探索対象とする(話者移動は時間的に急速には行われないため)。
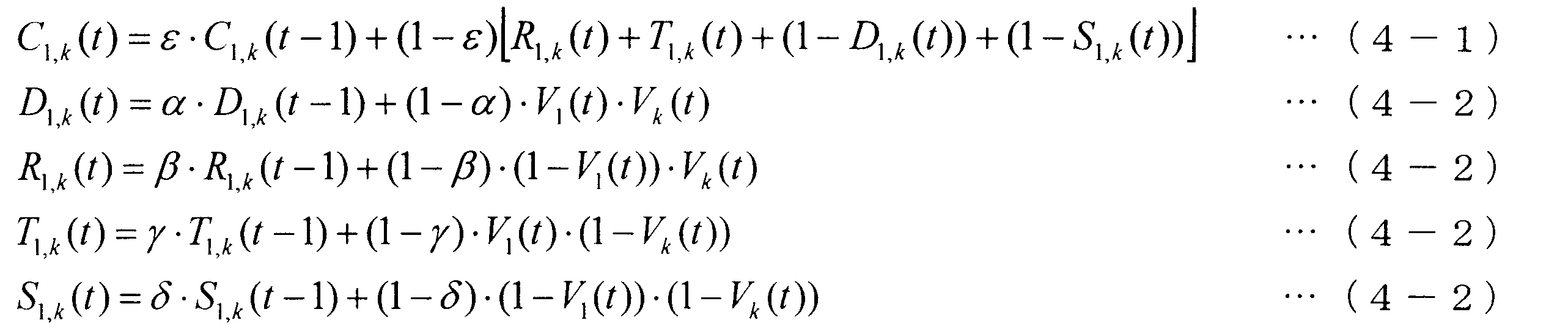
本実施の形態では、笑いの重なりに着目して、会話成立度を算出する。本実施の形態の具体的な構成及び動作を説明する前に、先ず、本発明者らが、笑いの重なりに着目した点について説明する。
「発話」:音声検出結果が音声で、かつ、笑い検出結果が非笑いであるフレーム
「無音」:音声検出結果が非音声で、かつ、笑い検出結果が非笑いであるフレーム
「笑い」:音声検出結果に関わらず、笑い検出結果が笑いであるフレーム

本実施の形態は、話者の発話比率に着目して、会話成立度を算出する。本実施の形態の具体的な構成及び動作を説明する前に、先ず、本発明者らが、話者の発話比率に着目した点について説明する。


本実施の形態では、発話の重なり又は沈黙の継続長、笑いの重なり、及び、話者の発話比率に着目して、会話成立度を算出する。
「発話」:音声検出結果が音声で、かつ、笑い検出結果が非笑いであるフレーム
「無音」:音声検出結果が非音声で、かつ、笑い検出結果が非笑いであるフレーム
「笑い」:音声検出結果に関わらず、笑い検出結果が笑いであるフレーム

110,220 マイクロホンアレイ
120,230 A/D変換部
130 音源分離部
140 音声検出部
150,310,410,510 識別パラメータ抽出部
151,511 発話重なり継続長分析部
152,512 沈黙継続長分析部
160,320,420,520 会話成立度計算部
170 会話相手判定部
180 出力音制御部
200 補聴器
210 補聴器本体
240 CPU
250 メモリ
260 イヤホン
311 笑い検出部
411,513 発話比率計算部
Claims (15)
- 複数の音源が入り混じった混合音信号を音源毎に分離する分離部と、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出部と、
前記音声区間情報を用いて、発話重なり継続長を計算し分析する発話重なり継続長抽出部と、前記沈黙継続長を計算し分析する沈黙継続長抽出部の少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算する会話成立度計算部と、
を具備する信号処理装置。 - 請求項1記載の信号処理装置において、
前記発話重なり継続長抽出部または前記沈黙継続長抽出部に代えて、
前記分離された複数の音源信号のそれぞれについて笑い検出を行い、前記識別パラメータとして、笑い区間情報を抽出する笑い検出部、を具備し、
前記会話成立度計算部は、
前記複数の音源信号の組み合わせについて、前記音声区間情報及び前記笑い区間情報を用いて、前記会話成立度を計算する、
信号処理装置。 - 請求項1記載の信号処理装置において、
前記発話重なり継続長抽出部または前記沈黙継続長抽出部に代えて、
前記複数の音源信号の組み合わせについて、前記識別パラメータとして、発話比率情報を抽出する発話比率計算部、を具備し、
前記会話成立度計算部は、
前記音声区間情報及び前記発話比率情報を用いて、前記会話成立度を計算する、
信号処理装置。 - 前記抽出部は、
前記発話重なり継続長分析部及び前記沈黙継続長分析部の少なくとも一方において、前記発話重なり継続長又は前記沈黙の継続長の長短の割合を、前記識別パラメータとして抽出する、
請求項1記載の信号処理装置 - 前記抽出部は、
前記発話重なり継続長分析部及び前記沈黙継続長分析部の少なくとも一方において、前記発話重なり継続長又は前記沈黙の継続長の平均値を、前記識別パラメータとして抽出する、
請求項1記載の信号処理装置。 - 前記会話成立度計算部は、
前記複数の音源信号で笑いが同時に検出された場合に、前記会話成立度を高くする、
請求項2記載の信号処理装置。 - 前記会話成立度計算部は、
前記複数の音源信号のうち、第1の音源信号で笑いが検出され、第2の音源信号で笑いが検出されなかった場合には、前記第一の音源信号と前記第2の音源信号との前記会話成立度を変化させない、又は、前記会話成立度を低くする、
請求項2記載の信号処理装置。 - 前記発話比率計算部は、
前記複数の音源信号のうち、過去一定時間窓内における第1の音源信号と第2の音源信号との発話区間比を、前記発話比率情報とする、
請求項3記載の信号処理装置。 - 複数の音源が入り混じった混合音信号を音源毎に分離する分離部と、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出部と、
前記複数の音源信号、又は、前記音声区間情報に基づいて、日常会話の特徴量を示す識別パラメータを抽出する抽出部と、
抽出された前記識別パラメータに基づいて、会話が成立している度合いを示す会話成立度を計算する会話成立度計算部と、を具備し、
前記抽出部は、
前記分離された複数の音源信号のそれぞれについて笑い検出を行って、笑い区間情報を抽出する笑い検出部と、
前記複数の音源信号の組み合わせについて、前記音声区間情報及び前記笑い区間情報を用いて、発話重なりの連続する区間の長さを示す発話重なり継続長を計算し分析する発話重なり継続長分析部、及び、沈黙の連続する区間の長さを示す沈黙継続長を計算し分析する沈黙継続長分析部の少なくとも一方と、
前記複数の音源信号の組み合わせについて、発話比率情報を抽出する発話比率計算部と、を具備し、
前記発話重なり継続長、前記沈黙継続長、前記笑い区間情報、又は、前記発話比率情報を、前記識別パラメータとして抽出する、
信号処理装置。 - 複数のマイクロホンを配置したマイクロホンアレイと、
前記マイクロホンアレイから入力されたアナログ領域の混合音信号をデジタル領域の信号に変換するA/D変換部と、
デジタル領域の前記混合音信号を入力とする請求項1記載の信号処理装置と、
前記会話成立度に応じて、デジタル領域の前記混合音信号を加工して出力する出力音制御部と、
を具備する信号処理装置。 - 前記出力音制御部は、
指向性制御によりデジタル領域の前記混合音信号を加工して出力する、
請求項10記載の信号処理装置。 - 複数のマイクロホンを配置したマイクロホンアレイと、
前記マイクロホンアレイから入力されたアナログ領域の混合音信号をデジタル領域の信号に変換するA/D変換部と、
前記変換されたデジタル領域の前記混合音信号を音源毎に分離する分離部と、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出部と、
前記複数の音源信号の組み合わせについて、前記音声区間情報を用いて、発話重なり継続長を計算し分析する発話重なり継続長抽出部、及び、前記沈黙継続長を計算し分析する沈黙継続長抽出部の少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算する会話成立度計算部と、
前記会話成立度に応じて、デジタル領域の前記混合音信号を加工して出力する出力音制御部と、
を具備する補聴器。 - 複数の音源が入り混じった混合音信号を音源毎に分離するステップと、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成するステップと、
前記複数の音源信号の組み合わせについて、前記音声区間情報を用いて、発話重なり継続長を計算し分析するステップ、及び、前記沈黙継続長を計算し分析するステップの少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算するステップと、
を記録した記憶媒体。 - 複数の音源が入り混じった混合音信号を音源毎に分離する分離ステップと、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出ステップと、
前記複数の音源信号の組み合わせについて、前記音声区間情報を用いて、発話重なり継続長を計算し分析するステップ、及び、前記沈黙継続長を計算し分析するステップの少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算する計算ステップと、
を有する信号処理方法。 - 前記抽出ステップは、
前記分離された複数の音源信号のそれぞれについて笑い検出を行って、笑い区間情報を抽出する笑い検出ステップと、
複数の音源信号の組み合わせについて、前記音声区間情報及び前記笑い区間情報を用いて、発話重なりの連続する区間の長さを示す発話重なり継続長を計算し分析する発話重なり継続長分析ステップ、及び、沈黙の連続する区間の長さを示す沈黙継続長を計算し分析する沈黙継続長分析ステップの少なくとも一方と、
前記複数の音源信号の組み合わせについて、発話比率情報を抽出する発話比率計算ステップと、を有し、
前記発話重なり継続長、前記沈黙継続長、前記笑い区間情報、又は、前記発話比率情報を、前記識別パラメータとして抽出する、
請求項14記載の信号処理方法。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201180001707.9A CN102388416B (zh) | 2010-02-25 | 2011-01-24 | 信号处理装置及信号处理方法 |
| JP2011523238A JP5607627B2 (ja) | 2010-02-25 | 2011-01-24 | 信号処理装置及び信号処理方法 |
| US13/262,690 US8498435B2 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| EP11746976.7A EP2541543B1 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| US13/927,429 US8682012B2 (en) | 2010-02-25 | 2013-06-26 | Signal processing method |
| US13/927,424 US8644534B2 (en) | 2010-02-25 | 2013-06-26 | Recording medium |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010-039698 | 2010-02-25 | ||
| JP2010039698 | 2010-02-25 |
Related Child Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/262,690 A-371-Of-International US8498435B2 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| US13/262,690 Continuation US8498435B2 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| US13/927,424 Division US8644534B2 (en) | 2010-02-25 | 2013-06-26 | Recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011105003A1 true WO2011105003A1 (ja) | 2011-09-01 |
Family
ID=44506438
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/000358 WO2011105003A1 (ja) | 2010-02-25 | 2011-01-24 | 信号処理装置及び信号処理方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (3) | US8498435B2 (ja) |
| EP (1) | EP2541543B1 (ja) |
| JP (1) | JP5607627B2 (ja) |
| CN (1) | CN102388416B (ja) |
| WO (1) | WO2011105003A1 (ja) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012042768A1 (ja) * | 2010-09-28 | 2012-04-05 | パナソニック株式会社 | 音声処理装置および音声処理方法 |
| JP2013140534A (ja) * | 2012-01-06 | 2013-07-18 | Fuji Xerox Co Ltd | 音声解析装置、音声解析システムおよびプログラム |
| JP2013225003A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | 音声データ分析装置、音声データ分析方法および音声データ分析プログラム |
| JP2013225002A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | データ分析装置、データ分析方法およびデータ分析プログラム |
| JP2015004928A (ja) * | 2013-06-24 | 2015-01-08 | 日本電気株式会社 | 応答対象音声判定装置、応答対象音声判定方法および応答対象音声判定プログラム |
| JP2016133774A (ja) * | 2015-01-22 | 2016-07-25 | 富士通株式会社 | 音声処理装置、音声処理方法および音声処理プログラム |
| JP2016170405A (ja) * | 2015-03-10 | 2016-09-23 | パナソニックIpマネジメント株式会社 | 音声処理装置、音声処理方法及び音声処理プログラム |
| JP2017063419A (ja) * | 2015-09-24 | 2017-03-30 | ジーエヌ リザウンド エー/エスGn Resound A/S | 雑音を受ける発話信号の客観的知覚量を決定する方法 |
| JP2017161731A (ja) * | 2016-03-09 | 2017-09-14 | 本田技研工業株式会社 | 会話解析装置、会話解析方法およびプログラム |
| JP2018097239A (ja) * | 2016-12-15 | 2018-06-21 | カシオ計算機株式会社 | 音声再生装置及びプログラム |
| JPWO2019139101A1 (ja) * | 2018-01-12 | 2021-01-28 | ソニー株式会社 | 情報処理装置、情報処理方法およびプログラム |
| WO2021125037A1 (ja) * | 2019-12-17 | 2021-06-24 | ソニーグループ株式会社 | 信号処理装置、信号処理方法、プログラムおよび信号処理システム |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5581329B2 (ja) * | 2010-06-30 | 2014-08-27 | パナソニック株式会社 | 会話検出装置、補聴器及び会話検出方法 |
| TWI403304B (zh) * | 2010-08-27 | 2013-08-01 | Ind Tech Res Inst | 隨身語能偵知方法及其裝置 |
| EP2727378B1 (en) | 2011-07-01 | 2019-10-16 | Dolby Laboratories Licensing Corporation | Audio playback system monitoring |
| US9135915B1 (en) * | 2012-07-26 | 2015-09-15 | Google Inc. | Augmenting speech segmentation and recognition using head-mounted vibration and/or motion sensors |
| US20140081637A1 (en) * | 2012-09-14 | 2014-03-20 | Google Inc. | Turn-Taking Patterns for Conversation Identification |
| US9814879B2 (en) * | 2013-05-13 | 2017-11-14 | Cochlear Limited | Method and system for use of hearing prosthesis for linguistic evaluation |
| KR20160006703A (ko) * | 2013-05-13 | 2016-01-19 | 톰슨 라이센싱 | 마이크로폰 오디오를 분리하기 위한 방법, 장치 및 시스템 |
| EP2876900A1 (en) | 2013-11-25 | 2015-05-27 | Oticon A/S | Spatial filter bank for hearing system |
| CN103903632A (zh) * | 2014-04-02 | 2014-07-02 | 重庆邮电大学 | 一种多声源环境下的基于听觉中枢系统的语音分离方法 |
| JP6641832B2 (ja) * | 2015-09-24 | 2020-02-05 | 富士通株式会社 | 音声処理装置、音声処理方法および音声処理プログラム |
| CN106920543B (zh) * | 2015-12-25 | 2019-09-06 | 展讯通信(上海)有限公司 | 语音识别方法及装置 |
| US9812149B2 (en) * | 2016-01-28 | 2017-11-07 | Knowles Electronics, Llc | Methods and systems for providing consistency in noise reduction during speech and non-speech periods |
| DK3396978T3 (da) | 2017-04-26 | 2020-06-08 | Sivantos Pte Ltd | Fremgangsmåde til drift af en høreindretning og en høreindretning |
| CN107895582A (zh) * | 2017-10-16 | 2018-04-10 | 中国电子科技集团公司第二十八研究所 | 面向多源信息领域的说话人自适应语音情感识别方法 |
| CN110858476B (zh) * | 2018-08-24 | 2022-09-27 | 北京紫冬认知科技有限公司 | 一种基于麦克风阵列的声音采集方法及装置 |
| EP4107723A4 (en) * | 2020-02-21 | 2023-08-23 | Harman International Industries, Incorporated | METHOD AND SYSTEM TO IMPROVE VOTING SEPARATION BY ELIMINATION OF OVERLAP |
| US20240089671A1 (en) | 2022-09-13 | 2024-03-14 | Oticon A/S | Hearing aid comprising a voice control interface |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0193298A (ja) | 1987-10-02 | 1989-04-12 | Pilot Pen Co Ltd:The | 自己音声感度抑圧型補聴器 |
| JP2001045454A (ja) * | 1999-08-03 | 2001-02-16 | Fuji Xerox Co Ltd | 対話情報配信システムおよび対話情報配信装置並びに記憶媒体 |
| JP2002006874A (ja) | 2000-06-27 | 2002-01-11 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| JP2003530051A (ja) * | 2000-03-31 | 2003-10-07 | クラリティー リミテッド ライアビリティ カンパニー | 音声信号抽出のための方法及び装置 |
| JP2004133403A (ja) | 2002-09-20 | 2004-04-30 | Kobe Steel Ltd | 音声信号処理装置 |
| JP2004243023A (ja) | 2003-02-17 | 2004-09-02 | Masafumi Matsumura | 笑い検出装置、情報処理装置および笑い検出方法 |
| JP2005037953A (ja) * | 2004-07-26 | 2005-02-10 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| JP2005202035A (ja) * | 2004-01-14 | 2005-07-28 | Toshiba Corp | 対話情報分析装置 |
| WO2009104332A1 (ja) * | 2008-02-19 | 2009-08-27 | 日本電気株式会社 | 発話分割システム、発話分割方法および発話分割プログラム |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7236929B2 (en) * | 2001-05-09 | 2007-06-26 | Plantronics, Inc. | Echo suppression and speech detection techniques for telephony applications |
| US7596498B2 (en) * | 2005-09-02 | 2009-09-29 | Microsoft Corporation | Monitoring, mining, and classifying electronically recordable conversations |
| JP4087400B2 (ja) * | 2005-09-15 | 2008-05-21 | 株式会社東芝 | 音声対話翻訳装置、音声対話翻訳方法および音声対話翻訳プログラム |
| JP4364251B2 (ja) * | 2007-03-28 | 2009-11-11 | 株式会社東芝 | 対話を検出する装置、方法およびプログラム |
-
2011
- 2011-01-24 US US13/262,690 patent/US8498435B2/en active Active
- 2011-01-24 JP JP2011523238A patent/JP5607627B2/ja active Active
- 2011-01-24 CN CN201180001707.9A patent/CN102388416B/zh active Active
- 2011-01-24 EP EP11746976.7A patent/EP2541543B1/en active Active
- 2011-01-24 WO PCT/JP2011/000358 patent/WO2011105003A1/ja active Application Filing
-
2013
- 2013-06-26 US US13/927,424 patent/US8644534B2/en active Active
- 2013-06-26 US US13/927,429 patent/US8682012B2/en active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0193298A (ja) | 1987-10-02 | 1989-04-12 | Pilot Pen Co Ltd:The | 自己音声感度抑圧型補聴器 |
| JP2001045454A (ja) * | 1999-08-03 | 2001-02-16 | Fuji Xerox Co Ltd | 対話情報配信システムおよび対話情報配信装置並びに記憶媒体 |
| JP2003530051A (ja) * | 2000-03-31 | 2003-10-07 | クラリティー リミテッド ライアビリティ カンパニー | 音声信号抽出のための方法及び装置 |
| JP2002006874A (ja) | 2000-06-27 | 2002-01-11 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| JP2004133403A (ja) | 2002-09-20 | 2004-04-30 | Kobe Steel Ltd | 音声信号処理装置 |
| JP2004243023A (ja) | 2003-02-17 | 2004-09-02 | Masafumi Matsumura | 笑い検出装置、情報処理装置および笑い検出方法 |
| JP2005202035A (ja) * | 2004-01-14 | 2005-07-28 | Toshiba Corp | 対話情報分析装置 |
| JP2005037953A (ja) * | 2004-07-26 | 2005-02-10 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| WO2009104332A1 (ja) * | 2008-02-19 | 2009-08-27 | 日本電気株式会社 | 発話分割システム、発話分割方法および発話分割プログラム |
Non-Patent Citations (2)
| Title |
|---|
| AKINORI ITO ET AL.: "Smile and Laughter Recognition using Speech Processing and Face Recognition from Conversation Video", 26 May 2005, TOHOKU UNIVERSITY |
| See also references of EP2541543A4 |
Cited By (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012042768A1 (ja) * | 2010-09-28 | 2012-04-05 | パナソニック株式会社 | 音声処理装置および音声処理方法 |
| JPWO2012042768A1 (ja) * | 2010-09-28 | 2014-02-03 | パナソニック株式会社 | 音声処理装置および音声処理方法 |
| US9064501B2 (en) | 2010-09-28 | 2015-06-23 | Panasonic Intellectual Property Management Co., Ltd. | Speech processing device and speech processing method |
| JP5740575B2 (ja) * | 2010-09-28 | 2015-06-24 | パナソニックIpマネジメント株式会社 | 音声処理装置および音声処理方法 |
| JP2013140534A (ja) * | 2012-01-06 | 2013-07-18 | Fuji Xerox Co Ltd | 音声解析装置、音声解析システムおよびプログラム |
| JP2013225003A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | 音声データ分析装置、音声データ分析方法および音声データ分析プログラム |
| JP2013225002A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | データ分析装置、データ分析方法およびデータ分析プログラム |
| JP2015004928A (ja) * | 2013-06-24 | 2015-01-08 | 日本電気株式会社 | 応答対象音声判定装置、応答対象音声判定方法および応答対象音声判定プログラム |
| JP2016133774A (ja) * | 2015-01-22 | 2016-07-25 | 富士通株式会社 | 音声処理装置、音声処理方法および音声処理プログラム |
| JP2016170405A (ja) * | 2015-03-10 | 2016-09-23 | パナソニックIpマネジメント株式会社 | 音声処理装置、音声処理方法及び音声処理プログラム |
| JP2017063419A (ja) * | 2015-09-24 | 2017-03-30 | ジーエヌ リザウンド エー/エスGn Resound A/S | 雑音を受ける発話信号の客観的知覚量を決定する方法 |
| JP2017161731A (ja) * | 2016-03-09 | 2017-09-14 | 本田技研工業株式会社 | 会話解析装置、会話解析方法およびプログラム |
| JP2018097239A (ja) * | 2016-12-15 | 2018-06-21 | カシオ計算機株式会社 | 音声再生装置及びプログラム |
| JPWO2019139101A1 (ja) * | 2018-01-12 | 2021-01-28 | ソニー株式会社 | 情報処理装置、情報処理方法およびプログラム |
| JP7276158B2 (ja) | 2018-01-12 | 2023-05-18 | ソニーグループ株式会社 | 情報処理装置、情報処理方法およびプログラム |
| US11837233B2 (en) | 2018-01-12 | 2023-12-05 | Sony Corporation | Information processing device to automatically detect a conversation |
| WO2021125037A1 (ja) * | 2019-12-17 | 2021-06-24 | ソニーグループ株式会社 | 信号処理装置、信号処理方法、プログラムおよび信号処理システム |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102388416B (zh) | 2014-12-10 |
| US8644534B2 (en) | 2014-02-04 |
| EP2541543A1 (en) | 2013-01-02 |
| US8682012B2 (en) | 2014-03-25 |
| US20130289982A1 (en) | 2013-10-31 |
| JPWO2011105003A1 (ja) | 2013-06-17 |
| US20140012576A1 (en) | 2014-01-09 |
| EP2541543B1 (en) | 2016-11-30 |
| CN102388416A (zh) | 2012-03-21 |
| JP5607627B2 (ja) | 2014-10-15 |
| US8498435B2 (en) | 2013-07-30 |
| EP2541543A4 (en) | 2013-11-20 |
| US20120020505A1 (en) | 2012-01-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5607627B2 (ja) | 信号処理装置及び信号処理方法 | |
| CN110268470B (zh) | 音频设备滤波器修改 | |
| JP5740575B2 (ja) | 音声処理装置および音声処理方法 | |
| JP5581329B2 (ja) | 会話検出装置、補聴器及び会話検出方法 | |
| JP6464449B2 (ja) | 音源分離装置、及び音源分離方法 | |
| JP4713111B2 (ja) | 発話区間検出装置、音声認識処理装置、送信システム、信号レベル制御装置、発話区間検出方法 | |
| CN107112026A (zh) | 用于智能语音识别和处理的系统、方法和装置 | |
| US20180054688A1 (en) | Personal Audio Lifestyle Analytics and Behavior Modification Feedback | |
| Bramsløw et al. | Improving competing voices segregation for hearing impaired listeners using a low-latency deep neural network algorithm | |
| JP2009178783A (ja) | コミュニケーションロボット及びその制御方法 | |
| EP3982358A2 (en) | Whisper conversion for private conversations | |
| Chatterjee et al. | ClearBuds: wireless binaural earbuds for learning-based speech enhancement | |
| JP2013142843A (ja) | 動作解析装置、音声取得装置、および、動作解析システム | |
| CN113921026A (zh) | 语音增强方法和装置 | |
| CN111199751B (zh) | 一种麦克风的屏蔽方法、装置和电子设备 | |
| JP4447857B2 (ja) | 音声検出装置 | |
| EP3288035B1 (en) | Personal audio analytics and behavior modification feedback | |
| US11736873B2 (en) | Wireless personal communication via a hearing device | |
| JP5672155B2 (ja) | 話者判別装置、話者判別プログラム及び話者判別方法 | |
| US20230217194A1 (en) | Methods for synthesis-based clear hearing under noisy conditions | |
| Dekens et al. | A Multi-sensor Speech Database with Applications towards Robust Speech Processing in hostile Environments. | |
| Brandstein et al. | Speaker Recognition Using Real vs. Synthetic Parallel Data for DNN Channel Compensation | |
| Aiken | Understanding the noise problem |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201180001707.9 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011523238 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13262690 Country of ref document: US |
|
| REEP | Request for entry into the european phase |
Ref document number: 2011746976 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011746976 Country of ref document: EP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11746976 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |