KR20230010255A - 폼페병의 치료에 유용한 조성물 - Google Patents
폼페병의 치료에 유용한 조성물 Download PDFInfo
- Publication number
- KR20230010255A KR20230010255A KR1020227043641A KR20227043641A KR20230010255A KR 20230010255 A KR20230010255 A KR 20230010255A KR 1020227043641 A KR1020227043641 A KR 1020227043641A KR 20227043641 A KR20227043641 A KR 20227043641A KR 20230010255 A KR20230010255 A KR 20230010255A
- Authority
- KR
- South Korea
- Prior art keywords
- leu
- gly
- pro
- ala
- ser
- Prior art date
Links
- 206010053185 Glycogen storage disease type II Diseases 0.000 title claims abstract description 91
- 208000032007 Glycogen storage disease due to acid maltase deficiency Diseases 0.000 title claims abstract description 90
- 201000004502 glycogen storage disease II Diseases 0.000 title claims abstract description 90
- 102100033448 Lysosomal alpha-glucosidase Human genes 0.000 title claims abstract description 87
- 239000000203 mixture Substances 0.000 title claims description 75
- 238000011282 treatment Methods 0.000 title claims description 40
- 239000013598 vector Substances 0.000 claims abstract description 151
- 210000000234 capsid Anatomy 0.000 claims abstract description 95
- 238000000034 method Methods 0.000 claims abstract description 83
- 108010076504 Protein Sorting Signals Proteins 0.000 claims abstract description 65
- 108020001507 fusion proteins Proteins 0.000 claims abstract description 62
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 61
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 59
- 239000002773 nucleotide Substances 0.000 claims abstract description 51
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 51
- 210000003205 muscle Anatomy 0.000 claims abstract description 39
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 39
- 230000007170 pathology Effects 0.000 claims abstract description 32
- 230000002159 abnormal effect Effects 0.000 claims abstract description 19
- 101001018026 Homo sapiens Lysosomal alpha-glucosidase Proteins 0.000 claims abstract description 10
- 102000045921 human GAA Human genes 0.000 claims abstract description 10
- 238000001990 intravenous administration Methods 0.000 claims description 108
- 150000001413 amino acids Chemical class 0.000 claims description 89
- 238000012384 transportation and delivery Methods 0.000 claims description 44
- 108091070501 miRNA Proteins 0.000 claims description 42
- 108091029500 miR-183 stem-loop Proteins 0.000 claims description 41
- 208000006111 contracture Diseases 0.000 claims description 24
- 239000000835 fiber Substances 0.000 claims description 23
- 210000001087 myotubule Anatomy 0.000 claims description 19
- 238000002641 enzyme replacement therapy Methods 0.000 claims description 16
- 230000009977 dual effect Effects 0.000 claims description 15
- 238000007913 intrathecal administration Methods 0.000 claims description 14
- 210000000663 muscle cell Anatomy 0.000 claims description 14
- 238000002560 therapeutic procedure Methods 0.000 claims description 14
- 230000002886 autophagic effect Effects 0.000 claims description 12
- 230000015572 biosynthetic process Effects 0.000 claims description 12
- 238000004806 packaging method and process Methods 0.000 claims description 11
- 208000035157 late-onset glycogen storage disease due to acid maltase deficiency Diseases 0.000 claims description 10
- 206010003694 Atrophy Diseases 0.000 claims description 9
- 230000037444 atrophy Effects 0.000 claims description 9
- 210000003934 vacuole Anatomy 0.000 claims description 9
- 238000009098 adjuvant therapy Methods 0.000 claims description 8
- 230000006907 apoptotic process Effects 0.000 claims description 8
- 238000002679 ablation Methods 0.000 claims description 5
- 208000036545 infantile onset glycogen storage disease due to acid maltase deficiency Diseases 0.000 claims description 5
- 210000003019 respiratory muscle Anatomy 0.000 claims description 5
- 230000009885 systemic effect Effects 0.000 claims description 5
- 229940124630 bronchodilator Drugs 0.000 claims description 4
- 239000000544 cholinesterase inhibitor Substances 0.000 claims description 4
- 238000012549 training Methods 0.000 claims description 4
- 239000000168 bronchodilator agent Substances 0.000 claims description 3
- 229940100578 Acetylcholinesterase inhibitor Drugs 0.000 claims 1
- 108090000623 proteins and genes Proteins 0.000 description 142
- 102000004169 proteins and genes Human genes 0.000 description 117
- 235000018102 proteins Nutrition 0.000 description 114
- 235000001014 amino acid Nutrition 0.000 description 100
- 229940024606 amino acid Drugs 0.000 description 90
- 150000007523 nucleic acids Chemical group 0.000 description 76
- 241000699670 Mus sp. Species 0.000 description 73
- 210000004027 cell Anatomy 0.000 description 63
- 125000003275 alpha amino acid group Chemical group 0.000 description 48
- 229920002527 Glycogen Polymers 0.000 description 44
- 229940096919 glycogen Drugs 0.000 description 44
- 238000009825 accumulation Methods 0.000 description 42
- 108091028043 Nucleic acid sequence Proteins 0.000 description 38
- 210000002216 heart Anatomy 0.000 description 37
- 230000000694 effects Effects 0.000 description 36
- 239000002679 microRNA Substances 0.000 description 30
- 108020004414 DNA Proteins 0.000 description 28
- 241000702421 Dependoparvovirus Species 0.000 description 28
- 241001465754 Metazoa Species 0.000 description 28
- 210000001519 tissue Anatomy 0.000 description 28
- -1 etc.) Proteins 0.000 description 26
- 230000004048 modification Effects 0.000 description 25
- 238000012986 modification Methods 0.000 description 25
- 108700019146 Transgenes Proteins 0.000 description 24
- 230000001105 regulatory effect Effects 0.000 description 24
- 102000004190 Enzymes Human genes 0.000 description 23
- 108090000790 Enzymes Proteins 0.000 description 23
- 229940088598 enzyme Drugs 0.000 description 23
- 108010050848 glycylleucine Proteins 0.000 description 23
- 239000013603 viral vector Substances 0.000 description 23
- 238000012217 deletion Methods 0.000 description 22
- 230000037430 deletion Effects 0.000 description 22
- 239000002245 particle Substances 0.000 description 22
- 210000002027 skeletal muscle Anatomy 0.000 description 22
- 210000003169 central nervous system Anatomy 0.000 description 21
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 21
- 238000002347 injection Methods 0.000 description 21
- 239000007924 injection Substances 0.000 description 21
- 108010083708 leucyl-aspartyl-valine Proteins 0.000 description 21
- 102000039446 nucleic acids Human genes 0.000 description 21
- 108020004707 nucleic acids Proteins 0.000 description 21
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 20
- 230000004900 autophagic degradation Effects 0.000 description 20
- 230000006240 deamidation Effects 0.000 description 20
- 210000000278 spinal cord Anatomy 0.000 description 20
- 108090000565 Capsid Proteins Proteins 0.000 description 19
- 102100023321 Ceruloplasmin Human genes 0.000 description 19
- 108091026890 Coding region Proteins 0.000 description 19
- 241000282414 Homo sapiens Species 0.000 description 19
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 19
- 108010037850 glycylvaline Proteins 0.000 description 19
- 238000010186 staining Methods 0.000 description 18
- 230000037396 body weight Effects 0.000 description 17
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 17
- 108010025306 histidylleucine Proteins 0.000 description 17
- 238000006467 substitution reaction Methods 0.000 description 17
- 230000003612 virological effect Effects 0.000 description 17
- 241000282326 Felis catus Species 0.000 description 16
- XLXPYSDGMXTTNQ-UHFFFAOYSA-N Ile-Phe-Leu Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=CC=C1 XLXPYSDGMXTTNQ-UHFFFAOYSA-N 0.000 description 15
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 15
- 108010029020 prolylglycine Proteins 0.000 description 15
- 208000002267 Anti-neutrophil cytoplasmic antibody-associated vasculitis Diseases 0.000 description 14
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 14
- 108010079364 N-glycylalanine Proteins 0.000 description 14
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 14
- 210000004556 brain Anatomy 0.000 description 14
- 108010054813 diprotin B Proteins 0.000 description 14
- 108010078144 glutaminyl-glycine Proteins 0.000 description 14
- 238000004519 manufacturing process Methods 0.000 description 14
- 108091023796 miR-182 stem-loop Proteins 0.000 description 14
- 210000004940 nucleus Anatomy 0.000 description 14
- 238000011002 quantification Methods 0.000 description 14
- 108010048818 seryl-histidine Proteins 0.000 description 14
- 210000003594 spinal ganglia Anatomy 0.000 description 14
- 241000702423 Adeno-associated virus - 2 Species 0.000 description 13
- 108700041152 Endoplasmic Reticulum Chaperone BiP Proteins 0.000 description 13
- 102100021451 Endoplasmic reticulum chaperone BiP Human genes 0.000 description 13
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 13
- 239000003623 enhancer Substances 0.000 description 13
- 239000012634 fragment Substances 0.000 description 13
- 238000001415 gene therapy Methods 0.000 description 13
- 108010049041 glutamylalanine Proteins 0.000 description 13
- 210000002161 motor neuron Anatomy 0.000 description 13
- 102000004196 processed proteins & peptides Human genes 0.000 description 13
- 230000002829 reductive effect Effects 0.000 description 13
- 230000001225 therapeutic effect Effects 0.000 description 13
- 108010061238 threonyl-glycine Proteins 0.000 description 13
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 12
- 239000004471 Glycine Substances 0.000 description 12
- 101001076292 Homo sapiens Insulin-like growth factor II Proteins 0.000 description 12
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 230000000295 complement effect Effects 0.000 description 12
- 201000010099 disease Diseases 0.000 description 12
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 12
- 108010036413 histidylglycine Proteins 0.000 description 12
- 108010090894 prolylleucine Proteins 0.000 description 12
- 108010026333 seryl-proline Proteins 0.000 description 12
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 11
- 102100025947 Insulin-like growth factor II Human genes 0.000 description 11
- QCSFMCFHVGTLFF-NHCYSSNCSA-N Leu-Asp-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O QCSFMCFHVGTLFF-NHCYSSNCSA-N 0.000 description 11
- FZHBZMDRDASUHN-NAKRPEOUSA-N Pro-Ala-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1)C(O)=O FZHBZMDRDASUHN-NAKRPEOUSA-N 0.000 description 11
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 11
- 108010068380 arginylarginine Proteins 0.000 description 11
- 210000004185 liver Anatomy 0.000 description 11
- 230000035772 mutation Effects 0.000 description 11
- 239000000523 sample Substances 0.000 description 11
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 10
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 10
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 10
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 10
- 108010087924 alanylproline Proteins 0.000 description 10
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 10
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 10
- 238000012937 correction Methods 0.000 description 10
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 10
- 230000010076 replication Effects 0.000 description 10
- BTBUEVAGZCKULD-XPUUQOCRSA-N Ala-Gly-His Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BTBUEVAGZCKULD-XPUUQOCRSA-N 0.000 description 9
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 9
- 208000036632 Brain mass Diseases 0.000 description 9
- XZUUUKNKNWVPHQ-JYJNAYRXSA-N Gln-Phe-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O XZUUUKNKNWVPHQ-JYJNAYRXSA-N 0.000 description 9
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 9
- 241000880493 Leptailurus serval Species 0.000 description 9
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 9
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 9
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 9
- WYKFHMXJQQQNQL-UHFFFAOYSA-N Tyr-Arg-Pro-Tyr Natural products C1CCC(C(=O)NC(CC=2C=CC(O)=CC=2)C(O)=O)N1C(=O)C(CCCN=C(N)N)NC(=O)C(N)CC1=CC=C(O)C=C1 WYKFHMXJQQQNQL-UHFFFAOYSA-N 0.000 description 9
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 9
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 9
- 108010044940 alanylglutamine Proteins 0.000 description 9
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 9
- 239000003814 drug Substances 0.000 description 9
- 238000009472 formulation Methods 0.000 description 9
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 9
- 230000001965 increasing effect Effects 0.000 description 9
- 239000013612 plasmid Substances 0.000 description 9
- 125000006850 spacer group Chemical group 0.000 description 9
- 239000004094 surface-active agent Substances 0.000 description 9
- 239000003981 vehicle Substances 0.000 description 9
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 9
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 8
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 8
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 8
- OMMIEVATLAGRCK-BYPYZUCNSA-N Asp-Gly-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)NCC(O)=O OMMIEVATLAGRCK-BYPYZUCNSA-N 0.000 description 8
- 101000834253 Gallus gallus Actin, cytoplasmic 1 Proteins 0.000 description 8
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 8
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 8
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 8
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 8
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 8
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 8
- 241000699666 Mus <mouse, genus> Species 0.000 description 8
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 8
- BONHGTUEEPIMPM-AVGNSLFASA-N Phe-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O BONHGTUEEPIMPM-AVGNSLFASA-N 0.000 description 8
- KAAPNMOKUUPKOE-SRVKXCTJSA-N Ser-Asn-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KAAPNMOKUUPKOE-SRVKXCTJSA-N 0.000 description 8
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 8
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 8
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 8
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 8
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 8
- 125000000539 amino acid group Chemical group 0.000 description 8
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 8
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 8
- 210000004957 autophagosome Anatomy 0.000 description 8
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 8
- 108010092114 histidylphenylalanine Proteins 0.000 description 8
- 230000003902 lesion Effects 0.000 description 8
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 8
- 108010057821 leucylproline Proteins 0.000 description 8
- 108020004999 messenger RNA Proteins 0.000 description 8
- 210000002569 neuron Anatomy 0.000 description 8
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 8
- 108010038745 tryptophylglycine Proteins 0.000 description 8
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 8
- FEGOCLZUJUFCHP-CIUDSAMLSA-N Ala-Pro-Gln Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FEGOCLZUJUFCHP-CIUDSAMLSA-N 0.000 description 7
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 7
- QJVZSVUYZFYLFQ-CIUDSAMLSA-N Glu-Pro-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O QJVZSVUYZFYLFQ-CIUDSAMLSA-N 0.000 description 7
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 7
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 7
- 102000003746 Insulin Receptor Human genes 0.000 description 7
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 7
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 7
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 7
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 7
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 7
- 108010066427 N-valyltryptophan Proteins 0.000 description 7
- 241000283973 Oryctolagus cuniculus Species 0.000 description 7
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 7
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 7
- DWUIECHTAMYEFL-XVYDVKMFSA-N Ser-Ala-His Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DWUIECHTAMYEFL-XVYDVKMFSA-N 0.000 description 7
- QGXCWPNQVCYJEL-NUMRIWBASA-N Thr-Asn-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QGXCWPNQVCYJEL-NUMRIWBASA-N 0.000 description 7
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 7
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 7
- WMIUTJPFHMMUGY-ZFWWWQNUSA-N Trp-Pro-Gly Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)NCC(=O)O WMIUTJPFHMMUGY-ZFWWWQNUSA-N 0.000 description 7
- RCMWNNJFKNDKQR-UFYCRDLUSA-N Tyr-Pro-Phe Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 RCMWNNJFKNDKQR-UFYCRDLUSA-N 0.000 description 7
- FMQGYTMERWBMSI-HJWJTTGWSA-N Val-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N FMQGYTMERWBMSI-HJWJTTGWSA-N 0.000 description 7
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 7
- 108010005233 alanylglutamic acid Proteins 0.000 description 7
- 238000010276 construction Methods 0.000 description 7
- 238000013461 design Methods 0.000 description 7
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 7
- 230000004927 fusion Effects 0.000 description 7
- 108010089804 glycyl-threonine Proteins 0.000 description 7
- 238000003364 immunohistochemistry Methods 0.000 description 7
- 150000002632 lipids Chemical class 0.000 description 7
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 7
- 108010015796 prolylisoleucine Proteins 0.000 description 7
- 239000000725 suspension Substances 0.000 description 7
- 230000001988 toxicity Effects 0.000 description 7
- 231100000419 toxicity Toxicity 0.000 description 7
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 6
- 239000013607 AAV vector Substances 0.000 description 6
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 6
- IKKVASZHTMKJIR-ZKWXMUAHSA-N Ala-Asp-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IKKVASZHTMKJIR-ZKWXMUAHSA-N 0.000 description 6
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 6
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 6
- 108010067770 Endopeptidase K Proteins 0.000 description 6
- JKDBRTNMYXYLHO-JYJNAYRXSA-N Gln-Tyr-Leu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 JKDBRTNMYXYLHO-JYJNAYRXSA-N 0.000 description 6
- FHPXTPQBODWBIY-CIUDSAMLSA-N Glu-Ala-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FHPXTPQBODWBIY-CIUDSAMLSA-N 0.000 description 6
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 6
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 6
- BNMRSWQOHIQTFL-JSGCOSHPSA-N Gly-Val-Phe Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 BNMRSWQOHIQTFL-JSGCOSHPSA-N 0.000 description 6
- 108010001127 Insulin Receptor Proteins 0.000 description 6
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 6
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 6
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 6
- 102220576120 Oligodendrocyte transcription factor 1_Y27W_mutation Human genes 0.000 description 6
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 6
- CPRLKHJUFAXVTD-ULQDDVLXSA-N Pro-Leu-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CPRLKHJUFAXVTD-ULQDDVLXSA-N 0.000 description 6
- AJNGQVUFQUVRQT-JYJNAYRXSA-N Pro-Pro-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 AJNGQVUFQUVRQT-JYJNAYRXSA-N 0.000 description 6
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 6
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 6
- GZYNMZQXFRWDFH-YTWAJWBKSA-N Thr-Arg-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O GZYNMZQXFRWDFH-YTWAJWBKSA-N 0.000 description 6
- NMCBVGFGWSIGSB-NUTKFTJISA-N Trp-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NMCBVGFGWSIGSB-NUTKFTJISA-N 0.000 description 6
- 241000700605 Viruses Species 0.000 description 6
- 102000016679 alpha-Glucosidases Human genes 0.000 description 6
- 108010028144 alpha-Glucosidases Proteins 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 235000009582 asparagine Nutrition 0.000 description 6
- 108010047857 aspartylglycine Proteins 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- 210000000188 diaphragm Anatomy 0.000 description 6
- 230000029087 digestion Effects 0.000 description 6
- 108010087823 glycyltyrosine Proteins 0.000 description 6
- 230000001976 improved effect Effects 0.000 description 6
- 230000002132 lysosomal effect Effects 0.000 description 6
- 108010003700 lysyl aspartic acid Proteins 0.000 description 6
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 6
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 6
- 108010051242 phenylalanylserine Proteins 0.000 description 6
- 239000000047 product Substances 0.000 description 6
- 108010031719 prolyl-serine Proteins 0.000 description 6
- 108010079317 prolyl-tyrosine Proteins 0.000 description 6
- 150000003839 salts Chemical class 0.000 description 6
- 208000024891 symptom Diseases 0.000 description 6
- 230000008685 targeting Effects 0.000 description 6
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 5
- HJGZVLLLBJLXFC-LSJOCFKGSA-N Ala-His-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O HJGZVLLLBJLXFC-LSJOCFKGSA-N 0.000 description 5
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 5
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 5
- NHWYNIZWLJYZAG-XVYDVKMFSA-N Ala-Ser-His Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N NHWYNIZWLJYZAG-XVYDVKMFSA-N 0.000 description 5
- CKIBTNMWVMKAHB-RWGOJESNSA-N Ala-Trp-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](N)C)C(O)=O)=CNC2=C1 CKIBTNMWVMKAHB-RWGOJESNSA-N 0.000 description 5
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 5
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 5
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 5
- FOWOZYAWODIRFZ-JYJNAYRXSA-N Arg-Tyr-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCCN=C(N)N)N FOWOZYAWODIRFZ-JYJNAYRXSA-N 0.000 description 5
- ORXCYAFUCSTQGY-FXQIFTODSA-N Asn-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)N)N ORXCYAFUCSTQGY-FXQIFTODSA-N 0.000 description 5
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 5
- TZFQICWZWFNIKU-KKUMJFAQSA-N Asn-Leu-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 TZFQICWZWFNIKU-KKUMJFAQSA-N 0.000 description 5
- MVXJBVVLACEGCG-PCBIJLKTSA-N Asn-Phe-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVXJBVVLACEGCG-PCBIJLKTSA-N 0.000 description 5
- VCJCPARXDBEGNE-GUBZILKMSA-N Asn-Pro-Pro Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 VCJCPARXDBEGNE-GUBZILKMSA-N 0.000 description 5
- XZFONYMRYTVLPL-NHCYSSNCSA-N Asn-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N XZFONYMRYTVLPL-NHCYSSNCSA-N 0.000 description 5
- FANQWNCPNFEPGZ-WHFBIAKZSA-N Asp-Asp-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FANQWNCPNFEPGZ-WHFBIAKZSA-N 0.000 description 5
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 5
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 5
- KBJVTFWQWXCYCQ-IUKAMOBKSA-N Asp-Thr-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KBJVTFWQWXCYCQ-IUKAMOBKSA-N 0.000 description 5
- MFDPBZAFCRKYEY-LAEOZQHASA-N Asp-Val-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFDPBZAFCRKYEY-LAEOZQHASA-N 0.000 description 5
- 102100037182 Cation-independent mannose-6-phosphate receptor Human genes 0.000 description 5
- 101710145225 Cation-independent mannose-6-phosphate receptor Proteins 0.000 description 5
- 241000701022 Cytomegalovirus Species 0.000 description 5
- 102220518120 DNA-directed RNA polymerases I and III subunit RPAC1_E6R_mutation Human genes 0.000 description 5
- 241000963438 Gaussia <copepod> Species 0.000 description 5
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 5
- NSORZJXKUQFEKL-JGVFFNPUSA-N Gln-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)N)N)C(=O)O NSORZJXKUQFEKL-JGVFFNPUSA-N 0.000 description 5
- HYPVLWGNBIYTNA-GUBZILKMSA-N Gln-Leu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HYPVLWGNBIYTNA-GUBZILKMSA-N 0.000 description 5
- AKDOUBMVLRCHBD-SIUGBPQLSA-N Gln-Tyr-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AKDOUBMVLRCHBD-SIUGBPQLSA-N 0.000 description 5
- VEYGCDYMOXHJLS-GVXVVHGQSA-N Gln-Val-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VEYGCDYMOXHJLS-GVXVVHGQSA-N 0.000 description 5
- AIGROOHQXCACHL-WDSKDSINSA-N Glu-Gly-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O AIGROOHQXCACHL-WDSKDSINSA-N 0.000 description 5
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 5
- RXESHTOTINOODU-JYJNAYRXSA-N Glu-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCC(=O)O)N RXESHTOTINOODU-JYJNAYRXSA-N 0.000 description 5
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 5
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 description 5
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 5
- YYPFZVIXAVDHIK-IUCAKERBSA-N Gly-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN YYPFZVIXAVDHIK-IUCAKERBSA-N 0.000 description 5
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 5
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 5
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 5
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 5
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 5
- 241000238631 Hexapoda Species 0.000 description 5
- JWTKVPMQCCRPQY-SRVKXCTJSA-N His-Asn-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JWTKVPMQCCRPQY-SRVKXCTJSA-N 0.000 description 5
- JMSONHOUHFDOJH-GUBZILKMSA-N His-Ser-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 JMSONHOUHFDOJH-GUBZILKMSA-N 0.000 description 5
- WZDCVAWMBUNDDY-KBIXCLLPSA-N Ile-Glu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C)C(=O)O)N WZDCVAWMBUNDDY-KBIXCLLPSA-N 0.000 description 5
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 5
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 5
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 5
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 5
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 5
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 5
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 5
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 5
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 5
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 5
- 241000282560 Macaca mulatta Species 0.000 description 5
- BLIPQDLSCFGUFA-GUBZILKMSA-N Met-Arg-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O BLIPQDLSCFGUFA-GUBZILKMSA-N 0.000 description 5
- ODFBIJXEWPWSAN-CYDGBPFRSA-N Met-Ile-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O ODFBIJXEWPWSAN-CYDGBPFRSA-N 0.000 description 5
- DBXMFHGGHMXYHY-DCAQKATOSA-N Met-Leu-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O DBXMFHGGHMXYHY-DCAQKATOSA-N 0.000 description 5
- YGNUDKAPJARTEM-GUBZILKMSA-N Met-Val-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O YGNUDKAPJARTEM-GUBZILKMSA-N 0.000 description 5
- 208000009525 Myocarditis Diseases 0.000 description 5
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 5
- 101710163270 Nuclease Proteins 0.000 description 5
- DRVIASBABBMZTF-GUBZILKMSA-N Pro-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@@H]1CCCN1 DRVIASBABBMZTF-GUBZILKMSA-N 0.000 description 5
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 5
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 5
- AWQGDZBKQTYNMN-IHRRRGAJSA-N Pro-Phe-Asp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC(=O)O)C(=O)O AWQGDZBKQTYNMN-IHRRRGAJSA-N 0.000 description 5
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 5
- VEUACYMXJKXALX-IHRRRGAJSA-N Pro-Tyr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VEUACYMXJKXALX-IHRRRGAJSA-N 0.000 description 5
- FIDNSJUXESUDOV-JYJNAYRXSA-N Pro-Tyr-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O FIDNSJUXESUDOV-JYJNAYRXSA-N 0.000 description 5
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 5
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 5
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 5
- SDFUZKIAHWRUCS-QEJZJMRPSA-N Ser-Trp-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CO)N SDFUZKIAHWRUCS-QEJZJMRPSA-N 0.000 description 5
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 5
- WFUAUEQXPVNAEF-ZJDVBMNYSA-N Thr-Arg-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CCCN=C(N)N WFUAUEQXPVNAEF-ZJDVBMNYSA-N 0.000 description 5
- ONNSECRQFSTMCC-XKBZYTNZSA-N Thr-Glu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ONNSECRQFSTMCC-XKBZYTNZSA-N 0.000 description 5
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 5
- DDDLIMCZFKOERC-SVSWQMSJSA-N Thr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N DDDLIMCZFKOERC-SVSWQMSJSA-N 0.000 description 5
- KZURUCDWKDEAFZ-XVSYOHENSA-N Thr-Phe-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O KZURUCDWKDEAFZ-XVSYOHENSA-N 0.000 description 5
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 5
- GQPQJNMVELPZNQ-GBALPHGKSA-N Thr-Ser-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O GQPQJNMVELPZNQ-GBALPHGKSA-N 0.000 description 5
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 5
- RPVDDQYNBOVWLR-HOCLYGCPSA-N Trp-Gly-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O RPVDDQYNBOVWLR-HOCLYGCPSA-N 0.000 description 5
- TVOGEPLDNYTAHD-CQDKDKBSSA-N Tyr-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TVOGEPLDNYTAHD-CQDKDKBSSA-N 0.000 description 5
- KCPFDGNYAMKZQP-KBPBESRZSA-N Tyr-Gly-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O KCPFDGNYAMKZQP-KBPBESRZSA-N 0.000 description 5
- HHFMNAVFGBYSAT-IGISWZIWSA-N Tyr-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N HHFMNAVFGBYSAT-IGISWZIWSA-N 0.000 description 5
- OBKOPLHSRDATFO-XHSDSOJGSA-N Tyr-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OBKOPLHSRDATFO-XHSDSOJGSA-N 0.000 description 5
- 101150049278 US20 gene Proteins 0.000 description 5
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 5
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 5
- HURRXSNHCCSJHA-AUTRQRHGSA-N Val-Gln-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HURRXSNHCCSJHA-AUTRQRHGSA-N 0.000 description 5
- QHFQQRKNGCXTHL-AUTRQRHGSA-N Val-Gln-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QHFQQRKNGCXTHL-AUTRQRHGSA-N 0.000 description 5
- APEBUJBRGCMMHP-HJWJTTGWSA-N Val-Ile-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 APEBUJBRGCMMHP-HJWJTTGWSA-N 0.000 description 5
- DJQIUOKSNRBTSV-CYDGBPFRSA-N Val-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](C(C)C)N DJQIUOKSNRBTSV-CYDGBPFRSA-N 0.000 description 5
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 5
- QIVPZSWBBHRNBA-JYJNAYRXSA-N Val-Pro-Phe Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O QIVPZSWBBHRNBA-JYJNAYRXSA-N 0.000 description 5
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 5
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 5
- 108010047495 alanylglycine Proteins 0.000 description 5
- 108010092854 aspartyllysine Proteins 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 230000003197 catalytic effect Effects 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 108010015792 glycyllysine Proteins 0.000 description 5
- 108010018006 histidylserine Proteins 0.000 description 5
- 208000015181 infectious disease Diseases 0.000 description 5
- 238000007914 intraventricular administration Methods 0.000 description 5
- 150000002500 ions Chemical class 0.000 description 5
- 108010027338 isoleucylcysteine Proteins 0.000 description 5
- 230000000366 juvenile effect Effects 0.000 description 5
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 5
- 210000003712 lysosome Anatomy 0.000 description 5
- 230000001868 lysosomic effect Effects 0.000 description 5
- 108010085203 methionylmethionine Proteins 0.000 description 5
- 108010073101 phenylalanylleucine Proteins 0.000 description 5
- 230000008488 polyadenylation Effects 0.000 description 5
- 108010070643 prolylglutamic acid Proteins 0.000 description 5
- 230000000241 respiratory effect Effects 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 238000012546 transfer Methods 0.000 description 5
- 108010045269 tryptophyltryptophan Proteins 0.000 description 5
- 241000701161 unidentified adenovirus Species 0.000 description 5
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 4
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 4
- 108020003589 5' Untranslated Regions Proteins 0.000 description 4
- UCIYCBSJBQGDGM-LPEHRKFASA-N Ala-Arg-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N UCIYCBSJBQGDGM-LPEHRKFASA-N 0.000 description 4
- NXSFUECZFORGOG-CIUDSAMLSA-N Ala-Asn-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXSFUECZFORGOG-CIUDSAMLSA-N 0.000 description 4
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 4
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 4
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 4
- LXAARTARZJJCMB-CIQUZCHMSA-N Ala-Ile-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LXAARTARZJJCMB-CIQUZCHMSA-N 0.000 description 4
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 4
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 4
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 4
- NLYYHIKRBRMAJV-AEJSXWLSSA-N Ala-Val-Pro Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N NLYYHIKRBRMAJV-AEJSXWLSSA-N 0.000 description 4
- LMPKCSXZJSXBBL-NHCYSSNCSA-N Arg-Gln-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O LMPKCSXZJSXBBL-NHCYSSNCSA-N 0.000 description 4
- UGJLILSJKSBVIR-ZFWWWQNUSA-N Arg-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)N)C(=O)NCC(O)=O)=CNC2=C1 UGJLILSJKSBVIR-ZFWWWQNUSA-N 0.000 description 4
- AZHXYLJRGVMQKW-UMPQAUOISA-N Arg-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCN=C(N)N)N)O AZHXYLJRGVMQKW-UMPQAUOISA-N 0.000 description 4
- PJOPLXOCKACMLK-KKUMJFAQSA-N Arg-Tyr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O PJOPLXOCKACMLK-KKUMJFAQSA-N 0.000 description 4
- MFFOYNGMOYFPBD-DCAQKATOSA-N Asn-Arg-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MFFOYNGMOYFPBD-DCAQKATOSA-N 0.000 description 4
- LJUOLNXOWSWGKF-ACZMJKKPSA-N Asn-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N LJUOLNXOWSWGKF-ACZMJKKPSA-N 0.000 description 4
- VKCOHFFSTKCXEQ-OLHMAJIHSA-N Asn-Asn-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VKCOHFFSTKCXEQ-OLHMAJIHSA-N 0.000 description 4
- ODBSSLHUFPJRED-CIUDSAMLSA-N Asn-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N ODBSSLHUFPJRED-CIUDSAMLSA-N 0.000 description 4
- IDUUACUJKUXKKD-VEVYYDQMSA-N Asn-Pro-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O IDUUACUJKUXKKD-VEVYYDQMSA-N 0.000 description 4
- RQYMKRMRZWJGHC-BQBZGAKWSA-N Asp-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)O)N RQYMKRMRZWJGHC-BQBZGAKWSA-N 0.000 description 4
- PAYPSKIBMDHZPI-CIUDSAMLSA-N Asp-Leu-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PAYPSKIBMDHZPI-CIUDSAMLSA-N 0.000 description 4
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 4
- JGLWFWXGOINXEA-YDHLFZDLSA-N Asp-Val-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 JGLWFWXGOINXEA-YDHLFZDLSA-N 0.000 description 4
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 4
- 241000124740 Bocaparvovirus Species 0.000 description 4
- PQHYZJPCYRDYNE-QWRGUYRKSA-N Cys-Gly-Phe Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PQHYZJPCYRDYNE-QWRGUYRKSA-N 0.000 description 4
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 4
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 4
- LPYPANUXJGFMGV-FXQIFTODSA-N Gln-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LPYPANUXJGFMGV-FXQIFTODSA-N 0.000 description 4
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 4
- CAXXTYYGFYTBPV-IUCAKERBSA-N Gln-Leu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CAXXTYYGFYTBPV-IUCAKERBSA-N 0.000 description 4
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 4
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 4
- RNPGPFAVRLERPP-QEJZJMRPSA-N Gln-Trp-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O RNPGPFAVRLERPP-QEJZJMRPSA-N 0.000 description 4
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 4
- GZWOBWMOMPFPCD-CIUDSAMLSA-N Glu-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N GZWOBWMOMPFPCD-CIUDSAMLSA-N 0.000 description 4
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 4
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 4
- QCMVGXDELYMZET-GLLZPBPUSA-N Glu-Thr-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QCMVGXDELYMZET-GLLZPBPUSA-N 0.000 description 4
- UMZHHILWZBFPGL-LOKLDPHHSA-N Glu-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O UMZHHILWZBFPGL-LOKLDPHHSA-N 0.000 description 4
- DLISPGXMKZTWQG-IFFSRLJSSA-N Glu-Thr-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O DLISPGXMKZTWQG-IFFSRLJSSA-N 0.000 description 4
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 4
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 4
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 4
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 4
- UEGIPZAXNBYCCP-NKWVEPMBSA-N Gly-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)CN)C(=O)O UEGIPZAXNBYCCP-NKWVEPMBSA-N 0.000 description 4
- LJXWZPHEMJSNRC-KBPBESRZSA-N Gly-Gln-Trp Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LJXWZPHEMJSNRC-KBPBESRZSA-N 0.000 description 4
- MOJKRXIRAZPZLW-WDSKDSINSA-N Gly-Glu-Ala Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MOJKRXIRAZPZLW-WDSKDSINSA-N 0.000 description 4
- TTYVAUJGNMVTRN-GJZGRUSLSA-N Gly-Met-Trp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)CN TTYVAUJGNMVTRN-GJZGRUSLSA-N 0.000 description 4
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 4
- DHNXGWVNLFPOMQ-KBPBESRZSA-N Gly-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)CN DHNXGWVNLFPOMQ-KBPBESRZSA-N 0.000 description 4
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 4
- WSWWTQYHFCBKBT-DVJZZOLTSA-N Gly-Thr-Trp Chemical compound C[C@@H](O)[C@H](NC(=O)CN)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O WSWWTQYHFCBKBT-DVJZZOLTSA-N 0.000 description 4
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 4
- HRGGKHFHRSFSDE-CIUDSAMLSA-N His-Asn-Ser Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N HRGGKHFHRSFSDE-CIUDSAMLSA-N 0.000 description 4
- FLYSHWAAHYNKRT-JYJNAYRXSA-N His-Gln-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FLYSHWAAHYNKRT-JYJNAYRXSA-N 0.000 description 4
- SKYULSWNBYAQMG-IHRRRGAJSA-N His-Leu-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SKYULSWNBYAQMG-IHRRRGAJSA-N 0.000 description 4
- LJUIEESLIAZSFR-SRVKXCTJSA-N His-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N LJUIEESLIAZSFR-SRVKXCTJSA-N 0.000 description 4
- LVXFNTIIGOQBMD-SRVKXCTJSA-N His-Leu-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O LVXFNTIIGOQBMD-SRVKXCTJSA-N 0.000 description 4
- KHUFDBQXGLEIHC-BZSNNMDCSA-N His-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 KHUFDBQXGLEIHC-BZSNNMDCSA-N 0.000 description 4
- JSQIXEHORHLQEE-MEYUZBJRSA-N His-Phe-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JSQIXEHORHLQEE-MEYUZBJRSA-N 0.000 description 4
- PBVQWNDMFFCPIZ-ULQDDVLXSA-N His-Pro-Phe Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 PBVQWNDMFFCPIZ-ULQDDVLXSA-N 0.000 description 4
- YERBCFWVWITTEJ-NAZCDGGXSA-N His-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N)O YERBCFWVWITTEJ-NAZCDGGXSA-N 0.000 description 4
- CKONPJHGMIDMJP-IHRRRGAJSA-N His-Val-His Chemical compound C([C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 CKONPJHGMIDMJP-IHRRRGAJSA-N 0.000 description 4
- JHCVYQKVKOLAIU-NAKRPEOUSA-N Ile-Cys-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)O)N JHCVYQKVKOLAIU-NAKRPEOUSA-N 0.000 description 4
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 4
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 4
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 4
- RMNMUUCYTMLWNA-ZPFDUUQYSA-N Ile-Lys-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RMNMUUCYTMLWNA-ZPFDUUQYSA-N 0.000 description 4
- YBKKLDBBPFIXBQ-MBLNEYKQSA-N Ile-Thr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)O)N YBKKLDBBPFIXBQ-MBLNEYKQSA-N 0.000 description 4
- KBDIBHQICWDGDL-PPCPHDFISA-N Ile-Thr-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N KBDIBHQICWDGDL-PPCPHDFISA-N 0.000 description 4
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 4
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 4
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 4
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 4
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 4
- WCTCIIAGNMFYAO-DCAQKATOSA-N Leu-Cys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O WCTCIIAGNMFYAO-DCAQKATOSA-N 0.000 description 4
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 4
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 4
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 4
- FMEICTQWUKNAGC-YUMQZZPRSA-N Leu-Gly-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O FMEICTQWUKNAGC-YUMQZZPRSA-N 0.000 description 4
- KEVYYIMVELOXCT-KBPBESRZSA-N Leu-Gly-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KEVYYIMVELOXCT-KBPBESRZSA-N 0.000 description 4
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 4
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 4
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 4
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 4
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 4
- MUCIDQMDOYQYBR-IHRRRGAJSA-N Leu-Pro-His Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N MUCIDQMDOYQYBR-IHRRRGAJSA-N 0.000 description 4
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 4
- LFSQWRSVPNKJGP-WDCWCFNPSA-N Leu-Thr-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O LFSQWRSVPNKJGP-WDCWCFNPSA-N 0.000 description 4
- WFCKERTZVCQXKH-KBPBESRZSA-N Leu-Tyr-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O WFCKERTZVCQXKH-KBPBESRZSA-N 0.000 description 4
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 4
- LUWJPTVQOMUZLW-UHFFFAOYSA-N Luxol fast blue MBS Chemical compound [Cu++].Cc1ccccc1N\C(N)=N\c1ccccc1C.Cc1ccccc1N\C(N)=N\c1ccccc1C.OS(=O)(=O)c1cccc2c3nc(nc4nc([n-]c5[n-]c(nc6nc(n3)c3ccccc63)c3c(cccc53)S(O)(=O)=O)c3ccccc43)c12 LUWJPTVQOMUZLW-UHFFFAOYSA-N 0.000 description 4
- AAORVPFVUIHEAB-YUMQZZPRSA-N Lys-Asp-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O AAORVPFVUIHEAB-YUMQZZPRSA-N 0.000 description 4
- VSRXPEHZMHSFKU-IUCAKERBSA-N Lys-Gln-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VSRXPEHZMHSFKU-IUCAKERBSA-N 0.000 description 4
- XBAJINCXDBTJRH-WDSOQIARSA-N Lys-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCCN)N XBAJINCXDBTJRH-WDSOQIARSA-N 0.000 description 4
- CSNNHWWHGAXBCP-UHFFFAOYSA-L Magnesium sulfate Chemical compound [Mg+2].[O-][S+2]([O-])([O-])[O-] CSNNHWWHGAXBCP-UHFFFAOYSA-L 0.000 description 4
- OLWAOWXIADGIJG-AVGNSLFASA-N Met-Arg-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(O)=O OLWAOWXIADGIJG-AVGNSLFASA-N 0.000 description 4
- IYXDSYWCVVXSKB-CIUDSAMLSA-N Met-Asn-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IYXDSYWCVVXSKB-CIUDSAMLSA-N 0.000 description 4
- YCUSPBPZVJDMII-YUMQZZPRSA-N Met-Gly-Glu Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O YCUSPBPZVJDMII-YUMQZZPRSA-N 0.000 description 4
- KSIPKXNIQOWMIC-RCWTZXSCSA-N Met-Thr-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KSIPKXNIQOWMIC-RCWTZXSCSA-N 0.000 description 4
- 206010062575 Muscle contracture Diseases 0.000 description 4
- 108091005461 Nucleic proteins Proteins 0.000 description 4
- LSXGADJXBDFXQU-DLOVCJGASA-N Phe-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 LSXGADJXBDFXQU-DLOVCJGASA-N 0.000 description 4
- PPHFTNABKQRAJV-JYJNAYRXSA-N Phe-His-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PPHFTNABKQRAJV-JYJNAYRXSA-N 0.000 description 4
- YCCUXNNKXDGMAM-KKUMJFAQSA-N Phe-Leu-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YCCUXNNKXDGMAM-KKUMJFAQSA-N 0.000 description 4
- AAERWTUHZKLDLC-IHRRRGAJSA-N Phe-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O AAERWTUHZKLDLC-IHRRRGAJSA-N 0.000 description 4
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 4
- BQMFWUKNOCJDNV-HJWJTTGWSA-N Phe-Val-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BQMFWUKNOCJDNV-HJWJTTGWSA-N 0.000 description 4
- AJLVKXCNXIJHDV-CIUDSAMLSA-N Pro-Ala-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O AJLVKXCNXIJHDV-CIUDSAMLSA-N 0.000 description 4
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 4
- DSGSTPRKNYHGCL-JYJNAYRXSA-N Pro-Phe-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O DSGSTPRKNYHGCL-JYJNAYRXSA-N 0.000 description 4
- UGDMQJSXSSZUKL-IHRRRGAJSA-N Pro-Ser-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O UGDMQJSXSSZUKL-IHRRRGAJSA-N 0.000 description 4
- 102220638483 Protein PML_K65R_mutation Human genes 0.000 description 4
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 4
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 4
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 4
- QBUWQRKEHJXTOP-DCAQKATOSA-N Ser-His-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QBUWQRKEHJXTOP-DCAQKATOSA-N 0.000 description 4
- ZFVFHHZBCVNLGD-GUBZILKMSA-N Ser-His-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFVFHHZBCVNLGD-GUBZILKMSA-N 0.000 description 4
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 4
- HKHCTNFKZXAMIF-KKUMJFAQSA-N Ser-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CC=C(O)C=C1 HKHCTNFKZXAMIF-KKUMJFAQSA-N 0.000 description 4
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 4
- PXQUBKWZENPDGE-CIQUZCHMSA-N Thr-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)O)N PXQUBKWZENPDGE-CIQUZCHMSA-N 0.000 description 4
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 4
- KEGBFULVYKYJRD-LFSVMHDDSA-N Thr-Ala-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KEGBFULVYKYJRD-LFSVMHDDSA-N 0.000 description 4
- MQBTXMPQNCGSSZ-OSUNSFLBSA-N Thr-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N MQBTXMPQNCGSSZ-OSUNSFLBSA-N 0.000 description 4
- LXWZOMSOUAMOIA-JIOCBJNQSA-N Thr-Asn-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O LXWZOMSOUAMOIA-JIOCBJNQSA-N 0.000 description 4
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 4
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 4
- YDWLCDQXLCILCZ-BWAGICSOSA-N Thr-His-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YDWLCDQXLCILCZ-BWAGICSOSA-N 0.000 description 4
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 4
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 4
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 4
- ZEJBJDHSQPOVJV-UAXMHLISSA-N Thr-Trp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZEJBJDHSQPOVJV-UAXMHLISSA-N 0.000 description 4
- IBBBOLAPFHRDHW-BPUTZDHNSA-N Trp-Asn-Arg Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N IBBBOLAPFHRDHW-BPUTZDHNSA-N 0.000 description 4
- DXDMNBJJEXYMLA-UBHSHLNASA-N Trp-Asn-Asp Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 DXDMNBJJEXYMLA-UBHSHLNASA-N 0.000 description 4
- DVIIYMVCSUQOJG-QEJZJMRPSA-N Trp-Glu-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DVIIYMVCSUQOJG-QEJZJMRPSA-N 0.000 description 4
- HLDFBNPSURDYEN-VHWLVUOQSA-N Trp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N HLDFBNPSURDYEN-VHWLVUOQSA-N 0.000 description 4
- QHWMVGCEQAPQDK-UMPQAUOISA-N Trp-Thr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O QHWMVGCEQAPQDK-UMPQAUOISA-N 0.000 description 4
- STKZKWFOKOCSLW-UMPQAUOISA-N Trp-Thr-Val Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)[C@@H](C)O)=CNC2=C1 STKZKWFOKOCSLW-UMPQAUOISA-N 0.000 description 4
- FHHYVSCGOMPLLO-IHPCNDPISA-N Trp-Tyr-Asp Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 FHHYVSCGOMPLLO-IHPCNDPISA-N 0.000 description 4
- RWTFCAMQLFNPTK-UMPQAUOISA-N Trp-Val-Thr Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)=CNC2=C1 RWTFCAMQLFNPTK-UMPQAUOISA-N 0.000 description 4
- DLZKEQQWXODGGZ-KWQFWETISA-N Tyr-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DLZKEQQWXODGGZ-KWQFWETISA-N 0.000 description 4
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 4
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 4
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 4
- YSGAPESOXHFTQY-IHRRRGAJSA-N Tyr-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N YSGAPESOXHFTQY-IHRRRGAJSA-N 0.000 description 4
- HNERGSKJJZQGEA-JYJNAYRXSA-N Tyr-Met-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N HNERGSKJJZQGEA-JYJNAYRXSA-N 0.000 description 4
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 4
- XUIOBCQESNDTDE-FQPOAREZSA-N Tyr-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XUIOBCQESNDTDE-FQPOAREZSA-N 0.000 description 4
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 4
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 4
- ZQGPWORGSNRQLN-NHCYSSNCSA-N Val-Asp-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZQGPWORGSNRQLN-NHCYSSNCSA-N 0.000 description 4
- CVIXTAITYJQMPE-LAEOZQHASA-N Val-Glu-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CVIXTAITYJQMPE-LAEOZQHASA-N 0.000 description 4
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 4
- WHVSJHJTMUHYBT-SRVKXCTJSA-N Val-Met-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(=O)O)N WHVSJHJTMUHYBT-SRVKXCTJSA-N 0.000 description 4
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 4
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- 238000007792 addition Methods 0.000 description 4
- 108010070944 alanylhistidine Proteins 0.000 description 4
- 229960001230 asparagine Drugs 0.000 description 4
- 108010093581 aspartyl-proline Proteins 0.000 description 4
- 108010068265 aspartyltyrosine Proteins 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 230000000747 cardiac effect Effects 0.000 description 4
- 238000012512 characterization method Methods 0.000 description 4
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 4
- 238000004590 computer program Methods 0.000 description 4
- 238000011304 droplet digital PCR Methods 0.000 description 4
- 238000013467 fragmentation Methods 0.000 description 4
- 238000006062 fragmentation reaction Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 108010081551 glycylphenylalanine Proteins 0.000 description 4
- 238000001802 infusion Methods 0.000 description 4
- 238000000185 intracerebroventricular administration Methods 0.000 description 4
- 238000002955 isolation Methods 0.000 description 4
- 239000002502 liposome Substances 0.000 description 4
- 108010010679 lysyl-valyl-leucyl-aspartic acid Proteins 0.000 description 4
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 4
- 108010034507 methionyltryptophan Proteins 0.000 description 4
- 239000000546 pharmaceutical excipient Substances 0.000 description 4
- 108010024607 phenylalanylalanine Proteins 0.000 description 4
- 239000003755 preservative agent Substances 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 238000003860 storage Methods 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 210000000115 thoracic cavity Anatomy 0.000 description 4
- 108010044292 tryptophyltyrosine Proteins 0.000 description 4
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 4
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 3
- 108020005345 3' Untranslated Regions Proteins 0.000 description 3
- 241001655883 Adeno-associated virus - 1 Species 0.000 description 3
- 241001164825 Adeno-associated virus - 8 Species 0.000 description 3
- XEXJJJRVTFGWIC-FXQIFTODSA-N Ala-Asn-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XEXJJJRVTFGWIC-FXQIFTODSA-N 0.000 description 3
- LGFCAXJBAZESCF-ACZMJKKPSA-N Ala-Gln-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O LGFCAXJBAZESCF-ACZMJKKPSA-N 0.000 description 3
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 3
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 3
- HUUOZYZWNCXTFK-INTQDDNPSA-N Ala-His-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N HUUOZYZWNCXTFK-INTQDDNPSA-N 0.000 description 3
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 3
- OMFMCIVBKCEMAK-CYDGBPFRSA-N Ala-Leu-Val-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O OMFMCIVBKCEMAK-CYDGBPFRSA-N 0.000 description 3
- NLOMBWNGESDVJU-GUBZILKMSA-N Ala-Met-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLOMBWNGESDVJU-GUBZILKMSA-N 0.000 description 3
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 3
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 3
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 3
- BOKLLPVAQDSLHC-FXQIFTODSA-N Ala-Val-Cys Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O)N BOKLLPVAQDSLHC-FXQIFTODSA-N 0.000 description 3
- 102000009027 Albumins Human genes 0.000 description 3
- 108010088751 Albumins Proteins 0.000 description 3
- YFWTXMRJJDNTLM-LSJOCFKGSA-N Arg-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YFWTXMRJJDNTLM-LSJOCFKGSA-N 0.000 description 3
- DBKNLHKEVPZVQC-LPEHRKFASA-N Arg-Ala-Pro Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O DBKNLHKEVPZVQC-LPEHRKFASA-N 0.000 description 3
- BIOCIVSVEDFKDJ-GUBZILKMSA-N Arg-Arg-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O BIOCIVSVEDFKDJ-GUBZILKMSA-N 0.000 description 3
- USNSOPDIZILSJP-FXQIFTODSA-N Arg-Asn-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O USNSOPDIZILSJP-FXQIFTODSA-N 0.000 description 3
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 3
- KBBKCNHWCDJPGN-GUBZILKMSA-N Arg-Gln-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KBBKCNHWCDJPGN-GUBZILKMSA-N 0.000 description 3
- AQPVUEJJARLJHB-BQBZGAKWSA-N Arg-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N AQPVUEJJARLJHB-BQBZGAKWSA-N 0.000 description 3
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 3
- UPKMBGAAEZGHOC-RWMBFGLXSA-N Arg-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O UPKMBGAAEZGHOC-RWMBFGLXSA-N 0.000 description 3
- NVPHRWNWTKYIST-BPNCWPANSA-N Arg-Tyr-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 NVPHRWNWTKYIST-BPNCWPANSA-N 0.000 description 3
- GMRGSBAMMMVDGG-GUBZILKMSA-N Asn-Arg-Arg Chemical compound C(C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N GMRGSBAMMMVDGG-GUBZILKMSA-N 0.000 description 3
- GFFRWIJAFFMQGM-NUMRIWBASA-N Asn-Glu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GFFRWIJAFFMQGM-NUMRIWBASA-N 0.000 description 3
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 3
- DJIMLSXHXKWADV-CIUDSAMLSA-N Asn-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(N)=O DJIMLSXHXKWADV-CIUDSAMLSA-N 0.000 description 3
- VITDJIPIJZAVGC-VEVYYDQMSA-N Asn-Met-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VITDJIPIJZAVGC-VEVYYDQMSA-N 0.000 description 3
- OEUQMKNNOWJREN-AVGNSLFASA-N Asp-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N OEUQMKNNOWJREN-AVGNSLFASA-N 0.000 description 3
- VFUXXFVCYZPOQG-WDSKDSINSA-N Asp-Glu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VFUXXFVCYZPOQG-WDSKDSINSA-N 0.000 description 3
- XLILXFRAKOYEJX-GUBZILKMSA-N Asp-Leu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLILXFRAKOYEJX-GUBZILKMSA-N 0.000 description 3
- VMVUDJUXJKDGNR-FXQIFTODSA-N Asp-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N VMVUDJUXJKDGNR-FXQIFTODSA-N 0.000 description 3
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 3
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 3
- WOKXEQLPBLLWHC-IHRRRGAJSA-N Asp-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 WOKXEQLPBLLWHC-IHRRRGAJSA-N 0.000 description 3
- 108010038061 Chymotrypsinogen Proteins 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- PRXCTTWKGJAPMT-ZLUOBGJFSA-N Cys-Ala-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O PRXCTTWKGJAPMT-ZLUOBGJFSA-N 0.000 description 3
- BNRHLRWCERLRTQ-BPUTZDHNSA-N Cys-Arg-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N BNRHLRWCERLRTQ-BPUTZDHNSA-N 0.000 description 3
- GHUVBPIYQYXXEF-SRVKXCTJSA-N Cys-Cys-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 GHUVBPIYQYXXEF-SRVKXCTJSA-N 0.000 description 3
- NMWZMKLDGZXRKP-BZSNNMDCSA-N Cys-Phe-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NMWZMKLDGZXRKP-BZSNNMDCSA-N 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 102220511796 F-actin-capping protein subunit beta_F26S_mutation Human genes 0.000 description 3
- YJIUYQKQBBQYHZ-ACZMJKKPSA-N Gln-Ala-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YJIUYQKQBBQYHZ-ACZMJKKPSA-N 0.000 description 3
- UWZLBXOBVKRUFE-HGNGGELXSA-N Gln-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N UWZLBXOBVKRUFE-HGNGGELXSA-N 0.000 description 3
- IPHGBVYWRKCGKG-FXQIFTODSA-N Gln-Cys-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O IPHGBVYWRKCGKG-FXQIFTODSA-N 0.000 description 3
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 3
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 3
- QKWBEMCLYTYBNI-GVXVVHGQSA-N Gln-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O QKWBEMCLYTYBNI-GVXVVHGQSA-N 0.000 description 3
- BJPPYOMRAVLXBY-YUMQZZPRSA-N Gln-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N BJPPYOMRAVLXBY-YUMQZZPRSA-N 0.000 description 3
- AQPZYBSRDRZBAG-AVGNSLFASA-N Gln-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N AQPZYBSRDRZBAG-AVGNSLFASA-N 0.000 description 3
- YJSCHRBERYWPQL-DCAQKATOSA-N Gln-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N YJSCHRBERYWPQL-DCAQKATOSA-N 0.000 description 3
- FGWRYRAVBVOHIB-XIRDDKMYSA-N Gln-Pro-Trp Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)N)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O FGWRYRAVBVOHIB-XIRDDKMYSA-N 0.000 description 3
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 3
- LXAUHIRMWXQRKI-XHNCKOQMSA-N Glu-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O LXAUHIRMWXQRKI-XHNCKOQMSA-N 0.000 description 3
- PVBBEKPHARMPHX-DCAQKATOSA-N Glu-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O PVBBEKPHARMPHX-DCAQKATOSA-N 0.000 description 3
- KUTPGXNAAOQSPD-LPEHRKFASA-N Glu-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O KUTPGXNAAOQSPD-LPEHRKFASA-N 0.000 description 3
- DVLZZEPUNFEUBW-AVGNSLFASA-N Glu-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N DVLZZEPUNFEUBW-AVGNSLFASA-N 0.000 description 3
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 3
- LZMQSTPFYJLVJB-GUBZILKMSA-N Glu-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LZMQSTPFYJLVJB-GUBZILKMSA-N 0.000 description 3
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 3
- NWOUBJNMZDDGDT-AVGNSLFASA-N Glu-Leu-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NWOUBJNMZDDGDT-AVGNSLFASA-N 0.000 description 3
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 3
- FGSGPLRPQCZBSQ-AVGNSLFASA-N Glu-Phe-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O FGSGPLRPQCZBSQ-AVGNSLFASA-N 0.000 description 3
- LPHGXOWFAXFCPX-KKUMJFAQSA-N Glu-Pro-Phe Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O LPHGXOWFAXFCPX-KKUMJFAQSA-N 0.000 description 3
- BIYNPVYAZOUVFQ-CIUDSAMLSA-N Glu-Pro-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O BIYNPVYAZOUVFQ-CIUDSAMLSA-N 0.000 description 3
- ARIORLIIMJACKZ-KKUMJFAQSA-N Glu-Pro-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ARIORLIIMJACKZ-KKUMJFAQSA-N 0.000 description 3
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 3
- MZZSCEANQDPJER-ONGXEEELSA-N Gly-Ala-Phe Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MZZSCEANQDPJER-ONGXEEELSA-N 0.000 description 3
- QIZJOTQTCAGKPU-KWQFWETISA-N Gly-Ala-Tyr Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 QIZJOTQTCAGKPU-KWQFWETISA-N 0.000 description 3
- VXKCPBPQEKKERH-IUCAKERBSA-N Gly-Arg-Pro Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N1CCC[C@H]1C(O)=O VXKCPBPQEKKERH-IUCAKERBSA-N 0.000 description 3
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 3
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 3
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 3
- OQQKUTVULYLCDG-ONGXEEELSA-N Gly-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)CN)C(O)=O OQQKUTVULYLCDG-ONGXEEELSA-N 0.000 description 3
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 3
- OCRQUYDOYKCOQG-IRXDYDNUSA-N Gly-Tyr-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 OCRQUYDOYKCOQG-IRXDYDNUSA-N 0.000 description 3
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 3
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 3
- 102220487360 Guanine nucleotide-binding protein G(i) subunit alpha-1_A54R_mutation Human genes 0.000 description 3
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 3
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 3
- SYMSVYVUSPSAAO-IHRRRGAJSA-N His-Arg-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O SYMSVYVUSPSAAO-IHRRRGAJSA-N 0.000 description 3
- AAXMRLWFJFDYQO-GUBZILKMSA-N His-Asp-Gln Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O AAXMRLWFJFDYQO-GUBZILKMSA-N 0.000 description 3
- VHHYJBSXXMPQGZ-AVGNSLFASA-N His-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N VHHYJBSXXMPQGZ-AVGNSLFASA-N 0.000 description 3
- PYNUBZSXKQKAHL-UWVGGRQHSA-N His-Gly-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O PYNUBZSXKQKAHL-UWVGGRQHSA-N 0.000 description 3
- ULRFSEJGSHYLQI-YESZJQIVSA-N His-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O ULRFSEJGSHYLQI-YESZJQIVSA-N 0.000 description 3
- FHKZHRMERJUXRJ-DCAQKATOSA-N His-Ser-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 FHKZHRMERJUXRJ-DCAQKATOSA-N 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- QLRMMMQNCWBNPQ-QXEWZRGKSA-N Ile-Arg-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)O)N QLRMMMQNCWBNPQ-QXEWZRGKSA-N 0.000 description 3
- QIHJTGSVGIPHIW-QSFUFRPTSA-N Ile-Asn-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N QIHJTGSVGIPHIW-QSFUFRPTSA-N 0.000 description 3
- KEKTTYCXKGBAAL-VGDYDELISA-N Ile-His-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N KEKTTYCXKGBAAL-VGDYDELISA-N 0.000 description 3
- XLXPYSDGMXTTNQ-DKIMLUQUSA-N Ile-Phe-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CC(C)C)C(O)=O XLXPYSDGMXTTNQ-DKIMLUQUSA-N 0.000 description 3
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 3
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 3
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 3
- 102220474905 Insulin-like 3_V43L_mutation Human genes 0.000 description 3
- 102000000588 Interleukin-2 Human genes 0.000 description 3
- 108010002350 Interleukin-2 Proteins 0.000 description 3
- 108091092195 Intron Proteins 0.000 description 3
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 3
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 3
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 3
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 3
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 3
- RVVBWTWPNFDYBE-SRVKXCTJSA-N Leu-Glu-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVVBWTWPNFDYBE-SRVKXCTJSA-N 0.000 description 3
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 3
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 3
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 3
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 3
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 3
- DDVHDMSBLRAKNV-IHRRRGAJSA-N Leu-Met-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O DDVHDMSBLRAKNV-IHRRRGAJSA-N 0.000 description 3
- MAXILRZVORNXBE-PMVMPFDFSA-N Leu-Phe-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 MAXILRZVORNXBE-PMVMPFDFSA-N 0.000 description 3
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 3
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 3
- YWFZWQKWNDOWPA-XIRDDKMYSA-N Leu-Trp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O YWFZWQKWNDOWPA-XIRDDKMYSA-N 0.000 description 3
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 3
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 3
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 3
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 3
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 3
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 3
- BMHIFARYXOJDLD-WPRPVWTQSA-N Met-Gly-Val Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O BMHIFARYXOJDLD-WPRPVWTQSA-N 0.000 description 3
- UDOYVQQKQHZYMB-DCAQKATOSA-N Met-Met-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDOYVQQKQHZYMB-DCAQKATOSA-N 0.000 description 3
- XIGAHPDZLAYQOS-SRVKXCTJSA-N Met-Pro-Pro Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 XIGAHPDZLAYQOS-SRVKXCTJSA-N 0.000 description 3
- CNFMPVYIVQUJOO-NHCYSSNCSA-N Met-Val-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O CNFMPVYIVQUJOO-NHCYSSNCSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 108091061960 Naked DNA Proteins 0.000 description 3
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 3
- 108091093037 Peptide nucleic acid Proteins 0.000 description 3
- FPTXMUIBLMGTQH-ONGXEEELSA-N Phe-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 FPTXMUIBLMGTQH-ONGXEEELSA-N 0.000 description 3
- SMFGCTXUBWEPKM-KBPBESRZSA-N Phe-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 SMFGCTXUBWEPKM-KBPBESRZSA-N 0.000 description 3
- IEOHQGFKHXUALJ-JYJNAYRXSA-N Phe-Met-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IEOHQGFKHXUALJ-JYJNAYRXSA-N 0.000 description 3
- JKJSIYKSGIDHPM-WBAXXEDZSA-N Phe-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1ccccc1)C(O)=O JKJSIYKSGIDHPM-WBAXXEDZSA-N 0.000 description 3
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 3
- ZVRJWDUPIDMHDN-ULQDDVLXSA-N Phe-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 ZVRJWDUPIDMHDN-ULQDDVLXSA-N 0.000 description 3
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 3
- ZYNBEWGJFXTBDU-ACRUOGEOSA-N Phe-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N ZYNBEWGJFXTBDU-ACRUOGEOSA-N 0.000 description 3
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 3
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 3
- 241000288906 Primates Species 0.000 description 3
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 3
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 3
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 3
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 3
- WWAQEUOYCYMGHB-FXQIFTODSA-N Pro-Asn-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 WWAQEUOYCYMGHB-FXQIFTODSA-N 0.000 description 3
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 3
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 3
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 3
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 3
- LPGSNRSLPHRNBW-AVGNSLFASA-N Pro-His-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 LPGSNRSLPHRNBW-AVGNSLFASA-N 0.000 description 3
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 3
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 3
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 3
- HBBBLSVBQGZKOZ-GUBZILKMSA-N Pro-Met-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O HBBBLSVBQGZKOZ-GUBZILKMSA-N 0.000 description 3
- AJBQTGZIZQXBLT-STQMWFEESA-N Pro-Phe-Gly Chemical compound C([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 AJBQTGZIZQXBLT-STQMWFEESA-N 0.000 description 3
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 3
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 3
- CWZUFLWPEFHWEI-IHRRRGAJSA-N Pro-Tyr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O CWZUFLWPEFHWEI-IHRRRGAJSA-N 0.000 description 3
- 241000125945 Protoparvovirus Species 0.000 description 3
- 101710118046 RNA-directed RNA polymerase Proteins 0.000 description 3
- 238000011529 RT qPCR Methods 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- QWZIOCFPXMAXET-CIUDSAMLSA-N Ser-Arg-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QWZIOCFPXMAXET-CIUDSAMLSA-N 0.000 description 3
- XVAUJOAYHWWNQF-ZLUOBGJFSA-N Ser-Asn-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O XVAUJOAYHWWNQF-ZLUOBGJFSA-N 0.000 description 3
- VDVYTKZBMFADQH-AVGNSLFASA-N Ser-Gln-Tyr Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 VDVYTKZBMFADQH-AVGNSLFASA-N 0.000 description 3
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 3
- MLSQXWSRHURDMF-GARJFASQSA-N Ser-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N)C(=O)O MLSQXWSRHURDMF-GARJFASQSA-N 0.000 description 3
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 3
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 3
- DKGRNFUXVTYRAS-UBHSHLNASA-N Ser-Ser-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DKGRNFUXVTYRAS-UBHSHLNASA-N 0.000 description 3
- QNBVFKZSSRYNFX-CUJWVEQBSA-N Ser-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N)O QNBVFKZSSRYNFX-CUJWVEQBSA-N 0.000 description 3
- DYEGLQRVMBWQLD-IXOXFDKPSA-N Ser-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CO)N)O DYEGLQRVMBWQLD-IXOXFDKPSA-N 0.000 description 3
- WMZVVNLPHFSUPA-BPUTZDHNSA-N Ser-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 WMZVVNLPHFSUPA-BPUTZDHNSA-N 0.000 description 3
- JOHPFOKBAAOQDI-UBHSHLNASA-N Ser-Trp-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N JOHPFOKBAAOQDI-UBHSHLNASA-N 0.000 description 3
- FGBLCMLXHRPVOF-IHRRRGAJSA-N Ser-Tyr-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FGBLCMLXHRPVOF-IHRRRGAJSA-N 0.000 description 3
- LHUBVKCLOVALIA-HJGDQZAQSA-N Thr-Arg-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LHUBVKCLOVALIA-HJGDQZAQSA-N 0.000 description 3
- RJBFAHKSFNNHAI-XKBZYTNZSA-N Thr-Gln-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)O RJBFAHKSFNNHAI-XKBZYTNZSA-N 0.000 description 3
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 3
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 3
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 3
- AHOLTQCAVBSUDP-PPCPHDFISA-N Thr-Ile-Lys Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O AHOLTQCAVBSUDP-PPCPHDFISA-N 0.000 description 3
- XYFISNXATOERFZ-OSUNSFLBSA-N Thr-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XYFISNXATOERFZ-OSUNSFLBSA-N 0.000 description 3
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 3
- VEIKMWOMUYMMMK-FCLVOEFKSA-N Thr-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VEIKMWOMUYMMMK-FCLVOEFKSA-N 0.000 description 3
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 3
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 3
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 3
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 3
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 3
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 3
- DTPARJBMONKGGC-IHPCNDPISA-N Trp-Cys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N DTPARJBMONKGGC-IHPCNDPISA-N 0.000 description 3
- 108090000631 Trypsin Proteins 0.000 description 3
- 102000004142 Trypsin Human genes 0.000 description 3
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 3
- UNUZEBFXGWVAOP-DZKIICNBSA-N Tyr-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UNUZEBFXGWVAOP-DZKIICNBSA-N 0.000 description 3
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 3
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 3
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 3
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 3
- 108091023045 Untranslated Region Proteins 0.000 description 3
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 3
- CWOSXNKDOACNJN-BZSNNMDCSA-N Val-Arg-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N CWOSXNKDOACNJN-BZSNNMDCSA-N 0.000 description 3
- FPCIBLUVDNXPJO-XPUUQOCRSA-N Val-Cys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O FPCIBLUVDNXPJO-XPUUQOCRSA-N 0.000 description 3
- FOADDSDHGRFUOC-DZKIICNBSA-N Val-Glu-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N FOADDSDHGRFUOC-DZKIICNBSA-N 0.000 description 3
- BVWPHWLFGRCECJ-JSGCOSHPSA-N Val-Gly-Tyr Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N BVWPHWLFGRCECJ-JSGCOSHPSA-N 0.000 description 3
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 3
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 3
- SVLAAUGFIHSJPK-JYJNAYRXSA-N Val-Trp-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CO)C(=O)O)N SVLAAUGFIHSJPK-JYJNAYRXSA-N 0.000 description 3
- VVIZITNVZUAEMI-DLOVCJGASA-N Val-Val-Gln Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O VVIZITNVZUAEMI-DLOVCJGASA-N 0.000 description 3
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 3
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 3
- 208000036142 Viral infection Diseases 0.000 description 3
- 238000010171 animal model Methods 0.000 description 3
- 239000007900 aqueous suspension Substances 0.000 description 3
- 108010008355 arginyl-glutamine Proteins 0.000 description 3
- 108010062796 arginyllysine Proteins 0.000 description 3
- 108010036533 arginylvaline Proteins 0.000 description 3
- 108010038633 aspartylglutamate Proteins 0.000 description 3
- 230000007845 axonopathy Effects 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- 108010016616 cysteinylglycine Proteins 0.000 description 3
- 230000002950 deficient Effects 0.000 description 3
- 230000007850 degeneration Effects 0.000 description 3
- 239000003085 diluting agent Substances 0.000 description 3
- 238000013213 extrapolation Methods 0.000 description 3
- 239000006260 foam Substances 0.000 description 3
- 108060003196 globin Proteins 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 108010079547 glutamylmethionine Proteins 0.000 description 3
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 3
- 210000005260 human cell Anatomy 0.000 description 3
- 239000003018 immunosuppressive agent Substances 0.000 description 3
- 230000002779 inactivation Effects 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 210000003734 kidney Anatomy 0.000 description 3
- 238000011813 knockout mouse model Methods 0.000 description 3
- 108010091871 leucylmethionine Proteins 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 239000002207 metabolite Substances 0.000 description 3
- 239000002105 nanoparticle Substances 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 239000008188 pellet Substances 0.000 description 3
- 230000002093 peripheral effect Effects 0.000 description 3
- 229920001983 poloxamer Polymers 0.000 description 3
- 229920001993 poloxamer 188 Polymers 0.000 description 3
- 229920001184 polypeptide Polymers 0.000 description 3
- 239000002243 precursor Substances 0.000 description 3
- 230000000750 progressive effect Effects 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 210000003314 quadriceps muscle Anatomy 0.000 description 3
- 239000013608 rAAV vector Substances 0.000 description 3
- 102220332512 rs1555032911 Human genes 0.000 description 3
- 102220297864 rs761846391 Human genes 0.000 description 3
- 102220274185 rs762526848 Human genes 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 210000001044 sensory neuron Anatomy 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 239000012588 trypsin Substances 0.000 description 3
- 108010051110 tyrosyl-lysine Proteins 0.000 description 3
- 238000011144 upstream manufacturing Methods 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- 230000009385 viral infection Effects 0.000 description 3
- 239000003643 water by type Substances 0.000 description 3
- 230000003442 weekly effect Effects 0.000 description 3
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 2
- OFHXPCLWHLXQHT-JKQORVJESA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2,6-diaminohexanoyl]amino]-3-methylbutanoyl]amino]-4-methylpentanoyl]amino]butanedioic acid Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN OFHXPCLWHLXQHT-JKQORVJESA-N 0.000 description 2
- WEZDRVHTDXTVLT-GJZGRUSLSA-N 2-[[(2s)-2-[[(2s)-2-[(2-aminoacetyl)amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]acetic acid Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 WEZDRVHTDXTVLT-GJZGRUSLSA-N 0.000 description 2
- 241001164823 Adeno-associated virus - 7 Species 0.000 description 2
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 2
- GSCLWXDNIMNIJE-ZLUOBGJFSA-N Ala-Asp-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GSCLWXDNIMNIJE-ZLUOBGJFSA-N 0.000 description 2
- MCKSLROAGSDNFC-ACZMJKKPSA-N Ala-Asp-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MCKSLROAGSDNFC-ACZMJKKPSA-N 0.000 description 2
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 2
- CZPAHAKGPDUIPJ-CIUDSAMLSA-N Ala-Gln-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CZPAHAKGPDUIPJ-CIUDSAMLSA-N 0.000 description 2
- BVSGPHDECMJBDE-HGNGGELXSA-N Ala-Glu-His Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BVSGPHDECMJBDE-HGNGGELXSA-N 0.000 description 2
- GRPHQEMIFDPKOE-HGNGGELXSA-N Ala-His-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O GRPHQEMIFDPKOE-HGNGGELXSA-N 0.000 description 2
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 2
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 2
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 2
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 2
- YCTIYBUTCKNOTI-UWJYBYFXSA-N Ala-Tyr-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCTIYBUTCKNOTI-UWJYBYFXSA-N 0.000 description 2
- JNJHNBXBGNJESC-KKXDTOCCSA-N Ala-Tyr-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JNJHNBXBGNJESC-KKXDTOCCSA-N 0.000 description 2
- JPOQZCHGOTWRTM-FQPOAREZSA-N Ala-Tyr-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPOQZCHGOTWRTM-FQPOAREZSA-N 0.000 description 2
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 2
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 2
- JQFJNGVSGOUQDH-XIRDDKMYSA-N Arg-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JQFJNGVSGOUQDH-XIRDDKMYSA-N 0.000 description 2
- KRQSPVKUISQQFS-FJXKBIBVSA-N Arg-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N KRQSPVKUISQQFS-FJXKBIBVSA-N 0.000 description 2
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 2
- WMEVEPXNCMKNGH-IHRRRGAJSA-N Arg-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WMEVEPXNCMKNGH-IHRRRGAJSA-N 0.000 description 2
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 2
- YVTHEZNOKSAWRW-DCAQKATOSA-N Arg-Lys-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O YVTHEZNOKSAWRW-DCAQKATOSA-N 0.000 description 2
- FKQITMVNILRUCQ-IHRRRGAJSA-N Arg-Phe-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O FKQITMVNILRUCQ-IHRRRGAJSA-N 0.000 description 2
- NGYHSXDNNOFHNE-AVGNSLFASA-N Arg-Pro-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O NGYHSXDNNOFHNE-AVGNSLFASA-N 0.000 description 2
- YFHATWYGAAXQCF-JYJNAYRXSA-N Arg-Pro-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YFHATWYGAAXQCF-JYJNAYRXSA-N 0.000 description 2
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 2
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 2
- HOIFSHOLNKQCSA-FXQIFTODSA-N Asn-Arg-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O HOIFSHOLNKQCSA-FXQIFTODSA-N 0.000 description 2
- AYZAWXAPBAYCHO-CIUDSAMLSA-N Asn-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N AYZAWXAPBAYCHO-CIUDSAMLSA-N 0.000 description 2
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 2
- GNKVBRYFXYWXAB-WDSKDSINSA-N Asn-Glu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O GNKVBRYFXYWXAB-WDSKDSINSA-N 0.000 description 2
- BKDDABUWNKGZCK-XHNCKOQMSA-N Asn-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O BKDDABUWNKGZCK-XHNCKOQMSA-N 0.000 description 2
- FTCGGKNCJZOPNB-WHFBIAKZSA-N Asn-Gly-Ser Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FTCGGKNCJZOPNB-WHFBIAKZSA-N 0.000 description 2
- MOHUTCNYQLMARY-GUBZILKMSA-N Asn-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MOHUTCNYQLMARY-GUBZILKMSA-N 0.000 description 2
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 2
- FHETWELNCBMRMG-HJGDQZAQSA-N Asn-Leu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FHETWELNCBMRMG-HJGDQZAQSA-N 0.000 description 2
- BKZFBJYIVSBXCO-KKUMJFAQSA-N Asn-Phe-His Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O BKZFBJYIVSBXCO-KKUMJFAQSA-N 0.000 description 2
- RVHGJNGNKGDCPX-KKUMJFAQSA-N Asn-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N RVHGJNGNKGDCPX-KKUMJFAQSA-N 0.000 description 2
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 2
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 2
- AMGQTNHANMRPOE-LKXGYXEUSA-N Asn-Thr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O AMGQTNHANMRPOE-LKXGYXEUSA-N 0.000 description 2
- DAYDURRBMDCCFL-AAEUAGOBSA-N Asn-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N DAYDURRBMDCCFL-AAEUAGOBSA-N 0.000 description 2
- BEHQTVDBCLSCBY-CFMVVWHZSA-N Asn-Tyr-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BEHQTVDBCLSCBY-CFMVVWHZSA-N 0.000 description 2
- WSWYMRLTJVKRCE-ZLUOBGJFSA-N Asp-Ala-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O WSWYMRLTJVKRCE-ZLUOBGJFSA-N 0.000 description 2
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 2
- ZLGKHJHFYSRUBH-FXQIFTODSA-N Asp-Arg-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLGKHJHFYSRUBH-FXQIFTODSA-N 0.000 description 2
- IXIWEFWRKIUMQX-DCAQKATOSA-N Asp-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O IXIWEFWRKIUMQX-DCAQKATOSA-N 0.000 description 2
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- UQBGYPFHWFZMCD-ZLUOBGJFSA-N Asp-Asn-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UQBGYPFHWFZMCD-ZLUOBGJFSA-N 0.000 description 2
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 2
- UGIBTKGQVWFTGX-BIIVOSGPSA-N Asp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O UGIBTKGQVWFTGX-BIIVOSGPSA-N 0.000 description 2
- RDRMWJBLOSRRAW-BYULHYEWSA-N Asp-Asn-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O RDRMWJBLOSRRAW-BYULHYEWSA-N 0.000 description 2
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 2
- QHHVSXGWLYEAGX-GUBZILKMSA-N Asp-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QHHVSXGWLYEAGX-GUBZILKMSA-N 0.000 description 2
- LIVXPXUVXFRWNY-CIUDSAMLSA-N Asp-Lys-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O LIVXPXUVXFRWNY-CIUDSAMLSA-N 0.000 description 2
- IDDMGSKZQDEDGA-SRVKXCTJSA-N Asp-Phe-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 IDDMGSKZQDEDGA-SRVKXCTJSA-N 0.000 description 2
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 2
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 2
- OYSYWMMZGJSQRB-AVGNSLFASA-N Asp-Tyr-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O OYSYWMMZGJSQRB-AVGNSLFASA-N 0.000 description 2
- OQMGSMNZVHYDTQ-ZKWXMUAHSA-N Asp-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N OQMGSMNZVHYDTQ-ZKWXMUAHSA-N 0.000 description 2
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 2
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 2
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 2
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 2
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 2
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 2
- 229920001661 Chitosan Polymers 0.000 description 2
- 108090000317 Chymotrypsin Proteins 0.000 description 2
- PKNIZMPLMSKROD-BIIVOSGPSA-N Cys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N PKNIZMPLMSKROD-BIIVOSGPSA-N 0.000 description 2
- CAXGCBSRJLADPD-FXQIFTODSA-N Cys-Pro-Asn Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O CAXGCBSRJLADPD-FXQIFTODSA-N 0.000 description 2
- MHYHLWUGWUBUHF-GUBZILKMSA-N Cys-Val-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N MHYHLWUGWUBUHF-GUBZILKMSA-N 0.000 description 2
- LPBUBIHAVKXUOT-FXQIFTODSA-N Cys-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N LPBUBIHAVKXUOT-FXQIFTODSA-N 0.000 description 2
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 2
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 2
- 102000016911 Deoxyribonucleases Human genes 0.000 description 2
- 108010053770 Deoxyribonucleases Proteins 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- CTKXFMQHOOWWEB-UHFFFAOYSA-N Ethylene oxide/propylene oxide copolymer Chemical compound CCCOC(C)COCCO CTKXFMQHOOWWEB-UHFFFAOYSA-N 0.000 description 2
- IGNGBUVODQLMRJ-CIUDSAMLSA-N Gln-Ala-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O IGNGBUVODQLMRJ-CIUDSAMLSA-N 0.000 description 2
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 2
- QYTKAVBFRUGYAU-ACZMJKKPSA-N Gln-Asp-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QYTKAVBFRUGYAU-ACZMJKKPSA-N 0.000 description 2
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 2
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 2
- NPTGGVQJYRSMCM-GLLZPBPUSA-N Gln-Gln-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPTGGVQJYRSMCM-GLLZPBPUSA-N 0.000 description 2
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 2
- GNMQDOGFWYWPNM-LAEOZQHASA-N Gln-Gly-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)CNC(=O)[C@@H](N)CCC(N)=O)C(O)=O GNMQDOGFWYWPNM-LAEOZQHASA-N 0.000 description 2
- OREPWMPAUWIIAM-ZPFDUUQYSA-N Gln-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N OREPWMPAUWIIAM-ZPFDUUQYSA-N 0.000 description 2
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 2
- HLRLXVPRJJITSK-IFFSRLJSSA-N Gln-Thr-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HLRLXVPRJJITSK-IFFSRLJSSA-N 0.000 description 2
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 2
- SDSMVVSHLAAOJL-UKJIMTQDSA-N Gln-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N SDSMVVSHLAAOJL-UKJIMTQDSA-N 0.000 description 2
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 2
- ZMXZGYLINVNTKH-DZKIICNBSA-N Gln-Val-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZMXZGYLINVNTKH-DZKIICNBSA-N 0.000 description 2
- SOEXCCGNHQBFPV-DLOVCJGASA-N Gln-Val-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SOEXCCGNHQBFPV-DLOVCJGASA-N 0.000 description 2
- NLKVNZUFDPWPNL-YUMQZZPRSA-N Glu-Arg-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O NLKVNZUFDPWPNL-YUMQZZPRSA-N 0.000 description 2
- LJLPOZGRPLORTF-CIUDSAMLSA-N Glu-Asn-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O LJLPOZGRPLORTF-CIUDSAMLSA-N 0.000 description 2
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 2
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 2
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 2
- OGNJZUXUTPQVBR-BQBZGAKWSA-N Glu-Gly-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OGNJZUXUTPQVBR-BQBZGAKWSA-N 0.000 description 2
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 2
- WVYJNPCWJYBHJG-YVNDNENWSA-N Glu-Ile-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O WVYJNPCWJYBHJG-YVNDNENWSA-N 0.000 description 2
- VGUYMZGLJUJRBV-YVNDNENWSA-N Glu-Ile-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O VGUYMZGLJUJRBV-YVNDNENWSA-N 0.000 description 2
- PMSMKNYRZCKVMC-DRZSPHRISA-N Glu-Phe-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCC(=O)O)N PMSMKNYRZCKVMC-DRZSPHRISA-N 0.000 description 2
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 2
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 2
- XUDLUKYPXQDCRX-BQBZGAKWSA-N Gly-Arg-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O XUDLUKYPXQDCRX-BQBZGAKWSA-N 0.000 description 2
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 2
- PMNHJLASAAWELO-FOHZUACHSA-N Gly-Asp-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PMNHJLASAAWELO-FOHZUACHSA-N 0.000 description 2
- IXKRSKPKSLXIHN-YUMQZZPRSA-N Gly-Cys-Leu Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O IXKRSKPKSLXIHN-YUMQZZPRSA-N 0.000 description 2
- BULIVUZUDBHKKZ-WDSKDSINSA-N Gly-Gln-Asn Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BULIVUZUDBHKKZ-WDSKDSINSA-N 0.000 description 2
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 2
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 2
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 2
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 2
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 2
- MKIAPEZXQDILRR-YUMQZZPRSA-N Gly-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN MKIAPEZXQDILRR-YUMQZZPRSA-N 0.000 description 2
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 2
- FKYQEVBRZSFAMJ-QWRGUYRKSA-N Gly-Ser-Tyr Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FKYQEVBRZSFAMJ-QWRGUYRKSA-N 0.000 description 2
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 2
- PNUFMLXHOLFRLD-KBPBESRZSA-N Gly-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 PNUFMLXHOLFRLD-KBPBESRZSA-N 0.000 description 2
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 2
- FNXSYBOHALPRHV-ONGXEEELSA-N Gly-Val-Lys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN FNXSYBOHALPRHV-ONGXEEELSA-N 0.000 description 2
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 2
- TVQGUFGDVODUIF-LSJOCFKGSA-N His-Arg-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CN=CN1)N TVQGUFGDVODUIF-LSJOCFKGSA-N 0.000 description 2
- BDHUXUFYNUOUIT-SRVKXCTJSA-N His-Asp-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BDHUXUFYNUOUIT-SRVKXCTJSA-N 0.000 description 2
- HYWZHNUGAYVEEW-KKUMJFAQSA-N His-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N HYWZHNUGAYVEEW-KKUMJFAQSA-N 0.000 description 2
- VIJMRAIWYWRXSR-CIUDSAMLSA-N His-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 VIJMRAIWYWRXSR-CIUDSAMLSA-N 0.000 description 2
- SWBUZLFWGJETAO-KKUMJFAQSA-N His-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)O SWBUZLFWGJETAO-KKUMJFAQSA-N 0.000 description 2
- 102000002265 Human Growth Hormone Human genes 0.000 description 2
- 108010000521 Human Growth Hormone Proteins 0.000 description 2
- 239000000854 Human Growth Hormone Substances 0.000 description 2
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 2
- CCHSQWLCOOZREA-GMOBBJLQSA-N Ile-Asp-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N CCHSQWLCOOZREA-GMOBBJLQSA-N 0.000 description 2
- DFFTXLCCDFYRKD-MBLNEYKQSA-N Ile-Gly-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N DFFTXLCCDFYRKD-MBLNEYKQSA-N 0.000 description 2
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 2
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 2
- PZWBBXHHUSIGKH-OSUNSFLBSA-N Ile-Thr-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PZWBBXHHUSIGKH-OSUNSFLBSA-N 0.000 description 2
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 2
- JTBFQNHKNRZJDS-SYWGBEHUSA-N Ile-Trp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](C)C(=O)O)N JTBFQNHKNRZJDS-SYWGBEHUSA-N 0.000 description 2
- ZYVTXBXHIKGZMD-QSFUFRPTSA-N Ile-Val-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ZYVTXBXHIKGZMD-QSFUFRPTSA-N 0.000 description 2
- 206010061218 Inflammation Diseases 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 2
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- STAVRDQLZOTNKJ-RHYQMDGZSA-N Leu-Arg-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STAVRDQLZOTNKJ-RHYQMDGZSA-N 0.000 description 2
- KTFHTMHHKXUYPW-ZPFDUUQYSA-N Leu-Asp-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KTFHTMHHKXUYPW-ZPFDUUQYSA-N 0.000 description 2
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 2
- NFHJQETXTSDZSI-DCAQKATOSA-N Leu-Cys-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NFHJQETXTSDZSI-DCAQKATOSA-N 0.000 description 2
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 2
- GLBNEGIOFRVRHO-JYJNAYRXSA-N Leu-Gln-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLBNEGIOFRVRHO-JYJNAYRXSA-N 0.000 description 2
- YVKSMSDXKMSIRX-GUBZILKMSA-N Leu-Glu-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YVKSMSDXKMSIRX-GUBZILKMSA-N 0.000 description 2
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 2
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 2
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 2
- USLNHQZCDQJBOV-ZPFDUUQYSA-N Leu-Ile-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O USLNHQZCDQJBOV-ZPFDUUQYSA-N 0.000 description 2
- KOSWSHVQIVTVQF-ZPFDUUQYSA-N Leu-Ile-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KOSWSHVQIVTVQF-ZPFDUUQYSA-N 0.000 description 2
- QLDHBYRUNQZIJQ-DKIMLUQUSA-N Leu-Ile-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QLDHBYRUNQZIJQ-DKIMLUQUSA-N 0.000 description 2
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 2
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 2
- BIZNDKMFQHDOIE-KKUMJFAQSA-N Leu-Phe-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 BIZNDKMFQHDOIE-KKUMJFAQSA-N 0.000 description 2
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 2
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 2
- XWEVVRRSIOBJOO-SRVKXCTJSA-N Leu-Pro-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O XWEVVRRSIOBJOO-SRVKXCTJSA-N 0.000 description 2
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 2
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 2
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 2
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 2
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 2
- WGCKDDHUFPQSMZ-ZPFDUUQYSA-N Lys-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCCN WGCKDDHUFPQSMZ-ZPFDUUQYSA-N 0.000 description 2
- ZXEUFAVXODIPHC-GUBZILKMSA-N Lys-Glu-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZXEUFAVXODIPHC-GUBZILKMSA-N 0.000 description 2
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 2
- GNLJXWBNLAIPEP-MELADBBJSA-N Lys-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCCCN)N)C(=O)O GNLJXWBNLAIPEP-MELADBBJSA-N 0.000 description 2
- IZJGPPIGYTVXLB-FQUUOJAGSA-N Lys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IZJGPPIGYTVXLB-FQUUOJAGSA-N 0.000 description 2
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 2
- ZJWIXBZTAAJERF-IHRRRGAJSA-N Lys-Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZJWIXBZTAAJERF-IHRRRGAJSA-N 0.000 description 2
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 2
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 2
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 2
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 2
- VWJFOUBDZIUXGA-AVGNSLFASA-N Lys-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCCCN)N VWJFOUBDZIUXGA-AVGNSLFASA-N 0.000 description 2
- 208000015439 Lysosomal storage disease Diseases 0.000 description 2
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 2
- DTICLBJHRYSJLH-GUBZILKMSA-N Met-Ala-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O DTICLBJHRYSJLH-GUBZILKMSA-N 0.000 description 2
- IHITVQKJXQQGLJ-LPEHRKFASA-N Met-Asn-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N IHITVQKJXQQGLJ-LPEHRKFASA-N 0.000 description 2
- TZLYIHDABYBOCJ-FXQIFTODSA-N Met-Asp-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O TZLYIHDABYBOCJ-FXQIFTODSA-N 0.000 description 2
- BCRQJDMZQUHQSV-STQMWFEESA-N Met-Gly-Tyr Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BCRQJDMZQUHQSV-STQMWFEESA-N 0.000 description 2
- OTKQHDPECKUDSB-SZMVWBNQSA-N Met-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 OTKQHDPECKUDSB-SZMVWBNQSA-N 0.000 description 2
- 208000010428 Muscle Weakness Diseases 0.000 description 2
- 206010028289 Muscle atrophy Diseases 0.000 description 2
- 206010028372 Muscular weakness Diseases 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 102000010292 Peptide Elongation Factor 1 Human genes 0.000 description 2
- 108010077524 Peptide Elongation Factor 1 Proteins 0.000 description 2
- VHWOBXIWBDWZHK-IHRRRGAJSA-N Phe-Arg-Asp Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHWOBXIWBDWZHK-IHRRRGAJSA-N 0.000 description 2
- BRDYYVQTEJVRQT-HRCADAONSA-N Phe-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O BRDYYVQTEJVRQT-HRCADAONSA-N 0.000 description 2
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 2
- GDBOREPXIRKSEQ-FHWLQOOXSA-N Phe-Gln-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GDBOREPXIRKSEQ-FHWLQOOXSA-N 0.000 description 2
- FMMIYCMOVGXZIP-AVGNSLFASA-N Phe-Glu-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O FMMIYCMOVGXZIP-AVGNSLFASA-N 0.000 description 2
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 2
- VJLLEKDQJSMHRU-STQMWFEESA-N Phe-Gly-Met Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O VJLLEKDQJSMHRU-STQMWFEESA-N 0.000 description 2
- HQCSLJFGZYOXHW-KKUMJFAQSA-N Phe-His-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N HQCSLJFGZYOXHW-KKUMJFAQSA-N 0.000 description 2
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 2
- RSPUIENXSJYZQO-JYJNAYRXSA-N Phe-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RSPUIENXSJYZQO-JYJNAYRXSA-N 0.000 description 2
- KDYPMIZMXDECSU-JYJNAYRXSA-N Phe-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KDYPMIZMXDECSU-JYJNAYRXSA-N 0.000 description 2
- QRUOLOPKCOEZKU-HJWJTTGWSA-N Phe-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CC=CC=C1)N QRUOLOPKCOEZKU-HJWJTTGWSA-N 0.000 description 2
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 2
- CVAUVSOFHJKCHN-BZSNNMDCSA-N Phe-Tyr-Cys Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CS)C(O)=O)C1=CC=CC=C1 CVAUVSOFHJKCHN-BZSNNMDCSA-N 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- RVGRUAULSDPKGF-UHFFFAOYSA-N Poloxamer Chemical compound C1CO1.CC1CO1 RVGRUAULSDPKGF-UHFFFAOYSA-N 0.000 description 2
- WCUXLLCKKVVCTQ-UHFFFAOYSA-M Potassium chloride Chemical compound [Cl-].[K+] WCUXLLCKKVVCTQ-UHFFFAOYSA-M 0.000 description 2
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 2
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 2
- FUVBEZJCRMHWEM-FXQIFTODSA-N Pro-Asn-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FUVBEZJCRMHWEM-FXQIFTODSA-N 0.000 description 2
- HXOLCSYHGRNXJJ-IHRRRGAJSA-N Pro-Asp-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HXOLCSYHGRNXJJ-IHRRRGAJSA-N 0.000 description 2
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 2
- KTFZQPLSPLWLKN-KKUMJFAQSA-N Pro-Gln-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KTFZQPLSPLWLKN-KKUMJFAQSA-N 0.000 description 2
- WVOXLKUUVCCCSU-ZPFDUUQYSA-N Pro-Glu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVOXLKUUVCCCSU-ZPFDUUQYSA-N 0.000 description 2
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 2
- CLJLVCYFABNTHP-DCAQKATOSA-N Pro-Leu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O CLJLVCYFABNTHP-DCAQKATOSA-N 0.000 description 2
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 2
- HOTVCUAVDQHUDB-UFYCRDLUSA-N Pro-Phe-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 HOTVCUAVDQHUDB-UFYCRDLUSA-N 0.000 description 2
- KDBHVPXBQADZKY-GUBZILKMSA-N Pro-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KDBHVPXBQADZKY-GUBZILKMSA-N 0.000 description 2
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 2
- NAIPAPCKKRCMBL-JYJNAYRXSA-N Pro-Pro-Phe Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=CC=C1 NAIPAPCKKRCMBL-JYJNAYRXSA-N 0.000 description 2
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 2
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 2
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 2
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 2
- ZTHYODDOHIVTJV-UHFFFAOYSA-N Propyl gallate Chemical compound CCCOC(=O)C1=CC(O)=C(O)C(O)=C1 ZTHYODDOHIVTJV-UHFFFAOYSA-N 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 108010079005 RDV peptide Proteins 0.000 description 2
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 2
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 2
- OOKCGAYXSNJBGQ-ZLUOBGJFSA-N Ser-Asn-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OOKCGAYXSNJBGQ-ZLUOBGJFSA-N 0.000 description 2
- UBRXAVQWXOWRSJ-ZLUOBGJFSA-N Ser-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)C(=O)N UBRXAVQWXOWRSJ-ZLUOBGJFSA-N 0.000 description 2
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 2
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 2
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 2
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 2
- XXNYYSXNXCJYKX-DCAQKATOSA-N Ser-Leu-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O XXNYYSXNXCJYKX-DCAQKATOSA-N 0.000 description 2
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 2
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 2
- KZPRPBLHYMZIMH-MXAVVETBSA-N Ser-Phe-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZPRPBLHYMZIMH-MXAVVETBSA-N 0.000 description 2
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 2
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 2
- BDMWLJLPPUCLNV-XGEHTFHBSA-N Ser-Thr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BDMWLJLPPUCLNV-XGEHTFHBSA-N 0.000 description 2
- QYBRQMLZDDJBSW-AVGNSLFASA-N Ser-Tyr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYBRQMLZDDJBSW-AVGNSLFASA-N 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- CDBYLPFSWZWCQE-UHFFFAOYSA-L Sodium Carbonate Chemical compound [Na+].[Na+].[O-]C([O-])=O CDBYLPFSWZWCQE-UHFFFAOYSA-L 0.000 description 2
- RAHZWNYVWXNFOC-UHFFFAOYSA-N Sulphur dioxide Chemical compound O=S=O RAHZWNYVWXNFOC-UHFFFAOYSA-N 0.000 description 2
- CAGTXGDOIFXLPC-KZVJFYERSA-N Thr-Arg-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CCCN=C(N)N CAGTXGDOIFXLPC-KZVJFYERSA-N 0.000 description 2
- JMZKMSTYXHFYAK-VEVYYDQMSA-N Thr-Arg-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O JMZKMSTYXHFYAK-VEVYYDQMSA-N 0.000 description 2
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 2
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 2
- SHOMROOOQBDGRL-JHEQGTHGSA-N Thr-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SHOMROOOQBDGRL-JHEQGTHGSA-N 0.000 description 2
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 2
- YSXYEJWDHBCTDJ-DVJZZOLTSA-N Thr-Gly-Trp Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O YSXYEJWDHBCTDJ-DVJZZOLTSA-N 0.000 description 2
- XOWKUMFHEZLKLT-CIQUZCHMSA-N Thr-Ile-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O XOWKUMFHEZLKLT-CIQUZCHMSA-N 0.000 description 2
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 2
- ISLDRLHVPXABBC-IEGACIPQSA-N Thr-Leu-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISLDRLHVPXABBC-IEGACIPQSA-N 0.000 description 2
- UJQVSMNQMQHVRY-KZVJFYERSA-N Thr-Met-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O UJQVSMNQMQHVRY-KZVJFYERSA-N 0.000 description 2
- IWAVRIPRTCJAQO-HSHDSVGOSA-N Thr-Pro-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O IWAVRIPRTCJAQO-HSHDSVGOSA-N 0.000 description 2
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 2
- UKULIGGCYQMLJE-UHFFFAOYSA-N Trp Gly Tyr Ser Chemical compound C=1NC2=CC=CC=C2C=1CC(N)C(=O)NCC(=O)NC(C(=O)NC(CO)C(O)=O)CC1=CC=C(O)C=C1 UKULIGGCYQMLJE-UHFFFAOYSA-N 0.000 description 2
- QNTBGBCOEYNAPV-CWRNSKLLSA-N Trp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O QNTBGBCOEYNAPV-CWRNSKLLSA-N 0.000 description 2
- VEYXZZGMIBKXCN-UBHSHLNASA-N Trp-Asp-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N VEYXZZGMIBKXCN-UBHSHLNASA-N 0.000 description 2
- XZLHHHYSWIYXHD-XIRDDKMYSA-N Trp-Gln-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XZLHHHYSWIYXHD-XIRDDKMYSA-N 0.000 description 2
- YXONONCLMLHWJX-SZMVWBNQSA-N Trp-Glu-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 YXONONCLMLHWJX-SZMVWBNQSA-N 0.000 description 2
- YRSOERSDNRSCBC-XIRDDKMYSA-N Trp-His-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)N[C@@H](CS)C(=O)O)N YRSOERSDNRSCBC-XIRDDKMYSA-N 0.000 description 2
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 2
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 2
- JTMZSIRTZKLBOA-NWLDYVSISA-N Trp-Thr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O JTMZSIRTZKLBOA-NWLDYVSISA-N 0.000 description 2
- SEXRBCGSZRCIPE-LYSGOOTNSA-N Trp-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O SEXRBCGSZRCIPE-LYSGOOTNSA-N 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 2
- SDNVRAKIJVKAGS-LKTVYLICSA-N Tyr-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N SDNVRAKIJVKAGS-LKTVYLICSA-N 0.000 description 2
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 2
- CYDVHRFXDMDMGX-KKUMJFAQSA-N Tyr-Asn-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O CYDVHRFXDMDMGX-KKUMJFAQSA-N 0.000 description 2
- RCLOWEZASFJFEX-KKUMJFAQSA-N Tyr-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RCLOWEZASFJFEX-KKUMJFAQSA-N 0.000 description 2
- JWGXUKHIKXZWNG-RYUDHWBXSA-N Tyr-Gly-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O JWGXUKHIKXZWNG-RYUDHWBXSA-N 0.000 description 2
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 2
- PRONOHBTMLNXCZ-BZSNNMDCSA-N Tyr-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PRONOHBTMLNXCZ-BZSNNMDCSA-N 0.000 description 2
- BYAKMYBZADCNMN-JYJNAYRXSA-N Tyr-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYAKMYBZADCNMN-JYJNAYRXSA-N 0.000 description 2
- QFXVAFIHVWXXBJ-AVGNSLFASA-N Tyr-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O QFXVAFIHVWXXBJ-AVGNSLFASA-N 0.000 description 2
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 2
- HZDQUVQEVVYDDA-ACRUOGEOSA-N Tyr-Tyr-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HZDQUVQEVVYDDA-ACRUOGEOSA-N 0.000 description 2
- QVYFTFIBKCDHIE-ACRUOGEOSA-N Tyr-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O QVYFTFIBKCDHIE-ACRUOGEOSA-N 0.000 description 2
- 101150110932 US19 gene Proteins 0.000 description 2
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 2
- OUUBKKIJQIAPRI-LAEOZQHASA-N Val-Gln-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OUUBKKIJQIAPRI-LAEOZQHASA-N 0.000 description 2
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 2
- PMDOQZFYGWZSTK-LSJOCFKGSA-N Val-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C PMDOQZFYGWZSTK-LSJOCFKGSA-N 0.000 description 2
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 2
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 2
- AGXGCFSECFQMKB-NHCYSSNCSA-N Val-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N AGXGCFSECFQMKB-NHCYSSNCSA-N 0.000 description 2
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 2
- RWOGENDAOGMHLX-DCAQKATOSA-N Val-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N RWOGENDAOGMHLX-DCAQKATOSA-N 0.000 description 2
- UZFNHAXYMICTBU-DZKIICNBSA-N Val-Phe-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UZFNHAXYMICTBU-DZKIICNBSA-N 0.000 description 2
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 2
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 2
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 2
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 2
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 2
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 2
- 102000013529 alpha-Fetoproteins Human genes 0.000 description 2
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 230000009435 amidation Effects 0.000 description 2
- 238000007112 amidation reaction Methods 0.000 description 2
- 125000003368 amide group Chemical group 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 230000000340 anti-metabolite Effects 0.000 description 2
- 229940100197 antimetabolite Drugs 0.000 description 2
- 239000002256 antimetabolite Substances 0.000 description 2
- 108010013835 arginine glutamate Proteins 0.000 description 2
- 108010060035 arginylproline Proteins 0.000 description 2
- 150000001508 asparagines Chemical class 0.000 description 2
- 108010077245 asparaginyl-proline Proteins 0.000 description 2
- 238000003556 assay Methods 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 208000030303 breathing problems Diseases 0.000 description 2
- 238000009395 breeding Methods 0.000 description 2
- 230000001488 breeding effect Effects 0.000 description 2
- 239000007975 buffered saline Substances 0.000 description 2
- 239000001110 calcium chloride Substances 0.000 description 2
- 229910001628 calcium chloride Inorganic materials 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 235000012000 cholesterol Nutrition 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 229960002376 chymotrypsin Drugs 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 239000012141 concentrate Substances 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 108010004073 cysteinylcysteine Proteins 0.000 description 2
- 230000007812 deficiency Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 239000000412 dendrimer Substances 0.000 description 2
- 229920000736 dendritic polymer Polymers 0.000 description 2
- 230000006866 deterioration Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 235000005911 diet Nutrition 0.000 description 2
- 230000037213 diet Effects 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 231100000673 dose–response relationship Toxicity 0.000 description 2
- 239000003937 drug carrier Substances 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- CBOQJANXLMLOSS-UHFFFAOYSA-N ethyl vanillin Chemical compound CCOC1=CC(C=O)=CC=C1O CBOQJANXLMLOSS-UHFFFAOYSA-N 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 238000002594 fluoroscopy Methods 0.000 description 2
- 239000012537 formulation buffer Substances 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 102000018146 globin Human genes 0.000 description 2
- 150000004676 glycans Chemical class 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 2
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 2
- 108010077515 glycylproline Proteins 0.000 description 2
- 210000005003 heart tissue Anatomy 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 230000002519 immonomodulatory effect Effects 0.000 description 2
- 238000010166 immunofluorescence Methods 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 229960003444 immunosuppressant agent Drugs 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000008595 infiltration Effects 0.000 description 2
- 238000001764 infiltration Methods 0.000 description 2
- 210000004969 inflammatory cell Anatomy 0.000 description 2
- 230000004054 inflammatory process Effects 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 239000010954 inorganic particle Substances 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 102000028416 insulin-like growth factor binding Human genes 0.000 description 2
- 108091022911 insulin-like growth factor binding Proteins 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- NBQNWMBBSKPBAY-UHFFFAOYSA-N iodixanol Chemical compound IC=1C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C(I)C=1N(C(=O)C)CC(O)CN(C(C)=O)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C1I NBQNWMBBSKPBAY-UHFFFAOYSA-N 0.000 description 2
- 229960004359 iodixanol Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 238000006317 isomerization reaction Methods 0.000 description 2
- 238000005304 joining Methods 0.000 description 2
- 210000003292 kidney cell Anatomy 0.000 description 2
- 238000011031 large-scale manufacturing process Methods 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 2
- 108010012058 leucyltyrosine Proteins 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 238000004811 liquid chromatography Methods 0.000 description 2
- 239000006194 liquid suspension Substances 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 238000009593 lumbar puncture Methods 0.000 description 2
- 229940091827 lumizyme Drugs 0.000 description 2
- 230000000527 lymphocytic effect Effects 0.000 description 2
- 108010017391 lysylvaline Proteins 0.000 description 2
- 229910052943 magnesium sulfate Inorganic materials 0.000 description 2
- 235000019341 magnesium sulphate Nutrition 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 230000034217 membrane fusion Effects 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 238000002887 multiple sequence alignment Methods 0.000 description 2
- 201000000585 muscular atrophy Diseases 0.000 description 2
- 230000004770 neurodegeneration Effects 0.000 description 2
- 210000004498 neuroglial cell Anatomy 0.000 description 2
- 208000018360 neuromuscular disease Diseases 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 229920001778 nylon Polymers 0.000 description 2
- 238000001543 one-way ANOVA Methods 0.000 description 2
- 230000000399 orthopedic effect Effects 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 239000012188 paraffin wax Substances 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 2
- 108010084572 phenylalanyl-valine Proteins 0.000 description 2
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 229960000502 poloxamer Drugs 0.000 description 2
- 229940044519 poloxamer 188 Drugs 0.000 description 2
- 229920001451 polypropylene glycol Polymers 0.000 description 2
- 230000002335 preservative effect Effects 0.000 description 2
- 210000001938 protoplast Anatomy 0.000 description 2
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 2
- 238000003753 real-time PCR Methods 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 230000008929 regeneration Effects 0.000 description 2
- 238000011069 regeneration method Methods 0.000 description 2
- 101150066583 rep gene Proteins 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 238000002864 sequence alignment Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 229960002930 sirolimus Drugs 0.000 description 2
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 238000012289 standard assay Methods 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 210000002784 stomach Anatomy 0.000 description 2
- 210000002330 subarachnoid space Anatomy 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 239000000375 suspending agent Substances 0.000 description 2
- 230000002195 synergetic effect Effects 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 230000014616 translation Effects 0.000 description 2
- 230000014621 translational initiation Effects 0.000 description 2
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 2
- 108010020532 tyrosyl-proline Proteins 0.000 description 2
- 241000701447 unidentified baculovirus Species 0.000 description 2
- 125000002987 valine group Chemical group [H]N([H])C([H])(C(*)=O)C([H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 2
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 2
- 210000002845 virion Anatomy 0.000 description 2
- FFJCNSLCJOQHKM-CLFAGFIQSA-N (z)-1-[(z)-octadec-9-enoxy]octadec-9-ene Chemical compound CCCCCCCC\C=C/CCCCCCCCOCCCCCCCC\C=C/CCCCCCCC FFJCNSLCJOQHKM-CLFAGFIQSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- CHHHXKFHOYLYRE-UHFFFAOYSA-M 2,4-Hexadienoic acid, potassium salt (1:1), (2E,4E)- Chemical compound [K+].CC=CC=CC([O-])=O CHHHXKFHOYLYRE-UHFFFAOYSA-M 0.000 description 1
- JVKUCNQGESRUCL-UHFFFAOYSA-N 2-Hydroxyethyl 12-hydroxyoctadecanoate Chemical compound CCCCCCC(O)CCCCCCCCCCC(=O)OCCO JVKUCNQGESRUCL-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- ZVEUWSJUXREOBK-DKWTVANSSA-N 2-aminoacetic acid;(2s)-2-amino-3-hydroxypropanoic acid Chemical group NCC(O)=O.OC[C@H](N)C(O)=O ZVEUWSJUXREOBK-DKWTVANSSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- WXNZTHHGJRFXKQ-UHFFFAOYSA-N 4-chlorophenol Chemical compound OC1=CC=C(Cl)C=C1 WXNZTHHGJRFXKQ-UHFFFAOYSA-N 0.000 description 1
- HRPVXLWXLXDGHG-UHFFFAOYSA-N Acrylamide Chemical compound NC(=O)C=C HRPVXLWXLXDGHG-UHFFFAOYSA-N 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 241000202702 Adeno-associated virus - 3 Species 0.000 description 1
- 241000580270 Adeno-associated virus - 4 Species 0.000 description 1
- 241001634120 Adeno-associated virus - 5 Species 0.000 description 1
- 241000972680 Adeno-associated virus - 6 Species 0.000 description 1
- 206010067484 Adverse reaction Diseases 0.000 description 1
- VBDMWOKJZDCFJM-FXQIFTODSA-N Ala-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N VBDMWOKJZDCFJM-FXQIFTODSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- RXTBLQVXNIECFP-FXQIFTODSA-N Ala-Gln-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RXTBLQVXNIECFP-FXQIFTODSA-N 0.000 description 1
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 1
- LTSBJNNXPBBNDT-HGNGGELXSA-N Ala-His-Gln Chemical compound N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(=O)O LTSBJNNXPBBNDT-HGNGGELXSA-N 0.000 description 1
- OKEWAFFWMHBGPT-XPUUQOCRSA-N Ala-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 OKEWAFFWMHBGPT-XPUUQOCRSA-N 0.000 description 1
- FAJIYNONGXEXAI-CQDKDKBSSA-N Ala-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 FAJIYNONGXEXAI-CQDKDKBSSA-N 0.000 description 1
- NMXKFWOEASXOGB-QSFUFRPTSA-N Ala-Ile-His Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NMXKFWOEASXOGB-QSFUFRPTSA-N 0.000 description 1
- PIXQDIGKDNNOOV-GUBZILKMSA-N Ala-Lys-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O PIXQDIGKDNNOOV-GUBZILKMSA-N 0.000 description 1
- VHEVVUZDDUCAKU-FXQIFTODSA-N Ala-Met-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O VHEVVUZDDUCAKU-FXQIFTODSA-N 0.000 description 1
- DRARURMRLANNLS-GUBZILKMSA-N Ala-Met-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O DRARURMRLANNLS-GUBZILKMSA-N 0.000 description 1
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 1
- FQNILRVJOJBFFC-FXQIFTODSA-N Ala-Pro-Asp Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N FQNILRVJOJBFFC-FXQIFTODSA-N 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 1
- NKBQZKVMKJJDLX-SRVKXCTJSA-N Arg-Glu-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NKBQZKVMKJJDLX-SRVKXCTJSA-N 0.000 description 1
- HPSVTWMFWCHKFN-GARJFASQSA-N Arg-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O HPSVTWMFWCHKFN-GARJFASQSA-N 0.000 description 1
- PPPXVIBMLFWNSK-BQBZGAKWSA-N Arg-Gly-Cys Chemical compound C(C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N PPPXVIBMLFWNSK-BQBZGAKWSA-N 0.000 description 1
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 1
- YKZJPIPFKGYHKY-DCAQKATOSA-N Arg-Leu-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YKZJPIPFKGYHKY-DCAQKATOSA-N 0.000 description 1
- WKPXXXUSUHAXDE-SRVKXCTJSA-N Arg-Pro-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O WKPXXXUSUHAXDE-SRVKXCTJSA-N 0.000 description 1
- 108010051330 Arg-Pro-Gly-Pro Proteins 0.000 description 1
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 1
- RYQSYXFGFOTJDJ-RHYQMDGZSA-N Arg-Thr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RYQSYXFGFOTJDJ-RHYQMDGZSA-N 0.000 description 1
- ZPWMEWYQBWSGAO-ZJDVBMNYSA-N Arg-Thr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZPWMEWYQBWSGAO-ZJDVBMNYSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 208000002109 Argyria Diseases 0.000 description 1
- UGXVKHRDGLYFKR-CIUDSAMLSA-N Asn-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(N)=O UGXVKHRDGLYFKR-CIUDSAMLSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- MYCSPQIARXTUTP-SRVKXCTJSA-N Asn-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N MYCSPQIARXTUTP-SRVKXCTJSA-N 0.000 description 1
- BKFXFUPYETWGGA-XVSYOHENSA-N Asn-Phe-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BKFXFUPYETWGGA-XVSYOHENSA-N 0.000 description 1
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 1
- REQUGIWGOGSOEZ-ZLUOBGJFSA-N Asn-Ser-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N REQUGIWGOGSOEZ-ZLUOBGJFSA-N 0.000 description 1
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 1
- HCZQKHSRYHCPSD-IUKAMOBKSA-N Asn-Thr-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HCZQKHSRYHCPSD-IUKAMOBKSA-N 0.000 description 1
- VTYQAQFKMQTKQD-ACZMJKKPSA-N Asp-Ala-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O VTYQAQFKMQTKQD-ACZMJKKPSA-N 0.000 description 1
- AMRANMVXQWXNAH-ZLUOBGJFSA-N Asp-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC(O)=O AMRANMVXQWXNAH-ZLUOBGJFSA-N 0.000 description 1
- YNCHFVRXEQFPBY-BQBZGAKWSA-N Asp-Gly-Arg Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N YNCHFVRXEQFPBY-BQBZGAKWSA-N 0.000 description 1
- BIVYLQMZPHDUIH-WHFBIAKZSA-N Asp-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)O BIVYLQMZPHDUIH-WHFBIAKZSA-N 0.000 description 1
- VIRHEUMYXXLCBF-WDSKDSINSA-N Asp-Gly-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O VIRHEUMYXXLCBF-WDSKDSINSA-N 0.000 description 1
- KHGPWGKPYHPOIK-QWRGUYRKSA-N Asp-Gly-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KHGPWGKPYHPOIK-QWRGUYRKSA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- JNNVNVRBYUJYGS-CIUDSAMLSA-N Asp-Leu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O JNNVNVRBYUJYGS-CIUDSAMLSA-N 0.000 description 1
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 1
- NAAAPCLFJPURAM-HJGDQZAQSA-N Asp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O NAAAPCLFJPURAM-HJGDQZAQSA-N 0.000 description 1
- NVMMUAUTQCWYHD-ABHRYQDASA-N Asp-Val-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 NVMMUAUTQCWYHD-ABHRYQDASA-N 0.000 description 1
- 108091005658 Basic proteases Proteins 0.000 description 1
- 102000006734 Beta-Globulins Human genes 0.000 description 1
- 108010087504 Beta-Globulins Proteins 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 238000011740 C57BL/6 mouse Methods 0.000 description 1
- 101100421200 Caenorhabditis elegans sep-1 gene Proteins 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 1
- 208000031229 Cardiomyopathies Diseases 0.000 description 1
- 206010051093 Cardiopulmonary failure Diseases 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 101710163595 Chaperone protein DnaK Proteins 0.000 description 1
- 101100091691 Chlorobium chlorochromatii (strain CaD3) rpoA gene Proteins 0.000 description 1
- 102100039501 Chymotrypsinogen B Human genes 0.000 description 1
- 101710178550 Chymotrypsinogen B2 Proteins 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- XABFFGOGKOORCG-CIUDSAMLSA-N Cys-Asp-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XABFFGOGKOORCG-CIUDSAMLSA-N 0.000 description 1
- YUZPQIQWXLRFBW-ACZMJKKPSA-N Cys-Glu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O YUZPQIQWXLRFBW-ACZMJKKPSA-N 0.000 description 1
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 1
- UDDITVWSXPEAIQ-IHRRRGAJSA-N Cys-Phe-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UDDITVWSXPEAIQ-IHRRRGAJSA-N 0.000 description 1
- ZFHXNNXMNLWKJH-HJPIBITLSA-N Cys-Tyr-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZFHXNNXMNLWKJH-HJPIBITLSA-N 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- 125000002353 D-glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- 208000027219 Deficiency disease Diseases 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 101710091045 Envelope protein Proteins 0.000 description 1
- 241000283074 Equus asinus Species 0.000 description 1
- 108091029865 Exogenous DNA Proteins 0.000 description 1
- 206010015719 Exsanguination Diseases 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 101150115151 GAA gene Proteins 0.000 description 1
- 241001343649 Gaussia princeps (T. Scott, 1894) Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 206010018341 Gliosis Diseases 0.000 description 1
- FJAYYNIXQNERSO-ACZMJKKPSA-N Gln-Cys-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FJAYYNIXQNERSO-ACZMJKKPSA-N 0.000 description 1
- ZQPOVSJFBBETHQ-CIUDSAMLSA-N Gln-Glu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZQPOVSJFBBETHQ-CIUDSAMLSA-N 0.000 description 1
- PNENQZWRFMUZOM-DCAQKATOSA-N Gln-Glu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O PNENQZWRFMUZOM-DCAQKATOSA-N 0.000 description 1
- JEFZIKRIDLHOIF-BYPYZUCNSA-N Gln-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(O)=O JEFZIKRIDLHOIF-BYPYZUCNSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- QBLMTCRYYTVUQY-GUBZILKMSA-N Gln-Leu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QBLMTCRYYTVUQY-GUBZILKMSA-N 0.000 description 1
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 1
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 1
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 1
- NVHJGTGTUGEWCG-ZVZYQTTQSA-N Gln-Trp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O NVHJGTGTUGEWCG-ZVZYQTTQSA-N 0.000 description 1
- VYOILACOFPPNQH-UMNHJUIQSA-N Gln-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N VYOILACOFPPNQH-UMNHJUIQSA-N 0.000 description 1
- RLZBLVSJDFHDBL-KBIXCLLPSA-N Glu-Ala-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RLZBLVSJDFHDBL-KBIXCLLPSA-N 0.000 description 1
- RFDHKPSHTXZKLL-IHRRRGAJSA-N Glu-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N RFDHKPSHTXZKLL-IHRRRGAJSA-N 0.000 description 1
- NUSWUSKZRCGFEX-FXQIFTODSA-N Glu-Glu-Cys Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O NUSWUSKZRCGFEX-FXQIFTODSA-N 0.000 description 1
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 1
- CBWKURKPYSLMJV-SOUVJXGZSA-N Glu-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CBWKURKPYSLMJV-SOUVJXGZSA-N 0.000 description 1
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 1
- WIKMTDVSCUJIPJ-CIUDSAMLSA-N Glu-Ser-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WIKMTDVSCUJIPJ-CIUDSAMLSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- 102100022624 Glucoamylase Human genes 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 1
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 1
- ADZGCWWDPFDHCY-ZETCQYMHSA-N Gly-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 ADZGCWWDPFDHCY-ZETCQYMHSA-N 0.000 description 1
- SIYTVHWNKGIGMD-HOTGVXAUSA-N Gly-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)CN SIYTVHWNKGIGMD-HOTGVXAUSA-N 0.000 description 1
- COVXELOAORHTND-LSJOCFKGSA-N Gly-Ile-Val Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O COVXELOAORHTND-LSJOCFKGSA-N 0.000 description 1
- PAWIVEIWWYGBAM-YUMQZZPRSA-N Gly-Leu-Ala Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O PAWIVEIWWYGBAM-YUMQZZPRSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 1
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 1
- JYPCXBJRLBHWME-IUCAKERBSA-N Gly-Pro-Arg Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JYPCXBJRLBHWME-IUCAKERBSA-N 0.000 description 1
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 1
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 1
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 1
- 101710178376 Heat shock 70 kDa protein Proteins 0.000 description 1
- 101710152018 Heat shock cognate 70 kDa protein Proteins 0.000 description 1
- 101710153306 Hemoglobin subunit beta-1 Proteins 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 206010019842 Hepatomegaly Diseases 0.000 description 1
- WGVPDSNCHDEDBP-KKUMJFAQSA-N His-Asp-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WGVPDSNCHDEDBP-KKUMJFAQSA-N 0.000 description 1
- UPGJWSUYENXOPV-HGNGGELXSA-N His-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N UPGJWSUYENXOPV-HGNGGELXSA-N 0.000 description 1
- NTXIJPDAHXSHNL-ONGXEEELSA-N His-Gly-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NTXIJPDAHXSHNL-ONGXEEELSA-N 0.000 description 1
- MPXGJGBXCRQQJE-MXAVVETBSA-N His-Ile-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O MPXGJGBXCRQQJE-MXAVVETBSA-N 0.000 description 1
- QCBYAHHNOHBXIH-UWVGGRQHSA-N His-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CN=CN1 QCBYAHHNOHBXIH-UWVGGRQHSA-N 0.000 description 1
- KFQDSSNYWKZFOO-LSJOCFKGSA-N His-Val-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KFQDSSNYWKZFOO-LSJOCFKGSA-N 0.000 description 1
- 101000823116 Homo sapiens Alpha-1-antitrypsin Proteins 0.000 description 1
- 101000941029 Homo sapiens Endoplasmic reticulum junction formation protein lunapark Proteins 0.000 description 1
- 101000821100 Homo sapiens Synapsin-1 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- SHBUUTHKGIVMJT-UHFFFAOYSA-N Hydroxystearate Chemical compound CCCCCCCCCCCCCCCCCC(=O)OO SHBUUTHKGIVMJT-UHFFFAOYSA-N 0.000 description 1
- 206010021118 Hypotonia Diseases 0.000 description 1
- 102000038455 IGF Type 1 Receptor Human genes 0.000 description 1
- 108010031794 IGF Type 1 Receptor Proteins 0.000 description 1
- 102100029199 Iduronate 2-sulfatase Human genes 0.000 description 1
- 101710096421 Iduronate 2-sulfatase Proteins 0.000 description 1
- LOXMWQOKYBGCHF-JBDRJPRFSA-N Ile-Cys-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O LOXMWQOKYBGCHF-JBDRJPRFSA-N 0.000 description 1
- PDTMWFVVNZYWTR-NHCYSSNCSA-N Ile-Gly-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O PDTMWFVVNZYWTR-NHCYSSNCSA-N 0.000 description 1
- SAEWJTCJQVZQNZ-IUKAMOBKSA-N Ile-Thr-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SAEWJTCJQVZQNZ-IUKAMOBKSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000000521 Immunophilins Human genes 0.000 description 1
- 108010016648 Immunophilins Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102100026720 Interferon beta Human genes 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102000004889 Interleukin-6 Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- AYRXSINWFIIFAE-SCLMCMATSA-N Isomaltose Natural products OC[C@H]1O[C@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)[C@@H](O)[C@@H](O)[C@@H]1O AYRXSINWFIIFAE-SCLMCMATSA-N 0.000 description 1
- YQEZLKZALYSWHR-UHFFFAOYSA-N Ketamine Chemical compound C=1C=CC=C(Cl)C=1C1(NC)CCCCC1=O YQEZLKZALYSWHR-UHFFFAOYSA-N 0.000 description 1
- 238000012313 Kruskal-Wallis test Methods 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- LEVWYRKDKASIDU-IMJSIDKUSA-N L-cystine Chemical compound [O-]C(=O)[C@@H]([NH3+])CSSC[C@H]([NH3+])C([O-])=O LEVWYRKDKASIDU-IMJSIDKUSA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 244000147568 Laurus nobilis Species 0.000 description 1
- 235000017858 Laurus nobilis Nutrition 0.000 description 1
- 206010024264 Lethargy Diseases 0.000 description 1
- CUXRXAIAVYLVFD-ULQDDVLXSA-N Leu-Arg-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CUXRXAIAVYLVFD-ULQDDVLXSA-N 0.000 description 1
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 1
- ZFNLIDNJUWNIJL-WDCWCFNPSA-N Leu-Glu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZFNLIDNJUWNIJL-WDCWCFNPSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- XBCWOTOCBXXJDG-BZSNNMDCSA-N Leu-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 XBCWOTOCBXXJDG-BZSNNMDCSA-N 0.000 description 1
- KTOIECMYZZGVSI-BZSNNMDCSA-N Leu-Phe-His Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 KTOIECMYZZGVSI-BZSNNMDCSA-N 0.000 description 1
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 1
- BGGTYDNTOYRTTR-MEYUZBJRSA-N Leu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(C)C)N)O BGGTYDNTOYRTTR-MEYUZBJRSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- NFLFJGGKOHYZJF-BJDJZHNGSA-N Lys-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN NFLFJGGKOHYZJF-BJDJZHNGSA-N 0.000 description 1
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 1
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 238000000585 Mann–Whitney U test Methods 0.000 description 1
- GVIVXNFKJQFTCE-YUMQZZPRSA-N Met-Gly-Gln Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O GVIVXNFKJQFTCE-YUMQZZPRSA-N 0.000 description 1
- HSJIGJRZYUADSS-IHRRRGAJSA-N Met-Lys-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HSJIGJRZYUADSS-IHRRRGAJSA-N 0.000 description 1
- FAKYXUOUQCRGMO-FDARSICLSA-N Met-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCSC)N FAKYXUOUQCRGMO-FDARSICLSA-N 0.000 description 1
- 101710081079 Minor spike protein H Proteins 0.000 description 1
- 208000007379 Muscle Hypotonia Diseases 0.000 description 1
- 206010028570 Myelopathy Diseases 0.000 description 1
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 1
- 208000036110 Neuroinflammatory disease Diseases 0.000 description 1
- 208000008457 Neurologic Manifestations Diseases 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 102100030991 Nucleolar and spindle-associated protein 1 Human genes 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 238000013324 OneBac system Methods 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- MECSIDWUTYRHRJ-KKUMJFAQSA-N Phe-Asn-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O MECSIDWUTYRHRJ-KKUMJFAQSA-N 0.000 description 1
- UEXCHCYDPAIVDE-SRVKXCTJSA-N Phe-Asp-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UEXCHCYDPAIVDE-SRVKXCTJSA-N 0.000 description 1
- HNFUGJUZJRYUHN-JSGCOSHPSA-N Phe-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HNFUGJUZJRYUHN-JSGCOSHPSA-N 0.000 description 1
- FXYXBEZMRACDDR-KKUMJFAQSA-N Phe-His-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O FXYXBEZMRACDDR-KKUMJFAQSA-N 0.000 description 1
- VADLTGVIOIOKGM-BZSNNMDCSA-N Phe-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CN=CN1 VADLTGVIOIOKGM-BZSNNMDCSA-N 0.000 description 1
- FXPZZKBHNOMLGA-HJWJTTGWSA-N Phe-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N FXPZZKBHNOMLGA-HJWJTTGWSA-N 0.000 description 1
- BYAIIACBWBOJCU-URLPEUOOSA-N Phe-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BYAIIACBWBOJCU-URLPEUOOSA-N 0.000 description 1
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- SRILZRSXIKRGBF-HRCADAONSA-N Phe-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N SRILZRSXIKRGBF-HRCADAONSA-N 0.000 description 1
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 1
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 1
- JLDZQPPLTJTJLE-IHPCNDPISA-N Phe-Trp-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CC(=O)O)C(=O)O)N JLDZQPPLTJTJLE-IHPCNDPISA-N 0.000 description 1
- DXWNFNOPBYAFRM-IHRRRGAJSA-N Phe-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N DXWNFNOPBYAFRM-IHRRRGAJSA-N 0.000 description 1
- 102000012288 Phosphopyruvate Hydratase Human genes 0.000 description 1
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 1
- 241000364051 Pima Species 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 229920001214 Polysorbate 60 Polymers 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 1
- XKHCJJPNXFBADI-DCAQKATOSA-N Pro-Asp-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O XKHCJJPNXFBADI-DCAQKATOSA-N 0.000 description 1
- FISHYTLIMUYTQY-GUBZILKMSA-N Pro-Gln-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 FISHYTLIMUYTQY-GUBZILKMSA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 1
- STASJMBVVHNWCG-IHRRRGAJSA-N Pro-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 STASJMBVVHNWCG-IHRRRGAJSA-N 0.000 description 1
- HATVCTYBNCNMAA-AVGNSLFASA-N Pro-Leu-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O HATVCTYBNCNMAA-AVGNSLFASA-N 0.000 description 1
- XYAFCOJKICBRDU-JYJNAYRXSA-N Pro-Phe-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O XYAFCOJKICBRDU-JYJNAYRXSA-N 0.000 description 1
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 1
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 1
- AIOWVDNPESPXRB-YTWAJWBKSA-N Pro-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2)O AIOWVDNPESPXRB-YTWAJWBKSA-N 0.000 description 1
- JRBWMRUPXWPEID-JYJNAYRXSA-N Pro-Trp-Cys Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CS)C(=O)O)C(=O)[C@@H]1CCCN1 JRBWMRUPXWPEID-JYJNAYRXSA-N 0.000 description 1
- QMABBZHZMDXHKU-FKBYEOEOSA-N Pro-Tyr-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O QMABBZHZMDXHKU-FKBYEOEOSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000002067 Protein Subunits Human genes 0.000 description 1
- 108010001267 Protein Subunits Proteins 0.000 description 1
- 101710136297 Protein VP2 Proteins 0.000 description 1
- 101710188315 Protein X Proteins 0.000 description 1
- 108091030071 RNAI Proteins 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 241001068295 Replication defective viruses Species 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 1
- NLQUOHDCLSFABG-GUBZILKMSA-N Ser-Arg-Arg Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NLQUOHDCLSFABG-GUBZILKMSA-N 0.000 description 1
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 1
- NRCJWSGXMAPYQX-LPEHRKFASA-N Ser-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CO)N)C(=O)O NRCJWSGXMAPYQX-LPEHRKFASA-N 0.000 description 1
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 1
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 1
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- UIIMBOGNXHQVGW-DEQYMQKBSA-M Sodium bicarbonate-14C Chemical compound [Na+].O[14C]([O-])=O UIIMBOGNXHQVGW-DEQYMQKBSA-M 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- ABBQHOQBGMUPJH-UHFFFAOYSA-M Sodium salicylate Chemical compound [Na+].OC1=CC=CC=C1C([O-])=O ABBQHOQBGMUPJH-UHFFFAOYSA-M 0.000 description 1
- 229920001304 Solutol HS 15 Polymers 0.000 description 1
- 206010058907 Spinal deformity Diseases 0.000 description 1
- 101710172711 Structural protein Proteins 0.000 description 1
- 102000017299 Synapsin-1 Human genes 0.000 description 1
- 108050005241 Synapsin-1 Proteins 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 1
- 235000005212 Terminalia tomentosa Nutrition 0.000 description 1
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 1
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 1
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 1
- YUOCMLNTUZAGNF-KLHWPWHYSA-N Thr-His-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N)O YUOCMLNTUZAGNF-KLHWPWHYSA-N 0.000 description 1
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 1
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- WVVOFCVMHAXGLE-LFSVMHDDSA-N Thr-Phe-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O WVVOFCVMHAXGLE-LFSVMHDDSA-N 0.000 description 1
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 1
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- NDLHSJWPCXKOGG-VLCNGCBASA-N Thr-Trp-Tyr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N)O NDLHSJWPCXKOGG-VLCNGCBASA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- TWJDQTTXXZDJKV-BPUTZDHNSA-N Trp-Arg-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O TWJDQTTXXZDJKV-BPUTZDHNSA-N 0.000 description 1
- PHNBFZBKLWEBJN-BPUTZDHNSA-N Trp-Glu-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PHNBFZBKLWEBJN-BPUTZDHNSA-N 0.000 description 1
- DZIKVMCFXIIETR-JSGCOSHPSA-N Trp-Gly-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O DZIKVMCFXIIETR-JSGCOSHPSA-N 0.000 description 1
- ARKBYVBCEOWRNR-UBHSHLNASA-N Trp-Ser-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O ARKBYVBCEOWRNR-UBHSHLNASA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- YGKVNUAKYPGORG-AVGNSLFASA-N Tyr-Asp-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YGKVNUAKYPGORG-AVGNSLFASA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- GULIUBBXCYPDJU-CQDKDKBSSA-N Tyr-Leu-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CC1=CC=C(O)C=C1 GULIUBBXCYPDJU-CQDKDKBSSA-N 0.000 description 1
- HRHYJNLMIJWGLF-BZSNNMDCSA-N Tyr-Ser-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 HRHYJNLMIJWGLF-BZSNNMDCSA-N 0.000 description 1
- 101150044878 US18 gene Proteins 0.000 description 1
- 101150114976 US21 gene Proteins 0.000 description 1
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 1
- UBTBGUDNDFZLGP-SRVKXCTJSA-N Val-Arg-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UBTBGUDNDFZLGP-SRVKXCTJSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 1
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 1
- USLVEJAHTBLSIL-CYDGBPFRSA-N Val-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C USLVEJAHTBLSIL-CYDGBPFRSA-N 0.000 description 1
- AJNUKMZFHXUBMK-GUBZILKMSA-N Val-Ser-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N AJNUKMZFHXUBMK-GUBZILKMSA-N 0.000 description 1
- GTACFKZDQFTVAI-STECZYCISA-N Val-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 GTACFKZDQFTVAI-STECZYCISA-N 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 210000003815 abdominal wall Anatomy 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000006838 adverse reaction Effects 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001412 amines Chemical group 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 239000003957 anion exchange resin Substances 0.000 description 1
- 210000002159 anterior chamber Anatomy 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 229940045719 antineoplastic alkylating agent nitrosoureas Drugs 0.000 description 1
- 239000003972 antineoplastic antibiotic Substances 0.000 description 1
- 229940045985 antineoplastic platinum compound Drugs 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 208000037875 astrocytosis Diseases 0.000 description 1
- 230000007341 astrogliosis Effects 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 230000006472 autoimmune response Effects 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 229940125717 barbiturate Drugs 0.000 description 1
- HNYOPLTXPVRDBG-UHFFFAOYSA-N barbituric acid Chemical compound O=C1CC(=O)NC(=O)N1 HNYOPLTXPVRDBG-UHFFFAOYSA-N 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000008499 blood brain barrier function Effects 0.000 description 1
- 210000001218 blood-brain barrier Anatomy 0.000 description 1
- 210000000133 brain stem Anatomy 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000007623 carbamidomethylation reaction Methods 0.000 description 1
- 235000011089 carbon dioxide Nutrition 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 108091092356 cellular DNA Proteins 0.000 description 1
- 230000004700 cellular uptake Effects 0.000 description 1
- 230000002490 cerebral effect Effects 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 238000005660 chlorination reaction Methods 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 210000003703 cisterna magna Anatomy 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 230000035071 co-translational protein modification Effects 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000010835 comparative analysis Methods 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 239000003636 conditioned culture medium Substances 0.000 description 1
- 239000000562 conjugate Substances 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 230000008602 contraction Effects 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- 238000011262 co‐therapy Methods 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 229960003067 cystine Drugs 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- CFCUWKMKBJTWLW-UHFFFAOYSA-N deoliosyl-3C-alpha-L-digitoxosyl-MTM Natural products CC=1C(O)=C2C(O)=C3C(=O)C(OC4OC(C)C(O)C(OC5OC(C)C(O)C(OC6OC(C)C(O)C(C)(O)C6)C5)C4)C(C(OC)C(=O)C(O)C(C)O)CC3=CC2=CC=1OC(OC(C)C1O)CC1OC1CC(O)C(O)C(C)O1 CFCUWKMKBJTWLW-UHFFFAOYSA-N 0.000 description 1
- 229960003964 deoxycholic acid Drugs 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- HRLIOXLXPOHXTA-NSHDSACASA-N dexmedetomidine Chemical compound C1([C@@H](C)C=2C(=C(C)C=CC=2)C)=CN=C[N]1 HRLIOXLXPOHXTA-NSHDSACASA-N 0.000 description 1
- 229960004253 dexmedetomidine Drugs 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 229940061607 dibasic sodium phosphate Drugs 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 238000007847 digital PCR Methods 0.000 description 1
- BNIILDVGGAEEIG-UHFFFAOYSA-L disodium hydrogen phosphate Chemical compound [Na+].[Na+].OP([O-])([O-])=O BNIILDVGGAEEIG-UHFFFAOYSA-L 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 238000002330 electrospray ionisation mass spectrometry Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000003366 endpoint assay Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- 229940073505 ethyl vanillin Drugs 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 239000013020 final formulation Substances 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 230000009368 gene silencing by RNA Effects 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 125000005456 glyceride group Chemical group 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 229960005150 glycerol Drugs 0.000 description 1
- 208000007345 glycogen storage disease Diseases 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 1
- 239000011544 gradient gel Substances 0.000 description 1
- 210000002064 heart cell Anatomy 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 102000051631 human SERPINA1 Human genes 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 229940072106 hydroxystearate Drugs 0.000 description 1
- 206010020871 hypertrophic cardiomyopathy Diseases 0.000 description 1
- 230000009851 immunogenic response Effects 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000012744 immunostaining Methods 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000001861 immunosuppressant effect Effects 0.000 description 1
- 229940125721 immunosuppressive agent Drugs 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000012750 in vivo screening Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000028709 inflammatory response Effects 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 239000003999 initiator Substances 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 108091009639 insulin receptor binding proteins Proteins 0.000 description 1
- 229940100601 interleukin-6 Drugs 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000005468 ion implantation Methods 0.000 description 1
- DLRVVLDZNNYCBX-RTPHMHGBSA-N isomaltose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)C(O)O1 DLRVVLDZNNYCBX-RTPHMHGBSA-N 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 230000000155 isotopic effect Effects 0.000 description 1
- 229960003299 ketamine Drugs 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 239000012160 loading buffer Substances 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 101710121537 mRNA (guanine-N(7))-methyltransferase Proteins 0.000 description 1
- 239000003120 macrolide antibiotic agent Substances 0.000 description 1
- 229940041033 macrolides Drugs 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 239000002122 magnetic nanoparticle Substances 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000005399 mechanical ventilation Methods 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical class ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 239000000693 micelle Substances 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 230000020763 muscle atrophy Effects 0.000 description 1
- 230000004220 muscle function Effects 0.000 description 1
- 238000009608 myelography Methods 0.000 description 1
- 229940103023 myozyme Drugs 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 239000002077 nanosphere Substances 0.000 description 1
- 230000007830 nerve conduction Effects 0.000 description 1
- 230000000955 neuroendocrine Effects 0.000 description 1
- 230000003959 neuroinflammation Effects 0.000 description 1
- 230000000926 neurological effect Effects 0.000 description 1
- 230000002981 neuropathic effect Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 229940005483 opioid analgesics Drugs 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 239000003002 pH adjusting agent Substances 0.000 description 1
- 229940090668 parachlorophenol Drugs 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 238000012510 peptide mapping method Methods 0.000 description 1
- 230000010412 perfusion Effects 0.000 description 1
- 229960003742 phenol Drugs 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 238000000554 physical therapy Methods 0.000 description 1
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Substances [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 1
- 150000003058 platinum compounds Chemical class 0.000 description 1
- 229960003171 plicamycin Drugs 0.000 description 1
- 229920001606 poly(lactic acid-co-glycolic acid) Polymers 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 229920000575 polymersome Polymers 0.000 description 1
- 229920000193 polymethacrylate Polymers 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 239000001103 potassium chloride Substances 0.000 description 1
- 235000011164 potassium chloride Nutrition 0.000 description 1
- 235000010241 potassium sorbate Nutrition 0.000 description 1
- 239000004302 potassium sorbate Substances 0.000 description 1
- 229940069338 potassium sorbate Drugs 0.000 description 1
- 230000003334 potential effect Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000007101 progressive neurodegeneration Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 235000010388 propyl gallate Nutrition 0.000 description 1
- 239000000473 propyl gallate Substances 0.000 description 1
- 229940075579 propyl gallate Drugs 0.000 description 1
- 108010053400 protease Ci Proteins 0.000 description 1
- 230000020978 protein processing Effects 0.000 description 1
- 238000001243 protein synthesis Methods 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 238000004725 rapid separation liquid chromatography Methods 0.000 description 1
- 238000001525 receptor binding assay Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000000611 regression analysis Methods 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 101150037064 rpoA gene Proteins 0.000 description 1
- 239000010979 ruby Substances 0.000 description 1
- 229910001750 ruby Inorganic materials 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229960005480 sodium caprylate Drugs 0.000 description 1
- 229910000029 sodium carbonate Inorganic materials 0.000 description 1
- FHHPUSMSKHSNKW-SMOYURAASA-M sodium deoxycholate Chemical compound [Na+].C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC([O-])=O)C)[C@@]2(C)[C@@H](O)C1 FHHPUSMSKHSNKW-SMOYURAASA-M 0.000 description 1
- 229940023144 sodium glycolate Drugs 0.000 description 1
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 1
- BYKRNSHANADUFY-UHFFFAOYSA-M sodium octanoate Chemical compound [Na+].CCCCCCCC([O-])=O BYKRNSHANADUFY-UHFFFAOYSA-M 0.000 description 1
- 229960004025 sodium salicylate Drugs 0.000 description 1
- JAJWGJBVLPIOOH-IZYKLYLVSA-M sodium taurocholate Chemical compound [Na+].C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(=O)NCCS([O-])(=O)=O)C)[C@@]2(C)[C@@H](O)C1 JAJWGJBVLPIOOH-IZYKLYLVSA-M 0.000 description 1
- FIWQZURFGYXCEO-UHFFFAOYSA-M sodium;decanoate Chemical compound [Na+].CCCCCCCCCC([O-])=O FIWQZURFGYXCEO-UHFFFAOYSA-M 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 238000007447 staining method Methods 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 238000005728 strengthening Methods 0.000 description 1
- 239000012609 strong anion exchange resin Substances 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 229940044609 sulfur dioxide Drugs 0.000 description 1
- 235000010269 sulphur dioxide Nutrition 0.000 description 1
- 230000003319 supportive effect Effects 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 238000012385 systemic delivery Methods 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 229960001967 tacrolimus Drugs 0.000 description 1
- QJJXYPPXXYFBGM-SHYZHZOCSA-N tacrolimus Natural products CO[C@H]1C[C@H](CC[C@@H]1O)C=C(C)[C@H]2OC(=O)[C@H]3CCCCN3C(=O)C(=O)[C@@]4(O)O[C@@H]([C@H](C[C@H]4C)OC)[C@@H](C[C@H](C)CC(=C[C@@H](CC=C)C(=O)C[C@H](O)[C@H]2C)C)OC QJJXYPPXXYFBGM-SHYZHZOCSA-N 0.000 description 1
- 238000004885 tandem mass spectrometry Methods 0.000 description 1
- 238000011287 therapeutic dose Methods 0.000 description 1
- 210000002303 tibia Anatomy 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 108091006107 transcriptional repressors Proteins 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 238000013520 translational research Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 229920000428 triblock copolymer Polymers 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- PIEPQKCYPFFYMG-UHFFFAOYSA-N tris acetate Chemical compound CC(O)=O.OCC(N)(CO)CO PIEPQKCYPFFYMG-UHFFFAOYSA-N 0.000 description 1
- JEJAMASKDTUEBZ-UHFFFAOYSA-N tris(1,1,3-tribromo-2,2-dimethylpropyl) phosphate Chemical compound BrCC(C)(C)C(Br)(Br)OP(=O)(OC(Br)(Br)C(C)(C)CBr)OC(Br)(Br)C(C)(C)CBr JEJAMASKDTUEBZ-UHFFFAOYSA-N 0.000 description 1
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 238000004704 ultra performance liquid chromatography Methods 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 230000002477 vacuolizing effect Effects 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images









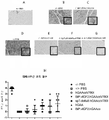
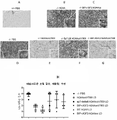








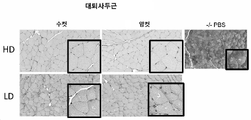
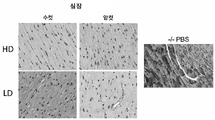


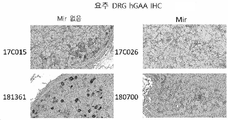




















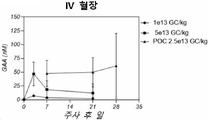
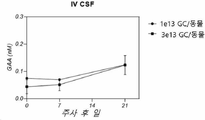


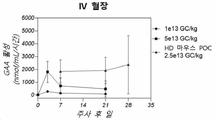

































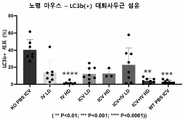


Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
- A61K48/0066—Manipulation of the nucleic acid to modify its expression pattern, e.g. enhance its duration of expression, achieved by the presence of particular introns in the delivered nucleic acid
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/18—Growth factors; Growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/43—Enzymes; Proenzymes; Derivatives thereof
- A61K38/46—Hydrolases (3)
- A61K38/47—Hydrolases (3) acting on glycosyl compounds (3.2), e.g. cellulases, lactases
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/65—Insulin-like growth factors (Somatomedins), e.g. IGF-1, IGF-2
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y302/00—Hydrolases acting on glycosyl compounds, i.e. glycosylases (3.2)
- C12Y302/01—Glycosidases, i.e. enzymes hydrolysing O- and S-glycosyl compounds (3.2.1)
- C12Y302/0102—Alpha-glucosidase (3.2.1.20)
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/07—Animals genetically altered by homologous recombination
- A01K2217/075—Animals genetically altered by homologous recombination inducing loss of function, i.e. knock out
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/0306—Animal model for genetic diseases
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14171—Demonstrated in vivo effect
Abstract
본원에서는 폼페병으로 진단 받았거나 폼페병에 걸린 것으로 의심되는 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는 방법이 제공된다. 상기 방법은 AAV 캡시드 및 이에 패키징된 벡터 게놈을 갖는 재조합 AAV (rAAV)를 환자에게 투여하는 것을 포함하고, 여기서 벡터 게놈은 (a) 5' 역전된 말단 반복서열 (ITR); (b) 프로모터; (c) 신호 펩티드 및 인간 산-α-글루코시다제 (hGAA)에 융합된 vIGF2 펩티드를 포함하는 키메라 융합 단백질을 인코딩하는 뉴클레오티드 서열; (d) 폴리 A; 및 (e) 3' ITR을 포함한다. 또한, 폼페병에 걸리거나 폼페병에 걸린 것으로 의심되는 환자를 치료하는데 사용하기 위한 본원에 기술된 rAAV를 포함하는 약제학적 조성물이 제공된다.
Description
제 Ⅱ형 글리코겐증으로도 알려진 폼페병은 심장 (심근병증), 근육, 및 운동 뉴런 (신경근육 질환)의 글리코겐 축적을 유도하는 산-α-글루코시다제 (GAA) 유전자의 돌연변이에 의해 유발된 리소좀 축적 질환이다. 고전적인 유아 폼페병에서, 심각한 GAA 활성 손실은 특히 심장 및 근육 내의 다계통 및 조기 발병 글리코겐 축적, 및 심폐 부전으로 인한 처음 수년 내 사망을 유발시킨다. 또한, 유아 폼페병은 뉴런 (특히, 운동 뉴런) 및 아교세포 내의 현저한 글리코겐 축적을 특징으로 한다. 현재의 치료 기준, 효소 대체 요법 (ERT)은 근육을 교정하는데 최적 이 하의 효율을 갖으며, 혈액-뇌 장벽을 통과할 수 없어 고전적인 영아 폼페병의 장기 생존자에서 진행성 신경 퇴화로 이어진다. 심장 교정에 의해 더 오래 생존한 ERT로 치료 받은 환자는 진행성 신경학적 표현형을 갖는 새로운 자연 병력을 드러낸다. 추가적으로, 재조합 인간 GAA는 면역원성이 높으며 골격근에 의한 흡수 불량으로 인해 매우 많은 정량이 투약되어야 한다.
폼페병의 치료를 위해, 질환의 CNS 구성요소의 교정에 대한 필요성, 근육 교정 개선에 대한 필요성, 및 현재의 ERT보다 효능이 더 크고/거나 면역원성이 더 적고/거나 더 간편한 대안에 대한 필요성을 포함하여, 여러 충족되지 않은 요구가 있다.
일 양태에서, 본원에서는 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는 방법으로서, 환자는 폼페병으로 진단 받았거나 폼페병에 걸린 것으로 의심되고, 방법은 환자에게 AAV 캡시드 및 이에 패키징된 벡터 게놈을 갖는 재조합 AAV (rAAV)를 투여하는 것을 포함하고, 여기서 벡터 게놈은 (a) 5' 역전된 말단 반복서열 (ITR); (b) 프로모터; (c) 신호 펩티드 및 인간 산-α-글루코시다제 (hGAA)에 융합된 vIGF2 펩티드를 포함하는 키메라 융합 단백질을 인코딩하는 뉴클레오티드 서열로서, 키메라 융합 단백질을 인코딩하는 서열은 이의 발현을 구동하는 조절 서열에 작동가능하게 연결되고, 서열번호 6의 아미노산 1번 내지 982번을 인코딩하는 서열번호 7 또는 이와 적어도 95% 일치하는 서열을 포함하는, 서열; (d) 폴리 A; 및 (e) 3' ITR을 포함하는, 방법이 제공된다. 특정 구현예에서, 프로모터는 전신발현 프로모터, 선택적으로 CAG 프로모터 또는 CB7 프로모터이다. 특정 구현예에서, 비정상 근육 병리는 (i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 한다. 특정 구현예에서, 환자는 후기 발병 폼페병을 갖는다. 특정 구현예에서, 환자는 유아 발병 폼페병을 갖는다. 특정 구현예에서, 벡터 게놈은 miR 표적 서열을 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개 또는 적어도 8개 추가로 포함하고, 선택적으로 miR 표적 서열 각각은 miR-183에 특이적이다. 특정 구현예에서, AAV 캡시드는 AAVhu68 캡시드이다. 특정 구현예에서, rAAV는 정맥내로 및/또는 경막내로 투여된다. 특정 구현예에서, rAAV는 환자에게 이중 투여 경로를 통해 투여되고, 선택적으로 이중 경로는 정맥내 투여 및 대수조내 (ICM) 투여이다.
일 양태에서, 본원에서는 AAV 캡시드 및 이에 패키징된 벡터 게놈을 갖는 재조합 AAV (rAAV)를 포함하는 약제학적 조성물로서, 벡터 게놈은 (a) 5' 역전된 말단 반복서열 (ITR); (b) 프로모터; (c) 신호 펩티드 및 인간 산-α-글루코시다제 (hGAA)에 융합된 vIGF2 펩티드를 포함하는 키메라 융합 단백질을 인코딩하는 뉴클레오티드 서열로서, 키메라 융합 단백질을 인코딩하는 서열은 이의 발현을 구동하는 조절 서열에 작동가능하게 연결되고, 서열번호 6의 아미노산 1번 내지 982번을 인코딩하는 서열번호 7 또는 이와 적어도 95% 일치하는 서열을 포함하는, 서열; (d) 폴리 A; 및 (e) 3' ITR을 포함하는, 약제학적 조성물이 제공된다. 특정 구현예에서, 프로모터는 전신발현 프로모터, 선택적으로 CAG 프로모터 또는 CB7 프로모터이다. 특정 구현예에서, 벡터 게놈은 miR 표적 서열을 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개 또는 적어도 8개 추가로 포함하고, 선택적으로 miR 표적 서열 각각은 miR-183에 특이적이다. 특정 구현예에서, AV 캡시드는 AAVhu68 캡시드이다. 특정 구현예에서, 조성물은 정맥내 및/또는 경막내 전달을 위해 제형되된다.
일 양태에서, 본원에서는 폼페병에 걸린 환자의 치료에 사용되는 약제학적 조성물로서, 치료가 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는, 약제학적 조성물이 제공된다. 특정 구현예에서, 비정상 근육 병리는 i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 한다. 특정 구현예에서, 환자는 후기 발병 폼페병을 갖는다. 특정 구현예에서, 환자는 유아 발병 폼페병을 갖는다. 특정 구현예에서, rAAV는 환자에게 이중 투여 경로를 통해 투여되고, 선택적으로 이중 경로는 정맥내 투여 및 대수조내 (ICM) 투여이다.
일 양태에서, 본원에 제공된 약제학적 조성물은 폼페병으로 진단 받았던 증상 이후의 환자에게 투여에 적합하다. 특정 구현예에서, 조성물은 폼페병에 걸린 증상 이후의 환자에서 비정상 근육 병리를 역전시키는데 적합하다. 특정 구현예에서, 비정상 근육 병리는 i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 한다. 특정 구현예에서, 약제학적 조성물은 보조요법으로 사용하기에 적합하고, 선택적으로 환자가 기관지 확장제, 아세틸콜린 에스테라제 저해제, 호흡기 근육 강도 훈련 (RMST), 효소 대체 요법 및/또는 횡격막 조율 요법으로의 치료를 추가로 받는 것을 특징으로 한다.
일 양태에서, 본원에 기술된 rAAV를 투여하여 본원에 제공된 이를 필요로 하는 환자에서 폼페병을 치료하는 것을 포함하는 약제학적 조성물의 용도로서, 치료가 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는, 용도가 제공된다.
본 발명의 다른 양태 및 장점은 본 발명의 하기 상세한 설명으로부터 쉽게 자명해질 것이다.
도 1a 및 도 1b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I (서열번호 4)에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 간에서의 hGAA 활성을 나타낸다. (도 1a) 저-용량 (1×1011개 GC). (도 1b) 고-용량 (1×1012개).
도 2a 및 도 2b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 심장에서의 hGAA 활성을 나타낸다. (도 2a) 저-용량 (1×1011개 GC). (도 2b) 고-용량 (1×1012개).
도 3a 및 도 3b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 골격근 (대퇴사두근)에서의 hGAA 활성을 나타낸다. (도 3a) 저용량 (1×1011개 GC). (도 3b) 고용량 (1×1012개).
도 4a 및 도 4b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 뇌에서의 hGAA 활성을 나타낸다. (도 4a) 저-용량 (1×1011개 GC). (도 4b) 고-용량 (1×1012개). CB7 활성 하에 발현하는 벡터는 두 가지 용량 모두에서 더 낮은 활성을 갖는 반면, CAG 또는 UbC 프로모터 하에 발현하는 벡터는 더 높은 용량에서 비슷한 활성을 갖는다.
도 5a 내지 도 5h는 AAVhu68.hGAA의 전달 4주 후 폼페병 마우스에서 심장의 조직학 (PAS 염색이 글리코겐 축적을 나타냄)을 나타낸다. 5가지 상이한 hGAA 발현 카세트를 포함하는 rAAVhu68 벡터를 생성하고 평가하였다. 비히클 대조군 폼페병 (-/-) (도 5D) 및 야생형 (+/+) (도 5A) 마우스는 PBS 주사를 수여받았다. "hGAA"는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩되는 기준 천연 효소 (hGAAV780)를 말한다 (도 5b). "BiP-vIGF2.hGAAco"는 처음 35개 아미노산의 결실을 포함하고, BiP 신호 펩티드 및 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와의 융합을 추가로 갖는 기준 hGAAV780 단백질에 대한 조작된 코딩 서열을 말한다 (도 5c). 비히클 처리된 대조군으로부터의 영상 (도 5d). "hGAAcoV780I"는 조작된 서열에 의해 인코딩되고 고유한 신호 펩티드를 포함하는 hGAAV780I 변이체를 말한다 (도 5e). "BiP-vIGF2.hGAAcoV780I"는 처음 35개 아미노산의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드 및 조작된 서열에 의해 인코딩되는 hGAAV780I를 추가로 갖는 hGAAcoV780I를 말한다 (도 5f). "Sp7.Δ8.hGAAcoV780I"는 이전 구조물과 동일한 조작된 서열에 의해 인코딩되는 처음 35개 아미노산의 결실이 있지만 고유한 신호 펩티드 대신에 B2 키모트립시노겐 신호 펩티드를 인코딩하는 서열을 포함하는 hGAAV780I 변이체를 말한다 (도 5g). 맹검 조직병리학 반-정량적 중증도 점수매김. 공인 수의 병리학자는 맹검 방식으로 슬라이드를 검토하고 글리코겐 축적 및 자가포식 구축을 기반으로 중증도 점수를 설정하였다 (도 5h).
도 6a 내지 도 6h는 다양한 hGAA를 인코딩하는 AAVhu68 (2.5×1013개 GC/㎏)의 투여 4주 후 폼페병 마우스에서 대퇴사두근 조직학의 결과 (PAS 염색)를 나타낸다. 대조군 폼페병 (-/-) (도 6d) 및 야생형 (+/+) (도 6a) 마우스는 PBS 주사를 수여받았다. "hGAA"는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩되는 기준 천연 효소 (hGAAV780)를 말한다 (도 6b). "hGAAcoV780I"는 조작된 서열에 의해 인코딩되고 고유한 신호 펩티드를 포함하는 hGAAV780I 변이체를 말한다 (도 6e). "Sp7.Δ8.hGAAcoV780I"는 이전 구조물과 동일한 조작된 서열에 의해 인코딩되는 처음 35개 아미노산의 결실이 있지만 고유한 신호 펩티드 대신에 B2 키모트립시노겐 신호 펩티드를 인코딩하는 서열을 포함하는 hGAAV780I 변이체를 말한다 (도 6f). "BiP-vIGF2.hGAAco"는 처음 35개 아미노산의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖고 조작된 서열에 의해 인코딩되는 기준 hGAAV780을 말한다 (도 6c). "BiP-vIGF2.hGAAcoV780I"는 처음 35개 아미노산의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖고, 조작된 서열에 의해 인코딩되는 hGAAV780I를 말한다 (도 6g). 맹검 조직병리학 반-정량적 중증도 점수매김. 공인 수의 병리학자는 맹검 방식으로 슬라이드를 검토하고 글리코겐 축적 및 자가포식 구축을 기반으로 중증도 점수를 설정하였다. 0점은 병변이 없음을 의미하고; 1점은 평균적으로 저장에 의해 이환된 근육 섬유의 9% 미만을 의미하며; 2점은 10% 내지 49%를 의미하고; 3점은 50% 내지 75%를 의미하며; 4점은 76% 내지 100%를 의미한다 (도 6h).
도 7a 내지 도 7h는 2.5×1012개 GC/㎏ (즉, 도 6a 내지 도 6h에서보다 10배 더 적은 용량)의 다양한 hGAA를 인코딩하는 AAVhu68의 투여 4주 후 폼페병 마우스로부터의 대퇴사두근 조직학의 결과 (과요오드산-쉬프 (PAS) 염색)를 나타낸다. 대조군 폼페병 (-/-) (도 7d) 및 야생형 (+/+) (도 7a) 마우스는 PBS 주사를 수여받았다. "hGAA"는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩되는 기준 천연 효소 (hGAAV780)를 말한다 (도 7b). "hGAAcoV780"는 조작된 서열에 의해 인코딩되고 고유한 신호 펩티드를 포함하는 hGAAV780I 변이체를 말한다 (도 7e). "Sp7.Δ8.hGAAcoV780I"는 이전 구조물과 동일한 조작된 서열에 의해 인코딩되는 처음 35개 AA의 결실이 있지만 고유한 신호 펩티드 대신에 B2 키모트립시노겐 신호 펩티드를 인코딩하는 서열을 포함하는 hGAAV780I 변이체를 말한다 (도 7f). "BiP-vIGF2.hGAAco"는 처음 35개 AA의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와의 융합된 BiP 신호 펩티드를 추가로 갖고, 조작된 서열에 의해 인코딩되는 기준 hGAAV780을 말한다 (도 7c). "BiP-vIGF2.hGAAcoV780I"는 처음 35개 AA의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖고, 조작된 서열에 의해 인코딩되는 hGAAV780I를 말한다 (도 7g). 맹검 조직병리학 반-정량적 중증도 점수매김. 공인 수의 병리학자는 맹검 방식으로 슬라이드를 검토하고 글리코겐 축적 및 자가포식 구축을 기반으로 중증도 점수를 설정하였다 (도 7h). 0점은 병변이 없음을 의미하고; 1점은 평균적으로 저장에 의해 이환된 근육 섬유의 9% 미만을 의미하며; 2점은 10% 내지 49%를 의미하고; 3점은 50% 내지 75%를 의미하며; 4점은 76% 내지 100%를 의미한다.
도 8은 고유한 hGAA, 또는 처음 35개 AA의 결실을 포함하고 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖으며 조작된 서열에 의해 인코딩되는 hGAAV780I ("BiP-vIGF2.hGAAcoV780I")를 인코딩하는 서열을 갖는 AAVhu68 (2.5×1012개 GC/㎏)의 투여 4주 후 폼페병 마우스로부터의 척수 조직학의 결과 (PAS 및 룩솔 패스트 블루 염색)를 나타낸다. 맹검 조직병리학 반-정량적 중증도 점수매김은 척수 절편에 대해 수행하였다.
도 9a 내지 도 9c는 혈장에서 hGAA 활성 및 IGF2/CI-MPR에 대한 결합을 나타낸다. 폼페병 마우스에게 야생형 hGAA 또는 BiP-vIGF2.hGAA를 인코딩하는 벡터를 저-용량 (2.5×1012개 GC)으로 투여하였다 (도 9a 및 도 9b). 정맥내 투여 4주 후 높은 수준의 야생형 및 조작된 hGAA 활성이 혈장에서 검출되었다 (도 9c). 조작된 hGAA는 CI-MPR에 효율적으로 결합한다.
도 10은 2.5×1012개 GC/kg (LD) 용량의 AAVhu68 구조물의 투여 4주 이후에 폼페병 마우스에서 글리코겐 제거 및 자가포식 구축의 해소를 나타낸다. 비복근의 파라핀 절편은 DAPI 및 항-LC3B 항체로 염색되었다.
도 11은 BiP-vIGF2.hGAAcoV780I.4xmiR183 구조물의 모식도를 나타낸다.
도 12는 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (drg-탈표적화 서열, miR183의 4개 사본을 포함함)의 정맥내 투여 4주 이후에 폼페병 마우스의 뇌간에서 글리코겐 축적 (PAS, 룩솔 블루 염색)을 나타낸다. 화살표는 뉴런 내의 PAS 양성 축적을 나타낸다.
도 13은 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 척수에서 글리코겐 축적 (PAS, 룩솔 블루 염색)을 나타낸다. 화살표는 뉴런 내의 PAS 양성 축적을 나타낸다.
도 14는 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 대퇴사두근에서 글리코겐 축적 (PAS 염색)을 나타낸다.
도 15는 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 심장에서 글리코겐 축적 (PAS 염색)을 나타낸다.
도 16은 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 대퇴사두근에서 자가포식 공포 마커 LC3b의 발현을 나타낸다.
도 17은 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 경추 DRG에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 18은 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 요추 DRG에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 19는 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 척추 하위 운동 뉴런에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 20은 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 심장에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 21a 내지 도 21c는 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 ICM 투여 35일 이후 레서스 머커크에 있는 경추 분절 (도 21a), 흉추 분절 (도 21b) 및 요추 분절 (도 21c)의 DRG에서 DRG 뉴런성 퇴화 및 염증 세포 침윤의 조직병리학적 점수매김을 나타낸다. AAVhu68 벡터는 이전에 설명된 바와 같이 형광 투시 하에 대수조 내에 주사되는 총 1 mL 부피의 멸균 인공 CSF (비히클)로 전달된다 (Katz et al., Hum. Gene Ther. Methods 2018, 29: 212-9). 벡터 실험군에 대한 맹검으로 공인 수의 병리학자는 0점이 병변 없음, 1점이 최소 (< 10%), 2점이 경증 (10% 내지 25%), 3점이 중등도 (25% 내지 50%), 4점이 현저함 (50% 내지 95%) 및 5점이 중증 (> 95%)으로서 정의된 중증도 등급을 확립하였다. 각 데이터 지점은 하나의 DRG이다. 분절 당 및 동물 당 최소 5개 DRG의 점수를 매긴다.
도 22a 내지 도 22c는 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 ICM 투여 이후 레서스 머커크에 대한 AST 수준 (도 22a), ALT 수준 (도 22b) 및 혈장 계수 (도 22c)를 나타낸다.
도 23은 고-용량 3×1013개 GC/kg의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183가 투여된 NHP에서 주사 0 내지 35일 이후에 혈장 hGAA 활성 수준을 나타낸다.
도 24a 내지 도 24g는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183가 투여된 (ICM, 3×1013개 GC) NHP에 대한 기저선 및 35일째 신경 전도 속도로부터의 결과를 나타낸다.
도 25a 및 도 25b는 생후 7개월에 질환의 상급 병기로 치료받고, 기저선에서 이미 증상이 있는 폼페병 마우스에서 벡터 주사 (0일)부터 주사 180일 이후까지의 체중 종단 추적 관찰을 나타낸다. 대안의 투여 경로 및 용량 수준, 고-용량 (HD)(1×1011개 GC) 또는 저-용량 (LD)(5×1010개 GC)으로 뇌실내 (ICV), HD (5×1013개 GC/kg) 또는 LD (1×1013개 GC/kg)로 정맥내 (IV), 및 저-용량 또는 고-용량의 ICV 및 IV의 조합을 사용하여 이들에게 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I를 투여하였다. 평균값 및 표준 편차가 도시된다. 각 시점에서 통계적 분석은 KO PBS 대조군 및 나머지 실험군 사이의 윌콕슨-만-휘트니 테스트에 의해 수행하였다. * p < 0.05; **p < 0.01.
도 26 및 도 27은 생후 7개월에 질환의 상급 병기로 치료받고, 기저선에서 이미 증상이 있는 폼페병 마우스에서 벡터 주사 (0일)부터 주사 180일 이후까지의 체중 종단 추적 관찰과 비교한 그립 강도를 나타낸다 (도 26). 대안의 투여 경로 및 용량 수준, 고-용량 (ICV HD: 1×1011개 GC)으로 뇌실내 (ICV), 고-용량 (ICV HD: 5×1013개 GC)으로 정맥내 (IV), 및 ICV 및 IV 고-용량 및 ICV 및 IV 저-용량의 조합을 사용하여 이들에게 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I를 투여하였다. 그립 강도는 송잡이 강도 측정기 (IITC 라이프 사이언스사)를 사용하여 다양한 시점에서 측정되었다. 그립 강도 측정기의 변환 장치는 양극 처리된 베이스 플레이트에 연결된 와이어 메쉬 그리드에 연결된다. 동물은 꼬리로 유지하고, 네 발로 그리드를 잡으면서 메쉬를 가만히 통과한다. 3가지 그립 힘 척도가 작성되고, 판독 평균이 특정한 시점의 동물의 그립 힘이다 (도 27). 값은 동물의 체중에 의해 정규화된다. 실험군 당 N = 4 수컷 및 N = 4 암컷. 각 시점에서 통계적 분석은 KO PBS 대조군과 대비하여 일방 ANOVA (도 26) 또는 이방 ANOVA (도 27), 사후 복수 비교 테스트에 의해 결정하였다. *p < 0.05, **p < 0.01, ***p < 0.001.
도 28은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 고-용량 (HD: 1×1011개 GC) 또는 저-용량 (LD: 5×1010개 GC) ICV 투여 이후에 증상 이후의 폼페병 마우스의 대퇴사두근, 심장 및 척수에서 글리코겐 축적을 나타낸다.
도 29는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 고-용량 (HD: 5×1013개 GC/kg) 또는 저-용량 (LD: 1×1013개 GC/kg) IV 투여 이후에 증상 이후의 폼페병 마우스의 대퇴사두근, 심장 및 척수에서 글리코겐 축적을 나타낸다.
도 30a 내지 도 30c는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 벡터가 IV, ICV, 또는 IV 및 ICV (이중 경로)로 투여된 폼페병 마우스의 혈장에서 30일째 (도 30a), 60일째 (도 30b) 및 90일째 (도 30c) hGAA 활성을 나타낸다.
도 31은 NHP에서 단일 (IV 또는 ICV) 및 이중 (IV + ICV) 투여 경로의 평가를 위한 연구 설계를 나타낸다.
도 32a 내지 도 32h는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV 또는 ICM 투여 이후에 hGAA (도 32a 및 도 32c - 혈장; 도 32b 및 도 32d - CSF) 및 hGAA 활성 (도 32e 및 도 32g - 혈장; 도 32f 및 도 32h -CSF)의 검출을 나타낸다.
도 33a 내지 도 33f는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM 또는 1×1014개 GC/kg IV 또는 1×1013개 GC/kg ICM) 투여 이후에 레서스 머카크에서 경추 분절 (도 33a), 흉추 분절 (도 33b) 및 요추 분절 (도 33c)의 DRG 뉴런성 퇴화 및 염증 세포 침윤, 및 경추 분절 (도 33d), 흉추 분절 (도 33e) 및 요추 분절 (도 33f)의 축수 축삭병증의 조직병리학적 점수매김을 나타낸다. 벡터 실험군에 대한 맹검으로 공인 수의 병리학자는 0점이 병변 없음, 1점이 최소 (< 10%), 2점이 경증 (10% 내지 25%), 3점이 중등도 (25% 내지 50%), 4점이 현저함 (50% 내지 95%) 및 5점이 중증 (> 95%)으로서 정의된 중증도 등급을 확립하였다.
도 34는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM) 투여 이후에 레서스 머카크의 혈장 GAA 활성을 나타낸다.
도 35a 내지 도 35d는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM) 투여 이후에 레서스 머카크로부터의 간 및 심장 (도 35a), 및 횡격막, 삼두근 및 전방 경골 (도 35b)에서 GAA 활성의 측정을 나타낸다.
도 36은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM) 투여 이후에 레서스 머커크로부터의 혈청에서 항-GAA 항체 역가를 나타낸다.
도 37은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 저-용량 (IV - 1×1013개 GC/kg, ICM - 5×1013개 GC) 투여 이후에 레서스 머카크의 대퇴사두근, 심장 및 척수에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 38은 고-용량 (HD: 2.5×1013개 GC/kg)의 BiP-vIGF2.hGAAcoV780I.4XmiR183 (AAV.hGAAeng), 또는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩된 hGAAV780I (AAV.hGAAnat)의 투여 4주 이후에 폼페병 마우스 대퇴사두근 및 심장 GAA 활성 및 글리코겐 축적 (PAS 염색)의 분석을 나타낸다.
도 39는 고-용량 (HD: 2.5×1013개 GC/kg)의 BiP-vIGF2.hGAAcoV780I.4XmiR183 (AAV.hGAAeng), 또는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩된 hGAAV780I (AAV.hGAAnat)의 투여 4주 이후에 폼페병 마우스 CNS GAA 활성 및 글리코겐 축적 (PAS 염색)의 분석을 나타낸다.
도 40은 BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 (IV - 2.5×1013개 GC/kg) 4주 이후에 폼페병 마우스의 대퇴사두근, 심장 및 척수에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 41은 다양한 용량의 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183의 IV 투여를 포함하는, 증상 이전의 (어린) 폼페병 마우스의 치료를 평가하는 연구에 관한 연구 개요를 나타낸다.
도 42는 어린 WT, PBS 처리된 대조군 GAA -/-, 및 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183 처리된 GAA -/- 마우스로부터의 대퇴사두근 절편의 대표적인 면역형광 영상을 나타낸다. WGA (세포막), DAPI (핵) 및 LC3b 항체 (자가포식소체).
도 43은 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 어린 폼페병 마우스로부터의 대퇴사두근에서 중앙 핵의 정량화를 나타낸다.
도 44는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 어린 폼페병 마우스로부터의 대퇴사두근에서 LC3b 염색 이후 자가포식 구축의 정량화를 나타낸다.
도 45는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 어린 폼페병 마우스로부터의 대퇴사두근에서 근육 섬유 직경의 정량화를 나타낸다.
도 46a 내지 도 46f는 다양한 용량의 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183의 IV 투여 이후에, 가자미근 (도 46a), 횡격막 (도 46b), 대퇴사두근 (도 46c), 삼두근 (도 46d), 비복근 (도 46e) 및 전방 경골근 (도 46f)에서 근육 리소좀 저장 병리 (공포 형성의 중증도)의 반정량적 점수매김을 나타낸다. 수컷 마우스의 경우 네모 표기, 암컷 마우스의 경우 원 표기. 통계: 일방 ANOVA (크루스칼 월리스 테스트)에 이어진 사후 던 복수 비교 테스트. 별표는 GAA KO 폼페병 PBS 실험군 (제 2열)과 비교한 유의성을 나타낸다. 점수매김: 공포와 근육 섬유의 비율 - 0: 0%, 1: 1% 내지 9%, 2: 10% 내지 24%, 3: 25% 내지 49%, 4: 50% 내지 74%, 및 5: > 5%.
도 47은 폼페병 GAA 녹아웃 마우스에서 IV, ICV, 및 IV + ICV 투여 경로를 평가하는 연구 설계를 나타낸다.
도 48은 생후 6 내지 7개월의 어린 WT, PBS 처리된 대조군 GAA -/-, 및 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183 처리된 GAA -/- 마우스로부터의 대퇴사두근 절편의 대표적인 면역형광 영상을 나타낸다. WGA (세포막), DAPI (핵) 및 LC3b 항체 (자가포식소체).
도 49는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 증상 이후의 폼페병 마우스로부터의 대퇴사두근에서 중앙 핵의 정량화를 나타낸다.
도 50은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.rBG의 IV, ICV, 및 IV + ICV 투여 이후에 GAA KO 마우스로부터의 대퇴사두근 조직의 LC3b 염색에 이어지는 자가포식 구축의 정량화를 나타낸다.
도 51은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.rBG의 IV, ICV, 및 IV + ICV 투여 이후에 폼페병 GAA 녹아웃 마우스의 근육 섬유 크기 분포를 나타낸다. 섬유 직경은 S = 소 (< 30 μm), M = 중 (30 μm 내지 50 μm) 및 L = 대 (> 50 μm)의 부류로 할당되었다.
도 52는 비-인간 영장류에게 AAVhu68.CAG.BiP-IGF2-hGAAcoV780I 벡터의 IV, ICM, 및 IV + ICM 투여 이후에 척수 분절에서 hGAA 발현하는 운동 뉴런의 정량화를 나타낸다.
도 2a 및 도 2b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 심장에서의 hGAA 활성을 나타낸다. (도 2a) 저-용량 (1×1011개 GC). (도 2b) 고-용량 (1×1012개).
도 3a 및 도 3b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 골격근 (대퇴사두근)에서의 hGAA 활성을 나타낸다. (도 3a) 저용량 (1×1011개 GC). (도 3b) 고용량 (1×1012개).
도 4a 및 도 4b는 CB6 (제 3열), CAG (제 4열) 또는 UbC 프로모터 (마지막 열)의 구동 하에 hGAAV780I에 대한 조작된 코딩 서열을 갖는 다양한 AAVhu68.hGAA의 정맥내 투여 4주 후 폼페병 (-/-) 마우스 뇌에서의 hGAA 활성을 나타낸다. (도 4a) 저-용량 (1×1011개 GC). (도 4b) 고-용량 (1×1012개). CB7 활성 하에 발현하는 벡터는 두 가지 용량 모두에서 더 낮은 활성을 갖는 반면, CAG 또는 UbC 프로모터 하에 발현하는 벡터는 더 높은 용량에서 비슷한 활성을 갖는다.
도 5a 내지 도 5h는 AAVhu68.hGAA의 전달 4주 후 폼페병 마우스에서 심장의 조직학 (PAS 염색이 글리코겐 축적을 나타냄)을 나타낸다. 5가지 상이한 hGAA 발현 카세트를 포함하는 rAAVhu68 벡터를 생성하고 평가하였다. 비히클 대조군 폼페병 (-/-) (도 5D) 및 야생형 (+/+) (도 5A) 마우스는 PBS 주사를 수여받았다. "hGAA"는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩되는 기준 천연 효소 (hGAAV780)를 말한다 (도 5b). "BiP-vIGF2.hGAAco"는 처음 35개 아미노산의 결실을 포함하고, BiP 신호 펩티드 및 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와의 융합을 추가로 갖는 기준 hGAAV780 단백질에 대한 조작된 코딩 서열을 말한다 (도 5c). 비히클 처리된 대조군으로부터의 영상 (도 5d). "hGAAcoV780I"는 조작된 서열에 의해 인코딩되고 고유한 신호 펩티드를 포함하는 hGAAV780I 변이체를 말한다 (도 5e). "BiP-vIGF2.hGAAcoV780I"는 처음 35개 아미노산의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드 및 조작된 서열에 의해 인코딩되는 hGAAV780I를 추가로 갖는 hGAAcoV780I를 말한다 (도 5f). "Sp7.Δ8.hGAAcoV780I"는 이전 구조물과 동일한 조작된 서열에 의해 인코딩되는 처음 35개 아미노산의 결실이 있지만 고유한 신호 펩티드 대신에 B2 키모트립시노겐 신호 펩티드를 인코딩하는 서열을 포함하는 hGAAV780I 변이체를 말한다 (도 5g). 맹검 조직병리학 반-정량적 중증도 점수매김. 공인 수의 병리학자는 맹검 방식으로 슬라이드를 검토하고 글리코겐 축적 및 자가포식 구축을 기반으로 중증도 점수를 설정하였다 (도 5h).
도 6a 내지 도 6h는 다양한 hGAA를 인코딩하는 AAVhu68 (2.5×1013개 GC/㎏)의 투여 4주 후 폼페병 마우스에서 대퇴사두근 조직학의 결과 (PAS 염색)를 나타낸다. 대조군 폼페병 (-/-) (도 6d) 및 야생형 (+/+) (도 6a) 마우스는 PBS 주사를 수여받았다. "hGAA"는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩되는 기준 천연 효소 (hGAAV780)를 말한다 (도 6b). "hGAAcoV780I"는 조작된 서열에 의해 인코딩되고 고유한 신호 펩티드를 포함하는 hGAAV780I 변이체를 말한다 (도 6e). "Sp7.Δ8.hGAAcoV780I"는 이전 구조물과 동일한 조작된 서열에 의해 인코딩되는 처음 35개 아미노산의 결실이 있지만 고유한 신호 펩티드 대신에 B2 키모트립시노겐 신호 펩티드를 인코딩하는 서열을 포함하는 hGAAV780I 변이체를 말한다 (도 6f). "BiP-vIGF2.hGAAco"는 처음 35개 아미노산의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖고 조작된 서열에 의해 인코딩되는 기준 hGAAV780을 말한다 (도 6c). "BiP-vIGF2.hGAAcoV780I"는 처음 35개 아미노산의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖고, 조작된 서열에 의해 인코딩되는 hGAAV780I를 말한다 (도 6g). 맹검 조직병리학 반-정량적 중증도 점수매김. 공인 수의 병리학자는 맹검 방식으로 슬라이드를 검토하고 글리코겐 축적 및 자가포식 구축을 기반으로 중증도 점수를 설정하였다. 0점은 병변이 없음을 의미하고; 1점은 평균적으로 저장에 의해 이환된 근육 섬유의 9% 미만을 의미하며; 2점은 10% 내지 49%를 의미하고; 3점은 50% 내지 75%를 의미하며; 4점은 76% 내지 100%를 의미한다 (도 6h).
도 7a 내지 도 7h는 2.5×1012개 GC/㎏ (즉, 도 6a 내지 도 6h에서보다 10배 더 적은 용량)의 다양한 hGAA를 인코딩하는 AAVhu68의 투여 4주 후 폼페병 마우스로부터의 대퇴사두근 조직학의 결과 (과요오드산-쉬프 (PAS) 염색)를 나타낸다. 대조군 폼페병 (-/-) (도 7d) 및 야생형 (+/+) (도 7a) 마우스는 PBS 주사를 수여받았다. "hGAA"는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩되는 기준 천연 효소 (hGAAV780)를 말한다 (도 7b). "hGAAcoV780"는 조작된 서열에 의해 인코딩되고 고유한 신호 펩티드를 포함하는 hGAAV780I 변이체를 말한다 (도 7e). "Sp7.Δ8.hGAAcoV780I"는 이전 구조물과 동일한 조작된 서열에 의해 인코딩되는 처음 35개 AA의 결실이 있지만 고유한 신호 펩티드 대신에 B2 키모트립시노겐 신호 펩티드를 인코딩하는 서열을 포함하는 hGAAV780I 변이체를 말한다 (도 7f). "BiP-vIGF2.hGAAco"는 처음 35개 AA의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와의 융합된 BiP 신호 펩티드를 추가로 갖고, 조작된 서열에 의해 인코딩되는 기준 hGAAV780을 말한다 (도 7c). "BiP-vIGF2.hGAAcoV780I"는 처음 35개 AA의 결실을 포함하고, 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖고, 조작된 서열에 의해 인코딩되는 hGAAV780I를 말한다 (도 7g). 맹검 조직병리학 반-정량적 중증도 점수매김. 공인 수의 병리학자는 맹검 방식으로 슬라이드를 검토하고 글리코겐 축적 및 자가포식 구축을 기반으로 중증도 점수를 설정하였다 (도 7h). 0점은 병변이 없음을 의미하고; 1점은 평균적으로 저장에 의해 이환된 근육 섬유의 9% 미만을 의미하며; 2점은 10% 내지 49%를 의미하고; 3점은 50% 내지 75%를 의미하며; 4점은 76% 내지 100%를 의미한다.
도 8은 고유한 hGAA, 또는 처음 35개 AA의 결실을 포함하고 인슐린 수용체에 대한 낮은 친화성을 갖는 IGF2 변이체와 융합된 BiP 신호 펩티드를 추가로 갖으며 조작된 서열에 의해 인코딩되는 hGAAV780I ("BiP-vIGF2.hGAAcoV780I")를 인코딩하는 서열을 갖는 AAVhu68 (2.5×1012개 GC/㎏)의 투여 4주 후 폼페병 마우스로부터의 척수 조직학의 결과 (PAS 및 룩솔 패스트 블루 염색)를 나타낸다. 맹검 조직병리학 반-정량적 중증도 점수매김은 척수 절편에 대해 수행하였다.
도 9a 내지 도 9c는 혈장에서 hGAA 활성 및 IGF2/CI-MPR에 대한 결합을 나타낸다. 폼페병 마우스에게 야생형 hGAA 또는 BiP-vIGF2.hGAA를 인코딩하는 벡터를 저-용량 (2.5×1012개 GC)으로 투여하였다 (도 9a 및 도 9b). 정맥내 투여 4주 후 높은 수준의 야생형 및 조작된 hGAA 활성이 혈장에서 검출되었다 (도 9c). 조작된 hGAA는 CI-MPR에 효율적으로 결합한다.
도 10은 2.5×1012개 GC/kg (LD) 용량의 AAVhu68 구조물의 투여 4주 이후에 폼페병 마우스에서 글리코겐 제거 및 자가포식 구축의 해소를 나타낸다. 비복근의 파라핀 절편은 DAPI 및 항-LC3B 항체로 염색되었다.
도 11은 BiP-vIGF2.hGAAcoV780I.4xmiR183 구조물의 모식도를 나타낸다.
도 12는 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (drg-탈표적화 서열, miR183의 4개 사본을 포함함)의 정맥내 투여 4주 이후에 폼페병 마우스의 뇌간에서 글리코겐 축적 (PAS, 룩솔 블루 염색)을 나타낸다. 화살표는 뉴런 내의 PAS 양성 축적을 나타낸다.
도 13은 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 척수에서 글리코겐 축적 (PAS, 룩솔 블루 염색)을 나타낸다. 화살표는 뉴런 내의 PAS 양성 축적을 나타낸다.
도 14는 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 대퇴사두근에서 글리코겐 축적 (PAS 염색)을 나타낸다.
도 15는 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 심장에서 글리코겐 축적 (PAS 염색)을 나타낸다.
도 16은 고-용량 (HD: 2.5×1013개 GC/kg) 또는 저-용량 (LD: 2.5×1012개 GC/kg)의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 4주 이후에 폼페병 마우스의 대퇴사두근에서 자가포식 공포 마커 LC3b의 발현을 나타낸다.
도 17은 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 경추 DRG에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 18은 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 요추 DRG에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 19는 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 척추 하위 운동 뉴런에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 20은 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I (왼쪽) 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183 (오른쪽)의 ICM 투여 35일 이후에 레서스 머커크의 심장에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 21a 내지 도 21c는 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 ICM 투여 35일 이후 레서스 머커크에 있는 경추 분절 (도 21a), 흉추 분절 (도 21b) 및 요추 분절 (도 21c)의 DRG에서 DRG 뉴런성 퇴화 및 염증 세포 침윤의 조직병리학적 점수매김을 나타낸다. AAVhu68 벡터는 이전에 설명된 바와 같이 형광 투시 하에 대수조 내에 주사되는 총 1 mL 부피의 멸균 인공 CSF (비히클)로 전달된다 (Katz et al., Hum. Gene Ther. Methods 2018, 29: 212-9). 벡터 실험군에 대한 맹검으로 공인 수의 병리학자는 0점이 병변 없음, 1점이 최소 (< 10%), 2점이 경증 (10% 내지 25%), 3점이 중등도 (25% 내지 50%), 4점이 현저함 (50% 내지 95%) 및 5점이 중증 (> 95%)으로서 정의된 중증도 등급을 확립하였다. 각 데이터 지점은 하나의 DRG이다. 분절 당 및 동물 당 최소 5개 DRG의 점수를 매긴다.
도 22a 내지 도 22c는 고-용량 3×1013개 GC의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183의 ICM 투여 이후 레서스 머커크에 대한 AST 수준 (도 22a), ALT 수준 (도 22b) 및 혈장 계수 (도 22c)를 나타낸다.
도 23은 고-용량 3×1013개 GC/kg의 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183가 투여된 NHP에서 주사 0 내지 35일 이후에 혈장 hGAA 활성 수준을 나타낸다.
도 24a 내지 도 24g는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 또는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.4XmiR183가 투여된 (ICM, 3×1013개 GC) NHP에 대한 기저선 및 35일째 신경 전도 속도로부터의 결과를 나타낸다.
도 25a 및 도 25b는 생후 7개월에 질환의 상급 병기로 치료받고, 기저선에서 이미 증상이 있는 폼페병 마우스에서 벡터 주사 (0일)부터 주사 180일 이후까지의 체중 종단 추적 관찰을 나타낸다. 대안의 투여 경로 및 용량 수준, 고-용량 (HD)(1×1011개 GC) 또는 저-용량 (LD)(5×1010개 GC)으로 뇌실내 (ICV), HD (5×1013개 GC/kg) 또는 LD (1×1013개 GC/kg)로 정맥내 (IV), 및 저-용량 또는 고-용량의 ICV 및 IV의 조합을 사용하여 이들에게 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I를 투여하였다. 평균값 및 표준 편차가 도시된다. 각 시점에서 통계적 분석은 KO PBS 대조군 및 나머지 실험군 사이의 윌콕슨-만-휘트니 테스트에 의해 수행하였다. * p < 0.05; **p < 0.01.
도 26 및 도 27은 생후 7개월에 질환의 상급 병기로 치료받고, 기저선에서 이미 증상이 있는 폼페병 마우스에서 벡터 주사 (0일)부터 주사 180일 이후까지의 체중 종단 추적 관찰과 비교한 그립 강도를 나타낸다 (도 26). 대안의 투여 경로 및 용량 수준, 고-용량 (ICV HD: 1×1011개 GC)으로 뇌실내 (ICV), 고-용량 (ICV HD: 5×1013개 GC)으로 정맥내 (IV), 및 ICV 및 IV 고-용량 및 ICV 및 IV 저-용량의 조합을 사용하여 이들에게 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I를 투여하였다. 그립 강도는 송잡이 강도 측정기 (IITC 라이프 사이언스사)를 사용하여 다양한 시점에서 측정되었다. 그립 강도 측정기의 변환 장치는 양극 처리된 베이스 플레이트에 연결된 와이어 메쉬 그리드에 연결된다. 동물은 꼬리로 유지하고, 네 발로 그리드를 잡으면서 메쉬를 가만히 통과한다. 3가지 그립 힘 척도가 작성되고, 판독 평균이 특정한 시점의 동물의 그립 힘이다 (도 27). 값은 동물의 체중에 의해 정규화된다. 실험군 당 N = 4 수컷 및 N = 4 암컷. 각 시점에서 통계적 분석은 KO PBS 대조군과 대비하여 일방 ANOVA (도 26) 또는 이방 ANOVA (도 27), 사후 복수 비교 테스트에 의해 결정하였다. *p < 0.05, **p < 0.01, ***p < 0.001.
도 28은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 고-용량 (HD: 1×1011개 GC) 또는 저-용량 (LD: 5×1010개 GC) ICV 투여 이후에 증상 이후의 폼페병 마우스의 대퇴사두근, 심장 및 척수에서 글리코겐 축적을 나타낸다.
도 29는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 고-용량 (HD: 5×1013개 GC/kg) 또는 저-용량 (LD: 1×1013개 GC/kg) IV 투여 이후에 증상 이후의 폼페병 마우스의 대퇴사두근, 심장 및 척수에서 글리코겐 축적을 나타낸다.
도 30a 내지 도 30c는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I 벡터가 IV, ICV, 또는 IV 및 ICV (이중 경로)로 투여된 폼페병 마우스의 혈장에서 30일째 (도 30a), 60일째 (도 30b) 및 90일째 (도 30c) hGAA 활성을 나타낸다.
도 31은 NHP에서 단일 (IV 또는 ICV) 및 이중 (IV + ICV) 투여 경로의 평가를 위한 연구 설계를 나타낸다.
도 32a 내지 도 32h는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV 또는 ICM 투여 이후에 hGAA (도 32a 및 도 32c - 혈장; 도 32b 및 도 32d - CSF) 및 hGAA 활성 (도 32e 및 도 32g - 혈장; 도 32f 및 도 32h -CSF)의 검출을 나타낸다.
도 33a 내지 도 33f는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM 또는 1×1014개 GC/kg IV 또는 1×1013개 GC/kg ICM) 투여 이후에 레서스 머카크에서 경추 분절 (도 33a), 흉추 분절 (도 33b) 및 요추 분절 (도 33c)의 DRG 뉴런성 퇴화 및 염증 세포 침윤, 및 경추 분절 (도 33d), 흉추 분절 (도 33e) 및 요추 분절 (도 33f)의 축수 축삭병증의 조직병리학적 점수매김을 나타낸다. 벡터 실험군에 대한 맹검으로 공인 수의 병리학자는 0점이 병변 없음, 1점이 최소 (< 10%), 2점이 경증 (10% 내지 25%), 3점이 중등도 (25% 내지 50%), 4점이 현저함 (50% 내지 95%) 및 5점이 중증 (> 95%)으로서 정의된 중증도 등급을 확립하였다.
도 34는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM) 투여 이후에 레서스 머카크의 혈장 GAA 활성을 나타낸다.
도 35a 내지 도 35d는 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM) 투여 이후에 레서스 머카크로부터의 간 및 심장 (도 35a), 및 횡격막, 삼두근 및 전방 경골 (도 35b)에서 GAA 활성의 측정을 나타낸다.
도 36은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 IV (1×1013개 GC/kg 또는 5×1013개 GC/kg), ICM (1×1013개 GC 또는 3×1013개 GC), 또는 IV + ICM (5×1013개 GC/kg IV + 3×1013개 GC ICM) 투여 이후에 레서스 머커크로부터의 혈청에서 항-GAA 항체 역가를 나타낸다.
도 37은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I의 저-용량 (IV - 1×1013개 GC/kg, ICM - 5×1013개 GC) 투여 이후에 레서스 머카크의 대퇴사두근, 심장 및 척수에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 38은 고-용량 (HD: 2.5×1013개 GC/kg)의 BiP-vIGF2.hGAAcoV780I.4XmiR183 (AAV.hGAAeng), 또는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩된 hGAAV780I (AAV.hGAAnat)의 투여 4주 이후에 폼페병 마우스 대퇴사두근 및 심장 GAA 활성 및 글리코겐 축적 (PAS 염색)의 분석을 나타낸다.
도 39는 고-용량 (HD: 2.5×1013개 GC/kg)의 BiP-vIGF2.hGAAcoV780I.4XmiR183 (AAV.hGAAeng), 또는 고유한 신호 펩티드를 갖는 야생형 서열에 의해 인코딩된 hGAAV780I (AAV.hGAAnat)의 투여 4주 이후에 폼페병 마우스 CNS GAA 활성 및 글리코겐 축적 (PAS 염색)의 분석을 나타낸다.
도 40은 BiP-vIGF2.hGAAcoV780I.4XmiR183의 정맥내 투여 (IV - 2.5×1013개 GC/kg) 4주 이후에 폼페병 마우스의 대퇴사두근, 심장 및 척수에서 hGAA 발현의 대표적인 영상 (hGAA에 대한 면역조직화학)을 나타낸다.
도 41은 다양한 용량의 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183의 IV 투여를 포함하는, 증상 이전의 (어린) 폼페병 마우스의 치료를 평가하는 연구에 관한 연구 개요를 나타낸다.
도 42는 어린 WT, PBS 처리된 대조군 GAA -/-, 및 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183 처리된 GAA -/- 마우스로부터의 대퇴사두근 절편의 대표적인 면역형광 영상을 나타낸다. WGA (세포막), DAPI (핵) 및 LC3b 항체 (자가포식소체).
도 43은 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 어린 폼페병 마우스로부터의 대퇴사두근에서 중앙 핵의 정량화를 나타낸다.
도 44는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 어린 폼페병 마우스로부터의 대퇴사두근에서 LC3b 염색 이후 자가포식 구축의 정량화를 나타낸다.
도 45는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 어린 폼페병 마우스로부터의 대퇴사두근에서 근육 섬유 직경의 정량화를 나타낸다.
도 46a 내지 도 46f는 다양한 용량의 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183의 IV 투여 이후에, 가자미근 (도 46a), 횡격막 (도 46b), 대퇴사두근 (도 46c), 삼두근 (도 46d), 비복근 (도 46e) 및 전방 경골근 (도 46f)에서 근육 리소좀 저장 병리 (공포 형성의 중증도)의 반정량적 점수매김을 나타낸다. 수컷 마우스의 경우 네모 표기, 암컷 마우스의 경우 원 표기. 통계: 일방 ANOVA (크루스칼 월리스 테스트)에 이어진 사후 던 복수 비교 테스트. 별표는 GAA KO 폼페병 PBS 실험군 (제 2열)과 비교한 유의성을 나타낸다. 점수매김: 공포와 근육 섬유의 비율 - 0: 0%, 1: 1% 내지 9%, 2: 10% 내지 24%, 3: 25% 내지 49%, 4: 50% 내지 74%, 및 5: > 5%.
도 47은 폼페병 GAA 녹아웃 마우스에서 IV, ICV, 및 IV + ICV 투여 경로를 평가하는 연구 설계를 나타낸다.
도 48은 생후 6 내지 7개월의 어린 WT, PBS 처리된 대조군 GAA -/-, 및 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183 처리된 GAA -/- 마우스로부터의 대퇴사두근 절편의 대표적인 면역형광 영상을 나타낸다. WGA (세포막), DAPI (핵) 및 LC3b 항체 (자가포식소체).
도 49는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183이 투여된 증상 이후의 폼페병 마우스로부터의 대퇴사두근에서 중앙 핵의 정량화를 나타낸다.
도 50은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.rBG의 IV, ICV, 및 IV + ICV 투여 이후에 GAA KO 마우스로부터의 대퇴사두근 조직의 LC3b 염색에 이어지는 자가포식 구축의 정량화를 나타낸다.
도 51은 AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.rBG의 IV, ICV, 및 IV + ICV 투여 이후에 폼페병 GAA 녹아웃 마우스의 근육 섬유 크기 분포를 나타낸다. 섬유 직경은 S = 소 (< 30 μm), M = 중 (30 μm 내지 50 μm) 및 L = 대 (> 50 μm)의 부류로 할당되었다.
도 52는 비-인간 영장류에게 AAVhu68.CAG.BiP-IGF2-hGAAcoV780I 벡터의 IV, ICM, 및 IV + ICM 투여 이후에 척수 분절에서 hGAA 발현하는 운동 뉴런의 정량화를 나타낸다.
폼페병에 걸린 환자에게 신호 펩티드 및 hGAA780I 효소의 적어도 활성 부분에 융합된 vIGF2 펩티드를 포함하는 융합 단백질을 전달하기 위한 조성물이 제공된다. 이들 조성물로 환자를 치료하기 위한 요법을 포함하여, 이를 제조하고 사용하는 방법이 본원에 기술되어 있다.
본 명세서에서 사용되는 바와 같이, 말타제 결핍증, 글리코겐 축적 질환 II형 (GSDII), 또는 글리코겐증 II형으로도 지칭되는 "폼페병"은 산 α-글루코시다제를 코딩하는 산 α-글루코시다제 (GAA) 유전자의 돌연변이에 의해 유발되는 리소좀 효소인 GAA의 전체 부재 또는 부분적 결핍을 특징으로 하는 유전적 리소좀 축적 장애를 지칭하는 것으로 의도된다. 상기 용어는 영아, 청소년 및 성인 발병 폼페병을 포함하나 이들에 한정되지 않는 질환의 초기 및 후기 발병 형태를 포함하나 이들에 한정되지 않는다.
그리스 문자 "알파" 및 기호 "α"는 본 명세서 전반에 걸쳐 상호교환적으로 사용됨이 이해될 것이다. 유사하게, 그리스 문자 "델타" 및 "Δ"는 본 명세서 전반에 걸쳐 상호교환적으로 사용된다.
본 명세서에서 사용되는 용어 "산-α-글루코시다제" 또는 "GAA"는 글리코겐, 말토스, 및 아이소말토스의 D-글루코스 단위 사이의 α-1,4 연결을 가수분해하는 리소좀 효소를 지칭한다. 대체 명칭은 리소좀 α-글루코시다제 (EC:3.2.1.20); 글루코아밀라제; 1,4-α-D-글루칸 글루코하이드롤라제; 아밀로글루코시다제; 감마-아밀라제 및 엑소-1,4-α-글루코시다제를 포함하지만, 이들로 제한되지 않는다. 인간 산 α-글루코시다제는 GAA 유전자 (미국 국립 생체공학 정보센터 (NCBI); 유전자 ID 2548)에 의해 인코딩되며, 상기 유전자는 17번 염색체의 긴 팔에 대해 매핑되었다 (위치 17q25.2-q25.3). 아미노산 잔기 516번 내지 521번에서 보존된 헥사펩티드 WIDMNE는 산 α-글루코시다제 단백질의 활성에 필요하다. 용어 "hGAA"는 인간 GAA에 대한 코딩 서열을 지칭한다.
본 명세서에서 사용되는 바와 같이, "rAAV.hGAA"는 최소한 GAA 효소에 대한 코딩 서열을 포함하는 벡터 게놈 (예로, 780I 변이체, 신호 펩티드 및 hGAA780I 효소의 적어도 활성 부분에 융합된 vIGF2 펩티드를 포함하는 융합 단백질)을 내부에 패키징한 AAV 캡시드를 갖는 rAAV를 지칭한다. rAAVhu68.hGAA 또는 rAAVhu68.hGAA는 AAV 캡시드가 본 명세서에 정의된 AAVhu68 캡시드인 rAAV를 말한다.
전장 hGAA의 번호매김을 참조하여, 아미노산 위치 1번 내지 27번에 신호 펩티드가 있다. 추가적으로, 효소는 다수의 성숙한 단백질, 즉, 아미노산 위치 70 내지 952번의 성숙한 단백질, 아미노산 위치 123번 내지 952번에 위치한 76 kD 성숙한 단백질, 및 204번 아미노산 내지 952번 아미노산의 70 kD 성숙한 단백질과 연관되어 있다. "활성 촉매 부위"는 헥사펩티드 WIDMNE (서열번호 3의 아미노산 잔기 516번 내지 521번)를 포함한다. 특정 구현예에서, 더 긴 단편, 예를 들면, 위치 516 내지 616번이 선택될 수 있다. 다른 활성 부위는 위치 376번, 404번, 405번, 441번, 481번, 516번, 518번, 519번, 600번, 613번, 616번, 649번, 674번 중 하나 이상에 위치할 수 있는 리간드 결합 부위를 포함한다.
달리 명시되지 않는 한, 용어 "hGAA780I" 또는 "hGAAV780I"는 서열번호 3으로 재현되는 아미노산 서열을 갖는 전장 프리-프로-단백질을 지칭한다. 일부 경우에, 용어 hGAAco780I 또는 hGAAcoV780I는 hGAA780I를 인코딩하는 조작된 서열을 지칭하는 데 사용된다. 앞의 단락에 기재된 hGAA 참조 단백질과 비교하여, hGAA780I는 참조 hGAA가 발린 (Val 또는 V)을 포함하는 780번 위치에 아이소류신 (Ile 또는 I)을 갖는다. 이러한 hGAA780I는 "기준 서열"로 문헌에 널리 기재되어 있는 780번 위치에 발린을 갖는 hGAA 서열 (hGAAV780)보다 더 우수한 효과 및 개선된 안전성 프로파일을 갖는 것으로 예기치 않게 발견되었다. 예를 들면, 도 5A 내지 5H에서 볼 수 있는 바와 같이, hGAAV780 기준 서열은 hGAA780I 효소에 의해 동일한 용량으로 보이지 않는 독성 (섬유화 심근염)을 유도한다. 따라서, hGAA780I의 사용으로 hGAA를 이용한 요법을 받는 환자의 섬유화 심근염을 감소시키거나 없앨 수 있다. hGAA 신호 펩티드, 성숙한 단백질, 활성 촉매 부위, 및 결합 부위, 즉 아미노산 위치 1번 내지 27번의 신호 펩티드; 아미노산 위치 70번 내지 952번의 성숙한 단백질; 아미노산 위치 123번 내지 952번에 위치한 76 kDa 성숙한 단백질, 및 아미노산 204번 아미노산 내지 952번의 70 kD 성숙한 단백질; 아미노산 잔기 516번 내지 521번의 헥사펩티드 WIDMNE를 포함하는 "활성 촉매 부위" (서열번호 61)의 위치는 서열번호 3으로 재현되는 hGAA780I에서 유사한 위치를 기반으로 결정될 수 있으며; 다른 활성 부위는 위치 376번, 404번, 405번, 441번, 481번, 516번, 518번, 519번, 600번, 613번, 616번, 649번, 674번 중 하나 이상에 위치할 수 있는 리간드 결합 부위를 포함한다.
특정 구현예에서, 서열번호 3의 hGAA780I와 적어도 95% 동일, hGAA780I와 적어도 97% 동일, 또는 hGAA780I와 적어도 99% 동일한 서열을 갖는 hGAA780I가 선택될 수 있다. 특정 구현예에서, 서열번호 3의 성숙한 hGAA780I 단백질과 적어도 95%, 적어도 97%, 또는 적어도 99% 동일한 서열이 제공된다. 특정 구현예에서, hGAA780I와 적어도 95% 내지 적어도 99% 동일성을 갖는 서열은 임의의 변화 없이 유지된 활성 촉매 부위에 대한 서열을 갖는다. 특정 구현예에서, 서열번호 3에 대한 hGAA780I에 대해 적어도 95% 내지 적어도 99% 동일성을 갖는 서열은 적절한 동물 모델에서 테스트할 때 참조 hGAAV780보다 개선된 생물학적 효과 및 더 우수한 안전성 프로파일을 갖는 것을 특징으로 한다. 특정 구현예에서, GAA 활성 검정은 이전에 기재된 바와 같이 (예로, J. Hordeaux, et. al., Acta Neuropathological Communications, (2107) 5: 66 참조) 또는 다른 적합한 방법을 사용하여 수행될 수 있다. 특정 구현예에서, hGAA780I 효소는 hGAA 아미노산 서열의 다른 위치에 변형을 포함한다. 특정 구현예에서, 이러한 돌연변이체 hGAA780I는 최소한 활성 촉매 부위의 WIDMNE (서열번호 61) 및 하기 기술된 780I 영역의 아미노산을 유지할 수 있다.
특정 구현예에서, 고유한 hGAA 신호 펩티드 이외의 리더 펩티드를 포함하는 신규 hGAA780I 융합 단백질이 제공된다. 특정 구현예에서, 이와 같은 외인성 리더 펩티드는 바람직하게는 인간 기원이고, 예를 들면, IL-2 리더 펩티드를 포함할 수 있다. 특정 구현예에서 작동 가능한 특정 외인성 신호 펩티드는 키모트립시노겐 B2 유래의 아미노산 1 내지 20개, 인간 알파-1-항트립신의 신호 펩티드, 이듀로네이트-2-설파타제 유래의 아미노산 1 내지 25개, 및 프로테아제 CI 저해제 유래의 아미노산 1 내지 23개를 포함한다. 예를 들면, 국제특허출원 제 WO 2018046774호 참조. 다른 신호/리더 펩티드는 특히 면역글로불린 (예를 들면, IgG), 사이토카인 (예를 들면, IL-2, IL-12, IL-18 등), 인슐린, 알부민, β-글루쿠로니다제, 알칼리성 프로테아제 또는 피브로넥틴 분비 신호 펩티드에서 자연적으로 발견될 수 있다. 또한, 예로 signalpeptide.de/index.php?m=listspdb_mammalia 참조.
이러한 키메라 hGAA780I는 전체 27개 아미노산의 고유한 신호 펩티드 대신에 외인성 리더를 갖을 수 있다. 선택적으로, hGAA780I 효소의 N-말단 절단으로 신호 펩티드 (예를 들면, 약 2개 내지 약 25개 아미노산, 또는 그 사이 값의 결실), 전체 신호 펩티드, 또는 신호 펩티드보다 더 긴 단편 (서열번호 3의 번호매김을 기준으로 하여 최대 70개 아미노산)의 단지 일부만 결여될 수 있다. 선택적으로, 이와 같은 효소는 길이가 약 5개, 10개, 15개 또는 20개 아미노산인 C-말단 절단을 포함할 수 있다.
특정 구현예에서, 융합 파트너에 결합되는 성숙한 hGAA780I 단백질 (aa 70 내지 952번), 성숙한 70 kD 단백질 (아미노산 123번 내지 아미노산 952번), 또는 성숙한 76 kD 단백질 (아미노산 204번 내지 952번)을 포함하는 신규 융합 단백질이 제공된다. 선택적으로, 융합 단백질은 hGAA에 고유하지 않은 신호 펩티드를 더 포함한다. 추가로 선택적으로, 이들 구현예 중 하나는 길이가 약 5개, 10개, 15개 또는 20개 아미노산인 C-말단 절단을 더 포함할 수 있다.
특정 구현예에서, hGAA780I 단백질을 포함하는 융합 단백질은 780번 위치에 Ile를 갖는 서열번호 3 (hGAA780I)의 적어도 204번 아미노산 내지 890번 아미노산, 또는 이와 적어도 95% 동일한 서열을 포함한다. 특정 구현예에서, hGAA780I 단백질은 780번 위치에 Ile를 갖는 서열번호 3의 적어도 204번 아미노산 내지 952번 아미노산 또는 이와 적어도 95% 동일한 서열을 포함한다. 특정 구현예에서, hGAA780I 단백질은 780번 위치에 Ile를 갖는 서열번호 3의 적어도 123번 아미노산 내지 890번 아미노산 또는 이와 적어도 95% 동일한 서열을 포함한다. 특정 구현예에서, hGAA780I 효소는 780번 위치에 Ile를 갖는 서열번호 3의 적어도 70번 아미노산 내지 952번 아미노산 또는 이와 적어도 95% 동일한 서열을 포함한다. 특정 구현예에서, hGAA780I 단백질은 780번 위치에 Ile를 갖는 서열번호 3의 적어도 70번 아미노산 내지 890번 아미노산, 또는 이와 적어도 95% 동일한 서열을 포함한다.
특정 구현예에서, 융합 단백질은 신호 및 리더 서열, 및 서열번호 7과 적어도 95% 동일성, 적어도 97% 동일성 또는 적어도 99% 동일성을 갖는 hGAA780I 서열을 포함하고, 활성 부위의 변화가 없고/거나 활성 부위에 대한 N-말단 및/또는 C-말단의 3개 내지 12개 아미노산에 변화가 없다. 바람직한 구현예에서, 조작된 hGAA 발현 카세트는 적어도, T - Val (V) - P - Ile (780I) - Glu (E) - Ala (A) - Leu (L) (서열번호 62)의 인간 hGAA780I 단편을 인코딩한다. 특정 구현예에서, 조작된 hGAA 발현 카세트는, Gln (Q) - T - V - P - 780I - E - A - L - Gly (G) (서열번호 63)의 더 긴 인간 hGAA780I 단편을 인코딩한다. 특정 구현예에서, 조작된 hGAA 발현 카세트는 적어도 PLGT - Trp (W) - Tyr (Y) - Asp (D) - LQTVP - 780I - EALG - (Ser 또는 S) - L - PPPPAA 서열 (서열번호 64)에 해당하는 단편을 인코딩한다. 유사하게, 바람직한 구현예에서 활성 결합 부위 (서열번호 3의 아미노산 518번 내지 521번)에 아미노산 변화가 없다. 특정 구현예에서, 위치 600번, 616번 및/또는 674번에서의 결합 부위는 변화되지 않은 상태로 유지된다. 특정 구현예에서, 융합 단백질은 신호 펩티드, 선택적인 vIGF + 2개 GS 연장, 선택적인 ER 단백질분해 펩티드, 및 hGAA의 처음 35개 아미노산의 결실이 있는 (즉, 고유한 신호 펩티드 및 아미노산 28번 내지 35번이 결여됨) hGAA780I 변이체를 포함한다.
특정 구현예에서, BiP 신호 펩티드, IGF2 + 2개 GS 연장 및 hGAA780I의 아미노산 61번 내지 952번 (hGAA780I의 아미노산 1번 내지 60번이 결실됨)을 포함하는 분비된 조작된 GAA가 제공된다. 특정 구현예에서, 본원에서는 서열번호 6 또는 이와 적어도 95% 일치하는 서열을 포함하는 융합 단백질이 제공된다. 특정 구현예에서, 융합 단백질은 서열번호 7 또는 이와 적어도 95% 일치하는 서열에 의해 인코딩된다. 특정 구현예에서, 융합 단백질은 서열번호 4의 서열 또는 이와 적어도 95% 일치하는 서열을 포함한다. 특정 구현예에서, 융합 단백질은 서열번호 5의 서열 또는 이와 적어도 95% 일치하는 서열을 포함한다.
본원에 제공된 융합 단백질의 구성요소는 하기에 추가로 설명된다.
CI-MPR에 결합하는 펩티드
본원에서는 CI-MPR에 결합하는 펩티드 (예로, vIGF2 펩티드)가 제공된다. 이러한 펩티드 및 hGAA780I 단백질을 포함하는 융합 단백질은 유전자 요법으로부터 발현될 때 hGAA780I를 필요한 세포에 표적시키고, 이러한 세포에 의한 세포성 흡수를 증가시키며, 치료용 단백질을 세포하위 위치 (예로, 리소좀)에 표적시킨다. 일부 구현예에서, 펩티드는 hGAA780I 단백질의 N-말단에 융합된다. 일부 구현예에서, 펩티드는 hGAA780I 단백질의 C-말단에 융합된다. 일부 구현예에서, 펩티드는 vIGF2 펩티드이다. 일부 vIGF2 펩티드는 CI-MPR에 대한 고-친화 결합을 유지하는 반면, IGF1 수용체, 인슐린 수용체 및 IGF 결합 단백질 (IGFBP)에 대한 이들의 친화도는 감소되거나 제거된다. 따라서, 일부 변이체 IGF2 펩티드는 실질적으로 더욱 선택적이고, 야생형 IGF2와 비교하여 감소된 안전성 위험을 갖는다. 본원에서 vIGF2 펩티드는 서열번호 46의 아미노산 서열을 갖는 펩티드를 포함한다. 변이체 IGF2 펩티드는 야생형 IGF2 (서열번호 34)와 비교하여 위치 6번, 26번, 27번, 43번, 48번, 49번, 50번, 54번, 55번 또는 65번에서 변이 아미노산을 갖는 펩티드를 추가로 포함한다. 일부 구현예에서, vIGF2 펩티드는 E6R, F26S, Y27L, V43L, F48T, R49S, S50I, A54R, L55R 및 K65R로 이루어진 군으로부터 선택된 하나 이상의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 E6R의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 F26S의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 Y27L의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 V43L의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 F48T의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 R49S의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 S50I의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 A54R의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 L55R의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 K65R의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 E6R, F26S, Y27L, V43L, F48T, R49S, S50I, A54R 및 L55R의 치환을 갖는 서열을 갖는다. 일부 구현예에서, vIGF2 펩티드는 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 1개 아미노산의 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 2개 아미노산의 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 3개 아미노산의 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 4개 아미노산의 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 4개 아미노산의 N-말단 결실, 및 E6R, Y27L 및 K65R의 치환을 갖는다. 일부 구현예에서, vIGF2 펩티드는 4개 아미노산의 N-말단 결실, 및 E6R 및 Y27L의 치환을 갖는다. 일부 구현예에서, vIGF2 펩티드는 5개 아미노산의 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 6개 아미노산의 N-말단 결실을 갖는다. 일부 구현예에서, vIGF2 펩티드는 7개 아미노산의 N-말단 결실, 및 Y27L 및 K65R의 치환을 갖는다.



신호 펩티드
본원에 제공된 조성물은, 일부 구현예에서 유전자 요법 구조물로 형질도입된 세포로부터 hGAA780I의 분비를 개선하는 신호 펩티드를 추가로 포함한다. 일부 구현예에서, 신호 펩티드는 치료용 단백질의 단백질 프로세싱을 개선하고, ER로 폴리펩티드-리보좀 복합체의 이동을 용이하게 하며, 적절한 보조-번역 및 번역-후 변형을 보장한다. 일부 구현예에서, 신호 펩티드는 (i) 신호 번역 개시 서열의 상류 위치, (ii) 번역 개시 서열 및 치료용 단백질 사이 또는 (iii) 치료용 단백질의 하류 위치에 위치한다. 유전자 요법 구조물에 유용한 신호 펩티드는 HSP70 단백질의 패밀리 (예로, HSP5, 열 충격 단백질 패밀리 A 구성원 5)로부터의 결합 면역글로불린 단백질 (BiP) 신호 펩티드, 가우시아 신호 펩티드 및 이들의 변이체를 포함하나 이에 한정되지 않는다. 이들 신호 펩티드는 신호 인식 입자에 대한 한외 고-친화성을 갖는다. BiP 및 가우시아 아미노산 서열의 예는 하기 표에 제공된다. 일부 구현예에서, 신호 펩티드는 서열번호 49 내지 53으로 이루어진 군으로부터 선택된 서열과 적어도 90% 일치하는 아미노산 서열을 갖는다. 일부 구현예에서, 신호 펩티드는 서열번호 49 내지 53으로 이루어진 군으로부터 선택된 서열과 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개의 아미노산(들)이 상이하다.

가우시아 신호 펩티드는 가우시아 프린셉스로부터의 루시페라제로부터 유래하고, 이 신호 펩티드에 융합된 치료용 단백질의 단백질 합성 및 분비의 증가를 유도한다. 일부 구현예에서, 가우시아 신호 펩티드는 서열번호 54와 적어도 90% 일치하는 아미노산 서열을 갖는다. 일부 구현예에서, 가우시아 신호 펩티드는 서열번호 54와 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개의 아미노산(들)이 상이하다.
링커
본원에 제공된 조성물은, 일부 구현예에서 표적화 펩티드 및 치료용 단백질 사이에 링커를 포함한다. 이러한 링커는, 일부 구현예에서 정확한 간격을 유지시키고, vIGF2 펩티드 및 치료용 단백질 사이의 입체적 마찰을 완화한다. 링커는, 일부 구현예에서 반복된 글리신 잔기, 반복된 글리신-세린 잔기 및 이들의 조합을 포함한다. 일부 구현예에서, 링커는 5개 내지 20개의 아미노산, 5개 내지 15개의 아미노산, 5개 내지 10개의 아미노산, 8개 내지 12개의 아미노산, 또는 약 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개 또는 13개의 아미노산으로 구성된다. 적합한 링커는 하기 표에 제공된 링커를 포함하나 이에 한정되지 않는다.

본 명세서 전반에 걸쳐, 다양한 발현 카세트, 벡터 게놈, 벡터, 및 조성물이 hGAA780I 코딩 서열 또는 hGAA780I 단백질 또는 융합 단백질을 포함하는 것으로 기재되어 있다. 달리 명시되지 않는 한, 본 명세서에 기재된 것과 같은 N-말단 절단, C-말단 절단, 및 융합 단백질을 포함하여 조작된 hGAA780I 단백질, 또는 이에 대한 코딩 서열 중 임의의 것이 발현 카세트, 벡터 게놈, 벡터, 및 조성물로 유사하게 조작될 수 있음을 이해할 것이다.
적합하게는, 본 명세서에 기재된 핵산 서열을 포함하는 발현 카세트가 제공된다.
발현 카세트
본 명세서에서 사용되는 바와 같이, "발현 카세트"는 표적 세포에서 발현을 구동하는 조절 서열, 프로모터에 작동가능하게 연결된 기능적 유전자 산물을 인코딩하는 핵산 서열 (예로, hGAA780I 융합 단백질 코딩 서열)을 포함하는 핵산 분자를 말하고, 이에 따라 다른 조절 서열을 포함할 수 있다. 필요한 조절 서열은 표적 세포에서 hGAA780I 융합 단백질 코딩 서열의 전사, 번역 및/또는 발현을 허용하는 방식으로 해당 코딩 서열에 작동가능하게 연결되어 있다.
특정 구현예에서, 발현 카세트는 미번역 영역(들)에 하나 이상의 miRNA 표적 서열을 포함할 수 있다. miRNA 표적 서열은 이식유전자 발현이 바람직하지 않고/않거나 감소된 수준의 이식유전자 발현이 요구되는 세포에 존재하는 miRNA에 의해 특이적으로 인식되도록 설계된다. 특정 구현예에서, 발현 카세트는 배근신경절에서 hGAA780I 융합 단백질의 발현을 특이적으로 감소시키는 miRNA 표적 서열을 포함한다. 특정 구현예에서, miRNA 표적 서열은 3' UTR, 5' UTR, 및/또는 3' 및 5' UTR 둘 다에 위치한다. 특정 구현예에서, 발현 카세트는 배근신경절 (DRG)-특이적 miRNA 서열의 적어도 2개의 일렬 반복서열을 포함하며, 여기서 적어도 2개의 일렬 반복서열은 동일하거나 상이할 수 있는 적어도 제1 miRNA 표적 서열 및 적어도 제2 miRNA 표적 서열을 포함한다. 특정 구현예에서, 적어도 2개의 drg-특이적 miRNA 일렬 반복서열 중 첫 번째 시작은 hGAA780I 융합 단백질-코딩 서열의 3' 말단으로부터 20개의 뉴클레오티드 이내이다. 특정 구현예에서, 적어도 2개의 DRG-특이적 miRNA 일렬 반복서열 중 첫 번째의 시작은 hGAA780I 융합 단백질 코딩 서열의 3' 말단으로부터 적어도 100개의 뉴클레오티드이다. 특정 구현예에서, miRNA 일렬 반복서열은 200 내지 1200개의 뉴클레오티드 길이를 포함한다. 특정 구현예에서, miR 표적의 포함은 miR 표적 서열이 결여된 발현 카세트 또는 벡터 게놈에 비해, 하나 이상의 표적 조직에서 치료용 이식유전자의 발현 또는 효능을 변형시키지 않는다.
특정 구현예에서, 벡터 게놈 또는 발현 카세트는 miR-183 표적 서열인 적어도 하나의 miRNA 표적 서열을 포함한다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 AGTGAATTCTACCAGTGCCATA (서열번호 26)를 포함하는 miR-183 표적 서열을 포함하며, 여기서 miR-183 시드 서열에 상보적인 서열은 밑줄이 그어져 있다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 miR-183 시드 서열에 100% 상보적인 서열의 하나 초과의 복제물 (예를 들면, 2개 또는 3개 복제물)을 포함한다. 특정 구현예에서, miR-183 표적 서열은 길이가 약 7개의 뉴클레오티드 내지 약 28개의 뉴클레오티드이고 miR-183 시드 서열에 적어도 100% 상보적인 적어도 하나의 영역을 포함한다. 특정 구현예에서, miR-183 표적 서열은 서열번호 26에 부분적인 상보성을 갖는 서열을 포함하고, 따라서 서열번호 2에 대해 정렬될 때, 하나 이상의 미스매치가 있다. 특정 구현예에서, miR-183 표적 서열은 서열번호 26에 대해 정렬될 때 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개 미스매치를 갖는 서열을 포함하며, 여기서 미스매치는 비-연속적일 수 있다. 특정 구현예에서, miR-183 표적 서열은 miR-183 표적 서열 길이의 적어도 30%를 또한 포함하는 100% 상보성의 영역을 포함한다. 특정 구현예에서, 100% 상보성의 영역은 miR-183 시드 서열에 100% 상보성을 갖는 서열을 포함한다. 특정 구현예에서, miR-183 표적 서열의 나머지는 miR-183에 적어도 약 80% 내지 약 99% 상보성을 갖는다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 절단된 서열번호 26, 즉, 서열번호 26의 5' 또는 3' 말단 중 어느 하나 또는 둘 다에서 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 뉴클레오티드가 결여된 서열을 포함하는 miR-183 표적 서열을 포함한다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 이식유전자 및 하나의 miR-183 표적 서열을 포함한다. 또 다른 구현예에서, 발현 카세트 또는 벡터 게놈은 적어도 2개, 3개 또는 4개의 miR-183 표적 서열을 포함한다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개 또는 적어도 8개의 miR-183 표적 서열을 포함한다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈 내의 적어도 2개, 3개 또는 4개의 miR-183 표적 서열의 포함은 심장과 같은 표적 조직에서 이식유전자의 수준 증가를 유도한다.
특정 구현예에서, 벡터 게놈 또는 발현 카세트는 miR-182 표적 서열인 적어도 하나의 miRNA 표적 서열을 포함한다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 AGTGTGAGTTCTACCATTGCCAAA (서열번호 27)를 포함하는 miR-182 표적 서열을 포함한다. 특정 구현예에서, 벡터 게놈 또는 발현 카세트는 miR-182 종자 서열에 100% 상보적인 서열의 하나 초과의 복제물 (예를 들면, 2개 또는 3개 복제물)을 포함한다. 특정 구현예에서, miR-182 표적 서열은 길이가 약 7개의 뉴클레오티드 내지 약 28개의 뉴클레오티드이고 miR-182 시드 서열에 적어도 100% 상보적인 적어도 하나의 영역을 포함한다. 특정 구현예에서, miR-182 표적 서열은 서열번호 27에 부분적인 상보성을 갖는 서열을 포함하고, 따라서 서열번호 27에 대해 정렬될 때, 하나 이상의 미스매치가 있다. 특정 구현예에서, miR-183 표적 서열은 서열번호 27에 대해 정렬될 때 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개 미스매치를 갖는 서열을 포함하며, 여기서 미스매치는 비-연속적일 수 있다. 특정 구현예에서, miR-182 표적 서열은 miR-182 표적 서열 길이의 적어도 30%를 또한 포함하는 100% 상보성의 영역을 포함한다. 특정 구현예에서, 100% 상보성의 영역은 miR-182 시드 서열에 100% 상보성을 갖는 서열을 포함한다. 특정 구현예에서, miR-182 표적 서열의 나머지는 miR-182에 적어도 약 80% 내지 약 99% 상보성을 가진다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 절단된 서열번호 27, 즉, 서열번호 27의 5' 또는 3' 말단 중 어느 하나 또는 둘 다에서 적어도 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 뉴클레오티드가 결여된 서열을 포함하는 miR-182 표적 서열을 포함한다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 이식유전자 및 하나의 miR-182 표적 서열을 포함한다. 또 다른 구현예에서, 발현 카세트 또는 벡터 게놈은 적어도 2개, 3개 또는 4개의 miR-182 표적 서열을 포함한다.
용어 "일렬 반복서열"는 본 명세서에서 2개 이상의 연속적인 miRNA 표적 서열의 존재를 말하는데 사용된다. 이러한 miRNA 표적 서열은 연속적일 수 있으며, 즉 하나의 3' 말단이 개입하는 서열 없이 다음의 5' 말단의 바로 상류에 있거나, 역으로 서로 바로 뒤에 위치할 수 있다. 또 다른 구현예에서, 2개 이상의 miRNA 표적 서열은 짧은 스페이서 서열에 의해 분리된다.
본 명세서에서 사용되는 바와 같이, "스페이서"는 2개 이상의 연속적인 miRNA 표적 서열 사이에 위치한, 예를 들면, 길이가 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 뉴클레오티드인 임의의 선택된 핵산 서열이다. 특정 구현예에서, 스페이서는 길이가 1 내지 8개의 뉴클레오티드, 길이가 2 내지 7개의 뉴클레오티드, 길이가 3 내지 6개의 뉴클레오티드, 길이가 4개의 뉴클레오티드, 4 내지 9개의 뉴클레오티드, 3 내지 7개의 뉴클레오티드, 또는 더 긴 값이다. 적합하게는, 스페이서는 비-코딩 서열이다. 특정 구현예에서, 스페이서는 네 (4)개의 뉴클레오티드를 가질 수 있다. 특정 구현예에서, 스페이서는 GGAT이다. 특정 구현예에서, 스페이서는 여섯 (6)개의 뉴클레오티드이다. 특정 구현예에서, 스페이서는 CACGTG 또는 GCATGC이다.
특정 구현예에서, 일렬 반복서열은 2, 3, 4개 또는 그 이상의 동일한 miRNA 표적 서열을 포함한다. 특정 구현예에서, 일렬 반복서열은 적어도 2개의 상이한 miRNA 표적 서열, 적어도 3개의 상이한 miRNA 표적 서열, 또는 적어도 4개의 상이한 miRNA 표적 서열 등을 포함한다. 특정 구현예에서, 일렬 반복서열은 2개 또는 3개의 동일한 miRNA 표적 서열 및 상이한 제 4 miRNA 표적 서열을 포함할 수 있다. 특정 구현예에서, 발현 카세트 또는 벡터 게놈은 적어도 1개, 적어도 2개, 적어도 3개 또는 적어도 4개의 miR-183 표적 서열의 조합, 및 적어도 1개, 적어도 2개, 적어도 3개 또는 적어도 4개의 miR-183 표적 서열을 포함한다.
특정 구현예에서, 발현 카세트에 일렬 반복서열의 적어도 2개의 상이한 세트가 있을 수 있다. 예를 들면, 3' UTR은 이식유전자의 바로 하류에 일렬 반복서열, UTR 서열, 및 UTR의 3' 말단에 더 가까운 2개 이상의 일렬 반복서열을 포함할 수 있다. 또 다른 예에서, 5' UTR은 1, 2개 또는 그 이상의 miRNA 표적 서열을 포함할 수 있다. 또 다른 예에서, 3'은 일렬 반복서열을 포함할 수 있고 5' UTR은 적어도 1개의 miRNA 표적 서열을 포함할 수 있다.
특정 구현예에서, 발현 카세트는 이식유전자에 대한 정지 코돈의 약 0 내지 20개의 뉴클레오티드 내에서 시작하는 2, 3, 4개 또는 그 이상의 일렬 반복서열을 포함한다. 다른 구현예에서, 발현 카세트는 이식유전자에 대한 종결 코돈으로부터 적어도 100개 내지 약 4000개의 뉴클레오티드의 miRNA 일렬 반복서열을 포함한다.
2019년 12월 20일에 제출되고 이제 국제출원 제 WO 2020/132455호로서 공개된 국제특허출원 제 PCT/US19/67872호 참조, 이는 2018년 12월 21일에 제출된 미국 가특허출원 제 US 62/783,956호에 대한 우선권을 주장하며, 이들은 본원에 참고문헌으로 통합된다. 또한, 2020년 5월 12일에 제출된 미국 가특허출원 제 US 63/023,593호, 2020년 6월 12일에 제출된 미국 가특허출원 제 US 63/038,488호, 2020년 6월 24일에 제출된 미국 가특허출원 제 US 63/043,562호, 2020년 9월 16일에 제출된 미국 가특허출원 제 US 63/079,299호, 2021년 2월 22일에 제출된 미국 가특허출원 제 US 63/152,042호, 2021년 5월 12일에 제출된 미국 가특허출원 제 PCT/US21/32003호 참조, 이들 모두는 본원에 참고문헌으로 통합된다.
본원에 사용된 바, "BiP-vIGF2.hGAAcoV780I.4xmir183"는 만능 CAG 프로모터의 조절 하에 변형된 BiP-vIGF2 신호 서열을 갖는 hGAA780I의 조작된 코딩 서열, 및 miR183 표적 서열의 4개 일렬 반복서열을 포함하는 발현 카세트 (예로, 도 11에 도시됨)를 말한다. 본원에 제공된 실시예에 도시된 바, V780I 돌연변이 및 BiP-vIGF2 변형은 안전성 및 효능의 개선에 기여한다. 특정 구현예에서, BiP-vIGF2.hGAAcoV780I.4xmir183은 서열번호 3 또는 이와 적어도 95% 일치하는 서열의 융합 단백질을 인코딩하는 서열을 포함한다. 특정 구현예에서, BiP-vIGF2.hGAAcoV780I.4xmir183은 서열번호 7 또는 이와 적어도 95% 내지 99% 일치하는 서열의 핵산 서열을 포함한다. 또 다른 구현예에서, 본원에서는 BiP-vIGF2.hGAAcoV780I.4xmir183가 5'ITR 및 3' ITR에 의해 연접되는 벡터 게놈이 제공된다. 특정 구현예에서, 벡터 게놈은 서열번호 30이다. 추가의 구현예에서, 서열번호 30과 적어도 95% 일치하는 서열을 포함하고, 서열번호 6의 융합 단백질을 인코딩하는 벡터 게놈이 제공된다.
본 명세서에서 사용된 바, "작동가능하게 연결된" 서열은 hGAA780I 코딩 서열과 인접한 발현 제어 서열 및 hGAA780I 코딩 서열을 제어하기 위해 트랜스 배향으로 또는 이격되어 작용하는 발현 조절 서열을 둘 다 포함한다. 이와 같은 조절 서열은 전형적으로, 예를 들면 프로모터, 인핸서, 인트론, 코작 서열, 폴리아데닐화 서열 및 TATA 신호 중 하나 이상을 포함한다.
특정 구현예에서, 조절 요소는 다수의 표적 세포를 치료하는 데 적합한 단일 발현 카세트의 작제 및 전달을 허용하기 위해, 폼페병에 의해 이환된 다수의 세포 및 조직에서 발현을 지시한다. 예를 들면, 간, 골격근, 심장 및 중추신경계 세포 중 둘 이상에서 발현하는 조절 요소 (예를 들면, 프로모터)가 선택될 수 있다. 예를 들면, 중추신경계 (예를 들면, 뇌) 세포, 및 골격근에서 발현하는 조절 요소 (예를 들면, 프로모터)가 선택될 수 있다. 다른 구현예에서, 조절 요소는 CNS, 골격근 및 심장에서 발현한다. 다른 구현예에서, 발현 카세트는 간, 골격근, 심장 및 중추신경계 세포 모두에서 인코딩된 hGAA780I의 발현을 허용한다. 다른 구현예에서, 조절 요소는 (예를 들면, 본 명세서에 기재된 drg-탈표적화 시스템의 사용 및/또는 조직-특이적 프로모터의 선택에 의해) 특정 조직을 표적화하고 특정 세포 또는 조직에서 발현을 회피하도록 선택될 수 있다. 특정 구현예에서, 상이한 조직을 우선적으로 표적화하는 본 명세서에서 제공되는 상이한 발현 카세트가 환자에게 투여된다.
조절 서열은 프로모터를 포함한다. 표적화된 세포에서 hGAAV780I 단백질을 발현할 프로모터를 포함하나 이에 한정되지 않는 적합한 프로모터가 선택될 수 있다.
특정 구현예에서, 전신발현 프로모터 또는 유도성/조절 프로모터가 선택된다. 전신발현 프로모터의 예는 닭 베타-액틴 프로모터이다. 다양한 닭 베타-액틴 프로모터가 단독으로, 또는 다양한 인핸서 요소와 조합하여 기재되었다 (예를 들면, CB7은 거대세포바이러스 인핸서 요소; 프로모터, 닭 베타 액틴의 제 1 엑손 및 제 1 인트론, 및 토끼 베타-글로빈 유전자의 스플라이스 수용체를 포함하는 CAG 프로모터; CBh 프로모터가 있는 닭 베타-액틴 프로모터임 (S. J. Gray et al., Hu. Gene Ther., 2011년 9월, 22 (9): 1143-1153)). 특정 구현예에서, 조절가능한 프로모터가 선택될 수 있다. 예를 들면, 본 명세서에 참고문헌으로 통합되는 국제특허출원 제 WO 2011/126808B2호 참조.
특정 구현예에서, 조직-특이적 프로모터가 선택될 수 있다. 조직-특이적인 프로모터의 예는 간 (알부민, Miyatake et al. (1997), J. Virol., 71: 5124-32; B형 간염 바이러스 코어 프로모터, Sandig et al. (1996). Gene Ther., 3: 1002-9; 알파-태아단백질 (AFP), Arbuthnot et al. (1996), Hum. Gene Ther., 7: 1503-14]), 중추신경계, 예로 뉴런 (예컨대, 뉴런-특이적 에놀라제 (NSE) 프로모터, Andersen et al. (1993), Cell. Mol. Neurobiol., 13: 503-15; 신경미세섬유 경쇄 유전자, Piccioli et al. (1991), Proc. Natl. Acad. Sci. USA, 88: 5611-5; 및 뉴런-특이적 vgf 유전자, Piccioli et al. (1995), Neuron, 15: 373-84), 심장 근육, 골격근, 폐, 및 다른 조직에 대하여 잘 알려져 있다. 또 다른 구현예에서, 적합한 프로모터는 연장인자 1 알파 (EF1 알파) 프로모터 (예로, Kim D. W. et al. Use of the human elongation factor 1 alpha promoter as a versatile and efficient expression system. Gene., 1990년 7월 16일, 91(2): 217-23 참조), 시냅신 1 프로모터 (예를 들면, Krugler S. et al., Human synapsin 1 gene promoter confers highly neuron-specific long-term transgene expression from an adenoviral vector in the adult rat brain depending on the transduced area. Gene Ther. 2003년 2월, 10(4): 337-47 참조), 뉴런-특이적 에놀라제 (NSE) 프로모터 (예로, Kim J. et al., Involvement of cholesterol-rich lipid rafts in interleukin-6-induced neuroendocrine differentiation of LNCaP prostate cancer cells. Endocrinology, 2004년 2월, 145(2): 613-9. Epub 2003년 10월 16일 참조), 또는 CB6 프로모터 (예로, Large-Scale Production of Adeno-Associated Viral Vector Serotype-9 Carrying the Human Survival Motor Neuron Gene, Mol. Biotechnol. 2016년 1월, 58(1): 30-6. doi: 10.1007/s12033-015-9899-5 참조)를 포함할 수 있으나 이들에 한정되지 않는다. 조직-특이적 프로모터를 이용하는 특정 구현예에서, 상이한 세포 유형을 표적화하는 조직-특이적 프로모터를 갖는 상이한 발현 카세트를 포함하는 공동-요법이 선택될 수 있다.
일 구현예에서, 조절 서열은 인핸서를 추가로 포함한다. 일 구현예에서, 조절 서열은 하나의 인핸서를 포함한다. 또 다른 구현예에서, 조절 서열은 2개 이상의 발현 인핸서를 포함한다. 이들 인핸서는 동일할 수 있거나 상이할 수 있다. 예를 들면, 인핸서는 알파 mic/bik 인핸서 또는 CMV 인핸서를 포함할 수 있다. 이러한 인핸서는 서로 인접하게 위치한 2개의 복제물로 존재할 수 있다. 대안적으로, 인핸서의 이중 복제물은 하나 이상의 서열에 의해 분리될 수 있다.
일 구현예에서, 조절 서열은 인트론을 추가로 포함한다. 추가 구현예에서, 인트론은 닭 베타-액틴 인트론이다. 다른 적합한 인트론은 인간 β-글로불린 인트론, 및/또는 상업적으로 입수가능한 프로메가® 인트론, 및 제 WO 2011/126808호에 기재된 것에 의해 당업계에 알려진 것을 포함한다.
일 구현예에서, 조절 서열은 폴리아데닐화 신호 (폴리 A)를 추가로 포함한다. 추가 구현예에서, 폴리 A는 토끼 글로빈 폴리 A이다. 예를 들면, 제 WO 2014/151341호 참조. 대안적으로, 또 다른 폴리 A, 예를 들면, 인간 성장 호르몬 (hGH) 폴리아데닐화 서열, SV40 폴리 A, 또는 합성 폴리 A가 발현 카세트에 포함될 수 있다.
본원에 기술된 발현 카세트에서의 조성물은 본 명세서 전반에 걸쳐 기술된 다른 조성물, 요법, 양태, 구현예 및 방법에 적용하도록 의도된 것으로 이해되어야 한다.
발현 카세트는 임의의 적합한 전달 시스템을 통해 전달될 수 있다. 적합한 비-바이러스 전달 시스템은 당업계에 알려져 있으며 (예로, Ramamoorth and Narvekar., J. Clin. Diagn. Res. 2015년 1월, 9 (1): GE01-GE06 참조, 이는 본 명세서에 참고문헌으로 통합됨) 당업자에 의해 용이하게 선택될 수 있고, 예를 들면 노출 DNA, 노출 RNA, 덴드리머, PLGA, 폴리메트아크릴레이트, 무기 입자, 지질 입자 (예로, 지질 나노입자 또는 LNP), 또는 키토산 기반의 제형물을 포함할 수 있다.
일 구현예에서, 벡터는 이의 기재된 발현 카세트, 예를 들면, "노출 DNA", "노출 플라스미드 DNA", RNA 및 mRNA; 예를 들면, 미셀, 리포좀, 양이온성 지질-핵산 조성물, 폴리-글리칸 조성물 및 다른 중합체, 지질 및/또는 콜레스테롤-기반 핵산 컨쥬게이트를 포함하는 나노 입자 및 다양한 조성물과 커플링된 발현 카세트, 및 본 명세서에 기재된 바와 같은 다른 구조물을 포함하는 비-바이러스 플라스미드이다. 예로, X. Su et al., Mol. Pharmaceutics, 2011년, 8(3): 774-787; 웹 공개 2011년 3월 21일]; 국제특허출원 제 WO 2013/182683호, 제 WO 2010/053572호 및 제 WO 2012/170930호 참조, 이들 모두는 본 명세서에 참고문헌으로 통합된다.
특정 구현예에서, 본 명세서에 기재된 바와 같은 hGAA780I 변이체, 융합 단백질, 또는 절단된 단백질을 인코딩하는 서열을 갖는 핵산 분자가 본 명세서에서 제공된다. 바람직한 일 구현예에서, hGAA780I는 서열번호 4의 조작된 서열 또는 hGAA780I 변이체를 인코딩하는 이와 적어도 95% 동일한 서열에 의해 인코딩된다. 특정 구현예에서, 서열번호 4는 780I 위치에서 Ile를 인코딩하는 코돈이 ATT 또는 ATC가 되도록 변형된다. 특정 구현예에서, 서열번호 4의 조작된 서열을 포함하는 핵산, 또는 이의 단편은 융합 단백질 또는 절단된 hGAA780I를 발현하는 데 사용된다. 덜 바람직하지만, 특정 구현예에서, hGAA780I는 서열번호 5에 의해 인코딩된다. 특정 구현예에서, 핵산 분자는 서열번호 6 또는 이와 적어도 95% 일치하는 서열의 아미노산 서열을 갖는 융합 단백질을 인코딩한다. 특정 구현예에서, 서열번호 7 또는 이와 적어도 95% 일치하는 서열의 서열을 갖는 핵산이 제공된다. 특정 구현예에서, 핵산 분자는 플라스미드이다.
벡터
본 명세서에서 사용되는 바와 같이 "벡터"는 핵산 서열의 복제 또는 발현을 위해 적절한 표적 세포로 도입될 수 있는 핵산 서열을 포함하는 생물학적 또는 화학적 모이어티이다. 벡터의 예는 재조합 바이러스, 플라스미드, 리포플렉스, 폴리머좀, 폴리플렉스, 덴드리머, 세포 투과 펩티드 (CPP) 컨쥬게이트, 자성 입자, 또는 나노입자를 포함하나 이들에 한정되지 않는다. 일 구현예에서, 벡터는 이후에 적절한 표적 세포 내로 도입될 수 있는, 기능적 유전자 산물을 인코딩하는 외인성 또는 이종성 조작된 핵산을 갖는 핵산 분자이다. 이와 같은 벡터는 바람직하게는 하나 이상의 복제 기원, 및 재조합 DNA가 삽입될 수 있는 하나 이상의 부위를 가진다. 벡터는 종종 벡터를 갖는 세포가 벡터가 없는 세포로부터 선택될 수 있는 수단을 가지며, 예를 들면, 벡터는 약물 내성 유전자를 인코딩한다. 일반적인 벡터는 플라스미드, 바이러스 게놈, 및 "인공 염색체"를 포함한다. 벡터의 생성, 생산, 특성화, 또는 정량화의 통상적인 방법은 당업자에게 이용가능하다.
특정 구현예에서, 본 명세서에 기재된 벡터는 기능적 hGAA780I 융합 단백질을 인코딩하는 핵산 서열을 포함하는 발현 카세트가 바이러스 캡시드 또는 외피에 패키징되는 합성 또는 인공 바이러스 입자를 말하는 "복제 결함성 바이러스" 또는 "바이러스성 벡터"이며, 여기서 바이러스 캡시드 또는 외피 내에 패키징되는 임의의 바이러스 게놈 서열은 복제 결함성이고; 즉, 이들은 자손 비리온을 생성할 수 없지만 표적 세포를 감염시키는 능력은 보유한다. 일 구현예에서, 바이러스 벡터의 게놈은 복제에 필요한 효소를 인코딩하는 유전자를 포함하지 않지만 (게놈은 "무기력" (인공 게놈의 증폭 및 패키징에 필요한 신호가 측접한 인코딩하는 핵산 서열만을 포함함)하도록 조작될 수 있음), 이들 유전자는 생성 동안 공급될 수 있다. 따라서, 복제에 필요한 바이러스 효소가 존재하는 경우를 제외하고 자손 비리온에 의한 복제 및 감염이 일어나지 못하므로 유전자 요법에 사용하기에 안전하다고 여겨진다.
본 명세서에서 사용되는 바와 같이, 재조합 바이러스 벡터는 원하는 세포 (들)를 표적화하는 임의의 적합한 바이러스 벡터이다. 따라서, 재조합 바이러스 벡터는 바람직하게는, 중추신경계 (예를 들면, 뇌), 골격근, 심장, 및/또는 간을 포함하는 폼페병에 의해 이환된 세포 및 조직 영향 중 하나 이상을 표적화한다. 특정 구현예에서, 바이러스 벡터는 적어도 중추신경계 (예를 들면, 뇌), 폐, 심장 세포, 또는 골격근을 표적화한다. 다른 구현예에서, 바이러스 벡터는 CNS (예를 들면, 뇌), 골격근 및/또는 심장을 표적화한다. 다른 구현예에서, 바이러스 벡터는 간, 골격근, 심장 및 중추신경계 세포를 모두 표적화한다. 예는 예시적인 재조합 아데노 관련 바이러스 (rAAV)를 제공한다. 그러나, 다른 적합한 바이러스 벡터는, 예를 들면, 재조합 아데노바이러스, 재조합 파보바이러스, 예컨대, 재조합 보카바이러스, 하이브리드 AAV/보카바이러스, 재조합 단순 헤르페스 바이러스, 재조합 레트로바이러스, 또는 재조합 렌티바이러스를 포함할 수 있다. 바람직한 구현예에서, 이들 재조합 바이러스는 복제 불능성이다.
본 명세서에서 사용된 용어 "숙주 세포"는 벡터 (예를 들면, 재조합 AAV)가 생성되는 패키징 세포주를 지칭할 수 있다. 숙주 세포는 임의의 수단, 예를 들면, 전기천공, 인산칼슘 침전, 미세주입, 형질전환, 바이러스 감염, 형질감염, 리포솜 전달, 막 융합 기법, 고속 DNA-코팅 펠릿, 바이러스 감염 및 원형질체 융합에 의해 세포 내로 도입된 외인성 또는 이종성 DNA를 포함하는 원핵 또는 진핵 세포 (예를 들면, 인간, 곤충, 또는 효모)일 수 있다. 숙주 세포의 예는 단리된 세포, 세포 배양물, 대장균 (에스케리키아 콜라이 (Escherichia coli)) 세포, 효모 세포, 인간 세포, 비-인간 세포, 포유동물 세포, 비-포유동물 세포, 곤충 세포, HEK-293 세포, 간 세포, 신장 세포, 중추신경계의 세포, 뉴런, 신경아교세포, 또는 줄기 세포를 포함할 수 있지만, 이들로 제한되지 않는다.
특정 구현예에서, 숙주 세포는 단백질이 단리 또는 정제를 위해 시험관내에서 충분한 양으로 생성되도록 hGAA780I의 생성을 위한 발현 카세트를 포함한다. 특정 구현예에서, 숙주 세포는 hGAA780I, 또는 이의 단편을 인코딩하는 발현 카세트를 포함한다. 본 명세서에서 제공되는 바와 같이, hGAA780I 단백질은 치료제 (즉, 효소 대체 요법)로서 대상체에게 투여되는 약제학적 조성물에 포함될 수 있다.
본 명세서에서 사용되는 바와 같이, 용어 "표적 세포"는 기능적 유전자 산물의 발현이 요구되는 임의의 표적 세포를 지칭한다.
본 명세서에서 사용되는 바와 같이, "벡터 게놈"은 바이러스 벡터 내부에 패키징된 핵산 서열을 지칭한다. 일 예에서, "벡터 게놈"은 최소한 5'에서 3'으로 벡터 특이적 서열, 표적 세포에서 발현을 지시하는 조절 제어 서열에 작동가능하게 연결된 기능적 유전자 산물 (예를 들면, hGAA780I, 융합 단백질 hGAA780I, 또는 또 다른 단백질)을 인코딩하는 핵산 서열, 벡터-특이적 서열, 및 선택적으로 미번역 영역 (들) 및 벡터-특이적 서열의 miRNA 표적 서열을 포함한다. 벡터-특이적 서열은 벡터 게놈을 바이러스 벡터 캡시드 또는 외피 단백질 내로 특이적으로 패키징하는 말단 반복 서열일 수 있다. 예를 들면, AAV 역전된 말단 반복서열은 AAV 및 다른 특정 파보바이러스 캡시드 내로 패키징하는 데 이용된다. 렌티바이러스 긴 말단 반복서열은 렌티바이러스 벡터 내로의 패키징이 요구되는 경우에 이용될 수 있다. 유사하게, 다른 말단 반복서열 (예를 들면, 레트로바이러스 긴 말단 반복서열) 등이 선택될 수 있다.
본 명세서에 기재된 벡터에서의 조성물은 본 명세서 전반에 걸쳐 기재된 다른 조성물, 요법, 양태, 구현예, 및 방법에 적용하도록 의도되는 것으로 이해되어야 한다.
아데노 관련 바이러스 (AAV)
일 양태에서, 본원에 기술된 hGAAV780I 융합 단백질 (효소)을 인코딩하는 AAV 캡시드 및 내부에 패키징된 벡터 게놈을 포함하는 재조합 AAV (rAAV)가 본 명세서에서 제공된다. 특정 구현예에서, 선택된 AAV 캡시드는 간, 근육, 신장, 심장 및/또는 중추신경계 세포 유형 중 둘 이상의 세포를 표적화한다. 특정 구현예에서, 간, 골격근, 심장, 신장 및/또는 적어도 하나의 중추신경계 세포 유형 중 적어도 둘 이상에서 hGAA780I 융합 단백질을 발현시키는 것이 바람직하다. 따라서, 일 구현예에서 선택된 AAV 캡시드는 심장 조직을 표적화한다. 특정 구현예에서, 심장 조직을 표적화하도록 선택된 AAV 캡시드는 AAV 1, 6, 8, 및 9로부터 선택된다 (예를 들면, 문헌[Katz et al. Hum Gene Ther Clin Dev. 2017 Sep 1; 28 (3): 157-164] 참조). 또 다른 구현예에서, 선택된 AAV 캡시드는 신장의 세포를 표적화한다. 일 구현예에서, 신장 세포를 표적화하기 위한 캡시드는 AAV1, 2, 6, 8, 9, 및 Anc80으로부터 선택된다 (예를 들면, Ikeda Y et al., J. Am. Soc. Nephrol. 2018년 9월, 29(9): 2287-2297 및 Ascio et al., Biochem. Biophys. Res. Commun. 2018년 2월 26일, 497 (1): 19-24 참조). 특정 구현예에서, AAV 캡시드는 고유한 또는 조작된 클라드 F 캡시드이다. 특정 구현예에서, 캡시드는 AAV9 캡시드 또는 AAVhu68 캡시드이다.
일 구현예에서, 벡터 게놈은 AAV 5' 역전된 말단 반복서열 (ITR), 본 명세서에 기재된 바와 같은 발현 카세트, 및 AAV 3' ITR을 포함한다. 일 구현예에서, 벡터 게놈은 rAAV 벡터를 형성하는 rAAV 캡시드 내부에 패키징된 핵산 서열을 지칭한다. 이와 같은 핵산 서열은 발현 카세트에 측접하는 AAV 역전된 말단 반복서열 서열 (ITR)을 포함한다. 일 예에서, AAV 또는 보카바이러스 캡시드로 패키징하기 위한 "벡터 게놈"은 최소한 5'에서 3'으로 AAV 5' ITR, 표적 세포에서 발현을 구동하는 조절 제어 서열에 작동가능하게 연결된 본 명세서에 기재된 바와 같은 기능적 hGAA780I 융합 단백질을 인코딩하는 핵산 서열, 및 AAV 3' ITR을 포함한다. 특정 구현예에서, ITR은 AAV2 유래이고 캡시드는 상이한 AAV 유래이다. 대안적으로, 다른 ITR이 사용될 수 있다. 특정 구현예에서, 벡터 게놈은 이식유전자 발현이 바람직하지 않고/않거나 감소된 수준의 이식유전자 발현이 바람직한 세포에서 miRNA 서열에 의해 특이적으로 인식되도록 설계된 미번역 영역 (들)에 miRNA 표적 서열을 추가로 포함한다. 특정 구현예에서, 벡터 게놈의 miRNA 표적 서열은 심장에서 이식유전자의 발현 증가를 유도한다.
ITR은 벡터 생성 동안 게놈의 복제 및 패키징을 담당하는 유전 요소이며 rAAV를 생성하는 데 필요한 유일한 바이러스 시스 배향 요소이다. 일 구현예에서, ITR은 캡시드를 공급하는 것과 상이한 AAV 유래이다. 바람직한 구현예에서, AAV2 유래의 ITR 서열, 또는 이의 결실된 형태 (ΔITR)는 편의를 위해 그리고 규제 승인을 가속화하기 위해 사용될 수 있다. 그러나, 다른 AAV 출처로부터의 ITR이 선택될 수 있다. ITR의 출처가 AAV2이고 AAV 캡시드가 또 다른 AAV 출처로부터 나오는 경우, 생성된 벡터는 슈도형으로 불릴 수 있다. 전형적으로, AAV 벡터 게놈은 AAV 5' ITR, hGAA780I 코딩 서열 및 임의의 조절 서열, 및 AAV 3' ITR을 포함한다. 그러나, 이들 요소의 다른 입체구조가 적합할 수 있다. D-서열 및 말단 분해 부위 (trs)가 결실된 ΔITR로 명명되는 5' ITR의 단축된 형태가 설명된 바 있다. 다른 구현예에서, 전장 AAV 5' 및 3' ITR이 사용된다. 다른 구현예에서, 전장의 AAV 5' ITR 및 AAV 3' ITR이 사용된다. 특정 구현예에서, 벡터 게놈은 130개 염기쌍의 단축된 5' 및/또는 3' AAV2 ITR을 포함하는 한편, 외부 "a" 요소는 결실된다. 단축된 ITR은 내부 A 요소를 주형으로서 사용한 벡터 DNA의 증폭 과정 동안 145개 염기쌍의 야생형 길이로 재전환된다.
본 명세서에서 사용되는 바와 같이 용어 "AAV"는 자연 발생 아데노 관련 바이러스, 당업자에게 입수가능한 및/또는 본 명세서에 기재된 구성 (들) 및 방법 (들)을 고려한 아데노 관련 바이러스뿐만 아니라, 인공 AAV를 말한다. 아데노 관련 바이러스 (AAV) 바이러스 벡터는 표적 세포로 전달하기 위해 AAV 역전된 말단 반복서열 서열 (ITR)이 측접한 발현 카세트에 패키징된 AAV 단백질 캡시드를 갖는AAV 뉴클레아제 (예를 들면, DNase)-내성 입자이다. 뉴클레아제-내성 재조합 AAV (rAAV)는 AAV 캡시드가 완전히 조립되었고 생성 공정에서 존재할 수 있는 오염 핵산을 제거하도록 설계된 뉴클레아제 인큐베이션 단계 동안 이들 패키징된 벡터 게놈 서열을 분해 (소화)로부터 보호함을 나타낸다. 많은 경우에, 본 명세서에 기재된 rAAV는 DNase 내성이다.
AAV 캡시드는 60개의 캡시드 (cap) 단백질 소단위체, VP1, VP2 및 VP3로 구성되고, 이는 선택된 AAV에 따라 대략 1 : 1: 10 내지 1 : 1 : 20 비의 정이십면체 대칭으로 배열된다. 다양한 AAV는 상기 확인된 AAV 바이러스성 벡터의 캡시드를 위한 출처로서 선택될 수 있다. 예로, 미국 특허출원 공개 제 US 2007-0036760-A1호; 제 US 2009-0197338-A1호; 유럽 특허 제 EP 1310571호 참조. 또한, 국제특허출원 제 WO 2003/042397호 (AAV7 및 다른 원숭이 AAV), 미국 특허 제 US 7790449호 및 제 US 7282199호 (AAV8), 제 WO 2005/033321호 및 제 US 7,906,111호 (AAV9), 및 제 WO 2006/110689호 및 제 WO 2003/042397호 (rh.10) 참조. 또한, 이들 문서는 AAV를 생성하기 위해 선택될 수 있는 다른 AAV를 기재하고 있으며, 참고문헌으로 통합된다. 인간 또는 비-인간 영장류 (NHP)로부터 단리되거나 조작되어 잘 특성화된 AAV 중에, 인간 AAV2는 유전자 전달 벡터로서 개발된 첫 번째 AAV이고, 이는 상이한 표적 조직 및 동물 모델에서 효율적인 유전자 전달 실험에 널리 사용되어 왔다. 달리 명시되지 않는 한, AAV 캡시드, ITR, 및 본원에 기술된 다른 선택된 AAV 구성요소는, AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV6.2, AAV7, AAV8, AAV9, AAV8bp, AAVrh10, AAVhu37, AAV7M8 and AAVAnc80, AAVrh90 (본원에 참고문헌으로 통합되는, 2020년 4월 28일에 제출된 국제특허출원 제 PCT/US20/30273호), AAVrh91 (본원에 참고문헌으로 통합되는, 2020년 4월 28일에 제출된 국제특허출원 제 PCT/US20/30266호), AAVrh92, rh93 및 rh91.93 (본원에 참고문헌으로 통합되는, 2020년 4월 28일에 제출된 국제특허출원 제 PCT/US20/30281호), 및 임의의 공지되거나 언급된 AAV의 변이체, 또는 아직 발견되지 않은 AAV 또는 이의 변이체 또는 혼합물을 포함하나 이에 한정되지 않는 임의의 AAV로부터 쉽게 선택될 수 있다. 예로, 본원에 참고문헌으로 통합되는 국제특허출원 제 WO 2005/033321호 참조. 일 구현예에서, AAV 캡시드는 AAV9 캡시드 또는 이의 변이체이다. 특정 구현예에서, 캡시드 단백질은 rAAV 벡터의 명칭에서 용어 "AAV"에 이어진 숫자 또는 숫자 및 문자의 조합에 의해 명명된다.
ITR 또는 다른 AAV 구성요소는 당업자에게 이용가능한 기법을 사용하여 AAV로부터 용이하게 단리되거나 조작될 수 있다. 이러한 AAV는 학문적, 상업적 또는 공공 출처 (예로, 미국 타입 배양물 수집기관, 미국 매너서스 소재)로부터 단리되거나, 조작되거나, 입수할 수 있다. 대안적으로, AAV 서열은, 예를 들면, GenBank, PubMed 등과 같은 데이터베이스 또는 문헌에서 이용가능한 것과 같은 공개된 서열을 참조하여 합성 또는 다른 적합한 수단을 통해 조작될 수 있다. AAV 바이러스는 통상적인 분자 생물학 기법에 의해 조작되어, 핵산 서열의 세포 특이적 전달, 면역원성의 최소화, 안정성 및 입자 수명 조정, 효율적인 분해, 핵으로의 정확한 전달 등을 위해 이러한 입자를 최적화하는 것을 가능하게 한다.
본 명세서에서 사용되는 바, 상호교환적으로 사용되는 용어 "rAAV" 및 "인공 AAV"는 캡시드 단백질 및 그 안에 패키징된 벡터 게놈을 포함하는 AAV를 의미하지만, 이로 제한되지 않으며, 여기서 벡터 게놈은 AAV에 이종성인 핵산을 포함한다. 일 구현예에서, 캡시드 단백질은 비-자연 발생 캡시드이다. 이와 같은 인공 캡시드는 선택된 AAV 서열 (예를 들면, vp1 캡시드 단백질의 단편)을 상이한 선택된 AAV, 동일한 AAV의 비-연속적인 부분, 비-AAV 바이러스 출처, 또는 비-바이러스 출처로부터 얻을 수 있는 이종성 서열과 조합하여 사용함으로써 임의의 적합한 기법에 의해 생성될 수 있다. 인공 AAV는 슈도형 AAV, 키메라 AAV 캡시드, 재조합 AAV 캡시드, 또는 "인간화" AAV 캡시드일 수 있지만, 이들로 제한되지 않는다. 하나의 AAV의 캡시드가 이종 캡시드 단백질로 대체된 슈도형 벡터가 본 발명에 유용하다. 일 구현예에서, AAV2/5 및 AAV2/8은 예시적인 슈도형 벡터이다. 선택된 유전 요소는 형질감염, 전기천공, 리포좀 전달, 막 융합 기법, 고속 DNA-코팅 펠릿, 바이러스 감염 및 원형질체 융합을 포함하는 임의의 적합한 방법에 의해 전달될 수 있다. 이와 같은 구조물을 제조하는 데 사용되는 방법은 핵산 조작의 숙련자에게 알려져 있으며, 유전 공학, 재조합 공학, 및 합성 기법을 포함한다. 예를 들면, Green and Sambrook, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Press, Cold Spring Harbor, NY (2012) 참조.
특정 구현예에서, AAV 캡시드는 자연 및 조작된 클라드 F 아데노 관련 바이러스로부터 선택된다. 하기 예에서, 클라드 F 아데노 관련 바이러스는 AAVhu68이다. 본 명세서에 전문이 참고문헌으로 통합되는 제 WO 2018/160582호 참조. 그러나, 다른 구현예에서, AAV 캡시드는 상이한 클라드, 예를 들면, 클라드 A, B, C, D, 또는 E로부터, 또는 이들 클라드 중 임의의 것의 외부 AAV 출처로부터 선택된다.
본 명세서에서 사용되는 바와 같이, AAV의 그룹과 관련되는 용어 "클라드"는 (적어도 1000개 복제물의) 적어도 75%의 부트스트랩 값에 의해 이웃 결합 알고리즘 (Neighbor-Joining algorithm) 및 AAV vp1 아미노산 서열의 정렬을 기반으로 0.05 이하의 푸아송 보정 거리 측정을 사용하여 결정된 서로 계통 발생적으로 관련된 AAV의 그룹을 지칭한다. 이웃 결합 알고리즘은 문헌에 설명된 바 있다. 예를 들면, M. Nei and S. Kumar, Molecular Evolution and Phylogenetics (뉴욕, 옥스포드 대학 출판사 (2000) 참조. 이 알고리즘을 구현하는 데 사용될 수 있는 컴퓨터 프로그램이 이용가능하다. 예를 들면, MEGA v2.1 프로그램은 변형된 Nei-Gojobori 방법을 구현한다. 이러한 기법 및 컴퓨터 프로그램, 및 AAV vp1 캡시드 단백질의 서열을 사용하여, 당업자는 선택된 AAV가 본 명세서에서 식별된 클라드 중 하나에 포함되는지, 다른 클라드에 포함되는지, 또는 이들 클라드의 외부에 있는지 여부를 용이하게 결정할 수 있다. 예를 들면, 클라드 A, B, C, D, E 및 F를 식별하고, GenBank 수탁번호 AY530553 내지 AY530629인 신규 AAV의 핵산 서열을 제공하는, G Gao, et al., J. Virol. 2004년 6월, 7810: 6381-6388 참조. 또한, 국제특허출원 제 WO 2005/033321호 참조.
본 명세서에서 사용되는 바와 같이, "AAV9 캡시드"는 (a) 본 명세서에 참고문헌으로 통합되는 GenBank 수탁번호 AAS99264의 아미노산 서열 및 AAV vp1 캡시드 단백질 및/또는 (b) GenBank 수탁번호 AY530579.1 (nt 1..2211)의 뉴클레오티드 서열에 의해 인코딩되는 아미노산 서열을 갖는 AAV9를 말한다. 이러한 인코딩된 서열로부터의 일부 변이는 본 발명에 포함되며, 이는 GenBank 수탁번호 AAS99264 및 제 US7906111호 (또한 제 WO 2005/033321호)의 참조된 아미노산 서열과 약 99% 동일성 (즉, 참조된 서열로부터 약 1% 미만의 변이)을 갖는 서열을 포함할 수 있다. 이와 같은 AAV는, 예를 들면, 자연 분리주 (예를 들면, hu31 또는 hu32), 또는 예를 들면, AAV9 캡시드와 정렬된 임의의 다른 AAV 캡시드에서 상응하는 위치로부터 "모집된" 대체 잔기로부터 선택되는 아미노산 치환을 포함하나 이에 한정되지 않는 아미노산 치환, 결실 또는 첨가가 있는 AAV9의 변이체; 예를 들면, 제 US 9,102,949호, 제 US 8,927,514호, 제 US 2015/349911호, 제 WO 2016/049230A1호, 제 US 9,623,120호, 및 제 US 9,585,971호에 기재된 것을 포함할 수 있다. 그러나, 다른 구현예에서, AAV9의 다른 변이체, 또는 상기 참조된 서열과 적어도 약 95% 동일성을 갖는 AAV9 캡시드가 선택될 수 있다. 예를 들면, 제 US 2015/0079038호 참조. 캡시드를 생성하는 방법, 이에 대한 코딩 서열, 및 rAAV 바이러스 벡터의 생성 방법은 설명된 바 있다. 예를 들면, Gao, et al., Proc. Natl. Acad. Sci. U.S.A. 100 (10): 6081-6086 (2003) 및 제 US 2013/0045186A1호 참조.
특정 구현예에서, AAVhu68 캡시드는 "Novel Adeno-associated virus (AAV) Clade F Vector and Uses Therefor"라는 제목의 국제특허출원 제 WO 2018/160582호에 기재된 바와 같으며, 이는 본원에서 참고문헌으로 통합된다. 특정 구현예에서, AAVhu68 캡시드는 서열번호 2의 1번 내지 736번의 예상되는 아미노산 서열을 인코딩하는 핵산 서열의 발현에 의해 생성되는 AAVhu68 vp1 단백질, 서열번호 1로부터 생성되는 vp1 단백질, 또는 서열번호 2의 1번 내지 736번의 예상되는 아미노산 서열을 인코딩하는 서열번호 1과 적어도 70% 동일한 핵산 서열로부터 생성되는 vp1 단백질; 서열번호 2의 적어도 약 138번 내지 736번 아미노산의 예상되는 아미노산 서열을 인코딩하는 핵산 서열로부터 발현에 의해 생성되는 AAVhu68 vp2 단백질, 서열번호 1의 적어도 412번 내지 2211번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp2 단백질, 또는 서열번호 2의 적어도 약 138번 내지 736번 아미노산의 예상되는 아미노산 서열을 인코딩하는 서열번호 1의 적어도 412번 내지 2211번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp2 단백질, 및/또는 서열번호 2의 적어도 약 203번 내지 736번 아미노산의 예상되는 아미노산 서열을 인코딩하는 핵산 서열로부터 발현에 의해 생성되는 AAVhu68 vp3 단백질, 서열번호 1의 적어도 607번 내지 2211번 뉴클레오티드를 포함하는 서열로부터 생성되는 vp3 단백질, 또는 서열번호 2의 적어도 약 203번 내지 736번 아미노산의 예상되는 아미노산 서열을 인코딩하는 서열번호 1의 적어도 607번 내지 2211번 뉴클레오티드와 적어도 70% 동일한 핵산 서열로부터 생성되는 vp3 단백질을 포함한다.
AAVhu68 vp1, vp2 및 vp3 단백질은 전형적으로 서열번호 2의 전장 vp1 아미노산 서열 (1 내지 736번 아미노산)을 인코딩하는 동일한 핵산 서열에 의해 인코딩되는 대안적인 스플라이스 변이체로서 발현된다. 선택적으로 vp1-인코딩 서열은 단독으로 vp1, vp2, 및 vp3 단백질을 발현하는 데 사용된다. 대안적으로, 이 서열은 vp1-고유 영역 (약 아미노산 1번 내지 약 아미노산 137번) 및/또는 vp2-고유 영역 (약 아미노산 1번 내지 약 아미노산 202번), 또는 이에 상보적인 가닥, 상응하는 mRNA (서열번호 1의 약 뉴클레오티드 607번 내지 약 뉴클레오티드 2211번), 또는 서열번호 2의 아미노산 203번 내지 736번을 인코딩하는 서열번호 1과 적어도 70% 내지 적어도 99% (예를 들면, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 98% 또는 적어도 99%) 동일한 서열 없이 서열번호 2의 AAVhu68 vp3 아미노산 서열 (약 아미노산 203번 내지 736번)을 인코딩하는 핵산 서열 중 하나 이상과 공동발현될 수 있다. 추가적으로, 또는 대안적으로, vp1 인코딩 및/또는 vp2 인코딩하는 서열은 vp1 독특한 영역 (약 아미노산 1번 내지 약 137번), 또는 이에 상보적인 가닥, 상응하는 mRNA (서열번호 1의 뉴클레오티드 412번 내지 뉴클레오티드 2211번), 또는 서열번호 2의 아미노산 138번 내지 736번을 인코딩하는 서열번호 1의 뉴클레오티드 412번 내지 2211번과 적어도 70% 내지 적어도 99% (예를 들면, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 98% 또는 적어도 99%) 동일한 서열 없이 서열번호 2의 AAVhu68 vp2 아미노산 서열 (약 아미노산 138번 내지 736번)을 인코딩하는 핵산 서열과 공동발현될 수 있다.
본 명세서에 기재된 바와 같이, rAAVhu68은 서열번호 2의 vp1 아미노산 서열을 인코딩하는 AAVhu68 핵산으로부터 캡시드를 발현하는 생성 시스템에서 생성되는 rAAVhu68 캡시드, 및 선택적으로, 예를 들면, vp1 및/또는 vp2 독특한 영역이 없는 vp3 단백질을 인코딩하는, 추가적인 핵산 서열을 갖는다. 단일 핵산 서열 vp1을 사용하는 생성으로부터 생성된 rAAVhu68은 vp1 단백질, vp2 단백질 및 vp3 단백질의 이종 집단을 생성한다. 보다 구체적으로, AAVhu68 캡시드는 서열번호 2의 예상되는 아미노산 잔기로부터 변형을 갖는 vp1 단백질 내, vp2 단백질 내 및 vp3 단백질 내의 하위집단을 포함한다. 이들 하위집단은 최소한 탈아마이드화된 아스파라긴 (N 또는 Asn) 잔기를 포함한다. 예를 들면, 아스파라긴-글리신 쌍의 아스파라긴은 고도로 탈아마이드화되어 있다.
일 구현예에서, AAVhu68 vp1 핵산 서열은 서열번호 1의 서열, 또는 이에 상보적인 가닥, 예를 들면, 상응하는 mRNA를 가진다. 특정 구현예에서, vp2 및/또는 vp3 단백질은, 예를 들면, 선택된 발현 시스템에서 vp 단백질의 비율을 변경하기 위해, vp1과 상이한 핵산 서열로부터 추가적으로 또는 대안적으로 발현될 수 있다. 특정 구현예에서, 또한 vp1 독특한 영역 (약 아미노산 1번 내지 약 아미노산 137번) 및/또는 vp2 독특한 영역 (약 아미노산 1번 내지 약 아미노산 202번)이 없는 서열번호 2의 AAVhu68 vp3 아미노산 서열 (약 아미노산 203번 내지 736번)을 인코딩하는 핵산 서열, 또는 이에 상보적인 가닥, 상응하는 mRNA (서열번호 2의 약 뉴클레오티드 607번 내지 약 뉴클레오티드 2211번)가 제공된다. 특정 구현예에서, 또한 vp1 독특한 영역 (약 아미노산 1번 내지 약 137번)이 없는 서열번호 2의 AAVhu68 vp2 아미노산 서열 (약 아미노산 138번 내지 736번)을 인코딩하는 핵산 서열, 또는 이에 상보적인 가닥, 상응하는 mRNA (서열번호 1의 뉴클레오티드 412번 내지 2211번)가 제공된다.
그러나, 서열번호 2의 아미노산 서열을 인코딩하는 다른 핵산 서열이 rAAVhu68 캡시드를 생성하는 데 사용하기 위해 선택될 수 있다. 특정 구현예에서, 핵산 서열은 서열번호 1의 핵산 서열 또는 서열번호 2를 인코딩하는 서열번호 1과 적어도 70% 내지 99% 동일, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99% 동일한 서열을 갖는다. 특정 구현예에서, 핵산 서열은 서열번호 1의 핵산 서열 또는 서열번호 2의 vp2 캡시드 단백질 (약 아미노산 138번 내지 736번)을 인코딩하는 서열번호 1의 약 뉴클레오티드 412번 내지 약 뉴클레오티드 2211번과 적어도 70% 내지 99%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 또는 적어도 99% 동일한 서열을 갖는다. 특정 구현예에서, 핵산 서열은 서열번호 1의 약 뉴클레오티드 607번 내지 약 뉴클레오티드 2211번의 핵산 서열 또는 서열번호 1의 vp3 캡시드 단백질 (약 아미노산 203번 내지 736번)을 인코딩하는 서열번호 1의 뉴클레오티드 412번 내지 약 뉴클레오티드 2211번과 적어도 70% 내지 99.%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 또는 적어도 99% 동일한 서열을 갖는다.
DNA (게놈 또는 cDNA), 또는 RNA (예를 들면, mRNA)를 포함하여, 이러한 AAVhu68 캡시드를 인코딩하는 핵산 서열을 설계하는 것은 당업계의 기술 범위에 속한다. 특정 구현예에서, AAVhu68 vp1 캡시드 단백질을 인코딩하는 핵산 서열은 서열번호 2에서 제공된다. 특정 구현예에서, AAVhu68 캡시드는 본 명세서에 기재된 바와 같은 변형 (예를 들면, 탈아마이드화된 아미노산)이 있는 서열번호 1의 핵산 서열 또는 서열번호 2의 vp1 아미노산 서열을 인코딩하는 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 또는 적어도 99% 서열을 사용하여 생성된다. 특정 구현예에서, vp1 아미노산 서열은 서열번호 2로 재현된다.
특정 구현예에서, 캡시드 탈아마이드화가 감소된 AAV 캡시드가 선택될 수 있다. 예를 들면, 국제특허출원 제 PCT/US19/19804호 및 제 PCT/US18/19861호 참조, 둘 다는 2019년 2월 27일에 출원되고 전문이 참고문헌으로 통합된다.
본 명세서에서 사용되는 바와 같이 vp 캡시드 단백질을 지칭하는 데 사용될 때, 용어 "이종" 또는 이의 임의의 문법적 변형은, 예를 들면, 상이한 변형된 아미노산 서열이 있는 vp1, vp2 또는 vp3 단량체 (단백질)를 갖는, 동일하지 않은 요소로 이루어진 집단을 지칭한다. 서열번호 2는 AAVhu68 vp1 단백질의 인코딩된 아미노산 서열을 제공한다. vp1, vp2 및 vp3 단백질 (대안적으로 이소형으로 명명됨)과 관련하여 사용될 때 용어 "이종"은 캡시드 내 vp1, vp2 및 vp3 단백질의 아미노산 서열의 차이를 지칭한다. AAV 캡시드는 vp1 단백질 내, vp2 단백질 내 및 vp3 단백질 내에 예상되는 아미노산 잔기로부터 변형이 있는 하위집단을 포함한다. 이러한 하위집단은, 최소한 특정 탈아마이드화된 아스파라긴 (N 또는 Asn) 잔기를 포함한다. 예를 들면, 특정 하위집단은 아스파라긴-글리신 쌍에서 적어도 1, 2, 3 또는 4개의 고도로 탈아마이드화된 아스파라긴 (N) 위치를 포함하고 선택적으로 다른 탈아마이드화된 아미노산을 더 포함하며, 여기서 탈아마이드화는 아미노산 변화 및 다른 선택적인 변형을 유도한다.
본 명세서에서 사용되는 바와 같이, vp 단백질의 "하위집단"은 달리 명시되지 않는 한, 공통적으로 적어도 하나의 정의된 특징을 가지고, 적어도 하나의 그룹 구성원 내지 참조 그룹의 모든 구성원보다 더 적은 수의 그룹 구성원으로 이루어진 vp 단백질의 그룹을 지칭한다. 예를 들면, vp1 단백질의 "하위집단"은 달리 명시되지 않는 한, 조립된 AAV 캡시드 내에 적어도 하나 (1)의 vp1 단백질이 있고 모든 vp1 단백질보다 더 적은 수의 vp1 단백질이 있다. vp3 단백질의 "하위집단"은 달리 명시되지 않는 한, 조립된 AAV 캡시드 내에 하나 (1)의 vp3 단백질 내지 모든 vp3 단백질보다 더 적은 수의 vp3 단백질이 있을 수 있다. 예를 들면, vp1 단백질은 vp 단백질의 하위집단일 수 있고; vp2 단백질은 vp 단백질의 별개의 하위집단일 수 있으며, vp3은 또한 조립된 AAV 캡시드 내의 vp 단백질의 추가의 하위집단이다. 또 다른 예에서, vp1, vp2 및 vp3 단백질은, 예를 들면, 아스파라긴-글리신 쌍에서 상이한 변형, 예를 들면, 적어도 1, 2, 3 또는 4개의 고도로 탈아마이드화된 아스파라긴을 갖는 하위집단을 포함할 수 있다.
달리 명시되지 않는 한, 고도로 탈아마이드화된 것은 참조된 아미노산 위치에서 예상되는 아미노산 서열과 비교하여, 참조된 아미노산 위치에서 적어도 45% 탈아마이드화된, 적어도 50% 탈아마이드화된, 적어도 60% 탈아마이드화된, 적어도 65% 탈아마이드화된, 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 97%, 적어도 99%, 또는 최대 약 100%의 탈아마이드화된 것을 지칭한다 (예를 들면, 서열번호 2[AAVhu68]의 번호매김을 기준으로 57번 아미노산에서 아스파라긴의 적어도 80%가 총 vp1 단백질을 기준으로 탈아미드화될 수 있고 총 vp1, vp2 및 vp3 단백질을 기준으로 탈아마이드화될 수 있음). 이와 같은 백분율은 2D-겔, 질량분석법 기법, 또는 다른 적합한 기법을 사용하여 결정될 수 있다.
따라서, rAAV는, 최소한 적어도 하나의 고도로 탈아마이드화된 아스파라긴을 포함하는 적어도 하나의 하위집단을 포함하는, 탈아마이드화된 아미노산이 있는 vp1, vp2, 및/또는 vp3 단백질의 rAAV 캡시드 내의 하위집단을 포함한다. 추가적으로, 다른 변형은 특히 선택된 아스파트산 (D 또는 Asp) 잔기 위치에서 이성질체화를 포함할 수 있다. 또 다른 구현예에서, 변형은 Asp 위치에서의 아마이드화를 포함할 수 있다.
특정 구현예에서, AAV 캡시드는 적어도 4 내지 적어도 약 25개의 탈아마이드화된 아미노산 잔기 위치를 갖는 vp1, vp2 및 vp3의 하위집단을 포함하며, 이의 적어도 1 내지 10%는 vp 단백질의 인코딩된 아미노산 서열과 비교하여 탈아마이드화된다. 이들 대부분은 N 잔기일 수 있다. 그러나, Q 잔기가 또한 탈아마이드화될 수 있다.
특정 구현예에서, rAAV는 실시예 1에서 제공되고 본 명세서에서 참고문헌으로 통합되는 표에 제시된 위치에서 2개, 3개 또는 4개 이상의 탈아마이드화된 잔기의 조합을 포함하는 하위집단을 갖는 vp1, vp2 및 vp3 단백질을 갖는 AAV 캡시드를 갖는다. rAAV에서의 탈아마이드화는 2D 겔 전기영동법, 질량 분석법 및/또는 단백질 모델링 기법을 사용하여 결정될 수 있다. 온라인 크로마토그래피는 어클레임 PepMap 칼럼 및 나노플렉스 소스가 있는 Q 이그잭티브 HF (써모피셔 사이언티픽사)에 커플링된 써모 울티메이트 3000 RSLC 시스템 (써모피셔 사이언티픽사)을 사용하여 수행될 수 있다. MS 데이터는 조사 스캔 (200 내지 2000 m/z)으로부터의 가장 풍부한 시퀸싱되지 않은 전구체 이온을 역동적으로 선택하는, Q 이그잭티브 HF에 대한 데이터 의존적인 상위 20 방법을 사용하여 획득된다. 시퀸싱은 예측된 자동 획득 제어로 결정된 1e5 이온의 목표 값으로의 고-에너지 충돌 분열 단편화를 통해서 수행되고, 전구체의 단리는 4 m/z의 창으로 수행되었다. 조사 스캔은 m/z 200에서 분해능 120,000으로 획득되었다. HCD 스펙트럼에 대한 분해능은 50㎳의 최대 이온 주입 시간 및 30의 정규화된 충돌 에너지를 이용하여 m/z 200에서 30,000으로 설정될 수 있다. S-렌즈 RF 수준은 50에서 설정되어, 소화로부터 펩티드에 의해서 점유된 m/z 영역의 최적의 전달을 제공할 수 있다. 전구체 이온은 단편화 선택으로부터 단일, 미배정, 또는 6 및 더 높은 전하 상태로 제외될 수 있다. 바이오파마 파인더 1.0 소프트웨어 (써모피셔 사이언티픽사)가 획득된 데이터의 분석에 사용될 수 있다. 펩티드 맵핑을 위해, 고정된 변형으로서 설정된 카바미도메틸화; 및 가변성 변형으로서 설정된 산화, 탈아마이드화 및 인산화, 10 ppm 질량 정확도, 높은 프로테아제 특이성 및 MS/MS 스펙트럼에 대한 신뢰 수준 0.8을 갖는 단기식 단백질 FASTA 데이터베이스를 사용하여 검색을 수행한다. 적합한 프로테아제의 예는, 예를 들면 트립신 또는 키모트립신을 포함할 수 있다. 탈아마이드화된 펩티드의 질량 분광분석적 식별은 비교적 간단한데, 그 이유는 탈아마이드화가 무손상 분자 +0.984 Da의 질량 (-OH 및 -NH2 기 사이의 질량 차이)에 추가되기 때문이다. 특정 펩티드의 탈아마이드화 백분율은 탈아마이드화된 펩티드의 질량 면적을, 탈아마이드화된 펩티드와 고유한 펩티드의 면적의 합으로 나눔으로써 결정된다. 가능한 탈아마이드화 부위의 수를 고려하여, 상이한 부위에서 탈아마이드화된 동중 원소종 (isobaric species)이 단일 피크에서 동시에 이동할 수 있다. 결론적으로, 다수의 잠재적인 탈아마이드화 부위가 있는 펩티드로부터 기원한 단편 이온을 사용하여 탈아마이드화의 다수의 부위를 배치하거나 구별할 수 있다. 이러한 경우에, 관찰된 동위원소 양상 내의 상대 강도를 사용하여 상이한 탈아마이드화된 펩티드 이성질체의 상대 풍부도를 구체적으로 결정할 수 있다. 이러한 방법은, 모든 이성질체 종에 대한 단편화 효율성이 동일하고, 탈아마이드화 부위에 독립적이라고 가정한다. 이러한 예시적인 방법에 대한 다수의 변경이 사용될 수 있음을 당업자는 이해할 것이다. 예를 들면, 적합한 질량 분석기는, 예를 들면, 사중극자 비행시간 질량 분석기 (QTOF), 예컨대 워터스 엑스보 또는 애질런트 6530 또는 오비트랩 기기, 예컨대 오비트랩 퓨전 또는 오비트랩 벨로스 (써모피셔사)를 포함할 수 있다. 적합하게 액체 크로마토그래피 시스템은, 예를 들면 워터스 또는 애질런트 시스템으로부터의 액퀴티 UPLC 시스템 (1100 또는 1200 시리즈)을 포함한다. 적합한 데이터 분석 소프트웨어는, 예를 들면, MassLynx (워터스), 핀포인트 및 펩파인더 (써모피셔 사이언티픽사), 마스코트 (매트릭스 사이언스사), 피크 DB (바이오인포매틱스 솔루션사)를 포함할 수 있다. 또 다른 기법은, 예를 들면 X. Jin et al., Hu. Gene Therapy Methods, Vol. 28, No. 5, pp. 255-267 (2017년 6월 16일자로 온라인 공개됨)에 기재될 수 있다.
탈아마이드화에 추가적으로, 다른 변형이 일어날 수 있는데, 이는 하나의 아미노산의 상이한 아미노산 잔기로의 전환을 초래하지 않는다. 이와 같은 변형은 아세틸화된 잔기, 이성질체화, 인산화 또는 산화를 포함할 수 있다.
탈아마이드화의 조정: 특정 구현예에서, AAV는 아스파라긴-글리신 쌍에서 글리신을 변화시키도록 변형되어, 탈아마이드화를 감소시킨다. 다른 구현예에서, 아스파라긴은 상이한 아미노산, 예를 들면, 더 느린 속도로 탈아마이드화시키는 글루타민으로; 또는 아마이드기가 결여된 아미노산 (예를 들면, 글루타민 및 아스파라긴은 아마이드기를 포함함)으로; 및/또는 아민기가 결여된 아미노산 (예를 들면, 라이신, 아르기닌 및 히스티딘은 아민기를 포함함)으로 변경된다. 본 명세서에서 사용되는 바와 같이, 아마이드 또는 아민 측쇄가 결여된 아미노산은, 예를 들면, 글리신, 알라닌, 발린, 류신, 아이소류신, 세린, 트레오닌, 시스틴, 페닐알라닌, 타이로신, 또는 트립토판, 및/또는 프롤린을 지칭한다. 예컨대, 기재된 변형은 인코딩된 AAV 아미노산 서열에서 발견되는 아스파라긴-글리신 쌍 중 1, 2 또는 3개에 존재할 수 있다. 특정 구현예에서, 이와 같은 변형은 아스파라긴-글리신 쌍 중 4개 모두에서 일어나지는 않는다. 따라서, AAV 및/또는 조작된 AAV 변이체의 탈아마이드화를 감소시키는 방법은 더 낮은 탈아마이드화 속도를 가진다. 추가적으로, 또는 대안적으로 하나 이상의 다른 아마이드 아미노산은 비-아마이드 아미노산으로 변화되어 AAV의 탈아마이드화를 감소시킬 수 있다. 특정 구현예에서, 본 명세서에 기재된 바와 같은 돌연변이체 AAV 캡시드는 아르기닌-글리신 쌍에서 돌연변이를 포함하여, 글리신은 알라닌 또는 세린으로 변화된다. 돌연변이체 AAV 캡시드는 1, 2 또는 3개의 돌연변이체를 포함할 수 있고, 여기서 참조 AAV는 본래 4개의 NG 쌍을 포함한다. 특정 구현예에서, AAV 캡시드는 1개, 2개, 3개 또는 4개의 이와 같은 돌연변이체를 포함할 수 있고, 여기서 참조 AAV는 본래 5개의 NG 쌍을 포함한다. 특정 구현예에서, 돌연변이체 AAV 캡시드는 NG 쌍 내에 단일 돌연변이만을 포함한다. 특정 구현예에서, 돌연변이체 AAV 캡시드는 2개의 상이한 NG 쌍 내에 돌연변이를 포함한다. 특정 구현예에서, 돌연변이체 AAV 캡시드는 AAV 캡시드에서 구조적으로 분리된 위치에 위치된 2개의 상이한 NG 쌍이다. 특정 구현예에서, 돌연변이는 VP1 독특한 영역에 존재하지 않는다. 특정 구현예에서, 돌연변이 중 하나는 VP1 독특한 영역에 존재한다. 선택적으로, 돌연변이체 AAV 캡시드는 NG 쌍 내에 어떠한 변형도 포함하지 않지만, NG 쌍의 위부에 위치된 하나 이상의 아스파라긴 또는 글루타민에서 탈아마이드화를 최소화 또는 제거하기 위해서 돌연변이를 포함한다. AAVhu68 캡시드 단백질에서, 4개의 잔기 (N57, N329, N452, N512)는 일상적으로 70% 초과의 탈아마이드화 수준을 나타내고 대부분의 경우 다양한 로트에 걸쳐 90% 초과의 수준을 나타낸다. 추가적인 아스파라긴 잔기 (N94, N253, N270, N304, N409, N477 및 Q599)는 또한 다양한 로트에 걸쳐 최대 약 20%의 탈아마이드화 수준을 나타낸다. 탈아마이드화 수준은 초기에 트립신 소화를 사용하여 확인하였고, 키모트립신 소화를 이용하여 검증하였다.
AAVhu68 캡시드는 서열번호 2의 예상되는 아미노산 잔기로부터 변형을 갖는 vp1 단백질 내, vp 단백질 내 및 vp3 단백질 내의 하위집단을 포함한다. 이들 하위집단은 최소한 특정 탈아마이드화된 아스파라긴 (N 또는 Asn) 잔기를 포함한다. 예를 들면, 특정 하위집단은 서열번호 2의 아스파라긴-글리신 쌍에서 적어도 1, 2, 3 또는 4개의 고도로 탈아마이드화된 아스파라긴 (N) 위치를 포함하고 선택적으로 다른 탈아마이드화된 아미노산을 더 포함하며, 여기서 탈아마이드화는 아미노산 변화 및 다른 선택적인 변형을 초래한다. 이들 및 다른 변형의 다양한 조합이 본 명세서에 기재되어 있다.
특정 구현예에서, 본 명세서에 기재된 바와 같은 rAAV는 자가-상보성 AAV이다. "자가-상보성 AAV"는 재조합 AAV 핵산 서열에 의해 운반되는 코딩 영역이 분자내 이중가닥 DNA 주형을 형성하도록 설계된 구조물을 지칭한다. 감염시, 두번째 가닥의 세포 매개 합성을 기다리기 보다는, scAAV의 2개의 상보적인 절반이 회합하여 즉각적인 복제 및 전사 준비가 된 하나의 이중가닥 DNA (dsDNA) 단위를 형성할 것이다. 예를 들면, D. M. McCarty et al., "Self-complementary recombinant adeno-associated virus (scAAV) vectors promote efficient transduction independently of DNA synthesis", Gene Therapy, (2001년 8월), Vol. 8, No. 16, pp 1248-1254 참조. 자가-상보성 AAV는, 예를 들면 미국 특허 제 US 6,596,535호; 제 US 7,125,717호; 및 제 US 7,456,683호에 기재되어 있으며, 이들 각각은 본 명세서에 전문이 참고문헌으로 통합된다.
본원에 기술된 재조합 아데노 관련 바이러스 (AAV)는 공지되어 있는 기법을 사용하여 생성될 수 있다. 예로, 국제특허출원 제 WO 2003/042397호; 제 WO 2005/033321호; 제 WO 2006/110689호; 미국 특허 제 US 7588772 B2호 참조. 이러한 방법은 AAV 캡시드를 인코딩하는 핵산 서열; 기능적 rep 유전자; 본원에 기술된, AAV 역전된 말단 반복서열 (ITR)에 의해 연접된 발현 카세트; 및 AAV 캡시드 단백질 내에 발현 카세트의 패키징을 허용하기에 충분한 헬퍼 기능을 포함하는 숙주 세포를 배양하는 것이 관여한다. 또한, 본원에서는 AAV 캡시드를 인코딩하는 핵산 서열; 기능적 rep 유전자; 본원에 기술된 벡터 게놈; 및 AAV 캡시드 단백질 내에 벡터 게놈의 패키징을 허용하기에 충분한 헬퍼 기능을 포함하는 숙주 세포가 제공된다. 일 구현예에서, 숙주 세포는 HEK 293 세포이다. 이러한 방법은 본원에 참고문헌으로 통합되는 국제특허출원 제 WO 2017160360 A2호에 더 자세하게 기술된다.
당업자에게 입수가능한 rAAV를 생산하는 다른 방법이 사용될 수 있다. 적합한 방법은 배큘로바이러스 발현 시스템 또는 효모를 통한 생산을 이에 한정되지 않고 포함할 수 있다. 예로, Robert M. Kotin, Large-scale recombinant adeno-associated virus production. Hum. Mol. Genet. 2011년 4월 15일, 15; 20(R1): R2-R6. 2011년 4월 29일 온라인 공개됨. doi: 10.1093/hmg/ddr141; Aucoin M. G. et al., Production of adeno-associated viral vectors in insect cells using triple infection: optimization of baculovirus concentration ratios. Biotechnol. Bioeng., 2006년 12월 20일, 95(6): 1081-92; SAMI S. THAKUR, Production of Recombinant Adeno-associated viral vectors in yeast. 플로리다 대학 대학원 졸업 논문, 2012년; Kondratov O. et al., Direct Head-to-Head Evaluation of Recombinant Adeno-associated Viral Vectors Manufactured in Human versus Insect Cells, Mol. Ther. 2017년 8월 10일, pii: S1525-0016(17)30362-3. doi: 10.1016/j.ymthe.2017.08.003. [인쇄 전 e 공개]; Mietzsch M. et al., OneBac 2.0: Sf9 Cell Lines for Production of AAV1, AAV2, and AAV8 Vectors with Minimal Encapsidation of Foreign DNA. Hum. Gene Ther. Methods 2017년 2월, 28(1): 15-22. doi: 10.1089/hgtb.2016.164.; Li L. et al., Production and characterization of novel recombinant adeno-associated virus replicative-form genomes: a eukaryotic source of DNA for gene transfer. PLoS One 2013년 8월 1일, 8(8): e69879. doi: 10.1371/journal.pone.0069879. 2013년 인쇄; Galibert L. et al., Latest developments in the large-scale production of adeno-associated virus vectors in insect cells toward the treatment of neuromuscular diseases. J. Invertebr. Pathol. 2011년 7월, 107 Suppl:S80-93. doi: 10.1016/j.jip.2011.05.008; 및 Kotin R. M., Large-scale recombinant adeno-associated virus production. Hum. Mol. Genet. 2011년 4월 15일, 20(R1): R2-6. doi: 10.1093/hmg/ddr141. Epub 2011년 4월 29일 참조.
높은 염 농도에서 두 단계 친화 크로마토그래피 정제에 이어진 음이온 교환 레진 크로마토그래피는 벡터 의약품을 정제하고, 빈 캡시드를 제거하는데 사용된다. 이러한 방법은 본원에 참고문헌으로 통합되는, "Scalable Purification Method for AAV9"라는 제목의 제 WO 2017/1603604호에 더 자세하게 기술된다. 간략하게, 게놈 결함성 AAV9 중간물로부터 패키징된 게놈 서열을 갖는 rAAV9 입자를 분리하는 방법은 재조합 AAV9 바이러스 입자 및 AAV9 캡시드 중간물을 포함하는 현탁액에 대해 신속 성능 액체 크로마토그래피를 시행하는 단계를 포함하고, 여기서 AAV9 바이러스 입자 및 AAV9 중간물은 pH 약 10.2에서 평형화된 강한 음이온 교환 레진에 결합되고, 용리물을 약 260 nm 및 약 280 nm의 자외선 흡광도에 대해 모니터링하면서 염 구배를 시행한다. rAAV9를 위한 최적은 아니지만, pH는 약 10.0 내지 10.4의 범위일 수 있다. 이러한 방법에서, AAV 완전한 캡시드는 A260/A280 비율이 감염점에 도달할 때 용리되는 분획으로부터 수집된다. 일 예에서, 친화 크로마토그래피 단계의 경우, 투과여과된 산물은 AAV2/9 혈청형을 효율적으로 포획하는 캡쳐 셀렉트TM 포로스 - 친화 레진 (라이프 테크놀로지사)에 적용될 수 있다. 이러한 이온 조건 하에, 유의한 백분율의 잔류 세포성 DNA 및 단백질은 컬럼을 통과하는 반면, AAV 입자는 효율적으로 포획된다.
rAAV의 특성화 또는 정량화를 위한 통상적인 방법은 당업자에게 사용가능하다. 비어있는 및 완전된 입자 내용물을 계산하기 위하여, 선택된 시료 (예로, 본원의 실시예에서, GC의 갯수 = 입자의 갯수인 이오딕산올 구배-정제된 제조물)에 대한 VP3 밴드 부피가 로딩된 GC 입자에 대응하여 좌표화된다. 결과로 나온 선형 방정식 (y = mx + c)이 테스트 항목 피크의 밴드 부피에서 입자의 갯수를 계산하는데 사용된다. 다음으로 로딩된 20 μL 당 입자의 갯수 (pt)에 50을 곱하여 입자 (pt)/mL을 수득한다. GC/mL로 나누기한 pt/mL은 입자 대 게놈 사본 (pt/GC) 비를 제공한다. Pt/mL - GC/mL은 비어있는 pt/mL를 제공한다. pt/mL로 나누기한 비어있는 pt/mL × 100은 비어있는 입자의 백분율을 제공한다. 일반적으로, 빈 캡시드 및 패키징된 게놈을 갖는 AAV 벡터 입자를 검정하는 방법은 당해 기술분야에 공지되어 있다. 예로, Grimm et al., Gene Therapy (1999), 6: 1322-1330; Sommer et al., Molec. Ther. (2003), 7: 122-128 참조. 변성된 캡시드를 테스트하기 위해, 방법은 처리된 AAV 스톡을 3가지 캡시드 단백질을 분리할 수 있는 임의의 겔, 예를 들면 완충액 중 3% 내지 8% 트리스-아세테이트를 포함한 구배 겔로 구성되는 SDS-폴리아크릴아미드 겔 전기영동을 시행하고, 다음으로 시료 물질이 분리될 때까지 겔을 전개시키고, 나일론 또는 니트로셀룰로스 막, 바람직하게 나일론 상에 겔을 블럿팅하는 단계를 포함한다. 다음으로 항-AAV 캡시드 항체, 바람직하게 항-AAV 캡시드 단일클론 항체, 가장 바람직하게 B1 항-AAV-2 단일클론 항체가 변성된 캡시드 단백질에 결합하는 일차 항체로서 사용된다 (Wobus et al., J. Virol. (2000), 74: 9281-9293). 다음으로 일차 항체에 결합하는 이차 항체가 사용되고, 일차 항체와 결합을 검출하기 위한 수단, 더욱 바람직하게 이에 공유 결합하는 검출 분자를 포함하는 항-IgG 항체, 가장 바람직하게 호스래디쉬 퍼옥시다제에 공유 결합된 양 항-마우스 IgG 항체를 포함한다. 결합을 검출하는 방법은 일차 및 이차 항체 사이의 결합을 반정량적으로 결정하는데 사용되고, 바람직하게 방사성 동위원소 방출, 전자기적 방사선 조사 또는 비색측정 변화를 검출할 수 있는 검출 방법, 가장 바람직하게는 화학발광 검출 키트이다. 예를 들면, SDS-PAGE의 경우, 컬럼 분획으로부터의 시료는 채취되어 환원제 (예로, DTT)를 포함한 SDS-PAGE 로딩 완충액에서 가열될 수 있으며, 캡시드 단백질은 미리 주입한 구배 폴리아크릴아미드 겔 (예로, 노벡스사) 상에서 분리되었다. 은 염색이 제조사의 지침에 따른 실버엑스프레스 (인비트로겐사, CA) 또는 다른 적합한 염색 방법, 즉 SYPRO 루비 또는 쿠마시 염색을 사용하여 수행될 수 있다. 일 구현예에서, 컬럼 분획에서 AAV 벡터 게놈 (vg)의 농도는 정량적 실시간 PCR (Q-PCR)에 의해 측정될 수 있다. 시료는 외인성 DNA를 제거하도록 희석하여 DNase I (또는 또 다른 적합한 뉴클레아제)로 소화시킨다. 뉴클레아제의 불활성화 이후에, 시료는 추가로 희석되고, 프라이머 및 프라이머의 DNA 서열에 특이적인 TaqManTM 형광생성 프로브를 사용하여 증폭된다. 정의된 수준의 형광에 도달하는데 필요한 주기의 횟수 (역치 주기, Ct)는 각 시료에 대해 어플라이드 바이오시스템 프리즘 7700 서열 검출 시스템으로 측정된다. AAV 벡터에 포함된 서열과 일치하는 서열을 포함하는 플라스미드 DNA는 Q-PCR 반응에서 표준 곡선을 생성하는데 채용된다. 시료로부터 획득된 주기 역치 (Ct) 값은 벡터 게놈 역가를 플라스미드 표준 곡선의 Ct 값으로 정규화함으로써 이를 결정하는데 사용된다. 디지털 PCR을 기초로 한 종결점 검정법도 사용될 수 있다.
일 양태에서, 광범위 스펙트럼 세린 프로테아제, 예로 프로테아제 K (예컨대 퀴아젠사로부터 구입가능함)를 사용하는 최적화된 q-PCR 방법이 사용된다. 보다 구체적으로, 최적화된 q-PCR 게놈 역가 검정법은 DNase I 소화 이후에 시료를 프로테아제 K 완충액으로 희석하여 프로테아제 K로 처리하고, 이어서 열 불활성화를 시행하는 점을 제외하고는 표준 검정법과 유사하다. 적합하게, 시료는 시료 크기와 동등한 양의 프로테아제 K 완충액으로 희석된다. 프로테아제 K 완충액은 2배 이상으로 농축될 수 있다. 전형적으로, 프로테아제 K 처리는 약 0.2 mg/mL이지만, 0.1 mg/mL 내지 약 1 mg/mL으로 변화될 수 있다. 처리 단계는 일반적으로 약 55℃에서 약 15분 동안 시행되지만, 더 낮은 온도 (예로, 약 37℃ 내지 약 50℃)에서 더 긴 시간 (예로, 약 20분 내지 약 30분) 동안, 또는 더 높은 온도 (예로, 최고 약 60℃)에서 더 짧은 시간 (예로, 약 5분 내지 10분) 동안 수행될 수 있다. 유사하게, 열 불활성화는 일반적으로 약 95℃에서 약 15분 동안이지만, 온도를 낮추고 (예로, 약 70℃ 내지 약 90℃) 시간을 연장할 수 있다 (예로, 약 20분 내지 30분). 다음으로 시료를 희석하고 (예로, 1,000배), 표준 검정법에서 설명된 바와 같이 TaqMan 분석에 착수한다.
추가적으로 또는 대안적으로, 비말 디지털 PCR (ddPCR)이 사용될 수 있다. 예를 들면, ddPCR에 의해 단일가닥 및 자가-상보적 AAV 벡터 게놈 역가를 결정하는 방법이 기재되어 있다. 예로, M. Lock et al., Hu Gene Therapy Methods, Hum. Gene Ther. Methods, 2014년 4월; 25(2): 115-25. doi: 10.1089/hgtb.2013.131. Epub 2014년 2월 14일 참조.
캡시드 단백질의 vp1, vp2 및 vp3 비율을 결정하는 방법도 사용가능하다. 예로, Vamseedhar Rayaprolu et al., Comparative Analysis of Adeno-Associated Virus Capsid Stability and Dynamics, J. Virol. 2013년 12월, 87(24): 13150-13160; Buller R. M., Rose J. A. 1978, Characterization of adenovirus-associated virus-induced polypeptides in KB cells. J. Virol., 25: 331-338; 및 Rose J. A., Maizel J. V., Inman J. K., Shatkin A. J. 1971, Structural proteins of adenovirus-associated viruses. J. Virol., 8: 766-770 참조.
본원에 기재된 rAAV에서 조성물은 본 명세서 전반에 걸쳐 기재된 다른 조성물, 요법, 양태, 구현예, 및 방법에 적용하도록 의도되는 것으로 이해되어야 한다.
약제학적 조성물
hGAA780I 융합 단백질, 또는 hGAA780I 융합 단백질 이식유전자를 포함하는 발현 카세트를 포함하는 약제학적 조성물은 액체 현탁액, 동결건조 또는 동결된 조성물, 또는 또 다른 적합한 제형물일 수 있다. 특정 구현예에서, 조성물은 hGAA780I 융합 단백질 또는 발현 카세트 및 현탁액을 형성하는 생리학적으로 적격한 액체 (예를 들면, 용액, 희석제, 담체)를 포함한다. 이러한 액체는 바람직하게 수성 기반이고, 완충제(들), 계면활성제(들), pH 조정제(들), 보존제(들), 또는 다른 적합한 부형제 중 하나 이상을 포함할 수 있다. 적합한 구성요소는 하기에 더 자세하게 논의된다. 약제학적 조성물은 수성 현탁액 및 임의의 선택된 부형제, 및 hGAA780I 융합 단백질 또는 발현 카세트를 포함한다.
특정 구현예에서, 약제학적 조성물은 이식유전자 및 비-바이러스 전달 시스템을 포함하는 발현카세트를 포함한다. 이는, 예를 들면, 노출 DNA, 노출 RNA, 무기 입자, 지질 또는 지질-유사 입자, 키토산 기반의 제형물, 및 당업계에 알려지고, 예를 들면 상기 인용된 라마무르스 및 나베카르에 의해 설명된 다른 것을 포함할 수 있다. 다른 구현예에서, 약제학적 조성물은 바이러스 벡터 시스템에서 조작된 이식유전자를 포함하는 발현 카세트를 포함하는 현탁액이다. 특정 구현예에서, 약제학적 조성물은 비-복제 바이러스 벡터를 포함한다. 적합한 바이러스 벡터는 예를 들면, 재조합 아데노바이러스, 재조합 렌티바이러스, 재조합 보카바이러스, 재조합 아데노 관련 바이러스 (AAV), 또는 또 다른 재조합 파보바이러스와 같은 임의의 적합한 전달 벡터를 포함할 수 있다. 특정 구현예에서, 바이러스 벡터는 이를 필요로 하는 환자에게 유전자 산물을 전달하기 위한 재조합 AAV이다.
일 구현예에서, 약제학적 조성물은 hGAA780I 융합 단백질, 또는 hGAA780I 융합 단백질에 대한 코딩 서열을 포함하는 발현 카세트, 및 뇌실내 (ICV), 경막내 (IT), 수조내, 또는 정맥내 (IV) 주사를 통한 전달에 적합한 제형물 완충액을 포함한다. 일 구현예에서, 발현 카세트는 재조합 바이러스 벡터 (즉, 융합 단백질을 보유하는 rAAV.hGAA780I)가 패키징된 벡터 게놈의 일부이다.
일 구현예에서, 약제학적 조성물은 효소 대체 요법 (ERT)로서 대상체에게 전달하기 위한 hGAA780I 단백질 또는 이의 기능적 단편을 포함한다. 이와 같은 약제학적 조성물은 보통 정맥내로 투여되지만, 일부 상황에서는 피내, 근육내 또는 경구 투여가 또한 가능하다. 조성물은 폼페병으로 고생하거나 이에 걸릴 위험이 있는 개체의 예방적 치료를 위해 투여될 수 있다. 치료적 적용을 위해, 약제학적 조성물은 확립된 질환으로 고생하는 환자에게 축적된 대사산물의 농도를 감소시키고/시키거나 대사산물의 추가 축적을 방지하거나 저지하기에 충분한 양으로 투여된다. 리소좀 효소 결핍 질환의 위험이 있는 개체의 경우, 약제학적 조성물은 대사산물의 축적을 방지하거나 저해하기에 충분한 양으로 예방적으로 투여된다. 본 명세서에 기재된 변형된 GAA 조성물은 치료적 유효량으로 투여된다. 일반적으로, 치료적 유효량은 대상체의 의학적 상태의 중증도뿐만 아니라, 대상체의 연령, 전반적인 상태, 및 성별에 따라 달라질 수 있다. 용량은 의사에 의해 결정될 수 있으며, 관찰된 치료의 효과에 맞게 필요에 따라 조정될 수 있다. 일 양태에서, hGAA780I 융합 단백질 또는 이의 기능적 단편의 단위 용량을 포함하도록 제형화된 ERT용 약제학적 조성물이 본 명세서에서 제공된다.
일 구현예에서, 조성물은 대상체에게 전달하기에 적합한 최종 제형물을 포함하고, 예를 들면, 생리학적으로 적격한 pH 및 염 농도로 완충된 수성 액체 현탁액이다. 선택적으로, 하나 이상의 계면활성제가 제형물에 존재한다. 또 다른 구현예에서, 조성물은 대상체에 투여하기 위해 희석되는 농축물로서 수송될 수 있다. 다른 구현예에서, 조성물은 동결건조되고 투여 시에 재구성될 수 있다.
일 구현예에서, 본 명세서에서 제공된 바와 같은 조성물은 수성 현탁액 액체에 용해된 계면활성제, 보존제, 부형제, 및/또는 완충액을 포함한다. 일 구현예에서, 완충액은 PBS이다. 또 다른 구현예에서, 완충액은 인공 뇌척수액 (aCSF), 예를 들면, 엘리엇 제형물 완충액; 또는 하바드 장치 관류액 (Harvard apparatus perfusion fluid) (다음과 같은 최종 이온 농도 (단위: mM)를 갖는 인공 CSF: Na 150; K 3.0; Ca 1.4; Mg 0.8; P 1.0; Cl 155). 완충 식염수, 계면활성제, 및 약 100mM 염화나트륨 (NaCl) 내지 약 250mM 염화나트륨과 동등한 이온 강도로 조정된 생리학적으로 적격한 염 또는 염의 혼합물, 또는 동등한 이온 농도로 조정된 생리학적으로 적격한 염을 포함하는 다양한 적합한 용액이 알려져 있다.
적합하게, 제형물은 생리학적으로 허용가능한 pH, 예를 들면, pH 6 내지 8, 또는 pH 6.5 내지 7.5, pH 7.0 내지 7.7, 또는 pH 7.2 내지 7.8의 범위로 조정된다. 뇌척수액의 pH가 약 7.28 내지 약 7.32이므로, 경막내 전달을 위해 이 범위 내의 pH가 바람직할 수 있는 반면, 정맥내 전달을 위해 pH 6.8 내지 약 7.2가 바람직할 수 있다. 그러나, 가장 넓은 범위 내의 다른 pH 및 이들의 하위범위가 다른 전달 경로를 위해 선택될 수 있다.
적합한 계면활성제, 또는 계면활성제의 조합이 무독성인 비-이온성 계면활성제 중에서 선택될 수 있다. 일 구현예에서, 예를 들면, 중성 pH를 가지고, 평균 분자량이 8400인 폴록사머 188로도 알려진 플루로닉® F68 [바스프사]과 같은 일차 히드록실기로 종결되는 이작용성 블록 공중합체 계면활성제가 선택된다. 다른 계면활성제 및 다른 폴록사머, 즉 폴리옥시에틸렌(폴리(에틸렌 옥사이드))의 2개 친수성 사슬에 의해 연접된 폴리옥시프로필렌(폴리(프로필렌 옥사이드))의 중심 소수성 사슬로 구성된 비이온성 삼중블록 공중합체, 솔루톨 HS 15 (마크로골-15 히드록시스테아레이트), 라브로졸 (폴리옥시 카프릴산 글리세리드), 폴리옥시 10 올레일 에터, 트윈 (폴리옥시에틸렌 솔비탄 지방산 에스테르), 에탄올 및 폴리에틸렌 글라이콜이 선택될 수 있다. 일 구현예에서, 제형물은 폴록사머를 포함한다. 이러한 공중합체는 일반적으로 문자 "P" (폴록사머의 경우) 뒤에 3자리 숫자가 있는 명칭으로 명명되며: 처음 2자리 숫자×100은 폴리옥시프로필렌 코어의 대략적 분자량을 제공하고, 마지막 숫자×10은 폴리옥시에틸렌 함량의 백분율을 제공한다. 일 구현예에서, 폴록사머 188이 선택된다. 계면활성제는 현탁액의 최대 약 0.0005% 내지 약 0.001%의 양으로 존재할 수 있다.
일 예에서, 제형물은, 예를 들면, 염화나트륨, 중탄산나트륨, 덱스트로스, 황산마그네슘 (예를 들면, 황산마그네슘·7H2O), 염화칼륨, 염화칼슘 (예를 들면, 염화칼슘·2H2O), 이염기성 인산나트륨, 및 이들의 혼합물 중 하나 이상을 물에 포함하는 완충된 식염수 용액을 포함할 수 있다. 적합하게, 경막내 전달의 경우 삼투도는 뇌척수액과 양립가능한 범위 (예를 들면, 약 275 내지 약 290) 이내이며, 예로 emedicine.medscape.com/article/2093316-overview 참조. 선택적으로, 경막내 전달을 위해 구입가능한 희석제가 현탁화제로서, 또는 또 다른 현탁화제 및 기타 선택적인 부형제와 조합하여 사용될 수 있다. 예를 들면, 엘리어트 B® 용액 [루카레 메디칼사] 참조.
다른 구현예에서, 제형물은 하나 이상의 투과 증진제를 포함할 수 있다. 적합한 투과 증진제의 예는, 예를 들면 만니톨, 소듐 글리콜레이트, 소듐 타우로콜레이트, 소듐 데옥시콜레이트, 소듐 살리실레이트, 소듐 카프릴레이트, 소듐 카프레이트, 소듐 라우릴 설페이트, 폴리옥시에틸렌-9-라우렐 에테르 또는 EDTA를 포함할 수 있다.
약제학적으로 허용가능한 담체 및 본 명세서에 기재된 바와 같은 핵산 서열을 포함하는 벡터를 포함하는 약제학적 조성물이 추가적으로 제공된다. 본 명세서에서 사용되는 바와 같이, "담체"는 임의의 모든 용매, 분산 매질, 비히클, 코팅제, 희석제, 항박테리아 및 항진균제, 등장화제 및 흡수 지연제, 완충액, 담체 용액, 현탁액, 콜로이드 등을 포함한다. 약제학적 활성 물질을 위한 이와 같은 매질 및 작용제의 사용은 당업계에 잘 알려져 있다. 보충 활성 성분이 또한 조성물에 포함될 수 있다. 전달 비히클, 예컨대, 리포좀, 나노캡슐, 마이크로입자, 마이크로스피어, 지질 입자, 소포 등이 본 명세서에 기재된 조성물을 적합한 숙주 세포 내로 도입하는 데 사용될 수 있다. 구체적으로, rAAV 벡터는 지질 입자, 리포좀, 비히클, 나노구체, 또는 나노입자 등에 피막화되는 전달을 위해 제형화될 수 있다. 일 구현예에서, 치료적 유효량의 벡터가 약제학적 조성물에 포함된다. 담체의 선택은 본 발명에서 제한이 없다. 다른 통상적인 약제학적으로 허용가능한 담체, 예컨대, 보존제, 또는 화학적 안정화제. 적합한 예시적인 보존제는 클로로뷰탄올, 솔빈산칼륨, 솔빈산, 이산화황, 프로필 갈레이트, 파라벤, 에틸 바닐린, 글리세린, 페놀, 및 파라클로로페놀을 포함한다. 적합한 화학적 안정화제는 젤라틴 및 알부민을 포함한다.
어구 "약제학적으로 허용가능한"은 숙주에게 투여될 때 알레르기 반응 또는 유사한 유해 반응을 생성하지 않는 분자적 실체 및 조성물을 말한다.
본 명세서에서 사용되는 바와 같이, 용어 "용량" 또는 "양"은 치료 과정에서 대상체에게 전달되는 총 용량 또는 양, 또는 단일 단위 (또는 다중 단위 또는 분할 용량) 투여로 전달되는 용량 또는 양을 지칭할 수 있다.
본 명세서에 기재된 수성 현탁액 또는 약제학적 조성물은 임의의 적합한 경로 또는 상이한 경로의 조합에 의해 이를 필요로 하는 대상체에게 전달하도록 설계된다. 일 구현예에서, 약제학적 조성물은 뇌실내 (ICV), 경막내 (IT), 또는 수조내 주사를 통해 전달하도록 제형화된다. 일 구현예에서, 본 명세서에 기재된 조성물은 정맥내 주사에 의해 이를 필요로 하는 대상체에게 전달하도록 설계된다. 대안적으로, 다른 투여 경로 (예를 들면, 경구, 흡입, 비강내, 기관내, 동맥내, 안내, 근육내, 및 다른 비경구 경로)가 선택될 수 있다.
본 명세서에서 사용되는 바와 같이, 용어 "경막내 전달" 또는 "경막내 투여"는 약물이 뇌척수액 (CSF)에 도달하도록 척추관으로, 보다 구체적으로는 지주막하 공간으로 주사를 통한 약물에 대한 투여 경로를 지칭한다. 경막내 전달은 요추 천자, 뇌실내, 후두하/수조내, 및/또는 C1-2 천자를 포함할 수 있다. 예를 들면, 물질은 요추 천자에 의해 지주막하 공간 전체에 확산을 위해 도입될 수 있다. 또 다른 예에서, 주사는 대조 내로 이루어질 수 있다. 수조내 전달은 벡터 확산을 증가시키고/거나 투여에 의해 유발되는 독성 및 염증을 감소시킬 수 있다. 예를 들면, Christian Hinderer et al., Widespread gene transfer in the central nervous system of cynomolgus macaques following delivery of AAV9 into the cisterna magna, Mol. Ther. Methods Clin. Dev. 2014년, 1: 14051. 2014년 12월 10일 온라인 공개됨, doi: 10.1038/mtm.2014.51 참조.
본 명세서에서 사용되는 바와 같이, 용어 "수조내 전달" 또는 "수조내 투여"는 뇌실의 뇌척수액으로 직접 또는 소뇌수질 내에, 보다 구체적으로 후두하 천자를 통한 또는 대수조내 직접 주사에 의한 또는 영구적으로 위치시킨 튜브를 통한 약물의 투여 경로를 말한다.
일 양태에서, 제형물 완충액 중에 본 명세서에 기재된 바와 같은 벡터를 포함하는 약제학적 조성물이 본 명세서에서 제공된다. 특정 구현예에서, 복제 결함성 바이러스 조성물은 인간 환자의 경우 (체중이 70 ㎏인 평균 대상체를 치료하기 위해) 약 1.0×109개 GC 내지 약 1.0×1016개 GC의 범위 (범위 내의 모든 정수 또는 분수 양을 포함함), 바람직하게는 1.0×1012개 GC 내지 1.0×1014개 GC인 복제 결함성 바이러스의 양을 포함하도록 투약 단위로 제형화될 수 있다. 일 구현예에서, 조성물은 용량 당 적어도 1×109, 2×109, 3×109, 4×109, 5×109, 6×109, 7×109, 8×109, 또는 9×109개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 또 다른 구현예에서, 조성물은 용량 당 적어도 1×1010, 2×1010, 3×1010, 4×1010, 5×1010, 6×1010, 7×1010, 8×1010, 또는 9×1010개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 또 다른 구현예에서, 조성물은 용량 당 적어도 1×1011, 2×1011, 3×1011, 4×1011, 5×1011, 6×1011, 7×1011, 8×1011, 또는 9×1011개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 또 다른 구현예에서, 조성물은 용량 당 적어도 1×1012, 2×1012, 3×1012, 4×1012, 5×1012, 6×1012, 7×1012, 8×1012, 또는 9×1012개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 또 다른 구현예에서, 조성물은 용량 당 적어도 1×1013, 2×1013, 3×1013, 4×1013, 5×1013, 6×1013, 7×1013, 8×1013, 또는 9×1013개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 또 다른 구현예에서, 조성물은 용량 당 적어도 1×1014, 2×1014, 3×1014, 4×1014, 5×1014, 6×1014, 7×1014, 8×1014, 또는 9×1014개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 또 다른 구현예에서, 조성물은 용량 당 적어도 1×1015, 2×1015, 3×1015, 4×1015, 5×1015, 6×1015, 7×1015, 8×1015, 또는 9×1015개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)를 포함하도록 제형화된다. 일 구현예에서, 인간 적용의 경우 용량은 용량 당 1×1010 내지 약 1×1012개 GC (범위 내의 모든 정수 또는 분수 양을 포함함)의 범위일 수 있다.
일 구현예에서, 제형물 완충액 중에 본 명세서에 기재된 바와 같은 rAAV를 포함하는 약제학적 조성물이 제공된다. 일 구현예에서, rAAV는 약 1×109개 게놈 복제물 (GC)/mL 내지 약 1×1014개 GC/mL로 제형화된다. 추가 구현예에서, rAAV는 약 3×109개 GC/mL 내지 약 3×1013개 GC/mL로 제형화된다. 추가의 구현예에서, rAAV는 약 1×109개 GC/mL 내지 약 1×1013개 GC/mL로 제형화된다. 일 구현예에서, rAAV는 적어도 약 1×1011개 GC/mL로 제형화된다.
일 구현예에서, 본 명세서에 기재된 바와 같은 rAAV를 포함하는 약제학적 조성물은 뇌 질량 그램 당 약 1×109개 GC 내지 뇌 질량 그램 당 약 1×1014개 GC의 용량으로 투여 가능하다.
본 명세서에 기재된 약제학적 조성물에서 조성물은 본 명세서 전반에 걸쳐 기재된 다른 조성물, 요법, 양태, 구현예, 및 방법에 적용되는 것으로 의도됨이 이해되어야 한다.
치료 방법
폼페병에 걸린 환자를 치료하기 위한 치료 요법으로서, 본원에 기술된 바와 같은 발현 카세트, rAAV, 및/또는 hGAA780I 융합 단백질을 선택적으로 면역조절제와 조합하여 포함하는, 치료 요법이 제공된다. 특정 구현예에서, 환자는 후기 발병 폼페병을 갖는다. 다른 구현예에서, 환자는 아동기 발병 폼페병을 갖는다. 특정 구현예에서, 보조치료제는 발현 카세트, rAAV, 또는 hGAA780I 단백질 또는 융합 단백질, 예컨대, 면역조절 요법과 함께 전달된다. 추가적으로, 또는 대안적으로, 보조요법은 기관지확장제, 아세틸콜린 에스테라제 저해제, 호흡근 강화 훈련 (RMST), 효소 대체 요법, 및/또는 횡격막 조율 요법 중 하나 이상을 포함할 수 있다. 특정 구현예에서, 환자는 rAAV의 단일 투여를 받는다. 특정 구현예에서, 환자는 본 명세서에 기재된 바와 같은 발현 카세트 및/또는 rAAV를 포함하는 조성물의 단일 투여를 받는다. 특정 구현예에서, 유효량의 발현 카세트를 포함하는 조성물의 이러한 단일 투여는 적어도 하나의 보조치료제를 포함한다. 특정 구현예에서, 환자는 2가지의 상이한 경로를 통해 실질적으로 동시에 발현 카세트, rAAV, 및/또는 hGAA780I 단백질 또는 융합 단백질 또는 본 명세서에 기재된 바와 같은 것을 투여받는다. 특정 구현예에서, 2가지 상이한 주사 경로는 정맥내 및 경막내 투여이다. 일 구현예에서, 조성물은 뇌실내, 경막내, 수조내, 또는 정맥내로 대상체에게 전달되는 현탁액이다. 특정 구현예에서, 알파-글루코시다제의 결핍이 있는 환자는 심장, 호흡기, 및/또는 골격근 기능 중 하나 이상을 개선시키기 위해 본 명세서에서 제공되는 바와 같은 조성물을 투여받는다. 특정 구현예에서, 치료의 결과로서 심장, CNS (뇌), 및/또는 골격근 중 하나 이상에서 글리코겐 축적 및/또는 자가포식 구축의 감소가 있다.
특정 구현예에서, 발현 카세트, rAAV, 바이러스 또는 비-바이러스 벡터는 약제를 제조하는 데 사용된다. 특정 구현예에서, 폼페병을 치료하기 위한 조성물의 용도가 제공된다.
이들 조성물은, 예를 들면, 면역요법, 효소 대체 요법 (예로, 사노피사의 젠자임으로 시판되는 루미자임 및 미국 외부에서 미오자임)을 포함하는 다른 요법과 조합하여 사용될 수 있다. 폼페병의 추가적인 치료는 대증적이고 지지적이다. 예를 들면, 호흡기 지원이 필요할 수 있고; 물리적 요법은 호흡근을 강화시키는 데 도움이 될 수 있으며; 일부 환자는 밤 및/또는 낮 시간 동안 기계적 인공호흡 (즉, 바이팝 (bipap) 또는 용적 인공호흡기)을 통한 호흡 보조를 필요로 할 수 있다. 추가적으로, 기도 감염 동안 추가적인 지원이 필요할 수 있다. 교정기를 포함하여 정형외과적 장치가 일부 환자에게 권장될 수 있다. 구축 또는 척추 변형과 같은 특정 정형외과적 증상에 대해 수술이 필요할 수 있다. 일부 영아는 코를 통해 식도를 거쳐 위로 이어지는 급식관 (비위관)의 삽입을 필요로 할 수 있다. 일부 아동에 있어서, 급식관은 복벽의 작은 수술 구멍을 통해 위로 직접 삽입될 필요가 있을 수 있다. 후기 발병 폼페병에 걸린 일부 개체는 연한 식사를 필요로 할 수 있지만 급식관을 필요로 하는 개체는 거의 없다.
ERT가 고전적인 유아 폼페병에 걸린 환자에서 생존을 유의하게 개선하지만, 부분적으로 효소가 리소좀에 도달하는 것을 억제하는 자가포식 구축으로 인해 골격근 병리를 완전히 역전시킬 수는 없다. 본 발명자들은 본원에 제공된 조성물이 근육 병리를 치료하고 역전시키는데 효과적임을 확인하였다. 예를 들면, 자가포식소체 축적은 치료 시 기존의 병리를 갖는 노령 폼페병 마우스에서 완전히 해소되었다. 또한, 연구는 본원에 제공된 벡터를 사용한 치료가 유의하게 골격근에서 큰 근육 섬유의 백분율을 증가시키고, 작은 근육 섬유의 백분율은 감소시킬 수 있음을 입증하고 있다. 따라서, 전형적으로 근육 섬유 크기 및 자가포식 구축과 같은 치료 내성 병리가 치료에 반응적이다.
특정 구현예에서, 본원에서는 폼페병으로 진단 받았거나 폼페병에 걸린 것으로 의심된 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는 방법이 제공된다. 특정 구현예에서, 환자는 증상 이전이다. 다른 구현예에서, 환자는 질환의 더 상급 병기를 갖는 노령 환자를 포함하여 증상 이후이다. 특정 구현예에서, 비정상 근육 병리는 (i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 한다. 특정 구현예에서, 방법은 환자의 호흡 및/또는 이동을 개선한다.
본 명세서에 기재된 바와 같이, 용어 "증가하다" (예를 들면, 조직, 혈액 등에서 측정된 바와 같이 hGAA780I 융합 단백질로 치료한 이후 hGAA 수준의 증가) 또는 "감소하다", "저하하다", "완화하다", "개선하다", "지연시키다", 또는 이들의 임의의 문법적 활용형, 또는 변화를 나타내는 임의의 유사한 용어는 달리 명시되지 않는 한, 상응하는 기준 (예를 들면, 미처리 대조군 또는 폼페병이 없는 정상 대조군의 대상체)과 비교하여 약 5배, 약 2배, 약 1배, 약 90%, 약 80%, 약 70%, 약 60%, 약 50%, 약 40%, 약 30%, 약 20%, 약 10%, 또는 약 5%의 변동을 의미한다.
본 명세서에서 상호교환적으로 사용되는 바, "환자" 또는 "대상체"는 인간, 수의 또는 농장 동물, 가축 또는 애완동물, 임상 연구에 일반적으로 사용되는 동물을 포함하여 수컷 또는 암컷 포유류 동물을 의미한다. 일 구현예에서, 이러한 방법 및 조성물의 대상체는 인간 환자이다. 일 구현예에서, 이러한 방법 및 조성물의 대상체는 남성 또는 여성 인간이다.
일 구현예에서, 현탁액은 pH가 7.28 내지 약 7.32이다.
이러한 용량 및 농도의 전달에 적합한 부피는 당업자에 의해 결정될 수 있다. 예를 들면, 약 1 μL 내지 150 mL의 부피가 선택될 수 있으며, 성인의 경우 더 많은 부피가 선택된다. 전형적으로, 신생아의 경우, 적합한 부피는 약 0.5 mL 내지 약 10 mL이고, 더 큰 영아의 경우, 약 0.5 mL 내지 약 15 mL가 선택될 수 있다. 유아의 경우, 약 0.5 mL 내지 약 20 mL의 부피가 선택될 수 있다. 아동의 경우, 최대 약 30 mL의 부피가 선택될 수 있다. 십대 초반 및 십대의 경우, 최대 약 50 mL의 부피가 선택될 수 있다. 또 다른 구현예에서, 환자는 선택된 약 5 mL 내지 약 15 mL, 또는 약 7.5 mL 내지 약 10 mL의 부피로 경막내 투여를 받을 수 있다. 다른 적합한 부피 및 용량이 결정될 수 있다. 용량은 임의의 부작용에 대한 치료적 이익의 균형을 맞추기 위해 조정될 것이며, 이러한 용량은 재조합 벡터가 이용되는 치료적 적용에 따라 달라질 수 있다.
일 구현예에서, 본 명세서에 기재된 바와 같은 rAAV를 포함하는 조성물은 뇌 질량의 그램 당 약 1×109개 GC 내지 뇌 질량의 그램 당 약 1×1014개 GC의 용량으로 투여가능하다. 특정 구현예에서, rAAV는 체중 ㎏ 당 약 1×109개 GC 내지 체중 ㎏ 당 약 1×1013개 GC의 용량으로 전신으로 공동-투여된다. 특정 구현예에서, rAAV는 체중 ㎏ 당 약 1×1011개 GC 내지 체중 ㎏ 당 약 5×1013개 GC의 용량으로 전신으로 투여되거나 공동-투여된다.
일 구현예에서, 대상체는 치료적 유효량의 본 명세서에 기재된 발현 카세트, rAAV 또는 hGAA780I 융합 단백질을 전달 받는다. 본 명세서에서 사용되는 바, "치료적 유효량"은 발현 카세트, rAAV 또는 hGAA780I, 또는 이들의 조합의 양을 말한다. 따라서, 특정 구현예에서 방법은 본원에 제공된 hGAA780I 융합 단백질 효소를 포함하는 조성물을 투여하는 것과 조합하여 hGAA780I 융합 단백질 인코딩하는 핵산 서열의 전달을 위한 rAAV 또는 발현 구조물을 대상체에게 투여하는 것을 포함한다.
일 구현예에서, 발현 카세트는 벡터 게놈으로 뇌 질량 그램 (g) 당 약 1×109개 게놈 복제물 (GC) 내지 뇌 질량 그램 당 약 1×1013개 GC (범위 내의 모든 정수 또는 분수 양 및 종점을 포함함)의 양으로 전달된다. 또 다른 구현예에서, 용량은 뇌 질량 그램 당 1×1010개 GC 내지 뇌 질량 그램 당 약 1×1013개 GC이다. 구체적인 구현예에서, 환자에게 투여되는 벡터의 용량은 적어도 약 1.0×109개 GC/g, 약 1.5×109개 GC/g, 약 2.0×109개 GC/g, 약 2.5×109개 GC/g, 약 3.0×109개 GC/g, 약 3.5×109개 GC/g, 약 4.0×109개 GC/g, 약 4.5×109개 GC/g, 약 5.0×109개 GC/g, 약 5.5×109개 GC/g, 약 6.0×109개 GC/g, 약 6.5×109개 GC/g, 약 7.0×109개 GC/g, 약 7.5×109개 GC/g, 약 8.0×109개 GC/g, 약 8.5×109개 GC/g, 약 9.0×109개 GC/g, 약 9.5×109개 GC/g, 약 1.0×1010개 GC/g, 약 1.5×1010개 GC/g, 약 2.0×1010개 GC/g, 약 2.5×1010개 GC/g, 약 3.0×1010개 GC/g, 약 3.5×1010개 GC/g, 약 4.0×1010개 GC/g, 약 4.5×1010개 GC/g, 약 5.0×1010개 GC/g, 약 5.5×1010개 GC/g, 약 6.0×1010개 GC/g, 약 6.5×1010개 GC/g, 약 7.0×1010개 GC/g, 약 7.5×1010개 GC/g, 약 8.0×1010개 GC/g, 약 8.5×1010개 GC/g, 약 9.0×1010개 GC/g, 약 9.5×1010개 GC/g, 약 1.0×1011개 GC/g, 약 1.5×1011개 GC/g, 약 2.0×1011개 GC/g, 약 2.5×1011개 GC/g, 약 3.0×1011개 GC/g, 약 3.5×1011개 GC/g, 약 4.0×1011개 GC/g, 약 4.5×1011개 GC/g, 약 5.0×1011개 GC/g, 약 5.5×1011개 GC/g, 약 6.0×1011개 GC/g, 약 6.5×1011개 GC/g, 약 7.0×1011개 GC/g, 약 7.5×1011개 GC/g, 약 8.0×1011개 GC/g, 약 8.5×1011개 GC/g, 약 9.0×1011개 GC/g, 약 9.5×1011개 GC/g, 약 1.0×1012개 GC/g, 약 1.5×1012개 GC/g, 약 2.0×1012개 GC/g, 약 2.5×1012개 GC/g, 약 3.0×1012개 GC/g, 약 3.5×1012개 GC/g, 약 4.0×1012개 GC/g, 약 4.5×1012개 GC/g, 약 5.0×1012개 GC/g, 약 5.5×1012개 GC/g, 약 6.0×1012개 GC/g, 약 6.5×1012개 GC/g, 약 7.0×1012개 GC/g, 약 7.5×1012개 GC/g, 약 8.0×1012개 GC/g, 약 8.5×1012개 GC/g, 약 9.0×1012개 GC/g, 약 9.5×1012개 GC/g, 약 1.0×1013개 GC/g, 약 1.5×1013개 GC/g, 약 2.0×1013개 GC/g, 약 2.5×1013개 GC/g, 약 3.0×1013개 GC/g, 약 3.5×1013개 GC/g, 약 4.0×1013개 GC/g, 약 4.5×1013개 GC/g, 약 5.0×1013개 GC/g, 약 5.5×1013개 GC/g, 약 6.0×1013개 GC/g, 약 6.5×1013개 GC/g, 약 7.0×1013개 GC/g, 약 7.5×1013개 GC/g, 약 8.0×1013개 GC/g, 약 8.5×1013개 GC/g, 약 9.0×1013개 GC/g, 약 9.5×1013개 GC/g, 또는 약 1.0×1014개 GC/g 뇌 질량이다.
특정 구현예에서, 본원에 기술된 rAAV를 포함하는 조성물은 약 1×1011개 GC/kg 체중 내지 약 5×1013개 GC/kg 체중의 용량으로 전신으로 투여된다. 특정 구현예에서, rAAV는 약 1×1012개 GC 내지 약 5×1013개 GC의 용량으로 ICM을 통해 투여된다. 또 다른 구현예에서, rAAV는 정맥내 및 ICM 경로를 통해 공동-투여되고, 여기서 환자에게 약 1×1011개 GC/kg 체중 내지 약 5×1013개 GC/kg 체중의 용량 (IV), 및 약 1×1012개 GC 내지 약 5×1013개 GC의 용량 (ICM)이 투여된다.
일 구현예에서, 치료 방법은 효소 대체 요법으로서 hGAA780I 융합 단백질의 전달을 포함한다. 특정 구현예에서, hGAA780I 융합 단백질은 유전자 요법 (본 명세서에서 제공되는 바와 같은 발현 카세트 또는 rAAV를 포함하나 이들에 한정되지 않음)과 조합하여 ERT로서 전달된다. 특정 구현예에서, 방법은 하나 이상의 ERT (예를 들면, hGAA780I 융합 단백질을 루미자임과 같은 또 다른 치료용 단백질과 조합하여 포함하는 조성물)를 대상체에게 투여하는 것을 포함한다. 본 명세서에 기재된 hGAA780I 융합 단백질을 포함하는 조성물은 매 1일, 2일, 3일, 4일, 5일, 6일, 7일, 8일, 9일 또는 10일 이상 대상체에게 투여될 수 있다. 투여는 매주, 매월, 또는 격월 투여가 처방된 외래 환자에게 정맥내 주입에 의할 수 있다. 화합물의 적절한 치료적 유효 용량은 치료하는 임상의에 의해 선택되며 약 1 μg/㎏ 내지 약 500 mg/kg, 약 10 mg/kg 내지 약 100 mg/kg, 약 20 mg/kg 내지 약 100 mg/kg 및 대략 20 mg/kg 내지 대략 50 mg/kg을 포함한다. 일부 구현예에서, 적합한 치료적 용량은, 예를 들면, 0.1 mg/kg, 0.25 mg/kg, 0.5 mg/kg, 0.75 mg/kg, 1 mg/kg, 5 mg/kg, 10 mg/kg, 15 mg/kg, 20 mg/kg, 30 mg/kg, 40 mg/kg, 50 mg/kg, 60 mg/kg, 70 mg/kg 및 100 ㎎/㎏으로부터 선택된다.
특정 구현예에서, 방법은 hGAA780I 융합 단백질을 환자에게 주 당 10 ㎎/환자 체중 ㎏ 이상의 용량으로 대상체에게 투여하는 단계를 포함한다. 종종 용량은 주 당 10 mg/kg 이상이다. 투약 요법은 주 당 10 mg/kg 내지 주 당 적어도 1000 mg/kg의 범위일 수 있다. 전형적으로 투약 요법은 주 당 10 mg/kg, 주 당 15 mg/kg, 주 당 20 mg/kg, 주 당 25 mg/kg, 주 당 30 mg/kg, 주 당 35 mg/kg, 주 당 40 mg/kg, 주 당 45 mg/kg, 주 당 60 mg/kg, 주 당 80 mg/kg 및 주 당 120 mg/kg이다. 바람직한 요법에서, 10 mg/kg, 15 mg/kg, 20 mg/kg, 30 mg/kg 또는 40 mg/kg이 매주 1회, 2회 또는 3회 투여된다. 치료는 전형적으로 적어도 4주, 때로 24주, 때로 환자의 평생 동안 계속된다. 선택적으로, 인간 알파-글루코시다제의 수준은 치료 이후 (예를 들면, 혈장 또는 근육에서) 모니터링되고, 검출된 수준이 실질적으로 정상인 갑 미만 (예를 들면, 20% 미만)으로 강하할 때 추가 용량이 투여된다. 일 구현예에서, hGAA780I는 초기에 "고"용량 (즉, "부하 용량")으로 투여되고, 다음으로 더 낮은 용량 (즉, "유지 용량")으로 투여된다. 부하 용량의 예는 주 당 1회 내지 3회 (예를 들면, 1주, 2주 또는 3주 동안) 적어도 약 40 ㎎/환자 체중 ㎏이다. 유지 용량의 예는 주당 적어도 약 5 내지 적어도 약 10 mg/kg 환자 체중 또는 그 이상, 예컨대, 주당 20 ㎎/㎏, 주당 30 ㎎/㎏, 주당 40 ㎎/㎏이다. 특정 구현예에서, 용량은 투약 기간 동안 증가하는 속도로 투여된다. 이는 유동 정맥내 주입의 속도를 증가시킴으로써 또는 일정한 속도로 투여되는 hGAA780I 융합 단백질의 농도를 증가시키는 구배를 사용함으로써 달성될 수 있다. 이러한 방식으로 투여하면 면역원성 반응의 위험을 감소시킬 수 있다. 특정 구현예에서, 정맥내 주입은 수 시간 (예를 들면, 1 내지 10시간, 바람직하게는 2 내지 8시간, 더 바람직하게는 3 내지 6시간)의 기간에 걸쳐 일어나고, 주입 속도는 투여 기간 동안 간격을 두고 증가된다.
일 구현예에서, 방법은 대상체가 면역억제 보조요법을 받는 것을 추가로 포함한다. 이와 같은 보조요법을 위한 면역억제제는 글루코코르티코이드, 스테로이드, 항대사물, T-세포 저해제, 매크롤리드 (예를 들면, 라파마이신 또는 라파로그), 및 알킬화제, 항-대사물, 세포독성 항생제, 항체, 또는 이뮤노필린에 대한 활성 제제를 포함하는 세포증식억제제를 포함하나 이들에 한정되지 않는다. 면역억제제는 질소 머스터드, 니트로소우레아, 백금 화합물, 메토트렉세이트, 아자티오프린, 머캅토퓨린, 플루오로우라실, 닥티노마이신, 안트라사이클린, 미토마이신 C, 블레오마이신, 미트라마이신, IL-2 수용체- 또는 CD3-유도 항체, 항-IL-2 항체, 사이클로스포린, 타크롤리무스, 시롤리무스, IFN-β, IFN-γ, 아편 또는 TNF-α (종양 괴사 인자-알파) 결합제를 포함할 수 있다. 특정 구현예에서, 면역억제제 요법은 유전자 요법 투여 0일, 1일, 2일 또는 7일 이상 이전에 시작될 수 있다. 이들 약물 중 하나 이상은 유전자 요법 투여 후 동일한 용량 또는 조정된 용량으로 계속될 수 있다. 이와 같은 요법은 필요에 따라 약 1주 (7일) 또는 약 60일 이상 동안일 수 있다.
일 구현예에서, 본 명세서에 기재된 바와 같은 발현 카세트를 포함하는 조성물은 필요로 하는 대상체에게 1회 투여된다. 특정 구현예에서, 발현 카세트는 rAAV를 통해 전달된다. 본 명세서에 기재된 조성물 및 방법이 본 명세서 전반에 걸쳐 기재된 다른 조성물, 요법, 양태, 구현예 및 방법에 적용되는 것으로 의도됨이 이해되어야 한다.
본 명세서에서 제공되는 조성물 및 방법은 유아 발병 폼페병 또는 후기 발병 폼페병 및/또는 이와 연관된 증상을 치료하는 데 사용될 수 있다. 특정 구현예에서, 효능은 질환의 하나 이상의 증상의 개선에 의해 또는 질환 진행의 둔화에 의해 결정될 수 있다. 유아 발병 폼페병의 증상은 근긴장 저하, 호흡기/호흡 문제, 간비대, 비후성 심근병증뿐만 아니라 심장, 근육, CNS (특히, 운동 뉴런)에의 글리코겐 축적을 포함하나 이들에 한정되지 않는다. 후기 발병 폼페병의 증상은 근위근 약화, 호흡기/호흡 문제뿐만 아니라 근육 및 운동 뉴런에의 글리코겐 축적을 포함하나 이들에 한정되지 않는다. 투여 경로는 환자의 상태 및/또는 진단을 기반으로 결정될 수 있다. 특정 구현예에서, IV 및 ICM 경로의 조합을 통한 hGAA780I 융합 단백질의 전달을 위해 본 명세서에 기재된 rAAV를 투여하는 단계를 포함하는, 유아 발병 폼페병 또는 후기 발병 폼페병으로 진단된 환자의 치료를 위한 방법이 제공된다. 일부 구현예에서, 후기 발병 폼페병에 걸린 것으로 확인된 환자는 rAAV의 전신 전달만을 포함하는 치료 (예를 들면, IV만)를 투여받는다. 본 명세서에 기재된 바와 같이, rAAV를 포함하는 조성물의 전달은 효소 대체 요법 (ERT)과 조합될 수 있다. 특정 구현예에서, ERT와 조합하여 본 명세서에 기재된 rAAV를 ICM 전달하는 것을 포함하는, 폼페병으로 진단된 대상체를 치료하기 위한 방법이 제공된다. 특정 구현예에서, 유아 발병 폼페병에 걸린 것으로 확인된 대상체는 ICM 주사를 통해 본 명세서에 기재된 rAAV를 투여받고 또한 말초 질환의 양상의 치료를 위해 ERT를 받는다.
본 명세서에 기재된 바와 같은 "핵산"은 RNA, DNA 또는 이들의 변형일 수 있고, 단일 또는 이중가닥일 수 있으며, 예를 들면, 관심이 있는 단백질을 인코딩하는 핵산, 올리고뉴클레오티드, 핵산 유사체, 예를 들면, 펩티드-핵산 (PNA), 슈도상보성 PNA (pc-PNA), 잠금 핵산 (LNA) 등을 포함하는 군으로부터 선택될 수 있다. 예를 들면, 이러한 핵산 서열은 예를 들면 전사 억제인자로 작용하는 단백질을 인코딩하는 핵산 서열, 안티센스 분자, 리보자임, 예를 들면 RNAi, shRNAi, siRNA, 마이크로RNAi (mRNAi), 안티센스 올리고뉴클레오티드 등에 한정되지 않는 작은 억제성 핵산 서열을 포함하나 이들에 한정되지 않는다.
단백질, 펩티드, 또는 폴리펩티드를 "역번역"하는 방법은 당업자에게 알려져 있다. 일단 단백질의 서열이 알려지면, 아미노산 서열을 핵산 코딩 서열로 역번역하는 웹-기반 및 상업적으로 이용가능한 컴퓨터 프로그램, 뿐만 아니라 서비스 기반의 회사가 있다. 예를 들면, 엠보스사에 의한 backtranseq (ebi.ac.uk/Tools/st에서 온라인으로 이용가능함); 유전자 인피니티 (geneinfinity.org/sms/sms_-backtranslation.html에서 온라인으로 이용가능함); ExPasy (expasy.org/tools/에서 온라인으로 이용가능함) 참조. 일 구현예에서, RNA 및/또는 cDNA 코딩 서열은 인간 세포에서 최적의 발현을 위해 설계된다.
핵산 서열과 관련하여 용어 "동일성 백분율 (%)", "서열 동일성", "서열 동일성 백분율", 또는 "동일한 백분율"은 관련성을 위해서 정렬되는 경우 동일한 2개의 서열에서의 잔기를 지칭한다. 서열 동일성 비교의 길이는 게놈의 전장, 유전자 코딩 서열의 전장, 또는 적어도 약 500 내지 5000개의 뉴클레오티드의 단편에 걸친 것일 수 있으며, 이것이 바람직하다. 그러나, 예를 들면, 적어도 약 9개의 뉴클레오티드, 보통 적어도 약 20 내지 24개의 뉴클레오티드, 적어도 약 28 내지 32개의 뉴클레오티드, 적어도 약 36개 이상의 뉴클레오티드의 더 작은 단편 간의 동일성이 또한 바람직할 수 있다.
동일성 백분율은 단백질의 전장, 폴리펩티드, 약 32개의 아미노산, 약 330개의 아미노산, 또는 이들의 펩티드 단편 또는 상응하는 핵산 서열 코딩 서열에 걸친 아미노산 서열에 대하여 용이하게 결정될 수 있다. 적합한 아미노산 단편은 적어도 약 8개의 아미노산 길이일 수 있고, 최대 약 700개의 아미노산일 수 있다. 일반적으로, 2개의 상이한 서열 사이의 "동일성", "상동성", 또는 "유사성"을 지칭하는 경우, "동일성", "상동성" 또는 "유사성"은 "정렬된" 서열을 참조로 결정된다. "정렬된" 서열 또는 "정렬"은, 종종 기준 서열과 비교하여 누락되거나 추가적인 염기 또는 아미노산에 대한 수정을 포함하는, 다수의 핵산 서열 또는 단백질 (아미노산) 서열을 지칭한다.
정렬은 다양한 공공 또는 상업적으로 입수 가능한 다중 서열 정렬 프로그램 중 임의의 것을 사용하여 수행된다. 서열 정렬 프로그램, 예를 들면, "크러스탈 X", "크러스탈 오메가", "MAP", "PIMA", "MSA", "블록메이커", "MEME" 및 "매치-박스" 프로그램이 아미노산 서열에 이용가능하다. 일반적으로, 이들 프로그램 중 임의의 것은 디폴트 설정으로 사용되지만, 당업자는 필요에 따라 이러한 설정을 변경할 수 있다. 대안적으로, 당업자는 적어도 참조된 알고리즘 및 프로그램에 의해 제공되는 것과 같은 동일성 또는 정렬의 수준을 제공하는 또 다른 알고리즘 또는 컴퓨터 프로그램을 이용할 수 있다. 예를 들면, J. D. Thomson et al., Nucl. Acids. Res., “A comprehensive comparison of multiple sequence alignments”, 27 (13): 2682-2690 (1999) 참조.
다중 서열 정렬 프로그램도 핵산 서열에 대해 이용가능하다. 이러한 프로그램의 예는 "크러스탈 W", "크러스탈 오메가", "CAP 서열 어셈블리", "BLAST", "MAP" 및 "MEME"를 포함하며, 이들은 인터넷 웹 서버를 통해 접근가능하다. 이러한 프로그램에 대한 다른 출처는 당업자에게 알려져 있다. 대안적으로, 벡터 NTI 유틸리티도 사용된다. 또한 상기 기재된 프로그램에 포함된 것을 포함하여, 뉴클레오티드 서열 동일성을 측정하는 데 사용될 수 있는 당업계에 알려진 다수의 알고리즘이 있다. 또 다른 예로서, 폴리뉴클레오티드 서열은 GCG 버전 6.1의 프로그램인 파스타™을 사용하여 비교될 수 있다. 파스타™은 질의 서열과 검색 서열 사이의 최상의 중복 영역의 정렬 및 서열 동일성 백분율을 제공한다. 예를 들면, 핵산 서열 사이의 서열 동일성 백분율은 본 명세서에 참고문헌으로 통합되는 GCG 버전 6.1에서 제공되는 바와 같이 디폴트 매개변수 (단어 크기 6, 득점 매트릭스에 대한 NOPAM 인자)와 함께 파스타™를 사용하여 결정될 수 있다.
본 명세서에서 사용되는 바와 같이, 용어 "조절 서열", 또는 "발현 조절 서열"은 작동가능하게 연결된 단백질 인코딩하는 핵산 서열의 전사를 유도, 억제, 또는 달리 조절하는 개시자 서열, 인핸서 서열, 및 프로모터 서열과 같은 핵산 서열을 말한다.
핵산 서열 또는 단백질을 설명하는 데 사용되는 용어 "외인성"은 핵산 또는 단백질이 염색체 또는 숙주 세포에 존재하는 위치에서 자연적으로 발생하지 않음을 의미한다. 외인성 핵산 서열은 또한 동일한 숙주 세포 또는 대상체로부터 유래되고 이들 내로 삽입되지만, 비-자연 상태, 예를 들면, 상이한 복제물 수, 또는 상이한 조절 요소의 제어 하에 존재하는 서열을 지칭한다.
핵산 서열 또는 단백질을 설명하는 데 사용되는 용어 "이종"은 핵산 또는 단백질이 단백질이 발현되는 숙주 세포 또는 대상체와 상이한 유기체 또는 동일한 유기체의 상이한 종으로부터 유래되었음을 의미한다. 플라스미드, 발현 카세트, 또는 벡터에서 단백질 또는 핵산과 관련하여 사용될 때 용어 "이종"은 단백질 또는 핵산이 당해 단백질 또는 핵산이 자연에서 서로 동일한 관계에서 발견되지 않는 또 다른 서열 또는 하위서열과 함께 존재함을 나타낸다.
"포함하는"은 다른 구성요소 또는 방법 단계를 포함하는 것을 의미하는 용어이다. "포함하는"이 사용될 때, 관련된 구현예는 다른 구성요소 또는 방법 단계를 배제하는 "로 구성되는" 용어, 및 구현예 또는 발명의 성질을 실질적으로 변화시키는 임의의 구성요소 또는 방법 단계를 배제하는 "로 필수적으로 구성되는" 용어를 사용하는 설명을 포함하는 것으로 이해되어야 한다. 본 명세서에 다양한 구현예가 "포함하는" 용어를 사용하여 제시되어 있지만, 다른 상황 하에서, 관련 구현예는 또한 "로 구성되는" 또는 "로 필수적으로 구성되는" 용어를 사용하여 기재되는 것으로 이해되어야 한다.
본 명세서에서 사용되는 바와 같이, 숫자 (nn) 값이 이어지는 용어 "e"는 지수를 지칭하며, 이 용어는 "× 10nn"과 상호교환적으로 사용된다. 예를 들면, 3e13은 3×1013과 동등하다.
용어 "하나"는 하나 이상을 지칭하며, 예를 들면, "벡터"는 하나 이상의 벡터 (들)를 나타내는 것으로 이해된다는 점에 유의해야 한다. 이와 같이, 용어 "하나", "하나 이상", 및 "적어도 하나"는 본 명세서에서 상호교환적으로 사용된다.
본 명세서에서 사용되는 바와 같이, 용어 "약"은 달리 명시되지 않는 한, 주어진 참조로부터 ± 10%의 변동성을 의미한다.
실시예
이제 하기 실시예를 참조하여 본 발명을 설명한다. 이들 실시예는 단지 예시의 목적으로 제공되며, 본 발명은 결코 이들 실시예로 제한되는 것으로 해석되어서는 안되고 본 명세서에서 제공되는 교시내용의 결과로서 명백해지는 임의의 그리고 모든 변형을 포괄하는 것으로 해석되어야 한다.
실시예 1: 재료 및 방법
벡터 생산
780번 위치에 Val이 있는 참조 GAA 서열, 및 V780I 돌연변이가 있는 서열을 역번역하고 뉴클레오티드 서열을 조작하여 CAG 프로모터 하에 발현 카세트를 이용하여 AAV 생성을 위한 시스-플라스미드를 생성하였다. 추가적으로, 조작되지 않은 서열과의 비교를 위해 고유한 hGAA (기준 서열)에 대한 cDNA 서열을 동일한 AAV-시스 배향 골격 내로 클로닝하였다. 앞서 기재된 바와 같이 AAVhu68 벡터를 생성하고 적정하였다. (Lock, et al. 2010, Hum Gene Ther 21 (10): 1259-1271). 간단히 말해서, HEK293 세포를 삼중 형질감염시킨 다음, 배양액 상청액을 수확하고, 농축시킨 다음, 이오딕사놀 구배를 이용하여 정제하였다. 정제된 벡터를 앞서 기재된 바와 같이 토끼 베타-글로빈 폴리 A 서열을 표적화하는 프라이머를 사용하여 액적 디지털 PCR로 적정하였다 (Lock, et al. (2014), Hum. Gene Ther. Methods, 25(2): 115-125).
동물
마우스
폼페병 마우스 (Gaa 녹아웃 (-/-), C57BL/6/129 배경) 원조를 Jackson Labs에서 구입하였다 (스톡 NO. 004154, 6네오 마우스라고도 함). 동일한 한배 새끼 내에서 무효 (null) 및 WT 대조군을 생성하기 위해 이형접합체 대 이형접합체 교배를 사용하여, 유전자 요법 프로그램 (Gene Therapy Program) AAALAC의 공인된 장벽 마우스 시설에서 번식 콜로니를 유지하였다. Gaa 녹아웃 마우스는 폼페병에 널리 사용되는 모델이다. 이는 심장, 중추신경계, 골격근, 및 횡경막에 리소좀 글리코겐의 점진적인 축적을 나타내며, 이동성이 감소하고 점진적인 근육 약화가 있다. 작은 크기, 재현가능한 표현형, 및 효율적인 교배는 전임상 후보 생체내 스크리닝에 최적인 신속한 연구를 가능하게 한다.
동물 수용실을 64℉ 내지 79℉ (18℃ 내지 26℃)의 온도 범위에서 30 내지 70%의 습도 범위로 유지하였다.
이유기까지 동물을 부모 및 한배 새끼와 함께 수용하였고, 그 다음 Translational Research Laboratories (TLR) GTP 동물 사육장에서 케이지 당 2 내지 5마리의 동물의 표준 케이지에 수용하였다. 모든 케이지 크기 및 수용 조건은 연구실 동물 관리 및 사용에 대한 지침을 준수하였다. 케이지, 물병, 및 침구 기재를 차단 시설로 고압멸균 처리하였다.
자동으로 제어되는 12시간 명/암 주기를 유지하였다. 각각의 암기는 1900시간 (± 30분)에 시작되었다. 음식은 임의로 제공하였다 (Purina, LabDiet®, 5053, Irradiated, PicoLab®, Rodent Diet 20, 25lb). 물은 각각의 수용 케이지에서 개별적으로 배치된 물병을 통해 모든 동물이 임의로 접근가능하였다. 최소한, 매주 케이지를 바꾸는 동안 일주일에 1회 물병을 교체하였다. 물 공급은 필라델피아 시에서 가져와 Getinge 정수기를 사용하여 염소 처리하였다. ULAR에 의해 염소화 수준을 매일 테스트하였고 2 내지 4 ppm (백만분율)으로 유지하였다. 각각의 수용 케이지에 농축물로서 Nestlets™를 제공하였다.
생체내 연구 및 조직학
측면 꼬리 정맥 (IV)을 통해 0.1 mL 중 5×1011개 GC (대략 2.5×1013개 GC/㎏) 용량 또는 5×1010개 GC (대략 2.5×1012개 GC/㎏) 용량의 AAVhu68.CAG.hGAA (다양한 hGAA 구조물)를 마우스에게 투여하고, 혈청 분리를 위해 벡터 투약 후 제7일 및 제21일에 채혈한 다음, (혈장 분리를 위해) 말기에 채혈하고, 주사하고 28일 후에 방혈에 의해 안락사시켰다. 뇌로 시작하여 조직을 즉시 수집하였다.
조직학용 조직을 표준 방법을 사용하여 포말린으로 고정시키고 파라핀에 포매시켰다. 표준 방법을 사용하여 뇌 및 척수 절편을 룩솔 패스트 블루 (룩솔 패스트 블루 염색 키트, Abcam ab150675)로 염색하고, 말초 장기를 PAS (과요오드산-쉬프)로 염색하여 조직에서 글리코겐과 같은 다당류를 검출하였다. hGAA에 대한 면역염색을 포말린-고정 파라핀-포매 시료에서 수행하였다. 절편을 탈파라핀화하고, 항원 회수를 위해 10 mM 시트레이트 완충액 (pH 6.0)에서 끓이며, PBS 중 1% 당나귀 혈청 + 0.2% 트리톤으로 15분 동안 차단한 다음, 1차 항체 (시그마사 HPA029126 항-hGAA 항체) 및 차단 완충액에 희석된 비오틴화된 2차 항체와 함께 순차적으로 인큐베이션하였고; HRP 기반 비색 반응을 사용하여 신호를 검출하였다.
공인 수의 병리학자에 의해 맹검 방식으로 슬라이드를 검토하였다. 반-정량적 점수매김 시스템을 확립하여 축적 및/또는 공포를 나타내는 세포의 총 백분율에 의해 결정되는 바, 근육의 폼페병 관련 조직학적 병변 (글리코겐 축적 및 자가포식 구축)의 중증도를 측정하였다.

적용가능할 때 벡터 관련 조직병리학적 병변도 추정하였다.
비-인간 영장류
벡터 투여를 위해, 레서스 머카크는 근육내 덱스메데토미딘 및 케타민으로 진정시키고, 단일 대수조내 (ICM) 주사 또는 정맥내 주사를 투여하였다. ICM 주사를 위한 바늘 위치는 이전에 기술된 바와 같이, 형광투시기 (OEC9800 C-Arm, GE)를 사용한 척수조영술을 통해 확인하였다 (Katz N. et al., Hum Gene Ther Methods. 2018년 10월, 29(5): 212-219). 동물은 바비튜레이트 과다용량에 의해 안락사되었다. 수집된 조직은 드라이아이스 위에서 즉시 냉동시키거나, 조직학용 10% 포르말린으로 고정하였다.
시험관내
hGAA780I 효소 성능의 특성화
GAA Activity
균질화된 조직의 혈장 또는 상청액을 5.6 mM 4-MU-α-글루코피라노시드 (pH 4.0)와 혼합하고 37℃에서 3시간 동안 인큐베이션하였다. 0.4 M 탄산나트륨 (pH 11.5)을 사용하여 반응을 중단시킨다. 빅터 3 형광측정기 (355 ㎚에서 여기 및 460 ㎚에서 방출)를 사용하여 상대 형광 단위 (RFU)를 측정한다. 4-MU의 표준 곡선으로부터의 외삽법에 의해 nmol/mL/시간 단위의 활성을 계산한다. 개별 조직 시료에서 활성 수준을 균질화물 상청액의 총 단백질 함량에 대해 정규화한다. 혈장 시료에 동등한 부피를 사용한다.
LC/MS에 의한 GAA 서명 펩티드
혈장은 100% 메탄올로 침전시켜 원심분리하였다. 상청액은 제거하였다. 펠렛은 내부 표준으로서 hGAA에 독특한 안정한 동위원소 표지된 펩티드로 스파이크 처리하고, 트립신으로 재현탁하며, 37℃에서 1시간 동안 배양하였다. 10% 포름산으로 소화를 중단하였다. 펩티드는 C-18 역상 크로마토그래피에 의해 분리시키고, ESI-질량 분광분석법에 의해 식별하여 정량화하였다. 혈장에서 총 GAA 농도는 서명 펩티드 농도로부터 계산하였다.
세포 표면 수용체 결합 검정
96-웰 플레이트는 수용체로 코팅하고, 세척하여 BSA로 차단시켰다. rhGAA 또는 조작된 GAA 둘 중 하나의 동등한 활성을 포함하는 CHO 배양 조정화 배지 또는 혈장이 일련으로 3배 희석되어 일련의 9가지 감소하는 농도를 제공하고, 보조-결합된 수용체와 함께 배양하였다. 배양 이후에, 플레이트를 세척하여 결합되지 않은 임의의 GAA 및 첨가된 4-MU-α-글루코피라노시드를 1시간 동안 37℃에서 제거하였다. 반응은 1.0 M 글리신, pH 10.5을 사용하여 중단시키고, RFU를 스펙트라맥스 형광측정기, 370 ㎚의 여기 및 460 ㎚의 방출에 의해 판독하였다. 각 시료에 대한 RFU는 4-MU의 표준 곡선으로부터의 외삽법에 의해 nmol/mL/시간으로 변환된다. 그래프패드 프리즘을 사용하여 비선형 회귀 분석을 시행한다.
글리코겐 -
TFA 가수분해
조직 균질화물은 100℃에서 4시간 동안 4 N TFA로 가수분해하고, 건조시켜 물에 재구성하였다. 가수분해된 물질은 펄스 전류측정 검출이 장착된 고-pH 음이온 교환 크로마토그래피 (HPAEC-PAD)에 의한 포도당 결정을 위한 카보팩 PA-10 2 × 250 mm 컬럼 내에 주입하였다. 각 시료에서 유리 포도당의 농도는 포도당 표준 곡선으로부터의 외삽법에 의해 계산하였다. 최종 데이터는 μg 글리코겐/mg 단백질로서 보고하였다.
실시예 2: 폼페병 마우스에서 rAAVhu68.hGAA 벡터의 평가
폼페병 마우스에 대한 IV 전달을 위해 AAV 벡터를 멸균 PBS로 희석하였다. 테스트 항목은 AAVhu68.CAG.hGAAco.rBG, AAVhu68.CAG.hGAAcoV780I.rBG, AAVhu68.CAG.BiP-vIGF2.hGAAco.rBG, AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.rBG 및 AAVhu68.CAG.sp7co.△8.hGAAcoV780I.rBG를 포함하였다. 야생형 및 비히클 대조군을 연구에 포함하였다.
hGAA 단백질 발현 및 활성은 간 (도 1a 및 도 1b), 심장 (도 2a 및 도 2b), 대퇴사두근 (도 3a 및 도 3b), 뇌 (도 4a 및 도 4b), 혈장 (도 9a)을 포함하여, 처리된 마우스로부터 수집된 다양한 조직에서 측정하였다. 모든 프로모터는 저-용량 및 고-용량 둘 다에서 간에서 동등하게 잘 수행하였다. UbC 프로모터 하에서 발현하는 벡터의 투여는 두 가지 용량 모두에서 골격근에서 더 낮은 활성을 유도하였고, CAG 프로모터가 있는 벡터는 최고의 전반적 활성을 보였다. UbC 프로모터가 있는 벡터는 또한 두 가지 용량 모두에서 심장에서 더 낮은 활성을 보였다.
폼페병 마우스 비히클 (PBS) 대조군 (도 5d)은 심장에서 뚜렷한 글리코겐 축적 (PAS로 염색된 절편에서 어두운 염색)을 나타내었다. 야생형 마우스 및 모든 벡터로 처리된 마우스는 축적의 거의 완전하거나 완전한 제거를 보였다. 그러나, hGAA 기준 서열 (V780)을 인코딩하는 벡터를 받은 2가지 실험군은 중등도 내지 뚜렷한 섬유화 림프구성 심근염을 나타내었으며 (도 5b 및 도 5c), 상기 섬유화 림프구성 심근염은 고유한 hGAA 이식유전자를 받은 8마리 동물 중 7마리 및 BiP 및 vIGF2 변형이 있는 조작된 hGAA를 받은 8마리 동물 중 3마리에 존재하였다. hGAAcoV780I 효소를 받은 마우스 중 어느 것도 심근염에 걸리지 않았기 때문에 (도 5e, 도 5f, 및 도 5g), 이러한 병변은 벡터 관련된 것, 보다 구체적으로는 hGAA 기준 서열 특이적인 것으로 간주되었다.
대퇴사두근 조직의 분석은, 야생형 마우스 및 추가 변형이 있거나 없이 V780I 변이체를 인코딩하는 벡터로 처리된 모든 마우스가 축적 및 자가포식 구축의 거의 완전하거나 완전한 제거를 보이는 것을 드러내었다 (도 6a 내지 도 6h). 그러나, hGAAV780의 기준 서열을 인코딩하는 벡터를 받은 2가지 실험군은 남아있는 최소 내지 중간 정도의 글리코겐 축적뿐만 아니라 자가포식 구축을 나타내었으며 (도 10), 이와 함께 폼페병의 2가지 주요 특징의 차선의 교정을 입증하였다. 최상의 결과는 고유한 형태로 또는 BiP-vIGF2 변형이 있는 V780I 변이체를 인코딩하는 2가지 벡터의 전달로부터 관찰되었다. sp7-델타8 변형은 폼페병에 기인한 조직학적 병변의 일관되지 않는 교정을 유발하는 것으로 나타났다. 기준 hGAAV780 서열을 인코딩하는 2가지 구조물은 글리코겐 축적 및 구축을 제거하는 데 차선책이었다.
고-용량 IV 투여 (5×1011개 = 2.5×1013개 GC/㎏)에서, hGAAcoV780I 및 BiP-vIGF2.hGAAcoV780I는 대퇴사두근에서 거의 정상의 글리코겐 수준을 나타내었고, 세포 내로의 hGAA 흡수가 현저하게 더 우수하였다 (도 7a 내지 도 7h 및 도 42). 전방 경골근 (TA) 및 비복근을 포함하는 다른 골격근의 평가는 유사한 결과를 나타내었다 (V780I 및 글리코겐 및 중앙 자가포식 공포 둘 다의 소거가 있는 변이체). 모든 구조물은 심장에서 글리코겐 축적을 감소시켰으며, 이 때 BiP-vIGF2.hGAAcoV780I 투여가 최저 수준을 유도하였다. 대퇴사두근의 글리코겐 수준이 거의 정상이지만, PAS 염색은 약간의 차이를 나타내었으며, hGAAcoV780I 및 BiP-vIGF2.hGAAcoV780I가 최상의 결과를 나타내었다. 투여받은 마우스의 골격근, 심장 및 척수에서 hGAA의 발현은 면역조직화학으로 검증하였다 (도 43).
저-용량 IV 투여 (5×1010개 = 2.5×1012개 GC/㎏)에서, BiP-vIGF2.hGAAcoV780I는 고유한 hGAAcoV780I보다 심장 및 대퇴사두근에서 더 양호한 글리코겐 감소를 입증하였다 (도 41). 뇌 및 척수의 글리코겐 수준은, 아마도 더 양호한 표적화로 인하여, BiP-vIGF2.hGAAcoV780I에 의해 거의 정상이었고, 심지어 약 15%의 조직 수준이었다. CNS에서, 조직된 구조물과 V780I 변이체 사이의 강력한 상승작용 효과가 관찰되었다. BiP-vIGF2.hGAAcoV780I만이 CNS 글리코겐을 소거하였다.
도 8에 나타낸 바와 같이, 척수 조직학의 평가는 AAVhu68.BiP-vIGF2.hGAAcoV780I로 처리된 마우스가 글리코겐 축적을의 거의 완전한 내지 완전한 제거를 보였던 반면, 기준 hGAAV780 효소를 인코딩하는 벡터로 처리된 마우스는 잔류하는 글리코겐 축적을 보였다. 또한, 뇌 및 척수 절편의 염색은 BiP-vIGF2.hGAAcoV780I를 사용한 교정을 드러낸 반면, 고유한 hGAAcoV780I로는 교정하지 못하였다 (도 42). 결과는 V780I 돌연변이 및 BiP-vIGF2 변형 둘 다의 기여를 입증하고 있다.
실시예 3: 폼페병 마우스의 hGAA 발현에 미치는
DRG-탈표적화의 효과
BiP-vIGF2.hGAAcoV780I는 miR-183 표적 부위 (BiP-vIGF2.hGAAcoV780I.4xmir183, 서열번호 30)를 포함하도록 변형시켜 (도 11) 및 AAVhu68 캡시드에 패키징하였다.
벡터 게놈은 하기 서열 요소를 포함한다:
역전된 말단 반복서열 (ITR): ITR은 벡터 게놈의 모든 구성요소와 연접하는, AAV2 (130 bp, GenBank: NC_001401)로부터 유래한 일치하는 역상보적인 서열이다. ITR은 AAV 및 아데노바이러스 헬퍼 기능이 트랜스 배향으로 제공될 때 벡터 DNA 복제의 원점 및 벡터 게놈을 위한 패키징 신호 둘 다로서 기능한다. 이와 같이, ITR 서열은 벡터 게놈 복제 및 패키징을 위해 요구되는 유일한 시스 배향 서열이다.
CAG 프로모터: 사이토메갈로바이러스 (CMV) 인핸서, 닭 베타-액틴 (CB) 프로모터 (282 bp, GenBank: X00182.1) 및 토끼 베타-글로빈 인트로으로 구성된 하이브리드 구조물.
코딩 서열: BiP-vIGF2.hGAAcoV780I (서열번호 31)을 인코딩하는 조작된 cDNA (서열번호 30의 뉴클레오티드 1141번 내지 4092번).
miR 표적 표적 서열: 4개의 일렬 miR-183 표적 서열 (서열번호 26).
토끼 β-글로빈 폴리아데닐화 신호 (rBG PolyA): rBG 폴리 A 신호 (127 bp)는 시스 배향으로 이식유전자 mRNA의 효율적인 폴리아데닐화를 용이하게 한다. 이러한 요소는 전사 종결, 미가공 전사체의 3' 말단에서 특이적 절단 과정 및 긴 폴리아데닐레이트 미단의 첨가를 위한 신호로서 작용한다.
BiP-vIGF2-hGAAcoV780I 벡터 게놈 내에 miR-183 표적 부위를 도입하는 것의 효과는 폼페병 마우스로의 AAVhu68의 IV 전달 이후에 평가하였다. BiP-vIGF2-hGAAcoV780I 구조물 (miR-183 표적이 없음)을 사용하여 관찰된 바와 같이, miR-183 표적 서열을 포함한 벡터의 고-용량 정맥내 투여 이후에 글리코겐 축적이 CNS에서 교정되었다 (도 12 및 도 13). 대퇴사두근에서 글리코겐 축적 및 자가포식 구축은 고-용량 정맥내 투여 이후에 완전히 교정된 반면, 저-용량 투여 이후에는 글리코겐 축적 교정 및 자가포식 구축의 일부 교정이 관찰되었다 (도 14). 또한, 글리코겐의 교정은 저-용량 및 고-용량으로 심장에서 관찰되었다 (도 15). CAG.BiP-vIGF2.hGAAcoV780I의 투여로 관찰된 것과 유사하게, 자가포식 구축은 고-용량에서 완전히 해소되고, 저-용량에서 현저하게 감소되었다 (도 16). 결과는 miR-183 표적의 첨가가 miR-183 표적 서열이 없는 상응하는 벡터와 비교하여 치료용 이식유전자의 효능을 변경시키지 않음을 검증하였다.
용량 범위 연구는 IV 투여 이후에 BiP-vIGF2.hGAAcoV780I.4xmir183 구조물에 대한 효능, 프로파일 및 MED를 결정하도록 수행하였다. 연구 설계는 하기 표에 제공된다.

근육 병리는 AAVhu68.BiP-vIGF2.hGAAcoV780I.4xmir183 벡터의 IV 투여 이후 60일째 PAS 염색된 근육 절편 상에서 점수 매겨졌다. 대퇴사두근 절편은 WGA (세포막; 근육 섬유 직경을 측정함), DAPI (핵; 중앙 핵의 존재를 정량함), 및 Lc3b (자가포식소체; 자가포식 구축을 정량함)으로의 염색을 사용한 면역조직화학에 의해 분석하였다. 절편을 스캔하고, 자동으로 디지탈화한 다음 비지오팜 소프트웨어를 사용하여 분석하였다.
중앙 핵 정량화
건강한 근육 섬유는 중앙 핵 (CN)을 거의 포함하지 않고 (야생형 근육에서 35% 미만), CN 존재는 근육 퇴화를 표시한다. CN을 갖는 섬유의 백분율은 WT 및 KO PBS 대조군 사이에 유의하게 상이하였다 (도 43). CN을 갖는 섬유의 백분율은 KO PBS 대조군 마우스와 비교하여 2 × 1011개 GC (1 × 1013개 GC/kg) 및 더 높은 벡터 용량으로 처리된 실험군에서 유의하게 감소하였다. 어린 마우스에서, CN을 증가시키는 퇴화/재생 주기가 연구의 시작 이전에 발생하지 않았으며, 처리에 의해 예방되어 폼페병 마우스에서 표형형 교정을 유도하였다.
LC3b 정량화
생산적인 자가포식의 정상 조건 하에, 자가포식소체는 리소좀에 의해 신속하게 분해되어, LC3 양성 구조가 그대로 검출가능하다. GAA KO 마우스에서, 손상된/기능이상 리소좀은 자가포식의 증가를 촉발시킬 수 있으며, 리소좀이 자가포식소체와 융합하지 못하고, 이의 내용물을 분해하여 자가포식 구축을 유도한다.
자가포식 구축 (LC3b + 세포의 %)이 5 × 1011개 GC (2.5 × 1013개 GC/kg)로부터 시작하여 모든 용량에서 예방되었다 (도 44). 유의한 자가포식소체 구축은 생후 3개월에 PBS 대조군에서 관찰하였다 (> 20% 섬유).
대퇴사두근 섬유의 더 작은 직경 정량화
야생형 대조군 동물과 비교할 때 섬유 크기의 차이를 정량화하기 위하여, 섬유 직경은 소 (< 30 μm), 중 (30 μm 내지 50 μm) 및 대 (> 50 μm) 부류로 구분하였다. KO PBS 대조군은 생후 3개월에 유의한 위축증을 나타낸다. KO PBS 실험군과 비교하여, 큰 대퇴사두근 섬유의 백분율의 유의한 증가 및 작은 대퇴사두근 섬유의 백분율의 감소가 있었다. 작은 섬유 (S)의 비율이 2 × 1011개 GC (1 × 1013개 GC/kg) 용량 이상으로 처리된 GAA -/- 마우스에서 유의하게 감소하고, 근육 위축증 예방을 나타내었다.
공포 형성의 중증도
결과는 평가된 모든 근육에서 리소좀 저장의 용량 의존적 교정을 보여주었다 (도 46a 내지 도 46f). 가자미근 및 횡격막에서 테스트된 가장 낮은 용량 (5 × 1012개 GC/kg, 1 × 1011개 GC)으로 교정이 달성된 반면, 테스트된 나머지 근육 대부분은 2 × 1013개 GC/kg (5 × 1011개 GC)의 중간 용량으로 GAA KO PBS 대조군 마우스와 비교하여 유의하게 개선되었다. 가장 높은 2가지 용량 - 5 × 1013개 GC/kg (1 × 1012개 GC) 및 1 × 1014개 GC/kg (2 × 1012개 GC)의 경우 근육 병리가 완벽하게 없었으며, 절편이 WT 마우스 근육과 유사한 것으로 관찰되었다.
실시예 4: 증상 이후의 노령 폼페병 마우스에서 투여 경로 및 용량 연구
hGAA 인코딩하는 AAVhu68 벡터 (예로, AAVhu68.CAG.BiP-vIGF2.hGAAcoV780I.rBG를 포함함)가 정맥내 (IV) 및/또는 뇌실내 (ICV) 주사를 통해 투여된 폼페병 마우스 (뿐만 아니라 야생형 및 비히클 대조군)에서 투여 경로 및 용량의 효과가 평가되었다. 동일한 벡터를 사용한 이중 투여 경로 접근법 (정맥 내 및 뇌척수액 내로의 주사)은 질환의 말초적 및 신경학적 소견 둘 다를 교정하여야 한다. 유전자 요법에 적격할 유의한 비율의 환자가 이미 상급 병리를 보일 것이기 때문에, 본 발명자들은 증상 이후의 폼페병 마우스 (생후 7개월의 6마리)를 선별하여 처리하고, 처리 후 적어도 6개월 동안 추적 관찰하였다.
마우스는 벡터의 2가지 용량 수준 (저-용량 또는 고-용량)을 정맥내 (IV), 뇌실내 (ICV) 또는 이중 투여 경로를 사용하여 투여 받았다. 본 연구에 사용된 용량 (5 × 1010개 GC 또는 1 × 1011개 GC ICV 및 1 × 1013개 GC/kg 또는 5 × 1013개 GC/kg IV)은 실시예 6에 기술된 NHP 연구에 사용된 저-용량 및 고-용량에 상응하고, 인간에게 투여에 적합한 용량 (1 × 1013개 GC/kg 및 5 × 1013개 GC/kg)이다. 마우스는 대략 주사 후 210일째, 생후 13개월 내지 14개월에 희생되어 분석을 위한 조직을 수집하였다. 연구 설계는 도 47에 제공되어 있다.
연구의 과정 동안, 마우스는 회전막대, 와이어 매달리기 및 그립 강도 평가를 사용하여 보행 활동에 대해 테스트하고, 체적변동기록을 수행하였다. hGAA 단백질 발현/활성 및 글리코겐 축적을 혈장, 대퇴사두근, 비복근, 횡격막 및 뇌를 포함하는, 처리된 마우스로부터 수집된 다양한 조직에서 측정하였다. 조직학을 수행하여 예를 들면 PAS (룩솔 패스트 블루 염색에 의함), hGAA 발현 및 신경염증 (별아교세포증)을 평가하였다. 조직 절편을 염색하여 자가포식 구축 또는 제거 (예를 들면, LC3B를 표지하는 항체를 사용함)를 평가하였다.
조직학적 연구는 고-용량 및 저-용량 ICV 처리된 (도 28), 및 고-용량 및 저-용량 IV 처리된 (도 29) 마우스로부터의 대퇴사두근, 심장 및 척수 시료에 대해 수행하였다. 글리코겐 축적은 ICV 경로를 통해 저- 또는 고-용량 벡터 용량을 투여받은 마우스의 척수에서 교정되었다. 고-용량 IV 투여는 대퇴사두근, 심장 및 척수에서 글리코겐 축적을 교정하는데 효과적이었다.
체중은 저-용량 및 고-용량 둘 다의 ICV 및 IV 벡터의 조합으로 처리된 수컷에서 유의하게 교정되었다 (도 25a). 단일 경로 (ICV 단독 또는 IV 단독)는 체중을 유의하게 교정하지 못하였다. 체중은 암컷 폼페병 마우스 및 WT 마우스 상이에 상이하지 않았다 (도 25b).
그립 강도는 고-용량 IV를 투여받은 마우스의 경우에 (기저선과 비교하여 및 PBS 대조군과 비교하여) 유의하게 개선되었다 (도 26). ICV 및 IV 투여된 저-용량 벡터 또는 이중 투여 경로 (ICV LD + IV LC) 투여의 경우 유의한 이익이 없었다. 그러나, 고-용량 IV 및 ICV 조합의 투여는 주사 후 30일 정도에 야생형 수준과 비교하여 강도를 복구하였고, 180일째 조합의 이익 증가가 있었다 (도 27).
근육 병리는 상이한 실험군 전체를 조사하여 폼페병과 관련된 결과를 관찰하였다. 폼페병 환자 및 6neo GAA KO 폼페병 마우스 모델로부터의 근육은 섬유 위축증, 부동세포증, 자가포식 구축 및 중앙 핵 형성과 같은 구조적 이상의 존재를 특징으로 한다 (도 48).
중앙 핵 정량화
6개월 이후에 처리된 마우스에서, 퇴화/재생 주기가 이미 처리 이전에 발생하였다 (도 49).
LC3b 정량화
기존의 병리를 갖는 폼페병 마우스의 처리는 IV HD (1 × 1012개 GC = 5 × 1013개 GC/kg), 및 ICV + IV HD (ICV 1 × 1011개 GC 및 IV 1 × 1012개 GC) 실험군에서 자가포식소체 축적을 역전시켰다 (도 50).
대퇴사두근 섬유 직경 정량화
6개월 이후에 처리된 마우스에서 근육 위축증이 이미 현저할 때, 작은 섬유 (S)의 비율이 ICV + IV HD 처리된 실험군 (ICV 1 × 1011개 GC 및 IV 1 × 1012개 GC)에서 감소되고, 큰 섬유 (L)의 비율은 IV HD 및 ICV + IV HD 처리된 실험군에서 개선되었다 (도 51). 이러한 처리 실험군에서, 근윤 섬유 크기 분포는 WT 마우스와 유사하고, PBS 대조군 폼페병 바우스와 비교하여 통계적으로 유의하게 복구되었으며, 상급 질환 증상 이후의 치료 파라다임에서 기존 병리의 구제를 나타낸다. 도 27에 나타낸 바와 같이, 결과는 동일한 실험군에서 WT 수준과 비교하여 그립 강도 복구와 상관된다. 또한, HD IV 처리도 병리 개선을 유도하고, 큰 섬유의 비율 증가 및 위축성 섬유의 감소 경향성을 보여준다 (도 51).
결과는 이중 투여 경로가 모든 양태의 질환을 표적하는데 바람직한 점을 뒷받침하고 있다. 벡터의 전달은 섬유의 위축 및 자가포식 구축과 같은 전형적으로 치료 저항성인 결과를 포함하는, 증상 이후의 노령 폼페병 마우스에서 기존의 근육 섬유 병리를 역전시켰다.
실시예 5: 비-인간 영장류에게 DRG-탈표적화 유전자 요법 벡터의 투여
NHP 영장류 연구는 독성을 측정하고, AAVhu68 캡시드에서 CAG.BiP-IGF2-hGAAcoV780I 또는 CAG.BiP-IGF2-hGAAcoV780I-4xmir183의 ICM 전달을 평가하도록 시행하였다. 벡터는 3 × 1013개 GC/kg으로 ICM 주사하고, 동물은 35일째 희생되었다.
4개의 miR-183의 일렬 반복서열의 첨가는 경추 DRG의 감각 뉴런에서 hGAA 이식유전자의 발현을 억압하였다 (도 17). mir183 벡터에 대한 hGAA 이식유전자 의 현저한 감도도 요추 DRG의 감각 뉴런에서 관찰되지만, 일부 발현은 남아있었다 (도 18). 놀랍게도, miR-183 표적 서열이 운동 뉴런에서 이식유전자의 발현을 변형하지 않았고 (도 19), 이는 벡터의 투여가 폼페병 환자의 운동 뉴런에서 글리코겐 축적을 감소시키는데 이익이 될 것임을 시사한다. 또한, miR-183 표적 서열 포함하는 구조물의 전달 이후에 심장에서 이식유전자 발현의 감소가 없었다 (도 20). 사실상, 심장에서 발현이 증가되는 것으로 보였으며, 폼페병 환자에서 심장병 치료를 위한 효능이 증진될 것임을 시사한다. 명백하게, miR-183 표적 서열의 일렬 반복서열은 경추 및 흉추 분절로부터 나온 DRG의 감각 뉴런에서 독성을 감소시켰다 (도 21a 및 도 21b). 이러한 용량 수준에서 요추 분절의 독성은 감소되지 않았으며 (도 21c), 도 18에 도시된 바와 같이 요추 수준에서 잔류 단백질 발현으로 인한 것 같다.
NHP에게 miR-183 표적 서열을 갖는 구조물의 IV 전달을 추가로 평가하는 연구 설계는 하기 표에 제공된다. 연구는 레서스 GAA (rhGAA) 서열을 포함하여 비-자가 면역 반응의 잠재적인 효과를 평가한다.

또한, CAG.BiP-IGF2-hGAAcoV780I-4xmir183 벡터의 안전성 프로파일은 용량 범위 연구를 사용하여 평가하였다. 용량 범위 연구에서 NHP는 3 × 1012개 GC, 6 × 1013개 GC 및 1 × 1013개 GC를 포함한 다양한 용량으로 ICM 투여되었다.

실시예 6: 비-인간 영장류에서 투여 경로 연구
NHP 영장류 연구는 독성을 측정하고, 대안의 또는 조합된 벡터 투여 경로를 평가하도록 시행하였다. AAVhu68.CAG.BiP-IGF2-hGAAcoV780I는 5 × 1013개 GC/kg (고-용량) 또는 1 × 1013개 GC/kg (저-용량)으로 IV 투여되거나, 3 × 1013개 GC (고-용량) 또는 1 × 1013개 GC (저-용량)으로 ICM 투여되었다. 또한, 이중 투여 경로의 유용성 및 독성도 예를 들면 IV 및 ICM 용량을 조합하여 (IV 5 × 1013개 GC/kg + ICM 3 × 1013개 GC, 또는 IV 1 × 1014개 GC/kg + ICM 1 × 1013개 GC) 투여함으로써 평가하였다. IV 및 ICM 용량의 조합은 폼페병 환자의 치료에 유익할 상승작용 효과를 나타낼 수 있다.
투여 경로 및 용량을 평가하기 위한 연구 설계는 도 31에 제공된다. 예비적인 연구는 저-용량 IV 주사된 동물이 대퇴사두근 및 심장에서 hGAA 발현을 보이는 것을 드러내었다 (도 37). 또한, IV 주사된 동물은 ICM 주사된 동물보다 낮은 등급의 척수 축삭병증을 나타내었다 (도 33d 내지 도 33f). 또한, hGAA의 발현은 저-용량 ICM 주사된 동물의 척수에서 조직학에 의해 관찰되었다 (도 37).
척수 분절에서 hGAA 발현하는 운동 뉴런의 정량화는 인간 GAA 이식유전자에 대해 면역염색된 슬라이드 상에서 시행하였다. 결과는 ICM 단독 투약된 동물 및 ICM + IV 투약된 동물이 이식유전자를 발현하는 의미있는 갯수의 척수 하부 운동 뉴런을 갖는 것을 나타내었다. 이러한 결과는 직접적인 CSF 투여가 운동 뉴런 별리를 교정하는데 유익할 것임을 시사한다. IV LD 용량 단독이 hGAA 양성 운동 뉴런을 유도하지 않는 반면, IV HD는 분산된 hGAA 양성 운동 뉴런을 유도하였다 (도 55).
ICM 주사된 동물에서 DRG 퇴화 및 척수 축삭병증은 용량 의존적이지 않았다 (도 33a 내지 도 33f). 또한, 1마리의 저-용량 동물 (RA3607: 1 × 1013개 GC/kg) 및 1마리의 IV + ICM 동물 (180717: IV 5 × 1013개 GC/kg + ICM 3 × 1013개 GC)은 IV 고-용량 주사된 동물보다 증가된 DRG 퇴화, 척수 축삭병증 및 더 높은 심장 염증 반응을 나타내었다. 그러나, miR 표적 서열을 갖는 구조물의 ICM 투여 이후에 심장 GAA 발현의 증가가 관찰되고, 염증은 없었다 (도 20).
(형식이 없는 서열목록 텍스트)
숫자 식별자 <223> 하에 형식이 없는 텍스트를 포함하는 서열에 대한 하기 정보를 제공한다.






본 명세서에 인용된 모든 문서는 본원에 참고문헌으로 통합된다. 본원에 함께 제출된 서열목록 ("21-9596PCT_ST25"로 라벨됨), 및 내부의 서열 및 텍스트는 참고문헌으로 통합된다. 2019년 4월 30에 제출된 미국 가특허출원 제 US 62/840,911호, 2019년 10월 10일에 제출된 미국 가특허출원 제 US 62/913,401호, 2020년 4월 29일에 제출된 국제특허출원 제 PCT/US20/30484호, 2020년 4월 29일에 제출된 국제특허출원 제 PCT/US20/30493호, 2020년 5월 14일에 제출된 미국 가특허출원 제 US 62/024,941호, 2020년 11월 4일에 제출된 미국 가특허출원 제 US 63/109,677호, 및 2021년 4월 27일에 제출된 미국 가특허출원 제 US 63/180,379호는 본원에 참고문헌으로 통합된다. 본 발명이 특정한 구현예를 참조하여 설명되는 한편, 본 발명의 정신을 벗어나지 않고도 변형이 만들어질 수 있음이 이해될 것이다. 이러한 변형은 첨부된 청구항의 범주 내에 속하도록 의도된다.
SEQUENCE LISTING
<110> THE TRUSTEES OF THE UNIVERSITY OF PENNSYLVANIA
AMICUS THERAPEUTICS, INC.
<120> COMPOSITIONS USEFUL FOR TREATING POMPE DISEASE
<130> UPN-21-9596.PCT
<150> US 63/024,941
<151> 2020-05-14
<150> US 63/109,677
<151> 2020-11-04
<150> US 63/180,379
<151> 2021-04-27
<160> 64
<170> PatentIn version 3.5
<210> 1
<211> 2211
<212> DNA
<213> adeno-associated virus hu.68
<220>
<221> CDS
<222> (1)..(2211)
<400> 1
atg gct gcc gat ggt tat ctt cca gat tgg ctc gag gac aac ctc agt 48
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
gaa ggc att cgc gag tgg tgg gct ttg aaa cct gga gcc cct caa ccc 96
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Gln Pro
20 25 30
aag gca aat caa caa cat caa gac aac gct cgg ggt ctt gtg ctt ccg 144
Lys Ala Asn Gln Gln His Gln Asp Asn Ala Arg Gly Leu Val Leu Pro
35 40 45
ggt tac aaa tac ctt gga ccc ggc aac gga ctc gac aag ggg gag ccg 192
Gly Tyr Lys Tyr Leu Gly Pro Gly Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
gtc aac gaa gca gac gcg gcg gcc ctc gag cac gac aag gcc tac gac 240
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
cag cag ctc aag gcc gga gac aac ccg tac ctc aag tac aac cac gcc 288
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
gac gcc gag ttc cag gag cgg ctc aaa gaa gat acg tct ttt ggg ggc 336
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
aac ctc ggg cga gca gtc ttc cag gcc aaa aag agg ctt ctt gaa cct 384
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Leu Leu Glu Pro
115 120 125
ctt ggt ctg gtt gag gaa gcg gct aag acg gct cct gga aag aag agg 432
Leu Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
cct gta gag cag tct cct cag gaa ccg gac tcc tcc gtg ggt att ggc 480
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Val Gly Ile Gly
145 150 155 160
aaa tcg ggt gca cag ccc gct aaa aag aga ctc aat ttc ggt cag act 528
Lys Ser Gly Ala Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
ggc gac aca gag tca gtc ccc gac cct caa cca atc gga gaa cct ccc 576
Gly Asp Thr Glu Ser Val Pro Asp Pro Gln Pro Ile Gly Glu Pro Pro
180 185 190
gca gcc ccc tca ggt gtg gga tct ctt aca atg gct tca ggt ggt ggc 624
Ala Ala Pro Ser Gly Val Gly Ser Leu Thr Met Ala Ser Gly Gly Gly
195 200 205
gca cca gtg gca gac aat aac gaa ggt gcc gat gga gtg ggt agt tcc 672
Ala Pro Val Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser Ser
210 215 220
tcg gga aat tgg cat tgc gat tcc caa tgg ctg ggg gac aga gtc atc 720
Ser Gly Asn Trp His Cys Asp Ser Gln Trp Leu Gly Asp Arg Val Ile
225 230 235 240
acc acc agc acc cga acc tgg gcc ctg ccc acc tac aac aat cac ctc 768
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
tac aag caa atc tcc aac agc aca tct gga gga tct tca aat gac aac 816
Tyr Lys Gln Ile Ser Asn Ser Thr Ser Gly Gly Ser Ser Asn Asp Asn
260 265 270
gcc tac ttc ggc tac agc acc ccc tgg ggg tat ttt gac ttc aac aga 864
Ala Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg
275 280 285
ttc cac tgc cac ttc tca cca cgt gac tgg caa aga ctc atc aac aac 912
Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn
290 295 300
aac tgg gga ttc cgg cct aag cga ctc aac ttc aag ctc ttc aac att 960
Asn Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile
305 310 315 320
cag gtc aaa gag gtt acg gac aac aat gga gtc aag acc atc gct aat 1008
Gln Val Lys Glu Val Thr Asp Asn Asn Gly Val Lys Thr Ile Ala Asn
325 330 335
aac ctt acc agc acg gtc cag gtc ttc acg gac tca gac tat cag ctc 1056
Asn Leu Thr Ser Thr Val Gln Val Phe Thr Asp Ser Asp Tyr Gln Leu
340 345 350
ccg tac gtg ctc ggg tcg gct cac gag ggc tgc ctc ccg ccg ttc cca 1104
Pro Tyr Val Leu Gly Ser Ala His Glu Gly Cys Leu Pro Pro Phe Pro
355 360 365
gcg gac gtt ttc atg att cct cag tac ggg tat cta acg ctt aat gat 1152
Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asp
370 375 380
gga agc caa gcc gtg ggt cgt tcg tcc ttt tac tgc ctg gaa tat ttc 1200
Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe
385 390 395 400
ccg tcg caa atg cta aga acg ggt aac aac ttc cag ttc agc tac gag 1248
Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Ser Tyr Glu
405 410 415
ttt gag aac gta cct ttc cat agc agc tat gct cac agc caa agc ctg 1296
Phe Glu Asn Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu
420 425 430
gac cga ctc atg aat cca ctc atc gac caa tac ttg tac tat ctc tca 1344
Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser
435 440 445
aag act att aac ggt tct gga cag aat caa caa acg cta aaa ttc agt 1392
Lys Thr Ile Asn Gly Ser Gly Gln Asn Gln Gln Thr Leu Lys Phe Ser
450 455 460
gtg gcc gga ccc agc aac atg gct gtc cag gga aga aac tac ata cct 1440
Val Ala Gly Pro Ser Asn Met Ala Val Gln Gly Arg Asn Tyr Ile Pro
465 470 475 480
gga ccc agc tac cga caa caa cgt gtc tca acc act gtg act caa aac 1488
Gly Pro Ser Tyr Arg Gln Gln Arg Val Ser Thr Thr Val Thr Gln Asn
485 490 495
aac aac agc gaa ttt gct tgg cct gga gct tct tct tgg gct ctc aat 1536
Asn Asn Ser Glu Phe Ala Trp Pro Gly Ala Ser Ser Trp Ala Leu Asn
500 505 510
gga cgt aat agc ttg atg aat cct gga cct gct atg gcc agc cac aaa 1584
Gly Arg Asn Ser Leu Met Asn Pro Gly Pro Ala Met Ala Ser His Lys
515 520 525
gaa gga gag gac cgt ttc ttt cct ttg tct gga tct tta att ttt ggc 1632
Glu Gly Glu Asp Arg Phe Phe Pro Leu Ser Gly Ser Leu Ile Phe Gly
530 535 540
aaa caa gga act gga aga gac aac gtg gat gcg gac aaa gtc atg ata 1680
Lys Gln Gly Thr Gly Arg Asp Asn Val Asp Ala Asp Lys Val Met Ile
545 550 555 560
acc aac gaa gaa gaa att aaa act acc aac cca gta gca acg gag tcc 1728
Thr Asn Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr Glu Ser
565 570 575
tat gga caa gtg gcc aca aac cac cag agt gcc caa gca cag gcg cag 1776
Tyr Gly Gln Val Ala Thr Asn His Gln Ser Ala Gln Ala Gln Ala Gln
580 585 590
acc ggc tgg gtt caa aac caa gga ata ctt ccg ggt atg gtt tgg cag 1824
Thr Gly Trp Val Gln Asn Gln Gly Ile Leu Pro Gly Met Val Trp Gln
595 600 605
gac aga gat gtg tac ctg caa gga ccc att tgg gcc aaa att cct cac 1872
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
acg gac ggc aac ttt cac cct tct ccg ctg atg gga ggg ttt gga atg 1920
Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Met
625 630 635 640
aag cac ccg cct cct cag atc ctc atc aaa aac aca cct gta cct gcg 1968
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
gat cct cca acg gct ttc aac aag gac aag ctg aac tct ttc atc acc 2016
Asp Pro Pro Thr Ala Phe Asn Lys Asp Lys Leu Asn Ser Phe Ile Thr
660 665 670
cag tat tct act ggc caa gtc agc gtg gag att gag tgg gag ctg cag 2064
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
aag gaa aac agc aag cgc tgg aac ccg gag atc cag tac act tcc aac 2112
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn
690 695 700
tat tac aag tct aat aat gtt gaa ttt gct gtt aat act gaa ggt gtt 2160
Tyr Tyr Lys Ser Asn Asn Val Glu Phe Ala Val Asn Thr Glu Gly Val
705 710 715 720
tat tct gaa ccc cgc ccc att ggc acc aga tac ctg act cgt aat ctg 2208
Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
taa 2211
<210> 2
<211> 736
<212> PRT
<213> adeno-associated virus hu.68
<400> 2
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Gln Pro
20 25 30
Lys Ala Asn Gln Gln His Gln Asp Asn Ala Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Gly Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Leu Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Val Gly Ile Gly
145 150 155 160
Lys Ser Gly Ala Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Thr Glu Ser Val Pro Asp Pro Gln Pro Ile Gly Glu Pro Pro
180 185 190
Ala Ala Pro Ser Gly Val Gly Ser Leu Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Val Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Gln Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Asn Ser Thr Ser Gly Gly Ser Ser Asn Asp Asn
260 265 270
Ala Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg
275 280 285
Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn
290 295 300
Asn Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile
305 310 315 320
Gln Val Lys Glu Val Thr Asp Asn Asn Gly Val Lys Thr Ile Ala Asn
325 330 335
Asn Leu Thr Ser Thr Val Gln Val Phe Thr Asp Ser Asp Tyr Gln Leu
340 345 350
Pro Tyr Val Leu Gly Ser Ala His Glu Gly Cys Leu Pro Pro Phe Pro
355 360 365
Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asp
370 375 380
Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe
385 390 395 400
Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Ser Tyr Glu
405 410 415
Phe Glu Asn Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu
420 425 430
Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser
435 440 445
Lys Thr Ile Asn Gly Ser Gly Gln Asn Gln Gln Thr Leu Lys Phe Ser
450 455 460
Val Ala Gly Pro Ser Asn Met Ala Val Gln Gly Arg Asn Tyr Ile Pro
465 470 475 480
Gly Pro Ser Tyr Arg Gln Gln Arg Val Ser Thr Thr Val Thr Gln Asn
485 490 495
Asn Asn Ser Glu Phe Ala Trp Pro Gly Ala Ser Ser Trp Ala Leu Asn
500 505 510
Gly Arg Asn Ser Leu Met Asn Pro Gly Pro Ala Met Ala Ser His Lys
515 520 525
Glu Gly Glu Asp Arg Phe Phe Pro Leu Ser Gly Ser Leu Ile Phe Gly
530 535 540
Lys Gln Gly Thr Gly Arg Asp Asn Val Asp Ala Asp Lys Val Met Ile
545 550 555 560
Thr Asn Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr Glu Ser
565 570 575
Tyr Gly Gln Val Ala Thr Asn His Gln Ser Ala Gln Ala Gln Ala Gln
580 585 590
Thr Gly Trp Val Gln Asn Gln Gly Ile Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Met
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asp Pro Pro Thr Ala Phe Asn Lys Asp Lys Leu Asn Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn
690 695 700
Tyr Tyr Lys Ser Asn Asn Val Glu Phe Ala Val Asn Thr Glu Gly Val
705 710 715 720
Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 3
<211> 952
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<220>
<221> MISC_FEATURE
<222> (1)..(27)
<223> Signal peptide
<220>
<221> MISC_FEATURE
<222> (70)..(952)
<220>
<221> MISC_FEATURE
<222> (123)..(952)
<223> 76kD GAA Protein with V780I
<220>
<221> MISC_FEATURE
<222> (204)..(952)
<223> 70 kD GAA Protein with V780I
<400> 3
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu Gly His Ile Leu Leu
20 25 30
His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val
35 40 45
Leu Glu Glu Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly
50 55 60
Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr
65 70 75 80
Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys
85 90 95
Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro
100 105 110
Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe
115 120 125
Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser
130 135 140
Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe
145 150 155 160
Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu
165 170 175
Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu
180 185 190
Val Pro Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu
195 200 205
Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg
210 215 220
Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe
225 230 235 240
Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr
245 250 255
Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser
260 265 270
Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly
275 280 285
Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly
290 295 300
Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val
305 310 315 320
Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile
325 330 335
Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln
340 345 350
Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly
355 360 365
Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr
370 375 380
Arg Gln Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val
385 390 395 400
Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe
405 410 415
Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His
420 425 430
Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser
435 440 445
Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg
450 455 460
Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val
465 470 475 480
Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu
485 490 495
Ala Trp Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe
500 505 510
Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly
515 520 525
Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val
530 535 540
Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser
545 550 555 560
Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly
565 570 575
Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly
580 585 590
Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg
595 600 605
Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu
610 615 620
Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro
625 630 635 640
Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu
645 650 655
Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg
660 665 670
Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser
675 680 685
Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala
690 695 700
Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly
705 710 715 720
Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser
725 730 735
Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile
740 745 750
Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro
755 760 765
Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly
770 775 780
Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser
785 790 795 800
Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val
805 810 815
His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr
820 825 830
Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr
835 840 845
Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser
850 855 860
Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala
865 870 875 880
Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly
885 890 895
Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala
900 905 910
Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr
915 920 925
Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly
930 935 940
Glu Gln Phe Leu Val Ser Trp Cys
945 950
<210> 4
<211> 2856
<212> DNA
<213> Artificial sequence
<220>
<223> Engineered hGAAI Coding sequence
<400> 4
atgggcgtta gacaccctcc ttgctctcac agactgctgg ccgtgtgtgc tctggtgtct 60
ctggctacag ctgccctgct gggacatatc ctgctgcacg actttctgct ggtgcccaga 120
gagctgtctg gcagctctcc tgtgctggaa gagacacacc ctgcacatca gcagggcgcc 180
tctagacctg gacctagaga cgctcaggcc catcctggca gacctagagc tgtgcccaca 240
cagtgtgacg tgccacctaa cagcagattc gactgcgccc ctgacaaggc catcacacaa 300
gagcagtgtg aagccagagg ctgctgctac atccctgcca aacaaggact gcagggcgct 360
cagatgggac agccctggtg cttcttccca ccatcttacc ccagctacaa gctggaaaac 420
ctgagcagca gcgagatggg ctacaccgcc acactgacca gaaccacacc tacattcttc 480
ccgaaggaca tcctgacact gcggctggac gtgatgatgg aaaccgagaa ccggctgcac 540
ttcaccatca aggaccccgc caatcggaga tacgaggtgc cactggaaac ccctcacgtg 600
cactctagag ccccatctcc actgtacagc gtggaatttt ccgaggaacc cttcggcgtg 660
atcgtgcgga gacagctgga tggaagagtg ctgctgaaca ccacagtggc ccctctgttc 720
ttcgccgacc agtttctgca gctgagcacc agcctgccta gccagtatat cacaggcctg 780
gccgagcacc tgtctccact gatgctgagc acatcctgga ccagaatcac cctgtggaac 840
agagatctgg cccctacacc tggcgccaac ctgtacggct ctcacccctt ttatctggcc 900
ctggaagacg gcggatctgc ccacggtgtt tttctgctga actccaacgc catggacgtg 960
gtgctgcagc catctcctgc tctgtcttgg agaagcacag gcggcatcct ggacgtgtac 1020
atctttctgg gccccgagcc taagagcgtg gtgcagcagt atctggacgt cgtgggctac 1080
cccttcatgc ctccttattg gggcctgggc ttccacctgt gcaggtgggg atacagcagc 1140
accgccatca ccagacaggt ggtggaaaac atgacccggg ctcacttccc actggacgtg 1200
cagtggaacg acctggacta catggacagc agacgggact tcaccttcaa caaggacggc 1260
ttcagagact tccccgccat ggtgcaagaa ctgcaccaag gcggcagacg gtacatgatg 1320
attgtggacc cagccatcag ctctagcggc cctgccggaa gctacagacc ttacgatgag 1380
ggcctgagaa gaggcgtgtt catcaccaac gagacaggcc agcctctgat cggcaaagtg 1440
tggcctggca gcacagcctt tccagacttc acaaacccca ccgctctggc ttggtgggaa 1500
gatatggtgg ccgagttcca cgatcaggtg cccttcgatg gcatgtggat cgacatgaac 1560
gagcccagca acttcatccg gggcagcgag gacggctgcc ccaacaacga actggaaaat 1620
cctccttacg tgcccggcgt tgtcggcgga acacttcagg ccgctacaat ctgtgccagc 1680
agccaccagt tcctcagcac ccactacaac ctgcacaacc tgtacggcct gaccgaggcc 1740
attgcctctc atagagccct ggttaaggcc agaggcaccc ggccttttgt gatcagcaga 1800
agcacattcg ccggccacgg cagatacgcc ggacattgga caggcgacgt gtggtctagt 1860
tgggagcagc tggctagcag cgtgccagag atcctgcagt tcaatctgct gggcgtgcca 1920
ctcgtgggag ccgacgtttg tggcttcctg ggcaacacca gcgaggaact gtgtgtgcgt 1980
tggacacagc tgggcgcctt ctatcccttc atgagaaacc acaacagcct gctgagcctg 2040
cctcaagagc cctacagctt tagcgagcct gcacagcagg ccatgagaaa ggccctgact 2100
ctgagatacg ctctgctgcc ccacctgtac accctgtttc accaggctca cgtggccggg 2160
gagacagtgg ctagacctct gttcctggaa tttcccaagg acagctccac ctggaccgtg 2220
gatcatcagc tgctgtgggg agaagccctg ctcatcacac ctgttctgca ggccggaaag 2280
gccgaagtga ccggctattt tcctctcggc acttggtacg acctgcagac cgtgcctatt 2340
gaggccctgg gatctcttcc tccacctcct gctgctccta gagagcctgc catccactct 2400
gaaggccagt gggttacact gcccgctcct ctggacacca tcaacgtgca cctgagagct 2460
ggctacatca tcccactgca aggccctggc ctgaccacaa ccgaatctag acagcagccc 2520
atggctctgg ccgtggctct tacaaaaggc ggagaggcta gaggcgagct gttctgggac 2580
gacggcgagt ctctggaagt gctggaacgg ggcgcttata cccaagtgat cttcctggcc 2640
agaaacaaca ccatcgtgaa cgaactcgtg cgcgtgacca gtgaaggtgc tggactgcaa 2700
ctgcagaaag tgaccgtgct cggagtggcc acagctcctc aacaggtgct gtctaacggc 2760
gtgcccgtgt ccaacttcac atacagcccc gacaccaagg tcctggacat ctgtgtgtca 2820
ctgctgatgg gcgagcagtt cctggtgtcc tggtgc 2856
<210> 5
<211> 2859
<212> DNA
<213> Homo sapiens
<400> 5
atgggagtga ggcacccgcc ctgctcccac cggctcctgg ccgtctgcgc cctcgtgtcc 60
ttggcaaccg ctgcactcct ggggcacatc ctactccatg atttcctgct ggttccccga 120
gagctgagtg gctcctcccc agtcctggag gagactcacc cagctcacca gcagggagcc 180
agtagaccag ggccccggga tgcccaggca caccccggcc gtcccagagc agtgcccaca 240
cagtgcgacg tcccccccaa cagccgcttc gattgcgccc ctgacaaggc catcacccag 300
gaacagtgcg aggcccgcgg ctgttgctac atccctgcaa agcaggggct gcagggagcc 360
cagatggggc agccctggtg cttcttccca cccagctacc ccagctacaa gctggagaac 420
ctgagctcct ctgaaatggg ctacacggcc accctgaccc gtaccacccc caccttcttc 480
cccaaggaca tcctgaccct gcggctggac gtgatgatgg agactgagaa ccgcctccac 540
ttcacgatca aagatccagc taacaggcgc tacgaggtgc ccttggagac cccgcatgtc 600
cacagccggg caccgtcccc actctacagc gtggagttct ccgaggagcc cttcggggtg 660
atcgtgcgcc ggcagctgga cggccgcgtg ctgctgaaca cgacggtggc gcccctgttc 720
tttgcggacc agttccttca gctgtccacc tcgctgccct cgcagtatat cacaggcctc 780
gccgagcacc tcagtcccct gatgctcagc accagctgga ccaggatcac cctgtggaac 840
cgggaccttg cgcccacgcc cggtgcgaac ctctacgggt ctcacccttt ctacctggcg 900
ctggaggacg gcgggtcggc acacggggtg ttcctgctaa acagcaatgc catggatgtg 960
gtcctgcagc cgagccctgc ccttagctgg aggtcgacag gtgggatcct ggatgtctac 1020
atcttcctgg gcccagagcc caagagcgtg gtgcagcagt acctggacgt tgtgggatac 1080
ccgttcatgc cgccatactg gggcctgggc ttccacctgt gccgctgggg ctactcctcc 1140
accgctatca cccgccaggt ggtggagaac atgaccaggg cccacttccc cctggacgtc 1200
cagtggaacg acctggacta catggactcc cggagggact tcacgttcaa caaggatggc 1260
ttccgggact tcccggccat ggtgcaggag ctgcaccagg gcggccggcg ctacatgatg 1320
atcgtggatc ctgccatcag cagctcgggc cctgccggga gctacaggcc ctacgacgag 1380
ggtctgcgga ggggggtttt catcaccaac gagaccggcc agccgctgat tgggaaggta 1440
tggcccgggt ccactgcctt ccccgacttc accaacccca cagccctggc ctggtgggag 1500
gacatggtgg ctgagttcca tgaccaggtg cccttcgacg gcatgtggat tgacatgaac 1560
gagccttcca acttcatcag gggctctgag gacggctgcc ccaacaatga gctggagaac 1620
ccaccctacg tgcctggggt ggttgggggg accctccagg cggccaccat ctgtgcctcc 1680
agccaccagt ttctctccac acactacaac ctgcacaacc tctacggcct gaccgaagcc 1740
atcgcctccc acagggcgct ggtgaaggct cgggggacac gcccatttgt gatctcccgc 1800
tcgacctttg ctggccacgg ccgatacgcc ggccactgga cgggggacgt gtggagctcc 1860
tgggagcagc tcgcctcctc cgtgccagaa atcctgcagt ttaacctgct gggggtgcct 1920
ctggtcgggg ccgacgtctg cggcttcctg ggcaacacct cagaggagct gtgtgtgcgc 1980
tggacccagc tgggggcctt ctaccccttc atgcggaacc acaacagcct gctcagtctg 2040
ccccaggagc cgtacagctt cagcgagccg gcccagcagg ccatgaggaa ggccctcacc 2100
ctgcgctacg cactcctccc ccacctctac acactgttcc accaggccca cgtcgcgggg 2160
gagaccgtgg cccggcccct cttcctggag ttccccaagg actctagcac ctggactgtg 2220
gaccaccagc tcctgtgggg ggaggccctg ctcatcaccc cagtgctcca ggccgggaag 2280
gccgaagtga ctggctactt ccccttgggc acatggtacg acctgcagac ggtgccaata 2340
gaggcccttg gcagcctccc acccccacct gcagctcccc gtgagccagc catccacagc 2400
gaggggcagt gggtgacgct gccggccccc ctggacacca tcaacgtcca cctccgggct 2460
gggtacatca tccccctgca gggccctggc ctcacaacca cagagtcccg ccagcagccc 2520
atggccctgg ctgtggccct gaccaagggt ggggaggccc gaggggagct tttctgggac 2580
gatggagaga gcctggaagt gctggagcga ggggcctaca cacaggtcat cttcctggcc 2640
aggaataaca cgatcgtgaa tgagctggta cgtgtgacca gtgagggagc tggcctgcag 2700
ctgcagaagg tgactgtcct gggcgtggcc acggcgcccc agcaggtcct ctccaacggt 2760
gtccctgtct ccaacttcac ctacagcccc gacaccaagg tcctggacat ctgtgtctcg 2820
ctgttgatgg gagagcagtt tctcgtcagc tggtgttag 2859
<210> 6
<211> 982
<212> PRT
<213> Artificial sequence
<220>
<223> Fusion Protein comprising hGAA780I
<400> 6
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
Phe Leu Val Ser Trp Cys
980
<210> 7
<211> 2952
<212> DNA
<213> Artificial sequence
<220>
<223> Engineered sequence encoding fusion protein comprising GAAV780I
<220>
<221> misc_feature
<222> (810)..(810)
<223> V810I
<400> 7
atgaagctgt ctctggtggc tgctatgctg ctgctcctgt ctgccgccag agccagcaga 60
acactttgtg gcggagagct ggtggacacc ctgcagtttg tgtgtggcga cagaggcttc 120
ctgttcagca gacctgccag ccgggtttcc agacggtcta gaggaatcgt ggaagagtgc 180
tgcttcagaa gctgcgatct ggccctgctg gaaacctact gtgccacacc agccagatct 240
gaaggcggcg gaggatctgg cggaggcgga tctagacctg gacctagaga cgcccaggct 300
caccctggta gacctagagc tgtgcctaca cagtgcgacg tgccacctaa cagcagattc 360
gactgcgccc ctgacaaggc catcacacaa gagcagtgtg aagccagagg ctgctgctac 420
atccctgcca aacaaggact gcagggcgcc cagatgggac agccttggtg cttcttccca 480
ccatcttacc ccagctacaa gctggaaaac ctgagcagct ccgagatggg ctacaccgcc 540
acactgacca gaaccacacc tacattcttc ccgaaggaca tcctgacact gcggctggac 600
gtgatgatgg aaaccgagaa ccggctgcac ttcaccatca aggaccccgc caatcggaga 660
tacgaggtgc ccctggaaac accccacgtg cactctagag caccctctcc actgtacagc 720
gtggaatttt ccgaggaacc cttcggcgtg atcgtgcgga gacagctgga tggcagagtg 780
ctcctgaata ccacagtggc ccctctgttc ttcgccgacc agtttctgca gctgagcacc 840
agcctgccta gccagtatat cacaggcctg gccgagcatc tgagccctct gatgctgagc 900
acatcctgga ccagaatcac cctgtggaac cgcgacctgg ctcctacacc tggcgccaat 960
ctgtacggct ctcacccctt ctacctggca ctggaagacg gtggatctgc ccacggtgtc 1020
tttctgctga atagcaacgc catggacgtg gtgctgcagc cctctcctgc actgtcttgg 1080
agatctacag gcggcatcct ggacgtgtac atctttctgg gccccgagcc taagagcgtg 1140
gtgcagcagt atctggacgt cgtgggctac cccttcatgc ctccttattg gggcctgggc 1200
ttccacctgt gtaggtgggg ctacagcagc accgccatca ccagacaggt ggtggaaaac 1260
atgacccggg ctcacttccc actggacgtg cagtggaacg acctggacta catggacagc 1320
agacgggact tcaccttcaa caaggacggc ttcagagact tccccgccat ggtgcaagag 1380
ctgcatcaag gcggacggcg gtacatgatg attgtggacc ctgccatcag cagctctgga 1440
ccagccggca gctacagacc ttacgatgag ggactgagaa gaggcgtgtt catcaccaac 1500
gagacaggcc agcctctgat cggcaaagtg tggcctggca gcacagcctt tccagacttc 1560
acaaacccca ccgctctggc ttggtgggaa gatatggtgg ccgagttcca cgatcaggtg 1620
cccttcgatg gcatgtggat cgacatgaac gagcccagca acttcatccg gggcagcgag 1680
gatggctgcc ccaacaacga actagaaaat cctccttacg tgcccggcgt tgtcggcgga 1740
acacttcagg ccgctacaat ctgtgccagc agccatcagt ttctgagcac ccactacaac 1800
ctgcacaacc tgtacggcct gaccgaggcc attgcctctc atagagccct ggttaaggcc 1860
agaggcaccc ggccttttgt gatcagcaga agcacattcg ccggccacgg cagatacgca 1920
ggacattgga caggcgacgt gtggtctagt tgggagcagc tggctagcag cgtgccagag 1980
atcctgcagt tcaatctgct gggcgtgcca ctcgtgggag ccgacgtttg tggcttcctg 2040
ggcaacacca gcgaggaact gtgtgtgcgt tggacacagc tgggcgcctt ctatcccttc 2100
atgagaaacc acaacagcct gctgagcctg cctcaagagc cctacagctt tagcgagcct 2160
gcacagcagg ccatgagaaa ggccctgact ctgagatacg ccctgctgcc tcacctgtac 2220
accctgtttc atcaggccca cgtggcaggc gagacagtgg ctagacctct gttcctggaa 2280
tttcccaagg acagctccac ctggaccgtg gatcatcagc tgctgtgggg agaagccctg 2340
ctgattacac cagtgctgca ggccggaaag gccgaagtga caggctattt ccctctcggc 2400
acttggtacg acctgcagac cgtgcctatc gaggctctgg gatctcttcc tccacctcct 2460
gccgctccta gagagcctgc cattcactct gaaggccagt gggttaccct gcctgctcct 2520
ctggacacca tcaacgtgca cctgagagcc ggctacatca tccctctgca aggccctggc 2580
ctgaccacaa ccgaatctag acagcagccc atggcactgg ccgtggctct tacaaaaggc 2640
ggagaggcta gaggcgagct gttctgggat gatggcgaga gcctagaagt gctggaacgg 2700
ggcgcttata cccaagtgat cttcctggcc agaaacaaca ccatcgtgaa cgaactcgtg 2760
cgcgtgacca gtgaaggtgc tggactgcaa ctgcagaaag tgaccgtgct cggagtggcc 2820
acagctcctc agcaggttct gtctaatggc gtgcccgtgt ccaacttcac atacagcccc 2880
gacaccaagg tcctggacat ctgtgtgtcc ctgcttatgg gcgagcagtt cctggtgtcc 2940
tggtgctgat aa 2952
<210> 8
<211> 934
<212> DNA
<213> Artificial sequence
<220>
<223> CAG promoter
<220>
<221> misc_feature
<222> (1)..(243)
<223> CMV early enhancer element
<220>
<221> misc_feature
<222> (244)..(525)
<223> Chicken Beta actin promoter
<220>
<221> misc_feature
<222> (526)..(934)
<223> hybrid intron in CAG (b-actin intron and rabbit beta 1-globin
<220>
<221> misc_feature
<222> (526)..(934)
<223> hybrid intron
<400> 8
attgacgtca ataatgacgt atgttcccat agtaacgcca atagggactt tccattgacg 60
tcaatgggtg gagtatttac ggtaaactgc ccacttggca gtacatcaag tgtatcatat 120
gccaagtacg ccccctattg acgtcaatga cggtaaatgg cccgcctggc attatgccca 180
gtacatgacc ttatgggact ttcctacttg gcagtacatc tacgtattag tcatcgctat 240
taccatggtc gaggtgagcc ccacgttctg cttcactctc cccatctccc ccccctcccc 300
acccccaatt ttgtatttat ttatttttta attattttgt gcagcgatgg gggcgggggg 360
gggggggggg cgcgcgccag gcggggcggg gcggggcgag gggcggggcg gggcgaggcg 420
gagaggtgcg gcggcagcca atcagagcgg cgcgctccga aagtttcctt ttatggcgag 480
gcggcggcgg cggcggccct ataaaaagcg aagcgcgcgg cgggcgggag tcgctgcgcg 540
ctgccttcgc cccgtgcccc gctccgccgc cgcctcgcgc cgcccgcccc ggctctgact 600
gaccgcgtta ctcccacagg tgagcgggcg ggacggccct tctcctccgg gctgtaatta 660
gcgcttggtt taatgacggc ttgtttcttt tctgtggctg cgtgaaagcc ttgaggggct 720
ccgggagggc cctttgtgcg gggggagcgg ctcggggctg tccgcggggg gacggctgcc 780
ttcggggggg acggggcagg gcggggttcg gcttctggcg tgtgaccggc ggctctagag 840
cctctgctaa ccatgttcat gccttcttct ttttcctaca gctcctgggc aacgtgctgg 900
ttattgtgct gtctcatcat tttggcaaag aatt 934
<210> 9
<211> 127
<212> DNA
<213> Artificial sequence
<220>
<223> Rabbit globin polyA
<400> 9
gatctttttc cctctgccaa aaattatggg gacatcatga agccccttga gcatctgact 60
tctggctaat aaaggaaatt tattttcatt gcaatagtgt gttggaattt tttgtgtctc 120
tcactcg 127
<210> 10
<211> 188
<212> DNA
<213> adeno-associated virus 2
<400> 10
gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc gggcgacctt 60
tggtcgcccg gcctcagtga gcgagcgagc gcgcagagag ggagtggcca actccatcac 120
taggggttcc ttgtagttaa tgattaaccc gccatgctac ttatctacgt agccatgctc 180
taggaaga 188
<210> 11
<211> 188
<212> DNA
<213> adeno-associated virus 2
<400> 11
tcttcctaga gcatggctac gtagataagt agcatggcgg gttaatcatt aactacaagg 60
aacccctagt gatggagttg gccactccct ctctgcgcgc tcgctcgctc actgaggccg 120
ggcgaccaaa ggtcgcccga cgcccgggct ttgcccgggc ggcctcagtg agcgagcgag 180
cgcgcagc 188
<210> 12
<211> 81
<212> DNA
<213> Artificial sequence
<220>
<223> Engineered hGAAV780I signal peptide
<220>
<221> sig_peptide
<222> (1)..(81)
<220>
<221> CDS
<222> (1)..(81)
<400> 12
atg ggc gtt aga cac cct cct tgc tct cac aga ctg ctg gcc gtg tgt 48
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
gct ctg gtg tct ctg gct aca gct gcc ctg ctg 81
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu
20 25
<210> 13
<211> 27
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic Construct
<400> 13
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu
20 25
<210> 14
<211> 2649
<212> DNA
<213> Artificial Sequence
<220>
<223> engineered hGAAV780I mature protein
<220>
<221> CDS
<222> (1)..(2649)
<400> 14
gcc cat cct ggc aga cct aga gct gtg ccc aca cag tgt gac gtg cca 48
Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys Asp Val Pro
1 5 10 15
cct aac agc aga ttc gac tgc gcc cct gac aag gcc atc aca caa gag 96
Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu
20 25 30
cag tgt gaa gcc aga ggc tgc tgc tac atc cct gcc aaa caa gga ctg 144
Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu
35 40 45
cag ggc gct cag atg gga cag ccc tgg tgc ttc ttc cca cca tct tac 192
Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr
50 55 60
ccc agc tac aag ctg gaa aac ctg agc agc agc gag atg ggc tac acc 240
Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr
65 70 75 80
gcc aca ctg acc aga acc aca cct aca ttc ttc ccg aag gac atc ctg 288
Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu
85 90 95
aca ctg cgg ctg gac gtg atg atg gaa acc gag aac cgg ctg cac ttc 336
Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg Leu His Phe
100 105 110
acc atc aag gac ccc gcc aat cgg aga tac gag gtg cca ctg gaa acc 384
Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr
115 120 125
cct cac gtg cac tct aga gcc cca tct cca ctg tac agc gtg gaa ttt 432
Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe
130 135 140
tcc gag gaa ccc ttc ggc gtg atc gtg cgg aga cag ctg gat gga aga 480
Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg
145 150 155 160
gtg ctg ctg aac acc aca gtg gcc cct ctg ttc ttc gcc gac cag ttt 528
Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe
165 170 175
ctg cag ctg agc acc agc ctg cct agc cag tat atc aca ggc ctg gcc 576
Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala
180 185 190
gag cac ctg tct cca ctg atg ctg agc aca tcc tgg acc aga atc acc 624
Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr
195 200 205
ctg tgg aac aga gat ctg gcc cct aca cct ggc gcc aac ctg tac ggc 672
Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly
210 215 220
tct cac ccc ttt tat ctg gcc ctg gaa gac ggc gga tct gcc cac ggt 720
Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly
225 230 235 240
gtt ttt ctg ctg aac tcc aac gcc atg gac gtg gtg ctg cag cca tct 768
Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser
245 250 255
cct gct ctg tct tgg aga agc aca ggc ggc atc ctg gac gtg tac atc 816
Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile
260 265 270
ttt ctg ggc ccc gag cct aag agc gtg gtg cag cag tat ctg gac gtc 864
Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val
275 280 285
gtg ggc tac ccc ttc atg cct cct tat tgg ggc ctg ggc ttc cac ctg 912
Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu
290 295 300
tgc agg tgg gga tac agc agc acc gcc atc acc aga cag gtg gtg gaa 960
Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu
305 310 315 320
aac atg acc cgg gct cac ttc cca ctg gac gtg cag tgg aac gac ctg 1008
Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu
325 330 335
gac tac atg gac agc aga cgg gac ttc acc ttc aac aag gac ggc ttc 1056
Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe
340 345 350
aga gac ttc ccc gcc atg gtg caa gaa ctg cac caa ggc ggc aga cgg 1104
Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly Gly Arg Arg
355 360 365
tac atg atg att gtg gac cca gcc atc agc tct agc ggc cct gcc gga 1152
Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly
370 375 380
agc tac aga cct tac gat gag ggc ctg aga aga ggc gtg ttc atc acc 1200
Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr
385 390 395 400
aac gag aca ggc cag cct ctg atc ggc aaa gtg tgg cct ggc agc aca 1248
Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr
405 410 415
gcc ttt cca gac ttc aca aac ccc acc gct ctg gct tgg tgg gaa gat 1296
Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp
420 425 430
atg gtg gcc gag ttc cac gat cag gtg ccc ttc gat ggc atg tgg atc 1344
Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly Met Trp Ile
435 440 445
gac atg aac gag ccc agc aac ttc atc cgg ggc agc gag gac ggc tgc 1392
Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys
450 455 460
ccc aac aac gaa ctg gaa aat cct cct tac gtg ccc ggc gtt gtc ggc 1440
Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly
465 470 475 480
gga aca ctt cag gcc gct aca atc tgt gcc agc agc cac cag ttc ctc 1488
Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu
485 490 495
agc acc cac tac aac ctg cac aac ctg tac ggc ctg acc gag gcc att 1536
Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile
500 505 510
gcc tct cat aga gcc ctg gtt aag gcc aga ggc acc cgg cct ttt gtg 1584
Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val
515 520 525
atc agc aga agc aca ttc gcc ggc cac ggc aga tac gcc gga cat tgg 1632
Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp
530 535 540
aca ggc gac gtg tgg tct agt tgg gag cag ctg gct agc agc gtg cca 1680
Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro
545 550 555 560
gag atc ctg cag ttc aat ctg ctg ggc gtg cca ctc gtg gga gcc gac 1728
Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp
565 570 575
gtt tgt ggc ttc ctg ggc aac acc agc gag gaa ctg tgt gtg cgt tgg 1776
Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp
580 585 590
aca cag ctg ggc gcc ttc tat ccc ttc atg aga aac cac aac agc ctg 1824
Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu
595 600 605
ctg agc ctg cct caa gag ccc tac agc ttt agc gag cct gca cag cag 1872
Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln
610 615 620
gcc atg aga aag gcc ctg act ctg aga tac gct ctg ctg ccc cac ctg 1920
Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu
625 630 635 640
tac acc ctg ttt cac cag gct cac gtg gcc ggg gag aca gtg gct aga 1968
Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr Val Ala Arg
645 650 655
cct ctg ttc ctg gaa ttt ccc aag gac agc tcc acc tgg acc gtg gat 2016
Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp
660 665 670
cat cag ctg ctg tgg gga gaa gcc ctg ctc atc aca cct gtt ctg cag 2064
His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln
675 680 685
gcc gga aag gcc gaa gtg acc ggc tat ttt cct ctc ggc act tgg tac 2112
Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr
690 695 700
gac ctg cag acc gtg cct att gag gcc ctg gga tct ctt cct cca cct 2160
Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro
705 710 715 720
cct gct gct cct aga gag cct gcc atc cac tct gaa ggc cag tgg gtt 2208
Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val
725 730 735
aca ctg ccc gct cct ctg gac acc atc aac gtg cac ctg aga gct ggc 2256
Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly
740 745 750
tac atc atc cca ctg caa ggc cct ggc ctg acc aca acc gaa tct aga 2304
Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg
755 760 765
cag cag ccc atg gct ctg gcc gtg gct ctt aca aaa ggc gga gag gct 2352
Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala
770 775 780
aga ggc gag ctg ttc tgg gac gac ggc gag tct ctg gaa gtg ctg gaa 2400
Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu
785 790 795 800
cgg ggc gct tat acc caa gtg atc ttc ctg gcc aga aac aac acc atc 2448
Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile
805 810 815
gtg aac gaa ctc gtg cgc gtg acc agt gaa ggt gct gga ctg caa ctg 2496
Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu
820 825 830
cag aaa gtg acc gtg ctc gga gtg gcc aca gct cct caa cag gtg ctg 2544
Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu
835 840 845
tct aac ggc gtg ccc gtg tcc aac ttc aca tac agc ccc gac acc aag 2592
Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys
850 855 860
gtc ctg gac atc tgt gtg tca ctg ctg atg ggc gag cag ttc ctg gtg 2640
Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val
865 870 875 880
tcc tgg tgc 2649
Ser Trp Cys
<210> 15
<211> 883
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 15
Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys Asp Val Pro
1 5 10 15
Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu
20 25 30
Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu
35 40 45
Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr
50 55 60
Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr
65 70 75 80
Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu
85 90 95
Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg Leu His Phe
100 105 110
Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr
115 120 125
Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe
130 135 140
Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg
145 150 155 160
Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe
165 170 175
Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala
180 185 190
Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr
195 200 205
Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly
210 215 220
Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly
225 230 235 240
Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser
245 250 255
Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile
260 265 270
Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val
275 280 285
Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu
290 295 300
Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu
305 310 315 320
Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu
325 330 335
Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe
340 345 350
Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly Gly Arg Arg
355 360 365
Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly
370 375 380
Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr
385 390 395 400
Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr
405 410 415
Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp
420 425 430
Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly Met Trp Ile
435 440 445
Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys
450 455 460
Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly
465 470 475 480
Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu
485 490 495
Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile
500 505 510
Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val
515 520 525
Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp
530 535 540
Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro
545 550 555 560
Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp
565 570 575
Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp
580 585 590
Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu
595 600 605
Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln
610 615 620
Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu
625 630 635 640
Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr Val Ala Arg
645 650 655
Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp
660 665 670
His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln
675 680 685
Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr
690 695 700
Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro
705 710 715 720
Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val
725 730 735
Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly
740 745 750
Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg
755 760 765
Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala
770 775 780
Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu
785 790 795 800
Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile
805 810 815
Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu
820 825 830
Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu
835 840 845
Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys
850 855 860
Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val
865 870 875 880
Ser Trp Cys
<210> 16
<211> 2304
<212> DNA
<213> Artificial sequence
<220>
<223> Engineered DNA for hGAA780I 123-890
<220>
<221> CDS
<222> (1)..(2304)
<400> 16
gga cag ccc tgg tgc ttc ttc cca cca tct tac ccc agc tac aag ctg 48
Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu
1 5 10 15
gaa aac ctg agc agc agc gag atg ggc tac acc gcc aca ctg acc aga 96
Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg
20 25 30
acc aca cct aca ttc ttc ccg aag gac atc ctg aca ctg cgg ctg gac 144
Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp
35 40 45
gtg atg atg gaa acc gag aac cgg ctg cac ttc acc atc aag gac ccc 192
Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro
50 55 60
gcc aat cgg aga tac gag gtg cca ctg gaa acc cct cac gtg cac tct 240
Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val His Ser
65 70 75 80
aga gcc cca tct cca ctg tac agc gtg gaa ttt tcc gag gaa ccc ttc 288
Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe
85 90 95
ggc gtg atc gtg cgg aga cag ctg gat gga aga gtg ctg ctg aac acc 336
Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr
100 105 110
aca gtg gcc cct ctg ttc ttc gcc gac cag ttt ctg cag ctg agc acc 384
Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr
115 120 125
agc ctg cct agc cag tat atc aca ggc ctg gcc gag cac ctg tct cca 432
Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro
130 135 140
ctg atg ctg agc aca tcc tgg acc aga atc acc ctg tgg aac aga gat 480
Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp
145 150 155 160
ctg gcc cct aca cct ggc gcc aac ctg tac ggc tct cac ccc ttt tat 528
Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr
165 170 175
ctg gcc ctg gaa gac ggc gga tct gcc cac ggt gtt ttt ctg ctg aac 576
Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn
180 185 190
tcc aac gcc atg gac gtg gtg ctg cag cca tct cct gct ctg tct tgg 624
Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp
195 200 205
aga agc aca ggc ggc atc ctg gac gtg tac atc ttt ctg ggc ccc gag 672
Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu
210 215 220
cct aag agc gtg gtg cag cag tat ctg gac gtc gtg ggc tac ccc ttc 720
Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe
225 230 235 240
atg cct cct tat tgg ggc ctg ggc ttc cac ctg tgc agg tgg gga tac 768
Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr
245 250 255
agc agc acc gcc atc acc aga cag gtg gtg gaa aac atg acc cgg gct 816
Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala
260 265 270
cac ttc cca ctg gac gtg cag tgg aac gac ctg gac tac atg gac agc 864
His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser
275 280 285
aga cgg gac ttc acc ttc aac aag gac ggc ttc aga gac ttc ccc gcc 912
Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala
290 295 300
atg gtg caa gaa ctg cac caa ggc ggc aga cgg tac atg atg att gtg 960
Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val
305 310 315 320
gac cca gcc atc agc tct agc ggc cct gcc gga agc tac aga cct tac 1008
Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr
325 330 335
gat gag ggc ctg aga aga ggc gtg ttc atc acc aac gag aca ggc cag 1056
Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln
340 345 350
cct ctg atc ggc aaa gtg tgg cct ggc agc aca gcc ttt cca gac ttc 1104
Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe
355 360 365
aca aac ccc acc gct ctg gct tgg tgg gaa gat atg gtg gcc gag ttc 1152
Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe
370 375 380
cac gat cag gtg ccc ttc gat ggc atg tgg atc gac atg aac gag ccc 1200
His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro
385 390 395 400
agc aac ttc atc cgg ggc agc gag gac ggc tgc ccc aac aac gaa ctg 1248
Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu
405 410 415
gaa aat cct cct tac gtg ccc ggc gtt gtc ggc gga aca ctt cag gcc 1296
Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala
420 425 430
gct aca atc tgt gcc agc agc cac cag ttc ctc agc acc cac tac aac 1344
Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn
435 440 445
ctg cac aac ctg tac ggc ctg acc gag gcc att gcc tct cat aga gcc 1392
Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala
450 455 460
ctg gtt aag gcc aga ggc acc cgg cct ttt gtg atc agc aga agc aca 1440
Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr
465 470 475 480
ttc gcc ggc cac ggc aga tac gcc gga cat tgg aca ggc gac gtg tgg 1488
Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp
485 490 495
tct agt tgg gag cag ctg gct agc agc gtg cca gag atc ctg cag ttc 1536
Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe
500 505 510
aat ctg ctg ggc gtg cca ctc gtg gga gcc gac gtt tgt ggc ttc ctg 1584
Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu
515 520 525
ggc aac acc agc gag gaa ctg tgt gtg cgt tgg aca cag ctg ggc gcc 1632
Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala
530 535 540
ttc tat ccc ttc atg aga aac cac aac agc ctg ctg agc ctg cct caa 1680
Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln
545 550 555 560
gag ccc tac agc ttt agc gag cct gca cag cag gcc atg aga aag gcc 1728
Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala
565 570 575
ctg act ctg aga tac gct ctg ctg ccc cac ctg tac acc ctg ttt cac 1776
Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His
580 585 590
cag gct cac gtg gcc ggg gag aca gtg gct aga cct ctg ttc ctg gaa 1824
Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu
595 600 605
ttt ccc aag gac agc tcc acc tgg acc gtg gat cat cag ctg ctg tgg 1872
Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp
610 615 620
gga gaa gcc ctg ctc atc aca cct gtt ctg cag gcc gga aag gcc gaa 1920
Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu
625 630 635 640
gtg acc ggc tat ttt cct ctc ggc act tgg tac gac ctg cag acc gtg 1968
Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val
645 650 655
cct att gag gcc ctg gga tct ctt cct cca cct cct gct gct cct aga 2016
Pro Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg
660 665 670
gag cct gcc atc cac tct gaa ggc cag tgg gtt aca ctg ccc gct cct 2064
Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro
675 680 685
ctg gac acc atc aac gtg cac ctg aga gct ggc tac atc atc cca ctg 2112
Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu
690 695 700
caa ggc cct ggc ctg acc aca acc gaa tct aga cag cag ccc atg gct 2160
Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala
705 710 715 720
ctg gcc gtg gct ctt aca aaa ggc gga gag gct aga ggc gag ctg ttc 2208
Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe
725 730 735
tgg gac gac ggc gag tct ctg gaa gtg ctg gaa cgg ggc gct tat acc 2256
Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr
740 745 750
caa gtg atc ttc ctg gcc aga aac aac acc atc gtg aac gaa ctc gtg 2304
Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val
755 760 765
<210> 17
<211> 768
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic Construct
<400> 17
Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu
1 5 10 15
Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg
20 25 30
Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp
35 40 45
Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro
50 55 60
Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val His Ser
65 70 75 80
Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe
85 90 95
Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr
100 105 110
Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr
115 120 125
Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro
130 135 140
Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp
145 150 155 160
Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr
165 170 175
Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn
180 185 190
Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp
195 200 205
Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu
210 215 220
Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe
225 230 235 240
Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr
245 250 255
Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala
260 265 270
His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser
275 280 285
Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala
290 295 300
Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val
305 310 315 320
Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr
325 330 335
Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln
340 345 350
Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe
355 360 365
Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe
370 375 380
His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro
385 390 395 400
Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu
405 410 415
Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala
420 425 430
Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn
435 440 445
Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala
450 455 460
Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr
465 470 475 480
Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp
485 490 495
Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe
500 505 510
Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu
515 520 525
Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala
530 535 540
Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln
545 550 555 560
Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala
565 570 575
Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His
580 585 590
Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu
595 600 605
Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp
610 615 620
Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu
625 630 635 640
Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val
645 650 655
Pro Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg
660 665 670
Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro
675 680 685
Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu
690 695 700
Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala
705 710 715 720
Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe
725 730 735
Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr
740 745 750
Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val
755 760 765
<210> 18
<211> 2247
<212> DNA
<213> Artificial sequence
<220>
<223> Engineered hGAA 70kD cDNA
<220>
<221> CDS
<222> (1)..(2247)
<400> 18
gcc cca tct cca ctg tac agc gtg gaa ttt tcc gag gaa ccc ttc ggc 48
Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly
1 5 10 15
gtg atc gtg cgg aga cag ctg gat gga aga gtg ctg ctg aac acc aca 96
Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr
20 25 30
gtg gcc cct ctg ttc ttc gcc gac cag ttt ctg cag ctg agc acc agc 144
Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser
35 40 45
ctg cct agc cag tat atc aca ggc ctg gcc gag cac ctg tct cca ctg 192
Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu
50 55 60
atg ctg agc aca tcc tgg acc aga atc acc ctg tgg aac aga gat ctg 240
Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu
65 70 75 80
gcc cct aca cct ggc gcc aac ctg tac ggc tct cac ccc ttt tat ctg 288
Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu
85 90 95
gcc ctg gaa gac ggc gga tct gcc cac ggt gtt ttt ctg ctg aac tcc 336
Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser
100 105 110
aac gcc atg gac gtg gtg ctg cag cca tct cct gct ctg tct tgg aga 384
Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg
115 120 125
agc aca ggc ggc atc ctg gac gtg tac atc ttt ctg ggc ccc gag cct 432
Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro
130 135 140
aag agc gtg gtg cag cag tat ctg gac gtc gtg ggc tac ccc ttc atg 480
Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met
145 150 155 160
cct cct tat tgg ggc ctg ggc ttc cac ctg tgc agg tgg gga tac agc 528
Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser
165 170 175
agc acc gcc atc acc aga cag gtg gtg gaa aac atg acc cgg gct cac 576
Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala His
180 185 190
ttc cca ctg gac gtg cag tgg aac gac ctg gac tac atg gac agc aga 624
Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg
195 200 205
cgg gac ttc acc ttc aac aag gac ggc ttc aga gac ttc ccc gcc atg 672
Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met
210 215 220
gtg caa gaa ctg cac caa ggc ggc aga cgg tac atg atg att gtg gac 720
Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp
225 230 235 240
cca gcc atc agc tct agc ggc cct gcc gga agc tac aga cct tac gat 768
Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp
245 250 255
gag ggc ctg aga aga ggc gtg ttc atc acc aac gag aca ggc cag cct 816
Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro
260 265 270
ctg atc ggc aaa gtg tgg cct ggc agc aca gcc ttt cca gac ttc aca 864
Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr
275 280 285
aac ccc acc gct ctg gct tgg tgg gaa gat atg gtg gcc gag ttc cac 912
Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe His
290 295 300
gat cag gtg ccc ttc gat ggc atg tgg atc gac atg aac gag ccc agc 960
Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser
305 310 315 320
aac ttc atc cgg ggc agc gag gac ggc tgc ccc aac aac gaa ctg gaa 1008
Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu
325 330 335
aat cct cct tac gtg ccc ggc gtt gtc ggc gga aca ctt cag gcc gct 1056
Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala
340 345 350
aca atc tgt gcc agc agc cac cag ttc ctc agc acc cac tac aac ctg 1104
Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu
355 360 365
cac aac ctg tac ggc ctg acc gag gcc att gcc tct cat aga gcc ctg 1152
His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu
370 375 380
gtt aag gcc aga ggc acc cgg cct ttt gtg atc agc aga agc aca ttc 1200
Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe
385 390 395 400
gcc ggc cac ggc aga tac gcc gga cat tgg aca ggc gac gtg tgg tct 1248
Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser
405 410 415
agt tgg gag cag ctg gct agc agc gtg cca gag atc ctg cag ttc aat 1296
Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn
420 425 430
ctg ctg ggc gtg cca ctc gtg gga gcc gac gtt tgt ggc ttc ctg ggc 1344
Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly
435 440 445
aac acc agc gag gaa ctg tgt gtg cgt tgg aca cag ctg ggc gcc ttc 1392
Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe
450 455 460
tat ccc ttc atg aga aac cac aac agc ctg ctg agc ctg cct caa gag 1440
Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu
465 470 475 480
ccc tac agc ttt agc gag cct gca cag cag gcc atg aga aag gcc ctg 1488
Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu
485 490 495
act ctg aga tac gct ctg ctg ccc cac ctg tac acc ctg ttt cac cag 1536
Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln
500 505 510
gct cac gtg gcc ggg gag aca gtg gct aga cct ctg ttc ctg gaa ttt 1584
Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe
515 520 525
ccc aag gac agc tcc acc tgg acc gtg gat cat cag ctg ctg tgg gga 1632
Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly
530 535 540
gaa gcc ctg ctc atc aca cct gtt ctg cag gcc gga aag gcc gaa gtg 1680
Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val
545 550 555 560
acc ggc tat ttt cct ctc ggc act tgg tac gac ctg cag acc gtg cct 1728
Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro
565 570 575
att gag gcc ctg gga tct ctt cct cca cct cct gct gct cct aga gag 1776
Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu
580 585 590
cct gcc atc cac tct gaa ggc cag tgg gtt aca ctg ccc gct cct ctg 1824
Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu
595 600 605
gac acc atc aac gtg cac ctg aga gct ggc tac atc atc cca ctg caa 1872
Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln
610 615 620
ggc cct ggc ctg acc aca acc gaa tct aga cag cag ccc atg gct ctg 1920
Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu
625 630 635 640
gcc gtg gct ctt aca aaa ggc gga gag gct aga ggc gag ctg ttc tgg 1968
Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp
645 650 655
gac gac ggc gag tct ctg gaa gtg ctg gaa cgg ggc gct tat acc caa 2016
Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln
660 665 670
gtg atc ttc ctg gcc aga aac aac acc atc gtg aac gaa ctc gtg cgc 2064
Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg
675 680 685
gtg acc agt gaa ggt gct gga ctg caa ctg cag aaa gtg acc gtg ctc 2112
Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu
690 695 700
gga gtg gcc aca gct cct caa cag gtg ctg tct aac ggc gtg ccc gtg 2160
Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val
705 710 715 720
tcc aac ttc aca tac agc ccc gac acc aag gtc ctg gac atc tgt gtg 2208
Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val
725 730 735
tca ctg ctg atg ggc gag cag ttc ctg gtg tcc tgg tgc 2247
Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
740 745
<210> 19
<211> 749
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic Construct
<400> 19
Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly
1 5 10 15
Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr
20 25 30
Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser
35 40 45
Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu
50 55 60
Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu
65 70 75 80
Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu
85 90 95
Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser
100 105 110
Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg
115 120 125
Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro
130 135 140
Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met
145 150 155 160
Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser
165 170 175
Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala His
180 185 190
Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg
195 200 205
Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met
210 215 220
Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp
225 230 235 240
Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp
245 250 255
Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro
260 265 270
Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr
275 280 285
Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe His
290 295 300
Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser
305 310 315 320
Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu
325 330 335
Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala
340 345 350
Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu
355 360 365
His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu
370 375 380
Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe
385 390 395 400
Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser
405 410 415
Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn
420 425 430
Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly
435 440 445
Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe
450 455 460
Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu
465 470 475 480
Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu
485 490 495
Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln
500 505 510
Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe
515 520 525
Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly
530 535 540
Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val
545 550 555 560
Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro
565 570 575
Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu
580 585 590
Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu
595 600 605
Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln
610 615 620
Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu
625 630 635 640
Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp
645 650 655
Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln
660 665 670
Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg
675 680 685
Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu
690 695 700
Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val
705 710 715 720
Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val
725 730 735
Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
740 745
<210> 20
<211> 2490
<212> DNA
<213> Artificial Sequence
<220>
<223> Engineered DNA for hGAAV780I 76 kD protein
<220>
<221> CDS
<222> (1)..(2490)
<400> 20
gga cag ccc tgg tgc ttc ttc cca cca tct tac ccc agc tac aag ctg 48
Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu
1 5 10 15
gaa aac ctg agc agc agc gag atg ggc tac acc gcc aca ctg acc aga 96
Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg
20 25 30
acc aca cct aca ttc ttc ccg aag gac atc ctg aca ctg cgg ctg gac 144
Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp
35 40 45
gtg atg atg gaa acc gag aac cgg ctg cac ttc acc atc aag gac ccc 192
Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro
50 55 60
gcc aat cgg aga tac gag gtg cca ctg gaa acc cct cac gtg cac tct 240
Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val His Ser
65 70 75 80
aga gcc cca tct cca ctg tac agc gtg gaa ttt tcc gag gaa ccc ttc 288
Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe
85 90 95
ggc gtg atc gtg cgg aga cag ctg gat gga aga gtg ctg ctg aac acc 336
Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr
100 105 110
aca gtg gcc cct ctg ttc ttc gcc gac cag ttt ctg cag ctg agc acc 384
Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr
115 120 125
agc ctg cct agc cag tat atc aca ggc ctg gcc gag cac ctg tct cca 432
Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro
130 135 140
ctg atg ctg agc aca tcc tgg acc aga atc acc ctg tgg aac aga gat 480
Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp
145 150 155 160
ctg gcc cct aca cct ggc gcc aac ctg tac ggc tct cac ccc ttt tat 528
Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr
165 170 175
ctg gcc ctg gaa gac ggc gga tct gcc cac ggt gtt ttt ctg ctg aac 576
Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn
180 185 190
tcc aac gcc atg gac gtg gtg ctg cag cca tct cct gct ctg tct tgg 624
Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp
195 200 205
aga agc aca ggc ggc atc ctg gac gtg tac atc ttt ctg ggc ccc gag 672
Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu
210 215 220
cct aag agc gtg gtg cag cag tat ctg gac gtc gtg ggc tac ccc ttc 720
Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe
225 230 235 240
atg cct cct tat tgg ggc ctg ggc ttc cac ctg tgc agg tgg gga tac 768
Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr
245 250 255
agc agc acc gcc atc acc aga cag gtg gtg gaa aac atg acc cgg gct 816
Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala
260 265 270
cac ttc cca ctg gac gtg cag tgg aac gac ctg gac tac atg gac agc 864
His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser
275 280 285
aga cgg gac ttc acc ttc aac aag gac ggc ttc aga gac ttc ccc gcc 912
Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala
290 295 300
atg gtg caa gaa ctg cac caa ggc ggc aga cgg tac atg atg att gtg 960
Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val
305 310 315 320
gac cca gcc atc agc tct agc ggc cct gcc gga agc tac aga cct tac 1008
Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr
325 330 335
gat gag ggc ctg aga aga ggc gtg ttc atc acc aac gag aca ggc cag 1056
Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln
340 345 350
cct ctg atc ggc aaa gtg tgg cct ggc agc aca gcc ttt cca gac ttc 1104
Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe
355 360 365
aca aac ccc acc gct ctg gct tgg tgg gaa gat atg gtg gcc gag ttc 1152
Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe
370 375 380
cac gat cag gtg ccc ttc gat ggc atg tgg atc gac atg aac gag ccc 1200
His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro
385 390 395 400
agc aac ttc atc cgg ggc agc gag gac ggc tgc ccc aac aac gaa ctg 1248
Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu
405 410 415
gaa aat cct cct tac gtg ccc ggc gtt gtc ggc gga aca ctt cag gcc 1296
Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala
420 425 430
gct aca atc tgt gcc agc agc cac cag ttc ctc agc acc cac tac aac 1344
Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn
435 440 445
ctg cac aac ctg tac ggc ctg acc gag gcc att gcc tct cat aga gcc 1392
Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala
450 455 460
ctg gtt aag gcc aga ggc acc cgg cct ttt gtg atc agc aga agc aca 1440
Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr
465 470 475 480
ttc gcc ggc cac ggc aga tac gcc gga cat tgg aca ggc gac gtg tgg 1488
Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp
485 490 495
tct agt tgg gag cag ctg gct agc agc gtg cca gag atc ctg cag ttc 1536
Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe
500 505 510
aat ctg ctg ggc gtg cca ctc gtg gga gcc gac gtt tgt ggc ttc ctg 1584
Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu
515 520 525
ggc aac acc agc gag gaa ctg tgt gtg cgt tgg aca cag ctg ggc gcc 1632
Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala
530 535 540
ttc tat ccc ttc atg aga aac cac aac agc ctg ctg agc ctg cct caa 1680
Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln
545 550 555 560
gag ccc tac agc ttt agc gag cct gca cag cag gcc atg aga aag gcc 1728
Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala
565 570 575
ctg act ctg aga tac gct ctg ctg ccc cac ctg tac acc ctg ttt cac 1776
Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His
580 585 590
cag gct cac gtg gcc ggg gag aca gtg gct aga cct ctg ttc ctg gaa 1824
Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu
595 600 605
ttt ccc aag gac agc tcc acc tgg acc gtg gat cat cag ctg ctg tgg 1872
Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp
610 615 620
gga gaa gcc ctg ctc atc aca cct gtt ctg cag gcc gga aag gcc gaa 1920
Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu
625 630 635 640
gtg acc ggc tat ttt cct ctc ggc act tgg tac gac ctg cag acc gtg 1968
Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val
645 650 655
cct att gag gcc ctg gga tct ctt cct cca cct cct gct gct cct aga 2016
Pro Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg
660 665 670
gag cct gcc atc cac tct gaa ggc cag tgg gtt aca ctg ccc gct cct 2064
Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro
675 680 685
ctg gac acc atc aac gtg cac ctg aga gct ggc tac atc atc cca ctg 2112
Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu
690 695 700
caa ggc cct ggc ctg acc aca acc gaa tct aga cag cag ccc atg gct 2160
Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala
705 710 715 720
ctg gcc gtg gct ctt aca aaa ggc gga gag gct aga ggc gag ctg ttc 2208
Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe
725 730 735
tgg gac gac ggc gag tct ctg gaa gtg ctg gaa cgg ggc gct tat acc 2256
Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr
740 745 750
caa gtg atc ttc ctg gcc aga aac aac acc atc gtg aac gaa ctc gtg 2304
Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val
755 760 765
cgc gtg acc agt gaa ggt gct gga ctg caa ctg cag aaa gtg acc gtg 2352
Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val
770 775 780
ctc gga gtg gcc aca gct cct caa cag gtg ctg tct aac ggc gtg ccc 2400
Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro
785 790 795 800
gtg tcc aac ttc aca tac agc ccc gac acc aag gtc ctg gac atc tgt 2448
Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys
805 810 815
gtg tca ctg ctg atg ggc gag cag ttc ctg gtg tcc tgg tgc 2490
Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
820 825 830
<210> 21
<211> 830
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 21
Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu
1 5 10 15
Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg
20 25 30
Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp
35 40 45
Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro
50 55 60
Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val His Ser
65 70 75 80
Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe
85 90 95
Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr
100 105 110
Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr
115 120 125
Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro
130 135 140
Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp
145 150 155 160
Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr
165 170 175
Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn
180 185 190
Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp
195 200 205
Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu
210 215 220
Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe
225 230 235 240
Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr
245 250 255
Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala
260 265 270
His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser
275 280 285
Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala
290 295 300
Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val
305 310 315 320
Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr
325 330 335
Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln
340 345 350
Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe
355 360 365
Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe
370 375 380
His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro
385 390 395 400
Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu
405 410 415
Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala
420 425 430
Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn
435 440 445
Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala
450 455 460
Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr
465 470 475 480
Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp
485 490 495
Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe
500 505 510
Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu
515 520 525
Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala
530 535 540
Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln
545 550 555 560
Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala
565 570 575
Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His
580 585 590
Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu
595 600 605
Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp
610 615 620
Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu
625 630 635 640
Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val
645 650 655
Pro Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg
660 665 670
Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro
675 680 685
Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu
690 695 700
Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala
705 710 715 720
Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe
725 730 735
Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr
740 745 750
Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val
755 760 765
Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val
770 775 780
Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro
785 790 795 800
Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys
805 810 815
Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
820 825 830
<210> 22
<211> 2952
<212> DNA
<213> Artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(2952)
<220>
<221> misc_feature
<222> (1)..(270)
<223> BiP signal peptide + vIGF2 + 2GS extension
<220>
<221> misc_feature
<222> (271)..(2952)
<223> engineered DNA for hGAA 61 - 952 780I
<220>
<221> misc_feature
<222> (2428)..(2430)
<223> Ile codon
<400> 22
atg aag ctg tct ctg gtg gct gct atg ctg ctg ctc ctg tct gcc gcc 48
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
aga gcc agc aga aca ctt tgt ggc gga gag ctg gtg gac acc ctg cag 96
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
ttt gtg tgt ggc gac aga ggc ttc ctg ttc agc aga cct gcc agc cgg 144
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
gtt tcc aga cgg tct aga gga atc gtg gaa gag tgc tgc ttc aga agc 192
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
tgc gat ctg gcc ctg ctg gaa acc tac tgt gcc aca cca gcc aga tct 240
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
gaa ggc ggc gga gga tct ggc gga ggc gga tct aga cct gga cct aga 288
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
gac gcc cag gct cac cct ggt aga cct aga gct gtg cct aca cag tgc 336
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
gac gtg cca cct aac agc aga ttc gac tgc gcc cct gac aag gcc atc 384
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
aca caa gag cag tgt gaa gcc aga ggc tgc tgc tac atc cct gcc aaa 432
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
caa gga ctg cag ggc gcc cag atg gga cag cct tgg tgc ttc ttc cca 480
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
cca tct tac ccc agc tac aag ctg gaa aac ctg agc agc tcc gag atg 528
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
ggc tac acc gcc aca ctg acc aga acc aca cct aca ttc ttc ccg aag 576
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
gac atc ctg aca ctg cgg ctg gac gtg atg atg gaa acc gag aac cgg 624
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
ctg cac ttc acc atc aag gac ccc gcc aat cgg aga tac gag gtg ccc 672
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
ctg gaa aca ccc cac gtg cac tct aga gca ccc tct cca ctg tac agc 720
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
gtg gaa ttt tcc gag gaa ccc ttc ggc gtg atc gtg cgg aga cag ctg 768
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
gat ggc aga gtg ctc ctg aat acc aca gtg gcc cct ctg ttc ttc gcc 816
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
gac cag ttt ctg cag ctg agc acc agc ctg cct agc cag tat atc aca 864
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
ggc ctg gcc gag cat ctg agc cct ctg atg ctg agc aca tcc tgg acc 912
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
aga atc acc ctg tgg aac cgc gac ctg gct cct aca cct ggc gcc aat 960
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
ctg tac ggc tct cac ccc ttc tac ctg gca ctg gaa gac ggt gga tct 1008
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
gcc cac ggt gtc ttt ctg ctg aat agc aac gcc atg gac gtg gtg ctg 1056
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
cag ccc tct cct gca ctg tct tgg aga tct aca ggc ggc atc ctg gac 1104
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
gtg tac atc ttt ctg ggc ccc gag cct aag agc gtg gtg cag cag tat 1152
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
ctg gac gtc gtg ggc tac ccc ttc atg cct cct tat tgg ggc ctg ggc 1200
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
ttc cac ctg tgt agg tgg ggc tac agc agc acc gcc atc acc aga cag 1248
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
gtg gtg gaa aac atg acc cgg gct cac ttc cca ctg gac gtg cag tgg 1296
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
aac gac ctg gac tac atg gac agc aga cgg gac ttc acc ttc aac aag 1344
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
gac ggc ttc aga gac ttc ccc gcc atg gtg caa gag ctg cat caa ggc 1392
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
gga cgg cgg tac atg atg att gtg gac cct gcc atc agc agc tct gga 1440
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
cca gcc ggc agc tac aga cct tac gat gag gga ctg aga aga ggc gtg 1488
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
ttc atc acc aac gag aca ggc cag cct ctg atc ggc aaa gtg tgg cct 1536
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
ggc agc aca gcc ttt cca gac ttc aca aac ccc acc gct ctg gct tgg 1584
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
tgg gaa gat atg gtg gcc gag ttc cac gat cag gtg ccc ttc gat ggc 1632
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
atg tgg atc gac atg aac gag ccc agc aac ttc atc cgg ggc agc gag 1680
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
gat ggc tgc ccc aac aac gaa cta gaa aat cct cct tac gtg ccc ggc 1728
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
gtt gtc ggc gga aca ctt cag gcc gct aca atc tgt gcc agc agc cat 1776
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
cag ttt ctg agc acc cac tac aac ctg cac aac ctg tac ggc ctg acc 1824
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
gag gcc att gcc tct cat aga gcc ctg gtt aag gcc aga ggc acc cgg 1872
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
cct ttt gtg atc agc aga agc aca ttc gcc ggc cac ggc aga tac gca 1920
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
gga cat tgg aca ggc gac gtg tgg tct agt tgg gag cag ctg gct agc 1968
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
agc gtg cca gag atc ctg cag ttc aat ctg ctg ggc gtg cca ctc gtg 2016
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
gga gcc gac gtt tgt ggc ttc ctg ggc aac acc agc gag gaa ctg tgt 2064
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
gtg cgt tgg aca cag ctg ggc gcc ttc tat ccc ttc atg aga aac cac 2112
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
aac agc ctg ctg agc ctg cct caa gag ccc tac agc ttt agc gag cct 2160
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
gca cag cag gcc atg aga aag gcc ctg act ctg aga tac gcc ctg ctg 2208
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
cct cac ctg tac acc ctg ttt cat cag gcc cac gtg gca ggc gag aca 2256
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
gtg gct aga cct ctg ttc ctg gaa ttt ccc aag gac agc tcc acc tgg 2304
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
acc gtg gat cat cag ctg ctg tgg gga gaa gcc ctg ctg att aca cca 2352
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
gtg ctg cag gcc gga aag gcc gaa gtg aca ggc tat ttc cct ctc ggc 2400
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
act tgg tac gac ctg cag acc gtg cct atc gag gct ctg gga tct ctt 2448
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
cct cca cct cct gcc gct cct aga gag cct gcc att cac tct gaa ggc 2496
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
cag tgg gtt acc ctg cct gct cct ctg gac acc atc aac gtg cac ctg 2544
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
aga gcc ggc tac atc atc cct ctg caa ggc cct ggc ctg acc aca acc 2592
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
gaa tct aga cag cag ccc atg gca ctg gcc gtg gct ctt aca aaa ggc 2640
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
gga gag gct aga ggc gag ctg ttc tgg gat gat ggc gag agc cta gaa 2688
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
gtg ctg gaa cgg ggc gct tat acc caa gtg atc ttc ctg gcc aga aac 2736
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
aac acc atc gtg aac gaa ctc gtg cgc gtg acc agt gaa ggt gct gga 2784
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
ctg caa ctg cag aaa gtg acc gtg ctc gga gtg gcc aca gct cct cag 2832
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
cag gtt ctg tct aat ggc gtg ccc gtg tcc aac ttc aca tac agc ccc 2880
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
gac acc aag gtc ctg gac atc tgt gtg tcc ctg ctt atg ggc gag cag 2928
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
ttc ctg gtg tcc tgg tgc tga taa 2952
Phe Leu Val Ser Trp Cys
980
<210> 23
<211> 982
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic Construct
<400> 23
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
Phe Leu Val Ser Trp Cys
980
<210> 24
<211> 2952
<212> DNA
<213> Artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(2952)
<220>
<221> misc_feature
<222> (1)..(270)
<223> BiP-vIGF peptide
<220>
<221> misc_feature
<222> (1)..(270)
<223> BiP signal peptide + vIGF2+2GS extension
<220>
<221> misc_feature
<222> (271)..(2952)
<223> hGAA 61-952 V780 DNA
<220>
<221> misc_feature
<222> (2428)..(2430)
<223> codon for hGAA 780 Valine
<400> 24
atg aag ctg tct ctg gtg gct gct atg ctg ctg ctc ctg tct gcc gcc 48
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
aga gcc agc aga aca ctt tgt ggc gga gag ctg gtg gac acc ctg cag 96
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
ttt gtg tgt ggc gac aga ggc ttc ctg ttc agc aga cct gcc agc cgg 144
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
gtt tcc aga cgg tct aga gga atc gtg gaa gag tgc tgc ttc aga agc 192
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
tgc gat ctg gcc ctg ctg gaa acc tac tgt gcc aca cca gcc aga tct 240
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
gaa ggc ggc gga gga tct ggc gga ggc gga tct aga cct gga cct aga 288
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
gac gcc cag gct cac cct ggt aga cct aga gct gtg cct aca cag tgc 336
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
gac gtg cca cct aac agc aga ttc gac tgc gcc cct gac aag gcc atc 384
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
aca caa gag cag tgt gaa gcc aga ggc tgc tgc tac atc cct gcc aaa 432
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
caa gga ctg cag ggc gcc cag atg gga cag cct tgg tgc ttc ttc cca 480
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
cca tct tac ccc agc tac aag ctg gaa aac ctg agc agc tcc gag atg 528
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
ggc tac acc gcc aca ctg acc aga acc aca cct aca ttc ttc ccg aag 576
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
gac atc ctg aca ctg cgg ctg gac gtg atg atg gaa acc gag aac cgg 624
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
ctg cac ttc acc atc aag gac ccc gcc aat cgg aga tac gag gtg ccc 672
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
ctg gaa aca ccc cac gtg cac tct aga gca ccc tct cca ctg tac agc 720
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
gtg gaa ttt tcc gag gaa ccc ttc ggc gtg atc gtg cgg aga cag ctg 768
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
gat ggc aga gtg ctc ctg aat acc aca gtg gcc cct ctg ttc ttc gcc 816
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
gac cag ttt ctg cag ctg agc acc agc ctg cct agc cag tat atc aca 864
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
ggc ctg gcc gag cat ctg agc cct ctg atg ctg agc aca tcc tgg acc 912
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
aga atc acc ctg tgg aac cgc gac ctg gct cct aca cct ggc gcc aat 960
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
ctg tac ggc tct cac ccc ttc tac ctg gca ctg gaa gac ggt gga tct 1008
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
gcc cac ggt gtc ttt ctg ctg aat agc aac gcc atg gac gtg gtg ctg 1056
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
cag ccc tct cct gca ctg tct tgg aga tct aca ggc ggc atc ctg gac 1104
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
gtg tac atc ttt ctg ggc ccc gag cct aag agc gtg gtg cag cag tat 1152
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
ctg gac gtc gtg ggc tac ccc ttc atg cct cct tat tgg ggc ctg ggc 1200
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
ttc cac ctg tgt agg tgg ggc tac agc agc acc gcc atc acc aga cag 1248
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
gtg gtg gaa aac atg acc cgg gct cac ttc cca ctg gac gtg cag tgg 1296
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
aac gac ctg gac tac atg gac agc aga cgg gac ttc acc ttc aac aag 1344
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
gac ggc ttc aga gac ttc ccc gcc atg gtg caa gag ctg cat caa ggc 1392
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
gga cgg cgg tac atg atg att gtg gac cct gcc atc agc agc tct gga 1440
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
cca gcc ggc agc tac aga cct tac gat gag gga ctg aga aga ggc gtg 1488
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
ttc atc acc aac gag aca ggc cag cct ctg atc ggc aaa gtg tgg cct 1536
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
ggc agc aca gcc ttt cca gac ttc aca aac ccc acc gct ctg gct tgg 1584
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
tgg gaa gat atg gtg gcc gag ttc cac gat cag gtg ccc ttc gat ggc 1632
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
atg tgg atc gac atg aac gag ccc agc aac ttc atc cgg ggc agc gag 1680
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
gat ggc tgc ccc aac aac gaa cta gaa aat cct cct tac gtg ccc ggc 1728
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
gtt gtc ggc gga aca ctt cag gcc gct aca atc tgt gcc agc agc cat 1776
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
cag ttt ctg agc acc cac tac aac ctg cac aac ctg tac ggc ctg acc 1824
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
gag gcc att gcc tct cat aga gcc ctg gtt aag gcc aga ggc acc cgg 1872
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
cct ttt gtg atc agc aga agc aca ttc gcc ggc cac ggc aga tac gca 1920
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
gga cat tgg aca ggc gac gtg tgg tct agt tgg gag cag ctg gct agc 1968
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
agc gtg cca gag atc ctg cag ttc aat ctg ctg ggc gtg cca ctc gtg 2016
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
gga gcc gac gtt tgt ggc ttc ctg ggc aac acc agc gag gaa ctg tgt 2064
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
gtg cgt tgg aca cag ctg ggc gcc ttc tat ccc ttc atg aga aac cac 2112
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
aac agc ctg ctg agc ctg cct caa gag ccc tac agc ttt agc gag cct 2160
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
gca cag cag gcc atg aga aag gcc ctg act ctg aga tac gcc ctg ctg 2208
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
cct cac ctg tac acc ctg ttt cat cag gcc cac gtg gca ggc gag aca 2256
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
gtg gct aga cct ctg ttc ctg gaa ttt ccc aag gac agc tcc acc tgg 2304
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
acc gtg gat cat cag ctg ctg tgg gga gaa gcc ctg ctg att aca cca 2352
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
gtg ctg cag gcc gga aag gcc gaa gtg aca ggc tat ttc cct ctc ggc 2400
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
act tgg tac gac ctg cag acc gtg cct atc gag gct ctg gga tct ctt 2448
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
cct cca cct cct gcc gct cct aga gag cct gcc att cac tct gaa ggc 2496
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
cag tgg gtt acc ctg cct gct cct ctg gac acc atc aac gtg cac ctg 2544
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
aga gcc ggc tac atc atc cct ctg caa ggc cct ggc ctg acc aca acc 2592
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
gaa tct aga cag cag ccc atg gca ctg gcc gtg gct ctt aca aaa ggc 2640
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
gga gag gct aga ggc gag ctg ttc tgg gat gat ggc gag agc cta gaa 2688
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
gtg ctg gaa cgg ggc gct tat acc caa gtg atc ttc ctg gcc aga aac 2736
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
aac acc atc gtg aac gaa ctc gtg cgc gtg acc agt gaa ggt gct gga 2784
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
ctg caa ctg cag aaa gtg acc gtg ctc gga gtg gcc aca gct cct cag 2832
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
cag gtt ctg tct aat ggc gtg ccc gtg tcc aac ttc aca tac agc ccc 2880
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
gac acc aag gtc ctg gac atc tgt gtg tcc ctg ctt atg ggc gag cag 2928
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
ttc ctg gtg tcc tgg tgc tga taa 2952
Phe Leu Val Ser Trp Cys
980
<210> 25
<211> 982
<212> PRT
<213> Artificial sequence
<220>
<223> Synthetic Construct
<400> 25
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
Phe Leu Val Ser Trp Cys
980
<210> 26
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> miRNA target sequence
<400> 26
agtgaattct accagtgcca ta 22
<210> 27
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> miRNA target sequence
<400> 27
agtgtgagtt ctaccattgc caaa 24
<210> 28
<211> 4581
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic construct
<220>
<221> misc_feature
<222> (1)..(130)
<223> 5' ITR
<220>
<221> enhancer
<222> (195)..(437)
<223> CMV IE Enhancer
<220>
<221> promoter
<222> (440)..(721)
<223> chicken beta-actin promoter
<220>
<221> Intron
<222> (721)..(1128)
<223> hybrid intron in CAG
<220>
<221> CDS
<222> (1141)..(4092)
<223> BiP-vIGF2-hGAAco
<220>
<221> misc_feature
<222> (3568)..(3570)
<223> Ile codon
<220>
<221> polyA_signal
<222> (4161)..(4287)
<223> rabbit beta-globin poly a
<220>
<221> misc_feature
<222> (4452)..(4581)
<223> 3' ITR
<400> 28
ctgcgcgctc gctcgctcac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt 60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact 120
aggggttcct tgtagttaat gattaacccg ccatgctact tatctacgta gccatgctct 180
aggaagatcg taccattgac gtcaataatg acgtatgttc ccatagtaac gccaataggg 240
actttccatt gacgtcaatg ggtggagtat ttacggtaaa ctgcccactt ggcagtacat 300
caagtgtatc atatgccaag tacgccccct attgacgtca atgacggtaa atggcccgcc 360
tggcattatg cccagtacat gaccttatgg gactttccta cttggcagta catctacgta 420
ttagtcatcg ctattaccat ggtcgaggtg agccccacgt tctgcttcac tctccccatc 480
tcccccccct ccccaccccc aattttgtat ttatttattt tttaattatt ttgtgcagcg 540
atgggggcgg gggggggggg ggggcgcgcg ccaggcgggg cggggcgggg cgaggggcgg 600
ggcggggcga ggcggagagg tgcggcggca gccaatcaga gcggcgcgct ccgaaagttt 660
ccttttatgg cgaggcggcg gcggcggcgg ccctataaaa agcgaagcgc gcggcgggcg 720
ggagtcgctg cgcgctgcct tcgccccgtg ccccgctccg ccgccgcctc gcgccgcccg 780
ccccggctct gactgaccgc gttactccca caggtgagcg ggcgggacgg cccttctcct 840
ccgggctgta attagcgctt ggtttaatga cggcttgttt cttttctgtg gctgcgtgaa 900
agccttgagg ggctccggga gggccctttg tgcgggggga gcggctcggg gctgtccgcg 960
gggggacggc tgccttcggg ggggacgggg cagggcgggg ttcggcttct ggcgtgtgac 1020
cggcggctct agagcctctg ctaaccatgt tcatgccttc ttctttttcc tacagctcct 1080
gggcaacgtg ctggttattg tgctgtctca tcattttggc aaagaattgg atccgccacc 1140
atg aag ctg tct ctg gtg gct gct atg ctg ctg ctc ctg tct gcc gcc 1188
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
aga gcc agc aga aca ctt tgt ggc gga gag ctg gtg gac acc ctg cag 1236
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
ttt gtg tgt ggc gac aga ggc ttc ctg ttc agc aga cct gcc agc cgg 1284
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
gtt tcc aga cgg tct aga gga atc gtg gaa gag tgc tgc ttc aga agc 1332
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
tgc gat ctg gcc ctg ctg gaa acc tac tgt gcc aca cca gcc aga tct 1380
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
gaa ggc ggc gga gga tct ggc gga ggc gga tct aga cct gga cct aga 1428
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
gac gcc cag gct cac cct ggt aga cct aga gct gtg cct aca cag tgc 1476
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
gac gtg cca cct aac agc aga ttc gac tgc gcc cct gac aag gcc atc 1524
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
aca caa gag cag tgt gaa gcc aga ggc tgc tgc tac atc cct gcc aaa 1572
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
caa gga ctg cag ggc gcc cag atg gga cag cct tgg tgc ttc ttc cca 1620
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
cca tct tac ccc agc tac aag ctg gaa aac ctg agc agc tcc gag atg 1668
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
ggc tac acc gcc aca ctg acc aga acc aca cct aca ttc ttc ccg aag 1716
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
gac atc ctg aca ctg cgg ctg gac gtg atg atg gaa acc gag aac cgg 1764
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
ctg cac ttc acc atc aag gac ccc gcc aat cgg aga tac gag gtg ccc 1812
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
ctg gaa aca ccc cac gtg cac tct aga gca ccc tct cca ctg tac agc 1860
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
gtg gaa ttt tcc gag gaa ccc ttc ggc gtg atc gtg cgg aga cag ctg 1908
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
gat ggc aga gtg ctc ctg aat acc aca gtg gcc cct ctg ttc ttc gcc 1956
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
gac cag ttt ctg cag ctg agc acc agc ctg cct agc cag tat atc aca 2004
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
ggc ctg gcc gag cat ctg agc cct ctg atg ctg agc aca tcc tgg acc 2052
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
aga atc acc ctg tgg aac cgc gac ctg gct cct aca cct ggc gcc aat 2100
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
ctg tac ggc tct cac ccc ttc tac ctg gca ctg gaa gac ggt gga tct 2148
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
gcc cac ggt gtc ttt ctg ctg aat agc aac gcc atg gac gtg gtg ctg 2196
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
cag ccc tct cct gca ctg tct tgg aga tct aca ggc ggc atc ctg gac 2244
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
gtg tac atc ttt ctg ggc ccc gag cct aag agc gtg gtg cag cag tat 2292
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
ctg gac gtc gtg ggc tac ccc ttc atg cct cct tat tgg ggc ctg ggc 2340
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
ttc cac ctg tgt agg tgg ggc tac agc agc acc gcc atc acc aga cag 2388
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
gtg gtg gaa aac atg acc cgg gct cac ttc cca ctg gac gtg cag tgg 2436
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
aac gac ctg gac tac atg gac agc aga cgg gac ttc acc ttc aac aag 2484
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
gac ggc ttc aga gac ttc ccc gcc atg gtg caa gag ctg cat caa ggc 2532
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
gga cgg cgg tac atg atg att gtg gac cct gcc atc agc agc tct gga 2580
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
cca gcc ggc agc tac aga cct tac gat gag gga ctg aga aga ggc gtg 2628
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
ttc atc acc aac gag aca ggc cag cct ctg atc ggc aaa gtg tgg cct 2676
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
ggc agc aca gcc ttt cca gac ttc aca aac ccc acc gct ctg gct tgg 2724
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
tgg gaa gat atg gtg gcc gag ttc cac gat cag gtg ccc ttc gat ggc 2772
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
atg tgg atc gac atg aac gag ccc agc aac ttc atc cgg ggc agc gag 2820
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
gat ggc tgc ccc aac aac gaa cta gaa aat cct cct tac gtg ccc ggc 2868
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
gtt gtc ggc gga aca ctt cag gcc gct aca atc tgt gcc agc agc cat 2916
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
cag ttt ctg agc acc cac tac aac ctg cac aac ctg tac ggc ctg acc 2964
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
gag gcc att gcc tct cat aga gcc ctg gtt aag gcc aga ggc acc cgg 3012
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
cct ttt gtg atc agc aga agc aca ttc gcc ggc cac ggc aga tac gca 3060
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
gga cat tgg aca ggc gac gtg tgg tct agt tgg gag cag ctg gct agc 3108
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
agc gtg cca gag atc ctg cag ttc aat ctg ctg ggc gtg cca ctc gtg 3156
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
gga gcc gac gtt tgt ggc ttc ctg ggc aac acc agc gag gaa ctg tgt 3204
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
gtg cgt tgg aca cag ctg ggc gcc ttc tat ccc ttc atg aga aac cac 3252
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
aac agc ctg ctg agc ctg cct caa gag ccc tac agc ttt agc gag cct 3300
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
gca cag cag gcc atg aga aag gcc ctg act ctg aga tac gcc ctg ctg 3348
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
cct cac ctg tac acc ctg ttt cat cag gcc cac gtg gca ggc gag aca 3396
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
gtg gct aga cct ctg ttc ctg gaa ttt ccc aag gac agc tcc acc tgg 3444
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
acc gtg gat cat cag ctg ctg tgg gga gaa gcc ctg ctg att aca cca 3492
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
gtg ctg cag gcc gga aag gcc gaa gtg aca ggc tat ttc cct ctc ggc 3540
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
act tgg tac gac ctg cag acc gtg cct atc gag gct ctg gga tct ctt 3588
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
cct cca cct cct gcc gct cct aga gag cct gcc att cac tct gaa ggc 3636
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
cag tgg gtt acc ctg cct gct cct ctg gac acc atc aac gtg cac ctg 3684
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
aga gcc ggc tac atc atc cct ctg caa ggc cct ggc ctg acc aca acc 3732
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
gaa tct aga cag cag ccc atg gca ctg gcc gtg gct ctt aca aaa ggc 3780
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
gga gag gct aga ggc gag ctg ttc tgg gat gat ggc gag agc cta gaa 3828
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
gtg ctg gaa cgg ggc gct tat acc caa gtg atc ttc ctg gcc aga aac 3876
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
aac acc atc gtg aac gaa ctc gtg cgc gtg acc agt gaa ggt gct gga 3924
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
ctg caa ctg cag aaa gtg acc gtg ctc gga gtg gcc aca gct cct cag 3972
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
cag gtt ctg tct aat ggc gtg ccc gtg tcc aac ttc aca tac agc ccc 4020
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
gac acc aag gtc ctg gac atc tgt gtg tcc ctg ctt atg ggc gag cag 4068
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
ttc ctg gtg tcc tgg tgc tga taa gcggccgcac gcgtggtacc tctagagtcg 4122
Phe Leu Val Ser Trp Cys
980
acccgggcgg cctcgaggac ggggtgaact acgcctgaga tctttttccc tctgccaaaa 4182
attatgggga catcatgaag ccccttgagc atctgacttc tggctaataa aggaaattta 4242
ttttcattgc aatagtgtgt tggaattttt tgtgtctctc actcggttaa caacaacaat 4302
tgcattcatt ttatgtttca ggttcagggg gagatgtggg aggtttttta aagcaagtaa 4362
aacctctaca aatgtggtaa aatcgataag gatcttccta gagcatggct acgtagataa 4422
gtagcatggc gggttaatca ttaactacaa ggaaccccta gtgatggagt tggccactcc 4482
ctctctgcgc gctcgctcgc tcactgaggc cgggcgacca aaggtcgccc gacgcccggg 4542
ctttgcccgg gcggcctcag tgagcgagcg agcgcgcag 4581
<210> 29
<211> 982
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 29
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
Phe Leu Val Ser Trp Cys
980
<210> 30
<211> 4687
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic construct
<220>
<221> misc_feature
<222> (1)..(130)
<223> 5' ITR
<220>
<221> enhancer
<222> (195)..(437)
<223> CMV IE Enhancer
<220>
<221> promoter
<222> (440)..(721)
<223> chicken beta-actin promoter
<220>
<221> Intron
<222> (721)..(1128)
<223> Hybrid intron in CAG
<220>
<221> CDS
<222> (1141)..(4092)
<223> BiP-vIGF2-hGAAco
<220>
<221> misc_feature
<222> (3568)..(3570)
<223> Ile codon
<220>
<221> misc_feature
<222> (4113)..(4134)
<223> miR-183 target
<220>
<221> misc_feature
<222> (4139)..(4160)
<223> miR-183 target
<220>
<221> misc_feature
<222> (4167)..(4188)
<223> miR-183 target
<220>
<221> misc_feature
<222> (4195)..(4216)
<223> miR-183 target
<220>
<221> polyA_signal
<222> (4267)..(4393)
<223> rabbit beta-globin poly a
<220>
<221> misc_feature
<222> (4558)..(4687)
<223> 3' ITR
<400> 30
ctgcgcgctc gctcgctcac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt 60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact 120
aggggttcct tgtagttaat gattaacccg ccatgctact tatctacgta gccatgctct 180
aggaagatcg taccattgac gtcaataatg acgtatgttc ccatagtaac gccaataggg 240
actttccatt gacgtcaatg ggtggagtat ttacggtaaa ctgcccactt ggcagtacat 300
caagtgtatc atatgccaag tacgccccct attgacgtca atgacggtaa atggcccgcc 360
tggcattatg cccagtacat gaccttatgg gactttccta cttggcagta catctacgta 420
ttagtcatcg ctattaccat ggtcgaggtg agccccacgt tctgcttcac tctccccatc 480
tcccccccct ccccaccccc aattttgtat ttatttattt tttaattatt ttgtgcagcg 540
atgggggcgg gggggggggg ggggcgcgcg ccaggcgggg cggggcgggg cgaggggcgg 600
ggcggggcga ggcggagagg tgcggcggca gccaatcaga gcggcgcgct ccgaaagttt 660
ccttttatgg cgaggcggcg gcggcggcgg ccctataaaa agcgaagcgc gcggcgggcg 720
ggagtcgctg cgcgctgcct tcgccccgtg ccccgctccg ccgccgcctc gcgccgcccg 780
ccccggctct gactgaccgc gttactccca caggtgagcg ggcgggacgg cccttctcct 840
ccgggctgta attagcgctt ggtttaatga cggcttgttt cttttctgtg gctgcgtgaa 900
agccttgagg ggctccggga gggccctttg tgcgggggga gcggctcggg gctgtccgcg 960
gggggacggc tgccttcggg ggggacgggg cagggcgggg ttcggcttct ggcgtgtgac 1020
cggcggctct agagcctctg ctaaccatgt tcatgccttc ttctttttcc tacagctcct 1080
gggcaacgtg ctggttattg tgctgtctca tcattttggc aaagaattgg atccgccacc 1140
atg aag ctg tct ctg gtg gct gct atg ctg ctg ctc ctg tct gcc gcc 1188
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
aga gcc agc aga aca ctt tgt ggc gga gag ctg gtg gac acc ctg cag 1236
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
ttt gtg tgt ggc gac aga ggc ttc ctg ttc agc aga cct gcc agc cgg 1284
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
gtt tcc aga cgg tct aga gga atc gtg gaa gag tgc tgc ttc aga agc 1332
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
tgc gat ctg gcc ctg ctg gaa acc tac tgt gcc aca cca gcc aga tct 1380
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
gaa ggc ggc gga gga tct ggc gga ggc gga tct aga cct gga cct aga 1428
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
gac gcc cag gct cac cct ggt aga cct aga gct gtg cct aca cag tgc 1476
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
gac gtg cca cct aac agc aga ttc gac tgc gcc cct gac aag gcc atc 1524
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
aca caa gag cag tgt gaa gcc aga ggc tgc tgc tac atc cct gcc aaa 1572
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
caa gga ctg cag ggc gcc cag atg gga cag cct tgg tgc ttc ttc cca 1620
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
cca tct tac ccc agc tac aag ctg gaa aac ctg agc agc tcc gag atg 1668
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
ggc tac acc gcc aca ctg acc aga acc aca cct aca ttc ttc ccg aag 1716
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
gac atc ctg aca ctg cgg ctg gac gtg atg atg gaa acc gag aac cgg 1764
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
ctg cac ttc acc atc aag gac ccc gcc aat cgg aga tac gag gtg ccc 1812
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
ctg gaa aca ccc cac gtg cac tct aga gca ccc tct cca ctg tac agc 1860
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
gtg gaa ttt tcc gag gaa ccc ttc ggc gtg atc gtg cgg aga cag ctg 1908
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
gat ggc aga gtg ctc ctg aat acc aca gtg gcc cct ctg ttc ttc gcc 1956
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
gac cag ttt ctg cag ctg agc acc agc ctg cct agc cag tat atc aca 2004
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
ggc ctg gcc gag cat ctg agc cct ctg atg ctg agc aca tcc tgg acc 2052
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
aga atc acc ctg tgg aac cgc gac ctg gct cct aca cct ggc gcc aat 2100
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
ctg tac ggc tct cac ccc ttc tac ctg gca ctg gaa gac ggt gga tct 2148
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
gcc cac ggt gtc ttt ctg ctg aat agc aac gcc atg gac gtg gtg ctg 2196
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
cag ccc tct cct gca ctg tct tgg aga tct aca ggc ggc atc ctg gac 2244
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
gtg tac atc ttt ctg ggc ccc gag cct aag agc gtg gtg cag cag tat 2292
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
ctg gac gtc gtg ggc tac ccc ttc atg cct cct tat tgg ggc ctg ggc 2340
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
ttc cac ctg tgt agg tgg ggc tac agc agc acc gcc atc acc aga cag 2388
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
gtg gtg gaa aac atg acc cgg gct cac ttc cca ctg gac gtg cag tgg 2436
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
aac gac ctg gac tac atg gac agc aga cgg gac ttc acc ttc aac aag 2484
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
gac ggc ttc aga gac ttc ccc gcc atg gtg caa gag ctg cat caa ggc 2532
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
gga cgg cgg tac atg atg att gtg gac cct gcc atc agc agc tct gga 2580
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
cca gcc ggc agc tac aga cct tac gat gag gga ctg aga aga ggc gtg 2628
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
ttc atc acc aac gag aca ggc cag cct ctg atc ggc aaa gtg tgg cct 2676
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
ggc agc aca gcc ttt cca gac ttc aca aac ccc acc gct ctg gct tgg 2724
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
tgg gaa gat atg gtg gcc gag ttc cac gat cag gtg ccc ttc gat ggc 2772
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
atg tgg atc gac atg aac gag ccc agc aac ttc atc cgg ggc agc gag 2820
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
gat ggc tgc ccc aac aac gaa cta gaa aat cct cct tac gtg ccc ggc 2868
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
gtt gtc ggc gga aca ctt cag gcc gct aca atc tgt gcc agc agc cat 2916
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
cag ttt ctg agc acc cac tac aac ctg cac aac ctg tac ggc ctg acc 2964
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
gag gcc att gcc tct cat aga gcc ctg gtt aag gcc aga ggc acc cgg 3012
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
cct ttt gtg atc agc aga agc aca ttc gcc ggc cac ggc aga tac gca 3060
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
gga cat tgg aca ggc gac gtg tgg tct agt tgg gag cag ctg gct agc 3108
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
agc gtg cca gag atc ctg cag ttc aat ctg ctg ggc gtg cca ctc gtg 3156
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
gga gcc gac gtt tgt ggc ttc ctg ggc aac acc agc gag gaa ctg tgt 3204
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
gtg cgt tgg aca cag ctg ggc gcc ttc tat ccc ttc atg aga aac cac 3252
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
aac agc ctg ctg agc ctg cct caa gag ccc tac agc ttt agc gag cct 3300
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
gca cag cag gcc atg aga aag gcc ctg act ctg aga tac gcc ctg ctg 3348
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
cct cac ctg tac acc ctg ttt cat cag gcc cac gtg gca ggc gag aca 3396
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
gtg gct aga cct ctg ttc ctg gaa ttt ccc aag gac agc tcc acc tgg 3444
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
acc gtg gat cat cag ctg ctg tgg gga gaa gcc ctg ctg att aca cca 3492
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
gtg ctg cag gcc gga aag gcc gaa gtg aca ggc tat ttc cct ctc ggc 3540
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
act tgg tac gac ctg cag acc gtg cct atc gag gct ctg gga tct ctt 3588
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
cct cca cct cct gcc gct cct aga gag cct gcc att cac tct gaa ggc 3636
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
cag tgg gtt acc ctg cct gct cct ctg gac acc atc aac gtg cac ctg 3684
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
aga gcc ggc tac atc atc cct ctg caa ggc cct ggc ctg acc aca acc 3732
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
gaa tct aga cag cag ccc atg gca ctg gcc gtg gct ctt aca aaa ggc 3780
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
gga gag gct aga ggc gag ctg ttc tgg gat gat ggc gag agc cta gaa 3828
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
gtg ctg gaa cgg ggc gct tat acc caa gtg atc ttc ctg gcc aga aac 3876
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
aac acc atc gtg aac gaa ctc gtg cgc gtg acc agt gaa ggt gct gga 3924
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
ctg caa ctg cag aaa gtg acc gtg ctc gga gtg gcc aca gct cct cag 3972
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
cag gtt ctg tct aat ggc gtg ccc gtg tcc aac ttc aca tac agc ccc 4020
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
gac acc aag gtc ctg gac atc tgt gtg tcc ctg ctt atg ggc gag cag 4068
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
ttc ctg gtg tcc tgg tgc tga taa gcggccgcac gcgtggtacc agtgaattct 4122
Phe Leu Val Ser Trp Cys
980
accagtgcca taggatagtg aattctacca gtgccataca cgtgagtgaa ttctaccagt 4182
gccatagcat gcagtgaatt ctaccagtgc catagcggcc gcctcgaccc gggcggcctc 4242
gaggacgggg tgaactacgc ctgagatctt tttccctctg ccaaaaatta tggggacatc 4302
atgaagcccc ttgagcatct gacttctggc taataaagga aatttatttt cattgcaata 4362
gtgtgttgga attttttgtg tctctcactc ggttaacaac aacaattgca ttcattttat 4422
gtttcaggtt cagggggaga tgtgggaggt tttttaaagc aagtaaaacc tctacaaatg 4482
tggtaaaatc gataaggatc ttcctagagc atggctacgt agataagtag catggcgggt 4542
taatcattaa ctacaaggaa cccctagtga tggagttggc cactccctct ctgcgcgctc 4602
gctcgctcac tgaggccggg cgaccaaagg tcgcccgacg cccgggcttt gcccgggcgg 4662
cctcagtgag cgagcgagcg cgcag 4687
<210> 31
<211> 982
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 31
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
Arg Ala Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln
20 25 30
Phe Val Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg
35 40 45
Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser
50 55 60
Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser
65 70 75 80
Glu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Pro Gly Pro Arg
85 90 95
Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys
100 105 110
Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile
115 120 125
Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys
130 135 140
Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro
145 150 155 160
Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met
165 170 175
Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys
180 185 190
Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg
195 200 205
Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro
210 215 220
Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser
225 230 235 240
Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu
245 250 255
Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala
260 265 270
Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr
275 280 285
Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr
290 295 300
Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn
305 310 315 320
Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser
325 330 335
Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu
340 345 350
Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp
355 360 365
Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr
370 375 380
Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly
385 390 395 400
Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln
405 410 415
Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp
420 425 430
Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys
435 440 445
Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly
450 455 460
Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly
465 470 475 480
Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val
485 490 495
Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro
500 505 510
Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp
515 520 525
Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly
530 535 540
Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu
545 550 555 560
Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly
565 570 575
Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His
580 585 590
Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr
595 600 605
Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg
610 615 620
Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala
625 630 635 640
Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser
645 650 655
Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val
660 665 670
Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys
675 680 685
Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His
690 695 700
Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro
705 710 715 720
Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu
725 730 735
Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr
740 745 750
Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp
755 760 765
Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro
770 775 780
Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly
785 790 795 800
Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly Ser Leu
805 810 815
Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly
820 825 830
Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu
835 840 845
Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr
850 855 860
Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly
865 870 875 880
Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu
885 890 895
Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn
900 905 910
Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly
915 920 925
Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln
930 935 940
Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro
945 950 955 960
Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln
965 970 975
Phe Leu Val Ser Trp Cys
980
<210> 32
<211> 67
<212> PRT
<213> Homo sapiens
<400> 32
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 33
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 F26S
<400> 33
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 34
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 Y27L
<400> 34
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 35
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> V43L
<400> 35
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Leu Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 36
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 F48T
<400> 36
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Thr
35 40 45
Arg Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 37
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 R49S
<400> 37
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Ser Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 38
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 S50I
<400> 38
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ile Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 39
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 A54R
<400> 39
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Arg Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 40
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 L55R
<400> 40
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Ala Arg Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 41
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 F26S, Y27L, V43L, F48T, R49S, S50I, A54R, L55R
<400> 41
Ala Tyr Arg Pro Ser Glu Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Ser Leu Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Leu Glu Glu Cys Cys Thr
35 40 45
Ser Ile Cys Asp Leu Arg Arg Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 42
<211> 61
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 delta1-6, Y27L, K65R
<400> 42
Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln Phe Val Cys Gly
1 5 10 15
Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg Val Ser Arg Arg
20 25 30
Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser Cys Asp Leu Ala
35 40 45
Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser Glu
50 55 60
<210> 43
<211> 60
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 delta1-7, Y27L, K65R
<400> 43
Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln Phe Val Cys Gly Asp
1 5 10 15
Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg Val Ser Arg Arg Ser
20 25 30
Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser Cys Asp Leu Ala Leu
35 40 45
Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser Glu
50 55 60
<210> 44
<211> 63
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 delta1-4, E6R, Y27L, K65R
<400> 44
Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln Phe Val
1 5 10 15
Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg Val Ser
20 25 30
Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser Cys Asp
35 40 45
Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Arg Ser Glu
50 55 60
<210> 45
<211> 63
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 delta1-4, E6R, Y27L
<400> 45
Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr Leu Gln Phe Val
1 5 10 15
Cys Gly Asp Arg Gly Phe Leu Phe Ser Arg Pro Ala Ser Arg Val Ser
20 25 30
Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe Arg Ser Cys Asp
35 40 45
Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala Lys Ser Glu
50 55 60
<210> 46
<211> 67
<212> PRT
<213> Artificial Sequence
<220>
<223> IGF2 E6R
<400> 46
Ala Tyr Arg Pro Ser Arg Thr Leu Cys Gly Gly Glu Leu Val Asp Thr
1 5 10 15
Leu Gln Phe Val Cys Gly Asp Arg Gly Phe Tyr Phe Ser Arg Pro Ala
20 25 30
Ser Arg Val Ser Arg Arg Ser Arg Gly Ile Val Glu Glu Cys Cys Phe
35 40 45
Arg Ser Cys Asp Leu Ala Leu Leu Glu Thr Tyr Cys Ala Thr Pro Ala
50 55 60
Lys Ser Glu
65
<210> 47
<211> 201
<212> DNA
<213> Homo sapiens
<400> 47
gcttaccgcc ccagtgagac cctgtgcggc ggggagctgg tggacaccct ccagttcgtc 60
tgtggggacc gcggcttcta cttcagcagg cccgcaagcc gtgtgagccg tcgcagccgt 120
ggcatcgttg aggagtgctg tttccgcagc tgtgacctgg ccctcctgga gacgtactgt 180
gctacccccg ccaagtccga g 201
<210> 48
<211> 189
<212> DNA
<213> Artificial Sequence
<220>
<223> vIGF2 delta1-4, E6R, Y27L, K65R
<400> 48
tctagaacac tgtgcggagg ggagcttgta gacactcttc agttcgtgtg tggagatcgc 60
gggttcctct tctctcgccc cgcttccaga gtttcacgga ggtctagggg tatagtagag 120
gagtgttgtt tcaggtcctg tgacttggcg ctcctcgaga cctattgcgc gacgccagcc 180
aggtccgaa 189
<210> 49
<211> 18
<212> PRT
<213> Homo sapiens
<400> 49
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Ala Ala
1 5 10 15
Arg Ala
<210> 50
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified BiP-1
<400> 50
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Leu Val
1 5 10 15
Ala Ala Met Leu Leu Leu Leu Ser Ala Ala Arg Ala
20 25
<210> 51
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified BiP-2
<400> 51
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Trp Val Ala
1 5 10 15
Leu Leu Leu Leu Ser Ala Ala Arg Ala
20 25
<210> 52
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified BiP-3
<400> 52
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ser Leu Val
1 5 10 15
Ala Leu Leu Leu Leu Ser Ala Ala Arg Ala
20 25
<210> 53
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified BiP-4
<400> 53
Met Lys Leu Ser Leu Val Ala Ala Met Leu Leu Leu Leu Ala Leu Val
1 5 10 15
Ala Leu Leu Leu Leu Ser Ala Ala Arg Ala
20 25
<210> 54
<211> 17
<212> PRT
<213> Gaussia princeps
<400> 54
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala
<210> 55
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> linker sequence
<400> 55
Gly Gly Gly Gly Ser Gly Gly Gly Gly
1 5
<210> 56
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> linker sequence
<400> 56
Gly Gly Gly Gly Ser
1 5
<210> 57
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> linker sequence
<400> 57
Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5
<210> 58
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> linker sequence
<400> 58
Gly Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 59
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> linker sequence
<400> 59
Gly Gly Ser Gly Ser Gly Ser Thr Ser
1 5
<210> 60
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> linker sequence
<400> 60
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 61
<211> 6
<212> PRT
<213> Homo sapiens
<400> 61
Trp Ile Asp Met Asn Glu
1 5
<210> 62
<211> 7
<212> PRT
<213> Homo sapiens
<400> 62
Thr Val Pro Ile Glu Ala Leu
1 5
<210> 63
<211> 9
<212> PRT
<213> Homo sapiens
<400> 63
Gln Thr Val Pro Ile Glu Ala Leu Gly
1 5
<210> 64
<211> 25
<212> PRT
<213> Homo sapiens
<400> 64
Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu
1 5 10 15
Gly Ser Leu Pro Pro Pro Pro Ala Ala
20 25
Claims (28)
- 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는 방법으로서, 상기 환자는 폼페병으로 진단 받았거나 폼페병에 걸린 것으로 의심되고, 상기 방법은 상기 환자에게 AAV 캡시드 및 이에 패키징된 벡터 게놈을 갖는 재조합 AAV (rAAV)를 투여하는 것을 포함하고, 상기 벡터 게놈은
(a) 5' 역전된 말단 반복서열 (ITR);
(b) 프로모터;
(c) 신호 펩티드 및 인간 산-α-글루코시다제 (hGAA)에 융합된 vIGF2 펩티드를 포함하는 키메라 융합 단백질을 인코딩하는 뉴클레오티드 서열로서, 상기 키메라 융합 단백질을 인코딩하는 서열은 이의 발현을 구동하는 조절 서열에 작동가능하게 연결되고, 서열번호 6의 아미노산 1번 내지 982번을 인코딩하는 서열번호 7 또는 이와 적어도 95% 일치하는 서열을 포함하는, 서열;
(d) 폴리 A; 및
(e) 3' ITR을 포함하는, 방법. - 제 1항에 있어서,
상기 프로모터는 전신발현 프로모터, 선택적으로 CAG 프로모터 또는 CB7 프로모터인, 방법. - 제 1항에 있어서,
상기 비정상 근육 병리는 (i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 하는, 방법. - 제 1항에 있어서,
상기 환자는 후기 발병 폼페병을 갖는, 방법. - 제 1항에 있어서,
상기 환자는 유아 발병 폼페병을 갖는, 방법. - 제 1항에 있어서,
상기 벡터 게놈은 miR 표적 서열을 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개 또는 적어도 8개 추가로 포함하고, 선택적으로 상기 miR 표적 서열 각각은 miR-183에 대해 특이적인, 방법. - 제 1항에 있어서,
상기 AAV 캡시드는 AAVhu68 캡시드인, 방법. - 제 1항에 있어서,
상기 rAAV는 정맥내 및/또는 경막내로 투여되는, 방법. - 제 1항에 있어서,
상기 rAAV는 상기 환자에게 이중 투여 경로를 통해 투여되고, 선택적으로 상기 이중 경로는 정맥내 투여 및 대수조내 (ICM) 투여인, 방법. - 제 1항에 있어서,
상기 rAAV는 약 1 × 1011개 게놈 사본 (GC)/kg 내지 약 5 × 1013개 GC/kg의 용량으로 정맥내로 투여되는, 방법. - 제 1항에 있어서,
상기 rAAV는 약 1 × 1012개 GC 내지 약 5 × 1013개 GC의 용량으로 ICM을 통해 투여되는, 방법. - 제 1항에 있어서,
상기 rAAV는 약 1 × 1011개 GC/kg 내지 약 5 × 1013개 GC/kg의 용량으로 정맥내로, 그리고 약 1 × 1012개 GC 내지 약 5 × 1013개 GC의 용량으로 ICM을 통해투여되는, 방법. - 제 1항에 있어서,
상기 환자에게 보조요법을 투여하는 것을 추가로 포함하고, 선택적으로 상기 보조요법은 기관지 확장제, 아세틸콜린 에스테라제 저해제, 호흡기 근육 강도 훈련 (RMST), 효소 대체 요법 및/또는 횡격막 조율 요법인, 방법. - AAV 캡시드 및 이에 패키징된 벡터 게놈을 갖는 재조합 AAV (rAAV)를 포함하는 약제학적 조성물로서, 상기 벡터 게놈은
(a) 5' 역전된 말단 반복서열 (ITR);
(b) 프로모터;
(c) 신호 펩티드 및 인간 산-α-글루코시다제 (hGAA)에 융합된 vIGF2 펩티드를 포함하는 키메라 융합 단백질을 인코딩하는 뉴클레오티드 서열로서, 상기 키메라 융합 단백질을 인코딩하는 서열은 이의 발현을 구동하는 조절 서열에 작동가능하게 연결되고, 서열번호 6의 아미노산 1번 내지 982번을 인코딩하는 서열번호 7 또는 이와 적어도 95% 일치하는 서열을 포함하는, 서열;
(d) 폴리 A; 및
(e) 3' ITR을 포함하는, 약제학적 조성물. - 제 14항에 있어서,
상기 프로모터는 전신발현 프로모터, 선택적으로 CAG 프로모터 또는 CB7 프로모터인, 약제학적 조성물. - 제 14항 또는 제 15항에 있어서,
상기 벡터 게놈은 miR 표적 서열을 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개 또는 적어도 8개 추가로 포함하고, 선택적으로 상기 miR 표적 서열 각각은 miR-183에 대해 특이적인, 약제학적 조성물. - 제 14항 내지 제 16항 중 어느 한 항에 있어서,
상기 AAV 캡시드는 AAVhu68 캡시드인, 약제학적 조성물. - 제 14항 내지 제 17항 중 어느 한 항에 있어서,
상기 조성물은 정맥내 및/또는 경막내 전달을 위해 제형되는, 약제학적 조성물. - 제 14항 내지 제 18항 중 어느 한 항에 있어서,
폼페병에 걸린 환자의 치료에 사용되고, 상기 치료는 상기 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는, 약제학적 조성물. - 제 19항에 있어서,
상기 비정상 근육 병리는 i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 하는, 약제학적 조성물. - 제 19항 또는 제 20항에 있어서,
상기 환자는 후기 발병 폼페병을 갖는, 약제학적 조성물. - 제 19항 또는 제 20항에 있어서,
상기 환자는 유아 발병 폼페병을 갖는, 약제학적 조성물. - 제 19항 내지 제 22항 중 어느 한 항에 있어서,
상기 rAAV는 상기 환자에게 이중 투여 경로를 통해 투여되고, 선택적으로 상기 이중 경로는 정맥내 투여 및 대수조내 (ICM) 투여인, 약제학적 조성물. - 제 14항 내지 제 18항 중 어느 한 항에 있어서,
폼페병으로 진단 받았던 증상 이후의 환자에게 투여에 적합한, 약제학적 조성물. - 제 14항 내지 제 18항 중 어느 한 항에 있어서,
폼페병에 걸린 증상 이후의 환자에서 비정상 근육 병리를 역전시키는데 적합한, 약제학적 조성물. - 제 25항에 있어서,
상기 비정상 근육 병리는 i) 중앙 핵을 갖는 근육 세포의 백분율 상승, (ii) 근육 섬유 위축증, (iii) 근육 세포 섬유의 부동세포증, (iv) 자가포식 구축, (v) 공포 형성, 및 (vi) 쇠약 중 하나 이상을 특징으로 하는, 약제학적 조성물. - 제 14항 내지 제 18항 또는 제 24항 내지 제 26항 중 어느 한 항에 있어서,
보조요법으로 사용하기에 적합하고, 선택적으로 상기 환자는 기관지 확장제, 아세틸콜린 에스테라제 저해제, 호흡기 근육 강도 훈련 (RMST), 효소 대체 요법 및/또는 횡격막 조율 요법으로의 치료를 추가로 받는 것을 특징으로 하는, 약제학적 조성물. - 폼페병을 필요로 하는 환자에서 치료하기 위한 제 14항 내지 제 18항 중 어느 한 항의 약제학적 조성물의 용도로서, 상기 치료는 상기 환자에서 비정상 근육 병리의 진행을 감소시키고/거나, 비정상 근육 병리를 역전시키는, 용도.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063024941P | 2020-05-14 | 2020-05-14 | |
| US63/024,941 | 2020-05-14 | ||
| US202063109677P | 2020-11-04 | 2020-11-04 | |
| US63/109,677 | 2020-11-04 | ||
| US202163180379P | 2021-04-27 | 2021-04-27 | |
| US63/180,379 | 2021-04-27 | ||
| PCT/US2021/032451 WO2021231863A1 (en) | 2020-05-14 | 2021-05-14 | Compositions useful for treatment of pompe disease |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230010255A true KR20230010255A (ko) | 2023-01-18 |
Family
ID=78525047
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227043641A KR20230010255A (ko) | 2020-05-14 | 2021-05-14 | 폼페병의 치료에 유용한 조성물 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20230173108A1 (ko) |
| EP (1) | EP4149519A1 (ko) |
| JP (1) | JP2023526923A (ko) |
| KR (1) | KR20230010255A (ko) |
| CN (1) | CN115916334A (ko) |
| AU (1) | AU2021273273A1 (ko) |
| BR (1) | BR112022022704A2 (ko) |
| CA (1) | CA3177954A1 (ko) |
| CL (1) | CL2022003132A1 (ko) |
| CO (1) | CO2022017224A2 (ko) |
| IL (1) | IL298178A (ko) |
| MX (1) | MX2022014255A (ko) |
| WO (1) | WO2021231863A1 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024003687A1 (en) * | 2022-06-28 | 2024-01-04 | Pfizer Inc. | Nucleic acids encoding acid alpha-glucosidase (gaa) and vectors for gene therapy |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120322861A1 (en) * | 2007-02-23 | 2012-12-20 | Barry John Byrne | Compositions and Methods for Treating Diseases |
| WO2013134530A1 (en) * | 2012-03-07 | 2013-09-12 | Amicus Therapeutics, Inc. | High concentration alpha-glucosidase compositions for the treatment of pompe disease |
| ES2862526T3 (es) * | 2014-01-21 | 2021-10-07 | Univ Brussel Vrije | Elementos reguladores de ácido nucleico específicos de músculo y métodos y uso de los mismos |
| US20170037431A1 (en) * | 2014-05-01 | 2017-02-09 | University Of Washington | In vivo Gene Engineering with Adenoviral Vectors |
| WO2019060454A2 (en) * | 2017-09-20 | 2019-03-28 | 4D Molecular Therapeutics Inc. | CAPSID VARIANT ADENO-ASSOCIATED VIRUSES AND METHODS OF USE |
| JP2021521851A (ja) * | 2018-04-30 | 2021-08-30 | アミカス セラピューティックス インコーポレイテッド | 遺伝子治療構築物及び使用方法 |
| KR20220004696A (ko) * | 2019-04-30 | 2022-01-11 | 더 트러스티스 오브 더 유니버시티 오브 펜실베니아 | 폼페병의 치료에 유용한 조성물 |
-
2021
- 2021-05-14 CA CA3177954A patent/CA3177954A1/en active Pending
- 2021-05-14 IL IL298178A patent/IL298178A/en unknown
- 2021-05-14 MX MX2022014255A patent/MX2022014255A/es unknown
- 2021-05-14 CN CN202180049054.5A patent/CN115916334A/zh active Pending
- 2021-05-14 BR BR112022022704A patent/BR112022022704A2/pt unknown
- 2021-05-14 JP JP2022569264A patent/JP2023526923A/ja active Pending
- 2021-05-14 US US17/998,371 patent/US20230173108A1/en active Pending
- 2021-05-14 EP EP21804731.4A patent/EP4149519A1/en active Pending
- 2021-05-14 WO PCT/US2021/032451 patent/WO2021231863A1/en unknown
- 2021-05-14 AU AU2021273273A patent/AU2021273273A1/en active Pending
- 2021-05-14 KR KR1020227043641A patent/KR20230010255A/ko active Search and Examination
-
2022
- 2022-11-10 CL CL2022003132A patent/CL2022003132A1/es unknown
- 2022-11-30 CO CONC2022/0017224A patent/CO2022017224A2/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CL2022003132A1 (es) | 2023-05-19 |
| CN115916334A (zh) | 2023-04-04 |
| BR112022022704A2 (pt) | 2023-03-28 |
| IL298178A (en) | 2023-01-01 |
| US20230173108A1 (en) | 2023-06-08 |
| JP2023526923A (ja) | 2023-06-26 |
| EP4149519A1 (en) | 2023-03-22 |
| WO2021231863A1 (en) | 2021-11-18 |
| MX2022014255A (es) | 2022-12-07 |
| CA3177954A1 (en) | 2021-11-18 |
| CO2022017224A2 (es) | 2023-02-16 |
| AU2021273273A1 (en) | 2023-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220193261A1 (en) | Compositions useful for treatment of pompe disease | |
| US20240009327A1 (en) | Gene therapy for mucopolysaccharidosis iiib | |
| US20230365955A1 (en) | Compositions and methods for treatment of fabry disease | |
| US20220370638A1 (en) | Compositions and methods for treatment of maple syrup urine disease | |
| KR20230010255A (ko) | 폼페병의 치료에 유용한 조성물 | |
| JP2022553406A (ja) | 導入遺伝子発現のdrg特異的低減のための組成物 | |
| US20240115733A1 (en) | Compositions and methods for treatment of niemann pick type a disease | |
| CN117897492A (zh) | 用于肌肉和cns中的基因表达的杂合启动子 | |
| WO2023102517A1 (en) | Compositions and methods for treatment of fabry disease |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |