KR20220165645A - 지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도 - Google Patents
지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도 Download PDFInfo
- Publication number
- KR20220165645A KR20220165645A KR1020220059678A KR20220059678A KR20220165645A KR 20220165645 A KR20220165645 A KR 20220165645A KR 1020220059678 A KR1020220059678 A KR 1020220059678A KR 20220059678 A KR20220059678 A KR 20220059678A KR 20220165645 A KR20220165645 A KR 20220165645A
- Authority
- KR
- South Korea
- Prior art keywords
- leu
- ala
- ser
- gly
- val
- Prior art date
Links
- 108090000623 proteins and genes Proteins 0.000 title claims abstract description 114
- YLOYKYXNDHOHHT-UHFFFAOYSA-N Atranorin Chemical compound CC1=C(O)C(C(=O)OC)=C(C)C=C1OC(=O)C1=C(C)C=C(O)C(C=O)=C1O YLOYKYXNDHOHHT-UHFFFAOYSA-N 0.000 title claims abstract description 68
- 230000015572 biosynthetic process Effects 0.000 title claims abstract description 45
- WXIWFYPSEZFDBC-UHFFFAOYSA-N Baeomycessaeure-methylester Natural products COC(=O)c1c(C)cc(OC(=O)c2c(C)cc(OC)c(C=O)c2O)c(C)c1O WXIWFYPSEZFDBC-UHFFFAOYSA-N 0.000 title claims abstract description 23
- CLXBGZHFHKNPHQ-UHFFFAOYSA-N atranorin Natural products COC(=O)c1c(C)cc(OC(=O)c2c(C)c(O)cc(C=O)c2O)c(C)c1O CLXBGZHFHKNPHQ-UHFFFAOYSA-N 0.000 title claims abstract description 23
- 241001040161 Stereocaulon alpinum Species 0.000 claims abstract description 51
- 241000222197 Ascochyta rabiei Species 0.000 claims abstract description 30
- 238000004519 manufacturing process Methods 0.000 claims abstract description 28
- 230000001851 biosynthetic effect Effects 0.000 claims description 47
- 244000005700 microbiome Species 0.000 claims description 42
- 239000002207 metabolite Substances 0.000 claims description 32
- 239000013604 expression vector Substances 0.000 claims description 27
- 241000894007 species Species 0.000 claims description 21
- COUKTHZXLGYKPK-UHFFFAOYSA-N Norbabatinsaeure Natural products CC1=CC(O)=C(C)C(O)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1C COUKTHZXLGYKPK-UHFFFAOYSA-N 0.000 claims description 18
- 238000000034 method Methods 0.000 claims description 18
- 238000003259 recombinant expression Methods 0.000 claims description 16
- 238000012258 culturing Methods 0.000 claims description 15
- DUIBXZLCROUOFD-UHFFFAOYSA-N Baeomycesic acid Chemical compound OC1=C(C=O)C(OC)=CC(C)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1C DUIBXZLCROUOFD-UHFFFAOYSA-N 0.000 claims description 10
- ODMVDRJFBPXTRQ-UHFFFAOYSA-N proatranorin I Chemical compound CC1=C(O)C(C(=O)OC)=C(C)C=C1OC(=O)C1=C(C)C=C(O)C(C)=C1O ODMVDRJFBPXTRQ-UHFFFAOYSA-N 0.000 claims description 6
- 229930000044 secondary metabolite Natural products 0.000 abstract description 15
- 239000000203 mixture Substances 0.000 abstract description 10
- 235000013305 food Nutrition 0.000 abstract description 5
- 235000013376 functional food Nutrition 0.000 abstract description 3
- 239000008194 pharmaceutical composition Substances 0.000 abstract description 3
- 241000221635 Cladonia Species 0.000 description 56
- 108010030975 Polyketide Synthases Proteins 0.000 description 55
- 108020004414 DNA Proteins 0.000 description 54
- 101150005771 ATR1 gene Proteins 0.000 description 40
- 241000233866 Fungi Species 0.000 description 31
- 235000018102 proteins Nutrition 0.000 description 29
- 102000004169 proteins and genes Human genes 0.000 description 29
- 150000001875 compounds Chemical class 0.000 description 28
- 239000013612 plasmid Substances 0.000 description 28
- WEYVVCKOOFYHRW-UHFFFAOYSA-N usnic acid Chemical compound CC12C(=O)C(C(=O)C)=C(O)C=C1OC1=C2C(O)=C(C)C(O)=C1C(C)=O WEYVVCKOOFYHRW-UHFFFAOYSA-N 0.000 description 28
- 101100328015 Arabidopsis thaliana CIPK21 gene Proteins 0.000 description 23
- 101100136773 Dictyostelium discoideum pks23 gene Proteins 0.000 description 23
- 102100029437 Serine/threonine-protein kinase A-Raf Human genes 0.000 description 23
- 230000014509 gene expression Effects 0.000 description 22
- 241000724790 Cladonia uncialis Species 0.000 description 21
- 239000002253 acid Substances 0.000 description 20
- 210000004027 cell Anatomy 0.000 description 20
- 102000004190 Enzymes Human genes 0.000 description 19
- 108090000790 Enzymes Proteins 0.000 description 19
- 241001087607 Cladonia borealis Species 0.000 description 18
- 241001469282 Cladonia metacorallifera Species 0.000 description 17
- 241000158001 Cladonia rangiferina Species 0.000 description 17
- 238000010367 cloning Methods 0.000 description 17
- 235000019867 fractionated palm kernal oil Nutrition 0.000 description 17
- 108091008053 gene clusters Proteins 0.000 description 17
- 239000000126 substance Substances 0.000 description 17
- 238000005481 NMR spectroscopy Methods 0.000 description 16
- 239000000463 material Substances 0.000 description 15
- 239000002773 nucleotide Substances 0.000 description 15
- 125000003729 nucleotide group Chemical group 0.000 description 15
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 14
- 238000004458 analytical method Methods 0.000 description 14
- 230000001054 cortical effect Effects 0.000 description 14
- YTJJRAWFHJBAMT-UHFFFAOYSA-N depside Natural products OC(=O)CC1=C(O)C=C(O)C=C1OC(=O)C1=CC=C(O)C(O)=C1 YTJJRAWFHJBAMT-UHFFFAOYSA-N 0.000 description 14
- ICTZCAHDGHPRQR-UHFFFAOYSA-N usnic acid Natural products OC1=C(C)C(O)=C(C(C)=O)C2=C1C1(C)C(O)=C(C(=O)C)C(=O)C=C1O2 ICTZCAHDGHPRQR-UHFFFAOYSA-N 0.000 description 14
- 229940004858 usnic acid Drugs 0.000 description 14
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 12
- 241001486095 Cladonia macilenta Species 0.000 description 12
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 12
- 101710128228 O-methyltransferase Proteins 0.000 description 12
- ZRWPUFFVAOMMNM-UHFFFAOYSA-N Patulin Chemical compound OC1OCC=C2OC(=O)C=C12 ZRWPUFFVAOMMNM-UHFFFAOYSA-N 0.000 description 12
- 238000010240 RT-PCR analysis Methods 0.000 description 12
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 12
- 101150037491 SOL1 gene Proteins 0.000 description 11
- 230000002068 genetic effect Effects 0.000 description 11
- 101100096184 Alternaria solani sol5 gene Proteins 0.000 description 10
- 101710116650 FAD-dependent monooxygenase Proteins 0.000 description 10
- 108091081630 PKS family Proteins 0.000 description 10
- 108010050848 glycylleucine Proteins 0.000 description 10
- 238000004128 high performance liquid chromatography Methods 0.000 description 10
- 239000002609 medium Substances 0.000 description 10
- HEMSJKZDHNSSEW-UHFFFAOYSA-N o-orsellinate depside Chemical compound CC1=CC(O)=CC(O)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1 HEMSJKZDHNSSEW-UHFFFAOYSA-N 0.000 description 10
- 241000351920 Aspergillus nidulans Species 0.000 description 9
- 101000894943 Aspergillus terreus (strain NIH 2624 / FGSC A1156) Non-reducing polyketide synthase ATEG_07661 Proteins 0.000 description 9
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 101100176930 Niallia circulans bgc gene Proteins 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 230000002538 fungal effect Effects 0.000 description 9
- 238000003012 network analysis Methods 0.000 description 9
- ATQPZSQVWCPVGV-UHFFFAOYSA-N Gyrophoric acid Chemical compound CC1=CC(O)=CC(O)=C1C(=O)OC(C=C1O)=CC(C)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1 ATQPZSQVWCPVGV-UHFFFAOYSA-N 0.000 description 8
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 8
- 108010047495 alanylglycine Proteins 0.000 description 8
- 238000010586 diagram Methods 0.000 description 8
- RHMXXJGYXNZAPX-UHFFFAOYSA-N emodin Chemical compound C1=C(O)C=C2C(=O)C3=CC(C)=CC(O)=C3C(=O)C2=C1O RHMXXJGYXNZAPX-UHFFFAOYSA-N 0.000 description 8
- VASFLQKDXBAWEL-UHFFFAOYSA-N emodin Natural products OC1=C(OC2=C(C=CC(=C2C1=O)O)O)C1=CC=C(C=C1)O VASFLQKDXBAWEL-UHFFFAOYSA-N 0.000 description 8
- 229930001119 polyketide Natural products 0.000 description 8
- 239000001965 potato dextrose agar Substances 0.000 description 8
- 239000000047 product Substances 0.000 description 8
- QQTKVXCQLZIJPP-UHFFFAOYSA-N salazinic acid Chemical compound O1C2=C3C(O)OC(=O)C3=C(O)C(CO)=C2OC(=O)C2=C1C(C=O)=C(O)C=C2C QQTKVXCQLZIJPP-UHFFFAOYSA-N 0.000 description 8
- MQSXZQXHIJMNAF-UHFFFAOYSA-N skyrin Chemical compound O=C1C2=C(O)C=C(C)C=C2C(=O)C2=C1C(O)=CC(O)=C2C1=C(C(=O)C=2C(=C(O)C=C(C=2)C)C2=O)C2=C(O)C=C1O MQSXZQXHIJMNAF-UHFFFAOYSA-N 0.000 description 8
- 108030002614 6-methylsalicylic acid synthases Proteins 0.000 description 7
- 101100496019 Arabidopsis thaliana CIPK16 gene Proteins 0.000 description 7
- VWDXGKUTGQJJHJ-UHFFFAOYSA-N Catenarin Natural products C1=C(O)C=C2C(=O)C3=C(O)C(C)=CC(O)=C3C(=O)C2=C1O VWDXGKUTGQJJHJ-UHFFFAOYSA-N 0.000 description 7
- 241001123662 Cladonia grayi Species 0.000 description 7
- 101100464225 Dictyostelium discoideum pks30 gene Proteins 0.000 description 7
- 101100244111 Dictyostelium discoideum stlA gene Proteins 0.000 description 7
- 239000010282 Emodin Substances 0.000 description 7
- RBLJKYCRSCQLRP-UHFFFAOYSA-N Emodin-dianthron Natural products O=C1C2=CC(C)=CC(O)=C2C(=O)C2=C1CC(=O)C=C2O RBLJKYCRSCQLRP-UHFFFAOYSA-N 0.000 description 7
- YOOXNSPYGCZLAX-UHFFFAOYSA-N Helminthosporin Natural products C1=CC(O)=C2C(=O)C3=CC(C)=CC(O)=C3C(=O)C2=C1O YOOXNSPYGCZLAX-UHFFFAOYSA-N 0.000 description 7
- 101100288095 Klebsiella pneumoniae neo gene Proteins 0.000 description 7
- 101100185019 Mycobacterium bovis (strain ATCC BAA-935 / AF2122/97) pks15/1 gene Proteins 0.000 description 7
- 101150084980 PKS1 gene Proteins 0.000 description 7
- NTGIIKCGBNGQAR-UHFFFAOYSA-N Rheoemodin Natural products C1=C(O)C=C2C(=O)C3=CC(O)=CC(O)=C3C(=O)C2=C1O NTGIIKCGBNGQAR-UHFFFAOYSA-N 0.000 description 7
- 101100136769 Sarocladium schorii aspks1 gene Proteins 0.000 description 7
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 7
- 239000000284 extract Substances 0.000 description 7
- 229910052757 nitrogen Inorganic materials 0.000 description 7
- PKUBGLYEOAJPEG-UHFFFAOYSA-N physcion Natural products C1=C(C)C=C2C(=O)C3=CC(C)=CC(O)=C3C(=O)C2=C1O PKUBGLYEOAJPEG-UHFFFAOYSA-N 0.000 description 7
- 101150118599 pks15 gene Proteins 0.000 description 7
- 150000003881 polyketide derivatives Chemical class 0.000 description 7
- 238000004885 tandem mass spectrometry Methods 0.000 description 7
- 239000013598 vector Substances 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 6
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 6
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 6
- 101100006464 Arabidopsis thaliana CIPK10 gene Proteins 0.000 description 6
- 101100496009 Arabidopsis thaliana CIPK11 gene Proteins 0.000 description 6
- 101100006448 Arabidopsis thaliana CIPK2 gene Proteins 0.000 description 6
- ABZLZZCDSLOCNF-UHFFFAOYSA-N Chloroatranorin Chemical compound CC1=C(O)C(C(=O)OC)=C(C)C=C1OC(=O)C1=C(C)C(Cl)=C(O)C(C=O)=C1O ABZLZZCDSLOCNF-UHFFFAOYSA-N 0.000 description 6
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 6
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 6
- 101100056018 Homo sapiens ARAF gene Proteins 0.000 description 6
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 6
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 6
- 101150028297 PKS2 gene Proteins 0.000 description 6
- 101150081455 PKS5 gene Proteins 0.000 description 6
- UTQKMDZXMYCSCI-UHFFFAOYSA-N Rhodocladonic acid Chemical compound C1=C2C(=O)C(OC)=C(O)C(=O)C2=C(O)C2=C1OC(C(C)=O)=C2O UTQKMDZXMYCSCI-UHFFFAOYSA-N 0.000 description 6
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 6
- 150000001413 amino acids Chemical group 0.000 description 6
- 229910052799 carbon Inorganic materials 0.000 description 6
- 229940125782 compound 2 Drugs 0.000 description 6
- 238000000605 extraction Methods 0.000 description 6
- 108010049041 glutamylalanine Proteins 0.000 description 6
- 239000003550 marker Substances 0.000 description 6
- IEVVSJFLBYOUCJ-UHFFFAOYSA-N norstictic acid Chemical compound O1C2=C3C(O)OC(=O)C3=C(O)C(C)=C2OC(=O)C2=C1C(C=O)=C(O)C=C2C IEVVSJFLBYOUCJ-UHFFFAOYSA-N 0.000 description 6
- 238000013081 phylogenetic analysis Methods 0.000 description 6
- 101150054749 pks16 gene Proteins 0.000 description 6
- 230000002829 reductive effect Effects 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- -1 ussnic acid) Chemical compound 0.000 description 6
- 101100496011 Arabidopsis thaliana CIPK12 gene Proteins 0.000 description 5
- 101100496015 Arabidopsis thaliana CIPK14 gene Proteins 0.000 description 5
- 101100496025 Arabidopsis thaliana CIPK19 gene Proteins 0.000 description 5
- 101100328017 Arabidopsis thaliana CIPK22 gene Proteins 0.000 description 5
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 5
- 102000002004 Cytochrome P-450 Enzyme System Human genes 0.000 description 5
- 101100297766 Dictyostelium discoideum pks14 gene Proteins 0.000 description 5
- 101100136771 Dictyostelium discoideum pks21 gene Proteins 0.000 description 5
- 101100136774 Dictyostelium discoideum pks24 gene Proteins 0.000 description 5
- 101000788834 Gibberella zeae (strain ATCC MYA-4620 / CBS 123657 / FGSC 9075 / NRRL 31084 / PH-1) Non-reducing polyketide synthase ZEA1 Proteins 0.000 description 5
- 241000003856 Parmelia Species 0.000 description 5
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 5
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 5
- HEDRZPFGACZZDS-UHFFFAOYSA-N chloroform Substances ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 5
- 229940125904 compound 1 Drugs 0.000 description 5
- 244000000004 fungal plant pathogen Species 0.000 description 5
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 5
- 108010077515 glycylproline Proteins 0.000 description 5
- 108010034529 leucyl-lysine Proteins 0.000 description 5
- 238000001294 liquid chromatography-tandem mass spectrometry Methods 0.000 description 5
- 238000013507 mapping Methods 0.000 description 5
- 108020004999 messenger RNA Proteins 0.000 description 5
- 230000002503 metabolic effect Effects 0.000 description 5
- 239000000049 pigment Substances 0.000 description 5
- 239000002243 precursor Substances 0.000 description 5
- 230000003595 spectral effect Effects 0.000 description 5
- 238000001228 spectrum Methods 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- ADTVCAUSELVFML-UHFFFAOYSA-N 1-heptyl-3-hydroxy-9-methoxy-7-methyl-6-oxobenzo[b][1,4]benzodioxepine-2-carboxylic acid Chemical compound CCCCCCCc1c2Oc3cc(OC)cc(C)c3C(=O)Oc2cc(O)c1C(O)=O ADTVCAUSELVFML-UHFFFAOYSA-N 0.000 description 4
- 101100442979 Alternaria brassicicola DEP5 gene Proteins 0.000 description 4
- NLXLAEXVIDQMFP-UHFFFAOYSA-N Ammonia chloride Chemical compound [NH4+].[Cl-] NLXLAEXVIDQMFP-UHFFFAOYSA-N 0.000 description 4
- 101100006452 Arabidopsis thaliana CIPK4 gene Proteins 0.000 description 4
- 241000894006 Bacteria Species 0.000 description 4
- NMKBRSYSHBPUPY-UHFFFAOYSA-N Barbatic acid Chemical compound OC1=C(C)C(OC)=CC(C)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1C NMKBRSYSHBPUPY-UHFFFAOYSA-N 0.000 description 4
- 101100188716 Beauveria bassiana (strain ARSEF 2860) OpS1 gene Proteins 0.000 description 4
- VTYYLEPIZMXCLO-UHFFFAOYSA-L Calcium carbonate Chemical compound [Ca+2].[O-]C([O-])=O VTYYLEPIZMXCLO-UHFFFAOYSA-L 0.000 description 4
- 108091026890 Coding region Proteins 0.000 description 4
- 101000979117 Curvularia clavata Nonribosomal peptide synthetase Proteins 0.000 description 4
- 241000229041 Cyanodermella asteris Species 0.000 description 4
- WJXSYUJKJSOJOG-UHFFFAOYSA-N Fallacinol Chemical compound C1=C(CO)C=C2C(=O)C3=CC(OC)=CC(O)=C3C(=O)C2=C1O WJXSYUJKJSOJOG-UHFFFAOYSA-N 0.000 description 4
- 101100120672 Gibberella zeae (strain ATCC MYA-4620 / CBS 123657 / FGSC 9075 / NRRL 31084 / PH-1) FSL1 gene Proteins 0.000 description 4
- 101000788825 Gibberella zeae (strain ATCC MYA-4620 / CBS 123657 / FGSC 9075 / NRRL 31084 / PH-1) Highly reducing polyketide synthase ZEA2 Proteins 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- 108091092195 Intron Proteins 0.000 description 4
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 4
- 241001326543 Lecanoromycetes Species 0.000 description 4
- 241000880493 Leptailurus serval Species 0.000 description 4
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 4
- CSNNHWWHGAXBCP-UHFFFAOYSA-L Magnesium sulfate Chemical compound [Mg+2].[O-][S+2]([O-])([O-])[O-] CSNNHWWHGAXBCP-UHFFFAOYSA-L 0.000 description 4
- 238000007476 Maximum Likelihood Methods 0.000 description 4
- 108010079364 N-glycylalanine Proteins 0.000 description 4
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 4
- DRYDKQOPVBDZMQ-UHFFFAOYSA-N Secalonic acid A Natural products COC(=O)C12Oc3ccc(c(O)c3C(=O)C1=C(O)CC(C)C2O)c4ccc5OC6(C(O)C(C)CC(=C6C(=O)c5c4O)O)C(=O)OC DRYDKQOPVBDZMQ-UHFFFAOYSA-N 0.000 description 4
- CPHXGYQLOSNELY-UHFFFAOYSA-N Sekikaic acid Chemical compound CCCC1=CC(OC)=CC(O)=C1C(=O)OC1=C(O)C(C(O)=O)=C(CCC)C=C1OC CPHXGYQLOSNELY-UHFFFAOYSA-N 0.000 description 4
- RNCJCRJLNVRWJX-UHFFFAOYSA-N Thamnolic acid Chemical compound OC1=C(C(O)=O)C(OC)=CC(C)=C1C(=O)OC1=C(C)C(C(O)=O)=C(O)C(C=O)=C1O RNCJCRJLNVRWJX-UHFFFAOYSA-N 0.000 description 4
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 4
- 241000003866 Umbilicaria Species 0.000 description 4
- RLRCNRNYRSKNOO-UHFFFAOYSA-N Umbilicaric acid Chemical compound COc1cc(O)cc(C)c1C(=O)Oc1cc(C)c(C(=O)Oc2cc(C)c(C(O)=O)c(O)c2)c(O)c1 RLRCNRNYRSKNOO-UHFFFAOYSA-N 0.000 description 4
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 4
- 108010087924 alanylproline Proteins 0.000 description 4
- 108010062796 arginyllysine Proteins 0.000 description 4
- 108010093581 aspartyl-proline Proteins 0.000 description 4
- 238000010276 construction Methods 0.000 description 4
- TXCDCPKCNAJMEE-UHFFFAOYSA-N dibenzofuran Chemical compound C1=CC=C2C3=CC=CC=C3OC2=C1 TXCDCPKCNAJMEE-UHFFFAOYSA-N 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 235000013312 flour Nutrition 0.000 description 4
- 239000007789 gas Substances 0.000 description 4
- 108010078144 glutaminyl-glycine Proteins 0.000 description 4
- 108010057821 leucylproline Proteins 0.000 description 4
- 108010003700 lysyl aspartic acid Proteins 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 150000007524 organic acids Chemical class 0.000 description 4
- 235000005985 organic acids Nutrition 0.000 description 4
- 108010053725 prolylvaline Proteins 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 235000002639 sodium chloride Nutrition 0.000 description 4
- 108010061238 threonyl-glycine Proteins 0.000 description 4
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 4
- 108010073969 valyllysine Proteins 0.000 description 4
- 101150100859 45 gene Proteins 0.000 description 3
- ZIWWTZWAKYBUOB-CIUDSAMLSA-N Ala-Asp-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O ZIWWTZWAKYBUOB-CIUDSAMLSA-N 0.000 description 3
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 3
- 101100496027 Arabidopsis thaliana CIPK20 gene Proteins 0.000 description 3
- 101100328019 Arabidopsis thaliana CIPK23 gene Proteins 0.000 description 3
- 101100006450 Arabidopsis thaliana CIPK3 gene Proteins 0.000 description 3
- 241000228212 Aspergillus Species 0.000 description 3
- 241001465318 Aspergillus terreus Species 0.000 description 3
- 108010078791 Carrier Proteins Proteins 0.000 description 3
- 101100244102 Dictyostelium discoideum pks17 gene Proteins 0.000 description 3
- 101100464229 Dictyostelium discoideum pks34 gene Proteins 0.000 description 3
- IDZVZCQOFFSQMO-UHFFFAOYSA-N Didymic acid Chemical compound O1C2=CC(OC)=CC(CCC)=C2C2=C1C=C(O)C(C(O)=O)=C2CCCCC IDZVZCQOFFSQMO-UHFFFAOYSA-N 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- 241001445901 Endocarpon pusillum Species 0.000 description 3
- OGPMEHXDIDDMDJ-UHFFFAOYSA-N Erythroglancin Natural products COc1cc(O)c2C(=O)c3c(O)cc(OC)c(O)c3C(=O)c2c1 OGPMEHXDIDDMDJ-UHFFFAOYSA-N 0.000 description 3
- 241000221778 Fusarium fujikuroi Species 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- 235000010469 Glycine max Nutrition 0.000 description 3
- 101710093129 Hybrid PKS-NRPS synthetase poxE Proteins 0.000 description 3
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 3
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 3
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 3
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 3
- 101100004147 Metarhizium anisopliae Ba17a gene Proteins 0.000 description 3
- 101710119097 Methylphloroacetophenone synthase Proteins 0.000 description 3
- 102000008109 Mixed Function Oxygenases Human genes 0.000 description 3
- 108010074633 Mixed Function Oxygenases Proteins 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- 101710198130 NADPH-cytochrome P450 reductase Proteins 0.000 description 3
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 3
- 241001123663 Penicillium expansum Species 0.000 description 3
- ZLGQEBCCANLYRA-RYUDHWBXSA-N Phe-Gly-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O ZLGQEBCCANLYRA-RYUDHWBXSA-N 0.000 description 3
- KWYUFKZDYYNOTN-UHFFFAOYSA-M Potassium hydroxide Chemical compound [OH-].[K+] KWYUFKZDYYNOTN-UHFFFAOYSA-M 0.000 description 3
- 241000696789 Sclerophora sanguinea Species 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- RKKPUBAAIGFXOG-YTXTXJHMSA-N Sorbicillin Chemical compound C\C=C\C=C\C(=O)C1=CC(C)=C(O)C(C)=C1O RKKPUBAAIGFXOG-YTXTXJHMSA-N 0.000 description 3
- 229920002472 Starch Polymers 0.000 description 3
- MHOOPNKRBMHHEC-UHFFFAOYSA-N Terrein Natural products CC=CC1=CC(=O)C(O)C1O MHOOPNKRBMHHEC-UHFFFAOYSA-N 0.000 description 3
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 3
- 240000008042 Zea mays Species 0.000 description 3
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 3
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 3
- 229910021529 ammonia Inorganic materials 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 3
- 108010047857 aspartylglycine Proteins 0.000 description 3
- 229940125898 compound 5 Drugs 0.000 description 3
- JJNLMPAFVQRTIH-UHFFFAOYSA-N condidymic acid Natural products O1C2=CC(O)=C(C(O)=O)C(CCCCC)=C2C2=C1C=C(OC)C=C2CCCCC JJNLMPAFVQRTIH-UHFFFAOYSA-N 0.000 description 3
- 235000005822 corn Nutrition 0.000 description 3
- HTNKGHXSGYCDDM-UHFFFAOYSA-N crystazarin Natural products COC1=CC(O)=C2C(=O)C(CC)=C(O)C(=O)C2=C1O HTNKGHXSGYCDDM-UHFFFAOYSA-N 0.000 description 3
- 239000012634 fragment Substances 0.000 description 3
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 3
- 238000012268 genome sequencing Methods 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 3
- 108010079547 glutamylmethionine Proteins 0.000 description 3
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 3
- 108010010147 glycylglutamine Proteins 0.000 description 3
- 238000002114 high-resolution electrospray ionisation mass spectrometry Methods 0.000 description 3
- 150000002500 ions Chemical class 0.000 description 3
- 108010017391 lysylvaline Proteins 0.000 description 3
- 108010056582 methionylglutamic acid Proteins 0.000 description 3
- 108010005942 methionylglycine Proteins 0.000 description 3
- 238000007069 methylation reaction Methods 0.000 description 3
- 238000002887 multiple sequence alignment Methods 0.000 description 3
- 230000003647 oxidation Effects 0.000 description 3
- 238000007254 oxidation reaction Methods 0.000 description 3
- FFWOKTFYGVYKIR-UHFFFAOYSA-N physcion Chemical compound C1=C(C)C=C2C(=O)C3=CC(OC)=CC(O)=C3C(=O)C2=C1O FFWOKTFYGVYKIR-UHFFFAOYSA-N 0.000 description 3
- 101150036718 pks12 gene Proteins 0.000 description 3
- 101150045441 pks18 gene Proteins 0.000 description 3
- 108010031719 prolyl-serine Proteins 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 108010071207 serylmethionine Proteins 0.000 description 3
- SJEYUYPBCPRFNM-UHFFFAOYSA-N sorbicillinol Natural products CC=CC=CC(=O)C1=CC(C)(O)C(=O)C(=C1O)C SJEYUYPBCPRFNM-UHFFFAOYSA-N 0.000 description 3
- 239000008107 starch Substances 0.000 description 3
- 235000019698 starch Nutrition 0.000 description 3
- 150000003505 terpenes Chemical class 0.000 description 3
- MHOOPNKRBMHHEC-HZIBQTDNSA-N terrein Chemical compound C\C=C\C1=CC(=O)[C@H](O)[C@H]1O MHOOPNKRBMHHEC-HZIBQTDNSA-N 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- QNQZPJLBGRQFDD-ZMSORURPSA-N (2r,3r,4r,5r)-2-[(1s,2s,3r,4s,6r)-4,6-diamino-3-[(2s,3r,4r,5s,6r)-3-amino-4,5-dihydroxy-6-[(1r)-1-hydroxyethyl]oxan-2-yl]oxy-2-hydroxycyclohexyl]oxy-5-methyl-4-(methylamino)oxane-3,5-diol;sulfuric acid Chemical compound OS(O)(=O)=O.O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H]([C@@H](C)O)O2)N)[C@@H](N)C[C@H]1N QNQZPJLBGRQFDD-ZMSORURPSA-N 0.000 description 2
- FUCWJKJZOHOLEO-UHFFFAOYSA-N 10-formyl-9-hydroxy-3-methoxy-4,7-dimethyl-6-oxo-1-benzo[b][1,4]benzodioxepincarboxylic acid Chemical compound O=C1OC2=C(C)C(OC)=CC(C(O)=O)=C2OC2=C(C=O)C(O)=CC(C)=C21 FUCWJKJZOHOLEO-UHFFFAOYSA-N 0.000 description 2
- GODLCSLPZIBRMG-UHFFFAOYSA-N 2-hydroxy-4-[(2-hydroxy-4-methoxy-6-methylphenyl)-oxomethoxy]-6-methylbenzoic acid Chemical compound OC1=CC(OC)=CC(C)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1 GODLCSLPZIBRMG-UHFFFAOYSA-N 0.000 description 2
- FKJXMYJPOKQPSS-UHFFFAOYSA-N 3,5,10-trihydroxy-7-methoxy-3-methyl-1,4-dihydrobenzo[g]isochromene-6,9-dione Chemical compound C1OC(C)(O)CC2=C1C(O)=C1C(=O)C=C(OC)C(=O)C1=C2O FKJXMYJPOKQPSS-UHFFFAOYSA-N 0.000 description 2
- JHEWMLHQNRHTQX-UHFFFAOYSA-N 3-hydroxy-9-methoxy-6-oxo-7-(1-oxopentyl)-1-pentyl-2-benzo[b][1,4]benzodioxepincarboxylic acid Chemical compound O=C1OC2=CC(O)=C(C(O)=O)C(CCCCC)=C2OC2=CC(OC)=CC(C(=O)CCCC)=C21 JHEWMLHQNRHTQX-UHFFFAOYSA-N 0.000 description 2
- DHLPMLVSBRRUGA-RXMQYKEDSA-N 6-hydroxymellein Chemical compound OC1=CC(O)=C2C(=O)O[C@H](C)CC2=C1 DHLPMLVSBRRUGA-RXMQYKEDSA-N 0.000 description 2
- 101710197633 Actin-1 Proteins 0.000 description 2
- 229920001817 Agar Polymers 0.000 description 2
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 2
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 2
- QHASENCZLDHBGX-ONGXEEELSA-N Ala-Gly-Phe Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QHASENCZLDHBGX-ONGXEEELSA-N 0.000 description 2
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 2
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 2
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 2
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 2
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 2
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 2
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 2
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 2
- 241000158050 Alectoria sarmentosa Species 0.000 description 2
- 239000004254 Ammonium phosphate Substances 0.000 description 2
- 101100496023 Arabidopsis thaliana CIPK18 gene Proteins 0.000 description 2
- RFXXUWGNVRJTNQ-QXEWZRGKSA-N Arg-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N RFXXUWGNVRJTNQ-QXEWZRGKSA-N 0.000 description 2
- LLUGJARLJCGLAR-CYDGBPFRSA-N Arg-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N LLUGJARLJCGLAR-CYDGBPFRSA-N 0.000 description 2
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 2
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 2
- XKRFYHLGVUSROY-UHFFFAOYSA-N Argon Chemical compound [Ar] XKRFYHLGVUSROY-UHFFFAOYSA-N 0.000 description 2
- 241001532591 Arthonia radiata Species 0.000 description 2
- AWXDRZJQCVHCIT-DCAQKATOSA-N Asn-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O AWXDRZJQCVHCIT-DCAQKATOSA-N 0.000 description 2
- VILLWIDTHYPSLC-PEFMBERDSA-N Asp-Glu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VILLWIDTHYPSLC-PEFMBERDSA-N 0.000 description 2
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 2
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 2
- GKWFMNNNYZHJHV-SRVKXCTJSA-N Asp-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O GKWFMNNNYZHJHV-SRVKXCTJSA-N 0.000 description 2
- BRRPVTUFESPTCP-ACZMJKKPSA-N Asp-Ser-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O BRRPVTUFESPTCP-ACZMJKKPSA-N 0.000 description 2
- 240000006439 Aspergillus oryzae Species 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- 101100447462 Brugia malayi G3PD gene Proteins 0.000 description 2
- 241001648266 Cetradonia linearis Species 0.000 description 2
- 244000045195 Cicer arietinum Species 0.000 description 2
- 235000010523 Cicer arietinum Nutrition 0.000 description 2
- 241000221197 Cladonia chlorophaea Species 0.000 description 2
- 241000195493 Cryptophyta Species 0.000 description 2
- 241000192700 Cyanobacteria Species 0.000 description 2
- GSNRZJNHMVMOFV-ACZMJKKPSA-N Cys-Asp-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N GSNRZJNHMVMOFV-ACZMJKKPSA-N 0.000 description 2
- 108010015742 Cytochrome P-450 Enzyme System Proteins 0.000 description 2
- DLVJMFOLJOOWFS-UHFFFAOYSA-N Depudecin Natural products CC(O)C1OC1C=CC1C(C(O)C=C)O1 DLVJMFOLJOOWFS-UHFFFAOYSA-N 0.000 description 2
- 101100366918 Dictyostelium discoideum StlB gene Proteins 0.000 description 2
- 101100136772 Dictyostelium discoideum pks22 gene Proteins 0.000 description 2
- 241001326550 Dothideomycetes Species 0.000 description 2
- 108700024394 Exon Proteins 0.000 description 2
- RTBAOFRCWWQFHB-UHFFFAOYSA-N Fragilin Chemical compound O=C1C2=CC(C)=CC(O)=C2C(=O)C2=C1C=C(OC)C(Cl)=C2O RTBAOFRCWWQFHB-UHFFFAOYSA-N 0.000 description 2
- 229930091371 Fructose Natural products 0.000 description 2
- 239000005715 Fructose Substances 0.000 description 2
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 2
- 241000223195 Fusarium graminearum Species 0.000 description 2
- YABASXUVOQODSH-UHFFFAOYSA-N Fusarubin Natural products COc1cc(O)c2C(=O)C3=C(CC(C)(O)OC3)C(=O)c2c1O YABASXUVOQODSH-UHFFFAOYSA-N 0.000 description 2
- 102100032863 General transcription factor IIH subunit 3 Human genes 0.000 description 2
- 241001460671 Glarea lozoyensis Species 0.000 description 2
- INKFLNZBTSNFON-CIUDSAMLSA-N Gln-Ala-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O INKFLNZBTSNFON-CIUDSAMLSA-N 0.000 description 2
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 2
- QYKBTDOAMKORGL-FXQIFTODSA-N Gln-Gln-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N QYKBTDOAMKORGL-FXQIFTODSA-N 0.000 description 2
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 2
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 2
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 2
- PBFGQTGPSKWHJA-QEJZJMRPSA-N Glu-Asp-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PBFGQTGPSKWHJA-QEJZJMRPSA-N 0.000 description 2
- LGYCLOCORAEQSZ-PEFMBERDSA-N Glu-Ile-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O LGYCLOCORAEQSZ-PEFMBERDSA-N 0.000 description 2
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 2
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 2
- VNCNWQPIQYAMAK-ACZMJKKPSA-N Glu-Ser-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O VNCNWQPIQYAMAK-ACZMJKKPSA-N 0.000 description 2
- PMNHJLASAAWELO-FOHZUACHSA-N Gly-Asp-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PMNHJLASAAWELO-FOHZUACHSA-N 0.000 description 2
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 2
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 2
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 2
- WZSHYFGOLPXPLL-RYUDHWBXSA-N Gly-Phe-Glu Chemical compound NCC(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CCC(O)=O)C(O)=O WZSHYFGOLPXPLL-RYUDHWBXSA-N 0.000 description 2
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 2
- NGRPGJGKJMUGDM-XVKPBYJWSA-N Gly-Val-Gln Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NGRPGJGKJMUGDM-XVKPBYJWSA-N 0.000 description 2
- 244000068988 Glycine max Species 0.000 description 2
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 2
- 101000666405 Homo sapiens General transcription factor IIH subunit 1 Proteins 0.000 description 2
- 101000655398 Homo sapiens General transcription factor IIH subunit 2 Proteins 0.000 description 2
- 101000655391 Homo sapiens General transcription factor IIH subunit 3 Proteins 0.000 description 2
- 101000655406 Homo sapiens General transcription factor IIH subunit 4 Proteins 0.000 description 2
- 101000655402 Homo sapiens General transcription factor IIH subunit 5 Proteins 0.000 description 2
- LPFBXFILACZHIB-LAEOZQHASA-N Ile-Gly-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)O)C(=O)O)N LPFBXFILACZHIB-LAEOZQHASA-N 0.000 description 2
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 2
- 108010025815 Kanamycin Kinase Proteins 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 2
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 2
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 2
- JKGHDYGZRDWHGA-SRVKXCTJSA-N Leu-Asn-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JKGHDYGZRDWHGA-SRVKXCTJSA-N 0.000 description 2
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 2
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 2
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 2
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 2
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 2
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 2
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 2
- QONKWXNJRRNTBV-AVGNSLFASA-N Leu-Pro-Met Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)O)N QONKWXNJRRNTBV-AVGNSLFASA-N 0.000 description 2
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 2
- 108090000364 Ligases Proteins 0.000 description 2
- 102000003960 Ligases Human genes 0.000 description 2
- RQGOSSYDPQTDRA-UHFFFAOYSA-N Lobaric acid Natural products O=C1OC2=CC(O)=C(C(O)=O)C(CCCCC)=C2OC2=CC(OC)=C(C(=O)CCCC)C=C21 RQGOSSYDPQTDRA-UHFFFAOYSA-N 0.000 description 2
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 2
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 2
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 2
- JHNOXVASMSXSNB-WEDXCCLWSA-N Lys-Thr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JHNOXVASMSXSNB-WEDXCCLWSA-N 0.000 description 2
- XUMBMVFBXHLACL-UHFFFAOYSA-N Melanin Chemical compound O=C1C(=O)C(C2=CNC3=C(C(C(=O)C4=C32)=O)C)=C2C4=CNC2=C1C XUMBMVFBXHLACL-UHFFFAOYSA-N 0.000 description 2
- IIPVSGPTPPURBD-UHFFFAOYSA-N Monascorubrin Natural products C1=C2C=C(C=CC)OC=C2C(=O)C2(C)C1=C(C(=O)CCCCCCC)C(=O)O2 IIPVSGPTPPURBD-UHFFFAOYSA-N 0.000 description 2
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- ZVLOGHYXGQMJBP-UHFFFAOYSA-N Oxyjavaucitin Natural products O=C1C(CO)=C(CC(C)=O)C(=O)C2=C(O)C(OC)=CC(O)=C21 ZVLOGHYXGQMJBP-UHFFFAOYSA-N 0.000 description 2
- HEULMVKOOVHXME-UHFFFAOYSA-N Parietinic acid Chemical compound C1=C(C(O)=O)C=C2C(=O)C3=CC(OC)=CC(O)=C3C(=O)C2=C1O HEULMVKOOVHXME-UHFFFAOYSA-N 0.000 description 2
- 108010077524 Peptide Elongation Factor 1 Proteins 0.000 description 2
- 239000001888 Peptone Substances 0.000 description 2
- 108010080698 Peptones Proteins 0.000 description 2
- XMPUYNHKEPFERE-IHRRRGAJSA-N Phe-Asp-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 XMPUYNHKEPFERE-IHRRRGAJSA-N 0.000 description 2
- OPEVYHFJXLCCRT-AVGNSLFASA-N Phe-Gln-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O OPEVYHFJXLCCRT-AVGNSLFASA-N 0.000 description 2
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 2
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- KVTYWHGIZSCFLG-UHFFFAOYSA-N Physodic acid Chemical compound O1C(C(=C(C(O)=O)C(O)=C2)CCCCC)=C2OC(=O)C2=C1C=C(O)C=C2CC(=O)CCCCC KVTYWHGIZSCFLG-UHFFFAOYSA-N 0.000 description 2
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 2
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 2
- HBBBLSVBQGZKOZ-GUBZILKMSA-N Pro-Met-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O HBBBLSVBQGZKOZ-GUBZILKMSA-N 0.000 description 2
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 2
- 108091008109 Pseudogenes Proteins 0.000 description 2
- 102000057361 Pseudogenes Human genes 0.000 description 2
- 108010079005 RDV peptide Proteins 0.000 description 2
- 239000013614 RNA sample Substances 0.000 description 2
- 241000007428 Ramalina intermedia Species 0.000 description 2
- 241001549706 Ramalina peruviana Species 0.000 description 2
- 238000012952 Resampling Methods 0.000 description 2
- 241000018659 Rusavskia elegans Species 0.000 description 2
- MESDJCNHLZBMEP-ZLUOBGJFSA-N Ser-Asp-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MESDJCNHLZBMEP-ZLUOBGJFSA-N 0.000 description 2
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 2
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 2
- IFPBAGJBHSNYPR-ZKWXMUAHSA-N Ser-Ile-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O IFPBAGJBHSNYPR-ZKWXMUAHSA-N 0.000 description 2
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 2
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 2
- UGTZYIPOBYXWRW-SRVKXCTJSA-N Ser-Phe-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O UGTZYIPOBYXWRW-SRVKXCTJSA-N 0.000 description 2
- QMCDMHWAKMUGJE-IHRRRGAJSA-N Ser-Phe-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O QMCDMHWAKMUGJE-IHRRRGAJSA-N 0.000 description 2
- 102000009105 Short Chain Dehydrogenase-Reductases Human genes 0.000 description 2
- 108010048287 Short Chain Dehydrogenase-Reductases Proteins 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- WCWYEXBIRSSVGF-UHFFFAOYSA-N Squamatic acid Chemical compound OC1=C(C(O)=O)C(OC)=CC(C)=C1C(=O)OC1=CC(C)=C(C(O)=O)C(O)=C1C WCWYEXBIRSSVGF-UHFFFAOYSA-N 0.000 description 2
- OOXFLIUVCWLPKE-UHFFFAOYSA-N Strepsilin Chemical compound O1C2=CC(O)=C3C(=O)OCC3=C2C2=C1C=C(O)C=C2C OOXFLIUVCWLPKE-UHFFFAOYSA-N 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 241001052560 Thallis Species 0.000 description 2
- DGDCHPCRMWEOJR-FQPOAREZSA-N Thr-Ala-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DGDCHPCRMWEOJR-FQPOAREZSA-N 0.000 description 2
- ZUUDNCOCILSYAM-KKHAAJSZSA-N Thr-Asp-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZUUDNCOCILSYAM-KKHAAJSZSA-N 0.000 description 2
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 2
- WDFPMSHYMRBLKM-NKIYYHGXSA-N Thr-Glu-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O WDFPMSHYMRBLKM-NKIYYHGXSA-N 0.000 description 2
- TZJSEJOXAIWOST-RHYQMDGZSA-N Thr-Lys-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N TZJSEJOXAIWOST-RHYQMDGZSA-N 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 241000209140 Triticum Species 0.000 description 2
- 235000021307 Triticum Nutrition 0.000 description 2
- RCLOWEZASFJFEX-KKUMJFAQSA-N Tyr-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RCLOWEZASFJFEX-KKUMJFAQSA-N 0.000 description 2
- 241000006302 Usnea Species 0.000 description 2
- 241000158087 Usnea florida Species 0.000 description 2
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 2
- JYVKKBDANPZIAW-AVGNSLFASA-N Val-Arg-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N JYVKKBDANPZIAW-AVGNSLFASA-N 0.000 description 2
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 2
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 2
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 2
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 2
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 2
- LTTQCQRTSHJPPL-ZKWXMUAHSA-N Val-Ser-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N LTTQCQRTSHJPPL-ZKWXMUAHSA-N 0.000 description 2
- VVIZITNVZUAEMI-DLOVCJGASA-N Val-Val-Gln Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O VVIZITNVZUAEMI-DLOVCJGASA-N 0.000 description 2
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 2
- 241001394403 Viridothelium virens Species 0.000 description 2
- 241001542640 Xanthoria parietina Species 0.000 description 2
- 108010084455 Zeocin Proteins 0.000 description 2
- 239000008272 agar Substances 0.000 description 2
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 2
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 235000001014 amino acid Nutrition 0.000 description 2
- 235000019270 ammonium chloride Nutrition 0.000 description 2
- 229910000148 ammonium phosphate Inorganic materials 0.000 description 2
- 235000019289 ammonium phosphates Nutrition 0.000 description 2
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 2
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 2
- 235000011130 ammonium sulphate Nutrition 0.000 description 2
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 2
- 150000004056 anthraquinones Chemical class 0.000 description 2
- 108010008355 arginyl-glutamine Proteins 0.000 description 2
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 2
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 2
- 229930187545 betaenone Natural products 0.000 description 2
- 229960001561 bleomycin Drugs 0.000 description 2
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 2
- 229910000019 calcium carbonate Inorganic materials 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 239000004202 carbamide Substances 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 230000034303 cell budding Effects 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- BBRAOTYOIAGHRI-UHFFFAOYSA-N citreorosein Natural products C1=C(CO)C=C2C(=O)C3=CC(C)=CC(O)=C3C(=O)C2=C1O BBRAOTYOIAGHRI-UHFFFAOYSA-N 0.000 description 2
- 230000004186 co-expression Effects 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 229930189999 curvupallide Natural products 0.000 description 2
- 108010060199 cysteinylproline Proteins 0.000 description 2
- YCJBWNIROIXYPD-UHFFFAOYSA-N depsidone Chemical compound O=C1OC2=CC=CC=C2OC2=CC=CC=C12 YCJBWNIROIXYPD-UHFFFAOYSA-N 0.000 description 2
- DLVJMFOLJOOWFS-INMLLLKOSA-N depudecin Chemical compound C[C@@H](O)[C@@H]1O[C@H]1\C=C\[C@H]1[C@H]([C@H](O)C=C)O1 DLVJMFOLJOOWFS-INMLLLKOSA-N 0.000 description 2
- 238000004807 desolvation Methods 0.000 description 2
- MNNHAPBLZZVQHP-UHFFFAOYSA-N diammonium hydrogen phosphate Chemical compound [NH4+].[NH4+].OP([O-])([O-])=O MNNHAPBLZZVQHP-UHFFFAOYSA-N 0.000 description 2
- 235000014113 dietary fatty acids Nutrition 0.000 description 2
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 2
- ZPWVASYFFYYZEW-UHFFFAOYSA-L dipotassium hydrogen phosphate Chemical compound [K+].[K+].OP([O-])([O-])=O ZPWVASYFFYYZEW-UHFFFAOYSA-L 0.000 description 2
- 108010054813 diprotin B Proteins 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 229930195729 fatty acid Natural products 0.000 description 2
- 239000000194 fatty acid Substances 0.000 description 2
- 150000004665 fatty acids Chemical class 0.000 description 2
- 238000004817 gas chromatography Methods 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 2
- 108010089804 glycyl-threonine Proteins 0.000 description 2
- 108010015792 glycyllysine Proteins 0.000 description 2
- 108010081551 glycylphenylalanine Proteins 0.000 description 2
- 108010037850 glycylvaline Proteins 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 244000038280 herbivores Species 0.000 description 2
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 108010085325 histidylproline Proteins 0.000 description 2
- 108010018006 histidylserine Proteins 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- ZGBMSNKHUHZKEP-UHFFFAOYSA-N isopatulin Chemical compound OC1OCC2=CC(=O)OC2=C1 ZGBMSNKHUHZKEP-UHFFFAOYSA-N 0.000 description 2
- 108010083708 leucyl-aspartyl-valine Proteins 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- QDLAGTHXVHQKRE-UHFFFAOYSA-N lichexanthone Chemical compound COC1=CC(O)=C2C(=O)C3=C(C)C=C(OC)C=C3OC2=C1 QDLAGTHXVHQKRE-UHFFFAOYSA-N 0.000 description 2
- 108010009298 lysylglutamic acid Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 108010054155 lysyllysine Proteins 0.000 description 2
- 229910052943 magnesium sulfate Inorganic materials 0.000 description 2
- 235000019341 magnesium sulphate Nutrition 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 125000001160 methoxycarbonyl group Chemical group [H]C([H])([H])OC(*)=O 0.000 description 2
- QPJVMBTYPHYUOC-UHFFFAOYSA-N methyl benzoate Chemical group COC(=O)C1=CC=CC=C1 QPJVMBTYPHYUOC-UHFFFAOYSA-N 0.000 description 2
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 2
- 230000011987 methylation Effects 0.000 description 2
- 230000000813 microbial effect Effects 0.000 description 2
- 150000007522 mineralic acids Chemical class 0.000 description 2
- 238000005065 mining Methods 0.000 description 2
- IIPVSGPTPPURBD-HAOIVFDCSA-N monascorubrin Chemical compound C1=C2C=C(\C=C\C)OC=C2C(=O)[C@@]2(C)C1=C(C(=O)CCCCCCC)C(=O)O2 IIPVSGPTPPURBD-HAOIVFDCSA-N 0.000 description 2
- 229910000402 monopotassium phosphate Inorganic materials 0.000 description 2
- 235000019796 monopotassium phosphate Nutrition 0.000 description 2
- BCMKHWMDTMUUSI-UHFFFAOYSA-N naphthalene-1,3,6,8-tetrol Chemical compound OC1=CC(O)=CC2=CC(O)=CC(O)=C21 BCMKHWMDTMUUSI-UHFFFAOYSA-N 0.000 description 2
- 108010000785 non-ribosomal peptide synthase Proteins 0.000 description 2
- 229920001778 nylon Polymers 0.000 description 2
- AMKYESDOVDKZKV-UHFFFAOYSA-N o-orsellinic acid Chemical compound CC1=CC(O)=CC(O)=C1C(O)=O AMKYESDOVDKZKV-UHFFFAOYSA-N 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 101150111336 patF gene Proteins 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 235000019319 peptone Nutrition 0.000 description 2
- 230000000144 pharmacologic effect Effects 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 108010051242 phenylalanylserine Proteins 0.000 description 2
- CWCMIVBLVUHDHK-ZSNHEYEWSA-N phleomycin D1 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC[C@@H](N=1)C=1SC=C(N=1)C(=O)NCCCCNC(N)=N)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C CWCMIVBLVUHDHK-ZSNHEYEWSA-N 0.000 description 2
- PJNZPQUBCPKICU-UHFFFAOYSA-N phosphoric acid;potassium Chemical compound [K].OP(O)(O)=O PJNZPQUBCPKICU-UHFFFAOYSA-N 0.000 description 2
- 230000000243 photosynthetic effect Effects 0.000 description 2
- TXCAIOLGHLMTEW-UHFFFAOYSA-N physodic acid Natural products O1C2=C(CCCCC)C(C(O)=O)=C(O)C(C)=C2OC(=O)C2=C1C=C(O)C=C2CC(=O)CCCCC TXCAIOLGHLMTEW-UHFFFAOYSA-N 0.000 description 2
- 108090000765 processed proteins & peptides Proteins 0.000 description 2
- 108010077112 prolyl-proline Proteins 0.000 description 2
- 108010079317 prolyl-tyrosine Proteins 0.000 description 2
- 108010070643 prolylglutamic acid Proteins 0.000 description 2
- 239000002994 raw material Substances 0.000 description 2
- 230000003252 repetitive effect Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 238000000527 sonication Methods 0.000 description 2
- 239000003549 soybean oil Substances 0.000 description 2
- 235000012424 soybean oil Nutrition 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 229960004793 sucrose Drugs 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 230000031068 symbiosis, encompassing mutualism through parasitism Effects 0.000 description 2
- 101150054961 terA gene Proteins 0.000 description 2
- 101150096590 terB gene Proteins 0.000 description 2
- 235000007586 terpenes Nutrition 0.000 description 2
- 108010044292 tryptophyltyrosine Proteins 0.000 description 2
- 108010020532 tyrosyl-proline Proteins 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 238000012795 verification Methods 0.000 description 2
- 239000003643 water by type Substances 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- 101710135150 (+)-T-muurolol synthase ((2E,6E)-farnesyl diphosphate cyclizing) Proteins 0.000 description 1
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- CWFMWBHMIMNZLN-NAKRPEOUSA-N (2s)-1-[(2s)-2-[[(2s,3s)-2-amino-3-methylpentanoyl]amino]propanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CWFMWBHMIMNZLN-NAKRPEOUSA-N 0.000 description 1
- PKOHVHWNGUHYRE-ZFWWWQNUSA-N (2s)-1-[2-[[(2s)-2-amino-3-(1h-indol-3-yl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)NCC(=O)N1CCC[C@H]1C(O)=O PKOHVHWNGUHYRE-ZFWWWQNUSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- 101150000874 11 gene Proteins 0.000 description 1
- 101150029062 15 gene Proteins 0.000 description 1
- PAWQVTBBRAZDMG-UHFFFAOYSA-N 2-(3-bromo-2-fluorophenyl)acetic acid Chemical compound OC(=O)CC1=CC=CC(Br)=C1F PAWQVTBBRAZDMG-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- GIBRZOCMRFRCOQ-UHFFFAOYSA-N 5-methylorsellinic acid Chemical compound CC1=C(C)C(C(O)=O)=C(O)C=C1O GIBRZOCMRFRCOQ-UHFFFAOYSA-N 0.000 description 1
- WLHQSAYHIOPMMJ-UOQFGJKXSA-N 7-aminocholesterol Chemical compound NC1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 WLHQSAYHIOPMMJ-UOQFGJKXSA-N 0.000 description 1
- XAIVUDQXALPCBH-UHFFFAOYSA-N 90cqx661te Chemical compound [Na+].CC12C(=O)[C-](C(=O)C)C(=O)C=C1OC1=C2C(O)=C(C)C(O)=C1C(C)=O XAIVUDQXALPCBH-UHFFFAOYSA-N 0.000 description 1
- 241000009794 Agaricomycetes Species 0.000 description 1
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- VBDMWOKJZDCFJM-FXQIFTODSA-N Ala-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N VBDMWOKJZDCFJM-FXQIFTODSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- QDRGPQWIVZNJQD-CIUDSAMLSA-N Ala-Arg-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QDRGPQWIVZNJQD-CIUDSAMLSA-N 0.000 description 1
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 1
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 1
- STACJSVFHSEZJV-GHCJXIJMSA-N Ala-Asn-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STACJSVFHSEZJV-GHCJXIJMSA-N 0.000 description 1
- IKKVASZHTMKJIR-ZKWXMUAHSA-N Ala-Asp-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IKKVASZHTMKJIR-ZKWXMUAHSA-N 0.000 description 1
- DAEFQZCYZKRTLR-ZLUOBGJFSA-N Ala-Cys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O DAEFQZCYZKRTLR-ZLUOBGJFSA-N 0.000 description 1
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 1
- BLGHHPHXVJWCNK-GUBZILKMSA-N Ala-Gln-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BLGHHPHXVJWCNK-GUBZILKMSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- LMFXXZPPZDCPTA-ZKWXMUAHSA-N Ala-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N LMFXXZPPZDCPTA-ZKWXMUAHSA-N 0.000 description 1
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 1
- CWEAKSWWKHGTRJ-BQBZGAKWSA-N Ala-Gly-Met Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O CWEAKSWWKHGTRJ-BQBZGAKWSA-N 0.000 description 1
- IVKWMMGFLAMMKJ-XVYDVKMFSA-N Ala-His-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N IVKWMMGFLAMMKJ-XVYDVKMFSA-N 0.000 description 1
- CBCCCLMNOBLBSC-XVYDVKMFSA-N Ala-His-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CBCCCLMNOBLBSC-XVYDVKMFSA-N 0.000 description 1
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 1
- NYDBKUNVSALYPX-NAKRPEOUSA-N Ala-Ile-Arg Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NYDBKUNVSALYPX-NAKRPEOUSA-N 0.000 description 1
- IFKQPMZRDQZSHI-GHCJXIJMSA-N Ala-Ile-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O IFKQPMZRDQZSHI-GHCJXIJMSA-N 0.000 description 1
- LBYMZCVBOKYZNS-CIUDSAMLSA-N Ala-Leu-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O LBYMZCVBOKYZNS-CIUDSAMLSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- OPZJWMJPCNNZNT-DCAQKATOSA-N Ala-Leu-Met Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N OPZJWMJPCNNZNT-DCAQKATOSA-N 0.000 description 1
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 1
- MLNSNVLOEIYJIU-ZUDIRPEPSA-N Ala-Leu-Thr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLNSNVLOEIYJIU-ZUDIRPEPSA-N 0.000 description 1
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 1
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 1
- XUCHENWTTBFODJ-FXQIFTODSA-N Ala-Met-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O XUCHENWTTBFODJ-FXQIFTODSA-N 0.000 description 1
- PVQLRJRPUTXFFX-CIUDSAMLSA-N Ala-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O PVQLRJRPUTXFFX-CIUDSAMLSA-N 0.000 description 1
- OMDNCNKNEGFOMM-BQBZGAKWSA-N Ala-Met-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O OMDNCNKNEGFOMM-BQBZGAKWSA-N 0.000 description 1
- DGLQWAFPIXDKRL-UBHSHLNASA-N Ala-Met-Phe Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N DGLQWAFPIXDKRL-UBHSHLNASA-N 0.000 description 1
- DEWWPUNXRNGMQN-LPEHRKFASA-N Ala-Met-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N DEWWPUNXRNGMQN-LPEHRKFASA-N 0.000 description 1
- RUXQNKVQSKOOBS-JURCDPSOSA-N Ala-Phe-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RUXQNKVQSKOOBS-JURCDPSOSA-N 0.000 description 1
- JAQNUEWEJWBVAY-WBAXXEDZSA-N Ala-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 JAQNUEWEJWBVAY-WBAXXEDZSA-N 0.000 description 1
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 1
- FEGOCLZUJUFCHP-CIUDSAMLSA-N Ala-Pro-Gln Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FEGOCLZUJUFCHP-CIUDSAMLSA-N 0.000 description 1
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 1
- AUFACLFHBAGZEN-ZLUOBGJFSA-N Ala-Ser-Cys Chemical compound N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O AUFACLFHBAGZEN-ZLUOBGJFSA-N 0.000 description 1
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- VRTOMXFZHGWHIJ-KZVJFYERSA-N Ala-Thr-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VRTOMXFZHGWHIJ-KZVJFYERSA-N 0.000 description 1
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 1
- SFPRJVVDZNLUTG-OWLDWWDNSA-N Ala-Trp-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFPRJVVDZNLUTG-OWLDWWDNSA-N 0.000 description 1
- PGNNQOJOEGFAOR-KWQFWETISA-N Ala-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 PGNNQOJOEGFAOR-KWQFWETISA-N 0.000 description 1
- IYKVSFNGSWTTNZ-GUBZILKMSA-N Ala-Val-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IYKVSFNGSWTTNZ-GUBZILKMSA-N 0.000 description 1
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 1
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- USFZMSVCRYTOJT-UHFFFAOYSA-N Ammonium acetate Chemical compound N.CC(O)=O USFZMSVCRYTOJT-UHFFFAOYSA-N 0.000 description 1
- 239000005695 Ammonium acetate Substances 0.000 description 1
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 101710130323 Anthrone oxygenase Proteins 0.000 description 1
- 101100006458 Arabidopsis thaliana CIPK7 gene Proteins 0.000 description 1
- 101100006460 Arabidopsis thaliana CIPK8 gene Proteins 0.000 description 1
- 235000017060 Arachis glabrata Nutrition 0.000 description 1
- 244000105624 Arachis hypogaea Species 0.000 description 1
- 235000010777 Arachis hypogaea Nutrition 0.000 description 1
- 235000018262 Arachis monticola Nutrition 0.000 description 1
- HULHGJZIZXCPLD-FXQIFTODSA-N Arg-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N HULHGJZIZXCPLD-FXQIFTODSA-N 0.000 description 1
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 1
- SBVJJNJLFWSJOV-UBHSHLNASA-N Arg-Ala-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SBVJJNJLFWSJOV-UBHSHLNASA-N 0.000 description 1
- JGDGLDNAQJJGJI-AVGNSLFASA-N Arg-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N JGDGLDNAQJJGJI-AVGNSLFASA-N 0.000 description 1
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 1
- VXXHDZKEQNGXNU-QXEWZRGKSA-N Arg-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N VXXHDZKEQNGXNU-QXEWZRGKSA-N 0.000 description 1
- QAODJPUKWNNNRP-DCAQKATOSA-N Arg-Glu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QAODJPUKWNNNRP-DCAQKATOSA-N 0.000 description 1
- UFBURHXMKFQVLM-CIUDSAMLSA-N Arg-Glu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UFBURHXMKFQVLM-CIUDSAMLSA-N 0.000 description 1
- GOWZVQXTHUCNSQ-NHCYSSNCSA-N Arg-Glu-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GOWZVQXTHUCNSQ-NHCYSSNCSA-N 0.000 description 1
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 1
- NKNILFJYKKHBKE-WPRPVWTQSA-N Arg-Gly-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NKNILFJYKKHBKE-WPRPVWTQSA-N 0.000 description 1
- CRCCTGPNZUCAHE-DCAQKATOSA-N Arg-His-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CN=CN1 CRCCTGPNZUCAHE-DCAQKATOSA-N 0.000 description 1
- CVKOQHYVDVYJSI-QTKMDUPCSA-N Arg-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N)O CVKOQHYVDVYJSI-QTKMDUPCSA-N 0.000 description 1
- UBCPNBUIQNMDNH-NAKRPEOUSA-N Arg-Ile-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O UBCPNBUIQNMDNH-NAKRPEOUSA-N 0.000 description 1
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 description 1
- AGVNTAUPLWIQEN-ZPFDUUQYSA-N Arg-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AGVNTAUPLWIQEN-ZPFDUUQYSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 1
- NIUDXSFNLBIWOB-DCAQKATOSA-N Arg-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NIUDXSFNLBIWOB-DCAQKATOSA-N 0.000 description 1
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 1
- WMEVEPXNCMKNGH-IHRRRGAJSA-N Arg-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WMEVEPXNCMKNGH-IHRRRGAJSA-N 0.000 description 1
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 1
- RIIVUOJDDQXHRV-SRVKXCTJSA-N Arg-Lys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O RIIVUOJDDQXHRV-SRVKXCTJSA-N 0.000 description 1
- CLICCYPMVFGUOF-IHRRRGAJSA-N Arg-Lys-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O CLICCYPMVFGUOF-IHRRRGAJSA-N 0.000 description 1
- GRRXPUAICOGISM-RWMBFGLXSA-N Arg-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GRRXPUAICOGISM-RWMBFGLXSA-N 0.000 description 1
- XSPKAHFVDKRGRL-DCAQKATOSA-N Arg-Pro-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XSPKAHFVDKRGRL-DCAQKATOSA-N 0.000 description 1
- NGYHSXDNNOFHNE-AVGNSLFASA-N Arg-Pro-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O NGYHSXDNNOFHNE-AVGNSLFASA-N 0.000 description 1
- AMIQZQAAYGYKOP-FXQIFTODSA-N Arg-Ser-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O AMIQZQAAYGYKOP-FXQIFTODSA-N 0.000 description 1
- AUIJUTGLPVHIRT-FXQIFTODSA-N Arg-Ser-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N AUIJUTGLPVHIRT-FXQIFTODSA-N 0.000 description 1
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 1
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 1
- WTFIFQWLQXZLIZ-UMPQAUOISA-N Arg-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O WTFIFQWLQXZLIZ-UMPQAUOISA-N 0.000 description 1
- YHZQOSXDTFRZKU-WDSOQIARSA-N Arg-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 YHZQOSXDTFRZKU-WDSOQIARSA-N 0.000 description 1
- NVPHRWNWTKYIST-BPNCWPANSA-N Arg-Tyr-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 NVPHRWNWTKYIST-BPNCWPANSA-N 0.000 description 1
- IZSMEUDYADKZTJ-KJEVXHAQSA-N Arg-Tyr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IZSMEUDYADKZTJ-KJEVXHAQSA-N 0.000 description 1
- KEZVOBAKAXHMOF-GUBZILKMSA-N Arg-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N KEZVOBAKAXHMOF-GUBZILKMSA-N 0.000 description 1
- LEFKSBYHUGUWLP-ACZMJKKPSA-N Asn-Ala-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LEFKSBYHUGUWLP-ACZMJKKPSA-N 0.000 description 1
- NUHQMYUWLUSRJX-BIIVOSGPSA-N Asn-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N NUHQMYUWLUSRJX-BIIVOSGPSA-N 0.000 description 1
- XWGJDUSDTRPQRK-ZLUOBGJFSA-N Asn-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O XWGJDUSDTRPQRK-ZLUOBGJFSA-N 0.000 description 1
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 1
- XQQVCUIBGYFKDC-OLHMAJIHSA-N Asn-Asp-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XQQVCUIBGYFKDC-OLHMAJIHSA-N 0.000 description 1
- XVAPVJNJGLWGCS-ACZMJKKPSA-N Asn-Glu-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N XVAPVJNJGLWGCS-ACZMJKKPSA-N 0.000 description 1
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 1
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 1
- OWUCNXMFJRFOFI-BQBZGAKWSA-N Asn-Gly-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O OWUCNXMFJRFOFI-BQBZGAKWSA-N 0.000 description 1
- MOHUTCNYQLMARY-GUBZILKMSA-N Asn-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MOHUTCNYQLMARY-GUBZILKMSA-N 0.000 description 1
- NKLRWRRVYGQNIH-GHCJXIJMSA-N Asn-Ile-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O NKLRWRRVYGQNIH-GHCJXIJMSA-N 0.000 description 1
- XLZCLJRGGMBKLR-PCBIJLKTSA-N Asn-Ile-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XLZCLJRGGMBKLR-PCBIJLKTSA-N 0.000 description 1
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 1
- FHETWELNCBMRMG-HJGDQZAQSA-N Asn-Leu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FHETWELNCBMRMG-HJGDQZAQSA-N 0.000 description 1
- NCFJQJRLQJEECD-NHCYSSNCSA-N Asn-Leu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O NCFJQJRLQJEECD-NHCYSSNCSA-N 0.000 description 1
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 1
- CDGHMJJJHYKMPA-DLOVCJGASA-N Asn-Phe-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CC(=O)N)N CDGHMJJJHYKMPA-DLOVCJGASA-N 0.000 description 1
- ZVUMKOMKQCANOM-AVGNSLFASA-N Asn-Phe-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVUMKOMKQCANOM-AVGNSLFASA-N 0.000 description 1
- YXVAESUIQFDBHN-SRVKXCTJSA-N Asn-Phe-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O YXVAESUIQFDBHN-SRVKXCTJSA-N 0.000 description 1
- YUOXLJYVSZYPBJ-CIUDSAMLSA-N Asn-Pro-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O YUOXLJYVSZYPBJ-CIUDSAMLSA-N 0.000 description 1
- VCJCPARXDBEGNE-GUBZILKMSA-N Asn-Pro-Pro Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 VCJCPARXDBEGNE-GUBZILKMSA-N 0.000 description 1
- IDUUACUJKUXKKD-VEVYYDQMSA-N Asn-Pro-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O IDUUACUJKUXKKD-VEVYYDQMSA-N 0.000 description 1
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 1
- GZXOUBTUAUAVHD-ACZMJKKPSA-N Asn-Ser-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GZXOUBTUAUAVHD-ACZMJKKPSA-N 0.000 description 1
- XHTUGJCAEYOZOR-UBHSHLNASA-N Asn-Ser-Trp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XHTUGJCAEYOZOR-UBHSHLNASA-N 0.000 description 1
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 1
- SKQTXVZTCGSRJS-SRVKXCTJSA-N Asn-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O SKQTXVZTCGSRJS-SRVKXCTJSA-N 0.000 description 1
- DPWDPEVGACCWTC-SRVKXCTJSA-N Asn-Tyr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O DPWDPEVGACCWTC-SRVKXCTJSA-N 0.000 description 1
- CBWCQCANJSGUOH-ZKWXMUAHSA-N Asn-Val-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O CBWCQCANJSGUOH-ZKWXMUAHSA-N 0.000 description 1
- JZLFYAAGGYMRIK-BYULHYEWSA-N Asn-Val-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O JZLFYAAGGYMRIK-BYULHYEWSA-N 0.000 description 1
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 1
- SYZWMVSXBZCOBZ-QXEWZRGKSA-N Asn-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)N)N SYZWMVSXBZCOBZ-QXEWZRGKSA-N 0.000 description 1
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 1
- GHWWTICYPDKPTE-NGZCFLSTSA-N Asn-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N GHWWTICYPDKPTE-NGZCFLSTSA-N 0.000 description 1
- SLHOOKXYTYAJGQ-XVYDVKMFSA-N Asp-Ala-His Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 SLHOOKXYTYAJGQ-XVYDVKMFSA-N 0.000 description 1
- XBQSLMACWDXWLJ-GHCJXIJMSA-N Asp-Ala-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XBQSLMACWDXWLJ-GHCJXIJMSA-N 0.000 description 1
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 1
- GVPSCJQLUGIKAM-GUBZILKMSA-N Asp-Arg-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GVPSCJQLUGIKAM-GUBZILKMSA-N 0.000 description 1
- SDHFVYLZFBDSQT-DCAQKATOSA-N Asp-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N SDHFVYLZFBDSQT-DCAQKATOSA-N 0.000 description 1
- CNKAZIGBGQIHLL-GUBZILKMSA-N Asp-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N CNKAZIGBGQIHLL-GUBZILKMSA-N 0.000 description 1
- DBWYWXNMZZYIRY-LPEHRKFASA-N Asp-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O DBWYWXNMZZYIRY-LPEHRKFASA-N 0.000 description 1
- XACXDSRQIXRMNS-OLHMAJIHSA-N Asp-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)O XACXDSRQIXRMNS-OLHMAJIHSA-N 0.000 description 1
- FRSGNOZCTWDVFZ-ACZMJKKPSA-N Asp-Asp-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O FRSGNOZCTWDVFZ-ACZMJKKPSA-N 0.000 description 1
- WCFCYFDBMNFSPA-ACZMJKKPSA-N Asp-Asp-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O WCFCYFDBMNFSPA-ACZMJKKPSA-N 0.000 description 1
- FANQWNCPNFEPGZ-WHFBIAKZSA-N Asp-Asp-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FANQWNCPNFEPGZ-WHFBIAKZSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- QQXOYLWJQUPXJU-WHFBIAKZSA-N Asp-Cys-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O QQXOYLWJQUPXJU-WHFBIAKZSA-N 0.000 description 1
- WLKVEEODTPQPLI-ACZMJKKPSA-N Asp-Gln-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O WLKVEEODTPQPLI-ACZMJKKPSA-N 0.000 description 1
- YDJVIBMKAMQPPP-LAEOZQHASA-N Asp-Glu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O YDJVIBMKAMQPPP-LAEOZQHASA-N 0.000 description 1
- NRIFEOUAFLTMFJ-AAEUAGOBSA-N Asp-Gly-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O NRIFEOUAFLTMFJ-AAEUAGOBSA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- ILQCHXURSRRIRY-YUMQZZPRSA-N Asp-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)O)N ILQCHXURSRRIRY-YUMQZZPRSA-N 0.000 description 1
- WSXDIZFNQYTUJB-SRVKXCTJSA-N Asp-His-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O WSXDIZFNQYTUJB-SRVKXCTJSA-N 0.000 description 1
- TZOZNVLBTAFJRW-UGYAYLCHSA-N Asp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N TZOZNVLBTAFJRW-UGYAYLCHSA-N 0.000 description 1
- YFSLJHLQOALGSY-ZPFDUUQYSA-N Asp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N YFSLJHLQOALGSY-ZPFDUUQYSA-N 0.000 description 1
- JNNVNVRBYUJYGS-CIUDSAMLSA-N Asp-Leu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O JNNVNVRBYUJYGS-CIUDSAMLSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- UJGRZQYSNYTCAX-SRVKXCTJSA-N Asp-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UJGRZQYSNYTCAX-SRVKXCTJSA-N 0.000 description 1
- CJUKAWUWBZCTDQ-SRVKXCTJSA-N Asp-Leu-Lys Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O CJUKAWUWBZCTDQ-SRVKXCTJSA-N 0.000 description 1
- KFAFUJMGHVVYRC-DCAQKATOSA-N Asp-Leu-Met Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O KFAFUJMGHVVYRC-DCAQKATOSA-N 0.000 description 1
- WNGZKSVJFDZICU-XIRDDKMYSA-N Asp-Leu-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N WNGZKSVJFDZICU-XIRDDKMYSA-N 0.000 description 1
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 1
- MYLZFUMPZCPJCJ-NHCYSSNCSA-N Asp-Lys-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MYLZFUMPZCPJCJ-NHCYSSNCSA-N 0.000 description 1
- QJHOOKBAHRJPPX-QWRGUYRKSA-N Asp-Phe-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 QJHOOKBAHRJPPX-QWRGUYRKSA-N 0.000 description 1
- LTCKTLYKRMCFOC-KKUMJFAQSA-N Asp-Phe-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LTCKTLYKRMCFOC-KKUMJFAQSA-N 0.000 description 1
- LIQNMKIBMPEOOP-IHRRRGAJSA-N Asp-Phe-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CC(=O)O)N LIQNMKIBMPEOOP-IHRRRGAJSA-N 0.000 description 1
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 1
- NONWUQAWAANERO-BZSNNMDCSA-N Asp-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 NONWUQAWAANERO-BZSNNMDCSA-N 0.000 description 1
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 1
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 1
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 1
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- XOASPVGNFAMYBD-WFBYXXMGSA-N Asp-Trp-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O XOASPVGNFAMYBD-WFBYXXMGSA-N 0.000 description 1
- KNOGLZBISUBTFW-QRTARXTBSA-N Asp-Trp-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O KNOGLZBISUBTFW-QRTARXTBSA-N 0.000 description 1
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 1
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 1
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 1
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 1
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 1
- JGLWFWXGOINXEA-YDHLFZDLSA-N Asp-Val-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 JGLWFWXGOINXEA-YDHLFZDLSA-N 0.000 description 1
- 101000890966 Aspergillus flavus (strain ATCC 200026 / FGSC A1120 / IAM 13836 / NRRL 3357 / JCM 12722 / SRRC 167) Non-reducing polyketide synthase afvB Proteins 0.000 description 1
- 101001096144 Aspergillus flavus (strain ATCC 200026 / FGSC A1120 / IAM 13836 / NRRL 3357 / JCM 12722 / SRRC 167) Non-reducing polyketide synthase pks27 Proteins 0.000 description 1
- 241001225321 Aspergillus fumigatus Species 0.000 description 1
- 241000228245 Aspergillus niger Species 0.000 description 1
- 235000002247 Aspergillus oryzae Nutrition 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 102000004031 Carboxy-Lyases Human genes 0.000 description 1
- 108090000489 Carboxy-Lyases Proteins 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 102000005469 Chitin Synthase Human genes 0.000 description 1
- 108700040089 Chitin synthases Proteins 0.000 description 1
- 241000195628 Chlorophyta Species 0.000 description 1
- 241000724697 Cladonia cristatella Species 0.000 description 1
- 241000221641 Cladoniaceae Species 0.000 description 1
- 241000894663 Coniocybomycetes Species 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 101001030456 Coprinopsis cinerea (strain Okayama-7 / 130 / ATCC MYA-4618 / FGSC 9003) Adenylate-forming reductase 03009 Proteins 0.000 description 1
- 101001000081 Coprinopsis cinerea (strain Okayama-7 / 130 / ATCC MYA-4618 / FGSC 9003) Adenylate-forming reductase 06235 Proteins 0.000 description 1
- GRNOCLDFUNCIDW-ACZMJKKPSA-N Cys-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N GRNOCLDFUNCIDW-ACZMJKKPSA-N 0.000 description 1
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 description 1
- KIHRUISMQZVCNO-ZLUOBGJFSA-N Cys-Asp-Asp Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KIHRUISMQZVCNO-ZLUOBGJFSA-N 0.000 description 1
- OLIYIKRCOZBFCW-ZLUOBGJFSA-N Cys-Asp-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)C(=O)O OLIYIKRCOZBFCW-ZLUOBGJFSA-N 0.000 description 1
- QJUDRFBUWAGUSG-SRVKXCTJSA-N Cys-Cys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CS)N QJUDRFBUWAGUSG-SRVKXCTJSA-N 0.000 description 1
- AVFGSUXQKHIQJS-QEJZJMRPSA-N Cys-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CS)N)C(O)=O)=CNC2=C1 AVFGSUXQKHIQJS-QEJZJMRPSA-N 0.000 description 1
- VBPGTULCFGKGTF-ACZMJKKPSA-N Cys-Glu-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VBPGTULCFGKGTF-ACZMJKKPSA-N 0.000 description 1
- BDWIZLQVVWQMTB-XKBZYTNZSA-N Cys-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N)O BDWIZLQVVWQMTB-XKBZYTNZSA-N 0.000 description 1
- MTNJRNQDDSWQQA-GQGQLFGLSA-N Cys-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CS)N MTNJRNQDDSWQQA-GQGQLFGLSA-N 0.000 description 1
- SSNJZBGOMNLSLA-CIUDSAMLSA-N Cys-Leu-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O SSNJZBGOMNLSLA-CIUDSAMLSA-N 0.000 description 1
- VXLXATVURDNDCG-CIUDSAMLSA-N Cys-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N VXLXATVURDNDCG-CIUDSAMLSA-N 0.000 description 1
- HSAWNMMTZCLTPY-DCAQKATOSA-N Cys-Met-Leu Chemical compound SC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O HSAWNMMTZCLTPY-DCAQKATOSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- CMYVIUWVYHOLRD-ZLUOBGJFSA-N Cys-Ser-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CMYVIUWVYHOLRD-ZLUOBGJFSA-N 0.000 description 1
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 1
- YQEHNIKPAOPBNH-DCAQKATOSA-N Cys-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N YQEHNIKPAOPBNH-DCAQKATOSA-N 0.000 description 1
- 108010090461 DFG peptide Proteins 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 101100352349 Dictyostelium discoideum pks7 gene Proteins 0.000 description 1
- 101710177451 Diels-Alderase Proteins 0.000 description 1
- 102000005454 Dimethylallyltranstransferase Human genes 0.000 description 1
- 108010006731 Dimethylallyltranstransferase Proteins 0.000 description 1
- 102000016680 Dioxygenases Human genes 0.000 description 1
- 108010028143 Dioxygenases Proteins 0.000 description 1
- 101000684540 Emericella nidulans (strain FGSC A4 / ATCC 38163 / CBS 112.46 / NRRL 194 / M139) Non-reducing polyketide synthase aptA Proteins 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 241000004871 Evernia Species 0.000 description 1
- 241000004873 Evernia prunastri Species 0.000 description 1
- QUCZMUVAQHIOID-UHFFFAOYSA-N Everninic acid Natural products COC1=CC(C)=C(C(O)=O)C(O)=C1 QUCZMUVAQHIOID-UHFFFAOYSA-N 0.000 description 1
- 241000308447 Exophiala lecanii-corni Species 0.000 description 1
- IERQJNGBILWLCY-UHFFFAOYSA-N Fragilin Natural products OC1C(O)C(O)C(COC(=O)C)OC1OC1=CC=CC=C1CO IERQJNGBILWLCY-UHFFFAOYSA-N 0.000 description 1
- 102100039556 Galectin-4 Human genes 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- 101710119400 Geranylfarnesyl diphosphate synthase Proteins 0.000 description 1
- 101710107752 Geranylgeranyl diphosphate synthase Proteins 0.000 description 1
- 101100281675 Gibberella fujikuroi (strain CBS 195.34 / IMI 58289 / NRRL A-6831) fsr4 gene Proteins 0.000 description 1
- 101100281676 Gibberella fujikuroi (strain CBS 195.34 / IMI 58289 / NRRL A-6831) fsr5 gene Proteins 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- IGNGBUVODQLMRJ-CIUDSAMLSA-N Gln-Ala-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O IGNGBUVODQLMRJ-CIUDSAMLSA-N 0.000 description 1
- DLOHWQXXGMEZDW-CIUDSAMLSA-N Gln-Arg-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DLOHWQXXGMEZDW-CIUDSAMLSA-N 0.000 description 1
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 1
- RRYLMJWPWBJFPZ-ACZMJKKPSA-N Gln-Asn-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RRYLMJWPWBJFPZ-ACZMJKKPSA-N 0.000 description 1
- WMOMPXKOKASNBK-PEFMBERDSA-N Gln-Asn-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WMOMPXKOKASNBK-PEFMBERDSA-N 0.000 description 1
- SSHIXEILTLPAQT-WHFBIAKZSA-N Gln-Asp Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSHIXEILTLPAQT-WHFBIAKZSA-N 0.000 description 1
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 1
- UZMWDBOHAOSCCH-ACZMJKKPSA-N Gln-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(N)=O UZMWDBOHAOSCCH-ACZMJKKPSA-N 0.000 description 1
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 1
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- FTIJVMLAGRAYMJ-MNXVOIDGSA-N Gln-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(N)=O FTIJVMLAGRAYMJ-MNXVOIDGSA-N 0.000 description 1
- FFVXLVGUJBCKRX-UKJIMTQDSA-N Gln-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCC(=O)N)N FFVXLVGUJBCKRX-UKJIMTQDSA-N 0.000 description 1
- DRNMNLKUUKKPIA-HTUGSXCWSA-N Gln-Phe-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)CCC(N)=O)C(O)=O DRNMNLKUUKKPIA-HTUGSXCWSA-N 0.000 description 1
- DOQUICBEISTQHE-CIUDSAMLSA-N Gln-Pro-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O DOQUICBEISTQHE-CIUDSAMLSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- MQJDLNRXBOELJW-KKUMJFAQSA-N Gln-Pro-Phe Chemical compound N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O MQJDLNRXBOELJW-KKUMJFAQSA-N 0.000 description 1
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 1
- NYCVMJGIJYQWDO-CIUDSAMLSA-N Gln-Ser-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NYCVMJGIJYQWDO-CIUDSAMLSA-N 0.000 description 1
- LGWNISYVKDNJRP-FXQIFTODSA-N Gln-Ser-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGWNISYVKDNJRP-FXQIFTODSA-N 0.000 description 1
- KVQOVQVGVKDZNW-GUBZILKMSA-N Gln-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KVQOVQVGVKDZNW-GUBZILKMSA-N 0.000 description 1
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 1
- NVHJGTGTUGEWCG-ZVZYQTTQSA-N Gln-Trp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O NVHJGTGTUGEWCG-ZVZYQTTQSA-N 0.000 description 1
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 1
- JTWZNMUVQWWGOX-SOUVJXGZSA-N Gln-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JTWZNMUVQWWGOX-SOUVJXGZSA-N 0.000 description 1
- QGWXAMDECCKGRU-XVKPBYJWSA-N Gln-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(N)=O)C(=O)NCC(O)=O QGWXAMDECCKGRU-XVKPBYJWSA-N 0.000 description 1
- GJLXZITZLUUXMJ-NHCYSSNCSA-N Gln-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GJLXZITZLUUXMJ-NHCYSSNCSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- SOEXCCGNHQBFPV-DLOVCJGASA-N Gln-Val-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SOEXCCGNHQBFPV-DLOVCJGASA-N 0.000 description 1
- FHPXTPQBODWBIY-CIUDSAMLSA-N Glu-Ala-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FHPXTPQBODWBIY-CIUDSAMLSA-N 0.000 description 1
- RLZBLVSJDFHDBL-KBIXCLLPSA-N Glu-Ala-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RLZBLVSJDFHDBL-KBIXCLLPSA-N 0.000 description 1
- IRDASPPCLZIERZ-XHNCKOQMSA-N Glu-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N IRDASPPCLZIERZ-XHNCKOQMSA-N 0.000 description 1
- MXOODARRORARSU-ACZMJKKPSA-N Glu-Ala-Ser Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N MXOODARRORARSU-ACZMJKKPSA-N 0.000 description 1
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 1
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 1
- DIXKFOPPGWKZLY-CIUDSAMLSA-N Glu-Arg-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O DIXKFOPPGWKZLY-CIUDSAMLSA-N 0.000 description 1
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 1
- DYFJZDDQPNIPAB-NHCYSSNCSA-N Glu-Arg-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O DYFJZDDQPNIPAB-NHCYSSNCSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- SAEBUDRWKUXLOM-ACZMJKKPSA-N Glu-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O SAEBUDRWKUXLOM-ACZMJKKPSA-N 0.000 description 1
- MXPBQDFWIMBACQ-ACZMJKKPSA-N Glu-Cys-Cys Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(O)=O MXPBQDFWIMBACQ-ACZMJKKPSA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- IQACOVZVOMVILH-FXQIFTODSA-N Glu-Glu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O IQACOVZVOMVILH-FXQIFTODSA-N 0.000 description 1
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 1
- XMPAXPSENRSOSV-RYUDHWBXSA-N Glu-Gly-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XMPAXPSENRSOSV-RYUDHWBXSA-N 0.000 description 1
- JGHNIWVNCAOVRO-DCAQKATOSA-N Glu-His-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O JGHNIWVNCAOVRO-DCAQKATOSA-N 0.000 description 1
- QIQABBIDHGQXGA-ZPFDUUQYSA-N Glu-Ile-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QIQABBIDHGQXGA-ZPFDUUQYSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 1
- LZMQSTPFYJLVJB-GUBZILKMSA-N Glu-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LZMQSTPFYJLVJB-GUBZILKMSA-N 0.000 description 1
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 1
- FGSGPLRPQCZBSQ-AVGNSLFASA-N Glu-Phe-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O FGSGPLRPQCZBSQ-AVGNSLFASA-N 0.000 description 1
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 1
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 1
- ZAPFAWQHBOHWLL-GUBZILKMSA-N Glu-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N ZAPFAWQHBOHWLL-GUBZILKMSA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- HZISRJBYZAODRV-XQXXSGGOSA-N Glu-Thr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O HZISRJBYZAODRV-XQXXSGGOSA-N 0.000 description 1
- YQAQQKPWFOBSMU-WDCWCFNPSA-N Glu-Thr-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O YQAQQKPWFOBSMU-WDCWCFNPSA-N 0.000 description 1
- UUTGYDAKPISJAO-JYJNAYRXSA-N Glu-Tyr-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 UUTGYDAKPISJAO-JYJNAYRXSA-N 0.000 description 1
- LZEUDRYSAZAJIO-AUTRQRHGSA-N Glu-Val-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZEUDRYSAZAJIO-AUTRQRHGSA-N 0.000 description 1
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 1
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- QIZJOTQTCAGKPU-KWQFWETISA-N Gly-Ala-Tyr Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 QIZJOTQTCAGKPU-KWQFWETISA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 1
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 1
- BGVYNAQWHSTTSP-BYULHYEWSA-N Gly-Asn-Ile Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BGVYNAQWHSTTSP-BYULHYEWSA-N 0.000 description 1
- FUTAPPOITCCWTH-WHFBIAKZSA-N Gly-Asp-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FUTAPPOITCCWTH-WHFBIAKZSA-N 0.000 description 1
- SUDUYJOBLHQAMI-WHFBIAKZSA-N Gly-Asp-Cys Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(O)=O SUDUYJOBLHQAMI-WHFBIAKZSA-N 0.000 description 1
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 1
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 1
- YYPFZVIXAVDHIK-IUCAKERBSA-N Gly-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN YYPFZVIXAVDHIK-IUCAKERBSA-N 0.000 description 1
- NTOWAXLMQFKJPT-YUMQZZPRSA-N Gly-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN NTOWAXLMQFKJPT-YUMQZZPRSA-N 0.000 description 1
- LHRXAHLCRMQBGJ-RYUDHWBXSA-N Gly-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN LHRXAHLCRMQBGJ-RYUDHWBXSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 1
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 1
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 1
- FQKKPCWTZZEDIC-XPUUQOCRSA-N Gly-His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 FQKKPCWTZZEDIC-XPUUQOCRSA-N 0.000 description 1
- TVDHVLGFJSHPAX-UWVGGRQHSA-N Gly-His-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 TVDHVLGFJSHPAX-UWVGGRQHSA-N 0.000 description 1
- IVSWQHKONQIOHA-YUMQZZPRSA-N Gly-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN IVSWQHKONQIOHA-YUMQZZPRSA-N 0.000 description 1
- LPCKHUXOGVNZRS-YUMQZZPRSA-N Gly-His-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O LPCKHUXOGVNZRS-YUMQZZPRSA-N 0.000 description 1
- QSVMIMFAAZPCAQ-PMVVWTBXSA-N Gly-His-Thr Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QSVMIMFAAZPCAQ-PMVVWTBXSA-N 0.000 description 1
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 1
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 1
- SXJHOPPTOJACOA-QXEWZRGKSA-N Gly-Ile-Arg Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N SXJHOPPTOJACOA-QXEWZRGKSA-N 0.000 description 1
- DENRBIYENOKSEX-PEXQALLHSA-N Gly-Ile-His Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DENRBIYENOKSEX-PEXQALLHSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 1
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 1
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- LOEANKRDMMVOGZ-YUMQZZPRSA-N Gly-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O LOEANKRDMMVOGZ-YUMQZZPRSA-N 0.000 description 1
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 1
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 1
- GAFKBWKVXNERFA-QWRGUYRKSA-N Gly-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 GAFKBWKVXNERFA-QWRGUYRKSA-N 0.000 description 1
- DHNXGWVNLFPOMQ-KBPBESRZSA-N Gly-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)CN DHNXGWVNLFPOMQ-KBPBESRZSA-N 0.000 description 1
- OCPPBNKYGYSLOE-IUCAKERBSA-N Gly-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN OCPPBNKYGYSLOE-IUCAKERBSA-N 0.000 description 1
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 1
- GLACUWHUYFBSPJ-FJXKBIBVSA-N Gly-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GLACUWHUYFBSPJ-FJXKBIBVSA-N 0.000 description 1
- MKIAPEZXQDILRR-YUMQZZPRSA-N Gly-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN MKIAPEZXQDILRR-YUMQZZPRSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 1
- UMBDRSMLCUYIRI-DVJZZOLTSA-N Gly-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN)O UMBDRSMLCUYIRI-DVJZZOLTSA-N 0.000 description 1
- MREVELMMFOLESM-HOCLYGCPSA-N Gly-Trp-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O MREVELMMFOLESM-HOCLYGCPSA-N 0.000 description 1
- WRFOZIJRODPLIA-QWRGUYRKSA-N Gly-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)O WRFOZIJRODPLIA-QWRGUYRKSA-N 0.000 description 1
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 1
- GJHWILMUOANXTG-WPRPVWTQSA-N Gly-Val-Arg Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GJHWILMUOANXTG-WPRPVWTQSA-N 0.000 description 1
- YDIDLLVFCYSXNY-RCOVLWMOSA-N Gly-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN YDIDLLVFCYSXNY-RCOVLWMOSA-N 0.000 description 1
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 1
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 1
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 1
- BNMRSWQOHIQTFL-JSGCOSHPSA-N Gly-Val-Phe Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 BNMRSWQOHIQTFL-JSGCOSHPSA-N 0.000 description 1
- 241000648226 Gyalolechia flavorubescens Species 0.000 description 1
- 101001124319 Heterobasidion annosum Adenylate-forming reductase Nps10 Proteins 0.000 description 1
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 1
- VSLXGYMEHVAJBH-DLOVCJGASA-N His-Ala-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O VSLXGYMEHVAJBH-DLOVCJGASA-N 0.000 description 1
- DZMVESFTHXSSPZ-XVYDVKMFSA-N His-Ala-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DZMVESFTHXSSPZ-XVYDVKMFSA-N 0.000 description 1
- TVQGUFGDVODUIF-LSJOCFKGSA-N His-Arg-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CN=CN1)N TVQGUFGDVODUIF-LSJOCFKGSA-N 0.000 description 1
- YPLYIXGKCRQZGW-SRVKXCTJSA-N His-Arg-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YPLYIXGKCRQZGW-SRVKXCTJSA-N 0.000 description 1
- MWWOPNQSBXEUHO-ULQDDVLXSA-N His-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 MWWOPNQSBXEUHO-ULQDDVLXSA-N 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- ZJSMFRTVYSLKQU-DJFWLOJKSA-N His-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ZJSMFRTVYSLKQU-DJFWLOJKSA-N 0.000 description 1
- UOAVQQRILDGZEN-SRVKXCTJSA-N His-Asp-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UOAVQQRILDGZEN-SRVKXCTJSA-N 0.000 description 1
- UPGJWSUYENXOPV-HGNGGELXSA-N His-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N UPGJWSUYENXOPV-HGNGGELXSA-N 0.000 description 1
- TXLQHACKRLWYCM-DCAQKATOSA-N His-Glu-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O TXLQHACKRLWYCM-DCAQKATOSA-N 0.000 description 1
- JCOSMKPAOYDKRO-AVGNSLFASA-N His-Glu-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N JCOSMKPAOYDKRO-AVGNSLFASA-N 0.000 description 1
- RGPWUJOMKFYFSR-QWRGUYRKSA-N His-Gly-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O RGPWUJOMKFYFSR-QWRGUYRKSA-N 0.000 description 1
- BDFCIKANUNMFGB-PMVVWTBXSA-N His-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CN=CN1 BDFCIKANUNMFGB-PMVVWTBXSA-N 0.000 description 1
- NDKSHNQINMRKHT-PEXQALLHSA-N His-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N NDKSHNQINMRKHT-PEXQALLHSA-N 0.000 description 1
- ORERHHPZDDEMSC-VGDYDELISA-N His-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ORERHHPZDDEMSC-VGDYDELISA-N 0.000 description 1
- VYUXYMRNGALHEA-DLOVCJGASA-N His-Leu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O VYUXYMRNGALHEA-DLOVCJGASA-N 0.000 description 1
- LVWIJITYHRZHBO-IXOXFDKPSA-N His-Leu-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LVWIJITYHRZHBO-IXOXFDKPSA-N 0.000 description 1
- XKIYNCLILDLGRS-QWRGUYRKSA-N His-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 XKIYNCLILDLGRS-QWRGUYRKSA-N 0.000 description 1
- CKRJBQJIGOEKMC-SRVKXCTJSA-N His-Lys-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O CKRJBQJIGOEKMC-SRVKXCTJSA-N 0.000 description 1
- RLAOTFTXBFQJDV-KKUMJFAQSA-N His-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CN=CN1 RLAOTFTXBFQJDV-KKUMJFAQSA-N 0.000 description 1
- JSQIXEHORHLQEE-MEYUZBJRSA-N His-Phe-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JSQIXEHORHLQEE-MEYUZBJRSA-N 0.000 description 1
- CUEQQFOGARVNHU-VGDYDELISA-N His-Ser-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUEQQFOGARVNHU-VGDYDELISA-N 0.000 description 1
- IAYPZSHNZQHQNO-KKUMJFAQSA-N His-Ser-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC2=CN=CN2)N IAYPZSHNZQHQNO-KKUMJFAQSA-N 0.000 description 1
- FCPSGEVYIVXPPO-QTKMDUPCSA-N His-Thr-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FCPSGEVYIVXPPO-QTKMDUPCSA-N 0.000 description 1
- CGAMSLMBYJHMDY-ONGXEEELSA-N His-Val-Gly Chemical compound CC(C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N CGAMSLMBYJHMDY-ONGXEEELSA-N 0.000 description 1
- 101000608765 Homo sapiens Galectin-4 Proteins 0.000 description 1
- DHLPMLVSBRRUGA-UHFFFAOYSA-N Hydroxymellein Natural products OC1=CC(O)=C2C(=O)OC(C)CC2=C1 DHLPMLVSBRRUGA-UHFFFAOYSA-N 0.000 description 1
- VSZALHITQINTGC-GHCJXIJMSA-N Ile-Ala-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)O)C(=O)O)N VSZALHITQINTGC-GHCJXIJMSA-N 0.000 description 1
- CISBRYJZMFWOHJ-JBDRJPRFSA-N Ile-Ala-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N CISBRYJZMFWOHJ-JBDRJPRFSA-N 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- FVEWRQXNISSYFO-ZPFDUUQYSA-N Ile-Arg-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N FVEWRQXNISSYFO-ZPFDUUQYSA-N 0.000 description 1
- DMHGKBGOUAJRHU-UHFFFAOYSA-N Ile-Arg-Pro Natural products CCC(C)C(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O DMHGKBGOUAJRHU-UHFFFAOYSA-N 0.000 description 1
- YPQDTQJBOFOTJQ-SXTJYALSSA-N Ile-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N YPQDTQJBOFOTJQ-SXTJYALSSA-N 0.000 description 1
- XENGULNPUDGALZ-ZPFDUUQYSA-N Ile-Asn-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N XENGULNPUDGALZ-ZPFDUUQYSA-N 0.000 description 1
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 1
- NKRJALPCDNXULF-BYULHYEWSA-N Ile-Asp-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O NKRJALPCDNXULF-BYULHYEWSA-N 0.000 description 1
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 1
- GYAFMRQGWHXMII-IUKAMOBKSA-N Ile-Asp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N GYAFMRQGWHXMII-IUKAMOBKSA-N 0.000 description 1
- AQTWDZDISVGCAC-CFMVVWHZSA-N Ile-Asp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AQTWDZDISVGCAC-CFMVVWHZSA-N 0.000 description 1
- PFTFEWHJSAXGED-ZKWXMUAHSA-N Ile-Cys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N PFTFEWHJSAXGED-ZKWXMUAHSA-N 0.000 description 1
- ZDNORQNHCJUVOV-KBIXCLLPSA-N Ile-Gln-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O ZDNORQNHCJUVOV-KBIXCLLPSA-N 0.000 description 1
- MVLDERGQICFFLL-ZQINRCPSSA-N Ile-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 MVLDERGQICFFLL-ZQINRCPSSA-N 0.000 description 1
- BEWFWZRGBDVXRP-PEFMBERDSA-N Ile-Glu-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BEWFWZRGBDVXRP-PEFMBERDSA-N 0.000 description 1
- LPXHYGGZJOCAFR-MNXVOIDGSA-N Ile-Glu-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N LPXHYGGZJOCAFR-MNXVOIDGSA-N 0.000 description 1
- JXMSHKFPDIUYGS-SIUGBPQLSA-N Ile-Glu-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N JXMSHKFPDIUYGS-SIUGBPQLSA-N 0.000 description 1
- NHJKZMDIMMTVCK-QXEWZRGKSA-N Ile-Gly-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N NHJKZMDIMMTVCK-QXEWZRGKSA-N 0.000 description 1
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 1
- UASTVUQJMLZWGG-PEXQALLHSA-N Ile-His-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)NCC(=O)O)N UASTVUQJMLZWGG-PEXQALLHSA-N 0.000 description 1
- KEKTTYCXKGBAAL-VGDYDELISA-N Ile-His-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N KEKTTYCXKGBAAL-VGDYDELISA-N 0.000 description 1
- WIZPFZKOFZXDQG-HTFCKZLJSA-N Ile-Ile-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O WIZPFZKOFZXDQG-HTFCKZLJSA-N 0.000 description 1
- RIVKTKFVWXRNSJ-GRLWGSQLSA-N Ile-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RIVKTKFVWXRNSJ-GRLWGSQLSA-N 0.000 description 1
- TWPSALMCEHCIOY-YTFOTSKYSA-N Ile-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)O)N TWPSALMCEHCIOY-YTFOTSKYSA-N 0.000 description 1
- CSQNHSGHAPRGPQ-YTFOTSKYSA-N Ile-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)O)N CSQNHSGHAPRGPQ-YTFOTSKYSA-N 0.000 description 1
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 1
- KLBVGHCGHUNHEA-BJDJZHNGSA-N Ile-Leu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)O)N KLBVGHCGHUNHEA-BJDJZHNGSA-N 0.000 description 1
- TWYOYAKMLHWMOJ-ZPFDUUQYSA-N Ile-Leu-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O TWYOYAKMLHWMOJ-ZPFDUUQYSA-N 0.000 description 1
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 1
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 1
- PNTWNAXGBOZMBO-MNXVOIDGSA-N Ile-Lys-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PNTWNAXGBOZMBO-MNXVOIDGSA-N 0.000 description 1
- MASWXTFJVNRZPT-NAKRPEOUSA-N Ile-Met-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(=O)O)N MASWXTFJVNRZPT-NAKRPEOUSA-N 0.000 description 1
- HQEPKOFULQTSFV-JURCDPSOSA-N Ile-Phe-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)O)N HQEPKOFULQTSFV-JURCDPSOSA-N 0.000 description 1
- IIWQTXMUALXGOV-PCBIJLKTSA-N Ile-Phe-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N IIWQTXMUALXGOV-PCBIJLKTSA-N 0.000 description 1
- IVXJIMGDOYRLQU-XUXIUFHCSA-N Ile-Pro-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O IVXJIMGDOYRLQU-XUXIUFHCSA-N 0.000 description 1
- FQYQMFCIJNWDQZ-CYDGBPFRSA-N Ile-Pro-Pro Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 FQYQMFCIJNWDQZ-CYDGBPFRSA-N 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 1
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 1
- OAQJOXZPGHTJNA-NGTWOADLSA-N Ile-Trp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N OAQJOXZPGHTJNA-NGTWOADLSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- ZYVTXBXHIKGZMD-QSFUFRPTSA-N Ile-Val-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ZYVTXBXHIKGZMD-QSFUFRPTSA-N 0.000 description 1
- KXUKTDGKLAOCQK-LSJOCFKGSA-N Ile-Val-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O KXUKTDGKLAOCQK-LSJOCFKGSA-N 0.000 description 1
- DLEBSGAVWRPTIX-PEDHHIEDSA-N Ile-Val-Ile Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)[C@@H](C)CC DLEBSGAVWRPTIX-PEDHHIEDSA-N 0.000 description 1
- JZBVBOKASHNXAD-NAKRPEOUSA-N Ile-Val-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N JZBVBOKASHNXAD-NAKRPEOUSA-N 0.000 description 1
- QSXSHZIRKTUXNG-STECZYCISA-N Ile-Val-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QSXSHZIRKTUXNG-STECZYCISA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 108010065920 Insulin Lispro Proteins 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 239000004166 Lanolin Substances 0.000 description 1
- 241000812339 Letharia lupina Species 0.000 description 1
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 1
- SUPVSFFZWVOEOI-UHFFFAOYSA-N Leu-Ala-Tyr Natural products CC(C)CC(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-UHFFFAOYSA-N 0.000 description 1
- SUPVSFFZWVOEOI-CQDKDKBSSA-N Leu-Ala-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-CQDKDKBSSA-N 0.000 description 1
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 1
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 1
- UILIPCLTHRPCRB-XUXIUFHCSA-N Leu-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(C)C)N UILIPCLTHRPCRB-XUXIUFHCSA-N 0.000 description 1
- YOZCKMXHBYKOMQ-IHRRRGAJSA-N Leu-Arg-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOZCKMXHBYKOMQ-IHRRRGAJSA-N 0.000 description 1
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 1
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- WGNOPSQMIQERPK-GARJFASQSA-N Leu-Asn-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N WGNOPSQMIQERPK-GARJFASQSA-N 0.000 description 1
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 1
- ILJREDZFPHTUIE-GUBZILKMSA-N Leu-Asp-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ILJREDZFPHTUIE-GUBZILKMSA-N 0.000 description 1
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 1
- IASQBRJGRVXNJI-YUMQZZPRSA-N Leu-Cys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)NCC(O)=O IASQBRJGRVXNJI-YUMQZZPRSA-N 0.000 description 1
- VPKIQULSKFVCSM-SRVKXCTJSA-N Leu-Gln-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPKIQULSKFVCSM-SRVKXCTJSA-N 0.000 description 1
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- BOFAFKVZQUMTID-AVGNSLFASA-N Leu-Gln-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BOFAFKVZQUMTID-AVGNSLFASA-N 0.000 description 1
- RSFGIMMPWAXNML-MNXVOIDGSA-N Leu-Gln-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RSFGIMMPWAXNML-MNXVOIDGSA-N 0.000 description 1
- QDSKNVXKLPQNOJ-GVXVVHGQSA-N Leu-Gln-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O QDSKNVXKLPQNOJ-GVXVVHGQSA-N 0.000 description 1
- DZQMXBALGUHGJT-GUBZILKMSA-N Leu-Glu-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O DZQMXBALGUHGJT-GUBZILKMSA-N 0.000 description 1
- RVVBWTWPNFDYBE-SRVKXCTJSA-N Leu-Glu-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVVBWTWPNFDYBE-SRVKXCTJSA-N 0.000 description 1
- YVKSMSDXKMSIRX-GUBZILKMSA-N Leu-Glu-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YVKSMSDXKMSIRX-GUBZILKMSA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 1
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 1
- OGUUKPXUTHOIAV-SDDRHHMPSA-N Leu-Glu-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGUUKPXUTHOIAV-SDDRHHMPSA-N 0.000 description 1
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 1
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 1
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 1
- QPXBPQUGXHURGP-UWVGGRQHSA-N Leu-Gly-Met Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N QPXBPQUGXHURGP-UWVGGRQHSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 1
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 1
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- IFMPDNRWZZEZSL-SRVKXCTJSA-N Leu-Leu-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O IFMPDNRWZZEZSL-SRVKXCTJSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 1
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 1
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 1
- RZXLZBIUTDQHJQ-SRVKXCTJSA-N Leu-Lys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O RZXLZBIUTDQHJQ-SRVKXCTJSA-N 0.000 description 1
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 1
- HDHQQEDVWQGBEE-DCAQKATOSA-N Leu-Met-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O HDHQQEDVWQGBEE-DCAQKATOSA-N 0.000 description 1
- NJMXCOOEFLMZSR-AVGNSLFASA-N Leu-Met-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NJMXCOOEFLMZSR-AVGNSLFASA-N 0.000 description 1
- ZDBMWELMUCLUPL-QEJZJMRPSA-N Leu-Phe-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 ZDBMWELMUCLUPL-QEJZJMRPSA-N 0.000 description 1
- GCXGCIYIHXSKAY-ULQDDVLXSA-N Leu-Phe-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GCXGCIYIHXSKAY-ULQDDVLXSA-N 0.000 description 1
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 1
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 1
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- RRVCZCNFXIFGRA-DCAQKATOSA-N Leu-Pro-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RRVCZCNFXIFGRA-DCAQKATOSA-N 0.000 description 1
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 1
- MUCIDQMDOYQYBR-IHRRRGAJSA-N Leu-Pro-His Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N MUCIDQMDOYQYBR-IHRRRGAJSA-N 0.000 description 1
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 1
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 1
- SQUFDMCWMFOEBA-KKUMJFAQSA-N Leu-Ser-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SQUFDMCWMFOEBA-KKUMJFAQSA-N 0.000 description 1
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 1
- FGZVGOAAROXFAB-IXOXFDKPSA-N Leu-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(C)C)N)O FGZVGOAAROXFAB-IXOXFDKPSA-N 0.000 description 1
- ODRREERHVHMIPT-OEAJRASXSA-N Leu-Thr-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ODRREERHVHMIPT-OEAJRASXSA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- IDGRADDMTTWOQC-WDSOQIARSA-N Leu-Trp-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IDGRADDMTTWOQC-WDSOQIARSA-N 0.000 description 1
- LSLUTXRANSUGFY-XIRDDKMYSA-N Leu-Trp-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(O)=O)C(O)=O LSLUTXRANSUGFY-XIRDDKMYSA-N 0.000 description 1
- RIHIGSWBLHSGLV-CQDKDKBSSA-N Leu-Tyr-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O RIHIGSWBLHSGLV-CQDKDKBSSA-N 0.000 description 1
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 1
- XZNJZXJZBMBGGS-NHCYSSNCSA-N Leu-Val-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XZNJZXJZBMBGGS-NHCYSSNCSA-N 0.000 description 1
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 1
- XOEDPXDZJHBQIX-ULQDDVLXSA-N Leu-Val-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOEDPXDZJHBQIX-ULQDDVLXSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108010022337 Leucine Enkephalin Proteins 0.000 description 1
- 241000007443 Lobaria pulmonaria Species 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 1
- NFLFJGGKOHYZJF-BJDJZHNGSA-N Lys-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN NFLFJGGKOHYZJF-BJDJZHNGSA-N 0.000 description 1
- WQWZXKWOEVSGQM-DCAQKATOSA-N Lys-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN WQWZXKWOEVSGQM-DCAQKATOSA-N 0.000 description 1
- YRWCPXOFBKTCFY-NUTKFTJISA-N Lys-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCCN)N YRWCPXOFBKTCFY-NUTKFTJISA-N 0.000 description 1
- BRSGXFITDXFMFF-IHRRRGAJSA-N Lys-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N BRSGXFITDXFMFF-IHRRRGAJSA-N 0.000 description 1
- NCTDKZKNBDZDOL-GARJFASQSA-N Lys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O NCTDKZKNBDZDOL-GARJFASQSA-N 0.000 description 1
- YEIYAQQKADPIBJ-GARJFASQSA-N Lys-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O YEIYAQQKADPIBJ-GARJFASQSA-N 0.000 description 1
- XFBBBRDEQIPGNR-KATARQTJSA-N Lys-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)O XFBBBRDEQIPGNR-KATARQTJSA-N 0.000 description 1
- WTZUSCUIVPVCRH-SRVKXCTJSA-N Lys-Gln-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WTZUSCUIVPVCRH-SRVKXCTJSA-N 0.000 description 1
- YFGWNAROEYWGNL-GUBZILKMSA-N Lys-Gln-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YFGWNAROEYWGNL-GUBZILKMSA-N 0.000 description 1
- MRWXLRGAFDOILG-DCAQKATOSA-N Lys-Gln-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MRWXLRGAFDOILG-DCAQKATOSA-N 0.000 description 1
- PAMDBWYMLWOELY-SDDRHHMPSA-N Lys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O PAMDBWYMLWOELY-SDDRHHMPSA-N 0.000 description 1
- GHOIOYHDDKXIDX-SZMVWBNQSA-N Lys-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCCN)C(O)=O)=CNC2=C1 GHOIOYHDDKXIDX-SZMVWBNQSA-N 0.000 description 1
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 1
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 1
- HAUUXTXKJNVIFY-ONGXEEELSA-N Lys-Gly-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAUUXTXKJNVIFY-ONGXEEELSA-N 0.000 description 1
- VLMNBMFYRMGEMB-QWRGUYRKSA-N Lys-His-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CNC=N1 VLMNBMFYRMGEMB-QWRGUYRKSA-N 0.000 description 1
- WOEDRPCHKPSFDT-MXAVVETBSA-N Lys-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCCN)N WOEDRPCHKPSFDT-MXAVVETBSA-N 0.000 description 1
- PGLGNCVOWIORQE-SRVKXCTJSA-N Lys-His-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O PGLGNCVOWIORQE-SRVKXCTJSA-N 0.000 description 1
- SLQJJFAVWSZLBL-BJDJZHNGSA-N Lys-Ile-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN SLQJJFAVWSZLBL-BJDJZHNGSA-N 0.000 description 1
- OJDFAABAHBPVTH-MNXVOIDGSA-N Lys-Ile-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O OJDFAABAHBPVTH-MNXVOIDGSA-N 0.000 description 1
- ZXFRGTAIIZHNHG-AJNGGQMLSA-N Lys-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N ZXFRGTAIIZHNHG-AJNGGQMLSA-N 0.000 description 1
- IZJGPPIGYTVXLB-FQUUOJAGSA-N Lys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IZJGPPIGYTVXLB-FQUUOJAGSA-N 0.000 description 1
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 1
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 1
- LJADEBULDNKJNK-IHRRRGAJSA-N Lys-Leu-Val Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LJADEBULDNKJNK-IHRRRGAJSA-N 0.000 description 1
- RIJCHEVHFWMDKD-SRVKXCTJSA-N Lys-Lys-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RIJCHEVHFWMDKD-SRVKXCTJSA-N 0.000 description 1
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- VSTNAUBHKQPVJX-IHRRRGAJSA-N Lys-Met-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O VSTNAUBHKQPVJX-IHRRRGAJSA-N 0.000 description 1
- LUAJJLPHUXPQLH-KKUMJFAQSA-N Lys-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCCN)N LUAJJLPHUXPQLH-KKUMJFAQSA-N 0.000 description 1
- BOJYMMBYBNOOGG-DCAQKATOSA-N Lys-Pro-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BOJYMMBYBNOOGG-DCAQKATOSA-N 0.000 description 1
- QBHGXFQJFPWJIH-XUXIUFHCSA-N Lys-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN QBHGXFQJFPWJIH-XUXIUFHCSA-N 0.000 description 1
- HYSVGEAWTGPMOA-IHRRRGAJSA-N Lys-Pro-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O HYSVGEAWTGPMOA-IHRRRGAJSA-N 0.000 description 1
- LECIJRIRMVOFMH-ULQDDVLXSA-N Lys-Pro-Phe Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LECIJRIRMVOFMH-ULQDDVLXSA-N 0.000 description 1
- UQJOKDAYFULYIX-AVGNSLFASA-N Lys-Pro-Pro Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 UQJOKDAYFULYIX-AVGNSLFASA-N 0.000 description 1
- HKXSZKJMDBHOTG-CIUDSAMLSA-N Lys-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN HKXSZKJMDBHOTG-CIUDSAMLSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- DYJOORGDQIGZAS-DCAQKATOSA-N Lys-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N DYJOORGDQIGZAS-DCAQKATOSA-N 0.000 description 1
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 1
- YRNRVKTYDSLKMD-KKUMJFAQSA-N Lys-Ser-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YRNRVKTYDSLKMD-KKUMJFAQSA-N 0.000 description 1
- GIKFNMZSGYAPEJ-HJGDQZAQSA-N Lys-Thr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O GIKFNMZSGYAPEJ-HJGDQZAQSA-N 0.000 description 1
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 1
- BDFHWFUAQLIMJO-KXNHARMFSA-N Lys-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N)O BDFHWFUAQLIMJO-KXNHARMFSA-N 0.000 description 1
- OEYKVQKYCHATHO-SZMVWBNQSA-N Lys-Trp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N OEYKVQKYCHATHO-SZMVWBNQSA-N 0.000 description 1
- YUTZYVTZDVZBJJ-IHPCNDPISA-N Lys-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 YUTZYVTZDVZBJJ-IHPCNDPISA-N 0.000 description 1
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 1
- DRRXXZBXDMLGFC-IHRRRGAJSA-N Lys-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN DRRXXZBXDMLGFC-IHRRRGAJSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102000015841 Major facilitator superfamily Human genes 0.000 description 1
- 108050004064 Major facilitator superfamily Proteins 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- JHKXZYLNVJRAAJ-WDSKDSINSA-N Met-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(O)=O JHKXZYLNVJRAAJ-WDSKDSINSA-N 0.000 description 1
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 1
- QRHWTCJBCLGYRB-FXQIFTODSA-N Met-Ala-Cys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(O)=O QRHWTCJBCLGYRB-FXQIFTODSA-N 0.000 description 1
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 1
- VIZLHGTVGKBBKO-AVGNSLFASA-N Met-Arg-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N VIZLHGTVGKBBKO-AVGNSLFASA-N 0.000 description 1
- WDTLNWHPIPCMMP-AVGNSLFASA-N Met-Arg-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O WDTLNWHPIPCMMP-AVGNSLFASA-N 0.000 description 1
- AHZNUGRZHMZGFL-GUBZILKMSA-N Met-Arg-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCNC(N)=N AHZNUGRZHMZGFL-GUBZILKMSA-N 0.000 description 1
- HDNOQCZWJGGHSS-VEVYYDQMSA-N Met-Asn-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HDNOQCZWJGGHSS-VEVYYDQMSA-N 0.000 description 1
- OSOLWRWQADPDIQ-DCAQKATOSA-N Met-Asp-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OSOLWRWQADPDIQ-DCAQKATOSA-N 0.000 description 1
- DNDVVILEHVMWIS-LPEHRKFASA-N Met-Asp-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DNDVVILEHVMWIS-LPEHRKFASA-N 0.000 description 1
- VOOINLQYUZOREH-SRVKXCTJSA-N Met-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N VOOINLQYUZOREH-SRVKXCTJSA-N 0.000 description 1
- TZHFJXDKXGZHEN-IHRRRGAJSA-N Met-His-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O TZHFJXDKXGZHEN-IHRRRGAJSA-N 0.000 description 1
- HZLSUXCMSIBCRV-RVMXOQNASA-N Met-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N HZLSUXCMSIBCRV-RVMXOQNASA-N 0.000 description 1
- HGAJNEWOUHDUMZ-SRVKXCTJSA-N Met-Leu-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O HGAJNEWOUHDUMZ-SRVKXCTJSA-N 0.000 description 1
- OCRSGGIJBDUXHU-WDSOQIARSA-N Met-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 OCRSGGIJBDUXHU-WDSOQIARSA-N 0.000 description 1
- UNPGTBHYKJOCCZ-DCAQKATOSA-N Met-Lys-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O UNPGTBHYKJOCCZ-DCAQKATOSA-N 0.000 description 1
- MIAZEQZXAFTCCG-UBHSHLNASA-N Met-Phe-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 MIAZEQZXAFTCCG-UBHSHLNASA-N 0.000 description 1
- IILAGWCGKJSBGB-IHRRRGAJSA-N Met-Phe-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N IILAGWCGKJSBGB-IHRRRGAJSA-N 0.000 description 1
- VQILILSLEFDECU-GUBZILKMSA-N Met-Pro-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O VQILILSLEFDECU-GUBZILKMSA-N 0.000 description 1
- XIGAHPDZLAYQOS-SRVKXCTJSA-N Met-Pro-Pro Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 XIGAHPDZLAYQOS-SRVKXCTJSA-N 0.000 description 1
- HLZORBMOISUNIV-DCAQKATOSA-N Met-Ser-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C HLZORBMOISUNIV-DCAQKATOSA-N 0.000 description 1
- DSZFTPCSFVWMKP-DCAQKATOSA-N Met-Ser-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN DSZFTPCSFVWMKP-DCAQKATOSA-N 0.000 description 1
- QQPMHUCGDRJFQK-RHYQMDGZSA-N Met-Thr-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QQPMHUCGDRJFQK-RHYQMDGZSA-N 0.000 description 1
- YIGCDRZMZNDENK-UNQGMJICSA-N Met-Thr-Phe Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YIGCDRZMZNDENK-UNQGMJICSA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- WOGNGBROIHHFAO-JYJNAYRXSA-N Met-Tyr-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCSC)C(=O)O)N WOGNGBROIHHFAO-JYJNAYRXSA-N 0.000 description 1
- VYXIKLFLGRTANT-HRCADAONSA-N Met-Tyr-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N VYXIKLFLGRTANT-HRCADAONSA-N 0.000 description 1
- IQJMEDDVOGMTKT-SRVKXCTJSA-N Met-Val-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IQJMEDDVOGMTKT-SRVKXCTJSA-N 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 101710132674 Monosaccharide transporter Proteins 0.000 description 1
- 101100194350 Mus musculus Rere gene Proteins 0.000 description 1
- JLTDJTHDQAWBAV-UHFFFAOYSA-N N,N-dimethylaniline Chemical compound CN(C)C1=CC=CC=C1 JLTDJTHDQAWBAV-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 108010066427 N-valyltryptophan Proteins 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- VZPLPGICHZXOCQ-UHFFFAOYSA-N Olivetoric acid Chemical compound CCCCCC(=O)CC1=CC(O)=CC(O)=C1C(=O)OC1=CC(O)=C(C(O)=O)C(CCCCC)=C1 VZPLPGICHZXOCQ-UHFFFAOYSA-N 0.000 description 1
- BAZIREYQKLPBSI-UHFFFAOYSA-N Olivetoric acid Natural products CCCCCCC(=O)c1cc(O)cc(O)c1C(=O)Oc2cc(O)c(C(=O)O)c(CCCCC)c2 BAZIREYQKLPBSI-UHFFFAOYSA-N 0.000 description 1
- 101150053185 P450 gene Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 241000222291 Passalora fulva Species 0.000 description 1
- 101001053399 Paxillus involutus Atromentin synthetase invA1 Proteins 0.000 description 1
- 101001053402 Paxillus involutus Atromentin synthetase invA2 Proteins 0.000 description 1
- 101000599707 Paxillus involutus Atromentin synthetase invA5 Proteins 0.000 description 1
- 101001053396 Paxillus involutus Inactive atromentin synthetase invA3 Proteins 0.000 description 1
- 101000599706 Paxillus involutus Inactive atromentin synthetase invA4 Proteins 0.000 description 1
- 101000599710 Paxillus involutus Inactive atromentin synthetase invA6 Proteins 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 241000228145 Penicillium brevicompactum Species 0.000 description 1
- ULECEJGNDHWSKD-QEJZJMRPSA-N Phe-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 ULECEJGNDHWSKD-QEJZJMRPSA-N 0.000 description 1
- LBSARGIQACMGDF-WBAXXEDZSA-N Phe-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 LBSARGIQACMGDF-WBAXXEDZSA-N 0.000 description 1
- UHRNIXJAGGLKHP-DLOVCJGASA-N Phe-Ala-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O UHRNIXJAGGLKHP-DLOVCJGASA-N 0.000 description 1
- VHWOBXIWBDWZHK-IHRRRGAJSA-N Phe-Arg-Asp Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHWOBXIWBDWZHK-IHRRRGAJSA-N 0.000 description 1
- YYRCPTVAPLQRNC-ULQDDVLXSA-N Phe-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CC1=CC=CC=C1 YYRCPTVAPLQRNC-ULQDDVLXSA-N 0.000 description 1
- PLNHHOXNVSYKOB-JYJNAYRXSA-N Phe-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CC=CC=C1)N PLNHHOXNVSYKOB-JYJNAYRXSA-N 0.000 description 1
- QCHNRQQVLJYDSI-DLOVCJGASA-N Phe-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 QCHNRQQVLJYDSI-DLOVCJGASA-N 0.000 description 1
- UUWCIPUVJJIEEP-SRVKXCTJSA-N Phe-Asn-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N UUWCIPUVJJIEEP-SRVKXCTJSA-N 0.000 description 1
- MGBRZXXGQBAULP-DRZSPHRISA-N Phe-Glu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MGBRZXXGQBAULP-DRZSPHRISA-N 0.000 description 1
- JWQWPTLEOFNCGX-AVGNSLFASA-N Phe-Glu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 JWQWPTLEOFNCGX-AVGNSLFASA-N 0.000 description 1
- BFYHIHGIHGROAT-HTUGSXCWSA-N Phe-Glu-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFYHIHGIHGROAT-HTUGSXCWSA-N 0.000 description 1
- ZZVUXQCQPXSUFH-JBACZVJFSA-N Phe-Glu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 ZZVUXQCQPXSUFH-JBACZVJFSA-N 0.000 description 1
- LWPMGKSZPKFKJD-DZKIICNBSA-N Phe-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O LWPMGKSZPKFKJD-DZKIICNBSA-N 0.000 description 1
- HGNGAMWHGGANAU-WHOFXGATSA-N Phe-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HGNGAMWHGGANAU-WHOFXGATSA-N 0.000 description 1
- CWFGECHCRMGPPT-MXAVVETBSA-N Phe-Ile-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O CWFGECHCRMGPPT-MXAVVETBSA-N 0.000 description 1
- RORUIHAWOLADSH-HJWJTTGWSA-N Phe-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=CC=C1 RORUIHAWOLADSH-HJWJTTGWSA-N 0.000 description 1
- YKUGPVXSDOOANW-KKUMJFAQSA-N Phe-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YKUGPVXSDOOANW-KKUMJFAQSA-N 0.000 description 1
- SMFGCTXUBWEPKM-KBPBESRZSA-N Phe-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 SMFGCTXUBWEPKM-KBPBESRZSA-N 0.000 description 1
- METZZBCMDXHFMK-BZSNNMDCSA-N Phe-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N METZZBCMDXHFMK-BZSNNMDCSA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- OQTDZEJJWWAGJT-KKUMJFAQSA-N Phe-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O OQTDZEJJWWAGJT-KKUMJFAQSA-N 0.000 description 1
- MJAYDXWQQUOURZ-JYJNAYRXSA-N Phe-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O MJAYDXWQQUOURZ-JYJNAYRXSA-N 0.000 description 1
- WLYPRKLMRIYGPP-JYJNAYRXSA-N Phe-Lys-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 WLYPRKLMRIYGPP-JYJNAYRXSA-N 0.000 description 1
- XZQYIJALMGEUJD-OEAJRASXSA-N Phe-Lys-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XZQYIJALMGEUJD-OEAJRASXSA-N 0.000 description 1
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 1
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 1
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 1
- PTDAGKJHZBGDKD-OEAJRASXSA-N Phe-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O PTDAGKJHZBGDKD-OEAJRASXSA-N 0.000 description 1
- GCFNFKNPCMBHNT-IRXDYDNUSA-N Phe-Tyr-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)NCC(=O)O)N GCFNFKNPCMBHNT-IRXDYDNUSA-N 0.000 description 1
- NHHZWPNMYQUNEH-ACRUOGEOSA-N Phe-Tyr-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N NHHZWPNMYQUNEH-ACRUOGEOSA-N 0.000 description 1
- CDHURCQGUDNBMA-UBHSHLNASA-N Phe-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 CDHURCQGUDNBMA-UBHSHLNASA-N 0.000 description 1
- YUPRIZTWANWWHK-DZKIICNBSA-N Phe-Val-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N YUPRIZTWANWWHK-DZKIICNBSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- WUUNPBLZLWVARQ-QAETUUGQSA-N Postin Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 WUUNPBLZLWVARQ-QAETUUGQSA-N 0.000 description 1
- CQZNGNCAIXMAIQ-UBHSHLNASA-N Pro-Ala-Phe Chemical compound C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O CQZNGNCAIXMAIQ-UBHSHLNASA-N 0.000 description 1
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 1
- HPXVFFIIGOAQRV-DCAQKATOSA-N Pro-Arg-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O HPXVFFIIGOAQRV-DCAQKATOSA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 1
- CYQQWUPHIZVCNY-GUBZILKMSA-N Pro-Arg-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CYQQWUPHIZVCNY-GUBZILKMSA-N 0.000 description 1
- ZSKJPKFTPQCPIH-RCWTZXSCSA-N Pro-Arg-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSKJPKFTPQCPIH-RCWTZXSCSA-N 0.000 description 1
- SMCHPSMKAFIERP-FXQIFTODSA-N Pro-Asn-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 SMCHPSMKAFIERP-FXQIFTODSA-N 0.000 description 1
- OBVCYFIHIIYIQF-CIUDSAMLSA-N Pro-Asn-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OBVCYFIHIIYIQF-CIUDSAMLSA-N 0.000 description 1
- UTAUEDINXUMHLG-FXQIFTODSA-N Pro-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 UTAUEDINXUMHLG-FXQIFTODSA-N 0.000 description 1
- KIGGUSRFHJCIEJ-DCAQKATOSA-N Pro-Asp-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O KIGGUSRFHJCIEJ-DCAQKATOSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 1
- VOZIBWWZSBIXQN-SRVKXCTJSA-N Pro-Glu-Lys Chemical compound NCCCC[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O VOZIBWWZSBIXQN-SRVKXCTJSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 1
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 1
- XQHGISDMVBTGAL-ULQDDVLXSA-N Pro-His-Phe Chemical compound C([C@@H](C(=O)[O-])NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1[NH2+]CCC1)C1=CC=CC=C1 XQHGISDMVBTGAL-ULQDDVLXSA-N 0.000 description 1
- AQSMZTIEJMZQEC-DCAQKATOSA-N Pro-His-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O AQSMZTIEJMZQEC-DCAQKATOSA-N 0.000 description 1
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 1
- FKVNLUZHSFCNGY-RVMXOQNASA-N Pro-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 FKVNLUZHSFCNGY-RVMXOQNASA-N 0.000 description 1
- UREQLMJCKFLLHM-NAKRPEOUSA-N Pro-Ile-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UREQLMJCKFLLHM-NAKRPEOUSA-N 0.000 description 1
- KLSOMAFWRISSNI-OSUNSFLBSA-N Pro-Ile-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 KLSOMAFWRISSNI-OSUNSFLBSA-N 0.000 description 1
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 1
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 1
- MCWHYUWXVNRXFV-RWMBFGLXSA-N Pro-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 MCWHYUWXVNRXFV-RWMBFGLXSA-N 0.000 description 1
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 1
- JUJCUYWRJMFJJF-AVGNSLFASA-N Pro-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 JUJCUYWRJMFJJF-AVGNSLFASA-N 0.000 description 1
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 1
- SMFQZMGHCODUPQ-ULQDDVLXSA-N Pro-Lys-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SMFQZMGHCODUPQ-ULQDDVLXSA-N 0.000 description 1
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 1
- WFIVLLFYUZZWOD-RHYQMDGZSA-N Pro-Lys-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WFIVLLFYUZZWOD-RHYQMDGZSA-N 0.000 description 1
- RPLMFKUKFZOTER-AVGNSLFASA-N Pro-Met-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 RPLMFKUKFZOTER-AVGNSLFASA-N 0.000 description 1
- AUYKOPJPKUCYHE-SRVKXCTJSA-N Pro-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 AUYKOPJPKUCYHE-SRVKXCTJSA-N 0.000 description 1
- ZVEQWRWMRFIVSD-HRCADAONSA-N Pro-Phe-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N3CCC[C@@H]3C(=O)O ZVEQWRWMRFIVSD-HRCADAONSA-N 0.000 description 1
- AJNGQVUFQUVRQT-JYJNAYRXSA-N Pro-Pro-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 AJNGQVUFQUVRQT-JYJNAYRXSA-N 0.000 description 1
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 1
- CZCCVJUUWBMISW-FXQIFTODSA-N Pro-Ser-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O CZCCVJUUWBMISW-FXQIFTODSA-N 0.000 description 1
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 1
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 1
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 1
- WVXQQUWOKUZIEG-VEVYYDQMSA-N Pro-Thr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O WVXQQUWOKUZIEG-VEVYYDQMSA-N 0.000 description 1
- QUBVFEANYYWBTM-VEVYYDQMSA-N Pro-Thr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUBVFEANYYWBTM-VEVYYDQMSA-N 0.000 description 1
- DCHQYSOGURGJST-FJXKBIBVSA-N Pro-Thr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O DCHQYSOGURGJST-FJXKBIBVSA-N 0.000 description 1
- AJJDPGVVNPUZCR-RHYQMDGZSA-N Pro-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1)O AJJDPGVVNPUZCR-RHYQMDGZSA-N 0.000 description 1
- RMJZWERKFFNNNS-XGEHTFHBSA-N Pro-Thr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMJZWERKFFNNNS-XGEHTFHBSA-N 0.000 description 1
- DIDLUFMLRUJLFB-FKBYEOEOSA-N Pro-Trp-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CC4=CC=C(C=C4)O)C(=O)O DIDLUFMLRUJLFB-FKBYEOEOSA-N 0.000 description 1
- BVRBCQBUNGAWFP-KKUMJFAQSA-N Pro-Tyr-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O BVRBCQBUNGAWFP-KKUMJFAQSA-N 0.000 description 1
- YHUBAXGAAYULJY-ULQDDVLXSA-N Pro-Tyr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O YHUBAXGAAYULJY-ULQDDVLXSA-N 0.000 description 1
- UIUWGMRJTWHIJZ-ULQDDVLXSA-N Pro-Tyr-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCCN)C(=O)O UIUWGMRJTWHIJZ-ULQDDVLXSA-N 0.000 description 1
- PGSWNLRYYONGPE-JYJNAYRXSA-N Pro-Val-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PGSWNLRYYONGPE-JYJNAYRXSA-N 0.000 description 1
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 1
- 241000963262 Pseudevernia furfuracea Species 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- FIXILCYTSAUERA-FXQIFTODSA-N Ser-Ala-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FIXILCYTSAUERA-FXQIFTODSA-N 0.000 description 1
- MWMKFWJYRRGXOR-ZLUOBGJFSA-N Ser-Ala-Asn Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC(N)=O)C)CO MWMKFWJYRRGXOR-ZLUOBGJFSA-N 0.000 description 1
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 1
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- IDQFQFVEWMWRQQ-DLOVCJGASA-N Ser-Ala-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IDQFQFVEWMWRQQ-DLOVCJGASA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 1
- UBRXAVQWXOWRSJ-ZLUOBGJFSA-N Ser-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)C(=O)N UBRXAVQWXOWRSJ-ZLUOBGJFSA-N 0.000 description 1
- VAIZFHMTBFYJIA-ACZMJKKPSA-N Ser-Asp-Gln Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(N)=O VAIZFHMTBFYJIA-ACZMJKKPSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- BYIROAKULFFTEK-CIUDSAMLSA-N Ser-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO BYIROAKULFFTEK-CIUDSAMLSA-N 0.000 description 1
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 1
- BTPAWKABYQMKKN-LKXGYXEUSA-N Ser-Asp-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BTPAWKABYQMKKN-LKXGYXEUSA-N 0.000 description 1
- DSSOYPJWSWFOLK-CIUDSAMLSA-N Ser-Cys-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O DSSOYPJWSWFOLK-CIUDSAMLSA-N 0.000 description 1
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 1
- CDVFZMOFNJPUDD-ACZMJKKPSA-N Ser-Gln-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CDVFZMOFNJPUDD-ACZMJKKPSA-N 0.000 description 1
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- SNVIOQXAHVORQM-WDSKDSINSA-N Ser-Gly-Gln Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O SNVIOQXAHVORQM-WDSKDSINSA-N 0.000 description 1
- IXCHOHLPHNGFTJ-YUMQZZPRSA-N Ser-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N IXCHOHLPHNGFTJ-YUMQZZPRSA-N 0.000 description 1
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 1
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 1
- MLSQXWSRHURDMF-GARJFASQSA-N Ser-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N)C(=O)O MLSQXWSRHURDMF-GARJFASQSA-N 0.000 description 1
- CAOYHZOWXFFAIR-CIUDSAMLSA-N Ser-His-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CAOYHZOWXFFAIR-CIUDSAMLSA-N 0.000 description 1
- JIPVNVNKXJLFJF-BJDJZHNGSA-N Ser-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N JIPVNVNKXJLFJF-BJDJZHNGSA-N 0.000 description 1
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 1
- DOSZISJPMCYEHT-NAKRPEOUSA-N Ser-Ile-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O DOSZISJPMCYEHT-NAKRPEOUSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- BYCVMHKULKRVPV-GUBZILKMSA-N Ser-Lys-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYCVMHKULKRVPV-GUBZILKMSA-N 0.000 description 1
- LRZLZIUXQBIWTB-KATARQTJSA-N Ser-Lys-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LRZLZIUXQBIWTB-KATARQTJSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- XGQKSRGHEZNWIS-IHRRRGAJSA-N Ser-Pro-Tyr Chemical compound N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O XGQKSRGHEZNWIS-IHRRRGAJSA-N 0.000 description 1
- AABIBDJHSKIMJK-FXQIFTODSA-N Ser-Ser-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O AABIBDJHSKIMJK-FXQIFTODSA-N 0.000 description 1
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- SQHKXWODKJDZRC-LKXGYXEUSA-N Ser-Thr-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQHKXWODKJDZRC-LKXGYXEUSA-N 0.000 description 1
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 1
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 1
- ATEQEHCGZKBEMU-GQGQLFGLSA-N Ser-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N ATEQEHCGZKBEMU-GQGQLFGLSA-N 0.000 description 1
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 1
- UBTNVMGPMYDYIU-HJPIBITLSA-N Ser-Tyr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UBTNVMGPMYDYIU-HJPIBITLSA-N 0.000 description 1
- HAYADTTXNZFUDM-IHRRRGAJSA-N Ser-Tyr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HAYADTTXNZFUDM-IHRRRGAJSA-N 0.000 description 1
- IAOHCSQDQDWRQU-GUBZILKMSA-N Ser-Val-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IAOHCSQDQDWRQU-GUBZILKMSA-N 0.000 description 1
- 101001124317 Serpula lacrymans var. lacrymans (strain S7.9) Adenylate-forming reductase Nps11 Proteins 0.000 description 1
- 101000577223 Serpula lacrymans var. lacrymans (strain S7.9) Adenylate-forming reductase Nps9 Proteins 0.000 description 1
- 101001124346 Serpula lacrymans var. lacrymans (strain S7.9) Atromentin synthetase nps3 Proteins 0.000 description 1
- 102000016813 Ssl1-like Human genes 0.000 description 1
- 108050006521 Ssl1-like Proteins 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 241000502305 Stereocaulaceae Species 0.000 description 1
- 241000502304 Stereocaulon Species 0.000 description 1
- SKCUFZLDTAYNBZ-UHFFFAOYSA-N Stictinsaeure Natural products O1C2=C(C(O)OC3=O)C3=C(O)C(C)=C2OC(=O)C2=C(C)C=C(OC)C(C=O)=C12 SKCUFZLDTAYNBZ-UHFFFAOYSA-N 0.000 description 1
- 101000983177 Streptomyces rimosus N,N-dimethyltransferase OxyT Proteins 0.000 description 1
- 101001034059 Suillus grevillei Atromentin synthetase greA Proteins 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- 235000019486 Sunflower oil Nutrition 0.000 description 1
- 108700005078 Synthetic Genes Proteins 0.000 description 1
- ATFNSNUJZOYXFC-UHFFFAOYSA-N Tenein-saeure Natural products O=C1C(C)=C(O)C(=O)C2OC21 ATFNSNUJZOYXFC-UHFFFAOYSA-N 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- MQBTXMPQNCGSSZ-OSUNSFLBSA-N Thr-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N MQBTXMPQNCGSSZ-OSUNSFLBSA-N 0.000 description 1
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 1
- SWIKDOUVROTZCW-GCJQMDKQSA-N Thr-Asn-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O SWIKDOUVROTZCW-GCJQMDKQSA-N 0.000 description 1
- TZKPNGDGUVREEB-FOHZUACHSA-N Thr-Asn-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O TZKPNGDGUVREEB-FOHZUACHSA-N 0.000 description 1
- PZVGOVRNGKEFCB-KKHAAJSZSA-N Thr-Asn-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N)O PZVGOVRNGKEFCB-KKHAAJSZSA-N 0.000 description 1
- LMMDEZPNUTZJAY-GCJQMDKQSA-N Thr-Asp-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O LMMDEZPNUTZJAY-GCJQMDKQSA-N 0.000 description 1
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 1
- JXKMXEBNZCKSDY-JIOCBJNQSA-N Thr-Asp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O JXKMXEBNZCKSDY-JIOCBJNQSA-N 0.000 description 1
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 1
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 1
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 1
- ZQUKYJOKQBRBCS-GLLZPBPUSA-N Thr-Gln-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O ZQUKYJOKQBRBCS-GLLZPBPUSA-N 0.000 description 1
- XXNLGZRRSKPSGF-HTUGSXCWSA-N Thr-Gln-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O XXNLGZRRSKPSGF-HTUGSXCWSA-N 0.000 description 1
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 1
- VULNJDORNLBPNG-SWRJLBSHSA-N Thr-Glu-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O VULNJDORNLBPNG-SWRJLBSHSA-N 0.000 description 1
- LKEKWDJCJSPXNI-IRIUXVKKSA-N Thr-Glu-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LKEKWDJCJSPXNI-IRIUXVKKSA-N 0.000 description 1
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 1
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 1
- MPUMPERGHHJGRP-WEDXCCLWSA-N Thr-Gly-Lys Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O MPUMPERGHHJGRP-WEDXCCLWSA-N 0.000 description 1
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 1
- ADPHPKGWVDHWML-PPCPHDFISA-N Thr-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N ADPHPKGWVDHWML-PPCPHDFISA-N 0.000 description 1
- LCCSEJSPBWKBNT-OSUNSFLBSA-N Thr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N LCCSEJSPBWKBNT-OSUNSFLBSA-N 0.000 description 1
- IHAPJUHCZXBPHR-WZLNRYEVSA-N Thr-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N IHAPJUHCZXBPHR-WZLNRYEVSA-N 0.000 description 1
- XYFISNXATOERFZ-OSUNSFLBSA-N Thr-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XYFISNXATOERFZ-OSUNSFLBSA-N 0.000 description 1
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 1
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- XNTVWRJTUIOGQO-RHYQMDGZSA-N Thr-Met-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O XNTVWRJTUIOGQO-RHYQMDGZSA-N 0.000 description 1
- SIEZEMFJLYRUMK-YTWAJWBKSA-N Thr-Met-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N)O SIEZEMFJLYRUMK-YTWAJWBKSA-N 0.000 description 1
- WYLAVUAWOUVUCA-XVSYOHENSA-N Thr-Phe-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O WYLAVUAWOUVUCA-XVSYOHENSA-N 0.000 description 1
- NZRUWPIYECBYRK-HTUGSXCWSA-N Thr-Phe-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O NZRUWPIYECBYRK-HTUGSXCWSA-N 0.000 description 1
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 1
- VEIKMWOMUYMMMK-FCLVOEFKSA-N Thr-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VEIKMWOMUYMMMK-FCLVOEFKSA-N 0.000 description 1
- NWECYMJLJGCBOD-UNQGMJICSA-N Thr-Phe-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O NWECYMJLJGCBOD-UNQGMJICSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- VTMGKRABARCZAX-OSUNSFLBSA-N Thr-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O VTMGKRABARCZAX-OSUNSFLBSA-N 0.000 description 1
- OLFOOYQTTQSSRK-UNQGMJICSA-N Thr-Pro-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLFOOYQTTQSSRK-UNQGMJICSA-N 0.000 description 1
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 1
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 1
- STUAPCLEDMKXKL-LKXGYXEUSA-N Thr-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O STUAPCLEDMKXKL-LKXGYXEUSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- BCYUHPXBHCUYBA-CUJWVEQBSA-N Thr-Ser-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O BCYUHPXBHCUYBA-CUJWVEQBSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 1
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 1
- MFMGPEKYBXFIRF-SUSMZKCASA-N Thr-Thr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFMGPEKYBXFIRF-SUSMZKCASA-N 0.000 description 1
- GRIUMVXCJDKVPI-IZPVPAKOSA-N Thr-Thr-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GRIUMVXCJDKVPI-IZPVPAKOSA-N 0.000 description 1
- IJKNKFJZOJCKRR-GBALPHGKSA-N Thr-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 IJKNKFJZOJCKRR-GBALPHGKSA-N 0.000 description 1
- JNKAYADBODLPMQ-HSHDSVGOSA-N Thr-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)=CNC2=C1 JNKAYADBODLPMQ-HSHDSVGOSA-N 0.000 description 1
- BZTSQFWJNJYZSX-JRQIVUDYSA-N Thr-Tyr-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O BZTSQFWJNJYZSX-JRQIVUDYSA-N 0.000 description 1
- DIHPMRTXPYMDJZ-KAOXEZKKSA-N Thr-Tyr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N)O DIHPMRTXPYMDJZ-KAOXEZKKSA-N 0.000 description 1
- VYVBSMCZNHOZGD-RCWTZXSCSA-N Thr-Val-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O VYVBSMCZNHOZGD-RCWTZXSCSA-N 0.000 description 1
- BRBCKMMXKONBAA-KWBADKCTSA-N Trp-Ala-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 BRBCKMMXKONBAA-KWBADKCTSA-N 0.000 description 1
- GTNCSPKYWCJZAC-XIRDDKMYSA-N Trp-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N GTNCSPKYWCJZAC-XIRDDKMYSA-N 0.000 description 1
- SSNGFWKILJLTQM-QEJZJMRPSA-N Trp-Gln-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SSNGFWKILJLTQM-QEJZJMRPSA-N 0.000 description 1
- NOFFAYIYPAUNRM-HKUYNNGSSA-N Trp-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC2=CNC3=CC=CC=C32)N NOFFAYIYPAUNRM-HKUYNNGSSA-N 0.000 description 1
- YDTKYBHPRULROG-LTHWPDAASA-N Trp-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YDTKYBHPRULROG-LTHWPDAASA-N 0.000 description 1
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 1
- NESIQDDPEFTWAH-BPUTZDHNSA-N Trp-Met-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O NESIQDDPEFTWAH-BPUTZDHNSA-N 0.000 description 1
- DDJHCLVUUBEIIA-BVSLBCMMSA-N Trp-Met-Phe Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)CCSC)C(O)=O)C1=CC=CC=C1 DDJHCLVUUBEIIA-BVSLBCMMSA-N 0.000 description 1
- BOESUSAIMQGVJD-RYQLBKOJSA-N Trp-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N BOESUSAIMQGVJD-RYQLBKOJSA-N 0.000 description 1
- YTVJTXJTNRWJCR-JBACZVJFSA-N Trp-Phe-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N YTVJTXJTNRWJCR-JBACZVJFSA-N 0.000 description 1
- GSCPHMSPGQSZJT-JYBASQMISA-N Trp-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O GSCPHMSPGQSZJT-JYBASQMISA-N 0.000 description 1
- CUHBVKUVJIXRFK-DVXDUOKCSA-N Trp-Trp-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC=3C4=CC=CC=C4NC=3)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CUHBVKUVJIXRFK-DVXDUOKCSA-N 0.000 description 1
- WNGMGTMSUBARLB-RXVVDRJESA-N Trp-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)N)C(=O)NCC(O)=O)=CNC2=C1 WNGMGTMSUBARLB-RXVVDRJESA-N 0.000 description 1
- KSVMDJJCYKIXTK-IGNZVWTISA-N Tyr-Ala-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KSVMDJJCYKIXTK-IGNZVWTISA-N 0.000 description 1
- ADBDQGBDNUTRDB-ULQDDVLXSA-N Tyr-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O ADBDQGBDNUTRDB-ULQDDVLXSA-N 0.000 description 1
- MTEQZJFSEMXXRK-CFMVVWHZSA-N Tyr-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N MTEQZJFSEMXXRK-CFMVVWHZSA-N 0.000 description 1
- HGEHWFGAKHSIDY-SRVKXCTJSA-N Tyr-Asp-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)O HGEHWFGAKHSIDY-SRVKXCTJSA-N 0.000 description 1
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 1
- KLGFILUOTCBNLJ-IHRRRGAJSA-N Tyr-Cys-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O KLGFILUOTCBNLJ-IHRRRGAJSA-N 0.000 description 1
- HDSKHCBAVVWPCQ-FHWLQOOXSA-N Tyr-Glu-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HDSKHCBAVVWPCQ-FHWLQOOXSA-N 0.000 description 1
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 1
- KSCVLGXNQXKUAR-JYJNAYRXSA-N Tyr-Leu-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KSCVLGXNQXKUAR-JYJNAYRXSA-N 0.000 description 1
- YKCXQOBTISTQJD-BZSNNMDCSA-N Tyr-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N YKCXQOBTISTQJD-BZSNNMDCSA-N 0.000 description 1
- GYKDRHDMGQUZPU-MGHWNKPDSA-N Tyr-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N GYKDRHDMGQUZPU-MGHWNKPDSA-N 0.000 description 1
- FDKDGFGTHGJKNV-FHWLQOOXSA-N Tyr-Phe-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N FDKDGFGTHGJKNV-FHWLQOOXSA-N 0.000 description 1
- VYTUETMEZZLJFU-IHRRRGAJSA-N Tyr-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)N[C@@H](CS)C(=O)O VYTUETMEZZLJFU-IHRRRGAJSA-N 0.000 description 1
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 1
- UUBKSZNKJUJQEJ-JRQIVUDYSA-N Tyr-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O UUBKSZNKJUJQEJ-JRQIVUDYSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 1
- MQUYPYFPHIPVHJ-MNSWYVGCSA-N Tyr-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)O MQUYPYFPHIPVHJ-MNSWYVGCSA-N 0.000 description 1
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 1
- KLOZTPOXVVRVAQ-DZKIICNBSA-N Tyr-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 KLOZTPOXVVRVAQ-DZKIICNBSA-N 0.000 description 1
- 241000003876 Umbilicaria muehlenbergii Species 0.000 description 1
- 241000965806 Umbilicaria pustulata Species 0.000 description 1
- FZSPNKUFROZBSG-ZKWXMUAHSA-N Val-Ala-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O FZSPNKUFROZBSG-ZKWXMUAHSA-N 0.000 description 1
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 1
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 1
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 1
- COYSIHFOCOMGCF-WPRPVWTQSA-N Val-Arg-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-WPRPVWTQSA-N 0.000 description 1
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 1
- ZSZFTYVFQLUWBF-QXEWZRGKSA-N Val-Asp-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N ZSZFTYVFQLUWBF-QXEWZRGKSA-N 0.000 description 1
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 1
- XKVXSCHXGJOQND-ZOBUZTSGSA-N Val-Asp-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N XKVXSCHXGJOQND-ZOBUZTSGSA-N 0.000 description 1
- IRLYZKKNBFPQBW-XGEHTFHBSA-N Val-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N)O IRLYZKKNBFPQBW-XGEHTFHBSA-N 0.000 description 1
- AAOPYWQQBXHINJ-DZKIICNBSA-N Val-Gln-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AAOPYWQQBXHINJ-DZKIICNBSA-N 0.000 description 1
- CVIXTAITYJQMPE-LAEOZQHASA-N Val-Glu-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CVIXTAITYJQMPE-LAEOZQHASA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 1
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 1
- FEFZWCSXEMVSPO-LSJOCFKGSA-N Val-His-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](C)C(O)=O FEFZWCSXEMVSPO-LSJOCFKGSA-N 0.000 description 1
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 1
- CPGJELLYDQEDRK-NAKRPEOUSA-N Val-Ile-Ala Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C)C(O)=O CPGJELLYDQEDRK-NAKRPEOUSA-N 0.000 description 1
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 1
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 1
- GVJUTBOZZBTBIG-AVGNSLFASA-N Val-Lys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N GVJUTBOZZBTBIG-AVGNSLFASA-N 0.000 description 1
- QRVPEKJBBRYISE-XUXIUFHCSA-N Val-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N QRVPEKJBBRYISE-XUXIUFHCSA-N 0.000 description 1
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 1
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 1
- JVGHIFMSFBZDHH-WPRPVWTQSA-N Val-Met-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)NCC(=O)O)N JVGHIFMSFBZDHH-WPRPVWTQSA-N 0.000 description 1
- WSUWDIVCPOJFCX-TUAOUCFPSA-N Val-Met-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N WSUWDIVCPOJFCX-TUAOUCFPSA-N 0.000 description 1
- MJFSRZZJQWZHFQ-SRVKXCTJSA-N Val-Met-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N MJFSRZZJQWZHFQ-SRVKXCTJSA-N 0.000 description 1
- UXODSMTVPWXHBT-ULQDDVLXSA-N Val-Phe-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N UXODSMTVPWXHBT-ULQDDVLXSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 1
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 1
- PGQUDQYHWICSAB-NAKRPEOUSA-N Val-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N PGQUDQYHWICSAB-NAKRPEOUSA-N 0.000 description 1
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- CEKSLIVSNNGOKH-KZVJFYERSA-N Val-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](C(C)C)N)O CEKSLIVSNNGOKH-KZVJFYERSA-N 0.000 description 1
- MNSSBIHFEUUXNW-RCWTZXSCSA-N Val-Thr-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N MNSSBIHFEUUXNW-RCWTZXSCSA-N 0.000 description 1
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 1
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- ZLMFVXMJFIWIRE-FHWLQOOXSA-N Val-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](C(C)C)N ZLMFVXMJFIWIRE-FHWLQOOXSA-N 0.000 description 1
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 1
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 1
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 1
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 1
- YKZVPMUGEJXEOR-JYJNAYRXSA-N Val-Val-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N YKZVPMUGEJXEOR-JYJNAYRXSA-N 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- RTYDQIKVNMHQMZ-UHFFFAOYSA-N YWA1 Chemical compound C1=C(O)C=C2C=C(OC(C)(O)CC3=O)C3=C(O)C2=C1O RTYDQIKVNMHQMZ-UHFFFAOYSA-N 0.000 description 1
- 230000036579 abiotic stress Effects 0.000 description 1
- 108020002494 acetyltransferase Proteins 0.000 description 1
- 102000005421 acetyltransferase Human genes 0.000 description 1
- SSNQAUBBJYCSMY-UHFFFAOYSA-N aigialomycin A Natural products C12OC2CC(O)C(O)C(=O)C=CCC(C)OC(=O)C=2C1=CC(OC)=CC=2O SSNQAUBBJYCSMY-UHFFFAOYSA-N 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010069490 alanyl-glycyl-seryl-glutamic acid Proteins 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- 239000012670 alkaline solution Substances 0.000 description 1
- 230000029936 alkylation Effects 0.000 description 1
- 238000005804 alkylation reaction Methods 0.000 description 1
- 108010045514 alpha-lactorphin Proteins 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 235000019257 ammonium acetate Nutrition 0.000 description 1
- 229940043376 ammonium acetate Drugs 0.000 description 1
- 239000001099 ammonium carbonate Substances 0.000 description 1
- 235000012501 ammonium carbonate Nutrition 0.000 description 1
- 150000003863 ammonium salts Chemical class 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 230000000845 anti-microbial effect Effects 0.000 description 1
- 239000002518 antifoaming agent Substances 0.000 description 1
- 229950006334 apramycin Drugs 0.000 description 1
- XZNUGFQTQHRASN-XQENGBIVSA-N apramycin Chemical compound O([C@H]1O[C@@H]2[C@H](O)[C@@H]([C@H](O[C@H]2C[C@H]1N)O[C@@H]1[C@@H]([C@@H](O)[C@H](N)[C@@H](CO)O1)O)NC)[C@@H]1[C@@H](N)C[C@@H](N)[C@H](O)[C@H]1O XZNUGFQTQHRASN-XQENGBIVSA-N 0.000 description 1
- 108010013835 arginine glutamate Proteins 0.000 description 1
- 108010080488 arginyl-arginyl-leucine Proteins 0.000 description 1
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 1
- 108010089975 arginyl-glycyl-aspartyl-serine Proteins 0.000 description 1
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 1
- 108010068380 arginylarginine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 229910052786 argon Inorganic materials 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 229940091771 aspergillus fumigatus Drugs 0.000 description 1
- 230000000712 assembly Effects 0.000 description 1
- 238000000429 assembly Methods 0.000 description 1
- 150000007514 bases Chemical class 0.000 description 1
- JEUUNKOFKDUVMN-UHFFFAOYSA-N benzo[f]chromen-1-one Chemical compound C1=CC=CC2=C3C(=O)C=COC3=CC=C21 JEUUNKOFKDUVMN-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000004790 biotic stress Effects 0.000 description 1
- JCMPMLXSEHQPQB-UHFFFAOYSA-N biruloquinone Natural products COc1cc2OC(=O)c3cc(C)c(O)c4C(=O)C(=O)c(c1O)c2c34 JCMPMLXSEHQPQB-UHFFFAOYSA-N 0.000 description 1
- 108010083912 bleomycin N-acetyltransferase Proteins 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 239000000828 canola oil Substances 0.000 description 1
- 235000019519 canola oil Nutrition 0.000 description 1
- 150000001721 carbon Chemical class 0.000 description 1
- 108010079058 casein hydrolysate Proteins 0.000 description 1
- 239000004359 castor oil Substances 0.000 description 1
- 235000019438 castor oil Nutrition 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 238000005660 chlorination reaction Methods 0.000 description 1
- 229940117229 cialis Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 239000003240 coconut oil Substances 0.000 description 1
- 235000019864 coconut oil Nutrition 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000010835 comparative analysis Methods 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 229910000365 copper sulfate Inorganic materials 0.000 description 1
- ARUVKPQLZAKDPS-UHFFFAOYSA-L copper(II) sulfate Chemical compound [Cu+2].[O-][S+2]([O-])([O-])[O-] ARUVKPQLZAKDPS-UHFFFAOYSA-L 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- 108010004073 cysteinylcysteine Proteins 0.000 description 1
- 108010016616 cysteinylglycine Proteins 0.000 description 1
- 230000007123 defense Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- 229910003460 diamond Inorganic materials 0.000 description 1
- 239000010432 diamond Substances 0.000 description 1
- 235000013681 dietary sucrose Nutrition 0.000 description 1
- CAXGJVQIPWBEJY-UHFFFAOYSA-N dihydromaldoxin Natural products COC(=O)C1=CC(OC)=C(Cl)C(O)=C1OC1=CC(C)=CC(O)=C1C(O)=O CAXGJVQIPWBEJY-UHFFFAOYSA-N 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 108010054812 diprotin A Proteins 0.000 description 1
- 239000012153 distilled water Substances 0.000 description 1
- VFNGKCDDZUSWLR-UHFFFAOYSA-N disulfuric acid Chemical compound OS(=O)(=O)OS(O)(=O)=O VFNGKCDDZUSWLR-UHFFFAOYSA-N 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- VVEKCQAFOLKNKB-UHFFFAOYSA-N emodine Natural products C1=CC=C2C(=O)C3=CC(O)=CC(O)=C3C(=O)C2=C1O VVEKCQAFOLKNKB-UHFFFAOYSA-N 0.000 description 1
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 1
- 239000004174 erythrosine Substances 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000021323 fish oil Nutrition 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- 239000006260 foam Substances 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 235000021433 fructose syrup Nutrition 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001641 gel filtration chromatography Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 1
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 1
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010023364 glycyl-histidyl-arginine Proteins 0.000 description 1
- 108010028188 glycyl-histidyl-serine Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010084389 glycyltryptophan Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 239000003630 growth substance Substances 0.000 description 1
- 239000004009 herbicide Substances 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 108010028295 histidylhistidine Proteins 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 239000000413 hydrolysate Substances 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- 108010002685 hygromycin-B kinase Proteins 0.000 description 1
- SSNQAUBBJYCSMY-KNTMUCJRSA-N hypothemycin Chemical compound O([C@@H](C)C\C=C/C(=O)[C@@H](O)[C@@H](O)C[C@H]1O[C@@H]11)C(=O)C=2C1=CC(OC)=CC=2O SSNQAUBBJYCSMY-KNTMUCJRSA-N 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000010921 in-depth analysis Methods 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 150000002484 inorganic compounds Chemical class 0.000 description 1
- 229910010272 inorganic material Inorganic materials 0.000 description 1
- 229910017053 inorganic salt Inorganic materials 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 229910000358 iron sulfate Inorganic materials 0.000 description 1
- BAUYGSIQEAFULO-UHFFFAOYSA-L iron(2+) sulfate (anhydrous) Chemical compound [Fe+2].[O-]S([O-])(=O)=O BAUYGSIQEAFULO-UHFFFAOYSA-L 0.000 description 1
- 108010031424 isoleucyl-prolyl-proline Proteins 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 229940039717 lanolin Drugs 0.000 description 1
- 235000019388 lanolin Nutrition 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- URLZCHNOLZSCCA-UHFFFAOYSA-N leu-enkephalin Chemical compound C=1C=C(O)C=CC=1CC(N)C(=O)NCC(=O)NCC(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=CC=C1 URLZCHNOLZSCCA-UHFFFAOYSA-N 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- VPEWYQPRZOSYDH-UHFFFAOYSA-N lichexanthone Natural products COC1=CC2Oc3cc(OC)cc(C)c3C(=O)C2C(=C1)O VPEWYQPRZOSYDH-UHFFFAOYSA-N 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 235000015250 liver sausages Nutrition 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 1
- 108010076718 lysyl-glutamyl-tryptophan Proteins 0.000 description 1
- 108010043322 lysyl-tryptophyl-alpha-lysine Proteins 0.000 description 1
- GVALZJMUIHGIMD-UHFFFAOYSA-H magnesium phosphate Chemical compound [Mg+2].[Mg+2].[Mg+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O GVALZJMUIHGIMD-UHFFFAOYSA-H 0.000 description 1
- 239000004137 magnesium phosphate Substances 0.000 description 1
- 229960002261 magnesium phosphate Drugs 0.000 description 1
- 229910000157 magnesium phosphate Inorganic materials 0.000 description 1
- 235000010994 magnesium phosphates Nutrition 0.000 description 1
- 229940099596 manganese sulfate Drugs 0.000 description 1
- 239000011702 manganese sulphate Substances 0.000 description 1
- 235000007079 manganese sulphate Nutrition 0.000 description 1
- SQQMAOCOWKFBNP-UHFFFAOYSA-L manganese(II) sulfate Chemical compound [Mn+2].[O-]S([O-])(=O)=O SQQMAOCOWKFBNP-UHFFFAOYSA-L 0.000 description 1
- 235000013372 meat Nutrition 0.000 description 1
- 230000008099 melanin synthesis Effects 0.000 description 1
- 230000003061 melanogenesis Effects 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 102000020235 metallo-beta-lactamase Human genes 0.000 description 1
- 108060004734 metallo-beta-lactamase Proteins 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 108010085203 methionylmethionine Proteins 0.000 description 1
- 108010068488 methionylphenylalanine Proteins 0.000 description 1
- 229940095102 methyl benzoate Drugs 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- LPUQAYUQRXPFSQ-DFWYDOINSA-M monosodium L-glutamate Chemical compound [Na+].[O-]C(=O)[C@@H](N)CCC(O)=O LPUQAYUQRXPFSQ-DFWYDOINSA-M 0.000 description 1
- 235000013923 monosodium glutamate Nutrition 0.000 description 1
- 239000004223 monosodium glutamate Substances 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- RQNVIKXOOKXAJQ-UHFFFAOYSA-N naphthazarin Chemical class O=C1C=CC(=O)C2=C1C(O)=CC=C2O RQNVIKXOOKXAJQ-UHFFFAOYSA-N 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 239000006199 nebulizer Substances 0.000 description 1
- 238000007857 nested PCR Methods 0.000 description 1
- 230000006855 networking Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 150000007523 nucleic acids Chemical group 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 235000014593 oils and fats Nutrition 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- AICOOMRHRUFYCM-ZRRPKQBOSA-N oxazine, 1 Chemical compound C([C@@H]1[C@H](C(C[C@]2(C)[C@@H]([C@H](C)N(C)C)[C@H](O)C[C@]21C)=O)CC1=CC2)C[C@H]1[C@@]1(C)[C@H]2N=C(C(C)C)OC1 AICOOMRHRUFYCM-ZRRPKQBOSA-N 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 101150106061 patD gene Proteins 0.000 description 1
- 101150074538 patO gene Proteins 0.000 description 1
- 235000020232 peanut Nutrition 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 229940098377 penicillium brevicompactum Drugs 0.000 description 1
- 238000005191 phase separation Methods 0.000 description 1
- SCOAVUHOIJMIBW-UHFFFAOYSA-N phenanthrene-1,2-dione Chemical class C1=CC=C2C(C=CC(C3=O)=O)=C3C=CC2=C1 SCOAVUHOIJMIBW-UHFFFAOYSA-N 0.000 description 1
- 108010074082 phenylalanyl-alanyl-lysine Proteins 0.000 description 1
- 108010082795 phenylalanyl-arginyl-arginine Proteins 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 230000029553 photosynthesis Effects 0.000 description 1
- 238000010672 photosynthesis Methods 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 101150093589 pks11 gene Proteins 0.000 description 1
- 229920001522 polyglycol ester Polymers 0.000 description 1
- 125000000830 polyketide group Chemical group 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 239000004810 polytetrafluoroethylene Substances 0.000 description 1
- 229920001343 polytetrafluoroethylene Polymers 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000002953 preparative HPLC Methods 0.000 description 1
- 229930010796 primary metabolite Natural products 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 102000004196 processed proteins & peptides Human genes 0.000 description 1
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 108010015796 prolylisoleucine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical compound CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 description 1
- 235000019260 propionic acid Nutrition 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 208000020016 psychiatric disease Diseases 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000001057 purple pigment Substances 0.000 description 1
- IUVKMZGDUIUOCP-BTNSXGMBSA-N quinbolone Chemical compound O([C@H]1CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)CC[C@@]21C)C1=CCCC1 IUVKMZGDUIUOCP-BTNSXGMBSA-N 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 239000001054 red pigment Substances 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 239000011435 rock Substances 0.000 description 1
- 238000005185 salting out Methods 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000024053 secondary metabolic process Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 101150033616 sol5 gene Proteins 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 235000020712 soy bean extract Nutrition 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- PHJADXZUQNOLEH-UZLBHIALSA-N stictic acid Natural products C[C@@H]1CCC(=C)C(C(O)=O)=CC=CC[C@@]1(C)CCC1=COC=C1 PHJADXZUQNOLEH-UZLBHIALSA-N 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 239000002600 sunflower oil Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- WOXKDUGGOYFFRN-IIBYNOLFSA-N tadalafil Chemical compound C1=C2OCOC2=CC([C@@H]2C3=C(C4=CC=CC=C4N3)C[C@H]3N2C(=O)CN(C3=O)C)=C1 WOXKDUGGOYFFRN-IIBYNOLFSA-N 0.000 description 1
- 101150090934 terD gene Proteins 0.000 description 1
- ATFNSNUJZOYXFC-RQJHMYQMSA-N terreic acid Chemical compound O=C1C(C)=C(O)C(=O)[C@@H]2O[C@@H]21 ATFNSNUJZOYXFC-RQJHMYQMSA-N 0.000 description 1
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 1
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 1
- 239000011573 trace mineral Substances 0.000 description 1
- 235000013619 trace mineral Nutrition 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 1
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 238000004704 ultra performance liquid chromatography Methods 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 1
- 108010003885 valyl-prolyl-glycyl-glycine Proteins 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 239000001052 yellow pigment Substances 0.000 description 1
Images







Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/93—Ligases (6)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/41—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from lichens
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N1/00—Microorganisms, e.g. protozoa; Compositions thereof; Processes of propagating, maintaining or preserving microorganisms or compositions thereof; Processes of preparing or isolating a composition containing a microorganism; Culture media therefor
- C12N1/14—Fungi; Culture media therefor
- C12N1/145—Fungal isolates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/80—Vectors or expression systems specially adapted for eukaryotic hosts for fungi
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/02—Preparation of oxygen-containing organic compounds containing a hydroxy group
- C12P7/22—Preparation of oxygen-containing organic compounds containing a hydroxy group aromatic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12R—INDEXING SCHEME ASSOCIATED WITH SUBCLASSES C12C - C12Q, RELATING TO MICROORGANISMS
- C12R2001/00—Microorganisms ; Processes using microorganisms
- C12R2001/645—Fungi ; Processes using fungi
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Mycology (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Virology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Physics & Mathematics (AREA)
- Botany (AREA)
- General Chemical & Material Sciences (AREA)
- Plant Pathology (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
본 발명은 지의류인 스테레오카울론 알피넘(Stereocaulon alpinum)으로부터 유래된 아트라노린 생합성 유전자, 상기 유전자가 도입된 아라트라노린 생산용 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP) 및 상기 균주를 이용한 아트라노린 생산 방법에 관한 것이다. 본 발명에 따른 아트라노린 생합성 유전자가 도입된 아스코키타 라비에이 ATR-11 균주로부터 지의류 유래 2차 대사산물, 특히 아트라노린을 생산할 수 있다. 상기 균주로부터 생산된 아트라노린은 약학 조성물, 식품 조성물, 건강기능식품, 사료 조성물 등에 다양하게 활용 및 산업화할 수 있다.
Description
본 발명은 지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도에 관한 것이다. 보다 상세하게는, 스테레오카울론 알피넘(Stereocaulon alpinum)으로부터 유래된 아트라노린 생합성 유전자, 상기 유전자가 도입된 아라트라노린 생산용 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC 83048BP) 및 상기 균주를 이용한 아트라노린 생산 방법에 관한 것이다.
지의류는 생태계 기능에서 중요한 역할을 하며 알려진 모든 균류의 약 20%를 차지한다. 폴리케타이드(Polyketide) 유래 천연물은 지의류 지의체(lichen thalli)의 피질층과 수질층에 축적되며, 이 중 일부는 생물 및 비생물적 스트레스(초식동물 공격 및 자외선 조사)로부터 보호하는 데 중요한 역할을 한다. 그러나, 현재까지 단일 지의류 제품은 유전적 증거가 있는 각각의 생합성 유전자와 연결되어 있지 않다.
지의류 형 성곰팡이(Lichen-forming fungi, LFF)는 광합성 파트너인 녹조류 또는 남조류와 공생하며, 때로는 두 가지 모두와 공생하며 LFF는 현재 알려진 모든 균류의 약 20%를 구성하는 것으로 추정된다. 지의류 공생은 이러한 유기체가 극도로 가혹한 서식지에 적응할 수 있게 하는 가장 성공적인 공생 중 하나이다. 조밀한 곰팡이 균사로 구성된 응집되고 종종 착색된 피질층은 광합성 파트너에게 기계적 안정화를 제공하고 수질의 균사로 둘러싸인 조류 세포는 광합성을 통해 LFF에 영양분을 제공한다. 폴리케타이드(polyketide) 기원의 이차 대사산물(SM), 즉 안트라퀴논, 뎁사이드, 뎁시돈 및 디벤조푸란(예컨대, 우스닉산)은 지의류 몸체의 피질 또는 수질층에 축적된다(Calcott MJ et.al., Chem Soc Rev., 47:1730-1760, 2018). 이 지의류 SM의 생태학적 역할은 거의 알려져 있지 않지만, 일부 연구에서는 피질 물질이 서식지 확장 및 초식 동물의 공격으로부터의 방어에 기여하였다는 증거를 제공한다.
뎁사이드 및 뎁시돈 계열 화합물은 지의류에서 피질 및 수질 물질로 널리 퍼져 있으며, 이들 중 다수는 지의류에서만 독점적으로 발견된다. 지의류 뎁사이드는 오르셀린산 또는 3-메틸오르셀린산(3MOA)의 이량체화에 의해 형성되고, 뎁사이드의 후속 산화는 뎁시돈에 대한 삼환식 스캐폴드를 제공한다. 이들 화합물은 추가로 알킬화, 염소화, 수산화 및 O-메틸화와 같은 오르셀린산 및 3MOA 모이어티 내에서 다양한 변형 조합을 거쳐 수백 가지의 구조적으로 다양한 화합물을 생성한다. 이를 위해, 지의류에서 뎁사이드/뎁시돈 생합성 경로는 화학다양성을 초래하는 생합성 효소의 기질 특이성을 연구하기 위한 모델 시스템이 될 수 있다. 그러나, 지금까지 지의류에서 특정 생합성 유전자를 피질 또는 수질 물질에 귀속시키는 것은 LFF에 대한 유전 정보가 부족하고, 유전자 변형에 대한 내성이 있는 LFF를 조작하기 위한 분자 도구의 부족으로 인해 지의류에서 저조하였다.
비환원 반복 유형 I 폴리케타이드 합성 효소(Nonreducing iterative type I polyketide synthases, NR-PKS)는 다중 도메인 효소이며, 단백질 서열 유사성 및 PKS 도메인 구조에 따라 7개 또는 8개의 주요 그룹으로 분류된다. 오르셀린산 및 3MOA는 박테리아, 곰팡이 및 식물의 다양한 SM에 대한 기본 골격이며, 사상균인 아스페르길루스 니둘란스(Aspergillus nidulans)에서 NR-PKS에 의해 생합성되나, 두 개의 NR-PKS가 지의류에서 기본 단위의 생합성을 담당할 것이라는 예측만 있었다. 아트라노린(3MOA 유래 뎁사이드) 및 우스닉산(디벤조퓨란)은 거대지의류의 가장 흔한 피질 물질이며, 이들의 분류학적, 생태학적 및 약학적 중요성 때문에 큰 주목을 받았다. 여러 연구에서 NR-PKS는 가능성이 높은 우스닉산에 기인한다. 그러나, 아스퍼질러스 오리제(A. oryzae)에서 추정되는 우스닉산 PKS 유전자의 이종 발현에 대한 노력은 성공하지 못하여 정확한 기능은 아직 밝혀지지 않았다.
최근 몇 년 동안, SM 연구는 박테리아, 곰팡이 및 식물에서 게놈 마이닝 접근법으로부터 광범위하게 혜택을 받았다. 남극 지역 지의류인 사슴지의과(Cladoniaceae)는 LFF의 가장 큰 과(family) 중 하나이며, 나무지의속(Stereocaulaceae)과 밀접한 관련이 있다. 역사적으로, 화학분류법은 사슴지의과에서 종의 경계를 해결하고 구분하기 위한 다상 접근법으로 사용되어 왔다. 또한, 클라도니아속(Cladonia)은 피질 및 수질 물질의 생합성을 위한 PKS 유전자 연구를 위한 모델로 이용되어 왔다(Armaleo D et.al., Mycologia, 103:741-754, 2011).
이에 본 발명자들은 지의류 폴리케타이드 합성 효소(PKS)를 분류하고, 이종 숙주에서 지의류의 주요 피질 물질인 아트라노린의 생합성 경로를 재구성하였다. 이에 따라, 지의류 피질 물질인 아트라노린의 생합성을 담당하는 유전자를 확보하고, 이를 도입한 새로운 이종 발현 시스템을 구축하여 신규한 아트라노린 생산용 균주를 개발함으로써, 본 발명을 완성하였다.
Calcott MJ et.al., Chem Soc Rev., 47:1730-1760, 2018
Armaleo D et.al., Mycologia, 103:741-754, 2011
본 발명의 목적은 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진, 아트라노린 생합성 유전자를 제공하기 위한 것이다.
본 발명의 다른 목적은 상기 아트라노린 생합성 유전자를 포함하는, 지의류 유래의 대사산물 생산용 재조합 발현 벡터를 제공하기 위한 것이다.
본 발명의 또 다른 목적은 상기 재조합 발현 벡터로 형질전환된 재조합 미생물을 제공하기 위한 것이다.
본 발명의 또 다른 목적은 상기 재조합 미생물을 배양하는 단계를 포함하는, 지의류 유래의 대사산물 생산 방법을 제공하기 위한 것이다.
본 발명의 또 다른 목적은 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)를 제공하기 위한 것이다.
본 발명의 또 다른 목적은 상기 균주를 배양하는 단계를 포함하는, 아트라노린 생산 방법을 제공하기 위한 것이다.
상기 목적을 달성하기 위해, 본 발명은 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진, 아트라노린 생합성 유전자를 제공한다.
또한, 본 발명은 상기 아트라노린 생합성 유전자를 포함하는, 지의류 유래의 대사산물 생산용 재조합 발현 벡터를 제공한다.
또한, 본 발명은 상기 재조합 발현 벡터로 형질전환된 재조합 미생물을 제공한다.
또한, 본 발명은 상기 재조합 미생물을 배양하는 단계를 포함하는, 지의류 유래의 대사산물 생산 방법을 제공한다.
또한, 본 발명은 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)를 제공한다.
또한, 본 발명은 상기 균주를 배양하는 단계를 포함하는, 아트라노린 생산 방법을 제공한다.
본 발명에 따른 지의류 유래 아트라노린 생합성 유전자가 도입된 이종 발현 시스템을 구축하고, 이를 적용한 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주로부터 지의류 유래 대사산물, 특히 아트라노린을 생합성할 수 있다. 상기 균주로부터 생산된 아트라노린은 약학 조성물, 식품 조성물, 건강기능식품, 사료 조성물 등에 다양하게 활용 및 산업화할 수 있다.
도 1은 지의류의 게놈-인코딩 대사 잠재력을 나타낸 도이다. 29종의 지의류-형성 곰팡이 및 시아노데르멜라 아스테리스(Cyanodermella asteris)(식물 내생식물)에 대해 병합-기반 종 트리를 재구성하였다. 이 트리는 엔도카르폰 푸실룸(Endocarpon pusillum)에 뿌리를 두고 있다. 노드 지원에 대한 모든 로컬 사후 확률은 화살표로 표시된 경우를 제외하고 0.98보다 높다. 접시지의강(Lecanoromycetes)의 다섯 목은 다른 색상으로 강조 표시되었으며, 한국 지의류 연구소에서 시퀀싱된 지의류 게놈은 굵게 표시되어 있다. BUSCO는 게놈 어셈블리의 완전성을 설명한다. 생합성 유전자 클러스터(BGC)의 수는 antiSMASH에 의해 예측되고, 거품 도표는 핵심 생합성 효소 범주의 상대적 풍부함을 나타낸다: NR-PKS, 비환원형 I PKS; R-PKS, 환원형 I PKS(PKS-NRPS 하이브리드 효소 포함); PKSIII, 유형 III PKS; NRPS, 비리보솜 펩티드 합성 효소(NRPS-유사 효소 포함); 및 테르펜, 테르페노이드 생산과 관련된 생합성 효소.
도 2는 클라도니아(Cladonia) 종에서의 폴리케타이드(polyketide) BGC 다양성을 나타낸 도면이다. (A) 6종의 클라도니아속(Cladonia spp.) 및 스테레오카울론 알피넘(Stereocaulon alpinum, S. alpinum)에서 유전자 클러스터 네트워크 분석에 의해 식별된 45개의 유전자 클러스터 패밀리(GCF)를 나타낸 것이다. 여기에서, PKS 패밀리와 관련된 GCF를 표지하였으며, 빨간색 숫자는 MIBiG 데이터베이스에 기탁된 특성화된 BGC에 연결된 PKS 패밀리를 나타낸 것이다. 노드(node)는 BGC를 나타내며, 종별로 색상으로 구분하였다. PKS8, PKS14 및 PKS16 하위 네트워크에서 빨간색 점선 원으로 둘러싸인 노드는 MIBiG 데이터베이스의 지의류 BGC이다. 알려진 BGC에 연결된 싱글톤 BGC는 M, 모나스코루브린(monascorubrin) BGC; H, 하이포테마이신(hypothemycin) BGC; S, 소르비실린(sorbicillin) BGC; T, 테레산(terreic acid) BGC; B, 베타에논(betaenones) BGC; D, 데푸데신(depudecin) BGC; C, 커브팔리드(curvupallides) BGC로 표지하였다. (B) 유전자 클러스터 네트워크 분석에 의해 입증된 PKS 패밀리의 계통 분포를 나타낸 것이다. 보라색과 황토색의 숫자는 각각 NR-PKS 및 R-PKS 제품군을 나타낸 것이다. 검은색 사각형은 PKS 패밀리의 존재를 나타내고, 회색 사각형은 불완전한 유전자 주석으로 인한 가유전자 또는 부분 유전자를 나타낸 것이다. 유전적 복제 제거에 의해 클라도니아속(Cladonia) PKS 패밀리와 연결된 시그니처 2차 대사산물은 볼드체로 표시하였다.
도 3은 추정되는 아트라노린 BGC의 구성을 나타낸 도이다. CORASON 분석 파이프라인을 사용하여, 30개의 게놈에서 검출된 1,527개의 BGC로부터 C. 랑기페리나(C. rangiferina)의 PKS23 BGC(Crg, 빨간색으로 표시) 중 하나에 상당한 히트를 나타내는 O-메틸트랜스퍼라제(O-methyltransferase)를 포함하는 15개의 BGC가 식별되었다. BGC를 보유하는 지의류 종은 도 1과 같이 약칭으로 표시하였다. 파란색 숫자는 Crg에 있는 것과 상동성 OMT의 단백질 서열 동일성을 백분율로 나타낸 것이다. 15개의 BGC 중, 7개의 BGC는 4개의 합성 유전자(회색 박스 표시): atr1 (PKS23), atr2, atr3 및 atr4를 보유하였다. 2차 대사와 관련된 유전자는 예측된 기능에 따라 색상으로 구분하였다: NR-PKS, 비환원형 I PKS; R-PKS, 환원형 I PRS; NRPS, 비리보솜 펩티드 합성 효소; TF, 전사 인자; RTA, 7-아미노콜레스테롤에 대한 내성.
도 4는 아트라노린 BGC의 기능적 검증 결과를 나타낸 도이다. (A) 아트라노린의 제안된 생합성 경로를 나타낸 것이다. (B) 아트라노린 BGC의 다양한 생합성 유전자 세트를 발현하는 "클린 숙주"의 배양 추출물의 HPLC 프로파일을 나타낸 것이다: 도입된 유전자 없음 (i), atr1만 있음 (ii), atr1 및 atr3 있음(iii), atr1 및 atr2 있음 (iv), 및 atr1, atr2 및 atr3 있음(v). 게놈-시퀀싱된 스테레오카울론 알피넘(Stereocaulon alpinum)에 대한 확증 표본의 아세톤 추출물에는 아트라노린 및 로바르산(tR = 33.1분) (vi)이 포함되어 있다. (C) 화합물 1 내지 6에 대해 m/z 값을 표시한 추출 이온 크로마토그램(EIC, Extracted ion chromatogram) 결과를 나타낸 것이다.
도 5는 곰팡이 비환원성 PKS 유전자의 9개의 계통군을 나타낸 도이다. 6개의 클라도니아속(Cladonia spp.) 및 스테레오카울론 알피넘(Stereocaulon alpinum)에서 103개의 NR-PKS의 최대 우도(likelihood) 트리와 비-지의류화된(non-lichenized) 곰팡이의 알려진 화합물에 연결된 82개의 NR-PKS는 케토신타제(ketosynthase) 및 생성물 주형 도메인의 연결된 시퀀스를 사용하여 재구성하였다. 외부 그룹(Outgroup)은 클라도니아속에서 발견되는 6-메틸살릴산 합성 효소(6-methylsalicylic acid synthase, 6MSAS)와 페니실리움 엑스판숨(Penicillium expansum)에서 파툴린(patulin) 생합성을 위한 6MSAS로 설정되었다. 분기는 부트스트랩 (BS) 값을 기반으로 색상으로 구분하였다. 척도는 부위당 0.5개의 아미노산 서열 치환을 나타낸다. 가장 바깥쪽 영역에 관련 번호가 있는 파란색 및 빨간색 스트립은 유전자 클러스터 네트워크 분석에 의해 식별된 PKS 패밀리를 나타낸다(도 2 참조). 9개의 NR-PKS 그룹 (그룹 I-IX)을 나타내는 계통발생 분기군은 다른 색상으로 음영 처리되었다. NR-PKS 그룹은 그룹 II를 제외하고, 75보다 큰 BS 값에 의해 지원된다. 새로 확인된 NR-PKS 그룹 (그룹 IX)에는 지의류의 피질 및 수질 물질에 대한 후보 PKS인 PKS1, PKS2 및 PKS23 패밀리가 포함된다. 빨간색 화살표는 NR-PKS의 C-메틸트랜스퍼라제 도메인의 다계통성 손실을 나타낸다.
도 6은 지의류의 피질 및 수질 물질의 화학 구조를 나타낸 도이다. 화학 구조에 따라, 9개의 화학 그룹으로 분류하였다 (표 2 참조). 여기에서, 3MOA는 3-메틸오르셀린산의 약어이다.
도 7은 PKS23의 이종 발현 검증 결과를 나타낸 도이다. (A) 스테레오카울론 알피넘(Stereocaulon alpinum)에서 PKS23(atr1) 유전자 구조의 개략도를 나타낸 것이다. 여기에서, 검은색 박스는 엑손이고, 회색 선은 인트론이다. 숫자는 염기쌍(bp)에서 엑손과 인트론의 크기를 나타낸 것이다. P1 및 P2는 RT-PCR 분석에 사용되는 프라이머 쌍이다. 상기 프라이머 쌍은 mRNA 발현이 게놈 DNA(gDNA, genomic DNA) 증폭과 구별될 수 있도록 하나 이상의 인트론 영역을 포함하도록 설계되었다. (B) 플라스미드 sol1::atr1/pDS35를 운반하는 2개의 추정 형질전환체 (T16 및 T25)의 RT-PCR 분석 결과를 나타낸 것이다. 액틴 1(Actin 1) 참조 유전자(mRNA의 경우 633 bp)에 대한 gDNA 앰플리콘에 해당하는 밴드가 관찰되지 않아, 게놈 DNA 오염이 없음을 나타낸다(좌측 하단 패널). 형질전환체 T25는 형질전환체 T16 (좌측 상단 패널)보다 도입된 atr1의 더 강한 발현을 나타내었다. atr1에서 4개의 인트론의 스플라이싱은 P1 및 P2 프라이머 쌍을 사용하여 플라스미드 sol1::atr1/pDS35(C)와 RNA 샘플(T25) 사이의 밴드 크기를 비교하여 확인하였다. mRNA 발현 및 플라스미드 DNA 증폭에 대한 예상 밴드 크기는 bp 단위로 겔 이미지의 좌측 및 우측에 숫자로 표시하였다. 여기에서, M은 100 bp DNA 크기 마커이다.
도 2는 클라도니아(Cladonia) 종에서의 폴리케타이드(polyketide) BGC 다양성을 나타낸 도면이다. (A) 6종의 클라도니아속(Cladonia spp.) 및 스테레오카울론 알피넘(Stereocaulon alpinum, S. alpinum)에서 유전자 클러스터 네트워크 분석에 의해 식별된 45개의 유전자 클러스터 패밀리(GCF)를 나타낸 것이다. 여기에서, PKS 패밀리와 관련된 GCF를 표지하였으며, 빨간색 숫자는 MIBiG 데이터베이스에 기탁된 특성화된 BGC에 연결된 PKS 패밀리를 나타낸 것이다. 노드(node)는 BGC를 나타내며, 종별로 색상으로 구분하였다. PKS8, PKS14 및 PKS16 하위 네트워크에서 빨간색 점선 원으로 둘러싸인 노드는 MIBiG 데이터베이스의 지의류 BGC이다. 알려진 BGC에 연결된 싱글톤 BGC는 M, 모나스코루브린(monascorubrin) BGC; H, 하이포테마이신(hypothemycin) BGC; S, 소르비실린(sorbicillin) BGC; T, 테레산(terreic acid) BGC; B, 베타에논(betaenones) BGC; D, 데푸데신(depudecin) BGC; C, 커브팔리드(curvupallides) BGC로 표지하였다. (B) 유전자 클러스터 네트워크 분석에 의해 입증된 PKS 패밀리의 계통 분포를 나타낸 것이다. 보라색과 황토색의 숫자는 각각 NR-PKS 및 R-PKS 제품군을 나타낸 것이다. 검은색 사각형은 PKS 패밀리의 존재를 나타내고, 회색 사각형은 불완전한 유전자 주석으로 인한 가유전자 또는 부분 유전자를 나타낸 것이다. 유전적 복제 제거에 의해 클라도니아속(Cladonia) PKS 패밀리와 연결된 시그니처 2차 대사산물은 볼드체로 표시하였다.
도 3은 추정되는 아트라노린 BGC의 구성을 나타낸 도이다. CORASON 분석 파이프라인을 사용하여, 30개의 게놈에서 검출된 1,527개의 BGC로부터 C. 랑기페리나(C. rangiferina)의 PKS23 BGC(Crg, 빨간색으로 표시) 중 하나에 상당한 히트를 나타내는 O-메틸트랜스퍼라제(O-methyltransferase)를 포함하는 15개의 BGC가 식별되었다. BGC를 보유하는 지의류 종은 도 1과 같이 약칭으로 표시하였다. 파란색 숫자는 Crg에 있는 것과 상동성 OMT의 단백질 서열 동일성을 백분율로 나타낸 것이다. 15개의 BGC 중, 7개의 BGC는 4개의 합성 유전자(회색 박스 표시): atr1 (PKS23), atr2, atr3 및 atr4를 보유하였다. 2차 대사와 관련된 유전자는 예측된 기능에 따라 색상으로 구분하였다: NR-PKS, 비환원형 I PKS; R-PKS, 환원형 I PRS; NRPS, 비리보솜 펩티드 합성 효소; TF, 전사 인자; RTA, 7-아미노콜레스테롤에 대한 내성.
도 4는 아트라노린 BGC의 기능적 검증 결과를 나타낸 도이다. (A) 아트라노린의 제안된 생합성 경로를 나타낸 것이다. (B) 아트라노린 BGC의 다양한 생합성 유전자 세트를 발현하는 "클린 숙주"의 배양 추출물의 HPLC 프로파일을 나타낸 것이다: 도입된 유전자 없음 (i), atr1만 있음 (ii), atr1 및 atr3 있음(iii), atr1 및 atr2 있음 (iv), 및 atr1, atr2 및 atr3 있음(v). 게놈-시퀀싱된 스테레오카울론 알피넘(Stereocaulon alpinum)에 대한 확증 표본의 아세톤 추출물에는 아트라노린 및 로바르산(tR = 33.1분) (vi)이 포함되어 있다. (C) 화합물 1 내지 6에 대해 m/z 값을 표시한 추출 이온 크로마토그램(EIC, Extracted ion chromatogram) 결과를 나타낸 것이다.
도 5는 곰팡이 비환원성 PKS 유전자의 9개의 계통군을 나타낸 도이다. 6개의 클라도니아속(Cladonia spp.) 및 스테레오카울론 알피넘(Stereocaulon alpinum)에서 103개의 NR-PKS의 최대 우도(likelihood) 트리와 비-지의류화된(non-lichenized) 곰팡이의 알려진 화합물에 연결된 82개의 NR-PKS는 케토신타제(ketosynthase) 및 생성물 주형 도메인의 연결된 시퀀스를 사용하여 재구성하였다. 외부 그룹(Outgroup)은 클라도니아속에서 발견되는 6-메틸살릴산 합성 효소(6-methylsalicylic acid synthase, 6MSAS)와 페니실리움 엑스판숨(Penicillium expansum)에서 파툴린(patulin) 생합성을 위한 6MSAS로 설정되었다. 분기는 부트스트랩 (BS) 값을 기반으로 색상으로 구분하였다. 척도는 부위당 0.5개의 아미노산 서열 치환을 나타낸다. 가장 바깥쪽 영역에 관련 번호가 있는 파란색 및 빨간색 스트립은 유전자 클러스터 네트워크 분석에 의해 식별된 PKS 패밀리를 나타낸다(도 2 참조). 9개의 NR-PKS 그룹 (그룹 I-IX)을 나타내는 계통발생 분기군은 다른 색상으로 음영 처리되었다. NR-PKS 그룹은 그룹 II를 제외하고, 75보다 큰 BS 값에 의해 지원된다. 새로 확인된 NR-PKS 그룹 (그룹 IX)에는 지의류의 피질 및 수질 물질에 대한 후보 PKS인 PKS1, PKS2 및 PKS23 패밀리가 포함된다. 빨간색 화살표는 NR-PKS의 C-메틸트랜스퍼라제 도메인의 다계통성 손실을 나타낸다.
도 6은 지의류의 피질 및 수질 물질의 화학 구조를 나타낸 도이다. 화학 구조에 따라, 9개의 화학 그룹으로 분류하였다 (표 2 참조). 여기에서, 3MOA는 3-메틸오르셀린산의 약어이다.
도 7은 PKS23의 이종 발현 검증 결과를 나타낸 도이다. (A) 스테레오카울론 알피넘(Stereocaulon alpinum)에서 PKS23(atr1) 유전자 구조의 개략도를 나타낸 것이다. 여기에서, 검은색 박스는 엑손이고, 회색 선은 인트론이다. 숫자는 염기쌍(bp)에서 엑손과 인트론의 크기를 나타낸 것이다. P1 및 P2는 RT-PCR 분석에 사용되는 프라이머 쌍이다. 상기 프라이머 쌍은 mRNA 발현이 게놈 DNA(gDNA, genomic DNA) 증폭과 구별될 수 있도록 하나 이상의 인트론 영역을 포함하도록 설계되었다. (B) 플라스미드 sol1::atr1/pDS35를 운반하는 2개의 추정 형질전환체 (T16 및 T25)의 RT-PCR 분석 결과를 나타낸 것이다. 액틴 1(Actin 1) 참조 유전자(mRNA의 경우 633 bp)에 대한 gDNA 앰플리콘에 해당하는 밴드가 관찰되지 않아, 게놈 DNA 오염이 없음을 나타낸다(좌측 하단 패널). 형질전환체 T25는 형질전환체 T16 (좌측 상단 패널)보다 도입된 atr1의 더 강한 발현을 나타내었다. atr1에서 4개의 인트론의 스플라이싱은 P1 및 P2 프라이머 쌍을 사용하여 플라스미드 sol1::atr1/pDS35(C)와 RNA 샘플(T25) 사이의 밴드 크기를 비교하여 확인하였다. mRNA 발현 및 플라스미드 DNA 증폭에 대한 예상 밴드 크기는 bp 단위로 겔 이미지의 좌측 및 우측에 숫자로 표시하였다. 여기에서, M은 100 bp DNA 크기 마커이다.
폴리케타이드 기원의 뎁사이드 및 뎁시돈 계열 화합물은 지의류 몸체(lichen thalli)의 피질 또는 수질층에 축적된다. 지의류 화학의 분류학적 및 생태학적 중요성과 약학적 잠재력에도 불구하고, 생합성 유전자와 지의류 물질을 연결하는 단일 유전적 증거는 없다. 따라서, 본 발명자들은 뎁사이드/뎁시돈 생산에 관여하는 생합성 유전자 클러스터(BGC)의 분류 및 식별을 위해 지의류 폴리케타이드 합성 효소(PKS, polyketide synthase)를 체계적으로 분석하였다. 클라도니아속(Cladonia)의 종간 PKS 다양성 및 관련된 남극 지의류 스테레오카울론 알피넘(Stereocaulon alpinum)에 대한 본 발명자들의 심층 분석은 45개의 BGC 패밀리를 식별하여, 지의류 PKS를 비-지의류화된 곰팡이에서 이전에 특성화된 15개의 PKS와 연결하였다. 이들 중에서, 본 발명자들은 아트라노린(뎁사이드)을 생산하는 지의류에서만 독점적으로 발견되는 고도로 합성된 BGC를 확인하였다. 추정 아트라노린 PKS(atr1 생성)의 이종 발현은 많은 지의류에서 전구체 화합물로서 발견되는 4-O-디메틸바르바트산(4-O-demethylbarbatic acid)을 생성하였으며, 이는 뎁사이드 형성을 위한 Atr1의 분자간 가교 활성을 나타낸다. 이종 숙주에 맞춤 효소를 계속 도입하면, 거대 지의류의 가장 흔한 피질 물질 중 하나인 아트라노린이 생성되었다. 곰팡이 PKS의 계통발생 분석은 Atr1이 뎁사이드 및 뎁시돈의 생합성에 관여할 가능성이 있는 두 개의 보존된 지의류-특이적 PKS 패밀리를 포함하는 새로운 PKS 계통군에 배치되는 것으로 나타났다. 본 발명에서 본 발명자들은 클라도니아속(Cladonia)의 PKS 패밀리의 포괄적인 카탈로그를 제공하고, 기능적으로 지의류의 생합성 유전자 클러스터를 특성화하여 다양한 지의류 물질의 유전학 및 화학적 진화를 연구하기 위한 초석을 확립하였다.
신규의 아트라노린 생합성 유전자
하나의 양태로서, 본 발명은 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진, 아트라노린 생합성 유전자를 제공한다.
본 명세서에 사용된 용어 "아트라노린(atranorin)"은 화학식명이 3-하이드록시-4-메톡시카보닐-2,5-다이메틸페닐-3-포밀-2,4-다이하이드록시-6-메틸벤조에이트이며, 하기 [화학식 1]의 구조식을 가진다. 이러한 아트라노린은 지의체의 이차 대사산물로서 지의체로부터 유래될 수 있다. 상기 아트라노린은 폐암 전이 억제 효능을 갖는 것으로 보고된 바 있다.
[화학식 1]

본 발명의 아트라노린은 아트라노린의 유사체, 유도체를 포함하는 의미로 사용될 수 있다.
본 명세서에 사용된 용어 "지의체(thallus)"는 지의류 공생 조류 또는 시아노박테리아의 세포, 및 지의류 형성 곰팡이의 균사로 이루어지고, 분아, 열아 또는 영양번식을 위한 지의류의 영양체를 말한다.
본 명세서에 사용된 용어 "지의류(lichen)"는 곰팡이(fungi, mycobionts)와 조류(algae, photobionts)가 복합체가 되어 생활하는 공생생물로서 모양, 크기 및 색깔이 매우 다양하며 주로 바위, 수피 및 토양에서 서식한다. 이러한 지의류는 디디믹 산(didymic acid), 스트렙실린(strepsilin), 소듐 우스네이트(sodium usnate), 레카노릭 산(lecanoric acid), 프소로믹 산(psoromic acid) 등 1, 2차 대사산물들을 생성하여 항미생물(곰팡이, 세균, 바이러스), 제초제, 항암, 면역강화, 정신질환 개선 등에 우수한 생리활성을 가지므로 예로부터 동서양을 막론하고 전통적으로 식품 또는 약재의 원료로 사용되어 왔다.
본 발명에 있어서, 상기 아트라노린 생합성 유전자는 지의류로부터 유래된 2차 대사산물, 일례로 아트라노린 발현을 유도할 수 있는 유전자로, 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어질 수 있다. 상기 지의류는 이에 제한되지는 않으나, 스테레오카울론 알피넘(Stereocaulon alpinum)일 수 있다.
상기 서열번호 1로 표시되는 염기서열은 atr1 유전자(NCBI Genbank No. MZ277879.1)로, 서열번호 3으로 표시되는 염기서열은 atr2 유전자(NCBI Genbank No. MZ277878.1)로, 서열번호 5로 표시되는 염기서열은 atr3 유전자(NCBI Genbank No. MZ277877.1)로 각각 명명될 수 있다.
또한, 상기 서열번호 1로 표시되는 염기서열은 서열번호 2의 아미노산 서열로 이루어진 atr1 단백질(NCBI Genbank No. QXF68953.1)로 암호화될 수 있다. 상기 서열번호 3으로 표시되는 염기서열은 서열번호 4의 아미노산 서열로 이루어진 atr2 단백질(NCBI Genbank No. QXF68952.1)로 암호화될 수 있다. 상기 서열번호 5로 표시되는 염기서열은 서열번호 6의 아미노산 서열로 이루어진 atr3 단백질(NCBI Genbank No. QXF68951.1)로 암호화될 수 있다.
지의류 유래 대사산물 생산용 재조합 발현 벡터
다른 하나의 양태로서, 본 발명은 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진 아트라노린 생합성 유전자를 포함하는, 지의류 유래의 대사산물 생산용 재조합 발현 벡터를 제공한다.
상기 "아트라노린 생합성 유전자"는 전술한 바와 같다.
본 명세서에 사용된 용어 "벡터(vector)"는 적합한 숙주 내에서 목적 단백질을 발현시킬 수 있도록 적합한 조절 서열에 작동 가능하게 연결된 특정 유전자를 함유하는 DNA 제조물로, 상기 조절 서열은 전사를 개시할 수 있는 프로모터, 그러한 전사를 조절하기 위한 임의의 오퍼레이터 서열, 적합한 mRNA 리보좀 결합부위를 코딩하는 서열, 및 전사 및 해독의 종결을 조절하는 서열을 포함한다. 벡터는 적당한 숙주세포 내로 형질전환 된 후, 숙주 게놈과 무관하게 복제되거나 기능할 수 있으며, 게놈 그 자체에 통합될 수 있다. 본 발명의 벡터는 당해 기술 분야에서 잘 알려진 유전자 재조합 기술을 이용하여 제조할 수 있으며, 부위-특이적 DNA 절단 및 연결은 당해 기술 분야에서 일반적으로 알려진 효소 등을 사용한다.
본 명세서에 사용된 용어 "발현 벡터"는 지의류 유래 아트라노린 생합성 유전자가 도입된 벡터로, 이종(heterologous)인 미생물 또는 숙주세포에서 자체적으로 발현시킬 수 없는 지의류 유래 대사산물을 인위적으로 발현시키기 위해, 지의류 유래 아트라노린 생합성 유전자를 이종 균주 내로 도입하여 지의류 유래 대사산물을 발현시킬 수 있는 재조합 발현 벡터를 의미한다.
구체적으로, 상기 도입된 아트라노린 생합성 유전자에 의해 지의류 유래의 2차 대사산물인 아트라노린(atranorin)을 비롯하여 4-O-디메틸바르바트산(4-O-demethylbarbatic acid), 프로아트라노린 I(proatranorin I), 프로아트라노린 II(proatranorin II), 프로아트라노린 III(Proatranorin III) 및 베오미세스산(baeomycesic acid) 등의 지의류 유래 대사산물을 이종 미생물 또는 숙주세포에서 발현시킬 수 있는 벡터를 의미한다. 본 발명에서 발현 벡터는 '벡터' 또는 '재조합 발현 벡터'와 혼용될 수 있다.
상기 발현 벡터는 바람직하게는 하나 이상의 선택성 마커를 포함할 수 있다. 상기 마커는 통상적으로 화학적인 방법으로 선택될 수 있는 특성을 갖는 핵산 서열로, 형질전환된 세포를 비 형질전환 세포로부터 구별할 수 있는 모든 유전자가 이에 해당된다. 그 예로는 앰피실린(ampicilin), 카나마이신(kanamycin), G418, 블레오마이신(Bleomycin), 하이그로마이신(hygromycin), 클로람페니콜(chloramphenicol), 아프라마이신(apramycin)과 같은 항생제 내성 유전자가 있으나, 이에 한정되는 것은 아니며, 당업자에 의해 적절히 선택 가능하다.
본 발명의 일 구체예에서, 스테레오카울론 알피넘(Stereocaulon alpinum) 유래 아트라노린 생합성 유전자가 도입된 벡터는 이종(heterologous)인 병아리 콩 역병 곰팡이균 아스코키타 라비에이(Ascochyta rabiei)에 형질전환되어 지의류 유래의 대사산물을 이종 발현시킬 수 있다.
아트라노린 생합성 유전자 함유 재조합 발현 벡터가 적재된 재조합 미생물
또 다른 하나의 양태로서, 본 발명은 상기 재조합 발현 벡터로 형질전환된 재조합 미생물을 제공한다.
상기 재조합 발현 벡터는 전술한 바와 같다.
본 명세서에 사용된 용어 "형질전환"은 외부로부터 주어진 DNA에 의하여 생물의 유전적인 성질이 변하는 것을 의미하며, 특히 본 발명에서는 특정 유전자, 즉 지의류 유래 아트라노린 생합성 유전자를 포함하는 벡터를 특정 이종 미생물 내에 도입하여 특정 이종 미생물 내에서 상기 유전자가 발현될 수 있도록 하는 것을 의미한다.
상기 재조합 발현 벡터는 특정 이종 미생물에 형질전환하여 재조합 미생물 균주를 제조하는데, 이때 상기 형질전환 방법은 공지된 기술이라면 특별히 이에 제한되지 않고 사용할 수 있다. 예를 들면 칼슘 클로라이드 방법 또는 전기천공법(Neumann, et al., EMBO J., 1:841, 1982)을 형질전환에 사용할 수 있다.
상기 특정 이종 미생물은 당업계에 널리 알려져 있는 미생물 또는 숙주세포라면 제한없이 사용할 수 있다. 본 발명의 지의류 유래 아트라노린 생합성 유전자의 도입 효율과 발현 효율이 높은 미생물 또는 숙주세포를 사용할 수 있는데, 예를 들면, 곰팡이, 박테리아, 효모를 포함할 수 있다.
구체적으로 상기 재조합 미생물은 곰팡이일 수 있고, 보다 구체적으로 아스코키타 라비에이(Ascochyta rabiei)일 수 있다. 보다 더 구체적으로, 상기 재조합 미생물은 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)일 수 있다.
지의류 유래의 대사산물의 생산 방법
또 다른 하나의 양태로서, 본 발명은 상기 재조합 미생물을 배양하는 단계를 포함하는, 지의류 유래의 대사산물 생산 방법을 제공한다.
상기 재조합 미생물은 전술한 바와 같이 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진 아트라노린 생합성 유전자를 포함하는, 지의류 유래의 대사산물 생산용 재조합 발현 벡터가 도입된 재조합 미생물일 수 있다.
상기 재조합 미생물은 이에 제한되지는 않으나, 4-O-디메틸바르바트산(4-O-demethylbarbatic acid), 프로아트라노린 I(proatranorin I), 프로아트라노린 II(proatranorin II), 프로아트라노린 III(Proatranorin III), 아트라노린(atranorin) 및 베오미세스산(baeomycesic acid)으로 이루어진 군으로부터 하나 이상 선택되는, 지의류 유래의 대사산물을 생산하는 것일 수 있다.
상기 지의류 유래의 대사산물 생산용 재조합 미생물의 배양 조건은 형질전환된 재조합 미생물 또는 숙주세포의 종류에 따라 달라질 수 있다. 상기 재조합 미생물 또는 숙주세포의 종류에 따라 당업자에게 공지된 조건에 따라, 즉, 통상의 온도 조건, 예컨대 25 내지 40℃ 및 pH 조건, 예컨대 pH 6 내지 8의 조건 하에서 배양될 수 있다. 이러한 조건 하에서 재조합 미생물 또는 숙주세포로부터 전술한 바와 같은 지의류 유래의 대사산물을 높은 수율로 대량 생산할 수 있다.
상기 재조합 미생물 또는 숙주세포는 전술한 바와 같이 지의류 유래 아트라노린 생합성 유전자의 도입 효율과 발현 효율이 높은 미생물 또는 숙주세포로서 당업계에 공지된 미생물 또는 숙주세포를 제한없이 사용할 수 있다. 구체적으로 상기 재조합 미생물은 곰팡이일 수 있고, 보다 구체적으로 아스코키타 라비에이(Ascochyta rabiei)일 수 있다. 보다 더 구체적으로, 상기 재조합 미생물은 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)일 수 있다.
또한, 상기 재조합 미생물 또는 숙주세포의 배양(또는 발효)에 사용되는 배지는 특정한 미생물 균주 또는 숙주세포의 요구조건을 적절하게 만족시키는 것을 적절히 선택할 수 있다. 상기 배지는 다양한 탄소원, 질소원, 인원 및 미량원소 성분을 포함할 수 있다. 배지 내 탄소원으로는 글루코즈, 사카로즈, 락토즈, 프락토즈, 말토즈, 전분, 셀룰로즈와 같은 당 및 탄수화물, 대두유, 해바라기유, 피마자유, 코코넛유 등과 같은 오일 및 지방, 팔미트산, 스테아린산, 리놀레산과 같은 지방산, 글리세롤, 에탄올과 같은 알코올, 아세트산과 같은 유기산을 예시할 수 있으나, 이에 제한되는 것은 아니다. 이들 물질은 개별적으로 또는 혼합물로서 사용될 수 있다. 상기 탄소원은 글리세롤, 포도당 또는 이들의 조합일 수 있다. 배지 내 질소원으로는 펩톤, 효모 추출물, 육즙, 맥아 추출물, 옥수수 침지액, 대두밀 및 요소 또는 무기 화합물, 예를 들면 황산암모늄, 염화암모늄, 인산암모늄, 탄산암모늄 및 질산암모늄을 예시할 수 있으나, 이에 제한되는 것은 아니다. 질소원 또한 개별적으로 또는 혼합물로서 사용할 수 있다. 배지 내 인원으로는 인산이수소칼륨 또는 인산수소이칼륨 또는 상응하는 나트륨-함유 염을 예시할 수 있으나, 이에 제한되는 것은 아니다. 또한, 배양 배지는 성장에 필요한 황산마그네슘 또는 황산철과 같은 금속염을 포함하거나, 아미노산 및 비타민과 같은 필수 성장 물질을 포함할 수 있으나, 이에 제한되는 것은 아니다. 상술된 원료들은 배양 과정에서 배양물에 적절한 방식에 의해 회분식으로 또는 연속식으로 첨가될 수 있다.
또한, 필요에 따라, 수산화나트륨, 수산화칼륨, 암모니아와 같은 기초 화합물 또는 인산 또는 황산과 같은 산 화합물을 적절한 방식으로 사용하여 배양물의 pH를 조절할 수 있다. 또한, 지방산 폴리글리콜 에스테르와 같은 소포제를 사용하여 기포 생성을 억제할 수 있다. 배양물의 온도는 통상 20℃ 내지 45℃, 또는 25℃ 내지 40℃를 유지할 수 있다. 배양은 원하는 대사산물, 예컨대 4-O-디메틸바르바트산, 프로아트라노린 I, 프로아트라노린 II, 프로아트라노린 III, 아트라노린 및 베오미세스산으로 이루어진 군으로부터 하나 이상 선택되는 지의류 유래의 2차 대사산물의 생산량이 최대로 얻어질 때까지 계속될 수 있다.
본 명세서에서 제공되는 지의류 유래의 대사산물의 생산 방법은, 상기한 배양 단계 이후에, 생산된 지의류 유래의 2차 대사산물을 회수 또는 분리하는 단계를 추가로 포함할 수 있다. 재조합 균주 또는 이의 배양물로부터 생산된 지의류 유래의 2차 대사산물을 회수 또는 분리하는 방법은 당업계에 널리 알려져 있는 방법 중에서 선택될 수 있다. 예컨대, 4-O-디메틸바르바트산, 프로아트라노린 I, 프로아트라노린 II, 프로아트라노린 III, 아트라노린 또는 베오미세스산의 회수 방법의 예로서, 원심분리, 초음파파쇄, 여과, 이온교환 크로마토그래피, 고성능 액체 크로마토그래피(high performance liquid chromatography: HPLC), 가스 크로마토그래피(gas chromatography: GC) 등의 방법이 있으나, 이들 예에 한정되는 것은 아니다.
본 명세서에서 제공되는 지의류 유래의 대사산물은 전술한 아트라노린 생합성 유전자들 중 1종 이상을 선택적으로 도입하여 형질전환시킨 재조합 미생물로부터 생산될 수 있다(하기 [반응식 1] 참조).
[반응식 1]
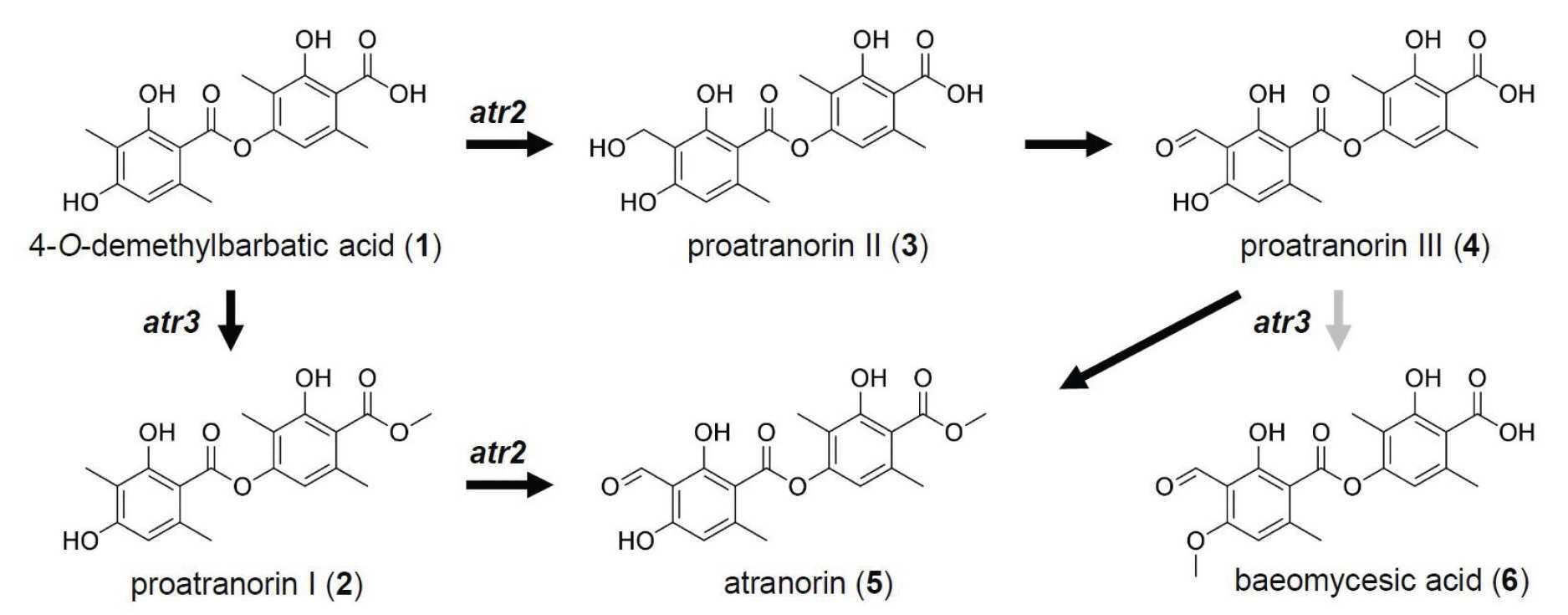
본 발명의 일 구체예에서, 상기 서열번호 1의 염기서열로 이루어진 atr1 유전자가 도입된 재조합 미생물을 소정의 조건 하에서 배양함으로써 4-O-디메틸바르바트산을 생산할 수 있다. 이때, 재조합 미생물은 이에 제한되지는 않으나 식물 병원성 곰팡이 아스코키타 라비에이(As. rabiei)일 수 있다.
본 발명의 일 구체예에서, 상기 서열번호 1의 염기서열로 이루어진 atr1 유전자 및 서열번호 5의 염기서열로 이루어진 atr3 유전자가 도입된 재조합 미생물을 소정의 조건 하에서 배양함으로써 프로아트라노린 I을 생산할 수 있다. 이때, 재조합 미생물은 이에 제한되지는 않으나 식물 병원성 곰팡이 아스코키타 라비에이(As. rabiei)일 수 있다.
본 발명의 일 구체예에서, 상기 상기 서열번호 1의 염기서열로 이루어진 atr1 유전자 및 서열번호 3의 염기서열로 이루어진 atr2 유전자가 도입된 재조합 미생물을 소정의 조건 하에서 배양함으로써 프로아트라노린 II 및 프로아트라노린 III을 생산할 수 있다. 이때, 재조합 미생물은 이에 제한되지는 않으나 식물 병원성 곰팡이 아스코키타 라비에이(As. rabiei)일 수 있다.
본 발명의 일 구체예에서, 상기 상기 서열번호 1의 염기서열로 이루어진 atr1 유전자, 서열번호 3의 염기서열로 이루어진 atr2 유전자 및 서열번호 5의 염기서열로 이루어진 atr3 유전자가 도입된 재조합 미생물을 소정의 조건 하에서 배양함으로써 아트라노린을 생산할 수 있다. 이때, 재조합 미생물은 이에 제한되지는 않으나 식물 병원성 곰팡이 아스코키타 라비에이(As. rabiei)일 수 있다.
아트라노린 생산용 아스코키타 라비에이(
Ascochyta rabiei
) ATR-11 균주
또 다른 하나의 양태로서, 본 발명은 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)를 제공한다.
본 명세서에 사용된 용어 "아스코키타 라비에이(Ascochyta rabiei)"는 병아리 콩 역병을 유발하는 식물 병원성 곰팡이균으로, 전술한 지의류 유래의 아트라노린 생합성 유전자를 도입하는 데 사용된 이종의 숙주 미생물이다.
상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)는 국립농업과학원 농업미생물은행(KACC)에 2021년 5월 28일자로 기탁번호 KACC 83048BP로 기탁된 아라트라노린 생산용 균주이다.
구체적으로, 상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주는 전술한 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진, 아트라노린 생합성 유전자가 도입된 균주로, 아트라노린을 생산할 수 있다. 상기 균주로부터 생산된 아트라노린은 약학 조성물, 식품 조성물, 건강기능식품, 사료 조성물 등에 다양하게 활용 및 산업화할 수 있다.
아스코키타 라비에이 ATR-11 균주를 이용한 아트라노린 생산 방법
또 다른 하나의 양태로서, 본 발명은 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)를 배양하는 단계를 포함하는, 아트라노린 생산 방법을 제공한다.
상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)는 전술한 바와 같다.
상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)의 배양 조건은 특별히 이에 제한되지 않으나,15 내지 25℃의 온도, 배양 시간 7일 내지 21일일 수 있고, 바람직하게는 18 내지 22℃의 온도, 배양 시간 14일 내지 18일일 수 있다.
또한, 상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)의 배양은 상기 균주가 효율적으로 이용할 수 있는 탄소원, 질소원, 무기염 등을 포함하는 천연 배지 또는 합성 배지를 사용할 수 있다. 사용될 수 있는 탄소원은 글루코오스, 프럭토오스, 수크로오스, 콩가루, 땅콩가루, 밀가루, 옥수수가루, 덱스트린, 콘밀, 과당 시럽과 같은 탄수화물; 녹말, 녹말의 가수분해물; 아세트산 및 프로피온산과 같은 유기산; 에탄올, 프로판올, 글리세롤과 같은 알코올; 콩기름, 올리브기름, 카놀라유, 땅콩기름, 생선기름 등의 기름류 등을 포함한다. 질소원은 암모니아; 염화암모늄, 암모늄설페이트, 암모늄아세테이트 및 암모늄포스페이트와 같은 무기산 또는 유기산의 암모늄염; 펩톤, 육추출물(meat extract), 이스트추출물, 옥수수 침지액, 카제인 가수분해물, 대두추출물, 대두가수분해물; 다양한 발효된 세포 및 이들의 분해물 등을 포함한다. 아미노산으로, 글루타민산나트륨, 메티오닌, 라이신, 루이신, 시스테인, 발린 등을 포함한다. 무기염은 포타슘디하이드로젠 포스페이트, 다이포타슘하이드로젠 포스페이트, 마그네슘 포스페이트, 마그네슘 설페이트, 소디엄 클로라이드, 망간 설페이트, 구리 설페이트, 칼슘 카보네이트 등을 포함한다.
상기 배지의 pH는 배양 중에서 바람직하게는 3.0 내지 9.0의 범위를 유지한다. 배지의 pH는 무기 또는 유기산, 알칼리 용액, 우레아, 칼슘 카보네이트, 암모니아 등으로 조절할 수 있다.
상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)를 배양한 후, 이로부터 아트라노린을 분리, 정제 및 회수하기 위해서는 공지의 다양한 방법을 이용할 수 있다. 예를 들면 균체를 원심분리를 통해 제거한 후, 염석, 에탄올 침전, 한외여과막, 겔 여과 크로마토그래피, 이온교환 칼럼 크로마토그래피 등의 공지된 적절한 방법이나 이들을 조합하여 분리 정제할 수 있다.
상기 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP)를 활용한 아트라노린의 생산은 실험실 규모에서 뿐만 아니라, 대규모 생산에도 적합하므로 상업적 활용에 용이하다.
상기 아트라노린은 이에 제한되지는 않으나, 지의류 스테레오카울론 알피넘(Stereocaulon alpinum)으로부터 유래한 아트라노린일 수 있다.
이하, 실시예를 통하여 본 발명의 구성 및 효과를 더욱 상세히 설명하고자 한다. 이들 실시예는 오로지 본 발명을 예시하기 위한 것일 뿐, 본 발명의 범위가 이들 실시예에 의해 한정되는 것은 아니다.
실시예 1: 계통 분석
게놈 시퀀싱된 29종의 지의류-형성 곰팡이(Lichen-forming fungi, LFF)와 내생 곰팡이(endophytic fungus)인 시아노데르멜라 아스테리스(Cyanodermella asteris)의 계통발생을 유추하기 위해 본 발명자들은 병합-기반 계통발생학 접근법을 추구하였다. LFF에 대한 배양, 게놈 시퀀싱 및 주석 절차는 하기 실시예 8에 설명되어 있다. 30개의 주석이 달린 게놈에서 추론된 단백질 서열의 단일-사본 오르토로그 클러스터(Single-copy ortholog cluster, SCO)는 인플레이션 계수가 2.5인 OrthoMCL(v2.0.9)을 사용하여 식별되었다. 393개의 SCO 각각에 대해, '자동' 설정과 함께 MAFFT(v7.310)를 사용하여 단백질 서열을 정렬하였으며, 매개변수: '-b4=5'과 함께 Gblock(v0.91b)을 사용하여 잘못 정렬된 영역에 대해 결과 393개의 다중 서열 정렬을 트리밍하였다. RAxML 프로그램(v82)은 각 다중 서열 정렬에 대해 100개의 최대 우도(likelihood) 트리를 계산하는 데 사용되었다. 병합-기반 트리를 생성하기 위해 두 개의 다중 위치 부트스트래핑 옵션(사이트 전용 리샘플링 및 유전자/사이트 리샘플링)이 있고 부트스트랩 옵션이 없는 ASTRAL-III(v5.7.4)를 사용하였다. 모든 트리는 동일한 토폴로지(topology)를 보여주었다.
실시예 2: 생합성 유전자 클러스터 패밀리 분석
30종의 게놈에서 BGC 식별을 위해, 게놈 어셈블리 및 주석 파일은 '--최소' 매개변수 설정으로 antiSMASH 프로그램(v5.0+)에 의해 처리되었다. 6종의 클라도니아속(Cladonia spp.) 및 남극 지의류 스테레오카울론 알피넘(Stereocaulon alpinum, S. alpinum)에서 발견된 BGC의 유전적 복제 제거를 위해 본 발명자들은 MIBiG 데이터베이스(v1.4)를 참조하여 BiG-SCAPE 프로그램을 사용하였다. 하나 이상의 반복 유형 I PKS를 포함하는 BGC를 분석하기 위해, 반복 유형 I PKS(PF00109 및 PF02801)와 관련된 Pfam 도메인만 포함하도록 구성 파일 'domain_whitelisttxt'를 수정하고 선택적 인수 -믹스' 및 '-- 하이브리드-오프'로 BiG-SCAPE 프로그램을 실행하였다. 도메인 유형의 자카드(Jaccard) 인덱스, 도메인 시퀀스 유사성 및 도메인 인접성 인덱스를 기반으로 BiG-SCAPE 프로그램은 더 작은 값이 더 큰 BGC 유사성을 나타내는 클러스터의 페어별 조합 간의 유사성 매트릭스를 계산하였다. 본 발명자들은 0.3-0.8의 엣지-길이 컷오프(edge-length cutoff)를 0.1 단계로 사용하여 BGC 네트워크를 평가하였고, 6종의 클라도니아속(Cladonia spp.) 및 S. alpinum에서 GCF의 대표로서 0.5의 컷오프(cutoff) 값을 사용하는 네트워크를 고려하였다. PKS 패밀리에 대한 개별 네트워크는 Python package NetworkX (v2.5)를 사용하여 시각화되었으며, BiG-SCAPE에 의해 계산된 BGC 쌍 간의 유사도 제곱으로 엣지-너비에 가중치가 부여되었다. 본 발명자들은 지의류 물질 생산을 담당하는 PKS 패밀리를 포함하는 BGC의 다중-위치, 대략 최대-우도, 계통수를 생성하는 CORASON 프로그램을 사용하였다. PKS23 패밀리의 경우 C. 랑기페리나(C. rangiferina)의 OMT(Crg06815)를 쿼리 유전자로 사용하여 30개의 시퀀싱된 종에서 검출된 총 1,527개의 BGC에서 상동성 BGC를 검색하였다. PKS1 패밀리의 경우 C. 랑기페리나(C. rangiferina)의 GAL4 유형 전사 인자(유전자 ID: Crg07068)를 쿼리 유전자로 사용하였다.
실시예 3: 곰팡이 NR-PKS의 계통발생 분석
반복 유형 I PKS의 KS 도메인은 진화적으로 보존된 것으로 간주되어, 전체 PKS의 유사성에 대한 프록시 역할을 할 수 있다. 본 발명자들은 6종의 클라도니아속(Cladonia spp.) 및 S. alpinum의 게놈에서 총 242개의 PKS를 확인하였으며, 그 중 4개의 PKS(Cgr01615, Cgr03964, Cgr08611 및 Cmt10189)에 KS 도메인이 누락되었다. KS 도메인 서열은 온라인 도구인 NaPDoS를 사용하여 238개의 PKS에서 추출하고 MUSCLE(v3.8.31)을 사용하여 정렬하였다. 클러스터링 분석을 위해, BuddySuite 프로그램의 AlignBuddy 기능을 사용하여 선택적 인수인 '-pi'를 사용하여 238개 PKS의 KS 도메인에 대한 전체-대-전체(all-versus-all) 유사성 매트릭스를 계산하였다. R package Superheat를 사용하여 k-평균값에 의해 클러스터링된 KS 도메인의 유사도 백분율을 보여주는 히트맵이 생성되었다. 곰팡이 NR351 PKS 계통발생의 경우, 본 발명자들은 6종의 클라도니아속(Cladonia spp.) 및 S. alpinum에서 발견된 103개의 NR-PKS의 KS 및 PT 도메인의 연결된 단백질 서열과 지의류가 없는 곰팡이의 알려진 화합물에 연결된 82개의 NR-PKS를 사용하였다. 본 발명자들은 처음에 6종의 클라도니아속(Cladonia spp.) 및 S. alpinum에서 106개의 NR-PKS를 확인하였으며, 여기에는 현재 게놈 어셈블리(유사유전자)에서 전체 서열을 안정적으로 정의할 수 없는 7개의 NR-PKS가 포함된다. 이러한 부분 PKS 중, 3개의 NR-PKS(Cbo04702, Cma06590 및 Cmt06606)는 KS 또는 PT 도메인이 없었고, 계통발생 분석에서 제외되었다. 지의류 NR-PKS의 PT 도메인은 이전에 특성화된 PKS의 도메인과 정렬하여 식별되었다. 페니실리움 엑스판숨(Penicillium expansum)에서 파툴린(UniProtKB: A0A075TRC0) 생합성을 담당하는 6-메틸살릴산 합성 효소(6-methylsalicylic acid synthase, 6MSAS)는 곰팡이 NR-PKS 계통발생에 대한 외부 그룹으로 설정되었다. 또한, 4개의 클라도니아속(Cladonia spp.)에서 발견된 4개의 6MSAS가 분석에 포함되었다(Cbo07291, Cgr05254, Cmt10005 및 Cuc03485). KS 및 PT 도메인의 단백질 서열은 MAFFT(v7.310)를 사용하여 '자동' 설정으로 정렬하고, 각 도메인의 거짓된 서열 또는 잘못 정렬된 영역은 'gappyout' 매개변수로 trimA1 프로그램(v1.2)을 사용하여 트리밍하였다. KS 및 PT 도메인에 대한 결과 다중 서열 정렬이 FASconCAT-G(v1.04)와 연결되었다. 연결된 서열에서 RAxML(v8.2)을 사용하여 매개변수 설정이 '-m PROTGAMMAWAG'인 사이트의 대체율에 대한 감마 분포를 사용하여 최대-우도 트리를 계산하였다. 노드 지원은 1,000개의 부트스트랩 복제에 의해 평가되었다. 최종 트리는 6MSAS 아웃그룹에 뿌리를 두고 iTOL(v5.7)로 주석을 달았다.
실시예 4: 아스코키타 라비에이(
Ascochyta rabiei
)에서 "클린 숙주"의 생성
분할-마커 전략을 사용하여 솔라나피론-마이너스 돌연변이체("클린 숙주")를 생성하였다. sol1의 다운스트림 영역(1,208 bp) 및 sol3의 업스트림 영역(1,459 bp)은 각각 L5/L3 및 R5/R3 프라이머 쌍을 사용하여 As. rabiei 분리주 AR628의 gDNA로부터 증폭되었다. 하이그로마이신 포스포트랜스퍼라제 유전자(hph) 카세트는 프라이머 쌍 HYG5/HYG3을 사용하여 pCB1004 플라스미드로부터 증폭되었다. L3 및 R5 프라이머는 각각 hph 카세트의 3' 및 5' 말단에 상보적인 27개의 ntlong 오버행 서열을 가지므로, 증폭된 sol1 다운스트림 및 sol3 업스트림 영역이 중첩 확장 PCR에 의해 hph 카세트에 융합될 수 있다. 마지막으로, N5/HY-R 및 YG-F/N3 프라이머 쌍을 사용하여 융합된 구성에서 분할 마커 구성을 증폭하였다. 분할 마커 구성물은 Hallen-Adams 등에 기술된 바와 같이 폴리에틸렌 글리콜-매개 유전자 변형에 의해 As. rabiei의 원형질체에 도입되었다. 유전자 교체에 사용된 프라이머는 하기 표 1에 나열되어 있다.
본 발명에 사용된 프라이머 정보를 하기 표 1에 정리하여 나타내었다.
| 프라이머 | 서열 (5'-3') | 서열번호 | 설명 |
| Sol1PpDS33_fwd | AGATCTCGGCACGTTTTGATCGCAAAG | 7 | pDS33으로 sol1 프로모터 클로닝 |
| Sol1PpDS33_rev | AAGCTTAGTAATATCTGGCGATGAAGCGTCAG | 8 | pDS33으로 sol1 프로모터 클로닝 |
| Inf_Sta046440_fwd | CAGATATTACTAAGCTCATGGCGTCTAACCATGAGGAG | 9 | pDS35로 PKS23 클로닝 |
| Inf_Sta046440_rev | GTAACGTTAAGTGGATCCTTACAACTAAAGCTCTCAATCAACCC | 10 | pDS35로 PKS23 클로닝 |
| Sta046440_check1F | GGACGATGAGAACGTCCTAG | 11 | PKS23 시퀀싱 |
| Sta046440_check2F | CGAGTCAGGTGATCCAGTG | 12 | PKS23 시퀀싱 |
| Sta046440_check3F | CCAATCATACTGAGCGCTG | 13 | PKS23 시퀀싱 |
| Sta046440_check4F | CACATGTCTGTGGCTTGAG | 14 | PKS23 시퀀싱 |
| Sta046440_check5F | CAACTCCGGTGATGATTG | 15 | PKS23 시퀀싱 |
| Sta046440_check6F | CAACCCTTCCACATATTGAG | 16 | PKS23 시퀀싱 |
| pII99_sol5_fwd | GAATTCAGAGCGACAGTGAAAGC | 17 | pII99로 sol5 프로모터 클로닝 |
| pII99_sol5_rev | AGATCTAGCTAGCTTGGCGTGATGTCAGTCAATGCTG | 18 | pII99로 sol5 프로모터 클로닝 |
| pII99_tef1a_fwd | GAATTCCAGCCGAGACAGCAGAATCAC | 19 | pII99로 tef1α 프로모터 클로닝 |
| pII99_tef1a_rev | AGATCTAGCTAGCGTGTTATGTTTTGTGGAATATAAAAGGG | 20 | pII99로 tef1α 프로모터 클로닝 |
| Inf95_Sta04642_fwd | ATCACGCCAAGCTAGCACGATGACTTCCGTTGATACAATG | 21 | pII95로 atr3 클로닝 |
| Inf98_Sta04642_fwd | AAACATAACACGCTAGCACGATGACTTCCGTTGATACAATG | 22 | pII98로 atr3 클로닝 |
| Inf99_Sta04642_rev | GGAGACCGGCAGATCCCGTCACATGTCCGTCATAATAAC | 23 | pII95 및 pII98로 atr3 클로닝 |
| Inf98_Sta04643_fwd | AAACATAACACGCTAGAACCATGGCTCTCCTAGACACAATTG | 24 | pII95로 atr2 클로닝 |
| Inf95_Sta04643_fwd | ATCACGCCAAGCTAGAACCATGGCTCTCCTAGACACAATTG | 25 | pII98로 atr2 클로닝 |
| Inf99_Sta04643_rev | GGAGACCGGCAGATCGAGGAGCAAAGGAACAAGGAACAG | 26 | pII95 및 pII98로 atr2 클로닝 |
| pII99_MK5 | CGTCAAGAGACCTACGAGACTG | 27 | 플라스미드 tef1α::atr2/pII98에서 nptII를 ble로 교체 |
| pII99_MK3 | GCTATACTTCTAGGTCTTGGAAGAG | 28 | 플라스미드 tef1α::atr2/pII98에서 nptII를 ble로 교체 |
| Inf_BLE_pII99_fwd | GTAGGTCTCTTGACGCATTAAGACCTCAGCGCTAGTGG | 29 | 플라스미드 tef1α::atr2/pII98에서 nptII를 ble로 교체 |
| Inf_BLE_pII99_rev | GACCTAGAAGTATAGCGGTGTTACGGAGCATTCACTAGG | 30 | 플라스미드 tef1α::atr2/pII98에서 nptII를 ble로 교체 |
| L5 | GAGGTCTTCACACCACAAGTTCG | 31 | "클린 숙주" 생성 |
| L3 | GGCAAAGGAATAGAGTAGATGCCGACCGGGCTCTTGCGTAGTGGTACAGATG | 32 | "클린 숙주" 생성 |
| R5 | GTTGACCTCCACTAGCTCCAGCCAAGCGAATAGGTAACAAAGCCAGCCGAG | 33 | "클린 숙주" 생성 |
| R3 | GAGAATTGCGGCGCAGGATGTTC | 34 | "클린 숙주" 생성 |
| N5 | CTGACTTTCTTCTTGCAGCCCTGC | 35 | "클린 숙주" 생성 |
| N3 | CTAACGATGTCGTTAGTCGCCTTG | 36 | "클린 숙주" 생성 |
| HYG-F | GCTTGGCTGGAGCTAGTGGAG | 37 | "클린 숙주" 생성 |
| HYG-R | CGGTCGGCATCTACTCTATTCCTT | 38 | "클린 숙주" 생성 |
| YG-F | CGATGTAGGAGGGCGTGGATATGTC | 39 | "클린 숙주" 생성 |
| HY-R | TGTAGTGTATTGACCGATTCCTTGCG | 40 | "클린 숙주" 생성 |
| P1_fwd | GGACGATGAGAACGTCCTAG | 41 | RT-PCR 분석 |
| P1_rev | GAGAGTTCCTCATGCTCGTC | 42 | RT-PCR 분석 |
| P2_fwd | CATCGACGACACGGAGATACTG | 43 | RT-PCR 분석 |
| P2_rev | GACCGTGAGATTCTTTGAAGAGG | 44 | RT-PCR 분석 |
| Actin1_fwd | CAATGGTTCGGGTATGTGCAAG | 45 | RT-PCR 분석 |
| Actin1_rev | GAAGAGCGAAACCCTCGTAGAT | 46 | RT-PCR 분석 |
실시예 5:
atr1
및 RT-PCR 분석의 이종(Heterologous) 발현
"클린 숙주"에서 외래 유전자의 효율적인 발현을 위해, sol1 유전자 프로모터(pDS35), sol5 유전자 프로모터(pII95) 또는 번역 연장 인자 1 알파 유전자 프로모터(pII98)를 운반하는 발현 벡터를 구성하였다. 그 다음, atr1, atr2 및 atr3 유전자를 발현 벡터에 개별적으로 클로닝하였다. 발현 벡터 구성 및 클로닝 절차에 대한 자세한 내용은 실시예 9 및 10에 기술되어 있다. atr1의 이종 발현을 위해, sol1::atr1/pDS35 플라스미드(5-10 μg)를 사용하여 "클린 숙주"를 형질전환하였다. 추정 형질전환체를 100 μg/ml의 노르세오트리신 설페이트 (clonNAT; GoldBio)를 함유하는 감자 덱스트로스 한천(PDA; BD Biosciences)에서 계대배양하였다. Sta04644-T16 및 Sta04644-T25로 명명된 2개의 형질전환체는 선택제에 내성을 보였고, RNA 추출을 위해 나일론 멤브레인으로 덮인 PDA에서 계대배양하였다. 배양 2주 후, PDA에서 자라는 균사체를 나일론 멤브레인으로부터 편날 면도날로 긁어내어 총 RNA를 추출하였다. 제조업체의 지침에 따라 TRIzol 시약(Thermo Fisher Scientific)을 사용하여 추가 추출 단계와 함께, 액체 질소에서 분쇄된 균사로부터 총 RNA를 추출하였다. 추가 추출 단계는 1회의 페놀(pH 4.6)-클로로포름-이소아밀 알코올(25:24:1) 추출에 뒤이어 초기 TRIzol-클로로포름 상 분리 후 1회의 클로로포름 추출 단계 RNA 펠렛을 88 μL의 뉴클레아제가 없는 물에 용해시키고, DNase 처리로 게놈 DNA를 절단하여 수행하였다(Qiagen). 이후, RNA Clean & Concentrator (Zymo research)를 사용하여 RNA 샘플을 농축하였다. 본 발명자들은 RT-PCR 분석에서 4개의 인트론으로 atr1의 발현과 인트론 접합을 확인하였다. 두 개의 프라이머 세트가 설계되었다: (i) atr1 코딩 서열의 5' 영역에 위치한 첫 번째 인트론의 측면 영역을 증폭하고, (ii) atr1 코딩 서열의 3' 영역에서 두 번째, 세 번째 및 네 번째(마지막) 인트론을 포함하는 영역을 증폭하였다. OneStep RT-PCR 키트(Qiagen)를 사용하여, 200 나노그램의 총 RNA를 역전사하고 atr1 및 액틴1(양성 대조군)을 증폭하였다. RT-PCR 분석 및 플라스미드 구성에 사용된 프라이머는 상기 표 1에 나열되어 있다.
실시예 6: 아트라노린을 생산하는 이종 숙주의 생성
atr1-발현 균주(Sta04644-T25)에 맞춤 효소를 도입하기 위해, 4개의 생성된 플라스미드(sol5::atr2/pII95, tef1α::atr2/pII98, sol5::atr3/pII95 및 tef1α::atr3/pII98)를 Sta04644-T25 균주로 개별적으로 형질전환시키고, 추정 형질전환체를 200 μg/ml의 G418 디설페이트(Sigma-Aldrich)를 함유하는 PDA 상에서 계대배양하였다. 대사산물 식별을 위해 G418 디설페이트에 내성이 있는 형질전환체를 선택하였다. sol1:: atr1/pDS35 및 sol5:: atr3/pII95를 모두 보유하는 균주를 아트라노린-생산 균주의 생성에 사용하였고, 이는 아트라노린의 직접적인 전구체인 화합물 2(프로아트라노린 I)의 가장 큰 생산을 나타내었다. G418 디설페이트에 내성을 부여하는 네오마이신 포스포트랜스퍼라제 II 유전자(nptII) 카세트가 이미 화합물 2를 생성하는 균주에 통합되었기 때문에, 본 발명자들은 tef1α::atr2/pII98 플라스미드의 nptII 카세트를 블레오마이신 내성 단백질 유전자(ble)로 교체하였으며, tef1α::atr2/pII98 플라스미드는 프라이머 쌍 'Inf_BLE_pII99_fwd' 및 'Inf_BLE_pII99_rev'를 사용하여 증폭되었고, ble는 pAC1750에서 증폭되었다. 이후, In-Fusion HD 클로닝 키트(Takara)를 사용하여 두 PCR 산물을 융합하였다. 생성된 플라스미드를 균주 생산 화합물 2로 형질전환하고, 추정 형질전환체를 200 μg/ml의 제오신(ThermoFisher Scientific에서 유통하는 블레오마이신 패밀리의 구성원)을 함유하는 PDA에서 계대배양하였다. 아트라노린을 생산하는 형질전환체를 선별하기 위해, 제오신 내성 형질전환체의 화학적 프로파일을 게놈 염기서열 LFF가 원래 분리된 S. alpinum 바우처 표본(국립수목원 등록번호: KHL0017342)과 비교하였다. HPLC, LC-MS/MS 및 배양 추출물 및 정제된 화합물에 대한 NMR 분광 분석에 대한 자세한 방법론은 실시예 11 내지 13에 자세히 기술되어 있다.
실시예 7: 데이터 유효성
이 전체 게놈 샷건 프로젝트는 C. 보레알리스(C. borealis), 파멜리아 cf. 스쿼로사(Parmelia cf. squarrosa) 및 S. 알피넘(S. alpinum)에 대해 각각 JAFEKC000000000, JAEUBB000000000 및 JAEUBA000000000 (바이오프로젝트: PRJNA693578, PRJNA693575, 및 PRJNA693574) 수탁하에 DDBJ/ENA/GenBank에 기탁되었다. LC-MS/MS 원 데이터는 MSV000087081이라는 등록번호로 MassIVE 데이터베이스(http://massive.ucsd.edu)에 기탁되었다.
실시예 8: 게놈 시퀀싱 및 주석
LFF는 남극 대륙 킹 조지 섬(S62˚13'51" W58˚46'32")에서 채집한 C. 보레알리스(C. borealis) 및 S. 알피넘(S. alpinum)과 한국 덕유산(N35˚51'24" E127˚44'54")에서 채집한 파멜리아 cf. 스쿼로사(Parmelia cf. squarrosa)에서 분리되었다. LFF는 맥아 추출물 한천 배지(BD Biosciences)에서 3-6개월 동안 배양되었다. 표준 페놀/클로로포름 추출 방법을 사용하여 게놈 DNA를 추출하고, Illumina HiSeq2000 또는 NovaSeq6000 기기에서 시퀀싱하여 150개의 뉴클레오티드 페어드-엔드 리드를 생성하였다. Illumina 어댑터를 트리밍하고 판독 품질을 평가하였으며, 콘티그(contig)를 Macrogen Inc.(Seoul, South Korea)에서 조립하였다. NCBI 데이터베이스에서 검색된 게놈 어셈블리는 GenSAS (v.6.0) 주석 파이프라인을 사용하여 주석을 달았다. 간단히 말해서, DNA 소스를 'Fungi'로 설정하여 RepeatModeler (v1.0.11) 및 RepeatMasker (v4.0.7) (www.repeatmasker.org)를 사용하여 복잡성이 낮은 영역과 반복을 마스킹하였다. ab initio 유전자 예측이 하기 도구를 사용하여 수행된 마스킹된 컨센서스 시퀀스가 생성되었다: (i) Augustus (v3.3.1), A. 니둘란스(A. nidulans)를 트레이닝된 유기체로 선택, (ii) GeneMarkES (v4.33), (iii) 인간 및 기타 척추동물에 대한 매개변수 설정을 사용하는 Genscan (v1.0) 및 (iv) GlimmerM (v2.5.1), 아스페르길루스(Aspergillus)를 트레이닝된 유기체로 선택. 상동성-기반 예측의 경우, (v) BLAST+ (v2.7.1) 및 (vi) DIAMOND (v0.9.22)를 사용하여 곰팡이(Fungi)에 대한 NCBI 참조 전사체 및 단백질 데이터베이스를 각각 검색하였다. EVidenceModeler (v06-25-2012)를 사용한 컨센서스 유전자 모델 예측의 경우, 전술한 독립형 유전자 예측에 다음과 같이 가중치를 부여하였다: (i)-5, (ii)-10, (iii)-1, (iv)-1, (v)-5 및 (vi)-5. 게놈 주석은 Ascomycota_odb9 데이터 세트를 사용하여 BUSCO (v5b)로 평가되었다.
실시예 9: PKS 발현을 위한 발현 벡터 구성
pDS23 플라스미드는 선택 마커로 노르세오트리신 아세틸트랜스퍼라제(nourseothricin acetyltransferase, nat) 유전자 카세트 및 아스페르길루스 니둘란스(Aspergillus nidulans)에서 파생된 글리세르알데히드-3-인산디히드로게나아제(glyceraldehyde-3-phosphate dehydrogenase) 유전자(G3PD)의 구성적 프로모터의 제어 하에 향상된 녹색 형광 단백질(eGFP)을 전달한다. pDS23에서 G3PD 프로모터를 다중 복제 부위로 대체하기 위해, 플라스미드를 AvrII 및 HindIII 제한 효소와 여러 제한 효소 부위(NheI, AatII, SacI, PmeI, BglII 및 SacII)는 플라스미드의 AvrII와 HindIII 부위 사이에 클로닝되었다. 생성된 플라스미드를 pDS33으로 명명하였다. As. rabiei의 고유 프로모터를 운반하는 발현 벡터를 생성하기 위해, As. rabiei 분리물 AR628의 gDNA에서 증폭된 sol1 (솔라나피론 합성 효소 인코딩) 유전자 프로모터를 포함하는 1,270-bp DNA 단편을 BglII 및 HindIII로 미리 절단된 pDS33에 클로닝하여 pDS35 플라스미드를 생성하였다. atr1의 코딩 서열(Sta04644)은 프라이머 쌍 'Inf_Sta046440_fwd' 및 'Inf_Sta046440_rev' (7,829 bp)로 증폭되었으며, In-Fusion HD 클로닝 키트(Takara)를 사용하여 eGFP 대신 HindIII 및 BamHI로 선형화된 pDS35에 클로닝하여 플라스미드 sol1::atr1/pDS35를 생성하였다.
실시예 10: 효소 발현 맞춤을 위한 발현 벡터 구축
pII99 플라스미드는 선택 마커로서 네오마이신 포스포트랜스퍼라제 II 유전자(nptII) 카세트를 운반한다. sol5의 프로모터(솔라나피론 생합성의 마지막 단계를 촉매하는 디엘스-알더레이즈(Diels-Alderase)를 인코딩함)를 운반하는 발현 벡터를 생성하기 위해, As. rabiei AR628 균주의 gDNA로부터 증폭된 sol5 프로모터를 포함하는 579-bp DNA 단편이 EcoRI 및 BglII로 미리 절단된 pII99에 클로닝하여 pII95 플라스미드를 생성하였다. 추가 제한 효소 부위를 도입하기 위해, sol5 프로모터 증폭을 위한 역방향 프라이머가 NheI 부위를 갖도록 설계되었다(상기 표 1 참조). pII95 플라스미드를 NheI 및 BglII로 절단하고, S. 알피넘(S. alpinum)의 gDNA로부터 증폭된 atr3 (Sta04642) 또는 atr2 (Sta04643)의 PCR 산물을 미리 절단된(precut) 플라스미드에 융합하여, 플라스미드 sol5::atr3/pII95 및 sol5::atr2/pII95를 생성하였다. 유사하게, A. 니둘란스(A. nidulans)로부터 유래된 번역 연장 인자 1 알파 유전자(translation elongation factor 1 alpha gene, tef1α)의 구성적 프로모터를 운반하는 발현 벡터를 생성하기 위해, 플라스미드 pII98은 pAC1750 플라스미드로부터 증폭된 tef1α 프로모터를 포함하는 880-bp DNA 단편을 pII99로 클로닝하여 생성되었으며, 코딩 서열과 atr3 및 atr2의 종결자 영역은 NheI 및 BglII로 미리 절단된 pII98에 개별적으로 융합되어 플라스미드 tef1α::atr3/pII98 및 tef1α::atr2/pII98을 생성하였다.
실시예 11: HPLC 분석 및 대사산물 정제
대사산물 추출 및 프로파일링을 위해, 형질전환체를 2-3주 동안 PDA에서 성장시키고 곰팡이 콜로니를 포함하는 전체 한천을 페트리 접시에서 잘라내고 50 ml 팔콘 튜브에 10 ml의 에틸 아세테이트에 담그었다. 30분 동안 초음파 처리한 후, 용액 1 ml의 분취량을 1.5 ml 미세원심분리 튜브로 옮기고, 증발 건조시키고, 100 ul의 메탄올로 재구성하고, 고성능 액체 크로마토그래피(HPLC) 분석을 수행하였다. S. 알피넘(S. alpinum) 바우처 표본(20-30 mg) 조각을 2 ml 미세원심분리기 튜브에서 300 μl의 아세톤에 담그었다. 30분 동안 초음파 처리한 후, 샘플을 HPLC에 주입하기 전에 0.4 mm 주사기 멤브레인을 통해 여과하였다. Prominence Modular LC-20A HPLC 기기(Shimadzu)를 사용하여 형질전환체의 화학적 프로파일링을 수행하였다. 샘플은 YMC-Pack ODS-A (컬럼 크기, 150×4.6 mm; 입자 크기, 5 μm; 기공 크기, 12 nm; 40℃)를 사용하고, 254 nm에서 포토다이오드 어레이 검출기(SPD-M20A, 범위 180-700 nm)를 사용하여 분석하였다. 이동상은 펌프 A의 경우 증류수/트리플루오로아세트산(99.9:0.1, v/v)과 펌프 B의 경우 메탄올/트리플루오로아세트산(99.9:0.1, v/v)으로 구성되었다. HPLC 분석은 1.0 ml/분: 0-30분, 20-100%; 30-40분, 100%; 40-52분, 펌프 B의 20% 유속에서 구배 프로그램을 사용하여 수행되었다. 본 발명자들은 지의류 표본에서 발견되는 대사산물을 식별하기 위해 HPLC 분석을 위해 지의류 물질 데이터베이스를 사용하였다. 구조적 식별을 위해, 화합물을 주요 대사산물로 생산하는 형질전환체의 배양 추출물에서 화합물 1, 2 및 4를 정제하였다. 20개의 PDA 배양물을 에틸 아세테이트로 3회 추출하였다. 배양 추출물을 회전 증발 농축기(Buchi)에서 증발 건조시키고, 메탄올로 재구성하고, 분취용 HPLC에 적용하였다. 254 nm에서 UV 모니터링과 함께 Kromasil C18-컬럼(250×10 mm, 5 μm, 10 nm; 40℃)을 사용하여 2.2 ml/분의 유속으로 HPLC에서 분리가 이루어졌다. 화합물 1을 66% 아세토니트릴을 사용하여 정제하였다(tR = 9.86분; 9.5 mg); 2는 85% 아세토니트릴을 사용하여 정제되었다(tR = 9.77분; 6.2 mg); 4를 80% 아세토니트릴을 사용하여 정제하였다(tR = 9.60분; 2.1 mg). 용매를 0.1% 트리플루오로아세트산으로 완충하였다. 정제된 화합물을 NMR 분광 분석에 적용하였다.
실시예 12: 생성물 식별을 위한 LC-MS/MS 분석
배양 추출물을 메탄올로 20배 희석하고, 022 μm PTFE 필터로 여과하였다. LC-MS 분석은 Waters VION IMS QTOF 질량 분석기(Waters Co.)에 연결된 Waters Acquity I-Class UPLC 시스템에서 수행되었으며, 이는 전자분무 이온화 인터페이스가 장착되어 있다. 이동상은 물 중 0.1% 포름산(펌프 A) 및 아세토니트릴(펌프 B)로 구성되었다. 0.3 ml/분의 일정한 유속에서 단계적 구배 방법을 사용하여 펌프 B의 20-100%(0-9분), 3분 세척 및 3분 재생 조건으로 컬럼을 용리하였다. 주입 부피는 2 μl이었다. 컬럼 온도 및 샘플 오거나이저를 각각 40℃ 및 20℃로 유지하였다. 탠덤 MS 분석은 m/z 50-1500 Da 범위의 음이온 모드 및 0.2초의 수집 시간을 갖는 데이터-독립 수집(MSE)에서 수행되었다. 전구체 이온의 검출을 위한 낮은 충돌 에너지는 6 eV로 설정되었고, 단편화를 위한 높은 충돌 에너지는 20-40 eV로 설정되었다. 이온화 조건은 다음과 같이 설정되었다: 모세관 전압은 2.5kV이고, 콘 전압은 40V이고, 소스 온도는 100℃이고, 탈용매 온도는 250℃이고, 콘 가스 유량은 0 l/h이고, 탈용매 가스 유량은 800 l/h이었다. 네블라이저 및 보조 가스는 고순도 질소를 사용하였고, 충돌 가스는 아르곤을 사용하였다. m/z 554.2615에서 류신 엔케팔린의 [M-H]- 이온은 질량 정확도 및 재현성을 보장하기 위해 잠금 질량으로 사용되었다. 형질전환체에서 검출된 주요 화합물의 MS/MS 스펙트럼 데이터 매칭은 MS-DIAL을 사용한 전처리 후 GNPS의 기능 기반-분자 네트워킹 워크플로에 의해 수행되었다.
실시예 13: NMR 분광 데이터 요약
실시예 13-1: 4-O-데메틸바르바트산(화합물 1)
1H NMR (400 MHz, CD3COCD3): δ H 11.65 (s, OH), 6.73 (s, 1H), 6.47 (s, 1H), 2.68 (s, 3H), 2.63 (s, 3H), 2.12 (각각 s, 3H x 2); 13C NMR (100 MHz, CD3COCD3): δ C 170.4, 164.0, 163.3, 160.6, 153.0, 140.9, 140.7, 116.7, 116.6, 111.3, 109.6, 109.2, 103.6, 23.8, 23.1, 8.6, 7.3; 카르복실기에 대한 13C NMR 신호는 관찰되지 않았거나 탄소 핵의 긴 이완 시간으로 인해 매우 낮은 강도일 수 있으며, 공개된 데이터에서 카르복실기의 δC는 174.1이었다. 1H NMR 및 13C NMR 데이터는 공개된 데이터와 비슷하였다. HRESIMS m/z 3450972 [M-H]-(C18H17O7에 대한 계산치, 345.0974); MS/MS 스펙트럼은 GNPS 스펙트럼 라이브러리에 보관되어 있다.
실시예 13-2: 프로아트라노린 I(화합물 2)
1H NMR (400 MHz, CDCl3): δ H 11.90(s, OH), 11.70(s, OH), 6.50(s, 1H), 6.29(s, 1H), 3.96(s, 3H), 2.60(s, 3H), 2.52(s, 3H), 2.12(s, 3H), 2.07(s, 3H); 13C NMR (100 MHz, CDCl3): δ C 172.4, 170.3, 164.2, 162.9, 159.0, 152.6, 140.7, 139.8, 117.0, 116.4, 111.2, 110.1, 109.0, 104.2, 52.3, 24.6, 24.1, 9.4, 7.7; 1H NMR (400 MHz, CDCl3) 데이터는 공개된 데이터와 비슷하였다. 13C NMR (100 MHz, CDCl3) 데이터는 화합물 2에 하나 이상의 산소-메틸 탄소(δ C 52.3)가 있다는 점을 제외하고는 4-O-데메틸바르바트산 데이터와 비슷하였다. HRESIMS m/z 3591132 [M-H]- (C19H19O7에 대한 계산치, 359.1131); MS/MS 스펙트럼은 GNPS 스펙트럼 라이브러리에 보관되어 있다.
실시예 13-3: 프로아트라노린 III (화합물 4)
1H NMR (400 MHz, CDCl3): δ H 12.54 (s, OH), 12.45 (s, OH),11.77(s, OH), 10.35(s, CHO), 6.54(s, 1H), 6.40(s, 1H), 2.68(s, 3H), 2.59(s, 3H), 2.08(s, 3H); 1H NMR (400 MHz, CDCl3) 데이터는 프로아트라노린 III (화합물 4)의 카르복실기에서 메틸기(δH 3.99)가 누락된 것을 제외하고는 아트라노린(화합물 5)의 공개된 데이터와 비슷하였다. HRESIMS m/z 3590771 [M-H]- (C18H15O8에 대한 계산치, 359.0767); MS/MS 스펙트럼은 GNPS 스펙트럼 라이브러리에 보관되어 있다.
실시예 14: 클라도니아속(
Cladonia
) PKS 패밀리 및 유전적 복제 제거에 대한 주석
실시예 14-1: 클라도니아속(
Cladonia
spp.)의 PKS 패밀리
Big-SCAPE 프로그램을 사용하여, 적어도 하나의 반복적인 I형 PKS 유전자를 포함하는 45개의 유전자 클러스터 패밀리(GCF)가 확인되었다. PKS1, PKS2, PKS4, PKS5, PKS15 및 PKS16 패밀리의 생합성 유전자 클러스터(BGC)는 6종의 클라도니아(Cladonia) 종과 S. alpinum에서 보존되었고, PKS3 및 PKS10 패밀리의 BGC는 6개의 클라도니아 종에서 보존되었다. 이전에, Timsina 등은 클로도니아 클로로피아(Cladonia chlorophaea) 종 복합체(PKS1, PKS2, PKS3, PKS5, PKS7, PKS10, PKS11, PKS12, PKS13, PKS14, PKS15, PKS16 및 MSAS)의 종에서 보존된 13개의 PKS 패밀리를 확인하였다. 본 발명자들은 또한 유전자 클러스터 네트워크 분석에서 이러한 PKS 패밀리를 식별하였다(도 2의 A). 그러나, 본 발명자들은 6종의 클라도니아(Cladonia) 종의 게놈에서 PKS12 상동체를 검출하는데 실패하였으며, PKS12 패밀리가 원래 확인된 C. 그레이(C. grayi) 게놈에서도 마찬가지였다. 유전자 주석이 불완전하고 단편화되어 antiSMASH 프로그램이 세가지 PKS, 즉 Cma06514(PKS3), Cgr07347(PKS10) 및 Cuc08442(PKS19)를 포함하는 BGC를 검출하지 못했기 때문에, 3개의 PKS가 수동으로 검출되어 각 PKS 패밀리에 연결된다.
실시예 15: 클라도니아 생합성 유전자 클러스터(BGC)의 유전적 복제 제거
6개의 클라도니아 속(Cladonia spp.) 및 S. alpinum의 알려지지 않은 생합성 유전자 클러스터를 다른 곰팡이의 알려진 화합물에 연결하기 위해, Big-SCAPE 프로그램에 의해 예측된 GCF는 MIBiG(Minimal Information about a Biosynthetic Gene cluster) 데이터베이스(v.1.4)에 기탁된 이전에 특성화된 BGC와 결합되었다. 그 결과, 8개의 GCF 및 7개의 싱글톤(singleton) BGC가 비-지의류화된(non-lichenized) 곰팡이에서 발견되는 알려진 BGC와 연결되었다(도 2의 A). 계통 발생학적으로 먼 종의 이러한 보존된 생합성 유전자 클러스터(BGC)는 지의류 및 비-지의류화된 곰팡이 사이의 생합성 경로의 공유 조상을 제시하였다. 그럼에도 불구하고, 이러한 보존된 BGC는 높은 수준의 유전자 함량 변이를 나타내어 화학적 다양성으로 이어질 수 있는 분기 경로를 제시하였다. MIBiG 데이터베이스에 3개의 지의류 BGC가 나열되어 있다. 구체적으로, C. uncialis의 PKS8, C. uncialis의 PKS14 및 C. grayi의 PKS16에 대한 BGC는 도 2의 A에서 빨간색 점선으로 표시되어 있다.
실시예 15-1: PKS8
C. uncialis에서 메틸플로로아세토페논 합성 효소(methylphloroacetophenone synthase, MPAS)로도 알려진 PKS8은 계통발생 분석 및 유전자 발현 연구를 기반으로 하여 우스닉산의 생합성에 관여하는 것으로 알려져 있다. PKS8/MPAS 패밀리의 GCF는 C. 보레알리스(C. borealis), C. 메타코랄리페라(C. metacorallifera), C. 랑기페리나(C. rangiferina) 및 C. 운시알리스(C. uncialis)에 의해 공유되었다. 그러나, 이 4가지 클라도니아(Cladonia) 종 중에서 우스닉산은 C. 랑기페리나(C. rangiferina)에서 검출되지 않았다.
실시예 15-2: PKS14
C. uncialis (BGC0001489)에서 발견된 추정 6-하이드록시멜레인 BGC(6-hydroxymellein BGC)는 C. borealis 및 C. grayi에서 PKS14 BGC와 함께 GCF를 형성하였다. 6-하이드록시멜레인 BGC의 유전자 구성원의 역할은 테레인(terrein) 생합성 경로를 기반으로 잠정적으로 지정되었으며, 여기서 terA 및 terB는 A. terreus에서 6-하이드록시멜레인을 생합성하기 위해 협력한다. 본 발명자들의 네트워크 분석에서, 테레인 BGC(MIBiG accession: BGC0000161)는 3개의 클라도니아 종의 6-하이드록시멜레인 BGC와 연결되지 않았으며, 아마도 이들 사이에서 관찰된 유전자 함량 변화 때문일 수 있다: A. terreus의 테레인 BGC의 11개 유전자 구성원 중 3개의 유전자(terA, terB 및 terD)만이 3개의 클라도니아 종의 6-하이드록시멜레인 BGC에 보존되었다.
실시예 15-3: PKS13 및 PKS15
6개의 클라도니아 속(Cladonia spp.)에 보존된 PKS15 패밀리의 BGC 및 S. alpinum은 다양한 곰팡이에서 멜라닌 생성을 담당하는 1,3,6,8-테트라히드록시나프탈렌(T4HN) 합성 효소를 포함하여 이전에 특성화된 많은 BGC에 연결되었다. 간결함을 위해, 도 2의 A는 PKS15 패밀리의 BGC에 연결된 T4HN 합성 효소(BGC0001257)를 포함하는 하나의 BGC만 보여주었다. 본 발명자들은 PKS13 BGC가 T4HN 합성 효소를 함유하는 알려진 BGC에도 연결되어 있음을 확인하였다. 6개의 클라도니아 속 및S. alpinum에 보존된 PKS15 패밀리와 달리, PKS13 패밀리는 클라도니아 속 및 S. alpinum에서 발견되지 않았으며, Exophiala lecanii-corni에서 멜라닌 생성을 담당하는 ElcPKS1과 51-54% 단백질 서열 동일성을 보여주었다(도 5). ElcPKS1 및 PKS13 패밀리는 PKS15 패밀리 및 기타 기존 T4HN과 구별되는 고도로 지원되는 계통군(99%의 부트스트랩 값)을 형성하였으며, 이는 일부 클라도니아 종이 다른 기원의 멜라닌 PKS의 두 복사본을 가지고 있음을 나타낸다.
실시예 15-4: PKS16
C. grayi (BGC0001266)에서 발견된 추정 회색조 BGC는 6개의 클라도니아 속 및 S. alpinum에서 보존된다. PKS16 BGC는 C. grayi에서 발견되는 오르셀린산(orsellinic acid)으로부터 유래된 그레이아닉산(뎁시돈)을 생산하기 위해 제안되었다.
실시예 15-5: PKS17
C. 보레알리스(C. borealis), C. 마실렌타(C. macilenta) 및 C. 메타코랄리페라(C. metacorallifera)가 공유하는 PKS17 패밀리의 GCF는 다양한 곰팡이가 생산하는 안트라퀴논인 에모딘의 생합성을 위한 BGC(BGC0001583)에 연결되었다. 에모딘 생합성에 필요하고 충분한 4가지 핵심 효소(NRPKS, 메탈로-β-락타마제, 디카르복실라제 및 안트론 옥시게나제) 외에도, 사이토크롬 P450 모노옥시게나제를 포함한 몇 가지 맞춤 효소가 상동 클라도니아 BGC에서 발견되었다. P450 모노옥시게나제는 클라도스포리움 풀범(Cladosporium fulvum)에서 2개의 에모딘 유도체의 커플링을 매개하는 ClaM과 39% 서열 동일성을 보여 P450 효소가 스카이린의 생합성에 관여할 수 있음을 시사한다. 흥미롭게도, 에모딘 생합성을 위한 4개의 핵심 유전자를 보유하고 있는 또 다른 BGC가 PKS17 BGC와 배열이 다르지만 C. 마실렌타(C. macilenta)의 게놈에서 발견되었다. 추정되는 에모딘 생합성을 위한 C. 마실렌타의 두 번째 BGC는 C. 운시알리스(C. uncialis)의 PKS18 BGC와 GCF를 형성하였으며, 이는 페스탈로티옵시스 픽시(Pestalotiopsis fici)에서 발견되는 에모딘 유도체인 페스테산(pestheic acid)의 BGC와 상동성이다.
실시예 15-6: PKS34
C. 마실렌타(C. macilenta) 및 C. 메타코랄리페라(C. metacorallifera)가 공유하는 PKS34 계열의 GCF는 푸사리움 푸지쿠로이(Fusarium fujikuroi)가 생산하는 적색 균사체 색소인 푸사루빈(fusarubin)의 생합성을 위한 BGC(BGC0001242)와 연결되었다. 그러나, BGC 내용은 매우 다양하였다. 푸사루빈 BGC에서 fsr1(NR-PKS 인코딩), fsr4(알코올 탈수소효소 인코딩) 및 fsr5(단쇄 탈수소효소 인코딩)의 추정 상동체만 PKS34 BGC에서 찾을 수 있었다.
실시예 15-7: PKS37
페니실리움 엑스판숨(Penicillium expansum)의 파툴린 BGC(BGC0000120)는 C. 보레알리스(C. borealis), C. 메타코랄리페라(C. metacorallifera) 및 C. 운시알리스(C. uncialis)가 공유하는 PKS37 패밀리의 GCF에 연결되었다. 파툴린 BGC의 15개 유전자 구성원 중, patF-patO와 상동성인 10개의 유전자는 파툴린의 직접적인 전구체인 네오파툴린의 생합성에 필요한 3개의 클라도니아 속(C. 보레알리스의 patF 제외)에서 찾을 수 있다. 네오파툴린의 파툴린으로의 최종 전환을 담당하는 patD 및 patE의 상동체는 클라도니아 게놈에 없었다. 대신, 발견된 다른 맞춤 효소는 C. 메타코랄리페라 및 C. 운시알리스에서 에피머라제, C. 보레알리스 및 C. 운시알리스에서 타우D유사 디옥시게나제(TauDlike dioxygenase), C. 운시알리스에서 두 개의 단쇄 탈수소효소이었다.
실시예 16: MIBiG 데이터베이스에 연결된 싱글톤 BGC
이전에 특성화된 여러 BGC가 단일 종(싱글톤 BGC)에서 발견된 BGC에 연결되었다. 이러한 싱글톤 BGC는 비-지의류화된 곰팡이에서 발견되는 상응하는 BGC에 대해 유전자 함량 변화가 거의 없고 서열 유사성이 높은 경향이 있어 이러한 BGC가 지의류에 최근 도입되었음을 시사한다. 비-지의류화된 곰팡이로부터 수평으로 옮겨졌을 가능성이 있는 BGC는 다음과 같다: C. 마실렌타의 BGC에 연결된 소르비실린 BGC(BGC0001404), C. 그레이(C. grayi)의 BGC에 연결된 테레산 BGC(BGC0000160), C. 랑기페리나(C. rangiferina)의 BGC에 연결된 하이포테마이신 BGC(BGC0000076), C. 운시알리스의 BGC에 연결된 쿠르부팔리데스(curvupallides) BGC (BGC0001563), 및 S. 알피넘(S. alpinum)의 BGC에 연결된 데푸데신 BGC(BGC0000046). 모나스코루브린(monascorubrin) BGC(BGC0000099) 및 베타에논(betaenone) BGC(BGC0001264)는 본 발명자들의 네트워크 분석 뿐만 아니라 C. 운시알리스 PKS의 상동성 매핑에 대한 초기 연구에서 C. 운시알리스의 BGC에도 연결되었다.
실시예 17: 클라도니아속(
Cladonia
) PKS 패밀리의 상동성 매핑에 대한 주석
실시예 17-1: 보존된 지의류 PKS 패밀리의 상동성 매핑
유전자 클러스터 네트워크 분석에서 많은 지의류 BGC가 높은 우도를 가진 알려진 화합물로 귀속되었지만, 높은 유전자 함량 변이로 인해 비-지의류화된 곰팡이에서 이전에 특성화된 BGC와 연결되지 않은 더 상동성인 BGC가 있을 수 있다. 따라서, 본 발명자들은 NCBI 비중복 단백질 서열 데이터베이스에 대해 45개의 PKS 패밀리에 대한 BLAST 검색을 수행하여 알려진 화합물이 있는 PKS 유전자와 상동성인 클라도니아속(Cladonia) PKS 패밀리를 식별하였다.
실시예 17-2: PKS4
PKS4 패밀리는 6개의 클라도니아 속 및 S. alpinum에 보존된 R-PKS 효소를 인코딩한다. PKS4 패밀리는 지의류화 및 비-지의류화된 곰팡이에서 찾을 수 있으며, 물리적으로 연관된 유형 III PKS와 공-진화(co-evolution)를 겪은 것으로 보인다.
실시예 17-3: PKS5
PKS5 패밀리는 글라레아 로조엔시스(Glarea lozoyensis)에서 제노로조에논(xenolozoyenone) PKS와 높은 서열 유사성을 나타내는 PKS-NRPS 하이브리드 효소를 인코딩하는 6개의 클라도니아 속 및 S. alpinum에서 보존되었다(단백질 서열 수준에서 56%). PKS5 패밀리의 상동체는 다양한 곰팡이에서 찾을 수 있다. 흥미롭게도, G. lozoyensis에서 제노로조에논 생합성을 위한 R-PKS 및 NRPS 효소를 인코딩하는 두 개의 직렬 유전자는 동일한 프로모터의 제어 하에 하나의 디시스트로닉(dicistronic) mRNA로 공동 전사된다. 따라서, 지의류의 PKS5 패밀리가 R-PKS 및 NRPS 효소에 대한 두 개의 개별 폴리펩티드 또는 PKS-NRPS 하이브리드 효소에 대한 단일 펩티드를 코딩하는지 여부를 조사해야 한다.
실시예 17-4: PKS9
PKS9 패밀리는 C. 보레알리스(C. borealis), C. 마실렌타(C. macilenta), C. 메타코랄리페라(C. metacorallifera) 및 C. 운시알리스(C. uncialis)에 의해 공유되었으며, 이는 이전의 상동성 매핑 연구에서 기술한 바와 같이 페니실리움 브레비콤팍툼(Penicillium brevicompactum)의 5-메킬오르셀린산(5-methylorsellinic acid)으로부터 유래된 마이코페놀산(mycophenolic acid)의 생합성을 담당하는 NR-PKS(MpaC)와 유사하다 (44% 단백질 서열 동일성). 또한, PKS9 패밀리는 아스페르길루스(Aspergillus) 및 페니실리움(Penicillium) 종의 3,5-디메틸오르셀린산 유래 메로테르페노이드의 생합성에 관여하는 NR-PKS(AdrD, AndM, AusA, NvfA, PrhL 및 Trt4)에 대해 43-45% 단백질 서열 동일성을 나타내었다. 그러나, 클라도니아속(Cladonia) 게놈의 PKS9 BGC에는 테르펜 생합성과 관련된 생합성 유전자, 예컨대 프레닐전달효소(prenyltransferase) 및 테르펜 시클라아제(terpene cyclase)가 부족하였다.
실시예 17-5: PKS18
C. 마실렌타(C. macilenta) 및 C. 운시알리스(C. uncialis)에서 공유하는 PKS18 패밀리는 이전 상동성 매핑 연구에서 기술한 바와 같이 페스탈로티옵시스 픽시(Pestalotiopsis fici)에서 에모딘 유도체인 페스테산의 생합성에 관여하는 NR-PKS(PtaA)에 대해 64-68% 단백질 서열 동일성을 보여주었다.
실시예 17-6: PKS21
보라색 색소 비루로퀴논(biruloquinone)은 엽상 지의류(foliose lichen) 파멜리아 비룰라에(Parmelia birulae)에서 처음 발견되었다. 비루로퀴논은 자연계의 클라도니아 종에서 발견되지 않았지만, 본 발명자들은 이전에 무균 배양에서 비루로퀴논을 생산하는 C. 마실렌타(C. macilenta)에서 분리된 게놈-시퀀싱된 균체(mycobiont)의 화학적 변이체를 확인하였다. 본 발명자들은 비루로퀴논 생성자와 비-생성자 사이의 전체-전사체 비교에 의해 비루로퀴논의 생합성에 PKS21 패밀리를 잠정적으로 지정하였다.
실시예 17-7: PKS22
나프타자린 유도체인 적색 색소 크리스타자린은 원래 C. 크리스타텔라(C. cristatella)의 균체 배양에서 확인되었다. 본 발명자들은 게놈-시퀀싱된 C. 메타코랄리페라(C. metacorallifera)에서 분리된 균체에서 크리스타자린 생산을 위한 최적의 배양 조건을 설정하고, PKS23이 C. 메타코랄리페라의 크리스타자린-유도 조건에서 고도로 상향조절된다는 관찰에 기초하여 PKS22 패밀리를 크리스타자린의 생합성으로 귀속시킨다.
실시예 17-8: PKS24
PKS24 패밀리는 C. 보레알리스(C. borealis), C. 마실렌타(C. macilenta), C. 메타코랄리페라(C. metacorallifera) 및 S. 알피넘(S. alpinum)에 의해 공유되었다. C. 메타코랄리페라(C. metacorallifera)의 PKS24 BGC는 단편화된 PKS24 유전자를 가진 다른 3종의 BGC와 약간 달랐다. PKS24 패밀리는 FgPKS14와 46-48% 단백질 서열 동일성을 보여주는, 푸사리움 그라미네아룸(Fusarium graminearum)에서 오르셀린산 생합성에 관여하는 FgPKS14와 함께 100% 부트스트랩에 의해 최대로 지지되는 단일계통 계통군을 형성하였다(도 5).
실시예 17-9: PKS30
PKS30 패밀리는 A. 니둘란스(A. nidulans)가 생산하는 나프토피론(naphthopyrone)인 분생포자 황색 색소(일명 YWA1)의 생합성을 담당하는 NR-PKS(wA)와 52-53%의 단백질 서열 동일성을 보여주었다. C. 보레알리스(C. borealis), C. 마실렌타(C. macilenta), C. 메타코랄리페라(C. metacorallifera) 및 C. 운시알리스(C. uncialis)에 보존된 PKS30 BGC는 C. 운시알리스에서 색소가 검출되지는 않았지만 적색 자낭반(apothecial) 색소인 로도클라돈산(rhodocladonic acid)의 생합성에 관여할 가능성이 있다. C. 보레알리스(C. borealis), C. 마실렌타(C. macilenta) 및 C. 메타코랄리페라(C. metacorallifera)라는 세 가지 적색 자낭반 색소 생성자가 공유하는 두 개의 GCF(PKS21 및 PKS30 패밀리)만 있었다. PKS21 및 PKS30 패밀리는 각각 NR-PKS 그룹 III 및 IV에 속하며, 이는 나프토피론-유래 화합물의 생합성에 관여하는 NR-PKS를 포함한다(도 5). PKS21 패밀리가 비루로퀴논(페난트렌퀴논)의 생합성에 잠정적으로 지정되었기 때문에, PKS30 패밀리는 세 개의 적색 자낭반 색소 생성자가 공유하는 마지막으로 남은 나프토피론 PKS이다. 이러한 추정적 지정은 PKS30 BGC에 있는 O-메틸트랜스퍼라제 및 2개의 모노옥시게나제와 같은 로도클라돈산의 생합성에 필요한 효소의 존재에 의해 강화되었다. 나프토피론 전구체로부터 로도클라돈산에 대한 제안된 생합성 경로는 하기 나타낸 바와 같다.

실시예 17-10: PkeA
C. 보레알리스(C. borealis) 및 C. 메타코랄리페라(C. metacorallifera)가 공유하는 BGC에는 A. 니둘란스(A. nidulans)에서 펠리논(felinone)의 생합성을 담당하는 PKeA(DbaI으로도 알려짐)에 대해 63-65% 단백질 서열 동일성을 나타내는 NR-PKS가 포함되었다. 본 발명자들은 PkeA/DbaI와 상동성인 NR-PKS에 대한 PKS 패밀리 번호를 지정하지 않았으며, 이는 그룹 VII에 속하는 다른 클라도니아속(Cladonia) NR-PKS(예를 들어, C. 마실렌타(C. macilenta)의 소르비실린 BGC)와 같이 클라도니아속(Cladonia)의 특정 계통에 특이적일 수 있다.
실시예 18: 지의류의 대사 잠재력
LFF의 진화적 관계를 조사하고 게놈-인코딩된 대사 잠재력을 비교하기 위해, 8개의 게놈을 사용하여 393개의 단일 복사본 이종 상동 유전자의 병합-기반 트리를 재구성하였으며, 본 발명자들은 2020년 9월 현재 NCBI 데이터베이스 및 JGI 웹사이트에서 사용할 수 있는 시퀀싱된 22개의 게놈 어셈블리를 가지고 있다. 시퀀싱된 종의 대다수(30개 중 26개)는 접시지의강(Lecanoromycetes)에 속하며, 4개의 LFF는 접시지의강 외부에 배치되었다: 아르토니아 라디아타(Arthonia radiata) (아르토니아강), 엔도카폰 푸실룸(Endocarpon pusillum) (유로티오미세테스), 스클레로포라 산귀니아(Sclerophora sanguinea) (코니오사이보마이세테스(Coniocybomycetes)) 및 비리도텔리움 비렌스(Viridothelium virens) (도티데오마이세테스(Dothideomycetes)). 알렉토리아 사르멘토사(Alectoria sarmentosa) 및 세트라도니아 리니어리스(Cetradonia linearis)의 게놈을 제외하고 BUSCO 분석에 의해 평가된 게놈의 완성도는 91% 이상이었다(도 1). 멸종 위기에 처한 지의류 세트라도니아 리니어리스(Ce. linearis) 및 스클레로포라 산귀니아(Sc. sanguinea)의 게놈은 20 Mbp보다 짧다(도 1). 이러한 두 종을 제외하고, 모든 게놈은 7,927-14,537개의 오픈 리딩 프레임(open reading frame)을 포함하는 26.3-56.1 Mbp 크기였다(도 1). 30종의 게놈-인코딩된 대사 가능성은 antiSMASH를 사용하여 BGC에 대한 게놈을 마이닝하여 조사되었다. 시퀀싱된 LFF의 대사 잠재력은 16-108의 BGC 수로 매우 가변적이었다(도 1); 파멜리아속(Parmelia sp.) KoLRI021559는 가장 큰 BGC 다양성을 보인 반면, 세트라도니아 리니어리스(Ce. linearis) 및 스클레로포라 산귀니아(Sc. sanguinea)의 게놈은 수축된 게놈 크기에 기인할 수 있는 가장 작은 BGC 세트를 보유하였다. 특히, 6개의 클라도니아속(Cladonia) 게놈은 52-65개의 BGC를 보유하고 유사한 수의 PKS를 인코딩한다; 평균 16개의 NR-PKS 및 20개의 환원형 PKS(R-PKS)(도 1). 6개의 클라도니아속(Cladonia spp.) 폴리케타이드 기원의 독특한 SM 세트를 생산하여(표 2 및 도 6 참조), 종간(inter-species) PKS 유전자 다양성을 연구하고 비교 분석을 통해 지의류의 피질 또는 수질 물질의 생합성을 담당하는 BGC를 식별하는 데 이상적이다.
하기 표 2에 30종의 게놈-염기서열 분석에서 보고된 지의류 물질을 정리하여 나타내었다.
| 종(speices) | 지의류 물질(Lichen substances) |
| 클라도니아 마실렌타 (Cladonia macilenta) |
바르바트산(barbatic acid), 디디믹산(didymic acid) |
| 클라도니아 메타코랄리페라 (Cladonia metacorallifera) |
탐놀산(thamnolic acid), 우스닉산(usnic acid), 디디믹산(didymic acid) |
| 클라도니아 보레알리스 (Cladonia borealis) |
바르바트산(barbatic acid), 우스닉산(usnic acid) |
| 클라도니아 운시알리스 (Cladonia uncialis) |
스쿼민산(squamatic acid), 우스닉산(usnic acid) |
| 클라도니아 랑기페리나 (Cladonia rangiferina) |
아트라노린(atranorin), 푸마프로토세트라르산(fumaprotocetraric acid) |
| 클라도니아 그레이이 (Cladonia grayi) |
그레이아닉산(grayanic acid), 푸마프로토세트라르산(fumaprotocetraric acid) |
| 세트라도니아 리니어리스 (Cetradonia linearis) |
- |
| 스테레오카울론 알피늄 (Stereocaulon alpinum) |
로바르산(lobaric acid), 아트라노린(atranorin), 스틱트산(stictic acid) |
| 레타리아 루피나 (Letharia lupina) |
아트라노린(atranorin), 노르스틱트산(norstictic acid) |
| 레타리아 컬럼비아나 (Letharia columbiana) |
아트라노린(atranorin) |
| 슈데베르니아 푸르푸라시아 (Pseudevernia furfuracea) |
올리베토르산(olivetoric acid), 피소드산(physodic acid), 아트라노린(atranorin)/클로로아트라노린(chloroatranorin) |
| 알렉토리아 사르멘토사 (Alectoria sarmentosa) |
알렉토론산(alectoronic acid), 우스닉산(usnic acid) |
| 에버니아 프루나스트리 (Evernia prunastri) |
레카노르산(lecanoric acid)/에베른산(evernic acid), 피소드산(physodic acid), 아트라노린(atranorin)/클로로아트라노린(chloroatranorin), 살라진산(salazinic acid), 우스닉산(usnic acid) |
| 파멜리아속 KoRLI021559 (Parmelia sp. KoRLI021559) |
아트라노린(atranorin)/클로로아트라노린(chloroatranorin), 살라진산(salazinic acid) |
| 우스네아 플로리다 (Usnea florida) |
탐놀산(thamnolic acid), 노르스틱트산(norstictic acid)/살라진산(salazinic acid), 우스닉산(usnic acid) |
| 우스네아 하코넨시스 (Usnea hakonensis) |
우스닉산(usnic acid) |
| 라말리나 인터미디아 (Ramalina intermedia) |
석화산(sekikaic acid), 아트라노린(atranorin), 우스닉산(usnic acid) |
| 라말리나 페루비아나 (Ramalina peruviana) |
석화산(sekikaic acid), 우스닉산(usnic acid) |
| 크산토리아 파리에티나 (Xanthoria parietina) |
파리에틴(parietin)/팔라시놀(fallacinol)/파리에틴산(parietinic acid)/에모딘(emodin) |
| 크산토리아 엘레간스 (Xanthoria elegans) |
파리에틴(parietin) |
| 기알로레키아 플레이버베센스 (Gyalolechia flavorubescens) |
파리에틴(parietin)/팔라시놀(fallacinol)/프라길린(fragilin)/에모딘(emodin) |
| 로바리아 풀모나리아 (Lobaria pulmonaria) |
기로포르산(gyrophoric acid), 아트라노린(atranorin), 노르스틱산(norstictic acid)/살라진산(salazinic acid) |
| 엄빌리카리아 퍼스투라타 (Umbilicaria pustulata) |
레카노르산(lecanoric acid)/기로포르산(gyrophoric acid)/움빌리카르산(umbilicaric acid), 스카이린(skyrin) |
| 엄빌리카리아 히스패니카 (Umbilicaria hispanica) |
레카노르산(lecanoric acid)/기로포르산(gyrophoric acid)/움빌리카르산(umbilicaric acid), 스카이린(skyrin) |
| 엄빌리카리아 무엘렌베르기 (Umbilicaria muehlenbergii) |
레카노르산(lecanoric acid)/기로포르산(gyrophoric acid) |
| 시아노더멜라 아스테리스 (Cyanodermella asteris) | 스카이린(skyrin) |
| 스클레로포라 산귀니아 (Sclerophora sanguinea) | - |
| 아르소니아 라디아타 (Arthonia radiata) |
검출되지 않음 |
| 비리도텔리움 비렌스 (Viridothelium virens) | 리헥산톤(lichexanthone) |
| 엔도카폰 푸실룸 (Endocarpon pusillum) |
- |
실시예 19: 클라도니아속(
Cladonia
) PKS의 유전적 복제 제거(dereplication)
지의류 폴리케타이드, 즉 뎁사이드 및 뎁시돈 계열 화합물의 생합성에 관여하는 PKS 유전자를 검색하기 위해, 본 발명자들은 6개의 클라도니아속(Cladonia spp.)과 관련 남극 지의류 S. 알피넘(S. alpinum)에서 적어도 하나의 PKS를 보유하는 226개의 BGC에 초점을 맞추었으며, 이로부터 총 242개의 PKS가 확인되었다. 본 발명자들은 먼저 각 PKS의 보존된 케토신타제(KS) 도메인에 대한 클러스터링 분석을 수행하고, 상동성 관계를 암시하는 많은 클러스터를 식별하였다. 클로도니아 클로로피아(Cladonia chlorophaea) 종 복합체에 대한 이전 연구에서 설명된 12개의 PKS 패밀리도 클러스터링 분석에서 검출되었으며, 이는 PKS 유전자의 상당 부분이 클라도니아속에 보존되어 있음을 나타낸다. 그러나, 이들의 생성물에 대해서는 알려진 바가 거의 없다. 따라서, 본 발명자들은 BGC 다양성을 서열 유사성 네트워크에 매핑하는 Big-SCAPE 프로그램을 사용하여 BGC를 비-지의류화된 곰팡이의 알려진 화합물에 연결하였다. 네트워크 분석은 BGC의 세 가지 속성을 그래픽으로 요약하는 데 사용되었다: (i) 네트워크와 관련된 PKS 생성물 (번호), (ii) 네트워크를 통한 종 분포 (노드), 및 (iii) BGC 쌍 간의 유사성 정도 (가장자리)(도 2의 A). 유전자 클러스터 네트워크에 의해 묘사된 바와 같이, 적어도 하나의 PKS 유전자를 보유하는 BGC는 45개의 유전자 클러스터 패밀리(GCF)로 그룹화되었다. 8개의 GCF 및 7개의 종별 BGC(빨간색으로 표시됨)는 MIBiG 데이터베이스에 기탁된 이전에 특성화된 BGC와 결합되었다. 도 2의 B는 클라도니아속(Cladonia) PKS 패밀리와 연결된 시그니처 SM을 나타내는 클라도니아속 PKS 패밀리의 계통 분포를 요약하였다.
실시예 20: 추정되는 아트라노린 BGC의 식별
6개의 클라도니아속(Cladonia spp.) 및 S. 알피넘(S. alpinum)의 유전자 클러스터 네트워크 분석 결과 45개의 GCF 중 PKS23 패밀리가 아트라노린의 생합성에 관여할 수 있음이 밝혀졌으며, 이느 두 아트라노린 생성자인 C. 랑기페리나(C. rangiferina) 및 S. 알피넘(S. alpinum)이 공유하는 유일한 GCF이기 때문에 다양한 거대 지의류의 주요 피질 물질이다 (도 2). 아트라노린은 다른 뎁사이드 및 뎁시돈 계열 화합물에서 거의 발견되지 않는 3MOA 모이어티 내에 메톡시카르보닐기를 갖는 구조가 독특하다. C. 랑기페리나(C. rangiferina)의 PKS23 BGC에서 O-메틸트랜스퍼라제(OMT)를 사용한 BLAST 검색은 테레토닌 (메로테르페노이드)의 생합성 동안 아스페르길루스 테레우스(A. terreus)의 3,5-디메틸오르셀린산 모이어티 내에서 메톡시카르보닐 그룹의 형성을 매개하는 OMT인 Trt5(UniProtKB: Q0C8A3)와 37% 단백질 서열 동일성을 보여주었다 (표 3).
하기 표 3에 클라도니아 랑기페리나의 PKS23 생합성 유전자 클러스터 정보를 정리하여 나타내었다.
| ORFa | 크기 (aa) | BLASTP 동족체(homolog)b | 동일성(%) | 보존된 도메인 (Conserved domain) |
E-값 |
| 06811 | 744 | MFS 단당류 수송체 | 71 | 당 수송체 (Pfam00083) | 1e-105 |
| 06812 | 306 | 수송 제어 단백질(export control protein) CHS7-유사 | 68 | 키틴 합성 효소 III 촉매 소단위 (Pfam12271) | 1e-131 |
| 06813 | 495 | TFIIH 복합체 p47 서브유닛 | 58 | TFIIH 복합체 소단위 Ssl1-유사 (Pfam04056) | 1e-82 |
| 06814 | 549 | MFS 다제 수송체 ( atr4 ) | 50 | 주요 촉진자 슈퍼패밀리 (Pfam07690) | 9e-31 |
| 06815 | 346 | Trt5, O-메틸트랜스퍼라제( atr3 ) | 37 | SAM-의존성 메틸트랜스퍼라제 (Pfam08241) | 1e-04 |
| 06816 | 508 | 시토크롬 P450 모노옥시게나제 ( atr2 ) | 43 | 시토크롬 P450 (Pfam00067) | 3e-57 |
| 06817 | 2,513 | 비환원성 폴리케타이드 합성 효소 ( atr1 ) | 44 | SAT-KS-AT-PT-ACP-MT-TE | |
| 06818 | 472 | 가상 단백질 | 33 | 인산전이효소 패밀리 (Pfam01636) | 4e-08 |
| 06819 | 2,377 | 환원성 폴리케타이드 합성 효소(R-PKS) | 40 | KS-AT-DH-ER-KR-ACP | |
| 06820 | 184 | 가상 단백질 | 40 | 미지 기능의 도메인, DUF3237 (Pfam11578) | 5e-22 |
| 06821 | 301 | 가상 단백질 | 34 | 미지 기능의 도메인, DUF2306 (Pfam10067) | 2e-09 |
| 06822 | 236 | 가상 단백질 | 28 | 검출되지 않음 | |
| 06823 | 356 | 가상 단백질 | 32 | 검출되지 않음 | |
| 06824 | 565 | 추정 디메틸아닐린 모노옥시게나제 | 41 | 플라빈-결합 모노옥시게나제-유사 (Pfam00743) | 3e-14 |
aORF: C. 랑기페리나(C. rangiferina) 오픈 리딩 프레임(open reading frame). 합성 핵심 유전자는 볼드체로 강조 표시됨.
bBLAST 검색의 경우, 4개의 아스페르길루스(Aspergillus) 종에 대한 NCBI 비중복 단백질 서열 데이터베이스가 사용됨: 아스페르길루스 푸미가투스(Aspergillus fumigatus; taxid 746128), A. 니둘란스(A. nidulans; taxid 162425), A. 니제르(A. niger; taxid 5061) 및 A. 테레우스(A. terreus; taxid 33178).
아트라노린을 생산하는 다른 지의류에서 보존된 PKS23 BGC의 존재를 조사하기 위해, 본 발명자들은 GCF 내 및 전체에서 BGC의 보존 및 변이를 연구하는 데 유용한 CORASON 파이프라인을 채택하였다. C. 랑기페리나(C. rangiferina)의 PKS23 BGC에서 OMT의 단백질 서열을 30개의 게놈에서 검출된 총 1,527개의 BGC에 대해 질의하였다. 본 발명자들은 각각 상당한 히트(>33% 단백질 서열 동일성)를 나타내는 OMT를 포함하는 15개의 BGC를 확인하였다(도 3). 15개의 BGC 중 7개의 BGC에는 4개의 합성 핵심 유전자가 포함되어 있다: PKS23(atr1 합성), 시토크롬 P450 모노옥시게나제(atr2), OMT(atr3) 및 수송체(atr4)(도 3 및 표 3). 이러한 합성 BGC는 30개의 시퀀싱된 종 중에서 아트라노린을 생성하는 지의류에서만 독점적으로 발견되었다(표 2 참조).
실시예 21: 아트라노린 생합성 경로의 재구성
아스퍼질러스 니둘란스(A. nidulans) 및 아스퍼질러스 오리제(A. oryzae)와 같은 잘 확립된 이종 숙주에서 지의류 PKS 유전자의 이종 발현을 위한 힘든 노력에도 불구하고, 시도는 아직 알려지지 않은 이유로 성공하지 못하였다. 따라서, 본 발명자들은 식물 병원성 곰팡이 아스코키타 라비에이(Ascochyta rabiei) (도티데오마이세테스(Dothideomycetes))를 사용하여 새로운 이종 발현 시스템을 구축하기 시작하였다. 추정되는 아트라노린 BGC에서 세 가지 생합성 유전자의 화학적 구조 및 예측된 기능을 기반으로 아트라노린에 대한 폴리케타이드 경로를 구상할 수 있었다(도 4의 A). 개별 유전자의 역할을 조사하기 위해, 먼저 본 발명자들은 야생형 아스코키타 라비에이(As. rabiei)에서 솔라나피론의 생합성을 위한 BGC를 제거하여 상당한 대사산물 생산을 보이지 않는 "클린 숙주"를 생성하였다(도 4의 B). 그런 다음 S. 알피넘(S. alpinum) gDNA에서 복제된 atr1을 "클린 숙주"에 도입하였다. atr1의 발현 및 올바른 인트론 스플라이싱은 RT-PCR 분석에 의해 확인되었다(도 7 참조). LC-MS/MS 및 NMR 분석은 알려진 지의류 뎁사이드, 4-O-데메틸바르바트산(4-O-demethylbarbatic acid, 화합물 1)이 atr1을 발현하는 균주에 의해 생성되었음을 나타내었고 (도 4의 B 및 도 4의 C 참조), 이는 2개의 3MOA 단위가 Atr1 자체에 의해 뎁사이드로 결합되었음을 시사한다.
화합물 1로부터 아트라노린의 생합성은 2개의 3MOA 단위 각각 내에서 메틸기의 산화 및 카르복실기의 메틸화를 필요로 하기 때문에(도 4의 A), 본 발명자들은 atr2 및 atr3을 코딩하는 유전자를 atr1 발현 균주에 개별적으로 도입하였다. atr3과 atr1의 동시-발현은 화합물 1의 7'-O-메틸화된 유사체, 프로아트라노린 I(proatranorin I) (화합물 2)를 산출하였으며, 이는 아스페르길루스 테레우스(A. terreus)의 Trt5와 마찬가지로 Atr3이 실제로 카르복실 메틸라제임을 나타낸다(도 4의 B 및 도 4의 C 참조). LC-MS/MS 분석은 atr1과 atr2의 동시-발현으로 화합물 3 및 4가 생성되었으며, 각각 화합물 1의 하이드록실화 유사체(프로아트라노린 II) 및 추가로 산화된 알데히드(프로아트라노린 III)로 주석이 달린 것으로 나타났다 (도 4의 B 및 도 4의 C 참조). 분리된 프로아트라노린 III(화합물 4)에 대한 NMR 분석은 Atr2에 의한 산화가 화합물 1의 C-9에서 발생함을 확인하였다. 마지막으로 atr1, atr2 및 atr3의 세 가지 유전자를 발현하는 균주를 생성하였다. 아트라노린(화합물 5)의 생성은 MS/MS 스펙트럼을 지의류 데이터베이스에서 아트라노린의 참조 스펙트럼과 일치시켜 확인하였다. 이는 또한 각각 피질 및 수질 물질로서 아트라노린(화합물 5)과 로바릭산(lobaric acid)을 생산하는 시퀀싱된 S. 알피넘(S. alpinum)에 대한 실제 바우처 표본과 화학적 프로파일을 비교하여 확인되었다(도 4의 B 및 도 4의 C). 흥미롭게도, 화합물 6의 MS/MS 스펙트럼 매칭은 자연에서 S. alpinum에서 보고되지 않은 또 다른 지의류 뎁사이드인 베오미세스산(baeomycesic acid)임을 확인하였으며, 이는 Atr3이 이종 숙주에서 이완된 기질 특이성을 나타냄을 시사한다.
실시예 22: 지의류 물질의 생합성을 담당하는 PKS의 새로운 계통발생 분기군
곰팡이 NR-PKS와 아트라노린 생산을 담당하는 Atr1의 진화적 관계를 연구하기 위해, 본 발명자들은 6종의 클라도니아속(Cladonia spp.) 및 S. alpinum에서 발견된 103개의 NR-PKS와 비-지의류화된 곰팡이의 알려진 화합물에 연결된 82개의 NR-PKS의 보존된 KS 및 생성물 주형 (PT) 도메인의 연결된 시퀀스의 계통발생 트리를 재구성하였다. 곰팡이 NR-PKS는 이전의 계통발생학적 분석에서 지금까지 크게 8개 그룹(그룹 I-VIII)으로 분류되었다. 본 발명에서, 본 발명자들은 PKS23 패밀리 뿐만 아니라 PKS1 및 PKS2 패밀리를 포함하는 100% 부트스트랩이 지원하는 새로운 NR-PKS 그룹(그룹 IX)을 확인하였다(도 5). PKS1 패밀리는 이전에 C. 랑기페리나(C. rangiferina)에서 3MOA-유래 지의류 물질을 생합성하기 위해 제안되었다. 그룹 IX의 지의류 NR-PKS의 경우, S. alpinum의 PKS2를 제외한 모든 것은 폴리케타이드 중간체의 메틸화와 관련된 C-메틸트랜스퍼라제(cMT) 도메인을 보유하였다. 흥미롭게도, 새로 확인된 그룹 IX에는 비-지의류화된 곰팡이에서 이전에 특성화된 3개의 NR-PKS인 AscC, StbA 및 TmPKS12가 포함되었다(도 5). 이러한 NR-PKS에는 cMT 도메인이 없으며, 오르셀린산을 생성하는 것으로 알려져 있다. 또한, 그룹 IX에 대한 그룹 VIII 기저에는 버섯-형성 곰팡이(주름균강(Agaricomycetes)) 및 푸사리움 그라미네아룸(Fusarium graminearum)의 오르셀린산-유래 화합물과 연결된 여러 NR-PKS가 포함되어 있다는 점에 주목해야 하며(도 5 참조), 이는 PKS1 및 PKS2 패밀리가 PKS23 패밀리와 같이 메틸화된 형태의 오르셀린산에서 유래된 지의류 물질의 생합성에 관여할 가능성이 있음을 나타낸다.
<110> INDUSTRY-ACADEMIC COOPERATION FOUNDATION OF SUNCHON NATIONAL UNIVERSITY
<120> Atranorin biosynthesis gene derived from lichens and uses thereof
<130> PA-21-0182
<150> KR 10-2021-1234567
<151> 2021-02-12
<160> 46
<170> KoPatentIn 3.0
<210> 1
<211> 7808
<212> DNA
<213> Artificial Sequence
<220>
<223> Stereocaulon alpinum atr1 gene(MZ277879)
<400> 1
atggcgtcta accatgagga gctaccttca atggtagtgt tcagcccgca gagcaaagcc 60
ccaaaagaag gatacctcga tgagttacgg tcatatctat gcggcaaggc tgaacttcga 120
cctttgcttg atggtatcga aaaccttcca aacacctggt caatctttgc tcaaaggaac 180
tccgacattg cagctctgac tcaaggaatc cggtacacac aggcactctc agactgggcc 240
aagcatggaa cttcgtcagg aatctcgaac gttatgtctg ggatcctatc gttgcctctc 300
ttgaccatca ttcaggtggt ccaatacttc caattccttg aagtgaaaaa gctccgtcac 360
agcgacttca tggagcgact gaggtgtagg ggtggagttc aagggtattg tggcggccta 420
atgcctgcca ttgccatcgc ctgctctgcg acagaagctg aggttgttac caacgctgtt 480
aaagcgatgg gtattgcact aggtgttggc gcttacgggg agcttgggga cgatgagaac 540
gtcctagggc caactacaat agttgtccgc ctcaagcagg agggccaagg tggagacatc 600
ataaaggact ttcctgacgt gagctgctcg ttccgcacct accaaactca ctaactttgt 660
tacaggcgca tatatcagct atcacggacc caaagaccgt cagcattgta gggtcagccc 720
catctttggc agagatacaa gcccgagtga agtctaacgg catgcaaacc caagccatgc 780
atctgcgtgg gaaagtgcat aatcccgaaa acgctaatct agcgctggag ctttgcatgc 840
tttgcgacga gcatgaggaa ctctctttgc caaacgcttc acacttgacg gctcctttga 900
gatctaacaa gacagggaag aagttattag atgtctctct tactcatgaa gcgatcgaaa 960
caatcctggc atcctgctgt caatggtacg accttctcaa aggggtgtgc aaagacttgg 1020
agaaaacagg aactcaatca caccttttcg catcgttcgg cattggcgac tgcatccctc 1080
tgacaccgtt tcatcaggca gggctacaga ttaccaaatt ggacgttctc tcctttgtca 1140
aagccttgat gccgcctgtt ctaccaatgt ccggtcacaa ccaccaatat gcttatccaa 1200
ctgacgctgt ggctgtcgtc ggaatggcgt gtcgcctacc gggtgccaac agcgtcgaag 1260
aactctggga tctgatctcg tccggtggtt caactgttac ccctgtccca gaagatcgga 1320
tggatattgc aggtagcttt cgagctatgc aagatccgaa gtgggctgct aagcaacaat 1380
ggtggggcaa ttttatctct gatattgccg gatttgacca cagcttcttc cgcatgagcc 1440
ctcgggaagc cgcatcgatg gatccacaac aacgcattct cctcgagaca gcataccaag 1500
caatggagtc gagtggctac cttggttcgc atcgacgcga gtcaggtgat ccagtgggag 1560
tattcctagg agcaagtttc gtcgagtacc tggacaatac ttcctcaaac ccaccgacag 1620
catacacctc cactggcaca atcagggcgt ttttgagcgg caagataagt tattactttg 1680
gctggaccgg tccttctgaa attctcgaca cagcatgctc gtcgtctctg gttgccatta 1740
acagggcctg caaggcgatt cagaacgatg agtgccccat ggcacttgct ggtggcgtta 1800
atctaattac tggtatccac aattatttgg atctcgcaaa agcaggcttc cttagtccta 1860
gtggacaatg caagccgttt gatggcgctg ctgatggcta ctgccgttcg gaaggcgcgg 1920
gtctcgttgt tctcaagcgg ttgagccagg cattgaccga tgggaatcag atccttggcg 1980
tcatcacggg ggctagcacc aatcaaggcg gtttaagtcc atcgctcaca gtcccgcaca 2040
gcgctgccca ggtcaaattg taccaaaaca ttcttcatca ggcgggaatg agaccggagc 2100
aagtttctta ttgcgagact catggcactg gcactcaagc aggcgatcct ctggagattg 2160
agagtgtgcg ggaggttttt ggtggtccta aaagacagga ttccatgcac ataggctcaa 2220
tcaaaggcaa cattggtcac tgtgagactg ctgcaggagt cgctggcctt ctcaaagcgc 2280
tcgtcatggt caacaaagct gcaataccgc ctctagcgag tcacaagagc ttgaatccga 2340
agattgccgc cctcgaacct gataagcttg ctatttcaag ttgtcttgaa gactggagag 2400
tctcgccgag agctgcattg gtaaacagct atggcgcggc cggaagtaat tctgctgtcc 2460
tactatgcca ggcccctgac attgacaacg cacctttaca ccgcgtagca accacagagc 2520
atacctatcc aatcatactg agcgctgcat cgaaaccaag tctactttcg aatgctgaaa 2580
acatagcaag ctatttgagg aaagcaactt ccaagtgcac gattgccgat gttgcgttca 2640
ctctcgtcaa acaacgtaaa cgccatccgt tacaatggat aacaatggag tcaagcatcg 2700
acggcttggt caagtccctg gggtctttgc aggacccctc aaatgctccg cagccaaaga 2760
aggtggttat gacattttct ggccaaagtc gacaatcgat tgggctcaac aaagaatggt 2820
atgactcttt ccctctgttc cggcgccatg tgaacgaatg cgacgacttg ctgcagcaga 2880
gcggatttcc ttcctgcaag tctgcaatgt tcgataagga gcctgctcgg gatgttgtgc 2940
cactccagtg tgcgatgttt gctgttcagt acgcatctgc cttgtcttgg atcgattgtg 3000
gacttcaagt agaagctgta attggccaca gcttcggtga gttgacagct ttggcagtgt 3060
cgggtaccct ttccctcaaa gatgctctca atcttgttgc tacccgagct acattgatgc 3120
aatcaaaatg ggggcctcac aaagggacca tgctcttgat cagtgcggct actgagatgg 3180
tacgtaaaat cattgcagga aaccgcgatg tcgagatcgc ttgccacaat gcaccaacaa 3240
gccaaattgt tgtaggtacg caagctgcta tctcggaggt tgaaaaagtt ctcgaaaaca 3300
atacggagta tcgcggcatc cagagtcagc gcctcaatgt tacgcacggc ttccattctc 3360
aattcaccga gccattactc gagaatcttt cagagagtgc cagatctcta gtcttccatg 3420
agccgaagat tttgctagag tgttgcactc ttgaagaact gaaccatgtg gggcctgatc 3480
acttagcacg acacactcgg gagcctgttt acttctacca cgctgtacgc cgcctcgagc 3540
agcgtcttgg cacatgtctg tggcttgagg ctggtttcga ctctccgatt ataccaatga 3600
ccaagagggc cgttgaattc ccagagagac acacctttct ggacatgaag actccgagtg 3660
ggacgaatcc cactaagatg ctcactaccg caacgatcaa cctttggcaa aacggtgcta 3720
catcctcctt ctggggcttc catcccatag agacaacaaa cattaaacag gtgtggctgc 3780
caccgtacca attcgatcgg acctcccatt ggatgcctta taccgatcat gctttggaga 3840
tgagcaaaat ccaagccgtc atcagcaatt ctgaaccctt ggtcgaatta tcaactaagc 3900
caccgcgact ggttgagcct cggacgaagc ccagtgagaa aggtgaattc tccatgaaca 3960
cacaagcgcg acgctatacc gaaattgttt ctggtcatgc tgttttgagt cgaccattgt 4020
gtcctgcagc tatgtacatg gaatgcgcaa tcatggccgc acagttgtct attggcaaca 4080
tcgtgggcca ggcgccgtgg ttcgagaatc tgacctttga ggctcccctc ggaatggatc 4140
ctgacaacga caccacagtg gtcttgaagg atgatggttc caaaagcaga tggtcatttg 4200
tcgcgaggag cacgagtagg agcaacccga aacgcaagcc agtcttgcac gccaaagggg 4260
acttcggttt cactacacaa actcaagttc atcgatatga gaggcttgta accgaccgca 4320
tgaggcattt gcagcactct aaaagcgaga cacttaagtc caagcgagct tatggacttt 4380
tctcccgaat cgttcgttat gcagagctat tgaagggaat ttcatcaatt actctaggtg 4440
attcagaagc atctgcaata atcgacgtac cgcttggcgc cagcaccgag gacagctcgg 4500
caacaggact ctgtgattgc gtggcacttg atgccttcat tcaagtggtc ggcttattga 4560
tcaactccgg tgatgattgt gccgaagatg aggtttttgt tgcaactggt gtcgagaact 4620
tctcaatgtc gttggcctgc gacttcgatc gctgcagaac ttggcttgta ttcgccatgt 4680
tcacaccatc gggtaatggt aaagcgatgg gagatgtttt catcctgacg agggacaatg 4740
tcctggtcat gacaatcatg ggtgtacaat ttaccaagct tccgattaca aggctggaga 4800
agctattgga ctcggccaat cccaaagctc acaatacgcc aattttgaag tcaagtcagc 4860
aagactccat cgtatcggcc agcagtagct ctagtacgga gcatagcgat gacgacagcg 4920
aggacgatgg atcacggtct cccagccaca gtgatacctc cgttgacagc gagtcagaag 4980
cgccagcgga caacggtgct gcaaagaaac taaagtctct cattgcatca tatgttggga 5040
tcgctgaaga cgctatttcc gatgatgcaa atattgcgga tcttggagtc gactctcttg 5100
ctgctacaga actagccgac gagatctcga acgacttcgc taaggaaatc gacggcggcg 5160
agcttcccat gatgacattt ggtgaacttt gtcgaatagt ggccccggag atggctgcaa 5220
agcctgcaaa ggcgaaaaag aagattccct acaaaggtaa agatgaagcg actgttgttg 5280
agtcacaccc aggtaaatca cagagtgaga tcaaggactt gaaggctgtg gtggagcctt 5340
tgccaagatc gactcccatg ttatcagata ccaccgtcgt ccgatctgat cctacccaag 5400
tccttcgcca aattgatacc atgtttcagt catctgctga tacattcggc ttcacggact 5460
actggacagc ggtcgcccca aagcagaata agttagtcct ggcatatatt ggcgaggagt 5520
tcagaaagct aggactcgat ctctgggcgg ttcaacctgg agcaaccctt ccacatattg 5580
agtaccttcc aaagcatgaa aaggttgtcc agagactgtg ggatattctt gctgatcatg 5640
gtattgtcta caattatgac gccgcaaagg tgcggtccag caaacctctt ccggacgctc 5700
cttccacggc tctcctcaat gagctcaacg ccttgttccc aaatttcgcc aatgagaatc 5760
ggctaatgtc tgtcacggcg cctcatttcg cggatggttt gaggggaaag actgatcata 5820
ttagtctgct gtttgggagt caacgtggcc aggaatgcct gaatgacttc tataacaatt 5880
cgcctcagtt ggccgtgatg accgatcact tgctcacttt ctttaagcag ctcctgaaag 5940
aagccccact tgaaggttca ctccgaatcc ttgaggtcgg tggcggcttt ggagggacga 6000
caaaacgact agcagaaatg ctggaggcac taggtcagcc ggtcgagtat acgttcacgg 6060
atgtctcgtc catgctagtg aaggaagcaa ggaaaaagtt ttccaaacat tcttggatgg 6120
actttcagtc cttgaatctt gaaaaggacc ctccagcttc tcttcaaagg acatacgata 6180
ttgtgattgg gactaatgta gtgcacgcaa catcgaacat tgtgaattcg acgacacgca 6240
tgcgaagtct tttgaggaag ggtggcttta tcgtcttatc tgaagtcacc cgcattgttg 6300
actggtacga tctggtttat ggactccttg atggctggtg ggccttcaaa gactctagga 6360
cgtatccttt gcagcctgcc gatgactggg tgagagacct catgaaagcg ggattcgaga 6420
ccgcatccta ctcgagggga gactccgagg agtccaacac acagcagctg attattggct 6480
cgaccaggcc aagcaaggta gcgtctacca gcgggctttc ggaagccagg ctaagtaagt 6540
cctatagaat tgagacaatg ccatacaaga tcatcgacga cacggagata ctggcggacg 6600
tcttcttccc agagcatgaa gtggcctcgg aagccatgcc tataggtaat cttctccagt 6660
gtgtctagca atctcacgca gccgctgact tctgacaagc cctcatgatc cacggtggcg 6720
gttttatgac actctccaaa acggccatca gaccctacca gacccaattc ctcgtggaaa 6780
acggctatct tcctatcagc atcgattacc gactttgccc cgagattgat ctaatcgctg 6840
gtccgatgac ggacgttcgt gacgctctaa cctgggtgcg aaaacagctg cctgcgattg 6900
ctcgtacccg cggcatcaat gtggacccaa cgaaagttgt agtcatcgga tggtccacag 6960
gtggtcatct ggccctgact acagcgtgga catgtgagga cattggagaa gagccacctg 7020
ttgcagtcct tagcttctac ggtccaacga acttcgaatc tgaaggtgcg cgtccattga 7080
cactcttttc tgggtgctag tgccacctgt ggtccaaacc gtagcttagg ctgcattcct 7140
acaagatcgc taattgttca taacagacat tgatcggagg cgtgcggaac agtacccaga 7200
acggactatg tcgttcgatc ggatccgcaa gtcattatcc acgaagcctg tgagtatctc 7260
cttgctattg caaattctcc taggccttga cattgcttcc ccatagcatt gttactcttc 7320
tactcactgc taataccctc ttccacacgc agatcacttc ctatgactgt cccaccggca 7380
cagacagcac cggtctcggc tgggtgcgtc ccggcgaccc acgctctgaa ctcgtcttgt 7440
ccctcttcaa agaatctcac ggtctgcaag tgatgcttaa cggtctttct gccgcagatt 7500
tggccaaacc tccgccattg gctaaaattc aggcgatcag cccgatggcg cagctcaagg 7560
ccgggaggta caacgtccca acttttgtaa ttcattcaga ttgtgatgag atcgcgccgt 7620
tcagggatag cgaggctttt gtggaggaac tggcgaggag aggggtgaag actggactag 7680
ggagggtgag gggcaagaag catattcatg acttggcgtt gaagccggag aaggacggat 7740
gggtggacgg tgcgggcgtt ggatatgagt tcattttcga tgttgttgga cgaggcgtta 7800
ggggttga 7808
<210> 2
<211> 2500
<212> PRT
<213> Artificial Sequence
<220>
<223> Stereocaulon alpinum atr1(QXF68953)
<400> 2
Met Ala Ser Asn His Glu Glu Leu Pro Ser Met Val Val Phe Ser Pro
1 5 10 15
Gln Ser Lys Ala Pro Lys Glu Gly Tyr Leu Asp Glu Leu Arg Ser Tyr
20 25 30
Leu Cys Gly Lys Ala Glu Leu Arg Pro Leu Leu Asp Gly Ile Glu Asn
35 40 45
Leu Pro Asn Thr Trp Ser Ile Phe Ala Gln Arg Asn Ser Asp Ile Ala
50 55 60
Ala Leu Thr Gln Gly Ile Arg Tyr Thr Gln Ala Leu Ser Asp Trp Ala
65 70 75 80
Lys His Gly Thr Ser Ser Gly Ile Ser Asn Val Met Ser Gly Ile Leu
85 90 95
Ser Leu Pro Leu Leu Thr Ile Ile Gln Val Val Gln Tyr Phe Gln Phe
100 105 110
Leu Glu Val Lys Lys Leu Arg His Ser Asp Phe Met Glu Arg Leu Arg
115 120 125
Cys Arg Gly Gly Val Gln Gly Tyr Cys Gly Gly Leu Met Pro Ala Ile
130 135 140
Ala Ile Ala Cys Ser Ala Thr Glu Ala Glu Val Val Thr Asn Ala Val
145 150 155 160
Lys Ala Met Gly Ile Ala Leu Gly Val Gly Ala Tyr Gly Glu Leu Gly
165 170 175
Asp Asp Glu Asn Val Leu Gly Pro Thr Thr Ile Val Val Arg Leu Lys
180 185 190
Gln Glu Gly Gln Gly Gly Asp Ile Ile Lys Asp Phe Pro Asp Ala His
195 200 205
Ile Ser Ala Ile Thr Asp Pro Lys Thr Val Ser Ile Val Gly Ser Ala
210 215 220
Pro Ser Leu Ala Glu Ile Gln Ala Arg Val Lys Ser Asn Gly Met Gln
225 230 235 240
Thr Gln Ala Met His Leu Arg Gly Lys Val His Asn Pro Glu Asn Ala
245 250 255
Asn Leu Ala Leu Glu Leu Cys Met Leu Cys Asp Glu His Glu Glu Leu
260 265 270
Ser Leu Pro Asn Ala Ser His Leu Thr Ala Pro Leu Arg Ser Asn Lys
275 280 285
Thr Gly Lys Lys Leu Leu Asp Val Ser Leu Thr His Glu Ala Ile Glu
290 295 300
Thr Ile Leu Ala Ser Cys Cys Gln Trp Tyr Asp Leu Leu Lys Gly Val
305 310 315 320
Cys Lys Asp Leu Glu Lys Thr Gly Thr Gln Ser His Leu Phe Ala Ser
325 330 335
Phe Gly Ile Gly Asp Cys Ile Pro Leu Thr Pro Phe His Gln Ala Gly
340 345 350
Leu Gln Ile Thr Lys Leu Asp Val Leu Ser Phe Val Lys Ala Leu Met
355 360 365
Pro Pro Val Leu Pro Met Ser Gly His Asn His Gln Tyr Ala Tyr Pro
370 375 380
Thr Asp Ala Val Ala Val Val Gly Met Ala Cys Arg Leu Pro Gly Ala
385 390 395 400
Asn Ser Val Glu Glu Leu Trp Asp Leu Ile Ser Ser Gly Gly Ser Thr
405 410 415
Val Thr Pro Val Pro Glu Asp Arg Met Asp Ile Ala Gly Ser Phe Arg
420 425 430
Ala Met Gln Asp Pro Lys Trp Ala Ala Lys Gln Gln Trp Trp Gly Asn
435 440 445
Phe Ile Ser Asp Ile Ala Gly Phe Asp His Ser Phe Phe Arg Met Ser
450 455 460
Pro Arg Glu Ala Ala Ser Met Asp Pro Gln Gln Arg Ile Leu Leu Glu
465 470 475 480
Thr Ala Tyr Gln Ala Met Glu Ser Ser Gly Tyr Leu Gly Ser His Arg
485 490 495
Arg Glu Ser Gly Asp Pro Val Gly Val Phe Leu Gly Ala Ser Phe Val
500 505 510
Glu Tyr Leu Asp Asn Thr Ser Ser Asn Pro Pro Thr Ala Tyr Thr Ser
515 520 525
Thr Gly Thr Ile Arg Ala Phe Leu Ser Gly Lys Ile Ser Tyr Tyr Phe
530 535 540
Gly Trp Thr Gly Pro Ser Glu Ile Leu Asp Thr Ala Cys Ser Ser Ser
545 550 555 560
Leu Val Ala Ile Asn Arg Ala Cys Lys Ala Ile Gln Asn Asp Glu Cys
565 570 575
Pro Met Ala Leu Ala Gly Gly Val Asn Leu Ile Thr Gly Ile His Asn
580 585 590
Tyr Leu Asp Leu Ala Lys Ala Gly Phe Leu Ser Pro Ser Gly Gln Cys
595 600 605
Lys Pro Phe Asp Gly Ala Ala Asp Gly Tyr Cys Arg Ser Glu Gly Ala
610 615 620
Gly Leu Val Val Leu Lys Arg Leu Ser Gln Ala Leu Thr Asp Gly Asn
625 630 635 640
Gln Ile Leu Gly Val Ile Thr Gly Ala Ser Thr Asn Gln Gly Gly Leu
645 650 655
Ser Pro Ser Leu Thr Val Pro His Ser Ala Ala Gln Val Lys Leu Tyr
660 665 670
Gln Asn Ile Leu His Gln Ala Gly Met Arg Pro Glu Gln Val Ser Tyr
675 680 685
Cys Glu Thr His Gly Thr Gly Thr Gln Ala Gly Asp Pro Leu Glu Ile
690 695 700
Glu Ser Val Arg Glu Val Phe Gly Gly Pro Lys Arg Gln Asp Ser Met
705 710 715 720
His Ile Gly Ser Ile Lys Gly Asn Ile Gly His Cys Glu Thr Ala Ala
725 730 735
Gly Val Ala Gly Leu Leu Lys Ala Leu Val Met Val Asn Lys Ala Ala
740 745 750
Ile Pro Pro Leu Ala Ser His Lys Ser Leu Asn Pro Lys Ile Ala Ala
755 760 765
Leu Glu Pro Asp Lys Leu Ala Ile Ser Ser Cys Leu Glu Asp Trp Arg
770 775 780
Val Ser Pro Arg Ala Ala Leu Val Asn Ser Tyr Gly Ala Ala Gly Ser
785 790 795 800
Asn Ser Ala Val Leu Leu Cys Gln Ala Pro Asp Ile Asp Asn Ala Pro
805 810 815
Leu His Arg Val Ala Thr Thr Glu His Thr Tyr Pro Ile Ile Leu Ser
820 825 830
Ala Ala Ser Lys Pro Ser Leu Leu Ser Asn Ala Glu Asn Ile Ala Ser
835 840 845
Tyr Leu Arg Lys Ala Thr Ser Lys Cys Thr Ile Ala Asp Val Ala Phe
850 855 860
Thr Leu Val Lys Gln Arg Lys Arg His Pro Leu Gln Trp Ile Thr Met
865 870 875 880
Glu Ser Ser Ile Asp Gly Leu Val Lys Ser Leu Gly Ser Leu Gln Asp
885 890 895
Pro Ser Asn Ala Pro Gln Pro Lys Lys Val Val Met Thr Phe Ser Gly
900 905 910
Gln Ser Arg Gln Ser Ile Gly Leu Asn Lys Glu Trp Tyr Asp Ser Phe
915 920 925
Pro Leu Phe Arg Arg His Val Asn Glu Cys Asp Asp Leu Leu Gln Gln
930 935 940
Ser Gly Phe Pro Ser Cys Lys Ser Ala Met Phe Asp Lys Glu Pro Ala
945 950 955 960
Arg Asp Val Val Pro Leu Gln Cys Ala Met Phe Ala Val Gln Tyr Ala
965 970 975
Ser Ala Leu Ser Trp Ile Asp Cys Gly Leu Gln Val Glu Ala Val Ile
980 985 990
Gly His Ser Phe Gly Glu Leu Thr Ala Leu Ala Val Ser Gly Thr Leu
995 1000 1005
Ser Leu Lys Asp Ala Leu Asn Leu Val Ala Thr Arg Ala Thr Leu Met
1010 1015 1020
Gln Ser Lys Trp Gly Pro His Lys Gly Thr Met Leu Leu Ile Ser Ala
1025 1030 1035 1040
Ala Thr Glu Met Val Arg Lys Ile Ile Ala Gly Asn Arg Asp Val Glu
1045 1050 1055
Ile Ala Cys His Asn Ala Pro Thr Ser Gln Ile Val Val Gly Thr Gln
1060 1065 1070
Ala Ala Ile Ser Glu Val Glu Lys Val Leu Glu Asn Asn Thr Glu Tyr
1075 1080 1085
Arg Gly Ile Gln Ser Gln Arg Leu Asn Val Thr His Gly Phe His Ser
1090 1095 1100
Gln Phe Thr Glu Pro Leu Leu Glu Asn Leu Ser Glu Ser Ala Arg Ser
1105 1110 1115 1120
Leu Val Phe His Glu Pro Lys Ile Leu Leu Glu Cys Cys Thr Leu Glu
1125 1130 1135
Glu Leu Asn His Val Gly Pro Asp His Leu Ala Arg His Thr Arg Glu
1140 1145 1150
Pro Val Tyr Phe Tyr His Ala Val Arg Arg Leu Glu Gln Arg Leu Gly
1155 1160 1165
Thr Cys Leu Trp Leu Glu Ala Gly Phe Asp Ser Pro Ile Ile Pro Met
1170 1175 1180
Thr Lys Arg Ala Val Glu Phe Pro Glu Arg His Thr Phe Leu Asp Met
1185 1190 1195 1200
Lys Thr Pro Ser Gly Thr Asn Pro Thr Lys Met Leu Thr Thr Ala Thr
1205 1210 1215
Ile Asn Leu Trp Gln Asn Gly Ala Thr Ser Ser Phe Trp Gly Phe His
1220 1225 1230
Pro Ile Glu Thr Thr Asn Ile Lys Gln Val Trp Leu Pro Pro Tyr Gln
1235 1240 1245
Phe Asp Arg Thr Ser His Trp Met Pro Tyr Thr Asp His Ala Leu Glu
1250 1255 1260
Met Ser Lys Ile Gln Ala Val Ile Ser Asn Ser Glu Pro Leu Val Glu
1265 1270 1275 1280
Leu Ser Thr Lys Pro Pro Arg Leu Val Glu Pro Arg Thr Lys Pro Ser
1285 1290 1295
Glu Lys Gly Glu Phe Ser Met Asn Thr Gln Ala Arg Arg Tyr Thr Glu
1300 1305 1310
Ile Val Ser Gly His Ala Val Leu Ser Arg Pro Leu Cys Pro Ala Ala
1315 1320 1325
Met Tyr Met Glu Cys Ala Ile Met Ala Ala Gln Leu Ser Ile Gly Asn
1330 1335 1340
Ile Val Gly Gln Ala Pro Trp Phe Glu Asn Leu Thr Phe Glu Ala Pro
1345 1350 1355 1360
Leu Gly Met Asp Pro Asp Asn Asp Thr Thr Val Val Leu Lys Asp Asp
1365 1370 1375
Gly Ser Lys Ser Arg Trp Ser Phe Val Ala Arg Ser Thr Ser Arg Ser
1380 1385 1390
Asn Pro Lys Arg Lys Pro Val Leu His Ala Lys Gly Asp Phe Gly Phe
1395 1400 1405
Thr Thr Gln Thr Gln Val His Arg Tyr Glu Arg Leu Val Thr Asp Arg
1410 1415 1420
Met Arg His Leu Gln His Ser Lys Ser Glu Thr Leu Lys Ser Lys Arg
1425 1430 1435 1440
Ala Tyr Gly Leu Phe Ser Arg Ile Val Arg Tyr Ala Glu Leu Leu Lys
1445 1450 1455
Gly Ile Ser Ser Ile Thr Leu Gly Asp Ser Glu Ala Ser Ala Ile Ile
1460 1465 1470
Asp Val Pro Leu Gly Ala Ser Thr Glu Asp Ser Ser Ala Thr Gly Leu
1475 1480 1485
Cys Asp Cys Val Ala Leu Asp Ala Phe Ile Gln Val Val Gly Leu Leu
1490 1495 1500
Ile Asn Ser Gly Asp Asp Cys Ala Glu Asp Glu Val Phe Val Ala Thr
1505 1510 1515 1520
Gly Val Glu Asn Phe Ser Met Ser Leu Ala Cys Asp Phe Asp Arg Cys
1525 1530 1535
Arg Thr Trp Leu Val Phe Ala Met Phe Thr Pro Ser Gly Asn Gly Lys
1540 1545 1550
Ala Met Gly Asp Val Phe Ile Leu Thr Arg Asp Asn Val Leu Val Met
1555 1560 1565
Thr Ile Met Gly Val Gln Phe Thr Lys Leu Pro Ile Thr Arg Leu Glu
1570 1575 1580
Lys Leu Leu Asp Ser Ala Asn Pro Lys Ala His Asn Thr Pro Ile Leu
1585 1590 1595 1600
Lys Ser Ser Gln Gln Asp Ser Ile Val Ser Ala Ser Ser Ser Ser Ser
1605 1610 1615
Thr Glu His Ser Asp Asp Asp Ser Glu Asp Asp Gly Ser Arg Ser Pro
1620 1625 1630
Ser His Ser Asp Thr Ser Val Asp Ser Glu Ser Glu Ala Pro Ala Asp
1635 1640 1645
Asn Gly Ala Ala Lys Lys Leu Lys Ser Leu Ile Ala Ser Tyr Val Gly
1650 1655 1660
Ile Ala Glu Asp Ala Ile Ser Asp Asp Ala Asn Ile Ala Asp Leu Gly
1665 1670 1675 1680
Val Asp Ser Leu Ala Ala Thr Glu Leu Ala Asp Glu Ile Ser Asn Asp
1685 1690 1695
Phe Ala Lys Glu Ile Asp Gly Gly Glu Leu Pro Met Met Thr Phe Gly
1700 1705 1710
Glu Leu Cys Arg Ile Val Ala Pro Glu Met Ala Ala Lys Pro Ala Lys
1715 1720 1725
Ala Lys Lys Lys Ile Pro Tyr Lys Gly Lys Asp Glu Ala Thr Val Val
1730 1735 1740
Glu Ser His Pro Gly Lys Ser Gln Ser Glu Ile Lys Asp Leu Lys Ala
1745 1750 1755 1760
Val Val Glu Pro Leu Pro Arg Ser Thr Pro Met Leu Ser Asp Thr Thr
1765 1770 1775
Val Val Arg Ser Asp Pro Thr Gln Val Leu Arg Gln Ile Asp Thr Met
1780 1785 1790
Phe Gln Ser Ser Ala Asp Thr Phe Gly Phe Thr Asp Tyr Trp Thr Ala
1795 1800 1805
Val Ala Pro Lys Gln Asn Lys Leu Val Leu Ala Tyr Ile Gly Glu Glu
1810 1815 1820
Phe Arg Lys Leu Gly Leu Asp Leu Trp Ala Val Gln Pro Gly Ala Thr
1825 1830 1835 1840
Leu Pro His Ile Glu Tyr Leu Pro Lys His Glu Lys Val Val Gln Arg
1845 1850 1855
Leu Trp Asp Ile Leu Ala Asp His Gly Ile Val Tyr Asn Tyr Asp Ala
1860 1865 1870
Ala Lys Val Arg Ser Ser Lys Pro Leu Pro Asp Ala Pro Ser Thr Ala
1875 1880 1885
Leu Leu Asn Glu Leu Asn Ala Leu Phe Pro Asn Phe Ala Asn Glu Asn
1890 1895 1900
Arg Leu Met Ser Val Thr Ala Pro His Phe Ala Asp Gly Leu Arg Gly
1905 1910 1915 1920
Lys Thr Asp His Ile Ser Leu Leu Phe Gly Ser Gln Arg Gly Gln Glu
1925 1930 1935
Cys Leu Asn Asp Phe Tyr Asn Asn Ser Pro Gln Leu Ala Val Met Thr
1940 1945 1950
Asp His Leu Leu Thr Phe Phe Lys Gln Leu Leu Lys Glu Ala Pro Leu
1955 1960 1965
Glu Gly Ser Leu Arg Ile Leu Glu Val Gly Gly Gly Phe Gly Gly Thr
1970 1975 1980
Thr Lys Arg Leu Ala Glu Met Leu Glu Ala Leu Gly Gln Pro Val Glu
1985 1990 1995 2000
Tyr Thr Phe Thr Asp Val Ser Ser Met Leu Val Lys Glu Ala Arg Lys
2005 2010 2015
Lys Phe Ser Lys His Ser Trp Met Asp Phe Gln Ser Leu Asn Leu Glu
2020 2025 2030
Lys Asp Pro Pro Ala Ser Leu Gln Arg Thr Tyr Asp Ile Val Ile Gly
2035 2040 2045
Thr Asn Val Val His Ala Thr Ser Asn Ile Val Asn Ser Thr Thr Arg
2050 2055 2060
Met Arg Ser Leu Leu Arg Lys Gly Gly Phe Ile Val Leu Ser Glu Val
2065 2070 2075 2080
Thr Arg Ile Val Asp Trp Tyr Asp Leu Val Tyr Gly Leu Leu Asp Gly
2085 2090 2095
Trp Trp Ala Phe Lys Asp Ser Arg Thr Tyr Pro Leu Gln Pro Ala Asp
2100 2105 2110
Asp Trp Val Arg Asp Leu Met Lys Ala Gly Phe Glu Thr Ala Ser Tyr
2115 2120 2125
Ser Arg Gly Asp Ser Glu Glu Ser Asn Thr Gln Gln Leu Ile Ile Gly
2130 2135 2140
Ser Thr Arg Pro Ser Lys Val Ala Ser Thr Ser Gly Leu Ser Glu Ala
2145 2150 2155 2160
Arg Leu Ser Lys Ser Tyr Arg Ile Glu Thr Met Pro Tyr Lys Ile Ile
2165 2170 2175
Asp Asp Thr Glu Ile Leu Ala Asp Val Phe Phe Pro Glu His Glu Val
2180 2185 2190
Ala Ser Glu Ala Met Pro Ile Ala Leu Met Ile His Gly Gly Gly Phe
2195 2200 2205
Met Thr Leu Ser Lys Thr Ala Ile Arg Pro Tyr Gln Thr Gln Phe Leu
2210 2215 2220
Val Glu Asn Gly Tyr Leu Pro Ile Ser Ile Asp Tyr Arg Leu Cys Pro
2225 2230 2235 2240
Glu Ile Asp Leu Ile Ala Gly Pro Met Thr Asp Val Arg Asp Ala Leu
2245 2250 2255
Thr Trp Val Arg Lys Gln Leu Pro Ala Ile Ala Arg Thr Arg Gly Ile
2260 2265 2270
Asn Val Asp Pro Thr Lys Val Val Val Ile Gly Trp Ser Thr Gly Gly
2275 2280 2285
His Leu Ala Leu Thr Thr Ala Trp Thr Cys Glu Asp Ile Gly Glu Glu
2290 2295 2300
Pro Pro Val Ala Val Leu Ser Phe Tyr Gly Pro Thr Asn Phe Glu Ser
2305 2310 2315 2320
Glu Asp Ile Asp Arg Arg Arg Ala Glu Gln Tyr Pro Glu Arg Thr Met
2325 2330 2335
Ser Phe Asp Arg Ile Arg Lys Ser Leu Ser Thr Lys Pro Ile Thr Ser
2340 2345 2350
Tyr Asp Cys Pro Thr Gly Thr Asp Ser Thr Gly Leu Gly Trp Val Arg
2355 2360 2365
Pro Gly Asp Pro Arg Ser Glu Leu Val Leu Ser Leu Phe Lys Glu Ser
2370 2375 2380
His Gly Leu Gln Val Met Leu Asn Gly Leu Ser Ala Ala Asp Leu Ala
2385 2390 2395 2400
Lys Pro Pro Pro Leu Ala Lys Ile Gln Ala Ile Ser Pro Met Ala Gln
2405 2410 2415
Leu Lys Ala Gly Arg Tyr Asn Val Pro Thr Phe Val Ile His Ser Asp
2420 2425 2430
Cys Asp Glu Ile Ala Pro Phe Arg Asp Ser Glu Ala Phe Val Glu Glu
2435 2440 2445
Leu Ala Arg Arg Gly Val Lys Thr Gly Leu Gly Arg Val Arg Gly Lys
2450 2455 2460
Lys His Ile His Asp Leu Ala Leu Lys Pro Glu Lys Asp Gly Trp Val
2465 2470 2475 2480
Asp Gly Ala Gly Val Gly Tyr Glu Phe Ile Phe Asp Val Val Gly Arg
2485 2490 2495
Gly Val Arg Gly
2500
<210> 3
<211> 1761
<212> DNA
<213> Artificial Sequence
<220>
<223> Stereocaulon alpinum atr2 gene(MZ277878)
<400> 3
atggctctcc tagacacaat tgaactgttc tccaacttct cccttagtgg agtgttcgct 60
ggcctagttc tagcttctct cctcgtaagt tcaaccactg ttacgtcgtc aaaatgtgcc 120
agccttccct ttgcgagaac tgacacataa gcaactagac cacaacttac tgcatttgga 180
acatcttcta caatatttac cttcatccct tgaaaggtta ccctggccca aaattcctca 240
caacttctcg gcttccatat ctcaaatgga tgttctcagg aacccttgtg cccaatttcc 300
aaaggctcca tgagcagtac ggtcctgttg ttcgtgttgc gcccaacgag ctctcgtaca 360
tcaacccgga agccttgaaa accatctacg gccaccgtca accaggcgag gggtttcgca 420
agaatccagc attcttccag ccagctacga atggcgttca ttccatcttg acctccgaag 480
gtgacgctca tagtagtgtc cgccggaaga tcctgcccgc tttctcggat aaggcgcttg 540
cggaacagca ggacatcctc cagcatttca cagatctgtt gatccggaaa ttgcgcgaga 600
gagtcgaagc atccaaaagc tcagaacctg ttgacatgtt cgaatggtac atctggacta 660
ccttcgactt gattggagat ctcgcatttg gcgagccgtt caactgcctc gaagcagcta 720
gctttacaga atgggtcgcc cttgtgttca acgcgtttaa gacttttgcg ttcatcaaca 780
tcaggtaagc aaggtagact caccccgcaa cgaataaaag aaacgcgctt acgaaaccga 840
actagcaaac agctagctcc ccttgacaag ctagtcagac tgatgatccc aaagtccatg 900
aaagcccggc aagacaaagt cttctccctg aacgtcgcca aagtcgaccg ccgcattgct 960
tccaaagcag accgtccaga cttcctatcg tacattatta agggcaagga cggggtagca 1020
atggcacttc cagaactcta cgcaaattcc acgctccttg tcctcgccgg tagcgagagc 1080
acagcatctg gcttggctgg cattaccttt gagctactca agcaccgaga ggctcagaag 1140
aaggccgtgg aagagatacg cagcgctttc aaaaccgaag atgagattgt acctgagagc 1200
gtcaagcgac ttccatacct tgcggccatg gtttccgaag ggctccgaat gtatccgccc 1260
ttcccagagg gacttcctcg tcttacacca cggcaagggg ctcagatctg tggccaatgg 1320
gtccctggag gagtaagcta tgacccccat cctccgggac tagctaatct tctcatatag 1380
acatatgtgc aatttagcac ccacgccgct caccgcgcca gcgccaattt tacagacccg 1440
aatgtcttcg cccctgagcg ctggcttggc gacacgaaat tcgcgtcgga tatcaaagaa 1500
gcttcgcagc ccttctcgat aggtccacgt agctgcattg gcaggaagtg agtactttgt 1560
tcgcctcatt tgcacgaaga gtactaatta tacgggaaac ccagtcttgc gtaccttgaa 1620
atgcgcttga ttctagcgcg tatgttgtgg agcttcgaca tgcaactcac tcccgaatgc 1680
gaagactggg acgaccagaa tagctggatc cagtgggaca agaaaccttt gatggtgaag 1740
ttgtcgcttg tcaaaagata g 1761
<210> 4
<211> 506
<212> PRT
<213> Artificial Sequence
<220>
<223> Stereocaulon alpinum atr2(QXF68952)
<400> 4
Met Ala Leu Leu Asp Thr Ile Glu Leu Phe Ser Asn Phe Ser Leu Ser
1 5 10 15
Gly Val Phe Ala Gly Leu Val Leu Ala Ser Leu Leu Thr Thr Thr Tyr
20 25 30
Cys Ile Trp Asn Ile Phe Tyr Asn Ile Tyr Leu His Pro Leu Lys Gly
35 40 45
Tyr Pro Gly Pro Lys Phe Leu Thr Thr Ser Arg Leu Pro Tyr Leu Lys
50 55 60
Trp Met Phe Ser Gly Thr Leu Val Pro Asn Phe Gln Arg Leu His Glu
65 70 75 80
Gln Tyr Gly Pro Val Val Arg Val Ala Pro Asn Glu Leu Ser Tyr Ile
85 90 95
Asn Pro Glu Ala Leu Lys Thr Ile Tyr Gly His Arg Gln Pro Gly Glu
100 105 110
Gly Phe Arg Lys Asn Pro Ala Phe Phe Gln Pro Ala Thr Asn Gly Val
115 120 125
His Ser Ile Leu Thr Ser Glu Gly Asp Ala His Ser Ser Val Arg Arg
130 135 140
Lys Ile Leu Pro Ala Phe Ser Asp Lys Ala Leu Ala Glu Gln Gln Asp
145 150 155 160
Ile Leu Gln His Phe Thr Asp Leu Leu Ile Arg Lys Leu Arg Glu Arg
165 170 175
Val Glu Ala Ser Lys Ser Ser Glu Pro Val Asp Met Phe Glu Trp Tyr
180 185 190
Ile Trp Thr Thr Phe Asp Leu Ile Gly Asp Leu Ala Phe Gly Glu Pro
195 200 205
Phe Asn Cys Leu Glu Ala Ala Ser Phe Thr Glu Trp Val Ala Leu Val
210 215 220
Phe Asn Ala Phe Lys Thr Phe Ala Phe Ile Asn Ile Ser Lys Gln Leu
225 230 235 240
Ala Pro Leu Asp Lys Leu Val Arg Leu Met Ile Pro Lys Ser Met Lys
245 250 255
Ala Arg Gln Asp Lys Val Phe Ser Leu Asn Val Ala Lys Val Asp Arg
260 265 270
Arg Ile Ala Ser Lys Ala Asp Arg Pro Asp Phe Leu Ser Tyr Ile Ile
275 280 285
Lys Gly Lys Asp Gly Val Ala Met Ala Leu Pro Glu Leu Tyr Ala Asn
290 295 300
Ser Thr Leu Leu Val Leu Ala Gly Ser Glu Ser Thr Ala Ser Gly Leu
305 310 315 320
Ala Gly Ile Thr Phe Glu Leu Leu Lys His Arg Glu Ala Gln Lys Lys
325 330 335
Ala Val Glu Glu Ile Arg Ser Ala Phe Lys Thr Glu Asp Glu Ile Val
340 345 350
Pro Glu Ser Val Lys Arg Leu Pro Tyr Leu Ala Ala Met Val Ser Glu
355 360 365
Gly Leu Arg Met Tyr Pro Pro Phe Pro Glu Gly Leu Pro Arg Leu Thr
370 375 380
Pro Arg Gln Gly Ala Gln Ile Cys Gly Gln Trp Val Pro Gly Gly Thr
385 390 395 400
Tyr Val Gln Phe Ser Thr His Ala Ala His Arg Ala Ser Ala Asn Phe
405 410 415
Thr Asp Pro Asn Val Phe Ala Pro Glu Arg Trp Leu Gly Asp Thr Lys
420 425 430
Phe Ala Ser Asp Ile Lys Glu Ala Ser Gln Pro Phe Ser Ile Gly Pro
435 440 445
Arg Ser Cys Ile Gly Arg Asn Leu Ala Tyr Leu Glu Met Arg Leu Ile
450 455 460
Leu Ala Arg Met Leu Trp Ser Phe Asp Met Gln Leu Thr Pro Glu Cys
465 470 475 480
Glu Asp Trp Asp Asp Gln Asn Ser Trp Ile Gln Trp Asp Lys Lys Pro
485 490 495
Leu Met Val Lys Leu Ser Leu Val Lys Arg
500 505
<210> 5
<211> 1254
<212> DNA
<213> Artificial Sequence
<220>
<223> Stereocaulon alpinum atr3 gene(MZ277877)
<400> 5
atgacttccg ttgatacaat gcctccaccg atggttcgcc tcgagagtca gcctgacgac 60
ttgatgggct cttctgatgt cgcggacgtt tcagaccttc ttccaggcca tacaaatgga 120
ctcgaggatg aagtgaaaat tccagcaacc aatggactca agagccatcc agtggttacg 180
acaggaacag aaaaaaccgg tgtgatgccg ccccttcagc ccgaaagcaa gaagaacaac 240
aaaggcgttc cgtggtaaga cctggacata caccgctctt tttgtcaagc catgactgtt 300
acgacttcct gttgttttct atcatttctc tgccagtagt gctgaggtag acaggtatca 360
cgcctcaccg aacgatatcg atcccgtgac tcgcggtctg ctcgaaaatt acagcaaaat 420
cccctcggat caagtacagc agcacgttat cgcaattgta agtttccaaa ggttactcct 480
tgatgttctg caaccggatt gcagttggcg cactagatgg ctctctccct agacaagcat 540
cgctaaaacc gtctttttct cccaaaacag cgcgaaaaag cctgggacgt ctacccctac 600
ccctgcatcg gccaattcct cttcctgaac ctaaccataa acctctcccc ctactacccg 660
tccctcgtct cccgcctccg cgatcaaaat caaacactcc tcgacctcgg ctgctgcttc 720
gcccaagacg tccgcaaact cgtctctgat ggcgccccga gtcaaaacat ctacggcgcc 780
gacctctatg gcgagttcat ggatctaggc tttgaactct ttcgcgaccg aaagacgctc 840
aaaagcacgt ttttcccgac tgatatacta aacgagcggg atctgctgtt gaagggcttg 900
gatggcgaga tggatgttgt ttatttgggg ctgtttttgc atcattttga ttttgagact 960
tgtgtcaaag tttgtacgcg cgttactagg ctcctgaagc ccaagccggg gagtctggtt 1020
atgggggtcc aggtggggag tttggtgggt gatactaaac ccattcctat tcctagtggt 1080
gggattttgt ggaggcatga tattgcgagt cttgaaaggg tttgggagga ggttggagcg 1140
ctgacgggga cgaagtggaa ggttgaggct aggttggaga ggggcaaagg gttcggggag 1200
aagtggcagc ttgaggggac gaggaggttg gggtttgagg tttataggct ttga 1254
<210> 6
<211> 346
<212> PRT
<213> Artificial Sequence
<220>
<223> Stereocaulon alpinum atr3(QXF68951)
<400> 6
Met Thr Ser Val Asp Thr Met Pro Pro Pro Met Val Arg Leu Glu Ser
1 5 10 15
Gln Pro Asp Asp Leu Met Gly Ser Ser Asp Val Ala Asp Val Ser Asp
20 25 30
Leu Leu Pro Gly His Thr Asn Gly Leu Glu Asp Glu Val Lys Ile Pro
35 40 45
Ala Thr Asn Gly Leu Lys Ser His Pro Val Val Thr Thr Gly Thr Glu
50 55 60
Lys Thr Gly Val Met Pro Pro Leu Gln Pro Glu Ser Lys Lys Asn Asn
65 70 75 80
Lys Gly Val Pro Trp Tyr His Ala Ser Pro Asn Asp Ile Asp Pro Val
85 90 95
Thr Arg Gly Leu Leu Glu Asn Tyr Ser Lys Ile Pro Ser Asp Gln Val
100 105 110
Gln Gln His Val Ile Ala Ile Arg Glu Lys Ala Trp Asp Val Tyr Pro
115 120 125
Tyr Pro Cys Ile Gly Gln Phe Leu Phe Leu Asn Leu Thr Ile Asn Leu
130 135 140
Ser Pro Tyr Tyr Pro Ser Leu Val Ser Arg Leu Arg Asp Gln Asn Gln
145 150 155 160
Thr Leu Leu Asp Leu Gly Cys Cys Phe Ala Gln Asp Val Arg Lys Leu
165 170 175
Val Ser Asp Gly Ala Pro Ser Gln Asn Ile Tyr Gly Ala Asp Leu Tyr
180 185 190
Gly Glu Phe Met Asp Leu Gly Phe Glu Leu Phe Arg Asp Arg Lys Thr
195 200 205
Leu Lys Ser Thr Phe Phe Pro Thr Asp Ile Leu Asn Glu Arg Asp Leu
210 215 220
Leu Leu Lys Gly Leu Asp Gly Glu Met Asp Val Val Tyr Leu Gly Leu
225 230 235 240
Phe Leu His His Phe Asp Phe Glu Thr Cys Val Lys Val Cys Thr Arg
245 250 255
Val Thr Arg Leu Leu Lys Pro Lys Pro Gly Ser Leu Val Met Gly Val
260 265 270
Gln Val Gly Ser Leu Val Gly Asp Thr Lys Pro Ile Pro Ile Pro Ser
275 280 285
Gly Gly Ile Leu Trp Arg His Asp Ile Ala Ser Leu Glu Arg Val Trp
290 295 300
Glu Glu Val Gly Ala Leu Thr Gly Thr Lys Trp Lys Val Glu Ala Arg
305 310 315 320
Leu Glu Arg Gly Lys Gly Phe Gly Glu Lys Trp Gln Leu Glu Gly Thr
325 330 335
Arg Arg Leu Gly Phe Glu Val Tyr Arg Leu
340 345
<210> 7
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Sol1PpDS33_fwd
<400> 7
agatctcggc acgttttgat cgcaaag 27
<210> 8
<211> 32
<212> DNA
<213> Artificial Sequence
<220>
<223> Sol1PpDS33_rev
<400> 8
aagcttagta atatctggcg atgaagcgtc ag 32
<210> 9
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf_Sta046440_fwd
<400> 9
cagatattac taagctcatg gcgtctaacc atgaggag 38
<210> 10
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf_Sta046440_rev
<400> 10
gtaacgttaa gtggatcctt acaactaaag ctctcaatca accc 44
<210> 11
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Sta046440_check1F
<400> 11
ggacgatgag aacgtcctag 20
<210> 12
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Sta046440_check2F
<400> 12
cgagtcaggt gatccagtg 19
<210> 13
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Sta046440_check3F
<400> 13
ccaatcatac tgagcgctg 19
<210> 14
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Sta046440_check4F
<400> 14
cacatgtctg tggcttgag 19
<210> 15
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> Sta046440_check5F
<400> 15
caactccggt gatgattg 18
<210> 16
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Sta046440_check6F
<400> 16
caacccttcc acatattgag 20
<210> 17
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> pII99_sol5_fwd
<400> 17
gaattcagag cgacagtgaa agc 23
<210> 18
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> pII99_sol5_rev
<400> 18
agatctagct agcttggcgt gatgtcagtc aatgctg 37
<210> 19
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> pII99_tef1a_fwd
<400> 19
gaattccagc cgagacagca gaatcac 27
<210> 20
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> pII99_tef1a_rev
<400> 20
agatctagct agcgtgttat gttttgtgga atataaaagg g 41
<210> 21
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf95_Sta04642_fwd
<400> 21
atcacgccaa gctagcacga tgacttccgt tgatacaatg 40
<210> 22
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf98_Sta04642_fwd
<400> 22
aaacataaca cgctagcacg atgacttccg ttgatacaat g 41
<210> 23
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf99_Sta04642_rev
<400> 23
ggagaccggc agatcccgtc acatgtccgt cataataac 39
<210> 24
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf98_Sta04643_fwd
<400> 24
aaacataaca cgctagaacc atggctctcc tagacacaat tg 42
<210> 25
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf95_Sta04643_fwd
<400> 25
atcacgccaa gctagaacca tggctctcct agacacaatt g 41
<210> 26
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf99_Sta04643_rev
<400> 26
ggagaccggc agatcgagga gcaaaggaac aaggaacag 39
<210> 27
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> pII99_MK5
<400> 27
cgtcaagaga cctacgagac tg 22
<210> 28
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> pII99_MK3
<400> 28
gctatacttc taggtcttgg aagag 25
<210> 29
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf_BLE_pII99_fwd
<400> 29
gtaggtctct tgacgcatta agacctcagc gctagtgg 38
<210> 30
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Inf_BLE_pII99_rev
<400> 30
gacctagaag tatagcggtg ttacggagca ttcactagg 39
<210> 31
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> L5
<400> 31
gaggtcttca caccacaagt tcg 23
<210> 32
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<223> L3
<400> 32
ggcaaaggaa tagagtagat gccgaccggg ctcttgcgta gtggtacaga tg 52
<210> 33
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> R5
<400> 33
gttgacctcc actagctcca gccaagcgaa taggtaacaa agccagccga g 51
<210> 34
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> R3
<400> 34
gagaattgcg gcgcaggatg ttc 23
<210> 35
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> N5
<400> 35
ctgactttct tcttgcagcc ctgc 24
<210> 36
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> N3
<400> 36
ctaacgatgt cgttagtcgc cttg 24
<210> 37
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> HYG-F
<400> 37
gcttggctgg agctagtgga g 21
<210> 38
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> HYG-R
<400> 38
cggtcggcat ctactctatt cctt 24
<210> 39
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> YG-F
<400> 39
cgatgtagga gggcgtggat atgtc 25
<210> 40
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> HY-R
<400> 40
tgtagtgtat tgaccgattc cttgcg 26
<210> 41
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> P1_fwd
<400> 41
ggacgatgag aacgtcctag 20
<210> 42
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> P1_rev
<400> 42
gagagttcct catgctcgtc 20
<210> 43
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> P2_fwd
<400> 43
catcgacgac acggagatac tg 22
<210> 44
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> P2_rev
<400> 44
gaccgtgaga ttctttgaag agg 23
<210> 45
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Actin1_fwd
<400> 45
caatggttcg ggtatgtgca ag 22
<210> 46
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Actin1_rev
<400> 46
gaagagcgaa accctcgtag at 22
Claims (12)
- 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진, 아트라노린 생합성 유전자.
- 제1항에 있어서, 상기 아트라노린 생합성 유전자는 지의류로부터 유래된 것인, 아트라노린 생합성 유전자.
- 제2항에 있어서, 상기 지의류는 스테레오카울론 알피넘(Stereocaulon alpinum)인 것인, 아트라노린 생합성 유전자.
- 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진 아트라노린 생합성 유전자를 포함하는, 지의류 유래의 대사산물 생산용 재조합 발현 벡터.
- 제4항에 있어서, 상기 지의류 유래의 대사산물은 4-O-디메틸바르바트산(4-O-demethylbarbatic acid), 프로아트라노린 I(proatranorin I), 프로아트라노린 II(proatranorin II), 프로아트라노린 III(Proatranorin III), 아트라노린(atranorin) 및 베오미세스산(baeomycesic acid)으로 이루어진 군으로부터 하나 이상 선택되는 것인, 지의류 유래의 대사산물 생산용 재조합 발현 벡터.
- 제4항 또는 제5항의 재조합 발현 벡터로 형질전환된 재조합 미생물.
- 제6항의 재조합 미생물을 배양하는 단계를 포함하는, 지의류 유래의 대사산물 생산 방법.
- 제7항에 있어서, 상기 지의류 유래의 대사산물은 4-O-디메틸바르바트산(4-O-demethylbarbatic acid), 프로아트라노린 I(proatranorin I), 프로아트라노린 II(proatranorin II), 프로아트라노린 III(Proatranorin III), 아트라노린(atranorin) 및 베오미세스산(baeomycesic acid)으로 이루어진 군으로부터 하나 이상 선택되는 것인, 지의류 유래의 대사산물 생산 방법.
- 아스코키타 라비에이(Ascochyta rabiei) ATR-11 균주(기탁번호: KACC83048BP).
- 제9항에 있어서, 상기 균주는 아라트라노린 생산용인, 균주.
- 제9항에 있어서, 상기 균주는 서열번호 1, 서열번호 3 및 서열번호 5로 이루어진 군으로부터 선택되는 1종 이상으로 이루어진, 아트라노린 생합성 유전자가 도입된 것인, 균주.
- 제9항 내지 제11항 중 어느 한 항의 균주를 배양하는 단계를 포함하는, 아트라노린 생산 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/KR2022/008015 WO2022260402A1 (ko) | 2021-06-07 | 2022-06-07 | 지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20210073669 | 2021-06-07 | ||
| KR1020210073669 | 2021-06-07 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220165645A true KR20220165645A (ko) | 2022-12-15 |
Family
ID=84439539
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020220059678A KR20220165645A (ko) | 2021-06-07 | 2022-05-16 | 지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20220165645A (ko) |
-
2022
- 2022-05-16 KR KR1020220059678A patent/KR20220165645A/ko unknown
Non-Patent Citations (2)
| Title |
|---|
| Armaleo D et.al., Mycologia, 103:741-754, 2011 |
| Calcott MJ et.al., Chem Soc Rev., 47:1730-1760, 2018 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11091787B2 (en) | Methods and materials for biosynthesis of mogroside compounds | |
| Li et al. | Towards understanding the biosynthetic pathway for ustilaginoidin mycotoxins in Ustilaginoidea virens | |
| KR102114493B1 (ko) | 스테비올 글리코시드의 재조합 생산 | |
| US11248248B2 (en) | Production of mogroside compounds in recombinant hosts | |
| US20150059018A1 (en) | Methods and compositions for producing drimenol | |
| AU2023241333A1 (en) | Metabolite production in endophytes (2) | |
| US11655477B2 (en) | Methods for thaxtomin production and engineered non-native Streptomyces with increased thaxtomin production | |
| KR20220165645A (ko) | 지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도 | |
| JP2013531976A (ja) | spnK菌株 | |
| US20070111293A1 (en) | Genes from a gene cluster | |
| US10550409B2 (en) | Drimenol synthases III | |
| WO2022260402A1 (ko) | 지의류로부터 유래된 아트라노린 생합성 유전자 및 이의 용도 | |
| CN110305881B (zh) | 一种聚酮类化合物neoenterocins的生物合成基因簇及其应用 | |
| WO2024082757A1 (zh) | 黄酮类化合物及其生物合成相关基因以及其应用 | |
| CN114561405B (zh) | 木霉菌Harzianolide的合成基因簇在制备提高植物灰霉病抗性制剂中的应用 | |
| KR20130097538A (ko) | 해양 미생물 하헬라 제주엔시스의 제주엔올라이드 생합성 유전자 클러스터 | |
| WO2013031975A1 (ja) | フシコクシンaの生合成中間体の製造方法、およびその合成酵素 | |
| Zhao et al. | Heterologous expression facilitates the discovery and characterization of marine microbial natural products | |
| van Kan et al. | The grey mould Botrytis cinerea employs multiple mechanisms to protect itself from antifungal plant metabolites | |
| KR20200111121A (ko) | Cgl1 및 cgl2의 발현이 억제된 형질전환 식물 및 이를 이용한 목적 단백질의 생산방법 | |
| Abdel-Hameed | Polyketide biosynthesis in lichen fungi Cladonia uncialis | |
| CN114150006A (zh) | 一种可提高米尔贝霉素产量的基因簇、重组菌及其制备方法与应用 | |
| KR100834257B1 (ko) | 프라디마이신의 생합성효소인 o―메틸트랜스퍼라제의유전자가 파괴된 액티노마두라 히비스카 변이균주 및 그생성물인 디메틸프라디마이신 | |
| DE10045182A1 (de) | Verwendung von Palatinase- und Trehalulase-Sequenzen als nutritive Marker in transformierten Zellen |