WO2010105256A1 - Rationally designed, synthetic antibody libraries and uses therefor - Google Patents
Rationally designed, synthetic antibody libraries and uses therefor Download PDFInfo
- Publication number
- WO2010105256A1 WO2010105256A1 PCT/US2010/027312 US2010027312W WO2010105256A1 WO 2010105256 A1 WO2010105256 A1 WO 2010105256A1 US 2010027312 W US2010027312 W US 2010027312W WO 2010105256 A1 WO2010105256 A1 WO 2010105256A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sequences
- library
- amino acid
- sequence
- cdrh3
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1093—General methods of preparing gene libraries, not provided for in other subgroups
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/005—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies constructed by phage libraries
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
- C40B40/04—Libraries containing only organic compounds
- C40B40/06—Libraries containing nucleotides or polynucleotides, or derivatives thereof
- C40B40/08—Libraries containing RNA or DNA which encodes proteins, e.g. gene libraries
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B50/00—Methods of creating libraries, e.g. combinatorial synthesis
- C40B50/06—Biochemical methods, e.g. using enzymes or whole viable microorganisms
Definitions
- Antibodies have profound relevance as research tools and in diagnostic and therapeutic applications. However, the identification of useful antibodies is difficult and once identified, antibodies often require considerable redesign or 'humanization' before they are suitable for therapeutic applications. Previous methods for identifying desirable antibodies have typically involved phage display of representative antibodies, for example human libraries derived by amplification of nucleic acids from B cells or tissues, or, alternatively, synthetic libraries. However, these approaches have limitations. For example, most human libraries known in the art contain only the antibody sequence diversity that can be experimentally captured or cloned from the source (e.g., B cells). Accordingly, the human library may completely lack or under-represent certain useful antibody sequences.
- Synthetic or consensus libraries known in the art have other limitations, such as the potential to encode non-naturally occurring (e.g., non-human) sequences that have the potential to be immunogenic.
- certain synthetic libraries of the art suffer from at least one of two limitations: (1) the number of members that the library can theoretically contain (i.e., theoretical diversity) may be greater than the number of members that can actually be synthesized, and (2) the number of members actually synthesized may be so great as to preclude screening of each member in a physical realization of the library, thereby decreasing the probability that a library member with a particular property may be isolated.
- a physical realization of a library capable of screening 10 12 library members will only sample about 10% of the sequences contained in a library with 10 13 members.
- a median CDRH3 length of about 12.7 amino acids Rock et al, J. Exp. Med., 1994, 179:323-328
- the number of theoretical sequence variants in CDRH3 alone is about 20 12'7 , or about 3.3 x 10 16 variants. This number does not account for known variation that occurs in CDRHl and CDRH2, heavy chain framework regions, and pairing with different light chains, each of which also exhibit variation in their respective CDRLl, CDRL2, and CDRL3.
- the antibodies isolated from these libraries are often not amenable to rational affinity maturation techniques to improve the binding of the candidate molecule.
- antibody libraries which (a) can be readily synthesized, (b) can be physically realized and, in certain cases, oversampled, (c) contain sufficient diversity to recognize all antigens recognized by the preimmune human repertoire (i.e., before negative selection), (d) are non-immunogenic in humans (i.e., comprise sequences of human origin), and (e) contain CDR length and sequence diversity, and framework diversity, representative of naturally-occurring human antibodies.
- Embodiments of the instant invention at least provide, for the first time, antibody libraries that have these desirable features.
- the present invention relates to, at least, synthetic polynucleotide libraries, methods of producing and using the libraries of the invention, kits and computer readable forms including the libraries of the invention.
- the libraries of the invention are designed to reflect the preimmune repertoire naturally created by the human immune system and are based on rational design informed by examination of publicly available databases of human antibody sequences. It will be appreciated that certain non-limiting embodiments of the invention are described below. As described throughout the specification, the invention encompasses many other embodiments as well.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least 10 6 unique antibody CDRH3 amino acid sequences comprising
- Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by B cells;
- the B cells are human B cells. In still other embodiments of the invention, the B cells are non-human B cells. In yet another embodiment of the invention, the B cells are vertebrate B cells.
- the invention provides that the non-human CDRH3 DH amino acid sequence is a sequence from a vertebrate species.
- the vertebrate species is selected from the group consisting of Mus musculus, Camelus sp., Llama sp., Camelidae sp., Raja sp., Ginglymostoma sp., Carcharhinus sp., Heterodontus sp., Hydrolagus sp., Ictalurus sp., Gallus sp., Bos sp., Marmaronetta sp., Aythya sp., Netta sp., Equus sp., Pentalagus sp., Bunolagus sp., Nesolagus sp., Romerolagus sp., Brachylagus sp., Sylvilagus sp., Oryctolag
- Centroscymnus sp. Scymnodon sp., Dalatias sp., Euprotomicrus sp., Isistius sp., Squaliolus sp., Heteroscymnoides sp., Somniosus sp. and Megachasma sp.
- an antibody may be isolated from the polypeptide expression products of any of the libraries described herein.
- the CDRH3 amino acid sequences are expressed as part of full-length heavy chains.
- the polynucleotides further encode an alternative scaffold.
- the library of polypeptides is encoded by the synthetic polynucleotide library described herein.
- a library of vectors may comprise the polynucleotide library described herein.
- a population of cells may comprise the vectors described herein.
- the cells are yeast cells (e.g., S. cerevisiae).
- the invention includes a method of preparing a synthetic polynucleotide library comprising providing the polynucleotide sequences of claim 1 and assembling said polynucleotide sequences in the order [N1]-[DH]-[N2]-[H3-JH].
- the invention provides a method of isolating one or more host cells expressing one or more antibodies, the method comprising: (i) expressing a polypeptide comprising a CDRH3 sequence of claim 1 in one or more host cells;
- the invention includes a kit comprising any of the libraries of synthetic polynucleotides described herein.
- the CDRH3 amino acid sequences encoded by the libraries of synthetic polynucleotides described herein are in computer readable form.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least 10 6 unique antibody CDRH3 amino acid sequences comprising:
- Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
- N2 amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the N2 amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least about 10 6 unique antibody CDRH3 amino acid sequences comprising: (i) an Nl amino acid sequence of O to about 3 amino acids, wherein:
- the most N-terminal Nl amino acid, if present, is selected from a group consisting of R, G, P, L, S, A, V, K, I, Q, T and D;
- the second most N-terminal Nl amino acid, if present, is selected from a group consisting of G, P, R, S, L, V, E, A, D, I, T and K;
- the third most N-terminal Nl amino acid is selected from the group consisting of G, R, P, S, L, A, V, T, E, D, K and F;
- N2 amino acid sequence of 0 to about 3 amino acids, wherein: (a) the most N-terminal N2 amino acid, if present, is selected from a group consisting of G, P, R, L, S, A, T, V, E, D, F and H;
- the second most N-terminal N2 amino acid is selected from a group consisting of G, P, R, S, T, L, A, V, E, Y, D and K; and
- the third most N-terminal N2 amino acid is selected from the group consisting of G, P, S, R, L, A, T, V, D, E, W and Q; and
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least about 10 6 unique antibody CDRH3 amino acid sequences that are at least about 80% identical to an amino acid sequence represented by the following formula: [X]-[N1]-[DH]-[N2]-[H3-JH], wherein: (i) X is any amino acid residue or no amino acid residue;
- Nl is an amino acid sequence selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP,
- TP VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA,
- DH is an amino acid sequence selected from the group consisting of all possible reading frames that do not include a stop codon encoded by IGHDl-I, IGHD 1-20, IGHD 1-26, IGHD 1-7, IGHD2-15, IGHD2- 2, IGHD2-21, IGHD2-8, IGHD3-10, IGHD3-16, IGHD3-22, IGHD3-3, IGHD3-9, IGHD4-17, IGHD4-23, IGHD4-4, IGHD-4-11, IGHD
- N2 is an amino acid sequence selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP,
- TP VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA,
- SD SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW, VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP, PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof; and
- H3-JH is an amino acid sequence selected from the group consisting of AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV
- the invention comprises wherein said library consists essentially of a plurality of polynucleotides encoding CDRH3 amino acid sequences that are at least about 80% identical to an amino acid sequence represented by the following formula: [X]-[N1]-[DH]-[N2]-[H3-JH], wherein:
- X is any amino acid residue or no amino acid residue
- Nl is an amino acid sequence selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG,
- VD VD
- VS WS
- YS AAE
- AYH DTL
- EKR ISR
- NTP PKS
- PRP PTA
- PTQ PTQ
- REL RPL
- SAA SAL
- SGL SSE
- DH is an amino acid sequence selected from the group consisting of all possible reading frames that do not include a stop codon encoded by IGHDl-I, IGHD 1-20, IGHD 1-26, IGHD 1-7, IGHD2-15, IGHD2- 2, IGHD2-21, IGHD2-8, IGHD3-10, IGHD3-16, IGHD3-22, IGHD3-3, IGHD3-9, IGHD4-17, IGHD4-23, IGHD4-4, IGHD-4-11, IGHD5-12, IGHD5-24, IGHD5-5, IGHD-5-18, IGHD6-13, IGHD6- 19, IGHD6-25, IGHD6-6, and IGHD7-27, and N- and C-terminal truncations thereof;
- N2 is an amino acid sequence selected from the group consisting of
- H3-JH is an amino acid sequence selected from the group consisting of AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV (SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY,
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode one or more full length antibody heavy chain sequences, and wherein the CDRH3 amino acid sequences of the heavy chain comprise:
- Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
- N2 amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the N2 amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
- one or more CDRH3 amino acid sequences further comprise an N-terminal tail residue.
- the N-terminal tail residue is selected from the group consisting of G, D, and E.
- the Nl amino acid sequence is selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT,
- the N2 amino acid sequence is selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT,
- the H3-JH amino acid sequence is selected from the group consisting of AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV (SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY, DY, Y, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, S, YYYYYGMDV (SEQ ID NO : 22), YYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, and MDV.
- the invention comprises a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the percent occurrence within the central loop of the CDRH3 amino acid sequences of at least one of the following i - i+1 pairs in the library is within the ranges specified below:
- Tyr-Tyr in an amount from about 2.5% to about 6.5%; Ser-Gly in an amount from about 2.5% to about 4.5%; Ser-Ser in an amount from about 2% to about 4%; Gly-Ser in an amount from about 1.5% to about 4%; Tyr-Ser in an amount from about 0.75% to about 2%;
- Tyr-Gly in an amount from about 0.75% to about 2%; and Ser-Tyr in an amount from about 0.75% to about 2%.
- the invention comprises a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the percent occurrence within the central loop of the CDRH3 amino acid sequences of at least one of the following i - i+2 pairs in the library is within the ranges specified below:
- Tyr-Tyr in an amount from about 2.5% to about 4.5%; Gly-Tyr in an amount from about 2.5% to about 5.5%; Ser-Tyr in an amount from about 2% to about 4%; Tyr-Ser in an amount from about 1.75% to about 3.75%; Ser-Gly in an amount from about 2% to about 3.5%; Ser-Ser in an amount from about 1.5% to about 3%; Gly-Ser in an amount from about 1.5% to about 3%; and Tyr-Gly in an amount from about 1% to about 2%.
- the invention comprises a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the percent occurrence within the central loop of the CDRH3 amino acid sequences of at least one of the following i - i+3 pairs in the library is within the ranges specified below: Gly-Tyr in an amount from about 2.5% to about 6.5%;
- Ser-Tyr in an amount from about 1% to about 5%
- Tyr-Ser in an amount from about 2% to about 4%;
- Ser-Ser in an amount from about 1% to about 3%;
- Gly-Ser in an amount from about 2% to about 5%; and Tyr-Tyr in an amount from about 0.75% to about 2%.
- At least 2, 3, 4, 5, 6, or 7 of the specified i - i+1 pairs in the library are within the specified ranges.
- the CDRH3 amino acid sequences are human.
- the polynucleotides encode at least about 10 6 unique CDRH3 amino acid sequences.
- the polynucleotides further encode one or more heavy chain chassis amino acid sequences that are N-terminal to the CDRH3 amino acid sequences, and the one or more heavy chain chassis sequences are selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 94 encoded by IGHV 1-2, IGHV1-3, IGHV1-8, IGHV1-18, IGHV1-24, IGHV1-45, IGHV1-46, IGHV1-58, IGHVl- 69, IGHV2-5, IGHV2-26, IGHV2-70, IGHV3-7, IGHV3-9, IGHV3-11, IGHV3-13, IGHV3-15, IGHV3-20, IGHV3-21, IGHV3-23, IGHV3-30, IGHV3-33, IGHV3-43, IGHV3-48, IGHV3-49, IGHV3-53, IGHV3-64, IGHV3-66, IGHV3-72, IGHV3
- the polynucleotides further encode one or more FRM4 amino acid sequences that are C-terminal to the CDRH3 amino acid sequences, wherein the one or more FRM4 amino acid sequences are selected from the group consisting of a FRM4 amino acid sequence encoded by IGHJl, IGHJ2, IGHJ3, IGHJ4, IGHJ5, and IGHJ6, or a sequence of at least about 80% identity to any of them.
- the polynucleotides further encode one or more immunoglobulin heavy chain constant region amino acid sequences that are C-terminal to the FRM4 sequence.
- the CDRH3 amino acid sequences are expressed as part of full-length heavy chains.
- the full-length heavy chains are selected from the group consisting of an IgGl, IgG2, IgG3, and IgG4, or combinations thereof.
- the CDRH3 amino acid sequences are from about 2 to about 30, from about 8 to about 19, or from about 10 to about 18 amino acid residues in length.
- the synthetic polynucleotides of the library encode from about 10 6 to about 10 14 , from about 10 7 to about 10 13 , from about 10 8 to about 10 12 , from about 10 9 to about 10 12 , or from about 10 10 to about 10 12 unique CDRH3 amino acid sequences.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody VKCDR3 amino acid sequences comprising about 1 to about 10 of the amino acids found at Kabat positions 89, 90, 91, 92, 93, 94, 95, 95 A, 96, and 97, in selected VKCDR3 amino acid sequences derived from a particular IGKV or IGKJ germline sequence.
- the synthetic polynucleotides encode one or more of the amino acid sequences listed in Table 33 or a sequence at least about 80% identical to any of them.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of unique antibody VKCDR3 amino acid sequences that are of at least about 80% identity to an amino acid sequence represented by the following formula:
- VK Chassis is an amino acid sequence selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGKV1-05, IGKV1-06, IGKV1-08, IGKV1-09, IGKVl-
- L3-VK is the portion of the VKCDR3 encoded by the IGKV gene segment
- JK* is an amino acid sequence selected from the group consisting of sequences encoded by IGJKl, IGJK2, IGJK3, IGJK4, and IGJK5, wherein the first residue of each IGJK sequence is not present.
- X may be selected from the group consisting of F, L, I, R, W, Y, and P.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of V ⁇ CDR3 amino acid sequences that are of at least about 80% identity to an amino acid sequence represented by the following formula:
- V ⁇ Chassis is an amino acid sequence selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IG ⁇ Vl-36, IG ⁇ Vl-40, IG ⁇ Vl-44, IG ⁇ Vl-47, IG ⁇ Vl-51, IG ⁇ V10-54, IG ⁇ V2-l l, IG ⁇ V2-14, IG ⁇ V2-18, IG ⁇ V2-23, IG ⁇ V2-8, IG ⁇ V3-l, IG ⁇ V3-10, IG ⁇ V3-12, IG ⁇ V3-16, IG ⁇ V3-19, IG ⁇ V3-21, IG ⁇ V3-25, IG ⁇ V3-27, IG ⁇ V3-9, IG ⁇ V4-3, IG ⁇ V4-60, IG ⁇ V4-69, IG ⁇ V5-39, IG ⁇ V5-45, IG ⁇ V6-57, IG ⁇ V7-43, IG ⁇ V7-46, IG ⁇ V8-61,
- IG ⁇ V9-49 and IG ⁇ V 10-54, or a sequence of at least about 80% identity to any of them;
- L3-V ⁇ is the portion of the V ⁇ CDR3 encoded by the IG ⁇ V segment; and (iii) J ⁇ is an amino acid sequence selected from the group consisting of sequences encoded by IG ⁇ Jl-01, IG ⁇ J2-01, IG ⁇ J3-01, IG ⁇ J3-02, IG ⁇ J6-01, IG ⁇ J7-01, and IG ⁇ J7-02, and wherein the first residue of each IGJ ⁇ sequence may or may not be deleted.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody proteins comprising:
- VKCDR3 amino acid sequence comprising about 1 to about 10 of the amino acids found at Kabat positions 89, 90, 91, 92, 93, 94, 95, 95 A, 96, and 97, in selected VKCDR3 sequences derived from a particular IGKV or IGKJ germline sequence.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody proteins comprising: (i) a CDRH3 amino acid sequence of claim 1; and
- VKCDR3 amino acid sequences of at least about 80% identity to an amino acid sequence represented by the following formula:
- VK Chassis is an amino acid sequence selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGKV1-05, IGKV1-06, IGKVl- 08, IGKV1-09, IGKV1-12, IGKV1-13, IGKV1-16, IGKVl- 17, IGKV1-27, IGKV1-33, IGKV1-37, IGKV1-39, IGKVlD- 16, IGKV1D-17, IGKV1D-43, IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2-40, IGKV2D-26,
- L3-VK is the portion of the VKCDR3 encoded by the IGKV gene segment; and (c) X is any amino acid residue;
- JK* is an amino acid sequence selected from the group consisting of sequences encoded by IGJKl, IGJK2, IGJK3, IGJK4, and IGJK5, wherein the first residue of each IGJK sequence is not present.
- the VKCDR3 amino acid sequence comprises one or more of the sequences listed in Table 33 or a sequence at least about 80% identical to any of them.
- the antibody proteins are expressed in a heterodimeric form.
- the human antibody proteins are expressed as antibody fragments.
- the antibody fragments are selected from the group consisting of Fab, Fab', F(ab')2, Fv fragments, diabodies, linear antibodies, and single-chain antibodies.
- the invention comprises an antibody isolated from the polypeptide expression products of any library described herein.
- polynucleotides further comprise a 5 ' polynucleotide sequence and a 3' polynucleotide sequence that facilitate homologous recombination.
- the polynucleotides further encode an alternative scaffold.
- the invention comprises a library of polypeptides encoded by any of the synthetic polynucleotide libraries described herein.
- the invention comprises a library of vectors comprising any of the polynucleotide libraries described herein. In certain other aspects, the invention comprises a population of cells comprising the vectors of the instant invention.
- the doubling time of the population of cells is from about 1 to about 3 hours, from about 3 to about 8 hours, from about 8 to about 16 hours, from about 16 to about 20 hours, or from 20 to about 30 hours.
- the cells are yeast cells.
- the yeast is Saccharomyces cerevisiae.
- the invention comprises a library that has a theoretical total diversity of N unique CDRH3 sequences, wherein N is about 10 6 to about 10 15 ; and wherein the physical realization of the theoretical total CDRH3 diversity has a size of at least about 3N, thereby providing a probability of at least about 95% that any individual CDRH3 sequence contained within the theoretical total diversity of the library is present in the actual library.
- the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody V ⁇ CDR3 amino acid sequences comprising about 1 to about 10 of the amino acids found at Kabat positions 89, 90, 91, 92, 93, 94, 95, 95A, 95B, 95C, 96, and 97, in selected V ⁇ CDR3 sequences encoded by a single germline sequence.
- the invention relates to a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the library has a theoretical total diversity of about 10 6 to about 10 15 unique CDRH3 sequences.
- the invention relates to a method of preparing a library of synthetic polynucleotides encoding a plurality of antibody VK amino acid sequences, the method comprising:
- VK Chassis amino acid sequences selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGKVl -05, IGKV1-06, IGKV 1-08, IGKV1-09, IGKV1-12, IGKV1-13, IGKV1-16, IGKVl -17, IGKV1-27, IGKVl -33, IGKV1-37, IGKV1-39, IGKV1D-16, IGKV1D-17, IGKV1D-43, IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2-40, IGKV2D-26, IGKV2D-29, IGKV2D-30, IGKV3-11, IGKV3-15, IGKV3-20, IGKV3D-07, IGKV3D
- JK* is an amino acid sequence selected from the group consisting amino acid sequences encoded by IGKJl,
- the invention relates to a method of preparing a library of synthetic polynucleotides encoding a plurality of antibody light chain CDR3 sequences, the method comprising:
- the invention relates to a method of preparing a library of synthetic polynucleotides encoding a plurality of antibody V ⁇ amino acid sequences, the method comprising:
- V ⁇ Chassis amino acid sequences selected from the group consisting of about Kabat residue 1 to about Kabat residue 88 encoded by IG ⁇ Vl-36, IG ⁇ Vl-40, IG ⁇ Vl-44, IG ⁇ Vl-47, IG ⁇ Vl-51, IG ⁇ V 10-54, IG ⁇ V2-l l, IG ⁇ V2-14, IG ⁇ V2- 18, IG ⁇ V2-23, IG ⁇ V2-8, IG ⁇ V3-l, IG ⁇ V3-10, IG ⁇ V3-12, IG ⁇ V3-16, IG ⁇ V3-19, IG ⁇ V3- 21, IG ⁇ V3-25, IG ⁇ V3-27, IG ⁇ V3-9, IG ⁇ V4-3, IG ⁇ V4-60, IG ⁇ V4-69, IG ⁇ V5-39, IG ⁇ V5- 45, IG ⁇ V6-57, IG ⁇ V7-43, IG ⁇ V7-46, IG ⁇ V8-61, IG ⁇ V9-49
- J ⁇ is an amino acid sequence selected from the group consisting of amino acid sequences encoded by IG ⁇ Jl-01, IG ⁇ J2- 01, IG ⁇ J3-01, IG ⁇ J3-02, IG ⁇ J6-01, IG ⁇ J7-01, and IG ⁇ J7-02 wherein the first amino acid residue of each sequence may or may not be present; and (ii) assembling the polynucleotide sequences to produce a library of synthetic polynucleotides encoding a plurality of human V ⁇ amino acid sequences represented by the following formula:
- amino acid sequences encoded by the polynucleotides of the libraries of the invention are human.
- the present invention is also directed to methods of preparing a synthetic polynucleotide library comprising providing and assembling the polynucleotide sequences of the instant invention.
- the invention comprises a method of preparing the library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, the method comprising:
- Nl amino acid sequences of about 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
- N2 amino acid sequences of about 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
- one or more of the polynucleotide sequences are synthesized via split- pool synthesis.
- the method of the invention further comprises the step of recombining the assembled synthetic polynucleotides with a vector comprising a heavy chain chassis and a heavy chain constant region, to form a full-length heavy chain.
- the method of the invention further comprises the step of providing a 5 ' polynucleotide sequence and a 3 ' polynucleotide sequence that facilitate homologous recombination.
- the method of the invention further comprises the step of recombining the assembled synthetic polynucleotides with a vector comprising a heavy chain chassis and a heavy chain constant region, to form a full-length heavy chain.
- the step of recombining is performed in yeast.
- the yeast is S. cerevisiae.
- the invention comprises a method of isolating one or more host cells expressing one or more antibodies, the method comprising: (i) expressing the human antibodies of any one of claims 40 and 46 in one or more host cells;
- the method of the invention further comprises the step of isolating one or more antibodies from the one or more host cells that present the antibodies which recognize the one or more antigens.
- the method of the invention further comprises the step of isolating one or more polynucleotide sequences encoding one or more antibodies from the one or more host cells that present the antibodies which recognize the one or more antigens.
- the invention comprises a kit comprising the library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, or any of the other sequences disclosed herein.
- the CDRH3 amino acid sequences encoded by the libraries of synthetic polynucleotides described herein, or any of the other sequences disclosed herein, are in computer readable form.
- Figure 1 depicts a schematic of recombination between a fragment (e.g., CDR3) and a vector (e.g., comprising a chassis and constant region) for the construction of a library.
- a fragment e.g., CDR3
- a vector e.g., comprising a chassis and constant region
- Figure 2 depicts the length distribution of the Nl and N2 regions of rearranged human antibody sequences compiled from Jackson et al. (J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety).
- Figure 3 depicts the length distribution of the CDRL3 regions of rearranged human kappa light chain sequences compiled from the NCBI database (Appendix A).
- Figure 4 depicts the length distribution of the CDRL3 regions of rearranged human lambda light chain sequences compiled from the NCBI database (Appendix B).
- Figure 5 depicts a schematic representation of the 424 cloning vectors used in the synthesis of the CDRH3 regions before and after ligation of the [DH]-[N2]-[JH] segment (DTAVYYCAR: SEQ ID NO: 579; DTAVYYCAK: SEQ ID NO: 578; SSASTK: SEQ ID NO: 580).
- Figure 6 depicts a schematic structure of a heavy chain vector, prior to recombination with a CDRH3.
- Figure 7 depicts a schematic diagram of a CDRH3 integrated into a heavy chain vector and the polynucleotide and polypeptide sequences of CDRH3_(SEQ ID NO: 581).
- Figure 8 depicts a schematic structure of a kappa light chain vector, prior to recombination with a CDRL3.
- Figure 9 depicts a schematic diagram of a CDRL3 integrated into a light chain vector and the polynucleotide and polypeptide sequences of CDRL3 (SEQ ID NO: 582).
- Figure 10 depicts the length distribution of the CDRH3 domain (Kabat positions 95-
- Figure 11 depicts the length distribution of the DH segment from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution.
- Figure 12 depicts the length distribution of the N2 segment from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution.
- Figure 13 depicts the length distribution of the H3-JH segment from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution.
- Figure 14 depicts the length distribution of the CDRH3 domains from 291 sequences prepared from yeast cells transformed according to the method outlined in Example 10.4, namely the co-transformation of vectors containing heavy chain chassis and constant regions with a CDRH3 insert (observed), as compared to the expected (i.e., designed) distribution.
- Figure 15 depicts the length distribution of the [TaU]-[Nl] region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the expected (i.e., designed) distribution.
- Figure 16 depicts the length distribution of the DH region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the theoretical (i.e., designed) distribution.
- Figure 17 depicts the length distribution of the N2 region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the theoretical (i.e., designed) distribution.
- Figure 18 depicts the length distribution of the H3-JH region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the theoretical (i.e., designed) distribution.
- Figure 19 depicts the familial origin of the JH segments identified in the 291 sequences (observed), as compared to the theoretical (i.e., designed) familial origin.
- Figure 20 depicts the representation of each of the 16 chassis of the library (observed), as compared to the theoretical (i.e., designed) chassis representation.
- VH3-23 is represented twice; once ending in CAR and once ending in CAK. These representations were combined, as were the ten variants of VH3-33 with one variant of VH3-30.
- Figure 21 depicts a comparison of the CDRL3 length from 86 sequences selected from the VKCDR3 library of Example 6.2 (observed) to human sequences (human) and the designed sequences (designed).
- Figure 22 depicts the representation of the light chain chassis amongst the 86 sequences selected from the library (observed), as compared to the theoretical (i.e., designed) chassis representation.
- Figure 23 depicts the frequency of occurrence of different CDRH3 lengths in an exemplary library of the invention, versus the preimmune repertoire of Lee et al. (Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety).
- Figure 24 depicts binding curves for 6 antibodies selected from a library of the invention.
- Figure 25 depicts binding data for 10 antibodies selected from a library of the invention binding to hen egg white lysozyme.
- the present invention is directed to, at least, synthetic polynucleotide libraries, methods of producing and using the libraries of the invention, kits and computer readable forms including the libraries of the invention.
- the libraries taught in this application are described, at least in part, in terms of the components from which they are assembled.
- the instant invention provides antibody libraries specifically designed based on the composition and CDR length distribution in the naturally occurring human antibody repertoire. It is estimated that, even in the absence of antigenic stimulation, a human makes at least about 10 7 different antibody molecules. The antigen- binding sites of many antibodies can cross-react with a variety of related but different epitopes. In addition the human antibody repertoire is large enough to ensure that there is an antigen-binding site to fit almost any potential epitope, albeit with low affinity.
- the mammalian immune system has evolved unique genetic mechanisms that enable it to generate an almost unlimited number of different light and heavy chains in a remarkably economical way, by combinatorially joining chromosomally separated gene segments prior to transcription.
- Each type of immunoglobulin (Ig) chain i.e., K light, ⁇ light, and heavy
- K light, ⁇ light, and heavy is synthesized by combinatorial assembly of DNA sequences selected from two or more families of gene segments, to produce a single polypeptide chain.
- the heavy chains and light chains each consist of a variable region and a constant (C) region.
- the variable regions of the heavy chains are encoded by DNA sequences assembled from three families of gene segments: variable (IGHV), joining (IGHJ) and diversity (IGHD).
- variable regions of light chains are encoded by DNA sequences assembled from two families of gene segments for each of the kappa and lambda light chains: variable (IGLV) and joining (IGLJ). Each variable region (heavy and light) is also recombined with a constant region, to produce a full-length immunoglobulin chain.
- B cell receptor locus After a B cell recognizes an antigen, it is induced to proliferate. During proliferation, the B cell receptor locus undergoes an extremely high rate of somatic mutation that is far greater than the normal rate of genomic mutation. The mutations that occur are primarily localized to the Ig variable regions and comprise substitutions, insertions and deletions. This somatic hypermutation enables the production of B cells that express antibodies possessing enhanced affinity toward an antigen. Such antigen- driven somatic hypermutation fine-tunes antibody responses to a given antigen.
- the present invention provides, for the first time, a fully synthetic antibody library that is representative of the human preimmune antibody repertoire (e.g., in composition and length), and that can be readily screened (i.e., it is physically realizable and, in some cases can be oversampled) using, for example, high throughput methods, to obtain, for example, new therapeutics and/or diagnostics
- the synthetic antibody libraries of the instant invention have the potential to recognize any antigen, including self-antigens of human origin.
- the ability to recognize self-antigens is usually lost in an expressed human library, because self-reactive antibodies are removed by the donor's immune system via negative selection.
- Another feature of the invention is that screening the antibody library using positive clone selection, for example, by FACS (florescence activated cell sorter) bypasses the standard and tedious methodology of generating a hybridoma library and supernatant screening.
- FACS fluorescence activated cell sorter
- the libraries, or sub-libraries thereof can be screened multiple times, to discover additional antibodies against other desired targets.
- antibody is used herein in the broadest sense and specifically encompasses at least monoclonal antibodies, polyclonal antibodies, multi-specific antibodies (e.g., bispecific antibodies), chimeric antibodies, humanized antibodies, human antibodies, and antibody fragments.
- An antibody is a protein comprising one or more polypeptides substantially or partially encoded by immunoglobulin genes or fragments of immunoglobulin genes.
- the recognized immunoglobulin genes include the kappa, lambda, alpha, gamma, delta, epsilon and mu constant region genes, as well as myriad immunoglobulin variable region genes.
- Antibody fragments comprise a portion of an intact antibody, for example, one or more portions of the antigen-binding region thereof.
- antibody fragments include Fab, Fab', F(ab') 2 , and Fv fragments, diabodies, linear antibodies, single-chain antibodies, and multi-specific antibodies formed from intact antibodies and antibody fragments.
- An "intact antibody” is one comprising full-length heavy- and light- chains and an Fc region.
- An intact antibody is also referred to as a "full-length, heterodimeric" antibody or immunoglobulin.
- variable refers to the portions of the immunoglobulin domains that exhibit variability in their sequence and that are involved in determining the specificity and binding affinity of a particular antibody (i.e., the "variable domain(s)"). Variability is not evenly distributed throughout the variable domains of antibodies; it is concentrated in sub- domains of each of the heavy and light chain variable regions. These sub-domains are called “hypervariable” regions or “complementarity determining regions” (CDRs). The more conserved (i.e., non-hypervariable) portions of the variable domains are called the "framework" regions (FRM).
- CDRs complementarity determining regions
- variable domains of naturally occurring heavy and light chains each comprise four FRM regions, largely adopting a ⁇ -sheet configuration, connected by three hypervariable regions, which form loops connecting, and in some cases forming part of, the ⁇ -sheet structure.
- the hypervariable regions in each chain are held together in close proximity by the FRM and, with the hypervariable regions from the other chain, contribute to the formation of the antigen-binding site (see Kabat et al. Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md., 1991, incorporated by reference in its entirety).
- the constant domains are not directly involved in antigen binding, but exhibit various effector functions, such as, for example, antibody-dependent, cell-mediated cytotoxicity and complement activation.
- the “chassis” of the invention represent a portion of the antibody heavy chain variable (IGHV) or light chain variable (IGLV) domains that are not part of CDRH3 or CDRL3, respectively.
- the chassis of the invention is defined as the portion of the variable region of an antibody beginning with the first amino acid of FRMl and ending with the last amino acid of FRM3.
- the chassis includes the amino acids including from about Kabat position 1 to about Kabat position 94.
- the chassis are defined as including from about Kabat position 1 to about Kabat position 88.
- the chassis of the invention may contain certain modifications relative to the corresponding germline variable domain sequences presented herein or available in public databases.
- modifications may be engineered (e.g., to remove N-linked glycosylation sites) or naturally occurring (e.g., to account for allelic variation).
- immunoglobulin gene repertoire is polymorphic (Wang et ah, Immunol. Cell. Biol., 2008, 86: 111; Collins et ah, Immunogenetics, 2008, DOI 10.1007/s00251-008-0325-z, published online, each incorporated by reference in its entirety); chassis, CDRs ⁇ e.g., CDRH3) and constant regions representative of these allelic variants are also encompassed by the invention.
- the allelic variant(s) used in a particular embodiment of the invention may be selected based on the allelic variation present in different patient populations, for example, to identify antibodies that are non-immunogenic in these patient populations.
- the immunogenicity of an antibody of the invention may depend on allelic variation in the major histocompatibility complex (MHC) genes of a patient population. Such allelic variation may also be considered in the design of libraries of the invention.
- the chassis and constant regions are contained on a vector, and a CDR3 region is introduced between them via homologous recombination.
- one, two or three nucleotides may follow the heavy chain chassis, forming either a partial (if one or two) or a complete (if three) codon. When a full codon is present, these nucleotides encode an amino acid residue that is referred to as the "tail,” and occupies position 95.
- CDRH3 numbering system used herein defines the first amino acid of CDRH3 as being at Kabat position 95 (the "tail,” when present) and the last amino acid of CDRH3 as position 102.
- the amino acids following the “tail” are called “Nl” and, when present, are assigned numbers 96, 96A, 96B, etc.
- the Nl segment is followed by the “DH” segment, which is assigned numbers 97, 97A, 97B, 97C, etc.
- the DH segment is followed by the "N2" segment, which, when present, is numbered 98, 98A, 98B, etc.
- the most C-terminal amino acid residue of the set of the "H3-JH” segment is designated as number 102.
- sequence diversity refers to a variety of sequences which are collectively representative of several possibilities of sequences, for example, those found in natural human antibodies.
- heavy chain CDR3 (CDRH3) sequence diversity may refer to a variety of possibilities of combining the known human DH and H3-JH segments, including the Nl and N2 regions, to form heavy chain CDR3 sequences.
- the light chain CDR3 (CDRL3) sequence diversity may refer to a variety of possibilities of combining the naturally occurring light chain variable region contributing to CDRL3 (i.e., L3-VL) and joining (i.e., L3-JL) segments, to form light chain CDR3 sequences.
- H3-JH refers to the portion of the IGHJ gene contributing to CDRH3.
- L3-VL and L3-JL refer to the portions of the IGLV and IGLJ genes (kappa or lambda) contributing to CDRL3, respectively.
- expression includes any step involved in the production of a polypeptide including, but not limited to, transcription, post-transcriptional modification, translation, post-translational modification, and secretion.
- the term "host cell” is intended to refer to a cell into which a polynucleotide of the invention. It should be understood that such terms refer not only to the particular subject cell but to the progeny or potential progeny of such a cell. Because certain modifications may occur in succeeding generations due to either mutation or environmental influences, such progeny may not, in fact, be identical to the parent cell, but are still included within the scope of the term as used herein.
- length diversity refers to a variety in the length of a particular nucleotide or amino acid sequence.
- the heavy chain CDR3 sequence varies in length, for example, from about 3 amino acids to over about 35 amino acids
- the light chain CDR3 sequence varies in length, for example, from about 5 to about 16 amino acids.
- sequence diversity or length diversity See, e.g., Hoet et ah, Nat. BiotechnoL, 2005, 23: 344; Kretzschmar and von Ruden, Curr. Opin. BiotechnoL, 2002 13: 598; and Rauchenberger et al, J.
- a sequence designed with "directed diversity” has been specifically designed to contain both sequence diversity and length diversity. Directed diversity is not stochastic.
- stochastic describes a process of generating a randomly determined sequence of amino acids, which is considered as a sample of one element from a probability distribution.
- library of polynucleotides refers to two or more polynucleotides having a diversity as described herein, specifically designed according to the methods of the invention.
- library of polypeptides refers to two or more polypeptides having a diversity as described herein, specifically designed according to the methods of the invention.
- library of synthetic polynucleotides refers to a polynucleotide library that includes synthetic polynucleotides.
- library of vectors refers herein to a library of at least two different vectors.
- human antibody libraries at least includes, a polynucleotide or polypeptide library which has been designed to represent the sequence diversity and length diversity of naturally occurring human antibodies.
- library is used herein in its broadest sense, and also may include the sub-libraries that may or may not be combined to produce libraries of the invention.
- synthetic polynucleotide refers to a molecule formed through a chemical process, as opposed to molecules of natural origin, or molecules derived via template-based amplification of molecules of natural origin (e.g., immunoglobulin chains cloned from populations of B cells via PCR amplification are not "synthetic" used herein).
- libraries of the invention that comprise multiple components (e.g., Nl, DH, N2, and/or H3-JH)
- the invention encompasses libraries in which at least one of the aforementioned components is synthetic.
- a library in which certain components are synthetic, while other components are of natural origin or derived via template -based amplification of molecules of natural origin would be encompassed by the invention.
- split-pool synthesis refers to a procedure in which the products of a plurality of first reactions are combined (pooled) and then separated (split) before participating in a plurality of second reactions.
- Example 9 describes the synthesis of 278 DH segments (products), each in a separate reaction. After synthesis, these 278 segments are combined (pooled) and then distributed (split) amongst 141 columns for the synthesis of the N2 segments. This enables the pairing of each of the 278 DH segments with each of the 141 N2 segments. As described elsewhere in the specification, these numbers are non- limiting.
- Preimmune antibody libraries have similar sequence diversities and length diversities to naturally occurring human antibody sequences before these sequences have undergone negative selection or somatic hypermutation.
- the set of sequences described in Lee et al. is believed to represent sequences from the preimmune repertoire.
- the sequences of the invention will be similar to these sequences ⁇ e.g., in terms of composition and length).
- such antibody libraries are designed to be small enough to chemically synthesize and physically realize, but large enough to encode antibodies with the potential to recognize any antigen.
- an antibody library comprises about 10 7 to about 10 20 different antibodies and/or polynucleotide sequences encoding the antibodies of the library.
- the libraries of the instant invention are designed to include 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , or 10 20 different antibodies and/or polynucleotide sequences encoding the antibodies.
- the libraries of the invention may comprise or encode about 10 3 to about 10 5 , about 10 5 to about 10 7 , about 10 7 to about 10 9 , about 10 9 to about 10 11 , about 10 11 to about 10 13 , about 10 13 to about 10 15 , about 10 15 to about 10 17 , or about 10 17 to about 10 20 different antibodies.
- the diversity of the libraries may be characterized as being greater than or less than one or more of the diversities enumerated above, for example greater than about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , or 10 20 or less than about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , or 10 20 .
- the probability of an antibody of interest being present in a physical realization of a library with a size as enumerated above is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% (see Library Sampling, in the Detailed Description, for more information on the probability of a particular sequence being present in a physical realization of a library).
- the antibody libraries of the invention may also include antibodies directed to, for example, self (i.e., human) antigens.
- the antibodies of the present invention may not be present in expressed human libraries for reasons including because self-reactive antibodies are removed by the donor's immune system via negative selection.
- novel heavy/light chain pairings may in some cases create self-reactive antibody specificity (Griffiths et al. US Patent 5,885,793, incorporated by reference in its entirety).
- the number of unique heavy chains in a library may be about 10, 50, 10 2 , 150, 10 3 , 10 4 , 10 5 ,10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , 10 20 , or more.
- the number of unique light chains in a library may be about 5, 10, 25, 50, 10 2 , 150, 500, 10 3 , 10 4 , 10 5 ,10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , 10 20 , or more.
- human antibody CDRH3 libraries at least includes, a polynucleotide or polypeptide library which has been designed to represent the sequence diversity and length diversity of naturally occurring human antibodies.
- "Preimmune" CDRH3 libraries have similar sequence diversities and length diversities to naturally occurring human antibody CDRH3 sequences before these sequences undergo negative selection and somatic hypermutation.
- Known human CDRH3 sequences are represented in various data sets, including Jackson et al., J. Immunol Methods, 2007, 324: 26; Martin, Proteins, 1996, 25: 130; and Lee et al., Immunogenetics, 2006, 57: 917, each of which is incorporated by reference in its entirety.
- an antibody library includes about 10 6 to about 10 15 different CDRH3 sequences and/or polynucleotide sequences encoding said CDRH3 sequences.
- the libraries of the instant invention are designed to about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , or 10 16 , different CDRH3 sequences and/or polynucleotide sequences encoding said CDRH3 sequences.
- the libraries of the invention may include or encode aboutlO 3 to about 10 6 , about 10 6 to about 10 8 , about 10 8 to about 10 10 , about 10 10 to about 10 12 , about 10 12 to about 10 14 , or about 10 14 to about 10 16 different CDRH3 sequences.
- the diversity of the libraries may be characterized as being greater than or less than one or more of the diversities enumerated above, for example greater than about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , or 10 16 or less than about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , or 10 16 .
- the probability of a CDRH3 of interest being present in a physical realization of a library with a size as enumerated above is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% (see Library Sampling, in the Detailed Description, for more information on the probability of a particular sequence being present in a physical realization of a library).
- the preimmune CDRH3 libraries of the invention may also include CDRH3s directed to, for example, self (i.e., human) antigens. Such CDRH3s may not be present in expressed human libraries, because self-reactive CDRH3s are removed by the donor's immune system via negative selection.
- Known human CDRL3 sequences are represented in various data sets, including the NCBI database (see Appendix A and Appendix B for light chain sequence data sets) and Martin, Proteins, 1996, 25: 130 incorporated by reference in its entirety.
- such CDRL3 libraries are designed to be small enough to chemically synthesize and physically realize, but large enough to encode CDRL3s with the potential to recognize any antigen.
- an antibody library comprises about 10 5 different CDRL3 sequences and/or polynucleotide sequences encoding said CDRL3 sequences.
- the libraries of the instant invention are designed to comprise about 10 1 , 10 2 , 10 3 , 10 4 , 10 6 , 10 7 , or 10 8 different CDRL3 sequences and/or polynucleotide sequences encoding said CDRL3 sequences.
- the libraries of the invention may comprise or encode about 10 1 to about 10 3 , about 10 3 to about 10 5 , or about 10 5 to about 10 8 different CDRL3 sequences.
- the diversity of the libraries may be characterized as being greater than or less than one or more of the diversities enumerated above, for example greater than about 10 1 , 10 2 , 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , or 10 8 or less than about 10 1 , 10 2 , 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , or 10 8 .
- the probability of a CDRL3 of interest being present in a physical realization of a library with a size as enumerated above is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% (see Library Sampling, in the Detailed Description, for more information on the probability of a particular sequence being present in a physical realization of a library).
- the preimmune CDRL3 libraries of the invention may also include CDRL3s directed to, for example, self (i.e., human) antigens.
- CDRL3s may not be present in expressed human libraries, because self-reactive CDRL3s are removed by the donor's immune system via negative selection.
- known heavy chain CDR3 sequences refers to heavy chain CDR3 sequences in the public domain that have been cloned from populations of human B cells. Examples of such sequences are those published or derived from public data sets, including, for example, Zemlin et al., JMB, 2003, 334: 733; Lee et al., Immunogenetics, 2006, 57: 917; and Jackson et al. J. Immunol Methods, 2007, 324: 26, each of which are incorporated by reference in their entirety.
- known light chain CDR3 sequences refers to light chain CDR3 sequences (e.g., kappa or lambda) in the public domain that have been cloned from populations of human B cells. Examples of such sequences are those published or derived from public data sets, including, for example, the NCBI database (see Appendices A and B filed herewith).
- antibody binding regions refers to one or more portions of an immunoglobulin or antibody variable region capable of binding an antigen(s).
- the antibody binding region is, for example, an antibody light chain (or variable region or one or more CDRs thereof), an antibody heavy chain (or variable region or one or more CDRs thereof), a heavy chain Fd region, a combined antibody light and heavy chain (or variable regions thereof) such as a Fab, F(ab') 2 , single domain, or single chain antibodies (scFv), or any region of a full length antibody that recognizes an antigen, for example, an IgG (e.g., an IgGl, IgG2, IgG3, or IgG4 subtype), IgAl, IgA2, IgD, IgE, or IgM antibody.
- an IgG e.g., an IgGl, IgG2, IgG3, or IgG4 subtype
- IgAl IgA2, IgD, IgE, or IgM
- framework region refers to the art-recognized portions of an antibody variable region that exist between the more divergent (i.e., hypervariable) CDRs.
- framework regions are typically referred to as frameworks 1 through 4 (FRMl, FRM2, FRM3, and FRM4) and provide a scaffold for the presentation of the six CDRs (three from the heavy chain and three from the light chain) in three dimensional space, to form an antigen-binding surface.
- canonical structure refers to the main chain conformation that is adopted by the antigen binding (CDR) loops. From comparative structural studies, it has been found that five of the six antigen binding loops have only a limited repertoire of available conformations. Each canonical structure can be characterized by the torsion angles of the polypeptide backbone. Correspondent loops between antibodies may, therefore, have very similar three dimensional structures, despite high amino acid sequence variability in most parts of the loops (Chothia and Lesk, J. MoI. Biol, 1987, 196: 901; Chothia et al., Nature, 1989, 342: 877; Martin and Thornton, J. MoI.
- Kabat numbering scheme is a widely adopted standard for numbering the amino acid residues of an antibody variable domain in a consistent manner. Additional structural considerations can also be used to determine the canonical structure of an antibody. For example, those differences not fully reflected by Kabat numbering can be described by the numbering system of Chothia et al. and/or revealed by other techniques, for example, crystallography and two or three-dimensional computational modeling. Accordingly, a given antibody sequence may be placed into a canonical class which allows for, among other things, identifying appropriate chassis sequences (e.g., based on a desire to include a variety of canonical structures in a library). Kabat numbering of antibody amino acid sequences and structural considerations as described by Chothia et al. , and their implications for construing canonical aspects of antibody structure, are described in the literature.
- CDR refers to a complementarity determining region (CDR) of which three make up the binding character of a light chain variable region (CDRLl, CDRL2 and CDRL3) and three make up the binding character of a heavy chain variable region (CDRHl, CDRH2 and CDRH3).
- CDRs contribute to the functional activity of an antibody molecule and are separated by amino acid sequences that comprise scaffolding or framework regions.
- the exact definitional CDR boundaries and lengths are subject to different classification and numbering systems. CDRs may therefore be referred to by Kabat, Chothia, contact or any other boundary definitions, including the numbering system described herein.
- CDR definitions according to these systems may therefore differ in length and boundary areas with respect to the adjacent framework region. See for example Kabat, Chothia, and/or MacCallum et al., (Kabat et al., in "Sequences of Proteins of Immunological Interest," 5 th Edition, U.S. Department of Health and Human Services, 1992; Chothia et al., J. MoI. Biol, 1987, 196: 901; and MacCallum et al., J. MoI. Biol, 1996, 262: 732, each of which is incorporated by reference in its entirety).
- amino acid typically refers to an amino acid having its art recognized definition such as an amino acid selected from the group consisting of: alanine (Ala or A); arginine (Arg or R); asparagine (Asn or N); aspartic acid (Asp or D); cysteine (Cys or C); glutamine (GIn or Q); glutamic acid (GIu or E); glycine (GIy or G); histidine (His or H); isoleucine (He or I): leucine (Leu or L); lysine (Lys or K); methionine (Met or M); phenylalanine (Phe or F); proline (Pro or P); serine (Ser or S); threonine (Thr or T); tryptophan (Trp or W); tyrosine (Tyr or Y); and valine (VaI or V), although modified, synthetic, or rare amino acids may be used as desired.
- alanine Al or A
- amino acids can be grouped as having a nonpolar side chain (e.g., Ala, Cys, He, Leu, Met, Phe, Pro, VaI); a negatively charged side chain (e.g., Asp, GIu); a positively charged sidechain (e.g., Arg, His, Lys); or an uncharged polar side chain (e.g., Asn, Cys, GIn, GIy, His, Met, Phe, Ser, Thr, Trp, and Tyr).
- a nonpolar side chain e.g., Ala, Cys, He, Leu, Met, Phe, Pro, VaI
- a negatively charged side chain e.g., Asp, GIu
- a positively charged sidechain e.g., Arg, His, Lys
- an uncharged polar side chain e.g., Asn, Cys, GIn, GIy, His, Met, Phe, Ser, Thr, Trp, and Tyr.
- polynucleotide(s) refers to nucleic acids such as DNA molecules and RNA molecules and analogs thereof (e.g., DNA or RNA generated using nucleotide analogs or using nucleic acid chemistry).
- the polynucleotides may be made synthetically, e.g., using art-recognized nucleic acid chemistry or enzymatically using, e.g., a polymerase, and, if desired, be modified. Typical modifications include methylation, biotinylation, and other art-known modifications.
- the nucleic acid molecule can be single-stranded or double-stranded and, where desired, linked to a detectable moiety.
- the term "physical realization" refers to a portion of the theoretical diversity that can actually be physically sampled, for example, by any display methodology.
- Exemplary display methodology include: phage display, ribosomal display, and yeast display.
- the size of the physical realization of a library depends on (1) the fraction of the theoretical diversity that can actually be synthesized, and (2) the limitations of the particular screening method.
- Exemplary limitations of screening methods include the number of variants that can be screened in a particular assay (e.g., ribosome display, phage display, yeast display) and the transformation efficiency of a host cell (e.g., yeast, mammalian cells, bacteria) which is used in a screening assay.
- an exemplary physical realization of the library (e.g., in yeast, bacterial cells, ribosome display, etc.; details provided below) that can maximally include 10 11 members will, therefore, sample about 10% of the theoretical diversity of the library.
- the physical realization of the library can maximally include 10 11 members, less than 10% of the theoretical diversity of the library is sampled in the physical realization of the library.
- a physical realization of the library that can maximally include more than 10 12 members would "oversample" the theoretical diversity, meaning that each member may be present more than once (assuming that the entire 10 12 theoretical diversity is synthesized).
- all possible reading frames encompasses at least the three forward reading frames and, in some embodiments, the three reverse reading frames.
- antibody of interest refers to any antibody that has a property of interest that is isolated from a library of the invention.
- the property of interest may include, but is not limited to, binding to a particular antigen or epitope, blocking a binding interaction between two molecules, or eliciting a certain biological effect.
- the term "functionally expressed” refers to those immunoglobulin genes that are expressed by human B cells and that do not contain premature stop codons.
- full-length heavy chain refers to an immunoglobulin heavy chain that contains each of the canonical structural domains of an immunoglobulin heavy chain, including the four framework regions, the three CDRs, and the constant region.
- full-length light chain refers to an immunoglobulin light chain that contains each of the canonical structural domains of an immunoglobulin light chain, including the four framework regions, the three CDRs, and the constant region.
- unique refers to a sequence that is different (e.g. has a different chemical structure) from every other sequence within the designed theoretical diversity. It should be understood that there are likely to be more than one copy of many unique sequences from the theoretical diversity in a particular physical realization. For example, a library comprising three unique sequences may comprise nine total members if each sequence occurs three times in the library. However, in certain embodiments, each unique sequence may occur only once.
- heterologous moiety is used herein to indicate the addition of a composition to an antibody wherein the composition is not normally part of the antibody.
- exemplary heterologous moieties include drugs, toxins, imaging agents, and any other compositions which might provide an activity that is not inherent in the antibody itself.
- percent occurrence of each amino acid residue at each position refers to the percentage of instances in a sample in which an amino acid is found at a defined position within a particular sequence. For example, given the following three sequences:
- sequences selected for comparison are human immunoglobulin sequences.
- the term "most frequently occurring amino acids" at a specified position of a sequence in a population of polypeptides refers to the amino acid residues that have the highest percent occurrence at the indicated position in the indicated polypeptide population.
- the most frequently occurring amino acids in each of the three most N-terminal positions in Nl sequences of CDRH3 sequences that are functionally expressed by human B cells are listed in Table 21, and the most frequently occurring amino acids in each of the three most N-terminal positions in N2 sequences of CDRH3 sequences that are functionally expressed by human B cells are listed in Table 22.
- a "central loop" of CDRH3 is defined. If the C-terminal 5 amino acids from Kabat CDRH3 (95-102) are removed, then the remaining sequence is termed the "central loop". Thus, considering the duplet occurrence calculations of Example 13, using a CDRH3 of size 6 or less would not contribute to the analysis of the occurrence of duplets.
- a CDRH3 of size 7 would contribute only to the i - i+1 data set, a CDRH3 of size 8 would also contribute to the i - i+2 data set, and a CDRH3 of size 9 and larger would also contribute to the i - i+3 data set.
- a CDR H3 of size 9 may have amino acids at positions 95-96-97-98- 99-100-100A-101-102, but only the first four residues (bolded) would be part of the central loop and contribute to the pair- wise occurrence (duplet) statistics.
- a CDRH3 of size 14 may have the sequence: 95-96-97-98-99-100-10OA-IOOB-IOOC-IOOD- lOOE-lOOF-101-102.
- only the first nine residues (bolded) contribute to the central loop.
- genotype-phenotype linkage is used in a manner consistent with its art-recognized meaning and refers to the fact that the nucleic acid (genotype) encoding a protein with a particular phenotype (e.g., binding an antigen) can be isolated from a library.
- an antibody fragment expressed on the surface of a phage can be isolated based on its binding to an antigen (e.g., Ladner et al.). The binding of the antibody to the antigen simultaneously enables the isolation of the phage containing the nucleic acid encoding the antibody fragment.
- the phenotype (antigen-binding characteristics of the antibody fragment) has been "linked" to the genotype (nucleic acid encoding the antibody fragment).
- Other methods of maintaining a genotype-phenotype linkage include those of Wittrup et al (US Patent Nos. 6,300,065, 6,331,391, 6,423,538, 6,696,251, 6,699,658, and US Pub. No. 20040146976, each of which is incorporated by reference in its entirety), Miltenyi (US Patent No. 7,166,423, incorporated by reference in its entirety), Fandl (US Patent No. 6,919,183, US Pub No. 20060234311, each incorporated by reference in its entirety), Clausell-Tormos et al. (Chem.
- the antibody libraries of the invention are designed to reflect certain aspects of the preimmune repertoire as naturally created by the human immune system. Certain libraries of the invention are based on rational design informed by the collection of human V, D, and J genes, and other large databases of human heavy and light chain sequences (e.g., publicly known germline sequences; sequences from Jackson et al., J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety; sequences from Lee et al., Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety; and sequences compiled for rearranged VK and V ⁇ - see Appendices A and B filed herewith).
- human V, D, and J genes e.g., publicly known germline sequences; sequences from Jackson et al., J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety; sequences from Lee et al., Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety; and
- cassettes representing the possible V, D, and J diversity found in the human repertoire, as well as junctional diversity are synthesized de novo as single or double-stranded DNA oligonucleotides.
- oligonucleotide cassettes encoding CDR sequences are introduced into yeast along with one or more acceptor vectors containing heavy or light chain chassis sequences. No primer- based PCR amplification or template-directed cloning steps from mammalian cDNA or mRNA are employed. Through standard homologous recombination, the recipient yeast recombines the cassettes (e.g., CDR3s) with the acceptor vector(s) containing the chassis sequence(s) and constant regions, to create a properly ordered synthetic, full-length human heavy chain and/or light chain immunoglobulin library that can be genetically propagated, expressed, displayed, and screened.
- cassettes e.g., CDR3s
- the chassis contained in the acceptor vector can be designed so as to produce constructs other than full-length human heavy chains and/or light chains.
- the chassis may be designed to encode portions of a polypeptide encoding an antibody fragment or subunit of an antibody fragment, so that a sequence encoding an antibody fragment, or subunit thereof, is produced when the oligonucleotide cassette containing the CDR is recombined with the acceptor vector.
- the invention provides a synthetic, preimmune human antibody repertoire comprising about 10 7 to about 10 20 antibody members, wherein the repertoire comprises:
- (a) selected human antibody heavy chain chassis i.e., amino acids 1 to 94 of the heavy chain variable region, using Rabat's definition
- (b) a CDRH3 repertoire designed based on the human IGHD and IGHJ germline sequences, the CDRH3 repertoire comprising the following: (i) optionally, one or more tail regions;
- Nl regions comprising about 0 to about 10 amino acids selected from the group consisting of fewer than 20 of the amino acid types preferentially encoded by the action of terminal deoxynucleotidyl transferase (TdT) and functionally expressed by human B cells;
- TdT terminal deoxynucleotidyl transferase
- N2 regions comprising about 0 to about 10 amino acids selected from the group consisting of fewer than 20 of the amino acids preferentially encoded by the activity of TdT and functionally expressed by human B cells;
- the heavy chain chassis may be any sequence with homology to Kabat residues 1 to
- heavy chain chassis is included in the Examples, and one of ordinary skill in the art will readily recognize that the principles presented therein, and throughout the specification, may be used to derive additional heavy chain chassis. As described above, the heavy chain chassis region is followed, optionally, by a
- the tail region comprises zero, one, or more amino acids that may or may not be selected on the basis of comparing naturally occurring heavy chain sequences. For example, in certain embodiments of the invention, heavy chain sequences available in the art may be compared, and the residues occurring most frequently in the tail position in the naturally occurring sequences included in the library (e.g., to produce sequences that most closely resemble human sequences). In other embodiments, amino acids that are used less frequently may be used. In still other embodiments, amino acids selected from any group of amino acids may be used. In certain embodiments of the invention, the length of the tail is zero (no residue) or one (e.g., G/D/E) amino acid.
- the first 2/3 of the codon encoding the tail residue is provided by the FRM3 region of the VH gene.
- the amino acid at this position in naturally occurring heavy chain sequences may thus be considered to be partially encoded by the IGHV gene (2/3) and partially encoded by the CDRH3 (1/3).
- the entire codon encoding the tail residue (and, therefore, the amino acid derived from it) is described herein as being part of the CDRH3 sequence.
- Nl and N2 are two peptide segments derived from nucleotides which are added by TdT in the naturally occurring human antibody repertoire. These segments are designated Nl and N2 (referred to herein as Nl and N2 segments, domains, regions or sequences).
- Nl and N2 are about 0, 1, 2, or 3 amino acids in length. Without being bound by theory, it is thought that these lengths most closely mimic the Nl and N2 lengths found in the human repertoire (see Figure 2). In other embodiments of the invention, Nl and N2 may be about 4, 5, 6, 7, 8, 9, or 10 amino acids in length.
- the composition of the amino acid residues utilized to produce the Nl and N2 segments may also vary.
- the amino acids used to produce Nl and N2 segments may be selected from amongst the eight most frequently occurring amino acids in the Nl and N2 domains of the human repertoire (e.g., G, R, S, P, L, A, V, and T).
- the amino acids used to produce the Nl and N2 segments may be selected from the group consisting of fewer than about 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, or 3 of the amino acids preferentially encoded by the activity of TdT and functionally expressed by human B cells.
- Nl and N2 may comprise amino acids selected from any group of amino acids. It is not required that Nl and N2 be of a similar length or composition, and independent variation of the length and composition of Nl and N2 is one method by which additional diversity may be introduced into the library.
- DH segments of the libraries are based on the peptides encoded by the naturally occurring IGHD gene repertoire, with progressive deletion of residues at the N- and C- termini.
- IGHD genes may be read in multiple reading frames, and peptides representing these reading frames, and their N- and C-terminal deletions are also included in the libraries of the invention.
- DH segments as short as three amino acid residues may be included in the libraries.
- DH segments as short as about 1, 2, 4, 5, 6, 7, or 8 amino acids may be included in the libraries.
- the H3-JH segments of the libraries are based on the peptides encoded by the naturally occurring IGHJ gene repertoire, with progressive deletion of residues at the N- terminus.
- the N-terminal portion of the IGHJ segment that makes up part of the CDRH3 is referred to herein as H3-JH.
- the H3-JH segment may be represented by progressive N-terminal deletions of one or more H3-JH residues, down to two H3-JH residues.
- the H3-JH segments of the library may contain N-terminal deletions (or no deletions) down to about 6, 5, 4, 3, 2, 1, or 0 H3-JH residues.
- the light chain chassis of the libraries may be any sequence with homology to Kabat residues 1 to 88 of naturally occurring light chain (K or ⁇ ) sequences.
- the light chain chassis of the invention are synthesized in combinatorial fashion, utilizing VL and JL segments, to produce one or more libraries of light chain sequences with diversity in the chassis and CDR3 sequences.
- the light chain CDR3 sequences are synthesized using degenerate oligonucleotides or trinucleotides and recombined with the light chain chassis and light chain constant region, to form full-length light chains.
- the instant invention also provides methods for producing and using such libraries, as well as libraries comprising one or more immunoglobulin domains or antibody fragments. Design and synthesis of each component of the claimed antibody libraries is provided in more detail below.
- chassis sequences which are based on naturally occurring variable domain sequences ⁇ e.g., IGHV and IGLV). This selection can be done arbitrarily, or by the selection of chassis that meet certain criteria.
- the Kabat database an electronic database containing non- redundant rearranged antibody sequences, can be queried for those heavy and light chain germline sequences that are most frequently represented.
- the BLAST search algorithm or more specialized tools such as SoDA (Volpe et al., Bioinformatics, 2006, 22: 438-44, incorporated by reference in its entirety), can be used to compare rearranged antibody sequences with germline sequences, using the V BASE2 database (Retter et al, Nucleic Acids Res., 2005, 33: D671-D674), or similar collections of human V, D, and J genes, to identify the germline families that are most frequently used to generate functional antibodies.
- SoDA Volpe et al., Bioinformatics, 2006, 22: 438-44, incorporated by reference in its entirety
- Chassis may also be chosen based on their representation in the peripheral blood of humans. In certain embodiments of the invention, it may be desirable to select chassis that correspond to germline sequences that are highly represented in the peripheral blood of humans. In other embodiments, it may be desirable to select chassis that correspond to germline sequences that are less frequently represented, for example, to increase the canonical diversity of the library. Therefore, chassis may be selected to produce libraries that represent the largest and most structurally diverse group of functional human antibodies.
- chassis may be selected based on both their expression in a cell of the invention (e.g., a yeast cell) and the diversity of canonical structures represented by the selected sequences. One may therefore produce a library with a diversity of canonical structures that express well in a cell of the invention.
- a cell of the invention e.g., a yeast cell
- the antibody library comprises variable heavy domains and variable light domains, or portions thereof. Each of these domains is built from certain components, which will be more fully described in the examples provided herein.
- the libraries described herein may be used to isolate fully human antibodies that can be used as diagnostics and/or therapeutics. Without being bound by theory, antibodies with sequences most similar or identical to those most frequently found in peripheral blood (for example, in humans) may be less likely to be immunogenic when administered as therapeutic agents.
- the VH domains of the library may be considered to comprise three primary components: (1) a VH "chassis", which includes amino acids 1 to 94 (using Kabat numbering), (2) the CDRH3, which is defined herein to include the Kabat CDRH3 proper (positions 95-102), and (3) the FRM4 region, including amino acids 103 to 113 (Kabat numbering).
- the overall VH structure may therefore be depicted schematically (not to scale) as:
- VH chassis sequences selected for use in the library may correspond to all functionally expressed human IGHV germline sequences.
- IGHV germline sequences may be selected for representation in a library according to one or more criteria.
- the selected IGHV germline sequences may be among those that are most highly represented among antibody molecules isolated from the peripheral blood of healthy adults, children, or fetuses.
- the design of the VH chassis may be desirable to base the design of the VH chassis on the utilization of IGHV germline sequences in adults, children, or fetuses with a disease, for example, an autoimmune disease.
- a disease for example, an autoimmune disease.
- analysis of germline sequence usage in the antibody molecules isolated from the peripheral blood of individuals with autoimmune disease may provide information useful for the design of antibodies recognizing human antigens.
- the selection of IGHV germline sequences for representation in a library of the invention may be based on their frequency of occurrence in the peripheral blood.
- IGHVl germline sequences (IGHV 1-2, IGHV1-18, IGHV1-46, and IGHV1-69) comprise about 80% of the IGHVl family repertoire in peripheral blood.
- the specific IGHVl germline sequences selected for representation in the library may include those that are most frequently occurring and that cumulatively comprise at least about 80% of the IGHVl family repertoire found in peripheral blood.
- An analogous approach can be used to select specific IGHV germline sequences from any other IGHV family (i.e., IGHVl, IGHV2, IGHV3, IGHV4, IGHV5, IGHV6, and IGHV7).
- the specific germline sequences chosen for representation of a particular IGHV family in a library of the invention may therefore comprise at least about 100%, 99%, 98%, 97%, 96% 95%, 94%, 93%, 92%, 91% 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 75%, 70%, 65%, 60%, 55%, 50%, 45%, 40%, 35%, 30%, 25%, 20%, 15%, 10%, 5%, or 0% of the particular IGHV family member repertoire found in peripheral blood.
- the selected IGHV germline sequences may be chosen to maximize the structural diversity of the VH chassis library.
- Structural diversity may be evaluated by, for example, comparing the lengths, compositions, and canonical structures of CDRHl and CDRH2 in the IGHV germline sequences.
- the CDRHl Kabat definition
- CDRH2 Kabat definition
- the amino acid compositions of the IGHV germline sequences and, in particular, the CDR domains may be evaluated by sequence alignments, as presented in the Examples.
- Canonical structure may be assigned, for example, according to the methods described by Chothia et ah, J. MoI. Biol, 1992, 227: 799, incorporated by reference in its entirety.
- VH chassis based on IGHV germline sequences that may maximize the probability of isolating an antibody with particular characteristics. For example, without being bound by theory, in some embodiments it may be advantageous to restrict the IGHV germline sequences to include only those germline sequences that are utilized in antibodies undergoing clinical development, or antibodies that have been approved as therapeutics. On the other hand, in some embodiments, it may be advantageous to produce libraries containing VH chassis that are not represented amongst clinically utilized antibodies. Such libraries may be capable of yielding antibodies with novel properties that are advantageous over those obtained with the use of "typical" IGHV germline sequences, or enabling studies of the structures and properties of "atypical" IGHV germline sequences or canonical structures.
- IGHV germline sequences for representation in a library of the invention. Any of the criteria described herein may also be combined with any other criteria. Further exemplary criteria include the ability to be expressed at sufficient levels in certain cell culture systems, solubility in particular antibody formats ⁇ e.g., whole immunoglobulins and antibody fragments), and the thermodynamic stability of the individual domains, whole immunoglobulins, or antibody fragments. The methods of the invention may be applied to select any IGHV germline sequence that has utility in an antibody library of the instant invention.
- the VH chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 94 of one or more of the following IGHV germline sequences: IGHV1-2, IGHV1-3, IGHVl -8, IGHV1-18, IGHVl- 24, IGHVl -45, IGHV1-46, IGHV 1-58, IGHV1-69, IGHV2-5, IGHV2-26, IGHV2-70, IGHV3-7, IGHV3-9, IGHV3-11, IGHV3-13, IGHV3-15, IGHV3-20, IGHV3-21, IGHV3- 23, IGHV3-30, IGHV3-33, IGHV3-43, IGHV3-48, IGHV3-49, IGHV3-53, IGHV3-64, IGHV3-66, IGHV3-72, IGHV3-73, IGHV3-74, IGHV4-4, IGHV4-28, IGHV4-31, IGHV
- a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the VH chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 94 of the following IGHV germline sequences: IGHV1-2, IGHV1-18, IGHV1-46, IGHV1-69, IGHV3-7, IGHV3-15, IGHV3-23, IGHV3- 30, IGHV3-33, IGHV3-48, IGHV4-31, IGHV4-34, IGHV4-39, IGHV4-59, IGHV4-61, IGHV4-B, and IGHV5-51.
- a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the amino acid sequences of these chassis are presented in Table 5.
- VH chassis While the selection of the VH chassis with sequences based on the IGHV germline sequences is expected to support a large diversity of CDRH3 sequences, further diversity in the VH chassis may be generated by altering the amino acid residues comprising the CDRHl and/or CDRH2 regions of each chassis selected for inclusion in the library (see Example 2).
- the alterations or mutations in the amino acid residues comprising the CDRHl and CDRH2 regions, or other regions, of the IGHV germline sequences are made after analyzing the sequence identity within data sets of rearranged human heavy chain sequences that have been classified according to the identity of the original IGHV germline sequence from which the rearranged sequences are derived. For example, from a set of rearranged antibody sequences, the IGHV germline sequence of each antibody is determined, and the rearranged sequences are classified according to the IGHV germline sequence. This determination is made on the basis of sequence identity. Next, the occurrence of any of the 20 amino acid residues at each position in these sequences is determined.
- alterations in the framework regions may impact antigen binding by altering the spatial orientation of the CDRs. After the occurrence of amino acids at each position of interest has been identified, alterations may be made in the VH chassis sequence, according to certain criteria.
- the objective may be to produce additional VH chassis with sequence variability that mimics the variability observed in the heavy chain domains of rearranged human antibody sequences (derived from respective IGHV germline sequences) as closely as possible, thereby potentially obtaining sequences that are most human in nature (i.e., sequences that most closely mimic the composition and length of human sequences).
- one may synthesize additional VH chassis sequences that include mutations naturally found at a particular position and include one or more of these VH chassis sequences in a library of the invention, for example, at a frequency that mimics the frequency found in nature.
- one may wish to include VH chassis that represent only mutations that most frequently occur at a given position in rearranged human antibody sequences.
- position 31 in the VH1-69 sequence would be varied to include S, N, T, and R.
- the libraries of the invention are not limited to heavy chain sequences that are diversified by this method, and any criteria can be used to introduce diversity into the heavy chain chassis, including random or rational mutagenesis.
- neutral and/or smaller amino acid residues may provide a more flexible and less sterically hindered context for the display of a diversity of CDR sequences.
- Example 2 illustrates the application of this method to heavy chains derived from a particular IGHV germline.
- this method can be applied to any germline sequence, and can be used to generate at least about 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 1000, 10 4 , 10 5 , 10 6 , or more variants of each heavy chain chassis.
- the light chain chassis of the invention may be based on kappa and/or lambda light chain sequences.
- the principles underlying the selection of light chain variable (IGLV) germline sequences for representation in the library are analogous to those employed for the selection of the heavy chain sequences (described above and in Examples 1 and 2).
- the methods used to introduce variability into the selected heavy chain chassis may also be used to introduce variability into the light chain chassis.
- the VL domains of the library may be considered to comprise three primary components: (1) a VL "chassis", which includes amino acids 1 to 88 (using Kabat numbering), (2) the VLCDR3, which is defined herein to include the Kabat CDRL3 proper (positions 89-97), and (3) the FRM4 region, including amino acids 98 to 107 (Kabat numbering).
- the overall VL structure may therefore be depicted schematically (not to scale) as:
- the VL chassis of the libraries include one or more chassis based on IGKV germline sequences.
- the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of one or more of the following IGKV germline sequences: IGKV 1-05, IGKV1-06, IGKV1-08, IGKV1-09, IGKV1-12, IGKV1-13, IGKV1-16, IGKV1-17, IGKV1-27, IGKV1-33, IGKV1-37, IGKV1-39, IGKV1D-16, IGKV1D-17, IGKV1D-43, IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2-40, IGKV2D-26, IGKV2D-29, IGKV2D-30, IGKVV
- a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of the following IGKV germline sequences: IGKVl -05, IGKV1-12, IGKV1-27, IGKVl -33, IGKV1-39, IGKV2-28, IGKV3-11, IGKV3-15, IGKV3-20, and IGKV4-1.
- a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the amino acid sequences of these chassis are presented in Table 11.
- the VL chassis of the libraries include one or more chassis based on IG ⁇ V germline sequences.
- the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of one or more of the following IG ⁇ V germline sequences: IG ⁇ V3-l, IG ⁇ V3-21, IG ⁇ V2-14, IG ⁇ Vl-40, IG ⁇ V3-19, IG ⁇ Vl-51, IG ⁇ Vl-44, IG ⁇ V6-57, IG ⁇ V2-8, IG ⁇ V3-25, IG ⁇ V2-23, IG ⁇ V3-10, IG ⁇ V4-69, IG ⁇ Vl-47, IG ⁇ V2-l l, IG ⁇ V7-43, IG ⁇ V7- 46, IG ⁇ V5-45, IG ⁇ V4-60, IG ⁇ V10-54, IG ⁇ V8-61, IG ⁇ V3-9, IG ⁇ Vl-36, IG ⁇ V2-18,
- a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 90%, 85%, 80%, 75%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of the following IG ⁇ V germline sequences: IG ⁇ V3-l, IG ⁇ V3-21, IG ⁇ V2-14, IG ⁇ Vl-40, IG ⁇ V3-19, IG ⁇ Vl-51, IG ⁇ Vl-44, IG ⁇ V6-57, IG ⁇ V4-69, IG ⁇ V7-43, and IG ⁇ V5-45.
- a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 90%, 85%, 80%, 75%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the amino acid sequences of these chassis are presented in Table 14.
- the CDHR3 region of naturally occurring human antibodies can be divided into five segments: (1) the tail segment, (2) the Nl segment, (3) the DH segment, (4) the N2 segment, and (5) the JH segment.
- the tail, Nl and N2 segments may or may not be present.
- the method for selecting amino acid sequences for the synthetic CDRH3 libraries includes a frequency analysis and the generation of the corresponding variability profiles of existing rearranged antibody sequences. In this process, which is described in more detail in the Examples section, the frequency of occurrence of a particular amino acid residue at a particular position within rearranged CDRH3s (or any other heavy or light chain region) is determined. Amino acids that are used more frequently in nature may then be chosen for inclusion in a library of the invention.
- the libraries contain CDRH3 regions comprising one or more segments designed based on the IGHD gene germline repertoire.
- DH segments selected for inclusion in the library are selected and designed based on the most frequent usage of human IGHD genes, and progressive N-terminal and C-terminal deletions thereof, to mimic the in vivo processing of the IGHD gene segments.
- the DH segments of the library are about 3 to about 10 amino acids in length. In some embodiments of the invention, the DH segments of the library are about 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 amino acids in length, or a combination thereof.
- the libraries of the invention may contain DH segments with a wide distribution of lengths ⁇ e.g., about 0 to about 10 amino acids).
- the length distribution of the DH may be restricted (e.g., about 1 to about 5 amino acids, about 3 amino acids, about 3 and about 5 amino acids, and so on).
- the shortest DH segments may be about 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 amino acids.
- libraries may contain DH segments representative of any reading frame of any IGHD germline sequence.
- the DH segments selected for inclusion in a library include one or more of the following IGHD sequences, or their derivatives ⁇ i.e., any reading frame and any degree of N-terminal and C-terminal truncation): IGHD3-10, IGHD3-22, IGHD6- 19, IGHD6-13, IGHD3-3, IGHD2-2, IGHD4-17, IGHD1-26, IGHD5-5 / 5-18, IGHD2-15, IGHD6-6, IGHD3-9, IGHD5-12, IGHD5-24, IGHD2-21, IGHD3-16, IGHD4-23, IGHDl- 1, IGHD 1-7, IGHD4-4/4-11, IGHD 1-20, IGHD7-27, IGHD2-8, and IGHD6-25.
- a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the DH segments selected for inclusion in a library include one or more of the following IGHD 15 sequences, or their derivatives ⁇ i.e., any reading frame and any degree N-terminal and C-terminal truncation): IGHD3-10, IGHD3-22, IGHD6-19, IGHD6-13, IGHD3-03, IGHD2-02, IGHD4-17, IGHD1-26, IGHD5-5/5-18, and IGHD2-15.
- a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the DH segments selected for inclusion in a library include one or more of the following IGHD sequences, wherein the notation "_x" denotes the reading frame of the gene, or their derivatives ⁇ i.e., any degree of N-terminal or C-terminal truncation): IGHD 1-26 1, IGHDl -26 3, IGHD2-2 2, IGHD2-2 3, IGHD2- 15 2, IGHD3-3 3, IGHD3-10 1, IGHD3-10 2, IGHD3-10 3, IGHD3-22 2, IGHD4-17 2, IGHD5-5 3, IGHD6-13 1, IGHD6-13 2, IGHD6-19 1, and IGHD6-19 2.
- IGHD 1-26 1, IGHDl -26 3, IGHD2-2 2, IGHD2-2 3, IGHD2- 15 2, IGHD3-3 3, IGHD3-10 1, IGHD3-10 2, IGHD3-10 3, IGHD3-22 2, IGHD4-17 2, IGHD5-5 3, IGHD6-13 1, IGHD6
- a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- the libraries are designed to reflect a predetermined length distribution of N- and C-terminal deleted IGHD segments.
- the DH segments of the library may be designed to mimic the natural length distribution of DH segments found in the human repertoire.
- Table 2 shows the relative occurrence of the top 68% of IGHD segments from Lee et al.
- these relative occurrences may be used to design a library with DH prevalence that is similar to the IGHD usage found in peripheral blood.
- the most commonly used reading-frames of the ten most frequently occurring IGHD sequences are utilized, and progressive N- terminal and C-terminal deletions of these sequences are made, thus providing a total of 278 non-redundant DH segments that are used to create a CDRH3 repertoire of the instant invention (Table 18).
- the methods described above can be applied to produce libraries comprising the top 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 expressed IGHD sequences, and progressive N-terminal and C-terminal deletions thereof.
- DH segments may be selected from among those that are commonly expressed, it is also within the scope of the invention to select these gene segments based on the fact that they are less commonly expressed. This may be advantageous, for example, in obtaining antibodies toward self-antigens or in further expanding the diversity of the library.
- DH segments can be used to add compositional diversity in a manner that is strictly relative to their occurrence in actual human heavy chain sequences.
- the progressive deletion of IGHD genes containing disulfide loop encoding segments may be limited, so as to leave the loop intact and to avoid the presence of unpaired cysteine residues.
- the presence of the loop can be ignored and the progressive deletion of the IGHD gene segments can occur as for any other segments, regardless of the presence of unpaired cysteine residues.
- the cysteine residues can be mutated to any other amino acid.
- DH segments from non-human vertebrates may be used in conjunction with human VH, Nl, N2, and H3-JH segments to produce CDRH3s and/or antibodies in which all segments except the DH segment are synthesized with reference to human sequences.
- Example 16 presents exemplary DH segments from a variety of species and outlines methods for their inclusion in the libraries of the invention. These methods may be readily applied to information derived from other species and/or sources of information other than those presented in Example 16. For example, as IGHD sequence data becomes available for additional species ⁇ e.g., as a result of focused sequencing efforts), one of ordinary skill in the art could use the teachings of this application to construct libraries with DH segments derived from these species.
- a library may contain one or more DH segments derived from the IGHD genes presented in Table 55. As further enumerated in Example 16, these sequences can be selected according to one or more non- limiting criteria, including diversity in length and sequence, maximal (or minimal) human "string content," and/or the absence or minimization of T cell epitopes. Like the human IGHD sequences discussed elsewhere in the application, the non-human IGHD segments of the invention may be deleted at their N- and/or C-termini to provide DH segments with a minimal length of 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 amino acids.
- Non-human DH segments include those derived from non-human IGHD genes according to the methods presented herein, allelic variants thereof, and amino acid and nucleotide sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
- IGHD segments may be obtained from multiple species, including camel, shark, mouse, rat, llama, fish, rabbit, and so on.
- Non-limiting exemplary species from which IGHD segments may be obtained include Mus musculus, Camelus sp., Llama sp., Camelidae sp., Raja sp., Ginglymostoma sp., Carcharhinus sp., Heterodontus sp., Hydrolagus sp., Ictalurus sp., Gallus sp., Bos sp., Marmaronetta sp., Ay thy a sp., Netta sp., Equus sp., Pentalagus sp., Bunolagus sp., Nesolagus sp., Romerolagus sp., Brachylagus sp., Sylvilagus sp., Ory
- Pristiophorus sp. Pliotrema sp., Squatina sp., Carcharia sp., Mitsukurina sp., Lamma sp., Isurus sp., Carcharodon sp.,
- Nl and N2 Given the degree of variability in Nl and N2, these segments might also be considered possible regions for substitution with non-human sequences, that is, sequences with composition biases not arising from those of human terminal deoxynucleotide transferase.
- the methods taught herein for the identification and analysis of the Nl and N2 regions of human antibodies are also readily applicable to non-human antibodies.
- IGHJ6 The amino acid sequences of the parent segments and the progressive N-terminal deletions are presented in Table 20 (Example 5). Similar to the N- and C-terminal deletions that the IGHD genes undergo, natural variation is introduced into the IGHJ genes by N- terminal "nibbling", or progressive deletion, of one or more codons by exonuclease activity.
- the H3-JH segment refers to the portion of the IGHJ segment that is part of
- the H3-JH segment of a library comprises one or more of the following sequences: AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV (SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY, DY, Y, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, S, YYYYYGMDV (SEQ ID NO: 22), YYYGMDV, YYYGMDV, YYGMDV, GMDV, MDV, and DV.
- a library may contain one or more of these sequences, allelic variations thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 60%, 55%, or 50% identical to one or more of these sequences.
- the H3-JH segment may comprise about 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or more amino acids.
- the H3-JH segment of JH1 4 (Table 20) has a length of three residues, while non-deleted JH6 has an H3-JH segment length of nine residues.
- the FRM4-JH region of the IGHJ segment begins with the sequence WG(Q/R)G (SEQ ID NO: 23) and corresponds to the portion of the IGHJ segment that makes up part of framework 4.
- there are 28 H3-JH segments that are included in a library there are 28 H3-JH segments that are included in a library.
- libraries may be produced by utilizing about 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, or 30 of the IGHJ segments enumerated above or in Table 20.
- Terminal deoxynucleotidyl transferase is a highly conserved enzyme from vertebrates that catalyzes the attachment of 5' triphosphates to the 3' hydroxyl group of single- or double-stranded DNA. Hence, the enzyme acts as a template-independent polymerase (Koiwai et al, Nucleic Acids Res., 1986, 14: 5777; Basu et al, Biochem. Biophys. Res. Comm., 1983, 111 : 1105, each incorporated by reference in its entirety).
- TdT is responsible for the addition of nucleotides to the V-D and D-J junctions of antibody heavy chains (Alt and Baltimore, PNAS, 1982, 79: 4118; Collins et al, J. Immunol, 2004, 172: 340, each incorporated by reference in its entirety). Specifically, TdT is responsible for creating the Nl and N2 (non-templated) segments that flank the D (diversity) region.
- the length and composition of the Nl and N2 segments are designed rationally, according to statistical biases in amino acid usage found in naturally occurring Nl and N2 segments in human antibodies.
- One embodiment of a library produced via this method is described in Example 5. According to data compiled from human databases (Jackson et ah, J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety), there are an average of 3.02 amino acid insertions for Nl and 2.4 amino acid insertions for N2, not taking into account insertions of two nucleotides or less (Figure 2).
- Nl and N2 segments are restricted to lengths of zero to three amino acids. In other embodiments of the invention, Nl and N2 may be restricted to lengths of less than about 4, 5, 6, 7, 8, 9, or 10 amino acids.
- the composition of these sequences may be chosen according to the frequency of occurrence of particular amino acids in the Nl and N2 sequences of natural human antibodies (for examples of this analysis, see, Tables 21 to 23, in Example 5).
- the eight most commonly occurring amino acids in these regions i.e., G, R, S, P, L, A, T, and V
- about the most 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, or 19 most commonly occurring amino acids may be used in the design of the synthetic Nl and N2 segments.
- all 20 amino acids may be used in these segments.
- the Nl and N2 segments may comprise amino acids selected from any group of amino acids, or designed according to other criteria considered for the design of a library of the invention.
- criteria used to design any portion of a library of the invention may vary depending on the application of the particular library. It is an object of the invention that it may be possible to produce a functional library through the use of Nl and N2 segments selected from any group of amino acids, no Nl or N2 segments, or the use of Nl and N2 segments with compositions other than those described herein.
- the libraries of the current invention are the consideration of the composition of naturally occurring duplet and triplet amino acid sequences during the design of the library.
- Table 23 shows the top twenty-five naturally occurring duplets in the Nl and N2 regions. Many of these can be represented by the general formula (G/P)(G/R/S/P/L/A/V/T) or (R/S/L/A/V/T)(G/P).
- the synthetic Nl and N2 regions may comprise all of these duplets.
- the library may comprise the top 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 most common naturally occurring Nl and/or N2 duplets.
- the libraries may include duplets that are less frequently occurring (i.e., outside of the top 25). The composition of these additional duplets or triplets could readily be determined, given the methods taught herein.
- the library may comprise the top 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 most commonly occurring Nl and/or N2 triplets.
- the libraries may include triplets that are less frequently occurring (i.e., outside of the top 25). The composition of these additional duplets or triplets could readily be determined, given the methods taught herein.
- Nl segments there are about 59 total Nl segments and about 59 total N2 segments used to create a library of CDRH3s. In other embodiments of the invention, the number of Nl segments, N2 segments, or both is increased to about 141 (see, for example, Example 5).
- compositions and lengths of the Nl and N2 segments vary from those presented in the Examples herein.
- sub-stoichiometric synthesis of trinucleotides may be used for the synthesis of Nl and N2 segments.
- Sub-stoichiometric synthesis with trinucleotides is described in Knappik et al. (U.S. Patent No. 6,300,064, incorporated by reference in its entirety). The use of sub-stoichiometric synthesis would enable synthesis with consideration of the length variation in the Nl and N2 sequences.
- a model of the activity of TdT may also be used to determine the composition of the Nl and N2 sequences in a library of the invention.
- the probability of incorporating a particular nucleotide base (A, C, G, T) on a polynucleotide, by the activity of TdT is dependent on the type of base and the base that occurs on the strand directly preceding the base to be added.
- Jackson et al (J. Immunol. Methods, 2007, 324: 26, incorporated by reference in its entirety) have constructed a Markov model describing this process.
- this model may be used to determine the composition of the Nl and/or N2 segments used in libraries of the invention.
- the parameters presented in Jackson et al could be further refined to produce sequences that more closely mimic human sequences.
- the CDRH3 libraries of the invention comprise an initial amino acid (in certain exemplary embodiments, G, D, E) or lack thereof (designated herein as position 95), followed by the Nl, DH, N2, and H3-JH segments.
- the overall design of the CDRH3 libraries can be represented by the following formula:
- compositions of each portion of a CDRH3 of a library of the invention are more fully described above, the composition of the tail presented above (G/D/E/-) is non- limiting, and that any amino acid (or no amino acid) can be used in this position.
- any amino acid or no amino acid
- certain embodiments of the invention may be represented by the following formula:
- a synthetic CDRH3 repertoire is combined with selected VH chassis sequences and heavy chain constant regions, via homologous recombination. Therefore, in certain embodiments of the invention, it may be necessary to include DNA sequences flanking the 5' and 3' ends of the synthetic CDRH3 libraries, to facilitate homologous recombination between the synthetic CDRH3 libraries and vectors containing the selected chassis and constant regions.
- the vectors also contain a sequence encoding at least a portion of the non-nibbled region of the IGHJ gene (i.e., FRM4-JH).
- a polynucleotide encoding an N-terminal sequence e.g., CA(K/R/T)
- a polynucleotide encoding a C-terminal sequence e.g., WG(Q/R)G; SEQ ID NO: 23
- WG(Q/R)G WG(Q/R)G
- SEQ ID NO: 23 polynucleotide encoding a C-terminal sequence
- sequence WG(QZR)G (SEQ ID NO: 23) is presented in this exemplary embodiment, additional amino acids, C-terminal to this sequence in FRM4-JH may also be included in the polynucleotide encoding the C-terminal sequence.
- the purpose of the polynucleotides encoding the N-terminal and C-terminal sequences, in this case, is to facilitate homologous recombination, and one of ordinary skill in the art would recognize that these sequences may be longer or shorter than depicted below.
- the overall design of the CDRH3 repertoire including the sequences required to facilitate homologous recombination with the selected chassis, can be represented by the following formula (regions homologous with vector underlined): cArR/ ⁇ / ⁇ i-rxi-rNii-rPHi-rN2i-rH3-jHi-rwG(o/R)Gi.
- the CDRH3 repertoire can be represented by the following formula, which excludes the T residue presented in the schematic above: CA ⁇ R/KI- ⁇ XI- ⁇ N ⁇ - ⁇ DHI- ⁇ N2I- ⁇ H3-JHI- ⁇ WG(O/R > )GI.
- references describing collections of V, D, and J genes include Scaviner et ah, Exp. Clin, Immunogenet., 1999, 16: 243 and Ruiz et ah, Exp. Clin. Immunogenet, 1999, 16: 173, each incorporated by reference in its entirety.
- the instant invention in addition to accounting for the composition of naturally occurring CDRH3 segments, the instant invention also takes into account the length distribution of naturally occurring CDRH3 segments.
- Surveys by Zemlin et al. (JMB, 2003, 334: 733, incorporated by reference in its entirety) and Lee et al. (Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety) provide analyses of the naturally occurring CDRH3 lengths. These data show that about 95% of naturally occurring CDRH3 sequences have a length from about 7 to about 23 amino acids.
- the instant invention provides rationally designed antibody libraries with CDRH3 segments which directly mimic the size distribution of naturally occurring CDRH3 sequences.
- the length of the CDRH3s may be about 2 to about 30, about 3 to about 35, about 7 to about 23, about 3 to about 28, about 5 to about 28, about 5 to about 26, about 5 to about 24, about 7 to about 24, about 7 to about 22, about 8 to about 19, about 9 to about 22, about 9 to about 20, about 10 to about 18, about 11 to about 20, about 11 to about 18, about 13 to about 18, or about 13 to about 16 residues in length.
- the length distribution of a CDRH3 library of the invention may be defined based on the percentage of sequences within a certain length range.
- CDRFBs with a length of about 10 to about 18 amino acid residues comprise about 84% to about 94% of the sequences of a the library.
- sequences within this length range comprise about 89% of the sequences of a library.
- CDRFBs with a length of about 11 to about 17 amino acid residues comprise about 74% to about 84% of the sequences of a library. In some embodiments, sequences within this length range comprise about 79% of the sequences of a library.
- CDRFBs with a length of about 12 to about 16 residues comprise about 57% to about 67% of the sequences of a library. In some embodiments, sequences within this length range comprise about 62% of the sequences of a library.
- CDRFBs with a length of about 13 to about 15 residues comprise about 35% to about 45% of the sequences of a library. In some embodiments, sequences within this length range comprise about 40% of the sequences of a library.
- the CDRL3 libraries of the invention can be generated by one of several approaches.
- the actual version of the CDRL3 library made and used in a particular embodiment of the invention will depend on objectives for the use of the library.
- More than one CDRL3 library may be used in a particular embodiment; for example, a library containing CDRH3 diversity, with kappa and lambda light chains is within the scope of the invention.
- a CDRL3 library is a VKCDR3 (kappa) library and/or a V ⁇ CDR3 (lambda) library.
- the CDRL3 libraries described herein differ significantly from CDRL3 libraries in the art. First, they consider length variation that is consistent with what is observed in actual human sequences. Second, they take into consideration the fact that a significant portion of the CDRL3 is encoded by the IGLV gene. Third, the patterns of amino acid variation within the IGLV gene-encoded CDRL3 portions are not stochastic and are selected based on depending on the identity of the IGLV gene.
- CDRL3 libraries that faithfully mimic observed patterns in human sequences cannot use a generic design that is independent of the chassis sequences in FRMl to FRM3.
- JL JL to CDRL3
- enumeration of each amino acid residue at the relevant positions is based on the compositions and natural variations of the JL genes themselves.
- a unique aspect of the design of the libraries of the invention is the germline or "chassis-based” aspect, which is meant to preserve more of the integrity and variability of actual human sequences. This is in contrast to other codon-based synthesis or degenerate oligonucleotide synthesis approaches that have been described in the literature and that aim to produce "one-size-fits-all” (e.g., consensus) libraries (e.g.,, Knappik, et al., J MoI Biol, 2000, 296: 57; Akamatsu et al., J Immunol, 1993, 151 : 4651, each incorporated by reference in its entirety).
- patterns of occurrence of particular amino acids at defined positions within VL sequences are determined by analyzing data available in public or other databases, for example, the NCBI database (see, for example, GI numbers in Appendices A and B filed herewith). In certain embodiments of the invention, these sequences are compared on the basis of identity and assigned to families on the basis of the germline genes from which they are derived. The amino acid composition at each position of the sequence, in each germline family, may then be determined. This process is illustrated in the Examples provided herein.
- the light chain CDR3 library is a VKCDR3 library.
- Certain embodiments of the invention may use only the most common VKCDR3 length, nine residues; this length occurs in a dominant proportion (greater than about 70%) of human VKCDR3 sequences.
- positions 89-95 are encoded by the IGKV gene and positions 96-97 are encoded by the IGKJ gene.
- Analysis of human kappa light chain sequences indicates that there are not strong biases in the usage of the IGKJ genes.
- each of the five the IGKJ genes can be represented in equal proportions to create a combinatorial library of (M VK chassis) x (5 JK genes), or a library of size Mx5.
- M VK chassis combinatorial library of (M VK chassis) x
- Mx5 a library of size Mx5.
- amino acid residue at position 96 may be one of these seven residues. In other embodiments of the invention, the amino acid at this position may be chosen from amongst any of the other 13 amino acid residues.
- the amino acid residue at position 96 may be chosen from amongst the top 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids that occur at position 96, or even residues that never occur at position 96.
- the occurrence of the amino acids selected to occupy position 96 may be equivalent or weighted.
- a minimalist VKCDR3 library may be represented by one or more of the following amino acid sequences:
- VK_Chassis represents any VK chassis selected for inclusion in a library of the invention (e.g., see Table 11). Specifically, VK Chassis comprises about Kabat residues 1 to 88 of a selected IGKV sequence. L3-VK represents the portion of the VKCDR3 encoded by the chosen IGKV gene (in this embodiment, Kabat residues 89-95).
- F, L, I, R, W, Y, and P are the seven most commonly occurring amino acids at position 96 of VKCDR3s with length nine, X is any amino acid, and JK* is an IGKJ amino acid sequence without the N-terminal residue (i.e., the N- terminal residue is substituted with F, L, I, R, W, Y, P, or X).
- 70 members could be produced by utilizing 10 VK chassis, each paired with its respective L3-VK, 7 amino acids at position 96 (i.e., X), and one JK* sequence.
- Another embodiment of the library may have 350 members, produced by combining 10 VK chassis, each paired with its respective L3-VK, with 7 amino acids at position 96, and all 5 JK* genes. Still another embodiment of the library may have 1,125 members, produced by combining 15 VK chassis, each paired with its respective H3-JK, with 15 amino acids at position 96 and all 5 JK* genes, and so on.
- a person of ordinary skill in the art will readily recognize that many other combinations are possible.
- the L3-VK regions may also be combinatorially varied with different VK chassis regions, to create additional diversity.
- the inclusion of a diversity of kappa light chain length variations in a library of the invention also enables one to include sequence variability that occurs outside of the amino acid at the VK-JK junction (i.e., position 96, described above).
- the patterns of sequence variation within the VK, and/or JK segments can be determined by aligning collections of sequences derived from particular germline sequences.
- the frequency of occurrence of amino acid residues within VKCDR3 can be determined by sequence alignments (e.g., see Example 6.2 and Table 30).
- this frequency of occurrence may be used to introduce variability into the VK Chassis, L3-VK and/or JK segments that are used to synthesize the VKCDR3 libraries.
- the top 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids that occur at any particular position in a naturally occurring repertoire may be included at that position in a VKCDR3 library of the invention.
- the percent occurrence of any amino acid at any particular position within the VKCDR3 or a VK light chain may be about 0%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%,
- the percent occurrence of any amino acid at any position within a VKCDR3 or kappa light chain library of the invention may be within at least about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9% 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 120%, 140%, 160%, 180%, or 200% of the percent occurrence of any amino acid at any position within a naturally occurring VKCDR3 or kappa light chain domain.
- a VKCDR3 library may be synthesized using degenerate oligonucleotides (see Table 31 for IUPAC base symbol definitions).
- the limits of oligonucleotide synthesis and the genetic code may require the inclusion of more or fewer amino acids at a particular position in the VKCDR3 sequences. An illustrative embodiment of this approach is provided in Example 6.2.
- oligonucleotide synthesis may, in some cases, require the inclusion of more or fewer amino acids at a particular position within VKCDR3 ⁇ e.g., Example 6.2, Table 32), in comparison to those amino acids found at that position in nature.
- This limitation can be overcome through the use of a codon-based synthesis approach (Virnekas et al. Nucleic Acids Res., 1994, 22: 5600, incorporated by reference in its entirety), which enables precise synthesis of oligonucleotides encoding particular amino acids and a finer degree of control over the proportion of any particular amino acid incorporated at any position.
- Example 6.3 describes this approach in greater detail.
- a codon-based synthesis approach may be used to vary the percent occurrence of any amino acid at any particular position within the VKCDR3 or kappa light chain.
- the percent occurrence of any amino acid at any position in a VKCDR3 or kappa light chain sequence of the library may be about 0%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, or 100%.
- the percent occurrence of any amino acid at any position may be about 1%, 2%, 3%, or 4%. In certain embodiments of the invention, the percent occurrence of any amino acid at any position within a VKCDR3 or kappa light chain library of the invention may be within at least about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 120%, 140%, 160%, 180%, or 200% of the percent occurrence of any amino acid at any position within a naturally occurring VKCDR3 or kappa light chain domain.
- the VKCDR3 (and any other sequence used in the library, regardless of whether or not it is part of VKCDR3) may be altered to remove undesirable amino acid motifs.
- peptide sequences with the pattern N- X-(S or T)-Z, where X and Z are different from P will undergo post-translational modification (N-linked glycosylation) in a number of expression systems, including yeast and mammalian cells.
- the introduction of N residues at certain positions may be avoided, so as to avoid the introduction of N-linked glycosylation sites. In some embodiments of the invention, these modifications may not be necessary, depending on the organism used to express the library and the culture conditions.
- N-linked glycosylation sites e.g., bacteria
- N-X-(S/T) sequences the antibodies isolated from such libraries may be expressed in different systems (e.g., yeast, mammalian cells) later (e.g., toward clinical development), and the presence of carbohydrate moieties in the variable domains, and the CDRs in particular, may lead to unwanted modifications of activity.
- the individual sub-libraries of different lengths e.g., one or more of lengths 5, 6, 7, 8, 9, 10, 11, or more
- mix the sub-libraries in proportions that reflect the length distribution of VKCDR3 in human sequences for example, in ratios approximating the 1 :9:2 distribution that occurs in natural VKCDR3 sequences of lengths 8, 9, and 10 (see
- V ⁇ CDR3 libraries of the invention The principles used to design the minimalist V ⁇ CDR3 libraries of the invention are similar to those enumerated above, for the VKCDR3 libraries, and are explained in more detail in the Examples.
- One difference between the V ⁇ CDR3 libraries of the invention and the VKCDR3 libraries of the invention is that, unlike the IGKV genes, the contribution of the IGV ⁇ genes to CDRL3 (i.e., L3-V ⁇ ) is not constrained to a fixed number of amino acid residues.
- VK including L3-VK
- JK segments with inclusion of position 96
- length variation may be obtained within a V ⁇ CDR3 library even when only the V ⁇ (including L3- V ⁇ ) and J ⁇ segments are considered.
- VKCDR3 sequences additional variability may be introduced into the VKCDR3
- V ⁇ CDR3 sequences via the same methods outlined above, namely determining the frequency of occurrence of particular residues within V ⁇ CDR3 sequences and synthesizing the oligonucleotides encoding the desired compositions via degenerate oligonucleotide synthesis or trinucleotides-based synthesis.
- both the heavy and light chain chassis sequences and the heavy and light chain CDR3 sequences are synthetic.
- the polynucleotide sequences of the instant invention can be synthesized by various methods. For example, sequences can be synthesized by split pool DNA synthesis as described in Feldhaus et al., Nucleic Acids Research, 2000, 28: 534; Omstein et al., Biopolymers, 1978, 17: 2341; and Brenner and Lerner, PNAS, 1992, 87: 6378 (each of which is incorporated by reference in its entirety).
- cassettes representing the possible V, D, and J diversity found in the human repertoire, as well as junctional diversity are synthesized de novo either as double-stranded DNA oligonucleotides, single-stranded DNA oligonucleotides representative of the coding strand, or single-stranded DNA oligonucleotides representative of the non-coding strand.
- These sequences can then be introduced into a host cell along with an acceptor vector containing a chassis sequence and, in some cases a portion of FRM4 and a constant region. No primer-based PCR amplification from mammalian cDNA or mRNA or template-directed cloning steps from mammalian cDNA or mRNA need be employed.
- the present invention exploits the inherent ability of yeast cells to facilitate homologous recombination at high efficiency.
- the mechanism of homologous recombination in yeast and its applications are briefly described below.
- homologous recombination can be carried out in, for example, Saccharomyces cerevisiae, which has genetic machinery designed to carry out homologous recombination with high efficiency.
- Exemplary S. cerevisiae strains include EM93, CEN.PK2, RMl 1-la, YJM789, and BJ5465. This mechanism is believed to have evolved for the purpose of chromosomal repair, and is also called "gap repair" or "gap filling". By exploiting this mechanism, mutations can be introduced into specific loci of the yeast genome.
- a vector carrying a mutant gene can contain two sequence segments that are homologous to the 5' and 3' open reading frame (ORF) sequences of a gene that is intended to be interrupted or mutated.
- the vector may also encode a positive selection marker, such as a nutritional enzyme allele (e.g., URA3) and/or an antibiotic resistant marker (e.g., Geneticin / G418), flanked by the two homologous DNA segments.
- a positive selection marker such as a nutritional enzyme allele (e.g., URA3) and/or an antibiotic resistant marker (e.g., Geneticin / G418), flanked by the two homologous DNA segments.
- URA3 nutritional enzyme allele
- an antibiotic resistant marker e.g., Geneticin / G418
- the surviving yeast cells will be those cells in which the wild-type gene has been replaced by the mutant gene (Pearson et ⁇ l., Yeast, 1998, 14: 391, incorporated by reference in its entirety). This mechanism has been used to make systematic mutations in all 6,000 yeast genes, or open reading frames (ORFs), for functional genomics studies.
- gene fragments or synthetic oligonucleotides can also be cloned into a plasmid vector without a ligation step.
- a target gene fragment i.e., the fragment to be inserted into a plasmid vector, e.g., a CDR3
- DNA sequences that are homologous to selected regions of the plasmid vector are added to the 5' and 3' ends of the target gene fragment.
- the plasmid vector may include a positive selection marker, such as a nutritional enzyme allele (e.g., URA3), or an antibiotic resistance marker (e.g., Geneticin / G418).
- a positive selection marker such as a nutritional enzyme allele (e.g., URA3), or an antibiotic resistance marker (e.g., Geneticin / G418).
- the plasmid vector is then linearized by a unique restriction cut located in-between the regions of sequence homology shared with the target gene fragment, thereby creating an artificial gap at the cleavage site.
- the linearized plasmid vector and the target gene fragment flanked by sequences homologous to the plasmid vector are co-transformed into a yeast host strain.
- the yeast is then able to recognize the two stretches of sequence homology between the vector and target gene fragment and facilitate a reciprocal exchange of DNA content through homologous recombination at the gap.
- the target gene fragment is inserted into the vector without ligation.
- the method described above has also been demonstrated to work when the target gene fragments are in the form of single stranded DNA, for example, as a circular M 13 phage derived form, or as single stranded oligonucleotides (Simon and Moore, MoI. Cell Biol, 1987, 7: 2329; Ivanov et al, Genetics, 1996, 142: 693; and DeMarini et al, 2001, 30: 520., each incorporated by reference in its entirety).
- the form of the target that can be recombined into the gapped vector can be double stranded or single stranded, and derived from chemical synthesis, PCR, restriction digestion, or other methods.
- the efficiency of the gap repair is correlated with the length of the homologous sequences flanking both the linearized vector and the target gene.
- about 20 or more base pairs may be used for the length of the homologous sequence, and about 80 base pairs may give a near-optimized result (Hua et al, Plasmid, 1997, 38: 91; Raymond et al, Genome Res., 2002, 12: 190, each incorporated by reference in its entirety).
- At least about 5, 10, 15, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34 35, 36, 37, 38, 39, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 187, 190, or 200 homologous base pairs may be used to facilitate recombination. In other embodiments, between about 20 and about 40 base pairs are utilized.
- the reciprocal exchange between the vector and gene fragment is strictly sequence-dependent, i.e. it does not cause a frame shift. Therefore, gap-repair cloning assures the insertion of gene fragments with both high efficiency and precision.
- yeast libraries of gene fragments have also been constructed in yeast using homologous recombination.
- a human brain cDNA library was constructed as a two-hybrid fusion library in vector pJG4-5 (Guidotti and Zervos, Yeast, 1999, 15: 715, incorporated by reference in its entirety). It has also been reported that a total of 6,000 pairs of PCR primers were used for amplification of 6,000 known yeast ORFs for a study of yeast genomic protein interactions (Hudson et al., Genome Res., 1997, 7: 1169, incorporated by reference in its entirety). In 2000, Uetz et al.
- a synthetic CDR3 (heavy or light chain) may be joined by homologous recombination with a vector encoding a heavy or light chain chassis, a portion of FRM4, and a constant region, to form a full-length heavy or light chain.
- the homologous recombination is performed directly in yeast cells.
- the method comprises:
- each of the CDR3 insert sequences comprises a nucleotide sequence encoding CDR3 and 5'- and 3 '-flanking sequences that are sufficiently homologous to the termini of the vector of (i) at the site of linearization to enable homologous recombination to occur between the vector and the library of CDR3 insert sequences;
- the CDR3 inserts may have a 5' flanking sequence and a 3' flanking sequence that are homologous to the termini of the linearized vector.
- a host cell for example, a yeast cell
- the "gap" the linearization site
- the homologous sequences at the 5' and 3' termini of these two linear double-stranded DNAs i.e., the vector and the insert.
- libraries of circular vectors encoding full-length heavy or light chains comprising variable CDR3 inserts is generated. Particular instances of these methods are presented in the Examples.
- Subsequent analysis may be carried out to determine the efficiency of homologous recombination that results in correct insertion of the CDR3 sequences into the vectors. For example, PCR amplification of the CDR3 inserts directly from selected yeast clones may reveal how many clones are recombinant. In certain embodiments, libraries with minimum of about 90% recombinant clones are utilized.
- libraries with a minimum of about 1%, 5% 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% recombinant clones are utilized.
- the same PCR amplification of selected clones may also reveal the insert size.
- a PCR amplification product with the correct size of insert may be "fingerprinted" with restriction enzymes known to cut or not cut within the amplified region. From a gel electrophoresis pattern, it may be determined whether the clones analyzed are of the same identity or of the distinct or diversified identity. The PCR products may also be sequenced directly to reveal the identity of inserts and the fidelity of the cloning procedure, and to prove the independence and diversity of the clones.
- Figure 1 depicts a schematic of recombination between a fragment (e.g., CDR3) and a vector (e.g., comprising a chassis, portion of FRM4, and constant region) for the construction of a library.
- a fragment e.g., CDR3
- a vector e.g., comprising a chassis, portion of FRM4, and constant region
- Libraries of polynucleotides generated by any of the techniques described herein, or other suitable techniques, can be expressed and screened to identify antibodies having desired structure and/or activity.
- Expression of the antibodies can be carried out, for example, using cell-free extracts (and e.g. , ribosome display), phage display, prokaryotic cells (e.g., bacterial display), or eukaryotic cells (e.g., yeast display).
- the antibody libraries are expressed in yeast.
- the polynucleotides are engineered to serve as templates that can be expressed in a cell-free extract. Vectors and extracts as described, for example in U.S. Patent Nos.
- Ribosome display and other cell-free techniques for linking a polynucleotide (i.e., a genotype) to a polypeptide (i.e., a phenotype) can be used, e.g., ProfusionTM (see, e.g., U.S. Patent Nos. 6,348,315; 6,261,804; 6,258,558; and 6,214,553, each incorporated by reference in its entirety).
- the polynucleotides of the invention can be expressed in an E. coli expression system, such as that described by Pluckthun and Skerra. (Meth. EnzymoL, 1989, 178: 476; Biotechnology, 1991, 9: 273, each incorporated by reference in its entirety).
- the mutant proteins can be expressed for secretion in the medium and/or in the cytoplasm of the bacteria, as described by Better and Horwitz, Meth. EnzymoL, 1989, 178: 476, incorporated by reference in its entirety.
- the single domains encoding VH and VL are each attached to the 3 ' end of a sequence encoding a signal sequence, such as the ompA, phoA or pelB signal sequence (Lei et al., J. Bacteriol., 1987, 169: 4379, incorporated by reference in its entirety).
- a signal sequence such as the ompA, phoA or pelB signal sequence
- These gene fusions are assembled in a dicistronic construct, so that they can be expressed from a single vector, and secreted into the periplasmic space of E. coli where they will refold and can be recovered in active form. (Skerra et al, Biotechnology, 1991, 9: 273, incorporated by reference in its entirety).
- antibody heavy chain genes can be concurrently expressed with antibody light chain genes to produce antibodies or antibody fragments.
- the antibody sequences are expressed on the membrane surface of a prokaryote, e.g., E. coli, using a secretion signal and lipidation moiety as described, e.g., in US20040072740; US20030100023; and US20030036092 (each incorporated by reference in its entirety).
- Higher eukaryotic cells such as mammalian cells, for example myeloma cells (e.g., NS/0 cells), hybridoma cells, Chinese hamster ovary (CHO), and human embryonic kidney (HEK) cells, can also be used for expression of the antibodies of the invention.
- mammalian cells for example myeloma cells (e.g., NS/0 cells), hybridoma cells, Chinese hamster ovary (CHO), and human embryonic kidney (HEK) cells
- mammalian cells e.g., myeloma cells (e.g., NS/0 cells), hybridoma cells, Chinese hamster ovary (CHO), and human embryonic kidney (HEK) cells
- Typically, antibodies expressed in mammalian cells are designed to be secreted into the culture medium, or expressed on the surface of the cell.
- the antibody or antibody fragments can be produced, for example, as intact antibody molecules or as individual VH and VL fragments, Fab
- antibodies can be expressed and screened by anchored periplasmic expression (APEx 2-hybrid surface display), as described, for example, in Jeong et ah, PNAS, 2007, 104: 8247 (incorporated by reference in its entirety) or by other anchoring methods as described, for example, in Mazor et ah, Nature Biotechnology, 2007, 25: 563 (incorporated by reference in its entirety).
- APIEx 2-hybrid surface display as described, for example, in Jeong et ah, PNAS, 2007, 104: 8247 (incorporated by reference in its entirety) or by other anchoring methods as described, for example, in Mazor et ah, Nature Biotechnology, 2007, 25: 563 (incorporated by reference in its entirety).
- antibodies can be selected using mammalian cell display (Ho et al, PNAS, 2006, 103: 9637, incorporated by reference in its entirety).
- the screening of the antibodies derived from the libraries of the invention can be carried out by any appropriate means. For example, binding activity can be evaluated by standard immunoassay and/or affinity chromatography. Screening of the antibodies of the invention for catalytic function, e.g., proteolytic function can be accomplished using a standard assays, e.g., the hemoglobin plaque assay as described in U.S. Patent No. 5,798,208 (incorporated by reference in its entirety).
- Determining the ability of candidate antibodies to bind therapeutic targets can be assayed in vitro using, e.g., a BIACORETM instrument, which measures binding rates of an antibody to a given target or antigen based on surface plasmon resonance.
- In vivo assays can be conducted using any of a number of animal models and then subsequently tested, as appropriate, in humans. Cell-based biological assays are also contemplated.
- the antibody library can be expressed in yeast, which have a doubling time of less than about 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, or 24 hours.
- the doubling times are about 1 to about 3 hours, about 2 to about 4, about 3 to about 8 hours, about 3 to about 24, about 5 to about 24, about 4 to about 6 about 5 to about 22, about 6 to about 8, about 7 to about 22, about 8 to about 10 hours, about 7 to about 20, about 9 to about 20, about 9 to about 18, about 11 to about 18, about 11 to about 16, about 13 to about 16, about 16 to about 20, or about 20 to about 30 hours.
- the antibody library is expressed in yeast with a doubling time of about 16 to about 20 hours, about 8 to about 16 hours, or about 4 to about 8 hours.
- the antibody library of the instant invention can be expressed and screened in a matter of hours, as compared to previously known techniques which take several days to express and screen antibody libraries.
- a limiting step in the throughput of such screening processes in mammalian cells is simply the time required to iteratively regrow populations of isolated cells, which, in some cases, have doubling times greater than the doubling times of the yeast used in the current invention.
- the composition of a library may be defined after one or more enrichment steps (for example by screening for antigen binding, or other properties).
- a library with a composition comprising about x% sequences or libraries of the invention may be enriched to contain about 2x%, 3x%, 4x%, 5x%, 6x%, 7x%, 8x%, 9x%, 10x%, 20x%, 25x%, 40x%, 50x%, 60x% 75x%, 80x%, 90x%, 95x%,or 99x% sequences or libraries of the invention, after one or more screening steps.
- sequences or libraries of the invention may be enriched about 2-fold, 3-fold, 4-fold, 5-fold, 6-fold, 7-fold, 8-fold, 9-fold, 10-fold, 100-fold, 1, 000-fold, or more, relative to their occurrence prior to the one or more enrichment steps.
- a library may contain at least a certain number of a particular type of sequence(s), such as CDRFBs, CDRL3s, heavy chains, light chains, or whole antibodies (e.g., at least about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , or 10 20 ).
- a particular type of sequence(s) such as CDRFBs, CDRL3s, heavy chains, light chains, or whole antibodies (e.g., at least about 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , 10 19 , or 10 20 ).
- these sequences may be enriched during one or more enrichment steps, to provide libraries com mpprriissiinngg aatt lleeaasstt aabboouutt 1100 2 , 10 3 , 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , 10 10 , 10 11 , 10 12 , 10 13 , 10 14 , 10 15 , 10 16 , 10 17 , 10 18 , or 10 19 of the respective sequence(s).
- antibody leads can be identified through a selection process that involves screening the antibodies of a library of the invention for binding to one or more antigens, or for a biological activity.
- the coding sequences of these antibody leads may be further mutagenized in vitro or in vivo to generate secondary libraries with diversity introduced in the context of the initial antibody leads.
- the mutagenized antibody leads can then be further screened for binding to target antigens or biological activity, in vitro or in vivo, following procedures similar to those used for the selection of the initial antibody lead from the primary library.
- Such mutagenesis and selection of primary antibody leads effectively mimics the affinity maturation process naturally occurring in a mammal that produces antibodies with progressive increases in the affinity to an antigen.
- only the CDRH3 region is mutagenized.
- the whole variable region is mutagenized.
- one or more of CDRHl, CDRH2, CDRH3, CDRLl, CDRL2, and/ CDRL3 may be mutagenized.
- "light chain shuffling" may be used as part of the affinity maturation protocol. In certain embodiments, this may involve pairing one or more heavy chains with a number of light chains, to select light chains that enhance the affinity and/or biological activity of an antibody.
- the number of light chains to which the one or more heavy chains can be paired is at least about 2, 5, 10, 100, 1000, 10 4 , 10 5 , 10 6 , 10 7 , 10 8 , 10 9 , or 10 10 .
- these light chains are encoded by plasmids.
- the light chains may be integrated into the genome of the host cell.
- the coding sequences of the antibody leads may be mutagenized by a wide variety of methods. Examples of methods of mutagenesis include, but are not limited to site- directed mutagenesis, error-prone PCR mutagenesis, cassette mutagenesis, and random PCR mutagenesis.
- oligonucleotides encoding regions with the desired mutations can be synthesized and introduced into the sequence to be mutagenized, for example, via recombination or ligation.
- Site-directed mutagenesis or point mutagenesis may be used to gradually change the CDR sequences in specific regions. This may be accomplished by using oligonucleotide- directed mutagenesis or PCR. For example, a short sequence of an antibody lead may be replaced with a synthetically mutagenized oligonucleotide in either the heavy chain or light chain region, or both. The method may not be efficient for mutagenizing large numbers of CDR sequences, but may be used for fine tuning of a particular lead to achieve higher affinity toward a specific target protein.
- Cassette mutagenesis may also be used to mutagenize the CDR sequences in specific regions.
- a sequence block, or a region, of a single template is replaced by a completely or partially randomized sequence.
- the maximum information content that can be obtained may be statistically limited by the number of random sequences of the oligonucleotides. Similar to point mutagenesis, this method may also be used for fine tuning of a particular lead to achieve higher affinity towards a specific target protein.
- Error-prone PCR may be used to mutagenize the CDR sequences by following protocols described in Caldwell and Joyce, PCR Methods and Applications, 1992, 2: 28; Leung et ah, Technique, 1989, 1 : 11; Shafikhani et ah, Biotechniques, 1997, 23: 304; and Stemmer et al, PNAS, 1994, 91 : 10747 (each of which is incorporated by reference in its entirety).
- Conditions for error prone PCR may include (a) high concentrations OfMn 2+ (e.g., about 0.4 to about 0.6 mM) that efficiently induces malfunction of Taq DNA polymerase; and (b) a disproportionally high concentration of one nucleotide substrate (e.g., dGTP) in the PCR reaction that causes incorrect incorporation of this high concentration substrate into the template and produces mutations. Additionally, other factors such as, the number of PCR cycles, the species of DNA polymerase used, and the length of the template, may affect the rate of misincorporation of "wrong" nucleotides into the PCR product.
- kits may be utilized for the mutagenesis of the selected antibody library, such as the "Diversity PCR random mutagenesis kit" (CLONTECHTM).
- the primer pairs used in PCR-based mutagenesis may, in certain embodiments, include regions matched with the homologous recombination sites in the expression vectors. This design allows facile re-introduction of the PCR products back into the heavy or light chain chassis vectors, after mutagenesis, via homologous recombination.
- PCR-based mutagenesis methods can also be used, alone or in conjunction with the error prone PCR described above.
- the PCR amplified CDR segments may be digested with DNase to create nicks in the double stranded DNA. These nicks can be expanded into gaps by other exonucleases such as BaI 31. The gaps may then be filled by random sequences by using DNA Klenow polymerase at a low concentration of regular substrates dGTP, dATP, dTTP, and dCTP with one substrate (e.g., dGTP) at a disproportionately high concentration. This fill-in reaction should produce high frequency mutations in the filled gap regions.
- These method of DNase digestion may be used in conjunction with error prone PCR to create a high frequency of mutations in the desired CDR segments.
- the CDR or antibody segments amplified from the primary antibody leads may also be mutagenized in vivo by exploiting the inherent ability of mutation in pre-B cells.
- the Ig genes in pre-B cells are specifically susceptible to a high-rate of mutation.
- the Ig promoter and enhancer facilitate such high rate mutations in a pre-B cell environment while the pre-B cells proliferate.
- CDR gene segments may be cloned into a mammalian expression vector that contains a human Ig enhancer and promoter. This construct may be introduced into a pre-B cell line, such as 38B9, which allows the mutation of the VH and VL gene segments naturally in the pre-B cells (Liu and Van Ness, MoI.
- the mutagenized CDR segments can be amplified from the cultured pre-B cell line and re-introduced back into the chassis- containing vector(s) via, for example, homologous recombination.
- a CDR "hit" isolated from screening the library can be re- synthesized, using degenerate codons or trinucleotides, and re-cloned into the heavy or light chain vector using gap repair.
- a library of the invention comprises a designed, non-random repertoire wherein the theoretical diversity of particular components of the library (for example, CDRH3), but not necessarily all components or the entire library, can be over-sampled in a physical realization of the library, at a level where there is a certain degree of statistical confidence (e.g., 95%) that any given member of the theoretical library is present in the physical realization of the library at least at a certain frequency (e.g., at least once, twice, three times, four times, five times, or more) in the library.
- a certain degree of statistical confidence e.g., 95%
- M ⁇ is the maximum theoretical repertoire size for which one can be 95% confident that any given member of the theoretical library will be sampled. It is important to note that there is a difference between a 95% chance that a given member is represented and a 95% chance that every possible member is represented.
- the instant invention provides a rationally designed library with diversity so that any given member is 95% likely to be represented in a physical realization of the library.
- the library is designed so that any given member is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% likely to be represented in a physical realization of the library.
- any given member is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% likely to be represented in a physical realization of the library.
- a library may have a theoretical total diversity of X unique members and the physical realization of the theoretical total diversity may contain at least about IX, 2X, 3X, 4X, 5X, 6X, 7X, 8X 9X, 10X, or more members.
- the physical realization of the theoretical total diversity may contain about IX to about 2X, about 2X to about 3X, about 3X to about 4X, about 4X to about 5X, about 5X to about 6X members.
- the physical realization of the theoretical total diversity may contain about IX to about 3X, or about 3X to about 5X total members.
- the invention relates to a polynucleotide that hybridizes with a polynucleotide taught herein, or that hybridizes with the complement of a polynucleotide taught herein.
- a polynucleotide that remains hybridized after hybridization and washing under low, medium, or high stringency conditions to a polynucleotide taught herein or the complement of a polynucleotide taught herein is encompassed by the present invention.
- Exemplary moderate stringency conditions include hybridization in about 40% to about 45% formamide, about 1 M NaCl, about 1% SDS at about 37 0 C, and a wash in about 0.5X to about IX SSC at abut 55 0 C to about 6O 0 C.
- Exemplary high stringency conditions include hybridization in about 50% formamide, about 1 M NaCl, about 1% SDS at about 37 0 C, and a wash in about 0.1X SSC at about 60° C to about 65° C.
- wash buffers may comprise about 0.1% to about 1% SDS.
- the duration of hybridization is generally less than about 24 hours, usually about 4 to about 12 hours.
- the libraries of the current invention are distinguished, in certain embodiments, by their human-like sequence composition and length, and the ability to generate a physical realization of the library which contains all members of (or, in some cases, even oversamples) a particular component of the library.
- Libraries comprising combinations of the libraries described herein (e.g., CDRH3 and CDRL3 libraries) are encompassed by the invention.
- Sub-libraries comprising portions of the libraries described herein are also encompassed by the invention (e.g., a CDRH3 library in a particular heavy chain chassis or a sub-set of the CDRH3 libraries).
- each of the libraries described herein has several components (e.g., CDRH3, VH, CDRL3, VL, etc.), and that the diversity of these components can be varied to produce sub-libraries that fall within the scope of the invention.
- libraries containing one of the libraries or sub-libraries of the invention also fall within the scope of the invention.
- one or more libraries or sub-libraries of the invention may be contained within a larger library, which may include sequences derived by other means, for example, non- human or human sequence derived by stochastic or semi-stochastic synthesis.
- at least about 1% of the sequences in a polynucleotide library may be those of the invention (e.g., CDRH3 sequences, CDRL3 sequences, VH sequences, VL sequences), regardless of the composition of the other 99% of sequences.
- At least about 0.001%, 0.01%, 0.1%, 2%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91,%, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% of the sequences in any polynucleotide library may be those of the invention, regardless of the composition of the other sequences.
- the sequences of the invention may comprise about 0.001% to about 1%, about 1% to about 2%, about 2% to about 5%, about 5% to about 10%, about 10% to about 15%, about 15% to about 20%, about 20% to about 25%, about 25% to about 30%, about 30% to about 35%, about 35% to about 40%, about 40% to about 45%, about 45% to about 50%, about 50% to about 55%, about 55% to about 60%, about 60% to about 65%, about 65% to about 70%, about 70% to about 75%, about 75% to about 80%, about 80% to about 85%, about 85% to about 90%, about 90% to about 95%, or about 95% to about 99% of the sequences in any polynucleotide library, regardless of the composition of the other sequences.
- libraries more diverse than one or more libraries or sub-libraries of the invention but yet still comprising one or more libraries or sub- libraries of the invention, in an amount in which the one or more libraries or sub-libraries of the invention can be effectively screened and from which sequences encoded by the one or more libraries or sub-libraries of the invention can be isolated, also fall within the scope of the invention.
- the amino acid products of a library of the invention may be displayed on an alternative scaffold.
- a CDRH3 or CDRL3 may be displayed on an alternative scaffold.
- Exemplary alternative scaffolds include those derived from fibronectin ⁇ e.g., AdNectin), the ⁇ -sandwich ⁇ e.g., iMab), lipocalin ⁇ e.g., Anticalin), EETI- II/AGRP, BPTI/LACI-D1/ITI-D2 ⁇ e.g., Kunitz domain), thioredoxin ⁇ e.g., peptide aptamer), protein A ⁇ e.g., Affibody), ankyrin repeats ⁇ e.g., DARPin), ⁇ B-crystallin/ubiquitin ⁇ e.g., Aff ⁇ lin), CTLD3 ⁇ e.g., Tetranectin), and (LDLR-A module ⁇ ⁇ e.g., Avimers).
- fibronectin ⁇ e.g., AdNectin
- iMab the ⁇ -sandwich ⁇ e.g., i
- the invention comprises a synthetic preimmune human antibody CDRH3 library comprising 10 7 to 10 8 polynucleotide sequences representative of the sequence diversity and length diversity found in known heavy chain CDR3 sequences.
- the invention comprises a synthetic preimmune human antibody CDRH3 library comprising polynucleotide sequences encoding CDRH3 represented by the following formula:
- [G/D/E/-] is represented by an amino acid sequence selected from the group consisting of: G, D, E, and nothing.
- [Nl] is represented by an amino acid sequence selected from the group consisting of: G, R, S, P, L, A, V, T, (G/P)(G/R/S/P/L/A/V/T), (R/S/L/A/V/T)(G/P), GG(G/R/S/P/L/A/WT), G(R/S/P/L/A/V/T)G, (R/S/P/L/A/V/T)GG, and nothing.
- [N2] is represented by an amino acid sequence selected from the group consisting of: G, R, S, P, L, A, V, T, (G/P)(G/R/S/P/L/A/V/T), (R/S/L/A/V/T)(G/P), GG(G/R/S/P/L/A/V/T), G(R/S/P/L/A/V/T)G, (R/S/P/L/A/V/T)GG, and nothing.
- [DH] comprises a sequence selected from the group consisting of: IGHD3- 10 reading frame 1 , IGHD3- 10 reading frame 2, IGHD3- 10 reading frame 3, IGHD3-22 reading frame 2, IGHD6-19 reading frame 1, IGHD6-19 reading frame 2, IGHD6-13 reading frame 1, IGHD6-13 reading frame 2, IGHD3-03 reading frame 3, IGHD2-02 reading frame 2, IGHD2-02 reading frame 3, IGHD4-17 reading frame 2, IGHD 1-26 reading frame 1, IGHD 1-26 reading frame 3, IGHD5-5/5-18 reading frame 3, IGHD2-15 reading frame 2, and all possible N-terminal and C-terminal truncations of the above-identified IGHDs down to three amino acids.
- [H3-JH] comprises a sequence selected from the group consisting of: AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, AFDV (SEQ ID NO: 19), FDV, DV, YFDY (SEQ ID NO: 20), FDY, DY, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, YYYYGMDV (SEQ ID NO: 22), YYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, MDV, and DV.
- sequences represented by [G/D/E/-][Nl][ext-DH][N2][H3-JH] comprise a sequence of about 3 to about 26 amino acids in length.
- sequences represented by [G/D/E/-][Nl][ext-DH][N2][H3-JH] comprise a sequence of about 7 to about 23 amino acids in length.
- the library comprises about 10 7 to about 10 10 sequences.
- the library comprises about 10 7 sequences.
- the polynucleotide sequences of the libraries further comprise a 5' polynucleotide sequence encoding a framework 3 (FRM3) region on the corresponding N-terminal end of the library sequence, wherein the FRM3 region comprises a sequence of about 1 to about 9 amino acid residues.
- FRM3 region comprises a sequence of about 1 to about 9 amino acid residues.
- the FRM3 region comprises a sequence selected from the group consisting of CAR, CAK, and CAT.
- the polynucleotide sequences further comprise a 3 ' polynucleotide sequence encoding a framework 4 (FRM4) region on the corresponding C-terminal end of the library sequence, wherein the FRM4 region comprises a sequence of about 1 to about 9 amino acid residues.
- FRM4 region comprises a sequence of about 1 to about 9 amino acid residues.
- the library comprises a FRM4 region comprising a sequence selected from WGRG (SEQ ID NO: 23) and WGQG (SEQ ID NO: 23).
- the polynucleotide sequences further comprise an FRM3 region coding for a corresponding polypeptide sequence comprising a sequence selected from the group consisting of CAR, CAK, and CAT; and an FRM4 region coding for a corresponding polypeptide sequence comprising a sequence selected from WGRG (SEQ ID NO: 23) and WGQG (SEQ ID NO: 23).
- the polynucleotide sequences further comprise 5 ' and 3 ' sequences which facilitate homologous recombination with a heavy chain chassis.
- the invention comprises a synthetic preimmune human antibody light chain library comprising polynucleotide sequences encoding human antibody kappa light chains represented by the formula:
- [IGKV (1-95)] is selected from the group consisting of IGKV3-20 (1-95), IGKV1-39 (1-95), IGKV3-11 (1-95), IGKV3-15 (1-95), IGKV1-05 (1-95), IGKV4-01 (1-95), IGKV2-28 (1-95), IGKV 1-33 (1-95), IGKV1-09 (1- 95), IGKV1-12 (1-95), IGKV2-30 (1-95), IGKV1-27 (1-95), IGKV1-16 (1-95), and truncations of said group up to and including position 95 according to Kabat.
- [F/L/I/R/W/Y] is an amino acid selected from the group consisting of F, L, I, R, W, and Y.
- [JK] comprises a sequence selected from the group consisting of TFGQGTKVEIK (SEQ ID NO: 528) and TFGGGT (SEQ ID NO: 529).
- the light chain library comprises a kappa light chain library.
- the polynucleotide sequences further comprise 5 ' and 3 ' sequences which facilitate homologous recombination with a light chain chassis.
- the invention comprises a method for producing a synthetic preimmune human antibody CDRH3 library comprising 10 7 to 10 8 polynucleotide sequences, said method comprising: a) selecting the CDRH3 polynucleotide sequences encoded by the CDRH3 sequences, as follows:
- TdT terminal deoxynucleotidyl transferase
- amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by TdT and preferentially functionally expressed by human B cells ⁇ , followed by
- the invention comprises a synthetic preimmune human antibody CDRH3 library comprising 10 7 to 10 10 polynucleotide sequences representative of known human IGHD and IGHJ germline sequences encoding CDRH3, represented by the following formula:
- ⁇ 0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by terminal deoxynucleotidyl transferase (TdT) and preferentially functionally expressed by human B cells ⁇ , followed by ⁇ all possible N or C-terminal truncations of IGHD alone and all possible combinations of N and C-terminal truncations ⁇ , followed by ⁇ 0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by TdT and preferentially functionally expressed by human B cells ⁇ , followed by
- TdT terminal deoxynucleotidyl transferase
- the invention comprises a synthetic preimmune human antibody heavy chain variable domain library comprising 10 7 to 10 10 polynucleotide sequences encoding human antibody heavy chain variable domains, said library comprising: a) an antibody heavy chain chassis, and b) a CDRH3 repertoire designed based on the human IGHD and IGHJ germline sequences, as follows:
- TdT terminal deoxynucleotidyl transferase
- amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by TdT and preferentially functionally expressed by human B cells ⁇ , followed by
- the synthetic preimmune human antibody heavy chain variable domain library is expressed as a full length chain selected from the group consisting of an IgGl full length chain, an IgG2 full length chain, an IgG3 full length chain, and an IgG4 full length chain.
- the human antibody heavy chain chassis is selected from the group consisting of IGHV4-34, IGHV3-23, IGHV5-51, IGHV1-69, IGHV3-30, IGHV4-39, IGHV1-2, IGHV1-18, IGHV2-5, IGHV2-70, IGHV3-7, IGHV6-1, IGHV1-46, IGHV3-33, IGHV4-31, IGHV4-4, IGHV4-61, and IGHV3-15.
- the synthetic preimmune human antibody heavy chain variable domain library comprises 10 7 to 10 10 polynucleotide sequences encoding human antibody heavy chain variable domains, said library comprising: a) an antibody heavy chain chassis, and b) a synthetic preimmune human antibody CDRH3 library.
- the polynucleotide sequences are single- stranded coding polynucleotide sequences. In certain embodiments of the invention, the polynucleotide sequences are single- stranded non-coding polynucleotide sequences.
- the polynucleotide sequences are double- stranded polynucleotide sequences.
- the invention comprises a population of replicable cells with a doubling time of four hours or less, in which a synthetic preimmune human antibody repertoire is expressed.
- the population of replicable cells are yeast cells.
- the invention comprises a method of generating a full- length antibody library comprising transforming a cell with a preimmune human antibody heavy chain variable domain library and a synthetic preimmune human antibody light chain library.
- the invention comprises a method of generating a full-length antibody library comprising transforming a cell with a preimmune human antibody heavy chain variable domain library and a synthetic preimmune human antibody light chain library.
- the invention comprises a method of generating an antibody library comprising synthesizing polynucleotide sequences by split-pool DNA synthesis.
- the polynucleotide sequences are selected from the group consisting of single-stranded coding polynucleotide sequences, single- stranded non-coding polynucleotide sequences, and double-stranded polynucleotide sequences.
- the invention comprises a synthetic full-length preimmune human antibody library comprising about 10 7 to about 10 10 polynucleotide sequences representative of the sequence diversity and length diversity found in known heavy chain CDR3 sequences.
- the invention comprises a method of selecting an antibody of interest from a human antibody library, comprising providing a synthetic preimmune human antibody CDRH3 library comprising a theoretical diversity of (N) polynucleotide sequences representative of the sequence diversity and length diversity found in known heavy chain CDR3 sequences, wherein the physical realization of that diversity is an actual library of a size at least 3(N), thereby providing a 95% probability that a single antibody of interest is present in the library, and selecting an antibody of interest.
- the theoretical diversity is about 10 7 to about 10 8 polynucleotide sequences.
- Example 1 Design of an Exemplary VH Chassis Library This example demonstrates the selection and design of exemplary, non- limiting VH chassis sequences of the invention. VH chassis sequences were selected by examining collections of human IGHV germline sequences (Scaviner et al, Exp. Clin. Immunogenet., 1999, 16: 234; Tomlinson et al, J. MoI. Biol, 1992, 227: 799; Matsuda et al, J. Exp. Med., 1998, 188: 2151, each incorporated by reference in its entirety). As discussed in the
- VH chassis sequences from these data sources or others, for inclusion in the library.
- Table 3 (adapted from information provided in Scaviner et al, Exp. Clin. Immunogenet., 1999, 16: 234; Matsuda et al, J. Exp. Med., 1998, 188: 2151; and Wang et al Immunol. Cell. Biol., 2008, 86: 111, each incorporated by reference in its entirety) lists the CDRHl and CDRH2 length, the canonical structure and the estimated relative occurrence in peripheral blood, for the proteins encoded by each of the human IGHV germline sequences.
- 17 germline sequences were chosen for representation in the VH chassis of the library (Table 4). As described in more detail below, these sequences were selected based on their relatively high representation in the peripheral blood of adults, with consideration given to the structural diversity of the chassis and the representation of particular germline sequences in antibodies used in the clinic. These 17 sequences account for about 76% of the total sample of heavy chain sequences used to derive the results of Table 4. As outlined in the Detailed Description, these criteria are non-limiting, and one of ordinary skill in the art will readily recognize that a variety of other criteria can be used to select the VH chassis sequences, and that the invention is not limited to a library comprising the 17 VH chassis genes presented in Table 4.
- VH chassis derived from sequences in the IGHV2, IGHV6 and IGHV7 germline families were not included. As described in the Detailed Description, this exemplification is not meant to be limiting, as, in some embodiments, it may be desirable to include one or more of these families, particularly as clinical information on antibodies with similar sequences becomes available, to produce libraries with additional diversity that is potentially unexplored, or to study the properties and potential of these IGHV families in greater detail.
- the modular design of the library of the present invention readily permits the introduction of these, and other, VH chassis sequences.
- the amino acid sequences of the VH chassis utilized in this particular embodiment of the library, which are derived from the IGHV germline sequences, are presented in Table 5. The details of the derivation procedures are presented below.
- Chassis I SEQ ID FRM1 I CDRH1 FRM2 I CDRH2 I FRM3 I
- the original KT sequence in VH3-15 was mutated to RA (bold/underlined) and TT to AR (bold/underlined), in order to match other VH3 family members selected for inclusion in the library.
- the modification to RA was made so that no unique sequence stretches of up to about 20 amino acids are created. Without being bound by theory, this modification is expected to reduce the odds of introducing novel T-cell epitopes in the VH3-15-derived chassis sequence.
- the avoidance of T cell epitopes is an additional criterion that can be considered in the design of certain libraries of the invention.
- Table 5 provides the amino acid sequences of the seventeen chassis.
- most of the corresponding germline nucleotide sequences include two additional nucleotides on the 3' end (i.e., two-thirds of a codon). In most cases, those two nucleotides are GA.
- nucleotides are added to the 3' end of the IGHV-derived gene segment in vivo, prior to recombination with the IGHD gene segment. Any additional nucleotide would make the resulting codon encode one of the following two amino acids: Asp (if the codon is GAC or GAT) or GIu (if the codon is GAA or GAG).
- One, or both, of the two 3 '-terminal nucleotides may also be deleted in the final rearranged heavy chain sequence. If only the A is deleted, the resulting amino acid is very frequently a G. If both nucleotides are deleted, this position is "empty,” but followed by a general V-D addition or an amino acid encoded by the IGHD gene. Further details are presented in Example 5.
- adding the tail to any chassis enumerated above (Table 5) can produce one of the following four schematic sequences, wherein the residue following the VH chassis is the tail:
- VH3-66, with canonical structure 1-1 may be included in the library.
- VH3-66 may compensate for the removal of other chassis from the library, which may not express well in yeast under some conditions (e.g., VH4-34 and VH4-59).
- Example 2 Design of VH Chassis Variants with Variation Within CDRHl and CDRH2 This example demonstrates the introduction of further diversity into the VH chassis by creating mutations in the CDRHl and CDRH2 regions of each chassis shown in Example 1. The following approach was used to select the positions and nature of the amino acid variation for each chassis: First, the sequence identity between rearranged human heavy chain antibody sequences was analyzed (Lee et ah, Immunogenetics, 2006, 57: 917; Jackson et al, J. Immunol. Methods, 2007, 324: 26) and they were classified by the origin of their respective IGHV germline sequence.
- the original germline sequence is provided in the second row of the tables, in bold font, beneath the residue number (Kabat system).
- the entries in the table indicate the number of times a given amino acid residue (first column) is observed at the indicated CDRHl (Table 6) or CDRH2 (Table 7) position.
- CDRHl CDRHl
- CDRH2 CDRH2
- position 33 the amino acid type G (glycine) is observed 24 times in the set of IGHVl -69-based sequences that were examined.
- variants were constructed with N at position 31 , L at position 32 (H can be charged, under some conditions), G and T at position 33, no variants at position 34 and N at position 35, resulting in the following VH 1-69 chassis CDRHl single-amino acid variant sequences:
- SIIPIFGTANYAQKFQG (SEQ ID NO: 46)
- GIAPIFGTANYAQKFQG (SEQ ID NO: 47)
- Example 3 Design of an Exemplary VK Chassis Library This example describes the design of an exemplary VK chassis library. One of ordinary skill in the art will recognize that similar principles may be used to design a V ⁇ library, or a library containing both VK and V ⁇ chassis. Design of a V ⁇ chassis library is presented in Example 4.
- IGKV germline genes (bolded in column 6 of Table 9) account for just over 90% of the usage of the entire repertoire in peripheral blood. From the analysis of Table 9, ten IGKV germline genes were selected for representation as chassis in the currently exemplified library (Table 10). All but Vl -12 and V 1-27 are among the top 10 most commonly occurring. IGKV germline genes VH2-30, which was tenth in terms of occurrence in peripheral blood, was not included in the currently exemplified embodiment of the library, in order to maintain the proportion of chassis with short ⁇ i.e., 11 or 12 residues in length) CDRLl sequences at about 80% in the final set of 10 chassis. Vl -12 was included in its place.
- Vl-17 was more similar to other members of the Vl family that were already selected ; therefore, V 1-27 was included, instead of Vl-17.
- the library could include 12 chassis ⁇ e.g., the ten of Table 10 plus Vl-17 and V2-30), or a different set of any "N" chassis, chosen strictly by occurrence (Table 9) or any other criteria.
- the ten chosen VK chassis account for about 80% of the usage in the data set believed to be representative of the entire kappa light chain repertoire.
- VK chassis is defined as Kabat residues 1 to 88 of the IGKV-encoded sequence, or from the start of FRMl to the end of FRM3.
- the portion of the VKCDR3 sequence contributed by the IGKV gene is referred to herein as the L3-VK region.
- V ⁇ chassis library This example, describes the design of an exemplary V ⁇ chassis library.
- VH and VK chassis sequences the sequence characteristics and occurrence of human Ig ⁇ V germline-derived sequences in peripheral blood were analyzed.
- assignment of V ⁇ sequences to a germline family was performed via SoDA and VBASE2 (Volpe and Kepler, Bioinformatics, 2006, 22: 438; Mollova et ah, BMS Systems Biology, 2007, IS: P30, each incorporated by reference in its entirety). The data are presented in Table 12.
- V ⁇ CDR3 is not considered part of the chassis as described herein.
- the V ⁇ chassis is defined as Kabat residues 1 to 88 of the IG ⁇ V-encoded sequence, or from the start of FRMl to the end of FRM3.
- the portion of the V ⁇ CDR3 sequence contributed by the IG ⁇ V gene is referred to herein as the L3-V ⁇ region.
- the CDRH3 sequence is derived from a complex process involving recombination of three different genes, termed IGHV, IGHD and IGHJ.
- these genes may also undergo progressive nucleotide deletions: from the 3' end of the IGHV gene, either end of the IGHD gene, and/or the 5' end of the IGHJ gene.
- Non-templated nucleotide additions may also occur at the junctions between the V, D and J sequences.
- Non-templated additions at the V-D junction are referred to as "Nl", and those at the D-J junction are referred to as "N2".
- the D gene segments may be read in three forward and, in some cases, three reverse reading frames.
- the codon (nucleotide triplet) or single amino acid was designated as a fundamental unit, to maintain all sequences in the desired reading frame.
- all deletions or additions to the gene segments are carried out via the addition or deletion of amino acids or codons, and not single nucleotides.
- CDRH3 extends from amino acid number 95 (when present; see Example 1) to amino acid 102.
- Example 5.1 Selection of the DH Segments
- selection of DH gene segments for use in the library was performed according to principles similar to those used for the selection of the chassis sequences.
- an analysis of IGHD gene usage was performed, using data from Lee et ah, Immunogenetics, 2006, 57: 917; Corbett et ah, PNAS, 1982, 79: 4118; and Souto-Carneiro et ah, J. Immunol., 2004, 172: 6790 (each incorporated by reference in its entirety), with preference for representation in the library given to those IGHD genes most frequently observed in human sequences.
- the degree of deletion on either end of the IGHD gene segments was estimated by comparison with known heavy chain sequences, using the SoDA algorithm (Volpe et al., Bioinformatics, 2006, 22: 438, incorporated by reference in its entirety) and sequence alignments.
- SoDA algorithm Volpe et al., Bioinformatics, 2006, 22: 438, incorporated by reference in its entirety
- sequence alignments For the presently exemplified library, progressively deleted DH segments, as short as three amino acids, were included.
- other embodiments of the invention comprise DH segments with deletions to a different length, for example, about 1, 2, 4, 5, 6, 7, 8, 9, or 10 amino acids.
- Table 15 shows the relative occurrence of IGHD gene usage in human antibody heavy chain sequences isolated mainly from peripheral blood B cells (list adapted from Lee et al., Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety).
- nucleotide sequences of IGHD5-5 and IGHD5-18 are 100% identical and thus indistinguishable in rearranged VH sequences.
- IGHD4-4 and IGHD4-11 are also 100% identical.
- IGHD 1-14 may also be included in the libraries of the invention.
- the translations of the ten most commonly expressed IGHD gene sequences found in naturally occurring human antibodies, in three reading frames, are shown in Table 16. Those reading frames which occur most commonly in peripheral blood have been highlighted in gray.
- Table 15 data regarding IGHD sequence usage and reading frame statistics were derived from Lee et al, 2006, and data regarding IGHD sequence reading frame usage were further complemented by data derived from Corbett et al, PNAS, 1982, 79: 4118 and Souto-Carneiro et al, J. Immunol, 2004, 172: 6790, each of which is incorporated by reference in its entirety.
- Reading frames highlighted in gray correspond to the most commonly used reading frames.
- the top 10 IGHD genes most frequently used in heavy chain sequences occurring in peripheral blood were chosen for representation in the library.
- Other embodiments of the library could readily utilize more or fewer D genes.
- the amino acid sequences of the selected IGHD genes, including the most commonly used reading frames and the total number of variants after progressive N- and C-terminal deletion to a minimum of three residues, are listed in Table 17. As depicted in Table 17, only the most commonly occurring alleles of certain IGHD genes were included in the illustrative library. This is, however, not required, and other embodiments of the invention may utilize IGHD reading frames that occur less frequently in the peripheral blood.
- TlIe reading frame (RF) is specified as RF after the name of the gene.
- variants were generated by systematic deletion from the N- and/or C-termini, until there were three amino acids remaining.
- the full sequence DYGDY (SEQ ID NO: 12) may be used to generate the progressive deletion variants: DYGD, YGDY, DYG, GDY and YGD.
- N any full-length sequence of size N, there will be a total of (N-l)*(N-2)/2 total variants, including the original full sequence.
- the progressive deletions were limited, so as to leave the loop intact i.e., only amino acids N-terminal to the first Cys, or C-terminal to the second Cys, were deleted in the respective DH segment variants.
- the foregoing strategy was used to avoid the presence of unpaired cysteine residues in the exemplified version of the library.
- other embodiments of the library may include unpaired cysteine residues, or the substitution of these cysteine residues with other amino acids.
- the variants In the cases where the truncation of the IGHD gene is limited by the presence of the Cys residues, only 9 variants (including the original full sequence) were generated; e.g., for IGHD2-2 2, the variants would be: GYCSSTSCYT (SEQ ID NO: 10), GYCSSTSCY, YCSSTSCYT, CSSTSCYT, GYCSSTSC, YCSSTSCY, CSSTSCY, YCSSTSC and CSSTSC. According to the criteria outlined above, 293 DH sequences were obtained from the selected IGHD gene segments, including the original IGHD gene segments. Certain sequences are redundant.
- YYY variant For example, it is possible to obtain the YYY variant from either IGHD3-10 2 (full sequence YYYGSGSYYN (SEQ ID NO: 2)), or in two different ways from IGHD3-22_2 (SEQ ID NO: 4) (YYYDSSGYYY).
- IGHD3-10 2 full sequence YYYGSGSYYN (SEQ ID NO: 2)
- IGHD3-22_2 SEQ ID NO: 4
- YYYDSSGYYYY the number of unique DH segment sequences in this illustrative embodiment of the library is 278. These sequences are enumerated in Table 18.
- TlIe sequence designation is formatted as follows: (IGHD Gene Name)_(Reading Frame)- (Variant Number)
- Table 19 shows the length distribution of the 278 DH segments selected according to the methods described above.
- IGHD-derived amino acids i.e., DH segments
- DH segments are numbered beginning with position 97, followed by positions 97A, 97B, etc.
- the shortest DH segment has three amino acids: 97, 97A and 97B, while the longest DH segment has 10 amino acids: 97, 97A, 97B, 97C, 97D, 97E, 97F, 97G, 97H and 971.
- IGHJ genes There are six human germline IGHJ genes. During in vivo assembly of antibody genes, these segments are progressively deleted at their 5' end. In this exemplary embodiment of the library, IGHJ gene segments with no deletions, or with 1, 2, 3, 4, 5, 6, or 7 deletions (at the amino acid level), yielding JH segments as short as 13 amino acids, were included (Table 20). Other embodiments of the invention, in which the IGHJ gene segments are progressively deleted (at their 5' / N-terminal end) to yield 15, 14, 12, or 11 amino acids are also contemplated.
- HS-JH is defined as the portion of the IGHJ segment included within the Kabat definition of CDRH3; FRM4 is defined as the portion of the IGHJ segment encoding framework region four.
- JH6 1 to CDRH3 the contribution of, for example, JH6 1 to CDRH3, would be designated by positions 99F, 99E, 99D, 99C, 99B, 99A, 100, 101 and 102 (Y, Y, Y, Y, G, M, D and V, respectively).
- the JH4 3 sequence would contribute amino acid positions 101 and 102 (D and Y, respectively) to CDRH3.
- the JH segment will contribute amino acids 103 to 113 to the FRM4 region, in accordance with the standard Kabat numbering system for antibody variable regions (Kabat, op. cit. 1991). This may not be the case in other embodiments of the library.
- Example 5.3 Selection of the Nl andN2 Segments While the consideration of V-D-J recombination enhanced by mimicry of the naturally occurring process of progressive deletion (as exemplified above) can generate enormous diversity, the diversity of the CDRH3 sequences in vivo is further amplified by non-templated addition of a varying number of nucleotides at the V-D junction and the D-J junction. Nl and N2 segments located at the V-D and D-J junctions, respectively, were identified in a sample containing about 2,700 antibody sequences (Jackson et al, J. Immunol.
- certain embodiments of the invention include Nl and N2 segments with rationally designed length and composition, informed by statistical biases in these parameters that are found by comparing naturally occurring Nl and N2 segments in human antibodies.
- Nl and N2 were fixed to a length of 0, 1, 2, or 3 amino acids. The naturally occurring composition of these sequences in human antibodies was used as a guide for the inclusion of different amino acid residues.
- Example 5.3.1 Selection of the Nl Segments Analysis of the identified Nl segments, located at the junction between V and D, revealed that the eight most frequently occurring amino acid residues were G, R, S, P, L, A, T and V (Table 21). The number of amino acid additions in the Nl segment was frequently none, one, two, or three ( Figure 2). The addition of four or more amino acids was relatively rare. Therefore, in the currently exemplified embodiment of the library, the Nl segments were designed to include zero, one, two or three amino acids.
- Nl segments of four, five, or more amino acids may also be utilized. G and P were always among the most commonly occurring amino acid residues in the Nl regions.
- the Nl segments that are dipeptides are of the form GX, XG, PX, or XP, where X is any of the eight most commonly occurring amino acids listed above. Due to the fact that G residues were observed more frequently than P residues, the tripeptide members of the exemplary Nl library have the form GXG, GGX, or XGG, where X is, again, one of the eight most frequently occurring amino acid residues listed above.
- the resulting set of Nl sequences used in the present exemplary embodiment of the library include the "zero" addition amounts to 59 sequences, which are listed in Table 24.
- the sequences enumerated in Table 24 contribute the following positions to CDRH3: the monomers contribute position 96, the dimers to 96 and 96A, and the trimers to 96, 96A and 96B.
- the corresponding numbers would go on to include
- N2 segments in the exemplary library an expanded set of sequences was utilized.
- the presently exemplified embodiment of the library therefore, contains 141 total N2 sequences, including the "zero" state.
- these 141 sequences may also be used in the Nl region, and that such embodiments are within the scope of the invention.
- the length and compositional diversity of the Nl and N2 sequences can be further increased by utilizing amino acids that occur less frequently than G, R, S, P, L, A, T and V, in the Nl and N2 regions of naturally occurring antibodies, and including Nl and N2 segments of four, five, or more amino acids in the library.
- Tables 21 to 23 and Figure 2 provides information about the composition and length of the Nl and N2 sequences in naturally occurring antibodies that is useful for the design of additional Nl and N2 regions which mimic the natural composition and length.
- N2 sequences will begin at position 98 (when present) and extend to 98A (dimers) and 98B (trimers). Alternative embodiments may occupy positions 98C, 98D, and so on.
- the CDRH3 in the exemplified library may be represented by the general formula:
- [G/D/E/-] represents each of the four possible terminal amino acid "tails"; Nl can be any of the 59 sequences in Table 24; DH can be any of the 278 sequences in Table 18; N2 can be any of the 141 sequences in Tables 24 and 25; and H3-JH can be any of the 28 H3-JH sequences in Table 20.
- the tail and Nl segments were combined, and redundancies were removed from the library.
- the sequence [VH Chassis]- [G] may be obtained in two different ways: [VH Chassis] + [G] + [nothing] or [VH Chassis] + [nothing] + [G]. Removal of redundant sequences resulted in a total of 212 unique [G/D/E/-]-[Nl] segments out of the 236 possible combinations (i.e., 4 tails x 59 Nl).
- Table 26 further illustrates specific exemplary sequences from the CDRH3 library described above, using the CDRH3 numbering system of the present application. In instances where a position is not used, the hyphen symbol (-) is included in the table instead.
- VKCDR3 libraries This example describes the design of a number of exemplary VKCDR3 libraries. As specified in the Detailed Description, the actual version(s) of the VKCDR3 library made or used in particular embodiments of the invention will depend on the objectives for the use of the library. In this example the Kabat numbering system for light chain variable regions was used.
- human kappa light chain sequences were obtained from the publicly available NCBI database (Appendix A).
- the heavy chain sequences (Example 2), each of the sequences obtained from the publicly available database was assigned to its closest germline gene, on the basis of sequence identity. The amino acid compositions at each position were then determined within each kappa light chain subset.
- This example describes the design of a "minimalist" VKCDR3 library, wherein the VKCDR3 repertoire is restricted to a length of nine residues.
- Examination of the VKCDR3 lengths of human sequences shows that a dominant proportion (over 70%) has nine amino acids within the Kabat definition of CDRL3: positions 89 through 97.
- the currently exemplified minimalist design considers only VKCDR3 of length nine.
- Examination of human kappa light chain sequences shows that there are not strong biases in the usage of IGKJ genes; there are five such IKJ genes in humans.
- Table 27 depicts IGKJ gene usage amongst three data sets, namely Juul et al. (Clin. Exp.
- five of the seven most commonly occurring amino acids found in position 96 of rearranged human sequences appear to originate from the first amino acid encoded by each of the five human IGKJ genes, namely, W, Y, F, L, and I.
- VKCDR3 a minimalist VKCDR3 library may be represented by the following amino acid sequence:
- VK Chassis represents any selected VK chassis (for non-limiting examples, see Table 11), specifically Kabat residues 1 to 88 encoded by the IGKV gene.
- L3-VK represents the portion of the VKCDR3 encoded by the chosen IGKV gene (in this embodiment, residues 89-95).
- F/L/I/R/W ⁇ 7P represents any one of amino residues F, L, I, R, W, Y, or P.
- IKJ4 (minus the first residue) has been depicted.
- the GGG amino acid sequence is expected to lead to larger conformational flexibility than any of the alternative IGKJ genes, which contain a GXG amino acid sequence, where X is an amino acid other than G.
- one implementation of the minimalist VKCDR3 library would have 70 members resulting from the combination of 10 VK chassis by 7 junction (position 96) options and one IGKJ-derived sequence (e.g., IGKJ4).
- IGKJ4 IGKJ4
- IGKJ4 IGKJ4
- another embodiment of the library may have 350 members (10 VK chassis by 7 junctions by 5 IGKJ genes).
- minimalist VKCDR3 libraries may be constructed using any of the IGKJ genes. Using the notation above, these minimalist VKCDR3 libraries may have sequences represented by, for example:
- JKl [VK Chassis]-[L3-VK]-[F/L/I/RA ⁇ A ⁇ /P]-[TFGQGTKVEIK];
- JK2 [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGQGTKLEIK]
- JK3 [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGPGTKVDIK]
- JK3 [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGPGTKVDIK]
- JK5 [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGQGTRLEIK].
- Example 6.2 A VKCDR3 Library of About 10 s Complexity
- the nine residue VKCDR3 repertoire described in Example 6.1 is expanded to include VKCDR3 lengths of eight and ten residues.
- the previously enumerated VKCDR3 library included the VK chassis and portions of the IGKJ gene not contributing to VKCDR3
- the presently exemplified version focuses only on residues comprising a portion of VKCDR3. This embodiment may be favored, for example, when recombination with a vector which already contains VK chassis sequences and constant region sequences is desired.
- VKCDR3 of lengths 8 and 10 represent, respectively, about 8.5% and about 16% of sequences in representative samples ( Figure 3).
- a more complex VKCDR3 library includes CDR lengths of 8 to 10 amino acids; this library accounts for over 95% of the length distribution observed in typical collections of human VKCDR3 sequences.
- This library also enables the inclusion of additional variation outside of the junction between the VK and JK genes.
- the present example describes such a library.
- the library comprises 10 sub-libraries, each designed around one of the 10 exemplary VK chassis depicted in Table 11.
- M may be less than or more than 10.
- the library employs a practical and facile synthesis approach using standard oligonucleotide synthesis instrumentation and degenerate oligonucleotides.
- the IUPAC code for degenerate nucleotides as given in Table 31 , will be used.
- the VKCDR3 library may be represented by the following four oligonucleotides (left column in Table 32), with the corresponding amino acids encoded at each position of CDRL3 (Kabat numbering) provided in the columns on the right.
- the first codon (CWG) of the first nucleotide of Table 32 corresponding to Kabat position 89, represents 50% CTG and 50% CAG, which encode Leu (L) and GIn (Q), respectively.
- the expressed polypeptide would be expected to have L and Q each about 50% of the time.
- the codon CBT represents 1/3 each of CCT, CGT and CTT, corresponding in turn to 1/3 each of Pro (P), Leu (L) and Arg (R) upon translation.
- the numbers are 864 for the first three oligonucleotides and 1,296 for the fourth oligonucleotide.
- the oligonucleotides encoding VKl -39 CDR3s of length nine contribute 3,888 members to the library.
- sequences with L or R at position 95A (when position 96 is empty) are identical to those with L or R at position 96 (and 95A empty). Therefore, the 3,888 number overestimates the LR contribution and the actual number of unique members is slightly lower, at 3,024.
- junction type 1 has position 96 as FY, type 2 as IL, type 3 as RW, and type 4 has a deletion.
- the second codon was CWT. In another embodiment, it was CWA or CWG.
- This example demonstrates how a more faithful representation of amino acid variation at each position may be obtained by using a codon-based synthesis approach (Virnekas et al. Nucleic Acids Res., 1994, 22: 5600).
- This synthetic scheme also allows for finer control of the proportions of particular amino acids included at a position. For example, as described above for the VKl -39 sequences, position 89 was designed as 50% Q and 50% L; however, as Table 30 shows, Q is used much more frequently than L.
- the more complex VKCDR3 libraries of the present example account for the different relative occurrence of Q and L, for example, 90% Q and 10% L. Such control is better exercised within codon-based synthetic schemes, especially when multiple amino acid types are considered.
- This example also describes an implementation of a codon-based synthetic scheme, using the ten VK chassis described in Table 11. Similar approaches, of course, can be implemented with more or fewer such chassis. As indicated in the Detailed Description, a unique aspect of the design of the present libraries, as well as those of the preceding examples, is the germline or chassis-based aspect, which is meant to preserve more of the integrity and variation of actual human kappa light chain sequences.
- the library of Table 34 would have 1.37 x 10 6 unique polypeptide sequences, calculated by multiplying together the numbers in the bottom row of the table.
- the underlined 0 entries for Asn (N) at certain positions represent regions where the possibility of having N-linked glycosylation sites in the VKCDR3 has been minimized or eliminated.
- Peptide sequences with the pattern N-X-(S or T)-Z, where X and Z are different from P may undergo post-translational modification in a number of expression systems, including yeast and mammalian cells. Moreover, the nature of such modification depends on the specific cell type and, even for a given cell type, on culture conditions. N-linked glycosylation may be disadvantageous when it occurs in a region of the antibody molecule likely to be involved in antigen binding (e.g., a CDR), as the function of the antibody may then be influenced by factors that may be difficult to control.
- a CDR antigen binding
- N-linked glycosylation sites e.g., bacteria
- N-X-(SAT) sequences the antibodies isolated from such libraries may be expressed in different systems (e.g., yeast, mammalian cells) later (e.g., toward clinical development), and the presence of carbohydrate moieties in the variable domains, and the CDRs in particular, may lead to unwanted modifications of activity.
- VKCDR3 libraries known in the art have not considered this effect, and thus a proportion of their members may have the undesirable qualities mentioned above.
- the present invention provides the compositions and methods for one of ordinary skill synthesizing VKCDR3 libraries corresponding to other VK chassis.
- This example describes the design of a minimalist V ⁇ CDR3 library.
- the principles used in designing this library are similar to those used to design the VKCDR3 libraries.
- the contribution of the Ig ⁇ V segment to CDRL3 is not constrained to a fixed number of amino acids. Therefore, length variation may be obtained in a minimalist V ⁇ CDR3 library even when only considering combinations between V ⁇ chassis and J ⁇ sequences.
- Examination of the V ⁇ CDR3 lengths of human sequences shows that lengths of 9 to 12 account for almost about 95% of sequences, and lengths of 8 to 12 account for about 97% of sequences (Figure 4).
- Table 36 shows the usage (percent occurrence) of the six known IG ⁇ J genes in the rearranged human lambda light chain sequences compiled from the NCBI database (see Appendix B), and Table 37 shows the sequences encoded by the genes.
- IG ⁇ J3-01 and IG ⁇ J7-02 are not represented among the sequences that were analyzed; therefore, they were not included in Table 36.
- IG ⁇ J 1-01, IG ⁇ J2-01, and IG ⁇ J3-02 are over-represented in their usage, and have thus been bolded in Table 37. In some embodiments of the invention, for example, only these three over-represented sequences may be utilized. In other embodiments of the invention, one may use all six segments, any 1, 2, 3, 4, or 5 of the 6 segments, or any combination thereof may be utilized.
- CDRL3 As shown in Table 14, the portion of CDRL3 contributed by the IG ⁇ V gene segment is 7, 8, or 9 amino acids.
- the remainder of CDRL3 and FRM4 are derived from the IG ⁇ J sequences (Table 37).
- the IG ⁇ J sequences contribute either one or two amino acids to CDRL3. If two amino acids are contributed by IG ⁇ J, the contribution is from the N-terminal two residues of the IG ⁇ J segment: YV (IG ⁇ Jl-01), VV (IG ⁇ J2-01), WV (IG ⁇ J3-01), VV (IG ⁇ J3-02), or AV (IG ⁇ J7-01 and IG ⁇ J7-02).
- one amino acid is contributed from IG ⁇ J, it is a V residue, which is formed after the deletion of the N- terminal residue of a IG ⁇ J segment.
- the FRM4 segment was fixed as FGGGTKLTVL, corresponding to IG ⁇ J2-01 and IG ⁇ J3-02 (i.e., portions of SEQ ID NOs: 558 and 560). Seven of the 11 selected chassis (V ⁇ l-40, V ⁇ 3-19, V ⁇ 3-21, V ⁇ 6-57, V ⁇ l-44, V ⁇ l-51, and V ⁇ 4-69) have an additional two nucleotides following the last full codon.
- (+) sequences are derived from their parents by the addition of an amino acid at the end of the respective CDR3 (bold underlined). H/Q can be introduced in a single sequence by use of the degenerate codon CAW or similar.
- the final set of chassis in the currently exemplified embodiment of the invention is 15: eleven contributed by the chassis in Table 14 and an additional four contributed by the chassis of Table 38.
- the corresponding L3-V ⁇ domains of the 15 chassis contribute from 7 to 10 amino acids to CDRL3.
- the total variation in the length of CDRL3 is 8 to 12 amino acids, approximating the distribution in Figure 4.
- the 15 chassis are V ⁇ l-40, V ⁇ l-44, V ⁇ l-51, V ⁇ 2-14, V ⁇ 3-1*, V ⁇ 3-19, V ⁇ 3-21, V ⁇ 4-69, V ⁇ 6-57, V ⁇ 5-45, V ⁇ 7-43, V ⁇ l- 40+, V ⁇ 3-19+, V ⁇ 3-21+, and V ⁇ 6-57+.
- the 5 IG ⁇ J-derived segments are YVFGGGTKLTVL (IG ⁇ Jl; SEQ ID NO: 568), VVFGGGTKLTVL (IG ⁇ J2; SEQ ID NO: 558), WVFGGGTKLTVL (IG ⁇ J3; SEQ ID NO: 559), AVFGGGTKLTVL (IG ⁇ J7; SEQ ID NO: 569), and -VFGGGTKLTVL (from any of the preceding sequences).
- CDRH3 sequences of human antibodies of interest that are known in the art (e.g., antibodies that have been used in the clinic) have close counterparts in the designed library of the invention.
- a set of fifteen CDRH3 sequences from clinically relevant antibodies is presented in Table 39.
- matches to a given input sequence may exist in a theoretical representation of such libraries
- the probability of synthesizing and then producing a physical realization of the theoretical library that contains such a sequence and then selecting an antibody corresponding to such a match may be remotely small.
- a CDRH3 of length 19 in the Knappik library may have over 10 19 distinct sequences.
- a tenth or so of the sequences may have length 19 and the largest total library may have in the order of 10 10 to 10 12 transformants; thus, the probability of a given pre-defined member being present, in practice, is effectively zero (less than one in ten million).
- Example 9 Split Pool Synthesis of Oligonucleotides Encoding the DH, N2, and H3- JH Segments
- Custom Primer SupportTM 200 dT40S resin (GE Healthcare) was used to synthesize the oligonucleotides, using a loading of about 39 ⁇ mol/g of resin.
- oligonucleotide leader sequences containing a randomly chosen 10 nucleotide sequence (ATGC ACAGTT; SEQ ID NO: 395), a BsrDI recognition site (GCAATG), and a two base "overlap sequence" (TG, AC, AG, CT, or GA) were synthesized. The purpose of each of these segments is explained below.
- the DH segments were synthesized; approximately 1 g of resin (with the 18 nucleotide segment still conjugated) was suspended in 20 mL of DCM/MeOH.
- the pooled resin (about 1.36 g) containing the 278 DH segments was subsequently suspended in about 17 mL of DCM/MeOH, and about 60 ⁇ L of the resulting slurry was distributed inside each of two sets of 141 columns.
- the 141 N2 segments enumerated in Tables 24 and 25 were then synthesized, in duplicate (282 total columns), 3' to the 278 DH segments synthesized in the first step.
- the resin from the 282 columns was then pooled, washed, and dried, as described above.
- the pooled resin obtained from the N2 synthesis (about 1.35 g) was suspended in about 17 mL of DCM/MeOH, and about 60 ⁇ L of the resulting slurry was distributed inside each of 280 columns, representing 28 H3-JH segments synthesized ten times each. A portion (described more fully below) of each of the 28 IGHJ segments, including H3-JH of Table 20 were then synthesized, 3' to the N2 segments, in ten of the columns. Final oligonucleotides were cleaved and deprotected by exposure to gaseous ammonia (85 0 C, 2 h, 60 psi).
- split pool synthesis was used to synthesize the exemplary CDRH3 library.
- the split pool synthesis described herein is, therefore, one possible means of obtaining the oligonucleotides of the library, but is not limiting.
- One other possible means of synthesizing the oligonucleotides described in this application is the use of trinucleotides. This may be expected to increase the fidelity of the synthesis, since frame shift mutants would be reduced or eliminated.
- Example 10 Construction of the CDRH3 and Heavy Chain Libraries
- This example outlines the procedures used to create exemplary CDRH3 and heavy chain libraries of the invention.
- a two step process was used to create the CDRH3 library. The first step involved the assembly of a set of vectors encoding the tail and Nl segments, and the second step involved utilizing the split pool nucleic acid synthesis procedures outlined in Example 9 to create oligonucleotides encoding the DH, N2, and H3-JH segments. The chemically synthesized oligonucleotides were then ligated into the vectors, to yield CDRH3 residues 95-102, based on the numbering system described herein.
- This CDRH3 library was subsequently amplified by PCR and recombined into a plurality of vectors containing the heavy chain chassis variants described in Examples 1 and 2.
- CDRHl and CDRH2 variants were produced by QuikChange ® Mutagenesis (Stratagene TM), using the oligonucleotides encoding the ten heavy chain chassis of Example 1 as a template.
- the plurality of vectors contained the heavy chain constant regions (i.e., CHl, CH2, and CH3) from IgGl, so that a full-length heavy chain was formed upon recombination of the CDRH3 with the vector containing the heavy chain chassis and constant regions.
- the recombination to produce the full-length heavy chains and the expression of the full-length heavy chains were both performed in S. cerevisiae.
- a light chain protein was also expressed in the yeast cell.
- the light chain library used in this embodiment was the kappa light chain library, wherein the VKCDR3s were synthesized using degenerate oligonucleotides (see Example 6.2).
- the light chain CDR3 oligonucleotides could be synthesized de novo, using standard procedures for oligonucleotide synthesis, without the need for assembly from sub-components (as in the heavy chain CDR3 synthesis).
- One or more light chains can be expressed in each yeast cell which expresses a particular heavy chain clone from a library of the invention.
- One or more light chains have been successfully expressed from both episomal (e.g., plasmid) vectors and from integrated sites in the yeast genome.
- the steps involved in the process may be generally characterized as (i) synthesis of 424 vectors encoding the tail and Nl regions; (ii) ligation of oligonucleotides encoding the [DH]-[N2]-[H3-JH] segments into these 424 vectors; (iii) PCR amplification of the CDRH3 sequences from the vectors produced in these ligations; and (iv) homologous recombination of these PCR-amplif ⁇ ed CDRH3 domains into the yeast expression vectors containing the chassis and constant regions.
- This example demonstrates the synthesis of 424 vectors encoding the tail and Nl regions of CDRH3.
- the tail was restricted to G, D, E, or nothing, and the Nl region was restricted to one of the 59 sequences shown in Table 24.
- Table 24 As described throughout the specification, many other embodiments are possible.
- a single "base vector” (pJM204, a pUC-derived cloning vector) was constructed, which contained (i) a nucleic acid sequence encoding two amino acids that are common to the C-terminal portion of all 28 IGHJ segments (SS), and (ii) a nucleic acid sequence encoding a portion of the CHl constant region from IgGl .
- the base vector contains an insert encoding a sequence that can be depicted as:
- oligonucleotides were cloned into the base vector, upstream (i.e., 5') from the region encoding the [SS]-[CHl-]. These 424 oligonucleotides were synthesized by standard methods and each encoded a C-terminal portion of one of the 17 heavy chain chassis enumerated in Table 5, plus one of four exemplary tail segments (G/D/E/-), and one of 59 exemplary Nl segments (Table 24).
- oligonucleotides therefore, encode a plurality of sequences that may be represented by: [ ⁇ FRM3]-[G/D/E/-]-[Nl], wherein -FRM3 represents a C-terminal portion of a FRM3 region from one of the 17 heavy chain chassis of Table 5, GfDfEI- represents G, D, E, or nothing, and Nl represents one of the 59 Nl sequences enumerated in Table 24.
- the invention is not limited to the chassis exemplified in Table 5, their CDRHl and CDRH2 variants (Table 8), the four exemplary tail options used in this example, or the 59 Nl segments presented in Table 24.
- the oligonucleotide sequences represented by the sequences above were synthesized in two groups: one group containing a -FRM3 region identical to the corresponding region on 16 of the 17 the heavy chain chassis enumerated in Table 5, and another group containing a -FRM3 region that is identical to the corresponding region on VH3-15.
- an oligonucleotide encoding DTAVYYCAR (SEQ ID NO: 397) was used for -FRM3.
- the V residue of VH5-51 was altered to an M, to correspond to the VH5-51 germline sequence.
- AISGSGGSTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAK (SEQ ID NO: 398) was used for -FRM3.
- Each of the two oligonucleotides encoding the -FRM3 regions were paired with oligonucleotides encoding one of the four tail regions (GfDfEI-) and one of the 59 Nl segments, yielding a total of 236 possible combinations for each -FRM3 (i.e., 1 x 4 x 59), or a total of 472 possible combinations when both -FRM3 sequences are considered.
- [CHl-] segments were cloned into the vector, as described above, additional sequences were added to the vector to facilitate the subsequent insertion of the oligonucleotides encoding the [DH] -[N2]-[H3 -JH] fragments synthesized during the split pool synthesis.
- These additional sequences comprise a polynucleotide encoding a selectable marker protein, flanked on each side by a recognition site for a type II restriction enzyme, for example:
- the selectable marker protein is ccdB and the type II restriction enzyme recognition sites are specific for BsrDI and Bbsl.
- the ccdB protein is toxic, thereby preventing the growth of these bacteria when the gene is present.
- SEQ ID NO: 570 An example of the 5' end of one of the 212 vectors with a -FRM3 region based on the VH3-23 chassis, D tail residue and an Nl segment of length zero is presented below (SEQ ID NO: 570):
- CTGTGCCGC CACATGATGA CGCGGTCTCT ccdB ! ⁇ ll/,l CCATTGCGCT TAGCCTAGGT TATATTCCCC AGAACATCAG GTTAATGGCG TTTTTGATGT CATTTTCGCG GTGGCTGAGA GGTAACGCGA ATCGGATCCA ATATAAGGGG TCTTGTAGTC CAATTACCGC AAAAACTACA GTAAAAGCGC CACCGACTCT ccdB lj.21 TCAGCCACTT CTTCCCCGAT AACGGAAACC GGCACACTGG CCATATCGGT GGTCATCATG CGCCAGCTTT CATCCCCGAT AGTCGGTGAA GAAGGGGCTA TTGCCTTTGG CCGTGTGACC GGTATAGCCA CCAGTAGTAC GCGGTCGAAA GTAGGGGCTA ccdB
- This example describes the cloning of the oligonucleotides encoding the [D]- [N2]-[H3-JH] segments (made via split pool synthesis; Example 9) into the 424 vectors produced in Example 10.1.
- the [DH] -[N2]-[H3- JH] oligonucleotides produced via split pool synthesis were amplified by PCR, to produce double- stranded oligonucleotides, to introduce restriction sites that would create overhangs complementary to those on the vectors (i.e., BsrDI and Bbsl), and to complete the 3' portion of the IGHJ segments that was not synthesized in the split pool synthesis.
- the amplified oligonucleotides were then digested with the restriction enzymes BsrDI
- oligonucleotide SEQ ID NO: 399 is one of the oligonucleotides synthesized during the split pool synthesis:
- the first 10 nucleotides represent a portion of a random sequence that is increased to 20 base pairs in the PCR amplification step, below. This portion of the sequence increases the efficiency of BsrDI digestion and facilitates the downstream purification of the oligonucleotides.
- Nucleotides 11-16 represent the BsrDI recognition site. The two base overlap sequence that follows this site (in this example TG; bold) was synthesized to be complementary to the two base overhang created by digesting certain of the 424 vectors with BsrDI (i.e., depending on the composition of the tail / Nl region of the particular vector).
- Other oligonucleotides contain different two-base overhangs, as described below.
- the two base overlap is followed by the DH gene segment (nucleotides 19-48), in this example, by a 30 bp sequence (TATTACTATGGATCTGGTTCTTACTATAAT, SEQ ID NO: 400) which encodes the ten residue DH segment YYYGSGS YYN (i.e., IGHD3-10 2 of Table 17; SEQ ID NO: 2).
- the region of the oligonucleotide encoding the DH segment is followed, in this example, by a nine base region (GTGGGCGGA; bold; nucleotides 49-57), encoding the N2 segment (in this case VGG; Table 24).
- the remainder of this exemplary oligonucleotide represents the portion of the JH segment that is synthesized during the split pool synthesis
- oligonucleotides After the split pool-synthesized oligonucleotides were cleaved from the resin and deprotected, they served as a template for a PCR reaction which added an additional randomly chosen 10 nucleotides (e.g., GACGAGCTTC; SEQ ID NO: 402) to the 5' end and the rest of the IGHJ segment plus the Bbsl restriction site to the 3' end. These additions facilitate the cloning of the [DH]-[N2]-[JH] oligonucleotides into the 424 vectors.
- additional randomly chosen 10 nucleotides e.g., GACGAGCTTC; SEQ ID NO: 402
- the last round of the split pool synthesis involves 280 columns: 10 columns for each of the oligonucleotides encoding one of 28 H3-JH segments.
- the oligonucleotide products obtained from these 280 columns are pooled according to the identity of their H3-JH segments, for a total of 28 pools.
- Each of these 28 pools is then amplified in five separate PCR reactions, using five forward primers that each encode a different two base overlap (preceding the DH segment; see above) and one reverse primer that has a sequence corresponding to the familial origin of the H3-JH segment being amplified.
- the sequences of these 11 primers are provided below:
- Amplifications were performed using Taq polymerase, under standard conditions.
- the oligonucleotides were amplified for eight cycles, to maintain the representation of sequences of different lengths. Melting of the strands was performed at 95 0 C for 30 seconds, with annealing at 58 0 C and a 15 second extension time at 72 0 C.
- the PCR amplification was performed using the TG primer and the JH6 primer, where the annealing portion of the primers has been underlined:
- the portion of the TG primer that is 5 ' to the annealing portion includes the random 10 base pairs described above.
- the portion of the JH6 primer that is 5' to the annealing portion includes the balance of the JH6 segment and the Bbsl restriction site.
- PCR product (SEQ ID NO: 414) is formed in the reaction (added sequences underlined): GACGAGCTTCATGCACAGTTGCAATGTGTATTACTATGGATCTGGTTCTTACTATAATGTGGGCGGATATTAT TACTACTATGGTATGGACGTATGGGGGCAAGGGACCACGGTCACCGTCTCCTCAGAGTCTTCCGTTAGTCGCA CTGATGCAG
- the PCR products from each reaction were then combined into five pools, based on the forward primer that was used in the reaction, creating sets of sequences yielding the same two-base overhang after BsrDI digestion.
- the five pools of PCR products were then digested with BsRDI and Bbsl (100 ⁇ g of PCR product; 1 mL reaction volume; 200 U Bbsl; 100 U BsrDI; 2h; 37 0 C; NEB Buffer 2).
- the digested oligonucleotides were extracted twice with phenol/chloroform, ethanol precipitated, air dried briefly and resolubilized in 300 ⁇ L of TE buffer by sitting overnight at 4 0 C.
- Each of the 424 vectors described in the preceding sections was then digested with BsrDI and Bbsl, each vector yielding a two base overhang that was complimentary to one of those contained in one of the five pools of PCR products.
- one of the five pools of restriction digested PCR products are ligated into each of the 424 vectors, depending on their compatible ends, for a total of 424 ligations.
- This example describes the PCR amplification of the CDRH3 regions from the 424 vectors described above.
- the 424 vectors represent two sets: one for the VH3-23 family, with FRM3 ending in CAK (212 vectors) and one for the other 16 chassis, with FRM3 ending in CAR (212 vectors).
- the CDRH3s in the VH3-23-based vectors were amplified using a reverse primer (EK137; see Table 41) recognizing a portion of the CHl region of the plasmid and the VH3-23-specific primer EK135 (see Table 41).
- Amplification of the CDRH3s from the 212 vectors with FRM3 ending in CAR was performed using the same reverse primer (EK137) and each of five FRM3- specific primers shown in Table 41 (EK139, EK140, EK141, EK143, and EK144). Therefore, 212 VH3-23 amplifications and 212 x 5 FRM3 PCR reactions were performed, for a total of 1,272 reactions.
- An additional PCR reaction amplified the CDRH3 from the 212 VH3-23-based vectors, using the EK 133 forward primer, to allow the amplicons to be cloned into the other 5 VH3 family member chassis while making the last three amino acids of these chassis CAK instead of the original CAR (VH3-23*).
- the primers used in each reaction are shown in Table 41.
- reaction products were pooled according to the respective VH chassis that they would ultimately be cloned into.
- Table 42 enumerates these pools, with the PCR primers used to obtain the CDRH3 sequences in each pool provided in the last two columns.
- Table 42 PCR Primers Used to Amplify CDRH3 Regions from 424 Vectors
- the heavy chain chassis expression vectors were pooled according to their origin and cut, to create a "gap" for homologous recombination with the amplified CDRH3s.
- Figure 6 shows a schematic structure of a heavy chain vector, prior to recombination with a CDRH3.
- a CDRH3 CDRH3
- VH 3-30 differs from VH3-33 by a single amino acid; thus VH3-30 was included in the VH3-33 pool of variants.
- the 4-34 VH family member was kept separate from all others and, in this exemplary embodiment, no variants of it were included in the library.
- a total of 16 pools, representing 17 heavy chain chassis, were generated from the 152 vectors.
- the vector pools were digested with the restriction enzyme Sfil, which cuts at two sites in the vector that are located between the end of the FRM3 of the variable domain and the start of the CHl (SEQ ID NO: 573).
- the gapped vector pools were then mixed with the appropriate (i.e., compatible) pool of CDRH3 amplicons, generated as described above, at a 50: 1 insert to vector ratio.
- the mixture was then transformed into electrocompetent yeast (S. cerevisiae), which already contained plasmids or integrated genes comprising a VK light chain library (described below).
- the degree of library diversity was determined by plating a dilution of the electroporated cells on a selectable agar plate. In this exemplified embodiment of the invention, the agar plate lacked tryptophan and the yeast lacked the ability to endogenously synthesize tryptophan.
- This example describes the mutation of position 94 in VH3-23, VH3-33, VH3- 30, VH3-7, and VH3-48.
- VH3-23 the amino acid at this position was mutated from K to R.
- VH3-33, VH3-30, VH3-7, and VH3-48 this amino acid was mutated from R to K.
- VH3-32 this position was mutated from K to R.
- the purpose of making these mutations was to enhance the diversity of CDRH3 presentation in the library. For example, in naturally occurring VH3-23 sequences, about 90% have K at position 94, while about 10% have position R. By making these changes the diversity of the CDRH3 presentation is increased, as is the overall diversity of the library.
- the amplification products from the 424 vectors (produced as described above) containing the DTAVYYCAR (SEQ ID NO: 579) sequence can be homologously recombined into the VH3-23 (CAR) vector, changing R to K in this framework and thus further increasing the diversity of CDRH3 presentation in this chassis.
- VH3-48 (240) TCTGCAAATGAACAGCCTGAGAGCTGAGGACACGGCGGTGTACTACTGCGCCAGA SEQ ID NO : ( 574)
- VH3-33/30(240) TCTGCAAATGAACAGCCTGAGAGCCGAGGACACGGCGGTGTACTACTGCGCCAGA
- VH3-23 (240) TCTGCAAATGAACAGCCTGAGAGCCGAGGACACGGCGGTGTACTACTGCGCCAAG
- VK library of the invention.
- the exemplary VK library described herein corresponds to the VKCDR3 library of about 10 5 complexity, described in Example 6.2.
- VK libraries are within the scope of the invention, as are V ⁇ libraries.
- FIG. 8 shows a schematic structure of a light chain vector, prior to recombination with a CDRL3.
- VKCDR oligonucleotide libraries were then synthesized, as described in Example 6.2, using degenerate oligonucleotides (Table 33). The oligonucleotides were then PCR amplified, as separate pools, to make them double stranded and to add additional nucleotides required for efficient homologous recombination with the gapped (by Sfil) vector containing the VK chassis and constant region sequences.
- the VKCDR3 pools in this embodiment of the invention represented lengths 8, 9, and 10 amino acids, which were mixed post- PCR at a ratio 1:8:1.
- a kappa light chain library pool was then produced, based on the approximate representation of the VK family members found in the circulating pool of B cells.
- the 10 kappa variable regions used and the relative frequency in the final library pool are shown in Table 44.
- This example shows the characteristics of exemplary libraries of the invention, constructed according to the methods described herein.
- Figure 19 depicts the familial origin of the JH segments identified in the 291 sequences
- Figure 20 shows the representation of 16 of the chassis of the library.
- the VH3-15 chassis was not represented amongst these sequences. This was corrected later by introducing yeast transformants containing the VH3-15 chassis, with CDRH3 diversity, into the library at the desired composition.
- Figure 22 shows the representation of the light chain chassis from amongst the 86 sequences selected from the library. About 91% of the CDRL3 sequences were exact matches to the design, and about 9% differed by a single amino acid.
- This example presents data on the composition of the CDRH3 domains of exemplary libraries, and a comparison to other libraries of the art. More specifically, this example presents an analysis of the occurrence of the 400 possible amino acid pairs (20 amino acids x 20 amino acids) occurring in the CDRH3 domains of the libraries. The prevalence of these pairs is computed by examination of the nearest neighbor (i - i+1; designated IPl), next nearest neighbor (i - i+2; designated IP2), and next-next nearest neighbor (i - i+3; designated IP3) of the i residue in CDRH3.
- Libraries previously known in the art e.g., Knappik et ah, J. MoI.
- the present invention represents the first recognition that, surprisingly, a position-specific bias does exist within the central portion of the CDRH3 loop, when the occurrences of amino acid pairs recited above are considered.
- This example shows that the libraries described herein more faithfully reproduce the occurrence of these pairs as found in human sequences, in comparison to other libraries of the art.
- the composition of the libraries described herein may thus be considered more "human” than other libraries of the art.
- the pair- wise composition of Lee et al. was determined based on the libraries depicted in Table 5 of Lee et al. , where the positions corresponding to those CDRH3 regions analyzed from the current invention and from Knappik et al. are composed of an "XYZ" codon in Lee et al.
- the XYZ codon of Lee et al. is a degenerate codon with the following base compositions: position 1 (X): 19% A, 17% C, 38% G, and 26% T; position 2 (Y): 34% A, 18% C, 31% G, and 17% T; and position 3 (Z): 24% G and 76% T.
- IP3 configurations can be computed for Knappik et al. and Lee et al. by multiplying together the individual amino acid compositions. For example, for Knappik et al., the occurrence of YS pairs in the library is calculated by multiplying 15% by 4.1%, to yield 6.1%; note that the occurrence of SY pairs would be the same. Similarly, for the XYZ codon-based libraries of Lee et al., the occurrence of YS pairs would be 6.86% (Y) multiplied by 9.35% (S), to give 6.4%; the same, again, for SY.
- the calculation is performed by ignoring the last five amino acids in the Kabat definition. By ignoring the C-terminal 5 amino acids of the human CDRH3, these sequences may be compared to those of Lee et al., based on the XYZ codons. While Lee et al. also present libraries with "NNK” and “NNS” codons, the pair- wise compositions of these libraries are even further away from human CDRH3 pair- wise composition.
- the XYZ codon was designed by Lee et al. to replicate, to some extent, the individual amino acid type biases observed in CDRH3.
- LUA-59 includes 59 Nl segments, 278 DH segments, 141 N2 segments, and 28 H3-JH segments (see Examples, above).
- LUA- 141 includes 141 Nl segments, 278 DH segments, 141 N2 segments, and 28 H3-JH segments (see Examples, above). Redundancies created by combination of the Nl and tail sequences were removed from the dataset in each respective library.
- the invention may be defined based on the percent occurrence of any of the 400 amino acid pairs, particularly those in Tables 47-49. In certain embodiments, the invention may be defined based on at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more of these pairs.
- the percent occurrence of certain pairs of amino acids may fall within ranges indicated by "LUA-" (lower boundary) and "LUA+” (higher boundary), in the following tables.
- the lower boundary for the percent occurrence of any amino acid pairs may be about 0.1, 0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3, 3.25, 3.5, 3.75, 4, 4.25, 4.5, 4.75, and 5.
- the higher boundary for the percent occurrence of any amino acid pairs may be about 0.1, 0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3, 3.25, 3.5, 3.75, 4, 4.25, 4.5, 4.75, 5, 5.25, 5.5, 5.75, 6, 6.25, 6.5, 6.75, 7, 7.25, 7.5, 7.75, and 8.
- any of the lower boundaries recited may be combined with any of the higher boundaries recited, to establish ranges, and vice-versa.
- the pairs in bold comprise about 19% to about 24% of occurrences (among the possible 400 pairs) for the Preimmune (Lee, et al, 2006), Humabs (Jackson, et al, 2007) and matured (Jackson minus Lee) sets. They account for about 27% to about 31% of the occurrences in the LUA libraries, but only about 12% in the HuCAL library and about 8% in the "XYZ" library. This is a reflection of the fact that pair- wise biases do exist in the human and LUA libraries, but not in the others. The last 2 columns indicate whether the corresponding pair-wise compositions fall within the LUA- and LUA+ boundaries: 0 if outside, 1 if within.
- the pairs in bold comprise about 18% to about 23% of occurrences (among the possible 400 pairs) for the Preimmune (Lee, et al, 2006), Humabs (Jackson, et al, 2007) and matured (Jackson minus Lee) sets. They account for about 27% to about 30% of the occurrences in the LUA libraries, but only about 12% in the HuCAL library and about 8% in the "XYZ" library. Because of the nature of the construction of the central loops in the HuCAL and XYZ libraries, these numbers are the same for the IPl, IP2, and IP3 pairs. The last 2 columns indicate whether the corresponding pair- wise compositions fall within the LUA- and LUA+ boundaries: 0 if outside, 1 if within.
- composition of the libraries of the present invention more closely mimics the composition of human sequences than other libraries known in the art.
- Synthetic libraries of the art do not intrinsically reproduce the composition of the "central loop" portion actual human CDRH3 sequences at the level of pair percentages.
- the libraries of the invention have a more complex pair-wise composition that closely reproduces that observed in actual human CDRH3 sequences.
- the exact degree of this reproduction versus a target set of actual human CDRH3 sequences may be optimized, for example, by varying the compositions of the segments used to design the CDRH3 libraries.
- ⁇ X ⁇ l O g 2 /
- / is the normalized frequency of occurrence of /, which may be an amino acid type (in which case N would be equal to 20).
- N is 20, and the resulting value of I would be -4.322.
- I is defined with base 2 logarithms, the units of I are bits.
- the I value for the HuCAL and XYZ libraries at the single position level may be derived from Tables 45 and 46, respectively, and are equal to -4.08 and -4.06.
- Table 50 The corresponding single residue frequency occurrences in the non-limiting exemplary libraries of the invention and the sets of human sequences previously introduced, taken within the "central loop" as defined above, are provided in Table 50.
- MI mutual information
- MI values decrease within sets of human sequences as those sequences undergo further somatic mutation, a process that over many independent sequences is essentially random. It is also worth noting that the MI values decrease as the pairs being considered sit further and further apart, and this is the case for both sets of human sequences, and exemplary libraries of the invention. In both cases, as the two amino acids in a pair become further separated the odds of their straddling an actual segment (V, D, J plus V-D or D-J insertions) increase, and their pair frequencies become closer to a simple product of singleton frequencies.
- Table 52 contains sequence information on certain immunoglobulin gene segments cited in the application. These sequences are non- limiting, and it is recognized that allelic variants exist and encompassed by the present invention. Accordingly, the methods present herein can be utilized with mutants of these sequences.
- Each of the IGHD nucleotide sequences can be read in three (3) forward reading frames, and, possibly, in 3 reverse reading frames.
- the nucleotide sequence given for IGHD1-1 may encode the full peptide sequences: GTTGT (SEQ ID NO: 517).
- VQLER SEQ ID NO: 518)and YNWND (SEQ ID NO: 519) in the forward direction, and VVPVV (SEQ ID NO: 520).
- SFQLY SEQ ID NO: 521
- RSSCT SEQ ID NO: 522
Abstract
The present invention overcomes the inadequacies inherent in the known methods for generating libraries of antibody-encoding polynucleotides by specifically designing the libraries with directed sequence and length diversity. The libraries are designed to reflect the preimmune repertoire naturally created by the human immune system, with or without DH segments derived from other species, and are based on rational design informed by examination of publicly available databases of antibody sequences.
Description
RATIONALLY DESIGNED, SYNTHETIC ANTIBODY LIBRARIES AND USES THEREFOR
RELATED APPLICATION This application claims priority to U.S. patent application serial number 12/404,059, filed March 13, 2009, which is a continuation in part of U.S. patent application serial number 12/210,072, filed September 12, 2008. This application also claims priority to U.S. provisional application serial number 60/993,785, filed September 14, 2007. These applications are all incorporated herein in their entirety by this reference. BACKGROUND OF THE INVENTION
Antibodies have profound relevance as research tools and in diagnostic and therapeutic applications. However, the identification of useful antibodies is difficult and once identified, antibodies often require considerable redesign or 'humanization' before they are suitable for therapeutic applications. Previous methods for identifying desirable antibodies have typically involved phage display of representative antibodies, for example human libraries derived by amplification of nucleic acids from B cells or tissues, or, alternatively, synthetic libraries. However, these approaches have limitations. For example, most human libraries known in the art contain only the antibody sequence diversity that can be experimentally captured or cloned from the source (e.g., B cells). Accordingly, the human library may completely lack or under-represent certain useful antibody sequences. Synthetic or consensus libraries known in the art have other limitations, such as the potential to encode non-naturally occurring (e.g., non-human) sequences that have the potential to be immunogenic. Moreover, certain synthetic libraries of the art suffer from at least one of two limitations: (1) the number of members that the library can theoretically contain (i.e., theoretical diversity) may be greater than the number of members that can actually be synthesized, and (2) the number of members actually synthesized may be so great as to preclude screening of each member in a physical realization of the library, thereby decreasing the probability that a library member with a particular property may be isolated. For example, a physical realization of a library (e.g., yeast display, phage display, ribosomal display, etc.) capable of screening 1012 library members will only sample about 10% of the sequences contained in a library with 1013 members. Given a median CDRH3 length of about 12.7 amino acids (Rock et al, J. Exp. Med., 1994, 179:323-328), the
number of theoretical sequence variants in CDRH3 alone is about 2012'7, or about 3.3 x 1016 variants. This number does not account for known variation that occurs in CDRHl and CDRH2, heavy chain framework regions, and pairing with different light chains, each of which also exhibit variation in their respective CDRLl, CDRL2, and CDRL3. Finally, the antibodies isolated from these libraries are often not amenable to rational affinity maturation techniques to improve the binding of the candidate molecule.
Accordingly, a need exists for smaller (i.e., able to be synthesized and physically realizable) antibody libraries with directed diversity that systematically represent candidate antibodies that are non-immunogenic (i.e., more human) and have desired properties (e.g., the ability to recognize a broad variety of antigens). However, obtaining such libraries requires balancing the competing objectives of restricting the sequence diversity represented in the library (to enable synthesis and physical realization, potentially with oversampling, while limiting the introduction of non-human sequences) while maintaining a level of diversity sufficient to recognize a broad variety of antigens. Prior to the instant invention, it was known in the art that "[aljthough libraries containing heavy chain CDR3 length diversity have been reported, it is impossible to synthesize DNA encoding both the sequence and the length diversity found in natural heavy chain CDR3 repertoires" (Hoet et al, Nat. Biotechnol., 2005, 23: 344, incorporated by reference in its entirety).
Therefore, it would be desirable to have antibody libraries which (a) can be readily synthesized, (b) can be physically realized and, in certain cases, oversampled, (c) contain sufficient diversity to recognize all antigens recognized by the preimmune human repertoire (i.e., before negative selection), (d) are non-immunogenic in humans (i.e., comprise sequences of human origin), and (e) contain CDR length and sequence diversity, and framework diversity, representative of naturally-occurring human antibodies. Embodiments of the instant invention at least provide, for the first time, antibody libraries that have these desirable features.
SUMMARY OF THE INVENTION
The present invention relates to, at least, synthetic polynucleotide libraries, methods of producing and using the libraries of the invention, kits and computer readable forms including the libraries of the invention. In some embodiments, the libraries of the invention are designed to reflect the preimmune repertoire naturally created by the human immune system and are based on rational design informed by examination of publicly available
databases of human antibody sequences. It will be appreciated that certain non-limiting embodiments of the invention are described below. As described throughout the specification, the invention encompasses many other embodiments as well.
In certain embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least 106 unique antibody CDRH3 amino acid sequences comprising
(i) an Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by B cells;
(ii) a non-human CDRH3 DH amino acid sequence, N- and C-terminal truncations thereof, or a sequence of at least about 80% identity to any of them; (iii) an N2 amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the N2 amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by B cells; and (iv) a human CDRH3 H3-JH amino acid sequence, N-terminal truncations thereof, or a sequence of at least about 80% identity to any of them.
In one aspect of the invention, the B cells are human B cells. In still other embodiments of the invention, the B cells are non-human B cells. In yet another embodiment of the invention, the B cells are vertebrate B cells.
In certain other embodiments, the invention provides that the non-human CDRH3 DH amino acid sequence is a sequence from a vertebrate species. In some embodiments, the vertebrate species is selected from the group consisting of Mus musculus, Camelus sp., Llama sp., Camelidae sp., Raja sp., Ginglymostoma sp., Carcharhinus sp., Heterodontus sp., Hydrolagus sp., Ictalurus sp., Gallus sp., Bos sp., Marmaronetta sp., Aythya sp., Netta sp., Equus sp., Pentalagus sp., Bunolagus sp., Nesolagus sp., Romerolagus sp.,
Brachylagus sp., Sylvilagus sp., Oryctolagus, sp., Poelagus sp., Ovis sp., Sus sp., Gadus sp., Salmo sp., Oncorhynchus sp, Macaca sp., Rattus sp., Pan sp., Hexanchus sp., Heptranchias sp., Notorynchus sp., Chlamydoselachus sp., Heterodontus sp. Pristiophorus sp., Pliotrema sp., Squatina sp., Carcharia sp., Mitsukurina sp., Lamma sp., Isurus sp., Carcharodon sp., Cetorhinus sp., Alopias sp., Nebrius sp., Stegostoma sp., Orectolobus sp., Eucrossorhinus sp., Sutorectus sp., Chiloscyllium sp., Hemiscyllium sp., Brachaelurus sp., Heteroscyllium sp., Cirrhoscyllium sp., Parascyllium sp., Rhincodon sp., Apήsturus sp., Atelomycterus sp., Cephaloscy ilium sp., Cephalurus sp., Dichichthys sp., Galeus sp., Halaelurus sp., Haploblepharus sp., Parmaturus sp., Pentanchus sp., Poroderna sp., Schroederichthys sp., Scyliorhinus sp., Pseudotriakis sp., Scylliogaleus sp., Furgaleus sp., Hemitriakis sp., Mustelus sp., Triakis sp., Iago sp., Galeorhinus sp., Hypogaleus sp., Chaenogaleus sp., Hemigaleus sp., Paragaleus sp., Galeocerdo sp., Prionace sp., Sciolodon sp., Loxodon sp., Rhizoprionodon sp., Aprionodon sp., Negaprion sp., Hypoprion sp., Carcharhinus sp., Isogomphodon sp., Triaenodon sp., Sphyrna sp., Echinorhinus sp., Oxynotus sp., Squalus sp., CentroscylHum sp., Etmopterus sp., Centrophorus sp., Cirrhigaleus sp., Deania sp.,
Centroscymnus sp., Scymnodon sp., Dalatias sp., Euprotomicrus sp., Isistius sp., Squaliolus sp., Heteroscymnoides sp., Somniosus sp. and Megachasma sp.
In other embodiments of the invention, an antibody may be isolated from the polypeptide expression products of any of the libraries described herein. In yet another embodiment, the CDRH3 amino acid sequences are expressed as part of full-length heavy chains. In one aspect of the invention, the polynucleotides further encode an alternative scaffold. In yet another embodiment, the library of polypeptides is encoded by the synthetic polynucleotide library described herein.
In certain embodiments of the invention, a library of vectors may comprise the polynucleotide library described herein. In still another embodiment, a population of cells may comprise the vectors described herein. In yet another embodiment, the cells are yeast cells (e.g., S. cerevisiae).
In yet another embodiment, the invention includes a method of preparing a synthetic polynucleotide library comprising providing the polynucleotide sequences of claim 1 and assembling said polynucleotide sequences in the order [N1]-[DH]-[N2]-[H3-JH]. In still another embodiment, the invention provides a method of isolating one or more host cells expressing one or more antibodies, the method comprising:
(i) expressing a polypeptide comprising a CDRH3 sequence of claim 1 in one or more host cells;
(ii) contacting the host cells with one or more antigens; and
(iii) isolating one or more host cells having antibodies that bind to the one or more antigens.
In certain aspects, the invention includes a kit comprising any of the libraries of synthetic polynucleotides described herein.
In other aspects of the invention, the CDRH3 amino acid sequences encoded by the libraries of synthetic polynucleotides described herein are in computer readable form. In certain embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least 106 unique antibody CDRH3 amino acid sequences comprising:
(i) an Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
(ii) a human CDRH3 DH amino acid sequence, N- and C-terminal truncations thereof, or a sequence of at least about 80% identity to any of them;
(iii) an N2 amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the N2 amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells; and
(iv) a human CDRH3 H3-JH amino acid sequence, N-terminal truncations thereof, or a sequence of at least about 80% identity to any of them.
In other embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least about 106 unique antibody CDRH3 amino acid sequences comprising:
(i) an Nl amino acid sequence of O to about 3 amino acids, wherein:
(a) the most N-terminal Nl amino acid, if present, is selected from a group consisting of R, G, P, L, S, A, V, K, I, Q, T and D; (b) the second most N-terminal Nl amino acid, if present, is selected from a group consisting of G, P, R, S, L, V, E, A, D, I, T and K; and
(c) the third most N-terminal Nl amino acid, if present, is selected from the group consisting of G, R, P, S, L, A, V, T, E, D, K and F;
(ii) a human CDRH3 DH amino acid sequence, N- and C-terminal truncations thereof, or a sequence of at least about 80% identity to any of them;
(iii) an N2 amino acid sequence of 0 to about 3 amino acids, wherein: (a) the most N-terminal N2 amino acid, if present, is selected from a group consisting of G, P, R, L, S, A, T, V, E, D, F and H;
(b) the second most N-terminal N2 amino acid, if present, is selected from a group consisting of G, P, R, S, T, L, A, V, E, Y, D and K; and
(c) the third most N-terminal N2 amino acid, if present, is selected from the group consisting of G, P, S, R, L, A, T, V, D, E, W and Q; and
(iv) a human CDRH3 H3-JH amino acid sequence, N-terminal truncations thereof, or a sequence of at least about 80% identity to any of them.
In still other embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode at least about 106 unique antibody CDRH3 amino acid sequences that are at least about 80% identical to an amino acid sequence represented by the following formula:
[X]-[N1]-[DH]-[N2]-[H3-JH], wherein: (i) X is any amino acid residue or no amino acid residue;
(ii) Nl is an amino acid sequence selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP,
TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA,
SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW, VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP, PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof; (iii) DH is an amino acid sequence selected from the group consisting of all possible reading frames that do not include a stop codon encoded by IGHDl-I, IGHD 1-20, IGHD 1-26, IGHD 1-7, IGHD2-15, IGHD2- 2, IGHD2-21, IGHD2-8, IGHD3-10, IGHD3-16, IGHD3-22, IGHD3-3, IGHD3-9, IGHD4-17, IGHD4-23, IGHD4-4, IGHD-4-11, IGHD5-12, IGHD5-24, IGHD5-5, IGHD-5-18, IGHD6-13, IGHD6-
19, IGHD6-25, IGHD6-6, and IGHD7-27, and N- and C-terminal truncations thereof;
(iv) N2 is an amino acid sequence selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP,
TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA,
SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW, VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP,
PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof; and
(v) H3-JH is an amino acid sequence selected from the group consisting of AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV
(SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY, DY, Y, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, S, YYYYYGMDV (SEQ ID NO: 22), YYYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, and MDV, or a sequence of at least 80% identity to any of them.
In still another embodiment, the invention comprises wherein said library consists essentially of a plurality of polynucleotides encoding CDRH3 amino acid sequences that are at least about 80% identical to an amino acid sequence represented by the following formula: [X]-[N1]-[DH]-[N2]-[H3-JH], wherein:
(i) X is any amino acid residue or no amino acid residue;
(ii) Nl is an amino acid sequence selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG,
RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA, SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW,
VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP, PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof;
(iii) DH is an amino acid sequence selected from the group consisting of all possible reading frames that do not include a stop codon encoded by IGHDl-I, IGHD 1-20, IGHD 1-26, IGHD 1-7, IGHD2-15, IGHD2- 2, IGHD2-21, IGHD2-8, IGHD3-10, IGHD3-16, IGHD3-22,
IGHD3-3, IGHD3-9, IGHD4-17, IGHD4-23, IGHD4-4, IGHD-4-11, IGHD5-12, IGHD5-24, IGHD5-5, IGHD-5-18, IGHD6-13, IGHD6- 19, IGHD6-25, IGHD6-6, and IGHD7-27, and N- and C-terminal truncations thereof; (iv) N2 is an amino acid sequence selected from the group consisting of
G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY,
DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA, SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW, VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP, PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof; and
(v) H3-JH is an amino acid sequence selected from the group consisting of AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV (SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY,
DY, Y, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, S, YYYYYGMDV (SEQ ID NO: 22), YYYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, and MDV, or a sequence of at least 80% identity to any of them. In another embodiment, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode one or more full length antibody heavy chain sequences, and wherein the CDRH3 amino acid sequences of the heavy chain comprise:
(i) an Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position
in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells;
(ii) a human CDRH3 DH amino acid sequence, N- and C-terminal truncations thereof, or a sequence of at least about 80% identity to any of them;
(iii) an N2 amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the N2 amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells; and
(iv) a human CDRH3 H3-JH amino acid sequence, N-terminal truncations thereof, or a sequence of at least about 80% identity to any of them.
The following embodiments may be applied throughout the embodiments of the instant invention. In one aspect, one or more CDRH3 amino acid sequences further comprise an N-terminal tail residue. In still another aspect, the N-terminal tail residue is selected from the group consisting of G, D, and E.
In yet another aspect, the Nl amino acid sequence is selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT, EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA, SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW, VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP, PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof. In certain other aspects, the Nl amino acid sequence may be of about 0 to about 5 amino acids.
In yet another aspect, the N2 amino acid sequence is selected from the group consisting of G, P, R, A, S, L, T, V, GG, GP, GR, GA, GS, GL, GT, GV, PG, RG, AG, SG, LG, TG, VG, PP, PR, PA, PS, PL, PT, PV, RP, AP, SP, LP, TP, VP, GGG, GPG, GRG, GAG, GSG, GLG, GTG, GVG, PGG, RGG, AGG, SGG, LGG, TGG, VGG, GGP, GGR, GGA, GGS, GGL, GGT, GGV, D, E, F, H, I, K, M, Q, W, Y, AR, AS, AT, AY, DL, DT,
EA, EK, FH, FS, HL, HW, IS, KV, LD, LE, LR, LS, LT, NR, NT, QE, QL, QT, RA, RD, RE, RF, RH, RL, RR, RS, RV, SA, SD, SE, SF, SI, SK, SL, SQ, SR, SS, ST, SV, TA, TR, TS, TT, TW, VD, VS, WS, YS, AAE, AYH, DTL, EKR, ISR, NTP, PKS, PRP, PTA, PTQ, REL, RPL, SAA, SAL, SGL, SSE, TGL, WGT, and combinations thereof. In certain other aspects, the N2 sequence may be of about 0 to about 5 amino acids.
In yet another aspect, the H3-JH amino acid sequence is selected from the group consisting of AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV (SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY, DY, Y, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, S, YYYYYGMDV (SEQ ID NO : 22), YYYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, and MDV.
In other embodiments, the invention comprises a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the percent occurrence within the central loop of the CDRH3 amino acid sequences of at least one of the following i - i+1 pairs in the library is within the ranges specified below:
Tyr-Tyr in an amount from about 2.5% to about 6.5%; Ser-Gly in an amount from about 2.5% to about 4.5%; Ser-Ser in an amount from about 2% to about 4%; Gly-Ser in an amount from about 1.5% to about 4%; Tyr-Ser in an amount from about 0.75% to about 2%;
Tyr-Gly in an amount from about 0.75% to about 2%; and Ser-Tyr in an amount from about 0.75% to about 2%.
In still other embodiments, the invention comprises a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the percent occurrence within the central loop of the CDRH3 amino acid sequences of at least one of the following i - i+2 pairs in the library is within the ranges specified below:
Tyr-Tyr in an amount from about 2.5% to about 4.5%; Gly-Tyr in an amount from about 2.5% to about 5.5%; Ser-Tyr in an amount from about 2% to about 4%;
Tyr-Ser in an amount from about 1.75% to about 3.75%; Ser-Gly in an amount from about 2% to about 3.5%; Ser-Ser in an amount from about 1.5% to about 3%; Gly-Ser in an amount from about 1.5% to about 3%; and Tyr-Gly in an amount from about 1% to about 2%.
In another embodiment, the invention comprises a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the percent occurrence within the central loop of the CDRH3 amino acid sequences of at least one of the following i - i+3 pairs in the library is within the ranges specified below: Gly-Tyr in an amount from about 2.5% to about 6.5%;
Ser-Tyr in an amount from about 1% to about 5%;
Tyr-Ser in an amount from about 2% to about 4%;
Ser-Ser in an amount from about 1% to about 3%;
Gly-Ser in an amount from about 2% to about 5%; and Tyr-Tyr in an amount from about 0.75% to about 2%.
In one aspect of the invention, at least 2, 3, 4, 5, 6, or 7 of the specified i - i+1 pairs in the library are within the specified ranges. In another aspect, the CDRH3 amino acid sequences are human. In yet another aspect, the polynucleotides encode at least about 106 unique CDRH3 amino acid sequences. In other aspects of the invention, the polynucleotides further encode one or more heavy chain chassis amino acid sequences that are N-terminal to the CDRH3 amino acid sequences, and the one or more heavy chain chassis sequences are selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 94 encoded by IGHV 1-2, IGHV1-3, IGHV1-8, IGHV1-18, IGHV1-24, IGHV1-45, IGHV1-46, IGHV1-58, IGHVl- 69, IGHV2-5, IGHV2-26, IGHV2-70, IGHV3-7, IGHV3-9, IGHV3-11, IGHV3-13, IGHV3-15, IGHV3-20, IGHV3-21, IGHV3-23, IGHV3-30, IGHV3-33, IGHV3-43, IGHV3-48, IGHV3-49, IGHV3-53, IGHV3-64, IGHV3-66, IGHV3-72, IGHV3-73, IGHV3-74, IGHV4-4, IGHV4-28, IGHV4-31, IGHV4-34, IGHV4-39, IGHV4-59, IGHV4- 61, IGHV4-B, IGHV5-51, IGHV6-1, and IGHV7-4-1, or a sequence of at least about 80% identity to any of them.
In another aspect, the polynucleotides further encode one or more FRM4 amino acid sequences that are C-terminal to the CDRH3 amino acid sequences, wherein the one or more FRM4 amino acid sequences are selected from the group consisting of a FRM4 amino acid sequence encoded by IGHJl, IGHJ2, IGHJ3, IGHJ4, IGHJ5, and IGHJ6, or a sequence of at least about 80% identity to any of them. In still another aspect, the polynucleotides further encode one or more immunoglobulin heavy chain constant region amino acid sequences that are C-terminal to the FRM4 sequence.
In yet another aspect, the CDRH3 amino acid sequences are expressed as part of full-length heavy chains. In other aspects, the full-length heavy chains are selected from the group consisting of an IgGl, IgG2, IgG3, and IgG4, or combinations thereof. In one embodiment, the CDRH3 amino acid sequences are from about 2 to about 30, from about 8 to about 19, or from about 10 to about 18 amino acid residues in length. In other aspects, the synthetic polynucleotides of the library encode from about 106 to about 1014, from about 107 to about 1013, from about 108 to about 1012, from about 109 to about 1012, or from about 1010 to about 1012 unique CDRH3 amino acid sequences.
In certain embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody VKCDR3 amino acid sequences comprising about 1 to about 10 of the amino acids found at Kabat positions 89, 90, 91, 92, 93, 94, 95, 95 A, 96, and 97, in selected VKCDR3 amino acid sequences derived from a particular IGKV or IGKJ germline sequence.
In one aspect, the synthetic polynucleotides encode one or more of the amino acid sequences listed in Table 33 or a sequence at least about 80% identical to any of them.
In some embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of unique antibody VKCDR3 amino acid sequences that are of at least about 80% identity to an amino acid sequence represented by the following formula:
[VK_Chassis]-[L3-VK]-[X]-[JK*], wherein:
(i) VK Chassis is an amino acid sequence selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGKV1-05, IGKV1-06, IGKV1-08, IGKV1-09, IGKVl-
12, IGKV1-13, IGKV1-16, IGKV1-17, IGKV1-27, IGKV1-33, IGKV1-37, IGKV1-39, IGKV1D-16, IGKV1D-17, IGKV1D-43,
IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2- 40, IGKV2D-26, IGKV2D-29, IGKV2D-30, IGKV3-11, IGKV3-15, IGKV3-20, IGKV3D-07, IGKV3D-11, IGKV3D-20, IGKV4-1, IGKV5-2, IGKV6-21, and IGKV6D-41, or a sequence of at least about 80% identity to any of them;
(ii) L3-VK is the portion of the VKCDR3 encoded by the IGKV gene segment; and
(iii) X is any amino acid residue; and
(iv) JK* is an amino acid sequence selected from the group consisting of sequences encoded by IGJKl, IGJK2, IGJK3, IGJK4, and IGJK5, wherein the first residue of each IGJK sequence is not present.
In still other aspects, X may be selected from the group consisting of F, L, I, R, W, Y, and P.
In certain embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of VλCDR3 amino acid sequences that are of at least about 80% identity to an amino acid sequence represented by the following formula:
[Vλ_Chassis]-[L3-Vλ]-[Jλ], wherein:
(i) Vλ Chassis is an amino acid sequence selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGλVl-36, IGλVl-40, IGλVl-44, IGλVl-47, IGλVl-51, IGλV10-54, IGλV2-l l, IGλV2-14, IGλV2-18, IGλV2-23, IGλV2-8, IGλV3-l, IGλV3-10, IGλV3-12, IGλV3-16, IGλV3-19, IGλV3-21, IGλV3-25, IGλV3-27, IGλV3-9, IGλV4-3, IGλV4-60, IGλV4-69, IGλV5-39, IGλV5-45, IGλV6-57, IGλV7-43, IGλV7-46, IGλV8-61,
IGλV9-49, and IGλV 10-54, or a sequence of at least about 80% identity to any of them;
(ii) L3-Vλ is the portion of the VλCDR3 encoded by the IGλV segment; and
(iii) Jλ is an amino acid sequence selected from the group consisting of sequences encoded by IGλJl-01, IGλJ2-01, IGλJ3-01, IGλJ3-02, IGλJ6-01, IGλJ7-01, and IGλJ7-02, and wherein the first residue of each IGJλ sequence may or may not be deleted. In further aspects, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody proteins comprising:
(i) a CDRH3 amino acid sequence of claim 1 ; and
(ii) a VKCDR3 amino acid sequence comprising about 1 to about 10 of the amino acids found at Kabat positions 89, 90, 91, 92, 93, 94, 95, 95 A, 96, and 97, in selected VKCDR3 sequences derived from a particular IGKV or IGKJ germline sequence.
In still further aspects, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody proteins comprising: (i) a CDRH3 amino acid sequence of claim 1; and
(ii) a VKCDR3 amino acid sequences of at least about 80% identity to an amino acid sequence represented by the following formula:
[VK_Chassis]-[L3-VK]-[X]-[JK*], wherein:
(a) VK Chassis is an amino acid sequence selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGKV1-05, IGKV1-06, IGKVl- 08, IGKV1-09, IGKV1-12, IGKV1-13, IGKV1-16, IGKVl- 17, IGKV1-27, IGKV1-33, IGKV1-37, IGKV1-39, IGKVlD- 16, IGKV1D-17, IGKV1D-43, IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2-40, IGKV2D-26,
IGKV2D-29, IGKV2D-30, IGKV3-11, IGKV3-15, IGKV3- 20, IGKV3D-07, IGKV3D-11, IGKV3D-20, IGKV4-1, IGKV5-2, IGKV6-21, and IGKV6D-41, or a sequence of at least about 80% identity to any of them; (b) L3-VK is the portion of the VKCDR3 encoded by the IGKV gene segment; and
(c) X is any amino acid residue; and
(d) JK* is an amino acid sequence selected from the group consisting of sequences encoded by IGJKl, IGJK2, IGJK3, IGJK4, and IGJK5, wherein the first residue of each IGJK sequence is not present.
In some aspects, the VKCDR3 amino acid sequence comprises one or more of the sequences listed in Table 33 or a sequence at least about 80% identical to any of them. In other aspects, the antibody proteins are expressed in a heterodimeric form. In yet another aspect, the human antibody proteins are expressed as antibody fragments. In still other aspects of the invention, the antibody fragments are selected from the group consisting of Fab, Fab', F(ab')2, Fv fragments, diabodies, linear antibodies, and single-chain antibodies.
In certain embodiments, the invention comprises an antibody isolated from the polypeptide expression products of any library described herein.
In still other aspects, the polynucleotides further comprise a 5 ' polynucleotide sequence and a 3' polynucleotide sequence that facilitate homologous recombination.
In one embodiment, the polynucleotides further encode an alternative scaffold.
In another embodiment, the invention comprises a library of polypeptides encoded by any of the synthetic polynucleotide libraries described herein.
In yet another embodiment, the invention comprises a library of vectors comprising any of the polynucleotide libraries described herein. In certain other aspects, the invention comprises a population of cells comprising the vectors of the instant invention.
In one aspect, the doubling time of the population of cells is from about 1 to about 3 hours, from about 3 to about 8 hours, from about 8 to about 16 hours, from about 16 to about 20 hours, or from 20 to about 30 hours. In yet another aspect, the cells are yeast cells. In still another aspect, the yeast is Saccharomyces cerevisiae.
In other embodiments, the invention comprises a library that has a theoretical total diversity of N unique CDRH3 sequences, wherein N is about 106to about 1015; and wherein the physical realization of the theoretical total CDRH3 diversity has a size of at least about 3N, thereby providing a probability of at least about 95% that any individual CDRH3 sequence contained within the theoretical total diversity of the library is present in the actual library.
In certain embodiments, the invention comprises a library of synthetic polynucleotides, wherein said polynucleotides encode a plurality of antibody VλCDR3 amino acid sequences comprising about 1 to about 10 of the amino acids found at Kabat positions 89, 90, 91, 92, 93, 94, 95, 95A, 95B, 95C, 96, and 97, in selected VλCDR3 sequences encoded by a single germline sequence.
In some embodiments, the invention relates to a library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, wherein the library has a theoretical total diversity of about 106to about 1015 unique CDRH3 sequences.
In still other embodiments, the invention relates to a method of preparing a library of synthetic polynucleotides encoding a plurality of antibody VK amino acid sequences, the method comprising:
(i) providing polynucleotide sequences encoding:
(a) one or more VK Chassis amino acid sequences selected from the group consisting of about Kabat amino acid 1 to about Kabat amino acid 88 encoded by IGKVl -05, IGKV1-06, IGKV 1-08, IGKV1-09, IGKV1-12, IGKV1-13, IGKV1-16, IGKVl -17, IGKV1-27, IGKVl -33, IGKV1-37, IGKV1-39, IGKV1D-16, IGKV1D-17, IGKV1D-43, IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2-40, IGKV2D-26, IGKV2D-29, IGKV2D-30, IGKV3-11, IGKV3-15, IGKV3-20, IGKV3D-07, IGKV3D-11, IGKV3D-20, IGKV4-1, IGKV5-2, IGKV6-21, and IGKV6D-41, or a sequence at least about 80% identical to any of them;
(b) one or more L3-VK amino acid sequences, wherein L3-VK the portion of the VKCDR3 amino acid sequence encoded by the IGKV gene segment;
(c) one or more X residues, wherein X is any amino acid residue; and
(d) one or more JK* amino acid sequences, wherein JK* is an amino acid sequence selected from the group consisting amino acid sequences encoded by IGKJl,
IGKJ2, IGKJ3, IGKJ4, and IGKJ5, wherein the first amino acid residue of each sequence is not present; and
(ii) assembling the polynucleotide sequences to produce a library of synthetic polynucleotides encoding a plurality of human VK sequences represented by the following formula:
[VK_Chassis]-[L3-VK]-[X]-[JK*].
In some embodiments, the invention relates to a method of preparing a library of synthetic polynucleotides encoding a plurality of antibody light chain CDR3 sequences, the method comprising:
(i) determining the percent occurrence of each amino acid residue at each position in selected light chain CDR3 amino acid sequences derived from a single germline polynucleotide sequence;
(ii) designing synthetic polynucleotides encoding a plurality of human antibody light chain CDR3 amino acid sequences, wherein the percent occurrence of any amino acid at any position within the designed light chain CDR3 amino acid sequences is within at least about 30% of the percent occurrence in the selected light chain CDR3 amino acid sequences derived from a single germline polynucleotide sequence, as determined in (i); and
(iii) synthesizing one or more polynucleotides that were designed in (ii).
In other embodiments, the invention relates to a method of preparing a library of synthetic polynucleotides encoding a plurality of antibody Vλ amino acid sequences, the method comprising:
(i) providing polynucleotide sequences encoding:
(a) one or more Vλ Chassis amino acid sequences selected from the group consisting of about Kabat residue 1 to about Kabat residue 88 encoded by IGλVl-36, IGλVl-40, IGλVl-44, IGλVl-47, IGλVl-51, IGλV 10-54, IGλV2-l l, IGλV2-14, IGλV2- 18, IGλV2-23, IGλV2-8, IGλV3-l, IGλV3-10, IGλV3-12, IGλV3-16, IGλV3-19, IGλV3- 21, IGλV3-25, IGλV3-27, IGλV3-9, IGλV4-3, IGλV4-60, IGλV4-69, IGλV5-39, IGλV5- 45, IGλV6-57, IGλV7-43, IGλV7-46, IGλV8-61, IGλV9-49, and IGλV10-54, or a sequence at least about 80% identical to any of them; (b) one ore more L3-Vλ sequences, wherein L3-Vλ is the portion of the VλCDR3 amino acid sequence encoded by the IGλV gene segment;
(c) one or more Jλ sequences, wherein Jλ is an amino acid sequence selected from the group consisting of amino acid sequences encoded by IGλJl-01, IGλJ2- 01, IGλJ3-01, IGλJ3-02, IGλJ6-01, IGλJ7-01, and IGλJ7-02 wherein the first amino acid residue of each sequence may or may not be present; and
(ii) assembling the polynucleotide sequences to produce a library of synthetic polynucleotides encoding a plurality of human Vλ amino acid sequences represented by the following formula:
[Vλ_Chassis]-[L3-Vλ]-[Jλ]. In certain embodiments, the amino acid sequences encoded by the polynucleotides of the libraries of the invention are human.
The present invention is also directed to methods of preparing a synthetic polynucleotide library comprising providing and assembling the polynucleotide sequences of the instant invention. In another aspect, the invention comprises a method of preparing the library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, the method comprising:
(i) providing polynucleotide sequences encoding:
(a) one or more Nl amino acid sequences of about 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells; (b) one or more human CDRH3 DH amino acid sequences, N- and C-terminal truncations thereof, or a sequence of at least about 80% identity to any of them;
(c) one or more N2 amino acid sequences of about 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by human B cells; and
(d) one or more human CDRH3 H3-JH amino acid sequences, N- terminal truncations thereof, or a sequence of at least about
80% identity to any of them; and
(ii) assembling the polynucleotide sequences to produce a library of synthetic polynucleotides encoding a plurality of human antibody CDRH3 amino acid sequences represented by the following formula:
[N1]-[DH]-[N2]-[H3-JH]. In one aspect, one or more of the polynucleotide sequences are synthesized via split- pool synthesis.
In another aspect, the method of the invention further comprises the step of recombining the assembled synthetic polynucleotides with a vector comprising a heavy chain chassis and a heavy chain constant region, to form a full-length heavy chain. In another aspect, the method of the invention further comprises the step of providing a 5 ' polynucleotide sequence and a 3 ' polynucleotide sequence that facilitate homologous recombination. In still another aspect, the method of the invention further comprises the step of recombining the assembled synthetic polynucleotides with a vector comprising a heavy chain chassis and a heavy chain constant region, to form a full-length heavy chain.
In some embodiments, the step of recombining is performed in yeast. In certain embodiments, the yeast is S. cerevisiae.
In certain other embodiments, the invention comprises a method of isolating one or more host cells expressing one or more antibodies, the method comprising: (i) expressing the human antibodies of any one of claims 40 and 46 in one or more host cells;
(ii) contacting the host cells with one or more antigens; and
(iii) isolating one or more host cells having antibodies that bind to the one or more antigens. In another aspect, the method of the invention further comprises the step of isolating one or more antibodies from the one or more host cells that present the antibodies which recognize the one or more antigens. In yet another aspect, the method of the invention further comprises the step of isolating one or more polynucleotide sequences encoding one or more antibodies from the one or more host cells that present the antibodies which recognize the one or more antigens.
In certain other embodiments, the invention comprises a kit comprising the library of synthetic polynucleotides encoding a plurality of antibody CDRH3 amino acid sequences, or any of the other sequences disclosed herein.
In still other aspects, the CDRH3 amino acid sequences encoded by the libraries of synthetic polynucleotides described herein, or any of the other sequences disclosed herein, are in computer readable form.
BRIEF DESCRIPTION OF THE DRAWINGS
Figure 1 depicts a schematic of recombination between a fragment (e.g., CDR3) and a vector (e.g., comprising a chassis and constant region) for the construction of a library.
Figure 2 depicts the length distribution of the Nl and N2 regions of rearranged human antibody sequences compiled from Jackson et al. (J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety).
Figure 3 depicts the length distribution of the CDRL3 regions of rearranged human kappa light chain sequences compiled from the NCBI database (Appendix A).
Figure 4 depicts the length distribution of the CDRL3 regions of rearranged human lambda light chain sequences compiled from the NCBI database (Appendix B).
Figure 5 depicts a schematic representation of the 424 cloning vectors used in the synthesis of the CDRH3 regions before and after ligation of the [DH]-[N2]-[JH] segment (DTAVYYCAR: SEQ ID NO: 579; DTAVYYCAK: SEQ ID NO: 578; SSASTK: SEQ ID NO: 580).
Figure 6 depicts a schematic structure of a heavy chain vector, prior to recombination with a CDRH3.
Figure 7 depicts a schematic diagram of a CDRH3 integrated into a heavy chain vector and the polynucleotide and polypeptide sequences of CDRH3_(SEQ ID NO: 581).
Figure 8 depicts a schematic structure of a kappa light chain vector, prior to recombination with a CDRL3.
Figure 9 depicts a schematic diagram of a CDRL3 integrated into a light chain vector and the polynucleotide and polypeptide sequences of CDRL3 (SEQ ID NO: 582). Figure 10 depicts the length distribution of the CDRH3 domain (Kabat positions 95-
102) from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution.
Figure 11 depicts the length distribution of the DH segment from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution.
Figure 12 depicts the length distribution of the N2 segment from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution.
Figure 13 depicts the length distribution of the H3-JH segment from 96 colonies obtained by transformation with 10 of the 424 vectors synthesized as described in Example 10 (observed), as compared to the expected (i.e., designed) distribution. Figure 14 depicts the length distribution of the CDRH3 domains from 291 sequences prepared from yeast cells transformed according to the method outlined in Example 10.4, namely the co-transformation of vectors containing heavy chain chassis and constant regions with a CDRH3 insert (observed), as compared to the expected (i.e., designed) distribution. Figure 15 depicts the length distribution of the [TaU]-[Nl] region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the expected (i.e., designed) distribution.
Figure 16 depicts the length distribution of the DH region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the theoretical (i.e., designed) distribution.
Figure 17 depicts the length distribution of the N2 region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the theoretical (i.e., designed) distribution.
Figure 18 depicts the length distribution of the H3-JH region from the 291 sequences prepared from yeast cells transformed according to the protocol outlined in Example 10.4 (observed), as compared to the theoretical (i.e., designed) distribution.
Figure 19 depicts the familial origin of the JH segments identified in the 291 sequences (observed), as compared to the theoretical (i.e., designed) familial origin.
Figure 20 depicts the representation of each of the 16 chassis of the library (observed), as compared to the theoretical (i.e., designed) chassis representation. VH3-23 is represented twice; once ending in CAR and once ending in CAK. These representations were combined, as were the ten variants of VH3-33 with one variant of VH3-30.
Figure 21 depicts a comparison of the CDRL3 length from 86 sequences selected from the VKCDR3 library of Example 6.2 (observed) to human sequences (human) and the designed sequences (designed).
Figure 22 depicts the representation of the light chain chassis amongst the 86 sequences selected from the library (observed), as compared to the theoretical (i.e., designed) chassis representation.
Figure 23 depicts the frequency of occurrence of different CDRH3 lengths in an exemplary library of the invention, versus the preimmune repertoire of Lee et al. (Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety). Figure 24 depicts binding curves for 6 antibodies selected from a library of the invention.
Figure 25 depicts binding data for 10 antibodies selected from a library of the invention binding to hen egg white lysozyme.
DETAILED DESCRIPTION OF THE INVENTION
The present invention is directed to, at least, synthetic polynucleotide libraries, methods of producing and using the libraries of the invention, kits and computer readable forms including the libraries of the invention. The libraries taught in this application are described, at least in part, in terms of the components from which they are assembled. In certain embodiments, the instant invention provides antibody libraries specifically designed based on the composition and CDR length distribution in the naturally occurring human antibody repertoire. It is estimated that, even in the absence of antigenic stimulation, a human makes at least about 107 different antibody molecules. The antigen- binding sites of many antibodies can cross-react with a variety of related but different epitopes. In addition the human antibody repertoire is large enough to ensure that there is an antigen-binding site to fit almost any potential epitope, albeit with low affinity.
The mammalian immune system has evolved unique genetic mechanisms that enable it to generate an almost unlimited number of different light and heavy chains in a remarkably economical way, by combinatorially joining chromosomally separated gene segments prior to transcription. Each type of immunoglobulin (Ig) chain (i.e., K light, λ light, and heavy) is synthesized by combinatorial assembly of DNA sequences selected from two or more families of gene segments, to produce a single polypeptide chain. Specifically, the heavy chains and light chains each consist of a variable region and a
constant (C) region. The variable regions of the heavy chains are encoded by DNA sequences assembled from three families of gene segments: variable (IGHV), joining (IGHJ) and diversity (IGHD). The variable regions of light chains are encoded by DNA sequences assembled from two families of gene segments for each of the kappa and lambda light chains: variable (IGLV) and joining (IGLJ). Each variable region (heavy and light) is also recombined with a constant region, to produce a full-length immunoglobulin chain.
While combinatorial assembly of the V, D and J gene segments make a substantial contribution to antibody variable region diversity, further diversity is introduced in vivo, at the pre-B cell stage, via imprecise joining of these gene segments and the introduction of non-templated nucleotides at the junctions between the gene segments.
After a B cell recognizes an antigen, it is induced to proliferate. During proliferation, the B cell receptor locus undergoes an extremely high rate of somatic mutation that is far greater than the normal rate of genomic mutation. The mutations that occur are primarily localized to the Ig variable regions and comprise substitutions, insertions and deletions. This somatic hypermutation enables the production of B cells that express antibodies possessing enhanced affinity toward an antigen. Such antigen- driven somatic hypermutation fine-tunes antibody responses to a given antigen.
Significant efforts have been made to create antibody libraries with extensive diversity, and to mimic the natural process of affinity maturation of antibodies against various antigens, especially antigens associated with diseases such as autoimmune diseases, cancer, and infectious disease. Antibody libraries comprising candidate binding molecules that can be readily screened against targets are desirable. However, the full promise of an antibody library, which is representative of the preimmune human antibody repertoire, has remained elusive. In addition to the shortcomings enumerated above, and throughout the application, synthetic libraries that are known in the art often suffer from noise (i.e., very large libraries increase the presence of many sequences which do not express well, and/or which misfold), while entirely human libraries that are known in the art may be biased against certain antigen classes (e.g., self-antigens). Moreover, the limitations of synthesis and physical realization techniques restrict the functional diversity of antibody libraries of the art. The present invention provides, for the first time, a fully synthetic antibody library that is representative of the human preimmune antibody repertoire (e.g., in composition and length), and that can be readily screened (i.e., it is physically realizable and, in some cases
can be oversampled) using, for example, high throughput methods, to obtain, for example, new therapeutics and/or diagnostics
In particular, the synthetic antibody libraries of the instant invention have the potential to recognize any antigen, including self-antigens of human origin. The ability to recognize self-antigens is usually lost in an expressed human library, because self-reactive antibodies are removed by the donor's immune system via negative selection. Another feature of the invention is that screening the antibody library using positive clone selection, for example, by FACS (florescence activated cell sorter) bypasses the standard and tedious methodology of generating a hybridoma library and supernatant screening. Still further, the libraries, or sub-libraries thereof, can be screened multiple times, to discover additional antibodies against other desired targets.
Before further description of the invention, certain terms are defined.
1. Definitions Unless defined otherwise, all technical and scientific terms used herein have the meaning commonly understood by one of ordinary skill in the art relevant to the invention. The definitions below supplement those in the art and are directed to the embodiments described in the current application.
The term "antibody" is used herein in the broadest sense and specifically encompasses at least monoclonal antibodies, polyclonal antibodies, multi-specific antibodies (e.g., bispecific antibodies), chimeric antibodies, humanized antibodies, human antibodies, and antibody fragments. An antibody is a protein comprising one or more polypeptides substantially or partially encoded by immunoglobulin genes or fragments of immunoglobulin genes. The recognized immunoglobulin genes include the kappa, lambda, alpha, gamma, delta, epsilon and mu constant region genes, as well as myriad immunoglobulin variable region genes.
"Antibody fragments" comprise a portion of an intact antibody, for example, one or more portions of the antigen-binding region thereof. Examples of antibody fragments include Fab, Fab', F(ab')2, and Fv fragments, diabodies, linear antibodies, single-chain antibodies, and multi-specific antibodies formed from intact antibodies and antibody fragments.
An "intact antibody" is one comprising full-length heavy- and light- chains and an Fc region. An intact antibody is also referred to as a "full-length, heterodimeric" antibody or immunoglobulin.
The term "variable" refers to the portions of the immunoglobulin domains that exhibit variability in their sequence and that are involved in determining the specificity and binding affinity of a particular antibody (i.e., the "variable domain(s)"). Variability is not evenly distributed throughout the variable domains of antibodies; it is concentrated in sub- domains of each of the heavy and light chain variable regions. These sub-domains are called "hypervariable" regions or "complementarity determining regions" (CDRs). The more conserved (i.e., non-hypervariable) portions of the variable domains are called the "framework" regions (FRM). The variable domains of naturally occurring heavy and light chains each comprise four FRM regions, largely adopting a β-sheet configuration, connected by three hypervariable regions, which form loops connecting, and in some cases forming part of, the β -sheet structure. The hypervariable regions in each chain are held together in close proximity by the FRM and, with the hypervariable regions from the other chain, contribute to the formation of the antigen-binding site (see Kabat et al. Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md., 1991, incorporated by reference in its entirety). The constant domains are not directly involved in antigen binding, but exhibit various effector functions, such as, for example, antibody-dependent, cell-mediated cytotoxicity and complement activation.
The "chassis" of the invention represent a portion of the antibody heavy chain variable (IGHV) or light chain variable (IGLV) domains that are not part of CDRH3 or CDRL3, respectively. The chassis of the invention is defined as the portion of the variable region of an antibody beginning with the first amino acid of FRMl and ending with the last amino acid of FRM3. In the case of the heavy chain, the chassis includes the amino acids including from about Kabat position 1 to about Kabat position 94. In the case of the light chains (kappa and lambda), the chassis are defined as including from about Kabat position 1 to about Kabat position 88. The chassis of the invention may contain certain modifications relative to the corresponding germline variable domain sequences presented herein or available in public databases. These modifications may be engineered (e.g., to remove N-linked glycosylation sites) or naturally occurring (e.g., to account for allelic variation). For example, it is known in the art that the immunoglobulin gene repertoire is
polymorphic (Wang et ah, Immunol. Cell. Biol., 2008, 86: 111; Collins et ah, Immunogenetics, 2008, DOI 10.1007/s00251-008-0325-z, published online, each incorporated by reference in its entirety); chassis, CDRs {e.g., CDRH3) and constant regions representative of these allelic variants are also encompassed by the invention. In some embodiments, the allelic variant(s) used in a particular embodiment of the invention may be selected based on the allelic variation present in different patient populations, for example, to identify antibodies that are non-immunogenic in these patient populations. In certain embodiments, the immunogenicity of an antibody of the invention may depend on allelic variation in the major histocompatibility complex (MHC) genes of a patient population. Such allelic variation may also be considered in the design of libraries of the invention. In certain embodiments of the invention, the chassis and constant regions are contained on a vector, and a CDR3 region is introduced between them via homologous recombination.
In some embodiments, one, two or three nucleotides may follow the heavy chain chassis, forming either a partial (if one or two) or a complete (if three) codon. When a full codon is present, these nucleotides encode an amino acid residue that is referred to as the "tail," and occupies position 95.
The "CDRH3 numbering system" used herein defines the first amino acid of CDRH3 as being at Kabat position 95 (the "tail," when present) and the last amino acid of CDRH3 as position 102. The amino acids following the "tail" are called "Nl" and, when present, are assigned numbers 96, 96A, 96B, etc. The Nl segment is followed by the "DH" segment, which is assigned numbers 97, 97A, 97B, 97C, etc. The DH segment is followed by the "N2" segment, which, when present, is numbered 98, 98A, 98B, etc. Finally, the most C-terminal amino acid residue of the set of the "H3-JH" segment is designated as number 102. The residue directly before (N-terminal) it, when present, is 101, and the one before (if present) is 100. For reasons of convenience, and which will become apparent elsewhere, the rest of the H3-JH amino acids are numbered in reverse order, beginning with 99 for the amino acid just N-terminal to 100, 99A for the residue N-terminal to 99, and so forth for 99B, 99C, etc. Examples of certain CDRH3 sequence residue numbers may therefore include the following:
13 Amino Acid CDR-H3 with Nl and N2
( 95 ) ( 96 ) ( 96A) ( 97 ) ( 97A) ( 97B) ( 97C ) ( 97D) ( 98 ) ( 99 ) ( 100 ) ( 101 ) ( 102 )
I - I -
Tail Nl DH N2 H3-JH
10 Amino Acid CDR-H3 without Nl and N2
( 97 ) ( 97A) ( 97B ) ( 97C ) ( 97 D ) ( 97E ) ( 97 F ) ( 97G ) ( 101 ) ( 102 ) i I i
DH H3 -JH
As used herein, the term "diversity" refers to a variety or a noticeable heterogeneity. The term "sequence diversity" refers to a variety of sequences which are collectively representative of several possibilities of sequences, for example, those found in natural human antibodies. For example, heavy chain CDR3 (CDRH3) sequence diversity may refer to a variety of possibilities of combining the known human DH and H3-JH segments, including the Nl and N2 regions, to form heavy chain CDR3 sequences. The light chain CDR3 (CDRL3) sequence diversity may refer to a variety of possibilities of combining the naturally occurring light chain variable region contributing to CDRL3 (i.e., L3-VL) and joining (i.e., L3-JL) segments, to form light chain CDR3 sequences. As used herein, H3-JH refers to the portion of the IGHJ gene contributing to CDRH3. As used herein, L3-VL and L3-JL refer to the portions of the IGLV and IGLJ genes (kappa or lambda) contributing to CDRL3, respectively. As used herein, the term "expression" includes any step involved in the production of a polypeptide including, but not limited to, transcription, post-transcriptional modification, translation, post-translational modification, and secretion.
As used herein, the term "host cell" is intended to refer to a cell into which a polynucleotide of the invention. It should be understood that such terms refer not only to the particular subject cell but to the progeny or potential progeny of such a cell. Because certain modifications may occur in succeeding generations due to either mutation or environmental influences, such progeny may not, in fact, be identical to the parent cell, but are still included within the scope of the term as used herein.
The term "length diversity" refers to a variety in the length of a particular nucleotide or amino acid sequence. For example, in naturally occurring human antibodies, the heavy chain CDR3 sequence varies in length, for example, from about 3 amino acids to over about 35 amino acids, and the light chain CDR3 sequence varies in length, for example, from about 5 to about 16 amino acids. Prior to the instant invention, it was known in the art that
it is possible to design antibody libraries containing sequence diversity or length diversity (see, e.g., Hoet et ah, Nat. BiotechnoL, 2005, 23: 344; Kretzschmar and von Ruden, Curr. Opin. BiotechnoL, 2002 13: 598; and Rauchenberger et al, J. Biol. Chem., 2003 278: 38194, each of which is incorporated by reference in its entirety); however, the instant invention is directed to, at least, the design of synthetic antibody libraries containing the sequence diversity and length diversity of naturally occurring human sequences. In some cases, synthetic libraries containing sequence and length diversity have been synthesized, however these libraries contain too much theoretical diversity to synthesize the entire designed repertoire and/or too many theoretical members to physically realize or oversample the entire library.
As used herein, a sequence designed with "directed diversity" has been specifically designed to contain both sequence diversity and length diversity. Directed diversity is not stochastic.
As used herein, "stochastic" describes a process of generating a randomly determined sequence of amino acids, which is considered as a sample of one element from a probability distribution.
The term "library of polynucleotides" refers to two or more polynucleotides having a diversity as described herein, specifically designed according to the methods of the invention. The term "library of polypeptides" refers to two or more polypeptides having a diversity as described herein, specifically designed according to the methods of the invention. The term "library of synthetic polynucleotides" refers to a polynucleotide library that includes synthetic polynucleotides. The term "library of vectors" refers herein to a library of at least two different vectors. As used herein, the term "human antibody libraries," at least includes, a polynucleotide or polypeptide library which has been designed to represent the sequence diversity and length diversity of naturally occurring human antibodies.
As described throughout the specification, the term "library" is used herein in its broadest sense, and also may include the sub-libraries that may or may not be combined to produce libraries of the invention. As used herein, the term "synthetic polynucleotide" refers to a molecule formed through a chemical process, as opposed to molecules of natural origin, or molecules derived via template-based amplification of molecules of natural origin (e.g., immunoglobulin chains cloned from populations of B cells via PCR amplification are not "synthetic" used
herein). In some instances, for example, when referring to libraries of the invention that comprise multiple components (e.g., Nl, DH, N2, and/or H3-JH), the invention encompasses libraries in which at least one of the aforementioned components is synthetic. By way of illustration, a library in which certain components are synthetic, while other components are of natural origin or derived via template -based amplification of molecules of natural origin, would be encompassed by the invention.
The term "split-pool synthesis" refers to a procedure in which the products of a plurality of first reactions are combined (pooled) and then separated (split) before participating in a plurality of second reactions. Example 9, describes the synthesis of 278 DH segments (products), each in a separate reaction. After synthesis, these 278 segments are combined (pooled) and then distributed (split) amongst 141 columns for the synthesis of the N2 segments. This enables the pairing of each of the 278 DH segments with each of the 141 N2 segments. As described elsewhere in the specification, these numbers are non- limiting. "Preimmune" antibody libraries have similar sequence diversities and length diversities to naturally occurring human antibody sequences before these sequences have undergone negative selection or somatic hypermutation. For example, the set of sequences described in Lee et al. (Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety) is believed to represent sequences from the preimmune repertoire. In certain embodiments of the invention, the sequences of the invention will be similar to these sequences {e.g., in terms of composition and length). In certain embodiments of the invention, such antibody libraries are designed to be small enough to chemically synthesize and physically realize, but large enough to encode antibodies with the potential to recognize any antigen. In one embodiment of the invention, an antibody library comprises about 107 to about 1020 different antibodies and/or polynucleotide sequences encoding the antibodies of the library. In some embodiments, the libraries of the instant invention are designed to include 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, or 1020 different antibodies and/or polynucleotide sequences encoding the antibodies. In certain embodiments, the libraries of the invention may comprise or encode about 103 to about 105, about 105 to about 107, about 107 to about 109, about 109 to about 1011, about 1011 to about 1013, about 1013 to about 1015, about 1015 to about 1017, or about 1017 to about 1020 different antibodies. In certain embodiments of the invention, the diversity of the libraries may be characterized as being greater than or less than one or more of the
diversities enumerated above, for example greater than about 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, or 1020 or less than about 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, or 1020. In certain other embodiments of the invention, the probability of an antibody of interest being present in a physical realization of a library with a size as enumerated above is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% (see Library Sampling, in the Detailed Description, for more information on the probability of a particular sequence being present in a physical realization of a library). The antibody libraries of the invention may also include antibodies directed to, for example, self (i.e., human) antigens. The antibodies of the present invention may not be present in expressed human libraries for reasons including because self-reactive antibodies are removed by the donor's immune system via negative selection. However, novel heavy/light chain pairings may in some cases create self-reactive antibody specificity (Griffiths et al. US Patent 5,885,793, incorporated by reference in its entirety). In certain embodiments of the invention, the number of unique heavy chains in a library may be about 10, 50, 102, 150, 103, 104, 105,106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, 1020, or more. In certain embodiments of the invention, the number of unique light chains in a library may be about 5, 10, 25, 50, 102, 150, 500, 103, 104, 105,106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, 1020, or more.
As used herein, the term "human antibody CDRH3 libraries," at least includes, a polynucleotide or polypeptide library which has been designed to represent the sequence diversity and length diversity of naturally occurring human antibodies. "Preimmune" CDRH3 libraries have similar sequence diversities and length diversities to naturally occurring human antibody CDRH3 sequences before these sequences undergo negative selection and somatic hypermutation. Known human CDRH3 sequences are represented in various data sets, including Jackson et al., J. Immunol Methods, 2007, 324: 26; Martin, Proteins, 1996, 25: 130; and Lee et al., Immunogenetics, 2006, 57: 917, each of which is incorporated by reference in its entirety. In certain embodiments of the invention, such CDRH3 libraries are designed to be small enough to chemically synthesize and physically realize, but large enough to encode CDRH3s with the potential to recognize any antigen. In one embodiment of the invention, an antibody library includes about 106 to about 1015 different CDRH3 sequences and/or polynucleotide sequences encoding said CDRH3
sequences. In some embodiments, the libraries of the instant invention are designed to about 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, or 1016, different CDRH3 sequences and/or polynucleotide sequences encoding said CDRH3 sequences. In some embodiments, the libraries of the invention may include or encode aboutlO3 to about 106, about 106 to about 108, about 108 to about 1010, about 1010 to about 1012, about 1012 to about 1014, or about 1014 to about 1016 different CDRH3 sequences. In certain embodiments of the invention, the diversity of the libraries may be characterized as being greater than or less than one or more of the diversities enumerated above, for example greater than about 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, or 1016 or less than about 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, or 1016. In certain embodiments of the invention, the probability of a CDRH3 of interest being present in a physical realization of a library with a size as enumerated above is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% (see Library Sampling, in the Detailed Description, for more information on the probability of a particular sequence being present in a physical realization of a library). The preimmune CDRH3 libraries of the invention may also include CDRH3s directed to, for example, self (i.e., human) antigens. Such CDRH3s may not be present in expressed human libraries, because self-reactive CDRH3s are removed by the donor's immune system via negative selection.
Libraries of the invention containing "VKCDR3" sequences and "VλCDR3" sequences refer to the kappa and lambda sub-sets of the CDRL3 sequences, respectively. These libraries may be designed with directed diversity, to collectively represent the length and sequence diversity of the human antibody CDRL3 repertoire. "Preimmune" versions of these libraries have similar sequence diversities and length diversities to naturally occurring human antibody CDRL3 sequences before these sequences undergo negative selection. Known human CDRL3 sequences are represented in various data sets, including the NCBI database (see Appendix A and Appendix B for light chain sequence data sets) and Martin, Proteins, 1996, 25: 130 incorporated by reference in its entirety. In certain embodiments of the invention, such CDRL3 libraries are designed to be small enough to chemically synthesize and physically realize, but large enough to encode CDRL3s with the potential to recognize any antigen.
In one embodiment of the invention, an antibody library comprises about 105 different CDRL3 sequences and/or polynucleotide sequences encoding said CDRL3 sequences. In some embodiments, the libraries of the instant invention are designed to comprise about 101, 102, 103, 104, 106, 107, or 108 different CDRL3 sequences and/or polynucleotide sequences encoding said CDRL3 sequences. In some embodiments, the libraries of the invention may comprise or encode about 101 to about 103, about 103 to about 105, or about 105 to about 108 different CDRL3 sequences. In certain embodiments of the invention, the diversity of the libraries may be characterized as being greater than or less than one or more of the diversities enumerated above, for example greater than about 101, 102, 103, 104, 105, 106, 107, or 108 or less than about 101, 102, 103, 104, 105, 106, 107, or 108. In certain embodiments of the invention, the probability of a CDRL3 of interest being present in a physical realization of a library with a size as enumerated above is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% (see Library Sampling, in the Detailed Description, for more information on the probability of a particular sequence being present in a physical realization of a library). The preimmune CDRL3 libraries of the invention may also include CDRL3s directed to, for example, self (i.e., human) antigens. Such CDRL3s may not be present in expressed human libraries, because self-reactive CDRL3s are removed by the donor's immune system via negative selection. As used herein, the term "known heavy chain CDR3 sequences" refers to heavy chain CDR3 sequences in the public domain that have been cloned from populations of human B cells. Examples of such sequences are those published or derived from public data sets, including, for example, Zemlin et al., JMB, 2003, 334: 733; Lee et al., Immunogenetics, 2006, 57: 917; and Jackson et al. J. Immunol Methods, 2007, 324: 26, each of which are incorporated by reference in their entirety.
As used herein, the term "known light chain CDR3 sequences" refers to light chain CDR3 sequences (e.g., kappa or lambda) in the public domain that have been cloned from populations of human B cells. Examples of such sequences are those published or derived from public data sets, including, for example, the NCBI database (see Appendices A and B filed herewith).
As used herein the term "antibody binding regions" refers to one or more portions of an immunoglobulin or antibody variable region capable of binding an antigen(s). Typically, the antibody binding region is, for example, an antibody light chain (or variable
region or one or more CDRs thereof), an antibody heavy chain (or variable region or one or more CDRs thereof), a heavy chain Fd region, a combined antibody light and heavy chain (or variable regions thereof) such as a Fab, F(ab')2, single domain, or single chain antibodies (scFv), or any region of a full length antibody that recognizes an antigen, for example, an IgG (e.g., an IgGl, IgG2, IgG3, or IgG4 subtype), IgAl, IgA2, IgD, IgE, or IgM antibody.
The term "framework region" refers to the art-recognized portions of an antibody variable region that exist between the more divergent (i.e., hypervariable) CDRs. Such framework regions are typically referred to as frameworks 1 through 4 (FRMl, FRM2, FRM3, and FRM4) and provide a scaffold for the presentation of the six CDRs (three from the heavy chain and three from the light chain) in three dimensional space, to form an antigen-binding surface.
The term "canonical structure" refers to the main chain conformation that is adopted by the antigen binding (CDR) loops. From comparative structural studies, it has been found that five of the six antigen binding loops have only a limited repertoire of available conformations. Each canonical structure can be characterized by the torsion angles of the polypeptide backbone. Correspondent loops between antibodies may, therefore, have very similar three dimensional structures, despite high amino acid sequence variability in most parts of the loops (Chothia and Lesk, J. MoI. Biol, 1987, 196: 901; Chothia et al., Nature, 1989, 342: 877; Martin and Thornton, J. MoI. Biol, 1996, 263: 800, each of which is incorporated by reference in its entirety). Furthermore, there is a relationship between the adopted loop structure and the amino acid sequences surrounding it. The conformation of a particular canonical class is determined by the length of the loop and the amino acid residues residing at key positions within the loop, as well as within the conserved framework (i.e., outside of the loop). Assignment to a particular canonical class can therefore be made based on the presence of these key amino acid residues. The term "canonical structure" may also include considerations as to the linear sequence of the antibody, for example, as catalogued by Kabat (Kabat et al., in "Sequences of Proteins of Immunological Interest," 5th Edition, U.S. Department of Heath and Human Services, 1992). The Kabat numbering scheme is a widely adopted standard for numbering the amino acid residues of an antibody variable domain in a consistent manner. Additional structural considerations can also be used to determine the canonical structure of an antibody. For example, those differences not fully reflected by Kabat numbering can be
described by the numbering system of Chothia et al. and/or revealed by other techniques, for example, crystallography and two or three-dimensional computational modeling. Accordingly, a given antibody sequence may be placed into a canonical class which allows for, among other things, identifying appropriate chassis sequences (e.g., based on a desire to include a variety of canonical structures in a library). Kabat numbering of antibody amino acid sequences and structural considerations as described by Chothia et al. , and their implications for construing canonical aspects of antibody structure, are described in the literature.
The terms "CDR", and its plural "CDRs", refer to a complementarity determining region (CDR) of which three make up the binding character of a light chain variable region (CDRLl, CDRL2 and CDRL3) and three make up the binding character of a heavy chain variable region (CDRHl, CDRH2 and CDRH3). CDRs contribute to the functional activity of an antibody molecule and are separated by amino acid sequences that comprise scaffolding or framework regions. The exact definitional CDR boundaries and lengths are subject to different classification and numbering systems. CDRs may therefore be referred to by Kabat, Chothia, contact or any other boundary definitions, including the numbering system described herein. Despite differing boundaries, each of these systems has some degree of overlap in what constitutes the so called "hypervariable regions" within the variable sequences. CDR definitions according to these systems may therefore differ in length and boundary areas with respect to the adjacent framework region. See for example Kabat, Chothia, and/or MacCallum et al., (Kabat et al., in "Sequences of Proteins of Immunological Interest," 5th Edition, U.S. Department of Health and Human Services, 1992; Chothia et al., J. MoI. Biol, 1987, 196: 901; and MacCallum et al., J. MoI. Biol, 1996, 262: 732, each of which is incorporated by reference in its entirety). The term "amino acid" or "amino acid residue" typically refers to an amino acid having its art recognized definition such as an amino acid selected from the group consisting of: alanine (Ala or A); arginine (Arg or R); asparagine (Asn or N); aspartic acid (Asp or D); cysteine (Cys or C); glutamine (GIn or Q); glutamic acid (GIu or E); glycine (GIy or G); histidine (His or H); isoleucine (He or I): leucine (Leu or L); lysine (Lys or K); methionine (Met or M); phenylalanine (Phe or F); proline (Pro or P); serine (Ser or S); threonine (Thr or T); tryptophan (Trp or W); tyrosine (Tyr or Y); and valine (VaI or V), although modified, synthetic, or rare amino acids may be used as desired. Generally, amino acids can be grouped as having a nonpolar side chain (e.g., Ala, Cys, He, Leu, Met, Phe,
Pro, VaI); a negatively charged side chain (e.g., Asp, GIu); a positively charged sidechain (e.g., Arg, His, Lys); or an uncharged polar side chain (e.g., Asn, Cys, GIn, GIy, His, Met, Phe, Ser, Thr, Trp, and Tyr).
The term "polynucleotide(s)" refers to nucleic acids such as DNA molecules and RNA molecules and analogs thereof (e.g., DNA or RNA generated using nucleotide analogs or using nucleic acid chemistry). As desired, the polynucleotides may be made synthetically, e.g., using art-recognized nucleic acid chemistry or enzymatically using, e.g., a polymerase, and, if desired, be modified. Typical modifications include methylation, biotinylation, and other art-known modifications. In addition, the nucleic acid molecule can be single-stranded or double-stranded and, where desired, linked to a detectable moiety.
The terms "theoretical diversity", "theoretical total diversity", or "theoretical repertoire" refer to the maximum number of variants in a library design. For example, given an amino acid sequence of three residues, where residues one and three may each be any one of five amino acid types and residue two may be any one of 20 amino acid types, the theoretical diversity is 5x20x5=500 possible sequences. Similarly if sequence X is constructed by combination of 4 amino acid segments, where segment 1 has 100 possible sequences, segment 2 has 75 possible sequences, segment 3 has 250 possible sequences, and segment 4 has 30 possible sequences, the theoretical total diversity of fragment X would be 100x75x200x30, or 5.6χlO5 possible sequences. The term "physical realization" refers to a portion of the theoretical diversity that can actually be physically sampled, for example, by any display methodology. Exemplary display methodology include: phage display, ribosomal display, and yeast display. For synthetic sequences, the size of the physical realization of a library depends on (1) the fraction of the theoretical diversity that can actually be synthesized, and (2) the limitations of the particular screening method. Exemplary limitations of screening methods include the number of variants that can be screened in a particular assay (e.g., ribosome display, phage display, yeast display) and the transformation efficiency of a host cell (e.g., yeast, mammalian cells, bacteria) which is used in a screening assay. For the purposes of illustration, given a library with a theoretical diversity of 1012 members, an exemplary physical realization of the library (e.g., in yeast, bacterial cells, ribosome display, etc.; details provided below) that can maximally include 1011 members will, therefore, sample about 10% of the theoretical diversity of the library. However, if less than 1011 members of the library with a theoretical diversity of 1012 are synthesized, and the physical realization
of the library can maximally include 1011 members, less than 10% of the theoretical diversity of the library is sampled in the physical realization of the library. Similarly, a physical realization of the library that can maximally include more than 1012 members would "oversample" the theoretical diversity, meaning that each member may be present more than once (assuming that the entire 1012 theoretical diversity is synthesized).
The term "all possible reading frames" encompasses at least the three forward reading frames and, in some embodiments, the three reverse reading frames.
The term "antibody of interest" refers to any antibody that has a property of interest that is isolated from a library of the invention. The property of interest may include, but is not limited to, binding to a particular antigen or epitope, blocking a binding interaction between two molecules, or eliciting a certain biological effect.
The term "functionally expressed" refers to those immunoglobulin genes that are expressed by human B cells and that do not contain premature stop codons.
The term "full-length heavy chain" refers to an immunoglobulin heavy chain that contains each of the canonical structural domains of an immunoglobulin heavy chain, including the four framework regions, the three CDRs, and the constant region. The term "full-length light chain" refers to an immunoglobulin light chain that contains each of the canonical structural domains of an immunoglobulin light chain, including the four framework regions, the three CDRs, and the constant region. The term "unique," as used herein, refers to a sequence that is different (e.g. has a different chemical structure) from every other sequence within the designed theoretical diversity. It should be understood that there are likely to be more than one copy of many unique sequences from the theoretical diversity in a particular physical realization. For example, a library comprising three unique sequences may comprise nine total members if each sequence occurs three times in the library. However, in certain embodiments, each unique sequence may occur only once.
The term "heterologous moiety" is used herein to indicate the addition of a composition to an antibody wherein the composition is not normally part of the antibody. Exemplary heterologous moieties include drugs, toxins, imaging agents, and any other compositions which might provide an activity that is not inherent in the antibody itself.
As used herein, the term "percent occurrence of each amino acid residue at each position" refers to the percentage of instances in a sample in which an amino acid is found
at a defined position within a particular sequence. For example, given the following three sequences:
K V R
K Y P K R P,
K occurs in position one in 100% of the instances and P occurs in position three in about 67% of the instances. In certain embodiments of the invention, the sequences selected for comparison are human immunoglobulin sequences.
As used herein, the term "most frequently occurring amino acids" at a specified position of a sequence in a population of polypeptides refers to the amino acid residues that have the highest percent occurrence at the indicated position in the indicated polypeptide population. For example, the most frequently occurring amino acids in each of the three most N-terminal positions in Nl sequences of CDRH3 sequences that are functionally expressed by human B cells are listed in Table 21, and the most frequently occurring amino acids in each of the three most N-terminal positions in N2 sequences of CDRH3 sequences that are functionally expressed by human B cells are listed in Table 22.
For the purposes of analyzing the occurrence of certain duplets (Example 13) and the information content (Example 14) of the libraries of the invention, and other libraries, a "central loop" of CDRH3 is defined. If the C-terminal 5 amino acids from Kabat CDRH3 (95-102) are removed, then the remaining sequence is termed the "central loop". Thus, considering the duplet occurrence calculations of Example 13, using a CDRH3 of size 6 or less would not contribute to the analysis of the occurrence of duplets. A CDRH3 of size 7 would contribute only to the i - i+1 data set, a CDRH3 of size 8 would also contribute to the i - i+2 data set, and a CDRH3 of size 9 and larger would also contribute to the i - i+3 data set. For example, a CDR H3 of size 9 may have amino acids at positions 95-96-97-98- 99-100-100A-101-102, but only the first four residues (bolded) would be part of the central loop and contribute to the pair- wise occurrence (duplet) statistics. As a further example, a CDRH3 of size 14 may have the sequence: 95-96-97-98-99-100-10OA-IOOB-IOOC-IOOD- lOOE-lOOF-101-102. Here, only the first nine residues (bolded) contribute to the central loop.
Library screening requires a genotype-phenotype linkage. The term "genotype- phenotype linkage" is used in a manner consistent with its art-recognized meaning and refers to the fact that the nucleic acid (genotype) encoding a protein with a particular
phenotype (e.g., binding an antigen) can be isolated from a library. For the purposes of illustration, an antibody fragment expressed on the surface of a phage can be isolated based on its binding to an antigen (e.g., Ladner et al.). The binding of the antibody to the antigen simultaneously enables the isolation of the phage containing the nucleic acid encoding the antibody fragment. Thus, the phenotype (antigen-binding characteristics of the antibody fragment) has been "linked" to the genotype (nucleic acid encoding the antibody fragment). Other methods of maintaining a genotype-phenotype linkage include those of Wittrup et al (US Patent Nos. 6,300,065, 6,331,391, 6,423,538, 6,696,251, 6,699,658, and US Pub. No. 20040146976, each of which is incorporated by reference in its entirety), Miltenyi (US Patent No. 7,166,423, incorporated by reference in its entirety), Fandl (US Patent No. 6,919,183, US Pub No. 20060234311, each incorporated by reference in its entirety), Clausell-Tormos et al. (Chem. Biol, 2008, 15: 427, incorporated by reference in its entirety), Love et al. (Nat. BiotechnoL, 2006, 24: 703, incorporated by reference in its entirety), and Kelly et al. (Chem. Commun., 2007, 14: 1773, incorporated by reference in its entirety). Any method which localizes the antibody protein with the gene encoding the antibody, in a way in which they can both be recovered while the linkage between them is maintained, is suitable.
2. Design of the Libraries The antibody libraries of the invention are designed to reflect certain aspects of the preimmune repertoire as naturally created by the human immune system. Certain libraries of the invention are based on rational design informed by the collection of human V, D, and J genes, and other large databases of human heavy and light chain sequences (e.g., publicly known germline sequences; sequences from Jackson et al., J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety; sequences from Lee et al., Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety; and sequences compiled for rearranged VK and Vλ - see Appendices A and B filed herewith). Additional information may be found, for example, in Scaviner et al., Exp. Clin. Immunogenet., 1999, 16: 234; Tomlinson et al, J. MoI. Biol, 1992, 227: 799; and Matsuda et al, J. Exp. Med., 1998, 188: 2151 each incorporated by reference in its entirety. In certain embodiments of the invention, cassettes representing the possible V, D, and J diversity found in the human repertoire, as well as junctional diversity (i.e., Nl and N2), are synthesized de novo as single or double-stranded DNA oligonucleotides. In certain embodiments of the invention,
oligonucleotide cassettes encoding CDR sequences are introduced into yeast along with one or more acceptor vectors containing heavy or light chain chassis sequences. No primer- based PCR amplification or template-directed cloning steps from mammalian cDNA or mRNA are employed. Through standard homologous recombination, the recipient yeast recombines the cassettes (e.g., CDR3s) with the acceptor vector(s) containing the chassis sequence(s) and constant regions, to create a properly ordered synthetic, full-length human heavy chain and/or light chain immunoglobulin library that can be genetically propagated, expressed, displayed, and screened. One of ordinary skill in the art will readily recognize that the chassis contained in the acceptor vector can be designed so as to produce constructs other than full-length human heavy chains and/or light chains. For example, in certain embodiments of the invention, the chassis may be designed to encode portions of a polypeptide encoding an antibody fragment or subunit of an antibody fragment, so that a sequence encoding an antibody fragment, or subunit thereof, is produced when the oligonucleotide cassette containing the CDR is recombined with the acceptor vector. In certain embodiments, the invention provides a synthetic, preimmune human antibody repertoire comprising about 107 to about 1020 antibody members, wherein the repertoire comprises:
(a) selected human antibody heavy chain chassis (i.e., amino acids 1 to 94 of the heavy chain variable region, using Rabat's definition); (b) a CDRH3 repertoire, designed based on the human IGHD and IGHJ germline sequences, the CDRH3 repertoire comprising the following: (i) optionally, one or more tail regions;
(ii) one or more Nl regions, comprising about 0 to about 10 amino acids selected from the group consisting of fewer than 20 of the amino acid types preferentially encoded by the action of terminal deoxynucleotidyl transferase (TdT) and functionally expressed by human B cells;
(iii) one or DH segments, based on one or more selected IGHD segments, and one or more N- or C-terminal truncations thereof;
(iv) one or more N2 regions, comprising about 0 to about 10 amino acids selected from the group consisting of fewer than 20 of the amino acids preferentially encoded by the activity of TdT and functionally expressed by human B cells; and
(v) one or more H3-JH segments, based on one or more IGHJ segments, and one or more N-terminal truncations thereof (e.g., down to XXWG);
(c) one or more selected human antibody kappa and/or lambda light chain chassis; and
(d) a CDRL3 repertoire designed based on the human IGLV and IGLJ germline sequences, wherein "L" may be a kappa or lambda light chain. The heavy chain chassis may be any sequence with homology to Kabat residues 1 to
94 of an immunoglobulin heavy chain variable domain. Non- limiting examples of heavy chain chassis are included in the Examples, and one of ordinary skill in the art will readily recognize that the principles presented therein, and throughout the specification, may be used to derive additional heavy chain chassis. As described above, the heavy chain chassis region is followed, optionally, by a
"tail" region. The tail region comprises zero, one, or more amino acids that may or may not be selected on the basis of comparing naturally occurring heavy chain sequences. For example, in certain embodiments of the invention, heavy chain sequences available in the art may be compared, and the residues occurring most frequently in the tail position in the naturally occurring sequences included in the library (e.g., to produce sequences that most closely resemble human sequences). In other embodiments, amino acids that are used less frequently may be used. In still other embodiments, amino acids selected from any group of amino acids may be used. In certain embodiments of the invention, the length of the tail is zero (no residue) or one (e.g., G/D/E) amino acid. For the purposes of clarity, and without being bound by theory, in the naturally occurring human repertoire, the first 2/3 of the codon encoding the tail residue is provided by the FRM3 region of the VH gene. The amino acid at this position in naturally occurring heavy chain sequences may thus be considered to be partially encoded by the IGHV gene (2/3) and partially encoded by the CDRH3 (1/3). However, for the purposes of clearly illustrating certain aspects of the invention, the entire codon encoding the tail residue (and, therefore, the amino acid derived from it) is described herein as being part of the CDRH3 sequence.
As described above, there are two peptide segments derived from nucleotides which are added by TdT in the naturally occurring human antibody repertoire. These segments are designated Nl and N2 (referred to herein as Nl and N2 segments, domains, regions or sequences). In certain embodiments of the invention, Nl and N2 are about 0, 1, 2, or 3 amino acids in length. Without being bound by theory, it is thought that these lengths most closely mimic the Nl and N2 lengths found in the human repertoire (see Figure 2). In other embodiments of the invention, Nl and N2 may be about 4, 5, 6, 7, 8, 9, or 10 amino acids
in length. Similarly, the composition of the amino acid residues utilized to produce the Nl and N2 segments may also vary. In certain embodiments of the invention, the amino acids used to produce Nl and N2 segments may be selected from amongst the eight most frequently occurring amino acids in the Nl and N2 domains of the human repertoire (e.g., G, R, S, P, L, A, V, and T). In other embodiments of the invention, the amino acids used to produce the Nl and N2 segments may be selected from the group consisting of fewer than about 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, or 3 of the amino acids preferentially encoded by the activity of TdT and functionally expressed by human B cells. Alternatively, Nl and N2 may comprise amino acids selected from any group of amino acids. It is not required that Nl and N2 be of a similar length or composition, and independent variation of the length and composition of Nl and N2 is one method by which additional diversity may be introduced into the library.
The DH segments of the libraries are based on the peptides encoded by the naturally occurring IGHD gene repertoire, with progressive deletion of residues at the N- and C- termini. IGHD genes may be read in multiple reading frames, and peptides representing these reading frames, and their N- and C-terminal deletions are also included in the libraries of the invention. In certain embodiments of the invention, DH segments as short as three amino acid residues may be included in the libraries. In other embodiments of the invention, DH segments as short as about 1, 2, 4, 5, 6, 7, or 8 amino acids may be included in the libraries.
The H3-JH segments of the libraries are based on the peptides encoded by the naturally occurring IGHJ gene repertoire, with progressive deletion of residues at the N- terminus. The N-terminal portion of the IGHJ segment that makes up part of the CDRH3 is referred to herein as H3-JH. In certain embodiments of the invention, the H3-JH segment may be represented by progressive N-terminal deletions of one or more H3-JH residues, down to two H3-JH residues. In other embodiments of the invention, the H3-JH segments of the library may contain N-terminal deletions (or no deletions) down to about 6, 5, 4, 3, 2, 1, or 0 H3-JH residues.
The light chain chassis of the libraries may be any sequence with homology to Kabat residues 1 to 88 of naturally occurring light chain (K or λ) sequences. In certain embodiments of the invention, the light chain chassis of the invention are synthesized in combinatorial fashion, utilizing VL and JL segments, to produce one or more libraries of light chain sequences with diversity in the chassis and CDR3 sequences. In other
embodiments of the invention, the light chain CDR3 sequences are synthesized using degenerate oligonucleotides or trinucleotides and recombined with the light chain chassis and light chain constant region, to form full-length light chains.
The instant invention also provides methods for producing and using such libraries, as well as libraries comprising one or more immunoglobulin domains or antibody fragments. Design and synthesis of each component of the claimed antibody libraries is provided in more detail below.
2.1. Design of the Antibody Library Chassis Sequences One step in building certain libraries of the invention is the selection of chassis sequences, which are based on naturally occurring variable domain sequences {e.g., IGHV and IGLV). This selection can be done arbitrarily, or by the selection of chassis that meet certain criteria. For example, the Kabat database, an electronic database containing non- redundant rearranged antibody sequences, can be queried for those heavy and light chain germline sequences that are most frequently represented. The BLAST search algorithm, or more specialized tools such as SoDA (Volpe et al., Bioinformatics, 2006, 22: 438-44, incorporated by reference in its entirety), can be used to compare rearranged antibody sequences with germline sequences, using the V BASE2 database (Retter et al, Nucleic Acids Res., 2005, 33: D671-D674), or similar collections of human V, D, and J genes, to identify the germline families that are most frequently used to generate functional antibodies.
Several criteria can be utilized for the selection of chassis for inclusion in the libraries of the invention. For example, sequences that are known (or have been determined) to express poorly in yeast, or other organisms used in the invention {e.g., bacteria, mammalian cells, fungi, or plants) can be excluded from the libraries. Chassis may also be chosen based on their representation in the peripheral blood of humans. In certain embodiments of the invention, it may be desirable to select chassis that correspond to germline sequences that are highly represented in the peripheral blood of humans. In other embodiments, it may be desirable to select chassis that correspond to germline sequences that are less frequently represented, for example, to increase the canonical diversity of the library. Therefore, chassis may be selected to produce libraries that represent the largest and most structurally diverse group of functional human antibodies. In other embodiments of the invention, less diverse chassis may be utilized, for example, if it
is desirable to produce a smaller, more focused library with less chassis variability and greater CDR variability. In some embodiments of the invention, chassis may be selected based on both their expression in a cell of the invention (e.g., a yeast cell) and the diversity of canonical structures represented by the selected sequences. One may therefore produce a library with a diversity of canonical structures that express well in a cell of the invention.
2.1.1. Design of the Heavy Chain Chassis Sequences
In certain embodiments of the invention, the antibody library comprises variable heavy domains and variable light domains, or portions thereof. Each of these domains is built from certain components, which will be more fully described in the examples provided herein. In certain embodiments, the libraries described herein may be used to isolate fully human antibodies that can be used as diagnostics and/or therapeutics. Without being bound by theory, antibodies with sequences most similar or identical to those most frequently found in peripheral blood (for example, in humans) may be less likely to be immunogenic when administered as therapeutic agents.
Without being bound by theory, and for the purposes of illustrating certain embodiments of the invention, the VH domains of the library may be considered to comprise three primary components: (1) a VH "chassis", which includes amino acids 1 to 94 (using Kabat numbering), (2) the CDRH3, which is defined herein to include the Kabat CDRH3 proper (positions 95-102), and (3) the FRM4 region, including amino acids 103 to 113 (Kabat numbering). The overall VH structure may therefore be depicted schematically (not to scale) as:
(1) ... (94) (95) ... (102) (103) ... (113) I 1 1
VH Chassis CDRH3 FRM4
The selection and design of VH chassis sequences based on the human IGHV germline repertoire will become more apparent upon review of the examples provided herein. In certain embodiments of the invention, the VH chassis sequences selected for use in the library may correspond to all functionally expressed human IGHV germline sequences. Alternatively, IGHV germline sequences may be selected for representation in a library according to one or more criteria. For example, in certain embodiments of the
invention, the selected IGHV germline sequences may be among those that are most highly represented among antibody molecules isolated from the peripheral blood of healthy adults, children, or fetuses.
In certain embodiments, it may be desirable to base the design of the VH chassis on the utilization of IGHV germline sequences in adults, children, or fetuses with a disease, for example, an autoimmune disease. Without being bound by theory, it is possible that analysis of germline sequence usage in the antibody molecules isolated from the peripheral blood of individuals with autoimmune disease may provide information useful for the design of antibodies recognizing human antigens. In some embodiments, the selection of IGHV germline sequences for representation in a library of the invention may be based on their frequency of occurrence in the peripheral blood. For the purposes of illustration, four IGHVl germline sequences (IGHV 1-2, IGHV1-18, IGHV1-46, and IGHV1-69) comprise about 80% of the IGHVl family repertoire in peripheral blood. Thus, the specific IGHVl germline sequences selected for representation in the library may include those that are most frequently occurring and that cumulatively comprise at least about 80% of the IGHVl family repertoire found in peripheral blood. An analogous approach can be used to select specific IGHV germline sequences from any other IGHV family (i.e., IGHVl, IGHV2, IGHV3, IGHV4, IGHV5, IGHV6, and IGHV7). The specific germline sequences chosen for representation of a particular IGHV family in a library of the invention may therefore comprise at least about 100%, 99%, 98%, 97%, 96% 95%, 94%, 93%, 92%, 91% 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 75%, 70%, 65%, 60%, 55%, 50%, 45%, 40%, 35%, 30%, 25%, 20%, 15%, 10%, 5%, or 0% of the particular IGHV family member repertoire found in peripheral blood. In some embodiments, the selected IGHV germline sequences may be chosen to maximize the structural diversity of the VH chassis library. Structural diversity may be evaluated by, for example, comparing the lengths, compositions, and canonical structures of CDRHl and CDRH2 in the IGHV germline sequences. In human IGHV sequences, the CDRHl (Kabat definition) may have a length of 5, 6 or 7 amino acids, while CDRH2 (Kabat definition) may have length of 16, 17, 18 or 19 amino acids. The amino acid compositions of the IGHV germline sequences and, in particular, the CDR domains, may be evaluated by sequence alignments, as presented in the Examples. Canonical structure may
be assigned, for example, according to the methods described by Chothia et ah, J. MoI. Biol, 1992, 227: 799, incorporated by reference in its entirety.
In certain embodiments of the invention, it may be advantageous to design VH chassis based on IGHV germline sequences that may maximize the probability of isolating an antibody with particular characteristics. For example, without being bound by theory, in some embodiments it may be advantageous to restrict the IGHV germline sequences to include only those germline sequences that are utilized in antibodies undergoing clinical development, or antibodies that have been approved as therapeutics. On the other hand, in some embodiments, it may be advantageous to produce libraries containing VH chassis that are not represented amongst clinically utilized antibodies. Such libraries may be capable of yielding antibodies with novel properties that are advantageous over those obtained with the use of "typical" IGHV germline sequences, or enabling studies of the structures and properties of "atypical" IGHV germline sequences or canonical structures.
One of ordinary skill in the art will readily recognize that a variety of other criteria can be used to select IGHV germline sequences for representation in a library of the invention. Any of the criteria described herein may also be combined with any other criteria. Further exemplary criteria include the ability to be expressed at sufficient levels in certain cell culture systems, solubility in particular antibody formats {e.g., whole immunoglobulins and antibody fragments), and the thermodynamic stability of the individual domains, whole immunoglobulins, or antibody fragments. The methods of the invention may be applied to select any IGHV germline sequence that has utility in an antibody library of the instant invention.
In certain embodiments of the invention, the VH chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 94 of one or more of the following IGHV germline sequences: IGHV1-2, IGHV1-3, IGHVl -8, IGHV1-18, IGHVl- 24, IGHVl -45, IGHV1-46, IGHV 1-58, IGHV1-69, IGHV2-5, IGHV2-26, IGHV2-70, IGHV3-7, IGHV3-9, IGHV3-11, IGHV3-13, IGHV3-15, IGHV3-20, IGHV3-21, IGHV3- 23, IGHV3-30, IGHV3-33, IGHV3-43, IGHV3-48, IGHV3-49, IGHV3-53, IGHV3-64, IGHV3-66, IGHV3-72, IGHV3-73, IGHV3-74, IGHV4-4, IGHV4-28, IGHV4-31, IGHV4- 34, IGHV4-39, IGHV4-59, IGHV4-61, IGHV4-B, IGHV5-51, IGHV6-1, and IGHV7-4-1. In some embodiments of the invention, a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%,
95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
In other embodiments, the VH chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 94 of the following IGHV germline sequences: IGHV1-2, IGHV1-18, IGHV1-46, IGHV1-69, IGHV3-7, IGHV3-15, IGHV3-23, IGHV3- 30, IGHV3-33, IGHV3-48, IGHV4-31, IGHV4-34, IGHV4-39, IGHV4-59, IGHV4-61, IGHV4-B, and IGHV5-51. In some embodiments of the invention, a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences. The amino acid sequences of these chassis are presented in Table 5.
2.1.1.1. Heavy Chain Chassis Variants
While the selection of the VH chassis with sequences based on the IGHV germline sequences is expected to support a large diversity of CDRH3 sequences, further diversity in the VH chassis may be generated by altering the amino acid residues comprising the CDRHl and/or CDRH2 regions of each chassis selected for inclusion in the library (see Example 2).
In certain embodiments of the invention, the alterations or mutations in the amino acid residues comprising the CDRHl and CDRH2 regions, or other regions, of the IGHV germline sequences are made after analyzing the sequence identity within data sets of rearranged human heavy chain sequences that have been classified according to the identity of the original IGHV germline sequence from which the rearranged sequences are derived. For example, from a set of rearranged antibody sequences, the IGHV germline sequence of each antibody is determined, and the rearranged sequences are classified according to the IGHV germline sequence. This determination is made on the basis of sequence identity. Next, the occurrence of any of the 20 amino acid residues at each position in these sequences is determined. In certain embodiments of the invention, one may be particularly interested in the occurrence of different amino acid residues at the positions within CDRHl and CDRH2, for example if increasing the diversity of the antigen-binding portion of the
VH chassis is desired. In other embodiments of the invention, it may be desirable to evaluate the occurrence of different amino acid residues in the framework regions. Without being bound by theory, alterations in the framework regions may impact antigen binding by altering the spatial orientation of the CDRs. After the occurrence of amino acids at each position of interest has been identified, alterations may be made in the VH chassis sequence, according to certain criteria. In some embodiments, the objective may be to produce additional VH chassis with sequence variability that mimics the variability observed in the heavy chain domains of rearranged human antibody sequences (derived from respective IGHV germline sequences) as closely as possible, thereby potentially obtaining sequences that are most human in nature (i.e., sequences that most closely mimic the composition and length of human sequences). In this case, one may synthesize additional VH chassis sequences that include mutations naturally found at a particular position and include one or more of these VH chassis sequences in a library of the invention, for example, at a frequency that mimics the frequency found in nature. In another embodiment of the invention, one may wish to include VH chassis that represent only mutations that most frequently occur at a given position in rearranged human antibody sequences. For example, rather than mimicking the human variability precisely, as described above, and with reference to exemplary Tables 6 and 7, one may choose to include only top 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1, amino acid residues that most frequently occur at each position. For the purposes of illustration, and with reference to Table 6, if one wished to include the top four most frequently occurring amino acid residues at position 31 of the VH 1-69 sequence, then position 31 in the VH1-69 sequence would be varied to include S, N, T, and R. Without being bound by theory, it is thought that the introduction of diversity by mimicking the naturally occurring composition of the rearranged heavy chain sequences is likely to produce antibodies that are most human in composition. However, the libraries of the invention are not limited to heavy chain sequences that are diversified by this method, and any criteria can be used to introduce diversity into the heavy chain chassis, including random or rational mutagenesis. For example, in certain embodiments of the invention, it may be preferable to substitute neutral and/or smaller amino acid residues for those residues that occur in the IGHV germline sequence. Without being bound by theory, neutral and/or smaller amino acid residues may provide a more flexible and less sterically hindered context for the display of a diversity of CDR sequences.
Example 2 illustrates the application of this method to heavy chains derived from a particular IGHV germline. One of ordinary skill in the art will readily recognize that this method can be applied to any germline sequence, and can be used to generate at least about 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 1000, 104, 105, 106, or more variants of each heavy chain chassis.
2.1.2. Design of the Light Chain Chassis Sequences
The light chain chassis of the invention may be based on kappa and/or lambda light chain sequences. The principles underlying the selection of light chain variable (IGLV) germline sequences for representation in the library are analogous to those employed for the selection of the heavy chain sequences (described above and in Examples 1 and 2). Similarly, the methods used to introduce variability into the selected heavy chain chassis may also be used to introduce variability into the light chain chassis. Without being bound by theory, and for the purposes of illustrating certain embodiments of the invention, the VL domains of the library may be considered to comprise three primary components: (1) a VL "chassis", which includes amino acids 1 to 88 (using Kabat numbering), (2) the VLCDR3, which is defined herein to include the Kabat CDRL3 proper (positions 89-97), and (3) the FRM4 region, including amino acids 98 to 107 (Kabat numbering). The overall VL structure may therefore be depicted schematically (not to scale) as:
(1) ... (88) (89) ... (97) (98) ... (107)
VL Chassis CDRL3 FRM4
In certain embodiments of the invention, the VL chassis of the libraries include one or more chassis based on IGKV germline sequences. In certain embodiments of the invention, the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of one or more of the following IGKV germline sequences: IGKV 1-05, IGKV1-06, IGKV1-08, IGKV1-09, IGKV1-12, IGKV1-13, IGKV1-16, IGKV1-17, IGKV1-27, IGKV1-33, IGKV1-37, IGKV1-39, IGKV1D-16, IGKV1D-17, IGKV1D-43, IGKV1D-8, IGKV2-24, IGKV2-28, IGKV2-29, IGKV2-30, IGKV2-40, IGKV2D-26,
IGKV2D-29, IGKV2D-30, IGKV3-11, IGKV3-15, IGKV3-20, IGKV3D-07, IGKV3D-11, IGKV3D-20, IGKV4-1, IGKV5-2, IGKV6-21, and IGKV6D-41. In some embodiments of the invention, a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
In other embodiments, the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of the following IGKV germline sequences: IGKVl -05, IGKV1-12, IGKV1-27, IGKVl -33, IGKV1-39, IGKV2-28, IGKV3-11, IGKV3-15, IGKV3-20, and IGKV4-1. In some embodiments of the invention, a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences. The amino acid sequences of these chassis are presented in Table 11.
In certain embodiments of the invention, the VL chassis of the libraries include one or more chassis based on IGλV germline sequences. In certain embodiments of the invention, the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of one or more of the following IGλV germline sequences: IGλV3-l, IGλV3-21, IGλV2-14, IGλVl-40, IGλV3-19, IGλVl-51, IGλVl-44, IGλV6-57, IGλV2-8, IGλV3-25, IGλV2-23, IGλV3-10, IGλV4-69, IGλVl-47, IGλV2-l l, IGλV7-43, IGλV7- 46, IGλV5-45, IGλV4-60, IGλV10-54, IGλV8-61, IGλV3-9, IGλVl-36, IGλV2-18, IGλV3-16, IGλV3-27, IGλV4-3, IGλV5-39, IGλV9-49, and IGλV3-12. In some embodiments of the invention, a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 90%, 85%, 80%, 75%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
In other embodiments, the VL chassis of the libraries may comprise from about Kabat residue 1 to about Kabat residue 88 of the following IGλV germline sequences: IGλV3-l, IGλV3-21, IGλV2-14, IGλVl-40, IGλV3-19, IGλVl-51, IGλVl-44, IGλV6-57,
IGλV4-69, IGλV7-43, and IGλV5-45. In some embodiments of the invention, a library may contain one or more of these sequences, one or more allelic variants of these sequences, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 90%, 85%, 80%, 75%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences. The amino acid sequences of these chassis are presented in Table 14.
2.2. Design of the Antibody Library CDRH3 Components
It is known in the art that diversity in the CDR3 region of the heavy chain is sufficient for most antibody specificities (Xu and Davis, Immunity, 2000, 13: 27-45, incorporated by reference in its entirety) and that existing successful libraries have been created using CDRH3 as the major source of diversification (Hoogenboom et al, J. MoI. Biol, 1992, 227: 381; Lee et al, J. MoI. Biol, 2004, 340: 1073 each of which is incorporated by reference in its entirety). It is also known that both the DH region and the N1/N2 regions contribute to the CDRH3 functional diversity (Schroeder et al, J. Immunol., 2005, 174: 7773 and Mathis et al, Eur J Immunol, 1995, 25: 3115, each of which is incorporated by reference in its entirety). For the purposes of the present invention, the CDHR3 region of naturally occurring human antibodies can be divided into five segments: (1) the tail segment, (2) the Nl segment, (3) the DH segment, (4) the N2 segment, and (5) the JH segment. As exemplified below, the tail, Nl and N2 segments may or may not be present.
In certain embodiments of the invention, the method for selecting amino acid sequences for the synthetic CDRH3 libraries includes a frequency analysis and the generation of the corresponding variability profiles of existing rearranged antibody sequences. In this process, which is described in more detail in the Examples section, the frequency of occurrence of a particular amino acid residue at a particular position within rearranged CDRH3s (or any other heavy or light chain region) is determined. Amino acids that are used more frequently in nature may then be chosen for inclusion in a library of the invention.
2.2.1. Design and Selection of the DH Segment Repertoire
In certain embodiments of the invention, the libraries contain CDRH3 regions comprising one or more segments designed based on the IGHD gene germline repertoire.
In some embodiments of the invention, DH segments selected for inclusion in the library are selected and designed based on the most frequent usage of human IGHD genes, and progressive N-terminal and C-terminal deletions thereof, to mimic the in vivo processing of the IGHD gene segments. In some embodiments of the invention, the DH segments of the library are about 3 to about 10 amino acids in length. In some embodiments of the invention, the DH segments of the library are about 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 amino acids in length, or a combination thereof. In certain embodiments, the libraries of the invention may contain DH segments with a wide distribution of lengths {e.g., about 0 to about 10 amino acids). In other embodiments, the length distribution of the DH may be restricted (e.g., about 1 to about 5 amino acids, about 3 amino acids, about 3 and about 5 amino acids, and so on). In certain embodiments of the library, the shortest DH segments may be about 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 amino acids.
In certain embodiments of the invention, libraries may contain DH segments representative of any reading frame of any IGHD germline sequence. In certain embodiments of the invention, the DH segments selected for inclusion in a library include one or more of the following IGHD sequences, or their derivatives {i.e., any reading frame and any degree of N-terminal and C-terminal truncation): IGHD3-10, IGHD3-22, IGHD6- 19, IGHD6-13, IGHD3-3, IGHD2-2, IGHD4-17, IGHD1-26, IGHD5-5 / 5-18, IGHD2-15, IGHD6-6, IGHD3-9, IGHD5-12, IGHD5-24, IGHD2-21, IGHD3-16, IGHD4-23, IGHDl- 1, IGHD 1-7, IGHD4-4/4-11, IGHD 1-20, IGHD7-27, IGHD2-8, and IGHD6-25. In some embodiments of the invention, a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
For the purposes of illustration, progressive N-terminal and C-terminal deletions of IGHD3-10, reading frame 1, are enumerated in the Table 1. N-terminal and C-terminal deletions of other IGHD sequences and reading frames are also encompassed by the invention, and one of ordinary skill in the art can readily determine these sequences using, for example, the non-limiting exemplary data presented in Table 16. and/or the methods outlined above. Table 18 (Example 5) enumerates certain DH segments used in certain embodiments of the invention.
Table 1: Example of Progressive N- and C-terminal Deletions of Reading Frame 1 for Gene IGHD3-10, Yielding DH Segments
(α): derived from SEQ ID NO: 1.
In certain embodiments of the invention, the DH segments selected for inclusion in a library include one or more of the following IGHD
 15 sequences, or their derivatives {i.e., any reading frame and any degree N-terminal and C-terminal truncation): IGHD3-10, IGHD3-22, IGHD6-19, IGHD6-13, IGHD3-03, IGHD2-02, IGHD4-17, IGHD1-26, IGHD5-5/5-18, and IGHD2-15. In some embodiments of the invention, a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
15 sequences, or their derivatives {i.e., any reading frame and any degree N-terminal and C-terminal truncation): IGHD3-10, IGHD3-22, IGHD6-19, IGHD6-13, IGHD3-03, IGHD2-02, IGHD4-17, IGHD1-26, IGHD5-5/5-18, and IGHD2-15. In some embodiments of the invention, a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
In certain embodiments of the invention, the DH segments selected for inclusion in a library include one or more of the following IGHD sequences, wherein the notation "_x" denotes the reading frame of the gene, or their derivatives {i.e., any degree of N-terminal or C-terminal truncation): IGHD 1-26 1, IGHDl -26 3, IGHD2-2 2, IGHD2-2 3, IGHD2- 15 2, IGHD3-3 3, IGHD3-10 1, IGHD3-10 2, IGHD3-10 3, IGHD3-22 2, IGHD4-17 2, IGHD5-5 3, IGHD6-13 1, IGHD6-13 2, IGHD6-19 1, and IGHD6-19 2. In some embodiments of the invention, a library may contain one or more of these sequences, allelic variants thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
In certain embodiments of the invention, the libraries are designed to reflect a predetermined length distribution of N- and C-terminal deleted IGHD segments. For example, in certain embodiments of the library, the DH segments of the library may be designed to mimic the natural length distribution of DH segments found in the human repertoire. For example, the relative occurrence of different IGHD segments in rearranged human antibody heavy chain domains from Lee et al. (Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety). Table 2 shows the relative occurrence of the top 68% of IGHD segments from Lee et al.
Table 2. Relative Occurrence of Top 68% of IGHD Gene Usage from Lee et al.

In certain embodiments, these relative occurrences may be used to design a library with DH prevalence that is similar to the IGHD usage found in peripheral blood. In other embodiments of the invention, it may be preferable to bias the library toward longer or shorter DH segments, or DH segments of a particular composition. In other embodiments, it may be desirable to use all DH segments selected for the library in equal proportion.
In certain embodiments of the invention, the most commonly used reading-frames of the ten most frequently occurring IGHD sequences are utilized, and progressive N- terminal and C-terminal deletions of these sequences are made, thus providing a total of 278 non-redundant DH segments that are used to create a CDRH3 repertoire of the instant invention (Table 18). In some embodiments of the invention, the methods described above can be applied to produce libraries comprising the top 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 expressed IGHD sequences, and progressive
N-terminal and C-terminal deletions thereof. As with all other components of the library, while the DH segments may be selected from among those that are commonly expressed, it is also within the scope of the invention to select these gene segments based on the fact that they are less commonly expressed. This may be advantageous, for example, in obtaining antibodies toward self-antigens or in further expanding the diversity of the library.
Alternatively, DH segments can be used to add compositional diversity in a manner that is strictly relative to their occurrence in actual human heavy chain sequences.
In certain embodiments of the invention, the progressive deletion of IGHD genes containing disulfide loop encoding segments may be limited, so as to leave the loop intact and to avoid the presence of unpaired cysteine residues. In other embodiments of the invention, the presence of the loop can be ignored and the progressive deletion of the IGHD gene segments can occur as for any other segments, regardless of the presence of unpaired cysteine residues. In still other embodiments of the invention, the cysteine residues can be mutated to any other amino acid.
2.2.1.2 Design and Selection of DH Segments from Non-Human Vertebrates
In certain embodiment of the invention, DH segments from non-human vertebrates may be used in conjunction with human VH, Nl, N2, and H3-JH segments to produce CDRH3s and/or antibodies in which all segments except the DH segment are synthesized with reference to human sequences. Without being bound by theory, it is anticipated that the extensive variability in the DH segment of antibodies, for example as the result of somatic hypermutation, may make this region more permissive to the inclusion of sequences that have non-human characteristics, without sacrificing the ability to recognize a broad variety of antigens or introducing immunogenic sequences. The general methods taught herein are readily applicable to information derived from species other than humans. Example 16 presents exemplary DH segments from a variety of species and outlines methods for their inclusion in the libraries of the invention. These methods may be readily applied to information derived from other species and/or sources of information other than those presented in Example 16. For example, as IGHD sequence data becomes available for additional species {e.g., as a result of focused sequencing efforts), one of ordinary skill in the art could use the teachings of this application to construct libraries with DH segments derived from these species.
In certain embodiments of the invention, a library may contain one or more DH
segments derived from the IGHD genes presented in Table 55. As further enumerated in Example 16, these sequences can be selected according to one or more non- limiting criteria, including diversity in length and sequence, maximal (or minimal) human "string content," and/or the absence or minimization of T cell epitopes. Like the human IGHD sequences discussed elsewhere in the application, the non-human IGHD segments of the invention may be deleted at their N- and/or C-termini to provide DH segments with a minimal length of 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 amino acids. The length distribution, reading frame, and frequency of inclusion of the non-human DH segments selected for inclusion in the library may be varied as presented for the human DH segments. Non-human DH segments include those derived from non-human IGHD genes according to the methods presented herein, allelic variants thereof, and amino acid and nucleotide sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 55%, or 50% identical to one or more of these sequences.
IGHD segments may be obtained from multiple species, including camel, shark, mouse, rat, llama, fish, rabbit, and so on. Non-limiting exemplary species from which IGHD segments may be obtained include Mus musculus, Camelus sp., Llama sp., Camelidae sp., Raja sp., Ginglymostoma sp., Carcharhinus sp., Heterodontus sp., Hydrolagus sp., Ictalurus sp., Gallus sp., Bos sp., Marmaronetta sp., Ay thy a sp., Netta sp., Equus sp., Pentalagus sp., Bunolagus sp., Nesolagus sp., Romerolagus sp., Brachylagus sp., Sylvilagus sp., Oryctolagus, sp., Poelagus sp., Ovis sp., Sus sp., Gadus sp., Salmo sp., Oncorhynchus sp, Macaca sp., Rattus sp., Pan sp., Hexanchus sp., Heptranchias sp., Notorynchus sp., Chlamydoselachus sp., Heterodontus sp. Pristiophorus sp., Pliotrema sp., Squatina sp., Carcharia sp., Mitsukurina sp., Lamma sp., Isurus sp., Carcharodon sp.,
Cetorhinus sp., Alopias sp., Nebrius sp., Stegostoma sp., Orectolobus sp., Eucrossorhinus sp., Sutorectus sp., Chiloscyllium sp., Hemiscyllium sp., Brachaelurus sp., Heteroscyllium sp., Cirrhoscyllium sp., Parascyllium sp., Rhincodon sp., Apristurus sp., Atelomycterus sp., Cephaloscy ilium sp., Cephalurus sp., Dichichthys sp., Galeus sp., Halaelurus sp., Haploblepharus sp., Parmaturus sp., Pentanchus sp., Poroderna sp., Schroederichthys sp., Scyliorhinus sp., Pseudotriakis sp., Scylliogaleus sp., Furgaleus sp., Hemitriakis sp., Mustelus sp., Triakis sp., Iago sp., Galeorhinus sp., Hypogaleus sp., Chaenogaleus sp., Hemigaleus sp., Paragaleus sp., Galeocerdo sp., Prionace sp., Sciolodon sp., Loxodon sp.,
Rhizoprionodon sp., Aprionodon sp., Negaprion sp., Hypoprion sp., Carcharhinus sp., Isogomphodon sp., Triaenodon sp., Sphyrna sp., Echinorhinus sp., Oxynotus sp., Squalus sp., Centroscyllium sp., Etmopterus sp., Centrophorus sp., Cirrhigaleus sp., Deania sp., Centroscymnus sp., Scymnodon sp., Dalatias sp., Euprotomicrus sp., Isistius sp., Squaliolus sp., Heteroscymnoides sp., Somniosus sp. and Megachasma sp.
Publications discussing IGHD segments from additional species and/or methods of obtaining such segments include, for example, Ye, Immunogenetics, 2004, 56: 399; De Genst et al, Dev. Comp. Immunol., 2006, 30: 187; Dooley and Flajnik, Dev. Comp. Immunol. 2006, 30: 43; Bengten et al, Dev. Comp. Immunol, 2006, 30: 77; Ratcliffe, Dev. Comp. Immunol, 2006, 30: 101; Zhao et al, Dev. Comp. Immunol, 2006, 30: 175; Lundqvist et al, Dev. Comp. Immunol, 2006, 30: 93; Wagner, Dev. Comp. Immunol. 2006, 30: 155; Mage et al, Dev. Comp. Immunol, 2006, 30: 137; Malecek et al, J. Immunol, 2005, 175: 8105; Jenne et al, Dev. Comp. Immunol, 2006, 30: 165; Butler et al, Dev. Comp. Immunol, 2006, 30: 199; Solem et al, Dev. Comp. Immunol, 2006, 30: 57; Das et al, Immunogenetics, 2008, 60: 47, and Kiss et al, Nucleic Acids Res., 2006, 34: el 32, each of which is incorporated by reference in its entirety.
Given the degree of variability in Nl and N2, these segments might also be considered possible regions for substitution with non-human sequences, that is, sequences with composition biases not arising from those of human terminal deoxynucleotide transferase. The methods taught herein for the identification and analysis of the Nl and N2 regions of human antibodies are also readily applicable to non-human antibodies.
2.2.2. Design and Selection of the H3-JH Segment Repertoire There are six IGHJ Coining) segments, IGHJl , IGHJ2, IGHJ3, IGHJ4, IGHJ5, and
IGHJ6. The amino acid sequences of the parent segments and the progressive N-terminal deletions are presented in Table 20 (Example 5). Similar to the N- and C-terminal deletions that the IGHD genes undergo, natural variation is introduced into the IGHJ genes by N- terminal "nibbling", or progressive deletion, of one or more codons by exonuclease activity. The H3-JH segment refers to the portion of the IGHJ segment that is part of
CDRH3. In certain embodiments of the invention, the H3-JH segment of a library comprises one or more of the following sequences: AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, H, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, L, AFDV
(SEQ ID NO: 19), FDV, DV, V, YFDY (SEQ ID NO: 20), FDY, DY, Y, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, S, YYYYYGMDV (SEQ ID NO: 22), YYYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, MDV, and DV. In some embodiments of the invention, a library may contain one or more of these sequences, allelic variations thereof, or encode an amino acid sequence at least about 99.9%, 99.5%, 99%, 98.5%, 98%, 97.5%, 97%, 96.5%, 96%, 95.5%, 95%, 94.5%, 94%, 93.5%, 93%, 92.5%, 92%, 91.5%, 91%, 90.5%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 77.5%, 75%, 73.5%, 70%, 65%, 60%, 60%, 55%, or 50% identical to one or more of these sequences. In other embodiments of the invention, the H3-JH segment may comprise about 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or more amino acids. For example, the H3-JH segment of JH1 4 (Table 20) has a length of three residues, while non-deleted JH6 has an H3-JH segment length of nine residues. The FRM4-JH region of the IGHJ segment begins with the sequence WG(Q/R)G (SEQ ID NO: 23) and corresponds to the portion of the IGHJ segment that makes up part of framework 4. In certain embodiments of the invention, as enumerated in Table 20, there are 28 H3-JH segments that are included in a library. In certain other embodiments, libraries may be produced by utilizing about 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, or 30 of the IGHJ segments enumerated above or in Table 20.
2.2.3. Design and Selection of the Nl and N2 Segment Repertoires
Terminal deoxynucleotidyl transferase (TdT) is a highly conserved enzyme from vertebrates that catalyzes the attachment of 5' triphosphates to the 3' hydroxyl group of single- or double-stranded DNA. Hence, the enzyme acts as a template-independent polymerase (Koiwai et al, Nucleic Acids Res., 1986, 14: 5777; Basu et al, Biochem. Biophys. Res. Comm., 1983, 111 : 1105, each incorporated by reference in its entirety). In vivo, TdT is responsible for the addition of nucleotides to the V-D and D-J junctions of antibody heavy chains (Alt and Baltimore, PNAS, 1982, 79: 4118; Collins et al, J. Immunol, 2004, 172: 340, each incorporated by reference in its entirety). Specifically, TdT is responsible for creating the Nl and N2 (non-templated) segments that flank the D (diversity) region.
In certain embodiments of the invention, the length and composition of the Nl and N2 segments are designed rationally, according to statistical biases in amino acid usage found in naturally occurring Nl and N2 segments in human antibodies. One embodiment
of a library produced via this method is described in Example 5. According to data compiled from human databases (Jackson et ah, J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety), there are an average of 3.02 amino acid insertions for Nl and 2.4 amino acid insertions for N2, not taking into account insertions of two nucleotides or less (Figure 2). In certain embodiments of the invention, Nl and N2 segments are restricted to lengths of zero to three amino acids. In other embodiments of the invention, Nl and N2 may be restricted to lengths of less than about 4, 5, 6, 7, 8, 9, or 10 amino acids.
In some embodiments of the invention, the composition of these sequences may be chosen according to the frequency of occurrence of particular amino acids in the Nl and N2 sequences of natural human antibodies (for examples of this analysis, see, Tables 21 to 23, in Example 5). In certain embodiments of the invention, the eight most commonly occurring amino acids in these regions (i.e., G, R, S, P, L, A, T, and V) are used to design the synthetic Nl and N2 segments. In other embodiments of the invention about the most 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, or 19 most commonly occurring amino acids may be used in the design of the synthetic Nl and N2 segments. In still other embodiments, all 20 amino acids may be used in these segments. Finally, while it is possible to base the designed composition of the Nl and N2 segments of the invention on the composition of naturally occurring Nl and N2 segments, this is not a requirement. The Nl and N2 segments may comprise amino acids selected from any group of amino acids, or designed according to other criteria considered for the design of a library of the invention. A person of ordinary skill in the art would readily recognize that the criteria used to design any portion of a library of the invention may vary depending on the application of the particular library. It is an object of the invention that it may be possible to produce a functional library through the use of Nl and N2 segments selected from any group of amino acids, no Nl or N2 segments, or the use of Nl and N2 segments with compositions other than those described herein.
One important difference between the libraries of the current invention and other libraries known in the art is the consideration of the composition of naturally occurring duplet and triplet amino acid sequences during the design of the library. Table 23 shows the top twenty-five naturally occurring duplets in the Nl and N2 regions. Many of these can be represented by the general formula (G/P)(G/R/S/P/L/A/V/T) or (R/S/L/A/V/T)(G/P). In certain embodiments of the invention, the synthetic Nl and N2 regions may comprise all of
these duplets. In other embodiments, the library may comprise the top 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 most common naturally occurring Nl and/or N2 duplets. In other embodiments of the invention, the libraries may include duplets that are less frequently occurring (i.e., outside of the top 25). The composition of these additional duplets or triplets could readily be determined, given the methods taught herein.
Finally, the data from the naturally occurring triplet Nl and N2 regions demonstrates that the naturally occurring Nl and N2 triplet sequences can often be represented by the formulas (G)(G)(G/R/S/P/L/A/V/T), (G)(R/S/P/L/A/V/T)(G), or (R/S/P/L/A/V/T)(G)(G). In certain embodiments of the invention, the library may comprise the top 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 most commonly occurring Nl and/or N2 triplets. In other embodiments of the invention, the libraries may include triplets that are less frequently occurring (i.e., outside of the top 25). The composition of these additional duplets or triplets could readily be determined, given the methods taught herein.
In certain embodiments of the invention, there are about 59 total Nl segments and about 59 total N2 segments used to create a library of CDRH3s. In other embodiments of the invention, the number of Nl segments, N2 segments, or both is increased to about 141 (see, for example, Example 5). In other embodiments of the invention, one may select a total of about 0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 220, 240, 260, 280, 300, 320, 340, 360, 380, 400, 420, 440, 460, 480, 500, 1000, 104, or more Nl and/or N2 segments for inclusion in a library of the invention.
One of ordinary skill in the art will readily recognize that, given the teachings of the instant specification, it is well within the realm of normal experimentation to extend the analysis detailed herein, for example, to generate additional rankings of naturally occurring duplet and triplet (or higher order) N regions that extend beyond those presented herein (e.g., using sequence alignment, the SoDA algorithm, and any database of human sequences (Volpe et ah, Bioinformatics, 2006, 22: 438-44, incorporated by reference in its entirety). An ordinarily skilled artisan would also recognize that, based on the information taught herein, it is now possible to produce libraries that are more diverse or less diverse (i.e., more focused) by varying the number of distinct amino acid sequences used in the Nl pool and/or N2 pool.
As described above, many alternative embodiments are envisioned, in which the compositions and lengths of the Nl and N2 segments vary from those presented in the Examples herein. In some embodiments, sub-stoichiometric synthesis of trinucleotides may be used for the synthesis of Nl and N2 segments. Sub-stoichiometric synthesis with trinucleotides is described in Knappik et al. (U.S. Patent No. 6,300,064, incorporated by reference in its entirety). The use of sub-stoichiometric synthesis would enable synthesis with consideration of the length variation in the Nl and N2 sequences.
In addition to the embodiments described above, a model of the activity of TdT may also be used to determine the composition of the Nl and N2 sequences in a library of the invention. For example, it has been proposed that the probability of incorporating a particular nucleotide base (A, C, G, T) on a polynucleotide, by the activity of TdT, is dependent on the type of base and the base that occurs on the strand directly preceding the base to be added. Jackson et al, (J. Immunol. Methods, 2007, 324: 26, incorporated by reference in its entirety) have constructed a Markov model describing this process. In certain embodiments of the invention, this model may be used to determine the composition of the Nl and/or N2 segments used in libraries of the invention. Alternatively, the parameters presented in Jackson et al could be further refined to produce sequences that more closely mimic human sequences.
2.2.4. Design of a CDRH3 Library Using the Nl, DH, N2, and H3-JH Segments
The CDRH3 libraries of the invention comprise an initial amino acid (in certain exemplary embodiments, G, D, E) or lack thereof (designated herein as position 95), followed by the Nl, DH, N2, and H3-JH segments. Thus, in certain embodiments of the invention, the overall design of the CDRH3 libraries can be represented by the following formula:
[G/D/E/-]-[Nl]-[DH]-[N2]-[H3-JH].
While the compositions of each portion of a CDRH3 of a library of the invention are more fully described above, the composition of the tail presented above (G/D/E/-) is non- limiting, and that any amino acid (or no amino acid) can be used in this position. Thus, certain embodiments of the invention may be represented by the following formula:
[X]-[N1]-[DH]-[N2]-[H3-JH], wherein [X] is any amino acid residue or no residue.
In certain embodiments of the invention, a synthetic CDRH3 repertoire is combined with selected VH chassis sequences and heavy chain constant regions, via homologous recombination. Therefore, in certain embodiments of the invention, it may be necessary to include DNA sequences flanking the 5' and 3' ends of the synthetic CDRH3 libraries, to facilitate homologous recombination between the synthetic CDRH3 libraries and vectors containing the selected chassis and constant regions. In certain embodiments, the vectors also contain a sequence encoding at least a portion of the non-nibbled region of the IGHJ gene (i.e., FRM4-JH). Thus, a polynucleotide encoding an N-terminal sequence (e.g., CA(K/R/T)) may be added to the synthetic CDRH3 sequences, wherein the N-terminal polynucleotide is homologous with FRM3 of the chassis, while a polynucleotide encoding a C-terminal sequence (e.g., WG(Q/R)G; SEQ ID NO: 23) may be added to the synthetic CDRH3, wherein the C-terminal polynucleotide is homologous with FRM4-JH. Although the sequence WG(QZR)G (SEQ ID NO: 23) is presented in this exemplary embodiment, additional amino acids, C-terminal to this sequence in FRM4-JH may also be included in the polynucleotide encoding the C-terminal sequence. The purpose of the polynucleotides encoding the N-terminal and C-terminal sequences, in this case, is to facilitate homologous recombination, and one of ordinary skill in the art would recognize that these sequences may be longer or shorter than depicted below. Accordingly, in certain embodiments of the invention, the overall design of the CDRH3 repertoire, including the sequences required to facilitate homologous recombination with the selected chassis, can be represented by the following formula (regions homologous with vector underlined): cArR/κ/τi-rxi-rNii-rPHi-rN2i-rH3-jHi-rwG(o/R)Gi.
In other embodiments of the invention, the CDRH3 repertoire can be represented by the following formula, which excludes the T residue presented in the schematic above: CAΓR/KI-ΓXI-ΓNΠ-ΓDHI-ΓN2I-ΓH3-JHI-ΓWG(O/R>)GI.
References describing collections of V, D, and J genes include Scaviner et ah, Exp. Clin, Immunogenet., 1999, 16: 243 and Ruiz et ah, Exp. Clin. Immunogenet, 1999, 16: 173, each incorporated by reference in its entirety.
2.2.5. CDRH3 Length Distributions
As described throughout this application, in addition to accounting for the composition of naturally occurring CDRH3 segments, the instant invention also takes into account the length distribution of naturally occurring CDRH3 segments. Surveys by
Zemlin et al. (JMB, 2003, 334: 733, incorporated by reference in its entirety) and Lee et al. (Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety) provide analyses of the naturally occurring CDRH3 lengths. These data show that about 95% of naturally occurring CDRH3 sequences have a length from about 7 to about 23 amino acids. In certain embodiments, the instant invention provides rationally designed antibody libraries with CDRH3 segments which directly mimic the size distribution of naturally occurring CDRH3 sequences. In certain embodiments of the invention, the length of the CDRH3s may be about 2 to about 30, about 3 to about 35, about 7 to about 23, about 3 to about 28, about 5 to about 28, about 5 to about 26, about 5 to about 24, about 7 to about 24, about 7 to about 22, about 8 to about 19, about 9 to about 22, about 9 to about 20, about 10 to about 18, about 11 to about 20, about 11 to about 18, about 13 to about 18, or about 13 to about 16 residues in length.
In certain embodiments of the invention, the length distribution of a CDRH3 library of the invention may be defined based on the percentage of sequences within a certain length range. For example, in certain embodiments of the invention, CDRFBs with a length of about 10 to about 18 amino acid residues comprise about 84% to about 94% of the sequences of a the library. In some embodiments, sequences within this length range comprise about 89% of the sequences of a library.
In other embodiments of the invention, CDRFBs with a length of about 11 to about 17 amino acid residues comprise about 74% to about 84% of the sequences of a library. In some embodiments, sequences within this length range comprise about 79% of the sequences of a library.
In still other embodiments of the invention, CDRFBs with a length of about 12 to about 16 residues comprise about 57% to about 67% of the sequences of a library. In some embodiments, sequences within this length range comprise about 62% of the sequences of a library.
In certain embodiments of the invention, CDRFBs with a length of about 13 to about 15 residues comprise about 35% to about 45% of the sequences of a library. In some embodiments, sequences within this length range comprise about 40% of the sequences of a library.
2.3. Design of the Antibody Library CDRL3 Components
The CDRL3 libraries of the invention can be generated by one of several approaches. The actual version of the CDRL3 library made and used in a particular embodiment of the invention will depend on objectives for the use of the library. More than one CDRL3 library may be used in a particular embodiment; for example, a library containing CDRH3 diversity, with kappa and lambda light chains is within the scope of the invention.
In certain embodiments of the invention, a CDRL3 library is a VKCDR3 (kappa) library and/or a VλCDR3 (lambda) library. The CDRL3 libraries described herein differ significantly from CDRL3 libraries in the art. First, they consider length variation that is consistent with what is observed in actual human sequences. Second, they take into consideration the fact that a significant portion of the CDRL3 is encoded by the IGLV gene. Third, the patterns of amino acid variation within the IGLV gene-encoded CDRL3 portions are not stochastic and are selected based on depending on the identity of the IGLV gene. Taken together, the second and third distinctions mean that CDRL3 libraries that faithfully mimic observed patterns in human sequences cannot use a generic design that is independent of the chassis sequences in FRMl to FRM3. Fourth, the contribution of JL to CDRL3 is also considered explicitly, and enumeration of each amino acid residue at the relevant positions is based on the compositions and natural variations of the JL genes themselves.
As indicated above, and throughout the application, a unique aspect of the design of the libraries of the invention is the germline or "chassis-based" aspect, which is meant to preserve more of the integrity and variability of actual human sequences. This is in contrast to other codon-based synthesis or degenerate oligonucleotide synthesis approaches that have been described in the literature and that aim to produce "one-size-fits-all" (e.g., consensus) libraries (e.g.,, Knappik, et al., J MoI Biol, 2000, 296: 57; Akamatsu et al., J Immunol, 1993, 151 : 4651, each incorporated by reference in its entirety).
In certain embodiments of the invention, patterns of occurrence of particular amino acids at defined positions within VL sequences are determined by analyzing data available in public or other databases, for example, the NCBI database (see, for example, GI numbers in Appendices A and B filed herewith). In certain embodiments of the invention, these sequences are compared on the basis of identity and assigned to families on the basis of the
germline genes from which they are derived. The amino acid composition at each position of the sequence, in each germline family, may then be determined. This process is illustrated in the Examples provided herein.
2.3.1. Minimalist VKCDR3 Libraries
In certain embodiments of the invention, the light chain CDR3 library is a VKCDR3 library. Certain embodiments of the invention may use only the most common VKCDR3 length, nine residues; this length occurs in a dominant proportion (greater than about 70%) of human VKCDR3 sequences. In human VKCDR3 sequences of length nine, positions 89-95 are encoded by the IGKV gene and positions 96-97 are encoded by the IGKJ gene. Analysis of human kappa light chain sequences indicates that there are not strong biases in the usage of the IGKJ genes. Therefore, in certain embodiments of the invention, each of the five the IGKJ genes can be represented in equal proportions to create a combinatorial library of (M VK chassis) x (5 JK genes), or a library of size Mx5. However, in other embodiments of the invention, it may be desirable to bias IGKJ gene representation, for example to restrict the size of the library or to weight the library toward IGKJ genes known to have particular properties.
As described in Example 6.1, examination of the first amino acid encoded by the IGKJ gene (position 96) indicated that the seven most common residues found at this position are L, Y, R, W, F, P, and I. These residues cumulatively account for about 85% of the residues found in position 96 in naturally occurring kappa light chain sequences. In certain embodiments of the invention, the amino acid residue at position 96 may be one of these seven residues. In other embodiments of the invention, the amino acid at this position may be chosen from amongst any of the other 13 amino acid residues. In still other embodiments of the invention, the amino acid residue at position 96 may be chosen from amongst the top 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids that occur at position 96, or even residues that never occur at position 96. Similarly, the occurrence of the amino acids selected to occupy position 96 may be equivalent or weighted. In certain embodiments of the invention, it may be desirable to include each of the amino acids selected for inclusion in position 96 at equivalent amounts. In other embodiments of the invention, it may be desirable to bias the composition of position 96 to include particular residues more or less frequently than others. For example, as presented in Example 6.1, arginine occurs at position 96 most frequently when the IGKJl germline
sequence is used. Therefore, in certain embodiments of the invention, it may be desirable to bias amino acid usage at position 96 according to the origin of the IGKJ germline sequence(s) and/or the IGKV germline sequence(s) selected for representation in a library. Therefore, in certain embodiments of the invention, a minimalist VKCDR3 library may be represented by one or more of the following amino acid sequences:
[VK Chassis]-[L3-VK]-[F/L/I/R/W/Y/P]-[JK*]
[VK_Chassis]-[L3-VK]-[X]-[JK*]
In these schematic exemplary sequences, VK_Chassis represents any VK chassis selected for inclusion in a library of the invention (e.g., see Table 11). Specifically, VK Chassis comprises about Kabat residues 1 to 88 of a selected IGKV sequence. L3-VK represents the portion of the VKCDR3 encoded by the chosen IGKV gene (in this embodiment, Kabat residues 89-95). F, L, I, R, W, Y, and P are the seven most commonly occurring amino acids at position 96 of VKCDR3s with length nine, X is any amino acid, and JK* is an IGKJ amino acid sequence without the N-terminal residue (i.e., the N- terminal residue is substituted with F, L, I, R, W, Y, P, or X). Thus, in one possible embodiment of the minimalist VKCDR3 library, 70 members could be produced by utilizing 10 VK chassis, each paired with its respective L3-VK, 7 amino acids at position 96 (i.e., X), and one JK* sequence. Another embodiment of the library may have 350 members, produced by combining 10 VK chassis, each paired with its respective L3-VK, with 7 amino acids at position 96, and all 5 JK* genes. Still another embodiment of the library may have 1,125 members, produced by combining 15 VK chassis, each paired with its respective H3-JK, with 15 amino acids at position 96 and all 5 JK* genes, and so on. A person of ordinary skill in the art will readily recognize that many other combinations are possible. Moreover, while it is believed that maintaining the pairing between the VK chassis and the L3-VK results in libraries that are more similar to human kappa light chain sequences in composition, the L3-VK regions may also be combinatorially varied with different VK chassis regions, to create additional diversity.
2.3.2. VKCDR3 Libraries of About 105 Complexity
While the dominant length of VKCDR3 sequences in humans is about nine amino acids, other lengths appear at measurable frequencies that cumulatively approach almost about 30% of VKCDR3 sequences. In particular, VKCDR3 of lengths 8 and 10 represent about 8.5% and about 16%, respectively, of VKCDR3 lengths in representative samples (Example 6.2; Figure 3). Thus, more complex VKCDR3 libraries may include CDR lengths of 8, 10, and 11 amino acids. Such libraries could account for a greater percentage of the length distribution observed in collections of human VKCDR3 sequences, or even introduce VKCDR3 lengths that do not occur frequently in human VKCDR3 sequences (e.g., less than eight residues or greater than 11 residues). The inclusion of a diversity of kappa light chain length variations in a library of the invention also enables one to include sequence variability that occurs outside of the amino acid at the VK-JK junction (i.e., position 96, described above). In certain embodiments of the invention, the patterns of sequence variation within the VK, and/or JK segments can be determined by aligning collections of sequences derived from particular germline sequences. In certain embodiments of the invention, the frequency of occurrence of amino acid residues within VKCDR3 can be determined by sequence alignments (e.g., see Example 6.2 and Table 30). In some embodiments of the invention, this frequency of occurrence may be used to introduce variability into the VK Chassis, L3-VK and/or JK segments that are used to synthesize the VKCDR3 libraries. In certain embodiments of the invention, the top 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids that occur at any particular position in a naturally occurring repertoire may be included at that position in a VKCDR3 library of the invention. In certain embodiments of the invention, the percent occurrence of any amino acid at any particular position within the VKCDR3 or a VK light chain may be about 0%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%,
85%, 90%, 95%, or 100%. In certain embodiments of the invention, the percent occurrence of any amino acid at any position within a VKCDR3 or kappa light chain library of the invention may be within at least about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9% 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 120%, 140%, 160%, 180%, or 200% of the percent occurrence of any amino acid at any position within a naturally occurring VKCDR3 or kappa light chain domain.
In some embodiments of the invention, a VKCDR3 library may be synthesized using degenerate oligonucleotides (see Table 31 for IUPAC base symbol definitions). In
some embodiments of the invention, the limits of oligonucleotide synthesis and the genetic code may require the inclusion of more or fewer amino acids at a particular position in the VKCDR3 sequences. An illustrative embodiment of this approach is provided in Example 6.2.
2.3.3. More Complex VKCDR3 Libraries
The limitations inherent in using the genetic code and degenerate oligonucleotide synthesis may, in some cases, require the inclusion of more or fewer amino acids at a particular position within VKCDR3 {e.g., Example 6.2, Table 32), in comparison to those amino acids found at that position in nature. This limitation can be overcome through the use of a codon-based synthesis approach (Virnekas et al. Nucleic Acids Res., 1994, 22: 5600, incorporated by reference in its entirety), which enables precise synthesis of oligonucleotides encoding particular amino acids and a finer degree of control over the proportion of any particular amino acid incorporated at any position. Example 6.3 describes this approach in greater detail.
In some embodiments of the invention, a codon-based synthesis approach may be used to vary the percent occurrence of any amino acid at any particular position within the VKCDR3 or kappa light chain. In certain embodiments, the percent occurrence of any amino acid at any position in a VKCDR3 or kappa light chain sequence of the library may be about 0%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, or 100%. In some embodiments of the invention, the percent occurrence of any amino acid at any position may be about 1%, 2%, 3%, or 4%. In certain embodiments of the invention, the percent occurrence of any amino acid at any position within a VKCDR3 or kappa light chain library of the invention may be within at least about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 120%, 140%, 160%, 180%, or 200% of the percent occurrence of any amino acid at any position within a naturally occurring VKCDR3 or kappa light chain domain.
In certain embodiments of the invention, the VKCDR3 (and any other sequence used in the library, regardless of whether or not it is part of VKCDR3) may be altered to remove undesirable amino acid motifs. For example, peptide sequences with the pattern N- X-(S or T)-Z, where X and Z are different from P, will undergo post-translational modification (N-linked glycosylation) in a number of expression systems, including yeast
and mammalian cells. In certain embodiments of the invention, the introduction of N residues at certain positions may be avoided, so as to avoid the introduction of N-linked glycosylation sites. In some embodiments of the invention, these modifications may not be necessary, depending on the organism used to express the library and the culture conditions. However, even in the event that the organism used to express libraries with potential N- linked glycosylation sites is incapable of N-linked glycosylation (e.g., bacteria), it may still be desirable to avoid N-X-(S/T) sequences, as the antibodies isolated from such libraries may be expressed in different systems (e.g., yeast, mammalian cells) later (e.g., toward clinical development), and the presence of carbohydrate moieties in the variable domains, and the CDRs in particular, may lead to unwanted modifications of activity.
In certain embodiments of the invention, it may be preferable to create the individual sub-libraries of different lengths (e.g., one or more of lengths 5, 6, 7, 8, 9, 10, 11, or more) separately, and then mix the sub-libraries in proportions that reflect the length distribution of VKCDR3 in human sequences; for example, in ratios approximating the 1 :9:2 distribution that occurs in natural VKCDR3 sequences of lengths 8, 9, and 10 (see
Figure 3). In other embodiments, it may be desirable to mix these sub-libraries at ratios that are different from the distribution of lengths in natural VKCDR3 sequences, for example, to produce more focused libraries or libraries with particular properties.
2.3.4. VλCDR3 Libraries
The principles used to design the minimalist VλCDR3 libraries of the invention are similar to those enumerated above, for the VKCDR3 libraries, and are explained in more detail in the Examples. One difference between the VλCDR3 libraries of the invention and the VKCDR3 libraries of the invention is that, unlike the IGKV genes, the contribution of the IGVλ genes to CDRL3 (i.e., L3-Vλ) is not constrained to a fixed number of amino acid residues. Therefore, while the combination of the VK (including L3-VK) and JK segments, with inclusion of position 96, yields CDRL3 with a length of only 9 residues, length variation may be obtained within a VλCDR3 library even when only the Vλ (including L3- Vλ) and Jλ segments are considered. As for the VKCDR3 sequences, additional variability may be introduced into the
VλCDR3 sequences via the same methods outlined above, namely determining the frequency of occurrence of particular residues within VλCDR3 sequences and synthesizing
the oligonucleotides encoding the desired compositions via degenerate oligonucleotide synthesis or trinucleotides-based synthesis.
2.4. Synthetic Antibody Libraries In certain embodiments of the invention, both the heavy and light chain chassis sequences and the heavy and light chain CDR3 sequences are synthetic. The polynucleotide sequences of the instant invention can be synthesized by various methods. For example, sequences can be synthesized by split pool DNA synthesis as described in Feldhaus et al., Nucleic Acids Research, 2000, 28: 534; Omstein et al., Biopolymers, 1978, 17: 2341; and Brenner and Lerner, PNAS, 1992, 87: 6378 (each of which is incorporated by reference in its entirety).
In some embodiments of the invention, cassettes representing the possible V, D, and J diversity found in the human repertoire, as well as junctional diversity, are synthesized de novo either as double-stranded DNA oligonucleotides, single-stranded DNA oligonucleotides representative of the coding strand, or single-stranded DNA oligonucleotides representative of the non-coding strand. These sequences can then be introduced into a host cell along with an acceptor vector containing a chassis sequence and, in some cases a portion of FRM4 and a constant region. No primer-based PCR amplification from mammalian cDNA or mRNA or template-directed cloning steps from mammalian cDNA or mRNA need be employed.
2.5. Construction of Libraries by Yeast Homologous Recombination
In certain embodiments, the present invention exploits the inherent ability of yeast cells to facilitate homologous recombination at high efficiency. The mechanism of homologous recombination in yeast and its applications are briefly described below.
As an illustrative embodiment, homologous recombination can be carried out in, for example, Saccharomyces cerevisiae, which has genetic machinery designed to carry out homologous recombination with high efficiency. Exemplary S. cerevisiae strains include EM93, CEN.PK2, RMl 1-la, YJM789, and BJ5465. This mechanism is believed to have evolved for the purpose of chromosomal repair, and is also called "gap repair" or "gap filling". By exploiting this mechanism, mutations can be introduced into specific loci of the yeast genome. For example, a vector carrying a mutant gene can contain two sequence segments that are homologous to the 5' and 3' open reading frame (ORF) sequences of a
gene that is intended to be interrupted or mutated. The vector may also encode a positive selection marker, such as a nutritional enzyme allele (e.g., URA3) and/or an antibiotic resistant marker (e.g., Geneticin / G418), flanked by the two homologous DNA segments. Other selection markers and antibiotic resistance markers are known to one of ordinary skill in the art. In some embodiments of the invention, this vector (e.g., a plasmid) is linearized and transformed into the yeast cells. Through homologous recombination between the plasmid and the yeast genome, at the two homologous recombination sites, a reciprocal exchange of the DNA content occurs between the wild type gene in the yeast genome and the mutant gene (including the selection marker gene(s)) that is flanked by the two homologous sequence segments. By selecting for the one or more selection markers, the surviving yeast cells will be those cells in which the wild-type gene has been replaced by the mutant gene (Pearson et αl., Yeast, 1998, 14: 391, incorporated by reference in its entirety). This mechanism has been used to make systematic mutations in all 6,000 yeast genes, or open reading frames (ORFs), for functional genomics studies. Because the exchange is reciprocal, a similar approach has also been used successfully to clone yeast genomic DNA fragments into a plasmid vector (Iwasaki et αl., Gene, 1991, 109: 81, incorporated by reference in its entirety).
By utilizing the endogenous homologous recombination machinery present in yeast, gene fragments or synthetic oligonucleotides can also be cloned into a plasmid vector without a ligation step. In this application of homologous recombination, a target gene fragment (i.e., the fragment to be inserted into a plasmid vector, e.g., a CDR3) is obtained (e.g., by oligonucleotides synthesis, PCR amplification, restriction digestion out of another vector, etc.). DNA sequences that are homologous to selected regions of the plasmid vector are added to the 5' and 3' ends of the target gene fragment. These homologous regions may be fully synthetic, or added via PCR amplification of a target gene fragment with primers that incorporate the homologous sequences. The plasmid vector may include a positive selection marker, such as a nutritional enzyme allele (e.g., URA3), or an antibiotic resistance marker (e.g., Geneticin / G418). The plasmid vector is then linearized by a unique restriction cut located in-between the regions of sequence homology shared with the target gene fragment, thereby creating an artificial gap at the cleavage site. The linearized plasmid vector and the target gene fragment flanked by sequences homologous to the plasmid vector are co-transformed into a yeast host strain. The yeast is then able to recognize the two stretches of sequence homology between the vector and target gene
fragment and facilitate a reciprocal exchange of DNA content through homologous recombination at the gap. As a consequence, the target gene fragment is inserted into the vector without ligation.
The method described above has also been demonstrated to work when the target gene fragments are in the form of single stranded DNA, for example, as a circular M 13 phage derived form, or as single stranded oligonucleotides (Simon and Moore, MoI. Cell Biol, 1987, 7: 2329; Ivanov et al, Genetics, 1996, 142: 693; and DeMarini et al, 2001, 30: 520., each incorporated by reference in its entirety). Thus, the form of the target that can be recombined into the gapped vector can be double stranded or single stranded, and derived from chemical synthesis, PCR, restriction digestion, or other methods.
Several factors may influence the efficiency of homologous recombination in yeast. For example, the efficiency of the gap repair is correlated with the length of the homologous sequences flanking both the linearized vector and the target gene. In certain embodiments, about 20 or more base pairs may be used for the length of the homologous sequence, and about 80 base pairs may give a near-optimized result (Hua et al, Plasmid, 1997, 38: 91; Raymond et al, Genome Res., 2002, 12: 190, each incorporated by reference in its entirety). In certain embodiments of the invention, at least about 5, 10, 15, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34 35, 36, 37, 38, 39, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 187, 190, or 200 homologous base pairs may be used to facilitate recombination. In other embodiments, between about 20 and about 40 base pairs are utilized. In addition, the reciprocal exchange between the vector and gene fragment is strictly sequence-dependent, i.e. it does not cause a frame shift. Therefore, gap-repair cloning assures the insertion of gene fragments with both high efficiency and precision. The high efficiency makes it possible to clone two, three, or more targeted gene fragments simultaneously into the same vector in one transformation attempt (Raymond et al, Biotechniques, 1999, 26: 134, incorporated by reference in its entirety). Moreover, the nature of precision sequence conservation through homologous recombination makes it possible to clone selected genes or gene fragments into expression or fusion vectors for direct functional examination (El-Deiry et al, Nature Genetics, 1992, 1 : 4549; Ishioka et al, PNAS, 1997, 94: 2449, each incorporated by reference in its entirety).
Libraries of gene fragments have also been constructed in yeast using homologous recombination. For example, a human brain cDNA library was constructed as a two-hybrid
fusion library in vector pJG4-5 (Guidotti and Zervos, Yeast, 1999, 15: 715, incorporated by reference in its entirety). It has also been reported that a total of 6,000 pairs of PCR primers were used for amplification of 6,000 known yeast ORFs for a study of yeast genomic protein interactions (Hudson et al., Genome Res., 1997, 7: 1169, incorporated by reference in its entirety). In 2000, Uetz et al. conducted a comprehensive analysis-of protein-protein interactions in Saccharomyces cerevisiae (Uetz et al., Nature, 2000, 403: 623, incorporated by reference in its entirety). The protein-protein interaction map of the budding yeast was studied by using a comprehensive system to examine two-hybrid interactions in all possible combinations between the yeast proteins (Ito et al., PNAS, 2000, 97: 1143, incorporated by reference in its entirety), and the genomic protein linkage map of Vaccinia virus was studied using this system (McCraith et al., PNAS, 2000, 97: 4879, incorporated by reference in its entirety).
In certain embodiments of the invention, a synthetic CDR3 (heavy or light chain) may be joined by homologous recombination with a vector encoding a heavy or light chain chassis, a portion of FRM4, and a constant region, to form a full-length heavy or light chain. In certain embodiments of the invention, the homologous recombination is performed directly in yeast cells. In some embodiments, the method comprises:
(a) transforming into yeast cells:
(i) a linearized vector encoding a heavy or light chain chassis, a portion of FRM4, and a constant region, wherein the site of linearization is between the end of FRM3 of the chassis and the beginning of the constant region; and (ii) a library of CDR3 insert nucleotide sequences that are linear and double stranded, wherein each of the CDR3 insert sequences comprises a nucleotide sequence encoding CDR3 and 5'- and 3 '-flanking sequences that are sufficiently homologous to the termini of the vector of (i) at the site of linearization to enable homologous recombination to occur between the vector and the library of CDR3 insert sequences; and
(b) allowing homologous recombination to occur between the vector and the CDR3 insert sequences in the transformed yeast cells, such that the CDR3 insert sequences are incorporated into the vector, to produce a vector encoding full- length heavy chain or light chain.
As specified above, the CDR3 inserts may have a 5' flanking sequence and a 3' flanking sequence that are homologous to the termini of the linearized vector. When the
CDR3 inserts and the linearized vectors are introduced into a host cell, for example, a yeast cell, the "gap" (the linearization site) created by linearization of the vector is filled by the CDR3 fragment insert through recombination of the homologous sequences at the 5' and 3' termini of these two linear double-stranded DNAs (i.e., the vector and the insert). Through this event of homologous recombination, libraries of circular vectors encoding full-length heavy or light chains comprising variable CDR3 inserts is generated. Particular instances of these methods are presented in the Examples.
Subsequent analysis may be carried out to determine the efficiency of homologous recombination that results in correct insertion of the CDR3 sequences into the vectors. For example, PCR amplification of the CDR3 inserts directly from selected yeast clones may reveal how many clones are recombinant. In certain embodiments, libraries with minimum of about 90% recombinant clones are utilized. In certain other embodiments libraries with a minimum of about 1%, 5% 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% recombinant clones are utilized. The same PCR amplification of selected clones may also reveal the insert size.
To verify the sequence diversity of the inserts in the selected clones, a PCR amplification product with the correct size of insert may be "fingerprinted" with restriction enzymes known to cut or not cut within the amplified region. From a gel electrophoresis pattern, it may be determined whether the clones analyzed are of the same identity or of the distinct or diversified identity. The PCR products may also be sequenced directly to reveal the identity of inserts and the fidelity of the cloning procedure, and to prove the independence and diversity of the clones. Figure 1 depicts a schematic of recombination between a fragment (e.g., CDR3) and a vector (e.g., comprising a chassis, portion of FRM4, and constant region) for the construction of a library.
2.6. Expression and Screening Systems
Libraries of polynucleotides generated by any of the techniques described herein, or other suitable techniques, can be expressed and screened to identify antibodies having desired structure and/or activity. Expression of the antibodies can be carried out, for example, using cell-free extracts (and e.g. , ribosome display), phage display, prokaryotic cells (e.g., bacterial display), or eukaryotic cells (e.g., yeast display). In certain embodiments of the invention, the antibody libraries are expressed in yeast.
In other embodiments, the polynucleotides are engineered to serve as templates that can be expressed in a cell-free extract. Vectors and extracts as described, for example in U.S. Patent Nos. 5,324,637; 5,492,817; 5,665,563, (each incorporated by reference in its entirety) can be used and many are commercially available. Ribosome display and other cell-free techniques for linking a polynucleotide (i.e., a genotype) to a polypeptide (i.e., a phenotype) can be used, e.g., Profusion™ (see, e.g., U.S. Patent Nos. 6,348,315; 6,261,804; 6,258,558; and 6,214,553, each incorporated by reference in its entirety).
Alternatively, the polynucleotides of the invention can be expressed in an E. coli expression system, such as that described by Pluckthun and Skerra. (Meth. EnzymoL, 1989, 178: 476; Biotechnology, 1991, 9: 273, each incorporated by reference in its entirety). The mutant proteins can be expressed for secretion in the medium and/or in the cytoplasm of the bacteria, as described by Better and Horwitz, Meth. EnzymoL, 1989, 178: 476, incorporated by reference in its entirety. In some embodiments, the single domains encoding VH and VL are each attached to the 3 ' end of a sequence encoding a signal sequence, such as the ompA, phoA or pelB signal sequence (Lei et al., J. Bacteriol., 1987, 169: 4379, incorporated by reference in its entirety). These gene fusions are assembled in a dicistronic construct, so that they can be expressed from a single vector, and secreted into the periplasmic space of E. coli where they will refold and can be recovered in active form. (Skerra et al, Biotechnology, 1991, 9: 273, incorporated by reference in its entirety). For example, antibody heavy chain genes can be concurrently expressed with antibody light chain genes to produce antibodies or antibody fragments.
In other embodiments of the invention, the antibody sequences are expressed on the membrane surface of a prokaryote, e.g., E. coli, using a secretion signal and lipidation moiety as described, e.g., in US20040072740; US20030100023; and US20030036092 (each incorporated by reference in its entirety).
Higher eukaryotic cells, such as mammalian cells, for example myeloma cells (e.g., NS/0 cells), hybridoma cells, Chinese hamster ovary (CHO), and human embryonic kidney (HEK) cells, can also be used for expression of the antibodies of the invention. Typically, antibodies expressed in mammalian cells are designed to be secreted into the culture medium, or expressed on the surface of the cell. The antibody or antibody fragments can be produced, for example, as intact antibody molecules or as individual VH and VL fragments, Fab fragments, single domains, or as single chains (scFv) (Huston et al., PNAS, 1988, 85: 5879, incorporated by reference in its entirety).
Alternatively, antibodies can be expressed and screened by anchored periplasmic expression (APEx 2-hybrid surface display), as described, for example, in Jeong et ah, PNAS, 2007, 104: 8247 (incorporated by reference in its entirety) or by other anchoring methods as described, for example, in Mazor et ah, Nature Biotechnology, 2007, 25: 563 (incorporated by reference in its entirety).
In other embodiments of the invention, antibodies can be selected using mammalian cell display (Ho et al, PNAS, 2006, 103: 9637, incorporated by reference in its entirety). The screening of the antibodies derived from the libraries of the invention can be carried out by any appropriate means. For example, binding activity can be evaluated by standard immunoassay and/or affinity chromatography. Screening of the antibodies of the invention for catalytic function, e.g., proteolytic function can be accomplished using a standard assays, e.g., the hemoglobin plaque assay as described in U.S. Patent No. 5,798,208 (incorporated by reference in its entirety). Determining the ability of candidate antibodies to bind therapeutic targets can be assayed in vitro using, e.g., a BIACORE™ instrument, which measures binding rates of an antibody to a given target or antigen based on surface plasmon resonance. In vivo assays can be conducted using any of a number of animal models and then subsequently tested, as appropriate, in humans. Cell-based biological assays are also contemplated.
One aspect of the instant invention is the speed at which the antibodies of the library can be expressed and screened. In certain embodiments of the invention, the antibody library can be expressed in yeast, which have a doubling time of less than about 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, or 24 hours. In some embodiments, the doubling times are about 1 to about 3 hours, about 2 to about 4, about 3 to about 8 hours, about 3 to about 24, about 5 to about 24, about 4 to about 6 about 5 to about 22, about 6 to about 8, about 7 to about 22, about 8 to about 10 hours, about 7 to about 20, about 9 to about 20, about 9 to about 18, about 11 to about 18, about 11 to about 16, about 13 to about 16, about 16 to about 20, or about 20 to about 30 hours. In certain embodiments of the invention, the antibody library is expressed in yeast with a doubling time of about 16 to about 20 hours, about 8 to about 16 hours, or about 4 to about 8 hours. Thus, the antibody library of the instant invention can be expressed and screened in a matter of hours, as compared to previously known techniques which take several days to express and screen antibody libraries. A limiting step in the throughput of such screening processes in mammalian cells is simply the time required to iteratively regrow populations of isolated
cells, which, in some cases, have doubling times greater than the doubling times of the yeast used in the current invention.
In certain embodiments of the invention, the composition of a library may be defined after one or more enrichment steps (for example by screening for antigen binding, or other properties). For example, a library with a composition comprising about x% sequences or libraries of the invention may be enriched to contain about 2x%, 3x%, 4x%, 5x%, 6x%, 7x%, 8x%, 9x%, 10x%, 20x%, 25x%, 40x%, 50x%, 60x% 75x%, 80x%, 90x%, 95x%,or 99x% sequences or libraries of the invention, after one or more screening steps. In other embodiments of the invention, the sequences or libraries of the invention may be enriched about 2-fold, 3-fold, 4-fold, 5-fold, 6-fold, 7-fold, 8-fold, 9-fold, 10-fold, 100-fold, 1, 000-fold, or more, relative to their occurrence prior to the one or more enrichment steps. In certain embodiments of the invention, a library may contain at least a certain number of a particular type of sequence(s), such as CDRFBs, CDRL3s, heavy chains, light chains, or whole antibodies (e.g., at least about 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, or 1020). In certain embodiments, these sequences may be enriched during one or more enrichment steps, to provide libraries com mpprriissiinngg aatt lleeaasstt aabboouutt 11002, 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, or 1019 of the respective sequence(s).
2.7. Mutagenesis Approaches for Affinity Maturation
As described above, antibody leads can be identified through a selection process that involves screening the antibodies of a library of the invention for binding to one or more antigens, or for a biological activity. The coding sequences of these antibody leads may be further mutagenized in vitro or in vivo to generate secondary libraries with diversity introduced in the context of the initial antibody leads. The mutagenized antibody leads can then be further screened for binding to target antigens or biological activity, in vitro or in vivo, following procedures similar to those used for the selection of the initial antibody lead from the primary library. Such mutagenesis and selection of primary antibody leads effectively mimics the affinity maturation process naturally occurring in a mammal that produces antibodies with progressive increases in the affinity to an antigen. In one embodiment of the invention, only the CDRH3 region is mutagenized. In another embodiment of the invention, the whole variable region is mutagenized. In other embodiments of the invention one or more of CDRHl, CDRH2, CDRH3, CDRLl, CDRL2,
and/ CDRL3 may be mutagenized. In some embodiments of the invention, "light chain shuffling" may be used as part of the affinity maturation protocol. In certain embodiments, this may involve pairing one or more heavy chains with a number of light chains, to select light chains that enhance the affinity and/or biological activity of an antibody. In certain embodiments of the invention, the number of light chains to which the one or more heavy chains can be paired is at least about 2, 5, 10, 100, 1000, 104, 105, 106, 107, 108, 109, or 1010. In certain embodiments of the invention, these light chains are encoded by plasmids. In other embodiments of the invention, the light chains may be integrated into the genome of the host cell. The coding sequences of the antibody leads may be mutagenized by a wide variety of methods. Examples of methods of mutagenesis include, but are not limited to site- directed mutagenesis, error-prone PCR mutagenesis, cassette mutagenesis, and random PCR mutagenesis. Alternatively, oligonucleotides encoding regions with the desired mutations can be synthesized and introduced into the sequence to be mutagenized, for example, via recombination or ligation.
Site-directed mutagenesis or point mutagenesis may be used to gradually change the CDR sequences in specific regions. This may be accomplished by using oligonucleotide- directed mutagenesis or PCR. For example, a short sequence of an antibody lead may be replaced with a synthetically mutagenized oligonucleotide in either the heavy chain or light chain region, or both. The method may not be efficient for mutagenizing large numbers of CDR sequences, but may be used for fine tuning of a particular lead to achieve higher affinity toward a specific target protein.
Cassette mutagenesis may also be used to mutagenize the CDR sequences in specific regions. In a typical cassette mutagenesis, a sequence block, or a region, of a single template is replaced by a completely or partially randomized sequence. However, the maximum information content that can be obtained may be statistically limited by the number of random sequences of the oligonucleotides. Similar to point mutagenesis, this method may also be used for fine tuning of a particular lead to achieve higher affinity towards a specific target protein. Error-prone PCR, or "poison" PCR, may be used to mutagenize the CDR sequences by following protocols described in Caldwell and Joyce, PCR Methods and Applications, 1992, 2: 28; Leung et ah, Technique, 1989, 1 : 11; Shafikhani et ah, Biotechniques, 1997,
23: 304; and Stemmer et al, PNAS, 1994, 91 : 10747 (each of which is incorporated by reference in its entirety).
Conditions for error prone PCR may include (a) high concentrations OfMn2+ (e.g., about 0.4 to about 0.6 mM) that efficiently induces malfunction of Taq DNA polymerase; and (b) a disproportionally high concentration of one nucleotide substrate (e.g., dGTP) in the PCR reaction that causes incorrect incorporation of this high concentration substrate into the template and produces mutations. Additionally, other factors such as, the number of PCR cycles, the species of DNA polymerase used, and the length of the template, may affect the rate of misincorporation of "wrong" nucleotides into the PCR product. Commercially available kits may be utilized for the mutagenesis of the selected antibody library, such as the "Diversity PCR random mutagenesis kit" (CLONTECH™).
The primer pairs used in PCR-based mutagenesis may, in certain embodiments, include regions matched with the homologous recombination sites in the expression vectors. This design allows facile re-introduction of the PCR products back into the heavy or light chain chassis vectors, after mutagenesis, via homologous recombination.
Other PCR-based mutagenesis methods can also be used, alone or in conjunction with the error prone PCR described above. For example, the PCR amplified CDR segments may be digested with DNase to create nicks in the double stranded DNA. These nicks can be expanded into gaps by other exonucleases such as BaI 31. The gaps may then be filled by random sequences by using DNA Klenow polymerase at a low concentration of regular substrates dGTP, dATP, dTTP, and dCTP with one substrate (e.g., dGTP) at a disproportionately high concentration. This fill-in reaction should produce high frequency mutations in the filled gap regions. These method of DNase digestion may be used in conjunction with error prone PCR to create a high frequency of mutations in the desired CDR segments.
The CDR or antibody segments amplified from the primary antibody leads may also be mutagenized in vivo by exploiting the inherent ability of mutation in pre-B cells. The Ig genes in pre-B cells are specifically susceptible to a high-rate of mutation. The Ig promoter and enhancer facilitate such high rate mutations in a pre-B cell environment while the pre-B cells proliferate. Accordingly, CDR gene segments may be cloned into a mammalian expression vector that contains a human Ig enhancer and promoter. This construct may be introduced into a pre-B cell line, such as 38B9, which allows the mutation of the VH and VL gene segments naturally in the pre-B cells (Liu and Van Ness, MoI. Immunol., 1999,
36: 461, incorporated by reference in its entirety). The mutagenized CDR segments can be amplified from the cultured pre-B cell line and re-introduced back into the chassis- containing vector(s) via, for example, homologous recombination.
In some embodiments, a CDR "hit" isolated from screening the library can be re- synthesized, using degenerate codons or trinucleotides, and re-cloned into the heavy or light chain vector using gap repair.
3. Library Sampling
In certain embodiments of the invention, a library of the invention comprises a designed, non-random repertoire wherein the theoretical diversity of particular components of the library (for example, CDRH3), but not necessarily all components or the entire library, can be over-sampled in a physical realization of the library, at a level where there is a certain degree of statistical confidence (e.g., 95%) that any given member of the theoretical library is present in the physical realization of the library at least at a certain frequency (e.g., at least once, twice, three times, four times, five times, or more) in the library.
In a library, it is generally assumed that the number of copies of a given clone obeys a Poisson probability distribution (see Feller, W. An Introduction to Probability Theory and Its Applications, 1968, Wiley New York, incorporated by reference in its entirety). The probability of a Poisson random number being zero, corresponding to the probability of missing a given component member in an instance of a library (see below), is e~N , where N is the average of the random number. For example, if there are 106 possible theoretical members of a library and a physical realization of the library has 107 members, with an equal probability of each member of the theoretical library being sampled, then the average number of times that each member occurs in the physical realization of the library is 107/106 =10, and the probability that the number of copies of a given member is zero is e~N = e~10 = 0.000045; or a 99.9955% chance that there is at least one copy of any of the 106 theoretical members in this 1OX oversampled library. For a 2.3X oversampled library one is 90% confident that a given component is present. For a 3X oversampled library one is 95% confident that a given component is present. For a 4.6X oversampled library one is 99% confident a given clone is present, and so on.
Therefore, if Mis the maximum number of theoretical library members that can be feasibly physically realized, then Mβ is the maximum theoretical repertoire size for which
one can be 95% confident that any given member of the theoretical library will be sampled. It is important to note that there is a difference between a 95% chance that a given member is represented and a 95% chance that every possible member is represented. In certain embodiments, the instant invention provides a rationally designed library with diversity so that any given member is 95% likely to be represented in a physical realization of the library. In other embodiments of the invention, the library is designed so that any given member is at least about 0.0001%, 0.001%, 0.01%, 0.1%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 99%, 99.5%, or 99.9% likely to be represented in a physical realization of the library. For a review, see, e.g., Firth and Patrick, Biomol. Eng., 2005 , 22 : 105 , and Patrick et al, Protein Engineering, 2003, 16: 451, each of which is incorporated by reference in its entirety.
In certain embodiments of the invention, a library may have a theoretical total diversity of X unique members and the physical realization of the theoretical total diversity may contain at least about IX, 2X, 3X, 4X, 5X, 6X, 7X, 8X 9X, 10X, or more members. In some embodiments, the physical realization of the theoretical total diversity may contain about IX to about 2X, about 2X to about 3X, about 3X to about 4X, about 4X to about 5X, about 5X to about 6X members. In other embodiments, the physical realization of the theoretical total diversity may contain about IX to about 3X, or about 3X to about 5X total members. An assumption underlying all directed evolution experiments is that the amount of molecular diversity theoretically possible is enormous compared with the ability to synthesize it, physically realize it, and screen it. The likelihood of finding a variant with improved properties in a given library is maximized when that library is maximally diverse. Patrick et al. used simple statistics to derive a series of equations and computer algorithms for estimating the number of unique sequence variants in libraries constructed by randomized oligonucleotide mutagenesis, error-prone PCR and in vitro recombination. They have written a suite of programs for calculating library statistics, such as GLUE, GLUE-IT, PEDEL, PEDEL-AA, and DRIVeR. These programs are described, with instructions on how to access them, in Patrick et al, Protein Engineering, 2003, 16: 45 land Firth et al, Nucleic Acids Res., 2008, 36: W281 (each of which is incorporated by reference in its entirety).
It is possible to construct a physical realization of a library in which some components of the theoretical diversity (such as CDRH3) are oversampled, while other
aspects (VH/VL pairings) are not. For example, consider a library in which 108 CDRH3 segments are designed to be present in a single VH chassis, and then paired with 105 VL genes to produce 1013 (= 108 * 105) possible full heterodimeric antibodies. If a physical realization of this library is constructed with a diversity of 109 transformant clones, then the CDRH3 diversity is oversampled ten-fold (= 109/108), however the possible VH/VL pairings are undersampled by 10~4 (= 109/1013). In this example, on average, each CDRH3 is paired only with 10 samples of the VL from the possible 105 partners. In certain embodiments of the invention, it is the CDRH3 diversity that is preferably oversampled.
3.1. Other Variants of the Polynucleotide Sequences of the Invention
In certain embodiments, the invention relates to a polynucleotide that hybridizes with a polynucleotide taught herein, or that hybridizes with the complement of a polynucleotide taught herein. For example, an isolated polynucleotide that remains hybridized after hybridization and washing under low, medium, or high stringency conditions to a polynucleotide taught herein or the complement of a polynucleotide taught herein is encompassed by the present invention.
Exemplary low stringency conditions include hybridization with a buffer solution of about 30% to about 35% formamide, about 1 M NaCl, about 1% SDS (sodium dodecyl sulphate) at about 370C, and a wash in about IX to about 2X SSC (2OX SSC=3.0 M NaCl/0.3 M trisodium citrate) at about 5O0C to about 550C.
Exemplary moderate stringency conditions include hybridization in about 40% to about 45% formamide, about 1 M NaCl, about 1% SDS at about 370C, and a wash in about 0.5X to about IX SSC at abut 550C to about 6O0C.
Exemplary high stringency conditions include hybridization in about 50% formamide, about 1 M NaCl, about 1% SDS at about 370C, and a wash in about 0.1X SSC at about 60° C to about 65° C.
Optionally, wash buffers may comprise about 0.1% to about 1% SDS.
The duration of hybridization is generally less than about 24 hours, usually about 4 to about 12 hours.
3.2. Sub-Libraries and Larger Libraries Comprising the Libraries or Sub-Libraries of the Invention
As described throughout the application, the libraries of the current invention are distinguished, in certain embodiments, by their human-like sequence composition and length, and the ability to generate a physical realization of the library which contains all members of (or, in some cases, even oversamples) a particular component of the library. Libraries comprising combinations of the libraries described herein (e.g., CDRH3 and CDRL3 libraries) are encompassed by the invention. Sub-libraries comprising portions of the libraries described herein are also encompassed by the invention (e.g., a CDRH3 library in a particular heavy chain chassis or a sub-set of the CDRH3 libraries). One of ordinary skill in the art will readily recognize that each of the libraries described herein has several components (e.g., CDRH3, VH, CDRL3, VL, etc.), and that the diversity of these components can be varied to produce sub-libraries that fall within the scope of the invention.
Moreover, libraries containing one of the libraries or sub-libraries of the invention also fall within the scope of the invention. For example, in certain embodiments of the invention, one or more libraries or sub-libraries of the invention may be contained within a larger library, which may include sequences derived by other means, for example, non- human or human sequence derived by stochastic or semi-stochastic synthesis. In certain embodiments of the invention, at least about 1% of the sequences in a polynucleotide library may be those of the invention (e.g., CDRH3 sequences, CDRL3 sequences, VH sequences, VL sequences), regardless of the composition of the other 99% of sequences. In other embodiments of the invention, at least about 0.001%, 0.01%, 0.1%, 2%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91,%, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% of the sequences in any polynucleotide library may be those of the invention, regardless of the composition of the other sequences. In some embodiments, the sequences of the invention may comprise about 0.001% to about 1%, about 1% to about 2%, about 2% to about 5%, about 5% to about 10%, about 10% to about 15%, about 15% to about 20%, about 20% to about 25%, about 25% to about 30%, about 30% to about 35%, about 35% to about 40%, about 40% to about 45%, about 45% to about 50%, about 50% to about 55%, about 55% to about 60%, about 60% to about 65%, about 65% to about 70%, about 70% to about 75%, about 75% to about 80%, about 80% to about 85%, about 85% to about 90%, about 90% to about 95%, or about 95% to about 99% of the sequences in any polynucleotide library, regardless of the composition of the other sequences. Thus, libraries more diverse than one or more libraries
or sub-libraries of the invention, but yet still comprising one or more libraries or sub- libraries of the invention, in an amount in which the one or more libraries or sub-libraries of the invention can be effectively screened and from which sequences encoded by the one or more libraries or sub-libraries of the invention can be isolated, also fall within the scope of the invention.
3.3. Alternative Scaffolds
In certain embodiments of the invention, the amino acid products of a library of the invention {e.g., a CDRH3 or CDRL3) may be displayed on an alternative scaffold. Several of these scaffolds have been shown to yield molecules with specificities and affinities that rival those of antibodies. Exemplary alternative scaffolds include those derived from fibronectin {e.g., AdNectin), the β-sandwich {e.g., iMab), lipocalin {e.g., Anticalin), EETI- II/AGRP, BPTI/LACI-D1/ITI-D2 {e.g., Kunitz domain), thioredoxin {e.g., peptide aptamer), protein A {e.g., Affibody), ankyrin repeats {e.g., DARPin), γB-crystallin/ubiquitin {e.g., Affϊlin), CTLD3 {e.g., Tetranectin), and (LDLR-A module^ {e.g., Avimers).
Additional information on alternative scaffolds are provided in Binz et ah, Nat. Biotechnol., 2005 23: 1257 and Skerra, Current Opin. in Biotech., 2007 18: 295-304, each of which is incorporated by reference in its entirety.
4. Other Embodiments of the Invention
In certain embodiments, the invention comprises a synthetic preimmune human antibody CDRH3 library comprising 107 to 108 polynucleotide sequences representative of the sequence diversity and length diversity found in known heavy chain CDR3 sequences.
In other embodiments, the invention comprises a synthetic preimmune human antibody CDRH3 library comprising polynucleotide sequences encoding CDRH3 represented by the following formula:
[G/D/E/-] [N 1 ] [DH] [N2] [H3 -JH] , wherein [G/D/E/-] is zero to one amino acids in length, [Nl] is zero to three amino acids, [DH] is three to ten amino acids in length, [N2] is zero to three amino acids in length, and [H3-JH] is two to nine amino acids in length.
In certain embodiments of the invention, [G/D/E/-] is represented by an amino acid sequence selected from the group consisting of: G, D, E, and nothing.
In some embodiments of the invention, [Nl] is represented by an amino acid sequence selected from the group consisting of: G, R, S, P, L, A, V, T, (G/P)(G/R/S/P/L/A/V/T), (R/S/L/A/V/T)(G/P), GG(G/R/S/P/L/A/WT), G(R/S/P/L/A/V/T)G, (R/S/P/L/A/V/T)GG, and nothing. In certain embodiments of the invention, [N2] is represented by an amino acid sequence selected from the group consisting of: G, R, S, P, L, A, V, T, (G/P)(G/R/S/P/L/A/V/T), (R/S/L/A/V/T)(G/P), GG(G/R/S/P/L/A/V/T), G(R/S/P/L/A/V/T)G, (R/S/P/L/A/V/T)GG, and nothing.
In some embodiments of the invention, [DH] comprises a sequence selected from the group consisting of: IGHD3- 10 reading frame 1 , IGHD3- 10 reading frame 2, IGHD3- 10 reading frame 3, IGHD3-22 reading frame 2, IGHD6-19 reading frame 1, IGHD6-19 reading frame 2, IGHD6-13 reading frame 1, IGHD6-13 reading frame 2, IGHD3-03 reading frame 3, IGHD2-02 reading frame 2, IGHD2-02 reading frame 3, IGHD4-17 reading frame 2, IGHD 1-26 reading frame 1, IGHD 1-26 reading frame 3, IGHD5-5/5-18 reading frame 3, IGHD2-15 reading frame 2, and all possible N-terminal and C-terminal truncations of the above-identified IGHDs down to three amino acids.
In certain embodiments of the invention, [H3-JH] comprises a sequence selected from the group consisting of: AEYFQH (SEQ ID NO: 17), EYFQH, YFQH, FQH, QH, YWYFDL (SEQ ID NO: 18), WYFDL, YFDL, FDL, DL, AFDV (SEQ ID NO: 19), FDV, DV, YFDY (SEQ ID NO: 20), FDY, DY, NWFDS (SEQ ID NO: 21), WFDS, FDS, DS, YYYYYGMDV (SEQ ID NO: 22), YYYYGMDV, YYYGMDV, YYGMDV, YGMDV, GMDV, MDV, and DV.
In some embodiments of the invention, the sequences represented by [G/D/E/-][Nl][ext-DH][N2][H3-JH] comprise a sequence of about 3 to about 26 amino acids in length.
In certain embodiments of the invention, the sequences represented by [G/D/E/-][Nl][ext-DH][N2][H3-JH] comprise a sequence of about 7 to about 23 amino acids in length.
In some embodiments of the invention, the library comprises about 107 to about 1010 sequences.
In certain embodiments of the invention, the library comprises about 107 sequences.
In some embodiments of the invention, the polynucleotide sequences of the libraries further comprise a 5' polynucleotide sequence encoding a framework 3 (FRM3) region on
the corresponding N-terminal end of the library sequence, wherein the FRM3 region comprises a sequence of about 1 to about 9 amino acid residues.
In certain embodiments of the invention , the FRM3 region comprises a sequence selected from the group consisting of CAR, CAK, and CAT. In some embodiments of the invention, the polynucleotide sequences further comprise a 3 ' polynucleotide sequence encoding a framework 4 (FRM4) region on the corresponding C-terminal end of the library sequence, wherein the FRM4 region comprises a sequence of about 1 to about 9 amino acid residues.
In certain embodiments of the invention, the library comprises a FRM4 region comprising a sequence selected from WGRG (SEQ ID NO: 23) and WGQG (SEQ ID NO: 23).
In some embodiments of the invention, the polynucleotide sequences further comprise an FRM3 region coding for a corresponding polypeptide sequence comprising a sequence selected from the group consisting of CAR, CAK, and CAT; and an FRM4 region coding for a corresponding polypeptide sequence comprising a sequence selected from WGRG (SEQ ID NO: 23) and WGQG (SEQ ID NO: 23).
In certain embodiments of the invention, the polynucleotide sequences further comprise 5 ' and 3 ' sequences which facilitate homologous recombination with a heavy chain chassis. In some embodiments, the invention comprises a synthetic preimmune human antibody light chain library comprising polynucleotide sequences encoding human antibody kappa light chains represented by the formula:
[IGKV (1-95)][F/L/I/R/W/Y][JK].
In certain embodiments of the invention, [IGKV (1-95)] is selected from the group consisting of IGKV3-20 (1-95), IGKV1-39 (1-95), IGKV3-11 (1-95), IGKV3-15 (1-95), IGKV1-05 (1-95), IGKV4-01 (1-95), IGKV2-28 (1-95), IGKV 1-33 (1-95), IGKV1-09 (1- 95), IGKV1-12 (1-95), IGKV2-30 (1-95), IGKV1-27 (1-95), IGKV1-16 (1-95), and truncations of said group up to and including position 95 according to Kabat.
In some embodiments of the invention, [F/L/I/R/W/Y] is an amino acid selected from the group consisting of F, L, I, R, W, and Y.
In certain embodiments of the invention, [JK] comprises a sequence selected from the group consisting of TFGQGTKVEIK (SEQ ID NO: 528) and TFGGGT (SEQ ID NO: 529).
In some embodiments of the invention, the light chain library comprises a kappa light chain library.
In certain embodiments of the invention, the polynucleotide sequences further comprise 5 ' and 3 ' sequences which facilitate homologous recombination with a light chain chassis.
In some embodiments, the invention comprises a method for producing a synthetic preimmune human antibody CDRH3 library comprising 107 to 108 polynucleotide sequences, said method comprising: a) selecting the CDRH3 polynucleotide sequences encoded by the CDRH3 sequences, as follows:
{0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by terminal deoxynucleotidyl transferase (TdT) and preferentially functionally expressed by human B cells}, followed by
{all possible N or C-terminal truncations of IGHD alone and all possible combinations of N and C-terminal truncations}, followed by
{0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by TdT and preferentially functionally expressed by human B cells}, followed by
{all possible N-terminal truncations of IGHJ, down to DXWG, wherein X is S, V, L, or Y} ; and b) synthesizing the CDRH3 library described in a) by chemical synthesis, wherein a synthetic preimmune human antibody CDRH3 library is produced.
In certain embodiments, the invention comprises a synthetic preimmune human antibody CDRH3 library comprising 107 to 1010 polynucleotide sequences representative of known human IGHD and IGHJ germline sequences encoding CDRH3, represented by the following formula:
{0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by terminal deoxynucleotidyl transferase (TdT) and preferentially functionally expressed by human B cells}, followed by {all possible N or C-terminal truncations of IGHD alone and all possible combinations of N and C-terminal truncations}, followed by
{0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by TdT and preferentially functionally expressed by human B cells}, followed by
{all possible N-terminal truncations of IGHJ, down to DXWG (SEQ ID NO: 530), wherein X is S, V, L, or Y} .
In certain embodiments, the invention comprises a synthetic preimmune human antibody heavy chain variable domain library comprising 107 to 1010 polynucleotide sequences encoding human antibody heavy chain variable domains, said library comprising: a) an antibody heavy chain chassis, and b) a CDRH3 repertoire designed based on the human IGHD and IGHJ germline sequences, as follows:
{0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by terminal deoxynucleotidyl transferase (TdT) and preferentially functionally expressed by human B cells}, followed by
{all possible N or C-terminal truncations of IGHD alone and all possible combinations of N and C-terminal truncations}, followed by
{0 to 5 amino acids selected from the group consisting of fewer than ten of the amino acids preferentially encoded by TdT and preferentially functionally expressed by human B cells} , followed by
{all possible N-terminal truncations of IGHJ, down to DXWG (SEQ ID NO: 530), wherein X is S, V, L, or Y} .
In some embodiments of the invention, the synthetic preimmune human antibody heavy chain variable domain library is expressed as a full length chain selected from the group consisting of an IgGl full length chain, an IgG2 full length chain, an IgG3 full length chain, and an IgG4 full length chain.
In certain embodiments of the invention, the human antibody heavy chain chassis is selected from the group consisting of IGHV4-34, IGHV3-23, IGHV5-51, IGHV1-69, IGHV3-30, IGHV4-39, IGHV1-2, IGHV1-18, IGHV2-5, IGHV2-70, IGHV3-7, IGHV6-1, IGHV1-46, IGHV3-33, IGHV4-31, IGHV4-4, IGHV4-61, and IGHV3-15.
In some embodiments of the invention, the synthetic preimmune human antibody heavy chain variable domain library comprises 107 to 1010 polynucleotide sequences encoding human antibody heavy chain variable domains, said library comprising:
a) an antibody heavy chain chassis, and b) a synthetic preimmune human antibody CDRH3 library.
In some embodiments of the invention, the polynucleotide sequences are single- stranded coding polynucleotide sequences. In certain embodiments of the invention, the polynucleotide sequences are single- stranded non-coding polynucleotide sequences.
In some embodiments of the invention, the polynucleotide sequences are double- stranded polynucleotide sequences.
In certain embodiments, the invention comprises a population of replicable cells with a doubling time of four hours or less, in which a synthetic preimmune human antibody repertoire is expressed.
In some embodiments of the invention, the population of replicable cells are yeast cells.
In certain embodiments, the invention comprises a method of generating a full- length antibody library comprising transforming a cell with a preimmune human antibody heavy chain variable domain library and a synthetic preimmune human antibody light chain library.
In some embodiments, the invention comprises a method of generating a full-length antibody library comprising transforming a cell with a preimmune human antibody heavy chain variable domain library and a synthetic preimmune human antibody light chain library.
In certain embodiments, the invention comprises a method of generating an antibody library comprising synthesizing polynucleotide sequences by split-pool DNA synthesis. In some embodiments of the invention, the polynucleotide sequences are selected from the group consisting of single-stranded coding polynucleotide sequences, single- stranded non-coding polynucleotide sequences, and double-stranded polynucleotide sequences.
In certain embodiments, the invention comprises a synthetic full-length preimmune human antibody library comprising about 107 to about 1010 polynucleotide sequences representative of the sequence diversity and length diversity found in known heavy chain CDR3 sequences.
In certain embodiments, the invention comprises a method of selecting an antibody of interest from a human antibody library, comprising providing a synthetic preimmune human antibody CDRH3 library comprising a theoretical diversity of (N) polynucleotide sequences representative of the sequence diversity and length diversity found in known heavy chain CDR3 sequences, wherein the physical realization of that diversity is an actual library of a size at least 3(N), thereby providing a 95% probability that a single antibody of interest is present in the library, and selecting an antibody of interest.
In some embodiments of the invention, the theoretical diversity is about 107 to about 108 polynucleotide sequences.
EXAMPLES
This invention is further illustrated by the following examples which should not be construed as limiting. The contents of all references, patents and published patent applications cited throughout this application are hereby incorporated by reference. In general, the practice of the present invention employs, unless otherwise indicated, conventional techniques of chemistry, molecular biology, recombinant DNA technology, PCR technology, immunology (especially, e.g., antibody technology), expression systems (e.g. , yeast expression, cell-free expression, phage display, ribosome display, and PROFUSION™), and any necessary cell culture that are within the skill of the art and are explained in the literature. See, e.g., Sambrook, Fritsch and Maniatis, Molecular Cloning: Cold Spring Harbor Laboratory Press (1989); DNA Cloning, VoIs. 1 and 2, (D.N. Glover, Ed. 1985); Oligonucleotide Synthesis (MJ. Gait, Ed. 1984); PCR Handbook Current Protocols in Nucleic Acid Chemistry, Beaucage, Ed. John Wiley & Sons (1999) (Editor); Oxford Handbook of Nucleic Acid Structure, Neidle, Ed., Oxford Univ Press (1999); PCR Protocols: A Guide to Methods and Applications, Innis et al, Academic Press (1990); PCR Essential Techniques: Essential Techniques, Burke, Ed., John Wiley & Son Ltd (1996); The PCR Technique: RT-PCR, Siebert, Ed., Eaton Pub. Co. (1998); Antibody Engineering Protocols (Methods in Molecular Biology), 510, Paul, S., Humana Pr (1996); Antibody Engineering: A Practical Approach (Practical Approach Series, 169), McCafferty, Ed., IrI Pr (1996); Antibodies: A Laboratory Manual, Harlow et al, C.S.H.L. Press, Pub. (1999); Current Protocols in Molecular Biology, eds. Ausubel et al., John Wiley & Sons (1992); Large-Scale Mammalian Cell Culture Technology, Lubiniecki, A., Ed., Marcel Dekker, Pub., (1990); Phage Display: A Laboratory Manual, C. Barbas (Ed.), CSHL Press, (2001);
Antibody Phage Display, P O'Brien (Ed.), Humana Press (2001); Border et al, Nature
Biotechnology, 1997, 15: 553; Border et al, Methods EnzymoL, 2000, 328: 430; ribosome display as described by Pluckthun et al in U.S. Patent No. 6,348,315, and Profusion™ as described by Szostak et al. in U.S. Patent Nos. 6,258,558; 6,261,804; and 6,214,553; and bacterial periplasmic expression as described in US20040058403A1. Each of the references cited in this paragraph is incorporated by reference in its entirety.
Further details regarding antibody sequence analysis using Kabat conventions and programs to screen aligned nucleotide and amino acid sequences may be found, e.g., in
Johnson et al, Methods MoI. Biol, 2004, 248: 11; Johnson et al, Int. Immunol, 1998, 10: 1801; Johnson et al, Methods MoI. Biol, 1995, 51 : 1; Wu et al, Proteins, 1993, 16: 1; and
Martin, Proteins, 1996, 25: 130. Each of the references cited in this paragraph is incorporated by reference in its entirety.
Further details regarding antibody sequence analysis using Chothia conventions may be found, e.g., in Chothia et al, J. MoI. Biol, 1998, 278: 457; Morea et al, Biophys. Chem., 1997, 68: 9; Morea et al, J. MoI. Biol, 1998, 275: 269; Al-Lazikani et al, J. MoI.
Biol, 1997, 273: 927. Barre et al, Nat. Struct. Biol, 1994, 1 : 915; Chothia et al, J. MoI.
Biol, 1992, 227: 799; Chothia et al, Nature, 1989, 342: 877; and Chothia et al, J. MoI.
Biol., 1987, 196: 901. Further analysis of CDRH3 conformation may be found in Shirai et al, FEBS Lett., 1999, 455: 188 and Shirai et al, FEBS Lett., 1996, 399: 1. Further details regarding Chothia analysis are described, for example, in Chothia et al, Cold Spring Harb.
Symp. Quant Biol., 1987, 52: 399. Each of the references cited in this paragraph is incorporated by reference in its entirety.
Further details regarding CDR contact considerations are described, for example, in
MacCallum et al., J. MoI. Biol., 1996, 262: 732, incorporated by reference in its entirety. Further details regarding the antibody sequences and databases referred to herein are found, e.g., in Tomlinson et al, J. MoI. Biol., 1992, 227: 776, VBASE2 (Retter et al,
Nucleic Acids Res., 2005, 33: D671); BLAST (www.ncbi.nlm.nih.gov/BLAST/); CDHIT
(bioinf ormatics . Ij erf. edu/cd-hi/) ; EMB OSS ( www.hgmp . mrc . ac .uk/S oftware/EMB OSS/);
PHYLIP (evolution.genetics.washington.edu/phylip.html); and FASTA (fasta.bioch.virginia.edu). Each of the references cited in this paragraph is incorporated by reference in its entirety.
Example 1: Design of an Exemplary VH Chassis Library
This example demonstrates the selection and design of exemplary, non- limiting VH chassis sequences of the invention. VH chassis sequences were selected by examining collections of human IGHV germline sequences (Scaviner et al, Exp. Clin. Immunogenet., 1999, 16: 234; Tomlinson et al, J. MoI. Biol, 1992, 227: 799; Matsuda et al, J. Exp. Med., 1998, 188: 2151, each incorporated by reference in its entirety). As discussed in the
Detailed Description, as well as below, a variety of criteria can be used to select VH chassis sequences, from these data sources or others, for inclusion in the library.
Table 3 (adapted from information provided in Scaviner et al, Exp. Clin. Immunogenet., 1999, 16: 234; Matsuda et al, J. Exp. Med., 1998, 188: 2151; and Wang et al Immunol. Cell. Biol., 2008, 86: 111, each incorporated by reference in its entirety) lists the CDRHl and CDRH2 length, the canonical structure and the estimated relative occurrence in peripheral blood, for the proteins encoded by each of the human IGHV germline sequences.


2Adapted from Table Sl of Wang et al, Immunol. Cell. Biol., 2008, 86: 111
In the currently exemplified library, 17 germline sequences were chosen for representation in the VH chassis of the library (Table 4). As described in more detail below, these sequences were selected based on their relatively high representation in the peripheral blood of adults, with consideration given to the structural diversity of the chassis and the representation of particular germline sequences in antibodies used in the clinic. These 17 sequences account for about 76% of the total sample of heavy chain sequences used to derive the results of Table 4. As outlined in the Detailed Description, these criteria are non-limiting, and one of ordinary skill in the art will readily recognize that a variety of other criteria can be used to select the VH chassis sequences, and that the invention is not limited to a library comprising the 17 VH chassis genes presented in Table 4.
Table 4. VH Chassis Selected for Use in the Exem lar Librar


In this particular embodiment of the library, VH chassis derived from sequences in the IGHV2, IGHV6 and IGHV7 germline families were not included. As described in the Detailed Description, this exemplification is not meant to be limiting, as, in some embodiments, it may be desirable to include one or more of these families, particularly as clinical information on antibodies with similar sequences becomes available, to produce libraries with additional diversity that is potentially unexplored, or to study the properties and potential of these IGHV families in greater detail. The modular design of the library of the present invention readily permits the introduction of these, and other, VH chassis sequences. The amino acid sequences of the VH chassis utilized in this particular embodiment of the library, which are derived from the IGHV germline sequences, are presented in Table 5. The details of the derivation procedures are presented below.
Table 5. Amino Acid Sequences for VH Chassis Selected for Inclusion in the Exemplary Library
I Chassis I SEQ ID FRM1 I CDRH1 FRM2 I CDRH2 I FRM3 I
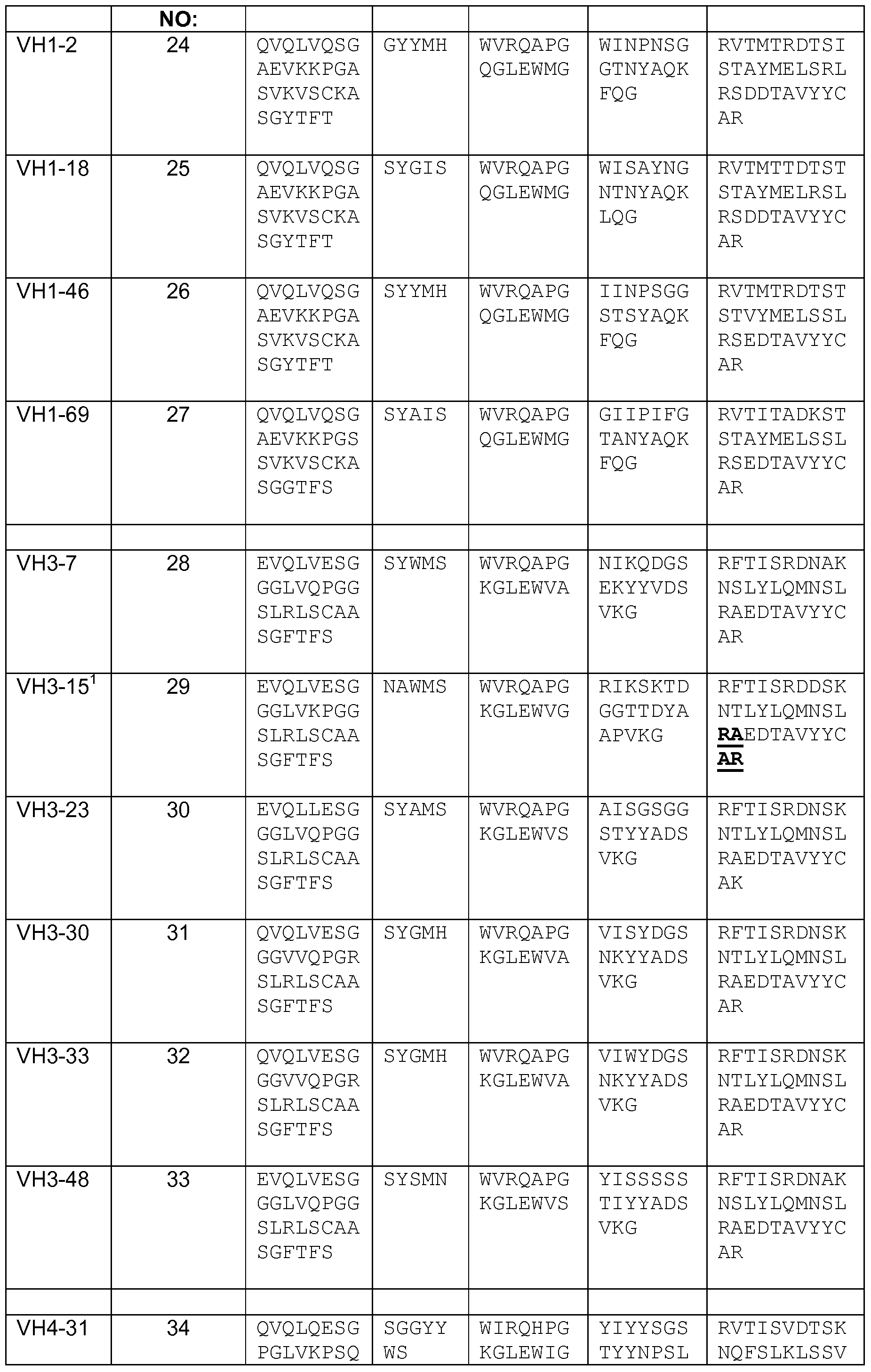

The original KT sequence in VH3-15 was mutated to RA (bold/underlined) and TT to AR (bold/underlined), in order to match other VH3 family members selected for inclusion in the library. The modification to RA was made so that no unique sequence stretches of up to about 20 amino acids are created. Without being bound by theory, this modification is expected to reduce the odds of introducing novel T-cell epitopes in the VH3-15-derived chassis sequence. The avoidance of T cell epitopes is an additional criterion that can be considered in the design of certain libraries of the invention.
2The original NHS motif in VH4-34 was mutated to DHS, in order to remove a possible N- linked glycosylation site in CDR-H2. In certain embodiments of the invention, for example, if the library is transformed into yeast, this may prevent unwanted N-linked glycosylation.
Table 5 provides the amino acid sequences of the seventeen chassis. In nucleotide space, most of the corresponding germline nucleotide sequences include two additional nucleotides on the 3' end (i.e., two-thirds of a codon). In most cases, those two nucleotides are GA. In many cases, nucleotides are added to the 3' end of the IGHV-derived gene segment in vivo, prior to recombination with the IGHD gene segment. Any additional
nucleotide would make the resulting codon encode one of the following two amino acids: Asp (if the codon is GAC or GAT) or GIu (if the codon is GAA or GAG). One, or both, of the two 3 '-terminal nucleotides may also be deleted in the final rearranged heavy chain sequence. If only the A is deleted, the resulting amino acid is very frequently a G. If both nucleotides are deleted, this position is "empty," but followed by a general V-D addition or an amino acid encoded by the IGHD gene. Further details are presented in Example 5. This first position, after the CAR or CAK motif at the C-terminus of FRM3 (Table 5), is designated the "tail." In the currently exemplified embodiment of the library, this residue may be G, D, E, or nothing. Thus, adding the tail to any chassis enumerated above (Table 5) can produce one of the following four schematic sequences, wherein the residue following the VH chassis is the tail:
(1) [VH_Chassis]-[G]
(2) [VH_Chassis]-[D]
(3) [VH_Chassis]-[E] (4) [VH Chassis]
These structures can also be represented in the format: [VH_Chassis]-[G/D/E/-], wherein the hyphen symbol (-) indicates an empty or null position. Using the CDRH3 numbering system defined in the Definitions section, the above sequences could be denoted to have amino acid 95 as G, D, or E, for instances (1), (2), and
(3), respectively, while the sequence of instance 4 would have no position 95, and CDRH3 proper would begin at position 96 or 97.
In some embodiments of the invention, VH3-66, with canonical structure 1-1 (five residues in CDRHl and 16 for CDRH2) may be included in the library. The inclusion of
VH3-66 may compensate for the removal of other chassis from the library, which may not express well in yeast under some conditions (e.g., VH4-34 and VH4-59).
Example 2: Design of VH Chassis Variants with Variation Within CDRHl and CDRH2 This example demonstrates the introduction of further diversity into the VH chassis by creating mutations in the CDRHl and CDRH2 regions of each chassis shown in Example 1. The following approach was used to select the positions and nature of the amino acid variation for each chassis: First, the sequence identity between rearranged human heavy chain antibody sequences was analyzed (Lee et ah, Immunogenetics, 2006, 57: 917; Jackson et al, J. Immunol. Methods, 2007, 324: 26) and they were classified by
the origin of their respective IGHV germline sequence. As an illustrative example, about 200 sequences in the data set exhibited greatest identity to the IGHV 1-69 germline, indicating that they were likely to have been derived from IGHV 1-69. Next, the occurrence of amino acid residues at each position within the CDRHl and CDRH2 segments, in each germline family selected in Example 1 was determined. For VH 1-69, these occurrences are illustrated in Tables 6 and 7. Second, neutral and/or smaller amino acid residues were favored, where possible, as replacements. Without being bound by theory, the rationale for the choice of these amino acid residues is the desire to provide a more flexible and less sterically hindered context for the display of a diversity of CDR sequences.
Table 6. Occurrence of Amino Acid Residues at Each Position Within IGHVl-69-derived CDRHl Sequences


The original germline sequence is provided in the second row of the tables, in bold font, beneath the residue number (Kabat system). The entries in the table indicate the number of times a given amino acid residue (first column) is observed at the indicated CDRHl (Table 6) or CDRH2 (Table 7) position. For example, at position 33 the amino acid type G (glycine) is observed 24 times in the set of IGHVl -69-based sequences that were examined. Thus, applying the criteria above, variants were constructed with N at position 31 , L at position 32 (H can be charged, under some conditions), G and T at position 33, no variants at position 34 and N at position 35, resulting in the following VH 1-69 chassis CDRHl single-amino acid variant sequences:
NYAIS (SEQ ID NO: 41)
SLAIS (SEQ ID NO: 42)
SYGIS (SEQ ID NO: 43)
SYTIS (SEQ ID NO: 44) SYAIN (SEQ ID NO: 45)
Similarly, the analysis that produced Table 7 provided a basis for choosing the following single-amino acid variant sequences for VH 1-69 chassis CDRH2s:
SIIPIFGTANYAQKFQG (SEQ ID NO: 46) GIAPIFGTANYAQKFQG (SEQ ID NO: 47)
GIIPILGTANYAQKFQG (SEQ ID NO: 48)
GIIPIFGTASYAQKFQG (SEQ ID NO: 49)
A similar approach was used to design and construct variants of the other selected chassis; the resulting CDRHl and CDRH2 variants for each of the exemplary chassis are provided in Table 8. One of ordinary skill in the art will readily recognize that the methods described herein can be applied to create variants of other VH chassis and VL chassis.
Table 8. VH Chassis Variants

O

O


O

O

O

O OO

O

Contains an N-linked glycosylation site which can be removed, if desired, as described herein.
As specified in the Detailed Description, other criteria can be used to select which amino acids are to be altered and the identity of the resulting altered sequence. This is true for any heavy chain chassis sequence, or any other sequence of the invention. The approach outlined above is meant for illustrative purposes and is non- limiting.
Example 3: Design of an Exemplary VK Chassis Library This example describes the design of an exemplary VK chassis library. One of ordinary skill in the art will recognize that similar principles may be used to design a Vλ library, or a library containing both VK and Vλ chassis. Design of a Vλ chassis library is presented in Example 4.
As was previously demonstrated in Example 1, for IGHV germline sequences, the sequence characteristics and occurrence of human IGKV germline sequences in antibodies from peripheral blood were analyzed. The data are presented in Table 9.


The 14 most commonly occurring IGKV germline genes (bolded in column 6 of Table 9) account for just over 90% of the usage of the entire repertoire in peripheral blood. From the analysis of Table 9, ten IGKV germline genes were selected for representation as chassis in the currently exemplified library (Table 10). All but Vl -12 and V 1-27 are among the top 10 most commonly occurring. IGKV germline genes VH2-30, which was tenth in terms of occurrence in peripheral blood, was not included in the currently exemplified embodiment of the library, in order to maintain the proportion of chassis with short {i.e., 11 or 12 residues in length) CDRLl sequences at about 80% in the final set of 10 chassis. Vl -12 was included in its place. Vl-17 was more similar to other members of the Vl family that were already selected ; therefore, V 1-27 was included, instead of Vl-17. In other embodiments, the library could include 12 chassis {e.g., the ten of Table 10 plus Vl-17 and V2-30), or a different set of any "N" chassis, chosen strictly by occurrence (Table 9) or any other criteria. The ten chosen VK chassis account for about 80% of the usage in the data set believed to be representative of the entire kappa light chain repertoire.
Table 10. VK Chassis Selected for Use in the Exem lar Librar


The amino acid sequences of the selected VK chassis enumerated in Table 10 are provided in Table 11.
Table 11. Amino Acid Sequences for VK Chassis Selected for Inclusion in the Exem lar Librar


Note that the portion of the IGKV gene contributing to VKCDR3 is not considered part of the chassis as described herein. The VK chassis is defined as Kabat residues 1 to 88 of the IGKV-encoded sequence, or from the start of FRMl to the end of FRM3. The portion of the VKCDR3 sequence contributed by the IGKV gene is referred to herein as the L3-VK region.
Example 4: Design of an Exemplary Vλ Chassis Library
This example, describes the design of an exemplary Vλ chassis library. As was previously demonstrated in Examples 1-3, for the VH and VK chassis sequences, the sequence characteristics and occurrence of human IgλV germline-derived sequences in peripheral blood were analyzed. As with the assignment of other sequences set forth herein to germline families, assignment of Vλ sequences to a germline family was performed via SoDA and VBASE2 (Volpe and Kepler, Bioinformatics, 2006, 22: 438; Mollova et ah, BMS Systems Biology, 2007, IS: P30, each incorporated by reference in its entirety). The data are presented in Table 12.


2Estimated from a set of human Vλ sequences compiled from the NCBI database; full set of GI codes set forth in Appendix B.
To choose a subset of the sequences from Table 12 to serve as chassis, those represented at less than 1% in peripheral blood (as extrapolated from analysis of published sequences corresponding to the GI codes provided in Appendix B) were first discarded. From the remaining 18 germline sequences, the top occurring genes for each unique canonical structure and contribution to CDRL3, as well as any germline gene represented at more than the 5% level, were chosen to constitute the exemplary Vλ chassis. The list of 11 such sequences is given in Table 13, below. These 11 sequences represent approximately 73% of the repertoire in the examined data set (Appendix B).
Table 13. Vλ Chassis Selected for Use in the Exemplary Library

Table 14. Amino Acid Sequences for Vλ Chassis Selected for Inclusion in the Exem lar Librar

VλCDR3 is not considered part of the chassis as described herein. The Vλ chassis is defined as Kabat residues 1 to 88 of the IGλV-encoded sequence, or from the start of FRMl to the end of FRM3. The portion of the VλCDR3 sequence contributed by the IGλV gene is referred to herein as the L3-Vλ region.
Example 5: Design of a CDRH3 Library
This example describes the design of a CDHR3 library from its individual components. In nature, the CDRH3 sequence is derived from a complex process involving recombination of three different genes, termed IGHV, IGHD and IGHJ. In addition to recombination, these genes may also undergo progressive nucleotide deletions: from the 3' end of the IGHV gene, either end of the IGHD gene, and/or the 5' end of the IGHJ gene. Non-templated nucleotide additions may also occur at the junctions between the V, D and J sequences. Non-templated additions at the V-D junction are referred to as "Nl", and those at the D-J junction are referred to as "N2". The D gene segments may be read in three forward and, in some cases, three reverse reading frames.
In the design of the present exemplary library, the codon (nucleotide triplet) or single amino acid was designated as a fundamental unit, to maintain all sequences in the desired reading frame. Thus, all deletions or additions to the gene segments are carried out via the addition or deletion of amino acids or codons, and not single nucleotides. According to the CDRH3 numbering system of this application, CDRH3 extends from amino acid number 95 (when present; see Example 1) to amino acid 102.
Example 5.1: Selection of the DH Segments In this illustrative example, selection of DH gene segments for use in the library was performed according to principles similar to those used for the selection of the chassis sequences. First, an analysis of IGHD gene usage was performed, using data from Lee et ah, Immunogenetics, 2006, 57: 917; Corbett et ah, PNAS, 1982, 79: 4118; and Souto-Carneiro et ah, J. Immunol., 2004, 172: 6790 (each incorporated by reference in its entirety), with preference for representation in the library given to those IGHD genes most frequently observed in human sequences. Second, the degree of deletion on either end of the IGHD gene segments was estimated by comparison with known heavy
chain sequences, using the SoDA algorithm (Volpe et al., Bioinformatics, 2006, 22: 438, incorporated by reference in its entirety) and sequence alignments. For the presently exemplified library, progressively deleted DH segments, as short as three amino acids, were included. As enumerated in the Detailed Description, other embodiments of the invention comprise DH segments with deletions to a different length, for example, about 1, 2, 4, 5, 6, 7, 8, 9, or 10 amino acids. Table 15 shows the relative occurrence of IGHD gene usage in human antibody heavy chain sequences isolated mainly from peripheral blood B cells (list adapted from Lee et al., Immunogenetics, 2006, 57: 917, incorporated by reference in its entirety).
Table 15. Usage of IGHD Genes Based on Relative Occurrence in Peripheral Blood*

2IGHD4-4 and IGHD4-11 are also 100% identical.
3Adapted from Lee et al. Immunogenetics, 2006, 57: 917, by merging the information for distinct alleles of the same IGHD gene.
* IGHD 1-14 may also be included in the libraries of the invention.
The translations of the ten most commonly expressed IGHD gene sequences found in naturally occurring human antibodies, in three reading frames, are shown in Table 16. Those reading frames which occur most commonly in peripheral blood have been highlighted in gray. As in Table 15, data regarding IGHD sequence usage and reading frame statistics were derived from Lee et al, 2006, and data regarding IGHD sequence reading frame usage were further complemented by data derived from Corbett et al, PNAS, 1982, 79: 4118 and Souto-Carneiro et al, J. Immunol, 2004, 172: 6790, each of which is incorporated by reference in its entirety.
Table 16. Translations of the Ten Most Common Naturally Occurring IGHD Sequences, in Three Reading Frames (RF)

# represents a stop codon.
Reading frames highlighted in gray correspond to the most commonly used reading frames.
In the presently exemplified library, the top 10 IGHD genes most frequently used in heavy chain sequences occurring in peripheral blood were chosen for representation in the library. Other embodiments of the library could readily utilize more or fewer D genes. The amino acid sequences of the selected IGHD genes, including the most commonly used reading frames and the total number of variants after progressive N- and C-terminal deletion to a minimum of three residues, are listed in Table 17. As depicted in Table 17, only the most commonly occurring alleles of certain IGHD genes were included in the illustrative library. This is, however, not required, and other embodiments of the invention may utilize IGHD reading frames that occur less frequently in the peripheral blood.
Table 17. D Genes Selected for use in the Exemplary Library


2In most cases the total number of variants is given by (N-I) times (N-2) divided by two, where N is the total length in amino acids of the intact D segment.
As detailed herein, the number of variants for segments containing a putative disulfide bond (two C or Cys residues) is limited in this illustrative embodiment.
For each of the selected sequences of Table 17, variants were generated by systematic deletion from the N- and/or C-termini, until there were three amino acids remaining. For example, for the IGHD4-17 2 above, the full sequence DYGDY (SEQ ID NO: 12) may be used to generate the progressive deletion variants: DYGD, YGDY, DYG, GDY and YGD. In general, for any full-length sequence of size N, there will be a total of (N-l)*(N-2)/2 total variants, including the original full sequence. For the disulfϊde-loop-encoding segments, as exemplified by reading frame 2 of both IGHD2-2 and IGHD2-15, (i.e., IGHD2-2 2 and IGH2-15 2), the progressive deletions were limited, so as to leave the loop intact i.e., only amino acids N-terminal to the first Cys, or C-terminal to the second Cys, were deleted in the respective DH segment variants. The foregoing strategy was used to avoid the presence of unpaired cysteine residues in the exemplified version of the library. However, as discussed in the Detailed Description, other embodiments of the library may include unpaired cysteine residues, or the substitution of these cysteine residues with other amino acids. In the cases where the truncation of the IGHD gene is limited by the presence of the Cys residues, only 9 variants (including the original full sequence) were generated; e.g., for IGHD2-2 2, the variants would be: GYCSSTSCYT (SEQ ID NO: 10), GYCSSTSCY, YCSSTSCYT, CSSTSCYT, GYCSSTSC, YCSSTSCY, CSSTSCY, YCSSTSC and CSSTSC.
According to the criteria outlined above, 293 DH sequences were obtained from the selected IGHD gene segments, including the original IGHD gene segments. Certain sequences are redundant. For example, it is possible to obtain the YYY variant from either IGHD3-10 2 (full sequence YYYGSGSYYN (SEQ ID NO: 2)), or in two different ways from IGHD3-22_2 (SEQ ID NO: 4) (YYYDSSGYYY). When redundant sequences are removed, the number of unique DH segment sequences in this illustrative embodiment of the library is 278. These sequences are enumerated in Table 18.
Table 18. DH Gene Segments Used in the Presently Exemplified Library*





1TlIe sequence designation is formatted as follows: (IGHD Gene Name)_(Reading Frame)- (Variant Number)
* Note that the origin of certain variants is rendered somewhat arbitrary when redundant segments are deleted from the library (i.e., certain segments may have their origins with more than one parent, including the one specified in the table).
(a) derived from SEQ ID NO: 13; (b) derived from SEQ ID NO: 14; (c) derived from SEQ ID NO: 10; (d) derived from SEQ ID NO: 11; (e) derived from SEQ ID NO: 16; (f) derived from SEQ ID NO: 9; (g) derived from SEQ ID NO: 1 ; (h) derived from SEQ ID NO: 2; (i) derived from SEQ ID NO: 3; Q) derived from SEQ ID NO: 4; (k) derived from SEQ ID NO: 12; (I) derived from SEQ ID NO: 15; (m) derived from SEQ ID NO: 7; (n) derived from SEQ ID NO: 5; (o) derived from SEQ ID NO: 6; Qp) derived from SEQ ID NO: 8.
Table 19 shows the length distribution of the 278 DH segments selected according to the methods described above.
Table 19 Length Distributions of DH Segments Selected for Inclusion in the Exemplary Library

As specified above, based on the CDRH3 numbering system defined in this application, IGHD-derived amino acids (i.e., DH segments) are numbered beginning with position 97, followed by positions 97A, 97B, etc. In the currently exemplified embodiment of the library, the shortest DH segment has three amino acids: 97, 97A and 97B, while the longest DH segment has 10 amino acids: 97, 97A, 97B, 97C, 97D, 97E, 97F, 97G, 97H and 971.
Example 5.2: Selection of the H3- JH Segments
There are six human germline IGHJ genes. During in vivo assembly of antibody genes, these segments are progressively deleted at their 5' end. In this exemplary
embodiment of the library, IGHJ gene segments with no deletions, or with 1, 2, 3, 4, 5, 6, or 7 deletions (at the amino acid level), yielding JH segments as short as 13 amino acids, were included (Table 20). Other embodiments of the invention, in which the IGHJ gene segments are progressively deleted (at their 5' / N-terminal end) to yield 15, 14, 12, or 11 amino acids are also contemplated.

(α) derived from SEQ ID NO: 253; (b) derived from SEQ ID NO: 254; (c) derived from SEQ ID NO: 255; (d) derived from SEQ ID NO: 256; (e) derived from SEQ ID NO: 257; (f) derived from SEQ ID NO: 258; (g) derived from SEQ ID NOs: 17 and 253; (h) derived from
SEQ ID NOs: 18 and 254; Q) derived from SEQ ID NOs: 19 and 255; Q) derived from SEQ ID NOs: 20 and 256; (k) derived from SEQ ID NOs: 21 and 257; (I) derived from SEQ ID NOs: 22 and 258. According to the CDRH3 numbering system of this application, the contribution of, for example, JH6 1 to CDRH3, would be designated by positions 99F, 99E, 99D, 99C, 99B, 99A, 100, 101 and 102 (Y, Y, Y, Y, Y, G, M, D and V, respectively). Similarly, the JH4 3 sequence would contribute amino acid positions 101 and 102 (D and Y, respectively) to CDRH3. However, in all cases of the exemplified library, the JH segment will contribute amino acids 103 to 113 to the FRM4 region, in accordance with the standard Kabat numbering system for antibody variable regions (Kabat, op. cit. 1991). This may not be the case in other embodiments of the library.
Example 5.3: Selection of the Nl andN2 Segments While the consideration of V-D-J recombination enhanced by mimicry of the naturally occurring process of progressive deletion (as exemplified above) can generate enormous diversity, the diversity of the CDRH3 sequences in vivo is further amplified by non-templated addition of a varying number of nucleotides at the V-D junction and the D-J junction. Nl and N2 segments located at the V-D and D-J junctions, respectively, were identified in a sample containing about 2,700 antibody sequences (Jackson et al, J. Immunol. Methods, 2007, 324: 26) also analyzed by the SoDA method of Volpe et al, Bioinformatics, 2006, 22: 438-44; (both Jackson et al, and Volpe et al, are incorporated by reference in their entireties). Examination of these sequences revealed patterns in the length and composition of Nl and N2. For the construction of the currently exemplified CDRH3 library, specific short amino acid sequences were derived from the above analysis and used to generate a number of Nl and N2 segments that were incorporated into the CDRH3 design, using the synthetic scheme described herein.
As described in the Detailed Description, certain embodiments of the invention include Nl and N2 segments with rationally designed length and composition, informed by statistical biases in these parameters that are found by comparing naturally occurring Nl and N2 segments in human antibodies. According to data compiled from human databases (see, e.g., Jackson et al, J. Immunol Methods, 2007, 324: 26, incorporated by reference in its entirety), there are an average of about 3.02 amino acid insertions for Nl and about 2.4 amino acid insertions for N2, not taking into account insertions of two
nucleotides or less. Figure 2 shows the length distributions of the Nl and N2 regions in human antibodies. In this exemplary embodiment of the invention, Nl and N2 were fixed to a length of 0, 1, 2, or 3 amino acids. The naturally occurring composition of these sequences in human antibodies was used as a guide for the inclusion of different amino acid residues.
The naturally occurring composition of single amino acid, two amino acids, and three amino acids Nl additions is defined in Table 21, and the naturally occurring composition of the corresponding N2 additions is defined in Table 22. The most frequently occurring duplets in the Nl and N2 set are compiled in Table 23.

* Defined as the sequence C-terminal to "CARX", or equivalent, of VH, wherein "X" is the "tail" (e.g., D, E, G, or no amino acid residue).

* Defined as the sequence C-terminal to the D segment but not encoded by IGHJ genes.
Table 23. Top Twenty-Five Naturally Occurring Nl and N2 Duplets

Example 5.3.1 Selection of the Nl Segments Analysis of the identified Nl segments, located at the junction between V and D, revealed that the eight most frequently occurring amino acid residues were G, R, S, P, L, A, T and V (Table 21). The number of amino acid additions in the Nl segment was frequently none, one, two, or three (Figure 2). The addition of four or more amino acids was relatively rare. Therefore, in the currently exemplified embodiment of the library, the Nl segments were designed to include zero, one, two or three amino acids.
However, in other embodiments, Nl segments of four, five, or more amino acids may also be utilized. G and P were always among the most commonly occurring amino acid residues in the Nl regions. Thus, in the present exemplary embodiment of the library, the Nl segments that are dipeptides are of the form GX, XG, PX, or XP, where X is any of the eight most commonly occurring amino acids listed above. Due to the fact that G
residues were observed more frequently than P residues, the tripeptide members of the exemplary Nl library have the form GXG, GGX, or XGG, where X is, again, one of the eight most frequently occurring amino acid residues listed above. The resulting set of Nl sequences used in the present exemplary embodiment of the library, include the "zero" addition amounts to 59 sequences, which are listed in Table 24.
Table 24. Nl Se uences Selected for Inclusion in the Exem lar Librar

In accordance with the CDRH3 numbering system of the application, the sequences enumerated in Table 24 contribute the following positions to CDRH3: the monomers contribute position 96, the dimers to 96 and 96A, and the trimers to 96, 96A and 96B. In alternative embodiments, where tetramers and longer segments could be included among the Nl sequences, the corresponding numbers would go on to include
96C, and so on.
Example 5.3.2 Selection of the N2 Segments
Similarly, analysis of the identified N2 segments, located at the junction between
D and J, revealed that the eight most frequently occurring amino acid residues were also
G, R, S, P, L, A, T and V (Table 22). The number of amino acid additions in the N2 segment was also frequently none, one, two, or three (Figure 2). For the design of the
N2 segments in the exemplary library, an expanded set of sequences was utilized.
Specifically, the sequences in Table 25 were used, in addition to the 59 sequences enumerated in Table 24, for Nl .
Table 25. Extra Se uences in N2 Additions


The presently exemplified embodiment of the library, therefore, contains 141 total N2 sequences, including the "zero" state. One of ordinary skill in the art will readily recognize that these 141 sequences may also be used in the Nl region, and that such embodiments are within the scope of the invention. In addition, the length and compositional diversity of the Nl and N2 sequences can be further increased by utilizing amino acids that occur less frequently than G, R, S, P, L, A, T and V, in the Nl and N2 regions of naturally occurring antibodies, and including Nl and N2 segments of four, five, or more amino acids in the library. Tables 21 to 23 and Figure 2 provides information about the composition and length of the Nl and N2 sequences in naturally occurring antibodies that is useful for the design of additional Nl and N2 regions which mimic the natural composition and length.
In accordance with the CDRH3 numbering system of the application, N2 sequences will begin at position 98 (when present) and extend to 98A (dimers) and 98B (trimers). Alternative embodiments may occupy positions 98C, 98D, and so on.
Example 5.4. A CDRH3 Library
When the "tail" (i.e., GfDfEI-) is considered, the CDRH3 in the exemplified library may be represented by the general formula:
[G/D/E/-]-[Nl]-[DH]-[N2]-[H3-JH]
In the currently exemplified, non- limiting, embodiment of the library, [G/D/E/-] represents each of the four possible terminal amino acid "tails"; Nl can be any of the 59 sequences in Table 24; DH can be any of the 278 sequences in Table 18; N2 can be any of the 141 sequences in Tables 24 and 25; and H3-JH can be any of the 28 H3-JH sequences in Table 20. The total theoretical diversity or repertoire size of this CDRH3
library is obtained by multiplying the variations at each of the components, i.e., 4 x 59 x 278 x 141 x 28 = 2.59 x 108.
However, as described in the previous examples, redundancies may be eliminated from the library. In the presently exemplified embodiment, the tail and Nl segments were combined, and redundancies were removed from the library. For example, considering the VH chassis, tail, and Nl regions, the sequence [VH Chassis]- [G] may be obtained in two different ways: [VH Chassis] + [G] + [nothing] or [VH Chassis] + [nothing] + [G]. Removal of redundant sequences resulted in a total of 212 unique [G/D/E/-]-[Nl] segments out of the 236 possible combinations (i.e., 4 tails x 59 Nl). Therefore, the actual diversity of the presently exemplified CDRH3 library is 212 x 278 x 141 x 28 = 2.11 x 108. Figure 23 depicts the frequency of occurrence of different CDRH3 lengths in this library, versus the preimmune repertoire of Lee et al.
Table 26 further illustrates specific exemplary sequences from the CDRH3 library described above, using the CDRH3 numbering system of the present application. In instances where a position is not used, the hyphen symbol (-) is included in the table instead.

Sequence Identifiers: No. 1 (SEQ ID NO: 542); No. 2 (SEQ ID NO: 543); No. 3 (SEQ ID NO: 544); No. 4 (SEQ ID NO: 545); No. 5 (SEQ ID NO: 546); No. 6 (SEQ ID NO: 547); No. 7 (SEQ ID NO: 548); No. 8 (SEQ ID NO: 549); No. 9 (SEQ ID NO: 550); No. 10 (SEQ ID
NO: 551).
Example 6: Design of VKCDR3 Libraries
This example describes the design of a number of exemplary VKCDR3 libraries. As specified in the Detailed Description, the actual version(s) of the VKCDR3 library made or used in particular embodiments of the invention will depend on the objectives for the use of the library. In this example the Kabat numbering system for light chain variable regions was used.
In order to facilitate examination of patterns of occurrence, human kappa light chain sequences were obtained from the publicly available NCBI database (Appendix A). As for the heavy chain sequences (Example 2), each of the sequences obtained from the publicly available database was assigned to its closest germline gene, on the basis of sequence identity. The amino acid compositions at each position were then determined within each kappa light chain subset.
Example 6.1.: A Minimalist VKCDR3 Library
This example describes the design of a "minimalist" VKCDR3 library, wherein the VKCDR3 repertoire is restricted to a length of nine residues. Examination of the VKCDR3 lengths of human sequences shows that a dominant proportion (over 70%) has nine amino acids within the Kabat definition of CDRL3: positions 89 through 97. Thus, the currently exemplified minimalist design considers only VKCDR3 of length nine. Examination of human kappa light chain sequences shows that there are not strong biases in the usage of IGKJ genes; there are five such IKJ genes in humans. Table 27 depicts IGKJ gene usage amongst three data sets, namely Juul et al. (Clin. Exp. Immunol., 1997, 109: 194, incorporated by reference in its entirety), Klein and Zachau (Eur. J. Immunol., 1993, 23: 3248, incorporated by reference in its entirety), and the kappa light chain data set provided in Appendix A (labeled LUA).
Table 27. IGKJ Gene Usage in Various Data Sets

Table 28. Occurrence of 20 Amino Acid Residues at Position 96 in Human VK Data Set

To determine the origins of the seven residues most commonly found in position 96, known human IGKJ amino acid sequences were examined (Table 29).

Without being bound by theory, five of the seven most commonly occurring amino acids found in position 96 of rearranged human sequences appear to originate
from the first amino acid encoded by each of the five human IGKJ genes, namely, W, Y, F, L, and I.
Less evident were the origins of the P and R residues. Without being bound by theory, most of the human IGKV gene nucleotide sequences end with the sequence CC, which occurs after (i.e., 3' to) the end of the last full codon (e.g., that encodes the C- terminal residue shown in Table 11). Therefore, regardless of which nucleotide is placed after this sequence (i.e., CCX, where X may be any nucleotide) the codon will encode a proline (P) residue. Thus, when the IGKJ gene undergoes progressive deletion (just as in the IGHJ of the heavy chain; see Example 5), the first full amino acid is lost and, if no deletions have occurred in the IGKV gene, a P residue will result.
To determine the origin of the arginine residue at position 96, the origin of IGKJ genes in rearranged kappa light chain sequences containing R at position 96 were analyzed. The analysis indicated that R occurred most frequently at position 96 when the IGKJ gene was IGKJl. The germline W (position 1; Table 29) for IGKJl is encoded by TGG. Without being bound by theory, a single nucleotide change of T to C (yielding CGG) or A (yielding AGG) will, therefore, result in codons encoding Arg (R). A change to G (yielding GGG) results in a codon encoding GIy (G). R occurs about ten times more often at position 96 in human sequences than G (when the IGKJ gene is IGKJl), and it is encoded by CGG more often than AGG. Therefore, without being bound by theory, C may originate from one of the aforementioned two Cs at the end of IGKV gene. However, regardless of the mechanism(s) of occurrence, R and P are among the most frequently observed amino acid types at position 96, when the length of VKCDR3 is 9. Therefore, a minimalist VKCDR3 library may be represented by the following amino acid sequence:
[VK Chassis]-[L3-VK]-[F/L/I/R/W/Y/P]-[TFGGGTKVEIK]
In this sequence, VK Chassis represents any selected VK chassis (for non-limiting examples, see Table 11), specifically Kabat residues 1 to 88 encoded by the IGKV gene. L3-VK represents the portion of the VKCDR3 encoded by the chosen IGKV gene (in this embodiment, residues 89-95). F/L/I/R/WΛ7P represents any one of amino residues F, L, I, R, W, Y, or P. In this exemplary representation, IKJ4 (minus the first residue) has been depicted. Without being bound by theory, apart from IGKJ4 being among the
most commonly used IGKJ genes in humans, the GGG amino acid sequence is expected to lead to larger conformational flexibility than any of the alternative IGKJ genes, which contain a GXG amino acid sequence, where X is an amino acid other than G. In some embodiments, it may be advantageous to produce a minimalist pre-immune repertoire with a higher degree of conformational flexibility. Considering the ten VK chassis depicted in Table 11, one implementation of the minimalist VKCDR3 library would have 70 members resulting from the combination of 10 VK chassis by 7 junction (position 96) options and one IGKJ-derived sequence (e.g., IGKJ4). Although this embodiment of the library has been depicted using IGKJ4, it is possible to design a minimalist VKCDR3 library using one of the other four IGKJ sequences. For example, another embodiment of the library may have 350 members (10 VK chassis by 7 junctions by 5 IGKJ genes).
One of ordinary skill in the art will readily recognize that one or more minimalist VKCDR3 libraries may be constructed using any of the IGKJ genes. Using the notation above, these minimalist VKCDR3 libraries may have sequences represented by, for example:
JKl: [VK Chassis]-[L3-VK]-[F/L/I/RA¥A^/P]-[TFGQGTKVEIK];
JK2: [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGQGTKLEIK]; JK3: [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGPGTKVDIK]; and
JK5: [VK Chassis]- [L3-VKHF/L/I/R/W/Y/P]- [TFGQGTRLEIK].
Example 6.2: A VKCDR3 Library of About 10s Complexity
In this example, the nine residue VKCDR3 repertoire described in Example 6.1 is expanded to include VKCDR3 lengths of eight and ten residues. Moreover, while the previously enumerated VKCDR3 library included the VK chassis and portions of the IGKJ gene not contributing to VKCDR3, the presently exemplified version focuses only on residues comprising a portion of VKCDR3. This embodiment may be favored, for example, when recombination with a vector which already contains VK chassis sequences and constant region sequences is desired.
While the dominant length of VKCDR3 sequences in humans is nine amino acids, other lengths appear at measurable rates that cumulatively approach almost 30% of kappa light chain sequences. In particular, VKCDR3 of lengths 8 and 10 represent,
respectively, about 8.5% and about 16% of sequences in representative samples (Figure 3). Thus, a more complex VKCDR3 library includes CDR lengths of 8 to 10 amino acids; this library accounts for over 95% of the length distribution observed in typical collections of human VKCDR3 sequences. This library also enables the inclusion of additional variation outside of the junction between the VK and JK genes. The present example describes such a library. The library comprises 10 sub-libraries, each designed around one of the 10 exemplary VK chassis depicted in Table 11. Clearly, the approach exemplified here can be generalized to consider M different chassis, where M may be less than or more than 10.
To characterize the variability within the polypeptide segment occupying Kabat positions 89 to 95, human kappa light chain sequence collections derived from each of the ten germline sequences of Example 3 were aligned and compared separately (i.e., within the germline group). This analysis enabled us to discern the patterns of sequence variation at each individual position in each kappa light chain sequence, grouped by germline. The table below shows the results for sequences derived from IGKV1-39.
Table 30. Percent Occurrence of Amino Acid Types in IGKVl-39-Derived Sequences

For example, at position 89, two amino acids, Q and L, account for about 99% of the observed variability, and thus in the currently exemplified library (see below), only
Q and L were included in position 89. In larger libraries, of course, additional, less frequently occurring amino acid types (e.g., H), may also be included.
Similarly, at position 93 there is more variation, with amino acid types S, T, N, R and I being among the most frequently occurring. The currently exemplified library thus aimed to include these five amino acids at position 93, although clearly others could be included in more diverse libraries. However, because this library was constructed via standard chemical oligonucleotide synthesis, one is bound by the limits of the genetic code, so that the actual amino acid set represented at position 93 of the exemplified library consists of S, T, N, R, P and H, with P and H replacing I (see exemplary 9 residue VKCDR3 in Table 32, below). This limitation may be overcome by using codon-based synthesis of oligonucleotides, as described in Example 6.3, below. A similar approach was followed at the other positions and for the other sequences: analysis of occurrences of amino acid type per position, choice from among most frequently occurring subset, followed by adjustment as dictated by the genetic code. As indicated above, the library employs a practical and facile synthesis approach using standard oligonucleotide synthesis instrumentation and degenerate oligonucleotides. To facilitate description of the library, the IUPAC code for degenerate nucleotides, as given in Table 31 , will be used.
Table 31. Degenerate Base Symbol Definition

(*) 33% is short hand here for 1/3 (i.e., 33.3333 ... %)
Using the VKl -39 chassis with VKCDR3 of length nine as an example, the VKCDR3 library may be represented by the following four oligonucleotides (left
column in Table 32), with the corresponding amino acids encoded at each position of CDRL3 (Kabat numbering) provided in the columns on the right.
Table 32. Exemplary Oligonucleotides Encoding a VKl -39 CDR3 Library***

For example, the first codon (CWG) of the first nucleotide of Table 32, corresponding to Kabat position 89, represents 50% CTG and 50% CAG, which encode Leu (L) and GIn (Q), respectively. Thus, the expressed polypeptide would be expected to have L and Q each about 50% of the time. Similarly, for Kabat position 95A of the fourth oligonucleotide, the codon CBT represents 1/3 each of CCT, CGT and CTT, corresponding in turn to 1/3 each of Pro (P), Leu (L) and Arg (R) upon translation. By multiplying the number of options available at each position of the peptide sequence, one can obtain the complexity, in peptide space, contributed by each oligonucleotide. For the VKl -39 example above, the numbers are 864 for the first three oligonucleotides and 1,296 for the fourth oligonucleotide. Thus, the oligonucleotides encoding VKl -39 CDR3s of length nine contribute 3,888 members to the library. However, as shown in Table 32, sequences with L or R at position 95A (when position 96 is empty) are identical to those with L or R at position 96 (and 95A empty). Therefore, the 3,888 number overestimates the LR contribution and the actual number of unique members is slightly lower, at 3,024. As depicted in Table 33, for the complete list of oligonucleotides that represent VKCDR3 of sizes 8, 9, and 10, for all 10 VK chassis, the overall complexity is about 1.3 x 105 or 1.2 x 105 unique sequences after correcting for over-counting of the LR contribution for the size 9 VKCDR3.
Table 33. Degenerate Oligonucleotides Encoding an Exemplary VKCDR3 Library

4-

4-


4-

4-

4-

4-
OO

(1) Junction type 1 has position 96 as FY, type 2 as IL, type 3 as RW, and type 4 has a deletion.
(2) Two embodiments are shown for the VKl -33 library. In one embodiment, the second codon was CWT. In another embodiment, it was CWA or CWG.
Example 6.3: More Complex VKCDR3 Libraries
This example demonstrates how a more faithful representation of amino acid variation at each position may be obtained by using a codon-based synthesis approach (Virnekas et al. Nucleic Acids Res., 1994, 22: 5600). This synthetic scheme also allows for finer control of the proportions of particular amino acids included at a position. For example, as described above for the VKl -39 sequences, position 89 was designed as 50% Q and 50% L; however, as Table 30 shows, Q is used much more frequently than L. The more complex VKCDR3 libraries of the present example account for the different relative occurrence of Q and L, for example, 90% Q and 10% L. Such control is better exercised within codon-based synthetic schemes, especially when multiple amino acid types are considered.
This example also describes an implementation of a codon-based synthetic scheme, using the ten VK chassis described in Table 11. Similar approaches, of course, can be implemented with more or fewer such chassis. As indicated in the Detailed Description, a unique aspect of the design of the present libraries, as well as those of the preceding examples, is the germline or chassis-based aspect, which is meant to preserve more of the integrity and variation of actual human kappa light chain sequences. This is in contrast to other codon-based synthesis or degenerate oligonucleotide synthesis approaches that have been described in the literature and that aim to produce "one-size- fits-all" {e.g., consensus) kappa light chain libraries {e.g.,, Rnappik, et al., J MoI Biol, 2000, 296: 57; Akamatsu et al., J Immunol, 1993, 151 : 4651).
With reference to Table 30, obtained for VKl -39, one can thus design the length nine VKCDR3 library of Table 34. Here, for practical reasons, the proportions at each position are denoted in multiples of five percentage points. As better synthetic schemes are developed, finer resolution may be obtained - for example to resolutions of one, two, three, or four percent.
Table 34. Amino Acid Composition (%) at Each VKCDR3 Position for VKl -39 Library With CDR Length of Nine Residues


(*) The composition of positions 96 and 97, determined largely by junction and IGKJ diversity, could be the same for length 9 VK CDR3 of all chassis.
The library of Table 34 would have 1.37 x 106 unique polypeptide sequences, calculated by multiplying together the numbers in the bottom row of the table.
The underlined 0 entries for Asn (N) at certain positions represent regions where the possibility of having N-linked glycosylation sites in the VKCDR3 has been minimized or eliminated. Peptide sequences with the pattern N-X-(S or T)-Z, where X and Z are different from P, may undergo post-translational modification in a number of expression systems, including yeast and mammalian cells. Moreover, the nature of such modification depends on the specific cell type and, even for a given cell type, on culture conditions. N-linked glycosylation may be disadvantageous when it occurs in a region of the antibody molecule likely to be involved in antigen binding (e.g., a CDR), as the function of the antibody may then be influenced by factors that may be difficult to control. For example, considering position 91 above, one can observe that position 92 is never P. Position 94 is not P in 95% of the cases. However, position 93 is S or T in 75 % (65 + 10) of the cases. Thus, allowing N at position 91 would generate the undesirable motif N-X-(TVS)-Z (with both X and Z distinct from P), and a zero occurrence has therefore been implemented, even though N is observed with some frequency in actual human sequences (see Table 30). A similar argument applies for N at positions 92 and 94. It should be appreciated, however, that if the antibody library were to be expressed in a system incapable of N-linked glycosylation, such as bacteria, or under culture conditions in which N-linked glycosylation did not occur, this
consideration may not apply. However, even in the event that the organism used to express libraries with potential N-linked glycosylation sites is incapable of N-linked glycosylation (e.g., bacteria), it may still be desirable to avoid N-X-(SAT) sequences, as the antibodies isolated from such libraries may be expressed in different systems (e.g., yeast, mammalian cells) later (e.g., toward clinical development), and the presence of carbohydrate moieties in the variable domains, and the CDRs in particular, may lead to unwanted modifications of activity. These embodiments are also included within the scope of the invention. To our knowledge, VKCDR3 libraries known in the art have not considered this effect, and thus a proportion of their members may have the undesirable qualities mentioned above.
We also designed additional sub-libraries, related to the library outlined in Table 34, for VKCDR3 of lengths 8 and 10. In these embodiments, the compositions at positions 89 to 94 and 97 remain the same as those depicted in Table 34. Additional diversity, introduced at positions 95 and 95 A, the latter being defined for VKCDR3 of length 10 only, are illustrated in Table 35.

(*) Position 96 is deleted in VKCDR3 of size 8.
(**) This is the same composition as in VKCDR3 of size 9.
The total number of unique members in the VK1-39 library of length 8, thus, can be obtained as before, and is 3.73 x 105 (or, 3 x 3 x 4 x 6 x 8 x 8 x 9 x 3). Similarly, the complexity of the VK1-39 library of length 10 would be 10.9 x 106 (or 8 times that of the library of size 9, as there is additional 8-fold variation at the insertion position 95A). Thus, there would be a total of 12.7 x 106 unique members in the overall VK1-39 library, as obtained by summing the number of unique members for each of the specified lengths. In certain embodiments of the invention, it may be preferable to create the individual sub-libraries of lengths 8, 9 and 10 separately, and then mix the sub-libraries in proportions that reflect the length distribution of VKCDR3 in human sequences; for example, in ratios approximating the 1 :9:2 distribution that occurs in natural VKCDR3 sequences (see Figure 3). The present invention provides the compositions and methods for one of ordinary skill synthesizing VKCDR3 libraries corresponding to other VK chassis.
Example 7: A Minimalist V1CDR3 Library
This example describes the design of a minimalist VλCDR3 library. The principles used in designing this library (or more complex Vλ libraries) are similar to those used to design the VKCDR3 libraries. However, unlike the VK genes, the contribution of the IgλV segment to CDRL3 is not constrained to a fixed number of amino acids. Therefore, length variation may be obtained in a minimalist VλCDR3 library even when only considering combinations between Vλ chassis and Jλ sequences. Examination of the VλCDR3 lengths of human sequences shows that lengths of 9 to 12 account for almost about 95% of sequences, and lengths of 8 to 12 account for about 97% of sequences (Figure 4). Table 36 shows the usage (percent occurrence) of the six known IGλJ genes in the rearranged human lambda light chain sequences compiled from the NCBI database (see Appendix B), and Table 37 shows the sequences encoded by the genes.
Table 36. IGλJ Gene Usage in the Lambda Light Chain Sequences Compiled from the NCBI Database (see Appendix B)


Table 37. Observed Human IGλJ Amino Acid Sequences

IGλJ3-01 and IGλJ7-02 are not represented among the sequences that were analyzed; therefore, they were not included in Table 36. As illustrated in Table 36, IGλJ 1-01, IGλJ2-01, and IGλJ3-02 are over-represented in their usage, and have thus been bolded in Table 37. In some embodiments of the invention, for example, only these three over-represented sequences may be utilized. In other embodiments of the invention, one may use all six segments, any 1, 2, 3, 4, or 5 of the 6 segments, or any combination thereof may be utilized.
As shown in Table 14, the portion of CDRL3 contributed by the IGλV gene segment is 7, 8, or 9 amino acids. The remainder of CDRL3 and FRM4 are derived from the IGλJ sequences (Table 37). The IGλJ sequences contribute either one or two amino acids to CDRL3. If two amino acids are contributed by IGλJ, the contribution is from the N-terminal two residues of the IGλJ segment: YV (IGλJl-01), VV (IGλJ2-01), WV (IGλJ3-01), VV (IGλJ3-02), or AV (IGλJ7-01 and IGλJ7-02). If one amino acid is contributed from IGλJ, it is a V residue, which is formed after the deletion of the N- terminal residue of a IGλJ segment. In this non- limiting exemplary embodiment of the invention, the FRM4 segment was fixed as FGGGTKLTVL, corresponding to IGλJ2-01 and IGλJ3-02 (i.e., portions of SEQ ID NOs: 558 and 560).
Seven of the 11 selected chassis (Vλl-40, Vλ3-19, Vλ3-21, Vλ6-57, Vλl-44, Vλl-51, and Vλ4-69) have an additional two nucleotides following the last full codon. In four of those seven cases, analysis of the data set provided in Appendix B showed that the addition of a single nucleotide (i.e. without being limited by theory, via the activity of TdT) lead to a further increase in CDRL3 length. This effect can be considered by introducing variants for the L3-Vλ sequences contributed by these four IGλV sequences (Table 38).
Table 38. Variants with an additional residue in CDRL3

(+) sequences are derived from their parents by the addition of an amino acid at the end of the respective CDR3 (bold underlined). H/Q can be introduced in a single sequence by use of the degenerate codon CAW or similar.
Thus, the final set of chassis in the currently exemplified embodiment of the invention is 15: eleven contributed by the chassis in Table 14 and an additional four contributed by the chassis of Table 38. The corresponding L3-Vλ domains of the 15 chassis contribute from 7 to 10 amino acids to CDRL3. When considering the amino acids contributed by the IGλJ sequences, the total variation in the length of CDRL3 is 8 to 12 amino acids, approximating the distribution in Figure 4. Thus, in this exemplary embodiment of the invention, the minimalist Vλ library may be represented by the following: 15 Chassis x 5 IGλJ-derived segments = 75 sequences. Here, the 15 chassis are Vλl-40, Vλl-44, Vλl-51, Vλ2-14, Vλ3-1*, Vλ3-19, Vλ3-21, Vλ4-69, Vλ6-57, Vλ5-45, Vλ7-43, Vλl- 40+, Vλ3-19+, Vλ3-21+, and Vλ6-57+. The 5 IGλJ-derived segments are YVFGGGTKLTVL (IGλJl; SEQ ID NO: 568), VVFGGGTKLTVL (IGλJ2; SEQ ID NO: 558), WVFGGGTKLTVL (IGλJ3; SEQ ID NO: 559), AVFGGGTKLTVL (IGλJ7; SEQ ID NO: 569), and -VFGGGTKLTVL (from any of the preceding sequences).
Example 8: Matching to "Reference" Antibodies
CDRH3 sequences of human antibodies of interest that are known in the art, (e.g., antibodies that have been used in the clinic) have close counterparts in the designed library of the invention. A set of fifteen CDRH3 sequences from clinically relevant antibodies is presented in Table 39.
Table 39. CDRH3 Se uences of Reference Antibodies


Each of the above sequences was compared to each of the members of the library of Example 5, and the member, or members, with the same length and fewest number of amino acid mismatches was, or were, recorded. The results are summarized in Table 40, below. For most of the cases, matches with 80% identity or better were found in the exemplified CDRH3 library. To the extent that the specificity and binding affinity of each of these antibodies is influenced by their CDRH3 sequence, without being bound by theory, one or more of these library members could have measurable affinity to the relevant targets.
Table 40. Match of Reference Antibody CDRH3 to Designed Library


(*) For the best-matching sequence(s) in library
Given that a physical realization of a library with about 108 distinct members could, in practice, contain every single member, then such sequences with close percent identity to antibodies of interest would be present in the physical realization of the library. This example also highlights one of many distinctions of the libraries of the current invention over those of the art; namely, that the members of the libraries of the invention may be precisely enumerated. In contrast, CDRH3 libraries known in the art cannot be explicitly enumerated in the manner described herein. For example, many libraries known in the art (e.g., Hoet et al, Nat. BiotechnoL, 2005, 23: 344; Griffiths et al, EMBO J., 1994, 13: 3245; Griffiths et al., EMBO J., 1993, 12: 725; Marks et al, J. MoI. Biol., 1991, 222: 581, each incorporated by reference in its entirety) are derived by cloning of natural human CDRH3 sequences and their exact composition is not characterized, which precludes enumeration. Synthetic libraries produced by other (e.g., random or semi-random / biased) methods (Knappik, et al, J MoI Biol, 2000, 296: 57, incorporated by reference in its entirety) tend to have very large numbers of unique members. Thus, while matches to a given input sequence (for example, at 80% or greater) may exist in a theoretical representation of such libraries, the probability of synthesizing and then producing a physical realization of the theoretical library that contains such a sequence and then selecting an antibody corresponding to such a match, in practice, may be remotely small. For example, a CDRH3 of length 19 in the Knappik library may have over 1019 distinct sequences. In a practical realization of such a library a tenth or so of the sequences may have length 19 and the largest total library may have in the order of 1010 to 1012 transformants; thus, the probability of a given pre-defined member being present, in practice, is effectively zero (less than one in ten million). Other libraries (e.g., Enzelberger et al WO2008053275 and Ladner US20060257937, each incorporated by reference in its entirety) suffer from at least one of the limitations described throughout this application. Thus, for example, considering antibody CAB14, there are seven members of the designed library of Example 5 that differ at just one amino acid position from the
sequence of the CDRH3 of CAB 14 (given in Table 39). Since the total length of this CDRH3 sequence is 13, the percent of identical amino acids is 12/13 or about 92% for each of these 7 sequences of the library of the invention. It can be estimated that the probability of obtaining such a match (or better) in the library of Knappik et al. is about 1.4 x 10~9; it would be lower still, about 5.5 x 10~10, in a library with equal amino acid proportions {i.e., completely random). Therefore, in a physical realization of the library with about 1010 transformants of which about a tenth may have length 13, there may be one or two instances of these best matches. However, with longer sequences such as CAB 12, the probability of having members in the Knappik library with about 89% or better matching are under about 10~15, so that the expected number of instances in a physical realization of the library is essentially zero. To the extent that sequences of interest resemble actual human CDRH3 sequences, there will be close matches in the library of Example 5, which was designed to mimic human sequences. Thus, one of the many relative advantages of the present library, versus those in the art, becomes more apparent as the length of the CDRH3 increases.
Example 9: Split Pool Synthesis of Oligonucleotides Encoding the DH, N2, and H3- JH Segments This example outlines the procedures used to synthesize the oligonucleotides used to construct the exemplary libraries of the invention. Custom Primer Support™ 200 dT40S resin (GE Healthcare) was used to synthesize the oligonucleotides, using a loading of about 39 μmol/g of resin. Columns (diameter = 30 μm) and frits were purchased from Biosearch Technologies, Inc. A column bed volume of 30 μL was used in the synthesis, with 120 nmol of resin loaded in each column. A mixture of dichloromethane (DCM) and methanol (MeOH), at a ratio of 400/122 (v/v) was used to load the resin. Oligonucleotides were synthesized using a Dr. Oligo ® 192 oligonucleotide synthesizer and standard phosphorothioate chemistry.
The split pool procedure for the synthesis of the [DH]-[N2]-[H3-JH] oligonucleotides was performed as follows: First, oligonucleotide leader sequences, containing a randomly chosen 10 nucleotide sequence (ATGC ACAGTT; SEQ ID NO: 395), a BsrDI recognition site (GCAATG), and a two base "overlap sequence" (TG, AC, AG, CT, or GA) were synthesized. The purpose of each of these segments is explained below. After synthesis of this 18 nucleotide sequence, the DH segments were
synthesized; approximately 1 g of resin (with the 18 nucleotide segment still conjugated) was suspended in 20 mL of DCM/MeOH. About 60 μL of the resulting slurry (120 nmol) was distributed inside each of 278 oligonucleotide synthesis columns. These 278 columns were used to synthesize the 278 DH segments of Table 18, 3' to the 18 nucleotide segment described above. After synthesis, the 278 DH segments were pooled as follows: the resin and frits were pushed out of the columns and collected inside a 20 mL syringe barrel (without plunger). Each column was then washed with 0.5 mL MeOH, to remove any residual resin that was adsorbed to the walls of the column. The resin in the syringe barrel was washed three times with MeOH, using a low porosity glass filter to retain the resin. The resin was then dried and weighed.
The pooled resin (about 1.36 g) containing the 278 DH segments was subsequently suspended in about 17 mL of DCM/MeOH, and about 60 μL of the resulting slurry was distributed inside each of two sets of 141 columns. The 141 N2 segments enumerated in Tables 24 and 25 were then synthesized, in duplicate (282 total columns), 3' to the 278 DH segments synthesized in the first step. The resin from the 282 columns was then pooled, washed, and dried, as described above.
The pooled resin obtained from the N2 synthesis (about 1.35 g) was suspended in about 17 mL of DCM/MeOH, and about 60 μL of the resulting slurry was distributed inside each of 280 columns, representing 28 H3-JH segments synthesized ten times each. A portion (described more fully below) of each of the 28 IGHJ segments, including H3-JH of Table 20 were then synthesized, 3' to the N2 segments, in ten of the columns. Final oligonucleotides were cleaved and deprotected by exposure to gaseous ammonia (850C, 2 h, 60 psi).
Split pool synthesis was used to synthesize the exemplary CDRH3 library. However, it is appreciated that recent advances in oligonucleotide synthesis, which enable the synthesis of longer oligonucleotides at higher fidelity and the production of the oligonucleotides of the library by synthetic procedures that involve splitting, but not pooling, may be used in alternative embodiments of the invention. The split pool synthesis described herein is, therefore, one possible means of obtaining the oligonucleotides of the library, but is not limiting. One other possible means of synthesizing the oligonucleotides described in this application is the use of trinucleotides. This may be expected to increase the fidelity of the synthesis, since frame shift mutants would be reduced or eliminated.
Example 10: Construction of the CDRH3 and Heavy Chain Libraries
This example outlines the procedures used to create exemplary CDRH3 and heavy chain libraries of the invention. A two step process was used to create the CDRH3 library. The first step involved the assembly of a set of vectors encoding the tail and Nl segments, and the second step involved utilizing the split pool nucleic acid synthesis procedures outlined in Example 9 to create oligonucleotides encoding the DH, N2, and H3-JH segments. The chemically synthesized oligonucleotides were then ligated into the vectors, to yield CDRH3 residues 95-102, based on the numbering system described herein. This CDRH3 library was subsequently amplified by PCR and recombined into a plurality of vectors containing the heavy chain chassis variants described in Examples 1 and 2. CDRHl and CDRH2 variants were produced by QuikChange ® Mutagenesis (Stratagene ™), using the oligonucleotides encoding the ten heavy chain chassis of Example 1 as a template. In addition to the heavy chain chassis, the plurality of vectors contained the heavy chain constant regions (i.e., CHl, CH2, and CH3) from IgGl, so that a full-length heavy chain was formed upon recombination of the CDRH3 with the vector containing the heavy chain chassis and constant regions. In this exemplary embodiment, the recombination to produce the full-length heavy chains and the expression of the full-length heavy chains were both performed in S. cerevisiae. To generate full-length, heterodimeric IgGs, comprising a heavy chain and a light chain, a light chain protein was also expressed in the yeast cell. The light chain library used in this embodiment was the kappa light chain library, wherein the VKCDR3s were synthesized using degenerate oligonucleotides (see Example 6.2). Due to the shorter length of the oligonucleotides encoding the light chain library (in comparison to those encoding the heavy chain library), the light chain CDR3 oligonucleotides could be synthesized de novo, using standard procedures for oligonucleotide synthesis, without the need for assembly from sub-components (as in the heavy chain CDR3 synthesis). One or more light chains can be expressed in each yeast cell which expresses a particular heavy chain clone from a library of the invention. One or more light chains have been successfully expressed from both episomal (e.g., plasmid) vectors and from integrated sites in the yeast genome.
Below are provided further details on the assembly of the individual components for the synthesis of a CDRH3 library of the invention, and the subsequent combination
of the exemplary CDRH3 library with the vectors containing the chassis and constant regions. In this particular exemplary embodiment of the invention, the steps involved in the process may be generally characterized as (i) synthesis of 424 vectors encoding the tail and Nl regions; (ii) ligation of oligonucleotides encoding the [DH]-[N2]-[H3-JH] segments into these 424 vectors; (iii) PCR amplification of the CDRH3 sequences from the vectors produced in these ligations; and (iv) homologous recombination of these PCR-amplifϊed CDRH3 domains into the yeast expression vectors containing the chassis and constant regions.
Example 10.1: Synthesis of Vectors Encoding the Tail and Nl Regions
This example demonstrates the synthesis of 424 vectors encoding the tail and Nl regions of CDRH3. In this exemplary embodiment of the invention, the tail was restricted to G, D, E, or nothing, and the Nl region was restricted to one of the 59 sequences shown in Table 24. As described throughout the specification, many other embodiments are possible.
In the first step of the process, a single "base vector" (pJM204, a pUC-derived cloning vector) was constructed, which contained (i) a nucleic acid sequence encoding two amino acids that are common to the C-terminal portion of all 28 IGHJ segments (SS), and (ii) a nucleic acid sequence encoding a portion of the CHl constant region from IgGl . Thus, the base vector contains an insert encoding a sequence that can be depicted as:
[SS]-[CHlH, wherein SS is a common portion of the C-terminus of the 28 IGHJ segments and CHl- is a portion of the CHl constant region from IgGl, namely: ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFP AVLQSSGLYSLSSVVTVPSSSLG (SEQ ID NO: 396).
Next, 424 different oligonucleotides were cloned into the base vector, upstream (i.e., 5') from the region encoding the [SS]-[CHl-]. These 424 oligonucleotides were synthesized by standard methods and each encoded a C-terminal portion of one of the 17 heavy chain chassis enumerated in Table 5, plus one of four exemplary tail segments (G/D/E/-), and one of 59 exemplary Nl segments (Table 24). These 424 oligonucleotides, therefore, encode a plurality of sequences that may be represented by: [~FRM3]-[G/D/E/-]-[Nl],
wherein -FRM3 represents a C-terminal portion of a FRM3 region from one of the 17 heavy chain chassis of Table 5, GfDfEI- represents G, D, E, or nothing, and Nl represents one of the 59 Nl sequences enumerated in Table 24. As described throughout the specification, the invention is not limited to the chassis exemplified in Table 5, their CDRHl and CDRH2 variants (Table 8), the four exemplary tail options used in this example, or the 59 Nl segments presented in Table 24.
The oligonucleotide sequences represented by the sequences above were synthesized in two groups: one group containing a -FRM3 region identical to the corresponding region on 16 of the 17 the heavy chain chassis enumerated in Table 5, and another group containing a -FRM3 region that is identical to the corresponding region on VH3-15. In the former group, an oligonucleotide encoding DTAVYYCAR (SEQ ID NO: 397) was used for -FRM3. During subsequent PCR amplification, the V residue of VH5-51 was altered to an M, to correspond to the VH5-51 germline sequence. In the latter group (that with a sequence common to VH3-15), a larger oligonucleotide, encoding the sequence
AISGSGGSTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAK (SEQ ID NO: 398) was used for -FRM3. Each of the two oligonucleotides encoding the -FRM3 regions were paired with oligonucleotides encoding one of the four tail regions (GfDfEI-) and one of the 59 Nl segments, yielding a total of 236 possible combinations for each -FRM3 (i.e., 1 x 4 x 59), or a total of 472 possible combinations when both -FRM3 sequences are considered. However, 48 of these combinations are redundant and only a single representation of these sequences was used in the currently exemplified CDRH3 library, yielding 424 unique oligonucleotides encoding [-FRM3]- [G/D/E/-]-[Nl] sequences. After the oligonucleotides encoding the [~FRM3]-[G/D/E/-]-[Nl] and [SS]-
[CHl-] segments were cloned into the vector, as described above, additional sequences were added to the vector to facilitate the subsequent insertion of the oligonucleotides encoding the [DH] -[N2]-[H3 -JH] fragments synthesized during the split pool synthesis. These additional sequences comprise a polynucleotide encoding a selectable marker protein, flanked on each side by a recognition site for a type II restriction enzyme, for example:
[Type II RS I]- [selectable marker protein] -[Type II RS 2].
In this exemplary embodiment, the selectable marker protein is ccdB and the type II restriction enzyme recognition sites are specific for BsrDI and Bbsl. In certain strains of E. coli, the ccdB protein is toxic, thereby preventing the growth of these bacteria when the gene is present. An example of the 5' end of one of the 212 vectors with a -FRM3 region based on the VH3-23 chassis, D tail residue and an Nl segment of length zero is presented below (SEQ ID NO: 570):
VH3-23 A I S G S G G S T Y
~ c l GCTATTAG TGGTAGTGGT GGTAGCACAT
CGATAATC ACCATCACCA CCATCGTGTA 1!?:??
Y A D S V K G R F T I S R D N S K N T L Y L Q M N S 1 C ] ACTACGCAGA
TGATGCGTCT
VH3-23 ccdB
L R A E D T A V Y Y C A K L ] CTGAGAGCCG AGGACACGGC GGTGTACTAC TGCGCCAAGG ACCATTGCGC TTAGCCTAGG TTATATTCCC CAGAACATCA GACTCTCGGC TCCTGTGCCG CCACATGATG ACGCGGTTCC TGGTAACGCG AATCGGATCC AATATAAGGG GTCTTGTAGT
An example of one of the 212 vectors with a -FRM3 region based on one of the other 16 chassis, with a D residue as the tail and an Nl segment of length zero is presented below (SEQ ID NO: 571):
Framework 3
D T A V Y Y C A R "V] GACACGGCG GTGTACTACT GCGCCAGAGA
CTGTGCCGC CACATGATGA CGCGGTCTCT ccdB !!~~~~ ll/,l CCATTGCGCT TAGCCTAGGT TATATTCCCC AGAACATCAG GTTAATGGCG TTTTTGATGT CATTTTCGCG GTGGCTGAGA GGTAACGCGA ATCGGATCCA ATATAAGGGG TCTTGTAGTC CAATTACCGC AAAAACTACA GTAAAAGCGC CACCGACTCT ccdB lj.21 TCAGCCACTT CTTCCCCGAT AACGGAAACC GGCACACTGG CCATATCGGT GGTCATCATG CGCCAGCTTT CATCCCCGAT AGTCGGTGAA GAAGGGGCTA TTGCCTTTGG CCGTGTGACC GGTATAGCCA CCAGTAGTAC GCGGTCGAAA GTAGGGGCTA ccdB
IzJl ATGCACCACC GGGTAAAGTT CACGGGAGAC TTTATCTGAC AGCAGACGTG CACTGGCCAG GGGGATCACC ATCCGTCGCC TACGTGGTGG CCCATTTCAA GTGCCCTCTG AAATAGACTG TCGTCTGCAC GTGACCGGTC CCCCTAGTGG TAGGCAGCGG ccdB
1_R1 CGGGCGTGTC AATAATATCA CTCTGTACAT CCACAAACAG ACGATAACGG CTCTCTCTTT TATAGGTGTA AACCTTAAAC GCCCGCACAG TTATTATAGT GAGACATGTA GGTGTTTGTC TGCTATTGCC GAGAGAGAAA ATATCCACAT TTGGAATTTG ccdB
Lf] TGCATTTCAC CAGCCCCTGT TCTCGTCAGC AAAAGAGCCG TTCATTTCAA TAAACCGGGC GACCTCAGCC ATCCCTTCCT ACGTAAAGTG GTCGGGGACA AGAGCAGTCG TTTTCTCGGC AAGTAAAGTT ATTTGGCCCG CTGGAGTCGG TAGGGAAGGA ccdB
]4^L GATTTTCCGC TTTCCAGCGT TCGGCACGCA GACGACGGGC TTCATTCTGC ATGGTTGTGC TTACCAGACC GGAGATATTG CTAAAAGGCG AAAGGTCGCA AGCCGTGCGT CTGCTGCCCG AAGTAAGACG TACCAACACG AATGGTCTGG CCTCTATAAC ccdB 1^] ACATCATATA TGCCTTGAGC AACTGATAGC TGTCGCTGTC AACTGTCACT GTAATACGCT GCTTCATAGC ATACCTCTTT TGTAGTATAT ACGGAACTCG TTGACTATCG ACAGCGACAG TTGACAGTGA CATTATGCGA CGAAGTATCG TATGGAGAAA ccdB
]^1L TTGACATACT TCGGGTATAC ATATCAGTAT ATATTCTTAT ACCGCAAAAA TCAGCGCGCA AATATGCATA CTGTTATCTG
AACTGTATGA AGCCCATATG TATAGTCATA TATAAGAATA TGGCGTTTTT AGTCGCGCGT TTATACGTAT GACAATAGAC CCdB CHl
Bbsl
A S T K G P S V F P L A P S -
1"Rl GCTTTTAGTA AGCCGCCTAG GTCATCAGAA GACAACTCAG CTAGCACCAA GGGCCCATCG GTCTTTCCCC TGGCACCCTC
CGAAAATCAT TCGGCGGATC CAGTAGTCTT CTGTTGAGTC GATCGTGGTT CCCGGGTAGC CAGAAAGGGG ACCGTGGGAG
CHl
10
• S K S T S G G T A A L G C L V K D Y F P E P V T V S W Hf] CTCCAAGAGC
GAGGTTCTCG
I5 ™
• N S G A L T S G V H T F P A V L Q S S G L ] t ' I GGAACTCAGG GACTC CCTTGAGTCC CTGAG 0 All 424 vectors were sequence verified. A schematic diagram of the content of the 424 vectors, before and after cloning of the [DH]-[N2]-[H3-JH] fragment is presented in Figure 5. Below is an exemplary sequence from one of the 424 vectors containing a FRM3 region from VH3-23 (SEQ ID NO: 572). 5 primer EMK135 VH3-23
30 A I S G S G G S T Y Y A D S V K G R F
J] GCTATTA GTGGTAGTGG
CGATAAT CACCATCACC VH3-23
35 T I S R D N S K N T L Y L Q M N S L R A E D T A V Y Y
"' I ACCATCTCCA
TGGTAGAGGT
VH3-23 D Jl 0
Nl 9 N2
• C A K D A G G Y Y Y G S G S Y Y N A A A Y Y Y Y Y G M 5 CTGCGCCAAG GACGCGGTTC JH6
50 .Jl^ rfl
Nhel
D V W G Q G T T V T V S S A S T K G P S V F P L A P KJ] TGGACGTGTG
55 ACCTGCACAC
CHl
S S K S T S G G T A A L G C L V K D Y F P E P V T V S t 3 I TCCTCCAAGA
60 AGGAGGTTCT
EK137 CHl Primer
CHl
65 - W N S G A L T S G V H T F P A V L Q S S G L Y S L S S
"^L GTGGAACTCA
CACCTTGAGT CHl
70 - V V T V P S S S L G
LO' ] GCGTGGTGAC CGTGCCCTCC AGCAGCTTGG GC CGCACCACTG GCACGGGAGG TCGTCGAACC CG
Example 10.2: Cloning of the Oligonucleotides Encoding the DH, N2, H3-JH Segments into the Vectors Containing the Tail and Nl Segments
This example describes the cloning of the oligonucleotides encoding the [D]- [N2]-[H3-JH] segments (made via split pool synthesis; Example 9) into the 424 vectors produced in Example 10.1. To summarize, the [DH] -[N2]-[H3- JH] oligonucleotides produced via split pool synthesis were amplified by PCR, to produce double- stranded oligonucleotides, to introduce restriction sites that would create overhangs complementary to those on the vectors (i.e., BsrDI and Bbsl), and to complete the 3' portion of the IGHJ segments that was not synthesized in the split pool synthesis. The amplified oligonucleotides were then digested with the restriction enzymes BsrDI
(cleaves adjacent to the DH segment) and Bbsl (cleaves near the end of the JH segment). The cleaved oligonucleotides were then purified and ligated into the 424 vectors which had previously been digested with BsrDI and Bbsl. After ligation, the reactions were purified, ethanol precipitated, and resolubilized. This process for one of the [DH]-[N2]-[H3-JH] oligonucleotides synthesized in the split pool synthesis is illustrated below. The following oligonucleotide (SEQ ID NO: 399) is one of the oligonucleotides synthesized during the split pool synthesis:
1 ATGCACAGTTGCAATGTGTATTACTATGGATCTGGTTCTTACTATAATGT 50
51 GGGCGGATATTATTACTACTATGGTATGGACGTATGGGGGCAAGGGACC 99
The first 10 nucleotides (ATGCACAGTT; SEQ ID NO: 395) represent a portion of a random sequence that is increased to 20 base pairs in the PCR amplification step, below. This portion of the sequence increases the efficiency of BsrDI digestion and facilitates the downstream purification of the oligonucleotides. Nucleotides 11-16 (underlined) represent the BsrDI recognition site. The two base overlap sequence that follows this site (in this example TG; bold) was synthesized to be complementary to the two base overhang created by digesting certain of the 424 vectors with BsrDI (i.e., depending on the composition of the tail / Nl region of the particular vector). Other oligonucleotides contain different two-base overhangs, as described below.
The two base overlap is followed by the DH gene segment (nucleotides 19-48), in this example, by a 30 bp sequence (TATTACTATGGATCTGGTTCTTACTATAAT, SEQ ID NO: 400) which encodes the ten residue DH segment YYYGSGS YYN (i.e., IGHD3-10 2 of Table 17; SEQ ID NO: 2).
The region of the oligonucleotide encoding the DH segment is followed, in this example, by a nine base region (GTGGGCGGA; bold; nucleotides 49-57), encoding the N2 segment (in this case VGG; Table 24).
The remainder of this exemplary oligonucleotide represents the portion of the JH segment that is synthesized during the split pool synthesis
(TATTATTACTACTATGGTATGGACGTATGGGGGCAAGGGACC; SEQ ID NO: 401; nucleotides 58-99; underlined), encoding the sequence YYYYYGMD VWGQGT (Table 20; residues 1-14 of SEQ ID NO: 258). The balance of the IGHJ segment is added during the subsequent PCR amplification described below. After the split pool-synthesized oligonucleotides were cleaved from the resin and deprotected, they served as a template for a PCR reaction which added an additional randomly chosen 10 nucleotides (e.g., GACGAGCTTC; SEQ ID NO: 402) to the 5' end and the rest of the IGHJ segment plus the Bbsl restriction site to the 3' end. These additions facilitate the cloning of the [DH]-[N2]-[JH] oligonucleotides into the 424 vectors. As described above (Example 9), the last round of the split pool synthesis involves 280 columns: 10 columns for each of the oligonucleotides encoding one of 28 H3-JH segments. The oligonucleotide products obtained from these 280 columns are pooled according to the identity of their H3-JH segments, for a total of 28 pools. Each of these 28 pools is then amplified in five separate PCR reactions, using five forward primers that each encode a different two base overlap (preceding the DH segment; see above) and one reverse primer that has a sequence corresponding to the familial origin of the H3-JH segment being amplified. The sequences of these 11 primers are provided below:
Forward primers
AC GACGAGCTTCAATGCACAGTTGCAATGAC (SEQ ID NO : 403 )
AG GACGAGCTTCAATGCACAGTTGCAATGAG (SEQ ID NO : 404)
CT GACGAGCTTCAATGCACAGTTGCAATGCT (SEQ ID NO : 405 )
GA GACGAGCTTCAATGCACAGTTGCAATGGA (SEQ ID NO : 406) TG GACGAGCTTCAATGCACAGTTGCAATGTG (SEQ ID NO : 407 )
Reverse Primers
DHl TGCATCAGTGCGACTAACGGAAGACTCTGAGGAGACGGTGACCAAGGTGCCCTGGCCCCA
(SEQ ID NO: 408) DH2 TGCATCAGTGCGACTAACGGAAGACTCTGAGGAGACAGTGACCAAGGTGCCACGGCCCCA
(SEQ ID NO: 409) DH3 TGCATCAGTGCGACTAACGGAAGACTCTGAAGAGACGGTGACCATTGTCCCTTGGCCCCA
(SEQ ID NO: 410) DH4 TGCATCAGTGCGACTAACGGAAGACTCTGAGGAGACGGTGACCAAGGTTCCTTGGCCCCA
(SEQ ID NO : 411 ) DH5 TGCATCAGTGCGACTAACGGAAGACTCTGAGGAGACGGTGACCAAGGTTCCCTGGCCCCA
(SEQ ID NO : 412)
DH6 TGCATCAGTGCGACTAACGGAAGACTCTGAGGAGACGGTGACCGTGGTCCCTTGCCCCCA (SEQ ID NO : 413)
Amplifications were performed using Taq polymerase, under standard conditions. The oligonucleotides were amplified for eight cycles, to maintain the representation of sequences of different lengths. Melting of the strands was performed at 950C for 30 seconds, with annealing at 580C and a 15 second extension time at 720C.
Using the exemplary split-pool derived oligonucleotide enumerated above as an example, the PCR amplification was performed using the TG primer and the JH6 primer, where the annealing portion of the primers has been underlined:
TG GACGAGCTTCAATGCACAGTTGCAATGTG (SEQ ID NO : 4Θ7 )
DH6 TGCATCAGTGCGACTAACGGAAGACTCTGAGGAGACGGTGACCGTGGTCCCTTGCCCCCA (SEQ ID NO : 413 ) The portion of the TG primer that is 5 ' to the annealing portion includes the random 10 base pairs described above. The portion of the JH6 primer that is 5' to the annealing portion includes the balance of the JH6 segment and the Bbsl restriction site. The following PCR product (SEQ ID NO: 414) is formed in the reaction (added sequences underlined): GACGAGCTTCATGCACAGTTGCAATGTGTATTACTATGGATCTGGTTCTTACTATAATGTGGGCGGATATTAT TACTACTATGGTATGGACGTATGGGGGCAAGGGACCACGGTCACCGTCTCCTCAGAGTCTTCCGTTAGTCGCA CTGATGCAG
The PCR products from each reaction were then combined into five pools, based on the forward primer that was used in the reaction, creating sets of sequences yielding the same two-base overhang after BsrDI digestion. The five pools of PCR products were then digested with BsRDI and Bbsl (100 μg of PCR product; 1 mL reaction volume; 200 U Bbsl; 100 U BsrDI; 2h; 370C; NEB Buffer 2). The digested oligonucleotides were extracted twice with phenol/chloroform, ethanol precipitated, air dried briefly and resolubilized in 300 μL of TE buffer by sitting overnight at 40C.
Each of the 424 vectors described in the preceding sections was then digested with BsrDI and Bbsl, each vector yielding a two base overhang that was complimentary to one of those contained in one of the five pools of PCR products. Thus, one of the five pools of restriction digested PCR products are ligated into each of the 424 vectors,
depending on their compatible ends, for a total of 424 ligations.
Example 10.3: PCR Amplification of the CDRH3from the 424 Vectors
This example describes the PCR amplification of the CDRH3 regions from the 424 vectors described above. As set forth above, the 424 vectors represent two sets: one for the VH3-23 family, with FRM3 ending in CAK (212 vectors) and one for the other 16 chassis, with FRM3 ending in CAR (212 vectors). The CDRH3s in the VH3-23-based vectors were amplified using a reverse primer (EK137; see Table 41) recognizing a portion of the CHl region of the plasmid and the VH3-23-specific primer EK135 (see Table 41). Amplification of the CDRH3s from the 212 vectors with FRM3 ending in CAR was performed using the same reverse primer (EK137) and each of five FRM3- specific primers shown in Table 41 (EK139, EK140, EK141, EK143, and EK144). Therefore, 212 VH3-23 amplifications and 212 x 5 FRM3 PCR reactions were performed, for a total of 1,272 reactions. An additional PCR reaction amplified the CDRH3 from the 212 VH3-23-based vectors, using the EK 133 forward primer, to allow the amplicons to be cloned into the other 5 VH3 family member chassis while making the last three amino acids of these chassis CAK instead of the original CAR (VH3-23*). The primers used in each reaction are shown in Table 41.
Table 41. Primers Used for Amplification of CDRH3 Sequences


Example 10.4: Homologous Recombination of PCR-Amplified CDRH3 Regions Into Heavy Chain Chassis
After amplification, reaction products were pooled according to the respective VH chassis that they would ultimately be cloned into. Table 42 enumerates these pools, with the PCR primers used to obtain the CDRH3 sequences in each pool provided in the last two columns. Table 42. PCR Primers Used to Amplify CDRH3 Regions from 424 Vectors

As described in Table 5, the potential site for N-lmked glycosylation was removed from CDRH2 of this chassis.
After pooling of the amplified CDRH3 regions, according to the process outlined above, the heavy chain chassis expression vectors were pooled according to their origin and cut, to create a "gap" for homologous recombination with the amplified CDRH3s.
Figure 6 shows a schematic structure of a heavy chain vector, prior to recombination with a CDRH3. In this exemplary embodiment of the invention, there were a total of
152 vectors encoding heavy chain chassis and IgGl constant regions, but no CDRH3.
These 152 vectors represent 17 individual variable heavy chain gene families (Table 5;
Examples 1 and 2). Fifteen of the families were represented by the heavy chain chassis sequences described in Table 5 and the CDRH1/H2 variants described in Table 8 (i.e., 150 vectors). VH 3-30 differs from VH3-33 by a single amino acid; thus VH3-30 was included in the VH3-33 pool of variants. The 4-34 VH family member was kept separate from all others and, in this exemplary embodiment, no variants of it were included in the library. Thus, a total of 16 pools, representing 17 heavy chain chassis, were generated from the 152 vectors. The vector pools were digested with the restriction enzyme Sfil, which cuts at two sites in the vector that are located between the end of the FRM3 of the variable domain and the start of the CHl (SEQ ID NO: 573).
~:"
VH3-48 VTVSS corrατion to all J
AGGACACGGC TCCTGTGCCG VTVSS common to all J
The gapped vector pools were then mixed with the appropriate (i.e., compatible)
pool of CDRH3 amplicons, generated as described above, at a 50: 1 insert to vector ratio. The mixture was then transformed into electrocompetent yeast (S. cerevisiae), which already contained plasmids or integrated genes comprising a VK light chain library (described below). The degree of library diversity was determined by plating a dilution of the electroporated cells on a selectable agar plate. In this exemplified embodiment of the invention, the agar plate lacked tryptophan and the yeast lacked the ability to endogenously synthesize tryptophan. This deficiency was remedied by the inclusion of the TRP marker on the heavy chain chassis plasmid, so that any yeast receiving the plasmid and recombining it with a CDRH3 insert would grow. The electroporated cells were then outgrown approximately 100-fold, in liquid media lacking tryptophan. Aliquots of the library were frozen in 50% glycerol and stored at -800C. Each transformant obtained at this stage represents a clone that can express a full IgG molecule. A schematic diagram of a CDRH3 integrated into a heavy chain vector and the accompanying sequence are provided in Figure 5. A heavy chain library pool was then produced, based on the approximate representation of the heavy chain family members as depicted in Table 43.
Table 43. Occurrence of Heavy Chain Chassis in Data Sets Used to Design Library,

Example 10.5: K94R Mutation in VH3-23 and R94K Mutation in VH3-33, VH3-30, VH3-7, and VH3-48
This example describes the mutation of position 94 in VH3-23, VH3-33, VH3- 30, VH3-7, and VH3-48. In VH3-23, the amino acid at this position was mutated from K to R. In VH3-33, VH3-30, VH3-7, and VH3-48, this amino acid was mutated from R to K. In VH3-32, this position was mutated from K to R. The purpose of making these mutations was to enhance the diversity of CDRH3 presentation in the library. For example, in naturally occurring VH3-23 sequences, about 90% have K at position 94, while about 10% have position R. By making these changes the diversity of the CDRH3 presentation is increased, as is the overall diversity of the library. *** Amplification was performed using the 424 vectors as a template. For the K94R mutation, the vectors containing the sequence DTAVYYCAK (VH3-23; SEQ ID NO: 578) were amplified with a PCR primer that changed the K to a R and added 5' tail for homologous recombination with the VH3-48, VH3-33, VH-30, and VH3-7. The "T" base in 3-48 does not change the amino acid encoded and thus the same primer with a T::C mismatch still allows homologous recombination into the 3-48 chassis.
Furthermore, the amplification products from the 424 vectors (produced as described above) containing the DTAVYYCAR (SEQ ID NO: 579) sequence can be homologously recombined into the VH3-23 (CAR) vector, changing R to K in this framework and thus further increasing the diversity of CDRH3 presentation in this chassis.
240 294
VH3-48 (240) TCTGCAAATGAACAGCCTGAGAGCTGAGGACACGGCGGTGTACTACTGCGCCAGA SEQ ID NO : ( 574)
VH3-33/30(240) TCTGCAAATGAACAGCCTGAGAGCCGAGGACACGGCGGTGTACTACTGCGCCAGA
SEQ ID NO: ( 575) VH3-7 ( 240) TCTGCAAATGAACAGCCTGAGAGCCGAGGACACGGCGGTGTACTACTGCGCCAGA
SEQ ID NO: ( 576)
VH3-23 (240) TCTGCAAATGAACAGCCTGAGAGCCGAGGACACGGCGGTGTACTACTGCGCCAAG
SEQ ID NO: ( 577)
Example 11: VK Library Construction
This example describes the construction of a VK library of the invention. The exemplary VK library described herein corresponds to the VKCDR3 library of about 105 complexity, described in Example 6.2. As described in Example 6, and throughout the application, other VK libraries are within the scope of the invention, as are Vλ libraries.
Ten VK chassis were synthesized (Table 11), which did not contain VKCDR3, but instead had two Sfil restriction sites in the place of VKCDR3, as for the heavy chain vectors. The kappa constant region followed the Sfil restriction sites. Figure 8 shows a schematic structure of a light chain vector, prior to recombination with a CDRL3.
Ten VKCDR oligonucleotide libraries were then synthesized, as described in Example 6.2, using degenerate oligonucleotides (Table 33). The oligonucleotides were then PCR amplified, as separate pools, to make them double stranded and to add additional nucleotides required for efficient homologous recombination with the gapped (by Sfil) vector containing the VK chassis and constant region sequences. The VKCDR3 pools in this embodiment of the invention represented lengths 8, 9, and 10 amino acids, which were mixed post- PCR at a ratio 1:8:1. The pools were then cloned into the respective Sfil gapped VK chassis via homologous recombination, as described for the CDRH3 regions, set forth above. A schematic diagram of a CDRL3 integrated into a light chain vector and the accompanying sequence are provided in Figure 9.
A kappa light chain library pool was then produced, based on the approximate representation of the VK family members found in the circulating pool of B cells. The 10 kappa variable regions used and the relative frequency in the final library pool are shown in Table 44.
Table 44. Occurrence of VK Chassis in Data Sets Used to Design Library, Expected (Designed) Library, and Actual (Observed) Library


(1) As indicated in Example 3, these 10 chassis account for about 80% of the occurrences in the entire data set of VK sequences examined.
(2) Rounded off ratios from the data in column 2, then normalized for actual experimental set up. The relative rounded ratios are 6 for VKl -39 and VK3-20, 3 for VK3-11 and VK4-1, 2 for VK-15, VK1-33, VK2-28 and VK3-15, and 1 for VKl-12 and VKl-27.
(3) Chassis usage in set of 86 sequences obtained from library; see also Figure 22.
Example 12: Characterization of Exemplary Libraries
This example shows the characteristics of exemplary libraries of the invention, constructed according to the methods described herein.
Example 12.1. Characterization of the Heavy Chains
To characterize the product of the split pool synthesis, ten of the 424 vectors containing the [Tail]-[N1]-[DH]-[N2]-[H3-JH] product were selected at random and transformed into E. coli. The split pool product had a theoretical diversity of about 1.1 x 106 (i.e., 278 x 141 x 28). Ninety-six colonies were selected from the transformation and forward and reverse sequences were generated for each clone. Of the 96 sequencing reactions, 90 yielded sequences from which the CDRH3 region could be identified, and about 70% of these sequences matched a designed sequence in the library. The length distribution of the sequenced CDRH3 segments from the ten vectors, as compared to the theoretical distribution (based on design), is provided in Figure 10. The length distribution of the individual DH, N2, and H3- JH segments obtained from the ten vectors are shown in Figures 11-13.
Once the length distribution of the CDRH3 components of the library that were contained in the vector matched design were verified, the CDRH3 domains and heavy chain family representation in yeast that had been transformed according to the process described in Example 10.4 were characterized. Over 500 single -pass sequences were obtained. Of these, 531 yielded enough sequence information to identify the heavy chain chassis and 291 yielded enough sequence information to characterize the CDRH3. These CDRH3 domains have been integrated with the heavy chain chassis and constant
region, according to the homologous recombination processes described herein. The length distribution of the CDRH3 domains from 291 sequences, compared to the theoretical length distribution, is shown in Figure 14. The mean theoretical length was 14.4 ± 4 amino acids, while the average observed length was 14.3 ± 3 amino acids. The observed length of each portion of the CDRH3, as compared to theoretical, is presented in Figures 15-18. Figure 19 depicts the familial origin of the JH segments identified in the 291 sequences, and Figure 20 shows the representation of 16 of the chassis of the library. The VH3-15 chassis was not represented amongst these sequences. This was corrected later by introducing yeast transformants containing the VH3-15 chassis, with CDRH3 diversity, into the library at the desired composition.
Example 12.2. Characterization of the Light Chains
The length distribution of the CDRL3 components, from the VKCDR3 library described in Example 6.2, were determined after yeast transformation via the methods described in Example 10.4. A comparison of the CDRL3 length from 86 sequences of the library to the human sequences and designed sequences is provided in Figure 21. Figure 22 shows the representation of the light chain chassis from amongst the 86 sequences selected from the library. About 91% of the CDRL3 sequences were exact matches to the design, and about 9% differed by a single amino acid.
Example 13: Characterization of the Composition of the Designed CDRH3 Libraries
This example presents data on the composition of the CDRH3 domains of exemplary libraries, and a comparison to other libraries of the art. More specifically, this example presents an analysis of the occurrence of the 400 possible amino acid pairs (20 amino acids x 20 amino acids) occurring in the CDRH3 domains of the libraries. The prevalence of these pairs is computed by examination of the nearest neighbor (i - i+1; designated IPl), next nearest neighbor (i - i+2; designated IP2), and next-next nearest neighbor (i - i+3; designated IP3) of the i residue in CDRH3. Libraries previously known in the art (e.g., Knappik et ah, J. MoI. Biol., 2000, 296: 57; Sidhu et ah, J. MoI. Biol., 2004, 338: 299; and Lee et ah, J. MoI. Biol. 2004, 340: 1073, each of which is incorporated by reference in its entirety) have only considered the occurrence of the 20 amino acids at individual positions within CDRH3, while maintaining the same composition across the center of CDRH3, and not the pair-wise occurrences
considered herein. In fact, according to Sidhu et al. (J. MoI. Biol., 2004, 338: 299, incorporated by reference in its entirety), "[i]n CDR-H3, there was some bias towards certain residue types, but all 20 natural amino acid residues occurred to a significant extent, and there was very little position-specific bias within the central portion of the loop". Thus, the present invention represents the first recognition that, surprisingly, a position-specific bias does exist within the central portion of the CDRH3 loop, when the occurrences of amino acid pairs recited above are considered. This example shows that the libraries described herein more faithfully reproduce the occurrence of these pairs as found in human sequences, in comparison to other libraries of the art. The composition of the libraries described herein may thus be considered more "human" than other libraries of the art.
To examine the pair-wise composition of CDRH3 domains, a portion of CDRH3 beginning at position 95 was chosen. For the purposes of comparison with data presented in Knappik et al. and Lee et al. , the last five residues in each of the analyzed CDRH3s were ignored. Thus, for the purposes of this analysis, both members of the pair i - i + X (X=I to 3) must fall within the region starting at position 95 and ending at (but including) the sixth residue from the C-terminus of the CDRH3. The analyzed portion is termed the "central loop" (see Definitions).
To estimate pair distributions in representative libraries of the invention, a sampling approach was used. A number of sequences were generated by choosing randomly and, in turn, one of the 424 tail plus Nl segments, one of the 278 DH segments, one of the 141 N2 segments and one of the 28 JH segments (the latter truncated to include only the 95 to 102 Kabat CDRH3). The process was repeated 10,000 times to generate a sample of 10,000 sequences. By choosing a different seed for the random number generation, an independent sample of another 10,000 sequences was also generated and the results for pair distributions were observed to be nearly the same. For the calculations presented herein, a third and much larger sample of 50,000 sequences was used. A similar approach was used for the alternative library embodiment (Nl-141), whereby the first segment was selected from 1068 tail+Nl segments (resulting after eliminating redundant sequences from 2 times 4 times 141 or 1128 possible combinations).
The pair- wise composition of Knappik et al. was determined based on the percent occurrences presented in Figure 7a of Knappik et al. (p.71). The relevant data
are reproduced below, in Table 45.
Table 45 i. Composition of CDRH3 positions 95-10Os (corresponding to positions 95- 99B of the libraries of the current invention) of CDRH3 of Knappik et al. (from Figure 7a of Knappik et al. )

The pair- wise composition of Lee et al. was determined based on the libraries depicted in Table 5 of Lee et al. , where the positions corresponding to those CDRH3 regions analyzed from the current invention and from Knappik et al. are composed of an "XYZ" codon in Lee et al. The XYZ codon of Lee et al. is a degenerate codon with the following base compositions: position 1 (X): 19% A, 17% C, 38% G, and 26% T; position 2 (Y): 34% A, 18% C, 31% G, and 17% T; and position 3 (Z): 24% G and 76% T. When the approximately 2% of codons encoding stop codons are excluded (these do not occur in functionally expressed human CDRH3 sequences), and the percentages are re- normalized to 100%, the following amino acid representation can be deduced from the composition of the XYZ codon of Lee et al. (Table 46).
Table 46. Composition of CDRH3 of Lee et al., Based on the Composition of the Degenerate XYZ Codon.

The occurrences of each of the 400 amino acid pairs, in each of the IPl, IP2, and
IP3 configurations, can be computed for Knappik et al. and Lee et al. by multiplying together the individual amino acid compositions. For example, for Knappik et al., the occurrence of YS pairs in the library is calculated by multiplying 15% by 4.1%, to yield 6.1%; note that the occurrence of SY pairs would be the same. Similarly, for the XYZ codon-based libraries of Lee et al., the occurrence of YS pairs would be 6.86% (Y) multiplied by 9.35% (S), to give 6.4%; the same, again, for SY.
For the human CDRH3 sequences, the calculation is performed by ignoring the last five amino acids in the Kabat definition. By ignoring the C-terminal 5 amino acids of the human CDRH3, these sequences may be compared to those of Lee et al., based on the XYZ codons. While Lee et al. also present libraries with "NNK" and "NNS" codons, the pair- wise compositions of these libraries are even further away from human CDRH3 pair- wise composition. The XYZ codon was designed by Lee et al. to replicate, to some extent, the individual amino acid type biases observed in CDRH3.
An identical approach was used for the libraries of the invention, after using the methods described above to produce sample sequences. While it is possible to perform these calculations with all sequences in the library, independent random samples of 10,000 to 20,000 members gave indistinguishable results. The numbers reported herein were thus generated from samples of 50,000 members.
Three tables were generated for IPl, IP2 and IP3, respectively (Tables 47, 48, and 49). Out of the 400 pairs, a selection from amongst the 20 most frequently occurring is included in the tables. The sample of about 1,000 human sequences (Lee et
ah, 2006) is denoted as "Preimmune," a sample of about 2,500 sequences (Jackson et ah, 2007) is denoted as "Humabs," and the more affinity matured subset of the latter, which excludes all of the Preimmune set, is denoted as "Matured." Synthetic libraries in the art are denoted as HuCAL (Knappik, et ah, 2000) and XYZ (Lee et ah, e 2004). Two representative libraries of the invention are included: LUA-59 includes 59 Nl segments, 278 DH segments, 141 N2 segments, and 28 H3-JH segments (see Examples, above). LUA- 141 includes 141 Nl segments, 278 DH segments, 141 N2 segments, and 28 H3-JH segments (see Examples, above). Redundancies created by combination of the Nl and tail sequences were removed from the dataset in each respective library. In certain embodiments, the invention may be defined based on the percent occurrence of any of the 400 amino acid pairs, particularly those in Tables 47-49. In certain embodiments, the invention may be defined based on at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more of these pairs. In certain embodiments of the invention, the percent occurrence of certain pairs of amino acids may fall within ranges indicated by "LUA-" (lower boundary) and "LUA+" (higher boundary), in the following tables. In some embodiments of the invention, the lower boundary for the percent occurrence of any amino acid pairs may be about 0.1, 0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3, 3.25, 3.5, 3.75, 4, 4.25, 4.5, 4.75, and 5. In some embodiments of the invention, the higher boundary for the percent occurrence of any amino acid pairs may be about 0.1, 0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3, 3.25, 3.5, 3.75, 4, 4.25, 4.5, 4.75, 5, 5.25, 5.5, 5.75, 6, 6.25, 6.5, 6.75, 7, 7.25, 7.5, 7.75, and 8. According to the present invention, any of the lower boundaries recited may be combined with any of the higher boundaries recited, to establish ranges, and vice-versa.
Table 47. Percent Occurrence of i - i+1 (IPl) Amino Acid Pairs in Human Sequences, Exemplary Libraries of the Invention, and the Libraries of Knappik et al. and Lee et al.

The pairs in bold comprise about 19% to about 24% of occurrences (among the possible 400 pairs) for the Preimmune (Lee, et al, 2006), Humabs (Jackson, et al, 2007) and matured (Jackson minus Lee) sets. They account for about 27% to about 31% of the occurrences in the LUA libraries, but only about 12% in the HuCAL library and about 8% in the "XYZ" library. This is a reflection of the fact that pair- wise biases do exist in the human and LUA libraries, but not in the others. The last 2 columns indicate whether the corresponding pair-wise compositions fall within the LUA- and LUA+ boundaries: 0 if outside, 1 if within.
Table 48. Percent Occurrence of i - i+2 (IP2) Amino Acid Pairs in Human Sequences, Exemplary Libraries of the Invention, and the Libraries of Knappik et al. and Lee et al.
06

5 The pairs in bold comprise about 18% to about 23% of occurrences (among the possible 400 pairs) for the Preimmune (Lee, et al, 2006), Humabs (Jackson, et al, 2007) and matured (Jackson minus Lee) sets. They account for about 27% to about 30% of the occurrences in the LUA libraries, but only about 12% in the HuCAL library and about 8% in the "XYZ" library. Because of the nature of the construction of the central loops in the HuCAL and XYZ libraries, these numbers are the same for the IPl, IP2, and IP3 pairs. The last 2 columns indicate whether the corresponding pair- wise compositions fall within the LUA- and LUA+ boundaries: 0 if outside, 1 if within.
10
Table 49. Percent Occurrence of i - i+3 (IP3) Amino Acid Pairs in Human Sequences, Exemplary Libraries of the Invention, and the Libraries of Knappik et al. and Lee et al.
06

5 The pairs in bold make up about 16 to about 21% of the occurrences (among the possible 400 pairs) for the Preimmune (Lee, et al, 2006), Humabs (Jackson, et al, 2007) and matured (Jackson minus Lee) sets. They account for 26 to 29% of the occurrences in the LUA libraris, but only about 12% in the HuCAL library and about 8% for the "XYZ" library. Because of the nature of the construction of the central loops in the HuCAL and XYZ libraries, these numbers are the same for the IPl, IP2, and IP3 pairs. The last 2 columns indicate whether the corresponding pair- wise compositions fall within the LUA- and LUA+ boundaries: 0 if outside, 1 if within.
10
The analysis provided in this example demonstrates that the composition of the libraries of the present invention more closely mimics the composition of human sequences than other libraries known in the art. Synthetic libraries of the art do not intrinsically reproduce the composition of the "central loop" portion actual human CDRH3 sequences at the level of pair percentages. The libraries of the invention have a more complex pair-wise composition that closely reproduces that observed in actual human CDRH3 sequences. The exact degree of this reproduction versus a target set of actual human CDRH3 sequences may be optimized, for example, by varying the compositions of the segments used to design the CDRH3 libraries. Moreover, it is also possible to utilize these metrics to computationally design libraries that exactly mimic the pair-wise compositional prevalence found in human sequences.
Example 14: Information Content of Exemplary Libraries
One way to quantify the observation that certain libraries, or collection of sequences, may be intrinsically more complex or "less random" than others is to apply information theory (Shannon, Bell Sys. Tech. J., 1984, 27: 379; Martin et al, Bioinformatics, 2005, 21 : 4116; Weiss et al, J. Theor. Biol, 2000, 206: 379, each incorporated by reference in its entirety). For example, a metric can be devised to quantify the fact that a position with a fixed amino acid represents less "randomness" than a position where all 20 amino acids may occur with equal probability. Intermediate situations should lead, in turn, to intermediate values of such a metric. According to information theory this metric can be represented by the formula:
^ = X^ lOg2 / Here,/ is the normalized frequency of occurrence of /, which may be an amino acid type (in which case N would be equal to 20). When all/ are zero except for one, the value of I is zero. In any other case the value of I would be smaller, i.e., negative, and the lowest value is achieved when all/ values are the same and equal to N. For the amino acid case, N is 20, and the resulting value of I would be -4.322. Because I is defined with base 2 logarithms, the units of I are bits. The I value for the HuCAL and XYZ libraries at the single position level may be derived from Tables 45 and 46, respectively, and are equal to -4.08 and -4.06. The corresponding single residue frequency occurrences in the non-limiting exemplary
libraries of the invention and the sets of human sequences previously introduced, taken within the "central loop" as defined above, are provided in Table 50.

The information content of these sets, computed by the formula given above, would then be -3.88, -3.93, -3.96, -3.56, and -3.75, for the preimmune, human, matured, LUA-59 and LUA-141 sets, respectively. As the frequencies deviate more from completely uniform (5% for each of the 20), then numbers tend to be larger, or less negative. The identical approach can be used to analyze pair compositions, or frequencies, by calculating the sum in the formula above over the 20x20 or 400 values of the frequencies for each of the pairs. It can be shown that any pair frequency made up of the simple product of two singleton frequency sets is equal to the sum of the individual singleton I values. If the two singleton frequency sets are the same or approximately so, this means that I (independent pairs) = 2 * 1 (singles). It is thus possible to define a special case of the mutual information, MI, for a general set of pair frequencies as MI (pair) = I(pair) - 2 * I (singles) to measure the amount of information gained by the structure of the pair frequencies themselves (compare to the standard definitions in Martin et at., 2005, for example, after considering that I (X) = -H(X) in their notation). When there is no such structure, the value of MI is simply zero.
Values of MI computed from the pair distributions discussed above (over the entire set of 400 values) are given in Table 51.
Table 51. Mutual Information Within Central Loop of CDRH3

It is notable that the MI values decrease within sets of human sequences as those sequences undergo further somatic mutation, a process that over many independent sequences is essentially random. It is also worth noting that the MI values decrease as the pairs being considered sit further and further apart, and this is the case for both sets of human sequences, and exemplary libraries of the invention. In both cases, as the two amino acids in a pair become further separated the odds of their straddling an actual segment (V, D, J plus V-D or D-J insertions) increase, and their pair frequencies become closer to a simple product of singleton frequencies.
Table 52 contains sequence information on certain immunoglobulin gene segments cited in the application. These sequences are non- limiting, and it is recognized that allelic variants exist and encompassed by the present invention. Accordingly, the methods present herein can be utilized with mutants of these sequences.
Table 52. Sequence Information for Certain Immunoglobulin Gene Segments Cited Herein

00


O


K>




ADS-Ol 1.26

(1 ) Each of the IGHD nucleotide sequences can be read in three (3) forward reading frames, and, possibly, in 3 reverse reading frames. For example, the nucleotide sequence given for IGHD1-1 , depending on how it inserts in full V-DJ rearrangement, may encode the full peptide sequences: GTTGT (SEQ ID NO: 517). VQLER (SEQ ID NO: 518)and YNWND (SEQ ID NO: 519) in the forward direction, and VVPVV (SEQ ID NO: 520). SFQLY (SEQ ID NO: 521 ) and RSSCT (SEQ ID NO: 522) in the reverse direction. Each of these sequences, in turn, could generate progressively deleted segments as explained in the Examples to produce suitable components for libraries of the invention.
196
B3730949.2
Example 15: Selection of Antibodies from the Library
In this example, the selection of antibodies from a library of the invention (described in Examples 9-11 and other Examples) is demonstrated. These selections demonstrate that the libraries of the invention encode antibody proteins capable of binding to antigens. In one selection, antibodies specific for "Antigen X", a protein antigen, were isolated from the library using the methods described herein. Figure 24 shows binding curves for six clones specifically binding Antigen X, and their Kd values. This selection was performed using yeast with the heavy chain on a plasmid vector and the kappa light chain library integrated into the genome of the yeast. In a separate selection, antibodies specific for a model antigen, hen egg white lysozyme (HEL) were isolated. Figure 25 shows the binding curves for 10 clones specifically binding HEL; each gave a Kd >500nM. This selection was performed using yeast with the heavy chain on a plasmid vector and the kappa light chain library on a plasmid vector. The sequences of the heavy and light chains were determined for clones isolated from the library and it was demonstrated that multiple clones were present. A portion of the FRJVBs (underlined) and the entire CDRH3s from four clones are shown below (Table 53 and Table 54, the latter using the numbering system of the invention).
Table 53. Sequences of CDRH3, and a Portion of FRM3, from Four HEL Binders

Table 54. Sequences of CDRH3 from Four HEL Binders in Numbering System of the Invention, According to the Numbering System of the Invention

Sequence Identifiers: CR080362 (SEQ ID NO: 523); CR080363 (SEQ ID NO: 524); CR080372 (SEQ ID NO: 525); EK080902 (SEQ ID NO:
526)
00
The heavy chain chassis isolated were VH3-23.0 (for EK080902 and CR080363), VH3-23.6 (for CR080362), and VH3-23.4 (for CR080372). These variants are defined in Table 8 of Example 2. Each of the four heavy chain CDRH3 sequences matched a designed sequence from the exemplified library. The CDRL3 sequence of one of the clones (ED080902) was also determined, and is shown below, with the surrounding FRM regions underlined:
CDRL3: YYCOESFHIP YTFGGG (SEQ ID NO: 527).
In this case, the CDRL3 matched the design of a degenerate VKl -39 oligonucleotide sequence in row 49 of Table 33. The relevant portion of this table is reproduced below, with the amino acids occupying each position of the isolated CDRL3 bolded and
10 underlined:

15 Example 16: Libraries Utilizing Non-Human DH Segments
This example illustrates a non- limiting selection of non-human vertebrate DH segments for use in the libraries of the invention. Non-human vertebrate DH segments were generally selected as follows. First, an exemplary survey of published IGHD sequences was performed as summarized below. Second, the degree of deletion on either end of the IGHD
20 gene segments was estimated by analogy with human sequences (see Example 4.1). For the presently exemplified library, progressively deleted DH segments as short as three amino acids were included. As enumerated in the Detailed Description, other embodiments of the invention comprise libraries with DH segments with a minimum length of about 1, 2, 4, 5, 6, 7, 8, 9, or 10 amino acids.
25 Table 55 lists IGHD segments for a variety of species, namely Mus musculus
(mouse; BALB/C and C57BL/6), Macaca mulatta (rhesus monkey), Oryctolagus cuniculus (rabbit), Rattus norvegicus (rat), Ictalurus punctatus (catfish), Gadus morhua L (Atlantic cod), Pan troglodytes (chimpanzee), Camelidae sp. (camel), and Bos sp. (cow). The sequences were obtained from the publications cited in Table 55. The DNA sequences
encoding the IGHD genes are presented together with their translations in all three forward reading frames and, in some cases, three reverse reading frames. It will be appreciated that a skilled artisan could readily translate the reverse reading frames in those cases where they are not provided herein. Without being bound by theory, it is generally believed that the forward reading frames tend to be favored for inclusion in actual complete antibody sequences.
For the rat sequences, a procedure was implemented to extract the IGHD information from the most recent genomic assembly. First, the genomic location of a typical IGHV gene, e.g., 138565773 on chromosome 6, was identified from the literature (Das et ah, Immunogenetics, 2008, 60: 47, incorporated by reference in its entirety). This location (i.e., 138565773 on chromosome 6) was then used to identify the contig and location within Genbank, and the approximately 150K bp upstream (because the genes of interest are in the minus strand) segment was extracted. Searches for canonical (e.g., mouse and human) recombination signal sequences (RSS) were conducted and candidate coding regions of lengths between about 10 and about 50 nucleotides were considered putative
IGHD genes. The results of this IGHD gene identification process were consistent with the data that was available in the literature (e.g., the IGHD sequence designated "D 15" in Table 55 is identical to the sequence highlighted in Figure 3A of Briiggemann et ah, Proc. Natl. Acad. Sci. USA, 1986, 83: 6075, incorporated by reference in its entirety). Finally, when the translation led to a stop codon, the longest open reading frame (ORF) was chosen to represent the peptide contribution. For example, translation in the first reverse reading frame (Rl) of the rabbit sequence D2a results in the sequence *HKHNQHNHKYSN, where '*' represents a stop codon; in such case the longest ORF would be HKHNQHNHKYSN, as reported in Table 55. Alternatively, in the case of long segments, such as those derived from the cow (see Table 55), appropriate sub-segments not comprising a stop codon would be considered. For example, translation of the cow DHl gene in the first reading frame, provides MIR[stop]VWL[stop]LL[stop]CCY, which naturally would give rise to the ORFs or sub-segments: MIR, VWL, and CCY, when keeping a minimum length of three amino acids. The procedure used above for the rat, was also used for the chimpanzee (Pan troglodytes) and the three sets of sequences that were determined using the foregoing
method are listed in Table 55. Only the forward reading frame translations are presented, but it will be appreciated that one of ordinary skill in the art could readily generate the corresponding reverse translations.
For each of the sequences set forth in the tables described above, variants may be generated by systematic deletion from the N- and/or C-termini, until there are three amino acids remaining. For example, for gene D6s 4 from the rhesus macaque, the full sequence GYSGTWN may be used to generate the progressive deletion variants: GYSGTW, GYSGT, GYSG, GYS, YSGTWN, SGTWN, GTWN, TWN, YSGTW, YSGT, YSG, SGTW, GTW, and so forth. This progressive deletion procedure is taught in detail herein in other parts of the specification. In general, and as shown in Example 4.1, for any full-length sequence of size N, there will be a total of (N-l)*(N-2)/2 variants, including the original full-length sequence, when the termini are progressively deleted to obtain a minimum of three amino acids per segment. The number of variants will increase or decrease accordingly, depending on the minimum length of the progressively deleted DH segment; e.g., (N-2)*(N-3)/2 for a minimum length of four and (N)*(N-l)/2 for a minimum length of two. This relationship can be generalized to (N+l-L)*(N+2-L)/2 where L is the number of amino acid residues in the shortest segment and L is always smaller than N. In the extreme case where L equals N, as expected, one obtains (l)*(2)/2, or just one segment, namely the original segment. For the disulfide-loop-encoding segments, as exemplified by sequence D2S3 of rhesus translated in the second forward reading frame (AHCSDSGCSS), the progressive deletions were limited, in the present exemplification of the library, so as to leave the loop intact; i.e., only amino acids N-terminal to the first Cys, or C-terminal to the second Cys were deleted in the respective D segment variants; i.e., AHCSDSGCS, AHCSDSGC, HCSDSGCSS, CSDSGCSS, HCSDSGCS, HCSDSGC, CSDSGCS, and CSDSGC. This choice was made to avoid the presence of unpaired cysteine residues in the currently exemplified version of the library. For the same reason, segments with an odd number of Cys residues may be avoided in library construction. For example, the peptide segment resulting from the first reverse translation of the mouse (C57BL/6 strain) DST4 gene is SLSC, with the last Cys being potentially unpaired. This segment may be ignored, or considered only in its C-terminal deleted derivative, SLS . However, as discussed in the
Detailed Description, other embodiments of the library may include unpaired cysteine residues, or the substitution of these cysteine residues with other amino acids.
According to the criteria outlined above and throughout the specification, a number of sequences, or subsets thereof, may be chosen for inclusion in a library of the invention. Selection of these segments may be carried out using a variety of criteria, individually or in combination. Exemplary non-limiting criteria include:
(a) choosing segments that are most diverse in length and sequence;
(b) choosing segments with maximal "human string content" (see, e.g., US Pub. No. 2006/0008883, incorporated by reference in its entirety); or (c) choosing segments with a minimal number of predicted T-cell epitopes (see, e.g.,
US Patent No. 5,712,120, WO 9852976, and US Pub. No. 2008/0206239, each of which is incorporated by reference in its entirety).
Table 55. IGHD segments from other vertebrates
O

O

O

O

O

O OO

O

O

Each of the following references are incorporated by reference in their entirety:
[1] Ye, Immimogenetics, 2004, 56: 399; [2] Shimizu and Yamagishi, EMBO J, 1992, 11 : 4869; [3] Kurosawa et al, Nature, 1981, 290: 565; [4] Dirkes et al, Immunogenetics, 1994, 40: 379; [5] Gerondakis et al. Immunogenetics, 1988, 28: 255; [6] Gu et al, Cell, 1991, 65: 47; [7] Link et al, Immunogenetics, 2002, 54: 240; [8] Friedman et al, J. Immunol, 1994, 152: 632; [9] GI code: 62651567; reverse strand 33906161-33793435; [10] Hayman et al, J. Immunol, 2000,
164: 1916; [11] Ghaffari and Lobb, J. Immunol. 1999, 162: 1519; [12] Solem and Stenvik, Dev. Comp. Immunol, 2006, 30: 57; [13] GI code: 114655167; reverse strand 203704-97555; [14] Nguyen et al, EMBO J, 2000, 19: 921 ; [15] GI code: 13345163; [16] Shojaei et al, MoI. Immunol, 2003, 40: 61.
10
EQUIVALENTS
Those skilled in the art will recognize, or be able to ascertain using no more than routine experimentation, many equivalents to the specific embodiments and methods described herein. Such equivalents are intended to be encompassed by the scope of the following claims.
Claims
1. A library of synthetic polynucleotides, wherein said polynucleotides encode at least 106 unique antibody CDRH3 amino acid sequences comprising:
(i) an Nl amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the Nl amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in Nl amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by B cells;
(ii) a non-human CDRH3 DH amino acid sequence, N- and C-terminal truncations thereof, or a sequence of at least about 80% identity to any of them;
(iii) an N2 amino acid sequence of 0 to about 3 amino acids, wherein each amino acid of the N2 amino acid sequence is among the 12 most frequently occurring amino acids at the corresponding position in N2 amino acid sequences of CDRH3 amino acid sequences that are functionally expressed by B cells; and
(iv) a human CDRH3 H3-JH amino acid sequence, N-terminal truncations thereof, or a sequence of at least about 80% identity to any of them.
2. The library of claim 1, wherein the B cells are human B cells.
3. The library of claim 1, wherein the B cells are non-human B cells.
4. The library of claim 1, wherein the B cells are vertebrate B cells.
5. The library of claim 1, wherein the non-human CDRH3 DH amino acid sequence is a sequence from a vertebrate species.
6. The library of claim 5, wherein the vertebrate species is selected from the group consisting of MM* musculus, Camelus sp., Llama sp., Camelidae sp., Raja sp.,
Ginglymostoma sp., Carcharhinus sp., Heterodontus sp., Hydrolagus sp., Ictalurus sp., Gallus sp., Bos sp., Marmaronetta sp., Aythya sp., Netta sp., Equus sp., Pentalagus sp., Bunolagus sp., Nesolagus sp., Romerolagus sp., Brachylagus sp., Sylvilagus sp., Oryctolagus, sp., Poelagus sp., Ovis sp., Sus sp., Gadus sp., Salmo sp., Oncorhynchus sp, Macaca sp., Rattus sp., Pan sp., Hexanchus sp., Heptranchias sp., Notorynchus sp., Chlamydoselachus sp., Heterodontus sp. Pristiophorus sp., Pliotrema sp., Squatina sp., Carcharia sp., Mitsukurina sp., Lamma sp., Isurus sp., Carcharodon sp., Cetorhinus sp., Alopias sp., Nebrius sp., Stegostoma sp.,
Orectolobus sp., Eucrossorhinus sp., Sutorectus sp., Chiloscyllium sp., Hemiscyllium sp., Brachaelurus sp., Heteroscyllium sp., Cirrhoscyllium sp., Parascyllium sp., Rhincodon sp., Apristurus sp., Atelomycterus sp., Cephaloscyllium sp., Cephalurus sp., Dichichthys sp., Galeus sp., Halaelurus sp., Haploblepharus sp., Parmaturus sp., Pentanchus sp., Poroderna sp., Schroederichthys sp.,
Scyliorhinus sp., Pseudotriakis sp., Scylliogaleus sp., Furgaleus sp., Hemitriakis sp., Mustelus sp., Triakis sp., Iago sp., Galeorhinus sp., Hypogaleus sp., Chaenogaleus sp., Hemigaleus sp., Paragaleus sp., Galeocerdo sp., Prionace sp., Sciolodon sp., Loxodon sp., Rhizoprionodon sp., Aprionodon sp., Negaprion sp., Hypoprion sp., Carcharhinus sp., Isogomphodon sp., Triaenodon sp., Sphyrna sp., Echinorhinus sp., Oxynotus sp., Squalus sp., Centroscyllium sp., Etmopterus sp., Centrophorus sp., Cirrhigaleus sp., Deania sp., Centroscymnus sp., Scymnodon sp., Dalatias sp., Euprotomicrus sp., Isistius sp., Squaliolus sp., Heteroscymnoides sp., Somniosus sp. and Megachasma sp.
7. An antibody isolated from the polypeptide expression products of the library of claim 1.
8. The library of claim 1, wherein the CDRH3 amino acid sequences are expressed as part of full-length heavy chains.
9. The library of claim 1, wherein the polynucleotides further encode an alternative scaffold.
10. A library of polypeptides encoded by the synthetic polynucleotide library of claim 1.
11. A library of vectors comprising the polynucleotide library of claim 1.
12. A population of cells comprising the vectors of claim 11.
13. The cells of claim 12, wherein the cells are yeast cells.
14. The cells of claim 12, wherein the cells are S. cerevisiae.
15. A method of preparing a synthetic polynucleotide library comprising providing the polynucleotide sequences of claim 1 and assembling said polynucleotide sequences in the order [N1]-[DH]-[N2]-[H3-JH].
16. A method of isolating one or more host cells expressing one or more antibodies, the method comprising:
(i) expressing a polypeptide comprising a CDRH3 sequence of claim 1 in one or more host cells;
(ii) contacting the host cells with one or more antigens; and (iii) isolating one or more host cells having antibodies that bind to the one or more antigens.
17. A kit comprising the library of synthetic polynucleotides of claim 1.
18. The CDRH3 amino acid sequences encoded by the library of synthetic polynucleotides of claim 1 in computer readable form.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/404,059 | 2009-03-13 | ||
| US12/404,059 US8877688B2 (en) | 2007-09-14 | 2009-03-13 | Rationally designed, synthetic antibody libraries and uses therefor |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2010105256A1 true WO2010105256A1 (en) | 2010-09-16 |
Family
ID=42289024
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2010/027312 WO2010105256A1 (en) | 2009-03-13 | 2010-03-15 | Rationally designed, synthetic antibody libraries and uses therefor |
Country Status (2)
| Country | Link |
|---|---|
| US (3) | US8877688B2 (en) |
| WO (1) | WO2010105256A1 (en) |
Cited By (119)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013046722A1 (en) | 2011-09-30 | 2013-04-04 | 中外製薬株式会社 | Ion concentration-dependent binding molecule library |
| WO2013047748A1 (en) | 2011-09-30 | 2013-04-04 | 中外製薬株式会社 | Antigen-binding molecule promoting disappearance of antigens having plurality of biological activities |
| WO2013047729A1 (en) | 2011-09-30 | 2013-04-04 | 中外製薬株式会社 | Antigen-binding molecule inducing immune response to target antigen |
| EP2593594A2 (en) * | 2010-07-16 | 2013-05-22 | Adimab LLC | Antibody libraries |
| WO2013156534A1 (en) | 2012-04-17 | 2013-10-24 | Arsanis Biosciences Gmbh | Cross-reactive staphylococcus aureus antibody |
| WO2014169076A1 (en) | 2013-04-09 | 2014-10-16 | Annexon,,Inc. | Methods of treatment for neuromyelitis optica |
| WO2014187746A2 (en) | 2013-05-21 | 2014-11-27 | Arsanis Biosciences Gmbh | Generation of highly potent antibodies neutralizing the lukgh (lukab) toxin of staphylococcus aureus |
| WO2015006504A1 (en) | 2013-07-09 | 2015-01-15 | Annexon, Inc. | Anti-complement factor c1q antibodies and uses thereof |
| WO2015055814A1 (en) | 2013-10-17 | 2015-04-23 | Arsanis Biosciences Gmbh | Cross-reactive staphylococcus aureus antibody sequences |
| WO2015153765A1 (en) | 2014-04-01 | 2015-10-08 | Adimab, Llc | Multispecific antibody analogs comprising a common light chain, and methods of their preparation and use |
| WO2015195917A1 (en) | 2014-06-18 | 2015-12-23 | Mersana Therapeutics, Inc. | Monoclonal antibodies against her2 epitope and methods of use thereof |
| EP2793921A4 (en) * | 2011-12-22 | 2016-05-04 | Childrens Medical Center | Saposin-a derived peptides and uses thereof |
| WO2016081640A1 (en) | 2014-11-19 | 2016-05-26 | Genentech, Inc. | Anti-transferrin receptor / anti-bace1 multispecific antibodies and methods of use |
| WO2016081639A1 (en) | 2014-11-19 | 2016-05-26 | Genentech, Inc. | Antibodies against bace1 and use thereof for neural disease immunotherapy |
| WO2016164637A1 (en) | 2015-04-07 | 2016-10-13 | Alector Llc | Anti-sortilin antibodies and methods of use thereof |
| WO2016164708A1 (en) | 2015-04-10 | 2016-10-13 | Adimab, Llc | Methods for purifying heterodimeric multispecific antibodies from parental homodimeric antibody species |
| WO2016166223A1 (en) | 2015-04-17 | 2016-10-20 | Arsanis Biosciences Gmbh | Anti-staphylococcus aureus antibody combination preparation |
| WO2016201388A2 (en) | 2015-06-12 | 2016-12-15 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| WO2016201389A2 (en) | 2015-06-12 | 2016-12-15 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| WO2017040301A1 (en) | 2015-08-28 | 2017-03-09 | Alector Llc | Anti-siglec-7 antibodies and methods of use thereof |
| WO2017062672A2 (en) | 2015-10-06 | 2017-04-13 | Alector Llc | Anti-trem2 antibodies and methods of use thereof |
| WO2017064258A1 (en) | 2015-10-16 | 2017-04-20 | Arsanis Biosciences Gmbh | Bactericidal monoclonal antibody targeting klebsiella pneumoniae |
| WO2017075432A2 (en) | 2015-10-29 | 2017-05-04 | Alector Llc | Anti-siglec-9 antibodies and methods of use thereof |
| WO2017152102A2 (en) | 2016-03-04 | 2017-09-08 | Alector Llc | Anti-trem1 antibodies and methods of use thereof |
| WO2017156488A2 (en) | 2016-03-10 | 2017-09-14 | Acceleron Pharma, Inc. | Activin type 2 receptor binding proteins and uses thereof |
| WO2017160754A1 (en) | 2016-03-15 | 2017-09-21 | Mersana Therapeutics,Inc. | Napi2b-targeted antibody-drug conjugates and methods of use thereof |
| WO2018029346A1 (en) | 2016-08-12 | 2018-02-15 | Arsanis Biosciences Gmbh | Klebsiella pneumoniae o3 specific antibodies |
| WO2018029356A1 (en) | 2016-08-12 | 2018-02-15 | Arsanis Biosciences Gmbh | Anti-galactan ii monoclonal antibodies targeting klebsiella pneumoniae |
| US9921224B2 (en) | 2013-03-14 | 2018-03-20 | Children's Medical Center Corporation | Use of CD36 to identify cancer subjects for treatment |
| WO2018085358A1 (en) | 2016-11-02 | 2018-05-11 | Jounce Therapeutics, Inc. | Antibodies to pd-1 and uses thereof |
| WO2018094300A1 (en) | 2016-11-19 | 2018-05-24 | Potenza Therapeutics, Inc. | Anti-gitr antigen-binding proteins and methods of use thereof |
| WO2018098363A2 (en) | 2016-11-23 | 2018-05-31 | Bioverativ Therapeutics Inc. | Bispecific antibodies binding to coagulation factor ix and coagulation factor x |
| WO2018113781A1 (en) | 2016-12-24 | 2018-06-28 | 信达生物制药(苏州)有限公司 | Anti-pcsk9 antibody and application thereof |
| WO2018119171A1 (en) | 2016-12-23 | 2018-06-28 | Potenza Therapeutics, Inc. | Anti-neuropilin antigen-binding proteins and methods of use thereof |
| WO2018177220A1 (en) | 2017-03-25 | 2018-10-04 | 信达生物制药(苏州)有限公司 | Anti-ox40 antibody and use thereof |
| WO2018183889A1 (en) | 2017-03-30 | 2018-10-04 | Potenza Therapeutics, Inc. | Anti-tigit antigen-binding proteins and methods of use thereof |
| WO2018213316A1 (en) | 2017-05-16 | 2018-11-22 | Alector Llc | Anti-siglec-5 antibodies and methods of use thereof |
| WO2018224682A1 (en) | 2017-06-08 | 2018-12-13 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| WO2018224685A1 (en) | 2017-06-08 | 2018-12-13 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| WO2018237157A1 (en) | 2017-06-22 | 2018-12-27 | Novartis Ag | Antibody molecules to cd73 and uses thereof |
| WO2019014328A2 (en) | 2017-07-11 | 2019-01-17 | Compass Therapeutics Llc | Agonist antibodies that bind human cd137 and uses thereof |
| WO2019023504A1 (en) | 2017-07-27 | 2019-01-31 | Iteos Therapeutics Sa | Anti-tigit antibodies |
| WO2019028283A1 (en) | 2017-08-03 | 2019-02-07 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| WO2019028292A1 (en) | 2017-08-03 | 2019-02-07 | Alector Llc | Anti-trem2 antibodies and methods of use thereof |
| US10206992B2 (en) | 2013-01-17 | 2019-02-19 | Arsanis Biosciences Gmbh | MDR E. coli specific antibody |
| WO2019034753A1 (en) | 2017-08-16 | 2019-02-21 | Tusk Therapeutics Ltd | Cd38 antibody |
| WO2019034752A1 (en) | 2017-08-16 | 2019-02-21 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| WO2019040780A1 (en) | 2017-08-25 | 2019-02-28 | Five Prime Therapeutics Inc. | B7-h4 antibodies and methods of use thereof |
| WO2019042285A1 (en) | 2017-08-29 | 2019-03-07 | 信达生物制药(苏州)有限公司 | Anti-cd47 antibody and use thereof |
| WO2019089753A2 (en) | 2017-10-31 | 2019-05-09 | Compass Therapeutics Llc | Cd137 antibodies and pd-1 antagonists and uses thereof |
| WO2019100052A2 (en) | 2017-11-20 | 2019-05-23 | Compass Therapeutics Llc | Cd137 antibodies and tumor antigen-targeting antibodies and uses thereof |
| WO2019102435A1 (en) | 2017-11-27 | 2019-05-31 | Euro-Celtique S.A. | Humanized antibodies targeting human tissue factor |
| WO2019129137A1 (en) | 2017-12-27 | 2019-07-04 | 信达生物制药(苏州)有限公司 | Anti-lag-3 antibody and uses thereof |
| WO2019149269A1 (en) | 2018-02-01 | 2019-08-08 | 信达生物制药(苏州)有限公司 | Fully human anti-b cell maturation antigen (bcma) single chain variable fragment, and application thereof |
| US10400038B2 (en) | 2014-04-03 | 2019-09-03 | Igm Biosciences, Inc. | Modified J-chain |
| WO2019169212A1 (en) | 2018-03-02 | 2019-09-06 | Five Prime Therapeutics, Inc. | B7-h4 antibodies and methods of use thereof |
| WO2019178269A2 (en) | 2018-03-14 | 2019-09-19 | Surface Oncology, Inc. | Antibodies that bind cd39 and uses thereof |
| WO2019182896A1 (en) | 2018-03-23 | 2019-09-26 | Board Of Regents, The University Of Texas System | Dual specificity antibodies to pd-l1 and pd-l2 and methods of use therefor |
| WO2019214707A1 (en) | 2018-05-11 | 2019-11-14 | 信达生物制药(苏州)有限公司 | Preparations comprising anti-pcsk9 antibodies and use thereof |
| WO2019226973A1 (en) | 2018-05-25 | 2019-11-28 | Alector Llc | Anti-sirpa antibodies and methods of use thereof |
| WO2019232244A2 (en) | 2018-05-31 | 2019-12-05 | Novartis Ag | Antibody molecules to cd73 and uses thereof |
| WO2020006374A2 (en) | 2018-06-29 | 2020-01-02 | Alector Llc | Anti-sirp-beta1 antibodies and methods of use thereof |
| WO2020023920A1 (en) | 2018-07-27 | 2020-01-30 | Alector Llc | Anti-siglec-5 antibodies and methods of use thereof |
| WO2020020281A1 (en) | 2018-07-25 | 2020-01-30 | 信达生物制药(苏州)有限公司 | Anti-tigit antibody and uses thereof |
| WO2020033923A1 (en) | 2018-08-09 | 2020-02-13 | Compass Therapeutics Llc | Antigen binding agents that bind cd277 and uses thereof |
| WO2020033925A2 (en) | 2018-08-09 | 2020-02-13 | Compass Therapeutics Llc | Antibodies that bind cd277 and uses thereof |
| WO2020033926A2 (en) | 2018-08-09 | 2020-02-13 | Compass Therapeutics Llc | Antibodies that bind cd277 and uses thereof |
| WO2020041541A2 (en) | 2018-08-23 | 2020-02-27 | Seattle Genetics, Inc. | Anti-tigit antibodies |
| WO2020069133A1 (en) | 2018-09-27 | 2020-04-02 | Tizona Therapeutics | Anti-hla-g antibodies, compositions comprising anti-hla-g antibodies and methods of using anti-hla-g antibodies |
| US10618978B2 (en) | 2015-09-30 | 2020-04-14 | Igm Biosciences, Inc. | Binding molecules with modified J-chain |
| WO2020144178A1 (en) | 2019-01-07 | 2020-07-16 | Iteos Therapeutics Sa | Anti-tigit antibodies |
| WO2020150496A1 (en) | 2019-01-16 | 2020-07-23 | Compass Therapeutics Llc | Formulations of antibodies that bind human cd137 and uses thereof |
| EP3719040A1 (en) | 2017-07-27 | 2020-10-07 | iTeos Therapeutics SA | Anti-tigit antibodies |
| WO2021062244A1 (en) | 2019-09-25 | 2021-04-01 | Surface Oncology, Inc. | Anti-il-27 antibodies and uses thereof |
| WO2021113655A1 (en) | 2019-12-05 | 2021-06-10 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2021119400A1 (en) | 2019-12-12 | 2021-06-17 | Alector Llc | Methods of use of anti-cd33 antibodies |
| US11046769B2 (en) | 2018-11-13 | 2021-06-29 | Compass Therapeutics Llc | Multispecific binding constructs against checkpoint molecules and uses thereof |
| WO2021139687A1 (en) | 2020-01-09 | 2021-07-15 | 信达生物制药(苏州)有限公司 | Application of combination of anti-cd47 antibody and anti-cd20 antibody in preparation of drugs for preventing or treating tumors |
| US11084875B2 (en) | 2014-08-08 | 2021-08-10 | Alector Llc | Anti-TREM2 antibodies and methods of use thereof |
| WO2021167964A1 (en) | 2020-02-18 | 2021-08-26 | Alector Llc | Pilra antibodies and methods of use thereof |
| WO2021173565A1 (en) | 2020-02-24 | 2021-09-02 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2021190431A1 (en) | 2020-03-23 | 2021-09-30 | 百奥泰生物制药股份有限公司 | Development and application of immune cell activator |
| WO2021203030A2 (en) | 2020-04-03 | 2021-10-07 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2021217024A1 (en) | 2020-04-24 | 2021-10-28 | Millennium Pharmaceuticals, Inc. | Anti-cd19 antibodies and uses thereof |
| WO2021233834A1 (en) | 2020-05-17 | 2021-11-25 | Astrazeneca Uk Limited | Sars-cov-2 antibodies and methods of selecting and using the same |
| WO2021259199A1 (en) | 2020-06-22 | 2021-12-30 | 信达生物制药(苏州)有限公司 | Anti-cd73 antibody and use thereof |
| WO2021262765A1 (en) | 2020-06-22 | 2021-12-30 | The Board Of Trustees Of The Leland Stanford Junior University | Tsp-1 inhibitors for the treatment of aged, atrophied or dystrophied muscle |
| US11214619B2 (en) | 2018-07-20 | 2022-01-04 | Surface Oncology, Inc. | Anti-CD112R compositions and methods |
| WO2022018040A2 (en) | 2020-07-20 | 2022-01-27 | Astrazeneca Uk Limited | Sars-cov-2 proteins, anti-sars-cov-2 antibodies, and methods of using the same |
| WO2022040345A1 (en) | 2020-08-18 | 2022-02-24 | Cephalon, Inc. | Anti-par-2 antibodies and methods of use thereof |
| WO2022098972A1 (en) | 2020-11-08 | 2022-05-12 | Seagen Inc. | Combination-therapy antibody drug conjugate with immune cell inhibitor |
| US11332524B2 (en) | 2018-03-22 | 2022-05-17 | Surface Oncology, Inc. | Anti-IL-27 antibodies and uses thereof |
| US11396546B2 (en) | 2018-07-13 | 2022-07-26 | Alector Llc | Anti-Sortilin antibodies and methods of use thereof |
| WO2022133325A3 (en) * | 2020-12-18 | 2022-07-28 | Kindred Biosciences, Inc. | Tnf alpha and ngf antibodies for veterinary use |
| WO2022162569A1 (en) | 2021-01-29 | 2022-08-04 | Novartis Ag | Dosage regimes for anti-cd73 and anti-entpd2 antibodies and uses thereof |
| US11447566B2 (en) | 2018-01-04 | 2022-09-20 | Iconic Therapeutics, Inc. | Anti-tissue factor antibodies, antibody-drug conjugates, and related methods |
| US11466074B2 (en) | 2015-02-17 | 2022-10-11 | X4 Pharmaceuticals (Austria) GmbH | Antibodies targeting a galactan-based O-antigen of K. pneumoniae |
| WO2022217026A1 (en) | 2021-04-09 | 2022-10-13 | Seagen Inc. | Methods of treating cancer with anti-tigit antibodies |
| EP4116327A1 (en) | 2017-10-11 | 2023-01-11 | Board Of Regents, The University Of Texas System | Human pd-l1 antibodies and methods of use therefor |
| WO2023018803A1 (en) | 2021-08-10 | 2023-02-16 | Byomass Inc. | Anti-gdf15 antibodies, compositions and uses thereof |
| WO2023016450A1 (en) | 2021-08-09 | 2023-02-16 | 普米斯生物技术(珠海)有限公司 | Anti-tigit antibody and use thereof |
| US11590224B2 (en) | 2015-10-01 | 2023-02-28 | Potenza Therapeutics, Inc. | Anti-TIGIT antigen-binding proteins and methods of uses thereof |
| WO2023028501A1 (en) | 2021-08-23 | 2023-03-02 | Immunitas Therapeutics, Inc. | Anti-cd161 antibodies and uses thereof |
| WO2023069421A1 (en) | 2021-10-18 | 2023-04-27 | Byomass Inc. | Anti-activin a antibodies, compositions and uses thereof |
| US11639389B2 (en) | 2015-09-30 | 2023-05-02 | Igm Biosciences, Inc. | Binding molecules with modified J-chain |
| WO2023081898A1 (en) | 2021-11-08 | 2023-05-11 | Alector Llc | Soluble cd33 as a biomarker for anti-cd33 efficacy |
| US11655303B2 (en) | 2019-09-16 | 2023-05-23 | Surface Oncology, Inc. | Anti-CD39 antibody compositions and methods |
| WO2023122213A1 (en) | 2021-12-22 | 2023-06-29 | Byomass Inc. | Targeting gdf15-gfral pathway cross-reference to related applications |
| WO2023147107A1 (en) | 2022-01-31 | 2023-08-03 | Byomass Inc. | Myeloproliferative conditions |
| US11732044B2 (en) | 2017-12-27 | 2023-08-22 | Innovent Biologics (Suzhou) Co., Ltd. | Anti-LAG-3 antibody and use thereof |
| WO2023164516A1 (en) | 2022-02-23 | 2023-08-31 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2023178192A1 (en) | 2022-03-15 | 2023-09-21 | Compugen Ltd. | Il-18bp antagonist antibodies and their use in monotherapy and combination therapy in the treatment of cancer |
| WO2023192976A1 (en) | 2022-04-01 | 2023-10-05 | Board Of Regents, The University Of Texas System | Dual specificity antibodies to human pd-l1 and pd-l2 and methods of use therefor |
| WO2023209177A1 (en) | 2022-04-29 | 2023-11-02 | Astrazeneca Uk Limited | Sars-cov-2 antibodies and methods of using the same |
| US11820979B2 (en) | 2016-12-23 | 2023-11-21 | Visterra, Inc. | Binding polypeptides and methods of making the same |
| US11844766B2 (en) | 2016-10-24 | 2023-12-19 | Janssen Pharmaceuticals, Inc. | ExPEC glycoconjugate vaccine formulations |
| US11873333B2 (en) | 2020-12-11 | 2024-01-16 | The University Of North Carolina At Chapel Hill | Compositions and methods comprising SFRP2 antagonists |
| US11931405B2 (en) | 2019-03-18 | 2024-03-19 | Janssen Pharmaceuticals, Inc. | Bioconjugates of E. coli O-antigen polysaccharides, methods of production thereof, and methods of use thereof |
| US11970538B2 (en) | 2021-05-20 | 2024-04-30 | Compass Therapeutics Llc | Multispecific binding constructs against checkpoint molecules and uses thereof |
Families Citing this family (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040067532A1 (en) | 2002-08-12 | 2004-04-08 | Genetastix Corporation | High throughput generation and affinity maturation of humanized antibody |
| MX344415B (en) | 2007-09-14 | 2016-12-15 | Adimab Inc | Rationally designed, synthetic antibody libraries and uses therefor. |
| US8877688B2 (en) | 2007-09-14 | 2014-11-04 | Adimab, Llc | Rationally designed, synthetic antibody libraries and uses therefor |
| WO2011140254A1 (en) * | 2010-05-04 | 2011-11-10 | Adimab, Llc | Antibodies against epidermal growth factor receptor (egfr) and uses thereof |
| US9409139B2 (en) | 2013-08-05 | 2016-08-09 | Twist Bioscience Corporation | De novo synthesized gene libraries |
| MA40835A (en) | 2014-10-23 | 2017-08-29 | Biogen Ma Inc | ANTI-GPIIB / IIIA ANTIBODIES AND THEIR USES |
| MA40861A (en) | 2014-10-31 | 2017-09-05 | Biogen Ma Inc | ANTI-GLYCOPROTEIN IIB / IIIA ANTIBODIES |
| US9981239B2 (en) | 2015-04-21 | 2018-05-29 | Twist Bioscience Corporation | Devices and methods for oligonucleic acid library synthesis |
| AU2016324296A1 (en) | 2015-09-18 | 2018-04-12 | Twist Bioscience Corporation | Oligonucleic acid variant libraries and synthesis thereof |
| US11512347B2 (en) | 2015-09-22 | 2022-11-29 | Twist Bioscience Corporation | Flexible substrates for nucleic acid synthesis |
| RU2021129189A (en) | 2016-01-22 | 2021-11-15 | Мерк Шарп И Доум Корп. | ANTIBODIES AGAINST COAGULATION FACTOR XI |
| KR20190026642A (en) | 2016-01-29 | 2019-03-13 | 소렌토 쎄라퓨틱스, 인코포레이티드 | The antigen-binding protein that binds to PD-L1 |
| WO2017218371A1 (en) | 2016-06-14 | 2017-12-21 | Merck Sharp & Dohme Corp. | Anti-coagulation factor xi antibodies |
| CA3034769A1 (en) | 2016-08-22 | 2018-03-01 | Twist Bioscience Corporation | De novo synthesized nucleic acid libraries |
| WO2018057526A2 (en) | 2016-09-21 | 2018-03-29 | Twist Bioscience Corporation | Nucleic acid based data storage |
| US20230139592A1 (en) | 2016-12-22 | 2023-05-04 | Wake Forest University Health Sciences | Sirp-gamma targeted agents for use in the treatment of cancer |
| CN110892485B (en) | 2017-02-22 | 2024-03-22 | 特韦斯特生物科学公司 | Nucleic acid-based data storage |
| EP3595674A4 (en) | 2017-03-15 | 2020-12-16 | Twist Bioscience Corporation | Variant libraries of the immunological synapse and synthesis thereof |
| WO2018231864A1 (en) | 2017-06-12 | 2018-12-20 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US10696965B2 (en) | 2017-06-12 | 2020-06-30 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| EP3681906A4 (en) | 2017-09-11 | 2021-06-09 | Twist Bioscience Corporation | Gpcr binding proteins and synthesis thereof |
| GB2583590A (en) | 2017-10-20 | 2020-11-04 | Twist Bioscience Corp | Heated nanowells for polynucleotide synthesis |
| AR113696A1 (en) | 2017-11-17 | 2020-06-03 | Merck Sharp & Dohme | SPECIFIC ANTIBODIES FOR IMMUNOGLOBULIN TYPE 3 (ILT3) SIMILAR TRANSCRIPT AND ITS USES |
| EP3561703B1 (en) * | 2018-04-25 | 2021-01-20 | Bayer AG | Identification of the mating of variable domains from light and heavy chains of antibodies |
| SG11202011467RA (en) | 2018-05-18 | 2020-12-30 | Twist Bioscience Corp | Polynucleotides, reagents, and methods for nucleic acid hybridization |
| EA202191122A1 (en) | 2018-10-23 | 2021-07-19 | Сколар Рок, Инк. | SELECTIVE TO RGMc INHIBITORS AND THEIR APPLICATION |
| EP3689905A3 (en) | 2019-01-30 | 2021-02-24 | Scholar Rock, Inc. | Ltbp complex-specific inhibitors of tgf-beta and uses thereof |
| KR20210133234A (en) | 2019-02-18 | 2021-11-05 | 바이오사이토젠 파마슈티컬스 (베이징) 컴퍼니 리미티드 | Genetically Modified Non-Human Animals Having Humanized Immunoglobulin Locus |
| WO2020176680A1 (en) * | 2019-02-26 | 2020-09-03 | Twist Bioscience Corporation | Variant nucleic acid libraries for antibody optimization |
| MX2021012160A (en) | 2019-04-08 | 2022-01-06 | Biogen Ma Inc | Anti-integrin antibodies and uses thereof. |
| CA3144644A1 (en) | 2019-06-21 | 2020-12-24 | Twist Bioscience Corporation | Barcode-based nucleic acid sequence assembly |
| WO2022154472A1 (en) | 2021-01-12 | 2022-07-21 | 에스지메디칼 주식회사 | Novel antibody to cd55 and uses thereof |
| WO2023283383A1 (en) * | 2021-07-07 | 2023-01-12 | Specifica Inc. | Antibody affinity maturation using natural liability-free cdrs |
Citations (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5324637A (en) | 1991-10-11 | 1994-06-28 | Promega Corporation | Coupled transcription and translation in eukaryotic cell-free extract |
| US5492817A (en) | 1993-11-09 | 1996-02-20 | Promega Corporation | Coupled transcription and translation in eukaryotic cell-free extract |
| US5665563A (en) | 1991-10-11 | 1997-09-09 | Promega Corporation | Coupled transcription and translation in eukaryotic cell-free extract |
| US5712120A (en) | 1994-06-30 | 1998-01-27 | Centro De Immunologia Molecular | Method for obtaining modified immunoglobulins with reduced immunogenicity of murine antibody variable domains, compositions containing them |
| US5798208A (en) | 1990-04-05 | 1998-08-25 | Roberto Crea | Walk-through mutagenesis |
| WO1998052976A1 (en) | 1997-05-21 | 1998-11-26 | Biovation Limited | Method for the production of non-immunogenic proteins |
| US5885793A (en) | 1991-12-02 | 1999-03-23 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| US6214553B1 (en) | 1997-01-21 | 2001-04-10 | Massachusetts General Hospital | Libraries of protein encoding RNA-protein fusions |
| US6261804B1 (en) | 1997-01-21 | 2001-07-17 | The General Hospital Corporation | Selection of proteins using RNA-protein fusions |
| US6300065B1 (en) | 1996-05-31 | 2001-10-09 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US6300064B1 (en) | 1995-08-18 | 2001-10-09 | Morphosys Ag | Protein/(poly)peptide libraries |
| US6348315B1 (en) | 1997-04-23 | 2002-02-19 | University of Zürich, Assignee for Josef Hanes | Polysome display in the absence of functional ssrA-RNA |
| US6423538B1 (en) | 1996-05-31 | 2002-07-23 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US20030036092A1 (en) | 1991-11-15 | 2003-02-20 | Board Of Regents, The University Of Texas System | Directed evolution of enzymes and antibodies |
| US20030100023A1 (en) | 1991-11-15 | 2003-05-29 | Board Of Regents, The University Of Texas System | Immunoassay and antibody selection methods using cell surface expressed libraries |
| US6696251B1 (en) | 1996-05-31 | 2004-02-24 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US20040058403A1 (en) | 2000-10-27 | 2004-03-25 | Harvey Barrett R. | Combinatorial protein library screening by periplasmic expression |
| US6919183B2 (en) | 2001-01-16 | 2005-07-19 | Regeneron Pharmaceuticals, Inc. | Isolating cells expressing secreted proteins |
| US20060008883A1 (en) | 2003-12-04 | 2006-01-12 | Xencor, Inc. | Methods of generating variant proteins with increased host string content and compositions thereof |
| US20060257937A1 (en) | 2000-12-18 | 2006-11-16 | Dyax Corp., A Delaware Corporation | Focused libraries of genetic packages |
| US7166423B1 (en) | 1992-10-21 | 2007-01-23 | Miltenyi Biotec Gmbh | Direct selection of cells by secretion product |
| WO2007056441A2 (en) * | 2005-11-07 | 2007-05-18 | Genentech, Inc. | Binding polypeptides with diversified and consensus vh/vl hypervariable sequences |
| WO2008053275A2 (en) | 2005-12-20 | 2008-05-08 | Morphosys Ag | Novel collection of hcdr3 regions and uses therefor |
| US20080206239A1 (en) | 2005-02-03 | 2008-08-28 | Antitope Limited | Human Antibodies And Proteins |
| WO2009036379A2 (en) * | 2007-09-14 | 2009-03-19 | Adimab, Inc. | Rationally designed, synthetic antibody libraries and uses therefor |
Family Cites Families (195)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4230685A (en) | 1979-02-28 | 1980-10-28 | Northwestern University | Method of magnetic separation of cells and the like, and microspheres for use therein |
| US4452773A (en) | 1982-04-05 | 1984-06-05 | Canadian Patents And Development Limited | Magnetic iron-dextran microspheres |
| US4661454A (en) | 1983-02-28 | 1987-04-28 | Collaborative Research, Inc. | GAL1 yeast promoter linked to non galactokinase gene |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| GB8408127D0 (en) | 1984-03-29 | 1984-05-10 | Nyegaard & Co As | Contrast agents |
| US5118605A (en) | 1984-10-16 | 1992-06-02 | Chiron Corporation | Polynucleotide determination with selectable cleavage sites |
| AU4434585A (en) | 1985-03-30 | 1986-10-23 | Marc Ballivet | Method for obtaining dna, rna, peptides, polypeptides or proteins by means of a dna recombinant technique |
| CA1293460C (en) | 1985-10-07 | 1991-12-24 | Brian Lee Sauer | Site-specific recombination of dna in yeast |
| US5618920A (en) | 1985-11-01 | 1997-04-08 | Xoma Corporation | Modular assembly of antibody genes, antibodies prepared thereby and use |
| US4770183A (en) | 1986-07-03 | 1988-09-13 | Advanced Magnetics Incorporated | Biologically degradable superparamagnetic particles for use as nuclear magnetic resonance imaging agents |
| DE3785186T2 (en) | 1986-09-02 | 1993-07-15 | Enzon Lab Inc | BINDING MOLECULE WITH SINGLE POLYPEPTIDE CHAIN. |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US5763192A (en) | 1986-11-20 | 1998-06-09 | Ixsys, Incorporated | Process for obtaining DNA, RNA, peptides, polypeptides, or protein, by recombinant DNA technique |
| DE3852304T3 (en) | 1987-03-02 | 1999-07-01 | Enzon Lab Inc | Organism as carrier for "Single Chain Antibody Domain (SCAD)". |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| US5688666A (en) | 1988-10-28 | 1997-11-18 | Genentech, Inc. | Growth hormone variants with altered binding properties |
| KR0184860B1 (en) | 1988-11-11 | 1999-04-01 | 메디칼 리써어치 카운실 | Single domain ligands receptors comprising said ligands methods for their production and use of said ligands |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| ES2067018T3 (en) | 1988-12-28 | 1995-03-16 | Stefan Miltenyi | PROCEDURE AND MATERIALS FOR THE SEPARATION IN HIGH MAGNETIC GRADIENT OF BIOLOGICAL MATERIALS. |
| US6291159B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for producing polymers having a preselected activity |
| US6969586B1 (en) | 1989-05-16 | 2005-11-29 | Scripps Research Institute | Method for tapping the immunological repertoire |
| US6291158B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for tapping the immunological repertoire |
| US6291161B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for tapping the immunological repertiore |
| US6680192B1 (en) | 1989-05-16 | 2004-01-20 | Scripps Research Institute | Method for producing polymers having a preselected activity |
| US6291160B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for producing polymers having a preselected activity |
| DE3920358A1 (en) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | BISPECIFIC AND OLIGO-SPECIFIC, MONO- AND OLIGOVALENT ANTI-BODY CONSTRUCTS, THEIR PRODUCTION AND USE |
| US5283173A (en) | 1990-01-24 | 1994-02-01 | The Research Foundation Of State University Of New York | System to detect protein-protein interactions |
| DE4002897A1 (en) | 1990-02-01 | 1991-08-08 | Behringwerke Ag | Synthetic human antibody library |
| ATE449853T1 (en) | 1990-02-01 | 2009-12-15 | Siemens Healthcare Diagnostics | PRODUCTION AND USE OF HUMAN ANTIBODIES GENE BANKS (ßHUMAN ANTIBODIES LIBRARIESß) |
| DE69129604T2 (en) | 1990-04-18 | 1998-10-15 | Gist Brocades Nv | Mutant beta-lactam acylase genes |
| US6916605B1 (en) | 1990-07-10 | 2005-07-12 | Medical Research Council | Methods for producing members of specific binding pairs |
| GB9206318D0 (en) | 1992-03-24 | 1992-05-06 | Cambridge Antibody Tech | Binding substances |
| US7063943B1 (en) | 1990-07-10 | 2006-06-20 | Cambridge Antibody Technology | Methods for producing members of specific binding pairs |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| US6172197B1 (en) | 1991-07-10 | 2001-01-09 | Medical Research Council | Methods for producing members of specific binding pairs |
| ATE164395T1 (en) | 1990-12-03 | 1998-04-15 | Genentech Inc | METHOD FOR ENRICHMENT OF PROTEIN VARIANTS WITH MODIFIED BINDING PROPERTIES |
| US5780279A (en) | 1990-12-03 | 1998-07-14 | Genentech, Inc. | Method of selection of proteolytic cleavage sites by directed evolution and phagemid display |
| IE921169A1 (en) | 1991-04-10 | 1992-10-21 | Scripps Research Inst | Heterodimeric receptor libraries using phagemids |
| US6072039A (en) | 1991-04-19 | 2000-06-06 | Rohm And Haas Company | Hybrid polypeptide comparing a biotinylated avidin binding polypeptide fused to a polypeptide of interest |
| US6492160B1 (en) | 1991-05-15 | 2002-12-10 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| US5871907A (en) | 1991-05-15 | 1999-02-16 | Medical Research Council | Methods for producing members of specific binding pairs |
| US6225447B1 (en) | 1991-05-15 | 2001-05-01 | Cambridge Antibody Technology Ltd. | Methods for producing members of specific binding pairs |
| US5962255A (en) | 1992-03-24 | 1999-10-05 | Cambridge Antibody Technology Limited | Methods for producing recombinant vectors |
| US5858657A (en) | 1992-05-15 | 1999-01-12 | Medical Research Council | Methods for producing members of specific binding pairs |
| JPH06509473A (en) | 1991-08-10 | 1994-10-27 | メディカル・リサーチ・カウンシル | Processing of cell populations |
| US5565332A (en) | 1991-09-23 | 1996-10-15 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| ES2241710T3 (en) | 1991-11-25 | 2005-11-01 | Enzon, Inc. | PROCEDURE TO PRODUCE MULTIVALENT PROTEINS FROM UNION TO ANTIGEN. |
| US5872215A (en) | 1991-12-02 | 1999-02-16 | Medical Research Council | Specific binding members, materials and methods |
| US5667988A (en) | 1992-01-27 | 1997-09-16 | The Scripps Research Institute | Methods for producing antibody libraries using universal or randomized immunoglobulin light chains |
| US5733743A (en) | 1992-03-24 | 1998-03-31 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| RU95105899A (en) | 1992-07-08 | 1997-03-20 | Унилевер Н.В. (NL) | Method of enzyme immobilization, polynucleotide, vector, chimeric protein, lower eucaryotic organisms, method of enzymatic process realization |
| DE69334095T2 (en) | 1992-07-17 | 2007-04-12 | Dana-Farber Cancer Institute, Boston | Method for intracellular binding of targeted molecules |
| ATE233814T1 (en) | 1992-09-30 | 2003-03-15 | Scripps Research Inst | HUMAN NEUTRALIZING MONOCLONAL ANTIBODY AGAINST THE VIRUS THAT CAUSES HUMAN IMMUNE DEFICIENCY |
| DE4237113B4 (en) | 1992-11-03 | 2006-10-12 | "Iba Gmbh" | Peptides and their fusion proteins, expression vector and method of producing a fusion protein |
| GB9225453D0 (en) | 1992-12-04 | 1993-01-27 | Medical Res Council | Binding proteins |
| AU690528B2 (en) | 1992-12-04 | 1998-04-30 | Medical Research Council | Multivalent and multispecific binding proteins, their manufacture and use |
| JP3695467B2 (en) | 1993-02-04 | 2005-09-14 | ボレアン ファーマ エー/エス | Improved method for regenerating proteins |
| DK0682710T3 (en) | 1993-02-10 | 2004-03-01 | Unilever Nv | Isolation method using immobilized proteins with specific capacities |
| GB9313509D0 (en) | 1993-06-30 | 1993-08-11 | Medical Res Council | Chemisynthetic libraries |
| US5874239A (en) | 1993-07-30 | 1999-02-23 | Affymax Technologies N.V. | Biotinylation of proteins |
| AU680685B2 (en) | 1993-09-22 | 1997-08-07 | Medical Research Council | Retargeting antibodies |
| US5922545A (en) | 1993-10-29 | 1999-07-13 | Affymax Technologies N.V. | In vitro peptide and antibody display libraries |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| US5525490A (en) | 1994-03-29 | 1996-06-11 | Onyx Pharmaceuticals, Inc. | Reverse two-hybrid method |
| US5695941A (en) | 1994-06-22 | 1997-12-09 | The General Hospital Corporation | Interaction trap systems for analysis of protein networks |
| GB9414506D0 (en) | 1994-07-18 | 1994-09-07 | Zeneca Ltd | Improved production of polyhydroxyalkanoate |
| US5888773A (en) | 1994-08-17 | 1999-03-30 | The United States Of America As Represented By The Department Of Health And Human Services | Method of producing single-chain Fv molecules |
| US5763733A (en) | 1994-10-13 | 1998-06-09 | Enzon, Inc. | Antigen-binding fusion proteins |
| GB9504344D0 (en) | 1995-03-03 | 1995-04-19 | Unilever Plc | Antibody fragment production |
| NZ306767A (en) | 1995-04-11 | 2000-03-27 | Univ Johns Hopkins | Method of identifying molecular interactions employing counterselection and at least two hybrid molecules or two hybrid systems |
| US6828422B1 (en) | 1995-08-18 | 2004-12-07 | Morphosys Ag | Protein/(poly)peptide libraries |
| FR2741892B1 (en) | 1995-12-04 | 1998-02-13 | Pasteur Merieux Serums Vacc | METHOD FOR PREPARING A MULTI-COMBINED BANK OF ANTIBODY GENE EXPRESSION VECTORS, BANK AND COLICLONAL ANTIBODY EXPRESSION SYSTEMS |
| DE19637718A1 (en) | 1996-04-01 | 1997-10-02 | Boehringer Mannheim Gmbh | Recombinant inactive core streptavidin mutants |
| ES2183166T3 (en) | 1996-04-26 | 2003-03-16 | Massachusetts Inst Technology | TRIAL TEST FOR HYBRID TRIPLE. |
| US6083693A (en) | 1996-06-14 | 2000-07-04 | Curagen Corporation | Identification and comparison of protein-protein interactions that occur in populations |
| DE19624562A1 (en) | 1996-06-20 | 1998-01-02 | Thomas Dr Koehler | Determination of the concentration ratio of two different nucleic acids |
| CZ296807B6 (en) | 1996-06-24 | 2006-06-14 | Zlb Behring Ag | Polypeptides capable of forming antigen-binding structures with specificity for the Rhesus D antigens, the DNA encoding such polypeptides and the process for their preparation and use |
| US5994515A (en) | 1996-06-25 | 1999-11-30 | Trustees Of The University Of Pennsylvania | Antibodies directed against cellular coreceptors for human immunodeficiency virus and methods of using the same |
| GB9712818D0 (en) | 1996-07-08 | 1997-08-20 | Cambridge Antibody Tech | Labelling and selection of specific binding molecules |
| US5948620A (en) | 1996-08-05 | 1999-09-07 | Amersham International Plc | Reverse two-hybrid system employing post-translation signal modulation |
| US5955275A (en) | 1997-02-14 | 1999-09-21 | Arcaris, Inc. | Methods for identifying nucleic acid sequences encoding agents that affect cellular phenotypes |
| US5925523A (en) | 1996-08-23 | 1999-07-20 | President & Fellows Of Harvard College | Intraction trap assay, reagents and uses thereof |
| WO1998013513A2 (en) | 1996-09-24 | 1998-04-02 | Cadus Pharmaceutical Corporation | Methods and compositions for identifying receptor effectors |
| DE19641876B4 (en) | 1996-10-10 | 2011-09-29 | Iba Gmbh | streptavidin muteins |
| US6255455B1 (en) | 1996-10-11 | 2001-07-03 | The Trustees Of The University Of Pennsylvania | Rh(D)-binding proteins and magnetically activated cell sorting method for production thereof |
| US5858671A (en) | 1996-11-01 | 1999-01-12 | The University Of Iowa Research Foundation | Iterative and regenerative DNA sequencing method |
| US5869250A (en) | 1996-12-02 | 1999-02-09 | The University Of North Carolina At Chapel Hill | Method for the identification of peptides that recognize specific DNA sequences |
| US6368813B1 (en) | 1997-03-14 | 2002-04-09 | The Trustees Of Boston University | Multiflavor streptavidin |
| EP0985033A4 (en) | 1997-04-04 | 2005-07-13 | Biosite Inc | Polyvalent and polyclonal libraries |
| US6057098A (en) | 1997-04-04 | 2000-05-02 | Biosite Diagnostics, Inc. | Polyvalent display libraries |
| CA2288994C (en) | 1997-04-30 | 2011-07-05 | Enzon, Inc. | Polyalkylene oxide-modified single chain polypeptides |
| EP1007967A2 (en) | 1997-08-04 | 2000-06-14 | Ixsys, Incorporated | Methods for identifying ligand specific binding molecules |
| US6391311B1 (en) | 1998-03-17 | 2002-05-21 | Genentech, Inc. | Polypeptides having homology to vascular endothelial cell growth factor and bone morphogenetic protein 1 |
| GB9722131D0 (en) | 1997-10-20 | 1997-12-17 | Medical Res Council | Method |
| DE69824757T2 (en) | 1997-11-27 | 2005-10-20 | MAX-PLANCK-Gesellschaft zur Förderung der Wissenschaften e.V. | IDENTIFICATION AND CHARACTERIZATION OF INTERACTIVE MOLECULES BY AUTOMATED INTERAGING PAIRING |
| EP1040201A4 (en) | 1997-11-28 | 2001-11-21 | Invitrogen Corp | Single chain monoclonal antibody fusion reagents that regulate transcription in vivo |
| US6759243B2 (en) | 1998-01-20 | 2004-07-06 | Board Of Trustees Of The University Of Illinois | High affinity TCR proteins and methods |
| WO1999039744A1 (en) | 1998-02-10 | 1999-08-12 | The Ohio State University Research Foundation | Compositions and methods for polynucleotide delivery |
| US6187535B1 (en) | 1998-02-18 | 2001-02-13 | Institut Pasteur | Fast and exhaustive method for selecting a prey polypeptide interacting with a bait polypeptide of interest: application to the construction of maps of interactors polypeptides |
| CA2323525C (en) | 1998-03-30 | 2011-03-01 | Gerald P. Murphy | Therapeutic and diagnostic applications based on the role of the cxcr-4 gene in tumorigenesis |
| US20020029391A1 (en) | 1998-04-15 | 2002-03-07 | Claude Geoffrey Davis | Epitope-driven human antibody production and gene expression profiling |
| US7244826B1 (en) | 1998-04-24 | 2007-07-17 | The Regents Of The University Of California | Internalizing ERB2 antibodies |
| EP1115854A1 (en) | 1998-09-25 | 2001-07-18 | G.D. Searle & Co. | Method of producing permuteins by scanning permutagenesis |
| GB2344886B (en) | 1999-03-10 | 2000-11-01 | Medical Res Council | Selection of intracellular immunoglobulins |
| US6531580B1 (en) | 1999-06-24 | 2003-03-11 | Ixsys, Inc. | Anti-αvβ3 recombinant human antibodies and nucleic acids encoding same |
| EP1144607B1 (en) | 1999-07-20 | 2008-12-17 | MorphoSys AG | Methods for displaying (poly)peptides/proteins on bacteriophage particles via disulfide bonds |
| US6171795B1 (en) | 1999-07-29 | 2001-01-09 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligands to CD40ligand |
| EP1224327A4 (en) | 1999-09-29 | 2004-09-08 | Xenoport Inc | Compounds displayed on replicable genetic packages and methods of using same |
| US7037706B1 (en) | 1999-09-29 | 2006-05-02 | Xenoport, Inc. | Compounds displayed on replicable genetic packages and methods of using same |
| AU2001253521A1 (en) | 2000-04-13 | 2001-10-30 | Genaissance Pharmaceuticals, Inc. | Haplotypes of the cxcr4 gene |
| US8288322B2 (en) | 2000-04-17 | 2012-10-16 | Dyax Corp. | Methods of constructing libraries comprising displayed and/or expressed members of a diverse family of peptides, polypeptides or proteins and the novel libraries |
| EP2308982B1 (en) | 2000-04-17 | 2014-11-26 | Dyax Corp. | Methods of constructing display libraries of genetic packages for members of a diverse family of peptides |
| US6358733B1 (en) | 2000-05-19 | 2002-03-19 | Apolife, Inc. | Expression of heterologous multi-domain proteins in yeast |
| US20050158838A1 (en) | 2000-06-19 | 2005-07-21 | Dyax Corp., A Delaware Corporation | Novel enterokinase cleavage sequences |
| US6410271B1 (en) | 2000-06-23 | 2002-06-25 | Genetastix Corporation | Generation of highly diverse library of expression vectors via homologous recombination in yeast |
| US6406863B1 (en) | 2000-06-23 | 2002-06-18 | Genetastix Corporation | High throughput generation and screening of fully human antibody repertoire in yeast |
| US6410246B1 (en) | 2000-06-23 | 2002-06-25 | Genetastix Corporation | Highly diverse library of yeast expression vectors |
| AU2001273287A1 (en) | 2000-07-13 | 2002-01-30 | The Curators Of The University Of Missouri | Large scale expression and purification of recombinant proteins |
| US6512263B1 (en) | 2000-09-22 | 2003-01-28 | Sandisk Corporation | Non-volatile memory cell array having discontinuous source and drain diffusions contacted by continuous bit line conductors and methods of forming |
| CA2424295A1 (en) | 2000-10-12 | 2002-04-18 | University Of Georgia Research Foundation, Inc. | Metal binding proteins, recombinant host cells and methods |
| US7083945B1 (en) | 2000-10-27 | 2006-08-01 | The Board Of Regents Of The University Of Texas System | Isolation of binding proteins with high affinity to ligands |
| US6610472B1 (en) | 2000-10-31 | 2003-08-26 | Genetastix Corporation | Assembly and screening of highly complex and fully human antibody repertoire in yeast |
| US20030165988A1 (en) | 2002-02-08 | 2003-09-04 | Shaobing Hua | High throughput generation of human monoclonal antibody against peptide fragments derived from membrane proteins |
| US6841359B2 (en) | 2000-10-31 | 2005-01-11 | The General Hospital Corporation | Streptavidin-binding peptides and uses thereof |
| US7138496B2 (en) | 2002-02-08 | 2006-11-21 | Genetastix Corporation | Human monoclonal antibodies against human CXCR4 |
| US7005503B2 (en) | 2002-02-08 | 2006-02-28 | Genetastix Corporation | Human monoclonal antibody against coreceptors for human immunodeficiency virus |
| EP1227321A1 (en) | 2000-12-28 | 2002-07-31 | Institut für Bioanalytik GmbH | Reversible MHC multimer staining for functional purification of antigen-specific T cells |
| US20020197691A1 (en) | 2001-04-30 | 2002-12-26 | Myriad Genetics, Incorporated | FLT4-interacting proteins and use thereof |
| DE10113776B4 (en) | 2001-03-21 | 2012-08-09 | "Iba Gmbh" | Isolated streptavidin-binding, competitively elutable peptide, this comprehensive fusion peptide, nucleic acid coding therefor, expression vector, methods for producing a recombinant fusion protein and methods for detecting and / or obtaining the fusion protein |
| WO2002077182A2 (en) | 2001-03-21 | 2002-10-03 | Xenoport, Inc. | Compounds displayed on icosahedral phage and methods of using same |
| US20050176070A1 (en) | 2001-04-05 | 2005-08-11 | Auton Kevin A. | Protein analysis |
| ATE343591T1 (en) | 2001-04-06 | 2006-11-15 | Univ Jefferson | ANTAGONIST FOR MULTIMERIZATION OF HIV-1 VIF PROTEIN |
| US20050048512A1 (en) | 2001-04-26 | 2005-03-03 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| JP4369662B2 (en) | 2001-04-26 | 2009-11-25 | アビディア インコーポレイテッド | Combinatorial library of monomer domains |
| US20050053973A1 (en) | 2001-04-26 | 2005-03-10 | Avidia Research Institute | Novel proteins with targeted binding |
| US20040175756A1 (en) | 2001-04-26 | 2004-09-09 | Avidia Research Institute | Methods for using combinatorial libraries of monomer domains |
| US20050089932A1 (en) | 2001-04-26 | 2005-04-28 | Avidia Research Institute | Novel proteins with targeted binding |
| DE10129815A1 (en) | 2001-06-24 | 2003-01-09 | Profos Ag | Process for the purification of bacterial cells and cell components |
| GB0118337D0 (en) | 2001-07-27 | 2001-09-19 | Lonza Biologics Plc | Method for selecting antibody expressing cells |
| US6833441B2 (en) | 2001-08-01 | 2004-12-21 | Abmaxis, Inc. | Compositions and methods for generating chimeric heteromultimers |
| WO2003025020A1 (en) | 2001-09-13 | 2003-03-27 | Institute For Antibodies Co., Ltd. | Method of constructing camel antibody library |
| ES2372029T3 (en) | 2001-09-25 | 2012-01-13 | F. Hoffmann-La Roche Ag | METHOD FOR A SPECIFIC BIOTINILATION OF IN VITRO POLYPEPTIDE SEQUENCE. |
| WO2003029462A1 (en) | 2001-09-27 | 2003-04-10 | Pieris Proteolab Ag | Muteins of human neutrophil gelatinase-associated lipocalin and related proteins |
| CA2464690A1 (en) | 2001-09-27 | 2003-04-10 | Pieris Proteolab Ag | Muteins of apolipoprotein d |
| ES2405551T3 (en) | 2001-10-01 | 2013-05-31 | Dyax Corporation | Multicatenary eukaryotic presentation vectors and uses thereof |
| DE10230147A1 (en) | 2001-10-09 | 2004-01-15 | Profos Ag | Process for non-specific enrichment of bacterial cells |
| DE10230997A1 (en) | 2001-10-26 | 2003-07-17 | Ribopharma Ag | Drug to increase the effectiveness of a receptor-mediates apoptosis in drug that triggers tumor cells |
| US7985553B2 (en) | 2001-10-29 | 2011-07-26 | Nathaniel Heintz | Method for isolating cell type-specific mRNAs |
| JP2005536184A (en) | 2002-03-01 | 2005-12-02 | エルドマン,ヴォルカー,エー. | Streptavidin-binding peptide |
| EP1492811B1 (en) | 2002-03-19 | 2011-09-21 | Cincinnati Childrens's Hospital Medical Center | Muteins of the c5a anaphylatoxin, nucleic acid molecules encoding such muteins, and pharmaceutical uses of muteins of the c5a anaphylatoxin |
| CA2482863A1 (en) | 2002-04-17 | 2003-10-30 | Roberto Crea | Universal libraries for immunoglobulins |
| ATE386810T1 (en) | 2002-06-14 | 2008-03-15 | Dyax Corp | RECOMBINATION OF NUCLEIC ACID LIBRARY MEMBERS |
| DE10393326D2 (en) | 2002-06-24 | 2005-06-02 | Profos Ag | Method for detection and removal of endotoxin |
| US20050053591A1 (en) | 2002-08-08 | 2005-03-10 | Insert Therapeutics, Inc. | Compositions and uses of motor protein-binding moieties |
| US20040067532A1 (en) | 2002-08-12 | 2004-04-08 | Genetastix Corporation | High throughput generation and affinity maturation of humanized antibody |
| CA2499995A1 (en) | 2002-09-23 | 2004-04-01 | Macrogenics, Inc. | Compositions and methods for treatment of herpesvirus infections |
| US20050058661A1 (en) | 2002-10-18 | 2005-03-17 | Sykes Kathryn F. | Methods and compositions for vaccination comprising nucleic acid and/or polypeptide sequences of the genus Borrelia |
| US20050233389A1 (en) | 2003-01-09 | 2005-10-20 | Massachusetts Institute Of Technology | Methods and compositions for peptide and protein labeling |
| US7172877B2 (en) | 2003-01-09 | 2007-02-06 | Massachusetts Institute Of Technology | Methods and compositions for peptide and protein labeling |
| BRPI0406662A (en) | 2003-01-09 | 2005-12-20 | Macrogenics Inc | Vector cell method of identifying a mab and composition |
| EP2368578A1 (en) | 2003-01-09 | 2011-09-28 | Macrogenics, Inc. | Identification and engineering of antibodies with variant Fc regions and methods of using same |
| EP1452601A1 (en) | 2003-02-28 | 2004-09-01 | Roche Diagnostics GmbH | Enhanced expression of fusion polypeptides with a biotinylation tag |
| EP1454981A1 (en) | 2003-03-03 | 2004-09-08 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Infectious pestivirus pseudo-particles containing functional erns, E1, E2 envelope proteins |
| US20060024676A1 (en) | 2003-04-14 | 2006-02-02 | Karen Uhlmann | Method of detecting epigenetic biomarkers by quantitative methyISNP analysis |
| US20040259162A1 (en) | 2003-05-02 | 2004-12-23 | Sigma-Aldrich Co. | Solid phase cell lysis and capture platform |
| US20090005257A1 (en) | 2003-05-14 | 2009-01-01 | Jespers Laurent S | Process for Recovering Polypeptides that Unfold Reversibly from a Polypeptide Repertoire |
| CA2531971A1 (en) | 2003-07-10 | 2005-01-27 | Blind Pig Proteomics, Inc. | Universal detection of binding |
| US7569215B2 (en) | 2003-07-18 | 2009-08-04 | Massachusetts Institute Of Technology | Mutant interleukin-2 (IL-2) polypeptides |
| EP1503161A3 (en) | 2003-08-01 | 2006-08-09 | Asahi Glass Company Ltd. | Firing container for silicon nitride ceramics |
| EP2325339A3 (en) | 2003-09-09 | 2011-11-02 | Integrigen, Inc. | Methods and compositions for generation of germline human antibody genes |
| WO2005040229A2 (en) | 2003-10-24 | 2005-05-06 | Avidia, Inc. | Ldl receptor class a and egf domain monomers and multimers |
| US20050191710A1 (en) | 2004-03-01 | 2005-09-01 | Hanrahan John W. | Method for labeling a membrane-localized protein |
| WO2006026248A1 (en) | 2004-08-25 | 2006-03-09 | Sigma-Aldrich Co. | Compositions and methods employing zwitterionic detergent combinations |
| GB2423819B (en) | 2004-09-17 | 2008-02-06 | Pacific Biosciences California | Apparatus and method for analysis of molecules |
| CA2591992A1 (en) | 2004-12-22 | 2006-06-29 | The Salk Institute For Biological Studies | Compositions and methods for producing recombinant proteins |
| WO2006084050A2 (en) | 2005-02-01 | 2006-08-10 | Dyax Corp. | Libraries and methods for isolating antibodies |
| US20070141548A1 (en) | 2005-03-11 | 2007-06-21 | Jorg Kohl | Organ transplant solutions and method for transplanting organs |
| WO2006138700A2 (en) | 2005-06-17 | 2006-12-28 | Biorexis Pharmaceutical Corporation | Anchored transferrin fusion protein libraries |
| ES2388932T3 (en) | 2005-12-02 | 2012-10-19 | Genentech, Inc. | Binding polypeptides and uses thereof |
| US20070275416A1 (en) | 2006-05-16 | 2007-11-29 | Gsf-Forschungszentrum Fuer Umwelt Und Gesundheit Gmbh | Affinity marker for purification of proteins |
| WO2008019366A2 (en) | 2006-08-07 | 2008-02-14 | Ludwig Institute For Cancer Research | Methods and compositions for increased priming of t-cells through cross-presentation of exogenous antigens |
| US7806137B2 (en) | 2006-08-30 | 2010-10-05 | Semba Biosciences, Inc. | Control system for simulated moving bed chromatography |
| US8807164B2 (en) | 2006-08-30 | 2014-08-19 | Semba Biosciences, Inc. | Valve module and methods for simulated moving bed chromatography |
| US7790040B2 (en) | 2006-08-30 | 2010-09-07 | Semba Biosciences, Inc. | Continuous isocratic affinity chromatography |
| WO2008042754A2 (en) | 2006-10-02 | 2008-04-10 | Sea Lane Biotechnologies, Llc | Design and construction of diverse synthetic peptide and polypeptide libraries |
| CA2671264C (en) | 2006-11-30 | 2015-11-24 | Research Development Foundation | Improved immunoglobulin libraries |
| SG178789A1 (en) | 2007-02-16 | 2012-03-29 | Merrimack Pharmaceuticals Inc | Antibodies against erbb3 and uses thereof |
| US8877688B2 (en) | 2007-09-14 | 2014-11-04 | Adimab, Llc | Rationally designed, synthetic antibody libraries and uses therefor |
| US8067339B2 (en) | 2008-07-09 | 2011-11-29 | Merck Sharp & Dohme Corp. | Surface display of whole antibodies in eukaryotes |
| KR20110112301A (en) | 2008-11-18 | 2011-10-12 | 메리맥 파마슈티컬즈, 인크. | Human serum albumin linkers and conjugates thereof |
| CA2773564A1 (en) | 2009-09-14 | 2011-03-17 | Dyax Corp. | Libraries of genetic packages comprising novel hc cdr3 designs |
| WO2011035205A2 (en) | 2009-09-18 | 2011-03-24 | Calmune Corporation | Antibodies against candida, collections thereof and methods of use |
| WO2012083425A1 (en) | 2010-12-21 | 2012-06-28 | The University Of Western Ontario | Novel alkali-resistant variants of protein a and their use in affinity chromatography |
| US20140080766A1 (en) | 2011-01-07 | 2014-03-20 | Massachusetts Institute Of Technology | Compositions and methods for macromolecular drug delivery |
| SG186552A1 (en) | 2011-06-08 | 2013-01-30 | Emd Millipore Corp | Chromatography matrices including novel staphylococcus aureus protein a based ligands |
-
2009
- 2009-03-13 US US12/404,059 patent/US8877688B2/en active Active
-
2010
- 2010-03-15 WO PCT/US2010/027312 patent/WO2010105256A1/en active Application Filing
-
2014
- 2014-04-18 US US14/256,126 patent/US10196635B2/en active Active
-
2018
- 2018-12-28 US US16/236,259 patent/US11008568B2/en active Active
Patent Citations (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5798208A (en) | 1990-04-05 | 1998-08-25 | Roberto Crea | Walk-through mutagenesis |
| US5665563A (en) | 1991-10-11 | 1997-09-09 | Promega Corporation | Coupled transcription and translation in eukaryotic cell-free extract |
| US5324637A (en) | 1991-10-11 | 1994-06-28 | Promega Corporation | Coupled transcription and translation in eukaryotic cell-free extract |
| US20030100023A1 (en) | 1991-11-15 | 2003-05-29 | Board Of Regents, The University Of Texas System | Immunoassay and antibody selection methods using cell surface expressed libraries |
| US20040072740A1 (en) | 1991-11-15 | 2004-04-15 | Board Of Regents, The University Of Texas System. | Directed evolution of enzymes and antibodies |
| US20030036092A1 (en) | 1991-11-15 | 2003-02-20 | Board Of Regents, The University Of Texas System | Directed evolution of enzymes and antibodies |
| US5885793A (en) | 1991-12-02 | 1999-03-23 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| US7166423B1 (en) | 1992-10-21 | 2007-01-23 | Miltenyi Biotec Gmbh | Direct selection of cells by secretion product |
| US5492817A (en) | 1993-11-09 | 1996-02-20 | Promega Corporation | Coupled transcription and translation in eukaryotic cell-free extract |
| US5712120A (en) | 1994-06-30 | 1998-01-27 | Centro De Immunologia Molecular | Method for obtaining modified immunoglobulins with reduced immunogenicity of murine antibody variable domains, compositions containing them |
| US6300064B1 (en) | 1995-08-18 | 2001-10-09 | Morphosys Ag | Protein/(poly)peptide libraries |
| US20040146976A1 (en) | 1996-05-31 | 2004-07-29 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US6699658B1 (en) | 1996-05-31 | 2004-03-02 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US6423538B1 (en) | 1996-05-31 | 2002-07-23 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US6300065B1 (en) | 1996-05-31 | 2001-10-09 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US6696251B1 (en) | 1996-05-31 | 2004-02-24 | Board Of Trustees Of The University Of Illinois | Yeast cell surface display of proteins and uses thereof |
| US6214553B1 (en) | 1997-01-21 | 2001-04-10 | Massachusetts General Hospital | Libraries of protein encoding RNA-protein fusions |
| US6261804B1 (en) | 1997-01-21 | 2001-07-17 | The General Hospital Corporation | Selection of proteins using RNA-protein fusions |
| US6258558B1 (en) | 1997-01-21 | 2001-07-10 | The General Hospital Corporation | Method for selection of proteins using RNA-protein fusions |
| US6348315B1 (en) | 1997-04-23 | 2002-02-19 | University of Zürich, Assignee for Josef Hanes | Polysome display in the absence of functional ssrA-RNA |
| WO1998052976A1 (en) | 1997-05-21 | 1998-11-26 | Biovation Limited | Method for the production of non-immunogenic proteins |
| US20040058403A1 (en) | 2000-10-27 | 2004-03-25 | Harvey Barrett R. | Combinatorial protein library screening by periplasmic expression |
| US20060257937A1 (en) | 2000-12-18 | 2006-11-16 | Dyax Corp., A Delaware Corporation | Focused libraries of genetic packages |
| US20060234311A1 (en) | 2001-01-16 | 2006-10-19 | Regeneron Pharmaceuticals, Inc. | Isolating cells expressing secreted proteins |
| US6919183B2 (en) | 2001-01-16 | 2005-07-19 | Regeneron Pharmaceuticals, Inc. | Isolating cells expressing secreted proteins |
| US20060008883A1 (en) | 2003-12-04 | 2006-01-12 | Xencor, Inc. | Methods of generating variant proteins with increased host string content and compositions thereof |
| US20080206239A1 (en) | 2005-02-03 | 2008-08-28 | Antitope Limited | Human Antibodies And Proteins |
| WO2007056441A2 (en) * | 2005-11-07 | 2007-05-18 | Genentech, Inc. | Binding polypeptides with diversified and consensus vh/vl hypervariable sequences |
| WO2008053275A2 (en) | 2005-12-20 | 2008-05-08 | Morphosys Ag | Novel collection of hcdr3 regions and uses therefor |
| WO2009036379A2 (en) * | 2007-09-14 | 2009-03-19 | Adimab, Inc. | Rationally designed, synthetic antibody libraries and uses therefor |
Non-Patent Citations (150)
| Title |
|---|
| "Antibody Engineering: A Practical Approach", vol. 169, 1996, IRL PR |
| "Antibody Phage Display", 2001, HUMANA PRESS |
| "Current Protocols in Molecular Biology", 1992, JOHN WILEY & SONS |
| "DNA Cloning", vol. 1, 2, 1985 |
| "Large-Scale Mammalian Cell Culture Technology", 1990, MARCEL DEKKER, PUB. |
| "Oligonucleotide Synthesis", 1984 |
| "Oxford Handbook ofNucleic Acid Structure", 1999, OXFORD UNIV PRESS |
| "PCR Essential Techniques: Essential Techniques", 1996, JOHN WILEY & SON LTD |
| "PCR Handbook Current Protocols in Nucleic Acid Chemistry", 1999, JOHN WILEY & SONS |
| "Phage Display: A Laboratory Manual", 2001, CSHL PRESS |
| "The PCR Technique: RT-PCR", 1998 |
| AKAMATSU ET AL., J IMMUNOL, vol. 151, 1993, pages 4651 |
| AL-LAZIKANI ET AL., J. MOL. BIOL., vol. 273, 1997, pages 927 |
| ALT; BALTIMORE, PNAS, vol. 79, 1982, pages 4118 |
| BARRE ET AL., NAT. STRUCT. BIOL., vol. 1, 1994, pages 915 |
| BASU ET AL., BIOCHEM. BIOPHYS. RES. COMM., vol. 111, 1983, pages 1105 |
| BENGTEN ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 77 |
| BETTER; HORWITZ, METH. ENZYMOL., vol. 178, 1989, pages 476 |
| BINZ ET AL., NAT. BIOTECHNOL., vol. 23, 2005, pages 1257 |
| BIOTECHNOLOGY, vol. 9, 1991, pages 273 |
| BORDER ET AL., METHODS ENZYMOL., vol. 328, 2000, pages 430 |
| BORDER ET AL., NATURE BIOTECHNOLOGY, vol. 15, 1997, pages 553 |
| BRENNER; LEMER, PNAS, vol. 87, 1992, pages 6378 |
| BRUGGEMANN ET AL., PROC. NATL. ACAD. SCI. USA, vol. 83, 1986, pages 6075 |
| BUTLER ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 199 |
| CALDWELL; JOYCE, PCR METHODS AND APPLICATIONS, vol. 2, 1992, pages 28 |
| CHOTHIA ET AL., COLD SPRING HARB. SYMP. QUANT BIOL., vol. 52, 1987, pages 399 |
| CHOTHIA ET AL., J. MOL. BIOL., vol. 196, 1987, pages 901 |
| CHOTHIA ET AL., J. MOL. BIOL., vol. 227, 1992, pages 799 |
| CHOTHIA ET AL., J. MOL. BIOL., vol. 278, 1998, pages 457 |
| CHOTHIA ET AL., NATURE, vol. 342, 1989, pages 877 |
| CHOTHIA; LESK, J. MOL. BIOL., vol. 196, 1987, pages 901 |
| CLAUSELL-TORMOS ET AL., CHEM. BIOL., vol. 15, 2008, pages 427 |
| COLLINS ET AL., IMMUNOGENETICS, 2008 |
| COLLINS ET AL., J. IMMUNOL., vol. 172, 2004, pages 340 |
| CORBETT ET AL., PNAS, vol. 79, 1982, pages 4118 |
| DAS ET AL., IMMUNOGENETICS, vol. 60, 2008, pages 47 |
| DE GENST ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 187 |
| DOOLEY; FLAJNIK, DEV. COMP. IMMUNOL., vol. 30, 2006, pages 43 |
| EL-DEIRY ET AL., NATURE GENETICS, vol. 1, 1992, pages 4549 |
| FELDHAUS ET AL., NUCLEIC ACIDS RESEARCH, vol. 28, 2000, pages 534 |
| FELLER, W.: "An Introduction to Probability Theory and Its Applications", 1968, WILEY |
| FELLOUSE ET AL: "High-throughput Generation of Synthetic Antibodies from Highly Functional Minimalist Phage-displayed Libraries", JOURNAL OF MOLECULAR BIOLOGY, LONDON, GB LNKD- DOI:10.1016/J.JMB.2007.08.005, vol. 373, no. 4, 3 October 2007 (2007-10-03), pages 924 - 940, XP022285568, ISSN: 0022-2836 * |
| FIRTH ET AL., NUCLEIC ACIDS RES., vol. 36, 2008, pages W281 |
| FIRTH; PATRICK, BIOMOL. ENG., vol. 22, 2005, pages 105 |
| FUH GERMAINE: "Synthetic antibodies as therapeutics", EXPERT OPINION ON BIOLOGICAL THERAPY, ASHLEY, LONDON, GB, vol. 7, no. 1, 1 January 2007 (2007-01-01), pages 73 - 87, XP009099132, ISSN: 1471-2598 * |
| GRIFFITHS ET AL., EMBO J., vol. 12, 1993, pages 725 |
| GRIFFITHS ET AL., EMBO J., vol. 13, 1994, pages 3245 |
| GUIDOTTI; ZERVOS, YEAST, vol. 15, 1999, pages 715 |
| HARLOW ET AL.: "Antibodies: A Laboratory Manual", 1999, C.S.H.L. PRESS |
| HO ET AL., PNAS, vol. 103, 2006, pages 9637 |
| HOET ET AL., NAT. BIOTCCHNOL., vol. 23, 2005, pages 344 |
| HOET ET AL., NAT. BIOTECHNOL., vol. 23, 2005, pages 344 |
| HOOGENBOOM ET AL., J. MOL. BIOL., vol. 227, 1992, pages 381 |
| HUA ET AL., PLASMID, vol. 38, 1997, pages 91 |
| HUDSON ET AL., GENOME RES., vol. 7, 1997, pages 1169 |
| HUSTON ET AL., PNAS, vol. 85, 1988, pages 5879 |
| INNIS ET AL.: "PCR Protocols: A Guide to Methods and Applications", 1990, ACADEMIC PRESS |
| ISHIOKA ET AL., PNAS, vol. 94, 1997, pages 2449 |
| ITO ET AL., PNAS, vol. 97, 2000, pages 1143 |
| IVANOV ET AL., GENETICS, vol. 142, 1996, pages 693 |
| IWASAKI ET AL., GENE, vol. 109, 1991, pages 81 |
| JACKSON ET AL., J. IMMUNOL METHODS, vol. 324, 2007, pages 26 |
| JACKSON ET AL., J. IMMUNOL. METHODS, vol. 324, 2007, pages 26 |
| JACKSON ET AL: "Identifying highly mutated IGHD genes in the junctions of rearranged human immunoglobulin heavy chain genes", JOURNAL OF IMMUNOLOGICAL METHODS, ELSEVIER SCIENCE PUBLISHERS B.V.,AMSTERDAM, NL LNKD- DOI:10.1016/J.JIM.2007.04.011, vol. 324, no. 1-2, 2 July 2007 (2007-07-02), pages 26 - 37, XP022138110, ISSN: 0022-1759 * |
| JENNE ET AL., DCV. COMP. IMMUNOL., vol. 30, 2006, pages 165 |
| JEONG ET AL., PNAS, vol. 104, 2007, pages 8247 |
| JOHNSON ET AL., INT. IMMUNOL., vol. 10, 1998, pages 1801 |
| JOHNSON ET AL., METHODS MOL. BIOL., vol. 248, 2004, pages 11 |
| JOHNSON ET AL., METHODS MOL. BIOL., vol. 51, 1995, pages 1 |
| JUUL ET AL., CLIN. EXP. IMMUNOL., vol. 109, 1997, pages 194 |
| KABAT ET AL.: "Sequences of Proteins of Immunological Interest", 1991, NATIONAL INSTITUTES OF HEALTH |
| KABAT ET AL.: "Sequences of Proteins of Immunological Interest", 1992 |
| KELLY ET AL., CHEM. COMMUN., vol. 14, 2007, pages 1773 |
| KISS ET AL., NUCLEIC ACIDS RES., vol. 34, 2006, pages E132 |
| KLEIN; ZACHAU, EUR. J. IMMUNOL., vol. 23, 1993, pages 3248 |
| KNAPPIK A ET AL: "Fully synthetic human combinatorial antibody libraries (HuCAL) based on modular consensus frameworks and CDRs randomized with trinucleotides", JOURNAL OF MOLECULAR BIOLOGY, LONDON, GB LNKD- DOI:10.1006/JMBI.1999.3444, vol. 296, no. 1, 11 February 2000 (2000-02-11), pages 57 - 86, XP004461525, ISSN: 0022-2836 * |
| KNAPPIK ET AL., J MOL BIOL, vol. 296, 2000, pages 57 |
| KNAPPIK ET AL., J. MOL. BIOL., vol. 296, 2000, pages 57 |
| KOIWAI ET AL., NUCLEIC ACIDS RES., vol. 14, 1986, pages 5777 |
| KRETZSCHMAR; VON RUDEN, CURR. OPIN. BIOTECHNOL., vol. 13, 2002, pages 598 |
| KRUIF DE J ET AL: "SELECTION AND APPLICATION OF HUMAN SINGLE CHAIN FV ANTIBODY FRAGMENTS FROM A SEMI-SYNTHETIC PHAGE ANTIBODY DISPLEY LIBRARY WITHDESIGNED CDR3 REGIONS", JOURNAL OF MOLECULAR BIOLOGY, LONDON, GB LNKD- DOI:10.1006/JMBI.1995.0204, vol. 248, no. 1, 21 April 1995 (1995-04-21), pages 97 - 105, XP000646544, ISSN: 0022-2836 * |
| LEE C E H ET AL: "Reconsidering the human immunoglobulin heavy-chain locus:; 1. An evaluation of the expressed human IGHD gene repertoire", IMMUNOGENETICS, SPRINGER, BERLIN, DE LNKD- DOI:10.1007/S00251-005-0062-5, vol. 57, no. 12, 1 January 2006 (2006-01-01), pages 917 - 925, XP019331634, ISSN: 1432-1211 * |
| LEE C V ET AL: "High-affinity Human Antibodies from Phage-displayed Synthetic Fab Libraries with a Single Framework Scaffold", JOURNAL OF MOLECULAR BIOLOGY, LONDON, GB LNKD- DOI:10.1016/J.JMB.2004.05.051, vol. 340, no. 5, 23 July 2004 (2004-07-23), pages 1073 - 1093, XP004518119, ISSN: 0022-2836 * |
| LEE ET AL., IMMUNOGENETICS, vol. 57, 2006, pages 917 |
| LEE ET AL., J. MOL. BIOL., vol. 340, 2004, pages 1073 |
| LEI ET AL., J. BACTERIOL., vol. 169, 1987, pages 4379 |
| LEUNG ET AL., TECHNIQUE, vol. 1, 1989, pages 11 |
| LIU; VAN NESS, MOL. IMMUNOL., vol. 36, 1999, pages 461 |
| LOVE ET AL., NAT. BIOTECHNOL., vol. 24, 2006, pages 703 |
| LUNDQVIST ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 93 |
| MACCALLUM ET AL., J. MOL. BIOL., vol. 262, 1996, pages 732 |
| MAGE ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 137 |
| MALECEK ET AL., J. IMMUNOL., vol. 175, 2005, pages 8105 |
| MARKS ET AL., J. MOL. BIOL., vol. 222, 1991, pages 581 |
| MARTIN ET AL., BIOINFORMATICS, vol. 21, 2005, pages 4116 |
| MARTIN, PROTEINS, vol. 25, 1996, pages 130 |
| MARTIN; THORNTON, J. MOL. BIOL., vol. 263, 1996, pages 800 |
| MATHIS ET AL., EUR J IMMUNOL., vol. 25, 1995, pages 3115 |
| MATSUDA ET AL., J. EXP. MED., vol. 188, 1998, pages 2151 |
| MAZOR ET AL., NATURE BIOTECHNOLOGY, vol. 25, 2007, pages 563 |
| MCCRAITH ET AL., PNAS, vol. 97, 2000, pages 4879 |
| MOLLOVA ET AL., BMS SYSTEMS BIOLOGY, vol. 1, 2007, pages 30 |
| MOREA ET AL., BIOPHYS. CHEM., vol. 68, 1997, pages 9 |
| MOREA ET AL., J. MOL. BIOL., vol. 275, 1998, pages 269 |
| OMSTEIN ET AL., BIOPOLYMERS, vol. 17, 1978, pages 2341 |
| PATRICK ET AL., PROTEIN ENGINEERING, vol. 16, 2003, pages 451 |
| PAUL, S.: "Antibody Engineering Protocols", vol. 510, 1996, HUMANA PR |
| PEARSON ET AL., YEAST, vol. 14, 1998, pages 391 |
| PLUCKTHUN; SKERRA, METH. ENZYMOL., vol. 178, 1989, pages 476 |
| RATCLIFFE, DEV. COMP. IMMUNOL., vol. 30, 2006, pages 101 |
| RAUCHENBERGER ET AL., J. BIOL. CHEM., vol. 278, 2003, pages 38194 |
| RAYMOND ET AL., BIOTECHNIQUES, vol. 26, 1999, pages 134 |
| RAYMOND ET AL., GENOME RES., vol. 12, 2002, pages 190 |
| RETTER ET AL., NUCLEIC ACIDS RES., vol. 33, 2005, pages D671 |
| RETTER ET AL., NUCLEIC ACIDS RES., vol. 33, 2005, pages D671 - D674 |
| ROCK ET AL., J. EXP. MED., vol. 179, 1994, pages 323 - 328 |
| RUIZ ET AL., EXP. CLIN. IMMUNOGENET, vol. 16, 1999, pages 173 |
| SAMBROOK; FRITSCH; MANIATIS: "Molecular Cloning", 1989, COLD SPRING HARBOR LABORATORY PRESS |
| SCAVINER ET AL., EXP. CLIN, IMMUNOGENET., vol. 16, 1999, pages 243 |
| SCAVINER ET AL., EXP. CLIN. IMMUNOGENET., vol. 16, 1999, pages 234 |
| SCHROEDER ET AL., J. IMMUNOL., vol. 174, 2005, pages 7773 |
| SHAFIKHANI ET AL., BIOTECHNIQUES, vol. 23, 1997, pages 304 |
| SHANNON, BELL SYS. TECH. J., vol. 27, 1984, pages 379 |
| SHIRAI ET AL., FEBS LETT., vol. 399, 1996, pages 1 |
| SHIRAI ET AL., FEBS LETT., vol. 455, 1999, pages 188 |
| SIDHU ET AL., J. MOL. BIOL., vol. 338, 2004, pages 299 |
| SIDHU S S ET AL: "Phage-displayed Antibody Libraries of Synthetic Heavy Chain Complementarity Determining Regions", JOURNAL OF MOLECULAR BIOLOGY, LONDON, GB LNKD- DOI:10.1016/J.JMB.2004.02.050, vol. 338, no. 2, 23 April 2004 (2004-04-23), pages 299 - 310, XP004500301, ISSN: 0022-2836 * |
| SIMON; MOORE, MOL. CELL BIOL., vol. 7, 1987, pages 2329 |
| SKERRA ET AL., BIOTECHNOLOGY, vol. 9, 1991, pages 273 |
| SKERRA, CURRENT OPIN. IN BIOTECH., vol. 18, 2007, pages 295 - 304 |
| SOLEM ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 57 |
| SOUTO-CARNEIRO ET AL., J. IMMUNOL, vol. 172, 2004, pages 6790 |
| STEMMER ET AL., PNAS, vol. 91, 1994, pages 10747 |
| TOMLINSON ET AL., J. MOL. BIOL., vol. 227, 1992, pages 776 |
| TOMLINSON ET AL., J. MOL. BIOL., vol. 227, 1992, pages 799 |
| UETZ ET AL., NATURE, vol. 403, 2000, pages 623 |
| VIMEKAS ET AL., NUCLEIC ACIDS RES., vol. 22, 1994, pages 5600 |
| VOLPE ET AL., BIOINFORMATICS, vol. 22, 2006, pages 438 |
| VOLPE ET AL., BIOINFORMATICS, vol. 22, 2006, pages 438 - 44 |
| VOLPE; KEPLER, BIOINFORMATICS, vol. 22, 2006, pages 438 |
| WAGNER, DEV. COMP. IMMUNOL., vol. 30, 2006, pages 155 |
| WANG ET AL., IMMUNOL. CELL. BIOL., vol. 86, 2008, pages 111 |
| WEISS ET AL., J. THEOR. BIOL., vol. 206, 2000, pages 379 |
| WU ET AL., PROTEINS, vol. 16, 1993, pages 1 |
| XU; DAVIS, IMMUNITY, vol. 13, 2000, pages 27 - 45 |
| YE, IMMUNOGENETICS, vol. 56, 2004, pages 399 |
| ZEMLIN ET AL., JMB, vol. 334, 2003, pages 733 |
| ZEMLIN M ET AL: "Expressed Murine and Human CDR-H3 Intervals of Equal Length Exhibit Distinct Repertoires that Differ in their Amino Acid Composition and Predicted Range of Structures", JOURNAL OF MOLECULAR BIOLOGY, LONDON, GB LNKD- DOI:10.1016/J.JMB.2003.10.007, vol. 334, no. 4, 5 December 2003 (2003-12-05), pages 733 - 749, XP004473368, ISSN: 0022-2836 * |
| ZHAO ET AL., DEV. COMP. IMMUNOL., vol. 30, 2006, pages 175 |
Cited By (193)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9354228B2 (en) | 2010-07-16 | 2016-05-31 | Adimab, Llc | Antibody libraries |
| EP2593594A2 (en) * | 2010-07-16 | 2013-05-22 | Adimab LLC | Antibody libraries |
| US10889811B2 (en) | 2010-07-16 | 2021-01-12 | Adimab, Llc | Antibody libraries |
| EP2593594A4 (en) * | 2010-07-16 | 2014-04-16 | Adimab Llc | Antibody libraries |
| US10138478B2 (en) | 2010-07-16 | 2018-11-27 | Adimab, Llc | Antibody libraries |
| AU2011279073B2 (en) * | 2010-07-16 | 2016-06-09 | Adimab, Llc | Antibody libraries |
| WO2013047748A1 (en) | 2011-09-30 | 2013-04-04 | 中外製薬株式会社 | Antigen-binding molecule promoting disappearance of antigens having plurality of biological activities |
| WO2013047729A1 (en) | 2011-09-30 | 2013-04-04 | 中外製薬株式会社 | Antigen-binding molecule inducing immune response to target antigen |
| EP3939996A1 (en) | 2011-09-30 | 2022-01-19 | Chugai Seiyaku Kabushiki Kaisha | Antigen-binding molecule promoting disappearance of antigens having plurality of biological activities |
| WO2013046722A1 (en) | 2011-09-30 | 2013-04-04 | 中外製薬株式会社 | Ion concentration-dependent binding molecule library |
| US11590196B2 (en) | 2011-12-22 | 2023-02-28 | Children's Medical Center Corporation | Saposin-A derived peptides and uses thereof |
| EP3560509A1 (en) * | 2011-12-22 | 2019-10-30 | Children's Medical Center Corporation | Saposin-a derived peptides and uses thereof |
| EP2793921A4 (en) * | 2011-12-22 | 2016-05-04 | Childrens Medical Center | Saposin-a derived peptides and uses thereof |
| US10736935B2 (en) | 2011-12-22 | 2020-08-11 | Children's Medical Center Corporation | Saposin-A derived peptides and uses thereof |
| EP4306123A3 (en) * | 2011-12-22 | 2024-04-17 | Children's Medical Center Corporation | Saposin-a derived peptides and uses thereof |
| WO2013156534A1 (en) | 2012-04-17 | 2013-10-24 | Arsanis Biosciences Gmbh | Cross-reactive staphylococcus aureus antibody |
| US9914767B2 (en) | 2012-04-17 | 2018-03-13 | Arsanis Biosciences Gmbh | Cross-reactive Staphylococcus aureus antibody |
| US10206992B2 (en) | 2013-01-17 | 2019-02-19 | Arsanis Biosciences Gmbh | MDR E. coli specific antibody |
| US11529405B2 (en) | 2013-01-17 | 2022-12-20 | Janssen Pharmaceuticals, Inc. | MDR E. coli immunogen |
| US10940191B2 (en) | 2013-01-17 | 2021-03-09 | X4 Pharmaceuticals (Austria) GmbH | MDR E. coli specific antibody |
| US10175243B2 (en) | 2013-03-14 | 2019-01-08 | Children's Medical Center Corporation | Use of CD36 to identify cancer subjects for treatment |
| US9921224B2 (en) | 2013-03-14 | 2018-03-20 | Children's Medical Center Corporation | Use of CD36 to identify cancer subjects for treatment |
| WO2014169076A1 (en) | 2013-04-09 | 2014-10-16 | Annexon,,Inc. | Methods of treatment for neuromyelitis optica |
| WO2014187746A2 (en) | 2013-05-21 | 2014-11-27 | Arsanis Biosciences Gmbh | Generation of highly potent antibodies neutralizing the lukgh (lukab) toxin of staphylococcus aureus |
| EP4252769A2 (en) | 2013-07-09 | 2023-10-04 | Annexon, Inc. | Anti-complement factor c1q antibodies and uses thereof |
| WO2015006504A1 (en) | 2013-07-09 | 2015-01-15 | Annexon, Inc. | Anti-complement factor c1q antibodies and uses thereof |
| WO2015055814A1 (en) | 2013-10-17 | 2015-04-23 | Arsanis Biosciences Gmbh | Cross-reactive staphylococcus aureus antibody sequences |
| EP4050026A1 (en) | 2014-04-01 | 2022-08-31 | Adimab, LLC | Method of obtaining or identifying one or more common light chains for use in preparing a multispecific antibody |
| WO2015153765A1 (en) | 2014-04-01 | 2015-10-08 | Adimab, Llc | Multispecific antibody analogs comprising a common light chain, and methods of their preparation and use |
| EP3825326A1 (en) | 2014-04-01 | 2021-05-26 | Adimab, LLC | Multispecific antibody analogs comprising a common light chain, and methods of their preparation and use |
| US10975147B2 (en) | 2014-04-03 | 2021-04-13 | Igm Biosciences, Inc. | Modified J-chain |
| US11555075B2 (en) | 2014-04-03 | 2023-01-17 | Igm Biosciences, Inc. | Modified J-chain |
| US10400038B2 (en) | 2014-04-03 | 2019-09-03 | Igm Biosciences, Inc. | Modified J-chain |
| WO2015195917A1 (en) | 2014-06-18 | 2015-12-23 | Mersana Therapeutics, Inc. | Monoclonal antibodies against her2 epitope and methods of use thereof |
| EP4285917A2 (en) | 2014-06-18 | 2023-12-06 | Mersana Therapeutics, Inc. | Monoclonal antibodies against her2 epitope and methods of use thereof |
| US11084875B2 (en) | 2014-08-08 | 2021-08-10 | Alector Llc | Anti-TREM2 antibodies and methods of use thereof |
| EP4066859A1 (en) | 2014-08-08 | 2022-10-05 | Alector LLC | Anti-trem2 antibodies and methods of use thereof |
| EP3845565A2 (en) | 2014-11-19 | 2021-07-07 | Genentech, Inc. | Antibodies against bace1 and use thereof for neural disease immunotherapy |
| WO2016081639A1 (en) | 2014-11-19 | 2016-05-26 | Genentech, Inc. | Antibodies against bace1 and use thereof for neural disease immunotherapy |
| WO2016081640A1 (en) | 2014-11-19 | 2016-05-26 | Genentech, Inc. | Anti-transferrin receptor / anti-bace1 multispecific antibodies and methods of use |
| US11466074B2 (en) | 2015-02-17 | 2022-10-11 | X4 Pharmaceuticals (Austria) GmbH | Antibodies targeting a galactan-based O-antigen of K. pneumoniae |
| US10428150B2 (en) | 2015-04-07 | 2019-10-01 | Alector Llc | Anti-sortilin antibodies and methods of use thereof |
| US11186645B2 (en) | 2015-04-07 | 2021-11-30 | Alector Llc | Isolated nucleic acids encoding anti-sortilin antibodies |
| US10087255B2 (en) | 2015-04-07 | 2018-10-02 | Alector Llc | Anti-sortilin antibodies and methods of use thereof |
| EP3991748A2 (en) | 2015-04-07 | 2022-05-04 | Alector LLC | Anti-sortilin antibodies and methods of use thereof |
| US10308718B2 (en) | 2015-04-07 | 2019-06-04 | Alector Llc | Anti-sortilin antibodies and methods of use thereof |
| US11339223B2 (en) | 2015-04-07 | 2022-05-24 | Alector Llc | Methods of use of anti-Sortilin antibodies for treating a disease, disorder, or injury |
| WO2016164637A1 (en) | 2015-04-07 | 2016-10-13 | Alector Llc | Anti-sortilin antibodies and methods of use thereof |
| US11208488B2 (en) | 2015-04-07 | 2021-12-28 | Alector Llc | Methods of increasing progranulin levels using anti-Sortilin antibodies |
| WO2016164708A1 (en) | 2015-04-10 | 2016-10-13 | Adimab, Llc | Methods for purifying heterodimeric multispecific antibodies from parental homodimeric antibody species |
| WO2016166223A1 (en) | 2015-04-17 | 2016-10-20 | Arsanis Biosciences Gmbh | Anti-staphylococcus aureus antibody combination preparation |
| US11174313B2 (en) | 2015-06-12 | 2021-11-16 | Alector Llc | Anti-CD33 antibodies and methods of use thereof |
| WO2016201388A2 (en) | 2015-06-12 | 2016-12-15 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| WO2016201389A2 (en) | 2015-06-12 | 2016-12-15 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| US11136390B2 (en) | 2015-06-12 | 2021-10-05 | Alector Llc | Anti-CD33 antibodies and methods of use thereof |
| US10590198B2 (en) | 2015-08-28 | 2020-03-17 | Alector Llc | Anti-siglec-7 antibodies and methods of use thereof |
| US11390680B2 (en) | 2015-08-28 | 2022-07-19 | Alector Llc | Anti-Siglec-7 antibodies and methods of use thereof |
| WO2017040301A1 (en) | 2015-08-28 | 2017-03-09 | Alector Llc | Anti-siglec-7 antibodies and methods of use thereof |
| US11542342B2 (en) | 2015-09-30 | 2023-01-03 | Igm Biosciences, Inc. | Binding molecules with modified J-chain |
| US11639389B2 (en) | 2015-09-30 | 2023-05-02 | Igm Biosciences, Inc. | Binding molecules with modified J-chain |
| US10618978B2 (en) | 2015-09-30 | 2020-04-14 | Igm Biosciences, Inc. | Binding molecules with modified J-chain |
| US11590224B2 (en) | 2015-10-01 | 2023-02-28 | Potenza Therapeutics, Inc. | Anti-TIGIT antigen-binding proteins and methods of uses thereof |
| WO2017062672A2 (en) | 2015-10-06 | 2017-04-13 | Alector Llc | Anti-trem2 antibodies and methods of use thereof |
| WO2017064258A1 (en) | 2015-10-16 | 2017-04-20 | Arsanis Biosciences Gmbh | Bactericidal monoclonal antibody targeting klebsiella pneumoniae |
| WO2017075432A2 (en) | 2015-10-29 | 2017-05-04 | Alector Llc | Anti-siglec-9 antibodies and methods of use thereof |
| US11667710B2 (en) | 2015-10-29 | 2023-06-06 | Alector Llc | Anti-Siglec-9 antibodies and methods of use thereof |
| US10800844B2 (en) | 2015-10-29 | 2020-10-13 | Alector Llc | Anti-Siglec-9 antibodies and methods of use thereof |
| WO2017152102A2 (en) | 2016-03-04 | 2017-09-08 | Alector Llc | Anti-trem1 antibodies and methods of use thereof |
| WO2017156488A2 (en) | 2016-03-10 | 2017-09-14 | Acceleron Pharma, Inc. | Activin type 2 receptor binding proteins and uses thereof |
| EP4302782A2 (en) | 2016-03-15 | 2024-01-10 | Mersana Therapeutics, Inc. | Napi2b-targeted antibody-drug conjugates and methods of use thereof |
| WO2017160754A1 (en) | 2016-03-15 | 2017-09-21 | Mersana Therapeutics,Inc. | Napi2b-targeted antibody-drug conjugates and methods of use thereof |
| US10759848B2 (en) | 2016-08-12 | 2020-09-01 | Arsanis Biosciences Gmbh | Klebsiella pneumoniae O3 specific antibodies |
| WO2018029356A1 (en) | 2016-08-12 | 2018-02-15 | Arsanis Biosciences Gmbh | Anti-galactan ii monoclonal antibodies targeting klebsiella pneumoniae |
| WO2018029346A1 (en) | 2016-08-12 | 2018-02-15 | Arsanis Biosciences Gmbh | Klebsiella pneumoniae o3 specific antibodies |
| US11844766B2 (en) | 2016-10-24 | 2023-12-19 | Janssen Pharmaceuticals, Inc. | ExPEC glycoconjugate vaccine formulations |
| WO2018085358A1 (en) | 2016-11-02 | 2018-05-11 | Jounce Therapeutics, Inc. | Antibodies to pd-1 and uses thereof |
| JP2022070873A (en) * | 2016-11-02 | 2022-05-13 | ジョンス セラピューティクス, インコーポレイテッド | Anti-pd-1 antibodies and uses thereof |
| US11384147B2 (en) | 2016-11-02 | 2022-07-12 | Jounce Therapeutics, Inc. | Anti-PD-1 antibodies and uses thereof |
| JP7086066B2 (en) | 2016-11-02 | 2022-06-17 | ジョンス セラピューティクス, インコーポレイテッド | Antibodies to PD-1 and its use |
| EP3988569A1 (en) | 2016-11-02 | 2022-04-27 | Jounce Therapeutics, Inc. | Antibodies to pd-1 and uses thereof |
| JP2019534008A (en) * | 2016-11-02 | 2019-11-28 | ジョンス セラピューティクス, インコーポレイテッド | Antibody against PD-1 and use thereof |
| US11905329B2 (en) | 2016-11-02 | 2024-02-20 | Jounce Therapeutics, Inc. | Anti-PD-1 antibodies and uses thereof |
| US10654929B2 (en) | 2016-11-02 | 2020-05-19 | Jounce Therapeutics, Inc. | Antibodies to PD-1 and uses thereof |
| RU2761640C2 (en) * | 2016-11-02 | 2021-12-13 | Джоунс Терапьютикс, Инк. | Antibodies to pd-1 and their application |
| WO2018094300A1 (en) | 2016-11-19 | 2018-05-24 | Potenza Therapeutics, Inc. | Anti-gitr antigen-binding proteins and methods of use thereof |
| WO2018098363A2 (en) | 2016-11-23 | 2018-05-31 | Bioverativ Therapeutics Inc. | Bispecific antibodies binding to coagulation factor ix and coagulation factor x |
| US11820979B2 (en) | 2016-12-23 | 2023-11-21 | Visterra, Inc. | Binding polypeptides and methods of making the same |
| WO2018119171A1 (en) | 2016-12-23 | 2018-06-28 | Potenza Therapeutics, Inc. | Anti-neuropilin antigen-binding proteins and methods of use thereof |
| WO2018113781A1 (en) | 2016-12-24 | 2018-06-28 | 信达生物制药(苏州)有限公司 | Anti-pcsk9 antibody and application thereof |
| US11485795B2 (en) | 2016-12-24 | 2022-11-01 | Innovent Biologics (Suzhou) Co., Ltd | Anti-PCSK9 antibody and use thereof |
| WO2018177220A1 (en) | 2017-03-25 | 2018-10-04 | 信达生物制药(苏州)有限公司 | Anti-ox40 antibody and use thereof |
| JP2020515247A (en) * | 2017-03-25 | 2020-05-28 | イノベント バイオロジックス (スウツォウ) カンパニー,リミテッド | Anti-OX40 antibody and use thereof |
| US11498972B2 (en) | 2017-03-25 | 2022-11-15 | Innovent Biologics (Suzhou) Co., Ltd. | Anti-OX40 antibody and use thereof |
| JP7046973B2 (en) | 2017-03-25 | 2022-04-04 | イノベント バイオロジックス (スウツォウ) カンパニー,リミテッド | Anti-OX40 antibody and its use |
| WO2018183889A1 (en) | 2017-03-30 | 2018-10-04 | Potenza Therapeutics, Inc. | Anti-tigit antigen-binding proteins and methods of use thereof |
| US11453720B2 (en) | 2017-03-30 | 2022-09-27 | Potenza Therapeutics, Inc. | Anti-TIGIT antigen-binding proteins and methods of use thereof |
| US11965023B2 (en) | 2017-05-16 | 2024-04-23 | Alector Llc | Anti-Siglec-5 antibodies and methods of use thereof |
| US11359014B2 (en) | 2017-05-16 | 2022-06-14 | Alector Llc | Anti-siglec-5 antibodies and methods of use thereof |
| WO2018213316A1 (en) | 2017-05-16 | 2018-11-22 | Alector Llc | Anti-siglec-5 antibodies and methods of use thereof |
| WO2018224685A1 (en) | 2017-06-08 | 2018-12-13 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| WO2018224682A1 (en) | 2017-06-08 | 2018-12-13 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| WO2018224683A1 (en) | 2017-06-08 | 2018-12-13 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| US11312783B2 (en) | 2017-06-22 | 2022-04-26 | Novartis Ag | Antibody molecules to CD73 and uses thereof |
| WO2018237157A1 (en) | 2017-06-22 | 2018-12-27 | Novartis Ag | Antibody molecules to cd73 and uses thereof |
| WO2019014328A2 (en) | 2017-07-11 | 2019-01-17 | Compass Therapeutics Llc | Agonist antibodies that bind human cd137 and uses thereof |
| US11752207B2 (en) | 2017-07-11 | 2023-09-12 | Compass Therapeutics Llc | Agonist antibodies that bind human CD137 and uses thereof |
| EP3719040A1 (en) | 2017-07-27 | 2020-10-07 | iTeos Therapeutics SA | Anti-tigit antibodies |
| WO2019023504A1 (en) | 2017-07-27 | 2019-01-31 | Iteos Therapeutics Sa | Anti-tigit antibodies |
| WO2019028283A1 (en) | 2017-08-03 | 2019-02-07 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| US10711062B2 (en) | 2017-08-03 | 2020-07-14 | Alector Llc | Anti-CD33 antibodies and methods of use thereof |
| WO2019028292A1 (en) | 2017-08-03 | 2019-02-07 | Alector Llc | Anti-trem2 antibodies and methods of use thereof |
| US10676525B2 (en) | 2017-08-03 | 2020-06-09 | Alector Llc | Anti-TREM2 antibodies and methods of use thereof |
| EP4248996A2 (en) | 2017-08-03 | 2023-09-27 | Alector LLC | Anti-trem2 antibodies and methods of use thereof |
| US11254743B2 (en) | 2017-08-03 | 2022-02-22 | Alector Llc | Anti-CD33 antibodies and methods of use thereof |
| US11634489B2 (en) | 2017-08-03 | 2023-04-25 | Alector Llc | Anti-TREM2 antibodies and methods of use thereof |
| WO2019034753A1 (en) | 2017-08-16 | 2019-02-21 | Tusk Therapeutics Ltd | Cd38 antibody |
| WO2019034752A1 (en) | 2017-08-16 | 2019-02-21 | Tusk Therapeutics Ltd | Cd38 modulating antibody |
| US11814431B2 (en) | 2017-08-25 | 2023-11-14 | Five Prime Therapeutics, Inc. | B7-H4 antibodies and methods of use thereof |
| WO2019040780A1 (en) | 2017-08-25 | 2019-02-28 | Five Prime Therapeutics Inc. | B7-h4 antibodies and methods of use thereof |
| US11306144B2 (en) | 2017-08-25 | 2022-04-19 | Five Prime Therapeutics, Inc. | B7-H4 antibodies and methods of use thereof |
| WO2019042285A1 (en) | 2017-08-29 | 2019-03-07 | 信达生物制药(苏州)有限公司 | Anti-cd47 antibody and use thereof |
| EP4116327A1 (en) | 2017-10-11 | 2023-01-11 | Board Of Regents, The University Of Texas System | Human pd-l1 antibodies and methods of use therefor |
| US11718679B2 (en) | 2017-10-31 | 2023-08-08 | Compass Therapeutics Llc | CD137 antibodies and PD-1 antagonists and uses thereof |
| WO2019089753A2 (en) | 2017-10-31 | 2019-05-09 | Compass Therapeutics Llc | Cd137 antibodies and pd-1 antagonists and uses thereof |
| WO2019100052A2 (en) | 2017-11-20 | 2019-05-23 | Compass Therapeutics Llc | Cd137 antibodies and tumor antigen-targeting antibodies and uses thereof |
| US11851497B2 (en) | 2017-11-20 | 2023-12-26 | Compass Therapeutics Llc | CD137 antibodies and tumor antigen-targeting antibodies and uses thereof |
| US11401345B2 (en) | 2017-11-27 | 2022-08-02 | Purdue Pharma L.P. | Humanized antibodies targeting human tissue factor |
| WO2019102435A1 (en) | 2017-11-27 | 2019-05-31 | Euro-Celtique S.A. | Humanized antibodies targeting human tissue factor |
| US11732044B2 (en) | 2017-12-27 | 2023-08-22 | Innovent Biologics (Suzhou) Co., Ltd. | Anti-LAG-3 antibody and use thereof |
| WO2019129137A1 (en) | 2017-12-27 | 2019-07-04 | 信达生物制药(苏州)有限公司 | Anti-lag-3 antibody and uses thereof |
| US11447566B2 (en) | 2018-01-04 | 2022-09-20 | Iconic Therapeutics, Inc. | Anti-tissue factor antibodies, antibody-drug conjugates, and related methods |
| US11807663B2 (en) | 2018-02-01 | 2023-11-07 | Innovent Biologics (Suzhou) Co., Ltd. | Fully humanized anti-B cell maturation antigen (BCMA) single-chain antibody and use thereof |
| WO2019149269A1 (en) | 2018-02-01 | 2019-08-08 | 信达生物制药(苏州)有限公司 | Fully human anti-b cell maturation antigen (bcma) single chain variable fragment, and application thereof |
| US11939383B2 (en) | 2018-03-02 | 2024-03-26 | Five Prime Therapeutics, Inc. | B7-H4 antibodies and methods and use thereof |
| WO2019169212A1 (en) | 2018-03-02 | 2019-09-06 | Five Prime Therapeutics, Inc. | B7-h4 antibodies and methods of use thereof |
| US10738128B2 (en) | 2018-03-14 | 2020-08-11 | Surface Oncology, Inc. | Antibodies that bind CD39 and uses thereof |
| WO2019178269A2 (en) | 2018-03-14 | 2019-09-19 | Surface Oncology, Inc. | Antibodies that bind cd39 and uses thereof |
| EP4043496A1 (en) | 2018-03-14 | 2022-08-17 | Surface Oncology, Inc. | Antibodies that bind cd39 and uses thereof |
| US10793637B2 (en) | 2018-03-14 | 2020-10-06 | Surface Oncology, Inc. | Antibodies that bind CD39 and uses thereof |
| US11332524B2 (en) | 2018-03-22 | 2022-05-17 | Surface Oncology, Inc. | Anti-IL-27 antibodies and uses thereof |
| WO2019182896A1 (en) | 2018-03-23 | 2019-09-26 | Board Of Regents, The University Of Texas System | Dual specificity antibodies to pd-l1 and pd-l2 and methods of use therefor |
| WO2019214707A1 (en) | 2018-05-11 | 2019-11-14 | 信达生物制药(苏州)有限公司 | Preparations comprising anti-pcsk9 antibodies and use thereof |
| WO2019226973A1 (en) | 2018-05-25 | 2019-11-28 | Alector Llc | Anti-sirpa antibodies and methods of use thereof |
| WO2019232244A2 (en) | 2018-05-31 | 2019-12-05 | Novartis Ag | Antibody molecules to cd73 and uses thereof |
| WO2020006374A2 (en) | 2018-06-29 | 2020-01-02 | Alector Llc | Anti-sirp-beta1 antibodies and methods of use thereof |
| US11396546B2 (en) | 2018-07-13 | 2022-07-26 | Alector Llc | Anti-Sortilin antibodies and methods of use thereof |
| US11279758B2 (en) | 2018-07-20 | 2022-03-22 | Surface Oncology, Inc. | Anti-CD112R compositions and methods |
| US11214619B2 (en) | 2018-07-20 | 2022-01-04 | Surface Oncology, Inc. | Anti-CD112R compositions and methods |
| WO2020020281A1 (en) | 2018-07-25 | 2020-01-30 | 信达生物制药(苏州)有限公司 | Anti-tigit antibody and uses thereof |
| US11370837B2 (en) | 2018-07-25 | 2022-06-28 | Innovent Biologics (Suzhou) Co., Ltd. | Anti-TIGIT antibody and use thereof |
| WO2020023920A1 (en) | 2018-07-27 | 2020-01-30 | Alector Llc | Anti-siglec-5 antibodies and methods of use thereof |
| WO2020033923A1 (en) | 2018-08-09 | 2020-02-13 | Compass Therapeutics Llc | Antigen binding agents that bind cd277 and uses thereof |
| WO2020033925A2 (en) | 2018-08-09 | 2020-02-13 | Compass Therapeutics Llc | Antibodies that bind cd277 and uses thereof |
| WO2020033926A2 (en) | 2018-08-09 | 2020-02-13 | Compass Therapeutics Llc | Antibodies that bind cd277 and uses thereof |
| WO2020041541A2 (en) | 2018-08-23 | 2020-02-27 | Seattle Genetics, Inc. | Anti-tigit antibodies |
| WO2020069133A1 (en) | 2018-09-27 | 2020-04-02 | Tizona Therapeutics | Anti-hla-g antibodies, compositions comprising anti-hla-g antibodies and methods of using anti-hla-g antibodies |
| US11046769B2 (en) | 2018-11-13 | 2021-06-29 | Compass Therapeutics Llc | Multispecific binding constructs against checkpoint molecules and uses thereof |
| WO2020144178A1 (en) | 2019-01-07 | 2020-07-16 | Iteos Therapeutics Sa | Anti-tigit antibodies |
| WO2020150496A1 (en) | 2019-01-16 | 2020-07-23 | Compass Therapeutics Llc | Formulations of antibodies that bind human cd137 and uses thereof |
| US11931405B2 (en) | 2019-03-18 | 2024-03-19 | Janssen Pharmaceuticals, Inc. | Bioconjugates of E. coli O-antigen polysaccharides, methods of production thereof, and methods of use thereof |
| US11655303B2 (en) | 2019-09-16 | 2023-05-23 | Surface Oncology, Inc. | Anti-CD39 antibody compositions and methods |
| WO2021062244A1 (en) | 2019-09-25 | 2021-04-01 | Surface Oncology, Inc. | Anti-il-27 antibodies and uses thereof |
| WO2021113655A1 (en) | 2019-12-05 | 2021-06-10 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2021119400A1 (en) | 2019-12-12 | 2021-06-17 | Alector Llc | Methods of use of anti-cd33 antibodies |
| WO2021139687A1 (en) | 2020-01-09 | 2021-07-15 | 信达生物制药(苏州)有限公司 | Application of combination of anti-cd47 antibody and anti-cd20 antibody in preparation of drugs for preventing or treating tumors |
| WO2021167964A1 (en) | 2020-02-18 | 2021-08-26 | Alector Llc | Pilra antibodies and methods of use thereof |
| WO2021173565A1 (en) | 2020-02-24 | 2021-09-02 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2021190431A1 (en) | 2020-03-23 | 2021-09-30 | 百奥泰生物制药股份有限公司 | Development and application of immune cell activator |
| WO2021203030A2 (en) | 2020-04-03 | 2021-10-07 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2021217024A1 (en) | 2020-04-24 | 2021-10-28 | Millennium Pharmaceuticals, Inc. | Anti-cd19 antibodies and uses thereof |
| WO2021233834A1 (en) | 2020-05-17 | 2021-11-25 | Astrazeneca Uk Limited | Sars-cov-2 antibodies and methods of selecting and using the same |
| WO2021262765A1 (en) | 2020-06-22 | 2021-12-30 | The Board Of Trustees Of The Leland Stanford Junior University | Tsp-1 inhibitors for the treatment of aged, atrophied or dystrophied muscle |
| WO2021259199A1 (en) | 2020-06-22 | 2021-12-30 | 信达生物制药(苏州)有限公司 | Anti-cd73 antibody and use thereof |
| WO2022018040A2 (en) | 2020-07-20 | 2022-01-27 | Astrazeneca Uk Limited | Sars-cov-2 proteins, anti-sars-cov-2 antibodies, and methods of using the same |
| US11725052B2 (en) | 2020-08-18 | 2023-08-15 | Cephalon Llc | Anti-PAR-2 antibodies and methods of use thereof |
| WO2022040345A1 (en) | 2020-08-18 | 2022-02-24 | Cephalon, Inc. | Anti-par-2 antibodies and methods of use thereof |
| WO2022098972A1 (en) | 2020-11-08 | 2022-05-12 | Seagen Inc. | Combination-therapy antibody drug conjugate with immune cell inhibitor |
| US11873333B2 (en) | 2020-12-11 | 2024-01-16 | The University Of North Carolina At Chapel Hill | Compositions and methods comprising SFRP2 antagonists |
| WO2022133325A3 (en) * | 2020-12-18 | 2022-07-28 | Kindred Biosciences, Inc. | Tnf alpha and ngf antibodies for veterinary use |
| WO2022162569A1 (en) | 2021-01-29 | 2022-08-04 | Novartis Ag | Dosage regimes for anti-cd73 and anti-entpd2 antibodies and uses thereof |
| WO2022217026A1 (en) | 2021-04-09 | 2022-10-13 | Seagen Inc. | Methods of treating cancer with anti-tigit antibodies |
| US11970538B2 (en) | 2021-05-20 | 2024-04-30 | Compass Therapeutics Llc | Multispecific binding constructs against checkpoint molecules and uses thereof |
| WO2023016450A1 (en) | 2021-08-09 | 2023-02-16 | 普米斯生物技术(珠海)有限公司 | Anti-tigit antibody and use thereof |
| WO2023018803A1 (en) | 2021-08-10 | 2023-02-16 | Byomass Inc. | Anti-gdf15 antibodies, compositions and uses thereof |
| WO2023028501A1 (en) | 2021-08-23 | 2023-03-02 | Immunitas Therapeutics, Inc. | Anti-cd161 antibodies and uses thereof |
| WO2023069421A1 (en) | 2021-10-18 | 2023-04-27 | Byomass Inc. | Anti-activin a antibodies, compositions and uses thereof |
| WO2023081898A1 (en) | 2021-11-08 | 2023-05-11 | Alector Llc | Soluble cd33 as a biomarker for anti-cd33 efficacy |
| WO2023122213A1 (en) | 2021-12-22 | 2023-06-29 | Byomass Inc. | Targeting gdf15-gfral pathway cross-reference to related applications |
| WO2023147107A1 (en) | 2022-01-31 | 2023-08-03 | Byomass Inc. | Myeloproliferative conditions |
| WO2023164516A1 (en) | 2022-02-23 | 2023-08-31 | Alector Llc | Methods of use of anti-trem2 antibodies |
| WO2023178192A1 (en) | 2022-03-15 | 2023-09-21 | Compugen Ltd. | Il-18bp antagonist antibodies and their use in monotherapy and combination therapy in the treatment of cancer |
| WO2023192976A1 (en) | 2022-04-01 | 2023-10-05 | Board Of Regents, The University Of Texas System | Dual specificity antibodies to human pd-l1 and pd-l2 and methods of use therefor |
| WO2023209177A1 (en) | 2022-04-29 | 2023-11-02 | Astrazeneca Uk Limited | Sars-cov-2 antibodies and methods of using the same |
Also Published As
| Publication number | Publication date |
|---|---|
| US20190203205A1 (en) | 2019-07-04 |
| US11008568B2 (en) | 2021-05-18 |
| US20100056386A1 (en) | 2010-03-04 |
| US20140221250A1 (en) | 2014-08-07 |
| US10196635B2 (en) | 2019-02-05 |
| US8877688B2 (en) | 2014-11-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230399386A1 (en) | Rationally designed, synthetic antibody libraries and uses therefor | |
| US11008568B2 (en) | Rationally designed, synthetic antibody libraries and uses therefor | |
| CA2805875C (en) | Libraries comprising segmental pools, and methods for their preparation and use | |
| US20230348901A1 (en) | Rationally designed, synthetic antibody libraries and uses therefor | |
| AU2019204933B2 (en) | Rationally designed, synthetic antibody libraries and uses therefor |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 10710130 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 10710130 Country of ref document: EP Kind code of ref document: A1 |