KR20230083316A - Sars-cov-2를 표적화하는 폴리펩티드, 및 관련 조성물 및 방법 - Google Patents
Sars-cov-2를 표적화하는 폴리펩티드, 및 관련 조성물 및 방법 Download PDFInfo
- Publication number
- KR20230083316A KR20230083316A KR1020237015177A KR20237015177A KR20230083316A KR 20230083316 A KR20230083316 A KR 20230083316A KR 1020237015177 A KR1020237015177 A KR 1020237015177A KR 20237015177 A KR20237015177 A KR 20237015177A KR 20230083316 A KR20230083316 A KR 20230083316A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- gly
- val
- thr
- leu
- Prior art date
Links
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 242
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 226
- 229920001184 polypeptide Polymers 0.000 title claims abstract description 221
- 230000008685 targeting Effects 0.000 title claims abstract description 23
- 238000000034 method Methods 0.000 title claims description 56
- 239000000203 mixture Substances 0.000 title claims description 32
- 239000002091 nanocage Substances 0.000 claims abstract description 206
- 239000000178 monomer Substances 0.000 claims abstract description 184
- 230000027455 binding Effects 0.000 claims abstract description 183
- 241001678559 COVID-19 virus Species 0.000 claims abstract description 162
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 124
- 108020001507 fusion proteins Proteins 0.000 claims abstract description 124
- 230000004927 fusion Effects 0.000 claims abstract description 113
- 239000012634 fragment Substances 0.000 claims abstract description 61
- 230000035772 mutation Effects 0.000 claims abstract description 40
- 238000008416 Ferritin Methods 0.000 claims description 159
- 102000008857 Ferritin Human genes 0.000 claims description 116
- 108050000784 Ferritin Proteins 0.000 claims description 116
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 110
- 108010002084 Apoferritins Proteins 0.000 claims description 89
- 102000000546 Apoferritins Human genes 0.000 claims description 89
- 108090000623 proteins and genes Proteins 0.000 claims description 75
- 102000004169 proteins and genes Human genes 0.000 claims description 60
- 210000004027 cell Anatomy 0.000 claims description 56
- 241000282414 Homo sapiens Species 0.000 claims description 50
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 29
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 29
- 150000007523 nucleic acids Chemical class 0.000 claims description 29
- 125000000539 amino acid group Chemical group 0.000 claims description 27
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 claims description 22
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 claims description 22
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 21
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 21
- 239000013598 vector Substances 0.000 claims description 20
- 102000039446 nucleic acids Human genes 0.000 claims description 19
- 108020004707 nucleic acids Proteins 0.000 claims description 19
- 230000000975 bioactive effect Effects 0.000 claims description 18
- 238000011068 loading method Methods 0.000 claims description 17
- 238000011282 treatment Methods 0.000 claims description 16
- 101000629318 Severe acute respiratory syndrome coronavirus 2 Spike glycoprotein Proteins 0.000 claims description 14
- 101000818390 Homo sapiens Ferritin light chain Proteins 0.000 claims description 13
- 241000124008 Mammalia Species 0.000 claims description 13
- 239000012867 bioactive agent Substances 0.000 claims description 10
- 102000005962 receptors Human genes 0.000 claims description 10
- 108020003175 receptors Proteins 0.000 claims description 10
- -1 E2P Proteins 0.000 claims description 8
- 210000004899 c-terminal region Anatomy 0.000 claims description 8
- 108091005774 SARS-CoV-2 proteins Proteins 0.000 claims description 6
- 108091006047 fluorescent proteins Proteins 0.000 claims description 6
- 102000034287 fluorescent proteins Human genes 0.000 claims description 6
- 230000002265 prevention Effects 0.000 claims description 6
- 230000001225 therapeutic effect Effects 0.000 claims description 6
- 108010068996 6,7-dimethyl-8-ribityllumazine synthase Proteins 0.000 claims description 5
- 101710088194 Dehydrogenase Proteins 0.000 claims description 5
- 229940096437 Protein S Drugs 0.000 claims description 5
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 claims description 5
- 101710198474 Spike protein Proteins 0.000 claims description 5
- 108010058432 Chaperonin 60 Proteins 0.000 claims description 4
- 239000000032 diagnostic agent Substances 0.000 claims description 4
- 229940039227 diagnostic agent Drugs 0.000 claims description 4
- 230000000069 prophylactic effect Effects 0.000 claims description 4
- 101710091045 Envelope protein Proteins 0.000 claims description 3
- 101710188315 Protein X Proteins 0.000 claims description 3
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 claims description 3
- 108010048367 enhanced green fluorescent protein Proteins 0.000 claims description 3
- 241000494545 Cordyline virus 2 Species 0.000 claims description 2
- 239000012216 imaging agent Substances 0.000 claims description 2
- 241000315672 SARS coronavirus Species 0.000 claims 2
- 102000006303 Chaperonin 60 Human genes 0.000 claims 1
- 102100021696 Syncytin-1 Human genes 0.000 claims 1
- 230000035939 shock Effects 0.000 claims 1
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 69
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 63
- 235000018102 proteins Nutrition 0.000 description 56
- 241001112090 Pseudovirus Species 0.000 description 51
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 51
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 49
- 235000001014 amino acid Nutrition 0.000 description 47
- 230000036515 potency Effects 0.000 description 45
- 229940024606 amino acid Drugs 0.000 description 44
- 238000006386 neutralization reaction Methods 0.000 description 44
- 150000001413 amino acids Chemical class 0.000 description 37
- 230000003472 neutralizing effect Effects 0.000 description 37
- 239000000427 antigen Substances 0.000 description 36
- 102000036639 antigens Human genes 0.000 description 36
- 108091007433 antigens Proteins 0.000 description 36
- 241000880493 Leptailurus serval Species 0.000 description 35
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 33
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 32
- 230000014509 gene expression Effects 0.000 description 24
- 241000699666 Mus <mouse, genus> Species 0.000 description 23
- 238000003556 assay Methods 0.000 description 22
- 239000002105 nanoparticle Substances 0.000 description 21
- 239000002245 particle Substances 0.000 description 21
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 18
- 108010089804 glycyl-threonine Proteins 0.000 description 18
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 17
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 17
- 241000700605 Viruses Species 0.000 description 17
- 108010050848 glycylleucine Proteins 0.000 description 17
- 108010017391 lysylvaline Proteins 0.000 description 17
- 108091028043 Nucleic acid sequence Proteins 0.000 description 16
- 239000013612 plasmid Substances 0.000 description 16
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 15
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 15
- 108010015792 glycyllysine Proteins 0.000 description 15
- 239000002773 nucleotide Substances 0.000 description 15
- 125000003729 nucleotide group Chemical group 0.000 description 15
- 230000003389 potentiating effect Effects 0.000 description 15
- 108020004414 DNA Proteins 0.000 description 14
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 14
- 239000003814 drug Substances 0.000 description 14
- 108091033319 polynucleotide Proteins 0.000 description 14
- 102000040430 polynucleotide Human genes 0.000 description 14
- 239000002157 polynucleotide Substances 0.000 description 14
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 13
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 13
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 13
- 108010008355 arginyl-glutamine Proteins 0.000 description 13
- 230000000694 effects Effects 0.000 description 13
- 108010037850 glycylvaline Proteins 0.000 description 13
- 108010054155 lysyllysine Proteins 0.000 description 13
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 12
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 12
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 12
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 12
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 12
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 12
- 239000003795 chemical substances by application Substances 0.000 description 12
- 238000000746 purification Methods 0.000 description 12
- 108010073969 valyllysine Proteins 0.000 description 12
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 11
- 208000025721 COVID-19 Diseases 0.000 description 11
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 11
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 11
- 108010065920 Insulin Lispro Proteins 0.000 description 11
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 11
- 241001465754 Metazoa Species 0.000 description 11
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 11
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 11
- 108010060199 cysteinylproline Proteins 0.000 description 11
- 238000013461 design Methods 0.000 description 11
- 238000002474 experimental method Methods 0.000 description 11
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 11
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 11
- 230000004044 response Effects 0.000 description 11
- 102100035765 Angiotensin-converting enzyme 2 Human genes 0.000 description 10
- 108090000975 Angiotensin-converting enzyme 2 Proteins 0.000 description 10
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 10
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 10
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 10
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 10
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 10
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 10
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 10
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 10
- 238000005516 engineering process Methods 0.000 description 10
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 10
- 229910052737 gold Inorganic materials 0.000 description 10
- 239000010931 gold Substances 0.000 description 10
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 10
- 108010031719 prolyl-serine Proteins 0.000 description 10
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 10
- 238000006467 substitution reaction Methods 0.000 description 10
- 108010044292 tryptophyltyrosine Proteins 0.000 description 10
- 230000003612 virological effect Effects 0.000 description 10
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 9
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 9
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 9
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 9
- 241000699670 Mus sp. Species 0.000 description 9
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 9
- 108010079364 N-glycylalanine Proteins 0.000 description 9
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 9
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 9
- 201000003176 Severe Acute Respiratory Syndrome Diseases 0.000 description 9
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 9
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 9
- 150000001875 compounds Chemical class 0.000 description 9
- 229940079593 drug Drugs 0.000 description 9
- 108010078144 glutaminyl-glycine Proteins 0.000 description 9
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 108010051242 phenylalanylserine Proteins 0.000 description 9
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 9
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 8
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 8
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 8
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 8
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 8
- KQFZKDITNUEVFJ-JYJNAYRXSA-N Leu-Phe-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CC=CC=C1 KQFZKDITNUEVFJ-JYJNAYRXSA-N 0.000 description 8
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 8
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 8
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 8
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 8
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 8
- 108010013835 arginine glutamate Proteins 0.000 description 8
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 8
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 8
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 8
- 238000012575 bio-layer interferometry Methods 0.000 description 8
- 238000010790 dilution Methods 0.000 description 8
- 239000012895 dilution Substances 0.000 description 8
- 108010049041 glutamylalanine Proteins 0.000 description 8
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 8
- 238000003384 imaging method Methods 0.000 description 8
- 239000002953 phosphate buffered saline Substances 0.000 description 8
- 239000011780 sodium chloride Substances 0.000 description 8
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 8
- 108010003137 tyrosyltyrosine Proteins 0.000 description 8
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 7
- 241000588724 Escherichia coli Species 0.000 description 7
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 7
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 7
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 7
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 7
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 7
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 7
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 7
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 7
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 7
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 7
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 7
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 7
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 7
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 7
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 7
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 7
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 7
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 7
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 7
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 7
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 7
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 7
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 7
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 7
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 7
- 230000000890 antigenic effect Effects 0.000 description 7
- 108010092854 aspartyllysine Proteins 0.000 description 7
- 239000011230 binding agent Substances 0.000 description 7
- 238000012217 deletion Methods 0.000 description 7
- 230000037430 deletion Effects 0.000 description 7
- 239000013604 expression vector Substances 0.000 description 7
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 7
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 7
- 108010062266 glycyl-glycyl-argininal Proteins 0.000 description 7
- 108010010147 glycylglutamine Proteins 0.000 description 7
- 230000001965 increasing effect Effects 0.000 description 7
- 238000002347 injection Methods 0.000 description 7
- 239000007924 injection Substances 0.000 description 7
- 230000003993 interaction Effects 0.000 description 7
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 7
- 239000000463 material Substances 0.000 description 7
- 108010068617 neonatal Fc receptor Proteins 0.000 description 7
- 108010061238 threonyl-glycine Proteins 0.000 description 7
- 108010080629 tryptophan-leucine Proteins 0.000 description 7
- 108010051110 tyrosyl-lysine Proteins 0.000 description 7
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 6
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 6
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 6
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 6
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 6
- WONGRTVAMHFGBE-WDSKDSINSA-N Asn-Gly-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N WONGRTVAMHFGBE-WDSKDSINSA-N 0.000 description 6
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 6
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 6
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 6
- YFSLJHLQOALGSY-ZPFDUUQYSA-N Asp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N YFSLJHLQOALGSY-ZPFDUUQYSA-N 0.000 description 6
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 6
- 238000011725 BALB/c mouse Methods 0.000 description 6
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 6
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 6
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 6
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 6
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 6
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 6
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 6
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 6
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 6
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 6
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 6
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 6
- XZNJZXJZBMBGGS-NHCYSSNCSA-N Leu-Val-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XZNJZXJZBMBGGS-NHCYSSNCSA-N 0.000 description 6
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 6
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 6
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 6
- 101100347578 Mus musculus Mb gene Proteins 0.000 description 6
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 6
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 6
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 6
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 6
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 6
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 6
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 6
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 6
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 6
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 6
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 6
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 6
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 6
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 6
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 6
- UDCHKDYNMRJYMI-QEJZJMRPSA-N Trp-Glu-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UDCHKDYNMRJYMI-QEJZJMRPSA-N 0.000 description 6
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 6
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 6
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 6
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 6
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 6
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 6
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 6
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 6
- 108010047857 aspartylglycine Proteins 0.000 description 6
- 108010068265 aspartyltyrosine Proteins 0.000 description 6
- 238000002591 computed tomography Methods 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 230000028993 immune response Effects 0.000 description 6
- 238000011534 incubation Methods 0.000 description 6
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 6
- 230000000670 limiting effect Effects 0.000 description 6
- 108010003700 lysyl aspartic acid Proteins 0.000 description 6
- 108010064235 lysylglycine Proteins 0.000 description 6
- 238000002823 phage display Methods 0.000 description 6
- 108010077112 prolyl-proline Proteins 0.000 description 6
- 108010070643 prolylglutamic acid Proteins 0.000 description 6
- 210000002966 serum Anatomy 0.000 description 6
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 6
- 238000007920 subcutaneous administration Methods 0.000 description 6
- 239000000126 substance Substances 0.000 description 6
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 6
- 101000868165 Acidianus ambivalens Sulfur oxygenase/reductase Proteins 0.000 description 5
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 5
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 5
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 5
- QUAWOKPCAKCHQL-SRVKXCTJSA-N Asn-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N QUAWOKPCAKCHQL-SRVKXCTJSA-N 0.000 description 5
- ZLGKHJHFYSRUBH-FXQIFTODSA-N Asp-Arg-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLGKHJHFYSRUBH-FXQIFTODSA-N 0.000 description 5
- XWKBWZXGNXTDKY-ZKWXMUAHSA-N Asp-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O XWKBWZXGNXTDKY-ZKWXMUAHSA-N 0.000 description 5
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 5
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 5
- 108010087819 Fc receptors Proteins 0.000 description 5
- 102000009109 Fc receptors Human genes 0.000 description 5
- PGPJSRSLQNXBDT-YUMQZZPRSA-N Gln-Arg-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O PGPJSRSLQNXBDT-YUMQZZPRSA-N 0.000 description 5
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 5
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 5
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 5
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 5
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 5
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 5
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 5
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 5
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 5
- LJUIEESLIAZSFR-SRVKXCTJSA-N His-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N LJUIEESLIAZSFR-SRVKXCTJSA-N 0.000 description 5
- ALPXXNRQBMRCPZ-MEYUZBJRSA-N His-Thr-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ALPXXNRQBMRCPZ-MEYUZBJRSA-N 0.000 description 5
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 5
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 5
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 5
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 5
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 5
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 5
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 5
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 5
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 5
- BOJYMMBYBNOOGG-DCAQKATOSA-N Lys-Pro-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BOJYMMBYBNOOGG-DCAQKATOSA-N 0.000 description 5
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 5
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 5
- MYKLINMAGAIRPJ-CIUDSAMLSA-N Met-Gln-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O MYKLINMAGAIRPJ-CIUDSAMLSA-N 0.000 description 5
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 5
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 5
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 5
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 5
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 5
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 5
- 108010076504 Protein Sorting Signals Proteins 0.000 description 5
- 102220510486 Ras-related C3 botulinum toxin substrate 2_N92T_mutation Human genes 0.000 description 5
- 108091005634 SARS-CoV-2 receptor-binding domains Proteins 0.000 description 5
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 5
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 5
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 5
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 5
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 5
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 5
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 5
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 5
- NDXSOKGYKCGYKT-VEVYYDQMSA-N Thr-Pro-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O NDXSOKGYKCGYKT-VEVYYDQMSA-N 0.000 description 5
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 5
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 5
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 5
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 5
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 5
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 5
- GAKBTSMAPGLQFA-JNPHEJMOSA-N Tyr-Thr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 GAKBTSMAPGLQFA-JNPHEJMOSA-N 0.000 description 5
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 5
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 5
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 5
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 5
- 108010081404 acein-2 Proteins 0.000 description 5
- 230000002776 aggregation Effects 0.000 description 5
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 5
- 108010005233 alanylglutamic acid Proteins 0.000 description 5
- 108010087924 alanylproline Proteins 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- 229960002685 biotin Drugs 0.000 description 5
- 239000011616 biotin Substances 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- 239000013078 crystal Substances 0.000 description 5
- 238000010494 dissociation reaction Methods 0.000 description 5
- 230000005593 dissociations Effects 0.000 description 5
- 239000003937 drug carrier Substances 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 5
- 108010025306 histidylleucine Proteins 0.000 description 5
- 238000001727 in vivo Methods 0.000 description 5
- 208000015181 infectious disease Diseases 0.000 description 5
- 108010027338 isoleucylcysteine Proteins 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 239000000523 sample Substances 0.000 description 5
- 108010026333 seryl-proline Proteins 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 4
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 4
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 4
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 4
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 4
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 4
- SNBHMYQRNCJSOJ-CIUDSAMLSA-N Arg-Gln-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SNBHMYQRNCJSOJ-CIUDSAMLSA-N 0.000 description 4
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 4
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 4
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 4
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 4
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 4
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 4
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 4
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 4
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 4
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 4
- 238000011740 C57BL/6 mouse Methods 0.000 description 4
- 102100031673 Corneodesmosin Human genes 0.000 description 4
- 101710139375 Corneodesmosin Proteins 0.000 description 4
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 4
- 102000053602 DNA Human genes 0.000 description 4
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 4
- MGJMFSBEMSNYJL-AVGNSLFASA-N Gln-Asn-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MGJMFSBEMSNYJL-AVGNSLFASA-N 0.000 description 4
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 4
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 4
- TWTWUBHEWQPMQW-ZPFDUUQYSA-N Gln-Ile-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWTWUBHEWQPMQW-ZPFDUUQYSA-N 0.000 description 4
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 4
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 4
- WPJDPEOQUIXXOY-AVGNSLFASA-N Gln-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WPJDPEOQUIXXOY-AVGNSLFASA-N 0.000 description 4
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 4
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 4
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 4
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 4
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 4
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 4
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 4
- UUTGYDAKPISJAO-JYJNAYRXSA-N Glu-Tyr-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 UUTGYDAKPISJAO-JYJNAYRXSA-N 0.000 description 4
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 4
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 4
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 4
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 4
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 4
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 4
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 4
- WTUSRDZLLWGYAT-KCTSRDHCSA-N Gly-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN WTUSRDZLLWGYAT-KCTSRDHCSA-N 0.000 description 4
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 4
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 4
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 4
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 4
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 4
- 239000007995 HEPES buffer Substances 0.000 description 4
- VSLXGYMEHVAJBH-DLOVCJGASA-N His-Ala-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O VSLXGYMEHVAJBH-DLOVCJGASA-N 0.000 description 4
- LVWIJITYHRZHBO-IXOXFDKPSA-N His-Leu-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LVWIJITYHRZHBO-IXOXFDKPSA-N 0.000 description 4
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 4
- HZWWOGWOBQBETJ-CUJWVEQBSA-N His-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O HZWWOGWOBQBETJ-CUJWVEQBSA-N 0.000 description 4
- CSTDQOOBZBAJKE-BWAGICSOSA-N His-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CN=CN2)N)O CSTDQOOBZBAJKE-BWAGICSOSA-N 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 4
- 101001037147 Homo sapiens Immunoglobulin heavy variable 1-69 Proteins 0.000 description 4
- 101001138089 Homo sapiens Immunoglobulin kappa variable 1-39 Proteins 0.000 description 4
- 241000725303 Human immunodeficiency virus Species 0.000 description 4
- 102100040232 Immunoglobulin heavy variable 1-69 Human genes 0.000 description 4
- 102100020910 Immunoglobulin kappa variable 1-39 Human genes 0.000 description 4
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 4
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 4
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 4
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 4
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 4
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 4
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 4
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 4
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 4
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 4
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 4
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 4
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 4
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 4
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 4
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 4
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 4
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 4
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 4
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 4
- IHRFZLQEQVHXFA-RHYQMDGZSA-N Met-Thr-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCCN IHRFZLQEQVHXFA-RHYQMDGZSA-N 0.000 description 4
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 4
- 108010066427 N-valyltryptophan Proteins 0.000 description 4
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 4
- JOXIIFVCSATTDH-IHPCNDPISA-N Phe-Asn-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JOXIIFVCSATTDH-IHPCNDPISA-N 0.000 description 4
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 4
- KDYPMIZMXDECSU-JYJNAYRXSA-N Phe-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KDYPMIZMXDECSU-JYJNAYRXSA-N 0.000 description 4
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 4
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 4
- FRMKIPSIZSFTTE-HJOGWXRNSA-N Phe-Tyr-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FRMKIPSIZSFTTE-HJOGWXRNSA-N 0.000 description 4
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 4
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 4
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 4
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 4
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 4
- YPUSXTWURJANKF-KBIXCLLPSA-N Ser-Gln-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YPUSXTWURJANKF-KBIXCLLPSA-N 0.000 description 4
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 4
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 4
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 4
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 4
- FVFUOQIYDPAIJR-XIRDDKMYSA-N Ser-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FVFUOQIYDPAIJR-XIRDDKMYSA-N 0.000 description 4
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 4
- 239000012505 Superdex™ Substances 0.000 description 4
- SKHPKKYKDYULDH-HJGDQZAQSA-N Thr-Asn-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SKHPKKYKDYULDH-HJGDQZAQSA-N 0.000 description 4
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 4
- JXKMXEBNZCKSDY-JIOCBJNQSA-N Thr-Asp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O JXKMXEBNZCKSDY-JIOCBJNQSA-N 0.000 description 4
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 4
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 4
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 4
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 4
- WLBZWXXGSOLJBA-HOCLYGCPSA-N Trp-Gly-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 WLBZWXXGSOLJBA-HOCLYGCPSA-N 0.000 description 4
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 4
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 4
- WYOBRXPIZVKNMF-IRXDYDNUSA-N Tyr-Tyr-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 WYOBRXPIZVKNMF-IRXDYDNUSA-N 0.000 description 4
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 4
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 4
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 4
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 4
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 4
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 4
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 4
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 4
- USXYVSTVPHELAF-RCWTZXSCSA-N Val-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N)O USXYVSTVPHELAF-RCWTZXSCSA-N 0.000 description 4
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 4
- 208000036142 Viral infection Diseases 0.000 description 4
- 238000004220 aggregation Methods 0.000 description 4
- 108010047495 alanylglycine Proteins 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 108010060035 arginylproline Proteins 0.000 description 4
- 108010038633 aspartylglutamate Proteins 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000012512 characterization method Methods 0.000 description 4
- 239000002299 complementary DNA Substances 0.000 description 4
- 230000021615 conjugation Effects 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 238000001493 electron microscopy Methods 0.000 description 4
- 238000002073 fluorescence micrograph Methods 0.000 description 4
- 239000005090 green fluorescent protein Substances 0.000 description 4
- 108010018006 histidylserine Proteins 0.000 description 4
- 229910052739 hydrogen Inorganic materials 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 230000005847 immunogenicity Effects 0.000 description 4
- 239000004615 ingredient Substances 0.000 description 4
- 238000004020 luminiscence type Methods 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 108020004999 messenger RNA Proteins 0.000 description 4
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 4
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 4
- 108010053725 prolylvaline Proteins 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 238000001338 self-assembly Methods 0.000 description 4
- 108010048818 seryl-histidine Proteins 0.000 description 4
- 238000001542 size-exclusion chromatography Methods 0.000 description 4
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- 230000009385 viral infection Effects 0.000 description 4
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 3
- 102100038222 60 kDa heat shock protein, mitochondrial Human genes 0.000 description 3
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 3
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 3
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 3
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 3
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 3
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 3
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 3
- XUCHENWTTBFODJ-FXQIFTODSA-N Ala-Met-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O XUCHENWTTBFODJ-FXQIFTODSA-N 0.000 description 3
- DWYROCSXOOMOEU-CIUDSAMLSA-N Ala-Met-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N DWYROCSXOOMOEU-CIUDSAMLSA-N 0.000 description 3
- OMDNCNKNEGFOMM-BQBZGAKWSA-N Ala-Met-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O OMDNCNKNEGFOMM-BQBZGAKWSA-N 0.000 description 3
- VQAVBBCZFQAAED-FXQIFTODSA-N Ala-Pro-Asn Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N VQAVBBCZFQAAED-FXQIFTODSA-N 0.000 description 3
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 3
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 3
- DBKNLHKEVPZVQC-LPEHRKFASA-N Arg-Ala-Pro Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O DBKNLHKEVPZVQC-LPEHRKFASA-N 0.000 description 3
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 3
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 3
- BMNVSPMWMICFRV-DCAQKATOSA-N Arg-His-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)CC1=CN=CN1 BMNVSPMWMICFRV-DCAQKATOSA-N 0.000 description 3
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 3
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 3
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 3
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 3
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 3
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 3
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 3
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 3
- TZFQICWZWFNIKU-KKUMJFAQSA-N Asn-Leu-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 TZFQICWZWFNIKU-KKUMJFAQSA-N 0.000 description 3
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 3
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 3
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 3
- JUWZKMBALYLZCK-WHFBIAKZSA-N Asp-Gly-Asn Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O JUWZKMBALYLZCK-WHFBIAKZSA-N 0.000 description 3
- LTCKTLYKRMCFOC-KKUMJFAQSA-N Asp-Phe-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LTCKTLYKRMCFOC-KKUMJFAQSA-N 0.000 description 3
- QTIZKMMLNUMHHU-DCAQKATOSA-N Asp-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QTIZKMMLNUMHHU-DCAQKATOSA-N 0.000 description 3
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 3
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 3
- MFDPBZAFCRKYEY-LAEOZQHASA-N Asp-Val-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFDPBZAFCRKYEY-LAEOZQHASA-N 0.000 description 3
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 3
- 208000035473 Communicable disease Diseases 0.000 description 3
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 3
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 3
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 3
- MWVDDZUTWXFYHL-XKBZYTNZSA-N Cys-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N)O MWVDDZUTWXFYHL-XKBZYTNZSA-N 0.000 description 3
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 3
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 3
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 3
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 3
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 3
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 3
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 3
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 3
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 3
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 3
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 3
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 3
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 3
- ZZIFPJZQHRJERU-WDSKDSINSA-N Glu-Cys-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O ZZIFPJZQHRJERU-WDSKDSINSA-N 0.000 description 3
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 3
- XMPAXPSENRSOSV-RYUDHWBXSA-N Glu-Gly-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XMPAXPSENRSOSV-RYUDHWBXSA-N 0.000 description 3
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 3
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 3
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 3
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 3
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 3
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 3
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 3
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 3
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 3
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 3
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 3
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 3
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 3
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 3
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 3
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 3
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 3
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 3
- SGLXGEDPYJPGIQ-ACRUOGEOSA-N His-Phe-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N SGLXGEDPYJPGIQ-ACRUOGEOSA-N 0.000 description 3
- 108091006905 Human Serum Albumin Proteins 0.000 description 3
- 102000008100 Human Serum Albumin Human genes 0.000 description 3
- GVNNAHIRSDRIII-AJNGGQMLSA-N Ile-Lys-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N GVNNAHIRSDRIII-AJNGGQMLSA-N 0.000 description 3
- QQFSKBMCAKWHLG-UHFFFAOYSA-N Ile-Phe-Pro-Pro Chemical compound C1CCC(C(=O)N2C(CCC2)C(O)=O)N1C(=O)C(NC(=O)C(N)C(C)CC)CC1=CC=CC=C1 QQFSKBMCAKWHLG-UHFFFAOYSA-N 0.000 description 3
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 3
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 3
- RFUBXQQFJFGJFV-GUBZILKMSA-N Leu-Asn-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RFUBXQQFJFGJFV-GUBZILKMSA-N 0.000 description 3
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 3
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 3
- PBGDOSARRIJMEV-DLOVCJGASA-N Leu-His-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O PBGDOSARRIJMEV-DLOVCJGASA-N 0.000 description 3
- AIRUUHAOKGVJAD-JYJNAYRXSA-N Leu-Phe-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIRUUHAOKGVJAD-JYJNAYRXSA-N 0.000 description 3
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 3
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 3
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 3
- LMDVGHQPPPLYAR-IHRRRGAJSA-N Leu-Val-His Chemical compound N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O LMDVGHQPPPLYAR-IHRRRGAJSA-N 0.000 description 3
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 3
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 3
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 3
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 3
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 3
- RIJCHEVHFWMDKD-SRVKXCTJSA-N Lys-Lys-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RIJCHEVHFWMDKD-SRVKXCTJSA-N 0.000 description 3
- YXPJCVNIDDKGOE-MELADBBJSA-N Lys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N)C(=O)O YXPJCVNIDDKGOE-MELADBBJSA-N 0.000 description 3
- DAHQKYYIXPBESV-UWVGGRQHSA-N Lys-Met-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O DAHQKYYIXPBESV-UWVGGRQHSA-N 0.000 description 3
- JCVOHUKUYSYBAD-DCAQKATOSA-N Lys-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCCCN)N)C(=O)N[C@@H](CS)C(=O)O JCVOHUKUYSYBAD-DCAQKATOSA-N 0.000 description 3
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 3
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 3
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 3
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 3
- DGNZGCQSVGGYJS-BQBZGAKWSA-N Met-Gly-Asp Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O DGNZGCQSVGGYJS-BQBZGAKWSA-N 0.000 description 3
- UNPGTBHYKJOCCZ-DCAQKATOSA-N Met-Lys-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O UNPGTBHYKJOCCZ-DCAQKATOSA-N 0.000 description 3
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 3
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 3
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 3
- 229930182555 Penicillin Natural products 0.000 description 3
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 3
- MPGJIHFJCXTVEX-KKUMJFAQSA-N Phe-Arg-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O MPGJIHFJCXTVEX-KKUMJFAQSA-N 0.000 description 3
- XMPUYNHKEPFERE-IHRRRGAJSA-N Phe-Asp-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 XMPUYNHKEPFERE-IHRRRGAJSA-N 0.000 description 3
- MQVFHOPCKNTHGT-MELADBBJSA-N Phe-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O MQVFHOPCKNTHGT-MELADBBJSA-N 0.000 description 3
- YKUGPVXSDOOANW-KKUMJFAQSA-N Phe-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YKUGPVXSDOOANW-KKUMJFAQSA-N 0.000 description 3
- OXKJSGGTHFMGDT-UFYCRDLUSA-N Phe-Phe-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C1=CC=CC=C1 OXKJSGGTHFMGDT-UFYCRDLUSA-N 0.000 description 3
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 3
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 3
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 3
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 3
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 3
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 3
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 3
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 3
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 3
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 3
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 3
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 3
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 3
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 3
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 3
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 3
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 3
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 3
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 3
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 3
- BDMWLJLPPUCLNV-XGEHTFHBSA-N Ser-Thr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BDMWLJLPPUCLNV-XGEHTFHBSA-N 0.000 description 3
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 3
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 3
- 101710167605 Spike glycoprotein Proteins 0.000 description 3
- 108010090804 Streptavidin Proteins 0.000 description 3
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 3
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 3
- ZUUDNCOCILSYAM-KKHAAJSZSA-N Thr-Asp-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZUUDNCOCILSYAM-KKHAAJSZSA-N 0.000 description 3
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 3
- XXNLGZRRSKPSGF-HTUGSXCWSA-N Thr-Gln-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O XXNLGZRRSKPSGF-HTUGSXCWSA-N 0.000 description 3
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 3
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 3
- UDNVOQMPQBEITB-MEYUZBJRSA-N Thr-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O UDNVOQMPQBEITB-MEYUZBJRSA-N 0.000 description 3
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 3
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 3
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 3
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 3
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 3
- LNGFWVPNKLWATF-ZVZYQTTQSA-N Trp-Val-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LNGFWVPNKLWATF-ZVZYQTTQSA-N 0.000 description 3
- XLMDWQNAOKLKCP-XDTLVQLUSA-N Tyr-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XLMDWQNAOKLKCP-XDTLVQLUSA-N 0.000 description 3
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 3
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 3
- WDGDKHLSDIOXQC-ACRUOGEOSA-N Tyr-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 WDGDKHLSDIOXQC-ACRUOGEOSA-N 0.000 description 3
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 3
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 3
- AUZADXNWQMBZOO-JYJNAYRXSA-N Tyr-Pro-Arg Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=C(O)C=C1 AUZADXNWQMBZOO-JYJNAYRXSA-N 0.000 description 3
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 3
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 3
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 3
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 3
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 3
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 3
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 3
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 3
- QPJSIBAOZBVELU-BPNCWPANSA-N Val-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N QPJSIBAOZBVELU-BPNCWPANSA-N 0.000 description 3
- 230000002378 acidificating effect Effects 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 108010059459 arginyl-threonyl-phenylalanine Proteins 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 239000011324 bead Substances 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 238000004132 cross linking Methods 0.000 description 3
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 3
- 238000002296 dynamic light scattering Methods 0.000 description 3
- 230000007717 exclusion Effects 0.000 description 3
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 3
- 108010081551 glycylphenylalanine Proteins 0.000 description 3
- 238000005286 illumination Methods 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 230000002458 infectious effect Effects 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 229910052742 iron Inorganic materials 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 108010038320 lysylphenylalanine Proteins 0.000 description 3
- 201000004792 malaria Diseases 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 108010005942 methionylglycine Proteins 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 229940049954 penicillin Drugs 0.000 description 3
- 108010012581 phenylalanylglutamate Proteins 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 230000035945 sensitivity Effects 0.000 description 3
- 150000003384 small molecules Chemical class 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 229960005322 streptomycin Drugs 0.000 description 3
- 238000010254 subcutaneous injection Methods 0.000 description 3
- 239000007929 subcutaneous injection Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 229940124597 therapeutic agent Drugs 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 238000000954 titration curve Methods 0.000 description 3
- 108010038745 tryptophylglycine Proteins 0.000 description 3
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 3
- 108010078580 tyrosylleucine Proteins 0.000 description 3
- 229910052720 vanadium Inorganic materials 0.000 description 3
- 108010027345 wheylin-1 peptide Proteins 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- LMDZBCPBFSXMTL-UHFFFAOYSA-N 1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide Substances CCN=C=NCCCN(C)C LMDZBCPBFSXMTL-UHFFFAOYSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- FPQQSJJWHUJYPU-UHFFFAOYSA-N 3-(dimethylamino)propyliminomethylidene-ethylazanium;chloride Chemical compound Cl.CCN=C=NCCCN(C)C FPQQSJJWHUJYPU-UHFFFAOYSA-N 0.000 description 2
- 208000010470 Ageusia Diseases 0.000 description 2
- VBDMWOKJZDCFJM-FXQIFTODSA-N Ala-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N VBDMWOKJZDCFJM-FXQIFTODSA-N 0.000 description 2
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 2
- UCIYCBSJBQGDGM-LPEHRKFASA-N Ala-Arg-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N UCIYCBSJBQGDGM-LPEHRKFASA-N 0.000 description 2
- SFNFGFDRYJKZKN-XQXXSGGOSA-N Ala-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C)N)O SFNFGFDRYJKZKN-XQXXSGGOSA-N 0.000 description 2
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 2
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 2
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 2
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 2
- VGMNWQOPSFBBBG-XUXIUFHCSA-N Ala-Leu-Leu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O VGMNWQOPSFBBBG-XUXIUFHCSA-N 0.000 description 2
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 2
- GKAZXNDATBWNBI-DCAQKATOSA-N Ala-Met-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N GKAZXNDATBWNBI-DCAQKATOSA-N 0.000 description 2
- VJVQKGYHIZPSNS-FXQIFTODSA-N Ala-Ser-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N VJVQKGYHIZPSNS-FXQIFTODSA-N 0.000 description 2
- SYIFFFHSXBNPMC-UWJYBYFXSA-N Ala-Ser-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N SYIFFFHSXBNPMC-UWJYBYFXSA-N 0.000 description 2
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 2
- 239000012099 Alexa Fluor family Substances 0.000 description 2
- 108010032595 Antibody Binding Sites Proteins 0.000 description 2
- IIABBYGHLYWVOS-FXQIFTODSA-N Arg-Asn-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O IIABBYGHLYWVOS-FXQIFTODSA-N 0.000 description 2
- FBLMOFHNVQBKRR-IHRRRGAJSA-N Arg-Asp-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FBLMOFHNVQBKRR-IHRRRGAJSA-N 0.000 description 2
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 2
- NKBQZKVMKJJDLX-SRVKXCTJSA-N Arg-Glu-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NKBQZKVMKJJDLX-SRVKXCTJSA-N 0.000 description 2
- SKTGPBFTMNLIHQ-KKUMJFAQSA-N Arg-Glu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SKTGPBFTMNLIHQ-KKUMJFAQSA-N 0.000 description 2
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 2
- WCZXPVPHUMYLMS-VEVYYDQMSA-N Arg-Thr-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O WCZXPVPHUMYLMS-VEVYYDQMSA-N 0.000 description 2
- YNSUUAOAFCVINY-OSUNSFLBSA-N Arg-Thr-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YNSUUAOAFCVINY-OSUNSFLBSA-N 0.000 description 2
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 2
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 2
- FAEFJTCTNZTPHX-ACZMJKKPSA-N Asn-Gln-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FAEFJTCTNZTPHX-ACZMJKKPSA-N 0.000 description 2
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 2
- MYCSPQIARXTUTP-SRVKXCTJSA-N Asn-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N MYCSPQIARXTUTP-SRVKXCTJSA-N 0.000 description 2
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 2
- BCADFFUQHIMQAA-KKHAAJSZSA-N Asn-Thr-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BCADFFUQHIMQAA-KKHAAJSZSA-N 0.000 description 2
- YQPSDMUGFKJZHR-QRTARXTBSA-N Asn-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N YQPSDMUGFKJZHR-QRTARXTBSA-N 0.000 description 2
- CXBOKJPLEYUPGB-FXQIFTODSA-N Asp-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N CXBOKJPLEYUPGB-FXQIFTODSA-N 0.000 description 2
- SVFOIXMRMLROHO-SRVKXCTJSA-N Asp-Asp-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SVFOIXMRMLROHO-SRVKXCTJSA-N 0.000 description 2
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 2
- WSXDIZFNQYTUJB-SRVKXCTJSA-N Asp-His-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O WSXDIZFNQYTUJB-SRVKXCTJSA-N 0.000 description 2
- OEDJQRXNDRUGEU-SRVKXCTJSA-N Asp-Leu-His Chemical compound N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O OEDJQRXNDRUGEU-SRVKXCTJSA-N 0.000 description 2
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 2
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 2
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 2
- NJLLRXWFPQQPHV-SRVKXCTJSA-N Asp-Tyr-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJLLRXWFPQQPHV-SRVKXCTJSA-N 0.000 description 2
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 2
- 108010040163 CREB-Binding Protein Proteins 0.000 description 2
- 102100021975 CREB-binding protein Human genes 0.000 description 2
- 101710132601 Capsid protein Proteins 0.000 description 2
- 101710094648 Coat protein Proteins 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 108091033380 Coding strand Proteins 0.000 description 2
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 2
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 2
- IIGHQOPGMGKDMT-SRVKXCTJSA-N Cys-Asp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N IIGHQOPGMGKDMT-SRVKXCTJSA-N 0.000 description 2
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 2
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 2
- 206010013975 Dyspnoeas Diseases 0.000 description 2
- 101710157275 Ferritin subunit Proteins 0.000 description 2
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 2
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 2
- TWHDOEYLXXQYOZ-FXQIFTODSA-N Gln-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N TWHDOEYLXXQYOZ-FXQIFTODSA-N 0.000 description 2
- IKDOHQHEFPPGJG-FXQIFTODSA-N Gln-Asp-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IKDOHQHEFPPGJG-FXQIFTODSA-N 0.000 description 2
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 2
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 2
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 2
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 2
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 2
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 2
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 2
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 2
- LGYZYFFDELZWRS-DCAQKATOSA-N Glu-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O LGYZYFFDELZWRS-DCAQKATOSA-N 0.000 description 2
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 2
- AIGROOHQXCACHL-WDSKDSINSA-N Glu-Gly-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O AIGROOHQXCACHL-WDSKDSINSA-N 0.000 description 2
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 2
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 2
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 2
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 2
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 2
- ZIYGTCDTJJCDDP-JYJNAYRXSA-N Glu-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZIYGTCDTJJCDDP-JYJNAYRXSA-N 0.000 description 2
- DDXZHOHEABQXSE-NKIYYHGXSA-N Glu-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O DDXZHOHEABQXSE-NKIYYHGXSA-N 0.000 description 2
- ZGXGVBYEJGVJMV-HJGDQZAQSA-N Glu-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O ZGXGVBYEJGVJMV-HJGDQZAQSA-N 0.000 description 2
- VJVAQZYGLMJPTK-QEJZJMRPSA-N Glu-Trp-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VJVAQZYGLMJPTK-QEJZJMRPSA-N 0.000 description 2
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 2
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 2
- 108010070675 Glutathione transferase Proteins 0.000 description 2
- 102000005720 Glutathione transferase Human genes 0.000 description 2
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 2
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 2
- LLXVQPKEQQCISF-YUMQZZPRSA-N Gly-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN LLXVQPKEQQCISF-YUMQZZPRSA-N 0.000 description 2
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 2
- CUYLIWAAAYJKJH-RYUDHWBXSA-N Gly-Glu-Tyr Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CUYLIWAAAYJKJH-RYUDHWBXSA-N 0.000 description 2
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 2
- QITBQGJOXQYMOA-ZETCQYMHSA-N Gly-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QITBQGJOXQYMOA-ZETCQYMHSA-N 0.000 description 2
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 2
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 2
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 2
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 2
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 2
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 2
- UVTSZKIATYSKIR-RYUDHWBXSA-N Gly-Tyr-Glu Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O UVTSZKIATYSKIR-RYUDHWBXSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 101710114810 Glycoprotein Proteins 0.000 description 2
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 2
- YPLYIXGKCRQZGW-SRVKXCTJSA-N His-Arg-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YPLYIXGKCRQZGW-SRVKXCTJSA-N 0.000 description 2
- SYMSVYVUSPSAAO-IHRRRGAJSA-N His-Arg-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O SYMSVYVUSPSAAO-IHRRRGAJSA-N 0.000 description 2
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 2
- NBWATNYAUVSAEQ-ZEILLAHLSA-N His-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O NBWATNYAUVSAEQ-ZEILLAHLSA-N 0.000 description 2
- ZNTSGDNUITWTRA-WDSOQIARSA-N His-Trp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O ZNTSGDNUITWTRA-WDSOQIARSA-N 0.000 description 2
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 2
- 101000998947 Homo sapiens Immunoglobulin heavy variable 1-46 Proteins 0.000 description 2
- 101000604674 Homo sapiens Immunoglobulin kappa variable 4-1 Proteins 0.000 description 2
- 101100459282 Homo sapiens MB gene Proteins 0.000 description 2
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 2
- ZGGWRNBSBOHIGH-HVTMNAMFSA-N Ile-Gln-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZGGWRNBSBOHIGH-HVTMNAMFSA-N 0.000 description 2
- RMNMUUCYTMLWNA-ZPFDUUQYSA-N Ile-Lys-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RMNMUUCYTMLWNA-ZPFDUUQYSA-N 0.000 description 2
- 102100036888 Immunoglobulin heavy variable 1-46 Human genes 0.000 description 2
- 102100038198 Immunoglobulin kappa variable 4-1 Human genes 0.000 description 2
- PIWKPBJCKXDKJR-UHFFFAOYSA-N Isoflurane Chemical compound FC(F)OC(Cl)C(F)(F)F PIWKPBJCKXDKJR-UHFFFAOYSA-N 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 2
- ILJREDZFPHTUIE-GUBZILKMSA-N Leu-Asp-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ILJREDZFPHTUIE-GUBZILKMSA-N 0.000 description 2
- RRSLQOLASISYTB-CIUDSAMLSA-N Leu-Cys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O RRSLQOLASISYTB-CIUDSAMLSA-N 0.000 description 2
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 2
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 2
- RSFGIMMPWAXNML-MNXVOIDGSA-N Leu-Gln-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RSFGIMMPWAXNML-MNXVOIDGSA-N 0.000 description 2
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 2
- ZFNLIDNJUWNIJL-WDCWCFNPSA-N Leu-Glu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZFNLIDNJUWNIJL-WDCWCFNPSA-N 0.000 description 2
- KEVYYIMVELOXCT-KBPBESRZSA-N Leu-Gly-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KEVYYIMVELOXCT-KBPBESRZSA-N 0.000 description 2
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 2
- CSFVADKICPDRRF-KKUMJFAQSA-N Leu-His-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CN=CN1 CSFVADKICPDRRF-KKUMJFAQSA-N 0.000 description 2
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 2
- ZAVCJRJOQKIOJW-KKUMJFAQSA-N Leu-Phe-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)CC1=CC=CC=C1 ZAVCJRJOQKIOJW-KKUMJFAQSA-N 0.000 description 2
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 2
- GOFJOGXGMPHOGL-DCAQKATOSA-N Leu-Ser-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C GOFJOGXGMPHOGL-DCAQKATOSA-N 0.000 description 2
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 2
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 2
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 239000005089 Luciferase Substances 0.000 description 2
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 2
- JGAMUXDWYSXYLM-SRVKXCTJSA-N Lys-Arg-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O JGAMUXDWYSXYLM-SRVKXCTJSA-N 0.000 description 2
- FACUGMGEFUEBTI-SRVKXCTJSA-N Lys-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCCCN FACUGMGEFUEBTI-SRVKXCTJSA-N 0.000 description 2
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 2
- KSFQPRLZAUXXPT-GARJFASQSA-N Lys-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)C(=O)O KSFQPRLZAUXXPT-GARJFASQSA-N 0.000 description 2
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 2
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 2
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 2
- KJIXWRWPOCKYLD-IHRRRGAJSA-N Lys-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N KJIXWRWPOCKYLD-IHRRRGAJSA-N 0.000 description 2
- WGILOYIKJVQUPT-DCAQKATOSA-N Lys-Pro-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WGILOYIKJVQUPT-DCAQKATOSA-N 0.000 description 2
- 101710125418 Major capsid protein Proteins 0.000 description 2
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 description 2
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 2
- LXCSZPUQKMTXNW-BQBZGAKWSA-N Met-Ser-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O LXCSZPUQKMTXNW-BQBZGAKWSA-N 0.000 description 2
- MIXPUVSPPOWTCR-FXQIFTODSA-N Met-Ser-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MIXPUVSPPOWTCR-FXQIFTODSA-N 0.000 description 2
- FXBKQTOGURNXSL-HJGDQZAQSA-N Met-Thr-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O FXBKQTOGURNXSL-HJGDQZAQSA-N 0.000 description 2
- 101000913073 Mus musculus High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 2
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 2
- 101710141454 Nucleoprotein Proteins 0.000 description 2
- 102000015636 Oligopeptides Human genes 0.000 description 2
- 108010038807 Oligopeptides Proteins 0.000 description 2
- LLGTYVHITPVGKR-RYUDHWBXSA-N Phe-Gln-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O LLGTYVHITPVGKR-RYUDHWBXSA-N 0.000 description 2
- HOYQLNNGMHXZDW-KKUMJFAQSA-N Phe-Glu-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O HOYQLNNGMHXZDW-KKUMJFAQSA-N 0.000 description 2
- SRILZRSXIKRGBF-HRCADAONSA-N Phe-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N SRILZRSXIKRGBF-HRCADAONSA-N 0.000 description 2
- BONHGTUEEPIMPM-AVGNSLFASA-N Phe-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O BONHGTUEEPIMPM-AVGNSLFASA-N 0.000 description 2
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 2
- 229920001213 Polysorbate 20 Polymers 0.000 description 2
- UTAUEDINXUMHLG-FXQIFTODSA-N Pro-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 UTAUEDINXUMHLG-FXQIFTODSA-N 0.000 description 2
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 2
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 2
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 2
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 2
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 2
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 2
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 2
- 101710083689 Probable capsid protein Proteins 0.000 description 2
- ATUOYWHBWRKTHZ-UHFFFAOYSA-N Propane Chemical compound CCC ATUOYWHBWRKTHZ-UHFFFAOYSA-N 0.000 description 2
- 102000002067 Protein Subunits Human genes 0.000 description 2
- 108010001267 Protein Subunits Proteins 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 108700008625 Reporter Genes Proteins 0.000 description 2
- 208000037847 SARS-CoV-2-infection Diseases 0.000 description 2
- FIXILCYTSAUERA-FXQIFTODSA-N Ser-Ala-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FIXILCYTSAUERA-FXQIFTODSA-N 0.000 description 2
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 2
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 2
- FFOKMZOAVHEWET-IMJSIDKUSA-N Ser-Cys Chemical compound OC[C@H](N)C(=O)N[C@@H](CS)C(O)=O FFOKMZOAVHEWET-IMJSIDKUSA-N 0.000 description 2
- RNFKSBPHLTZHLU-WHFBIAKZSA-N Ser-Cys-Gly Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N)O RNFKSBPHLTZHLU-WHFBIAKZSA-N 0.000 description 2
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 2
- OHKFXGKHSJKKAL-NRPADANISA-N Ser-Glu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHKFXGKHSJKKAL-NRPADANISA-N 0.000 description 2
- MOQDPPUMFSMYOM-KKUMJFAQSA-N Ser-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N MOQDPPUMFSMYOM-KKUMJFAQSA-N 0.000 description 2
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 2
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 2
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 2
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 2
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 2
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 2
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 2
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 2
- VAIWUNAAPZZGRI-IHPCNDPISA-N Ser-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N VAIWUNAAPZZGRI-IHPCNDPISA-N 0.000 description 2
- ZWSZBWAFDZRBNM-UBHSHLNASA-N Ser-Trp-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O ZWSZBWAFDZRBNM-UBHSHLNASA-N 0.000 description 2
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 2
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 101710172711 Structural protein Proteins 0.000 description 2
- DDPVJPIGACCMEH-XQXXSGGOSA-N Thr-Ala-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DDPVJPIGACCMEH-XQXXSGGOSA-N 0.000 description 2
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 2
- VIBXMCZWVUOZLA-OLHMAJIHSA-N Thr-Asn-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O VIBXMCZWVUOZLA-OLHMAJIHSA-N 0.000 description 2
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 2
- XDARBNMYXKUFOJ-GSSVUCPTSA-N Thr-Asp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDARBNMYXKUFOJ-GSSVUCPTSA-N 0.000 description 2
- NRBUKAHTWRCUEQ-XGEHTFHBSA-N Thr-Cys-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(O)=O NRBUKAHTWRCUEQ-XGEHTFHBSA-N 0.000 description 2
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 2
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 2
- KBLYJPQSNGTDIU-LOKLDPHHSA-N Thr-Glu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O KBLYJPQSNGTDIU-LOKLDPHHSA-N 0.000 description 2
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 2
- CYVQBKQYQGEELV-NKIYYHGXSA-N Thr-His-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CYVQBKQYQGEELV-NKIYYHGXSA-N 0.000 description 2
- MGJLBZFUXUGMML-VOAKCMCISA-N Thr-Lys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MGJLBZFUXUGMML-VOAKCMCISA-N 0.000 description 2
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 2
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 2
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 101710120037 Toxin CcdB Proteins 0.000 description 2
- 239000007983 Tris buffer Substances 0.000 description 2
- SLOYNOMYOAOUCX-BVSLBCMMSA-N Trp-Phe-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SLOYNOMYOAOUCX-BVSLBCMMSA-N 0.000 description 2
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 2
- TZXFLDNBYYGLKA-BZSNNMDCSA-N Tyr-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 TZXFLDNBYYGLKA-BZSNNMDCSA-N 0.000 description 2
- XQYHLZNPOTXRMQ-KKUMJFAQSA-N Tyr-Glu-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XQYHLZNPOTXRMQ-KKUMJFAQSA-N 0.000 description 2
- OLWFDNLLBWQWCP-STQMWFEESA-N Tyr-Gly-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O OLWFDNLLBWQWCP-STQMWFEESA-N 0.000 description 2
- GULIUBBXCYPDJU-CQDKDKBSSA-N Tyr-Leu-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CC1=CC=C(O)C=C1 GULIUBBXCYPDJU-CQDKDKBSSA-N 0.000 description 2
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 2
- JAGGEZACYAAMIL-CQDKDKBSSA-N Tyr-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JAGGEZACYAAMIL-CQDKDKBSSA-N 0.000 description 2
- GITNQBVCEQBDQC-KKUMJFAQSA-N Tyr-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O GITNQBVCEQBDQC-KKUMJFAQSA-N 0.000 description 2
- XDGPTBVOSHKDFT-KKUMJFAQSA-N Tyr-Met-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XDGPTBVOSHKDFT-KKUMJFAQSA-N 0.000 description 2
- FDKDGFGTHGJKNV-FHWLQOOXSA-N Tyr-Phe-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N FDKDGFGTHGJKNV-FHWLQOOXSA-N 0.000 description 2
- WPRVVBVWIUWLOH-UFYCRDLUSA-N Tyr-Phe-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CC2=CC=C(C=C2)O)N WPRVVBVWIUWLOH-UFYCRDLUSA-N 0.000 description 2
- KWKJGBHDYJOVCR-SRVKXCTJSA-N Tyr-Ser-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O KWKJGBHDYJOVCR-SRVKXCTJSA-N 0.000 description 2
- PQPWEALFTLKSEB-DZKIICNBSA-N Tyr-Val-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PQPWEALFTLKSEB-DZKIICNBSA-N 0.000 description 2
- BYOHPUZJVXWHAE-BYULHYEWSA-N Val-Asn-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N BYOHPUZJVXWHAE-BYULHYEWSA-N 0.000 description 2
- CPTQYHDSVGVGDZ-UKJIMTQDSA-N Val-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N CPTQYHDSVGVGDZ-UKJIMTQDSA-N 0.000 description 2
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 2
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 2
- BZOSBRIDWSSTFN-AVGNSLFASA-N Val-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N BZOSBRIDWSSTFN-AVGNSLFASA-N 0.000 description 2
- FMQGYTMERWBMSI-HJWJTTGWSA-N Val-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N FMQGYTMERWBMSI-HJWJTTGWSA-N 0.000 description 2
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 2
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 2
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 2
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 2
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 235000019666 ageusia Nutrition 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 108010093581 aspartyl-proline Proteins 0.000 description 2
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 2
- 239000012472 biological sample Substances 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 229960000074 biopharmaceutical Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 229910002091 carbon monoxide Inorganic materials 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 239000013626 chemical specie Substances 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000012761 co-transfection Methods 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 239000002131 composite material Substances 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 108010016616 cysteinylglycine Proteins 0.000 description 2
- 230000000120 cytopathologic effect Effects 0.000 description 2
- 238000013480 data collection Methods 0.000 description 2
- 230000006240 deamidation Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 2
- 238000000635 electron micrograph Methods 0.000 description 2
- 239000012149 elution buffer Substances 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 108010027225 gag-pol Fusion Proteins Proteins 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 230000005182 global health Effects 0.000 description 2
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 238000005734 heterodimerization reaction Methods 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 108010028295 histidylhistidine Proteins 0.000 description 2
- 108010092114 histidylphenylalanine Proteins 0.000 description 2
- 210000004408 hybridoma Anatomy 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 229960002725 isoflurane Drugs 0.000 description 2
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 2
- 108010053037 kyotorphin Proteins 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- 108010057821 leucylproline Proteins 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- 230000033001 locomotion Effects 0.000 description 2
- 229920002521 macromolecule Polymers 0.000 description 2
- 239000006249 magnetic particle Substances 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 238000004091 panning Methods 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 229920000136 polysorbate Polymers 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 108010029020 prolylglycine Proteins 0.000 description 2
- 108010090894 prolylleucine Proteins 0.000 description 2
- 238000010791 quenching Methods 0.000 description 2
- 230000000171 quenching effect Effects 0.000 description 2
- 230000002285 radioactive effect Effects 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 238000004064 recycling Methods 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- MFBOGIVSZKQAPD-UHFFFAOYSA-M sodium butyrate Chemical compound [Na+].CCCC([O-])=O MFBOGIVSZKQAPD-UHFFFAOYSA-M 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 239000012798 spherical particle Substances 0.000 description 2
- 230000004797 therapeutic response Effects 0.000 description 2
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 239000013638 trimer Substances 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- SFIHWLKHBCDNCE-UHFFFAOYSA-N uranyl formate Chemical compound OC=O.OC=O.O=[U]=O SFIHWLKHBCDNCE-UHFFFAOYSA-N 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- 238000012800 visualization Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 1
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 1
- GVJXGCIPWAVXJP-UHFFFAOYSA-N 2,5-dioxo-1-oxoniopyrrolidine-3-sulfonate Chemical compound ON1C(=O)CC(S(O)(=O)=O)C1=O GVJXGCIPWAVXJP-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- ZVEUWSJUXREOBK-DKWTVANSSA-N 2-aminoacetic acid;(2s)-2-amino-3-hydroxypropanoic acid Chemical group NCC(O)=O.OC[C@H](N)C(O)=O ZVEUWSJUXREOBK-DKWTVANSSA-N 0.000 description 1
- PMUNIMVZCACZBB-UHFFFAOYSA-N 2-hydroxyethylazanium;chloride Chemical compound Cl.NCCO PMUNIMVZCACZBB-UHFFFAOYSA-N 0.000 description 1
- OSJPPGNTCRNQQC-UWTATZPHSA-N 3-phospho-D-glyceric acid Chemical compound OC(=O)[C@H](O)COP(O)(O)=O OSJPPGNTCRNQQC-UWTATZPHSA-N 0.000 description 1
- 102000013563 Acid Phosphatase Human genes 0.000 description 1
- 108010051457 Acid Phosphatase Proteins 0.000 description 1
- 101100295756 Acinetobacter baumannii (strain ATCC 19606 / DSM 30007 / JCM 6841 / CCUG 19606 / CIP 70.34 / NBRC 109757 / NCIMB 12457 / NCTC 12156 / 81) omp38 gene Proteins 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 1
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 1
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- NMXKFWOEASXOGB-QSFUFRPTSA-N Ala-Ile-His Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NMXKFWOEASXOGB-QSFUFRPTSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- SDZRIBWEVVRDQI-CIUDSAMLSA-N Ala-Lys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O SDZRIBWEVVRDQI-CIUDSAMLSA-N 0.000 description 1
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 1
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 1
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 1
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 1
- 108010011170 Ala-Trp-Arg-His-Pro-Gln-Phe-Gly-Gly Proteins 0.000 description 1
- QDGMZAOSMNGBLP-MRFFXTKBSA-N Ala-Trp-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N QDGMZAOSMNGBLP-MRFFXTKBSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- 241001504639 Alcedo atthis Species 0.000 description 1
- 206010002091 Anaesthesia Diseases 0.000 description 1
- 244000303258 Annona diversifolia Species 0.000 description 1
- 235000002198 Annona diversifolia Nutrition 0.000 description 1
- 206010002653 Anosmia Diseases 0.000 description 1
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 1
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 1
- RVDVDRUZWZIBJQ-CIUDSAMLSA-N Arg-Asn-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O RVDVDRUZWZIBJQ-CIUDSAMLSA-N 0.000 description 1
- NTAZNGWBXRVEDJ-FXQIFTODSA-N Arg-Asp-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NTAZNGWBXRVEDJ-FXQIFTODSA-N 0.000 description 1
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 1
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 1
- XLWSGICNBZGYTA-CIUDSAMLSA-N Arg-Glu-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XLWSGICNBZGYTA-CIUDSAMLSA-N 0.000 description 1
- NXDXECQFKHXHAM-HJGDQZAQSA-N Arg-Glu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NXDXECQFKHXHAM-HJGDQZAQSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 1
- SLQQPJBDBVPVQV-JYJNAYRXSA-N Arg-Phe-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O SLQQPJBDBVPVQV-JYJNAYRXSA-N 0.000 description 1
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 1
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- VKCOHFFSTKCXEQ-OLHMAJIHSA-N Asn-Asn-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VKCOHFFSTKCXEQ-OLHMAJIHSA-N 0.000 description 1
- QHBMKQWOIYJYMI-BYULHYEWSA-N Asn-Asn-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O QHBMKQWOIYJYMI-BYULHYEWSA-N 0.000 description 1
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- IKLAUGBIDCDFOY-SRVKXCTJSA-N Asn-His-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IKLAUGBIDCDFOY-SRVKXCTJSA-N 0.000 description 1
- NLRJGXZWTKXRHP-DCAQKATOSA-N Asn-Leu-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLRJGXZWTKXRHP-DCAQKATOSA-N 0.000 description 1
- ZMUQQMGITUJQTI-CIUDSAMLSA-N Asn-Leu-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZMUQQMGITUJQTI-CIUDSAMLSA-N 0.000 description 1
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 1
- JTXVXGXTRXMOFJ-FXQIFTODSA-N Asn-Pro-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O JTXVXGXTRXMOFJ-FXQIFTODSA-N 0.000 description 1
- NJSNXIOKBHPFMB-GMOBBJLQSA-N Asn-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N NJSNXIOKBHPFMB-GMOBBJLQSA-N 0.000 description 1
- IDUUACUJKUXKKD-VEVYYDQMSA-N Asn-Pro-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O IDUUACUJKUXKKD-VEVYYDQMSA-N 0.000 description 1
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 1
- MYTHOBCLNIOFBL-SRVKXCTJSA-N Asn-Ser-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYTHOBCLNIOFBL-SRVKXCTJSA-N 0.000 description 1
- QYRMBFWDSFGSFC-OLHMAJIHSA-N Asn-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QYRMBFWDSFGSFC-OLHMAJIHSA-N 0.000 description 1
- ZUFPUBYQYWCMDB-NUMRIWBASA-N Asn-Thr-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZUFPUBYQYWCMDB-NUMRIWBASA-N 0.000 description 1
- FMNBYVSGRCXWEK-FOHZUACHSA-N Asn-Thr-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O FMNBYVSGRCXWEK-FOHZUACHSA-N 0.000 description 1
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 1
- PUUPMDXIHCOPJU-HJGDQZAQSA-N Asn-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O PUUPMDXIHCOPJU-HJGDQZAQSA-N 0.000 description 1
- KSZHWTRZPOTIGY-AVGNSLFASA-N Asn-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O KSZHWTRZPOTIGY-AVGNSLFASA-N 0.000 description 1
- DPWDPEVGACCWTC-SRVKXCTJSA-N Asn-Tyr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O DPWDPEVGACCWTC-SRVKXCTJSA-N 0.000 description 1
- AXXCUABIFZPKPM-BQBZGAKWSA-N Asp-Arg-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O AXXCUABIFZPKPM-BQBZGAKWSA-N 0.000 description 1
- LKIYSIYBKYLKPU-BIIVOSGPSA-N Asp-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O LKIYSIYBKYLKPU-BIIVOSGPSA-N 0.000 description 1
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 1
- DGKCOYGQLNWNCJ-ACZMJKKPSA-N Asp-Glu-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O DGKCOYGQLNWNCJ-ACZMJKKPSA-N 0.000 description 1
- GISFCCXBVJKGEO-QEJZJMRPSA-N Asp-Glu-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GISFCCXBVJKGEO-QEJZJMRPSA-N 0.000 description 1
- WBDWQKRLTVCDSY-WHFBIAKZSA-N Asp-Gly-Asp Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O WBDWQKRLTVCDSY-WHFBIAKZSA-N 0.000 description 1
- VIRHEUMYXXLCBF-WDSKDSINSA-N Asp-Gly-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O VIRHEUMYXXLCBF-WDSKDSINSA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 1
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 1
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 1
- GWOVSEVNXNVMMY-BPUTZDHNSA-N Asp-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N GWOVSEVNXNVMMY-BPUTZDHNSA-N 0.000 description 1
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 1
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 1
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 1
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 102100027314 Beta-2-microglobulin Human genes 0.000 description 1
- 241000008904 Betacoronavirus Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 102000000584 Calmodulin Human genes 0.000 description 1
- 108010041952 Calmodulin Proteins 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 108091006146 Channels Proteins 0.000 description 1
- 206010008479 Chest Pain Diseases 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 102100026735 Coagulation factor VIII Human genes 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 206010010741 Conjunctivitis Diseases 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000711573 Coronaviridae Species 0.000 description 1
- 206010011224 Cough Diseases 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 description 1
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 1
- ZEXHDOQQYZKOIB-ACZMJKKPSA-N Cys-Glu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZEXHDOQQYZKOIB-ACZMJKKPSA-N 0.000 description 1
- KXUKWRVYDYIPSQ-CIUDSAMLSA-N Cys-Leu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUKWRVYDYIPSQ-CIUDSAMLSA-N 0.000 description 1
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 1
- RESAHOSBQHMOKH-KKUMJFAQSA-N Cys-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CS)N RESAHOSBQHMOKH-KKUMJFAQSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- FCXJJTRGVAZDER-FXQIFTODSA-N Cys-Val-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O FCXJJTRGVAZDER-FXQIFTODSA-N 0.000 description 1
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 1
- 241000450599 DNA viruses Species 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 206010012735 Diarrhoea Diseases 0.000 description 1
- 208000000059 Dyspnea Diseases 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 201000011001 Ebola Hemorrhagic Fever Diseases 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241001131785 Escherichia coli HB101 Species 0.000 description 1
- 241001302584 Escherichia coli str. K-12 substr. W3110 Species 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- OTMSDBZUPAUEDD-UHFFFAOYSA-N Ethane Chemical compound CC OTMSDBZUPAUEDD-UHFFFAOYSA-N 0.000 description 1
- XZWYTXMRWQJBGX-VXBMVYAYSA-N FLAG peptide Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 XZWYTXMRWQJBGX-VXBMVYAYSA-N 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- RGXXLQWXBFNXTG-CIUDSAMLSA-N Gln-Arg-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O RGXXLQWXBFNXTG-CIUDSAMLSA-N 0.000 description 1
- RRYLMJWPWBJFPZ-ACZMJKKPSA-N Gln-Asn-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RRYLMJWPWBJFPZ-ACZMJKKPSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 1
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 1
- VGTDBGYFVWOQTI-RYUDHWBXSA-N Gln-Gly-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VGTDBGYFVWOQTI-RYUDHWBXSA-N 0.000 description 1
- PODFFOWWLUPNMN-DCAQKATOSA-N Gln-His-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PODFFOWWLUPNMN-DCAQKATOSA-N 0.000 description 1
- KKCJHBXMYYVWMX-KQXIARHKSA-N Gln-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N KKCJHBXMYYVWMX-KQXIARHKSA-N 0.000 description 1
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- DOQUICBEISTQHE-CIUDSAMLSA-N Gln-Pro-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O DOQUICBEISTQHE-CIUDSAMLSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 1
- YRHZWVKUFWCEPW-GLLZPBPUSA-N Gln-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O YRHZWVKUFWCEPW-GLLZPBPUSA-N 0.000 description 1
- SYTFJIQPBRJSOK-NKIYYHGXSA-N Gln-Thr-His Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 SYTFJIQPBRJSOK-NKIYYHGXSA-N 0.000 description 1
- BETSEXMYBWCDAE-SZMVWBNQSA-N Gln-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N BETSEXMYBWCDAE-SZMVWBNQSA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 1
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 1
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 1
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 1
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 1
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 1
- YGLCLCMAYUYZSG-AVGNSLFASA-N Glu-Lys-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 YGLCLCMAYUYZSG-AVGNSLFASA-N 0.000 description 1
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 1
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- ZAPFAWQHBOHWLL-GUBZILKMSA-N Glu-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N ZAPFAWQHBOHWLL-GUBZILKMSA-N 0.000 description 1
- ZTNHPMZHAILHRB-JSGCOSHPSA-N Glu-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)NCC(O)=O)=CNC2=C1 ZTNHPMZHAILHRB-JSGCOSHPSA-N 0.000 description 1
- ZSIDREAPEPAPKL-XIRDDKMYSA-N Glu-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N ZSIDREAPEPAPKL-XIRDDKMYSA-N 0.000 description 1
- RXJFSLQVMGYQEL-IHRRRGAJSA-N Glu-Tyr-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 RXJFSLQVMGYQEL-IHRRRGAJSA-N 0.000 description 1
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- XRTDOIOIBMAXCT-NKWVEPMBSA-N Gly-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)CN)C(=O)O XRTDOIOIBMAXCT-NKWVEPMBSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 1
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 1
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 1
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 1
- HPAIKDPJURGQLN-KBPBESRZSA-N Gly-His-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 HPAIKDPJURGQLN-KBPBESRZSA-N 0.000 description 1
- SXJHOPPTOJACOA-QXEWZRGKSA-N Gly-Ile-Arg Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N SXJHOPPTOJACOA-QXEWZRGKSA-N 0.000 description 1
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 1
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 1
- IKAIKUBBJHFNBZ-LURJTMIESA-N Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CN IKAIKUBBJHFNBZ-LURJTMIESA-N 0.000 description 1
- RVGMVLVBDRQVKB-UWVGGRQHSA-N Gly-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN RVGMVLVBDRQVKB-UWVGGRQHSA-N 0.000 description 1
- FEUPVVCGQLNXNP-IRXDYDNUSA-N Gly-Phe-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FEUPVVCGQLNXNP-IRXDYDNUSA-N 0.000 description 1
- IEGFSKKANYKBDU-QWHCGFSZSA-N Gly-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)CN)C(=O)O IEGFSKKANYKBDU-QWHCGFSZSA-N 0.000 description 1
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 1
- FKYQEVBRZSFAMJ-QWRGUYRKSA-N Gly-Ser-Tyr Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FKYQEVBRZSFAMJ-QWRGUYRKSA-N 0.000 description 1
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- RJVZMGQMJOQIAX-GJZGRUSLSA-N Gly-Trp-Met Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCSC)C(O)=O RJVZMGQMJOQIAX-GJZGRUSLSA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 1
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 1
- 206010019233 Headaches Diseases 0.000 description 1
- 241000589989 Helicobacter Species 0.000 description 1
- 241000590002 Helicobacter pylori Species 0.000 description 1
- 208000031220 Hemophilia Diseases 0.000 description 1
- 208000009292 Hemophilia A Diseases 0.000 description 1
- DCRODRAURLJOFY-XPUUQOCRSA-N His-Ala-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)NCC(O)=O DCRODRAURLJOFY-XPUUQOCRSA-N 0.000 description 1
- HRGGKHFHRSFSDE-CIUDSAMLSA-N His-Asn-Ser Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N HRGGKHFHRSFSDE-CIUDSAMLSA-N 0.000 description 1
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 1
- AKEDPWJFQULLPE-IUCAKERBSA-N His-Glu-Gly Chemical compound N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O AKEDPWJFQULLPE-IUCAKERBSA-N 0.000 description 1
- BKOVCRUIXDIWFV-IXOXFDKPSA-N His-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CN=CN1 BKOVCRUIXDIWFV-IXOXFDKPSA-N 0.000 description 1
- CMMBEMZGNGYJRJ-IHRRRGAJSA-N His-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N CMMBEMZGNGYJRJ-IHRRRGAJSA-N 0.000 description 1
- SVVULKPWDBIPCO-BZSNNMDCSA-N His-Phe-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O SVVULKPWDBIPCO-BZSNNMDCSA-N 0.000 description 1
- BRQKGRLDDDQWQJ-MBLNEYKQSA-N His-Thr-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O BRQKGRLDDDQWQJ-MBLNEYKQSA-N 0.000 description 1
- FBOMZVOKCZMDIG-XQQFMLRXSA-N His-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N FBOMZVOKCZMDIG-XQQFMLRXSA-N 0.000 description 1
- 102000006947 Histones Human genes 0.000 description 1
- 108010033040 Histones Proteins 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101001037140 Homo sapiens Immunoglobulin heavy variable 3-23 Proteins 0.000 description 1
- 101001047627 Homo sapiens Immunoglobulin kappa variable 2-28 Proteins 0.000 description 1
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 1
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 1
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 1
- QIHJTGSVGIPHIW-QSFUFRPTSA-N Ile-Asn-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N QIHJTGSVGIPHIW-QSFUFRPTSA-N 0.000 description 1
- NKRJALPCDNXULF-BYULHYEWSA-N Ile-Asp-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O NKRJALPCDNXULF-BYULHYEWSA-N 0.000 description 1
- AQTWDZDISVGCAC-CFMVVWHZSA-N Ile-Asp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AQTWDZDISVGCAC-CFMVVWHZSA-N 0.000 description 1
- WNQKUUQIVDDAFA-ZPFDUUQYSA-N Ile-Gln-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N WNQKUUQIVDDAFA-ZPFDUUQYSA-N 0.000 description 1
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 1
- GQKSJYINYYWPMR-NGZCFLSTSA-N Ile-Gly-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N GQKSJYINYYWPMR-NGZCFLSTSA-N 0.000 description 1
- VNDQNDYEPSXHLU-JUKXBJQTSA-N Ile-His-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N VNDQNDYEPSXHLU-JUKXBJQTSA-N 0.000 description 1
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 1
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 1
- PELCGFMHLZXWBQ-BJDJZHNGSA-N Ile-Ser-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)O)N PELCGFMHLZXWBQ-BJDJZHNGSA-N 0.000 description 1
- SAEWJTCJQVZQNZ-IUKAMOBKSA-N Ile-Thr-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SAEWJTCJQVZQNZ-IUKAMOBKSA-N 0.000 description 1
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 1
- QGXQHJQPAPMACW-PPCPHDFISA-N Ile-Thr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QGXQHJQPAPMACW-PPCPHDFISA-N 0.000 description 1
- BQIIHAGJIYOQBP-YFYLHZKVSA-N Ile-Trp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N3CCC[C@@H]3C(=O)O)N BQIIHAGJIYOQBP-YFYLHZKVSA-N 0.000 description 1
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- NJGXXYLPDMMFJB-XUXIUFHCSA-N Ile-Val-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N NJGXXYLPDMMFJB-XUXIUFHCSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 102100040220 Immunoglobulin heavy variable 3-23 Human genes 0.000 description 1
- 102100022950 Immunoglobulin kappa variable 2-28 Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 102000008133 Iron-Binding Proteins Human genes 0.000 description 1
- 108010035210 Iron-Binding Proteins Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- SUPVSFFZWVOEOI-CQDKDKBSSA-N Leu-Ala-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-CQDKDKBSSA-N 0.000 description 1
- SUPVSFFZWVOEOI-UHFFFAOYSA-N Leu-Ala-Tyr Natural products CC(C)CC(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-UHFFFAOYSA-N 0.000 description 1
- FJUKMPUELVROGK-IHRRRGAJSA-N Leu-Arg-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N FJUKMPUELVROGK-IHRRRGAJSA-N 0.000 description 1
- OXKYZSRZKBTVEY-ZPFDUUQYSA-N Leu-Asn-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OXKYZSRZKBTVEY-ZPFDUUQYSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 1
- WXHFZJFZWNCDNB-KKUMJFAQSA-N Leu-Asn-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 WXHFZJFZWNCDNB-KKUMJFAQSA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 1
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 1
- PDQDCFBVYXEFSD-SRVKXCTJSA-N Leu-Leu-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PDQDCFBVYXEFSD-SRVKXCTJSA-N 0.000 description 1
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 1
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 1
- REPBGZHJKYWFMJ-KKUMJFAQSA-N Leu-Lys-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N REPBGZHJKYWFMJ-KKUMJFAQSA-N 0.000 description 1
- KPYAOIVPJKPIOU-KKUMJFAQSA-N Leu-Lys-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O KPYAOIVPJKPIOU-KKUMJFAQSA-N 0.000 description 1
- VVQJGYPTIYOFBR-IHRRRGAJSA-N Leu-Lys-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)O)N VVQJGYPTIYOFBR-IHRRRGAJSA-N 0.000 description 1
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 1
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- IZPVWNSAVUQBGP-CIUDSAMLSA-N Leu-Ser-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IZPVWNSAVUQBGP-CIUDSAMLSA-N 0.000 description 1
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 1
- AEDWWMMHUGYIFD-HJGDQZAQSA-N Leu-Thr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O AEDWWMMHUGYIFD-HJGDQZAQSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- LFSQWRSVPNKJGP-WDCWCFNPSA-N Leu-Thr-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O LFSQWRSVPNKJGP-WDCWCFNPSA-N 0.000 description 1
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 1
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 1
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 1
- GKFNXYMAMKJSKD-NHCYSSNCSA-N Lys-Asp-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GKFNXYMAMKJSKD-NHCYSSNCSA-N 0.000 description 1
- WTZUSCUIVPVCRH-SRVKXCTJSA-N Lys-Gln-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WTZUSCUIVPVCRH-SRVKXCTJSA-N 0.000 description 1
- DUTMKEAPLLUGNO-JYJNAYRXSA-N Lys-Glu-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DUTMKEAPLLUGNO-JYJNAYRXSA-N 0.000 description 1
- WVJNGSFKBKOKRV-AJNGGQMLSA-N Lys-Leu-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVJNGSFKBKOKRV-AJNGGQMLSA-N 0.000 description 1
- PYFNONMJYNJENN-AVGNSLFASA-N Lys-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PYFNONMJYNJENN-AVGNSLFASA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- BDFHWFUAQLIMJO-KXNHARMFSA-N Lys-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N)O BDFHWFUAQLIMJO-KXNHARMFSA-N 0.000 description 1
- YUTZYVTZDVZBJJ-IHPCNDPISA-N Lys-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 YUTZYVTZDVZBJJ-IHPCNDPISA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102100025354 Macrophage mannose receptor 1 Human genes 0.000 description 1
- 108010031099 Mannose Receptor Proteins 0.000 description 1
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 1
- UYAKZHGIPRCGPF-CIUDSAMLSA-N Met-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N UYAKZHGIPRCGPF-CIUDSAMLSA-N 0.000 description 1
- WWWGMQHQSAUXBU-BQBZGAKWSA-N Met-Gly-Asn Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O WWWGMQHQSAUXBU-BQBZGAKWSA-N 0.000 description 1
- SLQDSYZHHOKQSR-QXEWZRGKSA-N Met-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCSC SLQDSYZHHOKQSR-QXEWZRGKSA-N 0.000 description 1
- BQHLZUMZOXUWNU-DCAQKATOSA-N Met-Pro-Glu Chemical compound CSCC[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N BQHLZUMZOXUWNU-DCAQKATOSA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- IIHMNTBFPMRJCN-RCWTZXSCSA-N Met-Val-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IIHMNTBFPMRJCN-RCWTZXSCSA-N 0.000 description 1
- 101100370002 Mus musculus Tnfsf14 gene Proteins 0.000 description 1
- 208000000112 Myalgia Diseases 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 206010028813 Nausea Diseases 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 241001635529 Orius Species 0.000 description 1
- 206010068319 Oropharyngeal pain Diseases 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 101150012394 PHO5 gene Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 206010034133 Pathogen resistance Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 201000007100 Pharyngitis Diseases 0.000 description 1
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 1
- UMKYAYXCMYYNHI-AVGNSLFASA-N Phe-Gln-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N UMKYAYXCMYYNHI-AVGNSLFASA-N 0.000 description 1
- SXJGROGVINAYSH-AVGNSLFASA-N Phe-Gln-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SXJGROGVINAYSH-AVGNSLFASA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- AUJWXNGCAQWLEI-KBPBESRZSA-N Phe-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AUJWXNGCAQWLEI-KBPBESRZSA-N 0.000 description 1
- YVIVIQWMNCWUFS-UFYCRDLUSA-N Phe-Met-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N YVIVIQWMNCWUFS-UFYCRDLUSA-N 0.000 description 1
- CBENHWCORLVGEQ-HJOGWXRNSA-N Phe-Phe-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 CBENHWCORLVGEQ-HJOGWXRNSA-N 0.000 description 1
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 1
- RVEVENLSADZUMS-IHRRRGAJSA-N Phe-Pro-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RVEVENLSADZUMS-IHRRRGAJSA-N 0.000 description 1
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 1
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 1
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 1
- ABEFOXGAIIJDCL-SFJXLCSZSA-N Phe-Thr-Trp Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 ABEFOXGAIIJDCL-SFJXLCSZSA-N 0.000 description 1
- VDTYRPWRWRCROL-UFYCRDLUSA-N Phe-Val-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VDTYRPWRWRCROL-UFYCRDLUSA-N 0.000 description 1
- 241000404883 Pisa Species 0.000 description 1
- 229920001030 Polyethylene Glycol 4000 Polymers 0.000 description 1
- 108010020346 Polyglutamic Acid Proteins 0.000 description 1
- 108010039918 Polylysine Proteins 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- IWNOFCGBMSFTBC-CIUDSAMLSA-N Pro-Ala-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IWNOFCGBMSFTBC-CIUDSAMLSA-N 0.000 description 1
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 1
- AMBLXEMWFARNNQ-DCAQKATOSA-N Pro-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 AMBLXEMWFARNNQ-DCAQKATOSA-N 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- FEVDNIBDCRKMER-IUCAKERBSA-N Pro-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEVDNIBDCRKMER-IUCAKERBSA-N 0.000 description 1
- STASJMBVVHNWCG-IHRRRGAJSA-N Pro-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 STASJMBVVHNWCG-IHRRRGAJSA-N 0.000 description 1
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 1
- VWHJZETTZDAGOM-XUXIUFHCSA-N Pro-Lys-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VWHJZETTZDAGOM-XUXIUFHCSA-N 0.000 description 1
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 1
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 1
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 1
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 241000725643 Respiratory syncytial virus Species 0.000 description 1
- 208000036071 Rhinorrhea Diseases 0.000 description 1
- 206010039101 Rhinorrhoea Diseases 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 1
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 1
- KMWFXJCGRXBQAC-CIUDSAMLSA-N Ser-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N KMWFXJCGRXBQAC-CIUDSAMLSA-N 0.000 description 1
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 1
- CDVFZMOFNJPUDD-ACZMJKKPSA-N Ser-Gln-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CDVFZMOFNJPUDD-ACZMJKKPSA-N 0.000 description 1
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 1
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 1
- PVDTYLHUWAEYGY-CIUDSAMLSA-N Ser-Glu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PVDTYLHUWAEYGY-CIUDSAMLSA-N 0.000 description 1
- YQQKYAZABFEYAF-FXQIFTODSA-N Ser-Glu-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQQKYAZABFEYAF-FXQIFTODSA-N 0.000 description 1
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 1
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- WEQAYODCJHZSJZ-KKUMJFAQSA-N Ser-His-Tyr Chemical compound C([C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 WEQAYODCJHZSJZ-KKUMJFAQSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 1
- FOOZNBRFRWGBNU-DCAQKATOSA-N Ser-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N FOOZNBRFRWGBNU-DCAQKATOSA-N 0.000 description 1
- RXSWQCATLWVDLI-XGEHTFHBSA-N Ser-Met-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RXSWQCATLWVDLI-XGEHTFHBSA-N 0.000 description 1
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 1
- GZGFSPWOMUKKCV-NAKRPEOUSA-N Ser-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO GZGFSPWOMUKKCV-NAKRPEOUSA-N 0.000 description 1
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- AXKJPUBALUNJEO-UBHSHLNASA-N Ser-Trp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O AXKJPUBALUNJEO-UBHSHLNASA-N 0.000 description 1
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108010017898 Shiga Toxins Proteins 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 208000006011 Stroke Diseases 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 102000002933 Thioredoxin Human genes 0.000 description 1
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 1
- DGDCHPCRMWEOJR-FQPOAREZSA-N Thr-Ala-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DGDCHPCRMWEOJR-FQPOAREZSA-N 0.000 description 1
- PQLXHSACXPGWPD-GSSVUCPTSA-N Thr-Asn-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PQLXHSACXPGWPD-GSSVUCPTSA-N 0.000 description 1
- DCLBXIWHLVEPMQ-JRQIVUDYSA-N Thr-Asp-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DCLBXIWHLVEPMQ-JRQIVUDYSA-N 0.000 description 1
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 1
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- OQCXTUQTKQFDCX-HTUGSXCWSA-N Thr-Glu-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O OQCXTUQTKQFDCX-HTUGSXCWSA-N 0.000 description 1
- XFTYVCHLARBHBQ-FOHZUACHSA-N Thr-Gly-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XFTYVCHLARBHBQ-FOHZUACHSA-N 0.000 description 1
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- ZSPQUTWLWGWTPS-HJGDQZAQSA-N Thr-Lys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZSPQUTWLWGWTPS-HJGDQZAQSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- FDQXPJCLVPFKJW-KJEVXHAQSA-N Thr-Met-Tyr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N)O FDQXPJCLVPFKJW-KJEVXHAQSA-N 0.000 description 1
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 1
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 1
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 1
- DOBIBIXIHJKVJF-XKBZYTNZSA-N Thr-Ser-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O DOBIBIXIHJKVJF-XKBZYTNZSA-N 0.000 description 1
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- CSNBWOJOEOPYIJ-UVOCVTCTSA-N Thr-Thr-Lys Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O CSNBWOJOEOPYIJ-UVOCVTCTSA-N 0.000 description 1
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 1
- LXXCHJKHJYRMIY-FQPOAREZSA-N Thr-Tyr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O LXXCHJKHJYRMIY-FQPOAREZSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- RTAQQCXQSZGOHL-UHFFFAOYSA-N Titanium Chemical compound [Ti] RTAQQCXQSZGOHL-UHFFFAOYSA-N 0.000 description 1
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 1
- RERRMBXDSFMBQE-ZFWWWQNUSA-N Trp-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERRMBXDSFMBQE-ZFWWWQNUSA-N 0.000 description 1
- UQHPXCFAHVTWFU-BVSLBCMMSA-N Trp-Phe-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O UQHPXCFAHVTWFU-BVSLBCMMSA-N 0.000 description 1
- HHPSUFUXXBOFQY-AQZXSJQPSA-N Trp-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O HHPSUFUXXBOFQY-AQZXSJQPSA-N 0.000 description 1
- DDHFMBDACJYSKW-AQZXSJQPSA-N Trp-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O DDHFMBDACJYSKW-AQZXSJQPSA-N 0.000 description 1
- YXSSXUIBUJGHJY-SFJXLCSZSA-N Trp-Thr-Phe Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)[C@H](O)C)C(O)=O)C1=CC=CC=C1 YXSSXUIBUJGHJY-SFJXLCSZSA-N 0.000 description 1
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 1
- CRCHQCUINSOGFD-JBACZVJFSA-N Trp-Tyr-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N CRCHQCUINSOGFD-JBACZVJFSA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 1
- QJBWZNTWJSZUOY-UWJYBYFXSA-N Tyr-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QJBWZNTWJSZUOY-UWJYBYFXSA-N 0.000 description 1
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 1
- MNMYOSZWCKYEDI-JRQIVUDYSA-N Tyr-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MNMYOSZWCKYEDI-JRQIVUDYSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 1
- OHNXAUCZVWGTLL-KKUMJFAQSA-N Tyr-His-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N)O OHNXAUCZVWGTLL-KKUMJFAQSA-N 0.000 description 1
- JJNXZIPLIXIGBX-HJPIBITLSA-N Tyr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JJNXZIPLIXIGBX-HJPIBITLSA-N 0.000 description 1
- MVFQLSPDMMFCMW-KKUMJFAQSA-N Tyr-Leu-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O MVFQLSPDMMFCMW-KKUMJFAQSA-N 0.000 description 1
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 1
- QPBJXNYYQTUTDD-KKUMJFAQSA-N Tyr-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QPBJXNYYQTUTDD-KKUMJFAQSA-N 0.000 description 1
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 1
- XYBNMHRFAUKPAW-IHRRRGAJSA-N Tyr-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XYBNMHRFAUKPAW-IHRRRGAJSA-N 0.000 description 1
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 1
- QFHRUCJIRVILCK-YJRXYDGGSA-N Tyr-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O QFHRUCJIRVILCK-YJRXYDGGSA-N 0.000 description 1
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 1
- YOTRXXBHTZHKLU-BVSLBCMMSA-N Tyr-Trp-Met Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCSC)C(O)=O)C1=CC=C(O)C=C1 YOTRXXBHTZHKLU-BVSLBCMMSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 1
- UDLYXGYWTVOIKU-QXEWZRGKSA-N Val-Asn-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UDLYXGYWTVOIKU-QXEWZRGKSA-N 0.000 description 1
- GNWUWQAVVJQREM-NHCYSSNCSA-N Val-Asn-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GNWUWQAVVJQREM-NHCYSSNCSA-N 0.000 description 1
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 1
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 1
- COSLEEOIYRPTHD-YDHLFZDLSA-N Val-Asp-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 COSLEEOIYRPTHD-YDHLFZDLSA-N 0.000 description 1
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 1
- XIFAHCUNWWKUDE-DCAQKATOSA-N Val-Cys-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N XIFAHCUNWWKUDE-DCAQKATOSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 1
- JTWIMNMUYLQNPI-WPRPVWTQSA-N Val-Gly-Arg Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N JTWIMNMUYLQNPI-WPRPVWTQSA-N 0.000 description 1
- DJEVQCWNMQOABE-RCOVLWMOSA-N Val-Gly-Asp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N DJEVQCWNMQOABE-RCOVLWMOSA-N 0.000 description 1
- GMOLURHJBLOBFW-ONGXEEELSA-N Val-Gly-His Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GMOLURHJBLOBFW-ONGXEEELSA-N 0.000 description 1
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 1
- KTEZUXISLQTDDQ-NHCYSSNCSA-N Val-Lys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KTEZUXISLQTDDQ-NHCYSSNCSA-N 0.000 description 1
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- PGQUDQYHWICSAB-NAKRPEOUSA-N Val-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N PGQUDQYHWICSAB-NAKRPEOUSA-N 0.000 description 1
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 1
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 1
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 1
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 1
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- 230000010530 Virus Neutralization Effects 0.000 description 1
- 206010047700 Vomiting Diseases 0.000 description 1
- 238000002441 X-ray diffraction Methods 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 238000005054 agglomeration Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000037005 anaesthesia Effects 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 239000000611 antibody drug conjugate Substances 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 229940049595 antibody-drug conjugate Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 101150042295 arfA gene Proteins 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 238000003738 britelite plus Methods 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 244000309466 calf Species 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000009920 chelation Effects 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000012539 chromatography resin Substances 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 238000003501 co-culture Methods 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000011443 conventional therapy Methods 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 210000000172 cytosol Anatomy 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 230000001687 destabilization Effects 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- UQLDLKMNUJERMK-UHFFFAOYSA-L di(octadecanoyloxy)lead Chemical compound [Pb+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O UQLDLKMNUJERMK-UHFFFAOYSA-L 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 229940126534 drug product Drugs 0.000 description 1
- 241001493065 dsRNA viruses Species 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- RDYMFSUJUZBWLH-UHFFFAOYSA-N endosulfan Chemical compound C12COS(=O)OCC2C2(Cl)C(Cl)=C(Cl)C1(Cl)C2(Cl)Cl RDYMFSUJUZBWLH-UHFFFAOYSA-N 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- CCIVGXIOQKPBKL-UHFFFAOYSA-M ethanesulfonate Chemical compound CCS([O-])(=O)=O CCIVGXIOQKPBKL-UHFFFAOYSA-M 0.000 description 1
- 206010016256 fatigue Diseases 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 229920000370 gamma-poly(glutamate) polymer Polymers 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 102000034238 globular proteins Human genes 0.000 description 1
- 108091005896 globular proteins Proteins 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Chemical group 0.000 description 1
- 230000002414 glycolytic effect Effects 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010008671 glycyl-tryptophyl-methionine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- OACGQKTUYKIPOZ-UHFFFAOYSA-K gold(3+);triformate Chemical compound [Au+3].[O-]C=O.[O-]C=O.[O-]C=O OACGQKTUYKIPOZ-UHFFFAOYSA-K 0.000 description 1
- 231100000869 headache Toxicity 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 229940037467 helicobacter pylori Drugs 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- 230000006058 immune tolerance Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000012405 in silico analysis Methods 0.000 description 1
- 229960000598 infliximab Drugs 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 239000002054 inoculum Substances 0.000 description 1
- 150000002484 inorganic compounds Chemical class 0.000 description 1
- 229910010272 inorganic material Inorganic materials 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 108010031424 isoleucyl-prolyl-proline Proteins 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 208000012396 long COVID-19 Diseases 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 238000002493 microarray Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000003032 molecular docking Methods 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 230000008693 nausea Effects 0.000 description 1
- 229910052759 nickel Inorganic materials 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 238000006384 oligomerization reaction Methods 0.000 description 1
- 101150087557 omcB gene Proteins 0.000 description 1
- 101150115693 ompA gene Proteins 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229960000402 palivizumab Drugs 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- MXHCPCSDRGLRER-UHFFFAOYSA-N pentaglycine Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)NCC(O)=O MXHCPCSDRGLRER-UHFFFAOYSA-N 0.000 description 1
- 230000003094 perturbing effect Effects 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 238000005498 polishing Methods 0.000 description 1
- 229920000729 poly(L-lysine) polymer Polymers 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 229920000656 polylysine Polymers 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 230000003334 potential effect Effects 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 1
- 108010079317 prolyl-tyrosine Proteins 0.000 description 1
- 108010015796 prolylisoleucine Proteins 0.000 description 1
- 239000001294 propane Substances 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 208000023504 respiratory system disease Diseases 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 238000007665 sagging Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 208000013220 shortness of breath Diseases 0.000 description 1
- 239000013605 shuttle vector Substances 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 210000004989 spleen cell Anatomy 0.000 description 1
- 238000001370 static light scattering Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 238000012916 structural analysis Methods 0.000 description 1
- 108020001568 subdomains Proteins 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 108060008226 thioredoxin Proteins 0.000 description 1
- 229940094937 thioredoxin Drugs 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 238000003325 tomography Methods 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 238000011277 treatment modality Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 108010009962 valyltyrosine Proteins 0.000 description 1
- 244000052613 viral pathogen Species 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 239000012855 volatile organic compound Substances 0.000 description 1
- 230000008673 vomiting Effects 0.000 description 1
- 230000004580 weight loss Effects 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 238000002424 x-ray crystallography Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images
































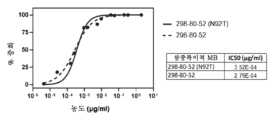

Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1002—Coronaviridae
- C07K16/1003—Severe acute respiratory syndrome coronavirus 2 [SARS‐CoV‐2 or Covid-19]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B82—NANOTECHNOLOGY
- B82Y—SPECIFIC USES OR APPLICATIONS OF NANOSTRUCTURES; MEASUREMENT OR ANALYSIS OF NANOSTRUCTURES; MANUFACTURE OR TREATMENT OF NANOSTRUCTURES
- B82Y5/00—Nanobiotechnology or nanomedicine, e.g. protein engineering or drug delivery
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/735—Fusion polypeptide containing domain for protein-protein interaction containing a domain for self-assembly, e.g. a viral coat protein (includes phage display)
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Virology (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Immunology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Pulmonology (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicinal Preparation (AREA)
Abstract
SARS-CoV-2 결합 모이어티에 연결된 나노케이지 단량체를 포함하는 융합 단백질이 본원에 제공되며, 복수개의 융합 단백질은 자가-조립하여 나노케이지를 형성한다. SARS-CoV-2를 표적화하는 삼중-특이적 항체 구축물 또한 제공된다. (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) 단편 결정화가능한 (Fc) 영역을 포함하는 융합 폴리펩티드 또한 제공되며, Fc 영역은 I253A 돌연변이를 포함하고, 넘버링은 EU 인덱스에 따른 것이다.
Description
본 발명은 폴리펩티드에 관한 것이다. 특히, 본 발명은 SARS-CoV-2-특이적 폴리펩티드, 및 관련 구축물, 조성물 및 방법에 관한 것이다.
나노입자는 다양한 분야의 발전에 기여하였다. 그들의 용도는 표적화된 전달을 부여하는 잠재성을 갖고, 촉매적 과정을 위해 정렬된 마이크로-어레이, 느린 방출 및 케이징된 미세환경의 조작을 가능하게 한다.
민감성이고 준안정성인 단백질을 함유하는 나노입자의 제작의 경우, 단백질 자가-조립은 매력적인 방법이다. 실제로, 자가-조립된 나노입자는 비공유적인 상호작용을 통해 생리학적 조건하에 형성되고, 균일하고 종종 대칭인 나노캡슐 또는 나노케이지를 신뢰가능하게 생성한다.
중증 급성 호흡기 증후군 코로나바이러스 2 (SARS-CoV-2)는 COVID-19 대유행을 일으킨 호흡기 질병인 코로나바이러스 질환 2019 (COVID-19)를 유발하는 코로나바이러스의 균주이다.
SARS-CoV-2의 치료 및/또는 예방을 위해 개선된 조성물 및 방법에 대한 필요성이 존재한다.
한 측면에 따라, SARS-CoV-2 결합 모이어티에 연결된 나노케이지 단량체를 포함하는 융합 단백질이 제공되고, 복수개의 융합 단백질은 자가-조립하여 나노케이지를 형성한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 SARS-CoV-2 S 당단백질을 표적화한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 조립된 나노케이지의 내부 및/또는 외부 표면, 바람직하게는 외부 표면을 장식한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 항체 또는 그의 단편을 포함한다.
한 측면에서, 항체 또는 그의 단편은 Fab 단편을 포함한다.
한 측면에서, 항체 또는 그의 단편은 scFab 단편, scFv 단편, sdAb 단편, VHH 도메인 또는 이들의 조합물을 포함한다.
한 측면에서, 항체 또는 그의 단편은 Fab 단편의 중쇄 및/또는 경쇄를 포함한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 단일 쇄 가변 도메인 VHH-72, BD23 및/또는 4A8을 포함한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 표 4에 나열된 mAb를 포함한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 표 4로부터의 mAb 298, 324, 46, 80, 52, 82, 또는 236을 포함한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 나노케이지 단량체의 N- 또는 C-말단에서 연결되거나, 또는 나노케이지 단량체의 N-말단에서 연결된 제1 SARS-CoV-2 결합 모이어티 및 C-말단에서 연결된 제2 SARS-CoV-2 결합 모이어티가 있고, 제1 및 제2 SARS-CoV-2 결합 모이어티는 동일하거나 또는 상이하다.
한 측면에서, 나노케이지 단량체는 SARS-CoV-2 결합 모이어티에 연결된 제1 나노케이지 단량체 서브유닛을 포함하고; 제1 나노케이지 단량체 서브유닛은 제2 나노케이지 단량체 서브유닛과 자가-조립하여 나노케이지 단량체를 형성한다.
한 측면에서, SARS-CoV-2 결합 모이어티는 제1 나노케이지 단량체의 N- 또는 C-말단에서 연결되거나, 또는 제1 나노케이지 단량체 서브유닛의 N-말단에서 연결된 제1 SARS-CoV-2 결합 모이어티 및 C-말단에서 연결된 제2 SARS-CoV-2 결합 모이어티가 있고, 제1 및 제2 SARS-CoV-2 결합 모이어티는 동일하거나 또는 상이하다.
한 측면에서, 융합 단백질은 제2 나노케이지 단량체 서브유닛과 조합되어 제공된다.
한 측면에서, 제2 나노케이지 단량체 서브유닛은 생물활성 모이어티에 연결된다.
한 측면에서, 생물활성 모이어티는 Fc 단편을 포함한다.
한 측면에서, Fc 단편은 IgG1 Fc 단편이다.
한 측면에서, Fc 단편은 융합 단백질의 반감기를 예를 들어 수분 또는 수시간에서 수일, 수주 또는 수개월로 조절하는 1개 이상의 돌연변이, 예컨대 LS, YTE, LALA, I253A, 및/또는 LALAP를 포함한다.
한 측면에서, Fc 단편은 scFc 단편이다.
한 측면에서, 약 3 내지 약 100개의 나노케이지 단량체, 예컨대 24, 32 또는 60개의 단량체, 또는 약 4 내지 약 200개의 나노케이지 단량체 서브유닛, 예컨대 4, 6, 8, 10, 12, 14, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50개 또는 그 초과가 임의적으로 1개 이상의 전체 나노케이지 단량체와 조합되어 자가-조립하여 나노케이지를 형성한다.
한 측면에서, 나노케이지 단량체는 페리틴, 아포페리틴, 엔캡슐린, SOR, 루마진 신타제, 피루베이트 데히드로게나제, 카르복시좀, 볼트 단백질, GroEL, 열 쇼크 단백질, E2P, MS2 외피 단백질, 그의 단편, 및 그의 변이체로부터 선택된다.
한 측면에서, 나노케이지 단량체는 아포페리틴, 임의적으로 인간 아포페리틴이다.
한 측면에서, 제1 및 제2 나노케이지 단량체 서브유닛은 상호교환적으로 아포페리틴의 "N" 및 "C" 영역을 포함한다.
한 측면에서, 아포페리틴의 "N" 영역은 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
MSSQIRQNYSTDVEAAVNSLVNLYLQASYTYLSLGFYFDRDDVALEGVSHFFRELAEEKREGYERLLKMQNQRGGRALFQDIKKPAEDEW.
한 측면에서, 아포페리틴의 "C" 영역은 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GKTPDAMKAAMALEKKLNQALLDLHALGSARTDPHLCDFLETHFLDEEVKLIKKMGDHLTNLHRLGGPEAGLGEYLFERLTLRHD
또는
GKTPDAMKAAMALEKKLNQALLDLHALGSARTDPHLCDFLETHFLDEEVKLIKKMGDHLTNLHRLGGPEAGLGEYLFERLTLKHD.
한 측면에서, 융합 단백질은 나노케이지 단량체 서브유닛과 생물활성 모이어티 사이에 링커를 추가로 포함한다.
한 측면에서, 링커는 가요성 또는 강직성이고, 약 1 내지 약 30개의 아미노산 잔기, 예컨대 약 8 내지 약 16개의 아미노산 잔기를 포함한다.
한 측면에서, 링커는 GGS 반복부, 예컨대 1, 2, 3, 4개 또는 그 초과의 GGS 반복부를 포함한다.
한 측면에서, 링커는 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GGGGSGGGGSGGGGSGGGGSGGGGSGG.
한 측면에서, 융합 단백질은 C-말단 링커를 추가로 포함한다.
한 측면에서, C-말단 링커는 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GGSGGSGGSGGSGGGSGGSGGSGGSG
한 측면에 따라, 본원에 기재된 적어도 하나의 융합 단백질, 및 융합 단백질과 자가-조립하여 나노케이지 단량체를 형성하는 적어도 하나의 제2 나노케이지 단량체 서브유닛을 포함하는 나노케이지가 제공된다.
한 측면에서, 각각의 나노케이지 단량체는 본원에 기재된 융합 단백질을 포함한다.
한 측면에서, 나노케이지 단량체의 약 20% 내지 약 80%는 본원에 기재된 융합 단백질을 포함한다.
한 측면에서, 나노케이지는 적어도 2, 3, 4, 5, 6, 7, 8, 9 또는 10개의 상이한 SARS-CoV-2 결합 모이어티, 예컨대 3개의 상이한 SARS-CoV-2 결합 모이어티를 포함한다.
한 측면에서, 나노케이지는 다가성 및/또는 다중특이적이다.
한 측면에서, 나노케이지는 표 4로부터의 하나 이상의 mAb를 포함한다.
한 측면에서, 나노케이지는 표 4로부터의 3가지 mAb를 포함한다.
한 측면에서, 나노케이지는 표 4로부터의 mAb 298, 324, 46, 52, 80, 82 및/또는 236을 포함한다.
한 측면에서, 나노케이지는 4:2:1:1: 비의 scFab1-인간 아포페리틴: scFc-인간 N-페리틴: scFab2-C-페리틴: scFab3-C-페리틴을 포함한다.
한 측면에서, 나노케이지는 적하(cargo) 분자, 예컨대 약제, 진단제, 및/또는 영상화제를 운반한다.
한 측면에서, 적하 분자는 융합 단백질에 융합되지 않고, 나노케이지 내부에 함유된다.
한 측면에서, 적하 분자는 단백질이고, 적하 분자가 나노케이지 내부에 함유되도록 융합 단백질에 융합된다.
한 측면에서, 적하 분자는 형광 단백질, 예컨대 GFP, EGFP, 아메트린, 및/또는 플라빈-기반 형광 단백질, 예컨대 LOV-단백질, 예컨대 iLOV이다.
한 측면에 따라, SARS-CoV-2를 표적화하는 삼중-특이적 항체 구축물이 제공된다.
한 측면에 따라, 본원에 기재된 나노케이지 또는 항체를 포함하는 SARS-CoV-2 치료적 또는 예방적 조성물이 제공된다.
한 측면에 따라, 본원에 기재된 융합 단백질을 코딩하는 핵산 분자가 제공된다.
한 측면에 따라, 본원에 기재된 핵산 분자를 포함하는 벡터가 제공된다.
한 측면에 따라, 본원에 기재된 벡터를 포함하고, 본원에 기재된 융합 단백질을 생성하는 숙주 세포가 제공된다.
한 측면에 따라, 본원에 기재된 나노케이지 또는 항체 또는 조성물을 투여하는 것을 포함하는, SARS-CoV-2를 치료하고/거나 예방하는 방법이 제공된다.
한 측면에 따라, SARS-CoV-2의 치료 및/또는 예방을 위한 본원에 기재된 나노케이지 또는 항체 또는 조성물의 용도가 제공된다.
한 측면에 따라, 치료 및/또는 예방 SARS-CoV-2에서 사용하기 위한 본원에 기재된 나노케이지 또는 항체 또는 조성물이 제공된다.
한 측면에 따라, 하기 표에 나열된 임의의 서열과 적어도 70% 동일성을 갖는 아미노산 서열을 포함하는 폴리펩티드 또는 그의 기능적 단편이 제공된다:


한 측면에서, 폴리펩티드는 나열된 서열과 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 서열 동일성을 포함한다.
한 측면에서, 폴리펩티드는 나열된 서열과 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 서열 동일성으로 이루어진다.
한 측면에 따라, 본원에 기재된 폴리펩티드를 포함하는 항체 또는 그의 단편이 제공된다.
한 측면에 따라, (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) 단편 결정화가능한 (Fc) 영역을 포함하는 융합 폴리펩티드가 제공되고, Fc 영역은 I253A 돌연변이를 포함하고, 넘버링은 EU 인덱스에 따른 것이다.
한 측면에서, Fc 영역은 LALAP (L234A/L235A/P329G) 돌연변이를 추가로 포함하고, 넘버링은 EU 인덱스에 따른 것이다.
한 측면에서, Fc 영역은 IgG1 Fc 영역이다.
한 측면에서, 나노케이지 단량체는 페리틴 단량체이다.
한 측면에서, 페리틴 단량체는 페리틴 경쇄이다.
한 측면에서, 페리틴 경쇄는 인간 페리틴 경쇄이다.
한 측면에서, Fc 영역은 아미노산 링커를 통해 나노케이지 단량체 또는 그의 서브유닛에 연결된다.
한 측면에서, Fc 영역은 나노케이지 단량체 또는 그의 서브유닛의 N-말단에 연결된다.
한 측면에서, Fc 영역은 단일 쇄 Fc (scFc)이다.
한 측면에서, Fc 영역은 Fc 단량체이다.
한 측면에 따라, 하기를 포함하는 자가-조립된 폴리펩티드 복합체가 제공된다:
(a) 복수개의 제1 융합 폴리펩티드, 여기서 각각의 제1 융합 폴리펩티드는 (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) Fc 영역을 포함함, 및
(b) 복수개의 제2 융합 폴리펩티드, 여기서 각각의 제2 융합 폴리펩티드는 (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) SARS-CoV-2-결합 항체 단편을 포함함.
한 측면에서, 나노케이지 단량체는 페리틴 단량체이다.
한 측면에서, 나노케이지 단량체는 페리틴 경쇄이다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 임의의 페리틴 중쇄, 또는 페리틴 중쇄의 서브유닛을 포함하지 않는다.
한 측면에서, 나노케이지 단량체는 인간 페리틴 경쇄이다.
한 측면에서, SARS-CoV-2-결합 항체 단편은 SARS-CoV-2의 수용체 결합 도메인 또는 스파이크 단백질에 결합한다.
한 측면에서, SARS-CoV-2-결합 항체 단편은 경쇄 가변 도메인 및 중쇄 가변 도메인을 포함한다.
한 측면에서, SARS-CoV-2-결합 항체 단편은 SARS-CoV-2에 결합할 수 있는 항체의 Fab를 포함한다.
한 측면에서, SARS-CoV-2-결합 항체 단편은 VK 도메인 및 VH 도메인을 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 1:1 비의 제1 융합 폴리펩티드 대 제2 융합 폴리펩티드를 특징으로 한다.
한 측면에서, Fc 영역은 IgG1 Fc 영역이다.
한 측면에서, Fc 영역은 아미노산 링커를 통해 나노케이지 단량체 또는 그의 서브유닛에 연결된다.
한 측면에서, Fc 영역은 나노케이지 단량체 또는 그의 서브유닛의 N-말단에 연결된다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 총 적어도 24개의 융합 폴리펩티드를 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 총 적어도 32개의 융합 폴리펩티드를 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 총 약 32개의 융합 폴리펩티드를 포함한다.
한 측면에 따라, 하기를 포함하는 자가-조립된 폴리펩티드 복합체가 제공된다:
(a) 복수개의 제1 융합 폴리펩티드, 여기서 각각의 제1 융합 폴리펩티드는 (2) 인간 페리틴 단량체 또는 그의 서브유닛에 연결된 (1) IgG1 Fc 영역을 포함하고, IgG1 Fc 영역은 LALAP (L234A/L235A/P329G) 및 I253A 돌연변이를 포함하고, 넘버링은 EU 인덱스에 따른 것임, 및
(b) 복수개의 제2 융합 폴리펩티드, 여기서 각각의 제2 융합 폴리펩티드는 (1) SARS-CoV-2 단백질에 결합할 수 있는 항체의 Fab 단편을 포함하고, Fab 단편은 (2) 인간 페리틴 단량체 또는 그의 서브유닛에 연결됨.
한 측면에서:
(1) 각각의 제1 융합 폴리펩티드는 C-절반-페리틴인 페리틴 단량체 서브유닛을 포함하고, 각각의 제2 융합 폴리펩티드는 N-절반-페리틴인 페리틴 단량체 서브유닛을 포함하거나; 또는
(2) 각각의 제1 융합 폴리펩티드는 N-절반 페리틴인 페리틴 단량체 서브유닛을 포함하고, 각각의 제2 융합 폴리펩티드는 C-절반-페리틴인 페리틴 단량체 서브유닛을 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 1:1 비의 제1 융합 폴리펩티드 대 제2 융합 폴리펩티드를 특징으로 한다.
한 측면에서, 각각의 제1 융합 폴리펩티드는 C-절반-페리틴인 페리틴 단량체 서브유닛이다.
한 측면에서, IgG1 Fc 영역은 아미노산 링커를 통해 C-절반-페리틴에 연결된다.
한 측면에서, IgG1 Fc 영역은 C-절반-페리틴의 N-말단을 통해 C-절반-페리틴에 연결된다.
한 측면에서, 각각의 제2 융합 폴리펩티드는 N-절반-페리틴인 페리틴 단량체 서브유닛을 포함한다.
한 측면에서, Fab 단편은 아미노산 링커를 통해 N-절반-페리틴에 연결된다.
한 측면에서, Fab 단편은 N-절반-페리틴의 N-말단을 통해 N-절반-페리틴에 연결된다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 복수개의 제3 융합 폴리펩티드를 추가로 포함하고, 각각의 제3 융합 폴리펩티드는 (2) SARS-CoV-2 단백질에 결합할 수 있는 항체의 Fab 단편에 연결된 (1) 인간 페리틴 단량체를 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 1:1:2 비의 제1 융합 폴리펩티드 대 제2 융합 폴리펩티드 대 제3 융합 폴리펩티드를 특징으로 한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 총 적어도 24개의 융합 폴리펩티드를 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 총 적어도 32개의 융합 폴리펩티드를 포함한다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 총 32개의 융합 폴리펩티드를 갖는다.
한 측면에서, Fab 단편은 VK 도메인 및 VH 도메인을 포함하고,
(1) VK 도메인은 서열식별번호:11의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:12의 아미노산 서열을 갖거나;
(2) VK 도메인은 서열식별번호:17의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:18의 아미노산 서열을 갖거나;
(3) VK 도메인은 서열식별번호:25 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:26 내의 VH의 아미노산 서열을 갖거나;
(4) VK 도메인은 서열식별번호:27 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:28 내의 VH의 아미노산 서열을 갖거나;
(5) VK 도메인은 서열식별번호:29 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:30 내의 VH의 아미노산 서열을 갖거나;
(6) VK 도메인은 서열식별번호:31 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:32 내의 VH의 아미노산 서열을 갖거나;
(7) VK 도메인은 서열식별번호:33 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:34 내의 VH의 아미노산 서열을 갖거나;
(8) VK 도메인은 서열식별번호:35 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:36 내의 VH의 아미노산 서열을 갖거나;
(9) VK 도메인은 서열식별번호:37 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:38 내의 VH의 아미노산 서열을 갖거나;
(10) VK 도메인은 서열식별번호:39 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:40 내의 VH의 아미노산 서열을 갖거나;
(11) VK 도메인은 서열식별번호:41 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:42 내의 VH의 아미노산 서열을 갖거나;
(12) VK 도메인은 서열식별번호:43 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:44 내의 VH의 아미노산 서열을 갖거나;
(13) VK 도메인은 서열식별번호:45 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:46 내의 VH의 아미노산 서열을 갖거나;
(14) VK 도메인은 서열식별번호:47 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:48 내의 VH의 아미노산 서열을 갖거나;
(15) VK 도메인은 서열식별번호:49 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:50 내의 VH의 아미노산 서열을 갖거나;
(16) VK 도메인은 서열식별번호:51 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:52 내의 VH의 아미노산 서열을 갖거나;
(17) VK 도메인은 서열식별번호:53 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:54 내의 VH의 아미노산 서열을 갖거나;
(18) VK 도메인은 서열식별번호:55 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:56 내의 VH의 아미노산 서열을 갖거나;
(19) VK 도메인은 서열식별번호:57 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:58 내의 VH의 아미노산 서열을 갖거나;
(20) VK 도메인은 서열식별번호:59 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:60 내의 VH의 아미노산 서열을 갖거나;
(21) VK 도메인은 서열식별번호:61 또는 서열식별번호:62 내의 VK의 아미노산 서열을 갖고, VH 도메인은 서열식별번호:63 내의 VH의 아미노산 서열을 갖거나; 또는
(22) VK 도메인이 서열식별번호:64 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:65 내의 VH의 아미노산 서열을 갖는다.
한 측면에서, 인간 페리틴 단량체는 인간 페리틴 경쇄이다.
한 측면에서, 자가-조립된 폴리펩티드 복합체는 임의의 페리틴 중쇄, 또는 페리틴 중쇄의 서브유닛을 포함하지 않는다.
한 측면에 따라, 대상체에게 본원에 기재된 자가-조립된 폴리펩티드 복합체를 포함하는 조성물을 투여하는 것을 포함하는, SARS-CoV-2-관련 상태를 치료하거나, 개선시키거나 또는 예방하는 방법이 제공된다.
한 측면에서, 대상체는 포유동물이다.
한 측면에서, 대상체는 인간이다.
본 발명의 신규한 특징은 본 발명의 하기 상세한 설명을 검토함으로써 관련 기술분야의 통상의 기술자에게 명백해질 것이다. 그러나, 본 발명의 사상 및 범위 내에서 다양한 변화 및 변형이 하기 본 발명의 상세한 설명 및 청구항으로부터 관련 기술분야의 통상의 기술자에게 명백해질 것이기 때문에, 본 발명의 상세한 설명 및 제시된 구체적인 실시예가 본 발명의 특정 측면을 나타내지만 단지 설명을 위한 목적으로 제공됨을 이해해야 한다.
본 발명은 도면을 참조하여 하기 설명으로부터 추가로 이해될 것이다:
도 1. 결합도(Avidity)는 SARS-CoV-2의 VHH의 결합 및 중화를 증강시킨다. a 단량체성 VHH 도메인, 및 통상적인 Fc (짙은 적색) 스캐폴드 또는 인간 아포페리틴 (회색)을 사용한 그의 다량체화의 개략적 표현. b 아포페리틴 단독 (회색) 및 VHH-72 아포페리틴 입자 (금색)의 크기 배제 크로마토그래피 및 SDS-PAGE. c VHH-72 아포페리틴 입자의 음성 염색 전자 현미경. (축척 막대 50 nm, 2회의 독립적인 실험을 대표함). d 2가 (짙은 적색) 또는 24-량체 (금색) 포맷으로 디스플레이될 때 SARS-CoV-2 S 단백질에 대한 VHH-72의 결합도 (겉보기 KD)의 비교. 막대는 n = 2 생물학적으로 독립적인 실험의 평균 값을 나타낸다. 10-12 M (점선)보다 낮은 겉보기 KD는 장비 검출 한계를 벗어난다. e SARS-CoV-2 PsV에 대한 중화 효능 (색상 코딩은 (d)에서와 같음). 유사한 결과를 갖는 2개의 생물학적으로 독립적인 반복 중 1개의 대표가 도시된다. 2개의 기술적 반복의 평균 값 ± SD는 플롯에 표시된다. 2개의 생물학적으로 독립적인 반복의 중간 IC50 값이 도시된다.
도 2. Fab 52 및 298과 RBD의 결합 계면. Fab 298 (a) 및 52 (b)와 RBD (코어 및 RBM 영역의 경우 각각 밝은 및 짙은 녹색)의 상호작용은 상보성 결정 영역 (CDR) 중쇄 (H) 1 (황색), H2 (오렌지색), H3 (적색), 카파 경쇄 (K) 1 (밝은 청색) 및 K3 (보라색)에 의해 매개된다. 중요한 결합 잔기는 막대 (삽도)로 도시된다. H-결합 및 염 가교는 흑색 점선으로 도시된다. Fab의 L 및 H 쇄는 각각 황갈색 및 흰색으로 도시된다. c) RBD에 결합된 ACE2 (좌측) 및 Fab 298 (우측)의 저면도 및 측면도. ACE2-RBD 및 Fab 298-RBD 복합체의 결합 계면의 일부인 RBD 측쇄는 분홍색으로 도시되는 반면에, 주어진 계면에 대해 고유한 RBD 측쇄는 황색으로 도시된다. ACE2의 표면, Fab 298 HC 및 Fab 298 KC의 가변 영역은 각각 흰색, 회색 및 황갈색으로 도시된다. RBD는 (a)에서와 같은 색상을 갖는다. d) RBD (녹색)에 결합될 때 Fab 46 (연분홍색) 및 52 (진분홍색)의 중첩은 2가지 mAb에 대한 뚜렷한 접근 각도를 나타낸다. e) 298-RBD 및 f) 52-RBD의 계면에서 1.3 시그마로 윤곽이 잡힌 합성 생략 맵 전자 밀도의 입체-영상.
도 3. 마우스 대용물 멀타바디(multabody)의 생체이용률, 생체분포, 및 면역원성. a 모 IgG와 비교하여 마우스 FcγRI (좌측), 및 엔도좀 (중간) 및 생리학적 (우측) pH에서 마우스 FcRn에 대한 WT 및 Fc-변형된 (LALAP 돌연변이) MB의 결합 동역학. 100 내지 3 nM (IgG) 및 10 내지 0.3 nM (MB)의 2배 희석 계열을 사용하였다. 적색선은 원시 데이터를 나타내고; 흑색선은 전역 대입을 나타낸다. b 그룹당 5마리의 수컷 C57BL/6 마우스를 사용하여 5 mg/kg의 피하 투여 후에 대용물 마우스 MB, Fc-변형된 MB (LALAP 돌연변이), 및 모 마우스 IgG (IgG1 및 IgG2a 아형)의 혈청 농도를 평가하였다. c MB 및 IgG2a 샘플을 라이브 비침습적 2D 전신 영상화를 통해 3마리의 수컷 BALB/c 마우스/그룹에게 피하 주사 후 그들의 생체분포의 시각화를 위해 알렉사(Alexa)-647로 표지하였다. 멀타바디와 유사한 Rh 값을 갖는 15 nm 형광-표지된 금 나노입자 (GNP)는 비교 대상으로서 도시된다. d 그룹당 5마리의 수컷 C57BL/6 마우스를 사용하여 모 IgG 및 헬리코박터 파이로리(Helicobacter pylori) 페리틴 (HpFerr)에 융합된 종-불일치 말라리아 PfCSP 펩티드와 비교하여 마우스 대용물 멀타바디에 의해 유도된 임의의 항-약물-항체 반응을 평가하였다. n = 5마리 마우스의 평균 값 ± SD는 (b) 및 (d)에 도시된다.
도 4. 대용물 마우스 멀타바디의 3D 생체분포는 그의 모 IgG와 비슷하다. 라이브 비침습적 3D 전신 영상화를 통해 BALB/c 마우스에게 피하 주사 후 알렉사-647로 표지된 15 nm 금 나노입자 (GNP), MB 및 IgG 샘플의 생체분포가 시각화되었다. a) PBS 주사 대조군으로부터의 CT 스캔으로 오버레이된 대표적인 3D 렌더링 형광 영상. b) CT 스캔으로 오버레이된 주요 마우스 장기의 국소화의 묘사. c) 금 나노입자 (상부), MB (3개의 중간 패널) 또는 IgG (하부 패널)의 피하 주사 후 1시간 (1H), 2일 (D2), 8일 (D8) 및 11일 (D11)째에 CT 스캔으로 오버레이된 3D 렌더링 형광 영상. CT 스캔으로 오버레이된 배면도 (우측), 뿐만 아니라 신호 국소화를 기반으로 하여 선택된 정면 (상부 좌측), 내측면 (중간), 및 횡단면 (하부 좌측)을 도시하는 각각의 3D 영상 세트가 디스플레이된다. 3D 형광 영상은 레인보우 룩업 표 (LUT)에 맵핑되었고, 색상 규모 최소값은 배경으로 설정되고, 최대값은 50 pmol M-1 cm-1 (GNP) 또는 1000 pmol M-1 cm-1 (MB 및 IgG)로 설정되었다.
도 5. SARS-CoV-2에 대한 IgG-유사 입자를 다량체화하기 위한 단백질 조작. a 인간 아포페리틴 분할 설계의 개략적 표현. b MB의 음성 염색 전자 현미경 사진. (축척 막대 50 nm, 2회의 독립적인 실험을 대표함). c MB의 유체역학적 반경 (Rh). d SARS-CoV-2 스파이크에 대한 4A8 (보라색) 및 BD23 (회색)의 결합 (겉보기 KD)의 결합도 효과. e FcγRI (상부 행), 엔도좀 pH에서 FcRn (중간 행) 및 생리학적 pH에서 FcRn (하부 행)에 결합하는 상이한 Fc 서열 변이체를 갖는 BD23 IgG 및 MB의 센소그램. 적색선은 원시 데이터를 나타내는 반면에, 흑색선은 전역 대입을 나타낸다. f 4A8 및 BD23 IgG 및 MB에 의한 SARS-CoV-2 PsV의 중화. 3개의 생물학적으로 독립적인 샘플의 대표적인 데이터. 2개의 기술적 반복에 대한 평균 값 ± SD가 각각의 중화 플롯에 도시된다. 3개의 생물학적으로 독립적인 반복의 중간 IC50 값이 표시된다.
도 6. 멀타바디는 파지 디스플레이로부터 인간 mAb의 효능을 증강시킨다. a MB 기술을 이용하여 강력한 항-SARS-CoV-2 중화제의 확인을 위한 작업 흐름. 바이오렌더(Biorender)에 의해 생성됨. b 파지 디스플레이로부터 유래된 동일한 인간 Fab 서열을 디스플레이하는 IgG (청록색)와 MB (분홍색) 사이의 중화 효능의 비교. c 다량체화시 IC50 값 증가 배수. d SARS-CoV-2 S 단백질과의 결합에 대해 그들의 IgG 대응물 (청록색)과 비교하여 가장 강력한 중화 MB (분홍색)의 겉보기 친화도 (KD), 회합 (kon) 및 해리 (koff) 속도. 3개의 생물학적 반복 및 그들의 평균이 (b) 및 (c)에서 IC50 값에 대해 도시된다.
도 7. SARS-CoV-2 RBD-표적화 멀타바디 및 그들의 모 IgG의 중화. a) IgG (흑색) 및 MB (짙은 적색)로서 디스플레이될 때 SARS-CoV-2 PsV에 대한 20가지 항체의 대표적인 중화 적정 곡선. 3개의 생물학적 반복에 대한 평균 IC50 값이 비교를 위해 디스플레이된다. 2개의 기술적 반복에 대한 평균 값 ± SD이 각각의 중화 플롯에 도시된다. b) SARS-CoV-2 PsV 표적화 293T-ACE2 (흑색) 및 HeLa-ACE2 (회색) 표적 세포에 대한 선택된 IgG 및 MB의 중화 프로파일. 3개 및 2개의 생물학적 반복의 평균 IC50 값 및 개별 IC50 값이 각각 293T-ACE2 및 HeLa-ACE2 세포에 대해 도시된다. c) 진정한 SARS-CoV-2/SB2-P4-PB 균주에 대한 3개의 생물학적 반복 (상이한 회색 음영)의 중화 적정 곡선. 평균 IC50이 표시된다. 재조합 mAb REGN10933 (적색) 및 REGN10987 (청색)의 중화 효능은 비교를 위한 벤치마커로서 (a) 및 (c)에 포함된다.
도 8. SARS-CoV-2 RBD-표적화 멀타바디의 발현 수율 및 균질성. a) 7가지 가장 강력한 IgG (흰색) 및 그들의 각각의 MB (짙은 적색)의 수율 (mg/L). 2개의 생물학적으로 독립적인 샘플에 대한 평균 값 ± SD. b) (a)에서와 같이 응집 온도 (Tagg, ℃) 비교. 실선은 2개의 생물학적으로 독립적인 샘플의 평균 Tagg 값을 나타낸다. c) 3회의 독립적인 발현 및 정제로부터 298 IgG (상부 행, 흑색) 및 298 MB (하부 행, 짙은 적색)의 SEC 크로마토그램. SEC 전에, 두 경우 모두에서, 단백질 A 친화도 크로마토그래피를 이용하여 샘플을 정제하였다. 화살표는 각각의 배치로부터 PsV 중화 검정을 수행하기 위해 사용된 피크를 나타낸다. IC50 값 (μg/mL)이 표시된다. 2개의 기술적 반복에 대한 평균 값 ± SD가 각각의 중화 플롯에 도시된다.
도 9. IgG 및 MB의 결합 프로파일. Ni-NTA 바이오센서 상에 고정된 SARS-CoV-2의 RBD (좌측) 및 S 단백질 (우측)에 결합하는 IgG 및 MB의 센소그램. 125 내지 4 nM (IgG) 및 16 내지 0.5 nM (MB)의 2배 희석 계열을 이용하였다. 적색선은 원시 데이터를 나타내고, 흑색선은 전역 대입을 나타낸다.
도 10. 가장 강력한 mAb 특이성의 에피토프 묘사. a RBD (코어의 경우 밝은 녹색, RBM의 경우 짙은 녹색) 및 ACE266 (밝은 갈색) 결합의 표면 및 카튠 표현. 결합 경쟁 실험을 도시하는 히트 맵. 높은 신호 반응 (적색)은 낮은 경쟁을 나타내는 반면에, 낮은 신호 반응 (흰색)은 높은 경쟁에 상응한다. 에피토프 빈은 점선 박스로 강조된다. b Fab 80 (황색), 298 (오렌지색), 및 324 (적색)와 복합체화된 스파이크 (회색)의 15.0 Å 여과된 cryo-EM 재구축. RBD 및 NTD는 각각 녹색 및 청색으로 도시된다. c Fab 46 (분홍색) 및 RBD (녹색) 복합체의 cryo-EM 재구축. RBD66 이차 구조 카튠은 RBD에 대해 관찰된 부분 밀도에 맞춰진다. d Fab 52 (보라색), Fab 298 (오렌지색), 및 RBD (녹색)에 의해 형성된 삼원 복합체의 결정 구조. e 이용가능한 PDB 또는 EMD 항목3,4,9,10,13,15,17,67,68,69,70,71,72에 의해 비리간드 (PDB 6XM4) 및 항체-결합된 SARS-CoV-2 스파이크의 측면도 및 상면도를 도시하는 합성 영상. 삽도: RBD 상의 상이한 항원 부위를 표적화하는 항체의 근접도. SARS-CoV-2 PsV에 대해 가장 낮은 보고된 IC50 값을 갖는 mAb는 빈의 대표적인 항체 (굵게 강조됨)로서 선택되었고, 유사한 결합 에피토프를 갖는 이들 항체는 동일한 색상으로 아래에 나열된다 (스파이크, NTD 및 RBD의 색상 코딩은 (b)에서와 같음). 비리간드 스파이크에서 개별 프로모터는 흰색, 분홍색, 및 보라색으로 도시된다.
도 11. 에피토프 비닝. 생물층 간섭법 (BLI)에 의해 측정되는 His-태그 부착된 RBD에 대한 mAb 결합 경쟁 실험. 50 μg/ml의 mAb 1을 3분 동안 인큐베이션한 후, 50 μg/ml의 mAb 2와 함께 5분 동안 인큐베이션하였다.
도 12. Fab-스파이크 및 Fab-RBD 복합체의 cryo-EM 분석. 대표적인 cryo-EM 현미경 사진 (축척 막대 50 nm, 상부 좌측), 선택된 2D 부류 평균 (상부 우측), 최종 3D 불균일 정련으로부터 푸리에(Fourier) 쉘 상관관계 곡선 (하부 좌측) 및 cryo-EM 맵의 표면 상에 플롯된 국소 해상도 (Å) (하부 우측)가 Fab 80-스파이크 복합체 (a), Fab 298-스파이크 복합체 (b), Fab 324-스파이크 복합체 (c), 및 Fab 46-RBD 복합체 (d)에 대해 도시된다.
도 13. 멀타바디는 SARS-CoV-2 서열 다양성을 극복한다. a 구체로서 4가지 천연 발생 돌연변이를 도시하는 RBD의 카튠 표현. mAb 52 (연분홍색) 및 298 (황색)의 에피토프는 각각의 빈의 대표적인 에피토프로서 도시된다. 각각 WT와 돌연변이된 RBD 및 PsV 사이의 b 친화도 및 c IC50 변화 배수 비교. d WT PsV와 비교하여 SARS-CoV-2 PsV 변이체에 대한 IgG (회색 막대) 대 MB (짙은 적색 막대)의 중화 효능. e WT SARS-CoV-2 PsV 및 변이체에 대한 2가지 IgG 칵테일 (3개의 IgG), 단일특이적 MB 칵테일 (3개의 MB) 및 삼중-특이적 MB의 중화 효능 비교. 칵테일 및 삼중-특이적 MB를 생성하기 위해 1가지 이상의 PsV 변이체 (d)에 대해 민감한 mAb가 선택되었다. f SARS-CoV-2 B.1.351 PsV 변이체에 대한 삼중-특이적 298-80-52 MB 중화 효능. g PsV에서 IC50 값 (y-축) 및 복제 가능 SARS-CoV-2 바이러스 (SB2-P4-PB: x-축)는 광범위한 mAb 특징 (청색 및 흑색)에 걸쳐 효능을 증강시키는 삼중-특이적 MB (적색)의 능력을 입증함. h 다량체화시 IC50 값 증가 배수. 3개의 생물학적 반복의 평균이 도시된다 (b-h).
도 14. MB는 SARS-CoV-2 서열 가변성을 강력하게 극복한다. a) WT PsV (짙은 적색) 및 더욱 감염성인 D614G PsV (회색)에 대한 선택된 IgG 및 MB의 중화 효능의 비교. b) MB 분할 설계를 이용하여 3가지 Fab 특이성 및 Fc 단편의 조합에 의해 생성된 삼중-특이적 MB의 개략적 표현. c) mAb 298, 80 및 52, 또는 298, 324 및 46의 특이성을 조합한 칵테일 및 삼중-특이적 MB를 생성하고, WT PsV에 대해 시험하였다. 2개의 기술적 반복에 대한 평균 값 ± SD는 각각의 대표적인 중화 플롯에 표시된다. 소스 데이터는 소스 데이터 파일로서 제공된다. d) WT PsV와 비교하여 위형 SARS-CoV-2 변이체에 대한 칵테일 및 삼중-특이적 MB의 중화 효능 변화. 칵테일 내의 개별 항체에 대해 민감성인 PsV 변이체를 선택하였다. 점선 내의 영역은 IC50 값에서 3배 변화를 나타낸다. 이 임계값은 증가된 민감도 (위쪽 막대) 또는 증가된 내성 (아래쪽 막대)에 대한 컷오프로서 확립되었다. e) 진정한 SARS-CoV-2/SB2-P4-PB 균주에 대한 칵테일 및 삼중-특이적 MB의 3개의 생물학적 반복을 도시하는 중화 적정 곡선. 3개의 생물학적으로 독립적인 반복의 평균 IC50 값이 도시된다.
도 15. N92T 돌연변이는 WT 슈도바이러스 중화 검정에서 IgG 또는 단일특이적 MB 둘 다로서 효능에 어떠한 영향도 미치지 않았다.
도 16. mAb 52의 VL에서 N92T 돌연변이를 함유하는 298-80-52 삼중특이적 MB를 P.1 PsV 중화 검정에서 스크리닝하였고, 그 결과 모 삼중특이적 MB와 비교하여 관찰된 효능에서 손실이 없었음이 확인되었다.
도 17. 예시적인 삼중특이적 MB, 298-80-52는 슈도바이러스 중화 검정에서 우려되는 변이체 (VOC)에 대한 효능에 대해 평가되었다.
도 1. 결합도(Avidity)는 SARS-CoV-2의 VHH의 결합 및 중화를 증강시킨다. a 단량체성 VHH 도메인, 및 통상적인 Fc (짙은 적색) 스캐폴드 또는 인간 아포페리틴 (회색)을 사용한 그의 다량체화의 개략적 표현. b 아포페리틴 단독 (회색) 및 VHH-72 아포페리틴 입자 (금색)의 크기 배제 크로마토그래피 및 SDS-PAGE. c VHH-72 아포페리틴 입자의 음성 염색 전자 현미경. (축척 막대 50 nm, 2회의 독립적인 실험을 대표함). d 2가 (짙은 적색) 또는 24-량체 (금색) 포맷으로 디스플레이될 때 SARS-CoV-2 S 단백질에 대한 VHH-72의 결합도 (겉보기 KD)의 비교. 막대는 n = 2 생물학적으로 독립적인 실험의 평균 값을 나타낸다. 10-12 M (점선)보다 낮은 겉보기 KD는 장비 검출 한계를 벗어난다. e SARS-CoV-2 PsV에 대한 중화 효능 (색상 코딩은 (d)에서와 같음). 유사한 결과를 갖는 2개의 생물학적으로 독립적인 반복 중 1개의 대표가 도시된다. 2개의 기술적 반복의 평균 값 ± SD는 플롯에 표시된다. 2개의 생물학적으로 독립적인 반복의 중간 IC50 값이 도시된다.
도 2. Fab 52 및 298과 RBD의 결합 계면. Fab 298 (a) 및 52 (b)와 RBD (코어 및 RBM 영역의 경우 각각 밝은 및 짙은 녹색)의 상호작용은 상보성 결정 영역 (CDR) 중쇄 (H) 1 (황색), H2 (오렌지색), H3 (적색), 카파 경쇄 (K) 1 (밝은 청색) 및 K3 (보라색)에 의해 매개된다. 중요한 결합 잔기는 막대 (삽도)로 도시된다. H-결합 및 염 가교는 흑색 점선으로 도시된다. Fab의 L 및 H 쇄는 각각 황갈색 및 흰색으로 도시된다. c) RBD에 결합된 ACE2 (좌측) 및 Fab 298 (우측)의 저면도 및 측면도. ACE2-RBD 및 Fab 298-RBD 복합체의 결합 계면의 일부인 RBD 측쇄는 분홍색으로 도시되는 반면에, 주어진 계면에 대해 고유한 RBD 측쇄는 황색으로 도시된다. ACE2의 표면, Fab 298 HC 및 Fab 298 KC의 가변 영역은 각각 흰색, 회색 및 황갈색으로 도시된다. RBD는 (a)에서와 같은 색상을 갖는다. d) RBD (녹색)에 결합될 때 Fab 46 (연분홍색) 및 52 (진분홍색)의 중첩은 2가지 mAb에 대한 뚜렷한 접근 각도를 나타낸다. e) 298-RBD 및 f) 52-RBD의 계면에서 1.3 시그마로 윤곽이 잡힌 합성 생략 맵 전자 밀도의 입체-영상.
도 3. 마우스 대용물 멀타바디(multabody)의 생체이용률, 생체분포, 및 면역원성. a 모 IgG와 비교하여 마우스 FcγRI (좌측), 및 엔도좀 (중간) 및 생리학적 (우측) pH에서 마우스 FcRn에 대한 WT 및 Fc-변형된 (LALAP 돌연변이) MB의 결합 동역학. 100 내지 3 nM (IgG) 및 10 내지 0.3 nM (MB)의 2배 희석 계열을 사용하였다. 적색선은 원시 데이터를 나타내고; 흑색선은 전역 대입을 나타낸다. b 그룹당 5마리의 수컷 C57BL/6 마우스를 사용하여 5 mg/kg의 피하 투여 후에 대용물 마우스 MB, Fc-변형된 MB (LALAP 돌연변이), 및 모 마우스 IgG (IgG1 및 IgG2a 아형)의 혈청 농도를 평가하였다. c MB 및 IgG2a 샘플을 라이브 비침습적 2D 전신 영상화를 통해 3마리의 수컷 BALB/c 마우스/그룹에게 피하 주사 후 그들의 생체분포의 시각화를 위해 알렉사(Alexa)-647로 표지하였다. 멀타바디와 유사한 Rh 값을 갖는 15 nm 형광-표지된 금 나노입자 (GNP)는 비교 대상으로서 도시된다. d 그룹당 5마리의 수컷 C57BL/6 마우스를 사용하여 모 IgG 및 헬리코박터 파이로리(Helicobacter pylori) 페리틴 (HpFerr)에 융합된 종-불일치 말라리아 PfCSP 펩티드와 비교하여 마우스 대용물 멀타바디에 의해 유도된 임의의 항-약물-항체 반응을 평가하였다. n = 5마리 마우스의 평균 값 ± SD는 (b) 및 (d)에 도시된다.
도 4. 대용물 마우스 멀타바디의 3D 생체분포는 그의 모 IgG와 비슷하다. 라이브 비침습적 3D 전신 영상화를 통해 BALB/c 마우스에게 피하 주사 후 알렉사-647로 표지된 15 nm 금 나노입자 (GNP), MB 및 IgG 샘플의 생체분포가 시각화되었다. a) PBS 주사 대조군으로부터의 CT 스캔으로 오버레이된 대표적인 3D 렌더링 형광 영상. b) CT 스캔으로 오버레이된 주요 마우스 장기의 국소화의 묘사. c) 금 나노입자 (상부), MB (3개의 중간 패널) 또는 IgG (하부 패널)의 피하 주사 후 1시간 (1H), 2일 (D2), 8일 (D8) 및 11일 (D11)째에 CT 스캔으로 오버레이된 3D 렌더링 형광 영상. CT 스캔으로 오버레이된 배면도 (우측), 뿐만 아니라 신호 국소화를 기반으로 하여 선택된 정면 (상부 좌측), 내측면 (중간), 및 횡단면 (하부 좌측)을 도시하는 각각의 3D 영상 세트가 디스플레이된다. 3D 형광 영상은 레인보우 룩업 표 (LUT)에 맵핑되었고, 색상 규모 최소값은 배경으로 설정되고, 최대값은 50 pmol M-1 cm-1 (GNP) 또는 1000 pmol M-1 cm-1 (MB 및 IgG)로 설정되었다.
도 5. SARS-CoV-2에 대한 IgG-유사 입자를 다량체화하기 위한 단백질 조작. a 인간 아포페리틴 분할 설계의 개략적 표현. b MB의 음성 염색 전자 현미경 사진. (축척 막대 50 nm, 2회의 독립적인 실험을 대표함). c MB의 유체역학적 반경 (Rh). d SARS-CoV-2 스파이크에 대한 4A8 (보라색) 및 BD23 (회색)의 결합 (겉보기 KD)의 결합도 효과. e FcγRI (상부 행), 엔도좀 pH에서 FcRn (중간 행) 및 생리학적 pH에서 FcRn (하부 행)에 결합하는 상이한 Fc 서열 변이체를 갖는 BD23 IgG 및 MB의 센소그램. 적색선은 원시 데이터를 나타내는 반면에, 흑색선은 전역 대입을 나타낸다. f 4A8 및 BD23 IgG 및 MB에 의한 SARS-CoV-2 PsV의 중화. 3개의 생물학적으로 독립적인 샘플의 대표적인 데이터. 2개의 기술적 반복에 대한 평균 값 ± SD가 각각의 중화 플롯에 도시된다. 3개의 생물학적으로 독립적인 반복의 중간 IC50 값이 표시된다.
도 6. 멀타바디는 파지 디스플레이로부터 인간 mAb의 효능을 증강시킨다. a MB 기술을 이용하여 강력한 항-SARS-CoV-2 중화제의 확인을 위한 작업 흐름. 바이오렌더(Biorender)에 의해 생성됨. b 파지 디스플레이로부터 유래된 동일한 인간 Fab 서열을 디스플레이하는 IgG (청록색)와 MB (분홍색) 사이의 중화 효능의 비교. c 다량체화시 IC50 값 증가 배수. d SARS-CoV-2 S 단백질과의 결합에 대해 그들의 IgG 대응물 (청록색)과 비교하여 가장 강력한 중화 MB (분홍색)의 겉보기 친화도 (KD), 회합 (kon) 및 해리 (koff) 속도. 3개의 생물학적 반복 및 그들의 평균이 (b) 및 (c)에서 IC50 값에 대해 도시된다.
도 7. SARS-CoV-2 RBD-표적화 멀타바디 및 그들의 모 IgG의 중화. a) IgG (흑색) 및 MB (짙은 적색)로서 디스플레이될 때 SARS-CoV-2 PsV에 대한 20가지 항체의 대표적인 중화 적정 곡선. 3개의 생물학적 반복에 대한 평균 IC50 값이 비교를 위해 디스플레이된다. 2개의 기술적 반복에 대한 평균 값 ± SD이 각각의 중화 플롯에 도시된다. b) SARS-CoV-2 PsV 표적화 293T-ACE2 (흑색) 및 HeLa-ACE2 (회색) 표적 세포에 대한 선택된 IgG 및 MB의 중화 프로파일. 3개 및 2개의 생물학적 반복의 평균 IC50 값 및 개별 IC50 값이 각각 293T-ACE2 및 HeLa-ACE2 세포에 대해 도시된다. c) 진정한 SARS-CoV-2/SB2-P4-PB 균주에 대한 3개의 생물학적 반복 (상이한 회색 음영)의 중화 적정 곡선. 평균 IC50이 표시된다. 재조합 mAb REGN10933 (적색) 및 REGN10987 (청색)의 중화 효능은 비교를 위한 벤치마커로서 (a) 및 (c)에 포함된다.
도 8. SARS-CoV-2 RBD-표적화 멀타바디의 발현 수율 및 균질성. a) 7가지 가장 강력한 IgG (흰색) 및 그들의 각각의 MB (짙은 적색)의 수율 (mg/L). 2개의 생물학적으로 독립적인 샘플에 대한 평균 값 ± SD. b) (a)에서와 같이 응집 온도 (Tagg, ℃) 비교. 실선은 2개의 생물학적으로 독립적인 샘플의 평균 Tagg 값을 나타낸다. c) 3회의 독립적인 발현 및 정제로부터 298 IgG (상부 행, 흑색) 및 298 MB (하부 행, 짙은 적색)의 SEC 크로마토그램. SEC 전에, 두 경우 모두에서, 단백질 A 친화도 크로마토그래피를 이용하여 샘플을 정제하였다. 화살표는 각각의 배치로부터 PsV 중화 검정을 수행하기 위해 사용된 피크를 나타낸다. IC50 값 (μg/mL)이 표시된다. 2개의 기술적 반복에 대한 평균 값 ± SD가 각각의 중화 플롯에 도시된다.
도 9. IgG 및 MB의 결합 프로파일. Ni-NTA 바이오센서 상에 고정된 SARS-CoV-2의 RBD (좌측) 및 S 단백질 (우측)에 결합하는 IgG 및 MB의 센소그램. 125 내지 4 nM (IgG) 및 16 내지 0.5 nM (MB)의 2배 희석 계열을 이용하였다. 적색선은 원시 데이터를 나타내고, 흑색선은 전역 대입을 나타낸다.
도 10. 가장 강력한 mAb 특이성의 에피토프 묘사. a RBD (코어의 경우 밝은 녹색, RBM의 경우 짙은 녹색) 및 ACE266 (밝은 갈색) 결합의 표면 및 카튠 표현. 결합 경쟁 실험을 도시하는 히트 맵. 높은 신호 반응 (적색)은 낮은 경쟁을 나타내는 반면에, 낮은 신호 반응 (흰색)은 높은 경쟁에 상응한다. 에피토프 빈은 점선 박스로 강조된다. b Fab 80 (황색), 298 (오렌지색), 및 324 (적색)와 복합체화된 스파이크 (회색)의 15.0 Å 여과된 cryo-EM 재구축. RBD 및 NTD는 각각 녹색 및 청색으로 도시된다. c Fab 46 (분홍색) 및 RBD (녹색) 복합체의 cryo-EM 재구축. RBD66 이차 구조 카튠은 RBD에 대해 관찰된 부분 밀도에 맞춰진다. d Fab 52 (보라색), Fab 298 (오렌지색), 및 RBD (녹색)에 의해 형성된 삼원 복합체의 결정 구조. e 이용가능한 PDB 또는 EMD 항목3,4,9,10,13,15,17,67,68,69,70,71,72에 의해 비리간드 (PDB 6XM4) 및 항체-결합된 SARS-CoV-2 스파이크의 측면도 및 상면도를 도시하는 합성 영상. 삽도: RBD 상의 상이한 항원 부위를 표적화하는 항체의 근접도. SARS-CoV-2 PsV에 대해 가장 낮은 보고된 IC50 값을 갖는 mAb는 빈의 대표적인 항체 (굵게 강조됨)로서 선택되었고, 유사한 결합 에피토프를 갖는 이들 항체는 동일한 색상으로 아래에 나열된다 (스파이크, NTD 및 RBD의 색상 코딩은 (b)에서와 같음). 비리간드 스파이크에서 개별 프로모터는 흰색, 분홍색, 및 보라색으로 도시된다.
도 11. 에피토프 비닝. 생물층 간섭법 (BLI)에 의해 측정되는 His-태그 부착된 RBD에 대한 mAb 결합 경쟁 실험. 50 μg/ml의 mAb 1을 3분 동안 인큐베이션한 후, 50 μg/ml의 mAb 2와 함께 5분 동안 인큐베이션하였다.
도 12. Fab-스파이크 및 Fab-RBD 복합체의 cryo-EM 분석. 대표적인 cryo-EM 현미경 사진 (축척 막대 50 nm, 상부 좌측), 선택된 2D 부류 평균 (상부 우측), 최종 3D 불균일 정련으로부터 푸리에(Fourier) 쉘 상관관계 곡선 (하부 좌측) 및 cryo-EM 맵의 표면 상에 플롯된 국소 해상도 (Å) (하부 우측)가 Fab 80-스파이크 복합체 (a), Fab 298-스파이크 복합체 (b), Fab 324-스파이크 복합체 (c), 및 Fab 46-RBD 복합체 (d)에 대해 도시된다.
도 13. 멀타바디는 SARS-CoV-2 서열 다양성을 극복한다. a 구체로서 4가지 천연 발생 돌연변이를 도시하는 RBD의 카튠 표현. mAb 52 (연분홍색) 및 298 (황색)의 에피토프는 각각의 빈의 대표적인 에피토프로서 도시된다. 각각 WT와 돌연변이된 RBD 및 PsV 사이의 b 친화도 및 c IC50 변화 배수 비교. d WT PsV와 비교하여 SARS-CoV-2 PsV 변이체에 대한 IgG (회색 막대) 대 MB (짙은 적색 막대)의 중화 효능. e WT SARS-CoV-2 PsV 및 변이체에 대한 2가지 IgG 칵테일 (3개의 IgG), 단일특이적 MB 칵테일 (3개의 MB) 및 삼중-특이적 MB의 중화 효능 비교. 칵테일 및 삼중-특이적 MB를 생성하기 위해 1가지 이상의 PsV 변이체 (d)에 대해 민감한 mAb가 선택되었다. f SARS-CoV-2 B.1.351 PsV 변이체에 대한 삼중-특이적 298-80-52 MB 중화 효능. g PsV에서 IC50 값 (y-축) 및 복제 가능 SARS-CoV-2 바이러스 (SB2-P4-PB: x-축)는 광범위한 mAb 특징 (청색 및 흑색)에 걸쳐 효능을 증강시키는 삼중-특이적 MB (적색)의 능력을 입증함. h 다량체화시 IC50 값 증가 배수. 3개의 생물학적 반복의 평균이 도시된다 (b-h).
도 14. MB는 SARS-CoV-2 서열 가변성을 강력하게 극복한다. a) WT PsV (짙은 적색) 및 더욱 감염성인 D614G PsV (회색)에 대한 선택된 IgG 및 MB의 중화 효능의 비교. b) MB 분할 설계를 이용하여 3가지 Fab 특이성 및 Fc 단편의 조합에 의해 생성된 삼중-특이적 MB의 개략적 표현. c) mAb 298, 80 및 52, 또는 298, 324 및 46의 특이성을 조합한 칵테일 및 삼중-특이적 MB를 생성하고, WT PsV에 대해 시험하였다. 2개의 기술적 반복에 대한 평균 값 ± SD는 각각의 대표적인 중화 플롯에 표시된다. 소스 데이터는 소스 데이터 파일로서 제공된다. d) WT PsV와 비교하여 위형 SARS-CoV-2 변이체에 대한 칵테일 및 삼중-특이적 MB의 중화 효능 변화. 칵테일 내의 개별 항체에 대해 민감성인 PsV 변이체를 선택하였다. 점선 내의 영역은 IC50 값에서 3배 변화를 나타낸다. 이 임계값은 증가된 민감도 (위쪽 막대) 또는 증가된 내성 (아래쪽 막대)에 대한 컷오프로서 확립되었다. e) 진정한 SARS-CoV-2/SB2-P4-PB 균주에 대한 칵테일 및 삼중-특이적 MB의 3개의 생물학적 반복을 도시하는 중화 적정 곡선. 3개의 생물학적으로 독립적인 반복의 평균 IC50 값이 도시된다.
도 15. N92T 돌연변이는 WT 슈도바이러스 중화 검정에서 IgG 또는 단일특이적 MB 둘 다로서 효능에 어떠한 영향도 미치지 않았다.
도 16. mAb 52의 VL에서 N92T 돌연변이를 함유하는 298-80-52 삼중특이적 MB를 P.1 PsV 중화 검정에서 스크리닝하였고, 그 결과 모 삼중특이적 MB와 비교하여 관찰된 효능에서 손실이 없었음이 확인되었다.
도 17. 예시적인 삼중특이적 MB, 298-80-52는 슈도바이러스 중화 검정에서 우려되는 변이체 (VOC)에 대한 효능에 대해 평가되었다.
특정 측면의 상세한 설명
정의
달리 설명되지 않는다면, 본원에서 사용된 모든 기술적 및 과학적 용어들은 본 개시내용이 속하는 기술분야의 통상의 기술자에 의해 일반적으로 이해되는 것과 동일한 의미를 갖는다. 분자 생물학에서 일반적인 용어의 정의는 [Benjamin Lewin, Genes V, published by Oxford University Press, 1994 (ISBN 0-19-854287-9); Kendrew et al. (eds.), The Encyclopedia of Molecular Biology, published by Blackwell Science Ltd., 1994 (ISBN 0-632-02182-9); and Robert A. Meyers (ed.), Molecular Biology and Biotechnology: a Comprehensive Desk Reference, published by VCH Publishers, Inc., 1995 (ISBN 1-56081-569-8)]에서 확인할 수 있다. 본원에 기재된 것과 유사하거나 또는 등가인 임의의 방법 및 물질이 본 발명의 시험을 위한 실시에서 사용될 수 있지만, 전형적인 물질 및 방법이 본원에 기재된다. 본 발명을 기재하고 청구하는데 있어서, 하기 용어가 사용될 것이다.
본원에서 사용된 용어가 단지 특정한 측면을 기재하기 위한 것이며, 제한하는 것으로 의도되지 않음을 또한 이해해야 한다. 여러 특허 출원, 특허 및 공보는 기재된 측면을 이해하는데 도움이 되도록 본원에서 참조된다. 이들 각각의 문헌은 그들의 전문이 본원에 참조로 포함된다.
본 출원의 범위를 이해하는데 있어서, 단수 형태는 하나 이상의 요소가 있음을 의미하는 것으로 의도된다. 추가로, 본원에서 사용된 용어 "포함하는" 및 그의 파생어는 명시된 특징, 요소, 성분, 그룹, 정수 및/또는 단계의 존재를 명시하는 개방형 용어로 의도되지만, 다른 명시되지 않은 특징, 요소, 성분, 그룹, 정수 및/또는 단계의 존재를 배제하지 않는다. 상기 내용은 유사한 의미를 갖는 단어, 예컨대 용어 "비롯한", "갖는" 및 그들의 파생어에 대해서도 적용된다.
특정 성분을 "포함하는" 것으로 기재된 임의의 측면이 또한 "이루어지는" 또는 "본질적으로 이루어지는" 것일 수 있음을 이해할 것이며, 여기서 "이루어지는"은 "폐쇄형" 또는 제한적인 의미를 갖고, "본질적으로 이루어지는"은 명시된 성분을 포함하지만, 불순물로서 존재하는 물질, 성분을 제공하기 위해 이용되는 과정의 결과로서 불가피하게 존재하는 물질, 및 본 발명의 기술적 효과를 달성하는 것이 아닌 목적을 위해 첨가된 성분을 제외한 다른 성분은 배제한다. 예를 들어, 문구 "본질적으로 이루어지는"을 이용하여 정의된 조성물은 임의의 공지된 허용가능한 첨가제, 부형제, 희석제, 담체 등을 포함한다. 전형적으로, 성분들의 집합으로 본질적으로 이루어지는 조성물은 5 중량% 미만, 전형적으로 3 중량% 미만, 더욱 전형적으로 1 중량% 미만, 및 훨씬 더 전형적으로 0.1 중량% 미만의 명시되지 않은 성분(들)을 포함할 것이다.
포함되는 것으로 본원에서 정의된 임의의 성분이 단서 또는 부정적인 제한의 방식으로 청구된 발명으로부터 명시적으로 제외될 수 있음을 이해할 것이다. 예를 들어, 일부 측면에서 본원에 기재된 나노케이지 및/또는 융합 단백질은 페리틴 중쇄를 배제할 수 있고/거나 철-결합 성분을 배제할 수 있다.
또한, 본원에 제공된 모든 범위는 명시적으로 언급되었는지 여부와 무관하게 범위의 종점 및 임의의 중간 범위 지점 또한 포함한다.
본원에서 사용된 "실질적으로", "약" 및 "대략"과 같은 정도의 용어는 최종 결과가 유의하게 변하지 않도록 변형된 용어의 합리적인 편차를 의미한다. 이들 정도의 용어는 편차가 수식하는 단어의 의미를 부정하지 않는다면 변형된 용어의 최대 및 적어도 ±5%의 편차를 포함하는 것으로 해석되어야 한다. 예를 들어, 용어 "약"은 참조된 값의 25%, 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, 또는 그 미만 이내에 속하는 값의 범위를 포함할 수 있다.
약어 "예를 들어"는 라틴어 "exempli gratia"로부터 파생되었으며, 비제한적인 예를 나타내기 위해 본원에서 사용된다. 따라서, 약어 "예를 들어"는 용어 "예를 들어" 또는 "예컨대"와 동의어이다. 단어 "또는"은 문맥상 달리 명확하게 나타내지 않는다면 "및"을 포함하는 것으로 의도된다.
본원에서 사용된 용어 "대상체"는 동물계의 임의의 구성원, 전형적으로 포유동물을 지칭한다. 용어 "포유동물"은 인간, 다른 고등 영장류, 가축 및 농장 동물, 및 동물원, 스포츠 또는 애완 동물, 예컨대 개, 고양이, 소, 말, 양, 돼지, 염소, 토끼 등을 비롯한 포유동물로서 분류되는 임의의 동물을 지칭한다. 전형적으로, 포유동물은 인간이다.
용어 "단백질 나노입자", "나노케이지" 및 "멀타바디"는 본원에서 상호교환적으로 사용되며, 다중-서브유닛, 단백질-기반 다면체 형상 구조를 지칭한다. 서브유닛 또는 나노케이지 단량체 각각은 단백질 또는 폴리펩티드 (예를 들어 글리코실화된 폴리펩티드)로 구성되고, 임의적으로 다음 중 단일 또는 다중 특징으로 구성된다: 핵산, 보결분자단, 유기 및 무기 화합물. 단백질 나노입자의 비제한적인 예에는 페리틴 나노입자 (예를 들어, [Zhang, Y. Int. J. Mol. Sci., 12:5406-5421, 2011] 참조, 본원에 참조로 포함됨), 엔캡슐린 나노입자 (예를 들어, [Sutter et al., Nature Struct, and Mol. Biol., 15:939-947, 2008] 참조, 본원에 참조로 포함됨), 황 옥시게나제 리덕타제 (SOR) 나노입자 (예를 들어, [Urich et al., Science, 311 :996-1000, 2006] 참조, 본원에 참조로 포함됨), 루마진 신타제 나노입자 (예를 들어, [Zhang et al., J. Mol. Biol., 306: 1099-1114, 2001] 참조) 또는 피루베이트 데히드로게나제 나노입자 (예를 들어, [Izard et al., PNAS 96: 1240-1245, 1999] 참조, 본원에 참조로 포함됨)가 포함된다. 페리틴, 아포페리틴, 엔캡슐린, SOR, 루마진 신타제, 및 피루베이트 데히드로게나제는 일부 경우에 각각 24, 60, 24, 60 및 60개의 단백질 서브유닛으로 이루어지는 구형 단백질 복합체로 자가-조립하는 단량체성 단백질이다. 페리틴 및 아포페리틴은 일반적으로 본원에서 상호교환적으로 지칭되고, 둘 다 본원에 기재된 융합 단백질, 나노케이지 및 방법에서 사용하기에 적합한 것으로 이해된다. 카르복시좀, 볼트 단백질, GroEL, 열 쇼크 단백질, E2P 및 MS2 외피 단백질 또한 나노케이지를 생성하고 본원에서 사용하기 위해 고려된다. 또한, 완전히 또는 부분적으로 합성인 자가-조립 단량체 또한 본원에서 사용하기 위해 고려된다.
각각의 나노케이지 단량체가 기능적 나노케이지 단량체로 자가-조립하는 2개 이상의 서브유닛으로 나뉘어질 수 있음을 이해할 것이다. 예를 들어, 페리틴 또는 아포페리틴은 N- 및 C- 서브유닛, 예를 들어 전장 페리틴을 실질적으로 절반으로 나눔으로써 수득된 N- 및 C- 서브유닛으로 나뉘어질 수 있고, 이로써 각각의 서브유닛은 나노케이지 단량체 및 이어서 나노케이지로의 후속적인 자가-조립을 위해 상이한 SARS-CoV-2 결합 모이어티 또는 생물활성 모이어티에 별도로 결합될 수 있다. 각각의 서브유닛은 일부 측면에서 양 말단에서 동일하거나 또는 상이하게 SARS-CoV-2 결합 모이어티 및/또는 생물활성 모이어티에 결합할 수 있다. "기능적 나노케이지 단량체"는 나노케이지 단량체가 본원에 기재된 바와 같이 이러한 다른 단량체와 함께 나노케이지로 자가-조립될 수 있는 것으로 의도된다.
용어 "페리틴" 및 "아포페리틴"은 본원에서 상호교환적으로 사용되고, 일반적으로 전형적으로 24개의 단백질 서브유닛을 포함하는 페리틴 복합체로 조립될 수 있는 폴리펩티드 (예를 들어, 페리틴 쇄)를 지칭한다. 페리틴이 임의의 종으로부터 유래될 수 있음을 이해할 것이다. 전형적으로, 페리틴은 인간 페리틴이다. 일부 실시양태에서, 페리틴은 야생형 페리틴이다. 예를 들어, 페리틴은 야생형 인간 페리틴일 수 있다. 일부 실시양태에서, 페리틴 경쇄는 나노케이지 단량체로서 사용되고/거나, 페리틴 경쇄의 서브유닛은 나노케이지 단량체 서브유닛으로서 사용된다. 일부 실시양태에서, 조립된 나노케이지는 임의의 페리틴 중쇄 또는 철에 결합할 수 있는 다른 페리틴 성분을 포함하지 않는다.
본원에서 사용된 용어 "다중특이적"은 적어도 2가지 상이한 결합 파트너, 예를 들어 항원 또는 수용체 (예를 들어, Fc 수용체)가 결합할 수 있는 적어도 2개의 결합 부위를 갖는 특징을 지칭한다. 예를 들어, 적어도 2개의 Fab 단편을 포함하는 나노케이지 (여기서, 2개의 Fab 단편 각각은 상이한 항원에 결합함)는 "다중특이적"이다. 추가의 예로서, Fc 단편 (Fc 수용체에 결합할 수 있음) 및 Fab 단편 (항원에 결합할 수 있음)을 포함하는 나노케이지는 "다중특이적"이다.
본원에서 사용된 용어 "다가성"은 결합 파트너, 예를 들어 항원 또는 수용체 (예를 들어, Fc 수용체)가 결합할 수 있는 적어도 2개의 결합 부위를 갖는 특징을 지칭한다. 적어도 2개의 결합 부위에 결합할 수 있는 결합 파트너는 동일하거나 또는 상이할 수 있다.
관련 기술분야에서 "면역글로불린" (Ig)으로 지칭되는 본원에서 사용된 용어 "항체"는 쌍을 형성한 중쇄 및 경쇄 폴리펩티드로부터 구축된 단백질을 지칭하며; IgA, IgD, IgE, IgG, 예컨대 IgG1, IgG2, IgG3, 및 IgG4, 및 IgM을 비롯한 다양한 Ig 이소타입이 존재한다. 항체가 인간, 마우스, 래트, 원숭이, 라마 또는 상어를 비롯한 임의의 종으로부터의 것일 수 있음을 이해할 것이다. 항체가 정확하게 폴딩될 경우, 각각의 쇄는 더욱 선형인 폴리펩티드 서열에 의해 결합된 수많은 별개의 구형 도메인으로 폴딩된다. 예를 들어, IgG의 경우, 면역글로불린 경쇄는 가변 (VL) 및 불변 (CL) 도메인으로 폴딩되는 반면에, 중쇄는 가변 (VH) 및 3개의 불변 (CH, CH2, CH3) 도메인으로 폴딩된다. 중쇄 및 경쇄 가변 도메인 (VH 및 VL)의 상호작용은 항원 결합 영역 (Fv)을 형성한다. 각각의 도메인은 관련 기술분야의 통상의 기술자에게 친숙한 널리 확립된 구조를 갖는다.
경쇄 및 중쇄 가변 영역은 표적 항원의 결합을 담당하고, 따라서 항체 사이의 유의한 서열 다양성을 나타낼 수 있다. 불변 영역은 적은 서열 다양성을 나타내고, 중요한 면역학적 사건을 유도하기 위해 수많은 천연 단백질의 결합을 담당한다. 항체의 가변 영역은 분자의 항원 결합 결정자를 함유하고, 따라서 표적 항원에 대한 항체의 특이성을 결정한다. 대부분의 서열 가변성은 6개의 초가변 영역 (가변 중쇄 및 경쇄당 각각 3개)에서 발생하고; 초가변 영역이 조합하여 항원-결합 부위를 형성하고, 항원 결정자의 결합 및 인식에 기여한다. 항원에 대한 항체의 특이성 및 친화도는 초가변 영역의 구조, 뿐만 아니라 항원에 제시되는 그들의 표면의 크기, 형상 및 화학에 의해 결정된다.
본원에서 지칭되는 "항체 단편"은 관련 기술분야에 공지된 임의의 적합한 항원-결합 항체 단편을 포함할 수 있다. 항체 단편은 천연 발생 항체 단편일 수 있거나, 또는 천연 발생 항체의 조작에 의해 또는 재조합 방법을 이용함으로써 수득될 수 있다. 예를 들어, 항체 단편에는 Fv, 단일-쇄 Fv (scFv; 펩티드 링커에 의해 연결된 VL 및 VH로 이루어진 분자), Fc, 단일-쇄 Fc, Fab, 단일-쇄 Fab, F(ab')2, 단일 도메인 항체 (sdAb; 단일 VL 또는 VH로 구성된 단편), 및 임의의 이들의 다가성 제시가 포함될 수 있으나 이로 제한되지 않는다.
본원에서 사용된 용어 "합성 항체"는 재조합 DNA 기술을 이용하여 생성된 항체를 의미한다. 상기 용어는 또한 항체를 코딩하는 DNA 분자의 합성에 의해 생성되었고, DNA 분자가 항체 단백질, 또는 항체를 지정하는 아미노산 서열을 발현하는 것인 항체를 의미하는 것으로 해석되어야 하며, DNA 또는 아미노산 서열은 관련 기술분야에서 이용가능하고 널리 공지된 합성 DNA 또는 아미노산 서열 기술을 이용하여 합성되었다.
용어 "에피토프"는 항원 결정자를 지칭한다. 에피토프는 항원성인, 즉, 특이적인 면역 반응을 유도하는 분자 상의 특정한 화학적 그룹 또는 펩티드 서열이다. 항체는 예를 들어 폴리펩티드 상의 특정한 항원 에피토프에 특이적으로 결합한다. 에피토프는 연속한 아미노산으로부터 또는 단백질의 3차 폴딩에 의해 병치된 연속하지 않은 아미노산으로부터 모두 형성될 수 있다. 연속한 아미노산으로부터 형성된 에피토프는 전형적으로 변성 용매에 노출시 유지되는 반면에, 3차 폴딩에 의해 형성된 에피토프는 전형적으로 변성 용매에 의한 처리시 손실된다. 에피토프는 전형적으로 고유의 공간적 형태로 적어도 3개, 및 더욱 일반적으로 적어도 5, 약 9, 약 11, 또는 약 8 내지 약 12개의 아미노산을 포함한다. 에피토프의 공간적 형태를 결정하는 방법에는 예를 들어 x-선 결정학 및 2차원 핵 자기 공명이 포함된다. 예를 들어, ["Epitope Mapping Protocols" in Methods in Molecular Biology, Vol. 66, Glenn E. Morris, Ed (1996)]을 참조한다.
본원에서 사용된 용어 "항원"은 면역 반응을 유발하는 분자로서 정의된다. 이 면역 반응은 항체 생성, 또는 특이적인 면역학적 능력이 있는 세포의 활성화, 또는 이들 둘 다를 수반할 수 있다. 숙련된 기술자는 사실상 모든 단백질 또는 펩티드를 비롯한 임의의 거대분자가 항원으로서 작용할 수 있음을 이해할 것이다. 추가로, 항원은 재조합 또는 게놈 DNA로부터 유래될 수 있다. 따라서, 숙련된 기술자는 면역 반응을 유도하는 단백질을 코딩하는 뉴클레오티드 서열 또는 부분 뉴클레오티드 서열을 포함하는 임의의 DNA가 본원에서 사용되는 용어인 "항원"을 코딩한다는 것을 이해할 것이다. 추가로, 관련 기술분야의 통상의 기술자는 항원이 유전자의 전장 뉴클레오티드 서열에 의해서만 코딩될 필요가 없음을 이해할 것이다. 본원에 기재된 측면이 1개 초과의 유전자를 갖는 부분 뉴클레오티드 서열의 사용을 포함하지만 이로 제한되지 않고, 이들 뉴클레오티드 서열이 원하는 면역 반응을 유도하기 위한 다양한 조합으로 배열될 수 있음이 매우 명백하다. 더욱이, 숙련된 기술자는 항원이 "유전자"에 의해 코딩될 필요가 전혀 없음을 이해할 것이다. 항원이 생물학적 샘플로부터 합성될 수 있거나 또는 유래될 수 있음이 매우 명백하다. 이러한 생물학적 샘플에는 조직 샘플, 세포, 또는 생물학적 유체가 포함될 수 있으나 이로 제한되지 않는다.
"코딩"은 정의된 서열의 뉴클레오티드 (예를 들어, rRNA, tRNA 및 mRNA) 또는 정의된 서열의 아미노산을 갖는 생물학적 과정에서 다른 중합체 및 거대분자의 합성을 위한 주형의 역할을 하는 폴리뉴클레오티드, 예컨대 유전자, cDNA 또는 mRNA에서 뉴클레오티드의 특이적 서열의 고유한 성질, 및 그로부터 생성된 생물학적 성질을 지칭한다. 따라서, 해당 유전자에 상응하는 mRNA의 전사 및 번역이 세포 또는 다른 생물학적 시스템에서 단백질을 생성하는 경우에 유전자는 단백질을 코딩한다. mRNA 서열과 동일하고 일반적으로 서열 목록에서 제공되는 뉴클레오티드 서열인 코딩 가닥, 및 유전자 또는 cDNA의 전사를 위한 주형으로서 사용되는 비코딩 가닥 둘 다 해당 유전자 또는 cDNA의 단백질 또는 다른 생성물을 코딩하는 것으로 지칭될 수 있다.
본원에서 사용된 용어 "발현"은 프로모터에 의해 유도되는 특정한 뉴클레오티드 서열의 전사 및/또는 번역으로 정의된다.
"단리된"은 천연 상태로부터 변경되거나 또는 제거된 것을 의미한다. 예를 들어, 살아있는 동물에 천연적으로 존재하는 핵산 또는 펩티드는 "단리된" 것이 아니지만, 그의 천연 상태의 공존하는 물질로부터 부분적으로 또는 완전히 분리된 동일한 핵산 또는 펩티드는 "단리된" 것이다. 단리된 핵산 또는 단백질은 실질적으로 정제된 형태로 존재할 수 있거나, 또는 예를 들어 숙주 세포와 같은 비천연 환경에서 존재할 수 있다.
달리 명시되지 않는다면, "아미노산 서열을 코딩하는 뉴클레오티드 서열"은 서로의 축퇴 버전이며 동일한 아미노산 서열을 코딩하는 모든 뉴클레오티드 서열을 포함한다. 문구 단백질 또는 RNA를 코딩하는 뉴클레오티드 서열은 또한 단백질을 코딩하는 뉴클레오티드 서열이 일부 버전에서 인트론(들)을 함유할 수 있는 정도로 인트론을 또한 포함할 수 있다.
본원에서 사용된 용어 "조절하는"은 처리 또는 화합물의 부재하에 대상체에서의 반응 수준과 비교하여 및/또는 그 외에는 동일하지만 비처리 대상체에서의 반응 수준과 비교하여 대상체에서 반응 수준의 검출가능한 증가 또는 감소를 매개하는 것을 의미한다. 상기 용어는 천연 신호 또는 반응을 교란시키고/거나 그에 영향을 미쳐서, 대상체, 전형적으로 인간에서 유익한 치료 반응을 매개하는 것을 포함한다.
용어 "작동가능하게 연결된"은 조절 서열과 이종성 핵산 서열 사이의 기능적 연결을 지칭하며, 그로 인해 후자가 발현된다. 예를 들어, 제1 핵산 서열이 제2 핵산 서열과 기능적 관계로 배치될 때, 제1 핵산 서열은 제2 핵산 서열과 작동가능하게 연결된 것이다. 예를 들어, 프로모터가 코딩 서열의 전사 또는 발현에 영향을 미치는 경우, 프로모터는 코딩 서열에 작동가능하게 연결된 것이다. 일반적으로, 작동가능하게 연결된 DNA 서열은 연속적이고, 필요에 따라 동일한 리딩 프레임에서 2개의 단백질 코딩 영역을 연결시킨다.
조성물의 "비경구" 투여에는 예를 들어 피하 (s.c.), 정맥내 (i.v.), 근육내 (i.m.), 또는 흉골내 주사 또는 주입 기술이 포함된다. 흡입 및 비내 투여 또한 포함된다.
본원에서 사용된 용어 "폴리뉴클레오티드"는 뉴클레오티드의 쇄로서 정의된다. 추가로, 핵산은 뉴클레오티드의 중합체이다. 따라서, 본원에서 사용된 핵산 및 폴리뉴클레오티드는 상호교환적이다. 관련 기술분야의 통상의 기술자는 핵산이 단량체성 "뉴클레오티드"로 가수분해될 수 있는 폴리뉴클레오티드라는 일반적인 지식을 갖고 있다. 단량체성 뉴클레오티드는 뉴클레오시드로 가수분해될 수 있다. 본원에서 사용된 폴리뉴클레오티드에는 비제한적으로 재조합 수단, 즉, 재조합 라이브러리 또는 세포 게놈으로부터 핵산 서열의 클로닝, 통상적인 클로닝 기술 및 PCR 등의 사용, 및 합성 수단을 비롯하여 관련 기술분야에서 이용가능한 임의의 수단에 의해 수득되는 모든 핵산 서열이 포함되나 이로 제한되지 않는다.
본원에서 사용된 용어 "펩티드", "폴리펩티드" 및 "단백질"은 상호교환적으로 사용되고, 펩티드 결합에 의해 공유 연결된 아미노산 잔기로 구성된 화합물을 지칭한다. 단백질 또는 펩티드는 적어도 2개의 아미노산을 함유해야 하고, 단백질 또는 펩티드의 서열을 포함할 수 있는 최대 아미노산의 수에는 제한이 없다. 폴리펩티드에는 펩티드 결합에 의해 서로 연결된 2개 이상의 아미노산을 포함하는 임의의 펩티드 또는 단백질이 포함된다. 본원에서 사용된 상기 용어는 일반적으로 관련 기술분야에서 예를 들어 펩티드, 올리고펩티드 및 올리고머로서 지칭되는 단쇄, 및 일반적으로 관련 기술분야에서 여러 유형의 단백질로서 지칭되는 장쇄 둘 다를 지칭한다. "폴리펩티드"에는 예를 들어 그 중에서도 생물학적으로 활성인 단편, 실질적으로 상동성인 폴리펩티드, 올리고펩티드, 동종이량체, 이종이량체, 폴리펩티드의 변이체, 변형된 폴리펩티드, 유도체, 유사체, 융합 단백질이 포함된다. 폴리펩티드에는 천연 펩티드, 재조합 펩티드, 합성 펩티드, 또는 이들의 조합물이 포함된다.
항체와 관련하여 본원에서 사용된 용어 "특이적으로 결합하는"은 특이적 항원을 인식하지만, 샘플에서 다른 분자를 실질적으로 인식하거나 또는 그에 결합하지 않는 항체를 의미한다. 예를 들어, 한 종으로부터의 항원에 특이적으로 결합하는 항체는 1가지 이상의 종으로부터의 해당 항원에도 결합할 수 있다. 그러나, 이러한 교차 종 반응성 자체가 항체의 분류를 특이적인 것으로 변경하지는 않는다. 또 다른 예에서, 항원에 특이적으로 결합하는 항체는 항원의 상이한 대립유전자 형태에도 결합할 수 있다. 그러나, 이러한 교차 반응성 자체가 항체의 분류를 특이적인 것으로 변경하지는 않는다. 일부 예에서, 용어 "특이적 결합" 또는 "특이적으로 결합하는"은 항체, 단백질 또는 펩티드와 제2 화학 종의 상호작용과 관련하여, 상호작용이 화학 종 상의 특정한 구조 (예를 들어, 항원 결정자 또는 에피토프)의 존재에 의존한다는 것을 의미하기 위해 사용될 수 있으며; 예를 들어 항체는 일반적으로 단백질이 아니라 특이적인 단백질 구조를 인식하고 그에 결합한다. 항체가 에피토프 "A"에 대해 특이적인 경우, 표지된 "A" 및 항체를 함유하는 반응에서, 에피토프 A (또는 유리, 비표지 A)를 함유하는 분자는 항체에 결합된 표지된 A의 양을 감소시킬 것이다.
용어 "치료 유효량", "유효량" 또는 "충분량"은 포유동물, 예를 들어 인간을 비롯한 대상체에게 투여될 때 원하는 결과를 달성하는데 충분한 양, 예를 들어 보호성 면역 반응을 유발하는데 효과적인 양을 의미한다. 본원에 기재된 화합물의 유효량은 분자, 대상체의 연령, 성별, 종 및 체중과 같은 인자에 따라 달라질 수 있다. 용량 또는 치료 레지멘은 숙련된 기술자에 의해 이해되는 바와 같이 최적의 치료 반응을 제공하기 위해 조정될 수 있다. 예를 들어, 본원에 기재된 융합 단백질의 치료 유효량의 투여는 일부 측면에서 COVID-19를 치료 및/또는 예방하는데 충분하다.
더욱이, 치료 유효량에 의한 대상체의 치료 방식은 단일 투여로 이루어질 수 있거나, 또는 대안적으로 일련의 적용을 포함할 수 있다. 치료 기간의 빈도 및 길이는 분자, 대상체의 연령, 작용제의 농도, 작용제에 대한 환자의 반응성, 또는 이들의 조합과 같은 다양한 인자에 따라 좌우된다. 치료를 위해 사용되는 작용제의 유효 용량이 특정한 치료 방식의 과정에 걸쳐 증가하거나 또는 감소할 수 있음을 또한 이해할 것이다. 용량의 변화는 관련 기술분야에 공지된 표준 진단 검정에 의해 일어나고 명백해질 수 있다. 본원에 기재된 융합 단백질은 일부 측면에서 해당 질환 또는 장애에 대한 통상적인 요법에 의해 치료 전에, 동안에 또는 후에 투여될 수 있다. 예를 들어, 본원에 기재된 융합 단백질은 바이러스 감염에 대한 통상적인 치료와 조합되어 특정한 용도를 가질 수 있다.
본원에서 사용된 용어 "형질감염된" 또는 "형질전환된" 또는 "형질도입된"은 외인성 핵산이 숙주 세포에 전달되거나 또는 도입되는 과정을 지칭한다. "형질감염된" 또는 "형질전환된" 또는 "형질도입된" 세포는 외인성 핵산으로 형질감염, 형질전환 또는 형질도입된 것이다. 세포에는 일차 대상체 세포 및 그의 자손이 포함된다.
본원에서 사용된 문구 "전사 제어하에" 또는 "작동가능하게 연결된"은 프로모터가 RNA 폴리머라제에 의한 전사 및 폴리뉴클레오티드의 발현의 개시를 제어하기 위해 폴리뉴클레오티드와 관련하여 정확한 위치 및 배향에 있음을 의미한다.
"벡터"는 단리된 핵산을 포함하고 단리된 핵산을 세포 내부로 전달하기 위해 사용될 수 있는 물질의 조성물이다. 선형 폴리뉴클레오티드, 이온성 또는 양친매성 화합물과 회합된 폴리뉴클레오티드, 플라스미드, 및 바이러스를 비롯하여 이로 제한되지 않는 수많은 벡터가 관련 기술분야에 공지되어 있다. 따라서, 용어 "벡터"에는 자가 복제 플라스미드 또는 바이러스가 포함된다. 상기 용어는 또한 세포로 핵산의 전달을 용이하게 하는 비-플라스미드 및 비-바이러스 화합물, 예를 들어 폴리리신 화합물, 리포솜 등을 포함하는 것으로 해석되어야 한다. 바이러스 벡터의 예에는 아데노바이러스 벡터, 아데노-관련 바이러스 벡터, 레트로바이러스 벡터 등이 포함되나 이로 제한되지 않는다.
하나 이상의 추가의 치료제와 "조합하여" 투여하는 것에는 동시에 (공동) 및 임의의 순서로 연속 투여가 포함된다.
용어 "제약상 허용가능한"은 화합물 또는 화합물의 조합물이 제약학적 용도를 위한 제형의 나머지 성분과 상용성이고, 미국 식품의약국에 의해 공표된 것들을 비롯하여 확립된 정부 표준에 따라 인간에게 투여하기에 일반적으로 안전하다는 것을 의미한다.
용어 "제약상 허용가능한 담체"에는 용매, 분산 매질, 코팅, 항박테리아제, 항진균제, 등장성제 및/또는 흡수 지연제 등이 포함되나 이로 제한되지 않는다. 제약상 허용가능한 담체의 용도는 널리 공지되어 있다.
"변이체"는 비교 서열 내의 1개 이상의 아미노산 잔기의 삽입, 결실, 변형 및/또는 치환에 의해 비교 서열과 상이한 아미노산 서열을 갖는 생물학적으로 활성인 융합 단백질, 항체, 또는 그의 단편이다. 변이체는 일반적으로 비교 서열과 100% 미만의 서열 동일성을 갖는다. 그러나, 일반적으로 생물학적으로 활성인 변이체는 비교 서열과 적어도 약 70% 아미노산 서열 동일성, 예컨대 적어도 약 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 서열 동일성을 갖는 아미노산 서열을 가질 것이다. 변이체에는 비교 서열의 생물학적 활성의 일부 수준을 유지하는 적어도 10개의 아미노산의 펩티드 단편이 포함된다. 변이체에는 또한 1개 이상의 아미노산 잔기가 비교 서열의 N- 또는 C-말단에 또는 내부에 부가된 폴리펩티드가 포함된다. 변이체에는 또한 수많은 아미노산 잔기가 결실되고/거나, 임의적으로 1개 이상의 아미노산 잔기로 치환된 폴리펩티드가 포함된다. 변이체는 또한 예를 들어 천연 발생 아미노산 이외의 모이어티에 의한 치환에 의해 또는 비-천연 발생 아미노산을 생성하기 위해 아미노산 잔기를 변형시킴으로써 공유적으로 변형될 수 있다.
"% 아미노산 서열 동일성"은 서열 동일성의 일부로서 임의의 보존적 치환을 고려하지 않고, 서열을 정렬시키고, 필요에 따라 최대 % 서열 동일성을 달성하기 위해 갭을 도입시킨 후에, 관심 서열, 예컨대 본 발명의 폴리펩티드의 잔기와 동일한 후보 서열의 아미노산 잔기의 백분율로서 본원에서 정의된다. 후보 서열에 대한 N-말단, C-말단 또는 내부 확장, 결실 또는 삽입이 서열 동일성 또는 상동성에 영향을 미치는 것으로 해석되지 않아야 한다. 정렬을 위한 방법 및 컴퓨터 프로그램, 예컨대 "BLAST"는 관련 기술분야에 널리 공지되어 있다.
본원의 목적을 위해 "활성인" 또는 "활성"은 본원에 기재된 융합 단백질의 생물학적 및/또는 면역학적 활성을 지칭하며, "생물학적" 활성은 융합 단백질에 의해 유발된 생물학적 기능 (억제성 또는 자극성)을 지칭한다.
본원에 기재된 융합 단백질은 변형을 포함할 수 있다. 이러한 변형에는 이펙터 분자에 대한 접합이 포함되나 이로 제한되지 않는다. 변형에는 검출가능한 리포터 모이어티에 대한 접합이 추가로 포함되나 이로 제한되지 않는다. 반감기를 연장시키는 변형 (예를 들어, PEG화) 또한 포함된다. 탈면역화에 대한 변형 또한 포함된다. 단백질 및 비-단백질 작용제는 관련 기술분야에 공지된 방법에 의해 융합 단백질에 접합될 수 있다. 접합 방법에는 직접 연결, 공유 부착된 링커를 통한 연결, 및 특이적인 결합 쌍 구성원 (예를 들어, 아비딘-비오틴)이 포함된다. 이러한 방법에는 예를 들어 [Greenfield et al., Cancer Research 50, 6600-6607 (1990)]에 기재된 것 (본원에 참조로 포함됨) 및 [Amon et al., Adv. Exp. Med. Biol. 303, 79-90 (1991) 및 Kiseleva et al, MoI. Biol. (USSR)25, 508-514 (1991)]에 기재된 것들 (둘 다 본원에 참조로 포함됨)이 포함된다.
융합 단백질
융합 단백질이 본원에 기재된다. 융합 단백질은 SARS-CoV-2 결합 모이어티에 연결된 나노케이지 단량체를 포함한다. 복수개의 융합 단백질은 자가-조립하여 나노케이지를 형성한다. 이러한 방식으로, SARS-CoV-2 결합 모이어티는 조립된 나노케이지의 내부 표면, 조립된 나노케이지의 외부 표면, 또는 이들 둘 다를 장식할 수 있다.
SARS-CoV-2 결합 모이어티는 전형적으로 항체 또는 그의 단편이고, 이는 SARS-CoV-2 바이러스의 임의의 부분을 표적화할 수 있지만, 전형적으로 SARS-CoV-2 S 당단백질을 표적화한다. SARS-CoV-2 결합 모이어티가 항체 또는 그의 단편일 필요가 없으며, 예를 들어 바이러스 또는 바이러스에서 RBD 도메인에 결합하고 그를 차단하는 단백질과 같은 분자일 수 있음을 이해할 것이다.
항체 또는 그의 단편이 예를 들어 Fab 단편의 중쇄 및/또는 경쇄를 포함할 수 있음을 이해할 것이다. 항체 또는 그의 단편은 예를 들어 scFab 단편, scFv 단편, sdAb 단편, 및/또는 VHH 영역을 포함할 수 있다. 임의의 항체 또는 그의 단편이 본원에 기재된 융합 단백질에서 사용될 수 있음을 이해할 것이다.
일반적으로, 본원에 기재된 융합 단백질은 Fab 경쇄 및/또는 중쇄와 회합하고, 이들은 융합 단백질과 별도로 또는 인접하여 생성될 수 있다.
예를 들어, SARS-CoV-2 결합 모이어티는 단일 쇄 가변 도메인 VHH-72, BD23 및/또는 4A8을 포함할 수 있다. 대안적으로 또는 추가로, SARS-CoV-2 결합 모이어티는 본원에서 표 4에 나열된 mAb 중 어느 하나 또는 이들의 조합물로부터 선택될 수 있다. 예를 들어, SARS-CoV-2 결합 모이어티는 표 4의 mAb 298, 324, 46, 80, 52, 82, 및 236 중 어느 하나 또는 이들의 조합물로부터 선택될 수 있다.
특정 측면에서, 본원에 기재된 나노케이지 단량체는 서브유닛으로 분할되어, 더 많은 SARS-CoV-2 결합 모이어티 또는 다른 모이어티가 다양한 비로 부착될 수 있게 한다. 예를 들어, 일부 측면에서, 나노케이지 단량체는 SARS-CoV-2 결합 모이어티에 연결된 제1 나노케이지 단량체 서브유닛을 포함한다. 사용시, 제1 나노케이지 단량체 서브유닛는 제2 나노케이지 단량체 서브유닛과 자가-조립하여 나노케이지 단량체를 형성한다. 상기 기재된 바와 같이, 복수개의 나노케이지 단량체가 자가-조립하여 나노케이지를 형성한다. 나노케이지 단량체 서브유닛은 단독으로 또는 조합으로 제공될 수 있고, 그에 융합된 동일한 또는 상이한 SARS-CoV-2 결합 모이어티를 가질 수 있다.
본원에 기재된 나노케이지 단량체 및/또는 나노케이지 단량체 서브유닛으로 제조된 나노케이지는 1개 이상의 SARS-CoV-2 결합 모이어티 이외에 포함된 생물활성 모이어티를 가질 수 있다.
예를 들어, 생물활성 모이어티는 예를 들어 Fc 단편의 1개 또는 둘 다의 쇄를 포함할 수 있다. Fc 단편은 이해되는 바와 같이 임의의 유형의 항체로부터 유래될 수 있지만, 전형적으로 IgG1 Fc 단편이다. Fc 단편은 융합 단백질 및/또는 융합 단백질을 포함하는 생성된 조립된 나노케이지의 반감기 및/또는 이펙터 기능을 조절하는 1개 이상의 돌연변이, 예컨대 LS, YTE, LALA, I253A, 및/또는 LALAP를 추가로 포함할 수 있다. 예를 들어, 반감기는 수분, 수일, 수주 또는 심지어 수개월의 규모일 수 있다.
더욱이, Fc 서열 변형 및 다른 작용제 (예를 들어 인간 혈청 알부민 펩티드 서열)의 첨가를 비롯하여 본원에 기재된 융합 단백질 및 나노케이지에서 다른 치환이 고려되며, 이는 생체이용률을 변화시키고 숙련된 기술자에 의해 이해될 것이다. 추가로, 본원에 기재된 융합 단백질 및 나노케이지는 순서대로 또는 다른 작용제의 첨가에 의해 변형되어 면역원성 및 항-약물 반응을 약화시킬 수 있다 (치료제, 예를 들어 숙주에 대한 서열 매칭, 또는 면역억제성 치료제의 첨가 [예를 들어, 류마티스성 관절염의 치료 또는 신생아 내성의 유도를 위해 인플릭시맙을 투여할 때 메토트렉세이트, 이는 FVIII에 대한 억제제의 발생을 감소시키는 일차 전략임 ([DiMichele DM, Hoots WK, Pipe SW, Rivard GE, Santagostino E. International workshop on immune tolerance induction: consensus recommendations. Haemophilia. 2007;13:1-22]에서 검토되고, 그의 전문이 본원에 참조로 포함됨]).
특정 실시양태에서, 단편 결정화가능한 (Fc) 영역은 I253A 돌연변이를 포함한다. 일부 실시양태에서, Fc 영역은 LALAP (L234A/L235A/P329G) 돌연변이를 추가로 포함한다. 달리 언급되지 않는다면, 본 개시내용 전반에 걸쳐 돌연변이의 넘버링은 EU 인덱스에 따른 것이다.
일부 실시양태에서, Fc 영역은 IgG1 Fc 영역 (예를 들어, 인간 IgG1 Fc 영역)이며, 즉, 본원에서 언급된 돌연변이를 제외하고, Fc 영역은 야생형 IgG1 Fc 내의 쇄와 실질적으로 유사한 아미노산 서열을 각각 갖는 Fc 쇄를 포함한다. 일부 실시양태에서, 야생형 참조 IgG1 Fc는 인간 IgG1 Fc이고, 각각의 Fc 쇄는 서열식별번호: 24의 아미노산 서열을 갖는다.
예를 들어, IgG1 Fc 영역은 야생형 IgG1 Fc 내의 Fc 쇄와 적어도 85%, 적어도 87.5%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99% 동일한 아미노산 서열을 갖는 Fc 쇄를 포함할 수 있다. 일부 실시양태에서, IgG1 Fc 영역은 해당 IgG1 Fc 영역에 대해 구체적으로 기재된 Fc 돌연변이를 포함하지만, 야생형 IgG1 Fc 내의 Fc 쇄와 100% 동일한 아미노산 서열을 갖는 Fc 쇄를 포함한다.
일부 실시양태에서, Fc 영역은 공유 링커에 의해, 예를 들어 아미노산 링커를 통해 함께 연결된 2개의 Fc 쇄를 포함하는 단일 쇄 Fc (scFc)이다. 일부 실시양태에서, Fc 영역은 단일 Fc 쇄를 포함하는 Fc 단량체이다.
항체 또는 그의 단편이 2개의 쇄, 예컨대 Fc 단편의 경우 제1 및 제2 쇄, 또는 중쇄 및 경쇄를 포함하는 경우, 2개의 쇄는 임의적으로 링커에 의해 분리된다. 링커는 가요성 또는 강직성일 수 있지만, 전형적으로 가요성이어서 쇄가 적당하게 폴딩되게 한다. 링커는 일반적으로 융합 단백질에 약간의 가요성을 부여하기에 충분히 길지만, 링커 길이가 나노케이지 단량체 및 생물활성 모이어티 서열, 및 융합 단백질의 3차원 형태에 따라 달라질 것임을 이해할 것이다. 따라서, 링커는 전형적으로 약 1 내지 약 130개의 아미노산 잔기, 예컨대 약 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 또는 125 내지 약 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 또는 130개의 아미노산 잔기, 예컨대 약 50 내지 약 90개의 아미노산 잔기, 예컨대 70개의 아미노산 잔기이다.
링커는 임의의 아미노산 서열일 수 있고, 한 전형적인 예에서, 링커는 GGS 반복부를 포함하고, 더욱 전형적으로, 링커는 약 2, 3, 4, 5 또는 6개의 GGS 반복부, 예컨대 약 4개의 GGS 반복부를 포함한다. 구체적인 측면에서, 링커는 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS.
특정 실시양태에서, 링커는 융합 폴리펩티드 내에서 및/또는 단일-쇄 분자, 예컨대 scFc 내에서 사용된다. 일부 실시양태에서, 링커는 아미노산 링커이다. 예를 들어, 본원에서 사용되는 링커는 약 1 내지 약 100개의 아미노산 잔기, 예를 들어 약 1 내지 약 70, 약 2 내지 약 70, 약 1 내지 약 30, 또는 약 2 내지 약 30개의 아미노산 잔기를 포함할 수 있다. 일부 실시양태에서, 링커는 적어도 2, 적어도 3, 적어도 4, 적어도 5, 적어도 6, 적어도 7, 적어도 8, 적어도 9, 또는 적어도 10개의 아미노산 잔기를 포함한다.
특정 실시양태에서, 링커는 링커 내에 적어도 1, 적어도 2, 적어도 3, 적어도 4, 적어도 5, 적어도 6, 적어도 7, 적어도 8, 적어도 9, 적어도 10, 적어도 11, 적어도 12, 적어도 13, 또는 적어도 14개의 카피로 존재하는 글리신-세린 서열, 예를 들어 (GnS)m 서열 (예를 들어, GGS, GGGS, 또는 GGGGS 서열)을 포함한다.
전형적인 측면에서, 항체 또는 그의 단편은 SARS-CoV-2와 연관된 항원에 특이적으로 결합한다. 전형적으로, 항원은 SARS-CoV-2와 연관이 있고, 항체 또는 그의 단편은 예를 들어 표 4로부터의 결합 도메인, 예컨대 결합 도메인 298, 52, 46, 80, 82, 236, 324 또는 이들의 조합물을 포함한다.
특정 실시양태에서, SARS-CoV-2-결합 항체 단편은 SARS-CoV-2의 수용체 결합 도메인 (RBD)에 결합할 수 있다. 특정 실시양태에서, SARS-CoV-2-결합 항체 단편은 SARS-CoV-2의 스파이크 단백질 (S 단백질)에 결합할 수 있다. 일부 실시양태에서, SARS-CoV-2-결합 항체 단편은 SARS-CoV-2의 S 단백질의 N-말단 도메인 (NTD)에 결합할 수 있다.
일부 실시양태에서, SARS-CoV-2-결합 항체 단편은 중쇄 가변 영역 (예를 들어, VH 또는 VHH)을 포함한다. 특정 실시양태에서, SARS-CoV-2-결합 항체 단편은 중쇄 가변 도메인 (예를 들어, VH) 및 경쇄 가변 도메인 (예를 들어, VL 또는 VK)을 포함한다. 특정 실시양태에서, SARS-CoV-2-결합 항체 단편은 중쇄 가변 도메인 (예를 들어, VH) 및 경쇄 가변 도메인 (예를 들어, VL 또는 VK)을 포함하는 Fab를 포함한다.
일부 실시양태에서, SARS-CoV-2-결합 항체 단편은 VH 중쇄 가변 도메인 및 VK 경쇄 가변 도메인을 포함한다. 일부 실시양태에서, SARS-CoV-2-결합 항체 단편은 VH 중쇄 가변 도메인 및 VK 경쇄 가변 도메인을 포함하는 Fab를 포함한다.
구체적인 예에서, 항체 또는 그의 단편은 하기 서열 중 하나 이상과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
Fc 쇄 1:

Fc 쇄 2:

298 경쇄

298 Fab 중쇄

52 경쇄

52 Fab 중쇄

46 경쇄

46 Fab 중쇄

80 경쇄

80 Fab 중쇄

82 경쇄

82 Fab 중쇄

236 경쇄

236 Fab 중쇄

324 경쇄

324 Fab 중쇄

또는 이들의 조합물.
추가의 측면에서, 항체 또는 그의 단편은 추가의 모이어티, 예컨대 검출가능한 모이어티 (예를 들어, 소분자, 형광 분자, 방사성 동위원소, 또는 자성 입자), 약제, 진단제, 또는 이들의 조합물에 접합되거나 또는 회합되며, 예를 들어 항체-약물 접합체를 포함할 수 있다.
생물활성 모이어티가 검출가능한 모이어티인 측면에서, 검출가능한 모이어티는 형광 단백질, 예컨대 GFP, EGFP, 아메트린, 및/또는 플라빈-기반 형광 단백질, 예컨대 LOV-단백질, 예컨대 iLOV를 포함할 수 있다.
생물활성 모이어티가 약제인 측면에서, 약제는 예를 들어 소분자, 펩티드, 지질, 탄수화물, 또는 독소를 포함할 수 있다.
전형적인 측면에서, 본원에 기재된 융합 단백질로부터 조립된 나노케이지는 약 3 내지 약 100개의 나노케이지 단량체, 예컨대 약 3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 55, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 또는 98 내지 약 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 55, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 또는 100개의 나노케이지 단량체, 예컨대 24, 32 또는 60개의 단량체를 포함한다. 나노케이지 단량체는 천연, 합성 또는 부분 합성인 임의의 공지된 나노케이지 단량체일 수 있고, 일부 측면에서 페리틴, 아포페리틴, 엔캡슐린, SOR, 루마진 신타제, 피루베이트 데히드로게나제, 카르복시좀, 볼트 단백질, GroEL, 열 쇼크 단백질, E2P, MS2 외피 단백질, 그의 단편, 및 그의 변이체로부터 선택된다. 전형적으로, 나노케이지 단량체는 페리틴 또는 아포페리틴이다.
아포페리틴이 나노케이지 단량체로서 선택되는 경우, 전형적으로 제1 및 제2 나노케이지 단량체 서브유닛은 상호교환적으로 아포페리틴의 "N" 및 "C" 영역을 포함한다. 다른 나노케이지 단량체가 본원에 기재된 아포페리틴과 같이 2부분 서브유닛으로 나뉘어져서, 서브유닛이 자가-조립하고, 각각 생물활성 모이어티와 융합될 수 있음을 이해할 것이다.
일부 실시양태에서, 나노케이지 단량체는 페리틴 단량체이다. 용어 "페리틴 단량체"는 다른 페리틴 쇄의 존재하에 복수개의 페리틴 쇄를 포함하는 폴리펩티드 복합체로 자가-조립될 수 있는 페리틴의 단일 쇄를 지칭하기 위해 본원에서 사용된다. 일부 실시양태에서, 페리틴 쇄는 24개 이상의 페리틴 쇄를 포함하는 폴리펩티드 복합체로 자가-조립된다. 일부 실시양태에서, 페리틴 단량체는 페리틴 경쇄이다. 일부 실시양태에서, 페리틴 단량체는 페리틴 중쇄, 또는 철에 결합할 수 있는 다른 페리틴 성분을 포함하지 않는다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체 내의 각각의 융합 폴리펩티드는 페리틴 경쇄, 또는 페리틴 경쇄의 서브유닛을 포함한다. 이들 실시양태에서, 자가-조립된 폴리펩티드 복합체는 임의의 페리틴 중쇄, 또는 페리틴 중쇄의 서브유닛을 포함하지 않는다.
일부 실시양태에서, 페리틴 단량체는 인간 페리틴 쇄, 예를 들어 인간 페리틴 경쇄, 예를 들어 서열식별번호:1의 적어도 잔기 2-175의 서열을 갖는 인간 페리틴 경쇄이다. 일부 실시양태에서, 페리틴 단량체는 마우스 페리틴 쇄이다.
페리틴 단량체의 "서브유닛"은 페리틴 단량체의 또 다른 별개의 서브유닛과 자발적으로 회합할 수 있는 페리틴 단량체의 일부를 지칭하며, 이로써 서브유닛은 함께 페리틴 단량체를 형성하고, 페리틴 단량체는 다른 페리틴 단량체와 자가-조립하여 폴리펩티드 복합체를 형성할 수 있다.
일부 실시양태에서, 페리틴 단량체 서브유닛은 페리틴 단량체의 대략 절반을 차지한다. 본원에서 사용된 용어 "N-절반 페리틴"은 절반이 페리틴 쇄의 N-말단을 포함하는 것인 페리틴 쇄의 대략 절반을 지칭한다. 본원에서 사용된 용어 "C-절반 페리틴"은 절반이 페리틴 쇄의 C-말단을 포함하는 것인 페리틴 쇄의 대략 절반을 지칭한다. 페리틴 쇄가 나뉘어져서 N-절반 페리틴 및 C-절반 페리틴을 형성할 수 있는 정확한 지점은 실시양태에 따라 달라질 수 있다. 인간 페리틴 경쇄를 기반으로 하는 페리틴 단량체 서브유닛의 맥락에서, 예를 들어 서열식별번호:1의 약 위치 75 내지 약 위치 100 사이의 위치에 상응하는 지점에서 절반이 나뉘어질 수 있다. 예를 들어, 일부 실시양태에서, 인간 페리틴 경쇄를 기반으로 하는 N-절반 페리틴은 서열식별번호:1의 잔기 1-95 (또는 그의 실질적인 부분)에 상응하는 아미노산 서열을 갖고, 인간 페리틴 경쇄를 기반으로 하는 C-절반 페리틴은 서열식별번호:1의 잔기 96-175 (또는 그의 실질적인 부분)에 상응하는 아미노산 서열을 갖는다.
일부 실시양태에서, 서열식별번호:1의 약 위치 85 내지 약 위치 92 사이의 위치에 상응하는 지점에서 절반이 나뉘어진다. 예를 들어, 일부 실시양태에서, 인간 페리틴 경쇄를 기반으로 하는 N-절반 페리틴은 서열식별번호:1의 잔기 1-90 (또는 그의 실질적인 부분)에 상응하는 아미노산 서열을 갖고, 인간 페리틴 경쇄를 기반으로 하는 C-절반 페리틴은 서열식별번호:1의 잔기 91-175 (또는 그의 실질적인 부분)에 상응하는 아미노산 서열을 갖는다.
전형적으로, 아포페리틴의 "N" 영역은 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
MSSQIRQNYSTDVEAAVNSLVNLYLQASYTYLSLGFYFDRDDVALEGVSHFFRELAEEKREGYERLLKMQNQRGGRALFQDIKKPAEDEW.
전형적으로, 아포페리틴의 "C" 영역은 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GKTPDAMKAAMALEKKLNQALLDLHALGSARTDPHLCDFLETHFLDEEVKLIKKMGDHLTNLHRLGGPEAGLGEYLFERLTLRHD
또는
GKTPDAMKAAMALEKKLNQALLDLHALGSARTDPHLCDFLETHFLDEEVKLIKKMGDHLTNLHRLGGPEAGLGEYLFERLTLKHD.
일부 측면에서, 본원에 기재된 융합 단백질은 나노케이지 단량체 서브유닛과 생물활성 모이어티 사이에 상기 기재된 링커와 같은 링커를 추가로 포함한다. 다시, 링커는 가요성 또는 강직성일 수 있지만, 전형적으로 가요성이어서 생물활성 모이어티가 활성을 유지하고 나노케이지 단량체 서브유닛의 쌍이 자가-조립 성질을 유지하게 한다. 링커는 일반적으로 융합 단백질에 약간의 가요성을 부여하기에 충분히 길지만, 링커 길이가 나노케이지 단량체 및 생물활성 모이어티 서열, 및 융합 단백질의 3차원 형태에 따라 달라질 것임을 이해할 것이다. 따라서, 링커는 전형적으로 약 1 내지 약 30개의 아미노산 잔기, 예컨대 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 또는 29 내지 약 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 또는 30개의 아미노산 잔기, 예컨대 약 8 내지 약 16개의 아미노산 잔기, 예컨대 8, 10 또는 12개의 아미노산 잔기이다.
링커는 임의의 아미노산 서열일 수 있고, 한 전형적인 예에서, 링커는 GGS 반복부를 포함하고, 더욱 전형적으로, 링커는 약 2, 3, 4, 5 또는 6개의 GGS 반복부, 예컨대 약 4개의 GGS 반복부를 포함한다. 구체적인 측면에서, 링커는 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GGGGSGGGGSGGGGSGGGGSGGGGSGG
유사하게, 융합 단백질은 융합 단백질의 하나 이상의 속성을 개선시키기 위해 C-말단 링커를 추가로 포함할 수 있다. 일부 측면에서, GGS 반복부를 포함하고, 더욱 전형적으로, 링커는 약 2, 3, 4, 5 또는 6개의 GGS 반복부, 예컨대 약 4개의 GGS 반복부를 포함한다. 구체적인 측면에서, C-말단 링커는 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어진다:
GGSGGSGGSGGSGGGSGGSGGSGGSG
상기 기재된 융합 단백질의 쌍 또한 본원에 기재되며, 쌍은 자가-조립하여 나노케이지 단량체를 형성하고, 제1 및 제2 나노케이지 단량체 서브유닛은 상이한 SARS-CoV-2 결합 모이어티에 융합한다. 이는 서브유닛 쌍으로부터 조립된 단일 나노케이지 단량체에 다가성 및/또는 다중특이성을 제공한다.
실질적으로 동일한 서열은 1개 이상의 보존적 아미노산 돌연변이를 포함할 수 있다. 참조 서열에 대한 1개 이상의 보존적 아미노산 돌연변이가 참조 서열과 비교하여 생리학적, 화학적 또는 기능적 성질에서 실질적인 변화없이 돌연변이체 펩티드를 생성할 수 있음이 관련 기술분야에 공지되어 있으며; 이러한 경우에, 참조 및 돌연변이체 서열은 "실질적으로 동일한" 폴리펩티드로 간주된다. 보존적 아미노산 돌연변이는 아미노산의 부가, 결실 또는 치환을 포함할 수 있고; 보존적 아미노산 치환은 아미노산 잔기를 유사한 화학적 성질 (예를 들어 크기, 전하 또는 극성)을 갖는 또 다른 아미노산 잔기로 치환하는 것으로 본원에서 정의된다.
비제한적인 예에서, 보존적 돌연변이는 아미노산 치환일 수 있다. 이러한 보존적 아미노산 치환은 염기성, 중성, 소수성 또는 산성 아미노산을 동일한 그룹의 또 다른 것으로 치환시킬 수 있다. 용어 "염기성 아미노산"은 7 초과의 측쇄 pK 값을 갖는 친수성 아미노산을 의미하며, 이는 전형적으로 생리학적 pH에서 양으로 하전된다. 염기성 아미노산에는 히스티딘 (His 또는 H), 아르기닌 (Arg 또는 R), 및 리신 (Lys 또는 K)이 포함된다. 용어 "중성 아미노산" (또한 "극성 아미노산")은 생리학적 pH에서 하전되지 않는 측쇄를 갖지만, 2개의 원자에 의해 공통으로 공유된 전자 쌍이 원자 중 1개에 의해 더 밀접하게 유지되는 것인 적어도 1개의 결합을 갖는 친수성 아미노산을 의미한다. 극성 아미노산에는 세린 (Ser 또는 S), 트레오닌 (Thr 또는 T), 시스테인 (Cys 또는 C), 티로신 (Tyr 또는 Y), 아스파라긴 (Asn 또는 N), 및 글루타민 (Gln 또는 Q)이 포함된다. 용어 "소수성 아미노산" (또는 "비극성 아미노산")은 아이젠버그 (Eisenberg 1984)의 정규화된 합의 소수성 규모에 따라 0보다 큰 소수성을 나타내는 아미노산을 포함하는 것을 의미한다. 소수성 아미노산에는 프롤린 (Pro 또는 P), 이소류신 (Ile 또는 I), 페닐알라닌 (Phe 또는 F), 발린 (Val 또는 V), 류신 (Leu 또는 L), 트립토판 (Trp 또는 W), 메티오닌 (Met 또는 M), 알라닌 (Ala 또는 A), 및 글리신 (Gly 또는 G)이 포함된다.
"산성 아미노산"은 7 미만의 측쇄 pK 값을 갖는 친수성 아미노산을 지칭하며, 전형적으로 생리학적 pH에서 음으로 하전된다. 산성 아미노산에는 글루타메이트 (Glu 또는 E), 및 아스파르테이트 (Asp 또는 D)가 포함된다.
서열 동일성을 이용하여 두 서열의 유사성을 평가하며; 이는 2개의 서열이 잔기 위치 사이의 최대 일치를 위해 정렬될 때 동일한 잔기의 %를 계산함으로써 결정된다. 임의의 공지된 방법을 이용하여 서열 동일성을 계산할 수 있고; 예를 들어 서열 동일성을 계산하기 위해 컴퓨터 소프트웨어가 이용가능하다. 제한되기를 바라지 않고, 서열 동일성은 스위스 인스티튜트 오브 바이오인포르마틱스(Swiss Institute of Bioinformatics) (및 ca.expasy.org/tools/blast/에서 확인됨)에 의해 유지되는 NCBI BLAST2 서비스, BLAST-P, Blast-N, 또는 FASTA-N과 같은 소프트웨어, 또는 관련 기술분야에 공지된 임의의 다른 적절한 소프트웨어에 의해 계산될 수 있다.
본 발명의 실질적으로 동일한 서열은 적어도 85% 동일할 수 있고; 또 다른 예에서, 실질적으로 동일한 서열은 본원에 기재된 서열의 아미노산 수준과 적어도 70, 75, 80, 85, 90, 95, 96, 97, 98, 99, 또는 100% (또는 이들 사이의 임의의 백분율) 동일할 수 있다. 구체적인 측면에서, 실질적으로 동일한 서열은 참조 서열의 활성 및 특이성을 유지한다. 비제한적인 실시양태에서, 서열 동일성의 차이는 보존적 아미노산 돌연변이(들)로 인한 것일 수 있다.
본 발명의 폴리펩티드 또는 융합 단백질은 또한 그들의 발현, 검출 또는 정제를 보조하기 위해 추가의 서열을 포함할 수 있다. 관련 기술분야의 통상의 기술자에게 공지된 임의의 이러한 서열 또는 태그가 사용될 수 있다. 예를 들어, 제한되기를 바라지 않고, 융합 단백질은 표적화 또는 신호 서열 (예를 들어, ompA로 제한되지 않음), 검출 태그를 포함할 수 있고, 예시적인 태그 카세트에는 Strep 태그, 또는 임의의 그의 변이체; (예를 들어, 미국 특허 번호 7,981,632 참조), His 태그, 서열 모티프 DYKDDDDK를 갖는 Flag 태그, Xpress 태그, Avi 태그, 칼모듈린 태그, 폴리글루타메이트 태그, HA 태그, Myc 태그, Nus 태그, S 태그, SBP 태그, Softag 1, Softag 3, V5 태그, CREB-결합 단백질 (CBP), 글루타티온 S-트랜스퍼라제 (GST), 말토스 결합 단백질 (MBP), 녹색 형광 단백질 (GFP), 티오레독신 태그, 또는 임의의 이들의 조합물; 정제 태그 (예를 들어, His5 또는 His6으로 제한되지 않음), 또는 이들의 조합물이 포함된다.
또 다른 예에서, 추가의 서열은 크로난(Cronan) 등의 WO 95/04069 또는 보게스(Voges) 등의 WO/2004/076670에 기재된 것과 같은 비오틴 인식 부위일 수 있다. 관련 기술분야의 통상의 기술자에게 공지된 바와 같이, 링커 서열은 추가의 서열 또는 태그와 함께 사용될 수 있다.
더욱 구체적으로, 태그 카세트는 높은 친화도 또는 결합도로 항체에 특이적으로 결합할 수 있는 세포외 성분을 포함할 수 있다. 단일 쇄 융합 단백질 구조 내에서, 태그 카세트는 (a) 커넥터 영역에 대해 바로 아미노-말단에, (b) 링커 모듈 사이에 개재되어 이들을 연결하여, (c) 결합 도메인에 대해 바로 카르복시-말단에, (d) 결합 도메인 (예를 들어, scFv 또는 scFab)과 이펙터 도메인 사이에 개재되어 이들을 연결하여, (e) 결합 도메인의 서브유닛 사이에 개재되어 이들을 연결하여, 또는 (f) 단일 쇄 융합 단백질의 아미노-말단에 위치할 수 있다. 특정 실시양태에서, 1개 이상의 접합 아미노산은 태그 카세트와 소수성 부분 사이에 배치되어 이들을 연결하거나, 또는 태그 카세트와 커넥터 영역 사이에 배치되어 이들을 연결하거나, 또는 태그 카세트와 링커 모듈 사이에 배치되어 이들을 연결하거나, 또는 태그 카세트와 결합 도메인 사이에 배치되어 이들을 연결할 수 있다.
다양한 방법을 이용하여 표면 상에 고정된 단리된 또는 정제된 융합 단백질, 폴리펩티드, 또는 그의 단편 또한 본원에 포함되며; 예를 들어, 제한되기를 바라지 않고, 폴리펩티드는 His-태그 커플링, 비오틴 결합, 공유 결합, 흡착 등을 통해 표면에 연결되거나 또는 커플링될 수 있다. 고체 표면은 임의의 적합한 표면일 수 있고, 예를 들어 마이크로플레이트의 웰 표면, 표면 플라즈몬 공명 (SPR) 센서칩의 채널, 막, 비드 (예컨대 자성-기반 또는 세파로스-기반 비드 또는 다른 크로마토그래피 수지), 유리, 필름, 또는 임의의 다른 유용한 표면일 수 있으나 이로 제한되지 않는다.
다른 측면에서, 융합 단백질은 적하 분자에 연결될 수 있고; 융합 단백질은 적하 분자를 원하는 부위로 전달할 수 있고, 관련 기술분야에 공지된 임의의 방법 (재조합 기술, 화학적 접합, 킬레이트화 등)을 이용하여 적하 분자에 연결될 수 있다. 적하 분자는 임의의 유형의 분자, 예컨대 치료제 또는 진단제일 수 있다.
일부 측면에서, 적하 분자는 단백질이고, 적하 분자가 나노케이지 내부에 함유되도록 융합 단백질에 융합된다. 다른 측면에서, 적하 분자는 융합 단백질에 융합되지 않고, 나노케이지 내부에 함유된다. 적하 분자는 전형적으로 단백질, 소분자, 방사성 동위원소, 또는 자성 입자이다.
본원에 기재된 융합 단백질은 그들의 표적에 특이적으로 결합한다. 항원의 특정한 에피토프에 대한 항체의 선택적인 인식을 지칭하는 본원에 기재된 항체 또는 단편의 항체 특이성은 친화도 및/또는 결합도를 기반으로 하여 결정될 수 있다. 항원과 항체의 해리에 대한 평형 상수 (KD)로 표현되는 친화도는 항원 결정자 (에피토프)와 항체 결합 부위 사이의 결합 강도를 측정한다. 결합도는 항체와 그의 항원 사이의 결합 강도의 척도이다. 항체는 전형적으로 10-5 내지 10-11 M의 KD로 결합한다. 10-4 M보다 높은 임의의 KD는 일반적으로 비-특이적 결합을 나타내는 것으로 간주된다. KD 값이 작을수록, 항원 결정자와 항체 결합 부위 사이의 결합이 더 강해진다. 일부 측면에서, 본원에 기재된 항체는 10-4 M, 10-5 M, 10-6 M, 10-7 M, 10-8 M, 10-9 M, 10-10 M, 10-11 M, 10-12 M, 10-13 M, 10-14 M, 또는 10-15 M 미만의 KD를 갖는다.
본원에 기재된 적어도 하나의 융합 단백질, 및 융합 단백질과 자가-조립하여 나노케이지 단량체를 형성하는 적어도 하나의 제2 나노케이지 단량체 서브유닛을 포함하는 나노케이지 또한 본원에 기재된다. 추가로, 융합 단백질의 쌍이 본원에 기재되고, 쌍은 자가-조립하여 나노케이지 단량체를 형성하고, 제1 및 제2 나노케이지 단량체 서브유닛은 상이한 생물활성 모이어티에 융합된다.
나노케이지가 다중 동일한 융합 단백질로부터, 다중 상이한 융합 단백질로부터 (따라서 다가성 및/또는 다중특이성임), 융합 단백질 및 야생형 단백질의 조합물로부터, 및 임의의 이들의 조합으로부터 자가-조립한다는 것을 이해할 것이다. 예를 들어, 나노케이지는 적어도 하나의 항-SARS-CoV-2 항체와 조합되어 본원에 기재된 융합 단백질 중 적어도 하나에 의해 내부적으로 및/또는 외부적으로 장식될 수 있다. 전형적인 측면에서, 나노케이지 단량체의 약 20% 내지 약 80%는 본원에 기재된 융합 단백질을 포함한다. 본원에 기재된 모듈식 해결책의 관점에서, 나노케이지는 이론적으로 나노케이지에 단량체가 있는 것보다 최대 2배 많은 생물활성 모이어티를 포함할 수 있으며, 이는 각각의 나노케이지 단량체가 2개의 서브유닛으로 나뉘어질 수 있고, 각각이 상이한 생물활성 모이어티에 독립적으로 결합할 수 있기 때문이다. 구체적인 예에서 4:2:1:1 비의 4가지 상이한 생물활성 모이어티로 본원에 기재된 바와 같이 임의의 원하는 비의 생물활성 모이어티를 달성하기 위해 이러한 모듈성이 활용될 수 있음을 이해할 것이다. 예를 들어, 본원에 기재된 나노케이지는 적어도 2, 3, 4, 5, 6, 7, 8, 9 또는 10개의 상이한 생물활성 모이어티를 포함할 수 있다. 이러한 방식으로, 나노케이지는 다가성 및/또는 다중특이적일 수 있고, 그 정도는 비교적 용이하게 제어될 수 있다.
일부 측면에서, 본원에 기재된 나노케이지는 나노케이지 단량체 서브유닛에 연결되는 것과 같이 임의적으로 본원에 기재된 생물활성 모이어티와 동일하거나 또는 상이할 수 있는 생물활성 모이어티에 융합된 적어도 1개의 전체 나노케이지 단량체를 추가로 포함할 수 있다.
전형적인 측면에서, 본원에 기재된 나노케이지는 서브유닛 또는 단량체에 대한 제1, 제2 및 제3 융합 단백질, 및 임의적으로 생물활성 모이어티에 임의적으로 융합된 적어도 1개의 전체 나노케이지 단량체를 포함하고, 제1, 제2 및 제3 융합 단백질 및 전체 나노케이지 단량체의 생물활성 모이어티는 서로 모두 상이하다.
더욱 전형적으로, 제1, 제2 및 제3 융합 단백질 각각은 N- 또는 C-절반 페리틴에 융합된 항체 또는 그의 Fc 단편을 포함하고, 제1, 제2 및 제3 융합 단백질 중 적어도 1개는 N-절반 페리틴에 융합되고, 제1, 제2 및 제3 융합 단백질 중 적어도 1개는 C-절반 페리틴에 융합된다. 예를 들어, 제1 융합 단백질의 항체 또는 그의 단편은 전형적으로 Fc 단편이고; 제2 및 제3 융합 단백질 각각은 전형적으로 바이러스, 예컨대 SARS-CoV-2의 상이한 항원에 대해 특이적인 항체 또는 그의 단편을 포함하고, 전체 나노케이지 단량체는 임의적으로 동일한 바이러스, 예컨대 SARS-CoV-2의 또 다른 상이한 항원에 대해 특이적인 생물활성 모이어티에 융합된다.
일부 측면에서, 제2 융합 단백질의 항체 또는 그의 단편은 46 또는 52이고; 제3 융합 단백질의 항체 또는 그의 단편은 324 또는 80이다. 전형적인 측면에서, 본원에 기재된 나노케이지는 하기 4가지 융합 단백질을 임의적으로 4:2:1:1: 비로 포함한다:
a. 전장 페리틴에 융합된 298 (임의적으로 sc298);
b. N-페리틴에 융합된 Fc (임의적으로 scFc);
c. C-페리틴에 융합된 46 또는 52 (임의적으로 sc46 또는 sc52); 및
d. C-페리틴에 융합된 324 또는 80 (임의적으로 sc324 또는 sc80).
일부 측면에서, 본원에 기재된 나노케이지는 하기 서열 중 하나 이상과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어지고, 페리틴 서브유닛은 굵게 표시되고, 링커는 밑줄 표시되고, 경쇄는 이탤릭체로 표시되고, 중쇄는 소문자로 표시된다:



한 측면에서, 본원에 개시된 복수개의 융합 폴리펩티드를 포함하는 자가-조립된 폴리펩티드 복합체가 제공된다. 여러 실시양태에서, 자가-조립된 폴리펩티드 복합체는 (1) 복수개의 제1 융합 폴리펩티드 (각각의 제1 융합 폴리펩티드는 본원에 개시된 바와 같이 나노케이지 단량체 (예를 들어, 페리틴 단량체, 예를 들어 인간 페리틴 단량체, 또는 그의 서브유닛)에 연결된 Fc 영역을 포함함); 및 (2) 복수개의 제2 융합 폴리펩티드 (각각의 제2 융합 폴리펩티드는 SARS-CoV-2-결합 항체 단편 (예를 들어, SARS-CoV-2 단백질 (예를 들어, 스파이크 단백질 또는 수용체-결합 도메인 (RBD))에 결합할 수 있는 항체의 Fab 단편)을 포함하고, SARS-CoV-2-결합 항체 단편은 나노케이지 단량체 (예를 들어, 페리틴 단량체, 예를 들어 인간 페리틴 단량체) 또는 그의 서브유닛에 연결됨)를 포함한다. 일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 복수개의 제3 융합 폴리펩티드를 추가로 포함하고, 각각의 제3 융합 폴리펩티드는 제2 융합 폴리펩티드와는 별개이고, 각각은 (2) SARS-CoV-2-결합 항체 단편 (예를 들어, SARS-CoV-2 단백질에 결합할 수 있는 항체의 Fab 단편)에 연결된 (1) 나노케이지 단량체 (예를 들어, 페리틴 단량체, 예를 들어, 인간 페리틴 단량체)를 포함한다.
일부 실시양태에서, 융합 폴리펩티드 (예를 들어, 제1 융합 폴리펩티드 또는 제2 융합 폴리펩티드) 중 하나는 N-절반 나노케이지 단량체 (예를 들어, N-절반 페리틴) (그러나 전장 나노케이지 (예를 들어, 페리틴) 단량체는 아님)를 포함하고, 다른 융합 폴리펩티드 중 하나는 C-절반 나노케이지 단량체 (예를 들어, C-절반 페리틴) (그러나 전장 나노케이지 (예를 들어, 페리틴) 단량체는 아님)를 포함한다. 이들 여러 실시양태에서, 자가-조립된 폴리펩티드 복합체 내에서 N-절반 나노케이지 단량체 (예를 들어, N-절반 페리틴)를 포함하는 융합 폴리펩티드 대 C-절반 나노케이지 단량체 (예를 들어, C-절반 페리틴)를 포함하는 융합 폴리펩티드의 비는 약 1:1이다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 24개의 융합 폴리펩티드를 포함한다. 일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 24개 초과의 융합 폴리펩티드, 예를 들어 적어도 26, 적어도 28, 적어도 30, 적어도 32개의 융합 폴리펩티드, 적어도 34개의 융합 폴리펩티드, 적어도 36개의 융합 폴리펩티드, 적어도 38개의 융합 폴리펩티드, 적어도 40개의 융합 폴리펩티드, 적어도 42개의 융합 폴리펩티드, 적어도 44개의 융합 폴리펩티드, 적어도 46개의 융합 폴리펩티드, 또는 적어도 48개의 융합 폴리펩티드를 포함한다. 일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 32개의 융합 폴리펩티드를 포함한다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 적어도 4, 적어도 5, 적어도 6, 적어도 7, 또는 적어도 8개의 제1 융합 폴리펩티드를 포함한다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 적어도 4, 적어도 5, 적어도 6, 적어도 7, 또는 적어도 8개의 제2 융합 폴리펩티드를 포함한다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 적어도 4, 적어도 5, 적어도 6, 적어도 7, 적어도 8, 적어도 9, 적어도 10, 적어도 11, 적어도 12, 적어도 13, 적어도 14, 적어도 15, 또는 적어도 16개의 제3 융합 폴리펩티드를 추가로 포함한다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체는 대략 1:1, 1:2, 1:3, 또는 1:4의 제1 융합 폴리펩티드 대 다른 모든 융합 폴리펩티드의 비를 포함한다.
일부 실시양태에서, 자가-조립된 폴리펩티드 복합체 내의 각각의 융합 폴리펩티드는 페리틴 경쇄, 또는 페리틴 경쇄의 서브유닛을 포함한다. 이들 실시양태에서, 자가-조립된 폴리펩티드 복합체는 임의의 페리틴 중쇄, 페리틴 중쇄의 서브유닛, 또는 철에 결합할 수 있는 다른 페리틴 성분을 포함하지 않는다.
나노케이지를 포함하는 조성물, 예컨대 치료적 또는 예방적 조성물 또한 본원에 기재된다. COVID-19의 치료 및/또는 예방을 위한 관련 방법 및 용도 또한 기재되며, 상기 방법 또는 용도는 본원에 기재된 나노케이지 또는 조성물을 그를 필요로 하는 대상체에게 투여하는 것을 포함한다.
본원에 기재된 융합 단백질 및 폴리펩티드를 코딩하는 핵산 분자, 뿐만 아니라 핵산 분자를 포함하는 벡터, 및 벡터를 포함하는 숙주 세포 또한 본원에 기재된다.
본원에 기재된 융합 단백질을 코딩하는 폴리뉴클레오티드에는 본 발명의 폴리뉴클레오티드의 핵산 서열과 실질적으로 동일한 핵산 서열을 갖는 폴리뉴클레오티드가 포함된다. "실질적으로 동일한" 핵산 서열은 2개의 서열을 최적으로 정렬하고 (적절한 뉴클레오티드 삽입 또는 결실이 있음) 비교하여, 2개의 서열 사이에서 뉴클레오티드의 정확한 일치를 결정할 때, 또 다른 핵산 서열과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95% 동일성을 갖는 서열로서 본원에서 정의된다.
항체의 단편을 코딩하는 폴리뉴클레오티드의 적합한 공급원에는 전장 항체를 발현하는 임의의 세포, 예컨대 하이브리도마 및 비장 세포가 포함된다. 단편은 그 자체로 항체 등가물로서 사용될 수 있거나, 또는 상기 기재된 바와 같이 등가물로 재조합될 수 있다. 이 섹션에 기재된 DNA 결실 및 재조합은 공지된 방법, 예컨대 "항체의 기능적 등가물"이라는 제목의 섹션에서 상기 나열된 공개된 특허 출원에 기재된 것들 및/또는 다른 표준 재조합 DNA 기술, 예컨대 하기 기재되는 것들에 의해 수행될 수 있다. DNA의 또 다른 공급원은 관련 기술분야에 공지된 바와 같이 파지 디스플레이 라이브러리로부터 생성된 단일 쇄 항체이다.
추가로, 발현 서열, 프로모터 및 인핸서 서열에 작동가능하게 연결된 이전에 기재된 폴리뉴클레오티드 서열을 함유하는 발현 벡터가 제공된다. 효모 및 포유동물 세포 배양 시스템을 비롯하여 이로 제한되지 않는 원핵생물, 예컨대 박테리아 및 진핵생물 시스템에서 항체 폴리펩티드의 효율적인 합성을 위해 다양한 발현 벡터가 개발되었다. 본 발명의 벡터는 염색체, 비-염색체 및 합성 DNA 서열의 세그먼트를 포함할 수 있다.
임의의 적합한 발현 벡터가 사용될 수 있다. 예를 들어, 원핵생물 클로닝 벡터에는 이. 콜라이(E. coli)로부터의 플라스미드, 예컨대 colEl, pCRl, pBR322, pMB9, pUC, pKSM, 및 RP4가 포함된다. 원핵생물 벡터에는 또한 파지 DNA의 유도체, 예컨대 Ml3 및 다른 사상 단일-가닥 DNA 파지가 포함된다. 효모에서 유용한 벡터의 예는 2μ 플라스미드이다. 포유동물 세포에서의 발현에 적합한 벡터에는 SV-40의 널리 공지된 유도체, 아데노바이러스, 레트로바이러스-유래된 DNA 서열, 및 기능성 포유동물 벡터의 조합물, 예컨대 상기 기재된 것들, 및 기능성 플라스미드 및 파지 DNA로부터 유래된 셔틀 벡터가 포함된다.
추가의 진핵생물 발현 벡터는 관련 기술분야에 널리 공지되어 있다 (예를 들어, [P J. Southern & P. Berg, J. Mol. Appl. Genet, 1:327-341 (1982); Subramani et al, Mol. Cell. Biol, 1: 854-864 (1981); Kaufinann & Sharp, "Amplification And Expression of Sequences Cotransfected with a Modular Dihydrofolate Reductase Complementary DNA Gene," J. Mol. Biol, 159:601-621 (1982); Kaufhiann & Sharp, Mol. Cell. Biol, 159:601-664 (1982); Scahill et al., "Expression And Characterization Of The Product Of A Human Immune Interferon DNA Gene In Chinese Hamster Ovary Cells," Proc. Nat'l Acad. Sci USA, 80:4654-4659 (1983); Urlaub & Chasin, Proc. Nat'l Acad. Sci USA, 77:4216-4220, (1980)]을 참조하며, 모두 본원에 참조로 포함됨).
발현 벡터는 전형적으로 발현될 DNA 서열 또는 단편에 작동가능하게 연결된 적어도 1개의 발현 제어 서열을 함유한다. 제어 서열은 클로닝된 DNA 서열의 발현을 제어하고 조절하기 위해 벡터에 삽입된다. 유용한 발현 제어 서열의 예는 lac 시스템, trp 시스템, tac 시스템, trc 시스템, 파지 람다의 주요 오퍼레이터 및 프로모터 영역, fd 외피 단백질의 제어 영역, 효모의 당분해 프로모터, 예를 들어 3-포스포글리세레이트 키나제를 위한 프로모터, 효모 산 포스파타제를 위한 프로모터, 예를 들어 Pho5, 효모 알파-교배 인자의 프로모터, 및 폴리오마, 아데노바이러스, 레트로바이러스 및 유인원 바이러스로부터 유래된 프로모터, 예를 들어 초기 및 후기 프로모터 또는 SV40, 및 원핵생물 또는 진핵생물 세포 및 그들의 바이러스의 유전자 또는 이들의 조합물의 발현을 제어하기 위해 공지된 다른 서열이다.
본원에 기재된 발현 벡터를 함유하는 재조합 숙주 세포 또한 본원에 기재된다. 본원에 기재된 융합 단백질은 하이브리도마 이외의 세포주에서 발현될 수 있다. 본 발명에 따른 폴리펩티드를 코딩하는 서열을 포함하는 핵산은 적합한 포유동물 숙주 세포의 형질전환을 위해 사용될 수 있다.
특히 선호하는 세포주는 높은 발현 수준, 관심 단백질의 구성적 발현, 및 숙주 단백질로부터 최소 오염을 기반으로 하여 선택된다. 발현을 위한 숙주로서 이용가능한 포유동물 세포주는 관련 기술분야에 널리 공지되어 있으며, 여러 불멸화 세포주, 예컨대 비제한적으로 HEK 293 세포, 중국 햄스터 난소 (CHO) 세포, 아기 햄스터 신장 (BHK) 세포 및 및 여러 다른 세포가 포함된다. 적합한 추가의 진핵생물 세포에는 효모 및 다른 진균이 포함된다. 유용한 원핵생물 숙주에는 예를 들어 이. 콜라이, 예컨대 이. 콜라이 SG-936, 이. 콜라이 HB 101, 이. 콜라이 W3110, 이. 콜라이 X1776, 이. 콜라이 X2282, 이. 콜라이 DHI, 및 이. 콜라이 MRC1, 슈도모나스(Pseudomonas), 바실루스(Bacillus), 예컨대 바실루스 서브틸리스(Bacillus subtilis) 및 스트렙토마이세스(Streptomyces)가 포함된다.
이들 존재하는 재조합 숙주 세포를 사용하여, 폴리펩티드의 발현을 허용하는 조건하에 세포를 배양하고, 숙주 세포, 또는 숙주 세포를 둘러싸는 배지로부터 폴리펩티드를 정제함으로써 융합 단백질을 생성할 수 있다. 재조합 숙주 세포에서 선택을 위해 발현된 폴리펩티드의 표적화는 관심 항체-코딩 유전자의 5' 말단에서 신호 또는 분비 리더 펩티드-코딩 서열을 삽입함으로써 용이해질 수 있다 ([Shokri et al, (2003) Appl Microbiol Biotechnol. 60(6): 654-664, Nielsen et al, Prot. Eng., 10:1-6 (1997); von Heinje et al., Nucl. Acids Res., 14:4683-4690 (1986)]을 참조하며, 모두 본원에 참조로 포함됨). 이들 분비 리더 펩티드 요소는 원핵생물 또는 진핵생물 서열로부터 유래될 수 있다. 따라서 적합하게는, 숙주 세포 시토졸 밖으로 폴리펩티드의 이동 및 배지로의 분비를 지시하기 위해 폴리펩티드의 N-말단에 결합된 아미노산인 분비 리더 펩티드가 사용된다.
본원에 기재된 융합 단백질은 추가의 아미노산 잔기에 융합될 수 있다. 이러한 아미노산 잔기는 예를 들어 단리를 용이하게 하기 위한 펩티드 태그일 수 있다. 특이적 장기 또는 조직으로 항체의 귀소를 위한 다른 아미노산 잔기 또한 고려된다.
Fab-나노케이지가 HC-페리틴 및 LC의 공동-형질감염에 의해 생성될 수 있음을 이해할 것이다. 대안적으로, 도 1c에 도시된 바와 같이 1개의 플라스미드의 형질감염만을 필요로 하는 단일-쇄 Fab-페리틴 나노케이지가 사용될 수 있다. 이는 LC 및 HC 사이에 상이한 길이의, 예를 들어 60 또는 70개 아미노산의 링커에 의해 수행될 수 있다. 단일-쇄 Fab가 사용되는 경우, 중쇄 및 경쇄가 쌍을 형성하는 것이 보장될 수 있다. 태그 (예를 들어 Flag, HA, myc, His6x, Strep 등)는 상기 기재된 바와 같이 정제의 용이성을 위해 구축물의 N 말단에서 또는 링커 내에 부가될 수 있다. 추가로, 태그 시스템을 사용하여, 상이한 Fab-나노입자 플라스미드가 공동-형질감염될 때, 직렬/부가 친화도 크로마토그래피 단계를 이용하여 여러 상이한 Fab가 동일한 나노입자 상에 존재하는 것을 확인할 수 있다. 이는 나노입자에 다중-특이성을 제공한다. 프로테아제 부위 (예를 들어 TEV, 3C 등)는 필요에 따라 발현 및/또는 정제 후에 링커 및 태그를 절단하기 위해 삽입될 수 있다.
임의의 적합한 방법 또는 경로를 이용하여 본원에 기재된 융합 단백질을 투여할 수 있다. 투여 경로에는 예를 들어 경구, 정맥내, 복강내, 피하, 또는 근육내 투여가 포함된다.
예방 또는 치료의 목적을 위해 포유동물에서 사용되는 본원에 기재된 융합 단백질이 제약상 허용가능한 담체를 추가로 포함하는 조성물의 형태로 투여될 것으로 이해된다. 적합한 제약상 허용가능한 담체에는 예를 들어 물, 식염수, 인산염 완충된 식염수, 덱스트로스, 글리세롤, 에탄올 등 중 하나 이상, 뿐만 아니라 이들의 조합이 포함된다. 제약상 허용가능한 담체는 결합 단백질의 보관 수명 또는 유효성을 증강시키는 소량의 보조 물질, 예컨대 습윤제 또는 유화제, 보존제 또는 완충제를 추가로 포함할 수 있다. 주사용 조성물은 관련 기술분야에 널리 공지된 것과 같이 포유동물에게 투여 후 활성 성분의 신속한, 지속된 또는 지연된 방출을 제공하도록 제형화될 수 있다.
인간 항체가 인간에게 투여하기에 특히 유용하지만, 이들은 다른 포유동물에게도 투여될 수 있다. 본원에서 사용된 용어 "포유동물"에는 인간, 실험실 동물, 애완 동물 및 농장 동물이 포함되는 것으로 의도되지만 이로 제한되지 않는다.
한 측면에서, 일반적으로 대상체에게 본 개시내용의 자가-조립된 폴리펩티드 복합체를 포함하는 조성물을 투여하는 단계를 포함하는, SARS-CoV-2-관련 상태를 치료하거나, 개선시키거나 또는 예방하는데 유용할 수 있는 방법이 제공된다.
"SARS-CoV-2-관련 상태"는 SARS-CoV-2에 의한 감염과 연관된 상태 (예를 들어, 증상 또는 징후)를 지칭한다. 일부 실시양태에서, 상태는 대상체 (예를 들어, 본원에 개시된 자가-조립된 폴리펩티드 복합체를 투여한 대상체)로부터의 샘플에서 SARS-CoV-2 RNA, 단백질, 또는 바이러스 입자의 수준이며, 수준은 SARS-CoV-2 감염의 지표이다 (예를 들어, 수준이 임계값을 충족시키거나 또는 SARS-CoV-2 감염을 나타내는 참조 수준을 초과하기 때문임). 일부 실시양태에서, 상태는 COVID-19 질환과 연관된 증상, 예를 들어 열, 기침, 피로, 숨가쁨 또는 호흡곤란, 근육통, 오한, 인후염, 콧물, 두통, 흉통, 결막염, 오심, 구토, 설사, 후각 상실, 미각 상실 또는 졸중)이다. 일부 실시양태에서, 증상은 COVID-19 질환의 후속 후유증과 연관이 있고/거나, 장기 COVID-19 질환의 증상이다.
일부 실시양태에서, 대상체는 포유동물, 예를 들어 인간이다.
대상체에게 투여하기 위한 조성물은 일반적으로 본원에 개시된 자가-조립된 폴리펩티드 복합체를 포함한다. 일부 실시양태에서, 이러한 조성물은 제약상 허용가능한 부형제를 추가로 포함한다.
조성물은 전신 경로 (예를 들어, 경구, 정맥내, 복강내, 피하, 또는 근육내 투여)를 비롯한 임의의 다양한 투여 경로로 투여하기 위해 제형화될 수 있다.
상기 개시내용은 일반적으로 본 발명을 개시한다. 하기 구체적인 실시예를 참조하여 더욱 완벽하게 이해할 수 있다. 이들 실시예는 단시 설명의 목적으로 제공되며, 달리 명시되지 않는다면 제한하는 것으로 의도되지 않는다. 따라서, 본 발명은 어떠한 방식으로도 하기 실시예로 제한되는 것으로 해석되어서는 안되며, 오히려 본원에 제공된 교시내용의 결과로서 명백해지는 임의의 모든 변동을 포함하는 것으로 해석되어야 한다.
하기 실시예는 벡터 및 플라스미드의 구축, 폴리펩티드를 코딩하는 유전자를 이러한 벡터 및 플라스미드에 삽입, 또는 플라스미드를 숙주 세포에 도입하는데 이용되는 것과 같은 통상적인 방법의 상세한 설명을 포함하지는 않는다. 이러한 방법은 관련 기술분야의 통상의 기술자에게 널리 공지되어 있으며, [Sambrook, J., Fritsch, E. F. and Maniatis, T. (1989), Molecular Cloning: A Laboratory Manual, 2nd edition, Cold Spring Harbor Laboratory Press] (본원에 참조로 포함됨)을 비롯한 수많은 공보에 기재되어 있다.
추가의 설명없이도 관련 기술분야의 통상의 기술자는 상기 설명 및 하기 예시적인 실시예를 이용하여 본 발명의 화합물을 제조 및 이용할 수 있고, 청구된 방법을 실시할 수 있는 것으로 믿는다. 따라서, 하기 실시예는 본 발명의 전형적인 측면을 구체적으로 지적하며, 본 개시내용의 나머지를 어떠한 방식으로도 제한하는 것으로 해석되어서는 안된다.
실시예
실시예 1: 다가성은 SARS-CoV-2 항체를 초강력 중화제로 변환시킨다
이 실시예는 아포페리틴에 의한 융합 단백질의 설계, 발현, 정제 및 특징분석을 기재한다. 아포페리틴 프로모터는 ~6 nm 유체역학적 반경 (Rh)을 가지며 24개의 동일한 폴리펩티드로 구성된 8면체 대칭 구조로 자가-조립된다. 각각의 아포페리틴 서브유닛의 N-말단은 구형 나노케이지의 바깥쪽을 가리키며, 따라서 관심 단백질의 유전자 융합에 접근할 수 있다. 융합 단백질은 폴딩시 아포페리틴 프로모터가 아포페리틴 말단에 융합된 24개의 단백질의 다량체화를 유도하는 빌딩 블록으로서 작용하도록 설계되었다.
개요
COVID-19의 원인이 되는 바이러스인 SARS-CoV-2는 세계적인 대유행을 일으켰다. 항체는 바이러스 감염과 싸우기 위한 강력학 생물치료제일 수 있다. 여기서, 본 발명자들은 항체 단편의 올리고머화를 유도하고 SARS-CoV-2를 표적화하는 항체를 매우 강력한 중화제로 변환시키기 위해 모듈식 서브유닛으로서 인간 아포페리틴 프로모터를 사용한다. 이 플랫폼을 이용하여, 상응하는 IgG와 비교하여 최대 10,000배 효능 증강의 결과로서 9 x 10-14 M만큼 낮은 최대 억제 농도의 절반 (IC50) 값이 달성된다. 단일 다가성 분자 상에서 3가지 상이한 항체 특이성 및 단편 결정화가능한 (Fc) 도메인의 조합은 우수한 효능 및 IgG-유사 생체이용률과 함께 바이러스 서열 가변성을 극복하는 능력을 부여하였다. 따라서, 다중-특이적, 다중-친화도 항체 (멀타바디 또는 MB) 플랫폼은 다중-특이성과 함께 결합도를 고유하게 활용하여, SARS-CoV-2에 대한 광범위한 초강력 중화제를 전달한다. 플랫폼의 모듈성은 또한 건강상 세계적으로 중요한 다른 감염성 질환에 대한 신속한 평가와 관련이 있게 만든다. 중화 항체는 SARS-CoV-2에 대한 유망한 치료제이다.
도입
새로운 SARS-CoV-2와 같은 호흡기 바이러스로 인한 공중 보건에 대한 지속적인 위협은 대유행과 싸우기 위한 예방적 및 치료적 개입을 신속하게 개발하고 배치해야 할 긴급한 필요성을 강조한다. 모노클로날 항체 (mAb)는 고위험 영아에서 호흡기 합포체 바이러스의 예방을 위한 팔리비주맙1 또는 에볼라의 치료를 위한 Zmapp, mAb114, 및 REGN-EB32에 의해 예시된 바와 같이 감염성 질환의 치료를 위해 효과적으로 사용되었다. 결과적으로, SARS-CoV-2의 스파이크 (S) 단백질을 표적화하는 mAb는 COVID-19에 대한 생물의학적 대체의 개발에 중점을 두었다. 지금까지, S 단백질을 표적화하는 몇몇 항체가 확인되었고3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19, 밤라니비맙은 2020년 11월에 SARS-CoV-2의 응급 치료를 위해 미국 식품의약국 (FDA)에 의해 승인된 최초의 항체이다. 세포 진입을 위한 수용체인 안지오텐신 전환 효소 2 (ACE2)에 대한 결합을 방해하는 수용체 결합 도메인 (RBD)-지정된 mAb20는 일반적으로 가장 높은 중화 효능과 연관이 있다6,18,19.
mAb는 감염된 공여자, 면역화된 동물로부터 B-세포 분류에 의해 또는 사전 조립된 라이브러리에서 결합제를 확인함으로써 단리될 수 있다. 이들 방법이 바이러스-특이적 mAb의 발견에 대해 확고하고 신뢰할 수 있음에도 불구하고, 최상의 항체 클론의 확인은 일반적으로 시간-비용 불이익과 연관이 있다. 추가로, RNA 바이러스는 DNA 바이러스에 비해 더 높은 돌연변이율을 갖고, 이러한 돌연변이는 중화된 항체의 효능을 유의하게 변경시킬 수 있다. 실제로, 몇몇 연구는 회복기 혈청으로부터의 중화 효능의 감소, 및 SARS-CoV-2에 대한 더욱 최근의 B.1.1.724, B.1.35125, 및 B.1.1.2826,27 변이체에 대한 특정 mAb의 내성21,22,23을 이미 나타내었다. 따라서, 항체 발견을 바이러스 서열 가변성에 덜 민감한 고도로 강력한 중화제의 신속한 확인 및 개발과 연결하는 플랫폼의 개발에 대한 요구가 충족되지 않는다.
항체의 효능은 그의 에피토프와 동시에 여러 번 상호작용하는 그의 능력에 큰 영향을 미친다28,29,30. 이러한 증강된 겉보기 친화도 (결합도로 공지됨)는 SARS-CoV-2에 대해 Fab8,10,16에 비해 나노바디31,32 및 IgG의 중화 효능을 증가시키는 것으로 이전에 보고되었다. 결합도의 전체 힘을 활용하기 위해, 본 발명자들은 항체 단편을 다량체화하고 mAb를 SARS-CoV-2에 대한 초강력 중화제로서 추진시키기 위해 모듈식 서브유닛으로서 인간 아포페리틴 프로모터를 사용하는 항체-스캐폴드 기술을 개발하였다. 실제로, 생성된 멀타바디 분자는 상응하는 IgG에 비해 최대 4자릿수까지 효능을 증가시킬 수 있다. 추가로, 본 발명자들은 스파이크에서 점 돌연변이를 더 잘 극복하기 위해 3가지 상이한 Fab 특이성을 조합하는 이 기술의 능력을 입증한다. 멀타바디는 SARS-CoV-2에 대한 mAb의 항바이러스 특징을 증강시키기 위해 다목적 IgG-유사 "플러그-앤-플레이(plug-and-play)" 플랫폼을 제공하고, 바이러스 병원체에 대해 활용되는 메카니즘으로서 결합도의 힘을 입증한다.
물질 및 방법
단백질 발현 및 정제
VHH-인간 아포페리틴 융합, Fc 융합, Fab, IgG, 및 RBD 돌연변이체를 코딩하는 유전자를 합성하고, 진아트(GeneArt) (라이프 테크놀로지즈(Life Technologies))에 의해 pcDNA3.4 발현 벡터로 클로닝하였다. 달리 명시되지 않는다면, 모든 구축물은 펙토프로(FectoPRO) (폴리플러스 트랜스펙션즈(Polyplus Transfections))를 사용하여 1:1 비로 200 mL의 세포당 50 μg의 DNA에 의해 HEK 293F 세포 (써모 피셔 사이언티픽(Thermo Fisher Scientific))에서 0.8 x 106 세포/mL의 밀도로 일시적으로 발현되었다. 멀티트론 프로(Multitron Pro) 진탕기 (인포어스 에이치티(Infors HT))에서 37℃, 8% CO2, 및 70% 습도하에 125 rpm 진동에서 6-7일 인큐베이션 후, 5000 x g에서 15분 동안 원심분리하여 세포 현탁액을 수확하고, 0.22 μm 스테리톱(Steritop) 여과기 (이엠디 밀리포어(EMD Millipore))를 통해 상청액을 여과하였다. Fab 및 IgG를 90 μg의 LC 및 HC (1:2 비)로 공동-형질감염시킴으로써 일시적으로 발현시키고, 용리 완충제로서 100 mM 글리신 pH 2.2를 사용하여 각각 카파셀렉트(KappaSelect) 친화도 컬럼 (지이 헬쓰케어(GE Healthcare)) 및 하이트랩(HiTrap) 단백질 A HP 컬럼 (지이 헬쓰케어)을 사용하여 정제하였다. 용리된 분획을 1 M Tris-HCl, pH 9.0으로 즉시 중화시키고, 수퍼덱스(Superdex) 200 증가 크기 배제 컬럼 (지이 헬쓰케어)을 사용하여 추가로 정제하였다. ACE2 및 VHH-72의 Fc 융합을 IgG와 동일한 방식으로 정제하였다. VHH-72 아포페리틴 융합은 하이트랩 페닐 HP 컬럼을 사용하여 소수성 상호작용 크로마토그래피에 의해 정제하고, 용리된 분획을 20 mM 인산나트륨 pH 8.0, 150 mM NaCl 중에서 수퍼로스(Superose) 6 10/300 GL 크기 배제 컬럼 (지이 헬쓰케어) 상에 로딩하였다. 마우스 및 인간으로부터 야생형 (BEI NR52309) 및 돌연변이체 RBD, 융합전 S 엑토도메인 (BEI NR52394) 및 Fc 수용체 (FcRn 및 FcγRI)를 히스트랩(HisTrap) Ni-NTA 컬럼 (지이 헬쓰케어)을 사용하여 정제하였다. Ni-NTA 정제 후, S 삼량체의 경우 수퍼로스 6 및 RBD 및 Fc 수용체의 경우 수퍼덱스 200 증가 크기 배제 컬럼 (지이 헬쓰케어)을 수행하였고, 모든 경우에 20 mM 인산염 pH 8.0, 150 mM NaCl 완충제를 사용하였다.
멀타바디의 설계, 발현 및 정제
본원에서 멀타바디로 지칭되는 모든 분자는 scFab 및 scFc 단편을 함유한다. 이종이량체 및 동종이량체 단편을 생성하기 위해 70개의 아미노산 가요성 링커 [(GGGGS)x14]를 사용하여 각각 scFab 및 scFc 폴리펩티드 구축물을 생성하였다. 구체적으로, Fab 경쇄의 C 말단을 링커를 통해 Fab 중쇄의 N 말단에 융합시킨다. scFc의 경우, 기능성 동종이량체 Fc를 형성하는 2개의 단일 Fc 쇄를 직렬로 융합시켰다. 개별 도메인을 25개 아미노산 링커: (GGGGS)x5에 의해 아포페리틴 단량체에 융합시킨다. 절반 아포페리틴에 연결된 scFab 및 scFc 단편을 코딩하는 유전자는 인간 아포페리틴의 경쇄의 잔기 1 내지 90 (C-페리틴) 및 91 내지 175 (N-페리틴)의 결실에 의해 생성되었다. HEK 293F 세포에서 멀타바디의 일시적인 형질감염은 66 μg의 플라스미드를 2:1:1 비의 scFab-인간 아포페리틴: scFc-인간 N-페리틴: scFab-C-페리틴과 혼합함으로써 수득되었다. scFab-인간 아포페리틴의 첨가는 효율적인 멀타바디 조립을 가능하게 하였고, 최종 분자에서 Fc와 비교하여 Fab의 수를 증가시켜, Fc 결합도에 비해 Fab 결합도를 선호하였다. 다중-특이적 멀타바디의 경우, 4:2:1:1 비의 scFab1-인간 아포페리틴: scFc-인간 N-페리틴: scFab2-C-페리틴: scFab3-C-페리틴을 사용하였다. DNA 혼합물을 여과하고, 실온 (RT)에서 66 μl의 펙토프로와 함께 인큐베이션한 후, 세포 배양물에 첨가하였다. 분할 멀타바디는 20 mM Tris pH 8.0, 3 M MgCl2 및 10% 글리세롤 용리 완충제에 의해 하이트랩 단백질 A HP 컬럼 (지이 헬쓰케어)을 사용하여 친화도 크로마토그래피에 의해 정제되었다. 단백질을 함유하는 분획을 농축시키고, 수퍼로스 6 10/300 GL 컬럼 (지이 헬쓰케어) 상에서 겔 여과에 의해 추가로 정제하였다.
음성 염색 전자 현미경
이전에 15 s 동안 공기 중에서 글로우-방전시키고, 30 s 동안 흡착시키고, 3 μL의 2% 우라닐 포르메이트로 염색한 탄소-코팅된 구리 그리드의 표면 상에 대략 0.02 mg/mL 농도의 멀타바디 3 마이크로리터를 놓았다. 와트만 넘버(Whatman No.) 1 여과지를 사용하여 과량의 염색을 그리드로부터 즉시 제거하고, 추가 3 μL의 2% 우라닐 포르메이트를 20 s 동안 첨가하였다. 200 kV에서 작동하고 오리우스(Orius) 전하-결합 소자 (CCD) 카메라 (가탄 인크(Gatan Inc))를 구비한 FEI 테크나이(Tecnai) T20 전자 현미경으로 그리드를 영상화하였다.
생물층 간섭법
25℃에서 PBS pH 7.4, 0.01% BSA, 및 0.002% Tween 중에서 옥텟(Octet) RED96 BLI 시스템 (사르토리우스 포르테바이오(Sartorius ForteBio))을 사용하여 직접 결합 동역학 측정을 수행하였다. His-태그 부착된 RBD, SARS-CoV-2 스파이크를 Ni-NTA (NTA) 바이오센서 (사르토리우스 포르테바이오) 상에 로딩하여 0.8 nm의 BLI 신호 반응에 도달하였다. 회합 속도는 로딩된 바이오센서를 250 내지 8 nM (Fab), 125 내지 4 nM (IgG), 및 16 내지 0.5 nM (MB)의 2배 희석 계열을 함유하는 웰로 옮겨서 측정되었다. 해리 속도는 바이오센서를 완충제-함유 웰에 담궈서 측정되었다. 각 단계의 기간은 180 s였다. 분할 멀타바디 설계에서 Fc 특징분석은 상기 나타낸 실험 조건 및 농도 범위에 따라 Ni-NTA (NTA) 바이오센서 상에 로딩된 hFcγRI 및 hFcRn에 대한 결합을 측정함으로써 평가되었다. 멀타바디가 엔도좀 재순환을 겪는 이론적 능력을 조사하기 위해, hFcRn β2-마이크로글로불린 복합체에 대한 결합을 생리학적 (7.4) 및 엔도좀 (5.6) pH에서 측정하였다. 유사하게, 마우스 대용물 MB의 Fc 특징분석은 Ni-NTA (NTA) 바이오센서 상에 사전 고정된 mFcγRI 및 mFcRn에 대한 결합을 측정함으로써 평가되었다. 100 내지 3 nM (IgG) 및 10 내지 0.3 nM (MB)의 2배 희석 계열을 이용하였다. 센소그램의 분석은 1:1 대입 모델에 의해 옥텟 소프트웨어를 이용하여 수행되었다. 경쟁 검정은 2-단계 결합 과정으로 수행되었다. His-태그 부착된 RBD로 사전 로딩된 Ni-NTA 바이오센서를 먼저 50 μg/mL의 일차 항체를 함유하는 웰에 180 s 동안 담궜다. 30 s 기준선 기간 후, 50 μg/ml의 이차 항체를 함유하는 웰에 센서를 추가 300 s 동안 담궜다. 모든 인큐베이션 단계는 25℃에서 PBS pH 7.4, 0.01% BSA, 및 0.002% Tween 중에서 수행되었다. ACE2-Fc를 사용하여 수용체 결합 부위에 결합하는 mAb를 맵핑하였다.
동적 광 산란
멀타바디의 Rh는 다이나프로(DynaPro) 플레이트 판독기 III (와트 테크놀로지(Wyatt Technology))을 사용하여 동적 광 산란 (DLS)에 의해 결정되었다. 1 mg/mL 농도의 멀타바디 약 20 μL를 384-웰 흑색의 투명 바닥 플레이트 (코닝(Corning))에 첨가하고, 25℃의 고정된 온도에서 판독당 5 s의 기간으로 측정하였다. 입자 크기 결정 및 다분산도는 다이나믹스(Dynamics) 소프트웨어 (와트 테크놀로지)를 사용하여 5회 판독의 축적으로부터 수득되었다.
응집 온도
멀타바디 및 모 IgG의 응집 온도 (Tagg)는 UNit 장비 (언체인드 랩스(Unchained Labs))를 사용하여 결정되었다. 샘플을 1.0 mg/mL로 농축하고, 1℃ 증분으로 25에서 95℃까지 열 상승에 적용하였다. Tagg는 기준선에 비해 266 nm 파장에서 정적 광산란의 50% 증가가 관찰되는 온도 (즉, 미분 곡선의 최대값)로 결정되었다. 2회의 독립적인 측정에 대한 평균 및 표준 편차는 UNit 분석 소프트웨어를 사용하여 계산되었다.
약동학 및 면역원성
마우스 아포페리틴 (m페리틴)의 경쇄의 N-말단에 융합된 마우스 HD37 (항-hCD19) IgG2a의 scFab 및 scFc 단편으로 구성된 대용물 멀타바디를 연구에 사용하였다. 상기 기재된 절차에 따라 2:1:1 비의 HD37 scFab-m페리틴: Fc-m페리틴: m페리틴을 형질감염시키고 정제하였다. L234A, L235A, 및 P329G (LALAP) 돌연변이를 마우스 IgG2a Fc-구축물에 도입시켜 멀타바디의 이펙터 기능을 침묵시켰다48. 생체내 연구는 찰스 리버(Charles River) (균주 코드: 027)로부터 구입하고, 12 h 명암 주기하에 (7 a.m./7 p.m.) 21-23℃의 온도 및 40-55%의 습도에서 개별적으로 환기되는 케이지에 하우징된 12주령 수컷 C57BL/6 마우스를 사용하여 수행되었다. 모든 절차는 유니버시티 오브 토론토 스카버러(University of Toronto Scarborough)의 지역 동물 관리 위원회(Local Animal Care Committee)에 의해 승인되었다. 200 μL의 PBS (pH 7.5) 중 ~5 mg/kg의 멀타바디 또는 대조군 샘플 (HD37 단일 쇄 IgG-IgG1 또는 IgG2a 아형) 및 헬리코박터 파이로리 페리틴 (Hp페리틴)-PfCSP 말라리아 펩티드의 단일 주사를 피하 주사하였다. 혈액 샘플을 여러 시점에서 수집하고, 혈청 샘플을 ELISA에 의해 순환 항체 및 항-약물 항체의 수준에 대해 평가하였다. 간략히, 96-웰 피어스(Pierce) 니켈 코팅된 플레이트 (써모 피셔)를 0.5 μg/ml의 His6x-태그 부착된 항원 hCD19로 50 μL 코팅하여, IgG 및 멀타바디에 대한 시약-특이적 표준 곡선을 이용하여 순환 HD37-특이적 농도를 결정하였다. HRP-단백질A (인비트로젠(Invitrogen))를 사용하여 결합된 IgG/MB (1:10,000 희석액)의 수준을 검출하였다. 항-약물-항체 투여를 위해, 눈크 맥시소프(Nunc MaxiSorp) 플레이트 (바이오레전드(Biolegend))를 12-량체 HD37 scFab-m페리틴으로 또는 Hp페리틴-PfCSP 말라리아 펩티드로 코팅하였다. 1:100 혈청 희석액을 실온에서 1 h 동안 인큐베이션하고, 이차 분자로서 HRP-단백질A (인비트로젠) (1:10,000 희석액)를 사용하여 추가로 진행시켰다. 시너지(Synergy) Neo2 다중-모드 검정 마이크로플레이트 판독기 (바이오텍 인스트루먼츠(Biotek Instruments))를 사용하여 450 nm에서 화학발광 신호를 정량화하였다.
생체분포
8주령의 수컷 BALB/c 마우스를 더 잭슨 래버러토리(The Jackson Laboratory)로부터 구입하고, 개별적으로 환기되는 케이지에 하우징하였다. 마우스를 20-21℃의 온도 및 40-60%의 습도하에 14 h 명/10 h 암에서 (새벽에서 황혼까지 강도를 단계적으로 하고, 정오에 최대임) 하우징하였다. 모든 절차는 유니버시티 오브 토론토(University of Toronto)에서 지역 동물 관리 위원회에 의해 승인되었다. 마우스 아포페리틴 경쇄의 N-말단에 융합된 마우스 HD37 IgG2a의 scFab 및 scFc 단편으로 구성된 멀타바디를 이 연구에 사용하였다. 제조자의 지침에 따라 알렉사 플루오르(Alexa Fluor)TM 647 항체 표지화 키트 (인비트로젠)를 사용하여 HD37 IgG2a 멀타바디 또는 대조군 샘플 (HD37 단일 쇄 IgG2a)을 알렉사-647과 형광 접합시켰다. 알렉사 플루오르TM 647로 표지된 15 nm 금 나노입자는 크리에이티브 다이아그노스틱스(Creative Diagnostics) (GFLV-15)로부터 구입하였다. 퍼킨엘머(PerkinElmer) IVIS 스펙트럼 (퍼킨엘머)을 이용하여 비침습적 생체분포 실험을 수행하였다. BALB/c 마우스의 어깨 위의 늘어진 피부로 200 μL의 PBS (pH 7.5) 중 ~5 mg/kg의 MB, HD37 IgG2a, 또는 금 나노입자를 피하 주사하고, 주사 후 0, 1 h, 6 h, 24 h, 2, 3, 4, 8 및 11 일의 시점에서 영상화하였다. 영상화 전에, 이소플루란 및 산소의 혼합물을 함유하는 마취 유도 챔버에 마우스를 1분 동안 두었다. 이어서, 마취된 마우스를 IVIS 영상화 시스템 (37℃에서 유지되고 이소플루란 및 산소의 혼합물이 공급됨) 내의 내장된 가열 도킹 시스템의 중심에 복와위로 두었다. 전신 2D 영상화를 위해, 마우스를 영상화 시스템 내부에서 1-2 s 동안 영상화하였다 (여기 640 nm 및 방출 680 nm). IVIS 소프트웨어 (IVIS용 리빙 영상 소프트웨어)를 사용하여 데이터를 분석하였다. 2D 에피-조명 영상으로부터 형광 신호를 확인한 후, 3 x 3 또는 3 x 4 투과조명 위치의 내장된 스캔 필드를 사용하여 관심 영역 상에서 3D 투과조명 형광 영상화 단층촬영 (FLIT)을 수행하였다. 640 여기 및 680 nm 방출을 이용하여 다양한 투과조명 위치에서 일련의 2D 형광 표면 복사 영상을 찍었다. 상응하는 위치에서 일련의 CT 스캔을 또한 찍었다. 형광 신호 및 CT 스캔을 조합하여 형광 신호의 3D 분포 맵을 재구축하였다. 생성된 3D 형광 영상은 상응하는 신체 위치에서 찍은 PBS 주사된 마우스의 3D 영상을 기반으로 하여 임계값이 지정되었다. 영상을 IVIS 소프트웨어에서 레인보우 LUT에 맵핑하였고, 색상 막대의 상단은 금 나노입자 주사된 마우스의 경우 50 pmol M-1 cm-1로 설정되고, MB 및 IgG2a 주사된 마우스의 경우 1 000 pmol M-1 cm-1로 설정되어, 시간 경과에 걸쳐 생체분포의 더 양호한 시각화를 가능하게 하였다. IVIS 소프트웨어의 마우스 장기 등록 기능은 3D 영상으로부터 샘플 신체 위치를 평가하기 위한 일반적인 지침으로 사용되었다.
SARS-CoV-2의 RBD에 대한 파지 라이브러리의 패닝
시판 수퍼휴먼(SuperHuman) 2.0 파지 라이브러리 (디스트리뷰티드 바이오(Distributed Bio)/찰스 리버 래버러토리즈(Charles River Laboratories))를 사용하여 SARS-CoV-2 RBD에 대한 모노클로날 항체 결합제를 확인하였다. 이를 위해, SARS-CoV-2의 RBD-Fc-Avi 태그 구축물을 EXPi-293 포유동물 발현 시스템에서 발현시켰다. 이 단백질을 후속적으로 단백질 G 다이나비즈(Dynabeads)에 의해 정제하고, 비오티닐화하고, 비오티닐화 및 ACE2 재조합 단백질 (시노 바이올로직스 인크(Sino Biologics Inc))에 대한 결합을 품질 제어하였다. 수퍼휴먼 2.0 파지 라이브러리 (5 x 1012)를 72℃에서 10분 동안 가열하고, 단백질 G 다이나비즈TM (인비트로젠), M-280 스트렙타비딘 다이나비즈TM (인비트로젠), 송아지 흉선 (시그마(Sigma)), 인간 IgG (시그마)로부터의 히스톤, 및 인테그레이티드 디앤에이 테크놀로지즈(Integrated DNA Technologies)로부터의 ssDNA-비오틴 NNK 및 인테그레이티드 디앤에이 테크놀로지즈로부터의 DNA-비오틴 NNK에 대해 선택 해제하였다. 다음으로, 킹피셔 플렉스(Kingfisher FLEX) (써모피셔) 상에서 자동화 프로토콜을 이용하여 M-280 스트렙타비딘 다이나비즈TM에 의해 포획된 RBD에 대해 라이브러리를 패닝하였다. 선택된 파지를 비드로부터 산 용리시키고, Tris-HCl pH 7.9 (텍노바(Teknova))를 사용하여 중화시켰다. ER2738 세포를 OD600 = 0.5에서 1:10 비로 중화된 파지 풀로 감염시키고, 37℃ 및 100 rpm에서 40 분 인큐베이션 후에, 파지 풀을 원심분리하고, 30℃에서 밤새 항생제 선택과 함께 한천 상에서 인큐베이션하였다. 구조된 파지를 PEG에 의해 침전시키고, 가용성-상 자동화 패닝의 3회 추가의 라운드에 적용하였다. PBST/1% BSA 완충제 및/또는 PBS/1% BSA를 선택 해제, 세척 및 선택 라운드에서 사용하였다.
SARS-CoV-2 RBD에 의해 박테리아 PPE에서 항-SARS-CoV-2 scFv의 스크리닝
파지 디스플레이로부터 선택된 항-SARS-CoV-2 RBD scFv를 발현시키고, 25℃에서 HC200M 센서 칩 (카테라(Carterra))을 구비한 카테라 LSA 어레이 SPR 장비 (카테라) 상에서 고처리량 표면 플라즈몬 공명 (SPR)을 이용하여 스크리닝하였다. V5 에피토프 태그를 scFv에 첨가하여, 표준 아민-커플링에 의해 칩 표면 상에 사전 고정시킨 고정된 항-V5 항체 (아브캄(Abcam), 메사추세츠주 캠브릿지)를 통해 포획을 가능하게 하였다. 간략히: 먼저 0.4 M 1-에틸-3-(3-디메틸아미노프로필) 카르보디이미드 히드로클로라이드 (EDC), 0.1 M N-히드록시술포숙신이미드 (sNHS) 및 0.1 M 2-(N-모르폴리노) 에탄술폰산 (MES) pH 5.5의 1:1:1 (v/v/v) 혼합물의 10분 주사에 의해 칩 표면을 활성화시켰다. 이어서, 10 mM 아세트산나트륨 pH 4.3 중에서 제조된 50 μg/ml의 항-V5 태그 항체를 14분 동안 커플링시키고, 10분 주사 동안에 과량의 반응성 에스테르를 1 M 에탄올아민 HCl pH 8.5로 차단시켰다. 스크리닝을 위해, scFv (scFv당 1 스폿)를 함유하는 조 박테리아 주변 세포질 추출물 (PPE)로 구성된 384-리간드 어레이를 제조하였다. 각각의 추출물은 작동 완충제 (10 mM HEPES pH 7.4, 150 mM NaCl, 3 mM EDTA, 및 0.01% (v/v) Tween-20 (HBSTE))에서 2배 희석으로 제조되었고, 항-V5 표면 상에 15분 동안 인쇄하였다. 이어서, SARS-CoV-2 RBD Avi Tev His 태그는 0.5 mg/ml BSA로 보충된 10 mM HEPES pH 7.4, 150 mM NaCl, 및 0.01% (v/v) Tween-20 (HBST) 중에서 0, 3.7, 11.1, 33.3, 100, 37, 및 300 nM으로 제조되었고, 피분석물로서 5분 동안 주입되었고, 15분 해리 시간을 가졌다. 샘플은 임의의 재생 단계없이 상승하는 농도로 주입되었다. 국소 참조 스폿으로부터의 결합 데이터를 사용하여 활성 스폿으로부터 신호를 차감하였고, 가장 가까운 완충제 블랭크 피분석물 반응을 차감하여, 데이터를 이중 참조하였다. 이중 참조된 데이터를 카테라의 동적 검사 도구 (버전 Oct. 2019)에서 간단한 1:1 랭뮤어(Langmuir) 결합 모델에 대입하였다. 파지 디스플레이 스크리닝으로부터 20개의 중간-친화도 결합제를 본 연구를 위해 선택하였다.
슈도바이러스 생성 및 중화
HIV-기반 렌티바이러스 시스템49을 약간 변형하여 SARS-CoV-2 위형 바이러스 (PsV)를 생성하였다. 간략히, 제조자의 지침에 따라 BioT 형질감염 시약 (바이오랜드 사이언티픽(Bioland Scientific))을 사용하여 루시페라제 리포터 유전자 (BEI NR52516)를 코딩하는 렌티바이러스 백본, 스파이크를 발현하는 플라스미드 (BEI NR52310), 및 HIV 구조 및 조절 단백질 Tat (BEI NR52518), Gag-pol (BEI NR52517), 및 Rev (BEI NR52519)를 코딩하는 플라스미드로 293T 세포를 공동-형질감염시켰다. 37℃에서 24 h 형질감염 후, 5 mM 나트륨 부티레이트를 배지에 첨가하고, 세포를 30℃에서 추가 24-30 h 동안 인큐베이션하였다. SARS-CoV-2 스파이크 돌연변이체 D614G는 친절하게도 디.알. 버튼(D.R. Burton) (더 스크립스 리서치 인스티튜트(The Scripps Research Institute))에 의해 제공되었고, SARS-COV-2 PsV 변이체 B.1.351은 친절하게도 디.디. 호(D.D. Ho) (콜롬비아 유니버시티(Columbia University))에 의해 제공되었고, 나머지 PsV 돌연변이체는 표 1에 기재된 프라이머를 사용하여 KOD-Plus 돌연변이 유발 키트 (토요보(Toyobo), 일본 오사카)를 사용하여 생성되었다. PsV 입자를 수확하고, 0.45 μm 공극 멸균 여과기에 통과시키고, 최종적으로 100 K 아미콘(Amicon) (머크 밀리포어 아미콘-울트라(Merck Millipore Amicon-Ultra) 2.0 원심분리 여과 장치)을 사용하여 농축시켰다.
표 1. 프라이머 서열

293T-ACE2 세포 (BEI NR52511) 및 HeLa-ACE2 세포 (디.알. 버튼에 의해 친절하게 제공됨; 더 스크립스 리서치 인스티튜트)를 사용하여 단일-주기 중화 검정에서 중화를 결정하였다. 실험 전날에 세포를 100 μl 부피에서 10,000 세포/웰의 밀도로 시딩하였다. 293T 세포의 경우, 플레이트를 폴리-L-리신 (시그마-알드리치(Sigma-Aldrich))으로 사전 코팅하였다. 실험 당일에, 50 μl의 계열 희석된 IgG 및 MB 샘플을 50 μl의 PsV와 함께 37℃에서 1 h 동안 인큐베이션하였다. 1 h 인큐베이션 후, 인큐베이션된 부피를 세포에 첨가하고, 48 h 동안 인큐베이션하였다. 50 μl 브리텔라이트 플러스(Britelite plus) 시약 (퍼킨엘머)을 50 μl의 세포에 첨가하여 PsV 중화를 모니터링하고, 2분 인큐베이션 후, 부피를 96-웰 흰색 플레이트 (시그마-알드리치)로 옮기고, 시너지 Neo2 다중-모드 검정 마이크로플레이트 판독기 (바이오텍 인스트루먼츠)를 사용하여 발광 (상대 발광 단위 (RLU))을 측정하였다. 2 내지 3개의 생물학적 반복과 2개의 기술적 반복 각각을 수행하였다. IC50 증가 배수는 다음과 같이 계산되었다:
IgG IC50 (μg/mL) / MB IC50 (μg/mL)
진정한 바이러스 중화
96 F 플레이트에서 100 U 페니실린, 100 U 스트렙토마이신, 및 10% FBS로 보충된 DMEM에서 VeroE6 세포를 30,000/웰의 농도로 시딩하였다. 세포를 플레이트에 부착시키고, 밤새 방치하였다. 24 h 후, IgG 및 MB 샘플의 5배 계열 희석액을 96 R 플레이트에서 100 U 페니실린 및 100 U 스트렙토마이신으로 보충된 DMEM에서 4벌식으로 제조하였다 (25 μL/웰). 약 25 μL의 SARS-CoV-2/SB2-P4-PB50 클론 1을 100TCID/웰로 각각의 웰에 첨가하고, 15분마다 진탕시키면서 37℃에서 1 h 동안 인큐베이션하였다. 공동-배양 후, VeroE6 플레이트로부터의 배지를 제거하고, 50 μL 항체-바이러스 샘플을 사용하여, 15분마다 진탕시키면서 37℃, 5% CO2에서 1 h 동안 VeroE6 세포를 4벌식으로 접종하였다. 1 h 접종 후, 접종물을 제거하고, 100U 페니실린, 100U 스트렙토마이신, 및 2% FBS로 보충된 200 μL의 신선한 DMEM을 각각의 웰에 첨가하였다. 플레이트를 5일 동안 추가로 인큐베이션하였다. 세포변성 효과 (CPE)를 모니터링하고, PRISM을 사용하여 IC50 값을 계산하였다. 3개의 생물학적 반복과 4개의 기술적 반복 각각을 수행하였다.
스파이크 단백질과 Fab 80, 298 및 324의 가교
약 100 μg의 스파이크 삼량체를 20 mM HEPES pH 7.0 및 150 mM NaCl 중에서 2x 몰 과량의 Fab 80, 298, 또는 324와 혼합하였다. 0.075% (v/v) 글루타르알데히드 (시그마 알드리치)를 첨가하여 단백질을 가교시키고, 실온에서 120분 동안 인큐베이션하였다. 복합체를 크기 배제 크로마토그래피 (수퍼로스6 증가 10/300 GL, 지이 헬쓰케어)를 통해 정제하고, 0.5 mg/mL로 농축시키고, cryo-EM 그리드 제조를 위해 직접 사용하였다.
Fab 46-RBD 복합체의 가교
약 100 μg의 Fab 46을 20 mM HEPES pH 7.0 및 150 mM NaCl 중에서 2x 몰 과량의 RBD와 혼합하였다. 0.05% (v/v) 글루타르알데히드 (시그마 알드리치)를 첨가하여 복합체를 가교시키고, 실온에서 45분 동안 인큐베이션하였다. 가교된 복합체를 크기 배제 크로마토그래피 (수퍼덱스 200 증가 10/300 GL, 지이 헬쓰케어)를 통해 정제하고, 2.0 mg/ml로 농축시키고, cryo-EM 그리드 제조를 위해 직접 사용하였다.
cryo-EM 데이터 수집 및 영상 처리
3 마이크로리터의 샘플을 사내에서 제조된 홀리 골드 그리드 상에 침착시키고51, 이를 사용하기 전에 펠코 이지글로우(PELCO easiGlow) (테드 펠라(Ted Pella))로 15 s 동안 공기 중에서 글로우-방전시켰다. -5의 오프셋을 이용하여 샘플을 변형된 FEI 마크 III 비트로봇(Vitrobot) (4℃ 및 100% 습도에서 유지됨)으로 6 s 동안 블롯팅하고, 후속적으로 액체 에탄 및 프로판의 혼합물에서 급랭시켰다. 250 프레임/s에서 전자 계수 모드로 작동하는 써모 피셔 사이언티픽 타이탄 크리오스(Titan Krios) G3 전자 현미경 및 프로토타입 팔콘(Falcon) 4 카메라에 의해 300 kV에서 데이터를 획득하였다. 29가지 노출 비율, ~5 e-/pix/s의 카메라 노출 속도, ~44 e-/Å2의 총 시편 노출에 의해 9.6 s 동안 동영상을 수집하였다. 대물렌즈 조리개는 사용되지 않았다. 픽셀 크기는 금 회절 표준으로부터 1.03 Å/픽셀로 보정되었다. 현미경은 EPU 소프트웨어 패키지에 의해 자동화되었고, 데이터 수집은 cryoSPARC Live52에 의해 모니터링되었다.
일부 샘플에서 발생하는 선호 배향을 극복하기 위해, 기울어진 데이터 수집을 이용하였다53. 스파이크-Fab 80 복합체의 경우, 820개의 0˚ 기울기 동영상 및 2790개의 40˚ 기울기 동영상을 수집하였다. 스파이크-Fab 298 복합체의 경우, 4259개의 0˚ 기울기 동영상 및 3513개의 40˚ 기울기 동영상을 수집하였다. 스파이크-Fab 324 복합체의 경우, 1098개의 0˚ 기울기 동영상 및 3380개의 40˚ 기울기 동영상을 수집하였다. RBD-Fab 46 복합체의 경우, 4722개의 0˚ 기울기 동영상을 수집하였다. 0˚ 기울기 동영상의 경우, cryoSPARC 패치 모션 수정이 수행되었다. 40˚ 기울기 동영상의 경우, 렐리온 모션코르(Relion MotionCorr)54,55를 사용하였다. 이어서, 현미경 사진을 cryoSPARC로 가져오고, 패치 CTF 추정을 수행하였다. cryoSPARC 라이브 세션 동안에 2D 분류로부터 생성된 주형을 입자의 주형 선택을 위해 사용하였다. 2D 분류를 이용하여 쓸모없는 입자 영상을 제거하여, 스파이크-Fab 80 복합체에 대해 80,951개의 입자 영상, 스파이크-Fab 298 복합체에 대해 203,138개의 입자 영상, 스파이크-Fab 324 복합체에 대해 64,365개의 입자 영상, 및 RBD-Fab 46 복합체에 대해 2,143,629개의 입자 영상의 데이터세트를 생성하였다. 다중-부류 순이론적 정련의 다중 라운드를 이용하여 입자 영상 스택을 정리하고, 균일한 정련을 이용하여 합의 구조를 수득하였다. 기울어진 입자의 경우, 이 단계에서 렐리온 내에서 입자 연마를 수행하고, cryoSPARC으로 다시 가져왔다. 스파이크-Fab 복합체의 경우, 광범위한 가요성이 관찰되었다. 3D 가변성 분석을 수행하고56, 존재하는 상이한 상태를 분류하기 위해 불균일 정련을 함께 사용하였다. 이어서, 입자 영상의 최종 세트에 대해 불균일 정련이 수행되었다57. RBD-Fab 46 복합체의 경우, 3개의 부류에 의한 cryoSPARC 순이론적 정련을 반복적으로 사용하여, 입자 영상 스택을 정리하였다. 그 후, 정련된 오일러(Euler) 각도에 의한 입자 영상 스택을 재구축을 위해 cisTEM으로 가져와서58, 4.0 Å 해상도 맵을 제공하였다. 렐리온과 cryoSPARC 사이의 데이터 전송은 pyem에 의해 수행되었다59.
결정화 및 구조 결정
20 mM Tris pH 8.0, 150 mM NaCl 중에서 200 μg의 RBD와 2x 몰 과량의 각각의 Fab를 혼합하여 52 Fab-298 Fab-RBD의 삼원 복합체를 수득하고, 후속적으로 크기 배제 크로마토그래피 (수퍼덱스 200 증가 10/300 GL, 지이 헬쓰케어)를 통해 정제하였다. 복합체를 함유하는 분획을 7.3 mg/ml로 농축시키고, 20% (w/v) 2-프로판올, 20% (w/v) PEG 4000, 및 0.1 M 시트르산나트륨 pH 5.6과 1:1 비로 혼합하였다. ~1일 후에 결정이 나타났고, 액체 질소에서 급랭시키기 전에 10% (v/v) 에틸렌 글리콜에서 동결 보호되었다.
아르곤 내셔널 래버러토리 어드밴스드 포톤 소스(Argonne National Laboratory Advanced Photon Source)에서 23-ID-D 빔라인에서 데이터를 수집하였다. 데이터세트는 XDS60 및 XPREP를 사용하여 가공하였다. 52 Fab에 대한 모델로서 CNTO88 Fab (PDB ID: 4DN3), 298 Fab에 대한 모델로서 20358 Fab (PDB ID: 5CZX), 및 RBD에 대한 검색 모델로서 PDB ID: 6XDG를 갖는 Phaser61를 사용하여 분자 대체에 의해 위상을 결정하였다. 구조의 정련은 phenix.refine62 및 Coot의 수동 빌딩의 반복63을 이용하여 수행하였다. 구조 분석 및 도면 렌더링을 위해 PyMOL을 사용하였다64. 모든 소프트웨어에 대한 접근은 SBGrid를 통해 지원되었다65. 2가지 Fab-RBD 계면에 대한 대표적인 전자 밀도는 도 2e, f에 도시된다.
물질 이용가능성
전자 현미경 맵은 전자 현미경 데이터 뱅크 (EMDB)에서 수탁 코드 EMD-22738, EMD-22739, EMD-22740, 및 EMD-22741로 기탁되었다 (표 2). 298-52-RBD 복합체의 결정 구조 (표 3)는 단백질 데이터 뱅크로부터 수탁 PDB ID: 7K9Z하에 이용가능하다. 사용된 모노클로날 항체의 서열은 본 명세서에 제공된다 (표 4). mAb에 의해 표적화된 상이한 에피토프 빈의 비교 분석을 수행하기 위해 추가의 PDB/EMDB 항목이 명세서 전반에 걸쳐 사용되었다. 이 분석에서 사용된 항목은 다음과 같다: REGN10933 (PDB ID: 6XDG), CV30 (PDB ID: 6XE1), C105 (PDB ID: 6XCM), COVA2-04 (PDB ID: 7JMO), COVA2-39 (PDB ID: 7JMP), CC12.1 (PDB ID: 6XC2), BD23 (PDB ID: 7BYR), B38 (PDB ID: 7BZ5), P2C-1F11 (PDB ID: 7BWJ), 2-4 (PDB ID: 6XEY), CB6 (PDB ID: 7C01), REGN10987 (PDB ID: 6XDG), S309 (PDB ID: 6WPS, 6WPT), EY6A (PDB ID: 6ZCZ), CR3022 (PDB ID: 6YLA), H014 (PDB ID: 7CAH), 4-8 (EMDB ID: 22159), 4A8 (PDB ID: 7C2L), 및 2-43 (EMDB ID: 22275).
표 2. cryo-EM 데이터 수집 및 영상 처리

표 3. X-선 결정학 데이터 수집 및 정련 통계

표 4.




물질 및 방법 참고문헌

결과
결합도는 중화 효능을 증강시킨다
본 발명자들은 SARS-CoV-2 S 당단백질을 표적화하는 항원 결합 모이어티를 다량체화하기 위해 인간 아포페리틴의 경쇄의 자가-조립을 이용하였다. 아포페리틴 프로모터는 24개의 동일한 폴리펩티드로 구성된 ~6 nm 유체역학적 반경 (Rh)을 갖는 8면체 대칭 구조로 자가-조립된다33. 각각의 아포페리틴 서브유닛의 N 말단은 구형 나노케이지의 바깥쪽을 가리키며, 따라서 관심 단백질의 유전자 융합에 접근할 수 있다. 폴딩시, 아포페리틴 프로모터는 그들의 N 말단에 융합된 24개 단백질의 다량체화를 유도하는 빌딩 블록으로서 작용한다 (도 1a).
먼저, 본 발명자들은 단일 쇄 가변 도메인 VHH-72가 바이러스 감염을 차단하는 능력에 대한 다가성의 영향을 조사하였다. VHH-72는 그의 1가 포맷이 아니라 Fc 도메인에 융합될 때 SARS-CoV-2를 중화시키는 것으로 이전에 기재되었다31. VHH-72의 24개 카피를 디스플레이하는 인간 아포페리틴의 경쇄가 단분산의 잘 형성된 구형 입자로 조립되었고 (도 1b, c), 2가 VHH-72-Fc와 비교하여 S 당단백질에 대해 증강된 결합도 (도 1d)를 나타내었다. 놀랍게도, 인간 아포페리틴의 경쇄 상에서 VHH-72의 디스플레이는 통상적인 Fc 융합과 비교하여 SARS-CoV-2 슈도바이러스 (PsV)에 대해 중화 효능의 ~10,000배 증가를 달성하였고 (도 1e), 이는 결합 모이어티를 강력한 중화제로 변환시키는 결합도의 힘을 입증한다.
멀타바디는 IgG-유사 성질을 갖는다
Fc는 신생아 Fc 수용체 (FcRn) 및 Fc 감마 수용체 (FcγR)와의 상호작용을 통해 각각 생체내 반감기 및 이펙터 기능을 IgG에 부여한다. 이들 IgG-유사 성질을 본 발명자들의 다량체성 스캐폴드에 부여하기 위해, 본 발명자들은 다음으로 결합 모이어티 및 Fc 도메인 둘 다를 통합하고자 하였다. Fab가 경쇄 및 중쇄로 이루어진 이종이량체이고, Fc가 동종이량체이기 때문에, 본 발명자들은 단일-쇄 Fab (scFab) 및 단일-쇄 Fc (scFc) 폴리펩티드 구축물을 생성하였다. scFab 및 scFc 도메인을 아포페리틴 프로모터의 N 말단에 직접 융합시켰다. 생체내 원리 증명 실험을 위해, 본 발명자들은 마우스 scFab 및 마우스 scFc에 대한 마우스 경쇄 아포페리틴 융합으로 구성된 종-일치 대용물 분자를 생성하였다 (IgG2a 아형). 결합 동역학은 생성된 MB 분자가 모 IgG와 유사하게 pH 의존적인 방식으로 (엔도좀 pH (5.6)에서는 결합하고, 생리학적 pH (7.4)에서는 결합하지 않음) 마우스 FcRn에 결합한다는 것을 나타내었다 (도 3a). 예상대로, 고친화도 마우스 FcγR1에 대한 결합은 모 IgG와 비교하여 결합도 효과를 통해 증강되었다. 따라서, 본 발명자들은 다량체성 맥락에서 Fc 결합을 저하시키기 위해 FcγR-침묵 돌연변이 LALAP를 포함하는 변형된 마우스 scFc 버전을 생성하였다 (도 3a). C57BL/6 또는 BALB/c 마우스에서 MB의 피하 투여는 잘 용인되었으며, 체중 감소 및 시각적인 부작용을 나타내지 않았다. MB는 유리한 IgG-유사 혈청 반감기를 나타내었고 (도 3b), WT MB와 비교하여 더 낮은 FcγR-결합 MB (LALAP Fc 서열)에 대해 혈청에서 연장된 검출가능한 역가를 나타내었으며, 이는 생체내 생체이용률을 나타내는데 있어서 Fc에 대한 역할의 지표이다. 라이브 2D 및 3D-영상화는 형광 표지된 MB가 임의의 특이적인 조직에서 축적되지 않고 상응하는 IgG와 같이 전신으로 생체분포된다는 것을 밝혀내었다 (도 3c 및 도 4). 대조적으로, MB와 유사한 Rh를 갖는 15 nm 금 나노입자 (GNP)는 주사 부위로부터 신속하게 퍼졌다 (도 3c 및 도 4). 아마도 모든 서열이 숙주로부터 유래되었기 때문에, 대용물 마우스 MB는 마우스에서 항-약물 항체 반응을 유도하지 않았고 (도 3d), 따라서 이는 MB 플랫폼의 IgG-유사 성질을 추가로 강조한다.
더 높은 결합가를 달성하기 위한 단백질 조작
마우스 MB 대용물에 대한 이러한 유리한 결과를 고려하여, 본 발명자들은 각각 SARS-CoV-2 스파이크 RBD 및 N-말단 도메인 (NTD)을 표적화하는 이전에 보고된 IgG BD2312 및 IgG 4A813으로부터 유래된 완전-인간 MB를 생성하는 것을 목적으로 하였다. MB에 scFc의 추가는 다량체화될 수 있는 scFab의 수를 감소시킨다. Fab 결합도 및 따라서 중화 효능을 손상시키지 않고 MB 플랫폼에 Fc를 부여하기 위해, 본 발명자들은 아포페리틴 프로모터가 입자당 24개 초과의 성분을 수용하도록 조작하였다. 그의 4개-나선 다발 폴딩을 기반으로 하여, 인간 아포페리틴 프로모터를 2개의 절반으로 분할하였다: 2개의 N-말단 α 나선 (N-페리틴) 및 2개의 C-말단 α 나선 (C-페리틴). 이 구성에서, 인간 IgG1의 scFc 단편 및 항-SARS-CoV-2 IgG의 scFab 각각은 각각의 아포페리틴 절반의 N 말단에 유전적으로 융합되었다. 분할 아포페리틴 보완은 2개 절반의 이종이량체화를 유도하였고, 결과적으로 융합된 단백질의 매우 효율적인 이종이량체화 과정을 생성하였다. 과량의 scFab-페리틴 유전자와 함께 scFab-C-페리틴 및 scFc-N-페리틴 유전자의 공동-발현은 나노케이지 주변에서 많은 수의 scFab 및 적은 수의 scFc를 디스플레이하는 완전 아포페리틴 자가-조립을 일으켰다 (도 5a 및 물질 및 방법). 편리하게는, 이 설계는 IgG 정제와 유사하게 단백질 A를 사용하는 MB의 간단한 정제를 가능하게 한다.
이 분할 MB 설계는 중단이 없는 밀도의 고리 및 규칙적인 간격으로 돌출된 scFab 및 scFc를 갖는 16 nm Rh 구형 입자를 생성한다 (도 5b, c). 따라서, MB는 천연 IgMs34의 더 작은 크기 범위에 있지만, 유사한 크기에 더 많은 중량을 포장하여 높은 다중-결합가를 달성한다. 결합 동역학 실험은 스파이크에 대한 MB의 높은 결합도가 Fc 단편의 부가시에 보존됨을 입증하였다 (도 5d 및 표 5). pH 5.6 및 7.4 둘 다에서 인간 FcγRI 및 FcRn에 대한 결합은 scFc가 분할 MB 설계에서 적절하게 폴딩되었음을 확인시켜 주었다 (표 6 및 7). 또한, 대용물 마우스 MB에서 이전에 관찰된 바와 같이 (도 3a), scFc에서 LALAP 돌연변이는 인간 FcγRI에 대한 결합 친화도를 저하시켰다 (도 5e). 분할 설계 MB에 의한 SARS-CoV-2 PsV 중화 검정은 스파이크에 대한 증강된 결합 친화도가 그들의 IgG 대응물과 비교하여 개선된 중화 효능으로 해석됨을 나타내며, BD23 및 4A8의 경우 각각 ~1600배 및 >2000배 증가하였다 (도 5f). 조합하면, 이 데이터는 상이한 스파이크 도메인 상의 에피토프에 대해 정교한 결합도 및 PsV 중화를 부여하는 IgG-유사 플랫폼으로서 MB의 추가 탐구를 뒷받침하였다.
표 5. BLI에 의해 결정되는 멀타바디의 SARS-CoV-2 스파이크 항원에 대한 동역학 상수 및 친화도.

표 6. SARS-CoV-2를 표적화하는 BD23 항체 (IgG1)로부터 유래된 인간 페리틴 멀타바디의 인간 FcRn에 대한 동역학 상수 및 친화도.

표 7. SARS-CoV-2를 표적화하는 BD23 항체 (IgG1)로부터 유래된 인간 페리틴 멀타바디의 인간 FcγRI에 대한 동역학 상수 및 친화도

멀타바디에서 평가된 IgG1 백본의 Fc 돌연변이에는 다음이 포함된다: FcγR에 대한 항체 결합을 감소시키는 LALAP (L234A, L235A 및 P329G) 및 I235A, 및 이들의 조합물. (넘버링은 EU 넘버링 방식을 따른 것임.)
멀타바디에 대해 결정된 kon, koff, 및 생성된 평형 해리 상수 (KD) 값을 표 6-10에 요약한다. 결합 동역학은 생성된 마우스 MB 분자가 모 IgG와 유사하게 pH 의존적인 방식으로 (엔도좀 pH (5.6)에서는 결합하고, 생리학적 pH (7.4)에서는 결합하지 않음) 마우스 FcRn에 결합한다는 것을 나타내었다 (도 3a). 고친화도 마우스 FcγR1에 대한 결합은 모 IgG와 비교하여 결합도 효과를 통해 증강되었다. 엔도좀 pH에서 인간 FcγRI 및 FcRn에 대한 인간 MB의 결합은 scFc가 분할 MB 설계에서 적절하게 폴딩되었고, LALAP 및 I253A 돌연변이가 각각 FcγRI 및 FcRn에 대한 결합 친화도를 저하시켰음을 확인시켜 주었다.
표 8. BLI에 의해 결정되는 CD19를 표적화하는 HD37 항체 (IgG2a)로부터 유래된 마우스 페리틴 멀타바디의 마우스 FcRn에 대한 동역학 상수 및 친화도.

표 9. BLI에 의해 결정되는 CD19를 표적화하는 HD37 항체 (IgG2)로부터 유래된 마우스 페리틴 멀타바디의 마우스 FcγRI에 대한 동역학 상수 및 친화도.

표 10. SARS-CoV-2를 표적화하는 BD23 항체 (IgG1)로부터 유래된 인간 페리틴 멀타바디의 인간 FcRn에 대한 동역학 상수 및 친화도.

항체 발견에서부터 초강력 중화제까지
본 발명자들은 다음으로 초기 파지 디스플레이 스크리닝으로부터 확인된 mAb 결합제를 SARS-CoV-2에 대한 강력한 중화제로 변환시키는 MB 플랫폼의 능력을 평가하였다 (도 6a). SARS-CoV-2의 RBD에 대한 표준 바이오패닝 프로토콜에 따라, 10-6 내지 10-8 M 범위의 중간 친화도를 갖는 20개의 인간 mAb 결합제를 선택하였다 (표 4; 표 11). 이들 mAb는 전장 IgG 및 MB로서 생성되었고, 바이러스 감염을 차단하는 그들의 능력을 SARS-CoV-2 PsV에 대한 중화 검정에서 비교하였다 (도 6b 및 도 7a). 특히, MB 발현 수율, 균질성 및 열안정성은 모 IgG와 유사하였고 (도 8 및 표 12), MB는 20개 중 18개의 (90%) IgG의 효능을 최대 4 자릿수만큼 증강시켰다 (표 13). 가장 큰 증분은 mAb 298에 대해 관찰되었고, 평균 IC50이 IgG의 경우 ~0.3 μg/mL에서부터 MB의 경우 0.0001 μg/mL까지였다. 놀랍게도, 11개의 mAb는 시험한 농도 범위에서 비중화 IgG로부터 중화 MB로 전환되었다. 7개의 MB는 이례적인 효능을 나타내었고, 2가지 상이한 표적 세포 (293T-ACE2 및 HeLa-ACE2 세포; 도 6b 및 도 7b)를 사용하여 SARS-CoV-2 PsV에 대해 0.2-2 ng/mL의 IC50 값을 가졌다. 벤치마커로서 재조합 mAb REGN10933 및 REGN10987을 사용하는 PsV 중화 검정은 이전에 보고된 것과 유사한 IC50 값 (각각 0.0044 및 0.030 μg/mL)을 나타내었고8, 따라서 본 발명자들의 검정에서 관찰된 MB의 놀라운 효능을 확인하였다. MB의 증강된 중화 효능은 2가지 재조합 REGN mAb에서 벤치마킹한 것과도 같이 가장 높은 효능을 갖는 mAb에 대한 진정한 SARS-CoV-2 바이러스에 의해 추가로 확인되었다 (도 6c 및 도 7c). PsV와 비교하여 진정한 바이러스에 대해 본 발명자들이 관찰한 덜 민감한 중화 표현형 또한 이전의 보고와 일치한다5,6,9,12.
표 11. SARS-CoV-2 RBD의 인간 mAb 결합제.

nb = 검출 한계 미만의 결합
표 12. 멀타바디 및 관련 항체의 응집 온도 (T
agg
).

표 13. RBD-표적화 멀타바디에 의한 SARS-CoV-2 중화


후향적으로, 모든 IgG 및 MB를 SARS-CoV-2의 스파이크 당단백질 및 RBD에 결합하는 그들의 능력에 대해 시험하였다 (도 9). 증가된 결합도는 스파이크 당단백질에 대한 검출가능한 오프율이 없이 더 높은 겉보기 결합 친화도를 생성하였고, 이는 높은 중화 효능으로 해석되는 스파이크간 가교 때문일 가능성이 매우 높다 (도 6b-d 및 도 9). 전반적으로, 데이터는 심지어 중간 정도의 중화 특징을 갖는 mAb에서 출발하더라도 MB 플랫폼이 초강력 IgG-유사 분자의 신속한 전달과 상용성임을 나타낸다.
에피토프 맵핑
그들의 중화 효능을 기반으로 하여, 추가의 특징분석을 위해 7개의 mAb를 추가로 선택하였다: 298 (IGHV1-46/IGKV4-1), 82 (IGHV1-46/IGKV1-39), 46 (IGHV3-23/IGKV1-39), 324 (IGHV1-69/IGKV1-39), 236 (IGHV1-69/IGKV2-28), 52 (IGHV1-69/IGKV1-39), 및 80 (IGHV1-69/IGKV4-1) (도 6b 및 표 4). 에피토프 비닝 실험은 이들 mAb가 RBD 상의 2개의 주요 부위 (이들 빈 중 하나는 ACE2 결합 부위와 중첩됨)를 표적화한다는 것으로 나타내었다 (도 10a 및 도 11). ~6-7 Å의 전체 해상도에서 Fab-SARS-CoV-2 S 복합체의 cryo-EM 구조는 mAb 324, 298, 및 80이 중첩 에피토프에 결합한다는 것을 확인시켜 주었다 (도 10b, 도 12a-c, 및 표 2). 다른 빈을 표적화하는 mAb의 결합에 대한 통찰력을 얻기 위해, 본 발명자들은 4.0 Å의 전체 해상도에서 RBD와 복합체화된 Fab 46의 cryo-EM 구조 (도 10c, 도 12d, 및 표 2), 및 2.95 Å 해상도에서 RBD와의 삼원 복합체로서 Fab 298 및 52의 결정 구조 (도 10d, 도 2, 및 표 3)를 수득하였다.
결정 구조는 Fab 298가 RBD (잔기 438-506)의 ACE2 수용체 결합 모티프 (RBM)에 거의 독점적으로 결합함을 나타낸다. 실제로, Fab 298 결합에 관여하는 16개 RBD 잔기 중에서, 12개는 ACE2-RBD 결합에도 관여한다 (도 2a-c 및 표 14). RBM은 Fab 298의 중쇄 및 경쇄 잔기로부터 11개의 수소 결합에 의해 안정화된다. 추가로, RBM Phe486은 ~170 Å2를 매립하는 11개의 Fab 298 잔기 (RBD 상에 매립된 총 표면적의 24%)와 접촉하며, 따라서 항체-항원 상호작용에 대한 중심이다 (도 2a 및 표 14).
RBD-52 Fab 계면의 상세한 분석을 통해 mAb 52의 에피토프가 RBM의 20개 잔기 및 코어 도메인의 7개 잔기를 포함하는 RBD의 코어를 향해 이동된다는 것이 나타났다 (도 10c, 도 2b, 및 표 14). 경쟁 데이터와 일치하게, 항체 52 및 항체 46은 유사한 결합 부위를 공유하지만, 이들은 약간 상이한 각도로 RBD에 접근한다 (도 10c, d 및 도 2d). RBD-항체 복합체의 이전에 보고된 구조의 조사를 통해 항체 46 및 52가 이전에 기재된 적이 없는 SARS-CoV-2 스파이크 상의 취약 부위를 표적화한다는 것이 나타났다 (도 10e). 이들 항체에 의해 표적화된 에피토프는 S "폐쇄형" 형태에서 NTD에 의해 부분적으로 차단되며, 이는 이 항체 부류의 작용 메카니즘이 스파이크 불안정화를 수반할 수 있음을 시사한다. 종합하면, 이들 데이터는 결합도를 통해 MB 플랫폼에 대해 관찰된 증강된 중화 효능이 RBD 상의 별개의 에피토프 빈을 표적화할 수 있는 mAb와 연관이 있음을 입증한다.
표 14. PISA에 의해 확인된 RBD-298 및 RBD-52 접촉 잔기





vdW: 반 데르 발스 상호작용 (5.0 Å 컷오프)
HB: 수소 결합 (3.8 Å 컷오프)
SB: 염 가교 (4.0 Å 컷오프)
멀타바디는 스파이크 서열 가변성을 극복한다
MB가 그들의 증강된 결합도를 통해 바이러스 탈출에 잠재적으로 저항할 수 있는지 여부를 탐구하기 위해, 본 발명자들은 가장 높은 효능을 갖는 7가지 인간 mAb의 결합 및 중화에 대한 4가지 천연 발생 RBD 돌연변이35의 효과를 시험하였다: L452R - 항체 46 및 52의 에피토프 내에 위치 (빈 1), A475V 및 V483A - ACE2 결합 부위 내에 위치 (빈 2), 및 순환 RBD 변이체 N439K36 (도 13a-c). 추가로, Asn234 (N-연결된 글리코실화 부위)의 Gln으로의 돌연변이의 영향을 또한 평가하였으며, 이 부위에서 글리코실화의 부재가 RBD35를 표적화하는 중화 항체에 대한 민감성을 감소시키는 것으로 보고되었기 때문이다. 더욱 감염성인 PsV 변이체 D614G37 또한 패널에 포함되었다. 예상된 바와 같이, 돌연변이 L452R은 mAb 52 및 46의 결합 및 효능을 유의하게 감소시킨 반면에, 항체 298은 돌연변이 A475V에 대해 민감하였다 (도 13b, c). 위치 Asn234에서 N-연결된 글리칸의 결실은 대부분의 항체, 특히 mAb 46, 80, 및 324에 대한 바이러스 내성을 증가시켰고, 이는 항원성에서 글리칸의 중요성을 강조한다 (도 13c). 놀랍게도, MB 포맷의 하기 항체 특이성은 임의의 S 돌연변이: 298, 80, 324, 및 236에 의해 그들의 이례적인 중화 효능에서 최소의 영향을 받았다 (도 13d). 돌연변이 L452R은 46-MB 및 52-MB의 민감성을 감소시켰지만, 그들의 모 IgG와 대조적으로 이 PsV 변이체에 대한 중화를 유지하였다 (도 13d). 더욱 감염성인 SARS-CoV-2 PsV 변이체 D614G는 IgG 및 MB 둘 다에 대해 WT PsV와 유사한 효능으로 중화되었다 (도 13c 및 도 14a).
3가지 단일특이적 MB로 구성된 MB 칵테일은 유의한 효능 손실없이 모든 PsV 변이체에 걸쳐 범-중화를 나타내었고, 따라서 상응하는 IgG 칵테일과 비교하여 100-1000배 높은 효능을 달성하였다 (도 13e 및 도 14c, d). 단일 분자 내에서 범위를 달성하기 위해, 본 발명자들은 다음으로 동일한 MB 조립에서 3가지 상이한 Fab를 디스플레이하는 다량체화 서브유닛을 조합함으로써 삼중-특이적 MB를 생성하였다 (도 14b). 특히, 생성된 삼중-특이적 MB는 B.1.351 PsV 변이체에 대한 것을 비롯하여 단일특이적 버전의 이례적인 중화 효능을 유지하면서 범-중화를 나타내었다 (도 13e, f 및 도 14c, d). 가장 높은 효능은 298-324-46 조합물에 대해 관찰되었으며 (도 14c, e), 삼중-특이적 MB는 지금까지 보고된 가장 강력한 IgG 중 일부에 대해 보고되고 본 발명자들이 이용가능한 서열로부터 재조합적으로 생성한 것을 벗어나는 이례적인 효능을 달성하였다 (도 13g). 추가로, MB 포맷은 PsV 및 살아있는 복제 SARS-CoV-2 바이러스에 대한 이들 이전에 보고된 고도로 강력한 IgG의 효능을 추가로 1 내지 2 자릿수만큼 증가시킬 수 있었으며 (도 13h), 따라서 이는 MB의 플러그-앤-플레이 성질, 및 효능 범위에 걸쳐 mAb의 중화 용량을 증가시키는 다가성의 능력을 강조한다.
중화의 중간 IC50에 대해 결정된 값이 표 13 및 표 15에 요약된다.
표 15. 멀타바디에 의한 SARS-CoV-2 중화

논의
이 연구에서, 본 발명자들은 결합도가 바이러스 돌연변이로부터 항체 중화 효능 및 내성을 추진시키는 효과적인 메카니즘으로서 어떻게 활용될 수 있는지 밝혀낸다. 이를 위해, 본 발명자들은 SARS-CoV-2를 표적화하는 mAb의 결합도를 증가시키는 플러그-앤-플레이 항체-다량체화 플랫폼을 개발하기 위해 단백질 조작을 이용하였다. 7가지 가장 강력한 MB는 SARS-CoV-2 PsVs에 대해, 따라서 본 발명자들이 아는 한 SARS-CoV-2에 대해 지금까지 보고된 가장 강력한 항체-유사 분자 내에서 0.2 내지 2 ng/mL (9 x 10-14 내지 9 x 10-13 M)의 IC50 값을 갖는다.
MB 플랫폼은 개발가능성 관점에서 주요 유리한 속성을 포함시키도록 설계되었다. 첫째로, 항체 효능을 증가시키는 능력은 항체 서열, 포맷 또는 표적화된 에피토프와 무관하다. 플랫폼의 모듈성 및 유연성은 2개의 SARS-CoV-2 S 서브-도메인 (RBD 및 NTD) 상의 중첩되지 않는 영역을 표적화하는 VHH 및 다중 Fab의 효능을 증강시킴으로써 예시되었다. VHH 도메인의 효능을 증강시키기 위해 MB를 사용하면 이 분자 부류에 대해 특정한 값이 제공될 수 있으며, 이는 그의 작은 크기가 고도로 효율적인 다량체화를 가능하게 하기 때문이다. 둘째로, 단일 쇄 가변 단편의 직렬 융합을 통해 결합도를 증강시키는 다른 접근법과는 대조적으로38,39, MB는 낮은 안정성을 겪지 않으며, 실제로 그들의 모 IgG와 유사한 응집 온도를 갖는 고도로 안정한 입자로 자가-조립된다. 셋째로, 스트렙타비딘40, 베로독소 B 서브유닛 스캐폴드41, 또는 바이러스-유사 나노입자42와 같은 대안적인 다량체화 전략은 Fc 단편의 부재 때문에 면역원성 문제 및/또는 불량한 생체이용률에 직면하고, 따라서 FcRn-매개된 재순환을 겪을 수 없다. 아포페리틴의 경쇄는 완전 인간이고, 생물학적으로 불활성이고, Fc 도메인을 포함하도록 조작되었으며, >24개 Fab/Fc 단편의 다량체화에도 불구하고 IgM과 유사한 Rh를 갖는다. 따라서, 대용물 마우스 MB는 마우스에서 항약물 항체를 유발하지 않고, 그 모 IgG와 유사하게 1 주일 넘게 혈청에서 검출가능하였다. 그러나, MB의 생체내 생체이용률은 FcγR에 대한 그의 결합 친화도에 의존하였고, 이는 MB를 임상으로 효율적으로 번역하기 위해 Fc 결합도가 주의해서 미세 조정되어야 함을 시사한다. 추가로, 해부학적 관심 부위, 예컨대 SARS-CoV-2 감염의 경우 폐에서 MB가 어떻게 분포하는지를 평가하기 위해 추가의 연구가 필요할 것이다. 멀타바디의 플러그-앤-플레이 성질은 또한 생체이용률이 이펙터 기능이 없는 유일한 원하는 특성인 경우, Fc 이외의 대안적인 반감기 연장 모이어티, 예를 들어 인간 혈청 알부민43, 또는 인간 혈청 알부민44,45에 결합하는 결합 모이어티를 탐구하는데 적합하다.
SARS-CoV-2에 대한 MB에 대해 시험한 상이한 mAb 서열에서 중화 효능의 상이한 증가가 관찰되었다. 이는 효능을 증강시키는 MB의 능력이 스파이크 상에서 에피토프 위치, 또는 중화를 달성하기 위해 Fab가 항원에 결합하는 기하학에 따라 달라질 수 있음을 시사한다. 20개의 SARS-CoV-2 RBD 결합제 중 2개의 중화가 MB 플랫폼에 의해 구조되지 않는다는 사실은 mAb 서열 및 결합 성질만을 기반으로 하는 한계를 시사한다. 그럼에도 불구하고, SARS-CoV-2 스파이크 상의 광범위한 에피토프 특이성에 걸쳐 결합도를 중화 효능으로 변환시키는 MB의 능력은 이 기술을 광범위하게 사용할 잠재성을 강조한다. HIV-146과 같이 낮은 표면 스파이크 밀도를 갖는 바이러스에 대한, 또는 종양 괴사 인자 수용체 수퍼패밀리와 같은 다른 표적에 대한 MB 플랫폼의 효능-증강 능력을 탐구하는 것은 흥미로울 것이며, 통상적인 항체의 2가는 그들의 효율적인 활성화를 제한한다47.
바이러스 탈출은 처리로부터 또는 자연 선택 동안에 선택적인 압력에 대한 반응으로 발생할 수 있다. 탈출 돌연변이체와 싸우기 위한 통상적인 접근법은 상이한 에피토프를 표적화하는 항체 칵테일을 사용하는 것이다. MB는 그들의 모 IgG와 비교하여 S 돌연변이에 대해 낮은 감수성을 나타내었으며, 이는 아마도 친화도의 손실이 증강된 결합도에 의해 보상되었기 때문일 것이다. 따라서, 칵테일에서 사용될 때, MB는 이례적인 효능으로 바이러스 서열 가변성을 극복하였다. 추가로, 분할 MB 설계는 단일 다량체화 분자 내에서 다중 항체 특이성의 조합을 가능하게 하여, MB 칵테일과 유사한 효능 및 범위를 생성하였다. 중요하게는, 몇몇 mAb의 중화를 탈출할 수 있는 우려되는 B.1.351 변이체21,22,23는 삼중-특이적 멀타바디에 의해 높은 효능으로 중화되어, 이들 분자가 바이러스 탈출에 저항하는 능력을 추가로 강조한다. 동일한 입자 내의 다중-특이성은 mAb의 올바른 조합에 대한 S내 결합도 및 상승작용과 같은 추가의 이점을 제공하여, MB에 대한 mAb 특이성의 상이한 조합을 추가로 조사하는 단계를 설정한다. 결합도 및 다중-특이성은 또한 베타코로나바이러스와 같은 바이러스 속에 걸쳐 강력하게 중화시키는 단일 분자를 전달하는데 활용될 수 있다.
전반적으로, MB 플랫폼은 광범위한 항체 발견 또는 조작 노력을 우회하면서 항체 친화도 한계를 능가하고 광범위하고 강력한 중화 분자를 생성하는 도구를 제공한다. 이 플랫폼은 결합도가 건강상 세계적으로 중요한 감염성 질환에 대한 가장 강력한 생물학적 제제의 발견을 위한 타임라인을 가속시키기 위해 어떻게 활용될 수 있는지에 대한 예이다.
참고문헌





실시예 2
바이러스 생성 및 슈도바이러스 중화 검정
이전에 기재된 바와 같이 HIV-기반 렌티바이러스 시스템44을 약간 변형시켜 SARS-CoV-2 위형 바이러스 (PsV)를 생성하였다. 간략히, 루시페라제 리포터 유전자를 코딩하는 렌티바이러스 백본 (BEI NR52516), 스파이크를 발현하는 플라스미드 (BEI NR52310), 및 HIV 구조 및 조절 단백질 Tat (BEI NR52518), Gag-pol (BEI NR52517) 및 Rev (BEI NR52519)를 코딩하는 플라스미드로 293T 세포를 공동-형질감염시켰다. 37℃에서 24 h 형질감염 후, 5 mM 나트륨 부티레이트를 배지에 첨가하고, 세포를 30℃에서 추가 24-30 h 동안 인큐베이션하였다. KOD-Plus 돌연변이 유발 키트 (토요보, 일본 오사카)를 사용하여 PsV 돌연변이체를 생성하였다. 우려되는 SARS-CoV-2 스파이크 변이체 B.1.117, B.1.351, P.1 및 B.1.617.2는 친절하게도 데이비드 호(David Ho) (콜롬비아(Columbia)에 의해 제공되었다. 중화는 293T-ACE2 세포 (BEI NR52511)를 사용하는 단일-주기 중화 검정에서 결정되었다. 브리텔라이트 플러스 시약 (퍼킨엘머)을 세포에 첨가하여 PsV 중화를 모니터링하고, 시너지 Neo2 다중-모드 검정 마이크로플레이트 판독기 (바이오텍 인스트루먼츠)를 사용하여 발광 (상대 발광 단위 (RLU))을 측정하였다. IC50 증가 배수는 다음과 같이 계산되었다: IgGIC50 (μg/mL) / MBIC50 (μg/mL). 2 내지 3개의 생물학적 반복과 2개의 기술적 반복 각각을 수행하였다.
결과
mAb 52에서 서열 책임의 확인
리드 VH/VL 서열의 인실리코 분석을 통해 위치 N92에서 mAb52의 CDRL3에서 탈아미드화 부위를 확인하였다. mAb에서 탈아미드화 부위는 약물 생성물에서 결합 동역학 및 불균일성의 변화 둘 다에 기여할 수 있다. 이러한 잠재적인 효과를 피하기 위해, 본 발명자들은 아스파라긴 잔기가 트레오닌으로 돌연변이된 (N92T) 변이체를 생성하였다. 도 15는 이 돌연변이가 WT 슈도바이러스 중화 검정에서 IgG 또는 단일특이적 MB 둘 다로서 효능에 어떠한 영향도 미치지 않았음을 도시한다. mAb 52의 VL에서 N92T 돌연변이를 함유하는 298-80-52 삼중특이적 MB를 후속적으로 P.1 PsV 중화 검정에서 스크리닝하였고, 그 결과 모 삼중특이적 MB와 비교하여 효능의 감소가 관찰되지 않았음이 확인되었다 (도 16).
우려되는 변이체에 걸쳐 삼중특이적 MB의 중화
예시적인 삼중특이적 MB, 298-80-52를 슈도바이러스 중화 검정에서 우려되는 변이체 (VOC)에 대한 효능에 대해 평가하였다. 표 16 및 도 17에 도시된 바와 같이, 이 MB는 VOC에 대해 활성을 유지하였고, WT, B.1.1.7, B.1.351 및 P.1 PsV 검정으로부터의 평균 IC50은 대략 0.2 ng/ml [97 fM]인 반면에, 상응하는 IgG 칵테일은 91 ng/ml [0.61 nM]의 평균 IC50을 가졌다 (n = 5 실험). 이는 ~200-1000배 (ng/ml) 또는 ~3000-16000배 (몰 농도)의 효능 증가를 나타낸다. 이들 결과는 삼중특이적 MB가 이례적인 효능으로 SARS-CoV-2의 바이러스 탈출을 극복하는 능력을 강조한다.
표 16.

서열 목록
서열식별번호:1 h페리틴LC

서열식별번호:2 링커1
서열식별번호:3 VHH-hFerr
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 h페리틴LC를 나타냄)

서열식별번호:4 VHH-Fc
(밑줄 표시는 링커 서열을 나타냄)

서열식별번호:5 N-h페리틴LC
서열식별번호:6 C-h페리틴LC
서열식별번호:7 신호 서열
서열식별번호:8 링커 1
서열식별번호:9 링커 2
서열식별번호:10 BD23-scFab-h페리틴LC
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 h페리틴LC를 나타냄)

서열식별번호:11 BD23에 대한 VK
서열식별번호:12 BD23에 대한 VH
서열식별번호:13 BD23-scFab-C_h페리틴LC
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 C_h페리틴LC를 나타냄)

서열식별번호:14 scFc-N_h페리틴LC
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 h페리틴LC를 나타냄)

서열식별번호:15 scFc(LALAP)
(야생형 Fc에 비해 돌연변이된 잔기(들)은 박스 표시됨.)

서열식별번호:16 4A8-scFab-h페리틴LC
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 h페리틴LC를 나타냄)

서열식별번호:17 4A8에 대한 VK
서열식별번호:18 4A8에 대한 VH
서열식별번호:19 4A8-scFab C_h페리틴LC
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 C_h페리틴LC를 나타냄)

서열식별번호:20 m페리틴

서열식별번호:21 HD37-scIgG
(밑줄 표시는 링커 서열을 나타냄)

서열식별번호:22 IgG2a Fc_mFerr
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 m페리틴을 나타냄)

서열식별번호:23 scFc-N-hFerr LALAP I253A
(밑줄 표시는 링커 서열을 나타내고; 굵은 표시는 h페리틴LC를 나타내고; 박스 표시는 야생형 IgG1 Fc에 비해 돌연변이된 잔기를 나타냄)

서열식별번호:24 야생형 인간 IgG1 Fc

서열식별번호:25 항체 56 경쇄

서열식별번호:26 항체 56 중쇄

서열식별번호:27 항체 349 경쇄

서열식별번호:28 항체 349 중쇄

서열식별번호:29 항체 178 경쇄

서열식별번호:30 항체 178 중쇄

서열식별번호:31 항체 108 경쇄

서열식별번호:32 항체 108 중쇄

서열식별번호:33 항체 128 경쇄

서열식별번호:34 항체 128 중쇄

서열식별번호:35 항체 160 경쇄

서열식별번호:36 항체 160 중쇄

서열식별번호:37 항체 368 경쇄

서열식별번호:38 항체 368 중쇄

서열식별번호:39 항체 192 경쇄

서열식별번호:40 항체 192 중쇄

서열식별번호:41 항체 158 경쇄

서열식별번호:42 항체 158 중쇄

서열식별번호:43 항체 180 경쇄

서열식별번호:44 항체 180 중쇄

서열식별번호:45 항체 254 경쇄

서열식별번호:46 항체 254 중쇄

서열식별번호:47 항체 120 경쇄

서열식별번호:48 항체 120 중쇄

서열식별번호:49 항체 64 경쇄

서열식별번호:50 항체 64 중쇄

서열식별번호:51 항체 298 경쇄

서열식별번호:52 항체 298 중쇄

서열식별번호:53 항체 82 경쇄

서열식별번호:54 항체 82 중쇄

서열식별번호:55 항체 46 경쇄

서열식별번호:56 항체 46 중쇄

서열식별번호:57 항체 324 경쇄

서열식별번호:58 항체 324 중쇄

서열식별번호:59 항체 236 경쇄

서열식별번호:60 항체 236 중쇄

서열식별번호:61 항체 52 경쇄

서열식별번호:62 항체 52 경쇄 N92T

서열식별번호:63 항체 52 중쇄

서열식별번호:64 항체 80 경쇄

서열식별번호:65 항체 80 중쇄

등가물 / 다른 실시양태
본 발명이 그의 구체적인 실시양태와 관련하여 기재되었지만, 추가의 변형이 있을 수 있음이 이해될 것이고, 본 출원은 일반적으로 본 발명이 속하는 기술분야 내에서 공지된 또는 관례적인 실행 내에 있으며 본원에서 앞서 설명된 본질적인 특징에 적용될 수 있는 본 개시내용으로부터 이러한 이탈을 비롯하여 본 발명의 원리에 따라 본 발명의 임의의 변형, 용도 또는 개조를 포괄하는 것으로 의도된다.
SEQUENCE LISTING
<110> The Hospital for Sick Children
<120> POLYPEPTIDES TARGETING SARS-COV-2 AND RELATED COMPOSITIONS AND
METHODS
<130> 3206-5041 (168294) ELL
<140> PCT/CA2021/051426
<141> 2021-10-08
<150> US 63/089782
<151> 2020-10-09
<150> US 63/197236
<151> 2021-07-12
<150> US 63/220929
<151> 2021-06-04
<160> 118
<170> PatentIn version 3.5
<210> 1
<211> 175
<212> PRT
<213> Homo sapiens
<400> 1
Met Ser Ser Gln Ile Arg Gln Asn Tyr Ser Thr Asp Val Glu Ala Ala
1 5 10 15
Val Asn Ser Leu Val Asn Leu Tyr Leu Gln Ala Ser Tyr Thr Tyr Leu
20 25 30
Ser Leu Gly Phe Tyr Phe Asp Arg Asp Asp Val Ala Leu Glu Gly Val
35 40 45
Ser His Phe Phe Arg Glu Leu Ala Glu Glu Lys Arg Glu Gly Tyr Glu
50 55 60
Arg Leu Leu Lys Met Gln Asn Gln Arg Gly Gly Arg Ala Leu Phe Gln
65 70 75 80
Asp Ile Lys Lys Pro Ala Glu Asp Glu Trp Gly Lys Thr Pro Asp Ala
85 90 95
Met Lys Ala Ala Met Ala Leu Glu Lys Lys Leu Asn Gln Ala Leu Leu
100 105 110
Asp Leu His Ala Leu Gly Ser Ala Arg Thr Asp Pro His Leu Cys Asp
115 120 125
Phe Leu Glu Thr His Phe Leu Asp Glu Glu Val Lys Leu Ile Lys Lys
130 135 140
Met Gly Asp His Leu Thr Asn Leu His Arg Leu Gly Gly Pro Glu Ala
145 150 155 160
Gly Leu Gly Glu Tyr Leu Phe Glu Arg Leu Thr Leu Arg His Asp
165 170 175
<210> 2
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 2
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25
<210> 3
<211> 326
<212> PRT
<213> Artificial Sequence
<220>
<223> VHH-hFerr
<400> 3
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Glu Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Thr Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Ala Gly Leu Gly Thr Val Val Ser Glu Trp Asp Tyr Asp Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Ser Ser Gln Ile Arg Gln Asn Tyr
145 150 155 160
Ser Thr Asp Val Glu Ala Ala Val Asn Ser Leu Val Asn Leu Tyr Leu
165 170 175
Gln Ala Ser Tyr Thr Tyr Leu Ser Leu Gly Phe Tyr Phe Asp Arg Asp
180 185 190
Asp Val Ala Leu Glu Gly Val Ser His Phe Phe Arg Glu Leu Ala Glu
195 200 205
Glu Lys Arg Glu Gly Tyr Glu Arg Leu Leu Lys Met Gln Asn Gln Arg
210 215 220
Gly Gly Arg Ala Leu Phe Gln Asp Ile Lys Lys Pro Ala Glu Asp Glu
225 230 235 240
Trp Gly Lys Thr Pro Asp Ala Met Lys Ala Ala Met Ala Leu Glu Lys
245 250 255
Lys Leu Asn Gln Ala Leu Leu Asp Leu His Ala Leu Gly Ser Ala Arg
260 265 270
Thr Asp Pro His Leu Cys Asp Phe Leu Glu Thr His Phe Leu Asp Glu
275 280 285
Glu Val Lys Leu Ile Lys Lys Met Gly Asp His Leu Thr Asn Leu His
290 295 300
Arg Leu Gly Gly Pro Glu Ala Gly Leu Gly Glu Tyr Leu Phe Glu Arg
305 310 315 320
Leu Thr Leu Arg His Asp
325
<210> 4
<211> 354
<212> PRT
<213> Artificial Sequence
<220>
<223> VHH-Fc
<400> 4
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Glu Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Thr Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Ala Gly Leu Gly Thr Val Val Ser Glu Trp Asp Tyr Asp Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly Ser Asp
115 120 125
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
130 135 140
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
145 150 155 160
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
165 170 175
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
180 185 190
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
195 200 205
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
210 215 220
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
225 230 235 240
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
245 250 255
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
260 265 270
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
275 280 285
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
290 295 300
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
305 310 315 320
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
325 330 335
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
340 345 350
Gly Lys
<210> 5
<211> 90
<212> PRT
<213> Artificial Sequence
<220>
<223> N-hFerritinLC
<400> 5
Met Ser Ser Gln Ile Arg Gln Asn Tyr Ser Thr Asp Val Glu Ala Ala
1 5 10 15
Val Asn Ser Leu Val Asn Leu Tyr Leu Gln Ala Ser Tyr Thr Tyr Leu
20 25 30
Ser Leu Gly Phe Tyr Phe Asp Arg Asp Asp Val Ala Leu Glu Gly Val
35 40 45
Ser His Phe Phe Arg Glu Leu Ala Glu Glu Lys Arg Glu Gly Tyr Glu
50 55 60
Arg Leu Leu Lys Met Gln Asn Gln Arg Gly Gly Arg Ala Leu Phe Gln
65 70 75 80
Asp Ile Lys Lys Pro Ala Glu Asp Glu Trp
85 90
<210> 6
<211> 85
<212> PRT
<213> Artificial Sequence
<220>
<223> C-hFerritinLC
<400> 6
Gly Lys Thr Pro Asp Ala Met Lys Ala Ala Met Ala Leu Glu Lys Lys
1 5 10 15
Leu Asn Gln Ala Leu Leu Asp Leu His Ala Leu Gly Ser Ala Arg Thr
20 25 30
Asp Pro His Leu Cys Asp Phe Leu Glu Thr His Phe Leu Asp Glu Glu
35 40 45
Val Lys Leu Ile Lys Lys Met Gly Asp His Leu Thr Asn Leu His Arg
50 55 60
Leu Gly Gly Pro Glu Ala Gly Leu Gly Glu Tyr Leu Phe Glu Arg Leu
65 70 75 80
Thr Leu Arg His Asp
85
<210> 7
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> Signal sequence
<400> 7
Met Gly Ile Leu Pro Ser Pro Gly Met Pro Ala Leu Leu Ser Leu Val
1 5 10 15
Ser Leu Leu Ser Val Leu Leu Met Gly Cys Val Ala Glu
20 25
<210> 8
<211> 70
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 8
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
50 55 60
Ser Gly Gly Gly Gly Ser
65 70
<210> 9
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 9
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25
<210> 10
<211> 714
<212> PRT
<213> Artificial Sequence
<220>
<223> BD23-scFab-hFerritinLC
<400> 10
Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
210 215 220
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
245 250 255
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
260 265 270
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu
275 280 285
Val Gln Ser Gly Ser Glu Leu Lys Lys Pro Gly Ala Ser Val Lys Val
290 295 300
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Ala Met Asn Trp
305 310 315 320
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Trp Ile Asn
325 330 335
Thr Asn Thr Gly Asn Pro Thr Tyr Ala Gln Gly Phe Thr Gly Arg Phe
340 345 350
Val Phe Ser Leu Asp Thr Ser Val Ser Thr Ala Tyr Leu Gln Ile Ser
355 360 365
Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Pro Gln
370 375 380
Gly Gly Ser Ser Trp Tyr Arg Asp Tyr Tyr Tyr Gly Met Asp Val Trp
385 390 395 400
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
405 410 415
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
420 425 430
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
435 440 445
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
450 455 460
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
465 470 475 480
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
485 490 495
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
500 505 510
Cys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
515 520 525
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Ser Ser Gln Ile
530 535 540
Arg Gln Asn Tyr Ser Thr Asp Val Glu Ala Ala Val Asn Ser Leu Val
545 550 555 560
Asn Leu Tyr Leu Gln Ala Ser Tyr Thr Tyr Leu Ser Leu Gly Phe Tyr
565 570 575
Phe Asp Arg Asp Asp Val Ala Leu Glu Gly Val Ser His Phe Phe Arg
580 585 590
Glu Leu Ala Glu Glu Lys Arg Glu Gly Tyr Glu Arg Leu Leu Lys Met
595 600 605
Gln Asn Gln Arg Gly Gly Arg Ala Leu Phe Gln Asp Ile Lys Lys Pro
610 615 620
Ala Glu Asp Glu Trp Gly Lys Thr Pro Asp Ala Met Lys Ala Ala Met
625 630 635 640
Ala Leu Glu Lys Lys Leu Asn Gln Ala Leu Leu Asp Leu His Ala Leu
645 650 655
Gly Ser Ala Arg Thr Asp Pro His Leu Cys Asp Phe Leu Glu Thr His
660 665 670
Phe Leu Asp Glu Glu Val Lys Leu Ile Lys Lys Met Gly Asp His Leu
675 680 685
Thr Asn Leu His Arg Leu Gly Gly Pro Glu Ala Gly Leu Gly Glu Tyr
690 695 700
Leu Phe Glu Arg Leu Thr Leu Arg His Asp
705 710
<210> 11
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> VK for BD23
<400> 11
Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 12
<211> 126
<212> PRT
<213> Artificial Sequence
<220>
<223> VH for BD23
<400> 12
Gln Val Gln Leu Val Gln Ser Gly Ser Glu Leu Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Asn Thr Gly Asn Pro Thr Tyr Ala Gln Gly Phe
50 55 60
Thr Gly Arg Phe Val Phe Ser Leu Asp Thr Ser Val Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Pro Gln Gly Gly Ser Ser Trp Tyr Arg Asp Tyr Tyr Tyr Gly
100 105 110
Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 13
<211> 627
<212> PRT
<213> Artificial Sequence
<220>
<223> BD23-scFab-C_hFerritinLC
<400> 13
Leu Glu Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
225 230 235 240
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
245 250 255
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
260 265 270
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val
275 280 285
Gln Leu Val Gln Ser Gly Ser Glu Leu Lys Lys Pro Gly Ala Ser Val
290 295 300
Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Ala Met
305 310 315 320
Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Trp
325 330 335
Ile Asn Thr Asn Thr Gly Asn Pro Thr Tyr Ala Gln Gly Phe Thr Gly
340 345 350
Arg Phe Val Phe Ser Leu Asp Thr Ser Val Ser Thr Ala Tyr Leu Gln
355 360 365
Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg
370 375 380
Pro Gln Gly Gly Ser Ser Trp Tyr Arg Asp Tyr Tyr Tyr Gly Met Asp
385 390 395 400
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
405 410 415
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
420 425 430
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
435 440 445
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
450 455 460
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
465 470 475 480
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
485 490 495
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
500 505 510
Lys Ser Cys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
515 520 525
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Lys
530 535 540
Thr Pro Asp Ala Met Lys Ala Ala Met Ala Leu Glu Lys Lys Leu Asn
545 550 555 560
Gln Ala Leu Leu Asp Leu His Ala Leu Gly Ser Ala Arg Thr Asp Pro
565 570 575
His Leu Cys Asp Phe Leu Glu Thr His Phe Leu Asp Glu Glu Val Lys
580 585 590
Leu Ile Lys Lys Met Gly Asp His Leu Thr Asn Leu His Arg Leu Gly
595 600 605
Gly Pro Glu Ala Gly Leu Gly Glu Tyr Leu Phe Glu Arg Leu Thr Leu
610 615 620
Arg His Asp
625
<210> 14
<211> 640
<212> PRT
<213> Artificial Sequence
<220>
<223> scFc-N_hFerritinLC
<400> 14
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
225 230 235 240
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
245 250 255
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Lys Thr His Thr Cys Pro
290 295 300
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
305 310 315 320
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
325 330 335
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
340 345 350
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
355 360 365
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
370 375 380
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
385 390 395 400
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
405 410 415
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
420 425 430
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
435 440 445
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
450 455 460
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
465 470 475 480
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
485 490 495
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
500 505 510
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Gly Gly Gly Gly
515 520 525
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
530 535 540
Gly Gly Gly Gly Ser Gly Gly Ser Ser Gln Ile Arg Gln Asn Tyr Ser
545 550 555 560
Thr Asp Val Glu Ala Ala Val Asn Ser Leu Val Asn Leu Tyr Leu Gln
565 570 575
Ala Ser Tyr Thr Tyr Leu Ser Leu Gly Phe Tyr Phe Asp Arg Asp Asp
580 585 590
Val Ala Leu Glu Gly Val Ser His Phe Phe Arg Glu Leu Ala Glu Glu
595 600 605
Lys Arg Glu Gly Tyr Glu Arg Leu Leu Lys Met Gln Asn Gln Arg Gly
610 615 620
Gly Arg Ala Leu Phe Gln Asp Ile Lys Lys Pro Ala Glu Asp Glu Trp
625 630 635 640
<210> 15
<211> 227
<212> PRT
<213> Artificial Sequence
<220>
<223> scFc(LALAP)
<400> 15
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 16
<211> 721
<212> PRT
<213> Artificial Sequence
<220>
<223> 4A8-scFab-hFerritinLC
<400> 16
Glu Ile Val Met Thr Gln Ser Pro Leu Ser Ser Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Ser Trp Leu Gln Gln Arg Pro Gly Gln Pro
35 40 45
Pro Arg Leu Leu Ile Tyr Lys Ile Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ala Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Thr Gln Ala
85 90 95
Thr Gln Phe Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gly Gly Gly Gly Ser
210 215 220
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
245 250 255
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
260 265 270
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
275 280 285
Ser Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly
290 295 300
Ala Ser Val Lys Val Ser Cys Lys Val Ser Gly Tyr Thr Leu Thr Glu
305 310 315 320
Leu Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
325 330 335
Met Gly Gly Phe Asp Pro Glu Asp Gly Glu Thr Met Tyr Ala Gln Lys
340 345 350
Phe Gln Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala
355 360 365
Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr
370 375 380
Cys Ala Thr Ser Thr Ala Val Ala Gly Thr Pro Asp Leu Phe Asp Tyr
385 390 395 400
Tyr Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser
405 410 415
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
420 425 430
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
435 440 445
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
450 455 460
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
465 470 475 480
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
485 490 495
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
500 505 510
Lys Lys Val Glu Pro Lys Ser Cys Gly Gly Gly Gly Ser Gly Gly Gly
515 520 525
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
530 535 540
Ser Gly Gly Ser Ser Gln Ile Arg Gln Asn Tyr Ser Thr Asp Val Glu
545 550 555 560
Ala Ala Val Asn Ser Leu Val Asn Leu Tyr Leu Gln Ala Ser Tyr Thr
565 570 575
Tyr Leu Ser Leu Gly Phe Tyr Phe Asp Arg Asp Asp Val Ala Leu Glu
580 585 590
Gly Val Ser His Phe Phe Arg Glu Leu Ala Glu Glu Lys Arg Glu Gly
595 600 605
Tyr Glu Arg Leu Leu Lys Met Gln Asn Gln Arg Gly Gly Arg Ala Leu
610 615 620
Phe Gln Asp Ile Lys Lys Pro Ala Glu Asp Glu Trp Gly Lys Thr Pro
625 630 635 640
Asp Ala Met Lys Ala Ala Met Ala Leu Glu Lys Lys Leu Asn Gln Ala
645 650 655
Leu Leu Asp Leu His Ala Leu Gly Ser Ala Arg Thr Asp Pro His Leu
660 665 670
Cys Asp Phe Leu Glu Thr His Phe Leu Asp Glu Glu Val Lys Leu Ile
675 680 685
Lys Lys Met Gly Asp His Leu Thr Asn Leu His Arg Leu Gly Gly Pro
690 695 700
Glu Ala Gly Leu Gly Glu Tyr Leu Phe Glu Arg Leu Thr Leu Arg His
705 710 715 720
Asp
<210> 17
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> VK for 4A8
<400> 17
Glu Ile Val Met Thr Gln Ser Pro Leu Ser Ser Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Ser Trp Leu Gln Gln Arg Pro Gly Gln Pro
35 40 45
Pro Arg Leu Leu Ile Tyr Lys Ile Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ala Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Thr Gln Ala
85 90 95
Thr Gln Phe Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105 110
<210> 18
<211> 128
<212> PRT
<213> Artificial Sequence
<220>
<223> VH for 4A8
<400> 18
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Tyr Thr Leu Thr Glu Leu
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asp Pro Glu Asp Gly Glu Thr Met Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Ser Thr Ala Val Ala Gly Thr Pro Asp Leu Phe Asp Tyr Tyr
100 105 110
Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 19
<211> 632
<212> PRT
<213> Artificial Sequence
<220>
<223> 4A8-scFab C_hFerritinLC
<400> 19
Glu Ile Val Met Thr Gln Ser Pro Leu Ser Ser Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Ser Trp Leu Gln Gln Arg Pro Gly Gln Pro
35 40 45
Pro Arg Leu Leu Ile Tyr Lys Ile Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ala Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Thr Gln Ala
85 90 95
Thr Gln Phe Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gly Gly Gly Gly Ser
210 215 220
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
245 250 255
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
260 265 270
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
275 280 285
Ser Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly
290 295 300
Ala Ser Val Lys Val Ser Cys Lys Val Ser Gly Tyr Thr Leu Thr Glu
305 310 315 320
Leu Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
325 330 335
Met Gly Gly Phe Asp Pro Glu Asp Gly Glu Thr Met Tyr Ala Gln Lys
340 345 350
Phe Gln Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala
355 360 365
Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr
370 375 380
Cys Ala Thr Ser Thr Ala Val Ala Gly Thr Pro Asp Leu Phe Asp Tyr
385 390 395 400
Tyr Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser
405 410 415
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
420 425 430
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
435 440 445
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
450 455 460
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
465 470 475 480
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
485 490 495
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
500 505 510
Lys Lys Val Glu Pro Lys Ser Cys Gly Gly Gly Gly Ser Gly Gly Gly
515 520 525
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
530 535 540
Ser Gly Gly Gly Lys Thr Pro Asp Ala Met Lys Ala Ala Met Ala Leu
545 550 555 560
Glu Lys Lys Leu Asn Gln Ala Leu Leu Asp Leu His Ala Leu Gly Ser
565 570 575
Ala Arg Thr Asp Pro His Leu Cys Asp Phe Leu Glu Thr His Phe Leu
580 585 590
Asp Glu Glu Val Lys Leu Ile Lys Lys Met Gly Asp His Leu Thr Asn
595 600 605
Leu His Arg Leu Gly Gly Pro Glu Ala Gly Leu Gly Glu Tyr Leu Phe
610 615 620
Glu Arg Leu Thr Leu Arg His Asp
625 630
<210> 20
<211> 183
<212> PRT
<213> Artificial Sequence
<220>
<223> mFerritin
<400> 20
Met Thr Ser Gln Ile Arg Gln Asn Tyr Ser Thr Glu Val Glu Ala Ala
1 5 10 15
Val Asn Arg Leu Val Asn Leu His Leu Arg Ala Ser Tyr Thr Tyr Leu
20 25 30
Ser Leu Gly Phe Phe Phe Asp Arg Asp Asp Val Ala Leu Glu Gly Val
35 40 45
Gly His Phe Phe Arg Glu Leu Ala Glu Glu Lys Arg Glu Gly Ala Glu
50 55 60
Arg Leu Leu Glu Phe Gln Asn Asp Arg Gly Gly Arg Ala Leu Phe Gln
65 70 75 80
Asp Val Gln Lys Pro Ser Gln Asp Glu Trp Gly Lys Thr Gln Glu Ala
85 90 95
Met Glu Ala Ala Leu Ala Met Glu Lys Asn Leu Asn Gln Ala Leu Leu
100 105 110
Asp Leu His Ala Leu Gly Ser Ala Arg Thr Asp Pro His Leu Cys Asp
115 120 125
Phe Leu Glu Ser His Tyr Leu Asp Lys Glu Val Lys Leu Ile Lys Lys
130 135 140
Met Gly Asn His Leu Thr Asn Leu Arg Arg Val Ala Gly Pro Gln Pro
145 150 155 160
Ala Gln Thr Gly Ala Pro Gln Gly Ser Leu Gly Glu Tyr Leu Phe Glu
165 170 175
Arg Leu Thr Leu Lys His Asp
180
<210> 21
<211> 747
<212> PRT
<213> HD37-scIgG
<400> 21
Asp Ile Leu Leu Thr Gln Thr Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Lys Ala Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Asp Ser Tyr Leu Asn Trp Tyr Gln Gln Ile Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Asp Ala Ser Asn Leu Val Ser Gly Ile Pro Pro
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Lys Val Asp Ala Ala Thr Tyr His Cys Gln Gln Ser Thr
85 90 95
Glu Asp Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
115 120 125
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
130 135 140
Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg Gln
145 150 155 160
Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu Arg
180 185 190
His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser Pro
195 200 205
Ile Val Lys Ser Phe Asn Arg Asn Glu Cys Gly Gly Ser Ser Gly Ser
210 215 220
Gly Ser Gly Ser Thr Gly Thr Ser Ser Ser Gly Thr Gly Thr Ser Ala
225 230 235 240
Gly Thr Thr Gly Thr Ser Ala Ser Thr Ser Gly Ser Gly Ser Gly Gly
245 250 255
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Gly Gly Thr Ala Thr Ala
260 265 270
Gly Ala Ser Ser Gly Ser Gly Ser Ser Gly Ser Ser Ser Ser Gly Gly
275 280 285
Thr Gly Thr Gly Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val
290 295 300
Arg Pro Gly Ser Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala
305 310 315 320
Phe Ser Ser Tyr Trp Met Asn Trp Val Lys Gln Arg Pro Gly Gln Gly
325 330 335
Leu Glu Trp Ile Gly Gln Ile Trp Pro Gly Asp Gly Asp Thr Asn Tyr
340 345 350
Asn Gly Lys Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp Glu Ser Ser
355 360 365
Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu Ala Ser Glu Asp Ser Ala
370 375 380
Val Tyr Phe Cys Ala Arg Arg Glu Thr Thr Thr Val Gly Arg Tyr Tyr
385 390 395 400
Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
405 410 415
Ser Gln Ser Phe Pro Asn Val Phe Pro Leu Val Ser Cys Glu Ser Pro
420 425 430
Leu Ser Asp Lys Asn Leu Val Ala Met Gly Cys Leu Ala Arg Asp Phe
435 440 445
Leu Pro Ser Thr Ile Ser Phe Thr Trp Asn Tyr Gln Asn Asn Thr Glu
450 455 460
Val Ile Gln Gly Ile Arg Thr Phe Pro Thr Leu Arg Thr Gly Gly Lys
465 470 475 480
Tyr Leu Ala Thr Ser Gln Val Leu Leu Ser Pro Lys Ser Ile Leu Glu
485 490 495
Gly Ser Asp Glu Tyr Leu Val Cys Lys Ile His Tyr Gly Gly Lys Asn
500 505 510
Arg Asp Leu His Val Pro Ile Pro Ser Lys Pro Cys Pro Pro Cys Lys
515 520 525
Cys Pro Ala Pro Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro
530 535 540
Pro Lys Ile Lys Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr
545 550 555 560
Cys Val Val Val Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser
565 570 575
Trp Phe Val Asn Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His
580 585 590
Arg Glu Asp Tyr Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile
595 600 605
Gln His Gln Asp Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn
610 615 620
Asn Lys Asp Leu Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys
625 630 635 640
Gly Ser Val Arg Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu
645 650 655
Glu Met Thr Lys Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe
660 665 670
Met Pro Glu Asp Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu
675 680 685
Leu Asn Tyr Lys Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr
690 695 700
Phe Met Tyr Ser Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg
705 710 715 720
Asn Ser Tyr Ser Cys Ser Val Val His Glu Gly Leu His Asn His His
725 730 735
Thr Thr Lys Ser Phe Ser Arg Thr Pro Gly Lys
740 745
<210> 22
<211> 734
<212> PRT
<213> Artificial Sequence
<220>
<223> IgG2a Fc_mFerr
<400> 22
Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro Asn Leu Leu Gly Gly
1 5 10 15
Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys Asp Val Leu Met Ile
20 25 30
Ser Leu Ser Pro Ile Val Thr Cys Val Val Val Asp Val Ser Glu Asp
35 40 45
Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn Asn Val Glu Val His
50 55 60
Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser Thr Leu Arg
65 70 75 80
Val Val Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met Ser Gly Lys
85 90 95
Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ala Pro Ile Glu
100 105 110
Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg Ala Pro Gln Val Tyr
115 120 125
Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys Lys Gln Val Thr Leu
130 135 140
Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp Ile Tyr Val Glu Trp
145 150 155 160
Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys Asn Thr Glu Pro Val
165 170 175
Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser Lys Leu Arg Val Glu
180 185 190
Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser Cys Ser Val Val His
195 200 205
Glu Gly Leu His Asn His His Thr Thr Lys Ser Phe Ser Arg Thr Pro
210 215 220
Gly Lys Gly Gly Ser Ser Gly Ser Gly Ser Gly Ser Thr Gly Thr Ser
225 230 235 240
Ser Ser Gly Thr Gly Thr Ser Ala Gly Thr Thr Gly Thr Ser Ala Ser
245 250 255
Thr Ser Gly Ser Gly Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly Gly
260 265 270
Ser Ala Gly Gly Thr Ala Thr Ala Gly Ala Ser Ser Gly Ser Gly Ser
275 280 285
Ser Gly Ser Ser Ser Ser Gly Gly Thr Gly Lys Pro Cys Pro Pro Cys
290 295 300
Lys Cys Pro Ala Pro Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe
305 310 315 320
Pro Pro Lys Ile Lys Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val
325 330 335
Thr Cys Val Val Val Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile
340 345 350
Ser Trp Phe Val Asn Asn Val Glu Val His Thr Ala Gln Thr Gln Thr
355 360 365
His Arg Glu Asp Tyr Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro
370 375 380
Ile Gln His Gln Asp Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val
385 390 395 400
Asn Asn Lys Asp Leu Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro
405 410 415
Lys Gly Ser Val Arg Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu
420 425 430
Glu Glu Met Thr Lys Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp
435 440 445
Phe Met Pro Glu Asp Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr
450 455 460
Glu Leu Asn Tyr Lys Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser
465 470 475 480
Tyr Phe Met Tyr Ser Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu
485 490 495
Arg Asn Ser Tyr Ser Cys Ser Val Val His Glu Gly Leu His Asn His
500 505 510
His Thr Thr Lys Ser Phe Ser Arg Thr Pro Gly Lys Ser Arg Ala Ser
515 520 525
Thr Ala Ser Ser Ala Ser Ser Gly Gly Gly Gly Gly Gly Ser Gly Gly
530 535 540
Ser Gly Gly Ser Gly Gly Ser Met Thr Ser Gln Ile Arg Gln Asn Tyr
545 550 555 560
Ser Thr Glu Val Glu Ala Ala Val Asn Arg Leu Val Asn Leu His Leu
565 570 575
Arg Ala Ser Tyr Thr Tyr Leu Ser Leu Gly Phe Phe Phe Asp Arg Asp
580 585 590
Asp Val Ala Leu Glu Gly Val Gly His Phe Phe Arg Glu Leu Ala Glu
595 600 605
Glu Lys Arg Glu Gly Ala Glu Arg Leu Leu Glu Phe Gln Asn Asp Arg
610 615 620
Gly Gly Arg Ala Leu Phe Gln Asp Val Gln Lys Pro Ser Gln Asp Glu
625 630 635 640
Trp Gly Lys Thr Gln Glu Ala Met Glu Ala Ala Leu Ala Met Glu Lys
645 650 655
Asn Leu Asn Gln Ala Leu Leu Asp Leu His Ala Leu Gly Ser Ala Arg
660 665 670
Thr Asp Pro His Leu Cys Asp Phe Leu Glu Ser His Tyr Leu Asp Lys
675 680 685
Glu Val Lys Leu Ile Lys Lys Met Gly Asn His Leu Thr Asn Leu Arg
690 695 700
Arg Val Ala Gly Pro Gln Pro Ala Gln Thr Gly Ala Pro Gln Gly Ser
705 710 715 720
Leu Gly Glu Tyr Leu Phe Glu Arg Leu Thr Leu Lys His Asp
725 730
<210> 23
<211> 640
<212> PRT
<213> Artificial Sequence
<220>
<223> scFc-N-hFerr LALAP I253A
<400> 23
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
225 230 235 240
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
245 250 255
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Lys Thr His Thr Cys Pro
290 295 300
Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe
305 310 315 320
Pro Pro Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val
325 330 335
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
340 345 350
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
355 360 365
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
370 375 380
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
385 390 395 400
Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
405 410 415
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
420 425 430
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
435 440 445
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
450 455 460
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
465 470 475 480
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
485 490 495
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
500 505 510
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Gly Gly Gly Gly
515 520 525
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
530 535 540
Gly Gly Gly Gly Ser Gly Gly Ser Ser Gln Ile Arg Gln Asn Tyr Ser
545 550 555 560
Thr Asp Val Glu Ala Ala Val Asn Ser Leu Val Asn Leu Tyr Leu Gln
565 570 575
Ala Ser Tyr Thr Tyr Leu Ser Leu Gly Phe Tyr Phe Asp Arg Asp Asp
580 585 590
Val Ala Leu Glu Gly Val Ser His Phe Phe Arg Glu Leu Ala Glu Glu
595 600 605
Lys Arg Glu Gly Tyr Glu Arg Leu Leu Lys Met Gln Asn Gln Arg Gly
610 615 620
Gly Arg Ala Leu Phe Gln Asp Ile Lys Lys Pro Ala Glu Asp Glu Trp
625 630 635 640
<210> 24
<211> 227
<212> PRT
<213> Homo sapiens
<400> 24
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 25
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 56 light chain
<400> 25
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Ser
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 26
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 56 heavy chain
<400> 26
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gly Pro Ile Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215
<210> 27
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 349 light chain
<400> 27
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Thr Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Thr Thr Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 28
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 349 heavy chain
<400> 28
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Ser Ala Gly Ser Ile Thr Asn Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Gly Asn His Ala Gly Thr Thr Val Thr Ser Glu Tyr Phe Gln His
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys
225
<210> 29
<211> 215
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 178 light chain
<400> 29
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ala Ser Gln Ser Val Ser Gly Thr
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln
65 70 75 80
Ser Glu Asp Phe Ala Val Tyr Tyr Cys Leu Gln Thr His Ser Tyr Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 30
<211> 225
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 178 heavy chain
<400> 30
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Ser Ser Trp Tyr Glu Ile Thr Lys Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys
225
<210> 31
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 108 light chain
<400> 31
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Thr Asn Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Thr Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Thr Phe Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 32
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 108 heavy chain
<400> 32
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Ser Arg Tyr
20 25 30
Ala Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Met Asn Pro Ile Ser Gly Asn Thr Asp Tyr Ala Pro Asn Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Gly Ser Gln Leu Ala Tyr Leu Val Glu Tyr Phe Gln His
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys
225
<210> 33
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 128 light chain
<400> 33
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Ile Ser Arg Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Gly Phe Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 34
<211> 225
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 128 heavy chain
<400> 34
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr His Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Ser Ser Ser Ala Ser Tyr Ser Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Arg Tyr Gly Ser Gly Ser Tyr Pro Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys
225
<210> 35
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 160 light chain
<400> 35
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Tyr Thr Thr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 36
<211> 224
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 160 heavy chain
<400> 36
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly His
20 25 30
Asp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Asn Ser Leu Arg Tyr Tyr Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 37
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 368 light chain
<400> 37
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Ala Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 38
<211> 220
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 368 heavy chain
<400> 38
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asp Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ala Ile Met Pro Met Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Ser Ser Gly Tyr Tyr Tyr Gly Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 39
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 192 light chain
<400> 39
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 40
<211> 224
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 192 heavy chain
<400> 40
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asn Ser Gly Gly Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Thr Tyr Tyr Tyr Asp Ser Ser Gly Tyr Ser Thr Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 41
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 158 light chain
<400> 41
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Arg Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 42
<211> 225
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 158 heavy chain
<400> 42
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Leu Asn Gly Gly Thr Asn Phe Ala Pro Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Pro Gly Gly Ser Tyr Ser Asn Asp Ala Phe Asp Ile Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys
225
<210> 43
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 180 light chain
<400> 43
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Gln Gln Tyr
85 90 95
Tyr Ser Ser Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 44
<211> 227
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 180 heavy chain
<400> 44
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Ser Pro Arg Ser Gly Gly Thr Lys Tyr Ala Gln Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ala Val Ala Gly Thr His Pro Gln Ala Gly Asp Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys
225
<210> 45
<211> 215
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 254 light chain
<400> 45
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Gln Ile Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Ser Tyr Ser Thr Pro Pro
85 90 95
Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 46
<211> 222
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 254 heavy chain
<400> 46
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Ser
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Glu Gly Asp Gly Tyr Asn Phe Tyr Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 47
<211> 215
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 120 light chain
<400> 47
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Arg
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln
65 70 75 80
Ser Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Tyr Thr Thr Pro
85 90 95
Arg Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 48
<211> 227
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 120 heavy chain
<400> 48
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asp Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Met Ile Asp Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Phe Gly Gly Gly Thr Arg Tyr Asp Tyr Trp Tyr Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys
225
<210> 49
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 64 light chain
<400> 49
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser His
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Thr Tyr Ser Thr Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 50
<211> 224
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 64 heavy chain
<400> 50
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Gln His
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Asp Arg Ser Gly Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Thr Tyr Gly Gly Lys Val Thr Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 51
<211> 220
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 298 light chain
<400> 51
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 52
<211> 222
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 298 heavy chain
<400> 52
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Thr Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Pro Asn Ser Gly Gly Thr Asp Leu Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Asp Pro Arg Asp Asp Ile Ala Gly Gly Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 53
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 82 light chain
<400> 53
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Phe Ser Pro Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 54
<211> 225
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 82 heavy chain
<400> 54
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Ser Phe Ser Thr Ser
20 25 30
Ala Phe Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Tyr Thr Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Arg Ala Leu Tyr Gly Ser Gly Ser Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys
225
<210> 55
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 46 light chain
<400> 55
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 56
<211> 220
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 46 heavy chain
<400> 56
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Asp Ser Arg Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr Met
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 57
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 324 light chain
<400> 57
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Thr Thr Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 58
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 324 heavy chain
<400> 58
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Asn Asn Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Met Asn Pro Asn Ser Gly Asn Thr Gly Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Gly Asp Tyr Gly Asp Tyr Ile Val Ser Pro Phe Asp Leu
100 105 110
Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys
225
<210> 59
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 236 light chain
<400> 59
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Pro Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 60
<211> 224
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 236 heavy chain
<400> 60
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Met Asn Pro Asn Ser Gly Asn Thr Gly Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Arg Gly Ile Gln Leu Leu Pro Arg Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 61
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 52 light chain
<400> 61
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Asn Asn
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Asn Gly Phe Pro Leu
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 62
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 52 light chain N92T
<400> 62
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Asn Asn
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Thr Gly Phe Pro Leu
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 63
<211> 220
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 52 heavy chain
<400> 63
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Met Phe Gly Thr Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Gly Asp Thr Ile Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 64
<211> 220
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 80 light chain
<400> 64
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Ala Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 65
<211> 227
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody 80 heavy chain
<400> 65
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Asn Arg Tyr
20 25 30
Ala Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Arg Glu Leu Pro Glu Val Val Asp Trp Tyr Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys
225
<210> 66
<211> 85
<212> PRT
<213> Artificial Sequence
<220>
<223> Cferritin
<400> 66
Gly Lys Thr Pro Asp Ala Met Lys Ala Ala Met Ala Leu Glu Lys Lys
1 5 10 15
Leu Asn Gln Ala Leu Leu Asp Leu His Ala Leu Gly Ser Ala Arg Thr
20 25 30
Asp Pro His Leu Cys Asp Phe Leu Glu Thr His Phe Leu Asp Glu Glu
35 40 45
Val Lys Leu Ile Lys Lys Met Gly Asp His Leu Thr Asn Leu His Arg
50 55 60
Leu Gly Gly Pro Glu Ala Gly Leu Gly Glu Tyr Leu Phe Glu Arg Leu
65 70 75 80
Thr Leu Lys His Asp
85
<210> 67
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 67
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Gly Ser
1 5 10 15
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly
20 25
<210> 68
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 68
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gly Pro Ile Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 69
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 69
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Ser Ala Gly Ser Ile Thr Asn Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Gly Asn His Ala Gly Thr Thr Val Thr Ser Glu Tyr Phe Gln His
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 70
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 70
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Ser Ser Trp Tyr Glu Ile Thr Lys Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 71
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 71
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Ser Arg Tyr
20 25 30
Ala Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Met Asn Pro Ile Ser Gly Asn Thr Asp Tyr Ala Pro Asn Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Gly Ser Gln Leu Ala Tyr Leu Val Glu Tyr Phe Gln His
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 72
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 72
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr His Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Ser Ser Ser Ala Ser Tyr Ser Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Arg Tyr Gly Ser Gly Ser Tyr Pro Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 73
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 73
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly His
20 25 30
Asp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Asn Ser Leu Arg Tyr Tyr Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 74
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 74
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asp Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ala Ile Met Pro Met Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Ser Ser Gly Tyr Tyr Tyr Gly Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 75
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 75
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asn Ser Gly Gly Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Thr Tyr Tyr Tyr Asp Ser Ser Gly Tyr Ser Thr Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 76
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 76
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Leu Asn Gly Gly Thr Asn Phe Ala Pro Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Pro Gly Gly Ser Tyr Ser Asn Asp Ala Phe Asp Ile Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 77
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 77
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Ser Pro Arg Ser Gly Gly Thr Lys Tyr Ala Gln Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ala Val Ala Gly Thr His Pro Gln Ala Gly Asp Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 78
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 78
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Ser
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Thr Gly Gly Asp Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Glu Gly Asp Gly Tyr Asn Phe Tyr Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 79
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 79
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asp Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Met Ile Asp Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Phe Gly Gly Gly Thr Arg Tyr Asp Tyr Trp Tyr Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 80
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 80
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Pro Phe Ser Gln His
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Asp Arg Ser Gly Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Thr Tyr Gly Gly Lys Val Thr Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 81
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 81
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Thr Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Pro Asn Ser Gly Gly Thr Asp Leu Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Asp Pro Arg Asp Asp Ile Ala Gly Gly Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 82
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 82
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Ser Phe Ser Thr Ser
20 25 30
Ala Phe Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Tyr Thr Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Arg Ala Leu Tyr Gly Ser Gly Ser Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 83
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 83
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Asp Ser Arg Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr Met
100 105 110
Val Thr Val Ser Ser
115
<210> 84
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 84
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Asn Asn Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Met Asn Pro Asn Ser Gly Asn Thr Gly Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Gly Asp Tyr Gly Asp Tyr Ile Val Ser Pro Phe Asp Leu
100 105 110
Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 85
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 85
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Met Asn Pro Asn Ser Gly Asn Thr Gly Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Arg Gly Ile Gln Leu Leu Pro Arg Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 86
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 86
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Met Phe Gly Thr Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Gly Asp Thr Ile Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 87
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 87
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Asn Arg Tyr
20 25 30
Ala Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Arg Glu Leu Pro Glu Val Val Asp Trp Tyr Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 88
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 88
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Ser
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 89
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 89
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Thr Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Thr Thr Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg
100 105
<210> 90
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 90
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ala Ser Gln Ser Val Ser Gly Thr
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln
65 70 75 80
Ser Glu Asp Phe Ala Val Tyr Tyr Cys Leu Gln Thr His Ser Tyr Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 91
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 91
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Thr Asn Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Thr Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Thr Phe Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 92
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 92
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Ile Ser Arg Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Gly Phe Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 93
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 93
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Tyr Thr Thr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 94
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 94
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Ala Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105 110
Arg
<210> 95
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 95
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg
<210> 96
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 96
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Arg Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Asp Ile Lys Arg
100 105
<210> 97
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 97
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Gln Gln Tyr
85 90 95
Tyr Ser Ser Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg
<210> 98
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 98
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Gln Ile Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Ser Tyr Ser Thr Pro Pro
85 90 95
Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 99
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 99
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Arg
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln
65 70 75 80
Ser Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Tyr Thr Thr Pro
85 90 95
Arg Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg
100 105
<210> 100
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 100
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser His
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Thr Tyr Ser Thr Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 101
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 101
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg
<210> 102
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 102
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Phe Ser Pro Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg
100 105
<210> 103
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 103
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg
100 105
<210> 104
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 104
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Thr Thr Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 105
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 105
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Pro Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105 110
Arg
<210> 106
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 106
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Asn Asn
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Asn Gly Phe Pro Leu
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg
100 105
<210> 107
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> Polypeptide
<400> 107
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Ala Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg
<210> 108
<211> 227
<212> PRT
<213> Artificial Sequence
<220>
<223> Fc Chain 1
<400> 108
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Leu
195 200 205
His Glu Ala Leu His Ser His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 109
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 109
cagatcaccc ggtttcagac actgctggcc 30
<210> 110
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 110
gatgccgatg ggcagatcca ccagggg 27
<210> 111
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 111
cggtaccggc tgttccggaa gtccaatctg 30
<210> 112
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Primer
<400> 112
Gly Thr Ala Ala Thr Thr Gly Thr Gly Thr Thr Gly Cys Cys Gly Cys
1 5 10 15
Cys Gly Ala Cys Thr Thr Thr Gly Gly
20 25
<210> 113
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 113
gtgggcagca ccccttgtaa cggcgtggaa g 31
<210> 114
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 114
ctgatagatc tcggtggaga tgtccc 26
<210> 115
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 115
gccgaaggct tcaactgcta cttcccactg c 31
<210> 116
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 116
gccgttacaa ggggtgctgc cggcc 25
<210> 117
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 117
aagaacctgg actccaaagt cggcggcaac tac 33
<210> 118
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer
<400> 118
gctgttccag gcaatcacac agccggtg 28
Claims (102)
- SARS-CoV-2 결합 모이어티에 연결된 나노케이지 단량체를 포함하는 융합 단백질로서, 복수개의 융합 단백질은 자가-조립하여 나노케이지를 형성하는 것인 융합 단백질.
- 제1항에 있어서, SARS-CoV-2 결합 모이어티가 SARS-CoV-2 S 당단백질을 표적화하는 것인 융합 단백질.
- 제1항 또는 제2항에 있어서, SARS-CoV-2 결합 모이어티가 조립된 나노케이지의 내부 및/또는 외부 표면, 바람직하게는 외부 표면을 장식하는 것인 융합 단백질.
- 제1항 내지 제3항 중 어느 한 항에 있어서, SARS-CoV-2 결합 모이어티가 항체 또는 그의 단편을 포함하는 것인 융합 단백질.
- 제4항에 있어서, 항체 또는 그의 단편이 Fab 단편을 포함하는 것인 융합 단백질.
- 제4항에 있어서, 항체 또는 그의 단편이 scFab 단편, scFv 단편, sdAb 단편, VHH 도메인 또는 이들의 조합물을 포함하는 것인 융합 단백질.
- 제4항에 있어서, 항체 또는 그의 단편이 Fab 단편의 중쇄 및/또는 경쇄를 포함하는 것인 융합 단백질.
- 제4항 내지 제7항 중 어느 한 항에 있어서, SARS-CoV-2 결합 모이어티가 단일 쇄 가변 도메인 VHH-72, BD23 및/또는 4A8을 포함하는 것인 융합 단백질.
- 제4항 내지 제8항 중 어느 한 항에 있어서, SARS-CoV-2 결합 모이어티가 표 4에 나열된 mAb를 포함하는 것인 융합 단백질.
- 제9항에 있어서, SARS-CoV-2 결합 모이어티가 표 4로부터의 mAb 298, 324, 46, 80, 52, 82, 또는 236, 또는 그의 변이체를 포함하는 것인 융합 단백질.
[청구항 10a]
제10항에 있어서, SARS-CoV-2 결합 모이어티가 표 4로부터의 mAb 298, 80, 및 52, 또는 그의 변이체를 포함하는 것인 융합 단백질. - 제1항 내지 제10항 중 어느 한 항에 있어서, SARS-CoV-2 결합 모이어티가 나노케이지 단량체의 N- 또는 C-말단에서 연결되거나, 또는 나노케이지 단량체의 N-말단에서 연결된 제1 SARS-CoV-2 결합 모이어티 및 C-말단에서 연결된 제2 SARS-CoV-2 결합 모이어티가 있고, 제1 및 제2 SARS-CoV-2 결합 모이어티가 동일하거나 또는 상이한 것인 융합 단백질.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 나노케이지 단량체가 SARS-CoV-2 결합 모이어티에 연결된 제1 나노케이지 단량체 서브유닛을 포함하고; 제1 나노케이지 단량체 서브유닛이 제2 나노케이지 단량체 서브유닛과 자가-조립하여 나노케이지 단량체를 형성하는 것인 융합 단백질.
- 제12항에 있어서, SARS-CoV-2 결합 모이어티가 제1 나노케이지 단량체의 N- 또는 C-말단에서 연결되거나, 또는 제1 나노케이지 단량체 서브유닛의 N-말단에서 연결된 제1 SARS-CoV-2 결합 모이어티 및 C-말단에서 연결된 제2 SARS-CoV-2 결합 모이어티가 있고, 제1 및 제2 SARS-CoV-2 결합 모이어티가 동일하거나 또는 상이한 것인 융합 단백질.
- 제12항 또는 제13항에 있어서, 제2 나노케이지 단량체 서브유닛과 조합된 융합 단백질.
- 제12항 내지 제14항 중 어느 한 항에 있어서, 제2 나노케이지 단량체 서브유닛이 생물활성 모이어티에 연결된 것인 융합 단백질.
- 제15항에 있어서, 생물활성 모이어티가 Fc 단편을 포함하는 것인 융합 단백질.
- 제16항에 있어서, Fc 단편이 IgG1 Fc 단편인 융합 단백질.
- 제15항 또는 제16항에 있어서, Fc 단편이 융합 단백질의 반감기를 예를 들어 수분 또는 수시간에서 수일, 수주 또는 수개월로 조절하는 1개 이상의 돌연변이, 예컨대 LS, YTE, LALA, I253A, 및/또는 LALAP를 포함하는 것인 융합 단백질.
- 제15항 내지 제18항 중 어느 한 항에 있어서, Fc 단편이 scFc 단편인 융합 단백질.
- 제1항 내지 제19항 중 어느 한 항에 있어서, 약 3 내지 약 100개의 나노케이지 단량체, 예컨대 24, 32 또는 60개의 단량체, 또는 약 4 내지 약 200개의 나노케이지 단량체 서브유닛, 예컨대 4, 6, 8, 10, 12, 14, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50개 또는 그 초과가 임의적으로 1개 이상의 전체 나노케이지 단량체와 조합되어 자가-조립하여 나노케이지를 형성하는 것인 융합 단백질.
- 제1항 내지 제20항 중 어느 한 항에 있어서, 나노케이지 단량체가 페리틴, 아포페리틴, 엔캡슐린, SOR, 루마진 신타제, 피루베이트 데히드로게나제, 카르복시좀, 볼트 단백질, GroEL, 열 쇼크 단백질, E2P, MS2 외피 단백질, 그의 단편, 및 그의 변이체로부터 선택되는 것인 융합 단백질.
- 제21항에 있어서, 나노케이지 단량체가 아포페리틴, 임의적으로 인간 아포페리틴인 융합 단백질.
- 제22항에 있어서, 제1 및 제2 나노케이지 단량체 서브유닛이 상호교환적으로 아포페리틴의 "N" 및 "C" 영역을 포함하는 것인 융합 단백질.
- 제23항에 있어서, 아포페리틴의 "N" 영역이 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어지는 것인 융합 단백질:
MSSQIRQNYSTDVEAAVNSLVNLYLQASYTYLSLGFYFDRDDVALEGVSHFFRELAEEKREGYERLLKMQNQRGGRALFQDIKKPAEDEW. - 제22항 또는 제23항에 있어서, 아포페리틴의 "C" 영역이 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어지는 것인 융합 단백질:
GKTPDAMKAAMALEKKLNQALLDLHALGSARTDPHLCDFLETHFLDEEVKLIKKMGDHLTNLHRLGGPEAGLGEYLFERLTLRHD
또는
GKTPDAMKAAMALEKKLNQALLDLHALGSARTDPHLCDFLETHFLDEEVKLIKKMGDHLTNLHRLGGPEAGLGEYLFERLTLKHD. - 제1항 내지 제25항 중 어느 한 항에 있어서, 나노케이지 단량체 서브유닛과 생물활성 모이어티 사이에 링커를 추가로 포함하는 융합 단백질.
- 제26항에 있어서, 링커가 가요성 또는 강직성이고, 약 1 내지 약 30개의 아미노산 잔기, 예컨대 약 8 내지 약 16개의 아미노산 잔기를 포함하는 것인 융합 단백질.
- 제26항 또는 제27항에 있어서, 링커가 GGS 반복부, 예컨대 1, 2, 3, 4개 또는 그 초과의 GGS 반복부를 포함하는 것인 융합 단백질.
- 제28항에 있어서, 링커가 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어지는 것인 융합 단백질:
GGGGSGGGGSGGGGSGGGGSGGGGSGG. - 제1항 내지 제29항 중 어느 한 항에 있어서, C-말단 링커를 추가로 포함하는 융합 단백질.
- 제30항에 있어서, C-말단 링커가 하기 서열과 적어도 70% (예컨대 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%) 동일한 서열을 포함하거나 또는 그로 이루어지는 것인 융합 단백질:
GGSGGSGGSGGSGGGSGGSGGSGGSG. - 제1항 내지 제31항 중 어느 한 항의 적어도 하나의 융합 단백질, 및 융합 단백질과 자가-조립하여 나노케이지 단량체를 형성하는 적어도 하나의 제2 나노케이지 단량체 서브유닛을 포함하는 나노케이지.
- 제32항에 있어서, 각각의 나노케이지 단량체가 제1항 내지 제31항 중 어느 한 항의 융합 단백질을 포함하는 것인 나노케이지.
- 제32항 또는 제33항에 있어서, 나노케이지 단량체의 약 20% 내지 약 80%가 제1항 내지 제27항 중 어느 한 항의 융합 단백질을 포함하는 것인 나노케이지.
- 제32항 내지 제34항 중 어느 한 항에 있어서, 적어도 2, 3, 4, 5, 6, 7, 8, 9 또는 10개의 상이한 SARS-CoV-2 결합 모이어티, 예컨대 3개의 상이한 SARS-CoV-2 결합 모이어티를 포함하는 나노케이지.
- 제32항 내지 제35항 중 어느 한 항에 있어서, 나노케이지가 다가성 및/또는 다중특이적인 나노케이지.
- 제32항 내지 제36항 중 어느 한 항에 있어서, 표 4로부터의 하나 이상의 mAb를 포함하는 나노케이지.
- 제37항에 있어서, 표 4로부터의 3가지 mAb를 포함하는 나노케이지.
- 제37항 또는 제38항에 있어서, 표 4로부터의 mAb 298, 324, 46, 52, 80, 82 및/또는 236을 포함하는 나노케이지.
- 제32항 내지 제39항 중 어느 한 항에 있어서, 4:2:1:1: 비의 scFab1-인간 아포페리틴: scFc-인간 N-페리틴: scFab2-C-페리틴: scFab3-C-페리틴을 포함하는 나노케이지.
- 제32항 내지 제40항 중 어느 한 항에 있어서, 적하 분자, 예컨대 약제, 진단제, 및/또는 영상화제를 운반하는 나노케이지.
- 제41항에 있어서, 적하 분자가 융합 단백질에 융합되지 않고, 나노케이지 내부에 함유되는 것인 나노케이지.
- 제42항에 있어서, 적하 분자가 단백질이고, 적하 분자가 나노케이지 내부에 함유되도록 융합 단백질에 융합되는 것인 나노케이지.
- 제41항 내지 제43항 중 어느 한 항에 있어서, 적하 분자가 형광 단백질, 예컨대 GFP, EGFP, 아메트린, 및/또는 플라빈-기반 형광 단백질, 예컨대 LOV-단백질, 예컨대 iLOV인 나노케이지.
- SARS-CoV-2를 표적화하는 삼중-특이적 항체 구축물.
- 제32항 내지 제44항 중 어느 한 항의 나노케이지 또는 제45항의 항체를 포함하는 SARS-CoV-2 치료적 또는 예방적 조성물.
- 제1항 내지 제31항 중 어느 한 항의 융합 단백질을 코딩하는 핵산 분자.
- 제47항의 핵산 분자를 포함하는 벡터.
- 제48항의 벡터를 포함하고, 제1항 내지 제31항 중 어느 한 항의 융합 단백질을 생성하는 숙주 세포.
- 제32항 또는 제33항의 나노케이지, 또는 제45항의 항체, 또는 제46항의 조성물을 투여하는 것을 포함하는, SARS-CoV-2를 치료하고/거나 예방하는 방법.
- SARS-CoV-2의 치료 및/또는 예방을 위한 제32항 또는 제33항의 나노케이지, 또는 제45항의 항체, 또는 제46항의 조성물의 용도.
- 제32항, 제33항, 제45항 및 제46항 중 어느 한 항에 있어서, SARS-CoV-2의 치료 및/또는 예방에서 사용하기 위한 나노케이지, 항체 또는 조성물.
- 하기 표에 나열된 임의의 서열과 적어도 70% 동일성을 갖는 아미노산 서열을 포함하는 폴리펩티드 또는 그의 기능적 단편:

.
- 제53항에 있어서, 나열된 서열과 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 서열 동일성을 포함하는 폴리펩티드.
- 제54항에 있어서, 나열된 서열과 적어도 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 서열 동일성으로 이루어진 폴리펩티드.
- 제53항 내지 제55항 중 어느 한 항의 폴리펩티드를 포함하는 항체 또는 그의 단편.
- (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) 단편 결정화가능한 (Fc) 영역을 포함하는 융합 폴리펩티드로서, Fc 영역은 I253A 돌연변이를 포함하고, 넘버링은 EU 인덱스에 따른 것인 융합 폴리펩티드.
- 제57항에 있어서, Fc 영역이 LALAP (L234A/L235A/P329G) 돌연변이를 추가로 포함하고, 넘버링이 EU 인덱스에 따른 것인 융합 폴리펩티드.
- 제57항 또는 제58항에 있어서, Fc 영역이 IgG1 Fc 영역인 융합 폴리펩티드.
- 제57항 내지 제59항 중 어느 한 항에 있어서, 나노케이지 단량체가 페리틴 단량체인 융합 폴리펩티드.
- 제60항에 있어서, 페리틴 단량체가 페리틴 경쇄인 융합 폴리펩티드.
- 제61항에 있어서, 페리틴 경쇄가 인간 페리틴 경쇄인 융합 폴리펩티드.
- 제57항 내지 제62항 중 어느 한 항에 있어서, Fc 영역이 아미노산 링커를 통해 나노케이지 단량체 또는 그의 서브유닛에 연결된 것인 융합 폴리펩티드.
- 제57항 내지 제63항 중 어느 한 항에 있어서, Fc 영역이 나노케이지 단량체 또는 그의 서브유닛의 N-말단에 연결된 것인 융합 폴리펩티드.
- 제57항 내지 제64항 중 어느 한 항에 있어서, Fc 영역이 단일 쇄 Fc (scFc)인 융합 폴리펩티드.
- 제57항 내지 제65항 중 어느 한 항에 있어서, Fc 영역이 Fc 단량체인 융합 폴리펩티드.
- 하기를 포함하는 자가-조립된 폴리펩티드 복합체:
(a) 복수개의 제1 융합 폴리펩티드, 여기서 각각의 제1 융합 폴리펩티드는 (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) Fc 영역을 포함함, 및
(b) 복수개의 제2 융합 폴리펩티드, 여기서 각각의 제2 융합 폴리펩티드는 (2) 나노케이지 단량체 또는 그의 서브유닛에 연결된 (1) SARS-CoV-2-결합 항체 단편을 포함함. - 제67항에 있어서, 나노케이지 단량체가 페리틴 단량체인 자가-조립된 폴리펩티드 복합체.
- 제68항에 있어서, 나노케이지 단량체가 페리틴 경쇄인 자가-조립된 폴리펩티드 복합체.
- 제69항에 있어서, 임의의 페리틴 중쇄, 또는 페리틴 중쇄의 서브유닛을 포함하지 않는 자가-조립된 폴리펩티드 복합체.
- 제68항 또는 제69항에 있어서, 나노케이지 단량체가 인간 페리틴 경쇄인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제71항 중 어느 한 항에 있어서, SARS-CoV-2-결합 항체 단편이 SARS-CoV-2의 수용체 결합 도메인 또는 스파이크 단백질에 결합하는 것인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제72항 중 어느 한 항에 있어서, SARS-CoV-2-결합 항체 단편이 경쇄 가변 도메인 및 중쇄 가변 도메인을 포함하는 것인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제73항 중 어느 한 항에 있어서, SARS-CoV-2-결합 항체 단편이 SARS-CoV-2에 결합할 수 있는 항체의 Fab를 포함하는 것인 자가-조립된 폴리펩티드 복합체.
- 제73항 또는 제74항에 있어서, SARS-CoV-2-결합 항체 단편이 VK 도메인 및 VH 도메인을 포함하는 것인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제75항 중 어느 한 항에 있어서, 자가-조립된 폴리펩티드 복합체가 1:1 비의 제1 융합 폴리펩티드 대 제2 융합 폴리펩티드를 특징으로 하는 것인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제76항 중 어느 한 항에 있어서, Fc 영역이 IgG1 Fc 영역인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제77항 중 어느 한 항에 있어서, Fc 영역이 아미노산 링커를 통해 나노케이지 단량체 또는 그의 서브유닛에 연결된 것인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제78항 중 어느 한 항에 있어서, Fc 영역이 나노케이지 단량체 또는 그의 서브유닛의 N-말단에 연결된 것인 자가-조립된 폴리펩티드 복합체.
- 제67항 내지 제79항 중 어느 한 항에 있어서, 총 적어도 24개의 융합 폴리펩티드를 포함하는 자가-조립된 폴리펩티드 복합체.
- 제80항에 있어서, 총 적어도 32개의 융합 폴리펩티드를 포함하는 자가-조립된 폴리펩티드 복합체.
- 제81항에 있어서, 총 약 32개의 융합 폴리펩티드를 갖는 자가-조립된 폴리펩티드 복합체.
- 하기를 포함하는 자가-조립된 폴리펩티드 복합체:
(a) 복수개의 제1 융합 폴리펩티드, 여기서 각각의 제1 융합 폴리펩티드는 (2) 인간 페리틴 단량체 또는 그의 서브유닛에 연결된 (1) IgG1 Fc 영역을 포함하고, IgG1 Fc 영역은 LALAP (L234A/L235A/P329G) 및 I253A 돌연변이를 포함하고, 넘버링은 EU 인덱스에 따른 것임, 및
(b) 복수개의 제2 융합 폴리펩티드, 여기서 각각의 제2 융합 폴리펩티드는 (1) SARS-CoV-2 단백질에 결합할 수 있는 항체의 Fab 단편을 포함하고, Fab 단편은 (2) 인간 페리틴 단량체 또는 그의 서브유닛에 연결됨. - 제83항에 있어서,
(1) 각각의 제1 융합 폴리펩티드가 C-절반-페리틴인 페리틴 단량체 서브유닛을 포함하고, 각각의 제2 융합 폴리펩티드가 N-절반-페리틴인 페리틴 단량체 서브유닛을 포함하거나; 또는
(2) 각각의 제1 융합 폴리펩티드가 N-절반 페리틴인 페리틴 단량체 서브유닛을 포함하고, 각각의 제2 융합 폴리펩티드가 C-절반-페리틴인 페리틴 단량체 서브유닛을 포함하는 것인 자가-조립된 폴리펩티드 복합체. - 제83항 또는 제84항에 있어서, 자가-조립된 폴리펩티드 복합체가 1:1 비의 제1 융합 폴리펩티드 대 제2 융합 폴리펩티드를 특징으로 하는 것인 자가-조립된 폴리펩티드 복합체.
- 제83항 내지 제85항 중 어느 한 항에 있어서, 각각의 제1 융합 폴리펩티드가 C-절반-페리틴인 페리틴 단량체 서브유닛을 포함하는 것인 자가-조립된 폴리펩티드 복합체.
- 제86항에 있어서, IgG1 Fc 영역이 아미노산 링커를 통해 C-절반-페리틴에 연결된 것인 자가-조립된 폴리펩티드 복합체.
- 제86항 또는 제87항에 있어서, IgG1 Fc 영역이 C-절반-페리틴의 N-말단을 통해 C-절반-페리틴에 연결된 것인 자가-조립된 폴리펩티드 복합체.
- 제83항 내지 제88항 중 어느 한 항에 있어서, 각각의 제2 융합 폴리펩티드가 N-절반-페리틴인 페리틴 단량체 서브유닛을 포함하는 것인 자가-조립된 폴리펩티드 복합체.
- 제89항에 있어서, Fab 단편이 아미노산 링커를 통해 N-절반-페리틴에 연결된 것인 자가-조립된 폴리펩티드 복합체.
- 제89항 또는 제90항에 있어서, Fab 단편이 N-절반-페리틴의 N-말단을 통해 N-절반-페리틴에 연결된 것인 자가-조립된 폴리펩티드 복합체.
- 제83항 내지 제91항 중 어느 한 항에 있어서, 복수개의 제3 융합 폴리펩티드를 추가로 포함하고, 각각의 제3 융합 폴리펩티드가 (2) SARS-CoV-2 단백질에 결합할 수 있는 항체의 Fab 단편에 연결된 (1) 인간 페리틴 단량체를 포함하는 것인 자가-조립된 폴리펩티드 복합체.
- 제92항에 있어서, 자가-조립된 폴리펩티드 복합체가 1:1:2 비의 제1 융합 폴리펩티드 대 제2 융합 폴리펩티드 대 제3 융합 폴리펩티드를 특징으로 하는 것인 자가-조립된 폴리펩티드 복합체.
- 제83항 내지 제93항 중 어느 한 항에 있어서, 총 적어도 24개의 융합 폴리펩티드를 포함하는 자가-조립된 폴리펩티드 복합체.
- 제94항에 있어서, 총 적어도 32개의 융합 폴리펩티드를 포함하는 자가-조립된 폴리펩티드 복합체.
- 제95항에 있어서, 총 32개의 융합 폴리펩티드를 갖는 자가-조립된 폴리펩티드 복합체.
- 제74항 및 제83항 내지 제93항 중 어느 한 항에 있어서, Fab 단편이 VK 도메인 및 VH 도메인을 포함하고,
(1) VK 도메인이 서열식별번호:11의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:12의 아미노산 서열을 갖거나;
(2) VK 도메인이 서열식별번호:17의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:18의 아미노산 서열을 갖거나;
(3) VK 도메인이 서열식별번호:25 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:26 내의 VH의 아미노산 서열을 갖거나;
(4) VK 도메인이 서열식별번호:27 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:28 내의 VH의 아미노산 서열을 갖거나;
(5) VK 도메인이 서열식별번호:29 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:30 내의 VH의 아미노산 서열을 갖거나;
(6) VK 도메인이 서열식별번호:31 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:32 내의 VH의 아미노산 서열을 갖거나;
(7) VK 도메인이 서열식별번호:33 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:34 내의 VH의 아미노산 서열을 갖거나;
(8) VK 도메인이 서열식별번호:35 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:36 내의 VH의 아미노산 서열을 갖거나;
(9) VK 도메인이 서열식별번호:37 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:38 내의 VH의 아미노산 서열을 갖거나;
(10) VK 도메인이 서열식별번호:39 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:40 내의 VH의 아미노산 서열을 갖거나;
(11) VK 도메인이 서열식별번호:41 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:42 내의 VH의 아미노산 서열을 갖거나;
(12) VK 도메인이 서열식별번호:43 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:44 내의 VH의 아미노산 서열을 갖거나;
(13) VK 도메인이 서열식별번호:45 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:46 내의 VH의 아미노산 서열을 갖거나;
(14) VK 도메인이 서열식별번호:47 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:48 내의 VH의 아미노산 서열을 갖거나;
(15) VK 도메인이 서열식별번호:49 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:50 내의 VH의 아미노산 서열을 갖거나;
(16) VK 도메인이 서열식별번호:51 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:52 내의 VH의 아미노산 서열을 갖거나;
(17) VK 도메인이 서열식별번호:53 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:54 내의 VH의 아미노산 서열을 갖거나;
(18) VK 도메인이 서열식별번호:55 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:56 내의 VH의 아미노산 서열을 갖거나;
(19) VK 도메인이 서열식별번호:57 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:58 내의 VH의 아미노산 서열을 갖거나;
(20) VK 도메인이 서열식별번호:59 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:60 내의 VH의 아미노산 서열을 갖거나;
(21) VK 도메인이 서열식별번호:61 또는 서열식별번호:62 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:63 내의 VH의 아미노산 서열을 갖거나; 또는
(22) VK 도메인이 서열식별번호:64 내의 VK의 아미노산 서열을 갖고, VH 도메인이 서열식별번호:65 내의 VH의 아미노산 서열을 갖는 것인 자가-조립된 폴리펩티드 복합체. - 제83항 내지 제97항 중 어느 한 항에 있어서, 인간 페리틴 단량체가 인간 페리틴 경쇄인 자가-조립된 폴리펩티드 복합체.
- 제98항에 있어서, 임의의 페리틴 중쇄, 또는 페리틴 중쇄의 서브유닛을 포함하지 않는 자가-조립된 폴리펩티드 복합체.
- 대상체에게 제67항 내지 제99항 중 어느 한 항의 자가-조립된 폴리펩티드 복합체를 포함하는 조성물을 투여하는 것을 포함하는, SARS-CoV-2-관련 상태를 치료하거나, 개선시키거나 또는 예방하는 방법.
- 제100항에 있어서, 대상체가 포유동물인 방법.
- 제101항에 있어서, 대상체가 인간인 방법.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063089782P | 2020-10-09 | 2020-10-09 | |
| US63/089,782 | 2020-10-09 | ||
| US202163197236P | 2021-06-04 | 2021-06-04 | |
| US63/197,236 | 2021-06-04 | ||
| US202163220929P | 2021-07-12 | 2021-07-12 | |
| US63/220,929 | 2021-07-12 | ||
| PCT/CA2021/051426 WO2022073138A1 (en) | 2020-10-09 | 2021-10-08 | Polypeptides targeting sars-cov-2 and related compositions and methods |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230083316A true KR20230083316A (ko) | 2023-06-09 |
Family
ID=81126329
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237015177A KR20230083316A (ko) | 2020-10-09 | 2021-10-08 | Sars-cov-2를 표적화하는 폴리펩티드, 및 관련 조성물 및 방법 |
Country Status (8)
| Country | Link |
|---|---|
| EP (1) | EP4225804A1 (ko) |
| JP (1) | JP2023544211A (ko) |
| KR (1) | KR20230083316A (ko) |
| AU (1) | AU2021356355A1 (ko) |
| BR (1) | BR112023006497A2 (ko) |
| CA (1) | CA3197642A1 (ko) |
| MX (1) | MX2023004023A (ko) |
| WO (1) | WO2022073138A1 (ko) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MX2023008912A (es) * | 2021-01-28 | 2023-10-23 | Hospital For Sick Children | Constructos, composiciones y métodos de anticuerpos multiespecíficos multiafinidad. |
| CA3226040A1 (en) * | 2021-07-12 | 2023-03-16 | The Hospital For Sick Children | Optimized multabody constructs, compositions, and methods |
| WO2024082067A1 (en) * | 2022-10-21 | 2024-04-25 | The Hospital For Sick Children | Multabody constructs, compositions, and methods targeting sarbecoviruses |
| KR20240058026A (ko) * | 2022-10-21 | 2024-05-03 | 충남대학교산학협력단 | SARS-CoV-2 S1 유래 단백질 및 항체 Fc 영역 단백질을 표면에 동시에 디스플레이하는 페리틴 단백질 구조체 및 이의 코로나바이러스 SARS-CoV-2에 대한 백신 용도 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6007420B2 (ja) * | 2009-11-04 | 2016-10-12 | ファブラス エルエルシー | 親和性成熟に基づく抗体最適化方法 |
| WO2015109212A1 (en) * | 2014-01-17 | 2015-07-23 | Pfizer Inc. | Anti-il-2 antibodies and compositions and uses thereof |
| CN109689689B (zh) * | 2016-07-22 | 2022-12-06 | 丹娜法伯癌症研究所公司 | 糖皮质激素诱导肿瘤坏死因子受体(gitr)抗体及其使用方法 |
| ES2923133T3 (es) * | 2017-08-04 | 2022-09-23 | Hospital For Sick Children | Plataforma de nanopartículas para el suministro de anticuerpos y vacunas |
-
2021
- 2021-10-08 CA CA3197642A patent/CA3197642A1/en active Pending
- 2021-10-08 JP JP2023521536A patent/JP2023544211A/ja active Pending
- 2021-10-08 AU AU2021356355A patent/AU2021356355A1/en active Pending
- 2021-10-08 BR BR112023006497A patent/BR112023006497A2/pt unknown
- 2021-10-08 KR KR1020237015177A patent/KR20230083316A/ko unknown
- 2021-10-08 WO PCT/CA2021/051426 patent/WO2022073138A1/en active Application Filing
- 2021-10-08 EP EP21876827.3A patent/EP4225804A1/en active Pending
- 2021-10-08 MX MX2023004023A patent/MX2023004023A/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022073138A1 (en) | 2022-04-14 |
| MX2023004023A (es) | 2023-07-07 |
| EP4225804A1 (en) | 2023-08-16 |
| BR112023006497A2 (pt) | 2023-11-21 |
| JP2023544211A (ja) | 2023-10-20 |
| AU2021356355A1 (en) | 2023-05-25 |
| CA3197642A1 (en) | 2022-04-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20230083316A (ko) | Sars-cov-2를 표적화하는 폴리펩티드, 및 관련 조성물 및 방법 | |
| CN111094341A (zh) | 在可变域和恒定域之间的肘区中具有功能域的抗体 | |
| US20240317842A1 (en) | Multabody constructs, compositions, and methods | |
| KR20220107151A (ko) | 다가 및 다중특이적 나노입자 플랫폼 및 방법 | |
| EP2921503B1 (en) | Human anti-human epidemic growth factor receptor antibody and encoding gene and application thereof | |
| CN116063509A (zh) | Cd40l-特异性tn3-衍生的支架及其使用方法 | |
| EP4157337A1 (en) | Cd40 binding protein | |
| US20240182544A1 (en) | Polypeptides targeting dr4 and/or dr5 and related compositions and methods | |
| EP3692060A1 (en) | Cysteine engineered antigen-binding molecules | |
| EP4416189A1 (en) | Modified multabody constructs, compositions, and methods targeting sars-cov-2 | |
| WO2023060358A1 (en) | Modified multabody constructs, compositions, and methods | |
| CN116615255A (zh) | 靶向SARS-CoV-2的多肽及相关组合物和方法 | |
| WO2019023812A1 (en) | VACCINE COMPOSITION AGAINST MALARIA AND METHOD THEREOF | |
| Rujas Díez et al. | Multivalency transforms SARS-CoV-2 antibodies into ultrapotent neutralizers | |
| WO2023111796A1 (en) | Pan-specific sars-cov-2 antibodies and uses thereof | |
| EP3947469A1 (en) | Antibody variants with ph-dependent antigen binding for selective targeting of solid tumors |